Embed Size (px)
Citation preview

Programación en Intel® Xeon Phi™Programación en Intel® Xeon Phi™
David Corbalán NavarroDavid Corbalán Navarro
Máster en Nuevas Tecnologías de la InformáticaMáster en Nuevas Tecnologías de la Informática

22
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

33
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

44
Introducción al paralelismoIntroducción al paralelismo
● Los primeros monocores● Límite de frecuencia de operación Explotar el ILP:→
– Pipeline escalares segmentados– Superescalares– Ejecución fuera de orden– Ejecución especulativa– …
● La carrera del gigahercio● Los primeros multiprocesadores
– Nuevo horizonte: paralelismo inter-proceso– Ahora el límite está en el aprovechamiento de los procesadores
● Manycores GPGPU→
55
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

66
Niveles de paralelismoNiveles de paralelismo
● ILP (Instruction Level Paralelism)– Grano muy fino– Estático: el compilador (SW) explota el ILP VLIW→– Dinámico: el propio HW explota el ILP superescalares→
● SIMD (Single Instruction Multiple Data)– Operaciones masivas en datos– Procesadores vectoriales: MMX, SSE, SSE2, SSE3, AVX…
● MIMD (Multiple Instruction Multiple Data)● SIMT (Single Instruction Multiple Threads)
– Paralelismo a nivel de hilo/proceso/nodo– Aparece el concepto de sincronización (entre hilos)

77
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

88
Paradigmas de programación Paradigmas de programación paralelaparalela
● Memoria compartida:– Elementos de cómputo: hilos– Todos los hilos comparten la misma memoria– Se comunican mediante sincronizaciones– Adecuado para su uso en procesadores multicore– Ejemplo extendido: OpenMP
● Paso de Mensajes:– Elementos de cómputo: procesos/nodos– Cada nodo tiene control sobre una porción de memoria determinada– Se comunican mediante mensajes– Adecuado para su uso en clústers– Ejemplo extendido: MPI
● Generalmente se combinan programación híbrida: OpenMP+MPI→– Motivación: un procesador puede integrar muchos cores, pero… ¡muchos computadores
pueden integrar muchos procesadores multicore!

99
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

1010
ManycoresManycores
● Aceleradores gráficos● Gran cantidad de cores pequeños implementados
en el mismo procesador● Lanzamiento de hilos poco costoso● Procesamiento masivo en datos● Ejemplos comerciales:
– Nvidia: CUDA y OpenCL– Intel® Xeon Phi™: Xeon Phi™ y OpenCL

1111
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

1212
Intel® Xeon Phi™Intel® Xeon Phi™
intel.com

1313
Intel® Xeon Phi™Intel® Xeon Phi™
● Arquitectura– Host: procesador principal– Dispositivos: aceleradores denominados MIC (Many
Integrated Core)– Bus PCI-express: interfaz que conecta el host con los
dispositivos
● Los dispositivos ejecutan su propio núcleo del sistema operativo (Linux)
● Posibilidad de conexión mediante ssh

1414
Intel® Xeon Phi™Intel® Xeon Phi™
intel.com

1515
Intel® Xeon Phi™Intel® Xeon Phi™
● Manycore● Paralelismo SIMT● Memoria compartida: dentro del propio dispositivo● Paso de mensajes: transferencia de datos entre el
host y los dispositivos

1616
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

1717
ProgramaciónProgramación
● Relativamente sencilla (si la comparamos con CUDA y OpenCL)
● Imprescindible el compilador de Intel: icc● No precisa de funciones dedicadas, ni de librerías
externas… sólo pragmas● Se programa en OpenMP, y se añade algo más (lo
veremos más adelante)● El runtime hace compatible el uso de código tanto para
dispositivos Intel® Xeon Phi™ como para procesadores convencionales (se ignoran los pragmas y punto)

1818
ProgramaciónProgramación
● Es necesario ejecutar antes:– source /opt/intel/composer_xe_2015/bin/compilervars.sh intel64– Intel64 es la arquitectura del host
● Para compilar xeon.c:– icc -o xeon -openmp xeon.c
● Se ha ejecutado todo en Venus

1919
Ejemplo: conteo de coresEjemplo: conteo de cores
● Forma tradicional de contar procesadores:
– Resultado:
● Con Xeon Phi
– Resultado:
int np = omp_get_num_procs();printf("Número de procesadores en el host: %d\n", np);
int np_mic;#pragma offload target(mic)
np_mic = omp_get_num_procs();printf("Número de procesadores en la Xeon Phi: %d\n", np_mic);
Número de procesadores en el host: 12
Número de procesadores en la Xeon Phi: 224

2020
Modelos offloadModelos offload
● Offload explícito● Offload implícito● Offload automático

2121
Offload explícitoOffload explícito
● La sincronización entre los hilos y las transferencias entre host y dispositivos se hace de manera explícita mediante transferencias de memoria y primitivas de sincronización
● Abstracción baja● Control alto de la arquitectura● Pragma principal:
#pragma offload target(mic[:dev])

2222
Offload explícitoOffload explícito
● Procedimiento:(1)Reservar memoria en el MIC(2)Copiar desde el host hacia el MIC(3)Computar(4)Copiar desde el MIC hacia el HOST(5)Liberar memoria en el MIC

2323
Offload explícitoOffload explícito
#define ALIGN __declspec(align(64))#define VECTOR_SIZE 1000000
ALIGN float v1[VECTOR_SIZE];ALIGN float v2[VECTOR_SIZE];
initArray(v1, VECTOR_SIZE);initArray(v2, VECTOR_SIZE);
float prodesc = 0.0;
#pragma offload target(mic){
#pragma omp parallel for private(i) reduction(+:prodesc)for (i = 0; i < VECTOR_SIZE; i++)
prodesc += v1[i] * v2[i];}
printf("Resultado: %.2f\n", prodesc);

2424
Offload explícitoOffload explícito
● Arrays dinámicos
posix_memalign((void**) &v1, 64, sizeof(float) * VECTOR_SIZE);posix_memalign((void**) &v2, 64, sizeof(float) * VECTOR_SIZE);
initArray(v1, VECTOR_SIZE);initArray(v2, VECTOR_SIZE);
...
#pragma offload target(mic) in(v1, v2 : length(VECTOR_SIZE)){
prodesc = 0.0;#pragma omp parallel for private(i) reduction(+:prodesc)for (i = 0; i < VECTOR_SIZE; i++)
prodesc += v1[i] * v2[i];}
printf("Resultado: %.2f\n", prodesc);

2525
Offload explícitoOffload explícito
● Arrays dinámicos:– La memoria se reserva alineada a 64 bits por motivos de
rendimiento– Tamaño explícito de los vectores de memoria: el MIC no
conoce, a priori, la memoria que tiene que copiar– Transferencias:
● in: datos de entrada transferencia implícita de host a MIC→● out: datos de salida transferencia implícita de MIC a host→● inout: datos de entrada y salida transferencias implícitas entre →
host y MIC● nocopy: datos internos del dispositivo

2626
Offload explícitoOffload explícito
● Ejecución selectiva: podemos decidir en qué MIC queremos que se ejecute el pragma:
#pragma offload target(mic:0) in(v1, v2 : length(VECTOR_SIZE)){
prodesc = 0.0;#pragma omp parallel for private(i) reduction(+:prodesc)for (i = 0; i < VECTOR_SIZE; i++)
prodesc += v1[i] * v2[i];}
2727
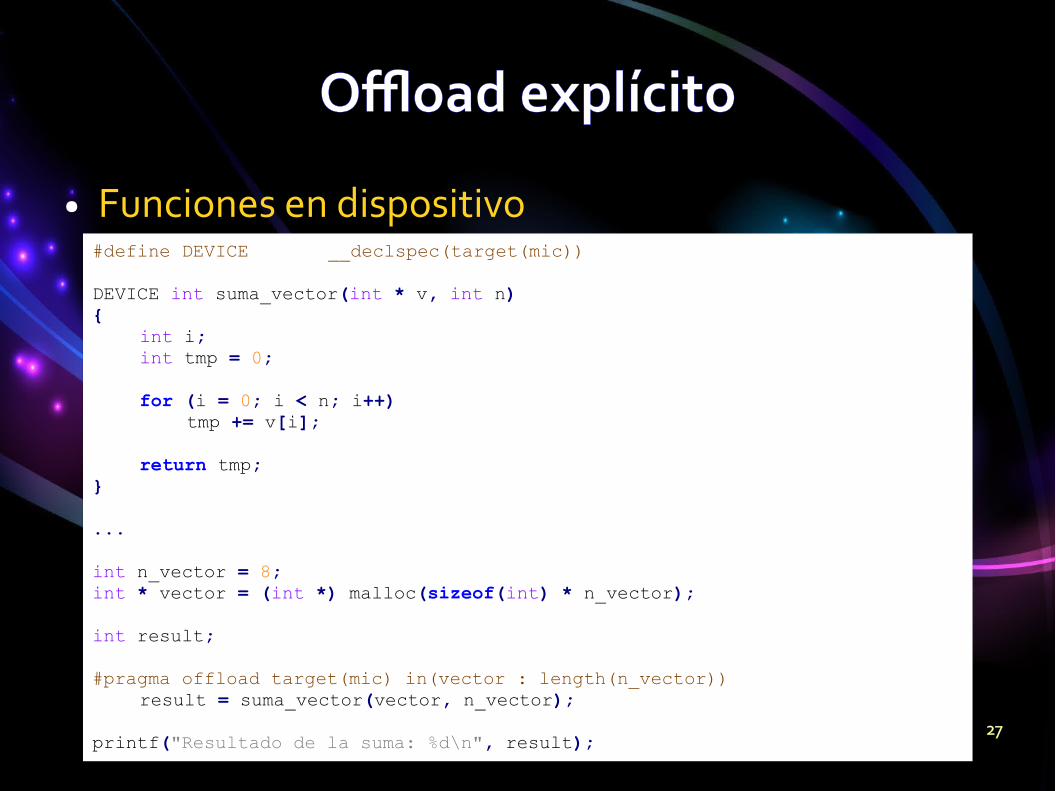
Offload explícitoOffload explícito
● Funciones en dispositivo#define DEVICE __declspec(target(mic))
DEVICE int suma_vector(int * v, int n){
int i;int tmp = 0;
for (i = 0; i < n; i++)tmp += v[i];
return tmp;}
...
int n_vector = 8;int * vector = (int *) malloc(sizeof(int) * n_vector);
int result;
#pragma offload target(mic) in(vector : length(n_vector))result = suma_vector(vector, n_vector);
printf("Resultado de la suma: %d\n", result);

2828
Offload explícitoOffload explícito
● Transferencias explícitas#define ALLOC alloc_if(1)#define FREE free_if(1)#define RETAIN free_if(0)#define REUSE alloc_if(0)
...
#pragma offload_transfer target(mic) in(v1, v2 : length(VECTOR_SIZE) ALLOC RETAIN)#pragma offload target(mic) nocopy(v1, v2 : length(VECTOR_SIZE) REUSE FREE){
prodesc = 0.0;#pragma omp parallel for private(i) reduction(+:prodesc)for (i = 0; i < VECTOR_SIZE; i++)
prodesc += v1[i] * v2[i];}

2929
Offload explícitoOffload explícito
● Ejecución asíncrona (barrera implícita)
int barrier = 1;
#pragma offload_transfer target(mic:0) in(v1, v2 : length(VECTOR_SIZE) ALLOC RETAIN) signal(&barrier)
<Computación solapada con la copia de host a MIC>
#pragma offload target(mic:0) nocopy(v1, v2 : length(VECTOR_SIZE) REUSE FREE) wait(&barrier)
{prodesc = 0.0;#pragma omp parallel for private(i) reduction(+:prodesc)for (i = 0; i < VECTOR_SIZE; i++)
prodesc += v1[i] * v2[i];}
¡Es necesario indicar el MIC al que va dirigido el evento!

3030
Offload explícitoOffload explícito
● Ejecución asíncrona (barrera explícita)
int barrier = 1;
#pragma offload_transfer target(mic:0) in(v1, v2 : length(VECTOR_SIZE) ALLOC RETAIN) signal(&barrier)
<Computación solapada con la copia de host a MIC>
#pragma offload_wait target(mic:0) wait(&barrier)
#pragma offload target(mic:0) nocopy(v1, v2 : length(VECTOR_SIZE) REUSE FREE){
prodesc = 0.0;#pragma omp parallel for private(i) reduction(+:prodesc)for (i = 0; i < VECTOR_SIZE; i++)
prodesc += v1[i] * v2[i];}
Barrera explícita

3131
Offload implícitoOffload implícito
● La sincronización entre los hilos y las transferencias entre host y dispositivos se hace de manera implícita mediante variables compartidas
● Abstracción media● Control medio de la arquitectura● Sólo para C/C++

3232
Offload implícitoOffload implícito
● _Cilk_shared: declara varialbes y funciones en el MIC
● _Cilk_offload: ejecuta funciones en el MIC
int _Cilk_shared mySharedInt;COrderedPair _Cilk_shared mySharedP1;
int _Cilk_shared incrementByReturn(int n);void _Cilk_shared incrementByRef(_Cilk_shared int& n);void _Cilk_shared modObjBySharedPtr(COrderedPair _Cilk_shared * ptrToShared);
mySharedInt = _Cilk_offload incrementByReturn(mySharedInt);_Cilk_offload modObjBySharedPtr(&mySharedP1);

3333
Offload automáticoOffload automático
● La potencia de Intel® Xeon Phi™ se explota mediante llamadas a funciones de la librería MKL
● MKL (Math Kernel Library): librería con algoritmos paralelos específicos optimizados para correr en dispositivos Intel® Xeon Phi™
● Abstracción alta● Control bajo de la arquitectura

3434
Offload automáticoOffload automático
● Ejemplo de multiplicación de matrices:#include "mkl.h"
...
int m = 8000;int p = 9000;int n = 10000;
...
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans, m, n, p, alpha, A, p, B, n, beta, C, n);
3535
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

3636
Monitorización y controlMonitorización y control
● Intel® Xeon Phi™ se monitoriza y controla a través de variables de entorno del sistema
● Se puede monitorizar conectándose mediante ssh al MIC concreto, y ejecutando top sobre él

3737
Monitorización y controlMonitorización y control
● Variables de entorno:– OFFLOAD_REPORT: puede ser 1, 2 ó 3. Indica el nivel de
información que suelta. Compilar con la opción:● -opt-report-phase=offload
– OMP_NUM_THREADS: número de threads de OpenMP ¡en el host! (Cuidado)
– MIC_OMP_NUM_THREADS: número de threads de OpenMP en el MIC
– MIC_STACKSIZE: tamaño máximo de la pila de un thread de Xeon Phi

3838
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

3939
ConclusionesConclusiones
● Sencillo de programar si estamos acostumbrados a OpenMP
● Cuenta con una potente librería: MKL● Gran rendimiento● Tecnología con mucho margen de investigación
para mejorar algoritmos paralelos● Innumerables aplicaciones

4040
ÍndiceÍndice
● Introducción al paralelismo● Niveles de paralelismo● Paradigmas de programación paralela● Manycores● Intel® Xeon Phi™● Programación● Monitorización y control● Conclusiones● Referencias bibliográficas

4141
Referencias bibliográficasReferencias bibliográficas
● TACC - Intel Xeon Phi MIC Offload Programming Models– portal.tacc.utexas.edu/documents/13601/901837/offload_slides_DJ2
013-3.pdf
● Intel - Intel® Xeon PhiTM Coprocessor DEVELOPER'S QUICK START GUIDE
● Dr Dobb's - Programming Intel's Xeon Phi: A Jumpstart Introduction– www.drdobbs.com/parallel/programming-intels-xeon-phi-a-
jumpstart/240144160
● PRACE - Best Practice Guide – Intel Xeon Phi– www.prace-ri.eu/best-practice-guide-intel-xeon-phi-html

Programación en Intel® Xeon Phi™Programación en Intel® Xeon Phi™
David Corbalán NavarroDavid Corbalán Navarro
Máster en Nuevas Tecnologías de la InformáticaMáster en Nuevas Tecnologías de la Informática