Embed Size (px)
Citation preview

[Digite o
título do
documento]
[Digite o subtítulo do documento]
Sherley
CIFRA DE HILL
Autor: Elaine da Silva Mantovani
Orientador: Sinval Braga de Freitas
Matemática
PRÓ-REITORIA DE GRADUAÇÃO TRABALHO DE CONCLUSÃO DE CURSO
Pró-Reitoria de Graduação Curso de Licenciatura em Matemática
Trabalho de Conclusão de Curso
O USO DO PACOTE ESTATÍSTICO R VOLTADO PARA O ENSINO DA DISCIPLINA DE ESTATÍSTICA NOS DIVERSOS
CURSOS SUPERIORES DA UNIVERSIDADE CATÓLICA DE BRASÍLIA - UCB
Autor: Luís Vieira GomesOrientadora: Valeria da Silva Cruz Shiguti
Brasília - DF 2012

LUÍS VIEIRA GOMES
O USO DO PACOTE ESTATÍSTICO R VOLTADO PARA O ENSINO DA DISCIPLINA DE ESTATÍSTICA NOS DIVERSOS CURSOS SUPERIORES DA
UNIVERSIDADECATÓLICA DE BRASÍLIA - UCB Artigo apresentado ao curso de graduação em Matemática da Universidade Católica de Brasília, como requisito parcial para obtenção do Título de Licenciado em Matemática. Orientadora: Valeria da Silva Cruz Shiguti
Brasília 2012

Artigo de autoria de Luís Vieira Gomes, intitulado “O USO DO PACOTE ESTATÍSTICO R
VOLTADO PARA O ENSINO DA DISCIPLINA DE ESTATÍSTICA NOS DIVERSOS
CURSOS SUPERIORES DA UNIVERSIDADE CATÓLICA DE BRASÍLIA - UCB”,
apresentado como requisito parcial para obtenção do grau de Licenciado em Matemática da
Universidade Católica de Brasília, em 29 de novembro de 2012, defendido e aprovado pela
banca examinadora abaixo assinada:
_____________________________________________________ Profª. MsC. Valéria da Silva Cruz Shiguti
Orientadora Matemática – UCB
_____________________________________________________ Profª. MsC. Ana Sheila Perdigão Faleiros
Matemática - UCB
_____________________________________________________ Prof. MsC. Wanderley Akira Shiguti
Matemática – UCB
Brasília 2012

A Rosa Braga de Lima Gomes e Antônio vieira Gomes, pessoas inesquecíveis. “Ainda que eu falasse a língua dos homens e dos anjos sem amor eu nada seria”. 1Co 13.1. Legião Urbana - Monte castelo.

AGRADECIMENTOS
Aos meus irmãos, a todos os amigos do curso de matemática, aos professores
responsáveis pela nossa aprendizagem, à direção do curso de Matemática na UCB, a minha orientadora, a todos que de uma forma ou de outra contribuiu para a conclusão deste trabalho e principalmente a Deus e a meus pais, seres inigualáveis que foram responsáveis pela a minha criação, minha educação e principalmente pela formação do meu caráter.

“Se as leis da Matemática referem-se à realidade, elas não estão corretas; e, se estiverem corretas, não se referem à realidade." Albert Einstein

O USO DO PACOTE ESTATÍSTICO R VOLTADO PARA O ENSINO DA DISCIPLINA DE ESTATÍSTICA NOS DIVERSOS CURSOS SUPERIORES DA
UNIVERSIDADECATÓLICA DE BRASÍLIA - UCB
LUÍS VIEIRA GOMES
Resumo: Este trabalho desenvolvido para formular um conceito didático da utilização do software R visa contribuir para a formação dos alunos, dos diversos cursos da Universidade Católica de Brasília – UCB, mas precisamente de alunos que cursam a disciplina de estatística, nos diversos cursos superiores da universidade católica de Brasília. Para isso fez-se necessário concatenar teoria e prática. Prática essa que se fundamenta em um pacote estatístico muito utilizado hoje em dia, o software R. Este software se diferencia dos demais pacotes pela sua facilidade de instalação, já que é freeware e pela sua forma de manuseio, a programação, visando com isso uma melhoria no aprendizado da disciplina de estatística no que tange a teoria e a prática. Palavras-chave: Disciplina de Estatística. Educação. Software R. 1. INTRODUÇÃO
Segundo PEREIRA ( 2007, citado por Francisco de Oliveira Mesquita; Walter Esfrain Pereira (2007, p. 1) ) : “A Estatística é uma área vasta do conhecimento que utiliza recursos da teoria probabilista com a finalidade de explicar os eventos, a relação de dados experimentais permitindo em qualquer ponto estratégico, tomar uma decisão através de análises matemáticas dos dados numéricos”.
A estatística por ser uma área, das exatas, bastante ampla, tem-se difundido largamente pelos diversos cursos das instituições de ensino superior no país. Essa concepção se deve a importância desta disciplina para a formação do aluno no que diz respeito a sua capacidade de síntese, abstração e tomada de decisão.
Com o intuito de promover e colaborar com um aprendizado conciso que agrega conhecimento específico do curso escolhido com um conteúdo vasto para aplicação das análises de dados e Tomada de Decisão. A disciplina de estatística foi incluída na grade de disciplina de forma obrigatória para complementação de créditos totais. Sua bibliografia é vasta, porém sua aplicação prática ainda caminha lentamente dependendo do conhecimento do tutor que lhe confere ou não tal importância.
A Universidade Católica de Brasília atualmente consta com 29 cursos destes, a maioria inclui a disciplina de estatística como Estatísticas Aplicadas I e II, Bioestatísticas, Estatística Aplicada a Psicologia, Probabilidade e Estatística, dentre outras. A aplicação prática que atualmente evidencia nesta disciplina é a utilização do Excel, pacote este, não específico desta disciplina, e em alguns cursos o SPSS (Statistical Package for the Social Sciences - pacote estatístico para as ciências sociais).
Para este trabalho a proposta é a inclusão de uma ferramenta acessível, própria para avaliação das análises de dados e tomadas de decisão, bem como um ambiente propício a programação de diversos conceitos relacionados à estatística, este software é conhecido como

R, é uma linguagem de computador desenvolvido por Ross Ihaka e por Robert Gentleman no departamento de Estatística da universidade de Auckland, Nova Zelândia, e foi elaborado por um esforço colaborativo de pessoas em vários locais do mundo. Sua aplicação vai além de conceitos básicos iniciais, porém para este trabalho fez-se necessário delimitar tal estudo à parte de formulação de Tabelas, Gráficos e da Estatística Descritiva tendo em vista que aplicação deste conceito permeia 60% do curso em que o aluno está matriculado.
Vale ressaltar que em momento algum se pretende eliminar a utilização dos demais pacotes estatísticos atualmente utilizados, mas poder trazer para o aluno mais uma opção nessa relação de ensino e aprendizagem. 2. INTRODUÇÃO A LINGUAGEM R
O R é uma linguagem de computador e um ambiente de desenvolvimento integrado, para cálculos estatísticos e gráficos. Originalmente foi criada por Ross Ihaka e por Robert Gentleman no departamento de Estatística da universidade de Auckland, Nova Zelândia, e foi desenvolvido por um esforço colaborativo de pessoas em vários locais do mundo.
Como fora dito anteriormente o R é um ambiente, e não um sistema estatístico, onde as técnicas estatística são implementadas. Podendo ser estendido conforme a necessidade dos usuários através de instalações dos pacotes expansivos.
O R conta com uma eficaz manipulação de dados, instalação de armazenamento, conjunto de conectivos e operadores para a realização de cálculos simples e complexos, instalações gráficas, para análises de dados e uma linguagem de programação simples e eficaz, que inclui condicionais, loops, funções pré-definidas e recursos para a criação de novas funções.
Este manual tem por finalidade familiarizar o usuário no uso do R estatístico no diz respeito à aplicação da estatística descritiva básica. 3. COMO INSTALAR O R ESTATÍSTICO Anexo a este trabalho há um CD com o programa a ser instalado. Para executar a instalação abra a unidade de CD-ROM e dê um clique duplo no ícone referente ao programa executável. Logo em seguida no botão executar. Escolha o idioma de sua preferência e clique OK. Leia as instruções das janelas e clique no botão avançar até concluir a instalação.
Figura 9 – ícone para instalar o programa
Para este trabalho utilizar-se-á versão R-2.15.0-win – Estatística.
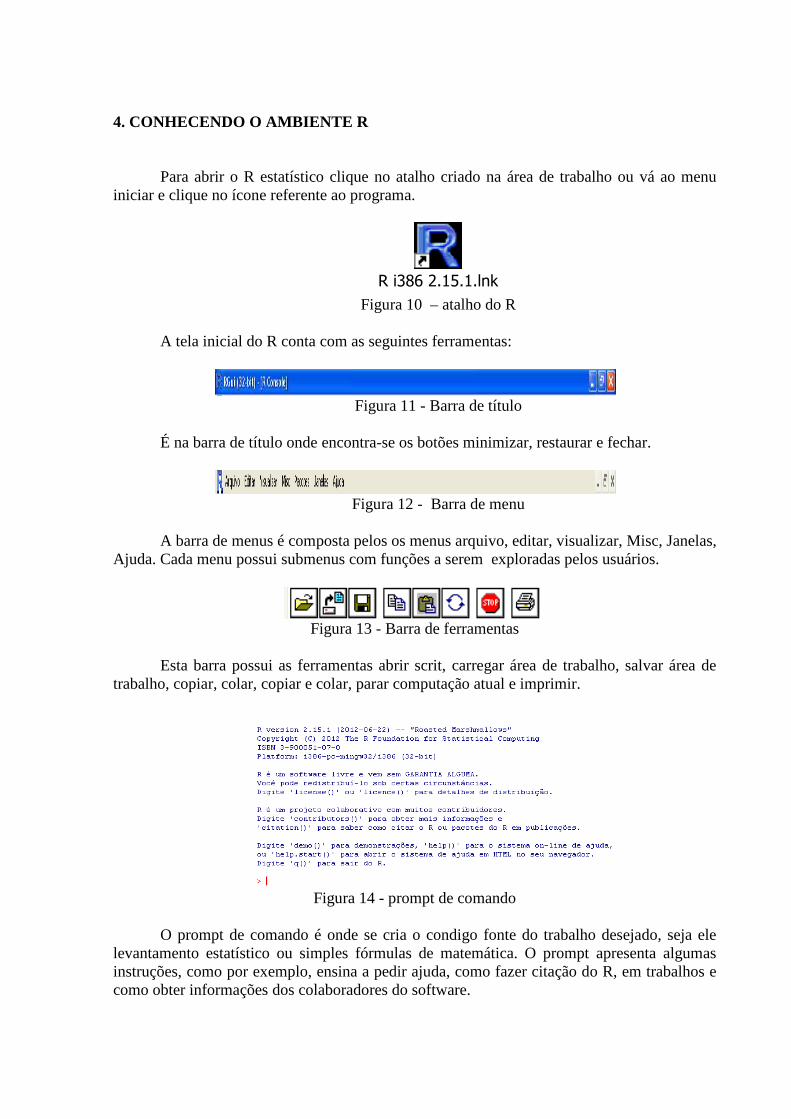
4. CONHECENDO O AMBIENTE R
Para abrir o R estatístico clique no atalho criado na área de trabalho ou vá ao menu iniciar e clique no ícone referente ao programa.
R i386 2.15.1.lnk Figura 10 – atalho do R
A tela inicial do R conta com as seguintes ferramentas:
Figura 11 - Barra de título
É na barra de título onde encontra-se os botões minimizar, restaurar e fechar.
Figura 12 - Barra de menu
A barra de menus é composta pelos os menus arquivo, editar, visualizar, Misc, Janelas,
Ajuda. Cada menu possui submenus com funções a serem exploradas pelos usuários.
Figura 13 - Barra de ferramentas
Esta barra possui as ferramentas abrir scrit, carregar área de trabalho, salvar área de
trabalho, copiar, colar, copiar e colar, parar computação atual e imprimir.
Figura 14 - prompt de comando
O prompt de comando é onde se cria o condigo fonte do trabalho desejado, seja ele
levantamento estatístico ou simples fórmulas de matemática. O prompt apresenta algumas instruções, como por exemplo, ensina a pedir ajuda, como fazer citação do R, em trabalhos e como obter informações dos colaboradores do software.

4.1 OBTENDO AJUDA NO R.
Existe diversas forma de obter ajuda no R. Neste trabalho será apresentada as formas mais simples e prática. Pode-se obter ajuda através do menu ajuda, onde está dividido em submenus.
Figura 15 – expansão do menu ajuda
Pode-se encontrar Manuais em PDF no submenu manuais, dentre eles estão: Uma
Introdução ao R, R Uma linguagem e ambiente para computação estatística, R Dados de Exportação e Importação, R linguagem de definição, Escrevendo Extensões R dentre outros. Para obter ajuda utilize a função help(nome da função) , ??nome da função, help.start(nome da função) iniciar ajuda no browser padrão instalado, help.search(“termo”) procurar por “termo” em todos os pacotes instalados. 5. IMPORTANDO DADOS PARA O R
Para importar uma base de dados para o R faz-se necessário exportar os dados em um
formato reconhecido pelo R. Contudo o documento deve ser salvo com extensão .txt ( a extensão coincide com sistema terminal ou simples editor) ou .CSV (Comma-separatedvalues ou em português Valores Separados por Vírgula). O procedimento a seguir fora realizado no Excel, para importar a tabela do anexo II.
Para salvar um documento de extensão.xls para a extensão.txt, execute os seguintes passos. Clique no Botão Office e em seguida em Opção do Excel, na janela que irá aparecer clique no nome Salvar, escolha o formato de sua preferência na caixa de diálogo salvar Arquivos neste formato, como exemplo “texto – (MS-DOS)”. Após escolher este formato abra uma nova planilha e copia os dados para esta nova planilha, salve-a com o nome desejado. Veja que após ter salvado o documento, o mesmo aparece com o formato .txt, que é reconhecido pelo R.
Após salvar os dados em um formato reconhecido pelo R, exportaremos os dados para o R. read.table ( ), esta função lê dados em formato de tabela e cria um quadro de dados a partir dele. É também a função responsável por importa os dados para o R. Para visualizar os dados importados tem que armazenar em uma variável na forma de data frame. Usaremos o editor do R para editar e alterar os dados e funções, a serem executadas no prompt de

comando do R, de nosso interesse. Todavia uma vez digitados no prompt de comando não se pode fazer as devidas correções.
Para abri o editor do R clique no menu arquivo e em seguida escolha novo script. No editor do R digite: amostra<-read.table(file.choose( ), header=T), este comando escolherá o arquivo e armazenará na variável amostra.
6. CRIANDO TABELAS
Sinteticamente será apresentado como criar tabela no R. Mas antes de iniciar o
processo de criação das tabelas, faremos alguns comando básico no R, para que o usuário se familiarize com o mesmo.
Ao iniciarmos criaremos uma variável no editor do R. Essa variável ou objeto pode conter número, caracter, vetor, matriz ou até mesmo um data frame, popularmente conhecido como tabela.
a<-3 b<-4 Diz-se aqui que a recebe o número três e b o número quatro. Para realizar as operações conhecidas como soma, subtração, multiplicação,
potenciação etc. Basta que o usuário saiba quais os operadores corresponde às respectivas operações.
c<- a+b c recebe a mais b, o valor de c é igual a 7, pois c=3+4. Vamos a mais um exemplo: d<-((c^a+2*b) – 4*(a-b))/5 Veja que o valor da variável d=71. O raciocínio segue para as demais operações. Para criarmos um vetor e uma matriz os procedimentos são semelhantes. e<-c(1,2,3,4,5), e recebe a concatenação dos valores 1,2,3,4,5, ou seja, e recebe o
vetor (1,2,3,4,5). A função c( ) quer dizer concatenar, juntar. f<-1:6, f recebe a seqüência de 1 a 6 g<-4:9, g recebe a seqüência de 4 a 9 h<-matrix(c(f,g),6,2), h recebe a matriz da concatenação de f e g, com 6 linhas e 2
colunas. Ou poderíamos usar h<-matrix(1:12,6,2), h recebe matriz de sequência de 1 a 12, com seis linhas e duas colunas. Veja, aqui, que o preenchimento da matriz se dar pelo o enchimento das colunas.
Temos outras formas de criar matrizes, mas não nos prenderemos a este detalhe. A função data.frame( ) é uma função que serve para a criação de uma espécie de
tabela, onde pode-se armazenar número e caracteres. i<-c("A","B","C","D","E","F") j<-data.frame("seq 1 a 6"=c(f),"seq de 4 a 9"=c(g),"seq de a a f "=c(i)) j recebe data frame de três colunas, onde a primeira é seqüência de 1 a 6 e a ultima a
seqüência dos caracteres. w<-c(seq(1,6),4:9) w recebe concatenação da sequencia 1 a 6 e da sequencia 4 a 9. talbe(w) A função table( ) mostra a freqüência dos valores de um dataframe, matriz ou vetor. Criaremos uma tabela a partir dos dados armazenados na variável w.
fi<-as.numeric(table(w)) fi recebe valores da freqüência de w.

xi<- (w[! duplicated(w)]) xi recebe os valores não duplicados de w. xifi<-xi*fi
tabela<data.frame("XI"=xi,"FI"=fi,"XI*FI "=xifi) Tabela recebe dataframe com três colunas e nove linhas. A primeira coluna chamada
XI, segunda FI e a terceira o produto de XI*FI. 7. CRIANDO GRÁFICOS
A seguir será apresentado comandos para visualizar exemplos de gráficos, já existente no R, e como criar gráficos.
demo(graphics) Este comando mostra os exemplos de gráficos. Pressione enter para visualizar os
modelos de gráficos. Execute o comando example(plot), example(barplot), example(pie) são os tipos de
gráficos de linha, colunas e pizza respectivamente. 7.1 GRÁFICO DE COLUNA Veja os comandos: w<-c(seq(1,6),4:9) w recebe concatenação da sequência de 1 a 6 e de 4 a 9. fi<-as.numeric(table(w)) fi recebe valores da freqüência de w. xi<- (w[! duplicated(w)]) xi recebe os valores não duplicados de w.
Para criar um gráfico de coluna usaremos o comando: barplot(w) Agora execute o comando: barplot(xi,fi,xlab="seg 1 a 6",ylab="seq 4 a 9",main="Título do gráfico",col="blue") Uma nova janela irá aparecer com o gráfico de coluna. barplot(xi,fi,xlab="seg 1 a 6",ylab="seq 4 a 9",main="Título do gráfico",col="blue")
Agora vamos entender o que essa seqüência de comandos quer dizer. Barplot significa gráficos de coluna, xi e fi são as variáveis de onde extrairemos as informações para criação do gráfico. xlab="seg 1 a 6" é o nome que receberá o eixo X, do mesmo modo para o eixo Y, main quer dizer principal neste caso o título, col=“blue” as colunas receberam a cor azul.
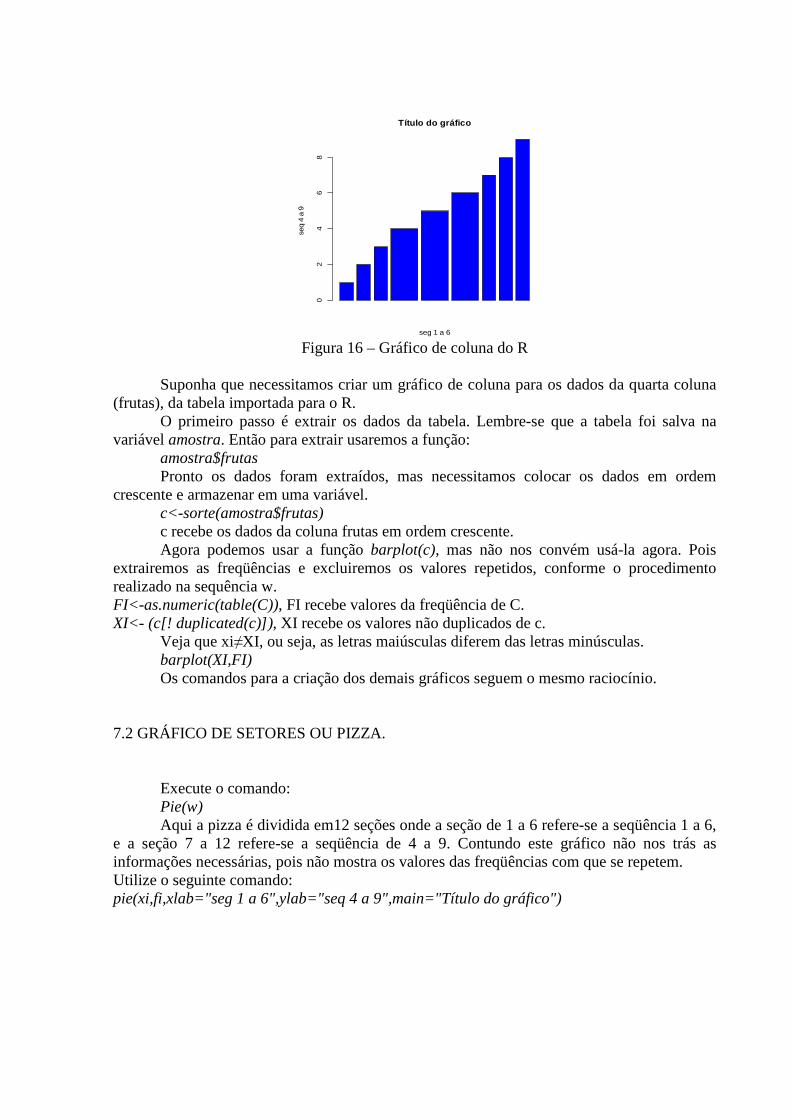
Figura 16 – Gráfico de coluna do R
Suponha que necessitamos criar um gráfico de coluna para os dados da quarta coluna
(frutas), da tabela importada para o R. O primeiro passo é extrair os dados da tabela. Lembre-se que a tabela foi salva na
variável amostra. Então para extrair usaremos a função: amostra$frutas Pronto os dados foram extraídos, mas necessitamos colocar os dados em ordem
crescente e armazenar em uma variável. c<-sorte(amostra$frutas) c recebe os dados da coluna frutas em ordem crescente. Agora podemos usar a função barplot(c), mas não nos convém usá-la agora. Pois
extrairemos as freqüências e excluiremos os valores repetidos, conforme o procedimento realizado na sequência w. FI<-as.numeric(table(C)), FI recebe valores da freqüência de C. XI<- (c[! duplicated(c)]), XI recebe os valores não duplicados de c.
Veja que xi≠XI, ou seja, as letras maiúsculas diferem das letras minúsculas. barplot(XI,FI) Os comandos para a criação dos demais gráficos seguem o mesmo raciocínio.
7.2 GRÁFICO DE SETORES OU PIZZA. Execute o comando: Pie(w) Aqui a pizza é dividida em12 seções onde a seção de 1 a 6 refere-se a seqüência 1 a 6,
e a seção 7 a 12 refere-se a seqüência de 4 a 9. Contundo este gráfico não nos trás as informações necessárias, pois não mostra os valores das freqüências com que se repetem. Utilize o seguinte comando: pie(xi,fi,xlab="seg 1 a 6",ylab="seq 4 a 9",main="Título do gráfico")
Título do gráfico
seg 1 a 6
seq
4 a
9
02
46
8
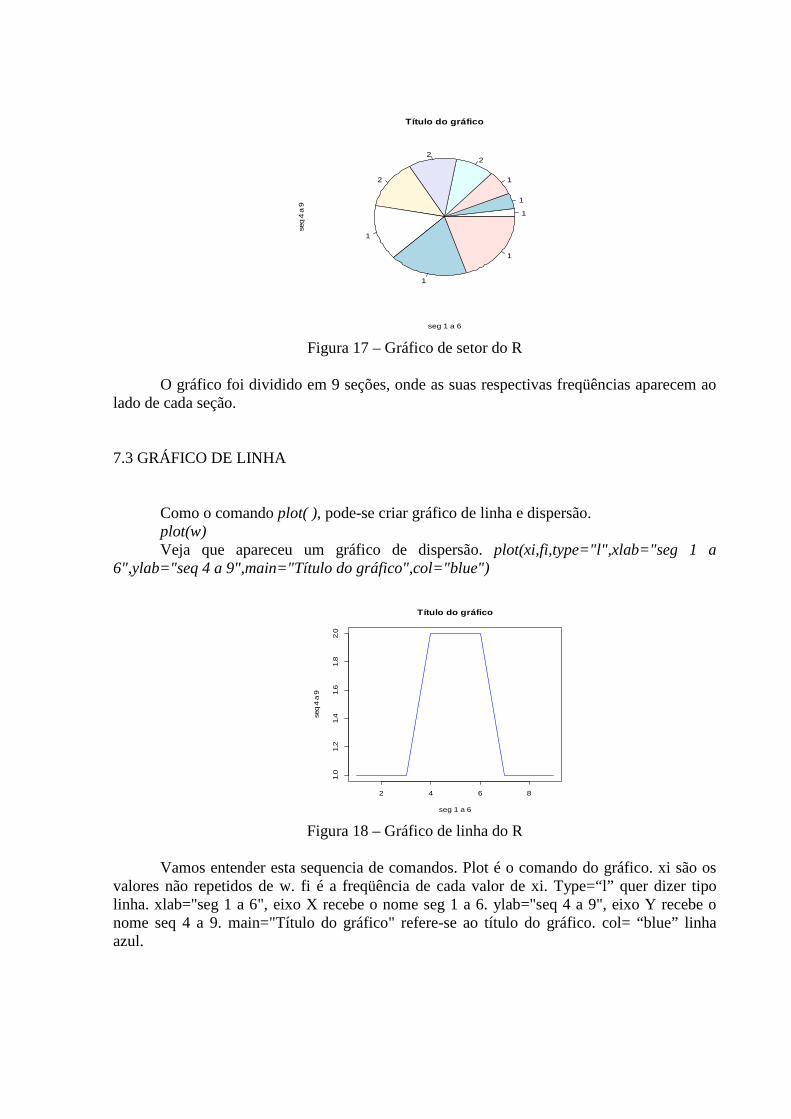
Figura 17 – Gráfico de setor do R
O gráfico foi dividido em 9 seções, onde as suas respectivas freqüências aparecem ao
lado de cada seção.
7.3 GRÁFICO DE LINHA Como o comando plot( ), pode-se criar gráfico de linha e dispersão. plot(w) Veja que apareceu um gráfico de dispersão. plot(xi,fi,type="l",xlab="seg 1 a
6",ylab="seq 4 a 9",main="Título do gráfico",col="blue")
Figura 18 – Gráfico de linha do R
Vamos entender esta sequencia de comandos. Plot é o comando do gráfico. xi são os
valores não repetidos de w. fi é a freqüência de cada valor de xi. Type=“l” quer dizer tipo linha. xlab="seg 1 a 6", eixo X recebe o nome seg 1 a 6. ylab="seq 4 a 9", eixo Y recebe o nome seq 4 a 9. main="Título do gráfico" refere-se ao título do gráfico. col= “blue” linha azul.
1
1
1
22
2
1
1
1
Título do gráfico
seg 1 a 6
seq 4
a 9
2 4 6 8
1.0
1.2
1.4
1.6
1.8
2.0
Título do gráfico
seg 1 a 6
seq
4 a
9

7.4 GRÁFICO BOXPLOT boxplot(w) boxplot(w,xlab="seg 1 a 6",ylab="seq 4 a 9",main="Título do gráfico",col="blue")
Figura 19 – Gráfico boxplot do R
No boxplot, a linha grossa do meio representa a mediana, a caixa representa o 1° e
3°quartil, e os “bigodes” podem representar os valores máximos e mínimos. Execute o comando: par(mfrow=c(2,2)) Este comando divide a janela do gráfico em duas linhas e duas colunas, podendo
assim visualizar quatro gráficos ao mesmo tempo em uma só janela.
8. MEDIDAS DE TENDÊNCIA CENTRAL E SEPARATRIZES 8.1 MEDIDAS DE TENDÊNCIA CENTRAL 8.1.1 Calculando média
Antes de iniciarmos os cálculos das tendências centrais, colocaremos os dados em
ordem crescente para facilitar o cálculo. Veja que as colunas 3(três) e 4(quatro), da tabela do anexo II, não estão classificadas em ordem crescente ou decrescente. Para classificar os dados brutos em ordem crescente ou decrescente execute o seguinte comando.
amostra[order(amostra$frutas),] Este comando classifica os dados em ordem crescente conforme os dados da coluna 4
(frutas), para colocar em ordem decrescente use o seguinte argumento amostra[order(amostra$frutas,decreasing=TRUE),].
Existem várias formas de calcular a média no R. Segue algumas das várias formas para calcular as respectivas tendências centrais. Cálculo a média no R. mean(amostra$frutas) mean(amostra[,"frutas"]).
24
68
Título do gráfico
seg 1 a 6
seq
4 a
9

Podemos criar outras funções. A seguir exemplos de como criar uma função, ou seja, uma seqüência de comandos lógicos para obter os mesmos resultados das funções já existentes no R.
função para calcular a média. media<-function(amostra){sum(amostra$frutas)/length(amostra$frutas)}
media(amostra) 8.1.2 Calculando mediana
Para calcular a Mediana (Md) no R, basta executar o seguinte comando: median(amostra$frutas) Função para calcular a mediana
mediana<-function(amostra) { a<-length(amostra$frutas) if(a%%2==0){ b<-(a+1)/2 c<-sort(amostra$frutas) md<-((c[b-0.5]+c[b+0.5])/2) print(md)} else { b<-(a+1)/2 md<-c[b] print(md)} } mediana(amostra)
8.1.3 Calculando moda
Observe a tabela, em anexo, e veja que a coluna 3 (três) ou colunas das frutas é uma
freqüência polimodal, pois os valores 6,15,20,35 repetem duas vezes cada um. O calculo da moda no R de um determinado conjunto é dado por:
subset(table(amostra$frutas),table(amostra$frutas)==max(table(amostra$frutas))) No comando da moda temos alguns termos técnicos. Subset (subconjunto), table
(fornece as freqüências dos valores da variável), max( ) extrai o(s) maior(es) valor do conjunto, neste caso os elementos de maior frequência. Em outras palavras o comando extrai os valores com maior freqüência dentro da amostra e cria um subconjunto com esses valores.
Função para calcular a moda. amostra<-read.table(file.choose(),header=TRUE) md<-function(moda){ moda<-
subset(table(amostra$frutas),table(amostra$frutas)==max(table(amostra$frutas))) if (length(moda)==length(amostra$frutas)) { print("Distribuição AMODAL")} if (length(moda)==1) { print("Distribuição MODAL") print(moda)}

if (length(moda)==2) { print ("Distribuição bimodal") print(moda)} if(length(moda)>2){ print ("Distribuição polimodal") print(moda)} } md(moda) Esta função além de calcular a moda, também a classifica.
8.2 CÁLCULO DAS SEPARATRIZES
8.2.1 Os qurtis O quartil divide o rol em quatro partes proporcionais. Q1 divide o rol em duas partes,
tais que deixa 25% dos valores são menores e 75% dos valores são maiores. Q2 é equivalente a mediana, onde temos 50% dos valores menores e 50% maiores. Q3 deixa 75% abaixo dele e 25% acima.
No R temos a função quantile( ), na qual serve para calcular os quartis, decis e centis. Para calcular os quartis da coluna frutas da tabela em anexo faremos: quantile(amostra$frutas), esta função imprime todos os quartis. Pode-se determinar qual o quartil a ser calculado para isso basta que o usuário
especifique-o. quantile(amostra$frutas,0.25) Esta função representa o primeiro quartil. Os demais seguem de modo análogo. Exemplos: Q1 = quantile(amostra$frutas,0.25) Q2 = quantile(amostra$frutas,0.50) Q3 = quantile(amostra$frutas,0.75)
8.2.2 Os decis
O cálculo do decis segue a mesma lógica do quartis. A função que determina os valores dos decis é a mesma dos quartis, ha diferença
apenas no acréscimo de uma sequência de 0.1 a 0.9 com intervalo de 0.1. Por exemplo: quantile(amostra$frutas,seq(0.1,0.9, 0.1)) Esta função determina todos os decis. Para expecificar qual o decil a ser calculardo faça: dec<- seq(0.1,0.9,0.1) quantile(amostra$frutas,dec[2])

8.2.3 Os centis
De modo análogo, aos decis, segue o centis, apenas com a mudança da sequência para seq(0.01,0.99,0.01), dessa forma obtemos os centis pela função: quantile(amostra$frutas,seq(0.01,0.9,0.01)) Imprime todos os centis Para indicar qual o centil a ser calculado faremos: cent<-seq(0.01,0.9,0.01) quantile(amostra$frutas,cent[18]) 9. MEDIDAS DE DISPERSÃO
9.1 AMPLITUDE TOTAL
Levar-se-á em conta apenas o desvio em relação à média, para o cálculo realizado no
R, todavia o procedimento é semelhante para o desvio em relação à mediana, podendo apenas substituir a média pela.
desvio<-function(des) { dm<-0 c<-sort(amostra$frutas) for(i in 1 : length(c)) {dm<-abs(c[i]-mean(c))+dm} desmedio<-dm/length(c) print(desmedio) } desvio(des) Esta pequena função serve para calcular o desvio médio no R. Entendendo a função: Diz-se que desvio recebe a função (des), dm recebe zero, c
recebe a coluna frutas em ordem crescente. for é um loop de repetição, ou seja, o usuário informa quantas vezes deverá executar o processo dentro da chave. Neste caso diz-se que de i de 1 (i=1) até length(c) , ou tamanho do vetor coluna, dm recebe o módulo de cada valor da coluna frutas menos a média da mesma coluna, mais o próprio dm. desmédio recebe dm dividido pelo tamanho do vetor coluna “length(c)”. desvio(des) imprime o valor do desvio médio.
9.2 VARIÂNCIA Há duas formas de calcular a variância no R. A primeira consiste em usar a função
var().Vejamos o exemplo: var(c) = 101,7132. Podemos criar uma função para o cálculo da variância. Esta função foi criada de forma
lógica, mas cada usuário pode desenvolver sua lógica, porém o resultado deve ser o mesmo. vari<-function(v){ c<-sort(amostra$frutas) var1<-0

a<-length(amostra$frutas) for (i in 1: a) { var1<-((c[i]-mean(c))^2+var1)} variancia<-var1/(a-1) print(variancia)} vari(v)
9.3 DESVIO PADRÃO O calcular o desvio padrão também pode ser feito aplicando a função sd(). sd(amostra$frutas)= 10.08529 Ou usar a segunda função, e não mais difícil, que extrai a raiz quadrada variância da
função acima. sqrt(vari(v))
9.4 COEFICIENTE DE VARIAÇÃO Para calcularmos o coeficiente de variação faremos: c<-sort(amostra$frutas) cv<-((sd(c)/mean(c))*100) Para classificar o coeficiente de variação faremos a seguinte função: clascv<-function(cv) { cv<-((sd(c)/mean(c))*100) if(cv<=15){ print("Dispersão baixa")} if(cv>15 & cv<30){ print("Dispersão média”)} if(cv>=3,0){ print("Dispersão alta")} } clascv(cv)
10. MEDIDAS DE ASSIMETRIA E CURTOSE 10.1 ASSIMETRIA
10.1.1 Assimetria de Perason
Aplicando as funções já conhecidas, obtemos assim o coeficiente de Pearson: c<-sort(amostra$frutas), coluna frutas em ordem crescente mean(c), media median(c) , mediana

mod<-as.numeric(names(moda)), mod recebe ao valores numéricos da moda. sd(c) , desvio padrão Mo= {6, 15,20,35} X�= 19.65 Md= 17.5 S= 10.08529 asp<-(mean(c)-mod)/sd(c) , asp recebe média menos moda dividido pelo desvio
padrão. Asp = 1.35345 Este valor do coeficiente é apenas para Mo = 6, para os demais valores temos:
Asp= 0.4610674, AS= -0.0347040 e Asp= -1.5220181, respectivamente. 10.1.2 Assimetria de Bowley.
Podemos calcular e classificar o coeficiente de Bowley com a seguinte função. Q1<-quantile(amostra$frutas,0.25) ,determina o Q1 ou primeiro quartil Q3<-quantile(amostra$frutas,0.75), determina o Q3 ou terceiro quartil
asb<-as.numeric(((Q3+Q1)-2*median(c))/(Q3-Q1)), asb recebe Q3 mais Q1 menos duas vezes a mediana tudo isso dividido por Q3 menos Q1. Q1= 11,75 Q3=26,5 Md = 17,5 asb = 0.220339
Seja L um conjunto com amostras do lançamento de um dado 20 vezes. L={6,6,1,4,1,2,4,4,4,4,6,3,6,4,1,4,6,3,1,2} L={ 1,1,1,1,2,2,3,3,4,4,4,4,4,4,4,6,6,6,6,6} Para calcular o coeficiente do conjunto L, podemos usar a função skewness( ), esta
encontra o quoeficiente de assimetria. Contudo, para utilizar a função skewness ( ) deve-se instalar o pacote agricolae e em seguida requerer o uso do pacote. A install.packages( ) é a função na qual instala os pacotes, para isso, basta escrever o nome entre aspas dentro do parêntese, neste caso install.packages(“agricolae”). A gora solicitar o uso do pacote com a função require("agricolae").
Após os procedimentos acima digite skewness(L) = -0.09108999 Podemos criar essa amostra de dados no R. Veja o exemplo: dado<-1:6 L<-sample(dado, size=20, replace = TRUE)
, onde dado é conjunto de onde serão retiradas as amostras, size é o número de amostras e replace é onde você indica se a amostra deve ser feita com reposição (TRUE) ou sem reposição (FALSE).
10.2 CURTOSE
Podemos calcular o coeficiente de curtose da seguinte forma. Conhecendo os valores, temos:

Q1 = 11.75 Q3 = 26.5 P10 = 7.8 P90 = 35
� = �� ��∗(�������)=> � = ��.����.��
�∗(����.�) =>
K = 0.2711397 c<-sort(amostra$frutas) Q1<-as.numeric(quantile(c,0.25)), recebe somete o valor do Q1 ou primeiro quartil Q3<-as.numeric(quantile(c,0.75)), recebe somete ovalor de Q3 ou terceiro quartil cent<-seq(0.01,0.99,0.01) , cent recebe sequência de 0.01 a 0.99 com intervalos de 0.01 P10<-as.numeric(quantile(c,cent[10])) , P10 recebe o valor numérico do quantile 10. O que é equivalente ao centil 10. P30<-as.numeric(quantile(c,cent[30])) , P30 recebe centil 30 P90<-as.numeric(quantile(c,cent[90])) , P90 recebe centil 90 kurt<-as.numeric((Q3-Q1)/(2*(P90-P10))) kurt = 0.2711397
Outro meio para determinar o coeficiente de Curtose é utilizando a função kurtosis( ). Para isso após ter instalado o pacote agricolae, deve carregá-lo com o comando
require("agricolae"). Em seguida basta executar o comando kurtosis(L), “L” indica a distribuição a ser calculada, neste caso a amostra do lançamento de um dado 20 vezes. kurtosis(L)= -1.144029
11. CONSIDERAÇÕES FINAIS
Este trabalho fora desenvolvido com o intuito de contribuir para a formação dos alunos nos quais cursam a disciplina de estatística. Para isso, foi apresentada uma seqüência didática com alguns conceitos de estatística descritiva, entrelaçado com os conceitos básicos da utilização da linguagem R.
Em face, mostrar a eficiência e a importância do R nas universidades como uma ferreamente, a mais, para melhorar o desempenho dos alunos. Todavia, o R fornece uma ampla variedade de estatísticas e técnicas gráficas, e é altamente extensível. Tendo como um dos pontos fortes a facilidade do manuseio de símbolos e fórmulas matemáticas, quando necessário. Além dos alunos utilizarem as funções já existentes no R, há a possibilidade de desenvolver outras funções conforme haja necessidade. Dessa forma o aluno desenvolve o seu próprio modo de pensar e executar os cálculos diversos. 12. REFERÊNCIAS BIBLIOGRÁFICAS FONSECA, Jairo Simon da; MARTINS, Gilberto de Andrade. Curso de estatística. 6. ed. São Paulo: Atlas, 1996. TOLEDO, Geraldo Luciano; OVALLE, Ivo Izidoro. Estatística básica. 2. São Paulo: Atlas, 1985.

MADIN, Daniel. Estatística descomplicada. 11.ed. Brasília: Ed. Vestcon, 2006 KAZMIER, Leonard. Estatística descomplicada à administração e economia; Tradução: Adriano Silva Vale Cardoso. 4.ed. Porto Alegre: Bookman, 2007 FERREIRA , Eric Batista; OLIVEIRA, Marcelo Silva de. Introdução à estatística básica com r. Minas Gerais. 2008. 116 p. curso de pós-graduação “lato sensu” (especialização) à distância em gestão de empresas com ênfase em qualidade. Universidade Federal de Lavras – UFLA. Disponível em: <http://www2.ufersa.edu.br/portal/view/uploads/setores/215/est_basica_r.pdf>. Acesso em: 28 maio 2012 LANDEIRO , Victor Lemes. Introdução ao ambiente estatístico R. Amazônia. 2011. 42 p. Programa de Pós Graduação em Ecologia. Instituto Nacional de Pesquisas da Amazônia. Disponível em: <http://amazonpire.org/documents/Introducao_ao_R.pdf>. Acesso em: 28 maio 2012. MEMÓRIA, José Maria Pompeu. Breve história da estatística. Brasília. 2004. 116p. Embrapa Informação Tecnológica. Disponível em: <http://www.im.ufrj.br/~lpbraga/prob1/historia_estatistica.pdf>. Acesso em: 01 jun 2012. UNIVERSIDADE DE SÃO PAULO. Biblioteca Universitária.Programa [email protected]. Disponível em: <http://educar.sc.usp.br/licenciatura/2003/hm/page01.htm>. Acesso em: 02 jun 2012. MESQUITA, Francisco de Oliveira; PEREIRA , Walter Esfrain. desempenho dos alunos das disciplinas estatística geral e experimental do centro de ciências agrárias no período 2007.1. Paraíba, 2007. 6p. Centro de Ciências Agrárias/Departamento de Ciências Fundamentais e Sociais. Disponível em: <http://www.prac.ufpb.br/anais/xenex_xienid/xi_enid/monitoriapet/ANAIS/Area4/4CCADCFSMT02-P.pdf >. Acesso em: 01 maio 2012. SANTOS, Acácia, A. A.; NATÁRIO, Elisete,G. ; ALVARENGA, Cacilda, E.A. Influência do Desempenho Acadêmico na Evasão de Universitários. Campinas. 1p. 2010. Grupo de pesquisa de psicologia e educação superior da Universidade Estadual de Campinas - Unicamp.Disponível em: <http://www.e-science.unicamp.br/pes/publicacoes/publicacoes_completo.php?id_publicacao=1143&categoriapublicacao=852>. Acesso em: 05 jun 2012. Luís Vieira Gomes ([email protected]) Curso de Matemática, Universidade Católica de Brasília EPCT – QS 07 – Lote 01 – Águas Claras – Taguatinga – CEP.: 72966-700

APÊNDICE A
Tabela 5 - CONHECENDO OS OPERADORES, CONECTIVOS E
ALGUMAS FUNÇÕES MAIS ULTILIZADA NA LINGUAGUEM R
Operadores, conectivos & funções
Descrição
<- Atribui valor a um objeto.
a< - 5, diz-se “a’’ recebe 5
+ Adição
- Subtração
* Multiplicação
/ Divisão
** ou^ Exponencial
> Maior que
< Menor que
>= Maior igual a
<= Menor igual a
=! Diferente de
& Equivale ao valor lógico E (conjunção)
| Equivalente ao valor lógico OU (disjunção)
, Separa um argumento de outro dentro de uma mesma função
“ ” Delimita um caracter
( ) Delimita uma função
{ } Inicio e fim de uma função
[ ] Seleciona parte de um objeto
# Adiciona um comentário
~ Em função de
%% Fornece o resto da divisão de a%%b
%*% Multiplicação entre matriz Mb*a%*%Mi*j
%/% Fornece o quociente de uma divisão de a/b
? Obtêm ajuda ou informações sobre uma função ??nome.da.função
c( ) Cocatena ou junta os caracteres, números, ou valores lógicos. vetores unidimensional.
Matrix(c(),i,j) Essa função tem como
argumentos o conjunto de dados, o número de linhas (i) e o número de colunas(j) da matriz, nessa
ordem.
data.frame() Função para criar tabelas, letras e números
ls( ) Lista todos os objetos criados
q( ) Sair do R
save.image() Salva o trabalho realizado
read.table("exemplo.txt",header=TRUE)
A função Read.table () importa tabela para o R. Para visualizar tem que armazenar em uma variável na forma de data frame. O argumento Reader =TRUE, significa que os dados possui cabeçalho.
attach() Extrai dados do dataframe.
nomesataframe$colunaoucoluna
Extrai dados do dataframe. Nome da variável cifrão nomes da coluna.
rm(a) Remove o objeto dentro do parêntese
choose(n,k) Combinação de n combinado k a k.
factorial(n) Fatorial de n.
sqrt(n) Raiz quadrada de n
abs(n) Módulo de n
help.start Busca ajuda na internet
example(name.da.funçao)
Mostra exemplos da função ou gráficos conforme informado.
helpe(nome.da.função) Fornece informação da função entre parêntese.
prod(a,b) Faz o produto de a por b
log(a) Logarítimo natural de al
log(a,b) Logarítimo de a na base b
cos(x), sin(x), tan(x) Funções trigonométricas de x, cosseno, seno, tangente
acos(x), asin(x), atan(x) Funções inversas trigonométricas de x, secante, cossecante, cotangente
length(n) Fornece o número de observação do objeto dentro do parêntese.
round(n) Arredonda o valor de n para o inteiro mais próximo.
max(n) Fornece o valor máximo dentro do objeto.
min(n) Fornece o valor mínimo dentro do objeto.
Sum(n) Faz a soma dos valores dentro do objeto.
mean(n) Média dos valores dentro do objeto
median(n) Mediana dos valores dentro do objeto
subset(table(n),table(n)==max(table(n)))
Expressa o valor modal da variável dentro do parêntese
quartile( ) Calcular o quartil, decil e percentil
var(X) indica a variância de X.
sd(X) indica o desviopadrão.
sample(x, size=1, replace = FALSE)
onde x é conjunto de dados do qual as amostras serão retiradas, size é o número de amostras e replace é onde você indica se a amostra deve ser feita com reposição (TRUE) ou sem reposição (FALSE).
table(n) fornece as freqüências dos valores da variável dentro do parêntese, neste caso n.
max(X)-min(X) Amplitude total
Range(X) Maio e menor valor, do conjuto
seq(a,b,c) Gera uma seqüência de a à b com o intervalo de c elementos
rep(a,n) Repete o valor a n vezes.
runif(n, min=a, max=b) #
gera uma distribuição uniforme com n valores, começando em min e terminando em max.
sort(v) para colocar em ordem, crescente ou decrescente, os valores dentro do objeto
order(v) Retorna a posião original dos valores dentro do objeto
rank(v) atribui postos (ranks) aos valores do dentro do objeto.
plot(x,y) Gera um gráfico
text(cooX,cooY,"texto")
Insere texto no gráfico. cooX é equivalente a coordenada do eixo X e cooY a do Eixo Y.
par(mfrow=c(nlin,ncol))
nlin indica o número de linhas e ncol o número de colunas que a janela deverá ter. Serve principalmente para fazer análise e comparação de dois ou mais gráficos.
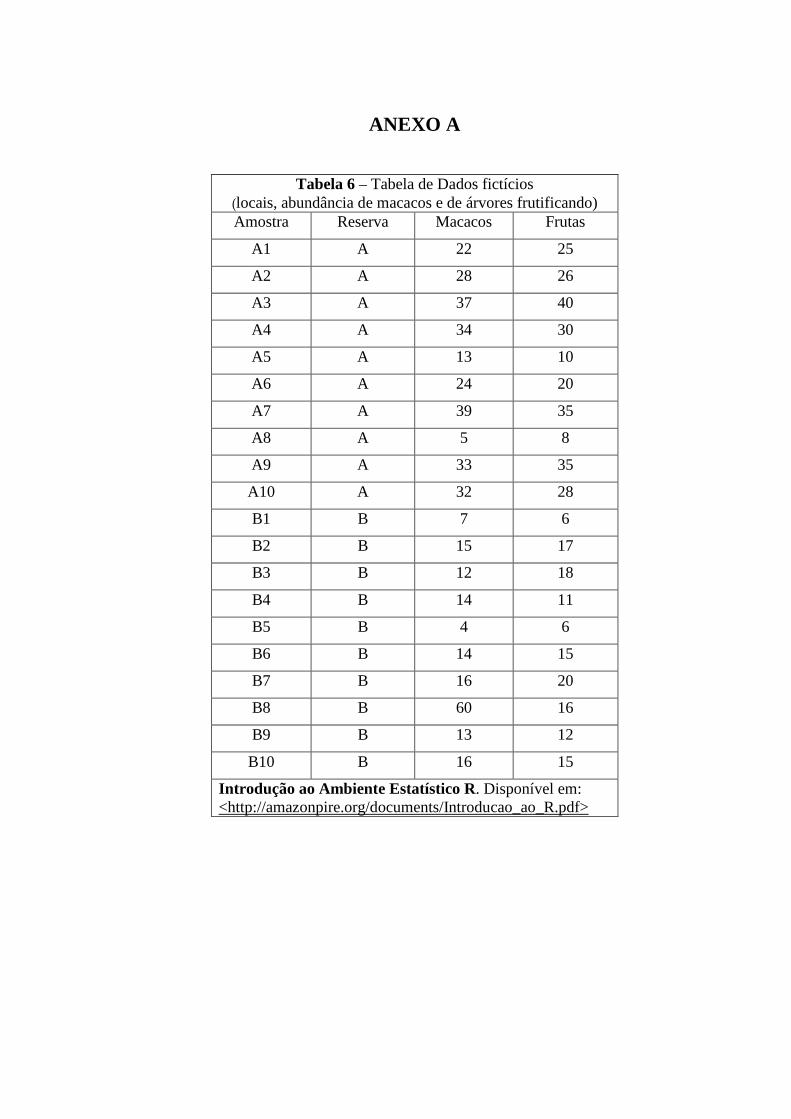
ANEXO A
Tabela 6 – Tabela de Dados fictícios
(locais, abundância de macacos e de árvores frutificando) Amostra Reserva Macacos Frutas
A1 A 22 25
A2 A 28 26
A3 A 37 40
A4 A 34 30
A5 A 13 10
A6 A 24 20
A7 A 39 35
A8 A 5 8
A9 A 33 35
A10 A 32 28
B1 B 7 6
B2 B 15 17
B3 B 12 18
B4 B 14 11
B5 B 4 6
B6 B 14 15
B7 B 16 20
B8 B 60 16
B9 B 13 12
B10 B 16 15
Introdução ao Ambiente Estatístico R. Disponível em: <http://amazonpire.org/documents/Introducao_ao_R.pdf>

ANEXO B 1. CONCEITOS INICIAIS DO ESTUDO DA ESTATÍSTICA 1.1 A ESTATÍSTICA
A definição de estatística não é única, a estatística abrange muito mais do que um simples traçado de gráficos e cálculos de medidas. Uma definição seria: A estatística é uma coleção de métodos para planejar experimentos, obter dados e organizá-los, resumi-lo, analisá-los interpretá-los e deles extrair conclusões. 1.2 A NATUREZA DA ESTATÍSTICA
Podemos descrever duas variáveis para um estudo: Variável qualitativa – (ou dados categóricos) podem ser separados em diferentes
categorias, atributos, que se distinguem por alguma característica não numérica. Variável quantitativa – consistem em números que representam contagens ou medidas.
Dividem-se em: Variáveis quantitativas discretas – resultam de um conjunto finito, enumerável de
valores possíveis. Ex: número de filhos. Variáveis quantitativas contínuas – resultam de números infinitos de valores possíveis
que podem ser associados a pontos em uma escala contínua. Ex: peso, altura. Outras definições: População – é a coleção de todos os elementos (valores, pessoas, medidas, etc) a serem
estudados. Censo – é a coleção de dados relativos a todos os elementos da população. Amostra – é uma parte do todo, ou seja, é um subconjunto da população. Parâmetro – é a medida numérica que descreve uma característica da população. Estatística – é a medida numérica que descreve uma característica da amostra.
2 CONCEITOS DE TÉCNICAS E OS E TIPOS DE AMOSTRAGEM 2.1 TÉCNICAS DE AMOSTRAGEM
Probabilística - São amostragem em que a seleção é aleatória de tal forma que cada elemento tem igual probabilidade de ser sorteado para a amostra.
Amostragem aleatória simples - Também conhecida por amostragem ocasional, acidental, casual, randômica, etc. A amostragem simples ao acaso destaca-se por ser um processo de seleção bastante fácil e muito usado. Neste processo, todos os elementos da população tem igual probabilidade de serem escolhidos, não antes de ser iniciado, como também até completo processo de coleta.

Amostragem sistemática - Trata-se de uma variação da amostragem simples ao acaso, muito conveniente quando a população está naturalmente ordenada, como fichas em um fichário, listas telefônicas etc. Requer uma lista dos itens da população, e , assim, padece das mesmas restrições já mencionadas na aleatória ao acaso.
Amostragem estratificada - Utilizada no caso de possuir uma população com uma certa característica heterogênea, na qual podemos distinguir subpopulações mais ou menos homogêneas, estratificar uma população em L subpopulações denominadas estratos, tais que: n1 + n2 + ... + nL = nonde os estratos são mutuamente exclusivos.Se as diversas sub-amostras tiverem tamanhos proporcionais ao respectivo número de elementos no estratos, teremos a estratificação proporcional.
Não-probabilisticas ou intencionadas- São amostragem em que há uma escolha deliberada dos elementos da amostra.
3 DEFINIÇÃO E CONSTRUÇÃO DE TABELAS ESTATÍSTICASE T IPOS DE SÉRIES ESTATÍSTICAS 3.1 DEFINIÇÃO DE TABELAS
Tabela - É uma forma de apresentar resumidamente um conjunto de dados. Objetivos - Um dos objetivos da estatística é sintetizar os valores que uma ou mais
variáveis podem assumir, para que tenhamos uma visão global da variação da(s) mesma(s).
3.2 DEFINIÇÃO DE SÉRIE ESTATÍSTICA
Uma série estatística define-se como toda e qualquer coleção de dados estatísticos referidos a uma mesma ordem de classificação: Quantitativa. Em um sentido mais amplo, série é uma sequência de números que se refere a uma certa variável. Para diferenciar uma série estatística de outra, temos que levar em consideração três fatores: a época; o local e o fenômeno.
Tipos de séries estatísticas: Tipos de Séries Estatísticas: São cinco os tipos de séries estatísticas conforme a
variação de um dos fatores: série temporal; série geográfica; série específica; série conjugada e distribuição de freqüência.
4 DEFINIÇÃO E CONSTRUÇÃO DE GRÁFICOS ESTATÍSTICOS E TIPOS DE GRÁFICOS 4.1 CONSTRUÇÃO DE GRÁFICOS
Finalidade - Representar os resultados de forma simples, clara e verdadeira;Demonstrar a
evolução do fenômeno em estudo;Observar a relação dos valores da série.
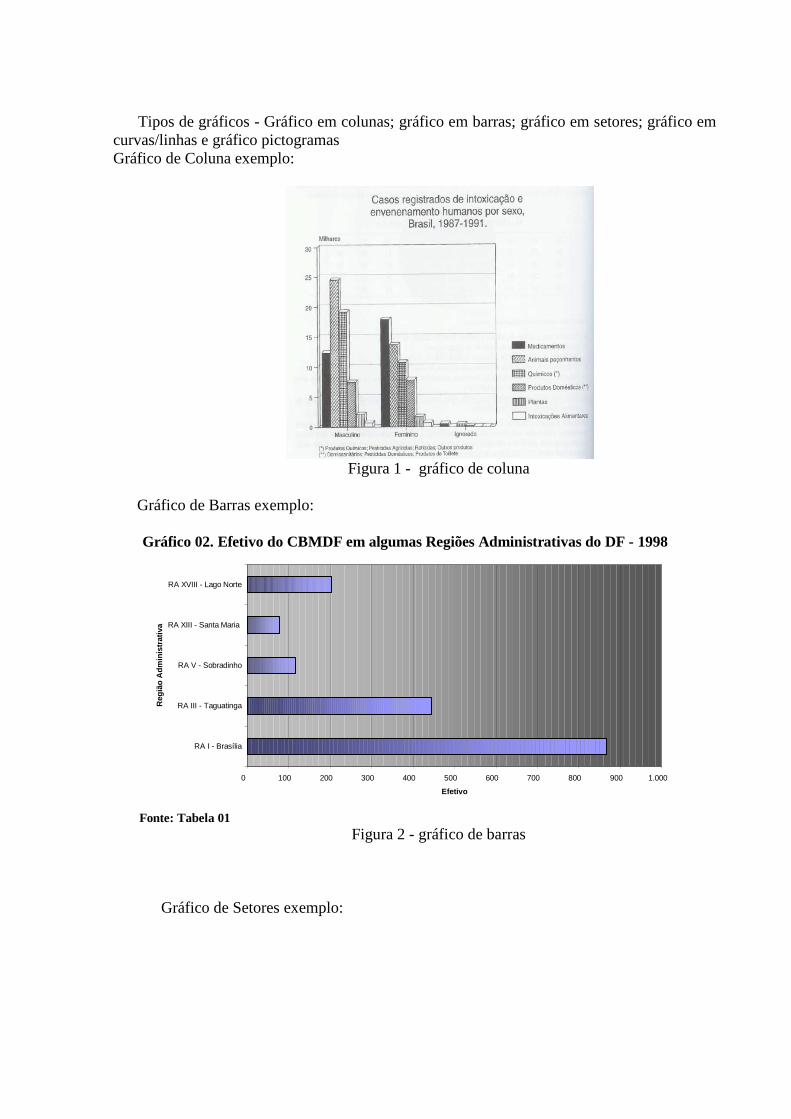
Tipos de gráficos - Gráfico em colunas; gráfico em barras; gráfico em setores; gráfico em curvas/linhas e gráfico pictogramas Gráfico de Coluna exemplo:
Figura 1 - gráfico de coluna
Gráfico de Barras exemplo:
Figura 2 - gráfico de barras
Gráfico de Setores exemplo:
Gráfico 02. Efetivo do CBMDF em algumas Regiões Administrativas do DF - 1998
Fonte: Tabela 01
0 100 200 300 400 500 600 700 800 900 1.000
RA I - Brasília
RA III - Taguatinga
RA V - Sobradinho
RA XIII - Santa Maria
RA XVIII - Lago Norte
Reg
ião
Adm
inis
trat
iva
Efetivo
Figura 3 - gráfico de setor
Gráfico de Linha exemplo:
Figura – 4 gráfico de coluna
5. MEDIDAS DE TENDÊNCIA CENTRAL E POSICIONAMENTO
As medidas Média e Moda são chamadas de medidas de Tendência central, pois as
mesmas não possuem um local especifico quando avaliadas numa reta real porém a Mediana e as Separatrizes são chamada de medidas de posicionamento pois numa reta real cada uma representa uma posição importante de classificação de resultados, por exemplo a Mediana que com intuito de descrever 50% das relações terá seu valor cadastrado no meio da reta real avaliada, já o 1º quartil uma das medidas de separatrizes representa a posição referente a primeira quarta parte ou seja 25% dos dados.
Observe abaixo esta relação:
Para os cálculos referentes a essas medidas temos as seguintes formulas: Média:
PIE CHART OF PREVUSE
28,8%
71,2%
USED
NEVER
Número de livros vendidos em uma livraria no segundo semestre do ano de 2008
0
100
200
300
400
500
600
julho agosto setembro outubro novembro dezembro
M eses do segundo semestre
100%
Q1 Q2 = Md Q3
0% 25% 50% 75%

��� = ∑ !"#$%& (1)
Mediana: Se n par
�'()(*+) = &,�� (2)
Se n ímpar
�'()(*+) = &� .
&� + 1 (3)
Moda: Avaliar o elemento que mais apareceu, ou seja, o que mais se repete no conjunto de
dados. 5.1 SEPARATRIZES
É nas separatrizes que aprendemos a dividir o conjunto de dados de uma outra maneira , através dos Quartis, Decis e Percentis. Quartis:
Decis:
Percentis:
Tabela 1 – Quadro para cálculos das separatrizes Separatrizes 1º passo
Posição da Medida 2º Passo
Identificação do valor da medida Quartil
Qi
i=1,2,3
Pos(Qi) = 54 . 7
Identificação pelo Rol Decil
Di
i=1,2,3…9
Pos(Qi) = 510. 7
Centil Ci
i=1,2,3…50…99
Pos(Qi) = 599. 7
Importante:
100%
Q1 Q2 = Md Q3
0% 25% 50% 75%
D8 D9D2 D3 D4 D5 D6 D7
90% 100%0%
D1
50% 60% 70% 80%10% 20% 30% 40%
.. .
.30%..
.P80 .. .P90 ...P20 .. .P30 .. .P40 .. .P50 .. .P60 .. .P70 ..
.90%.. .100% 0%..
.P10 ..
.50%.. .60%.. .70%.. .80%...10%.. .20%.. .40%..

a. As medidas anteriormente citadas podem ser avaliadas de acordo com a estrutura que se encontram os dados, ou seja, no rol, numa distribuição de frequência simples ou em classes.
b. O nosso estudo direcionou as análises apenas na primeira situação dados distribuídos no rol. Não aplicamos aqui as características de montagem das tabelas de Distribuição de frequência.
c. O aluno deve se atentar que todas as fórmulas citadas nas separatrizes e no cálculo da mediana são para encontrar o posicionamento. O resultado final deverá ser evidenciado junto ao conjunto de dados.
d. Dentre todas as medidas citadas anteriormente a mais importante delas é a média, utilizada em diversos conceitos avaliados nos estudos Estatísticos, principalmente na área da Inferência Estatística.
e. Quando do conhecimento de valores discrepante, valores que fogem e muito das observações avaliada no conjunto de dado, não devemos avaliar a situação somente pela média tendo em vista que a mesma é sensível a valores discrepantes. Neste caso a medida mais apropriada para o estudo é a mediana ou a moda.
f. Valor discrepante foge ao estudo que nos propusemos a avaliar aqui, porém poderá ser visto em diversas literaturas.
6. MEDIDAS DE DISPERSÃO
As medidas de dispersão indicam se os valores estão relativamente próximos um dos outros, ou separados em torno de uma medida de posição: a MÉDIA. São medidas de dispersão:
• DESVIO MÉDIO • VARIÂNCIA • DESVIO-PADRÃO • COEFICIENTE DE VARIAÇÃO Fórmula para o cálculo do desvio Médio
Populacional:
(4)
Amostral:
(5) Fórmula para o calculo da Variância e do Desvio Padrão: Variância Populacional (6) Variância Amostral
(7)
N
||σ
2 ∑ −=
µxi
N
||σ
2 ∑ −=
xxi
( )N
µxσ
2i2 ∑ −
=
( )1-n
xxS
2i2 ∑ −
=

Desvio Padrão Populacional e Desvio Padrão Amostral deverão ser calculado mediante o cálculo da Raiz quadrada das respectivas variâncias. Fórmula do Coeficiente de Variação:
Coeficiente de Variação Populacional e Coeficiente de Variação Amostral (8) Importante:
a. As medidas anteriormente citadas podem ser avaliadas de acordo com a estrutura que se encontram os dados, ou seja, no rol, numa distribuição de frequência simples ou em classes.
b. O nosso estudo direcionou as análise apenas na primeira situação dados distribuídos no rol. Não aplicamos aqui as características de montagem das tabelas de Distribuição de frequência.
c. De todos os cálculo acima relacionado o de maior importância é o cálculo da variância e do desvio padrão sendo o mesmo utilizado em diversos outros conceitos avaliados na Estatística e principalmente no caso da Inferência Estatística.
d. O Cálculo do Coeficiente de Variação só deverá ser utilizado quando necessitamos da comparação das variáveis em estudo.
7. MEDIDAS DE ASSIMETRIA E CURTOSE 7.1 CONCEITO DE ASSIMETRIA
Grau de deformação de uma distribuição em relação ao eixo de simetria. Caso de Simetria
Figura 5 - distribuição simétrica �� = *+ = *8
Casos de Assimetria:
100x
SCV OU 100
µ
σCV ⋅=⋅=
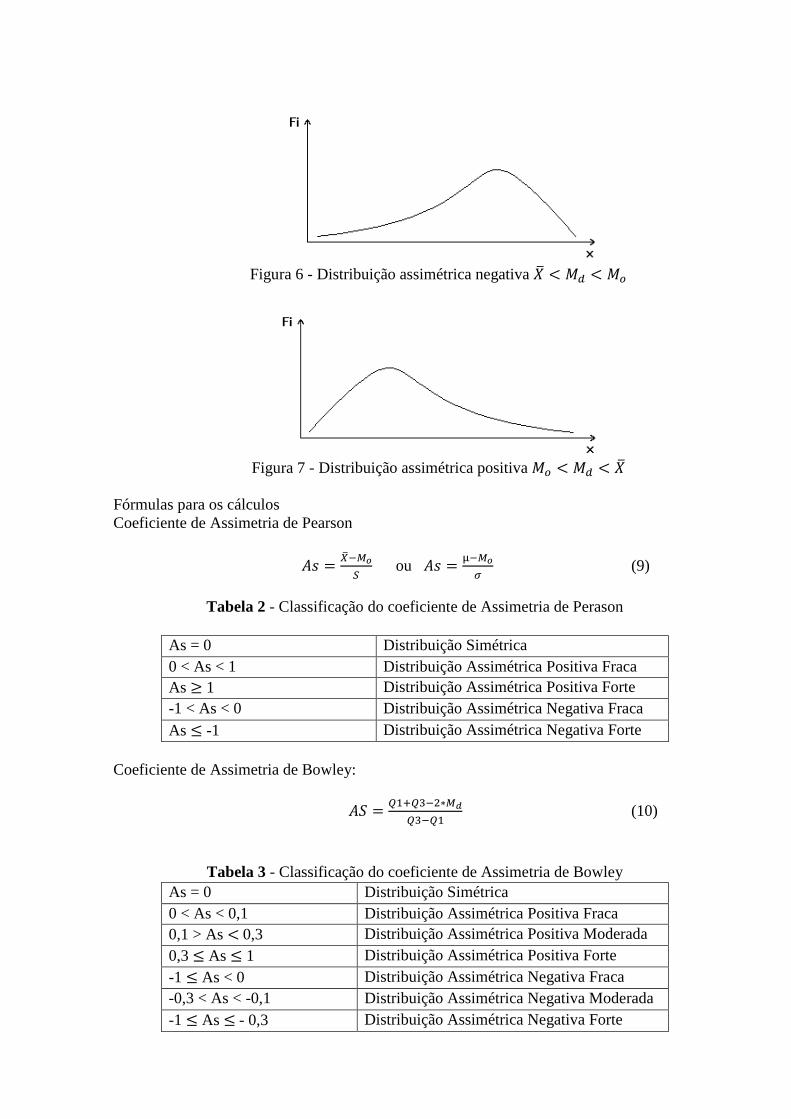
Figura 6 - Distribuição assimétrica negativa �� 9 *+ 9 *8
Figura 7 - Distribuição assimétrica positiva *8 9 *+ 9 ��
Fórmulas para os cálculos Coeficiente de Assimetria de Pearson
:) = ��;<= ou :) = >�;<
? (9)
Tabela 2 - Classificação do coeficiente de Assimetria de Perason
As = 0 Distribuição Simétrica 0 < As < 1 Distribuição Assimétrica Positiva Fraca As @ 1 Distribuição Assimétrica Positiva Forte -1 < As < 0 Distribuição Assimétrica Negativa Fraca As A -1 Distribuição Assimétrica Negativa Forte
Coeficiente de Assimetria de Bowley:
:B = �, ���∗;C �� � (10)
Tabela 3 - Classificação do coeficiente de Assimetria de Bowley As = 0 Distribuição Simétrica 0 < As < 0,1 Distribuição Assimétrica Positiva Fraca 0,1 > As 90,3 Distribuição Assimétrica Positiva Moderada 0,3 A As A 1 Distribuição Assimétrica Positiva Forte -1 A As < 0 Distribuição Assimétrica Negativa Fraca -0,3 < As < -0,1 Distribuição Assimétrica Negativa Moderada -1 A As A- 0,3 Distribuição Assimétrica Negativa Forte

7.2 CONCEITO DE CURTOSE
Entende-se por curtose o grau de achatamento de uma distribuição.
Figura 8 – Representação do grau de achatamento
O primeiro caso representa um caso Platicúrtico o segundo Mesocúrtico e o terceiro
Leptocúrtico. Fórmula para o caso da Curtose:
� = �� ��∗(�������) (11)
Tabela 4 - Classificação do coeficiente de Curtose K=0,263 Curva Mesocúrtica K > 0,263 Curva Platicústica K< 0,263 Curva Leptocútica