Embed Size (px)
Citation preview

Redes Neuronales Artificiales
Introducción a la Robótica Inteligente
Álvaro Gutiérrez11 de abril de 2018
www.robolabo.etsit.upm.es
N

N

Mapas
N

Predicción
N

Robótica
S2 S3 S4 S5 S6 S8S7S1
ijW
M l M r
N

NeurocienciaCopiar Reconocer Aprender
Memoria Contar Responder
Crear Razonar Memoria
N

Índice
1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

Por qué usar ANNs
◮ Las redes neuronales son muy utilizadas por suspropiedades:
◮ Carácter no lineal.◮ Adaptabilidad.◮ Generalización.◮ Tolerancia a fallos.◮ Descomposición de tareas.◮ Escalabilidad.
◮ También cuentan con desventajas.◮ Complejidad en el diseño de la arquitectura.◮ Gran cantidad de parámetros a ajustar.◮ Dificultad para entrenar las redes.
N

Por qué usar ANNs
◮ Reconocimiento de patrones: asignación de objetivo a undato de entrada
◮ Reconocimiento de caracteres◮ Reconocimiento de fonemas en voz◮ Toma de decisiones◮ Compresión de imágenes y reducción de dimensionalidad◮ Predicción de series temporales◮ Identificación y control de sistemas◮ ....
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

Neurona Biológica
N

Neurona Biológica
N

Neurona Biológica
N

Neurona Biológica
N

Neurona Biológica
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

Revisión histórica
1936 −→ Alan Turing comienza a estudiar el cerebro humano.1943 −→ McCulloch y Pitts, primeros modelos de neurona.1949 −→ Hebb publica la “regla de Hebb” para el aprendizaje.1958 −→ Rosemblatt desarrolla el perceptrón simple.1960 −→ Widrow y Hoff desarrollan ADALINE (ADAptativeLINear Elements).1960-1980 −→ se frena la investigaicón, al probar la debilidaddel perceptrón, Minsky y Papert.Años 80 −→ aparecen redes de Hopfield y el algoritmobackpropagation.Actualidad −→ uso en gran variedad de aplicaciones y areasde conocimiento.Recientemente aparecen modelos computacionales mássimilares a como el cerebro procesa la información(Neurociencia).
N

ANN - Representación
N1 N2w12w21
w11 w22
y1 y2
x1 x2θ1 θ2
N1 N2
N 01 N 0
2 N 03 N 0
4 N 11 N 1
2 ... N 18 N 2
1 N 31 N 3
2 ... N 38
N 41 N 4
2 N 43 N 4
4 N 51 N 5
2 N 53 N 5
4
N 61 N 6
2
IR0 IR1 IR6 IR7 L0 L1 L7 GM0 BL0 BL1 BL7
VL VR
N

ANN - Representación
Neural Network Design (Ed. 2)Hagan, Demuth, Beale & de Jesús
http://hagan.okstate.edu/NNDesign.pdf
N

ANN - Una entrada
N

ANN - Una entrada
a = f (wp + b) (1)
p,w, b, a ∈ R
n = (wp + b)
¿Qué es f ? → Función de Activación/Transferencia
(MATLAB: nnd2n1)
N

ANN - ¿ f ?
a =
{
0 if n < 0
1 if n ≥ 0
a = n
a =1
1 + e−n
(MATLAB: nnd2n1)N

ANN - Varias entradas
N

ANN - Varias entradas
N

ANN - Varias entradas
a = f (Wp + b) (2)
p,W, b, a ∈ R
n = (Wp + b)
(MATLAB: nnd2n2)
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

Sintonización de ANNs◮ Consiste en buscar los parámetros libres de la red
(W, b, ..).
◮ Diversos tipos:◮ Sintonización manual: redes pequeñas◮ Algoritmos de aprendizaje: Los más utilizados.
Algoritmos de búsqueda local.◮ Algoritmos genéticos: Algoritmos de búsqueda global.◮ Otras técnicas de optimización ...
N

Aprendizaje: Tipos
◮ Supervisado. Se dispone de pares de vectores deentrada y salida deseada. El error se establece entre lasalida de la red y la salida deseada.
◮ Por refuerzo. Es un aprendizaje supervisado donde no seproporciona la salida deseada durante el entrenamiento.Se proporciona una señal de refuerzo para ajustar losparámetros.
◮ No supervisado o autoorganizado. Se estima unafunción de densidad de probalidad para el conjunto deentradas. Se estima la “bondad” de la salida en función delconjunto de entradas.
◮ Los algoritmos más utilizados son los supervisados.
N

Aprendizaje: Operativa
◮ 3 fases:◮ Entrenamiento: Se entrena la red neuronal con un
subconjunto de los datos disponibles. Se intenta minimizarel error u obtener la mejor solución con los datos deentrenamiento.
◮ Prueba: Se prueban los resultados de la red con unsubconjunto de los datos que no se han utilizado para elentrenamiento.
◮ Operativa: Se comprueba la funcionalidad de la redneuronal con un subconjunto de los datos distintos de losde prueba y entrenamiento.
N

Aprendizaje: Esquema
N

Aprendizaje: Problemas◮ Underfitting: el error del entrenemiento y de prueba son
altos.◮ Causas: red simple, insuficiente aprendizaje.
◮ Overfitting: el error de entrenemiento es bajo pero el deprueba es alto.
◮ Causas: red compleja, no hay suficientes datos para elentrenamiento.
◮ Mínimos locales: el entrenamiento alcanza un errormínimo que no es abosoluto.
◮ Solución: reinicializar los pesos, utilizar algoritmos debúsqueda globlal, ...
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

Perceptrón
◮ Contexto:◮ 1943 - McCulloch & Pitts → Salida binaria◮ 1958 - Rosenbaltt → Perceptron & Learning Rule
◮ Condiciones iniciales aleatorias◮ Convergencia garantizada ↔ si la solución existe
◮ 1969 - Minsky & Papert → Limitaciones del Perceptron
N

Perceptrón: Notación
N

Perceptrón: Notación
a = f (n) | n = (Wp + b) (3)
p,W, b ∈ R, a ∈ {−1, 1}
f (ni) =
{
−1 if ni < 0
1 if ni ≥ 0
(MATLAB: hardlim/hardlims)
N

Perceptrón: Notación
p =
p1
p2
...pR
b =
b1
b2
...bS
W =
w1,1 w1,2 . . . w1,R
w2,1 w2,2 . . . w2,R
...... . . .
...wS,1 wS,2 . . . wS,R
wi =
wi,1
wi,2
...wi,R
W =
wT1
wT2
...wT
S
ai = f (wTi p + bi) (4)
N
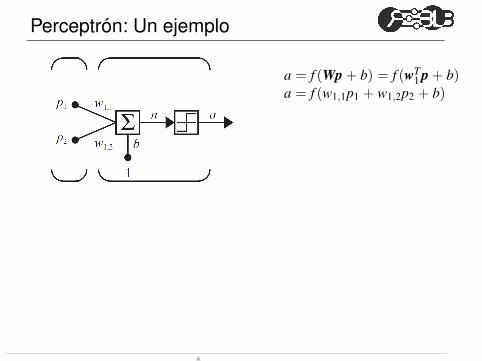
Perceptrón: Un ejemplo
a = f (Wp + b) = f (wT1
p + b)a = f (w1,1p1 + w1,2p2 + b)
N

Perceptrón: Un ejemplo
a = f (Wp + b) = f (wT1
p + b)a = f (w1,1p1 + w1,2p2 + b)
W =[
−1 1]
b = −1
a =
{
−1 if (−p1 + p2 − 1) < 0
1 if (−p1 + p2 − 1) ≥ 0
(MATLAB: nnd4db)
N
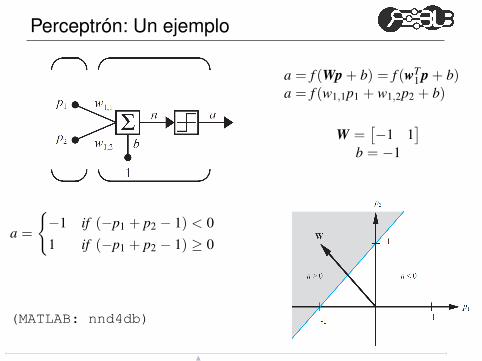
Perceptrón: Un ejemplo
a = f (Wp + b) = f (wT1
p + b)a = f (w1,1p1 + w1,2p2 + b)
W =[
−1 1]
b = −1
a =
{
−1 if (−p1 + p2 − 1) < 0
1 if (−p1 + p2 − 1) ≥ 0
(MATLAB: nnd4db)
N

Perceptrón: OR
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 1
}
{
p3 =
[
1
0
]
, t3 = 1
} {
p4 =
[
1
1
]
, t4 = 1
}
N

Perceptrón: OR
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 1
}
{
p3 =
[
1
0
]
, t3 = 1
} {
p4 =
[
1
1
]
, t4 = 1
}
p1, p2 ∈ {0, 1} | W, b ∈ R
N

Perceptrón: OR
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 1
}
{
p3 =
[
1
0
]
, t3 = 1
} {
p4 =
[
1
1
]
, t4 = 1
}
p1, p2 ∈ {0, 1} | W, b ∈ R
p1
p2
N

Perceptrón: OR
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 1
}
{
p3 =
[
1
0
]
, t3 = 1
} {
p4 =
[
1
1
]
, t4 = 1
}
p1, p2 ∈ {0, 1} | W, b ∈ R
p1
p2
N

Perceptrón: OR
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 1
}
{
p3 =
[
1
0
]
, t3 = 1
} {
p4 =
[
1
1
]
, t4 = 1
}
p1, p2 ∈ {0, 1} | W, b ∈ R
p1
p2
N

Perceptrón: AND
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 0
}
{
p3 =
[
1
0
]
, t3 = 0
} {
p4 =
[
1
1
]
, t4 = 1
}
p1, p2 ∈ {0, 1} | W, b ∈ R
p1
p2
N

Perceptrón: AND
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 0
}
{
p3 =
[
1
0
]
, t3 = 0
} {
p4 =
[
1
1
]
, t4 = 1
}
p1, p2 ∈ {0, 1} | W, b ∈ R
p1
p2
N

Perceptrón: AND
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 0
}
{
p3 =
[
1
0
]
, t3 = 0
} {
p4 =
[
1
1
]
, t4 = 1
}
p1, p2 ∈ {0, 1} | W, b ∈ R
p1
p2
N

Perceptrón: Aprendizaje
◮ ¿Cómo sintonizamos los pesos?
N

Perceptrón: Aprendizaje
◮ ¿Cómo sintonizamos los pesos?◮ Perceptron Learning Rule◮ Aprendizaje supervisado
N

Perceptrón: Aprendizaje
◮ ¿Cómo sintonizamos los pesos?◮ Perceptron Learning Rule◮ Aprendizaje supervisado
◮ Un ejemplo sencillo{
p1 =
[
1
2
]
, t1 = 1
} {
p2 =
[
−1
2
]
, t2 = 0
} {
p3 =
[
0
−1
]
, t3 = 0
}
N

Perceptrón: Aprendizaje
◮ Asegurar que el problema tiene solución
N

Perceptrón: Aprendizaje
◮ Iniciar aleatoriamente el vector de pesos
wT1=
[
1.0 −0.8]
◮ ¿Qué ocurre para p1?
{
p1 =
[
1
2
]
, t1 = 1
}
N

Perceptrón: Aprendizaje
◮ Iniciar aleatoriamente el vector de pesos
wT1=
[
1.0 −0.8]
◮ ¿Qué ocurre para p1?
{
p1 =
[
1
2
]
, t1 = 1
}
a = f (wT1
p1) = f
(
[
1.0 −0.8]
[
1
2
])
= f (−0.6) = 0 6= 1
N

Perceptrón: Aprendizaje
◮ Iniciar aleatoriamente el vector de pesos
wT1=
[
1.0 −0.8]
◮ ¿Qué ocurre para p1?
{
p1 =
[
1
2
]
, t1 = 1
}
a = f (wT1
p1) = f
(
[
1.0 −0.8]
[
1
2
])
= f (−0.6) = 0 6= 1
N

Perceptrón: Aprendizaje
◮ Inventemos una regla de actualización
w1 = p1
N

Perceptrón: Aprendizaje
◮ Inventemos una regla de actualización
w1 = p1
→
N

Perceptrón: Aprendizaje
◮ Inventemos una regla de actualización
w1 = p1
→ →
N

Perceptrón: Aprendizaje
◮ Inventemos una regla de actualización
w1 = p1
→ →
¡¡ No nos vale !!
N

Perceptrón: Aprendizaje
◮ Otro intento
Si t1 = 1 y a = 0 → wnew1
= wold1
+ p1
N

Perceptrón: Aprendizaje
◮ Otro intento
Si t1 = 1 y a = 0 → wnew1
= wold1
+ p1
wnew1
= wold1
+ p1 =
[
1.0
−0.8
]
+
[
1
2
]
=
[
2.0
1.2
]
N

Perceptrón: Aprendizaje
◮ Otro intento
Si t1 = 1 y a = 0 → wnew1
= wold1
+ p1
wnew1
= wold1
+ p1 =
[
1.0
−0.8
]
+
[
1
2
]
=
[
2.0
1.2
]
→
N

Perceptrón: Aprendizaje
◮ ¿Que ocurre con el resto de entradas/objetivos?
wT1=
[
2.0 1.2]
{
p2 =
[
−1
2
]
, t2 = 0
}
a = f (wT1
p2) = f
(
[
2.0 1.2]
[
−1
2
])
= f (0.4) = 1 6= 0
N

Perceptrón: Aprendizaje
◮ Iteremos sobre la idea anterior
Si t1 = 1 y a = 0 → wnew1
= wold1
+ p1
N

Perceptrón: Aprendizaje
◮ Iteremos sobre la idea anterior
Si t1 = 1 y a = 0 → wnew1
= wold1
+ p1
Si t2 = 0 y a = 1 → wnew1
= wold1
− p2
N

Perceptrón: Aprendizaje
◮ Iteremos sobre la idea anterior
Si t1 = 1 y a = 0 → wnew1
= wold1
+ p1
Si t2 = 0 y a = 1 → wnew1
= wold1
− p2
wnew1
= wold1
− p2 =
[
2.0
1.2
]
+
[
−1
2
]
=
[
3.0
−0.8
]
→
N

Perceptrón: Aprendizaje
◮ ¿Que ocurre con p3?
wT1=
[
3.0 −0.8]
{
p3 =
[
0
−1
]
, t2 = 0
}
a = f (wT1
p3) = f
(
[
3.0 −0.8]
[
0
−1
])
= f (0.8) = 1 6= 0
N

Perceptrón: Aprendizaje
◮ ¿Que ocurre con p3?
wT1=
[
3.0 −0.8]
{
p3 =
[
0
−1
]
, t2 = 0
}
a = f (wT1
p3) = f
(
[
3.0 −0.8]
[
0
−1
])
= f (0.8) = 1 6= 0
wnew1
= wold1
− p3 =
[
3.0
−0.8
]
+
[
0
−1
]
=
[
3.0
0.2
]
→
N

Perceptrón: Aprendizaje◮ Reformulemos nuestra regla
wnew1
=
wold1
+ p if t = 1 and a = 0
wold1
− p if t = 0 and a = 1
wold1
if t = a
N

Perceptrón: Aprendizaje◮ Reformulemos nuestra regla
wnew1
=
wold1
+ p if t = 1 and a = 0
wold1
− p if t = 0 and a = 1
wold1
if t = a
◮ Definamos el error
e = t − a
wnew1
=
wold1
+ p if e = 1
wold1
− p if e = −1
wold1
if e = 0
N

Perceptrón: Aprendizaje◮ Reformulemos nuestra regla
wnew1
=
wold1
+ p if t = 1 and a = 0
wold1
− p if t = 0 and a = 1
wold1
if t = a
◮ Definamos el error
e = t − a
wnew1
=
wold1
+ p if e = 1
wold1
− p if e = −1
wold1
if e = 0
◮ Un paso más allá
wnew1 = wold
1 + ep (5)
N

Perceptrón: Aprendizaje
◮ Extendamos al sesgo{
wnew1
= wold1
+ ep
bnew = bold + e
N

Perceptrón: Aprendizaje
◮ Extendamos al sesgo{
wnew1
= wold1
+ ep
bnew = bold + e
◮ ¿Para S neuronas?{
wnewi = wold
i + eip
bnewi = bold
i + ei
N

Perceptrón: Aprendizaje
◮ Extendamos al sesgo{
wnew1
= wold1
+ ep
bnew = bold + e
◮ ¿Para S neuronas?{
wnewi = wold
i + eip
bnewi = bold
i + ei
◮ Notación matricial
{
Wnew = Wold + epT
bnew = bold + e(6)
(MATLAB:nnd4pr)
N

Preceptrón: Limitaciones
◮ ¿Qué problemas podemos resolver?
N

Preceptrón: Limitaciones
◮ ¿Qué problemas podemos resolver?◮ Una neurona puede dividir el espacio en 2 regiones◮ La separabilidad viene determinada por:
◮ wT1 p + b = 0
◮ Separabilidad lineal: Hiperplano
N
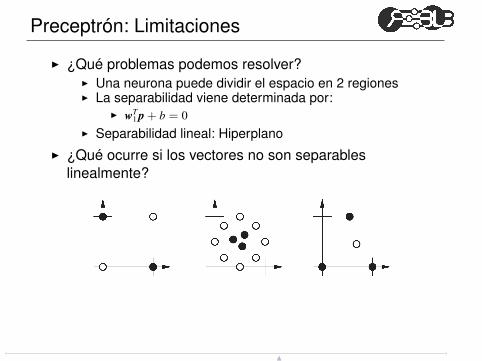
Preceptrón: Limitaciones
◮ ¿Qué problemas podemos resolver?◮ Una neurona puede dividir el espacio en 2 regiones◮ La separabilidad viene determinada por:
◮ wT1 p + b = 0
◮ Separabilidad lineal: Hiperplano
◮ ¿Qué ocurre si los vectores no son separableslinealmente?
N

Preceptrón: Limitaciones
◮ ¿Qué problemas podemos resolver?◮ Una neurona puede dividir el espacio en 2 regiones◮ La separabilidad viene determinada por:
◮ wT1 p + b = 0
◮ Separabilidad lineal: Hiperplano
◮ ¿Qué ocurre si los vectores no son separableslinealmente?
¡No es posible utilizar el perceptrón!
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

ADALINE◮ Contexto:
◮ ADALINE: ADAptive LInear NEuron◮ 1960 - Widrow & Hoff - ADALINE + LMS (Least Mean
Square)◮ LMS - Media de mínimos cuadrados◮ Minimiza el Error Cuadrático Medio (MSE)
◮ Similar al perceptron - Función activación lineal◮ Perceptron: El hiperplano está cerca de los límites de
decisión◮ ADALINE: Minimiza el Error Cuadrático Medio (MSE)
N

ADALINE
N

ADALINE
a = f (n) | n = (Wp + b) (7)
p,W, b, a ∈ R
f (ni) = ni
a = Wp + b (8)
(MATLAB: purelim)N

ADALINE: Un ejemplo
a = f (Wp + b) = wT1
p + b = w1,1p1 + w1,2p2 + b
N

ADALINE: Aprendizaje
◮ ¿Cómo sintonizamos los pesos?◮ No podemos utilizar la Perceptron Learning Rule
N

ADALINE: Aprendizaje
◮ ¿Cómo sintonizamos los pesos?◮ No podemos utilizar la Perceptron Learning Rule
◮ Least Mean Square (LMS) - Descenso de gradiente◮ Aprendizaje supervisado
N

ADALINE: Aprendizaje
◮ ¿Cómo sintonizamos los pesos?◮ No podemos utilizar la Perceptron Learning Rule
◮ Least Mean Square (LMS) - Descenso de gradiente◮ Aprendizaje supervisado
◮ ¿Función objetivo?
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

Perceptrón multicapa◮ Contexto:
◮ 1969 - Minsky & Papert → Limitaciones del Perceptron◮ 1974 - Werbos → Entrenamientos de ANNs con varias
capas◮ 1986 - Rumelhart, Hinton & Williams → backpropagation◮ 1985 - Parker → backpropagation◮ 1985 - Le Cun → backpropagation
N

Perceptrón multicapa: MLP
a1 = f 1(W1p + b1) a2 = f 2(W2a1 + b2) a3 = f 3(W3a2 + b3)
a3 = f 3(W3f 2(W2f 1(W1p + b1) + b2) + b3)
◮ Notación: R − S1 − S2 − S3
◮ R: Número de entradas - S: Número de neuronas en cada capaN

Perceptrón multicapa: MLP
a1 = f 1(W1p + b1) a2 = f 2(W2a1 + b2) a3 = f 3(W3a2 + b3)
a3 = f 3(W3f 2(W2f 1(W1p + b1) + b2) + b3)
◮ Notación: R − S1 − S2 − S3
◮ R: Número de entradas - S: Número de neuronas en cada capa
N

MLP: XOR
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 1
}
{
p3 =
[
1
0
]
, t3 = 1
} {
p4 =
[
1
1
]
, t4 = 0
}
N

MLP: XOR
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 1
}
{
p3 =
[
1
0
]
, t3 = 1
} {
p4 =
[
1
1
]
, t4 = 0
}
N

MLP: XOR
p1
p2
a
{
p1 =
[
0
0
]
, t1 = 0
} {
p2 =
[
0
1
]
, t2 = 1
}
{
p3 =
[
1
0
]
, t3 = 1
} {
p4 =
[
1
1
]
, t4 = 0
}
Red: 2-2-1
N

MLP: XOR
Red: 2-2-1
N

MLP: XOR
Red: 2-2-1
N

MLP: XOR
Red: 2-2-1
N

MLP: XOR
Red: 2-2-1
N

MLP: Aprendizaje
◮ ¿Cómo entrenamos redes multicapa?
N

MLP: Aprendizaje
◮ ¿Cómo entrenamos redes multicapa?◮ Perceptron Learning Rule ??◮ Least Mean Square ??
N

MLP: Aprendizaje
◮ ¿Cómo entrenamos redes multicapa?◮ Perceptron Learning Rule ??◮ Least Mean Square ??
No son válidos!!!
Que ocurre en las capas intermedias??
N

MLP: Aprendizaje
◮ ¿Cómo entrenamos redes multicapa?◮ Perceptron Learning Rule ??◮ Least Mean Square ??
No son válidos!!!
Que ocurre en las capas intermedias??
¡BackPropagation!
N

BackPropagation - Resumen
1. Ejecutar la red hacia adelante
a0 = p
am+1 = f m+1(Wm+1am + bm+1) para m = 0, 1, ...,M − 1
a = aM
(9)2. Calcular las sensibilidades
{
sM = −2FM(nM)(t − a)
sm = Fm(nm)(Wm+1)T(sm+1) para m = M − 1, ..., 2, 1
(10)3. Actualizar los pesos y sesgos
{
Wm(k + 1) = Wm(k)− αsm(am−1)T
bm(k + 1) = bm(k)− αsm(11)
(MATLAB: nnd11bc)
N

MLP y BackPropagation - Dificultades
◮ Entrenamiento incremental o grupal◮ Selección de la arquitectura
◮ Capas, neuronas, funciones de activación, ...
◮ Muchas capas/neuronas → Sobre-especialización◮ Pocas capas/neuronas → Bajo rendimiento
(MATLAB: nnd11fa, nnd11gn)
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

DNN
◮ Hemos visto redes neuronales estáticas◮ La salida puede ser calculada con la entrada instantánea◮ Podemos aproximar funciones◮ ¿Qué ocurre con el tiempo?◮ ¿Predicciones temporales, series temporales,..?
N

DNN
◮ Hemos visto redes neuronales estáticas◮ La salida puede ser calculada con la entrada instantánea◮ Podemos aproximar funciones◮ ¿Qué ocurre con el tiempo?◮ ¿Predicciones temporales, series temporales,..?
◮ En las redes dinámicas, la salida puede depender de:◮ La entrada instantánea◮ La entrada en instantes anteriores◮ La salida en instantes anteriores◮ Los estados en instantes anteriores
N

DNN - Retardo
◮ Introduzcamos el operador retardo
a(t) = u(t − 1)
N

DNN - Retardo
a(t) = iw1,1(0)p(t) + iw1,1(1)p(t − 1) + iw1,1(2)p(t − 2)
N

DNN - Retardo
a(t) = iw1,1(0)p(t) + iw1,1(1)p(t − 1) + iw1,1(2)p(t − 2)
iw1,1(0) =1
3, iw1,1(1) =
1
3, iw1,1(2) =
1
3
Señal cuadrada
N

DNN - Retardo
a(t) = iw1,1(0)p(t) + iw1,1(1)p(t − 1) + iw1,1(2)p(t − 2)
iw1,1(0) =1
3, iw1,1(1) =
1
3, iw1,1(2) =
1
3
Señal cuadrada
N

DNN - Recurrencia
a(t) = iw1,1p(t) + lw1,1(1)a(t − 1)
N

DNN - Recurrencia
a(t) = iw1,1p(t) + lw1,1(1)a(t − 1)
iw1,1 = 1
2, lw1,1(1) =
1
2
Señal cuadrada
N

DNN - Recurrencia
a(t) = iw1,1p(t) + lw1,1(1)a(t − 1)
iw1,1 = 1
2, lw1,1(1) =
1
2
Señal cuadrada
N

DNN - Ejemplos
Dinámica RecurrenteFiltro FIR Filtro IIR
(MATLAB: nnd14fir, nnd14iir)N

DNN - Estructura
nm(t) =∑
l∈Lfm
∑
d∈DLm,l
LWm,l(d)al(t − d) +∑
l∈Im
∑
d∈Im,l
IWm,l(d)pl(t − d) + bm
am(t) = f m(nm(t))
N

DNN - Aprendizaje
◮ No podemos utilizar Backpropagation◮ 2 algoritmos fundamentales:
◮ BackPropagation Through Time (BPTT)◮ Se calcula la respuesta para todos los instantes de tiempo◮ Se calcula el gradiente en el último instante de tiempo
◮ Real Time Recurrent Learning (RTRL)◮ Se calcula la respuesta en cada instante de tiempo◮ Se calcula el gradiente a la vez que la respuesta
◮ Existe una gran variedad de algoritmos
N

1 IntroducciónNeurona BiológicaNeurona ArtificialSintonización de parámetros
2 Neuronas y Redes NeuronalesPerceptrónADALINEPerceptrón Multicapa y BackpropagationRedes Neuronales Dinámicas
3 Conclusiones
N

Conclusiones◮ Inspiradas en el sistema nervioso.◮ Procesan la información de manera paralela y distribuida.◮ Operaciones en tiempo real para grandes cantidades de
datos.◮ Sistemas distribuido con altas capacidades de computo.
◮ Reconocimiento de patrones: asignación de objetivo a undato de entrada
◮ Reconocimiento de caracteres◮ Reconocimiento de fonemas en voz◮ Toma de decisiones◮ Compresión de imágenes y reducción de dimensionalidad◮ Predicción de series temporales◮ Identificación y control de sistemas◮ ....
N

Conclusiones-Dificultades
◮ Datos existentes◮ Número de capas◮ Número de neuronas◮ Funciones de activación◮ Algoritmos de aprendizaje◮ ...
Mucho por explorar!!
N

Gracias
GRACIAS!!
N

Gracias
GRACIAS!!
N