Embed Size (px)
Citation preview

Modelli e procedure per l’educazione degli adulti
Pedagogia sperimentale.
CdL SEAFC – a.a. 2016-2017 – II semestre

T6.Modelli e procedure di valutazioneUltimo appuntamento con le attività pratiche di valutazione del corso ”Pedagogia sperimentale. Modelli e procedure per l’educazione degli adulti”

Che cosa faremo
▪ Impostazione di un archivio di dati ▪ Pulizia dei dati ▪ Calcolo delle frequenze ▪ Difficoltà e discriminativita ▪ Misure di tendenza centrale e di
dispersione ▪ Centili, punti z e punti T ▪ Distribuzione pentenaria e punteggi
soglia ▪ Rappresentazione grafica ▪ Alcuni test (t-test, !2, phi) ▪ Correlazione (Pearson, Spearman)

Statistica inferenziale
• t-test (t di Student)• Il test del !2
• phi

Disegni tra i soggetti
• I disegni tra i soggetti sono i disegni in cui si hanno due o piu gruppi indipendenti e in cui ogni soggetto viene sottoposto ad una sola condizione sperimentale
• In questo tipo di disegno il ricercatore è interessato a verificare l’ipotesi di differenza tra due o piu medie
• per verificare l’esistenza di una differenza tra le medie, il ricercatore calcola le medie dei veri gruppi relative alla variabile di interesse (ad es., prestazione ad un compito di matematica) e trova che le due medie sono diverse

Differenza tra le medie▪ questa diversità tra le medie (variabilità tra i gruppi) può essere
attribuita a tre diverse fonti: ▫ l’effetto del trattamento (ad es., il nuovo metodo per insegnare la matematica)▫ le differenze individuali (ad es., alcuni studenti, a prescindere dal trattamento
sono più bravi in matematica)▫ l’errore casuale (ad es., alcune parsone hanno sbagliato a riportare i risultati).▪ le ultime due fonti di variazione sono accidentali, poiché il ricercatore
non può prevederne la variabilità
▪ la variabilità entro i gruppi è invece dovuta alla variazione delle risposte dei soggetti, poiché è difficile, che i soggetti appartenenti ad uno stesso gruppo rispondano in modo identico
▪ in questo caso, esistono due fonti di variazione: ▪ le differenze individuali ▪ L’errore casuale

t-test
▪ quando le medie sono solo due si può utilizzare il t di Student (detto anche test t o t-test)
▪ è un test statistico di tipo parametrico con lo scopo di verificare se il valore medio di una distribuzione si discosta significativamente da un certo valore di riferimento
▪ una volta ottenuto t si verifica di quanto si discosta dal valore critico con quei gradi di libertà:
▪ se il t ottenuto supera il valore critico, allora possiamo rifiutare l’ipotesi nulla e accettare l’ipotesi alternativa secondo la differenza tra le medie è dovuta al trattamento

Passo indietro: T di Student
▪ è una distribuzione descritta per primo da William Sealy Gosset nel 1908 (usò lo pseudonimo Student perché la fabbrica della Guinnes in cui lavorava non voleva che si pubblicassero articoli per paura di divulgazione dei segreti di produzione)
▪ è una distribuzione di probabilità continua che governa il rapporto tra due variabili aleatorie, la prima con distribuzione normale e la seconda, al quadrato, segue una distribuzione chi quadrato
▪ questa distribuzione interviene nella stima della media di una popolazione che segue la distribuzione normale, e viene utilizzata negli omonimi test t di Student per la significatività e per ogni intervallo di confidenza della differenza tra due medie

Passo indietro: I gradi di libertà▪ è un concetto ricorrente nella statistica inferenziale▪ I gradi di libertà di una statistica esprimono il numero minimo di dati
sufficienti a valutare la quantità d'informazione contenuta nella statistica
▪ quando un dato non è indipendente, l'informazione che esso fornisce è già contenuta implicitamente negli altri
▪ ed è possibile calcolare le statistiche utilizzando solo i dati indipendenti

Passo indietro: I gradi di libertà▪ si pensi a tre numeri x1, x2 e x3▪ siamo completamente liberi di pensare a qualsiasi numero (positivi,
negativi, interi o frazionari ecc...) ossia godiamo di tre gradi di libertà (uno per ciascun numero)
▪ se però poniamo un vincolo del tipo x1 + x2 + x3 = 10▪ non godiamo più di tre gradi di libertà in quanto fissati a completo
arbitrio x1 e x2, il terzo (x3) risulta determinato per il vincolo posto▪ godiamo quindi solo di due gradi di libertà▪ I gradi di libertà sono in generale calcolati come n-1
▪ es: x1=12, x2=7 necessariamente x3=-9 (12+7-9=10), gradi di libertà 3-1 = 2, infatti sono due le variabili che possiamo scegliere liberamente

Test del !2
▪ quando si hanno scale nominali o ordinali, non è possibile calcolare il t, poiché non abbiamo medie, ma solo frequenze
▪ in questi casi, per verificare se un evento si verifica, in due o più gruppi, con la stessa frequenza o meno, si usa il test del !2 (la cui distribuzione è nota)
▪ Il test !2 verifica se vi è una differenza tra le frequenze osservate, ovvero quelle ottenute dalla rilevazione dei dati, e le frequenze attese (o frequenze teoriche), ovvero le frequenze che ci si aspetta di trovare
▪ per ognuna delle categorie si calcola il quadrato della differenza tra le frequenze osservate e quelle attese, dividendo il risultato per le frequenze attese
▪ Il χ2 è dato dalla somma dei risultati di questa operazione, effettuata per ognuna delle categorie

Test del !2
▪ a questo punto, si confronta il valore ottenuto !2 con quello critico, tendendo conto dei gradi di libertà
▪ se il valore ottenuto è superiore al valore critico si può scartare l’ipotesi nulla e accettare l’ipotesi alternativa
▪ sappiamo che la differenza esiste ma non sappiamo dove risieda, né quale sia l’intensità, nè quale sia la causa
▪ risultati affidabili solo su scale nominali e ordinali (no continue), per frequenze attese sempre superiori all’unità

ϕ (phi), l’intensità del !2
▪ il φ (phi) misura l’effetto della dimensione del campione sul chi quadrato
▪ corrisponde alla radice quadrata del rapporto tra chi quadrato e numero di studenti considerati
▪ Si interpreta così:� <0,1 debole
<0,3 modesto� <0,5 moderato� <0,8 forte � >0,8 molto forte

Correlazione
• La correlazione lineare• I coefficienti di correlazione

LA CORRELAZIONELa correlazione indica la tendenza che hanno due variabili (X e Y) a variare insieme, ovvero, a covariare. Ad esempio, si può supporre che vi sia una relazione tra l’insoddisfazione della madre e l’aggressività del bambino, nel senso che all’aumentare dell’una aumenta anche l’altra. Quando si parla di correlazione bisogna prendere in considerazione due aspetti: il tipo di relazione esistente tra due variabili e la forma della relazione (ossia la direzione e l’entità).
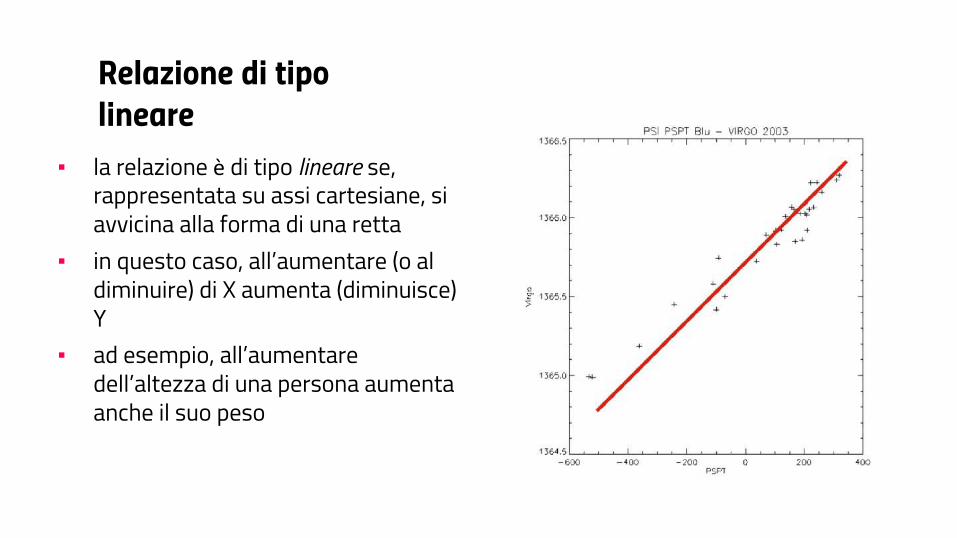
Relazione di tipo lineare
▪ la relazione è di tipo lineare se, rappresentata su assi cartesiane, si avvicina alla forma di una retta
▪ in questo caso, all’aumentare (o al diminuire) di X aumenta (diminuisce) Y
▪ ad esempio, all’aumentare dell’altezza di una persona aumenta anche il suo peso
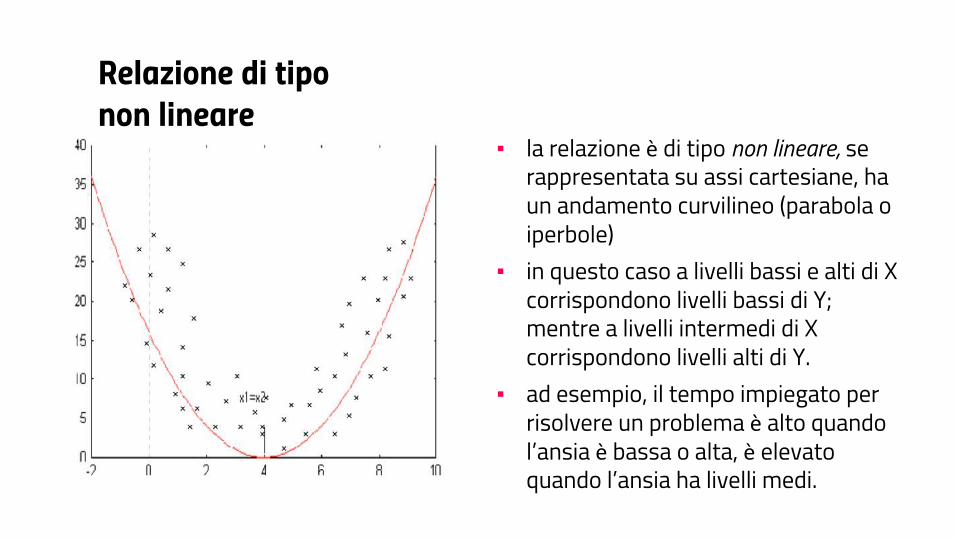
Relazione di tiponon lineare
▪ la relazione è di tipo non lineare, se rappresentata su assi cartesiane, ha un andamento curvilineo (parabola o iperbole)
▪ in questo caso a livelli bassi e alti di X corrispondono livelli bassi di Y; mentre a livelli intermedi di X corrispondono livelli alti di Y.
▪ ad esempio, il tempo impiegato per risolvere un problema è alto quando l’ansia è bassa o alta, è elevato quando l’ansia ha livelli medi.
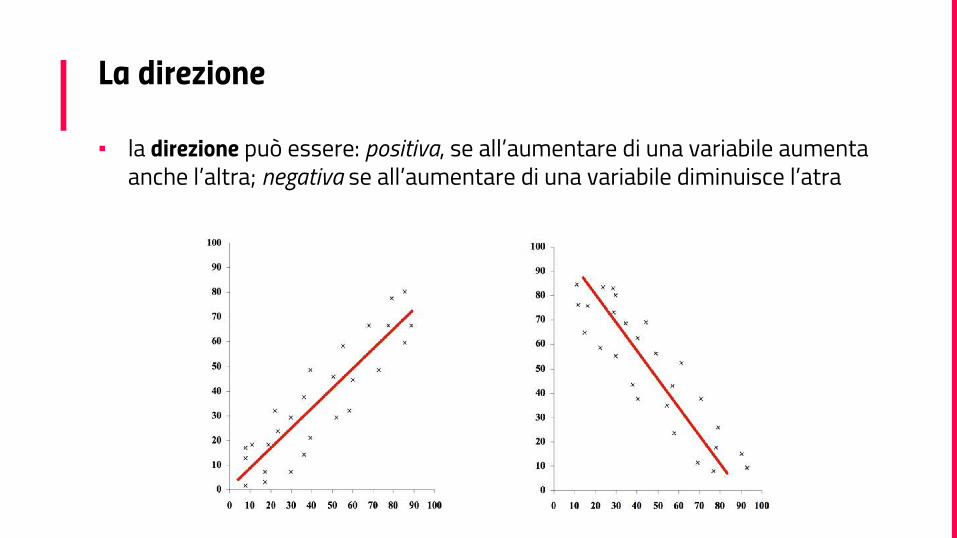
La direzione
▪ la direzione può essere: positiva, se all’aumentare di una variabile aumenta anche l’altra; negativa se all’aumentare di una variabile diminuisce l’atra

L’entità
▪ l’entità si riferisce alla forza della relazione esistente tra due variabili▪ quanto più i punteggi sono raggruppati attorno ad una retta, tanto più
forte è la relazione tra due variabili▪ se i punteggi sono dispersi in maniera uniforme, invece, tra le due
variabili non esiste alcuna relazione▪ ad esempio, quanto più elevata è la temperatura, tanto più si suda

I coefficienti di correlazione▪ per esprimere la relazione si utilizza il coefficiente di correlazione▪ il coefficiente è standardizzato e può assumere valori che vanno da –
1.00 (correlazione perfetta negativa) e +1.00 (c. perf. positiva). Una correlazione uguale a 0 indica che tra le due variabili non vi è alcuna relazione
▪ Nota: la correlazione non include il concetto di causa-effetto, ma solo quello di rapporto tra variabili. La correlazione ci permette di affermare che tra due variabili c’è una relazione sistematica, ma non che una causa l’altra
▪ Per le scale a intervalli o rapporti equivalenti si usa il coefficiente r di Pearson.
▪ Per le scale ordinali si usano il coefficiente rs di Spearman

Il coefficiente di correlazione r di Pearson
▪ serve a misurare la correlazione tra variabili a intervalli o a rapporti equivalenti, meglio se su scale continue
▪ è dato dalla somma dei prodotti dei punteggi standardizzati delle due variabili diviso il numero dei soggetti (o delle osservazioni)
▪ si può calcolare solo su coppie di valori che si riferiscono allo stesso individuo
▪ può assumere valori che vanno da –1.00 (corr. perf. neg.) e + 1.00 (corr. perf. positiva). Se 0 tra le due variabili non vi è alcuna relazione
▪ per stabilire se una correlazione è significativa, si fa riferimento alla distribuzione campionaria di r, tabulata in apposite tavole, in corrispondenza dei gradi di libertà (N – 2) del coefficiente

Il coefficiente di correlazione r di Spearman
▪ serve per misurare la correlazione tra due ▪ variabili di tipo ordinale ▪ è dato dalla somma dei prodotti dei punteggi
standardizzati delle due variabili diviso il numero dei soggetti (o delle osservazioni)
▪ è un’approssimazione del coefficiente di Pearson ▪ la relazione tra X e Y è espressa tenendo conto delle
concordanti o differenti posizioni di ciascun soggetto nelle due graduatorie





























