Embed Size (px)
Citation preview

IBM Research – Tokyo
September 3, 2015 © 2015 IBM Corporation
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures
Hiroshi Inoue†‡ and Kenjiro Taura‡
† IBM Research – Tokyo ‡ University of Tokyo

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Our Goal
Develop a fast algorithm for sorting an array of structures
Our approach:
To use SIMD-based multiway mergesort as the basis
To exploit SIMD instructions to accelerate mergesort kernel
To avoid random memory accesses that cause excessive
cache misses 2
struct Record {
int32_t key;
int32_t dataX;
int32_t dataY;
...
};
struct Record array[N];
key payload key payload
record i record i +1
payload

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Outline
Goal
Background: SIMD multiway mergesort for integers
Performance problems in existing approaches
Our approach
Performance results
3

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Background: Mergesort with SIMD for sorting integers [Inoue et al. PACT 2007, Chhugani et al. PVLDB 2008 etc.]
Merge operation for 32-bit or 64-bit integers can be
efficiently implemented with SIMD by:
– merging multiple values in vector registers using SIMD min
and max instructions (i.e. without conditional branches)
– integrating the in-register vector merge into usual
comparison-based merge operation
SIMD min and max instructions can accelerate sorting by
– parallelizing comparisons
– avoiding unpredictable conditional branches
4
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
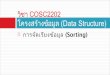
Background: SIMD-based merge for values in two vector registers
5
2 3
Input
two vector registers contain
four presorted values in each
Output
eight values in two vector
registered are now sorted
SIMD merging
one SIMD comparison and
“shuffle” operations for
each stage without
conditional branch
1 4 7 8
stage 1
stage 2
stage 3
input
output
< < < <
< <
< < <
2 3 5 6
1 4 7 8 5 6
sorted sorted
sorted
(example of odd-even merge)

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
21 23
17 18
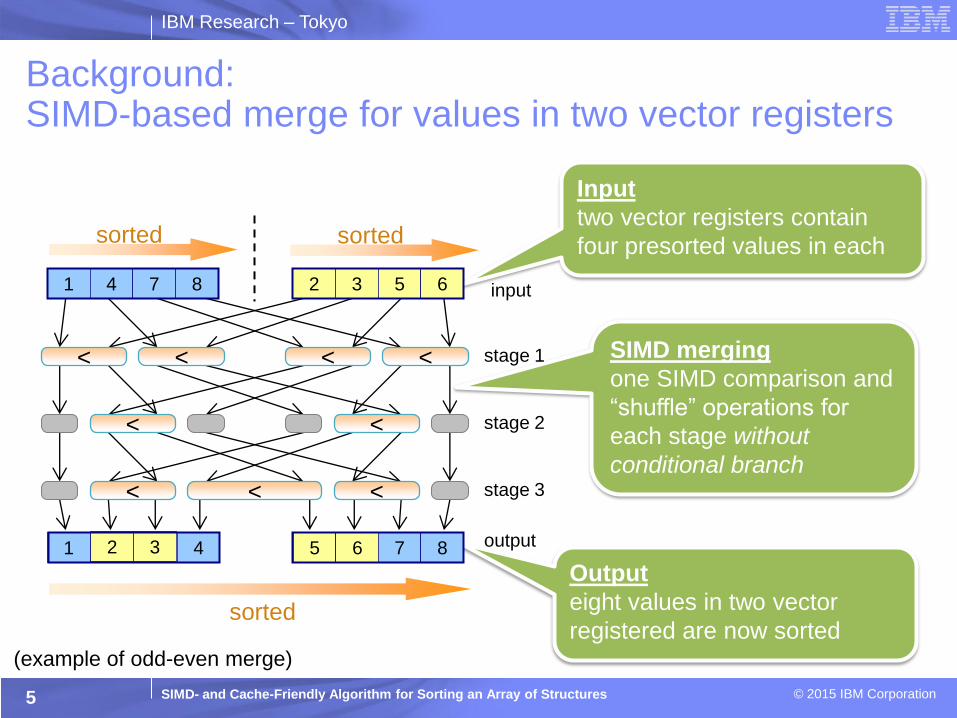
Background: Integrating Odd-even merge into usual merge
sorted array 1 1 4 7 9
sorted array 2 2 3 5 6
10 11 12 14
8 13 15 16
sorted
sorted
6

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
21 23
17 18
sorted array 1
sorted array 2
1 4 7 9 2 3 5 6 vector registers
1 4 7 9
2 3 5 6
10 11 12 14
8 13 15 16
register-level merge
Background: Integrating Odd-even merge into usual merge
sorted sorted
7

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
21 23
17 18
1 4 7 9
2 3 5 6
Background: Integrating Odd-even merge into usual merge
sorted array 1
sorted array 2
· · ·
· · ·
1 4 7 9 2 3 5 6 vector registers
10 11 12 14
8 13 15 16
sorted
8
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
1 4 7 9
2 3 5 6
21 23
17 18
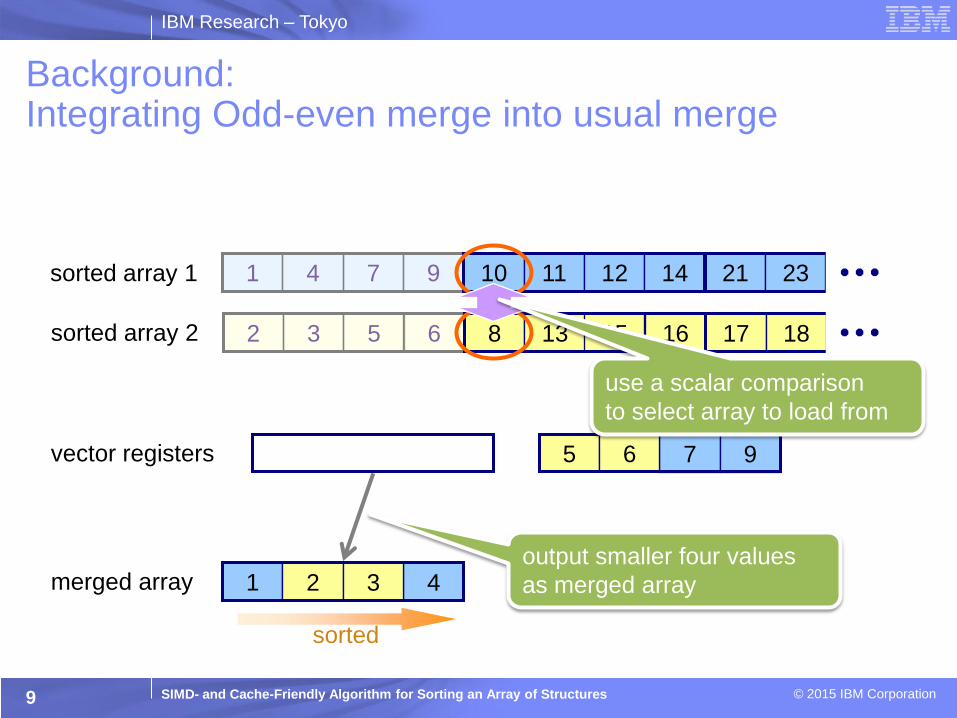
Background: Integrating Odd-even merge into usual merge
sorted array 1 10 11 12 14
sorted array 2
vector registers
merged array 1 4 2 3
8 13 15 16
7 9 5 6
use a scalar comparison
to select array to load from
output smaller four values
as merged array
sorted
9
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
1 4 7 9
2 3 5 6
21 23
17 18 8 13 15 16
8 13 15 16
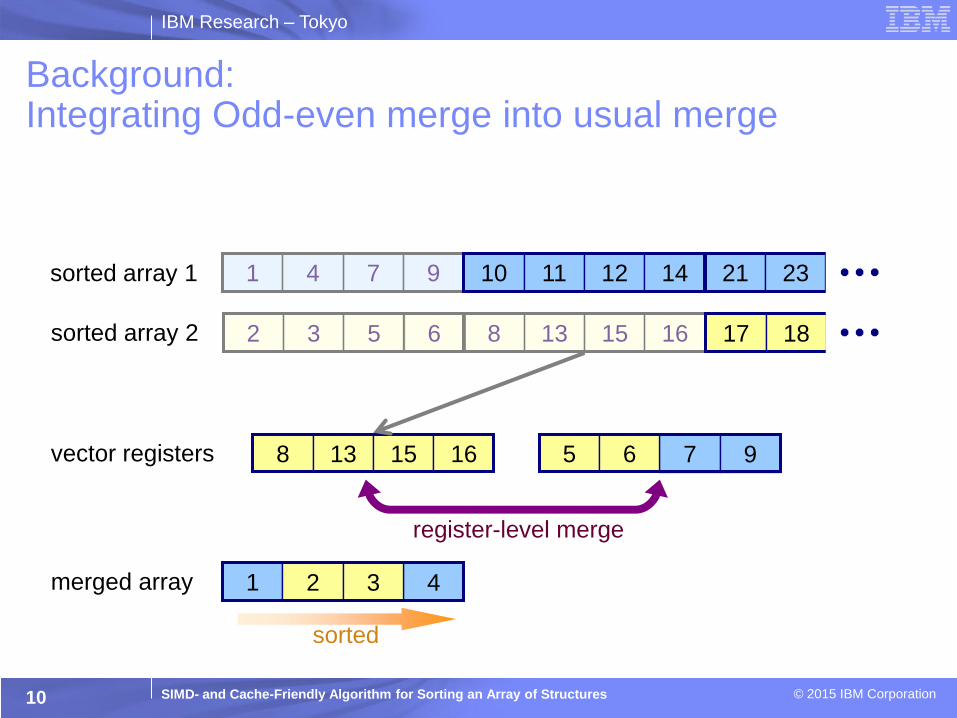
Background: Integrating Odd-even merge into usual merge
sorted array 1
sorted array 2
vector registers
merged array
register-level merge
7 9 5 6
1 4 2 3
10 11 12 14
sorted
10
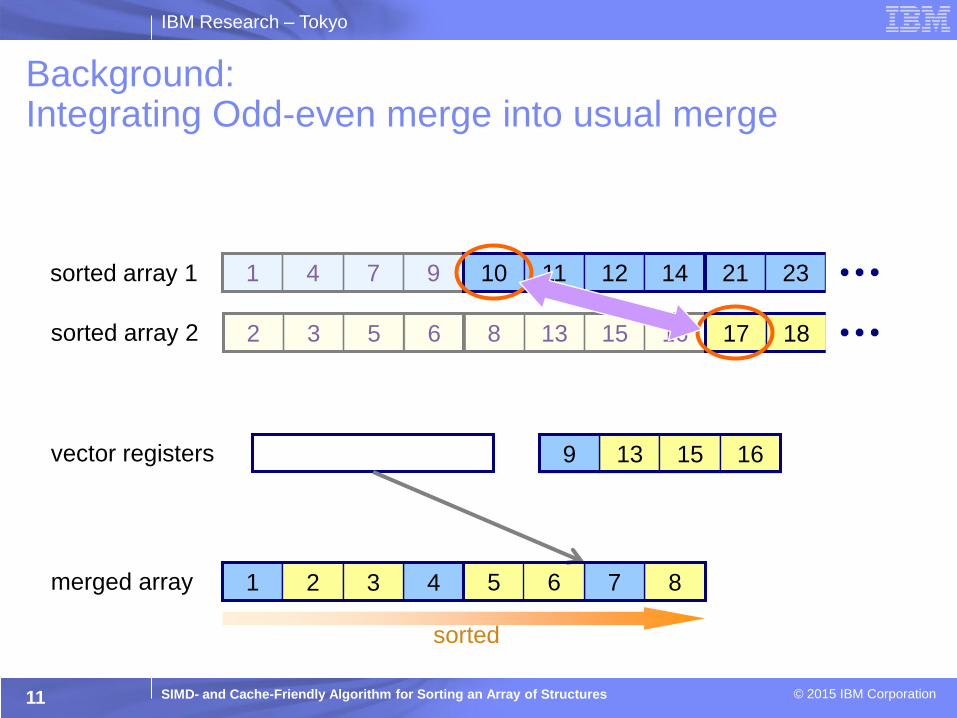
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
1 4 7 9
2 3 5 6 8 13 15 16
10 11 12 14
13 15 16 9
8
Background: Integrating Odd-even merge into usual merge
sorted array 1 21 23
sorted array 2 17 18
vector registers
merged array 7 5 6 1 4 2 3
sorted
11
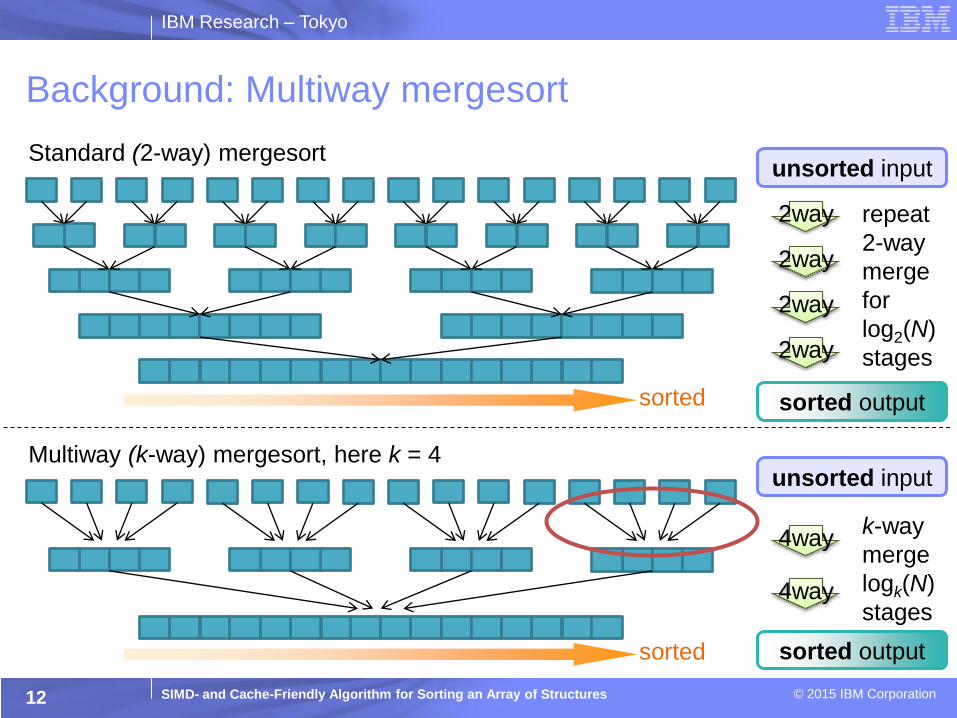
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Background: Multiway mergesort
12
unsorted input
sorted output
2way
2way
2way
2way
repeat
2-way
merge
for
log2(N)
stages
Standard (2-way) mergesort
sorted
unsorted input
sorted output
4way
4way
k-way
merge
logk(N)
stages
Multiway (k-way) mergesort, here k = 4
sorted
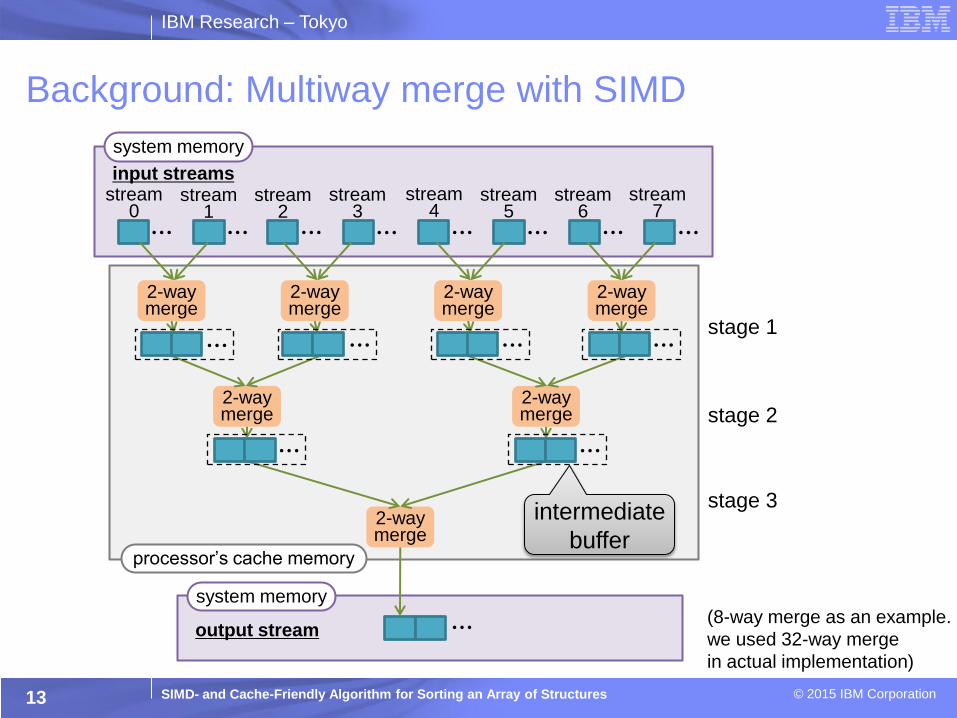
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
system memory
input streams
stream 0
stream 1
stream 2
stream 3
stream 4
stream 5
stream 6
stream 7
Background: Multiway merge with SIMD
13
intermediate
buffer
output stream
system memory
(8-way merge as an example.
we used 32-way merge
in actual implementation)
processor’s cache memory
2-way merge
2-way merge
2-way merge
2-way merge
2-way merge
2-way merge
2-way merge
stage 1
stage 2
stage 3

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Outline
Goal
Background: SIMD multiway mergesort for integers
Performance problems in existing approaches
Our approach
Performance results
14

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Existing approach for sorting structures with SIMD
For sorting structures with SIMD mergesort, a frequently
used approach (key-index approach) is
1. pack key and index for each record into an integer.
2. sort the key-index pairs with SIMD, and then
3. rearrange the records based on the sorted key-
index pairs
15
Costly due to random
accesses for main memory

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Performance problems in existing approaches
Existing approaches for sorting structures with SIMD
instructions have performance problems
– Key-index approach: SIMD friendly but not cache
friendly due to random memory accesses
– Direct approach: cache friendly but not SIMD friendly
Our approach takes the benefits of both approaches
16
key payload key payload
record i record i +1
because the keys are not
stored contiguously in
memory
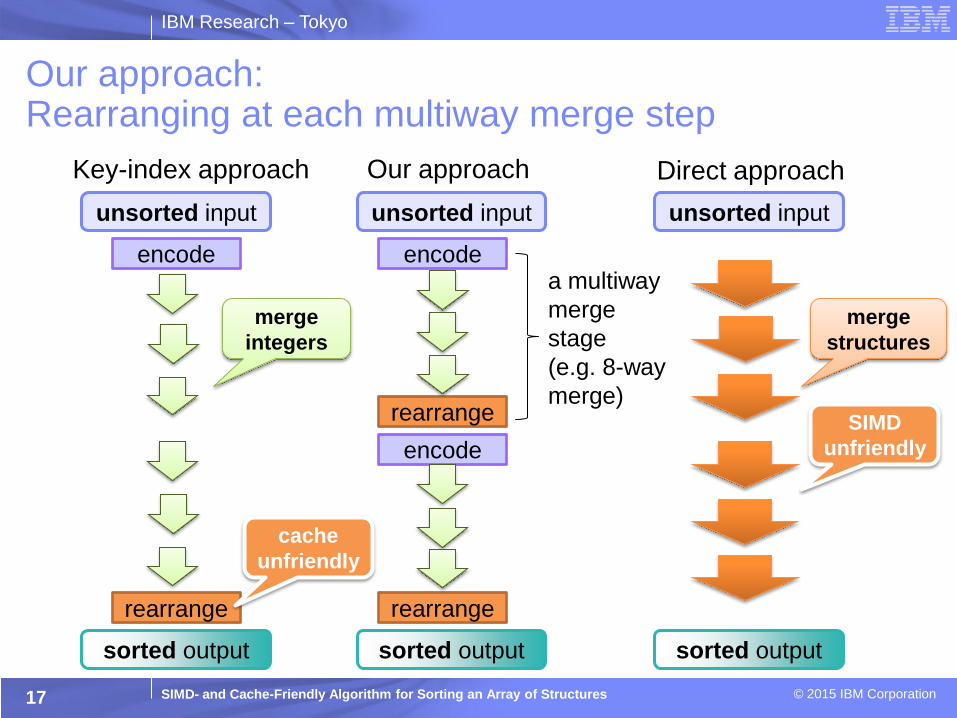
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
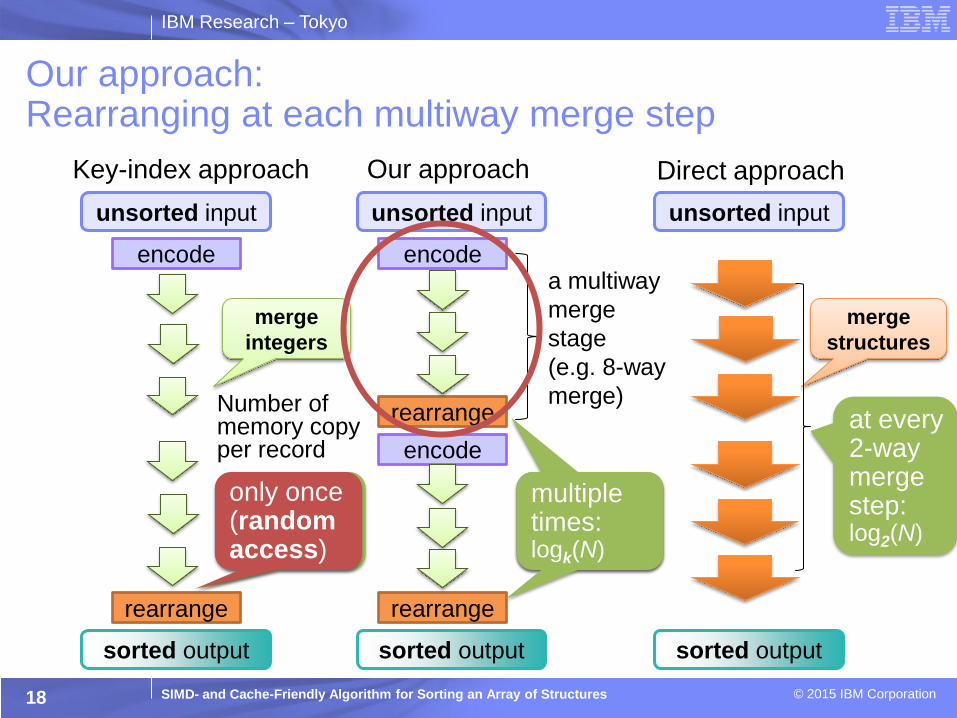
unsorted input
sorted output
Direct approach Key-index approach
encode
rearrange
unsorted input
sorted output
Our approach: Rearranging at each multiway merge step
17
Our approach
unsorted input
sorted output
a multiway
merge
stage
(e.g. 8-way
merge)
encode
rearrange
encode
rearrange
merge
integers
merge
structures
cache
unfriendly
SIMD
unfriendly
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
unsorted input
sorted output
Direct approach Key-index approach
encode
rearrange
unsorted input
sorted output
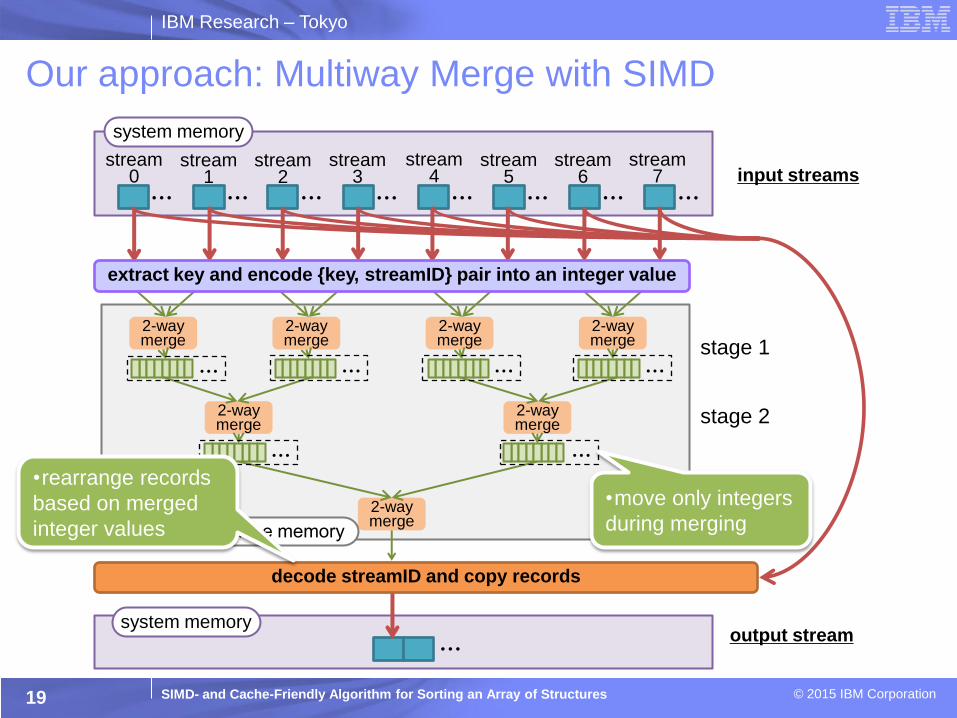
Our approach: Rearranging at each multiway merge step
18
Our approach
unsorted input
sorted output
a multiway
merge
stage
(e.g. 8-way
merge)
encode
rearrange
encode
rearrange
merge
integers
merge
structures
multiple times logk(N)
multiple times: logk(N)
at every 2-way merge step: log2(N)
Number of memory copy per record
only once only once (random access)
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
system memory
input streams
stream 0
stream 1
stream 2
stream 3
stream 4
stream 5
stream 6
stream 7
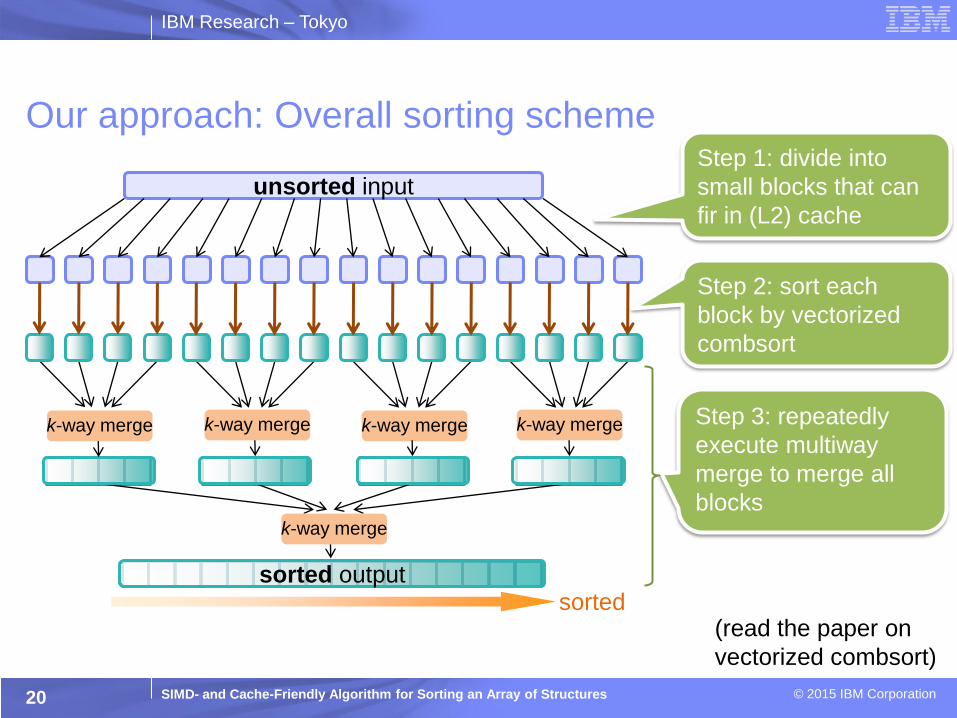
Our approach: Multiway Merge with SIMD
19
output stream system memory
2-way merge
2-way merge
2-way merge
2-way merge
2-way merge
2-way merge
2-way merge
stage 1
stage 2
stage 3
processor’s cache memory
extract key and encode {key, streamID} pair into an integer value
decode streamID and copy records
•move only integers
during merging
•rearrange records
based on merged
integer values
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Our approach: Overall sorting scheme
20
sorted
unsorted input
sorted output
k-way merge k-way merge k-way merge k-way merge
k-way merge
Step 1: divide into
small blocks that can
fir in (L2) cache
Step 2: sort each
block by vectorized
combsort
Step 3: repeatedly
execute multiway
merge to merge all
blocks
(read the paper on
vectorized combsort)

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Performance Evaluations
System
– 2.9-GHz Xeon E5-2690 (SandyBridge-EP) processors
• 2 sockets x 8 cores = 16 cores
• using SSE instructions (128-bit SIMD)
– 96 GB of system memory
– Redhat Enterprise Linux 6.4, gcc-4.8.2
We compared the performance of following algorithms
– Multiway mergesort (k = 32 way)
• Our approach, key-index approach, direct approach
– Radix sort, STL std::stable_sort, STL (unstable) std::sort
21
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
0
10
20
30
40
50
60
70
80
90
100
110
Our approach
Key-index approach
Direct approach
Radix sort STLstable_sort
STL sort(unstable)
executio
n ti
me (
sec)
with SIMD without SIMD
multiway mergesort
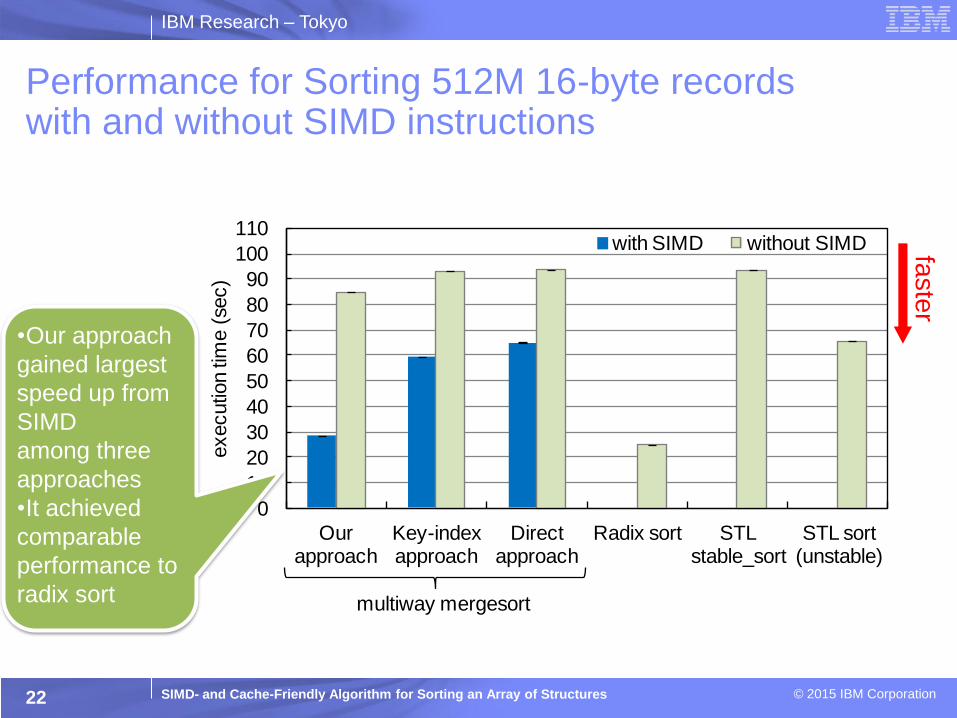
Performance for Sorting 512M 16-byte records with and without SIMD instructions
22
•Our approach
gained largest
speed up from
SIMD
among three
approaches
•It achieved
comparable
performance to
radix sort
faste
r
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
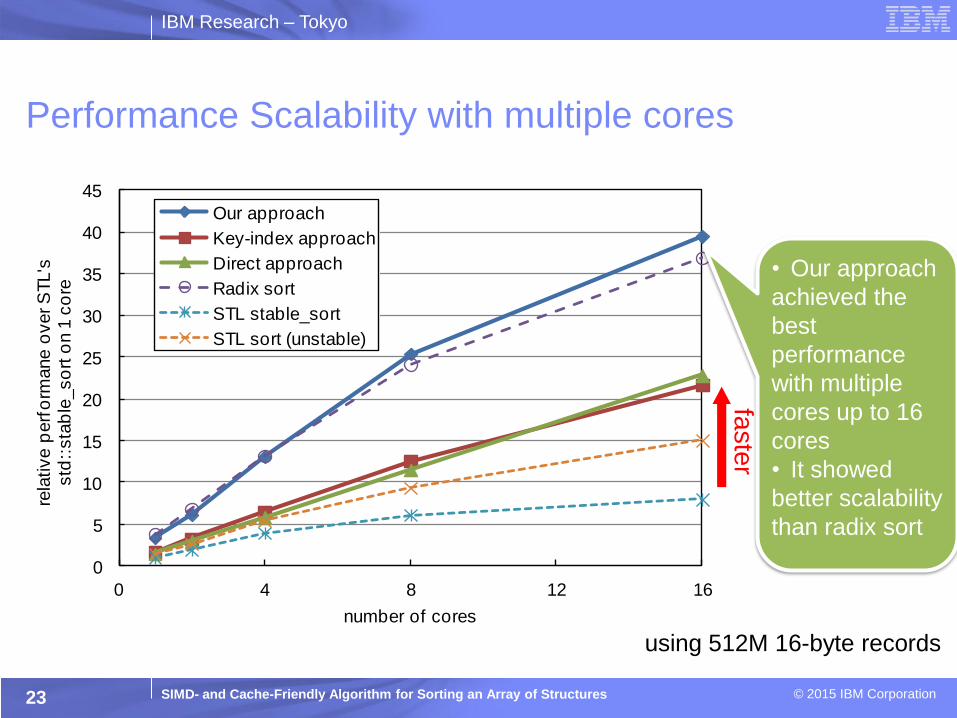
Performance Scalability with multiple cores
23
0
5
10
15
20
25
30
35
40
45
0 4 8 12 16
rela
tive p
erf
orm
ane o
ver S
TL's
std
::sta
ble
_so
rt o
n 1
co
re
number of cores
Our approach
Key-index approach
Direct approach
Radix sort
STL stable_sort
STL sort (unstable)
using 512M 16-byte records
• Our approach
achieved the
best
performance
with multiple
cores up to 16
cores
• It showed
better scalability
than radix sort
faste
r
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
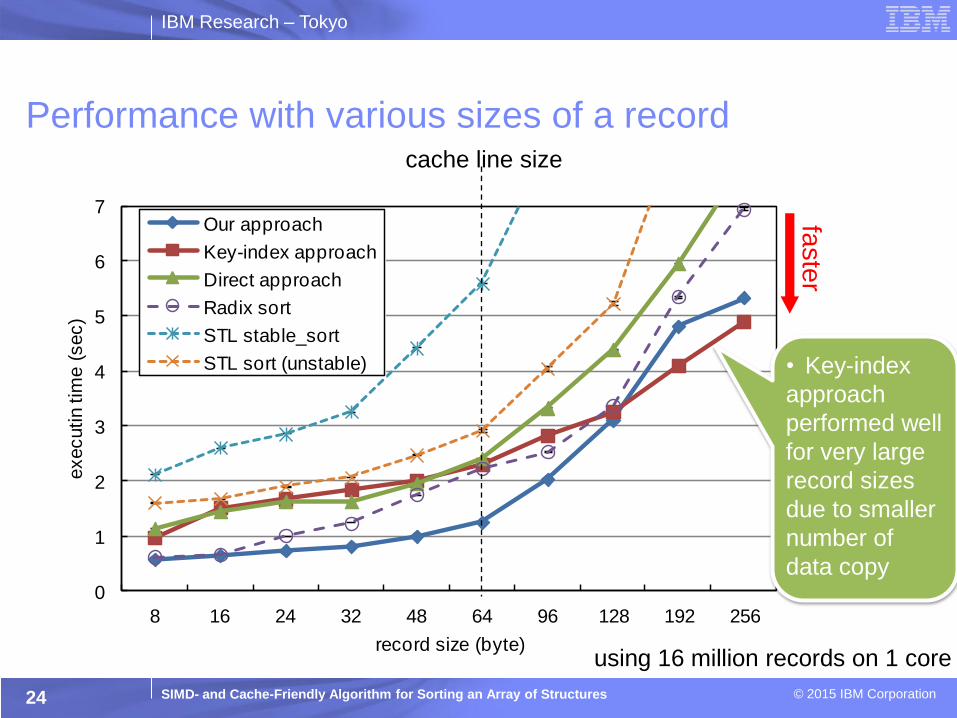
Performance with various sizes of a record
24
cache line size
0
1
2
3
4
5
6
7
8 16 24 32 48 64 96 128 192 256
executin tim
e (
sec)
record size (byte)
Our approach
Key-index approach
Direct approach
Radix sort
STL stable_sort
STL sort (unstable) • Key-index
approach
performed well
for very large
record sizes
due to smaller
number of
data copy
faste
r
using 16 million records on 1 core

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Summary
We developed a new algorithm for sorting an array of
structures, that enables
– efficient use of SIMD instructions
– efficient use of cache memory (no random accesses)
Our new algorithm outperformed the key-index
approaches in multiway mergesort especially when
each record is smaller than a cache line
It outperformed the radix sort for records larger than 16
byte and showed better scalability with multiple cores
Read the paper for more detail:
efficient 4-wide SIMD exploitation, results with 10-byte
ASCII key, sorting for variable-length strings
25

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
backup
26

IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
Optimization techniques: partial key comparison
To use 4-wide SIMD (32 bit x 4) instead of 2-wide SIMD
(64 bit x 2)
– Increasing data parallelism and giving the higher
performance
– Sorting based on a partial key
• We confirm that the sorted order is correct using the entire
key when rearranging records using scalar comparison
27
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
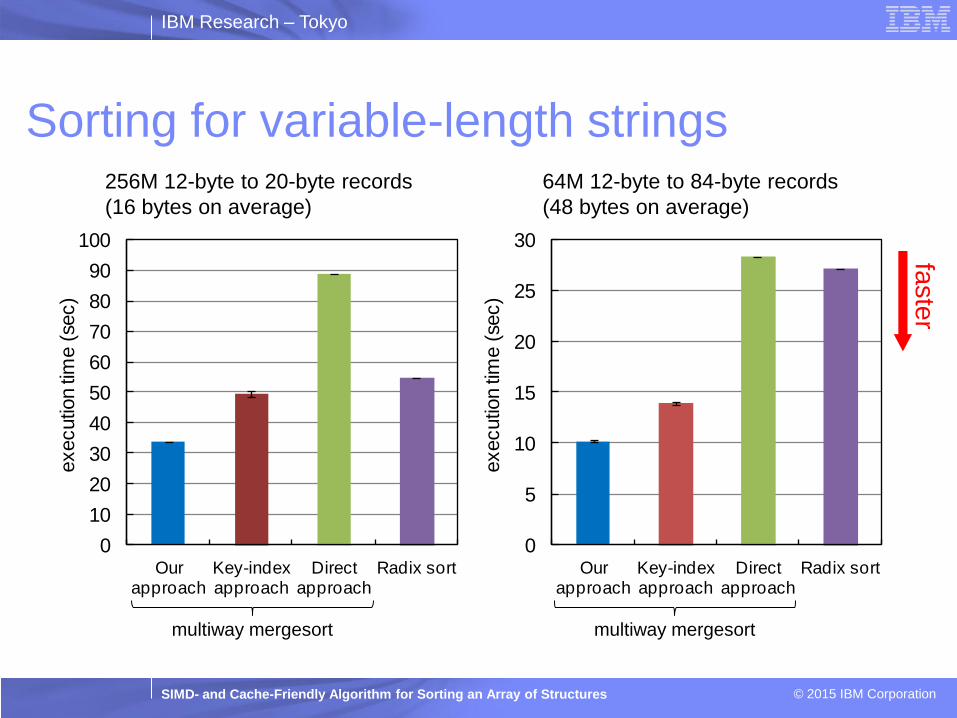
Sorting for variable-length strings 256M 12-byte to 20-byte records
(16 bytes on average)
64M 12-byte to 84-byte records
(48 bytes on average)
28
faste
r
0
10
20
30
40
50
60
70
80
90
100
Our approach
Key-index approach
Direct approach
Radix sort
executio
n ti
me (
sec)
0
5
10
15
20
25
30
Our approach
Key-index approach
Direct approach
Radix sort
executio
n ti
me (
sec)
multiway mergesort multiway mergesort
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
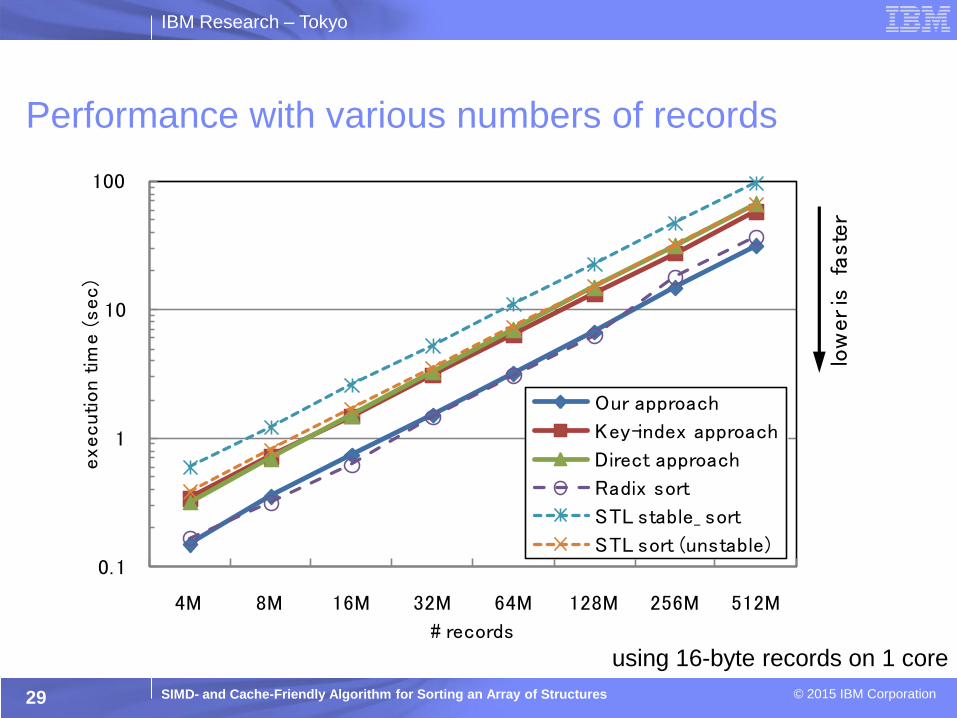
Performance with various numbers of records
0.1
1
10
100
4M 8M 16M 32M 64M 128M 256M 512M
execution t
ime (
sec)
# records
Our approach
Key-index approach
Direct approach
Radix sort
STL stable_ sort
STL sort (unstable)
low
er is
fa
ste
r
29
using 16-byte records on 1 core
IBM Research – Tokyo
SIMD- and Cache-Friendly Algorithm for Sorting an Array of Structures © 2015 IBM Corporation
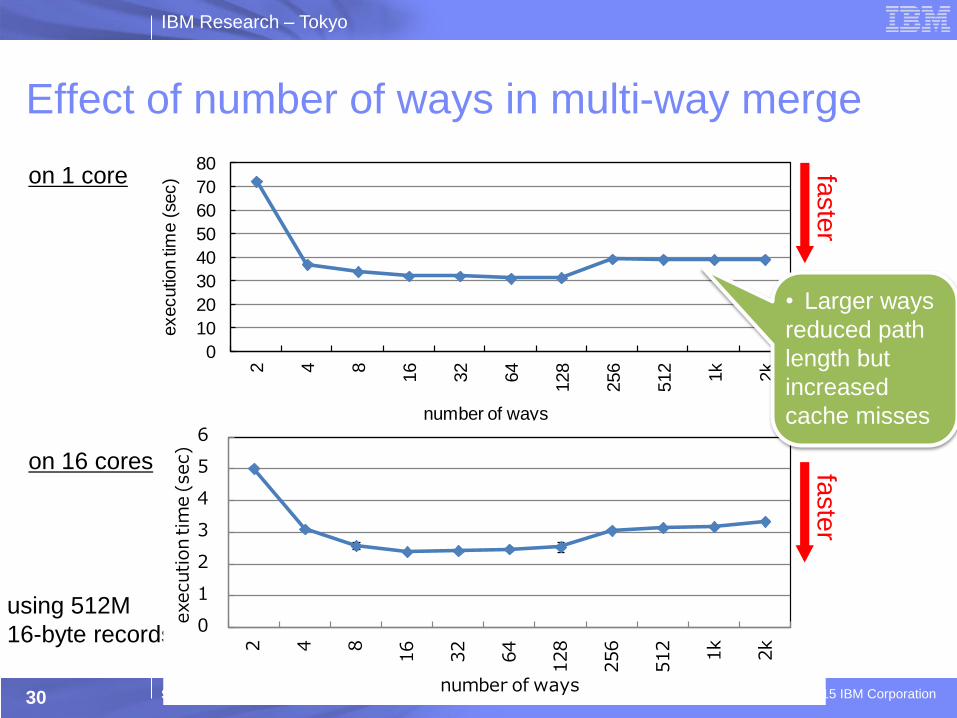
Effect of number of ways in multi-way merge
30
using 512M
16-byte records
0
10
20
30
40
50
60
70
80
2 4 8
16
32
64
128
256
512
1k
2k
executio
n ti
me (
sec)
number of ways
0
1
2
3
4
5
6
2 4 8
16
32
64
128
256
512
1k
2k
execution tim
e (sec)
number of ways
• Larger ways
reduced path
length but
increased
cache misses
on 1 core
on 16 cores
faste
r fa
ste
r












![[10] sorting](https://img.pdfslide.tips/doc/110x75/55b27a9bbb61eb95158b475e/10-sorting.jpg)