Embed Size (px)
Citation preview

Prozeduren – Funktionen –
Methoden
Inhalt
1 Funktionen in Python 2 1.1 def 2 1.2 Namensräume 5
2 Prozeduren – Funktionen – Methoden 8 2.1 Grundsätzliche Ziele 8 2.2 Die Parameterübergabe 9 2.3 Funktionen versus Prozeduren 11 2.4 Wirkung und Nebenwirkung 12
3 Rekursive Grundstrukturen 13 4 Funktionen in Modulen, Paketen und Klassen 17
4.1 Beispiel: Das Modul "Stack" 17 4.2 Klassen und Methoden. 20
Vorlesungen
5

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
1
Methoden und Prozedu-
ren
Lernziele:
Nach der Iteration lernen wir die Rekursion als grundlegende mathematische und informatische Lösungsmethode kennen und deren Realisierungen in Pro-grammiersprachen. Notwendig für die Grundmechanismen der Rekursion sind die Mechanismen zur Parameterübergabe und die Konzepte "Proze-dur", "Funktion", "Methode". Unterprogramme dienen auch zur Struktu-rierung von Programmen, mit den Aspekten Namensräume, Kapselung, Abstraktion.
Alle diese Konzepte finden in Python eine konkrete Ausprägung. Diese ler-nen wir, grundsätzlich einzuordnen und anzuwenden.
Sammlungen von Prozeduren werden in Modulen und Sammlungen von Modulen in Paketen abgelegt. Gleiches gilt für Klassendefinitionen. Beispielhaft soll dieses exploriert und die Mächtigkeit und Eleganz des Punktoperators erkannt werden.
Vorlesung
5

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
2
1 Funktionen in Python
Bevor wir die Methode der Rekursion kennen lernen ist es notwendig, die Mechanismen, die die Methode verwendet, genauer zu untersuchen. Elemnetarer Bestandteil ist die Unterglei-derung von Programmcode in Abschnitte, die besonders gekennzeichnet werden und einen Namen erhalten, unter dem man sie aufrufen kann. Solche Codeabschnitte heißen Prozedu-ren, Methoden oder auch Funktionen. Über eine Liste von Argumenten, die man ihnen beim Aufruf übergibt, kann man Daten dem Codeabschnitt übergeben und wieder heraus-holen. Der gesamte Codeabschnitt verhält sich dabei wie ein Block aus den Kontrollstruktu-ren: Der Namensraum der Variablen (Gültigkeitsbereich) ist auf den Block beschränkt.
Wir beginnen mit der Realisierung von Funktionen in Python. Die Sprache Python erlaubt es, Funktionen sehr einfach zu definieren, bedient sich aber auch einer Reihe von Ideen aus der funktionalen Programmierung, um einige Aufgaben zu erleichtern.
1.1 def
Die Funktionen, Prozeduren und Methoden werden in Python mit der def -Anweisung definiert.
>>> def add (x,y): return x+y >>>
Achtung: Der Funktionsrumpf muss eingerückt (indent) werden (macht IDLE automatisch); das Ende der Funktionsdefinition wird durch Rücknehmen der Einrückung (dedent) angege-ben (macht IDLE bei Eingabe einer Leerzeile auch automatisch).
Eine Funktion wird aufgerufen, indem ihrem Namen ein Tupel von Argumenten unmit-telbar nachgestellt wird, wie in
>>> add (3,4) 7 Die Reihenfolge und Anzahl von Argumenten müssen mit jenen der Funktionsdefinition übereinstimmen. Anderenfalls wird eine TypeError -Ausnahme ausgelöst. Durch die Zu-weisung von Werten in der Funktionsdefinition können für die Parameter einer Funktion Standardwerte voreingestellt werden, z.B.: def foo(x, y, z = 42):
Definiert eine Funktion einen Parameter mit einer Voreinstellung (engl. default parameter), so ist dieser Parameter wie auch alle nachfolgende optional. Falls nicht allen optionalen Parame-tern in der Funktionsdefinition eine Voreinstellung gegeben wird, so wird eine SyntaxEr-ror -Ausnahme ausgelöst.
Voreinstellungswerte (Argumentvoreinstellungswerte) sind immer jene Objekte, die als Wert bei der Funktionsdefinition angegeben worden sind.
Voreinstellungswerte werden nur zum Zeitpunkt der Funktionsdefinition ausgewertet. D.h. das der Ausdruck genau einmal berechnet wird und dann als ‚pre-computed’ Wert für je-den Aufruf gültig ist, sofern er nicht durch einen aktuellen Parameterwert ersetzt wird.
V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
3
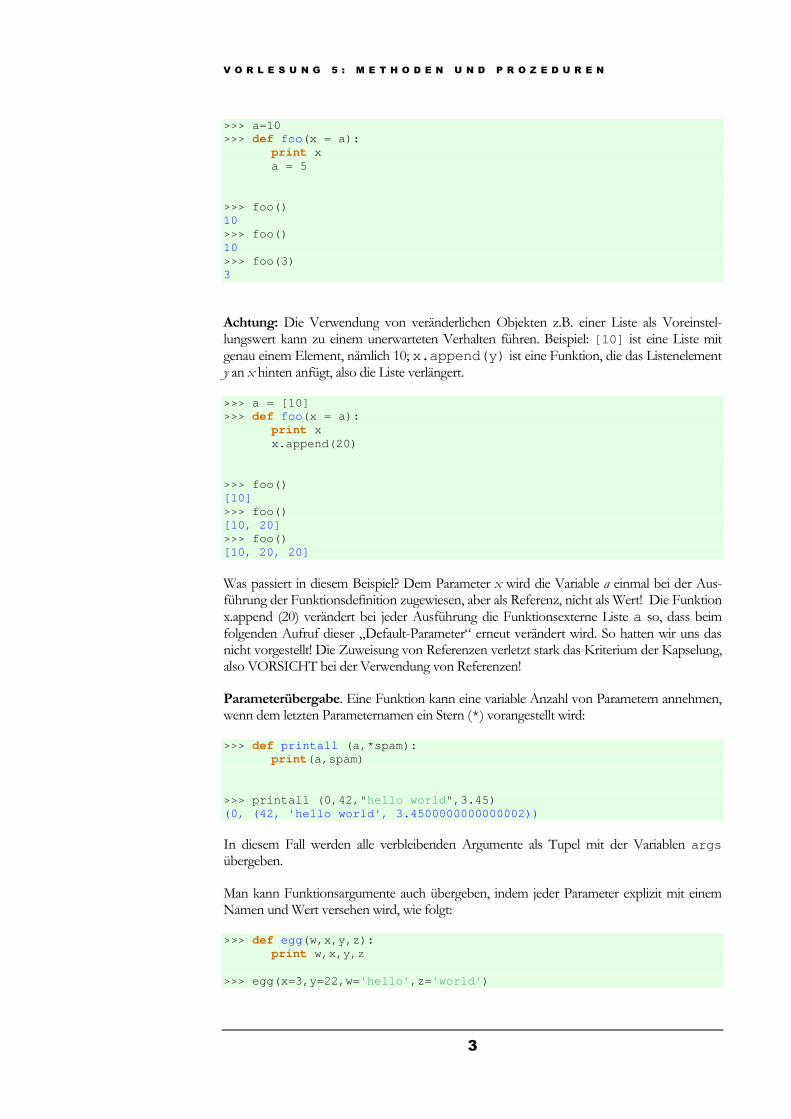
>>> a=10 >>> def foo (x = a): print x a = 5 >>> foo() 10 >>> foo() 10 >>> foo(3) 3
Achtung: Die Verwendung von veränderlichen Objekten z.B. einer Liste als Voreinstel-lungswert kann zu einem unerwarteten Verhalten führen. Beispiel: [10] ist eine Liste mit genau einem Element, nämlich 10; x.append(y) ist eine Funktion, die das Listenelement y an x hinten anfügt, also die Liste verlängert.
>>> a = [10] >>> def foo (x = a): print x x.append(20) >>> foo() [10] >>> foo() [10, 20] >>> foo() [10, 20, 20]
Was passiert in diesem Beispiel? Dem Parameter x wird die Variable a einmal bei der Aus-führung der Funktionsdefinition zugewiesen, aber als Referenz, nicht als Wert! Die Funktion x.append (20) verändert bei jeder Ausführung die Funktionsexterne Liste a so, dass beim folgenden Aufruf dieser „Default-Parameter“ erneut verändert wird. So hatten wir uns das nicht vorgestellt! Die Zuweisung von Referenzen verletzt stark das Kriterium der Kapselung, also VORSICHT bei der Verwendung von Referenzen!
Parameterübergabe. Eine Funktion kann eine variable Anzahl von Parametern annehmen, wenn dem letzten Parameternamen ein Stern (* ) vorangestellt wird:
>>> def printall (a,*spam): print (a,spam) >>> printall (0,42," hello world ",3.45) (0, (42, 'hello world', 3.4500000000000002)) In diesem Fall werden alle verbleibenden Argumente als Tupel mit der Variablen args übergeben.
Man kann Funktionsargumente auch übergeben, indem jeder Parameter explizit mit einem Namen und Wert versehen wird, wie folgt:
>>> def egg (w,x,y,z): print w,x,y,z >>> egg(x=3,y=22,w= 'hello' ,z= 'world' )

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
4
hello 3 22 world
Dabei kann aber jeder Bezeichner nur einmal erscheinen: >>> egg(w=3,y=22,w= 'hello' ,z= 'world' ) SyntaxError: duplicate keyword argument
Bei diesen Schlüsselwort-Argumenten spielt die Reihenfolge keine Rolle. Allerdings muss man alle Funktionsparameter namentlich angeben, wenn man keine Voreinstellungswerte benutzt. Wenn man einen der benötigten Parameter weglässt oder wenn der Name eines Schlüsselwortes mit keinem Parameternamen der Funktionsdefinition übereinstimmt, wird eine TypeError -Ausnahme ausgelöst. Doppelt zugewiesene Namen werden als Syn-taxError erkannt. Wenn Positions- und Schlüsselwort-Argumente im gleichen Funkti-onsaufruf vorkommen, werden Positionsargumente vor allen Schlüsselwort-Argumenten zugewiesen.
Beispiel:
>>> egg(3,22,z='world',y='hello') 3 22 hello world
Wenn dem letzten Argument einer Funktionsdefinition zwei Sterne vorausgehen (** ), wer-den alle weiteren Schlüsselwort-Argumente (jene, die mit keinen Parameternamen überein-stimmen) in einer Wortliste (Dictionary) an die Funktion übergeben. Aber dies wäre ein deut-licher Vorgriff auf Verbunddatentypen (aggregierte Datentypen). Wir kommen später auf diese Parameter-Variante zurück.
Betrachten wir jetzt die Art der Parameter-Übergabe und Rückgabewerte noch etwas ge-nauer: Wenn eine Funktion aufgerufen wird, werden ihre Parameter als Referenzen (call by reference) (und damit als Speicheradresse statt Speicherinhalt) übergeben. Falls ein veränderli-ches Objekt (z.B. eine Liste) an eine Funktion übergeben wird und in der Funktion verändert wird, so werden diese Veränderungen auch in der aufrufenden Umgebung sichtbar.
Beispiel:
>>> a = [1, 2, 3, 4, 5] # a ist eine Liste, also ve ränderlich >>> def foo (x): x[3] = -55 # Verändere ein Element von x >>> foo (a) >>> a [1, 2, 3, -55, 5]
Für unveränderliche Objekte hat dies allerdings keine Veränderung zur Folge, sondern führt zu einem Fehler:
>>> a = "1, 2, 3, 4, 5" # a ist jetzt ein String, also unveränderlich >>> foo (a) Traceback (most recent call last): File "<pyshell#82>", line 1, in -toplevel- foo (a) File "<pyshell#78>", line 2, in foo x[3] = -55 # Verändere ein Element von x TypeError: object does not support item assignment >>> a[3] # gibt es natürlich, warum ist das aber '2 '?? Überlegen Sie! '2'

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
5
Die return -Anweisung gibt einen Wert aus der Funktion zurück. Wird kein Wert angegeben oder wird die return -Anweisung weggelassen, so wird das Objekt None zurückgegeben. Um mehrere Werte zurückzugeben, setzt man diese in ein Tupel:
>>> def factor (a): d = 2 while (d < (a/2)): if ((a/d)*d == a): return ((a/d), d) d = d + 1 return (a, 1) >>> factor(8) (4, 2) >>> factor(9) (3, 3 ) >>> factor(65) (13, 5) >>> factor(64) (32, 2) Mehrere Rückgabewerte in einem Tupel können individuellen Variablen wie folgt zugewie-sen werden: >>> x, y = factor(1243) # Gibt Werte in x und y zur ück >>> x 113 >>> y-1 10
Python unterscheidet also nicht explizit zwischen Prozeduren und Funktionen: Wenn bei der Ausführung der Befehl return() vorliegt, wird der in Klammern angegebene Ausdruck ausgewertet und als Funktionswert zurückgegeben. Eine Python-Funktion kann sogar beide Ausprägungen gleichzeitig annehmen.
1.2 Namensräume
Namen haben einen Gültigkeitsbereich. So gelten die Namen immer nur in dem Block, in dem sie definiert werden, etwa dem Hauptprogramm. Ist ein weiterer Block in dem Block definiert wie etwa eine Funktion, so hat dieser Unterblock seinen eigenen Namensraum. Gilt ein Bezeichner (ein Name) in allen Namensräumen (globaler Namensraum), so wird dies globale Variable genannt, ansonsten ist es eine lokale Variable. In Python werden globale Variable typischerweise auf Modulebene definiert und gelten dann in allen Unterblöcken, wie Kontrollblöcken und Funktionen, sowie in den Unterblöcken der Blöcke, usw. zum Lesen, wenn in einem Unterblock mit seinem lokalen Namensraum der Name nicht neu definiert wird, etwa durch Zuweisung. In Abbildung 1 ist dies illustriert.
Grundsätzlich soll ein Unterprogramm (eine Funktion in Python) auch der Kapselung, min-destens einer Namenskapselung, dienen. Jedes Mal, wenn eine Funktion ausgeführt wird, wird deshalb ein neuer lokaler Namensraum erzeugt. Dieser Namensraum enthält die Namen der Funktionsparameter sowie die Namen von Variablen, die in der eigentlichen Funktion definiert werden.

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
6
Namen sind nur im Block definiert (Namenskapselung)
Modul
Funktion
Kontrollblock
Kontrollblock
Abbildung 1 Blockstrukturen in einem Modul
Bei der Auflösung (Ermittelung der Speicheradresse) von Namen (z.B. wenn sie in einem Ausdruck stehen) sucht der Interpreter zunächst im lokalen Namensbereich, und dann in den lokalen Bereichen aller umgebenden Blöcke (von innen nach außen, sofern vorhanden). Wenn nichts Passendes gefunden wird, geht die Suche im globalen Namensraum weiter. Der globale Namensbereich einer Funktion besteht immer aus dem Modul, in welchem die Funktion definiert wurde. Wenn der Interpreter auch hier keine Übereinstimmung findet, führt er eine letzte Suche im eingebauten Namensraum durch. Wenn auch diese fehlschlägt, wird eine NameError -Ausnahme ausgelöst.
Eine Besonderheit von Namensräumen ist die Manipulation der sogenannten globalen Vari-ablen innerhalb einer Funktion. Man betrachte z.B. folgende Codestücke:
>>> a = 42 >>> b = 3 >>> def foo (): a = 13 print b >>> foo() 3 >>> a 42
>>> a = 42 >>> def foo (): global a a = 13 >>> foo() >>> a 13
Wenn der Code links ausgeführt wird, wird der Wert für b ausgedruckt, da er im Unterblock bekannt ist. Außerdem wird der Wert 42 ausgegeben, obwohl es den Anschein hat, dass wir die Variable a innerhalb der Funktion foo() verändern. Aber: Wenn an Variablen in einer Funktion zugewiesen wird, sind diese immer an den lokalen Namensraum der Funktion ge-bunden. Daher bezieht sich die Variable a im Funktionsrumpf auf ein gänzlich neues Objekt mit dem Wert 13. Um dieses Verhalten zu ändern, verwendet man die global -Anweisung, siehe rechter Codeteil. Das Schlüsselwort global markiert lediglich eine Liste von Namen als solche, die zum globalen Namensraum gehören, und wird nur dann gebraucht, wenn glo-bale Variablen verändert werden. Diese Anweisung darf (auch mehrfach) überall im Rumpf einer Funktion vorkommen. Allerdings muss sie nur vor der Zuweisung zu dieser Variablen erfolgen, sonst gibt es einen SyntaxError : name 'x' is assigned to before global declaration .

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
7
Globale Variablen sind manchmal praktisch, können aber zu schwer durchschaubaren Feh-lern und einer Fehlerverschleppung führen, also Vorsicht! (Für die Zukunft: Man kann eine globale Variable vermeiden, indem man stattdessen Attribute eines globalen Objekts setzt.)
Python erlaubt auch die Verwendung von verschachtelten Funktionsdefinitionen. Damit entstehen auch verschachtelte Geltungsbereiche. Seit Version 2.2 wird ein Name x
• erst im aktuellen lokalen Geltungsbereich gesucht
• dann im Geltungsbereich aller umgebenden Funktionen (von innen nach außen)
• dann im aktuellen globalen Bereich (im Modul)
• und dann im eingebauten Bereich (__builtin__ des Moduls)
Bei globalen Variablen beginnt die Suche im globalen Geltungsbereich. Ein Beispiel:
>>> def bar (): x = 3 def spam(): # Verschachtelte Funktionsdefinition print 'x is ' , x # Sucht nach x im globalen Geltungsbereich while x > 0: spam() x = x - 1 >>> bar () x is 3 x is 2 x is 1 Wenn die verschachtelte Funktion spam() ausgeführt wird, ist dessen globaler Namensraum genau der Gleiche wie der für bar() (das Modul, in dem die Funktion definiert ist). Aus diesem Grund löst spam() die Symbole des Namensraumes von bar() auf.
In der Praxis werden verschachtelte Funktionen nur in besonderen Umständen verwendet, etwa dann, wenn ein Programm eine Funktion abhängig vom Ergebnis einer Bedingung an-ders definieren möchte.
Ab Version 2.4 kann einer Funktionsdefinition eine Deklarationssyntax vorausgehen, die die folgende Funktion beschreibt, so genannte „Dekoratoren“. Sie ersetzen verschiedene funkti-onale Techniken und werden erst in PRG-2 behandelt. Ohne diese haben wir für die Funkti-onsdefinition folgende Syntax:
funcdef ::= "def" funcname "(" [parameter_list] ") " ":" suite parameter_list ::= (defparameter ",")* ( "*" identifier [, "**" identifier] | "**" identifier | defparameter [","] ) defparameter ::= parameter ["=" expression] sublist ::= parameter ("," parameter)* [","] parameter ::= identifier | "(" sublist ")" funcname ::= identifier suite ::= stmt_list NEWLINE|NEWLINE INDENT statement + DEDENT

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
8
Für den Aufruf von Funktionen ist es notwendig, dass die gerufene Funktion definiert ist und als „callable object“ erkannt wurde. Nehmen wir „primary“ als Name der Funktion an, dann gilt folgende Syntax:
call ::= primary "(" [argument_list [","]] ") argument_list ::= positional_arguments ["," keyword _arguments] ["," "*" expression] ["," "**" expression] | keyword_arguments ["," "*" expression] ["," "**" expression] | "*" expression ["," "**" expression] | "**" expression positional_arguments ::= expression ("," expression )* keyword_arguments ::= keyword_item ("," keyword_ite m)* keyword_item ::= identifier "=" expression
Nach den positional arguments darf, muss aber kein Komma gesetzt werden.
Alle Argument-Ausdrücke (aktuelle Parameter) werden ausgewertet, bevor der eigentliche Aufruf ausgeführt wird.
2 Prozeduren – Funktionen – Methoden
Nahezu alle modernen Programmiersprachen unterstützen das Unterprogrammkonzept. In Programmiersprachen werden Unterprogramme durch Funktionen und Prozeduren rep-räsentiert.
2.1 Grundsätzliche Ziele
Seit der Frühzeit des Computings werden Unterprogramme (engl. subroutines) eingesetzt, um verschiedene Ziele zu erreichen:
• eine bessere Strukturierung von Programmen,
• zur Abstraktion: was gemacht wird muss klar sein, aber nicht wie.
• zur Modularisierung: Ein Unterprogramm wird eingesetzt, um Anweisungsfolgen, die an mehreren Stellen in einem Programmsystem verwendet werden, zusammen-gefasst an nur einer Stelle anzugeben.
• bei mehrfacher Verwendung zum Einsparen von (Programm-)Speicherplatz, also mit dem Ziel, den Code möglichst kompakt zu halten und der Wiederverwendung von Codeteilen.
Gelegentlich wird Subroutine (oder auch einfach Routine) als Sammelbegriff für Funktion und Prozedur verwendet, aber die Sprechweisen sind in der Fachterminologie nicht einheitlich. Dabei wird eine Folge von Anweisungen unter einem Namen zusammengefasst. Es können Parameter an diese Folge übergeben, und ggf. auch ein Wert zurückgeliefert werden. Die Parameter werden in der Regel durch Reihenfolge, Typ und Anzahl und/oder durch Namen festgelegt.
In den meisten Programmiersprachen können Unterprogramme auch weitere Unterpro-gramme aufrufen (Schachtelung). Kann ein Unterprogramm sich selbst aufrufen, oder kön-nen sich Unterprogramme gegenseitig aufrufen, spricht man von Rekursion, siehe oben.
In objektorientierten Sprachen wird anstelle von

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
9
• Programmaufruf eher von Nachricht und
• anstelle von Prozedur oder Funktion eher von Methode
gesprochen. Gemeint ist jedoch dasselbe Prinzip, Daten an eigenständige Programmab-schnitte zu übergeben und die Resultate davon zu erhalten.
In Programmablaufplänen und in einem Nassi-Shneiderman-Diagramm sieht der Aufruf eines Unterprogramms folgendermaßen aus:
Unterprogramm- aufruf
Call Sub (a,b,...)
oder sub(a,b,…)
Achtung: Hierfür ist eigentlich kein Symbol definiert, man verwendet ggf. das entsprechende Symbol aus Pro-grammablaufplänen.
2.2 Die Parameterübergabe
Unterprogramme können Argumente haben, die üblicherweise Parameter genannt werden. In der Unterprogrammdefinition nennt man sie formale Parameter (Platzhalter), denn sie werden beim Aufruf des Unterprogramms durch aktuelle Parameter ersetzt. Ggf. ist auch die Rückgabe von Werten über diese Parameter möglich.
Der Compiler/Interpreter vergleicht und überprüft bei der Parameterübergabe normalerwei-se Anzahl und Typ des aktuellen und des formalen Parametersatzes anhand ihrer Signaturen. Wenn diese nicht übereinstimmen, wird eine Fehlermeldung generiert.
Die Mechanismen zur Parameterübergabe sind sehr verschieden. Wir unterscheiden:
• Referenzparameter (call by reference)
• Wertparameter (call by value)
• Namensparameter (call by name)
Referenzparameter (engl. call by reference) sind Parameter von Unterprogrammen, die die Übergabe und Rückgabe von Werten ermöglichen. Ihr Name kommt daher, dass der Com-piler oder Interpreter die Adresse des Speicherbereichs einer Variablen oder eines Feldele-ments übergibt (also einen „Zeiger“ auf die Variable), die als Referenz aufgefasst werden kann.
Beim Aufruf des Unterprogramms wird die Adresse im formalen Parameter gespeichert. Jede Operation mit diesem formalen Parameter wirkt sofort auf den aktuellen Parameter und bleibt auch nach Verlassen des Unterprogramms erhalten, also auch im rufenden Programm.
Wertparameter (engl. call by value) sind Parameter von Unterprogrammen, die die Übergabe, jedoch nicht die Rückgabe von Werten ermöglichen. Beim Aufruf des Unterprogramms wird der Wert des formalen Parameters bestimmt und dieser Wert dem formalen Parameter zu-
Sub Sub (a,b,...)

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
10
gewiesen. Ist der aktuelle Parameter eine einfache Variable, so entsteht eine Kopie. Änderun-gen an dieser Kopie (dem formalen Parameter) wirken sich im rufenden Programm nicht aus. Im Gegensatz zu einem Referenzparameter wird das rufende Programm insbesondere auch vor ungewollten Veränderungen „geschützt“. Wir haben eine echte Kapselung erreicht!
Ein Namensparameter (engl. call by name) ist ein Parameter eines Unterprogramms, der nicht bei seiner Übergabe, sondern erst bei seiner Benutzung innerhalb des Unterprogramms (entsprechend der Signatur des Parameters) jedes Mal neu ermittelt wird. Wird er nie be-nutzt, so wird er auch nie ermittelt. Namensparameter ermöglichen sowohl die Übergabe als auch Rückgabe von Werten. Ganz offensichtlich gibt es bei dieser Technik einen schweren Nachteil: Ist der Parameter ein Ausdruck (z.B. eine Berechnung), so wird dieser Ausdruck unter Umständen mehr als einmal ausgewertet, was sehr lange dauern kann! Diese Art der Parameterübergabe wurde vor allem in der Programmiersprache Cobol, daneben auch in ALGOL 60 genutzt, ist jedoch in modernen Sprachen unüblich.
In einer Variante des Namensparameters, dem so genannten call by need wird dieses Prob-lem behoben, indem man sich bereits ausgewertete Ausdrücke merkt. Es wird von Pro-grammiersprachen wie Haskell verwendet. Die bedarfsgesteuerte Auswertung erlaubt, zykli-sche Ausdrücke zu schreiben. Mit anderen Worten, man erhält „unendliche“ Datenstruktu-ren. Eine besonders wichtige derartige Datenstruktur ist der „Strom“, eine potenziell unend-liche und bei Bedarf berechnete Liste. Dieses wird in PRG-2 beim funktionalen Program-mieren noch ausführlich behandelt werden.
Wir beschränken uns im Weiteren auf die Behandlung von call by reference und call by value und wollen deren Eigenschaften gegenüberstellen.
V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
11
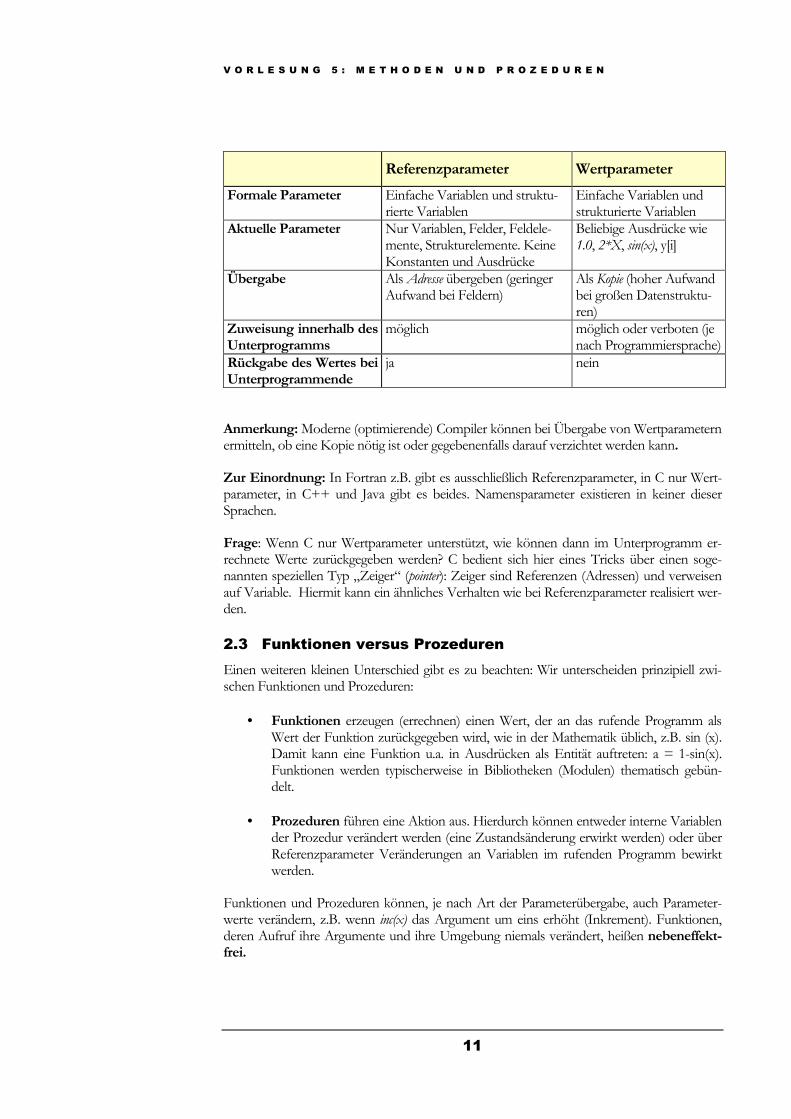
Referenzparameter Wertparameter
Formale Parameter Einfache Variablen und struktu-rierte Variablen
Einfache Variablen und strukturierte Variablen
Aktuelle Parameter Nur Variablen, Felder, Feldele-mente, Strukturelemente. Keine Konstanten und Ausdrücke
Beliebige Ausdrücke wie 1.0, 2*X, sin(x), y[i]
Übergabe Als Adresse übergeben (geringer Aufwand bei Feldern)
Als Kopie (hoher Aufwand bei großen Datenstruktu-ren)
Zuweisung innerhalb des Unterprogramms
möglich möglich oder verboten (je nach Programmiersprache)
Rückgabe des Wertes bei Unterprogrammende
ja nein
Anmerkung: Moderne (optimierende) Compiler können bei Übergabe von Wertparametern ermitteln, ob eine Kopie nötig ist oder gegebenenfalls darauf verzichtet werden kann.
Zur Einordnung: In Fortran z.B. gibt es ausschließlich Referenzparameter, in C nur Wert-parameter, in C++ und Java gibt es beides. Namensparameter existieren in keiner dieser Sprachen.
Frage: Wenn C nur Wertparameter unterstützt, wie können dann im Unterprogramm er-rechnete Werte zurückgegeben werden? C bedient sich hier eines Tricks über einen soge-nannten speziellen Typ „Zeiger“ (pointer): Zeiger sind Referenzen (Adressen) und verweisen auf Variable. Hiermit kann ein ähnliches Verhalten wie bei Referenzparameter realisiert wer-den.
2.3 Funktionen versus Prozeduren
Einen weiteren kleinen Unterschied gibt es zu beachten: Wir unterscheiden prinzipiell zwi-schen Funktionen und Prozeduren:
• Funktionen erzeugen (errechnen) einen Wert, der an das rufende Programm als Wert der Funktion zurückgegeben wird, wie in der Mathematik üblich, z.B. sin (x). Damit kann eine Funktion u.a. in Ausdrücken als Entität auftreten: a = 1-sin(x). Funktionen werden typischerweise in Bibliotheken (Modulen) thematisch gebün-delt.
• Prozeduren führen eine Aktion aus. Hierdurch können entweder interne Variablen der Prozedur verändert werden (eine Zustandsänderung erwirkt werden) oder über Referenzparameter Veränderungen an Variablen im rufenden Programm bewirkt werden.
Funktionen und Prozeduren können, je nach Art der Parameterübergabe, auch Parameter-werte verändern, z.B. wenn inc(x) das Argument um eins erhöht (Inkrement). Funktionen, deren Aufruf ihre Argumente und ihre Umgebung niemals verändert, heißen nebeneffekt-frei.

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
12
2.4 Wirkung und Nebenwirkung
Gerade im Zusammenhang mit Unterprogrammen, aber nicht nur hier, ist die Diskussion der Begriffe „Wirkung“ und „Nebenwirkung“ bedeutsam.
Eine Wirkung bezeichnet in der Informatik die Veränderung eines Zustands, in dem sich ein Computersystem (oder ein anderer Teil der Welt) befindet. Beispiele sind das Verändern von Inhalten des Speichers oder die Ausgabe eines Textes auf Bildschirm oder Drucker.
Neben Wirkung werden synonym auch die Bezeichnungen Nebenwirkung, Nebeneffekt oder Sei-teneffekt verwendet. Letzteres ist eine wortwörtliche Rückübersetzung des englischen side effect, was wiederum eigentlich "Nebenwirkung" bedeutet. Einfach könnte man interpretieren: Wirkung ist das erwünschte (das positive). Nebenwirkung, Nebeneffekt oder Seiteneffekt ist das unerwünschte (das negative). Leider ist der Sprachgebrauch nicht einheitlich.
Wirkungen haben in Programmiersprachen eine wichtige Funktion. Beispielsweise basieren Zuweisungsausdrücke darauf, dass es eine Wirkung gibt. Es folgt ein Beispiel, das in einer der Programmiersprachen Java, C++, C oder Python geschrieben sein könnte:
a = 2
Die Wirkung des Ausdrucks a = 2 besteht darin, dass die Variable a nach Abarbeitung des Ausdrucks ihren Zustand geändert hat, indem sie nämlich den neuen "Inhalt" 2 gespeichert hat. Bei der Betrachtung des folgenden Ausdrucks
(++i) – (++i)
könnte man auf den ersten Blick meinen, dass der Ausdruck den Wert von (i+1) – (i+1), also 0, hat. Das ist nur in Python so, sonst aber nicht der Fall, da der Teilausdruck ++i nicht nur i+1 zurückliefert, sondern als Nebeneffekt i um eins erhöht und dieses Ergebnis dann zurückliefert.
Dabei gibt es einen wichtigen Unterschied zwischen verschiedenen Programmierspra-chen: Während nämlich in Java der rechte Operand der Subtraktion einen um 1 höheren Wert als der linke hat, und dadurch das Resultat eindeutig ist (-1), gibt es in C und C++ keine definierte Reihenfolge für die Abarbeitung der beiden Teilausdrücke (++i).
Manchmal wird sogar die Auffassung vertreten, die Notwendigkeit zur Berücksichtigung von Wirkungen erschwere generell das Verständnis von Programmen. So kommt man u.a. zu den reinen funktionalen Programmiersprachen, bei denen die Auswertung von Ausdrücken grundsätzlich keine (Neben-)Wirkung hat.
Ein Grundsatz: Programmieren muss so gestaltet sein, das es für Programmierer übersicht-lich und die Wirkungen möglichst eindeutig und einfach durchschaubar sind. Das heißt ins-besondere, dass möglichst nur Wirkungen in einem „lokalen“ gut zu überschauenden Be-reich stattfinden sollen. Insbesondere ist der Programmierer (sei er noch so intelligent) vor unerwünschten oder schwer zu überschauenden Nebeneffekten zu schützen.
Verschiedene Programmiersprachen erbringen diese Leistung auf sehr unterschiedliche Art und Weise. Das Konzept des Unterprogramms reflektiert sehr stark das jeweilige Program-mierparadigma. Außerdem wählen verschiedene Sprachen aus der Fülle der Möglichkeiten unterschiedlich aus: Man kann durchaus sagen: Das Unterprogrammkonzept ist jeweils kennzeichnend für eine bestimmte Programmiersprache und verdient immer besondere Aufmerksamkeit!

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
13
3 Rekursive Grundstrukturen
Was ist Rekursion? Eine Rekursion, auch Rekurrenz oder Rekursivität, bedeutet Selbstbezüg-lichkeit (von lateinisch recurrere = zurücklaufen; eng. recursion). Sie tritt immer dann auf, wenn etwas auf sich selbst verweist. Ein rekursives Element muss nicht immer direkt auf sich selbst verweisen (direkte Rekursion), eine Rekursion kann auch über mehrere Zwischen-schritte entstehen. Rekursion kann dazu führen, dass „merkwürdige Schleifen“ entstehen. So ist z.B. der Satz „Dieser Satz ist unwahr“ rekursiv, da er von sich selber spricht (Frage: Ist er wahr?). Eine etwas subtilere Form der Rekursion (indirekte Rekursion) kann auftreten, wenn zwei Dinge gegenseitig aufeinander verweisen. Ein Beispiel sind die beiden Sätze: „Der folgende Satz ist wahr“ „Der vorhergehende Satz ist nicht wahr“.
Im Zusammenhang mit der Definition der Rekursion werden des Öfteren folgende Sätze genannt:
„Um Rekursion zu verstehen, muss man erst einmal Rekursion verstehen.“ „Kürzeste Definition für Rekursion: siehe Rekursion.“
Rekursion ist ein allgemeines Prinzip (wie die Iteration) zur Lösung von Problemen. In vielen Fällen ist die Rekursion eine von mehreren möglichen Problemlösungsstrategien, sie führt oft zu „eleganten“ Lösungen.
Als Rekursion bezeichnet man den Aufruf oder die Definition einer Funktion (hier wird Funktion sowohl wie in der Mathematik im Sinne von Abbildung gebraucht als auch im Sin-ne einer speziellen Prozedur, die einen Wert zurückgibt, siehe unten) durch sich selbst. Ohne geeignete Abbruchbedingung geraten solche rückbezüglichen Aufrufe in einen so genannten „infiniten Regress“ (umgangssprachlich auch oft „Endlosschleife“ genannt, siehe vorige Vorlesung).
Zur Vermeidung von infinitem Regress insbesondere in Programmen bedient man sich der sog. „semantischen Verifikation“ von rekursiven Funktionen. Der Beweis, dass kein infiniter Regress vorliegt, wird dann zumeist mittels einer sog. „Schleifeninvariante“ geführt. Dieser Beweis ist al-lerdings nicht immer möglich (z.B. bei dem sog. „Halteproblem“, das später in der Theoretischen Informatik behandelt wird).
Wir benutzen im Weiteren Funktionen auf natürlichen Zahlen, um uns das Prinzip klarzu-machen. Rekursion oder rekursive Definitionen sind allerdings grundsätzlich nicht auf natür-liche Zahlen beschränkt.
Die Grundidee der rekursiven Definition einer Funktion f ist folgende: Der Funktions-wert f(n+1) einer Funktion f: N0 → N0 ergibt sich durch Einbeziehung bereits vorher be-rechneter Werte f(n), f(n-1), ... miteinander Falls außerdem die Funktionswerte von f für hin-reichend viele Startargumente bekannt sind, kann jeder Funktionswert von f berechnet wer-den. Das heißt im Klartext: Bei einer rekursiven Definition einer Funktion f ruft sich die Funktion so oft selber auf, bis ein vorgegebenes Argument (meistens 0) erreicht ist, so dass die Funktion sich nicht erneut aufruft und normal terminiert.
Die Definition von rekursiv festgelegten Funktionen ist eine grundsätzliche Vorgehensweise in der sog. funktionalen Programmierung. Ausgehend von einigen gegebenen Funktionen (wie z. B. der Summen-Funktion) werden neue Funktionen definiert. Mit diesen können wei-tere Funktionen definiert werden, usw.

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
14
Ein Spezialfall der Rekursion ist die primitive Rekursion, die durch eine Iteration ersetzt werden kann. Bei einer solchen Rekursion enthält der Aufruf-Baum keine Verzweigungen, das heißt er ist eigentlich eine Aufruf-Kette: das ist immer dann der Fall, wenn eine rekursive Funktion sich selbst jeweils nur einmal aufruft, insbesondere am Anfang (Head Recursion) oder nur am Ende (Tail Recursion) der Funktion. Umgekehrt kann jede Iteration durch eine primitive Rekursion ersetzt werden, ohne dass sich dabei die „Komplexität des Algorithmus“ ändert.
Beispiel:
Die Funktion sum: N0 → N0 sei definiert durch: sum(n) = 0 + 1 + 2 +...+ n; sie berech-net also die Summe der ersten n Zahlen. Anders ausgedrückt:
sum(n) = sum(n-1) + n (Rekursionsschritt)
Das heißt also, die Summe der ersten n Zahlen lässt sich berechnen, indem man die Summe der ersten n - 1 Zahlen berechnet und dazu die Zahl n addiert. Damit die Funk-tion terminiert, legt man hier für
sum(0) = 0 (Rekursionsanfang)
ohne Rekursionsaufruf fest. Mit diesen Angaben lässt sich eine rekursive Definition an-geben, die eine beliebige (hier: natürliche) Zahl x berechnet. Die Definition lautet also zusammenfassend:
0 falls n 0 (Rekursionsanfang) sum(n)
sum(n 1) n falls n 1 (Rekursionsschritt)
== − + ≥
Man errechnet so
sum(3) sum(2) 3
sum(1) 2 3
sum(0) 1 2 3
0 1 2 3
6
= += + += + + += + + +=
Im Fall von primitiv-rekursiven Funktionen steht es dem Programmierer frei, eine iterative oder eine rekursive Implementation zu wählen. Dabei ist die rekursive Umsetzung meist „eleganter“, während die iterative Umsetzung effizienter ist (insbesondere weil der Overhead für den wiederholten Funktionsaufruf entfällt.
Beispiel Fakultät. Betrachten wir nun ein weiteres Beispiel bei dem eine rekursive Lösung einer iterativen Lösung gegenübergestellt wird: die Berechnung der Fakultät einer Zahl („Gamma-Funktion“, wenn es auf den reellen Zahlen definiert ist):
Für alle natürlichen Zahlen N∈n sei
nnknn
k
⋅−⋅⋅⋅⋅== ∏=
)1(...321!1
also: • 6321!3 =⋅⋅=

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
15
• 12054321!5 =⋅⋅⋅⋅=
• Häufig definiert man zusätzlich 0! = 1 (hier liegt das leere Produkt vor).
Der rekursiven Variante soll nun eine iterative Variante gegenüber gestellt werden. Betrach-ten wir dazu ein Beispiel. Sei n die Zahl, deren Fakultät berechnet werden soll. Dann ist die rekursive Variante
fakultät_rekursiv (n) if n <= 1 then return 1 else return n * fakultät_rekursiv (n-1)
Die Rekursion kommt in Zeile 3 zum Ausdruck, wo die Funktion sich selbst mit einem um 1 verringerten Argument aufruft. Eine iterative Lösung dagegen sieht wie folgt aus:
fakultät_iterativ(n) fakultät := 1 faktor := 2 while faktor <= n fakultät := fakultät * faktor faktor := faktor + 1 return fakultät
Hier wird die Funktion fakultät_iterativ nur einmal aufgerufen und arbeitet dann den gege-benen Algorithmus in einer Schleife ab.
Betrachten wir als Beispiel in Python die oben behandelte Fakultätsfunktion: >>> def fakultaet_rekursiv (n): if n<=1: return (1) else: return (n*fakultaet_rekursiv(n-1)) >>> fakultaet_rekursiv(3) 6 >>> fakultaet_rekursiv(5) 120 >>> fakultaet_rekursiv(100) 933262154439441526816992388562667004907159682643816 214685929638952175999932299156089414639761565182862536979208272237582 51185210916864000000000000000000000000L >>> float (_) 9.3326215443944151e+157 Sie sehen an diesem Beispiel einerseits, wie schnell die Fakultätsfunktion wächst, andererseits, wie mühelos Python eine Integer in eine Long Integer wandelt, immerhin in diesem Fall eine Zahl mit 158 Dezimalstellen.
Manche Programmiersprachen (insbesondere in der Funktionalen Programmierung) erlau-ben keine Iteration, sodass immer die rekursive Umsetzung gewählt werden muss. Solche Sprachen setzen häufig zur Optimierung primitive Rekursionen intern als Iterationen um ; insbesondere einige Interpreter für die Programmiersprachen Lisp und Scheme verfahren so.

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
16
Die Rekursion ist ein wesentlicher Bestandteil einiger Entwurfsstrategien für effiziente Algo-rithmen, insbesondere der Teile-und-herrsche-Strategie (Divide and Conquer). Andere Ansätze, zum Beispiel sogenannte Greedy-Algorithmen, verlangen ein iteratives Vorgehen.
Rekursion und primitiv-rekursive Funktionen spielen eine große Rolle in der theoretischen Informatik, insbesondere in der Komplexitätstheorie und Berechenbarkeitstheorie.
Beispiel Baumstruktur. Ein anderes, recht schön anzusehendes Beispiel ist der rekursive Pythagoras-Baum.
Der rekursive Algorithmus sieht folgendermaßen aus:
• Errichte über zwei gegebenen Punkten ein Quadrat
• Auf der Oberseite zeichne ein Dreieck mit vorgegebenen Winkeln bzw. Höhe
• Rufe diese Funktion für die beiden Schenkel dieses Dreieckes auf.
Damit wird auf den Schenkeln jeweils wieder ein Quadrat errichtet, auf diesen wieder das Pythagoras-Dreieck und auf den Dreiecksschenkeln wieder die Quadrate usw. Dies wird bis zu einer vorgegebenen Rekursions-Tiefe wiederholt.
Nach vielen Rekursions-Schritten und entsprechenden Einfärbungen ähnelt dieses rekursiv definierte Gebilde dann immer mehr einem Baum:
Als Algorithmus ist die Iteration oft effizienter als der elegantere rekursive Weg. Imple-mentiert wird die Rekursion in Programmen dadurch, dass sich Unterprogramme (Routinen, Subroutinen, Funktionen) selbst wieder aufrufen, wobei für die Effizienz dieses Verfahrens ausschlaggebend ist, wie effizient die Argumente übergeben werden. Dazu sehen wir uns im Folgenden die Prozeduren und Funktionen genauer an.

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
17
4 Funktionen in Modulen, Paketen und
Klassen
Sie haben jetzt gelernt, Unterprogramme zu schreiben und dieses in Hauptprogrammen auf-zurufen, zu benutzen. Ich hoffe, Sie werden die erlernten Fähigkeiten intensiv nutzen und viele Programme schreiben. Sie sollen zusätzlich die verschiedenen Varianten des „Punkt-operators“ (. ) kennen lernen, der in verschiedenen Kontexten benutzt wird und jeweils eine spezifische Bedeutung hat.
Sobald Ihr Programm an Länge zunimmt, werden Sie es vermutlich (hoffentlich(!), denn Sie sollten Übersichtlichkeit über alles schätzen lernen, modulares Programmieren ist unser Ziel) in mehrere Dateien aufspalten wollen, damit es leichter gewartet werden kann. Dazu erlaubt es Python, Definitionen in eine Datei zu setzen und sie als Modul zu benutzen, das in ande-ren Programmen verwendet werden kann. Um ein Modul zu erzeugen, legen Sie die relevan-ten Anweisungen und Definitionen in eine Datei ab, die denselben Namen trägt wie der ge-wünschte Modulname. (Bemerkung: Die Datei muss die Erweiterung .py haben.)
Und noch nicht genug der Ordnung: Ggf. wollen Sie mehrere solcher Module als Paket in einem Ordner (Directory) zusammenfassen. Als Beispiel nennen wir dieses Directory GPR und legen es im Directory c:\Python24 (unter Windows) ab. Ohne auf die vollständige Syn-tax und das „Umgebungshandling“ von Python einzugehen ist diese „Verortung“ des Direc-tories GPR wichtig, damit Python ihre Module auch (im Standard-Suchpfad) findet! In die-sem Directory müssen Sie jetzt eine (zunächst!) leere Datei __init__.py anlegen1.
Der Ordner GPR ist jetzt ein Paket in dem Python Module „erwartet“.
4.1 Beispiel: Das Modul "Stack"
Als Beispiel für ein Modul wählen wir uns eine wichtige Datenstruktur und ihre Operationen darauf: ein Stack (Stapelspeicher, Kellerspeicher oder kurz Stapel bzw. Keller)2 zur Verfü-gung stellt. Ein Stapel kann eine beliebige Menge von Objekten aufnehmen und gibt diese entgegengesetzt zur Reihenfolge der Aufnahme wieder zurück.
1 Sorry für diese vielleicht „unverständlichen“ Notwendigkeiten. Wir werden später kennen lernen, dass man mit dieser Datei einige Interessante Dinge steuern kann, aber das würde jetzt deutlich zu weit führen!
2 Die Verwendung eines Stapelspeichers (zur Übersetzung von Programmiersprachen) wurde 1957 von Friedrich Ludwig Bauer und Klaus Samelson unter dem Namen "Kellerprinzip" patentiert: Verfahren zur automatischen Verarbeitung von kodierten Daten und Rechenmaschine zur Ausübung des Verfahrens. Die lange ausgebliebene internationale Anerkennung und Ehrung ihrer Leistung erfolgte erst im Jahre 1988: Friedrich Ludwig Bauer erhielt (als einziger Überlebender) den renommierten Computer Pioneer Award (IEEE) für „Computer Stacks“.
In der theoretischen Informatik werden Kellerspeicher benutzt, um bestimmte Problemklassen theoretisch betrachten zu können (z.B. als Kellerautomat). Manchmal unterscheidet man genauer zwischen einem ech-ten Kellerspeicher (kurz Keller), bei dem kein Element außer dem obersten gelesen werden kann, und einem Stapelspeicher, bei dem ohne Veränderung der Daten jedes Element betrachtet werden kann. Die-se Unterscheidung spielt jedoch in der Praxis kaum eine Rolle. Unsere Implementation ist ein echter Keller!

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
18
Genau dies ist der Basismechanismus, der von den meisten Programmiersprachen verwendet wird, um einer Prozedur oder Methode die Argumente zu übergeben: Die Argumente wer-den von dem aufrufenden Programm in ihrer Reihenfolge auf den Stack geschoben und dann von der Methode in der entgegen gesetzten Reihenfolge wieder ausgelesen.
Dazu stellen Stapel die Operationen
• push (einkellern) zum Hinzufügen eines Objektes und
• pop (auskellern) zum Zurückholen und Entfernen eines Objektes
bereit. Als erweiterte Funktion wird length realisiert, das die Anzahl der Objekte im Stapel zurückgibt.
Ein Stack arbeitet nach dem Last In - First Out-Prinzip (deutsch zuletzt hinein - zuerst heraus, kurz LIFO) gearbeitet, das heißt es wird von pop immer das Objekt von dem Stapel zurück-gegeben, welches als letztes mit push hineingelegt wurde. In Abbildung 2 ist dies an einem Beispiel von drei Argumenten gezeigt, die nacheinander in den Stack geschrieben und wieder herausgenommen werden.
leer
er S
tape
l
push
(„B
erta
“)
leng
th=
2
push
(5)
leng
th=
3
pop
= 5
push
(„A
nton
“)
leng
th=
1
leng
th=
2
leng
th=
1
pop=
„Ber
ta“
A n to nA n to nB e r ta
B e r taB e r ta A n to nA n to n
A n to n
5
Abbildung 2: Funktionsprinzip des Stacks (Stapelspeicher, Kellerspeicher)
Ein Modul M_Stack erzeugen Sie, indem Sie folgendes Codestückchen z.B. aus IDLE unter ... \GBR\M_Stack.py abspeichern.
def push (self, Wert): self.append(Wert) def pop (self): return self.pop() def length (self): return len(self)
Anmerkungen: Dieses von uns erstellte Modul hat noch keine angemessene Dokumentati-on. Die hierzu vorhandenen Methoden lernen wir später kennen. Das Modul arbeitet auf einem Datentyp Liste , den wir auch genauer erst später kennen lernen. Listen sind verän-derliche Felder aus Objektzeigern auf die per Offset (wie bei Strings) zugegriffen werden kann. Insbesondere kennen Listen die folgende (bereits benutzten) Operationen:
• liste.append (x): Füge Objekt x am Ende der Liste ein (Ändert die Liste an Ort und Stelle)
• liste.pop (): Lösche letztes Element in der Liste und gib es zurück
• len (liste): eine Operation, die auf allen Sequenztypen funktioniert: Gibt die Länge der Sequenz (=Anzahl der Objekte) zurück.

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
19
Um Ihr Modul in anderen Programmen zu verwenden, können Sie die import -Anweisung benutzen. Sie importiert ein Modul als „Ganzes“. Module enthalten Namen, die mittels Qua-lifikation zur Verfügung stehen (z.B. bezeichnet GPR.M_Stack.push() die Funktion Funk-tion push () im Modul M_Stack im Paket GPR. GPR liegt im Suchpfad des Interpreters und darum findet dieser die Funktionen.
Achtung: Namen müssen immer voll (vom Suchpfad aus) qualifiziert angegeben werden (Punktnotation, nicht die Betriebssystemspezifische Notation mit \ oder /). Entsprechend führt die direkte Benutzung von push mit push (a,"Minna") zu einem NameError . >>> import GPR.M_Stack >>> a = [] #Erzeuge eine leere Liste >>> GPR.M_Stack.push (a, "Anton") >>> GPR.M_Stack.length (a) 1 >>> GPR.M_Stack.push (a, "Berta") >>> GPR.M_Stack.pop (a) 'Berta' >>> push (a, "Minna") Traceback (most recent call last): File "<pyshell#80>", line 1, in -toplevel- push (a,"Berta") NameError: name 'push' is not defined Der Befehl import erzeugt einen neuen Namensraum, der alle im Modul definierten Ob-jekte enthält. Um auf diesen Namensraum zuzugreifen, verwendet man einfach den Namen des Paket.Modul als Präfix , wie oben gezeigt.
Um spezielle, einzelne Definitionen in den aktuellen Namensraum zu importieren, benutzt man die from-Anweisung:
from GPR.M_Stack import push push (a, "OttO") # Kein Präfix GPR.M_Stack mehr nötig.
Um den gesamten „Inhalt“ eines Moduls in den aktuellen Namensraum zu importieren, kann man auch Folgendes Statement benutzen:
from GPR.M_Stack import *
Schauen Sie sich folgendes Beispiel an:
>>> from GPR.M_Stack import * >>> a = [] >>> push (a, ”Anton”) >>> push (a, "Berta") >>> length (a) 2 >>> pop (a) 'Berta' >>> pop (a) 'Anton'
Soweit die Konzepte der Strukturierten Programmierung: Wir gliedern unsere Programme in Hauptprogramm (dem rufenden Programm, z.B. der interaktive Interpreter im IDLE), in Pakete (in unserem Beispiel GPR), in Module (in unserem Beispiel M_Stack) und dann in die (Prozeduren, Funktionen). Wenn wir „vorsichtig“, d.h. restriktiv, mit der import-Anweisung umgehen, können wir Namenskonflikte (gleicher Name für verschiedene Objek-

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
20
te, die zum Beispiel von verschiedenen Programmierern mit geschrieben wurden) weitge-hend vermeiden: der Schlüssel ist der Qualifizierte Name, der mithilfe der Punktnotation die verschiedenen Namensräume abtrennt.
Die Punktnotation wurde durch die objektorientierte Programmierung populär und wird in Python fast durchgängig für alle eingebauten (builtin) Funktionen verwendet.
4.2 Klassen und Methoden.
Zur Verwaltung gleichartiger Objekte bedienen sich die meisten Programmiersprachen des Konzeptes der Klasse. Klassen sind Vorlagen, aus denen Objekte zur Laufzeit erzeugt wer-den. Im Programm werden dann nicht einzelne Objekte, sondern eine Klasse gleichartiger Objekte definiert. Man kann sich die Erzeugung von Objekten aus einer Klasse vorstellen wie das Fertigen von Autos aus dem Konstruktionsplan eines bestimmten Fahrzeugtyps. Klassen sind die Konstruktionspläne für Objekte.
Die Klasse entspricht dabei einerseits einem Datentyp wie in der prozeduralen Programmie-rung, geht aber darüber hinaus: Sie legt nicht nur die Datentypen fest, aus denen die erzeug-ten Objekte bestehen, sie definiert zudem die Algorithmen, die auf diesen Daten operieren, also die Semantik. Während also zur Laufzeit eines Programmes einzelne Objekte (die In-stanzen) miteinander interagieren, wird das Grundmuster dieser Interaktion durch die Defini-tion der einzelnen Klassen festgelegt.
In Python (wie in vielen anderen objektorientierten Programmiersprachen) gibt es außerdem zu jeder Klasse wiederum ein bestimmtes Objekt, das so genannte Klassenobjekt, das dazu dient, die Klasse selbst zur Laufzeit zu repräsentieren. Dieses Klassenobjekt ist dann auch zuständig für die Erzeugung der Objekte der Klasse und den Aufruf des passenden Algo-rithmus.
Klassen werden in der Regel in Form von Klassenbibliotheken zusammengefasst, die häu-fig thematisch organisiert sind. So können Anwender einer objektorientierten Programmier-sprache Klassenbibliotheken erwerben, die beispielsweise den Zugriff auf Datenbanken er-möglichen.
Die einer Klasse von Objekten zugeordneten Algorithmen bezeichnet man auch als Metho-den. Häufig wird der Begriff Methode synonym zu Funktion oder Prozedur gebraucht, ob-wohl die Funktion oder Prozedur eher als Implementierung einer Methode zu betrachten ist. Im täglichen Sprachgebrauch sagt man auch "Objekt A ruft Methode m von Objekt B auf."
Spezielle Methoden zur Erzeugung bzw. "Zerstörung" von Objekten heißen Konstruktoren und Destruktoren.
In Python wird die class-Anweisung verwendet, um neue Typen von Objekten zu definie-ren. Im folgenden Beispiel wird wie oben derselbe einfache Stapel definiert:
class Stack : def __init__ ( self ): # Initialisiere Stapel (Konstruktor) self . stack = [ ] def push ( self , other ): self . stack . append ( other ) def pop ( self ): return self . stack . pop () def length ( self ) : return len ( self .st ack)

V O R L E S U N G 5 : M E T H O D E N U N D P R O Z E D U R E N
21
Speichern Sie diese Klassendefinition in einem Modul Stapel in GPR ab.
Auch in einer Klassendefinition werden Methoden mit der def-Anweisung definiert. Als Konvention bezieht das erste Argument jeder Methode sich immer auf das Objekt selbst Hierfür wird der Name »self« verwendet (ähnlich wie sich »this« in C++ auf das eigene Ob-jekt bezieht). Alle Operationen auf den Attributen eines Objektes müssen sich explizit auf die Variable self beziehen. Methoden mit doppelten Unterstrichen am Anfang und Ende im Namen sind spezielle Methoden. Python ruft diese u.a. dann zur Realisierung von Opera-toren „automatisch“ auf, wenn Instanzen dieser Klasse z.B. in Ausrücken vorkommen.
__init__() wird verwendet, um ein Objekt (eine Instanz) zu erzeugen und zu initialisieren und aufgerufen, wenn Klassenname () benutzt wird. Um eine Klasse zu benutzen, schreibt man etwa Code wie folgenden; natürlich muss man den Modul in dem die Klassendefinition steht importiert haben, bevor man die Klasse benutzen kann.
>>> import GPR.Stack # Mache die Klassendefinition bekannt >>> s=GPR.Stack.Stack ()# Erzeuge einen neuen Stape l >>> s.push( "Anton" ) # Lege ein paar Dinge auf den Stapel >>> s.push( "Berta" ) # in Punktnotation >>> from GPR.Stack import Stack # Mache Stack bekannt >>> Stack.push (s,5) # Alternativer Aufruf der Meth ode push >>> s.length () 3 >>> s.pop () 5 >>> x = s.pop () # x enthält 'Berta' >>> x 'Berta' >>> s.pop () 'Anton' >>> del s #Zerstöre s
Beachten Sie die Einfachheit und Mächtigkeit des Punktoperators. Wenn in einem Pro-gramm z.B. die Anweisung import foo erscheint, wird der Name foo dem entspre-chenden Modulobjekt zugeordnet. Module definieren einen Namensraum, der nach dem Import zugänglich ist. Wenn ein Objekt der Klasse Stack erzeugt wurde, im Beispiel s, stehen alle Methoden zur Verfügung, die in der Klassendefinition angegeben sind. Insbesondere kann der Punktoperator, z.B. s.push(x) , genutzt werden, an s die Nachricht push (x) ge-sendet wird, um Methoden auf s auszuführen. Diese Methodenaufrufe können dann in je-dem beliebigen Ausdruck vorkommen.
Wenn zusätzlich die Klasse Stack bekannt gemacht wird ( from GPR. Stack import Stack ) , sind die Methoden von Stack auch direkt aufrufbar, wie Stack . push ( s,5 ) .





























