Embed Size (px)
Citation preview

AKADEMIA GÓRNICZO-HUTNICZA IM. STANISŁAWA STASZICA W KRAKOWIE
WYDZIAŁ ELEKTROTECHNIKI, AUTOMATYKI,INFORMATYKI I INZYNIERII BIOMEDYCZNEJ
Praca dyplomowa magisterska
Zastosowanie uczenia maszynowego do personalizacji parametrówobrazu w systemie rekonstrukcji tomogramów
Machine learning for personalized imaging in computer tomographysystem
Autor: inz. Piotr CiazynskiKierunek studiów: Inzynieria biomedycznaOpiekun pracy: dr inz. Jakub Gałka
Kraków, 2017

Uprzedzony o odpowiedzialnosci karnej na podstawie art. 115 ust. 1 i 2 ustawy z dnia 4 lu-tego 1994 r. o prawie autorskim i prawach pokrewnych (t.j. Dz.U. z 2006 r. Nr 90, poz. 631z pózn. zm.): „Kto przywłaszcza sobie autorstwo albo wprowadza w bład co do autorstwa ca-łosci lub czesci cudzego utworu albo artystycznego wykonania, podlega grzywnie, karze ogra-niczenia wolnosci albo pozbawienia wolnosci do lat 3. Tej samej karze podlega, kto rozpo-wszechnia bez podania nazwiska lub pseudonimu twórcy cudzy utwór w wersji oryginalnejalbo w postaci opracowania, artystycznego wykonania albo publicznie zniekształca taki utwór,artystyczne wykonanie, fonogram, wideogram lub nadanie.”, a takze uprzedzony o odpowie-dzialnosci dyscyplinarnej na podstawie art. 211 ust. 1 ustawy z dnia 27 lipca 2005 r. Prawoo szkolnictwie wyzszym (t.j. Dz. U. z 2012 r. poz. 572, z pózn. zm.): „Za naruszenie przepisówobowiazujacych w uczelni oraz za czyny uchybiajace godnosci studenta student ponosi odpo-wiedzialnosc dyscyplinarna przed komisja dyscyplinarna albo przed sadem kolezenskim samo-rzadu studenckiego, zwanym dalej «sadem kolezenskim».”, oswiadczam, ze niniejsza prace dy-plomowa wykonałem(-am) osobiscie i samodzielnie i ze nie korzystałem(-am) ze zródeł innychniz wymienione w pracy.

Serdecznie dziekuje dr inz. Jakubowi Gałce za po-moc przy realizacji niniejszej pracy.


Spis tresci
1. Wprowadzenie ................................................................................................................................ 7
1.1. Cel pracy................................................................................................................................ 7
2. Uczenie maszynowe oraz sztuczne sieci neuronowe.................................................................... 9
2.1. Elementy teorii uczenia maszynowego ................................................................................. 9
2.1.1. Typy problemów rozwiazywanych za pomoca uczenia maszynowego ..................... 10
2.1.2. Dostepne metody uczenia maszynowego................................................................... 10
2.2. Podstawy sztucznych sieci neuronowych.............................................................................. 11
2.2.1. Perceptron wielowarstwowy ...................................................................................... 11
2.3. Splotowe sieci neuronowe ..................................................................................................... 12
2.3.1. Operacja splotu .......................................................................................................... 12
2.3.2. Architektura sieci splotowych.................................................................................... 13
2.3.3. Zalety sieci splotowych.............................................................................................. 14
3. Standard DICOM .......................................................................................................................... 15
3.1. Struktura danych w plikach DICOM..................................................................................... 15
3.2. Obrazy medyczne w formacie DICOM................................................................................. 16
4. Przeglad literatury ......................................................................................................................... 19
4.1. Korekta histogramu ............................................................................................................... 19
4.1.1. Rozciagniecie histogramu .......................................................................................... 19
4.1.2. Wyrównanie histogramu ............................................................................................ 20
4.2. Poprawa obrazów MRI za pomoca prostych sieci neuronowych.......................................... 21
4.2.1. Wskaznik przejrzystosci obrazu medycznego ........................................................... 21
4.2.2. Działanie systemu ...................................................................................................... 22
4.3. Odszumianie obrazów za pomoca sieci typu autoenkoder.................................................... 23
4.4. Zastosowanie głebokiego bilateralnego uczenia maszynowego do poprawy obrazów ......... 25
4.5. Zastosowane rozwiazanie ...................................................................................................... 26
5. Platforma TIRS Adjust ................................................................................................................. 27
5.1. Załozenia ............................................................................................................................... 27

6 SPIS TRESCI
5.2. Wykorzystane technologie..................................................................................................... 28
5.2.1. Czesc serwerowa – platforma Node.js ....................................................................... 28
5.2.2. Czesc przegladarkowa – biblioteka Angular.js .......................................................... 28
5.3. Interfejs platformy ................................................................................................................. 29
5.4. Architektura i działanie systemu ........................................................................................... 30
6. Realizacja i testy zastosowanego systemu .................................................................................... 33
6.1. Wykorzystane oprogramowanie ............................................................................................ 34
6.2. Baza obrazów medycznych ................................................................................................... 34
6.2.1. Podział bazy na zbiór uczacy, walidacyjny oraz testowy........................................... 35
6.3. Architektura sieci neuronowej............................................................................................... 36
6.4. Poszukiwanie optymalnej architektury oraz metaparametrów.............................................. 37
6.5. Uczenie sieci neuronowej z wykorzystaniem optymalnych metaparametrów ...................... 38
6.5.1. Ocena skutecznosci sieci neuronowej........................................................................ 39
6.5.2. Wizualizacja działania systemu ................................................................................. 40
7. Podsumowanie ................................................................................................................................ 43
7.1. Osiagniete cele....................................................................................................................... 43
7.2. Napotkane problemy ............................................................................................................. 43
7.3. Planowany rozwój ................................................................................................................. 43
7.3.1. Zbudowanie recznie anotowanej bazy obrazów medycznych.................................... 43
7.3.2. Uzycie autoenkodera w celu odszumiania obrazów .................................................. 44
7.3.3. Wytrenowanie osobnych sieci dla róznych tkanek..................................................... 44
7.4. Uwagi koncowe ..................................................................................................................... 44
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

1. Wprowadzenie
W niniejszej pracy przedstawiony zostanie projekt zastosowania metod uczenia maszynowego w celu
stworzenia platformy do personalizacji parametrów obrazu medycznego. Zamierzeniem jest stworzenie
interaktywnej platformy pomagajacej w przyspieszeniu pracy lekarza podczas przegladania zdjec me-
dycznych. Platforma tego rodzaju moze byc zbudowana jako aplikacja internetowa przechowujaca ob-
razy medyczne w chmurze oraz zapamietujaca preferencje lekarza dotyczace parametrów prezentacji
obrazu medycznego. Dzieki temu lekarz moze miec dostep do obrazów medycznych swoich pacjentów,
z dowolnego miejsca z dostepem do internetu. Dodatkowo automatyczna poprawa parametrów prezenta-
cji obrazów medycznych moze odciazyc lekarza z koniecznosci wykonywania tego zadania, zwiekszajac
komfort jego pracy.
Pomysł stworzenia takiego systemu narodził sie podczas tworzenia innych aplikacji internetowych
słuzacych do manipulacji obrazami medycznymi, zwłaszcza obrazami tomograficznymi (tomogramami)
oraz obrazami pochodzacymi z rezonansu magnetycznego. Pierwsza aplikacja słuzyła do rekonstrukcji
sinogramów (surowego zapisu danych z projekcji tomograficznych). Druga aplikacja słuzyła do tworze-
nia trójwymiarowych modeli narzadów wewnetrznych z serii obrazów tomograficznych.
Elementem wspólnym obydwu aplikacji jest przegladarka zdjec tomograficznych (lub rezonanso-
wych). Warto dodac, ze przegladarka obrazów medycznych DICOM jest niezbednym elementem co-
dziennej pracy lekarza radiologa. Aby badanie obrazowania medycznego było uzyteczne, lekarz musi
byc w stanie poprawnie ocenic stan badanych tkanek oraz zauwazyc wszelkie zmiany patologiczne
(przykładowo nowotwory). W tym celu konieczne jest dostosowanie jasnosci oraz kontrastu obrazu me-
dycznego.
Autor tego opracowania, pracujac nad rozwojem wyzej wspomnianych aplikacji, miał mozliwosc
współpracy z lekarzami. Warto podkreslic, ze lekarze sa chetni do wykorzystywania mozliwosci jakie
daja nowe technologie. Jednakze jest tak tylko wtedy gdy dana innowacja rzeczywiscie przyczynia sie do
skrócenia czasu oraz wysiłku lekarza, oraz wtedy, gdy lekarz nadal posiada pełna kontrole nad systemem.
1.1. Cel pracy
Celem ogólnym tej pracy jest zbadanie mozliwosci jakie daje dziedzina uczenia maszynowego (ang.
machine learning) aby stworzyc system optymalizujacy parametry prezentacji obrazów medycznych.
8 1.1. Cel pracy
Celem pomocniczym jest stworzenie aplikacji internetowej do zbudowania bazy zdjec medycznych z po-
prawnie ustawionymi parametrami obrazu przez lekarzy radiologów. Za cel szczegółowy obrano opraco-
wanie architektur oraz wykorzystanie splotowych sieci neuronowych do zbudowania systemu zdolnego
do ustawiania prawidłowych wartosci jasnosci oraz kontrastu obrazów DICOM. W przypadku obrazów
DICOM, jasnosc i kontrast ustawiane sa za pomoca wartosci szerokosci oraz połozenia okna histogramu
(WW, WC), zob. rozdział 3.
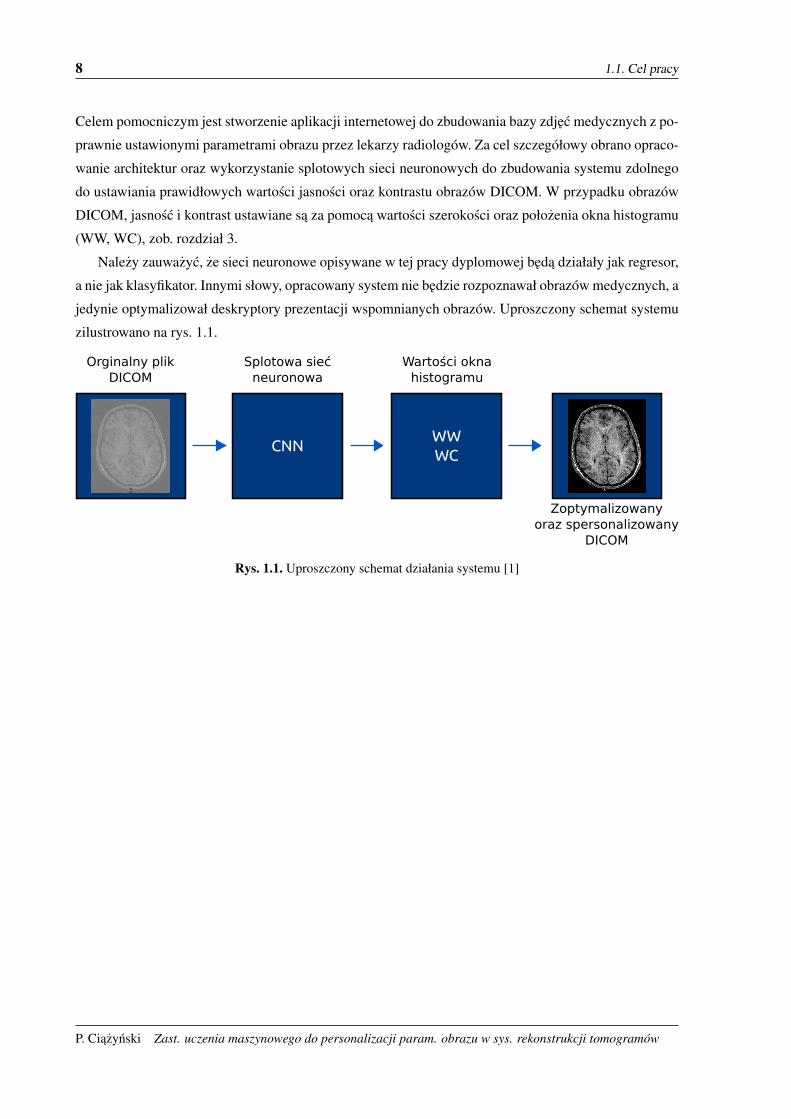
Nalezy zauwazyc, ze sieci neuronowe opisywane w tej pracy dyplomowej beda działały jak regresor,
a nie jak klasyfikator. Innymi słowy, opracowany system nie bedzie rozpoznawał obrazów medycznych, a
jedynie optymalizował deskryptory prezentacji wspomnianych obrazów. Uproszczony schemat systemu
zilustrowano na rys. 1.1.
CNNWWWC
Orginalny plikDICOM
Splotowa siećneuronowa
Wartości oknahistogramu
Zoptymalizowanyoraz spersonalizowany
DICOM
Rys. 1.1. Uproszczony schemat działania systemu [1]
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

2. Uczenie maszynowe oraz sztuczne sieci neuronowe
Metody uczenia maszynowego oraz sztuczne splotowe sieci neuronowe stanowia najwazniejsze na-
rzedzia wykorzystane przy tworzeniu tej pracy. Z tego wzgledu ponizej przedstawiono przeglad podsta-
wowych pojec i zagadnien zwiazanych z tymi dziedzinami.
2.1. Elementy teorii uczenia maszynowego
Uczenie maszynowe (ang. machine learning – ML) jest dziedzina sztucznej inteligencji, polegajaca
na uczeniu komputerów (oprogramowania) bez programowania ich w sposób bezposredni. Ten sposób
uczenia komputerów rózni sie od tradycyjnego, w którym komputery programowane sa za pomoca jasno
okreslonych, precyzyjnych algorytmów, sprecyzowanych wczesniej przez informatyków i matematyków.
Czesto jednak spotykamy sie z sytuacja, w której sformułowanie precyzyjnego, tradycyjnego al-
gorytmu jest bardzo trudne lub nawet całkowicie niemozliwe. Jednym z takich przykładów jest próba
stworzenia systemu rozpoznajacego przedmioty na zdjeciach. Zdrowy, dorosły człowiek nie ma z tym za-
daniem najmniejszego problemu – rozpoznawanie dokonywane jest przez nas mózg w ułamku sekundy.
Jak to mozliwe? Przez całe zycie spotykamy sie z róznymi przedmiotami, słyszymy ich nazwy oraz
widzimy ich zastosowanie. Pozwala to na zbudowanie wewnetrznej reprezentacji danego obiektu przez
nasz mózg, a nastepnie bezproblemowe rozpoznawanie przedmiotów. Mimo to, nie potrafimy czesto ja-
sno okreslic jakie dokładnie cechy sa potrzebne aby dany przedmiot zaklasyfikowac do danej kategorii –
rozpoznawanie dokonywane jest podswiadomie.
Idea uczenia maszynowego polega na zastosowaniu podobnych metod w jakie wyposazony jest
ludzki mózg. Uczenie sie (zarówno człowieka jak i maszyn) polega na wielokrotnym powtarzaniu oraz
wymaga duzej ilosci danych. Uczenie to proces, w którym duze ilosci danych sa przetwarzane do wiedzy.
Wiedza moze zostac wykorzystana pózniej do rozpoznawania podobnych, lecz niewidzianych wczesniej
danych. Dziedzina machine learning (ML) przezywa swój ogromny rozkwit własnie teraz, poniewaz do-
piero od niedawna mamy dostep do tanich, duzych przestrzeni dyskowych, szybkich procesorów oraz
Internetu. Dzieki temu mozliwe stało sie gromadzenie danych na niespotykana wczesniej skale oraz
przetwarzanie ich za pomoca ogromnych mocy obliczeniowych. Dodatkowo, na rozpowszechnienie me-
tod uczenia maszynowego pozytywnie wpływa równiez pojawienie sie łatwych do opanowania bibliotek
ML, udostepnianych na licencjach otwarto-zródłowych.

10 2.1. Elementy teorii uczenia maszynowego
2.1.1. Typy problemów rozwiazywanych za pomoca uczenia maszynowego
Istnieje bardzo wiele mozliwych zastosowan uczenia maszynowego i ciagle rozwijane sa nowe.
Mozna jednak zastosowac podział ze wzgledu na sposób uczenia sie oraz zadanie do wykonania [1]:
1. Uczenie nadzorowane
(a) klasyfikacja
(b) regresja
2. Uczenie nienadzorowane
(a) klasteryzacja (znana tez jako grupowanie lub analiza skupien)
(b) redukcja wymiarowosci
3. Uczenie ze wzmocnieniem
Z uczeniem nadzorowanym mamy do czynienia gdy dane treningowe (uczace) posiadaja ustalona
strukture oraz sa juz prawidłowo sklasyfikowane (posiadaja etykiety) czy odpowiednio zmierzone. Do
uczenia nadzorowanego zaliczamy problem klasyfikacji oraz regresji.
Klasyfikacja jest metoda, w której etykiety sa nieciagłe oraz naleza do skonczonego zbioru. Przykła-
dowo w problemie klasyfikacji, danymi treningowymi moga byc zbiory obrazów z prawidłowo przypisa-
nymi etykietami mówiacymi o tym co znajduje sie na obrazie. Innym przykładem sa zbiory wiadomosci
e-mail z przypisanymi etykietami klasyfikujacymi wiadomosci jako pozadane lub jako spam.
W przypadku regresji dane wyjsciowe sa najczesciej ciagłe. Regresja słuzy przewidywaniu wyników,
które moga przyjac dowolne wartosci liczbowe. W problemie regresji poszukujemy zwiazku pomiedzy
zmiennymi wejsciowymi a ciagłymi zmiennym wyjsciowymi. Przykładem danych, które mozna wyko-
rzystac do trenowania regresji moze byc zbiór danych dotyczacy cen mieszkan lub domów w zaleznosci
od róznych czynników. W tym przykładzie regresja pomaga przewidziec cene nowego mieszkania.
2.1.2. Dostepne metody uczenia maszynowego
Sposród wielu dostepnych metod i algorytmów uczenia maszynowego wymienic mozna ponizsze:
– naiwny klasyfikator bayesowski (ang. naïve Bayes classifier)
– maszyna wektorów nosnych (ang. support vector machine – SVM)
– drzewa decyzyjne (ang. decision trees)
– sztuczne sieci neuronowe (ang. artificial neural networks – ANN)
– mikstury gaussowskie (ang. gaussian mixture model – GMM)
– ukryte modele Markova (ang. hidden Markov models – HMM)
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

2.2. Podstawy sztucznych sieci neuronowych 11
– analiza skupien (ang. clustering analysis)
– algorytmy genetyczne (ang. genetic algorithms)
2.2. Podstawy sztucznych sieci neuronowych
Powstanie sztucznych sieci neuronowych było zainspirowane badaniami biologicznych neuronów
oraz naturalnych sieci neuronowych. Pierwszych prób łaczacych badania nad mózgiem oraz tworzeniem
prostych sztucznych sieci neuronowych dokonywano juz w latach czterdziestych dwudziestego wieku
[1]. Najczesciej stosowana architektura sztucznych sieci neuronowych jest siec typu MLP, zwana równiez
perceptronem wielowarstwowym.
2.2.1. Perceptron wielowarstwowy
Przykładowy perceptron wielowarstwowy (ang. multilayer perceptron — MLP) przedstawiono na
rys. 2.1. Siec MLP w przeciwienstwie do perceptronu jednowarstwowego moze byc wykorzystywana
do klasyfikowania zbiorów, które nie sa liniowo separowalne [2]. Siec tego typu składa sie zazwyczaj
z warstwy wejsciowej, kilku warstw ukrytych (ang. hidden layers) oraz z warstwy wyjsciowej. Rozmiar
warstwy wejsciowej musi odpowiadac rozmiarowi danych jakie siec ma za zadanie przetworzyc, nato-
miast rozmiar warstwy wyjsciowej musi byc równa liczbie klas (w przypadku klasyfikacji) lub liczbie
estymowanych parametrów (w przypadku regresji). Warstwa wyjsciowa moze składac sie z neuronów
liniowych (w przypadku regresji liniowej) lub neuronów nieliniowych (gdy mamy do czynienia z klasy-
fikacja).
Wejscie #1
Wejscie #2
Wejscie #3
Wejscie #4
Wyjscie
Wyjscie
Wyjscie
Warstwaukryta
Warstwaukryta
Warstwawejsciowa
Warstwawyjsciowa
Rys. 2.1. Przykładowy perceptron wielowarstwowy [2]
Warstwy ukryte składaja sie najczesciej z tzw. neuronów McCullocha-Pitsa. Aby wykorzystac sieci
neuronowe do rozwiazywania problemów nalezy okreslic ilosc warstw ukrytych oraz neuronów znaj-
dujacych sie w poszczególnych warstwach ukrytych. Jest to zagadnienie, które moze byc rozwiazane,
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

12 2.3. Splotowe sieci neuronowe
za pomoca metody prób i błedów, przeszukiwania wszystkich mozliwosci lub zastosowania bardziej
zaawansowanych metod takich jak estymator Parzena o strukturze drzewa.
Trenowanie perceptronu wielowarstwowego mozliwe jest dzieki zastosowaniu metody wstecznej
propagacji błedów [3].
Perceptron wielowarstwowy w wersji podstawowej jest siecia, bez sprzezenia zwrotnego, w przeci-
wienstwie do sieci zwanych sieciami rekurencyjnymi [4]. Na bazie sieci MLP zbudowane sa splotowe
sieci neuronowe (zob. 2.3), słuzace do rozpoznawania obrazów i wykorzystane w tej pracy [4].
Perceptron wielowarstwowy mozna opisac jako funkcje:
y = f(x, θ) (2.1)
y – wyjscie sieci
x – wejscie sieci
θ – parametry (zwane równiez wagami), okreslone podczas trenowania sieci neuronowej
Funkcja f z powyzszego wzoru jest w przypadku perceptronu wielowarstwowego złozeniem wielu
funkcji:
f(x) = fn(. . . f3(f2(f1(x)))) (2.2)
gdzie
n – numer warstwy sieci
2.3. Splotowe sieci neuronowe
Splotowe sieci neuronowe znane równiez pod nazwa konwolucyjne sieci neuronowe (ang. convolutio-
nal neural networks – CNN) sa odmiana sieci neuronowych, zoptymalizowanych pod katem przetwarza-
nia obrazów [5]. Podstawowa róznica w stosunku do zwykłych sieci jest stosowanie wielowymiarowej
operacji splotu za pomoca zestawu filtrów, których współczynniki dobierane sa podczas trenowania sieci.
Dzieki tej operacji powstaja mapy cech (zwane równiez mapami aktywacji), na których, w kolejnych
warstwach ponownie dokonywana jest operacja splotu. Dodatkowo w kolejnych warstwach zmniejszany
jest rozmiar obrazów (map aktywacji) – dokonywana jest operacja podpróbkowania obrazów (ang. po-
oling).
2.3.1. Operacja splotu
Operacje splotu s miedzy funkcjami x oraz w oznaczamy znakiem gwiazdki:
s(t) = (x ∗ w)(t) (2.3)
W ogólnosci operacje splotu s, zwana równiez operacja konwolucji lub mnozeniem splotowym de-
finiujemy jako [4]:
s(t) =
∫x(a)w(t− a)da (2.4)
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

2.3. Splotowe sieci neuronowe 13
gdzie:
s – wynik operacji splotu
x – funkcja poddawana operacji splotu
w(a) – funkcja wagowa
W przypadku operacji dyskretnych operacja splotu przyjmuje postac:
s(t) =∑
x(a)w(t− a)da (2.5)
W konwolucyjnych sieciach neuronowych najczesciej wykorzystuje sie dwuwymiarowa, zmodyfi-
kowana operacje, bedaca formalnie korelacja krzyzowa [4]:
S(i, j) = (I ∗K)(i, j) =∑m
∑n
I(i+m, j + n)K(m,n) (2.6)
gdzie:
S – wynik dwuwymiarowej operacji korelacji krzyzowej
I – obraz wejsciowy
K – dwuwymiarowe jadro przekształcenia
i, j,m, n –współrzedne obrazu oraz jadra przekształcenia
2.3.2. Architektura sieci splotowych
Warstwe splotowa sieci CNN mozna przedstawic za pomoca trójwymiarowych bloków, jak na rys.
2.2.
Rys. 2.2. Trójwymiarowe warstwy sieci CNN [3]
Pełna architektura splotowych sieci neuronowych zawiera w sobie równiez tradycyjne, w pełni po-
łaczone (ang. fully connected) niekonwolucyjne warstwy MLP. Tego typu warstwy stosowane sa najcze-
sciej jako ostatnia warstwa ukryta oraz jako warstwa wyjsciowa. Pogladowy schemat pełnej konwolu-
cyjnej sieci neuronowej przedstawiono na rys. 2.3.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

14 2.3. Splotowe sieci neuronowe
Rys. 2.3. Uproszczony schemat splotowej sieci neuronowej [4]
2.3.3. Zalety sieci splotowych
Warto zauwazyc, ze splotowe sieci neuronowe sa jedynie specjalnym rodzajem perceptronu wielo-
warstwowego opisanego powyzej, w sekcji 2.2.1. Nalezy nadmienic, ze dzieki wykorzystaniu operacji
splotu, sieci te sa znacznie lepiej przystosowane do przetwarzania obrazów. Innymi słowy architektura
sieci CNN umotywowana jest trzema załozeniami, które starano sie osiagnac przy ich projektowaniu [4]:
– luzne połaczenia miedzy warstwami (ang. sparse interactions)
– współdzielenie wag miedzy neuronami (ang. parameter sharing)
– reprezentacje niezalezne wzgledem przesuniec (ang. equivariant representations)
Luzne połaczenia miedzy warstwami w przeciwienstwie do połaczenia pełnego (ang. fully connec-
ted) mozna zrozumiec jako połaczenie neuronów tylko z pewnym, małym obszarem obrazu wejscio-
wego, tak jak na rys. 2.4.
Rys. 2.4. Pole widzenia pojedynczego neuronu sieci splotowej [5]
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

3. Standard DICOM
DICOM to skrótowiec od angielskiego sformułowania Digital Imaging and Communications in Me-
dicine, które mozna przetłumaczyc jako obrazowanie cyfrowe i wymiana obrazów w medycynie. DI-
COM jest norma opracowana przez stowarzyszenie National Electrical Manufacturers Association oraz
przez instytut American College of Radiology w celu ustandaryzowania wymiany danych medycznych
(w szczególnosci obrazów, ale nie tylko). DICOM oznacza równiez format pliku komputerowego opi-
sywanego przez norme. W plikach typu DICOM mozliwe jest przechowywanie obrazów medycznych
takich jak tomogramy komputerowe, obrazy rezonansu magnetycznego, badania ultrasonograficzne, ob-
razy pozytonowej tomografii emisyjnej i wielu innych. Co wazne, wraz z obrazami w plikach DICOM
przechowywane sa równiez metadane o pacjencie, lekarzu czy szczegółach wykonanego badania.
3.1. Struktura danych w plikach DICOM
Plik DICOM jest zbiorem danych składajacym sie z wielu elementów danych. Pojedynczy element
danych jest szczegółowo zdefiniowany przez standard [6].
Element danych - - - - - - -
TagVR VL
rozmiarelementu
Value Field
Zbiór danych
Element danych
Element danych Element danych Element danych
typ danych pole z danymi
Rys. 3.1. Struktura danych w standardzie DICOM [6]
Mozna wyróznic w nim nastepujace elementy:
1. znacznik elementu danych (ang. data element tag)
2. reprezentacja wartosci – typ danych (ang. value representation)

16 3.2. Obrazy medyczne w formacie DICOM
3. rozmiar elementu (ang. value length)
4. pole z własciwymi danymi (ang. value field)
Opisana powyzej struktura przedstawiona została na rys. 3.1.
Znacznik danych składa sie z dwóch liczb oznaczajacej grupe oraz element grupy i okreslajacego
jakie dane umieszczone sa w opisywanym elemencie danych. Przykładowym znacznikiem moze byc
wiek pacjenta — PatientAge, zapisany za pomoca liczb (0010, 1010).
Typ danych okresla w jaki sposób dane zapisane sa w polu z własciwymi danymi. Typ danych moze
byc szczegółowy jak Person Name (imie pacjenta), numeryczny jak Floating Point Double
(typ zmiennoprzecinkowy, podwójnej precyzji) lub bardzo ogólny jak Unknown (nieznany).
Rozmiar elementu okresla ile bajtów zajmuje pole z własciwymi danymi.
Pole z własciwymi danymi przechowuje wartosc konkretnych danych. Moga to byc dane bardzo
proste i krótkie jak wiek pacjenta lub imie pacjenta, jak równiez moga byc to dane zawierajace wartosci
wszystkich pikseli znajdujacych sie w przechowywanym obrazie medycznym.
3.2. Obrazy medyczne w formacie DICOM
W przypadku gdy plik DICOM zawiera obraz medyczny, to piksele tego obrazu beda znajdowały
sie w elemencie danych oznaczonych znacznikiem PixelData. Piksele w pliku DICOM przechowy-
wane sa jako wartosci surowe, zalezne od konkretnego sprzetu. To oznacza, ze piksele moga przyjmowac
wartosci z dowolnego zakresu (wartosci pikseli moga byc nawet ujemne). W pliku DICOM poza elemen-
tem danych PixelData znajduja sie równiez inne elementy zawierajace nie tylko dane personalne czy
dane dotyczace szpitala ale równiez dane opisujace w jaki sposób nalezy zinterpretowac wartosci pik-
seli. Przykładem takiego pomocniczego pola jest element danych o nazwie TransferSyntax, który
okresla czy dane obrazu sa przechowywane w postaci skompresowanej, a jezeli tak to jaki algorytm
kompresji został uzyty.
surowe wartości
pikseli
piksele mające sens fizycznynp. jednostkiHounsfielda
wartości wyświetla-
ne
Transformacjamodalności:
• współczynnik kierunkowy
• wyraz wolny
TransformacjaVOI:
• szerokość okna• położenie okna
Rys. 3.2. Proces przetwarzania wartosci pikseli w obrazie DICOM [7]
Pełen proces przekształcania wartosci pikseli obrazu DICOM przedstawiony jest na rys. 3.2. Aby
wyswietlic obraz, przegladarka obrazów DICOM dekompresuje dane (jesli zachodzi taka potrzeba),
a nastepnie przeskalowuje wartosci sprzetowe pikseli do wartosci majacych sens fizyczny (np. do
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

3.2. Obrazy medyczne w formacie DICOM 17
jednostek Hounsfielda w przypadku tomogramów komputerowych). Do przeskalowania pikseli po-
trzebne sa wartosci przechowywane w polach RescaleSlope (współczynnik kierunkowy) oraz
RescaleIntercept (wyraz wolny). Przekształcenie to nazywane jest transformacja modalnosci.
Wartosc piksela PV (ang. pixel value) po transformacji modalnosci dana jest wzorem:
PV = OV ·RS +RI (3.1)
gdzie:
PV – wartosc piksela po transformacji modalnosci (ang. pixel value)
OV – oryginalna wartosc piksela zapisana w pliku DICOM, po dekompresji (ang. original value)
RS – współczynnik kierunkowy (ang. rescale slope)
RI – wyraz wolny (ang. rescale intercept)
Kolejnym etapem jest przekształcenie wartosci pikseli z jednostek fizycznych takich jak jednostki
Hounsfielda do standardowego zakresu jaki zazwyczaj przyjmuja obrazy komputerowe (np. do zakresu
od 0 do 255 w przypadku obrazów osmiobitowych). Przeskalowanie to nazywa sie transformacja VOI(ang. Values of Interest) i zalezne jest od tego jaka jasnosc i kontrast obrazu jest pozadana. Przekształce-
nie VOI dokonywane jest przy pomocy wartosci zwanych szerokoscia okna (element WindowWidth)
oraz połozeniem okna (element WindowCenter), które równiez zapisane sa w pliku DICOM. Wartosci
te moga byc dowolnie zmodyfikowane przez uzytkownika, co jest podstawowa funkcjonalnoscia kazdej
przegladarki obrazów medycznych. Wartosc piksela do wyswietlenia zalezy od tego jaki zakres wartosci
moze wyswietlic dany monitor.
Jezeli system wyswietlania obrazu jest osmio-bitowy to wartosci wyswietlane musza przybierac war-
tosci miedzy 0 a 255. W takim przypadku wartosc piksela do wyswietlenia oznaczona jako GL (ang.
Gray Level) dana jest wzorem:
GL =PV −WC
WW/256+ 128 (3.2)
gdzie:
GL – wartosc piksela do wyswietlenia, po transformacji VOI (ang. gray level)
PV – wartosc piksela po transformacji modalnosci (ang. pixel value), patrz równanie 3.1
WC – połozenie okna (ang. window center)
WW – szerokosc okna (ang. window width)
Dodatkowo wartosci GL które sa mniejsze od zera, musza przyjac wartosc 0, natomiast wartosci
wieksze od 255 musza przyjac wartosc 255:
GL(GL < 0) = 0 (3.3)
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

18 3.2. Obrazy medyczne w formacie DICOM
GL(GL > 255) = 255 (3.4)
Podsumowujac, piksele przechowywane sa w surowej postaci zaleznej od konkretnego sprzetu ob-
razujacego. Przegladarka obrazów DICOM przeskalowuje te wartosci do dobrze znanych jednostek, po
to aby mozliwa stała sie identyfikacja tkanek (jednostki Hounsfielda w przypadku obrazów pochodza-
cych z tomografu komputerowego przyjmuja zblizone wartosci dla tych samych tkanek). Nastepnie, aby
radiolog mógł dokonac własciwej oceny tkanek, jasnosc i kontrast obrazu musi byc odpowiednio dosto-
sowana. Dzieje sie to automatycznie, przy czym lekarz ma mozliwosc dostosowania tych parametrów
według własnej potrzeby.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

4. Przeglad literatury
Rozdział ten poswiecony jest przegladowi rozwiazan opisanych w literaturze, które staraja sie osia-
gnac podobne cele jak w tej pracy magisterskiej.
4.1. Korekta histogramu
Najprostszym, dobrze znanym sposobem na automatyczne dostosowanie kontrastu i jasnosci obrazu
medycznego jest korekta histogramu [7].
4.1.1. Rozciagniecie histogramu
Istnieje kilka metod korekty histogramu, do najprostszej nalezy rozciagniecie histogramu, która sto-
suje sie w przypadku gdy piksele obrazu przyjmuja wartosci z zakresu mniejszego niz dostepny.
Rys. 4.1. Rysunek pogladowy przedstawiajacy operacje rozciagniecia histogramu [8]
Przykładowo, dla obrazów 8-bitowych dostepny zakres skali szarosci miesci sie od 0 do 255. Jezeli
najmniejsza wartosc pikseli przyjmuje wartosc wieksza od 0, a najwieksza mniejsza od 255, to wtedy
mozna zastosowac metode rozciagniecia histogramu. Przekształcenie to przyjmuje postac:
GL′ =255
max−min· (GL−min) (4.1)
gdzie:
GL′ – wartosc piksela po transformacji
GL – wartosc piksela przed transformacja

20 4.1. Korekta histogramu
max – maksymalna wartosc jaka przyjmuja piksele danego obrazu
min – minimalna wartosc jaka przyjmuja piksele danego obrazu
4.1.2. Wyrównanie histogramu
Wyrównanie histogramu jest operacja majaca na celu takie przekształcenie histogramu, aby był on
mozliwie płaski. Operacje te wykonuje sie za pomoca odpowiednio przygotowanej tabeli podstawienio-
wej (tabeli LUT).
Rys. 4.2. Rysunek pogladowy przedstawiajacy operacje wyrównania histogramu [9]
Poczatkowo okresla sie dystrybuante rozkładu prawdopodobienstwa za pomoca wzoru:
D(n) =h0 + h1 + . . .+ hn
s(4.2)
gdzie:
D(n) – dystrybuanta rozkładu prawdopodobienstwa wartosci pikseli
hn – ilosc punktów na danym obrazie o n-tym poziomie szarosci
s – liczba wszystkich punktów obrazu
Na podstawie tak obliczonej dystrybuanty otrzymujemy tablice podstawien, zadana ponizszym wzo-
rem:
LUT (i) =D(i)−D0
1−D0· (k − 1) (4.3)
gdzie:
LUT (i) – i-ta pozycja tablicy podstawieniowej
D(i) – i-ta wartosc dystrybuanty
k – liczba mozliwych wartosci składowych obrazu
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

4.2. Poprawa obrazów MRI za pomoca prostych sieci neuronowych 21
4.2. Poprawa obrazów MRI za pomoca prostych sieci neuronowych
Jedna z pierwszych prac opisujacych zastosowanie sieci neuronowych do optymalizacji wyswietlania
obrazów medycznych jest japonska praca z 1991 roku [8]. Autorzy opisywanego artykułu skupili sie na
obrazach medycznych pochodzacych z obrazowania rezonansu magnetycznego. Problem dostosowania
jasnosci oraz kontrastu obrazów MRI sprowadzony został, tak jak w przypadku niniejszej pracy magi-
sterskiej do poszukiwania optymalnych wartosci szerokosci i połozenia okna histogramu (czyli wartosci
WW oraz WC).
W artykule przedstawiono trzy rozwiazania:
1. zdefiniowanie wskaznika EW (ang. evaluation value) bedacego ilosciowa miara przejrzystosci
(ang. clarity) obrazu medycznego dla zadanych wartosci WW/WC w odniesieniu do obrazu me-
dycznego ustawionego recznie przez eksperta
2. wytrenowanie prostej sztucznej sieci neuronowej, której wejsciem beda wybrane cechy histogramu
dostosowanego obrazu medycznego, a wyjsciem przejrzystosc obrazu medycznego
3. uzycie metody najwiekszego wzrostu (ang. hill climbing) w celu znalezienia optymalnych wartosci
WW/WC (w taki sposób, aby przejrzystosc obrazu była najwieksza)
4.2.1. Wskaznik przejrzystosci obrazu medycznego
Wskaznik przejrzystosci obrazu medycznego EW zdefiniowany został jako srednia wazona sumy
kwadratów róznic pomiedzy wartosciami pikseli po transformacji VOI pomiedzy obrazem dostosowa-
nym przez eksperta a obrazem dostosowanym przez system. Wskaznik EW okreslony jest za pomoca
ponizszego równania:
EW =1
16
√∑N W (GLr) · (GLr −GLs)2∑N W (GLr)(4.4)
gdzie:
EW – wskaznik przejrzystosci obrazu medycznego – wartosc ewaluacyjna (ang. evalutaion value)
GLr – wartosc piksela po transformacji VOI (patrz równanie 3.2), dostosowanego przez eksperta
GLs – wartosc piksela po transformacji VOI (patrz równanie 3.2), dostosowanego przez system
N – całkowita liczba pikseli obrazu
W (GLr) –funkcja wagowa (najwieksza waga przypisana jest do srodkowych wartosci szarosci, piksele
bardzo ciemne, oraz bardzo jasne maja mniejsza wage)
Nastepnie autorzy opisywanego artykułu przeprowadzili subiektywne badania z udziałem lekarzy, na
podstawie których stwierdzono, ze:
– wskaznik EW dobrze odzwierciedla jakosc optymalizacji poziomów szarosci obrazu medycznego
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

22 4.2. Poprawa obrazów MRI za pomoca prostych sieci neuronowych
– ocena przejrzystosci obrazów medycznych rózni sie pomiedzy ekspertami
– algorytm prostego wyrównania histogramu jest nie wystarczajacy – lekarze oceniali, ze obrazy
dostosowywane za pomoca algorytmu wyrównania histogramu wymagaja dalszej, manualnej po-
prawy.
Powyzsze stwierdzenia maja duze znaczenie dla załozen niniejszej pracy magisterskiej. Po pierwsze,
opisywany artykuł udowadnia, ze zastosowanie prostych metod poprawy jasnosci oraz kontrastu obrazów
medycznych jest niewystarczajace, co uzasadnia poszukiwanie bardziej skomplikowanych rozwiazan.
Po drugie, poniewaz udowodniono, ze preferencje lekarzy róznia sie miedzy soba, warto opracowac
rozwiazania, które umozliwiaja personalizacje poprawy obrazów.
4.2.2. Działanie systemu
Podstawa systemu opisanego w artykule [8] jest sztuczna siec neuronowa, potrafiaca ocenic przej-
rzystosc obrazu medycznego na podstawie jego histogramu. Wejsciem sieci neuronowej jest szesc cech
wyliczanych na podstawie histogramu obrazu po transformacji VOI (patrz rozdział 3.2). Do cech tych
naleza:
– poziom szarosci najwiekszego piku w histogramie
– maksymalny poziom szarosci tła
– czestosc wybranych poziomów szarosci
– balans jasnosci
– kontrast
Na wejscie sieci wchodza równiez sinus oraz kosinus powyzszych cech. W sumie na wejscie sieci wcho-
dzi 18 cech.
Dane treningowe generowane sa w nastepujacy sposób: wybierane jest wiele róznych wartosci
WW/WC, dla kazdej z nich dokonywana jest transformacja VOI, a nastepnie wyliczana jest wartosc EQ
(która jest odpowiednio przeskalowana wartoscia EW oznaczajaca przejrzystosc obrazu). W ten sposób
sztuczna siec neuronowa ma mozliwosc nauczyc sie tego jak wartosci WW/WC wpływaja na przejrzy-
stosc obrazu.
Autorzy artykułu uzywaja dwóch niezaleznie wytrenowanych sieci neuronowych, jednej sieci do
przeszukiwania wartosci WW/WC w szerokim zakresie, oraz drugiej do przeszukiwania w waskim za-
kresie. Siec składa sie tylko z jednej warstwy ukrytej, składajacej sie z 20 neuronów. Do trenowania
wykorzystano algorytm propagacji wstecznej.
Gotowe sieci neuronowe wykorzystywane sa w nastepujacy sposób: dla nowego obrazu medycznego,
którego parametry chcemy poprawic, generowane sa histogramy dla wielu róznych potencjalnych war-
tosci WW/WC (przeprowadzana jest transformacja VOI dla kazdej mozliwosci). Nastepnie, parametry
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

4.3. Odszumianie obrazów za pomoca sieci typu autoenkoder 23
powyzszych histogramów wchodza na wejscie wytrenowanej sieci neuronowej, która zwraca przewidy-
wana wartosc przejrzystosci obrazu. Tak zebrane wartosci tworza trójwymiarowa przestrzen, w której
wartosci optymalne poszukiwane sa za pomoca metody najwiekszego wzrostu (ang. hill climbing).
Ewaluacja systemu (za pomoca subiektywnej oceny lekarzy) wykazała, ze powyzszy system jest
skuteczny i ma wieksza skutecznosc od prostego wyrównywania histogramu.
4.3. Odszumianie obrazów za pomoca sieci typu autoenkoder
Autoenkoder jest siecia neuronowa, w której ilosc neuronów wyjsciowych jest równa ilosci neuro-
nów wejsciowych [4]. Autoenkoder jest zbudowany zazwyczaj jako zwykła, nierekurencyjna siec typu
MLP (zob. 2.2.1). Nie ma równiez zadnych przeszkód, aby autoenkoder był zbudowany jako siec kon-
wolucyjna (zob. 2.3), aby lepiej radzic sobie z przetwarzaniem obrazów. Przykładowa architekture auto-
enkoderów przedstawiono na rys. 4.3 oraz rys. 4.4.
Rys. 4.3. Diagram przedstawiajacy prosty autoenkoder, z jedna warstwa ukryta [10]
Gdyby autoenkoder na wyjsciu idealnie odwzorowywał wejscie, to nie byłby on zbyt uzyteczny.
Warto jednak zauwazyc, ze liczba neuronów w warstwach ukrytych autoenkodera jest mniejsza od liczby
neuronów wejsciowych i wyjsciowych. Dzieki temu tego typu siec uczy sie jakie cechy obrazu sa naj-
istotniejsze. Autoenkoder mozna wiec rozpatrywac jako specyficzny algorytm kompresji lub jako jedna
z metod redukcji wymiarowosci [9].
Aby nauczyc siec typu autoenkoder poprawnie odwzorowywac obrazy, nalezy zaprezentowac jej
wiele róznych par obrazów. W kazdej parze na wejsciu i na wyjsciu musi znajdowac sie ten sam obraz.
Jezeli podczas treningu sieci obrazy na wejsciu oraz na wyjsciu beda identyczne to wtedy autoenkoder
bedzie niczym wiecej jak wspomnianym wczesniej algorytmem kompresji czy metoda redukcji wy-
miarowosci. Jednakze gdy autoenkoderowi podczas trenowania beda prezentowane na wejsciu obrazy
uszkodzone, a na wyjsciu obrazy poprawne to wtedy autoenkoder moze stac sie algorytmem poprawy
jakosci obrazów. Przykładowo wejsciem moga byc mocno zaszumione obrazy pisma odrecznego, a wyj-
sciem oryginalne, niezaszumione obrazy przedstawiajace te same znaki [9]. Wtedy autoenkoder nauczy
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

24 4.3. Odszumianie obrazów za pomoca sieci typu autoenkoder
Rys. 4.4. Rysunek przedstawiajacy autoenkoder z trzema warstwami ukrytymi [11]
sie rozpoznawania odrecznych znaków w zaszumionym obrazie oraz generowania tych samych cyfr, ale
bez szumu.
Korzystajac z powyzszego przykładu z odszumianiem obrazów warto zwrócic uwage, ze autoenkoder
składa sie z dwóch symetrycznych czesci (patrz rys. 4.4). Warstwy wejsciowe oraz pierwsza połowa
warstw ukrytych stanowia enkoder, czyli siec, która uczy sie kodowania najistotniejszych informacji
z danych wejsciowych. Druga połowa warstw ukrytych oraz warstwa wyjsciowa to dekoder, który uczy
sie generowania pełnego obrazu na podstawie zakodowanej przez enkoder informacji.
Artykuł [10] opisuje zastosowanie głebokich, konwolucyjnych autoenkoderów w celu odtwarzania
uszkodzonych obrazów. Odtwarzanie uszkodzonych obrazów moze obejmowac takie zagadnienia jak:
– odszumianie obrazów
– inteligentne zwiekszanie rozdzielczosci obrazów
– przywracanie ostrosci rozmytych obrazów
– przywracanie zamalowanych czesci obrazów
Tak zaawansowane czynnosci sa mozliwe dzieki zastosowaniu bardzo głebokich, wielowarstwowych
autoenkoderów, oraz dodanie dodatkowych połaczen miedzy enkoderem a dekoderem, pomijajacych
niektóre warstwy (ang. skip connections), dzieki czemu obrazy wejsciowe sa w stanie zachowac wiecej
szczegółów niz w przypadku tradycyjnych sieci.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

4.4. Zastosowanie głebokiego bilateralnego uczenia maszynowego do poprawy obrazów 25
Opisane powyzej rozwiazania dotycza obrazów dowolnego typu, co stanowi pole aby badac mozli-
wosc ich wykorzystania do odszumiania czy wyostrzania obrazów medycznych.
4.4. Zastosowanie głebokiego bilateralnego uczenia maszynowego dopoprawy obrazów
Kolejnym przykładem rozwiazania pozwalajacego poprawiac obrazy, jest artykuł [11] z 2017 roku
zatytułowany „Zastosowanie głebokiego uczenia bilateralnego do poprawy obrazów w czasie rzeczywi-
stym”. W artykule tym przedstawiono zaawansowana architekture splotowych sieci neuronowych, uczo-
nych za pomoca par obrazów – obrazu oryginalnego oraz obrazu poprawionego. System opisany w ar-
tykule jest w stanie nauczyc sie przekształcen dokonanych zarówno za pomoca innych automatycznych
algorytmów, jak równiez przekształcen dokonanych przez eksperta. Przykładowym przekształceniem
opisanym w artykule jest transformacja HDR+, poprawiajaca kolory zdjecia.
Głównym załozeniem postawionym przy budowaniu systemu była wydajnosc obliczeniowa systemu.
Zbudowany system pozwala na dokonywanie transformacji w czasie rzeczywistym na smartfonie w ciagu
kilkudziesieciu milisekund, co pozwala na zastosowanie filtrów w czasie rzeczywistym podczas pod-
gladu z kamery w smartfonie.
Architektura systemu składa sie z dwóch torów przetwarzania – toru niskiej rozdzielczosci oraz toru
wysokiej rozdzielczosci. Tor niskiej rozdzielczosci został zastosowany przede wszystkim ze wzgledu
na krótszy czas przetwarzania, natomiast tor wysokiej rozdzielczosci pozwala na zachowanie krawedzi,
dzieki czemu transformacja dobrze wyglada na obrazie o wysokiej rozdzielczosci.
Tor niskiej rozdzielczosci składa sie z nastepujacych elementów:
1. podpróbkowanie obrazu
2. warstwy konwolucyjne przetwarzajace cechy niskiego poziomu
3. równolegle: warstwy konwolucyjne przetwarzajace cechy lokalne oraz warstwy konwolucyjne
przetwarzajace cechy globalne obrazu
4. fuzja cech
5. zbudowanie siatki bilateralnej (ang. bilateral grid) współczynników przekształcenia
Tor wysokiej rozdzielczosci wykorzystuje obraz w pełnej rozdzielczosci do zbudowania mapy wska-
zówek (ang. guidance map) pozwalajacej na przeskalowanie do wyzszej rozdzielczosci współczynników
siatki bilateralnej pochodzacej z toru przetwarzania niskiej rozdzielczosci. Dzieki temu współczynniki
przekształcenia uzyskane w niskiej rozdzielczosci sa przeskalowane w taki sposób, aby uwzgledniały
krawedzie obrazu z pełnej rozdzielczosci. Koncowym etapem jest zastosowanie przekształcenia na ob-
razie w pełnej rozdzielczosci.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

26 4.5. Zastosowane rozwiazanie
Kluczowym elementem jest zastosowanie siatki bilateralnej, która jest przyblizeniem filtrów bilate-
ralnych pozwalajacym na bardzo szybkie wykonywanie przekształcenia. Autorzy artykułu przetestowali
system na jednym ze smartfonów firmy Google, udowadniajac wysoka wydajnosc obliczeniowa opraco-
wanego systemu.
4.5. Zastosowane rozwiazanie
Celem niniejszej pracy magisterskiej jest optymalizacja parametrów prezentacji obrazów medycz-
nych DICOM. W przypadku obrazów DICOM, dostosowywanie jasnosci oraz kontrastu jest dokony-
wane poprzez zmiane parametrów szerokosci oraz połozenia okna histogramu (parametry WW/WC).
Stwierdzono, ze najlepszym rozwiazaniem jest opracowanie systemu, który bazował bedzie na bezpo-
sredniej optymalizacji parametrów WW/WC, tak jak zostało to opisane w artykule [8] (patrz podrozdz.
4.2).
Do najwazniejszych róznic w stosunku do artykułu [8], zaliczyc mozna wykorzystanie głebokich,
konwolucyjnych sieci neuronowych (w przeciwienstwie do prostej sieci neuronowej z jedna warstwa)
oraz rezygnacja z przeszukiwania wartosci WW/WC za pomoca metody najwiekszego wzrostu. In-
nymi słowy, zbudowany zostanie system, w którym siec neuronowa bedzie w stanie przyblizyc wartosci
WW/WC bezposrednio z obrazu wejsciowego. Zaleta takiego rozwiazania jest fakt, ze tak zbudowana
siec neuronowa powinna byc w stanie uwzgledniac równiez rodzaj tkanek jakie znajduja sie na zdjeciach
wejsciowych.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

5. Platforma TIRS Adjust
Jak zostało wspomniane we wstepie tej pracy, głównym celem jest wykorzystanie metod uczenia
maszynowego do personalizacji parametrów obrazów medycznych (zob. rozdz. 1). Metody nadzoro-
wanego uczenia maszynowego charakteryzuja sie tym, ze potrzebne jest zebranie duzej ilosci, dobrze
zaanotowanych danych (zob. rozdz. 2). Z tego wzgledu integralna czescia niniejszej pracy dyplomowej
jest stworzenie platformy, słuzacej do zebrania bazy obrazów medycznych o parametrach ustawionych
według potrzeb lekarzy radiologów. Platforma przyjeła nazwe TIRS Adjust. Platforma była rozwijana
w ramach projektu komercyjnego w firmie badawczo-rozwojowej.
5.1. Załozenia
– stworzenie platformy o nazwie TIRS Adjust słuzacej do poprawiania jasnosci oraz kontrastu ob-
razów medycznych DICOM
– zebranie preferencji lekarzy odnosnie optymalnych wartosci jasnosci i kontrastu obrazów medycz-
nych w zaleznosci od ich rodzaju
– zapamietywanie parametrów obrazu dla kazdego badania oraz dla kazdego uzytkownika osobno
– lekarze powinni miec łatwy dostep do aplikacji, a zebrana baza ma byc łatwo dostepna dla autora
platformy
– umozliwienie wysyłania nowych obrazów medycznych na serwer
– obrazy maja byc widoczne dla wszystkich uzytkowników platformy, ale parametry obrazów po-
winny byc zapamietywane osobno dla kazdego uzytkownika
– grupowanie warstw danego badania tomograficznego w jedno badanie i współdzielenie parame-
trów obrazu dla wszystkich warstw
– rozdzielanie warstw danego badania rezonansowego i ustawianie parametrów obrazu osobno dla
kazdej warstwy

28 5.2. Wykorzystane technologie
5.2. Wykorzystane technologie
W tym podrozdziale przedstawione zostana platformy programistyczne (ang. frameworks) oraz bi-
blioteki wykorzystane do stworzenia platformy TIRS Adjust.
5.2.1. Czesc serwerowa – platforma Node.js
Node.js jest srodowiskiem, które pozwala uruchomic kod napisany w jezyku JavaScript bez uzycia
przegladarki internetowej. Dzieki temu jezyk JavaScript moze byc wykorzystany równiez do zbudowania
serwerowej czesci aplikacji internetowej (ang. backend). Platforma Node.js jest rozszerzeniem silnika
JavaScript o nazwie V8, wykorzystywanego równiez w przegladarkach Chromium i Google Chrome.
To, co odróznia srodowisko Node.js od innych platform serwerowych jest wykorzystanie asynchronicz-
nego, nieblokujacego systemu I/O (wejscia/wyjscia) [12]. Rozwiazanie takie ułatwia skalowanie apli-
kacji (dobrze napisana aplikacja Node.js bez wiekszych problemów obsłuzy zarówno mała jak i duza
liczbe uzytkowników). Dla przykładu, odczytywanie duzego pliku z dysku czy oczekiwanie na pobra-
nie pliku z innego miejsca w Internecie nie zablokuje działania aplikacji serwerowej. Aplikacja bedzie
nadal odpowiadała na biezaco na inne zdarzenia, takie jak zapytania od przegladarki. Asynchronicznosc
wymaga jednak zastosowania innego stylu programowania zwanego continuation-passing style, w któ-
rym kazda funkcja przyjmuje dodatkowy argument, nazywany wywołaniem zwrotnym (ang. callback).
Innymi słowy, gdy funkcja nadrzedna zakonczy swoje działanie, to sterowanie przekazywane jest do
funkcji callback, a nie do nastepnej funkcji znajdujacej sie w kodzie. Dodatkowo w nowszych wersjach
Node.js co raz czesciej wykorzystuje sie tzw. promesy.
Platforma Node.js jest zaawansowanym srodowiskiem programistycznym, posiadajacym jedynie ni-
skopoziomowe funkcje serwera HTTP. Z tego powodu, pisanie bardziej złozonych aplikacji wymaga za-
stosowania dodatkowej biblioteki. Express.js jest jedna z bibliotek napisanych dla srodowiska Node.js,
który ułatwia odpowiednie zaprogramowanie serwera HTTP, reagowanie na zapytania od przegladarki
oraz pisanie złozonych aplikacji.
5.2.2. Czesc przegladarkowa – biblioteka Angular.js
AngularJS to framework napisany w jezyku JavaScript, zaprojektowany i rozwijany przez firme Go-
ogle. AngularJS słuzy do budowania aplikacji webowych po stronie klienta na pojedynczej stronie (ang.
single page application – SPA). W takim podejsciu aplikacja internetowa sprawia wrazenie spójnej cało-
sci, i przypomina bardziej zwykła, graficzna aplikacje, która szybko reaguje na polecenia uzytkownika,
w przeciwienstwie do tradycyjnych witryn internetowych składajacych sie z wielu osobnych podstron.
Dodatkowa zaleta tej platformy jest zastosowanie deklaratywnego paradygmatu programowania [13].
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

5.3. Interfejs platformy 29
W takim podejsciu, w przeciwienstwie do programów napisanych w paradygmacie imperatywnym, opi-
suje sie to co chcemy osiagnac, a nie szczegółowa sekwencje kroków, które do niego prowadza. Angu-
larJS umozliwia takze rozszerzenie jezyka HTML o nowe dyrektywy i atrybuty, czym wyróznia sie od
innych platform tego typu.
5.3. Interfejs platformy
Interfejs platformy TIRS Adjust zbudowany został przy uzyciu biblioteki Angular Material. Logo
platformy oraz grafika na stronie logowania zostały opracowane przez grafika w ramach szerszego pro-
jektu TIRS realizowanego w firmie. Zrzuty ekranu działajacej aplikacji przedstawiono na rysunkach 5.1
oraz 5.2.
(a) Panel logowania (b) Strona powitalna
(c) Wysyłanie nowych badan na serwer (d) Widok ustawien
Rys. 5.1. Interfejs aplikacji TIRS Adjust [12]
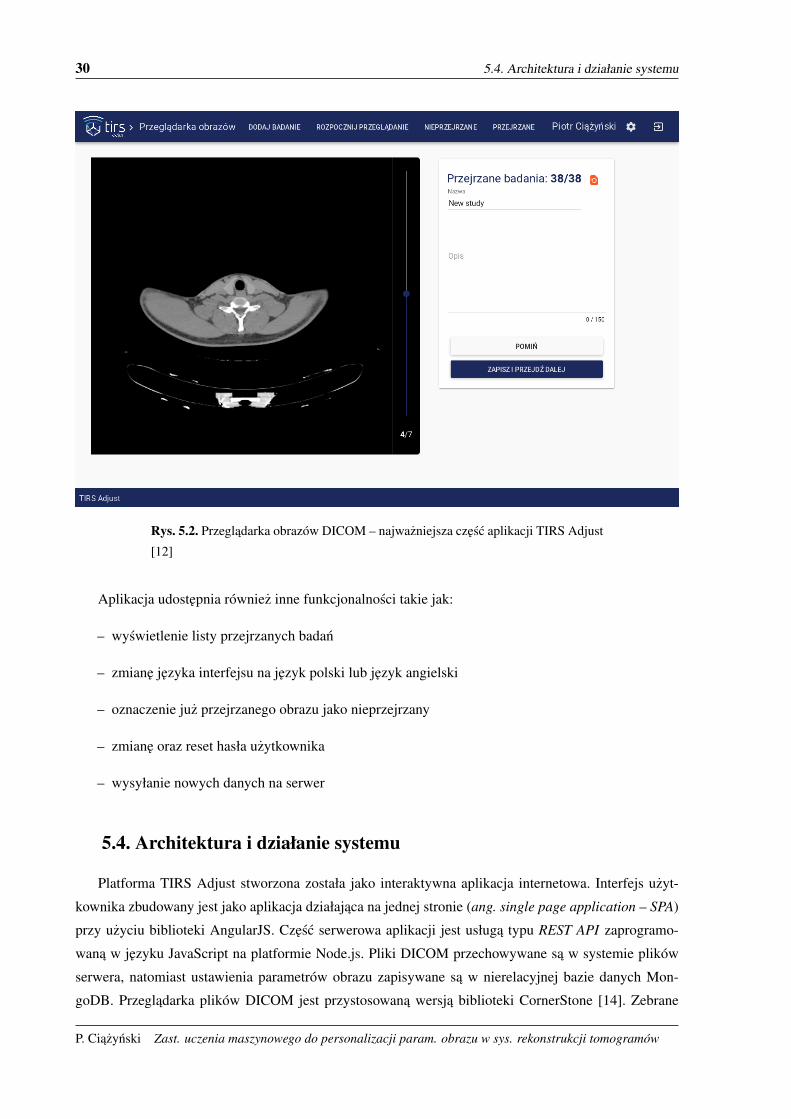
Najwazniejszym elementem aplikacji jest przegladarka obrazów DICOM, przedstawiona na rys. 5.2.
Przegladarka ta umozliwia zmiane warstwy danego badania, umozliwia powiekszenie lub pomniejszenie
obrazu, ale przede wszystkim pozwala na zmiane jasnosci oraz kontrastu wyswietlanego obrazu. Zada-
niem uzytkownika jest ustawienie parametrów obrazu, tak, zeby tkanki były najlepiej rozróznialne. Po
ustawieniu uzytkownik musi nacisnac przycisk ZAPISZ I PRZJEDZ DALEJ. Wyswietlone zostanie wtedy
nastepne badanie. Po przejrzeniu i poprawieniu parametrów obrazu wszystkich badan dostepnych aktu-
alnie w aplikacji, wyswietli sie stosowny komunikat.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów
30 5.4. Architektura i działanie systemu
Rys. 5.2. Przegladarka obrazów DICOM – najwazniejsza czesc aplikacji TIRS Adjust
[12]
Aplikacja udostepnia równiez inne funkcjonalnosci takie jak:
– wyswietlenie listy przejrzanych badan
– zmiane jezyka interfejsu na jezyk polski lub jezyk angielski
– oznaczenie juz przejrzanego obrazu jako nieprzejrzany
– zmiane oraz reset hasła uzytkownika
– wysyłanie nowych danych na serwer
5.4. Architektura i działanie systemu
Platforma TIRS Adjust stworzona została jako interaktywna aplikacja internetowa. Interfejs uzyt-
kownika zbudowany jest jako aplikacja działajaca na jednej stronie (ang. single page application – SPA)
przy uzyciu biblioteki AngularJS. Czesc serwerowa aplikacji jest usługa typu REST API zaprogramo-
wana w jezyku JavaScript na platformie Node.js. Pliki DICOM przechowywane sa w systemie plików
serwera, natomiast ustawienia parametrów obrazu zapisywane sa w nierelacyjnej bazie danych Mon-
goDB. Przegladarka plików DICOM jest przystosowana wersja biblioteki CornerStone [14]. Zebrane
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

5.4. Architektura i działanie systemu 31
dane moga zostac nastepnie eksportowane z serwera i moga posłuzyc do wytrenowania sieci neurono-
wych automatycznie poprawiajacych kontrast i jasnosc obrazów medycznych.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

32 5.4. Architektura i działanie systemu
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów
6. Realizacja i testy zastosowanego systemu
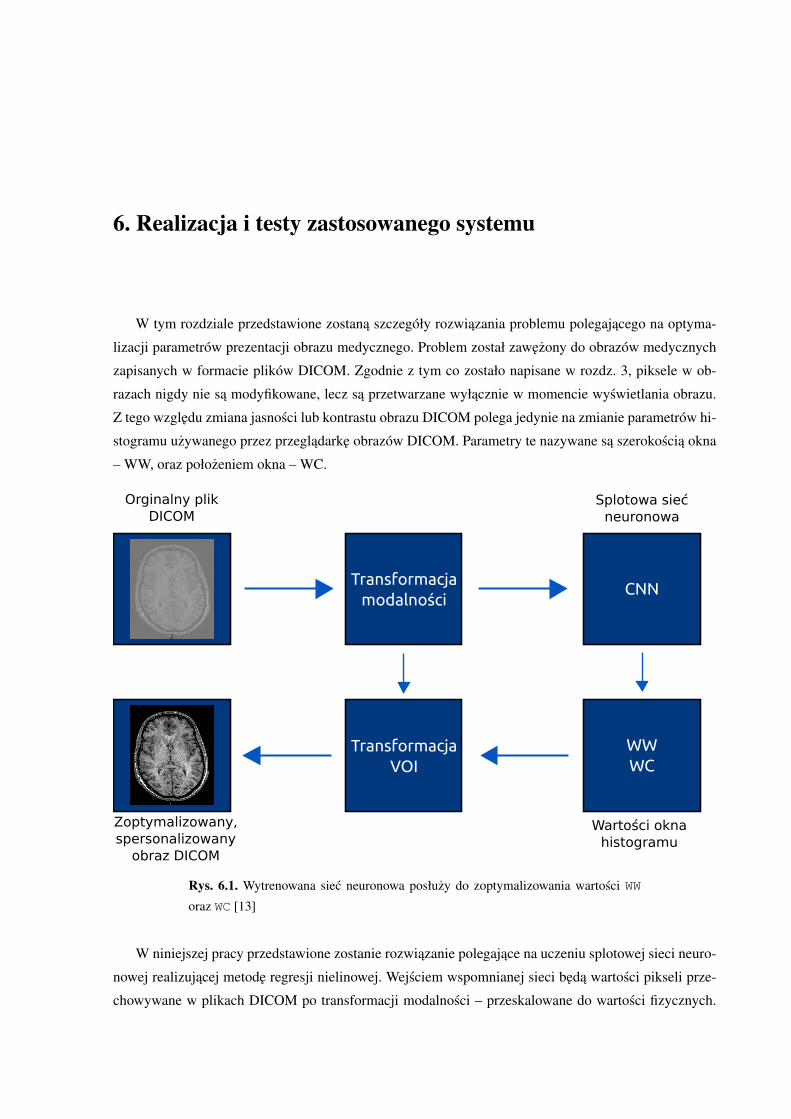
W tym rozdziale przedstawione zostana szczegóły rozwiazania problemu polegajacego na optyma-
lizacji parametrów prezentacji obrazu medycznego. Problem został zawezony do obrazów medycznych
zapisanych w formacie plików DICOM. Zgodnie z tym co zostało napisane w rozdz. 3, piksele w ob-
razach nigdy nie sa modyfikowane, lecz sa przetwarzane wyłacznie w momencie wyswietlania obrazu.
Z tego wzgledu zmiana jasnosci lub kontrastu obrazu DICOM polega jedynie na zmianie parametrów hi-
stogramu uzywanego przez przegladarke obrazów DICOM. Parametry te nazywane sa szerokoscia okna
– WW, oraz połozeniem okna – WC.
CNNTransformacjamodalności
TransformacjaVOI
WWWC
Orginalny plikDICOM
Splotowa siećneuronowa
Wartości oknahistogramu
Zoptymalizowany,spersonalizowany
obraz DICOM
Rys. 6.1. Wytrenowana siec neuronowa posłuzy do zoptymalizowania wartosci WW
oraz WC [13]
W niniejszej pracy przedstawione zostanie rozwiazanie polegajace na uczeniu splotowej sieci neuro-
nowej realizujacej metode regresji nielinowej. Wejsciem wspomnianej sieci beda wartosci pikseli prze-
chowywane w plikach DICOM po transformacji modalnosci – przeskalowane do wartosci fizycznych.

34 6.1. Wykorzystane oprogramowanie
Kazdy z obrazów przed wejsciem do sieci pomniejszany jest do rozmiaru 128x128 pikseli. Wyjsciem
sieci neuronowej sa dwie wartosci – szerokosc i połozenie okna histogramu (wartosci WW i WC).
6.1. Wykorzystane oprogramowanie
W opisywanym rozwiazaniu postanowiono wykorzystac jezyk skryptowy Python. Wybrano jezyk
Python poniewaz wspiera on wiele, wysokiej jakosci, otwarto-zródłowych bibliotek dotyczacych uczenia
maszynowego.
Jedna z nich jest biblioteka Keras [15], która słuzy to trenowania sztucznych sieci neuronowych.
Keras jest biblioteka umozliwiajaca bardzo łatwe, wysokopoziomowe definiowanie architektury sztucz-
nej sieci neuronowej. Biblioteka Keras bazuje na nizej poziomowych bibliotekach do uczenia głebokich
sieci neuronowych. Wykorzystany moze byc TensorFlow, Microsoft CNTK lub Theano. W tej pracy
dyplomowej wykorzystano Keras działajacy na platformie TensorFlow.
Druga wykorzystana biblioteka jest scikit-learn. Scikit-learn jest biblioteka implementujaca wiele
róznorodnych metod uczenia maszynowego oraz metod walidacji skutecznosci trenowanych klasyfika-
torów. Biblioteka scikit-learn wykorzystana została w celu przeprowadzenia walidacji krzyzowej (kro-
swalidacji), słuzacej do weryfikacji skutecznosci trenowanych sieci neuronowych.
Poniewaz sztuczne sieci neuronowe wymagaja ustawienia wielu metaparametrów, takich jak liczba
warstw, liczba neuronów w poszczególnych warstwach i wielu innych, postanowiono wykorzystac prze-
szukiwanie róznych mozliwosci za pomoca estymatora Parzena o strukturze drzewa przy wykorzystaniu
biblioteki Hyperas. Hyperas łatwo integruje sie z kodem napisanym przy uzyciu biblioteki Keras i umoz-
liwia zdefiniowanie jakie metaparametry i w jakim przedziale maja byc zoptymalizowane.
6.2. Baza obrazów medycznych
Aplikacja internetowa TIRS Adjust, opisana w rozdziale 5, posłuzyła do zbudowania oraz ujednoli-
cenia bazy obrazów medycznych zapisanych w formacie DICOM.
Opisywana baza danych składa sie z 43 serii obrazów tomograficznych oraz 18 serii obrazów po-
chodzacych z obrazowania rezonansu magnetycznego. Zdjecia pochodza z róznych zródeł, z których
wymienic mozna nastepujace:
– badania własne autora pracy
– badania ogólnodostepne w Internecie
– badania udostepnione przez firme RehaSport
– badania udostepnione przez Zakład Medycyny Sadowej w Warszawie
Wsród obrazowanych czesci ciała w zebranej bazie wyróznic mozna zdjecia:
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

6.2. Baza obrazów medycznych 35
– mózgowia
– klatki piersiowej
– jamy brzusznej
– nóg i podbrzusza
Niestety, ze wzgledu na pracochłonnosc tego zadania, obrazy znajdujace sie w bazie nie zostały po-
prawione przez wystarczajaca liczbe lekarzy. Jednakze, w przypadku obrazów DICOM, wartosci jasno-
sci oraz kontrastu najczesciej sa juz wstepnie ustawione oraz zapisane w nagłówkach plików DICOM.
Wartosci te pochodza z oprogramowania producentów sprzetu medycznego. Z tego wzgledu, do treningu
sieci neuronowych wykorzystano własnie te wartosci WW/WC, które juz znajdowały sie w nagłówkach
plików DICOM. Celem takiego działania jest pokazanie, ze konwolucyjne sieci neuronowe sa w stanie
nauczyc sie odwzorowania prostszych algorytmów automatycznych. Tak przygotowane sieci neuronowe
moga byc ponownie wytrenowane w przyszłosci przy uzyciu danych pochodzacych od ekspertów.
6.2.1. Podział bazy na zbiór uczacy, walidacyjny oraz testowy
Opisywana powyzej kolekcja obrazów medycznych DICOM składajaca sie z 61 serii obrazów tomo-
graficznych oraz rezonansowych została podzielona na dwa zbiory: zbiór testowy oraz zbiór do grupowo
niezaleznej walidacji krzyzowej (przy podziale danych zadbano o niemieszanie serii obrazów miedzy
soba). Zbiór testowy został całkowicie wykluczony z etapu poszukiwania metaparametrów i posłuzył do
oceny jakosci koncowej, najlepszej sieci neuronowej. Zbiór do walidacji krzyzowej został przeznaczony
do przeprowadzenia pieciokrotnej, grupowej walidacji krzyzowej. Podział danych został przedstawiony
na rysunku 6.2.
Walidacja krzyzowa, znana równiez pod nazwa kroswalidacji, jest sposobem na zbadanie skutecz-
nosci uczonego klasyfikatora lub regresora, zapewniajac uniezaleznienie sie od konkretnych danych.
Innymi słowy, walidacja krzyzowa jest sposobem na sprawdzenie jaka skutecznosc bedzie przykładowo
miała trenowana sztuczna siec neuronowa, w przypadku gdy bedzie operowała na danych innych niz
te, które słuzyły do jej uczenia. Dzieki temu walidacja krzyzowa pozwala zobaczyc jak dobrze siec
neuronowa jest w stanie generalizowac nauczona wiedze. Uzytkownikowi metod uczenia maszynowego
zalezy na tym, aby znalezc takie metaparametry w których dany algorytm dobrze generalizuje wiedze.
W przeciwnym wypadku moze sie zdarzyc, ze siec neuronowa dokładnie zapamieta dane treningowe
i nie bedzie w stanie działac w przypadku nowych danych.
W badaniach wykorzystano walidacje krzyzowa, grupowo niezalezna, zorientowana na serie obrazu
medycznego. Ten wariant zapewnia, ze do zbioru walidacyjnego trafiaja obrazy z innych serii niz do
zbioru uczacego. Jak wspomniano powyzej, poniewaz zebranie odpowiednio duzej bazy zdjec medycz-
nych poprawionych przez lekarzy radiologów nie powiodło sie, postanowiono wykorzystac automatycz-
nie wyznaczone wartosci szerokosci i połozenia okna, które zapisane sa razem z wartosciami pikseli
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

36 6.3. Architektura sieci neuronowej{Wszystkie dane
Zbiór uczący Zb
iór
wal
idac
yjny
Zbiór uczącyZb
iór
wal
idac
yjny
Kroswalidacja Zbiórtestowy
::
::
:: k = 5
grupowo-niezależna
Rys. 6.2. Rysunek pogladowy przedstawiajacy podział bazy obrazów medycznych
[14]
w plikach DICOM. Z tego wzgledu pierwszym etapem badan była próba nauczenia sieci neuronowych
odwzorowania prostych algorytmów dostosowywania histogramu.
6.3. Architektura sieci neuronowej
Bazujac na artykule [16] postanowiono wykorzystac prosta architekture konwolucyjnych sieci neu-
ronowych, przedstawiona na rysunku 6.3. Opis oznaczen zastosowanych na rysunku 6.3 znajduje sie
w tabeli 6.1.
Tabela 6.1. Rozwiniecie oznaczen zastosowanych na rys. 6.3
CNN Trójwymiarowa warstwa splotowa
Dense Tradycyjna warstwa MLP, w pełni połaczona
ReLU Funkcja aktywacji – prostownicza jednostka liniowa
AvgPool Podpróbkowanie obrazu bazujace na wartosci sredniej
Dropout Regularyzacja – usuwanie losowo wybranych neuronów
? Oznaczenie warstwy opcjonalnej
WW Szerokosc okna histogramu
WC Połozenie okna histogramu
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

6.4. Poszukiwanie optymalnej architektury oraz metaparametrów 37
WWWC
Wejście:plik DICOM
Wyjście:Wartości okna
histogramu
CNN1ReLU
CNN2
CNN3
ReLU AvgPool1
ReLU
AvgPool2[
[
?Dropout1D
ense
1ReLU
Dropout2
Rys. 6.3. Szczegółowy schemat architektury trenowanej sieci neuronowej [15]
Czesc parametrów sieci, przyjeto odgórnie po przeprowadzeniu kilku testów manualnych. Parametry
te zebrano w tabeli 6.2.
Tabela 6.2. metaparametry sieci niepodlegajace przeszukiwaniu
Funkcja kosztu sredni bład absolutny
(ang. mean absolute error – MAE)
Algorytm optymalizacji rmsprop
Funkcja aktywacji warstw ukrytych ReLU
Funkcja aktywacji warstwy wyjsciowej liniowa
Rozmiar po przeskalowaniu wejsciowego obrazu 128x128
Liczba iteracji w walidacji krzyzowej 5
W nawiasach kwadratowych przedstawiono fragment, który był dodawany wyłacznie w niektórych
wariantach podczas przeszukiwania najlepszych metaparametrów oraz architektury zastosowanej sieci
neuronowej.
6.4. Poszukiwanie optymalnej architektury oraz metaparametrów
Pojedyncza iteracja optymalizacji metaparametrów składa sie z pieciokrotnego treningu sieci neu-
ronowej w schemacie bedacym grupowa walidacja krzyzowa. metaparametry przeszukiwane były za
pomoca biblioteki Hyperas, która wykorzystuje estymator Parzena o strukturze drzewa. W tabeli 6.3
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

38 6.5. Uczenie sieci neuronowej z wykorzystaniem optymalnych metaparametrów
przedstawiono warianty parametrów, które były brane podczas przeszukiwania. Za element ogranicza-
jacy przeszukiwania wybrano liczbe iteracji równa 500.
Tabela 6.3. Lista metaparametrów badanych sieci neuronowych
CNN1 Liczba filtrów (neuronów) 16 / 32 / 64
CNN1 Rozmiar maski filtru 2x2 / 3x3 / 5x5
CNN2 Liczba filtrów (neuronów) 16 / 32 / 64
CNN2 Rozmiar maski filtru 2x2 / 3x3 / 5x5
AvgPool1 Rozmiar maski podpróbkowania 2x2 / 4x4
CNN3 i AvgPool2 Dodanie warstwy tak / nie
CNN3 Liczba filtrów (neuronów) 16 / 32 / 64
CNN3 Rozmiar maski filtru 2x2 / 3x3 / 5x5
AvgPool2 Rozmiar maski podpróbkowania 2x2 / 4x4
Dropout1 Czesc neuronów do usuniecia 0,01 do 0,99
Dense Liczba neuronów 64 / 128 / 256
Dropout2 Czesc neuronów do usuniecia 0,01 do 0,99
Wykonano 500 iteracji z róznymi kombinacjami parametrów przedstawionych w tabeli 6.3. War-
toscia optymalizowana jest wartosc funkcji straty, zwanej równiez funkcja kosztu (ang. loss function).
Wartosci zwracana przez zastosowana funkcje kosztu to sredni bład absolutny w jednostkach wejscio-
wych wartosci WW i WC.
Sredni wartosc funkcji straty wyniosła:
loss = 480, 74 + /− 65, 19 (6.1)
Wartosc minimalna oraz maksymalna:
min(loss) = 390, 13 (6.2)
max(loss) = 915, 89 (6.3)
Metaparametry optymalne (dla których funkcja kosztu przyjeła wartosc minimalna) zebrano w tabeli
6.4.
6.5. Uczenie sieci neuronowej z wykorzystaniem optymalnych metapa-rametrów
Dla najlepszych metaparametrów (wypisanych w tabeli 6.4) wytrenowano siec przy wykorzystaniu
wszystkich danych przeznaczonych do przeprowadzania walidacji krzyzowej. Siec została wytrenowana
za pomoca biblioteki Keras wykorzystujac karte graficzna NVidia Tesla K40, dedykowana do wyma-
gajacych obliczen równoległych. Uczenie sieci przebiegało za pomoca algorytmu propagacji wstecznej,
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

6.5. Uczenie sieci neuronowej z wykorzystaniem optymalnych metaparametrów 39
Tabela 6.4. Wartosci najlepszych znalezionych metaparametrów
CNN1 Liczba filtrów (neuronów) 16
CNN1 Rozmiar maski filtru 2x2
CNN2 Liczba filtrów (neuronów) 16
CNN2 Rozmiar maski filtru 2x2
AvgPool1 Rozmiar maski podpróbkowania 2x2
CNN3 i AvgPool2 Dodanie warstwy tak
CNN3 Liczba filtrów (neuronów) 32
CNN3 Rozmiar maski filtru 2x2
AvgPool2 Rozmiar maski podpróbkowania 4x4
Dropout1 Czesc neuronów do usuniecia 0,208
Dense Liczba neuronów 128
Dropout2 Czesc neuronów do usuniecia 0,082
przy wykorzystaniu minimalnego błedu absolutnego jako funkcji kosztu. Jako optymalizator wybrano
algorytm RMSProp, który jest wariantem metody stochastycznego gradientu prostego.
6.5.1. Ocena skutecznosci sieci neuronowej
Do oceny skutecznosci sieci neuronowej postanowiono wykorzystac wartosc PSNR, tj. szczytowy
stosunek sygnału do szumu (ang. peak signal-to-noise ratio). Wartosc PSNR oblicza sie najczesciej sie
na podstawie współczynnika MSE obliczanego na podstawie pikseli dwóch obrazów, które sie ze soba
porównuje [17]:
MSE =1
N ·M
N∑i=1
M∑j=1
([f(i, j)− f ′(i, j)]2) (6.4)
N,M – wymiary obrazu wyrazone w pikselach
f(i, j) – wartosc piksela na współrzednych i,j
f ′(i, j) – wartosc piksela na współrzednych i,j drugiego obrazu
PSNR definiuje sie jako:
PSNR = 10 · log10[max(f(i, j))]2
MSE(6.5)
Skutecznosc sieci wyrazono jako srednia wartosci PSNR, obliczanych dla wszystkich obrazów
w zbiorze. Na kazda pare obrazów przypadaja obrazy DICOM po transformacji VOI, jeden dla wartosci
WW/WC zapisanych w pliku DICOM, a drugi dla wartosci WW/WC obliczonych przez siec neuronowa.
Tak zdefiniowana srednia skutecznosc, dla zbioru uczacego wyniosła:
PSNRtrain = 27, 61 + /− 8, 00 (6.6)
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów
40 6.5. Uczenie sieci neuronowej z wykorzystaniem optymalnych metaparametrów
W przypadku zbioru testowego, srednia skutecznosc PSNR wyniosła:
PSNRtest = 22, 97 + /− 8, 07 (6.7)
6.5.2. Wizualizacja działania systemu
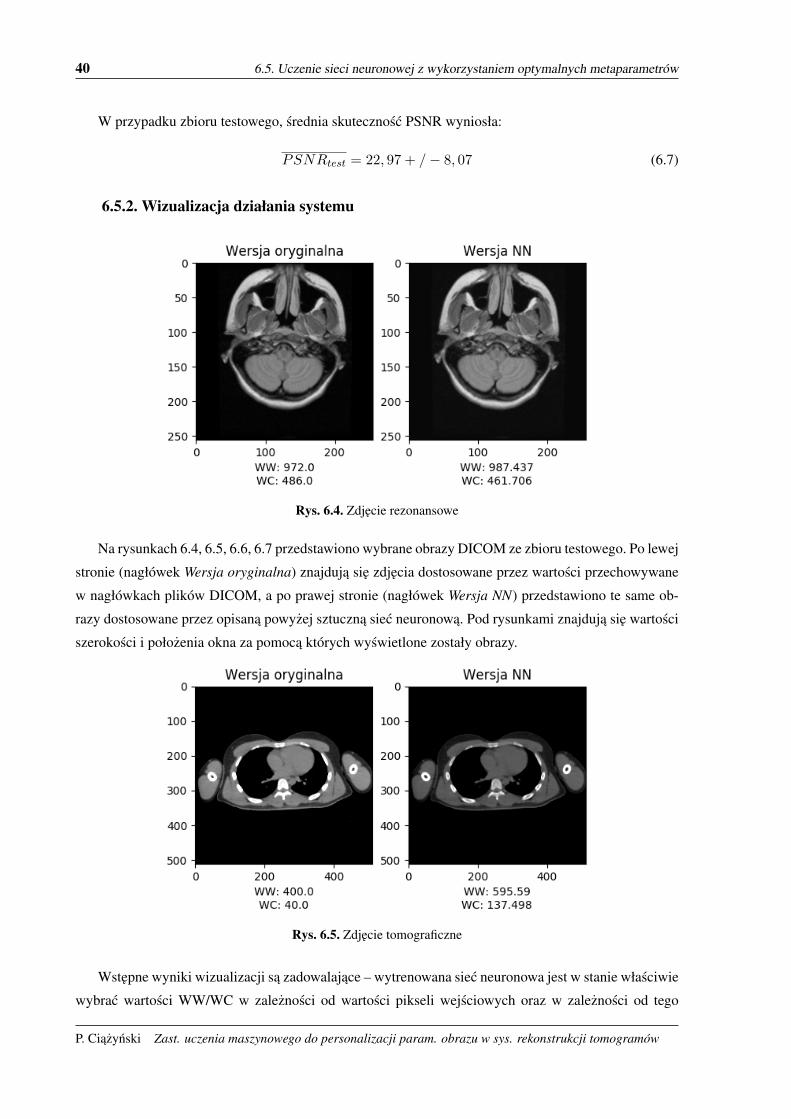
Rys. 6.4. Zdjecie rezonansowe
Na rysunkach 6.4, 6.5, 6.6, 6.7 przedstawiono wybrane obrazy DICOM ze zbioru testowego. Po lewej
stronie (nagłówek Wersja oryginalna) znajduja sie zdjecia dostosowane przez wartosci przechowywane
w nagłówkach plików DICOM, a po prawej stronie (nagłówek Wersja NN) przedstawiono te same ob-
razy dostosowane przez opisana powyzej sztuczna siec neuronowa. Pod rysunkami znajduja sie wartosci
szerokosci i połozenia okna za pomoca których wyswietlone zostały obrazy.
Rys. 6.5. Zdjecie tomograficzne
Wstepne wyniki wizualizacji sa zadowalajace – wytrenowana siec neuronowa jest w stanie własciwie
wybrac wartosci WW/WC w zaleznosci od wartosci pikseli wejsciowych oraz w zaleznosci od tego
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów
6.5. Uczenie sieci neuronowej z wykorzystaniem optymalnych metaparametrów 41
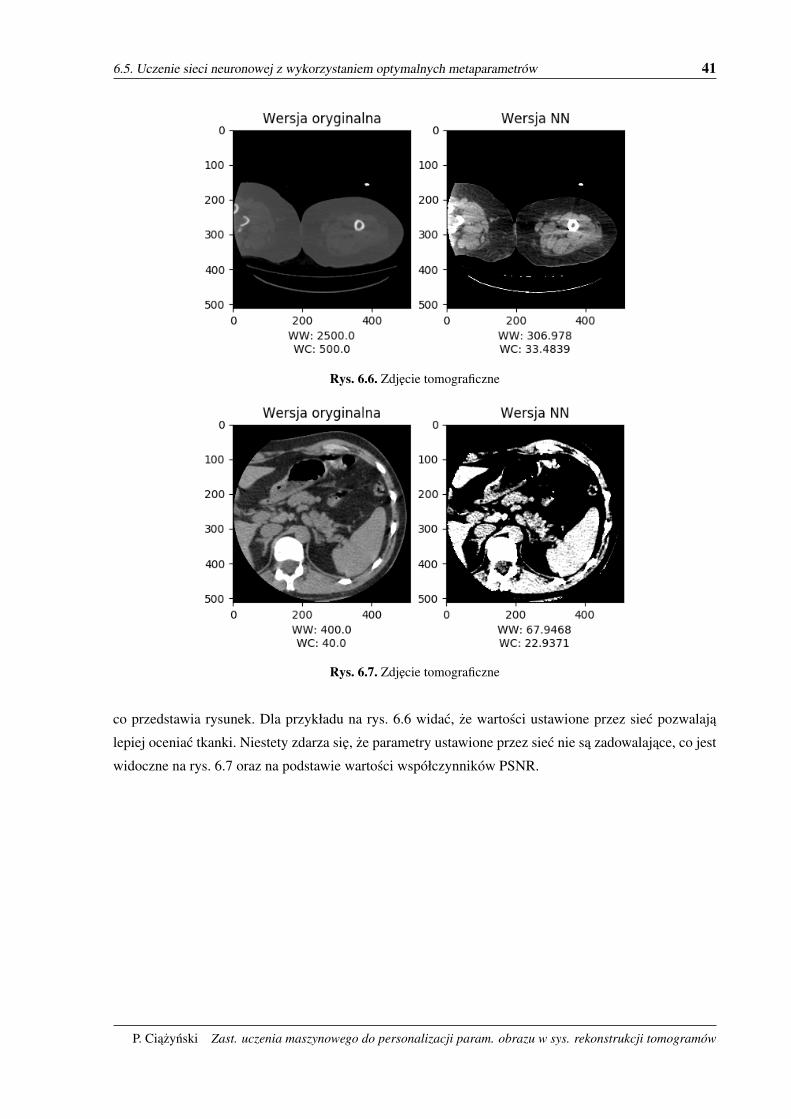
Rys. 6.6. Zdjecie tomograficzne
Rys. 6.7. Zdjecie tomograficzne
co przedstawia rysunek. Dla przykładu na rys. 6.6 widac, ze wartosci ustawione przez siec pozwalaja
lepiej oceniac tkanki. Niestety zdarza sie, ze parametry ustawione przez siec nie sa zadowalajace, co jest
widoczne na rys. 6.7 oraz na podstawie wartosci współczynników PSNR.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

42 6.5. Uczenie sieci neuronowej z wykorzystaniem optymalnych metaparametrów
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

7. Podsumowanie
7.1. Osiagniete cele
Warto na koniec podsumowac osiagniete cele. Pierwszym etapem prac był przeglad literatury do-
tyczacy metod poprawiania jakosci i parametrów obrazu. W dalszym etapie opracowano rozwiazanie
majace zastosowanie w przypadku medycznych obrazów zapisanych w formacie plików DICOM. Po-
myslnie zaprojektowano i zbudowano takze platforme w postaci aplikacji internetowej słuzaca do gro-
madzenia bazy obrazów medycznych.
Zrealizowano równiez czesciowo cel wytrenowania sztucznych sieci neuronowych majacych za za-
danie automatyczne poprawianie parametrów zdjec medycznych. Opisane rozwiazanie, po dopracowaniu
moze byc zintegrowane z opisana wyzej aplikacja internetowa.
7.2. Napotkane problemy
Realizujac zadania przedstawione powyzej napotkano jednak na kilka problemów. Jednym z nich
jest duza trudnosc w zgromadzeniu odpowiednio duzej bazy danych, jezeli wymaga to aktywnej pracy
wykwalifikowanych specjalistów. Drugim problem posrednio wynika z pierwszego – przy braku wystar-
czajaco duzej bazy danych uzyskanie algorytmu uczenia maszynowego o wysokiej skutecznosci stanowi
bardzo powazne wyzwanie.
7.3. Planowany rozwój
Przy realizacji opisanych w tej pracy zadan oraz podczas współpracy z lekarzami pojawiło sie wiele
pomysłów, które nie zostały zrealizowane, ale stanowia dobry punkt wyjscia dla ewentualnych prac
w przyszłosci.
7.3.1. Zbudowanie recznie anotowanej bazy obrazów medycznych
Najwazniejszym krokiem, który powinien byc podjety w celu dalszego rozwoju przedstawionego
w tej pracy systemu jest zebranie znacznie wiekszej ilosci obrazów medycznych oraz namówienie do
współpracy wykwalifikowanych lekarzy radiologów. Dzieki temu mozliwe stałoby sie wytrenowanie

44 7.4. Uwagi koncowe
sieci neuronowych, które potrafiłyby optymalizowac parametry prezentacji obrazów medycznych lepiej
niz prostsze algorytmy z dziedziny przetwarzania obrazów.
Po odpowiednio długim czasie zbierania danych dotyczacych preferencji lekarzy radiologów kolej-
nym krokiem moze byc wytrenowanie spersonalizowanych sieci neuronowych, dostosowujacych obrazy
medyczne zgodnie z osobistymi preferencjami lekarzy.
7.3.2. Uzycie autoenkodera w celu odszumiania obrazów
Kolejnym z pomysłów jest wykorzystanie architektury autoenkodera do zbudowania programu od-
szumiajacego obrazy medyczne. W tym wypadku baza danych nie musi byc przegladana przez ludzi
– wystarczy zgromadzenie odpowiednio duzej bazy obrazów medycznej, a nastepnie automatyczne ich
zaszumianie. Jest to wiec problem z dziedziny nienadzorowanego uczenia maszynowego.
7.3.3. Wytrenowanie osobnych sieci dla róznych tkanek
Podczas anotowania tomogramów lekarze zostali poinstruowani, ze powinni ustawic obrazy w taki
sposób, aby najłatwiej było im odróznic tkanki na przegladanym obrazie. Mozna jednak łatwo wyobrazic
sobie sytuacje, w której ustawienia jasnosci oraz kontrastu sa rózne w zaleznosci od tego jakie tkanki
chcemy wyróznic. Z tego wzgledu jednym z nastepnych etapów moze byc zbudowanie bazy obrazów me-
dycznych o parametrach ustawionych w zaleznosci od konkretnej tkanki (kosci, tkanki miekkie). Baza
danych tego typu umozliwiłaby stworzenie kilku sztucznych sieci neuronowych, z których kazda usta-
wiałaby parametry obrazu ze wzgledu na wybrana tkanke.
7.4. Uwagi koncowe
Mozna wysunac wniosek, ze głebokie, konwolucyjne sieci neuronowe sa w stanie odwzorowac dzia-
łanie automatycznych algorytmów dostosowywania obrazów medycznych stosowanych przez produ-
centów sprzetu medycznego. Wyniki jednak nie sa wystarczajaco dobre, aby przedstawiona wyzej siec
mogła zostac zastosowana w praktyce. Podstawowym problemem jest prawdopodobnie zbyt mała baza
obrazów medycznych oraz brak dostosowania obrazów przez lekarzy. Wniosek taki mozna wysunac na
podstawie obserwacji, mówiacej, ze wyniki sieci nie potrafia przekroczyc pozadanej skutecznosci nieza-
leznie od róznych architektur oraz hiperparametrów. Prawdopodobnie najwieksza poprawe moze przy-
niesc zastosowanie znacznie wiekszej, recznie anotowanej bazy obrazów medycznych. Warto jednak
zwrócic uwage, ze dzieki przygotowanym powyzej narzedziom, wytrenowanie sieci o wiekszej skutecz-
nosci nie powinno stanowic problemu w przypadku dostepu do lepszej bazy danych.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

Bibliografia
[1] Sebastian Raschka. Python Machine Learning. Packt Publishing, 2015.
[2] Stephen Marsland. Machine learning, An Algorithmic Perspective. CRC Press, 2015.
[3] Ryszard Tadeusiewicz Maciej Szaleniec. Leksykon sieci neuronowych. Wydawnictwo Fundacji
„Projekt nauka”, 2015.
[4] Ian Goodfellow, Yoshua Bengio i Aaron Courville. Deep Learning. MIT Press, 2016.
[5] mgr Andrzej Rutkowski. Wstep do sieci neuronowych, wykład 12 — Splotowe sieci neuronowe.
Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika. 2017.
[6] NEMA – The Association of Electrical Equipment and Medical Imaging Manufacturers. The DI-
COM Standard. 2017. URL: http://dicom.nema.org/standard.html.
[7] mgr Maciej Radzienski. Cyfrowe przetwarzanie sygnałów. Akademia Morska w Gdyni, 2007.
[8] Akinami Ohhashi, S. Yamada, K. Haruki, H. Hatano et al. „Application of a Neural Network to
Automatic Gray-level Adjustment for Medical Images”. W: IEEE (1991).
[9] François Chollet. Building Autoencoders in Keras. 2016. URL: https://blog.keras.io/
building-autoencoders-in-keras.html.
[10] Xiao-Jiao Mao, Chunhua Shen, Yu-Bin Yang. „Image Restoration Using Convolutional Auto-
encoders with Symmetric Skip Connections”. W: arXiv (2016).
[11] Michael Gharbi, Jiawen Chen, Jonathan T. Barron et al. „Deep Bilateral Learning for Real-Time
Image Enhancement”. W: ACM Transactions on Graphics, Vol 36. No. 4, Article 118 (lip. 2017).
[12] Node.js Foundation. Dokumentacja techniczna platformy Node.js. URL: https://nodejs.
org/.
[13] Google. Dokumentacja techniczna biblioteki Angular.js. URL: https://angularjs.org/.
[14] Chris Hafey. Dokumentacja techniczna biblioteki CornerStone. URL: https://github.com/
chafey/cornerstone.
[15] François Chollet. Dokumentacja techniczna biblioteki Keras. URL: https://keras.io/.
[16] Josef Sivic Ignacio Rocco Relja Arandjelovic. „Convolutional neural network architecture for
geometric matching”. W: arXiv (kw. 2017).

46 ILUSTRACJE
[17] D. Salomon, G. Motta i D. Bryant. Data Compression: The Complete Reference. Molecular bio-
logy intelligence unit. Springer London, 2007. ISBN: 9781846286032.
Ilustracje
[1] Piotr Ciazynski. Ilustracja uzycia sieci CNN wytrenowanej w ramach tej pracy dyplomowej. Praca
własna. 2017.
[2] Kjell Magne Fauske, tłumaczenie: Piotr Ciazynski. Neural network. Licencja CC BY 2.5. [Dostep
on-line: 14.10.2017]. 2006. URL: http://www.texample.net/tikz/examples/
neural-network/.
[3] Aphex34, tłumaczenie: Piotr Ciazynski. CNN layers arranged in 3-D volumes. Licencja CC BY-
SA 4.0. [Dostep on-line: 14.10.2017]. 2015. URL: https://en.wikipedia.org/wiki/
File:Conv_layers.png.
[4] Aphex34, tłumaczenie: Piotr Ciazynski. Typical CNN architecture. Licencja CC BY-SA 4.0. [Do-
step on-line: 14.10.2017]. 2015. URL: https://en.wikipedia.org/wiki/File:
Typical_cnn.png.
[5] Aphex34. Typical CNN architecture. Licencja CC BY-SA 4.0. [Dostep on-line: 19.10.2017]. 2015.
URL: https://en.wikipedia.org/wiki/File:Typical_cnn.png.
[6] ZEEs, tłumaczenie: Piotr Ciazynski. DICOM Data Element Structure. Udostepnione w ramach
domeny publicznej. [Dostep on-line: 19.10.2017]. 2008. URL: https://pl.wikipedia.
org/wiki/Plik:DICOMDataElement.svg.
[7] Piotr Ciazynski. Proces przetwarzania wartosci pikseli w obrazie DICOM. Praca własna. 2017.
[8] Zefram. Schematische Darstellung einer Histogrammspreizung. Udostepnione w ramach domeny
publicznej. [Dostep on-line: 19.11.2017]. 2006. URL: https://pl.wikipedia.org/
wiki/Plik:Histogrammspreizung.png.
[9] Zefram. Schematische Darstellung einer Histogrammeinebnung. Udostepnione w ramach domeny
publicznej. [Dostep on-line: 19.11.2017]. 2006. URL: https://en.wikipedia.org/
wiki/File:Histogrammeinebnung.png.
[10] Max La. Autoencoder. Licencja CC BY-SA 3.0. [Dostep on-line: 21.10.2017]. 2014. URL:
https://commons.wikimedia.org/wiki/File:%D0%90%D0%B2%D1%82%
D0%BE%D1%8D%D0%BD%D0%BA%D0%BE%D0%B4%D0%B5%D1%80.png.
[11] Chervinskii, tłumaczenie: Piotr Ciazynski. Schematic picture of an autoencoder architecture.
Licencja CC BY-SA 4.0. [Dostep on-line: 21.10.2017]. 2015. URL: https://commons.
wikimedia.org/wiki/File:Autoencoder_structure.png.
[12] Piotr Ciazynski. Zrzut ekranu aplikacji TIRS Adjust. Praca własna. 2017.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów

ILUSTRACJE 47
[13] Piotr Ciazynski. Ilustracja działania systemu. Praca własna. 2017.
[14] Piotr Ciazynski. Podział danych na zbiór treningowy, testowy i walidacyjny. Praca własna. 2017.
[15] Piotr Ciazynski. Architektura zastosowanej sieci neuronowej. Praca własna. 2017.
P. Ciazynski Zast. uczenia maszynowego do personalizacji param. obrazu w sys. rekonstrukcji tomogramów





























