Embed Size (px)
Citation preview

Elaborato finale in Basi di Dati
Natural Language Processing: la piattaforma
GATE/ANNIE e le Ontologie
Anno Accademico 2017/2018
Candidato:
Aniello Allegretta
matr. N46003054
Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica

Indice
1. Introduzione ....................................................................................................................................... 4
2. Trattamento Automatico del Testo e Information Extraction .......................................................... 7
2.1 Natural Language Processing .......................................................................................................... 7
2.1.1 Cenni storici ............................................................................................................................... 8
2.1.3 Processo di Trattamento Semantico Dell’Informazione ......................................................... 11
2.1.4 Principali Tool ......................................................................................................................... 13
2.2 Information Extraction .................................................................................................................. 14
2.2.1 Task di Information Extraction .............................................................................................. 14
3. Le Ontologie ed il Web semantico ................................................................................................... 15
3.1 Web Semantico ............................................................................................................................... 15
3.1.1 L’architettura del Web Semantico .......................................................................................... 16
3.2 Ontologie ........................................................................................................................................ 19
3.2.1 RDFS ........................................................................................................................................ 20
3.2.2 OWL ........................................................................................................................................ 21
4. GATE ............................................................................................................................................... 22
4.1 GATE IDE ...................................................................................................................................... 23
4.1.1 Caricamento di documenti ...................................................................................................... 24
4.1.2 Annotazioni .............................................................................................................................. 25
4.1.3 Coreferenza.............................................................................................................................. 26
4.1.4 Caricamento di Processing Resources..................................................................................... 26
4.1.5 Persistenza delle risorse ........................................................................................................... 27
4.2 GATE Embedded ........................................................................................................................... 29
4.2.1 CREOLE.................................................................................................................................. 30
4.2.2 Language Resources ................................................................................................................ 31
4.2.3 Processing Resources ............................................................................................................... 32
4.3 JAPE ............................................................................................................................................... 34

4.4 ANNIE ............................................................................................................................................ 36
4.4.1 Document Reset ....................................................................................................................... 37
4.4.2 Tokeniser ................................................................................................................................. 37
4.4.3 Gazetteer .................................................................................................................................. 38
4.4.4 Sentence Splitter ...................................................................................................................... 39
4.4.6 Semantic Tagger (ANNIE Named Entity Transducer) .......................................................... 40
4.4.7 Orthographic Coreference (OrthoMatcher) ........................................................................... 41
4.5 GATE e le Ontologie ...................................................................................................................... 42
4.5.1 Modello dei dati per Ontologie ................................................................................................ 42
4.5.2 Ontology Plugin ....................................................................................................................... 43
4.5.3 Ontology-Tools Plugin ............................................................................................................. 43
4.6 Esempio di annotazione semantica in GATE Developer ............................................................... 46
4.6.1 Annotazione Semantica manuale con Ontology Annotation Tool ........................................... 46
4.6.2 Annotazione semantica automatica con OntoGazetteer .......................................................... 48
5. Conclusioni ....................................................................................................................................... 52
Bibliografia .............................................................................................................................................. 53

1. Introduzione
Il linguaggio (scritto e parlato) è al centro di tutti gli aspetti della comunicazione. Con
l’avvento dei contenuti digitali redatti in linguaggio naturale e successivamente
scambiati all’interno del Web è nata, contemporaneamente alla diffusione delle
informazioni digitali, l’esigenza di sviluppare strumenti in grado di comprendere,
analizzare e processare in modo del tutto automatico questi contenuti, con lo scopo di
fornire servizi in grado di: semplificare la traduzione dei testi, l’estrapolazione di
informazioni utili, la gestione dei documenti sulla rete e la loro ricerca per contenuto.
Alla luce di queste esigenze è nato un sottocampo dell’intelligenza artificiale definito
Natural Language Processing (NLP), ovvero lo studio della modellazione matematica
e computazionale di vari aspetti del linguaggio e dello sviluppo di una vasta gamma di
sistemi. L’obiettivo principale è quello di far si che le macchine possano comprendere
e produrre informazioni scritte in linguaggio umano, agevolando così la comunicazione
tra la macchina e l’utente inesperto senza addentrarsi nel linguaggio specifico della
macchina. Per processare il linguaggio naturale ed uniformarlo, a causa della vastità di
linguaggi naturali nel mondo, quest’ultimo viene visto come un sistema costituito da
una serie di regole e simboli dove:
I simboli sono combinati ed utilizzati per trasportare o emettere l’informazione.
Le regole limitano la gestione dei simboli.
È possibile, inoltre, suddividere NLP in due attività principali:
Natural Language Understanding: analisi e comprensione del linguaggio
naturale.
Natural Language Generation: produzione di informazioni in linguaggio
naturale a partire da una data rappresentazione.
L’attività di natural language understanding è possibile dividerla a sua volta in speech
understanding e language understanding: con la prima si intende la comprensione del
linguaggio parlato mentre la seconda si occupa della comprensione di testi scritti. Uno

dei campi più interessanti del NLP è Information Extraction (IE), cioè l’estrazione dal
testo di informazioni utili riguardo l’argomento o il dominio di interesse in una forma
strutturata adatta per il popolamento dei database. Con informazioni strutturate si
intendono dati il cui contenuto è organizzato secondo un modello preciso e quindi
facilmente processabili da un calcolatore.
In questo lavoro si fornisce una panoramica di NLP e IE, per poi approfondire un
particolare campo di IE legato all’ontologia di un testo e come è possibile trattarla
attraverso una tra le più importanti piattaforme per il language processing, GATE.


2. Trattamento Automatico del Testo e Information
Extraction
2.1 Natural Language Processing
Il Trattamento Automatico del Testo, in inglese conosciuto come Natural Language
Processing (NLP), è quel campo dell’intelligenza artificiale che si occupa di interazioni
tra le macchine e il linguaggio naturale, cioè i sistemi di comunicazione comunemente
usati dagli esseri umani in forma scritta, orale o gestuale.
I calcolatori lavorano con informazioni strutturate, ovvero informazioni esatte, i
documenti in linguaggio naturale invece presentano ambiguità nelle parole e nei
significati, le quali possono essere cancellate solo conoscendo il contesto del testo.
L’obiettivo del NLP è proprio quello di fornire al calcolatore tutti quegli strumenti
necessari per:
assistere gli esseri umani riguardo la comprensione e l’elaborazione di
documenti, anche multimediali, in linguaggio naturale (traduzioni da lingua a
lingua, gestione di documenti ecc.);
comunicare con gli esseri umani (assistenti vocali);
estrarre, analizzare o classificare informazioni di documenti scritti in linguaggio
naturale (information extraction, summarization ecc.);
estendere le proprie conoscenze linguistiche, tramite tecniche di apprendimento
automatico.

2.1.1 Cenni storici
La ricerca sull’elaborazione del linguaggio naturale è in corso da diversi decenni, e
pone le sue origini nel 1940. La prima applicazione computer-based legata al
linguaggio naturale fu la cosiddetta machine translation (MT). I primi lavori in MT
adottarono la visione semplicistica che le uniche differenze tra le lingue risiedevano
nei loro vocabolari e nell’ordine consentito delle parole. I sistemi sviluppati da questa
prospettiva utilizzavano semplici ricerche all’interno dei dizionari per una traduzione
appropriata delle parole, successivamente queste venivano ordinate seguendo le regole
imposte dal linguaggio preso in esame, senza però tener conto in alcun modo
dell’ambiguità lessicale inerente al linguaggio naturale. I risultati furono davvero
scarsi. Il fallimento fece si che i ricercatori si rendessero conto del fatto che il lavoro
era molto più arduo delle aspettative, per cui c’era bisogno di un approccio più
adeguato.
Negli anni ’60, l’inadeguatezza dei sistemi allora esistenti e l’eccessivo entusiasmo,
portarono l’organizzazione ALPAC (Automatic Language Processing Advisory
Committee) a stilare un documento nel quale si sconsigliava di finanziare ulteriori
ricerche su MT, questo fece rallentare di gran lunga il progresso nel settore del NLP.
A partire dalla fine degli anni ’60 fino agli inizi degli anni ’70 l’attenzione fu rivolta a
lavori prettamente teorici legati alle problematiche di rappresentazione del significato
e dello sviluppo computazionale di soluzioni trattabili, che le teorie della grammatica
allora esistenti ancora non erano in grado di produrre. Alla fine degli anni ’70, invece,
vi si concentrò sui problemi legati alla semantica e quelli legati alla comunicazione.
Solo all’inizi degli anni ’80, grazie alla maggiore disponibilità di risorse
computazionali, ripresero progressivamente le ricerche di machine learning.
Negli ultimi dieci anni il campo del NLP è stato oggetto di numerosi studi grazie alla
disponibilità di numerosi testi scritti in formato elettronico, a calcolatori più potenti e
all’avvento di Internet e del Web. (Elizabeth D. Liddy, 2001, Syracuse University).

2.1.2 Metodologie per il Trattamento Semantico Dell’Informazione
Le metodologie per il trattamento semantico dell’informazione aiutano a migliorare la
qualità delle informazioni contenute nei testi, attraverso le quali viene effettuata
un’analisi concettuale del testo, ovvero non vengono analizzate le singole parole ma il
loro significato.
Il processo di analisi semantica è costituito dall’estrazione e dalla formalizzazione delle
informazioni di interesse, a partire dai documenti acquisiti, al fine di consentire
l’accesso per contenuto alle informazioni rilevanti presenti nel documento.
L’estrazione consiste nell’estrapolare dal testo tutti gli elementi più importanti come
nomi e verbi, la formalizzazione, invece, si occupa di etichettare le parole estratte
attraverso dei tag, tali etichette forniscono informazioni su cosa rappresentano le parole
estratte.
Un’applicazione di questo trattamento del testo attraverso analisi semantica è la ricerca
per contenuto, come ad esempio quella effettuata da Google, infatti ogni qualvolta
viene effettuata una ricerca non vengono restituite solo le pagine contenenti le parole
cercate ma anche tutte le pagine che trattano lo stesso argomento, questo è possibile
proprio grazie all’analisi semantica di ogni parola.
Le principali problematiche legate alla ricerca delle informazioni nella rete sono:
Comparsa di documenti erroneamente segnalati come rilevanti (ovvero
documenti che presentano le parole chiave ricercate, ma utilizzate con un
significato diverso)
Omissione di documenti rilevanti: presenza di documenti utili all’utente che non
vengono restituiti dalla ricerca.
Gli aspetti innovativi legati al trattamento semantico del testo possono essere
utilizzati per la progettazione di motori per la gestione della conoscenza, che offrano
procedure di ricerca di informazioni per contenuto, in modo tale da:
Superare i limiti imposti dalla ricerca per parole chiave;

Risultare tollerante agli errori (come ad esempio la digitazione e l’ortografia);
Possibilità di formulare interrogazioni in linguaggio naturale;
Suggerire eventuali risultati collegati agli argomenti di interesse ricercati
dall’utente.

2.1.3 Processo di Trattamento Semantico Dell’Informazione
Il processo di trattamento semantico dell’informazione, ad alto livello, è suddiviso in
diverse fasi di analisi, corrispondenti, in parte, a quelle dell’analisi del linguaggio.
Analisi lessicale: è la prima operazione che viene effettuata sul testo in analisi, al
fine di distinguere le parole (token), dai separatori.
Analisi sintattica: utilizzata per determinare la struttura sintattica e grammaticale di
ogni frase analizzata classificando i token e organizzarli in strutture sintattiche.
Analisi semantica: assegnazione di un significato alla struttura sintattica, ed
eventuale disambiguazione.
Pragmatica: è un processo che specializza l’assegnazione del significato alla
struttura sintattica basandosi sul contesto e sulle informazioni pregresse.
Ad un livello più basso, le principali operazioni ed elaborazioni del testo sono:
Parsing: distingue l’insieme dei caratteri dell’alfabeto dall’insieme dei
separatori (spazio, punto, virgola). In tal modo vengono definiti i token, cioè la
singola unità di analisi.
Normalization: uniforma le differenti variazioni ortografiche di un token in
modo che siano ricondotte ad un’unica forma grafica.
Part of Speech (POS) Tagging: associa a ciascun token la corretta categoria
grammaticale o parte del discorso. Ad ogni token si associa un’etichetta (tag),
rappresentate la propria categoria grammaticale. Questa operazione è finalizzata
alla disambiguazione degli elementi lessicali nel testo, utilizzando una tipo di
classificazione delle parole basato su: parole lessicali o piene cioè nomi, verbi,
aggettivi e avverbi, parole grammaticali o vuote cioè articoli, preposizioni,
congiunzioni. Le parole lessicali contribuiscono significativamente
all’interpretazione del testo in quanto contengono informazioni rilevanti per la
comprensione, mentre, le parole grammaticali non esprimono un contenuto utile
ai fini dell’analisi.

Lemmatization: estrae il lemma relativo agli elementi lessicali classificati come
non ambigui. Per i nomi il lemma coincide con il singolare maschile mentre per
i verbi con l’infinito.
Word sense disambiguation: consiste nel precisare il significato di una parola,
che presenta significati diversi a seconda del contesto in cui è usata.
Identification of relationships: individua le relazioni che legano i concetti
estratti dal testo, così da ottenere una conoscenza maggiore del documento. Le
relazioni semantiche considerate son di tipo: associativo, sinonimia e
gerarchico.

2.1.4 Principali Tool
I principali strumenti applicativi per il trattamento automatico del testo sono:
GATE/ANNIE: software open-source nato all'interno dell’University of
Sheffield, è una suite di strumenti per LP. ANNIE è il set di algoritmi
specializzati in IE su testi non strutturati.
Stanford CoreNLP: è un framework open-source per l'analisi e l’elaborazione di
testi, sviluppato alla Stanford University e scritto in linguaggio Java.
UIMA: sviluppato da Apache Software Foundation, è un software per l'analisi
di testi, video e audio non strutturati, scritto in Java e C++.
OpenNLP: sviluppato da Apache Software Foundation, è un software per LP
scritto in Java. Utilizza algoritmi machine learning

2.2 Information Extraction
Nello scenario del NLP assume una particolare importanza l’Information Extraction
(IE), che ha lo scopo di ricavare specifiche informazioni da documenti scritti in
linguaggio naturale e non la comprensione totale del testo. Specificate inizialmente
delle classi di entità, relazioni ed eventi in linguaggio naturale (template), l’Information
Extraction si definisce come il processo di identificazione di istanze appartenenti a
queste classi e l’estrazione delle proprietà rilevanti delle entità, relazioni o eventi
identificati. I sistemi di information extraction lavorano in termini di database per cui
al termine di un processo di IE viene creata una rappresentazione strutturata delle
informazioni selezionate dal testo analizzato (Piskorski, Yangarber, 2012).
2.2.1 Task di Information Extraction
L’applicazione di IE su di un testo ha l’obiettivo di creare una visione strutturata delle
informazioni che si comprensibile ad una macchina. Un processo di IE include i
seguenti tasks:
Named Entity Recognition (NER): riconoscimento e classificazione di entità
presenti nel testo all’interno di specifiche categorie, come nomi propri (di
persone, organizzazioni, luoghi ecc.), espressioni temporali, espressioni
numeriche e di valuta.
Coreference Resolution (COR): ricerca di espressioni di coreferenza, cioè di
richiami ad una medesima entità all’interno di un testo. Un richiamo ad una
stessa entità può essere di tipo: nominale, pronominale ed implicito.
Relation Extraction (RE): riconoscimento e classificazione delle relazioni tra le
entità identificate all’interno del testo.
Event Extraction (EE): identificazione di eventi ed estrazione di informazioni
dettagliate e strutturate da essi.

3. Le Ontologie ed il Web semantico
Attualmente il Web può essere considerato come un enorme “archivio” dove trovare
una grande quantità di documenti, ciò che manca è una connessione tra i contenuti
stabilita dal loro significato (semantica), che permetta la risposta ad interrogazioni
anche complesse, formulate in linguaggio naturale. Se effettuiamo un’interrogazione
in linguaggio naturale ad un motore di ricerca, esso cercherà le parole chiave
all’interno del database, probabilmente estrarrà dei documenti che contengono la
domanda e, con un po’ di fortuna, anche la definizione che si sta cercando. Il Web
Semantico è considerato la naturale evoluzione di Internet. Per costruire relazioni
semantiche e processarle in modo automatico si ha bisogno di una qualche
formalizzazione che le descriva nel modo più completo possibile. Questo tipo di
formalizzazione si chiama nel linguaggio della logica: Ontologia.
3.1 Web Semantico
Lo scenario del World Wide Web (WWW) è quello di un insieme di testi collegati in
qualche modo tra di loro. Una peculiarità essenziale del WWW è la sua universalità,
infatti attraverso i link ipertestuali ogni elemento all’interno del Web può essere
collegato ad un altro indistintamente. Possiamo distinguere i collegamenti tra le pagine
web in due classi:
collegamenti sintattici: sono esclusivamente legati al funzionamento di un
qualche codice di programmazione. Sono piuttosto solidi in quanto attraverso un
URL viene identificata univocamente una risorsa;
collegamenti semantici: descrivono il significato di un collegamento. Questi
sono piuttosto deboli in quanto, oltre a portare in un determinato luogo un
collegamento dovrebbe descrivere il luogo verso cui porta.
Il termine Web Semantico è stato proposto per la prima volta nel 2001 da Tim Berners-
Lee. Da allora il termine è stato associato all’idea di un Web nel quale agiscano agenti
intelligenti (creati senza ricorrere all’intelligenza artificiale ad alti livelli), cioè

applicazioni in grado di comprendere il significato dei testi presenti sulla rete e di
conseguenza guidare l’utente direttamente verso l’informazione ricercata, oppure
sostituirsi ad esso nello svolgimento di alcune operazioni. Un agente dovrebbe essere
in grado di:
comprendere il significato dei testi presenti sulla rete;
creare percorsi in base alle informazioni richieste dall’utente, guidandolo poi
verso di essere (in alcuni casi si può anche sostituire ad esso);
spostarsi di sito in sito collegando logicamente elementi diversi
dell’informazione richiesta;
Utilizzando questa tecnologia si può automatizzare la ricerca delle pagine, poiché
all’atto della creazione del contenuto delle pagine le informazioni sono definite ed
inserite secondo precise regole semantiche (per questo è stato coniato il termine Web
Semantico).
“Il Web Semantico è un’estensione del web corrente in cui le informazioni hanno un
ben preciso significato e in cui computer e utenti lavora in cooperazione”. (Semantic
Web – Scientific American, Maggio 2001).
3.1.1 L’architettura del Web Semantico
La scrittura di codice in grado di compiere operazioni semantiche dipende fortemente
dallo schema utilizzato per archiviare le informazioni. Lo schema è un insieme di
regole sull’organizzazione dei dati, può definire relazioni fra i dati ed esprimere vincoli
tra classi di dati. L’idea del Web Semantico nasce estendendo l’idea di utilizzare schemi
per descrivere domini di informazione. Dei metadati (informazioni comprensibili da
una macchina e relativi ad una risorsa web) devono mappare i dati rispetto a classi, o
concetti, di questo schema di dominio; in questo modo si hanno strutture in grado di
descrivere e automatizzare i collegamenti esistenti fra i dati. Il Web Semantico è un
ambiente dichiarativo in cui si specifica il significato dei dati, e non il modo in cui si
intende utilizzarli. La semantica dei dati consiste nel dare alla macchina delle
informazioni utili in modo che essa possa utilizzare i dati nel modo corretto,

convertendoli eventualmente. Di conseguenza, è possibile strutturare il Web Semantico
in tre livelli fondamentali:
1. i dati;
2. i metadati, che riportano questi dati ai concetti di uno schema;
3. lo schema, all’interno del quale si esprimono le relazioni fra concetti, che
diventano classi di dati.
Figura 1: architettura a livelli Web Semantico
Questa architettura a livelli non è ancora stata però sviluppata completamente, il che
avverrà nei prossimi anni. In Figura 1 è mostrata l’architettura a livelli del Web
Semantico, che viene descritta nel dettaglio qui di seguito:
1. il Web Semantico si basa sullo standard URI (Uniform Resource Identifiers), per
la definizione univoca di indirizzi Internet;
2. al livello superiore si trova XML (eXtensible Markup Language), con il quale è
possibile modellare, senza troppi vincoli, la realtà che si considera per questo è
un linguaggio che porta con sé alcune informazioni sulla semantica degli oggetti.
Questa eccessiva libertà lo rende poco adatto, però, a definire completamente la

struttura e l’interscambio di informazioni tra diverse realtà, ragion per cui è stata
favorita la creazione di un nuovo linguaggio;
3. RDF (Resource Description Framework) e RDF Schema, che costituiscono il
linguaggio per descrivere le risorse e i loro tipi;
4. al livello superiore si pone il livello ontologico. Una Ontologia permette di
descrivere le relazioni tra i tipi di elementi senza però fornire informazioni su
come utilizzare queste relazioni dal punto di vista computazionale;
5. la firma digitale è fondamentale per stabilire la provenienza delle ontologie e
delle deduzioni, oltre che dei dati;
6. il livello logico è il livello immediatamente superiore, dove le asserzioni esistenti
sul Web possono essere utilizzate per derivare nuova conoscenza.

3.2 Ontologie
La definizione di ontologia data da Thomas R. Gruber nel 1993 è:
“Un’ontologia è una specificazione di una concettualizzazione” (Gruber, T. 1993)
Più semplicemente un’ontologia permette di specificare, in modo aperto e significativo,
i concetti e le relazioni che caratterizzano un certo dominio di conoscenza. Un esempio
potrebbero essere i concetti di “vino bianco” e “vino rosso”, di “enoteca”, di “varietà
di uva” e così via, che caratterizzano il dominio di conoscenza “vino”; all’interno di
questo dominio vi sono anche relazioni tra questi concetti come ad esempio “i vini
hanno un anno di produzione” e “le enoteche vendono il vino”.
Questo esempio di “Ontologia del Vino” potrebbe essere realizzata inizialmente per
una particolare applicazione, come ad esempio un sistema di gestione magazzino di un
grande rivenditore. Potrebbe, quindi, essere considerata come l’analogo di un
“database schema” ben definito. Il vantaggio che però possiede una ontologia è di
essere una descrizione esplicita qualitativamente avanzata. Quindi pur essendo
prodotta per uno scopo particolare può essere pubblicata e riutilizzata per fini
differenti. Ad esempio, una certa vineria potrebbe utilizzare questa ontologia per
collegare il suo programma di produzione al sistema di gestione citato prima. Oppure
un eventuale programma di suggerimento potrebbe usarla unitamente ad una
descrizione di differenti alimenti per proporre i vini migliori abbinabili ad un dato
menù.
Ci sono differenti modi di scrivere una ontologia e molte opinioni su quali tipi di
definizione vadano inserite all’interno di essa. Tuttavia, forma e contenuto di
un’ontologia sono fortemente guidati dal tipo di applicazione per la quale sarà
utilizzata. Poiché questo lavoro è orientato alle ontologie costruite per lo sviluppo del
Web Semantico, vengono esaminati i formalismi costruiti sul linguaggio RDF/XML.
Questo linguaggio è incentrato sulla descrizione delle risorse digitali e si presta di
conseguenza ad essere ulteriormente raffinato e formalizzato per poter descrivere i vari
domini di conoscenza nel contesto del Web. Vi sono tre linguaggi basati su RDF/XML

utilizzati per la definizione di ontologie: RDFS, OWL (il più utilizzato ed orientato al
Web Semantico) e DAML+OIL (la somma di due linguaggi da cui è scaturito OWL).
Essendo il terzo linguaggio ormai sempre più in disuso, vengono approfonditi qui di
seguito i primi due.
3.2.1 RDFS
Il linguaggio Resource Description Framework Schema (RDFS) è quel linguaggio
basato su schemi RDF, ovvero insiemi di proprietà ed elementi che definiscono un
contesto per la descrizione di determinate categorie di risorse. Un RDFS proprio per le
sue caratteristiche può essere utilizzato anche per dare una semplice struttura
semantica, permettendo di costruire una gerarchia di concetti e di relazioni. Di seguito
è illustrata una porzione di tassonomia (una tassonomia è un caso particolare di
Ontologia):
Figura 2: esempio di semplice gerarchia di concetti
Usando RDFS possiamo dire che questa ontologia ha 5 classi e che Pianta è sottoclasse
di Organismo e così via. Queste classi possono essere viste come descrizione di un
insieme di individui: Organismo descrive un insieme di essere viventi dei quali alcuni

sono animali e alcuni sono Piante e così via. Per descrivere gli attributi di una classe è
poi possibile associare proprietà ad essa. Ad esempio, un dato organismo potrebbe
avere degli organi sensoriali. Possiamo associare proprietà ad una classe stabilendo che
la proprietà ha una certa classe come dominio ed un’altra classe come codominio.
Definire una gerarchia come questa è piuttosto semplice con RDFS, si incontrano più
difficoltà di fronte a concettualizzazioni più complesse.
3.2.2 OWL
Il Web Ontology Language (OWL) estende RDFS permettendo una notevole ricchezza
semantica. Una caratteristica fondamentale di OWL è infatti la possibilità di descrivere
le classi in modo più ricco, infatti in riferimento all’esempio precedente, è possibile
definire Animali e Piante come classi disgiunte: quindi nessun individuo (o istanza)
può appartenere ad entrambe le classi. Oppure si può definire una classe come
intersezione di altre due (o più). Anche per le proprietà è possibile dare descrizioni
molto ricche. Ad esempio, è possibile restringere (e raffinare) determinate proprietà
sulle classi: se la classe Animali ha le proprietà “ricoperto di”, si può far si che la
sottoclasse “Mammiferi” abbia valori per questa proprietà che risiedono nella classe
“Peli”, così come per i “Rettili” ha valori nella classe “Scaglie”. Inoltre, tramite OWL,
si può distinguere tra proprietà transitive, simmetriche e funzionali. Infine,
un’evoluzione importante è la possibilità di distinguere tra proprietà che hanno come
valori (codominio) dati semplici o vere e proprie classi. Un’ultima importante
osservazione è che se da una parte OWL è definito a partire dal linguaggio RDF/XML
e può essere visto come una sua estensione, tuttavia può essere anche considerato come
un linguaggio XML a sé stante. Entrambi i punti di vista possono essere considerati
validi e sono stati utilizzati per vari tipi di applicazioni ed interfacce.

4. GATE
GATE (General Architecture for Text Engineering) è un sistema open-source gratuito
sviluppato dall’Università di Sheffield che offre agli utenti una piattaforma completa
di Language Processing (LP). Più nello specifico, GATE è contemporaneamente
un’architettura, un Integrated Development Environment (IDE), un Framework e una
Web App (Cunningham, 2014).
Come architettura, GATE definisce un’organizzazione ad alto livello dei sistemi
per LP e assicura una corretta interazione tra i componenti.
Come IDE (GATE Developer), aiuta gli utenti a sviluppare in modo semplice ed
efficiente applicazioni per NLP, fornendo una GUI e funzionalità per il
debugging.
Come Framework (GATE Embedded), offre una libreria di componenti che può
essere inclusa dagli sviluppatori in vari applicativi ed eventualmente estesa.
Come Web App (GATE Teamware), permette di annotare collettivamente un set
di documenti.
GATE è dunque un sistema completo di Language Engineering (LE), che include
componenti per LP come parsers, strumenti di machine learning, strumenti per la
manipolazione di testi e l’inserimento di annotazioni, tool per IE e per effettuare
valutazioni e benchmark e un linguaggio per la scrittura di regole. Il suo sviluppo è
iniziato nel 1995 e attualmente il suo team di sviluppo è il più grande nell’ambito del
software open-source indirizzato a NLP (Cunningham, 2014).

4.1 GATE IDE
GATE Developer fornisce un ambiente grafico per lo sviluppo di software dedicato al
trattamento testuale (LP), in particolare, lo scopo principale è l’annotazione dei
documenti, la creazione di corpora e l’utilizzo delle risorse fornite dal framework di
GATE.
Facendo riferimento alla Figura 1 possiamo suddividere l’interfaccia di GATE in
diversi parti:
In alto a sinistra: albero delle risorse (Files, Option, Tools, Help e i bottoni
relativi alle azioni più comuni);
In basso a sinistra: anteprima delle risorse
Al centro: viewer principale delle risorse
In basso: la barra dei messaggi
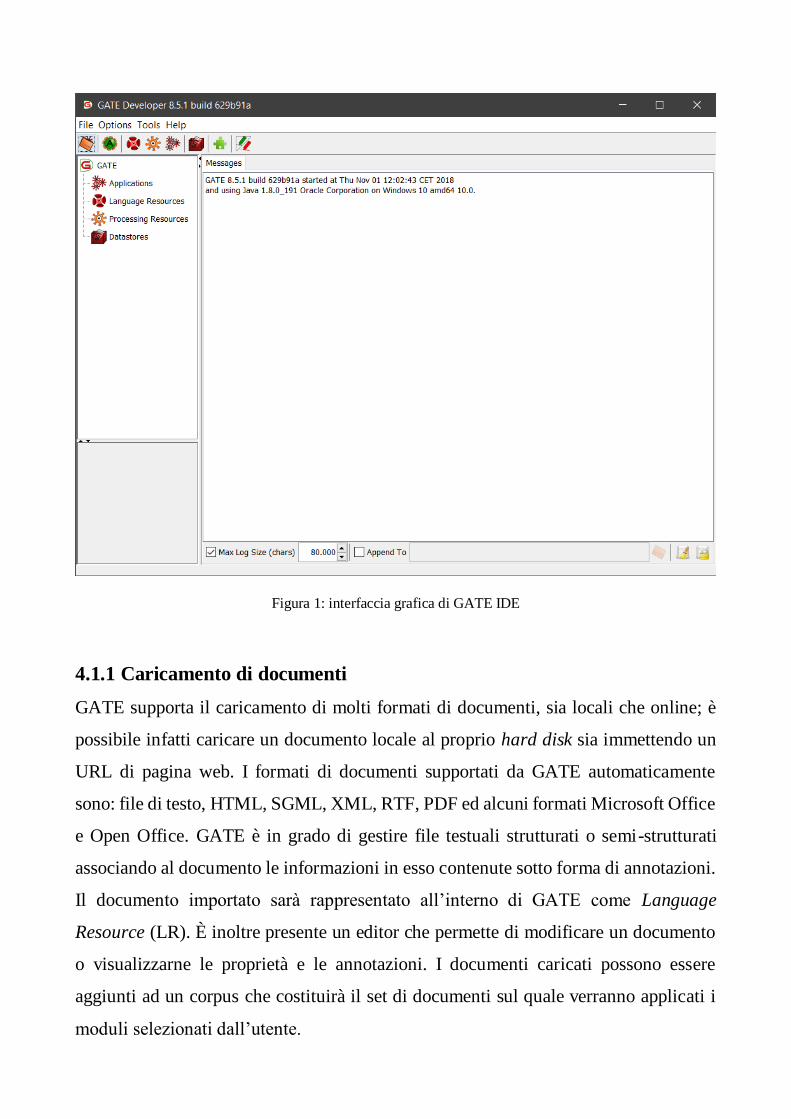
Figura 1: interfaccia grafica di GATE IDE
4.1.1 Caricamento di documenti
GATE supporta il caricamento di molti formati di documenti, sia locali che online; è
possibile infatti caricare un documento locale al proprio hard disk sia immettendo un
URL di pagina web. I formati di documenti supportati da GATE automaticamente
sono: file di testo, HTML, SGML, XML, RTF, PDF ed alcuni formati Microsoft Office
e Open Office. GATE è in grado di gestire file testuali strutturati o semi-strutturati
associando al documento le informazioni in esso contenute sotto forma di annotazioni.
Il documento importato sarà rappresentato all’interno di GATE come Language
Resource (LR). È inoltre presente un editor che permette di modificare un documento
o visualizzarne le proprietà e le annotazioni. I documenti caricati possono essere
aggiunti ad un corpus che costituirà il set di documenti sul quale verranno applicati i
moduli selezionati dall’utente.
4.1.2 Annotazioni
Come anticipato precedentemente uno dei compiti principali di GATE è l’annotazione
di documenti, questa operazione di annotazione può essere effettuata manualmente,
semi-manualmente, aggiungendo annotazioni a documenti già precedentemente
processati e annotati, o automaticamente attraverso i componenti forniti da GATE. È
possibile definire nuovi tipi di annotazioni o modificare quelle già esistenti.
Tramite l’interfaccia grafica è possibile gestire e analizzare le annotazioni presenti nel
documento: ad esempio GATE permette di selezionare le tipologie di annotazioni
visibili sul testo e per ogni annotazione permette di visualizzare le proprietà e i dettagli.
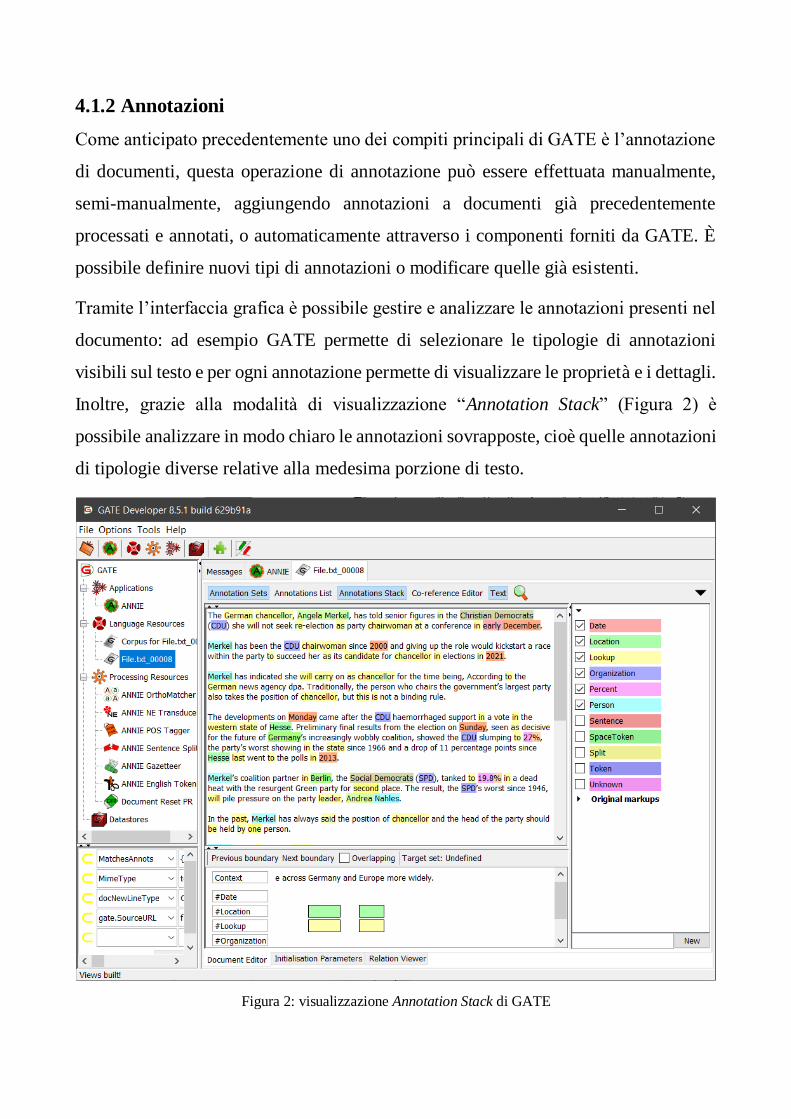
Inoltre, grazie alla modalità di visualizzazione “Annotation Stack” (Figura 2) è
possibile analizzare in modo chiaro le annotazioni sovrapposte, cioè quelle annotazioni
di tipologie diverse relative alla medesima porzione di testo.
Figura 2: visualizzazione Annotation Stack di GATE
4.1.3 Coreferenza
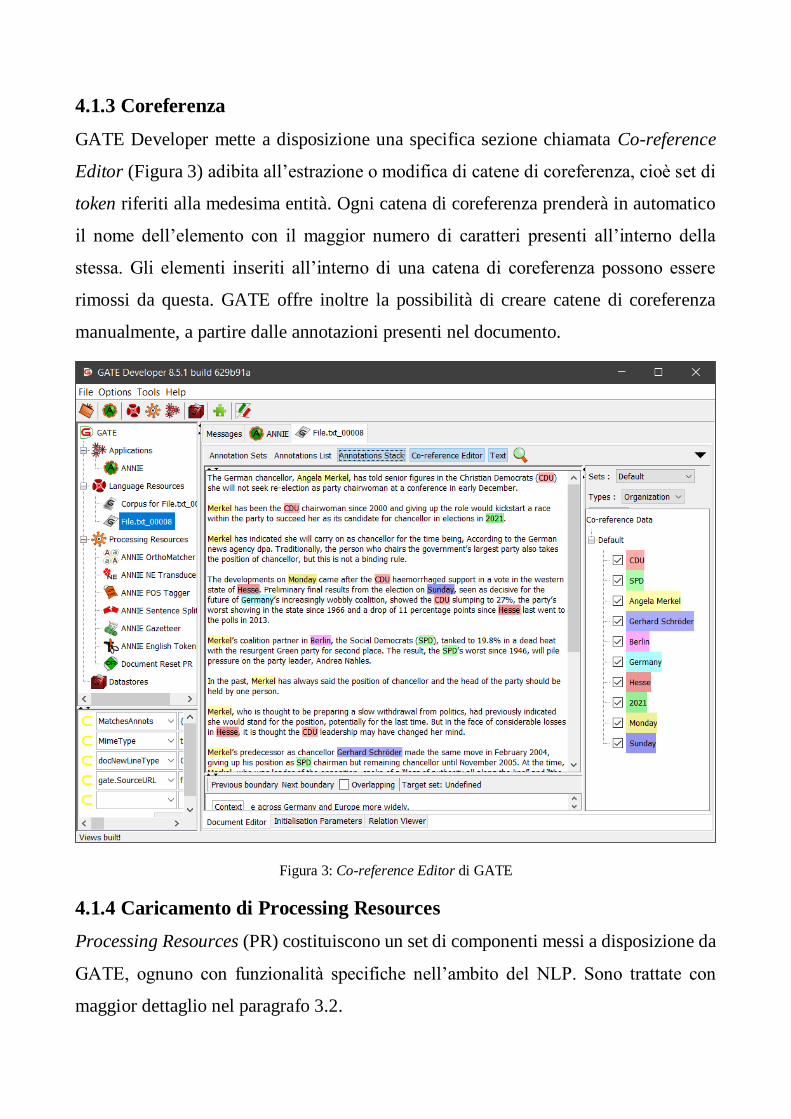
GATE Developer mette a disposizione una specifica sezione chiamata Co-reference
Editor (Figura 3) adibita all’estrazione o modifica di catene di coreferenza, cioè set di
token riferiti alla medesima entità. Ogni catena di coreferenza prenderà in automatico
il nome dell’elemento con il maggior numero di caratteri presenti all’interno della
stessa. Gli elementi inseriti all’interno di una catena di coreferenza possono essere
rimossi da questa. GATE offre inoltre la possibilità di creare catene di coreferenza
manualmente, a partire dalle annotazioni presenti nel documento.
Figura 3: Co-reference Editor di GATE
4.1.4 Caricamento di Processing Resources
Processing Resources (PR) costituiscono un set di componenti messi a disposizione da
GATE, ognuno con funzionalità specifiche nell’ambito del NLP. Sono trattate con
maggior dettaglio nel paragrafo 3.2.

Le PR possono essere utilizzate singolarmente, in quanto moduli indipendenti, o essere
combinate tra di loro all’interno di application (applicazioni), cioè controller che
regolano il flusso di esecuzione. Creata una nuova applicazione, si scelgono i
componenti che dovranno essere eseguiti, l’ordine di esecuzione, i documenti o il
corpus che devono essere processati ed eventuali condizioni: a questo punto è possibile
lanciare l’applicazione.
GATE offre di default applicazioni che comprendono già uno specifico set di PR e che
possono essere utilizzate rapidamente senza particolari configurazioni: una di queste è
ANNIE, i cui componenti sono trattati in modo approfondito nel paragrafo 3.3.
4.1.5 Persistenza delle risorse
Esistono tre modalità principali di salvataggio dei documenti annotati in GATE:
preservando il documento originale, aggiungendo esclusivamente le annotazioni
ritenute utili, escludendo tutte le altre;
utilizzando il formato di serializzazione XML di GATE;
scrivendo un proprio algoritmo per persistere il documento.
Laddove i corpora sono piuttosto estesi, la memoria disponibile potrebbe non essere
sufficiente per avere tutti i documenti aperti contemporaneamente, ragione per cui
GATE offre la possibilità di salvataggio su datastore: in questo modo i documenti
verranno salvati su disco e aperti solo quando necessario.
Infine, in GATE è possibile persistere le applicazioni create e il loro stato: in questo
modo un’applicazione potrà essere caricata da file anche in un secondo momento.
Questo tipo di salvataggio comprende la persistenza dello stato dell’applicazione ma
non delle risorse utilizzate, ciò vuol dire che caricando l’applicazione su una macchina
diversa possono emergere errori legati all’assenza di tutte le risorse necessarie e alla
posizione di queste nel file system, che potrebbe non coincidere con quella indicata sul
file. Nel caso in cui si desideri salvare un’applicazione per usarla su più macchine, per
garantire il corretto funzionamento delle risorse, è possibile esportarla utilizzando la
modalità “Export for GATE-Cloud.net”. In questo modo viene creato un file ZIP

contenente non solo lo stato dell’applicazione ma anche tutte le risorse utilizzate,
rendendo così l’applicazione utilizzabile su macchine differenti da quella della
creazione.

4.2 GATE Embedded
GATE Embedded è un framework object-oriented implementato in Java e costituisce
il vero e proprio cuore dell’architettura GATE. È stata progettato per consentire agli
sviluppatori di incorporare all’interno di diverse applicazioni funzionalità di NLP.
GATE Embedded è un software open-source, con licenza GNU Lesser Genereal Public
License 3.0. Possiamo immaginare GATE Embedded come un’interfaccia alla quale
possono essere connessi vari componenti; questi componenti forniscono le funzionalità
base per attività di LP. GATE Embedded è suddiviso in diverse API, come mostrato in
Figura 4, che vengono analizzate nei successivi sotto paragrafi.
Figura 4: architettura GATE Embedded.

4.2.1 CREOLE
L’architettura di GATE si basa su componenti, ovvero blocchi riutilizzabili di software,
indipendenti tra di loro, con interfacce ben definite che possono essere implementate
in una varietà di contesti di LP: l’insieme di tali componenti è definito CREOLE (a
Collection of REusable Objects for Language Engineering). I componenti di GATE,
definiti anche come resources, sono di tre tipi.
Language Resources (LR): rappresentano entità come il lessico, i corpora, le
annotazioni, le ontologie.
Processing Resources (PR): rappresentano entità principalmente algoritmiche,
come parsers, POS-taggers ecc.
Visual Resources (VR): rappresentano componenti di visualizzazione e modifica
che partecipano alla GUI.
Tale distinzione evidenzia l’importanza, nell’architettura di GATE, della separazione
dei compiti tra i vari componenti, per ragioni di manutenibilità, estendibilità e di facilità
di utilizzo.
I componenti più importanti forniti da GATE sono:
LR per la gestione di documenti, corpora e annotazioni;
PR per la definizione degli algoritmi di LP;
Gazzetters;
Ontologie;
Tool per machine learning;
Parser e tagger.
Gli elementi che costituiscono CREOLE possono essere facilmente caricati in modo
indipendente proprio grazie al framework fornito da GATE, che costituisce
un’interfaccia (o backplane) su cui effettuare il “plug” dei componenti. L’utente
fornisce al sistema un elenco di URL e il sistema si occuperà di caricare i componenti
localizzati negli indirizzi specificati. L’unione del framework (backplane) e dei

componenti rappresenta la porzione di software che può essere esportata negli
applicativi sviluppati dagli sviluppatori.
Tutte le risorse di CREOLE sono associate ad un file XML “creole.xml”, che definisce
le proprietà, i parametri necessari e i valori di default dei componenti: quando una
risorsa deve essere caricata, viene ricercato il file creole.xml relativo all’URL della
risorsa fornito dall’utente e il suo contenuto è utilizzato per inizializzarne i parametri e
per caricare le classi necessarie, solitamente contenute all’interno di file jar. Inoltre,
tutte le risorse di GATE sono basate su classi Java Bean, il modello di Java per
componenti software. Il modello Java Bean è utilizzato per incapsulare più oggetti
all’interno di un unico oggetto detto bean, che garantisce una maggiore gestibilità. Java
Bean impone il rispetto di determinate convenzioni alle classi che vogliono aderire a
tale modello, con lo scopo di aumentare la riusabilità e la facilità di sostituzione dei
bean.
4.2.2 Language Resources
Le LR sono quelle componenti che si occupano di gestire i documenti, i corpora e le
annotazioni. Le proprietà di ogni LR sono gestite tramite collezioni di coppie
chiave/valore, definite come FeatureMap.
Documenti: i documenti in GATE sono modellati come l’unione di contenuto ed
annotazioni. Il contenuto di un documento può essere qualsiasi sottoclasse di
“DocumentContent” di cui deve implementarne l’interfaccia, le annotazioni
sono invece inserite all’interno di Set Java (una collezione di elementi che non
contiene duplicati) definiti come AnnotationSet.
Corpora: un corpus in GATE è un Set Java i cui membri sono documenti.
Annotazioni: un’annotazione è una forma di metadato associato ad una specifica
porzione di documento. Le annotazioni in GATE sono organizzate in grafici, i
cui archi sono proprio le annotazioni mentre i nodi rappresentano specifiche parti
del contenuto di un documento. Un’annotazione possiede un ID, un tipo, un

nodo iniziale, un nodo finale, e diversi attributi inseriti all’interno di
FeatureMap.
Figura 5: organizzazione delle annotazioni in GATE.
Infine, GATE è in grado di assicurare la persistenza delle sue risorse. I tipi di
archiviazione persistente utilizzati per le LR sono:
salvataggio su database;
salvataggio su file tramite Java serialization;
salvataggio su file con formato XML.
In ogni caso, i documenti potranno essere esportati nuovamente nel loro formato
originale, scegliendo eventualmente di includere o meno le annotazioni.
4.2.3 Processing Resources
Le PR rappresentano i veri e propri algoritmi di elaborazione del linguaggio naturale,
eseguibili in GATE. Possono essere utilizzate singolarmente, in quanto moduli
indipendenti, o essere combinate insieme ad altre per formare delle applicazioni o
controller, cioè controlli che ne regolano la sequenza e il flusso di esecuzioni. GATE
supporta esclusivamente delle esecuzioni sequenziali, cioè in pipeline, delle PR.
Esistono due tipi di pipeline:
Simple pipelines, in cui le PR sono eseguite una alla volta sequenzialmente.

Corpus pipelines, in cui le PR sono eseguite su documenti e corpora. Tutte le PR
che compongono l’applicazione vengono eseguite sequenzialmente su un
documento prima di aprire il successivo all’interno del corpus, sul quale
verranno ripetute le stesse operazioni.
Sono inoltre presenti le versioni condizionali delle pipeline, che permettono di eseguire
o meno una PR, sulla base di determinate condizioni decise dall’utente.

4.3 JAPE
JAPE (Java Annotation Patterns Engine) è un linguaggio di programmazione di
pattern-matching sviluppato specificamente per GATE, che permette di scrivere ed
applicare regole ad annotazioni presenti nel testo: queste regole vengono tradotte in
codice Java ed applicate alle annotazioni già presenti, generando in output nuove
annotazioni oppure la modifica di quelle già esistenti. Nonostante l’organizzazione in
grafi delle annotazioni in GATE, quindi una struttura più complessa rispetto a quelle
normalmente gestibili da linguaggi regolari, spesso i dati descritti da grafi di
annotazioni possono essere considerati come semplici sequenze e permettono un
riconoscimento di tipo deterministico. In altri casi, tuttavia, la maggiore complessità
del dato in input può rendere non sufficiente la potenza computazionale di un automa
a stati finiti e implicare la necessità di un’elaborazione alternativa da parte di JAPE.
Un JAPE grammar, in particolare, consiste in un set di fasi di elaborazione, disposte
secondo un preciso ordine logico, in modo tale che annotazioni temporanee generate
da una prima fase, possano essere fornite come input per una successiva. Ogni fase è
un set di regole composte da pattern, il cui riconoscimento innesca l’esecuzione di
azioni specificate. Una regola è formata da due parti:
Left Hand Side (LHS), che contiene la descrizione dei pattern da riconoscere
sulle annotazioni.
Right Hand Side (RHS), che definisce invece le istruzioni da eseguire su
annotazioni sulle quali i pattern siano stati riconosciuti.
Una JAPE grammar presenta, inoltre, per ogni fase un header che ne specifica il nome,
l’input e alcune opzioni aggiuntive relative alle modalità di applicazione delle regole.
Qui di seguito è riportato un semplice esempio di regola JAPE, la quale permette di
trovare tutti i nomi delle Università (in questo caso per esempio “University of
Sheffield”).

Phase: University Input: Lookup Options: control = appelt Rule: University1 ( {Token.string == "University"} {Token.string == "of"} {Lookup.minorType == city} ):orgName --> :orgName.Organisation = {kind = "university", rule = "University"}
In questo caso la fase si aspetta come input almeno un Lookup, mentre la sezione
Options indica che il metodo per il matching è appelt. La fase è inoltre costituita da
una singola regola, Chiamata University1, che riesce a riconoscere le Università tramite
il pattern definito dalla LHS (codice che precede l’operatore “”) e, in caso di match,
aggiunge un’annotazione University tramite la RHS (codice che segue l’operatore
“”).
JAPE rappresenta il principale strumento per lo sviluppo di applicazioni NLP con
approccio rule-based. Non rientrando tra gli obiettivi del presente testo quello di
approfondire tale approccio, non viene fornita una descrizione dettagliata del
linguaggio JAPE e di relative funzionalità più avanzate; per un eventuale
approfondimento si rimanda alla documentazione presente sul sito di GATE
(https://gate.ac.uk/sale/tao/splitch8.html).

4.4 ANNIE
GATE fu inizialmente sviluppato nel contesto della ricerca su IE (Cunningham, 2014),
ragion per cui una parte fondamentale della propria piattaforma è dedicata proprio a
tale task di NLP. Si tratta di ANNIE (A Nearly New Information Extraction system),
un potente tool per IE basato su algoritmi a stati finiti e su istruzioni JAPE, che
permettono di elaborare annotazioni utilizzabili per vari task di IE. La Figura 6 mostra
le componenti di cui è composto ANNIE, disposti a formare una pipeline e qui di
seguito elencati.
Document Reset.
Tokeniser.
Gazzetter.
Sentence splitter.
Part Of Speech (POS) tagger.
Semantic tagger
Orthographic reference.
Figura 6: rappresentazione dei componenti di ANNIE.

4.4.1 Document Reset
La risorsa Document Reset consente di riportare il documento allo stato originario,
rimuovendo tutte le annotazioni presenti dovute ad elaborazioni precedenti. È possibile
comunque decidere di resettare solo determinate annotazioni, lasciando inalterate le
altre. È generalmente eseguita all’inizio di ogni applicazione per ottenere un risultato
non alterato da altre annotazioni.
4.4.2 Tokeniser
Il Tokeniser ha il compito di dividere il testo in componenti semplici, come numeri,
punteggiatura, spazi, simboli, parole, che vengono definiti token. Questa PR utilizza
un approccio rule-based: viene riportata qui di seguito la regola per identificare una
parola che inizia con una sola lettera maiuscola:
'UPPERCASE_LETTER' 'LOWERCASE_LETTER'* > Token; orth = upperInitial; kind = word;
Se una porzione di testo rispetta questa regola viene annotata come token, di tipo
“word” (“parola”). Le annotazioni risultanti dall’esecuzione di un tokeniser su un
documento hanno ad esse associate le seguenti feature:
string, il valore della stringa del token a cui è associata l’annotazione;
length, il numero di caratteri di cui è composta la stringa;
kind, attributo che distingue diversi tipi di token.
In GATE esistono cinque tipi di token predefiniti:
1. Word: definito come un qualunque insieme di lettere maiuscole o minuscole
contigue, incluso un trattino (ma non altre forme di punteggiatura). Un token di
tipo word possiede un attributo definito orth, per il quale sono definiti quattro
valori:
o upperInitial, se con la prima lettera maiuscola e tutte le altre minuscole;
o allCaps, se con tutte lettere maiuscole;
o lowerCase, se con tutte lettere minuscole;

o mixedCaps, se con insieme di lettere maiuscole e minuscole non incluse
nelle categorie precedenti.
2. Number: è definito come una qualunque combinazione di cifre contigue.
3. Symbol: può essere di due tipi, di valuta (ad esempio “$”, “€”) o standard (ad
esempio “&”).
4. Punctuation: sono definiti tre tipi di punteggiatura.
o start_punctuation: ad esempio “(“;
o end_punctuation: ad esempio “)”;
o other_punctuation: ad esempio”:”;
5. Space Token: rappresenta uno spazio bianco tra le parole e può essere di due tipi,
space e control, a seconda che si tratti di puri caratteri spaziali o di caratteri di
controllo.
In ANNIE è compreso di default l’English Tokeniser, che si compone di un normale
tokeniser e di un JAPE transducer, quest’ultimo viene utilizzato per ottimizzare i
risultati in base alle caratteristiche della lingua inglese. Un compito di questo
transducer è, ad esempio, quello di processare il risultato di tokenization del costrutto
“don’t” per portarlo da tre token (“don”, “’”, “t”) a due (“do”,” n’t”).
4.4.3 Gazetteer
Il compito del gazetteer è quello di identificare i nomi delle entità nel testo basato su
liste, definite lookup list; ogni lista consiste in un semplice file di testo contenente i
nomi propri comuni relativi a diverse categorie di entità, come nomi di persone, città,
organizzazioni, giorni della settimana ecc. Una lista di valute, ad esempio, potrebbe
contenere una porzione simile a questa:

Ecu European Currency Units FFr Fr German mark German marks New Taiwan dollar New Taiwan dollars NT dollar NT dollars
Per accedere alle liste il gazetteer utilizza un file indice lists.def, all’interno del quale
per ogni lista viene specificato un tipo principale ed eventualmente un tipo minore:
list_filename.lst:major_type:minor_type. La prima colonna si riferisce al nome del file
della lista, la seconda al tipo principale e la terza al tipo secondario. Per ogni token del
testo compatibile con una delle entry delle liste viene creata un’annotazione con i valori
presenti nella colonna del tipo primario e del tipo secondario. Infine, la forma
precedentemente esposta può essere integrata con una quarta colonna per l’indicazione
della lingua dei termini contenuti nella lista e con una quinta che specifichi un tipo
personalizzato di annotazione.
4.4.4 Sentence Splitter
Il sentence splitter ha il compito di suddividere il testo in periodi, cioè in porzioni di
testo dotate di significato e organizzate secondo precise regole grammaticali e
sintattiche. Ogni periodo viene annotato come “Sentence”, e ogni segno di
terminazione del periodo viene annotato come “Split”. Le annotazioni di tipo split
hanno un attributo “kind” che può assumere due valori, internal se il segno di
terminazione corrisponde ad un numero di punti da uno a quattro, a un punto
esclamativo o interrogativo o alla combinazione di quest’ultimi, external se
corrisponde ad un ritorno a capo. In alternativa alla PR fornita da ANNIE, è possibile
utilizzare RegEx Sentence Splitter, basato su regular expression, scritte in Java, più
robusto e con performance migliori su input irregolari.

4.4.5 Part-Of-Speech Tagger
POS tagger ha il compito di individuare ed annotare le parti del discorso, cioè parole
o simboli di un testo con proprietà o funzionalità simili che possono quindi essere
organizzate in classi. Ad esempio, le parti del discorso nella lingua italiana si
distinguono tradizionalmente in diverse classi: nome, aggettivo, articolo, pronome,
verbo, avverbio, preposizione, congiunzione e interiezione. Il numero delle classi e la
loro definizione dipendono dalla lingua a cui si sta facendo riferimento. Il risultato di
questa PR consiste nell’aggiunta di un attributo category ad ogni annotazione di tipo
token; il valore assunto da questo attributo corrisponde ad una parte del discorso della
lingua del testo ed è rappresentato da un codice costituito da lettere e simboli.
4.4.6 Semantic Tagger (ANNIE Named Entity Transducer)
Semantic Tagger (chiamato in GATE “ANNIE NE Transducer”) ha il compito di
analizzare le annotazioni apposte durante le fasi precedenti, per generare entità
annotate, disambiguando tra i vari significati possibili tramite il confronto con pattern.
Ad esempio, la parola “May” ha diversi significati nella lingua inglese: può
rappresentare il mese di maggio (“May 2015”), un cognome (“Steve May”) o un verbo
(“It may rain today”). Semantic Tagger, inoltre, è in grado di combinare più
annotazioni in singole entità: ad esempio nel caso di date espresse secondo il pattern
giorno, mese, anno, viene creata un’unica annotazione di tipo “Date” che comprenderà
tutte e tre le espressioni.
I tipi di annotazione che possono essere assegnate sono basate sulla definizione delle
entità di MUC (Message Understanding Conference):
Person
o gender: male, female
Location
o locType: region, airport, city, country, county, province, other
Organization

o orgType: company, department, government, newspaper, team, other
Money
Percent
Date
o kind: date, time, dateTime
Address
o kind: e-mail, url, phone, postcode, complete, ip, other
Identifier
Unknown
Questa PR, infine, è basata su regole scritte in linguaggio JAPE, che descrivono i
pattern che devono essere rispettati. Qui di seguito è riportato un esempio di regola
JAPE per l’individuazione di indirizzi ip.
Rule: IPaddress1 ( {Token.kind == number} {Token.string == "."} {Token.kind == number} {Token.string == "."} {Token.kind == number} {Token.string == "."} {Token.kind == number}
4.4.7 Orthographic Coreference (OrthoMatcher)
Orthographic Coreference ha il compito di individuare relazioni di coreferenza tra le
entità annotate dal Semantic Tagger, effettuando cioè una analisi delle coreferenze
basandosi su informazioni di tipo ortografico. Una coreferenza è presente quando due
diverse stringhe all’interno del testo rappresentano la stessa entità. Le regole per
definire una relazione di coreferenza vengono invocate tra due parole solo se queste
sono già state categorizzate come entità dello stesso tipo o se una di loro è stata
categorizzata come “unknown”, in modo da non sovrascrivere le precedenti
annotazioni. Per riconoscere relazioni tra token che identificano la medesima entità ma
che sono rappresentati ortograficamente in modo differente viene utilizzata una tabella
di aliases.

4.5 GATE e le Ontologie
GATE fornisce un’API per modellare e manipolare le ontologie attraverso un plug-in
che deve essere caricato manualmente. Le ontologie in GATE sono classificate come
LR. Per creare una LR legata all’ontologia, è necessario caricare inizialmente il plug-
in contenente un’implementazione dell’ontologia stessa.
I plug-in messi a disposizione da GATE per le ontologie sono:
Ontology: fornisce l’implementazione standard dell’API di ontologia GATE.
Ontology-Tools: fornisce un semplice editor grafico ontologico e OCAT, uno
strumento per l’annotazione di documenti basati su ontologie.
Gazetteer-Ontology-Based: fornisce “OntoRootGazetter” per la creazione
automatica di un gazetteer da un’ontologia.
Il linguaggio supportato da GATE per le ontologie è OWL, in particolare la sua variante
Lite.
Il supporto alle ontologie di GATE mira a semplificare l’uso di queste sia all’interno
dell’insieme di strumenti di GATE sia per colore che utilizzano esclusivamente le API
di Ontologia fornite. Quest’ultime nascondono i dettagli dell’implementazione e
consentono una manipolazione semplificate delle ontologie modellando le risorse
ontologiche come oggetti Java facili da usare. Infine, le ontologie possono essere
caricate e salvate in vari formati di serializzazione.
4.5.1 Modello dei dati per Ontologie
Un’ontologia non è altro che un insieme di concetti (istanze e classi) e le relazioni tra
di essi, dove ogni classe può avere più di una sottoclasse ed ogni istanza può avere più
di una classe; questo è il motivo per il quale le ontologie sono grafi e non alberi. La
gerarchia in classi (o tassonomia) gioca un ruolo centrale nel modello ontologico dei
dati. Questa consiste, all’interno dell’API fornita da GATE, in un insieme di oggetti
della classe OClass collegati da relazioni di: subClassOf (sottoclasse di), superClassOf
(superclasse di) ed equivalentClassAs (uguale a). Le istanze sono oggetti che
appartengono alle classi, nell’API fanno parte della classe OInstance e tra di loro

possono avere relazioni di: sameInstanceAs (indica che i valori delle proprietà
assegnati a due divere istanze sono gli stessi) e DifferentInstanceAs (india che le due
istanze sono disgiunte tra di loro).
4.5.2 Ontology Plugin
L’Ontology Plugin messo a disposizione da GATE contiene l’attuale implementazione
dell’API per la gestione delle ontologie. Questo non fa parte delle librerie di default
per questo deve essere scaricato e caricato in GATE separatamente. Una volta caricato
tra le LR verranno incluse:
OWLIMOntology: è la LR standard da utilizzare nella maggior parte delle
situazioni. Questa consente all’utente di creare una nuova ontologia oppure di
caricarla da file.
ConnectSesameOntology: questa LR consente l’uso di ontologie già
memorizzate nel datastore (Sesame2 repository), ed è molto utile per riutilizzare
rapidamente un’ontologia molto grande che è stata precedentemente creata
tramite la risorsa esplicata al punto precedente.
CreateSesameOntology: quest’ultima LR consente di creare una nuova
ontologia vuota specificando i parametri della configurazione per far si di creare
la Sesame repository.
Questo plugin è alla base della creazione delle ontologie in GATE, ma ciò che ci
permette di gestirle e di utilizzarle come task del NLP è l’Ontology-Tools Plugin.
4.5.3 Ontology-Tools Plugin
L’Ontology-Tools Plugin è presente all’interno delle librerie di default di GATE,
ragion per cui non vi è la necessità di caricarlo esternamente ma è possibile trovarlo
all’interno della lista dei CREOLE plugin.
Figura 8: Ontology Tools
Questo plugin è il più importante in quanto fornisce un GATE Ontology Editor per la
modellazione vera e propria delle ontologie (figura 9), ma soprattutto fornisce
l’Ontology Annotation Tool attraverso il quale è possibile effettuare manualmente
un’annotazione semantica del testo, per effettuarla in maniera del tutto automatica,
invece, il plugin mette a disposizione l’OntoGazetteer.
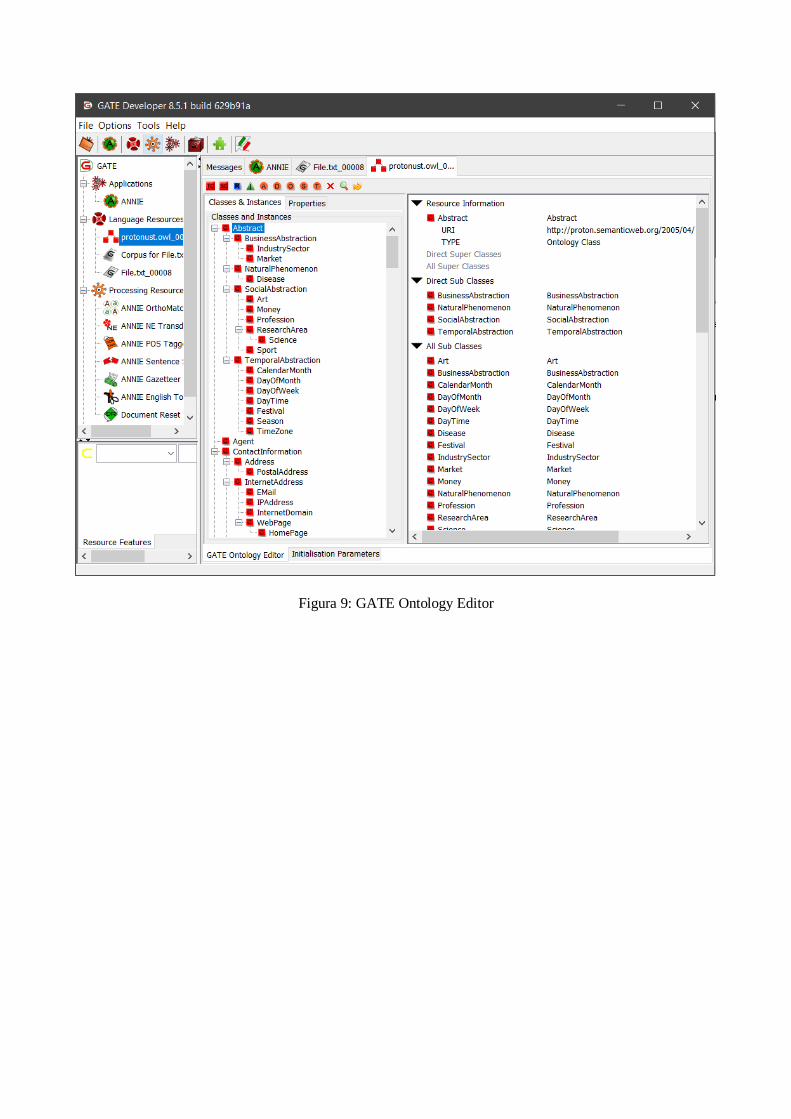
Figura 9: GATE Ontology Editor
4.6 Esempio di annotazione semantica in GATE Developer
Per rendere più chiare le modalità di utilizzo dei plugin messi a disposizione da GATE
per annotare semanticamente un testo, si fornisce un esempio svolto in GATE
Developer in combinazione con ANNIE.
4.6.1 Annotazione Semantica manuale con Ontology Annotation Tool
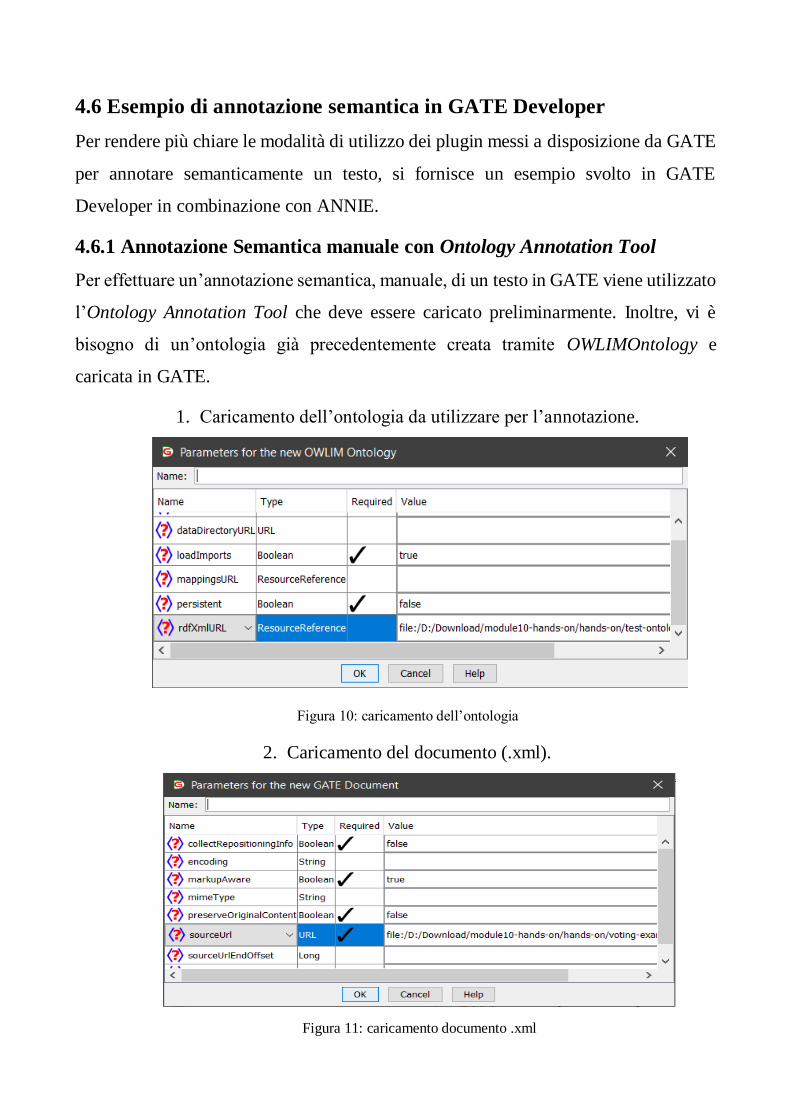
Per effettuare un’annotazione semantica, manuale, di un testo in GATE viene utilizzato
l’Ontology Annotation Tool che deve essere caricato preliminarmente. Inoltre, vi è
bisogno di un’ontologia già precedentemente creata tramite OWLIMOntology e
caricata in GATE.
1. Caricamento dell’ontologia da utilizzare per l’annotazione.
Figura 10: caricamento dell’ontologia
2. Caricamento del documento (.xml).
Figura 11: caricamento documento .xml
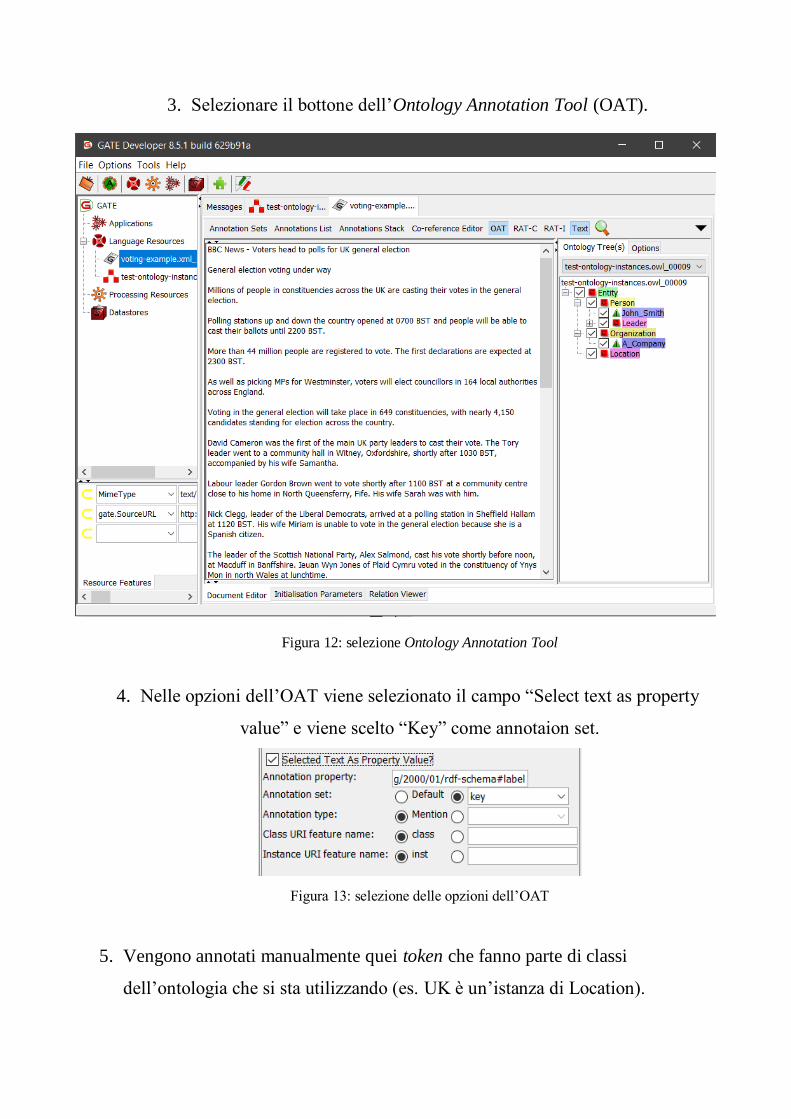
3. Selezionare il bottone dell’Ontology Annotation Tool (OAT).
Figura 12: selezione Ontology Annotation Tool
4. Nelle opzioni dell’OAT viene selezionato il campo “Select text as property
value” e viene scelto “Key” come annotaion set.
Figura 13: selezione delle opzioni dell’OAT
5. Vengono annotati manualmente quei token che fanno parte di classi
dell’ontologia che si sta utilizzando (es. UK è un’istanza di Location).
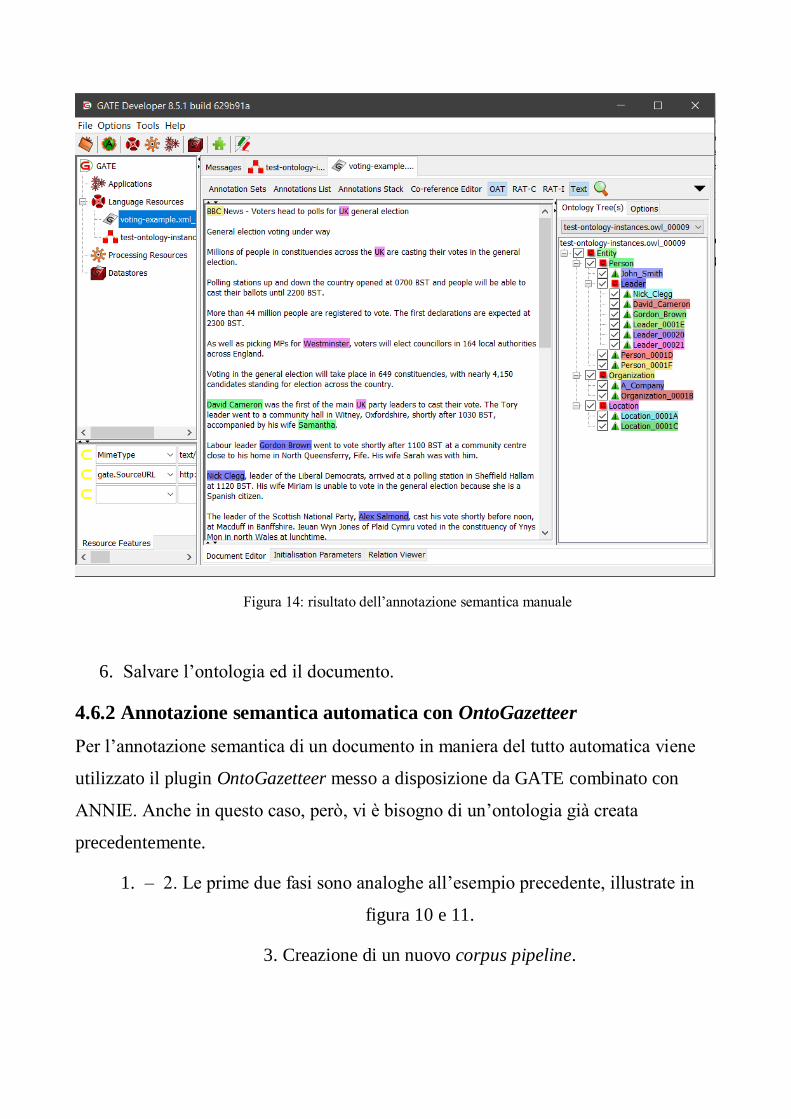
Figura 14: risultato dell’annotazione semantica manuale
6. Salvare l’ontologia ed il documento.
4.6.2 Annotazione semantica automatica con OntoGazetteer
Per l’annotazione semantica di un documento in maniera del tutto automatica viene
utilizzato il plugin OntoGazetteer messo a disposizione da GATE combinato con
ANNIE. Anche in questo caso, però, vi è bisogno di un’ontologia già creata
precedentemente.
1. – 2. Le prime due fasi sono analoghe all’esempio precedente, illustrate in
figura 10 e 11.
3. Creazione di un nuovo corpus pipeline.

Figura 15: creazione dell’applicazione per una pipeline su un corpus
4. Caricamento, in ordine, delle seguenti PR: Document Reset PR, ANNIE
English Tokeniser, ANNIE POS Tagger, GATE Morphological Analyser,
ANNIE Sentence Splitter (tutte con i parametri di default).
Figura 16: caricamento delle PR
5. Creazione e configurazione di OntoRootGazetteer con i parametri di default,
con l’ontologia da utilizzare e con la pipeline creata precedentemente.
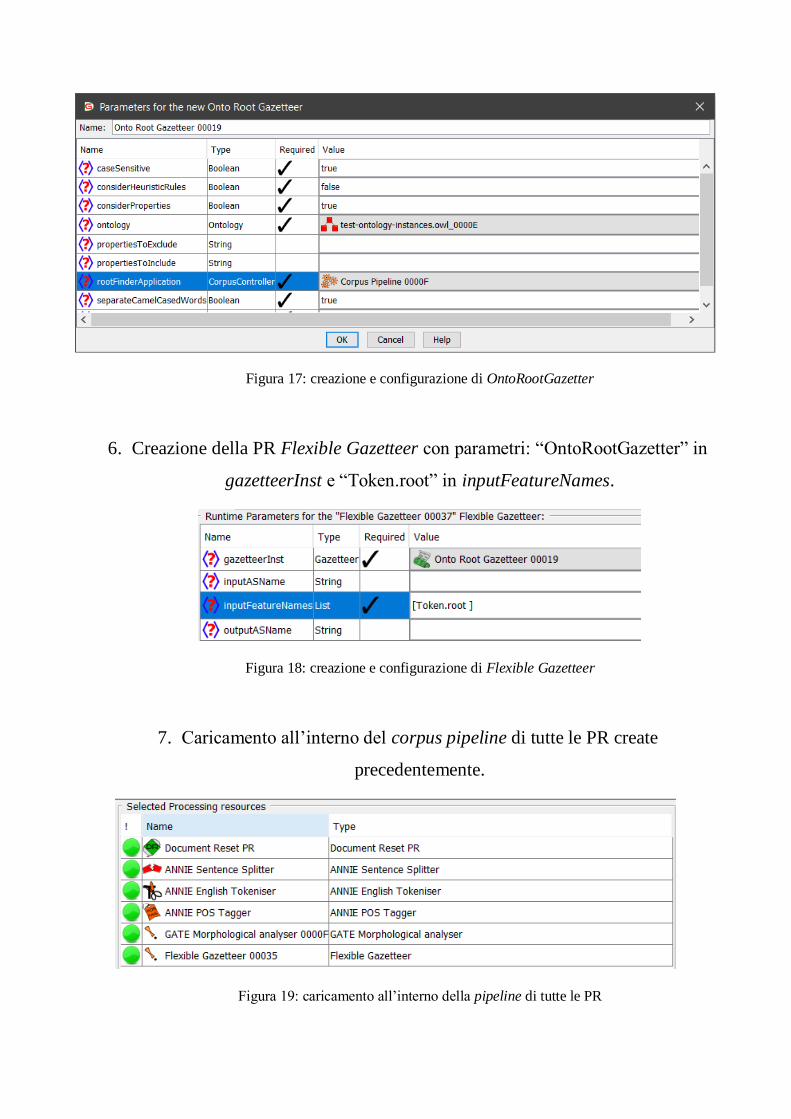
Figura 17: creazione e configurazione di OntoRootGazetter
6. Creazione della PR Flexible Gazetteer con parametri: “OntoRootGazetter” in
gazetteerInst e “Token.root” in inputFeatureNames.
Figura 18: creazione e configurazione di Flexible Gazetteer
7. Caricamento all’interno del corpus pipeline di tutte le PR create
precedentemente.
Figura 19: caricamento all’interno della pipeline di tutte le PR
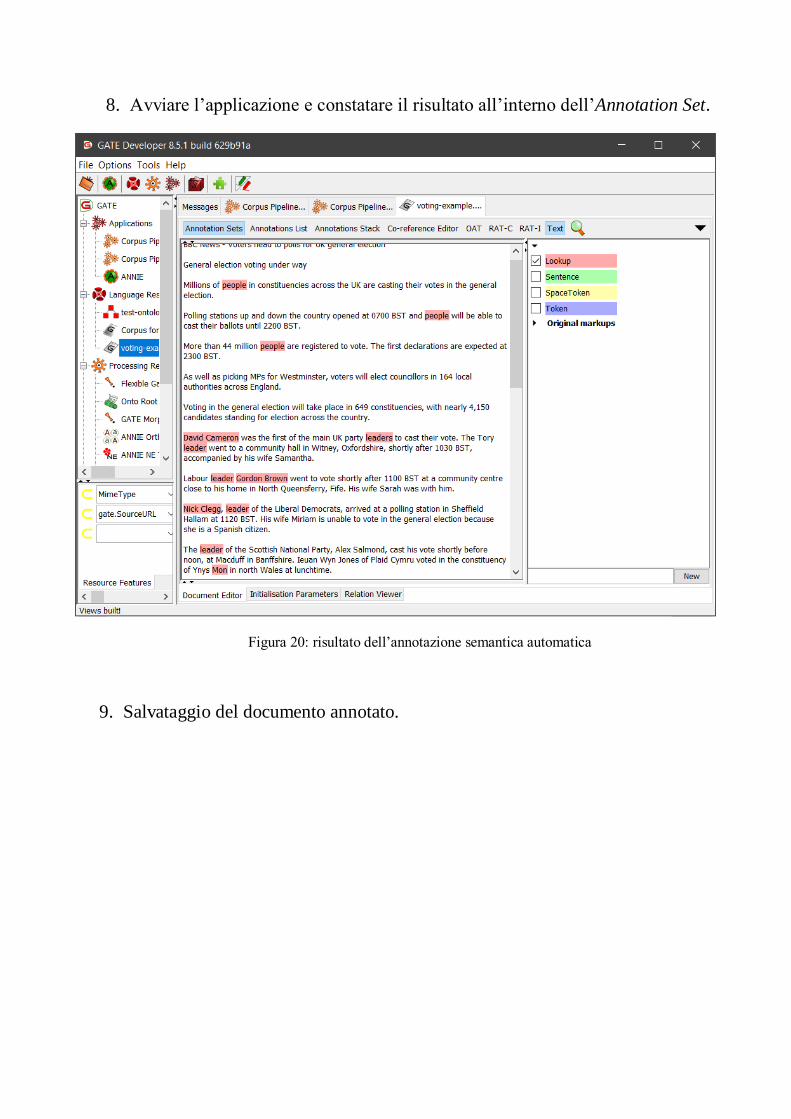
8. Avviare l’applicazione e constatare il risultato all’interno dell’Annotation Set.
Figura 20: risultato dell’annotazione semantica automatica
9. Salvataggio del documento annotato.

5. Conclusioni
Nel corso di questo testo sono stati analizzati diversi aspetti del Natural Language
Processing e delle attività correlate. In primo luogo, si è cercato di individuare ed
analizzare le problematiche relative all’elaborazione da parte delle macchine del
linguaggio naturale. In seguito, tra le attività di NLP, è stato approfondito il processo
di IE e della sua suddivisione in sub-task prestando particolare attenzione a quella di
Named Entity Recognition. Successivamente l’attenzione è stata focalizzata sulla
semantica del linguaggio naturale e come questa influisca all’interno del Web con la
ricerca dei documenti, introducendo il concetto di Web Semantico. Inoltre, sono state
trattate nello specifico le Ontologie come metodo per correlare semanticamente tra di
loro i dati. Si è dato spazio ad una panoramica sul sistema GATE, una delle principali
piattaforme per l’elaborazione del linguaggio naturale, descrivendone la struttura e le
caratteristiche. Infine, è presente una parte sperimentale nella quale è stata adoperata
la piattaforma GATE per l’analisi semantica di un testo una volta costruita
l’ontologia.
L’analisi effettuata sull’argomento nel corso del testo ha evidenziato come le sfide e
le possibili applicazioni legate all’NLP possano rappresentare un argomento al centro
dell’attenzione nei prossimi decenni. Questo è motivato dal continuo aumento di
contenuti testuali in linguaggio umano, dovuto soprattutto all’esplosione dei social
network e alla pervasività sempre maggiore della tecnologia nella società. Per questo
motivo, per rendere ancora più efficiente l’interazione dell’uomo con la macchina,
bisognerebbe porre l’attenzione proprio sull’analisi semantica che restringerebbe la
distanza che c’è tra il modo di interpretare la realtà da parte dei sistemi informatici e
dell’uomo; una distanza che rende ancora difficile, ad esempio, creare un Web
Semantico che possa permettere realmente di accedere a conoscenze mirate, nei
contesti più disparati, in modo semplice e naturale.

Bibliografia
Liddy, E. D. (2001). Natural Language Processing
Jakub Piskorski, R. Y. (2012). Information Extraction: Past, Present and Future. In S. H. Poibeau T, Multi-
source, Multilingual Information Extraction and Summarization (p. 24). Springer.
Tim Berners-Lee, J. H. (2001). The Semantic Web. In Scientific American, May 2001.
Gruber, T. R. (1993). A translation approach to portable ontologies. In Knowledge Acquisition (p.199-220).
Cunningham (2014). Developing Language Processing Components with GATE Version 8.
University of Sheffield Department of Computer Science.
Saggion, H. (2007). Ontology-based Information Extraction for Business Intelligence.
University of Sheffield Department of Computer Science.
Treccani. (2015). Dizionario Treccani. Treccani.





























