Embed Size (px)
Citation preview

© LPI-Japan / EDUCO all rights reserved.
OSS-DB Exam Silver技術解説無料セミナー
2021/7/25 開催
NTT テクノクロス株式会社上原 ⼀樹
本⽇の講師
主題 DBの環境設計・運⽤設計の基礎
副題 物理設計(テーブル設計、インデックス設計)運⽤設計(DBメンテナンス、セキュリティ)

2© LPI-Japan all rights reserved.
#OSS-DB講師紹介
n上原 ⼀樹� NTTテクノクロス株式会社 DBチーム所属� PostgreSQL関連業務に従事
- テクニカルサポート、コンサルティング- データベースの移⾏⽀援- 研修講師
nNTTテクノクロス株式会社(https://www.ntt-tx.co.jp/)� DBチームでは、PostgreSQLを中⼼に各種サポートを提供。
- オンプレのPostgreSQL、パブリッククラウド上のマネージドサービスを対象。- PostgreSQLに対応する周辺ツールについても対応(pg_statsinfo, pg_hint_plan等々)
� 技術ブログ(情報畑でつかまえて)では、DBをはじめ、様々な技術情報を投稿しています。

3© LPI-Japan all rights reserved.
#OSS-DBプロモーション
nOSSクラウド基盤トータルサービス� https://www.ntt-tx.co.jp/products/osscloud/� PostgreSQL移⾏・運⽤⽀援サービス、チケットサービスを提供しています。

4© LPI-Japan all rights reserved.
#OSS-DBOSS-DB/オープンソースデータベース技術者認定試験
nOSS-DBとはオープンソースのデータベースソフトウェア「PostgreSQL」を扱うことができる技術⼒の認定です。様々な分野でPostgreSQLの利⽤拡⼤が進む中でOSS-DBの認定を持つことは、⾃分のキャリアのアピールにもつながります。
üOSS-DB Goldは設計やコンサルティングができる技術⼒の証明PostgreSQLについての深い知識を持ち、データベースの設計や開発のほか、パフォーマンスチューニングやトラブルシューティングまで⾏えることが証明できます
üOSS-DB Silverは導⼊や運⽤ができる技術⼒の証明PostgreSQLについての基本的な知識を持ち、データベースの運⽤管理が⾏えるエンジニアとしての証明ができます
ü対象のバージョンはPostgreSQL 11

5© LPI-Japan all rights reserved.
#OSS-DB認定試験の傾向と対策
n公式ドキュメントは使⽤するバージョンのドキュメントを読むべき︕� バージョンによって、機能の違いがあるため、採⽤するバージョンとあったものを読む。� 本セミナー資料でも参考として、バージョン11のPostgreSQL⽂書のリンクを記載する。
nGUCパラメータやシステムテーブル・ビューは、単純に意味を覚えるのではなく、影響まで理解しなければならない
例 deadlock_timeout
n実機での動作確認は極めて重要� ⾃分が予想した通りに動作しなければ、何かしら理解不⾜があるということ。
意味: ロック状態になった時にデッドロック検出処理を開始するまでの待機時間
影響: 値を⼩さくすると、デッドロックの検出は早くなるが、 実際にはデッドロックが発⽣していないのに検出処理が 動くことが多くなるため、CPUに無駄な負荷がかかる可能性も⾼くなる

6© LPI-Japan all rights reserved.
#OSS-DBセミナーのテーマについて
n本⽇のテーマ� 設計の基礎として、「PostgreSQLの設計要素には何があるのか」、「設計のポイントはどういったところにあるか」について解説を⾏います。- 過去のセミナで解説済み且つ、補⾜説明する必要がないものは、対象から外しています。
� 本セミナーはSilverの範囲を中⼼に解説を⾏います。ただし、普段の業務で活かせるようにPostgreSQLを利⽤する上でぜひ理解してもらいたいというものは、Gold範囲であっても紹介だけはさせていただきます。
n過去のオンラインセミナーのテーマ(どれも重要なテーマですので、ご活⽤ください。)� 「PostgreSQLのバックアップ⽅法」
- https://oss-db.jp/__/download/5f0fb75b37471d78510554e4/20200719-silver-01.pdf� 「VACUUM、ANALYZEの⽬的と使い⽅」と「⾃動バキュームの概念と動作」
- https://oss-db.jp/__/download/5f3de5a37ea72b5fa4113218/20200905-silver-01.pdf� 「トランザクションの概念、SQLコマンド、Ver.2.0で追加された項⽬」
- https://oss-db.jp/__/download/5f90e6a2c1fa8478bd3cd9a0/20201017-silver-01.pdf� 「標準ツールの使い⽅、SQLコマンド(データ操作、データ型、インデックス)」
- https://oss-db.jp/__/download/6073d1843701c51de41e20ee/20210410-silver-02.pdf� 「運⽤管理、設定ファイル」
- https://ferret-one.akamaized.net/files/60dae99cd38ec80f4ec003f8/20210629-silver.pdf

7© LPI-Japan all rights reserved.
#OSS-DBアジェンダ
n物理設計� テーブル設計、インデックス設計
- 容量設計(サイジング)- テーブル定義
– データ型– HOT、FILLFACTOR
- インデックス設計- テーブルスペース
� パラメータ設計- メモリ設計
– shared_buffers, work_mem
n運⽤設計� DBのメンテナンス
- VACUUM、ANALYZE、FREEZE- autovacuum
� バックアップ・リカバリ- バックアップの種類
� セキュリティ- ROLE- GRANT, REVOKE
設計の詳細は、基本的にGoldの範囲となります。本⽇はSilverの範囲で各項⽬から
設計の基礎となる要素について解説を⾏います。
⻩⾊の項⽬︓
8© LPI-Japan all rights reserved.
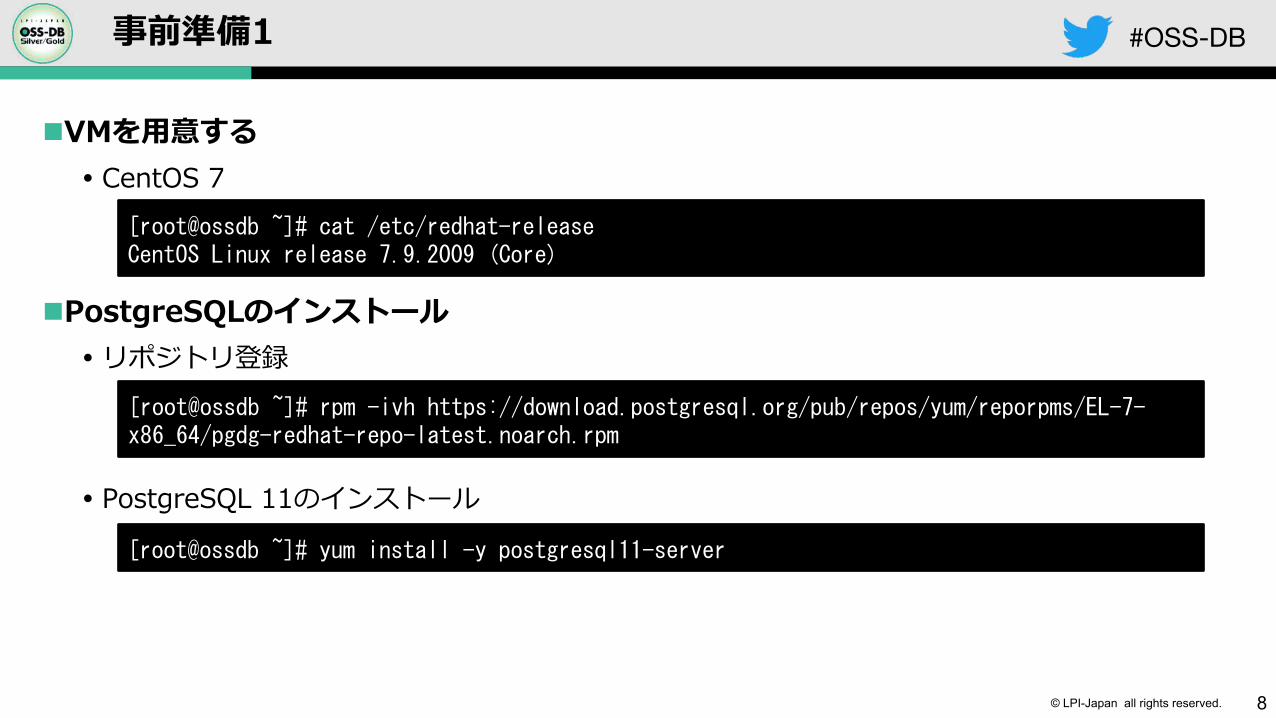
#OSS-DB事前準備1
nVMを⽤意する� CentOS 7
nPostgreSQLのインストール� リポジトリ登録
� PostgreSQL 11のインストール
[root@ossdb ~]# rpm -ivh https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
[root@ossdb ~]# yum install -y postgresql11-server
[root@ossdb ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core)

9© LPI-Japan all rights reserved.
#OSS-DB事前準備2
nOSユーザを切り替える� postgresユーザはRPMを⽤いたインストールで⾃動で作成される。
n環境変数の設定� postgresユーザの .bash_profile は、~/.pgsql_profile を読み込む仕様になっている。
� 再ログインまたは、sourceコマンドで環境変数を反映する。
[root@ossdb ~]# su - postgres
[postgres@ossdb ~]$ cat << EOF > ~/.pgsql_profilePATH=/usr/pgsql-11/bin:$PATHPGDATA=/var/lib/pgsql/local/11/dataexport PATH PGDATAEOF
[postgres@ossdb ~]$ source ~/.pgsql_profile

10© LPI-Japan all rights reserved.
#OSS-DB事前準備3
nDBクラスタ作成� initdbコマンドでDBクラスタを作成する。
nPostgreSQLの起動� pg_ctlコマンドで起動を⾏う。
� psqlでPostgreSQLに接続することができる。
[postgres@ossdb ~] $ initdb -D ~/local/pg11/data --encoding=utf8 --no-locale
[postgres@ossdb ~] $ pg_ctl -D ~/local/pg11/data start
[postgres@ossdb ~]$ psql postgrespsql (11.12)Type "help" for help.
postgres=#

11© LPI-Japan all rights reserved.
#OSS-DB物理設計
n物理設計� テーブル設計、インデックス設計
- 容量設計(サイジング)- テーブル定義
– データ型– HOT、FILLFACTOR
- インデックス設計- テーブルスペース
� パラメータ設計- メモリ設計
– shared_buffers, work_mem
n運⽤設計� DBのメンテナンス
- VACUUM、ANALYZE、FREEZE- autovacuum
� バックアップ・リカバリ- バックアップの種類
� セキュリティ- ROLE- GRANT, REVOKE
まずは物理設計として、テーブル設計、インデックス設計、また、それらに関連する項⽬について解説します。
パラメータ設計はGoldの範囲であるため、紹介のみとなります。
⻩⾊の項⽬︓

12© LPI-Japan all rights reserved.
#OSS-DB【物理設計】容量設計(サイジング)
(Silver範囲外であるため、本⽇は設計要素としての紹介のみ⾏う)
PostgreSQLの容量設計では、以下の領域について⾒積もりを⾏う必要がある。
nデータ領域(テーブルやインデックスが使⽤する領域)� データ型、レコード数、後述のFILLFACTORの設定から⾒積もることが可能。� インデックスの⾒積もりは格納されている想定レコード数から算出が可能。
- ただし、インデックスの種類によって構造は異なるため、同じデータでも種類によってサイズは異なる。
nWAL領域(Write-Ahead Logファイルを格納する領域)� postgresql.confのmax_wal_sizeでおおよその値が決まる。� min_wal_sizeの設定次第ではあるが、WALファイルの再利⽤、削除によって使⽤量は増減する。
nアーカイブ領域(アーカイブされたWALファイルを格納する領域)� アーカイブWALの保存期間、その期間で処理する業務で発⽣するWAL量から⾒積もることが可能。
n⼀時領域(ソートやインデックス作成時に⼀時的に使⽤する領域)� テーブルに格納されるデータと実⾏するSQLによって決まる。
nその他� ログ出⼒︓設定によっては⼤量のメッセージが出⼒されることもあるため、注意が必要。

13© LPI-Japan all rights reserved.
#OSS-DB【物理設計】データ型
nデータ型のサイズ� PostgreSQL⽂書でデータ型の格納サイズを確認することができる。
nデータ型の選択について� 適切なデータ型を選択することで様々なメリットがあり、逆に不適切なものを選択した場合にはデメリットが存在することを念頭に設計を⾏う必要がある。
� 次ページではデータ型選択で考慮すべき点をいくつか紹介する。
PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/datatype-numeric.html

14© LPI-Japan all rights reserved.
#OSS-DB【物理設計】データ型
n⽂字列型� PostgreSQLでは、固定⻑⽂字列を選択することによるメリットはない。� 可変⻑⽂字列型を選択することでデータサイズが節約され、処理速度もわずかではあるが可変⻑のほうが⻑さチェックがない分有利となる。
n⽇付型� タイムスタンプ情報は基本的に⽇付型に格納することを推奨する。� ⽂字列型で格納した場合、提供されている演算⼦、⽇付関数を使⽤できない。
postgres=# CREATE TABLE bar (id int, create_time timestamp, drop_time text);CREATE TABLEpostgres=# INSERT INTO bar VALUES (1, '2021-07-25 00:00:00', '2021-07-25 00:00:00');INSERT 0 1postgres=# SELECT create_time - interval '40 day' as timestamp FROM bar WHERE id = 1;
timestamp ---------------------2021-06-15 00:00:00
(1 row)postgres=# SELECT drop_time - interval '40 day' as timestamp FROM bar WHERE id = 1;ERROR: operator does not exist: text - intervalLINE 1: SELECT drop_time - interval '40 day' as timestamp FROM bar W...
^HINT: No operator matches the given name and argument types. You might need to add explicit type casts.
7/25の40⽇前を算出するには︓
⽂字列型では演算⼦を使⽤できない。

15© LPI-Japan all rights reserved.
#OSS-DB【物理設計】データ型
n数値型- 必要以上にnumeric型を使⽤しない。特にOracleからの移⾏において、選択されるケースが多いがnumeric型はデータサイズが⼤きく、処理速度が他の数値型に劣る点には注意が必要。- 処理速度の例として、それぞれの列でsum(),avg(),max(),min()に掛かる時間を⽐較すると、int型に⽐べて、15%程度低速となった。
-bash-4.2$ pgbench -n -T 10 -f agg_int.sql ...number of transactions actually processed: 75718latency average = 0.132 mstps = 7571.398165 (including connections establishing)tps = 7573.133113 (excluding connections establishing)
-bash-4.2$ pgbench -n -T 10 -f agg_num.sql ...number of transactions actually processed: 64291latency average = 0.156 mstps = 6426.681201 (including connections establishing)tps = 6430.121681 (excluding connections establishing)
postgres=# CREATE TABLE suchi (i int,n numeric); -- 検証用にint型、numeric型の列を定義するCREATE TABLEpostgres=# INSERT INTO suchi SELECT *,* FROM generate_series(1,100); -- 各列には同じ値のデータを100件挿入するINSERT 0 100postgres=# SELECT * FROM suchi LIMIT 3 ; -- テストデータを3件分確認するi | n
---+---1 | 12 | 23 | 3
(3 rows)同じ値が格納してもINT型の列での処理に⽐べてnumeric型は低速となる。

16© LPI-Japan all rights reserved.
#OSS-DB【物理設計】HOTとFILLFACTOR
n追記型アーキテクチャについて� PostgreSQLは追記型のアーキテクチャであり、UPDATEやDELETEで削除された古いレコードは不要領
域(dead tuple)として残る。� 追記型アーキテクチャのイメージは以下のとおり。
� 不要領域(dead tuple)は、そのままでは再利⽤できない。- DBのメンテナンス処理(VACUUM)によって、不要領域の回収を⾏う必要がある。- VACUUMを適切に実施しないとデータ量が拡⼤し、テーブル肥⼤化等の原因となる。
レコード A
レコード B
レコード C
レコード A
レコード B
レコード C
レコード D (追加)
INSERT
レコード A
レコード B
レコード C
レコード A
レコード B(不要領域)
レコード C
レコード B' (追加)
UPDATE
レコード A
レコード B
レコード C
レコード A
レコードB(不要領域)
レコード CDELETE
レコード A
レコード B
レコード C
レコード A
レコードB(不要領域)
レコード CDELETE
VACUUM レコード A
(再利⽤可能)
レコード C
INSERTレコード A
レコードB(不要領域)
レコード C
レコード D
レコード A
レコード D
レコード C
INSERT
そのまま
(Silver範囲外であるため、本⽇は設計要素としての紹介のみ)

17© LPI-Japan all rights reserved.
#OSS-DB【物理設計】HOTとFILLFACTOR
nHeap only tuple(HOT) とは� PostgreSQLでは、HOTという機能が提供されており、
主な効果は次のとおり。- この機能を利⽤した更新処理ではインデックスエントリの
追加処理が発⽣せず、更新性能が向上する。- 更新処理によって発⽣した不要領域はVACUUMによる回
収を待たずに再利⽤可能となる。� 本機能は以下の両⽅の条件を満たす場合に⾃動で有効
となる。(無効にはできない)- 更新対象がインデックスを持たない列である- 更新対象と同じページ(*1)内に空き領域がある
*1 PostgreSQLアクセスする最⼩単位(8KB)。ブロックとも呼ばれる。
ID NAME stock
1 item_A 25
2 item_B 30
3 item_C 27
インデックス
ID NAME stock
1 item_A 25
2 item_B 30
3 item_C 27
2 item_B 29
インデックス
インデックス自体の更新は行わない
ITEMテーブルを更新して、item_Bのstockを1減らす
新しいレコードへのポインタが追加される
(Silver範囲外であるため、本⽇は設計要素としての紹介のみ)
18© LPI-Japan all rights reserved.
#OSS-DB【物理設計】HOTとFILLFACTOR
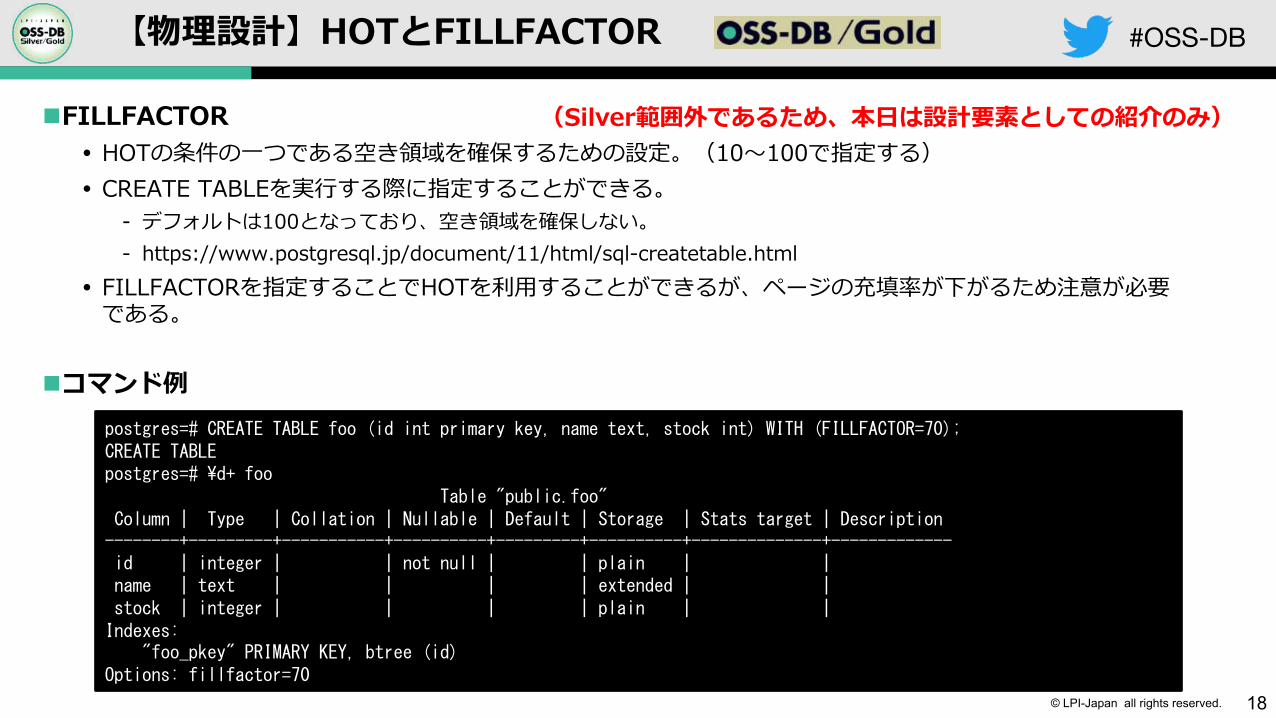
nFILLFACTOR� HOTの条件の⼀つである空き領域を確保するための設定。(10〜100で指定する)� CREATE TABLEを実⾏する際に指定することができる。
- デフォルトは100となっており、空き領域を確保しない。- https://www.postgresql.jp/document/11/html/sql-createtable.html
� FILLFACTORを指定することでHOTを利⽤することができるが、ページの充填率が下がるため注意が必要である。
nコマンド例postgres=# CREATE TABLE foo (id int primary key, name text, stock int) WITH (FILLFACTOR=70);CREATE TABLEpostgres=# ¥d+ foo
Table "public.foo"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------id | integer | | not null | | plain | | name | text | | | | extended | | stock | integer | | | | plain | |
Indexes:"foo_pkey" PRIMARY KEY, btree (id)
Options: fillfactor=70
(Silver範囲外であるため、本⽇は設計要素としての紹介のみ)

19© LPI-Japan all rights reserved.
#OSS-DB【物理設計】HOTとFILLFACTOR
nHOTとFILLFACTORについて� FILLFACTORを使⽤する際、容量設計にどのように影響を与えるか確認する。- pgbenchのテーブルがFILLFACTORの設定有無でどのように変化するか確認する。- デフォルト(FILLFACTOR=100)の場合、pgbench_accountsのサイズは128MBとなる。
- FILLFACTOR=70に設定した場合、同じデータ量でテーブルサイズはどのように変化するか︖
$ pgbench -i -s 10$ psql postgres -c "¥d+"
List of relationsSchema | Name | Type | Owner | Size | Description
--------+----------------------+---------------+----------+------------+-------------public | pgbench_accounts | table | postgres | 128 MB | public | pgbench_branches | table | postgres | 40 kB | public | pgbench_history | table | postgres | 0 bytes | public | pgbench_tellers | table | postgres | 40 kB |
(4 rows)
$ pgbench -i -s 10 --fillfactor=70$ psql postgres -c "¥d+"
(Silver範囲外であるため、本⽇は設計要素としての紹介のみ)

20© LPI-Japan all rights reserved.
#OSS-DB【物理設計】HOTとFILLFACTOR
nHOTとFILLFACTORについて� FILLFACTORによるテーブルサイズの変化
- デフォルト(FILLFACTOR=100)の場合、pgbench_accountsのサイズは128MBだったが、FILLFACTORを設定したことでデータの充填率が下がり、テーブルサイズは182MBに増えている。
$ pgbench -i -s 10 --fillfactor=70 postgres
$ psql postgres -c "¥d+"
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------------------+-------+----------+---------+-------------
public | pgbench_accounts | table | postgres | 182 MB |
public | pgbench_branches | table | postgres | 40 kB |
public | pgbench_history | table | postgres | 0 bytes |
public | pgbench_tellers | table | postgres | 40 kB |
(4 rows)
(Silver範囲外であるため、本⽇は設計要素としての紹介のみ)

21© LPI-Japan all rights reserved.
#OSS-DB【物理設計】インデックス設計
nPostgreSQLがサポートする主なインデックスの種類
nインデックス設計のポイントについて� 必要な分だけインデックスを定義する。
- インデックスは作成した分、当該テーブルの更新性能に影響を与える。また、インデックスファイル⾃体がディスクサイズの圧迫の原因となるため、必要最低限だけ定義する。
� インデックスの種類によって、⽤途(強み、弱み)は異なる。- 種類によって、インデックスファイルのサイズ⾃体も異なる。
名称 バージョン 説明B-tree ALL ⼀般的なインデックスで利⽤され、CREATE INDEXでのデフォルト。B-treeの
みが⼀意性インデックスをサポートする。hash ALL 9.6までは⾮推奨。PostgreSQL10以降はWAL対応。⼀致検索のみサポート。GiST ALL 主に全⽂検索で使⽤する。GINとの違いはマニュアルを参照。GIN 8.2〜 主に全⽂検索で使⽤する。GiSTとの違いはマニュアルを参照。BRIN 9.5〜 データウェアハウス向けのデータに対して利⽤する。
PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/sql-createindex.htmlhttps://www.postgresql.jp/document/11/html/textsearch-indexes.html

22© LPI-Japan all rights reserved.
#OSS-DB【物理設計】インデックス設計
n不必要にインデックスを作成している場合の影響の例� 以下の例では、pgbench_accountsに対してインデックスを追加した場合の性能の変化を確認する。� 確認としてpgbenchを3回実⾏したところ、対象テーブルの更新性能が20%ほど低下していることを確認した。
$ for i in 1 2 3 ; do pgbench -T 30 -r postgres | grep "UPDATE pgbench_accounts"; done
0.115 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
0.122 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
0.122 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
Table "public.pgbench_accounts"Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | |
Indexes:"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Table "public.pgbench_accounts"Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | |
Indexes:"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)"pgbench_accounts_abalance_aid_idx" btree (abalance, aid)"pgbench_accounts_abalance_idx" btree (abalance)"pgbench_accounts_aid_abalance_idx" btree (aid, abalance)
$ for i in 1 2 3 ; do pgbench -T 30 -r postgres | grep "UPDATE pgbench_accounts"; done
starting vacuum...end.0.148 UPDATE pgbench_accounts SET abalance =
abalance + :delta WHERE aid = :aid;starting vacuum...end.
0.150 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
starting vacuum...end.0.163 UPDATE pgbench_accounts SET abalance =
abalance + :delta WHERE aid = :aid;
3つのインデックスを追加
この状態で
処理を流す
インデックスを
追加した結果

23© LPI-Japan all rights reserved.
#OSS-DB【物理設計】インデックス設計
nインデックスの種類によって、⽤途(強み、弱み)は異なっている。� インデックスはそれぞれ異なった構造をしており、投⼊されるデータや利⽤⽤途によって向き
不向きが存在する。� ⽤途に応じて使い分けることで、より効果的な設計となる。
- btree︓多くのケースで利⽤できるので基本的にはbtreeを選択することになる。- hash︓⼀致検索しかサポートしていないが、安定した性能を発揮する。- brin︓データウェアハウスでの利⽤に適しているが、更新系には適していない。
nインデックスの種類によって、インデックスサイズは異なる。� pgbench_accounts.aidに対して、btree, hash, brinを作成した結果は以下のとおり。
postgres=# ¥di+ pgbench_accounts_aid_*List of relations
Schema | Name | Type | Owner | Table | Size | Description --------+----------------------------+-------+----------+------------------+-------+-------------public | pgbench_accounts_aid_brin | index | postgres | pgbench_accounts | 48 kB | public | pgbench_accounts_aid_btree | index | postgres | pgbench_accounts | 21 MB | public | pgbench_accounts_aid_hash | index | postgres | pgbench_accounts | 32 MB |
(3 rows)

24© LPI-Japan all rights reserved.
#OSS-DB【物理設計】インデックス設計
nINDEX作成について� インデックス作成時に取得されるロックについて
- インデックス作成時は対象のテーブルに強いロック(SHARE)が取得され、INSERT、UPDATE、SELECTと競合するため、基本的にサービス中に実施することはできない。
� CONCURRENTLYオプション- このオプションを使⽤した場合、INSERT、UPDATE、SELECTと競合しない。
– ロックレベルが下がり、 SHARE UPDATE EXCLUSIVEとなる。- 利⽤にあたって、以下の点に注意が必要となる。(詳細はPostgreSQL⽂書を参照。)
– 実⾏中のすべてのトランザクションが終わるまで待機する。» ロングトランザクションが存在する場合、いつまで処理が完了しない。
– 通常の⽅式よりも総処理時間がかかり、また、完了するまでの時間が⻑くなる。– インデックス作成によりCPUや⼊出⼒に余分に負荷が掛かるため、他の操作や処理に性能影響
を与える可能性がある。– 何らかの問題によって、CREATE INDEXが失敗すると「無効な」インデックスが残る。
PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/explicit-locking.htmlhttps://www.postgresql.jp/document/11/html/sql-createindex.html#SQL-CREATEINDEX-CONCURRENTLY

25© LPI-Japan all rights reserved.
#OSS-DB【物理設計】インデックス設計
nマルチカラムインデックス(複数列インデックス)� インデックスは、テーブルの2つ以上の列に定義することができ、最⼤で32列までをサポートしている。
- B-tree、GiST、GIN、BRINのみがマルチカラムインデックスに対応している。
� コマンド例︓
� 設計のポイント
- アプリケーションのワークロードを考慮し、どのようなインデックスを組み合わせて使⽤するかベストな形を探すこと。
– 絞り込みでx列とy列に対する絞り込みが必ず⾏われるなら複数列インデックスが最善になることがある。
– ただし、絞り込みでx列のみ、y列のみのケースが存在する場合、複数列インデックスはy列のみ
のケースでは複数列インデックスが有効に機能しない可能性がある。x列のみであれば複数列インデックスは有効であるが、x列の単⼀列インデックスに⽐べると低速になる。
PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/indexes-multicolumn.htmlhttps://www.postgresql.jp/document/11/html/indexes-bitmap-scans.html
postgres=# CREATE INDEX test2_mm_idx ON test2 (major, minor); -- majorとminorカラムに対するインデックスを作成

26© LPI-Japan all rights reserved.
#OSS-DB【物理設計】インデックス設計
n部分インデックス� インデックスを作成する際に対象の⾏を絞り込むことで、インデックスサイズを抑えることができ、性能を向上させることができる。
� 設計のポイント- 絞り込み条件において、頻出値がわかっている(決まっている)場合に有効。
� コマンド例︓
� 以下のケースでインデックスが有効なのはどちらか︖
PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/indexes-partial.html
postgres=# CREATE TABLE bar (id int, val double precision); -- 確認用のテーブル作成CREATE TABLEpostgres=# INSERT INTO bar SELECT *,random() FROM generate_series(1, 3000); -- テストデータを挿入INSERT 0 3000postgres=# CREATE INDEX ON bar USING btree (id) WHERE NOT (id > 400 AND id < 599); -- 部分インデックス作成CREATE INDEX
postgres=# EXPLAIN ANALYZE SELECT * FROM bar WHERE id = 700;postgres=# EXPLAIN ANALYZE SELECT * FROM bar WHERE id = 500;

27© LPI-Japan all rights reserved.
#OSS-DB【物理設計】インデックス設計
n部分インデックス� コマンド例(続き)︓
PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/indexes-partial.html
postgres=# EXPLAIN ANALYZE SELECT * FROM bar WHERE id = 700; -- OKパターンQUERY PLAN
-----------------------------------------------------------------------------------------------------------------Index Scan using bar_id_idx on bar (cost=0.28..8.30 rows=1 width=12) (actual time=0.020..0.021 rows=1 loops=1)Index Cond: (id = 700)
Planning Time: 0.340 msExecution Time: 0.038 ms
(4 rows)
postgres=# EXPLAIN ANALYZE SELECT * FROM bar WHERE id = 500; -- NGパターンQUERY PLAN
-----------------------------------------------------------------------------------------------Seq Scan on bar (cost=0.00..54.50 rows=1 width=12) (actual time=0.167..0.985 rows=1 loops=1)Filter: (id = 500)Rows Removed by Filter: 2999
Planning Time: 0.077 msExecution Time: 0.999 ms
(5 rows)

28© LPI-Japan all rights reserved.
#OSS-DBサンプル問題(インデックス設計)
nOSS-DB Silver サンプル問題/例題解説 から本テーマに関するものを紹介します。� 2分後に解説を⾏うので、ぜひ回答を考えてみてください。
※この例題は実際のOSS-DB技術者認定試験とは異なります。

29© LPI-Japan all rights reserved.
#OSS-DBサンプル問題 3.46
n以下のSQL⽂でテーブルを作成した。
CREATE TABLE sample (id INTEGER, val TEXT);
このテーブルのid列に⼀意のインデックスを作成したい。
以下のSQL⽂で適切なものを2つ選びなさい。
A) ALTER TABLE sample ADD UNIQUE INDEX ON id;B) ALTER TABLE sample ALTER COLUMN id UNIQUE;C) ALTER TABLE sample ADD UNIQUE(id);D) CREATE UNIQUE INDEX ON sample(id);E) CREATE INDEX sample_id_unique ON sample(id);
n引⽤元
� https://oss-db.jp/sample/silver_development_03/46_141001
セミナーでは解説していない部分になりますが、実⾏できる環境を持っている⽅は、ぜひ実際に試して、その結果をご確認ください。
実⾏する際は、以下のようにテーブルを作成しておく必要があります。CREATE TABLE sample(id int);

30© LPI-Japan all rights reserved.
#OSS-DB【物理設計】テーブルスペース(テーブル空間)
nPostgreSQLのファイル構成のおさらい� PostgreSQLでは、テーブルやインデックス等のオブジェクトは実ファイルとして管理されている。- デフォルト設定でテーブルを作成すると $PGDATA/base配下に作成される。- ファイルパスを調べるための関数も提供されている。
nテーブルスペースの設計について� テーブルスペースを使⽤することで、データベースオブジェクトのレイアウトを制御することができる。- IOが集中するテーブルやインデックスを⾼速・⾼可⽤なディスク配置することや、ディスクを分離してIO負荷を分散させるかどうかがポイントなる。
PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/manage-ag-tablespaces.html
postgres=# SELECT pg_relation_filepath(oid) FROM pg_class WHERE relname = 'foo';pg_relation_filepath
----------------------base/13881/34005
(1 row)
環境によってファイルパスは異なる

31© LPI-Japan all rights reserved.
#OSS-DB【物理設計】テーブルスペース(テーブル空間)
nコマンド例︓
PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/manage-ag-tablespaces.html
postgres=# CREATE TABLESPACE fastspace LOCATION '/ssd1/postgresql/data'; -- テーブルスペースを作成するCREATE TABLESPACEpostgres=# CREATE TABLE foo(i int) TABLESPACE fastspace; -- 作成したテーブルスペース上にオブジェクトを作成するCREATE TABLEpostgres=# SELECT pg_relation_filepath(oid) FROM pg_class WHERE relname = 'foo'; -- ファイルパスを参照する
pg_relation_filepath ---------------------------------------------pg_tblspc/34119/PG_11_201809051/13881/34120
(1 row)postgres=# ¥q-bash-4.2$ ll local/11/data/pg_tblspc/ # シンボリックリンクで指定された領域が使用されていることを確認できるtotal 0lrwxrwxrwx 1 postgres postgres 21 Jun 28 16:35 34119 -> /ssd1/postgresql/data
postgres=# CREATE TABLESPACE fastspace2 LOCATION '/ssd2/postgresql/data'; -- テーブルスペースを作成するCREATE TABLESPACEpostgres=# SET default_tablespace = fastspace2; -- デフォルトで使用されるテーブルスペースを変更するSETpostgres=# CREATE TABLE foo(i int); -- 設定変更後はTABLESPACEの指定は不要となるCREATE TABLE

32© LPI-Japan all rights reserved.
#OSS-DBサンプル問題(テーブルスペース(テーブル空間))
nOSS-DB Silver サンプル問題/例題解説 から本テーマに関するものを紹介します。� 2分後に解説を⾏うので、ぜひ回答を考えてみてください。
※この例題は実際のOSS-DB技術者認定試験とは異なります。

33© LPI-Japan all rights reserved.
#OSS-DBサンプル問題 3.113
nテーブルスペース(テーブル空間、tablespace)の使い⽅として、間違っているものを1つ選びなさい。
A) CREATE TABLESPACE コマンドでテーブルスペースとして使⽤するディレクトリを指定するが
、このディレクトリは既存で、かつ空でなければならない。
B) テーブルを作成する際、 CREATE TABLE (…テーブル定義…) TABLESPACE テーブルスペース
名; のようにすれば、指定したテーブルスペースが使⽤される。
C) パラメータ default_tablespace でテーブルスペース名を指定すると、CREATE TABLE などで
作成されるオブジェクトは、設定されたテーブルスペースを使⽤する。
D) テーブルスペース内にオブジェクトを作成するには、そのテーブルスペースについての CREATE
権限が必要である。
E) DROP TABLESPACEコマンドでテーブルスペースを削除するとき、その中にあるオブジェクト
も⾃動的に削除される。
n引⽤元� https://oss-db.jp/sample/silver_development_06/113_200326

34© LPI-Japan all rights reserved.
#OSS-DB【物理設計】パラメータ設計
nメモリ設計� メモリは⼤きく分けて、共有メモリとプロセスメモリが存在する。それぞれの役割については以下
のとおり。- 共有メモリ
– 各プロセスから共通で利⽤できる共有のメモリ領域。PostgreSQL起動時に確保される。– 共有バッファ、WALバッファ、Visibility Map(*1)、Free Space Map(*2)に分けて使⽤される。
- プロセスメモリ– バックエンドプロセス(セッション)ごとに確保される領域。確保したプロセスのみが利⽤できる。
� これらは postgresql.conf で設定することができる。- shared_buffers, wal_buffers, work_mem 等々
n設計のポイント� 性能に直結する設計要素であるため、特に注意が必要となる。� PostgreSQLはディスクから読み込んだデータは共有バッファ上で操作を⾏うため、共有バッファが
⼩さすぎるとディスクアクセスが発⽣し、処理性能が低くなる。� 扱うデータサイズ、実⾏するSQLに合わせて値を決定する必要がある。
(Silver範囲外であるため、本⽇は設計要素としての紹介のみ)
*1 Visibility Map︓データの可視性を管理する領域。VACUUM処理等で利⽤される。*2 Free Space Map︓対象のリレーション無いで利⽤可能な領域を追跡するための情報をもつ領域。

35© LPI-Japan all rights reserved.
#OSS-DB運⽤設計
n物理設計� テーブル設計、インデックス設計
- 容量設計(サイジング)- テーブル定義
– データ型– HOT、FILLFACTOR
- インデックス設計- テーブルスペース
� パラメータ設計- メモリ設計
– shared_buffers, work_mem
n運⽤設計� DBのメンテナンス
- VACUUM、ANALYZE、FREEZE- autovacuum
� バックアップ・リカバリ- バックアップの種類
� セキュリティ- ROLE- GRANT, REVOKE
続いて運⽤設計について解説します。
⻩⾊の項⽬︓

36© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】DBのメンテナンス
nVACUUM︓データベースの不要領域を回収する� 追記型アーキテクチャを採⽤しており、削除された領域はVACUUM処理で回収するまで再利⽤することができない。
� 設計のポイント- 不要領域を適正なタイミングで回収し、テーブルの肥⼤化を発⽣させない。
– VACUUMを過剰に実施しても、無駄なリソースの消費につながる。
� 現在存在する不要領域を確認する⽅法- n_dead_tupとしてシステムカタログから確認することができる。
postgres=# postgres=# select n_dead_tup from pg_stat_user_tables where relname = 'pgbench_accounts';n_dead_tup
------------3850
(1 row)3850レコードが不要領域として存在

37© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】DBのメンテナンス
nFREEZE︓タプルを凍結しXIDを再利⽤する� PostgreSQLはトランザクション処理をトランザクションID(XID)で管理しており、32bitの
数値(約40億)を再利⽤しながら使⽤している。- XIDの回収ができずに、使い切ってしまうとDBは最悪停⽌してしまう。- XIDはDBクラスタ単位で管理されている。
postgres=# SELECT datname,age(datfrozenxid) FROM pg_database ;datname | age
-----------+-------postgres | 18713template1 | 18713template0 | 18713
(3 rows)postgres=# VACUUM FREEZE;VACUUMpostgres=# SELECT datname,age(datfrozenxid) FROM pg_database ;datname | age
-----------+-------postgres | 0template1 | 18713template0 | 18713
(3 rows)
age()で、XIDがどれだけ消費されているか確認できる。
VACUUM FREEZEによって、XIDの回収をおこなったことでカウントが「0」に戻った。

38© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】DBのメンテナンス
nFREEZE(続き)� 設計のポイント
- FREEZE処理は、VACUUM FREEZEで明⽰的に実⾏することもできるが、VACUUM処理を実⾏した際、裏でFREEZE処理は⾏われている。
– VACUUM処理の中でFREEZEされる範囲はチューニング要素。
- 注意が必要な要素ではあるが、VACUUM処理が⼗分に実⾏できていれば、FREEZEをシビアに考える必要はない。
postgres=# SELECT datname,age(datfrozenxid) FROM pg_database WHERE datname = 'postgres';datname | age
----------+------------postgres | 1610593462
(1 row)postgres=# VACUUM;VACUUMpostgres=# SELECT datname,age(datfrozenxid) FROM pg_database WHERE datname = 'postgres';datname | age
----------+----------postgres | 50000000
(1 row)
XIDが消費された状態
5000万XID分を残して、FREEZEされた。
テーブルを指定しない場合、DB全体にVACUUMが⾏われる。

39© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】DBのメンテナンス
nANALYZE︓データベース内のテーブルの内容に関する統計情報を収集する� PostgreSQLは与えられたSQL問い合わせに対して、統計情報やデータ分布等の情報を利⽤して、その処理を実⾏するためのベストな⼿順(実⾏計画)を作成している。
- 実⾏計画は以下のようにEXPLAIN⽂で確認することができる。
� 設計のポイント- 統計情報がうまく利⽤できないケースがあり、そういった状況においては不適切な実⾏計画が採⽤され、性能問題等の原因になることがある。
- バックアップからリストアした直後は統計情報がクリアされるため、統計情報の取得が必要。
- データ分布が変わるような⼤量のデータ操作を⾏った後には、統計情報の更新が必要。
postgres=# EXPLAIN SELECT pc.relname, pl.mode FROM pg_locks pl ,pg_class pc WHERE pl.relation = pc.oid AND locktype = 'relation';
QUERY PLAN -----------------------------------------------------------------------------------Hash Join (cost=12.56..34.74 rows=5 width=96)Hash Cond: (pc.oid = l.relation)-> Seq Scan on pg_class pc (cost=0.00..20.18 rows=518 width=68)-> Hash (cost=12.50..12.50 rows=5 width=36)
-> Function Scan on pg_lock_status l (cost=0.00..12.50 rows=5 width=36)Filter: (locktype = 'relation'::text)
(6 rows)
JOINの⽅法、スキャンの⽅法等
が書かれている。

40© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】DBのメンテナンス
nこれらのDBのメンテナンス処理は、必要なタイミングで処理を⾏う必要がある。� PostgreSQLでは、これらのメンテナンス処理(VACUUM、ANALYZE、FREEZE)を⾃動で⾏うautovacuum機能(⾃動バキューム機能)が備わっている。
n設計のポイント� autovacuumによるメンテナンス処理の閾値- autovacuumが起動する際の閾値を制御できる。INSERT、UPDATE、DELETE等にデータが操作された量を監視しており、閾値を超えた場合にautovacuumのworkerプロセスが起動される。
� autovacuumによるVACUUMの処理負荷の制御- 全⼒で不要領域の回収を⾏わせるか- IO負荷を軽減するために加減しながら回収を⾏うか
� DBのメンテナンス処理を阻害する要因を理解する- 阻害の主な要因としてあげられるのが、ロングトランザクション(トランザクションを開始した状態が⻑時間続いている処理)が存在するケース。PostgreSQLでは、アクセスされる可能性があるデータは回収して再利⽤することができない。不要領域もXIDも同様。

41© LPI-Japan all rights reserved.
#OSS-DBサンプル問題(DBのメンテナンス)
nOSS-DB Silver サンプル問題/例題解説 から本テーマに関するものを紹介します。� 2分後に解説を⾏うので、ぜひ回答を考えてみてください。
※この例題は実際のOSS-DB技術者認定試験とは異なります。

42© LPI-Japan all rights reserved.
#OSS-DBサンプル問題 1.109
nバキューム(VACUUM)と⾃動バキュームの違いの説明として適切なものを3つ選びなさい。A) VACUUMはオプションで指定しなければ不要領域の回収のみを実⾏するのに対し、⾃動バキュー
ムは不要領域の回収と解析(ANALYZE)の両⽅を実⾏する。B) VACUUMは対象とするテーブルのリストを指定する必要があるが、⾃動バキュームは挿⼊・更新
・削除されたデータが⼀定量以上のテーブルが⾃動的に対象となる。C) VACUUMは⼀時テーブル(temporary table)を対象とできるが、⾃動バキュームでは⼀時テー
ブルは対象外である。D) VACUUMはオプションを指定することでファイルサイズを縮⼩することができるが、⾃動バキュ
ームには同等の機能がない。E) VACUUMはOSの機能などを使って定期的に⾃動実⾏するようにできる。⾃動バキュームは
PostgreSQLサーバの稼働中で、トランザクションの実⾏量が少ないときに⾃動的に実⾏されるので、OSの機能の設定は不要である。
n引⽤元� https://oss-db.jp/sample/silver_management_06/109_201029

43© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】バックアップ・リカバリ
nPostgreSQLが提供するバックアップ
� 論理バックアップ- pg_dumpコマンド、pg_dumpallコマンドが提供されている。- 論理バックアップではPostgreSQLの設定ファイルのバックアップはできない。
� 物理バックアップ- オンラインで実施する場合は、pg_basebackupコマンド, pg_start_backup(), pg_stop_backup()が提供されている。- オフラインであれば、DBを停⽌後にcpコマンド等で取得することができる。
– オフラインで取得するバックアップはコールドバックアップと呼びます。
nPostgreSQLが提供するバックアップ⽅式と各⽅式の主な特徴
項⽬ pg_dump, pg_dumpall pg_basebackuppg_start_backup,
pg_stop_backup
概要 DBを論理的な形に変換する⽅式
レプリケーション機能を利⽤した⽅式 停⽌点を作って⾏う⽅式
取得条件 オンライン オンライン オンラインバックアップ対象 オブジェクト単位で指定可能 DBクラスタ全体 DBクラスタ全体
WALによるリカバリ 不要 必要 必要

44© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】バックアップ・リカバリ
nバックアップ・リカバリの⼿順について� 詳細な⼿順については過去のセミナー資料を参照。- 「PostgreSQLのバックアップ⽅法」- https://oss-db.jp/__/download/5f0fb75b37471d78510554e4/20200719-silver-01.pdf
n設計のポイント� バックアップ⽅式の選定- 何をバックアップする必要があるか︖
– どういった障害に備える必要があるかによって取得対象は変わる。- バックアップ、リカバリに掛けてもよい時間がどれだけあるか︖
– ⽅式によってバックアップの取得に掛かる時間、バックアップからの復旧に掛かる時間は異なる。※システム要件に合わせた⽅式を選択する必要がある。
� バックアップファイルの管理- 不要になったもののバックアップファイルを定期的に削除する(アーカイブWAL等)- バックアップファイルの管理機能はPostgreSQLでは提供されていないため、サードパーティ製品の利⽤が必要か検討が必要。

45© LPI-Japan all rights reserved.
#OSS-DBサンプル問題(バックアップ・リカバリ)
nOSS-DB Silver サンプル問題/例題解説 から本テーマに関するものを紹介します。� 2分後に解説を⾏うので、ぜひ回答を考えてみてください。
※この例題は実際のOSS-DB技術者認定試験とは異なります。

46© LPI-Japan all rights reserved.
#OSS-DBサンプル問題 1.101
nコールドバックアップ(データベースを停⽌した状態で取得するバックアップ)について適切なものを3つ選びなさい。
A) cp などのコマンドを利⽤して、データベースクラスタのディレクトリのコピーを作成する。
B) tar などのコマンドを利⽤して、データベースクラスタのディレクトリのアーカイブを作成する。
C) rsyncなどのコマンドを利⽤して、データベースクラスタのディレクトリの複製をネットワーク上の他のホストに作成する。
D) pg_basebackup コマンドを利⽤して、データベースクラスタのベースバックアップを作成する。
E) pg_dumpall コマンドを利⽤して、データベースクラスタ全体のバックアップを作成する。
n引⽤元� https://oss-db.jp/sample/silver_management_06/101_200212

47© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】セキュリティ
nROLE� データベースオブジェクトを所有することができ、データベース権限を持つことができる実体。� ロールは、使⽤状況に応じて「ユーザ」、「グループ」、もしくは、その両⽅として利⽤することができる。
- 例えば、DBに接続する際に使⽤するユーザは、ログイン権限を持つロールであり、実体は同じものである。
n⾃動で作成されるロールについて� RPMでインストールした場合、デフォルトで postgres ロールが作成される。
- postgresロールは強⼒な superuser権限 が付与されているため、取り扱いには注意が必要。� デフォルトロール
- 監視機能や権限をもつユーザにしか参照できない情報へのアクセスを容易に設定するための権限のセット。これを利⽤することで権限の管理が少しやりやすくなる。
- https://www.postgresql.jp/document/11/html/default-roles.html
nロールの作成について� CREATE ROLE⽂で作成可能。似たSQLとして、CREATE USER⽂があるが作成されたロールがデフォルトでロ
グイン権限を持つか持たないかの違いしかない。� PostgreSQLにはスキーマが存在するが、ロールとは異なる権限の管理構造であり、ロール作成時に⾃動作成さ
れることはない。(特にOracleとは扱いが異なるので注意が必要。)
PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/sql-createrole.html

48© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】セキュリティ
n設計のポイント� superuserは権限として強⼒すぎるため、通常の業務では使⽤しない。
- superuserは制限なく全てのオブジェクトにアクセス可能で、OSのroot権限相当の扱い。� データベースオブジェクトにアクセスするための最⼩権限を付与する。
- 例えば、DBの管理タスクを⾏うためのロール、Read Onlyのロール、ReadWriteのロール等、複数のロールを作成し、それらのロールをアプリケーションが使⽤するユーザ(ログイン権限をもつロール)に付与する。
オブジェクトの作成・削除等を許可
admin ロール
reporter ロール
application_user ロール
Read 権限
ReadWrite権限
CREATE権限
ROLEごとに権限を分ける運⽤(イメージ)
テーブルA
テーブルAへのSELCTを許可
テーブルAへのSELCT/UPDATE/
INSERT/DELETEを許可

49© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】セキュリティ
nGRANT(権限付与)/REVOKE(権限取り消し)� ロールに対して、データベースオブジェクトに対する権限を付与する。� 指定したロール内のメンバ資格を他のロールに付与します。
nコマンド例︓PostgreSQL⽂書︓https://www.postgresql.jp/document/11/html/sql-grant.html
-bash-4.2$ psql postgres -U application_user # application_userでPostgreSQLに接続psql (11.6)Type "help" for help.
postgres=> SELECT count(*) FROM pgbench_accounts; -- 権限の無い参照はエラーERROR: permission denied for table pgbench_accountspostgres=> ¥dp pgbench_accounts
Access privilegesSchema | Name | Type | Access privileges | Column privileges | Policies
--------+------------------+-------+---------------------------+-------------------+----------public | pgbench_accounts | table | postgres=arwdDxt/postgres | |
(1 row)
postgres=# CREATE USER application_user; -- LOGIN権限を持つ application_user ロールを作成するCREATE ROLE
Accessprivilegesの読み⽅︓role名=与えられた権限/権限付与したrole名
権限︓a︓INSERTr︓SELECTw︓UPDATEd︓DELETE ... 詳細はマニュアル参照

50© LPI-Japan all rights reserved.
#OSS-DB【運⽤設計】セキュリティ
nコマンド例(続き)︓
-bash-4.2$ psql postgres -U application_userpsql (11.6)Type "help" for help.
postgres=> SELECT count(*) FROM pgbench_accounts;count
---------1000000
(1 row)postgres=> ¥dp pgbench_accounts
Access privilegesSchema | Name | Type | Access privileges | Column privileges | Policies
--------+------------------+-------+---------------------------+-------------------+----------public | pgbench_accounts | table | postgres=arwdDxt/postgres+| |
| | | readwrite=arwd/postgres | | (1 row)
postgres=# CREATE ROLE readwrite;CREATE ROLEpostgres=# GRANT SELECT, UPDATE, INSERT, DELETE ON ALL TABLES IN SCHEMA public TO readwrite;GRANTpostgres=# GRANT readwrite TO application_user ;GRANT ROLE
pgbench_accountsに対して、readwireteロールはINSERT, SELECT, UPDATE, DELETE権限をpostgres ロールから付与された という情報が記録されている。

51© LPI-Japan all rights reserved.
#OSS-DBサンプル問題(ROLE)
nOSS-DB Silver サンプル問題/例題解説 から本テーマに関するものを紹介します。� 2分後に解説を⾏うので、ぜひ回答を考えてみてください。
※この例題は実際のOSS-DB技術者認定試験とは異なります。

52© LPI-Japan all rights reserved.
#OSS-DBサンプル問題 1.106
nPostgreSQLにおけるCREATE USERとCREATE ROLEの違いの説明として、適切なものを2つ選びなさい。
A) CREATE ROLEは⼀般ユーザでも実⾏できるが、CREATE USER の実⾏はスーパーユーザ権限が必要である。
B) CREATE ROLEで作成したロールを GRANT コマンドによりユーザに付与することができるが、CREATE USERで作成したユーザをGRANTで他のユーザに付与することはできない。
C) CREATE ROLEで作成したロールのLOGIN属性はNOLOGIN、CREATE USERで作成した場合はLOGINがデフォルトになっている。
D) CREATE USERでユーザを作成したら、同じ名前のスキーマが⾃動的に作成されるが、CREATE ROLEの場合はスキーマが作成されない。
E) OSのコマンドラインからCREATE USERと同等の機能を実⾏するために createuser というコマンドが提供されているが、createrole というコマンドは提供されていない。
n引⽤元� https://oss-db.jp/sample/silver_management_06/106_200708

53© LPI-Japan all rights reserved.
#OSS-DB
■お問い合わせ■NTTテクノクロス株式会社 ソフト道場
https://www.ntt-tx.co.jp/products/soft_dojyo/



























![[C31] OSS-DB Exam Silver 技術解説セミナー by Ryota Watabe](https://img.pdfslide.tips/doc/110x75/547ce24cb37959892b8b514b/c31-oss-db-exam-silver-by-ryota-watabe.jpg)
