Embed Size (px)
Citation preview

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 1�
Regresión Logística Resumen El procedimiento de Regresión Logística está diseñado para ajustarse a un modelo de regresión en el que la variable dependiente Y caracteriza un evento con sólo dos posibles resultados. Pueden modelarse dos tipos de datos:
1. Datos en los que Y consiste en un conjunto de 0’s y 1’s, donde 1 representa la ocurrencia de uno de los dos resultados.
2. Datos en los que Y representa la proporción de tiempo de uno de los dos resultados ocurridos.
El modelo de regresión ajustado relaciona Y con una o más variables predictoras X, las cuales pueden ser cuantitativas o categóricas. En este procedimiento, se asume que la probabilidad de un evento está relacionada con los predictores a través de una función logística. El Análisis Probit puede usarse para ajustar el mismo tipo de datos, pero usa una forma funcional distinta. El procedimiento ajusta un modelo usando máxima verosimilitud o mínimos cuadrados ponderados. La selección de variables por pasos es una opción. Se realizan pruebas de radio verosimilitud para probar la importancia de los coeficientes del modelo. El modelo ajustado puede graficarse y generar predicciones a partir de la gráfica. Residuos átipicos son identificados y graficados. StatFolio Muestra: logistic.sgp Datos de Muestra: Se considerarán dos ejemplos. El primero, de Myers (1990), está contenido en el archivo fabric.sf3. Describe la falla de especimenes de una fábrica sujetos a diferentes cargas.
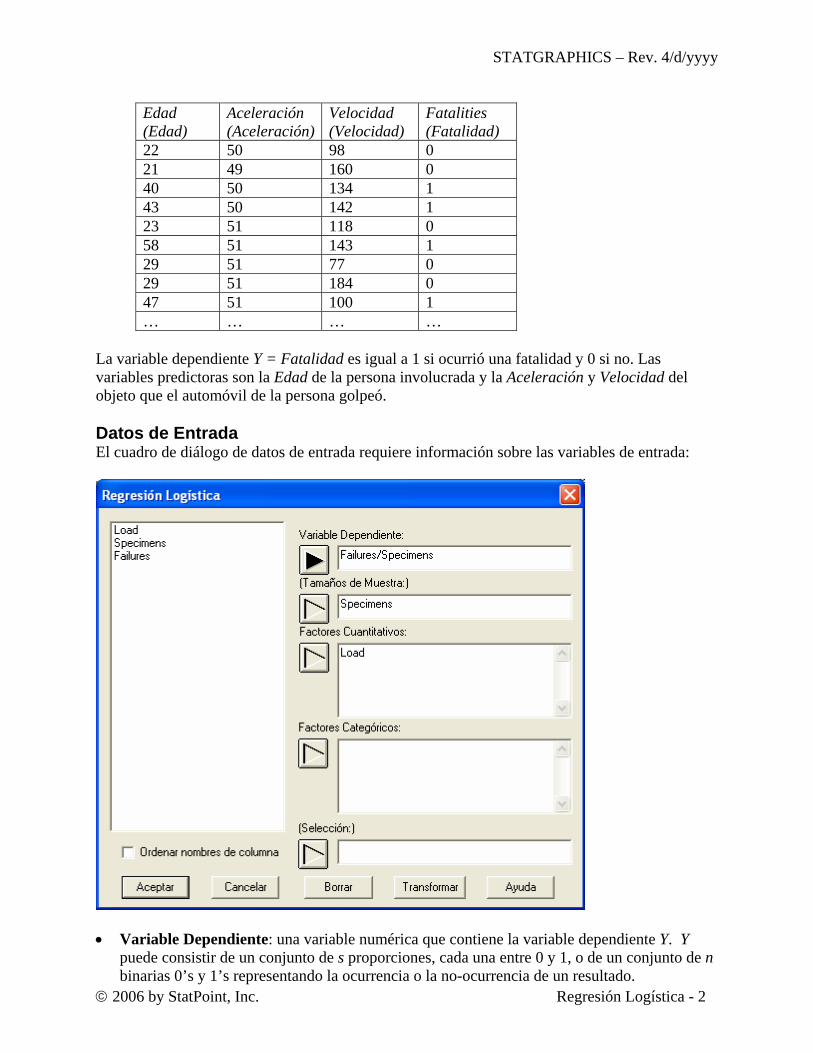
Load (Carga)
Specimens (Especimenes)
Failures (Fallas)
5 600 13 35 500 95 70 600 189 80 300 95 90 300 130
Para estos datos, la variable dependiente Y es la proporción de especimenes que fallan en una carga dada, calculada por Y = fallas / especimenes. Hay una solo variable predictora X = Carga. Hay un total de n = 2,300 especimenes. El segundo archivo de datos, collisions.sf6, es de Härdle y Stoker (1989). Describe n = 58 colisiones de lado de automóviles. La variable de respuesta es binaria, cuantificando si la colisión resulto en una fatalidad o no. Una porción del archivo se muestra abajo.
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 2�
Edad (Edad)
Aceleración (Aceleración)
Velocidad (Velocidad)
Fatalities (Fatalidad)
22 50 98 0 21 49 160 0 40 50 134 1 43 50 142 1 23 51 118 0 58 51 143 1 29 51 77 0 29 51 184 0 47 51 100 1 … … … …
La variable dependiente Y = Fatalidad es igual a 1 si ocurrió una fatalidad y 0 si no. Las variables predictoras son la Edad de la persona involucrada y la Aceleración y Velocidad del objeto que el automóvil de la persona golpeó. Datos de Entrada El cuadro de diálogo de datos de entrada requiere información sobre las variables de entrada:
• Variable Dependiente: una variable numérica que contiene la variable dependiente Y. Y
puede consistir de un conjunto de s proporciones, cada una entre 0 y 1, o de un conjunto de n binarias 0’s y 1’s representando la ocurrencia o la no-ocurrencia de un resultado.
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 3�
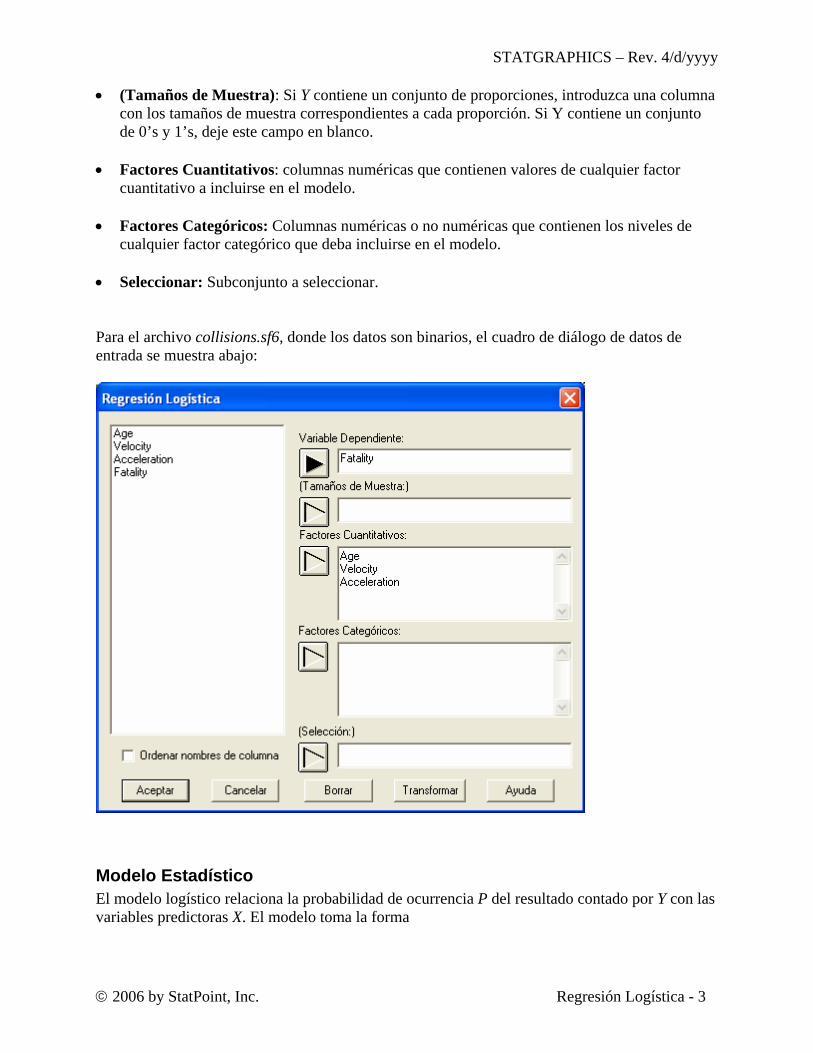
• (Tamaños de Muestra): Si Y contiene un conjunto de proporciones, introduzca una columna
con los tamaños de muestra correspondientes a cada proporción. Si Y contiene un conjunto de 0’s y 1’s, deje este campo en blanco.
• Factores Cuantitativos: columnas numéricas que contienen valores de cualquier factor
cuantitativo a incluirse en el modelo. • Factores Categóricos: Columnas numéricas o no numéricas que contienen los niveles de
cualquier factor categórico que deba incluirse en el modelo. • Seleccionar: Subconjunto a seleccionar. Para el archivo collisions.sf6, donde los datos son binarios, el cuadro de diálogo de datos de entrada se muestra abajo:
Modelo Estadístico El modelo logístico relaciona la probabilidad de ocurrencia P del resultado contado por Y con las variables predictoras X. El modelo toma la forma

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 4�
[ ])...(exp11)(
22110 kk XXXXP
ββββ ++++−+= (1)
Alternativamente, el modelo puede escribirse de la forma
)...exp()(1
)(log 22110 kk XXXXP
XP ββββ ++++=⎟⎟⎠
⎞⎜⎜⎝
⎛− (2)
Donde el lado izquierdo de la ecuación de arriba se conoce como la transformación logit.
Resumen del Análisis El Resumen del Análisis despliega una tabla que muestra el modelo estimado y las pruebas de significancia para los coeficientes del modelo. El resultado depende del método usado para estimar el modelo. Estimación de Máxima Verosimilitud La estimación de máxima verosimilitud puede usarse si Y es binaria o si contiene proporciones. Un resultado típico de cuando se usa máxima verosimilitud se muestra abajo Regresión Logística - fallas/especimenes Variable dependiente: fallas/especimenes Tamaños de muestra: especimenes Factores: Carga Modelo Estimado de Regresión (Máxima Verosimilitud)
Análisis de Desviación
Porcentaje de desviación explicado por el modelo = 88.6561 Porcentaje ajustado = 87.4033 Pruebas de Razón de Verosimilitud
Análisis de Residuos
El resultado incluye: • Resumen de Datos: un resumen de los datos de entrada.
Error Razón de Momios Parámetro Estimado Estándar Estimada CONSTANTE -2.9949 0.145939 Carga 0.0307699 0.00209432 1.03125 Fuente Desviación Gl Valor-P Modelo 283.056 1 0.0000 Residuo 36.2181 3 0.0000 Total (corr.) 319.274 4
Factor Chi-Cuadrada Gl Valor-P Carga 283.056 1 0.0000
Estimación Validación n 5 CME 0.159284 MAE 0.0299959 MAPE 23.9252 ME -0.000979783 MPE -10.6729

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 5�
• Modelo Estimado de Regresión: estima los coeficientes en el modelo de regresión, con errores estándar y razones de momios estimadas. Las razones de momios se calculan a partir de los coeficientes del modelo jβ̂ por:
Razón de momios = ( )jβ̂exp (3)
La razón de momios representa el incremento porcentual de las probabilidades de un resultado para cada unidad incrementada en X.
• Análisis de Desviación: descomposición de la desviación de los datos en un componente
explicado (Modelo) y un componente no explicado (Residuo). La desviación compara la función de verosimilitud de un modelo con el valor más grande que la función de verosimilitud puede alcanzar, de tal manera que un modelo perfecto tendría desviación igual a cero. Hay tres líneas en la tabla:
1. Total (corr.) – la desviación del modelo con sólo un término constante, λ(β0).
2. Residuo – la desviación restante después que el modelo ha sido ajustado.
3. Modelo – la reducción en la desviación debido a las variables predictoras,
λ(β1,β2,…,βk|β0), son iguales a la diferencia entre los otros dos componentes.
El P-Valor del Modelo prueba si la adición de las variables predictoras reduce significativamente la desviación, comprándose con un modelo que contenga sólo un término constante. Un P-Valor pequeño (menos de 0.05 si se está operando a un nivel de significancia del 5%) indica que el modelo ha reducido significativamente la desviación y por lo tanto es útil para predecir la probabilidad del resultado estudiado. El P-Valor para el término Residuo prueba si existe una pérdida-de-ajuste significativa; i.e. si sería posible un mejor modelo. Un P-Valor pequeño indica que desviación significativa permanece en los residuos, así que sería posible un mejor modelo.
• Porcentaje de Desviación – el porcentaje de desviación explicado por el modelo, calculado
por
( )( )0
0212 |,...,,βλ
ββββλ kR = (4)
Es similar a un estadístico R-cuadrado en regresión múltiple, y cuyo rango puede estar desde 0% hasta 100%. Una desviación ajustada también se calcula a partir de
( )
( )0
0212 2|,...,,βλ
ββββλ pR k
adj−
= (5)
donde p es igual al número de coeficientes en el modelo ajustado, incluyendo el término constante. Es similar al estadístico R-Cuadrado ajustado en el sentido de que compensa el número de variables en el modelo.

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 6�
• Pruebas de Razón de Verosimilitud – Una prueba de significancia para cada efecto en el modelo ajustado. Estas pruebas comparan la función de verosimilitud del modelo completo con la del modelo en el que solo arroja el efecto indicado. Pequeños P-valores indican que el modelo se ha mejorado significativamente por el efecto correspondiente.
• Análisis de Residuos – si un conjunto de filas en la hoja de datos ha sido excluido del análisis usando el campo Seleccionar en el cuadro de diálogo de datos de entrada, el modelo ajustado es usado para hacer predicciones de los Y valores para esas filas. Esta tabla muestra estadísticos en los errores de predicción, definidos por:
)(ˆiii XPye −= (6)
Están incluidos el error cuadrático medio (MSE), el error absoluto medio (MAE), el error porcentual absoluto medio (MAOE), el error medio (ME) y el error porcentual medio (MPE). Estos estadísticos de validación pueden compararse con los estadísticos del modelo ajustado para determinar que tan bien el modelo predice observaciones fuera de los datos usados para ajustarlo.
El modelo ajustado para los datos muestrales es
[ ])oad0.03076999949.2(exp11)(
LfallaP
+−−+= (7)
La regresión explica cerca del 88.7% de la desviación de un modelo sin Carga. El P-valor para Carga es muy pequeño, que es un estadístico predictor significativo para la proporción de Fallas. La razón de momios es aproximadamente 1.03, indicando un incremento del 3% en las probabilidades de falla para cada unidad de incremento en Carga. Note que el P-valor de los Residuos también es significativo, indicando que una pérdida-de-ajuste significativa permanece sin ser explicada. Esto puede rectificarse regresando al cuadro de diálogo de datos de entrada e introduciendo LOG(Carga) como variable predoctora en lugar de Carga. El resultado es un modelo loglogístico , como se muestra abajo:

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 7�
Regresión Logística - fallas/especimenes Variable dependiente: fallas/especimenes Tamaños de muestra: especimenes Factores: LOG(Carga) Modelo Estimado de Regresión (Máxima Verosimilitud)
Análisis de Desviación
Porcentaje de desviación explicado por el modelo = 98.3123 Porcentaje ajustado = 97.0595 Pruebas de Razón de Verosimilitud
Note el incremento en el porcentaje de desviación explicado a más del 98%. Además, el P-valor de los Residuos ya no muestra pérdida de juste significativa Regresión de Mínimos Cuadrados Ponderados Cuando los datos de entrada Y consisten en un conjunto de proporciones, el modelo puede estimarse usando mínimos cuadrados ponderados en vez de máxima verosimilitud. El resultado entonces toma la siguiente forma:
Error Razón de Momios Parámetro Estimado Estándar Estimada CONSTANTE -5.5784 0.368202 LOG(Carga) 1.13997 0.0892554 3.12667 Fuente Desviación Gl Valor-P Modelo 313.886 1 0.0000 Residuo 5.38828 3 0.1455 Total (corr.) 319.274 4
Factor Chi-Cuadrada Gl Valor-P LOG(Carga) 313.886 1 0.0000

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 8�
Regresión Logística - fallas/especimenes Variable dependiente: fallas/especimenes Tamaños de muestra: especimenes Factores: Carga Modelo Estimado de Regresión (Mínimos Cuadrados Ponderados)
Análisis de Varianza
R-Cuadrada = 81.3871 porciento R-Cuadrada (ajustada por g.l.) = 75.1828 porciento Error estándar del est. = 3.18267 Error medio absoluto = 0.168476 Estadístico Durbin-Watson = 2.15796 Autocorrelación residual de retardo 1 = -0.390383 Suma de Cuadrados Tipo III
Análisis de Residuos
La tabla difiere del resultado de la opción del MLE de muchas maneras:
1. Cada coeficiente se muestra junto a un t-estadístico y un P-valor asociado, que prueban si un coeficiente específico puede ser igual a 0.
2. El análisis de desviación es remplazado por un análisis de varianza estándar. La Razón-F prueba la significancia estadística del modelo como un todo.
3. El porcentaje de desviación es reemplazado por un estadístico R-Cuadrado estándar. 4. Las pruebas de radio verosimilitud de los efectos son remplazados por F pruebas
basadas en sumas de cuadrados Tipo III. La misma interpretación de los P-valores aplica, sin embargo, con P-valores pequeños correspondientes a efectos significativos.
Para mayor explicación de los estadísticos de regresión, vea la documentación sobre Modelos Lineales Generales.
Error Estadístico Razón de Momios Parámetro Estimado Estándar t Valor-P Estimada CONSTANTE -2.72665 0.525557 -5.18811 0.0139 Carga 0.0272839 0.00753311 3.62186 0.0362 1.02766 Fuente Suma de Cuadrados Gl Cuadrado Medio Razón-F Valor-P Modelo 132.876 1 132.876 13.12 0.0362 Residuo 30.3881 3 10.1294 Total (Corr.) 163.264 4
Fuente Suma de Cuadrados Gl Cuadrado Medio Razón-F Valor-P Carga 132.876 1 132.876 13.12 0.0362 Residuo 30.3881 3 10.1294
Estimación Validación n 5 CME 10.1294 MAE 0.168476 MAPE 254.223 ME 3.19675E-17 MPE -171.933

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 9�
Opciones de Análisis
• Método: método usado para estimar los coeficientes del modelo. Para Y binarias, la única
opción es la Máxima Verosimilitud. • Proporción Menor: Para datos Y que consistan en proporciones, la proporción más pequeña
admisible Pmin. Todas las observaciones menores a Pmin se fijan iguales a Pmin, mientras que todas las observaciones mayores 1- Pmin se fijan iguales a 1- Pmin.
• Modelo: orden del modelo a ajustarse. Los modelos de primer orden solamente incluyen
efectos principales. Los de segundo orden incluyen efectos cuadráticos para factores cuantitativos e interacciones bifactoriales entre todas las variables.
• Incluir Constante: Si esta opción no está seleccionada, el término constante β0 será omitido
en el modelo. • Ajustar: Especifica si todas las variables independientes especificadas en el cuadro de
diálogo de datos de entrada deben incluirse en el modelo final, o si debe aplicarse una selección paso a paso de variables. La selección paso a paso de variables intenta encontrar un modelo parsimonioso que contenga solo variables significativas estadísticamente. Un ajuste Paso a paso hacia delante comienza sin variables en el modelo. Un ajuste Paso a paso hacia atrás comienza con todas las variables en el modelo.
• P-para-Introducir – En un ajuste paso a paso, las variables se introducirán al modelo en un
paso dado si sus P-valores son menores o iguales a al P-para-Introducir valor especificado. • P-para-Eliminar - En un ajuste paso a paso, las variables se removerán del modelo en un
paso dado si sus P-valores son mayores que el P-para-Eliminar valor especificado. • Pasos Máximos: número máximo de pasos permitidos al hacer un ajuste paso a paso.
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 10�
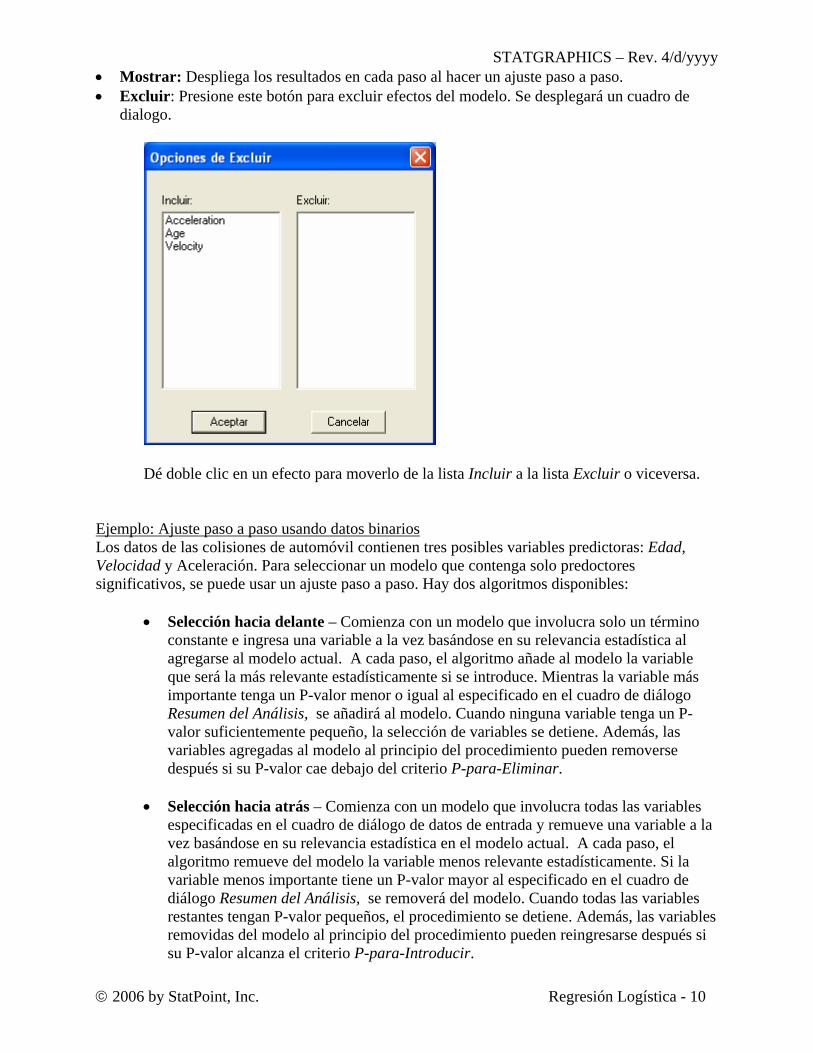
• Mostrar: Despliega los resultados en cada paso al hacer un ajuste paso a paso. • Excluir: Presione este botón para excluir efectos del modelo. Se desplegará un cuadro de
dialogo.
Dé doble clic en un efecto para moverlo de la lista Incluir a la lista Excluir o viceversa.
Ejemplo: Ajuste paso a paso usando datos binarios Los datos de las colisiones de automóvil contienen tres posibles variables predictoras: Edad, Velocidad y Aceleración. Para seleccionar un modelo que contenga solo predoctores significativos, se puede usar un ajuste paso a paso. Hay dos algoritmos disponibles:
• Selección hacia delante – Comienza con un modelo que involucra solo un término constante e ingresa una variable a la vez basándose en su relevancia estadística al agregarse al modelo actual. A cada paso, el algoritmo añade al modelo la variable que será la más relevante estadísticamente si se introduce. Mientras la variable más importante tenga un P-valor menor o igual al especificado en el cuadro de diálogo Resumen del Análisis, se añadirá al modelo. Cuando ninguna variable tenga un P-valor suficientemente pequeño, la selección de variables se detiene. Además, las variables agregadas al modelo al principio del procedimiento pueden removerse después si su P-valor cae debajo del criterio P-para-Eliminar.
• Selección hacia atrás – Comienza con un modelo que involucra todas las variables
especificadas en el cuadro de diálogo de datos de entrada y remueve una variable a la vez basándose en su relevancia estadística en el modelo actual. A cada paso, el algoritmo remueve del modelo la variable menos relevante estadísticamente. Si la variable menos importante tiene un P-valor mayor al especificado en el cuadro de diálogo Resumen del Análisis, se removerá del modelo. Cuando todas las variables restantes tengan P-valor pequeños, el procedimiento se detiene. Además, las variables removidas del modelo al principio del procedimiento pueden reingresarse después si su P-valor alcanza el criterio P-para-Introducir.

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 11�
El siguiente resultado muestra lo que resulta de un ajuste paso a paso hacia atrás: Regresión Logística - Fatalidad Variable dependiente: Fatalidad Factores: Edad Velocidad Aceleración Modelo Estimado de Regresión (Máxima Verosimilitud)
Análisis de Desviación
Porcentaje de desviación explicado por el modelo = 42.3793 Porcentaje ajustado = 34.7527 Pruebas de Razón de Verosimilitud
Error Razón de Momios Parámetro Estimado Estándar Estimada CONSTANTE -16.9845 5.14861 Edad 0.162501 0.041448 1.17645 Velocidad 0.233906 0.0862681 1.26353
Fuente Desviación Gl Valor-P Modelo 33.3408 2 0.0000 Residuo 45.3315 55 0.8206 Total (corr.) 78.6723 57

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 12�
Análisis de Residuos
Selección de factores por etapas Método: selección hacia atrás P-para-introducir: 0.05 P-para-eliminar: 0.05 Paso 0: 3 factores en el modelo. 54 g.l. para el error. Porcentaje de desviación explicada = 44.10% Porcentaje ajustado = 33.93% Paso 1: Eliminando el factor Aceleración con P-para-eliminar = 0.244299 2 factores en el modelo. 55 g.l. para el error. Porcentaje de desviación explicada = 42.38% Porcentaje ajustado = 34.75% Modelo final seleccionado.
El algoritmo comienza con un modelo que contiene los tres predictores. Luego remueve Aceleración, ya que su P-valor es grande. El modelo final involucra solo Edad y Velocidad, cuyos P-valores son mayores o iguales a 0.05.
Factor Chi-Cuadrada Gl Valor-P Edad 29.9333 1 0.0000 Velocidad 10.0497 1 0.0015
Estimación Validación n 58 CME 0.0221508 MAE 0.340955 MAPE ME 0.00127246 MPE

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 13�
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 14�
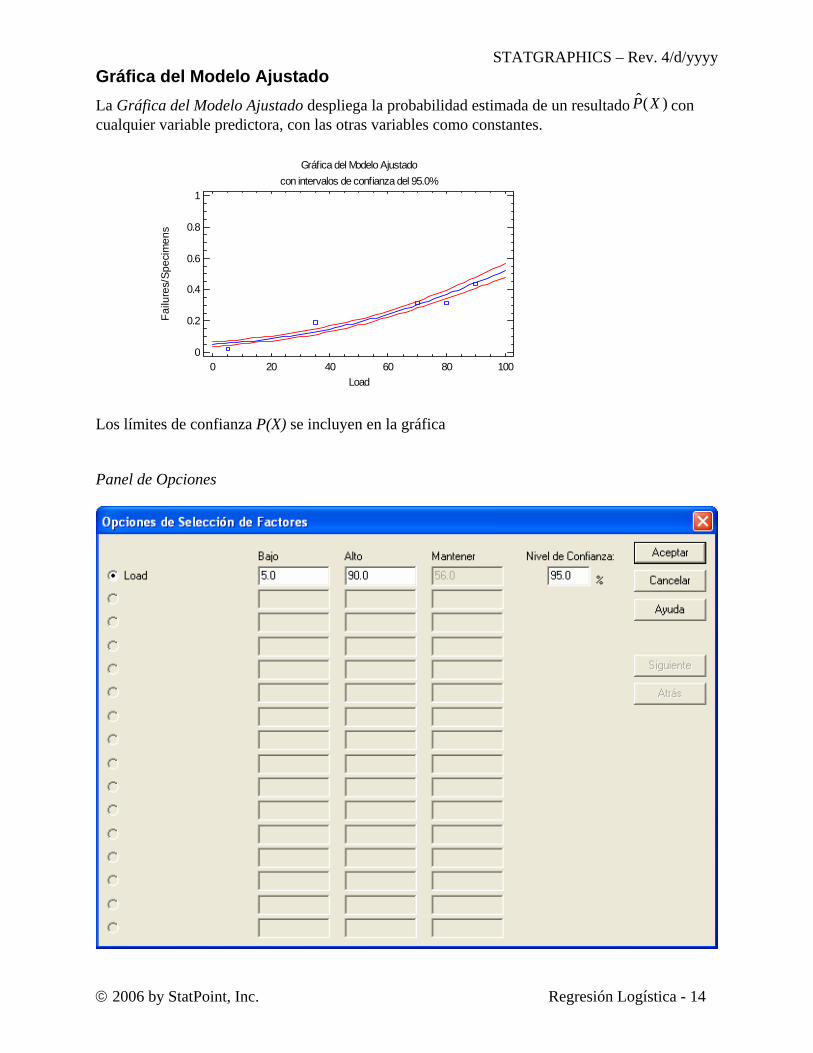
Gráfica del Modelo Ajustado La Gráfica del Modelo Ajustado despliega la probabilidad estimada de un resultado )(ˆ XP con cualquier variable predictora, con las otras variables como constantes.
0 20 40 60 80 100Load
Gráfica del Modelo Ajustadocon intervalos de confianza del 95.0%
0
0.2
0.4
0.6
0.8
1
Failu
res/
Spec
imen
s
Los límites de confianza P(X) se incluyen en la gráfica Panel de Opciones
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 15�
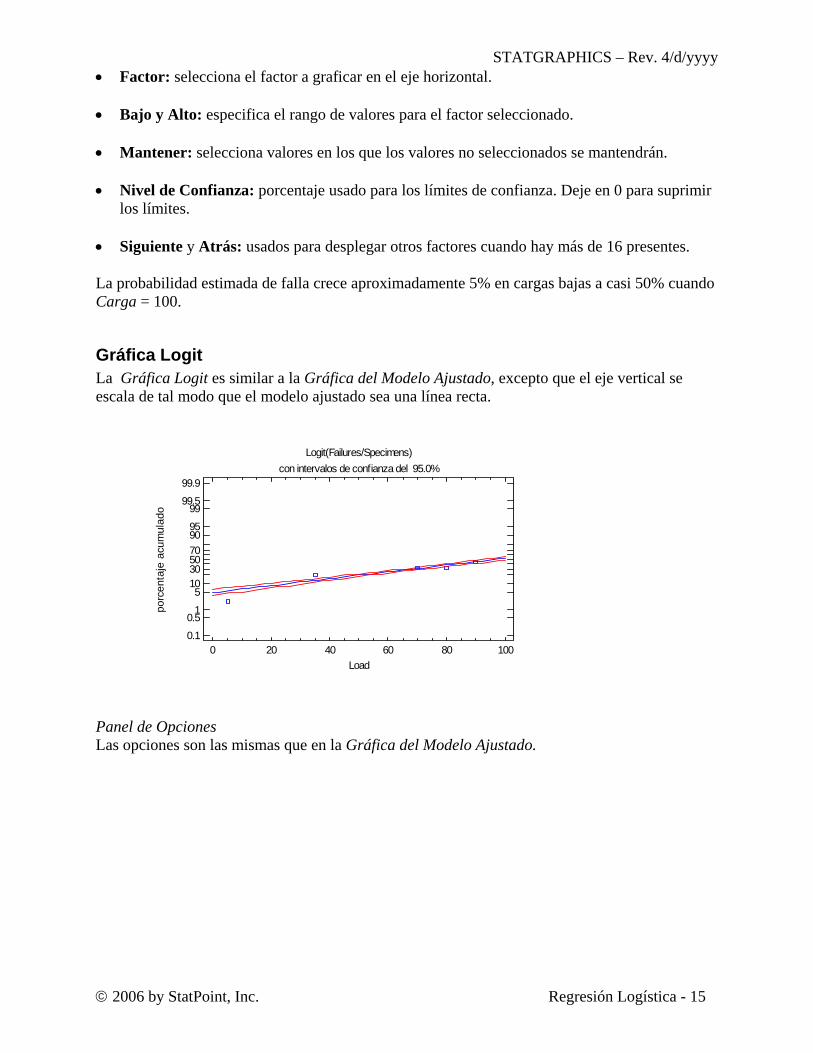
• Factor: selecciona el factor a graficar en el eje horizontal. • Bajo y Alto: especifica el rango de valores para el factor seleccionado. • Mantener: selecciona valores en los que los valores no seleccionados se mantendrán. • Nivel de Confianza: porcentaje usado para los límites de confianza. Deje en 0 para suprimir
los límites. • Siguiente y Atrás: usados para desplegar otros factores cuando hay más de 16 presentes. La probabilidad estimada de falla crece aproximadamente 5% en cargas bajas a casi 50% cuando Carga = 100.
Gráfica Logit La Gráfica Logit es similar a la Gráfica del Modelo Ajustado, excepto que el eje vertical se escala de tal modo que el modelo ajustado sea una línea recta.
0 20 40 60 80 100Load
Logit(Failures/Specimens)con intervalos de confianza del 95.0%
0.1
0.51
5103050709095
9999.5
99.9
porc
enta
je a
cum
ulad
o
Panel de Opciones Las opciones son las mismas que en la Gráfica del Modelo Ajustado.
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 16�
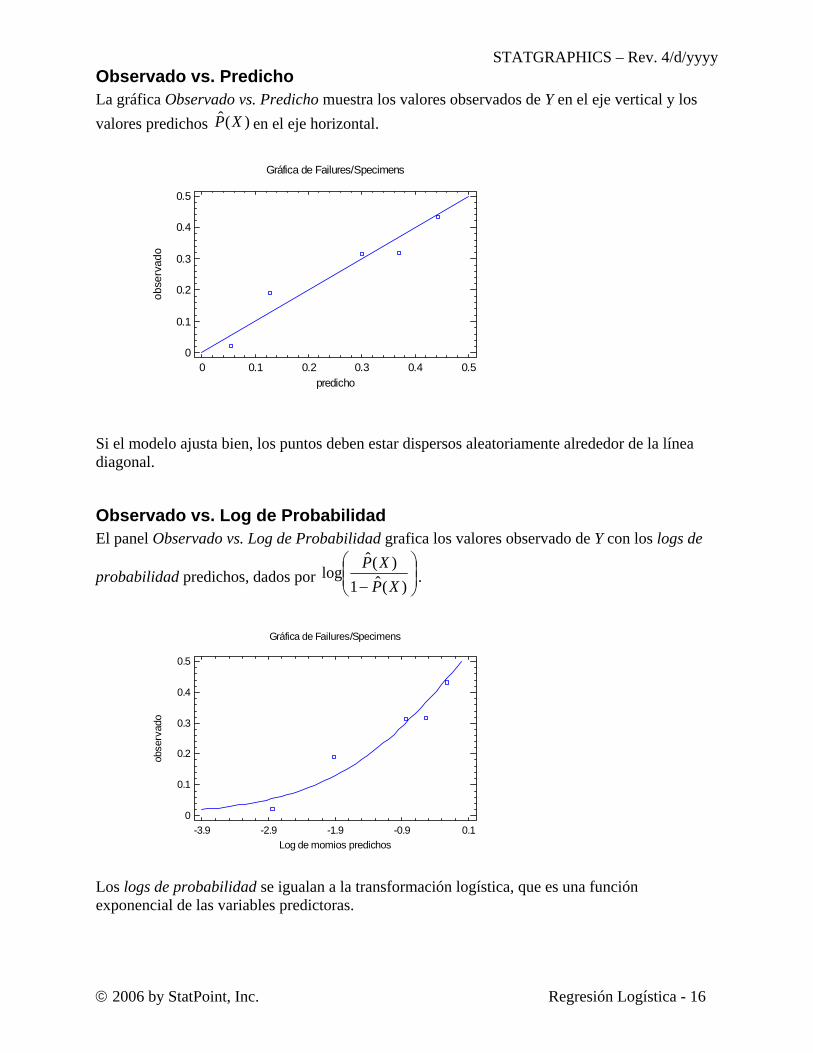
Observado vs. Predicho La gráfica Observado vs. Predicho muestra los valores observados de Y en el eje vertical y los valores predichos )(ˆ XP en el eje horizontal.
Gráfica de Failures/Specimens
0 0.1 0.2 0.3 0.4 0.5predicho
0
0.1
0.2
0.3
0.4
0.5
obse
rvad
o
Si el modelo ajusta bien, los puntos deben estar dispersos aleatoriamente alrededor de la línea diagonal.
Observado vs. Log de Probabilidad El panel Observado vs. Log de Probabilidad grafica los valores observado de Y con los logs de
probabilidad predichos, dados por ⎟⎟⎠
⎞⎜⎜⎝
⎛
− )(ˆ1)(ˆ
logXP
XP.
Gráfica de Failures/Specimens
-3.9 -2.9 -1.9 -0.9 0.1Log de momios predichos
0
0.1
0.2
0.3
0.4
0.5
obse
rvad
o
Los logs de probabilidad se igualan a la transformación logística, que es una función exponencial de las variables predictoras.
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 17�
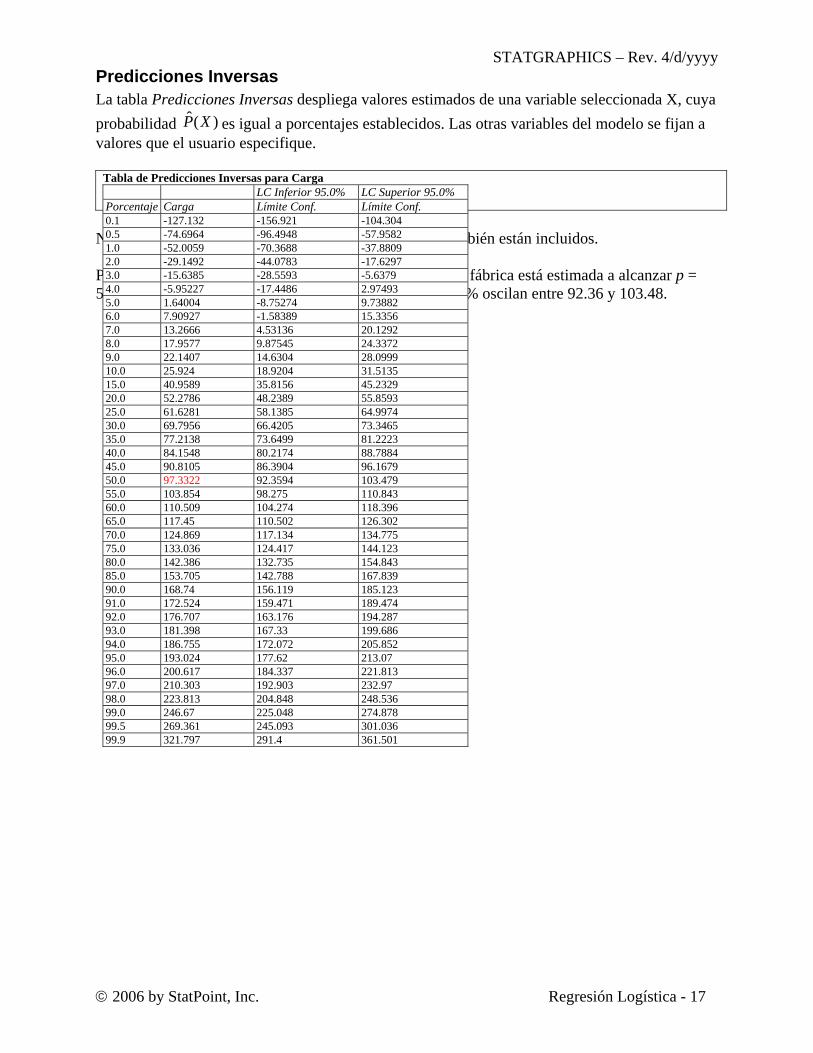
Predicciones Inversas La tabla Predicciones Inversas despliega valores estimados de una variable seleccionada X, cuya probabilidad )(ˆ XP es igual a porcentajes establecidos. Las otras variables del modelo se fijan a valores que el usuario especifique.
Tabla de Predicciones Inversas para Carga
Niveles de confianza fidedignos para los valores de X también están incluidos. Por ejemplo, la probabilidad de falla para el ejemplo de la fábrica está estimada a alcanzar p = 50% en la Carga = 97.33. Los límites de confianza del 95% oscilan entre 92.36 y 103.48.
LC Inferior 95.0% LC Superior 95.0% Porcentaje Carga Límite Conf. Límite Conf. 0.1 -127.132 -156.921 -104.304 0.5 -74.6964 -96.4948 -57.9582 1.0 -52.0059 -70.3688 -37.8809 2.0 -29.1492 -44.0783 -17.6297 3.0 -15.6385 -28.5593 -5.6379 4.0 -5.95227 -17.4486 2.97493 5.0 1.64004 -8.75274 9.73882 6.0 7.90927 -1.58389 15.3356 7.0 13.2666 4.53136 20.1292 8.0 17.9577 9.87545 24.3372 9.0 22.1407 14.6304 28.0999 10.0 25.924 18.9204 31.5135 15.0 40.9589 35.8156 45.2329 20.0 52.2786 48.2389 55.8593 25.0 61.6281 58.1385 64.9974 30.0 69.7956 66.4205 73.3465 35.0 77.2138 73.6499 81.2223 40.0 84.1548 80.2174 88.7884 45.0 90.8105 86.3904 96.1679 50.0 97.3322 92.3594 103.479 55.0 103.854 98.275 110.843 60.0 110.509 104.274 118.396 65.0 117.45 110.502 126.302 70.0 124.869 117.134 134.775 75.0 133.036 124.417 144.123 80.0 142.386 132.735 154.843 85.0 153.705 142.788 167.839 90.0 168.74 156.119 185.123 91.0 172.524 159.471 189.474 92.0 176.707 163.176 194.287 93.0 181.398 167.33 199.686 94.0 186.755 172.072 205.852 95.0 193.024 177.62 213.07 96.0 200.617 184.337 221.813 97.0 210.303 192.903 232.97 98.0 223.813 204.848 248.536 99.0 246.67 225.048 274.878 99.5 269.361 245.093 301.036 99.9 321.797 291.4 361.501

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 18�
Panel de Opciones
• Factor: selecciona el factor del que se calcularán las predicciones inversas. • Bajo y Alto: Ignorado. • Mantener: selecciona valores en los que los valores no seleccionados se mantendrán. • Nivel de Confianza: porcentaje usado para los límites de confianza. • Siguiente y Atrás: usados para desplegar otros factores cuando hay más de 16 presentes.

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 19�
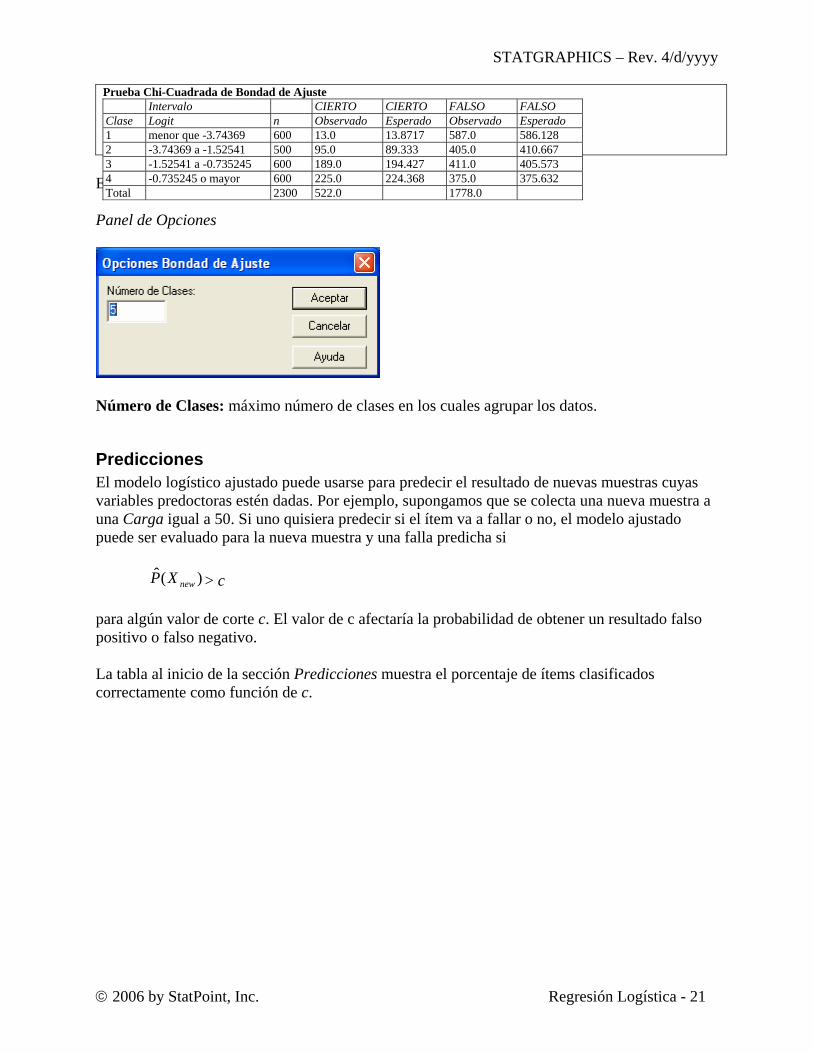
Bondad de Ajuste El panel Bondad-de-ajuste realiza una prueba de Ji-Cuadrada para determinar si el modelo ajustado describe adecuadamente los datos observados. Lo hace dividiendo los logit valores ajustados en clases (grupos) y realizando una prueba de ji-cuadrada para comparar los valores observados con los ajustados en cada intervalo.
Prueba Chi-Cuadrada de Bondad de Ajuste
Chi-cuadrada = 33.1125 con 2 g.l. valor-P = 6.45217E-8 Al crear las clases, el programa trata de crear grupos de más o menos el mismo tamaño. La tabla muestras la siguiente información de cada clase:
1. Logit intervalo – el rango de los logit valores ⎟⎟⎠
⎞⎜⎜⎝
⎛
− )(ˆ1)(ˆ
logXP
XPcorrespondientes a esa clase.
2. n – el número total de muestras con valores ajustados en esa clase.
3. CIERTO Observado – del número de muestras en ese intervalo, cuántas se observó que
fueron VERDAD (1).
4. CIERTO Esperado – del número de muestras en ese intervalo, cuántas el modelo ajustado predijo que serían VERDAD.
5. FALSO Observado – del número de muestras en ese intervalo, cuántas se observó que
fueron FALSO (1).
Intervalo CIERTO CIERTO FALSO FALSO Clase Logit n Observado Esperado Observado Esperado 1 menor que -2.84105 600 13.0 33.0874 587.0 566.913 2 -2.84105 a -1.91796 500 95.0 64.0449 405.0 435.955 3 -1.91796 a -0.841008 600 189.0 180.793 411.0 419.207 4 -0.841008 o mayor 600 225.0 244.074 375.0 355.926 Total 2300 522.0 1778.0

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 20�
6. FALSO Esperado – del número de muestras en ese intervalo, cuántas el modelo ajustado
predijo que serían FALSO. Por ejemplo, un total de 600 muestras de la fábrica han predicho logit valores menores a –2.84105 (correspondiente a la fila 1 del archivo de datos). 13 fallas fueron observadas y se predijo un valor de aproximadamente 33. Para comparar los conteos observados con los esperados, se realiza una prubea ji-cuadrada de bondad de ajuste. Un P-valor pequeño (menor a 0.05 operando a un nivel de significancia del 5%) lleva a la conclusión de que el modelo ajustado no encaja adecuadamente con los datos. En el ejemplo, el P-valor es muy pequeño, indicando un pobre ajuste del modelo logístico. Para propósitos de comparación, note la prueba para el modelo loglogistico con X = LOG(Carga):
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 21�
Prueba Chi-Cuadrada de Bondad de Ajuste
Chi-cuadrada = 0.720702 con 2 g.l. valor-P = 0.697432 En ese caso, el P-valor no muestra pérdida-de-ajuste significativa. Panel de Opciones
Número de Clases: máximo número de clases en los cuales agrupar los datos.
Predicciones El modelo logístico ajustado puede usarse para predecir el resultado de nuevas muestras cuyas variables predoctoras estén dadas. Por ejemplo, supongamos que se colecta una nueva muestra a una Carga igual a 50. Si uno quisiera predecir si el ítem va a fallar o no, el modelo ajustado puede ser evaluado para la nueva muestra y una falla predicha si
)(ˆnewXP > c
para algún valor de corte c. El valor de c afectaría la probabilidad de obtener un resultado falso positivo o falso negativo. La tabla al inicio de la sección Predicciones muestra el porcentaje de ítems clasificados correctamente como función de c.
Intervalo CIERTO CIERTO FALSO FALSO Clase Logit n Observado Esperado Observado Esperado 1 menor que -3.74369 600 13.0 13.8717 587.0 586.128 2 -3.74369 a -1.52541 500 95.0 89.333 405.0 410.667 3 -1.52541 a -0.735245 600 189.0 194.427 411.0 405.573 4 -0.735245 o mayor 600 225.0 224.368 375.0 375.632 Total 2300 522.0 1778.0
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 22�
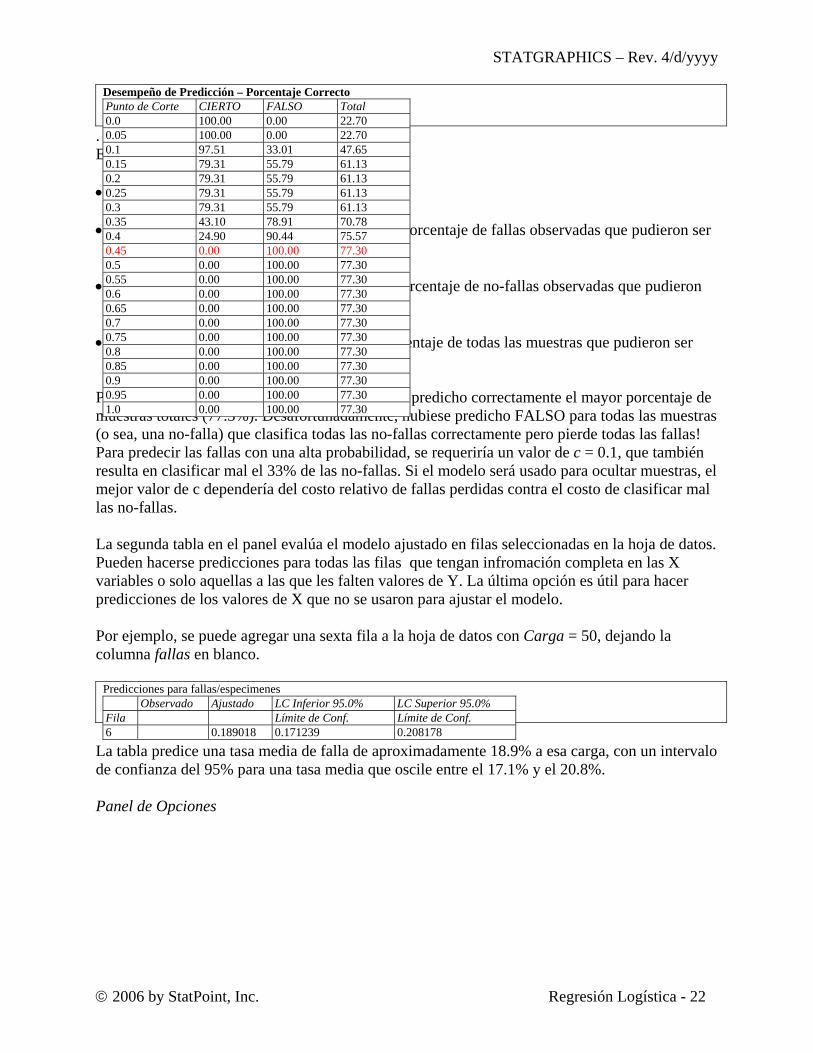
Desempeño de Predicción – Porcentaje Correcto
. Están incluidos en la tabla: • Punto deCorte – el valor de c. • CIERTO – usando el valor de c indicado, el porcentaje de fallas observadas que pudieron ser
predichas correctamente. • FALSO – usando el valor de c indicado, el porcentaje de no-fallas observadas que pudieron
ser predichas correctamente. • Total - usando el valor de c indicado, el porcentaje de todas las muestras que pudieron ser
predichas correctamente. Por ejemplo, usando un corte c = 0.45 se hubiera predicho correctamente el mayor porcentaje de muestras totales (77.3%). Desafortunadamente, hubiese predicho FALSO para todas las muestras (o sea, una no-falla) que clasifica todas las no-fallas correctamente pero pierde todas las fallas! Para predecir las fallas con una alta probabilidad, se requeriría un valor de c = 0.1, que también resulta en clasificar mal el 33% de las no-fallas. Si el modelo será usado para ocultar muestras, el mejor valor de c dependería del costo relativo de fallas perdidas contra el costo de clasificar mal las no-fallas. La segunda tabla en el panel evalúa el modelo ajustado en filas seleccionadas en la hoja de datos. Pueden hacerse predicciones para todas las filas que tengan infromación completa en las X variables o solo aquellas a las que les falten valores de Y. La última opción es útil para hacer predicciones de los valores de X que no se usaron para ajustar el modelo. Por ejemplo, se puede agregar una sexta fila a la hoja de datos con Carga = 50, dejando la columna fallas en blanco.
Predicciones para fallas/especimenes
La tabla predice una tasa media de falla de aproximadamente 18.9% a esa carga, con un intervalo de confianza del 95% para una tasa media que oscile entre el 17.1% y el 20.8%. Panel de Opciones
Punto de Corte CIERTO FALSO Total 0.0 100.00 0.00 22.70 0.05 100.00 0.00 22.70 0.1 97.51 33.01 47.65 0.15 79.31 55.79 61.13 0.2 79.31 55.79 61.13 0.25 79.31 55.79 61.13 0.3 79.31 55.79 61.13 0.35 43.10 78.91 70.78 0.4 24.90 90.44 75.57 0.45 0.00 100.00 77.30 0.5 0.00 100.00 77.30 0.55 0.00 100.00 77.30 0.6 0.00 100.00 77.30 0.65 0.00 100.00 77.30 0.7 0.00 100.00 77.30 0.75 0.00 100.00 77.30 0.8 0.00 100.00 77.30 0.85 0.00 100.00 77.30 0.9 0.00 100.00 77.30 0.95 0.00 100.00 77.30 1.0 0.00 100.00 77.30
Observado Ajustado LC Inferior 95.0% LC Superior 95.0% Fila Límite de Conf. Límite de Conf. 6 0.189018 0.171239 0.208178
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 23�
• Punto de Corte: el rango de valores e incremento para c en la tabla de porcentajes de
predicción • Mostrar: si despliega o no predicciones para Todos los Valores (filas) en la hoja de datos o
Sólo Pronósticos (filas con un valor faltante para Y). • Nivel de Confianza: Porcentaje de confianza para los límites de confianza.
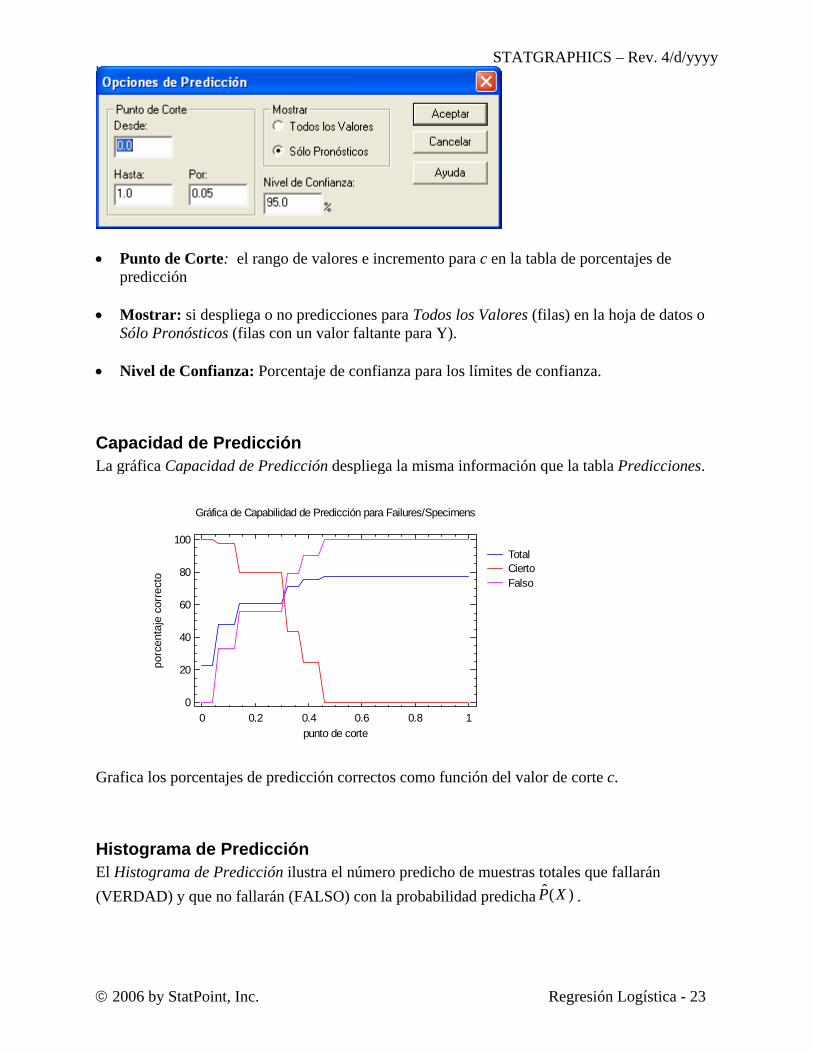
Capacidad de Predicción La gráfica Capacidad de Predicción despliega la misma información que la tabla Predicciones.
Gráfica de Capabilidad de Predicción para Failures/Specimens
0 0.2 0.4 0.6 0.8 1punto de corte
0
20
40
60
80
100
porc
enta
je c
orre
cto
TotalCiertoFalso
Grafica los porcentajes de predicción correctos como función del valor de corte c.
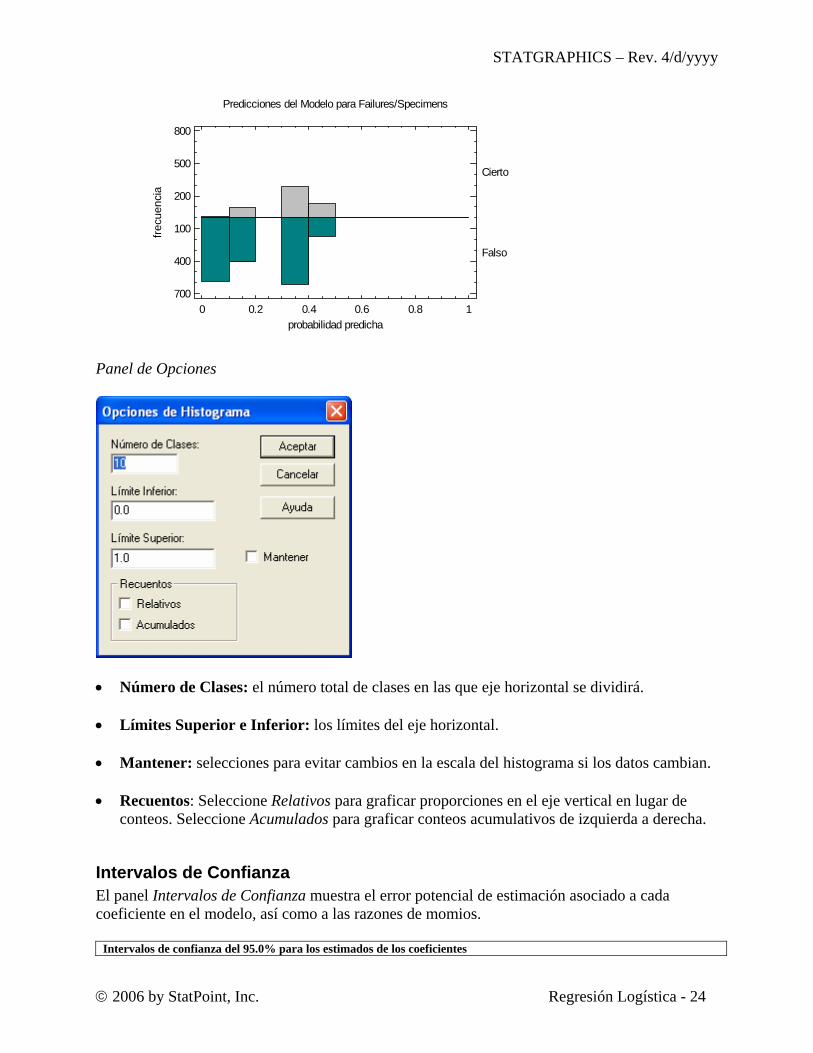
Histograma de Predicción El Histograma de Predicción ilustra el número predicho de muestras totales que fallarán (VERDAD) y que no fallarán (FALSO) con la probabilidad predicha )(ˆ XP .
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 24�
Cierto
Falso
Predicciones del Modelo para Failures/Specimens
0 0.2 0.4 0.6 0.8 1probabilidad predicha
700
400
100
200
500
800
frecu
enci
a
Panel de Opciones
• Número de Clases: el número total de clases en las que eje horizontal se dividirá. • Límites Superior e Inferior: los límites del eje horizontal. • Mantener: selecciones para evitar cambios en la escala del histograma si los datos cambian. • Recuentos: Seleccione Relativos para graficar proporciones en el eje vertical en lugar de
conteos. Seleccione Acumulados para graficar conteos acumulativos de izquierda a derecha.
Intervalos de Confianza El panel Intervalos de Confianza muestra el error potencial de estimación asociado a cada coeficiente en el modelo, así como a las razones de momios.
Intervalos de confianza del 95.0% para los estimados de los coeficientes
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 25�
Intervalos de confianza del 95.0% para la razón de momios
Panel de Opciones
• Nivel de Confianza: Nivel porcentual para los intervalos de confianza.
Matriz de Correlación La Matriz de Correlación despliega estimaciones de la correlación entre los coeficientes estimados.
Matriz de correlación para los coeficientes estimados
Error Parámetro Estimado Estándar Límite Inferior Límite Superior CONSTANTE -2.9949 0.145939 -3.45934 -2.53046 Carga 0.0307699 0.00209432 0.0241049 0.037435
Parámetro Estimado Límite Inferior Límite Superior Carga 1.03125 1.0244 1.03814

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 26�
Esta tabla puede ser de ayuda al determinar qué tan bien se separaron entre sí los efectos de diferentes variables independientes.
Residuos Atípicos Una vez que el modelo ha sido ajustado, es útil estudiar los residuos para determinar si existe algún outlier que deba removerse de los datos. El panel Residuos Atípicos enlista todas las observaciones que tienen residuos inusualmente grandes.
Residuos Atípicos para fallas/especimenes
La tabla despliega:
• Fila – el número de fila en la hoja de datos. • Y – el valor observado de Y. • Y Predicha – el valor ajustado )(ˆ XP . • Residuo – la diferencia entre los valores observados y predichos, definida por
)(ˆ XPYei −= (8) • Residuo Pearson – un residuo estandarizado en el que cada residuo se divide por un
estimación de su error estándar.
( )i
ii
ii
nXPXP
er
)(ˆ1)(ˆ −=
(9)
• Residuo de Desviación – un residuo que mide la contribución de cada observación a la
desviación residual.
CONSTANTE Carga CONSTANTE 1.0000 -0.9320 Carga -0.9320 1.0000
Y Residuo Residuo de Fila Y Predicha Residuo Pearson Desviación 1 0.0216667 0.0551456 -0.033479 -3.59 -4.07 2 0.19 0.12809 0.0619103 4.14 3.91
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 27�
( )⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎟⎟⎠
⎞⎜⎜⎝
⎛
−
−−+⎟
⎟⎠
⎞⎜⎜⎝
⎛=
)(ˆ11
ln1)(ˆln2)(
i
iii
i
iiiii XP
yyn
XPy
ynesignd (10)
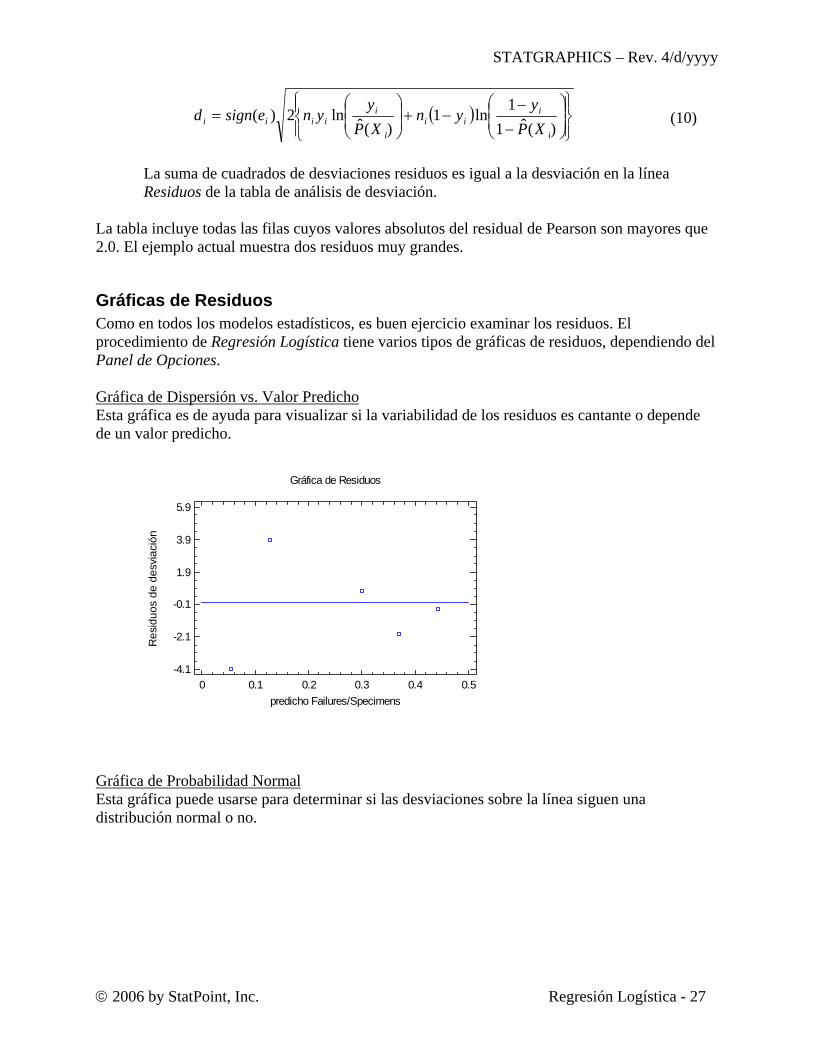
La suma de cuadrados de desviaciones residuos es igual a la desviación en la línea Residuos de la tabla de análisis de desviación.
La tabla incluye todas las filas cuyos valores absolutos del residual de Pearson son mayores que 2.0. El ejemplo actual muestra dos residuos muy grandes.
Gráficas de Residuos Como en todos los modelos estadísticos, es buen ejercicio examinar los residuos. El procedimiento de Regresión Logística tiene varios tipos de gráficas de residuos, dependiendo del Panel de Opciones. Gráfica de Dispersión vs. Valor Predicho Esta gráfica es de ayuda para visualizar si la variabilidad de los residuos es cantante o depende de un valor predicho.
0 0.1 0.2 0.3 0.4 0.5predicho Failures/Specimens
Gráfica de Residuos
-4.1
-2.1
-0.1
1.9
3.9
5.9
Res
iduo
s de
des
viac
ión
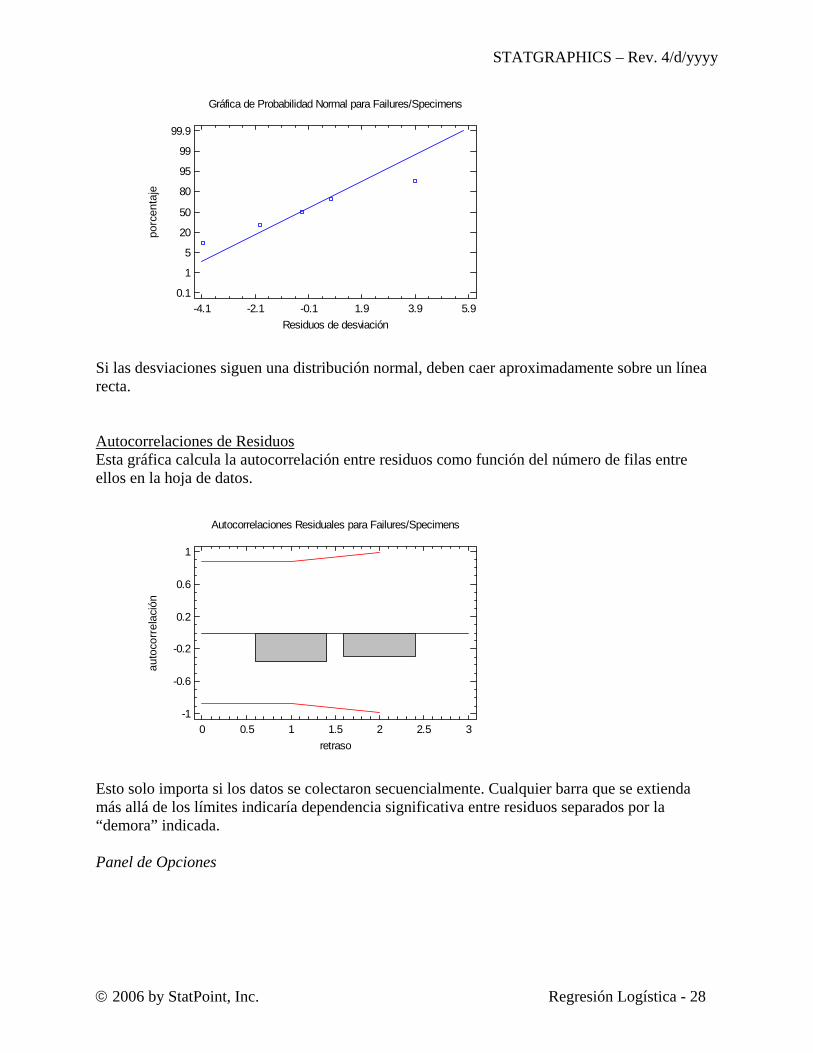
Gráfica de Probabilidad Normal Esta gráfica puede usarse para determinar si las desviaciones sobre la línea siguen una distribución normal o no.
STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 28�
Gráfica de Probabilidad Normal para Failures/Specimens
-4.1 -2.1 -0.1 1.9 3.9 5.9Residuos de desviación
0.1
1
5
20
50
80
95
99
99.9
porc
enta
je
Si las desviaciones siguen una distribución normal, deben caer aproximadamente sobre un línea recta. Autocorrelaciones de Residuos Esta gráfica calcula la autocorrelación entre residuos como función del número de filas entre ellos en la hoja de datos.
Autocorrelaciones Residuales para Failures/Specimens
0 0.5 1 1.5 2 2.5 3retraso
-1
-0.6
-0.2
0.2
0.6
1
auto
corr
elac
ión
Esto solo importa si los datos se colectaron secuencialmente. Cualquier barra que se extienda más allá de los límites indicaría dependencia significativa entre residuos separados por la “demora” indicada. Panel de Opciones

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 29�
• Graficar: el tipo de residuos a graficar:
1. Residuos – los valores observados menos los valores ajustados. 2. Residuos Pearson – los residuos divididos entre sus errores estándar estimados. 3. Residuos de Desviación – residuos escalados de tal manera que su suma de cuadrados
es igual a la desviación residual.
• Tipo: el tipo de gráfica a crearse. Se usa un Diagrama de Dispersión para probar curvatura; una Gráfica de Probabilidad Normal, para determinar si los residuos del modelo vienen de una distribución normal; y una Función de Autocorrelación para probar dependencia entre residuos consecutivos.
• Graficar versus: para una Gráfica de Dispersión, la cantidad a graficar el eje horizontal. • Número de Retrasos: Para una Función de Autocorrelación, el número máximo de de
demoras. Para conjuntos pequeños de datos, el número de demoras graficadas puede ser menor a este valor.
• Nivel de Confianza: Para una Función de Autocorrelación , el nivel usado para crear los
límites de probabilidad.
Guardar Resultados Los siguientes resultados pueden guardarse en la hoja de datos:
1. Valores Predichos – los valores ajustados )(ˆiXP correspondientes a cada fila de la hoja
de datos.

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 30�
2. Límites Inferiores – los límites inferiores de confianza para )(ˆiXP .
3. Límites Superiores – los límites superiores de confianza para )(ˆiXP .
4. Residuos – los residuos ordinarios. 5. Residuos Pearson – los residuos de Pearson estandarizados. 6. Residuos de Desviación – los residuos de desviación. 7. LeverEdads– si el modelo fue ajustado usando mínimos cuadrados ponderados, los
leverEdads de cada fila. 8. Porcentajes – los porcentajes a los cuales se hicieron las predicciones inversas. 9. Predicciones Inversas – las predicciones inversas. 10. Límites Fiduciarios Inferiores – los límites de confianza inferiores para las predicciones
inversas. 11. Límites Fiduciarios Superiores – los límites de confianza superiores para las predicciones
inversas.

STATGRAPHICS – Rev. 4/d/yyyy
© 2006 by StatPoint, Inc. Regresión Logística - 31�
Cálculos Función de Verosimilitud
Para Y consistente en proporciones: ( )[ ] ( )[ ]∏=
−−=s
i
rni
ri
iii XPXPL1
1 donde ri=nipi (11)
Para Y binaria:
( )
( )[ ]∏
∏
=
=
+= n
ii
n
i
Yi
XP
XPL
i
1
1
1 (12)
Ponderaciones para Mínimos Cuadrados Ponderados
( )iii yy
w−
=1
1 (13)
Desviación
Para Y consistente en proporciones: ( ) ( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
⎟⎟⎠
⎞⎜⎜⎝
⎛ −⎟⎟⎠
⎞⎜⎜⎝
⎛−=
∏=
−s
i
rn
i
ii
r
i
iiii
nrn
nr
L
1
ˆln2 ββλ (14)
Para Y binaria: ( ) ( )( ) ( )( )
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
−−=
∏=
−s
i
yi
yi
ii yy
L
1
11
ˆln2 ββλ (15)