Presentasi Tugas IF5133 Sistem Komputer Kelompok 4 : Claudio
Franciscus 23511009 Rizfi Syarif 23511013 Alif Finandhita 23511034
Andhik Budi Cahyono 23511081 Yadhi Aditya Permana 23511112
GPU computing (General Purpose GPU GPGPU) merupakan konsep
pemrograman parallel yang menggunakan GPU sebagai media komputasi
untuk memproses komputasi yang umumnya dikerjakan CPU. Model untuk
komputasi GPU adalah dengan menggunakan CPU dan GPU bersama-sama
dalam suatu model komputasi heterogen co-processing. Bagian
berurutan aplikasi berjalan pada CPU dan bagian komputasi-intensif
dipercepat oleh GPU. Dari sudut pandang pengguna, aplikasi akan
berjalan lebih cepat karena menggunakan kinerja-tinggi dari GPU
untuk meningkatkan kinerja.
Konsep ini menghasilkan kecepatan proses yang jauh lebih baik
dibanding kecepatan CPU untuk kasus kasus tertentu. Keunggulan yang
dimiliki oleh GPU ini bukan berarti menggantikan peran CPU. CPU
lebih spesifik menangani permasalahan logika, sedangkan
permasalahan komputasi diserahkan kepada GPU. GPU berevolusi
menjadi sebuah manycore processor dengan kemampuan komputasi dan
memory bandwith yang tinggi.
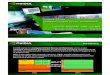
Operasi floating-point CPU dan GPU
Operasi floating-point CPU GPU dan memory bandwith untuk CPU
GPU
Perbedaan floating-point operation dan memory bandwith ada
karena GPU dispesialisasikan untuk menangani komputasi secara
paralel. Pada GPU dirancang lebih banyak transistor yang
didedikasikan untuk mengolah data daripada data caching dan flow
control.
Secara spesifik GPU cocok untuk mengatasi masalah yang dapat
dikategorikan sebagai data-parallel computations (program yang sama
dieksekusi pada banyak data elemen secara paralel) Komputasi
dilakukan dengan intensitas aritmatika yang tinggi, oleh karenanya
proses tersebut lebih baik dilakukan secara langsung daripada
disimpan di memori. Dalam GPGPU data disimpan di tekstur
menggunakan format floating-points sehingga suatu pixel tidak lagi
merepresentasikan warna melainkan suatu nilai numerik.
Inti dari komputasi parallel di GPU :Memanfaatkan banyak core
yang tersedia di GPU Semakin banyak core maka akan semakin banyak
thread yang dapat dihandle oleh GPU
Cara memanfaatkan kemampuan komputasi parallel pada GPU :Metode
Klasik Shader Programming Metode Setengah Modern Brook GPU Metode
Modern CUDA
Metode Klasik
Shared Programming :
Tidak standalone (memanfaatkan rendering pipeline), harus
bekerja dengan Graphics API, contoh : OpenGL atau Direct3D. Bahasa
pemrograman : OpenGL Shading Language (GLSL).
Metode Setengah Modern
BrookGPU :
Masih memanfaatkan rendering pipeline dan bekerja dengan Open
GL/Direct3D tapi dengan konsep stream processing yang lebih
terbuka.
Metode Modern
CUDA :
Akses untuk mengontrol elemen-elemen paralel di GPU, seperti
manajemen thread, register, akses memory di multiprocessor atau di
DRAM dengan performa yang lebih baik dari shader programming.
Berawal dari riset NVIDIA terhadap GPGPU. NVIDIA merevolusi
GPGPU dan mengakselerasi dunia komputasi dengan memperkenalkan
arsitektur parallel CUDA (terdiri dari ratusan core processor).
CUDA = Compute Unified Device Architecture. Merupakan arsitektur
pemrosesan paralel yang diimplementasikan ke dalam GPU buatan
NVIDIA Teknologi yang dikembangkan oleh NVIDIA untuk mempermudah
utilitasi GPU untuk keperluan umum (non-grafis).
Arsitektur CUDA
Arsitektur CUDA ini memungkinkan pengembang perangkat lunak
untuk membuat program yang berjalan pada GPU buatan NVIDIA dengan
syntax yang mirip dengan syntax C/C++/Fortran yang sudah banyak
dikenal. Kemampuan pemrosesan GPU dapat dimanfaatkan lebih mudah
oleh developer dalam hal mengkomputasi program yang mereka buat.
Arsitektur CUDA menuntun para developer untuk membagi masalah
kedalam sub-masalah yang dapat diselesaikan secara independen dalam
proses paralel.
Proses komputasi parallel GPU dengan CUDA
Processing flow pada CUDA
Bagaimana menjalankan aplikasi pada GPU yang kompatibel dengan
CUDA :CUDA menyediakan ekstensi pada bahasa C berupa fungsi yang
ditandai khusus _global_ CPU akan menjalankan fungsi tersebut di
dalam GPU. Setelah memulai eksekusi pada GPU, program akan segera
mengeksekusi perintah berikutnya, tidak harus menunggu eksekusi GPU
selesai. Hal ini memungkinkan pemrogram untuk menjalankan komputasi
secara paralel antara CPU dan GPU. Selain dengan keyword __global__
, kernel juga dapat dideklarasikan dengan keyword __device__.
Bedanya, kernel __device__ini hanya dapat dipanggil oleh kernel
yang lain, alias oleh fungsi yang sudah berjalan pada GPU.
CUDA x86 Compiler, hasil kerja sama NVIDIA dan Portland Group
untuk membuat aplikasi dengan menggunakan CUDA. MATLAB ANSYS,
spesialisasi di bidang desain dan simulasi yang memanfaatkan CUDA
untuk melakukan simulasi. Satu proses simulasi, misalnya simulasi
kemungkinan masalah yang terjadi pada roda pesawat terbang,
membutuhkan kemampuan proses yang tinggi.
Autodesk,menambahkan dukungan terhadap CUDA pada aplikasi
populer mereka, 3ds Max, melalui plugin iray. iray memungkinkan
rendering objek 3D dilakukan dengan menggunakan GPU yang mendukung
CUDA. Autodesk juga menunjukkan sebuah proyek masa depan dimana
pengguna 3ds Max bisa melakukan editing dari jarak jauh pada
aplikasi 3ds Max yang terpasang di server yang didukung tenaga 32
GPU Fermi, hanya melalui sebuah browser.
NVIDIA Corporation, CUDA, Parallel Programming Made Easy ,
http://www.nvidia.com/objects/cuda_home_new.html, 2011 NVIDIA
Corporation, What is GPU Computing? ,
http://www.nvidia.com/objects/GPU_computing.html, 2011 David
Luebke, CUDA : Scalable Parallel Programming for High Performance
Scientific Computing , IEEE ISBI, 2008, pp. 836 838. J. Nickolls,
I. Buck, M. Garland & K. Skadron, Scalable Parallel Programming
with CUDA , ACM Queue, 6(2), 2008, pp. 40 53.

![Программно-аппаратная архитектура CUDA, осень 2015 [Открытое прочтение]: Программная модель CUDA](https://img.pdfslide.tips/doc/110x75/588468ba1a28abbd308b6965/-cuda--591390cfeebd1.jpg)