Embed Size (px)
Citation preview

STATISTICAL APPROACH TO
CLASSIFICATIONNaïve Bayes Classifier

Bayesian Classifier 2
Remember…
Red = 2.125
Yellow = 6.143
Mass = 134.32
Volume = 24.21
Apple
Sensors, scales, etc…
8/29/03

Bayesian Classifier 3
0 2 4 6 8
0.0
00
00
.00
05
0.0
01
00
.00
15
0.0
02
0
Distribution of Redness Values
Redness
De
nsi
ty
Fruit
ApplesPeachesOrangesLemons
Redness Let’s look at one dimension
For a given redness value which is the most probable fruit
8/29/03

Bayesian Classifier 4
Redness What if we wanted to ask the question
“what is the probability that some fruit with a given redness value is an apple?”
8/29/03
0 2 4 6 8
0.0
00
00
.00
05
0.0
01
00
.00
15
0.0
02
0
Distribution of Redness Values
Redness
De
nsi
ty
Fruit
ApplesPeachesOrangesLemons Could we just
look at how far away it is from the apple peak?
Is it the highest PDF above the X-value in question?

Bayesian Classifier 5
Redness of Apples and Oranges
Redness
1 2 3 4 5 6 7
05
01
00
15
02
00
25
0
Probability it’s an apple
If a fruit has a redness of 4.05 do we know the probability that it’s an apple?
What do we know?
8/29/03
• We know the total number of fruit at that redness (10+25)
• We know the fraction of apples at that redness (10)
• Probability that a fruit with a redness value of 4.05 is an apple is
• If it is a histogram of counts then it straight forward• Probability it’s an apple
28.57%• Probability it’s an orange
71.43%• Getting the probability is simple

Bayesian Classifier 6
But what if working PDF
Probability density function Continuous Probability not count Might be tempted
to use the same approach
8/29/03
0 2 4 6 8
0.0
00
00
.00
05
0.0
01
00
.00
15
0.0
02
0
Distribution of Redness Values
Redness
De
nsi
ty
Fruit
ApplesPeachesOrangesLemons
P(a fruit with redness 4.05 is apple)?=
Parametric ( and parameters)
vs. non-parametric

Bayesian Classifier 7
Problem
What if had trillion oranges and only 100 apples
Might be the most common apple and have a higher value at 4.05 than oranges even though the universe would have way more oranges at that value
8/29/03
0 2 4 6 8
0.0
00
00
.00
05
0.0
01
00
.00
15
0.0
02
0
Distribution of Redness Values
Redness
De
nsi
ty
Fruit
ApplesPeachesOrangesLemons
Wouldn’t change the PDFsbut…

Bayesian Classifier 8
Redness of Apples and Oranges
Redness
1 2 3 4 5 6 7
05
01
00
15
02
00
25
0
Let’s revisit but using probabilities instead of counts
2506 apples 2486 oranges If a fruit has a
redness of 4.05 do we know the probability that it’s an apple if we don’t have specific counts at 4.05?
8/29/03
Conditional Probability
If we know it is an apple, then the…But what we want

Bayesian Classifier 9
Bayes Theorem
8/29/03
Above from the book h is hypothesis, D is training Data
𝑃 (h|𝐷 )=𝑃 (𝐷|h ) 𝑃 (h)
𝑃 (𝐷)
𝑃 (𝑎𝑝𝑝𝑙𝑒|𝑟𝑒𝑑𝑛𝑒𝑠𝑠=4.05 )=𝑃 (𝑟𝑒𝑑𝑛𝑒𝑠𝑠=4.05|𝑎𝑝𝑝𝑙𝑒 )𝑃 (𝐴𝑝𝑝𝑙𝑒)
𝑃 (𝑅𝑒𝑑𝑛𝑒𝑠𝑠=4.05)
Does this make sense?
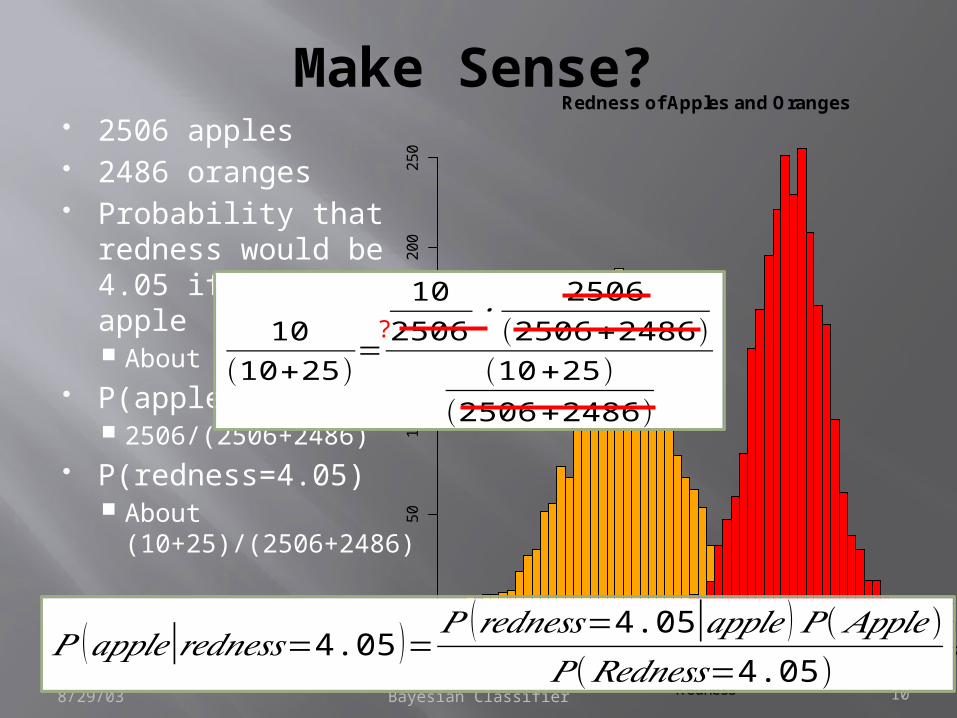
Bayesian Classifier 10
Redness of Apples and Oranges
Redness
1 2 3 4 5 6 7
05
01
00
15
02
00
25
0
Make Sense? 2506 apples 2486 oranges Probability that
redness would be 4.05 if know an apple About 10/2506
P(apple)? 2506/(2506+2486)
P(redness=4.05) About
(10+25)/(2506+2486)
8/29/03
𝑃 (𝑎𝑝𝑝𝑙𝑒|𝑟𝑒𝑑𝑛𝑒𝑠𝑠=4.05 )=𝑃 (𝑟𝑒𝑑𝑛𝑒𝑠𝑠=4.05|𝑎𝑝𝑝𝑙𝑒 )𝑃 (𝐴𝑝𝑝𝑙𝑒)
𝑃 (𝑅𝑒𝑑𝑛𝑒𝑠𝑠=4.05)
10(10+25)
=
102506
∙2506
(2506+2486)(10+25)
(2506+2486)
?

Bayesian Classifier 11
Can find the probability
Whether have counts or PDF How do we classify?
Simply find the most probable class
8/29/03
h=argmaxh∈𝐻
𝑃 (h∨𝐷)

Bayesian Classifier 12
Bayes
I think of the ratio of P(h) to P(D) as an adjustment to the easily determined P(D|h) in order to account for differences in sample size
8/29/03
𝑃 (h|𝐷 )=𝑃 (𝐷|h ) 𝑃 (h)
𝑃 (𝐷)
Prior Probabilities or Priors
Posterior Probability

Bayesian Classifier 13
MAP Maximum a posteriori hypothesis (MAP)
ä-(ˌ)pō-ˌstir-ē-ˈor-ē Relating to or derived by reasoning from
observed facts; inductive A priori: relating to or derived by reasoning
from self-evident propositions; deductive Approach: Brute-force MAP learning
algorithm
8/29/03
h𝑀𝐴𝑃=argmaxh∈𝐻
𝑃 (h∨𝐷)
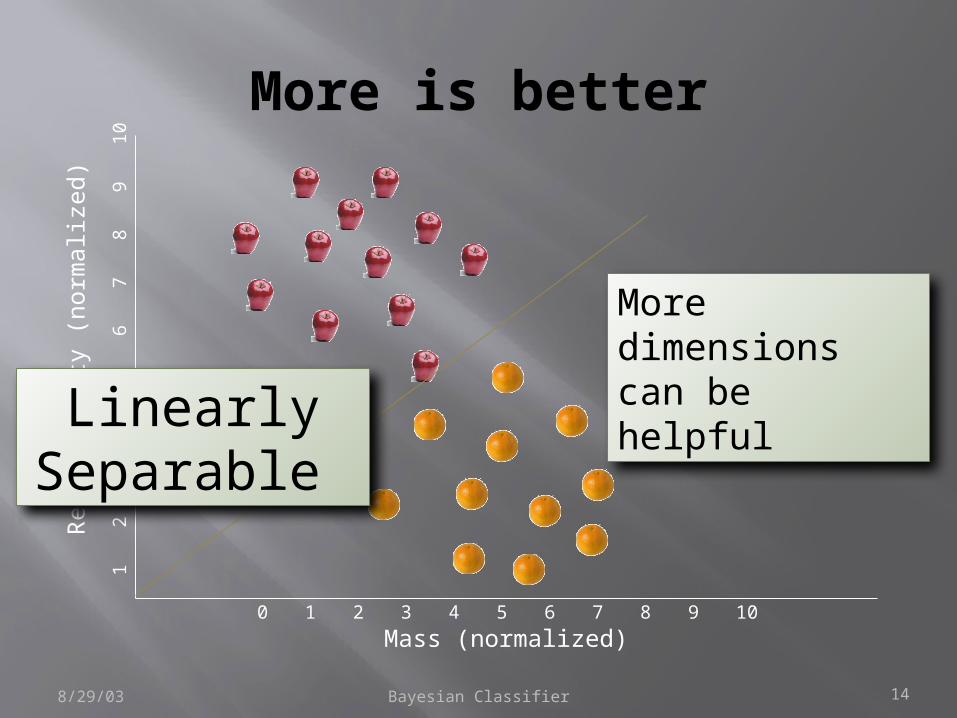
Bayesian Classifier 14
More is better
Mass (normalized)0 1 2 3 4 5 6 7 8 9 10
12
34
56
78
910
Red Inte
nsi
ty (
norm
aliz
ed)
More dimensions can be helpful
8/29/03
Linearly Separable

Bayesian Classifier 15
What if some of the dims disagree
Color (red and yellow) says apple but mass and volume say orange?
Take a vote?
8/29/03
How handle multiple dimensions?

Bayesian Classifier 16
Can cheat
Assume each dimension is independent (doesn’t co-vary with any other dimension)
Can use the product rule The probability that a fruit is an apple
given a set of measurements (dimensions) is:
8/29/03
P (h|𝐷𝑟𝑒𝑑 )∗P (h|𝐷𝑦𝑒𝑙𝑙𝑜𝑤 )∗ P (h|𝐷𝑣𝑜𝑙𝑢𝑚𝑒 )∗ P (h|𝐷𝑚𝑎𝑠𝑠 )

Bayesian Classifier 17
Naïve Bayes Classifier Known as a Naïve Bayes Classifier
Where vj is class and ai is an attribute Derivation
8/29/03
𝑣𝑁𝐵=argmax𝑣 𝑗∈𝑉
𝑃 (𝑣 𝑗)∏𝑖
𝑃 (𝑎𝑖∨𝑣 𝑗)
Where is the denominator?

Bayesian Classifier 188/29/03
Example You wish to classify an instance with the
following attributes 1.649917 5.197862 134.898820 16.137695
The first column is redness, then yellowness, followed by mass then volume
The training data has in the redness histogram bin in which the instance falls 0 apples, 0 peaches, 9 oranges, and 22 lemons
In the bin for yellowness there are 235, 262, 263, and 239
In the bin for mass there are 106, 176, 143, and 239
In the bin for vol there are What 3, 57, 7, and 184
What are each of the probabilities that it is an • Apple• Peach• Orange• Lemon

Bayesian Classifier 198/29/03
Solution
Red Yellow Mass Vol
Apples
0 235 106 3
peaches
0 262 176 57
oranges
9 263 143 7
lemons
22 239 239 184
Total 31 999 664 251
apples
0 0.24 0.16 0.01 0
peaches
0 0.26 0.27 0.23 0
oranges
0.29 0.26 0.22 0.03 0.0005
lemons
0.71 0.24 0.36 0.73 0.0044

Bayesian Classifier 208/29/03
Zeros Is it really a zero percent chance that it’s an apple? Are these really probabilities
(hint: 0.0005 + 0.0044 not equal to 1)? What of the bin size?
Red Yellow Mass Vol
apples
0 235 106 3
peaches
0 262 176 57
oranges
9 263 143 7
lemons
22 239 239 184
Total 31 999 664 251
apples
0 0.24 0.16 0.01 0
peaches
0 0.26 0.27 0.23 0
oranges
0.29 0.26 0.22 0.28 0.0004
lemons
0.71 0.24 0.36 0.73 0.0044

Bayesian Classifier 218/29/03
Zeros
Estimating probabilities is an estimate of the probability m-estimate The choice of m is often some upper bound
to n and p is often 1/m This ensures a numerator is at least 1 (never
zero) Denominator starts at upper bound and goes
up to twice that No loss of order, would be zeros are very
small

Bayesian Classifier 228/29/03
Curse of dimensionality
Do too many dimensions hurt?
What if only some dimensions contribute to ability to classify? What would the other dimensions do to the probabilities?

Bayesian Classifier 238/29/03
All about representation
With imagination and innovation can learn to classify many things you wouldn’t expect
What if you wanted to learn to classify documents, how might you go about it?

Bayesian Classifier 248/29/03
Example
Learning to classify text Collect all words in examples Calculate P(vj) and P(wk|vj) Each instance will be a vector of size |
vocabulary| Classes (v’s) (category) Each word (w) is a dimension
𝑣 𝑁𝐵=argmax𝑣 𝑗∈𝑉
𝑃 (𝑣𝑗) ∏𝑖∈ 𝑃𝑜𝑠𝑖𝑡𝑖𝑜𝑛𝑠
𝑃 (𝑎𝑖∨𝑣𝑗)

Bayesian Classifier 258/29/03
Paper
20 News groups 1000 training documents from each
group The groups were the classes
89% classification accuracy
89 out of every 100 times could tell which newsgroup a document came from

Bayesian Classifier 268/29/03
Another example: RNA
Rift Valley fever virus Basically RNA (like DNA but with
an extra oxygen – the D in DNA is deoxy)
Encapsulated in a protein sheath Important protein involved in the
encapsulation process Nucleocapsid

Bayesian Classifier 278/29/03
SELEX SELEX (Systematic Evolution of Ligands
by Exponential Enrichment) Identify RNA segments that have a high
affinity for nucleocapsid (aptamer vs. non-aptamer)

Bayesian Classifier 288/29/03
Could we build a classifier
Each known aptamer was 30 nucleotides long A 30 character string
4 nucleotides (ACGU) What would the data
look-like How would we “bin” the
data?

Bayesian Classifier 298/29/03
Discrete or real valued?
Have seen Fruit example Documents RNA (nucleotides)
Which is best for Bayesian?
Integers
StringsFloating Point

Bayesian Classifier 308/29/03
Results

Bayesian Classifier 318/29/03
Gene Expression Experiments
The brighter the spot, the greater the mRNA concentration

Bayesian Classifier 328/29/03
Can we use expression profiles to detect disease
Thousands of genes (dimensions) Many genes not affected (distributions for
disease and normal same in that dimension)
gene
patient
g1 g2 g3 … gndisea
se
p1 x1,1 x1,2 x1,3 … x1,n Y
p2 x2,1 x2,2 x2,3 … x2,n N...
.
.
.
pm xm,1 xm,2 xm,3 … xm,n ?

Bayesian Classifier 338/29/03
Rare Moss Growth Conditions
Perhaps at good growth locations pH Average temperature Average sunlight
exposure Salinity Average length of day
What else? What would the data
look-like?

Bayesian Classifier 348/29/03
Proof Taken from “Pattern Recognition” third edition
Sergios Theodoridis and Konstantinos Koutroumbas
The Bayesian classifier is optimal with respect to minimizing the classification error probability
Proof: let R1 be the region of the feature space in which we decide tin favor of w1 and R2 be the corresponding region for w2. Then an error is made if although it belongs to w2 of if although it belongs to w1.
𝑃𝑒=𝑃 (𝑥∈𝑅2 ,𝑤1 )+𝑃 (𝑥∈𝑅1 ,𝑤2 )
0 2 4 6 8
0.0
00
00
.00
05
0.0
01
00
.00
15
0.0
02
0
Distribution of Redness Values
Redness
De
nsi
ty
Fruit
ApplesPeachesOrangesLemons

Bayesian Classifier 358/29/03
Proof Joint probability
Using Bayes Rule
It is now easy to see that the error is minimized if the partitioning regions R1 and R2 of the feature space are chosen so that:

Bayesian Classifier 368/29/03
Proof Indeed, since the union of the regions R1,
R2 covers all the space, from the definition of a probability density function we have that
Combining
This suggests that the probability of error is minimized if R1 is the region of space in which . Then R2 becomes the region where the reverse is true.

Bayesian Classifier 378/29/03




























![Turkey Point Plant Units 3 and 4, License Amendment ...< 28% 2.125 3.2-3 (2) Augmented Surveillance (MIDS) If [FQ]n, as predicted by approved physics calculations, exceeds [FnQL tfen](https://img.pdfslide.tips/doc/110x75/5f0decda7e708231d43cc21f/turkey-point-plant-units-3-and-4-license-amendment-28-2125-32-3-2.jpg)