Embed Size (px)
Citation preview

PROCESAMIENTO EN TIEMPO REAL DE VARIABLES FISIOLÓGICAS
Carlos A. Ramírez R Miguel A. Hernández [email protected] [email protected]
Universidad Nacional Experimental del TáchiraDecanato de Investigación – Grupo de Bioingeniería.
INTRODUCCION
El material que se presenta a continuación, brevemente ilustra las tres etapas involucradas
en el diseño de un dispositivo que tenga como objetivo adquirir, visualizar y procesar en tiempo
real, variables fisiológicas tomadas de un ser vivo. En particular, se hace énfasis en el diseño de
estos dispositivos tomando como herramienta el computador personal. Se hace mención a las
técnicas de programación multitarea, que permiten mejorar la velocidad de adquisición de
muestras y visualización de los datos. De igual manera, se describen brevemente dos técnicas
(redes neurales y lógica difusa) para el reconocimiento de patrones que en años recientes se han
establecido como herramientas robustas y computacionalmente económicas para el
procesamiento de señales en tiempo real.
1. INSTRUMENTACIÓN BIOMÉDICA
Los instrumentos biomédicos son todos aquellos empleados para medir, registrar y/o
controlar el valor de cualquier parámetro fisiológico en observación. Unos se utilizan para
obtener información o aplicar energía a los seres vivos y otros están destinados a ofrecer una
ayuda funcional o a la sustitución de funciones orgánicas. Todo sistema de instrumentación
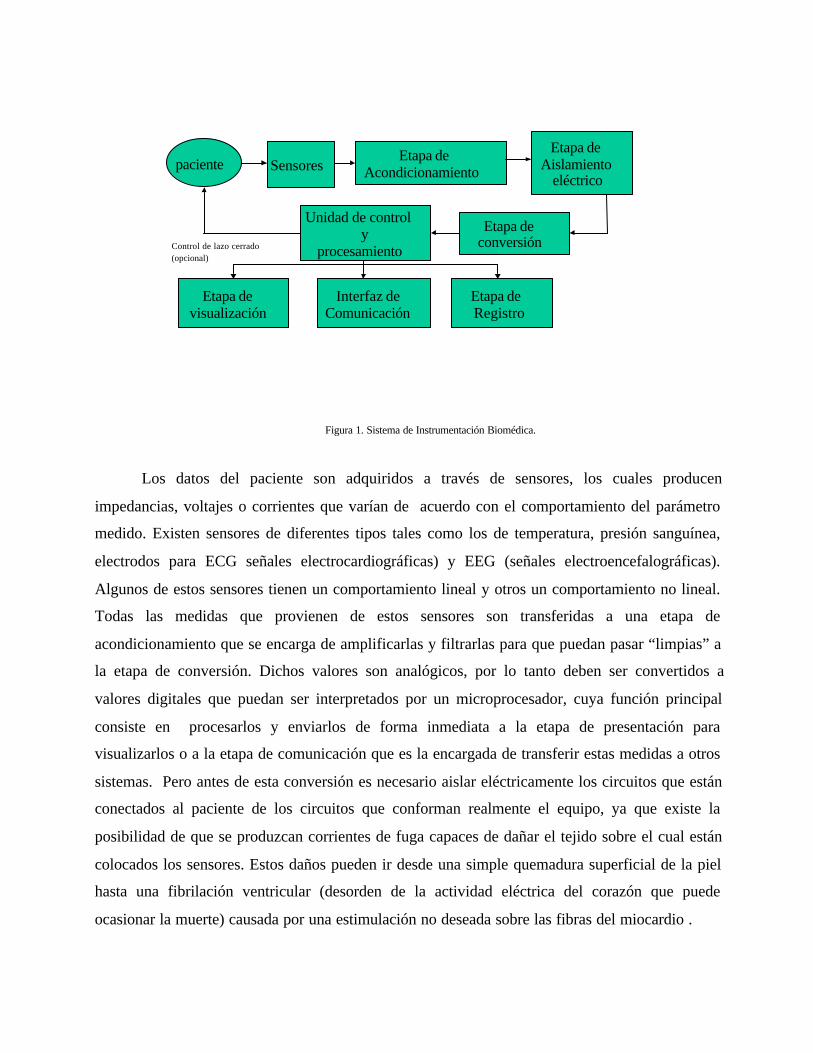
biomédica presenta una estructura muy similar a la de la Figura 1
paciente SensoresEtapa de
Acondicionamiento
Etapa deconversión
Unidad de controly
procesamiento
Etapa devisualización
Interfaz deComunicación
Etapa deRegistro
Etapa deAislamiento
eléctrico
Control de lazo cerrado(opcional)
Figura 1. Sistema de Instrumentación Biomédica.
Los datos del paciente son adquiridos a través de sensores, los cuales producen
impedancias, voltajes o corrientes que varían de acuerdo con el comportamiento del parámetro
medido. Existen sensores de diferentes tipos tales como los de temperatura, presión sanguínea,
electrodos para ECG señales electrocardiográficas) y EEG (señales electroencefalográficas).
Algunos de estos sensores tienen un comportamiento lineal y otros un comportamiento no lineal.
Todas las medidas que provienen de estos sensores son transferidas a una etapa de
acondicionamiento que se encarga de amplificarlas y filtrarlas para que puedan pasar “limpias” a
la etapa de conversión. Dichos valores son analógicos, por lo tanto deben ser convertidos a
valores digitales que puedan ser interpretados por un microprocesador, cuya función principal
consiste en procesarlos y enviarlos de forma inmediata a la etapa de presentación para
visualizarlos o a la etapa de comunicación que es la encargada de transferir estas medidas a otros
sistemas. Pero antes de esta conversión es necesario aislar eléctricamente los circuitos que están
conectados al paciente de los circuitos que conforman realmente el equipo, ya que existe la
posibilidad de que se produzcan corrientes de fuga capaces de dañar el tejido sobre el cual están
colocados los sensores. Estos daños pueden ir desde una simple quemadura superficial de la piel
hasta una fibrilación ventricular (desorden de la actividad eléctrica del corazón que puede
ocasionar la muerte) causada por una estimulación no deseada sobre las fibras del miocardio .

Opcionalmente, el instrumento puede contener un sistema de registro para guardar
secuencias prolongadas de estos parámetros durante intervalos de tiempo considerables y útiles
para estudios clínicos posteriores. Estos registros pueden ser grabados en un papel especial o
pueden ser almacenados en formato digital en un archivo de disco. Algunos sistemas de medición
pueden necesitar de un control de lazo cerrado, por ejemplo, los estimuladores cardiacos
utilizados para diagnosticar arritmias cardiacas, ya que estos deben emitir pulsos de corriente
sobre el tejido con una frecuencia determinada por el comportamiento del corazón ante el
estímulo. Otros equipos como los monitores utilizados en una unidad de cuidados intensivos
(UCI) no necesitan de este sistema, salvo en el caso de detectar algún electrodo que no haya sido
conectado en el paciente debidamente.
2. INSTRUMENTOS MÉDICOS BASADOS EN COMPUTADORES
Los instrumentos médicos basados en computadores tienen la capacidad de presentar las
imágenes, señales y otros parámetros biomédicos en la pantalla de un computador. Los sistemas
más avanzados, tienen la capacidad de procesar digitalmente señales e imágenes. Pero se debe
tomar en cuenta, que toda la posibilidad que tenga un sistema computarizado médico de realizar
estas tareas depende de las características de los datos y de la arquitectura del hardware asociado.
Por ejemplo, una computadora puede procesar señales o imágenes, aplicando un conjunto
de filtros por software útiles para eliminar de la señal las interferencias no deseadas. De igual
manera, se pueden implementar algoritmos útiles para suprimir algunos componentes de una
señal y así poder estudiar un fenómeno asociado solo a un componente de la misma, como es el
caso de la cancelación del complejo QRS de la señal ECG.
Estos algoritmos requieren computadoras con altas velocidades de procesamiento,
preferiblemente basadas en procesadores RISC, tales como los de la serie SPARC de Sun
Microsystems, o procesadores superescalares como los Pentium II, III y IV de la Intel (ver figura
2.2. ), y en algunos casos no es un mito pensar en la implementación de una maquina paralela
(SIMD o MIMD) conformada por varios microprocesadores. Además de los métodos netamente
matemáticos, existen otras formas de procesar y analizar señales, basadas en algoritmos de
inteligencia artificial aplicando redes neurales y reconocimiento de patrones, que también
requieren de las arquitecturas anteriormente mencionadas.

Figura. 2. Computadores RISC vs CISC
Pero no solo de la capacidad de procesamiento depende el éxito de la interpretación y el
análisis confiable de una imagen o una señal médica. También es importante que el sistema de
adquisición sea veloz y que obtenga la mayor cantidad de muestras de los datos que sea posible
en un intervalo de tiempo determinado. En la actualidad, existen tarjetas de adquisición de datos
especiales para obtener imágenes o señales médicas. Estas tarjetas tienen características
peculiares, tales como la posibilidad de realizar transferencias a través de acceso directo a
memoria y buffering1, ya que muchas de estas contienen circuitos integrados de DMA2 y
memorias FIFO3, adicionales a las que pueda tener el propio computador. El principal fabricante
de este tipo de hardware es la conocida compañía NATIONAL INSTRUMENTS. Otras tarjetas
más costosas incluyen chips DSP4 los cuales son microprocesadores especiales para el
procesamiento de señales digitales.
Sin embargo, no siempre es indispensable una tarjeta de adquisición de datos.
Actualmente el puerto paralelo de capacidades extendidas, proporciona una velocidad de muestro
de 1 Mhz e incluye transferencias con DMA y compresión de datos codificadas en RLE5. Por otra
parte, el puerto proporciona velocidades de transmisión de datos en el orden de los 14.1
1 Técnica donde se interpone una memoria de almacenamiento temporal de datos entre un dispositivo de altavelocidad con uno de baja velocidad, con la finalidad de evitar la perdida de datos.2 Siglas en ingles que significan Acceso Directo a Memoria.3 First In, First Out. El primer elemento que se almacena en la memoria es el último que sale.4 Siglas en ingles que se traducen como Procesamiento Digital de Señales5 Método de compresión de datos denominado Run Length Encoding.

Megabits por segundo. Estos puertos están incluidos en todas las computadoras personales que
actualmente se fabrican.
3. SOFTWARE PARA EL DESARROLLO DE INSTRUMENTOS BIOMÉDICOS
BASADOS EN COMPUTADORA
Para que el hardware funcione de manera apropiada, el software con el cual se desarrollan
las rutinas de adquisición y presentación de las señales, también desempeña un papel
fundamental. En algunos casos, ciertas rutinas se deben implementar en lenguajes de bajo nivel
para poder acceder a los componentes del hardware de la forma más rápida posible, aunque
implique más trabajo y conocimientos por parte del programador. Por otra parte, con la aparición
de los lenguajes orientados a objetos y los ambientes de desarrollo visuales, se ha hecho más fácil
la programación de las pantallas de presentación de los datos y el manejo de los archivos de
almacenamiento.
Por esta razón, una aplicación médica implantada en un equipo basado en computador,
debe estar conformada por rutinas de bajo y alto nivel para poder gozar de una velocidad
aceptable de adquisición y procesamiento, sin dejar atrás la realización de una interfaz gráfica
con el usuario lo más sencilla y agradable posible.Algunos de los lenguajes utilizados para la
programación de estas aplicaciones son: MASM32, TASM32, BORLAND C/C++, BUILDER
C++, VISUAL C++, LABVIEW.
Es importante destacar que mientras más alto sea el nivel del lenguaje de programación, el
desempeño en términos de velocidad de procesamiento será menor. En la figura 2.3 se ilustra
gráficamente el tiempo en que dura un programador una aplicación vs. el tiempo de ejecución de
la misma.

Figura. No 3.. Tiempo de desarrollo vs. Tiempo de ejecución. Tomada de [.
4. ADQUISICIÓN DE DATOS.
Un sistema de adquisición de datos esta constituido por un conjunto de elementos de
hardware y software cuya principal función consiste en obtener datos provenientes del mundo
exterior y convertirlos en valores que puedan ser procesados y representados en un computador o
en otro sistema de visualización. De esta manera, es posible estudiar la mayoría de los fenómenos
de la naturaleza más subjetivamente, debido a que los datos, ya sean señales o simples valores,
pueden ser analizados con mayor precisión y exactitud. En el campo de la bioingeniería, estos
sistemas se emplean para convertir fenómenos fisiológicos tales como temperatura, presión
arterial, señales electrocardiográficas, etc. en valores digitales que son interpretados en una
unidad de control.
El concepto de convertir una señal continua en el tiempo a su representación discreta
utilizable por un microprocesador, radica en el hecho de que se puede representar dicha señal
continua por medio de sus valores de amplitudes instantáneas tomados en intervalos periódicos
de tiempo . De esta manera, es posible reconstruir la señal original perfectamente con los valores
obtenidos, ya que el tiempo transcurrido entre la adquisición de un valor y el próximo se puede
determinar, conociendo el número de valores por segundo que pueden ser adquiridos sin que se
pierdan datos (ver figura 3), es decir, conociendo la velocidad de muestreo o de adquisición.

Este concepto ha sido explotado en el cine, donde los marcos individuales son fotografías
de alta velocidad de una escena continua cambiante. Cuando dichos marcos proyectan en una
secuencia de alta velocidad, es posible tener una representación casi exacta de la escena original
[.
Figura 4. A) Señal Analógica, continua. B) Señal digitalizada, como se observa en la figura, esta conformada por una serie de puntos donde cada
uno de los mismos tienen su respectivo valor de amplitud y están separados por un mismo intervalo de tiempo C) Señal Reconstruida a partir de la
señal digitalizada.
Los datos digitalizados, se utilizan para reconstruir la señal, como se observa en la figura
4. La señal reconstruida es una buena reproducción de la señal analógica original. Esto se debe a
que esta última no presenta variaciones rápidas que superen la velocidad de muestreo a la que se
adquieren las diferentes muestras. En el caso contrario, la señal reconstruida sería una versión
mucho menos exacta que la original. Por lo general, la velocidad de muestreo, depende de la
velocidad de conversión de la señal analógica a digital, es decir, depende de la velocidad de
respuesta de los circuitos y del software que participa en esta tarea. En algunos casos, se pueden
perder algunas muestras de la señal, pero no una cantidad excesiva, ya que la morfología de dicha
señal al reconstruirla será totalmente distinta. Sin embargo, el Teorema de Muestreo inicialmente
desarrollado por Shannon, garantiza que la señal puede ser reconstruida a partir de sus muestras
sin ninguna perdida de información, siempre y cuando una señal que no tenga componentes mas
altas que una frecuencia fc, sea muestreada a una velocidad al menos de 2fc muestras por
segundo. A dicha frecuencia (2fc) de le denomina Frecuencia de Nyquist .
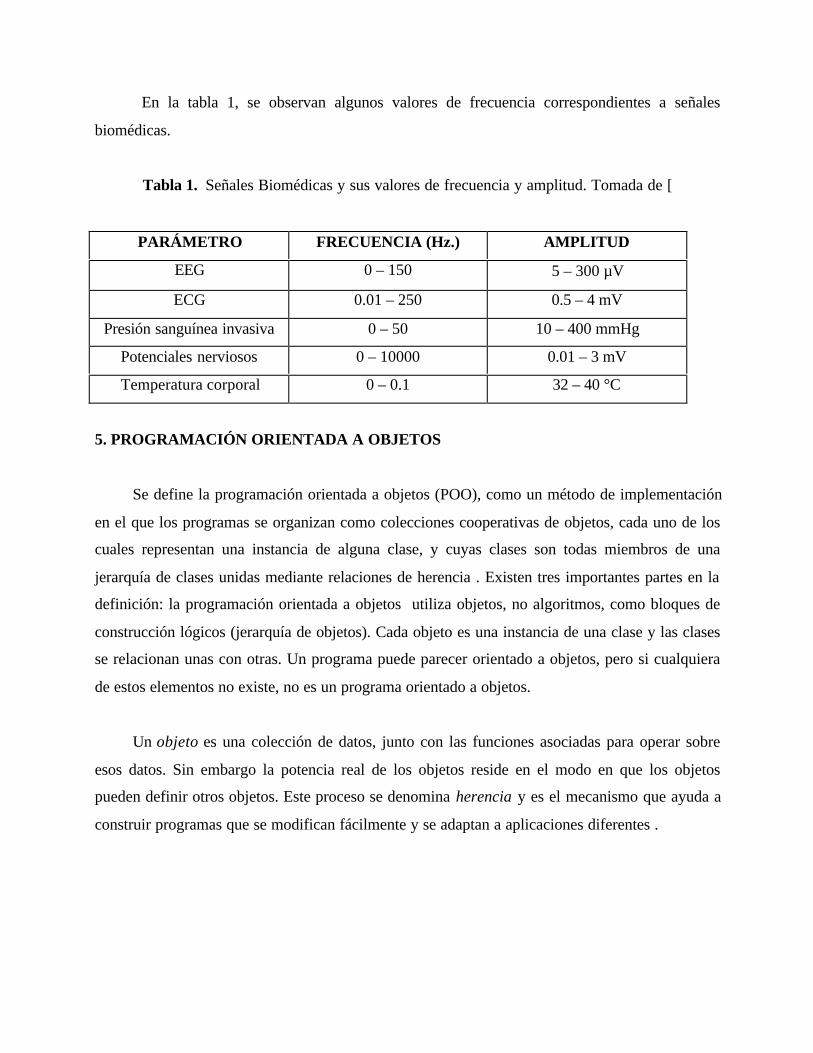
En la tabla 1, se observan algunos valores de frecuencia correspondientes a señales
biomédicas.
Tabla 1. Señales Biomédicas y sus valores de frecuencia y amplitud. Tomada de [
PARÁMETRO FRECUENCIA (Hz.) AMPLITUD
EEG 0 – 150 5 – 300 µV
ECG 0.01 – 250 0.5 – 4 mV
Presión sanguínea invasiva 0 – 50 10 – 400 mmHg
Potenciales nerviosos 0 – 10000 0.01 – 3 mV
Temperatura corporal 0 – 0.1 32 – 40 °C
5. PROGRAMACIÓN ORIENTADA A OBJETOS
Se define la programación orientada a objetos (POO), como un método de implementación
en el que los programas se organizan como colecciones cooperativas de objetos, cada uno de los
cuales representan una instancia de alguna clase, y cuyas clases son todas miembros de una
jerarquía de clases unidas mediante relaciones de herencia . Existen tres importantes partes en la
definición: la programación orientada a objetos utiliza objetos, no algoritmos, como bloques de
construcción lógicos (jerarquía de objetos). Cada objeto es una instancia de una clase y las clases
se relacionan unas con otras. Un programa puede parecer orientado a objetos, pero si cualquiera
de estos elementos no existe, no es un programa orientado a objetos.
Un objeto es una colección de datos, junto con las funciones asociadas para operar sobre
esos datos. Sin embargo la potencia real de los objetos reside en el modo en que los objetos
pueden definir otros objetos. Este proceso se denomina herencia y es el mecanismo que ayuda a
construir programas que se modifican fácilmente y se adaptan a aplicaciones diferentes .

6. MULTIPROGRAMACIÓN
La multiprogramación es la gestión de varios procesos en un solo procesador. Es un modo
de trabajo en el que se pueden ejecutar varios procesos simultáneamente con el fin de aprovechar
al máximo los recursos de la computadora. Consiste en aprovechar la inactividad del procesador
durante la ejecución de una operación de entrada o salida de un proceso para atender a otro.
Desde el punto de vista de cada proceso, todos están siendo atendidos al mismo tiempo por un
procesador, que se puede considerar virtual, debido a que en realidad todos son atendidos por
este, pero no al mismo tiempo, este conmuta entre uno y otro constantemente, dando la
impresión de la ejecución simultanea. Desde el punto de vista del usuario, se considera que los
procesos se ejecutan simultáneamente, sin tener en cuenta que en cada quantum de tiempo se
atiende solo a uno de ellos. Esto último es debido a que la velocidad de conmutación del
procesador es tan alta que hace transparente al usuario los cambios entre la ejecución de un
proceso y otro, y por lo tanto siempre parece que los procesos se ejecutan paralelamente. La
mayoría de los computadores personales, estaciones de trabajo y sistemas operativos actuales
para estas maquinas, tales como UNIX, Windows, OS/2 y el sistema 7 de Macintosh, dan soporte
a la multiprogramación.
6.1. PROCESOS
Un proceso es básicamente un programa en ejecución. Consta de un programa ejecutable,
sus datos y pila, el registro contador y otros, además de toda la información necesaria para
ejecutar el programa . Cuando un proceso se detiene en forma temporal, este debe volverse a
iniciar en el mismo estado en el que se encontraba al detenerse, es decir, el sistema operativo
debe almacenar toda la información relativa al proceso, durante la suspensión del mismo en una
estructura única para cada proceso conocida como bloque de control del proceso (BCP).

6.2 HEBRAS O HILOS
Una hebra es un camino de ejecución dentro de un proceso. Es una unidad remitente de
código ejecutable que se puede ejecutar independientemente, es decir, una hebra puede ser una
función dentro de un programa que se planifica y se conmuta como un proceso. El planificador de
procesos del sistema decide cuando debe ejecutar dicha hebra y cuando debe dejar de hacerlo,
para dar paso a la ejecución de otra hebra u otro proceso [.
De acuerdo a esto, un programa puede ser dividido en múltiples partes para aumentar su
efectividad, por lo tanto, un proceso tendrá una hebra como mínimo, pero es posible que dos o
más de sus fragmentos estén ejecutándose simultáneamente, en otras palabras, el proceso puede
estar conformado por varías hebras, donde cada una de estas, al igual que los procesos, podrá
estar planificada y en cualquier estado de actividad o inactividad. Algo aproximado a este
enfoque lo hacen los sistemas operativos como Windows NT, Windows 98, OS/2, Solaris y
Linux. Los beneficios clave de los hilos se derivan de las implicaciones del rendimiento, es decir,
dura mucho menos tiempo la creación de un hilo dentro de un proceso existente, que la creación
de una nueva tarea como un proceso. Por otra parte, se tarda menos en terminar un hilo y aun
mayor es la velocidad de conmutación6 entre hilos que entre procesos. Por ello, si una aplicación
o una función se puede implementar como un conjunto de unidades de ejecución relacionadas, es
mas eficiente hacerlo con una colección de hilos que con una colección de procesos. Si el sistema
de computo es multiprocesador, se podrán ejecutar varios hilos de la misma tarea en diferentes
procesadores. Si es monoprocesador, se podrán planificar varios hilos para ser ejecutados cuando
en el momento que les corresponda [.
6.3 SINCRONIZACIÓN ENTRE LOS PROCESOS
Una de las características inherentes a la multiprogramación es la concurrencia y se
define como la existencia de varias actividades ejecutándose simultáneamente que necesitan
6 La velocidad de conmutación se rige por el tiempo que tarda el cambio de contexto del procesador, es decir, parasuspender la ejecución de un proceso y ejecutar otro que este en la cola de preparados.

sincronizarse para actuar conjuntamente. Es importante resaltar que para que dos actividades sean
concurrentes, es necesario que tengan alguna relación entre sí, como puede ser la cooperación en
un trabajo determinado o el uso de información compartida .
La existencia de la multiprogramación es una condición necesaria, pero no suficiente para
que exista concurrencia, ya que los procesos pueden ejecutarse de forma totalmente
independiente. Por ejemplo, un editor y un compilador pueden estar ejecutándose
simultáneamente en una computadora sin que exista concurrencia entre ellos. Por otra parte, si un
programa se está ejecutando y se encuentra grabando datos en un archivo, y otro programa
también en ejecución está leyendo datos del mismo archivo, si existe concurrencia entre ellos, ya
que el funcionamiento de uno interfiere en el otro .
Al usar múltiples hilos o procesos concurrentes, es necesario sincronizar las actividades
de los mismos. La razón más frecuente se debe a que la compartición de recursos globales está
llena de riesgos. Aparece cuando dos o más procesos o hilos tienen que acceder a un recurso
compartido que solo puede ser utilizado por uno solo a la vez. Por ejemplo, si dos procesos hacen
uso al mismo tiempo de la misma variable global y ambos llevan a cabo tanto lecturas como
escrituras sobre la variable, el orden en que se ejecuten es crítico. Las situaciones como esta, en
la que dos o mas procesos o hilos leen o escriben ciertos datos compartidos y el resultado final
depende de quien ejecuta que y en que momento, reciben el nombre de condiciones de
competencia .
Para evitar las condiciones de competencia, se debe evitar que más de un proceso escriba
o lea datos compartidos al mismo tiempo, en otras palabras, se debe garantizar la exclusión
mutua. Esta es una forma de sincronización donde una actividad impide que otras puedan tener
acceso a un dato mientras se encuentra realizando una operación sobre el mismo .
Un proceso concurrente se puede encontrar ejecutando labores que no conducen a
condiciones de competencia. Sin embargo, es posible que otra parte del mismo proceso accese a
una región de datos compartidos, desempeñando labores sobre los mismos que puedan ocasionar
conflictos. A estas porciones del proceso se les denominan secciones críticas .

En resumen, para evitar las condiciones de competencia, se deben tomar en cuenta los
siguientes factores:
ü En un grupo de procesos concurrentes, solamente uno podrá estar dentro de su sección
crítica a la vez.
ü No se deben hacer hipótesis sobre la velocidad de los procesadores ni sobre el número de
los mismos.
ü Ningún proceso que este en ejecución debe esperar eternamente para entrar a su sección
crítica.
ü Ningún proceso que este en ejecución fuera de su sección crítica puede bloquear a otro
proceso.
Existen varios métodos para lograr la exclusión mutua y así evitar las condiciones de
competencia. Algunas de estas soluciones fallan en algunos casos, generando un caos en el
sistema, otras presentan un alto porcentaje de efectividad o son simplemente infalibles. Dichas
soluciones se clasifican en dos grupos:
ü Exclusión mutua con espera ocupada.
ü Exclusión mutua sin espera ocupada.
La exclusión mutua con espera ocupada esta conformada por todos aquellos algoritmos
que controlan la entrada a la sección crítica, haciendo que el proceso espere en un bucle que será
roto en el momento en que se cumpla una determinada condición. En este caso, el proceso no
queda bloqueado durante su ejecución, sino que estará compitiendo por el procesador
constantemente. Por esta razón, estas soluciones sobrecargan al sistema innecesariamente. La
espera ocupada puede ocasionar el caos del sistema cuando hay dos procesos concurrentes; Uno
de muy alta prioridad y otro de muy baja. El proceso de menor prioridad inicialmente se
encuentra en su sección crítica. Posteriormente el procesador conmuta y comienza a ejecutar una
espera ocupada en el proceso de mayor prioridad. Como la prioridad es tan alta que imposibilita
la planificación de los demás procesos, entonces el proceso de menor prioridad jamás saldrá de su

sección crítica, debido a que nunca será planificado. A este problema se le conoce como
inversión de prioridad .
Por estas razones, los algoritmos utilizados para evitar las condiciones de competencia no
se basan en la espera ocupada. Entre estos algoritmos, se destacan aquellos que utilizan secciones
críticas, semáforos clásicos y binarios, ya que se pueden implantar sobre la mayoría de los
sistemas operativos actuales. Las soluciones que no utilizan la espera ocupada, basan su
funcionamiento en primitivas de comunicación que bloquean un proceso cuando el mismo no
puede entrar en su sección crítica. De esta manera, el procesador puede ejecutar un proceso
preparado. Cuando el proceso que se encontraba dentro de la sección crítica libera a la misma, lo
hace a través de una primitiva de comunicación que indica al sistema operativo que el proceso
bloqueado puede ser planificado para ejecutarse, ya que puede entrar en su sección crítica.
Las primitivas más sencillas de comunicación son dormir (SLEEP) y despertar
(WAKEUP). La primera es una llamada al sistema que provoca el bloqueo de quien hizo la
llamada, es decir, que sea suspendido hasta que otro proceso lo despierte. La llamada WAKEUP
tiene un parámetro, el proceso por despertar.
7-. RECONOCIMIENTO DE PATRONES PARA EL PROCESAMIENTO DE SEÑALES.
El campo de Reconocimiento de Patrones es considerado un área de estudio inexacta
dentro de las ciencias de la computación. Su estudio permite la aplicación y generación de
distintas técnicas, algunas complementarias, algunas veces competitivas, para aproximarse de la
manera más óptima a la solución de un problema dado. Actualmente, constituye un área donde
se emplea gran cantidad de esfuerzo en términos de investigación y desarrollo guiado por la
necesidad de procesar información obtenida por la interacción entre la comunidad científica y la
sociedad en general. El área de Reconocimientos de patrones es usualmente dividida en cuatro
sub-areas conocidas como: descripción de procesos, análisis de características, agrupamiento
natural y diseño de clasificadores. Ejemplos de problemas relacionados con reconocimientos de
patrones involucran la adquisición de datos, su análisis y posterior transformación para extraer
información y estructura de ellos. Esto con la finalidad de interpretar los fenómenos presentes en
el entorno que nos rodea.

7.1 Reconocimiento Inteligente de Patrones
Hasta años recientes, el tratamiento de problemas relacionados con reconocimiento de
patrones recibía un tratamiento netamente estadístico. Sin embargo, en años recientes con el
advenimiento de poderosos sistemas de computo y el avance de la tecnología informática ha
surgido un área de estudio conocida como Reconocimiento Inteligente de Patrones (RIP). El RIP
involucra la aplicación de técnicas extraídas del campo de la Inteligencia Artificial a la solución
de problemas relacionados con reconocimiento de patrones. Estas técnicas incluyen pero no se
limita a: Sistemas expertos, redes neurales, algoritmos genéricos, sistemas difusos y cualquier
técnica que se encuentre bajo la sombra de la llamada computación emergente. La idea consiste
en pasar de los modelos matemáticos formales a modelos que asemejan de alguna manera la
forma en que un ser humano procesa datos para extraer de los mismos información relevante,
pudiendo desechar aquella que esta de más o genera incertidumbre para el proceso de toma de
decisiones. El Grupo de Bioingenieria en su sub-área de Reconocimiento Inteligente de Patrones,
realiza investigaciones que contemplan la aplicación y el desarrollo de nuevas técnicas
enmarcadas en la descripción anterior. Específicamente, se encuentra aplicando modelos de
redes neurales para el tratamiento de señales Electrocardiográficas, el modelado de sistemas
biológicos basado en su análisis de relación de estructuras cuantitativas (QSAR) y en el análisis
de variables discriminantes dado un conjunto de variables de entrada a un proceso de
clasificación, predicción o toma de decisiones.

7.2 REDES NEURALES
Redes neurales es un área de investigación dentro de una rama de ciencias de la
computación conocida como computación inteligente que se encarga del estudio de modelos
computacionales capaces de exhibir comportamiento inteligente y de aprendizaje basados en
experiencias pasadas. El propósito de este estudio es el desarrollo de entidades capaces de
realizar procesos humanos de una manera automatizada y en algunos casos más óptima.
Los modelos neurales están compuestos de una cantidad de elementos computacionales
no-lineales trabajando en paralelo estructurados en conexiones que tienen semejanza a las redes
neurales biológicas. Dentro de las áreas de aplicación de redes neurales se incluye: El análisis de
señales e imágenes, la robótica, el diagnóstico médico, la teoría de decisiones, el análisis
numérico, la optimización, el control dinámico, los sistemas cognitivos, la econometría, el diseño
de sistemas expertos y muchas más. El papel de las redes neurales en el mundo tecnológico
actual es fácilmente apreciado por el alto número de publicaciones científicas en las cuales se
resalta la versatilidad de esta técnica en la solución de problemas de ingeniería.
Al igual que las redes neurales biológicas consisten de muchas unidades de procesamiento
simple, altamente interconectadas llamadas neuronas. Las neuronas artificiales están conectadas
por canales de un solo sentido a través de los cuales las señales se transmiten. Cada neurona
recibe varias señales sobre sus conexiones de entrada, algunas de estas conexiones provienen de
otras neuronas o del mundo exterior. Sin embargo, una neurona nunca produce mas de una
salida. La mayoría de las conexiones de salida terminar como entrada a otra neurona o terminan
afuera de la red donde generan una señal de control o un patrón de respuesta. El valor de la
salida, que es enviado de una neurona hacia otra depende de un factor de peso que determina
cuanto del valor de la salida llega realmente a la neurona receptora .
La manera en la cual estas conexiones son organizadas y la metodología usada para
determinar los parámetros de peso (el diámetro de las tuberías en nuestro ejemplo), genera una
amplia variedad de modelos y algoritmos de entrenamiento. La Figura 5 muestra como ejemplo,

una red neural creada mediante la interconexión de varias capas de neuronas. Este modelo es
conocido como la red neural multicapa.
E n t r a d a S a l i d a
R e d N e u r a l
Figura 5. Red neural multicapa.
Una red neural artificial puede definirse entonces como: Un conjunto de unidades para el
procesamiento de información llamadas neuronas, arregladas para producir un procesador
inherentemente paralelo y distribuido que tiene un mecanismo natural para guardar
conocimiento proveniente de la experiencia y que permite a su vez hacer uso del mismo. Las
redes neurales artificiales se asemejan al cerebro en dos aspectos:
• El conocimiento es adquirido por la red a través de un proceso de aprendizaje.
• Los valores asociados a cada conexión inter-neural conocidos como “pesos”, son usados para
guardar este conocimiento.
El procedimiento utilizado durante el proceso de aprendizaje es llamado algoritmo de
aprendizaje, y su función es modificar los pesos en las conexiones de la red para alcanzar cierta
función objetiva. Existen numerosos tipos de redes neurales, entre las cuales tenemos las redes
recurrentes, los modelos de auto-organización, redes de resonancia.
APLICACIONES DE LAS REDES NEURALES
En el Grupo de Bioingeniería, las redes neurales son aplicadas a tres áreas básicas de
investigación:

Clasificación:
Proceso que consiste en diseñar un modelo neural que permita tomar como entrada un
patrón desconocido y asignarlo a una clase definida. Básicamente, la idea consiste en generar
una superficie de decisión n-dimensional que permita separar el universo de las variables en
clases o áreas definidas, tal como lo muestra la Figura 6 para dos clases en un espacio bi-
dimensional.
X
Y
Clase 1
Clase 2
Función deDecisión
Figura 6. Proceso de clasificación bi-dimensional
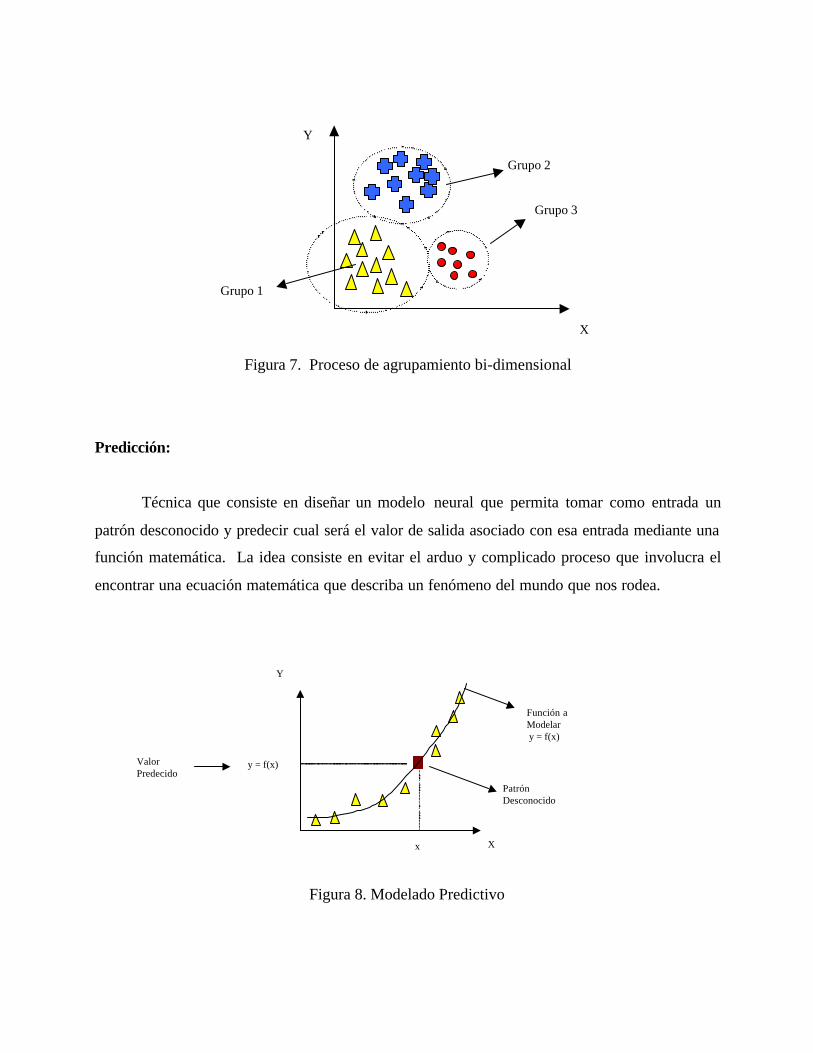
Agrupamiento natural:
Proceso que consiste en diseñar un modelo neural que permita tomar como entrada un
grupo de patrones desconocidos y conforman con ellos grupos naturales basado en criterios de
distancia, separación grupal, volumen del grupo y disposición espacial. La idea general consiste
en formar grupos de datos con aquellos patrones que presentan ciertas características homogeneas
que permiten que los mismos puedan ser considerados como pertenecientes a una misma clase,
tal como lo muestra la Figura 7 para tres grupos en un espacio bi-dimensional.
X
Y
Grupo 1
Grupo 2
Grupo 3
Figura 7. Proceso de agrupamiento bi-dimensional
Predicción:
Técnica que consiste en diseñar un modelo neural que permita tomar como entrada un
patrón desconocido y predecir cual será el valor de salida asociado con esa entrada mediante una
función matemática. La idea consiste en evitar el arduo y complicado proceso que involucra el
encontrar una ecuación matemática que describa un fenómeno del mundo que nos rodea.
Figura 8. Modelado Predictivo
X
Y
PatrónDesconocido
Función aModelar y = f(x)
y = f(x)ValorPredecido
x

En este caso, la red neural actúa como un modelo general que adapta sus parámetros al
fenómeno bajo estudio representado por un conjunto de muestras históricas sobre su desempeño
bajo ciertas condiciones. Un ejemplo de este proceso se muestra la Figura 8 para el modelado
de un fenómeno bastante conocido como lo es el crecimiento poblacional.
Variables Discriminantes:
Esta técnica consiste en utilizar las conexiones internar de una red neural multicapa para
determinar cual sub-conjunto de variables involucradas en un modelo de toma de decisiones, ya
sea de clasificación o predicción, conformar el más significativo en términos de su capacidad
discriminatoria o representativa. Esto se muestra en la Figura 9, donde se aprecia, que la variable
X, constituye la variable discriminativa al lograr separar las clases, lo cual no sucede con la
variable Y.
X
Y
Clase 2Clase 1
Función dedecisión
Variablediscriminante
Figura 9. Análisis de variables discriminantes

7.3 LÓGICA DIFUSA
La lógica difusa (fuzzy logic) es considerada una generalización de la teoría general de
conjuntos que permite que los elementos de un conjunto tengan grados intermedios de
pertenencia por medio de una función característica. Con esta idea se modifica el concepto de
bivalencia (0s y 1s) de la lógica booleana, el cual pasa a ser un caso particular de los conjuntos
difusos. La teoría de lógica difusa ha generado en los últimos años la segunda generación de
modelos de representación de conocimiento, mejor conocidos como sistemas expertos difusos.
También, ha revolucionado el mercado japonés de electrodomésticos al incorporar de forma
sencilla conocimiento humano experto en sistemas de control con características no-lineales.
Esto, gracias a lo sencillo del diseño de los sistemas difusos y al alto grado de precisión logrado
en los sistemas de control y decisión creados con esta lógica. Areas de aplicación incluyen, pero
no se limita a: Comunicaciones entre hombre-maquina, medicina, robótica, estudio y estimación
de recursos naturales, análisis de señales e imágenes, sistemas de control, electrodomésticos y
computadoras.
¿ QUE ES LÓGICA DIFUSA ?
Las ciencias utilizan concepto tanto vagos como precisos. Nacimiento, muerte, blanco y
negro, son conceptos precisos; fiebre, anemia y obesidad son vagos. Usualmente, conceptos
vagos son tratados como si fueran precisos. Por ejemplo, se podría insistir en un diagnostico
médico de que fiebre, anemia y obesidad están presentes o ausentes. Este tipo de clasificaciones
impuestas son a veces el producto de valores preestablecidos que tienen que ser excedidos por
una variable de cierta importancia. Aunque la clasificación binaria puede que sea conveniente
para el diseño de un esquema de decisiones, esta frecuentemente produce un modelo
distorsionado que puede impedir significativamente las decisiones.
Lógica difusa provee una herramienta para preservar el concepto de vaguedad en vez de
eliminarlo mediante la imposición arbitraria de sentencias ciertas o falsas provenientes de la
lógica bivalente. Mucha de la lógica detrás del razonamiento humano no esta basada en blancos
y negros, ceros y unos sino en matices de grises y de valores intermedios. Esto se refleja en el

hecho de que la experticia humana, la cual los sistemas expertos pretenden transferir a las
máquinas, es muy frecuentemente dependiente del ambiente, incompleta y de poca confiabilidad.
De esta misma manera, la mayoría de las decisiones en el mundo real se llevan a cabo en un
ambiente en el cual los objetivos, las restricciones y las consecuencias de las acciones posibles no
son conocidas con precisión. Para manejar la imprecisión cuantitativamente, usualmente se
emplean los conceptos y técnicas de la teoría de probabilidades y, particularmente, las
herramientas proporcionadas por la teoría de decisiones, la teoría de control y la teoría de la
información. Al hacer esto, nosotros estamos aceptando la premisa de que imprecisión,
cualquiera sea su naturaleza puede ser reducida a procesos aleatorios. Esto desde el punto de
vista de la lógica difusa, es incorrecto.
Específicamente, los adeptos a la lógica difusa proponen la necesidad de una
diferenciación entre procesos aleatorios y procesos difusos. Por procesos difusos, se entiende un
tipo de imprecisión que esta asociada con conjuntos difusos, esto es, clases en las cuales no hay
una transición tajante de pertenencia a no pertenencia. Por ejemplo, la clase de objetos azules es
un conjunto difuso. Al igual lo son las clase de objetos caracterizados por adjetivos tan comunes
como: largo, pequeño, significante, importante, caliente, frío, serio, simple, etc. Realmente en el
mundo que nos rodea hay pocas clases en las cuales existan fronteras bien delimitadas que
separan aquellos objetos que pertenecen a una clase de aquellos que no pertenecen.
En este sentido es importante notar que en las comunicaciones entre humanos,
expresiones como “Juan es varios metros mas alto que Pedro” , “x es mucho más largo que y”
conllevan información a pesar de lo impreciso de su definición. De hecho, se podría decir que la
mayor diferencia entre inteligencia humana y la inteligencia en máquinas recae en la habilidad
exhibida por los humanos para manejar conceptos difusos y a responder a instrucciones difusas.
Es así como hoy en día es imposible decirle a una computadora que mueva “un poquito” el cursor
hacia la derecha sin caer en la necesidad de aportar el dato numérico exacto para realizar dicha
operación.
Para resumir un poco todas estas ideas podemos establecer que por una parte, los
conjuntos difusos son utilizados para representar la imprecisión asociada a la definición de los
limites de un conjunto (ver Figura 10).

Frío Tibio Caliente
0 25 50 75
Temperatura
0 25 50 75
Frío Tibio Caliente
1 1
Figura 10. Conjuntos difusos para la variable temperatura.
En la Figura 10 podemos observar como los conjuntos Frío, Tibio y Caliente son vistos
desde el punto de vista de la teoría clásica de conjuntos y de la teoría de los conjuntos difusos,
respectivamente. En el primer caso, la pertenencia de una temperatura cualquiera en estos
conjuntos es mutuamente exclusiva. Es decir de acuerdo a esta definición, la lectura de un
termómetro es o frío o tibio o caliente. Los limites que definen estos conjuntos son tajantes ya
que a partir de 25 grados se considera que de frío pasamos inmediatamente a tibio. En el caso de
los conjuntos difusos esta transición es gradual en todos los conjuntos; lo cual se ajusta mucho
más a la imprecisión asociada a la definición de las fronteras de estos conjuntos.
RAZONAMIENTO DIFUSO
El razonamiento permite sacar conclusiones lógicas a partir de un conjunto de premisas.
En un nivel de abstracción más elevado, permite generar una respuesta acorde a situaciones que
no han sido analizadas con anterioridad. Un ejemplo sencillo de razonamiento difuso podría ser:
Premisa 1 Si x es A entonces y es B
Premisa x es A’
Conclusión y es B’
donde x y y son objetos y A,A’ y B,B’ son conjuntos difusos en los conjuntos universales U y V
respectivamente.

En esta forma de razonamiento difuso, A y A’ junto con B y B’ no son necesariamente
iguales. Si A’ = A y B = B’, el método de razonamiento recién descrito se reduce a lo que se
conoce en lógica como el modus ponens. En otras palabras:
Premisa 1 Si el tomate esta rojo entonces el tomate esta maduro
Premisa El tomate esta bien rojo
Conclusión El tomate esta bien maduro
Dada la condición “Si x es A entonces y es B”, es fácil deducir que se trata de una
implicación del tipo A→B, la cual expresa una relación entre A y B. Como se estudio en la
sección III.2, existen muchos mecanismos para lograr obtener la función característica de una
implicación. Para efectos de ilustrar el mecanismo de inferencia de un sistema difuso,
adoptaremos la formula de implicación de Mandani (Rc).
Aún siendo capaces de resolver el valor de la implicación todavía no sabemos como
obtener B’. La conclusión B’ puede obtenerse tomando la composición del conjunto difuso A’
con la condición difusa A→B ( la regla composicional de inferencia) la cual esta dada por:
′ = ′ →B A RA Bo
Esta regla es implementada como una operación de máximos y mínimos entre el “vector”
A’ y la “matriz” R. Su finalidad es la de utilizar A’ para reducir R a la dimensionalidad y el
orden del universo de discurso de B o B’. Matemáticamente:
( )µ µ µ′ ′=B u A Rmaxmin u u v( ), ( , )
Si A’ es tal que µ ′ =A u( )0 1 para algún u0 ∈ U, entonces:
µ µ′ =B Rv u v( ) ( , )0
ahora,
( )µ µ µR c A Bu v R u v( , ) ( ), ( )0 0=

lo cual corresponde simplemente al mínimo entre µA u( )0 y µB v( ) . En el caso de varias reglas
Ak → Bk , simplemente se busca el valor µAku( )0 y se forma el subconjunto B’ como el
subconjunto de B cuyo valor más largo no excede µAku( )0 . Para reglas del tipo “Si x es A y y es
B entonces z es C” se representa la implicación de la forma (A ∧ B)→ C de manera de formar
una relación difusa.
La decisión B’ es un conjunto difuso y como tal puede que no sea de utilidad en una
aplicación dada. Por ejemplo, en el área de control se requiere saber el valor exacto a aplicar a un
determinado proceso. A partir del conjunto difuso B’, un valor v0 debe ser escogido como el
valor representativo. Varios métodos heurísticos pueden ser empleados para seleccionar v0 tales
como el valor al cual B’ alcanza su punto máximo o el punto el cual corresponde al centro de
gravedad del conjunto difuso (método del centroide). En la mayoría de las aplicaciones de hoy
en día, el método del centroide constituye la alternativa más frecuentemente utilizada. Este se
calcula como:
v
v v
v
B j jj
p
jj
p01
1
=′
=
=
∑
∑
µ ( )
(1)
El centroide difuso es único y utiliza toda la información en la distribución del conjunto
difuso B’. En el caso de distribuciones simétricas y de una sola moda, el centroide difuso y la
moda coinciden. En algunos casos es necesario remplazar las sumas discretas con integrales.
Es importante resaltar a este punto que las operaciones de la regla composicional de
inferencia se han podido simplificar gracias al hecho de que los antecedentes corresponden a
valores discretos y no a conjuntos difusos. Si uno o más de los antecedentes fuesen conjuntos
difusos, otras formas de simplificación y aproximación son necesarios. Más aun, todas las
formas matemáticas discutidas aquí asumen que los universos de discurso son conjuntos discretos
y que los conjuntos difusos pueden ser representados en la forma de vectores. Claro, es posible
usar universos de discurso continuos y representar los conjuntos difusos como simples funciones
matemáticas. En ese caso, la derivación matemática de B’ y en particular su implementación en
un computador difieren bastante de lo expresado aquí.

SISTEMAS DIFUSOS PARA RECONOCIMIENTO DE PATRONES
Sistemas de toma de decisiones basados en lógica difusa es el nombre que se le da a un
conjunto de reglas agrupadas de manera de formar una matriz de relaciones. Este tipo de
representación es particularmente útil cuando el número de antecedentes es menor que dos. La
visualización gráfica de los antecedentes y las conclusiones proporciona una manera de presentar
en forma compacta las distintas reglas que conforman la base de conocimiento del sistema difuso.
Un ejemplo de un banco de memorias asociativas se muestra en la Figura 11.
Error Global
IteracionesP
M
G
P M G
G M M
M M P
M P P
P = PequeñoM = MedianoG = Grande
Figura 11. Banco de memorias asociativas para controlar la tasa de aprendizaje de una red
multicapa
Los bancos de memorias asociativas permiten la creación de superficies de control no-
lineales en n-dimensiones. El mecanismo de inferencia representado por la regla composicional,
permite establecer una relación de entrada y salida que es tan no-lineal como se defina en las
reglas que componen el banco de memorias. Al ser las reglas definidas lingüísticamente, surge
entonces un método que permite trasladar el conocimiento experto de un ser humano a un modelo
matemático general y de simple definición. Se dice que el modelo es general porque permite
modelar sistemas lineales o no-lineales. Para ilustrar el mecanismo de inferencia de un banco de
memorias asociativas basado en la regla de composición max-min se tiene el siguiente ejemplo
que emplea solo dos reglas para el proceso de inferencia. Ejemplo:

Reglas:
Si la temperatura es alta y la humedad es mediana entonces la presión debe ser alta.
Si la temperatura es mediana y la humedad es baja entonces la presión debe ser mediana.
Banco de memorias asociativas:
Temperatura
HumedadB
M
A
B M A
M
A
B = BajaM = MedianaA = Alta
Funciones de pertenencia para los conjuntos difusos:
Temp.
0
1AltaMediana
Presión
0
Humedad
0
1Baja Mediana
1AltaMediana
0 15 20 25 30 0 30 40 50
0 100 200 250
Suponga ahora que los siguientes valores de temperatura y presión son suministrados:
Temperatura: 24 o C. Humedad relativa: 34 %. Se desea entonces conseguir el valor adecuado
de presión para el sistema que se pretende controlar con el banco de memorias asociativas. El
primer paso consiste en evaluar los valores puntuales dentro de las funciones de pertenencia, esto
es:

Temp.
0.2
0.8
AltaMediana
Humedad
0.4
0.6
Baja Mediana
0 15 20 30 0 30 40 50
24 34
Esto es,
µtemp_alta(24) = 0.8 y µhumedad_mediana(34) = 0.4
µtemp_mediana(24) = 0.2 y µhumedad_baja(34) = 0.6
Aplicando la regla composicional de inferencia max-min, tenemos que los antecedentes de las
reglas tienen los siguientes grados de activación:
Para la primera regla: µtemp_alta ∧ humedad_mediana (24,34) = min (0.8,0.4) = 0.4
Para la segunda regla: µtemp_mediana ∧ humedad_baja (24,34) = min (0.2,0.6) = 0.2
Al aplicar la regla de implicación de Mandani tenemos que los conjuntos difusos Mediana’ y
Alta’ del universo Presión están dados por:
Presión
0.2
0.4
AltaMediana
0 100 200 250
Como se mencionó anteriormente, estos conjuntos difusos como tales puede que no sean
de mucha utilidad cuando se necesita un valor puntual de control. Para obtener este valor se
aplica entonces el método del centroide. De esta manera nuestro valor de presión deseado
corresponde a:

Presión
0.2
0.4
0 220
De esta manera queda defuzzificada la salida del sistema de decisión, quedando la misma,
lista para ser utilizada.
8. DISCUSIÓN FINAL
En esta breve introducción al procesamiento de señales en tiempo real, se han tocado
brevemente algunas etapas claves en el diseño de un dispositivo de adquisición, visualización y
procesamiento en tiempo real, de señales fisiológicas basado en una computadora personal. Se
ha dado como una alternativa de bajo costo y alto rendimiento, el diseño de programas basado en
la multiprogramación. Asimismo, se ha dado una breve introducción a dos áreas del
reconocimiento de patrones con marcado auge en años recientes: las redes neurales y la lógica
difusa. Quedan por cubrir tópicos tales como reconocimiento de patrones basado en estadística,
algoritmos genéticos, data fusión y muchas otras más. La literatura que se presenta a
continuación puede servir de base para profundizar en los temas ilustrados en este material.
9. BIBLIOGRAFIA DE CONSULTA
Alcalde E. “Conceptos Básicos de Sistemas Operativos”. Introducción a los SistemasOperativos. Primera Edición, McGraw Hill.
Beebe D. “Signal Conversión”. Biomedical Digital Signal Processing. Editorial Prentice Hall.University of Wisconsin. Madison, Wisconsin E.U.A. 1993
Belandría L., Sandoval A., Hernández M. “Diseño de un Sistema de Adquisición de SeñalesElectrocardiográficas”. Tendencias Actuales en Bioingeniería. Sociedad Venezolanade Bioingeniería. Ramírez C - Bravo A Editores. VI Coloquio Nacional deBioingeniería, UNET. San Cristóbal, Estado Táchira. 2000

Booch G. Análisis y Diseño Orientado a Objetos con Aplicaciones. Segunda edición, AdissonWesley / Díaz de Santos, 1995.
Callejas V., Luis M. “Sistema de Adquisición de Parámetros Fisiológicos de Ocho Canales”.Trabajo presentado como tesis de grado para optar al título de Ingeniero enComputación. Universidad Fermín Toro, Cabudare, Estado Lara. 1995
Castro G, Pinilla M “ Diseño y Construcción de un Sistema de Ablación Cardíaca porRadiofrecuencia”. Trabajo de grado desarrollado en el Laboratorio de Bioingenieríade la Universidad Nacional Experimental del Táchira. San Cristóbal, Estado Táchira.1999.
Castro G, Pinilla M, Hernández M., Sandoval A. “ Optimización de un Sistema de AblaciónCardíaca por Radiofrecuencia”. Tendencias Actuales en Bioingeniería. SociedadVenezolana de Bioingeniería. Ramírez C - Bravo A Editores. VI Coloquio Nacionalde Bioingeniería, UNET. San Cristóbal, Estado Táchira. 2000
Chacón G, Salas R . “Diseño y Construcción de un Monitor ECG a través del Computador”.Trabajo de grado desarrollado en el Laboratorio de Bioingeniería de la UniversidadNacional Experimental del Táchira. San Cristóbal, Estado Táchira. 1999.
Fu LiMin., Neural Networks in Computer Intelligence. Edit. McGraw-Hill, 1994.Hernández M., Fernández O. “Adquisición y Presentación de Señales Biomédicas Utilizando
Programación Basada en Multihebras”. Tendencias Actuales en Bioingeniería.Sociedad Venezolana de Bioingeniería. Ramírez C - Bravo A Editores. VI ColoquioNacional de Bioingeniería, UNET. San Cristóbal, Estado Táchira. 2000.
Olson W. “Basic Concepts of Medical Intrumentation”. Medical Instrumentation, Applicationand Design. John G. Webster Editor. Third Edition. New York, E.U.A. . 1998.
Pallas R. “Transductores Bioeléctricos”. Introducción a la Bioingeniería. Varios autores bajo lacoordinación de Mompin J. Serie Mundo Electrónico, Editorial Marcombo.Barcelona, España. 1988.
Parra H., Hugo E. “Central de Monitoreo de los Parámetros Fisiológicos del Cuerpo Humano”.Trabajo de grado desarrollado en el Laboratorio de Bioingeniería de la UniversidadNacional Experimental del Táchira. San Cristóbal, Estado Táchira. 2000.
Ramirez-Rodriguez C., Vladimirova T. “A hierarchical fuzzy neural system for ECGclassification”. En 3rd European Congress on Intelligent Techniques and SoftComputing (EUFIT'95). Acchen, Alemania, Pag. III 1668-1672, Agosto 1995.
Ramírez-Rodríguez C.A. "Detección de Episodios de fibrilación auricular utilizando redesnuerales multicapa". En I Congreso Venezolano de Ingeniería Eléctrica. Mérida,Venezuela, Octubre 1998.
Stallings W. “Concurrencia: exclusión mutua y sincronización”. Sistemas Operativos. SegundaEdición, Prentice Hall, 1997.
Tanenbaum A. Sistemas Operativos Modernos. Primera Edición, Prentice Hall. México 1993.Tocci R. “Interfaz con el Mundo Analógico”. Sistemas Digitales. Editorial Prentice hall, Quinta
Edición. México, 1993.Valentinuzzi M. “Objetivos de la Bioingeniería”. Introducción a la Bioingeniería. Varios autores
bajo la coordinación de Mompin J. Serie Mundo Electrónico, Editorial Marcombo.Barcelona, España. 1988





























