Embed Size (px)
Citation preview

ISI 2012
Rapport du mini-projet en apprentissage et Datamining

1
Sommaire
Introduction……………………………………………………………………………………………………………………………………….2
Description des jeux de données utilisés…………………………………………………………………………………………...2
Application des algorithmes sur les bases de données……………………………………………………………………….3
IONOSPHERE.ARFF ................................................................................................................................. 3
Réseau de neurones ............................................................................................................................ 3
Boosting ............................................................................................................................................... 3
Arbre de décision ................................................................................................................................ 4
Boosting ............................................................................................................................................... 4
SVM ..................................................................................................................................................... 5
Boosting ............................................................................................................................................... 5
SONOR.ARFF ............................................................................................................................................ 6
Réseau de neurones ............................................................................................................................ 6
Boosting ............................................................................................................................................... 6
Arbre de decision ................................................................................................................................ 6
Boosting ............................................................................................................................................... 7
SVM ..................................................................................................................................................... 7
Boosting ............................................................................................................................................... 8
HEART-STATLOG ...................................................................................................................................... 8
Réseau de neurones ............................................................................................................................ 8
Boosting ............................................................................................................................................... 8
Arbre de décision ................................................................................................................................ 9
Boosting ............................................................................................................................................... 9
SVM ................................................................................................................................................... 10
Boosting ............................................................................................................................................. 10
Tableau récapitulatif…………………………………………………………………………………………………………………………11
Conclusion ……………………………………………………………………………………………………………………………………....12

2
Introduction
Ce travail consiste à expérimenter quelque algorithme d’apprentissage artificiel sur 3 bases de
données différentes ,et de tester l’effet du boosting sur ces bases et sur ces algorithmes .
L’outil utilisé c’est TANAGRA.
Descriptiondesjeuxdedonneesutilises
IONOSPHERE.ARFF (source UCI IRVINE – format de données WEKA).
Le fichier comporte 351 observations, 34descripteurs continus ; l’attribut classe est binaire.
SONOR.ARFF( format de données WEKA)
Le fichier comporte 208 observations ,60 descripteur continus , l’attribut class est binaire
HEART-STATLOG .arff(format de données WEKA)
Le fichier comporte 270 observations , 13 descripteur continus , l’attribut classe est binaire
Sur chaque base de données j’ai appliqué les 3 algorithmes de l’apprentissage artificiel
� Réseau de neurones (perceptron multicouches)
� Arbre de décision(C4.5)
� SVM
Apres l’application de l’algorithme j’applique directement le boosting , pour comparer les résultats

3
Applicationdesalgorithmessurlesbases
dedonnees
IONOSPHERE.ARFF
Réseau de neurones
J’ai appliqué le réseau de neurones avec 10 neurones dans couche cachée
Dans la matrice de confusion on voit bien que :
221 exemples de la classe « g »sont bien classés et seulement 4 exemples sont mal classés .
111 exemples de la classe « b » sont bien classés , 15 exemples mal classé.
Sur 351 exemples , seulement 19 qui sont mal classés ce qui présente selon la matrice de
confusion un taux d’erreur de 0.05.
Boosting

4
Le boosting a amélioré le résultat de la classification, il a bien classé les exemples. on voit que le
taux d’erreur est égale a 0.
Arbre de décision
224 exemples de la classe « g »sont bien classés et seulement 1 exemple est mal classé.
111 exemples de la classe « b » sont bien classés , 15 exemples mal classé.
Sur 351 exemples , seulement 16 qui sont mal classés ce qui présente selon la matrice de
confusion un taux d’erreur de 0.045.
L’arbre de décision propose une typologie en 6 classes (le nombre de feuilles de l’arbre).
La dernière section du résultat décrit l’arbre de décision produit lors de l’induction. Il est
constitué de 11 noeuds dont 6 sont des feuilles. On remarque que les attributs a05,a01,a03,a08 et
a14 semblent les plus déterminants.
Boosting
Tous les exemples sont bien classé en utilisant le boosting .

5
SVM
220 exemples de la classe « g »sont bien classés et seulement 5 exemples sont mal classés.
104 exemples de la classe « b » sont bien classés , 22 exemples mal classés.
Sur 351 exemples , seulement 27 qui sont mal classés ce qui présente selon la matrice de
confusion un taux d’erreur de 0.076.
Boosting
Le boosting a amélioré le résultat de la classification, il a diminué le taux d’erreur a 0.025 .
Remarque :
Sur ce jeu données l’algorithme le plus performant c’est C4.5 sans ou avec le boosting il a fait le
meilleur résultat de classification.

6
SONOR.ARFF
Réseau de neurones
J’ai appliqué le réseau de neurones avec 10 neurones dans couche cachée
92 exemples de la classe « Rock »sont bien classés et seulement 5 exemples sont mal classés.
107 exemples de la classe « mine » sont bien classés , 4 exemples mal classés.
Sur 208 exemples , seulement 9 qui sont mal classés ce qui présente selon la matrice de
confusion un taux d’erreur de 0.043.
Boosting
En appliquant le boosting , le résultat est optimal il n’y a aucune erreur, tous les exemples sont bien
classés.
Arbre de decision
91 exemples de la classe « Rock »sont bien classés et seulement 6 exemples sont mal classés.
97 exemples de la classe « mine » sont bien classés , 14exemples mal classés.
Sur 208 exemples , seulement 20 qui sont mal classés ce qui présente selon la matrice de
confusion un taux d’erreur de 0.096.

7
La dernière section du résultat décrit l’arbre de décision produit lors de l’induction. Il est
constitué de 19 noeuds dont 10 sont des feuilles. On remarque que les attributs attribute_11,
attribute_1, attribute_4, attribute_17, attribute_13et attribute_6 semblent les plus déterminants.
L’arbre de décision propose une typologie en 10 classes (le nombre de feuilles de l’arbre).
Boosting
En appliquant le boosting , le résultat est optimal il n’y a aucune erreur, tous les exemples sont bien
classés.
SVM
85 exemples de la classe « Rock »sont bien classés et 12 exemples sont mal classés.
97 exemples de la classe « mine » sont bien classés , 14 exemples mal classés.
Sur 208 exemples , 26 sont mal classés ce qui présente selon la matrice de confusion un taux
d’erreur de 0.12.
8
Boosting
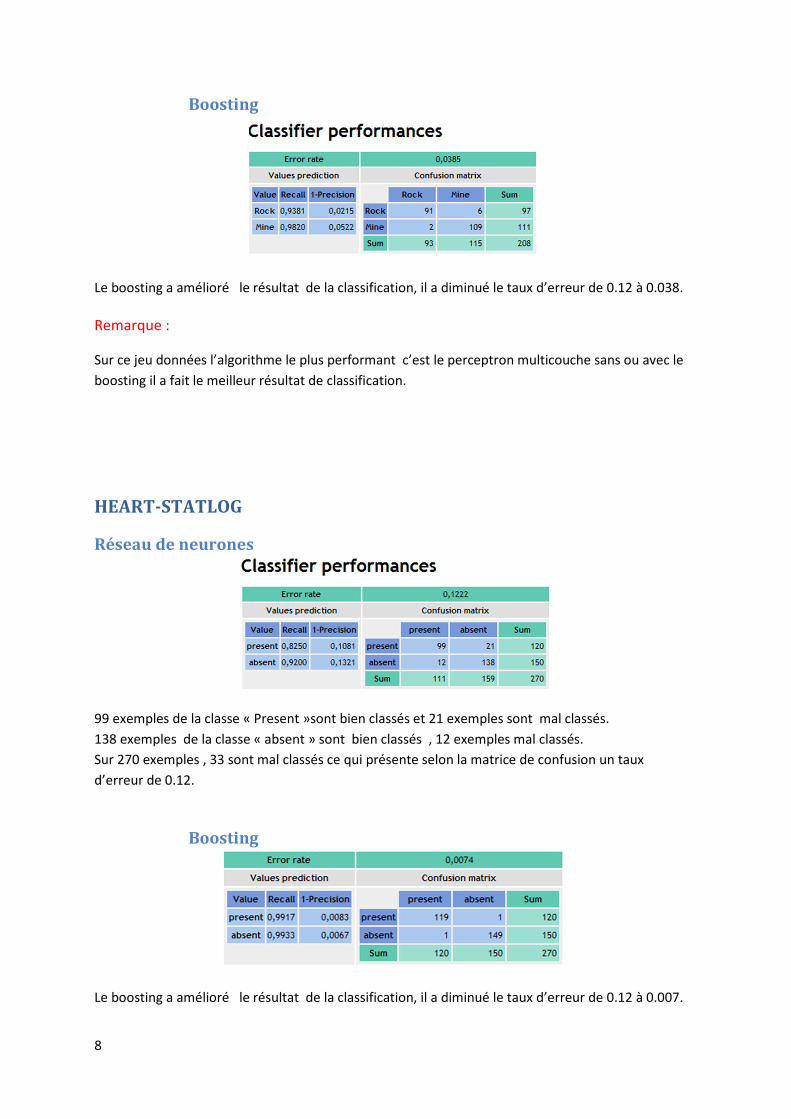
Le boosting a amélioré le résultat de la classification, il a diminué le taux d’erreur de 0.12 à 0.038.
Remarque :
Sur ce jeu données l’algorithme le plus performant c’est le perceptron multicouche sans ou avec le
boosting il a fait le meilleur résultat de classification.
HEART-STATLOG
Réseau de neurones
99 exemples de la classe « Present »sont bien classés et 21 exemples sont mal classés.
138 exemples de la classe « absent » sont bien classés , 12 exemples mal classés.
Sur 270 exemples , 33 sont mal classés ce qui présente selon la matrice de confusion un taux
d’erreur de 0.12.
Boosting
Le boosting a amélioré le résultat de la classification, il a diminué le taux d’erreur de 0.12 à 0.007.

9
Arbre de décision
110 exemples de la classe « Present »sont bien classés et 10 exemples sont mal classés.
130 exemples de la classe « absent » sont bien classés , 20 exemples mal classés.
Sur 270 exemples , 30 sont mal classés ce qui présente selon la matrice de confusion un taux
d’erreur de 0.11.
L’arbre de décision produit lors de l’induction est constitué de 29 nœuds dont 15 sont des feuilles. les
attributs les plus déterminants apparaissent dans la figure au-dessus.il propose une typologie en 15
classes (le nombre de feuilles de l’arbre).
Boosting

10
En appliquant le boosting , le résultat est optimal il n’y a aucune erreur, tous les exemples sont bien
classés.
SVM
98 exemples de la classe « Present »sont bien classés et 22 exemples sont mal classés.
132 exemples de la classe « absent » sont bien classés , 18 exemples mal classés.
Sur 270 exemples , 40 sont mal classés ce qui présente selon la matrice de confusion un taux
d’erreur de 0.11.
Boosting
Le boosting de l’SVM dans ce de données n’a rien ajouté de plus. le résultat est toujours le même.
Remarque :
Sur ce jeu données l’algorithme le plus performant c’est le C4.5 avec un taux d’erreur de 0.11 par
rapport aux autres algorithmes, avec le boosting il a fait le meilleur résultat de classification sans
erreur.
11
Tableaurecapitulatif
Pour chaque jeu de données, il Ya un algorithme d’apprentissage approprié qui donne le
meilleur résultat ,
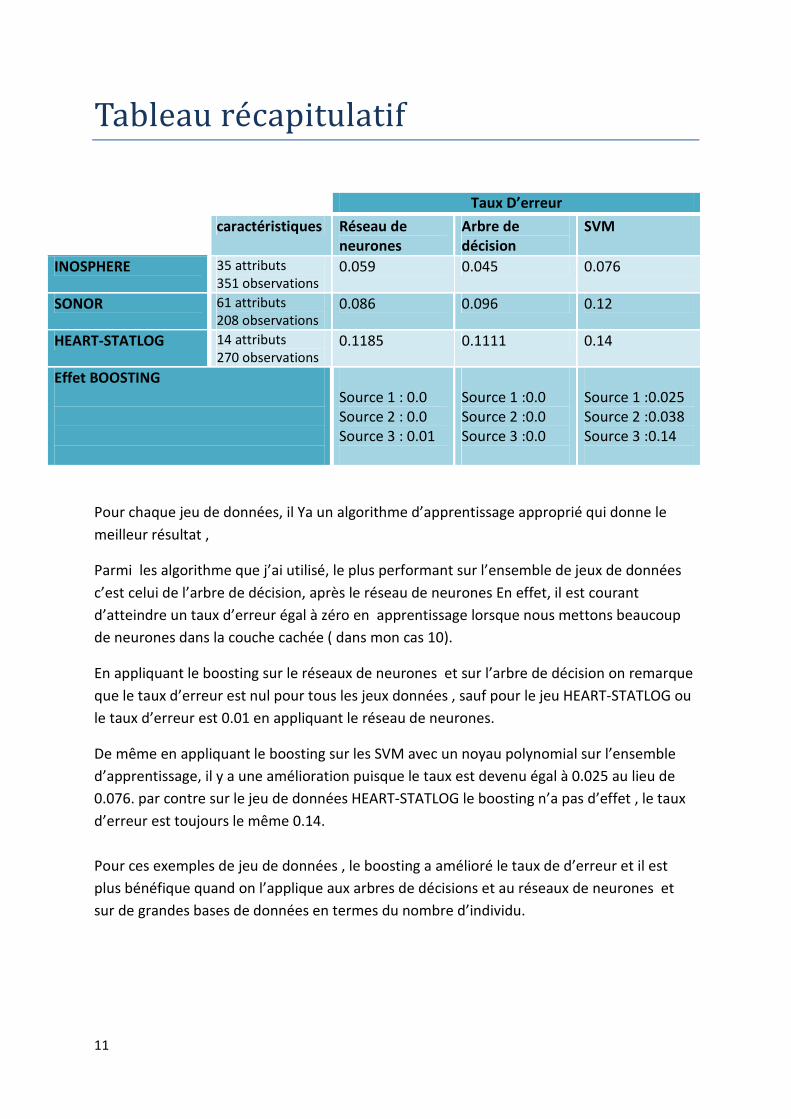
Parmi les algorithme que j’ai utilisé, le plus performant sur l’ensemble de jeux de données
c’est celui de l’arbre de décision, après le réseau de neurones En effet, il est courant
d’atteindre un taux d’erreur égal à zéro en apprentissage lorsque nous mettons beaucoup
de neurones dans la couche cachée ( dans mon cas 10).
En appliquant le boosting sur le réseaux de neurones et sur l’arbre de décision on remarque
que le taux d’erreur est nul pour tous les jeux données , sauf pour le jeu HEART-STATLOG ou
le taux d’erreur est 0.01 en appliquant le réseau de neurones.
De même en appliquant le boosting sur les SVM avec un noyau polynomial sur l’ensemble
d’apprentissage, il y a une amélioration puisque le taux est devenu égal à 0.025 au lieu de
0.076. par contre sur le jeu de données HEART-STATLOG le boosting n’a pas d’effet , le taux
d’erreur est toujours le même 0.14.
Pour ces exemples de jeu de données , le boosting a amélioré le taux de d’erreur et il est
plus bénéfique quand on l’applique aux arbres de décisions et au réseaux de neurones et
sur de grandes bases de données en termes du nombre d’individu.
Taux D’erreur
caractéristiques Réseau de
neurones
Arbre de
décision
SVM
INOSPHERE 35 attributs
351 observations 0.059 0.045 0.076
SONOR 61 attributs
208 observations 0.086 0.096 0.12
HEART-STATLOG 14 attributs
270 observations 0.1185 0.1111 0.14
Effet BOOSTING
Source 1 : 0.0
Source 2 : 0.0
Source 3 : 0.01
Source 1 :0.0
Source 2 :0.0
Source 3 :0.0
Source 1 :0.025
Source 2 :0.038
Source 3 :0.14

12
Conclusion
Ce travail m’a permis de tester les performances des classifieurs sur plusieurs jeux de
données, à partir du résultat que j’ai obtenu, je peux dire que :
il n’y pas d’algorithme d’apprentissage qui donne un résultat optimal pour tous les jeux
données.
l’application du boosting améliore le résultat, mais parfois il n’a pas d’effet ( SVM sur le jeux
de données HEART-STATLOG )
L’application du boosting est plus fiable quand on l’applique aux arbres de décisions
Il m’a permis aussi de découvrir l’outil TANAGRA ,et de mieux comprendre le principe de
l’apprentissage artificiel.





























