Embed Size (px)
Citation preview

1
MODELO ALTERNATIVO DEL PROTOCOLO ZRTP UTILIZANDO ALGORITMOS
GENÉTICOS
Trabajo de Grado Número 1259
VICTOR ESTEBAN ORTIZ PULIDO
PROYECTO DE GRADO PRESENTADO PARA OPTAR POR EL TÍTULO DE INGENIERO
ELECTRÓNICO
DIRECTOR:
INGENIERO MAURICIO DEJESUS DONADO AMAYA M. Sc.
PONTIFICIA UNIVERSIDAD JAVERIANA
FACULTAD INGENIERÍA
CARRERA DE INGENIERÍA ELECTRÓNICA
BOGOTÁ D.C.
NOVIEMBRE DE 2013

2
AGRADECIMIENTOS
Quiero dedicar este trabajo de grado a Dios, y en Él a cada una de las personas que puso en mi
camino para culminar con éxito esta etapa tan importante en mi vida.
A mis padres, Virginia Patricia y José Joaquín, por su entrega, dedicación, apoyo y paciencia
durante todos estos años y su sincero anhelo de entregar sus vidas por el desarrollo pleno de sus
hijos.
A mis hermanos, María Virginia, Andrea y Chepe que no se rindieron en motivarme e impulsarme
para vencer muchos obstáculos y lograr la meta tan anhelada.
A mis abuelitos y tíos que siempre se unieron en oración para que sobrepasara las dificultades.
A mis hermanos en la fe que batallando hombro a hombro no dejaron de creer en mí y que con su
ejemplo me llenaron de fuerzas para perseverar.
A mi director de tesis, Mauricio, y a mis compañeros de la oficina y Universidad por su apoyo y
motivación incondicional.
Y en especial quiero darle gracias a María por su dulce compañía, Ella como excelente Madre
estuvo a mi lado cada segundo de mi carrera, gozando, sufriendo y trasnochando conmigo.
Victor Esteban.

3
CONTENIDO
1. INTRODUCCIÓN 6
2. MARCO TEÓRICO 7
2.1 ZRTP .......................................................................................................................................................... 7 2.1.1 Descripción del protocolo ZRTP ....................................................................................................... 9 2.1.2 Vulnerabilidades del protocolo ZRTP ............................................................................................. 10
2.2 NÚMEROS PSEUDO-ALEATORIOS............................................................................................................. 12 2.2.1 Congruencial lineal ....................................................................................................................... 12 2.2.2 LFSR (Linear Feed Back Shift Register) ........................................................................................... 12 2.2.3 AES-CM (AES en modo contador) .................................................................................................. 12
2.3 ALGORITMOS GENÉTICOS ........................................................................................................................ 13 2.3.1 Conceptos básicos......................................................................................................................... 13 2.3.2 Componentes de los algoritmos genéticos .................................................................................... 13 2.3.3 Aplicación de los Algoritmos genéticos en la generación de números pseudo-aleatorios ............... 15
2.4 PRUEBAS DE ALEATORIEDAD ................................................................................................................... 16 2.4.1 NIST .............................................................................................................................................. 16
3. ESPECIFICACIONES 20
3.1 FUNCIONALIDAD .......................................................................................................................................... 20 3.2 LENGUAJE .................................................................................................................................................. 20 3.3 ENTORNO ................................................................................................................................................... 20 3.4 INDIVIDUOS ................................................................................................................................................ 20 3.5 DIAGRAMA DE FLUJO GENERAL ........................................................................................................................ 21 3.6 ENTRADAS Y SALIDAS DEL SISTEMA ................................................................................................................... 22 3.7 TIEMPO DE EJECUCIÓN .................................................................................................................................. 22 3.8 FUNCIÓN OBJETIVO. ...................................................................................................................................... 23
3.8.1 Prueba de Sumas Acumuladas (Cusum) ........................................................................................ 23 3.9 PRUEBAS DE ALEATORIEDAD NIST .................................................................................................................... 23
3.9.1 Especificaciones de pruebas .......................................................................................................... 23 3.9.2 Proporción de secuencias para aprobar una prueba ..................................................................... 24
4. DESARROLLOS 25
4.1 REPRODUCCIÓN ........................................................................................................................................... 26 4.2 MUTACIÓN ................................................................................................................................................. 28 4.3 FUNCIÓN OBJETIVO ....................................................................................................................................... 33
4.3.1 Sumas Acumuladas (Cusum) ......................................................................................................... 34 4.3.2 Peso total ..................................................................................................................................... 35
4.4 SELECCIÓN MEJOR HIJO .................................................................................................................................. 35 4.5 SELECCIÓN FUTUROS PADRES .......................................................................................................................... 36 4.6 NÚMERO DE GENERACIONES ........................................................................................................................... 37
5. ANÁLISIS DE RESULTADOS 37
5.1 NÚMERO DE PADRES Y NÚMERO DE GENERACIONES.............................................................................................. 38 5.2 VARIACIÓN DE LA VARIABLE DE ENTRADA “SIP_CALL_ID”...................................................................................... 47
5.2.1 “SIP_call_ID” básico ...................................................................................................................... 48 5.2.2 “SIP_call_ID” tomado de la cabecera del paquete SIP ................................................................... 54
5.3 PRUEBAS DEL NIST....................................................................................................................................... 61 5.3.1 “SIP_call_ID” básico ...................................................................................................................... 61 5.3.2 “Encryption_key” generado por “SIP_call_ID” básico .................................................................... 62 5.3.3 “SIP_call_ID” tomado de cabecera del paquete SIP ....................................................................... 63 5.3.4 “Encryption_key” generado por “SIP_call_ID” tomado de cabecera del paquete SIP ..................... 63
6. CONCLUSIONES 65

4
7. BIBLIOGRAFÍA 66
8. ANEXOS 67
TABLA DE FIGURAS
Figura 1. Voice-over-IP protocol stack. Tomado de [1] ............................................................................... 7 Figura 2. Intercambio de llaves con Diffie-Hellman .................................................................................... 9 Figura 3. Establishment of SRTP session key using ZRTP. Tomado de [1] ................................................. 9 Figura 4. Intercambio de llaves en el protocolo ZRTP. .............................................................................. 11 Figura 5. Ataque MitM en comunicación VoIP.......................................................................................... 11 Figura 6. Ejemplo de LFSR. Tomado de (17) ............................................................................................ 12 Figura 7. Representación cromosómica del individuo. ............................................................................... 14 Figura 8. Operador de cruce basado en punto ............................................................................................ 15 Figura 9. Operador de mutación ................................................................................................................. 15 Figura 10. Descripción del individuo. ........................................................................................................ 21 Figura 11. Diagrama de flujo del algoritmo genético ................................................................................. 21 Figura 12. Entradas y Salidas del sistema. ................................................................................................. 22 Figura 13. Diagrama del flujo algoritmo implementado ............................................................................. 25 Figura 14. Matriz Población inicial ............................................................................................................ 25 Figura 15. Variable “Packet_index” ........................................................................................................... 26 Figura 16. Variable “Padres” ...................................................................................................................... 26 Figura 17. Función Reproducción .............................................................................................................. 27 Figura 18. Matriz “Padres” ......................................................................................................................... 27 Figura 19. Descripción de reproducción para este proyecto. ...................................................................... 28 Figura 20. Variable “Padres_Hijos” ........................................................................................................... 28 Figura 21. Función Mutación ..................................................................................................................... 29 Figura 22. Matriz “Padres_Hijos” en mutación .......................................................................................... 29 Figura 23. Servidor SIP “FreeSwitch” ....................................................................................................... 30 Figura 24. Configuración X-lite ................................................................................................................. 31 Figura 25. Captura Wireshark paquetes SIP ............................................................................................... 31 Figura 26 . Variable “cada_mutadora” ....................................................................................................... 32 Figura 27. Variable "Matriz_cadenas_mutadoras" ..................................................................................... 32 Figura 28. Mutación implementada. ........................................................................................................... 33 Figura 29. Matriz "Hijos_totales" ............................................................................................................... 33 Figura 30. Función objetivo ....................................................................................................................... 34 Figura 35. Matriz "Hijos_totales" en Peso Cusum ..................................................................................... 35 Figura 36. Vector "Peso_Cusum" ............................................................................................................... 35 Figura 37. Función selección del mejor hijo............................................................................................... 36 Figura 38. Función selección futuros padres .............................................................................................. 36 Figura 39. Máquina virtual Ubuntu para aplicación de pruebas del NIST .................................................. 37 Figura 40. Variable "SIP_call_ID" ............................................................................................................. 38 Figura 41. Peso Función Objetivo Vs. Número de Generación Prueba 1 ................................................... 38 Figura 42. Peso Función Objetivo Vs. Número de Generación Prueba 2 ................................................... 39 Figura 43. Peso Función Objetivo Vs. Número de Generación Prueba 3 ................................................... 40 Figura 44. Peso Función Objetivo Vs. Número de Generación Prueba 4 ................................................... 40 Figura 45. Peso Función Objetivo Vs. Número de Generación Prueba 5 ................................................... 41 Figura 46. Peso Función Objetivo Vs. Número de Generación Prueba 6 ................................................... 42 Figura 47. Peso Función Objetivo Vs. Número de Generación Prueba 7 ................................................... 43 Figura 48. Peso Función Objetivo Vs. Número de Generación Prueba 8 ................................................... 43 Figura 49. Peso Función Objetivo Vs. Número de Generación Prueba 9 ................................................... 44 Figura 50. Peso Función Objetivo Vs. Número de Generación Prueba 10 ................................................. 45 Figura 51. Peso Función Objetivo Vs. Número de Generación Prueba 11 ................................................. 45

5
Figura 52. Peso Función Objetivo Vs. Número de Generación Prueba 12 ................................................. 46 Figura 53. Peso Función Objetivo Vs Número de Generación - Muestra 1 básico ..................................... 48 Figura 54. Peso Función Objetivo Vs Número de Generación - Muestra 2 básico ..................................... 49 Figura 55. Peso Función Objetivo Vs Número de Generación - Muestra 3 básico ..................................... 49 Figura 56. Peso Función Objetivo Vs Número de Generación - Muestra 4 básico ..................................... 50 Figura 57. Peso Función Objetivo Vs Número de Generación - Muestra 5 básico ..................................... 50 Figura 58. Peso Función Objetivo Vs Número de Generación - Muestra 6 básico ..................................... 51 Figura 59. Peso Función Objetivo Vs Número de Generación - Muestra 7 básico ..................................... 52 Figura 60. Peso Función Objetivo Vs Número de Generación - Muestra 8 básico ..................................... 52 Figura 61. Peso Función Objetivo Vs Número de Generación - Muestra 9 básico ..................................... 53 Figura 62. Peso Función Objetivo Vs Número de Generación - Muestra 10 básico ................................... 53 Figura 63. Peso Función Objetivo Vs Número de Generación - Muestra 1 Call-ID ................................... 54 Figura 64. Peso Función Objetivo Vs Número de Generación - Muestra 2 Call-ID ................................... 55 Figura 65. Peso Función Objetivo Vs Número de Generación - Muestra 3 Call-ID ................................... 55 Figura 66. Peso Función Objetivo Vs Número de Generación - Muestra 4 Call-ID ................................... 56 Figura 67. Peso Función Objetivo Vs Número de Generación - Muestra 5 Call-ID ................................... 57 Figura 68. Peso Función Objetivo Vs Número de Generación - Muestra 6 Call-ID ................................... 57 Figura 69. Peso Función Objetivo Vs Número de Generación - Muestra 7 Call-ID ................................... 58 Figura 70. Peso Función Objetivo Vs Número de Generación - Muestra 8 Call-ID ................................... 59 Figura 71. Peso Función Objetivo Vs Número de Generación - Muestra 9 Call-ID ................................... 59 Figura 72. Peso Función Objetivo Vs Número de Generación - Muestra 10 Call-ID ................................. 60
TABLAS
Tabla 1. Valores para prueba de la carrera en bloques. Tomado de (12) .................................................... 18 Tabla 2. Número de padres y número de generaciones .............................................................................. 47 Tabla 3. Resultados NIST muestras básicas ............................................................................................... 64 Tabla 4. Resultados NIST muestras Call-ID .............................................................................................. 64

6
1. INTRODUCCIÓN
Cada vez son más las organizaciones que han decidido dejar la telefonía regular e implementar la voz
sobre IP (VoIP) para suplir con sus necesidades de comunicación por voz. Esta migración se ha debido
principalmente al ahorro económico generado al aprovechar la infraestructura de internet y redes locales.
A su vez, el tema de la seguridad en este tipo de comunicaciones ha tomado mucha relevancia ya que la
voz está expuesta a los mismos ataques que se presentan en la red de datos, como DoS (Denial of
Services), MitM (Man in the Middle), fuerza bruta, entre otros, como se expone en [1].
A inicios del año 2004 fue publicado, por la IETF1, el documento RFC
2 3711. Éste define el protocolo
SRTP (Secure Real Time Protocol) diseñado por un grupo de expertos de Cisco y Ericsson cuyo fin
principal es brindar cifrado y autenticación del mensaje para los datos del protocolo RTP (Real Time
Protocol), utilizado para VoIP.
El protocolo ZRTP (Zimmerman Real Time Protocol) es una extensión del protocolo SRTP. Este se ha
popularizado principalmente pues tiene la característica de no hacer uso de infraestructura de clave
pública, generando así una reducción en gastos adicionales para contar con dicho servicio, sin embargo,
cuenta con el problema de estar expuesto a ataques MitM. En [1] los autores exponen el ataque referente a
la autenticación, donde el intruso se ubica en medio de la comunicación y al capturar el tráfico puede
realizar una serie de modificaciones con las que le es posible conocer las llaves privadas que aseguran el
canal. En el mismo artículo se menciona que para contrarrestar este ataque se utiliza autenticación por
medio de SAS (Short Authentication String), no obstante, el intruso podría suplantar al destinatario y así
continuar con el ataque.
Al vulnerar el canal seguro que establece Diffie-Hellman, un intruso puede acceder a las llaves de sesión
utilizadas para el algoritmo de cifrado simétrico utilizado por ZRTP. Como se expone en [2], estas llaves
son intercambiadas al inicio y durante cada sesión variando de manera pseudo-aleatoria.
En [3], se identifica la importancia de la aleatoriedad en la generación de las llaves de sesión, ya que si un
intruso logra acceder a varias sesiones de comunicación con el ataque MitM, podría estimar la secuencia
de estos números pseudo-aleatorios y así descifrar los paquetes capturados, tanto de sesiones pasadas
como futuras.
Por su parte, los algoritmos genéticos, una técnica de inteligencia artificial desarrollada en sus inicios por
John Hollad, están basados en la teoría de Charles Darwin de supervivencia del más apto [4]. Estos
algoritmos utilizan operaciones como selección, reproducción y mutación. Por lo general son utilizados
para dar solución a problemas de optimización, sin embargo, diversas investigaciones han demostrado que
mediante el uso de esta técnica, es posible replicar las características aleatorias presentes en la naturaleza
como modelo de generación de números pseudo-aleatorios. De esta manera se explora un horizonte
distinto a las técnicas usadas actualmente como el “Advanced Encryption Estandar”, “Linear Congruential
Generator”, “Quadratic Congruential Generator”, entre otros, que son basadas en modelos matemáticos
[5].
En [6], [7] y [8], los autores exponen el uso de los algoritmos genéticos para generar cadenas de números
pseudo-aleatorios. Estas investigaciones tuvieron en cuenta criterios de diseño para aplicaciones como el
cifrado de código ASCII, sin embargo, no se ha explorado su uso teniendo en cuenta los requerimientos
específicos del protocolo ZRTP, expuestos más adelante en este documento.
1 Engineering Task Force: grupo especial sobre ingeniería de Internet. 2 Request For Comments: documento que describe los métodos, comportamientos, investigaciones o innovaciones aplicables al funcionamiento de
Internet y los sistemas conectados a internet y los sistemas conectados a Internet.

7
Es así como el objetivo de este trabajo es modelar y proponer modificaciones al protocolo ZRTP,
realizando el diseño, implementación y validación del algoritmo de generación de llaves pseudo-aleatorias
utilizando la técnica de inteligencia artificial llamada algoritmos genéticos.
2. MARCO TEÓRICO
2.1 ZRTP
En una comunicación de voz sobre IP (VoIP) se involucran varios protocolos que permiten su óptimo
funcionamiento e integración dentro de una red. Como se expone en [1], estos se pueden organizar y
analizar dentro de cuatro capas como se muestra en la figura 1: “Signaling”, “Session Description”, “Key
Exchange” y “Media Transport”.
Figura 1. Voice-over-IP protocol stack. Tomado de [1]
La capa “Signaling” es un mecanismo de control utilizado para crear, modificar y terminar sesiones de
VoIP con uno o más participantes. Algunos protocolos de señalización son el SIP (Session Initiation
Protocol), H.323 y MGCP.
En la capa “Session Description” se encuentra el protocolo SDP (Session Description Protocol), el cual es
utilizado para inicializar sesiones de multimedia y establece el tipo de contenido, como voz o video. En
esta capa también se encuentra la sub-capa “Key Exchange” que provee un canal seguro para poder
establecer llaves de sesión secretas entre dos o más participantes dentro de una comunicación en un canal
no confiable. Este bloque es fundamental para el establecimiento de una sesión segura donde se
encuentran los protocolos SDES (Session Description Protocol Security Descriptions) y MIKEY
(Multimedia Internet Keying).
Los datagramas de voz son transmitidos en la capa “Media Transport”. Si se busca una comunicación
cifrada de los paquetes RTP (Real Time Protocol) se puede hacer uso del protocolo SRTP (Secure Real
Time Protocol), donde por medio del establecimiento del canal seguro definido en la capa “Key
Exchange”, se pueden intercambiar llaves de sesión obtenidas por un generador de números pseudo-
aleatorios, y que permiten cifrar dicho tráfico con el uso de algoritmos de cifrado simétricos.

8
El protocolo MIKEY se usa específicamente para establecer el canal seguro por medio del cual, SRTP
podrá intercambiar las llaves de sesión, teniendo varios métodos para cumplir con dicho objetivo. Entre
estos métodos se encuentran “Pre-shared Key”, “Public Key” y “Diffie Hellman”.
El método “Pre-shared Key” presupone disponer de un canal de comunicación lo suficientemente seguro
para poder establecer previamente la llave en común y así realizar el cifrado en forma simétrica. A su vez,
el método “Public Key” requiere de PKI (Public Key Infraestructure) que permite autenticar a los usuarios
frente a otros, y usar información (cómo las claves públicas de otros usuarios) para cifrar y descifrar
mensajes.
El método “Diffie Hellman” utilizado en el protocolo MIKEY, para establecer el canal seguro para el
SRTP, fue desarrollado por Phil Zimmerman, y recibe el nombre de ZRTP (Zimmerman Real Time
Protocol). Con este algoritmo es posible generar una llave compartida entre las partes, utilizando un canal
inseguro y sin necesidad de haber tenido un contacto ni autenticación previa. Éste fue publicado
inicialmente por Whitfield Diffie y Martin Hellman en 1976, sin embargo ya había sido desarrollado
previamente por la inteligencia Británica por Malcom J Williamsom. La funcionalidad de ZRTP radica
principalmente en que se evita el uso de la infraestructura de clave pública PKI, y así no hay dependencia
con terceros, como lo son las entidades certificadoras confiables ya que los costos por sus servicios son
elevados.
El algoritmo de Diffie Hellman se basa en la dificultad de calcular un algoritmo discreto, que es la función
inversa de la potencia discreta, es decir, de calcular una potencia y aplicar una función mod. A
continuación se describe el funcionamiento del algoritmo en detalle:
Potencia discreta:
[E.1]
Logaritmo discreto
[E.2]
A manera de ejemplo, Alice será la que inicia la comunicación. Su llave pública será y su llave
privada será . Igualmente, Bob será el receptor de la comunicación, cuya llave pública será y su
llave privada . Las llaves privadas se obtendrán mediante un generador de números pseudo-aleatorios.
Para la generación de las llaves públicas se busca un número grande y primo llamado p. A su vez, se
busca g, el generador del grupo de Diffie Hellman, que debe ser raíz primitiva de p. Para que g sea raíz
primitiva de p, los valores: deben ser números
diferentes. Cabe aclarar que los valores g y p son públicos y serán compartidos por ambas partes.
Como se muestra en la figura 2, Alice y Bob generan sus llaves privadas y respectivamente.
Posteriormente computan los valores de las llaves públicas y que son transmitidas por el canal
público hacia el destinatario.
Los valores de K son iguales gracias a la propiedad distributiva de la multiplicación, donde:
[E.3]
[E.4]
[E.5]

9
Figura 2. Intercambio de llaves con Diffie-Hellman
Como se expone en [15], los criptoanalistas que solo disponen de g, p, y , necesitarían conocer
alguna de las llaves privadas. Para ello deben realizar el algoritmo discreto o ,
donde el cálculo de estas funciones requiere de una gran capacidad de procesamiento computacional y a
su vez el tiempo requerido para solucionarlas es muy elevado.
2.1.1 Descripción del protocolo ZRTP
Figura 3. Establishment of SRTP session key using ZRTP. Tomado de [1]
La figura 3 muestra el establecimiento de una sesión SRTP utilizando ZRTP, donde los usuarios en la
comunicación son Alice y Bob. El mensaje HELLO contiene las opciones de configuración de la
comunicación SRTP, como lo son el algoritmo de cifrado, la llave pública y el hash; además de un
único ZID, que es utilizado para recuperar los secretos compartidos que están almacenados en caché
gracias a comunicaciones previas.
Como se muestra en la figura 3, el receptor, en este caso Bob, responde con un mensaje de HELLOACK y
con un HELLO con las mismas características del recibido por el emisor, Alice. Posteriormente, Alice

10
responde un con HELLOACK para que Bob se convierta en el iniciador de la comunicación. Bob envía
un mensaje COMMIT con el hash, el tipo de cifrado y la llave pública escogidos de la intersección de
algoritmos en el envío y recepción de los mensajes HELLO. Además de esto, Bob escoge una llave
pseudo-aleatoria y computa el valor , donde g y p son determinados por el valor de
la llave pública .
Una vez recibido el mensaje de COMMIT, Alice genera su propio valor secreto y lo computa para
obtener . De esta manera, Alice envía el primer mensaje DHPART1, cuya respuesta es el mensaje
DHPART2 generado por Bob, donde se realiza el procedimiento explicado anteriormente para obtener la
clave simétrica compartida y conocida solo por ellos para el cifrado y descifrado de la comunicación.
Puesto que ya está establecido el canal seguro, Alice envía un mensaje CONFIRM1, al que Bob responde
con CONFIRM2 para confirmar que se pueden intercambiar las llaves de sesión pseudo-aleatorias
utilizadas para realizar el cifrado simétrico de la información RTP mediante el protocolo SRTP y así
iniciar una comunicación segura.
2.1.2 Vulnerabilidades del protocolo ZRTP
Pese a las ventajas que brinda el intercambio de llaves generado por el algoritmo de Diffie-Hellman, éste
presenta algunas vulnerabilidades que se presentarán a continuación.
2.1.2.1 Negación de Servicios (DoS)
El protocolo ZRTP es potencialmente vulnerable a los ataques de denegación de servicios [1], donde los
atacantes envían mensajes HELLO falsos. De esta manera, en respuesta de cada mensaje HELLO, ZRTP
crea una conexión con dicho punto y almacena los parámetros en memoria, llegando al límite de memoria
y generando que los nuevos mensajes HELLO de usuarios legítimos sean rechazados.
2.1.2.2 Autenticación (MiTM)
Como se expone en [1], este protocolo presenta una fuerte vulnerabilidad frente al ataque MiTM (Man in
The Middle) o su traducción al español, hombre en el medio.
Como se muestra en la figura 4, al establecer el canal seguro por Diffie-Hellman, se genera la misma llave
compartida a cada lado de la comunicación (Llave 1). Con la Llave 1 se cifra la primera llave de sesión
(Llave A) de la comunicación SRTP, y así esta llave de sesión se envía del iniciador de la comunicación al
receptor. Habiendo compartido esta llave de sesión, los datos RTP se envían cifrados de lado a lado
utilizando la llave de sesión A.

11
Figura 4. Intercambio de llaves en el protocolo ZRTP.
Contemplando el escenario de llamadas por medio de un softphone hacia usuarios presentes en la red
WAN (figura 5), la vulnerabilidad se presenta en la situación descrita a continuación:
Alice inicia una llamada con Bob. Para esto se establece la comunicación inicial por medio de los
protocolos SIP, SDP y MIKEY. Posteriormente, un atacante, Eva, realiza el ataque MitM interviniendo
la comunicación definida por el protocolo ZRTP. Eva suplanta a Bob para intercambiar las llaves descritas
en la figura 4.
Figura 5. Ataque MitM en comunicación VoIP
De dicha manera, sólo con el establecimiento de la llamada, el atacante ya ha cumplido con su labor pues
conoce la llave de sesión A. Este ataque se puede replicar muchas veces interviniendo las llamadas que
Alice desea establecer con usuarios en la red WAN, almacenando así muchas llaves de sesión A.
Como se mencionaba previamente en este documento, estas llaves de sesión A son producidas por un
algoritmo generador de números pseudo-aleatorios. Si este algoritmo no es lo suficientemente robusto, el
atacante podría reconocer patrones con los que llegaría a predecir las futuras llaves de sesión (o incluso
previas) para así descifrar el tráfico RTP.
Otra situación de ataque MitM sucede cuando Eva, además de establecer la conexión con Alice, genera
una conexión paralela con Bob. Con esto, Eva recibe el tráfico RTP enviado por Alice y lo descifra (ya
que conoce las llaves de sesión). Posteriormente envía dicho tráfico a Bob, cifrándolo con las llaves de
sesión establecidas en la conexión paralela. A su vez, Eva descifra el tráfico recibido por Bob y lo envía a
Alice, con lo que Eva puede conocer toda la información intercambiada en la llamada.

12
2.2 NÚMEROS PSEUDO-ALEATORIOS
Los números pseudo-aleatorios son números generados a partir de algoritmos determinísticos, esto es, si
se conocen las entradas del algoritmo, siempre se producirá la misma salida y la máquina interna pasará
por la misma secuencia de estados. Las secuencias de estos números cumplen con la característica de
repetirse con un periodo determinado, diferenciándose así de las secuencias aleatorias.
El funcionamiento de un generador de números pseudo-aleatorios consiste en elegir una semilla inicial
cualquiera . A partir de ella se genera una sucesión de valores mediante una relación de recurrencia
, donde cada uno de estos valores proporciona un número pseudo-aleatorio definido a
través de alguna relación
En el contexto criptográfico, los generadores de números pseudo-aleatorios son usados en vez de los
puramente aleatorios [13]. Esto se debe a que los generadores aleatorios que utilizan una fuente no
determinística (como el ruido presente en un circuito eléctrico), presentan un tiempo de ejecución muy
elevado.
Algunos tipos de generadores pseudo-aleatorios se presentan a continuación.
2.2.1 Congruencial lineal
Este método expuesto en [16], está definido por la relación de recurrencia:
[E.6]
Donde es la secuencia de valores aleatorios y A, B y M son constantes que se especifican en el
generador.
2.2.2 LFSR (Linear Feed Back Shift Register)
En un registro de corrimiento realimentado linealmente se hace uso de la operación lógica Xor, donde el
valor de las entradas del sistema se establece por medio de una función lineal que hace uso de los valores
actuales de las posiciones del registro. En la figura 6 se muestra un ejemplo de registro con condiciones
iniciales 0110.
Figura 6. Ejemplo de LFSR. Tomado de (17)
2.2.3 AES-CM (AES en modo contador)
El algoritmo de cifrado simétrico AES se puede usar en modo contador como generador de números
pseudo-aleatorios. En este método, la entrada al bloque AES es la salida de un contador; así que
aplicando el operador lógico Xor a este valor y a la llave de entrada, es posible generar una cadena de
números pseudo-aleatorios.

13
El algoritmo AES trabaja con bloques de datos de 128 bits y longitudes de claves de 128, 192 ó 256 bits.
A su vez AES tiene 10, 12, o 14 rondas respectivamente, donde cada ronda consiste en la aplicación de
una ronda estándar, entendiendo por rondas como el conjunto de 4 transformaciones básicas y la última
ronda es especial porque consiste de 3 operaciones básicas, añadiendo siempre una ronda inicial [18].
Para encontrar otra alternativa que permita brindar seguridad en el protocolo ZRTP, se explora la
inteligencia artificial como herramienta para la generación de números pseudo-aleatorios.
2.3 ALGORITMOS GENÉTICOS
A continuación se explican los conceptos básicos de la técnica de inteligencia artificial llamada algoritmos
genéticos.
2.3.1 Conceptos básicos
En el año 1970, el científico estadounidense Jhon Holland [9] introdujo los algoritmos genéticos
inspirándose en el proceso observado en la evolución natural de los seres vivos.
Los algoritmos genéticos son métodos adaptativos que pueden usarse para resolver problemas de
búsqueda y optimización. Esta técnica está basada en la teoría de la evolución de Charles Darwin [10],
donde se postula que todas las especies de seres vivos han evolucionado con el tiempo a partir de un
antepasado común, mediante un proceso denominado selección natural.
A su vez, Mendel [10] aportó para la teoría evolutiva que los caracteres de un individuo se toman de los
genes del padre o de la madre, dependiendo de su carácter dominante o recesivo. De tal manera, las
buenas características se propagan a través de una población a lo largo de las generaciones.
Un algoritmo genético cuenta con un conjunto de individuos que conforman una población inicial
(padres). A partir de estos individuos, se lleva a cabo el proceso de reproducción donde se produce una
nueva población de hijos.
Tanto los hijos como los padres, representan una solución factible a un problema donde cada uno es
evaluado para medir su calidad frente al problema específico. A cada individuo se le asigna un valor que
equivale a la efectividad de un organismo para competir.
Los padres e hijos son sometidos al proceso de selección natural donde aquellos con mayor adaptación al
medio predominan para la siguiente generación, convirtiéndose en los futuros padres. De esta manera se
vuelve a repetir el proceso hasta el número definido de generaciones y así seleccionar a los individuos más
aptos como soluciones óptimas al problema.
2.3.2 Componentes de los algoritmos genéticos
A continuación se exponen los elementos constitutivos y de diseño de los algoritmos genéticos [9].
2.3.2.1 Representación cromosómica
Los algoritmos genéticos requieren que cada posible solución al problema se codifique en un cromosoma.
A partir de la base teórica de la biología [20], un cromosoma es una estructura organizada de ADN y
proteína que se encuentra en las células. Esta estructura está constituida por genes que contienen el
genotipo, es decir, la información genética de un organismo en particular. A su vez, la expresión del
genotipo es conocida como fenotipo.

14
Figura 7. Representación cromosómica del individuo.
A manera de ejemplo, como se muestra en la figura 7, un individuo puede poseer un solo cromosoma que
podría ser una cadena de bits. Cada bit representaría un gen y así se conformaría el genotipo. El fenotipo
podría ser la representación de esta cadena en forma decimal.
2.3.2.2 Población inicial
Se debe generar una población inicial para que el algoritmo proceda a evolucionar, es decir, a producir
nuevas generaciones. Por lo general, la población inicial se genera aleatoriamente. No obstante, es posible
utilizar métodos heurísticos para generar soluciones iniciales de buena calidad.
2.3.2.3 Función Objetivo (Fitness)
La función objetivo (fitness) permite establecer un parámetro real a cada individuo, mediante el cual es
posible calificarlos como aptos o no, dependiendo de las características del problema. Cada individuo es
evaluado al dársele una puntación en función de lo aproximado que esté a la mejor solución o a los
umbrales definidos para ello.
2.3.2.4 Selección
Para seleccionar a los hijos con mejores características, existen diversos métodos como el proporcional, el
determinístico, el de torneo, el elitista, el puro y el de ruleta. Por ejemplo, en el elitista sólo los individuos
que tienen mejores cromosomas son los seleccionados. En la selección pura, todo el conjunto de
individuos tiene opción de ser seleccionado. En el método de ruleta se definen distintas probabilidades
para los individuos de acuerdo a su función fitness con el fin de seleccionarlos a partir de los diferentes
pesos de probabilidad.
2.3.2.5 Reproducción
El objetivo de la reproducción es la generación de nuevos individuos que, gracias a las características de
sus padres, presenten mejores soluciones al problema. La reproducción se realiza mediante operadores
genéticos como el cruce basado en un punto y la mutación.
En el operador cruce, basado en punto, se toman dos padres seleccionados; cada uno de ellos se divide en
un punto escogido al azar. Los segmentos resultantes son utilizados para producir dos nuevos
cromosomas completos como se muestra en la figura 8, donde ambos descendientes heredan genes de
cada uno de los padres.

15
Figura 8. Operador de cruce basado en punto
El operador de mutación se aplica a cada hijo de manera individual, y consiste en la alteración aleatoria de
cada gen componente del cromosoma.
Podría pensarse que el operador de cruce es más importante que el de mutación, no obstante, la mutación
asegura que ningún punto del espacio de búsqueda tenga probabilidad cero de ser examinado, además de
asegurar la convergencia de los algoritmos genéticos.
La figura 9 muestra la mutación del quinto gen del cromosoma.
Figura 9. Operador de mutación
2.3.3 Aplicación de los Algoritmos genéticos en la generación de números pseudo-aleatorios
Los algoritmos genéticos han sido usados en recientes investigaciones como motores de generación de
números pseudo-aleatorios. En específico, Sonia Goyat, investigadora del departamento de ciencia
computacional y aplicaciones de la Universidad Maharshi Dayanand en la India, realizó una aproximación
a este tema obteniendo resultados positivos [7]. A continuación se expone de manera general lo
desarrollado en el mismo.
En ese trabajo de investigación los individuos del algoritmo genético son los números pseudo-aleatorios.
Se estableció que un individuo está conformado por un conjunto de cromosomas, que a su vez están
conformados por 25 genes que se representan de forma binaria.
Se inicia con una población inicial fija, de donde se seleccionan algunos individuos para que cumplan con
la función de ser padres. Esta selección se realiza según el criterio de que el fenotipo de cada individuo,
es decir, el individuo representado en forma decimal, sea mayor a un umbral definido en el diseño del
algoritmo.
En un siguiente paso, los padres seleccionados se reproducen con el operador genético de cruce,
generando así una nueva población. A esta última también se le aplica el operador de mutación para
seleccionar los individuos de la población final y almacenarlos en un archivo. Este proceso se repite “n”
veces para alcanzar a tener “n” individuos finales.

16
A cada individuo final se le aplicó la función objetivo (fitness), que es basada en el coeficiente de
correlación. Con estos valores, en esta investigación, se aplicó la operación de selección elitista,
resultando como población final a los individuos con mejores valores de la función objetivo.
De esta manera 214 cadenas fueron obtenidas y analizadas, presentando buenos valores de acuerdo con la
prueba del chi cuadrado.
Además de la investigación expuesta, existen trabajos como [6] donde los autores exponen el uso de los
algoritmos genéticos para generar cadenas de números pseudo-aleatorios en aplicaciones como el cifrado
de código ASCII, y donde se busca llegar a coeficientes de autocorrelación muy bajos con el uso de esta
técnica [8].
2.4 PRUEBAS DE ALEATORIEDAD
La mejor manera de medir qué tan correlacionados son los datos es basarse en medidas estadísticas, las
cuales en la literatura se han venido reconociendo como “Pruebas de aleatoriedad”, y se fundamentan en la
suposición de aleatoriedad de las secuencias a analizar.
2.4.1 NIST
El NIST es el instituto nacional de estándares y tecnología dirigido por el departamento de comercio de
Estados Unidos. Esta entidad publicó una pila de pruebas estadísticas para validar la aleatoriedad de
generadores de números aleatorios y pseudo-aleatorios [13], para propósitos en el ámbito de la
criptografía.
Varios test estadísticos pueden ser aplicados a una secuencia con el objetivo de comparar y evaluar la
presencia o ausencia de patrones frente a una secuencia realmente aleatoria. La aleatoriedad es una
propiedad probabilística, es decir, las propiedades de una secuencia aleatoria pueden ser caracterizadas y
descritas en términos de probabilidad.
Los test estadísticos son formulados para medir una hipótesis nula (H0). En relación al documento del
NIST [13], la hipótesis nula establecerá que la secuencia que está siendo medida es aleatoria. Para cada
test aplicado, una decisión o conclusión es derivada, aceptando o rechazando la hipótesis nula.
Para cada test, el NIST establece una distribución teórica como referencia por medio de métodos
matemáticos, como por ejemplo la caminata aleatoria, y evalúa en ellas parámetros como valores finales,
promedios y momentos especiales de las secuencias y sub-secuencias generadas a partir de la original.
Con estos parámetros se tiene un punto de referencia para calcular el P-valor que resumirá la evidencia
frente a la hipótesis nula. El P-valor es la probabilidad de que un generador aleatorio perfecto hubiese
producido una secuencia menos aleatoria que la secuencia que fue medida. Si el P-valor para un test es
igual a 1, entonces la secuencia parecería tener aleatoriedad perfecta. Si el P-valor es igual a cero, la
secuencia parece ser completamente no aleatoria.
En bajos porcentajes se puede dar el caso de que la secuencia analizada sea, en verdad, aleatoria, y se
obtenga una conclusión que rechace la hipótesis nula. Dicha conclusión recibe el nombre de error Tipo I.
La probabilidad de que exista un error Tipo I es usualmente nombrada nivel de significancia del test y se
denota con la letra griega Alfa (α). Esta probabilidad es escogida típicamente como 0.01 para aplicaciones
en criptografía.
Si Alfa es igual a 0.01, y el P-valor es mayor o igual que dicho valor, esto indicará que la secuencia
analizada puede ser considerada como aleatoria, con una confianza del 99%. Si el P-valor es menor que
Alfa, esto indicará que la secuencia puede ser considerada como NO aleatoria, con una confianza del 99%.

17
A continuación se exponen algunas de las pruebas que componen la batería de pruebas del NIST, que se
encuentran debidamente desarrolladas y explicadas en el documento de referencia [13].
2.4.1.1 Prueba de frecuencia – Monobit
Esta prueba se basa en la caminata aleatoria, por lo tanto a la secuencia a analizar se opera de tal forma
que se obtenga la secuencia , donde es la secuencia de bits a analizar.
El objetivo de esta prueba es medir si la proporción de ceros y unos de la secuencia entera es
aproximadamente la misma que se esperaría en una secuencia realmente aleatoria. Si la proporción es
aproximadamente la misma se podría esperar que sea una secuencia aleatoria.
Al calcular la suma , la probabilidad de obtener 1, es 0.5, donde n es la longitud de
la secuencia analizada. Para valores amplios de n, se puede aproximar a una distribución normal como se
muestra a continuación.
[E.7]
Teniendo esta referencia, bajo la hipótesis de que la prueba es aleatoria, el valor de Sn debe ser cercano a
la media de la distribución. En caso de alejarse, es altamente probable que no se trate de una secuencia
aleatoria. De dicha manera se calcula el P-valor con la siguiente ecuación.
[E.8]
O lo que es lo mismo:
[E.9]
2.4.1.2 Prueba de frecuencia en bloques
En esta prueba se divide la secuencia en M bloques descartando los bits sobrantes. Si la secuencia fuese
generada de manera aleatoria, cada bloque debería tener la misma cantidad de unos y ceros. Puesto que
son varias sub-secuencias, la distribución final es una chi-cuadrado como se muestra a continuación.
[E.10]
Donde el valor de se obtiene de la siguiente ecuación.
[E.11]
Dado esto, el P-valor se obtiene de la siguiente manera, haciendo uso de la función gama incompleta.
[E.12]
2.4.1.3 Prueba de la carrera “Run Test”
Esta prueba consiste en determinar si el número de unos y ceros seguidos en una secuencia son
congruentes con los esperados en una señal aleatoria. En particular, esta prueba determina si la oscilación
entre ceros y unos es muy rápida o muy baja.

18
La porción de número de unos en la secuencia se puede medir realizando el siguiente cálculo, donde este
promedio es idealmente 0.5.
[E.13]
Si el valor de es muy lejano de 0.5, se puede concluir que este secuencia de antemano no es aleatoria,
por tanto si el valor absoluto de la diferencia entre y 0.5 es mayor que
, se puede concluir que la
secuencia es no aleatoria.
En caso de que la diferencia no supere el valor definido, se debe calcular , que se define como se
muestra a continuación.
[E.14]
De dicha manera se define la siguiente estadística:
[E.15]
Para esta estadística se calcula el siguiente P-valor, haciendo uso de la función de error complementaria:
[E.16]
2.4.1.4 Prueba de la carrera en bloques
Esta prueba basada en la prueba anterior (Run Test), se toma la secuencia y se divide en N bloques de
longitud M, y así se determina la estadística de secuencia de unos en cada bloque. En este caso, se
determinan K clases dependiendo del tamaño de la secuencia.
Esta prueba compara las probabilidades teóricas contra las frecuencias empíricas medidas de
manera consecuente con las K clases.
Como se expone en [12], La primera clase mide la probabilidad de que hayan menos de unos en la
subsecuencia, la segunda mide la probabilidad de haya unos en la subsecuencia y de manera sucesiva
hasta que la última clase mide la probabilidad de que hayan más de m unos en la sub-secuencia. Los
valores de y , dependen del tamaño de la secuencia, como se muestra en la siguiente tabla tomada de
[12].
K M
3 8 1 4
5 128 4 9
5 512 6 11
5 1000 7 12
6 10000 10 16
Tabla 1. Valores para prueba de la carrera en bloques. Tomado de (12)

19
Como se expone en [12], la probabilidad de encontrar menos de unos en las sub-secuencias está dada
por las siguientes ecuaciones.
[E.17]
[E.18]
[E.19]
Así es como las frecuencias de cada sub-secuencia están definidas por la estadística chi-cuadrado como se
muestra a continuación.
[E.20]
De manera que, utilizando la función gama incompleta, el P-valor se define así:
[E.21]
2.4.1.5 Sumas acumuladas (Cusum)
Con esta prueba se pretende determinar la máxima excursión de la caminata aleatoria desde cero por
medio de sumas acumuladas de secuencias parciales.
Esta prueba se basa en el límite del máximo de los valores absolutos de las sumas parciales definiéndose
como se expone a continuación.
[E.22]
Y el respectivo P-valor está definido de esta manera:
[E.23]
Donde es la función normal estándar acumulada definida así:
[E.24]
2.4.1.6 Prueba de la FFT
Esta prueba busca medir si existen componentes de frecuencia apreciables que evidencien los parámetros
periódicos que caracterizan las secuencias aleatorias. Calculando el umbral T y el error d, se realiza una
medición de los picos observados cuyo valor supere el mencionado umbral.
El umbral T, para el cual se espera que solo 5% de los picos de la señal sean superiores a este valor, se
calcula como se muestra a continuación, bajo la hipótesis de aleatoriedad.
[E.25]

20
El error d, se calcula entre el número de picos obtenidos y , que es el número de picos esperados que
superen el umbral T. Este error se calcula como se expone en [13] de la siguiente manera:
[E.26]
Ya con estos valores se puede proceder a calcular el P-valor, utilizando la ecuación de error
complementaria.
[E.27]
Las demás pruebas del NIST, Rango de la matriz binaria, No solapamiento de patrón, Solapamiento de
patrón, Estadística Universal de Maurer, Complejidad lineal, Entropía aproximada, Excursiones aleatorias
y Excursión de la variante aleatoria, no son aplicables para este proyecto debido a que el tamaño de la
llave definido para este trabajo de grado es menor a las especificaciones descritas para estas pruebas en
[13]. Así mismo las pruebas de Frecuencia, y de la Carrera no se van a analizar en este trabajo de grado
por estar incluidas dentro de las pruebas de Frecuencia en bloques (Block Frecuency) y Carrera en bloques
(Longest Run Test).
3. ESPECIFICACIONES
3.1 Funcionalidad
El algoritmo realizado cumple con la funcionalidad de generar números pseudo-aleatorios con validez
para implementarse dentro del protocolo ZRTP y con un nivel de seguridad aceptable para criptografía.
3.2 Lenguaje
El algoritmo está realizado completamente en el lenguaje de M, de la herramienta MATLAB.
3.3 Entorno
Las pruebas y ejecución del algoritmo se realizaron en un PC con procesador Intel Core i3 de 2.10 GHz y
memoria RAM de 4 GB, cumpliendo con el requisito de que se pudiese correr el software en un equipo de
usuario final, donde usualmente se podría hacer uso de un softphone.
3.4 Individuos
A semejanza de la naturaleza, un algoritmo genético cuenta con un conjunto de individuos que conforman
una población. Para este proyecto los individuos son las llaves pseudo-aleatorias y una población es el
conjunto de llaves generadas por el algoritmo.
Un individuo está constituido por un cromosoma de 128 genes, donde cada gen está representado por un
bit, guardando así la relación con la longitud de llave mínima estándar utilizada para criptografía simétrica
con el algoritmo AES, con la cual se define un buen nivel de seguridad y un procesamiento no muy
elevado.

21
Figura 10. Descripción del individuo.
3.5 Diagrama de flujo general
El algoritmo fue desarrollado con base al diagrama de flujo expuesto en la figura 11.
Figura 11. Diagrama de flujo del algoritmo genético
De la población inicial se generan los descendientes o población de hijos haciendo uso de los operadores
genéticos reproducción y mutación. Seguidamente se realiza el cálculo de la función objetivo (expuesta
más adelante en este documento) asignándole un valor real a cada uno.
Con el valor de peso para cada individuo, el siguiente proceso en el algoritmo es la aplicación de la
función de selección natural obteniendo un grupo selecto de individuos con características deseables en lo
concerniente a los objetivos de este proyecto.
De dicha manera, se realiza este mismo procedimiento varias generaciones, tomando como futuros padres
al grupo selecto de individuos obtenido en cada generación del algoritmo. Al final de todas las

22
generaciones se selecciona el mejor “futuro padre” de todas las generaciones para que sea la salida de este
sistema.
Por último al final de la ejecución del algoritmo, validando que la función objetivo converja al valor
esperado se procede a la validación de aleatoriedad de las secuencias obtenidas, haciendo uso de las
prueba del NIST.
3.6 Entradas y salidas del sistema
Según el RFC-3711, las entradas al algoritmo de generación de llaves pseduo-aleatorias “Key Derivation
Algorithm” son las variables “Master_Key” y “Packet Index” [11].
La variable “Master Key” viene de una fuente externa, y la variable “Packet Index” indica el índice del
paquete RTP de la comunicación. De esta manera, para este trabajo las entradas descritas son entradas al
generador implementado. Es importante aclarar que en el mencionado RFC se indica que el valor de
“Packet Index” empieza en cero y su empleo dentro de la derivación de llaves radica en que se toma el
índice del paquete anterior, evitando así latencia en la comunicación RTP.
A su vez, otra variable de entrada es “SIP Call-ID” obtenida en la etapa de la comunicación de
señalización (SIP) donde al establecerse una llamada, se genera un identificador único.
Por último la salida del sistema es la variable “Encryption_Key” que representa la llave pseudo-aleatoria
de 128 bits obtenida por el generador de números pseudo-aleatorios utilizando algoritmos genéticos.
Figura 12. Entradas y Salidas del sistema.
3.7 Tiempo de ejecución
La variable de desempeño seleccionada fue el tiempo de ejecución máximo del algoritmo. Como se
expuso en el marco teórico, después de establecerse la comunicación por medio del protocolo SIP, y de
haber utilizado el algoritmo de Diffie-Hellman para establecer el canal seguro de comunicación, el
protocolo SRTP debe establecer algunos parámetros como el algoritmo de cifrado simétrico y la llave de
sesión para dicho cifrado. Es en el establecimiento de estos parámetros donde el tiempo de ejecución del
algoritmo está limitado por los requerimientos descritos en el RFC-6189 [2], donde se describe por
completo el protocolo ZRTP.
Según lo expuesto se exponía en la sección 2.1.1, y lo definido en el RFC-6189, después de recibir Alice
un mensaje COMMIT y antes de recibir un mensaje CONFIRM2, si no ha recibido ningún mensaje por
parte de Bob por más de 10 segundos, Alice enviará un mensaje de error de “timeout” y se terminará la
comunicación.

23
Teniendo en cuenta esto, se alcanzó satisfactoriamente para este trabajo que el tiempo de ejecución del
algoritmo no excediera los 10 segundos especificados.
3.8 Función objetivo.
La función objetivo está compuesta por la prueba de sumas acumuladas expuesta en [13]:
3.8.1 Prueba de Sumas Acumuladas (Cusum)
Se calcula para cada individuo la prueba de sumas acumuladas del NIST. Como se expuso en la sección
2.4.1.5 de este documento, en esta prueba se mide si la proporción de ceros y unos de la secuencia entera
es aproximadamente la misma que se esperaría en una secuencia realmente aleatoria teniendo en cuenta su
ubicación dentro de la secuencia. Si la proporción es aproximadamente la misma y está distribuida a
semejanza de la caminata aleatoria se podría esperar que sea una secuencia aleatoria. El resultado de la
prueba es un valor de probabilidad (P-valor) que debe ser mayor o igual a 0.01.
Para este trabajo, el resultado para cada individuo será 1- el P-valor obtenido, teniendo con esto un rango
de valores entre 0 y 0.99 como valores válidos, siendo 0 el mejor valor que puede tener un individuo. Si
el valor excede el rango descrito el valor es de 100, con lo que el individuo es totalmente descartado.
3.9 Pruebas de aleatoriedad NIST
En este trabajo se aplicaron las pruebas de aleatoriedad desarrolladas por el NIST [13], descritas en la
sección 2.4.1. El software publicado por esta entidad gubernamental no está sujeto a derechos de autor y
es del dominio público. Para este trabajo de grado se utilizó la versión sts-2.1.1 de Agosto 11 del 2010,
disponible en la página oficial del NIST.
Para cada una de las pruebas de aleatoriedad establecidas por el NIST se obtiene un P-valor, que establece
si la secuencia analizada se asemeja a una secuencia realmente aleatoria.
Para aplicaciones en criptografía, como es el caso de esta investigación, en el que la llave obtenida se
utilizará para cifrar el tráfico RTP de la comunicación de VoIP, se debe establecer que el P-valor de cada
prueba sea mayor o igual al nivel de significancia . Este valor es comúnmente seleccionado como
0.01. Este valor indicará que la secuencia analizada puede ser considerada como pseudo-aleatoria o no,
con una confianza del 99%.
Para las secuencias analizadas en este trabajo se obtuvieron resultados positivos, dándoles validez con el
cumplimiento de las siguientes especificaciones de las pruebas, tomadas del documento del NIST [13].
3.9.1 Especificaciones de pruebas
3.9.1.1 Prueba de frecuencia en bloques
Los resultados obtenidos en esta prueba son válidos ya que se especifica un mínimo de longitud de la
secuencia de 100 bits y la longitud de cada bloque (M) a analizar debe cumplir que M>0.01n, donde n es
la longitud de la secuencia a analizar. Puesto que las secuencias son de 128 bits, la longitud de cada
bloque se seleccionará M=8, con lo que el análisis es válido ya que M>1.
3.9.1.2 Prueba de la carrera en bloques
Los resultados obtenidos en esta prueba son válidos ya que el mínimo requerido de longitud de la
secuencia es de 128 bits y longitud de bloque M=8, lo que es adecuado frente a las muestras analizadas.

24
3.9.1.3 Sumas acumuladas (Cusum)
Los resultados obtenidos en esta prueba son válidos ya que la longitud de las secuencias es de 128 bits y el
mínimo requerido es de 100.
3.9.1.4 Prueba de la FFT
Para obtener resultados válidos sobre los picos presentes en la transformada discreta de Fourier, es
necesario que la secuencia tenga una longitud mínima de 1000 bits. Puesto que cada secuencia obtenida
del generador de números pseudo-aleatorios implementado es de 128 bits, no es posible aplicar esta
prueba a cada secuencia individualmente ya que se obtendrían resultados inválidos. Sin embargo, se
concatenaron las 1000 secuencias obtenidas y se tomó esto como una muestra individual de 128000 bits
para realizar un análisis válido sobre esta prueba.
Como se expuso en la sección 2.4.1, las demás pruebas del NIST, Rango de la matriz binaria, No
solapamiento de patrón, Solapamiento de patrón, Estadística Universal de Maurer, Complejidad lineal,
Entropía aproximada, Excursiones aleatorias y Excursión de la variante aleatoria, no son aplicables para
este proyecto debido a que el tamaño de la llave definido para este trabajo de grado (128 bits) es menor a
las especificaciones descritas para estas pruebas en [13]. Así mismo las pruebas de Frecuencia, y de la
Carrera no se van a analizar en este trabajo de grado por estar incluidas dentro de las pruebas de
Frecuencia en bloques (Block Frecuency) y Carrera en bloques (Longest Run Test).
3.9.2 Proporción de secuencias para aprobar una prueba
Puesto que los resultados de las pruebas se obtienen para cada secuencia individualmente, es necesario
definir la proporción de secuencias de las que se obtengan resultados positivos, para dar validez al
algoritmo.
El rango de proporción aceptable es determinado utilizando el intervalo de confidencia definido en el
documento del NIST [13], de la siguiente manera:
[E.30]
Donde , y m es el tamaño de la muestra.
Este intervalo fue calculado utilizando una distribución normal, como una aproximación de la distribución
binomial, que es razonablemente adecuada para muestras de 1000 secuencias como mínimo.
Por esta razón, para este trabajo se analizaron 1000 secuencias a las cuales se les aplicaron las pruebas
previamente descritas. A su vez, para 1000 secuencias analizadas, mínimo deben haber 980 secuencias
que tengan características deseables en las pruebas.
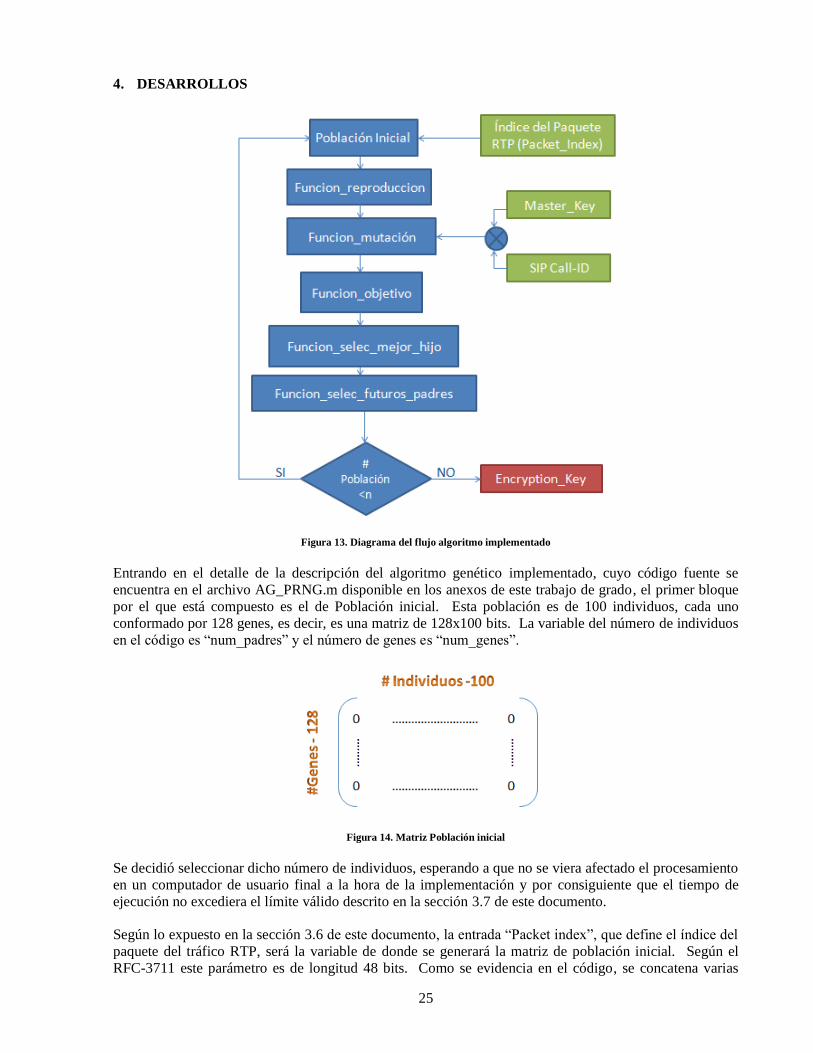
25
4. DESARROLLOS
Figura 13. Diagrama del flujo algoritmo implementado
Entrando en el detalle de la descripción del algoritmo genético implementado, cuyo código fuente se
encuentra en el archivo AG_PRNG.m disponible en los anexos de este trabajo de grado, el primer bloque
por el que está compuesto es el de Población inicial. Esta población es de 100 individuos, cada uno
conformado por 128 genes, es decir, es una matriz de 128x100 bits. La variable del número de individuos
en el código es “num_padres” y el número de genes es “num_genes”.
Figura 14. Matriz Población inicial
Se decidió seleccionar dicho número de individuos, esperando a que no se viera afectado el procesamiento
en un computador de usuario final a la hora de la implementación y por consiguiente que el tiempo de
ejecución no excediera el límite válido descrito en la sección 3.7 de este documento.
Según lo expuesto en la sección 3.6 de este documento, la entrada “Packet index”, que define el índice del
paquete del tráfico RTP, será la variable de donde se generará la matriz de población inicial. Según el
RFC-3711 este parámetro es de longitud 48 bits. Como se evidencia en el código, se concatena varias

26
veces la variable “Packet_index” para formar el primer individuo de 128 genes, es decir de 128 bits,
descartando los sobrantes.
Figura 15. Variable “Packet_index”
Posteriormente este individuo será la referencia para crear a los demás padres, desplazando un bit la
secuencia como se muestra a continuación:
Figura 16. Variable “Padres”
De esta manera se genera la matriz de población inicial o matriz “Padres”.
Para las pruebas realizadas en este trabajo siempre se tomó la variable “Packet_index” como un vector de
ceros, generando así, que la matriz “Padres” sea una matriz de ceros de 128x100 bits. Esto para
contemplar el caso más crítico y así asegurar que el funcionamiento del algoritmo es válido en estas
condiciones.
4.1 Reproducción
En el archivo AG_PRNG.m la función de reproducción está definida como “Funcion_reproduccion”. Sus
entradas y salidas se exponen en la siguiente figura.

27
Figura 17. Función Reproducción
En esta función se agrupan los individuos en 50 parejas para aplicar el operador genético de cruce basado
en un punto y así obtener 2 hijos por pareja. El punto de cruce es en el bit 64, es decir en la mitad del
número de genes, y los descendientes se generan como se muestra en la siguiente figura:
Figura 18. Matriz “Padres”

28
Figura 19. Descripción de reproducción para este proyecto.
De dicha manera en total hay 100 individuos hijos con las características genéticas de sus padres.
Seguidamente, la población de hijos se unirá o concatenará con la de padres para continuar con las
operaciones genéticas, esta población será almacenada en la variable “Padres_Hijos”. Se decidió que la
población incluyera a hijos como a padres porque a semejanza de la naturaleza ambos pueden convivir en
el mismo medio, y ambos pueden aportar características importantes para el desarrollo de la población.
Figura 20. Variable “Padres_Hijos”
4.2 Mutación
En el archivo AG_PRNG.m la función de mutación está definida como “Funcion_mutacion” y sus
entradas y salidas se exponen en la siguiente figura.

29
Figura 21. Función Mutación
Con esta función se simulan las variaciones genéticas presentes en la naturaleza, las cuales se producen sin
patrón alguno y cuya procedencia puede deberse a cambios en el medio externo. Esta es aplicada a la
mitad de la población obtenida en la reproducción, esto es a los individuos impares de la matriz
“Padres_Hijos”. Así, se realiza la mutación a un 50% de la población porque según [14], esta operación
genera mucha variabilidad genética, y para los fines de este trabajo de grado es necesario que haya
diversidad en los genes de los individuos.
Figura 22. Matriz “Padres_Hijos” en mutación
La variable “num_padres_hijos”, indica el número total de individuos en la matriz “Padres_hijos” que es
dos veces el número de individuos iniciales, esto es 200.
La primera parte de la función consiste en generar la variable “cadena_mutadora_base”, vector de 128
bits, con la que se genera la variable “Matriz_cadenas_mutadoras” de tamaño num_genes x
num_generaciones, es decir 128x100 bits.

30
Para obtener la variable “cadena_mutadora_base”, se utiliza un parámetro específico llamado “Call-ID”.
Este parámetro se genera en la señalización de la llamada y se encuentra en la cabecera del paquete SIP,
como se expone en el documento RFC-3261 [19], donde se describen en detalle las características y
normatividades de dicho protocolo.
Para la obtención del parámetro “Call-ID”, se configuró un servidor SIP local y se configuró el softphone
X-lite, de libre distribución, en dos equipos para realizar varias llamadas de prueba y tomar muestras de
este parámetro con la ayuda del analizador de protocolos de red Wireshark.
Se instaló y configuró el software “FreeSwitch”, desarrollado por Anthony Minessale, Michael Jerris,
Brian West, entre otros. Este programa está disponible en la página oficial (www.freeswitch.org) con
licencia de software libre MPL (Mozilla Public License).
Haciendo uso de este software se activó un servidor SIP, en el equipo con dirección IP 192.168.1.3. En la
configuración de este servicio se habilitaron 2 extensiones, 2020 y 1000, en otros dos equipos de la red
local.
Figura 23. Servidor SIP “FreeSwitch”
En la siguiente figura se muestra la configuración en el softphone X-lite.

31
Figura 24. Configuración X-lite
Realizando las llamadas de pruebas, en la captura obtenida en Wireshark se seleccionaron los paquetes
SIP y en ellos la cabecera del mensaje contiene el parámetro “Call-ID” como se muestra a continuación.
Figura 25. Captura Wireshark paquetes SIP

32
Como se observa este parámetro se encuentra en formato ASCII por lo que se realizó la debida conversión
de estos valores a binario para generar los vectores de 128 bits de la variable “SIP_call_ID”.
Puesto que por definición de los algoritmos genéticos, la mutación debe ser impredecible y única [9], el
parámetro “Call-ID” es ideal para establecer los genes a ser mutados en cada generación, ya que como se
expuso, es único para cada llamada.
Además, como el parámetro “Call-ID” viaja en texto claro del emisor de la comunicación al receptor, se
definió que la variable “cadena_mutadora_base” sea el resultado de la aplicación de la función Xor entre
la cadena del mencionado parámetro y la variable “Master_Key”, expuesta en la sección 3.6 de este
documento, y que no se transmite públicamente.
Figura 26 . Variable “cada_mutadora”
La variable “cadena_mutadora_base”, es la referencia para generar la matriz
“Matriz_cadenas_mutadoras”, desplazando un bit la secuencia como se muestra a continuación:
Figura 27. Variable "Matriz_cadenas_mutadoras"
Cada fila de la variable “Matriz_cadenas_mutadoras” define la variable
“cadena_mutadora_generacion_n”, que representa la cadena con la que se realiza la función de mutación a
la población en cada generación. Esto eso, la fila 1 es la cadena con la que se realiza la mutación a la
matriz con la población “Padres_Hijos” obtenidos en la primera generación. La fila 2, es la cadena para la
población obtenida en la segunda generación y así hasta la generación 300. El número de generación en la
que se encuentra el algoritmo está definida por la variable “n”.
En esta función se aplica la operación lógica Xor entre los individuos impares de la población
“Padres_Hijos” y la variable “cadena_mutadora_generacion_n”. La posición donde exista un bit con
valor 1 en la “cadena mutadora_generacion_n”, será la misma posición en la cadena de bits del individuo
donde habrá mutación del gen, como se expone en la siguiente figura.

33
Figura 28. Mutación implementada.
Para el análisis de este caso de estudio, la variable “Master_Key” se dejó fija como un vector de ceros de
tamaño 128 bits. Esto para contemplar el caso más crítico y así asegurar que el funcionamiento del
algoritmo es válido en estas condiciones. El valor que va a cambiar es el de la variable “SIP_call_ID”.
Las salidas de esta función son los individuos mutados que se almacenan en la matriz
“Padres_Hijos_mutados” de tamaño 128x100 bits. Además de los individuos que no mutaron, que se
almacenan en la matriz “Padres_Hijos_NO_mutados” de tamaño 128x100 bits.
Por último se toma como población resultante la variable “Hijos_totales”, en donde se concatenan las
matrices “Padres_Hijos_mutados” y “Padres_Hijos_NO_mutados”. Cuyo tamaño está definido por la
variable “num_hijos_totales” que es igual al número de individuos de la matriz “Padres_Hijos”, esto es
128x200 bits.
Figura 29. Matriz "Hijos_totales"
4.3 Función objetivo
Como se muestra en la figura 13, el siguiente paso es calcular el valor de la función objetivo (fitness) para
cada individuo. En el archivo AG_PRNG.m la función objetivo está definida como “Funcion_objetivo” y
sus entradas y salidas se exponen en la siguiente figura.

34
Figura 30. Función objetivo
Para obtener el valor de salida “Peso_total” y “Peso_total_aux”, la función objetivo está compuesta por la
prueba de Sumas acumuladas del NIST:
4.3.1 Sumas Acumuladas (Cusum)
Se selecciona cada individuo de la matriz “Hijos_totales” y se almacena en el vector “sec”.
Posteriormente para convertir cada bit de la secuencia a 1 y -1 se calcula 2 veces el valor del bit menos la
unidad, para así calcular la estadística “z” como se expone en [13]:
[E.31]
Donde n es 128 bits, la longitud de las secuencias, y es el valor absoluto más alto de las
sumas parciales de la secuencia .
Con esta estadística se procede a calcular el P-valor, haciendo uso de la función normal estándar
acumulada.
[E.32]
Donde, como se explicaba en las especificaciones en la sección 3.9, si el valor es mayor al nivel de
significancia “alfa”, definido como 0.01, la secuencia pasa la prueba.
Para los fines de este trabajo de grado el peso se almacena en la variable “Pv_modificado”.
[E.33] si > 0.01
[E.34] si < 0.01

35
Figura 31. Matriz "Hijos_totales" en Peso Cusum
Al finalizar el cálculo para cada individuo, el valor obtenido en la variable “Pv_modificado” se almacena
en el vector “Peso_Cusum” en la misma posición del número de individuo. Es decir, el valor obtenido
para el individuo en la posición 1 se almacena en la posición 1 del vector “Peso_Cusum”. Para el
individuo 2 en la posición 2 y así hasta guardar los valores de todos los individuos.
Figura 32. Vector "Peso_Cusum"
4.3.2 Peso total
La variable “Peso_total” está definida por el vector “Peso_Cusum”, anteriormente descrita.
[E.35]
A su vez, la variable “Peso_total_aux” es una réplica de “Peso_total” que será utilizada posteriormente.
4.4 Selección mejor hijo
En el archivo AG_PRNG.m la función objetivo está definida como “Funcion_selec_mejor_hijo” y sus
entradas y salidas se exponen en la siguiente figura.

36
Figura 33. Función selección del mejor hijo
Para aplicar esta función es necesario calcular el valor mínimo del vector “Peso_total”, obteniendo las
variables “mejor_peso_hijo” e “indice_mejor_hijo” haciendo uso de la función (min) de Matlab.
En esta función se almacena el individuo con menor peso en la variable “mejor_hijo”, utilizando la
variable “indice_mejor_hijo”.
A su vez, la salida de esta función es almacenada en la matriz “Mejores_hijos”, que es conformada en sus
columnas por los mejores hijos de cada generación.
También se almacena el valor de la función objetivo de “mejor_hijo”, esto es “mejor_peso_hijo”, en el
vector “ pesos_generaciones”, para las 300 generaciones que se corren en este algoritmo.
4.5 Selección futuros padres
En el archivo AG_PRNG.m la función objetivo está definida como “Funcion_selec_futuros_padres” y sus
entradas y salidas se exponen en la siguiente figura.
Figura 34. Función selección futuros padres
Antes de aplicar esta función, es necesario calcular el valor mínimo del vector “Peso_total_aux”,
obteniendo las variables “mejor_peso_hijo_aux” e “indice_mejor_hijo_aux” haciendo uso de la función
(min) de Matlab.
Es así como los individuos con menor valor de la función objetivo son almacenados en las columnas de la
matriz “Futuros_padres”. El número de individuos seleccionado es igual al número de individuos

37
iniciales, es decir, el valor de “num_padres”, para que así, estos puedan pasar a ser la matriz “Padres” de
la siguiente generación y se vuelva a repetir el proceso.
4.6 Número de generaciones
En el archivo AG_PRNG.m la variable “n” indica el número de generación en la que en determinado
momento se encuentra el algoritmo genético. Esto es, n empieza en 1, para la primera generación y
termina en “num_generaciones”.
Al finalizar todas las generaciones, se obtiene del vector “pesos_generaciones”, las variables
“peso_mejor_generacion” e “indice_peso_mejor_generacion”, los cuales indican el menor peso obtenido
en todas las generaciones y el índice en el vector “pesos_generaciones” respectivamente.
Con la variable “indice_peso_mejor_generacion” se obtiene de la matriz “Mejores_hijos” la salida final
del sistema “Encryption_key”, que es la secuencia con valor más cercano al límite definido para la función
objetivo y con la que se realiza el cifrado del tráfico RTP.
Para la validación de aleatoriedad de esta secuencia se procede a aplicar las pruebas estadísticas del NIST.
Para esto se ejecutó el programa suministrado por el NIST en un servidor con sistema operativo Ubuntu.
Figura 35. Máquina virtual Ubuntu para aplicación de pruebas del NIST
5. ANÁLISIS DE RESULTADOS
A continuación se exponen los resultados, gráficas y tablas obtenidas con la implementación del algoritmo
genético como generador de números pseudo-aleatorios aplicado al protocolo ZRTP. Para todas estas
pruebas, las variables de entrada “Packet_index” y “Master_key” son vectores en ceros. Esto es, los
padres son fijos y son una matriz de ceros, y la variable “cadena_mutadora” contienen la información
solamente de la variable “SIP_call_ID”. De esta manera, las variaciones en la entrada se darán
únicamente en la variable “SIP_call_ID”, con el objetivo de analizar el comportamiento del algoritmo ante
este escenario y garantizar que se cumplan con los requerimientos del trabajo bajo condiciones básicas.

38
5.1 Número de padres y número de generaciones
Para la prueba inicial de validación del número de padres y número de generaciones definidos, se toma
como entrada al sistema la variable “SIP_call_ID”, como un vector de 128 bits cuyo primer bit es 1 y los
demás son 0. Esto para contemplar el caso más extremo de entrada no aleatoria.
Figura 36. Variable "SIP_call_ID"
Según lo expuesto en la sección de desarrollo de este documento, el número de padres es 100 y el número
de generaciones corridas en el algoritmo es 100. Para estos valores se obtuvieron los siguientes
resultados:
Figura 37. Peso Función Objetivo Vs. Número de Generación Prueba 1
En la gráfica 41 se visualiza la variación del peso de la función objetivo para cada generación del
algoritmo. Así es como hasta la generación 25 se realizan los suficientes cambios en la matriz
“Hijos_totales” como para que disminuya el valor de la función objetivo de su nivel máximo 100 (por la
prueba de Sumas Acumuladas). De esta manera desde la generación 25 con un peso de 0.984 se cumple
con el criterio, y al continuar realizándose el proceso se alcanza en la generación 100 un peso de 0.9457.
A su vez, uno de los criterios que se debe cumplir es que el tiempo de ejecución sea de 10 segundos. Por
lo que estos valores de número de padres y número de generaciones no son válidos, ya que se obtuvo un
tiempo de ejecución de 43 segundos aproximadamente.
Por esta razón se realizan varias pruebas en que se varía el número de padres y generaciones, tomando
como prueba inicial la expuesta anteriormente.
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.9457
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984
X: 11
Y: 100

39
Para la prueba 2 se mantuvieron los 100 padres y se redujo el número de generaciones a 70 obteniendo los
siguientes resultados:
Figura 38. Peso Función Objetivo Vs. Número de Generación Prueba 2
Como se observa en la figura 42, se presenta una gráfica similar a la que fue expuesta en la prueba inicial,
sólo que se trunca en la generación 70. La diferencia está en que el tiempo de ejecución para este número
de generaciones es de 23 segundos aproximadamente, y el peso más bajo de la función objetivo es de
0.9457 en la generación 70. Puesto que no se cumple con el criterio del tiempo de ejecución, se procede a
contemplar otro escenario.
En la prueba 3, se mantuvieron los 100 padres y se redujo el número de generaciones a 50 obteniendo los
siguientes resultados:
0 10 20 30 40 50 60 700
10
20
30
40
50
60
70
80
90
100
X: 25
Y: 0.984
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 70
Y: 0.9457

40
Figura 39. Peso Función Objetivo Vs. Número de Generación Prueba 3
Como se observa en la figura 43, se presenta una gráfica similar a la del caso inicial, pero esta vez se
trunca en la generación 50. La diferencia está en que el tiempo de ejecución para este número de
generaciones es de 19 segundos aproximadamente, y el peso más bajo de la función objetivo es de
0.9457en la generación 50. Puesto que no se cumple con el criterio del tiempo de ejecución, se procede a
contemplar otro escenario.
En la prueba 4 se mantuvieron los 100 padres y se redujo el número de generaciones a 40 obteniendo los
siguientes resultados:
Figura 40. Peso Función Objetivo Vs. Número de Generación Prueba 4
0 5 10 15 20 25 30 35 40 45 500
10
20
30
40
50
60
70
80
90
100
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984
X: 50
Y: 0.9457
0 5 10 15 20 25 30 35 400
10
20
30
40
50
60
70
80
90
100
X: 40
Y: 0.9457
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984

41
Como se observa en la figura 44, se presenta una gráfica similar a la del caso inicial, sólo que se trunca en
la generación 40. La diferencia está en que el tiempo de ejecución para este número de generaciones es de
15 segundos aproximadamente, y el peso más bajo de la función objetivo es de 0.9457 en la generación
40. Puesto que no se cumple con el criterio del tiempo de ejecución, se procede a contemplar otro
escenario.
En la prueba 5 se mantuvieron los 100 padres y se redujo el número de generaciones a 25 obteniendo los
siguientes resultados:
Figura 41. Peso Función Objetivo Vs. Número de Generación Prueba 5
Como se observa en la figura 45, se presenta una gráfica similar a la del caso inicial, pero ahora se trunca
en la generación 25. La diferencia está en que el tiempo de ejecución para este número de generaciones es
de 13 segundos aproximadamente, y el peso más bajo de la función objetivo es de 0.984 en la generación
25.
Como el tiempo de ejecución máximo puede ser de 10 segundos, se decide explorar los cambios en la
reducción del número de padres, ya que si se desea reducir el tiempo de ejecución por debajo de los 13
segundos obtenidos en la prueba 5, es decir, si se busca reducir aún más el número de generaciones para
un número de 100 padres, se excedería el límite definido para el peso de la función objetivo que es de
0.99.
En la prueba 6 se mantuvo el número de generaciones como el inicial, 100, y se seleccionaron 70 padres,
obteniendo los siguientes resultados:
0 5 10 15 20 250
10
20
30
40
50
60
70
80
90
100
X: 25
Y: 0.984
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo

42
Figura 42. Peso Función Objetivo Vs. Número de Generación Prueba 6
En la figura 46 se observa que se mantiene la característica obtenida en la simulación inicial, en donde,
hasta la generación 25 se realizan los suficientes cambios en la matriz “Hijos_totales” como para que
disminuya el valor de la función objetivo de su nivel máximo 100 (por la prueba de Sumas Acumuladas).
A su vez, se obtiene que en la generación 100 se alcanza el peso más bajo para la función objetivo con un
valor de 0.9457, el cual es un valor válido dentro del límite definido. Puesto que el tiempo de ejecución
obtenido es de 20 segundos, es necesario hacer una reducción en el número de padres.
En la prueba 7 se mantuvo el número de generaciones en 100, y se seleccionaron 50 padres, obteniendo
los siguientes resultados:
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984
X: 100
Y: 0.9457
43
Figura 43. Peso Función Objetivo Vs. Número de Generación Prueba 7
Como se observa en la figura 47, se alcanza en la generación número 100 el peso de 0.9457. Con este
resultado se mantiene el peso obtenido previamente, y el tiempo de ejecución se redujo a 13 segundos, con
lo que cada vez está más cerca el valor indicado de número de padres y generaciones.
En la prueba 8 se mantuvo el número de generaciones en 100, y se seleccionaron 40 padres, obteniendo
los siguientes resultados:
Figura 44. Peso Función Objetivo Vs. Número de Generación Prueba 8
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.9457
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.9457
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984

44
Como se observa en la figura 48, se alcanza en la generación número 100 el peso de 0.9457. Con este
resultado se mantiene el peso obtenido previamente, y el tiempo de ejecución se redujo a 10 segundos, con
lo que se cumple satisfactoriamente con el criterio. Aún así se exploran otras pruebas para encontrar
mejores resultados.
En la prueba 9 se mantuvo el número de generaciones en 100, y se seleccionaron 30 padres, obteniendo
los siguientes resultados:
Figura 45. Peso Función Objetivo Vs. Número de Generación Prueba 9
Como se observa en la figura 49, se alcanza en la generación número 100 el peso de 0.9457. Con este
resultado se mantiene el peso obtenido previamente, y el tiempo de ejecución se redujo a 8 segundos, con
lo que se cumple satisfactoriamente con el criterio. Aún así se exploran otras pruebas para encontrar
mejores resultados.
En la prueba 10 se mantuvo el número de generaciones en 100, y se seleccionaron 20 padres, obteniendo
los siguientes resultados:
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.9457
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984

45
Figura 46. Peso Función Objetivo Vs. Número de Generación Prueba 10
Como se observa en la figura 50, se alcanza en la generación número 100 el peso de 0.9457. Con este
resultado se mantiene el peso obtenido previamente, y el tiempo de ejecución se redujo a 4 segundos, con
lo que se cumple satisfactoriamente con el criterio. Aún así se exploran otras pruebas para encontrar
mejores resultados.
En la prueba 11 se mantuvo el número de generaciones en 100, y se seleccionaron 5 padres, obteniendo
los siguientes resultados:
Figura 47. Peso Función Objetivo Vs. Número de Generación Prueba 11
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.9457
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.9457
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984

46
Como se observa en la figura 51, se alcanza en la generación número 100 el peso de 0.9457. Con este
resultado se mantiene el peso obtenido previamente, y el tiempo de ejecución se redujo a 2 segundos, con
lo que se cumple satisfactoriamente con el criterio. Aún así se exploran otras pruebas para encontrar
mejores resultados.
En la prueba 12 se mantuvo el número de generaciones en 100 y se seleccionaron 4 padres, obteniendo los
siguientes resultados:
Figura 48. Peso Función Objetivo Vs. Número de Generación Prueba 12
Como se puede observar en la figura 52, para 4 padres se obtuvo un valor de la función objetivo de 0.9569
en la generación 100, siendo este valor mayor que el obtenido para 5 padres.
Los resultados obtenidos se sintetizan en la siguiente tabla:
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.9569
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 25
Y: 0.984

47
Número
de prueba
Número
de padres (num_padres)
Número de
generaciones (n)
Tiempo de ejecución aproximado
(s)
Peso función objetivo
(Peso_total)
1 100 100 43 0.9457
2 100 70 23 0.9457
3 100 50 19 0.9457
4 100 40 15 0.9457
5 100 25 13 0.984
6 70 100 20 0.9457
7 50 100 13 0.9457
8 40 100 10 0.9457
9 30 100 8 0.9457
10 20 100 4 0. 9457
11 5 100 2 0.9453
12 4 100 1 0.9569
Tabla 2. Número de padres y número de generaciones
De acuerdo a los resultados expuestos en la tabla 2, se selecciona como mejor opción la prueba 11, con
número de padres igual a 5 y 100 como número de generaciones. Esto debido a que, según los resultados
de las pruebas, la mejor opción fue disminuir el número de individuos, por lo que se dejó fijo el número de
generaciones y se empezó a observar el comportamiento con distintos valores. Disminuyendo de 100 a 40
padres se pudo obtener un tiempo de ejecución de 10 segundos aproximadamente y un valor de la función
objetivo de 0.9457, con lo que se cumplen los criterios definidos para este trabajo de grado. Aún así
contemplando otros escenarios se encontró que era posible disminuir un poco más el número de
individuos para alcanzar un mejor tiempo de ejecución, sin embargo si se seguía disminuyendo hasta 4
padres, aunque el tiempo de ejecución seguía decreciendo, el valor de la función objetivo se veía afectado,
debido a que no habían los suficientes individuos para generar variabilidad genética en las poblaciones
producidas durante el transcurso del algoritmo, generando así un decrecimiento más lento de la función
objetivo.
5.2 Variación de la variable de entrada “SIP_call_ID”
A continuación se expondrán los resultados obtenidos al realizar variaciones en la entrada “SIP_call_ID”
observando el tiempo de ejecución y el valor de función objetivo alcanzados para cada caso.

48
Primero se analizarán 10 entradas básicas, es decir, la variable “SIP_call_ID” tomará valores donde no
existen patrones de aleatoriedad, esto es, secuencias de 128 bits donde sólo algunos bits se definen con
valor 1.
Posteriormente, se analizarán 10 entradas cuyos valores están definidos por el parámetro “Call-ID”,
presente en la cabecera del paquete SIP, como se expuso en la sección 4.2 de este documento.
5.2.1 “SIP_call_ID” básico
Las muestras SIP_call_ID con secuencias básicas se encuentran dentro de los anexos de este trabajo en el
archivo Muestras_SIP_call_ID_basico.txt. En el archivo se encuentran las muestras concatenadas, donde
la primera secuencia será denotada como Muestra 1, la siguiente Muestra 2, etc.
Para la Muestra 1, se obtuvieron los siguientes resultados:
Figura 49. Peso Función Objetivo Vs Número de Generación - Muestra 1 básico
Como se observa en la figura 53, se obtuvo un peso mínimo de 0.01584 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
Para la Muestra 2, se obtuvieron los siguientes resultados:
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.01584
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo

49
Figura 50. Peso Función Objetivo Vs Número de Generación - Muestra 2 básico
Como se observa en la figura 54, se obtuvo un peso mínimo de 0.01584 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
Para la Muestra 3, se obtuvieron los siguientes resultados:
Figura 51. Peso Función Objetivo Vs Número de Generación - Muestra 3 básico
Como se observa en la figura 55, se obtuvo un peso mínimo de 0.05073 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.01584
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.05073
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo

50
Para la Muestra 4, se obtuvieron los siguientes resultados:
Figura 52. Peso Función Objetivo Vs Número de Generación - Muestra 4 básico
Como se observa en la figura 56, se obtuvo un peso mínimo de 0.01584 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
Para la Muestra 5, se obtuvieron los siguientes resultados:
Figura 53. Peso Función Objetivo Vs Número de Generación - Muestra 5 básico
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.01584
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 100
Y: 0.01584

51
Como se observa en la figura 57, se obtuvo un peso mínimo de 0.01584 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
Para la Muestra 6, se obtuvieron los siguientes resultados:
Figura 54. Peso Función Objetivo Vs Número de Generación - Muestra 6 básico
Como se observa en la figura 58, se obtuvo un peso mínimo de 0.05073 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
Para la Muestra 7, se obtuvieron los siguientes resultados:
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.05073
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo

52
Figura 55. Peso Función Objetivo Vs Número de Generación - Muestra 7 básico
Como se observa en la figura 59, se obtuvo un peso mínimo de 0.01584 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
Para la Muestra 8, se obtuvieron los siguientes resultados:
Figura 56. Peso Función Objetivo Vs Número de Generación - Muestra 8 básico
Como se observa en la figura 60, se obtuvo un peso mínimo de 0.01584 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.01584
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.01584
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo

53
Para la Muestra 9, se obtuvieron los siguientes resultados:
Figura 57. Peso Función Objetivo Vs Número de Generación - Muestra 9 básico
Como se observa en la figura 61, se obtuvo un peso mínimo de 0.01584 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
Para la Muestra 10, se obtuvieron los siguientes resultados:
Figura 58. Peso Función Objetivo Vs Número de Generación - Muestra 10 básico
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.01584
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
0 10 20 30 40 50 60 70 80 90 1000
10
20
30
40
50
60
70
80
90
100
X: 100
Y: 0.05073
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo

54
Como se observa en la figura 62, se obtuvo un peso mínimo de 0.05073 en la generación 100. Además de
obtenerse un tiempo de ejecución de 2 segundos aproximadamente.
Tomando 10 muestras, de longitud 128 bits, conformadas por 3 bits en 1 y los demás en 0, se observa la
característica de convergencia hacia cero, valor óptimo para la función objetivo basada en la prueba del
NIST de sumas acumuladas. Además se cumple con el requisito de no exceder en 10 segundos el tiempo
de ejecución en un entorno de usuario final.
A su vez, se observa que para todas las muestras se obtuvo el mismo tiempo de ejecución, es decir, 2
segundos aproximadamente, confirmando que este tiempo depende de las variables, “num_padres” y
“num_generaciones” y no de la entrada del algoritmo. También es importante resaltar que según lo
observado para estas muestras, entre la generación 10 y la 30 se producen las variaciones en la matriz
“Hijos_totales” para que se dé la disminución del valor total (100) que puede tomar la función objetivo.
5.2.2 “SIP_call_ID” tomado de la cabecera del paquete SIP
Las muestras SIP_call_ID con secuencias tomadas de la cabecera del paquete SIP de las llamadas de
prueba realizadas, se encuentran dentro de los anexos de este trabajo en el archivo
Muestras_SIP_call_ID.txt. En el archivo se encuentran las muestras concatenadas, donde la primera
secuencia será denotada como Muestra 1, la siguiente Muestra 2, etc.
Para la Muestra 1, se obtuvieron los siguientes resultados:
Figura 59. Peso Función Objetivo Vs Número de Generación - Muestra 1 Call-ID
Como se observa en la figura 63, en la primera generación se cuenta con un valor de la función objetivo de
0.6303. Posteriormente hay una reducción en la generación 4 con un valor de 0.01584. Más adelante,
desde la generación 11 se alcanza un valor de 0.0023 hasta que desde la generación 98 hasta la 100 se
obtiene un valor de 6.586e-5. El tiempo de ejecución fue de 2 segundos aproximadamente.
Para la Muestra 2, se obtuvieron los siguientes resultados:
0 10 20 30 40 50 60 70 80 90 1000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 1
Y: 0.6303
X: 4
Y: 0.01584X: 80
Y: 0.0023
X: 100
Y: 6.586e-005

55
Figura 60. Peso Función Objetivo Vs Número de Generación - Muestra 2 Call-ID
Como se observa en la figura 64, desde la primera generación hasta la generación 12 se cuenta con un
valor de la función objetivo de 0.01584. Después se alcanza y se mantiene hasta la generación 100 un
valor de 6.586e-5. El tiempo de ejecución fue de 2 segundos aproximadamente.
Para la Muestra 3, se obtuvieron los siguientes resultados:
Figura 61. Peso Función Objetivo Vs Número de Generación - Muestra 3 Call-ID
Como se observa en la figura 65, en la primera generación se cuenta con un valor de la función objetivo de
0.108. En la tercera generación se alcanza el valor de 6.586e-5 hasta la generación 79 donde empieza a
0 10 20 30 40 50 60 70 80 90 1000
0.002
0.004
0.006
0.008
0.01
0.012
0.014
0.016
X: 11
Y: 0.01584
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 12
Y: 6.586e-005
X: 100
Y: 6.586e-005
0 10 20 30 40 50 60 70 80 90 1000
0.02
0.04
0.06
0.08
0.1
0.12
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 1
Y: 0.108
X: 3
Y: 6.586e-005
X: 79
Y: 6.586e-005
X: 100
Y: 3.053e-008

56
disminuir para obtenerse en la generación 100 un valor de 6.586e-5. El tiempo de ejecución fue de 2
segundos aproximadamente.
Para la Muestra 4, se obtuvieron los siguientes resultados:
Figura 62. Peso Función Objetivo Vs Número de Generación - Muestra 4 Call-ID
Como se observa en la figura 66, en la primera generación se cuenta con un valor de la función objetivo de
0.5001. Posteriormente se da una reducción y en la séptima generación con un valor de 0.05073. Desde
la octava generación hasta la última se mantiene un valor de 0.0023. El tiempo de ejecución fue de 2
segundos aproximadamente.
Para la Muestra 5, se obtuvieron los siguientes resultados:
0 10 20 30 40 50 60 70 80 90 1000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
X: 1
Y: 0.5001
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 7
Y: 0.05073X: 100
Y: 0.0023

57
Figura 63. Peso Función Objetivo Vs Número de Generación - Muestra 5 Call-ID
Como se observa en la figura 67, en la primera generación se cuenta con un valor de la función objetivo de
0.5001. En la tercera a la generación se da una reducción alcanzando un valor de 0.0573 y posteriormente
desde la generación 16 hasta la 100 se tiene un valor de 6.586e-5. El tiempo de ejecución fue de 2
segundos aproximadamente.
Para la Muestra 6, se obtuvieron los siguientes resultados:
Figura 64. Peso Función Objetivo Vs Número de Generación - Muestra 6 Call-ID
0 10 20 30 40 50 60 70 80 90 1000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
X: 1
Y: 0.5001
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 3
Y: 0.05073X: 100
Y: 6.586e-005
0 10 20 30 40 50 60 70 80 90 1000
0.02
0.04
0.06
0.08
0.1
0.12
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 1
Y: 0.108
X: 3
Y: 6.586e-005
X: 79
Y: 6.586e-005

58
Como se observa en la figura 68, en la primera generación se cuenta con un valor de la función objetivo de
0.108. Dando continuidad a la ejecución del algoritmo, desde la generación 3 y hasta la última generación
se obtuvo el menor peso de la función objetivo, con un valor de 6.586e-5. A su vez, se alcanzó un tiempo
de ejecución de 2 segundos aproximadamente.
Para la Muestra 7, se obtuvieron los siguientes resultados:
Figura 65. Peso Función Objetivo Vs Número de Generación - Muestra 7 Call-ID
Como se observa en la figura 69, en la primera generación se cuenta con un valor de la función objetivo de
0.0023. Posteriormente se encuentra que desde la generación 19 hasta la generación 100 se obtuvo el
menor peso de la función objetivo, con una valor de 6.586e-5. A su vez, se obtuvo un tiempo de ejecución
de 2 segundos aproximadamente.
Para la Muestra 8, se obtuvieron los siguientes resultados:
0 10 20 30 40 50 60 70 80 90 1000
0.5
1
1.5
2
2.5x 10
-3
X: 1
Y: 0.0023
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 19
Y: 6.586e-005
X: 100
Y: 6.586e-005

59
Figura 66. Peso Función Objetivo Vs Número de Generación - Muestra 8 Call-ID
Como se observa en la figura 70, en la primera generación se cuenta con un valor de la función objetivo
de 0.8458. A su vez, en la quinta generación se encuentra una reducción con un valor de 0.5001.
Adicionalmente desde la sexta hasta la última generación se alcanza un valor mínimo de la función
objetivo con 6.586e-5. El tiempo de ejecución fue de 2 segundos aproximadamente.
Para la Muestra 9, se obtuvieron los siguientes resultados:
Figura 67. Peso Función Objetivo Vs Número de Generación - Muestra 9 Call-ID
0 10 20 30 40 50 60 70 80 90 1000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 1
Y: 0.8458
X: 5
Y: 0.5001
X: 6
Y: 6.586e-005
X: 100
Y: 6.586e-005
0 10 20 30 40 50 60 70 80 90 1000
0.01
0.02
0.03
0.04
0.05
0.06
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 1
Y: 0.05073
X: 39
Y: 0.05073
X: 41
Y: 0.01584
X: 42
Y: 0.0023 X: 100
Y: 6.586e-005

60
Como se observa en la figura 71, en la primera generación se cuenta con un valor de la función objetivo de
0.05073. Seguidamente se da una reducción en la generación 41 con un valor de 0.01584, y en la 42 con
0.0023. Finalmente desde la generación 65 hasta la 100 se obtuvo el menor peso de la función objetivo,
con un valor de 6.586e-5. A su vez, se obtuvo un tiempo de ejecución de 2 segundos aproximadamente.
Para la Muestra 10, se obtuvieron los siguientes resultados:
Figura 68. Peso Función Objetivo Vs Número de Generación - Muestra 10 Call-ID
Como se observa en la figura 72, desde la primera generación se cuenta con un valor de la función
objetivo de 0.01584. Dando continuidad a la ejecución del algoritmo, en la generación 26 se obtuvo una
reducción con un valor de 0.0023. Posteriormente desde la generación 68 hasta la 100 se alcanzó el
menor peso de la función objetivo, con un valor de 6.586e-5. A su vez, se obtuvo un tiempo de ejecución
de 2 segundos aproximadamente.
Según los resultados obtenidos para las muestras tomadas del parámetro “Call-ID” de la cabecera del
paquete SIP, se encuentra que el valor de inicio de la función objetivo, es decir, el peso después de la
primera corrida del algoritmo era cercano al límite definido (0), es decir, para todos los casos, en la
primera generación ya se daba cumplimiento al requerimiento de que fuese menor que 100 según la
definición expuesta de la función objetivo. Esto era un resultado esperado, ya que al comparar esto con
las muestras básicas de la sección anterior, las secuencias de entrada ya tienen de por sí los genes
variados, es decir, algunos en 1 o otros en 0, de acuerdo a lo definido durante el establecimiento de la
señalización en el protocolo SIP, por medio del parámetro “Call-ID”. Aún así, cabe resaltar que con el
pasar de las generaciones se alcanza un valor de la función objetivo menor, agregando así mayor calidad a
la salida del sistema.
Se puede observar cómo en las muestras tomadas del paquete SIP, se obtuvo un peso mínimo de la
función objetivo de 6.586e-5, teniendo congruencia con el obtenido con las muestras básicas que fue de
0.01584.
Con todas las muestras obtenidas, se valida el cumplimiento del tiempo de ejecución en concordancia con
los ajustes realizados al número de padres y número de generaciones, expuestos en la sección 5.1 de este
documento.
0 10 20 30 40 50 60 70 80 90 1000
0.002
0.004
0.006
0.008
0.01
0.012
0.014
0.016
X: 1
Y: 0.01584
Peso Función Objetivo Vs Generaciones
Número de Generación
Pe
so
Fu
nció
n O
bje
tivo
X: 26
Y: 0.0023
X: 68
Y: 6.586e-005
X: 100
Y: 6.586e-005

61
Como se puede observar en los resultados para los dos tipos de muestra, gracias al operador de
reproducción se heredan los genes de generación en generación que determinan la característica del
individuo frente a la prueba del NIST de Sumas Acumuladas (Forward), así como los genes a los que se le
aplica el operador de mutación. Es así como la convergencia y optimización característica de los
algoritmos genéticos es evidenciada en este proyecto al obtenerse una disminución del peso de la función
objetivo conforme al desarrollo del algoritmo, donde gracias al análisis de la excursión de la caminata
aleatoria aplicada a cada secuencia se alcanzan resultados óptimos en las pruebas de NIST como se
expone en la siguiente sección.
5.3 Pruebas del NIST
En esta sección se exponen los resultados de las pruebas del NIST [13] aplicadas a las secuencias
generadas por el algoritmo, almacenadas en la variable “Encryption_key”, así como las secuencias de
entrada que las generaron, almacenadas en la variable “SIP_call_ID”.
Primero se analizan 1000 secuencias de las muestras básicas de “SIP_call_ID”, encontradas en el archivo
Muestras_SIP_call_ID_basico.txt. Seguidamente se analizan las 1000 secuencias que se generaron con
dichas entradas al algoritmo, encontradas en el archivo Encryption_keys_SIP_call_ID_basico.txt. Como
se mencionaba en la sección anterior, para las muestras básicas se tomaron secuencias de 128 bits donde
sólo algunos bits se definen con valor 1.
Posteriormente, se analizarán las secuencias obtenidas a partir de las muestras de “SIP_call_ID”, tomadas
de la cabecera del paquete SIP, encontradas en el archivo Muestras_SIP_call_ID.txt. A su vez, se
realizará el análisis de las salidas del algoritmo con dichas entradas, encontradas en el archivo
Encryption_keys_SIP_call_ID.txt.
Toda la información generada por el programa que aplica las pruebas del NIST se encuentra en los anexos
de este documento.
5.3.1 “SIP_call_ID” básico
5.3.1.1 Prueba de frecuencia en bloques
Aplicando la prueba de frecuencia en bloques de longitud de 8 bits para cada secuencia, esto es 16 bloques
por secuencia, se obtuvo que ninguno tuviese un P-valor mayor que 0.01, es decir, ningún bloque presenta
aproximadamente el mismo número de bits en 1 y 0.
5.3.1.2 Prueba de la carrera en bloques
En esta prueba se divide cada secuencia en 16 bloques de 8 bits cada uno; así, se determina la prueba de la
carrera para cada una. En esta prueba se inspecciona que los resultados de oscilaciones en las sub-
secuencias sea aproximadamente el mismo que se esperaría al dividir una secuencia aleatoria y analizarla
por bloques.
Para este caso se encontró, que ninguna secuencia tuviera un P-valor mayor que 0.01, es decir, ninguna
secuencia parece ser aleatoria.
5.3.1.3 Sumas acumuladas hacia adelante (forward)
En la prueba de sumas acumuladas hacia adelante, se suman los bits de las secuencia empezando por el
primero y aumentando uno cada vez, hasta llegar al bit en la posición 128. En este caso los bits en cero se
convierten en (-1) y así al final de la suma sacando el valor absoluto, se identifica si hay muchos unos o
ceros en las primeras etapas de la secuencia. De dicha manera se compara si la secuencia tiene el número
de suma acumulada que se espera obtener en las primeras etapas de una secuencia realmente aleatoria.

62
Para este caso, se encontró que ninguna de las secuencias presentaba las características de una secuencia
aleatoria, obteniendo P-valores menores que 0.01 en todos los casos.
5.3.1.4 Sumas acumuladas hacia atrás (reverse)
En la prueba de sumas acumuladas hacia atrás, se suman los bits de las secuencia empezando por el último
y disminuyendo uno cada vez, hasta llegar al bit en la posición 1. En este caso los bits en cero se
convierten en (-1) y así al final de la suma, sacando el valor absoluto, se identifica si hay muchos unos o
ceros en las últimas etapas de la secuencia. De dicha manera, se compara si la secuencia tiene el número
de suma acumulada que espera obtener en las últimas etapas de una secuencia realmente aleatoria.
Para este caso se encontró que ninguna de las secuencias presentaba las características de una secuencia
aleatoria, obteniendo P-valores menores que 0.01 en todos los casos.
5.3.1.5 Prueba de la FFT
En esta prueba se analizan los componentes en frecuencia de las secuencias. Si más del 5% de los picos
de la señal son superiores al umbral calculado, se esperaría que la secuencia no sea aleatoria.
Para este caso se analizó solo 1 secuencia de 128000 bits, es decir, se concatenaron las 1000 muestras de
128 bits utilizadas para las pruebas descritas anteriormente. En los resultados se obtuvo que el P-valor es
menor que 0.01, es decir, no presenta características de aleatoriedad frente a esta prueba.
5.3.2 “Encryption_key” generado por “SIP_call_ID” básico
5.3.2.1 Prueba de frecuencia en bloques
Para este caso se obtuvo que 990 de las 1000 secuencias presentan un P-valor mayor que 0.01, es decir,
para esta prueba solo 10 secuencias no presentan características aleatorias, cuando estas son analizadas por
bloques de 8 bits. Se puede observar la efectividad del algoritmo respecto a la característica de
aleatoriedad que presenta esta prueba ya que todas las secuencias antes de ser procesadas por el algoritmo
fallaron, y después de ser procesadas pasaron en un alto porcentaje.
5.3.2.2 Prueba de la carrera en bloques
Analizando las secuencias por bloques, se encontró que 988 del conjunto total de las secuencias presentan
buenas características respecto a esta prueba, dejando 12 secuencias bajo la conclusión de no aleatoriedad.
La efectividad del algoritmo se puede evidenciar en esta prueba, ya que todas las secuencias antes de ser
procesadas por el algoritmo fallaron, y después de ser procesadas pasaron en un alto porcentaje.
5.3.2.3 Sumas acumuladas hacia adelante (forward)
En esta prueba, gracias al funcionamiento del algoritmo, la totalidad de las secuencias de salida tienen el
número de sumas acumuladas esperadas en las primeras etapas de una secuencia aleatoria. Es importante
aclarar cómo antes de que las secuencias sean procesadas por el algoritmo, ninguna secuencia pasa esta
prueba, y después de ser aplicadas las transformaciones a las secuencias, todas presentan las
características necesarias para obtener P-valor mayor que 0.01.
5.3.2.4 Sumas acumuladas hacia atrás (reverse)
En esta prueba, gracias al funcionamiento del algoritmo, la totalidad de las secuencias de salida tienen el
número de sumas acumuladas esperadas en las últimas etapas de una secuencia aleatoria. Es importante
aclarar cómo antes de que las secuencias sean procesadas por el algoritmo, ninguna secuencia pasa esta

63
prueba, y después de ser aplicadas las transformaciones a las secuencias, todas presentan las
características necesarias para obtener P-valor mayor que 0.01.
5.3.2.5 Prueba de la FFT
Para esta muestra tomada de las salidas del algoritmo, cuando las entradas son “SIP_call_ID” básicas, se
obtuvo un P-valor mayor que 0.01, indicando que no se generan cadenas periódicas.
5.3.3 “SIP_call_ID” tomado de cabecera del paquete SIP
5.3.3.1 Prueba de frecuencia en bloques
Aplicando la prueba de frecuencia en bloques de longitud de 8 bits para cada secuencia, esto es 16 bloques
por secuencia, se obtuvo, que solo 5 de la totalidad de las muestras presentan un P-valor menor que 0.01.
5.3.3.2 Prueba de la carrera en bloques
Cuando se analiza la prueba de la carrera dividiendo cada secuencia en bloques, para el caso de estas
muestras se obtuvo que 14 tienen un P-valor menor que 0.01, por lo que se analiza que a pesar de no ser
un porcentaje muy alto de secuencias fallidas, para ser un generador de interno el que las produce, debería
estar más cercano a que la totalidad de las muestras presenten buenas características frente a esta prueba.
5.3.3.3 Sumas acumuladas hacia adelante (forward)
En la prueba de sumas acumuladas hacia adelante, se encontró que 4 de la totalidad de las secuencias no
presentan las características de una secuencia aleatoria, obteniendo P-valores menores que 0.01.
5.3.3.4 Sumas acumuladas hacia atrás (reverse)
En la prueba de sumas acumuladas hacia atrás, se encontró que 3 de la totalidad de las secuencias no
presentan las características de una secuencia aleatoria, obteniendo P-valores menores que 0.01.
5.3.3.5 Prueba de la FFT
Para este caso se analizó la secuencia de 128000 bits, compuesta por las 1000 muestras obtenidas de las
cabeceras de los paquetes SIP analizados. En los resultados se obtuvo que el P-valor es menor que 0.01,
es decir, no presenta características de aleatoriedad frente a esta prueba.
5.3.4 “Encryption_key” generado por “SIP_call_ID” tomado de cabecera del paquete SIP
5.3.4.1 Prueba de frecuencia en bloques
En la prueba de frecuencia por bloques, se obtuvo que todas las muestras presentan las características de
aleatoriedad deseadas, con lo que se sigue corroborando la efectividad del algoritmo al pasar de 5
secuencias fallidas en las muestras de entrada a ninguna en la salida.
5.3.4.2 Prueba de la carrera en bloques
Cuando se analiza la prueba de la carrera dividiendo cada secuencia en bloques, para el caso de estas
muestras se evidencia la efectividad del algoritmo ya que solo 5 no pasaron la prueba.

64
5.3.4.3 Sumas acumuladas hacia adelante (Forward)
Para esta prueba la totalidad de las muestras presentaron P-valor mayor que 0.01, es decir, todas tienen el
número de sumas acumuladas esperadas en las primeras etapas de una secuencia idealmente aleatoria.
5.3.4.4 Sumas acumuladas hacia atrás (Reverse)
Para esta prueba la totalidad de las muestras presentaron P-valor mayor que 0.01, es decir, todas tienen el
número de sumas acumuladas esperadas en las últimas etapas de una secuencia idealmente aleatoria.
5.3.4.5 Prueba de la FFT
En este caso se analizó la secuencia de 128000 bits, compuesta por las 1000 muestras obtenidas a la salida
del algoritmo, cuando las entradas son las muestras del parámetro “Call-ID”. En los resultados se obtuvo
que el P-valor es mayor que 0.01, indicando que no se generan cadenas periódicas.
Los resultados obtenidos a partir de las muestras básicas se exponen en la siguiente tabla:
MUESTRAS PRUEBA
SIP_call_ID_basico
Encryption_keys_SIP_call_ID_basico
Frecuencia en Bloques (M=8) 0/1000 990/1000
Carrera en bloque (M=8) 0/1000 988/1000
Sumas acumuladas (Forward) 0/1000 1000/1000
Sumas acumuladas (Reverse) 0/1000 1000/1000
FFT (Transformada de Fourier) 0/1 1/1
Tabla 3. Resultados NIST muestras básicas
Los resultados obtenidos a partir de las muestras de utilizando el parámetro “Call-ID” se exponen en la
siguiente tabla:
MUESTRAS PRUEBA
SIP_call_ID
Encryption_keys_SIP_call_ID
Frecuencia en Bloques (M=8) 995/1000 1000/1000
Carrera en bloques (M=8) 986/1000 995/1000
Sumas acumuladas (Forward) 996/1000 1000/1000
Sumas acumuladas (Reverse) 997/1000 1000/1000
FFT (Transformada de Fourier) 0/1 1/1
Tabla 4. Resultados NIST muestras Call-ID
Como se expuso en el marco teórico en la sección 2.4.1, de este documento, las pruebas de aleatoriedad
del NIST presentan distintas formas de analizar la aleatoriedad en una secuencia. A su vez, no existe
predominancia de una prueba sobre otra. El NIST recomienda realizar el análisis de las 15 pruebas que se
presentan en [13].
Como se exponía en la sección 2.4.1, las demás pruebas del NIST: Rango de la matriz binaria, No
solapamiento de patrón, Solapamiento de patrón, Estadística Universal de Maurer, Complejidad lineal,

65
Entropía aproximada, Excursiones aleatorias y Excursión de la variante aleatoria, no son aplicables para
este proyecto debido a que el tamaño de la llave definido para este trabajo de grado (128 bits) es menor a
las especificaciones descritas para estas pruebas en [13]. Igualmente las pruebas de Frecuencia y de la
Carrera no fueron incluidas porque se centró el análisis en la prueba de Frecuencia en bloques y Carrera
en bloques.
Dentro de las pruebas expuestas, se pueden observar características muy importantes sobre el
funcionamiento y efectividad del algoritmo. Al analizar los resultados de las salidas del sistema
“Encryption_key”, se obtuvo para todos los casos la proporción mínima necesaria para que el conjunto de
pruebas analizadas sea válido. Como se exponía en la sección 3.9.2, para realizar una aproximación de la
distribución binomial, se concluía que mínimo se debían analizar 1000 secuencias generadas por el
algoritmo, así como que la proporción mínima debe ser de 980 secuencias con buenas características
dentro de cada prueba, esto es, solo 20 pueden tener P-valor menor que el nivel de significancia (0.01).
Con este nivel de significancia, se afirma que los resultados acá expuestos tiene una fiabilidad del 99%,
porcentaje requerido dentro de las aplicaciones en criptografía.
6. CONCLUSIONES
I. Este trabajo contribuye de manera significativa a la criptografía en lo referente a la generación de
llaves de cifrado de manera pseudo-aleatoria, donde el esquema basado en la dinámica evolutiva
descrita por Charles Darwin y plasmado por Jhon Holland en la técnica de inteligencia artificial,
algoritmos genéticos, resulta ser viable respecto a las pruebas de aleatoriedad del NIST y su
aplicación dentro del protocolo ZRTP.
II. Gracias a la convergencia al valor límite especificado para la función objetivo, se alcanzaron
resultados óptimos donde el uso de la prueba del NIST, Sumas acumuladas, fue de gran
importancia para alcanzar los objetivos del proyecto.
III. El requerimiento de tiempo de ejecución, delimitado por el establecimiento de la comunicación
utilizando el protocolo ZRTP, fue uno de los retos más grandes de este proyecto. Esto debido a
que la velocidad del algoritmo estaba sujeta al uso de un procesador con características básicas,
como el que se utiliza en un entorno de usuario final.
IV. Los resultados obtenidos de las pruebas de aleatoriedad del NIST tienen una fiabilidad del 99%, y
son satisfactorios y coherentes con el diseño del algoritmo. Al realizar el análisis de las salidas
del algoritmo, cuando las entradas son muestras básicas que presentan sólo algunos bits con valor
uno y los demás cero, se obtuvieron resultados positivos validando que bajo dichas condiciones, el
funcionamiento del algoritmo es apropiado. Así mismo, cuando las entradas son muestras
tomadas de la cabecera del paquete SIP con el parámetro “Call-ID”, se pudo observar cómo las
salidas obtenidas alcanzan resultados óptimos en todas las pruebas analizadas.
V. El uso de algoritmos genéticos es amplio dentro de aplicaciones como optimización,
programación automática, economía, ecología y sistemas sociales. De modo que con este trabajo
de grado, se abre un campo poco explorado en su aplicación en la generación de números pseudo-
aleatorios dentro del contexto criptográfico para comunicaciones por VoIP.
VI. Como futuras investigaciones, se formula ampliar la longitud de las secuencias de las llaves
generadas por el algoritmo, y así realizar un análisis válido de las pruebas del NIST que no
aplicaron para el presente trabajo de grado.

66
A su vez, se propone que se realice la implementación del algoritmo en un Softphone, donde se
pueda analizar el comportamiento del mismo en una comunicación real establecida por medio del
protocolo ZRTP.
Por último, se plantea explorar el uso del algoritmo genético desarrollado, dentro de un esquema
en el que sea posible realizar una autenticación segura al utilizar el protocolo ZRTP.
7. BIBLIOGRAFÍA
[1] P. Gupta and V. Shmatikov, “Security Analysis of Voice-over-IP Protocols”, IEEE Computer Security
Foundations Symposium (CSF'07), 2007.
[2] P. Zimmermann, A. Johnston, Avaya and J. Callas, “ZRTP: Media Path Key Agreement for Unicast
Secure RTP”, RFC 6189, Abril 2011.
[3] N. Joyshree and D. Debanjan, “An Integrated Symmetric key Cryptography Algorithm using
Generalised modified Vernam Cipher method and DJSA method: DJMNA symmetric key algorithm”,
2011.
[4] D. Rui, “From Charles Darwin to Evolutionary Genetic Algorithms”, Lisboa Science Academy, Mayo
2009.
[5] A. Menezes, P. van Oorschot, and S. Vanstone, “Handbook of Applied Cryptography”, MIT Press,
1996.
[6] N. Nalini and G. Raghavendra, “A New Encryption and Decryption algorithm combining the features
of Genetic Algorithm and Cryptography”, International Conference on Cognitive Systems, Diciembre
2004.
[7] S. Goyat, “Genetic Key Generation for Public Key Criptography”, International Journal of Soft
Computing and Engineering Department of computer science and applications, Julio 2012.
[8] E. Halm and M. Helvensteijm, Leiden University, “The low autocorrelation problem-A genetic
algorithm approach”, Diciembre 2007.
[9] D. Goldberg, “Genetic Algorithm in Search, Optimization, and Machine Laerning”, Universidad de
Alabama, Addison-Wesley, Enero 1989.
[10] M. Luna, “Charles Darwin y el Natura Non Facit Saltus”, Departamento de Filosofía y Lógica,
Universidad de Sevilla, 1995.
[11] M. Baugher, D. McGrew, M. Naslund, E. Carrara, K. Norrman, “SRTP: The Secure Real-time
Transport Protocol (SRTP)”, RFC 3711, Marzo 2004.
[12] M. Donado, “Análisis de la decorrelación de datos cifrados, aplicado al criptoanálisis forense”,
Departamento Ingeniería Electrónica, Pontificia Universidad Javeriana, Enero 2010.
[13] A. Rukhin, J. Soto, J. Nechvatal, M. Smid, E. Barker, S. Leigh, M. Levenson, M. Vangel, D. Banks,
A. Heckert, J. Dray and S. Vo, Computer Security Division, Statistical Engineering Division, Information
Technology Laboratory, NIST, U.S Department of commerce, Abril 2010.

67
[14] A.Caro, F. Lopéz, J. Ortiz, “Control multivariable para un helicóptero de dos grados de libertad
utilizando algoritmos genéticos”, Departamento Ingeniería Electrónica, Pontificia Universidad Javeriana,
Julio 2005.
[15] M. Martorell, “Criptología” Departamento de Telecomunicaciones, Universidad Politécnica de
Mataró.
[16] C. Kenny, “Random Number Generators: An Evaluation and Comparison of Random.org and some
Commonly Used Generators”, Departamento de Ciencias de la computación, Trinity College Dublin,
Abril 2005.
[17] K. Saluja, “Linear Feedback Shift Registers Theory and Applications”, Departamento de Ingeniería
de Sistemas y Eléctrica, Universidad de Wisconsin, Madison, 1991.
[18] J. Daemen, V. Rijmen, “AES Proposal: Rijndael”, Proton World Intl., Universidad Católica de
Leuven, Bélgica, Septiembre 1999.
[19] J. Rosenberg, H. Schulzrinne, G. Camarillo, A. Johnston, J. Peterson, R. Sparks, M. Handley, E.
Schooler, “SIP: Session Initiation Protocol”, RFC 3261, Junio 2002.
[20] C. Starr and R. Taggart, “Biología, La unidad y la diversidad de la vida,” 2007.
8. ANEXOS
[1] Código fuente del algoritmo genético. (CD del proyecto).
[2] Muestras empleadas. (CD del proyecto).
[3] Llaves de cifrado obtenidas a partir de las muestras empleadas. (CD del proyecto).
[4] Resultados pruebas del NIST. (CD del proyecto).





























