Embed Size (px)
Citation preview

UNIVERSIADE FEDERAL DE SANTA CATARINA
SCRG – Sistema de Coleta de Recursos em Grids Utilizando o Globus Toolkit 4
Florianópolis, 26 de fevereiro de 2007

UNIVERSIDADE FEDERAL DE SANTA CATARINADEPARTAMENTO DE INFORMÁTICA E
ESTATÍSTICACURSO DE SISTEMAS DE INFORMAÇÃO
SCRG – Sistema de Coleta de Recursos em Grids Utilizando o Globus Toolkit 4
Guilherme Zanetta Simoni
Trabalho de conclusão de curso apresentado como parte dos requisitos para obtenção do grau de Bacharel em Sistemas de Informação.
Florianópolis – SC2006/2

Guilherme Zanetta Simoni
SCRG – Sistema de Coleta de Recursos em Grids Utilizando o Globus Toolkit 4
Trabalho de conclusão de curso apresentado como parte dos requisitos para obtenção do grau de Bacharel em Sistemas de Informação.
Orientador: Frank Auguto Siqueira
Banca Examinadora:
Mário Antônio Ribeiro Dantas
Luís Fernando Friedrich

SUMÁRIO
1.Introdução 72.Ambientação 92.1Sistemas Distribuídos 92.2Grids Computacionais 92.3 Globus Toolkit 112.3.1 Gerenciamento de Arquivos 132.3.1.1 Protocolo GridFTP 152.3.1.2 Serviço de Transferência Confiável 162.3.1.3 Replicação dos Dados 172.3.1.4 Replicação de Alto Nível 172.3.2 Segurança 182.3.3 Escalonamento de Processos 202.4 Web Services 222.4.1 Vantagens e Desvantagens 232.4.2 SOAP 242.4.3 eXtensible Markup Language 252.4.4 Web Services Description Language 262.4.5 Universal Description, Discovery and Integration 283. Monitoramento 303.1 SNMP 313.1.1 Visão Geral 313.1.2 Comunidades 313.1.3 Problemas com SNMP 333.2 MDS/WebMDS. 334. Desenvolvimento 354.1 Ferramentas 354.1.1 Eclipse IDE 354.1.2 Apache Web Server 364.1.3 PHP 364.1.4 GDTE (Globus Development Tools for Eclipse) 374.1.5 RRDTool 374.1.6 Java Standard Edition 384.2 Modelo de Desenvolvimento 394.3 SCRG (Sistema Coletor de Recursos em Grid) 394.3.1 Pré-Requisitos 394.3.2 Funcionamento 404.3.2.1 Arquivos de Configuração 404.3.2.2 Sistema de Arquivos /proc 414.3.2.3 Kolector 424.3.2.4 KolectorClient 444.3.2.5 PHP-Kolector 444.3.2.6 Apresentação 464.3.3 Processo de Instalação 46

4.3.4 Testes 474.3.5 Dificuldades Encontradas 485. Conclusão 496. Referências Bibliográficas 517. Apêndice 53

LISTA DE FIGURAS
1.Demonstração da utilização de um grid 10
2.Visão Geral da Arquitetura Interna do Globus 12
3.Integração entre o GT4, OSGA e WSRF 13
4.Integração do GT4, OSGA, WSRF numa visão em camadas 13
5.Exemplo de utilizaçao do RLS 17
6.Visão Geral do GSI e seus diferentemente métodos de proteção
19
7.Componentes do WS-GRAM 21
8.Diagrama de estados de um job durante sua existência 21
9.Interação e comunicação entre os elementos de uma aplicação WebService
23
10.Exemplo de mensagem SOAP 25
11.Exemplo de arquivo XML 26
12.Demonstração da utilizaçao do SNMP versão 3 com MIB-II 31
13.Ambiente de desenvolvimento utilizando Eclipse 36
14.Demonstração de código escrito em PHP 37
15.Exemplo de gráfico gerado pelo RRDTool 38
16.Demonstração do conteúdo do arquivo de configuração ips.conf
41
17.Diagrama de Fluxo de Dados do Kolector 43
18.Método principal do KolectorClient 44
19.Utilização de CPU 45
20.Demonstração do HTML gerado 46
21.Inicialização e encerramento do Globus 48

1.INTRODUÇÃO
Com o passar dos anos, a partir da década de noventa, através do
amadurecimento de técnicas de modelagem, de programação e de
melhorias de processo, os softwares foram ficando cada vez mais robustos.
Com o crescente avanço da automatização nos modelos de processos de
negócios e a complexidade dos sistemas atuais, se torna necessário cada
vez mais poder computacional e maior confiabilidade das máquinas. A
solução encontrada foi distribuir o processamento destes softwares em
diferentes máquinas, mas mantendo esta arquitetura transparente para o
usuário final. Através desse método pode-se tanto gerar uma alta
disponiblidade dos serviços prestados, pois o problema do ponto único de
falha é resolvido, como utilizar-se do poder de processamento ocioso
disponível em outras máquinas.
Neste contexto se encaixam os Grids Computacionais, que são a mais
nova tecnologia de distribuir serviços pela internet, encapsulando o método
de como isso é feito. Grids são formados por máquinas que trocam
informações entre si para processar algoritmos mais eficientemente e
rapidamente sem que exista a necessidade de estarem na mesma rede.
No entanto para um bom planejamento, gerenciamento e
escalonamento de recursos físicos, torna-se necessário o monitoramento dos
recursos disponíveis nos Grids.
Seguindo este raciocínio, desde o início tornou-se motivador codificar
tais aplicações. O objetivo deste trabalho consiste em desenvolver um
aplicação que exerça a função de avaliar a disponibilidade dos recursos
computacionais das máquinas do grid e disponibilizar estas informações em
um servidor central para as mesmas possam ser analizadas e avaliadas
pelo(s) gerente(s) do grid. Para este projeto tenha sucesso será necessário
realizar estudos da plataforma de grid e observar como este se comporta em
ambientes simulados. Um estudo mais aprofundado sobre comunicação com
WebServices e GridServices também será necessário.

Atualmente existem vários projetos de grids sendo desenvolvidos ao
redor do mundo, como o Globus [1], GridBus [2], InteGrade [3] e o OurGrid
[4]. O mais maduro e amplamente utilizado destes projetos é o Globus [1]
que está ativo desde 1997. Desde de suas primeiras versões o Globus já
possui um sistema de monitoramento que é capaz de realizar as funções
necessárias e informar o usuário de suas análises.
Embora o Globus [1] já possua um sistema para monitoramento, o
software que exerce a função de colher informações das máquinas do Grid e
exibi-las para o usuário administrador, requer a instalação de outros
softwares adicionais que consomem muitos recursos da máquina e geram
uma árvore de dependências entre aplicativos e bibliotecas que torna a sua
instalação extremamente dificultada. A solução apresentada neste trabalho
não irá requerer uma infra-estrutura complexa de instalar, manter e que
consuma muitos recursos das máquinas servidoras.
Este trabalho se dividirá nas seguintes etapas: no capítulo dois, será
apresentada uma ambientação e um estudo sobre sistemas distribuídos e o
sistema de grid que será utilizado neste trabalho. No capítulo seguinte será
apresentada uma análise sobre funcionalidades e características de
monitoramento e algumas arquiteturas como o SNMP e o WebMDS. No
capítulo quatro será apresentada a proposta do trabalho em si, como
funcionará e porque ela se tornará muito fácil de se instalar e operar. Nos
capítulos 4 e 5, serão apresentados, respectivamente, o desenvolvimento e a
conclusão do trabalho.

2.AMBIENTAÇÃO
2.1 Sistemas Distribuídos
Segundo George Coulouris [5], um sistema distribuído é aquele no
qual componentes localizados em diferentes redes se comunicam e
cordenam suas ações através da troca de mensagens.
Através deste conceito, podemos imaginar o poder que isto trás à
computação. Com este tipo de paradigma, podemos desenvolver sistemas
muito mais eficientes e que podem processar muito mais informação do que
se alocássemos todo o processamento em uma única máquina.
Com o avanço das redes de computadores, este tipo de sistema
evoluiu e mecanismos foram desenvolvidos para resolver alguns problemas
enfrentados pelos programadores, tais como: controle de concorrência,
falhas independentes e sincronização de mensagens e horários.
Um dos novos paradigmas de sistemas distribuídos que está
crescendo aos olhos dos pesquisadores são os Grids Computacionais. Isto
está acontecendo porque eles proporcionam um aumento da produtividade
de aplicações graças ao seu poder de serem altamente escaláveis.
2.2 Grids Computacionais
A maioria das grandes e médias empresas possui em seu parque
tecnológico vários computadores entre servidores e desktops. Na maioria
dos casos os sistemas operacionais destes computadores são heterogêneos,
passando desde máquinas Windows, Linux, variantes de Unix (HP-UX, AIX,
Solaris) até sistemas operacionais para mainframes.
Como essas máquinas geralmente são dedicadas a um único fim,
como os servidores que são responsáveis por email, web, impressão, e os
desktops que são utilizados na sua maioria por usuários que não exploram
toda a capacidade de processamento, elas possuem processamento

potencial sem ser utilizado. A utilização em médias de servidores fica entre
5% a 10%, chegando em média a 40% de sua capacidade em horário de
pico. A situação dos desktops ainda é mais impressionante porque
geralmente das 168 horas que uma semana possui, em apenas 40 horas em
média uma máquina desktop fica em utilização. Além disto, sua utilização é
bem abaixo do processamento máximo que o hardware proporciona. Na
média o consumo do processador é muito baixo, ficando em torno de apenas
3% a 5% do total. Tendo isto em vista, se torna claro que há um imenso
poder computacional ocioso dentro das organizações.
De acordo com Cezar Taurion Chefe [6], Grids Computacionais
tratam-se de um conjunto de softwares de middleware que gerenciam
recursos distribuídos e espalhados pela organização, disponibilizando como
recursos os servidores e eventualmente os desktops da empresa.
A figura 1 demonstra a utilização de um grid de computadores, para
que uma tarefa seja executada.
Figura 1: Demonstração da utilização de um grid. Fonte: http://www.redbooks.ibm.com
Os Grids Computacionais servem para que as organizações possam

compartilhar suas aplicações em milhares de computadores pelo planeta
todo, não interessando em quais redes estejam.
A grande vantagem dos Grids é poder executar uma aplicação
remotamente, agregando poder de processamento, sem que o usuário final
da aplicação tenha conhecimento disto. Esta característica só se torna
possível graças aos suportes de middleware existentes, pois são eles que
exercem toda a função de escalonamento de processos, concorrência, e
entrega dos resultados a uma interface.
Como mencionado anteriormente, um dos projetos de middleware
para grid mais maduros atualmente é o Globus Project [1], e por este motivo
este trabalho será realizado sobre esta plataforma.
2.3 Globus Toolkit
O Globus Tookit é um pacote Open Source para montar arquiteturas
Grid. Os usuários das VO's (Virtual Organizations – entidades que se utilizam
o Grid), podem ser universidades, empresas privadas, entidades
governamentais, entre outras, podem compartilhar processamento, banco de
dados e outras funcionalidades pela internet sem necessariamente perder a
autonomia de sua própria organização.
O GT4 (Globus Toolkit version 4) é formado por uma série de pacotes
e cada um deles provê um tipo de serviço, tais como compartilhamento de
processos, monitoramento, segurança, entre outros. Estes pacotes são
demonstrados na figura 2:
Esses módulos interagem entre si para funcionar como um todo. Para
que isto fosse possível, foi preciso estabelecer um padrão de interface.
O OGSA (Open Source Grid Services Architecture) visa definir
aplicações para grids com um padrão de comunicação comum.
Atualmente o OGSA já definiu um padrão para praticamente todas as
aplicações que são geralmente encontradas em grids como gerenciamento
de recursos, segurança de serviços, gerenciamento de processos, dentre
outros.

Figura 2: Visão Geral da Arquitetura Interna do Globus. Fonte: http://www.globus.org
Quando os desenvolvedores criaram esta arquitetura, eles
perceberam que precisariam adotar algum tipo de middleware, já que
queriam que seus padrões fossem aceitos mais facilmente pelas indústrias.
Apesar de terem optado por Web Services, os mesmos não suportam
a principal característica necessária para funcionamento do OGSA: eles têem
que manter estado entre invocações (ou seja, são serviços stateful). Embora
na teoria eles possam manter estado ou não, geralmente não os mantém, e
não há padrões definidos para esta característica. Sendo assim foi criado o
WSRF.
O WSRF (Web Services Resource Framework) especifica como
podemos fazer um web service agregar a funcionalidade de manter estado,

adicionando algumas características interessantes.
Figura 3 : Integração entre o GT4, OSGA e WSRF. Fonte: http://www.globus.org
A 3 mostra a interação entre o GT4, o OSGA e o WSRF. E a figura 4
mostra a interação entre eles em uma forma de camadas:
Figura 4: Integração do GT4, OSGA, WSRF numa visão em camadas. Fonte: http://www.globus.org
2.3.1 Gerenciamento de Arquivos
Durante o desenvolvimento do middleware, seus desenvolvedores
perceberam que o acesso a transferência de arquivos em um ambiente
distribuído era tão importante quanto acessar recursos distribuídos, isto

porque tanto aplicações científicas como de engenharia acessam grandes
volumes de dados.
A partir deste momento, começou a ser projetado um sistema que
fosse capaz de realizar essa tarefa. Outros sistemas de arquivos distribuídos
já existiam como o HPSS (High Performance Storage System), criado pela
IBM, o DPSS (Distributed Parallel Storage System) do LBNL (Lawrence
Berkley National Laboratory) e o SRB (Storage Resource Broker) do SDSC
(San Diego Supercomputer Center).
Desenvolver um novo sistema de armazenamento distribuído, para
que seja reconhecido como padrão aberto e para manter compatibilidade
com os outros, era necessário implementar todas as suas funcionalidades já
estabelecidas.
Para garantir a compatibilidade com os outros sistemas, foram
inicialmente cogitadas duas abordagens para o desenvolvimento.
A primeira era criar uma camada interoperabilidade em cima do
sistema de armazenamento. Isto envolveria a tarefa de desenvolver um
meta-sistema de armazenamento que seria uma abstração de um sistema já
existente. Somente seria subsituída a camada de alto-nível, mantendo-se as
funcionalidades já implementadas. Esta metodologia tem a vantagem de que
pode-se chegar ao objetivo sem aplicar nenhuma mudança na parte de
transferência de arquivos propriamente dita dos sistemas já existentes. Por
outro lado, seria necessário a criar de uma interface para cada um deles e
para outros que possam surgir.
Uma segunda abordagem, que foi a tomada, era construir a interface
de interoperabilidade embaixo, influenciando diretamente nas
funcionalidades de transferência de arquivos. Esta metodologia envolve
desacoplar o sub-sistema de transferência de arquivos e incorporar um
protocolo único e universal nos outros sistemas de armazenamento de
arquivos distribuídos existentes. Como a maioria destes já foram
desenvolvidos com o mecanismo de alto-nível desacoplado do de baixo nível,
esta operação não seria muito custosa.
Analisando as várias possibilidades de protocolos já existentes, optou-

se por implementar o sistema de armazenamento em cima do protocolo FTP.
Esta decisão foi tomada principalmente porque o FTP trabalha com
transferência de grandes volumes de dados e as partes de autenticar (login)
e transferência (bulk) são desacopladas.
2.3.1.1 Protocolo GridFTP
Foi defino pelo Global Grid Forum Recommendation no documento
GFD.020, posteriormente sendo aceito e descrito no seguintes documentos:
RFC 959, RFC 2228 e RFC 2389. Suas especificações descrevem métodos
robustos, eficientes e seguros para tranferências de arquivos em larga
escala. O GTK4 implementa as funcionalidades mais comuns como servidor,
uma interface em linha de comando e um conjunto de bibliotecas de
desenvolvimento.
Entre suas principais características pode-se citar:
• Suporte à Infra-estrutura de Segurança para Grids (GSI) e ao
Kerberos: sistema de segurança que garante uma autenticação
flexível, integridade confidencialidade para aplicações em ambiente
Grid. Também tem a possibilidade de utilizar Kerberos.
• Controles externos para transferência: se for necessário utilizar de
controles de conexão quando houver um volume grande dados entre
dois servidores, é oferecido à API de segurança para que estes
controles sejam implementados.
• Transferências Paralelas: utilizar várias conexões TCP simultâneas
pode aumentar o tamanho máximo de banda do que se usar uma
única conexão. O GridFTP suporte múltiplas através de extensões de
comando FTP ou então através de vários canais de dados.
• Dados Particionados: transferir porções de dados distribuídos por
várias conexões pode aumentar a banda utilizada, de modo a agilizar
a transferência.
• Dados Parciais: algumas aplicações requerem a transferência de
arquivos parciais. Embora o FTP necessite que os arquivos sejam

enviados e/ou recebidos por completo ou então uma marcação de
onde o arquivo terminou, o GridFTP introduz novas funcionalidades
que permitem a transferência de partes de arquivos.
• Suporte a transferências confiáveis: robustez e controles sobre falhas
são requisitos necessários para muitas aplicações. O FTP define
alguns métodos para continuar uma transferência em que houve erro,
porém não são amplamente implementadas. O GridFTP implementa e
estende estes mecanismos.
2.3.1.2 Serviço de Transferência Confiável
Embora o GridFTP seja um protocolo bastante robusto, há algumas
características nele que não são interessantes quando fala-se de
transferências confiáveis.
Primeiramente, ele não é um protocolo orientado a web services.
Outro ponto é que se faz necessário manter uma conexão aberta durante
toda a operação entre os servidores ou entre cliente e servidor. Isto, no caso
de arquivos muito grandes, requer mais tempo para a transmissão, o que
não é interessante quando usa-se uma estações de trabalho móveis como
laptops. Os mecanismos de transferência confiável prevêem erros no
servidor ou no meio de comunicação, porém não há nada implementado
quando há um erro no cliente, já que neste cenário os arquivos estão na
memória do cliente e não no servidor.
Para contornar estes problemas, foi desenvolvido o RTS (Reliable
Transfer Service) . O RTS é um web service que provê um serviço
semelhante a um escalonador de serviços. Toma como entrada uma lista de
URLs contendo os arquivos e diretórios a serem movidos e os mesmos são
cadastrados em uma base de dados para que comecem as transferências.
Após o RTS receber as requisições, este funciona como qualquer
outro escalonador. Sua interface ainda fornece métodos para se buscar o
estado das transferências e notificações sobre eventos.

2.3.1.3 Replicação de Dados
O Serviço de Localização de Réplicas (RLS) é um serviço que serve
para localizar cópias ou réplicas pelo ambiente de Grid. Ele tem a habilidade
de criar registros distribuidamente de onde estas cópias estão fisicamente.
Isto implica em ter vários servidores trocando informações dentro do Grid.
Esta abordagem se torna interessante, porque ela permite a eliminação de
pontos únicos de falha.
Os arquivos são criados e posteriormente, através de requisições, o
protocolo descobre onde estão localizadas fisicamente as cópias. Duas
nomenclaturas são utilizadas:
• Nome lógico do arquivo: -identificador único perante o Grid.
• Nome físico do arquivo: -identificador da réplica localizada no sistema
de armazenamento local.
Figura 5: Exemplo de utilizaçao do RLS. Font: Globus Alliance.
2.3.1.4 Replicação em Alto Nível
O Serviço de Replicação de Dados (DRS) é um serviço que se localiza
na camada de alto nível, que se utiliza de dois outros componentes de baixo
nível do middleware: o RLS e o RTS.
A função do DRS é assegurar que um ou mais arquivos específico(s)
existem em um repositório de armazenamento. Sua operação começa
enviando requisições ao RLS para descobrir em qual servidor o arquivo
desejado se encontra. Após isto, envia requisições ao RTS para que sejam
criadas as conexões no escalonador para que então as transferências

comecem. Caso haja algum problema no lado do servidor, as técnicas de
tolerância a falhas do GridFTP atuam e em caso da falha ser no lado do
cliente, quem atua é o próprio RTS.
2.3.2 Segurança
Grids surgiram como uma solução para aplicações distribuídas inter-
operacionais e dinâmicas. O projeto Globus foi projetado para suportar esses
ambientes e ser utilizado em todo o mundo. O Grid Security Infrastructure
(GSI) é o módulo que tem a responsabilidade de gerenciar a segurança
envolvida nas transações de dados e tarefas.
No Globus Toolkit versão 4 (GT4) dois mecanismos são utilizados
para incrementar a proteção das trocas de mensagens SOAP: o nível de
transporte e o nível de mensagem. O nível de transporte utiliza-se do
protocolo TLS com suporte a certificados x.509 através de proxys para
realizar a autenticação. Já o nível de mensagem provê compatibilidade com
os padrões WS-Security e o WS-SecureConversation para criptografar as
mensagens SOAP.
Embora seja importante suportar os padrões WS-Security e o WS-
SecureConversation para manter compatibilidade com o protocolo básico
de segurança para WebSevices (WS- Interoperability Basic Security
Profile ), ele não é muito utilizado pois sua performance é baixa e por esta
razão o GT4 vem configurado para fazer uso do protocolo TLS.
A segurança no nível de transporte utiliza TLS para encapsular a
mensagem SOAP com criptografia através do grid. Isso garante a integridade
e a privacidade das mensagens. Esta tecnologia é suportada como uma
alternativa de alto desempenho a de nível de mensagem.
Este mecanismo é comumente utilizado em conjunto com credenciais
X.509 para autenticação, entretanto seu funcionamento pode se dar sem
autenticação, conhecida como anonymous transport- level security .
Nesta categoria o processo de reconhecimento do usuário deve ser feito em
outro estágio, com usuário e senha dentro de uma mensagem SOAP ou

então completamente sem autenticação.
O GSI implementa em seu message- level security os padrões WS-
Security e o WS-SecureConversation para proteger a comunicação
SOAP. O WS-Security é um padrão elaborado pela OASIS que define um
framework para estabelecer um nível aplicado de segurança para cada
troca de mensagem. Já o WS-SecureConversation , que é um protocolo
proposto pela Microsoft e IBM, define um contexto inicial de segurança para
a troca de mensagens, desta maneira consumindo menos poder
computacional. Embora seja interessante este último modo de
contextualização da segurança, ele funciona somente assossiado a
certificados X.509. Já com o WS-Security , pode-se tanto permirtir
autenticação via credenciais X.509 ou com usuário e senha.
As credenciais X.509 são utilizadas para identificar entidades
persistentes como usuários e serviços, já que garantem uma única
identificação para cada entidade e também um método de assegurar que a
identidade pertence mesmo ao indivíduo em questão.
Figura 6: Visão Geral do GSI e seus diferentemente métodos de proteção.
O GSI trabalha com delegação e single sign-on junto com proxys de
certificados para propagar os privilégios de quem originou uma solicitação de
serviço para outras entidades.
Os três tipos diferentes de proxys são:
• Old : são mantidos apenas como legado. Referentes ao rascunho do
RFC 3820.

• Default GT4: seguem o formado do RFC 3820, exceto por
possuírem um conjunto proprietário de OIDs. Serão depreciados nas
próximas versões do Globus Toolkit.
• Fully RFC 3824 : são completamente compatíveis com o RFC 3820.
Será o padrão adotado futuramente.
A delegação de serviços é realizada utilizando o padrão WS-Trust e
sempre será do mesmo tipo de proxy do qual originou o serviço.
2.3.3 Escalonamento de processos
O Globus Toolkit trata o escalonamento de processos através de um
conjunto de aplicações que unidas são chamadas de GRAM (Grid Resource
Allocation and Management) e sua implementação sob o conceito de
webservices WS GRAM.
Embora possua seu próprio mecanismo de escalonamento, sua
principal função é distribuir as tarefas, ou jobs pelos nodos do Grid. Para
isso ser realizado, foi implementada uma interface entre o escalonador do
Grid e o do próprio sistema operacional que roda no nodo.
Uma visão geral sobre seus componentes é mostrado na figura 6:

Figura 7: Componentes do WS-GRAM. Fonte: http://www-unix.globus.org/toolkit/docs/4.0/
Cada job submetido ao Grid é identificado unicamente por um serviço
chamado de ManagedJob. Este serviço possui uma interface onde é
possível verificar o estado deste job ou então terminá-lo. O seu
comportamento dentro do escalonador local do sistema operacional é
identificado por um tipo especializado dentro da abstração da interface.
Figura 8: Diagrama de estados de um job durante sua existência. Fonte: http://www-
unix.globus.org/toolkit/docs/4.0/

2.4 Web Services
De acordo com a W3C [12], Web Services são sistemas
desenvolvidos com a característica de suportar interoperabilidade entre
máquinas através de uma rede. Isto é possível devido a sua descrição de
interface em um formato independente de sistema operacional como a
WDSL.
A interatividade entre as pontas da comunicação se dá por troca de
mensagens encapsuladas pelo protocolo SOAP, que por sua vez também é
encapsulado em um protocolo de aplicação, comumente sendo o HTTP.
Sistemas projetados para serem WebServices se utilizam de várias
tecnologias, dentre as principais estão listadas abaixo:
• XML: todos os dados trocados durante a comunicação são formatados
em XML. A codificação das mensagens devem estar de acordo com o
padrão estabelecido pelo SOAP;
• Protocolos de Alto Nível: é através deles que os dados são
transportados entre as aplicações. Podem ser estes protocolos: HTTP,
FTP, SMTP e XMPP;
• WSDL: linguagem que serve para descrever as interfaces públicas de
um Web Service. É baseada em XML.
• UDDI: a publicação das interfaces em repositórios públicos é feita com
este protocolo. Isto habilita as aplicações procurarem por informações
de outros WebServices;
• WS-Security: o WebServices Security Protocol foi aceito pela OASIS
como um padrão. Esse mesmo permite a autenticação dos atores e a
confidencialidade das mensagens enviadas;
• WS-ReliableExchange: uma especificação baseada no SOAP com o
objetivo de garantir que toda mensagem será entregue. É visto em
ambientes de alta criticidade. Também foi aceito como um padrão pela
OASIS.

Figura 9: Interação e comunicação entre os elementos de uma aplicação WebService.
2.4.1 Vantagens e Desvantagens
Como já mencionado antes, WS mantém um alto grau de
interoperabilidade entre plataformas e sistemas operacionais. Isto é possível
porque sua pilha de protocolos é formada por protocolos abertos e
intependentes de registros e marcas. Como a passagem de mensagens é
realizada através de métodos já estabelecidos como HTTP e FTP, não há
necessidade de alterações nos firewalls das organizações envolvidas como
outras formas de invocação remota de métodos necessitam. Juntamente ao
fato das aplicações que se encaixam neste modelo de desenvolvimento
serem altamente distribuídas e publicadas, tem-se uma alta reusabilidade de
componentes.
Embora WS apresentem vários benefícios, estes possuem certas
desvantagens como não possuir suporte a transações simultâneas entre
vários hosts, como CORBA possui, e sua performance é baixa compara
com outras linguagens para a construção de sistemas distribuídos. Isto se
deve aos objetivos de projetos da tecnologia que não foram voltados a

eficiência e parsing .
2.4.2 SOAP
SOAP é um protocolo para o intercâmbio de mensagens entre pontos
através da internet/intranet baseado em XML, normalmente utilizando HTTP.
Forma a camada fundamental para a implementação de WebServices,
fornecendo um framework que camadas mais acima podem ser
implementadas.
Há vários padrões de diferentes tipos de mensagem, mas o mais
conhecido é a chamada de procedimento remoto (RPC), que em um nodo
cliente manda uma requisição e um outro nodo servidor retorna uma
resposta.
Embora alguns protocolos de alto nível são válidos para fazer o
transporte de mensagens SOAP, o HTTP tem se destacado e sido usado
com mais freqüência pois ele trabalha bem com a atual intra-estrutura da
internet, especialmente porque geralmente não é bloqueado por firewalls .
Esta é a maior vantagem sobre protocolos de sistemas distribuídos
como GIOP/IIOP ou DCOM que são comumente filtrados. Um ponto que está
sob discussão é se o HTTP é a forma correta de transporte devido a sua
característica de ser assíncrono.
A XML foi escolhida como padrão de formato das mensagens devido a sua
grande aceitação por corporações e seu padrão aberto. Além disto, existem
várias ferramentas livres de fácil aprendizagem que podem ser utilizadas
para migrar suas aplicações para o modelo SOAP.

Figura 10: Exemplo de mensagem SOAP.
2.4.3 eXtensible Markup Language
XML é uma linguagem de marcação de uso geral, capaz de descrever
vários tipos de dados, recomendada pela W3C para a criação de outras
linguagens para uso específico. Sua função primária é o compartilhamento
de dados por diferentes sistemas, em particular, os conectados à internet.
Linguagens baseadas em XML são definidas através de um modelo formal,

permitindo que programas ou usuário possam modificar ou validar
documentos sem prévio conhecimento de sua forma.
Figura 11: Exemplo de arquivo XML.
Esta meta linguagem define um meio de descrever as informações em
uma estrutura de árvore. Isto permite a fácil visualização das próprias por
seres humanos. Por ser uma descendente da SGML, sua hierarquia de
dados é definida por tags, do mesmo modo que HTML, e também garante
uma alta estabilidade e padronização, já que a SGML é mundialmente aceita.
Por ser uma meta-lingüagem, é capaz de se definir outras linguagens,
geralmente de uso específico como a MathML (para utilização matemática) e
SyncML (sincronização de dados).
2.4.4 Web Services Description Language
Como já mencionado antes, WSDL (linguagem de descrição de
WebServices) é a linguagem utilizada para dizer ao programa cliente quais
são os métodos e atributos disponíveis no Web Service.
Segundo Cleuton Sampaio [13] um WSDL é um documento XML

baseado no esquema: http://schemas.xmlsoap.org/wsdl, que define um
WebService. Através do WSDL é possível criar um Cliente que acessa o
Web Service.
Segue abaixo um exemplo de arquivo WDSL:
<?xml version="1.0"?>
<definitions name="StockQuote"
targetNamespace="http://example.com/stockquote.wsdl" xmlns:tns="http://example.com/stockquote.wsdl" xmlns:xsd1="http://example.com/stockquote.xsd" xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/" xmlns="http://schemas.xmlsoap.org/wsdl/">
<types> <schema targetNamespace="http://example.com/stockquote.xsd" xmlns="http://www.w3.org/2000/10/XMLSchema"> <element name="TradePriceRequest"> <complexType> <all> <element name="tickerSymbol" type="string"/> </all> </complexType> </element> <element name="TradePrice"> <complexType> <all> <element name="price" type="float"/> </all> </complexType> </element> </schema> </types>
<message name="GetLastTradePriceInput"> <part name="body" element="xsd1:TradePriceRequest"/> </message>
<message name="GetLastTradePriceOutput"> <part name="body" element="xsd1:TradePrice"/> </message>
<portType name="StockQuotePortType"> <operation name="GetLastTradePrice"> <input message="tns:GetLastTradePriceInput"/> <output message="tns:GetLastTradePriceOutput"/> </operation> </portType>
<binding name="StockQuoteSoapBinding" type="tns:StockQuotePortType"> <soap:binding style="document" transport="http://schemas.xmlsoap.org/soap/http"/> <operation name="GetLastTradePrice"> <soap:operation

soapAction="http://example.com/GetLastTradePrice"/> <input> <soap:body use="literal"/> </input> <output> <soap:body use="literal"/> </output> </operation> </binding>
<service name="StockQuoteService"> <documentation>My first service</documentation> <port name="StockQuotePort" binding="tns:StockQuoteBinding"> <soap:address location="http://example.com/stockquote"/> </port> </service>
</definitions>
2.4.5 Universal Description, Discovery and Integration
UDDI é um acrônimo para Universal Description, Discovery and
Integration que é uma notação para o registro, independente de plataforma,
baseado em XML visando que organizações de todo o planeta registrem
informações, de forma centralizada, de quais serviços elas estão oferecendo.
O registro UDDI é formado de três componentes:
• Páginas Brancas: contém endereços, contatos;
• Páginas Amarelas: categorias industriais baseadas em taxonomias
padronizadas;
• Páginas Verdes: informações técnicas sobre os serviços oferecidos
pela organização.
UDDI é um dos principais padrões que fazem parte da tecnologia de
Web Services. Foi projetado para receber requisições de mensagens SOAP
e prover acesso para as interfaces WSDL que descrevem como interagir com
o serviço.
Um exemplo de registro UDDI é mostrado abaixo:
<businessEntity businessKey="ba744ed0-3aaf-11d5-80dc-002035229c64"
operator="www.ibm.com/services/uddi" authorizedName="0100001QS1"> <discoveryURLs>

<discoveryURL useType="businessEntity">http://www.ibm.com/services/uddi/uddiget?businessKey=BA744ED0-3AAF-11D5-80DC-002035229C64</discoveryURL> </discoveryURLs> <name>XMethods</name> <description xml:lang="en">Web services resource site</description> <contacts> <contact useType="Founder"> <personName>Tony Hong</personName> <phone useType="Founder" /> <email useType="Founder">[email protected]</email> </contact> </contacts> <businessServices> <businessService serviceKey="d5921160-3e16-11d5-98bf-002035229c64" businessKey="ba744ed0-3aaf-11d5-80dc-002035229c64"> <name>XMethods Delayed Stock Quotes</name> <description xml:lang="en">20-minute delayed stock quotes</description> <bindingTemplates> <bindingTemplate bindingKey="d594a970-3e16-11d5-98bf-002035229c64" serviceKey="d5921160-3e16-11d5-98bf-002035229c64"> <description xml:lang="en">SOAP binding for delayed stock quotes service</description> <accessPoint URLType="http">http://services.xmethods.net:80/soap</accessPoint> <tModelInstanceDetails> <tModelInstanceInfo tModelKey="uuid:0e727db0-3e14-11d5-98bf-002035229c64" /> </tModelInstanceDetails> </bindingTemplate> </bindingTemplates> </businessService> </businessServices></businessEntity>

3.MONITORAMENTO
O monitoramento de recursos é uma das partes mais importantes da
disponibilização de serviços e/ou recursos, pois deste modo pode-se saber
quais serviços têm sido mais acessados, como os recursos estão sendo
utilizados, quais os horários de pico, ou seja, são disponibilizados dados
importantes para o gerenciamento do grid .
A tarefa de monitoramento tem que ser feita de forma a não interferir
significantemente no processamento da máquina a ser monitorada e também
ser robusto e preciso nas informações recolhidas.
Geralmente o processo de monitorar informações provenientes de
dispositivos espalhados pela rede se dá em três etapas: recolhimento,
armazenamento e apresentação.
A etapa de recolhimento é onde se obtém os dados vindos dos
dispositivos, o que pode ser feito através de testes remotos com comandos
como ping , queso e dig, como também pela instalação de agentes nos
próprios servidores, desktops e demais elementos ativos do grid .
Após recolhidos os dados, ocorre a etapa de armazenamento, na qual
os dados obtidos na etapa de recolhimento são armazenados. Pode-se
guardar estas informações em arquivos com formatos proprietários, arquivos
textos, XML, ou em um banco de dados.
A última das três etapas consiste na disponibilização dos dados
processados para o usuário final do sistema. Pode-se usar várias tecnologias
nesta etapa, desde páginas web até softwares especializados para este fim.
Nas redes baseadas em protocolos da pilha TCP/IP existe um
procotolo já especificado para monitoramento e gerência de dispositivos
chamado SNMP (Simple Network Management Protocol) . No caso do
Globus [1], temos um sistema de monitoramento já existente que é
denominado Monitoring and Discovering System (MDS).

3.1 SNMP
O SNMP é um protocolo padrão da Internet que serve para gerenciar
vários recursos de dispositivos de rede IP. Dentro esses dispositivos estão os
ativos de rede, tais como switches, routers, modems ou então ainda
estações de trabalho e servidores. O SNMP ajuda os administradores de
redes a organizar melhor suas redes e também a saber quando ocorre um
problema.
3.1.1 Visão Geral
No mundo do gerencimanento de rede com SNMP, a base de
funcionamento está nos agentes e gerentes. Os gerentes são comumente
chamados de NMS (Network Management Stations). Essas NMS não são
nada mais que servidores rodando um software capaz de tratar as tarefas de
gerenciamento de uma rede. Esta mesma é responsável pelas operações de
polling e receber as traps dos agentes.
Uma operação de poll é o método utilizado pela NMS para fazer
alguma consulta aos seus agentes em algum ativo que está sendo
monitorado. Esses dados podem ser armazenados para futuramente gerar
estatísticas e saber se ocorreu algum sinistro no ativo. Em contra partida
uma trap é uma mensagem enviada por um agente para dizer que algo
aconteceu.
O agente é um software incorporado nos dispositivos de rede
(switches, hubs, servidores, routers) que responde às pollings da NMS e
envia as traps caso ocorra algo de anormal.
3.1.2 Comunidades
O conceito de comunidade é utilizado pelas versões 1 e 2 do protocolo
SNMP. Essas comunidades são usadas para fornecer um certo mecanismo
de autenticação. Elas são subdivididas em três tipos: read-only, read-write, e

trap. A comunidade read-only pode só ler valores mas não alterá-los, já a
comunidade read-write pode além de ler, alterar esses dados. Por último, a
comunidade trap pode apenas receber traps dos agentes.
Um agente é configurado com três strings de comunidades. Essas
strings são as senhas para a comunicação, portanto, deve-se tomar cuidado
com as senhas utilizadas. É também recomendado, que se configure no
agente o destino das traps.
Ocorre um problema com esse conceito, porque ele não utiliza
criptografia, o que faz com que essas strings sejam passadas em texto plano
pela rede.

Figura 12 : Demonstração da utilizaçao do SNMP versão 3 com MIB-II.
3.1.3 Problemas do SNMP
Como o protocolo SNMP foi projetado quando a internet estava
apenas começando a se popularizar, logo não foram consideradas várias
características de segurança na sua implementação. Várias técnicas de
firewall foram desenvolvidas na tentativa de sanar estes problemas de
segurança, que embora ajudem, não os resolvem por completo.
Somente a partir da versão 3 da especificação do protocolo foram
abordados aspectos referentes à segurança da informação que trafega pela
rede. Isto inclui certificados digitais, listas de acesso e autenticação temporal
das mensagens. Mesmo com todas estas características de segurança
implementadas, o SNMP é um protocolo binário que requer a abertura de
portas para o meio exterior, o que aumenta o risco para a segurança dos
dispositivos.
Considerando os problemas apresentados acima e levando em conta
que o próprio middleware do grid já possui um sistema próprio de
segurança, o SNMP não será utilizado neste trabalho.
3.2 MDS / WebMDS
O MDS (Monitoring and Discovery System) é um conjunto de serviços
web para monitorar e descobrir recursos e serviços no grid. Esse sistema
permite aos usuários saber quais serviços são pertencentes a determinada
VO e monitorar esses recursos. Todas estas informações são postas em um
único servidor que está à disposição dos administradores do grid.
Este sistema de monitoramento possui dois tipos de serviços: o Index
Service , que coleta dados de várias fontes e provê a visualização dos
serviços que cada VO disponibiliza; e o Trigger Service , que coleta os
dados das máquinas e pode ser configurado para agir de acordo com os
resultados da coleta.
O Index Service é um registro similar ao UDDI, mas é mais flexível. A

informação sobre os serviços é coletada e posta como propriedades do
recurso. Os índices podem ser registrados de forma hierárquica com o
objetivo de agregar informações em diferentes camadas. Cada índice tem um
tempo de vida e pode ser removido caso não seja renovado antes de
expirar.
O Trigger Service coleta a informação e compara os dados com um
conjunto de condições definidas em um arquivo de configuração. Quando
uma condição é atingida, é tomada uma ação, que pode, ser o envio de um
email ao administrador do sistema quando o disco do computador estiver
próximo de sua capacidade total.
O MDS foi depreciado, não terá novas versões e inclusive será
retirado nas próximas atualizações do GT4. Para substituí-lo, foi
desenvolvido o WebMDS que funciona de forma semelhante, porém atua
como um servlet. Para instalar este serviço se faz necessário também
instalar o Tomcat, e um dos kits de monitoramento separados: Glanglia
Information Provider e/ou Hawkeye Information Provider.
São estes kits de monitoramento que fornecem as informações para o
WebMDS disponibilizar para os usuários.

4. DESENVOLVIMENTO
4.1 Ferramentas
Para a confecção deste trabalho de conclusão de curso, foram
utilizadas ferramentas de apoio para facilitar o seu desenvolvimento.
Foi dada preferência para utilitários considerados softwares livres
visando o não pagamento de licenças de uso durante o andamento do
trabalho e principalmente quando o software desenvolvido for utilizado.
4.1.1 Eclipse IDE
“ Eclipse is an open source community whose projects are
focused on building an open development platform comprised of
extensible frameworks, tools and runtimes for building, deploying
and managing software across the lifecycle. A large and vibrant
ecosystem of major technology vendors, innovative start- ups,
universities, research institutions and individuals extend,
complement and support the Eclipse platform.”
- Fundação Eclipse

Figura 13: Ambiente de desenvolvimento utilizando Eclipse.
4.1.2 Apache Web Server
O Apache Web Server é o atual servidor web livre mais bem sucedido.
Criado em 1995 através da aplicação de vários patchs sobre o NCSA httpd
que teve seu desenvolvimento interrompido na época.
Seu desenvolvimento é ajudado pela comunidade e mantido pela
Fundação Apache, sendo seu principal projeto.
4.1.3 PHP
PHP é um acrônimo recursivo para PHP Hypertext Preprocessor
que é uma linguagem de programação orientada a objetos e voltada para ser
utilizada em páginas web.
A linguagem PHP foi criada em 1994 por Ramsus Lerdof, com
pequenos scripts e formada por um subconjunto de funções de Perl . Em
junho de 2004 foi lançada a versão 5 que incluiu várias características e
dentre elas o suporte a orientação a objetos, a tornando uma linguagem

poderosa e flexível.
Figura 14: Demonstração de código escrito em PHP.
4.1.4 GDTE (Globus Development Tools for Eclipse)
O GDTE é um projeto recém aprovado como Incubado pela Globus
Alliance. Seu objetivo é criar uma gama de ferramentas que integradas ao
framework Eclipse, se torne um poderoso ambiente de desenvolvimento para
Grid Computing .
Suas ferramentas permitem que boa parte da programação e
configuração de parâmetros necessários seja encapsulada por uma API de
desenvolvimento. Sendo assim, o desenvolvedor pode se concentrar no seu
software propriamente dito.
4.1.5 RRDTool
O RRDTool é um acrônimo para Round Robin Database . É um
sistema que armazena e gera gráficos a partir de uma base própria que é
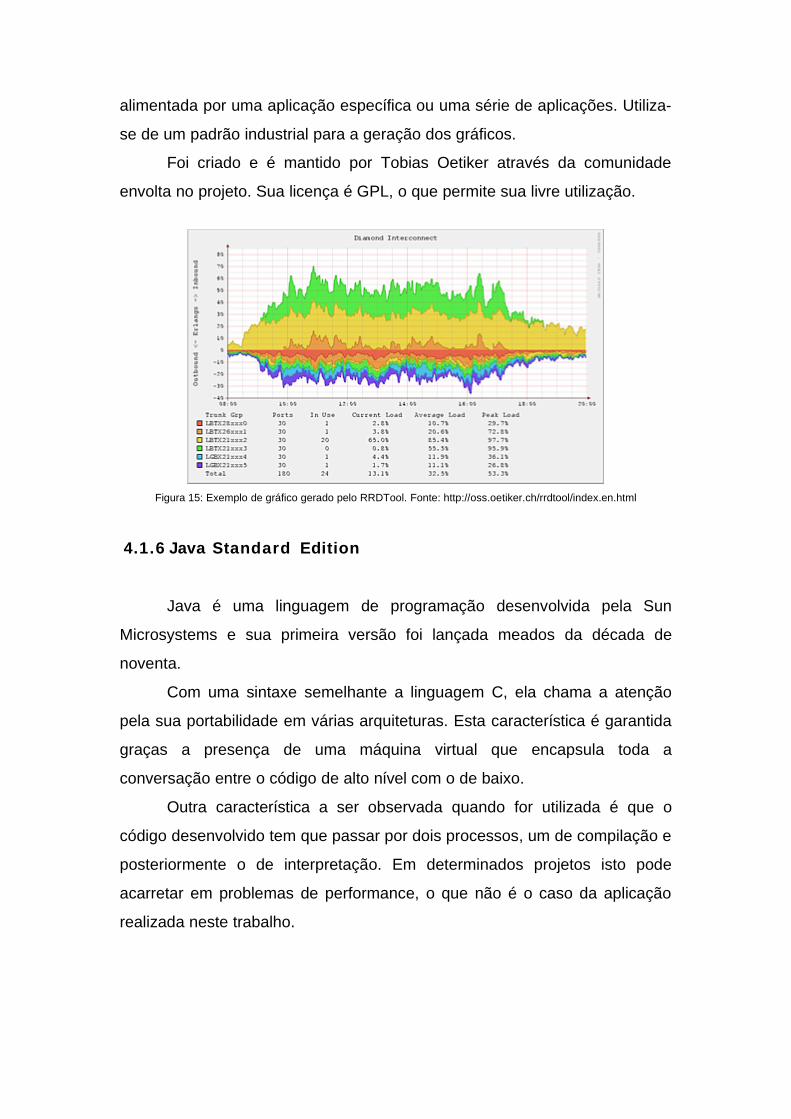
alimentada por uma aplicação específica ou uma série de aplicações. Utiliza-
se de um padrão industrial para a geração dos gráficos.
Foi criado e é mantido por Tobias Oetiker através da comunidade
envolta no projeto. Sua licença é GPL, o que permite sua livre utilização.
Figura 15: Exemplo de gráfico gerado pelo RRDTool. Fonte: http://oss.oetiker.ch/rrdtool/index.en.html
4.1.6 Java Standard Edition
Java é uma linguagem de programação desenvolvida pela Sun
Microsystems e sua primeira versão foi lançada meados da década de
noventa.
Com uma sintaxe semelhante a linguagem C, ela chama a atenção
pela sua portabilidade em várias arquiteturas. Esta característica é garantida
graças a presença de uma máquina virtual que encapsula toda a
conversação entre o código de alto nível com o de baixo.
Outra característica a ser observada quando for utilizada é que o
código desenvolvido tem que passar por dois processos, um de compilação e
posteriormente o de interpretação. Em determinados projetos isto pode
acarretar em problemas de performance, o que não é o caso da aplicação
realizada neste trabalho.

4.2 Modelo de Desenvolvimento
O emprego de modelos de desenvolvimento de software, embora
bastante difundido no meio de desenvolvedores e analistas, não se trata um
conceito amplamente aceito e bem formado. Entende-se como uma série de
passos perante um procedimento maior que devem ser seguidosdurante o
desenvolvimento de um sistema de informação (Yourdon, 1995, p. 97).
O modelo empregado neste trabalho foi o modelo Espiral, criado em
1998 por Boehm. Dentro suas principais características, está a definição
clara de etapas que podem ser consideradas “fases”, análise de riscos e
prototipação. A cada nova estapa concluída, o software é prototipado e
testado, e é refeita uma análise de riscos sobre o que pode dar errado.
4.3 SCRG (Sistema Coletor de Recursos em Grid)
O SCRG é uma aplicação que visa recolher e armazenar informações
vitais para um administrador de servidores como carga de CPU, memória
RAM utilizada, dentre outras informações.
Estes dados tornam-se importantes na medida que os computadores
de certa VO participam do Grid e seu processamento se torna compartilhado
perante todas as outras máquinas.
Neste contexto, no qual um servidor que também serviços para
usuários da rede interna ou usuários públicos, é extremamente necessário o
monitoramento dos recursos disponibilizados.
Este monitoramento pode evitar problemas que possam gerar
desconforto para os usuários e também prever novos upgrades de
hardware.
4.3.1 Pré- Requisitos
Para a instalação do SCRG se faz necessário instalar alguns
softwares no sistema operacional. Abaixo segue a lista dos mesmos:

– Java SDK 1.5+;
– Ant 1.6+ (para instalação do Globus Toolkit);
– GNU C Compiler 3.x / 2.95.X (para instalação do Globus Toolkit);
– GNU sed (para instalação do Globus Toolkit);
– GNU tar;
– zLib 1.4.x (para instalação do Globus Toolkit);
– GNU Make (para instalação do Globus Toolkit);
– Perl (Para alguns recursos do Globus Toolkit);
– Sudo (para instalação do Globus Toolkit);
– Apache Web Server;
– PHP 5.x;
– Linux 2.6.16+ com sistema /proc;
– Globus Toolkit 4.x;
– RRDTool 1.2.12+;
– Crontab.
4.3.2 Funcionamento
A aplicação desenvolvida neste trabalho possui quatro partes bastante
distintas assim denominadas: Kolector , KolectorClient , PHP-Kolector e
Apresentação .
Cada um destes sub-sistemas se encarrega de funções específicas
para mostrar ao administrador o resultados de suas coletas de dados.
4.3.2.1 Arquivos de Configuração
Os arquivos de configuração para o funcionamento do software estão
localizados dentro do diretório /etc/scrg . São apenas dois arquivos: o
ips.conf e o config.ini .
Em ips.conf são postos os endereços IP para os quais serão
efetuadas as requisições sobre informações de recursos.

Figura 16: Demonstração do conteúdo do arquivo de configuração ips.conf.
Já no arquivo config.ini estão contidas algumas variáveis para o
funcionamento principalmente do PHP-Kolector. Abaixo segue a descrição
das mesmas:
– ips_path: caminho de onde se encontra o arquivo que contém os
endereços Ips a serem pesquisados, por padrão se localiza em
/etc/scrg/ips.conf ;
– output_path: caminho do diretório onde ficarão os HTML's da
apresentação. Precisa ser um local onde seu servidor web possa
exibi-los;
– kolector_path: caminho onde se localiza o binário do
KolectorClient;
– rrd_path: caminho para o binário do RRDTool;
– rrdupdate_path: caminho para o binário do RRDTool Update;
4.3.2.2 Sistema de arquivos /proc
O sistema de arquivos /proc encontrado no sistema operacional Linux

é uma parte importante do processo, pois é dele que são retiradas as
informações que serão passadas ao Kolector.
Ele serve para acessar várias estruturas providas pelo kernel sem
precisar utilizar funções de ioctl(), que são de certa forma complicadas de
utilizar.
Sua principal função é dar visibilidade a estatísticas sobre o sistema e
informações sobre hardware em tempo real. Através dele também é possível
setar variáveis para se fazer tunning de sistema operacional.
Os principais usos para este sub-sistema são:
– ver informações estatísticas;
– descobrir hardware;
– modificar parâmetros em tempo real;
– obter informações sobre memória e desempenho.
É importante notar que a estrutura de diretórios e informações nela
contida pode mudar de uma máquina para outra, já que essas podem possuir
hardware e configurações diferenciados.
4.3.2.3 Kolector
O Kolector é um serviço propriamente dito que foi construído sobre o
Globus. Sua função primária é coletar os dados do computador o qual está
instalado para ser acessado pelo cliente que fará a requisição por essas
informações.
As informações obtidas são: tempo desde a inicialização da máquina
(uptime) , quantidade total de memória RAM, quantidade utilizada de
memória RAM, tipo de processador, velocidade do processador, arquitetura
do computador, nome do Sistema Operacional e versão do Sistema
Operacional.
Os dados são obtidos através de pipes ao Sistema Operacional. A
fonte de obtenção dos mesmos é no sub sistema conhecido como /proc
encontrado no Sistema Operacional Linux.

Após a extração primária é feito um pequeno parsing em cima dos
dados para que os mesmos não sejam passados totalmente brutos pela
rede. Isto ajuda a não prejudicar o desempenho de link de dados. Como
última etapa são posicionados em um array chamado Status para que este
seja retornado quando for solicitado.
Todo código que faz a interatividade com o Globus Toolkit, geração de
WSDL's e XML's é gerado automaticamente pelo GTDE, somente passando
alguns parâmetros de configuração na criação do projeto inicial. O
desenvolvedor tem uma classe principal onde pode começar seu código e
expandi-lo para outras caso necessário.
Os métodos e variáveis que são acessíveis pelos outros nodos do
Grid estão precedidos respectivamente pelas diretivas @GridMethod e
@GridAttribute . No caso do Kolector, apenas o método principal
getStatus() e o array Status estão disponíveis, garantindo que a
visibilidade dos outros métodos seja interna ao próprio nodo.
Figura 17: Diagrama de Fluxo de Dados do Kolector.

4.3.2.4 KolectorClient
O KolectorClient é o sub-sistema que faz a chamada pelo Kolector
dentro do Grid e imprime na tela as informações recebidas.
O endereço IP para onde apontará sua requisição é passada por
argumento em linha de comando.
Todo o código necessário para a interação com o Globus Toolkit é
gerado automaticamente através do GDTE, deixando somente a codificação
do método principal para o programador. Um exemplo deste código é
apresentado na figura 18.
public static void main(String[] args) {
if (args[1] == null){
System.out.println("Uso: "+ args[0] +" <endereço IP>");System.exit(0);
} String instanceURI="http://"+ args[1]
+":8080/wsrf/services/KolectorService"; String factoryURI="http://"+ args[1] +":8080/wsrf/services/KolectorFactoryService";
try { KolectorClient client = new KolectorClient(factoryURI, instanceURI); String[] Status = client.getStatus(); int i = 0; for (i = 0 ; i < Status.length ; i++){ System.out.println(Status[i]); } } catch (Exception e) { System.out.println("Não foi possível obter informações de Kolector no ip:" + args[1] + "\n"); e.printStackTrace(); } }
Figura 18: Método principal do KolectorClient.
4.3.2.5 PHP- Kolector
O PHP-Kolector é o sub-sistema de interação entre todo os outros
sub-sistemas. É através dele que o serviço instalado é chamado para
execução.
Suas principais atrubuições são:
– Chamada do KolectorClient;
– Parsing dos dados obtidos;
– Criação dos diretórios (raiz e específicos para cada nodo);
– Verificação dos diretórios existentes (caso não estejam
criados, ele os cria);
– Criação das Bases RRD;
– Verificação das bases existentes (caso não estejam criadas,
ele as cria);
– Incrementação das Bases RRD;
– Geração dos HTML's;
– Geração do Menu.
Como sugere o nome, todo seu código é escrito em PHP. Para que
seu funcionamento seja automático, é preciso utilizar a Crontab com a
configuração para que seja executado a cada cinco minutos.
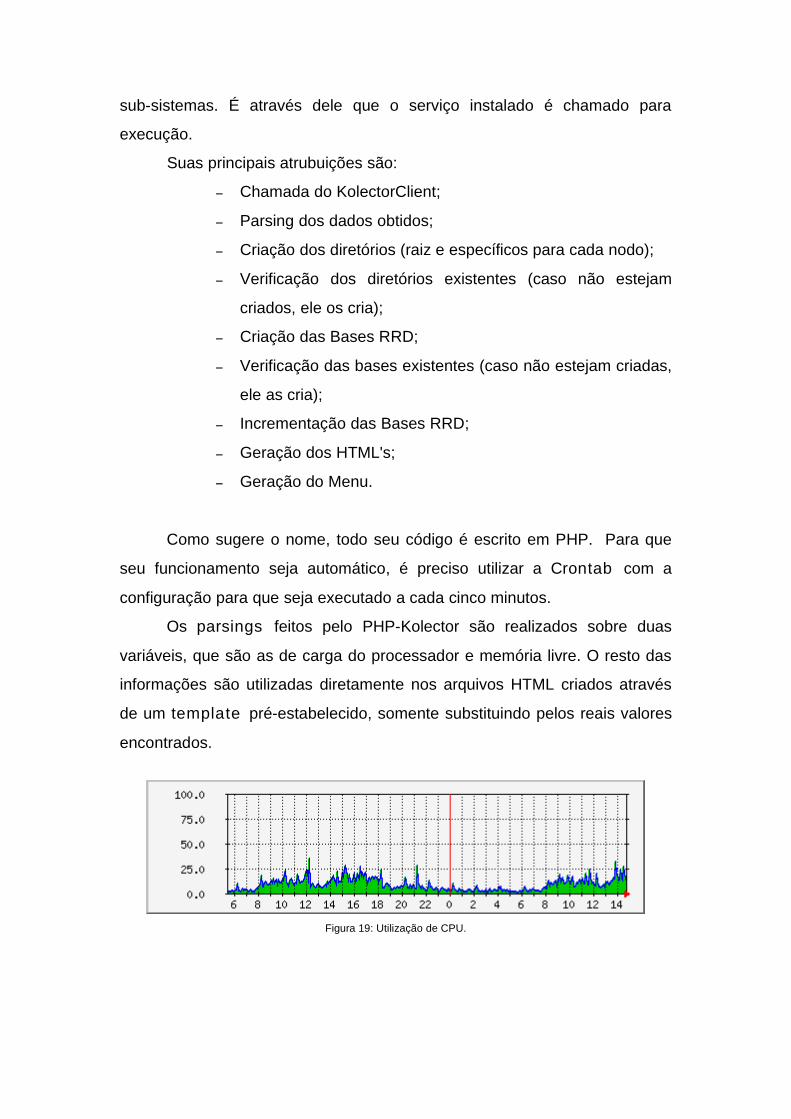
Os parsings feitos pelo PHP-Kolector são realizados sobre duas
variáveis, que são as de carga do processador e memória livre. O resto das
informações são utilizadas diretamente nos arquivos HTML criados através
de um template pré-estabelecido, somente substituindo pelos reais valores
encontrados.
Figura 19: Utilização de CPU.

4.3.2.6 Apresentação
Apresentacao é onde o usuário final da aplicacão, seja ele um simples
usuário ou então o administrador do Grid , verá as informacões colhidas.
Toda interacão entre ator principal e software se dá através da WWW (world
wide web) , podendo o mesmo verificar as informacões de qualquer lugar do
planeta, desde que possua permissão de acesso.
Através de uma interface simples e objetiva pode-se navegar entre os
vários nodos do e ir procurando as informacões que se deseja.
Figura 20: Demonstração do HTML gerado.
4.3.3 Processo de Instalação
Após obter o pacote compactado do software (scrg-v0.1.tgz) deve-se
decompactá-lo para começar o processo de instalação. Primeiramente crie
os diretórios /etc/scrg e /etc/scrg/rrd. Copie o arquivo config.ini que está
dentro do diretório scrg/Kolector/ para o recém-criado diretório /etc/scrg,
configure-o as próprias necessidades e execute o comando: $touch

/etc/scrg/ips.conf .
Dentro do arquivo /etc/scrg/ips.conf coloque os endereços IP (um
por linha) dos nodos pelo qual há o interesse de fazer a coleta dos dados.
Ao descompactar o arquivo da aplicação, será fornecido o arquivo
br_eti_zanetta_scrg_kolector_Kolector.gar . Neste arquivo deve-se
utilizar uma ferramenta fornecida pelo próprio Globus para fazer a instalação
do SCRG dentro do ambiente Grid. Obtém-se este processo entrando no
diretório de instalação do Globus e digitando: # globus-deploy- gar
{ localização do gar} .
Depois de executar esses passos, coloca-se o script PHP-Kolector
dentro da configuração da Crontab . Usa-se o comando 'crontab -e' para
editar a tabela e poe-se a linha a seguir : 0-55/5 * * * * { localicação do
script PHP-Kolector } .
Em torno de meia hora aponte o browser para o diretório especificado
no arquivo de configuração para verificar os gráficos e informações.
4.3.4 Testes
Os testes foram realizados em um único computador formando um
Grid de apenas de um nodo. O motivo da escolha por este método foi a
conveniência e facilidade para os mesmos fossem realizados.
A configuração básica do computador de teste é a seguinte:
– Processador Intel Centrino 1.5Ghz;
– 512Mb de memória RAM;
– 60Gb de disco rígido;
Por se tratar de uma instalação em localhost do Globus Toolkit, não
foi preciso a utilização dos módulos de Transferência de arquivos, WebMDS
e Replicação da Dados. Isso inclui os protocolos: GridFTP, RLS, RTS e
várias aplicações requeridas pelo WebMDS que possuem seus próprios
protocolos.
Os certificados utilizados para a autorização das requisições foram

fornecidos pela própria Globus Alliance, que possui certificados que servem
para testes de conectividade e funcionamento. Esses não habilitam todas as
funções do GSI, porém suas funcionalidades básicas ainda estão ativas.
Figura 21: Inicialização e encerramento do Globus.
4.3.5 Dificuldades Encontradas
Como todo trabalho exige, um grande estudo foi feito sobre o assunto.
Por ser uma área nova e ainda não amplamente explorada ainda não é fácil
achar documentacão boa e atualizada.
A codificacão de programas para o Globus Toolkit foi outra dificuldade
encontrada, já que o mesmo necessita de vários arquivos extras como
WSDL's, XML's e uma estrutura de diretórios extremamente complexos e
difíceis de se manter.

5. CONCLUSÃO
O objetivo principal deste trabalho era construir uma aplicação que
permitisse a coleta de certas informações sobre os recursos computacionais
de equipamentos pertencentes a uma grade sem que este software afetasse
ou interferisse incisivamente sobre a performance da máquina. Além disto
este software deveria ser fácil de instalar e não depender de outros
aplicativos de difícil instalação, como o WebMDS necessita.
Como demonstrado no item 4.3.1, a maioria das dependências
exitentes para o funcionamento do SCRG são as necessárias para a
instalação do próprio Globus Toolkit. As que não seguem este padrão são
facilmente encontrou adas em qualquer distribuição do sistema operacional
Linux.
Nas figuras 19 e 20 são mostradas os gráficos de utilização de CPU e
memória livre. Nesses mesmos pode-se perceber que mesmo em horário de
bastante utilização do computador, como horário de trabalho, o desempenho
em relação a estes dois aspectos estão em níveis muito satisfatórios.
Caso o projeto SCRG seja continuado, pode vir a se tornar uma
opção interessante para monitoramento de recursos computacionais para
Grids que utilizam o Globus Toolkit como middleware de comunicação.
Juntamente com o projeto desenvolvido pelo mestrando Glauco Antônio
Ludwig na universidade de Rio dos Sinos, que visa a contabilização de
utilização de CPU sobre cada processo submetido ao Grid, pode-se obter
uma arquitetura robusta e ao mesmo tempo leve para determinar dados
estatísticos sobre a grade.
Com os objetivos atingidos vizualisa-se os trabalhos futuros que são:
– Melhorar a interface, torná-la mais amigável e ergonômica;
– Elencar mais dados estatísticos e fazer a disponibilização
dos mesmos;
– Tornar o SCRG utilizável para mais sistemas operacionais
como OpenBSD, FreeBSD;
– Disponibilizar gráficos temporais de mês e ano;

– Realizar testes em grades reais e não somente em
ambiente simulado.
Finalizando, o SCRG torna a tarefa de monitoramento mais fácil,
rápida e leve, permitiondo que inclusive equipamentos desktop participem da
grade. Assim sendo o projeto descrito neste trabalho, torna-se uma
alternativa muito interessante ao sistema nativo do próprio Globus Toolkit.

6. REFERÊNCIAS BIBLIOGRÁFICAS
[1] The Globus Project, Globus Alliance, http://www.globus.org
[2] The GridBus Project, Universidade de Melbourne, GRIDS Lab,
http://www.gridbus.org
[3] InteGrade, Universidade de São Paulo,
http://gsd.ime.usp.br/integrade/
[4] OurGrid Projetc, Universidade Federal de Campina Grande,
http://www.ourgrid.org
[5] COULOURIS, George; DOLLIMORE, Jean; KINDBERG, Tim;
Distributed Systems, Concepts and Design; 3rd Edition; Editora Addison
Wesley, Ano 2001.
[6] CHEDE, Cezar Taurion; Grid Computing: Um Novo Paradigma
Computcional; 1a Edição; Editora Brasport, Ano 2004.
[7] GLOBUS ALLIANCE, Installing GT 4.0 (System Administrator
Guide. Disponível em
<http://www.globus.org/toolkit/docs/4.0/admin/docbook/>. Acesso em 24 de
junho de 2005.
[8] GLOBUS ALLIANCE, GT4 Key Concepts (A Globus Primer).
Disponível em:
<http://www.globus.org/toolkit/docs/4.0/admin/docbook/admin.pdf>. Acesso
em 01 de julho de 2005.
[9] GLOBUS ALLIANCE, GT 4.0 Component Fact Sheet: WS MDS
WebMDS. Disponível em:
<http://www.globus.org/toolkit/docs/4.0/info/webmds/WSMDSWebMDSFacts.
html>. Acesso em 29 de junho de 2005.
[10] THE GLOBUS SECURITY TEAM, Globus Toolkit Version 4 Grid
Security Infrastrutucre: A Standards Perspective, Version 4, 12 de Setembro
de 2005.
[11] WIKIPEDIA, Disponível em:
<http://en.wikipedia.org/wiki/Web_service>. Acesso em 07 de junho de 2006.
[12] WORLD WIDE WEB CONSORTIUM, Disponível em:

<http://www.w3.org/>. Acesso em 07 de junho de 2006.
[13] BERSTIS Viktor, Fundamentals of Grid Computing, RedBooks
Paper IBM, 2002.
[14] FERREIRA Luis, BERSTIS Viktor, ARMSTRONG Jonathan, et al,
Introduction to Grid Computing with Globus, RedBooks Paper IBM, 2003.
[15] FERREIRA Luis, WILSON B. Lee, MOSBY Dennis, et al, Grid
Computing with IBM Grid Tool Box, RedBooks Paper IBM, 2004.

7. APÊNDICE
7.1 Apêndice 1: Código Java do Kolector
package br.eti.zanetta.scrg.kolector;
import java.io.InputStream;
import de.fb12.gdt.GridService;
import de.fb12.gdt.GridAttribute;
import de.fb12.gdt.GridMethod;
@GridService (name = "Kolector",
namespace = "http://susie.zanetta.eti.br/scrg/kolector",
targetPackage = "br.eti.zanetta.scrg.kolector",
serviceStyle = "SSTYLE_FACTORY",
resourceStyle = "RSTYLE_MAGE",
operationProvider = "GetRPProvider")
public class Kolector {
@GridAttribute private String[] status;
@GridMethod public String[] getStatus() {
Runtime runtime = Runtime.getRuntime();
this.makeCPU(runtime);
this.makeMem(runtime);
this.makeProperties(runtime);
this.makeUptime(runtime);

return status;
}
public void setStatus(String[] status) {
this.status = status;
}
private void makeUptime(Runtime runtime){
try {
Process processo = runtime.exec("uptime");
processo.waitFor();
InputStream input = processo.getInputStream();
int output;
while ((output = input.read()) != -1) {
status[7] = (String) (status[7] + (char)output);
}
input.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
private void makeMem(Runtime runtime){
/*
* Descobrindo memória total

*/
try {
Process processo = runtime.exec("cat /proc/meminfo |grep
'MemTotal' | cut -d : -f2 ");
processo.waitFor();
InputStream input = processo.getInputStream();
int output;
while ((output = input.read()) != -1) {
status[2] = (String) (status[2] + (char)output);
}
input.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
Process processo = runtime.exec("cat /proc/meminfo |grep
'MemFree' | cut -d : -f2 ");
processo.waitFor();
InputStream input = processo.getInputStream();
int output;
while ((output = input.read()) != -1) {
status[3] = (String) (status[3] + (char)output);
}

input.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
private void makeCPU(Runtime runtime){
/**
* Descobrindo Modelo do processador
*/
try {
Process processo = runtime.exec("cat /proc/cpuinfo |grep name
| cut -d : -f2 ");
processo.waitFor();
InputStream input = processo.getInputStream();
int output;
while ((output = input.read()) != -1) {
status[0] = (String) (status[0] + (char)output);
}
input.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}

/**
* Descobrindo quantidade de MHz
*/
try {
Process processo = runtime.exec("cat /proc/cpuinfo |grep 'cpu
MHz' | cut -d : -f2 ");
processo.waitFor();
InputStream input = processo.getInputStream();
int output;
while ((output = input.read()) != -1) {
status[1] = (String) (status[1] + (char)output);
}
input.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
private void makeProperties(Runtime runtime){
this.status[4] = (String)System.getProperty("os.arch");
this.status[5] = (String)System.getProperty("os.name");
this.status[6] = (String)System.getProperty("os.version");
}

7.2 Apêndice 2: Código Java do KolectorClient:
package br.eti.zanetta.scrg.kolector.client;import org.apache.axis.message.addressing.Address;import org.apache.axis.message.addressing.EndpointReferenceType;import org.globus.axis.util.Util;import java.rmi.RemoteException;import br.eti.zanetta.scrg.kolector.impl.*;//import br.eti.zanetta.scrg.kolector.stubs.*;//import br.eti.zanetta.scrg.kolector.stubs.bindings.*;//import br.eti.zanetta.scrg.kolector.stubs.service.*;import br.eti.zanetta.scrg.kolector.kolectorService.stubs.*;import br.eti.zanetta.scrg.kolector.kolectorService.stubs.bindings.*;import br.eti.zanetta.scrg.kolector.kolectorService.stubs.service.*;import org.oasis.wsrf.lifetime.Destroy;import org.oasis.wsrf.properties.GetResourcePropertyResponse;import org.oasis.wsrf.properties.InvalidResourcePropertyQNameFaultType;import org.oasis.wsrf.properties.ResourceUnknownFaultType;import org.apache.axis.types.URI.MalformedURIException;import javax.xml.rpc.ServiceException;import org.oasis.wsrf.lifetime.ResourceNotDestroyedFaultType;import org.apache.commons.beanutils.BeanUtils;import java.lang.reflect.InvocationTargetException;import java.util.Iterator;import java.util.List;
public class KolectorClient implements KolectorNamespaces{
static { Util.registerTransport(); }
private KolectorPortType port =null;
private String instanceURI="http://127.0.0.1:8080/wsrf/services/KolectorService";
private String factoryURI="http://127.0.0.1:8080/wsrf/services/KolectorFactoryService";
private KolectorFactoryPortType factoryPort = null;
public KolectorPortType getPort(String factoryURI, String instanceURI) throws MalformedURIException, ServiceException, RemoteException { KolectorFactoryServiceAddressingLocator factoryLocator = new KolectorFactoryServiceAddressingLocator(); EndpointReferenceType factoryEPR, instanceEPR; KolectorServiceAddressingLocator locator = new KolectorServiceAddressingLocator(); factoryEPR = new EndpointReferenceType(); factoryEPR.setAddress(new Address(factoryURI));

factoryPort = factoryLocator.getKolectorFactoryPortTypePort(factoryEPR); CreateResourceResponse createResponse = factoryPort .createResource(new CreateResource()); instanceEPR = createResponse.getEndpointReference(); KolectorPortType port = locator.getKolectorPortTypePort(instanceEPR); return port; } public KolectorClient(String factoryURI,String instanceURI) throws MalformedURIException, RemoteException, ServiceException { this.port=getPort(factoryURI,instanceURI);this.factoryURI=factoryURI; this.instanceURI=instanceURI; }
/** * * @generated */public java.lang.String[] getStatus() throws RemoteException {
java.lang.String[] retVal= port.getStatus(new GetStatus()).getGetStatusReturn();
return retVal;
}
/** * @generated */public org.oasis.wsrf.properties.GetResourcePropertyResponse
getResourceProperty(javax.xml.namespace.QName getResourcePropertyRequest) throws org.oasis.wsrf.properties.InvalidResourcePropertyQNameFaultType, org.oasis.wsrf.properties.ResourceUnknownFaultType, RemoteException { return port.getResourceProperty(getResourcePropertyRequest); }
/** * @generated */public org.oasis.wsrf.properties.GetResourcePropertyResponse
getStatusAsResourceProperty() throws Exception, InvalidResourcePropertyQNameFaultType, ResourceUnknownFaultType, RemoteException { return getResourceProperty(RP_STATUS);
}
public static void main(String[] args) {
if (args[1] == null){
System.out.println("Uso: "+ args[0] +" <endereço IP>");System.exit(0);
}

String instanceURI="http://"+ args[1] +":8080/wsrf/services/KolectorService"; String factoryURI="http://"+ args[1] +":8080/wsrf/services/KolectorFactoryService";
try { KolectorClient client = new KolectorClient(factoryURI, instanceURI); String[] Status = client.getStatus(); int i = 0; for (i = 0 ; i < Status.length ; i++){ System.out.println(Status[i]); } } catch (Exception e) { System.out.println("Não foi possÃvel obter informações de Kolector no ip:" + args[1] + "\n"); e.printStackTrace(); } }
}





























