Embed Size (px)
Citation preview

O COFICINA
Manipulação e análise de microdados do SPAECEmicrodados do SPAECE

Módulo I ‐ Estrutura de Banco de Dados
Módulo II – Importação de Dados
Módulo III – Explorando os Dados
Módulo IV – Manipulando os Dados
Módulo V – Integração e Criação de Bancos de Dados

Módulo I Estrutura de Banco de DadosEstrutura de Banco de Dados

Módulo I ‐ Estrutura do Banco de Dados
1.1. Dados 1.7. Chave1.1. Dados
1.2. Informação
1.7. Chave
1.8. Variáveis1.2. Informação
1.3. Conhecimento
1.8. Variáveis
1.9. Tipos de Variáveis1.3. Conhecimento
1.4. Banco de Dados
1.9. Tipos de Variáveis
1.10. Níveis de Medida1.4. Banco de Dados
1.5. Microdados
1.10. Níveis de Medida
1.11. Exemplo1.5. Microdados
1.6. Metadados
1.11. Exemplo
1.12. Estudo de Caso1.6. Metadados 1.12. Estudo de Caso

Módulo I ‐ Estrutura do Banco de Dados
1.1. Dados
• São elementos brutos, sem significado edesvinculados da realidade (ANGELONI 2003);desvinculados da realidade (ANGELONI, 2003);
• Constituem a matéria prima da informação;• Constituem a matéria‐prima da informação;
• Dados sem qualidade levam a informações e• Dados sem qualidade levam a informações edecisões da mesma natureza.

Módulo I ‐ Estrutura do Banco de Dados
1.2. Informação
“Informação é todo conjunto de dadosorganizados de forma a terem sentido e valor paraseu destinatário.” (Wetherbe, 2004).

Módulo I ‐ Estrutura do Banco de Dados
1.3. Conhecimento
Prática de agregar valor à informação paradisponibilizá‐la para uso.

Módulo I ‐ Estrutura do Banco de Dados
1.4. Banco de Dados
“É uma coleção de dados inter‐relacionados,d i f õ b d í irepresentando informações sobre um domínio
específico” (Korth, 1994).

Módulo I ‐ Estrutura do Banco de Dados
1.4.1. Sistema de Banco de Dados
Um sistema de banco de dados pode ser definidocomo um conjunto de quatro componentescomo um conjunto de quatro componentesbásicos: dados, hardware, software e usuários.

Módulo I ‐ Estrutura do Banco de Dados
1 4 1 Sistema de Banco de Dados1.4.1. Sistema de Banco de Dados

Módulo I ‐ Estrutura do Banco de Dados
1.4.2 Estrutura da base1.4.2 Estrutura da base
• Tabela estrutura interna de um banco de dados• Tabela: estrutura interna de um banco de dadosem linhas e colunas. Colunas e linhas formam umatabelatabela.
• Linha: contém todas as informações sobre um• Linha: contém todas as informações sobre umobjeto na tabela.
• Coluna: define um tipo de dado armazenado emuma tabelauma tabela.

Módulo I ‐ Estrutura do Banco de Dados
1.5. Microdados
São informações ao nível dos participantesi di id i j id d d b ã éindividuais, ou seja, a unidade de observação é oindivíduo e as respostas são registradas em
iá i dvariáveis separadas.
l fô ál d dEx.: Lista Telefônica, catálogo de CD ou um sistema decontrole de RH.

Módulo I ‐ Estrutura do Banco de Dados
1.6. Metadados
Representam “dados sobre dados”.
Ex.: Saber se uma determinada base de dados existe ei ã t ib t t í tiquais são seus atributos e características.

Módulo I ‐ Estrutura do Banco de Dados
1.7. Chave
É um conjunto de um ou mais atributos qued i i id d d d ideterminam a unicidade de cada registro.
A b l l i à éAs tabelas relacionam‐se umas às outras atravésde chaves.

Módulo I ‐ Estrutura do Banco de Dados
1.7. Chave

Módulo I ‐ Estrutura do Banco de Dados
1.7. Chave1.7. Chave
• Chave primária chave que identifica cada• Chave primária: chave que identifica cadaregistro dando‐lhe unicidade. Nunca se repetirá.Ex : Sequencial do alunoEx.: Sequencial do aluno
• Chave Estrangeira: chave formada através de um• Chave Estrangeira: chave formada através de umrelacionamento com a chave primária de outratabelatabela.Ex.: Código da Escola

Módulo I ‐ Estrutura do Banco de Dados
1.8. Variáveis
É um identificador associado a um nomed i d ldestinado a representar um valor.
d l ód d lEx.: Nome do aluno, código da escola.

Módulo I ‐ Estrutura do Banco de Dados
1.9. Tipos de Variáveis
As variáveis podem ser de dois tipos básicos:
• QuantitativasQ• Qualitativas.

Módulo I ‐ Estrutura do Banco de Dados
1.9. Tipos de Variáveis
• Quantitativas: são aquelas numericamente mensuráveis.
Ex.: Idade, altura e o peso.

Módulo I ‐ Estrutura do Banco de Dados
1.9. Tipos de Variáveis
• Qualitativas: são aquelas que se baseiam eml d d d áqualidades e não podem ser mensuráveis
numericamente.
Ex.: Sexo, raça e cor dos olhos.

Módulo I ‐ Estrutura do Banco de Dados
1.10. Níveis de Medida
E l Utili d iá i tit tiEscalar: Utilizado em variáveis quantitativas.
Ex.: Proficiência do aluno.

Módulo I ‐ Estrutura do Banco de Dados
1.10. Níveis de Medida
O di l Utili d iá i lit tiOrdinal: Utilizado em variáveis qualitativasordinais.

Módulo I ‐ Estrutura do Banco de Dados
1.10. Níveis de Medida
i l ã é l d áNominal: Esta opção é utilizada para variáveisqualitativas nominais.

Módulo I ‐ Estrutura do Banco de Dados
1.11. Exemplo
Banco de Dados


CREDE MUNICÍPIO ESCOLA NM_ALUNO DT_ NASCIMENTO RESP 1 RESP 2 ...
Fortaleza R2 Fortaleza Andreza 15/09/1994 A C ...
Acarau Itarema João 05/06/1994 A D ...
Fortaleza R2 Fortaleza Maria 30/12/1993 B C ...
... ... ... ... ... ... ... ...

Módulo I ‐ Estrutura do Banco de Dados
1.12. Estudo de caso
Como uma escola com percentuais pequenos nosd õ i b i d l ipadrões mais baixos da escala e com o maior
percentual no padrão desejável tem proficiênciaédi i f i l lmédia inferior a uma escola com percentual
menor no padrão desejável?

Módulo I ‐ Estrutura do Banco de Dados
1.12. Estudo de caso1.12. Estudo de caso
75,00%
4,17% 4,17% 8,33% 8,33%
81,82%
3,03% 0,00% 6,06% 9,09%

Módulo I ‐ Estrutura do Banco de Dados
1.12. Estudo de caso1.12. Estudo de caso
Solução
O fato em questão é estatisticamente explicável. A Escola A temuma porcentagem menor de alunos no Padrão Desejável do quea Escola B e, no entanto, possui uma proficiência média maior.Isso é explicável porque os valores extremos na escala podemtendenciar a média Nos gráficos abaixo temos a distribuiçãotendenciar a média. Nos gráficos abaixo temos a distribuiçãodos alunos dentro do Padrão Desejável. Nela podemos observarclaramente que mais alunos da Escola A, dentro do PadrãoDesejável, possuem uma proficiência média maior neste padrãodo que os alunos da Escola B. Assim, a média da Escola A tendea ficar um pouco maior do que a média da Escola B mesmo estaa ficar um pouco maior do que a média da Escola B, mesmo estapossuindo uma maior proporção de alunos no Desejável.

Módulo I ‐ Estrutura do Banco de Dados
1.12. Estudo de caso
12
ESCOLA A
uenc
y
10
8
Freq
u
6
4 12
ESCOLA B
310,00290,00270,00250,00230,00210,00190,00170,00150,00
2
0
Mean =216,99�Std. Dev. =35,216�
N =87en
cy10
8
Freq
ue
6
4
310,00290,00270,00250,00230,00210,00190,00170,00150,00
2
0
Mean =199,42�Std. Dev. =31,996�
N =54

Módulo I ‐ Estrutura do Banco de Dados
1.12. Estudo de caso
Exemplificando:E l A 10 lEscola A = 10 alunosEscola B = 10 alunos
Percentual de alunos no Padrão Desejável na Escola A = 100%Percentual de alunos no Padrão Desejável na Escola B = 100%
Proficiência média da Escola A = 150,00 (alunos com proficiência mais próximas do intervalo de 150)proficiência mais próximas do intervalo de 150)Proficiência média da Escola B = 250,00 (alunos com proficiência bem maiores do intervalo de 150)

Módulo II ImportaçãoImportação

Módulo II ‐ Importação
2.1. Introdução
2.2. Importação no SPSS
2.3. Criando Labels e Value Lables
2.4. Configurando Missing Values
2 5 Data View2.5. Data View
2.6. Variable View
2.7. Output
2.8. Laboratório

Módulo II ‐ Importação
2.1. Introdução
• SPSS Statistics (antes PASW) é um software aplicativodo tipo científico. Lançado pela primeira vez em 1968 é
id d i d áli d d d t tí ticonsiderado o rei das análises de dados estatísticos.Apesar de tantos anos em atividade o software continuaatualizado eficaz e muito práticoatualizado, eficaz e muito prático.
• A versão mais atual é o SPSS 21.0.0 lançado em agostoç gde 2012.



Módulo II ‐ Importação
2.1. Introdução
• Arquivos suportados pelo SPSS (StatisticalPackage for Social Science): “ csv” “ xls” “ xlsx”Package for Social Science): .csv , .xls , .xlsx ,“.dat”, “.txt” e entre outros.
• Formato de arquivo padrão: “.csv”.

Módulo II ‐ Importação
2.1. Introdução
• CSV: (Comma Separated Values), é um formatode arquivo para armazenamento de informaçõesde arquivo para armazenamento de informaçõesem base de dados, que qualquer aplicativo deplanilha eletrônica como Excel por exemplo éplanilha eletrônica, como Excel por exemplo, écapaz de abrir.

Módulo II ‐ Importação
2.1. Introdução
Vantagens do “.csv”:
• Grandes massas de dados podem sercompactadas em arquivos pequenos.
• Não têm limite de linhas e colunas como osarquivos “.xls” que tem limite de 65.536 linhas e256 colunas.

Módulo II ‐ Importação
2.2. Importação no SPSS
• O procedimento de importação é superior aooutros métodos por ser mais segurooutros métodos por ser mais seguro.
• A Interface do SPSS permite controle da• A Interface do SPSS permite controle daimportação e configuração de todas as variáveis.

Módulo II ‐ Importação
2.2. Importação no SPSS
• Delimitação do “.csv”: ponto e vírgula (no SPSS:semicolon)semicolon)
• Cada variável deve conter um título único e sem• Cada variável deve conter um título único e semespaço ou caracteres especiais.
• Cada linha representa um caso, e cada colunaum atributo do casoum atributo do caso.

Módulo II ‐ Importação
2.2. Importação no SPSS
Tipos de variáveis mais utilizados:
Numeric: permite apenas caracteres numéricos.
String: permite letras e números.
At ã h l t iá l t i dAtenção: se houver letras numa variável categorizada como “numeric” esses caracteres serão apagados.

Módulo II ‐ Importação
2.2. Importação no SPSS
• Padrão “Width” (tamanho) utilizado para asvariáveis String e Numéricasvariáveis String e Numéricas.
• A configuração do “Width” impede que valores• A configuração do “Width” impede que valoressejam truncados ou cortados durante aimportaçãoimportação.

Módulo II ‐ Importação
2.2. Importação no SPSS
Padrões utilizados:
• Numeric: 16 ‐ com 8 casas decimais.
• String: 255

Módulo II ‐ Importação
2.2. Importação no SPSS
Syntax: arquivo do SPSS, onde os comandosli d l ã d frealizados pelo programa são gravados em forma
de texto. Todos os comandos podem serli d irealizados via syntax.
• A manipulação de syntax exige conhecimento• A manipulação de syntax exige conhecimentoavançado e experiência em manipulação e análise dedados.dados.


Módulo II ‐ Importação
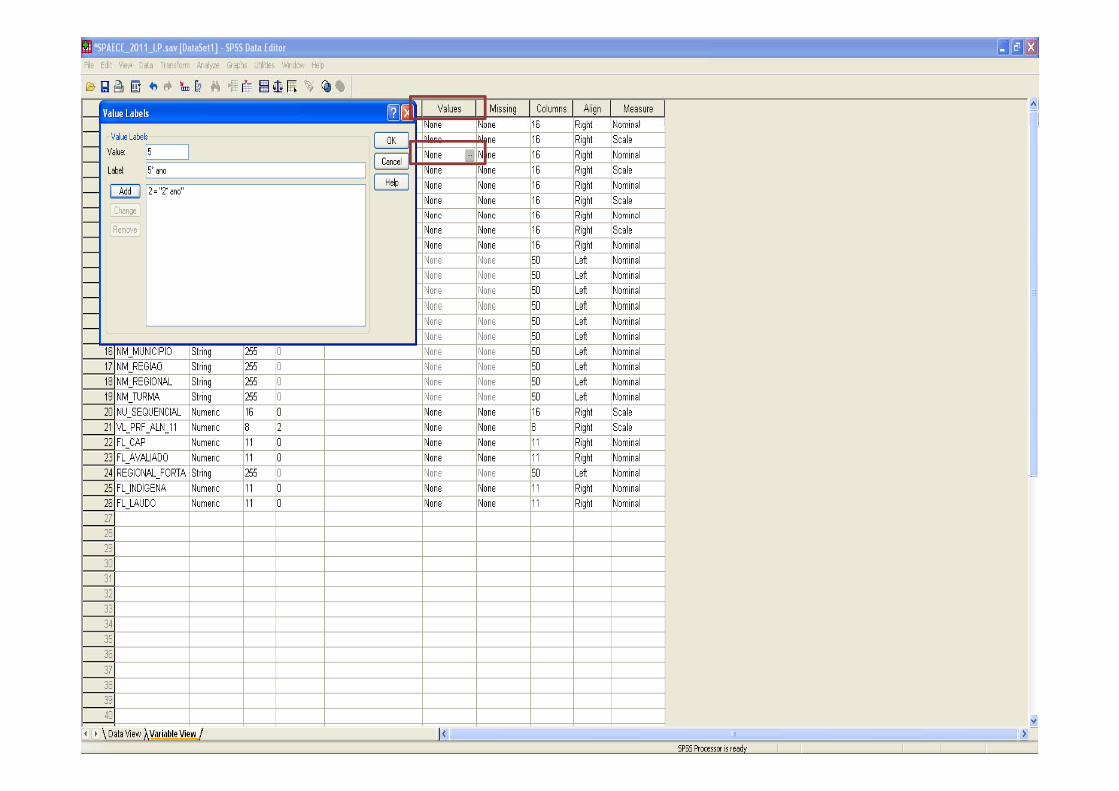
2.3. Criando Labels e Values Labels
• Labels de variáveis e de values são muitoimportantes para dar sentido aos dados. Eles devemser adicionados no variable view.
O l b l d fi d d d• Os labels podem ser configurados de acordo com apreferência do usuário. Os value labels devem serregistrados para cada categoria da variável Valueregistrados para cada categoria da variável. Valuelabels só fazem sentido para variáveis qualitativas.


Módulo II ‐ Importação
2.4. Configurando Missing Values
• Consideramos como Missing data casos de umavariável que não contém dados Nas bases devariável que não contém dados. Nas bases dedesempenho de alunos não avaliados, semproficiência são considerados missing data Se oproficiência, são considerados missing data. Se obanco de dados contiver dados originais dequestionários, serão também consideradas missingq , gdata, erros de preenchimento e questões anuladas.

Módulo II ‐ Importação
2.5. Data View
• O Data View permite visualizar e editar osd ddados.
• Cada janela do SPSS contém uma barra demenus. A maioria dos menus é comum paratodas as janelas.

Barra de Menus

File: usado para criar, salvar e salvar comosalvar e salvar como.

Edit: usado para localizar campos, irpara caso ou variável específica epara caso ou variável específica, eeditar funcionalidades específicas(menu Options).

View: usado para ativar/desativar visualização de linhas de grade devisualização de linhas de grade, de botões de atalho e de value labels.

Data: usado para inserir, re‐nomear, eordenar variáveis unir arquivos criarordenar variáveis, unir arquivos, criarsubgrupos para análise, selecionar casosespecíficos de acordo com algumascondiçõescondições.

Transform: permite criar, recodificar e fazer operações com variáveise fazer operações com variáveis.

Analyze: possui diversos procedimentosrelacionados às análises estatísticas disponíveisrelacionados às análises estatísticas disponíveisno pacote SPSS. Dentre os mais utilizadospodemos citar as estatísticas descritivas,regressão correlação entre outrasregressão, correlação entre outras.

Graphs: usado para criar e modificargráficos (linha barra coluna pizzagráficos (linha, barra, coluna, pizza,histograma, dispersão, etc).

Utilities: utilizado para obter informaçõessobre as variáveis e o banco de dadossobre as variáveis e o banco de dados,controlar a lista de variáveis em qualquertipo de janela, modificar e personalizarmenus dentre outrasmenus, dentre outras.
Window: usado para movimentação entrevárias janelas abertas simultaneamentevárias janelas abertas simultaneamentedurante uma sessão de SPSS.

Help: abre uma janela de ajuda‐padrão quecontém informações sobre como usar ascontém informações sobre como usar asferramentas e funcionalidades do SPSS. Oconteúdo da ajuda está disponível em caixas dediálogo com exemplos ilustrativosdiálogo com exemplos ilustrativos.

Módulo II ‐ Importação
2.6. Variable View
• O variable view exibe todas as variáveis epermite alterar as propriedades das variáveispermite alterar as propriedades das variáveis,inserir labels, value labels, configurar missing datae o tipo de medida das variáveise o tipo de medida das variáveis.


Name: nome da variável.

Type: tipo da variável(string ou numeric).
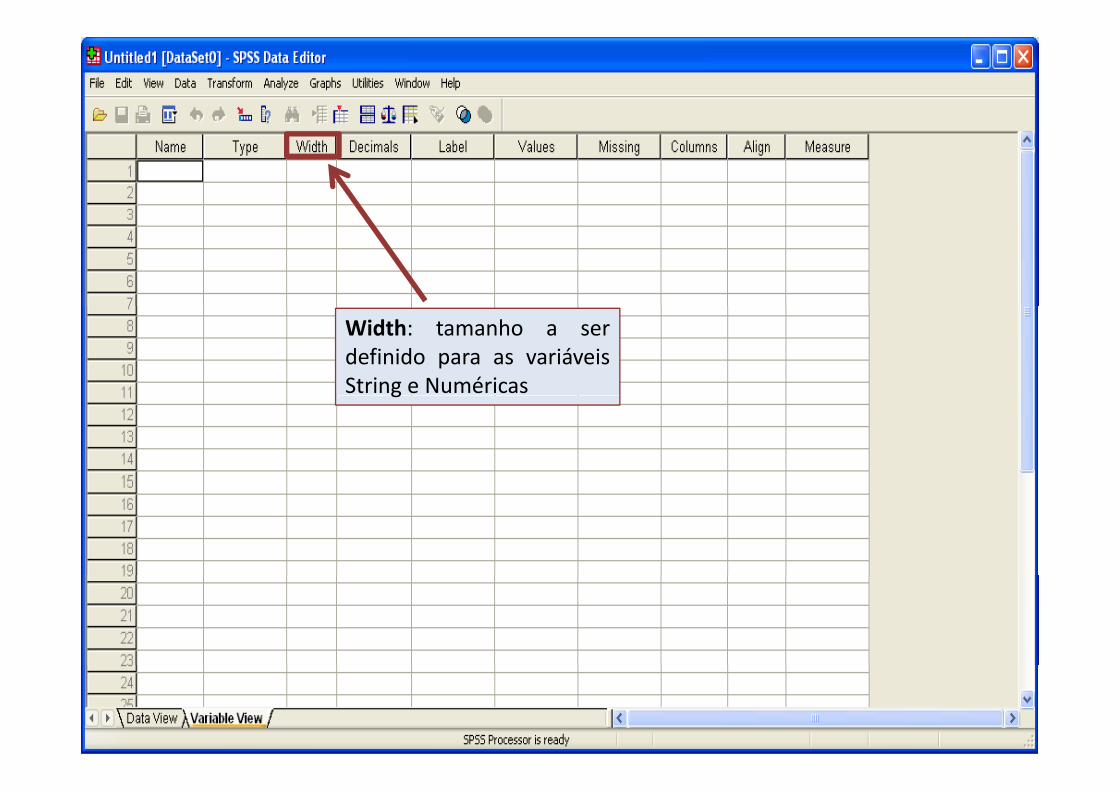
Width: tamanho a serdefinido para as variáveisString e Numéricasg

Decimals: número decasas decimais para o tiponumeric.

Label: rótulo (descrição)da variável.

Values: valores destinadosas variáveis qualitativas.

Missing: casos de umavariável que não contémdados ou são inválidos.

Columns: quantidade decaracteres que a coluna iráapresentar.p

Align: alinhamento doscasos.

Measure: tipo de medida.

Módulo II ‐ Importação
2.7. Output
• O output é a tela onde são exibidos os resultadosde todas as operações feitas no SPSS Ele é ativadode todas as operações feitas no SPSS. Ele é ativadoautomaticamente assim que cada operação éconcluídaconcluída.
• Uma função importante: o SPSS permite• Uma função importante: o SPSS permiteexportar gráficos e tabelas para outros aplicativoscomo o Excel eWordcomo o Excel eWord.


Módulo I ‐ Estrutura do Banco de Dados
ã 0Demonstração 01

Módulo I ‐ Estrutura do Banco de Dados
2.8. Laboratório
• Os laboratórios são momentos onde serál d á i d i didcolocada em prática toda a teoria aprendida.
O bj i d l b ó i é dú id• O objetivo deste laboratório é sanar as dúvidassobre o manuseio do software. Para isso, faremos
í i lh i ã l dexercícios semelhantes a uma situação real deprodução de resultados.

Laboratório
Suponhamos que é preciso preparar uma apresentação dos resultados dasSuponhamos que é preciso preparar uma apresentação dos resultados das
CREDEs, sendo solicitado a você a produção de algumas medidas e gráficos.
Utili d SPSS h i t d i id d t l til êUtilizando o SPSS, o conhecimento adquirido durante as aulas e a apostila, você
irá produzir, ao longo dos laboratórios, os seguintes resultados:
1. Criar labels e values para as variáveis CD_ETAPA e CD_REDE;
2. Quantitativo e percentual de alunos indígenas para cada etapa de
escolaridade e rede de ensino;escolaridade e rede de ensino;
3. Histograma da proficiência para cada etapa de escolaridade e rede de
iensino;

Laboratório
4. Proficiência média, máxima, mínima e desvio padrão para cada
etapa de escolaridade e rede de ensino;
5. Percentual de alunos por padrão de desempenho para cada CREDE;
6. Proficiência média, máxima, mínima e desvio padrão para cada
CREDE;
7. Verificar unicidade dos códigos de CREDE;
8. Gráfico de barras por CREDE, etapa de escolaridade e rede de
ensino;
9. Gráfico de pizza por CREDE, etapa de escolaridade e rede de ensino;
10. Boxplot por CREDE, etapa de escolaridade e rede de ensino.10. Boxplot por CREDE, etapa de escolaridade e rede de ensino.

Laboratório I
2 8 Laboratório2.8. LaboratórioPara iniciar a geração destes dados é necessário que seja feita a importação dos
microdados do SPAECE 2011, que você recebeu em “.csv”, para a extensão do
arquivo “.sav”, ou seja, o arquivo deve estar em SPSS.
Para isso, faça os seguintes passos:
a) Importe o arquivo SPAECE_2011_LP.csv para o SPSS (extensão “sav”);
b) Configure a syntax (numérico/string);b) Configure a syntax (numérico/string);
c) Salve o arquivo.

Módulo III Explorando os DadosExplorando os Dados

Módulo III – Explorando os Dados
3.1. Tipos de Variáveis
3.2. Frequência
3 3 C b3.3. Crosstabs
3.4. Histogramag
3.5. Descriptives
3.6. Boxplot
3 7 S lit Fil3.7. Split File
3.8. Case Summaries
3.9. Laboratório

Módulo III – Explorando os Dados
3.1. Tipos de Variáveis
• Variáveis discretas: São as variáveis que nãopossuem valores intermediários ou seja quepossuem valores intermediários, ou seja, quepertencem ao conjunto dos números inteiros.
Ex.: Número de alunos avaliados, número de alunosprevistos numa avaliaçãoprevistos numa avaliação.

Módulo III – Explorando os Dados
3.1. Tipos de Variáveis
• Variáveis contínuas: São variáveis que possuemvalores intermediários ou seja pertencem aovalores intermediários, ou seja, pertencem aoconjunto dos números reais.
Ex.: Proficiência, IDEB.

Módulo III – Explorando os Dados
3.1. Tipos de Variáveis
• Variáveis categóricas são discretas.
•Variáveis escalares ou de razão podem serdiscretas ou contínuasdiscretas ou contínuas.

Módulo III – Explorando os Dados
3.1. Tipos de Variáveis
Por que é importante conhecer os níveis demedida e o tipo das variáveis?medida e o tipo das variáveis?
Porque ferramentas foram desenvolvidasPorque ferramentas foram desenvolvidasespecificamente para cada tipo de variável. Autilização da ferramenta inadequada pode levar autilização da ferramenta inadequada pode levar aerros de interpretação e travamento do software.

Módulo III – Explorando os Dados
3.1. Tipos de Variáveis
Menu ‘analise’ tem ferramentas de exploração dedados para todos os tipos de variáveisdados para todos os tipos de variáveis.
Ferramentas para variáveis categóricas:Ferramentas para variáveis categóricas:Frequencia, Crosstabs;
Ferramentas para variáveis escalares e de razão:Histograma Box plot sumarize casesHistograma, Box plot, sumarize cases.

Módulo III – Explorando os Dados
3.2. Frequência
• A frequência é uma ferramenta apropriada paravariáveis categóricas ou qualitativas com pequenovariáveis categóricas ou qualitativas, com pequenonúmero de categorias.


Módulo III – Explorando os Dados
3.2. Frequência
• O SPSS cria uma tabela onde são exibidas ascategorias o número de cada categoria ocategorias, o número de cada categoria, opercentual bruto de cada categoria, considerandoos missing data o percentual válido (excluindo osos missing data, o percentual válido (excluindo osmissing data) e um percentual acumulado.
Missing data: são campos em branco ou com erros depreenchimento.preenchimento.

Módulo III – Explorando os Dados
3.2. FrequênciaExemplo:Exemplo:
6. Há quanto tempo você é diretor nesta escola?
Frequency Percent Valid PercentCumulative Percentq y
Valid A) Há menos de 1 ano. 1619 16,3 17,3 17,3
B) Entre 1 e 5 anos. 4775 48,1 50,9 68,2
C) Entre 6 e 10 anos. 1856 18,7 19,8 88,0
D) Entre 11 e 15 anos. 896 9,0 9,6 97,6
E) Entre 16 e 20 anos. 101 1,0 1,1 98,7
F) Há mais de 21 anos. 126 1,3 1,3 100,0
Total 9373 94,5 100,0
Missing Nulas. 14 ,1
Brancas. 532 5,4
Total 546 5,5
Total 9919 100,0

Módulo III – Explorando os Dados
3.3. Crosstabs
• O crosstabs também chamado de tabela cruzadaou de contingência é um recurso muito útil àexploração e análise de dados.
• Possibilita que para cada categoria de umavariável sejam exibidas valores das categorias deoutra variável.



Módulo III – Explorando os Dados
3.3. Crosstabs
• Vantagem: exploração de duas variáveissimultaneamente e uma em função da outra.
• Desvantagem: só pode ser usada para duasvariáveis por vez.
Recomendação: para facilitar a visualização da sua tabela coloque na linha a variável com menos categorias.

Módulo III – Explorando os Dados
3 3 Crosstabs3.3. Crosstabs
CD ETAPA * NM REGIONAL CrosstabulationCD_ETAPA NM_REGIONAL Crosstabulation
Count
NM_REGIONAL Total
CREDE ACARAU CREDE CAMOCIMCREDE
MARACANAU CREDE TIANGUACD_ETAPA 2 43 0 106 0 149
5 54 0 115 0 169
9 242 82 1704 441 2469
10 4182 3410 14447 5308 27347
11 3384 2706 12296 5113 23499
12 2674 2017 10256 4251 19198
Total 10579 8215 38924 15113 72831

Módulo III – Explorando os Dados
3.3. Crosstabs
• A tabela anterior contém o número das duasvariáveis É possível também utilizar o crosstabsvariáveis. É possível também utilizar o crosstabspara produzir outras medidas como o percentualrelativo à coluna ou à linharelativo à coluna ou à linha.
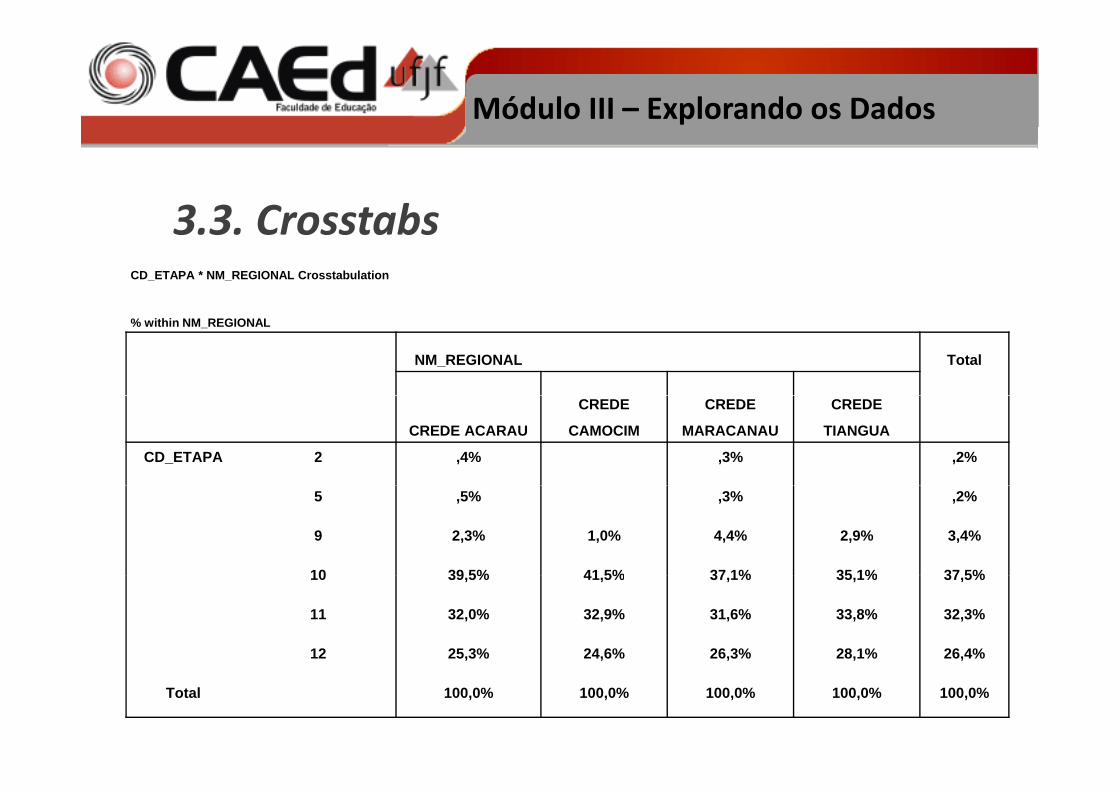
Módulo III – Explorando os Dados
3 3 Crosstabs3.3. CrosstabsCD_ETAPA * NM_REGIONAL Crosstabulation
% within NM_REGIONAL
NM_REGIONAL Total
CREDE ACARAU
CREDE
CAMOCIM
CREDE
MARACANAU
CREDE
TIANGUA
CD_ETAPA 2 ,4% ,3% ,2%
5 ,5% ,3% ,2%
9 2,3% 1,0% 4,4% 2,9% 3,4%
10 39 5% 41 5% 37 1% 35 1% 37 5%10 39,5% 41,5% 37,1% 35,1% 37,5%
11 32,0% 32,9% 31,6% 33,8% 32,3%
12 25,3% 24,6% 26,3% 28,1% 26,4%
Total 100,0% 100,0% 100,0% 100,0% 100,0%

Módulo III – Explorando os Dados
3.4. Histograma
• Ferramenta elaborada para variáveisquantitativas.
• O histograma é um tipo de gráfico de barrasmuito útil para avaliar a distribuição das variáveis.
• No eixo horizontal está o valor das proficiências eno eixo vertical a freqüência observada para avariável.




Módulo III – Explorando os Dados
3.3. Histograma

Módulo III – Explorando os Dados
3.5. Descriptives
• O Descriptives do SPSS possibilita a visualização devárias estatísticas descritivas como a média o mínimovárias estatísticas descritivas como a média, o mínimo,o máximo e o desvio padrão. O histograma anteriorrefere‐se a distribuição da proficiênciarefere se a distribuição da proficiência.

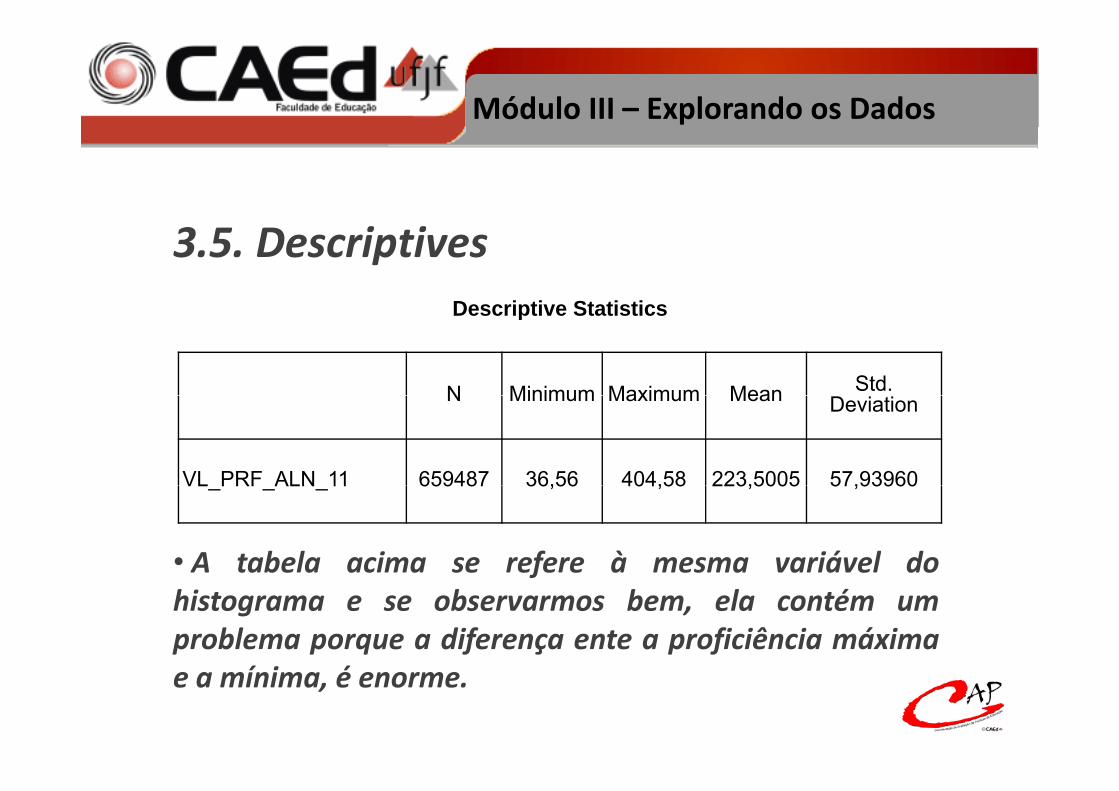
Módulo III – Explorando os Dados
3.5. DescriptivesDescriptive StatisticsDescriptive Statistics
N Minimum Maximum Mean Std. N Minimum Maximum Mean Deviation
VL PRF ALN 11 659487 36,56 404,58 223,5005 57,93960VL_PRF_ALN_11 659487 36,56 404,58 223,5005 57,93960
• A tabela acima se refere à mesma variável dofhistograma e se observarmos bem, ela contém umproblema porque a diferença ente a proficiência máximae a mínima, é enorme.

Módulo III – Explorando os Dados
3.5. Descriptives
• Isso aconteceu porque examinamos a variávelproficiência sem considerar as etapas avaliadas. Ou seja, as
d d d b l dmedidas da tabela anterior consideraram ao mesmotempo alunos do 2º, 5º e 9º anos do Ensino Fundamental eetapas do Ensino Médio Isso distorceu as estatísticasetapas do Ensino Médio. Isso distorceu as estatísticaspodendo levar a erros de interpretação.
• Uma forma de resolver esse problema é dividir o output usando um recurso chamado split file.

Módulo III – Explorando os Dados
3.6. Boxplot
• É a representação gráfica dos quartis de umadistribuição. Ele apresenta, de forma compacta,ç p pdiversas informações sobre uma variável.




Módulo III – Explorando os Dados
3.6. Boxplot
• A linha central(4) representa o(4) representa opercentil 50 oumedianamediana.

Módulo III – Explorando os Dados
3.6. Boxplot
• As linhasinferiores (5) einferiores (5) esuperiores (3) dacaixa são ocaixa são opercentil 25 e 75respectivamenterespectivamente.

Módulo III – Explorando os Dados
3.6. Boxplot
• As linhas verticaisdemarcam dadosentre os percentis 25entre os percentis 25e 75 e os valoresmínimo e máximo davariável,desconsiderando osoutliers e casosoutliers e casosextremos, se houver.

Módulo III – Explorando os Dados
3.6. Boxplot
• Outliers (2) sãovaloresvaloresdiscrepantes, elessão assinaladossão assinaladoscom um círculo.

Módulo III – Explorando os Dados
3.6. Boxplot
• Casos extremos(1) são valores(1) são valoresainda maisatípicos estes sãoatípicos, estes sãoassinalados nográfico com umgráfico com umasterisco.
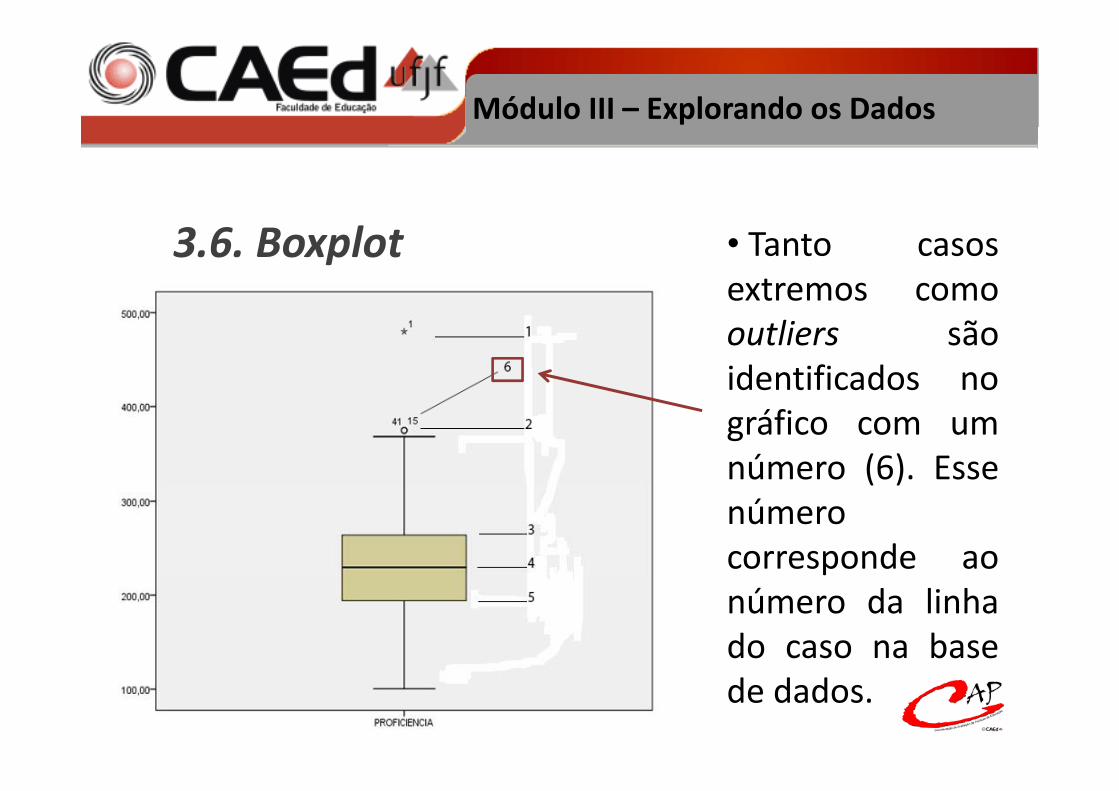
Módulo III – Explorando os Dados
3.6. Boxplot • Tanto casosextremos comooutliers sãoidentificados nográfico com umnúmero (6). Esse( )númerocorresponde aopnúmero da linhado caso na basede dados.

Módulo III – Explorando os Dados
3.7. Split File
• O Split file é um recurso útil para dividir o outputsegundo um critério específicosegundo um critério específico.
• Muito útil para analisar medidas de etapasMuito útil para analisar medidas de etapasdiferentes em bases agregadas por disciplina ou redede ensino.



Módulo III – Explorando os Dados
3.8. Case Summaries
• Outro recurso interessante para exploração de dados e de estatísticas descritivas é Case Summaries.
• Permite que sejam produzidas mais estatísticas que o descriptives e não necessita do split file.



Módulo I ‐ Estrutura do Banco de Dados
ã 02Demonstração 02

Laboratório II
3.9. LaboratórioVamos agora criar labels e values para as variáveis de etapa de escolaridade e rede de ensino na
base SPAECE_2011_LP.sav. Desta forma:
a) Faça um Crosstab das variáveis CD_ETAPA e DC_ETAPA e das variáveis CD_REDE e
DC_REDE para saber os códigos que cada uma possui e suas respectivas descrições;
b) Crie os labels e os values das duas variáveis;
Para fazer os tópicos 2), 3) e 4) de sua apresentação é necessário:
c) Fazer um Split File das variáveis CD_ETAPA e CD_REDE;
d) Fazer uma frequência da variável FL_INDIGENA;
e) Criar os histogramas para a variável VL_PRF_ALN_11 por CD_ETAPA e CD_REDE;
f) Usar o comando Descriptives para fazer a proficiência média, máxima, mínima e o desvio
padrão por etapa de escolaridade e rede de ensino;

Módulo IVManipulando os DadosManipulando os Dados

Módulo IV – Manipulando os Dados
4.1. Recode
4.2. Recode in Diferente Variable
4.3. Compute
4.4. Select Cases (Filter)
4.5. Aggregate
4.6. Correlação de Pearson
4.7. Laboratório

Módulo IV – Manipulando os Dados
4.1. Recode
• Permite alterar campos numa mesma variável. EssesPermite alterar campos numa mesma variável. Essescampos podem ser numéricos ou string, mas apenasvariáveis de um mesmo tipo podem ser recodificadasp ppor vez.



Módulo IV – Manipulando os Dados
4.2. Recode in Diferente Variables
• Esse recurso permite criar uma variável segundocritérios de uma variável existentecritérios de uma variável existente.
• Pode ser utilizado para vários fins em análisesPode ser utilizado para vários fins, em análiseseducacionais é importante para criar a distribuiçõespor padrões de desempenho.p p p



Módulo IV – Manipulando os Dados
4.3. Compute
• É um recurso importante na manipulação devariáveis Muito utilizado para produção devariáveis. Muito utilizado para produção deindicadores e índices.
• Possui vários recursos adequados para variáveisnuméricas e stringnuméricas e string.



Módulo IV – Manipulando os Dados
4.4. Select Cases (Filter)
• É um recurso que permite fazer filtros no banco ded d d di õ ífidados segundo condições específicas.
• Um filtro muito utilizado é o de alunos com laudo• Um filtro muito utilizado é o de alunos com laudo,que não são contabilizados para produção dasproficiências médias Mas contados no cálculo deproficiências médias. Mas contados no cálculo departicipação.




Módulo IV – Manipulando os Dados
4 5 Aggregate4.5. Aggregate
• É uma agrupamento de dados onde podemosgerar também as médias, o desvio‐padrão, dentreoutras medidas.
• Pode ser realizada na própria base ou gerandoem uma nova.



Módulo IV – Manipulando os Dados
4.6. Correlação de Pearsonç
A correlação é uma estatística de associação entre duas variáveis. Elapode variar de 1 a ‐1. Uma correlação igual a 1 representa umacorrelação perfeita, portanto para duas variáveis correlacionadas comcorrelação perfeita, portanto para duas variáveis correlacionadas comessa magnitude; se uma delas aumentar ou diminuir seus valores emuma unidade, a outra variável irá variar da mesma forma. Se acorrelação for de ‐1 para cada valor acrescido a uma variável haverá umcorrelação for de ‐1 para cada valor acrescido a uma variável, haverá umdecréscimo na outra variável.Pode‐se observar a aplicação da correlação de Pearson utilizando‐se aproficiência e o Índice Socioeconômicoproficiência e o Índice Socioeconômico.A correlação de Pearson é uma estatística apropriada para variáveisescalares.


Módulo I ‐ Estrutura do Banco de Dados
ã 03Demonstração 03

Laboratório III
4.7. LaboratórioSeguindo a lista das medidas solicitadas temos o item 5). Para
d i did i i P d õ dproduzir essa medida precisamos antes criar os Padrões de
Desempenho. Os Padrões de Desempenho são os intervalos de
proficiência em que cada aluno está alocado. Para o 2° ano do
Ensino Fundamental são cinco padrões: Não AlfabetizadoEnsino Fundamental são cinco padrões: Não Alfabetizado,
Alfabetização Incompleta, Intermediário, Suficiente e Desejável.
Para as outras etapas de escolaridade são quatro: Muito Crítico,
Crítico, Intermediário e Adequado.
Laboratório III
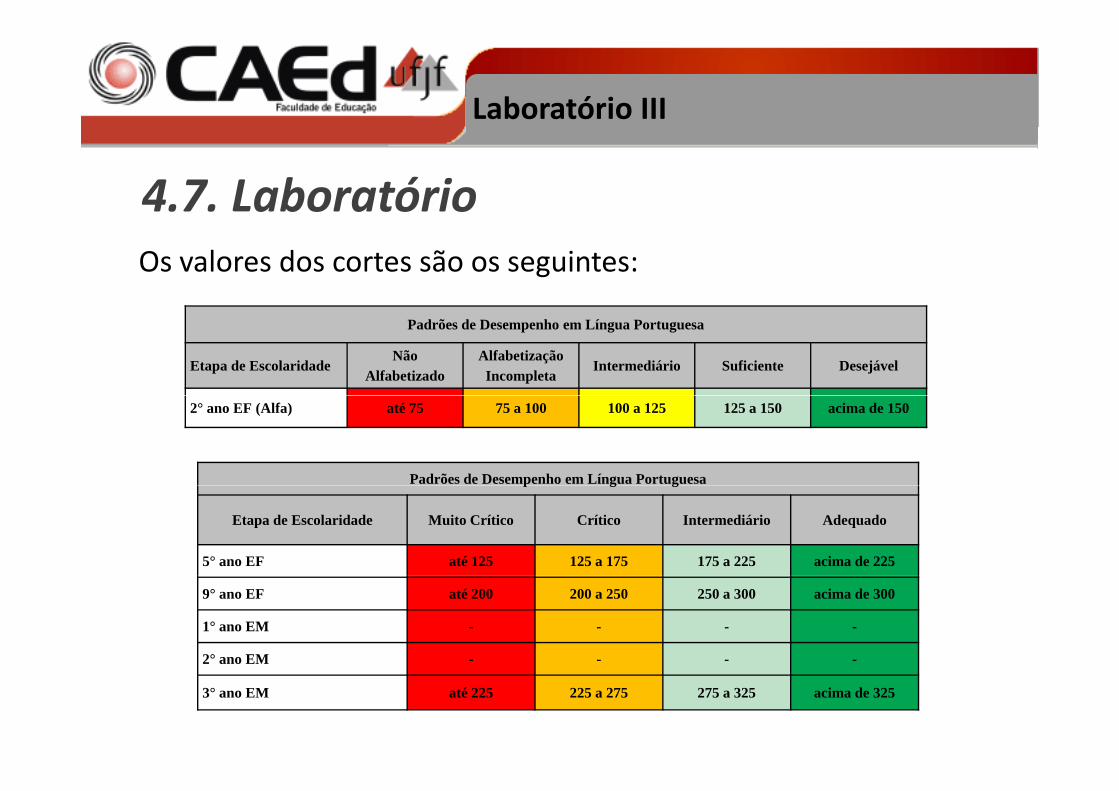
4.7. LaboratórioOs valores dos cortes são os seguintes:
Padrões de Desempenho em Língua Portuguesa
Etapa de EscolaridadeNão
AlfabetizadoAlfabetização Incompleta
Intermediário Suficiente Desejável
2° ano EF (Alfa) até 75 75 a 100 100 a 125 125 a 150 acima de 150
Padrões de Desempenho em Língua Portuguesap g g
Etapa de Escolaridade Muito Crítico Crítico Intermediário Adequado
5° ano EF até 125 125 a 175 175 a 225 acima de 225
9° ano EF até 200 200 a 250 250 a 300 acima de 300
1° ano EM - - - -
2° ano EM - - - -
3° ano EM até 225 225 a 275 275 a 325 acima de 325

Laboratório III
4.7. LaboratórioPor questões de praticidade, vamos nos ater ao 2° e 5° anos do EnsinoFundamental; para as demais etapas o procedimento é o mesmo.
L fLogo, façamos:
a) Crie os padrões de desempenho na base de dados utilizando os
comandos compute e recode. Lembre‐se: cada aluno só pode estar
alocado em um padrão de desempenho;
Para os próximos itens é necessário que seja feito um filtro na base.
Veja a seguir:

Laboratório III
4.7. Laboratório• 2° ano do Ensino Fundamental (Alfa)
A tabela abaixo mostra quais escolas entrarão nos resultados deproficiência e participação de determinado extrato.
Escola Escolas EstaduaisEscolas Municipais
Escolas Indígenas
Resultado do Estado, por rede de ensino. x x x
Resultado da CREDE, por rede de ensino. x x x
Resultado do Município, por rede de ensino. X (1) x X (2)
Observações:(1) Em Fortaleza há escolas estaduais com o 2° ano; portanto, para o município de Fortaleza, além das escolas da Rede Municipal, há as da Rede Estadual.(2) Como as escolas indígenas fazem parte da Rede Estadual de educação, elas devem ser contabilizadas no cálculo da Rede Estadual de d i í i l íd d ál l d R d M i i lcada município e excluídas do cálculo da Rede Municipal.

Laboratório III
4.7. Laboratório• 5° ano do Ensino Fundamental
A tabela abaixo mostra quais escolas do 5° ano do Ensino Fundamentalentrarão nos resultados de proficiência e participação de determinadoextrato.
Escola Escolas EstaduaisEscolas Municipais
Escolas Indígenas
Escolas EJA
Resultado do Estado, por rede de ensino. x x x x
Resultado da CREDE, por rede de ensino. x x x x
Resultado do Município, por rede de ensino. x x X (1) x
Resultado da Escola x x x x
Observação:(1)Como as escolas indígenas fazem parte da Rede Estadual de educação, elas devem ser contabilizadas no cálculo da rede estadual de cada município e excluídas do cálculo da Rede Municipal.p pPara os alunos com laudo temos a aplicação de um filtro. A configuração deste filtro é bastante simples, os alunos com laudo entrarão nos dados de participação, mas não são contados no cálculo de Proficiência Média.

Laboratório III
4.7. Laboratório
Você reparou que, ao calcular a Proficiência média) d l ê ã f f l fno item 4) de sua lista, você não fez o filtro, o fato
de não fazer o filtro pode acarretar uma variaçãofi iê i d b l i ãna Proficiência. Para poder observar tal variação,
faça:
b) O fil l l db) O filtro para os alunos com laudo.

Módulo VIntegração e Criação deIntegração e Criação de Banco de DadosBanco de Dados

Módulo V – Integração e Criação de Banco de Dados
5.1. Merge Files
5.2. Identify Duplicate Cases
5.3. Sort Cases
5.4. Laboratório

Módulo V – Integração e Criação de Banco de Dados
5.1. Merge Files
• Add Cases: consiste colocar um banco de dados“embaixo do outro”, isto é, adicionar linhas.
• Add Variables: é quando desejamos acrescentarinformações em um banco existente Para isso éinformações em um banco existente. Para isso énecessário uma variável comum entre os dois bancos,o que chamamos de variável chave Esta variável deveo que chamamos de variável chave. Esta variável deveser única, ou seja, não pode haver duplicidade, devemestar ordenadas e geralmente são códigos.estar ordenadas e geralmente são códigos.







Módulo V – Integração e Criação de Banco de Dados
5.2. Identify Duplicate Cases
• Esse recurso permite identificar rapidamente seexistem casos duplicados Pode ser usado comexistem casos duplicados. Pode ser usado comvárias variáveis.
• Missing data são considerados na análise, portanto se houverdois casos com campos vazios um deles será considerado opcampo primário e o outro duplicado.



Módulo V – Integração e Criação de Banco de Dados
5.3. Sort Cases
• Consiste na ordenação de variáveis em ordemcrescente ou decrescente. Deve ser feito emordem crescente em todas as variáveis utilizadascomo chave para o Merge.



Módulo I ‐ Estrutura do Banco de Dados
ã 0Demonstração 04

Laboratório IV
5.4. Laboratório
Vamos refazer o item 4) de sua lista. Para isto, você usará o comando de
agregação (Aggregate). Assim:
a) Refaça o item 4) agora com filtro e usando o comando de agregaçãoa) Refaça o item 4), agora com filtro, e usando o comando de agregação.
Utilize também a rede de ensino na hora de agregar. Lembre‐se de gerar
b S l b “PROJETO”uma nova base. Salve essa base com o nome “PROJETO”;
b) Gere uma nova base com a proficiência média, máxima, mínima e o) p , ,
desvio padrão para cada CREDE. Salve essa base com o nome “CREDE”;
c) Verifique a unicidade dos códigos de CREDE;

Laboratório IV
5.4. Laboratório
d) Encontre o percentual de alunos por padrão de desempenho para cada
CREDE gerando uma nova base. Salve essa base com o nome
“PADROES_CREDE”;
Você possui duas bases: uma com os dados de proficiência média das CREDEs
(“CREDE.sav”) e uma com os dados de padrão de desempenho por CREDE
(“PADROES_CREDE.sav”). Precisamos ter estas informações em uma única
base. Sendo assim:
e) Faça um merge adicionando variáveis das duas bases Salve esta basee) Faça um merge adicionando variáveis das duas bases. Salve esta base
com o nome “CREDE_FINAL”;

Laboratório IV
5.4. Laboratório
Recebemos um e‐mail pedindo que fosse acrescentada uma nova CREDE aos
nossos resultados. Os dados desta CREDE seguem na tabela abaixo:
CD_REDE CD_ETAPA CD_REGIONAL DC_REDE DC_ETAPA NM_REGIONAL PRF_MEDIA PRF_MAX PRF_MIN DESVIO_PADRAO
1 2 99 ESTADUAL 2º ANO CENTRO 225,91 239,44 130,78 45,15
1 5 99 ESTADUAL 5º ANO CENTRO 154,72 226,05 125,91 42,14
2 2 99 MUNICIPAL 2º ANO CENTRO 186,33 294,67 173,93 52,06
2 5 99 MUNICIPAL 5º ANO CENTRO 179,89 337,86 142,52 44,39
f) Acrescente esta CREDE à nossa base principal (“CREDE_FINAL”)
adicionando casos.

Laboratório V
5.4. LaboratórioVamos agora montar alguns gráficos. Para isso utilizaremos o menu “Graphs”:Graphs :
a) Faça o gráfico de barras por CREDE, etapa de escolaridade e rede de ensino;
b) Faça o gráfico de pizza por CREDE, etapa de escolaridade e redeb) Faça o gráfico de pizza por CREDE, etapa de escolaridade e rede de ensino;
) b l d l id d d dc) Faça o boxplot por CREDE, etapa de escolaridade e rede de ensino.

Obrigado!g





























