Embed Size (px)
Citation preview

RINGKASAN METODE STATISTIKA
Dewasa ini metode statistika sudah berkembang sangat luas, untuk
mengakomodasi berbagai kondisi data. Karena dalam aplikasinya hampir
tidak bisa lepas dari peranankomputer, sebagian besar metode tersebut telah
idiimplementasikan dalam berbagai paket statist ka.
Untuk memberikan gambaran umum tentang metode statistika, terutama
yang telah banyak diimplementasikan pada paket‐paket komputer, pada
akhir bab ini diberikan ringkasan metode statistika elementer yang banyak
dipergunakan di kalangan peneliti dan semuanya tersedia pada R hanya
beberapa metode tidak tersedia dalam menu RCommander (lihat Bab 1).
Berdasarkan asumsi sebaran yang dipergunakan, metode statistika dapat
bedakan menjadi dua bagdi ian utama yaitu:
1. Statistika Parametrik: yaitu analisis yang didasarkan atas asumsi bahwa
data memiliki sebaran tertentu (diskrit atau kontinu, normal atau tidak
normal) dengan parameter yang belum diketahui. Fungsi metode
statistika adalah untuk meramal parameter, melakukan uji parameter,
atau semata‐mata melakukan eksplorasi berdasarkan informasi yang ada
pada data.
2. Statistika Nonparametrik: yaitu analisis yang tidak didasarkan atas
asumsi distribusi pada data. Umumnya teknikini dipakai untuk data
dengan uuran kecil sehingga tidak cukupkuat untuk mengasumsikan
distribusi tertentu pada data.
Selain dua kelompok metode di atas, belakangan ini, dengan kemajuan pesat
di bidang komputasi, telah berkembang metode statistika berbasis simulasi.
Karena lebih banyak bergantung pada komputer, metodei ini sering disebut
sebagai CIS (Computer Intensive Statistics)

Ringkasan Metode Statistika 2/27
1 STATISTIKA PARAMETRIK
Sebagian besar metode statistika diturunkan secara analitik dan deduktif
berdasarkan asumsi fungsi kepadatan. Oleh karena itu, untuk bisa
memanfaatkan metode tersebut dengan benar, data harus mengikuti sebaran
tertentu (misalnya Binomial, Poisson, Normal, Eksponensial, Gamma dan
sejenisnya). Persoalan yang dihadapi pada umumnya adalah menduga atau
menguji partemeter yang belum diketahui dari distribusi tertentu yang
dianggap sesuai dengan kondisi data. Metode statistika yang diturunkan
seperti ini disebut metode parametrik. Namun tidak semua metode
parametrik melakukan uji parameter (uji hipotesis), beberapa diantaranya
hanya melakukan eksplorasi informasi yang melaporkan kesimpulan yang
iperoleh dari eksplorasi tersebut. d
1.1 STATISTIKA DENGAN UJI HIPOTESIS
Dalam beberapa kondisi, peneliti telah memiliki gambaran (dugaan) tentang
populasi (bisa berdasarkan kajian teori, atau hasil penelitian terkait
sebelumnya). Dalam hal ini, tujuan utama peneliti adalah membuktikan,
dengan alat statistika, apakah dugaan yang yang dimilikidapat

Ringkasan Metode Statistika 3/27
dibuktikanbenar atau sebaliknya. Ada dua kelopok besar yang dapat
dila kku an dengan uji hipotesis yaitu:
1. Uji hipotesis terkait uji rerata yaitu untuk menguji atau mengestimasi
besarnya rerata 1 kelompok, menguji beda dua kelompok atau lebih,
dengan berbagai kondisi kelompok (saling bebas atau berpasangan/
tidak saling bebas).
2. Uji hubungan baik terbatas pada besarnya derajat asosiasi (uji
korelasi) atau mencari bentuk hubungan fungsional beberapa variabel
(uji regresi). Uji regresi saat ini juga telah berkembang sangat luas
tergantung distribusi variabel respon yang dihadapi.
UJI RERATA
Dalam statistika parametrik, salah satu parameter yang banyak menarik
perhatian untuk diuji atau diramal adalah parameter rerata (mean). Untuk
data dengan 1 subpopulasi atau 2 subpopulasi (sering juga disebut
kelompok dengan satu atau dua kategori,) uji yang dipakai adalah uji Z atau
T. Sedangkan untuk subpopulasi lebih dari dua dipergunakan uji F atau lebih
ikenal dengan analisi variansi (ANAVA) d
‐1 UJI T DAN Z (KELOMPOK DENGAN SATU DUA KATEGORI)
Misalkan kita memiliki data dengan kelompok terdiriatas 1‐2 kategori atau
subpopulasi (misalnya kelompok kaya‐miskin, laki‐perempuan, eksperimen‐
kontrol). Dalam hal ini ada beberapa tujuan dan kondisi data yang
berpengaruh pada pemilihan uji statistika yang dapat dilakukan. Beberapa
kondisi yang bisa ini diantaranya:

Ringkasan Metode Statistika 4/27
1. Kita ingin menguji apakah rerata keseluruhan populasi sama dengan
angka tertentu. Dalam hal ini ada dua uji statistika yang dapat dilakukan
yaitu:
a. Uji T satu kelompok jika ukuran sampel kecil dan variansi populasi
tidak diketahui.
b. Uji Z satu kelompok jika ukuran sampel cukup besar atau variansi
populasi diketahui.
2. Kita ingin menguji apakah rerata dua kelompok (yang ada secara
alamiah, misalnya laki‐perempuan, dalam kota‐luar kota) sama atau
berbeda. Dengan kata lain apakah suatu atribut (jenis kelamin, status
sosial, tempat tinggal) berpengaruh terhadap suatu kondisi yang menjadi
per tiha an.
a. Uji T dua kelompok saling bebas jika ukuran sampel kecil dan
variansi populasi tidak diketahui.
b. Uji Z dua kelompok saling bebas jika ukuran sampel cukup besar
atau variansi populasi diketahui.
3. Kita ingin menguji apakah rerata dua kelompok (yang muncul dari
rekayasa, misalnya kelompok eksperimen‐kontrol) sama atau berbeda.
Dengan kata lain apakah suatu eksperimen memberi dampak seperti yang
diperkirakan. Dalam hal ini dua subpopulasi yang terbentuk merupakan
subpopulasi yang tidak saling bebas atau bahkan (satu kelompok dengan
dua atribut, pre & post treatment/test atau dua subpopulasi yang saling
ber s apa ang n, eksperimen‐kontrol)
a. Uji T dua kelompok berpasangan jika ukuran sampel kecil dan
variansi populasi tidak diketahui.
b. Uji Z dua kelompok berpasangan jika ukuran sampel cukup besar
atau variansi populasi diketahui.

Ringkasan Metode Statistika 5/27
UJI F/ANAVA (KELOMPOK DENG2 AN KATEGORI ATAU LEBIH)
Jika banyaknya subpopulasi lebih dari dua (tiga atau lebih), maka uji yang
dapat dilakukan adalah uji ANAVA/ANOVA (Analisis variansi/analysis of
variance). Pada umumnya uji anava dibatasi pada subpopulasi yang saling
bebas yaitu subpopulasi satu dengan lainnya bukan merupakan subpopulasi
yang sama, juga bukan merupakan subpopulasi yang berpasangan. Uji
yANAVA dibedakan menjadi dua macam aitu:
1. ANAVA satu arah (jika hanya ada satu pengelompokan yang menjadi
perhatian, misalnya status sosial: kaya, menengah,miskin)
2. ANAVA multi arah (jika hanya ada lebih dari satu pengelompokan yang
menjadi perhatian, misalnya beda rata‐rata tekanan darah penduduk
dilihat dari status sosial (kaya, menengah, miskin) dan pendidikan (dasar,
menengah, tinggi), atau yang lainnya (suku bangsa: jawa, bali dan
lainnya)
3. MANAVA/MANOVA*)1 (Multivariat Anava) yaitu ANAVA untuk respon
yang tidak saling bebas (multivariat). Data multivariat ini terjadi apabila
kelompok yang sama diamati untuk lebih dari dua atribut (misalnya
untuk mahasiswa dilihat nilai Tugas, Nilai Ujian Mid dan Nilai Ujian Akhir,
atau satu atribut di amati lebih dari dua kali (tekanan darah pasien pagi,
siang dan malam hari). Uji MANOVA kadang‐kadang disebut juga uji
profil.
1 Uji dengan tanda *) menunjukkan termasuk metode tingkat menengah atau lanjut
(advanced statistical method) yang diberikan pada tingkat S2/S3. Sedangkan uji‐uji lainnya
termasuk metode statistika dasar yangdiberikan di tingkat S1

Ringkasan Metode
Statistika 6/27
A
. UJI PROPORSI
UJI HUBUNGAN
Selain melakukan uji beda rerata beberapa kelompok, kadang‐kadang kita
ingin menguji apakah dua peubah (atribut masyarakat) saling berhubungan
atau tidak. Dalam hal ini ada dua hal yang umum dilakukan yaitu (i) hany
aingin mengetahui derajat asosiasi (apakah dua variabel berhubungan positif
atau negatif), (ii) ingin mengetahui hubungan fungsional antara dua variabel
tau lebih. a
3 UJI KORELASI
Uji korelasi hanya ingin mengetahui besarnya derajat asosiasi antara
beberapa variabel (misalnya, antara berat badan, tinggi badan, tekanan
darah dan lainnya). Koefisien korelasi yang biasa dihitung untuk data
berdistribusi Normal adalah koefisien korelasi poroduk momen Karl Pearson
dari Besarnya derajat asosiasi dinyatakan dengan bilangan r dengan kisaran
nilai . 1 1r− ≤ ≤
4 UJI REGRESI
Berbeda dengan uji korelasi, dengan uji regresi kita lebih tertarik pada
hubungan fungsional antara suatu peubah (misalnya y) dengan beberapa
peubah lainnya (misalnya 1 2, ,...x x ) yang dinyatakan dalam bentuk
e1 2( , , )y f x x + . = β

Ringkasan Metode Statistika 7/27
Variabel y disebut variabel respon (terikat) dan xi disebut variabel bebas atau
variabel penjelas. Dari bentuk umum di atas diperoleh beberapa bentuk
analisis regresi khusus yang dilihat dari jenis distribusi datanya.
A. REGRESI NORMAL (NORMAL LINEAR MODEL),
yaitu regresi dengan data respon (y) berdistribusi Normal dan saling bebas.
B. REGRESI NORMAL CAMPURAN (NORMAL MIXED MODEL)*,
yaitu regresi untuk data respon berdistribusi normal tetapi merupakan data
tidak saling bebas (bisa berasal dari pengamatan berulang, seperti tekanan
darah dalam tiga waktu berbeda)
C. REGRESI TERGENERALISIR (GENERALIZED LINEAR MODEL)*,
yaitu regresi dengan data respon yang tidak berdistribusi normal (misalnya
Binomial, Poisson, Eksponensial). Termasuk dalam jenis ini adalah analisis
probit atau logit atau regresi logistik (untuk data berdistribusi Binomial) dan
analisis log‐linier untuk data berdistribusi Poisson.
D. REGRESI CAMPURAN TERGENERALISIR (GENERALIZED LINEAR
MIXED MODEL)*,
yaitu regresi untuk data yang tidak berdistribusi normal juga tidak bebas.
Termasuk dalam analisi ini adalah GEE (Generalized Estimating Equation),
GLMM, HGLM (Hierarchical Generalized Linear Model), GRASP untuk data
bersipat spasial.
E. REGRESI DENGAN MULTIKOLINIERITAS
Selain berdasarkan distribusi sebaran, dalam penerapannya analisis regresi
juga bervariasi jika dilihat kompleksitas variabel penjelas xi, misalya apakah
diantaranya ada variabel kategorik berupa kelompok atau faktor (misalnya
jenis kelamin, etnik dan sejenisnya), demikian juga apakah diantara variabel

Ringkasan Metode Statistika 8/27
penjelas ada yang saling berkorelasi satu dengan lainnya (ada tidaknya
multikolinieritas).
F. REGRESI NONLINIER (ADITIF)
Regresi‐regresi (model) di atas dikelompokkan dalam regresi (model) linier
karena masukknya parameter ke dalam model, khususnya kaitannya dengan
peubah penjelas. Berupa hubungan linier 1
p
ij jj
x β=∑ yang selanjutnya
dihubungkan dengan berbagai fungsi link, ( )1
ij jj
g xp
μ β=
=∑ . Untuk regresi non
linier khususnya regresi aditif (GAM) bentuk hubungannya adalah
( ) ( )ij jg f xμ β=
G. REGRESI DENGAN PENGHALUSAN (SEMI PARAMETRIK)
Ada kalanya selain membentuk fungsi nonlinier dengan parameter jβ , dapat
juga dikombinasikan dengan komponen penghalus yang biasa disebut fungsi
nonparametrik. Keduanya menghasilkan regresi semiparametrik
( ) ( ) (ij jg f x s )μ β θ= + .
H. REGRESI DENGAN DIRI SENDIRI (ANALISIS DERET WAKTU/ TIME
SERIES)*.
Sering peneliti tertarik melihat tren dari suatu fenomena dari waktu ke
waktu dalam jangka waktu yang relatif lama. Misalnya harga rata‐rata barang
perbulan dalam jangka waktu 2‐3 tahun, biaya listrik ataupun tilpun
perbulan selama 2‐3 tahun. Analisis deret waktu (time series) berkembang
cukup luas dan telah menjadi bidang kajian tersendiri yang banyak
aplikasinya dalam bidang ekonomi (ekonometrik).

Ringkasan Metode Statistika 9/27
1.2 EKSPLORATIF (ANALISIS EKSPLORASI DATA)
Tidak semua analsis statistika bertujuan menguji atau meramal parameter.
Ada beberapa analisis, umumnya untuk data multi variabel, lebih bersifat
eksploratif dan hanya melaporkan hasil eksplorasi tanpa harus didahului
oleh pendugaan parameter. Namun, analisis ini di sisi lain masih didasarkan
atas asumsi bahwa respon yang diamati mengikuti sebaran normal. Beberapa
analisis multivariat (peubah ganda) yang termasuk dalam kelompok ini
diantaranya adalah analisis gerombol, analisi diskriminan, analisis komponen
utama.
5 ANALISIS KOMPONEN UTAMA
Analisis komponen utama (AKU) disebut juga PCA (Principal Components
Analysis). Jika kita berhadapan dengan data yang memiliki sangat banyak
variabel, sangat mungkin beberapa variabel yang ada saling berhubungan
satu dengan lainnya sehingga jumlah variabel yang sangat banyak tersebut
dapat direduksi menjadi beberapa komponen yang penting. Reduksi dimensi
variabel ini sangat membantu dalam representasi grafik (yang umumnya
berdimenasi 2 atau 3). Selain itu dalam analisis regresi penggunaan analisis
komponen utama ini dapat menghindarkan adanya persoalan kondisi buruk
akibat adanya matrik singuler atau mendekati singuler. Kondisi buruk akibat
adanya matrik singuler atau mendekati singuler, dapat berakibat tidak
konvergennya pendugaan parameter dalam analisis regresi, sehingga
analisis regresi menjadi tidak menghasilkan estimasi atau menghasilkan
stimasi yang sesungguhnya tidak benar. e
6 ANALISIS GEROMBOL (CLUSTER ANALYSIS)*
Jika kita menghadapi populasi dengan sangat banyak atribut (misalnya
potensi daerah suatu kabupaten yang terdiri atas banyak variabel potensi
wilayah), kitamungkin ingin mengetahui pengelompokan wilayah atas dasar

Ringkasan Metode Statistika 10/27
kedekatan potensi sehingga memudahkan pemerintah daerah membuat
kebijakanyang sesuai dengan wilayah tersebut. Analisis untuk
pengelompokkan seperti ini disebut analisis gerombol. Analisis gerombol ini
da yang bersifat hirarkis (bertingkat) ada juga yang tidak. a
LIS RI 7 ANA IS DISK MINAN
Berbeda dengan kondisi sebelumnya dimana pada dasarnya
pengelompokkan belum ada dan peneliti ingin mengelompokkan suatu
populasi menjadi beberapa kelompok yang relatif homogin. Dalam analisis
diskriminan pengelompokan telah ada (misalnya jurusan pada suatu
fakultas) dan tugas peneliti adalah merumuskan fungsi yang membedakan
(diskriminan) masing‐masing kelompok yang ada berdasarkan variabel‐
variabel yang dimiliki kelompok yang ada (misalnya dalam hal
pengelompokan jurusan dapat dilihat nilai NEM, NilaiUjian SPMB atau Nilai
IP Semester untuk bidang MIPA, Matematika, Fisika, Biologi, Kimia). Hal ini
bermanfaat untuk melakukan pengelompokan ulang yang lebih sesuai atau
engelompokkan anggota baru ke dalam salah satu kelompok yang telah ada. p

Ringkasan Metode Statistika 11/27
2 STATISTIKA NONPARAMETRIK
Statistika nonparametrik tidak didasarkan atas asumsi distribusi pada data.
Oleh karena itu analisis ini sering disebut sebagai analisis statistika bebas
distribusi (distribution free statistical anaysis). Kondisi ini biasanya
diberlakukan pada data dengan ukuran kecil dan dengan skala pengukuran
yang jauh dari skala interrval. Karena ukuran data yang kecil, ukuran
emusatan yang menjadi fokus tidak lagi rata‐rata atau rerata, tetapi median. p
2.1 UJI KELOMPOK LING BEBAS SA
Uji ini bertujuan untuk menguji adanya beda median antara dua kelompok
yang saling bebas. Uji ini ekuivalen dengan uji beda mean untuk kelompok
saling bebas pada uji parametrik dengan menggunakan uji‐Z atau uji‐T. Ada
dua uji nonparametrik (keduanya sesungguhnya ekuivalen) yang dapat
dilakukan yaitu:
1. Uji U Man‐Whitney
2. ji Wilcoxon untuk kelompok saling bebas. U

Ringkasan Metode Statistika 12/27
2.2 UJI KELOMPOK BERPASANGAN
Uji ini ekuivalen dengan uji‐Z atau uji‐T untuk sampel berpasangan pada uji
parametrik. Bedanya terletak pada kondisi sebaran data yang juga terkait
dengan sekala pengukuran data. Uji yang dapat dipergunakan adalah Uji
Wilcoxon untuk data berpasangan.
2.3 UJI LEBIH DARI DUA KELOMPOK SALING BEBAS
Uji ini ekuivalen dengan uji ANAVA pada uju parametrik. Bedanya terletak
pada kondisi sebaran data yang juga terkait dengan sekala pengukuran data.
Uji yang dapat dipergunakan adalah uji H KruskalWalis.
2.4 KORELASI RANK SPEARMAN DAN REGRESI TEGAR
(ROBUST)
Analisis ini ekuivalen dengan analsis korelasi produk momen untuk uji
parametrik. Untuk uji nonparametrik, karena datanya pad a umumnya pada
skala rank order, korelasi yang dihitung adalah korelasi rank dari Spearman.
Untuk data yang tidak bersebaran normal yang ditandai dengan adanya
beberapa pencilan analisis regresi yang dapat dipakai diantaranya adalah
egresi tegar/robust. Ada beberapa pendekatan untuk regresi tegar. r

Ringkasan Metode Statistika 13/27
3 METODE STATISTIKA BERBASIS SIMULASI
Pada dasarnya metode statistika berbasis simulasi ini diaplikasikan untuk
data dengan ukuran relatif kecil, sehingga tidak cukup informasi untuk
mengasumsikan distribusi pada data. Pada metode nonparametrik,
perhitungan dilakukan berdasar ukuran pemusatan data yang sedikit yang
umumnya merupakan sekala rank, sehingga memungkinkan dilakukan
perhitungan secara manual. Belakangan berkembang metode dengan
merekonstruksi data baru dari data yang telah ada yang dilakukan secara
berulang‐ulang, Selanjutnya interval keyakinan dari parameter yang
diestimasi dapat diperoleh dari interval persentil statistik emperik yang
dihasilkan dari perhitungan berulang‐ulang tadi.
3.1 BOOTSTRA & JACKNIFE P
Metode statistika berbasis simulasi, merekonstruksi data artifisial dalam
ukuran relatif besar dan sangat banyak sekali baik dengan cara resampling
(bootstrap), yaitu mengambil sampel yang ada secara berulang‐ulang dan
tiap pengambilan sampel merupakan sampel dengan pengembalian.
Sedangkan dengan jacknife sampling dilakukan berulang‐ulang dengan
mengeluarkan salah satu data pada sampel awal sampel.

Ringkasan Metode Statistika 14/27
3.2 MCMC (MCMC: MARKOV CHAINED MONTE CARLO)
Merekonstruksi sampel baru dengan karakteristik yang sesuai. Selanjutnya
estimasi dan uji keseluruhan dilakukan berdasarkan informasi yang
diperoleh estimasi pada masing‐masing data simulasi tadi.

Ringkasan Metode Statistika 15/27
4 PAKET STATISTIKA R
Paket statistika R dapat diakses dengan dua cara umum yaitu melalui menu
untuk metode statistika yang umum, salah satu menu (Rgui) yang populer
adalah Rcommander. Cara lain adalah dengan mrelalui skrip pemrograman
(CLI). Informasi lebih lanjut dapat dicari pada Situs R (http://www.r‐
project.org) Untuk informasi awal berbahasa Indonesia dapat dicari pada
Situ R di Unej (http://r.unej.ac.id)
4.1 STRUKTUR MENU RCOMMANDER
Panel-----|-- Data set aktif |-- Edit data set |-- Lihat data set |-- Model aktif |-- Submit (Eksekusi) Menu Data ------|--Data set Baru |--Impor data --------|--Dari Teks |--Dari SPSS |--Dari Minitab |--Data pada R -------|--Daftar data |--Data dari paket aktif Statistika-|--Ringkasan ---------|--Data set aktif |--Numerik |--Matriks korelasi |--Tabel kontingensi -|--Satu arah

Ringkasan Metode Statistika 16/27
|--Multi arah |--Analisis dua arah |--Proporsi ----------|--Sampel Tunggal |--Sampel ganda |--Variansi ----------|--Uji F beda variansi |--Uji Bartlett |--Uji Levene |--Nonparametrik -----|--Uji Wilcoxon sampel tunggal |--Uji Wilcoxon sampel ganda |--Uji Kruskal Walis |--Regresi -----------|--Regresi Sederhana |--Model Linier |--Model Linier Tergeneralisir (GLM) |--Uji Beda ----------|--Uji t sampel tunggal |--Uji t sampel ganda |--Uji t sampel berpasangan |--Uji anava satu faktor |--Uji anava multi faktor |--Analisis ---------|--Reliabilitas skala dimensional |--Analisis Komponen Utama (RKU/PCA) |--Analisis faktor |--Analisis klaster Grafik-----|--Grafik indeks |--Histogram |--Boxplot |--QQplot |--Diagram kuantil-kuantil |--Diagram pencar |--Matriks diagram Pencar |--Grafik garis |--Diagram rata-rata |--Grafik batang |--Grafik lingkaran |--Grafik 3D Distribusi-|--Distribusi Kontinu--|--Distribusi Normal |--Distribusi t |--Distribusi Chi-kwadrat |--Distribusi Seragam |-- ... |--Distribusi Gumbel -|--Distribusi Diskrit--|--Distribusi Binomial |--Distribusi Poisson |-- ... |--Distribusi Hipergeometrik

Ringkasan Metode Statistika 17/27
Alat ------|--Aktifkan paket |--Aktifkan Plug-in |--Pilihan Bantuan ---|--Bantuan Commander |--Pengantar RCommander
|--Bantuan data (jika ada) |--Tentang Rcmdr

Ringkasan Metode Statistika 18/27
5 OUTPUT RCOMMANDER
Berikut adalah beberapa contoh keluaran analisis dengan RCommander.
5.1 UJI BEDA
Berikut adalah contoh keluaran dengan hipotesis alternatif dua arah dengan
penjelasannya (nomor baris ditambahkan untuk memudahkan pembahasan)
1. One Sample t-test
2. data: ContohData$NMat
3. t = 3.7437, df = 79, p-value = 0.0003426
4. alternative hypothesis: true mean is not equal to 70 5. 95 percent confidence interval:
6. 72.34711 77.67638
7. sample estimates:
8. mean of x
9. 75.01174
Keterangan keluaran
1. Judul/nama uji, dalam hal ini uji t satu sampel (one sample test)
2. Nama data danvariabel yang diuji, dalam contoh ini datanya adalah
ContohData, variabelnya adalah Mat.

Ringkasan Metode Statistika 19/27
3. Hasil perhitungan t‐hitung yaitu 3,74, derajat kebebasan (df= degree of
freedom), yaitu 79 dan nilai p atau (p‐value), yaitu 0,00034.
4. Rumusan hipotesis alternatif, dalamcontoh ini menggunakan Ha dua arah.
5. Judul interval keyakinan yang dihitung (dalam hal ini, interval keyakinan
99%)
6. Besarnya batas bawah dan batas atas interal keyakinan, dalam hal ini
(72,35; 77,68).
7. Judul penduga sampel
X) 8. Statistiksampel yang dihitung (dalam hal ini rata‐rata sampel, mean of
. Besarnya statistik sampel yang dimaksud (rata‐rata sampel = 75,01). 9
Dengan hipotesis alternatif dua arah (rerata kedua kelompok tidak sama atau
selisih rerata kedua kelompok tidak sama dengan nol) , dan asumsi variansi
sama, diperoleh hasil berikut
1. Two Sample t-test
2. data: NMat by JKelamin
3. t = 1.1171, df = 78, p-value = 0.2674
4. alternative hypothesis: true difference in means is not equal to 0
5. 95 percent confidence interval:
-2.335705 8.308270
6. sample estimates:
mean in group L mean in group P
76.50488 73.51860
Keterangan keluaran
1. Judul analisis (Uji tdua sampel)
2. Nama data (Nmat) dan faktor pengelompokan (Jenis Kelamin)

Ringkasan Metode 20/27
3. Nilai t hitung (t = 1,1171) ,derajat kebebasan (df = 78), dan nilai –
Statistika
p (p-value = 0,2674).
4. Rumusan hipotesis alternatif (Beda rerata yang sebenarnya tidak sama
dengan nol)
5. Interval keyakinan 95% dari beda rerata kelompok Laki dan Perempuan
yaitu (‐2,34; 8,31).
6. Penduga rerata (rata‐rata masing‐masing kelompo Laki danPerempuan),
yaitu masing‐masing L:76,5 dan P:73,52
5.2 UJI KORELASI
1. Pearson's product-moment correlation
2. data: DataSim$NFis and DataSim$NMat
3. t = 12.4323, df = 78, p-value < 2.2e-16
4. alternative hypothesis: true correlation is not equal
to 0
5. 95 percent confidence interval:
0.7254628 0.8777313
6. sample estimates:
cor
7. 0.8152343
Keterangan

Ringkasan Metode Statistika 21/27
1. Judul uji yaitu Uji korelas produk momen dari Pearson
2. Nama data dan variabel yang korelasinya diuji, yaitu data “DataSim”
varianel “NFis” dan “NMat”.
3. Besarnya nilai t hitung (12,43), derajat kebebasan (78) dan nilai
peluang p (<1%, yang berarti sangat signifikan).
) 4. Rumusan hipotesis alternatif (yaitu korelasi tidak sama dengan 0
lasi populasi yaitu [0,73; 0,88]. 5. Interval keyakinan 95% dari kore
6. Korelasi sampel (cor), yaitu 0,82.

Ringkasan Metode
Statistika 22/27
5.3 UJI REGRESI
Keluaran dari program tersebut adalah seperti berikut ini. Keluaran tersebut
diberi nomor untuk memudahkan penjelasan.
1. lm(formula = NFis ~ NMat, data = DataSim)
2. Residuals:
Min 1Q Median 3Q Max
-29.4726 -2.6436 -0.5996 1.0129 34.2166
3. Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.55473 5.12003 1.671 0.0988 .
NMat 0.83811 0.06741 12.432 <2e-16 ***
---
4. Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 5. Residual standard error: 7.175 on 78 degrees of freedom
6. Multiple R-Squared: 0.6646, Adjusted R-squared: 0.6603
7. F-statistic: 154.6 on 1 and 78 DF, p-value: < 2.2e-16
Keterangan keluaran
1. Menunjukkan fungsi R yang dipanggil dengan data dan variabel terkait.
Pada contoh di atas data diambi dari DataSim dengan bentuk model
NFis=f(NMat), yaitu variabel respon NFis dan variabel penjelas NMat.
Dalam konteks ini peneliti ingin memperoleh hubungan fungsional antara
Nilai tNilaiUjian Fisika dengan Ujian Matema ika.
2. Menunjukkan sebaran (statistik ringkas) dari kesalahan (sisa), yaitu
penyimpangan antara dugaan garis regresi dengan data.
3. Menunjukkan hasil pendugaan koefisien dan uji signifikansinya. Pada
contoh di atas diperoleh

Ringkasan Metode Statistika 23/27
a. Intercept (titk potong/konstanta) a=8,55 dengan nilai p = 0,099.
Angka ini menunjukkan bahwa konstanta regresi tidak signifikan.
Walaupun nilainya cukup besar (8,55) tetapi secara statistik dapat
dianggap 0. Dengan kata lain model yang lebih tepat adalah model
Y=bX. Ini juga menunjukkan bahwa pada saat tingkat nilai X=0,
maka Y juga cenderung 0. Namun kusus untuk uji konstanta
(intercept), nilai 9% dapat dianggap sebagai nilai marjinal
(dekatdengan 5%),oleh karena itu konstanta cenderung dibiarkan
pada model.
b. Koefisien regresi untuk variabel NMat, b,besarnya 0,83 dengan
nilai p <2e-16. Ini menunjukkan bahwa koefisien ini sangat
signifikan (walaupun secara matematis nominalnya jauh lebih
kecil dibanding konstanta).
4. Menunjukkan tingkat signifikansi yang diperoleh (0%, 0,1%, 1%, 5%,
10% dan 100%)
5. Menunjukan kesalahan baku dan derajat kebebasan (besarnya n‐2) dari
sisa.
6. Menunjukkan koefisien determinasi dan koefisien determinasi yang telah
disesuaikan. Koefisien determinasi yang baik adalah yang mendekati 1.
Semakin mendekati 1, semakin baik. Koefisien determinasi yang rendah
menunjukkan banyak data yang pemyebar jauh dari garis regresi.
Besarnya koefisien determinasi berbanding terbalik dengan besarnya
kesalahan baku sisa. Jika kesalahan baku besar, koefisien determinasi
cenderung kecil (Lihat contoh keluaran berikutnya).
7. Menunjukkan uji signifikansi secara keseluruhan yang menggunakan uji F
pada derajat kebebasan (1 dan n‐2). Pada contoh ini hasilnya signifikan.
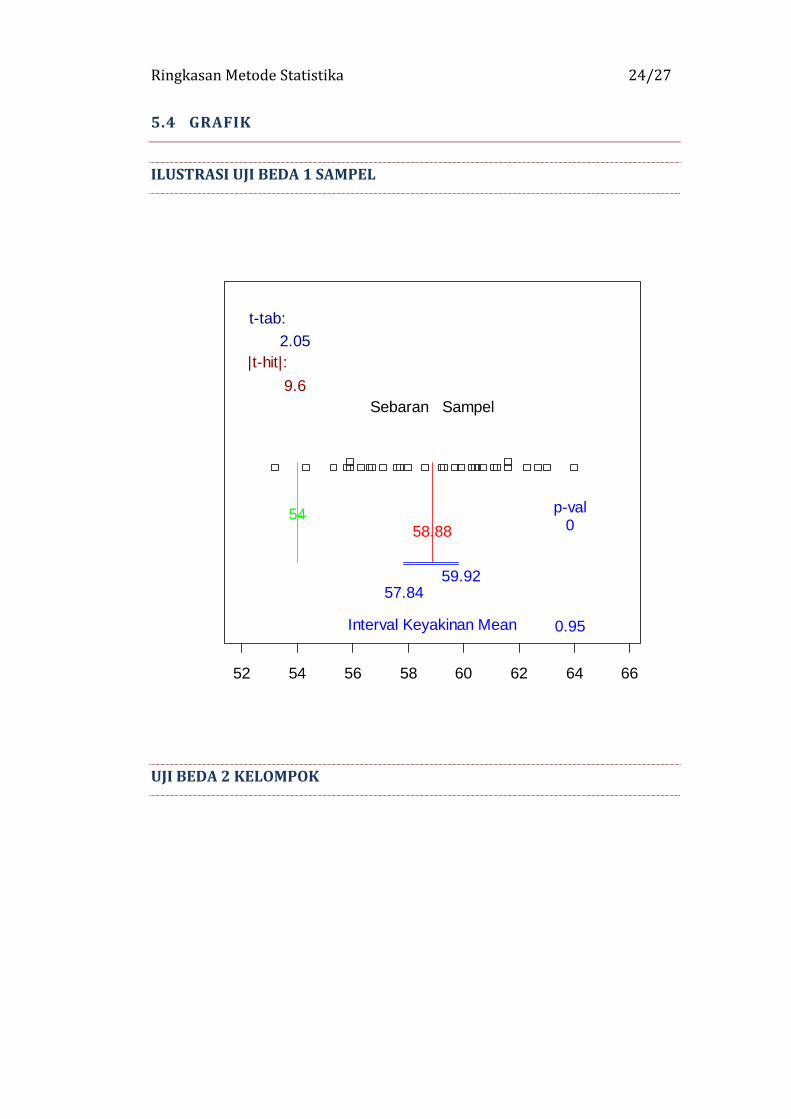
Ringkasan Metode Statistika 24/27
5.4 GRAFIK
ILUSTRASI UJI BEDA 1 SAMPEL
52 54 56 58 60 62 64 66
Sebaran Sampel
5458.88
0.95
57.8459.92
Interval Keyakinan Mean
t-tab:2.05
0p-val
|t-hit|:9.6
UJI BEDA 2 KELOMPOK

Ringkasan Metode Statistika 25/27
40 50 60 70 80
49.0764.15
t-tab:2.0017
0p-val
Sebaran Sampel
Rata-rata Sampel
IK Beda Mean(M-B)0.95
-12.46-17.7
|t-hit|:11.5291
DIAGRAM PENCAR DENGAN VARIABEL KELOMPOK

Ringkasan Metode Statistika 26/27
50 60 70 80 90
5060
7080
90
NMat
NFi
s
JKelaminLP
MATRIKS DIAGRAM PENCAR DENGAN VARIABEL KELOMPOK

Ringkasan Metode Statistika 27/27
| | || | || ||| | | || ||| | || || || |||| || || || || || || | || ||| ||| ||| ||| || | ||
y1100 150 200 250 30 40 50 60 70
120
160
200
100
150
200
250
| | || ||| ||| || || ||| | || || || |||| |||||| || || || | || || ||||||| ||| || | ||
y2
||| || | ||| |||| | | | ||| || || |||| || || ||| ||| || |||| || ||| | | || || ||| | ||
y3
-20
-10
010
120 160 200
3040
5060
70
-20 -10 0 10
| | || | || ||| | | || ||| | || || || | ||| || || || || || || | || || ||||||| ||| || | ||
x1LP





























