Embed Size (px)
Citation preview

MARIE-CLAUDE BOLDUC, B.A.A.
PLANIFICATION DU TRANSPORT DE CHARGES PARTIELLES D’UN DÉPÔT : RÉPARTITION, LIVRAISON
ET REVENU DE RETOUR
Essai présenté dans le cadre du programme de Maîtrise en administration des affaires,
concentration Gestion manufacturière et logistique, pour l’obtention du grade de maître en administration des affaires (M.B.A.)
Directeur : Monsieur Gilles d’Avignon, Ph. D. Codirecteur : Monsieur Jacques Renaud, Ph. D.
DÉPARTEMENT OPÉRATIONS ET SYSTÈMES DE DÉCISION
FACULTÉ DES SCIENCES DE L’ADMINISTRATION UNIVERSITÉ LAVAL
QUÉBEC
JUILLET 2003 © Marie-Claude Bolduc, 2003

i
Résumé
Les entreprises de transport sont un maillon important de la chaîne logistique. En effet,
elles permettent le déplacement des marchandises entre les autres maillons de la chaîne.
Entre le Canada et les États-Unis, les marchandises transitent par camions dans plus de
70 % des cas (Industrie Canada 2003). Dans le contexte de juste-à-temps, ceci implique
que les expéditions sont fréquentes et parfois de tailles réduites. Dès lors, les entreprises de
transport doivent gérer la demande liée aux charges partielles. Cette planification nécessite
la prise de plusieurs décisions rapidement.
Sur le marché actuel, les logiciels disponibles pour accomplir cette tâche sont dispendieux
et nécessitent beaucoup de temps d’implantation et de formation des employés. De plus, il
est impossible de valider les méthodes de résolution utilisées. Dès lors, aucune garantie
n’est apportée quant à la qualité de la solution générée.
Habituellement, les petites et moyennes entreprises de transport ne peuvent s’offrir ces
logiciels. Elles doivent donc se tourner vers d’autres moyens afin d’être en mesure de faire
la planification des tournées correctement. Or, ce travail est complexe compte tenu des
nombreuses décisions qui doivent être prises en même temps, c’est-à-dire le nombre de
camions qui seront utilisés, la répartition des marchandises entre ces camions et
l’organisation de la tournée de chacun d’eux. En plus, lorsque des revenus de retour
potentiels en fin de tournées sont considérés, les décisions se complexifient davantage.
Toutefois, ce travail est nécessaire afin de tendre vers une meilleure rentabilité.
Dans cet essai, un système intégré d’aide à la décision (SIAD) permettant de faire la
répartition, la livraison et la collecte des marchandises est présenté. Ledit système a été
développé à l’aide de logiciels courants, tels que Microsoft Visual Basic et Microsoft
Excel. Il est démontré qu’il permet d’obtenir d’excellentes solutions en peu de temps et
qu’il nécessite peu d’investissements. Il représente donc une solution au problème de
transport des marchandises en charges partielles avec revenu de retour en fin de tournée.
Mots clés : Transport de marchandises, charges partielles, problème de tournées de
véhicules, répartition, revenu de retour, livraison, SIAD.

ii
Remerciements
Depuis toujours, j’ai écouté les paroles de chacun et fait le tri au fond de moi-même. Le chemin que j’ai parcouru a été semé d’embûches, toutes et chacune d’entre elles m’ont rendu plus forte et m’ont mené là où j’en suis. En prenant du recul, je suis moi-même étonnée du parcours qui m’a conduit ici. Jamais je n’aurais cru que la recherche, malgré la patience qu’elle demande souvent, ferait partie de ces choses passionnantes de la vie. Cet essai a été marqué par plusieurs personnes qui, chacune à leur façon, ont permis sa réalisation.
Je tiens d’abord à remercier mon directeur, Monsieur Gilles d’Avignon, qui m’a mené au domaine du transport et à cet essai. Je tiens également à exprimer ma gratitude à mon codirecteur, Monsieur Jacques Renaud, qui a su me donner une opinion constructive tout au long du projet. Mes remerciements vont également à la Fondation pour la formation professionnelle en transport routier des marchandises du Québec qui m’a octroyé la bourse Manac 2002 pour la recherche en transport et la bourse Jean Delangis 2003 pour la recherche en transport sur l’économie d’énergie. Je tiens également à souligner la collaboration de Monsieur Jean Guilbault du Groupe Guilbault qui a soulevé le problème traité et qui a participé à sa première expérimentation. Dans la même entreprise, je tiens aussi à remercier Monsieur André Desjardins, qui a su critiquer de façon constructive le générateur d’expéditions. La participation de toutes ces entreprises prouve à quel point la recherche est essentielle; ce soutien se doit de demeurer.
Je ne peux passer sous silence l’appui inconditionnel de mes parents, Lisette et Gilles, qui ont toujours su me laisser me faire une opinion par moi-même et qui m’ont aidé à canaliser mes énergies avec les passions qui m’habitent. Ils sont le premier moteur qui me pousse à avancer. Je tiens également à remercier toutes les personnes (elles se reconnaîtront!) qui ont su répondre à mes questions, donner leur opinion ou si justement revoir mon texte; soyez assuré de ma gratitude.

iii
Table des matières
Chapitre I Introduction ........................................................................................................1 1. Présentation ....................................................................................................................1 2. Organisation ...................................................................................................................4 3. Terminologie ..................................................................................................................5 4. Problématique ................................................................................................................8
4.1. Énoncé du problème................................................................................................8 4.2. Objectif de l’essai..................................................................................................13
5. Méthodologie ...............................................................................................................13 Chapitre II Revue de la littérature....................................................................................15
1. Problème de tournées ...................................................................................................15 1.1. Problème du voyageur de commerce ....................................................................15 1.2. Problème de tournées de véhicules .......................................................................20
2. Systèmes intégrés d’aide à la décision.........................................................................30 2.1. A.Maze ..................................................................................................................30 2.2. Truckmate pour Windows (TM4Win) ..................................................................31 2.3. Millogiciel .............................................................................................................32
Chapitre III Modélisation...................................................................................................33 1. Concepts de base ..........................................................................................................33 2. Notations ......................................................................................................................37 3. Modèle mathématique..................................................................................................38
3.1. Fonction objectif ...................................................................................................38 3.2. Contraintes ............................................................................................................40
4. Évaluation de la taille du modèle d’optimisation ........................................................45 Chapitre IV Approche de résolution.................................................................................47
1. Considération préliminaire...........................................................................................47 2. Méthode heuristique de résolution...............................................................................49
2.1. Étape 1 : Initialisation des données.......................................................................50 2.2. Étape 2 : Formation des routes..............................................................................51 2.3. Étape 3 : Amélioration individuelle des routes.....................................................52 2.4. Étape 4 : Amélioration des routes .........................................................................55
3. Présentation du SIAD...................................................................................................56 3.1. Initialisation de la source de données ...................................................................56 3.2. Aide à l’utilisateur.................................................................................................57 3.3. Inscription des données .........................................................................................58 3.4. Répartition.............................................................................................................61 3.5. Visualisation des résultats .....................................................................................62
Chapitre V Évaluation numérique ....................................................................................64 1. Structuration des tests numériques...............................................................................64 2. Résultats .......................................................................................................................69
2.1. Observations..........................................................................................................69 2.2. Comparaison des solutions....................................................................................72 2.3. Comparaison des distances parcourues.................................................................76 2.4. Comparaison des temps de résolution...................................................................78
Chapitre VI Conclusion......................................................................................................80

iv
Références ............................................................................................................................83 Annexe A Résultats des tests numériques........................................................................87 Annexe B Article présenté à l’Association Québécoise du Transport et des Routes (AQTR)...............................................................................................................................119 Annexe C Article présenté à l’Association des Sciences Administratives du Canada (ASAC) ...............................................................................................................................138 Annexe D Article de la revue Gestion Logistique ..........................................................150 Annexe E Données des tests et fichiers des résultats obtenus avec les deux méthodes (sur CD)…………………………………….………………………………………………... Annexe F Système développé (sur CD)……...…………………………………………….

v
Table des figures
1.1 – Schématisation de la notion de distribution .................................................................. 7 1.2 – Ensemble de nœuds (expéditions)................................................................................. 9 1.3 – Réseau associé à une solution ..................................................................................... 10 2.1 – Heuristique du plus proche voisin............................................................................... 17 2.2 – Heuristique de l’insertion la moins coûteuse .............................................................. 17 2.3 – Heuristique 2-opt......................................................................................................... 19 2.4 – Heuristique 3-opt......................................................................................................... 19 2.5 – Fusion de deux tournées par l’algorithme de Clarke et Wright .................................. 24 2.6 – Méthode de fusion des tournées.................................................................................. 25 2.7 – Algorithme de construction par balayage ................................................................... 26 2.8 – Échanges-λ retenues pour λ = 2.................................................................................. 28 2.9 – Heuristique d’amélioration de Osman ........................................................................ 28 2.10 – Position de l’optimum global .................................................................................... 29 3.1 – Ensemble des arcs 0-j.................................................................................................. 34 3.2 – Ensemble des arcs 1-j.................................................................................................. 34 3.3 – Réseau incluant un sous tour....................................................................................... 35 3.4 – Construction en cinq étapes d’un réseau avec l’indicateur sak .................................... 36 3.5 – Modélisation du dépôt................................................................................................. 44 4.1 – Méthode heuristique intégrée dans le système développé .......................................... 50 4.2 – Interface initiale du SIAD ........................................................................................... 57 4.3 – Instructions du SIAD................................................................................................... 58 4.4 – Exécution du bouton Données et expéditions ............................................................. 59 4.5 – Feuille Data du fichier dispatch.................................................................................. 59 4.6 – Feuille Shipping du fichier dispatch ........................................................................... 60 4.7 – Exécution du bouton Répartition ................................................................................ 62 4.8 – Feuille FR1 du fichier dispatch................................................................................... 63 4.9 – Feuille Result du fichier dispatch................................................................................ 63 5.1 – Temps où la meilleure solution obtenue par Ilog Cplex a été générée ....................... 75

vi
Liste des tableaux
5.1 – Compilation détaillée des deltas ................................................................................. 73 5.2 – Moyenne des deltas pour les tests optimaux............................................................... 73 5.3 – Moyenne des deltas pour les tests arrêtés après quinze heures de résolution............. 73 5.4 – Moment d’obtention des meilleures solutions avec Ilog Cplex et gap lors de l’arrêt 74 5.5 – Compilation des erreurs de distances.......................................................................... 77 5.6 – Moyenne des deltasdist. pour les tests optimaux .......................................................... 77 5.7 – Temps de résolution (en secondes) des deux méthodes.............................................. 79

Chapitre I
Introduction
1. PRÉSENTATION
Le transport routier des marchandises a subi de nombreux bouleversements au cours des
dernières années. D’abord, la déréglementation survenue en 1980 aux États-Unis, en 1988
au Canada et en 1992 en Europe a modifié les pratiques qui prévalaient jusque-là. Ces
règles permettaient auparavant à toutes les entreprises de détenir des parts de marché ou,
pour certaines, l’exclusivité, puisque les prix étaient fixés. En les éliminant, le libre marché
créé fit accroître la compétitivité dans l’offre de service. Dès lors, l’avenir de chacune des
entreprises œuvrant dans le domaine du transport est devenu dépendant de leur capacité
d’adaptation. Seulement pour l’année 2001, Transports Canada a dénombré quelques 900
faillites dans l’industrie du camionnage, soit un nombre record pour les dix dernières
années (Transports Canada 2002). Ces données sont une première alarme signalant que des
changements au niveau de la gestion des entreprises de transport s’imposent.
L’effet de la mondialisation a également contribué aux transformations. Autrefois, seules
les grandes entreprises pouvaient viser un marché national, les autres étant limitées à une
clientèle locale ou régionale. Aujourd’hui, non seulement « un camion traverse la frontière
entre le Canada et les États-Unis à toutes les 2,5 secondes » (Industrie Canada 2003) mais
de plus, les petites entreprises de transport ont désormais accès à un marché international.
Ceci est principalement dû à la spécialisation de chacun des membres de la chaîne
logistique et à l’avènement des technologies qui permettent la transmission continue
d’informations en une fraction de seconde, et ce, partout dans le monde. Le domaine du
transport routier a donc dû s’adapter à ce nouveau modèle de marché en étant de plus en
plus performant et compétitif.

2
La mondialisation a aussi impliqué la hausse des exigences des expéditeurs d’autant plus
que ces derniers veulent également réduire leurs coûts au plus bas niveau possible. Parmi
les coûts à diminuer se retrouvent les coûts de stockage qui peuvent être réduits en
conservant les inventaires les plus bas possible, c’est-à-dire le niveau minimum
d’inventaires qui permet de satisfaire les clients de façon adéquate pour l’entreprise. Ceci
implique donc une gestion en juste-à-temps, c’est-à-dire que les marchandises soient au
bon endroit, en bon état et au bon moment. Souvent, de ce type de gestion découle
également l’envoi plus fréquent d’expéditions plus petites.
Lorsque les entreprises expédient des marchandises, elles veulent bénéficier d’un mode de
transport qui répond adéquatement à leurs besoins. Le choix d’un transporteur repose
d’abord sur le prix, la quantité, le type de produits à transporter et le lieu de destination de
celles-ci. Actuellement, le transport des marchandises entre le Canada et les États-Unis se
fait par camions dans plus de 70 % des cas (Industrie Canada 2003). Ce mode de transport
a la qualité d’être flexible autant au niveau temporel que physique, c’est-à-dire que les
départs sont nombreux et que l’endroit précis de livraison est déterminé par l’expéditeur.
Ces qualités permettent à ce type de transport de livrer les marchandises dans un laps de
temps raisonnable.
Compte tenu des investissements que cela implique et parfois de leurs trop faibles
volumes, plusieurs entreprises préfèrent avoir recours à un transporteur spécialisé au lieu
de posséder leurs propres camions. Ceci leur évite le fardeau de la gestion du transport, ce
qui leur permet de concentrer toutes leurs énergies dans leur spécialité.
Due à la contrainte temporelle, il arrive régulièrement que les entreprises aient à faire
acheminer des marchandises en petites quantités. Dès lors, l’espace d’un plein camion
n’est pas nécessaire, donc l’expéditeur aura recours au transport de charges partielles. Ce
type de transport peut également être nommé LTL, tiré de l’anglais less-than-truckload. Le
transport de charges partielles peut être défini comme étant le déplacement d’un « lot de
marchandises insuffisant quant à son poids ou à son volume pour l'application d'un tarif
d'envoi par camion complet » (Grand dictionnaire Avril 2003). Ces expéditions sont
constituées de marchandises utilisant habituellement entre une et huit palettes et pesant

3
chacune entre 500 et 10 000 lbs. La définition est ici limitée au gros LTL, c’est-à-dire le
transport de marchandises comportant au moins une palette de 500 lbs, puisque les charges
moindres sont habituellement considérées comme étant du vrac.
Pour les expéditeurs, le transport de charges partielles permet de profiter d’un service
adapté. Pour en bénéficier, ils devront toutefois défrayer un coût plus élevé compte tenu de
la gestion supplémentaire que cela impose au transporteur. Malgré tout, ils acceptent ce
sacrifice compte tenu des avantages qui y sont liés.
Pour le transporteur, les marchandises en charges partielles nécessitent un travail de
regroupement des marchandises qui seront expédiées vers une même zone. Cette tâche est
très importante puisqu’elle permet à la fois de remplir une remorque et de potentiellement
rentabiliser son déplacement.
Pour rester compétitives, les entreprises de transport doivent donc offrir un service adéquat
à un coût intéressant. Pour se faire, l’emphase doit être mise sur le service à la clientèle et
sur la spécialisation, ceci tout en travaillant à optimiser les façons de faire. Le client désire
que ses marchandises soient traitées en juste-à-temps. Pour qu’un tel traitement soit
adéquat, les entreprises de transport doivent se spécialiser. Ainsi, chaque entreprise se
différencie de ses concurrents et maximise ses profits en se concentrant sur ce qu’elle fait
le mieux : livrer un type précis de marchandises. Les spécialités sont variées passant du
transport général au transport de matières particulières, tel que l’essence, les produits
chimiques, le courrier ou le vrac, allant de la manutention de charges pleines à celle de
marchandises en charges partielles.
Pour faire leur travail convenablement, ces entreprises doivent optimiser leurs façons de
faire. Ceci passe par la circulation des marchandises en juste-à-temps et par une
amélioration des outils mis à la disposition des travailleurs. En effet, les entreprises de
transport doivent se doter d’outils leur permettant d’améliorer leur rentabilité. De tels
outils, en plus d’assurer aux transporteurs d’avoir la meilleure rentabilité pour les
expéditions à distribuer, permettent aux répartiteurs d’utiliser le temps épargné pour
réaliser d’autres activités.

4
Donc, la compétitivité des entreprises de transport passe par l’optimisation de leurs
opérations. Toutefois, les entreprises de transport doivent prendre en considération un
nouvel élément : l’environnement. Le Canada a signé, en décembre 2002, le protocole de
Kyoto, traité sur la réduction des gaz à effet de serre. Ainsi, le pays s’est engagé à réduire
ses émissions de 6 % par rapport à 1990 (Radio-Canada 2003). Or, selon une étude sur la
consommation d’énergie secondaire en 1999, le domaine du transport est responsable de
36 % de l’émission des gaz à effets de serre au Canada en raison du pétrole consommé
(Transports Canada 2002). Compte tenu du fait que le Québec est l’une des provinces les
moins polluantes au Canada grâce en grande partie à l’hydroélectricité qui évite d’utiliser
des gaz dans plusieurs cas, le fait de se voir imposer de réduire l’émission des gaz à effet
de serre impliquera forcément des changements sur les routes québécoises. Ainsi, les
entreprises œuvrant dans le domaine du transport routier doivent dès maintenant tenter de
réduire leur consommation d’essence. Étant donné la protection de l’environnement et le
prix sans cesse croissant des carburants, la planification de tournées de livraisons devient
importante.
Ceci soulève plusieurs questions : est-il possible de doter les entreprises de transport
routier de marchandises d’un outil simple leur permettant d’augmenter leur rentabilité tout
en étant préoccupé par l’environnement ? Dans les pages suivantes, un intérêt a été porté
sur la planification du transport de marchandises en charges partielles du Québec vers les
États-Unis, plus précisément, au travail de répartition qui constitue la pierre angulaire de la
livraison des marchandises.
2. ORGANISATION
Le présent document est subdivisé en six chapitres, qui sont eux-mêmes divisés en section
ou sous-section au besoin. Le Chapitre I permet de présenter l’environnement du transport
routier des marchandises, de préciser la terminologie utilisée, de définir le problème traité
ainsi que la méthodologie utilisée. Le Chapitre II expose la revue de la littérature. Plus
précisément, il met en évidence les recherches pertinentes et/ou récentes traitant des
concepts liés à la problématique. Le Chapitre III présente un modèle optimal et précise le
type de problèmes pour lesquels il peut être utilisé. En plus d’élaborer de façon détaillée de

5
quelle façon un réseau est conçu, ce chapitre met également en lumière la complexité du
problème traité. Le Chapitre IV se divise en deux sections. D’abord, une description de la
méthode heuristique est faite. Par après, le système intégré d’aide à la décision développé,
qui comprend cette méthode, est présenté. Ce chapitre apporte une solution au problème
défini au premier chapitre. Dans le Chapitre V, les résultats de diverses expérimentations
(Annexe A) sont exposés et les observations liées à celles-ci sont décrites. Ce chapitre
explique la pertinence de la méthode développée dans le chapitre précédent. Par la suite, le
Chapitre VI présente les conclusions de l’essai.
Les annexes B, C et D présentent des articles tirés de cet essai. La première, l’Annexe B,
est constituée d’un article qui a été présenté dans le cadre du 38e Congrès de l’Association
Québécoise du Transport et des Routes à Sherbrooke le 7 avril 2003. L’Annexe C, quant à
elle, inclut un article présenté dans le cadre du Congrès de l’Association des Sciences
Administratives du Canada à Halifax le 16 juin 2003. Enfin, l’Annexe D présente un article
publié dans l’édition de mai 2003 de la revue Gestion logistique.
3. TERMINOLOGIE
Avant d’aborder spécifiquement la problématique étudiée, la définition de certains termes
doit être clarifiée. Dans le langage courant, certains mots sont utilisés comme étant des
synonymes sans que cela ne pose problème. Toutefois, dans un contexte plus technique, le
fait d’utiliser un synonyme peut fausser la signification d’une phrase. Il est donc important
de clarifier la définition de certains mots, afin d’éviter une mauvaise perception lors de la
lecture.
Les termes distribution, répartition et livraison font partie de ces mots qui sont
couramment employés au gré des rédacteurs. Cependant, ils ont chacun une signification
propre et distincte.
Le dictionnaire universel francophone Hachette (mai 2003) spécifie que la distribution est
la « répartition (de choses) entre plusieurs personnes ». Cette définition primaire implique
que la distribution est et inclut une forme de répartition. Sur ce point, la source vient

6
appuyer le fait que ces termes sont régulièrement confondus. Une autre référence,
l’encyclopédie Encarta (mai 2003), évite ce piège et définit la distribution comme suit :
« Ensemble des opérations qui vont de la commercialisation d’un bien (à
l’issue de sa production) jusqu’à son achat par un consommateur final. Le
secteur de la distribution, qui constitue une branche du commerce, comprend
l’ensemble des personnes physiques et des entreprises qui participent à ce
processus. »
Ici, la notion de processus est intéressante et la distribution ne se limite pas à un simple
déplacement de marchandises, mais bien à une commercialisation. Cependant, la notion
peut être définie plus précisément. Le Grand dictionnaire écrit (mai 2003) :
« La distribution physique prend en charge le produit fini et assure la mise à
disposition des acheteurs – qu'ils soient transformateurs ou consommateurs –
des biens ou des services. La distribution physique comprend le transport,
l'entreposage, la gestion des stocks, la manutention, le suivi des commandes, le
conditionnement des produits, le traitement informatique de l'ensemble des
activités qui succèdent à la gestion des matières. »
La distribution prend ainsi un aspect plus spécifique où elle comprend non seulement le
transport, mais également l’entreposage. Ainsi, la gestion des marchandises est à la fois
aux niveaux dynamique et statique.
Tompkins et Harmelink (1994) définissent clairement la distribution dans un contexte de
gestion :
« Distribution is the management of inventory to achieve customer satisfaction.
The overall management of inventory requires the management of inventory
both when in motion and while at rest. The management of inventory in motion
is the profession of transportation, the management of inventory at rest is the
profession of warehousing. »

7
La Figure 1.1 illustre le point de vue de ces derniers auteurs. En effet, le processus débute
avec des produits qui doivent être distribués. La distribution est la gestion des inventaires
dans le but de satisfaire les clients. Ainsi, elle englobe toutes les fonctions d’entreposage et
de transport. L’entreposage est une gestion statique des marchandises, puisqu’elles
demeureront dans un même lieu. Ainsi, cette fonction comprend entre autre le
transbordement, la gestion des flux et la gestion des inventaires. Quant au transport, il
constitue la gestion dynamique des marchandises. Il comprend diverses fonctions dont la
répartition, le chargement et la livraison.
Figure 1.1 – Schématisation de la notion de distribution
Globalement, la Figure 1.1 illustre que la répartition est une fonction du transport qui est
une fonction de la distribution. La répartition peut être définie comme une fonction
d’organisation des marchandises dans le but de les livrer. Ainsi, lors de la répartition,
l’ordre de chargement des marchandises et le choix du camion sont établis. Ceci implique
une connaissance cartographique afin de construire des tournées réalisables. Donc, la
répartition ne se préoccupe que des marchandises au moment où elles sont prêtes à être
transportées vers une ou plusieurs destinations différentes du lieu d’origine.
Une fois la répartition terminée, le chargement des marchandises dans les divers camions
est fait. Puis vient le moment de livrer les marchandises. La livraison est donc l’action de
rendre les marchandises chez le client. Il est important de bien comprendre la nuance avec
le terme distribution. La distribution s’occupe des marchandises tout au long du processus,

8
et ce, à partir du moment où la conception est terminée, alors que la livraison ne s’occupe
que de faire passer les marchandises d’un point A à un point B.
Il est donc crucial de s’attarder à ces trois termes. En effet, ils sont trop souvent utilisés
comme étant des synonymes alors qu’ils impliquent des activités différentes. Dans les
sections qui suivent, ils ont été utilisés dans leur sens très précis.
4. PROBLÉMATIQUE
La gestion de charges partielles implique un travail considérable pour les entreprises de
transport. En fait, les répartiteurs doivent prendre de nombreuses décisions qui peuvent
influencer positivement ou négativement la contribution totale générée par la livraison des
marchandises. La contribution doit être perçue comme étant le profit (revenus des charges
partielles + revenu des charges de retour – coûts de transport) de l’opération. Toutefois,
elle ne constitue pas un profit net pour l’entreprise puisque cette valeur ne tient pas compte
de ses autres coûts, tel que les frais d’administration. Donc, chacune des décisions prises
par les répartiteurs influencera la décision suivante. Ainsi, le travail de répartition est
complexe et peut nécessiter plusieurs heures de travail.
La répartition est au cœur de la problématique étudiée. Les prochaines lignes ont pour but
d’exposer la problématique étudiée et de définir les objectifs de l’essai.
4.1. Énoncé du problème
Afin de bien comprendre le travail de répartition, il est d’abord important de présenter une
schématisation du problème. L’ensemble des expéditions à distribuer est illustré par des
nœuds numérotés (Figure 1.2). Ces expéditions ont des caractéristiques connues, c’est-à-
dire qu’elles ont un poids en livres, qu’elles occupent un espace en nombre de palettes,
qu’elles génèrent un revenu et qu’elles doivent être livrées à une destination précise.
Chacun des destinataires peut recevoir plus d’une expédition, mais celles-ci ne seront pas
nécessairement transportées par le même camion. Pour cette raison chacun des nœuds sera
défini comme représentant une expédition distincte et non simplement un destinataire.

9
Figure 1.2 – Ensemble de nœuds (expéditions)
Le dépôt est un nœud qui doit être identifié d’une façon particulière : il est unique et
constitue à la fois le point de départ et de retour de chacune des tournées puisqu’il est le
lieu de consolidation des marchandises. Ainsi, toutes les expéditions se trouvent au dépôt
avant d’être livrées. Afin d’enchaîner les nœuds, des arcs ont été utilisés. Lorsqu’un
ensemble de nœuds et d’arcs forment un trajet orienté partant du dépôt, visitant des nœuds
et retournant au dépôt, une tournée est créée. L’ensemble de ces tournées constitue un
réseau, c’est-à-dire un graphique orienté dans lequel l’ordre de visite de chacun des nœuds
est déterminé.
La Figure 1.3 présente l’exemple d’un réseau. Le nombre de tournées inclut dans celui-ci
représente la quantité de camions qui sont nécessaires à la livraison des marchandises.
Ainsi, trois tournées nécessiteront l’utilisation de trois camions. Les arcs, illustrés par des
flèches, permettent de joindre les divers nœuds et impliquent l’ordonnancement de chacun
d’eux afin de former les tournées. Pour chacune de ces tournées, tous les arcs la constituant
doivent être orientés dans la même direction, sans quoi la tournée est irréalisable. La
longueur des arcs, quant à elle, représente la distance parcourue entre les nœuds.

10
Figure 1.3 – Réseau associé à une solution
Une fois les tournées constituées, l’ordre de livraison des expéditions est déterminé et
celui-ci est très important. D’abord, le chargement des marchandises dans chacun des
camions sera fait dans l’ordre inverse de la livraison des expéditions. Ainsi, la moindre
petite modification de la tournée doit être faite avant le chargement du camion qui y est
assigné. De plus, l’ordre de livraison établit influencera aussi la distance totale que le
camion aura à parcourir, un changement dans la tournée impliquant généralement une
distance globale différente. Enfin, la dernière destination est également importante.
Puisque le camion est vide une fois sa dernière expédition déchargée, il lui est possible de
faire la collecte d’une charge pleine (TL – truckload) sur le marché de cette destination
avant de revenir au dépôt. Cette charge constitue un revenu de retour (backhaul) qui
influencera considérablement la contribution totale générée par la tournée et,
implicitement, elle aura une incidence sur la répartition des expéditions. Ainsi, il est
parfois préférable de revoir l’ordre de livraison des marchandises afin de rendre possible la
collecte d’une charge pleine à une destination particulière. Le fait de changer l’ordre de
livraison pourrait donc modifier considérablement la contribution totale générée par ce
transport. Globalement, toutes ces modifications auront une incidence sur la contribution
totale générée par les expéditions. Le répartiteur doit donc prendre des décisions en étant
conscient de l’influence de chacune.

11
La problématique abordée est donc complexe et nécessite la prise en compte de diverses
décisions. Plus précisément, elle est une variante du problème traditionnel de tournées de
véhicules : un ensemble d’expéditions doivent être livrées sur un territoire donné. À ce
problème, une caractéristique particulière a été ajoutée : à chaque expédition peut être
également associée un revenu de retour potentiel. Pour que ce dernier soit encaissé, le
client doit être visité en dernier sur la route du camion. Ceci complique la tâche des
planificateurs qui doivent faire un travail de répartition efficace afin de rentabiliser les
tournées. L’objectif du répartiteur est donc de déterminer le nombre adéquat de véhicules,
de leur assigner un ensemble d’expéditions respectant les contraintes de chargement afin
de maximiser la contribution totale de l’opération.
La répartition doit être faite en fonction de divers critères. Ainsi, les caractéristiques des
expéditions à transporter, le nombre de camions assignés au transport et leurs
caractéristiques (capacité en poids et en palettes), les coûts (par mille et par arrêt), les
revenus de retour potentiel et les distances entre chacune des destinations influencent la
façon dont les marchandises seront réparties entre les camions. Les possibilités
d’assignation sont donc multiples et les risques d’erreurs élevés.
Pour que le répartiteur puisse faire son travail correctement, il faut que toutes les
expéditions à livrer soient connues au moment de faire la répartition. Leurs caractéristiques
(poids, nombre de palettes, destinations) devront rester les mêmes tout au long du
processus. Les revenus de retour disponibles dans les différents marchés devront également
être connus. Toutefois, le répartiteur peut, s’il le juge plus avantageux, faire terminer la
tournée d’un véhicule dans un marché où aucune marchandise de retour n’est disponible.
Dès lors, le camion rentrerait à vide au dépôt.
Pour répondre à la demande, il est pris pour acquis que l’entreprise dispose d’une flotte de
taille variable, c’est-à-dire d’un nombre suffisant de camions ayant des caractéristiques
définies au départ. Bien sûr, la capacité de chacun d’eux limite le poids total et le nombre
de palettes qu’ils pourront transporter. Toutefois, il n’y a aucune contrainte reliée au type
d’équipement pour manipuler les marchandises puisqu’il s’agit de chargements de palettes
standards. De plus, les heures de conduites ne posent aucune contrainte, car en pratique la

12
tarification basée sur la distance en tient compte implicitement. Les conducteurs prennent
alors simplement des périodes de repos lorsqu’ils atteignent le nombre maximal d’heures
de conduite imposées par la loi.
Il est pris pour acquis que les distances entre chacune des destinations sont connues au
moment de faire la répartition. Toutefois, compte tenu des longues distances, les distances
à parcourir pour livrer deux expéditions dans une même ville seront négligées, et ce, même
lorsque les deux expéditions impliquent deux clients distincts.
Le réseau étudié ne comporte aucun entrepôt qui pourrait servir de point de ravitaillement
ou de consolidation en cours de tournée. Ainsi, il faut faire preuve de stratégie dans la
livraison des marchandises. Toutes les tournées doivent être conçues dans le but d’obtenir
la meilleure contribution totale possible tout en économisant autant que possible sur la
distance parcourue.
Également, il est pris pour acquis que toutes les palettes de marchandises sont de format
standard. Ceci simplifiera beaucoup le travail de répartition puisque toutes les unités seront
équivalentes.
Enfin, aucune variable temporelle ne sera prise en compte. En effet, la présence de fenêtres
de temps impliquant que certaines marchandises devraient être rendues à destination à un
moment précis compliquerait le travail de répartition. Dans les faits, compte tenu que les
problèmes étudiés impliquent de longues distances à parcourir, l’ajout de ces variables
temporelles peut impliquer des détours considérables, la problématique de cette étude se
voulant plus globale. Pour les cas pratiques observés, puisque la livraison des
marchandises sur de longues distances peut s’échelonner sur plusieurs jours, aucune
fenêtre de temps n’est considérée sous ces conditions.
Plusieurs des contraintes mises à l’écart pourrait être intégrées dans de futures études.
Certaines l’ont été mises volontairement afin de mettre en évidence d’autres éléments.

13
4.2. Objectif de l’essai
Le répartiteur a donc un travail où il doit tenir compte de beaucoup d’éléments en même
temps. Pour les aider dans leur tâche, les grandes entreprises ont, pour la plupart, en leur
possession des logiciels de répartition. Ces applications sont des outils d’aide à la décision
qui permettent de créer des routes en tenant compte de plusieurs paramètres en même
temps, ce qu’un répartiteur peut difficilement faire en travaillant de façon manuelle.
L’implantation de tels logiciels nécessite de gros investissements, autant au niveau de
l’acquisition de l’application qu’au niveau de son implantation. De plus, les concepteurs de
ces logiciels sont peu bavards quant aux méthodes utilisées pour faire le travail de
répartition. Pour les petites et moyennes entreprises, ce type d’application est difficilement
accessible. Dès lors, elles doivent développer d’autres méthodes afin d’être en mesure de
tout de même faire le travail de répartition.
Les logiciels courants, tels que Microsoft Excel, Microsoft MapPoint ou PC*Miller de Alk
Technologies, sont des applications couramment utilisées dans l’industrie. Or, cet essai
analyse le problème décrit précédemment et présente un système solutionnant celui-ci,
nécessitant peu d’investissements tout en étant facile d’utilisation. Plus précisément, un
système intégré d’aide à la décision a été mis au point à partir de logiciels facilement
accessibles. Ce système permet de faire la répartition des marchandises, c’est-à-dire qu’il
détermine à la fois le nombre de camions nécessaires à la livraison et ordonne les
marchandises dans chacun d’eux, ce qui permet de maximiser la contribution totale
obtenue tout en tendant à diminuer la distance totale.
5. MÉTHODOLOGIE
La méthodologie préconisée pour aborder la problématique exposée à la section précédente
se divise en quatre volets. D’abord, la revue de la littérature permet de présenter les
nombreuses recherches faites sur le problème du voyageur de commerce et sur le problème
de tournées de véhicules. Ce volet explore les diverses méthodes, tant optimales
qu’heuristiques, développées au fil des ans et qui tentent de résoudre l’un ou l’autre de ces
problèmes. Également, il est relaté les divers systèmes intégrés d’aide à la décision (SIAD)

14
en répartition disponibles sur le marché et des exemples d’entreprises qui utilisent cette
solution.
Le deuxième volet décrit la façon dont la problématique peut être représenté sous la forme
d’un modèle optimal. Ici est présenté un modèle mathématique qui permet de résoudre le
problème de façon exacte. Toutefois, en tenant compte de la complexité du problème, il y
est soulevé qu’il est impossible de solutionner de façon optimale des problèmes
d’envergures. L’explication de cette complexité est d’ailleurs présentée.
Le troisième volet vient compléter le second. En effet, ce dernier explore la problématique
de façon heuristique. Ainsi, en plus d’exposer les divers éléments à considérer dans ce
problème, il est également précisé la méthode développée qui permet de le résoudre. Cette
méthode est détaillée en deux parties : la résolution heuristique, qui précise les diverses
méthodes utilisées, et la présentation du SIAD, laquelle expose le procédé d’intégration des
diverses applications permettent de solutionner le problème.
Le dernier volet est constitué d’une évaluation numérique. Ainsi, divers tests viennent
prouver la pertinence de la méthode développée et son impact pour les entreprises de
transport et pour les répartiteurs.

Chapitre II
Revue de la littérature
1. PROBLÈME DE TOURNÉES
La répartition et le transport des marchandises en charges partielles correspondent à un
problème de tournées de véhicules. Ce problème retient l’attention de plusieurs chercheurs
depuis de nombreuses années, et ce, partout dans le monde. Avant de considérer le
problème de tournées de véhicules dans son ensemble, il est opportun d’étudier le cas
d’une seule tournée, soit le problème du voyageur de commerce. Selon Lawler et al.
(1985), le premier livre relatant du sujet a été imprimé en Allemagne en 1832. Depuis, la
littérature qui traite des problèmes de tournées est prolifique. Ainsi, cette revue littéraire ne
couvre pas tous les écrits dans ce domaine, mais les plus importants, les plus récents et les
plus étroitement liés à la problématique abordée.
Plusieurs auteurs ont effectué des revues littéraires qui traitent des problèmes de tournées.
Parmi ceux-ci figurent celles de Bodin et al. (1983) et de Laporte (1992a, 1992b, 1993).
Laporte et Osman (1995) ont également fait une bibliographie qui compte quelques
500 références.
Pour faciliter l’exposé, la revue de la littérature a été divisée en deux parties : le problème
du voyageur de commerce (traveling salesman problem – TSP) et le problème de tournées
de véhicules (vehicle routing problem – VRP).
1.1. Problème du voyageur de commerce
Dans la Section I.3, le TSP a été exposé comme étant un problème d’ordonnancement des
visites dans une tournée. Ainsi, l’ordre de livraison des marchandises (l’ordre de visite des

16
clients) doit être déterminé avant que puisse être fait le chargement du camion qui fera cette
tournée. Le défi qu’implique ce problème a suscité l’intérêt de nombreux chercheurs :
Lawler et al. (1985) ont répertorié près de 600 références traitant du sujet.
Étant difficile à solutionner de façon optimale, les chercheurs ont tenté de résoudre le
problème grâce à des approches heuristiques. Encore là, de nombreuses méthodes ont été
développées. Elles ont été subdivisées en trois catégories : les approches de construction, les
approches d’amélioration et les approches composites.
a. Approches de construction
Ce type d’approche est utilisé afin de créer une tournée réalisable. Ainsi, l’idée est de
regrouper les nœuds afin de constituer un ordre de visite. Pour l’instant, il est pris pour
acquis que tous les nœuds doivent être insérés dans la même tournée. Bien entendu, plusieurs
approches ont été développées; parmi celles-ci figurent l’heuristique du plus proche voisin et
l’heuristique de l’insertion la moins coûteuse (Rosenkrantz et al. 1977).
Heuristique du plus proche voisin (Rosenkrantz et al. 1977)
Dans cette heuristique, le déplacement doit toujours être fait vers le nœud le plus près qui n’a
pas encore été visité. Plus précisément, elle doit être appliquée de la façon suivante :
1. À partir du dépôt, trouver le nœud a le plus près. Créer l’arc 0-a. Le nœud actif est
maintenant le nœud a.
2. À partir du nœud actif, trouver le nœud non visité le plus près. Créer l’arc liant ces deux
nœuds. Le nœud qui était non visité devient le nœud actif.
3. Répéter l’étape 2 jusqu’à ce que tous les nœuds soient visités.
4. Créer un arc partant du nœud actif et se rendant au dépôt.
La Figure 2.1 présente un exemple d’application de cette heuristique.
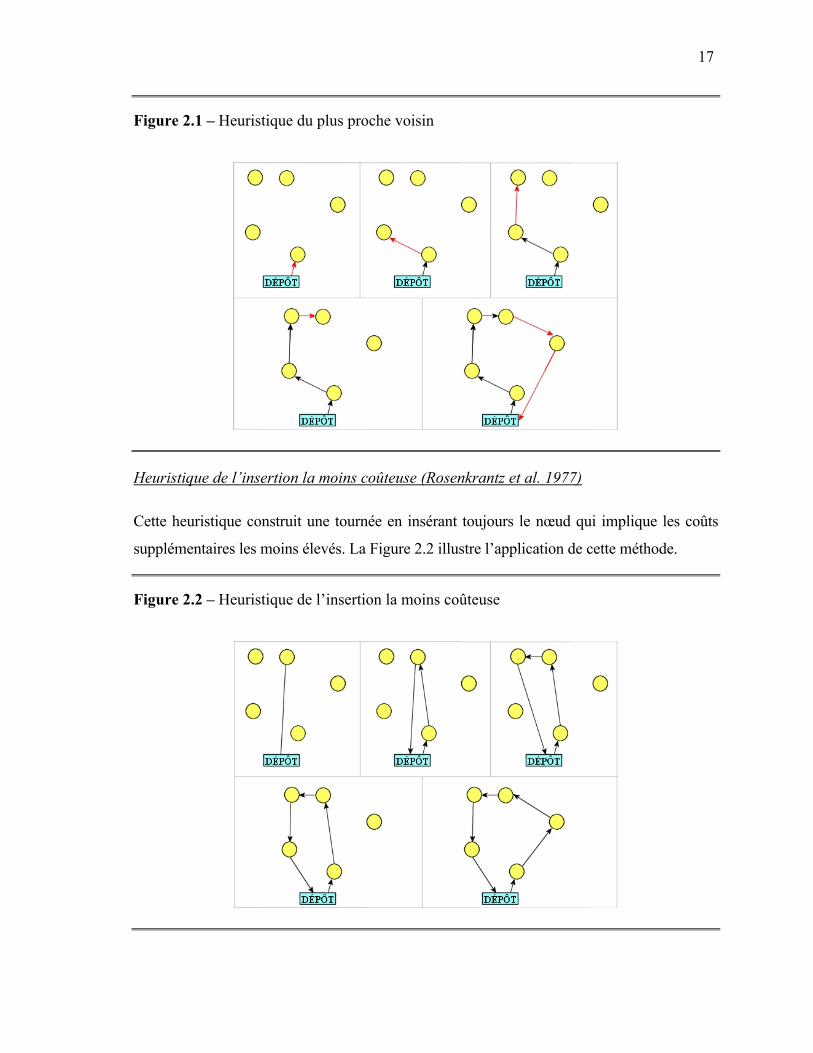
17
Figure 2.1 – Heuristique du plus proche voisin
Heuristique de l’insertion la moins coûteuse (Rosenkrantz et al. 1977)
Cette heuristique construit une tournée en insérant toujours le nœud qui implique les coûts
supplémentaires les moins élevés. La Figure 2.2 illustre l’application de cette méthode.
Figure 2.2 – Heuristique de l’insertion la moins coûteuse

18
Plus précisément, la tournée se construit comme suit :
1. À partir du dépôt, trouver le nœud a le plus loin. Créer l’arc 0-a.
2. Calculer les coûts supplémentaires d’ajouts de chacun des nœuds non visités de façon
individuelle. Ces valeurs se calculent ainsi :
Coût d’insérer le nœud i sur l’arc a1-a2 = 2121 aaiaia ccc −+ (2.1)
où cij représente le coût pour circuler du nœud i au nœud j
3. Insérer le nœud non visité le moins dispendieux à intégrer à la tournée actuelle.
4. Répéter les étapes 2 et 3 jusqu’à ce que tous les nœuds soient visités.
Il existe une multitude d’approches de construction et il ne serait pas pertinent de toutes les
présenter ici. Le lecteur intéressé peut se référer aux revues de la littérature citées
précédemment.
b. Approches d’amélioration
Ce type d’approche permet de corriger les défauts générés lors de la construction d’une
tournée dans un souci d’obtenir une tournée se rapprochant, autant que possible, de la
solution optimale. Bien entendu, les recherches en quête d’une heuristique idéale sont
nombreuses. Toutefois, certaines heuristiques, telles que celles développées par Lin (1965) et
Lin et Kernighan (1973), sont particulièrement intéressantes.
Heuristique r-opt (Lin 1965)
L’idée de base de l’heuristique r-opt est de faire des échanges d’au plus r arcs dans une
tournée, où { }... ;3 ;2∈r . Ce type d’échanges permet d’éliminer les erreurs d’assignation,
comme les détours.
En raison de leur simplicité d’application, les heuristiques 2-opt (Figure 2.3) et 3-opt
(Figure 2.4) sont couramment utilisés. Mis à part le nombre d’échanges possibles qui diffère,
le fonctionnement de ces heuristiques est identique :

19
1. Tester tous les échanges possibles d’au plus r arcs dans la tournée et évaluer l’impact de
ces échanges.
2. Appliquer l’échange ayant le meilleur impact.
3. Recommencer à l’étape 1 tant que des améliorations sont possibles.
Figure 2.3 – Heuristique 2-opt
Image tirée de Renaud 2002
Figure 2.4 – Heuristique 3-opt
Image tirée de Renaud 2002
Heuristique r-opt modifiée (Lin et Kernighan 1973)
Ces chercheurs ont développé une méthode utilisant l’heuristique r-opt de façon dynamique,
c’est-à-dire qu’à chaque itération est déterminé le nombre d’arcs r à remplacer. Ainsi,
l’algorithme teste un échange à r arcs, puis valide si l’échange de 1+r arcs donnerait un
meilleur résultat. Cette heuristique était initialement très lente et très complexe d’utilisation.

20
Toutefois, Helsgaum (2000) a proposé une version améliorée de l’algorithme de Lin et
Kernighan, qui allie à la fois rapidité et précision. L’implantation de Helsgaum procure
presque toujours des résultats optimaux. Depuis, les articles traitant du sujet sont moindres.
c. Approches composites
Les approches composites sont des méthodes qui combinent diverses heuristiques
complémentaires. L’objectif de ces approches est d’obtenir rapidement une bonne solution.
Parmi les méthodes développées se trouvent, entre autre, GENIUS (Gendreau, Hertz et
Laporte 1992) et I3 (Renaud, Boctor et Laporte 1996a).
Méthode GENIUS (Gendreau, Hertz et Laporte 1992)
Cette méthode construit une tournée en insérant chacun des points entre deux de ses p plus
proches voisins. Elle considère ainsi plus de possibilités que la méthode habituelle
d’insertion entre deux points et s’assure d’insérer le point là où cela sera le plus avantageux
tout en considérant la possibilité d’inverser le sens de certaines portions de la tournée. La
méthode fonctionne en deux parties : d’abord, une procédure d’insertion (GENI) puis, une
méthode d’amélioration (US).
Méthode I3 (Renaud, Boctor et Laporte 1996a)
La méthode I3 a été développée pour solutionner le problème du voyageur de commerce
ayant une matrice de distance symétrique. Comme son nom l’indique, elle fonctionne en
trois étapes : la construction d’un sous tour initial, l’insertion des nœuds délaissés par la
première étape et l’amélioration de la tournée à l’aide de l’heuristique 4-opt* restreinte
développée par les auteurs.
1.2. Problème de tournées de véhicules
Tout comme pour le problème du voyageur de commerce, Golden et Assad (1988) ont
présenté les problèmes de tournées de véhicules comme étant des problèmes faciles à
expliquer mais difficiles à résoudre. Leur ouvrage présente une synthèse des connaissances
dans ce domaine divisé en cinq blocs : les théories et pratiques des tournées de véhicules, les

21
variantes du problème, telles que les fenêtres de temps et les revenus de retour, les tournées
dans des environnements complexes, les applications et les systèmes commerciaux de
tournées. À l’époque, les auteurs présentaient aussi les défis des études futures dans le
domaine.
Par conséquent, les recherches concernant cette problématique sont nombreuses. Elles se
subdivisent en trois grandes catégories : les méthodes exactes, les heuristiques classiques et
les métaheuristiques.
À nouveau, le lecteur intéressé à obtenir plus d’informations sur les méthodes de résolution
est invité à lire les revues de Bodin et al. (1983), de Laporte (1992b, 1993) et la
bibliographique de Laporte et Osman (1995). Le guide d’utilisation des algorithmes VRP de
Cordeau et al. (2002) est également un excellent tutorial pour toute personne désirant
implanter des algorithmes VRP. Finalement, Laporte et al. (2000) ont évalués la
performance de divers algorithmes VRP classiques.
a. Méthodes exactes
Ces méthodes permettent d’obtenir la solution optimale d’un problème. De façon générale,
les méthodes exactes peuvent se diviser en deux catégories : la programmation dynamique
et la programmation linéaire, cette dernière regroupant la séparation et l’évaluation
progressive (branch and bound), la génération de colonnes et la génération de coupes
(branch and cut). La programmation linéaire est basée sur des équations linéaires et
nécessite l’utilisation d’un logiciel d’optimisation. La résolution optimale est longue et
complexe puisqu’elle nécessite l’essai de toutes les possibilités afin d’obtenir la solution
idéale.
Il existe plusieurs variantes du problème de tournées de véhicules et tout autant de
méthodes exactes. L’intérêt a été porté sur le modèle de Kohl et Madsen (1997) compte
tenu de sa simplicité. Ces chercheurs ont élaboré un modèle mathématique qui traite le
problème de tournées de véhicules en prenant en compte des fenêtres de temps pour
chacun des nœuds à visiter. Leur modèle est formulé comme suit :

22
(2.2)
où
Si le camion k visite le nœud i suivi immédiatement du nœud j
=,0
,1ijkx
Sinon
aks : Ordre d’arrivée au nœud a avec le camion k
Ce modèle sera explicité plus en détails dans une section subséquente.

23
b. Heuristiques classiques
Les heuristiques classiques ont la particularité d’apporter une solution à un problème dans un
temps raisonnable. Toutefois, le résultat obtenu n’est pas forcément la solution optimale du
problème. Ces heuristiques se divisent en deux catégories : les heuristiques de construction et
les heuristiques d’amélioration.
Heuristiques de construction
Ces heuristiques permettent de concevoir des tournées. Dans les faits, elles en construisent
plusieurs en même temps. Ainsi, chacun des nœuds est assigné à la tournée la plus
avantageuse en fonction des possibilités. Ici encore, de nombreuses permutations sont
possibles. Dès lors, le défi des chercheurs a été de développer des méthodes de plus en plus
efficaces. Plusieurs heuristiques de construction sont disponibles dans la littérature.
Toutefois, deux d’entre elles sont particulièrement intéressantes et connues : l’algorithme de
Clarke et Wright (1964) et l’algorithme de balayage (Gillett et Miller 1974).
Algorithme de Clarke et Wright (1964)
Dans la réalité, pour livrer les expéditions d’un même secteur, il est souvent préférable
d’utiliser un seul camion plutôt que deux. L’algorithme de Clarke et Wright exploite ce
concept. Ainsi, la construction des tournées est faite par un regroupement de nœuds basé sur
les meilleures économies possibles (Figure 2.5). Celles-ci sont calculées à l’aide de
l’équation suivante :
ijjiij cccs −+= 00 (2.3)
où i : Numéro du nœud (arc sortant du nœud i)
j : Numéro du nœud (arc entrant au nœud j)
cij : Distance ou coût entre le nœud i et le nœud j { } { }( )jinjni ≠∈∈ , ...; ;1 ;0, ...; ;1 ;0
sij : Économie réalisée en circulant directement du nœud i au nœud j sans passer par le
dépôt

24
Figure 2.5 – Fusion de deux tournées par l’algorithme de Clarke et Wright
Image tirée de Renaud 2002
Ainsi, le processus de construction des tournées est le suivant :
1. Construire n routes initiales. Ainsi, chacune des expéditions est présumée être
livrée par un camion distinct, qui partira du dépôt, la livrera et retournera au dépôt.
2. Calculer la matrice d’économies sij.
3. Trouver la meilleure économie ** jis réalisable. L’économie est réalisable si i* et j*
sont les premiers et derniers nœuds visités sur leur route respective.
4. Fusionner les deux tournées ( )** et ji zz en une seule en allant directement du
nœud i* vers le nœud j*, comme démontré dans la méthode de la Figure 2.6.
5. Retour à l’étape 3 tant que des économies réalisables sont possibles, c’est-à-dire
aussi longtemps qu’il existe un 0≠ijs .
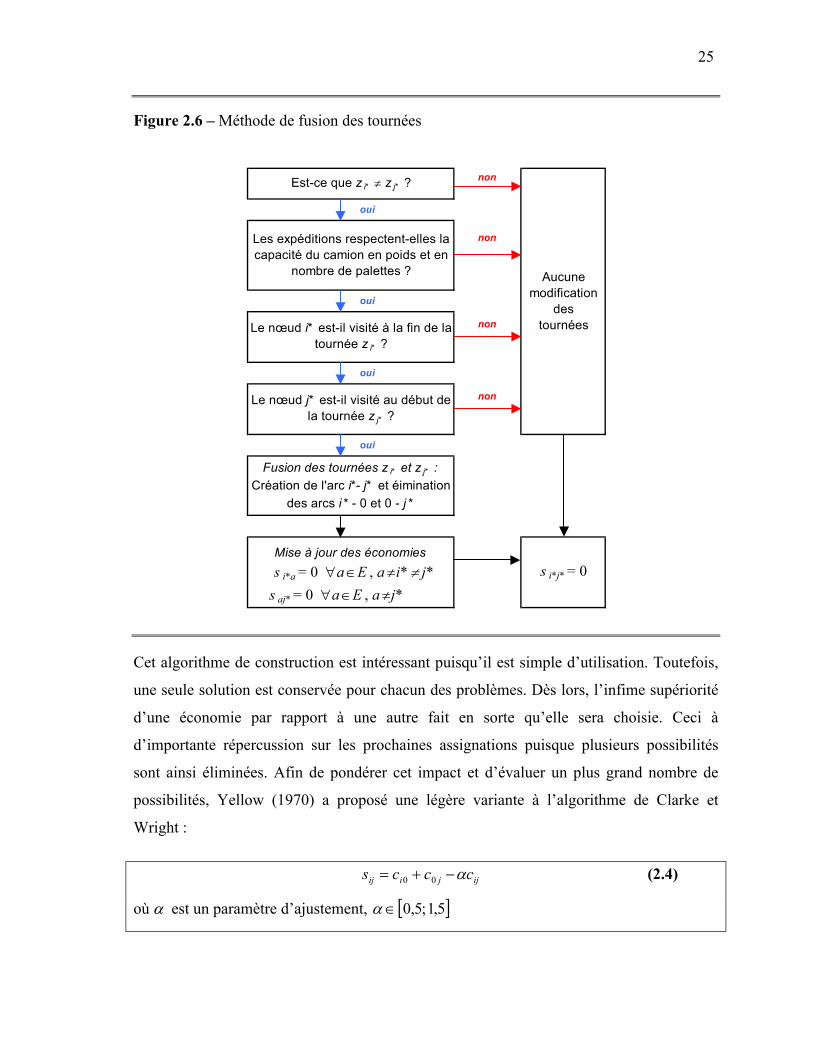
25
Figure 2.6 – Méthode de fusion des tournées
oui
oui
oui
oui
Mise à jour des économies s i*a = 0 ∀a ∈E , a ≠i* ≠ j*
s aj* = 0 ∀a ∈E , a ≠j*
Le nœud j* est-il visité au début de la tournée z j* ?
Fusion des tournées z i* et z j* : Création de l'arc i*- j* et éimination
des arcs i * - 0 et 0 - j *
s i*j* = 0
Est-ce que z i* ≠ z j* ?
Aucune modification
des tournées
non
non
non
non
Les expéditions respectent-elles la capacité du camion en poids et en
nombre de palettes ?
Le nœud i* est-il visité à la fin de la tournée z i* ?
Cet algorithme de construction est intéressant puisqu’il est simple d’utilisation. Toutefois,
une seule solution est conservée pour chacun des problèmes. Dès lors, l’infime supériorité
d’une économie par rapport à une autre fait en sorte qu’elle sera choisie. Ceci à
d’importante répercussion sur les prochaines assignations puisque plusieurs possibilités
sont ainsi éliminées. Afin de pondérer cet impact et d’évaluer un plus grand nombre de
possibilités, Yellow (1970) a proposé une légère variante à l’algorithme de Clarke et
Wright :
ijjiij cccs α−+= 00 (2.4)
où α est un paramètre d’ajustement, [ ]5,1 ;5,0∈α

26
Le paramètre d’ajustement permet de pondérer l’impact du regroupement des deux
tournées. En variant α, les économies peuvent être différentes et l’ordre de répartition des
nœuds peut l’être également, ce qui permet d’explorer diverses solutions.
Algorithme de balayage (Gillett et Miller 1974)
Cet algorithme permet de faire l’assignation des expéditions aux camions à l’aide des
coordonnées polaires de chacun des nœuds. Elle a été développée par Gillett et Miller
(1974). La confection des tournées s’opère comme suit (Figure 2.7) :
1. Trier les nœuds dans l’ordre croissant de leur coordonnée θi.
2. Sélectionner un camion vide; il devient alors le camion courant.
3. Si la capacité du camion courant le permet, assigner le nœud non visité ayant le plus
petit θi.
4. Répéter l’étape 3 tant que la capacité du camion le permet.
5. Si la capacité du camion est dépassée et qu’il reste des nœuds à visiter, retour à
l’étape 2.
Figure 2.7 – Algorithme de construction par balayage
dépôt
12
3Élaboration des tournées Tournées finales
dépôt axe de référence
Cet algorithme est sensible à l’emplacement de l’axe de référence. Ainsi, tout
dépendamment de sa position, les mesures des angles θi des différents nœuds i prennent
des valeurs différentes ce qui influence les résultats obtenus. L’idée de balayage est
toutefois intéressante; elle a été reprise par de nombreux chercheurs, dont Renaud, Boctor
et Laporte (1996b). Ces derniers ont développés une méthode appelée 2-pétales. Cette

27
méthode améliore le balayage original en permettant de construire deux tournées en même
temps.
Heuristiques d’amélioration
Les heuristiques d’amélioration ont pour objectif de corriger les défauts des tournées en
permutant un ou plusieurs nœuds qui appartiennent à des routes distinctes. Osman (1993) a
développé la méthode d’échanges-λ. La méthode est appliquée à toutes les combinaisons
possibles de deux routes A et B. Toutes les combinaisons d’au plus λ nœuds appartenant à la
Route A sont échangées avec toutes les combinaisons d’au plus λ nœuds appartenant à la
Route B. Tel que mentionné par Osman (1993), le grand nombre d’échanges possibles limite
l’application de cette méthode à λ = 2. Ici, une restriction de la méthode originale de Osman
(1993) sera utilisée. Cette restriction, qui limite à onze le nombre d’échanges possibles pour
λ = 2, a été utilisée avec succès par Renaud, Boctor et Laporte (1996b) pour le problème de
tournées de véhicules. Cette restriction est appliquée à toutes les combinaisons possibles de
deux routes A et B. Par contre, seules les combinaisons d’au plus λ nœuds successifs
appartenant à la Route A sont échangées avec chacune des combinaisons d’au plus λ nœuds
successifs appartenant à la Route B. La Figure 2.8 illustre les onze permutations retenues
pour λ = 2 à partir de deux routes distinctes, tel qu’utilisées par Renaud, Boctor et Laporte
(1996b). Dans cette figure, les échanges #1 à #3 correspondent à des échanges avec λ = 1.
Les échanges #4 à #11 correspondent à des échanges avec λ = 2 qui considèrent toutes les
orientations possibles.
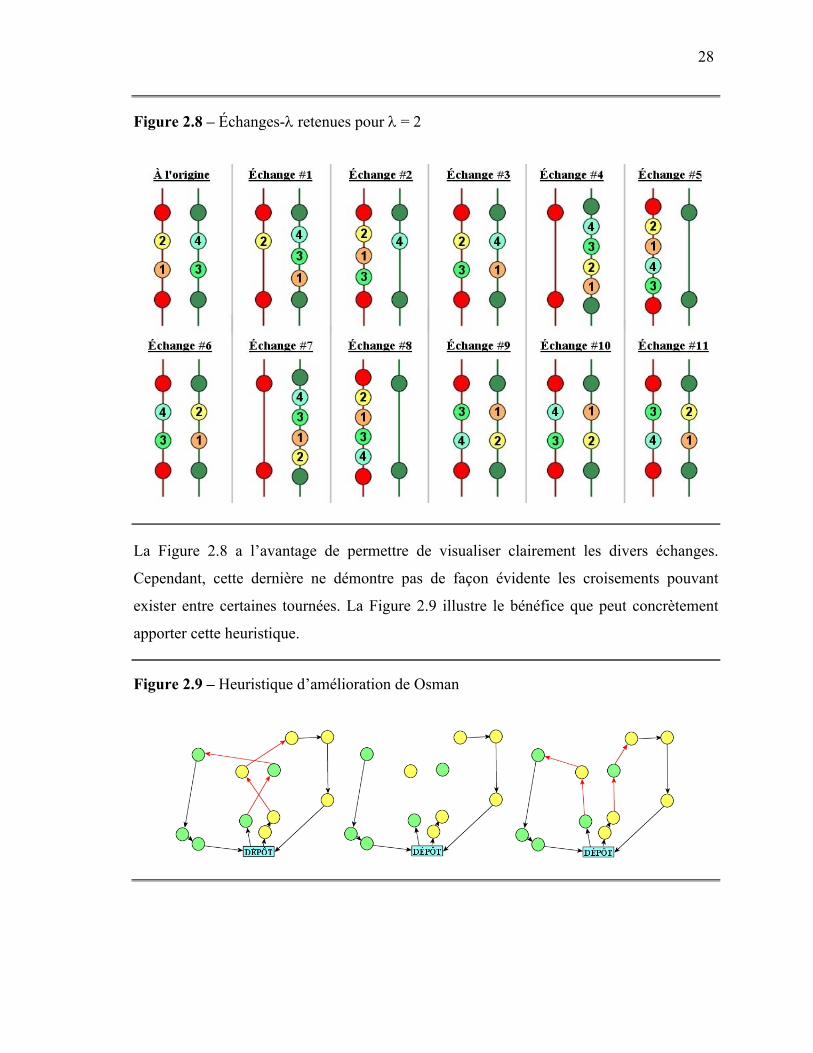
28
Figure 2.8 – Échanges-λ retenues pour λ = 2
La Figure 2.8 a l’avantage de permettre de visualiser clairement les divers échanges.
Cependant, cette dernière ne démontre pas de façon évidente les croisements pouvant
exister entre certaines tournées. La Figure 2.9 illustre le bénéfice que peut concrètement
apporter cette heuristique.
Figure 2.9 – Heuristique d’amélioration de Osman
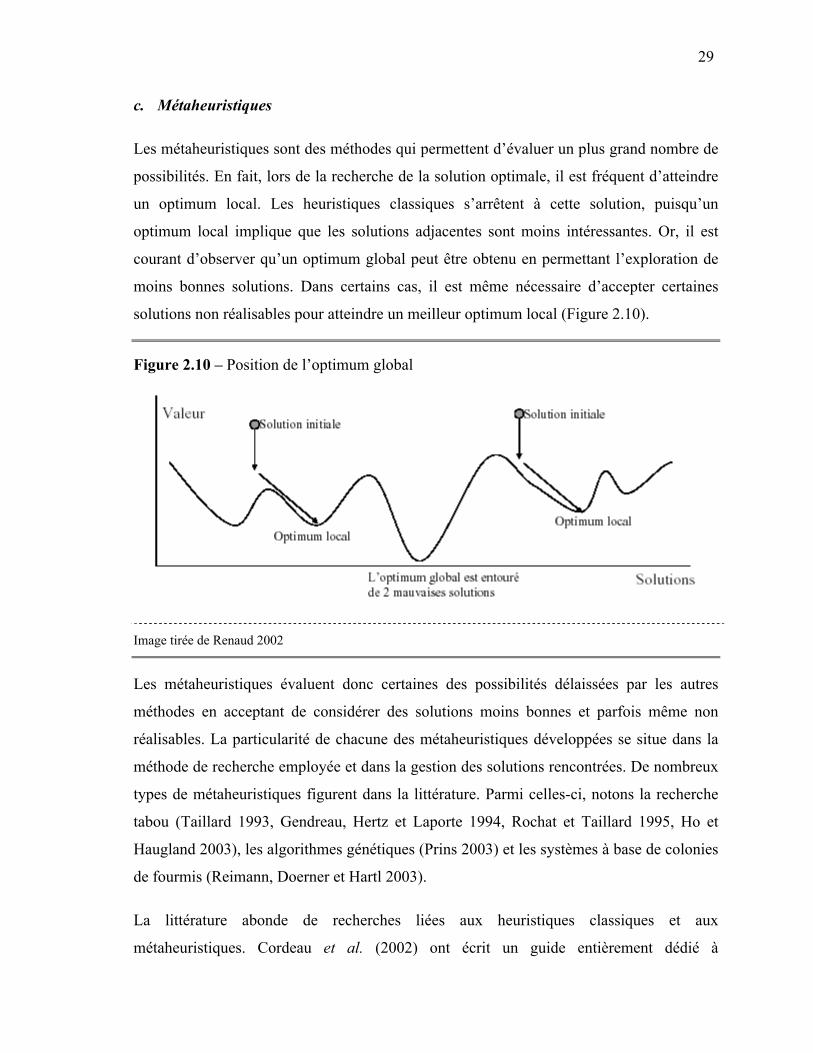
29
c. Métaheuristiques
Les métaheuristiques sont des méthodes qui permettent d’évaluer un plus grand nombre de
possibilités. En fait, lors de la recherche de la solution optimale, il est fréquent d’atteindre
un optimum local. Les heuristiques classiques s’arrêtent à cette solution, puisqu’un
optimum local implique que les solutions adjacentes sont moins intéressantes. Or, il est
courant d’observer qu’un optimum global peut être obtenu en permettant l’exploration de
moins bonnes solutions. Dans certains cas, il est même nécessaire d’accepter certaines
solutions non réalisables pour atteindre un meilleur optimum local (Figure 2.10).
Figure 2.10 – Position de l’optimum global
Image tirée de Renaud 2002
Les métaheuristiques évaluent donc certaines des possibilités délaissées par les autres
méthodes en acceptant de considérer des solutions moins bonnes et parfois même non
réalisables. La particularité de chacune des métaheuristiques développées se situe dans la
méthode de recherche employée et dans la gestion des solutions rencontrées. De nombreux
types de métaheuristiques figurent dans la littérature. Parmi celles-ci, notons la recherche
tabou (Taillard 1993, Gendreau, Hertz et Laporte 1994, Rochat et Taillard 1995, Ho et
Haugland 2003), les algorithmes génétiques (Prins 2003) et les systèmes à base de colonies
de fourmis (Reimann, Doerner et Hartl 2003).
La littérature abonde de recherches liées aux heuristiques classiques et aux
métaheuristiques. Cordeau et al. (2002) ont écrit un guide entièrement dédié à

30
l’implantation des heuristiques pour les problèmes de tournées de véhicules. Les diverses
méthodes ont été décrites et comparées sous quatre critères : l’exactitude, la vitesse, la
simplicité et la flexibilité. Pour leur part, Gendreau et al. (2002) ont présenté une revue
détaillée des métaheuristiques pour le VRP. À ce jour, les meilleurs algorithmes sont en
mesure de résoudre de façon exacte les problèmes d’au plus 50 nœuds (Toth et Vigo 1998).
La recherche d’une heuristique performante est donc au cœur des études liées au problème
de tournées de véhicules.
2. SYSTÈMES INTÉGRÉS D’AIDE À LA DÉCISION
Les systèmes intégrés d’aide à la décision, appelés SIAD, sont conçus pour appuyer le
gestionnaire dans son travail. En fait, ils permettent à la fois de faire l’analyse de
l’information tout en suggérant des solutions. Ils ont la particularité de permettre l’essai de
divers scénarios dans le but de prendre la meilleure décision. Le fonctionnement de ces
systèmes est assez complexe.
Dans le marché des logiciels, de nombreux concepteurs se font concurrence. Toutefois, ils
ont tous un point en commun : ils sont peu loquaces quant aux méthodes de résolution
utilisées par leur application. Ainsi, la description des logiciels disponibles sur le marché
ne peut être faite que sommairement. Parmi les applications liées à la répartition, trois
retiennent l’attention : A.Maze, Truckmate et Millogiciel.
2.1. A.Maze
Cette application a été développée par GEOCOMtms. Sur le site de l’entreprise, elle est
décrite comme permettant d’optimiser les problèmes de routage à grande échelle grâce à
l’intégration de services disponibles sur Internet. De plus, il est spécifié que grâce à cette
application, les entreprises ont vu une baisse de leurs coûts de livraison de l’ordre de 10 à
20 %. A.Maze est utilisé par diverses entreprises, dont Ameublements Tanguay Inc., Alex
Coulombe Ltée et Courrier Purolator Ltée.
Ameublements Tanguay Inc. a implanté A.Maze dans le but d’améliorer son service à la
clientèle. En effet, l’entreprise voulait à la fois répondre adéquatement aux besoins des

31
clients tout en offrant un service de livraison dans des temps raisonnables. Par le fait
même, elle tenait également à réduire ses coûts d’opérations, tout en faisant l’acquisition
d’une application qui serait en mesure de gérer ses périodes de pointes. Selon un article
publié dans Stores (Seideman 2002), seul A.Maze pouvait à la fois répondre à ces attentes
tout en étant en mesure de s’adapter à la cartographie très précise des régions où
Ameublements Tanguay Inc. livre ses marchandises. Également, un autre article (Leclerc
et Thiboutot 2003) spécifie que l’application a permis de doter les répartiteurs d’un outil
capable de prendre en compte des contraintes de modélisation, tout en augmentant le
niveau d’exactitude lors des livraisons.
De son côté, Alex Coulombe Ltée a acquis cette application pour améliorer l’efficacité de
leur répartition tout en répondant aux besoins variés de leurs clients. Encore une fois,
GEOCOMtms précise que seule leur application pouvait répondre au besoin
cartographique de l’entreprise. Également, il est mentionné qu’en plus de répondre au
besoin spécifié par Alex Coulombe Ltée, A.Maze a permis de réduire la taille de la flotte
de camions et le temps de répartition de 70 %.
Quant à Courrier Purolator Ltée, dans un article publié dans la revue Gestion logistique en
avril 2002, l’entreprise spécifie qu’elle a choisi cette application à la suite de plusieurs
tests. Le défi pour GEOCOMtms était de faire fonctionner une application avec
énormément d’opérations sur un vaste territoire. Selon Courrier Purolator Ltée, A.Maze lui
a permis d’obtenir des améliorations considérables en améliorant, entre autre, son routage,
ses horaires et ses processus de livraisons.
2.2. Truckmate pour Windows (TM4Win)
Truckmate pour Windows (Truckmate for Windows – TM4Win) est une application
concurrente qui a été développée par Maddocks Systems Inc. Celle-ci permet de minimiser
la distance parcourue tout en gérant le transbordement lié aux charges partielles. Afin
d’être compétitif, une association a été conclue en 2002 avec GEOCOMtms. Une telle
entente permet désormais de lier les deux applications, lesquelles offrent aux utilisateurs
une solution qui rend possible une meilleure gestion de leur flotte. Peu d’informations sont
disponibles quant à l’utilisation de Truckmate. Toutefois, selon le site web de Maddocks

32
Systems, des entreprises telles que Eassons Transport, Canadian Freight Assembly et Mill
Creek Freight utilisent cette application.
2.3. Millogiciel
Un autre compétiteur, le Groupe Millobit, a également conçu son logiciel : Millogiciel. En
2002, une entente est intervenue avec Cancom Tracking, qui se spécialise en
communication par satellite. L’intégration Cancom-Millogiciel a permis de créer une
application alliant à la fois le repérage et la gestion intelligente des flottes. Autrefois, un
lien entre le Groupe Millobit et Cancom Tracking (Omni-Tracs) se formait uniquement
pour la création d’applications sur mesure, ce qui impliquait des coûts très élevés. Grâce à
cette alliance, le nouveau logiciel offert est un peu plus accessible. Cancom Tracking a
également comme partenaire Maddocks Systems Inc. et compte parmi ses clients, entre
autres, Magna Transportation, Quick X Transport et Transport Gaston Nadeau, tous trois
œuvrant dans le transport de charges partielles.
Pour tous ces logiciels, aucune information n’est disponible quand à leurs réels bénéfices
dans la profitabilité de l’entreprise.

Chapitre III
Modélisation
1. CONCEPTS DE BASE
Pour obtenir la répartition générant la meilleure contribution, il est nécessaire de construire
un modèle d’optimisation correspondant au problème. Ce modèle permettra à la fois
d’obtenir le détail des meilleures tournées et de comparer la solution obtenue avec celle
générée par une méthode heuristique.
Tel qu’illustré à la Figure 1.2 du Chapitre I, chacune des expéditions est représentée par un
nœud. Pour lier chacun d’eux, des arcs doivent être créés. Le but du modèle d’optimisation
est d’évaluer toutes les associations d’arcs possibles permettant de livrer toutes les
expéditions. Ainsi, diverses solutions réalisables seront créées et parmi elles, uniquement
la solution répondant le mieux à l’objectif défini sera conservée. Dans le cas présent,
l’objectif est de maximiser la contribution totale. Il faut donc trouver la répartition qui
répond le mieux à cette exigence.
Pour permettre au modèle d’évaluer toutes les possibilités, un lien entre chacune des paires
d’expéditions doit être créé. L’utilité des arcs prend ici tout son sens. Par exemple dans la
Figure 3.1, les divers arcs sortant du dépôt initial (nœud 0) sont illustrés. Chacun de ces
arcs peut être défini comme étant l’arc 0-j, où 0 est le nœud de départ (dépôt) et j, le nœud
de destination. Bien entendu, les nœuds 0 et j sont deux nœuds distincts, puisqu’il est
inutile de quitter un nœud pour immédiatement y revenir. Globalement, comme la
Figure 3.1 l’illustre, il existe autant d’arcs partant du dépôt qu’il y a d’expéditions, soit
douze dans cet exemple. Grâce à ces arcs, l’application pourra sélectionner lequel des
nœuds sera visité en premier au cours de la tournée.

34
Figure 3.1 – Ensemble des arcs 0-j
Par la suite, comme l’illustre la Figure 3.2, le même principe doit s’appliquer au nœud 1.
Ainsi, les arcs 1-j sont créés, où j est toujours le nœud de destination. Ces arcs sortants
permettront au modèle de faire le choix du nœud visité immédiatement après le nœud 1.
Bien entendu, parmi les possibilités figurent le retour au dépôt, puisque les tournées
devront s’y terminer éventuellement. Dans ce cas-ci, le dépôt final est nommé le nœud 13,
soit le nœud 1+n de façon générale.
Figure 3.2 – Ensemble des arcs 1-j
Déjà, dans ces deux figures (3.1 et 3.2), très peu des arcs illustrés seront réellement utilisés.
Quant aux autres, ils seront simplement inutilisés. Cet exemple démontre que le nombre

35
d’arcs qui s’avèreront éventuellement inutiles est grand. Toutefois, il est impossible de
faire le tri a priori parmi ceux-ci. Dès lors, l’évaluation de toutes les associations d’arcs
possibles permet de prendre une décision éclairée quant à l’ordonnancement des nœuds à
visiter.
Ce même exercice doit être fait pour tous les nœuds du problème. Ceci permet de créer
tous les arcs i-j envisageables. Toutefois, dans la problématique abordée, de nombreux cas
nécessiteront l’utilisation de plusieurs camions. Afin de distinguer les divers camions et de
créer des tournées distinctes pour chacun d’eux, un indice supplémentaire est nécessaire :
k. Ainsi, il est défini le terme (i-j)k, où i est le nœud de départ, j est le nœud de destination
et k est le numéro du camion utilisé. En conséquence, l’origine, la destination et le camion
les reliant seront continuellement connus.
Même si les termes (i-j)k sont maintenant clairement définies, leur association ne formera
pas nécessairement des tournées réalisables, comme l’illustre la Figure 3.3. Ici, la visite des
nœuds 6, 11 et 12 n’est pas précédée par le départ du dépôt, ce qui est irréaliste. Ce type
d’erreurs correspond à un sous tour, c’est-à-dire un ensemble de nœuds regroupés pour la
livraison des expéditions mais qui ne débute ni ne se termine au dépôt, donc la tournée est
irréalisable.
Figure 3.3 – Réseau incluant un sous tour

36
Afin d’éviter ce type d’erreur, le terme aks est utilisé, où a représente le nœud visité et k
spécifie le numéro du camion utilisé. Ces termes permettent de construire une tournée
réalisable lors de l’attribution des expéditions aux camions. Plus précisément, leurs valeurs
correspondent à l’ordre d’arrivée au nœud a du camion k, en contraignant la séquence des
valeurs des termes à continuellement augmenter. Dès lors, puisque ces valeurs
s’accroissent au fur et à mesure que la tournée progresse, elles préviennent la création de
sous tours. Par exemple, dans la Figure 3.4, la séquence des termes aks rend impossible la
création des arcs pointillés, tout en permettant l’attribution des quatre expéditions au
camion k.
Figure 3.4 – Construction en cinq étapes d’un réseau avec l’indicateur sak
Les indicateurs aks pourraient facilement être utilisées dans un problème où des fenêtres
de temps doivent être considérées. Une telle modification nécessiterait seulement quelques
ajustements mineurs. Toutefois, ceci outre passe les limites fixées dans la problématique
étudiée. Ainsi, aucune fenêtre de temps ne sera considérée dans l’étude.

37
2. NOTATIONS
Pour être en mesure de solutionner le problème à l’aide d’un modèle d’optimisation, il est
d’abord nécessaire de définir les notations qui seront utilisées. Elles se subdivisent en deux
catégories : les paramètres et les variables de décisions.
Voici la liste des paramètres :
r : Nombre de camions
n : Nombre d’expéditions
K : Ensemble des camions { }( )rK ...; ;2 ;1=
E : Ensemble des expéditions { }( )nE ...; ;2 ;1=
L : Ensemble des nœuds (dépôt initial + expéditions) { }( )nL ...; 1; ;0=
N : Ensemble des nœuds (expéditions + dépôt final) { }( )1 ...; ;2 ;1 += nN
w : Poids maximal par camion
p : Nombre maximal de palettes par camion
cm : Coût par mille parcouru
cs : Coût par arrêt
M : Une grande valeur
i : Numéro du nœud (arc sortant) ( )Lii ∈== initial,dépôt 0 si
j : Numéro du nœud (arc entrant) ( )Njnj ∈=+= final,dépôt 1 si
k : Numéro du camion
ip : Nombre de palettes de l’expédition i ( )Ei ∈
iw : Poids de l’expédition i ( )Ei ∈
ir : Revenus générés par l’expédition i ( )Ei ∈
ib : Revenu de retour attaché à l’expédition i ( )Ei ∈
ijd : Distance parcourue en allant du nœud i au nœud j
ijc : Coûts encourus pour circuler du nœud i au nœud j
avec 1 si ,
1 si ,
+=+−
+≠=
njcsbcmdnjcmd
ciij
ijij

38
Les indices i et j semblent laisser croire que le dépôt initial et le dépôt final sont deux lieux
distincts. Or, le dépôt initial (nœud 0) est défini comme étant le même lieu physique que le
dépôt final (nœud 1+n ). Toutefois, au niveau de la formulation du problème, la distinction
est nécessaire afin de s’assurer que les tournées prennent toutes fin au dépôt, c’est-à-dire
qu’elles débuteront obligatoirement au nœud 0 et qu’elles se termineront au nœud 1+n .
Les raisons et les impacts de cette particularité seront plus évidents lors de l’élaboration
des contraintes du problème, soit dans la Section 3.2 de ce chapitre.
Une fois tous les paramètres définis, les variables de décision du modèle ont été établies
comme suit :
Si le camion k visite le nœud i suivi immédiatement du nœud j
=,0,1
ijkx Sinon
aks : Ordre d’arrivée au nœud a avec le camion k ( )0≥aks
3. MODÈLE MATHÉMATIQUE
La constitution d’un tel modèle permettra d’évaluer toutes les solutions possibles à l’aide
du logiciel d’optimisation Ilog Cplex et d’en extraire celle qui maximise la contribution
totale.
Le modèle sera présenté en deux volets. D’abord, la fonction objectif spécifiera le but à
atteindre lors de la résolution du problème. Puis, viendront les contraintes du problème, qui
formeront les balises auxquelles le problème a été astreint. Le modèle proposé est une
adaptation du modèle de Kohl et Madsen (1997) présenté au Chapitre II.
3.1. Fonction objectif
Afin d’obtenir des résultats adéquats, la définition de la fonction objectif doit déterminer
précisément le but ultime à atteindre. Compte tenu des coûts qu’elle implique, la distance
totale parcourue semble être l’élément à minimiser. Il est vrai que le modèle aura tendance
à suivre cet optique puisqu’en écourtant la distance, les coûts diminueront et la
contribution totale augmentera. Toutefois, compte tenu du fait que la problématique tient
compte de la possibilité d’un revenu de retour provenant du marché de la dernière

39
destination visitée, il est envisageable qu’un léger détour impliquant une fin de tournée
dans un lieu différent permette d’obtenir un revenu de retour plus intéressant. De plus, les
entreprises œuvrant dans le domaine du transport ont un objectif principal en tête : la
rentabilité. En tenant compte de ces deux arguments, la conclusion vient d’elle-même : le
modèle doit avoir comme objectif de maximiser la contribution totale obtenue grâce à la
livraison de toutes les expéditions ainsi qu’aux revenus de retour. Techniquement parlant,
la fonction objectif est écrite ainsi :
Contribution totale = ( )( ) )( ncsxcrKk
jiLi Nj
ijkiji −−∑∑∑∈
≠∈ ∈
(3.1)
Afin d’être en mesure de comprendre plus aisément la fonction objectif élaborée à
l’Équation 3.1, il est plus pratique de la réécrire en trois termes distincts qui constitueront
la contribution totale :
Contribution totale = )( Kk
jiLi
ncsxcxrKk
jiLi Nj
ijkijNj
ijki −− ∑∑∑∑∑∑∈
≠∈ ∈∈
≠∈ ∈
(3.2)
Le premier terme, ∑∑∑∈
≠∈ ∈Kk
jiLi Nj
ijki xr , représente les revenus totaux générés par la livraison des
marchandises. Plus clairement, il regroupe le total des frais demandé aux expéditeurs par le
transporteur pour répondre à leur besoin. Toutefois, les revenus de retour ne sont pas pris
en compte ici. Les raisons de cette exception seront expliquées dans le prochain terme.
Le deuxième terme, ∑∑∑∈
≠∈ ∈Kk
jiLi Nj
ijkij xc , représente les coûts totaux liés à la distance parcourue
pour distribuer toutes les expéditions. De ces coûts a été préalablement retranché le revenu
de retour associé à la dernière destination visitée par chacun des camions et additionné le
coût d’arrêt associé à ce revenu. Ceci permet de tenir compte uniquement des revenus de
retour transportés et non de tous ceux possible au moment de faire la répartition.

40
Finalement, le dernier terme, )(ncs , représente le total des coûts d’arrêt impliqués lors de
la livraison des n expéditions. Ce sont donc les coûts liés au déchargement des
marchandises et à l’attente à chacun des nœuds.
Globalement, ces trois termes représentent la contribution totale générée par la livraison
des n expéditions ainsi que par les revenus de retour. Puisque le premier et le troisième
terme sont des constantes (ils ne dépendent pas de la solution), ils doivent être éliminés du
modèle d’optimisation. La fonction objectif du modèle se résume donc à maximiser :
Contribution totale = ∑∑∑∈
≠∈ ∈
−Kk
jiLi Nj
ijkij xc (3.2b)
Ce qui revient à minimiser :
Coût de livraison = ∑∑∑∈
≠∈ ∈Kk
jiLi Nj
ijkij xc (3.2c)
Ce qui nous ramène bien à un problème de tournées de véhicules.
3.2. Contraintes
Pour toute entreprise, il est toujours préférable d’avoir les coûts d’exploitation les plus bas
possible et les revenus les plus élevés. Le domaine du transport ne fait pas exception. La
livraison des expéditions implique des coûts liés principalement à l’exploitation des
camions. Ce type de machinerie est contraint à des règlements qui en régissent l’utilisation.
Au moment de définir le modèle mathématique, il est important de tenir compte de ces
contraintes, lesquelles affectent grandement la répartition des marchandises.
Dans la problématique traitée, cinq grands types de contraintes ont été considérées : les
contraintes de visite, d’espace, de tournées, d’ordonnancement et de négativité.

41
a. Contraintes de visite
Dans certains cas, le fait de livrer certaines expéditions rend les tournées moins rentables.
Dans une vision d’optimalité, il pourrait être plus avantageux de ne pas faire une livraison
qui apporterait une contribution négative. Toutefois, ceci n’implique pas un bon service à
la clientèle, élément que les entreprises de transport doivent prendre en considération. Il
peut arriver à l’occasion qu’un client important demande de livrer une marchandise
impliquant une perte de revenus. Compte tenu que le transporteur tient à conserver cette
clientèle, il se permettra de prendre ces expéditions moins rentables.
La première contrainte considérée est donc une contrainte de visite, l’idée étant que toutes
les expéditions doivent être distribuées. Cependant, dans certaines situations, il est possible
que l’assignation des marchandises à l’un ou l’autre des camions disponibles génère la
même contribution. Malgré tout, les expéditions doivent être distribuées en totalité par un
et un seul camion. Ceci peut se traduire de la façon suivante :
EixKk
ijNj
ijk ∈∀=∑∑∈
≠∈
,1 (3.3)
Cette équation spécifie qu’à chacun des nœuds i, une seule sortie vers un nœud j
quelconque et utilisant le camion k quelconque doit être faite. Puisque le nombre d’arcs
sortant est ainsi régi, ceci permet d’éviter qu’un nœud soit visité plus d’une fois.
b. Contraintes d’espace par camion
La capacité de chacun des camions est restreinte par la réglementation routière et par le
volume qu’ils peuvent contenir. D’abord, les lois impliquent qu’un camion ne pourra
transporter plus d’un certain poids. Cette limite se formalise comme suit :
KkwxwjiEi Nj
ijki ∈∀≤∑ ∑≠∈ ∈
, (3.4)

42
Ainsi, l’Équation 3.4 spécifie que le poids total des expéditions contenues dans le camion k
ne peut excéder w, soit le poids imposé par la réglementation.
Quant à l’espace disponible dans le camion, il peut être spécifié de diverses façons : par
exemple en volume (pieds cube) ou en nombre de palettes. L’hypothèse que les palettes
utilisées sont standards quant à leur grandeur (longueur, largeur et hauteur) est ici émise.
Ceci permet de limiter le nombre de palettes comme suit :
KkpxpjiEi Nj
ijki ∈∀≤∑ ∑≠∈ ∈
, (3.5)
Ainsi, l’Équation 3.5 spécifie que le nombre total de palettes dans le camion k est au plus
égal à p palettes, soit la limite d’espace disponible. Bien entendu, une seconde hypothèse
est définie implicitement : tous les camions ont la même capacité. Ceci implique que
plusieurs camions identiques sont disponibles pour faire le transport des marchandises
spécifiées et que l’entreprise de transport possède un nombre suffisant de camions pour
répondre à la demande.
c. Contraintes de tournées
L’ordre de visite des clients par les camions doit maintenant être spécifié. La
problématique abordée implique l’utilisation d’un dépôt unique et d’aucun entrepôt en
cours de tournée. Dès lors, chacun des camions disponibles pourrait partir du dépôt. Ceci
peut être écrit de la façon suivante :
KkxEj
jk ∈∀≤∑∈
,10 (3.6)
Ainsi, il est spécifié que chacun des camions k peut être utilisé ou non, d’où l’utilisation
d’une restriction ouverte (≤) au lieu d’une limite fermée (=). Dans le cas où le modèle
utilise le camion k, il devra obligatoirement débuter sa tournée au dépôt (x0jk = 1 pour un
nœud j quelconque). Autrement, le camion k ne sera pas utilisé, ce qui signifie que
Ejx jk ∈∀= ,00 .

43
Une fois la tournée débutée, c’est-à-dire que le camion k a quitté le dépôt, il devra livrer
toutes les marchandises qu’il contient. Pour se faire, il doit obligatoirement arriver à une
destination (nœud h), décharger les marchandises et repartir pour se rendre au lieu suivant.
Chacune des étapes d’arrivée et de départ à un nœud h s’illustre comme ceci :
KkNhxxhjNj
hjk
hiLi
ihk ∈∀∈∀=− ∑∑≠∈
≠∈
, ,0 (3.7)
Cette équation spécifie qu’un camion k devra avoir visité un nœud i quelconque juste avant
le nœud h et qu’il quittera obligatoirement ce nœud pour aller visiter immédiatement après
le nœud j quelconque.
Finalement, une fois que le camion k a terminé sa tournée et qu’il a ramassé les
marchandises constituant le revenu de retour (s’il existe), il doit absolument revenir au
dépôt. Ce qui revient à écrire :
KkxEi
kni ∈∀≤∑∈
+ ,1,1, (3.8)
L’Équation 3.8 spécifie que si le camion k est utilisé, un et un seul arc en partance du
nœud i arrivera au dépôt 1+n . Autrement, aucun arc ne sera créé. Cette équation a la
même utilité que l’Équation 3.6, sauf qu’elle implique des arcs entrants au lieu d’arcs
sortants.
Il est important de remarquer que le dépôt final est ici noté comme étant le nœud 1+n
alors que le dépôt initial est noté nœud 0. Le point soulevé dans la Section 2 de ce chapitre
prend ici toute son importance. En effet, afin de s’assurer que le modèle distingue le début
et la fin de la tournée, le dépôt est représenté par deux nœuds différents. Comme l’illustre
les deux schémas de la Figure 3.5, ceci permet à l’application de créer des tournées sous la
forme de chaînes linéaires au lieu de boucles fermées. Ainsi, il ne peut jamais y avoir de
confusion entre le nœud qui débute et celui qui termine la route. Sans cette modélisation,
l’application peut voir le dépôt comme un nœud à visiter dans toutes les tournées, sans
toutefois l’insérer automatiquement comme le nœud débutant et terminant la tournée. Dans
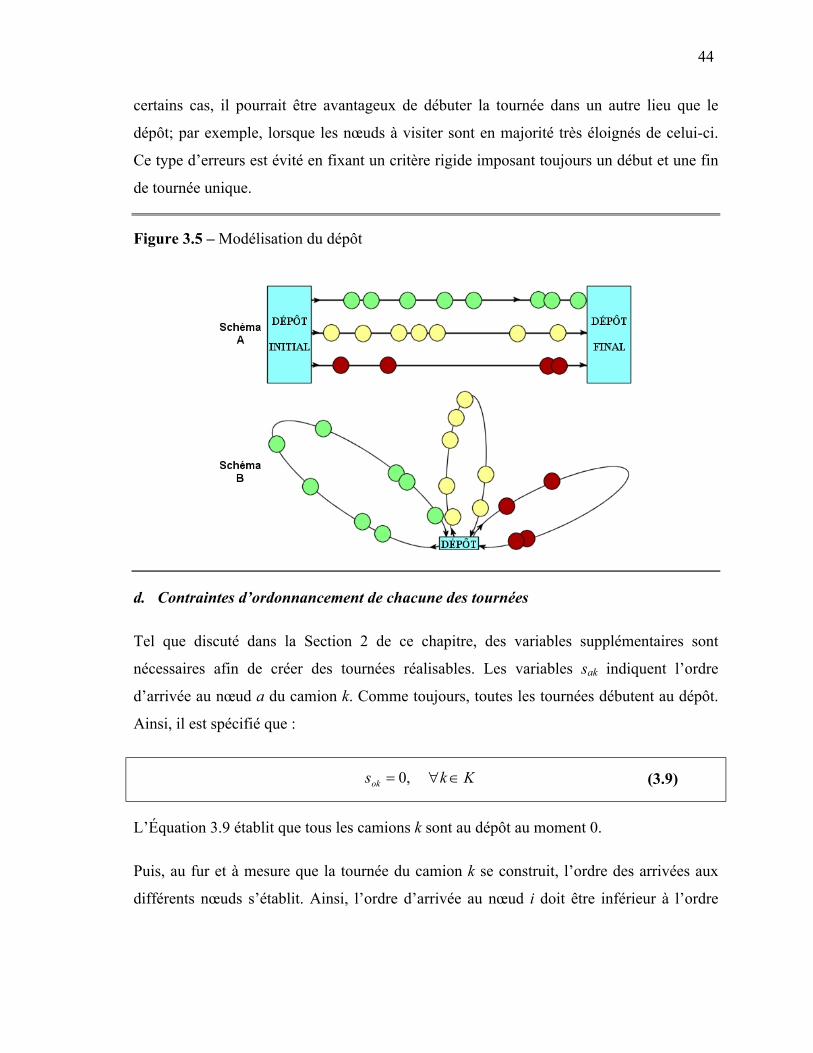
44
certains cas, il pourrait être avantageux de débuter la tournée dans un autre lieu que le
dépôt; par exemple, lorsque les nœuds à visiter sont en majorité très éloignés de celui-ci.
Ce type d’erreurs est évité en fixant un critère rigide imposant toujours un début et une fin
de tournée unique.
Figure 3.5 – Modélisation du dépôt
d. Contraintes d’ordonnancement de chacune des tournées
Tel que discuté dans la Section 2 de ce chapitre, des variables supplémentaires sont
nécessaires afin de créer des tournées réalisables. Les variables sak indiquent l’ordre
d’arrivée au nœud a du camion k. Comme toujours, toutes les tournées débutent au dépôt.
Ainsi, il est spécifié que :
Kksok ∈∀= ,0 (3.9)
L’Équation 3.9 établit que tous les camions k sont au dépôt au moment 0.
Puis, au fur et à mesure que la tournée du camion k se construit, l’ordre des arrivées aux
différents nœuds s’établit. Ainsi, l’ordre d’arrivée au nœud i doit être inférieur à l’ordre

45
d’arrivée au nœud j pour le camion k lorsque 1=ijkx . Cette exigence est formulée par la
contrainte suivante :
( ) { } jiNjKknixMss ijkjkik ≠∈∀∈∀∈∀−<− , , , ...; ;0 ,1 (3.10)
En appliquant l’Équation 3.10 à chacun des camions, l’ordre de livraison des expéditions
sera réalisable et les sous tours seront éliminés.
e. Contraintes d’intégrité et de non négativité
Ce type de contraintes permet d’orienter le modèle d’optimisation dans le choix de la
valeur des variables de décisions. Ceci permet d’éviter que le logiciel d’optimisation
génère une solution non réalisable. Cette contrainte peut s’écrire comme suit :
{ }1 ;0∈ijkx (3.11)
L’imposition de cette contrainte binaire aux variables ijkx permet d’assurer qu’elles
tiendront compte uniquement de l’une ou de l’autre des valeurs.
Quant aux variables d’ordonnancement des arrivées aux différents nœuds, elles doivent
toutes prendre une valeur positive. Ceci permet de garantir un ordre adéquat de livraison
des expéditions par le camion k.
Easak ∈> ,0 (3.12)
4. ÉVALUATION DE LA TAILLE DU MODÈLE D’OPTIMISATION
La problématique abordée tient sa complexité dans la multitude de possibilités à considérer
impliquant un grand nombre de variables de décision. Au départ, la problématique semble
fort simple, mais l’est-elle vraiment ? Déjà, pour les tournées ne nécessitant qu’un seul
camion, des décisions quant à l’ordre de livraison des marchandises doivent être prises.
L’ordonnancement des n nœuds implique n! permutations possibles. Ainsi, la répartition de
5 nœuds implique 120 possibilités, alors que celle de 6 nœuds en implique 720 ! En tenant

46
compte que pour chacune des possibilités, la distance parcourue, les coûts par arrêt et par
mille ainsi que les revenus générés doivent être évalués, la tâche est colossale.
Déjà avec ce petit exemple, la solution optimale est difficile d’accès. De surcroît, en y
ajoutant la possibilité du choix du camion, les permutations possibles font un bon de n! à
( )!nr . Ainsi, simplement pour 5 expéditions qui peuvent être divisées en 2 camions, ce
n’est plus 120, mais bien 240 possibilités à évaluer !
La taille du modèle d’optimisation sera très grande. En effet, chaque problème contient
( )1+nnr variables ijkx et nr variables aks , pour un total de ( )2+nnr variables de décision.
Étant donné que le modèle renferme ( )1+nnr variables binaires et que ce nombre
augmente rapidement dû au nombre n d’expéditions, la résolution d’un seul problème peut
facilement nécessiter plusieurs jours. En gardant en tête que les entreprises de transport
n’ont pas des heures de calculs à consacrer, il est crucial de songer à des méthodes
heuristiques afin d’être en mesure d’obtenir une solution ayant une valeur près de la
solution optimale, sans toutefois avoir des temps de calculs aussi grands.

Chapitre IV
Approche de résolution
1. CONSIDÉRATION PRÉLIMINAIRE
Tel que mentionné précédemment, le problème étudié est très complexe. Le fait de vouloir
le résoudre de façon exacte nécessite l’utilisation d’un modèle d’optimisation et la
résolution à l’aide d’un logiciel d’optimisation tel que Ilog Cplex. Par ailleurs, ce type de
logiciel implique un coût d’implantation important puisqu’en plus de son coût
d’acquisition, il nécessite un système informatique puissant pour fonctionner
adéquatement. Dès lors, seuls les centres de recherche ont la possibilité de se doter de tels
logiciels.
Pour une entreprise de transport, il est irréaliste d’acquérir ce type de logiciel qui est peu
convivial et très complexe. Dans le quotidien de ces entreprises, les décisions doivent être
prises rapidement. Donc, une solution de qualité moindre que la solution optimale est
acceptable dans la mesure où elle est disponible immédiatement et qu’elle assure une
contribution intéressante. Dès lors, une résolution au moyen de méthodes heuristiques
répond pertinemment au besoin.
Avant de détailler la méthode heuristique intégrée au système développé pour apporter une
solution au problème, certaines précisions doivent être faites quant à la problématique
abordée. D’abord, la particularité du problème réside dans le fait qu’au départ, le nombre
de camions nécessaires au transport des marchandises est inconnu. En fonction de la
capacité de chacun d’eux, un nombre minimal de camions est nécessaire pour être en
mesure de livrer les marchandises. Toutefois, il est possible que ce minimum ne constitue

48
pas la meilleure solution en raison, entre autre, des revenus de retour. Dès lors, la méthode
développée doit prendre des dispositions afin de prendre la meilleure décision à ce niveau.
Mis à part la capacité des camions, ce sont les revenus de retour qui ont le plus grand
impact sur l’ordre de livraison des marchandises. En conséquence, la méthode heuristique
doit être en mesure de pondérer cet impact dans un souci d’obtenir une solution près de
l’optimum.
Les coûts ont également un impact important puisqu’ils varient en fonction des
regroupements. Deux catégories de coûts ont été considérées : les coûts d’arrêt et les coûts
de route. Les premiers sont les frais impliqués dans le processus de livraison lorsque le
camion est en arrêt. Ceux-ci comprennent principalement le coût du conducteur lorsqu’il
décharge les marchandises chez un client. Ainsi, chaque fois qu’une expédition est intégrée
dans une tournée, elle implique un coût d’arrêt supplémentaire puisqu’elle nécessitera
d’être déchargée. En plus, un coût d’arrêt a également été considéré lors de la collecte du
revenu de retour; ce coût représente le temps de chargement des marchandises. Quant aux
coûts de route, ce sont les coûts liés à la distance parcourue. Ainsi, ils comprennent à la
fois les coûts de carburant et le salaire du conducteur. Dans ce cas-ci, les données utilisées
sont basées sur une estimation des coûts obtenus d’une entreprise de transport.
Quant aux revenus générés par la livraison des expéditions, ce sont des données non
pertinentes. En effet, puisque les marchandises doivent toutes être livrées, ces revenus
seront toujours générés, et ce, peu importe les tournées créées. Dès lors, ils doivent être
pris en compte lors du calcul de la contribution des tournées, mais n’ont aucune incidence
sur les décisions de répartition. Ainsi, la contribution totale sera calculée comme suit :
arrêtd' Coûts route de Coûts
retour de Revenus livraisons lespar générés Revenus on totaleContributi −−
+= (4.1)
La méthode de résolution heuristique présentée dans la prochaine section tient compte de
tous ces éléments et elle constitue le fondement du système intégré d’aide à la décision
présenté à la Section IV.3.

49
2. MÉTHODE HEURISTIQUE DE RÉSOLUTION
De façon conceptuelle, la méthode développée considère le choix du nombre de tournées
qui doivent être faites pour maximiser la contribution totale. Dès lors, la méthode construit
les tournées, puis les améliore pour finalement générer la meilleure solution obtenue.
Globalement, l’heuristique développée fonctionne de façon itérative, c’est-à-dire que
diverses tournées seront conçues et améliorées dans le but de conserver en bout de ligne
uniquement la meilleure solution. Tout au long du processus, les notations suivantes sont
nécessaires :
Z : Valeur de la solution courante
S : Ensemble des routes de la solution courante
Z* : Valeur de la meilleure solution trouvée
S* : Ensemble des routes de la meilleure solution trouvée
α : Paramètre d’ajustement pour la formation des routes, où { }5,1 ...; ;6,0 ;5,0∈α
β : Paramètre d’ajustement pour la formation des routes, où { }5,1 ...; ;6,0 ;5,0∈β
De façon générale, la méthode heuristique fonctionne comme suit :
1. Initialisation des données (Sous-Section IV.2.1)
a. Enregistrement des caractéristiques des expéditions.
b. Construction de la matrice des coûts.
c. Initialisation : Z* = ∞, S* = ∅, α = 0,5 et β = 0,5.
2. Formation des routes (Sous-Section IV.2.2)
3. Amélioration individuelle des routes (Sous-Section IV.2.3)
4. Amélioration des routes (Sous-Section IV.2.4)
5. Si β < 1,5, incrémenter de 0,1 le paramètre et retour à l’étape 2.
6. Si α < 1,5, incrémenter de 0,1 le paramètre, fixer β = 0,5 et retour à l’étape 2.
7. Sortie de la meilleure solution.

50
La procédure développée est basée sur plusieurs des heuristiques présentées dans le
Chapitre II. La Figure 4.1 illustre l’organigramme de cette méthode.
Figure 4.1 – Méthode heuristique intégrée dans le système développé
oui
oui
α = α + 0,1
non
Heuristique du plus proche voisinHeuristique de l'insertion la moins coûteuse
β = β + 0,1
β < 1,5 ?
Formation des routes
Initialisation des données
α = 0,5
Heuristique de construction
Affichage de la meilleure solution
Méthode d'inversionAmélioration des routes individuelles
β = 0,5
non
α < 1,5 ?
Heuristique 3-opt (Lin 1965)
Amélioration des routesÉchanges inter-routes (Osman 1993)
Validation et conservation de la meilleure solution
Les quatre sous-sections suivantes expliquent plus en détails les étapes de cette méthode.
2.1. Étape 1 : Initialisation des données
Cette première étape consiste principalement à recueillir les données concernant chacune
des expéditions qui devront être livrées. Ainsi, pour chacune d’entre elles, l’entreprise de
transport doit connaître le poids des marchandises à transporter, le nombre de palettes

51
qu’elles utilisent, les revenus qu’elles génèrent et la destination de ces marchandises. En
plus, si dans le marché de cette destination un revenu de retour est possible, il devra
également être rattaché à cette expédition puisqu’il vient contrebalancer les coûts
impliqués par le déplacement vers cette ville.
Une fois cette information rassemblée, la matrice des coûts C est calculée. Enfin, certaines
variables sont initialisées : Z* = ∞, S* = ∅, α = 0,5 et β = 0,5.
2.2. Étape 2 : Formation des routes
Cette seconde étape consiste à construire une première version des tournées. Cette
construction est faite à l’aide d’une version modifiée de l’algorithme de Yellow (1970)
présenté dans la Sous-Section II.1.2. En effet, il a été démontré que cet algorithme
améliore considérablement les solutions par rapport à l’algorithme de Clarke et Wright
(1964). Cependant, ces algorithmes ne tiennent pas compte, dans leur forme actuelle, de la
possibilité d’un revenu supplémentaire (revenu de retour) sur le marché de la dernière
destination visitée. Ainsi, une modification du calcul des économies est proposée afin de
prendre en compte la particularité de ce revenu lorsqu’un nœud est la dernière destination
visitée. Contrairement aux revenus générés par le transport des marchandises, ce revenu de
retour est différent tout dépendamment des disponibilités du marché de la dernière
destination visitée. Tout ceci rend la matrice des coûts asymétriques puisque ce revenu doit
être soustrait des coûts liés à la visite de ce dernier marché. Ainsi, la formule permettant de
calculer des économies doit être modifiée comme suit :
iijjiij bcccs −−+= α00 (4.2)
où bi représente le revenu de retour dans le marché du nœud i initialement visité en fin de
tournée
Grâce à cette modification, les revenus de retour sont considérés uniquement en fin de
tournées. Par contre, ces revenus ont une influence considérable sur la matrice
d’économies. Ici encore, l’infime supériorité d’une économie par rapport à une autre peut
impliquer d’énormes conséquences dans l’ordre d’assignation des marchandises. Afin de

52
pondérer l’impact des revenus de retour, une seconde modification a été apportée au calcul
des économies :
iijjiij bcccs βα −−+= 00 (4.3)
où [ ]5,1 ;5,0∈β
Le fait que les paramètres d’ajustement α et β soient distincts est intentionnel. En effet, en
faisant varier ces deux paramètres de façon indépendante, le nombre de possibilités
envisagées est plus important. L’utilisation unique du paramètre α permettait de considérer
11 possibilités puisque le paramètre a 11 valeurs possibles. Or, en ajoutant le paramètre β
qui possède également 11 valeurs et qui varie de façon indépendante au paramètre α, le
nombre de possibilités est multiplié par 11 pour ainsi atteindre 121. Dès lors, l’éventail de
tournées différentes étudiées est beaucoup plus grand et permet d’envisager de légères
modifications qui auraient été omises sans ces paramètres. Le caractère unique de chacun
des paramètres est également justifiable par leur impact complètement différent sur les
tournées, l’un influençant les arcs liant chacun des nœuds, l’autre influençant uniquement
la destination finale.
Globalement, l’algorithme de construction fonctionne selon la même séquence décrite lors
de l’élaboration de l’algorithme de Clarke et Wright au Chapitre II, les contraintes
considérées étant les contraintes d’espace dans le camion en nombre de palettes et de poids
total. Pour cette étape et les subséquentes, le terme « solution » désignera les routes
formées lors d’une itération. Une solution est formée d’un ensemble S de routes et a une
valeur Z indiquant la contribution totale des routes.
2.3. Étape 3 : Amélioration individuelle des routes
L’étape précédente génère les tournées, ce qui permet de définir le nombre de camions
nécessaires à la livraison des marchandises. Ici, chacune des routes d’une solution sera
traitée de façon indépendante puisqu’il est possible que les routes générées par
l’algorithme de construction ne soient pas les meilleures. Une amélioration consiste à
augmenter la contribution générée par une route en minimisant sa longueur. Cela

53
correspond à un problème du voyageur de commerce. Pour accomplir cette tâche, le
système développé utilise une méthode d’inversion ainsi que trois heuristiques décrites à la
Section II.1 : les deux heuristiques de Rosenkrantz et al. (1977) et le r-opt. Lors de
l’application de chacune de ces méthodes, si une amélioration est enregistrée, l’ensemble S
est mis à jour ainsi que la valeur de la solution Z.
a. Méthode d’inversion
Cette méthode consiste tout simplement à évaluer la contribution générée si l’orientation
de la route est inversée. Dans certaines situations, il a été observé que ce changement est
bénéfique. Cette méthode ne sera utilisée que lorsqu’une ou des tournées ont subi une
transformation. La méthode fonctionne comme suit :
1. Changer l’orientation de la tournée.
2. Calculer la valeur de Z.
3. Si Z < Z*, une meilleure solution a été trouvée, mettre Z* = Z et S* = S.
b. Heuristique du plus proche voisin
L’heuristique du plus proche voisin sert à optimiser la tournée des nœuds attachés à une
route précise. Cette heuristique doit être appliquée comme elle a été décrite dans la Sous-
Section II.1.1. Son application sera faite à l’aide de la matrice des coûts C. Voici les étapes
de l’heuristique :
1. À partir du dépôt, trouver le nœud a le moins coûteux à insérer. Créer l’arc 0-a. Le nœud
actif est maintenant le nœud a.
2. À partir du nœud actif, trouver le nœud non visité le moins coûteux. Créer l’arc liant ces
deux nœuds. Le nœud qui était non visité devient le nœud actif.
3. Répéter l’étape 2 jusqu’à ce que tous les nœuds soient visités.
4. Créer un arc partant du nœud actif et se rendant au dépôt.
5. Calculer la valeur de Z.
6. Si Z < Z*, une meilleure solution a été trouvée.
a. Mettre Z* = Z et S* = S.
b. Appliquer la méthode d’inversion.

54
La méthode du plus proche voisin est efficace pour améliorer les tournées dans certains
cas. Cependant, il est évident qu’elle ne peut régler tous les problèmes. Pour cette raison,
d’autres méthodes d’amélioration sont également utilisées dans la méthode développée.
c. Heuristique de l’insertion la moins coûteuse
Tout comme la méthode précédente, cette heuristique est efficace dans certaines situations.
L’explication de l’heuristique a été décrite dans la Sous-Section II.1.1. Voici les étapes
d’application de la méthode :
1. À partir du dépôt, trouver le nœud a le plus loin. Créer l’arc 0-a.
2. Calculer les coûts supplémentaires d’ajouts de chacun des nœuds non visités de façon
individuelle. Ces coûts se calculent avec l’Équation 2.1 présentée au Chapitre II.
3. Insérer le nœud non visité le moins dispendieux à intégrer dans la tournée actuelle.
4. Répéter les étapes 2 et 3 jusqu’à ce que tous les nœuds soient visités.
5. Calculer la valeur de Z.
6. Si Z < Z*, une meilleure solution a été trouvée.
a. Mettre Z* = Z et S* = S.
b. Appliquer la méthode d’inversion.
d. Heuristiques r-opt
Ces heuristiques ont également été exposées dans la Sous-Section II.1.1. Dans un but
d’amélioration des routes, les heuristiques 2-opt et 3-opt sont utilisées. Dans les faits,
l’heuristique 3-opt inclut les permutations du 2-opt. Toutefois, l’application du 2-opt suivi
du 3-opt est plus rapide que l’utilisation seule du 3-opt puisque les permutations déplaçant
deux arcs sont déjà effectuées au moment de faire celles impliquant trois arcs.
Ces heuristiques ont été exposées précédemment. Toutefois, voici l’ordre d’application des
deux méthodes réunies :
1. Appliquer l’heuristique 2-opt.
2. Calculer la valeur de Z.
3. Si Z < Z*, une meilleure solution a été trouvée.

55
a. Mettre Z* = Z et S* = S.
b. Appliquer la méthode d’inversion.
4. Recommencer à l’étape 1 tant que des échanges sont possibles.
5. Appliquer l’heuristique 3-opt.
6. Calculer la valeur de Z.
7. Si Z < Z*, une meilleure solution a été trouvée.
a. Mettre Z* = Z et S* = S.
b. Appliquer la méthode d’inversion.
8. Recommencer à l’étape 5 tant que des échanges sont possibles.
2.4. Étape 4 : Amélioration des routes
L’amélioration individuelle des routes étant terminée, une amélioration de l’ensemble des
routes est maintenant envisagée. C’est ici qu’intervient l’heuristique d’échanges-λ de
Osman (1993) avec λ = 2 (Sous-Section II.1.2). Cette fois-ci, au lieu d’essayer d’améliorer
une seule route, les échanges inter-routes rendent possible une amélioration de la
contribution totale des routes. Ainsi, il est possible, dans certaines situations, que la
contribution générée par une route soit diminuée dans l’optique où cela permet
d’augmenter celle d’une autre route et que la contribution totale s’en voit améliorée.
Globalement, chacune des permutations présentées à la Figure 2.7 doit être testée pour
toutes les combinaisons de quatre nœuds consécutifs et pour toutes les paires de deux
routes. Bien entendu, seuls les échanges avantageux (Z < Z*) seront conservées, où Z* = Z
et S* = S.
Finalement, l’exploration des diverses solutions passent par l’incrémentation des
paramètres α et β. L’exécution de la méthode se terminera quand toutes les valeurs de α et
β auront été évaluées. La meilleure solution trouvée est S* et sa valeur est Z*.
Bien sûr, chacune des méthodes heuristiques proposées ci-dessus pourrait faire place à
d’autres méthodes toutes aussi efficaces. Comme il en a été fait mention dans la revue de la
littérature (Chapitre II), plusieurs chercheurs ont comparé diverses méthodes. Ici, le choix a

56
reposé sur la complémentarité de chacune d’entre elles et sur la facilité de les intégrer à
l’intérieur d’un SIAD performant, rapide et convivial.
3. PRÉSENTATION DU SIAD
Le système développé avait comme premiers objectifs d’être facile d’utilisation et de
nécessiter peu de frais d’implantation. Dès lors, l’utilisation d’applications courantes, telles
que Microsoft Excel, Microsoft Visual Basic, Microsoft MapPoint et PC*Miller de ALK
Technologies, a été priorisée. Pour la majorité d’entre elles, qu’elles soient grandes ou
petites, les entreprises de transport possèdent déjà l’une ou plusieurs de ses applications.
C’est dans cette optique que l’interface permettant de faire le travail de répartition a été
créée.
De façon générale, le système développé devait être en mesure de lire les données initiales,
puis faire le travail de répartition pour qu’enfin la livraison des marchandises et la collecte
d’une expédition de retour puissent se faire. Le système a donc été conçu pour simplifier la
tâche de répartition des charges partielles. L’interface a été développée à l’aide du logiciel
Microsoft Visual Basic. Le logiciel utilisé pour la conception a deux principaux avantages :
il interagit bien avec d’autres applications et il permet la création d’applications de type
exécutable, c’est-à-dire que l’utilisateur peut bénéficier de l’outil sans avoir à acquérir
l’application qui a servi à le développer.
L’utilisation du logiciel de répartition des charges partielles a été divisée en cinq parties :
l’initialisation de la source de données, l’aide à l’utilisateur, l’inscription des données, la
répartition et la visualisation des résultats.
3.1. Initialisation de la source de données
Dans cette première étape, l’utilisateur devra définir, dans l’interface développée, le
répertoire source où est enregistré le fichier Microsoft Excel renfermant les données de
répartition préformatées, ainsi que le nom de ce même fichier (dans la Figure 4.2 :
dispatch).

57
Figure 4.2 – Interface initiale du SIAD
Pour la gestion des charges partielles, l’utilisation de Microsoft Excel simplifie l’entrée des
données. En effet, les avantages du tableur permettent de bénéficier des fonctions de
calculs et de macro-commandes simples. Le choix s’est d’abord arrêté sur cette application
compte tenu de son accessibilité. Également, plusieurs entreprises adoptent cette
application en raison de sa simplicité par rapport à d’autres interfaces de saisie de données.
Le fichier Microsoft Excel est utilisé à toutes les étapes de la planification des charges
partielles. Cependant, puisque la méthode heuristique développée implique la manipulation
de plusieurs données, l’utilisation d’une application plus stable, plus efficace et plus
versatile que le code Visual Basic for Application disponible en Microsoft Excel s’est
avérée nécessaire. L’utilisation de Microsoft Visual Basic s’est ainsi imposée afin de
répondre à ces attentes.
3.2. Aide à l’utilisateur
Le bouton Instructions permet à l’utilisateur d’avoir accès aux directives de
fonctionnement du système développé. La Figure 4.2 illustre ce qu’affiche le système après
avoir appuyé sur le bouton Instructions. Ainsi, il est précisé à l’utilisateur le mode
d’emploi. Dans ce cas-ci, la lecture de la feuille Instructions du fichier Microsoft Excel
(Figure 4.3) permettra à l’utilisateur de prendre connaissance du fonctionnement général
du système.

58
Figure 4.3 – Instructions du SIAD
3.3. Inscription des données
Le second bouton, Données et expéditions, prépare le système à l’entrée des données. La
Figure 4.4 illustre les instructions précisées à l’utilisateur lors de l’activation de ce bouton.
Ce dernier active donc la feuille Data du fichier dispatch. Celle-ci contient les
caractéristiques générales et les données à entrer pour ce transport, comme l’affiche la
Figure 4.5.

59
Figure 4.4 – Exécution du bouton Données et expéditions
Figure 4.5 – Feuille Data du fichier dispatch
Ainsi, dans les cases prévues à cet effet, l’utilisateur peut modifier les caractéristiques
générales des camions (capacité en poids et en palettes) ainsi que les coûts de transport
(coût par mille et coût par arrêt). Ces éléments auront une incidence cruciale sur la gestion
des charges partielles puisque l’assignation sera faite en tenant compte des contraintes
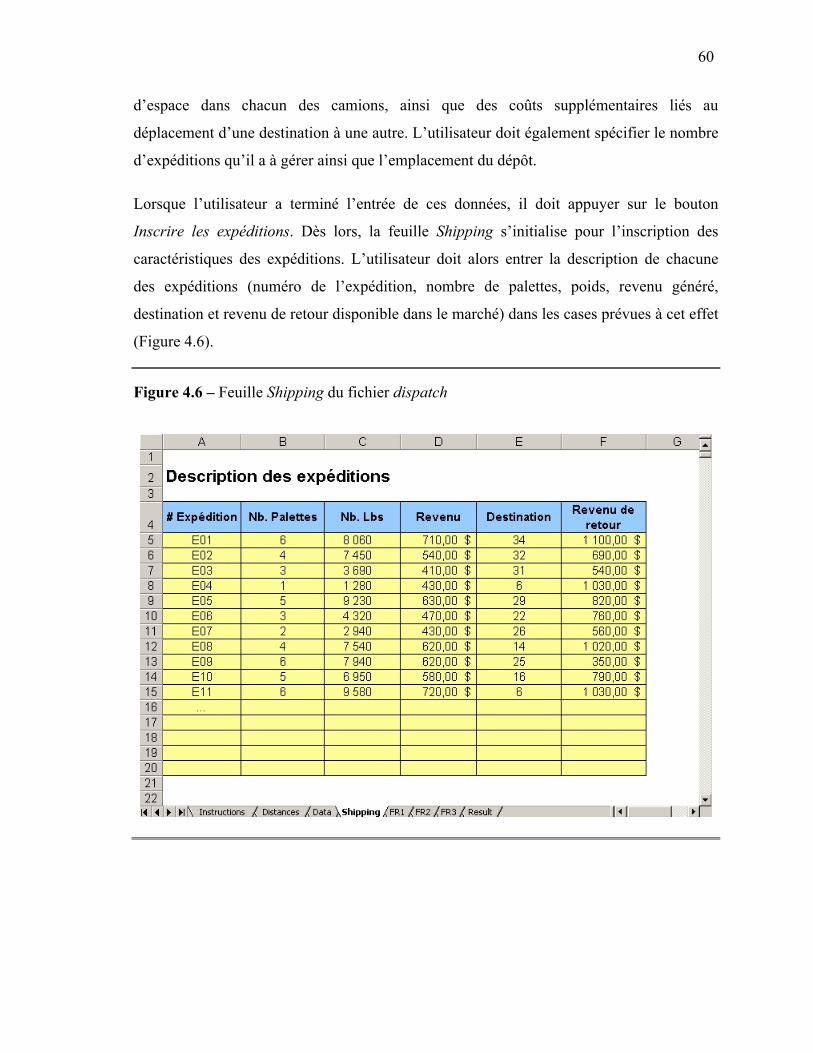
60
d’espace dans chacun des camions, ainsi que des coûts supplémentaires liés au
déplacement d’une destination à une autre. L’utilisateur doit également spécifier le nombre
d’expéditions qu’il a à gérer ainsi que l’emplacement du dépôt.
Lorsque l’utilisateur a terminé l’entrée de ces données, il doit appuyer sur le bouton
Inscrire les expéditions. Dès lors, la feuille Shipping s’initialise pour l’inscription des
caractéristiques des expéditions. L’utilisateur doit alors entrer la description de chacune
des expéditions (numéro de l’expédition, nombre de palettes, poids, revenu généré,
destination et revenu de retour disponible dans le marché) dans les cases prévues à cet effet
(Figure 4.6).
Figure 4.6 – Feuille Shipping du fichier dispatch

61
3.4. Répartition
Une fois la feuille Shipping remplie, la majeure partie des données nécessaires à la
répartition des marchandises sont connues. Dans les faits, seules les distances entre les
destinations sont inconnues à la fin de l’étape précédente. Dans le SIAD développé, une
matrice de distances regroupant 34 villes américaines importantes a été insérée dans la
feuille Distances du fichier dispatch. Ces distances ont été mesurées à l’aide de
l’application PC*Miller de Alk Technologies sous le critère d’utilisation des routes
praticables. Toutefois, le SIAD peut aisément être adaptée afin de permettre la livraison
vers un plus grand nombre de villes. Ainsi, un lien entre le SIAD développé et Microsoft
MapPoint ou PC*Miller de Alk Technologies est facilement intégrable.
Ici, le choix d’un logiciel de cartographie dépendra principalement de la précision dont
l’entreprise de transport a besoin. En effet, le logiciel PC*Miller de Alk Technologies ne
contient pas les routes secondaires de chacune des villes, donc il utilise une fonction afin
de calculer l’approximation de la distance alors que le logiciel Microsoft MapPoint rend
accessible une géographie beaucoup plus détaillée et permet de calculer des distances
beaucoup plus précises en tenant compte de contraintes réelles. PC*Miller de Alk
Technologies est très rapide mais dispendieux. À l’opposé, Microsoft MapPoint est plutôt
lent mais peu onéreux. Dans le système développé, le fait d’intégrer une matrice de
distances permettait simplement d’éviter de recalculer continuellement les mêmes tournées
entre les 34 villes ciblées. Ce choix peut également être retenu par l’entreprise.
Maintenant que les distances entre chacune des expéditions sont disponibles, l’application
de la méthode de résolution heuristique décrite à la Section 2 de ce chapitre est nécessaire.
Ainsi, le bouton Répartition permet de résoudre le problème de tournées à l’aide de la
méthode développée, génère le modèle mathématique du problème dans un fichier de type
texte et les feuilles de route de la solution obtenue dans le fichier dispatch. Une barre de
progression permet à l’utilisateur de suivre l’évolution de l’exécution du travail de
répartition. Lorsque ce travail est terminé, le système en fait mention (Figure 4.7).

62
Figure 4.7 – Exécution du bouton Répartition
3.5. Visualisation des résultats
La résolution terminée, il est maintenant temps de visualiser les résultats obtenus. Le
bouton Résultats active la première des feuilles de route, soit la feuille FR1, du fichier
dispatch (Figure 4.8). Celle-ci contient le détail de la tournée du premier véhicule. Ainsi, il
y est spécifié les expéditions à livrer dans l’ordre où elles doivent être chargées, le total en
poids et en palettes des marchandises que contiendra le camion, la distance que ce dernier
aura à parcourir, les revenus générés par cette tournée et les coûts qu’elle implique.
De façon générale, une feuille de route est créée pour chacune des tournées. Ainsi, le
fichier dispatch peut contenir plusieurs feuilles nommées FR suivi d’un numéro. De son
côté, la feuille Result (Figure 4.9) affiche les résultats totaux des tournées. Grâce à celle-ci,
l’utilisateur connaît précisément les coûts d’arrêt et de route qu’impliquent le transport de
ces expéditions, les revenus qu’elles génèrent ainsi que la contribution totale.
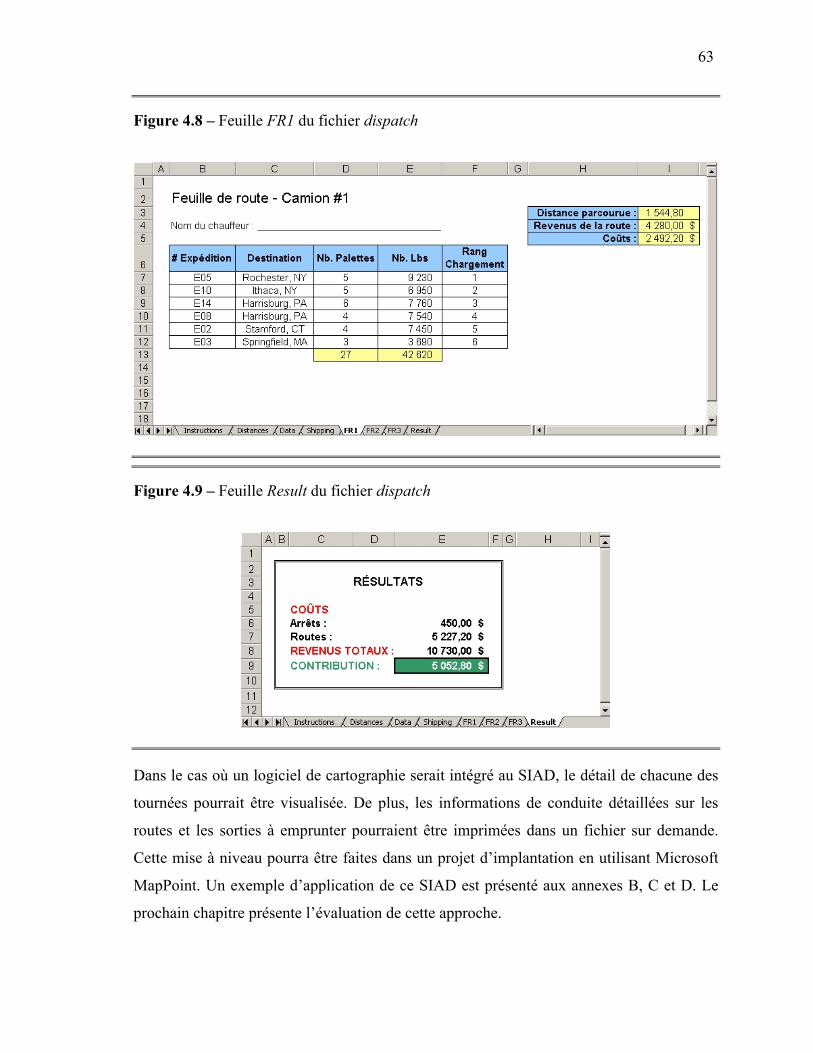
63
Figure 4.8 – Feuille FR1 du fichier dispatch
Figure 4.9 – Feuille Result du fichier dispatch
Dans le cas où un logiciel de cartographie serait intégré au SIAD, le détail de chacune des
tournées pourrait être visualisée. De plus, les informations de conduite détaillées sur les
routes et les sorties à emprunter pourraient être imprimées dans un fichier sur demande.
Cette mise à niveau pourra être faites dans un projet d’implantation en utilisant Microsoft
MapPoint. Un exemple d’application de ce SIAD est présenté aux annexes B, C et D. Le
prochain chapitre présente l’évaluation de cette approche.

Chapitre V
Évaluation numérique
1. STRUCTURATION DES TESTS NUMÉRIQUES
Ce chapitre a pour objectif de présenter les résultats des comparaisons entre la méthode
heuristique développée, proposée au Chapitre IV, et la méthode exacte, exposée au
Chapitre III. Ainsi, la méthode développée a été testée afin de valider si elle génère une
solution acceptable en peu de temps.
La validation est toutefois contrainte par la complexité du problème, notion exposée dans
la Section III.4. Dès lors, les comparaisons ont été faites avec de petits problèmes, c’est-à-
dire des problèmes pouvant être résolus de façon exacte dans un laps de temps raisonnable.
Pour entamer la phase de tests, des exemples d’expéditions étaient indispensables. Des
données réelles ont permis de faire le test1601 présenté à l’Annexe A, ce test étant
répertorié parmi les problèmes à 16 expéditions et noté comme étant le premier (01).
D’ailleurs, les annexes B, C et D présentent l’utilisation du SIAD développé pour la
planification de ces 16 expéditions et démontre sa pertinence. Cependant, aucun exemple
supplémentaire n’était disponible. La création d’un générateur de données s’est révélée
nécessaire.
Lors de la création du générateur, une attention particulière a été apportée à chacune des
données pertinentes à la résolution du problème. Avant de préciser les détails dudit
générateur, il a d’abord été nécessaire de définir les caractéristiques générales et les détails
nécessaires pour le transport (voir la Figure 4.6 du Chapitre IV). Ainsi, chacun des camions
a une capacité de 46 000 lbs et de 28 palettes. Quant aux coûts liés aux livraisons, ils ont

65
été fixés à 25 $/arrêt et à 1,50 $/mille (sauf pour le test1601 dont les coûts de route ont été
fixés à 1,25 $/mille, ce test ayant été fait avant la majoration des coûts du mazout). Enfin,
pour cette évaluation, le dépôt a été positionné à Saint-Georges de Beauce, situé dans la
partie sud-est du Québec, soit à environ 30 milles au nord de la frontière américaine.
Le générateur a été créé afin de confectionner des expéditions. Chacune des
caractéristiques d’une expédition (le numéro de l’expédition, son nombre de palettes, son
poids, le revenu qu’elle génère, sa destination et le revenu de retour disponible dans ce
marché) a été traitée selon des critères particuliers.
Le numéro de l’expédition est unique et sert à l’identifier en la distinguant des autres. Le
générateur inscrit un numéro séquentiel croissant. De son côté, le nombre de palettes a été
généré de façon aléatoire. Ainsi, chacune des expéditions aura entre 1 et 6 palettes. Quant
au poids des expéditions, il a également été généré de façon aléatoire. Cette fois-ci, il est
fonction du nombre de palettes et le poids total de l’expédition doit être situé entre 500 et
10 000 lbs.
La destination est une variable importante et elle est ici décrite avant les revenus
puisqu’elle les influence. La destination de chacune des expéditions a donc été générée de
façon aléatoire parmi les 34 villes américaines disponibles.
Quant à eux, les revenus sont influencés, entre autre, par la destination des marchandises.
Habituellement, cette caractéristique est obtenue à l’aide d’un logiciel de tarification,
lequel fixe les prix facturés aux expéditeurs. Toutefois, puisqu’une telle application n’était
pas accessible, une analyse en profondeur de cette variable a été nécessaire. Les revenus
sont à la fois influencés par le poids, par le nombre de palettes et par la distance entre le
dépôt et la destination des marchandises. Donc, à partir des données initiales obtenues pour
le test1601, une régression linéaire a été faite afin de pondérer l’influence de chacune des
variables et ainsi en extirper une relation (Équation 5.1).
035876,001754099167,2841814128 iiii d+ w,+ p + ,R = (5.1)

66
La précision démontrée dans cette formule est volontaire, chaque dollar pouvant changer la
perception de l’expédition lors de sa planification. Toutefois, il a été important de valider
ces résultats avec la réalité. L’aide de l’entreprise qui avait fourni les premières
informations a de nouveau été sollicitée. Dès lors, le calcul des revenus a dû subir quelques
modifications afin d’être conforme à la réalité. Ainsi, les revenus obtenus pour les
expéditions en destination de la Virginie de l’Ouest ont été diminués de 20 %; ceux vers le
Rhodes Islands ont été majorés de 15 %, alors que ceux du New Hampshire, du Maine et
de la ville de New York ont été augmentés de 20 %. Une fois toutes ces modifications
apportées, les revenus ont été arrondis aux dizaines près. Cet ajustement n’altère en rien la
précision mentionnée plus tôt, un dollar pouvant faire la différence entre une majoration à
10 $ et un abaissement.
Quant aux revenus de retour, ils dépendent simplement de la distance à parcourir entre le
marché où ils sont disponibles et le dépôt. Ainsi, si 300 milles sont à franchir, l’expéditeur
se verra facturé 300 milles à 1,50 $/mille, soit un total de 450 $. Tout comme la
caractéristique précédente, ces revenus ont été arrondis aux dizaines près. Toutefois, un
prix plancher a été fixé pour rentabiliser les revenus de retour provenant des villes les plus
près du dépôt. Ainsi, l’expéditeur devra payer au minimum 350 $ pour faire transporter ses
marchandises.
Grâce à ce générateur, le nombre d’expéditions réalistes qu’il serait possible de générer est
infini. Tout est maintenant en place pour la phase des tests. Compte tenu de la complexité
des problèmes, il a été jugé préférable de commencer par de petits cas et de majorer le
nombre d’expéditions traitées de façon progressive. Ainsi, au moment où les comparaisons
deviendraient impossibles, les tests seraient terminés.
Comme il en a été fait mention dans la Section IV.3, le système développé génère
automatiquement le modèle d’optimisation. Ainsi, chacun des problèmes sera d’abord
résolu à l’aide de la méthode heuristique intégrée dans le système développé (méthode
développée), puis de façon exacte grâce au modèle d’optimisation et au logiciel de
résolution Ilog Cplex (méthode exacte). Enfin, les solutions seront comparées afin
d’évaluer la précision de la méthode développée.

67
Les tests des deux méthodes ont été faits dans des conditions différentes. Toutefois, ceci
influencera uniquement le temps de résolution. Or, la variable temporelle est peu
intéressante compte tenu du fait qu’avant même de résoudre un problème, il est prévisible
que les temps de résolution de la méthode exacte seront très longs en raison de la
complexité du problème. Donc, la méthode développée a été exécutée sur un Pentium III,
750Mhz, 128 Mo SDRAM, alors que Ilog Cplex a été exécuté sur un Pentium III, 1,26Ghz,
1 800 Mo SDRAM. Pour la méthode développée, en raison du fait que les tests ont été
exécutés pour la première fois, aucune feuille de route n’existait au départ. Ainsi, lors de
l’exécution, aucune perte de temps n’a été attribuable à la destruction des anciennes
feuilles de route.
Quant à la méthode exacte, le logiciel Ilog Cplex a été nécessaire. Compte tenu de la
complexité du problème, les paramètres par défaut de Ilog Cplex ont été légèrement
modifiés. Ainsi, une limite de temps a été fixée à quinze heures de résolution. Puisqu’au
départ le temps de résolution est inconnu, ceci évite l’attente d’une solution pendant
plusieurs jours. De plus, il est fort possible que l’application obtienne la meilleure solution
du modèle rapidement, mais puisque toutes les solutions doivent être envisagées, Ilog
Cplex continue son travail.
Une seconde modification a été apportée aux conditions de branchements de Ilog Cplex : le
strong branching. Celui-ci permet de diviser le problème en plusieurs sous-problèmes.
Ainsi, pour chacun des sous-problèmes, le nombre de solutions traitées en même temps est
moindre. Cette diminution nécessite moins de mémoire lors de l’enregistrement des bonnes
solutions.
Afin d’optimiser les temps de calculs de Ilog Cplex, une modification supplémentaire a été
apportée au modèle d’optimisation. En effet, il a été observé que le logiciel d’optimisation
est sensible à l’ordre d’écriture des contraintes. Ainsi, dépendamment de cet ordre, Ilog
Cplex prendra plus ou moins de temps à obtenir une solution. Aucune technique n’existe
afin de connaître précisément l’ordre dans lequel les contraintes doivent être écrites. Ainsi,
une procédure d’essais et erreurs a été utilisée. Au terme de ces essais, la contrainte définie
à l’Équation 3.10 suivi de celle de l’Équation 3.9 ont été écrites comme étant les premières

68
contraintes à considérer, et ce, avant l’Équation 3.3. Toutes les modifications mentionnées
semblent fournir une solution le plus rapidement et le plus efficacement possible avec Ilog
Cplex.
Techniquement parlant, Ilog Cplex est désormais prêt à résoudre des problèmes. Or, avant
que cette résolution ne soit possible, un dernier détail essentiel a dû être pris en compte
pour la conception du modèle d’optimisation : le nombre de camions utilisés pour la
tournée. Ainsi, au départ, le nombre de camions est inconnu. Dans certaines situations, il
est possible que le nombre de véhicules obtenu par la méthode développée ne soit pas le
nombre optimal de camions. En effet, il est possible que l’ajout d’un camion soit
avantageux dans certaines situations, tout comme le retrait d’un autre. Ainsi, pour l’écriture
du modèle d’optimisation, le nombre de camions obtenu dans la solution de la méthode
développée ne peut être considéré comme une borne valable. Donc, ce nombre ne peut être
utilisé dans la conception du modèle d’optimisation.
Malgré cela, certains faits sont connus. Ainsi, dans le pire des cas, il sera nécessaire
d’utiliser autant de camions qu’il y a d’expéditions pour répondre à la demande. Par
exemple, si 10 expéditions sont à planifier, cela impliquera 10 camions au maximum. Dès
lors, le nombre de possibilités évaluées est important. Ceci rend le problème très complexe
et implique une trop grande multitude de possibilités pour être résolu dans un temps
raisonnable avec Ilog Cplex.
Toutefois, seuls les cas extrêmes nécessiteront autant de camions que d’expéditions et dans
ces cas, la méthode développée fonctionnera adéquatement. De plus, le nombre de camions
nécessaires tendra généralement vers le minimum, ce qui s’explique par le coût élevé
d’ajout d’un camion supplémentaire. Donc, la décision du nombre de camions insérés dans
le modèle d’optimisation est très importante.
Ce nombre a donc été fixé à la suite de l’analyse des résultats obtenus à l’aide de la
méthode développée. Ainsi, la méthode prend en considération 121 solutions possibles.
Ces solutions sont le résultat de nombreuses permutations dues à l’évaluation de diverses
économies. Or, puisque ces solutions impliquent des associations différentes d’expéditions,
le nombre de tournées dans chacune des solutions peut différer. Ainsi, parmi les

69
possibilités envisagées pour un même problème, le nombre de tournées peut facilement
passer de deux à quatre, par exemple. Dès lors, en conservant le nombre de tournées
maximal obtenu à l’aide de la méthode développée, c’est-à-dire la solution qui implique le
plus grand nombre de camions, il peut être pris pour acquis que les solutions les plus
intéressantes à envisager sont toutes considérées. Ainsi, ce nombre de camions maximal est
utilisé comme étant la borne supérieure du modèle d’optimisation. De cette façon, dans le
meilleur des cas, le modèle tendra à réduire ce nombre.
Maintenant que tous les paramètres ont été fixés, il ne reste plus qu’à déterminer la
séquence des tests. Afin de solutionner un problème de VRP et non simplement un
problème de TSP, les premiers tests devaient nécessiter, pour la majorité, au moins deux
camions. Ainsi, les premiers problèmes devaient comporter suffisamment d’expéditions
pour requérir la création de deux tournées dans la majorité des cas. Commencer les tests
avec des problèmes à 10 expéditions a semblé être approprié. Ce type de problèmes
implique généralement deux camions, donc un nombre restreint de possibilités, tout en
permettant de progresser tranquillement vers des tests plus complexes. Ainsi, dix
problèmes à 10 expéditions ont été traités, puis dix problèmes à 12 expéditions, puis dix
problèmes à 14 expéditions, puis dix problèmes à 16 expéditions, puis dix problèmes à 18
expéditions et finalement dix problèmes à 20 expéditions, ceci pour un total de 60
problèmes. Les tests ont été arrêtés lorsque la solution optimale est devenue difficile à
atteindre dans un temps raisonnable.
2. RÉSULTATS
2.1. Observations
Au cours de l’expérimentation, certains détails ont pu être notés dans les 60 problèmes
étudiés (Annexe A). Ces observations mettent en évidence certaines particularités de la
problématique abordée.

70
a. Permutation des expéditions allant dans une même ville
Comme il en a été fait mention lors de l’élaboration de la problématique (Section I.4), la
distance parcourue pour livrer deux expéditions dans une même ville est considérée
comme étant inexistante. Dans la réalité, tel n’est pas le cas. Toutefois, cette distance est
négligeable compte tenu des longs trajets à parcourir d’une ville à une autre. Ainsi, cette
hypothèse n’altère que légèrement la contribution totale de la solution. Malgré tout, les
deux méthodes utilisées peuvent générer des solutions dans un ordre différent. Ainsi, par
exemple dans le test1006, les expéditions 8 et 10 sont situées dans la même ville. La
solution obtenue avec la méthode développée sur la route 1 livre les expéditions dans
l’ordre 8, 10 et 5, alors que la solution obtenue avec la méthode exacte sur la route 2 livre
les expéditions dans l’ordre 10, 8 et 5. Dans ce cas-ci, un léger travail devra être fait par le
répartiteur afin de déterminer le meilleur ordre de tournées dans une même ville.
Finalement, dans le cas où les distances réelles seraient insérées dans l’application, ce type
d’erreur ne serait pas rencontré. Cela pourrait être fait aisément.
b. Regroupement en une seule tournée
Dans le test1007, la méthode développée regroupe les 10 expéditions dans une seule
tournée, tout comme la méthode exacte. L’intérêt est alors porté sur l’ordre de livraison des
expéditions, qui est le même dans les deux méthodes. Ceci vient appuyer la pertinence de
la méthode développée et son efficacité.
c. Tournée à perte
La particularité observée dans le test1009 est fort intéressante. Dans ce problème, l’une des
deux tournées obtenues à une contribution négative. Ainsi, les deux méthodes considèrent
qu’il est plus avantageux d’engendrer une perte pour cette tournée, dans le but de générer
une contribution plus importante dans l’autre. Cette particularité suscite un
questionnement : est-il avantageux pour l’entreprise de transport de livrer ces expéditions ?
La négative est la première réponse qui vient à l’esprit. Toutefois, en y réfléchissant bien,
tout dépendamment de la situation dans laquelle se trouve l’entreprise de transport, la
réponse n’est pas aussi évidente. Ainsi, si la demande de transport émane d’un important

71
client qui génère de bons revenus au transporteur, ce dernier acceptera probablement de
faire le transport. À l’opposé, si la demande est unique ou ponctuelle, il est fort probable
que la demande de transport soit refusée. Le transporteur a également une autre
alternative : attendre avant de faire ce transport. Ainsi, d’autres expéditions s’ajouteront
parmi celles à livrer et elles permettront peut-être de rentabiliser le déplacement.
d. Nombre de tournées
Tout dépendamment du problème, il est possible que le nombre de tournées diffère entre la
solution obtenue par la méthode développée et celle produite par la méthode exacte. Le
test1010 présente ce type de situation, où la solution optimale implique deux camions alors
que la méthode développée en a utilisé trois. L’erreur de la seconde méthode est
probablement due à une décision prise lors de la répartition qui a éliminé certaines
possibilités. Dès lors, même si la solution obtenue est excellente, la solution optimale était
impossible à atteindre.
e. Arrêt de résolution de la méthode exacte
Comme mentionné précédemment, une limite de temps a été imposée à la méthode exacte,
soit quinze heures. Lorsque Ilog Cplex atteint cette limite, la résolution se termine et il
affiche le meilleur résultat obtenu à ce moment-là ainsi que le pourcentage d’écart entre la
meilleure solution trouvée et la borne inférieure, appelé gap. Le test1401 est le premier
exemple où cette situation survient. Toutefois, dans ce test, la solution obtenue par la
méthode exacte est la même que celle obtenue par la méthode développée. La conclusion
est donc que la solution obtenue est bonne, mais qu’elle n’est pas nécessairement la
meilleure. Malgré tout, il est possible que même si Ilog Cplex avait eu le temps de résoudre
tout le problème, il aurait obtenu la même solution. Toutefois, ceci aurait nécessité
d’augmenter le temps de résolution, tout en étant incertain d’obtenir une meilleure solution
que le résultat actuel.
f. Mauvaise solution de la méthode exacte
Tout comme dans le problème précédent, la résolution optimale du test1803 s’est terminée
au bout de quinze heures. Toutefois, cet exemple revêt un caractère particulier : la solution

72
obtenue par la méthode exacte est moins bonne que celle générée par la méthode
développée. Il est certain qu’en laissant Ilog Cplex continuer sa résolution, une meilleure
solution aurait été obtenue, résultat qui serait au moins aussi bon que celui de la méthode
développée. Toutefois, le temps nécessaire pour obtenir cette solution est imprévisible. De
plus, l’avantage peut être mineur par rapport à la perte de temps liée.
2.2. Comparaison des solutions
Le but premier des nombreux tests était de valider la qualité de la méthode développée.
Ainsi, si la méthode est performante, le système développé nécessitera un court laps de
temps pour afficher les résultats et les solutions seront, en moyenne, près de l’optimum.
Afin de calculer la déviation moyenne entre la solution de la méthode développée et
l’optimum, seules les valeurs monétaires pertinentes (notées vp) ont été prises en
considération. Ainsi, comme il en a été fait mention au Chapitre IV, les revenus générés
par la livraison des marchandises et les coûts d’arrêt liés au déchargement des expéditions
ne sont pas des valeurs pertinentes. Donc, ces valeurs ne seront pas considérées lors de la
comparaison des résultats. Dès lors, pour chacune des méthodes, les valeurs pertinentes ont
été calculées comme suit :
( )sexpéditiond' Nombrearrêtd'Coût
Revenuson totaleContributi spertinente Valeurs
−
−= ∑ (5.2)
Cette considération a permis de prendre en compte uniquement les valeurs qui pouvaient
être influencées lors de la modification des tournées. Ainsi, la déviation moyenne (appelée
delta) entre la solution obtenue par la méthode développée (utilisant Microsoft Excel) et
celle de la méthode exacte (utilisant Ilog Cplex) a été calculée de la façon suivante :
exacte méthode
exacte méthode développée méthode Deltavp
vpvp −= (5.3)
Le Tableau 5.1 présente les deltas obtenus pour les 60 problèmes évalués. Compte tenu du
fait que parmi ces problèmes certains ont une solution qui n’est pas optimale (cellules
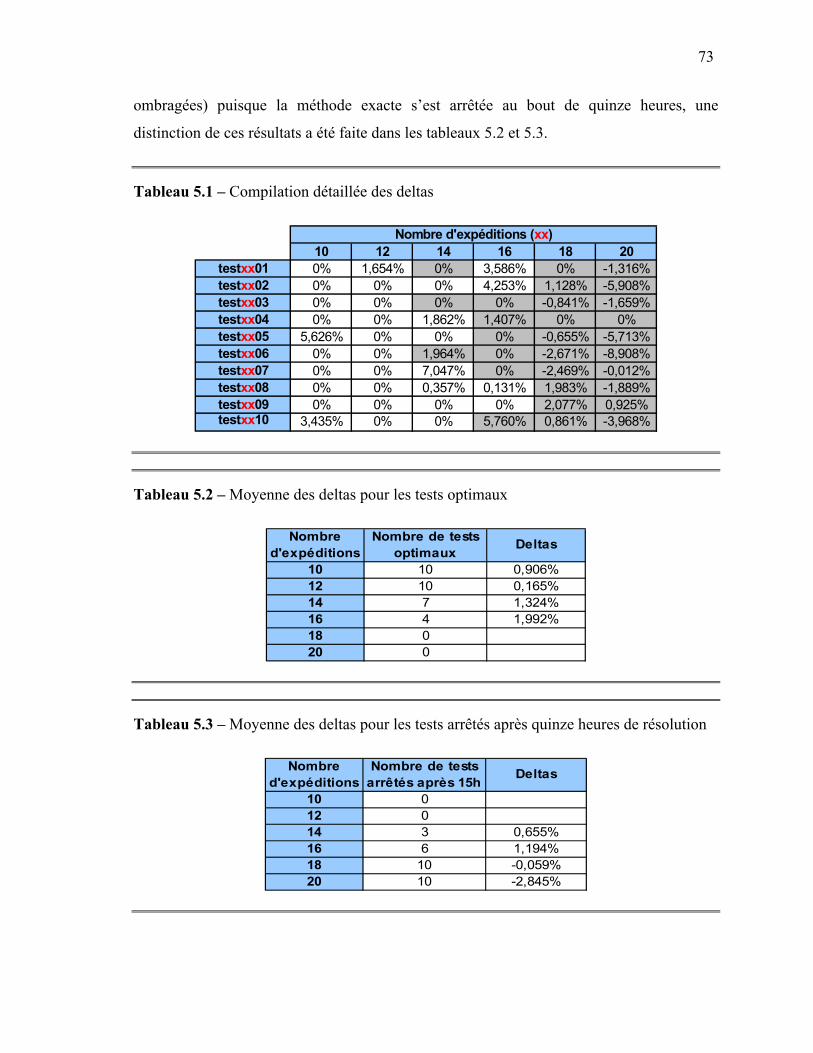
73
ombragées) puisque la méthode exacte s’est arrêtée au bout de quinze heures, une
distinction de ces résultats a été faite dans les tableaux 5.2 et 5.3.
Tableau 5.1 – Compilation détaillée des deltas
10 12 14 16 18 20testxx01 0% 1,654% 0% 3,586% 0% -1,316%testxx02 0% 0% 0% 4,253% 1,128% -5,908%testxx03 0% 0% 0% 0% -0,841% -1,659%testxx04 0% 0% 1,862% 1,407% 0% 0%testxx05 5,626% 0% 0% 0% -0,655% -5,713%testxx06 0% 0% 1,964% 0% -2,671% -8,908%testxx07 0% 0% 7,047% 0% -2,469% -0,012%testxx08 0% 0% 0,357% 0,131% 1,983% -1,889%testxx09 0% 0% 0% 0% 2,077% 0,925%testxx10 3,435% 0% 0% 5,760% 0,861% -3,968%
Nombre d'expéditions (xx)
Tableau 5.2 – Moyenne des deltas pour les tests optimaux
Nombre d'expéditions
Nombre de tests optimaux Deltas
10 10 0,906%12 10 0,165%14 7 1,324%16 4 1,992%18 020 0
Tableau 5.3 – Moyenne des deltas pour les tests arrêtés après quinze heures de résolution
Nombre d'expéditions
Nombre de tests arrêtés après 15h Deltas
10 012 014 3 0,655%16 6 1,194%18 10 -0,059%20 10 -2,845%
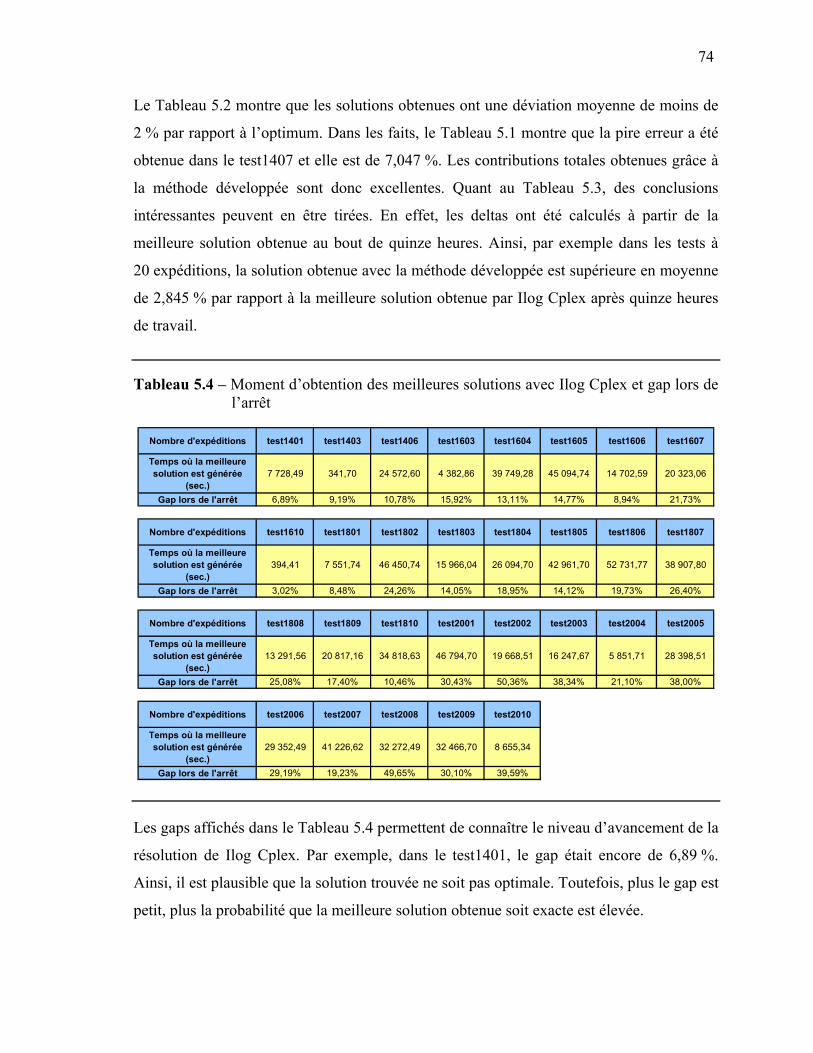
74
Le Tableau 5.2 montre que les solutions obtenues ont une déviation moyenne de moins de
2 % par rapport à l’optimum. Dans les faits, le Tableau 5.1 montre que la pire erreur a été
obtenue dans le test1407 et elle est de 7,047 %. Les contributions totales obtenues grâce à
la méthode développée sont donc excellentes. Quant au Tableau 5.3, des conclusions
intéressantes peuvent en être tirées. En effet, les deltas ont été calculés à partir de la
meilleure solution obtenue au bout de quinze heures. Ainsi, par exemple dans les tests à
20 expéditions, la solution obtenue avec la méthode développée est supérieure en moyenne
de 2,845 % par rapport à la meilleure solution obtenue par Ilog Cplex après quinze heures
de travail.
Tableau 5.4 – Moment d’obtention des meilleures solutions avec Ilog Cplex et gap lors de l’arrêt
Nombre d'expéditions test1401 test1403 test1406 test1603 test1604 test1605 test1606 test1607
Temps où la meilleure solution est générée
(sec.)7 728,49 341,70 24 572,60 4 382,86 39 749,28 45 094,74 14 702,59 20 323,06
Gap lors de l'arrêt 6,89% 9,19% 10,78% 15,92% 13,11% 14,77% 8,94% 21,73%
Nombre d'expéditions test1610 test1801 test1802 test1803 test1804 test1805 test1806 test1807
Temps où la meilleure solution est générée
(sec.)394,41 7 551,74 46 450,74 15 966,04 26 094,70 42 961,70 52 731,77 38 907,80
Gap lors de l'arrêt 3,02% 8,48% 24,26% 14,05% 18,95% 14,12% 19,73% 26,40%
Nombre d'expéditions test1808 test1809 test1810 test2001 test2002 test2003 test2004 test2005
Temps où la meilleure solution est générée
(sec.)13 291,56 20 817,16 34 818,63 46 794,70 19 668,51 16 247,67 5 851,71 28 398,51
Gap lors de l'arrêt 25,08% 17,40% 10,46% 30,43% 50,36% 38,34% 21,10% 38,00%
Nombre d'expéditions test2006 test2007 test2008 test2009 test2010
Temps où la meilleure solution est générée
(sec.)29 352,49 41 226,62 32 272,49 32 466,70 8 655,34
Gap lors de l'arrêt 29,19% 19,23% 49,65% 30,10% 39,59%
Les gaps affichés dans le Tableau 5.4 permettent de connaître le niveau d’avancement de la
résolution de Ilog Cplex. Par exemple, dans le test1401, le gap était encore de 6,89 %.
Ainsi, il est plausible que la solution trouvée ne soit pas optimale. Toutefois, plus le gap est
petit, plus la probabilité que la meilleure solution obtenue soit exacte est élevée.

75
Un indice permet tout de même de valider la qualité des meilleures solutions obtenues : le
moment où elles ont été générées. Le Tableau 5.4 présente ces temps. Ainsi, plus le
moment entre l’obtention de la meilleure solution et l’arrêt du test est grand, plus il est
probable que la solution obtenue soit excellente. Par exemple, la solution obtenue dans le
test1403 est fort probablement plus près de l’optimal que celle présentée dans le test1806.
Toutefois, il faut demeurer conscient qu’une seule itération supplémentaire peut changer la
meilleure solution obtenue. Dès lors, peu de conclusions peuvent être tirées sur ces
résultats.
Figure 5.1 – Temps où la meilleure solution obtenue par Ilog Cplex a été générée
Malgré tout, la Figure 5.1 permet d’observer que les 29 tests qui n’ont pu être solutionnés
de façon optimale sont variés. En effet, le moment d’obtention de la meilleure solution
diffère et est réparti de façon assez uniforme tout au long de la ligne de temps.
Une autre relation peut être établie, basée à la fois sur les tableaux 5.1 et 5.4. Grâce au
Tableau 5.1, les problèmes pour lesquels le delta est négatif sont connus. Ainsi, pour ces
tests, la meilleure solution est inférieure à celle de la méthode développée. Dès lors, il est
évident que pour ces cas, la solution optimale se trouve dans le gap affiché à la fin de la
résolution. Plusieurs des tests dans cette situation, soit environ les deux tiers, ont obtenu
leur meilleure solution dans la deuxième moitié de la résolution, c’est-à-dire après
7,5 heures. Pour ces problèmes, comme mentionné plus tôt, il était peu probable que la
solution obtenue soit exacte. Dès lors, le fait d’affirmer que la meilleure solution obtenue
n’est pas la solution optimale n’a rien d’étonnant. Toutefois, le test2010 présente un intérêt
particulier. En effet, compte tenu du delta obtenu, le fait que la meilleure solution n’est pas

76
la solution optimale est indéniable. Malgré tout, il est étonnant de remarquer que ladite
solution a été obtenue après seulement 8 655,34 secondes. Cela signifie donc que pendant
les quelques 45 000 secondes suivantes, aucune meilleure solution n’a été obtenue. Ceci
vient appuyer le fait qu’il est difficile de faire des conclusions solides en se basant
uniquement sur la meilleure solution.
2.3. Comparaison des distances parcourues
Les distances totales parcourues avec les deux méthodes sont également intéressantes. Le
problème étudié comporte une particularité : la solution optimale n’implique pas
nécessairement une distance totale minimale puisque le but premier est de maximiser la
contribution totale. Dès lors, la solution optimale peut impliquer un trajet plus long pour la
collecte de ce revenu supplémentaire. Les distances totales permettent donc de valider le
comportement de la méthode développée par rapport à la méthode exacte. Pour faire cette
comparaison, un pourcentage d’erreurs (deltadist.) a été utilisé. Ici, seules les distances
totales seront prises en considération dans le calcul, ce qui peut être représenté ainsi :
optimalesolution totaledistanceoptimalesolution totaledistance eheuristiqusolution totaledistance Deltadist.
−= (5.4)
Le Tableau 5.5 présente les diverses déviations de distances (deltasdist.) obtenues. Quant au
Tableau 5.6, il présente les déviations de distances uniquement pour les problèmes où les
résultats optimaux sont connus.
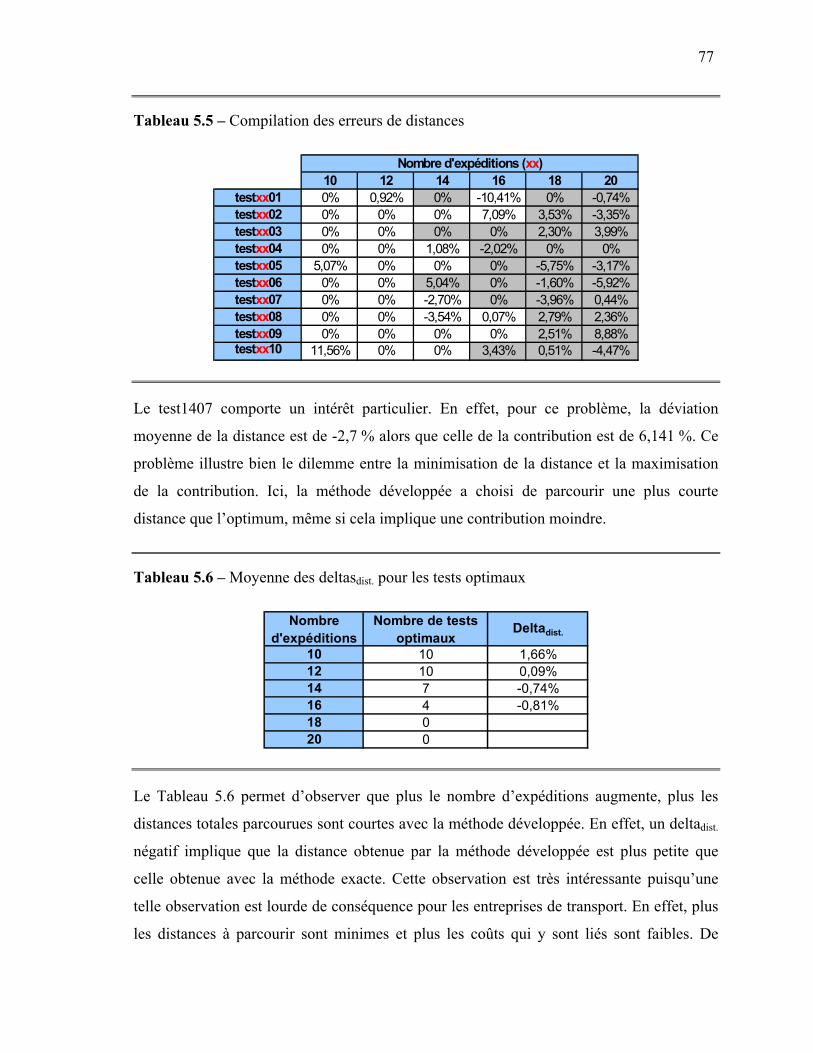
77
Tableau 5.5 – Compilation des erreurs de distances
10 12 14 16 18 20testxx01 0% 0,92% 0% -10,41% 0% -0,74%testxx02 0% 0% 0% 7,09% 3,53% -3,35%testxx03 0% 0% 0% 0% 2,30% 3,99%testxx04 0% 0% 1,08% -2,02% 0% 0%testxx05 5,07% 0% 0% 0% -5,75% -3,17%testxx06 0% 0% 5,04% 0% -1,60% -5,92%testxx07 0% 0% -2,70% 0% -3,96% 0,44%testxx08 0% 0% -3,54% 0,07% 2,79% 2,36%testxx09 0% 0% 0% 0% 2,51% 8,88%testxx10 11,56% 0% 0% 3,43% 0,51% -4,47%
Nombre d'expéditions (xx)
Le test1407 comporte un intérêt particulier. En effet, pour ce problème, la déviation
moyenne de la distance est de -2,7 % alors que celle de la contribution est de 6,141 %. Ce
problème illustre bien le dilemme entre la minimisation de la distance et la maximisation
de la contribution. Ici, la méthode développée a choisi de parcourir une plus courte
distance que l’optimum, même si cela implique une contribution moindre.
Tableau 5.6 – Moyenne des deltasdist. pour les tests optimaux
Nombre d'expéditions
Nombre de tests optimaux
Deltadist.
10 10 1,66%12 10 0,09%14 7 -0,74%16 4 -0,81%18 020 0
Le Tableau 5.6 permet d’observer que plus le nombre d’expéditions augmente, plus les
distances totales parcourues sont courtes avec la méthode développée. En effet, un deltadist.
négatif implique que la distance obtenue par la méthode développée est plus petite que
celle obtenue avec la méthode exacte. Cette observation est très intéressante puisqu’une
telle observation est lourde de conséquence pour les entreprises de transport. En effet, plus
les distances à parcourir sont minimes et plus les coûts qui y sont liés sont faibles. De

78
surcroît, plus la tournée est terminée rapidement, plus vite il est possible de satisfaire
d'autres demandes. Globalement, le Tableau 5.5 montre que dans le pire des cas, la
méthode développée générera une distance à parcourir de 11,56 % plus élevée que la
solution optimale au niveau de la contribution (test1010). Cependant, l’opposé est tout
aussi vrai, puisque le test1601 montre une distance totale à parcourir de 10,41 % inférieure
à la méthode exacte. Dès lors, la variation des distances entre la méthode exacte et la
méthode développée est de plus ou moins 10 %.
2.4. Comparaison des temps de résolution
Plus tôt, il a été mentionné qu’une solution de moindre qualité que la solution optimale
serait pertinente si elle est obtenue rapidement. Ainsi, le temps de résolution doit être pris
en compte. Le Tableau 5.7 présente le temps de résolution de chacun des tests pour les
deux méthodes. Dans ce tableau, les problèmes ayant été arrêtés après quinze heures sont
encore une fois ombragés; bien entendu, le temps de ces tests par la méthode exacte est
automatiquement de 54 000 secondes. Par contre, les résultats obtenus pour les 31 tests qui
ont pu être solutionnés de façon exacte sont intéressants. En effet, déjà pour les problèmes
à 10 expéditions, le temps moyen de résolution de la méthode exacte (37,54 secondes) est
plus élevé que celui de la méthode développée (25,67 secondes). Puis, en passant aux
problèmes à 14 expéditions, le temps moyen de résolution de la méthode exacte fait un
bond à 23 624,40 secondes, alors que celui de la méthode développée passe simplement à
34,25 secondes. En prenant en considération que le système informatique ayant généré la
solution exacte est beaucoup plus puissant que celui utilisé pour la méthode développée, il
est facile de conclure que la solution heuristique est obtenue très rapidement.
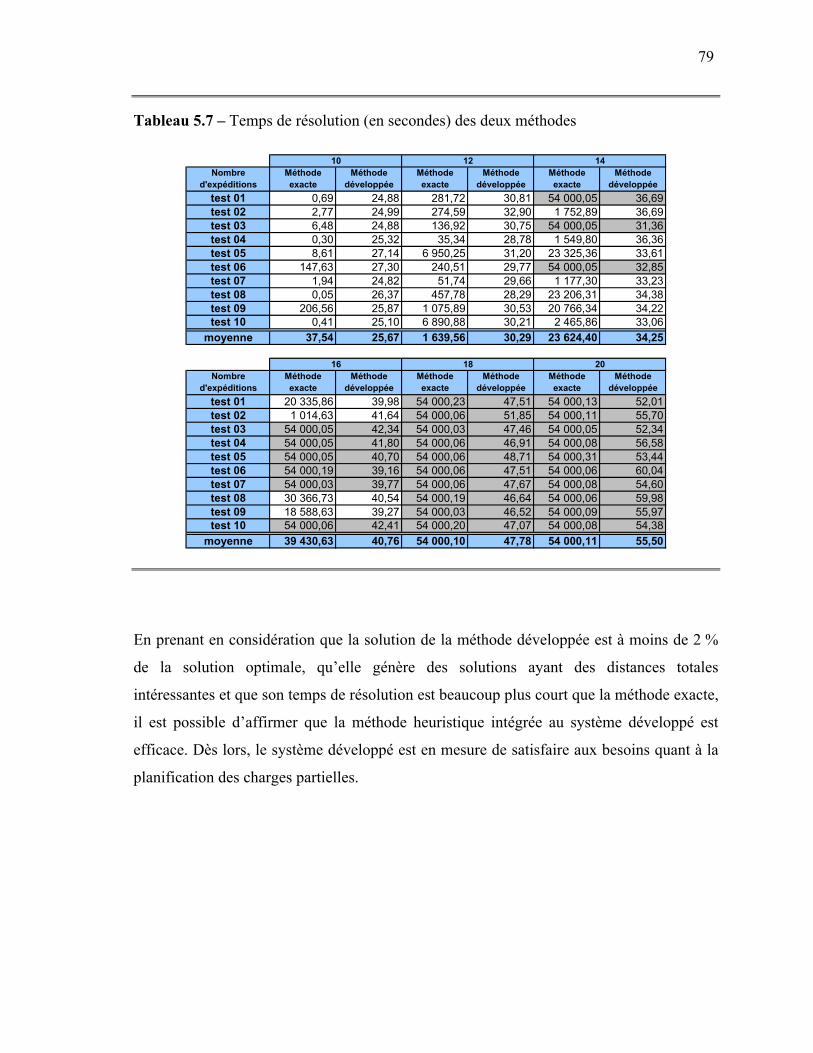
79
Tableau 5.7 – Temps de résolution (en secondes) des deux méthodes
Nombre d'expéditions
Méthode exacte
Méthode développée
Méthode exacte
Méthode développée
Méthode exacte
Méthode développée
test 01 0,69 24,88 281,72 30,81 54 000,05 36,69test 02 2,77 24,99 274,59 32,90 1 752,89 36,69test 03 6,48 24,88 136,92 30,75 54 000,05 31,36test 04 0,30 25,32 35,34 28,78 1 549,80 36,36test 05 8,61 27,14 6 950,25 31,20 23 325,36 33,61test 06 147,63 27,30 240,51 29,77 54 000,05 32,85test 07 1,94 24,82 51,74 29,66 1 177,30 33,23test 08 0,05 26,37 457,78 28,29 23 206,31 34,38test 09 206,56 25,87 1 075,89 30,53 20 766,34 34,22test 10 0,41 25,10 6 890,88 30,21 2 465,86 33,06
moyenne 37,54 25,67 1 639,56 30,29 23 624,40 34,25
Nombre d'expéditions
Méthode exacte
Méthode développée
Méthode exacte
Méthode développée
Méthode exacte
Méthode développée
test 01 20 335,86 39,98 54 000,23 47,51 54 000,13 52,01test 02 1 014,63 41,64 54 000,06 51,85 54 000,11 55,70test 03 54 000,05 42,34 54 000,03 47,46 54 000,05 52,34test 04 54 000,05 41,80 54 000,06 46,91 54 000,08 56,58test 05 54 000,05 40,70 54 000,06 48,71 54 000,31 53,44test 06 54 000,19 39,16 54 000,06 47,51 54 000,06 60,04test 07 54 000,03 39,77 54 000,06 47,67 54 000,08 54,60test 08 30 366,73 40,54 54 000,19 46,64 54 000,06 59,98test 09 18 588,63 39,27 54 000,03 46,52 54 000,09 55,97test 10 54 000,06 42,41 54 000,20 47,07 54 000,08 54,38
moyenne 39 430,63 40,76 54 000,10 47,78 54 000,11 55,50
18 20
10 12 14
16
En prenant en considération que la solution de la méthode développée est à moins de 2 %
de la solution optimale, qu’elle génère des solutions ayant des distances totales
intéressantes et que son temps de résolution est beaucoup plus court que la méthode exacte,
il est possible d’affirmer que la méthode heuristique intégrée au système développé est
efficace. Dès lors, le système développé est en mesure de satisfaire aux besoins quant à la
planification des charges partielles.

Chapitre VI
Conclusion
À partir des pages précédentes, il est facile de conclure que le problème de planification
des charges partielles est complexe. En effet, ce travail implique de répondre à plusieurs
questions en même temps : Combien de camions doivent être utilisés pour transporter les
expéditions ? Dans quel camion seront transportées chacune des expéditions ? Dans quel
ordre les expéditions seront-elles livrées ? Sur le marché de quelle destination la collecte
d’un revenu de retour sera-t-elle faite ? Les réponses à ces questions sont nombreuses et
demande un esprit d’analyse et de synthèse.
Cette planification est toutefois essentielle pour les entreprises de transport puisque leur
objectif premier est la rentabilité. Actuellement, aucune application sur le marché ne
permet d’obtenir la solution optimale à ce type de problème. Si certains fabricants de
logiciels affirment détenir une telle application, le mensonge est leur argument de ventes,
car aucune méthode exacte permettant d’obtenir la solution optimale en peu de temps n’a
été découverte à ce jour. Ainsi, tous les logiciels développés sont basés sur des méthodes
heuristiques qui permettent d’obtenir une solution acceptable dans un temps raisonnable.
Jusqu’à maintenant, deux choix s’offraient aux entreprises de transport : acquérir un
logiciel dispendieux permettant de faire la planification des charges partielles ou en faire le
traitement manuellement. Les logiciels disponibles sur le marché, relatés au Chapitre II,
nécessitent de gros investissements monétaires et temporels pour les entreprises. En effet,
en plus des frais d’acquisition, les entreprises qui implantent ces logiciels doivent prévoir
une longue période d’adaptation, ce qui implique des pertes de temps et donc une perte
monétaire pour le transporteur. Seules les grandes entreprises ont les moyens d’acquérir de
tels logiciels qui pourtant ne s’adaptent pas forcément à leur besoin réel. En plus, cet achat

81
est fait en fonction des arguments de ventes des fabricants, éléments difficiles à valider tant
que le logiciel n’est pas intégré à l’entreprise. Qui plus est, la validation de la pertinence
des solutions générées par ces logiciels est impossible à faire, les fabricants étant peu
loquaces quant aux méthodes employées. Il est fort probable que ces logiciels contiennent
diverses méthodes générales qui fonctionnent plus ou moins bien ensemble pour couvrir
divers types de problèmes. Ainsi, puisqu’ils ne sont pas conçus pour répondre à un
problème précis, la qualité des solutions qu’ils obtiennent est fort probablement douteuse.
Quant au traitement manuel des expéditions, il comporte de nombreux risques. Le fait de
répondre à plusieurs questions très liées implique que chacune des décisions a des
conséquences sur les suivantes. Dès lors, les probabilités d’erreurs sont grandes et les
chances d’obtenir une solution rapidement sont faibles. D’ailleurs, les annexes B, C et D
montrent une comparaison entre le traitement de l’information par un répartiteur et celles
de méthodes informatisées. Il y est démontré que le traitement manuel des expéditions
n’est pas une bonne alternative, d’autant plus que la moindre petite erreur peut impliquer
une perte considérable pour l’entreprise. Le dépassement de la capacité des camions ou une
erreur dans le parcours entrent dans cette catégorie.
Le Chapitre IV a permis de présenter un nouveau système permettant de faire cette
planification. Il a été démontré au Chapitre V que la méthode heuristique intégrée dans le
SIAD génère une solution rapidement. Ledit système permet aux répartiteurs d’économiser
du temps pour faire la planification, ce qui les laisse libres pour d’autres tâches. En plus
d’être simple d’utilisation, le SIAD est peu dispendieuse puisqu’il a été conçu à l’aide de
logiciels courants. Ainsi, les données initiales sont recueillies par un fichier Microsoft
Excel. La méthode heuristique fait la planification des expéditions à l’aide du système
développé en Microsoft Visual Basic. Enfin, un lien pourrait être créé avec un logiciel de
cartographie, tel que Microsoft MapPoint ou PC*Miller de Alk Technologies, afin de
mesurer les distances et de visualiser les routes générées.
Le SIAD développé est accessible à tous puisque contrairement aux logiciels de
planification dont il est fait mention au Chapitre II, il est facile d’implantation et nécessite
peu d’investissements. De plus, le temps de formation des travailleurs qui auront à utiliser

82
ce système est minime puisque celui-ci fait appel à des connaissances déjà acquises. Seule
une brève présentation sera nécessaire afin de les familiariser. Cette simplicité d’utilisation,
couplée à un développement sur mesure, permettra aux petits transporteurs de bénéficier
d’un avantage concurrentiel aussi important que celui des grandes entreprises, ceci en
échange d’investissements mineurs.
Le SIAD développé, grâce à la méthode heuristique intégrée, assure une excellente
contribution totale à l’entreprise de transport. En effet, la méthode conserve les revenus de
retour qu’elle considère les plus pertinents compte tenu de la distance supplémentaire
qu’ils peuvent parfois impliquer. La méthode voit également à réduire, dans la plupart des
cas, la distance totale parcourue. Ceci est avantageux pour l’entreprise de transport, car
plus le camion est de retour tôt au dépôt, plus rapidement la ressource est disponible pour
le prochain transport. De plus, en réduisant la distance totale parcourue, le carburant
consommé est moindre, ce qui suit la vague écologiste actuelle. Ceci sera sans aucun doute
davantage pris en compte dans les années futures, particulièrement en considérant le
Protocole de Kyoto et ses impacts sur le mode de vie actuel. Les entreprises devront donc
s’adapter à de nouvelles contraintes et celles qui auront su prendre une longueur d’avance
seront sans aucun doute récompensées.

Références
[1] “Ameublements Tanguay adopte la solution A.MAZE Routes de GEOCOMtms.” Québec PME (Mai 2002). Disponible au http://www.quebecpme.ca/Actualites/index.asp?article=656. [Accès le 13 janvier 2003].
[2] Bodin, L., Golden, B., Assad, A. et Ball, M. “Routing and scheduling of vehicles and crews. The state of the art.” Computers and Operations Research, 10, 2, Special Issue, 1983, 63-211.
[3] “Cancom et Millogiciel intègrent leurs solutions.” Gestion logistique, Éditions Bomart, Avril 2002, 40.
[4] Cancom Tracking. Disponible au http://www.cancomtracking.com. [Accès le 23 juin 2003].
[5] Clarke, G. et Wright, J. W. “Scheduling of vehicles from a central depot to a number of delivery points.” Operation Research, 12, 1964, 568-581.
[6] Cordeau, J.-F., Gendreau M., Laporte G., Potvin J.-Y. et Semet F. “A Guide to Vehicle Routing Heuristics.” Journal of the Operational Research Society, 53, 2002, 512-522.
[7] Dictionnaire universel francophone Hachette. Disponible au http://www.francophonie.hachette-livre.fr. [Accès le 29 mai 2003].
[8] Encyclopédie Encarta. Disponible au http://encarta.msn.fr/. [Accès le 15 mai 2003].
[9] Gendreau, M., Hertz, A. et Laporte, G. “A Tabu Search Heuristic for the Vehicle Routing Problem.” Management Science, 40, 1994, 1276-1290.
[10] Gendreau, M., Hertz, A. et Laporte, G. “New Insertion and Postoptimization Procedures for the Traveling Salesman Prolem.” Operations Research, 40, 1992, 1086-1094.
[11] Gendreau, M., Laporte, G. et Potvin, J.-Y. “Metaheuristics for the Capacitated VRP.” dans The Vehicle Routing Problem, ed. Toth, P. et Vigo, D., SIAM Monography on Discrete Mathematics and Applications, 2002, 129-154.
[12] GEOCOMtms. Disponible au http://www.geocomtms.com/. [Accès le 23 juin 2003].
[13] “GEOCOMtms et Maddocks unissent leurs efforts pour intégrer la technologie.” Gestion logistique, Éditions Bomart, Décembre 2002, 88.

84
[14] Gillett, B. E. et Miller, L. R. “A Heuristic Algorithm for the Vehicle-Dispatch Problem.” Operations Research, 22, 1974, 340-349.
[15] Golden, B. L. et Assad, A. A., ed. Vehicle routing: Methods and Studies. Elsevier Science Publishers B. V., North-Holland, 1988.
[16] Grand dictionnaire terminologique. Office québécoise de la langue française. Disponible au http://granddictionnaire.com/btml/fra/r_motclef/index1024_1.asp. [Accès le 25 juillet 2003].
[17] Groupe Millobit. Disponible au http://www.millogiciel.ca/millogiciel.htm. [Accès le 23 juin 2003].
[18] Helsgaum, K. “An effective implementation of the Lin-Kernighan traveling salesman heuristic.” European Journal of Operational Research, 126, 2000, 106-130.
[19] Ho, S. C. et Haugland, D. “A tabu search heuristic for the vehicle routing problem with time windows and split deliveries.” Computers and Operations Research, 2003, à parraître.
[20] Industrie Canada. “Faits sur le camionnage.” Disponible au http://strategis.ic.gc.ca/SSGF/ti01148f.html. [Accès le 19 février 2003].
[21] Kohl, N. et Madsen, O. B. G. “An optimization algorithm for the vehicle routing problem with time windows based on lagrangian relaxation.” Operations Research, 45, 1997, 395-406.
[22] Laporte, G. “Recent algorithmic Developments for the traveling salesman problem and the vehicle routing problem.” Ricerca Operativa, 23, 68, 1993, 5-27.
[23] Laporte, G. “The traveling salesman problem: An overview of exact and approximate algorithms.” European Journal of Operational Research, 59, 1992a, 231-247.
[24] Laporte, G. “The vehicle routing problem: An overview of exact and approximate algorithms.” European Journal of Operational Research, 59, 1992b, 345-358.
[25] Laporte, G., Gendreau, M., Potvin, J.-Y. et Semet, F. “Classical and modern heuristics for the vehicle routing problem.” International Transactions in Operationnal Research, 7, 2000, 285-300.
[26] Laporte, G. et Osman, I. H. “Routing Problems : A Bibliography.” Annals of Operations Research, 61, 1995, 227-262.
[27] Lawler, E. L., Lenstra, J. K., Rinnooy Kan, A. H. G. et Shmoys, D. B. The traveling salesman problem. A guided tour of combinatorial optimisation. John Wiley & Sons, 1985.

85
[28] Leclerc, L. et Thiboutot, S. “A.maze Routes & Zones – Transportation management system offers fleet scheduling solutions for large organizations.” ORMS Today, 30, 3, 2003, 42-47.
[29] Lin, S. “Computer solutions of the traveling salesman problem.” The Bell System Technical Journal, 1965, 2245-2269.
[30] Lin S. et Kernighan B. W. “An effective heuristic algorithm for the traveling salesman problem.” Operations Research, 20, 1973, 498-516.
[31] Maddocks Systems Inc. Disponible au http://www.maddocks.ca. [Accès le 23 juin 2003].
[32] Osman, I. H. “Metastrategy simulated annealing and tabu search algorithms for the vehicle routing problem.” Annals of Operations Research, 41, 1993, 421-451.
[33] Prins, C. “A simple and effective evolutionary algorithm for the vehicle routing problem.” Computers and Operations Research, 2003, à paraître.
[34] “Purolator choisit le logiciel A.MAZE.” Gestion logistique, Éditions Bomart, Avril 2002, 18.
[35] Radio-Canada. “Protocole de Kyoto.” Disponible au http://www.radio-canada.ca/nouvelles/dossiers/kyoto/. [Accès le 11 mars 2003].
[36] Reimann, M., Doerner, K. et Hartl, R.F. “Analyzing a unified Ant System for VRPs and some of its variations.” Applications of Evolutionary Computing, 2003, à parraître.
[37] Renaud, J. Cueillettes et livraisons de marchandises. Notes de cours GSO-60795 – Optimisation des flux de matières et entreposage, Faculté des sciences de l’administration, Université Laval, Québec, Hiver 2002.
[38] Renaud, J., Boctor, F. F. et Laporte, G. “A fast composite heuristic for the symmetric traveling salesman problem. INFORMS Journal on Computing, 8, 2, 1996a, 134-143.
[39] Renaud, J., Boctor, F. F. et Laporte, G. “An improved petal heuristic for the vehicle routing problem.” Journal of the Operational Research Society, 47, 1996b, 329-336.
[40] Rochat, Y. et Taillard, E. D. “Probabilistic diversification and intensification in local search for vehicle routing.” Journal of Heuristics, 1, 1995, 147-167.
[41] Rosenkrantz, D. J., Stearns, R. E. et Lewis II, P. M. “An analysis of several heuristics for the traveling salesman problem.” SIAM Journal on Computing, 6, 3, 1977, 563-581.

86
[42] Seideman, T. “Tanguay Furniture Routes Trucks Toward Profitability.”, Stores, Decembre 2002, 50-52. Disponible au http://www.geocomtms.com/images/upload/STORESMagazine200212.pdf. [Accès le 24 juin 2003].
[43] Taillard, E. D. “Parallel iterative search methods for vehicle routing problems.” Networks, 23, 1993, 661-673.
[44] Tompkins, J. A. et Harmelink, D. The distribution management handbook. McGraw-Hill, 1994.
[45] Toth, P. et Vigo D. “Exact solution of the Vehicle Routing Problem.” dans Fleet Management and Logistics, ed. Crainic, T. G. et Laporte, G., Kluwer, Boston, 1998, 1-31.
[46] Transports Canada, “Les transports au Canada 2001. Rapport annuel.” Disponible au http://www.tc.gc.ca/pol/fr/anre2001/tc2001af.pdf, 2002. [Accès le 12 mars 2003].
[47] Yellow, P. C. “A computationnal modification to the saving method of vehicle scheduling.” Operational Research Quarterly, 21, 1970, 281-283.





























