Embed Size (px)
Citation preview

Reinforcement Learning
I tay Ey lon | 307872515 Nadav Weiss | 203389903 Natanel Beber | 308480284 Wednesday | 13 Apr i l | 2016

Introduction Multi-armed bandit

Definition | What we are talking about?
• “Reinforcement learning problems involve learning what to do - how to map situations to actions – in order to maximize a numerical reward signal.”
• Principles:
• Learn to make good decisions in unknown - dynamic environments
• Learning from experience: success or failures
• Examples: learning to ride a bicycle, play chess, autonomous robotics, playing in stochastic market ...

Definition (continue)
• Environment: can be stochastic (Tetris), adversarial (Chess), partially unknown (bicycle), partially observable (robot)
• Available information: the reinforcement (may be delayed)
• Goal: maximize the expected sum of future rewards.

Exploration vs. Exploitation • Online decision making involves a fundamental
choice:
• Exploitation: make the best decision given current information
• Exploration: gather more information
• The best long-term strategy may involve short-term sacrifices
• Gather enough information to make the best overall decisions

Examples of using RL
https://youtu.be/CIF2SBVY-J0
So what is the difference from what we have learned so far?
Supervised Learning
Unsupervised Learning
Reinforcement Learning

Reminder:
Supervised Learning • Based on given data, we need to classify new samples
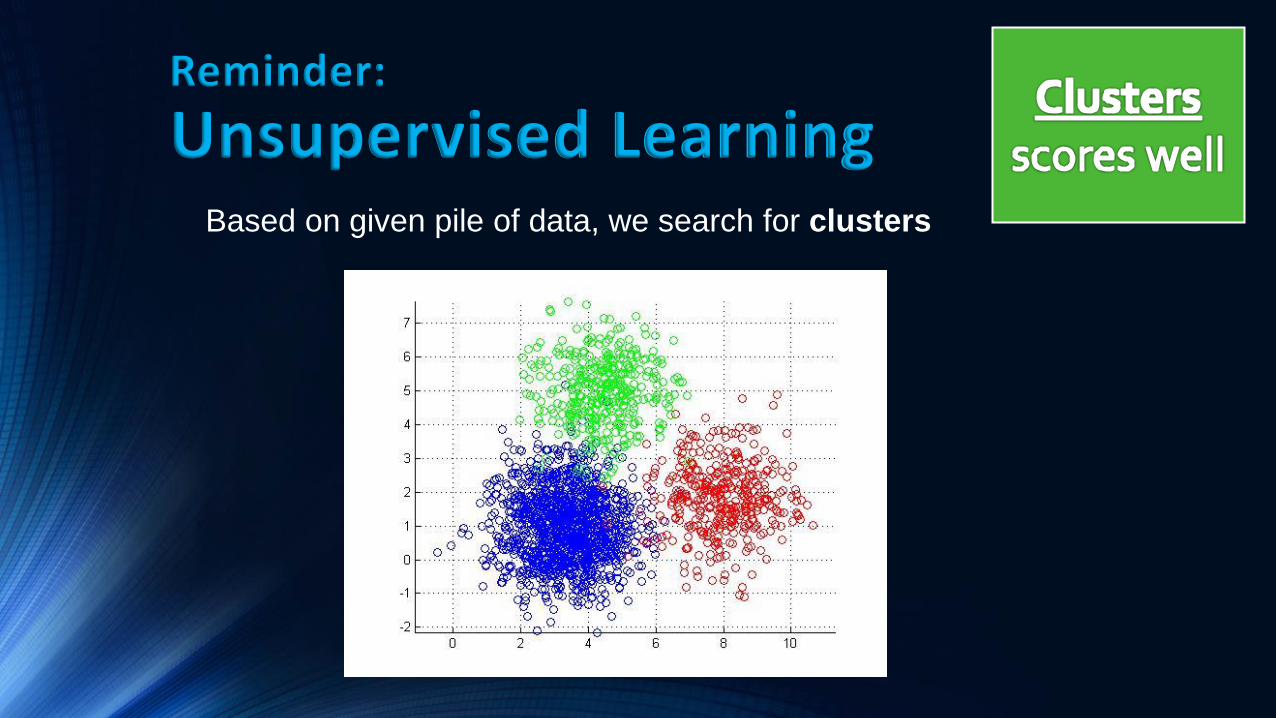
Reminder:
Unsupervised Learning Based on given pile of data, we search for clusters
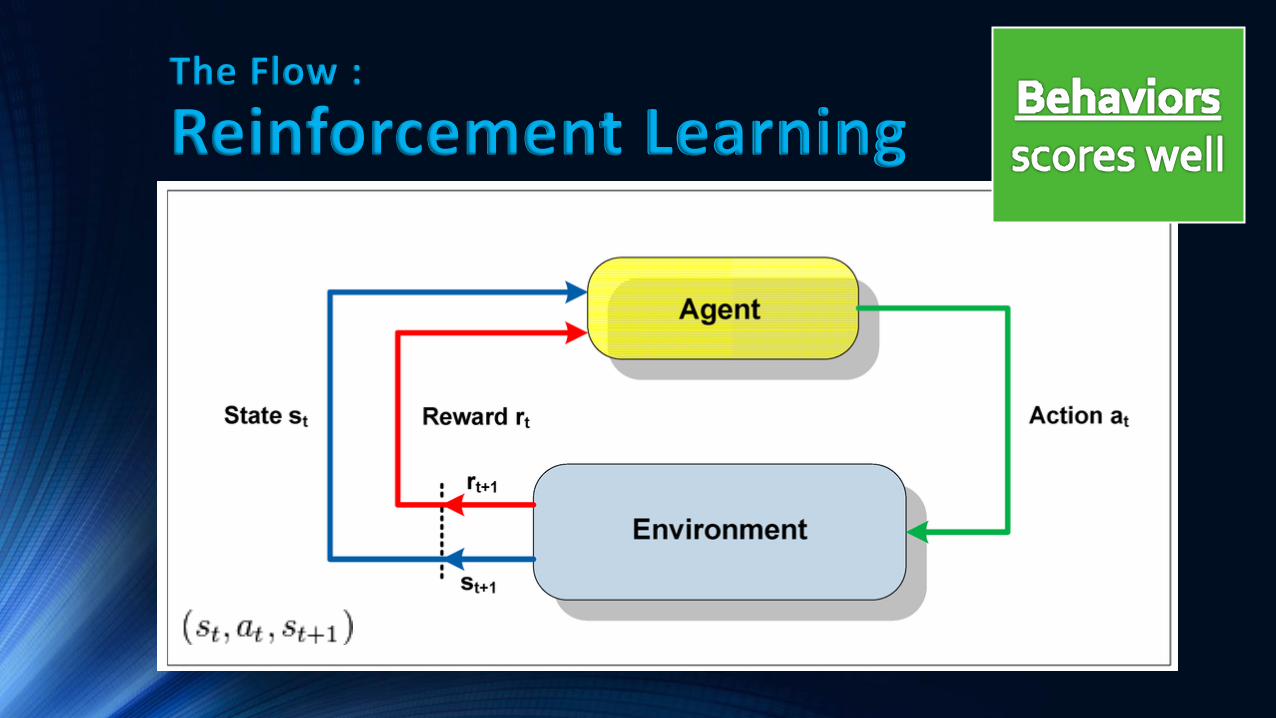
The Flow :
Reinforcement Learning

Main Elements
Policy
Reward Function
Value Function
Model of the Environment
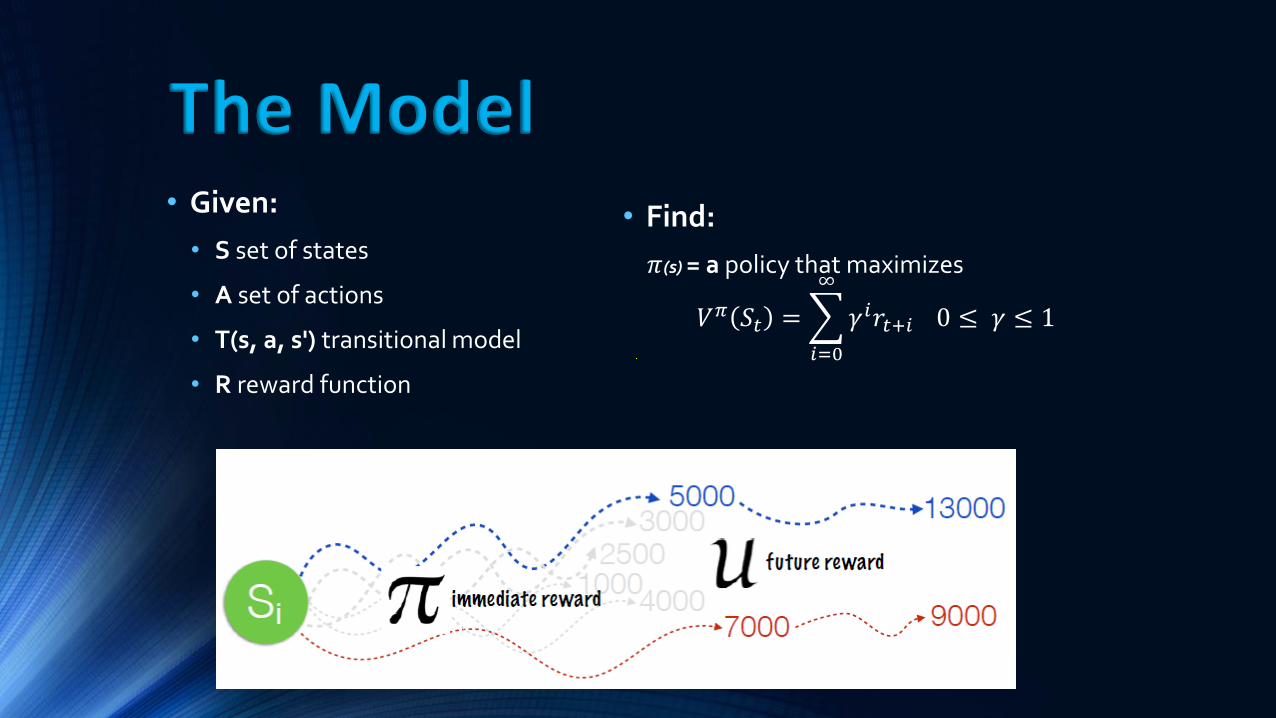
The Model • Given:
• S set of states
• A set of actions
• T(s, a, s') transitional model
• R reward function
• Find:
𝜋(s) = a policy that maximizes
𝑉𝜋 𝑆𝑡 = 𝛾𝑖𝑟𝑡+𝑖
∞
𝑖=0
0 ≤ 𝛾 ≤ 1
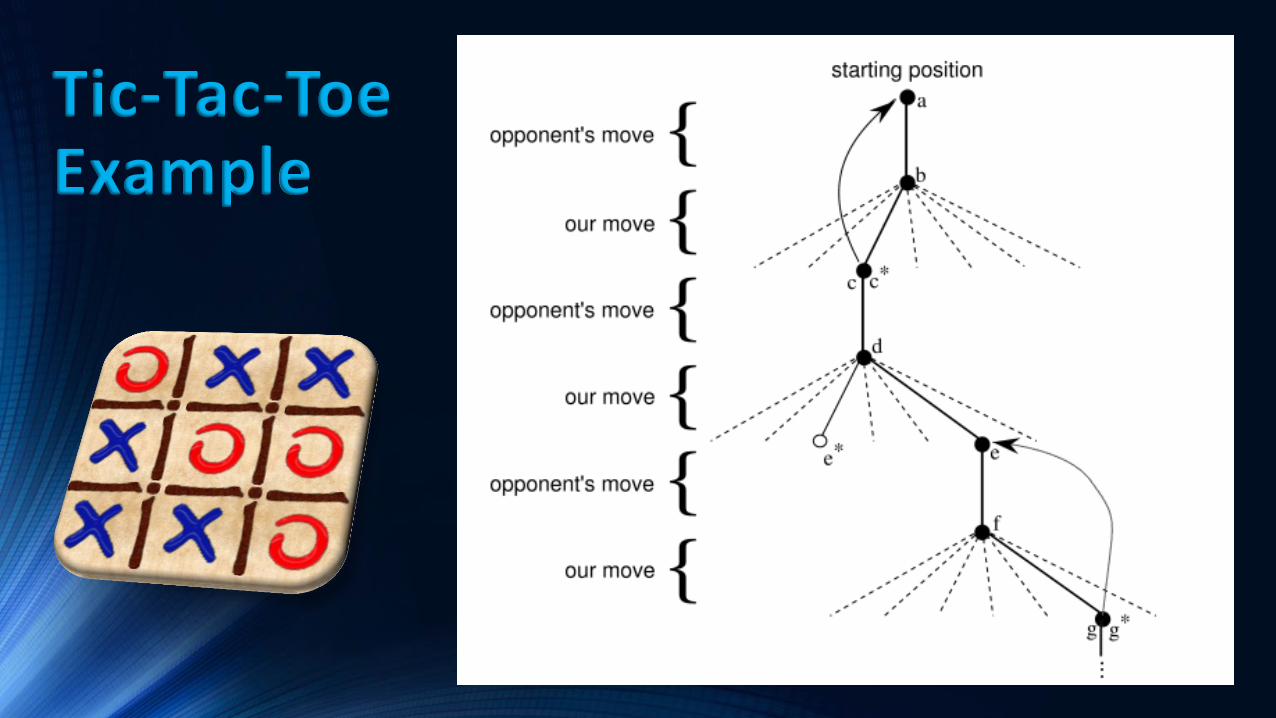
Tic-Tac-Toe Example
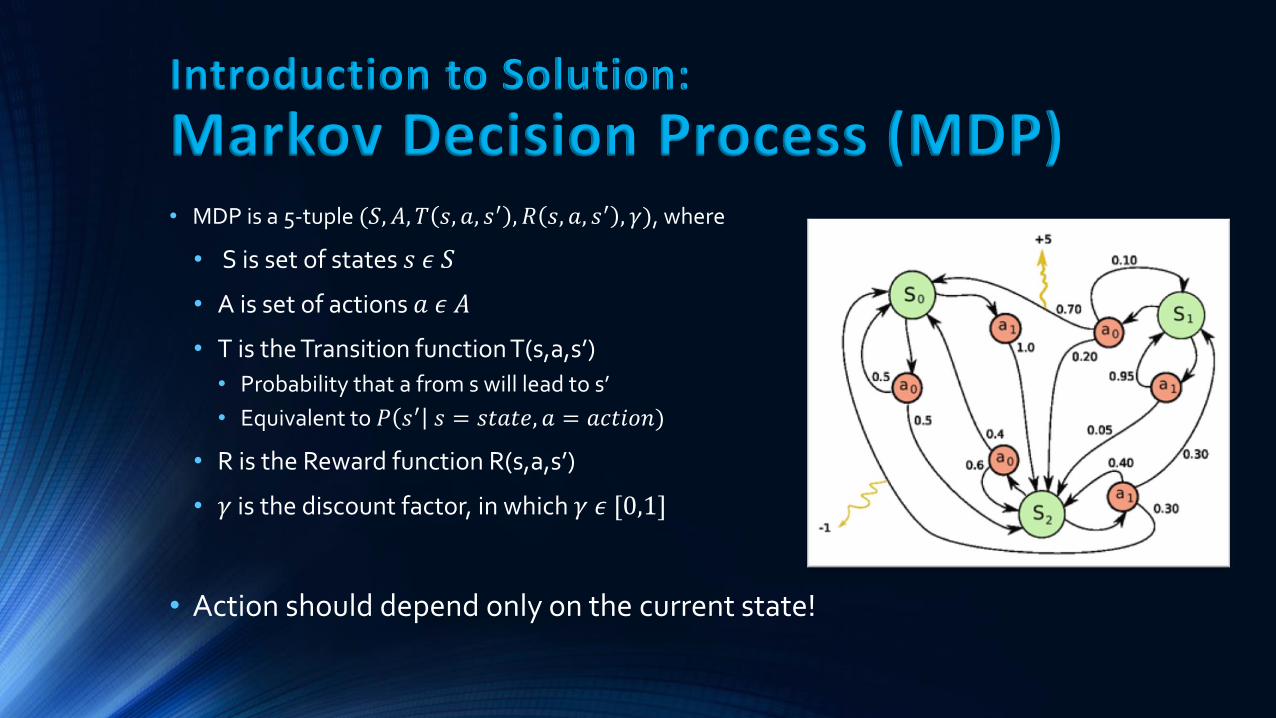
Introduction to Solution:
Markov Decision Process (MDP) • MDP is a 5-tuple (𝑆, 𝐴, 𝑇 𝑠, 𝑎, 𝑠′ , 𝑅 𝑠, 𝑎, 𝑠′ , 𝛾), where
• S is set of states 𝑠 𝜖 𝑆
• A is set of actions 𝑎 𝜖 𝐴
• T is the Transition function T(s,a,s’)
• Probability that a from s will lead to s’
• Equivalent to 𝑃 𝑠′ 𝑠 = 𝑠𝑡𝑎𝑡𝑒, 𝑎 = 𝑎𝑐𝑡𝑖𝑜𝑛)
• R is the Reward function R(s,a,s’)
• 𝛾 is the discount factor, in which 𝛾 𝜖 [0,1]
• Action should depend only on the current state!

• For MDP’s we want an optimal policy 𝜋∗: 𝑆 → 𝐴
• A policy 𝜋 gives an action for each state
• An optimal policy is one that maximizes expected value reward
• The policy defines the agent
Markov Decision Process :
The Optimal Policy
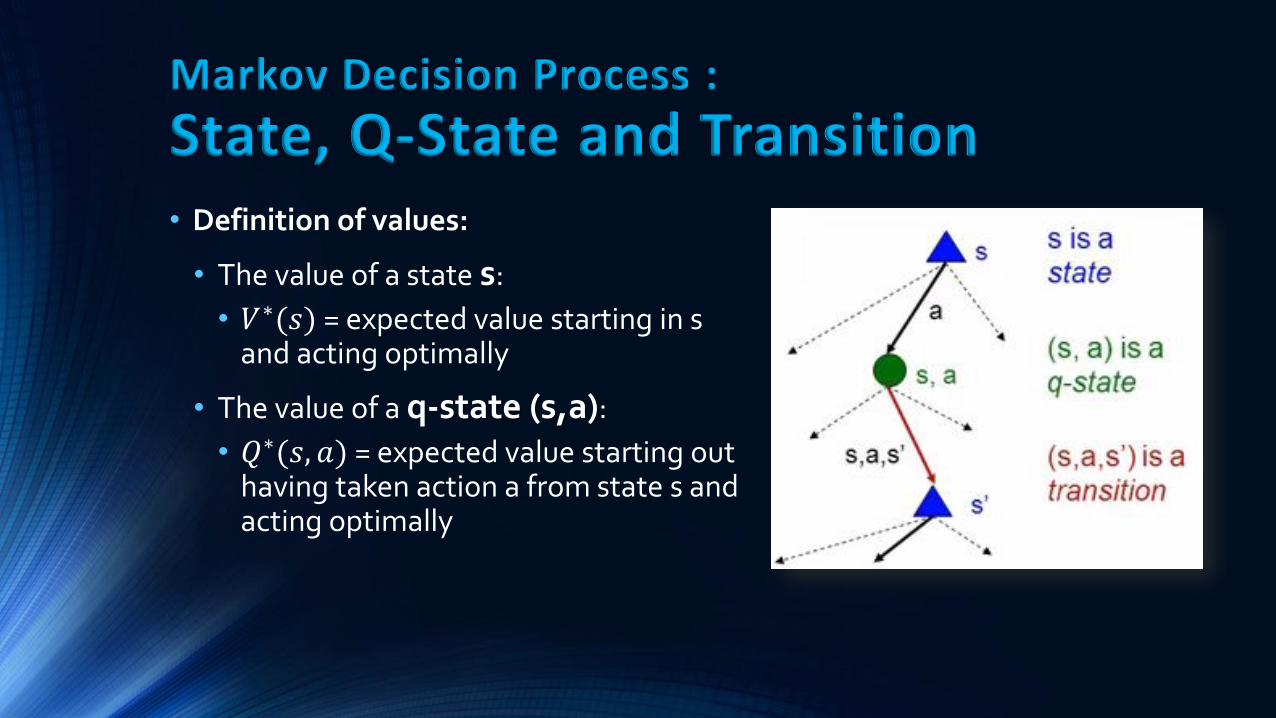
• Definition of values:
• The value of a state s:
• 𝑉∗(𝑠) = expected value starting in s and acting optimally
• The value of a q-state (s,a):
• 𝑄∗(𝑠, 𝑎) = expected value starting out having taken action a from state s and acting optimally
Markov Decision Process :
State, Q-State and Transition
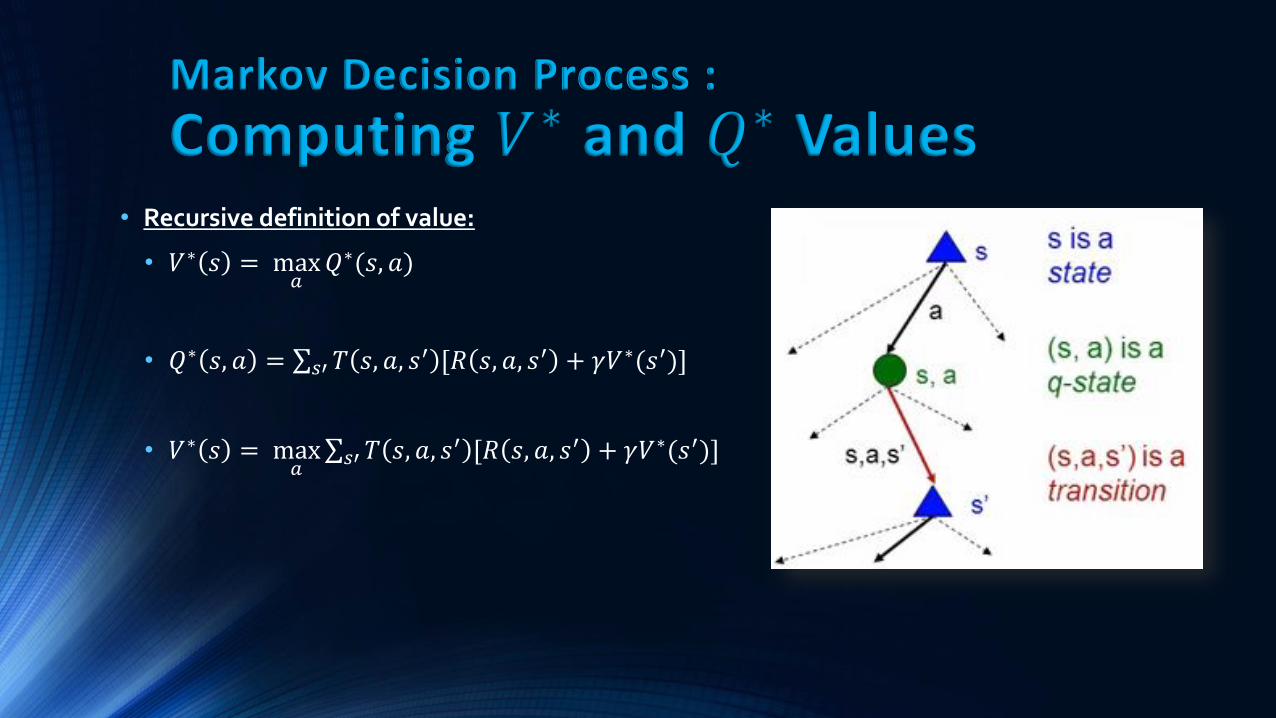
• Recursive definition of value:
• 𝑉∗ 𝑠 = max𝑎𝑄∗(𝑠, 𝑎)
• 𝑄∗ 𝑠, 𝑎 = 𝑇 𝑠, 𝑎, 𝑠′ [𝑅 𝑠, 𝑎, 𝑠′ + 𝛾𝑉∗(𝑠′)]𝑠′
• 𝑉∗ 𝑠 = max𝑎 𝑇 𝑠, 𝑎, 𝑠′ [𝑅 𝑠, 𝑎, 𝑠′ + 𝛾𝑉∗(𝑠′)]𝑠′
Markov Decision Process :
Computing 𝑉∗ and 𝑄∗ Values

• Algorithm:
• Start with 𝑉0 𝑠 = 0 for all states
• Compute for each state:
• 𝑉𝑘+1 𝑠 ← max𝑎 𝑇 𝑠, 𝑎, 𝑠′ [𝑅 𝑠, 𝑎, 𝑠′ + 𝛾𝑉𝑘(𝑠′)]𝑠′
• Complexity of each iteration: 𝑂(𝑆2𝐴)
Markov Decision Process :
Value Iteration

Markov Decision Process :
Value Iteration Simulation

• Policy Evaluation: calculate rewards for some fixed policy until convergence
• Policy Improvement: update policy using one-step look-ahead with resulting converged rewards as future values.
Evaluation:
𝑉𝑘+1𝜋𝑖 (𝑠) ← 𝑇 𝑠, 𝜋𝑖 𝑠 , 𝑠
′ [𝑅 𝑠, 𝜋𝑖 𝑠 , 𝑠′ + 𝛾𝑉𝑘
𝜋𝑖(𝑠′)]𝑠′
Improvement:
𝜋𝑖+1 𝑠 = argmax𝑎 𝑇 𝑠, 𝑎, 𝑠′ [𝑅 𝑠, 𝑎, 𝑠′ + 𝛾𝑉𝜋𝑖(𝑠′)]𝑠′
• Iterative computation of the value functions for a given
policy 𝜋0𝐸→𝑉𝜋0
𝐼→𝜋1
𝐸→𝑉𝜋1
𝐼→𝜋2
𝐸→…
𝐼→𝜋∗
𝐸→𝑉∗
where E denotes a policy evaluation and I denotes a policy improvement.
Markov Decision Process :
Policy Iteration: Evaluation & Improvement

Different Solution Approaches
• There are 3 main methods for RL implementation:
1. Dynamic Programming
2. Monte Carlo Methods
3. Temporal-difference Learning
• All of these methods solve the full version of the problem, including delayed rewards.
• The differences are mainly in efficiency and speed of convergence.
1. Dynamic Programming
Definition and Behavior
• Depends on complete and accurate model of the environment as a MDP.
• Compute optimal policy.
The Key Ideas
• Using value functions to organize and develop the search for good policies.
• Obtain optimal policies after finding the optimal value functions, 𝑉∗ or 𝑄∗.
Why is it a limited utility?
• Assumption of a perfect model (known environment as a finite MDP).
• Great computational expense

2. Monte Carlo Methods
• Definition and Behavior:
• Unlike DP methods, the environment is not
fully known.
• Require only experience.
• Based on averaging complete returns.
• Designed for episodic tasks:
• Experience is divided into episodes.
• All episodes eventually terminate no matter what actions are selected.
• Only after episode complete, that value estimates and policies can be changed.

3. Temporal Difference Learning
• Temporal difference (TD) learning is a prediction-based machine learning method
• TD is a combination of Monte Carlo and dynamic programming.
• Like MC method, TD methods learns by sampling the environment according to some policy
• And as the method of dynamic programming, updating current estimate based on previously learned estimates
• The core idea of TD learning is that one adjusts predictions to match other, more accurate, predictions about the future

Advantages of TD • TD methods learn their estimates in part on the basis of other estimates
• TD methods have an advantage over DP methods in that they do not require a model of the environment
• With Monte Carlo methods we must wait until the end of an episode, because only then is the return known, whereas with TD methods we need wait only one time step

Temporal Difference Learning :
Q-Learning • Q-learning is a model-free reinforcement learning technique.
• Q-learning can be used to find an optimal action-selection policy for any given (MDP).
• A policy is a rule that the agent follows in selecting actions, given the state it is in. When such an action-value function is learned, the optimal policy can be constructed by simply selecting the action with the highest value in each state.
• Q-learning able to compare the expected utility of the available actions without requiring a model of the environment.

DEMO http://www.cs.cmu.edu/~awm/rlsim/

Things to Consider:
Exploration vs. Exploitation • Two Common Ways:
1. Random Actions (𝜀-greedy)
• Every step, flip a coin
• With (small) probability 𝜀, act randomly
• With (large) probability 1-𝜀, act based on current policy
• 𝜀 can be changed from episode to episode
2. Exploration Function
• Takes a value estimate u and a visit count n, and return optimistic reward, e.g. 𝑓 𝑢, 𝑛 = 𝑢 + 𝑘/𝑛
Modified Q-Update: 𝑄 𝑠, 𝑎𝑎←𝑅 𝑠, 𝑎, 𝑠′ + 𝛾max
𝑎′𝑓(𝑄 𝑠′, 𝑎′ , 𝑁(𝑠′, 𝑎′))
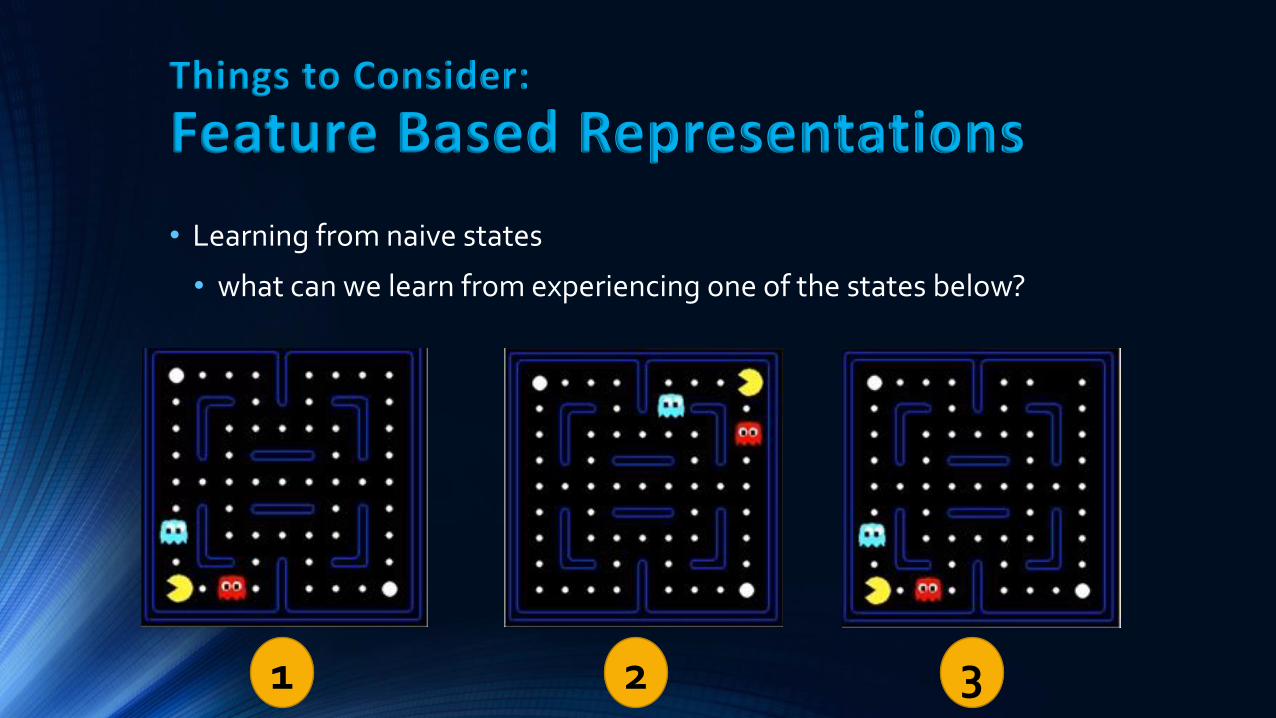
Things to Consider:
Feature Based Representations
• Learning from naive states
• what can we learn from experiencing one of the states below?
1 2 3

Things to Consider:
Feature Based Representations • Solution: Describe a state using a vector of features (properties).
• Features are functions from states to real numbers (often 0/1) that capture important properties of the state.
• Example features: • Distance to closest ghost
• Distance to closest dot
• Number of ghosts
• Is Pacman in a tunnel (0/1) ?
• Can also describe a q-state (s, a) with features
(e.g. action moves closer to food).

Reinforcement Learning
Summary & Questions • Definition
• Exploitation vs. Exploration
• The Flow
• Main Elements
• The Model
• Markov Decision Process
• Different Solution Approaches
• Things to Consider
• Cat Facts

VIDEO https://www.youtube.com/watch?v=opsmd5yuBF0

Bibliography • https://en.wikipedia.org/wiki/Reinforcement_learning
• https://webdocs.cs.ualberta.ca/~sutton/book/ebook/node28.html
• http://webee.technion.ac.il/people/shimkin/LCS11/ch4_RL1.pdf
• Algorithms for Reinforcement Learning
• https://www.ualberta.ca/~szepesva/papers/RLAlgsInMDPs.pdf
• https://youtu.be/jUoZg513cdE?list=PLw__D5OTvqiZn3NrGJpn7vFTgaBwRDH7F

















![[한국어] Neural Architecture Search with Reinforcement Learning](https://img.pdfslide.tips/doc/110x75/5a650eee7f8b9aa2548b66b5/-neural-architecture-search-with-reinforcement-learning.jpg)











