Embed Size (px)
Citation preview

0Research Methodology Seminar; 19 Apr. 2007
Sample size and samplingfor quantitative research
SNU DHPM; Research Methodology Seminar
19 Apr. 2007
CiEHR; Mi-Sook Kwak
A. Bowling; Research Methods in Health(2002): pp.116-192

1Research Methodology Seminar; 19 Apr. 2007
Contents
Calculation of sample size, statistical significance and samplingThe sampling unitCalculation of sample size and statistical powerTesting hypotheses, statistical significance, the null hypothesisTypeⅠ and TypeⅡ errorsOne- or two-sided hypothesis testingStatistical, social and clinical significanceSampling framesSamplingConfidence intervals and the normal distributionExternal validity of the sample results
Methods of samplingRandom samplingNon-random sampling: quota samplingSampling for qualitative researchSampling for telephone interviews

2Research Methodology Seminar; 19 Apr. 2007
Calculation of sample size,statistical significance and sampling

3Research Methodology Seminar; 19 Apr. 2007
Contents
Calculation of sample size, statistical significance and sampling
The sampling unit
Calculation of sample size and statistical power
Testing hypotheses, statistical significance, the null hypothesis
TypeⅠ and TypeⅡ errors
One- or two-sided hypothesis testing
Statistical, social and clinical significance
Sampling frames
Sampling
Confidence intervals and the normal distribution
External validity of the sample results

4Research Methodology Seminar; 19 Apr. 2007
The sampling unit
표본추출 단위
표본집단의구성단위
– e.g., 개인, 조직, 지역등…
표본추출단위설정
– 표본추출절차의가장기본적인절차
– 표본추출단위를명확하게설정: 연구목적고려• e.g., 표본추출 단위: 가구? 가계 구성원(개인)?, 둘 다?
다수준 분석(Multi-level analysis)을 위한 표본추출 단위분석에필요한여러개의표본단위를모두포함
– e.g., 병원특성연구: 병원, 의원, 의사, 환자등…
각수준에서표본수를계산하여야함.– e.g., 의원, 의사, 환자의표본추출수계산
생태학적 오류(Ecological fallacy)발생가능성– 집단적수준의관련성으로부터개인적수준의관련성을유추하는오류
– 분석시변수의상호관계가불명확한경우다른수준의분석의외삽(extrapolation) 발생
• e.g., : 의원 VS. 환자:

5Research Methodology Seminar; 19 Apr. 2007
Calculation of sample size and statistical power
표본 수를 결정하는 통계학적 접근법
검정값(Power)을통해계산
– 대립가설(H1)이참일때, 귀무가설(H0)를기각시키고대립가설을채택하는확률
유의수준(α)
– 귀무가설(H0) 이참인데도불구하고대립가설(H1)을잘못선택할확률의최대값
통계적 검정력(Statistical power)
– 두집단간차이가있음을검정하는힘
– α=0.05(0.1, 0.01, 0.001), р>0.8
– р값과 α를 서로 비교• р > α : 귀무가설 H0를 채택, р <= α 대립가설 H1을 채택
통계적 검정력을 통한 표본크기 결정 시 고려할 점
하위집단(Subgroup) 분석시
– 필요한표본크기보다큰표본을선택: 표본감소및무응답고려
– 너무작은표본크기: 통계적검정력이제한적, 하위집단분석바람직하지않음.
연구마다다른계산법사용, 신중하게결정

6Research Methodology Seminar; 19 Apr. 2007
Testing hypotheses,statistical significance, the null hypothesis
귀무가설(Null hypothesis): H0특정 변수와 관련이 없음.
가설검정(Testing hypotheses)
귀무가설이 ‘참’임을 가정
우연에 의한 발생확률도 포함하여 검증
통계적 유의성(Statistical Significance)
확률론(Probability Theory)– 관찰된결과가우연에의한것인지아닌지를규명
– 통계적유의수준(α) : 0.05, 0.01, 0.001• e.g., р< 0.05
– 차이가 5% 수준에서유의하다
– 차이가없다. 귀무가설채택, 대립가설기각
• e.g., р= 0.001
– 귀무가설기각, 대립가설채택

7Research Methodology Seminar; 19 Apr. 2007
TypeⅠ and TypeⅡ errors
제 1종 오류(TypeⅠ Errors)귀무가설이 ‘참’인데기각하는경우
α오류
제 2종 오류(TypeⅡ Errors)귀무가설이 ‘거짓’인데수용하는경우
ß 오류
αand ß 오류 간의 관계역관계: α오류의 위험이 작을 수록 ß오류의발생위험이증가
ß(제 2종오류)1- α수용(Accept )
1- ßα(제 1종오류)기각(Reject)
거짓참
귀무가설(Ho)
검정통계량분포
기각역
채택역
기각치
검정통계량분포
기각역
채택역
검정통계량분포
기각역
채택역
기각역
채택역
기각치
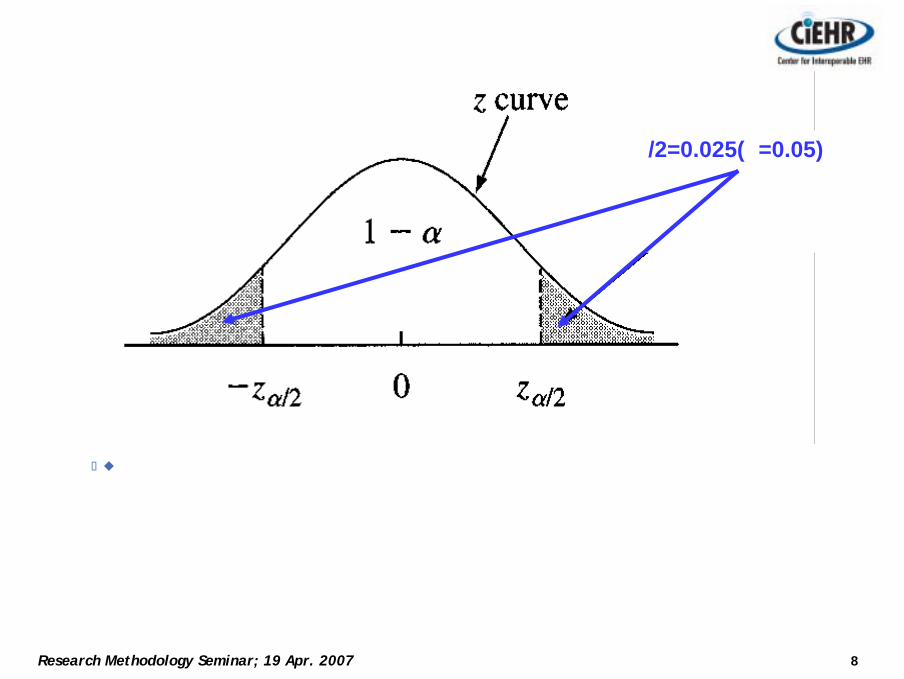
8Research Methodology Seminar; 19 Apr. 2007
α/2=0.025(α=0.05)
제 1종 오류를 더 중요시
제 1종오류의 α를 고정: α= 0.10, 0.05, 0.01, 0.001
귀무가설을기각하지않으려면, 유의수준 0.10을고려해서제 2종오류의발생을줄임(역관계).
α(제 1종오류) = 0.05, ß (제 2종오류) = 0.20
1-α=0.95
ß /2=0.10(ß=0.20)
1-ß=0.80

9Research Methodology Seminar; 19 Apr. 2007
표본의크기와제 1종, 제 2종 오류
큰표본 수: 통계적으로 유의한 결과 도출, ‘제 1종 오류의 가능성이항상 존재’
작은 표본 수: 유의한 차이의 구분 실패할 확률 높음.
표본 수는 관심 있는 집단을 대표할 수 있을 정도: 연구결과의일반화 적용
유의성 검사 반복(Multiple significance testing)과 제 1종 오류
가설검정을 여러 번 하게 되면 차이가 있을 가능성이 증가
제 1종 오류의 가능성이 증가: α 값이 증가
유의성 검사(significance tests)의적절한사용
가설및 단점/종점(endpoint)의 결정
– 유의성검정해석과제 1종오류를감소
– α 값 보다는, 실제 р값과 자료의 실제 차이의 크기와 신뢰구간을표현요구
통계적 검정은 전통적인 실험연구에 적절

10Research Methodology Seminar; 19 Apr. 2007
One- or two-sided hypothesis testing
표본 수를 결정하기 위해 단측 or 양측 검정 결정
양측 검정에서 유의하면, 단측 검정에서도 유의
e.g.,
– 단측: 새로운치료법이예전치료법보다효과가있다.
– 양측: 새로운치료법이예전치료법과차이가있다(효과가더좋거나혹은나쁘거나).
단측 검정의
유의확률%6≈ %3≈
양측검정 단측검정

11Research Methodology Seminar; 19 Apr. 2007
Statistical, social and clinical significance
임상적유의성판단기준
2개 치료법의 효과 판단: 부작용(side effect), 장기 합병증, 다른비용 등
최소한의 임상적으로 유의한 차이(smallest clinically important difference): 20%
통계적유의성 ≠ 임상적 유의성
큰표본 수는 그룹 간 차이를 발견할 가능성이 큼.
– 수천명표본: 집단간작은차이 5% 유의수준에서유의할수있음.
– 표본수가 20명: 집단간관찰된큰차이는 5% 유의수준에서유의하지않을수있음.
(사회/)임상적 관련성은 р값보다 관찰된 실제 표본크기, 신뢰구간이더 중요함.

12Research Methodology Seminar; 19 Apr. 2007
Sampling frames
표본추출목록/틀/프레임
표본추출을 할 수 있는 집단 구성원의 목록
표적 집단은 모든 요소들을 완벽하게 갖추어야 함: 외적타당도(External validity)
– e.g., 우편주소: 거주지변경시표본추출재작업(표본수영향없도록)
– e.g., 선거인명부: 등록을하지않은사람은부재, 불완전
– e.g., 병원자료: 다른자료와비교하여이용할수있는목록을점검해야함.
우편번호 주소록
– 영국통계청: 1984년이전선거인명부, 1984년 이후우편번호주소록이용
환자목록
– 영국: NHS 자료와 선거인명부
• 주소변경, 사망인문제: 98% 국민이 NHS 의사에등록
• 질병, 입원환자대상연구: 주소지의업데이트, 모집단대표성의문제
– e.g., 병원입원/퇴원환자의경우는업데이트시간

13Research Methodology Seminar; 19 Apr. 2007
Sampling
표본 추출
집단의구성원이너무많을경우실시
장점
– 시간과돈을절약
– 더좋은자료취득가능
모든 표본추출의 결과는 표본오차에영향, 집단의성격에대한설명도필요
확률에의한우연에의한방법을시행
– e.g., 동전던지기
– But, 작은표본에서의확률화는전체모집단을대표하지못함.
표본 오차(sampling error)모집단의일부인표본을사용하여모집단의특성치를추정하기때문에발생하는필연적인오차
– 표본값이참값(모집단)과의차이를보여줌.
– 전체집단을부정확하게반영하는표본집단의발생
완전히 제거할 수는 없지만, 수용할수있을정도로줄여야함.
표본오차는제 1종오류와제 2종오류를범할가능성이항상있음을의미

14Research Methodology Seminar; 19 Apr. 2007
Confidence intervalsand the normal distribution
정규분포(The normal distribution)
대부분의변수들이정규분포
– e.g., 몸무게, IQ
충분히큰표본인경우대부분정규분포
– e.g., 예외: 월급
If 정규분포집단에서표본추출
– 표본오차발생
– 큰표본을추출: 표본집단은전체집단을반영하고정규분포의가능성이증가
정규분포 곡선
평균과표준편차로표현
표준정규분포
– 평균: 0, 표준편차: 1

15Research Methodology Seminar; 19 Apr. 2007
표본평균분포(Sampling distribution of the means)
표본분포
– 모집단에서확률적으로동일한크기의여러개의표본추출
– 통계량으로추정될수있는모든가능한값들의분포
표본평균본포: 표본들의 평균의 분포
중심극한정리(Central limit theorem)– 정규분포하지않는모집단에서표본추출이라하더라도,
– 표본의크기가크면, 정규분포를하는모집단에서표본을뽑은것과동일하게정규분포
– 표본의크기: 30개적절(일반적)
표본 평균 = 모집단의 평균
표본 표준 편차(=표준오차) ≠(<) 모집단의 편차– 큰표본은표준편차가작음.
– 모집단의변이가크면표본의평균분포변이도큼.
– 표준오차(standard error):
16Research Methodology Seminar; 19 Apr. 2007
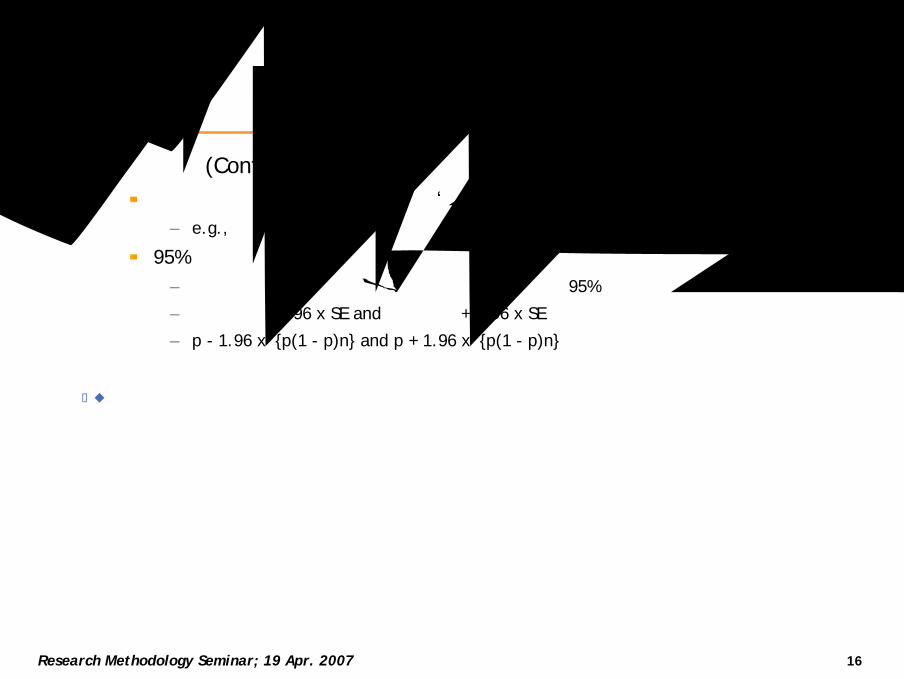
신뢰구간(Confidence intervals)관심있는변수의모집단에서의 ‘참’값을구하기위해, 표본으로부터추정
– e.g., 모집단의평균값추정
95% 신뢰구간– 모집단의평균이신뢰구간사이에있다는추정을 95% 신뢰할수있다는의미
– 표본평균 - 1.96 x SE and 표본평균 + 1.96 x SE
– p - 1.96 x√{p(1 - p)n} and p + 1.96 x√{p(1 - p)n}
오차의 분포(Distribution of errors)표본평균 = 모집단의평균 but, 정확하게일치 X
계통오차(Systematic error)– 표본추출이제대로되지않아편향된표본인경우
확률 오차/우연오차(Random error)– 표본추출시영향을주는우연한요인때문
– 비정상적으로대표적이지않은표본을추출한경우
– (이론상으로) 정규분포, 평균 = 0

17Research Methodology Seminar; 19 Apr. 2007
External validity of the sample results
외적 타당도(External validity)연구의결과를전체대상으로일반화하는것과관련
연구대상선정과정
내적 타당도(Internal validity)측정도구상의문제: 연구결과의차이가측정도구에얼마나기인한것인가?
– 평가: 삐툴림, 교란, 통계학적변이고려
연구자료의 수집 및 분석 과정
표본 추출 시 고려사항
표본추출단위?표적집단(target population)?표적집단의정보를얻는데어려운점?윤리위원회의승인이필요?표적집단의정보를얻는데누구의허락이필요?어떤표본?
– e.g., 실험연구에서, 실험군(experimental group), 대조군(control group)이필요한가?
표본의크기?

18Research Methodology Seminar; 19 Apr. 2007
Methods of sampling

19Research Methodology Seminar; 19 Apr. 2007
Contents
Methods of sampling
Random sampling
Non-random sampling: quota sampling
Sampling for qualitative research
Sampling for telephone interviews
20Research Methodology Seminar; 19 Apr. 2007
Random sampling
표본추출이론은확률표본추출(무작위추출)을 가정
표본단위는 추출의 동일한 가능성을 가짐.
표본 집단의 대표성을 보장
표본추출의 방법
– 무제한무작위추출(Unrestricted random sampling)
– 단순무작위추출(Simple random sampling)
– 등간추출/계통적무작위추출(Systematic ramdom sampling)
– 층화추출/계층적무작위추출(Stratified random sampling)
– 군집 표본추출(Cluster sampling)
– 다단표본추출(Multistage sampling)
– 확률비례추출법(Sampling with probability proportional to size(PPS))
21Research Methodology Seminar; 19 Apr. 2007
무제한무작위추출(Unrestricted random sampling)
난수표를 이용한 확률추출
선택된 표본은 다시 채워 넣음.
– 표본단위는한번이상선택가능
– 각각집단의구성원은동일한선택의기회
단순무작위추출(Simple random sampling)
난수표를 이용한 확률추출
선택된 표본이 다시 채워지지 않고 표본추출
– 각표본단위는한번만선택

22Research Methodology Seminar; 19 Apr. 2007
등간 추출/계통적 무작위추출(Systematic ramdom sampling)목록에서추출하는방식: 일련번호로명단이되어있을때단순무작위추출과반대개념
표본추출의시작점을결정해주면나머지추출된표본들은자동적으로결정
일정한간격을이용해서조사단위(대상)을추출– e.g., 1000 인구를 10명으로등간하여 100명추출
But, 경향성자료: 심각하게편향된결과도출가능성
층화 추출/계층적 무작위 추출(Stratified random sampling)연구내용에가장영향을크게미친다고예상되는변수를선정
몇개의계층으로분류하고각계층별로독립적으로무작위추출하는방법
– e.g., 의사, 간호사, 물리치료사, 환자로층화하여단순무작위추출 or 계통적무작위추출
모집단의 특성 반영
– 층내의동질성(internal homogeneity)– 층간의이질성(external heterogeneity)
방법– 비례층화추출(Proportional stratified sampling): 각층의전체집단을일정비율추출
– 非비례층화추출(Disproportional stratified sampling): 층간똑같은수를추출
23Research Methodology Seminar; 19 Apr. 2007
군집표본추출(Cluster sampling)
모집단을 많은 수의 군집으로 분리하여 하나의 집단을 뽑아추출하는 방법
장점: 추출 용이, 비용과 시간이 적게 듬.
– e.g.,넓은인터뷰비용이많이드는도시에서 200000명 -> 200명표본추출: 하나의지역을무작위추출로선택하고, 표본추출
단점: 추출명단이 없을 때 용이 but, 표본오차가 높음.
다단표본추출(Multistage sampling)
군집 표본추출은 다단 표본추출, 경제적
– e.g., 00시 -> 선거구추출 -> 가계추출
확률비례추출법(Sampling with probability proportional to size(PPS))
다단 표본추출에서 일반적인데, 크기가 다른 표본단위를 가짐.
크기가 다른 표본단위에서 무작위추출
– 큰표본: 많이추출, 작은표본: 작게추출
– 개인선택의가능성은동일

24Research Methodology Seminar; 19 Apr. 2007
Non-random sampling: quota sampling
모집단의특성고려하여비확률표본추출
e.g., 시장연구가
– 지역등범주를무작위선정
– 인터뷰할남성, 여성의사례수배정
– 인터뷰대상자선택: 면접자
– 각각의그룹에할당된사례수를채워나감.
장점: 층화의 효과
단점: 조사자의 편견 개입 가능성, 표본 오차 클 수 있음.

25Research Methodology Seminar; 19 Apr. 2007
Sampling for qualitative research
임의표본추출(Convenience sampling)
연구자가 임의로 선정한 표본
특정한 기준 없음.
복잡한 주제의 연구를 위한 추출방법
– e.g., 경제성평가, 건강상태평가
유의 표본추출(Purposive sampling)
조사자가 일정한 목표/기준을 갖고 조사자의 의지대로 표본을추출하는 방법
주관적 판단 중시
– e.g., 병원의중견관리자의의견
실험연구 설계에도 종종 이용
– e.g., 유방암환자들에대한새로운임상치료의효과성연구: 일반집단확대적용 X
26Research Methodology Seminar; 19 Apr. 2007
누적 표본추출/눈덩이 표본추출(Snowballing)
최초에무선적으로추출된표본의추천에의해추가로추출된표본
표본추출의틀(Sampling frame)이없음.
방법: 어떤개인과접촉이시작되고그사람과관련이있는사람이연구에참여할수있는지물어보고참여시킴.
단점: 특정네트워크구성원들만포함
이론적 표본추출(Theoretical sampling)
필요한자료를제공할수있는사물이나사람이면무엇이든지표본
목적: 이전의면접결과로얻어진가설을개발하고발전시키기위함.
방법
– 몇개의유사한인터뷰시행, 특별한현상에대해깊게면접
– 가정을개발하기위해다른시도를하는예외를인정
– 표본추출은더이상새로운분석의관점이없는경우중단
표본추출 과정 중 데이터의 코딩과 분석을함께진행

27Research Methodology Seminar; 19 Apr. 2007
Sampling for telephone interviews
표본틀: 전화번호부
전화소유율이높더라도, 전화번호부에목록이 없는 사람이있을수있음.
병원자료 이용 보완(e.g., 영국 NHS)
무작위번호걸기(Random digit dialling: RDD)
지역 번호, 국번(multi stage)을 먼저 임의로 선택한 후 나머지 4 자리의 전화 번호를 임의로 (systematic) 전화를 검.
전화번호부에 목록이 없는 사람들도 대상으로 할 수 있음.
전체 인구집단 or 시장연구 조사에 적합
전화 실패 or 무응답이 많이 때문에 원하는 수 이상의 전화번호가필요
면접자가 접촉 했을 때 접촉을 원하는 가구원만을 대상
단점: 고 비용, 시간소비적– e.g., 65세이상의 80명 면접: 500시간, 55세이상대상자면접: 젊은사람의 2배이상시간소요






























