Embed Size (px)
DESCRIPTION
Programação Concorrente / RPC / Deadlock
Citation preview

PROGRAMAÇÃO CONCORRENTE
CHAMADA DE PROCEDIMENTO REMOTO - RPC
DEADLOCK
SÃO PAULO
2014

PROGRAMAÇÃO CONCORRENTE
CHAMADA DE PROCEDIMENTO REMOTO - RPC
DEADLOCK
Trabalho apresentado no curso de
graduação de Tecnologia em Análise e
Desenvolvimento de Sistemas, ao
XXXXXXXXXXXXXXXXXX, para
complemento da avaliação semestral da
disciplina de Sistemas Operacionais, sob
orientação do Prof. XXXXXXXXXXXXX.
SÃO PAULO
2014

RESUMO
Neste trabalho são abordados três temas:
Programação Concorrente: conjunto de computadores completos e
autônomos, logo, fracamente acoplados, interligados por uma rede,
através do qual se comunicam por mensagens, visando o
compartilhamento de recursos e a cooperação.
Chamada de Procedimento Remoto (acrônimo de Remote Procedure
Call): é uma tecnologia de comunicação entre processos que permite a
um programa de computador chamar um procedimento em outro espaço
de endereçamento (geralmente em outro computador, conectado por
uma rede);
Deadlock: é uma situação em que ocorre um impasse e dois ou mais
processos ficam impedidos de continuar suas execuções, ou seja, ficam
bloqueados.
Palavras-chave: Programação concorrente, thread, processo, pseudo-paralela, chamada de
procedimento remoto, RPC, modelo síncrono, modelo assíncrono, deadlock, impasse.

SUMÁRIO
RESUMO 4
1 PROGRAMAÇÃO CONCORRENTE 0
1.1 Introdução..........................................................................................................0
1.2 Diferença entre programação concorrente e paralela........................................0
1.3 Motivação e finalidade.......................................................................................0
1.4 Interação e comunicação concorrente...............................................................0
1.4.1 Comunicação por memória compartilhada 0
1.4.2 Comunicação por troca de mensagens 0
1.5 Diferença entre thread e processo.....................................................................0
1.5.1 Estados de um processo 0
1.6 Criação e Manutenção de Processos................................................................0
1.7 Suporte em linguagens......................................................................................0
2 CHAMADA DE PROCEDIMENTO REMOTO - RPC 0
2.1 Introdução..........................................................................................................0
2.2 Operação de uma RPC......................................................................................0
2.2.1 Representação gráfica da operação de uma RPC: 0

2.3 Modelo síncrono e modelo assíncrono..............................................................0
2.4 Possíveis Falhas durante uma RPC..................................................................0
2.4.1 Crash do servidor 0
2.4.2 Crash do cliente 0
3 DEADLOCK 0
3.1 Definições de deadlock......................................................................................0
3.2 Condições necessárias para a ocorrência de deadlock.....................................0
3.3 Representação de deadlock em grafos.............................................................0
3.4 Métodos para tratamento de deadlocks.............................................................0
3.4.1 Algoritmo do avestruz 0
3.5 Prevenção de deadlock.....................................................................................0
3.6 Como evitar deadlock........................................................................................0
3.7 Detecção de deadlock.......................................................................................0
3.8 Recuperação do deadlock.................................................................................0
3.8.1 Abortar um ou mais processos para interromper a espera circular 0
3.8.2 Preemptar alguns recursos: 0
3.9 Conclusões sobre deadlock...............................................................................0
Referências Bibliográficas 0

1 PROGRAMAÇÃO CONCORRENTE
1.1 Introdução
Programação concorrente é um paradigma (modelo) de programação
para a construção de programas de computador que contem múltiplas atividades
que interagem entre si e progridem em paralelo (atividades iniciadas, mas não
terminadas, ou seja, estão em andamento, em algum ponto intermediário da
execução). Isto é uma propriedade de um sistema - que pode ser um programa
individual, um computador ou uma rede.
O termo “programação concorrente” provém do inglês: concurrent
programming, onde “concurrent” significa “acontecendo ao mesmo tempo”. É
relacionado com programação paralela, porém, tem seu foco na interação entre as
tarefas.
A grande maioria dos programas escritos são seqüenciais, ou seja, exige
a execução seqüencial, em ordem, respeitando início e término de cada componente
do programa. O problema é dividido em uma série de instruções que são executadas
uma após a outra. Neste caso, existe somente um fluxo de controle no programa.
Já na programação concorrente, um trabalho é particionado em várias
tarefas que são executadas quase que ao mesmo tempo pelo processador. O
processador atua tão rapidamente que temos a impressão de que as tarefas estão
sendo executadas simultaneamente (pseudo-paralelo). Estas tarefas trocam
informações entre si.

1.2 Diferença entre programação concorrente e paralela
Não devemos confundir programação concorrente com a computação
paralela simplesmente, em que ocorre somente o processamento simultâneo físico,
e não lógico. O programa concorrente gera vários processos que cooperam para a
realização de uma tarefa através de entrelaçamento e ações (interleaving). Por
exemplo, os processos simultâneos podem ser executados em um único núcleo do
processador intercalando as etapas de execução de cada processo através de uma
divisão de tempo: apenas um processo é executado de cada vez, e se ele não for
concluído durante a sua fatia de tempo, é pausado o seu cálculo, um outro processo
começa ou retoma, e depois o processo original é retomado. Desta forma, vários
processos estão em andamento, mas apenas um processo está sendo executado
em um determinado instante. Como dito acima, embora relacionada com
programação paralela, programação concorrente foca mais na interação entre as
tarefas. Em computação paralela, a execução, literalmente, ocorre no mesmo
instante; por exemplo, em uma máquina com multi-processadores. A computação
paralela é impossível em um único processador, já que apenas um cálculo pode
ocorrer em um mesmo instante (durante um único ciclo de clock).
A execução concorrente admite a seguinte possibilidade de progressão:
Pseudo-paralela: execução em um único processador. Este
reveza-se entre as atividades. Não é simultânea. O processador executa
rapidamente um pouco de cada instrução em frações de segundo, de forma
que, para o usuário, parece que estão sendo realizadas ao mesmo tempo;
Já o paralelismo real:
Paralela: execução em vários processadores que compartilham
uma memória. Cada processo do programa está sendo executado em um
processador diferente;

Distribuída: execução em vários processadores independentes,
sem compartilhamento de memória.
1.3 Motivação e finalidade
O aumento de desempenho e agilidade é, com certeza, uma das grandes
vantagens deste modelo de programação, pois aumenta-se a quantidade de tarefas
sendo executadas em determinado período de tempo. Também destaca-se a
possibilidade de uma melhor modelagem de programas, pois determinados
problemas computacionais são concorrentes por natureza.
A programação concorrente é mais complexa que a programação
seqüencial. Um programa concorrente pode apresentar todos os tipos de erros que
aparecem nos programas seqüenciais e, adicionalmente, os erros associados com
as interações entre os processos. Alguns erros são difíceis de reproduzir e de
identificar.
Apesar da maior complexidade, existem muitas áreas nas quais a
programação concorrente é vantajosa. Em sistemas nos quais existem vários
processadores (máquinas paralelas ou sistemas distribuídos), é possível aproveitar
esse paralelismo e acelerar a execução do programa. Mesmo em sistemas com um
único processador, existem, obviamente, razões para o seu uso em vários tipos de
aplicações.
Considere um programa que deve ler registros de um arquivo, colocar em
um formato apropriado e então enviar para uma impressora física (em oposição a
uma impressora lógica ou virtual, implementada com arquivos). Podemos fazer isso
com um programa seqüencial que, dentro de um laço, faz as três operações (ler,
formatar e imprimir registro).
Figura 1.1 - Programa seqüencial acessando arquivo e impressora.

Inicialmente o processo envia um comando para a leitura do arquivo e fica
bloqueado. O disco então é acionado para realizar a operação de leitura. Uma vez
concluída a leitura, o processo realiza a formatação e inicia a transferência dos
dados para a impressora. Como se trata de uma impressora física, o processo
executa um laço no qual os dados são enviados para a porta serial ou paralela
apropriada. Como o buffer da impressora é relativamente pequeno, o processo fica
preso até o final da impressão. O disco e a impressora nunca trabalham
simultaneamente, embora isso seja possível. É o programa seqüencial que não
consegue ocupar ambos.
Vamos agora considerar um programa concorrente como o mostrado na
figura 2 para realizar a impressão do arquivo. Dois processos dividem o trabalho. O
processo leitor é responsável por ler registros do arquivo, formatar e colocar em um
buffer na memória. O processo impressor retira os dados do buffer e envia para a
impressora. É suposto aqui que os dois processos possuem acesso à memória onde
está o buffer. Este programa é mais eficiente, pois consegue manter o disco e a
impressora trabalhando simultaneamente. O tempo total para realizar a impressão
do arquivo vai ser menor.
Figura 1.2. - Programa concorrente acessando arquivo e impressora.
O uso da programação concorrente é natural nas aplicações que
apresentam paralelismo intrínseco, ditas aplicações inerentemente paralelas.

Nessas aplicações pode-se distinguir facilmente funções para serem realizadas em
paralelo. Este é o caso do spooling de impressão, exemplo que será apresentado a
seguir. Pode-se dizer que, em geral, a programação concorrente tem aplicação
natural na construção de sistemas que tenham de implementar serviços que são
requisitados de forma imprevisível [DIJ65]. Nesse caso, o programa concorrente terá
um processo para realizar cada tipo de serviço.
A seguir é considerado um servidor de impressão para uma rede local. A
figura 3 ilustra uma rede local na qual existem diversos computadores pessoais (PC)
utilizados pelos usuários e existe um computador dedicado ao papel de servidor de
impressão. O servidor usa um disco magnético para manter os arquivos que estão
na fila de impressão.
Figura 1.3. - Rede local incluindo um servidor de impressão dedicado.
É importante observar que o programa "servidor de impressão" possui
paralelismo intrínseco. Ele deve: (1) receber mensagens pela rede; (2) escrever em
disco os pedaços de arquivos recebidos; (3) enviar mensagens pela rede (contendo,
por exemplo, respostas às consultas sobre o seu estado); (4) ler arquivos
previamente recebidos (para imprimi-los); (5) enviar dados para a impressora. Todas
essas atividades podem ser realizadas "simultaneamente". Uma forma de programar
o servidor de impressão é usar vários processos, cada um responsável por uma
atividade em particular. Obviamente, esses processos vão precisar trocar
informações para realizar o seu trabalho.
A figura 4 mostra uma das possíveis soluções para a organização interna
do programa concorrente "servidor de impressão". Cada círculo representa um
processo. Cada flecha representa a passagem de dados de um processo para o

outro. Essa passagem de dados pode ser feita, por exemplo, através de variáveis
que são compartilhadas pelos processos envolvidos na comunicação.
Vamos agora descrever a função de cada processo. O processo
"Receptor" é responsável por receber mensagens da rede local. Ele faz isso através
de chamadas de sistema apropriadas e descarta as mensagens com erro. As
mensagens corretas são então passadas para o processo "Protocolo". Ele analisa o
conteúdo das mensagens recebidas à luz do protocolo de comunicação suportado
pelo servidor de impressão. É possível que seja necessário a geração e o envio de
mensagens de resposta. O processo "Protocolo" gera as mensagens a serem
enviadas e passa-as para o processo "Transmissor", que as envia através de
chamadas de sistema apropriadas.
Algumas mensagens contêm pedaços de arquivos a serem impressos. É
suposto aqui que o tamanho das mensagens tenha um limite (alguns Kbytes). Dessa
forma, um arquivo deve ser dividido em várias mensagens para transmissão através
da rede. Quando o processo "Protocolo" identifica uma mensagem que contém um
pedaço de arquivo, ele passa esse pedaço de arquivo para o processo "Escritor".
Passa também a identificação do arquivo ao qual o pedaço em questão pertence.
Cabe ao processo "Escritor" usar as chamadas de sistema apropriadas para
escrever no disco. Quando o pedaço de arquivo em questão é o último de seu
arquivo, o processo "Escritor" passa para o processo "Leitor" o nome do arquivo, que
está pronto para ser impresso.

Figura 1.4. - Servidor de impressão como programa concorrente.
O processo "Leitor" executa um laço no qual ele pega um nome de
arquivo, envia o conteúdo do arquivo para o processo "Impressor" e então remove o
arquivo lido. O envio do conteúdo para o processo "Impressor" é feito através de um
laço interno composto pela leitura de uma parte do arquivo e pelo envio dessa parte.
Finalmente, o processo "Impressor" é encarregado de enviar os pedaços de arquivo
que ele recebe para a impressora. O relacionamento entre os processos "Leitor" e
"Escritor" foi descrito antes, no início desta seção.
O servidor de impressão ilustra o emprego da programação concorrente
na construção de uma aplicação com paralelismo intrínseco. O resultado é uma
organização interna clara e simples para o programa. Um programa seqüencial
equivalente seria certamente menos eficiente

1.4 Interação e comunicação concorrente
Em alguns sistemas computacionais concorrentes, a comunicação entre
os componentes é escondida do programador, enquanto em outros a comunicação
deve ser lidada explicitamente. A comunicação explícita pode ser dividida em duas
classes: por memória compartilhada ou por troca de mensagens.
1.4.1 Comunicação por memória compartilhada
Os componentes concorrentes comunicam-se ao alterar o conteúdo de
áreas de memória compartilhadas, o que geralmente requer o desenvolvimento de
alguns métodos de trava para gerenciar a utilização de um determinado recurso
entre as tarefas.
1.4.2 Comunicação por troca de mensagens
Componentes concorrentes comunicam-se ao trocar mensagens, cuja
leitura pode ser feita assincronamente (também denominada como "enviar e rezar",
apesar da prática padrão ser reenviar mensagens que não são sinalizadas como
recebidas) ou pelo método rendezvous, no qual o emissor é bloqueado até que a
mensagem seja recebida (comunicação síncrona).
A comunicação por mensagens tende a ser mais simples que a
comunicação por memória compartilhada, e é considerada uma forma mais robusta
de programação concorrente.

1.5 Diferença entre thread e processo
Um processo é aquilo que executa um conjunto de instruções associadas
a um programa (programa este que pode ter vários processos a si associados),
tendo cada um uma zona de memória independente. Cada processo possui também
um identificador único (o process identification ou simplesmente pid). Por sua vez,
cada processo pode ser constituído por várias threads (linhas de execução), que
partilham as variáveis globais e a heap, mas têm uma stack (pilha) independente.
Ter vários processos e/ou threads em execução “em simultâneo” é um requisito
essencial para que se tire partido de um processador multi-core. O fato de
partilharem recursos torna as threads mais leves do que os processos, permitindo
também uma comunicação mais simples entre elas. Por estes motivos, a utilização
de várias threads é habitualmente a melhor opção para programação concorrente.
O que melhor distingue uma thread de um processo é o espaço de
endereçamento. Todas as threads de um processo trabalham no mesmo espaço de
endereçamento, que é a memória lógica do “processo hospedeiro”. Isto é, quando se
tem um conjunto de threads dentro de um processo, todas as threads executam o
código do processo e compartilham as suas variáveis. Por outro lado, quando se tem
um conjunto de processos, cada processo trabalha num espaço de endereçamento
próprio, com um conjunto separado de variáveis.
No caso de um processo com N threads, tem-se um único registro
descritor (o registro do processo hospedeiro) e N mini-descritores de threads. O
mini-descritor de cada thread é usado para salvar os valores dos registradores da
UCP (PC, PSW, etc.). Adicionalmente, cada thread possui uma pilha, que é usada
para as chamadas e retornos de procedimentos.
É mais fácil chavear a execução entre threads (de um mesmo processo)
do que entre processos, pois se tem menos informações para salvar e restaurar. Por
esse motivo, as threads são chamadas também de "processos leves".

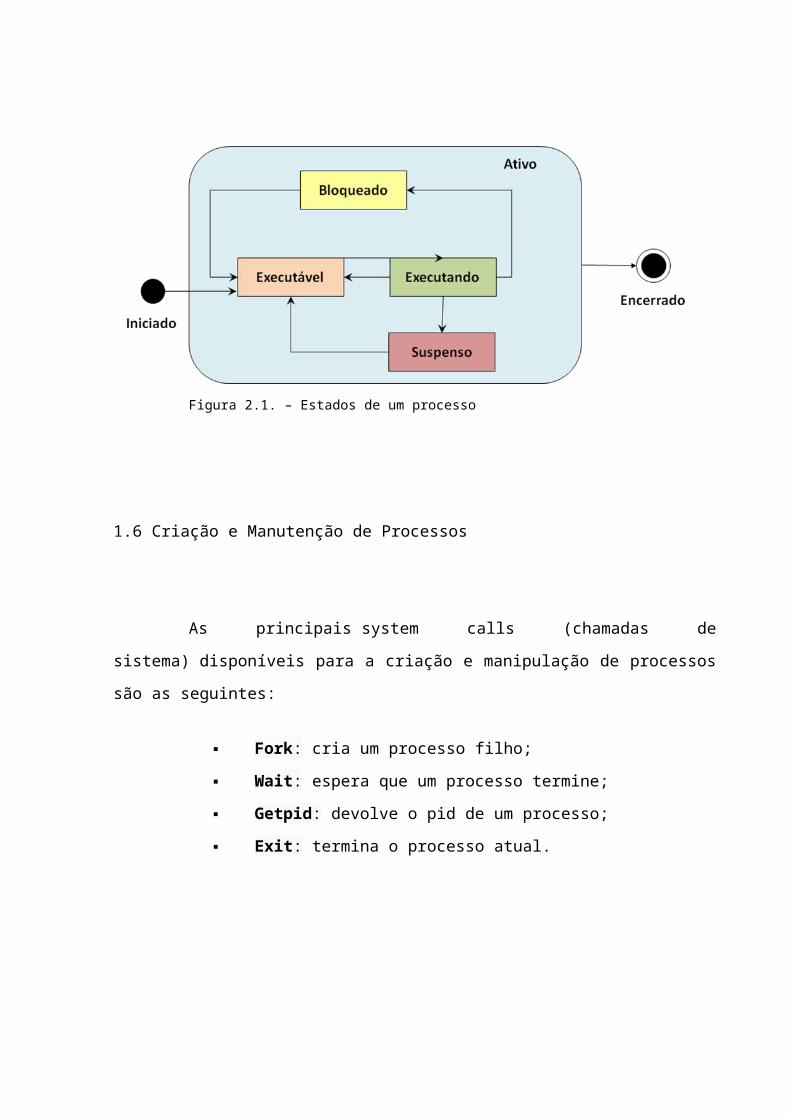
1.5.1 Estados de um processo
Executando (Running): Utilizando a CPU
Executável ou Pronto (Runnable ou Ready): Esperando para ser escalonado para
usar a CPU
Suspenso (Suspended): Recebeu um sinal para ser suspenso
Bloqueado (Blocked): Esperando pela conclusão de algum serviço solicitado ao
S.O.
Figura 2.1. – Estados de um processo
1.6 Criação e Manutenção de Processos
As principais system calls (chamadas de sistema) disponíveis para a
criação e manipulação de processos são as seguintes:
Fork: cria um processo filho;
Wait: espera que um processo termine;
Getpid: devolve o pid de um processo;

Exit: termina o processo atual.
Figura 2.2. – Espaço de endereçamento de um processo
1.7 Suporte em linguagens
Atualmente, as linguagens mais utilizadas para tais construções são Java
e C#. Ambas utilizam o modelo de memória compartilhada, com o bloqueio sendo
fornecido por monitores. Entretanto, o modelo de troca de mensagens pode ser
implementado sobre o modelo de memória compartilhada. Entre linguagens que
utilizam o modelo de troca de mensagens, Erlang é possivelmente a mais utilizada
pela indústria atualmente. Várias linguagens de programação concorrente foram
desenvolvidas como objeto de pesquisa, como por exemplo Pict. Apesar disso,
linguagens como Erlang, Limbo e Occam tiveram uso industrial em vários momentos
desde a década de 1980. Várias outras linguagens oferecem o suporte à
concorrência através de bibliotecas, como por exemplo C e C++.

2 CHAMADA DE PROCEDIMENTO REMOTO - RPC
2.1 Introdução
Remote Procedure Call, também traduzido como Chamada de
Procedimento Remoto, ou ainda, Chamada de Procedimentos à Distância é um tipo
de comunicação entre processos em que um computador local solicita serviços a um
servidor que executa a solicitação e envia a resposta ao computador cliente. Esta
operação é realizada por meio da estrutura da rede de computadores, ou seja, a
solicitação e execução dos serviços ocorrem em computadores distintos (cliente e
servidor), sendo utilizada a rede de computadores para realizar a comunicação e
viabilizar este procedimento.
A Chamada de Procedimento Remoto tem como objetivo possibilitar que
procedimentos encontrados em servidores possam ser chamados como se tivessem
no computador local onde foi solicitada a chamada. O código que está no servidor,
utiliza os serviços de comunicação oferecido pela rede para receber as solicitações
de serviço e também para enviar as respostas.
Na prática a RPC funciona da seguinte forma: O programa cliente faz a
chamada de procedimentos e usuário imagina que a execução está ocorrendo no
computador local, porém, os procedimentos serão executados no servidor. O
servidor possui o código que implementa a lógica da aplicação e o código inserido
pelo ambiente de desenvolvimento. O código inserido recebe as solicitações do
cliente, chama o procedimento local inerente à chamada e envia os resultados de
volta.
Para que haja sucesso na comunicação é necessário que aconteça
compatibilidade das informações entre o cliente e o servidor, ou seja, o cliente deve
receber a mesma quantidade e tipos de parâmetros processados pelo servidor. A
compatibilidade das informações é controlada por um arquivo usado quanto da

compilação tanto do cliente, quando do servidor. Neste arquivo são encontradas as
definições dos procedimentos, quantidade e tipos dos argumentos e também a
quantidade e tipo dos valores obtidos.
O RPC é um mecanismo muito utilizado em sistemas distribuídos e nos
sistemas de máquinas paralelas sem memória comum, organizados de acordo com
o modelo cliente/servidor.
A idéia principal é permitir a chamada de um procedimento em uma
máquina por um programa sendo executado em outra máquina. Em uma RPC, um
programa em uma máquina P, (cliente) chama um procedimento em uma máquina
Q, (servidor) enviando os parâmetros adequados. O cliente é suspenso e a
execução do procedimento começa. Os resultados são enviados da máquina Q para
a máquina P e o cliente é acordado.
2.2 Operação de uma RPC
O mecanismo da RPC tem que ser transparente, ou seja, as chamadas
têm que parecer locais. Ao ser feita uma chamada a um procedimento remoto, da
mesma forma que em uma chamada local, os parâmetros são colocados na pilha,
assim como é guardado o endereço de retorno.

2.2.1 Representação gráfica da operação de uma RPC:
No processo de uma RPC, a função dos servidores é de atender às
demandas dos clientes, sendo que cada servidor fica responsável por um conjunto
de serviços, por exemplo, o File System é responsável pelas funções de gerência de
arquivos, o Memory manager pelas funções de gerência de memória, etc. Os
servidores executam o seguinte procedimento:
• Pegar a primeira mensagem da fila;
• Identificar a função;
• Verificar o número de parâmetros;
• Chamar o procedimento correspondente.
As etapas de uma chamada local são as seguintes:
1. O cliente chama o procedimento e envia os parâmetros;
2. O cliente fica suspenso;
3. Constrói a mensagem;

4. Envia a mensagem para o núcleo local de comunicação;
5. O núcleo de comunicação analisa o cabeçalho da mensagem e
descobre que o servidor é local (mesmo processador);
6. Aloca um buffer;
7. Faz uma cópia da mensagem para o buffer;
8. Coloca o endereço do buffer na fila de mensagens do servidor;
9. Acorda o servidor;
10. O servidor pega a mensagem;
11. Analisa os parâmetros;
12. Dispara os procedimentos correspondentes ao serviço;
13. Prepara a mensagem de resposta;
14. Envia a mensagem de resposta ao núcleo de comunicação;
15. O núcleo de comunicação acorda o cliente;
16. O stub client extrai os resultados;
17. O cliente que fez a chamada inicial recomeça.
No que diz respeito às chamadas de servidores distantes, a diferença é a
ação do núcleo de comunicação:
1. Procura em sua tabela de servidores a identificação do servidor;
2. Envia a mensagem endereçada a este servidor;
3. O núcleo de comunicação do processador destinatário recebe a
mensagem;
4. Analisa seu header e determina o servidor destinatário;
5. Aloca um buffer e copia a mensagem;
6. Coloca o endereço do buffer na fila de mensagens do servidor e o
acorda;
2.3 Modelo síncrono e modelo assíncrono
Existem dois modelos de Chamada de Procedimento Remoto. O modelo
síncrono e o modelo assíncrono.
Modelo síncrono: O processo trata cada chegada de mensagem por vez,
enquanto isso, o computador cliente fica suspenso até o momento que a resposta
chegue. Este modelo não é adequado porque não existe paralelismo entre o cliente
e servidor nas arquiteturas paralelas ou distribuídas. Caso haja uma desconexão o
cliente ficará bloqueado. Um RPC síncrono trata as chamadas locais e distantes de
maneira idêntica.
Modelo assíncrono: O cliente envia as requisições para todos os
servidores em sequencia e depois espera por todas as respostas. A chamada não
suspende o cliente e as respostas são recebidas quando elas são necessárias,
assim, o cliente continua a sua execução em paralelo com o servidor.
2.4 Possíveis Falhas durante uma RPC
Cliente não consegue localizar o Servidor: Isto pode acontecer por duas
razões: o servidor ficar fora do ar ou então determinado programa foi compilado com
um client stub desatualizado. A solução para este problema é disparar um timer

após enviar cada solicitação; se o timer expirar, será necessário enviar o pedido
novamente até que seja atingido um limite máximo de repetições. Se o limite for
alcançado, ocorrerá uma exceção, que precisa ser tratada pelo programa cliente.
Perda de mensagens de Solicitação de Serviços: Uma mensagem pode
se perder na rede e então o serviço solicitado deixará de ser executado não por
falha do servidor, mas porque este não recebeu o pedido devido. A solução também
é usar um timer para controlar o reenvio das mensagens.
Perda de mensagens de Resposta: Também é utilizado um timer para
solucionar o problema.
Crash do Servidor: É uma situação em que é muito difícil descobrir o que
aconteceu, já que, com o servidor quebrado, não é possível obter nenhuma
informação sobre o resultado da RPC.

2.4.1 Crash do servidor
Na representação, o caso (a) é aquele em que tudo dá certo e não há
com que se preocupar. No caso (b), a solicitação foi executada e, portanto, não
sendo a operação idempotente, não é possível executá-la de novo. Na situação (c),
por sorte nada foi feito antes que o servidor quebrasse.
2.4.2 Crash do cliente
Quando um cliente pára de operar, as solicitações dele que estavam
sendo processadas perdem o sentido, pois não há ninguém aguardando o resultado
de seu trabalho. Estas solicitações são chamadas de órfãs e precisam ser tratadas
com cuidado, uma vez que desperdiçam tempo de processador e podem estar
executando bloqueios em alguns recursos valiosos do sistema.
Para este tipo de falha há várias soluções:

Escrever um log de cada chamada RPC, a fim de ser possível
desfazê-la, se necessário;
Usar a chamada reencarnação: o tempo é dividido em intervalos
numerado sequencialmente denominados épocas; quando um cliente é
reiniciado, este declara o nascimento de uma nova época enviando um
broadcast pela rede. Os servidores, ao receberem a mensagem, verificam se
possuem algum procedimento em execução de uma época anterior; se o
encontram, então este é “abortado”. Se for usada a reencarnação “gentil”,
então os servidores tentam localizar o proprietário de cada operação órfã a
fim de aproveitar o serviço que já foi realizado.
Usar o mecanismo de expiração. Neste caso, cada RPC recebe
um tempo máximo em que pode ficar executando, ao final do qual ela é
destruída. A dificuldade é que, dada a diversidade de tipos de chamadas
possíveis, fica complicado estabelecer um intervalo médio de tempo que se
aplique a todos os casos.

3 DEADLOCK
3.1 Definições de deadlock
Deadlock, também traduzido como blocagem ou impasse, é um termo
utilizado para traduzir um problema que ocorre quando um grupo de processos
compete entre si, ou seja, há um impasse e dois ou mais processos ficam impedidos
de continuar suas execuções e ficam bloqueados. Segundo Tanenbaum, “um
conjunto de processos estará em situação de deadlock se todo processo
pertencente ao conjunto estiver esperando por um evento que somente outro
processo desse mesmo conjunto poderá fazer acontecer”.
Deadlock acontece porque, em um ambiente multiprogramado, vários
processos podem competir por um número finito de recursos. Um processo requisita
recursos, se não houver disponibilidade do recurso naquele momento, o processo
entra em estado de espera e pode nunca mais mudar de estado se os recursos
requisitados ficarem retidos por outros processos no estado de espera.
Segundo Silberchatz, "em um deadlock, os processos nunca terminam de
executar, e os recursos do sistema ficam retidos, impedindo que outras tarefas
sejam iniciadas."
Um exemplo que pode facilitar a compreensão de deadlock é a seguinte
analogia: Imagine dois carros movimentando em direções opostas em uma rua que
permite a passagem de apenas um deles. Nesta situação, ao se aproximar, os dois
ficam impedidos de continuar seu percurso.

3.2 Condições necessárias para a ocorrência de deadlock
Para que ocorra um deadlock as quatro condições a seguir devem ser
atendidas de forma simultânea em um sistema.
Condição de não-preempção: Nestas condições, recursos que já estão
devidamente alocados a um processo não podem ser tomados a força. Ele só pode
ser liberado de forma voluntária pelo processo que detém depois deste processo
concluir sua tarefa, ou seja, precisa ser explicitamente liberado pelo processo que
detém a sua posse. De uma forma resumida se o recurso for tirado do processo
atual ocorrerão falhas;
Condição de espera circular: Deve existir uma cadeia circular de dois ou
mais processos, cada um deles ficam esperando por um recurso que está sendo
usado pelo próximo membro da cadeia;
Condição de exclusão mútua: Somente um processo por vez pode usar
o recurso, ou seja, em um determinado instante. Se outro processo requisitar esse
recurso, o processo requisitante deverá ser adiado até a liberação do recurso.
Resumindo, cada recurso estará entre duas situações: ou associado a um único
processo ou disponível;
Condição de posse e espera: Um processo precisa estar de posse de
pelo menos um recurso e esperando para obter a posse de outros recursos que
estão ocupados em outros processos;
3.3 Representação de deadlock em grafos

É comum a demonstração de deadlock por meio de grafos direcionados,
onde o processo é representado por um círculo e o recurso, por um quadrado.
Quando um processo solicita um recurso, uma seta é dirigida do círculo ao
quadrado. Quando um recurso é alocado a um processo, uma seta é dirigida do
quadrado ao círculo. Se o grafo não tiver ciclo, nenhum processo no sistema está
em deadlock, porém, se o grafo tiver um ciclo, poderá haver deadlock.
Representação de deadlock em grafos de alocação de recursos, com dois
processos A e B, e dois recursos R1 e R2.
Acima pode ser visto dois processos diferentes (A e B), cada um com um
recurso diferente alocado (R1 e R2). Este é um exemplo clássico de deadlock. A
condição de espera circular é facilmente visível nos processos, onde cada um
solicita o recurso que está alocado ao outro processo.
Representação de: P1 → R1→ P2→R3→ R2 → P1 →P2 → R3 →P3 →
R2 → P2

Os processos P1, P2, P3, estão em deadlock. O processo P2 está
aguardando o recurso R3, em posse do processo P3. O processo P3 está
aguardando que o processo P1 ou o processo P2 libere o recurso R2. É possível
identificar também que o processo P1 está aguardando o processo P2 liberar o
recurso R1.
Representação de: P1 → R1→ P3→R2→ P1
Neste grafo, apesar de haver um ciclo, não existe deadlock. O processo

P4 pode liberar sua instância do recurso R2 e este recurso ser alocado pelo processo
P3, rompendo o ciclo.
3.4 Métodos para tratamento de deadlocks
Podemos considerar quatro formas de lidar com problemas de deadlock:
Ignorar a situação e fingir que este problema não ocorre no sistema;
Detectar o deadlock e recuperar o sistema, ou seja, deixar que os deadlocks
ocorram, detectá-los e agir;
Usar um protocolo para prevenir ou evitar deadlock, garantindo que o sistema
não entre em estado de deadlock;
Anulação dinâmica por meio de uma alocação cuidadosa de recursos.
3.4.1 Algoritmo do avestruz
O algoritmo do avestruz defende a idéia de que a melhor solução é fingir
que nada está acontecendo. Este nome é utilizado porque há um mito que diz que
quando o avestruz está com muito medo ele enterra a cabeça. Daí a citação que
explica o nome do algoritmo: “Enterre a cabeça na areia e finja que nada está
acontecendo.” Há muitas criticas acerca desta estratégia, inclusive, muitos
matemáticos consideram totalmente inaceitável e defendem que os problemas de
deadlock devem ser evitados. Porém, outros defendem que a frequência em que
ocorre este tipo de evento é muito baixa para que seja necessário sobrecarregar a
CPU com códigos de tratamento, e que, ocasionalmente, é aceitável reiniciar o
sistema de forma manual, como uma ação corretiva.

3.5 Prevenção de deadlock
Tendo em vista que para a ocorrência de um deadlock é necessário que
as quatro condições (não-preempção, espera circular, exclusão mútua e posse e
espera) aconteçam simultaneamente, garantindo que pelo menos uma dessas
condições não seja atendida, o sistema estará prevenindo do deadlock. Desta forma,
prevenção de deadlock pode ser definida como um conjunto de métodos aplicados
para garantir que pelo menos uma das quatro condições não seja satisfeita.
Se não houver nenhum algoritmo no sistema para prevenção ou para
evitar deadlock é possível a ocorrência deste fator. Um sistema pode ter um
algoritmo que examina seu estado para certificar da ocorrência de um deadlock e
um outro algoritmo capaz de recuperar do deadlock. Se um sistema não possuir
nenhum algoritmo de detecção e recuperação de deadlock ele pode chegar a uma
situação em que estará em estado de deadlock, porém não haverá como reconhecer
o que aconteceu. Neste caso, o deadlock não detectado resultará em degradação do
desempenho do sistema, tendo em vista que os recursos estão sendo mantidos por
processos que não podem ser executados e também porque, à medida que fizerem
requisições dos recursos, mais e mais processos entrarão em estado de deadlock
até chegar ao ponto de parar de funcionar e necessitar de ser reiniciado
manualmente.
3.6 Como evitar deadlock
Para evitar a ocorrência de deadlock o sistema operacional deve receber
com antecedência informações adicionais com relação às quais recursos um
processo irá requisitar e usará durante o seu tempo de vida. Com esta informação e
conhecimento adicional é possível decidir, para cada requisição, se o processo deve
esperar ou não. Para decidir se a requisição atual pode ser satisfeita ou se precisa
ser adiada, o sistema irá considerar os recursos disponíveis, os recursos alocados a
cada processo e também as requisições e liberações futuras de cada processo.

Um algoritmo para evitar deadlock examina dinamicamente o estado de
alocação de recursos para garantir que pelo menos uma das condições necessárias
para a ocorrência de deadlock nunca exista, ou seja, previnem os deadlocks
restringindo o modo como as restrições são feitas e isso diminui a utilização de
dispositivos e a redução do thoughput. Um método alternativo para evitar deadlocks
é exigir informações adicionais sobre como os recursos devem ser requisitados.
3.7 Detecção de deadlock
Para a detecção do deadlock é necessário um algoritmo que examine o
estado do sistema para determinar se houve a ocorrência do impasse. Um esquema
de detecção e recuperação exige custo adicional com tempo de execução e da
manutenção das informações necessárias para execução do algoritmo de detecção
e também com as perdas inerentes à recuperação de um deadlock. Só o mero
procedimento de atualização dessas estruturas já gera uma sobrecarga no sistema,
pois toda vez que um processo aloca, libera ou requisita um recurso, as estruturas
precisam ser atualizadas.
São conhecidos vários recursos de detecção de ciclos em grafos
dirigidos. Será mostrado a seguir um algoritmo que inspeciona o grafo e termina nas
seguintes condições: O algoritmo percorre o grafo e termina, quando encontra um
ciclo ou quando percebe que não existe um ciclo. Ele usa uma estrutura de dados, L,
uma lista de nós e uma lista de arcos. Durante a execução do algoritmo, os arcos
são marcados para indicar que já foram inspecionados para evitar repetições.

Baseado na figura acima, o algoritmo deve seguir os seguintes passos:
1-Para cada nó do grafo, N, execute os seguintes passos, usando o N
como inicial.
2-Inicialize L como lista vazia e assinale os arcos como desmarcados.
3- Acrescente o nó atual ao final de L e verifique se o nó parece em L
duas vezes. Se sim, o grafo contém um ciclo e o algoritmo termina.
4- A partir do referido nó, veja se existem quaisquer arcos de saída não
marcados. Se sim, vá para o passo 5; senão vá para o passo 6.
5- Pegue qualquer arco de saída não marcado aleatoriamente e marque-
o. Então siga para o próximo nó corrente e vá para o passo 3.
6- Se esse nó for o inicial, o grafo não conterá um ciclo e será o fim do
algoritmo. Caso contrário, o fim ainda não foi alcançado, então volte para
o nó anterior, marque como atual e vá para o passo 3.
O que este algoritmo faz é tomar cada nó, um após o outro, e fazer uma
busca do tipo depth-first. Se passar novamente por um nó já percorrido, significa que
encontrou um ciclo. Se já tiver percorrido todos os arcos a partir de um nó qualquer,
ele retorna ao nó anterior. Se esta propriedade for satisfeitas em todos nós o
sistema não terá deadlock.

3.8 Recuperação do deadlock
Há várias alternativas disponíveis quando um algoritmo de detecção
determina que existe um deadlock. Uma das alternativas é informar ao operador da
ocorrência do deadlock e deixar que ele trate o deadlock manualmente. Outra
alternativa é deixar o sistema se recuperar do deadlock automaticamente. Há duas
opções para desfazer um deadlock: Uma é abortar um ou mais processos para
interromper a espera circular e a outro é preemptar alguns recursos de um ou mais
processos em deadlock.
3.8.1 Abortar um ou mais processos para interromper a espera circular
Há dois métodos para eliminar deadlock abordando um processo:
Abordar todos os processos em deadlock: É um método que visa
desfazer o ciclo de deadlock. Este método possui um custo alto porque
os processos de deadlock podem ter sido executados por muito tempo
e os resultados da computação parcial precisam ser descartados e
provavelmente terão de ser refeitos mais tarde.
Abortar um processo de cada vez até que o ciclo de deadlock seja
eliminado:Também possui um custo considerável, tendo em vista que
depois de cada processo ser abortado, um algoritmo de detecção de
deadlock precisa ser invocado para determinar se ainda há processos
em deadlock.
O método de abortar processos não é uma alternativa fácil. Se por
exemplo o processo estiver no meio de uma atualização de um arquivo, seu
cancelamento deixará esse arquivo em estado incorreto. Na pratica, se um processo
estivesse no meio de uma impressão e fosse interrompido, o sistema teria que

reiniciar a impressora para um estado correto antes de liberar a impressora para
imprimir a próxima tarefa.
Se a escolha for o método de término parcial, será necessário determinar
quais processos em deadlock devem ser terminados. Esta determinação é uma
decisão política, semelhante às decisões de escalonamento de CPU.
3.8.2 Preemptar alguns recursos:
Para eliminar deadlocks com a técnica de preempção de recursos é
necessário apropriar de alguns recursos de processos com sucesso e entregar
esses recursos a outra processos, até que o ciclo de deadlock seja desfeito.
Três questões precisam ser resolvidas se a preempção tiver que lidar com
deadlocks:
Seleção de uma vítima: Assim como no término de processo é necessário
determinar a ordem da preempção para minimizar o custo. Os fatores de
custo podem incluir parâmetros como número de recursos que um processo
em deadlock está mantendo e o tempo que o processo consumiu durante sua
execução.
Reversão (Rollback): Ao apropriar de um recurso de um processo, o
processo não poderá continuar com sua execução normal, uma vez que não
terá um recurso necessário. Assim será necessário fazer o rollback do
processo até algum estado seguro e reiniciá-lo a partir deste estado. Pelo fato
de ser difícil determinar qual é o estado seguro, a solução mais simples é
fazer um rollback total.
Starvation: Em um sistema em que a escolha da vítima é normalmente
baseada em fatores de custo, pode ocorrer que o mesmo processo sempre
seja o escolhido. Desta forma esse processo nunca completará sua tarefa.
Por este motivo é necessário garantir que um processo seja escolhido como
vítima em um número finito e pequeno de vezes. Normalmente isso ocorre
incluindo o número de rollbacks no fator de custo.

3.9 Conclusões sobre deadlock
Um estado de deadlock ocorre quando dois ou mais processos estão
esperando indefinidamente por um evento que só pode ser causado por um dos
processos em espera.
Existem quatro estratégias para lidar com os deadlocks:
Ignorar a situação e fingir que este problema não ocorre no sistema;
Detectar o deadlock e recuperar o sistema, ou seja, deixar que os deadlocks
ocorram detectá-los e agir;
Usar um protocolo para prevenir ou evitar deadlock, garantindo que o sistema
não entre em estado de deadlock;
Anulação dinâmica por meio de uma alocação cuidadosa de recursos.
Um deadlock só ocorrerá se as quatro condições necessárias forem
satiristas simultaneamente. Estas condições são:
Condição de não-preempção;
Condição de espera circular;
Condição de exclusão mútua;
Condição de posse e espera.
Para prevenir um deadlock, basta garantir que pelo menos uma das
condições necessárias nunca seja satisfeita.
Referências Bibliográficas
TANENBAUM, A. S. Sistemas Operacionais Modernos – Andrew Stuart
Tanenbaum – São Paulo: Pearson Prentice Hall, 2009.
COLOURIS, G. S. Fundamentos de Tolerância a Falhas – Andrew Stuart
Tanenbaum – São Paulo: Pearson Prentice Hall, 2009.
SILBERSCHATZ, A. Sistemas Operacionais: conceitos e aplicações - Abraham
Silberschatz - Editora Elsevier 8.

DEITEL, H. M.; DEITEL, P. J.; CHOFFNES, D. R. Sistemas Operacionais. 3 ed. – Harvey M. Deitel, Paul J. Deitel, David R. Choffnes - São Paulo: Pearson Prentice Hall, 2005.





























