Embed Size (px)
Citation preview

Linguistica Computazionale
4 ottobre 2017

2
(Dal lat. corpus, “corpo”, pl. corpora)
Un corpus è una collezione di testi selezionati e organizzati in maniera tale da soddisfare specifici criteri che li rendono funzionali
per le analisi linguistiche
Corpora
l I corpora rappresentano fonti di dati linguistici “ecologici”, ovvero raccolti nei loro “habitat naturali”l lingua scritta
l libri (saggistica, narrativa, poesia, ecc.), giornali, riviste, pagine Web, produzioni “effimere” (e-mail, pubblicità, chat, tweet, ecc.
l lingua parlata (trascritta)l notiziari radio-televisivi, conversazioni telefoniche, conversazioni
faccia-a-faccia, ecc.
3
Corpora Strumenti e applicazioni di NLP
sviluppo
valutazione
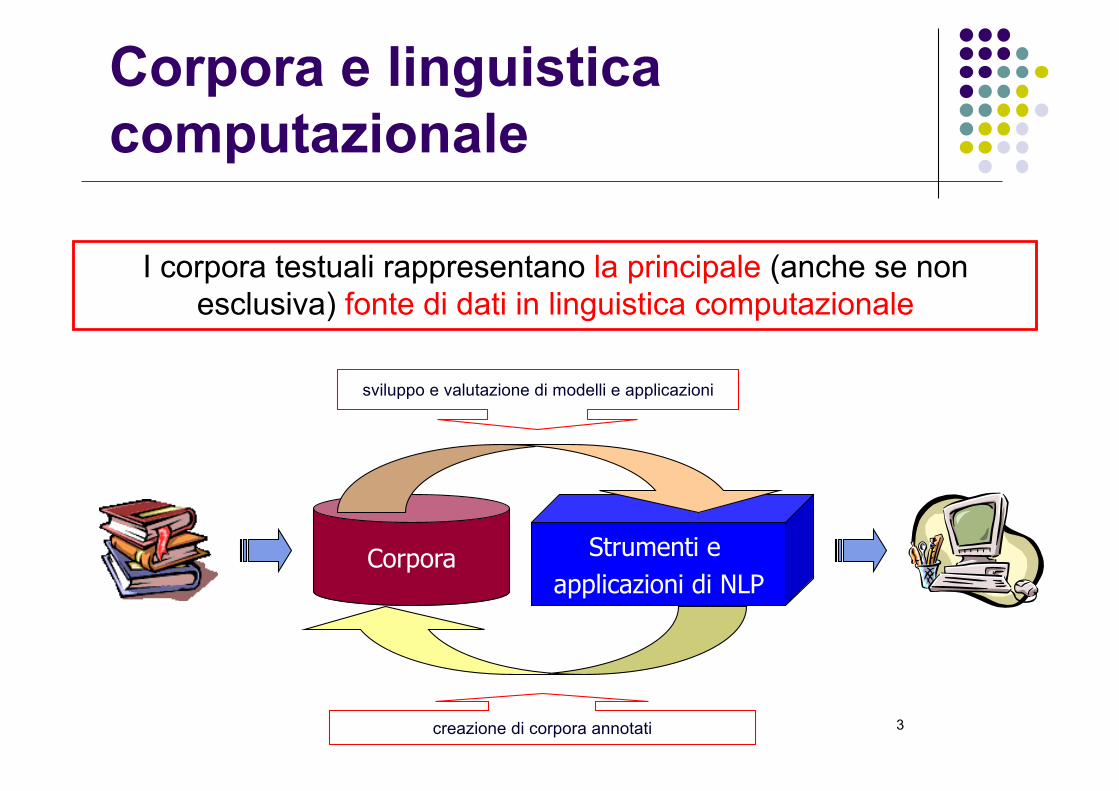
I corpora testuali rappresentano la principale (anche se non esclusiva) fonte di dati in linguistica computazionale
Corpora e linguistica computazionale
sviluppo e valutazione di modelli e applicazioni
creazione di corpora annotati

4
Anni ’50Prime applicazioni del computer ai testi letterari
(Padre Busa, Pisa)
1957Nasce la Grammatica Generativa
(Chomsky)
Anni ’60-’80Modelli simbolici
Logica & Intelligenza Artificiale
Natural Language Understanding
(Minsky, Schank, Winograd, et al.)
Metà anni ’60I primi corpora elettronici
(Francis & Kucera)
Anni ’60-’80Sviluppo della Corpus Linguistics e della statistica linguistica
(Leech, Sinclair, Herdan, et al.)
Anni ’90-OggiEmpirical NLP
NLP statistico
Machine Learning, Deep Learning
(Charniak, Church, et al.)
Corpora e linguistica computazionale

5
Ogni corpus è per sua definizione il risultato di un’opera di selezione
i criteri che guidano questa scelta determinano la natura stessa del corpus e condizionano lo spettro dei suoi usi possibili
Tipologia ed uso
l Parametri rilevanti per classificare i corporal generalitàl modalitàl cronologial lingual integrità dei testil codifica digitale dei testi

6
Tipi di corporageneralità
l corpus specialisticol orientato alla descrizione di una particolare varietà del linguaggio
(sublanguage) o a un ristretto dominio applicativol linguaggio giornalisticol linguaggio infantilel linguaggio giuridico, medico, ecc.l linguaggio dei controllori di volo, ecc.
l corpus generale o di riferimento (reference corpus)l trasversale rispetto alle diverse varietà di un linguaggio Ll plurifunzionalel orientato a rappresentare tutti gli aspetti caratteristici di L,
proponendosi come risorsa di riferimento per la descrizione di Ll può essere organizzato in vari sottocorpora specializzati per
varietà di L

7
Tipi di corporamodalità
l corpus di scrittol solo testi di linguaggio scritto
l corpus di parlatol solo trascrizioni di linguaggio parlato
l corpus mistol testi scritti e trascrizioni di parlato (in proporzioni variabili)
l speech database (corpus audio)l campioni di linguaggio parlato in forma di segnale acustico
(più eventualmente la trascrizione ortografica)l corpus multimediale (audio-video)
l testi scritti, video, parlato in forma di segnato acustico, ecc.

8
Tipi di corporacronologia e lingual corpus sincronico
l descrive un particolare stadio del linguaggio (i testi appartengono tutti ad una stessa finestra temporale)
l corpus diacronicol descrive il mutamento linguistico (i testi appartengono a diverse
finestre temporali)l corpus monolingue
l contiene testi di una sola lingual corpus bi/plurilingue
l corpus parallelo – lo stesso testo è rappresentato (in traduzione) in più di una lingual corpus allineato – ciascuna frase (parola) della lingua L1 è
esplicitamente collegata col suo traducente nella lingua L2l corpus comparabile – testi in più lingue (non in traduzione)
appartenenti alle stesse tipologie (ciascuna lingua è rappresentata da testi diversi)

9
Tipi di corporaintegrità e codifica dei testi
l Un corpus può contenere testi interi o porzioni di testi di lunghezza prefissata
l Corpora codificatil i testi sono arricchiti con etichette (codici) che ne rendono
esplicite vari tipi di informazione (es. struttura testuale, composizione, ecc.)
l Corpora annotatil le informazioni codificate sul testo riguardano la struttura
linguistica del testo a livelli diversi di rappresentazione (es. morfologica, sintattica, semantica, ecc.)

10
Evoluzione della dimensione dei corpora
corpora di prima generazioneanni 60-70 milioni di parole
corpora di seconda generazioneanni 80-90 decine di milioni di parole2000-oggi centinaia di milioni di parole
corpora di ultima generazioneoggi - … miliardi di parole
Dimensione del corpusl Numero di parole (token) contenute nel corpus
l numero di ore di registrazione, per corpora di parlatol Regola generale: “The larger, the better!”

11
Corpora di prima generazioneBrown Corpus
l Il primo corpus computazionale in formato elettronico, iniziato nel 1961l Francis e Kucera (Brown University)l corpus standard di American English contemporaneo
l Dimensionel 1 milione di parole tratte da materiale pubblicato nel 1961 appartenente
a vari generil Tratti caratteristici:
l generalel sincronicol monolingue
l Registrato su 100.000 schede perforate e trasferito su nastri magnetici nel 1964. Disponibile su CD-ROM
l Modello di riferimento per tutti i corpora di prima generazione

12
Corpora di prima generazioneBrown Corpus

13
Corpora di seconda generazioneBritish National Corpus (BNC)
l Corpus del British English (1991-1994)l creato da un consorzio accademico (Oxford, Lancaster, ecc.) ed editoriale
(Oxford University Press, Longman, ecc.)l Dimensione:
l 100 milioni di parolel Tratti caratteristici
l generalel monolinguel sincronicol misto
l 90% testi scritti di vari generil 10% testi di parlato trascritto (conversazioni spontanee)
l codificato e annotatol http://www.natcorp.ox.ac.uk/

14
Corpora di seconda generazioneLa Repubblica
l Corpus monolingue dell’italiano giornalisticol SSLiMIT Forlì (Baroni et al. 2004)l http://dev.sslmit.unibo.it/corpora/corpus.php?path=&name=Repu
bblical Dimensione
l ca. 326 milioni di parolel Tratti caratteristici:
l generale come dominio tematico, ma specialistico come tipologia testuale
l scrittol monolinguel annotato
l il corpus è lemmatizzato e annotato a livello morfosintattico

15
Corpora di parlatol Map Task Corpus (1992)
l University of Edimburgh (HCRC) e University of Glasgowl 18 h, 128 dialoghi semi-spontanei “task-oriented” (map-task),
trascritti e comprensivi di segnale acusticol http://www.hcrc.ed.ac.uk/maptask/maptask-description.html
l Archivio di Varietà di Italiano Parlato (AVIP) (2001)l 3,5 h, 44 dialoghi semi-spontanei “task-oriented” (map-task) (39
prodotti da adulti e 5 da bambini), trascrittil registrazioni effettuate a Pisa, Napoli e Bari
l C-ORAL-ROMl corpus audio della lingua parlata spontanea. Il corpus è
comparabile con altri corpora per spagnolo, francese e portoghese
l registrazioni audio per un totale di 300.000 parole, trascritte

16
Corpora parallelil European Parliament Proceedings Parallel Corpus (1996-2011)
l estratti dagli atti del Parlamento Europeol include versioni allineate a livello di frase in 21 lingue europee (l’inglese
è la lingua pivot)l francese, italiano, spagnolo, portoghese, inglese, olandese, tedesco,
danese, svedese, greco, finlandese, etc.l la sezione italiana contiene ca. 52 milioni di parole
l finalizzato alla traduzione automatica statistical http://www.statmt.org/europarl/index.html
17
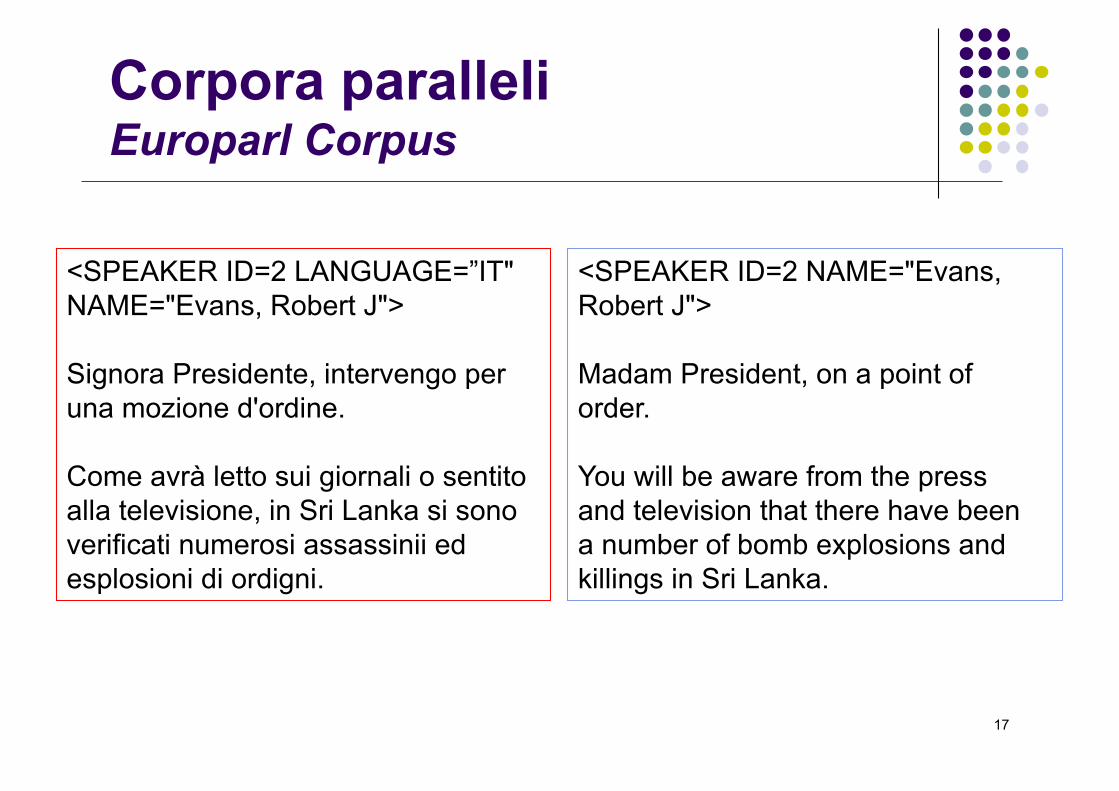
Corpora paralleliEuroparl Corpus
<SPEAKER ID=2 LANGUAGE=”IT"NAME="Evans, Robert J">
Signora Presidente, intervengo peruna mozione d'ordine.
Come avrà letto sui giornali o sentitoalla televisione, in Sri Lanka si sonoverificati numerosi assassinii edesplosioni di ordigni.
<SPEAKER ID=2 NAME="Evans,Robert J">
Madam President, on a point oforder.
You will be aware from the pressand television that there have beena number of bomb explosions andkillings in Sri Lanka.

18
Corpora specialisticil Switchboard Corpus (1992)
l 2.400 conversazioni telefoniche registrate in varie regioni degli USA e trascritte (ca. 3 milioni di parole)
l applicazioni: Automatic Speech Recognition (ASR), Speaker Identification, ecc.
l Child Language Data Exchange (CHILDES) (B. MacWhinney)l database di interazioni conversazionali di bambini in fase di
apprendimento linguistico o di soggetti con patologie del linguaggio
l finalità: studio dell’apprendimento linguisticol “meta-corpus”:
l sistema per la raccolta, trascrizione e trattamento di di dati linguistici
l collezione di dati apertal http://childes.psy.cmu.edu/

19
Corpora multimodalil Human Speechome Project (Deb Roy, MIT Media Lab)
l 10 ore al giorno di registrazione continua audio-video di un bambino dalla nascita a 3 anni nella sua abitazione
l ca. 90K ore di video e 140K ore di audio registrazioni, parzialmente trascritte in modo automaticol “To study a corpus of this scale and richness, current methods of
developmental cognitive science are inadequate” (Roy 2009)

Corpora diacronicil MIDIA (http://www.corpusmidia.unito.it/)
l corpus diacronico di ca. 7,5 milioni di tokens di testi italiani dal XIII and XX secolo
l Voci della Grande Guerra (http://www.vocidellagrandeguerra.it/)l corpus di ca. 1 milione di parole di testi relativi alla
Prima Guerra Mondialel testi letterari, lettere, diari, testi ufficiali, ecc.
20

21
I corpora oggil I corpora generali più recenti ospitano spesso proporzioni variabili di
parlato trascrittol Esiste un numero crescente di corpora audio e corpora multilingui
(soprattutto paralleli allineati), diacronici, e specialisticil Il numero di lingue per le quali esistono corpora di varie tipologie è
in continuo aumentol Si preferisce includere in un corpus testi interi per garantire la
massima naturalezza dei dati linguistici estraibili l I testi sono riccamente codificati e sempre più estensivamente
annotatil Strumenti informatici sofisticati (basi di dati, interfacce di ricerca,
ecc.) potenziano la fruibilità dei dati linguistici nei corpora

22
Corpora di grandi dimensioni e di varie tipologie esistono per un numero crescente di lingue
Collezioni di corpora
l Agenzie per la distribuzione di corporal Language Data Consortium (LDC)
l http://www.ldc.upenn.edu/l European Language Resources Association (ELRA)
l http://www.elra.info/
l Consultazione on-line di corpora (a pagamento)l Sketchengine (http://www.sketchengine.co.uk)

23
corpus1corpus2
corpus2
linguaggio
Il corpus come campionel Il linguaggio è un sistema potenzialmente illimitato
l è possibile comprendere e generare un numero potenzialmente infinito di frasi
l in termini statistici: l le frasi di un linguaggio formano una popolazione infinita
l Un corpus è una porzione finita di un linguaggio dalla quale cerchiamo di ricostruire le proprietà dell’intero sistemal in termini statistici il corpus è un campione di un linguaggio

24
A corpus seeks to represent a language or some part of a language. The appropriate design for a corpus therefore depends upon what is meant to represent. Representativeness of the corpus, in turn, determines the kind of research questions that can be addressed and the generalizability of
the results of the research.Biber (1998): 246
Corpus e rappresentatività
l Per essere rappresentativo di una lingua o varietà un corpus deve tenere traccia dell’intero ambito di variabilità dei suoi tratti e proprietàl cf. un ”modello in scala” della lingua

25
La complessità dell’operazione di selezione dipende dalla generalitàdella lingua che il corpus deve rappresentare
Rappresentatività e tipi di corpora
l Corpora specialisticil varietà ristrette di lingua
l i corpora per lo studio della lingua di un autorel i corpora di domini linguistici settoriali (ad es. il gergo dei
controllori del traffico aereo, ecc.) l i corpora di testi che appartengono a generi particolari (ad
es. sms, bollettini meteorologici, notiziari stampa, ecc.)l la variabilità interna limitata e l’elevata omogeneità
linguistica garantiscono la possibilità di ottenere un alto grado di rappresentatività

26
Rappresentatività e tipi di corporal Corpora generali (Biber 1993)
l devono essere diversificati (bilanciati) rispetto a un ampio spettro di tipi testuali l 200 milioni di parole di uno stesso tipo testuale non costituiscono
un corpus di riferimento per una lingual Corpora bilanciati (balanced corpora)
l includono testi che coprono le diverse varietà testuali e linguistiche della popolazione
l presuppongono la creazione di una “mappa” che fornisca una descrizione accurata della popolazione linguistica di riferimento:l confini spaziali e temporali (quali testi sono inclusi o esclusi dalla
popolazione) l tipologia dei testi (l’articolazione in strati della popolazione)
l “random sampling” di testi appartenenti alle varie categorie individuate nella popolazionel ogni categoria deve essere rappresentata

27
Corpora bilanciatil British National Corpus
l standard de facto per i criteri di bilanciamentol lingua scritta
§ dominio (scienze, arte, pensiero, economia e finanza, ecc.)§ “medium” (libri, giornali, brochures, lettere, ecc.)
l lingua parlata§ selezione demografica§ selezione contestualizzata (conferenze, discorsi politici,
ecc.)

28
COLFISCorpus e lessico di frequenza dell’italiano scritto
l Corpus di 3.800.000 parole dell’italiano scritto bilanciato in modo da essere rappresentativo dell’italiano effettivamente letto dai parlantil bilanciamento effettuato sulla base delle statistiche ISTAT
delle abitudini di lettura degli italianil Composizione del corpus
l 50% quotidianil 33,3% periodici
l settimanali più rappresentati dei mensilil 16,7% libri
l argomenti selezionati in maniera da rappresentare le preferenze dei lettori