Embed Size (px)
Citation preview

www.fors.ru
Oracle и Hadoop. Рецепты приготовления блюд из этих двух ингредиентов
Александр Кучеренко
ведущий инженер ЦТП «ФОРС»
Oracle Certified Master

www.fors.ru
Структурированные (карточный процессинг, биллинг услуг связи и т.п.)
Неструктурированные (соцсети, измерительные устройства, аудио- и видеорегистрация, лог-файлы серверов)
Вложенные объекты (файлы документов)
Типы данных у бизнеса

www.fors.ru
Большие данные - тренд №2 в мире (Gartner)
История вопроса берет начало с конца 2000-x.
Определение включает в себя серию подходов и терминов
Заблуждения и предубеждения связаны с разнообразным трактованием методов
www.fors.ru
Объединить. Обеспечить доступ к разным типам данных в режиме «одного окна».
Классические средства ETL и т.п. дорого и не всегда быстро.
Требуется адаптация приложений, а то и написание новых.
Что делать, если нужно всё и сразу?
Сложности при использовании ETL.
При решении этой задачи необходимы интеграция, организация и
управление разными типами данных.
А также управление процессами доступности и тем, как это всё
будет сосуществовать.

www.fors.ru
Где хранить и как управлять?
Транзакции
СУРБД
Hadoop Логи
NoSQL
Профили
ПАК (Teradata, Exadata,
Big Data Appliance и т.п.)

www.fors.ru
2004 – 2005 г. – парадигма MapReduce представлена Google
2008 г. – Hadoop как проект начинает развитие под эгидой Apache
2013 г. – YARN (Yet Another Resource
Negotiator)
Hadoop. История
Начиная с версии 0.23 – MapReduce пережил капитальный ремонт и теперь известен под
именем MapReduce v2 или YARN

www.fors.ru
http://hadoop.apache.org
для истинных ценителей ручной установки, с правкой конфигурационных файлов, установкой пакетов и «танцев с бубном»
http://www.cloudera.com
любим Oracle, поставляется с Big Data Appliance
http://www.hortonworks.com
наиболее приближен к оригиналу
использует в Hive – Tez
Дистрибутивы

www.fors.ru
• MapReduce основной фреймворк Hadoop
• HDFS распределенная кластерная
файловая система
Основа Hadoop
www.fors.ru
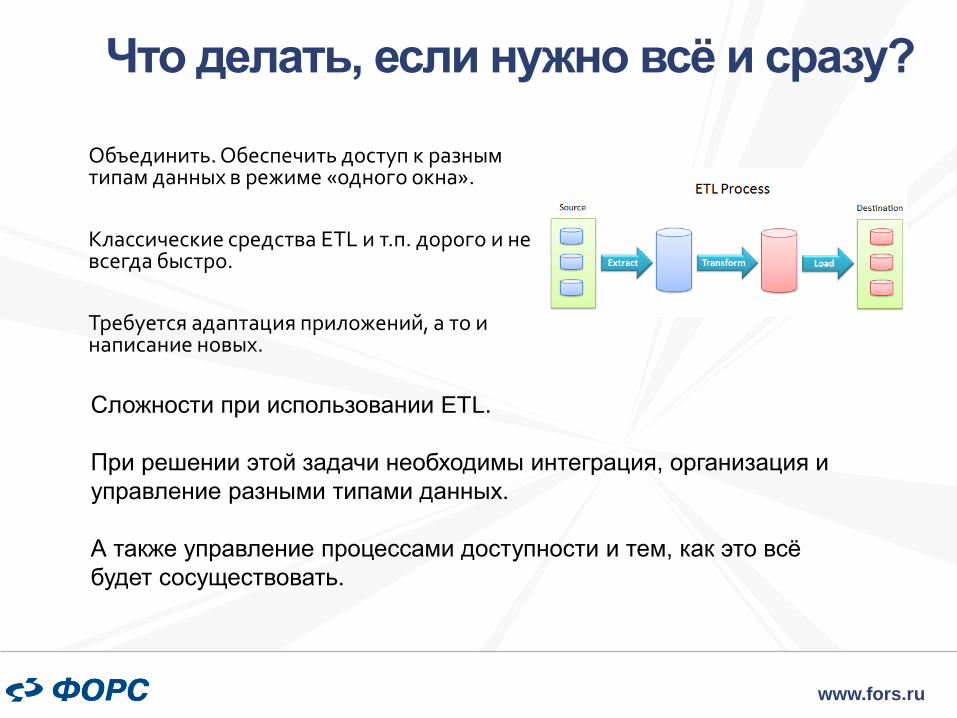
MapReduce Фреймворк по пакетной обработке данных
MapReduce состоит из двух фаз:
1. map — выполняется
параллельно и (по
возможности) локально
над каждым блоком
данных, всё, что не
требует перемешивания и
перемещения данных
(shuffle)
2. reduce — дополняет map
агрегирующими
операциями
www.fors.ru
Большое, горизонтально масштабируемое хранилище данных
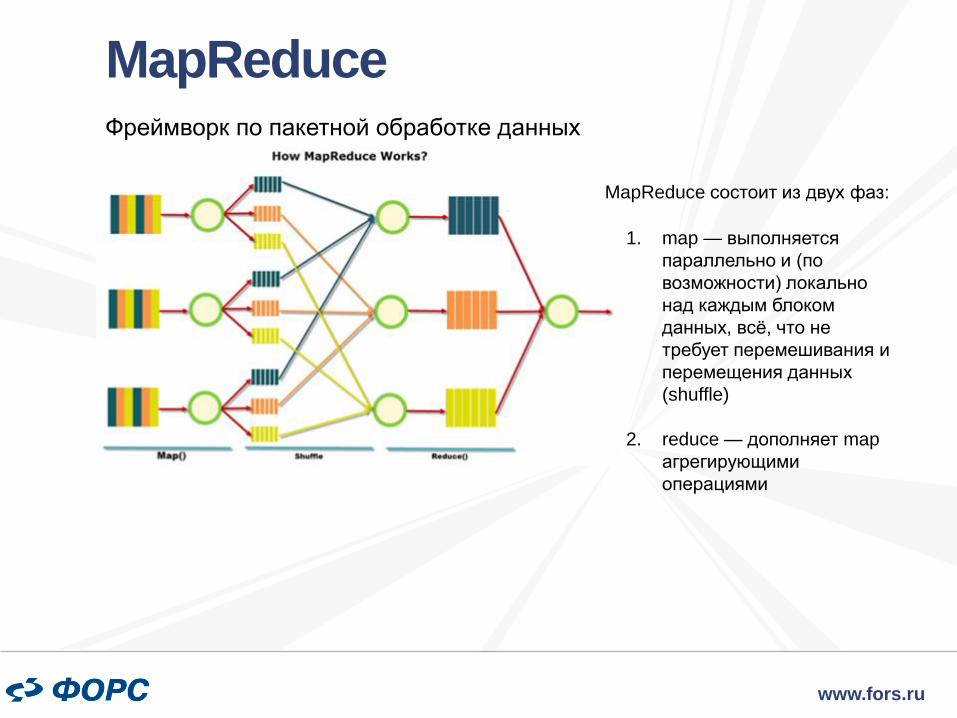
Hadoop Distributed File System
• HDFS – это то, что обычно имеют
в виду, когда говорят о Hadoop
• HDFS – это как обычная
файловая система, только
больше
• Вместо таблицы файловых дескрипторов используется специальный сервер —
сервер имён (NameNode)
• Данные не сосредоточены в одном месте, а разбросаны по серверам данных
(DataNode)
• Данные разбиты на блоки (обычно по 64Мб или 128Мб), для каждого файла сервер
имён хранит его путь, список блоков и их реплик
www.fors.ru
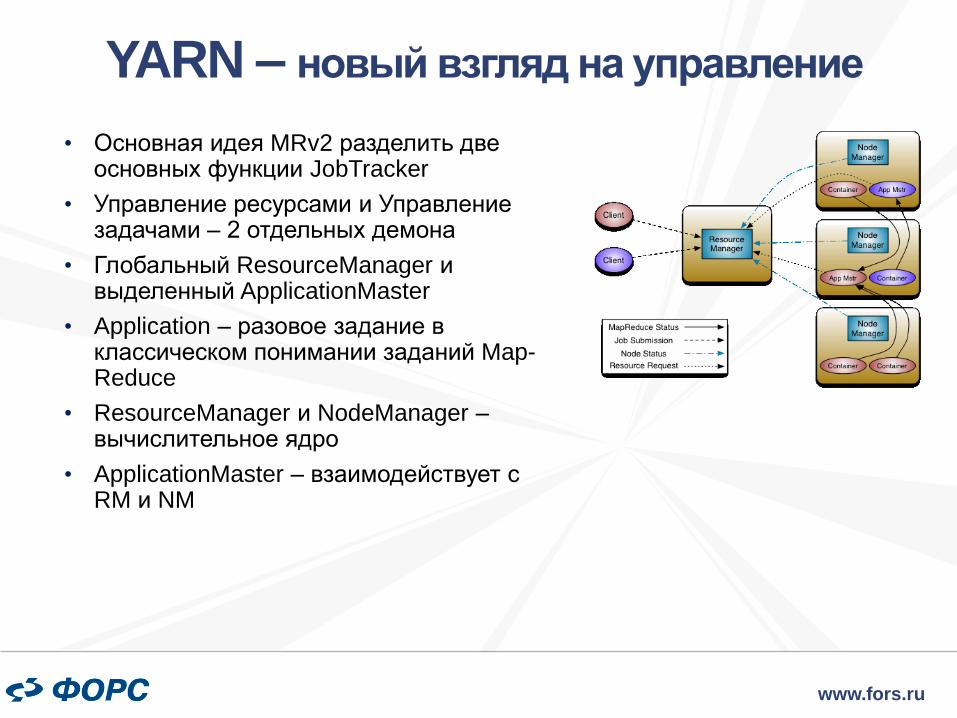
• Основная идея MRv2 разделить две основных функции JobTracker
• Управление ресурсами и Управление задачами – 2 отдельных демона
• Глобальный ResourceManager и выделенный ApplicationMaster
• Application – разовое задание в классическом понимании заданий Map-Reduce
• ResourceManager и NodeManager – вычислительное ядро
• ApplicationMaster – взаимодействует с RM и NM
YARN – новый взгляд на управление

www.fors.ru
Hive
Impala
SparkSQL
Apache Flink
SQL в Hadoop

www.fors.ru
• Последняя версия – 2.0.0 от 15.02.2016г.
• Использует Tez в качестве фреймворка
• Есть CBO (cost-based optimizer)
• Есть Storage Indexes
• Поддерживает row level изменения и ACID транзакции
• Простая интеграция с Oracle
Hive – SQL субд на платформе Hadoop

www.fors.ru
HBase
NoSQL
• HBase – это распределённая версионированная нереляционная СУБД,
эффективно поддерживающая случайное чтение и запись
• главное – это то, что HBase позволяет работать с отдельными записями в
реальном времени, и это важное дополнение к инфраструктуре Hadoop
• запросы к таблицам HBase можно делать напрямую из Hive и Impala
.
www.fors.ru
• Выгоднее перенести архивные данные из СУРБД на менее дорогое хранилище Hadoop
• Из неструктурированных данных часто требуются отдельные поля разных типов
Задачи объединения-разделения
www.fors.ru
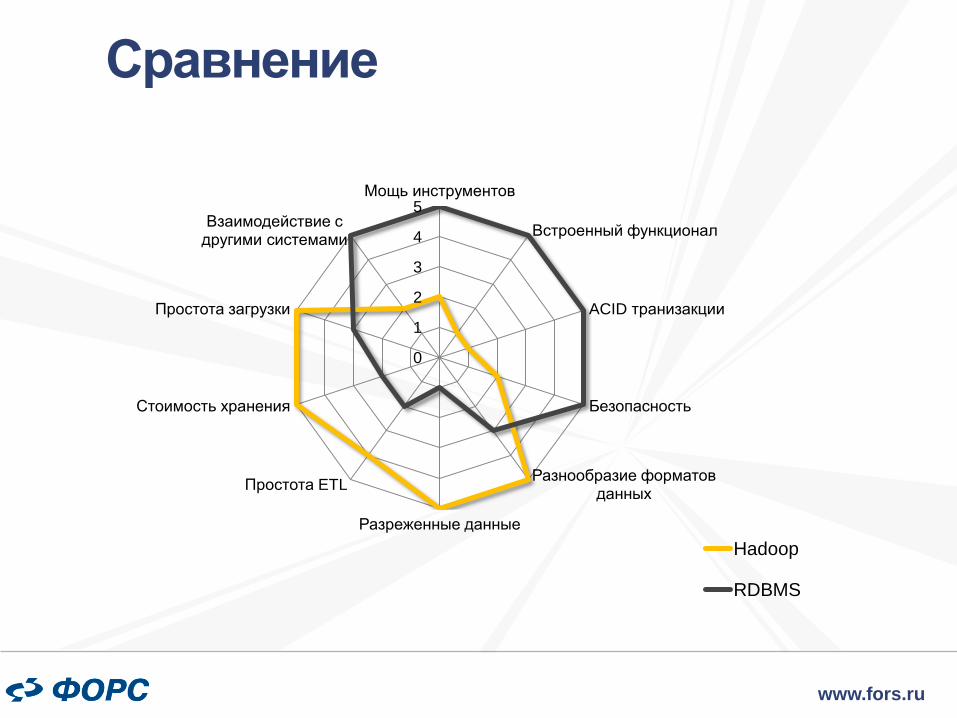
Сравнение
0
1
2
3
4
5Мощь инструментов
Встроенный функционал
ACID транизакции
Безопасность
Разнообразие форматов данных
Разреженные данные
Простота ETL
Стоимость хранения
Простота загрузки
Взаимодействие с другими системами
Hadoop
RDBMS
www.fors.ru
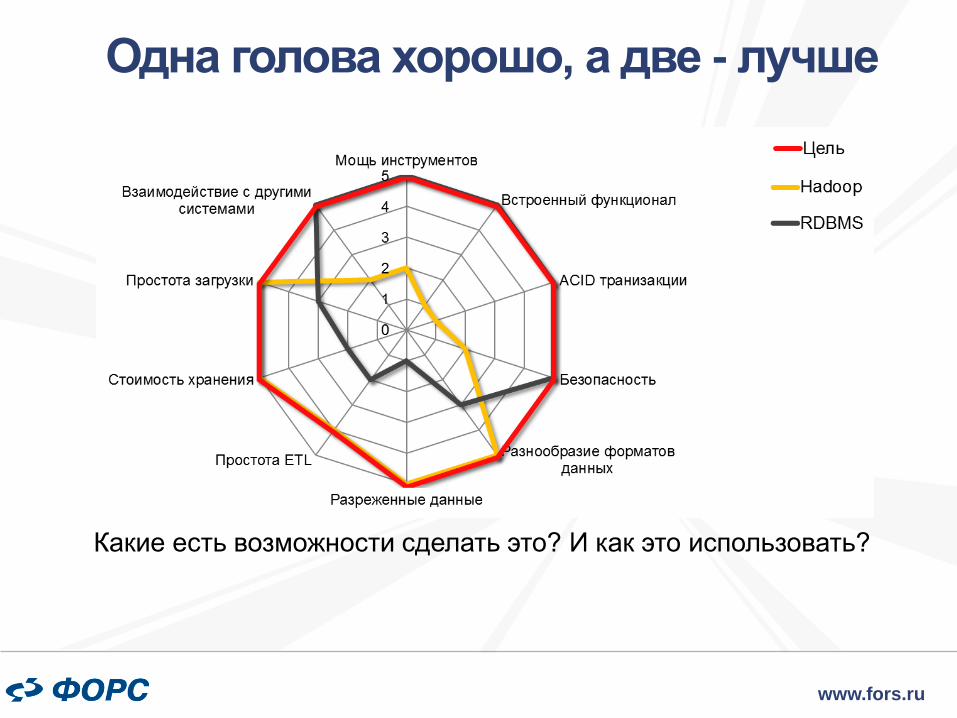
Какие есть возможности сделать это? И как это использовать?
Одна голова хорошо, а две - лучше

www.fors.ru
Load и Off-Load
Flume (потоково-событийная интеграция данных)
Удобно собирать данные из нескольких источников
для дальнейшей загрузки их в Hadoop
Oracle Loader for Hadoop (OLH)
MapReduce задание, которое осуществляет
предобработку и конвертацию данных в формат
Oracle RDBMS, используя ресурсы узлов Hadoop
Sqoop (пакетный обмен таблиц реляционных БД)
JDBC <-> HDFS инструмент для параллельного копирования
Возможно лучшее средство для пакетного перемещения данных
www.fors.ru
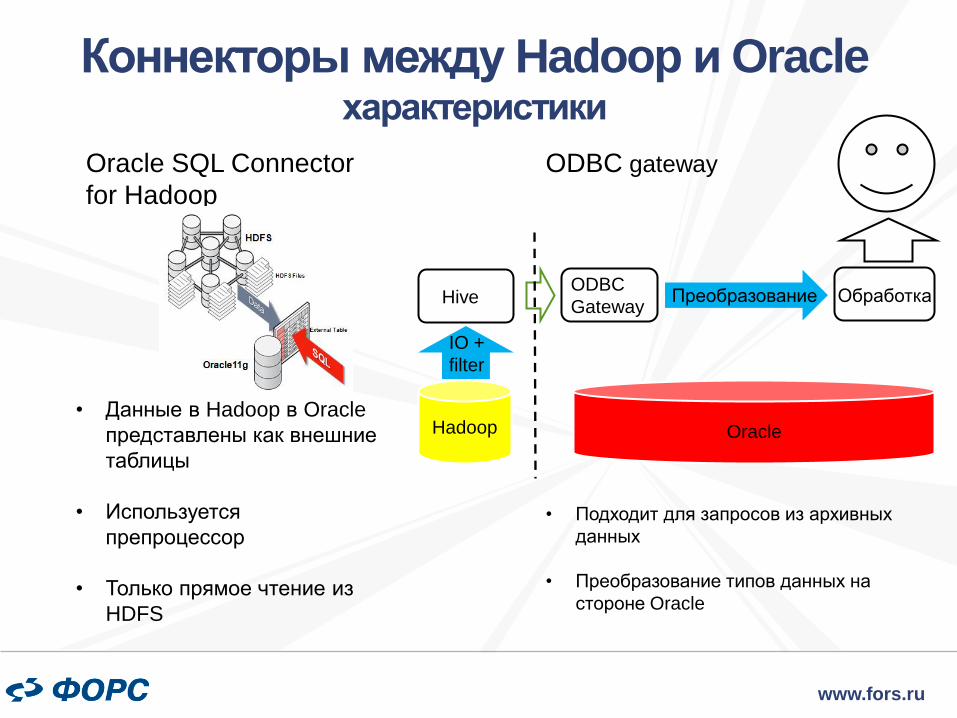
Oracle SQL Connector
for Hadoop
Коннекторы между Hadoop и Oracle характеристики
ODBC gateway
• Данные в Hadoop в Oracle
представлены как внешние
таблицы
• Используется
препроцессор
• Только прямое чтение из
HDFS
Hadoop
Hive
IO +
filter
Oracle
ODBC
Gateway Преобразование Обработка
• Подходит для запросов из архивных
данных
• Преобразование типов данных на
стороне Oracle
www.fors.ru
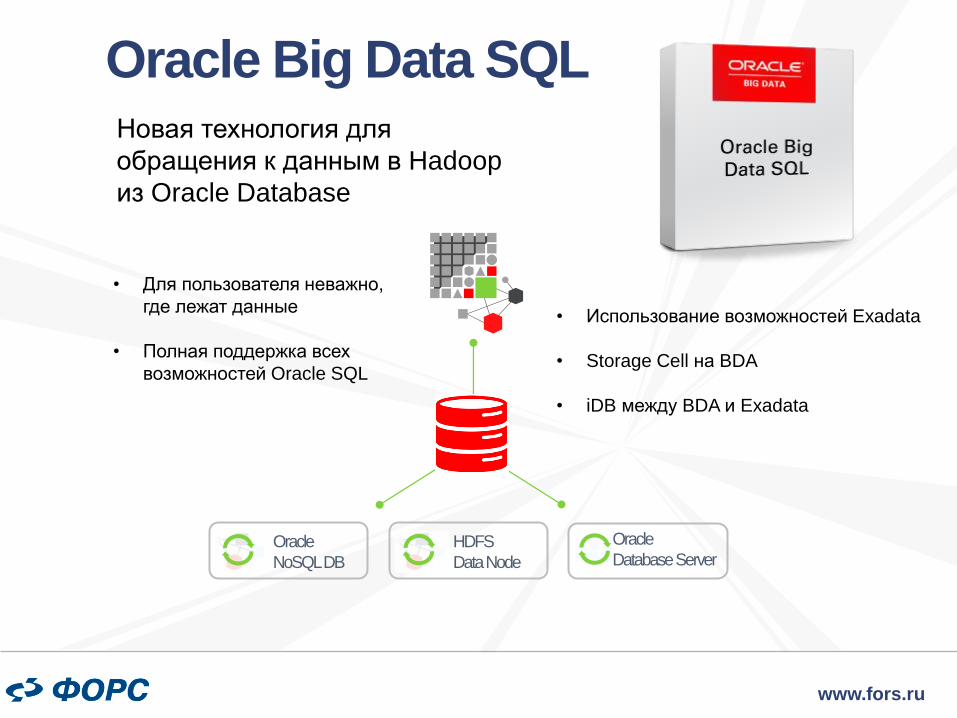
Новая технология для
обращения к данным в Hadoop
из Oracle Database
Oracle Big Data SQL
Oracle
NoSQL DB
HDFS
Data Node
Oracle
Database Server
• Для пользователя неважно,
где лежат данные
• Полная поддержка всех
возможностей Oracle SQL
• Использование возможностей Exadata
• Storage Cell на BDA
• iDB между BDA и Exadata
www.fors.ru
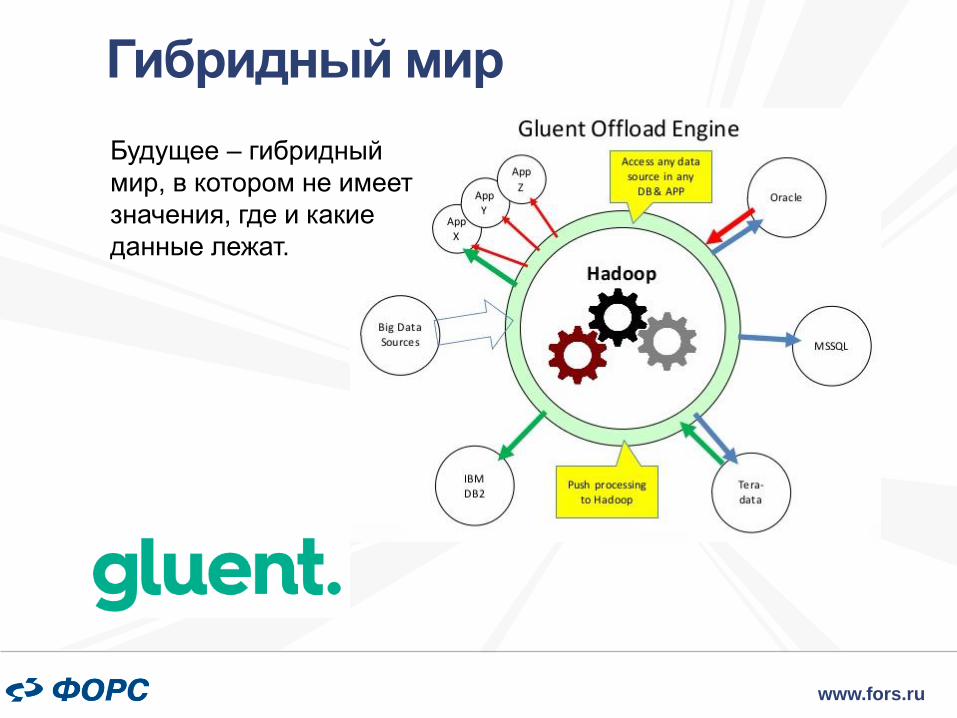
Будущее – гибридный
мир, в котором не имеет
значения, где и какие
данные лежат.
Гибридный мир

www.fors.ru
Спасибо за
внимание!