Embed Size (px)
Citation preview
분류
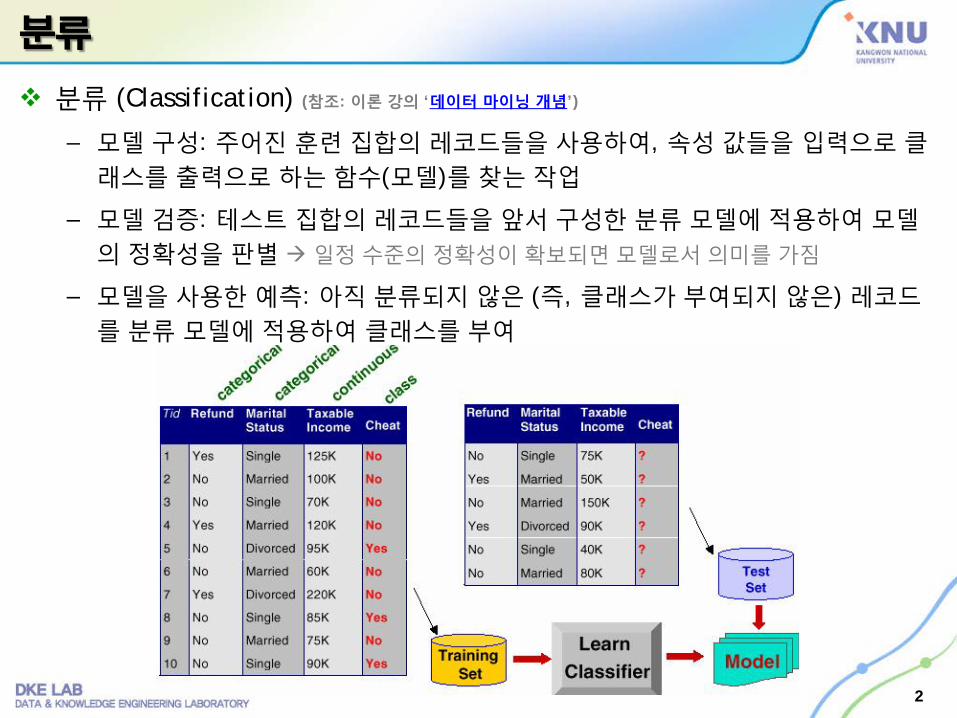
분류 (Classification) (참조: 이론강의 ‘데이터 마이닝개념’)
– 모델구성: 주어진 훈련집합의 레코드들을사용하여, 속성값들을 입력으로클래스를출력으로 하는함수(모델)를찾는작업
– 모델검증: 테스트 집합의레코드들을 앞서구성한분류 모델에적용하여 모델의정확성을 판별 일정수준의정확성이확보되면모델로서의미를가짐
– 모델을사용한 예측: 아직분류되지 않은 (즉, 클래스가부여되지않은) 레코드를분류 모델에적용하여 클래스를부여
2
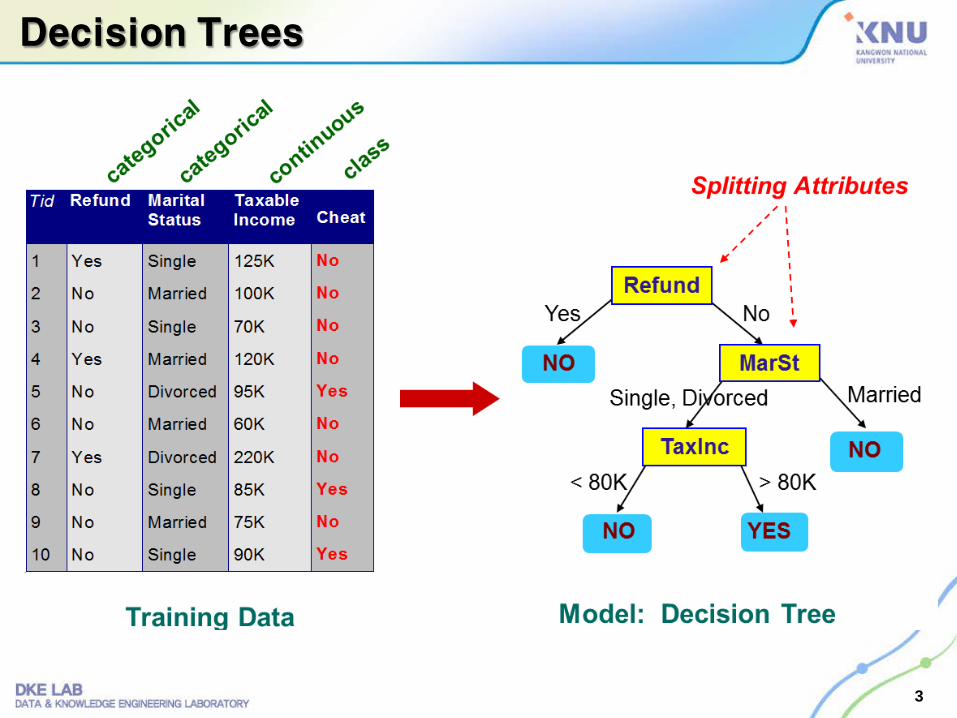
Decision Trees
3

Example 1: Iris
Datasets: 150개의 Iris 꽃 데이터
– Sepal.Length: 꽃 받침길이
– Sepal.Width: 꽃받침 너비
– Petal.Length: 꽃잎길이
– Petal.Width: 꽃잎너비
– Species: 화종
• setosa
• versicolor
• virginica
4
# Sepal.Length Sepal.Width Petal.Length Petal.Width Species1 5.1 3.5 1.4 0.2setosa2 4.9 3 1.4 0.2setosa3 4.7 3.2 1.3 0.2setosa4 4.6 3.1 1.5 0.2setosa5 5 3.6 1.4 0.2setosa6 5.4 3.9 1.7 0.4setosa7 4.6 3.4 1.4 0.3setosa8 5 3.4 1.5 0.2setosa9 4.4 2.9 1.4 0.2setosa
10 4.9 3.1 1.5 0.1setosa11 5.4 3.7 1.5 0.2setosa12 4.8 3.4 1.6 0.2setosa13 4.8 3 1.4 0.1setosa14 4.3 3 1.1 0.1setosa15 5.8 4 1.2 0.2setosa
새로운 Iris 데이터의종을파악할수있을까?

Ex.1: 필수 패키지 설치
Decision Tree를 생성하기 위해 필요한 패키지 설치
– http://cran.r-project.org/web/packages/party/index.html
– http://cran.r-project.org/web/packages/zoo/index.html
– http://cran.r-project.org/web/packages/sandwich/index.html
– http://cran.r-project.org/web/packages/strucchange/index.html
– http://cran.r-project.org/web/packages/modeltools/index.html
– http://cran.r-project.org/web/packages/coin/index.html
– http://cran.r-project.org/web/packages/mvtnorm/index.html
다운로드 받은 패키지를 R에서 로딩
5
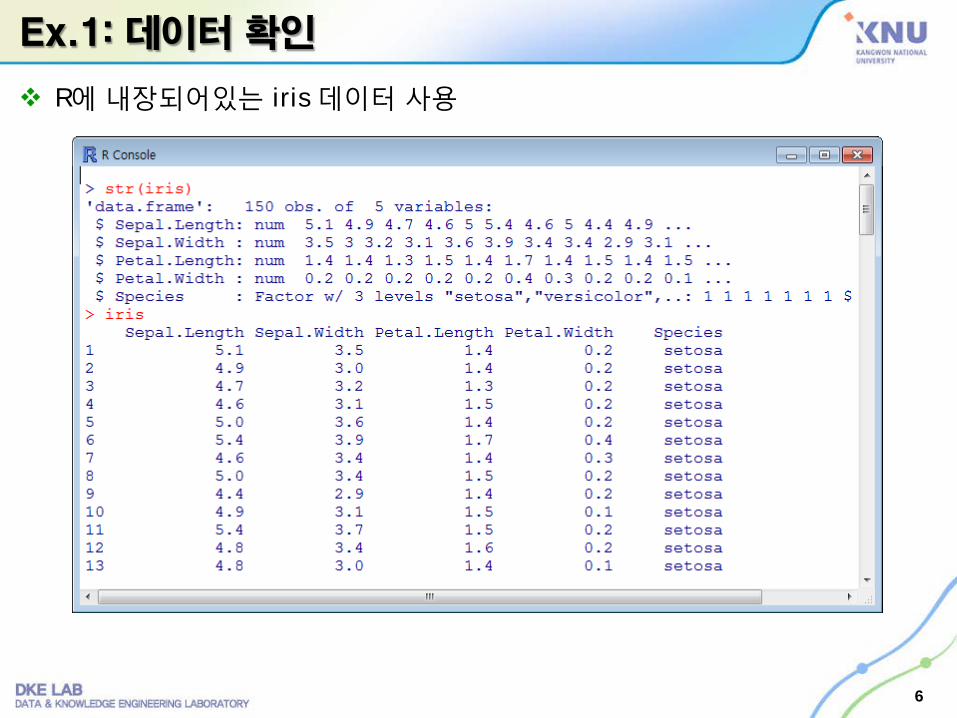
Ex.1: 데이터 확인
R에 내장되어있는 iris 데이터 사용
6
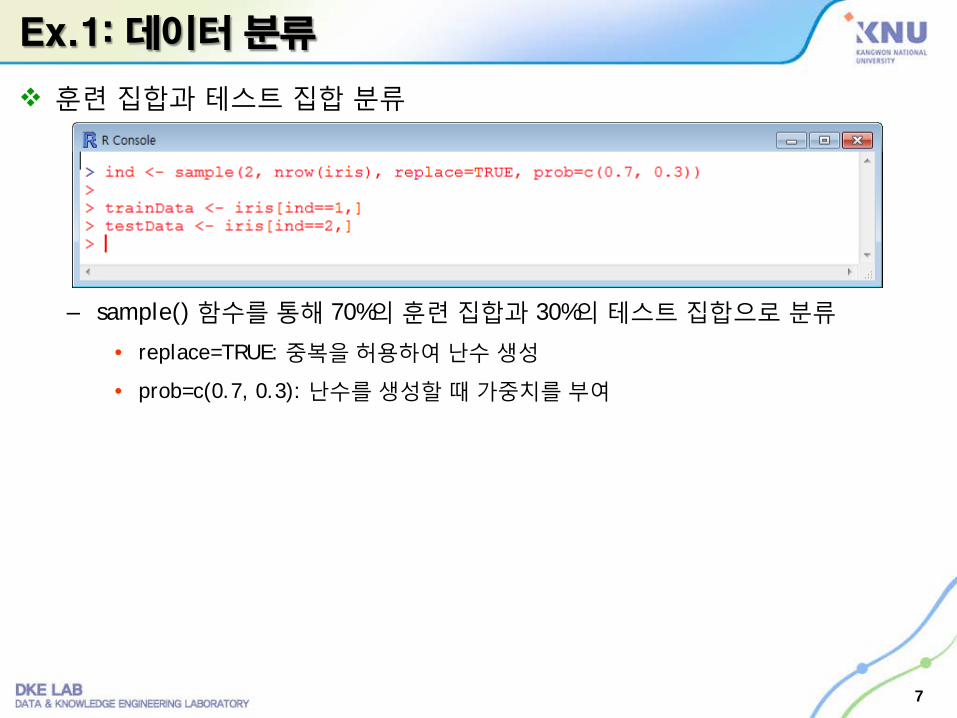
Ex.1: 데이터 분류
훈련 집합과 테스트 집합 분류
– sample() 함수를통해 70%의 훈련집합과 30%의 테스트집합으로 분류
• replace=TRUE: 중복을허용하여난수생성
• prob=c(0.7, 0.3): 난수를생성할때가중치를부여
7

Ex.1: Decision Tree 생성
ctree() 함수: Decision Tree를 생성하는 함수
8
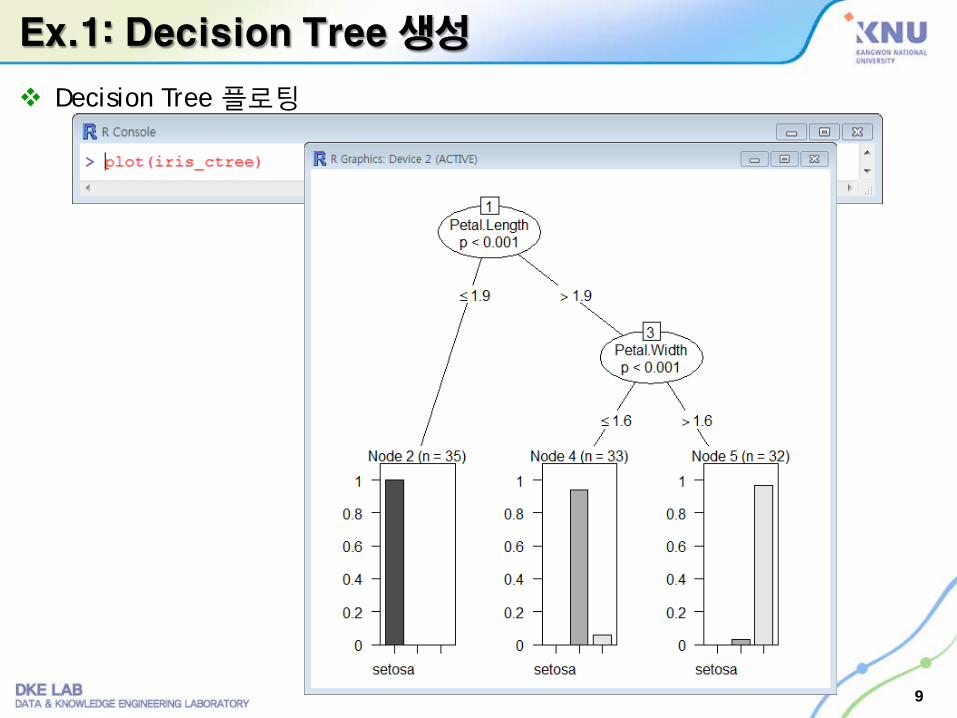
Ex.1: Decision Tree 생성
Decision Tree 플로팅
9
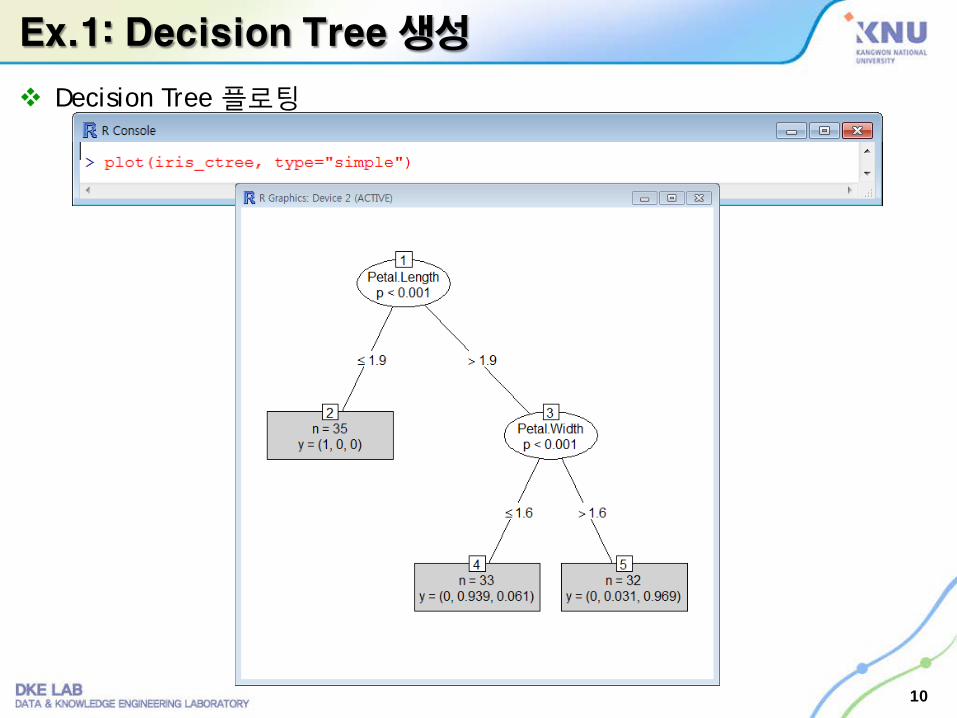
Ex.1: Decision Tree 생성
Decision Tree 플로팅
10
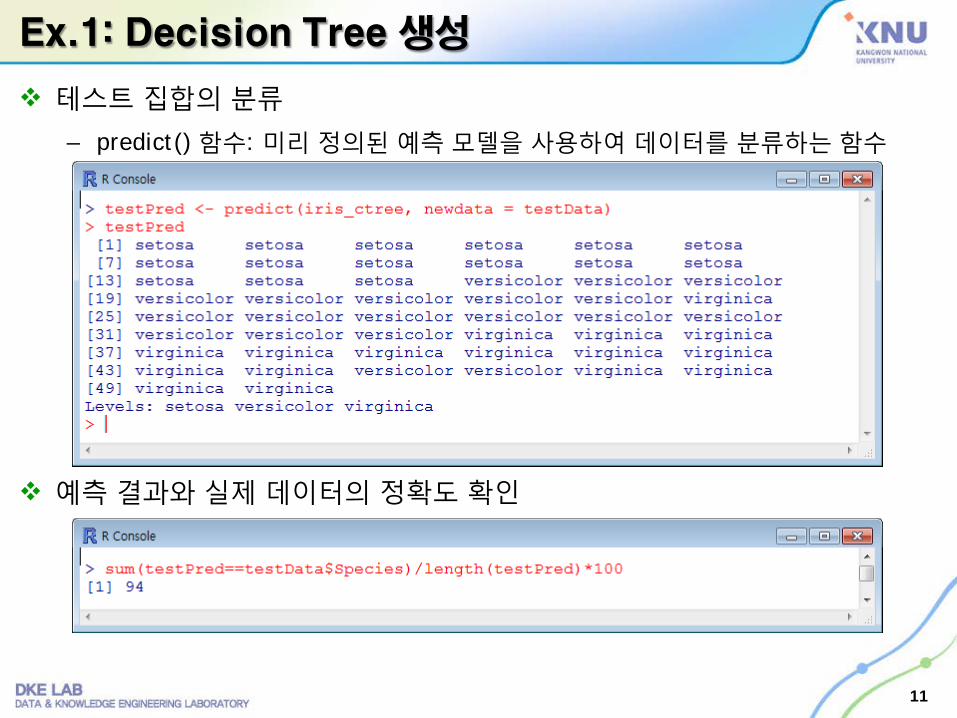
Ex.1: Decision Tree 생성
테스트 집합의 분류
– predict() 함수: 미리 정의된예측모델을 사용하여데이터를 분류하는함수
예측 결과와 실제 데이터의 정확도 확인
11
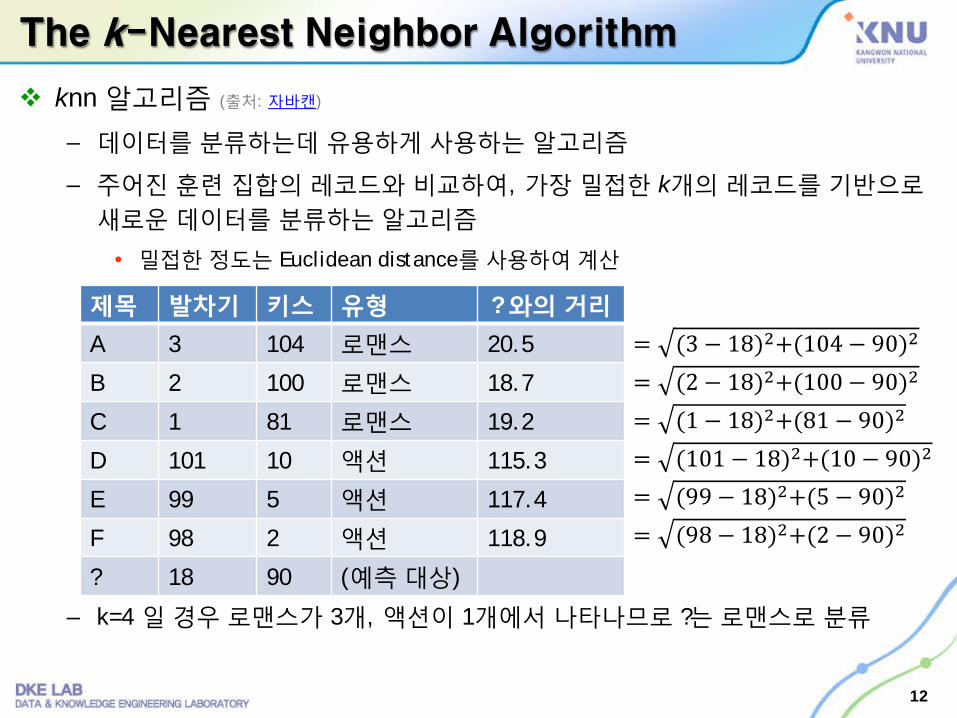
The k-Nearest Neighbor Algorithm
knn 알고리즘 (출처: 자바캔)
– 데이터를분류하는데 유용하게사용하는 알고리즘
– 주어진훈련 집합의레코드와 비교하여, 가장밀접한 k개의 레코드를기반으로새로운데이터를 분류하는알고리즘
• 밀접한정도는 Euclidean distance를사용하여계산
– k=4 일경우로맨스가 3개, 액션이 1개에서 나타나므로 ?는로맨스로 분류
12
제목 발차기 키스 유형 ? 와의 거리
A 3 104 로맨스 20.5
B 2 100 로맨스 18.7
C 1 81 로맨스 19.2
D 101 10 액션 115.3
E 99 5 액션 117.4
F 98 2 액션 118.9
? 18 90 (예측대상)
= (3 − 18)2+(104 − 90)2
= (2 − 18)2+(100 − 90)2
= (1 − 18)2+(81 − 90)2
= (101 − 18)2+(10 − 90)2
= (99 − 18)2+(5 − 90)2
= (98 − 18)2+(2 − 90)2
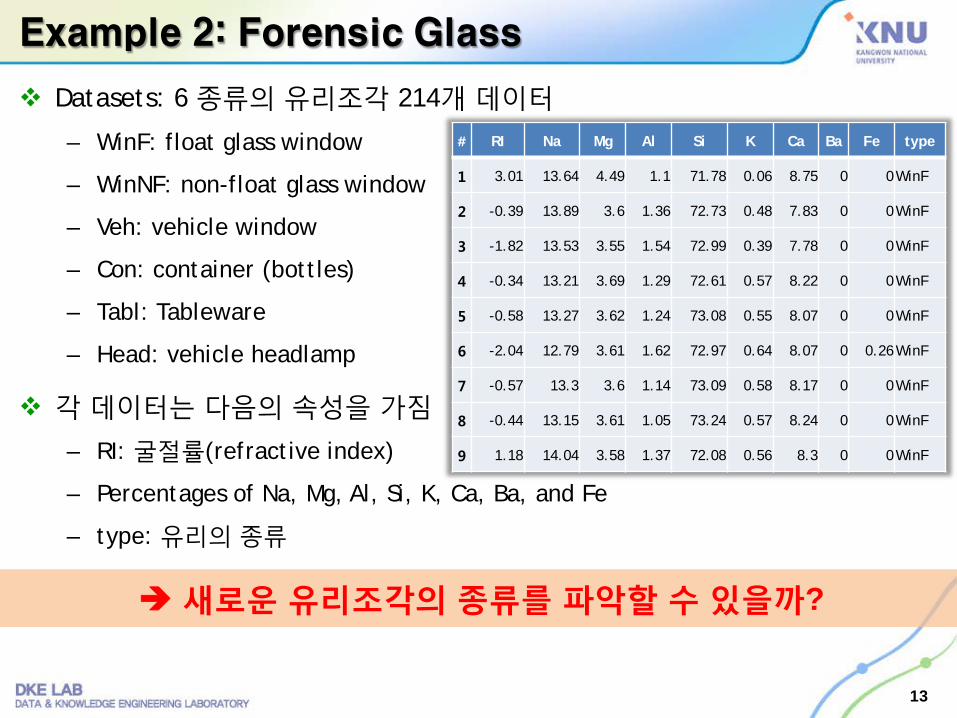
Example 2: Forensic Glass
Datasets: 6 종류의 유리조각 214개 데이터
– WinF: float glass window
– WinNF: non-float glass window
– Veh: vehicle window
– Con: container (bottles)
– Tabl: Tableware
– Head: vehicle headlamp
각 데이터는 다음의 속성을 가짐
– RI: 굴절률(refractive index)
– Percentages of Na, Mg, Al, Si, K, Ca, Ba, and Fe
– type: 유리의 종류
13
새로운유리조각의종류를 파악할수있을까?
# RI Na Mg Al Si K Ca Ba Fe type
1 3.01 13.64 4.49 1.1 71.78 0.06 8.75 0 0WinF
2 -0.39 13.89 3.6 1.36 72.73 0.48 7.83 0 0WinF
3 -1.82 13.53 3.55 1.54 72.99 0.39 7.78 0 0WinF
4 -0.34 13.21 3.69 1.29 72.61 0.57 8.22 0 0WinF
5 -0.58 13.27 3.62 1.24 73.08 0.55 8.07 0 0WinF
6 -2.04 12.79 3.61 1.62 72.97 0.64 8.07 0 0.26WinF
7 -0.57 13.3 3.6 1.14 73.09 0.58 8.17 0 0WinF
8 -0.44 13.15 3.61 1.05 73.24 0.57 8.24 0 0WinF
9 1.18 14.04 3.58 1.37 72.08 0.56 8.3 0 0WinF
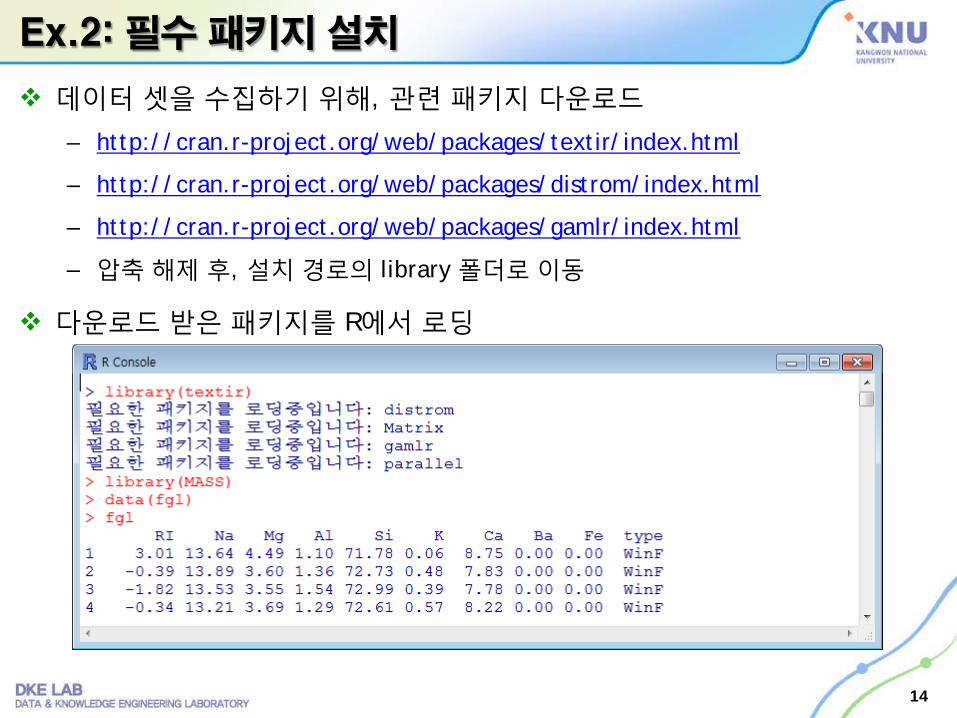
Ex.2: 필수 패키지 설치
데이터 셋을 수집하기 위해, 관련 패키지 다운로드
– http://cran.r-project.org/web/packages/textir/index.html
– http://cran.r-project.org/web/packages/distrom/index.html
– http://cran.r-project.org/web/packages/gamlr/index.html
– 압축해제 후, 설치경로의 library 폴더로이동
다운로드 받은 패키지를 R에서 로딩
14
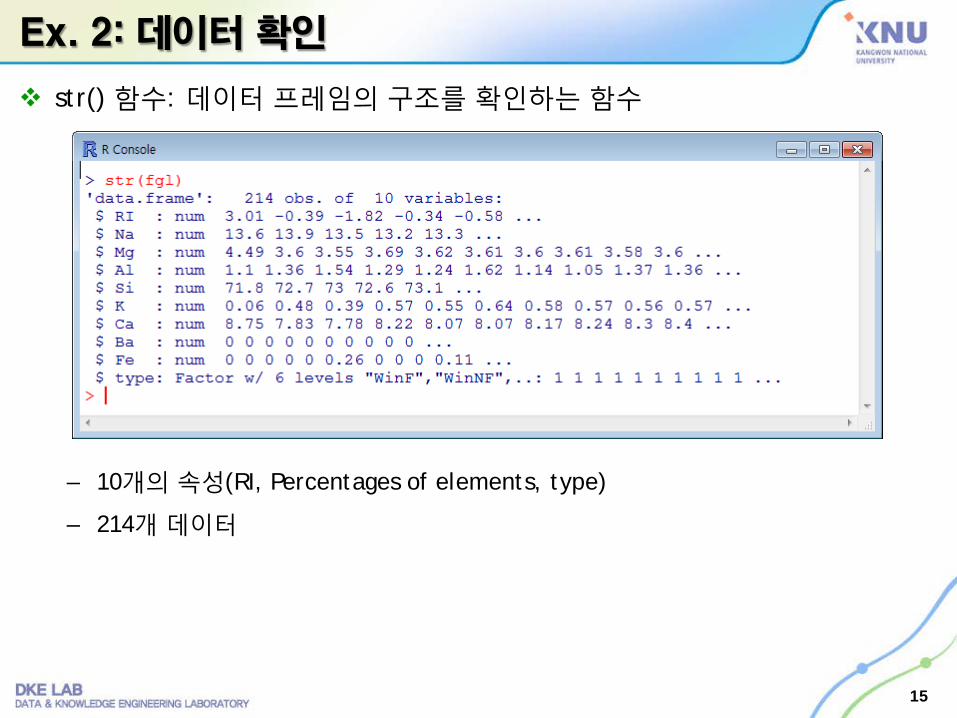
Ex. 2: 데이터 확인
str() 함수: 데이터 프레임의 구조를 확인하는 함수
– 10개의 속성(RI, Percentages of elements, type)
– 214개 데이터
15

Ex. 2: Box plots (1/2)
다른 속성과 type간의 관계를 box plot으로 표현
– par() 함수: 그래프의공간을 배열형태로 미리할당
› par(mfrow=c(3,3), mai=c(.3,.6,.1,.1))
› plot(RI ~ type, data=fgl, col=c(grey(.2),2:6))
› plot(Al ~ type, data=fgl, col=c(grey(.2),2:6))
› plot(Na ~ type, data=fgl, col=c(grey(.2),2:6))
› plot(Mg ~ type, data=fgl, col=c(grey(.2),2:6))
› plot(Ba ~ type, data=fgl, col=c(grey(.2),2:6))
› plot(Si ~ type, data=fgl, col=c(grey(.2),2:6))
› plot(K ~ type, data=fgl, col=c(grey(.2),2:6))
› plot(Ca ~ type, data=fgl, col=c(grey(.2),2:6))
› plot(Fe ~ type, data=fgl, col=c(grey(.2),2:6))
16
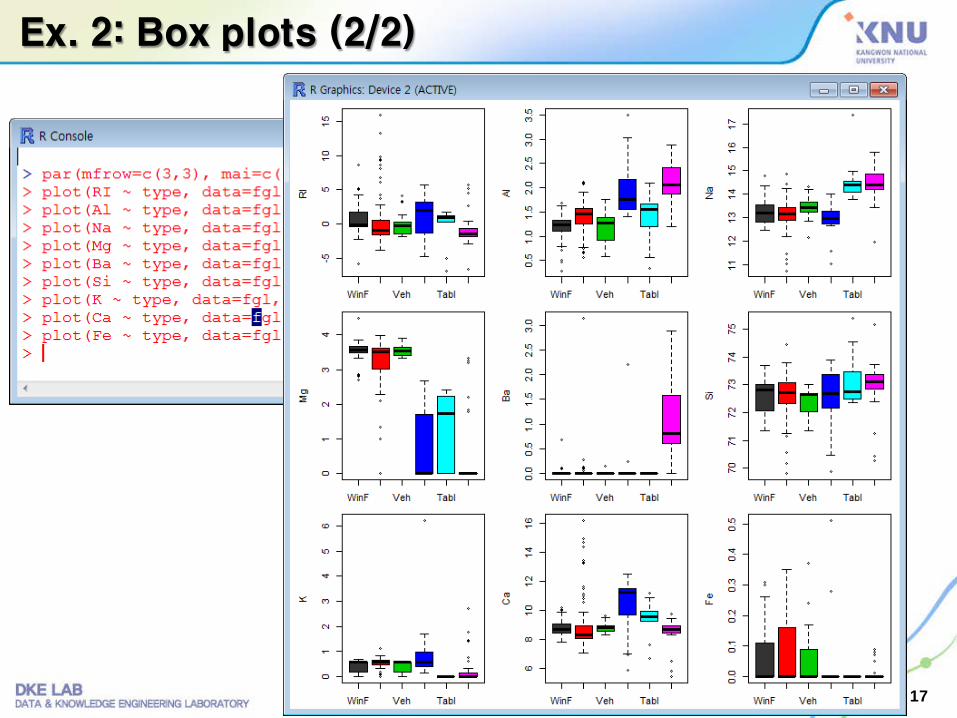
Ex. 2: Box plots (2/2)
17

Ex. 2: RIxAl 기반 분류
훈련 집합(200개)과 테스트 집합(14개) 구분
– nt 변수: 트레이닝 데이터의수
– sample(x, size, …) 함수: x 벡터에서 size개의난수 데이터추출
– x 변수: fgl 데이터로부터 RI와 Al 정보만추출
18

Ex. 2: RIxAl 기반 분류
kNN 알고리즘 수행 및 결과
19
훈련 집합 테스트 집합 분류 대상

Ex. 2: RIxAl 기반 분류
kNN 알고리즘 결과를 plot
– plot() 함수로훈련 집합을표현
• 결과는 open symbol
– points() 함수로테스트 집합을표현
• 결과는 solid symbol
20

Ex. 2: RIxAl 기반 분류
kNN 알고리즘 결과의 성능 평가
– kNN의결과와 실제 type이같은경우의 확률을계산
– 1NN은 78.6이며, 5NN은 71.4의 결과가나타남
• 항상같은결과가나타나지는않음
21

과제 #4
유리 데이터 셋에 포함된 다른 속성들을 모두 사용하여 분류
– 앞의예제는 RI와 Al만을사용하여 분류함
– 과제는 RI 및 Percentages of Na, Mg, Al, Si, K, Ca, Ba, and Fe를 사용하여분류
– 214개의 데이터에서 임의로훈련집합과 테스트집합을 설정
– 분류한결과(데이터프레임)와성능 평가까지진행
제출 방법
– 과제는 [email protected]로 제출
– 제목양식: [학번][이름]HW#4
– 과제에서설정한 훈련및 테스트집합과분류한 결과및 성능평과결과를 캡쳐
– 제출기한은 다음실습 수업시간전까지이며, 그후에 제출할경우 20% 감점
22








![[오픈콘텐츠랩] 꿈꾸는 프레젠테이션](https://img.pdfslide.tips/doc/110x75/55a2fc6c1a28ab25748b4702/-55a2fc6c1a28ab25748b4702.jpg)


![[오픈컨텐츠랩] 도해생각정리기술_꿈꾸는 프레젠테이션](https://img.pdfslide.tips/doc/110x75/55b50594bb61eb7e2e8b4640/-55b50594bb61eb7e2e8b4640.jpg)


















