Embed Size (px)
Citation preview

Hoofdstuk 3 : Evaluatie Hoofdstuk 3 : Evaluatie en bibliometrische en bibliometrische
aspectenaspecten
Finding the norm

1. Inleiding (1)1. Inleiding (1)
Waarom evalueren?
Efficientie en effectiviteit van IRS Uitbreiding hiervan :
Geld Invloed eindgebruiker

1. Inleiding (2)1. Inleiding (2)
Criteria voor evaluatie :
Recall and precision Response time Gebruiksvriendelijkheid Presentatievorm Collectiebereik

2. Evaluatie van 2. Evaluatie van ongerangschikte resultaten ongerangschikte resultaten (1)(1)
1.Precision :
2.Recall :

2. Evaluatie van 2. Evaluatie van ongerangschikte resultaten ongerangschikte resultaten (2)(2)
3.Miss : Fractie van relevante niet gevonden documenten
4.Fall-out :

2. Evaluatie van 2. Evaluatie van ongerangschikte resultaten ongerangschikte resultaten (3)(3)
5.Accuracy : Fractie van juist geklasseerde resultaten
6.F-Measure : Gewogen gemiddelde van Precision en recall

2. Evaluatie van 2. Evaluatie van ongerangschikte resultaten ongerangschikte resultaten (4)(4)
R en P zijn omgekeerd evenredig
Records zijn relevant of niet-relevant, zonder tussenweg
Moeilijk om relevantie te bepalen
Nog moeilijker om recall te bepalen

2. Oefening (1)2. Oefening (1)
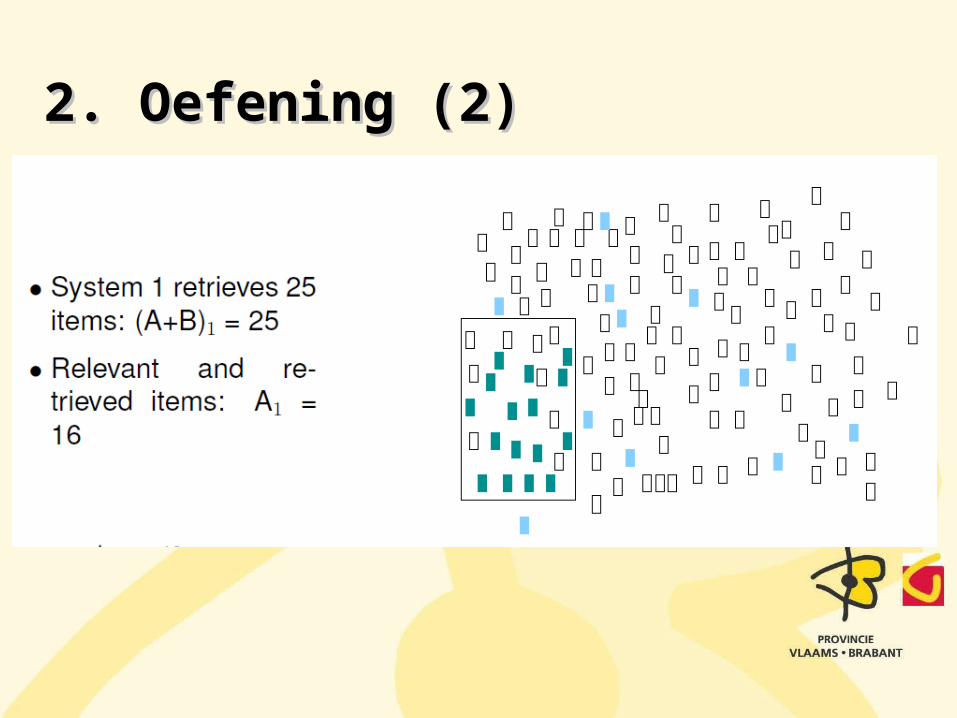
2. Oefening (2)2. Oefening (2)
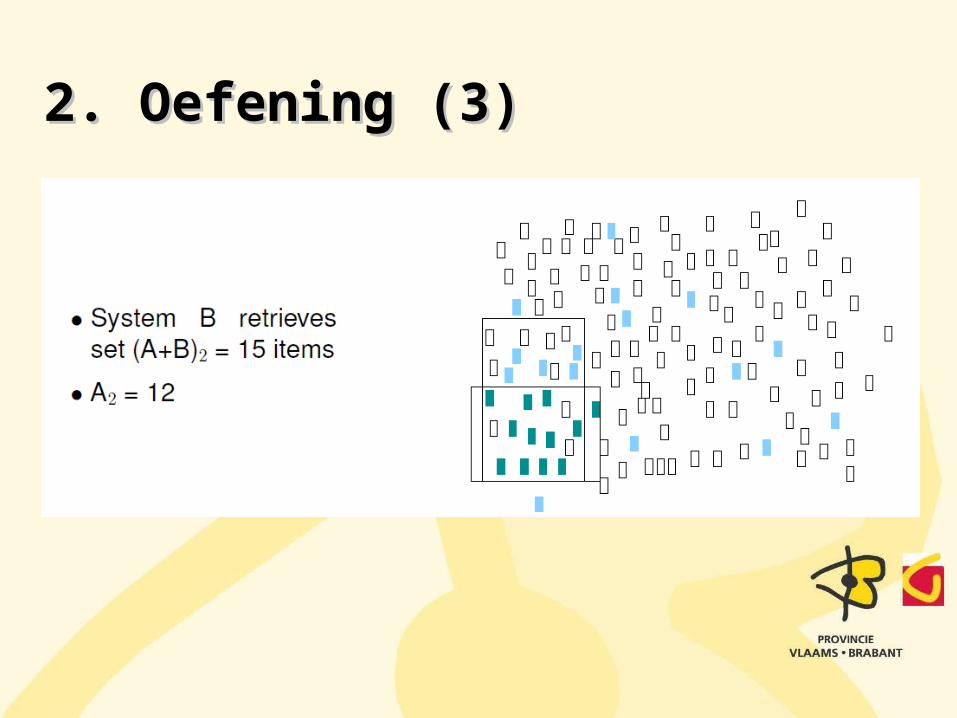
2. Oefening (3)2. Oefening (3)

2. Oefening (4)2. Oefening (4)
Bereken telkens :
Recall Precision Accuracy Miss (F-Measure)

2. P en R in IR (1)2. P en R in IR (1)
P en R = Goede maten voor discipline gebonden DB
Maar niet voor “moderne” zoekmachines Exhausitiviteit is niet belangrijk Veel informatie Precision is belangrijk Relevantie is minder belangrijk ranking
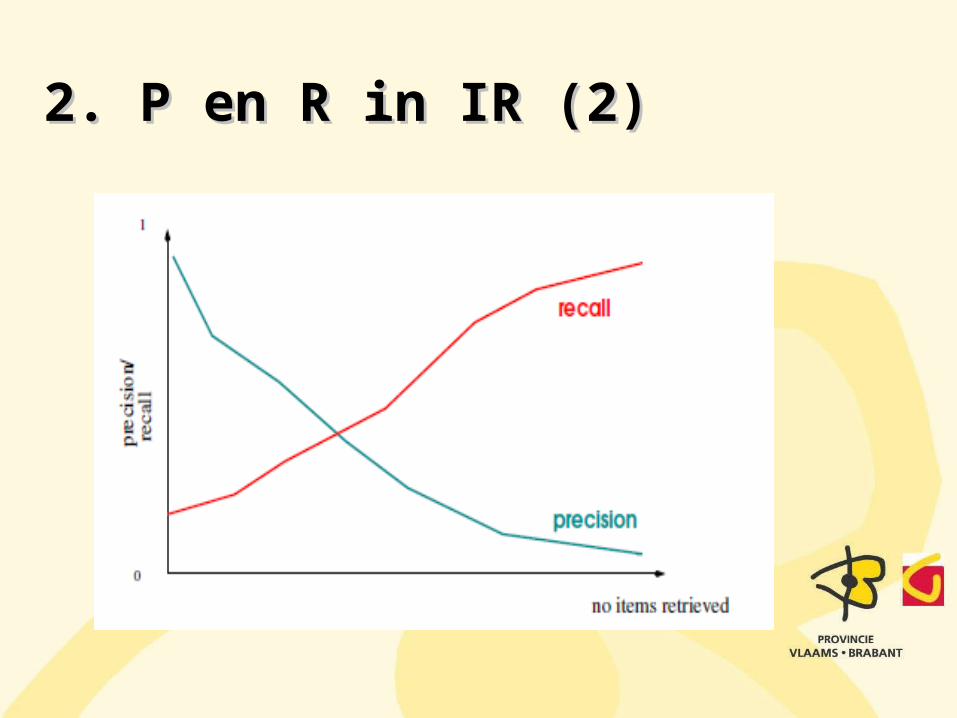
2. P en R in IR (2)2. P en R in IR (2)
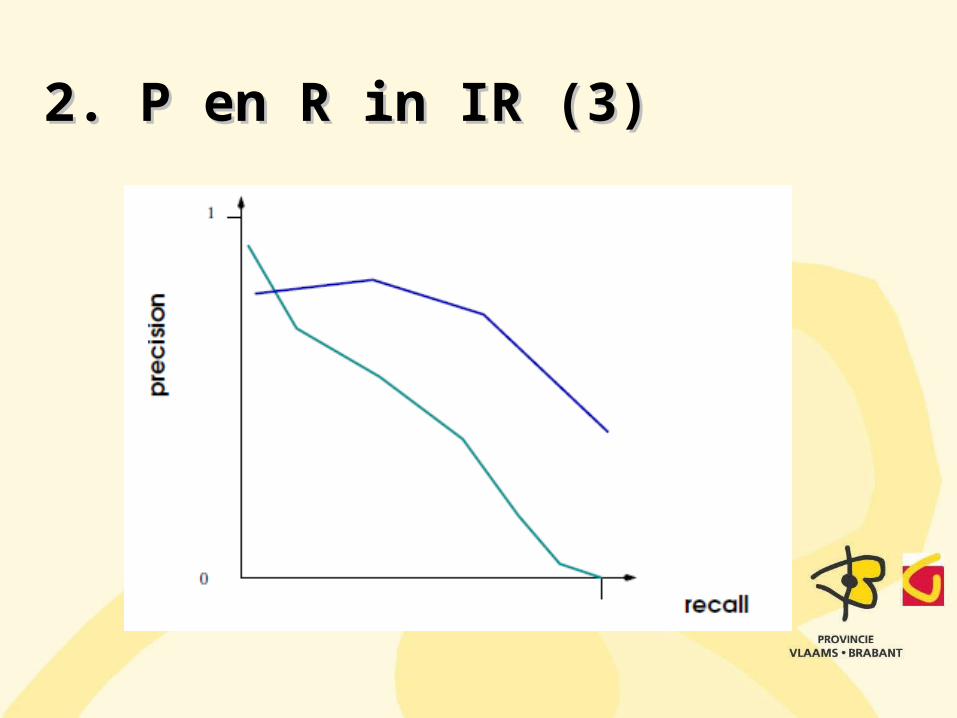
2. P en R in IR (3)2. P en R in IR (3)

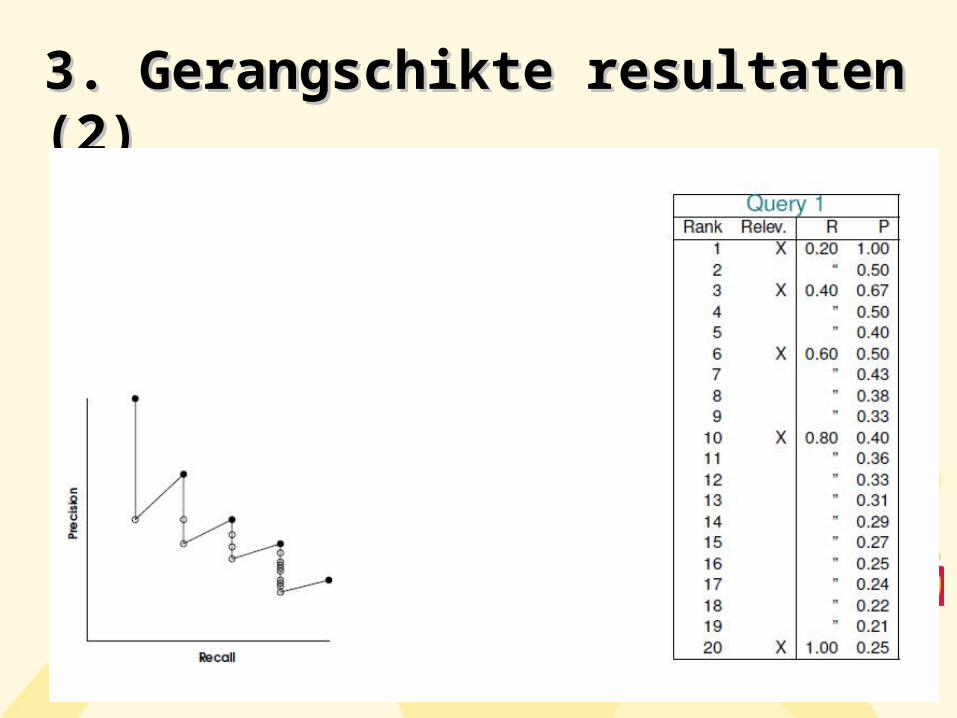
3. Gerangschikte resultaten 3. Gerangschikte resultaten (1)(1)
Problematiek van gerangschikte resultaten :
Zie voorbeeld
Dus Nieuwe criteria voor beoordeling : vb.
Precision bij een bepaalde rangschikking Precision bij laatste relevante document Precision bij een bepaalde recall
3. Gerangschikte resultaten 3. Gerangschikte resultaten (2)(2)
3. Gerangschikte resultaten 3. Gerangschikte resultaten (3)(3)
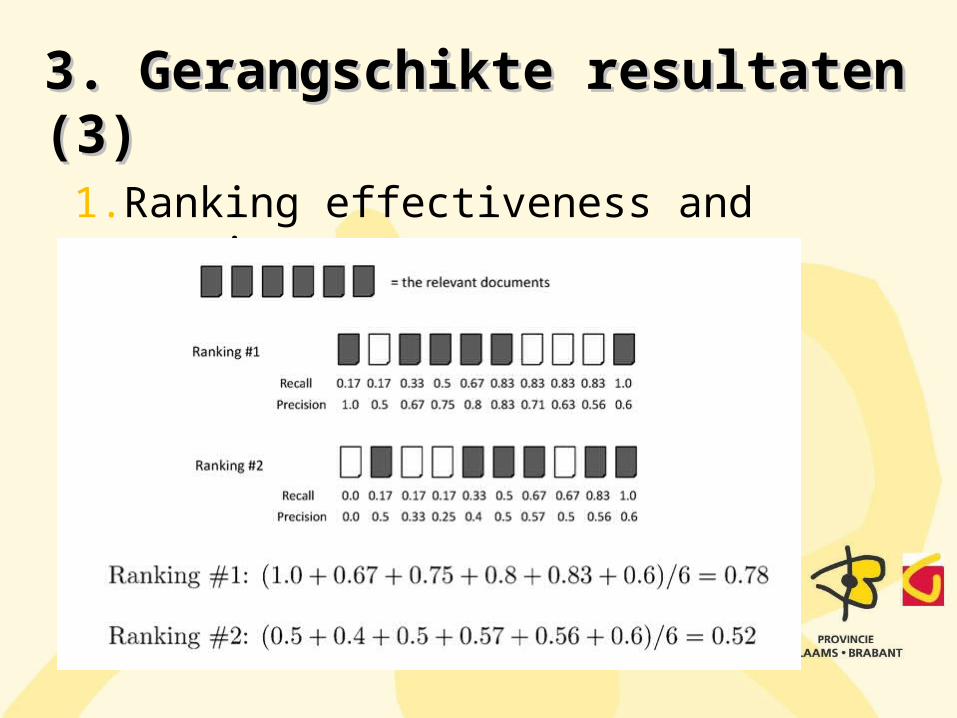
1. Ranking effectiveness and avering
3. Gerangschikte resultaten 3. Gerangschikte resultaten (4)(4)
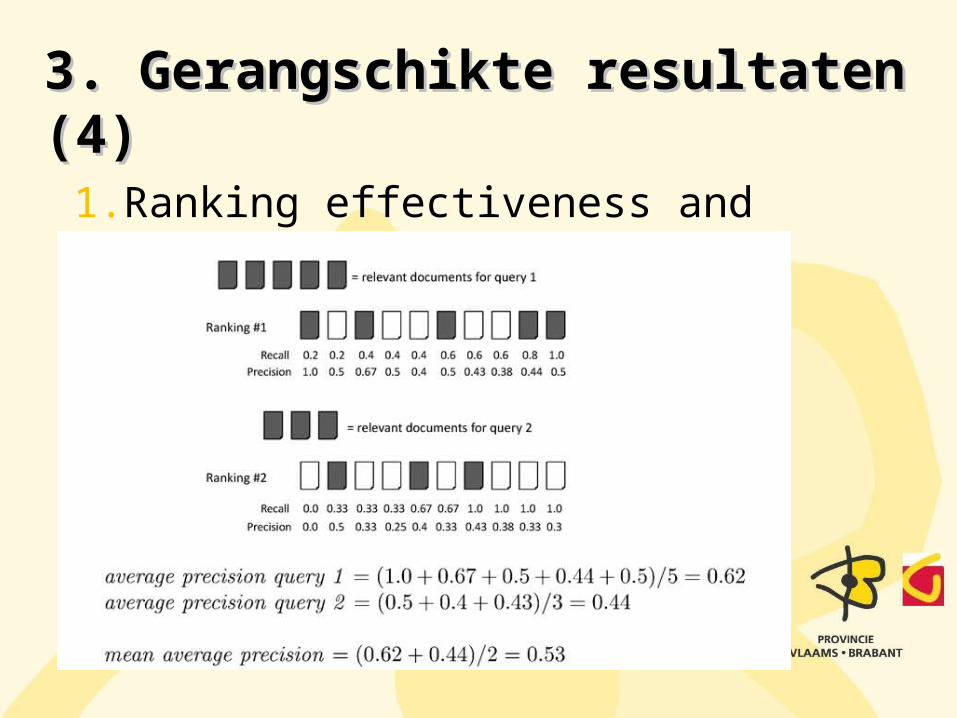
1. Ranking effectiveness and avering

3. Gerangschikte resultaten 3. Gerangschikte resultaten (5)(5)
2. Top documents focus
Eindgebruikers : bekijken enkel top documenten
Recall is niet van belang Meten hoe goed een IRS
topdocumenten weergeeft Recall vastleggenop bepaalde
rankings Precision berekenen op die rankings

3. Gerangschikte resultaten 3. Gerangschikte resultaten (6)(6)
3. Discounted cumulative gain
Uitgangspunt Hoger gerangschikt is relevanter Lager gerangschikt is minder nut
Graded relevance berekenen “Gain” cumuleren “Gain” neemt relatief af

3. Gerangschikte resultaten 3. Gerangschikte resultaten (7)(7)
3. Discounted cumulative gain

4. Kwalitatieve benadering4. Kwalitatieve benadering
Elapsed indexing time :
Indexing processor time :
Query throughput :
Query latency :
Indexing temporary space :
Index size :

5. Andere bibliometrische 5. Andere bibliometrische berekeningen (1)berekeningen (1)
Bibliometrische informatieVs.Bibliografische informatie
Twee databanken :WoSGoogle Scholar

5. Andere bibliometrische 5. Andere bibliometrische berekeningen (2)berekeningen (2)
1. WoS
Journal Impact factor 2-jaarlijks 5-jaarlijks
Journal self cites Journal immediacy index Journal cited half-life Journal citing half-life

5. Andere bibliometrische 5. Andere bibliometrische berekeningen (3)berekeningen (3)
1. WoS
Eigen factor Gebaseerd op JIF Houdt rekening met gewicht citerende TS
Journal influence score Gebaseerd op Eigenfactor Mediaan =1

5. Andere bibliometrische 5. Andere bibliometrische berekeningen (4)berekeningen (4)
1. WoS : Researchers
Totaal artikels Totaal citaties H-index

5. Andere bibliometrische 5. Andere bibliometrische berekeningen (5)berekeningen (5)
2. Google Scholar : Tijdschriften
H-index H5-index
2. Google Scholar : Onderzoekers
H-index H5-index I5-index

5. Andere bibliometrische 5. Andere bibliometrische berekeningen (6)berekeningen (6)
Nadelen
Impactfactor is te eenvoudig Nadelen voor humane wetenschappen
Geen boeken / vaktijdschriften / nationale publicaties
Vooral Engelstalig Te korte berekeningsperiodes
Grote databanken Fouten in persoonsnamen Fouten in instelllingen Nieuwe publicaties duurt lang

5. Andere bibliometrische 5. Andere bibliometrische berekeningen (7)berekeningen (7)
Nadelen
Google Scholar Onduidelijkheid over herkomst Vindt niet alles Fouten en onnauwkeurigheden
Gemakkelijk fraude Citatie-analyse context

5. Andere bibliometrische 5. Andere bibliometrische berekeningen (8)berekeningen (8)
Voordelen
Duidelijke (kwantitatieve) manier van werken
Geeft indicaties over de kwaliteit Relaties tussen publicaties en
onderzoekers Er is niets anders Bruikbaar in een breder veld





























![大垣市 · ˝˛12345 m¿ /À c7k c7` ´ˆ ˜~ ¯˘ ˙¨ c7 ŠÉ ˚¸c7 RS \] ¯˘Ì˝k ˛ˇ— CÑHYˇ IGÑIB ˝kOÒ c7Ó $%& " Ì ÔGÕCBÔH c7 Ö×ØÙ ÚÛxz!fifl](https://img.pdfslide.tips/doc/110x75/5f2dc1d5e628d06bd419b879/-12345-m-c7k-c7-oe-c7-c7-rs-oek.jpg)