Embed Size (px)
Citation preview

Tavoitteena tehokkaat eräajot
Ville Hurmalainen
OpinnäytetyöLiiketalouden ylempi ammattikorkea-koulututkintoTietojenkäsittelyn koulutusohjelma
2010

Tiivistelmä
11.5.2010
Tietojenkäsittelyn koulutusohjelma
TekijätVille Hurmalainen
RyhmäX
Opinnäytetyön nimiTavoitteena tehokkaat eräajot
Sivu- ja liitesivumäärä72 + 1
OhjaajatMartti Laiho
OP-Pohjolan vakuustusjärjestelmissä käytetään runsaasti eräajoja. Tässä opinnäytetyössä tutkitaan, miksi uusissa sovelluksissa juuri eräajot ovat yllättävän hitaita ja kalliita, haitaten tosiaikaisten ia ja verkkopohjaisten sovellusten käyttöä. Kuitenkin nykyään pystytään käsittelemän tietoja tarvittaessa miljoonia tavuja sekunnissa, jopa levyltä luettuna. Nykyaikaiset ”code once, run everywhere” ja muut yleiset periaatteet, jossa laitteiston monimutkaisuus peitetään helppokäyttöisillä rajapinnoilla, saattavat olla eräajojen ja jopa koko sovelluksen kustannusten kannalta hyvinkin haitallisia. Laitteistojen tekniset ominaisuudet asettavat tiettyjä rajoituksia. Nämä rajoitukset pitää huomioida ohjelmiston suunnittelutyössä aivan alusta alkaen, jotta lopputulos olisi hyvä.
Opinnäytetyössä tehdyt empiiriset kokeet osoittavat, että tietojen peräkkäiskäsittely on huomattavasti tehokkaampaa kuin hajakäsittely. Tälle perustalle tässä työssä on suunniteltu kaksi periaatetta, käsittely fyysisessä järjestyksessä eli klusteri -järjestyksessä (COP) ja suunnittelumalli IPO, jossa ohjelmisto jaetaan kolmeen osioon: luku-, käsittely- ja kirjoitusvaiheeseen (IPO).
Tulokset osoittavat, että näillä periaatteilla rakennettu ohjelmisto on paitsi käyttökustannuksiltaan, niin myös rakentamis- ja ylläpitomielessä järkevämpi ratkaisu, kuin tosiaikakoodin keinotekoinen käyttäminen eräohjelmassa.
AsiasanatKustannustehokkuus, ohjelmistotekniikka, relaatiotietokannat, tiedostot, levymuistit, kiintolevyt

Abstract
Date 11 May 2010
The Degree Programme in Information Systems
AuthorsVille Hurmalainen
Group
The title of thesisFaster Batch Programs
Number of pages and ap-pendices72 + 1
Supervisors
Martti Laiho
The OP-Pohjola's Insurance branch utilizes a great many batch programs for various purposes. Currently used new programs are slow, expensive and by locking database resources they easily harms web usage. How-ever, there are ways to manipulate millions byte of data per second, even when the data is located to a hard disk. The purpose of this thesis was to design and develop faster and more economical batch programs. Various tests made for this thesis will show, that the sequential fetch is really desirable instead of commonly used random fetch technique. Two new techniques are now developed to facil-itate sequential reading: COP (Cluster Order Processing) and IPO (Input, Process and Output phases).
Results are very promising. When the new techinques are used, both runtime costs and used time are reduced. Even building and maintaining is more sensible using dedicated batch techniques instead of incorrect usage of the online modules.
Key wordsCost-effective Batch job, Programming technology, Relational Database, Sequential File, Hard Disk Drive, Mass Memory

1/99
SISÄLLYS
TIIVISTELMÄ……………………………………………………………ii
ABSTRACT……………………………………………………………….iii
SISÄLTÖ ………………………………………………………………….iv
1 Johdanto........................................................................................41.1 Tutkimuksen taustat........................................41.2 Tutkimusongelma, -kysymykset ja -tavoitteet. 51.3 Käytettävät tutkimusmenetelmät....................61.4 Rajaus..............................................................71.5 Viitekehys........................................................71.6 Raportin rakenne.............................................8
2 Metodologia..................................................................................93 Kirjallisuuskatsaus......................................................................11
3.1 Laitteistot......................................................113.1.1 Laitteistojen kehityshistoria.........................11
3.1.2 Muistilaitteet................................................12
3.1.3 Käyttöjärjestelmät........................................14
3.1.4 Yhteistoiminta verkon ylitse.........................15
3.2 Suunnittelu ja toteutus..................................173.2.1 Ohjelmoinnin ajatusmallit.............................17
3.2.2 Ohjelmien algoritmien ajan ja tilankäyttö....19
3.3 Tiedonhallinta................................................203.3.1 Tiedostojärjestelmät.....................................20
3.3.2 Tietokannat...................................................21
3.4 Tietojärjestelmän käyttö, huolto ja viritys.....253.4.1 Monitorointi..................................................25
3.4.2 Säännölliset huoltotoimet eli ”Three R's”.....26

2/99
3.4.3 Commit välit..................................................26
3.4.4 Lukitukset.....................................................27
3.4.5 CPU kustannusten arviointi..........................29
3.4.6 Valmisohjelman virittäminen........................29
4 Eräajot käytännössä...................................................................314.1 Tehottomat eräajot........................................314.2 Kalliit tosiaikatapahtumat.............................314.3 Tehokkaat eräajot..........................................324.4 Taulujen lomittaminen toisiinsa....................334.5 Esimerkki tehokkaasta peräkkäiskäsittelystä364.6 Ohjelmistojen kustannukset..........................36
4.6.1 Hankintakustannukset..................................36
4.6.2 Ylläpitokustannukset....................................37
4.6.3 Käyttökustannukset......................................37
4.6.4 Tehokkaan erä ohjelman rakennus ja käyttökus-tannukset 38
4.7 AULI eli autoturvakannan eräkäsittely.........394.7.1 Testiperiaatteet............................................39
4.7.2 Oletusratkaisu...............................................39
4.7.3 Tietokantaperusteinen ratkaisu....................40
4.7.4 Ratkaisujen vertailua....................................41
4.8 Tiedon välittäminen tosiaikasovelluksista eräajoille43
5 Mallin kehittäminen....................................................................455.1 Tietojen käsittely fyysisessä järjestyksessä...455.2 Suunnittelumalli IPO.....................................455.3 Nopea taulu ilman indeksejä.........................465.4 Lukitusratkaisut tehokkaissa eräajoissa.......475.5 Tietokannan ryvästyksen suunnittelu eräajoille sopivaksi 48
5.6. Parannettu IPO tekniikka.............................56

3/99
6 Ratkaisun toimivuuden todentaminen........................................586.1 Suorituskyky..................................................58
6.1.1 Tuotantotestit Autoturvasovelluksessa.........58
6.1.2 Tuotantotestit LARE sovelluksessa...............59
6.2 Toimintavarmuus...........................................596.2.1 Autoturvan toimintavarmuus........................60
6.2.2 LARE järjestelmän toimintavarmuus............60
6.3 Rakentamisen ja testaamisen kustannukset. 606.3.1 Autoturvajärjestelmän rakennus ja testauskustan-nukset 60
6.3.2 LARE järjestelmien viritys- ja testauskustannukset61
7 Yhteenveto ja johtopäätökset.....................................................62
Sanasto..................................................................................... .....64Lähdeluettelo..................................................................................... ..................................................................................................69

4/99
1 Johdanto
1.1 Tutkimuksen taustat Sovelluksien kehittämisessä on ollut selvä trendi. Monimutkaisuus lisääntyy, tietojen ajantasaisuus koetaan aina vain tarpeellisemmaksi, sovellusten kehittäminen on muuttunut kalliimmaksi ja samalla laiteiden suorituskyky paranee ja suhteellinen hinta halpenee. Kaiken tämän lisäksi liiketoiminnassa haluttaisiin vielä saada ITC -kustannukset kuriin, koska kyseessä on kuitenkin varsinaisen liiketoiminnan aputoiminto.
Tutkija on työskennellyt viimeiset kymmenen vuotta keskellä tätä murrosta. Ihmetystä on herättänyt, miten on mahdollista, että kaikkein vanhin, tärkein ja tehokkain tapa tietojenkäsittelyyn on laiminlyöty tai jopa jätetty suorastaan tuuliajoille. Kyse on eräajoista. Eräajot olivat ensimmäinen tapa käsitellä tietoja silloin kun muistivälineinä olivat reikäkortit ja magneettinauhat. Eräajojen rinnalle on tullut osituskäyttöä, transaktioiden hallintajärjestelmiä ja useita muita tapoja, joilla mahdollistetaan keskusteleminen käyttäjän kanssa.
Kuitenkin tarve käyttää eräajoja on edelleen olemassa. Tämä riippuu hyvin paljon siitä, mistä liiketoiminnasta on kyse. Tässä esimerkkinä on vakuutusliiketoiminta, jossa eräajojen tarve on huomattavan suuri:
Haluat ottaa autovakuutuksen. Marssit vakuutusyhtiön tiskille ja myyjä aloittaa perustietojesi syöttämisen järjestelmään. Seuraavaksi käsitellään sinun autosi eli vakuutettava kohde ja sen jälkeen myyjä kyselee mitä kaikkia mahdollisia valinnaisia osia eli turvia haluat mukaan vakuutussopimukseesi. Kaikki tämä vie aikaa alle kymmenen minuuttia. Virkailija käytti tosiaikaista järjestelmää, joten sinulla on nyt lähtiessäsi konttorista mukana vakuutuskirja, vakuutuksesi on kirjattu yhtiön järjestelmiin ja autovakuutuksesi elinkaari alkaa.
Seuraavat viisi vuotta kuluvat rauhallisesti. Vakuutusyhtiö muistaa sinua säännöllisesti uusitulla vakuutuskirjalla ja laskulla,

5/99
jonka maksettuasi kaikki jatkuu jokseenkin ennallaan. Vakuutuskirjan uusiminen on kuitenkin tehtävä, jossa otetaan huomioon paljon erilaisia asioita. Esimerkiksi: koska sinulle ei ole tullut vahinkoja, vakuutusyhtiö haluaa palkita sinunlaisesi varovaiset ajajat bonuksilla. Samalla sinun autosi ikääntyy. Tämäkin otetaan huomioon, sillä vanhan auton korvaussumma ei ole sama kuin uuden. Kaikki nämä tehtävät suoritetaan vuosittain, jopa useamminkin, jos olet valinnut maksutavaksesi useampia maksueriä. Tätä rutiinia ei kuitenkaan käsittele yksikään virkailija, vaan koko prosessi hoidetaan säännöllisesti ajettavilla eräajoilla. Vasta kun vaihdat autoa, myyt sen tai olet joutunut onnettomuuteen, vakuutuksesi otetaan tosiaikaiseen käsittelyyn. Ajallisesti ja IT -kustannusten kannalta suurin osa vakuutuksen elinkaaresta pyörii siis eräajojen avulla.
Nykyaikaisissa sovelluksissa nimenomaan laitteistot pyritään abstrahoimaan, jotta sovellukset olisivat mahdollisimman hyvin siirrettävissä ja jotta sovellusta voidaan tarjota useammallekin asiakkaalle valmispakettina. Tyypillisesti uutta ohjelmistotekniikkaa sisältävissä ratkaisuissa halutaan käyttää mahdollisimman paljon uudelleenkäytettäviä rutiineita, jotta sovelluksen rakentaminen olisi mahdollisimman kustannustehokasta. Käytännössä varsin usein tällaiset modulaariset tai oliopohjaiset sovellukset ovat eräkäytössä resurssisyöppöjä. Vaikuttaa siltä, että jostain syystä suunnittelussa suurin ja tärkein osa tietojenkäsittelystä jätetään hyvin vähälle huomiolle.
1.2 Tutkimusongelma, -kysymykset ja -tavoitteet Useat Pohjolan vakuutussovelluksista ovat rakennettu uudenaikaisia periaatteita noudattaen, mutta silti suorituskyky ei ole täysin tyydyttävä. Suorituskyvyn puute ilmenee erityisesti verrailuissa muihin liiketoiminta-alueisiin, jotka käyttävät samaa laitealustaa. Ongelma ei rajoitu yksinomaan Pohjolan järjestelmiin, sillä on tiedossa, että muissakin vakuutusyhtiöissä vakuutussovellukset ovat osoittautuneet haasteellisiksi. Työn kohteiksi on valittu kaksi

6/99
OPK/vakuutusjärjestelmien ohjelmistoa: LARE eli laskutus- ja reskontra ja AULI eli auto- ja liikennevakuutusjärjestelmä.
Ylläpitoa suorittavien henkilöiden tiedossa on ollut, että LARE eli laskutuksen tietokannan fyysinen järjestys ei ole eräkäsittelyn kannalta optimaalisessa järjestyksessä. Käytännön tavoitteena on, että olemassa olevaa ohjelmistoa muokataan mahdollisimman vähän, mutta tietokannan puolella pyrittäisiin hyödyntämään COP -periaatetta (Cluster Order Processing) eli tiedon käsittelemistä tiedon fyysisessä järjestyksessä. Tämä vaatii tietokannan uudelleensuunnittelua ja muutostöitä. Kustannus- ja resurssisyistä kuitenkin on haluttu rajata itse ohjelmistoon tehtävät muutokset pois käytettävien keinojen valikoimasta.
Toisena kohteena on jo tätä kirjoitettaessa valmiina oleva AULI, eli autoturva-järjestelmä. Autoturvassa voitiin toteuttaa kokonaan tyhjästä rakennetut erärutiinit, jolloin fyysisesti oikea järjestys voidaan hyödyntää täysin. Vertailemalla näitä kahta järjestelmää, LAREa ja AULIa, saadaan näkemys, kuinka suuri ero on järjestelmillä, joista ensimmäisessä järjestys on oikea, mutta ohjelmistot hyödyntävät täysin valmiita tosiaikamoduuleita. Toisessa puolestaan sekä kannan fyysinen järjestys että ohjelmistot hyödyntävät tietokantojen peräkkäiskäsittelyä mahdollisimman tehokkaasti.
Oikean fyysisen järjestyksen tuomaa tehokkuutta tukevat seuraavat havainnot:
1) Ohjelmassa käsiteltävän materiaalin määrä ei ole kohtuuton
2) IBM:n ohjelmoimat apuohjelmat pystyvät käsittelemään samankokoisen tietomäärän jopa kymmenen kertaa nopeammin ja halvemmalla.
Kyse ei ole siis laitteiston asettamasta ehdottomasta rajasta, koska sama määrä tietoa voidaan käsitellä paljon nopeammin tietyin edellytyksin.
Tavoitteen on selvittää, kuinka eräajojen suorituskyky tulee huomioida nykyaikaisissa sovelluksissa. Samalla on hyödyllistä tutkia, mitkä ovat

7/99
eräajojen tuottamisen periaatteet ja mitkä ovat realistiset reunaehdot hyvälle tehokkuudelle. Teoriaosuuteen liittyvä kysymys on tässä:
K1. Mitkä ovat eräajojen keskeiset periaatteet, ominaisuudet ja perusteet, onko näihin perusteisiin tullut ohjelmistojen ja laitteistojen kehittyessä muutoksia, pitäisikö tällaiset muutokset huomioida ja miten se tehdään?
Tavoitteena on saada aikaiseksi tapa, jolla olemassa olevaan ohjelmistoon saadaan lisää nopeutta niin, että lopputyö on taloudellisestikin työnantajalle kannattava. Käyttökelpoisilla periaatteilla on enemmänkin käyttöä, paitsi talon sisäisiä projekteja työstettäessä, niin myös ostettaessa valmispaketteja, jolloin voidaan arvioida, ovatko kyseiset paketit suunniteltu kestävälle pohjalle.
K2. Miten Osuuspankkikeskuksen ympäristössä rakennetaan tai ylläpidetään sovellusta, jossa kriittiset eräajo periaatteet ovat toteutetut ja miten tämä työ tulee organisoida?
Ensiksi selvitetään Osuuspankkikeskuksen vastuulla olevien vakuutusjärjestelmien eräajojen koko laajuus. Tämän jälkeen tutkimme valittuja ohjelmistoja ja samalla tutkimme, minkälaiset prosessit niissä on. Perusteiden selvittämisen jälkeen ryhdyn toteuttamaan ohjelmistoa hyödyntäen teoriaosuudessa havaittuja perusteita ja vaatimuksia.
1.3 Käytettävät tutkimusmenetelmätTutkimus koostuu kirjallisuuskatsauksesta ja empiriasta. Kirjallisuuskatsaus liittyy kysymykseen K1 ja empiria kysymykseen K2. Empiriassa hyödynnetään myös kirjallisuudesta löytyneitä tuloksia. Tutkimusprosessin aikana tutkija on ollut työsuhteessa tutkimuksen kohteena olevassa yrityksessä.
Tutkimusotteena tässä työssä käytetään konstruktiivista otetta. Työssä pyritään ratkaisemaan eräajojen ongelmat ja osoittamaan ratkaisun toimivuus.

8/99
1.4 RajausTässä yhteydessä tarkastellaan kaupallishallinnollisia sovelluksia ja niiden eräajoilla tarkoitetaan sellaisia kausittain ajettavia rutiineita, joissa käsitellään huomattavan suuri tietomäärä kerrallaan. Esimerkiksi vakuutusliiketoiminnan laskutusajo on tällainen rutiini, jossa voidaan joutua käsittelemään tuhannesta satoihin tuhansiin yksittäistä laskua.
Opinnäytetyön kaikki testiajot rajataan z/OS käyttöjärjestelmän piiriin. Teoriaosassa käsitellään myös muita käyttöjärjestelmiä, mutta ratkaisumallin toimivuudessa pääpaino on tilaaja-organisaation keskuskoneympäristössä. Samalla tavalla tutkittava tietokantaohjelmisto rajataan tilaaja-organisaation keskuskoneympäristössä käytettävään DB2 for z/OS V8 järjestelmään. Teoriaosassa käsitellään muita tietokantajärjestelmiä ja niiden käyttämiä tekniikoita, mutta niihin ei syvennytä tarkemmin.
1.5 Viitekehys
Kuva 1. Konstruktiivinen tutkimus (Kasanen et. al., 1991) Tässä tutkimuksessa tutkitaan miten voidaan rakentaa nopeita ja kustannustehokkaita eräohjelmia. Viitekehyksen tutkimusongelmalle luo laitteistotekniikka ja ennen kaikkea sen huomioiminen tai huomiotta jättäminen suunniteltaessa ohjelmistoja. Kaupallishallinnollisissa sovelluksissa on olennaista, että liiketoiminnan

9/99
kannalta kriittiset lähdetiedot ovat tallennettu pysyvään muistiin. Pysyvällä muistilla tarkoitetaan käytännössä levylaitteita, vaikka vähemmän käytettyjä tiedostoja, kuten arkistoja, talletetaan edelleen magneettinauhakaseteille. Sitä vastoin prosessorien rekisterit, cache muistit ja keskusmuistit ovat muutamia harvoja poikkeuksia lukuun ottamatta ei-pysyvää muistia. Kaikkien näiden muistien nopeus, hinta ja kapasiteetti ovat erilaisia.
Levylaitteet ovat kahdessakymmenessä vuodessa kehittyneet rajusti. Mutta kaikki ominaisuudet eivät ole kehittyneet samassa suhteessa. Levylaitteiden muistikapasiteetti on kasvanut 50.000 kertaa suuremmaksi. Tiedon siirtonopeus on parantunut 1300 kertaa nopeammaksi. Mutta tiedon hakuaika on parantunut ainoastaan seitsemänkertaisesti. Syynä tähän on ollut se, että hakuaika on riippuvainen fyysisistä, liikkuvista osista. Edestakaisin liikkuvan levyn hakuvarren nopeutumista rajoittaa mekaniikka ja fysiikka. Raju kapasiteetin paraneminen on saavutettu tiivistämällä tietoa, hieman samalla tavalla kuin elektroniikassa tapahtunut muukin kehitys on saavutettu. (Tannenbaum, 2008, 361)
Yksi suuri periaatteellinen näkökulma sovellusten rakentamiseen on ollut se, että ohjelmoinnissa pyritään lähestymään varsinaista liiketoimintalogiikkaa ja samalla peitetään monimutkaiset laitteistot erilaisilla rajapinnoilla ja abstraktiolla (Tapanainen, 2007). Tehokkaiden eräohjelmien suunnitteluun tämä periaate aiheuttaa suuria ongelmia, kun esimerkiksi olio-ohjelmoinnissa olion pysyvyyden hallinta pyritään piilottamaan. Silloin kun haettava tietoalkio tai olio on keskusmuistissa, siihen viittaaminen on 1.000.000 kertaa nopeampaa verrattuna hakemiseen levyltä. Kuitenkin lähes aina tällainen olion luominen tai muu viittaus pysyvään tietovarastoon on hyvin syvällä ohjelmalogiikan uumenissa. Ohjelmissa, joissa pyritään suurimpaan mahdolliseen tehokkuuteen, ei saa jättää tehokkuuden kannalta tärkeimpiä ominaisuuksia, eli tässä tapauksessa levykäsittelyä, makaamaan abstraktiotasojen alle. Rakentamisvaiheessa levykäsittelyn hitautta on vaikea havaita, sillä jos moduulien, komponenttien tai olioiden tehomittauksia tehdään vain satunnaisesti käytettävän

10/99
tosiaikasovelluksen kannalta, ei tämä hitaus tule esille, sillä vasteajalla ole kovin suurta eroa, olipa se 10 millisekuntia tai 10 nanosekuntia.(Pekkala, 2004)
1.6 Raportin rakenne
Tutkimus rakentuu johdannosta, lyhyestä kuvauksesta käytetystä metodologiasta, kirjallisuuskatsauksesta ja käytännön osiosta (luvut 1-4). Luvussa viisi käydään lävitse ratkaisumallia ja seuraavassa luvussa arvioidaan onko malli onnistunut ja täyttääkö se asetetut vaatimukset. Kohdassa seitsemän käydään lävitse johtopäätökset ja muodostetaan yhteenveto. Lisäksi tutkimukseen on lisätty sanasto, jossa selvitetään muissa luvuissa käsiteltyjä termejä tarkemmin. Viimeisenä on lähdeluettelo, joka on selvyyden vuoksi jaettu normaaliin kirjallisuuteen ja internetistä löytyneisiin artikkeleihin tai muihin dokumentteihin.

11/99
2 MetodologiaTässä opinnäytetyössä käytetään konstruktiivista tutkimusotetta, koska konstruktiivinen tutkimus soveltuu hyvin case-tutkimukseen ja suppean tutkimuskohdemäärän analysointiin.
Tilaajaorganisaatiossa on kiinnitetty huomiota eräajoihin ja erityisesti siihen, miten niiden pitkä ajoaika haittaa ympärivuorokautista verkkokäyttöä. Myös kustannukset vaikuttavat liian suurilta, vaikka eräajojen pitäisi olla tehokkaita suurten tietomäärien käsittelyssä. Tämän käytännöllisen ongelman ratkaisemiseksi konstruktiivinen tutkimus soveltuu erinomaisesti. Käytännön ongelma voidaan kiteyttää selkeästi eräohjelmien nopeus- ja kustannusongelmiin. Empiriaa voidaan valottaa tutkimalla ajettujen ajojen tilastoja ja käyttäytymistä, sekä perehdytty alan teorioihin. (Kasanen et. al., 1991, 314-318)
Konstruktiivisen tutkimuksen mukaan vaihejako on Kasasen mukaan on seuraava:
1. Relevantin tutkimuksellisesti mielenkiintoisen ongelman etsiminen
2. Ensiymmärryksen hankinta tutkimusotteeseen
3. Innovaatiovaihe, ratkaisumallin konstruoiminen
4. Ratkaisun toimivuuden testaus eli konstruktion oikeellisuuden osoittaminen
5. Ratkaisussa käytettyjen teoriakytkentöjen näyttäminen ja ratkaisu
6. Ratkaisun soveltamisalueen laajuuden tarkastelu
Kytkentä teoriaan eli kirjallisuuskatsaus tuo mielenkiintoisen haasteen. Ohjelmistotekniikassa eräohjelmat ovat olleet hyvin ”epämuodikas” aihealue, josta syystä suurin osa eräajoja koskevista kirjoista ovat todella vanhoja. Ohjelmistotekniikassa on selvästi painopiste tosiaikasovellusten rakentamisessa, olio-ohjelmoinnissa ja erilaisten web-tekniikoiden käyttöönotossa.

12/99
Laitetekniikan alueelta löytyy kirjallisuudesta hyvin paljon tietoa teknologioista, joita voisi käyttää sovellusten tehostamiseen, mutta eräajojen kannalta kokonaiskuva jää puuttumaan. Oikeastaan hyvin erikoista on, että laitteistoteknologia tarjoaa yhä parempia keinoja tietojenkäsittelyyn, mutta ohjelmistoteknologia tekee kaikkensa, jotta laitteistoja tarvitsisi huomioida lainkaan. Näyttäisi että kyseessä on ”code once, run everywhere” -filosofian ja laiteteknologian välinen ristiriita.
Innovaatiovaiheessa, eli osiossa jossa konstruoidaan ongelman ratkaisu, on tässä työssä kehitetty kaksi periaatetta: "Tietojen käsittely fyysisessä järjestyksessä" eli COP periaate sekä IPO periaatteeseen. IPO periaate on moduuleiden jakaminen laitteistoläheisiin lukumoduuleihin, varsinaisen logiikan sisältäviin prosessointimoduuleihin ja jälleen laitteistoja hyödyntäviin kirjoitusmoduuleihin.
Konstruktion arviointi voi sisältää kvantitatiivista ja kvalitatiivista materiaalia. Tässä tapauksessa nimenomaan numeeriset arviot ratkaisevat konstruktion toimivuuden, eli kyseessä on ns. pragmaattinen totuuskäsitys: "se mikä toimii, on totta".
Luvussa kuusi arvioidaan, onko tilaajaorganisaatio saanut olennaiseen ongelmaansa tieteellisen analyysin ja siihen käyttökelpoisen ratkaisun. Lisäksi arvioidaan, onko lopputulos merkityksellinen, yksinkertainen ja helppokäyttöinen.

13/99
3 Kirjallisuuskatsaus
Kirjallisuuskatsaus asettaa mielenkiintoisia haasteita. Tehokkuusnäkö-kulmasta ei eräajoja ole juurikaan käsitelty tai sitten teokset ovat vanhoja, peräisin ajalta jolloin ei muuta käsittelytapaa käytetty. Valtaosa tuoreesta ohjelmointia käsittelevästä kirjallisuudesta keskittyy interaktiivisiin sovelluksiin, kuten perinteisiin tosiaikasovelluksiin tai web-käyttöisiin Java-ohjelmointikielellä toteutettuihin sovelluksiin.
Toinen näkökulma eli laitteiston kapasiteetti ja ominaisuudet ovat puolestaan kirjallisuudessa hyvin esillä, mutta näissä teoksissa jää sittenkin epäselväksi, miten laitteita voitaisiin käyttää niiden kannalta optimaalisesti.
Kolmas kirjallinen näkökulma eli tietokantaohjelmistojen ominaisuudet, löytyy hyvin kirjallisuudesta. Teokset sisältävät teho-asioita hyvinkin monipuolisesti, mutta silti eräajoja ja niiden ongelmia käsitellään hieman sivulauseissa ja pääpaino näyttäisi olevan tosiaikasovelluksissa.
Tietojärjestelmän tehokkuutta käsitellään tässä kolmesta eri näkökulmasta. Ensimmäisenä käsitellään laitteistojen kehittyminen sekä myös käyttöjärjestelmät, jotka ohjelmistoina ovat kuitenkin hyvin laiteläheisiä. Toisena on ohjelmistojen suunnitellun ja toteutuksen näkökulma. Erilaiset ohjelmointiparadigmat ja algoritmit vaikuttavat lopputuloksena syntyvään tietojärjestelmään paljon. Tässä luvussa käsitellään myös tiedonhallintaa eli tiedostoja ja tietokantoja. Vaikka tiedostot ovat hyvin vanha periaate ja sellaisenaan hyvin laiteläheinen lähestymistapa, tiedostojen käyttäminen tai käyttämättömyys vaikuttaa ohjelmistoihin suuresti.
3.1 Laitteistot3.1.1 Laitteistojen kehityshistoria Eräajojen ja laiteiden historiaa ei voida erottaa toisistaan. Alkuaikana jokainen ohjelma oli eräajo ja kaikkia tietojenkäsittelylaitteita käytettiin eräajoissa.
Reikäkortit sisälsivät 80 merkkiä, eli suunnilleen sen verran tietoa, mitä pystyyn asemoidun A4 arkin riville mahtuu tietoa.

14/99
Reikäkorttilaitteiden nopeus oli vaatimaton ja käytännössä ajettavissa ohjelmissa pyrittiin ottamaan käyttöön nopeampia massamuistilaitteita mahdollisimman ripeässä tahdissa. Eräs tällainen laitekonfiguraatio oli IBM:n 1401 kortinlukija ja magneettinauha laitteisto, yhdistettynä IBM 7094 tietokoneeseen, joka lukee ja kirjoittaa magneettinauhaa. Viimeisenä ketjussa oli IBM 1401 laite, jossa oli nauha-asema lukemista varten ja rivikirjoitin, jolla tulokset saatetaan luettavaan muotoon. (Tannenbaum, 2008, s. 8-9)
Magneettinauhat mahdollistivat selvästi reikäkortteja ja -nauhoja tehokkaamman tietojenkäsittelyn, mutta niissäkin oli omat ongelmansa. Niiden operointi vaati koulutettua operointihenkilöstöä, usein jopa kolmessa vuorossa.
Levylaitteet olivat alussa erittäin kalliita, mutta hinta on laskenut todella rajusti. Mielenkiintoista kuitenkin, että levylaitteet olivat jo historian alkuvaiheessa suhteellisen nopeita ja kehitys on ilmentynyt lähinnä laitteiden koon pienenemisenä sekä talletuskapasiteetin kasvamisena.
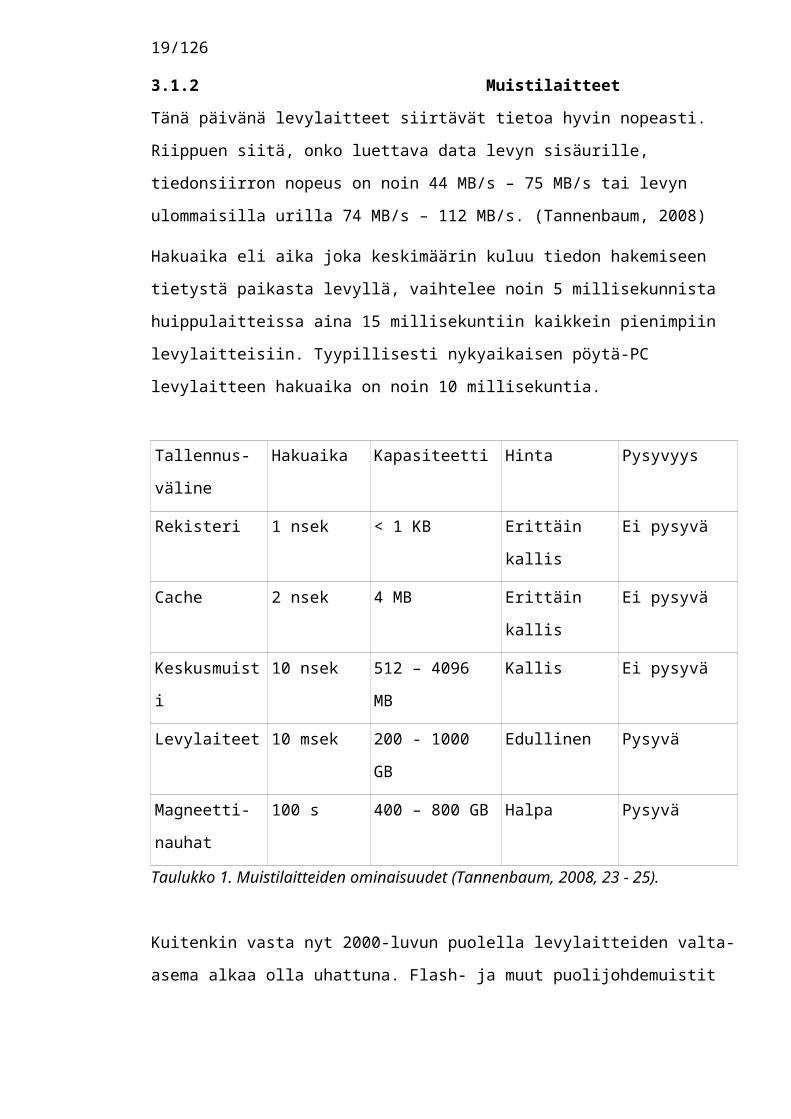
3.1.2 MuistilaitteetTänä päivänä levylaitteet siirtävät tietoa hyvin nopeasti. Riippuen siitä, onko luettava data levyn sisäurille, tiedonsiirron nopeus on noin 44 MB/s – 75 MB/s tai levyn ulommaisilla urilla 74 MB/s – 112 MB/s. (Tannenbaum, 2008)
Hakuaika eli aika joka keskimäärin kuluu tiedon hakemiseen tietystä paikasta levyllä, vaihtelee noin 5 millisekunnista huippulaitteissa aina 15 millisekuntiin kaikkein pienimpiin levylaitteisiin. Tyypillisesti nykyaikaisen pöytä-PC levylaitteen hakuaika on noin 10 millisekuntia.
Tallennus- väline
Hakuaika Kapasiteetti Hinta Pysyvyys
Rekisteri 1 nsek < 1 KB Erittäin kallis
Ei pysyvä
Cache 2 nsek 4 MB Erittäin Ei pysyvä

15/99
kallis
Keskusmuisti 10 nsek 512 – 4096 MB Kallis Ei pysyvä
Levylaiteet 10 msek 200 - 1000 GB Edullinen Pysyvä
Magneetti- nauhat
100 s 400 – 800 GB Halpa Pysyvä
Taulukko 1. Muistilaitteiden ominaisuudet (Tannenbaum, 2008, 23 - 25). Kuitenkin vasta nyt 2000-luvun puolella levylaitteiden valta-asema alkaa olla uhattuna. Flash- ja muut puolijohdemuistit alkavat olla nopeita ja luotettavia, eikä hinta ole enää samalla tavalla esteenä.
Flash muistin merkittävänä etuna on hajakäsittelyn nopeus. Hajakäsittelyä tapahtuu tyypillisesti tosiaikaisissa tietokantasovelluksissa ja ”code once, run everywhere” periaatteen takia myös erittäin paljon nykyaikaisissa eräajoissa. Oheisissa kaavioissa esitetään, miten erään SSD (eli Solid State Disk) laitteiston hajalukuoperaatiota pystytään tekemään noin 7 kertaa enemmän saman ajan kuluessa, jos puskurointia ja cache-muistia ei pystytä käyttämään.(Bruni et. al., 2007) Toisaalta kirjoitusoperaatioita pystytään tekemään SSD laitteilla vähemmän, laitetyypistä riippuen jopa vain 1/3 levylaitteiden operaatiosta. Tällä hetkellä kaikkein raskaimmat tosiaikatapahtumat kärsivät juuri hitaista kirjoitustoiminnoista. Tästä on kirjoitettu tarkemmin empiriaosuudessa.

16/99
Kuva 2. Kuvassa esitetään SSD laitteiden hajalukemisen teho verrattuna levylaitteisiin. Kuvasta käy ilmi, miten lukeminen hajajärjestyksessä (oikealla) on paljon tehokkaampaa SSD laitteilla verrattuna kovalevyihin. Vasemmalla kuvataan, miten kirjoittaminen hajajärjestyksessä on edelleen tehokkaampaa perinteisillä kovalevyillä.
Peräkkäiskäsittelyn kannalta SSD-laitteet eivät tuo mitään etua, sillä perinteiset kovalevyt ovat erittäin tehokkaita siirtämään tietovirtaa. Tehokkuuden saavuttamiseksi I/O operaatioiden vähentäminen on olennaista, sillä keskusmuisti on kuitenkin paljon nopeampaa. ”Electrons move faster than disk heads”(Clevinger, 2005).
Keskusmuisti Uudet 64 bittiset käyttöjärjestelmät mahdollistaisivat teoriassa jopa 16 eksatavun keskusmuistin. Käytännössä keskusmuistit ovat huomattavasti pienempiä. Tiedon hakeminen keskusmuistista on erittäin nopeata. Tietoa haetaan muistista tarkalla osoitteella ja kaikki muistiosoitteet ovat samanarvoisessa asemassa, jolloin, toisin kuin levylaitteilla, hakujärjestyksellä ei ole mitään merkitystä. Peräkkäisten muistialueiden lukeminen on kuitenkin siinä mielessä tehokasta, sillä muistiosoittimen kasvattaminen yhdellä on yksinkertaisin kuviteltavissa oleva osoitteen hakurutiini. Periaatteena voitaisiin sanoa, että tehokkaissa eräajoissa muistia tulee käyttää niin paljon kuin on järkevästi mahdollista.
SivuttaminenJärkevät muistin käytön rajat on mahdollista ylittää. Nykyaikaisissa käyttöjärjestelmissä on määriteltyä eli virtuaalista muistia enemmän kuin fyysistä muistia. Syynä on se, että nykyaikaisissa järjestelmissä voi olla hyvinkin paljon käynnissä olevia prosesseja, jotka ovat kuitenkin suhteellisen passiivisia. Sivuttamalla (swapping) eli kirjoittamalla levymuistiin, epäaktiivisten prosessien varaaman muistin, saadaan järjestelmiin paljon enemmän kapasiteettia, eikä muistin loppuminen ole samanlainen katastrofi kuin alkuaikojen PC-DOS käyttöjärjestelmässä. (Ramamurthy, 2009)
Trashing

17/99
Ohjelman käyttäessä paljon keskusmuistia sen muistialueet (eli sivut) joutuvat melko todennäköisesti sivuutetuksi. Tällöin suorituskyky kärsii ja ohjelma hidastuu huomattavasti. Ääritapauksissa on mahdollista, että runsaasti muistia käyttävä ohjelma suorastaan pysähtyy. Tätä ilmiötä, ruuhkautumista, kutsutaan englanninkielellä "trashing". Ruuhkautumisessa voi pahimmillaan käydä niin, että koko CPU-kapasiteetti käytetään lataamaan sivuja muistiin ja kirjoittamaan sivuja pois muistista. (Arpaci-Dusseau & Arpaci-Dusseau & Gunawi, 2009)
Ruuhkautumista estetään ajosuunnittelulla. Raskaimpia prosesseja ei kannata ajaa muutenkin kiireisinä ajankohtina. Jos kuitenkin käy niin, että ohjelma alkaa sivuttaa jopa hiljaisena aikana, tulee ohjelman käyttämää muistinvarausta pienentää uudelleensuunnittelulla ja -ohjelmoinnilla. On tuhlausta lukea dataa levyltä liian suuria määriä muistiin, jos käyttöjärjestelmä kuitenkin heti kohta sivuuttaa sen takaisin levylle.
3.1.3 Käyttöjärjestelmät Tässä kohdassa on tarkoitus tutkia hieman eri käyttöjärjestelmien eroja, miten ne suhtautuvat eräajoihin.
z/OS – tässä ympäristössä eräajo on kokonaisuus (JOB) jossa useita peräkkäisiä prosesseja eli steppejä. Näitä steppejä kontrolloidaan JCL ohjauskielellä. Tosiaikatapahtumat ovat yksittäisiä prosesseja, kuten TSO käyttö tai sitten tosiaikatapahtumia varten pyöritetään erillistä tapahtumamonitoria, kuten IMS tai CICS.

18/99
Kuva 3. z/OS käyttöjärjestelmän muistiavaruus (Pruni et.al.). Kuvasta käy ilmi, miten z/OS pystyy hyödyntämään muistiavaruutta aina 16 Exabyteen asti, mutta osa käyttöjärjestelmän palveluista ja vanhemman sukupolven ohjelmistot voivat olla rajoittuneita, pystyen osoittamaan vain 24-bitin tai 31 bitin muistiosoitteisiin.
UNIX – kaikki ohjelmat ovat prosesseja, jotka ovat järjestetty prosessipuun avulla yhdeksi hierarkkiseksi kokonaisuudeksi. Eräajot eli daemon-prosessit poikkeavat interaktiivisista prosesseista siinä, että niille ei ole varattu päätelaitetta.
Windows – kaikki ohjelmat ovat tapahtumia. Tapahtumat voivat olla linkitettyinä toisiinsa, mutta mitään hierarkkista kokonaisuutta ei ole. Eräajot ajetaan merkkipohjaisen Command Prompt -ikkunan alaisuudessa.
3.1.4 Yhteistoiminta verkon ylitse Heti tietokoneiden alkuaikoina yhdistettiin useampia erikoistuneita laitteita kaapeloinneilla toisiinsa, mutta näissä tapauksissa ei ollut kyse mistään tietoliikenneverkosta. Seuraavaksi tietokoneita liitettiin

19/99
toisiinsa hyödyntäen puhelinverkkoa modeemilaitteiden avulla. Mutta kun tänä päivänä puhutaan verkosta, tarkoitetaan lähes aina Internettiä, joka kehittyi 1960 luvulla rakennetun ARPAnet tietoverkon pohjalle.
Yhteistoiminta verkon ylitse on ollut eräajojen näkökulmasta hyvin alkeellista. Etäpäätteeltä on voitu antaa komentoja, jotka puolestaan käynnistävät halutun ajosarjan. Tietoja on ajosarjojen jälkeen siirretty tarvittaessa TCP/IP protokollaa käyttäen toisiin organisaatioihin, joissa puolestaan on mahdollisesti oma ajosarja saadun tiedoston tarkistamiseksi ja jatkokäsittelyä varten.
Nyt uusimmat hajautetut ympäristöt, jotka tunnetaan myös nimellä Cloud Computing, tai SaaS (Software-as-a-Service) ovat luoneet ehkä merkittävimmän arkkitehtuurin, jossa eräajoja ja niiden tehokkuutta näytetään kehitettävän. Tavoitteena on mahdollistaa suuren luokan tietojenkäsittelyä käyttäen pienten ja keskisuurien laiteympäristöjen suhteellista edullisuutta hyväkseen. Google hakukoneen palvelut ovat ehkä tunnetuin tällainen hajautettuja palveluita käyttävä sovellus.
Hajautetun "pilven" käyttö houkuttelee suuresti palveluiden tarjoajia helppoudellaan ja potentiaalisia käyttäjiä puolestaan lupauksena saada käyttöön entistä helpommin halpojen servereiden yhdistetyn kapasiteetin. (Farber, 2009). Kuitenkin pilven käytössä on edessä monia ongelmia. Yksi suurimmista on verkkoliikenteen siirtoviive (eli latency).
Siirtoviive tarkoittaa vakiomittaista aikaa, joka kuluu ennen kuin ensimmäistäkään bittiä dataa on vastaanotettu. Tämä aika on tätä kirjoitettaessa luokkaa 10-100 ms (Immonen et. al., 2006), mutta riippuu vahvasti käytetystä laitteisto- ja ohjelmistotekniikasta. Siirtoviiveen olemassaolo tarkoittaa kuitenkin sitä, että kovin monimutkaisten tosiaikaisten palveluiden rakentaminen on erittäin haastavaa. Myös eräprosesseissa siirtoviiveen olemassaolo on huomioitava, käytännössä niin, että ensisijaisesti tulee rajoittaa siirrettävien tiedostojen määrää ja vasta toisella sijalla on siirrettävän datan määrään minimointi. (White, 2009, s.43)

20/99
Google on kehittänyt menetelmän, nimeltään Map-Reduce, jossa tietolähteistä muodostetaan yksi tai useampi peräkkäistiedosto (Map -vaihe), lajitellaan ja lomitetaan toisten lajiteltujen tietolähteiden kanssa (Reduce -vaihe). Jaettuna useammalle, jopa tuhansille palvelimille, pystytään läpimenoaikaa lyhentämään merkittävästi (White, 2009, 1-13). Googlelle on myönnetty ohjelmistopatentti tälle MapReduce periaatteelle, mikä on eurooppalaisesta näkökulmasta katsottuna omituista - onhan vastaavia tietojenkäsittelyperiaatteita hyödynnetty jo 1960 luvulta alkaen. (The Register, 22.2.2010) (United States Patent 7.650.331, Dean et al., 2010)
Huomattavaa on, että MapReduce periaatteella ei hyödynnetä mitään tietokantojen erikoisominaisuuksia, lukuun ottamatta datan purkamista SQL-kielellä tai fyysisemmillä UNLOAD apuohjelmilla, vaan käsittely tehdään perinteisillä peräkkäistiedostoilla. Peräkkäistiedostojen käsittely on nopeata, kuten tässäkin tutkimuksessa on osoitettu. MapReduce ei ota kantaa tulosjoukon päivittämiseen lähdetietokantoihin, mutta hajautuksen ja perinteisien peräkkäistiedostojen käyttäminen ei mahdollista minkään tietokannanhallintajärjestelmän ylläpitämän palvelun käyttöä, lukuun ottamatta aikaleimapohjaista optimistista lukitusta.
MapReduce ratkaisun yksinkertaisuutta on kritisoitu, esimerkiksi Ron Brachman, Yahoon laboratorioiden ja tutkimusyksiköiden varajohtaja arvioi, että MapReducen täysin toisistaan riippumattomat prosessit eivät välttämättä pysty palvelemaan monimutkaisempia verkkosovelluksia. (The Register, 16.2.2010)
MapReduce ratkaisu on jo nyt vapaasti käytettävissä, sillä Cloudera niminen yritys on kehittänyt avoimen lähdekoodin sovelluksen nimeltä Hadoop World. Ohjelmistolla on mahdollista hallita suuria eräajoja Hadoop klustereissa, seurata klusterin tilaa ja selata ajokokonaisuudesta saatua tulosta. (White, 2009, s.7-11)
3.2 Suunnittelu ja toteutusOhjelmointi on periaatteessa yksinkertaista, kyse on ohjeiden kirjoittamista tietokoneelle. Kuitenkin ensimmäiset koneet
21/99
”ymmärsivät” vain hyvin koneläheisiä käskyjä, jolloin ohjelmointi oli vaikeaa ja inhimilliset ongelmat olivat vaikeasti toteutettavissa sen ajan vaatimattomille koneresursseille.
3.2.1 Ohjelmoinnin ajatusmallitNykyään koneet ovat kehittyneet, mutta samanaikaisesti monimutkaistuneet. Sama pätee myös ohjelmointiin. Ohjelmoinnin ”maailma” voidaan jakaa karkeimmalla tasolla eri ohjelmointiparadigmoihin, eli ohjelmoinnin ajatusmalleihin. Tärkeimmät ohjelmointiparadigmat ovat seuraavat:
1. Imperatiivinen paradigma
2. Funktionaalinen paradigma
3. Looginen paradigma
4. Olio-orientoitunut paradigma
Imperatiivisesta paradigmasta voidaan yksinkertaistetusti sanoa, että kyseisessä mallissa ohjelma on sarja käskyjä: ”Ensin tee näin ja seuraavaksi tee näin”. Reaalimaailmassa tyypillisiä esimerkkejä tästä ajattelusta on reseptit tai autojen huolto-ohjeet. Tämä ajattelumalli vastaa täysin Von Neumannin teorioita. Jotta ohjelmien rakenne olisi hallittavissa, imperatiiviseen ohjelmointiin on kehitetty tekniikka, jossa valmiiksi rakennettuja rutiineita eli proseduureja käyttäen voidaan rakentaa suurempia kokonaisuuksia.
Funktionaalinen paradigma puolestaan on lähempänä matemaattista ajattelua. Se voidaan kiteyttää: ”Ratkaise yhtälö ja tulosta käytetään hyväksi jossakin”. Puhtaassa funktionaalisessa ohjelmoinnissa kaikki ohjelmat ovat funktioita. Tämä näkökulma on hyödyllinen arvioitaessa etukäteen algoritmeista koostuvan ohjelman tehokkuutta.
Looginen paradigma hylkää suoritusjärjestyksen kokonaan, koska siinä ohjelmisto on vain kokoelma loogisia sääntöjä ja faktoja. Ohjelma toimii periaatteella: ”Vastaus kysymykseen saadaan käymällä säännöt ja faktat lävitse”.
Olio-orientoitunut paradigma lähtee siitä, että ryhmittelemällä erilaisia ominaisuuksia luokiksi ja aliluokiksi, voidaan hallita entistä suurempia

22/99
ohjelmistokokonaisuuksia. Vaikka olio-ohjelmoinnin juuret ovat peräisin imperatiivisesta paradigmasta, olio-orientoituneen paradigman perusperiaate on: ”lähetä viestejä eri olioiden välillä ja muuta näin olioita tilasta toiseen, jäljitellen näin tosielämän ilmiöitä”. (Nørmark, 2008)
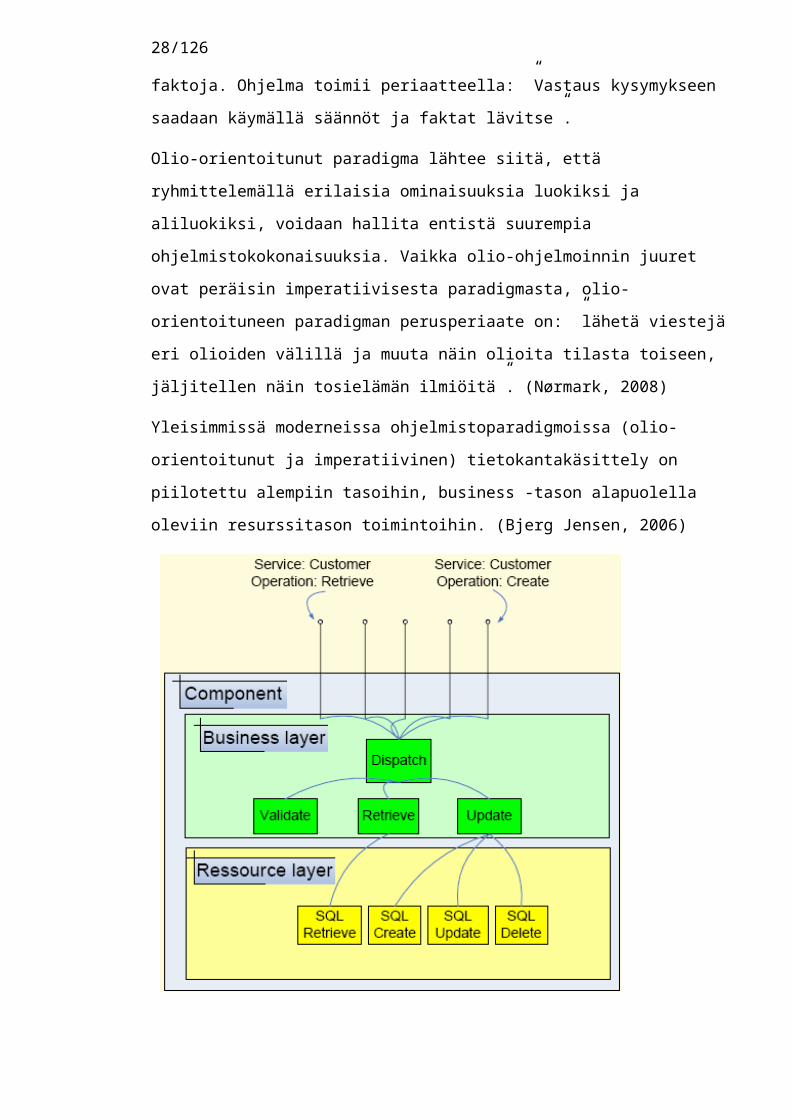
Yleisimmissä moderneissa ohjelmistoparadigmoissa (olio-orientoitunut ja imperatiivinen) tietokantakäsittely on piilotettu alempiin tasoihin, business -tason alapuolella oleviin resurssitason toimintoihin. (Bjerg Jensen, 2006)
Kuva 4. Miten tietokantakäsittely sijoittautuu olio-paradigman mukaisessa mallissa (Bjerg Jensen, 2006). Huomionarvoista tässä kuvassa on se, että resurssikerros on kokonaan alistettu liiketoimintakerrokselle. Tämä on esteenä resurssien kokonaisvaltaiselle optimoinnille.
Näin toteutettuna tietokantakäsittely palvelee liiketoimintatason olioita/moduuleita hyvin ja tosiaikasovelluksien suorituskyky on varsin tyydyttävä, niin samaa koodia käytettäessä eräohjelmistossa ohjelma

23/99
joutuu väkisinkin tekemään periaatteessa peräkkäiset I/O toiminnot hitaammalla mahdollisella tavalla eli hajakäsittelyllä.
3.2.2 Ohjelmien algoritmien ajan ja tilankäyttö Ohjelmissa ratkaistaan tosielämän ongelmia käyttämällä erilaisia algoritmeja. Algoritmit voidaan luokitella tehokkuuden ja ongelman ratkaisemiseen käytettävän aineiston suhteen seuraavasti
1. Vakioaikainen algoritmi, suoritusaika pysyy vakiona riippumatta lähtöaineistosta.
2. Logaritminen algoritmi, jossa suoritusaika riippuu logaritmisesti aineiston määrästä.
3. Lineaarinen algoritmi, suoritusaika on suoraan riippuvainen aineiston määrästä.
4. Eksponentiaalinen algoritmi, jossa suoritusaika kasvaa eksponentiaalisesti aineiston määrän kasvaessa.
Tehokkaissa eräajoissa tavoitteena on saada mahdollisimman paljon hyödynnettyä logaritmisia algoritmeja. Tietokannoissa esimerkiksi juuri indeksikäsittely perustuu siihen, että tietomassan kasvaessa hakuaika EI kasva samassa suhteessa. Vakioaikaiset ja logaritmiset algoritmit ovat erittäin suositeltavia, sillä niissä voidaan aineiston määrää kasvattaa ilman, että suoritusaika kärsisi merkittävästi. Valitettavasti kaikissa tapauksissa ei tehokkaita algoritmeja voida käyttää, vaan eräiden ongelmien ratkaisuun tarvitaan eksponentiaalisia algoritmeja. Eksponentiaalisen algoritmin ajankäyttö kasvaa räjähdysmäisesti.(Saarelainen, 2009)
Oheinen taulukko osoittaa miten suuren tietomäärän käsittely keskusmuistissa on riippuvainen algoritmin aikavaativuudesta. Taulukossa ensimmäisessä sarakkeessa O(n) on yksinkertainen laskutoimitus, joita pystytään suorittamaan 10 miljoonaa kertaa sekunnissa.
Aikaraja
O(n) O(n * log(n)) O(n
2) O(n
3) O(2
n) O(3
n)

24/99
sekunti 10 miljoonaa 500000 3000 200 23 15
minuutti
600 miljoonaa 25 miljoonaa
25000 850 29 18
tunti 35 miljardia miljardi 200000 3000 35 22
päivä 850 miljardia 25 miljardia
miljoona 10000 40 25
vuosi 300000 miljardia
7000 miljardia
20 miljoonaa
70000 48 30
Taulukko 2. Algoritmien suorituskyvyn vertailua.
Tyypillisessä kaupallishallinnollisissa sovelluksissa eräajossa suoritetaan useita yksittäisiä tapahtumia yhdessä ajossa. Yksittäisellä tapahtumalla ei ole mitään loogista kytkentää toiseen; käytännön esimerkkinä vaikkapa hinnoiteltavan vakuutuksen uudistettu maksu on täysin sama riippumatta siitä, millainen vakuutus seuraavaksi käsitellään. Tässä mielessä eräajon aikavaativuus on O(N) - eli kyseessä on lineaarinen algoritmi. Siis jos yhden vakuutussopimuksen käsittelyaika on x sekuntia, niin 100.000 sopimuksen käsittelyaika olisi 100.000 kertaa x sekuntia.
Silloinkin kun ongelman ratkaisua varten käytettävissä on lineaarinen algoritmi, voi silti olla mahdotonta hyödyntää valmista tosiaikakäsittelyyn rakennettua ohjelmaa. Esimerkiksi tosiaikakäytössä tyydyttävä 2 sekunnin vasteaika tarkoittaa 100.000 tapauksen eräkäsittelyssä 55½ tuntia eli reilusti yli 2 vuorokautta., mikä aiheuttaa suuria ongelmia. Käytännössä eräkäsittelyn ehdoton vaatimus on, että kaikki käsiteltävät tapaukset tulee käsitellä tietyssä aikaikkunassa, esimerkiksi yhden yön aikana. Koska eräajot eivät saa aiheuttaa yhteentörmäyksiä tosiaikakäytön kanssa, niin havaitaan oikeiden algoritmien käyttämisen merkitys:
logaritminen tai vakioaikainen algoritmi olisi selkeästi tavoiteltava vaihtoehto

25/99
eksponentiaaliset algoritmit eivät ole suositeltavia suurien tietomassojen käsittelyssä
3.3 Tiedonhallinta 3.3.1 TiedostojärjestelmätKaikki tietokonejärjestelmät tallentavat ja hakevat tietoja. Kun jokin prosessi on käynnissä, se voi tallentaa vain rajallisen määrän tietoa keskusmuistiin sen omaan osoitetilaansa. Käytettävän muistin määrää rajoittaa teoriassa järjestelmän virtuaalinen muistiavaruus ja käytännössä myös fyysinen muistin määrä. Joillekin sovelluksille riittää keskusmuisti hyvin, eivätkä ne välttämättä tarvitse ulkopuolista muistivarastoa, mutta toisille järjestelmille muistin tarve on valtava. Esimerkkeinä tästä ovat lentoyhtiöiden paikanvaraus, pankkijärjestelmät tai suurten yritysten kirjanpito.
Toinen ongelma keskusmuistin käytössä on, mitä tapahtuu tiedoille kun prosessi loppuu, mahdollisesti tahattomasti. Häviävätkö tällöin tiedot? Monissa sovelluksissa tietoja pitää säilyttää viikkoja, vuosia tai jopa ennalta määräämättömiä aikoja. Prosessin pysähtyminen ei saa missään nimessä hävittää tai turmella näitä tietoja.
Kolmas ongelma on, että tallennettuihin tietoihin pitää päästä käsiksi useammalla samanaikaisesti käytössä olevalla prosessilla. Eli tietojen on oltava jaetusti ja laajasti käytettävissä, joten yksittäisen prosessin osoitetilaa ei voi käyttää.
Tietojen tallentamiseen on käytetty vuosien ajan magneettisia levyjä. Myös magneettinauhat ja optiset levyt ovat mahdollisia, mutta ovat hitaampia tai muuten epäkäytännöllisiä. Selkeästi voimakkaimmin kehittyvä massamuistilaite on puolijohdemuistilaitteet, eli SSD (Solid State Disk) laitteet. Nykyisin yleinen USB porttiin liitettävä muistitikku edustaa tätä teknologiaa.
Tiedostot ovat sinällään yksinkertaista ohjelmistotekniikkaa ja tehokkaiden eräajojen kannalta on tärkeää ymmärtää, että peräkkäistiedoston käsittely on varsin nopeaa. Tähän ei pidä kuitenkaan luottaa sokeasti, sillä levytilan varaaminen levylaitteilta on itse asiassa tavattoman monimutkaista. Käyttöjärjestelmä ei

26/99
välttämättä pysty takaamaan, että tiedoston tiedot olisivat kokonaan peräkkäisillä levysektoreilla, vaan on mahdollista että levylaitteilla tiedostojärjestelmä voi olla pahasti pirstoutunut. Tätä pirstoutumista ei käsitellä tarkemmin tässä työssä, vaan tehokkuuden kannalta riittää tieto siitä, että järjestelmän ylläpitäjien tulee varmistua siitä, että uudelleenorganisoinnit (eli defragmentoimiset) ovat säännöllisesti suoritettu. (Microsoft TechNet, 2009)
3.3.2 TietokannatMikä on tietokanta? Tietokanta on kokoelma tietoja, joilla on yhteys toisiinsa, eikä sen edes välttämättä tarvitse olla elektronisessa muodossa. Käytännössä on useimmiten kyse ohjelmistoista, joissa mallinnetaan tietty sovellusalue, esimerkiksi relaatiomallin avulla. Tietokantoja käyttävät ohjelmistot ovat korvanneet laajalti varhaisemmat, yksinomaan tiedostoja käyttävät sovellukset.
Miksi käytetään tietokantoja? Niistä kuitenkin aiheutuu haittoja, kuten monimutkaisuus, koko, ohjelmistokustannukset, laitekustannukset ja lisäksi niistä muodostuu helposti riskikeskittymä.
Syitä on useita. Perimmäisin syy on ollut, että vain käyttämällä tietokantoja saadaan tiedon toistuminen hallintaan. Myös tiedon laatu ja eheys on parempi sekä tiedon yhdisteleminen tuo itse asiassa lisää informaatiota. Koska tietokantatuotteissa on standardisoidut rajapinnat, useimmiten SQL-kieli, on tiedon käyttäminen helpompaa ja tietoturva on parempi kuin tiedostopohjaisilla ratkaisuilla. Keskittämällä saavutetaan kustannusetuja, varmistaminen on luotettavampaa ja tietojen samanaikainen käytettävyys paranee. Näistä syistä on selvä, että eräprosesseissa käytettään tietokantoja, vaikka peräkkäistiedostot olisivatkin suorituskyvyltään nopeampia.(Hovi & Huotari & Lahdenmäki, 2003)
Poikkeuksiakin löytyy, esimerkiksi Googlen teknisten julkaisujen joukossa on tekniikka, MapReduce, jossa erittäin massiivinen eräajo voidaan hajauttaa tuhansille palvelimille ilman että ratkaisussa käytettäisiin tietokantoja. (Dean & Ghemawat, 2009). MapReduce:n

27/99
perusideana on, että tiedot luetaan ensin tiedostoihin (Map-vaihe), lajitellaan, lomitetaan (Reduce), jonka jälkeen suoritetaan varsinainen liiketoiminnan vaatima prosessointi. MapReduce ei kuitenkaan poissulje tietokantojen käyttämistä ja tulemme huomaamaan, että AULI:a eli auto- ja liikenneturvaa varten kehitetty COP-ratkaisu muistuttaa sitä.
Indeksien käsittely
Tietokantojen hakemistot eli indeksit mahdollistavat yksittäisen tietorivin hakemisen kannasta ilman että koko taulutilaa (eli tiedostoa) tarvitsee lukea lävitse. Indeksien rooli on tehokkaan tietojenkäsittelyn kannalta olennainen.
Kuva 5. Indeksien B-puu rakenne. (Pollari-Malmi, 2002)
Indeksien rakenteessa käytetään tyypillisesti B-puu-indeksiä. B-puu mahdollistaa tiedon hakemisen hyvinkin suuresta tietomassasta nopeasti. Puun alimmat sivut, lehtisivut, ovat avaimen mukaisessa järjestyksessä ja niiltä on suora osoite tietokantasivuille. Ylempänä ovat välitason sivut ja ylimpänä on juurisivu. Teoriassa tarvitaan vain O(logk
N) levyhakua, missä N on indeksin rivien määrä ja k on indeksirivien määrä yhdellä tietokantasivulla. (Pollari-Malmi, 2002)
Tyypillisesti indekseissä tasojen määrä on kolme tai neljä tasoa. Jos ylimmät tasot pysyvät keskusmuistissa, tarvitaan siis tiedon hakemiseen noin kaksi levy I/O operaatiota (yksi indeksiin ja toinen varsinaiselle datariville). B-puu tarjoaa kaksi tehokasta hakutapaa, joko a) suorahaku, yhden tietyn rivin hakeminen avaintiedolla tai b) haku

28/99
järjestyksessä, jokin tietty arvoväli tai osa avaimesta. (Hovi & Huotari & Lahdenmäki, 2003)
Eräajojen kannalta indeksit ovat samanaikaisesti tärkeitä, mutta myös ongelmallisia. Jos eräajo päivittää suurinta osaa tietokannasta, on todennäköistä että indeksien B-puun ylläpito muodostaa suurimman kustannuserän. (White, 2009, 5-6)
Death by Random I/O
Indeksit mahdollistavat tietojen käsittelyn hajajärjestyksessä. Hajajärjestys on kuitenkin selvästi tehottomampaa kuin peräkkäiskäsittely. Tämä ilmiö, tietokantakonsultti Michael Hannan kertoi DB2 IDUG konferenssissa vuonna 2002, tunnetaan yleisesti nimeltä "Death by Random I/O". Hannan ei pystynyt selvittämään tarkkaan termin alkuperää, mutta epäilee, että tunnettu kehittäjä Joel Goldstein (Responsive Systems) voisi olla termin alkuperäinen käyttäjä. Ilmiönä tämä tarkoittaa kuitenkin tilannetta, jossa hyvin suuri tietomassa käydään lävitse yksinomaan hajalukua käyttäen. Hannan luonnehtii ominaisuutta kaikkein harmillisimmaksi viaksi nykyaikaisissa tietokonejärjestelmissä - ”Most troublesome fault of modern computer systems. ”(Hannan, 2002)
OO- ohjelmoinnin ongelmat relaatiokantojen kanssa
Rakennettaessa ohjelmistoja olio-ohjelmoinnilla, usein yritetään tulla toimeen vähillä resursseilla ja tarvittaessa turvautua alihankintaan. Tällöin projekti hajaantuu useampaan toimipisteeseen, jolloin kommunikointiongelmat heikentävät tehokkuutta. Tällaisissa valmis- tai räätälöintiprojekteissa ei oteta tehokkuusnäkökulmaa riittävän ajoissa huomioon.
Näistä teho-ongelmista on John Campbell (IBM) Oslossa 2006 pidetyssä konferenssissa kertonut, miten monimutkaiset framework -ratkaisut, kolmansien osapuolien kirjastojen laaja käyttö ja liian tiukka Java sovelluskehittäjän näkemys yhdessä aiheuttavat tilanteen, jossa ohjelmiston toiminnallisuus on tilaajaa tyydyttävä, mutta suorituskyky ei.

29/99
Campbellin mukaan tuloksena on usein sellainen tietokantaratkaisu, jossa jäljitellään lähinnä sellaista tyhmää tiedostojärjestelmää, jossa tietojen haku tapahtuu ainoastaan perusavainta käyttäen. Varsinkin oliotekniikoilla toteutettuja eräohjelmia hän kuvailee lähinnä ”luupissa” pyöriviksi tosiaikatapahtumiksi. (Campbell, 2006)
Useat tietokanta-asiantuntijat varoittavat erityisesti keinotekoisen eli surrogaattiavaimen käytöstä. Olio-ohjelmoinnissa tällainen ”object-id” on hyvin keskeinen periaate. Tehokkuuden kannalta tietojen tallentaminen täysin satunnaisen ja keinotekoisen avaimen mukaisessa ei ole suotavaa. Erityisesti eräajot kärsivät täysin hajanaisesta tietokannasta – hajaluku on juuri se piirre, jossa nykyaikaiset levylaitteistot ovat kaikkein heikoimmillaan. (Bonnie Baker, 2003)
Hannan varoittaa myös yksinkertaistetuista oliomalleista, joissa olion tunniste (object ID) on generoitu luomisjärjestyksessä. Jos jokaisessa taulussa avaimet ovat generoitu toisistaan riippumatta, niin prosessin kannalta tämä järjestys voi olla täysin käyttökelvoton, eikä avaimen avulla voida kunnolla liittämään suurta määrää rivejä eri tauluissa toisiinsa - tuloksena on tavaton määrä hajalukuja.
Hannan ehdottaa, että oikea käsittelyjärjestys saadaan lukemalla tiedot tavallisiin peräkkäistiedostoihin ja sen jälkeen lajittelemalla aineisto sellaiseen muotoon, että tiedonhaku DB2:sta tapahtuu käyttäen tehokasta peräkkäislukua. (Hannan, 2002). Tämä on ollut usein myös Oracleen pohjautuvissa järjestelmissä varsin toimivaksi havaittu tapa.
Yleismoduuliratkaisu saatetaan ratkaista niin, että voidaan päätyä niin sanottuun ”sudenkuoppaan”. Oheisessa esimerkissä on ollut tehtävänä rakentaa moduuliin sellainen toiminto, että nimitiedot voidaan hakea täsmälleen annetulla nimellä tai sitten nimen osalla:
SELECT nimi, sarake1, sarake2
FROM ISOTAULU
WHERE SARA = :H1
AND ( ( :TASMAHAKU = ’Y’ AND NIMI = :HAKUAVAIN1 )
OR ( :TASMAHAKU = ’N’ AND NIMI LIKE :HAKUAVAIN2 )
30/99
Taulukko 3a. Nimitiedon hakeminen täsmähakuna tai nimen osalla.
Ratkaisuna tämä on ohjelmoijan kannalta näppärän tuntuinen haku, joka näyttää toimivan nimen täsmähaulla tai nimen osalla haettaessa. Käytännössä suoritus hakee ensin näillä molemmilla ehdoilla.
NIMI = :HAKUAVAIN1
NIMI LIKE :HAKUAVAIN2
Taulukko 3b. Nimitiedon hakeminen täsmähakuna tai nimen osalla.
Vasta tämän jälkeen suoritetaan nämä toiseen vaiheen hakuehdot, joissa ei voi käyttää indeksiä apuna:
:TASMAHAKU = ’Y’
:TASMAHAKU = ’N’
Taulukko 3c. Nimitiedon hakeminen täsmähakuna tai nimen osalla.
Käytännössä DB2 hakee molemmilla tavoilla ja sitten juuri ennen tuloksen palauttamista eliminoi tulosjoukosta ei-halutut rivit. Tehokkuuden kannalta tämä on hyvin huono ratkaisu. (Bonnie Baker, 2003)
Suositeltavat ratkaisut ohjelmoinnissa käytettäessä relaatiokantoja
Tosiaikaiset tapahtumat perustuvat tapahtumiin, eräajot ovat prosesseja. Prosesseissa on tehtäviä, jotka voidaan tehdä yhdellä kerralla. Esimerkiksi pienet taulut kannattaa lukea kerralla muistiin. Samaten hän suosittelee, että päivitykset taulukoitaisiin ja tehtäisiin vasta ohjelman lopussa kerralla kuntoon. Jos ajossa/ ohjelmassa tehdään päivityksiä tai lisäyksiä, ensimmäiset 1 ja 2 päivitystä ovat kohtuullisen nopeita, sen jälkeen käynnistetään update tai insert rutiini, jonka takia 3 tai 4 operaatiota ovat kalliita, mutta 5 tai enemmän operaatiota ovat jo halvempia kuin yksittäisesti suoritetut tapahtuma. Huomioitavaa on, että COMMIT nollaa nämä dynaamiset update proceduurit, kuin myös insert proceduurit, dynaamisen

31/99
prefetchin, indeksejen muistiintaulukoinnit ja muut massakäsittelyä tehostavat ominaisuudet. (Yevich & Lawson, 2000)
3.4 Tietojärjestelmän käyttö, huolto ja viritysEräohjelmien virittämisessä on seitsemän avainkohtaa:
1. Varmistettava, että ajoympäristö on konfiguroitu kunnolla2. Sijoitetaan mahdollisuuksien mukaan tiedot keskusmuistiin3. Vähennetään ja optimoidaan I/O operaatiot4. Jaetaan työ rinnakkaisiin prosesseihin5. Varautuminen ohjelma- ja laitteistohäiriöihin6. Ohjelmistojen tehostaminen
Näiden avainkohtien saavuttamiseksi on olennaista, että nähdään miten ympäristöt ja järjestelmät toimivat, varmistetaan huoltotoimenpiteiden säännöllisestä suorittamisesta, pidetään huolta siitä, että ohjelmisto osaa myös vapauttaa käyttämänsä resurssit ja varaudutaan resurssien lukitsemisiin ja lukitusten tuottamiin ongelmiin - kuitenkin niin, että myös itse ei aiheuteta lisää ongelmia.
3.4.1 MonitorointiMonitoroinnilla tarkoitetaan toimenpiteitä joilla seurataan, valvotaan ja mitataan järjestelmän toimintaa. Tietokantojen monitoroinnissa DB2 ympäristössä turvaudutaan z/OS järjestelmässä IBM:n Instrumentation Facility (IF) ohjelmistokomponenttiin, joka on osa DB2 System Services Address Space [DSNMSTR] palveluita. Tällä palvelulla pystytään tuottamaan tietoja laskutuksen ja tilastoinnin tarpeisiin sekä raportteja suorituskyvyn seuraamiseksi. IF tuottaa seuraavia SMF-tietueita: SMF101 on tarkoitettu laskutusta varten, SMF100 ja SMF102 tietueet tilastointiin ja SMF102 suorituskykyä varten. Riippuen käynnistetystä monitorointitasosta saadaan selville eritasoisia tietoja suorituskyvystä:
Class 1 – Vasteaika (Elapsed time)Class 2 – DB2:ssa käytetty aika (In-DB2 time)Class 3 – Odotusaika (Wait times)Class 7 – Suorituskyky moduulitasolla (Package level In-DB2)Class 8 – Odotusaika moduulitasolla (Package level Wait)

32/99
Pelkkä IF ei tarjoa SMF-tietuiden katselemiseen ja analysointiin mitään käyttöliittymää. OP-Pohjolassa on käytössä BMC:n Mainview tuoteperhe, johon kuuluu DB2 monitori. Mainview hyödyntää IF:n tuottamia tietueita ja muokkaa niistä ennalta valittujen kriteerien mukaan tapahtumakohtaista raporttia. Toinen tässä tutkimuksessa käytetty ohjelmisto on BMC Apptune, joka kerää itse suorituskykytietoja omiin tiedostoihin SMF-tietueiden sijasta.
3.4.2 Säännölliset huoltotoimet eli ”Three R's”Tietokannat eivät pysy optimaalisessa järjestyksessä kovinkaan pitkään. Toistuvien päivitysten, lisäyksien ja poistojen seurauksena tietojen järjestys muuttuu. Esimerkiksi lisättäessä rivejä, uudet rivit pyritään lisäämään fyysisesti oikeaan järjestykseen, mahdollisimman lähelle sitä sivua minne rivi kluster-järjestyksen mukaisesti kuuluisikin. Käytännössä tyhjää tilaa ei riitä kovinkaan pitkään, koska lisäykset todennäköisesti keskittyvät tiettyihin "kuumiin pisteisiin". Tämän takia elävää tietokantaa pitää hyvin säännöllisesti huoltaa.
Huoltotoimenpiteistä Bonnie Bakerin tärkein ohje on englanninkielessä tunnetut perustaidot ”reading, 'riting and 'ritmetics” (lukeminen, kirjoittaminen ja laskento), eli kolmen ärrää. DB2 ympäristössä kolme tärkeintä taitoa ovat:
REORG (Reading) - uudelleenorganisointi
RUNSTATS (’Riting) - tilastointi
REBIND (’Ritmetics) - uudelleensidonta
Uudelleenorganisointi eli REORG lukee koko tietokantataulun lävitse, lajittelee materiaalin klusteri-indeksin mukaiseen järjestykseen ja kirjoittaa datan takaisin tauluun. Samalla päivitetään indeksien fyysiset RID viittaukset kuntoon. Indekseille tehtäessä tuo uudelleenorganisointi on hyvin samankaltainen, mutta tällöin järjestys riippuu indeksin omista sarakkeista eikä fyysisiä pointtereita tarvitse samalla tavalla kuin taulutilan organisoinnissa päivittää.
Kun kanta on uudelleenorganisoitu, olisi erittäin suotavaa että DB2:n optimoija tuntee millaista dataa ja kuinka paljon on tauluissa REORGin jälkeen. Uusimmissa versioissa DB2 ei tyydy yksinomaan rivimäärien

33/99
laskemiseen, vaan nyt tilastoidaan myös valittujen sarakkeiden kohdalla mahdollinen epätasainen jakauma. Versio 9:ssä on uutena piirteenä ajonaikaisesti päivittyvää statistiikkaa, jolloin dynaamiset lauseet mukautuvat välittömästi muuttuneisiin tilastoihin.
Staattisten SQL-lauseiden, jotka muodostavat valtaosan DB2 z/OS järjestelmien SQL lauseista, hakupolut EIVÄT muutu automaattisesti. Tätä varten kun tiettyihin tauluihin on ajettu RUNSTATS, pitää ajaa samoja tauluja käyttävien ohjelmien paketeille REBIND eli uudelleensidonta. Vasta tällöin vanhentuneilla tiedoilla optimoidut hakupolut osaavat valita tehokkaammat hakupolut. (Bonnie Baker, 2003)
3.4.3 Commit välitKoska tavoitteena ovat sellaiset eräohjelmistot, että hiljaiseen aikaan ajettavat tosiaikasovellukset eivät merkittävästi kärsi, on olennaisen tärkeää, että eräohjelmistot ottavat COMMIT-pisteen riittävän usein. COMMIT käskyllä ilmaistaan, että tietty osa aineistosta on käsitelty kokonaan, niitä voidaan nyt käyttää ja vapauttaa otetut tietokantalukot. Tämä voi olla tehokkuuden kannalta ongelma. Jos tietokantatuote ei tue ratkaisua, jossa luettavat tiedot, eli avattu tulosjoukko (eli CURSOR) pysyy auki myös COMMITin jälkeen (eli CURSOR WITH HOLD optio), joudutaan tulosjoukko avaamaan uudestaan. Uudelleenavaus on raskaampaa, koska nyt ylimääräisenä vaatimuksena tulosjoukkoon ei saa sisällyttää niitä rivejä, jotka on ohjelmassa jo käsitelty. Näin tehtynä uudelleenkohdistus on kallista. Missään tapauksessa ei tule rakentaa sellaista logiikkaa, jossa samaa kursorinavauslogiikkaa käytetään normaalissa ajossa ja uudelleenavauksessa. Tällainen SQL toimii huonosti kummassakin tapauksessa. (Bonnie Baker, 2003)
Tietokantatuotteissa joissa on käytössä WITH HOLD optio, tulosjoukko pysyy käytettävissä myös väli-COMMITin jälkeen. Tämä tehostaa eräajoa paljon sekä helpottaa ohjelman rakentamista, mutta ei kokonaan ilman ongelmia. Joissakin moduuleissa/ palveluissa virheen sattuessa tehdään automaatisesti ROLLBACK, jolloin tulosjoukko pitää sittenkin avata uudelleen.

34/99
Vaihtoehtona väli-COMMITien käytölle ovat ohjelmat, joissa ei oteta lainkaan tietokantalukkoja. Tähän päästään DB2 ohjelmistoissa käyttämällä WITH UR optiota, eli käyttämällä ns. likaista lukemista (dirty read). Suurin osa kirjallisuudesta muistaa varoittaa likaisen lukemisen vaaroista, mutta harkiten käytettynä ja mahdollisesti hyödyntäen optimistista lukitusta tämä ominaisuus on erittäin hyödyllinen tehokkaiden ohjelmistojen rakentamisessa. (Mullins, 2006)
Tietokantaa muokkaavat lauseet
Normaalisti tietokannan tietosisältöä muokkaavia lauseita ei pidetä tietokantavirittämisessä kovinkaan otollisina kohteina, koska tietokantasivut pitää joka tapauksessa päivittää (Lahdenmäki & Leach, 2005, s. 117). Eräajoissa tämä ei välttämättä pidä paikkaansa, sillä niissä voidaan hyödyntää esimerkiksi tietokannan mukana toimitettuja apuohjelmia, erilaisia LOAD ohjelmistoja. Kehittyneimmissä apuohjelmissa voidaan tauluun ladata rivejä ilman että koko taulu olisi lukittuna. (Pruni et.al., 2004).
3.4.4 LukituksetTietokantajärjestelmissä mahdollistetaan tietojen samanaikainen käyttö ja päivittäminen, mutta ei ilman rajoituksia. Tietojen eheys varmistetaan lukitsemalla osa tietokannasta lukemisen sekä erityisesti päivittämisen ajaksi. Perinteisesti tehokkain tapa huolehtia lukituksista eräajoissa on ottaa taulutilalukko kaikkiin käsiteltäviin tauluihin. Näin saavutetaan vähimmillä resurssienkäytöllä laajin mahdollinen eheys.
Valitettavasti nykyaikaisissa 24x7 käytettävyysvaatimuksissa ei tällaista koko kannan laajuista lukkoa voida käyttää, koska myös hiljaisena aikana on internetin kautta tulevaa tosiaikakäyttöä. Tämän takia on käytettävä hienojakoisempaa lukitsemista. Tosiaikasovelluksissa käytetään yleensä, mikäli mahdollista, melko kevyitä tietokantalukkoja – tyypillisesti esimerkiksi käyttämällä SQL standardin lukitustasoa READ COMMITTED (DB2:ssa ISOLATION LEVEL = CS), missä lukot vapautetaan heti kun mahdollista.
Rivitasoinen lukitus

35/99
Yksi tapa vähentää lukkojen laajuutta, on käyttää rivitasoisia tietokantalukkoja. Rivitasoinen lukitus ei ollut alunperin kaikkien tietokantajärjestelmien ominaisuusvalikoimassa ja hyvästä syystä. Rivitasolla otetut lukot vievät 30 – 40 kertaa enemmän muistia lukkojärjestelmästä verrattuna sivutasoisiin lukkoihin ja aiheuttavat samassa suhteessa ylimääräistä CPU-kuormaa.
Tällä hetkellä rivilukitusta pyritään rajoittamaan tosiaikasovelluksissakin ainoastaan erikoistilanteisiin. Eräajoissa rivilukitusta ei tule missään nimessä käyttää (Bonnie Baker, 2004). Erityisesti z/OS laitteistot, joissa käytetään Parallel Sysplex optiota jakamaan kuormaa useamman fyysisen laitteen kesken, on tavattoman herkkä liian suurille lukkovarauksille. Syynä tähän on, että lukot pitää sijoittaa koko systeemin yhteiseen muistiin - joka puolestaan hyvin kallis ja rajallinen resurssi. (Alastrué i Soler et.al, 2004)
Optimistinen aikaleimapohjainen lukitus
Termi optimistinen lukitus tarkoittaa, että tapahtumalle oletetaan, että mitään samanaikaista käyttöä ei yleensä ole. Vasta kirjoitusvaiheessa varmistetaan, että tapahtuman aikaleima ei ole päivitettävien tietojen aikaleimaa vanhempi. Mikäli jollekin tapahtumalle havaitaan kannan aikaleiman olevan uudempi, tapahtuman päivitykset hylätään. (Garcia-Molina et. al., 2009, sivu 993).
Optimistinen lukitus on terminä harhaanjohtava, koska sitä käytettäessä ei itse asiassa lukita mitään. Vasta päivityksiä tehtäessä tarkistetaan että rivin versio on pysynyt samana ensimmäisen lukemisen ja päivityksen välisen ajan. Englanniksi tällaista menetelmää kutsutaan Row Version Verifying eli RVV. Suomeksi tämä termi voisi olla rivin version verifiointi. (Laiho & Laux, 2009)
Käytännössä kiivaasti käytetyissä tosiaikatapahtumissa tietokantalukot voivat olla usein tehokkaampi vaihtoehto, sillä vaikka lukot voivat viivyttää tapahtumia, on lukoilla hoidetussa samanaikaisuuden hallinnassa etuja:
1. ei tällöin tarvitse peruuttaa päivityksiä.

36/99
2. prosessointia tarvitaan vähemmän, sillä tapahtuma peruutetaan kun lukko-odotus käy liian pitkäksi.
3. osa tapahtumista, jotka jäävät odottamaan lukkojen vapautumista, menevät lävitse.
Rivin versiotarkistuksella on puolestaan käyttöä niissä tapauksissa, joissa tietokannan päivitystiheys on suhteellisen pieni tai jos tietojen eheydenvalvonta joudutaan ulottamaan useampaan peräkkäiseen prosessiin. Esimerkkinä voisi olla web-käyttö tai pitkäkestoiset eräajot.
3.4.5 CPU kustannusten arviointiTiedon hakujen tietokannasta vähentäminen pienentää CPU kustannuksia merkittävästi. Vaikka hajasaannin aiheuttamat I/O:t ovat merkittävin komponentti sovellusten käytettävyyden kannalta, niin myös CPU:n aiheuttamat kustannukset ovat erityisesti keskuskonelaitteistoissa taloudellisesti merkittävä tekijä. Keskuskoneen CPU käytön kustannus voidaan arvioida olevan 1000€ tunnissa (ei todellinen OP-Pohjolan maksama kustannus), lähinnä käytössä olevien ohjelmistojen lisenssien takia. Muissa ympäristöissä (Linux, Unix tai Windows) CPU kustannukset voivat olla merkittävästi pienemmät, mutta tällöinkin tehostaminen voi olla tärkeää, sillä jossain vaiheessa yksi palvelin ei enää riitä. Vaihtoehtoisessa ratkaisussa, jossa järjestelmä hajautetaan useammalle palvelimelle, tietojen synkronisointi puolestaan aiheuttaa ylimääräistä CPU ja levylaitekuormaa, sekä voi aiheuttaa vaikeasti ratkaistavia lukitusongelmia. (Lahdenmäki & Leach, 2005)
Palvelukeskukset voivat myydä käyttöpalveluita veloittamalla käytetystä CPU:sta tai sitten kiinteään hintaan tiettyyn kattoon asti. Sopimus, jossa on kiinteä hinta, voi vähentää kiinnostusta rakentaa CPU kulutuksen kannalta tehokkaita ohjelmistoja. Kuitenkin tällaista sopimusta hyödyntävien organisaatioiden tulee ymmärtää, että tehottomia sovelluksia ei pystytä nopeasti tehostamaan tilanteissa, joissa esimerkiksi CPU-katto lähestyy ja uusi tarvittava palvelutaso on kiusallisen paljon kalliimpi. Järkevämpää on kiinteähintaisessa

37/99
sopimuksessa silti pitää sisäinen laskutus veloittamalla CPU käytöstä toteutuman mukaisesti.
3.4.6 Valmisohjelman virittäminenValmis- tai räätälöidyn ohjelmiston ostaminen on yhä yleisempää. Taloudellisesti on mielekästä monistaa kertaalleen tuotettu laadukas ohjelmisto useammalle kuin yhdelle yritykselle. Käytännössä kun ohjelmistot ostetaan ”black box” periaatteella, ostaja ei saa haltuunsa lainkaan ohjelmiston lähdekoodia, vaan ainoastaan oikeuden käyttää valmiiksi käännettyä konekielistä ohjelmistoa. Usein tällaisien valmisohjelmistojen rakentajat ovat erikoistuneet nimenomaan liiketoiminnan erikoisosaamiseen ja järjestelmäosaaminen on puolestaan kohtuullisen vaatimattomalla tasolla. Ohjelmiston omatoiminen korjaaminen tai tehostaminen muuttamalla koodia ei ole tällöin mahdollista, vaikka siihen olisikin tarvetta. (Skalberg, 2006).
Silti tällaisessa tapauksessa järjestelmäasiantuntija ei ole kokonaan ilman välineitä, vaan tehostamiseen on silti useita mahdollisuuksia. Virittämisen tärkein näkökulma, eli I/O operaatioiden vähentäminen, on mahdollista toteuttaa muuttamalla tietokannan puskurointia, muuttamalla tietokannan tai taulutilan asetuksia, vaikuttamalla lukituksiin tai lokikäsittelyyn sekä dynaamisen SQL:n puskurointiin. Valitettavasti kaikista vahvin virityslääke, ohjelmiston logiikan muuttaminen, ei ole käytettävissä.
Yksinkertaisin tapa tehostaa valmisohjelman läpimenoaikaa on rinnakkaisuuden hyödyntäminen. Kaksi (tai useampia) I/O operaatioiden kannalta raskasta sovellusta voidaan ajaa rinnakkain. I/O operaatiot limittyvät ja prosessorien kuormitus pysyy tasaisena, jolloin läpimenoaika paranee. Tätä rinnakkaisuutta ei ole tässä työssä käsitelty laajemmin, osittain koska rinnakkaisuus ei merkittävästi pienennä CPU-kustannuksia. Poikkeuksena voi mainita, että moniytimisissä prosessoreissa monisäikestetty ohjelmisto voi tietyissä erikoistapauksissa tehokkaampi kuin yksisäikeinen ohjelma. (Pulkkinen, 1998)

38/99
4 Eräajot käytännössäOpinnäytetyössä tutkitaan lähinnä tilaajaorganisaation ohjelmistoja. Nykyään hyvin merkittävä osa liiketoiminnan kannalta olennaisista tiedoista on talletettu tietokantoihin, yleisimpänä tyyppinä käytössä on relaatiotietokannat.
4.1 Tehottomat eräajotAsiakaspalautteen perusteella ja tutkimalla tilastoja on osoittautunut, että Pohjolan eräajot ovat hitaita ja kalliita. Mutta mikä on perimmäisenä syynä tähän ilmiöön?
Epäiltyjä osa-alueita on kolme:
1) Itse DB2 järjestelmä? Ei missään tapauksessa. Yksittäisillä SQL lauseilla saadaan jo nyt käsiteltyä 10 miljoonia rivejä muutamassa minuutissa. Esimerkiksi siirtyminen markka-ajasta euroihin, eli Euro-konversio saatiin tehtyä DB2 ympäristössä erittäin tehokkaasti - alle 13 tuntia, vaikka konvertoitava rivimäärä oli yli 400 miljoonaa riviä.
2) Gen kehitin? Todennäköisesti ei, koska vanhemmat DB2:sta käyttävät eräajot eivät ole olennaisesti parempia. Lisäksi Genin tuottamaa koodia on jo pidemmän aikaa tutkittu ja on arvioitu, että generoitu COBOL-koodi on suhteellisen hyvää - se tekee juuri sitä mitä pyydetään ilman ylimääräisiä temppuja.
3) Menetelmät, periaatteet ja tapa toimia? Todennäköisesti kyllä. Kun meillä on selvitelty jälkikäteen syitä, miksi ohjelmat ovat rakennettu nykyisellä tavalla, vastauksena oli kolme periaatetta:
"kerralla kuntoon" tai "vakuutus kerrallaan" -periaate "kyettävä ajamaan ajoja myös online-aikaan..." -periaate "ei tarvitse maksaa erikseen online- ja eräohjelmien ylläpidosta."
-periaateKaksi ensimmäistä periaatetta ovat tulleet suoraan asiakkailta, eikä niitä ole asetettu kyseenalaisiksi. Nyt nämä periaatteet tulee asettaa kriittisen arvioinnin kohteeksi.
4.2 Kalliit tosiaikatapahtumatSamalla kun tutkitaan tehottomia eräajoja, voidaan hieman selvittää, mitä olennaisia piirteitä on kaikkein raskaimmissa ja kalleimmissa

39/99
tosiaikatapahtumissa. Tosiaikasovelluksissa raskaimmat tapahtumat sisältävät paljon päivitys- ja lisäystoimintoja. Tästä esimerkkinä YK-systeemialueen hyväksymistapahtuma YK86, jossa INSERT, UPDATE ja DELETE aiheuttavat 26 % kustannuksista. Oheinen listaus sisältää 110 tosiaikatapahtuman 15 kalleinta SQL lauseita otettuna BMC Apptune monitoriohjelmalla.
Subsys: DBP1 AppGrp: xxx User: xxx ConnID: xxx
Plan: YK86 CorrID: xxx
Program Type Calls Elapsed % CPU %
AAM170 INSERT 14496 00:41,77892 9,1% 00:02,43769 6,1%
IVA019 INSERT 6918 00:51,80880 11,3% 00:01,77734 4,5%
PAA015 INSERT 7628 00:57,37830 12,6% 00:01,53899 3,9%
RAX154 SELECT 110 00:34,74289 7,6% 00:01,38906 3,5%
AGX052 INSERT 8642 00:26,92513 5,9% 00:01,38857 3,5%
AGXC57 UPDATE 2863 00:09,67758 2,1% 00:01,33981 3,4%
AGX153 DELETE 2863 00:07,10047 1,6% 00:01,10204 2,8%
AGA092 OPEN 9095 00:01,68064 0,4% 00:00,99153 2,5%
AGA098 OPEN 4382 00:02,82593 0,6% 00:00,74006 1,9%
AGX153 UPDATE 2863 00:04,70297 1,0% 00:00,70234 1,8%
PHA023 UPDATE 2087 00:12,99323 2,8% 00:00,67591 1,7%
AGA040 FETCH 37536 00:01,02826 0,2% 00:00,66477 1,7%
AGA013 OPEN 2725 00:00,72939 0,2% 00:00,59160 1,5%
AGA049 FETCH 25142 00:00,95771 0,2% 00:00,57890 1,5%
Taulukko 4. Tosiaikaisen hyväksymisapahtuman viisitoista kalleinta SQL-lausetta. Päivittämisen ja lisäämisen raskaus johtuu useammasta seikasta. Ensinnäkin kaikista päivityksistä ja lisäyksistä pitää kirjoittaa lokia, jolla varmistetaan kannan eheys mahdollisissa häiriötilanteissa. INSERT tai UPDATE lauseita voidaan tehostaa hieman taulun sarakkeiden oikealla järjestyksellä. Myös useamman samalle sivulle kohdistuvan päivityksen suorittaminen samassa loogisessa työkokonaisuudessa (LUW, logical Unit of Work) vähentää I/O operaatioiden määrää. INSERT lauseesta on olemassa multi-row-insert vaihtoehto, jossa samalla lauseella voidaan lisätä useampia rivejä kerralla.
Toiseksi päivittäminen ja lisääminen joutuvat ylläpitämään varsinaisen tietokantataulun lisäksi mahdollisissa indekseissä olevaa rakennetta.

40/99
Verrattuna pelkkään kirjoittamiseen peräkkäistiedostoon päivittämisen tai lisäämisen kustannus voi olla monikymmenkertainen.
Kalliissa tosiaikatapahtumassa kantaa päivittävien lauseiden osuus on suuri. Osa päivitettävistä tiedoista voitaisiin huoletta kirjoittaa kantaan erillisillä eräajoilla, mutta tällöin ongelmana voi olla luotettavuuden ja ylläpidettävyyden heikkeneminen.
4.3 Tehokkaat eräajotEsimerkkeinä tehokkaista eräajoista voidaan tutkia ainakin tietokantaohjelmiston huolto- ja apuohjelmia. Koska monet apuohjelmat vaativat koko taulutilan itselleen, pitää näiden apuohjelmien olla mahdollisimman nopeita.
Muitakin esimerkkejä löytyy, esimerkiksi Data Warehouse käyttöön tarkoitetut Data-Extractor tuotteet pyrkivät lukemaan halutun datan lävitse niin nopeasti ja kustannustehokkaasti kuin mahdollista.
Yhteistä kaikille tehokkaille eräajoille on, että niissä käytetään apuna tavallisia peräkkäistiedostoja, joko suoraan tai sitten erillisinä työtiedostoina. Myös lajittelua käytetään runsaasti tehokkaissa eräajoratkaisuissa. 4.4 Taulujen lomittaminen toisiinsaOraclen tietokantatuotteissa on ollut mahdollista sijoittaa useampia tauluja samaan taulutilaan niin että rivit ryvästyvät yhteisen avaimen mukaisesti. Eli isätaulun riviä seuraavat heti sen lapsirivit, kunnes taas tulee uusi isärivi ja sen lapsirivit. Sijoittamalla data näin saadaan yhdellä I/O:lla isä ja sen lapset. Suorituskyky paranee, olettaen että lapsirivejä on rajoitetusti ja että tämä isärivien ja lapsirivien liitos on yleisin hakutarve.
Voidaanko tällaista toteuttaa DB2:lla? Yhden taulun sisällä rivijärjestys on helppo muuttaa. Entäpä jos yksi fyysinen taulu jaettaisiin näkemyksillä useammaksi loogiseksi tauluksi? Tällöin voisi helposti saada aikaiseksi vastaava tilanne kuin Oraclen data-klusterilla. Tätä kokeiltiin tämän lopputyön yhteydessä myös DB2 z/OS ympäristössä.
Toteutustapa oli seuraava. Ensimmäiseksi määritetään, mitä täysin samoja kenttiä limitettävillä tauluilla on. Ne sijoitetaan pohjatauluun

41/99
sellaisinaan. Sitten selvitetään, mitkä kentät sisältävät täysin eri tietoja, mutta ovat sattumalta samanmuotoisia. Nämä kentät voidaan määritellä toistensa "päälle" ja niille annetaan "perustaulussa" suhteellisen yleinen nimi.
Kolmanneksi ne kentät, joilla tallennusmuoto on täysin uniikki, määritetään sellaisenaan, mutta niin, että tietomuodolla on aina olemassa jokin oletusarvo (NOT NULL WITH DEFAULT). Viimeisenä pohjatauluun määritetään taulun tunniste kenttä. Tätä tarvitaan, jotta voimme rakentaa pohjataulun päälle loogiset taulut niin, että näkemyksiin tulee luettaessa vain kyseisen loogisen taulun rivejä. Tämä kenttä pitää tehtäessä INSERT käskyjä pohjustaa TRIGGERillä niin, että näkemyksen WITH CHECK täyttyy - eli uuden rivin pitää pystyä näkymään kyseisen näkemyksen kautta luettaessa.
Näin saadaan toteutettua esimerkin mukainen limittyminen, jolloin tehtäessä liitoksia näiden taulujen välillä, on varsin todennäköistä, että rivit ovat samalla tietokantasivulla. Näin saisimme I/O operaatiot vähenemään 50% tai enemmän.
Tämä teoria piti testata käytännössä, sillä laskutus ja reskontra-sovelluksissa tehdään paljon taulujen liittämistä. Testissä kokeiltiin hyvin yleistä tilannetta, jossa meillä on SOPIMUS isätaulu, jolla voi olla useampia lisätietorivejä samanaikaisesti voimassa. Ohessa taulukko, josta käy ilmi SOPIMUS ja SOP-LISATIETO taulujen kentät ja miten niistä muodostettiin POHJA-SOPIMUS taulu.
SOPIMUS SOP-LISATIETO POHJA-SOPIMUSTAULU_TUN CHAR(4)
TUN FK_SOPTUN TUN INTEGERJARJ_NO FK_SOPJARJ_NO JARJ_NO1 INTEGER
JARJ_NO JARJ_NO2 INTEGERTYYPPI TYYPPI TYYPPI CHAR(3)ALI_TYYPPI ALI_TYYPPI ALI_TYYPPI CHAR(6)
LUONTI_PVM LUONTI_PVM DATELUONTI_AIKA LUONTI_AIKA TIMEHIST_PVM HIST_PVM DATE

42/99
HIST_AIKA HIST_AIKA TIMEALK_PVM_DER ALK_PVM ALK_PVM DATEALK_SYY_DER ALK_SYY CHAR(2)LOP_PVM_DER LOP_PVM LOP_PVM DATELOP_SYY_DER LOP_SYY CHAR(2)VOIMASSAOLO STATUS CHAR(2)TEKSTI_L TEKSTI_L CHAR(1)SOP_TUN_VIIT SOP_TUN_VIIT INTEGERAIKALEIMA AIKALEIMA TIMESTAMPFK_1TARJ FK_1TARJ DECIMAL(13,0)FK_2TARJ FK_2TARJ INTEGERFK_1TARJ_JARJ_NO FK_1TARJ_JARJ_NO INTEGERKAYTTAJA KAYTTAJA CHAR(8)
VALUUTTA VALUUTTA CHAR(3)RAHA RAHA DECIMAL(15,2)RAJOITUS RAJOITUS DECIMAL(15,2)PROSENTTIA PROSENTTIA DECIMAL(15,6)LKM LKM INTEGERPVM PVM DATE
LISATEKSTI LISATEKSTI VARCHAR(45)
Taulukko 5. Useamman taulun lomittaminen samaan tauluun.
Nyt loogiset taulut voidaan luoda käyttämällä näkemyksiä, niin että näkemyksen WHERE -lausekkeessa kerrotaan yksiselitteisesti, mikä on kyseisen rivin taulutunnus (TAULU-TUN). Koska näissä näkemyksissä ei ole liitoksia, voidaan perustaulua päivittää niiden kautta sekä lisätä niihin uusia rivejä.
Näin toteutettuna levytilaa jää käyttämättä. Kustannusten kannalta käytetyn levytilan määrä ei ole huomioitava tekijä, mutta tarpeettoman runsas levytilan käyttö luettaessa tietoja hajajärjestyksessä aiheuttaa hitautta. Tässä testissä käytettiin DB2 tiivistystä, joten "hukkaantuva" levytila oli noin 40 % sijasta vain noin 15 %.

43/99
Kuva 6. Ruutukopio BMC Apptune raportista.
Uusien rivien lisäämisessä on pieni ongelma. Jotta tämä ratkaisu vastaisi täysin olemassa olevia SOPIMUS ja SOP-LISATIETO tauluja, ei näkemyksessä saa olla taulutunnusta (TAULU_TUN) kenttää. Mutta ilman taulutunnuksen arvoa ei pystytä päättelemään mihin loogiseen tauluun rivi kuuluu. Tämä ongelma voidaan kiertää käyttämällä tietokannan triggereitä.
BEFORE INSERT triggeri laukeaa tehtäessä lisäystä pohjatauluun. Tällöin voidaan triggeriin rakentaa logiikka, jossa tutkitaan onko pohjataulun JARJ_NO2 annettu arvo. Jos annettu arvo löytyy, niin taulutunnukseen voidaan päivittää arvo "SOLI", joka tarkoittaa rivin kuuluvan loogiseen SOP-LISATIETO tauluun. Annetun arvon puuttuessa taulutunnukseksi tulee arvo "SOP ", jolloin rivi kuuluu SOPIMUS tauluun.
Tämän jälkeen oli mahdollista testata käytännössä SOPIMUS/SOP-LISATIETO taulujen käyttäytymistä. Alla on eräs ajetuista seuranta raporteista. Uusi, ryvästetty tapa on ensimmäisenä ja vertailtavana on täysin sama SQL lause ajettuna normaalina isä-lapsitaulun liitoksena.
Kaikkien testituloksen perusteella voidaan sanoa, että näin toteutettuna DB2 dataryvästys toimii kuten suunniteltu. Perustaulun sivujen määrä on perinteistä ratkaisua suurempi, sillä rivin pituus kasvaa käyttämättömien sarakkeiden takia. Luettujen sivujen määrä on tällä tavalla suurempi, josta johtuen suoraan levyltä luettaessa vasteaika heikompi, mutta sellaisessa tilanteessa jossa sivut ovat jo keskusmuistissa eli tietokannan puskurialtaassa, vasteaika on uudella

44/99
tavalla selvästi nopeampi. Molemmissa tapauksissa CPU-aika eli kustannus on noin 30 % pienempi.
Kirjallisuudessa ei ollut mainintaa sitä, että käytännössä tämäntyylinen data-ryvästys olisi puhtaasti hajakäsittelyä varten suunniteltu ratkaisu. Testit, joissa luettiin yksittäisiä sopimuksia ja niiden lapsirivejä, osoittivat että tällöin ei "hukkaantuva" levytila pääse lisäämään I/O kuormaa ja data-ryvästys, ollessaan optimaalisessa järjestyksessä, todella toimii.
Pelkän kustannussäästön kannalta tämä voisi olla suositeltava rakennemuutos, mutta tämän testauksen tiimoilta löytyi useita käytännön ongelmia.
1. Erilaiset apuohjelmat eivät välttämättä osaa käsitellä näkemyksiä, vaan turvautuvat perustaulun käsittelyyn. Tämä aiheuttaisi paljon muutoksia jo tehtyihin ohjelmistoihin.
2. Pohjataulun perusavain muuttuu, sillä siihen tulee nyt uusi sarake (TAULU-TUN). Viittaukset isätauluun kannan muista osista eivät säilyisi siis ennallaan.
3. Samalla tavalla, kuin Oraclen dataklusterissa, taulun vapaan tilan täyttyminen ja yksittäisen loogisen taulun läpilukeminen aiheuttavat ongelmia.
Edellä mainituista syistä tätä muutostyötä ei tässä vaiheessa toteuteta OP-Pohjolan järjestelmissä.
4.5 Esimerkki tehokkaasta peräkkäiskäsittelystäRivien poistaminen on esimerkki siitä, miten tietokannan käsittely on suhteellisen tehokasta, vaikka kyseessä on suuri tietomassa ja operaatiot vaativat paljon levykäsittelyä. Tässä tapauksessa testattiin 2,8 miljoonan rivin poistamista kyselytaulusta. Rivien poistossa ainoa poistoehto on tiettyyn kuukauteen rajattu päivämääräväli. Taulussa ei ollut indeksiä, joka olisi tukenut päivämäärien käsittelyä. Ilman sopivaa indeksiä ainoa mahdollinen tapa päästä käsiksi haluttuihin riveihin on koko taulutilan läpiluku.

45/99
Poisto-operaatio vei 11 minuuttia ja CPU-aika oli 2 minuuttia. Käsittelyaika oli siis 0,2 millisekuntia riviä kohden ja 42 mikrosekuntia CPU-aikaa yhtä riviä kohden. Valtaosa käsittelystä oli asynkronista peräkkäislukua. Prosessorina oli tässä testissä IBM Z9.
4.6 Ohjelmistojen kustannukset4.6.1 HankintakustannuksetOhjelmisto voi olla joko a) valmisohjelmisto tai b) yksilöllisesti tuotettu ohjelmisto (räätälöity tai itse tehty). Molemmissa tapauksissa toimittaja pyrkii minimoimaan ohjelmiston kehittämisessä käytetyn työmäärän ja optimoimaan koodin uudelleenkäytettävyyden. Myös hyvä ylläpidettävyys on tavoiteltava ominaisuus.
Tehokkaiden eräajojen kannalta minimoitu kehittämis- ja toteutustyö johtaa helposti epätyydyttävään ratkaisuun - eräajot ovat rakennettu käyttäen tosiaikaohjelmiston moduuleita ja komponentteja. Kuitenkin ohjelmiston toteuttaminen eli koodaaminen muodostaa vain 30 % - 35 % koko ohjelmiston elikaaren aikana kertyvistä kustannuksista. Tästä herää kysymys: kuinka paljon lisäkustannuksia tulee, jos eräajot huomioitaisiin alusta alkaen JA uudelleenkäytettävyys olisi edelleen olennainen vaatimus.
Hankintakustannuksia laskettaessa on tässä tutkimuksessa käytetty lähdekoodin rivimäärää (SLOC - source line of code) ohjelmiston koon mittauksessa, vaikka kirjallisuudessa on osoitettu tämä mittaustapa äärimmäisen epäluotettavaksi (Pressman, 2004). Kuitenkin koska käytetty kieli, koodaustyyli ja ympäristö ovat kautta tutkimuksen samoja, niin lukuja voidaan karkealla tasolla verrata toisiinsa.
4.6.2 YlläpitokustannuksetYlläpitokustannuksia on äärimmäisen vaikeata arvioida etukäteen. Osa ylläpidosta aiheutuu, kun varusohjelmistojen versioita joudutaan vaihtamaan, jolloin ohjelmistoihin saattaa tulla pakollisia muutostöitä. Suurempi osuus ylläpitotöistä aiheutuu kuitenkin liiketoimintatarpeiden muutoksista, joko niin että liiketoimintamalli tai organisaatio muuttuu, tai sitten sellaisista viranomaismääräyksistä, jotka aiheuttavat ohjelmistologiikkaan muutoksia. Likiarvona tässä

46/99
tutkimuksessa on käytetty suhteellisen suurta työmääräarviota, 20 henkilötyötuntia jokaista 1000 koodiriviä kohden. Arvion perusteena on käytetty Pohjolan PANVALETiin ja GEN Encyklopediaan kirjaantuneita muutoshistorioita.
4.6.3 KäyttökustannuksetTilaajaorganisaation sopimuksissa ei ole huomioitu erillisiä tariffeja, joissa huomioitaisiin liiketoiminnan ruuhkahuiput ja palkittaisiin ratkaisuja, joissa työtä saadaan teetettyä yöaikaan. Vuorokauden ajasta riippumaton tariffi on helpompi liiketoiminnalle ennakoinnin ja systeemien suunnittelemisen kannalta, mutta ei ole kapasiteetin käytön kannalta edullista. Tehokkaiden eräajojen kannalta yöajan pyhittäminen eräajoille ja eräajojen välttäminen päiväsaikaan olisi suotavaa, mutta nykyajan internet-käytön vaatimukset eivät mahdollista kiinteitä käyttörajoja. Tämän takia tehokkaiden eräajojen on siedettävä samanaikaista tosiaikakäyttöä, vaikka se kasvattaa käyttökustannuksia.
Keskuskoneympäristössä käyttökustannukset muodostavat koko sovelluksen elinkaaren kustannukset huomioon ottaen valtaosan. Ohessa esimerkki:
Ohjelma IS30Koostuu 53 moduulista
Kunkin moduulin keskimääräinen koko on 60 riviä
Ohjelman yhteenlaskettu rivimäärä 3180
1000 rivin keskimääräinen hinta 5000 €
Koodauskustannus n. 16.000 €
Muu projektityö n. 32.000 €
Rakennuskustannukset n. 48.000 €
Käyttökustannukset kuukaudessa 1.550 €.
Sovelluksen arvioitu käyttöikä on 20 vuotta.
Käyttökustannukset n. 372.000 €
Järjestelmän ylläpito 3.000 € vuodessa.
Ylläpito n. 60.000 €
YHTEENSÄ 432.000 €
Taulukko 6. Ohjelman IS30 elinkaaren aikaiset kustannukset.

47/99
Tästä huomaamme, että suhteellisen pienen ohjelman raskas käyttö aiheuttaa yli 85 % prosenttia elinkaaren aikana syntyneistä kustannuksista, ollen merkittävin kustannuksien aiheuttaja. 4.6.4 Tehokkaan eräohjelman rakennus ja käyttökustannuksetHankintakustannukset ovat korkeammat, jos ohjelmistoa rakennettaessa joudutaan ottamaan huomioon tietokantakäsittelyn optimointi peräkkäiskäsittelyä varten ja yleismoduuleiden eristäminen I/O-toiminnoista. Esimerkkinä auto- ja liikenneturvan eräajot, joista saamme seuraavat luvut:
Eräajotehokas ohjelmisto 11.300 riviä
Uudelleen käytettävät I/O moduulit 4.800 riviä
Päivitys ja lukitus logiikka 800 riviä
Varsinainen logiikka 5.700 riviä
Tosiaika-moduuleista koottuna 11.860 riviä
Tosiaika I/O moduulit 6.160 riviä
Varsinainen logiikka 5.700 riviä
Taulukko 7. Ohjelman IS30 elinkaaren aikaiset kustannukset.
Pelkästään rivimäärillä ei kustannuksia voi laskea, sillä tosiaika I/O-moduuleiden uudelleenkäyttöaste on korkea, moduuleita käytetään keskimäärin viidessä sovelluksessa. Tällöin suhteellinen työmäärä on vain 1/5 kokonaisuudesta. Eräohjelmien I/O-moduuleita voisi myös käyttää uudelleen, mutta rajoitetummin. Koska uudelleenkäyttöä ei vielä ole, joten tässä tutkimuksessa käytetään arviona hyvin vaatimatonta kerrointa 2/3.
Näillä arvoilla laskettaessa päädymme erätehokkaan ohjelman rakennuskustannuksissa ohjelmointityön hinta-arvioon 48.500 € ja online-moduuleista kootun eräajon rakennuskustannukset ovat 34.660 €. Vaikutus kokonaishintaan on vain 10 % korkeampi kuin online-moduuleita käyttävällä ratkaisulla. Hankintahinnassa on otettu huomioon, että muut projektikustannukset (testaus, määrittely ja projektinhallinta) pysyvät samalla tasolla. Myöskään ylläpitokustannukset eivät poikkea ratkaisujen välillä merkittävästi. (Jones, 2009)

48/99
Verrattaessa saatua tulosta käyttökustannuksiin, jotka pienenivät mitatusti yli 80 %, pääsemme edellisen esimerkiksi ohjelman IS30 luvuilla seuraavanlaisiin johtopäätöksiin:
Tehokkaan eräajon kustannukset verrattuna tosiaika-moduuleista koottuun.
Hankintahinta +10 % -4.800 €
Käyttökustannukset -80 % +297.600 €
Kokonaiskustannukset -69 % +292.800 €
Taulukko 8. Tehokkaan eräajon ja perinteisen ohjelman elinkaaren kustannusvertailu.
Säästöä tulisi järjestelmän koko elinkaaren aikana noin 70 %.
4.7 AULI eli autoturvakannan eräkäsittelyAutoturvajärjestelmä on OP-Pohjolan uusin suuri vakuutusjärjestelmä. Autoturvajärjestelmää rakennettaessa ensisijainen huolenaihe oli riittävän suorituskyvyn saavuttaminen, koska OP-Pohjolalla on merkittävä markkinaosuus auto- ja liikennevakuutuksista. Käsiteltävien tietojen määrä on siis suuri.
Tässä lopputyössä kuvataan, miten Autoturvajärjestelmän rakentamisen yhteydessä saavutettiin huomattavia tehostumisia. Luvussa viisi kerrotaan tarkemmin, minkälaisen mallin näiden kokeiden perusteella pystyttiin luomaan.
4.7.1 TestiperiaatteetTestiohjelmat tehtiin käyttäen Easytrieve ohjelmointikieltä. Ensimmäinen testiympäristö oli DB2U eli systeemitesti. Testissä haluttiin vertailla nykyisen P2000-ohjelmistoarkkitehtuurin mukaisen ratkaisun tehokkuutta suhteessa muihin vaihtoehtoihin. Testiä varten tehdyt ohjelmat eivät ole täydellisiä, mutta ne jäljittelevät nykyratkaisua kantakäsittelyn osalta riittävän pitkälle.
4.7.2 OletusratkaisuVakuutusjärjestelmissä on ollut käytössä oletusratkaisu, jossa tosiaikasovelluksia varten rakennetuista moduulikokonaisuuksista rakennetaan eräajo hyvin yksinkertaisella ajuri-pääohjelmalla. Pääohjelmassa hoidetaan vain ajon kannalta pakolliset COMMIT

49/99
käskyt, ajotilaston täyttäminen ja virhetilanteiden hoitaminen. Kaikki muu logiikka on moduulikokonaisuuksissa, joita käytetään sellaisenaan myös tosiaikatapahtumissa.
Mittaturvakannasta luetaan eri taulujen tietoja Mittaturvan kotisivua ja tulostusta varten käyttäen palvelua YKM589, joka toimii suurin piirtein näin:
Palvelu saa parametrina sopimustunnuksen.
Sopimustunnuksella luetaan Agmt_ag-taulusta yksi rivi (VAK).
Seuraavaksi sopimustunnuksella luetaan Agmt_rlship_ag-taulun kautta Agmt_ag-taulussa olevat sopimukseen liittyvät tuotteet taulukkoon.
Tuotetaulukko käydään läpi yksi kerrallaan ja jokaisen tuotteen osalta haetaan erikseen kannasta loput tarvittavat tiedot. Esim. haetaan tuotteeseen liitetty Agmt_object_ag-taulun rivi, josta saadaan viite Object_ob-tauluun ja sen jälkeen haetaan erikseen kohteen tiedot ja kohteisiin liittyvien paikkojen tiedot …
Näin toimitaan kunnes kaikki (kotisivulla ja/tai tulosteella) tarvittavat tiedot on kerätty erilaisiin taulukoihin.
Kaikki tietojenhakutoiminnot ovat palveluita, jotka toimivat itsenäisesti välitettyjen parametrien mukaisesti.
4.7.3 Tietokantaperusteinen ratkaisuEräs tehokkuuden kannalta tärkeä periaate hyödynnettäessä relaatiotietokantoja on, että mikäli mahdollista, teetä mahdollisimman paljon työtä relaatiotietokannanhallintajärjestelmässä (Bonnie Baker, 2003). Periaatteen "villakoiran ydin" on siinä, että kannattaa pyrkiä ratkaisuun, jossa
1. tehdään mahdollisimman vähän tietokantakutsuja
2. välitetään tietokannasta ohjelmaan mahdollisimman vähän tietoja
3. annetaan tietokannan optimoijalle mahdollisimman iso kokonaisuus hallittavaksi

50/99
Tietoja voidaan poimia käsittelyyn myös yhdessä ohjelmassa yhdistämällä eri taulut hakulausekkeessa sopivalla tavalla. Esimerkiksi määritellään kursori, jonka varassa luetaan kerralla sopimus, sopimuksen vakuutukset ja vakuutuksiin liittyvät kohteet.
Tässä on esimerkki yhdeksän taulun liittämisestä toisiinsa jo tietojen hakuvaiheessa.
SELECT AG.ID AS TUNNUS
, AG.SEQ_NO AS NUMERO
, COALESCE (VUO.AMT, 0 ) AS VUOSIMAKSU
, COALESCE (BON.PCT, -1 ) AS BONUSPROSENTTI
, COALESCE (OMA.AMT, -1 ) AS OMAVASTUU
, COALESCE (SEI.SEQ_NO , 0 ) AS SEISONTA
, COALESCE (ULO.SEQ_NO, 0 ) AS ULOSOTTO
, COALESCE (PAK.TEXT0, ' ') AS PAKETTI
, COALESCE (OBJ.FK_OBJECT_OBID, 0 ) AS KOHDE
, COALESCE (OBJ.FK_OBJECT_OBSEQ_NO, 0 ) AS KOHDE_NRO
, COALESCE (BF.FK_PARTY_ID , 0) AS JASEN
, DATE ('01.01.0001') AS KAUSI_APVM
, PVM.KALENT_PVM AS KAUSI_PPVM
FROM POHJOLA…. AG -- VARSINAISET VAKUUTUKSET (1) *)
LEFT OUTER JOIN POHJOLA…. PVM -- KALENTERI-APUTAULU (2)
ON PVM.KALENT_PVM >= '01.01.0001'
LEFT OUTER JOIN POHJOLA…. VUO -- VUOSIMAKSU (3)
ON VUO.FK_AGMTID = AG.ID AND VUO.FK_AGMTSEQ_NO = AG.SEQ_NO
AND VUO.APPR_FLAG <= '5' AND VUO.TYPE = 'VUO'
AND VUO.DETAIL_TYPE = 'VAKKAU'
AND VUO.START_DATE <= PVM.KALENT_PVM AND VUO.END_DATE >= PVM.KALENT_PVM
LEFT OUTER JOIN POHJOLA…. BON -- BONUSTIEDOT (4)
ON BON.FK_1AGMTID = AG.ID AND BON.FK_1AGMTSEQ_NO = AG.SEQ_NO
AND BON.TYPE = 'BON' AND BON.APPR_FLAG <= '5'
AND BON.START_DATE <= PVM.KALENT_PVM AND BON.END_DATE >= PVM.KALENT_PVM
LEFT OUTER JOIN POHJOLA…. OMA -- OMAVASTUU (5)
ON OMA.FK_1AGMTID = AG.ID
AND OMA.FK_1AGMTSEQ_NO = AG.SEQ_NO AND OMA.TYPE = 'OMA'
AND OMA.DETAIL_TYPE = 'OMAVAS' AND OMA.APPR_FLAG <= '5'
AND OMA.START_DATE <= PVM.KALENT_PVM AND OMA.END_DATE >= PVM.KALENT_PVM
LEFT OUTER JOIN POHJOLA…. SEI -- SEISONTA-AIKA (6)
ON SEI.FK_AGMTID = AG.ID
AND SEI.FK_AGMTSEQ_NO = AG.SEQ_NO AND SEI.TYPE = 'SEI'
AND SEI.APPR_FLAG <= '5' AND SEI.START_DATE <= VUO.END_DATE
AND SEI.END_DATE >= VUO.START_DATE
LEFT OUTER JOIN POHJOLA…. ULO -- ULOSOTTOTIEDOT (7)
ON ULO.FK_AGMTID = AG.ID AND ULO.FK_AGMTSEQ_NO = AG.SEQ_NO
AND ULO.TYPE = 'ULO' AND ULO.APPR_FLAG <= '5'
AND ULO.START_DATE <= PVM.KALENT_PVM AND ULO.END_DATE >= PVM.KALENT_PVM
LEFT OUTER JOIN POHJOLA…. PAK -- PAKETTITIEDOT (8)
ON PAK.FK_AGMTID = AG.ID AND PAK.FK_AGMTSEQ_NO = AG.SEQ_NO
AND PAK.TYPE = 'PAK' AND PAK.APPR_FLAG <= '5'
AND PAK.START_DATE <= PVM.KALENT_PVM AND PAK.END_DATE >= PVM.KALENT_PVM

51/99
LEFT OUTER JOIN POHJOLA…. OBJ -- KOHDETIEDOT (9)
ON OBJ.FK_AGMT_AGID = AG.ID AND OBJ.FK_AGMT_AGSEQ_NO = AG.SEQ_NO
AND OBJ.APPR_FLAG <= '5' AND OBJ.START_DATE <= AG.END_DATE_DER
AND OBJ.END_DATE >= AG.END_DATE_DER
LEFT OUTER JOIN POHJOLA…. BF -- JÄSENYYSTIEDOT (10)
ON BF.FK_AGMT_ID = AG.ID AND BF.FK_AGMT_SEQ_NO = AG.SEQ_NO
AND BF.APPR_FLAG <= '5' AND BF.START_DATE <= PVM.KALENT_PVM
AND BF.END_DATE >= PVM.KALENT_PVM AND BF.ROLE = 'BF'
Lauseen suoritustiedot:
Call Sect Stmt +--- SQL ---+ +- Total IN-SQL Time -+
Program Type No. No. Calls Errors Elapsed CPU
-------- -------- ----- ----- ------ ------ ----------- -----------
OBA136 FETCH 2 1331 21182 0 04:46,72445 00:08,12585
Averages: 00:00,01354 00:00,00038
*)lauseesta otettu pois luettavuuden kannalta epäolennaisia, luottamuksellisina pidettäviä taulujen nimiä. Nämä kohdat tunnistaa kolmesta pisteestä …
Taulukko 9. Yhdeksän taulun liittäminen taulujen fyysisessä järjestyksessä.
Näin tehtynä kymmenen taulun läpikäynti pystytään suorittamaan yhdellä lauseella. Kustannus 0,38 ms on edullinen verrattuna yksittäisiin kutsuihin samoihin tauluihin, jotka ovat luokkaa 0,09 - 0,07 ms tai vähintäänkin 0,9 - 0,7 ms kun käydään kaikissa kymmenessä taulussa. Karkeasti arvioiden liitosta käytettäessä kustannukset putosivat puoleen. Isolla liitoksella vasteaika ei käyttäydy tosiaikapalvelussa yhtä hyvin, koska tämä liitos ei vähennä yhtään I/O operaatiota, vaan halutut tiedot pitää lukea levyltä asti.
4.7.4 Ratkaisujen vertailuaOletusratkaisussa kontrolli on ohjelmissa, jotka poimivat tiedon sieltä, toisen täältä yksitellen, jolloin DB2 ei voi optimoida käsittelyä. Lisäksi käytettäessä oletusratkaisua eräajoissa, hajanaiset I/O operaatiot estävät tietokannanhallintajärjestelmää havaitsemasta milloin kantaa luetaan fyysisessä järjestyksessä eikä tällöin asynkroninen peräkkäishaku käynnisty.
Tietokantaperusteinen ratkaisu antaa DB2:lle mahdollisuuden toimia mahdollisimman tehokkaasti. Käsiteltäessä aineistoa massamaisesti eräajoissa, ylimääräisenä etuna on mahdollisen prefetch eli

52/99
asynkronisen peräkkäishaun käynnistyminen, erityisesti jos kaikki liitettävät taulut ovat järjestetty fyysisesti samaan järjestykseen. Toteutustavasta riippumatta lopputulos on sama, koska kaikki tarvittavat tiedot saadaan käsittelyyn.
Testitulokset systeemitestiympäristössä
Z187MK01 – ohjelma toimii kuten YKM589. Pääkursori on sopimuksen lukua varten, jokaista muuta taulua varten on oma kursori. Pääkursori avataan ohjelman alussa ja suljetaan lopussa. Muiden taulujen käsittelyä varten kursorit avataan erikseen aina käsiteltäessä uutta sopimusta, uutta tuotetta ja uutta kohdetta. Testiaineistoa oli 10.574 kohdetta (eli 1909 vakuutusta) ja testissä mitattu cpu kulutus oli 54,72 cpu sekuntia.
Z187MK02 – ohjelmassa on yksi kursori, joka avataan ohjelman alussa ja suljetaan lopussa. Aineistona sama 10.574 kohdetta, nyt mitattu cpu kulutus oli 5,25 sekuntia.
Z187MK03 – kuten Z187MK02, mutta Object_ob-taulua ei luettu. Kustannukset hieman pienemmät, 4,25 cpu sekuntia.
Z187MK04 – kuten Z187MK02 mutta ohjelma lukee sopimustunnukset tiedostosta, jolloin kursori on pakko avata ja sulkea jokaisen sopimuksen kohdalla. Käsittely muistuttaa yksittäisen sopimuksen käsittelyä, jota toistetaan mitattavien testitulosten aikaansaamiseksi. Nyt kustannukset olivat 13,93 cpu sekuntia.
Z187MK05 – kuten Z187MK01 mutta ohjelma lukee sopimustunnukset tiedostosta, jolloin myös pääkursori on pakko avata ja sulkea jokaisen sopimuksen kohdalla. Käsittely muistuttaa yksittäisen sopimuksen käsittelyä, jota toistetaan mitattavien testitulosten aikaansaamiseksi. Kustannus kaikista kallein, 63,87 cpu sekuntia.

53/99
Kuva 7. Systeemitestissä havaitut tulokset.
4.8 Tiedon välittäminen tosiaikasovelluksista eräajoilleTosiaikasovelluksissa on usein tarve välittää tietoja niin, että tiedot käsitellään vastaanottavassa sovelluksessa eräkäsittelynä. Tämä on järkevää silloin kun käsiteltävällä aineistolla ei ole erityistä vaatimusta ajantasaisuuteen.
Ongelmana on, että tosiaikajärjestelmissä ei voida käyttää perinteistä peräkkäistiedostoa, koska esimerkiksi CICS järjestelmissä tiedostojen varaaminen ja käsittely vaatii järjestelmän pysäyttämisen. Eikä peräkkäistiedostojen ominaisuudet yleensä täytä ACID eheysvaatimuksia.
Tästä syystä usein tällaiseen tiedon välittämiseen käytetään tietokantoja. Usein päädytään tilanteeseen, jossa tiedot kirjoitetaan suoraan siihen tauluun, jossa lopullinen tietojen käsittely ja mahdollisesti myös arkistointi tapahtuu.
Käytännössä tällainen ratkaisu ei ole kovin tyydyttävä. Suora lisääminen operatiiviseen tauluun, jossa on runsaasti indeksejä ja paljon rivejä, on raskasta.
Jos sitä vastoin tiedon välivarastona käytetään sellaista taulua, jossa ei ole indeksejä ja jossa uudet rivit lisätään aina tiedoston perään, eli jos

54/99
tiedostojärjestys on HEAP eli läjä, niin lisääminen on aina hyvin nopeaa.
Uusi partitiotapa
DB2 z/OS V8 myötä on saatu käyttöön uusi tapa hallita partitiontia. Kyseessä on taulun valvoman partitionti eli TABLE CONTROLLED PARTITIONING. Se tunnetaan myös nimellä DATA CONTROLLED PARTITIONING. Sen sijaan, että jokaisessa taulussa olisi pakollinen indeksi, jonka avulla ohjataan mihin osioon eli partitioon uusi rivi sijoitetaan, niin nyt tämä sama säännöstö talletetaan taulun rakenteeseen DB2 kataloogiin.
Aikaisemmissa DB2 z/OS versiossa aina versioon 7 asti tällainen partitionti on vaatinut erillisen partitioivan indeksin. Tätä nyt vanhentunutta piirrettä kutsutaan indeksin valvomaksi partitiontitavaksi eli INDEX CONTROLLED PARTITIONING. Erityisen ikäväksi muodostui sovelluksen kannalta se, että kyseistä indeksiä ei voitu hyödyntää mihinkään muuhun käyttöön. Lisättäessä tietoja kantaan ylimääräinen indeksi hidastaa toimintaa. Nyrkkisääntönä lisäämisen nopeus on suoraan verrannollinen indeksien määrään, kaavalla käytetty aika N = 1 + n, missä n on taulun indeksien määrä.

55/99
5 Mallin kehittäminen Käytännön mittausten ja havaintojen jälkeen tutkittiin alan kirjallisuutta. Lähdeteoksista käy hyvin selville, että fyysisen tiedostojärjestelmän vaikutus käsittelynopeuteen on merkittävä.
5.1 Tietojen käsittely fyysisessä järjestyksessäSekä kirjallisuus että suoritetut empiiriset kokeet osoittavat, että tehokkaimpaan lopputulokseen päästään, kun tietokantojen käsittely suoritetaan hyödyntäen laitteistojen ja ohjelmistojen suurta tehokkuutta juuri peräkkäiskäsittelyssä.
Niissä tietokannoissa, joissa peräkkäiskäsittelyyn on varauduttu, tunnetaan termi klusteri -järjestys. Jos tietoa osataan käsitellä fyysisessä järjestyksessä, levylaitteet pääsevät suorittamaan asynkronista peräkkäislukua, jolloin yhden tietokantasivun lukeminen on vain 2 ms. Verrattuna hajakäsittelyyn, jossa samankokoisen sivun hakeminen vie 20 ms, tämä on 10 kertaa tehokkaampaa (Bonnie Barker, 2003).
Tämä periaate on nyt OP-Pohjolassa nimetty COP -periaatteeksi (Cluster Order Processing). Kun tämä järjestysperiaate otetaan huomioon kannan suunnittelussa ja kun myös ohjelmistot hyödyntävät periaatetta, on odotettavissa merkittäviä suoritusaika- ja kustannussäästöjä.
5.2 Suunnittelumalli IPOTulee huomata, että tämä suunnittelumalli ei ole sukua 1980-luvulla käytetylle IPO kuvaustekniikalle, vaikka perusajatus syötteen, käsittelyn ja tulosten erottamiseksi on sama.
Koska tavoitteena on kuitenkin hyödyntää yhteistä koodipohjaa tosiaikaohjelmien kanssa, on välttämätöntä jakaa ohjelmisto kolmeen loogiseen osioon. Esimerkkinä tässä on vakuutuksen uudistusohjelman toiminta

56/99
Kuva 8. IPO mallin periaate. Vasemmalla siniset kaaviot kuvaavat INPUT osioita, keskellä vihreät kuvaavat PROCESS osoita ja oikealla keltaiset kaaviot kuvaata OUTPUT osiota.Ensimmäisessä osiossa, INPUT osiossa, joka voi koostua useista eri ohjelmista, haetaan tarvittavat tiedot mahdollisimman nopeasti hyödyntäen tietokantojen tehokkuutta tiedon peräkkäiskäsittelyssä.
Tämän jälkeen kun tiedot ovat haettu, voidaan rakentaa PROCESS osio niin, että kaikki tiedot ovat tarjolla ja tässä vaiheessa tehdään vain laskenta, päättely ja muokkaustoimintoja vain edellisessä osiossa haettuihin tietoihin. Silloin kun moduulit tai ohjelmat noudattavat tätä IPO -periaatetta, niitä voidaan käyttää myös tosiaikaohjelmistoissa.
Viimeisenä osiona on OUTPUT osio. Tämän osion rakentaminen on työssä kaikkein haasteellisin vaihe. Vaikka käsittely voidaan tehdä tehokkaaksi, nyt pitää varautua siihen, että häiriötilanteista selvitään ilman että kannan tilanne jäisi epäeheäksi.
5.3 Nopea taulu ilman indeksejäKohdassa 4.9 mainittu ongelmallinen tiedonvälitysratkaisu on ollut lopputyöni kohteena olevassa LARE järjestelmässä. Käytössä ollut
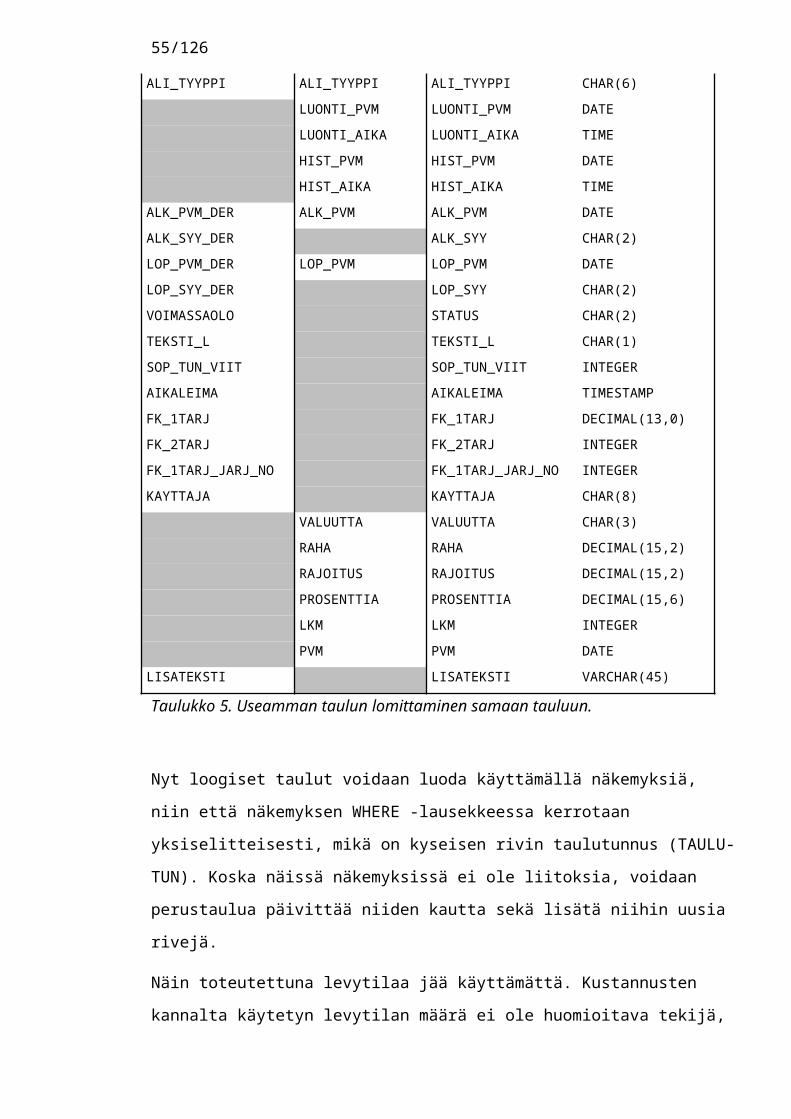
57/99
OUTPUT-PMT taulu täyttyy kovaa vauhtia, indeksien määrä vaikeuttaa tiedon lisäämistä ja uusien rivien käsittely eli niiden lukeminen ja merkitseminen historiatiedoksi, on hidasta.
Ratkaisuksi ei löytynyt muuta vaihtoehtoa kuin vanhasta poikkeavan välivaraston eli ”tuulikaappitaulun” kehittäminen tähän kohtaan; näin online-tapahtumat ja eräajot tehostuvat. Rakennettaessa tätä taulua haluttiin, että poikkeava rakenne näkyisi taulun nimessä asti: postfix NOX tarkoittaa, että taulussa ei ole lainkaan indeksejä. Tosiaikaohjelmissa ei tehdä mitään muuta kuin tietojen lisäämistä ja eräajot puolestaan käsittelevät suurimman osan niistä riveistä, jotka ovat välivarastossa. Tällöin taulutilan läpiluku on tehokkain tapa käsitellä näitä tietoja.
OUTPUT-PMTModuuli SQL lauseita Suoritusaika CPU-
aikaM864Y01 60 2,02372 0,03979Keskiarvo 0,02758 0,00064Suurin 0,66588 0,00517Pienin 0,00006 0,00006
OUTPUT-NOXModuli SQL lauseita Suoritusaika CPU-
aikaM864Y02 60 0,30318 0,01716Keskiarvo 0,00422 0,00028Suurin 0,09344 0,00294Pienin 0,00003 0,00003
Taulukko 10. Indeksitön välitystaulu verrattuna perinteiseen indeksoituun tauluun.
Näiden tulosten perusteella voidaan todeta, että tarpeettoman indeksin ylläpitäminen itse asiassa haittaa sovelluksen tehokkuutta. Kun

58/99
välitaulua käytetään vain tilapäiseen tiedon tallentamiseen ja varsinainen historiointi kyselytarpeineen hoidetaan omalla, arkistointia varten suunnitellulla taululla, saavutetaan huomattavia suoritusaika ja CPU-ajan säästöjä. Tässä tapauksessa suoritusaika parani 84 % ja CPU-aika 56 %.
5.4 Lukitusratkaisut tehokkaissa eräajoissaEräs Autoturvajärjestelmän vaatimuksista oli mahdollisuus ajaa uudistuseräajoa samaan aikaan tosiaikakäytön kanssa. Normaalisti uudistuseräajo ajetaan hiljaiseen aikaan, mutta koska asiakkaat voivat käyttää järjestelmää verkon kautta, ei tosiaikapalveluita saa katkaista vaan eräajon tulee sietää vähäinen muu käyttö. Käytännössä tämä tarkoittaa, että meillä on kaksi vaihtoehtoa eräajoarkkitehtuurille:
1. perättäisiä transaktioita, jotka lukitsevat kaikki tarvitsemansa tiedot hetkeksi ja sitten kun sopimus on käsitelty, vapautetaan lukot tekemällä COMMIT.
2. ratkaisu, jossa luotetaan siihen, että todellisuudessa vain harvoja ajossa käsiteltäviä sopimuksia muutetaan ajon aikana.
Koska ensimmäinen vaihtoehto ei pysty hyödyntämään peräkkäislukemista kuin harvoissa erikoistapauksissa, niin tehokkaita eräajoja varten valittiin ratkaisu, jossa hyödynnetään optimistista lukitusta.
Optimistinen lukitus toteutettiin näin: eräajoketjun alussa otetaan talteen DB2 järjestelmän aikaleima. Aikaleimasta vähennetään systeemiin määritetty TIMEOUT maksimi, jolloin voimme olla varmoja, että kaikki ne aineistoon tehdyt muutokset, jotka saavat tulla mukaan ajoon, on tehty ennen tätä eräajon aloitusleimaa.
Tällöin tyypilliset aikaleiman avulla ratkaistut samanaikaisuushallinnan ongelmat read-too-late ja dirty-read (Garcia-Molina et. al., 2009, sivu 995) saadaan estettyä. Ensimmäisenä aloitusleiman jälkeen haetaan sopimustietoja sisältävästä tauluryhmästä ne sopimukset, joiden pääeräpäivä osuu käsiteltävälle ajanjaksolle.

59/99
5.5 Tietokannan ryvästyksen suunnittelu eräajoille sopivaksiAikaisemmissa järjestelmissä peräkkäiskäsittelyn haittana on ollut se, että sopimusnumero ja pääeräpäivä eivät välttämättä korreloi keskenään ja että kaikki tiedot on järjestetty vakuutusnumeron, asiakasnumeron tai vastaavan tunnisteen eli ID:n perusteella. Tietokannan käsittelyn kannalta järjestyksellä on merkitystä.
Kaikkein parasta olisi, että käsiteltävät tiedot ovat juuri samassa järjestyksessä kuin eräajo niitä pyrkii käsittelemään ja mahdollisimman lähellä toisiaan. DB2 järjestelmä pystyy tosin hyödyntämään hyppivää perättäislukua, jossa osaa riveistä ei käsitellä, mutta siitä huolimatta voidaan käyttää asynkroonista lukua.
Nyt kuitenkin esimerkiksi Autoturvajärjestelmässä suurin käsittelytarve on pääeräpäivään perustuva uudistus. Tällöin ihanteellisinta olisi, että vakuutussopimukset olisivat ryhmitelty systeemin, pääeräpäivän ja juoksevan numeron perusteella yhteen, tiiviiseen joukkoon. Käytännössä tämä toteutettiin niin, että vakuutustunnuksen kolme ensimmäistä numeroa kertovat sovellustunnuksen eli mistä vakuutuslajista on kyse. Seuraavat kaksi numeroa ovat pääeräpäivästä johdettu juokseva tunniste. Tämä tunniste on juokseva päivän numero vuoden alusta jaettuna vakiolla 3,7. Tällöin syntyy kaksinumeroinen tunniste, joka ryhmittelee vakuutukset sovelluksen sisällä summittaisen pääeräpäivän mukaiseen järjestykseen.
Vakuutuksen ID muodostuu siis "XXX YY NNNNNNN T" -formaatissa, missä
XXX = sovellustunnusYY = pääeräpäivän juokseva tunniste jaettuna 3,7:llaNNNNN = normaali vakuutuskohtainen tunniste T = tarkistusmerkki
Taulukko 11. Sopimusnumeron muodostaminen fyysisen käsittelyjärjestyksen mukaan. Näin tehtynä pääeräpäivään perustuva uudistus tehostuu merkittävästi, testien mukaan nopeus on nelinkertainen ja hinta 28% edullisempi.

60/99
Jos ryvästys on kunnossa, voidaa käsiteltävää aineistoa hakea kannasta peräkkäistiedostoihin hyödyntäen COP periaatetta, yksi tauluryhmä kerrallaan ja ilman mitään lukituksia (lukitustaso uncommitted read eli UR). Jos ajoon tulee mukaan liian tuoreita rivejä, ne hylätään ja sen sopimuksen numero, johon nämä tiedot ovat sidoksissa, kirjataan ohitettavaksi. Rivi havaitaan liian tuoreeksi, jos rivin LAST_MOD-TIMESTAMP (eli aikaleima, joka kertoo koska viimeisin päivitys on tehty) on ajokokonaisuuden aloitushetkeä tuoreempi.
Kun kaikki tauluryhmät ovat käsitelty, lajitellaan tiedot sopimuksittain. Varsinainen eräohjelma, kuten uudistus, käsittelee nyt sopimukset yksi kerrallaan hyödyntäen peräkkäistiedostoa. Varsinaista tietokantakäsittelyä on hyvin vähän, lähinnä lukija erilaisista parametritauluista - ja niissäkin hyödyntäen aina kuin mahdollista muistinvaraista puskurointia.
Päivittävät rutiinit kirjoittavat lisättävät ja päivitettävät tiedot peräkkäistiedostoon. Vasta seuraavassa vaiheessa nämä muutokset kirjoitetaan operatiiviseen kantaan. Tätä kirjoitusta varten Autoturvassa joudutaan päivitettävät sopimukset lukitsemaan. Useampaan osaan jaetussa ajossa lukituksia ei voida toteuttaa tietokantaohjelmiston lukoilla, vaan kyseessä on itse koodattu ohjelmallinen lukitus. Samalla tarkistetaan, ettei käsiteltäviin sopimuksiin ole tehty muutoksia eräajon aloitusleiman jälkeen. Ne sopimukset, joita on muutettu eräajon aloituksen jälkeen tosiaikaliittymästä, hylätään. Muutos todennäköisesti vaikuttaisi hinnoitteluun ja koko sopimus pitää käsitellä kokonaan uudestaan seuraavassa eräajossa.
Kaikki lisäykset tehdään LOAD apuohjelmalla, optiolla SHRLEVEL CHANGE. Kun kanta on suunniteltu sellaiseksi, että yksittäiseen sopimukseen voidaan lisätä rivejä sen eheyden kärsimättä, ei mitään lukituksia periaatteessa tarvita. Kuitenkin eräajot kannattaa suunnitella sellaiseksi, että LOAD ajon ollessa käynnissä ja sen mahdollisesti keskeytyessä ei osittain ladattuja sopimuksia pääsisi päivittämään. Tämä ratkaisussa lukitus on nyt toteutettu loogisilla lukoilla eli järjestelmään toteutettiin muutos, jossa sopimuksen ylimmän tason

61/99
rivillä on "käsittely-kesken?" attribuutti ilmoittamaan sopimuksen olevan vielä kesken. Tästä syystä tarvitaan vielä onnistuneen ajon päätteeksi ajo, joka päivittää "käsittely-kesken" attribuutin arvoon, josta käy ilmi sopimuksen olevan taas täysin käytettävissä.
Tietokannan ryvästyksen muuttaminen jälkikäteen
Opinnäytetyössä oli tarkoitus tutkia myös olemassa olevan, jo kokonaan toteutetun ohjelmiston ja tietokannan tehostaminen. Tämä ohjelmisto, LARE eli Laskutus ja Reskontra, hyödyntää P2000 tietokantaa, joka jakaantuu useampaan kohdealueeseen. Yksi näistä kohdealueista, laskualue, käyttää kannan klusteroivana avaimena laskunumeroa. Koska eräkäsittelyssä käsitellään tietoja lähes poikkeuksetta sopimusalueen mukaisessa järjestyksessä, aiheutuu tästä epäyhteensopivasta järjestyksestä hajakäsittelyä. Tämä on ollut alkuperäisessä suunnitelmassa eräs tärkeimmistä tehostuskohteista. Kuitenkin on huomattava, että LARE tehostus ei ole missään nimessä puhdas COP/IPO ratkaisu, vaan siinä on yritetty saada peräkkäiskäsittelyn etuja koskematta perinteisellä tavalla toteutetun ohjelmiston logiikkaan.
LARE eli laskutuksen ja reskontran tietokannassa on 6 tietokantataulua. Tällä hetkellä on tiedossa, että nykyinen tietokannan rakenne, missä tiedot ovat järjestetty maksusuorituksen mukaan, ei ole tehokas, varsinkin kun sitä verrataan muihin tietokanta-alueisiin, joissa tietojen ryvästys eli tallennusjärjestys on määritetty yksinomaan pääavaimella, kuten sopimusnumerolla. Maksut kuitenkin talletetaan saapumisjärjestyksessä, jolloin täsmäytettäessä niitä joudutaan lukemaan sopimustietokantaa satunnaisessa järjestyksessä. Tällöin peräkkäiskäsittely ei ole mahdollista.
LARE kannan klusteroinnin muuttamisella on tarkoitus tehostaa järjestelmiä, erityisesti LAREn maksunkirjausohjelmistoa. Kolmessa taulussa tallennusjärjestykseksi muutetaan sopimusnumeron mukainen klusterointi. Tällöin I/O operaatioiden määrä vähenee ja ohjelmiston suorituskyky paranee.

62/99
Jotta opinnäytetyötä varten voidaan todentaa ohjelmistojen suorituskyvyn parantumista, tarvitaan sopiva testiohjelma. Alun perin oli tarkoitus käyttää testaamisessa varsinaista maksunkirjaamisohjelmistoa, jonka päämoduuli on M144MVK.
Hyvin yksityiskohtainen analyysi LARE maksunkirjausohjelmasta osoitti kuitenkin, että kyseessä on tavattoman monimutkainen ohjelma, sillä esimerkiksi kutsupuu, eli CAB-tree raportti tuottaa 11750 riviä. Ajatus siitä, että maksunkirjausohjelmistoa voitaisiin käyttää suoraan tai rakentamalla siitä oma ajokelpoinen kopion olisi ollut työmäärältään lamauttava.
Tarkempi analyysi osoitti, että tehostettavan maksunkirjausohjelman kuormasta lähes 70 % aiheutuu kuudessa eri alimoduulissa, joissa on suhteellisen vähän toiminnallisuutta. SQL-lausetta näissä oli vain 29. Näiden lauseiden kopiointi COBOL kielisistä moduuleista ja järjellisen logiikan selvittäminen oli selvästi vähemmän vaativa tehtävä, kuin alkuperäiseen ohjelmistoon puuttuminen.
Testiohjelma
Testausta varten luotiin PL/1 kielinen testiohjelma, johon otettiin mukaan merkittävä osa LARE:n maksunkirjausohjelman raskaista SQL-lauseista.
Ohjelman nimi on M144Z01, sen lähdekoodi sijaitsee normaaliin tapaan Panvaletissa, P070.TEST.PVLSCE(M144Z01) ja lähdekoodin koko on 1175 riviä, mukaan lukien ohjelman kommentointi. Ohjelmaa ajetaan IKJEFT01 alla, eli kyseessä on erä-TSO.
Koska INSERT lauseet ovat merkittävä kuormanaiheuttaja ja koska klusteroinnin muutoksen pitäisi vaikuttaa juuri INSERTien tehostumisessa, testiohjelmassa pitää olla mukana INSERT lauseita. Toisaalta tietokantaan ei saisi muodostua mitään asiaankuulumattomia rivejä. Tämä on ratkaistu sillä, että ohjelmassa lisätään rivejä, mutta ohjelman lopussa on COMMIT komennon sijasta ROLLBACK-komento, jolloin testirivit eivät jää häiritsemään varsinaista dataa.

63/99
Oikeastaan ainoa merkittävä poikkeama alkuperäissuunnitelmasta on ollut moduulin IVA0021 jättäminen pois, mutta se ei 1,6 % osuudella ollut mitenkään merkittävä.
Testiohjelman syötteen muodostaminen
Alkuperäisessä maksunkirjausohjelmassa maksut tulevat INPUT-taulun kautta käsiteltäväksi. Nyt tässä testiohjelmassa jäljitellään maksujenmuodostamista, niin että kaikki kantaluvut muodostetaan takaperin. Nyt lähdetään jo olemassa olevista ACCT_ENTRY_RA tiedoista ja liitetään mukaan kaikki isätaulut, jolloin muodostuu syöttötiedosto, jota voidaan käyttää näiden SQL-lauseiden hakuehtojen toteuttamiseen. Tässä on lista käytetyistä tauluista (huom. taulujen nimet muutettu tietoturvasyistä):
POHJOLA.MAKSU_RA
POHJOLA.KP_VIENTI_RA
POHJOLA.LASKUN_DET_RA
POHJOLA.LASKU_RA
POHJOLA.VELO_PALAUTUS _AG
Koska testiaineisto generoidaan jo olemassa olevista tapauksista, ei kannan ja testitiedoston välille pääse muodostumaan ristiriitaa.
Kuva 8. Maksukirjausajon kuormituksen muodostuminen sekä ajoaikana että CPU-kulutuksena mitaten.
Materiaalin järjestys

64/99
Materiaali tulee käsittelyyn täsmälleen siinä aikajärjestyksessä, missä se saapuu INPUT-tauluun. Seurauksena on, että käsiteltävä aineisto ei ole asiakkaan tai vakuutussopimuksen mukaisessa järjestyksessä. Tämä väistämättä heikentää ohjelman nykyistä toimintaa ja heikentää tietokannan fyysisen järjestyksen muutostyöstä saatavaa tehostamisvaikutusta.
Ohjelmistossa löytyi SQL-lause, joka tarkistaa COMMIT / CHECK-pointin jälkeen, että synkronisointi on kunnossa ja kantaan ei olla ajamassa useampaan kertaan samaa materiaalia. Tätä kyselyä helpottavaa indeksiä DB2T.POHJOLA.RA0331N2 ei ole vielä implementoitu tuotantoon. Indeksi luodaan nyt tämä lopputyön yhteydessä, jolloin ajokustannukset pienenevät arviolta 10 prosenttia. Huomattavaa on, että läpimenoaika ei parane kovin merkittävästi uuden indeksin avulla, johtuen materiaalin pysymisestä puskurialtaassa.
Testiajon suorituksesta
Oletuksena oli, että koska laskut luodaan asiakkaan itse valitseman eräpäivän mukaisesti, niin laskujen järjestys olisi täysin hajanainen ja käsittely olisi valtaosin hajakäsittelyä. Erätestiohjelmaa ajettaessa testikannassa ei tällaista hajakäsittelyä ollut läheskään niin paljon kun olisi voinut olettaa. Satunnaiset otokset tuotantokannasta osoittavat, että ajoittain sopimusnumeroiden ja laskunumeroiden järjestys on yllättäen täysin yhtenevä. Toisaalta löytyi myös otoksia, jossa laskunumeron järjestys poikkesi merkittävästi sopimusnumerojärjestyksestä.
Syynä tähän hieman yllättävään yhdenmukaiseen järjestykseen on ilmeisesti laskujen syntyhistoria. Normaalisti sopimusnumerolla ja laskunumerolla ei ole mitään yhteyttä toisiinsa, mutta koska sopimusten ja sopimusnumeroiden luominen tapahtuu nousevassa järjestyksessä, tämä luontijärjestys määrää koska sopimus uudistetaan ja koska laskut syntyvät. Vain niissä tapauksissa, jossa asiakas on erikseen muuttanut oletuksenvaraista eräpäivää tai sopimukseen on tehty muita maksutapaan liittyviä muutoksia, rikkoutuu lasku- ja

65/99
sopimusnumeron järjestyksen yhtenevyys. Nyt tässä yhteydessä on käynyt ilmi, että asiakas käyttää tätä valinnanvapautta suhteellisen harvoin, jolloin sopimuksen elinkaaren alussa sattumalta sopimus- ja laskunumerojärjestys täsmäävät.
Kuinka epäjärjestystä mitataan?
DB2 tulkitsee tietojen olevan järjestyksessä, jos sivu on "sivujärjestyksessä" (page-sequential) eli jos luettava sivu on viimeisimmästä sivusta korkeintaan 16 sivun päässä eteenpäin. Jos neljä viimeisimmästä kahdeksasta sivusta ovat sivujärjestyksessä, tietojen katsotaan olevan järjestyksessä (data-sequential).
Miten selvitetään, kannattaako klusteri-avainta vaihtaa? Tämän selvittäminen ei ollut kovin helppo tehtävä. Seuraavia testijärjestelyjä harkittiin:
1. Halutun aineiston sisältävästä tietokantataulusta voidaan tuottaa tiedosto, joka ensin lajitellaan INVOICE_ID mukaiseen järjestykseen. Toinen tiedosto muodostetaan samasta taulusta, mutta nyt lajiteltuna AGMT_ID mukaiseen järjestykseen. Vertailemalla tiedostoja olisi mahdollista saada selville järjestyksen muutos.
2. Järjestys voidaan määrittää myös yhden tiedoston sisältöä tutkimalla. Tällöin muodostaan tiedosto, joka lajitellaan olemassa olevaan laskunumero eli INVOICE_ID mukaiseen järjestykseen. Vertaamalla tämän jälkeen tiedostossa olevia sopimusnumeroita (AGMT_ID) voidaan päätellä, onko aineisto järjestyksessä.
Näissä molemmissa oli kuitenkin se ongelma, että käytettävissä ei ollut ohjelmaa, jolla olisi voinut tutkia tavallisen peräkkäistiedoston epäjärjestyksen asteen sillä tavoin kuin DB2 järjestyksen tulkitsee. Itse asiassa DB2:n määritelmä järjestyksestä ei ole niin tiukka kuin voisi luulla. Kaksi riviä, joiden tulisi olla peräkkäin ja joiden välissä on muita rivejä, voivat sittenkin olla DB2:n kannalta järjestyksessä, kunhan ne ovat samalla sivulla.
Ratkaisu epäjärjestyksen mittaamiseen

66/99
Tutkimalla DB2:ssa käytettyä määritelmää järjestyksestä, ratkaisu oli melko ilmeinen. Koska DB2:lle on hyvin tärkeää, onko aineisto omalta kannaltaan klusterijärjestyksessä, vertailussa tulee käyttää vain DB2:n omia CLUSTERED ja CLUSTERRATIO tunnuslukuja. Tämä saadaan aikaiseksi muodostamalla edellisessä kappaleessa kuvattu laskunumerojärjestyksessä oleva tiedosto ja lataamalla se omaan taulutilaan (ja tauluun) siinä järjestyksessä.
Kun aineisto on ladattu tauluun, luodaan taululle klusteroiva indeksi sopimusnumerojärjestystä varten. Mitään uudelleenjärjestelyitä ei saa tässä yhteydessä tehdä. Kun indeksi on luotu, ajetaan taulutilalle RUNSTATS ajo, jonka raportti paljastaa, kuinka hyvässä sopimusjärjestyksessä laskunumerot ovat.
Saadut tulokset
Testikannassa ajettu analyysi 35.000 riville paljasti, että ryvästysjärjestys sopimusten ja laskujen suhteen on 84 %. Tällöin olisi ollut hieman kyseenalaista toteuttaa taulujen uudelleen klusterointi, koska saadut hyödyt eivät vastaisi vaadittavaa työpanosta. Toisaalta järjestys on aavistuksen verran liian huono, sillä DB2 jätti indeksille NOT CLUSTERED tilan päälle.
Koska testikannan tulokset antoivat kriittisen tuloksen, ei tuotantokannasta kannattanut ottaa otoksia, vaan tässä projektissa päätettiin analysoida koko 32 miljoonan rivin laskutaulu. Lukuun ottamatta suurempia tilavarauksia tehtävä oli varsin suoraviivainen. Pienellä apuohjelmalla muodostettiin tiedosto, jossa oli laskunumerot ja sopimusnumerot, eikä mitään muuta dataa. Järjestyksenä oli laskunumerojärjestys.
Tuotantotiedoista muodostettu tiedosto ladattiin LOAD apuohjelmalla tätä varten luotuun aputauluun. LOAD apuohjelma jättää taulun samaan järjestykseen kuin ladattava tiedosto. Tämän jälkeen luotiin klusteroiva indeksi sopimusnumerojärjestystä varten. Tällä kertaa DB2:n runstats ajo raportoi vain 41 % järjestystä. Näin huono järjestys laukaisee luonnollisesti myös NOT CLUSTERED tilan eli taulua ei kannattaisi lukea peräkkäisesti laskunumerojärjestystä tukevaa

67/99
indeksiä käyttäen. Tämä on selvästi huonompi tulos kuin testikannassa ja tällaisessa tapauksessa taulun ryvästysjärjestyksen muutostyö on perusteltua.
Mikä oli syynä testikannan ja tuotantokannan erilaiseen järjestykseen? Todennäköinen selitys on, että testitapaukset ovat useimmiten luodut tiettyyn tilanteeseen. Niissä ei näy pidemmän elinkaaren aiheuttamia vaikutuksia, mikä ei normaalisti tuo ongelmia.
LARE kannan partitiotavan muuttaminen
Työn edetessä osoittautui, että kolmessa LARE tietokannan taulussa ei ole lainkaan saraketta, josta kävisi ilmi mihin sopimukseen kyseiset rivit kuuluvat. Tällöin partitionti on suoritettu erillisellä PART-ID attribuutilla, joka kertoo ylimalkaisen sopimuslajin. Tämä piirre vaikeuttaa huomattavasti tehokkaan kantaratkaisun toteutumista, mutta kyseessä on niin perustavaa lajia oleva ongelma, että sitä ei voida tämän työn puitteissa korjata.
Eräajojen tehostuminen jäänyt näyttämättä toteen
Laskunkirjausajon testiohjelma ajettiin 30.9.2009 tuotantokantaa vasten. Tällöin vasteaika per SQL-lause oli 47 ms ja CPU kulutus lausetta kohden oli 2,2 ms. Viimeisimmän kerran testiohjelma ajettiin tuotantokantaa vasten 16.4.2010. Tällöin tulokset näyttivät vasteajan osalta 22 ms ja CPU kulutus oli 1,4 ms. Tulokset näyttävät siis hyvin lupaavilta.
Ovatko luvut vertailukelpoisia? Onko tehostaminen siis onnistunut? Tarkemmin tutkimalla osoittautui, että mittauksen kalibroinnissa käytetty SET HOST lause osoittaa sekä vasteajan että CPU kulutuksen osalta erittäin merkittävää paranemista - mitä ei olisi pitänyt ilmetä. Samaa ilmenee myös niissä tauluissa, joihin ei ole muutostyön osalta koskettu eli maksu- ja maksutapahtumataulujen käsittelyssä.
Erityisesti vasteaika on hyvin vaikeasti mitattavissa, koska laiteympäristössä oleva muu kuorma vaikuttaa mittauksiin. Myös CPU kulutus kasvaa tilanteissa joissa keskuskone on hyvin kuormitettuna. Tästä syystä tarkastelussa pitää kiinnittää huomiota niihin kohteisiin, joita projektissa on työstetty. Veloitustietojen käsittely olisi numeroiden

68/99
valossa tehostunut 30 % ja veloitusrivien käsittely 17 %. Suurin osa tästä säästöstä näyttää muodostuvat pienentyneenä I/O operaatioiden (eli getpage) määrässä. Uudelleenorganisoidut tiedot ovat nyt kannassa lähempänä toisiaan ja samoilta sivuilta saadaan esille enemmän käsiteltäviä rivejä. Käytännössä saavutettu tehokkuusero on kuitenkin liian lähellä normaalia suorituskykyvaihteluväliä, joten näiden lukemien perusteella ei voida havaita merkittävää tehostumista.
Se mitä tässä testeissä ei ole havaittu, on DB2 peräkkäislukemisen käynnistyminen. Tästä voimme todeta, että LARE ei muutostyön jälkeen noudata edelleenkään COP-periaatetta. Koska ohjelma käsittelee vain yhden sopimuksen maksutapahtumat kerrallaan, käyden useammassa tietokantataulussa, niin peräkkäislukua kontrolloivat sisäiset laskurit eivät ehdi huomata prosessin etenevän taulujen lukemisessa aidosti nousevassa järjestyksessä. Johtopäätös on selvä, paljon hajakäsittelyä tekevää prosessia ei DB2 pysty optimoimaan edes niiden taulujen osalta, joissa peräkkäiskäsittely olisi mahdollista ja suotavaa.
Tosiaikainen käyttö tehostunut
Vaikka LARE kantamuutos ei tuottanut haluttua lopputulosta eräkäytössä, niin muutostyö on ollut hyödyllinen. Ensimmäinen seikka oli että nyt partitiojako vastaa selkeämmin sovellusten tuottamia rivimääriä. Itse asiassa vanhalla tavalla tehty partitiojako olisi täyttynyt arvioiden mukaan puolen vuoden sisällä, joten muutostyö oli välttämätön.
Toinen piirre on ollut tehostunut tosiaikakäyttö. IVA019 moduuli on käytössä kolmessa tosiaikatapahtumassa, joiden kuormitus jakaantuu Mittaturvan hyväksymisen 61 % ja Autoturvan hyväksymisen 39 %. Oiva-järjestelmän kuormitus on alle 1 %.
Vertailtuna Mittaturvan hyväksymisen käyttäytymisen muutosta, havaitsemme että aikaisemmin kallein IVA019 moduulissa tapahtuva rivien lisääminen (eli INSERT) on nopeutunut ja kuormittaa tapahtumaa 4,2 % aikaisemman 6,4 % sijasta. Nämä havainnot on tehty pidemmän aikajakson kuluessa, jolloin satunnaiset kuormitushuiput ole päässeet vaikuttamaan tilastoihin. Voimme arvioida, että paremmin

69/99
tapahtumien järjestystä noudattava tietokanta vähentää I/O operaatioiden määrä ja siten tehostaa toimintaa.
5.6 Parannettu IPO tekniikkaOngelmana IPO tekniikassa on selvästi jälkikäteen tehtävä ohjelmien tehokkuuden korjaaminen. Tietokantakutsuja ei käytännössä pysty korvaamaan peräkkäistiedostoilla, koska kantaa lukevien käskyjen tarkkaa järjestystä ei käytännössä pysty määrittelemään, esimerkiksi erilaisten ehdollisten toimintojen takia.
I/O-toimintojen täydellinen eristäminen muusta logiikasta on erittäin työläs vaihtoehto. Erään OP-Pohjolan järjestelmän uudistusajon uudelleenkirjoittamisen työmääräarvio oli 10 henkilötyövuotta. Tämä pidentää takaisinmaksuaikaa huomattavasti ja yhdistettynä siihen, että varsinaisen CPU-tunnin hinta on ollut jatkuvasti laskussa, investointihalukkuus jää täysin ymmärrettävästi heikoksi.
Pystyisikö olemassa olevia ohjelmia muuttamaan niin, että varsinaisen logiikan seassa olevat tietokanta I/O-moduulit lukisivatkin jo muistissa olevia tietoja? Tehtävä on yllättävän haastava, koska tapa, jolla keskuskoneessa käytössä olevat COBOL, PL/1 tai C varaavat muistia kun ohjelma koostuu aliohjelmista, ei mahdollista yhteisten muistialueiden käyttöä. Ainoana poikkeuksena on muistialue, jota välitetään pääohjelmasta aliohjelmiin kutsurakenteessa (käytännössä itse asiassa kutsuissa välitetään osoitetta muistialueeseen). Jos yhteistä muistialuetta halutaan välittää kattavasti pääohjelmasta kaikkein alimpiin moduuleihin - tässä tapauksessa juuri I/O-operaatioita kontrolloiviin rutiineihin, joudutaan kaikkien ohjelmien kutsulauseita ja kutsurajapintaa muuttamaan kautta linjan. Tällainen vaihtoehto ei ole OP-Pohjolan ympäristössä mahdollista vaaditun työn laajuuden takia.
Onko olemassa mitään keinoa välittää aliohjelmaan pääohjelman muistialueen osoitetta ilman että käyttää kutsurakennetta? Eräs ratkaisu on tallentaa muistialueen osoite ulkoiseen tiedostoon. Vaikka ulkoinen tietolähde on paljon huonompi ratkaisu kuin muistialueen osoittaminen, näin toteutettuna voidaan jättää huomioimatta kaikki aliohjelmakutsut.

70/99
Jotta tämä ratkaisu voidaan testata, tarvittiin testiohjelma, jolla mitataan kuinka nopeata on lukea tilapäisestä taulusta sinne talletettu muistialueen osoite. Ohjelma M998U03 luo tilapäistaulun, kirjoittaa sinne yhden rivin, joka sisältää muistialueen osoitteen ja lukee sen 10.000 kertaa. Saatua tulosta voidaan verrata ohjelmaan, joka lukee tietokantaa 10.000 kertaa.

71/99
Stmt Call Sect Stmt SQL +------- Total IN-SQL Time -------+ Program Type Type No. No. Calls Elapsed % CPU % M998U03 STATIC SELECT 4 68 10001 00:04,69638 87,2% 00:00,12302 79,5% Averages: 00:00,00047 00:00,00001 Highs: 00:01,29735 00:00,00195 Lows: 00:00,00001 00:00,00001 +-----------------------------------------------------------------------M998U03 STATIC DECLARE 1 35 2 00:00,54169 10,1% 00:00,02720 17,6% M998U03 STATIC SELECT 3 57 2 00:00,12532 2,3% 00:00,00223 1,4% M998U03 STATIC INSERT 2 46 2 00:00,02165 0,4% 00:00,00190 1,2%
YK05 10356 00:40,44190 1,0% 00:00,96942 0,5% Averages: 00:00,00391 00:00,00009 Highs: 00:00,71791 00:00,00375 Lows: 00:00,00000 00:00,00000
Taulukko 12. Välitaulun käyttäminen muistiviittausten välittämiseen.
Tulos on suhteellisen suotuisa. Muistista haetut tiedot saadaan tällä keinolla keskimäärin 1/9 kustannuksella, vaikka olettaisimme että jokainen tietokantaa käsittelevä moduuli palauttaisi vain yhden rivin. Rivien lataaminen muistiin aiheuttaa oman kustannuksen, mutta asynkronisesti läpiluettu tietokanta tuottaa tulosjoukon niin paljon nopeammin ja edullisemmin, että todennäköisesti tämä kuvattu ratkaisu voisi olla realistinen.
Suurin työ olisi tällä mallilla rakentaa erilliset tietokantakäsittelymoduulit, jotka osaavat a) hakea dataa osoitteen määräämästä muistipaikasta ja b) palauttaa sen samalla formaatilla kuin tosiaikakäyttöön tarkoitetut moduulit tekevät. Tämä parannettu IPO malli ei kuitenkaan enää kuulu lopputyön aihealueeseen.

72/99
6 Ratkaisun toimivuuden todentaminen
6.1 SuorituskykySuorituskyky on koko opinnäytetyön ydin. Jos uusi malli ei ole riittävän suorituskykyinen, ei ole mitään järkeä rakentaa erillistä eräohjelmistoa, varsinkin kun samoja toimintoja joudutaan rakentamaan myös tosiaikasovelluksiin.
6.1.1 Tuotantotestit AutoturvasovelluksessaTestiympäristössä ajettuja testejä vastaavat testit ajettiin tuotantoympäristössä (db2p) sunnuntaina. Tuotantotestissä otettiin mittaturvasopimuksista 10 % otanta numerovälirajauksella. Tätä joukkoa karsittiin lisäksi eräpäivärajauksella. Näin poimittu joukko on 10 % mittaturvasopimuksista, joiden vakuutuskauden päättymispäivä on 15. – 31.12.2008.
Ajon nimi Cpu
sek.
Suoritusai
ka
Sopimuksi
a
Tuottei
ta
Kohteit
a
Z187mk51 71,38 7.18,83 2 694 16 864 16 948
Z187mk52 9,75 1.42,48 2 694 16 864 16 948
Z187mk53 5,56 0.13,68 2 694 16 864 -
Laskuja
Z187mk54 64,39 3.22,44 2 592 4 338 -
Z187mk55 79,25 4.44,84 2 694 4 338 -
Z187mk57 78,66 4.34,32 2 694 4 338 -
Taulukko 13. Tuotantomateriaalilla havaitut erot erilaisien ratkaisujen (COP ja perinteinen tapa) välillä.
Ajojen ominaisuudet ja erityispiirteet
Z187mk51- Erikseen luetaan sopimuksen tuotteet, edelleen erikseen tuotteeseen liittyvät kohdeyhteydet, edelleen erikseen kohde. Tämä vastaa täysin perinteistä ohjelmointityyliä.

73/99
Z187mk52 - Käytetään COP-tekniikkaa varten suunniteltua pääkursoria, johon on liitetty tuoteyhteydet, tuotteet, kohdeyhteydet ja kohteet.
Z187mk53 - Kuten Z187mk52, mutta kohteita ei luettu.
Z187mk54 - Pääkursoriin on liitetty myös laskut, laskujen detaljitiedot, tilitykset, tilitysten detaljitiedot, maksutiedot ja maksajan nimitiedot. Laskujen fyysinen järjestys ei ole COP tekniikan suositusten mukainen, mutta näin tehtynä ohjelmassa on vähemmän ohjelmoitavaa.
Z187mk55 - Pääkursorin sijasta käytetään apukursoria, jolla haetaan laskut, laskujen detaljitiedot, tilitykset, tilitysten detaljitiedot, maksutiedot ja maksajan nimitiedot. COP suositusta ei huomioitu lisä-tietojen hakemisessa.
Z187mk57 - Kuten Z187mk55, mutta nimitietoja ei haettu.
Tuotantomateriaalista voitiin päätellä, että COP tekniikka tuottaa erinomaisia tuloksia, mutta asynkroninen tiedonhaku häiriintyy helposti, jos ohjelma poikkeaa fyysisestä järjestyksestä. Tehostumisvaikutus on kustannusten suhteen (mk51 vs. mk52) 87 % ja läpimenoajan suhteen erittäin merkittävä 97 %.
6.1.2 Tuotantotestit LARE sovelluksessaLARE järjestelmän muutostyö kohdistui yksinomaan tietokantaan. Sovelluksen muuttamiseen ja muutoksen testaamiseen ei ollut resursseja. Testiajot osoittivat, että vaikka I/O-kuorma muuttui hieman otollisempaan suuntaan, ei tehostumisefekti ollut lähelläkään Autoturvajärjestelmän tuloksia. Syitä tähän on useita.
1) Syötteenä toimiva materiaali ei ole riittävän hyvin sopimusjärjestyksessä.
2) Kaikkia tauluja ei saatu partitioitua sopimusnumeron mukaiseen järjestykseen.
3) Ohjelmistot lukevat samanaikaisesti myös muita DB2 tauluja, jolloin tietokannanhallintajärjestelmä ei pysty optimoimaan hakutoimintoja.
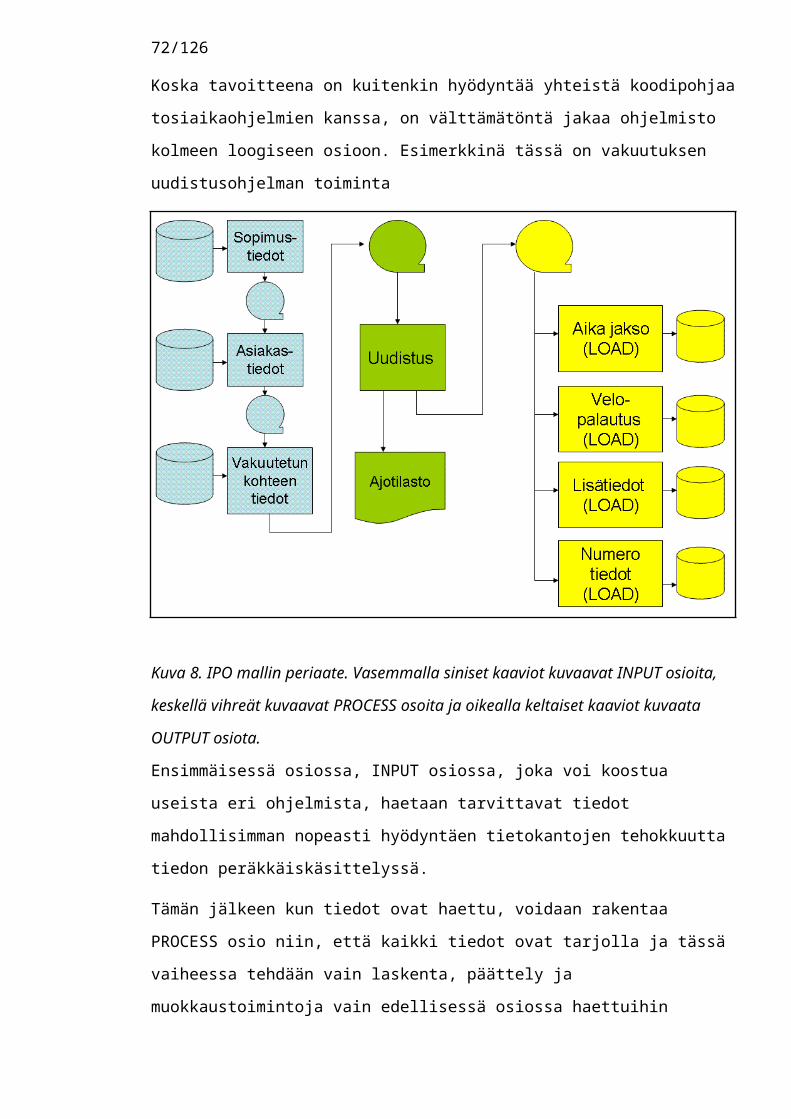
74/99
DB2 ei pysty käynnistämään peräkkäislukua eli dynaamista prefetch-toimintoa, koska samassa loogisessa työkokonaisuudessa eli LUW:ssa luetaan runsaasti muitakin tauluja.
Peräkkäisluvun puute tekee olemassa olevan ohjelman tehostamisen lähes mahdottomaksi, jos sovelluslogiikkaan ei puututa. Tässä työssä on hahmoteltu parannettua IPO ratkaisua, mutta se on vielä teorian tasolla. Havainnot siitä, että valmiin ratkaisun tehostaminen on vaikeaa tai lähes mahdotonta, tukee COP/IPO ratkaisun merkitystä. Myös LARE järjestelmän testit osoittavat, miten asynkroninen tietojen lukeminen on vaikea saavuttaa.. Hyviin tuloksiin ei voi päästä, ellei työtä tehdä alusta alkaen tehokkuuden näkökulmaa huomioiden.
6.2 ToimintavarmuusToimintavarmuus on tyypillisesti eräajoissa hyvin tärkeä näkökulma. Tällä tarkoitetaan lähinnä sitä, että jos ohjelma ilmoittaa käsitelleensä 5000 sopimusta, niin todellakin nämä ovat käsiteltyinä. Eräajo voi kaatua eli päättyä virhetilanteeseen missä vaiheessa tahansa. IPO – menetelmässä lähdetään siitä, että kaikki Input ja Process vaiheet voidaan uudelleen käynnistää ilman että tietojen eheys häiriintyy.
6.2.1 Autoturvan toimintavarmuusAutoturvajärjestelmässä toimintavarmuus on taattu usealla eri keinolla. Lukevat INPUT prosessit ovat hyvin keveitä ja ne voidaan tarvittaessa ajaa uudestaan. Tällöin ei tarvita monimutkaisia rutiineita ajon uudelleenaloittamiseen ja jo poimitun materiaalin synkronisointiin. Muuten virherutiineissa on normaalit varotoimenpiteet sisäisten ja ulkoisten virheiden varalta. Itse varsinainen Autoturvan uudistus, eli PROCESS osio, ei päivitä lainkaan kantaa ja on sellaisenaan myös kokonaan ajettavissa uudestaan.
OUTPUT osiossa joudutaan hieman monimutkaisempien ongelmien kanssa tekemisiin. Teoriassa on mahdollista suunnitella tietokanta, jossa rivien lisääminen kantaan ei aiheuta mitään päivitystarvetta muihin riveihin, mutta käytännössä haluttiin estää tilanne, jossa käyttäjä käsittelisi jonkin häiriötilanteen takia osittain uudistettua sopimusta.

75/99
Autoturvassa on nyt käytetty pitkään COP/IPO tekniikalla toteutettuja eräajoja ja häiriöt ovat erittäin harvinaisia. Lisäksi häiriöistä toipuminen on helppoa ja poikkeustapauksissa on nyt uuden tekniikan myötä täysin mahdollista ajaa eräajoja myös päiväsaikaan häiritsemättä merkittävästi tosiaikaisia palveluita.
6.2.2 LARE järjestelmän toimintavarmuusLARE järjestelmässä toimintavarmuus parani merkittävästi muutostyön jälkeen, koska uuden kantaratkaisun myötä otettiin käyttöön extended address volumes (EAV) ominaisuus, jonka avulla tietokannan tiedostojen kokorajoitukset väljenivät huomattavasti. Kokorajoitusten väljentäminen tuo operointiin varmuutta ja poistaa yhden potentiaalisen virhemahdollisuuden. Muutoin LARE muutostöissä ei koskettu sovelluslogiikkaan, joten toimintavarmuus tältä osin pysyi ennallaan.
6.3 Rakentamisen ja testaamisen kustannuksetTämä osio perustuu yksinomaan opinnäytetyön käytännön osioihin. Tässä työssä oli harviainen mahdollisuus verrata kahta erilaista lähestymistapaa, eli Autoturvan COP/IPO ratkaisu ja LARE järjestelmän perinteinen ratkaisu, jossa käytetään tosiaikaisia moduuleita ja rutiineita myös eräajojen toteuttamisessa.
6.3.1 Autoturvajärjestelmän rakennus ja testauskustannuksetAutoturvajärjestelmässä tapahtuneen kehitystyön osuutta oli vaikea arvioida. Syynä tähän oli budjetin ja muiden resurssien varaaminen normaaleista malleista poikkeavalla toteutukselle ja se, että siitä seuranneiden hyvin kattavien testien laajuus oli suuri. Mutta jos arvioidaan pelkästään COP/IPO tekniikkaa ja sen aiheuttamia kustannuksia, niin luvussa 4.6.4 esitetyt arviot pitävät riittävän tarkasti paikkaansa ja eri tavalla toteutettuihin moduuleihin ei kulunut merkittävästi enempää aikaa kuin normaaleihin yleiskäyttöisiin moduuleihin kuluu.
Autoturvajärjestelmässä havaittiin käytettäessä COP/IPO tekniikkaa, että testaaminen oli itse asiassa vaivattomampaa kuin normaalisti tietokantasovelluksia rakennettaessa. Syynä oli COP/IPO ratkaisuissa

76/99
käytettävät tiedostot, joita oli mahdollista tallettaa, muokata, monistaa, kirjoittaa käsin alusta alkaen tai käyttää jotain apuohjelmia materiaalin muokkaukseen. Koska tiedostoissa ei ole mitään viite-eheyksiä, niin materiaalin ei tarvittu olla täydellistä, vaan tapauksesta riippuen joidenkin osa-alueiden testaamisessa voitiin käyttää paljon todellista suppeampaa materiaalia. Kustannuksista ei pystynyt kuitenkaan saamaan mitään todellisia lukuja, koska eräajot olivat projektille vain yksi monista osatehtävistä. Silti voidaan arvioida, että rakentamisessa kuluu hieman enemmän aikaa, vastaten luvun 4.6.4 teoreettisia laskelmia ja että testaaminen oli joustavampaa ja nopeampaa kuin normaalisti.
6.3.2 LARE järjestelmien viritys- ja testauskustannuksetLARE tehostamisessa itse tietokannan uudelleenmäärittely ja sen toteutus olivat varsin suoraviivaisia operaatioita, vaikka ne järjestelmien korkeiden käytettävyysvaatimuksien takia jouduttiin toteuttamaan viikonloppuisin yöaikaan. Sitä vastoin olemassa olevan järjestelmän testaaminen on hankalaa, varsinkin kun testiympäristöjä tarvitaan myös normaaleihin virheenselvityksiin ja pienkehityshankkeisiin.
Tästä syystä LARE tehostamisessa rakennettiin testiohjelma, jolla voitiin testata olennaisimpia kohtia kantarakenteesta jäljittelemällä normaalia maksunkirjaustoimintaa. Tällaista testiohjelmaa ei tarvinnut kirjoittaa kokonaan tyhjästä, vaan esimerkiksi kaikki SQL lauseet saatiin kopioitua olemassa olevista ohjelmistoista. Silti ison ohjelman kirjoittaminen ja testaaminen vei aikaa noin 8 henkilötyöpäivää, josta 4 päivää kokonaan omalla ajalla. Ohjelman koon eli n. 1200 rivin mukaan laskettuna työarvio olisi 5000 €, mikä vastaa riittävällä tarkkuudella toteumia.
Testiohjelmaa ei ehkä olisi tarvittu, jos tehostamishankkeessa olisi tyydytty vain toteuttamaan teoreettisesti edullinen muutos ja vasta jälkeenpäin olisi laskutusraporteilla osoitettu muutostyön tuoma etu. Opinnäytetyön vaatima tieteellinen näkökulma kuitenkin puolsi vahvasti erillisen testiohjelman rakentamista - mutta testiohjelmaa ja

77/99
sen rakentamisen kustannuksia ei tule pitää normiratkaisuna tämänkaltaisissa rakennemuutosprojekteissa.

78/99
7 Yhteenveto ja johtopäätöksetMittaukset osoittavat, että fyysisessä järjestyksessä tapahtuva tiedonkäsittely on tehokkaampaa ja nopeampaa kuin hajajärjestyksessä tapahtuva käsittely. Perusongelma on se, että eräajojen tarpeita ei oteta huomioon riittävän ajoissa, jos ollenkaan, ja oletetaan pelkän tosiaikakäsittelyyn suunnitellun ohjelmiston kykenevän riittävän suorituskykyiseen käsittelyyn. Kuitenkaan huolella tehty eräajojen suunnittelu ei ole ristiriidassa tosiaikaohjelmistojen kanssa ja tarvittaessa erä- ja tosiaikaohjelmistot voivat hyödyntää yhteisiä komponentteja. Tämä suunnittelu pitää tehdä ennen ohjelmistojen toteuttamista, sillä valmiisiin ohjelmiin ei pystytä kohtuullisilla kustannuksilla jälkikäteen tekemään prosessien ja I/O-toimintojen erottamista toistaan.
Ihmistyö on uusien järjestelmien rakentamisessa kaikkein kallein menoerä. Tästä syystä nykyaikaisissa järjestelmissä on erittäin järkevää käyttää hyväkseen työtä, joka on jo kertaalleen tehty. Tämä uudelleenkäytettävyys on eräs ICT teknologian tuottavuuden lisäämiseen tarkoitetuista kulmakivistä. Valitettavasti I/O-toimintojen hajauttaminen vaikeuttaa uudelleenkäytettävyyttä. Erottelemalla tarkoin toistaan tiedon haku, tietoliikenne ja varsinainen tiedon prosessointi pystytään rakentamaan paremmin uudelleenkäytettäviä rutiineita. Tämä on kuitenkin tiedettävä jo rakennusvaiheessa. Jälkikäteen tehtävä korjaus ei ole helppoa.
Peräkkäisyyden hyödyntäminen käyttämällä tosiaikasovelluksia varten tehtyjä moduuleita tai olioita on useimmiten mahdotonta. Ainoastaan sellaisia rutiineita, joissa ei ole kantakutsuja tai käytettäessä olio-ohjelmointia, muita olion pysyvyyteen liittyviä kutsuja, on mahdollista käyttää tehokkaissa, peräkkäiskäsittelyä hyödyntävissä eräohjelmistoissa.
Vaikka tässä lopputyössä kustannuksilla on hyvin suuri osuus, ovat suoraan laitteistoista aiheutuneet käyttökustannukset pienentyneet jatkuvasti myös keskuskoneympäristössä. Valitettavasti osa

79/99
kustannuksista aiheutuu varusohjelmistoista, joiden lisenssihinnat eivät ole halventuneet vaan useimmiten ne ovat sidoksissa käytettyyn prosessoritehoon. Mitä enemmän järjestelmässä on ohjelmistoja, sitä tärkeämpää on työllistää prosessorit tasaisesti sekä optimoida suurimmat prosessoriajan syöpöt mahdollisimman tehokkaiksi.
Yleensä pienten ja keskisuurien yrityksien taloushallinnolliset rutiinit sisältävät siinä määrin vähän dataa, että niiden tarpeisiin rakennetuissa sovelluksissa voidaan käyttää myös tosiaikaa varten rakennettuja rutiineita, vaikka silloin tulee helposti esille lopputyössä käsitelty levyn hajakäsittelyn nopeudesta aiheuttava pullonkaula. Suurissa tai muuten runsaasti dataa käsittelevissä yrityksissä kannattaa sovellukset rakentaa huomioiden sovelluskehityksessä ensisijaisesti eräajot ja vasta tämän jälkeen rakentaa tosiaikasovellukset, mieluiten niin, että kriittiset liiketoimintaprosessit ovat yhteiskäyttöisiä ilman I/O-operaatioita. Tinkiminen rakennuskustannuksista kostautuu hyvin nopeasti ja vaatii paljon koneresursseja ja aikaa.
Massamuistien uusi puolijohdepiirejä käyttävä teknologia tulee tehostamaan tehokkuuden kannalta epäoptimaalisella tavalla rakennettuja sovelluksia, jolloin houkuttimet eräajojen kokonaan erilaiseen käsittelyyn tulevat mahdollisesti heikentymään entisestään. Toisaalta mitä enemmän tarvitaan 24 tuntia vuorokaudessa käytössä olevia verkkosovelluksia, sitä vähemmän jää aikaa hyvin raskaille eräsovelluksille, jotka ovat suunniteltu käyttämään tosiajan kanssa yhteisiä palveluita.
Vaikka vanha keskuskoneympäristö ei pysty samalla tavalla houkuttelemaan mediassa ja tietotekniikassa kuumien teknologia-alustojen osaajia, niin eräajojen suhteen kehitystä on havaittavissa. Uudet ilmiöt, kuten hajautettu tietojenkäsittely eli Cloud Computing voivat esimerkiksi Googlen suunnitteleman MapReduce menetelmän kanssa, johtaa hyvin samankaltaisiin ratkaisuihin, kuin tässä lopputyössä on esitetty. Cloud Computing ratkaisuiden siirtoviiveongelmat itse asiassa vaikeuttavat täysin tosiaikaisten sovellusten rakentamista, joten on luultavaa että hajautetun

80/99
tietojenkäsittelyn kehitys painottuu enemmän asynkronisiin ja eräpohjaisiin palveluihin.
Loppulauseena voisi sanoa, että eräpohjainen käsittely on edelleen äärimmäisen tärkeätä ja vaatii hyviä ja tehokkaita ratkaisuja. Tässä työssä on saatu kehitettyä periaatteet, joiden perusteella tehokkaita eräajoja on mahdollista rakentaa ilman että rakennuskustannukset olisivat kokonaisuuteen nähden kohtuuttomat.

81/99
Sanasto
CPU aika
CPU aika on ohjelman tai prosessin vaatima työmäärä prosessorilta, eli Central Prosessing Unit (CPU). Tämä työmäärä on riippuvainen prosessorin tehosta. Jos kyseessä on eri koneissa ajetut CPU-aika mittaukset, eivät ne siis välttämättä ole keskenään vertailukelpoisia.
Joskus raportoitu CPU-aika on normeerattu niin, että luvut ovat vertailukelpoisia tiettyyn, sovitun standardiprosessorin suorituskykyyn. Ongelmana normeerauksessa on kuitenkin, että normeeraus on saatavissa vain hyvin rajoitettuun osaa raporteista ja että kulloinenkin normeerauskaava ei ole kovin helposti saatavissa.
CPU-aika on erittäin riippuvainen keskusmuistissa tapahtuvista operaatioista ja selvästi vähemmän I/O toiminnoista. Huomattavaa on kuitenkin, että jos olio tai dataelementti ei ole valmiina tietokannan välimuistissa (eli puskurialtaassa), niin tällöin vasteaika heikkenee merkittävästi, mutta myös CPU ajan kulutus kasvaa merkittävästi.
CPU aikaveloitus
CPU aikaveloitus on ohjelman tai prosessin käytettyyn työmäärään perustuva rahallinen veloitus. Liiketoiminnan kannalta tämä on selkein ja käyttökelpoisin mittari, mutta CPU-aikaan perustuvalla veloituksella on useita tariffeja riippuen millä tavalla ja millä prioriteetilla kyseinen ohjelma suoritetaan.
Vasteaika (myös läpimenoaika)
Eräajojen ollessa kyseessä, vasteajalla tarkoitetaan läpimenoaikaa, joka lasketaan ohjelman käynnistämisestä siihen hetkeen asti, kun ohjelma on suoritettu. Vasteajalla on merkitystä erityisesti silloin kun ohjelmat tai prosessit lukitsevat yhteisiä resursseja niin, että tosiaikapalveluita tai toisia eräajoja ei voi ajaa samanaikaisesti järjestelmässä. Samanaikainen käyttö on resurssien käytön kannalta erittäin suotavaa, joten niissä tapauksissa joissa ohjelmat eivät lukitse eivätkä

82/99
muutenkaan varaa kriittisiä resursseja, vasteajan merkitys on selvästi pienempi. Historiallisista ja varovaisuus syistä läpimenoajan painoarvo tulkitaan kuitenkin kuten täysin lukitsevalla ajolla.
Vasteaika on hyvin riippuvainen kaikista I/O toiminnoista ja vähemmän keskusmuistissa tapahtuvista operaatioista.

83/99
Eräohjelma (myös taustaprosessi)
Eräohjelma on ohjelma, jota ajetaan tietokoneessa ilman että se käyttää mitään päätelaitteita. Käynnistämisen jälkeen eräohjelma tai prosessi hyödyntää tietokantoja, tiedostoja ja muita resursseja itsenäisesti ilman käyttäjän antamia syötteitä. UNIX ympäristön daemon- eli taustaprosessit ovat myös eräohjelmia, vaikka tyypillisesti tällaiset prosessit ovat suorituksessa aina siihen saakka, kun järjestelmä suljetaan eli ajetaan alas.
Ohjelma (myös prosessi)
Ohjelma on itsenäinen, suorituskelpoinen, yleensä konekielelle käännetty tehtäväkokonaisuus. Käännetystä ohjelmasta poiketen tulkattavat kielet tarvitsevat tulkkiohjelman tai virtuaalisen koneen, jonka alla ohjelma suoritetaan. Tämän tutkimuksen kannalta ei ole merkitystä suoritetaanko eräajoa käännetyllä vai tulkkaavalla ohjelmalla, jos ohjelma on muuten riittävän nopea. Joissakin tapauksissa tulkkauksen vaatima CPU-aika voi olla merkittävä rasite suorituskyvyn kannalta.
Moduuli (myös aliohjelma)
Moduuli on rutiini, joka ei ole sellaisenaan ajokelpoinen, vaan se saa pääohjelmasta syötteitä ja/tai tietorakenteita ja jolle se palauttaa kontrollin suorituksensa jälkeen.
Lähdekoodin rivimäärä (SLOC - Source Line of Code)
Lähdekoodin rivimäärää on käytetty systeemityön mittauksissa määrittämään ohjelmiston kokoa. Lähdekoodin rivimäärä on epäluotettava mittari, sillä eri ohjelmointikielet ja erilaiset koodin muotoilun tyyliseikat vaikuttavat asiaan paljon. Esimerkiksi assembler kieli vaatii satoja rivejä koodia, kun sama ohjelma kirjoitettuna vaikka APL kielellä vaatii vain muutaman symbolin. Myös ohjelmoijan tapa kirjoittaa ja jäsentää koodia vaikuttaa suuresti rivimäärään.
LOAD...SHRLEVEL CHANGE
LOAD apuohjelma on yleensä ohjelma, joka pystyy muodostamaan tietokannan fyysisiä rakenteita ohitse varsinaisen

84/99
tietokannanhallintajärjestelmän. Näin LOAD pystyy hyödyntämään tiedostojen peräkkäisyyttä, sekä välttämään lukkojenhallinnan tai lokiresursejen käyttämistä. LOAD ohjelma ottaa normaalisti koko taulutilan haltuunsa, eikä samanaikainen tietojen käyttö ole mahdollista.
Optiolla SHRLEVE CHANGE apuohjelma poikkeaa tavallisesta LOAD apuohjelmasta siinä, että ladattavien taulujen muu samanaikainen käyttö on sallittua. Normaali LOAD ajo lukitsee koko taulutilan ajon ajaksi. Tässä mielessä LOAD...SHRLEVEL CHANGE muistuttaa lähinnä ohjelmaa, joka tekee nopeasti INSERT + COMMIT käskyjä. Suorituskyky on kuitenkin itse tehtyä vastaavaa ohjelmaa huomattavasti parempi. Testeissä on mitattu viisinkertainen suoritutusnopeus INSERT-lauseisiin verrattuna. Normaali LOAD on kuitenkin selvästi nopeampi kuin SHRLEVEL CHANGE-tyyppinen latausajo.
Tauluryhmä
Englanninkielinen termi SUBJECT AREA. Tarkoittaa joukkoa tietokantatauluja, joissa on sama avain tai avaimen osa, sekä joiden oletusjärjestys on tuon samaisen avaimen (tai avaimenosan) mukaisessa järjestyksessä. Käytännössä tämä tarkoittaa sitä, että nämä taulut voidaan liittää toisiinsa ilman, että asynkrooninen peräkkäisluku siitä häiriintyisi. Oraclen tietokantaratkaisuja käytettäessä tämä saadaan aikaiseksi klusteroimalla useampia tauluja keskenään. Muissa tietokannoissa tauluryhmä saadaan aikaiseksi kontrolloimalla taulun järjestystä niin, että tauluissa olevat avaimet ja/tai viiteavaimet pakottavat fyysisen järjestyksen samanlaiseksi.
Likainen lukeminen
Englanninkielessä Dirty-Read. Tällä tarkoitetaan tilannetta, jossa kannasta luetaan dataa, jonka käsittely on kesken. Tunnetaan myös nimellä Uncommited Read.
Klusteri-indeksi/ ryvästävä indeksi
Hakemistot eli indeksit mahdollistavat tietorivin hakemisen kannasta. Hakemisto, joka määritetty klusteri-indeksiksi, tukee normaaleiden

85/99
hakuoperaatioiden lisäksi taulun fyysisen järjestyksen ylläpitämistä. Kun taululle tehdään uudelleenjärjestely, taulun rivit järjestetään klusteri-indeksin mukaiseen järjestykseen.
Klusteri-indeksi tunnetaan myös nimellä ryvästävä indeksi.
Staattinen SQL lause
Suoritussuunnitelma, eli tapa miten SQL-kielellä muodostettu lause toteutetaan, voidaan perinteisen ohjelman käännöksen yhteydessä ratkaista ja tallentaa tietokannan katalogiin. Tällöin ohjelmaa ajettaessa ei tarvitse optimoida joka kerta suoritussuunnitelmaa, jolloin suorituskyky pysyy hyvänä. Staattinen SQL lause ei kuitenkaan pysty mukautumaan äkillisesti muuttuneisiin tietokannan volyymimuutoksiin.
Dynaaminen SQL lause
Käytettäessä tulkattavia kieliä tai suorakäyttövälineitä, ei suoritussuunnitelmaa voida luonnollisesti määrittää etukäteen. Tällöin suoritussuunnitelma ratkaistaan ajon aikaisesti joka kerta kun lausetta suoritetaan.

86/99
Tulosjoukko
Haettaessa tietoa relaatiotietokannasta, voi SQL kysely tuottaa nolla, yhden tai useamman rivin. Tätä rivijoukkoa kutsutaan tulosjoukoksi. Käytettäessä perinteisiä ohjelmointikieliä, joudutaan tulosjoukko prosessoimaan yksi rivi kerrallaan ohjelmassa.
Looginen työkokonaisuus, LUW
Tietokannan käsittelyssä voidaan tarvitaan useita lauseita tietyn tehtävän suorittamiseksi. Tyypillinen esimerkki on tilisiirto. Rahaa otetaan maksajan tililtä JA se lisätään vastaanottajan tilille. Tämä kokonaisuus tulee suorittaa joko kokonaan tai ei ollenkaan. Tällaista kokonaisuutta nimitetään loogiseksi työkokonaisuudeksi, englanniksi termi on Logical Unit of Work (LUW).
COMMIT, ROLLBACK
SQL-kielessä tarvittavat käskyt, joilla hallitaan tietokannan eheyttä ja loogisia työkokonaisuuksia. COMMIT tarkoittaa, että yksi jakamaton ja eheä osakokonaisuus on suoritettu, jolloin tietokanta voidaan vapauttaa ja tehdyt muutokset voidaan tallettaa pysyvästi tietokantaan. ROLLBACK puolestaan tarkoittaa, että prosessissa on tapahtunut joko tekninen tai looginen virhe tai muu tilanne, jonka takia tätä osakokonaisuutta ei tule tallentaa pysyvästi kantaan vaan kyseinen työkokonaisuus ja sen tekemät muutokset perutaan.
Joskus nämä termit ovat käännetty suomenkielessä VAHVISTA ja PERUUTA, mutta suurimmassa osassa aineistoa pidättäydytään englannikielisissä, standardin mukaisissa nimissä.
Kuuma piste, Hot Spot
Englannikielessä Hot Spot tarkoittaa tiettyä tietokantasivua, johon kohdistuu paljon kyselyitä ja ennen kaikkea paljon päivityksiä samanaikaisesti. Kuuma piste aiheuttaa lukitus- ja käytettävyysongelmia ja niiden muodostumista yritetään välttää mahdollisimman paljon huolellisella kantasuunnittelulla.
Eräajon aloitusleima

87/99
Ensimmäinen toimenpide, minkä eräajo tekee, on aloitusleiman hakeminen tietokannanhallintajärjestelmästä. Ohjelman käyttöjärjestelmältä saatava aikaleima on käytännössä yhtä hyvä, mutta siirrettävyyden kannalta pitää varautua siihen, että ohjelma mahdollisesti käyttää tietokantaa eri palvelimella etäyhteyden päästä.
Viimeisimmän päivityksen aikaleima
Englanniksi LAST_MOD-TIMESTAMP. Mieluiten tietokannan hallintajärjestelmän kontrolloima taulun sarake, josta käy ilmi koska kyseistä taulun riviä ollaan viimeksi päivitetty. DB2 V9 for z/OS tukee tällaista saraketta (sarakkeen tyyppi: GENERATED ALWAYS FOR EACH ROW ON UPDATE AS ROW CHANGE TIMESTAMP), mutta aikaisemmissa versioissa aikaleiman päivitykseen piti määritellä TRIGGERI.
Tietomalli, Data Model
Tietomalli on tapa kuvata tietoja, tietojen välisiä suhteita eli relaatioita ja tietojen sisällölle muodostettuja rajoituksia eli viite-eheyksiä.
Tiedon pysyvyys, Data Persistence
Ominaisuus, jonka avulla tiedot pystyvät tallessa vaikka tietoja tuottaneen ohjelma suoritus lopetetaan tai keskeytetään
Tiedon jakaminen, Data Sharing
Ominaisuutta, jolla useamman sovelluksen, laitteen yms. pääsy samoihin tietohin on mahdollista, tunnetaan nimellä tiedon jakaminen (Data Sharing). IBM ympäristöissä Data Sharing tarkoittaa lisäksi useamman keskuskoneen liittämistä yhdeksi suureksi kokonaisuudeksi.
Luotettavuus, Reliability
Tietokantojen luotettavuus (Reliability) tarkoittaa, että niihin talletetut tiedot ovat suojattu ohjelmisto- ja laitevioilta.
Skaalattavuus, Scalability
Skaalattavuus tarkoittaa, että samaa prosessia pystytään käyttämään niin pienten kuin myös suurten massojen käsittelyyn.
Tietoturva ja eheys, Security and integrity

88/99
Tietoturva ja eheys tarkoittavat, että tiedot ovat suojattu asiattomalta käytöltä ja sitä, että tiedot täyttävät ennalta määrätyt kriteerit, kuten muodon, oikeellisuuden ja eheyssäännöt.
Extended address volumes, EAVIBM z/OS versio 1.11 tarjoaa extended address volumes (EAV) tuen peräkkäis- ja VSAM-tiedostoille. EAV tuki tarkoittaa, että yhdellä fyysisellä levylaitteella voi olla nykyään 262,668 sylinteriä. Tämä tarkoittaa, että yhdelle laitteelle voidaan nyt tallentaa huomattavasti enemmän tietoa kuin ennen.

89/99
Lähdeluettelo
Kirjat
Alastrué i Soler et.al., Parallel Sysplex Application Considerations, 2004, IBM Redbooks
Date, An Introduction to DATABASE SYSTEMS, 2000, Addison-Wesley
Connolly & Begg & Strachan, Database Systems - A Practical Approach to Design, Implementation, and Management, 1999, Addison-Wesley
Elmasri & Navathe, Fundamentals of Database Systems, Fundamentals of Database Systems, The Benjamin/Cummings Publish Company Inc.
Greenwald & Stackowiak & Stern, Oracle Essentials (Fourth Edition Oracle Database 11g), 2007, O'Reilly
Hennessy & Patterson, Computer Organization and Design: The Hard-ware/Software Interface, 2nd ed., Morgan Kaufmann, 1998
Hovi & Huotari & Lahdenmäki, 2003, Tietokantojen suunnittelu & indeksointi, Docendo
Capers Jones, 2009, Software Engineering Best Practices, McGraw Hill Professional
IBM, DB2 for z/OS version 9 - Utility Guide and Reference, 2009, United Kingdom.
Lahdenmäki & Leach, 2005, Relational database index design and opti-mizers: DB2, Oracle, SQL Server et al, Wiley

90/99
Tannenbaum, 2003, Modern Operating Systems, Prentice Hall
Leavens & Sitaramans, Foundations of Component-Based Systems, Cambridge University press
Mullins, DB2 Developer's Guide, Fourth Edition, SAMS
Menendez & Lowe, Murach's OS/390 and z/OS JCL, Mike Murach & As-sociates Inc.
Tapanainen, Imperatiivisten ohjelmien organisointiparadigmojen historia, 2007, Helsingin yliopisto, tietojenkäsittelytieteen laitos, Tietojenkäsittelytieteen historia -seminaari.
Pekkala, Pysyvyyden toteuttaminen Java-sovelluksissa erityisesti ORM menetelmän avulla, 2004, Tampereen yliopisto, Pro-Gradu - Tietojenkäsittelytieteiden laitos
Pollari-Malmi, Batch Updates and Concurrency Control in B-Trees, 2002, Helsinki University of Tecnology (Espoo, Finland)
Pruni et.al., IBM Redbook - DB2 for z/OS and OS/390 Version 7 Perfor-mance Topics, 2004, United Kingdom.
Matti P. Pullkinen, Java on monisäikeinen juttu, MicroPC; numero 12/1998.
Roger Pressman, Software Engineering - A Practitioner's Approach, 2004, McGraw-Hill
Packer et.al., System/390 MVS Parallel Sysplex Batch Performance (IBM Redbook), 1995, IBM Redbook, United Kingdom.
United States Patent 7.650.331, Dean et al., January 19, 2010

91/99
White, Tom White, Hadoop: The Definitive Guide, O'Reilly Media Inc., 2009
Yevich & Lawson, DB2 High Performance Design and Tuning, 2000, Prentice Hall PTR 2 edition.
VerkkojulkaisutBonnie Barker, Things i wish they’d told me, luentosarjan kolmas osa, pidetty IBM:n tiloissa 15.5.2003, www.cmg.org/proceedings/2004/4115.pdf.
BMC Software, BMC MAINVIEW Batch Optimizer Family for Mainframes, http://documents.bmc.com/products/documents/98/03/69803/69803.pdf, luettu 28.2.2009.Computing Network Services - CNS, z/OS: Submitting z/OS (OS/390) BatchJobs to CNS, http://docweb.cns.ufl.edu/docs/d0072/d0072.pdf, luettu 28.2.2009.
Stonebraker & Madden & Abadi & Harizopoulos & Hachem & Helland, The End of an Architectural Era (Its Time for a Complete Rewrite), 2007
Dean & Ghemawat, MapReduce: Simplied Data Processing on Large Clusters, http://labs.google.com/papers/mapreduce.html, luettu 31.12.2009
Hurmalainen, DB2 Batch Job efficiency, GSE Nordic Technical Confer-ence, 2004
IBM, DB2 Version 9.1 for z/OS SQL Reference SC18-9854-07, http://publib.boulder.ibm.com/epubs/pdf/dsnsqk17.pdf, luettu 05.01.2008

92/99
Laiho & Laux, On SQL Concurrency Technologies - considering the needs of ICT industry, http://www.DBTechNet.org/papers/SQL_Concur-rencyTechnologies.pdf , luettu 26.2.2009.
Laiho & Laux, On Row Version Verifying (RVV) Data Access Discipline for avoiding Lost Updates, http://www.DBTechNet.org/papers/RVV_Pa-per.pdf, luettu 25.2.2009
Mellor, Compellent adopts solid state, 2008, The Register http://com-ments.theregister.co.uk/2008/10/13/compellent_adds_ssd , luettu 28.10.2008.
Hannan, DB2 Performance with COOL:GEN, 2002, CPT Global Ltd., In-ternational DB2 Users Group, http://www.dugs.org.au/Presentations/High%20Performance%20SQL.ppt. , luettu 11.12.2008.
Campbell, Hard Performance Lessons learned when OO meets Rela-tional (IBM), GSE Nordic Region DB2 Workgroup Conference, Oslo; Norway 2006
Clevinger, DB2 UDB Application Tuning 101: The Nuts and Bolts, 2005, Colorado DB2 Users Group For Z/OS
Imation SSD Performance, www.imation.com/PageFiles/83/Imation-SSD-Performance-White-Paper.pdf, luettu 25.1.2009.
Storage Techniques for tuning an OS/390 Batch Run, http://www.las-con.co.uk/d006000.htm, luettu 8.1.2009.
Curt Monash, Why MapReduce matters to SQL data warehousing (Au-gust 26, 2008), http://www.dbms2.com/2008/08/26/why-mapreduce-matters-to-sql-data-warehousing/, luettu 1.4.2010

93/99
Curt Monash, More patent nonsense — Google MapReduce (February 11, 2010), http://www.dbms2.com/2010/02/11/google-mapreduce-patent/, luettu 7.4.2010
Nørmark, www.cs.aau.dk/~normark/prog3-03/html/notes/paradigms_themes-paradigm-overview-section.html, 2008, Department of Computer Science, Aalborg University, Denmark, luettu 9.2.2009.
Seppänen, 2004, Kontruktiivinen tutkimus, http://media.tol.oulu.fi/video/jtmk/konstruktiivinen_tutkimus.ppt#256,1,Konstruktiivinen tutkimus, luettu 10.12.2009
Solid-State Disks Invading Storage World, Chris Preimesberger, http://www.eweek.com/c/a/Data-Storage/SolidState-Disks-Invading-Storage-World-283814/, luettu 8.3.2009
Future Storage Technologies: A Look Beyond the Horizon, Mark H. Kryder, Seagate Technology, http://www.snwusa.com/documents/pre-sentations-s06/MarkKryder.pdf , luettu 15.6.2009
How Disk Defragmenter Works, Microsoft TechNet, http://technet.mi-crosoft.com/en-us/library/cc778290.aspx, luettu 17.6.2009
Mainframe Migration Alliance/ Microsoft & Fujitsu, Batch Applications—The HiddenAsset, www.microsoft.com/mainframe, luettu 14.3.2010.
A CORNUCOPIA OF OPPORTUNITIES: DB2 APPLICATION PERFOR-MANCE, Craig Hodgins, Compuware Corporation, http://www.cmg.org/conference , luettu 10.11.2009
Arpaci-Dusseau & Arpaci-Dusseau & Gunawi, CS 537 Introduction to Operating Systems/ Clock (part 2) and Trashing, http://pages.cs.wis-c.edu/~haryadi/537/slides/lec10-clock.ppt#256 ,1,Clock (part 2) and
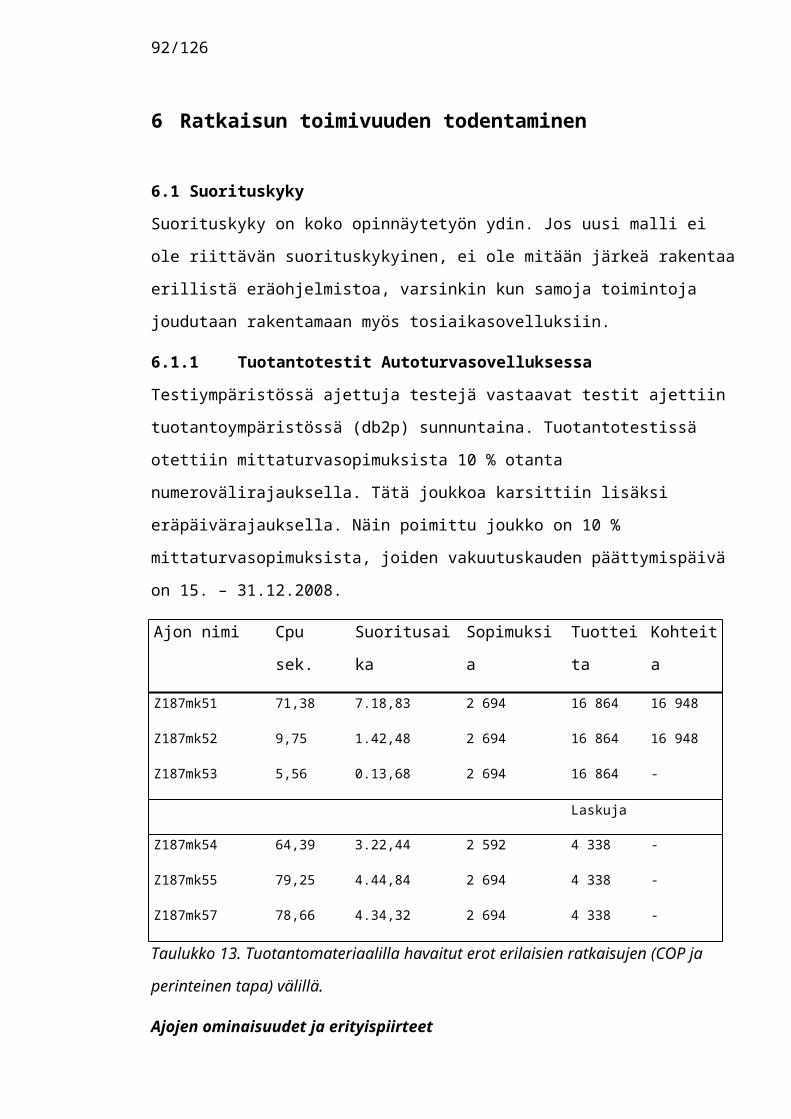
94/99
Trashing, luettu 5.2.2009
Ramamurthy, Virtual Memory Management, http://www.cse.buffa-lo.edu/~bina/cse421/spring01/mar19.ppt#259, 12,Space and Time, luettu 5.2.2009
Coleman Troy (Softbase), z/OS Tablespace Partitioning for DB2 V8: Maintenance, Performance and more, DB2 Regional User Group – NEODEBUG, 2008
Akira Shibamiya, DB2 9 for z/OS Select, Insert, Update, Delete SQL Ap-plication Performance, IBM Silicon Valley Laboratory, 2008, http://www.mdug.org/Newsletter-2008-06.pdf , luettu 5.2.2009
Saarelainen Teemu, Tietorakenteet ja algoritmit/ Algoritmianalyysi, Kymenlaakson Ammattikorkeakoulu, http://www2.kyamk.fi/~atesa/tirak/ , luettu 17.8.2009
Gareth Jones, DB2 9 for z/OS Performance Update, IBM Silicon Valley Laboratory, 2009
John Campbell, DB2 for z/OS Optimizing INSERT Performance, IBM Silicon Valley Laboratory, 2009
The Register, 22.2.2010, http://www.theregister.co.uk/2010/02/22/google_mapreduce_patent/, luettu 23.2.2010.
The Register, 16.2.2010, http://www.theregister.co.uk/2010/02/16/ya-hoo_and_ron_brachman_on_mapreduce/, luettu 23.2.2010.
The Register, 2.10.2009, http://www.theregister.co.uk/2009/10/02/cloudera_desktop/, luettu 12.1.2010.
Rob Farber, 2009, Cloud Computing: Pie in the sky?/ Infrastructure of-fers potentially big changes, http://www.scientificcomputing.com/arti-cles-HPC-Cloud-Computing-Pie-in-the-sky-120109.aspx, luettu 10.4.2010.

95/99





























