Embed Size (px)
Citation preview

北高性能计算校级公共平台快速入门

内容
• 1 平台概况
• 2 账号获取
• 3 登录集群
• 4 使用集群现有软件
• 5 作业调度系统使用
• 6 编译安装软件
• 7 python环境使用
2

1 平台概况

北京大学高性能计算校级公共平台现有3套集群,未名一号、未名生科一号、未名教学一号。其中未名一号及未
名生科一号主要用于科研,性能优异,为收费集群,“未名教学一号”主要用于教学,提供并行环境,为免费集群。
4
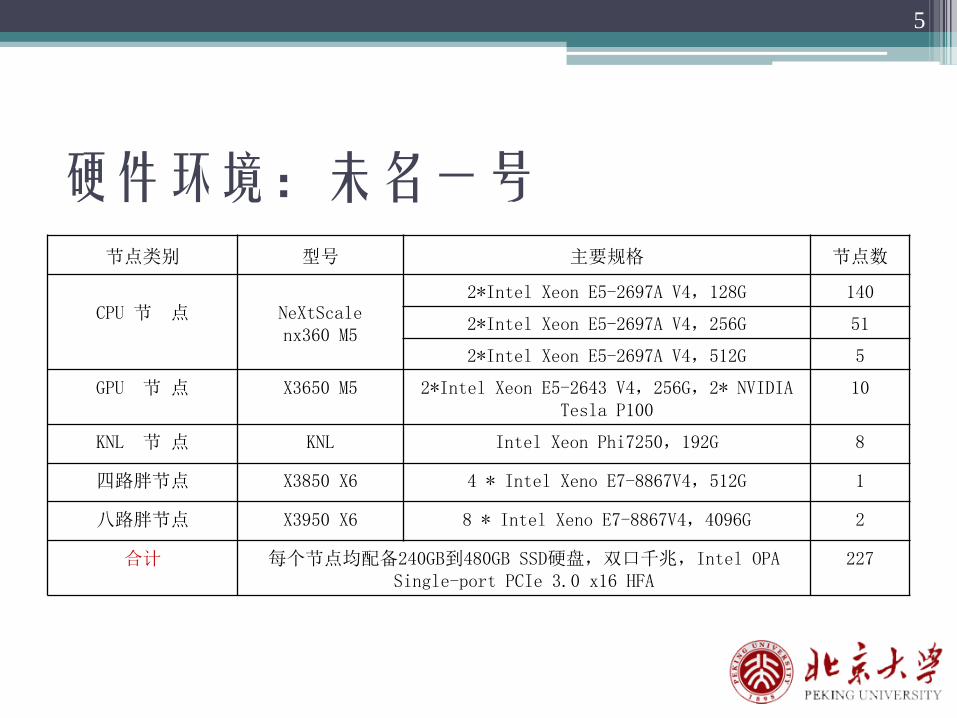
硬件环境:未名一号节点类别 型号 主要规格 节点数
CPU 节 点 NeXtScalenx360 M5
2*Intel Xeon E5-2697A V4,128G 140
2*Intel Xeon E5-2697A V4,256G 51
2*Intel Xeon E5-2697A V4,512G 5
GPU 节 点 X3650 M5 2*Intel Xeon E5-2643 V4,256G,2* NVIDIA Tesla P100
10
KNL 节 点 KNL Intel Xeon Phi7250,192G 8
四路胖节点 X3850 X6 4 * Intel Xeno E7-8867V4,512G 1
八路胖节点 X3950 X6 8 * Intel Xeno E7-8867V4,4096G 2
合计 每个节点均配备240GB到480GB SSD硬盘,双口千兆,Intel OPA Single-port PCIe 3.0 x16 HFA
227
5
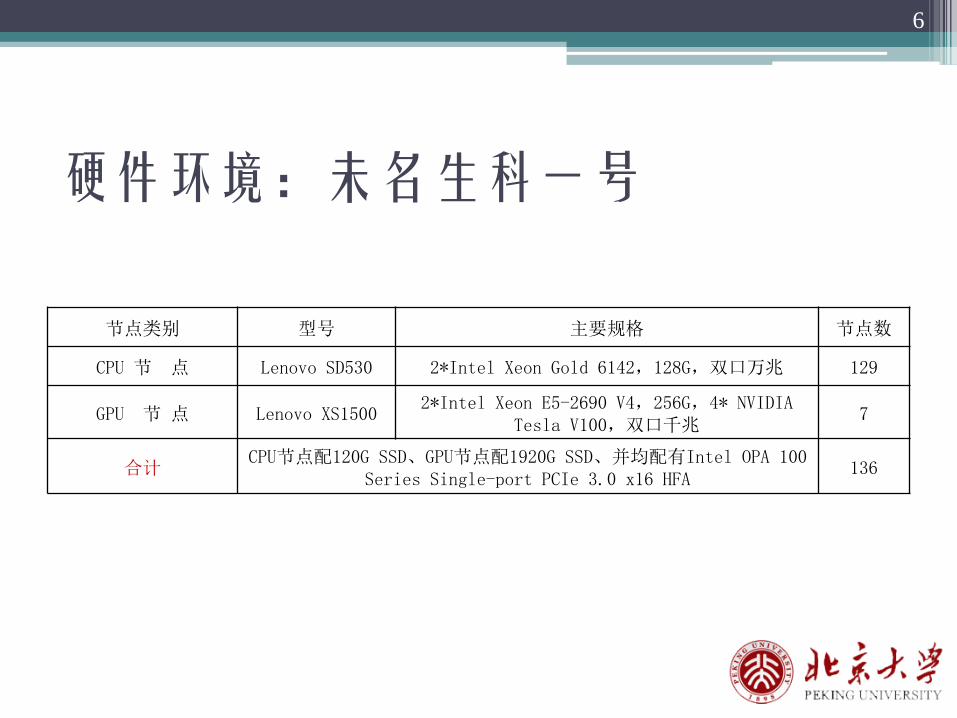
硬件环境:未名生科一号
节点类别 型号 主要规格 节点数
CPU 节 点 Lenovo SD530 2*Intel Xeon Gold 6142,128G,双口万兆 129
GPU 节 点 Lenovo XS15002*Intel Xeon E5-2690 V4,256G,4* NVIDIA
Tesla V100,双口千兆7
合计CPU节点配120G SSD、GPU节点配1920G SSD、并均配有Intel OPA 100
Series Single-port PCIe 3.0 x16 HFA136
6
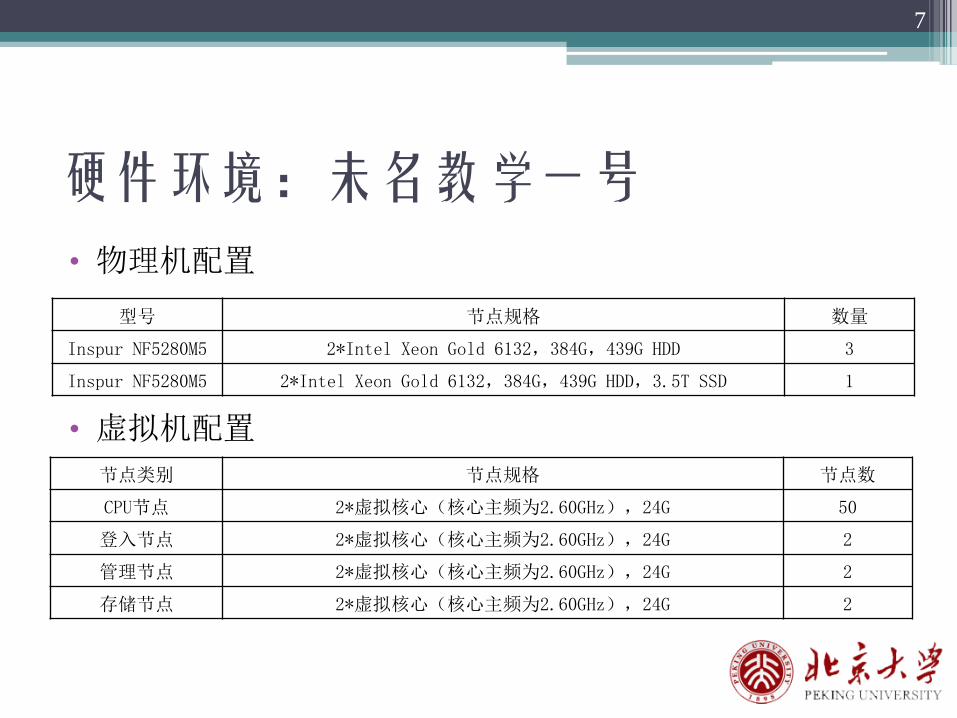
硬件环境:未名教学一号
7
节点类别 节点规格 节点数
CPU节点 2*虚拟核心(核心主频为2.60GHz),24G 50
登入节点 2*虚拟核心(核心主频为2.60GHz),24G 2
管理节点 2*虚拟核心(核心主频为2.60GHz),24G 2
存储节点 2*虚拟核心(核心主频为2.60GHz),24G 2
• 物理机配置
• 虚拟机配置
型号 节点规格 数量
Inspur NF5280M5 2*Intel Xeon Gold 6132,384G,439G HDD 3
Inspur NF5280M5 2*Intel Xeon Gold 6132,384G,439G HDD,3.5T SSD 1

收费标准
未名一号和未名生科一号为收费集群,其中CPU节点及胖节点按照核心计费,GPU节点按照GPU卡计费,KNL以台为单位计费。收费详情请查看(http://hpc.pku.edu.cn/guide_6.html)
8
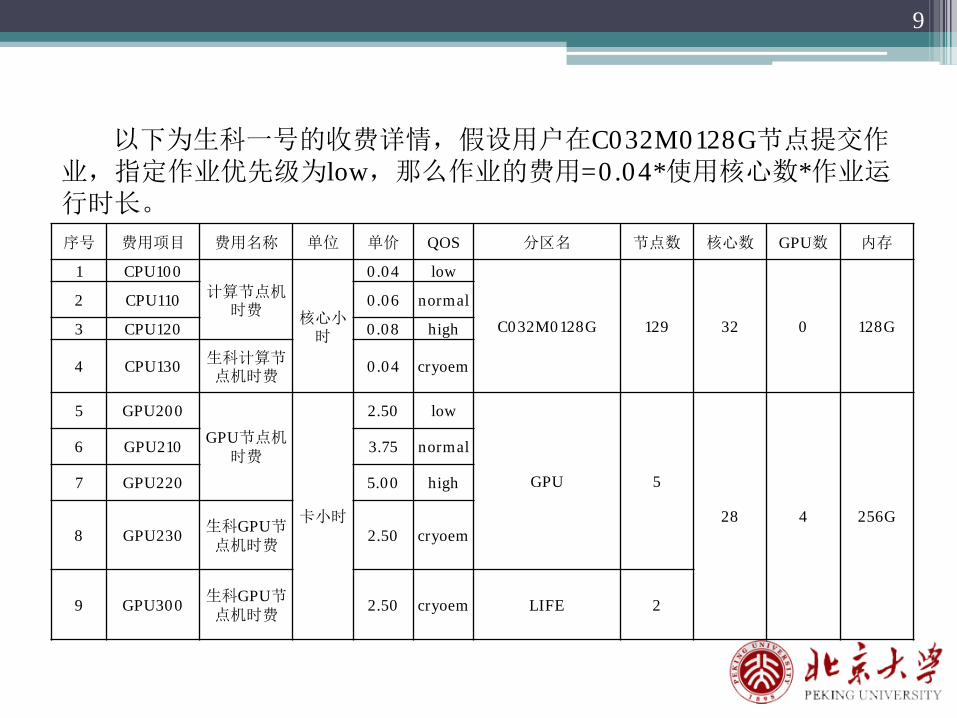
序号 费用项目 费用名称 单位 单价 QOS 分区名 节点数 核心数 GPU数 内存
1 CPU100计算节点机
时费核心小时
0.04 low
C032M0128G 129 32 0 128G
2 CPU110 0.06 normal
3 CPU120 0.08 high
4 CPU130 生科计算节点机时费
0.04 cryoem
5 GPU200
GPU节点机时费
卡小时
2.50 low
GPU 5
28 4 256G
6 GPU210 3.75 normal
7 GPU220 5.00 high
8 GPU230 生科GPU节点机时费
2.50 cryoem
9 GPU300 生科GPU节点机时费
2.50 cryoem LIFE 2
9
以下为生科一号的收费详情,假设用户在C032M0128G节点提交作业,指定作业优先级为low,那么作业的费用=0.04*使用核心数*作业运行时长。

2 账号获取

• 科研系列
未名一号
未名生科一号
• 教学系列
未名教学一号
11

2.1 科研系列账号获取1 点击连接(http://hpc.pku.edu.cn/guide.html);2 下载《北京大学高性能计算校级公共平台用户申请表》;
3 填写相关信息,其中项目负责人需为老师,申请人可为学生也可为老师,项目相关信息为将在集群上跑的项目;
4 签字盖章后交到理科一号楼1156S;5 成功开通后项目负责人还可以点击高性能左上方登录键登录高性能,为其他学生开通上机账号。
12

2.2 教学系列账号获取教学系列用户可直接进入链接
(http://hpc.pku.edu.cn/guide.html)后点击进入在线申请填入相关信息即可。
13

3 登录集群
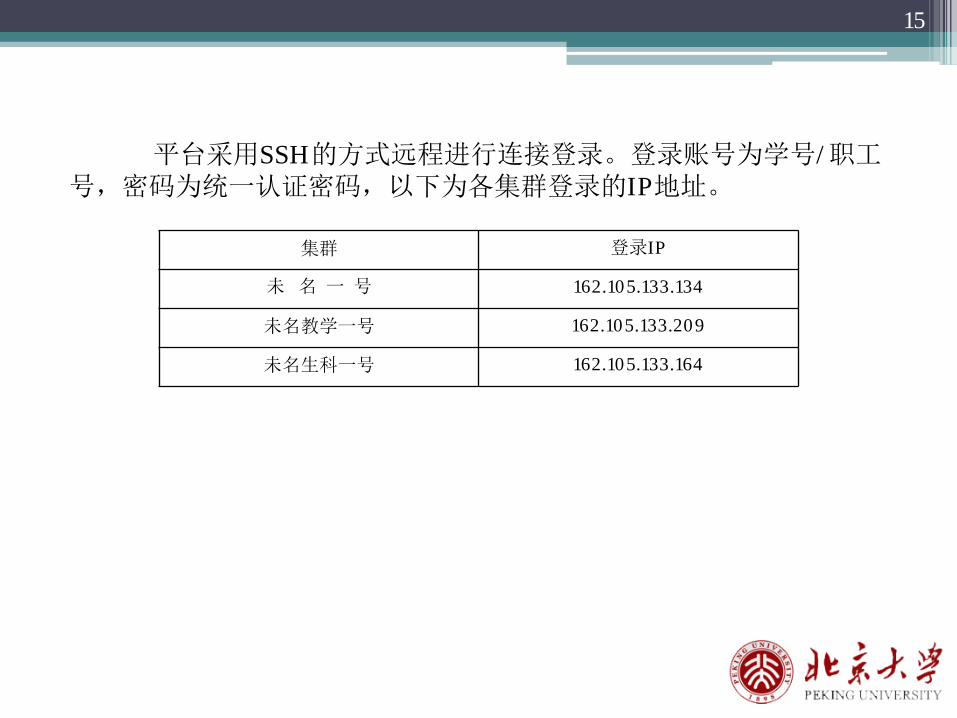
平台采用SSH的方式远程进行连接登录。登录账号为学号/职工号,密码为统一认证密码,以下为各集群登录的IP地址。
15
集群 登录IP
未 名 一 号 162.105.133.134
未名教学一号 162.105.133.209
未名生科一号 162.105.133.164

3.1 Linux/Mac用户登录$ ssh username@ip_address$ ssh -X username@ip_address
16
其中uername为统一认证账号,ip_address为需要登录集群的IP,如果需要使用图形界面的话还需要加参数-X。

3.2 Windows用户
Windows用户可以使用xshell、MobaXterm或者putty等,需要使用图形界面的推荐使用MobaXterm,以下为对应的下载地址。
• xshell:https://www.netsarang.com/zh/free-for-home-school/下载时选择两者(xshell和xftp,xftp用于传输数据)
• MobaXterm:https://mobaxterm.mobatek.net/download-home-edition.html
• putty:https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
17
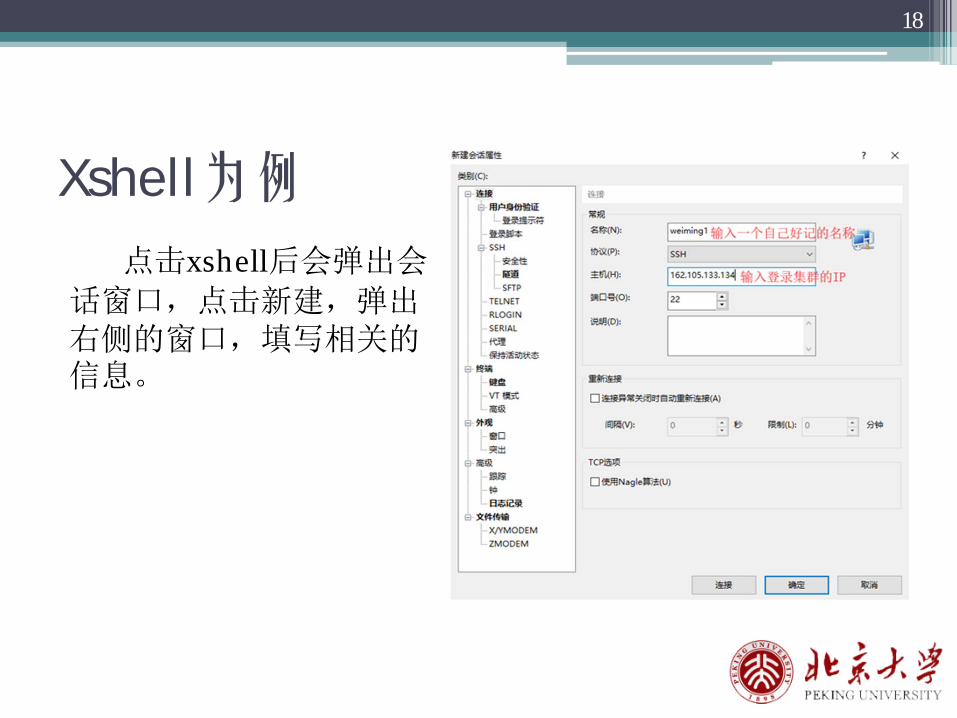
Xshell为例
点击xshell后会弹出会
话窗口,点击新建,弹出右侧的窗口,填写相关的信息。
18
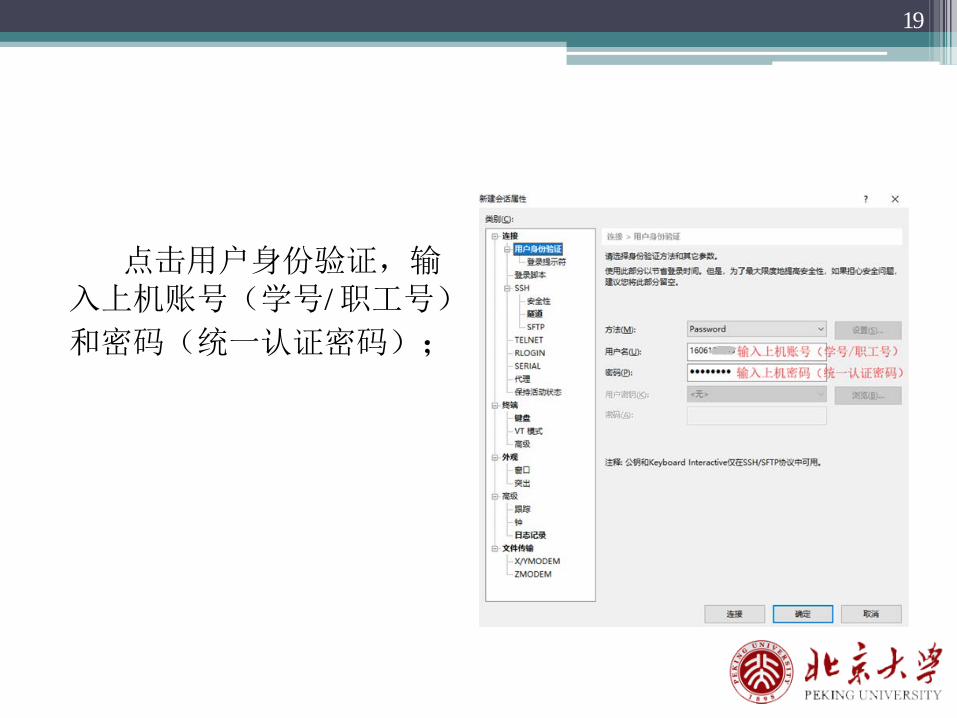
点击用户身份验证,输入上机账号(学号/职工号)
和密码(统一认证密码);
19

3.3 Linux/Mac 传输数据可使用scp和rsync口令上传和下载数据
20
$ scp [-r] file username@ip_address:~/# 该命令将会把本地的名为file的文件上传到集群的home目录下,如果file是一个目录的话还需要加上参数r$ scp [-r] username@ip_address:~/file ./# 该命令将会把服务器上home目录下名为file的文件下载到本地当前文件夹下
$ rsync [-Pr] file username@ip_address:~/# 该命令将会把本地的名为file的文件上传到集群的home目录下,如果file是一个目录的话还需要加上参数r$ rsync [-Pr] username@ip_address:~/file ./# 该命令将会把服务器上home目录下名为file的文件下载到本地当前文件夹下
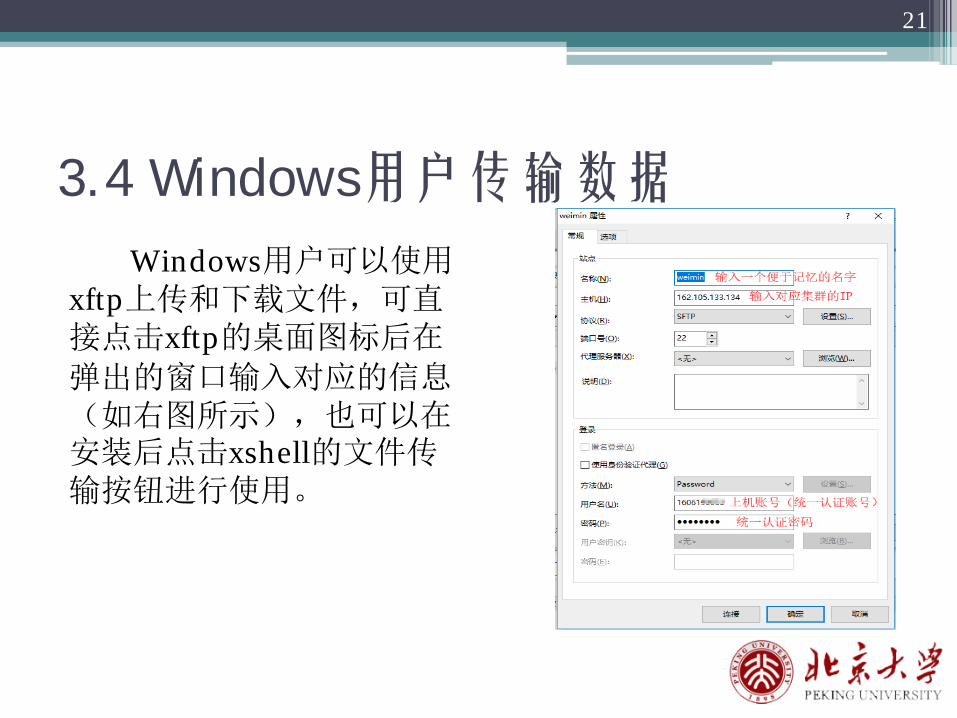
3.4 Windows用户传输数据
21
Windows用户可以使用xftp上传和下载文件,可直接点击xftp的桌面图标后在
弹出的窗口输入对应的信息(如右图所示),也可以在安装后点击xshell的文件传输按钮进行使用。

3.5 常见错误密码错误:密码为开通上机账号时统一认证密码,如果
后期修改了密码,登录集群的密码并不会随之改变,仍需要使用旧的统一认证密码才可登录,如果想要同步最新的统一认证密码,需联系管理员。
22

4 使用集群现有的软件环境

环境变量
export JAVA_HOME=/usr/java/jdkexport CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/libexport PATH=$JAVA_HOME/bin:$PATH
24
环境变量是在操作系统中一个具有特定名字的对象,它包含了一个或多个应用程序将使用到的信息。

大部分Linux用户管理环境变量的方式都是,export 相应的环境变量到~/.bashrc文件中,当使用软件多了以后会不利于管理。而Module则是由管理员将不同软件的环境配置写好,然后用户在登陆之后,只需要用module load 相应的软件环境变量即可。
25

4.1 module 常见命令module help 显示帮助信息;
module avail 查看所有可用的软件环境变量;
module load 导入对应的环境变量;
module list 查看已导入的环境变量;
module unload 删除已导入的环境变量;
module switch [mod1] mod2 删除mod1并导入mod2;
26

4.2 例子$ module avail matlab # 查看可用的matlab$ module load matlab/R2017a # 导入matlab/R2017a的环境变量$ module unload matlab/R2017a # 删除matlab/R2017a的环境变量
27

4.3 编写modulefile用户也可以将自己的所需要的环境变量编写成
modulefile,使用module进行管理。步骤如下:
第一步:添加自己的modulefile路径;
28
$ mkdir ${HOME}/mymodulefile$ echo 'export MODULEPATH=${HOME}/mymodulefile:$MODULEPATH' >> ~/.bashrc$ source ~/.bashrc
# set:设置modulefile内部的变量# setenv:设置环境变量# prepend-path :效果类似export PATH=/xxx/xxx:$PATH# append-path : 效果类似export PATH=$PATH:/xxx/xxx
第二步:编写modulefile放入该路径下,语法如下;

modulefile例子:
29
#%Module1.0####module-whatis "my first modulefile about [email protected]"
set topdir "gpfs/share/home/xxxxxxxxx/gcc/7.2.0"prepend-path MANPATH "${topdir}/gcc/7.2.0/share/man"prepend-path PATH "${topdir}/bin"prepend-path LIBRARY_PATH "${topdir}/lib"prepend-path LD_LIBRARY_PATH "${topdir}/lib"prepend-path CPATH "${topdir}/include"

5 作业调度系统使用
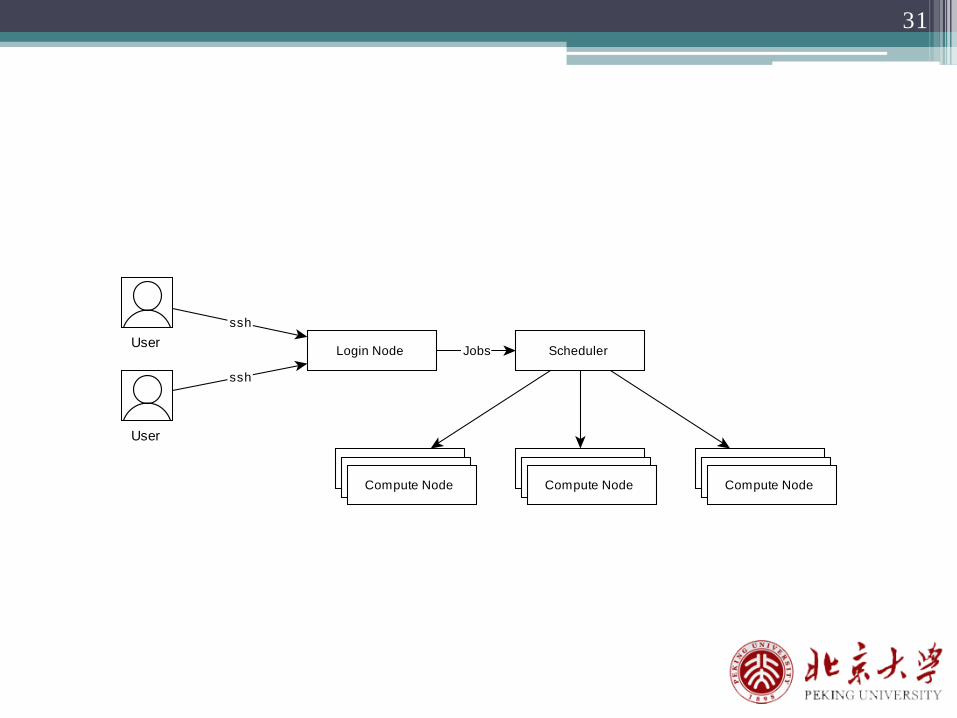
31
User
User
Login Node Scheduler
Compute Node Compute NodeCompute NodeCompute Node Compute NodeCompute NodeCompute Node Compute NodeCompute Node
ssh
ssh
Jobs

平台使用SLURM作为作业调度系统,用户需要了解相关的指令,来进行作业的提交,查看,取消等。SLURM常见的指令有sbatch、squeue、scancel、sinfo、salloc等。
参考:https://slurm.schedmd.com/man_index.html
32

• 5.1 account、qos、partition• 5.2 sbatch• 5.3 squeue• 5.4 scancel• 5.5 sinfo• 5.6 salloc
33

5.1 account、partition 、qosaccount、partition、qos并非SLURM的相关指令,但
在使用SLURM提交作业的时候会涉及到这些概念。
34

account我们登录集群使用的是上机账号,上机账号实际上是关
联有一个至多个账户,用于计费。
开户后项目负责人将获得账户,登录hpc.pku.edu.cn,可为自己的学生开通上机账号。
目前未名一号及生科一号的account为hpc加项目负责人工号,教学一号的account为自身学号,通过以下指令可以查看自己可用的账户:
如果出现提交作业出现以下提示表明没正确指定账户:
35
$ sacctmgr show ass user=`whoami` format=account%15 |uniq
error: Job submit/allocate failed: Invalid account or account/partition combination specified

partition提交作业的时候需要指定分区,不同的分区会有不同的
属性,如GPU分区的节点含GPU卡,C032M0128G的分区节点内存为128G, life 分区为电镜组使用的专用分区等。
通过以下命令可以查看可以使用的分区
还可以通过以下命令查看各分区节点的可用状态
36
$ sacctmgr show ass user=`whoami` format=part |uniq
$ sinfo

目前各集群所有的分区如下:
37
未名一号: C032M0128G、C032M256G、C032M0512G、C072M0512G、C144M4096G、GPU、KNL。
生科一号: C032M0128G、 GPU
教学一号: compute
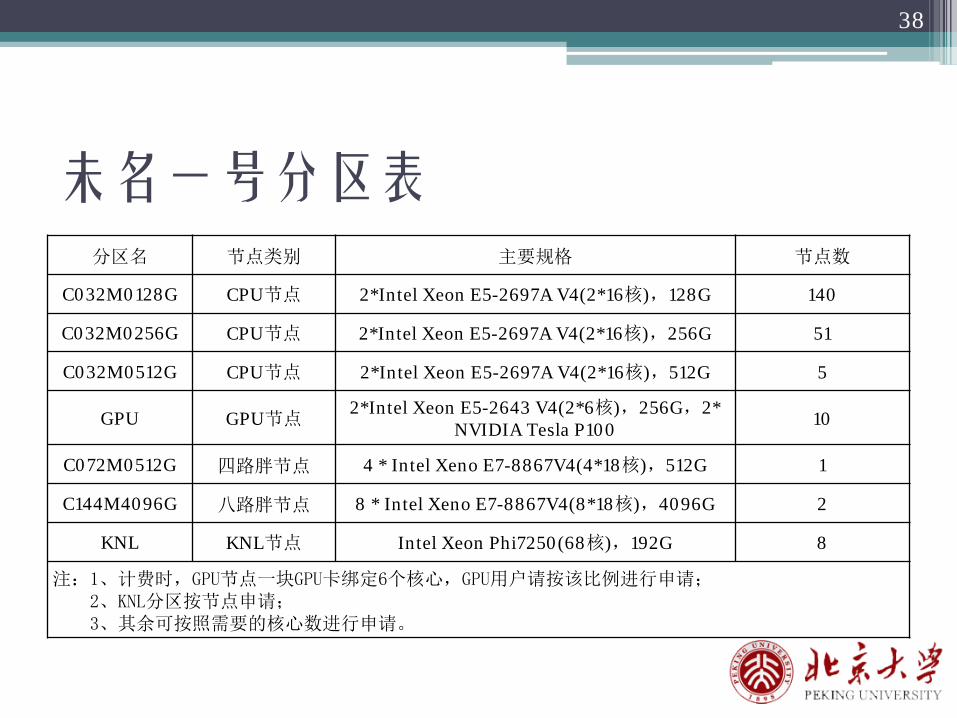
未名一号分区表
38
分区名 节点类别 主要规格 节点数
C032M0128G CPU节点 2*Intel Xeon E5-2697A V4(2*16核),128G 140
C032M0256G CPU节点 2*Intel Xeon E5-2697A V4(2*16核),256G 51
C032M0512G CPU节点 2*Intel Xeon E5-2697A V4(2*16核),512G 5
GPU GPU节点2*Intel Xeon E5-2643 V4(2*6核),256G,2*
NVIDIA Tesla P100 10
C072M0512G 四路胖节点 4 * Intel Xeno E7-8867V4(4*18核),512G 1
C144M4096G 八路胖节点 8 * Intel Xeno E7-8867V4(8*18核),4096G 2
KNL KNL节点 Intel Xeon Phi7250(68核),192G 8
注:1、计费时,GPU节点一块GPU卡绑定6个核心,GPU用户请按该比例进行申请;2、KNL分区按节点申请;3、其余可按照需要的核心数进行申请。
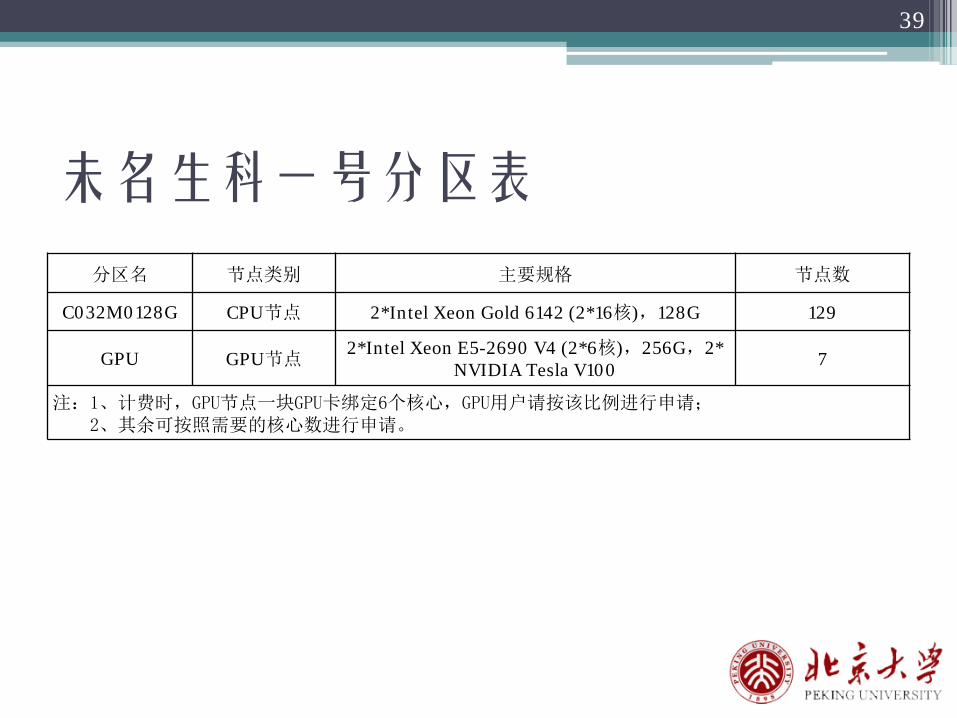
未名生科一号分区表
39
分区名 节点类别 主要规格 节点数
C032M0128G CPU节点 2*Intel Xeon Gold 6142 (2*16核),128G 129
GPU GPU节点2*Intel Xeon E5-2690 V4 (2*6核),256G,2*
NVIDIA Tesla V100 7
注:1、计费时,GPU节点一块GPU卡绑定6个核心,GPU用户请按该比例进行申请;2、其余可按照需要的核心数进行申请。

未名教学一号分区表
40
分区名 节点类别 主要规格 节点数
compute CPU节点 2*虚拟核心(核心主频为2.60GHz),24G 50

qosqos为服务质量,提交作业的时候需指定qos(不指定的
话会使用缺省的qos)。不同的qos有不同的属性,如作业优先级,可使用的核心数等。不同qos收费不用。
目前未名一号以及未名生科一号普通用户设有的qos为low、normal和high,未名教学一号为normal。以下命令可以查看不同qos的对应属性。
41
$ sacctmgr show ass user=`whoami` format=user,part,qos
$ sacctmgr show qos format=Name,Priority,MaxWall,MaxJobsPU,MaxTRESPerAccount

5.2 sbatchsbatch用于提交作业脚本。用法为先按指定方式编写作
业脚本,编写完作业脚本后按下列指令提交。
42
$ sbatch [作业脚本名]

sbatch 参数--help-A <account>--get-user-env--gres=<list>-J, --job-name=<jobname>--mail-type=<type>
--mail-user=<user>-N, --nodes=<number>-n, --ntasks=<number>-c, --cpus-per-task=<ncpus>--ntasks-per-node=<ntasks>
-o, --output=<filename pattern>-p, --partition=<partition_names>-q, --qos=<qos>-t, --time=<time>
# 显示sbatch命令的使用帮助信息;# 指定计费账户;# 获取用户的环境变量;# 使用gpu这类资源,如申请两块gpu则--gres=gpu:2# 指定该作业的作业名;# 指定状态发生时,发送邮件通知,有效状态为(NONE, BEGIN, END, FAIL, REQUEUE, ALL);# 发送给对应邮箱;# 申请的节点数# 申请的任务数# 每个任务所需要的核心数,默认为1;# 每个节点的任务数,--ntasks参数的优先级高于该参数,如果使用--ntasks这个参数,那么将会变为每个节点最多运行的任务数;# 输出文件,作业脚本中的输出将会输出到该文件;# 将作业提交到对应分区;# 指定QOS;# 设置限定时间;
43

以下是一个sbatch脚本例子,执行sbatch job.sh提交即可将该作业提交到作业调度系统中(假设脚本名为job.sh)
44
#!/bin/bash#SBATCH -o job.%j.out#SBATCH --partition=C032M0128G#SBATCH --qos=low#SBATCH -A hpcxxxxxx#SBATCH -J myFirstJob#SBATCH --get-user-env#SBATCH --nodes=2#SBATCH --ntasks-per-node=4#SBATCH --mail-type=end#SBATCH [email protected]#SBATCH --time=120:00:00
srun hostname -s | sort -n >slurm.hostsmodule load intel/2017.1mpiicc -o hellompi.o hellompi.cmpirun -n 8 -machinefileslurm.hosts ./hellompi.orm -rf slurm.hosts
# 输出,运行脚本指令的输出将输出到该文件# 指定作业分区# 指定qos# 指定account# 作业名# 获取当前用户环境# 申请节点数# 每个节点申请多少个核心# 指定作业结束后发送邮件# 发送到指定邮箱# 指定作业运行时间

方法二:申请64个核心,核心分配在哪些节点上由调度系统调度
45
以下是申请资源数量相关的参数# -N 申请的节点数,缺省为1# -n 申请的核心数,缺省为1# --ntasks-per-node 每个节点需要执行的任务数,缺省为1# -c 每个任务数需要的核心,缺省为1
#SBATCH -N 2#SBATCH --ntasks-per-node=32#SBATCH -c 1
#SBATCH -n 64#SBATCH -c 1
例:我的作业需要64个核心需要怎么申请?
方法一:申请两个节点,每个节点32个核心

提交作业后常见错误
46

error: Job submit/allocate failed: Invalid account or account/partition combination specified
错误原因:没有指定正确的
账户,可通过以下指令获取可用账户。
47
$ sacctmgr show ass user=`whoami` format=account%15 |uniq
#!/bin/bash#SBATCH -o job.%j.out#SBATCH --partition=C032M0128G#SBATCH --qos=low#SBATCH -A hpcxxxxxx#SBATCH -J myFirstJob#SBATCH --get-user-env#SBATCH --nodes=2#SBATCH --ntasks-per-node=32#SBATCH --mail-type=end#SBATCH [email protected]#SBATCH --time=120:00:00

error: Job submit/allocate failed: Invalid partition name specified
错误原因:未指定正确的partition,可通过以下指令获取可用的分区。
48
#!/bin/bash#SBATCH -o job.%j.out#SBATCH --partition=error#SBATCH --qos=low#SBATCH -A hpcxxxxxx#SBATCH -J myFirstJob#SBATCH --get-user-env#SBATCH --nodes=2#SBATCH --ntasks-per-node=32#SBATCH --mail-type=end#SBATCH [email protected]#SBATCH --time=120:00:00
$ sacctmgr show ass user=`whoami` format=part |uniq

(QOSMaxWallDurationPerJobLimit)
错误原因:指定-t, --time=<time>参数时,时间超过qos允许的时长,通过以下命令可以查看目前每个qos允许运行的最大时长。
注:当前未名一号和生科一号最大时长限制为5天,教学一号时长限制为2天,可能会根据使用情况修改。
49
#!/bin/bash#SBATCH -o job.%j.out#SBATCH --partition=C032M0128G#SBATCH --qos=low#SBATCH -A hpcxxxxxx#SBATCH -J myFirstJob#SBATCH --get-user-env#SBATCH --nodes=2#SBATCH --ntasks-per-node=4#SBATCH --mail-type=end#SBATCH [email protected]#SBATCH --time=130:00:00
$ sacctmgr show qos format=name,MaxWall

batch job submission failed: Requested node configuration is not available
错误原因:申请资源的节点
配置不匹配,如右侧所示,C032M0128G的每个节点只有32个核心,并且该分区上节点没有GPU卡。
50
#!/bin/bash#SBATCH -o job.%j.out#SBATCH --partition=C032M0128G#SBATCH --qos=low#SBATCH -A hpcxxxxxx#SBATCH -J myFirstJob#SBATCH --get-user-env#SBATCH --nodes=2#SBATCH --gres=gpu:1#SBATCH --ntasks-per-node=33#SBATCH --mail-type=end#SBATCH [email protected]#SBATCH --time=120:00:00

(QOSNotAllowed)
没有指定正确的qos,以下命令可以查看不同分区下可用的qos。
51
#!/bin/bash#SBATCH -o job.%j.out#SBATCH --partition=C032M0128G#SBATCH --qos=error#SBATCH -A hpcxxxxxx#SBATCH -J myFirstJob#SBATCH --get-user-env#SBATCH --nodes=2#SBATCH --ntasks-per-node=32#SBATCH --mail-type=end#SBATCH [email protected]#SBATCH --time=120:00:00
sacctmgr show ass user=`whoami` format=user,part,qos

(AccountNotAllowed)
出现该错误的原因通常为账户没有余额
52

关于内存
以C032M0128G节点为例,单个节点有32个核心以及128G内存,每个核心配4G内存,如果想要使用更大内存,只能申请更多核心或者在更大内存的节点上运行程序。
53

5.3 squeuesqueue用于查看作业调度系统中的作业。
54

squeue 参数
55
--help-A <account_list>-i <seconds>-j <job_id_list>-n <name_list>-t <state_list>-u <user_list>-w <hostlist>
# 显示squeue命令的使用帮助信息;# 显示指定账户下所有用户的作业,如果是多个账户的话用逗号隔开;# 每隔相应的秒数,对输出的作业信息进行刷新# 显示指定作业号的作业信息,如果是多个作业号的话用逗号隔开;# 显示指定节点上的作业信息,如果指定多个节点的话用逗号隔开;# 显示指定状态的作业信息,如果指定多个状态的话用逗号隔开;# 显示指定用户的作业信息,如果是多个用户的话用逗号隔开;# 显示指定节点上运行的作业,如果是多个节点的话用逗号隔开;

按指定格式输出squeue信息,默认输出的信息格式为“JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)”
56
-o <output_format> 显示指定的输出信息,指定的方式为%[[.]size]type,size表示输出项的显示长度,type为需要显示的信息。可以指定显示的常见信息如下;%a 账户信息%C 核心数%D 节点数%i 作业ID%j 作业名%l 作业时限%P 分区%q 优先级%R 状态PD作业显示原因,状态R的作业显示节点%T 状态%u 用户%M 已运行时间例:squeue -o “%.18i %.9P %.12j %.12u %.12T %.12M %.16l %.6D %R”

例
57
$ squeue
$ squeue -u `whoami`
$ alias sq='squeue -o "%.18i %.9P %.12j %.12u %.12T %.12M %.16l %.6D %R" -u `whoami` '
# 查看系统中所有作业的信息
# 查看自己账号下的作业
# 将左侧命令输入到~/.bashrc文件中,下次登录集群输入sq即可显示自己账号下提交的作业及指定的信息

5.4 scancelscancel 用于取消作业调度系统中的队列。
58

scancel 参数
59
--help-A <account>-n <job_name>-p <partition_name>-q <qos>-t <job_state_name>-u <user_name>
#显示scancel命令的使用帮助信息;# 取消指定账户的作业,如果没有指定job_id,将取消所有;# 取消指定作业名的作业;# 取消指定分区的作业;# 取消指定qos的作业;# 取消指定作态的作业,"PENDING", "RUNNING" 或 "SUSPENDED";# 取消指定用户下的作业;

例
60
$ scancel 123456
$ scancel -u `whoami`
$ scancel -t PENDING -u `whoami`
# 取消作业号为123456的作业
# 取消自己账号下所有队列中的作业
# 取消自己账号下所有状态为PENDING的作业

5.5 sinfosinfo用于查看分区和节点状态信息。
61

sinfo 参数--help-d-i <seconds>-n <name_list>-N-p <partition>-r-R
# 显示sinfo命令的使用帮助信息;# 查看集群中没有响应的节点;# 每隔相应的秒数,对输出的分区节点信息进行刷新# 显示指定节点的信息,如果指定多个节点的话用逗号隔开;# 按每个节点一行的格式来显示信息;# 显示指定分区的信息,如果指定多个分区的话用逗号隔开;# 只显示响应的节点;# 显示节点不正常工作的原因;
62

按指定格式输出sinfo信息,默认输出的信息格式为“PARTITION AVAIL TIMELIMIT NODES STATE NODELIST”
63
-o <output_format> 显示指定的输出信息,指定的方式为%[[.]size]type,“.”表示右对齐,不加的话表示左对齐;size表示输出项的显示长度;type为需要显示的信息。可以指定显示的常见信息如下;%a 是否可用状态%A 以"allocated/idle"的格式来显示节点数,不要和"%t" or "%T"一起使用%c 节点的核心数%C “allocated/idle/other/total”格式显示核心总数%D 节点总数%E 节点不可用的原因%m 每个节点的内存大小(单位为M)%N 节点名%O CPU负载%P 分区名,作业默认分区带“*”%r 只有root可以提交作业(yes/no)%R 分区名%t 节点状态(紧凑形式)%T 节点的状态(扩展形式)例:sinfo -o "%.15P %.5a %.10l %.6D %.6t %N"

例
64
$ sinfo
$ sinfo -p C032M0128G,C032M0256G
# 查看集群分区节点信息
# 查看C032M0128G,C032M0256G的状态信息

5.6 salloc占用资源,用于调试或者运行交互式的作业,不推荐使
用,使用的话,请确保运行完作业后退出资源,否则系统将继续计费。
65

salloc 参数--help-A <account>--get-user-env--gres=<list>-J, --job-name=<jobname>--mail-type=<type>
--mail-user=<user>-N, --nodes=<number>-n, --ntasks=<number>-c, --cpus-per-task=<ncpus>--ntasks-per-node=<ntasks>
-o, --output=<filename pattern>-p, --partition=<partition_names>-q, --qos=<qos>-t, --time=<time>
# 显示sbatch命令的使用帮助信息;# 指定计费账户;# 获取用户的环境变量;# 使用gpu这类资源,如申请两块gpu则--gres=gpu:2# 指定该作业的作业名;# 指定状态发生时,发送邮件通知,有效状态为(NONE, BEGIN, END, FAIL, REQUEUE, ALL);# 发送给对应邮箱;# 申请的节点数# 申请的任务数# 每个任务所需要的核心数,默认为1;# 每个节点的任务数,--ntasks参数的优先级高于该参数,如果使用--ntasks这个参数,那么将会变为每个节点最多运行的任务数;# 输出文件,作业脚本中的输出将会输出到该文件;# 将作业提交到对应分区;# 指定QOS;# 设置限定时间;
66

例在GPU分区申请一个节点,6个CPU核、1块GPU显卡
,使用的QOS为low,并指定最大占用时间为1天。
67
$ salloc -p GPU -N1 -n6 --gres=gpu:1 -q low -t 24:00:00salloc: Granted job allocation 1078858salloc: Waiting for resource configurationsalloc: Nodes gpu05 are ready for job
$ ssh gpu05 # 登录到gpu05使用对应资源$ exit #运行结束后退出gpu05$ exit #退出作业$ squeue -j 1078858 #确保作业已经退出# 如果显示该作业还在运行运行以下命令释放资源$ scancel 1078858

6 编译安装软件

一般情况下,普通用户可以使用源码安装软件到自己的home目录下,在安装时只需要指定安装路径即可。
以下编译两个软件,一个为gcc,另一个为netcdf-c。
69

编译安装gcc 7.2.0$ wget http://mirrors-usa.go-parts.com/gcc/releases/gcc-7.2.0/gcc-7.2.0.tar.gz $ tar xf gcc-7.2.0.tar.gz$ cd gcc-7.2.0$ ./contrib/download_prerequisites$ ./configure --help$ ./configure --prefix=${HOME}/gcc/7.2.0 --disable-multilib$ make$ make install
70

编译安装netcdf-c 4.6.3# 安装netcdf时需要安装zlib、hdf5,以下是编译过程# 编译zlib$ wget https://phoenixnap.dl.sourceforge.net/project/libpng/zlib/1.2.11/zlib-1.2.11.tar.gz$ tar xf zlib-1.2.11.tar.gz$ cd zlib-1.2.11$ ./configure --prefix=${HOME}/netcdf$ make && make install# 编译hdf5$ wget https://support.hdfgroup.org/ftp/HDF5/releases/hdf5-1.8/hdf5-1.8.19/src/hdf5-1.8.19.tar.gz$ tar xf hdf5-1.8.19.tar.gz$ cd hdf5-1.8.19$ ./configure --prefix=${HOME}/netcdf --with-zlib=${HOME}/netcdf$ make && make install# 编译netcdf-c 4.6.3$ wget ftp://ftp.unidata.ucar.edu/pub/netcdf/netcdf-c-4.6.3.tar.gz$ tar xf netcdf-c-4.6.3.tar.gz$ cd netcdf-c-4.6.3$ CPPFLAGS="-I${HOME}/netcdf/include"$ LDFLAGS="-L${HOME}/netcdf/lib" # 这两句表示编译时先从指定的文件夹下找.h文件和链接库$ ./configure --prefix=${HOME}/netcdf$ make && make install
71

七 python环境使用

平台使用anaconda来对python环境进行管理,使用anaconda可以在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。
73

7.1 anaconda基本命令conda info -esource activate env_namesource deactivate env_nameconda create --name env_name [python=<ver>]conda remove -n env_name --allconda install [-n env_name] pkg_nameconda list [-n env_name]conda search pkg_nameconda update pkg_nameconda remove pkg_name
# 查看当前所有的python环境;# 进入指定python环境;# 退出指定python环境;# 创建python环境,可指python版本;# 删除指定python环境;# 给对应的环境安装包;# 查看已安装的包;# 查找指定的安装包;# 更新现有的安装包;# 卸载指定的安装包包;
74

7.2 使用现有的python环境
75
$ conda info -e $ conda activate tensorflow-1.8.0$ cat << EOF > helloworld.pyimport tensorflow as tfhello = tf.constant('Hello, TensorFlow!')sess = tf.Session()print(sess.run(hello))EOF$ python helloworld.py
# 查看现有的python环境;# 使用其中名为tensorflow-1.8.0的python环境;# 测试用的python代码
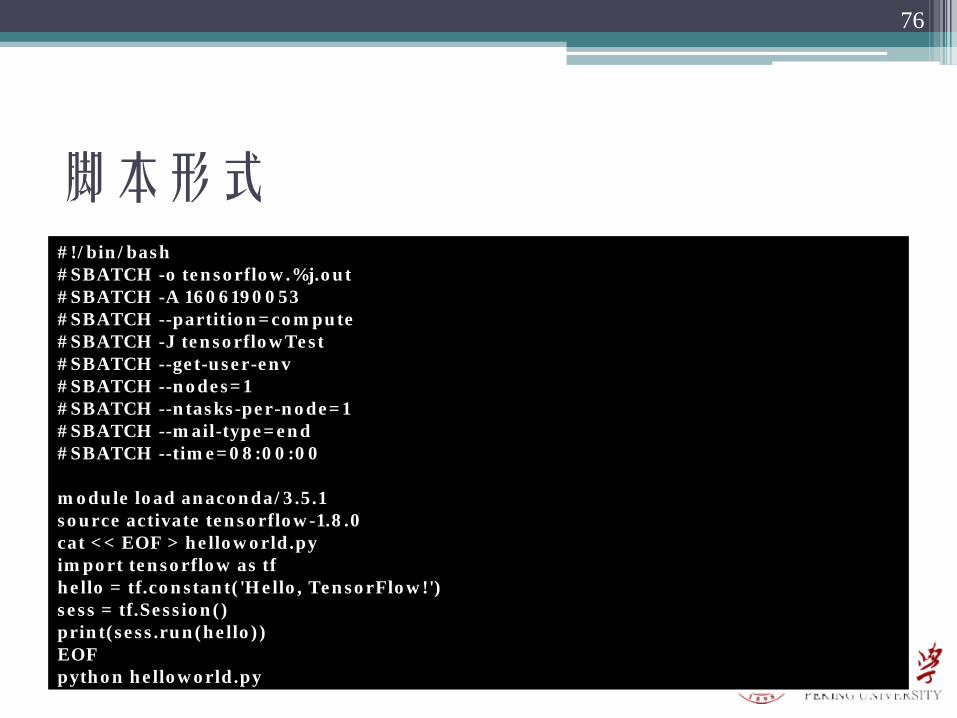
脚本形式#!/bin/bash #SBATCH -o tensorflow.%j.out#SBATCH -A 1606190053 #SBATCH --partition=compute #SBATCH -J tensorflowTest#SBATCH --get-user-env #SBATCH --nodes=1#SBATCH --ntasks-per-node=1#SBATCH --mail-type=end #SBATCH --time=08:00:00
module load anaconda/3.5.1source activate tensorflow-1.8.0cat << EOF > helloworld.pyimport tensorflow as tfhello = tf.constant('Hello, TensorFlow!')sess = tf.Session()print(sess.run(hello))EOFpython helloworld.py
76

7.3 搭建自己的python环境
77
$ conda create --name test python=3.7.3 $ conda install -n test numpy$ source activate test$ conda search tensorflow$ conda install tensorflow=1.13.1 $ python helloworld.py
# 创建名为test的环境,使用python 3.7.3# 给test环境安装numpy# 进入test环境# 查找可用的tensorflow# 安装1.13.1版本的tensorflow# 测试





























