Embed Size (px)
Citation preview

Représentation par graphe de mots manuscrits dans les
images pour la recherche par similarité Peng Wang1,2, Véronique Eglin1, Christophe Garcia1
1Université de Lyon, LIRIS UMR5205, INSA-Lyon, France { peng.wang, veronique.eglin, christophe.garcia}@liris.cnrs.fr Christine Largeron2
2LAHC, CNRS UMR5516 Université Jean Monnet, Saint Etienne, France, [email protected] Josep Lladós, Alicia Fornés Computer Vision Center, Universitat Autònoma de Barcelona, Espagne {j osep, afornes}@cvc.uab.es
RÉSUMÉ. Dans ce papier, nous proposons une nouvelle approche de la recherche de mots par similarité reposant sur une structure de graphes intégrant des informations sur la topologie, la morphologie locale des mots ainsi que des informations contextuelles dans le voisinage de FKDTXH� SRLQW� G¶LQWpUrW�� &KDTXH� PRW� LPDJH� HVW� UHSUpVHQWp� SDU� XQH� VpTXHQFH� GH� JUDSKHV associés chacun à un objet connexe��8Q�JUDSKH�HVW�FRQVWUXLW�VXU�OD�EDVH�G¶XQ�VTXHOHWWH�GpFULW�par un descripteur riche et compact en chaque point sommet: le contexte de formes. Afin G¶rWUH�UREXVWH�DX[�GLVWRUVLRQV�GH�O¶pFULWXUH�HW�DX[�FKDQJHPHQWs GH�VFULSWHXUV��O¶DSSDULHPHQW�entre mots repose sur une distance dynamique et un usage adapté du coût G¶pGLWLRQ�approximé entre graphes. Les expérimentations sont réalisées sur la base de George Washington et la base de registres de mariages célébrés en la cathédrale de Barcelone. /¶DQDO\VH� GH� SHUIRUPDQFHV� PRQWUH� OD� SHUWLQHQFH� GH� O¶DSSURFKH� comparativement aux approches structurelles actuelles. MOTS-CLÉS : recherche de mots par similarité, représentation par graphes, contexte de IRUPHV��GLVWDQFH�G¶édition��'7:��IXVLRQ�G¶LQIRUPDWLRQ��LQWHUURJDWLRQ�SDU�O¶H[HPSOH.
ABSTRACT. Effective information retrieval on handwritten document images has always been a challenging task. In this paper, we propose a novel handwritten word spotting approach based on graph representation. The presented model comprises both topological and morphological signatures of handwriting. Skeleton-based graphs with the Shape Context labeled vertexes are established for connected components. Each word image is represented as a sequence of graphs. In order to be robust to the handwriting variations, an exhaustive merging process based on DTW alignment results introduced in the similarity measure between word images. With respect to the computation complexity, an approximate graph edit distance approach using bipartite matching is employed for graph matching. The experiments on the George Washington dataset and the marriage records from the Barcelona Cathedral dataset demonstrate that the proposed approach outperforms the state-of-the-art structural methods. KEYWORDS: word spotting, graph-based representation, shape context description, graph edit distance, DTW, block merging, query by example.
CIFED 2014, pp. 233–248, Nancy, 18-21 mars 2014

234 P. Wang, V. Églin, C. Garcia, C. Largeron, J. Lladós, A. Fornés
1. Introduction
/HV� DSSOLFDWLRQV� IRQGpHV� VXU� O¶H[SORLWDWLRQ� GHV� PDQXVFULWV� UHSRVHQW� SRXU�
XQH�JUDQGH�SDUWLH�VXU�GHV�YHUVLRQV�QXPpULVpHV��/¶DFFqV�DX�FRQWHQX�QpFHVVLWH�DORUV�GH�
pouvoir considérer les textes à travers une représentation qui doit être concise, discriminante et informante. Ce sont sur ces représentations que sont fondées les techniques de recherche par le contenu (recherche par similarités de formes, word retrieval, word spotting«���'H�QRPEUHX[�GpILV�VFLHQWLILTXHV�VRQW�DLQVL�DVVRFLpV�j�OD�recherche par le contenu dans les images de traits. Autour de la recherche par VLPLODULWp� GH� IRUPHV� pFULWHV�� XQ� pOpPHQW� FHQWUDO� FRQFHUQH� O¶pWXGH� GH� OD� YDULDELOLWp�
interne des écritures ainsi que celle qui permet de distinguer deux écritures de mains dif férentes. Il est désormais communément admis que les techniques G¶2&5�VRQW�totalement inopérantes sur la plupart des textes écrits, en particulier sur les supports anciens et historiques souvent très dégradés et présentant des particularités graphiques associée à une grande diversité de VW\OHV�G¶pFULWXUH.
Généralement on associe le word spotting j�GHX[� W\SHV�G¶Dpproches : une première famille repose sur la considération de mots prédéfinis en lien avec des PpFDQLVPHV�G¶DSSUHQWLVVDJH�VSpFLILTXH�GpGLpV�j�FHV�PRWV��2Q�peut citer les travaux décrits par Fischer et Rodriguez dans [1] et [2] par exemple reposant sur des modèles de Markov cachés et des vocabulaires spécif iques. A côté de ces approches, on généralise les techniques de word spotting par le développement de techniques de UHSUpVHQWDWLRQ�HW�GH�SURFHVVXV�G¶DSSDULHPHQW� IOH[LEOH�PHWWDQW� OHV�PRWV� UHTXrWHV�HQ�
FRUUHVSRQGDQFH�DYHF�OHV�FLEOHV�LVVXHV�GH�O¶LPDJH [3], [4]. 'DQV�OHV�GHX[�FDV��O¶DFFqV�DX�FRQWHQX�GDQV�O¶LPDJH�QpFHVVLWH�GH�GLVSRVHU�GH�UHSUpVHQWDWLRQV�FRPSOqWHV assurant à la fois une bonne rigueur de description et une souplesse nécessaire pour absorber les variations présentes dans OHV�SDJHV�G¶pFULWXUHV [1], [2], [3]. )LQDOHPHQW�F¶HVW�VXU�la mesure de similarité permettant de déterminer les appariements acceptables TX¶XQH�DWWHQWLRQ�SDUWLFXOLqUH�GRLW�rWUH�SRUWpH��&HWWH�PHVXUH�GRLW�pJDOHPHQW�RIIULU� OH�
PD[LPXP� GH� UREXVWHVVH� DX[� GpIRUPDWLRQV�� DX[� FKDQJHPHQWV� G¶pFKHOOHV� HW�
irrégularités dans la formation des traits et enfin aux dégradations entamant généralement la description des contours et des extrémités de formes.
Les représentations structurelles des formes fondées sur les graphes sont très populaires pour leur reconnaissance car elles permettent de modéliser très finement les dimensions structurelles et topologiques des objets. Dans certains GRPDLQHV� GH� O¶LPDJHULH� JUDSKLTXH�� FRPPH� HQ� UHFRQQDLVVDQFH� GH� V\PEROHV� HW� GH�
formules chimiques, ces techniques ont trouvé un essor considérable ces dernières années [20]. Cependant, on constate que les représentations graphiques demeurent WUqV� LQVXIILVDPPHQW� H[SORLWpHV� GDQV� OH� GRPDLQH� GH� O¶pFULW� RX� ELHQ� VRXYHQW� FH� VRQW�
des mécanismes moins rigides qui sont employés car ils assurent une meilleure tolérance aux variations internes de l¶écriture. On peut cependant citer quelques tentatives réali sées dans ce domaine et qui auront abouti à des premiers résultats prometteurs pour la reconnaissance du chinois et des textes à la dimension structurelle particulièrement prégnante [5], [6]. Bien que le modèle hiérarchique proposé dans [5] reflète la nature complexe des caractères écrits chinois, les mécanismes de représentation associés aux textes écrits sont généralement plus sophistiqués pour permettre de distinguer des formes similaires. On peut citer ici les

Représentation par graphe de mots manuscrits dans les images. . .235
travaux de Fischer et al. dans [7] et [8] qui ont développé un modèle de représentation de graphique basé sur le squelette de l 'image des mots à partir de O¶HQFRGDJH�GHV�VRPPHWV. En ajoutant une quantité suffisante de points d'intersection VpOHFWLRQQpV� SDUPL� OHV� SRLQWV� G¶LQWpUrW� GH� O¶LPDJH�� les informations structurelles demeurent préservées et peuvent prévenir des nombreuses insuffisances liées à O¶XVDJH�H[FOXVLI�G¶XQH�représentation fondée sur un squelette potentiellement bruité ou incomplet. /H�ULVTXH�DORUV�HVW�GH�GLVSRVHU�G¶XQ�WURS�JUDQG�QRPEUH�GH�VRPPHWV�HW�de complexifier les calculs : les mécanismes fondés sur les graphes présentent par définition une complexité calculatoire exceptionnelle. En effet, le coût des correspondances entre formes graphiques, les transformations des représentations graphiques en leur équivalent vectoriel (vecteurs de caractéristique) rappellent ces considérations calculatoires importantes [9]. Dans [9], les auteurs présentent la FRQVWUXFWLRQ� G¶XQ� JUDSKH� GLUHFW� acyclique pour chaque sous-mot présent dans le texte converti ensuite en un vecteur exprimant la signature topologique des mots. Lladós et al. dans [10] ont adapté le concept de sérialisation de graphes pour des DSSOLFDWLRQV�G¶DSSDULHPHQW�GH�JUDSKHV�DSSOLTXpV�DX�ZRUG spotting. En extrayant et en classifiant les chemins acycliques du graphe en une représentation unidimensionnelle, les auteurs ont pu créer un mécanisme de description des mots fondé sur des « sacs de chemins » (Bag of Paths, BoP). Les performances restent encore faibles pour des applications de word spotting où les irrégularités, et les imprécisions demeurent omniprésentes.
Notre motivation à exploiter une représentation structurelle reposant sur une construction de graphe (plutôt TXH�GH�SDUWLU�G¶XQ PRGqOH�G¶DSSDUHQFH�DVVRFLp�j�XQH�GHVFULSWLRQ�HQ�SRLQWV�G¶LQWpUrW�SDU�H[HPSOH�RX�j�XQ�HQVHPEOH�G¶LQGLFDWHXUV�GH�
formes, tels que les histogrammes de projection de points de contours, de courbures RX� G¶RULHQWDWLRQV�� HVW� OLp� j� OD� VWDELOLWp� VWUXFWXUHOOH� GHV�PRWV�� ,O� H[LVWH� HQ� HIIHW� GHV�
UqJOHV� G¶H[pFXWLRQ� UHSURGXFWLEOHV� TXH� OHV� SRLQWV� GH� Monction, de bifurcation et extrêPDX[� SUpVHQWV� VXU� OHV� WUDLWV� G¶pFULWXUH� SHUPHWWHQW� G¶HQFRGHr [19]. Les caractéristiques topologiques des traits et la nature bidimensionnelle GH� O¶pFULWXUH nous semblent être des indications suffisantes pour écarter les descriptions unidimensionnelles reposant sur des valeurs scalaires uniquement [9].
Dans ce papier nous proposons une approche générique de word spotting ne QpFHVVLWDQW� DXFXQ� SDUDPpWUDJH� DPRQW�� Q¶D\DQW� SDV� UHFRXUV� j� O¶DSSUHQWLVVDJH� HW�
reposant sur une représentation des mots par graphe. La description du graphe est fondée sur des primitives morphologiques obtenues par le descripteur contextuel de Contexte de formes (SC : Shape Context descriptor [11]). Cette description est intégrée au modèle de représentation pour indiquer localement en chaque sommet du graphe la nature de son voisinage et les relations de proximité que les contours ont entre eux. Ce descripteur est estimé sur la longueur totale G¶XQ�PRW�HQ�WRXW�SRLQW�GX�graphe. Chaque mot est finalement représenté par une séquence de graphes formés à partir des connexités initialement UHSpUpV� ORUV� G¶XQH� pWDSH� GH� SUpWUDLWHPHQW� La comparaison entre les mots image (requête et cibles) est finalement obtenue par le FDOFXO�GH�OD�PR\HQQH�GHV�GLVWDQFHV�G¶pGLWLRQ�HQWUH�JUDSKHV�SDLU�j�SDLU��$X�SUpDODEOH��
une mesure dynamique (Dynamic Time Warping) est exploitée entre les graphes Requête et Cibles comme processus de fusion de connexités garantissant les meilleures correspondances et les meilleurs appariements de graphes. Une distance

236 P. Wang, V. Églin, C. Garcia, C. Largeron, J. Lladós, A. Fornés
G¶pGLWLRQ�DSSUR[LPpH� LQLWLDOHPHQW�GpILQLH�GDQV [12] a été choisie dans nos travaux DILQ�GH�JDJQHU�HQ�WHPSV�GH�FDOFXO�HW�GRQF�HQ�UDSLGLWp�G¶H[pFXWLRQ��Les performances de la description FRPSDUpHV�j�G¶DXWUHV�DSSURFKHV�VRQW�étudiées pour des applications G¶LQWHUURJDWLRQV�SDU�O¶H[HPSOH�
La suite du papier est organisée de la façon suivante: après une brève LQWURGXFWLRQ� SRUWDQW� VXU� OHV� pWDSHV� GH� SUpWUDLWHPHQW� QpFHVVDLUH� j� O¶REWHQWLRQ� G¶XQ�
squelette, des contours et des points structurels exploitables, nous présentons formellement le concept de graphe pour la représentation des formes écrites (section III). Nous développons ensuite les métriques retenues pour assurer une comparaison GH�JUDSKHV� UREXVWH� DX[� YDULDWLRQV� LQWHUQHV�G¶pFULWXUH : la comparaison des graphes requêtes et cibOHV� SDU� O¶DSSOLFDWLRQ� GH� OD� '7:� permet de produire les meilleures configurations internes (fusion de graphes) qui sont ensuite évaluées par la distance G¶pGLWLRQ� DSSUR[LPpH� HQWUH� JUDSKHV� �Vection IV). Les résultats expérimentaux et O¶DQDO\VH�GHV�SHUIRUPDQFHV� UHSRVHQW� VXU� OD� FRPSDUDison entre quatre approches de word spotting du domaine avec notre proposition (section V). Nous conclusions le papier sur de possibles améliorations pour des applications de word spotting sans segmentation.
2. Prétraitements
Afin de produire un système comparable à O¶H[Lstant, nous sommes partis GH�O¶D�SULRUL�GH�O¶H[LVWHQFH�G¶XQe segmentation en mots. Nous disposons donc pour ce travail de mots Requêtes ELHQ�LGHQWLILpV�GDQV�OH�EHQFKPDUN�GH�O¶pWXGH��HW�TXL�VHUD�détaillé en section V) et de mots Cibles que nous avons extraits pour les besoins de O¶pWXGH��(Q�UpDOLWp��FHWWH�pWDSH�HVW�SXUHPHQW�DUWLILFLHOOH�FDU le mécanisme complet de UHFKHUFKH�GH�PRWV�QH�SHXW� VH�SDVVHU�G¶XQH� DSSURFKH�EDV�QLYHDX�GH� ORFDOLVDWLRQ�GH�
UpJLRQV�G¶LQWpUrW��&HWWH�FRQWULEXWLRQ�Q¶HVW pas présentée dans ce papier. Pour obtenir les informations topologiques de l'écriture et un squelette unitaire constituant O¶HQWUpH� GX� PpFDQLVPH� GH� VpOHFWLRQ� GH� SRLQWV� VWUXFWXUHOV�� QRXV� DYRQV� DSSOLTXp�
O¶DOJRULWKPH� GH� squelettisation de Zhang et Suen défini dans [13]. Cet algorithme possède une version parallélisable applicable sur des images binaires, voir Figure ��F��&HWWH�UHSUpVHQWDWLRQ�SHUPHW�G¶H[WUDLUH�DLVpPHQW�OHV�SRLQWV�GH�VWUXFWXUH�FODVVLILpV�
en trois familles : des points de forte courbure, des points de croisement, des points extrémaux. Ces points sont très génériques et totalement indépendants des types de ODQJXH� HW� G¶pFULWXUH considérés. /D� PpWKRGH� G¶H[WUDFWLRQ� HW� GH� FODVVLILFDWLRQ� GHV�points est présentée dans [14]. La Figure 1.d illustre cette décomposition en SURGXLVDQW� XQH� YHUVLRQ� VHJPHQWpH� GH� O¶pFULWXUH� HQ� VHJPHQWV� �OLJQH� HW� FRXUEHV�
FRQFDYHV�RX�FRQYH[HV��VpSDUpV�SDU�GHV�SRLQWV�G¶DFFURFKH. Afin de caractériser les informations morphologiques des mots, nous avons
FKRLVL� G¶Xtiliser le contour extérieur de l'écriture. Après une étape de comblement des trous et des zones de discontinuités dans le tracé, le détecteur de contour de Canny-Deriche est utilisé pour extraire des bords [21]. Une procédure de suivi de contour est ensuite appliquée pour assurer une extraction continue sans rupture de tracé (voir la Figure 1 (b)).

Représentation par graphe de mots manuscrits dans les images. . .237
(a)
(b)
(c)
(d)
Figure 1. (a) mot manuscrit (b) son contour (c) son squelette (d) points structurels (cercle : points extrémaux, carré : points de haute courbure, croix : point de croisement)
3. Modèle de graphe pour la représentation structurelle des mots
Les représentations reposant sur les modèles de graphes possèdent O¶DYDQWDJH�GH�SUpVHUYHU�OHV�SURSULpWpV�WRSRORJLTXHV�HW�GLVSRVLWLRQQHOOHV�GHV�VHJPHQWV�
internes pUpVHQWV� GDQV� O¶pFULWXUH�� 1RXV� DYRQV� FKRLVL� GH� UHSUpVHQWHU� OHV� SURSULpWpV�VWUXFWXUHOOHV�GH�O¶pFULWXUH�HQ�QRXV�LQWpUHVVDQW�j�VRQ�VTXHOHWWH�TXL�FRQWLHQW�j�OXL�VHXO�
toutes les indications morphologiques que nous souhaitons retenir. Les sommets du graphe corresSRQGHQW�DX[�SRLQWV�VWUXFWXUHOV�H[WUDLWV�SDU�O¶DQDO\VH�GHV�FRQILJXUDWLRQV�locales du squelette et les arêtes (voir Figure 3). /µinformation morphologique contextuelle de chaque sommet en relation avec son proche voisinage est décrite par le contexte de formes (SC : Shape Context descriptor [11]), qui capture la GLVWULEXWLRQ�GH�FRQWRXUV�GX�YRLVLQDJH�G¶XQ�SRLQW�HQ�XQ�YHFWHXU�riche et informant. Ce descripteur a été exploité dans des contextes similaires pour la reconnaissance de formes graphiques [18], voir Figure 2. Il est associé ici à chaque sommet du graphe. Les arêtes du graphe sont également décrites par la longueur des segments estimée à partir du décompte de points du squelette entre deux sommets adjacents.

238 P. Wang, V. Églin, C. Garcia, C. Largeron, J. Lladós, A. Fornés
Figure 2. Illustration du descripteur de Contexte de Formes (SC) [11].
Chaque composante connexe génère ainsi un graphe propre. Un mot est donc
FRQVWLWXp� G¶XQ� HQVHPEOH� GH� JUDSKHV� GpILQLV� LQGLYLGXHOOHPHQW� HW� j� FH� VWDGH� QH�
possédant aucune connexion entre eux. La Figure 3 illustre une représentation en VpTXHQFH�GH�JUDSKHV�GX�PRW� ´Savay´ : les trois graphes sont réellement constitués GHV�SRUWLRQV�GH�PRWV�´S ��´av �HW�´ay � La définition du graphe peut ainsi se présenter de la façon suivante: Défini tion 1. (Graph) Un graphe est un 4-tuple C L :8á'áäá R;, où x 8 UHSUpVHQWH�O¶HQVHPEOH�GHV�VRPPHWV�FRUUHVSRQGDQW�DX[�SRLQWV�VWUXFWXUHOV x ' C 8�H �8 HVW� O¶ensemble des arêtes, correspondant aux segments entre deux
sommets adjacents x äã8 \ �.� est la fonction qui associe à chaque sommet son vecteur de contexte
de formes (SC : 5 niveaux concentriques et 12 secteurs angulaires, soit 60 dimensions)
x Rã' \ .ñ est la fonction qui associe à chaque arête du graphe sa longueur estimée entre deux sommets.
Figure 3. 5HSUpVHQWDWLRQ�HQ�XQH�VpTXHQFH�GH�WURLV�JUDSKHV�GX�PRW�³Savay³�

Représentation par graphe de mots manuscrits dans les images. . .239
4. Appariements entre mots et mesures de similarité
Au-delà des métriques reposant sur une comparaison exhaustive des composants du graphe et interdisant toute distorsion ou souplesse dans O¶DOLJQHPHQW�GHV�DUrWHV�HW�GHV�Q°XGV�j�FRPSDUHU��QRXV�DYRQV�FKRLVL�G¶H[SORLWHU�GHV�PHVXUHV�GH�
similarités non linéaires permettant : - De comparer chaque paire de composantes FRQQH[HV�G¶XQ�PRW�j� O¶DXWUH à
O¶DLGH�G¶XQH�GLVWDQFH�G¶pGLWLRQ�DSSUR[LPpH��GpILQLH�Hn section 4.1) - '¶HVWLPHU�OHV�VLPLODULWpV�LQWHUQHV�interprétées comme des critères de fusion,
simplifiant ainsi le modèle de représentation des mots cibles en diminuant leur nombre de connexités (section 4.2)
- '¶HVWLPHU� OD� GLVWDQFH� ILQDOH� HQWUH� GHX[� PRWV� SDU le cumul des distances internes
/¶DSSURFKH� VWUXFWXUHOOH� VXU� ODTXHOOH� QRXV� IRQGRQV� OD� FRPSDUDLVRQ� GH� PRWV�
VRXOLJQH� WRXW� � O¶LQWpUrW� GH� OD� SULVH� HQ� FRPSWH� GH� OD� VWUXFWXUH� GHV� HQWLWpV� GDQV� OD�
métrique de comparaison, complexifiant inévitablement la vision qui ramène le problème à un espace mathématique où les objets sont comparables linéairement selon un calcul de distance entre vecteurs de caractéristiques. /¶LGpH�GH�SURFpGHU�j�XQH� DSSURFKH� UHOHYDQW� GH� O¶pWXGH� GH� O¶DOLJQHPHQW� VWUXFWXUHO� HQWUH� GHX[� JUDSKHV�
revient donc à prendre en compte non seulement les correspondances entre sommets mais aussi les ressemblances dans leurs connexions (arêtes). 4.1 CoUUHVSRQGDQFH�HQWUH�JUDSKHV�HW�GLVWDQFH�G¶pGLWLRQ�DSSUR[LPpH
Puisque les composantes connexes sont représentées par des graphes, leur comparaison se ramène à un problème de correspondance de graphes. $ILQ�G¶éviter les débordements calculatoires vite atteints dans de telles situations, nous avons opté SRXU� O¶H[SORLWDWLRQ� G¶XQH� FRPSDUDLVRQ� DSSUR[LPpH� HQWUH� JUDSKHs proposée initialement par K. Riesen and H. Bunke dans [12] reposant sur la recherche du coût G¶pGLWLRQ�PLQLPDO�HQWUH�GHX[�JUDSKHV� Défini tion 2. ('LVWDQFH�G¶pGLWLRQ�HQWUH�JUDSKHV) Soit �5 L :�5á�5á J5á �5; le graphe DVVRFLp� j� OD� UHSUpVHQWDWLRQ� GH� O¶LPDJH� Requête et �6 L :�6á�6á J6á �6; le graphe DVVRFLp� j� O¶LPDJH�Cible. /D� GLVWDQFH� G¶pGLWLRQ� HQWUH� OHV� GHX[� JUDSKHV� g1 et g2est définie par :
�:�5á �6; �L ����:c-áåáca;Ð�:e-áe.; à �:�g;ig@5 (1)
où Û:C5áC6; UHSUpVHQWH� O¶HQVHPEOH� GHV� FKHPLQV� SRVVLEOHs permettant la transformation du graphe g1 en graphe g2. La fonction ?:AÜ; représente le coût cumulant les coûts intermédiaires nécessaires pour transformer le graphe g1 en g2. Les opérations indépendantes de coût AÜ peuvent être ��GHV�RSpUDWLRQV�G¶insertion, de suppression ou de substitution GH�VRPPHWV�HW�G¶DUrWHV.
/¶DOJRULWKPH�GH�FRPSDUDLVRQ�VRXV-optimal est basé sur la considération des graphes internes à chaque connexité (une connexité étant, rappelons-le constituée de

240 P. Wang, V. Églin, C. Garcia, C. Largeron, J. Lladós, A. Fornés
n sommets et m arêtes). Les graphes internes sont donc ici définis comme un ensemble centré en un sommet et sa structure adjacente locale. Par conséquent, la GLVWDQFH�G¶pGLWLRQ�HQWUH�GHX[�JUDSKHV�SHXW�rWUH�UHIRUPXOpe comme la recherche G¶XQ�optimal entre sommets et leurs structures locales respectives. $X� OLHX�G¶XWLOLVHU� OHV�UHVVRXUFHV�FR�WHXVHV�GH�OD�SURJUDPPDWLRQ�G\QDPLTXH��O¶DSSDULHPHQW�ELSDUWLWH�HQWUH�
deux graphes est adapté et rapide. /¶DSSDULHPHQW�GH�JUDSKHV�HVW�GRQF�WUDLWp�FRPPH�XQ�SUREOqPH�G¶DIIHFWDWLRQ. Pour cela O¶DOJRULWKPH�hongrois de Munkres (Hungarian matrix) a été choisi pour résoudre ce problème de recherche G¶RSWLPDO�HQWUH�JUDSKHV�PLQLPLVDQW� OH� FR�W� OLp� DX[� WUDQVIRUPDWLRQV� GH� VRPPHWV� HW� G¶DUrWHV� GHV� JUDSKHV�
considérés. $ILQ� G¶HVWLPHU� OHV� FR�WV� GH� VXEVWLWXWLRQ� G¶XQ� VRPPHW� HQ� XQ� DXWUH�� GHX[�
composantes ont été mesurées : le premier indice permet de comparer la description locale reposant sur le contexte de formes entre deux sommets et le second repose sur la comparaison de la structure locale entre deux graphes impliquant les longueurs de segments séparant deux sommets (voir Equation 2).
1RXV� DYRQV� DLQVL� WHVWp� OHV� SHUIRUPDQFHV� GH� OD� GLVWDQFH� G¶pGLWLRQ� HQWUH�
graphes avec différentes valeurs de pondérations de ces coûts intermédiaires : S5= 0.2 et S6= 0.8, S5= 0.5 et S6= 0.5, S5= 0.8 et S6= 0.2. Constatant sur un grand jeu de tests que la description reposant sur la description des sommets par le contexte de IRUPHV� GHPHXUH� SOXV� GLVFULPLQDQWH� TXH� O¶LQIRUPDWLRQ� FRQWHQXH� GDQV� OD� VWUXFWXUH�
voisine de chaque sommet, nous avons choisi de fixer les valeurs de poids à 0.8 pour S5 et 0.2 pour S6 . Les deux constantes a et d ont été choisies expérimentalement.
Csubstitution = w1 CSC_cost + w2 Clocal_structure (2) Csuppression = d (3) Cinsertion = a (4)
Compte tenu les intervalles de valeurs choisis pour exprimer les coûts de
substitution, les deux constantes restantes OLpHV�DX�FR�W�G¶LQVHUWLRQ�HW�GH�VXSSUHVVLRQ�sont fixées à 0.5. �%̼ � représente le coût associé au descripteur de contexte de formes des sommets. ,O� V¶H[SULPH� SDU� la distance du ï6 square entre deux descripteurs de contexte de formes et %ßâÖÔß4æçåèÖçèåØ� le coût de substitution lié aux valeurs de longueurs des arêtes. Pour un sommet considéré, on estime le coût de substitution de la façon suivante : %ßâÖÔß4æçåèÖçèåØ = sF AæÛâåç�AßâáÚ, avec AæÛâåç la longueur du contour le plus court rattachant le sommet considéré à un voisin direct et AßâáÚ la longueur la plus importante.
TypiquemenW�� OD� GLVWDQFH� G¶pGLWLRQ� HQWUH� JUDSKHV� HVW� FDOFXOpe avec une approche de type recherche arborescente présentant une complexité calculatoire H[SRQHQWLHOOH�� /¶XWLOLVDWLRQ� G¶XQH� DSSUR[LPDWLRQ� GH� OD� GLVWDQFH� G¶pGLWLRQ� SDU�
O¶DOJRrithme de Munkres résout ce problème en temps polynomial. Ces différences sont importantes à considérer pour le traitement de masses de données conséquentes, FH� TXL� HVW� QRWDPPHQW� OH� FDV� SRXU� OHV� DSSOLFDWLRQV� G¶H[SORUDWLRQ� GH� FROOHFWLRQV�
manuscrites anciennes.

Représentation par graphe de mots manuscrits dans les images. . .241
4.2 Appariement complet de mots
Puisque un mot est représenté par une séquence de graphes (représentant les objets connexités), la distance dynamique DTW est la mesure la plus adaptée pour permettre un appariement souple entre graphes en intégrant la distance G¶pGLWLRQ�SUpsentée en section 4.1. Un des éléments fondamentaux de cette distance HVW�GH�SHUPHWWUH�G¶LQWpJUHU�XQH�YDULDWLRQ�SDUIRLV�LPSRUWDQWH�GH�FRQQH[LWpV�HQWUH�GHX[�
mots à comparer. En effet, on peut rapidement observer que les mots présents dans un texte manuscrit sont marqués par la présence de ruptures en des points non réguliers du texte, ceci VH� WUDGXLW� SDU� OD� SUpVHQFH� G¶REMHWV connexités en nombre YDULDEOH� HQWUH� O¶LPDJH�Requête HW� O¶LPDJH�Cible. Ces variations sont remarquables entre scripteurs mais également pour un même scripteur, voir Figure 4. Cette figure SUpVHQWH� XQ� H[HPSOH� GH� GHX[� LQVWDQFHV� G¶XQ� PrPH� PRW� pFULW� SDU� OD� PrPH� PDLQ�
possédant respectivement cinq et trois connexités. Cette particularité graphique va plus généralement pouvoir se résoudre par la comparaison de n graphes (issus du mot Requête) avec m graphes (issus du mot Cible).
(a) (b)
Figure 4. Exemple de deux instances GX� PRW� ´Otheos � FRPSRVpHV� G¶XQ� QRPEUH�variable de connexités (Correspondances clandestines 18ème siècle, projet CITERE : ANR Blanc SHS 2009-������&LUFXODWLRQV��7HUULWRLUHV�HW�5pVHDX[�GH�O¶kJH�FODVVLTXH�aux Lumières.)
Pour rendre la mesure de similarité robuste aux variations internes de
connexités, nous avons proposé de les reconsidérer en réduisant leur nombre par un processus de fusion. Les graphes affectés j� XQH� PrPH� FRQQH[LWp� j� O¶LVVXH� GH�O¶DSSDULHPHQW�SDU�'7:�VRQW�SURSRVpV�j�OD�IXVLRQ�HW�UHFRQVLGpUpV�comme un unique graphe. Dans ce cas, la séquence de graphes de la Requête HW�OD�VpTXHQFH�GH�O¶LPDJH�Cible peuvent être transformées. $�O¶LVVXH�GH�FHV�RSpUDWLRQV�GH� IXVLRQ�� OD�GLVWDQFH�G¶pGLWLRQ� HQWUH� JUDSKHV� HVW� à nouveau calculée créant ainsi de nouvelles correspondances. /D� GLVWDQFH� PR\HQQH� REWHQXH� j� O¶LVVXH� GH� FHV� QRXYHOOHV�évaluations internes entre graphes est la mesure finale retenue entre les deux mots. Considérons pour cela un exemple reposant sur un mot de taille moyenne : ´Otheos �représenté à la Figure 4. On considère = L CÔ
5 á® áCÔ9 la séquence de graphes
représentant le mot de la Figure 4(a) et bL CÕ5á® áCÕ
7 représente le mot de la Figure 4(b). A O¶LVVXH�GH�O¶pWDSH�G¶DOLJQHPHQW�REWHQXH�SDU�OD�GLVWDQFH�G\QDPLTXH�DTW, les graphes CÔ
5 et CÕ5 sont appariés, et les graphes CÔ
6 et CÔ7 associés au graphe CÕ
6 et les trois graphes CÔ
7, CÔ8,�CÔ
9 au graphe CÕ7. Par conséquent, en respectant la procédure de
fusion, les graphes CÔ6 , CÔ
7 , CÔ8 et CÔ
9 sont rassemblés en un seul et même JUDSKHUHQRPPp� SRXU� O¶H[HPSOH :CÔ
6;ñ , ayant en commun le graphe CÔ7 réagissant

242 P. Wang, V. Églin, C. Garcia, C. Largeron, J. Lladós, A. Fornés

Représentation par graphe de mots manuscrits dans les images. . .243
5.1 Données expérimentales et évaluation de performances
La première base sur laquelle repose les tests est la base composée de vingt pages de la collection de lettres manuscrites de George Washington (GW) [3]. La VHFRQGH�pYDOXDWLRQ�UHSRVH�VXU�O¶H[SORLWDWLRQ�GHV�GRQQpHV�LVVXHV�GH�YLQJW�VHSW�SDJHV��
du registre de mariages de la Cathédrale de Barcelone (5CofM) [16]. Les deux FRUSXV�VRQW�FRQoXV�FRPPH�GHV�FRUSXV�pWDORQV�GLVSRVDQW�G¶XQH�VHJPHQWDWLRQ�HQ�PRWV�
transcrits et permettant donc de réaliser une étude de performance pertinente. Pour la collection GW, on dispose de 4860 mots segmentés avec 1124 transcriptions, et pour la collection 5CofM on dispose de 6544 mots associés à 1751 transcriptions. Tous les mots possédant au minimum 3 lettres et apparaissant au minimum 10 fois dans la collection sont sélectionnés comme mot requête. Par conséquent, les expérimentations se fondent sur précisément 1847 requêtes correspondant à 68 mots différents pour la base GW et 514 requêtes de 32 mots pour la base 5CofM. La Figure 6 illustre quelques extraits de mots de la base des registres de mariages (5CofM).
Figure 6. Exemples de mots du registre de mariages de la cathédrale de Barcelone, 5CofM (1825).
$ILQ� G¶pYDOXHU� OHV� SHUIRUPDQFHV� GH� O¶DSSURFKH� TXH� QRXV� DYRQV� SURSRVpH��
nous avons choisi trois indices relevant des valeurs de rappel et de précision. Considérant une requête, on notera Rel O¶HQVHPEOH� GH� UpSRQVHV� SHUWLQHQWHV�relativement à cette requête et Ret O¶HQVHPEOH�GHV�pOpPHQWV�HIIHFWLYHPHQW�UHWURXYpV�dans la base de tests. x P@n ² est la précision obtenue au rang n, considérant uniquement les n
premiers retours du système. Dans nos tests, nous ne considérons que les retours aux rangs n= 10 et 20.
x R-Précision ² la R-Précision est la précision obtenue après que R images aient été retrouvées, avec R le nombre de documents pertinents pour la requête considérée.
x mAP (mean Average Precision) ² mAP ou moyenne des précisions obtenues FKDTXH� IRLV� TX¶XQ� PRW� LPDJH� SHUWLQHQW� HVW� UHWURXYp�� ,O� FRUUHVSRQG� j O¶LQGLFH�calculé à partir de chaque valeur de précision pour chaque rang. Pour une requête donnée, en notant r(n) la fonction indiquant le nombre de retours positifs du système au rang n, FHWWH� SUpFLVLRQ� PR\HQQH� V¶H[SULPH� FRPPH� OH�rapport suivant :
I#2 Là :É7áHå:á;;�ÝÐß�Ù8-
�åØß� (5)
244 P. Wang, V. Églin, C. Garcia, C. Largeron, J. Lladós, A. Fornés
5.2 Résultats et discussion
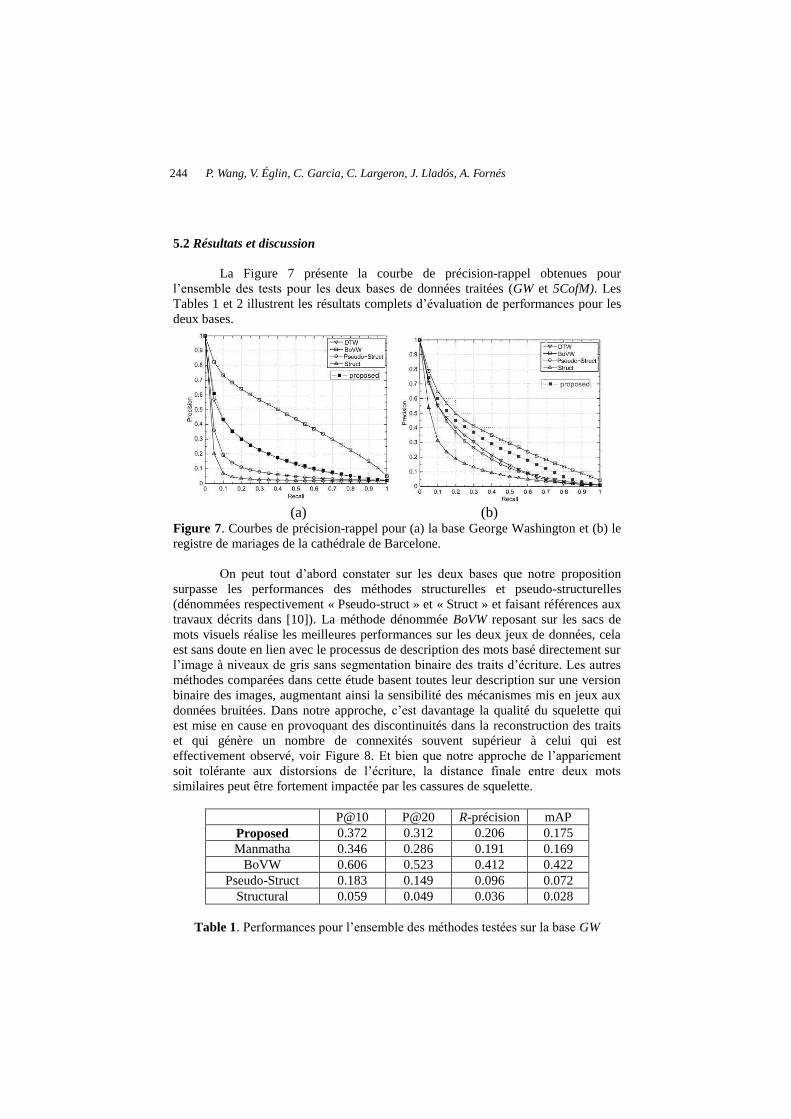
La Figure 7 présente la courbe de précision-rappel obtenues pour O¶HQVHPEOH� GHV� WHVWV� SRXU� OHV� GHX[� EDVHs de données traitées (GW et 5CofM). Les Tables 1 et 2 illustrent les résultats completV�G¶pYDOXDWLRQ�GH�SHUIRUPDQFHV�pour les deux bases.
(a) (b)
Figure 7. Courbes de précision-rappel pour (a) la base George Washington et (b) le registre de mariages de la cathédrale de Barcelone.
2Q� SHXW� WRXW� G¶DERUG� FRQVWDWHU� VXU� OHV� GHX[� EDVHV� TXH� QRWUH� proposition
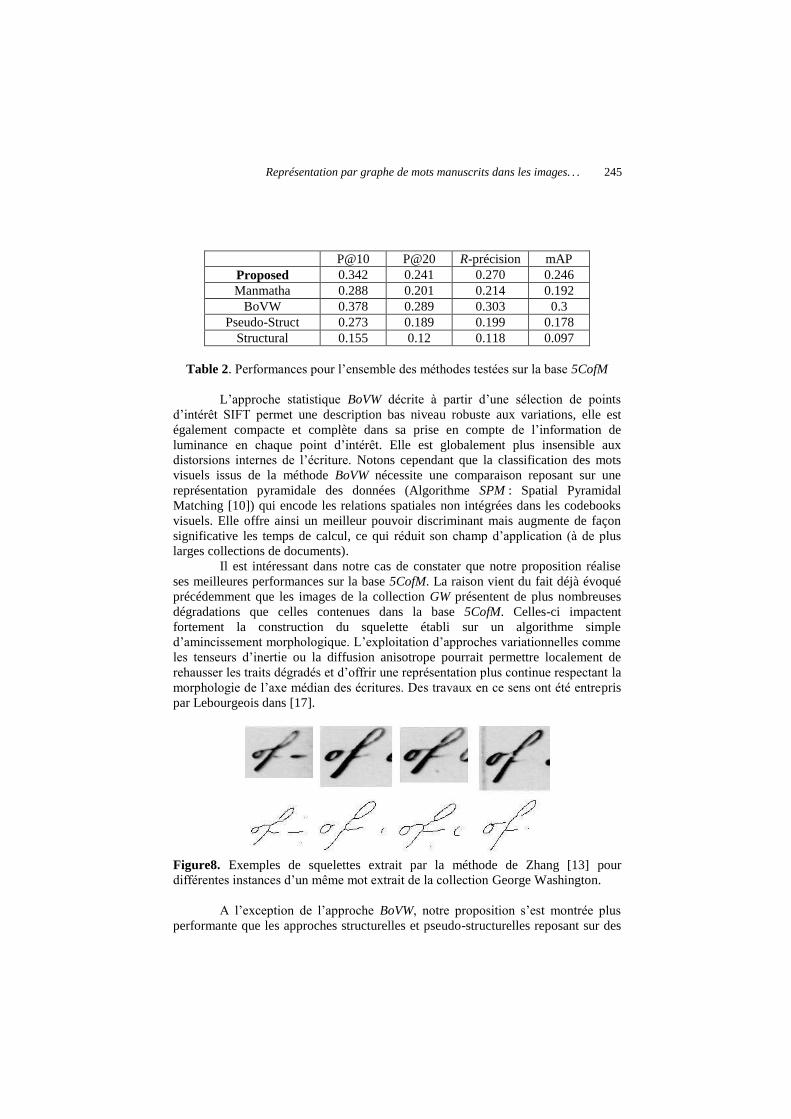
surpasse les performances des méthodes structurelles et pseudo-structurelles (dénommées respectivement « Pseudo-struct » et « Struct » et faisant références aux travaux décrits dans [10]). La méthode dénommée BoVW reposant sur les sacs de mots visuels réalise les meilleures performances sur les deux jeux de données, cela est sans doute en lien avec le processus de description des mots basé directement sur O¶LPDJH�j�QLYHDX[�GH�JULV VDQV�VHJPHQWDWLRQ�ELQDLUH�GHV�WUDLWV�G¶pFULWXUH��/HV�DXWUHV�méthodes comparées dans cette étude basent toutes leur description sur une version binaire des images, augmentant ainsi la sensibilité des mécanismes mis en jeux aux données bruitées. Dans notre approche, F¶HVW davantage la qualité du squelette qui est mise en cause en provoquant des discontinuités dans la reconstruction des traits et qui génère un nombre de connexités souvent supérieur à celui qui est effectivement observé, voir Figure 8. (W�ELHQ�TXH�QRWUH�DSSURFKH�GH� O¶DSSDULHPHQW�soit tolérante aux GLVWRUVLRQV� GH� O¶pFULWXUH�� OD� GLVWDQFH� ILQDOH� HQWUH� GHX[� PRWV�similaires peut être fortement impactée par les cassures de squelette.
P@10 P@20 R-précision mAP
Proposed 0.372 0.312 0.206 0.175 Manmatha 0.346 0.286 0.191 0.169
BoVW 0.606 0.523 0.412 0.422 Pseudo-Struct 0.183 0.149 0.096 0.072
Structural 0.059 0.049 0.036 0.028
Table 1. 3HUIRUPDQFHV�SRXU�O¶HQVHPEOH�GHV�PpWKRGHV�WHVWpHV�VXU�OD�EDVH�GW
Représentation par graphe de mots manuscrits dans les images. . .245
P@10 P@20 R-précision mAP
Proposed 0.342 0.241 0.270 0.246 Manmatha 0.288 0.201 0.214 0.192
BoVW 0.378 0.289 0.303 0.3 Pseudo-Struct 0.273 0.189 0.199 0.178
Structural 0.155 0.12 0.118 0.097
Table 2. 3HUIRUPDQFHV�SRXU�O¶HQVHPEOH�GHV�PpWKRGHV�WHVWpHV�VXU�OD�EDVH�5CofM
L¶DSSURFKH� VWDWLVWLTXH� BoVW GpFULWH� j� SDUWLU� G¶XQH� VpOHFWLRQ� GH� SRLQWV�G¶LQWpUrW� 6,)7� SHUPHW une description bas niveau robuste aux variations, elle est également compacte et complète dans sa prise en compte dH� O¶LQIRUPDWLRQ de luminance HQ� FKDTXH� SRLQW� G¶LQWpUrW. Elle est globalement plus insensible aux GLVWRUVLRQV� LQWHUQHV� GH� O¶pFULWXUH��Notons cependant que la classification des mots visuels issus de la méthode BoVW nécessite une comparaison reposant sur une représentation pyramidale des données (Algorithme SPM : Spatial Pyramidal Matching [10]) qui encode les relations spatiales non intégrées dans les codebooks visuels. Elle offre ainsi un meilleur pouvoir discriminant mais augmente de façon significative les temps de calcul, ce qui UpGXLW� VRQ� FKDPS�G¶DSSOLFDWLRQ� �j� GH�SOXV�larges collections de documents).
Il est intéressant dans notre cas de constater que notre proposition réalise ses meilleures performances sur la base 5CofM. La raison vient du fait déjà évoqué précédemment que les images de la collection GW présentent de plus nombreuses dégradations que celles contenues dans la base 5CofM. Celles-ci impactent fortement la construction du squelette établi sur un algorithme simple G¶DPLQFLVVHPHQW�PRUSKRORJLTXH��/¶H[SORLWDWLRQ�G¶DSSURFKHV�YDULDWLRQQHOOHV�FRPPH�
OHV� WHQVHXUV� G¶LQHUWLe ou la diffusion anisotrope pourrait permettre localement de UHKDXVVHU�OHV�WUDLWV�GpJUDGpV�HW�G¶RIIULU�XQH�UHSUpVHQWDWLRQ�SOXV�FRQWLQXH�UHVSHFWDQW la PRUSKRORJLH�GH�O¶D[H�PpGLDQ�GHV�pFULWXUHV��'HV�WUDYDX[�HQ�FH�VHQV�RQW�pWp�HQWUHpris par Lebourgeois dans [17].
Figure8. Exemples de squelettes extrait par la méthode de Zhang [13] pour GLIIpUHQWHV�LQVWDQFHV�G¶XQ�PrPH�PRW�H[WUDLW�GH�OD�FROOHFWLRQ�George Washington.
$� O¶H[FHSWLRQ� GH� O¶DSSURFKH� BoVW�� QRWUH� SURSRVLWLRQ� V¶HVW� PRQWUpH� SOXV�performante que les approches structurelles et pseudo-structurelles reposant sur des
246 P. Wang, V. Églin, C. Garcia, C. Largeron, J. Lladós, A. Fornés
JUDSKHV� HW� SURFpGDQW� VDQV� DSSUHQWLVVDJH��&HOD� LOOXVWUH� HQ� SDUWLFXOLHU� O¶HIILFDFLWp� GX�
choix de points structurels définis sur le squelette des mots pour diriger la structure du graphe qui le décrit, au lieu de points maximisant XQH�YDULDWLRQ�ORFDOH�G¶LQWHQVLWp�OXPLQHXVH�� FRPPH� FHOD� HVW� JpQpUDOHPHQW� OH� FDV� SRXU� OHV� SRLQWV� G¶LQWpUrW� SOXV�
standards. Par ailleurs, les informations contextuelles apportées par une description par contexte de formes (SC) constituent une description très riche de ces points.
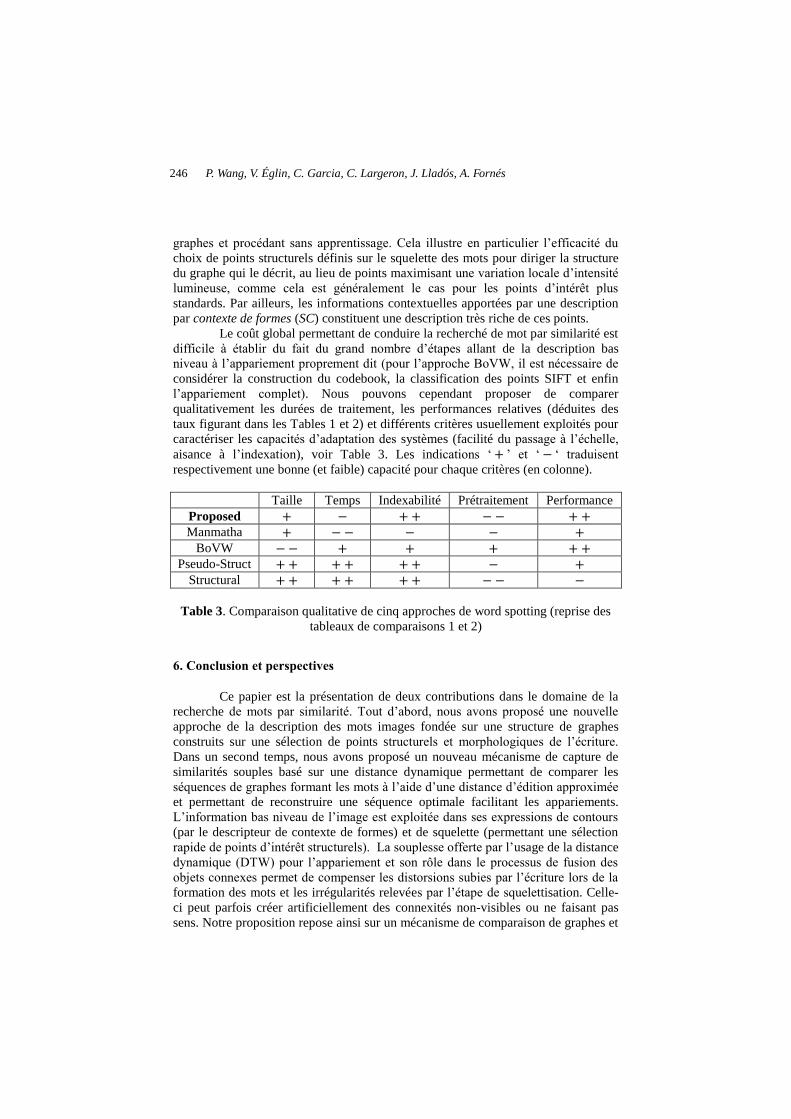
Le coût global permettant de conduire la recherché de mot par similarité est GLIILFLOH� j� pWDEOLU� GX� IDLW� GX� JUDQG� QRPEUH� G¶pWDSHV� DOODQW� de la description bas QLYHDX�j�O¶DSSDULHPHQW�SURSUHPHQW�GLW �SRXU�O¶DSSURFKH�%R9:��LO�HVW�QpFHVVDLUH�GH�considérer la construction du codebook, la classification des points SIFT et enfin O¶DSSDULHPHQW� FRPSOHW�. Nous pouvons cependant proposer de comparer qualitativement les durées de traitement, les performances relatives (déduites des taux figurant dans les Tables 1 et 2) et différents critères usuellement exploités pour caractériser les FDSDFLWpV�G¶DGDSWDWLRQ�GHV�systèmes (facilité du SDVVDJH�j�O¶pFKHOOH��aisance à O¶LQGH[DWLRQ), voir Table 3. Les indLFDWLRQV� µE ¶� HW� µF µ� WUDGXLVHQW�respectivement une bonne (et faible) capacité pour chaque critères (en colonne).
Taille Temps Indexabilité Prétraitement Performance
Proposed E F EE F F E E Manmatha E F F F F E
BoVW FF E E E E E Pseudo-Struct EE E E EE F E
Structural EE E E EE F F F
Table 3. Comparaison qualitative de cinq approches de word spotting (reprise des tableaux de comparaisons 1 et 2)
6. Conclusion et perspectives
Ce papier est la présentation de deux contributions dans le domaine de la recherche GH�PRWV� SDU� VLPLODULWp�� 7RXW� G¶DERUG�� QRXV� DYRQV� SURSRVp� XQH� QRXYHOOH�approche de la description des mots images fondée sur une structure de graphes construits sur une sélection de points sWUXFWXUHOV� HW� PRUSKRORJLTXHV� GH� O¶pFULWXUH��Dans un second temps, nous avons proposé un nouveau mécanisme de capture de similarités souples basé sur une distance dynamique permettant de comparer les VpTXHQFHV�GH�JUDSKHV�IRUPDQW�OHV�PRWV�j�O¶DLGH�G¶XQH�GLVWDQFH�G¶pGLWLRQ�DSSUR[LPpH�
et permettant de reconstruire une séquence optimale facilitant les appariements. /¶LQIRUPDWLRQ�EDV�QLYHDX�GH�O¶LPDJH�HVW�H[SORLWpH�GDQV�VHV�H[SUHVVLRQV�GH�FRQWRXUV�
(par le descripteur de contexte de formes) et de squelette (permettant une sélection UDSLGH�GH�SRLQWV�G¶LQWpUrW�VWUXFWXUHOV����/D�VRXSOHVVH�RIIHUWH�SDU�O¶usage de la distance G\QDPLTXH� �'7:��SRXU� O¶DSSDULHPHQW�HW� VRQ� U{OH�GDQV� OH�SURFHVVXV�GH� IXVLRQ�GHV�
REMHWV�FRQQH[HV�SHUPHW�GH�FRPSHQVHU�OHV�GLVWRUVLRQV�VXELHV�SDU�O¶pFULWXUH�ORUV�GH�OD�
formation des mots et les irrégularités relevéeV�SDU�O¶pWDSH�GH�VTXHOHWtisation. Celle-ci peut parfois créer artificiellement des connexités non-visibles ou ne faisant pas sens. Notre proposition repose ainsi sur un mécanisme de comparaison de graphes et

Représentation par graphe de mots manuscrits dans les images. . .247
XQ� XVDJH� LQWHQVLI� G¶XQH� GLVWDQFH� G¶pGLWLRQ� DSSUR[LPpH� VDQV� DXFXQ� DSSUHQWissage SUpDODEOH��&HWWH�DSSURFKH�Q¶Dvait jamais été exploitée dans un contexte de recherche GH�PRWV�PDQXVFULWV��/¶DSSOLFDWLRQ�j�GH�QRXYHDX[�FRUSXV�SOXV�YROXPLQHX[�FRQVWLWXH�
le prochain enjeu de cette étude, en lien avec les données du projet ANR CITERE aux YROXPHV�WUqV�FRQVpTXHQWV��&¶HVW�GRQF�VXU�OD�FRPSOH[LWp�FDOFXODWRLUH�TX¶XQ�HIIRUW�devra être réalisé, sachant que la comparaison de graphes même partielle est très FRQVRPPDWULFH� GH� SXLVVDQFH� GH� FDOFXOV� �'7:�� FR�W� G¶pGLWLRQ� HQ� GHX[� SDVVHV� HW�
itérations en uQ� WUqV� JUDQG� QRPEUH� GH� IHQrWUHV� G¶DQDO\VH� VXU� XQH� SDJH� GH� WH[WH�exploitant un descripteur de formes de dimension 60). Notre volonté de conserver les deux dimensions de la représentation par graphe au lieu de ramener la description à une séquence 1D de caractéristiques est un défi que nous tenterons de PDLQWHQLU�PDOJUp�O¶DXJPHQWDWLRQ�GH�WDLOOH�GHV�FRUSXV�j�DQDO\VHU�
$FWXHOOHPHQW�� QRV� WUDYDX[� SRUWHQW� VXU� O¶pODERUDWLRQ� G¶XQH� VWUDWpJLH�
complète pré-VpOHFWLRQQDQW�GHV�UpJLRQV�G¶LQWpUrW�GDQV�OHV�LPDJHV�DX�IRUW�SRWentiel en rapport avec les propriétés morphologiques du mot-requête soumis au système. Cette étape vise ainsi à rejeter massivement des propositions non pertinentes et de ne WUDLWHU� TXH� OHV� IHQrWUHV� G¶DQDO\VH� FDQGLGDWHV�� 8QH� UHFRQVLGpUDWLRQ� ORFDOH� GH� OD�
description par contexte de formes autour des sommets des graphes décrivant les objets connexes pourrait ainsi soutenir cette étape de recherche de zones candidates.
7. Remerciements
Nous tenons à remercier le professeur Antony McKenna responsable du projet CITERE et G¶XQ� IRQG� GH� PDQXVFULWV� QXPpULVpV� XQLTXHV : « Les FRUUHVSRQGDQFHV� FODQGHVWLQHV� GH� O¶(XURSH� GHV� /XPLqUHV » ainsi que « Les correspondances de Pierre Bayle ». Cette recherche est soutenue par un projet UpJLRQDO�G¶$RC de la région Rhônes-Alpes en lien avec le projet ANR CITERE et soutenue également par le projet espagnol TIN2012-37475-C02-02 ainsi que le projet européen ERC-2010-AdG- 20100407-269796 au sein du CVC de Barcelone.
8. Références
[1] A. Fischer, A. Keller, V. Frinken, and +��%XQNH��³+00-based word spotting in KDQGZULWWHQ� GRFXPHQWV� XVLQJ� VXEZRUG� PRGHOV�´� LQ� 3URF�� of the ICPR, pp. 3416±3419, 2010. [2] J. Rodriguez-Serrano, DQG� )�� 3HUURQQLQ�� ³+DQGZULWWHQ� ZRUG spotting using hidden markov models and universal YRFDEXODULHV�´�35��YRO�� ���� QR��9, pp. 2106±2116, 2009. [3] T. Rath, DQG�5��0DQPDWKD��³:RUG�VSRWWLQJ�IRU�KLVWRULFDO�GRFXPHQWV�´ in Proc. of the ICDAR, vol. 9, no. 2-4, pp. 139±152, 2007. >�@�<��/H\GLHU��$��2XML��)��/H%RXUJHRLV��DQG�+��(PSWR]��³7RZDUGV�DQ omnilingual word retrieval system for ancient PDQXVFULSWV�´�35��YRO����� no. 9, pp. 2089±2105, 2009. >�@� 6�� /X��<��5HQ�� DQG�&�� 6XHQ�� ³+LHUDUFKLFDO attributed graph representation and recognition of handwritten Chinese FKDUDFWHUV�´� 35�� YRO�� ���� QR�� �� pp. 617±632,

248 P. Wang, V. Églin, C. Garcia, C. Largeron, J. Lladós, A. Fornés
1991. >�@�0��=DVODYVNL\��)��%DFK��DQG�-��9HUW��³$�SDWK following algorithm for the graph matching SUREOHP�´�3$0,��YRO������QR� 12, pp. 2227±2241, 2009. >�@�$��)LVFKHU��&��<��6XHQ��9��)ULQNHQ��.��5LHVHQ��DQG�+��%XQNH��³$ fast matching algorithm for graph-based KDQGZULWLQJ�UHFRJQLWLRQ�´�LQ Lecture Notes in Computer Science, vol. 7887, pp. 194±203, 2013. >�@�$��)LVFKHU��.��5LHVHQ��DQG�+��%XQNH��³*UDSK�VLPLODULW\ features for HMM-based KDQGZULWLQJ�UHFRJQLWLRQ�LQ�KLVWRULFDO�GRFXPHQWV�´� LQ�3URF� of the ICFHR, pp. 253±258, 2010. >�@�<��&KKHUDZDOD��5��:LVQRYVN\�� DQG�0��&KHULHW�� ³7VY-lr: Topological signature vector-based lexicon reduction for fast recognition of premodern Arabic subwRUGV�´�in Proc. of the workshop HIP, pp. 6±13, 2011. [10] J. Lladós, M. Rusinol, A. FornéV�� '�� )HUQDQGH]�� DQG� $�� 'XWWD�� ³2Q the influence of word representations for handwritten word spotting in historical GRFXPHQWV�´�3DWWHUQ�5HFRJQLWLRQ�DQG�$UWLILFLDO�,QWHOOLJHQFH� vol. 26, no. 5, pp. 1 263 002.1±1 263 002.25, 2012. [11] J. 3X]LFKD��6��%HORQJLH��DQG�-��0DOLN��³6KDSH�PDWFKLQJ�DQG�REMHFW recognition using shape FRQWH[WV�´�3$0,��YRO� 24, pp. 509±522, 2002. [12] K. Riesen, DQG�+��%XQNH�� ³$SSUR[LPDWH� JUDSK� HGLW� GLVWDQFH� FRPSXWDWLRQ by means of bipartite graph PDWFKLQJ�´� ,PDJH� DQG�Vision Computing, vol. 27, no. 7, pp. 950±959, 2009. [13] T. Y. Zhang, DQG�&��<�� 6XHQ�� ³$� IDVW parallel algorithm for thinning digital SDWWHUQV�´�LQ Communication of the ACM, vol. 27, pp. 236±239, 1984. [14] P. Wang, V. Eglin, C. Largeron, A. McKenna, and &�� *DUFLD�� ³$ comprehensive representation model for handwriting dedicated to word spoWWLQJ�´�LQ�Proc. of the ICDAR, pp. 450-454, 2013. >��@�-��0XQNUHV��³$OJRULWKPV�IRU�WKH�DVVLJQPHQW�DQG�WUDQVSRUWDWLRQ�SUREOHPV�´ the Society for Industrial and Applied Mathematics, vol. 5, pp. 32±38, 1957. [16] D. Fernandez, J. Lladós, and A. FornéV�� ³+DQGZULWWHQ� ZRUG� VSRWWLQJ� LQ old manuscript images using a pseudo-structural descriptor organized in a hash VWUXFWXUH�´�3DWWHUQ�5HFRJQLWLRQ�DQG�,PDJH�$QDO\VLV��YRO������� pp. 628±635, 2011. [17] F. Lebourgeois, and H. (PSWR]�� ³6NHOHWRQL]DWLRQ� E\�*UDGLHQW�5HJXODUL]DWLRQ�DQG�'LIIXVLRQ�´ In Proc. of the ICDAR, pp.1118-1122, 2007 [18] T-H. Do, S. Tabbone, and O.R. 7HUUDGHV�� ³1HZ� $SSURDFK� IRU� 6\PERO�Recognition Combining Shape Context of Interest Points with Sparse 5HSUHVHQWDWLRQ�´�In Proc. of the ICDAR, pp. 265-269, 2013. [19] D. Hani, V. Eglin, S. Bres, and N. Vincent, ³$� QHZ� DSSURDFK� IRU� FHQWHUOLQH�extraction in handwritten VWURNHV��DQ�DSSOLFDWLRQ�WR�WKH�FRQVWLWXWLRQ�RI�D�FRGHERRN�´�International Workshop on Document Analysis Systems, pp. 425-425, 2010. [20] M.M. Luqman, J-Y. Ramel, J. Lladós, and T. Brouard, ³6XEJUDSK� 6SRWWLQJ�through Explicit Graph Embedding: An Application to Content Spotting in Graphic 'RFXPHQW� ,PDJHV�´� International Conference on Document Analysis and Recognition, pp. 870-874, 2011. [21] R. Deriche, ³8VLQJ Canny's criteria to derive a recursively implemented RSWLPDO�HGJH�GHWHFWRU�´�Int. J. Computer Vision, vol. 1, pp. 167±187, 1987.