Embed Size (px)
Citation preview

Mozcソースコード徹底解説
#tokyotextmining
@nokuno

Twitter: @nokuno
はてな:id:nokuno
自然言語処理勉強会を主催
PRML/R/Python/Hadoopなど
自己紹介 2
2002~2006:コミケで同人ゲーム売ってた2007~2008:未踏でSocial IMEの開発2009~現在:Web業界勤務

Mozcのアーキテクチャ
統計的かな漢字変換エンジンの原理
コンバータ層の設計
辞書圧縮の技術
学習機能の実装
予測変換のアルゴリズム
今日の話題 3

OSS版は変換エンジンとLinuxクライアントのみ
Web由来の辞書とWindowsクライアントは非公開
Google日本語入力とMozc 4
Data
Client
ConverterRenderer
Client Client
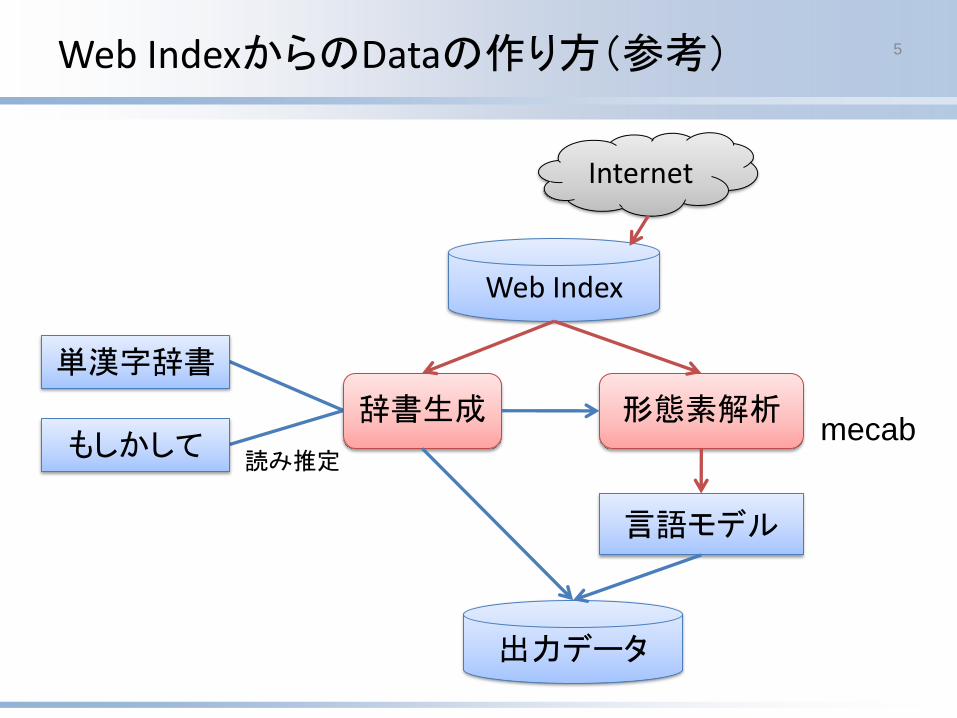
Web IndexからのDataの作り方(参考) 5
Web Index
言語モデル
単漢字辞書
もしかして
出力データ
形態素解析辞書生成
読み推定
Internet
mecab
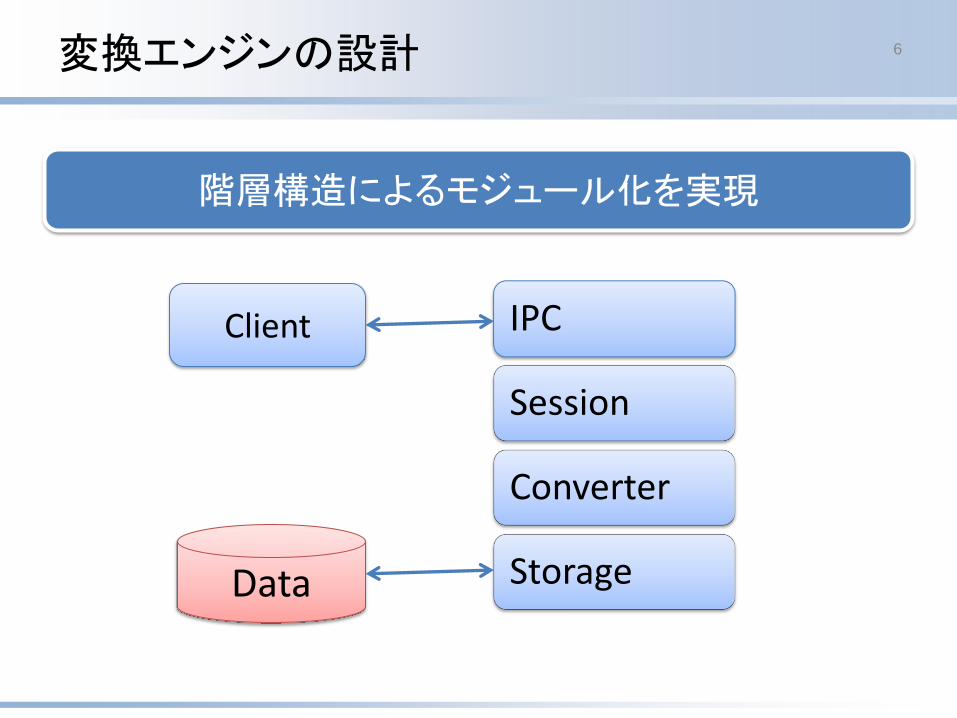
階層構造によるモジュール化を実現
変換エンジンの設計 6
IPC
Session
Converter
StorageData
Client

全体で11万行くらいのC++コード
ソースコード:全体像 7
$ ls
DEPS* build_mozc.py* client/ converter/ debian/ gui/ ipc/
net/ protobuf/ server/ storage/ third_party/ unix/
base/ build_tools/ composer/ data/ dictionary/ gyp/
mozc_version_template.txt* prediction/ rewriter/ session/ testing/
transliteration/ usage_stats/
$ wc **/*.cc **/*.h
(中略)117164 397237 4078068 合計

言語モデル:クラスbigram
Viterbiアルゴリズム・Lattice構造
品詞情報を使って文節にまとめ上げ
文節内の候補にNベスト解探索
かな漢字変換としてはオーソドックスな設計
コンバーター層 8

言語モデルとかな漢字モデルに分解
確率モデルによる仮名漢字変換
)|(maxargˆ yxPxx
x :出力する変換候補:入力の読みy
c.f.ベイズの定理)|()(maxarg xyPxPx
P(x):確率的言語モデルxの日本語らしさ
P(y|x):確率的かな漢字モデルxの読みがyである確率
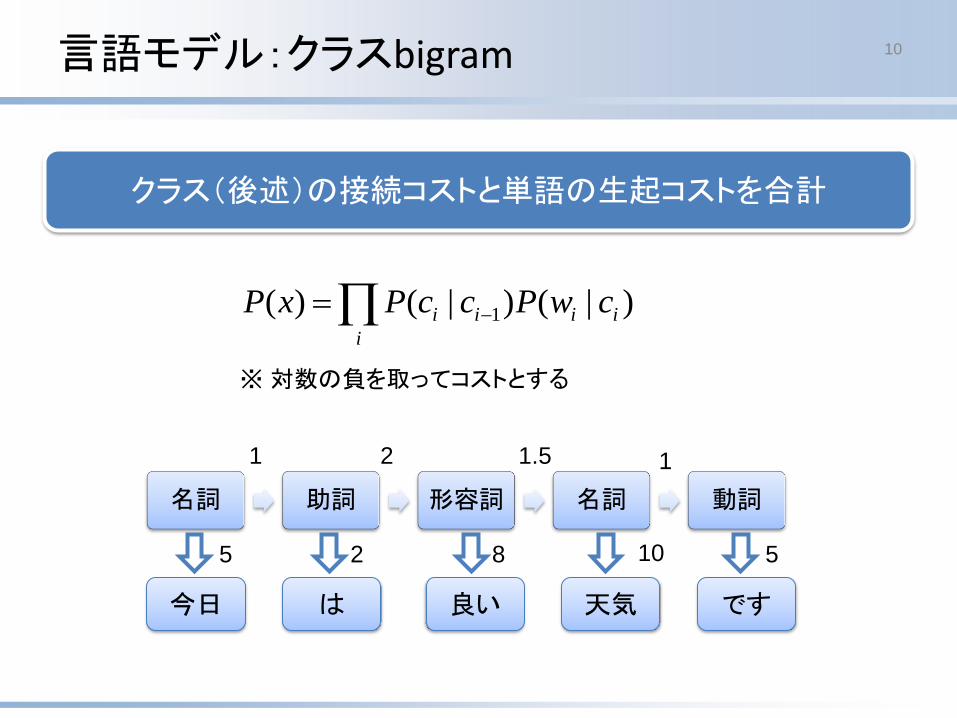
クラス(後述)の接続コストと単語の生起コストを合計
言語モデル:クラスbigram 10
i
iiii cwPccPxP )|()|()( 1
名詞 助詞 形容詞 名詞 動詞
1 2 1.5 1
5 2 8 10 5
今日 は 良い 天気 です
※対数の負を取ってコストとする

品詞
IPAdicの品詞体系
文節区切りやヒューリスティックな処理に品詞は必須
単語クラスタリング
同じ品詞の単語をいくつかのグループにクラスタリング
語彙化
助詞や助動詞などの頻度の高い単語をクラスに昇格
クラスタリングと語彙化のテクニックで粒度を調節
言語モデル:クラス定義 11

ソースコード:辞書ファイル 12
<data/dictionary/dictionary0.txt>
すげのたに 2305 2305 6668 菅谷りょうすけ 2303 2303 5113 良輔みずな 2239 2239 5813 水菜へいだん 2239 2239 10974 併談あじきなけりゃ 2612 2612 9871 あじきなけりゃいきづまろ 1331 1331 7519 行き詰ろつづらおり 2239 2239 9456 葛折あいのさとしじょう 2305 2305 7623 あいの里四条しつり 2304 2304 7979 志津利あですがた 2239 2239 8931 あで姿
$ cat dictionary*.txt | sort -nk 4,4 | head
あ 1022 1022 0 ああ 1974 1974 0 ああい 2220 2220 0 あいあい 2227 2227 0 合いあう 2182 2182 0 あうあう 2190 2190 0 合うあえ 2164 2164 0 あえあえ 2171 2171 0 合えあえ 2173 2173 0 あえあえ 2180 2180 0 合え
よみ左ID 右ID コスト 表記
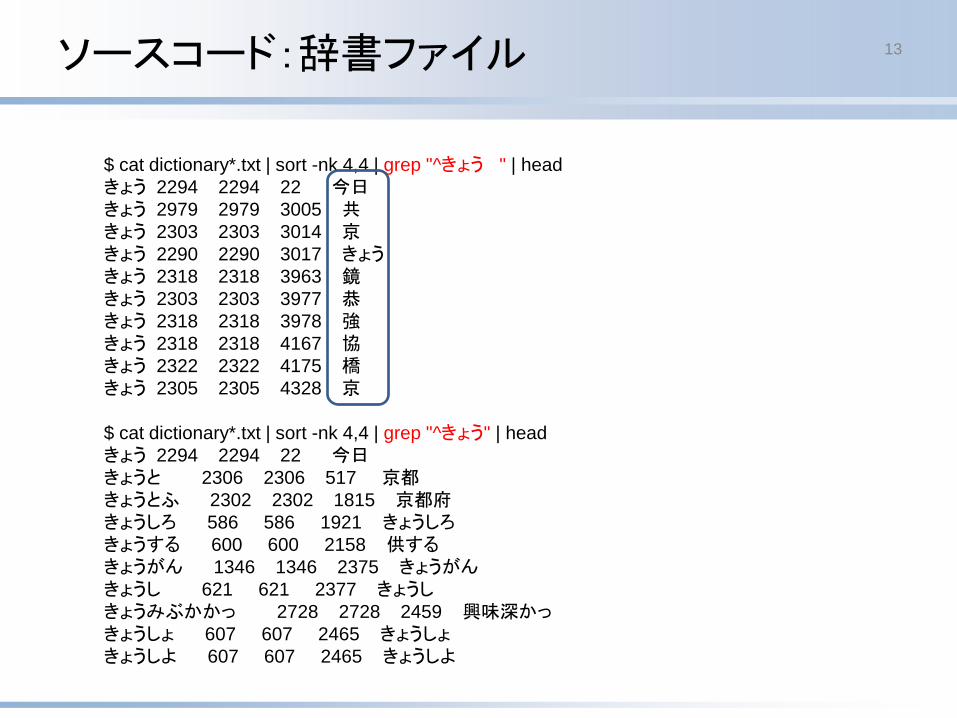
ソースコード:辞書ファイル 13
$ cat dictionary*.txt | sort -nk 4,4 | grep "^きょう " | head
きょう 2294 2294 22 今日きょう 2979 2979 3005 共きょう 2303 2303 3014 京きょう 2290 2290 3017 きょうきょう 2318 2318 3963 鏡きょう 2303 2303 3977 恭きょう 2318 2318 3978 強きょう 2318 2318 4167 協きょう 2322 2322 4175 橋きょう 2305 2305 4328 京
$ cat dictionary*.txt | sort -nk 4,4 | grep "^きょう" | head
きょう 2294 2294 22 今日きょうと 2306 2306 517 京都きょうとふ 2302 2302 1815 京都府きょうしろ 586 586 1921 きょうしろきょうする 600 600 2158 供するきょうがん 1346 1346 2375 きょうがんきょうし 621 621 2377 きょうしきょうみぶかかっ 2728 2728 2459 興味深かっきょうしょ 607 607 2465 きょうしょきょうしよ 607 607 2465 きょうしよ

ソースコード:言語モデル 14
<data/dictionary/id.def>
2301 名詞,固有名詞,一般,*,*,*,*
2302 名詞,固有名詞,人名,一般,*,*,*
2303 名詞,固有名詞,人名,名,*,*,*
2304 名詞,固有名詞,人名,姓,*,*,*
4 副詞,一般,*,*,*,*,1
5 副詞,一般,*,*,*,*,2
6 副詞,一般,*,*,*,*,3
7 副詞,一般,*,*,*,*,4
432 動詞,接尾,*,*,一段,未然ウ接続,られる433 動詞,接尾,*,*,一段,未然ウ接続,れる434 動詞,接尾,*,*,一段,未然形,させる435 動詞,接尾,*,*,一段,未然形,しめる
<data/dictionary/connection.txt>
0 0 14936
0 1 6195
0 2 3024
0 3 4978
0 4 4759
0 5 3326
左クラスID右クラスID 接続コスト
クラスID 品詞(CSV)
クラスタ番号
語彙化
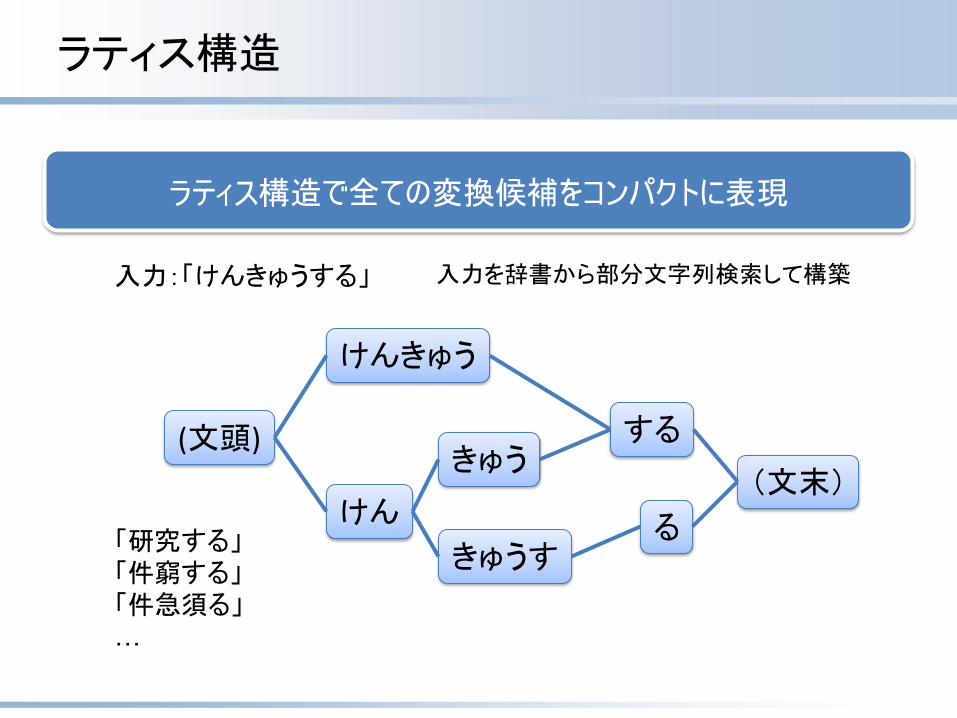
ラティス構造で全ての変換候補をコンパクトに表現
ラティス構造
けんきゅう
(文頭)
けん
きゅうす
きゅうする
る
(文末)
入力:「けんきゅうする」
「研究する」「件窮する」「件急須る」…
入力を辞書から部分文字列検索して構築
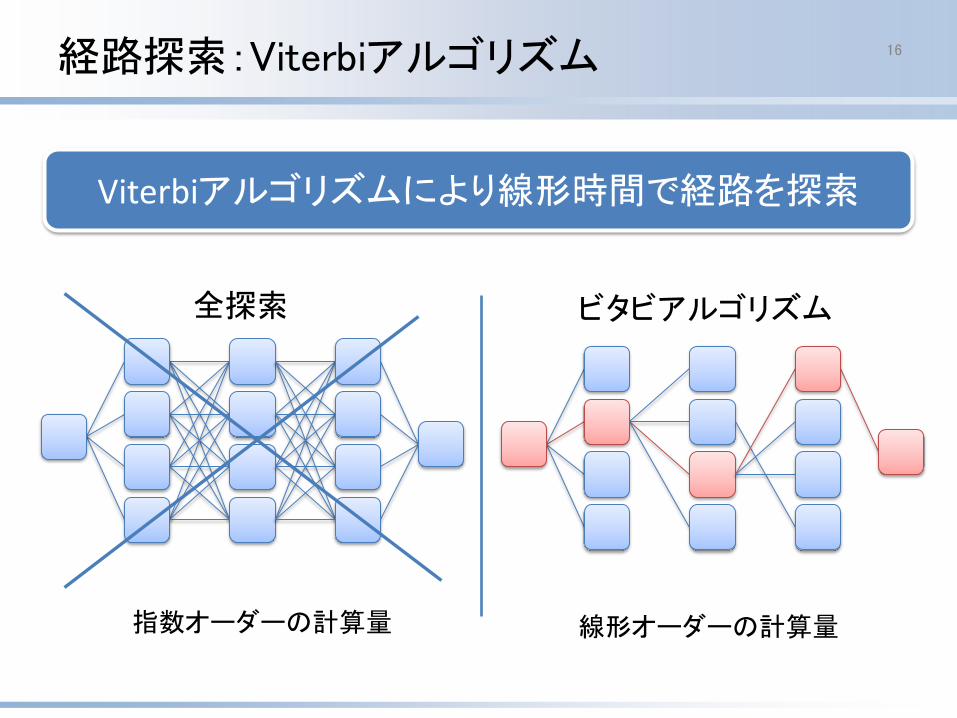
Viterbiアルゴリズムにより線形時間で経路を探索
経路探索:Viterbiアルゴリズム 16
指数オーダーの計算量 線形オーダーの計算量
全探索 ビタビアルゴリズム

ソースコード:Viterbiアルゴリズム 17
フォワード再帰
バックトラック
<converter/immutable_converter.cc>
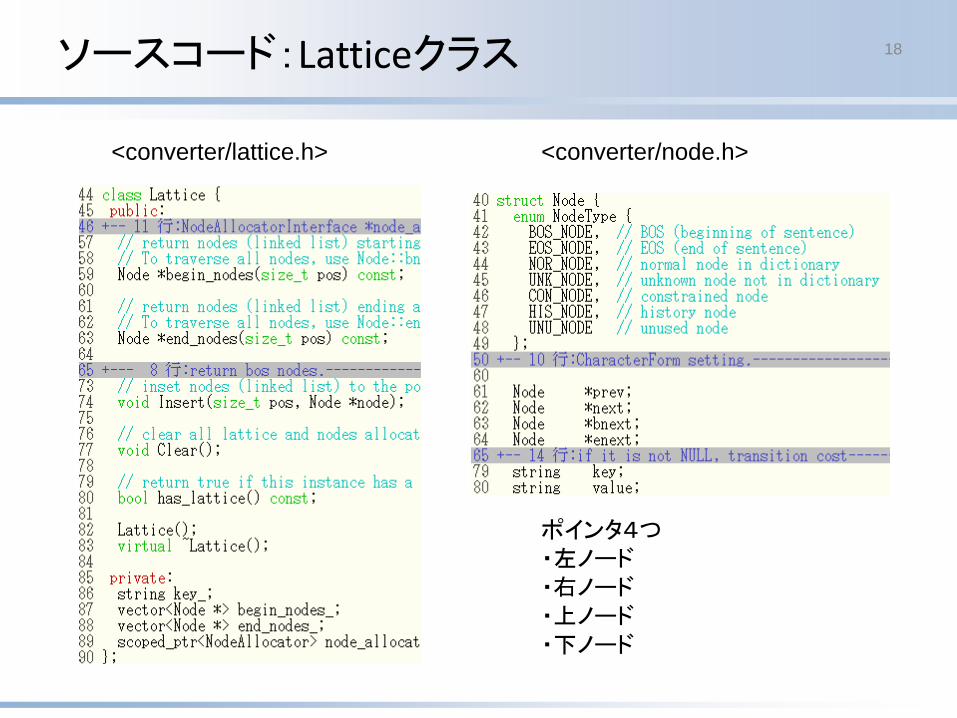
ソースコード:Latticeクラス 18
<converter/lattice.h> <converter/node.h>
ポインタ4つ・左ノード・右ノード・上ノード・下ノード

LOUDSによるコンパクトなTrieインデックス
ハフマンコーディングによるバリューの圧縮
接続コスト格納のための疎行列の圧縮
NG語彙フィルタのためのBloom Filter
LRU(Least Resently Used)キャシュ
メモリ消費量を最小限に抑えるよう工夫
ストレージ層 19
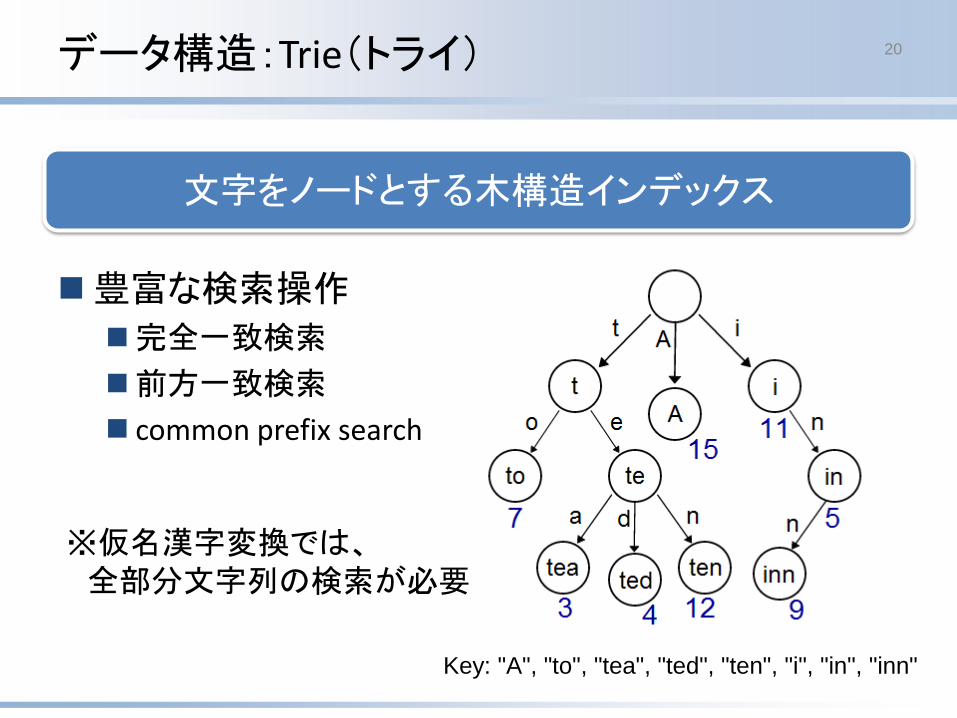
豊富な検索操作
完全一致検索
前方一致検索
common prefix search
文字をノードとする木構造インデックス
データ構造:Trie(トライ) 20
Key: "A", "to", "tea", "ted", "ten", "i", "in", "inn"
※仮名漢字変換では、全部分文字列の検索が必要

ビット配列で木構造をコンパクトに表現
データ構造:LOUDS 21
a
b c
d e
f
g h
i
a b c d e f g h i
10 11110 0 110 0 10 0 0 10 0
※ノード数*2+1 = 19ビットで表現
実際には補助インデックスも必要
ソースコード:LOUDS 22
<third_party/rx/v1_0rc2/rx.c>
←キモイ(tx読んだほうが…)
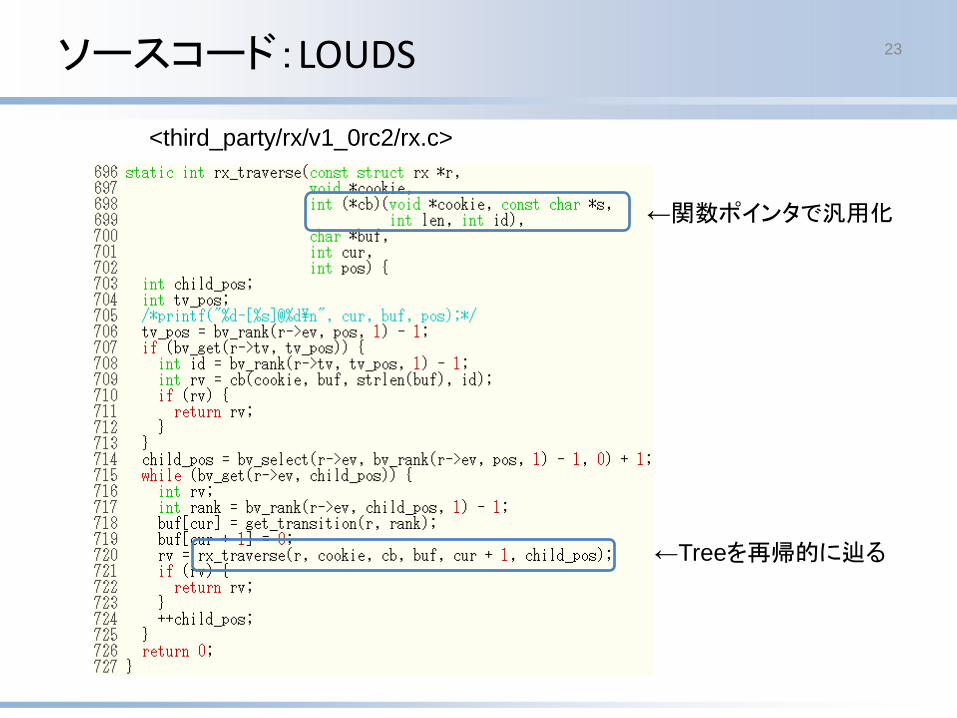
ソースコード:LOUDS 23
<third_party/rx/v1_0rc2/rx.c>
←関数ポインタで汎用化
←Treeを再帰的に辿る

学習機能(文節区切り、文節内の順序)
共起コーパスの反映
数字、単漢字、記号変換機能
日付変換機能、顔文字変換機能、電卓機能
福笑い機能、おみくじ機能
様々なヒューリスティックをRewriterで実装
Rewriter候補の書き換え 24
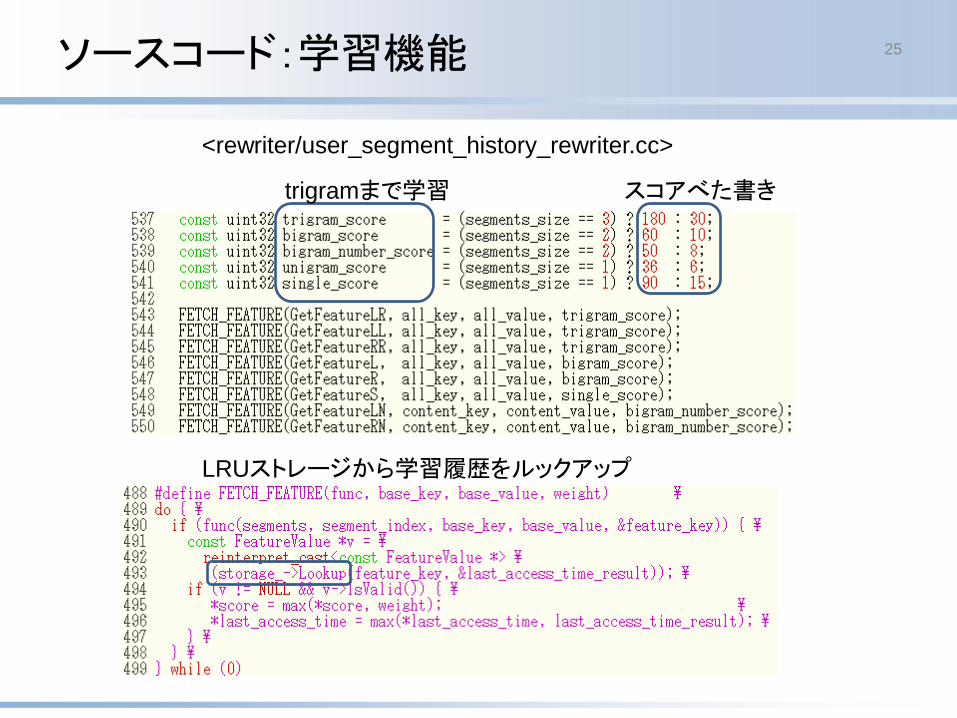
ソースコード:学習機能 25
スコアべた書き
LRUストレージから学習履歴をルックアップ
trigramまで学習
<rewriter/user_segment_history_rewriter.cc>

ソースコード:イースターエッグ 26
<rewriter/emoticon_rewriter.cc>
<rewriter/fortune_rewriter.cc> <rewriter/number_rewriter.cc>
←「おみくじ」機能
←「ふくわらい」機能
↑「Googol」機能
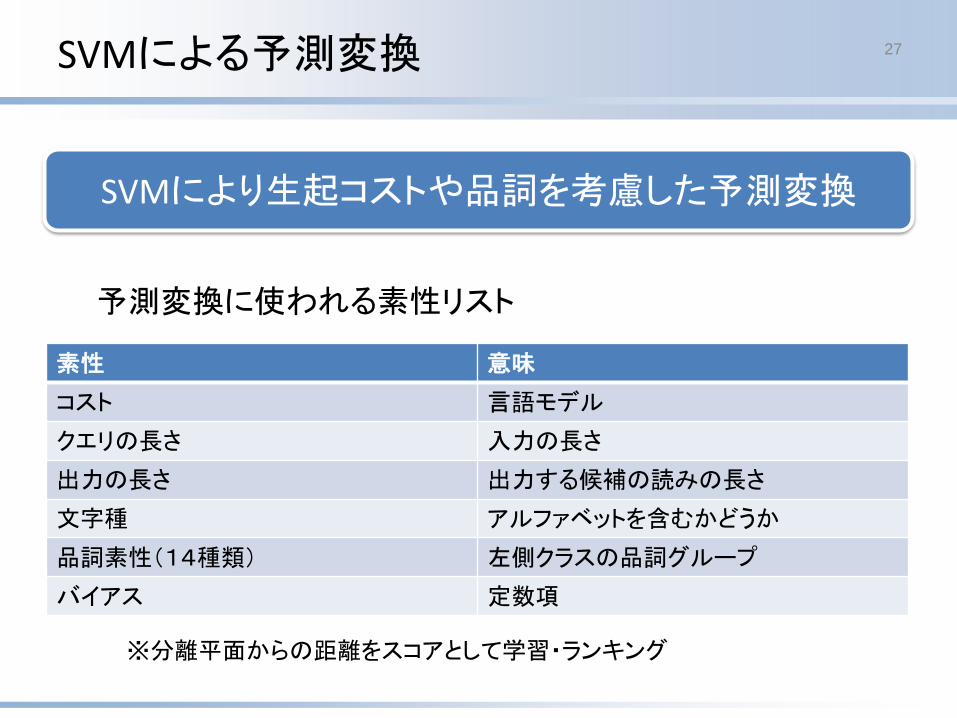
SVMにより生起コストや品詞を考慮した予測変換
SVMによる予測変換 27
素性 意味
コスト 言語モデル
クエリの長さ 入力の長さ
出力の長さ 出力する候補の読みの長さ
文字種 アルファベットを含むかどうか
品詞素性(14種類) 左側クラスの品詞グループ
バイアス 定数項
予測変換に使われる素性リスト
※分離平面からの距離をスコアとして学習・ランキング

ソースコード:予測変換 28
<prediction/dictionary_predictor.cc>
<prediction/user_history_predictor.cc>
オフセット+品詞グループID
仮名漢字変換と予測変換は辞書を共有している
予測にだけ出したくない候補を動的にフィルタリング
Bloom Filterにより高速かつ省メモリに実装
予測変換に出さない候補をフィルタリング
Bloom Filter 29

Google日本語入力で絶対サジェストされない単語
パチンコ
フェラーリ
ピエロ
例:Bloom Filter 30

Google日本語入力で絶対サジェストされない単語
パチンコ
フェラーリ
ピエロ
例:Bloom Filter 31
※変換はできるので辞書にないわけではない
IMEは「総合格闘技」
自然言語処理
機械学習
データ構造
データ圧縮
…
クライアントアプリならではの難しさも
統計的な手法とヒューリスティックの使い分け
まとめ 32