Embed Size (px)
Citation preview

Spis treściWprowadzenie do hurtowni danych.....................................................................................................5
Czym jest hurtownia danych?..........................................................................................................5Definicja Kimballa......................................................................................................................5Definicja Inmona.........................................................................................................................5
Co oferują hurtownie danych?.........................................................................................................6Czym różnią się hurtownie danych od baz operacyjnych?..............................................................6
Model wielowymiarowy.......................................................................................................................7Struktury Star i Snowflake oraz Star Transformation..........................................................................9
Star Transformation.........................................................................................................................9Schemat „Star”.................................................................................................................................9Schemat „Snowflake”....................................................................................................................11Star Query......................................................................................................................................12Star Transformation.......................................................................................................................15
Sposób działania Star Transformation......................................................................................15ETL – Ekstrakcja, przekształcanie i ładowanie..................................................................................18Problemy związane z czasem.............................................................................................................19
Opis problematyki..........................................................................................................................19Rozwiązanie problemów z czasem................................................................................................20
Zastępowanie zmienianych wartości nowymi..........................................................................20Stosowanie kontroli wersji........................................................................................................22Pobieranie najnowszej wersji danych.......................................................................................23Przeglądanie wersji danych obowiązujących we wskazanym okresie......................................25
Tabele zewnętrzne..............................................................................................................................26Oracle loader..................................................................................................................................27Oracle data pump...........................................................................................................................31Modyfikowanie tabel zewnętrznych..............................................................................................35Zmiana parametrów dostępu..........................................................................................................35Dodawanie kolumny......................................................................................................................36Modyfikacja kolumny....................................................................................................................36Usuwanie kolumny........................................................................................................................37Zmiana katalogu domyślnego........................................................................................................37Zmiana plików zewnętrznych........................................................................................................38
SQL*Loader.......................................................................................................................................39Podstawowe opcje jakie możemy użyć przy uruchamianiu SQL*Loadera:..................................46
Export i Import danych.......................................................................................................................52Export i Import danych za pomocą programów EXP/IMP............................................................52
Eksport całej bazy.....................................................................................................................53Eksport schematu/ schematów..................................................................................................53Eksport tabeli/tabel...................................................................................................................53Eksport przestrzeni tabel...........................................................................................................54Import całej bazy.......................................................................................................................54Import schematu........................................................................................................................54Import tabeli..............................................................................................................................54Import przestrzeni tabel.............................................................................................................55Eksport/import przy użyciu pliku parametrów.........................................................................55Informacje o parametrach jakie mozna wykorzystać podczas wykonywania eksportu............56Informacje o parametrach jakie mozna wykorzystać podczas wykonywania importu.............57
Export i Import danych za pomocą programów EXPDP/IMPDP..................................................58
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 1/311

Eksport całej bazy:....................................................................................................................59Eksport schematu/schematów:..................................................................................................59Eksport tabeli/tabel:..................................................................................................................60Eksport przestrzeni tabel:..........................................................................................................60Export przy użyciu opcji include:.............................................................................................60Export przy użyciu opcji exclude:.............................................................................................61Import całej bazy:......................................................................................................................61Import schematu/schematów:....................................................................................................61Import tabeli/tabel:....................................................................................................................62Import przestrzeni tabel:...........................................................................................................62
Różnice pomiędzy EXP/IMP a EXPDP/IMPDP...........................................................................63Poziomy izolacji w Oracle..................................................................................................................64
Wprowadzenie...............................................................................................................................64Włączanie poszczególnych trybów izolacji...................................................................................65Sposób działania poszczególnych poziomów izolacji w przykładach...........................................66SERIALIZABLE...........................................................................................................................70
Tryb flashback....................................................................................................................................75Instrukcja Merge.................................................................................................................................77Wyrażenie CASE................................................................................................................................89Operatory Exists i Not Exists.............................................................................................................93Grupowanie i funkcje agregujące.......................................................................................................95
Funkcje agregujące........................................................................................................................95AVG...........................................................................................................................................95COUNT.....................................................................................................................................95MAX.........................................................................................................................................96SUM..........................................................................................................................................96
Grupowanie....................................................................................................................................97group by....................................................................................................................................97Klazula having..........................................................................................................................98Rollup .......................................................................................................................................99Cube........................................................................................................................................101Grouping.................................................................................................................................103Grouping sets..........................................................................................................................105
Pivot (tabele przestawne)..................................................................................................................112Wykorzystanie funkcji analitycznych...............................................................................................125
Partycje....................................................................................................................................125Okna........................................................................................................................................125Bieżący wiersz........................................................................................................................125Ogólna składnia funkcji analitycznych...................................................................................125Wprowadzenie do funkcji analitycznych na podstawie funkcji rankingu..............................126Składnia analitycznych funkcji rankingu................................................................................126Dense_rank()...........................................................................................................................127Podział wierszy na partycje.....................................................................................................128Rank()......................................................................................................................................131Row_number()........................................................................................................................132Wyświetlanie TOP N wierszy.................................................................................................133
Funkcje strumieniowe......................................................................................................................136Tablice..............................................................................................................................................140
Atrybuty tablic.............................................................................................................................141Operacje masowe..............................................................................................................................142
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 2/311

Wyjątki w operacjach masowych................................................................................................149Widoki zmaterializowane.................................................................................................................152
Odświeżanie widoków zmaterializowanych................................................................................156Automatyczne odświeżanie widoków zmaterializowanych........................................................161Mechanizm query rewrite............................................................................................................164
Tabele partycjonowane.....................................................................................................................168Tworzenie tabeli partycjonowanej...............................................................................................168Tabela utworzona względem klucza range partitioning...............................................................169Tabela utworzona względem klucza list partitioning...................................................................171Tabela utworzona względem klucza hash partitioning................................................................173Automatyczne dodawanie nowych partycji.................................................................................175Podpartycje..................................................................................................................................178Indeksowanie partycji..................................................................................................................180Zarządzanie tabelami partycjonowanymi....................................................................................181
Usuwanie partycji z tabeli.......................................................................................................181Dodawanie nowej partycji do tabeli........................................................................................181Dzielenie partycji....................................................................................................................181Scalanie partycji......................................................................................................................182Czyszczenie partycji................................................................................................................182Przeniesienie partycji tabeli do innej przestrzeni tabel...........................................................182
Wprowadzenie do optymalizacji SQL..............................................................................................185Główne powody nieefektywnego wykonywania zapytań...........................................................187Przykłady nieoptymalnie napisanych zapytań.............................................................................188Co więc możemy zrobić by zapytania na naszej bazie danych wykonywały się efektywnie?....190Kilka wskazówek w projektowaniu struktur danych...................................................................191
Wprowadzenie do optymalizatora kosztowego................................................................................192Kolejne kroki wykonywania zapytania SQL...............................................................................192Do czego służy optymalizator kosztowy?...................................................................................194
Interpretacja planów wykonania.......................................................................................................196Przeglądanie planów wykonania.................................................................................................197
Metody dostępu do danych...............................................................................................................201Tabele...........................................................................................................................................202
Full Table Scan........................................................................................................................202Rowid Scan.............................................................................................................................203Sample Table Scan..................................................................................................................204
Indeksy.........................................................................................................................................205Rodzaje indeksów...................................................................................................................205Skany po indeksach.................................................................................................................206Unique Scan............................................................................................................................206Range Scan..............................................................................................................................207Full Scan.................................................................................................................................208Fast Full Scan..........................................................................................................................209Skip Scan.................................................................................................................................209Łączenie indeksów..................................................................................................................211Skany po tabelach indeksowych.............................................................................................212Operatory złączeniowe............................................................................................................213Nested loops............................................................................................................................213Sort Merge Join.......................................................................................................................214Hash join.................................................................................................................................215Cartesian Join..........................................................................................................................216
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 3/311

Łączenia nierównościowe (OUTER)......................................................................................217Antijoin...................................................................................................................................218Indeksy bitmapowe łączeniowe..............................................................................................219
Statystyki..........................................................................................................................................223 Czym są statystyki?....................................................................................................................223Rodzaje statystyk.........................................................................................................................224
Statystyki tabel........................................................................................................................224Statystyki indeksów................................................................................................................224Statystyki systemowe..............................................................................................................224Statystyki kolumn...................................................................................................................224
Histogramy...................................................................................................................................225Odświeżanie statystyk i histogramów..........................................................................................225
Odświeżanie statystyk systemowych:.....................................................................................225Odświeżanie statystyk indeksu:..............................................................................................225Odświeżanie statystyk tabeli...................................................................................................225Odświeżanie statystyk schematu.............................................................................................226Odświeżanie statystyk całej bazy danych...............................................................................226Kasowanie statystyk................................................................................................................226Blokowanie statystyk..............................................................................................................226Odtwarzanie statystyk.............................................................................................................227Historia statystyk.....................................................................................................................227
Prosty interfejs WEBowy dla hurtowni – Oracle Apex....................................................................228Instalacja poprzez PL/SQL Gateway...........................................................................................228Tworzenie przestrzeni roboczej...................................................................................................240Zarządzanie administratorami i użytkownikami w przestrzeni roboczej....................................243Tworzenie aplikacji......................................................................................................................250
Dodawanie raportów...............................................................................................................265Edycja stron.................................................................................................................................270Wykresy.......................................................................................................................................273Wykorzystanie procedur PL/SQL................................................................................................289Elementy nawigacyjne – listy......................................................................................................294Zarządzanie menu........................................................................................................................302
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 4/311

Wprowadzenie do hurtowni danych
Czym jest hurtownia danych?
Hurtownie danych nie mają spójnej definicji uznawanej powszechnie. Istnieją dwa główne nurty oparte o twierdzenia Billa Inmona i Ralpha Kimballa.
Definicja Kimballa
„Hurtownia danych jest to system, który pozyskuje dane z systemów źródłowych, przekształca je i ładuje do wielowymiarowych struktur, a następnie dostarcza zapytania i analizy wspierające podejmowanie decyzji”
Definicja Inmona
„Hurtownia to baza danych mająca służyć wspomaganiu procesu podejmowania decyzji która jest :
• zorientowana tematycznie
• nieulotna
• zintegrowana
• zróżnicowana czasowo
”
Zorientowanie tematyczne odnosi się do zorientowania bazy na jeden określony temat – np. analiza sprzedaży. Nieulotność – hurtownia przechowuje dane w sposób trwały. Jeśli pojawią się nowe wersje danych, archiwalne powinny tam pozostać ewentualnie w jakiś sposób oznaczone. Zintegrowanie odnosi się do spójności formatów, postaci a także np. sposobu kodowania. Zróżnicowana czasowo oznacza że hurtownia przechowuje dane archiwalne.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 5/311

Co oferują hurtownie danych?
• Odseparowanie danych niezbędnych do analiz od systemów transakcyjnych• Przetworzenie danych do postaci gotowej do analiz• Zagregowanie danych z różnych źródeł w jednym miejscu • Ujednolicenie danych (np. formatu daty)• Agregaty uwzględniające różne poziomy granulacji
Czym różnią się hurtownie danych od baz operacyjnych?
• Bazy danych optymalizuje się pod kątem aktualizacji danych, a hurtownie pod kątem ich czytania (przykładowo w bazach OLTP nie powinno używać się indeksów bitmapowych ze względu na specyfikę zakładania przez nie blokad podczas aktualizacji danych)
• Hurtownie zazwyczaj są oparte o struktury typu star czy snowflake, ponadto często są również zdenormalizowane.
• W bazach OLTP dane ciągle się zmieniają, w hurtowniach są z reguły nieulotne.
• W hurtowniach danych gromadzone są dane historyczne, które nie są przechowywane w bazach operacyjnych.
• Dane w hurtowniach często pochodzą z różnych źródeł i są cyklicznie ładowane.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 6/311

Model wielowymiarowy
Hurtownie często opisywane są jako struktury wielowymiarowe. Ale co to właściwie oznacza? Przypuśćmy że mamy do czynienia z hurtownią danych firmy szkoleniowej ;) Analizie podlega sprzedaż szkoleń z różnych dziedzin, w różnych okresach i różnych rejonach kraju. Informacje o transakcjach sprzedaży będą gromadzone w tabelce centralnej (nazywanej w hurtownianej nomenklaturze tabelą faktów), informacje rozszerzające do których odnoszą się wiersze z tabeli faktów znajdują się w tabelach wymiarów. Struktura przedstawiona poniżej jest klasycznym przykładem struktury schematu gwiazdy występującej bardzo często w hurtowniach danych.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 7/311

Analitycy odpytują bazę w celu odpowiedzi na pytania takie jak:
• Jaka była suma sprzedaży szkoleń z dziedziny DB2 na Śląsku w 2006 roku?
• Jaki okres w historii firmy był najlepszy?
• Która dziedzina szkoleń sprzedawała się najlepiej na Pomorzu w całym roku 2006?
Gdyby wyobrazić sobie przedstawienie tabel z poprzedniej ilustracji uzyskalibyśmy obraz jak powyżej. Taka struktura pozwala nam się poruszać po danych jak po swoistej przestrzeni, z tym że w tym przypadku nie jest to przestrzeń fizyczna tylko przestrzeń danych. Struktura typu gwiazda pozwala nam w łatwy sposób przeprowadzać analizy oparte o wiele wymiarów. Wymiarów może być oczywiście więcej niż 3, jednak ciężko byłoby to przedstawić jako rysunek ;)
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 8/311

Struktury Star i Snowflake oraz Star Transformation
Star Transformation
Star Transformation jest metodą łączenia tabel używaną w środowiskach hurtowni danych w celu podniesienia wydajności wykonywania zapytań. Ta metoda zastępuje tradycyjne sposoby łączenia tabel : nested loops, sort merge join i hash join. Metoda Star Transformation jest dostępna od wersji 8i Oracle.
Schemat „Star”
Schemat gwiazdy jest najprostszym schematem hurtowni danych. Nazwa pochodzi od konstrukcji samego schematu, przypomina ona nieco kształt gwiazdy. W tym schemacie mamy jedną tabelę faktu , stanowiącą centralny element schematu, oraz przynajmniej dwie tabele wymiarów będące rozszerzeniami tabeli faktu.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 9/311
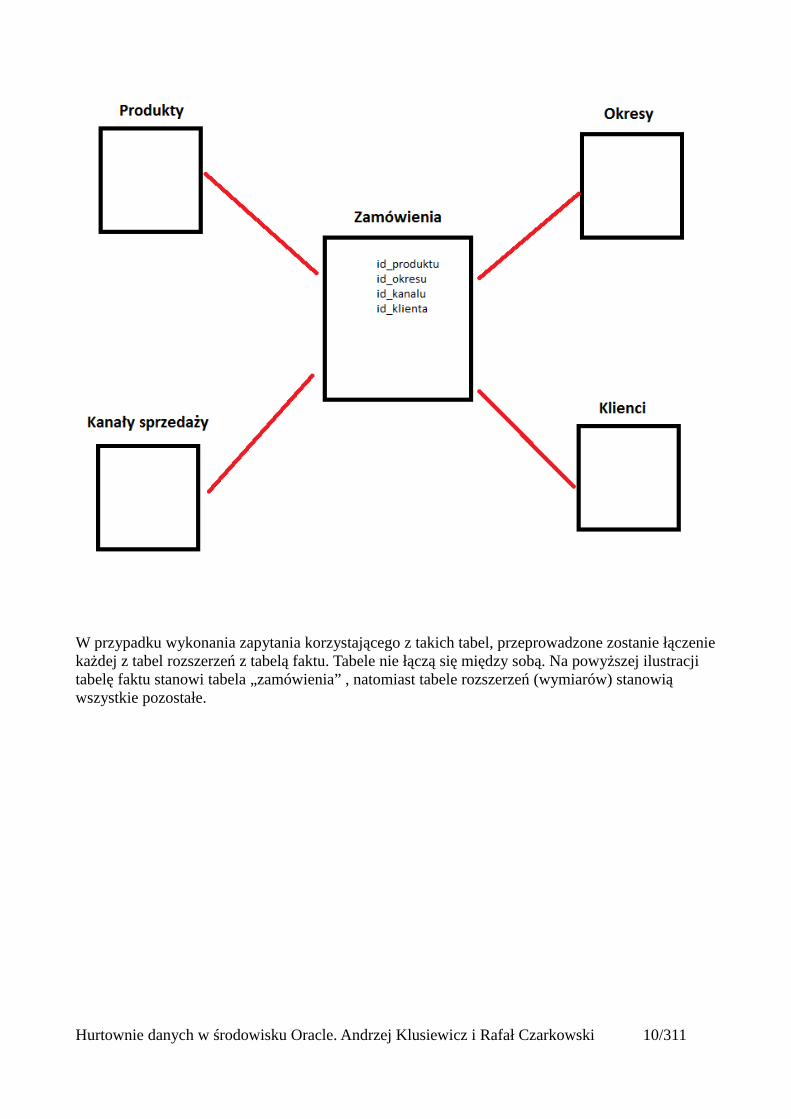
W przypadku wykonania zapytania korzystającego z takich tabel, przeprowadzone zostanie łączeniekażdej z tabel rozszerzeń z tabelą faktu. Tabele nie łączą się między sobą. Na powyższej ilustracji tabelę faktu stanowi tabela „zamówienia” , natomiast tabele rozszerzeń (wymiarów) stanowią wszystkie pozostałe.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 10/311
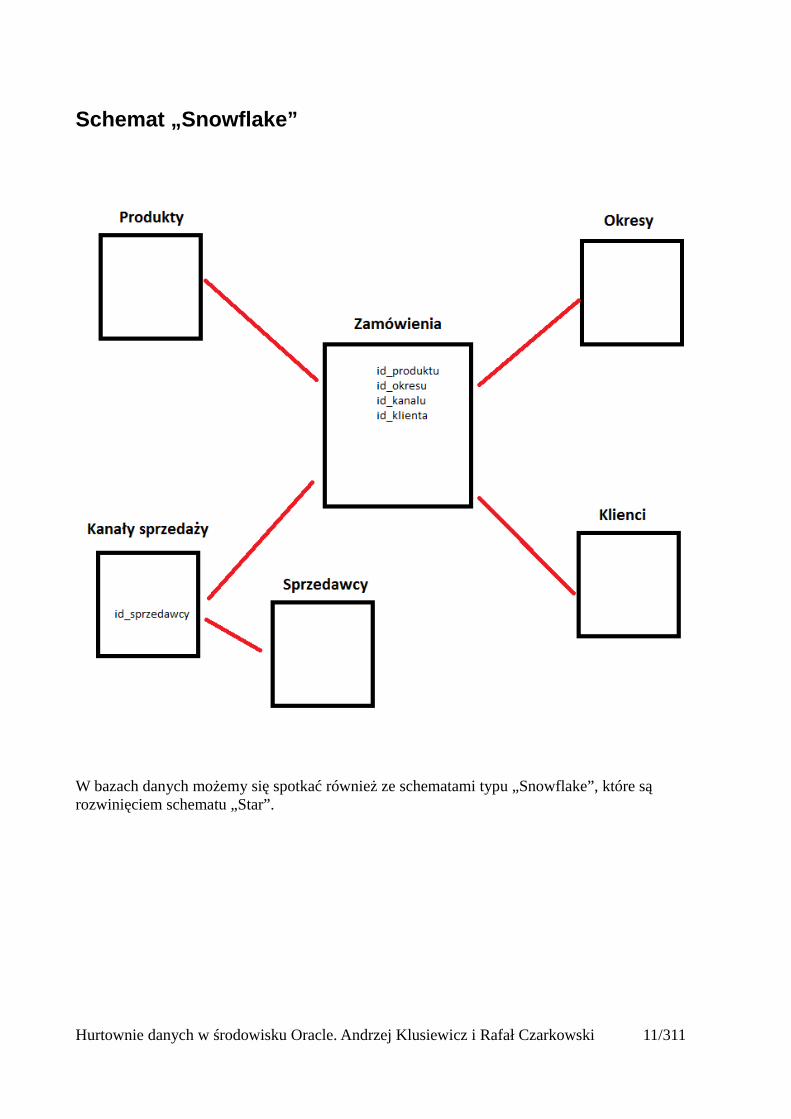
Schemat „Snowflake”
W bazach danych możemy się spotkać również ze schematami typu „Snowflake”, które są rozwinięciem schematu „Star”.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 11/311

Star Query
Ideą Star Transformation jest zmniejszenie ilości full table skanów dużych tabelach – w tym przypadku na tabeli faktu – sales. W typowych zapytaniach na strukturze gwiazdy duża tabela faktujest łączona z wielokrotnie mniejszymi tabelami rozszerzeń. Tabela faktu ma zazwyczaj po jednym kluczu obcym dla każdej tabeli rozszerzenia.
select ch.channel_class,cu.cust_city,t.calendar_year,sum(s.amount_sold) suma_sprzedazyfrom sales s,channels ch,customers cu, times t wheres.time_id=t.time_id and ch.channel_id=s.channel_idand s.cust_id=cu.cust_id and channel_class in ('Direct','Internet') and cust_state_province='CA' and t.calendar_year ='1998'group by ch.channel_class,cu.cust_city,t.calendar_year;
Bez stosowania Star Transformation, łączenie przebiega w taki sposób, że tabela faktu (w tym przypadku tabela Sales) jest łączona osobno z każdą z tabel. Mimo, że w efekcie końcowym zapytania zostanie wyświetlona bardzo nieznaczna część tabeli sales, przeprowadzany jest na niej full scan. Im większa jest tabela faktu, tym większa utrata wydajności. Przyjrzyjmy się sposobowi wykonania tego zapytania w „tradycyjny” sposób:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 12/311
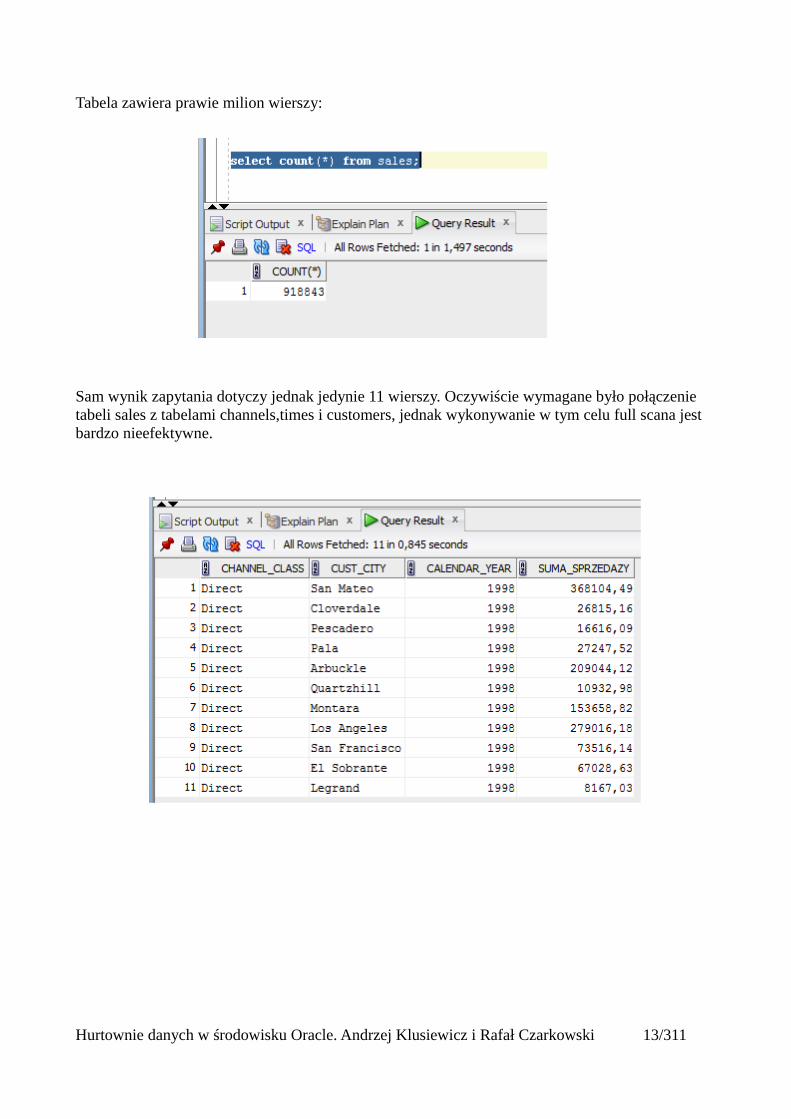
Tabela zawiera prawie milion wierszy:
Sam wynik zapytania dotyczy jednak jedynie 11 wierszy. Oczywiście wymagane było połączenie tabeli sales z tabelami channels,times i customers, jednak wykonywanie w tym celu full scana jest bardzo nieefektywne.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 13/311

Star Transformation
Optymalizator kosztowy rozpoznaje takie struktury i stosuje dla zapytań na nich specjalnie zoptymalizowane plany wykonania przy użyciu metody Star Transformation. Aby jednak było to możliwe, musi zostać spełnione kilka warunków:
• na kluczach obcych tabeli faktu powinny zostać założone indeksy bitmapowe. W tym przypadku osobne indeksy bitmapowe powinny zostaćzałożone na kolumnach: channel_id,time_id,cust_id tabeli sales.
• Parametr STAR_TRANSFORMATION_ENABLED musi być włączony dla sesji lub bazy danych.
• Muszą być przynajmniej dwie tabele wymiarów i jedna tabela faktu.• Statystyki wszystkich obiektów biorących udział w zapytaniu muszą być świeże.
Kiedy te warunki będą spełnione, optymalizator kosztowy będzie automatycznie wybierał metodę Star Transformation która jest bardzo efektywna dla zapytań typu star query (tj. takich jak omawiane wcześniej). Dla użytkownika fakt zmiany metody wykonywania zapytania jest niezauważalny (poza przyspieszeniem :) ). Zastosowanie Star Transformation nigdy nie doprowadzido odmiennych niż pierwotne wyników zapytania.
Sposób działania Star Transformation
W jaki sposób działa metoda Star Transformation? Przebiega zasadniczo w dwóch fazach.W pierwszej fazie, system stosuje filtry na tabeli rozszerzeń i określa wartości klucza głownego dla wybranych wierszy. W drugiej fazie mając już ograniczone dane z tabeli rozszerzenia, system przeszukuje indeksy bitmapowe założone na kluczach obcych tabeli faktu w celu wybrania tylko niezbędnych wierszy z tabeli faktu.
Przeprowadzimy teraz testy. Włączam parametr star_transformation_enabled dla sesji i ponawiam generowanie planu wykonania dla tego samego zapytania:
alter session set star_transformation_enabled=true;
select ch.channel_class,cu.cust_city,t.calendar_year,sum(s.amount_sold) suma_sprzedazyfrom sales s,channels ch,customers cu, times t wheres.time_id=t.time_id and ch.channel_id=s.channel_idand s.cust_id=cu.cust_id and channel_class in ('Direct','Internet') and cust_state_province='CA' and t.calendar_year ='1998'group by ch.channel_class,cu.cust_city,t.calendar_year;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 14/311

Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 15/311
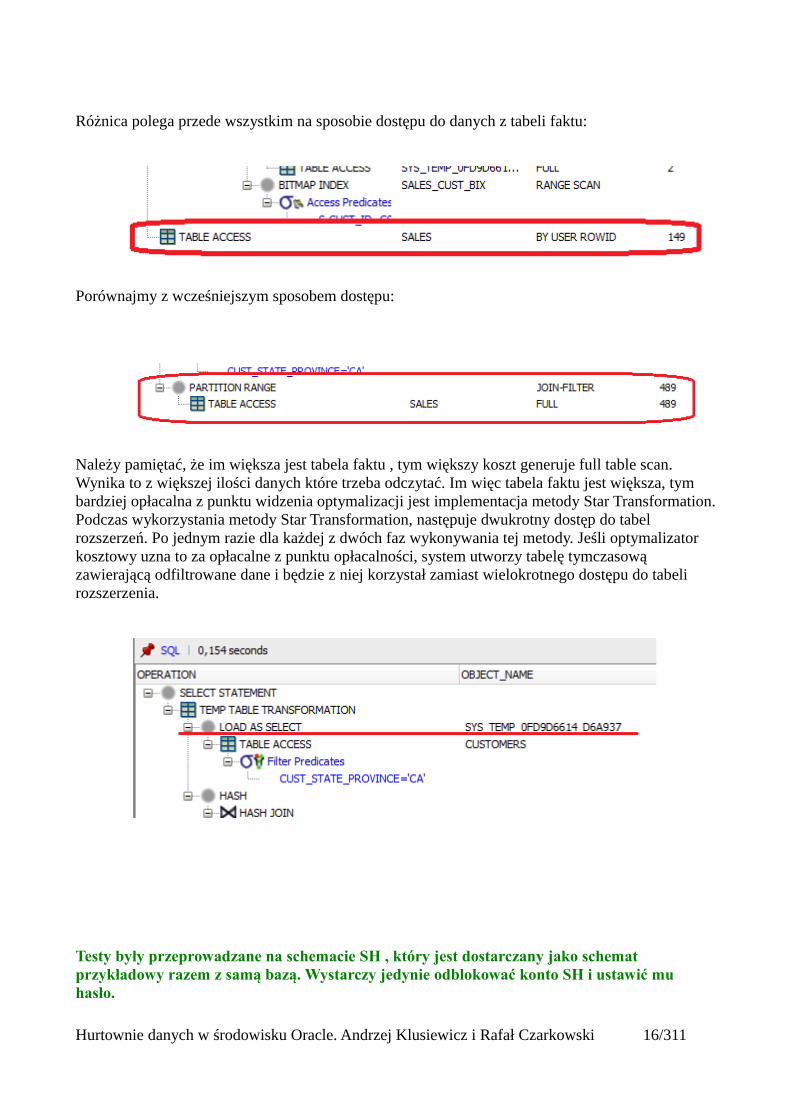
Różnica polega przede wszystkim na sposobie dostępu do danych z tabeli faktu:
Porównajmy z wcześniejszym sposobem dostępu:
Należy pamiętać, że im większa jest tabela faktu , tym większy koszt generuje full table scan. Wynika to z większej ilości danych które trzeba odczytać. Im więc tabela faktu jest większa, tym bardziej opłacalna z punktu widzenia optymalizacji jest implementacja metody Star Transformation.Podczas wykorzystania metody Star Transformation, następuje dwukrotny dostęp do tabel rozszerzeń. Po jednym razie dla każdej z dwóch faz wykonywania tej metody. Jeśli optymalizator kosztowy uzna to za opłacalne z punktu opłacalności, system utworzy tabelę tymczasową zawierającą odfiltrowane dane i będzie z niej korzystał zamiast wielokrotnego dostępu do tabeli rozszerzenia.
Testy były przeprowadzane na schemacie SH , który jest dostarczany jako schemat przykładowy razem z samą bazą. Wystarczy jedynie odblokować konto SH i ustawić mu hasło.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 16/311

ETL – Ekstrakcja, przekształcanie i ładowanie
Zanim dane pojawią się w hurtowni muszą przejść kilka etapów. W pierwszej kolejności muszą zostać pobrane z systemów źródłowych – np. innych baz danych, płaskich plików CSV, usług sieciowych. Ten proces nazywamy ekstrakcją. Następnie muszą zostać przekształcone do postaci właściwej dla naszej hurtowni. Zostają wyliczone agregaty, formaty dat, walut etc. zostają zunifikowane, dane są czyszczone z błędów – ten proces nazywamy przekształcaniem. Na koniec pobrane i przekształcone dane muszą zostać załadowane do hurtowni implementując jednocześnie np. metody rozwiązywania problemów ze zmiennością danych w czasie, dostosowując się do struktur logicznych w samej hurtowni. Ten ostatni proces nazywamy ładowaniem.
Sama nazwa procesów ETL bierze się z angielskich słów – Extract, Transform, Load. Niekiedy na potrzeby tych procesów wykorzystywany jest tak zwany obszar przejściowy (występujący także pod nazwą obszar tymczasowy). W takim obszarze przechowywane są dane pobrane z zewnętrznych systemów, w tym samym miejscu są również przetwarzane zanim trafią do obszarów przejściowych. Taki obszar tworzony jest w celu zmniejszenia obciążenia systemów źródłowych oraz zapewnienia spójności danych. Długotrwałe pobieranie danych ze źródeł w sytuacji gdy jednocześnie te dane są przetwarzane po pierwsze obciąża te systemy, po drugie dane mogą zmienićsię podczas tego przetwarzania, a to doprowadziłoby do niespójności logicznej danych w hurtowni. Możemy oczywiście zastosować pewne „sztuczki” - jak np. używanie zapytań retrospektywnych lub odpowiedniego poziomu izolacji. Lepiej jest jednak pobrać dane ze źródeł w jak najkrótszym czasie, a następnie przetwarzać je już w obszarze przejściowym. Dzięki takiemu obszarowi łatwiej jest też nam połączyć dane z różnych typów baz danych. Taki obszar przejściowy jest jedynie obszarem roboczym. Zapytania analityczne w żadnym wypadku nie powinny korzystać z niego, ponieważ dane w nim ulegają zmianom i mogą być niespójne.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 17/311

Problemy związane z czasem
Opis problematyki
Przypuśćmy że mamy do czynienia z bazą operacyjną systemu CRM. W tej bazie mamy klientów firmy dokonujących zakupów różnych produktów naszej firmy. Klienci są przypisani do regionów –województw, miast, kodów pocztowych. Analitycy przeprowadzają analizy skuteczności reklam w tych obszarach. Jeśli klient zmieni adres, w bazie operacyjnej powinien znaleźć się oczywiście aktualny adres. Jeśli jednak zaktualizujemy również adres klienta w hurtowni danych, analizy będą wprowadzały w błąd. Przykładowo klient wcześniej mieszkał w obszarze X, przeprowadził się do obszaru Y. W obszarze X prowadzona była intensywna kampania reklamowa. Klient zrobił bardzo duże zamówienie w naszej firmie, a następnie przeprowadził się do obszaru Y w którym przykładowo była prowadzona inna kampania reklamowa. Jeśli adres klienta został zmieniony również w hurtowni bez zachowania jego wcześniejszego adresu, to analiza wskaże skuteczność której kampanii reklamowej i w jakim obszarze? Analiza wykaże że klient przyszedł do naszej firmy skuszony reklamą z obszaru Y a nie X. Jeśli więc będziemy przechowywać informacje o zmianach danych w czasie, taki problem nie wystąpi. Wyobraźmy sobie teraz że w bazie operacyjnej faktycznie zmieniamy adres na aktualny, ale w hurtowni mamy informację że adres z obszaru X obowiązywał do 1 czerwca 2016, a adres z obszaru Y obowiązuje od 2 czerwca 2016. Kampania reklamowa była prowadzona w okresie kwiecień-maj 2016. Czy w takiej sytuacji nasze analizy również będą wprowadzały w błąd? Z tych samych powodów z hurtowni danych nie powinniśmy usuwać informacji o osobach które przestały być naszymi klientami.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 18/311

Rozwiązanie problemów z czasem
Zastępowanie zmienianych wartości nowymi
W tym rozwiązaniu stare wartości zastępowane są nowymi, jednak w związku z tym brakuje nam informacji o historycznych wartościach. Jest to rozwiązanie najprostsze i występujące najczęściej wbazach OLTP. Przykładowa struktura:
Informacje o klientach przechowywane są w jednej tabeli, ewentualnie adresy mogą zostać oddelegowane do osobnej tabeli. W obu wypadkach nie ma miejsca na przechowywanie danych archiwalnych i stare dane są zastępowane nowymi. Żeby zobrazować ten problem, poza tabelką klienci przygotowałem też tabelkę „zamówienia” w której umieściłem dwa zamówienia dokonane przez jednego pokazanego wcześniej klienta:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 19/311
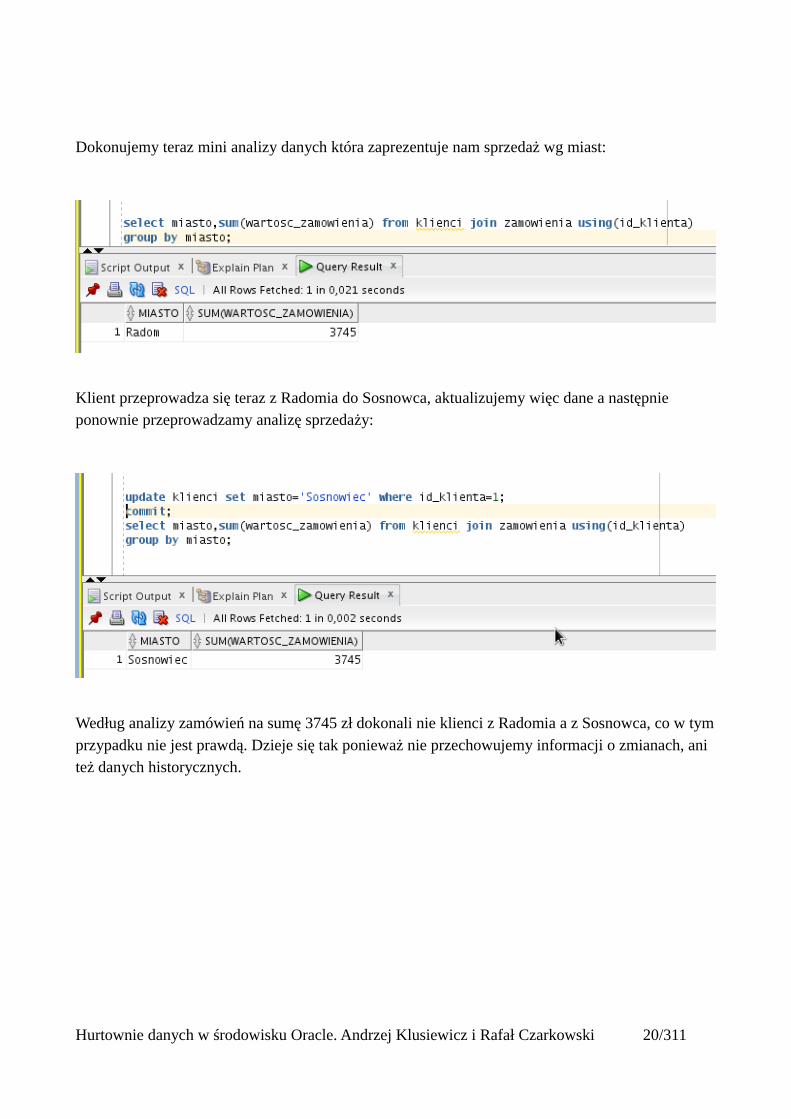
Dokonujemy teraz mini analizy danych która zaprezentuje nam sprzedaż wg miast:
Klient przeprowadza się teraz z Radomia do Sosnowca, aktualizujemy więc dane a następnie ponownie przeprowadzamy analizę sprzedaży:
Według analizy zamówień na sumę 3745 zł dokonali nie klienci z Radomia a z Sosnowca, co w tymprzypadku nie jest prawdą. Dzieje się tak ponieważ nie przechowujemy informacji o zmianach, ani też danych historycznych.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 20/311

Stosowanie kontroli wersji
Przy każdej zmianie atrybutów wiersza tworzony jest osobny rekord. Wszystkie atrybuty których nie zmienialiśmy pozostają nie zmienione. Tylko atrybuty podlegające aktualizacji mają nowe wartości. Pozostaje nam do rozwiązania problem identyfikacji aktualnego stanu i odróżnienia go od danych historycznych. Być może zaistnieje też konieczność wybrania wierszy które będą prezentowały stan informacji o kliencie we wskazanym czasie. Istnieje kilka metod na rozwiązanie tego problemu. Możemy dodać kolumnę z numerem wersji, dzięki czemu będziemy mogli łatwo wybrać najnowsze wersje danych, jednak nie będziemy mogli przeprowadzać analiz dotyczących wskazanego czasu. Możemy też dodać dwie kolumny z okresem obowiązywania stanu danych od i do. Zrobimy obie te wersje i porównamy.
Do tabeli klienci dodałem zarówno kolumnę z numerem wersji jak i kolumny z okresem obowiązywania stanu danych. Ponieważ w tabeli będziemy teraz przechowywać kilka wersji tego samego klienta, może pojawić się problem ze zgrupowaniem kilku wersji jednego klienta. Wartość w kolumnie ID_KLIENTA pozostanie przecież taka sama dla wszystkich wersji, więc ta kolumna nie może być kluczem głównym, ponieważ pojawiałyby się zduplikowane wartości. Kolumna ID_KLIENTA staje się więc kluczem technicznym służącym identyfikacji wersji tgo samego klienta, a do tabeli dodaję kolejną kolumnę ID która przejmie rolę klucza głównego. Na potrzeby tego przykładu dodałem też kolejną wersję danych klienta:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 21/311

Pobieranie najnowszej wersji danych
Przypuśćmy teraz że chcemy przejrzeć aktualny stan danych dla wszystkich klientów. Przy takie jakwyżej zaprezentowana strukturze, mamy trzy możliwości dokonania tego. Możemy oprzeć wybór o najnowszy numer wersji:
select * from klienci kl where wersja=(select max(wersja) from klienci where id_klienta=kl.id_klienta);
Przy założeniu że ID będzie uzupełniane z sekwencji, a więc kolejne wersje tego samego klienta będą miały coraz większe numery ID możemy się posłużyć również tym polem:
select * from klienci kl where id=(select max(id) from klienci where id_klienta=kl.id_klienta);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 22/311

I jeszcze wersja chyba najprostsza i najwydajniejsza jeśli chodzi o wykonanie zapytania – wykorzystanie pola OKRES_OBOWIAZYWANIA_DO. Przyjąłem założenie, że jeśli zmienia się stan danych dla klienta, w wierszu reprezentującym dotychczasową wersję uzupełniamy pole OKRES_OBOWIAZYWANIA_DO, a w wierszu reprezentującym wersję nową pozostawiamy to pole puste. Chcąc więc zobaczyć najnowsze wersje wszystkich klientów wystarczy wybrać wierszez NULLem w polu OKRES_OBOWIAZYWANIA_DO:
select * from klienci where okres_obowiazywania_do is null;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 23/311

Przeglądanie wersji danych obowiązujących we wskazanym okresie
Taką możliwość mamy tylko przy zastosowaniu pól określających okres obowiązywania wersji danych. Przykładowe zapytanie wybierające stan danych na dzień 26 maja 2015 roku:
select * from klienci
where
to_date('26-05-2015','dd-mm-yyyy') between
okres_obowiazywania_od and nvl(okres_obowiazywania_do,sysdate);
W rzeczywistości zapytania w hurtowniach obsługujących zmiany danych na przestrzeni czasu zawsze są zapytaniami przeglądającymi dane w stanie w określonym czasie, przy czym nawet jeśli tego czasu nie określamy przyjmowany jest czas „teraz”. Zastanów się nad prawidłowością zliczania klientów z wcześniej opisywanej tabeli w ten sposób:
select count(*) from klienci;
Takie zapytanie oczywiście zwróci błędny wynik, ponieważ w tabeli mamy jednego klienta ale w 2 wersjach. Należałoby więc zastosować zapytanie kształtu :
select count(*) from klienci where okres_obowiazywania_do is null;
Na koniec tego rozdziału chciałbym jeszcze zwrócić uwagę na jedną kwestię: jeśli stosujemy
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 24/311

kolumny określające czas trwania stanu, to zakresy czasowe nigdy nie mogą na siebie nachodzić!
Tabele zewnętrzne
Dzięki tabelo zewnętrznym użytkownik może korzystać z zewnętrznych plików tak, japkby byłyone tabelami bazy danych. Strukturę i lokalizację tabeli zewnętrznej definiuje się w systemieOracle. Podczas wykonania zapytania na tabeli zewnętrznej, wynik odczytywany jest w taki sposóbjakby dany były przechowywane w bazie danych. Z uwagi na to, iż są one jednak zapisane pozabazą, nie trzeba się martwić procesem ich ładowania, co stanowi istotną korzyść dla jurtownidanych i dużych baz.
Mają one jednak istotne ograniczenia, nie można w nich modyfikować ani usuwać danych zpoziomu systemu Oracle oraz nie można ich indeksować. Z uwagi na to, iż mogą one stanowićczęść bazy danych, nalezy pamietać aby uwzględniać je przy tworzeniu kopii zapasowych bazydanych jak i jej odtwarzaniu.
Aby móc z nich skorzystać należy zamapować katalog gdzie będą przechowywane te pliki, poprzezpolecenie CREATE DIRECTORY (pamietamy oczywiście o tym, że katalog tworzymy samifizycznie w systemie operacyjnym) a nastepnie nadać uzytkownikowi z którego będziemy chcielikorzystać możliwość zapisu i odczytu danych z tego katalogu.
W Oracle mamy dostępne dwa rodzaje tabel zewnętrznych. Pierwszy opiera się o pliki płaskie (txt,csv itd), na podstawie których możemy utworzyć tabelę,zaczytać dane z takiego pliku i wykonywać po nim selecty, mając na uwadze to, że jeśli zawartośćtakiego pliku ulegnie zmianie, to my poprzez bazę tę zmianę też zobaczymy.Drugi natomiast bazuje na plikach data pump, które możemy utworzyć na podstawie zapytania ipraktycznie od razu wczytać je do innej bazy.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 25/311

Oracle loader
Do utworzonego katalogu wrzucam wcześniej przygotowany plik z danymi, a następnie wydajępolecenie które w oparciu o ten plik utworzy mi tabelę i wyświetli mi w niej odpowiednie dane.
CREATE TABLE pracownicy_ext (id int,imie varchar2(100),nazwisko varchar2(100),telefon varchar2(100),mail varchar2(100),adres varchar2(100),miasto varchar2(100),kraj varchar2(100),kod varchar2(100),pensja number(10,2),data_zatrudnienia varchar2(100),numer int)ORGANIZATION EXTERNAL (TYPE oracle_loaderDEFAULT DIRECTORY plikiACCESS PARAMETERS(FIELDS TERMINATED BY ';'MISSING FIELD VALUES ARE NULL(id,imie,nazwisko,telefon,mail,adres,miasto,kraj,kod,pensja,data_zatrudnienia,numer))LOCATION ('pracownicy_ext.dsv'))REJECT LIMIT UNLIMITED;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 26/311
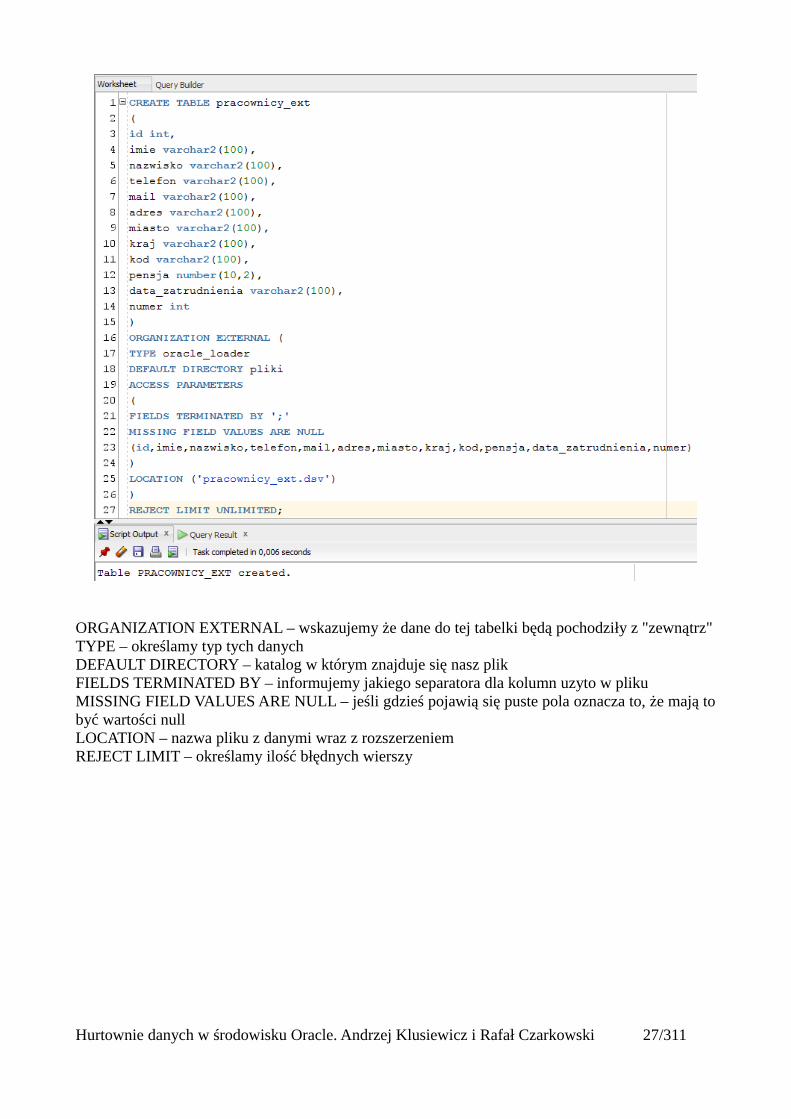
ORGANIZATION EXTERNAL – wskazujemy że dane do tej tabelki będą pochodziły z "zewnątrz"TYPE – określamy typ tych danychDEFAULT DIRECTORY – katalog w którym znajduje się nasz plikFIELDS TERMINATED BY – informujemy jakiego separatora dla kolumn uzyto w plikuMISSING FIELD VALUES ARE NULL – jeśli gdzieś pojawią się puste pola oznacza to, że mają tobyć wartości nullLOCATION – nazwa pliku z danymi wraz z rozszerzeniemREJECT LIMIT – określamy ilość błędnych wierszy
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 27/311
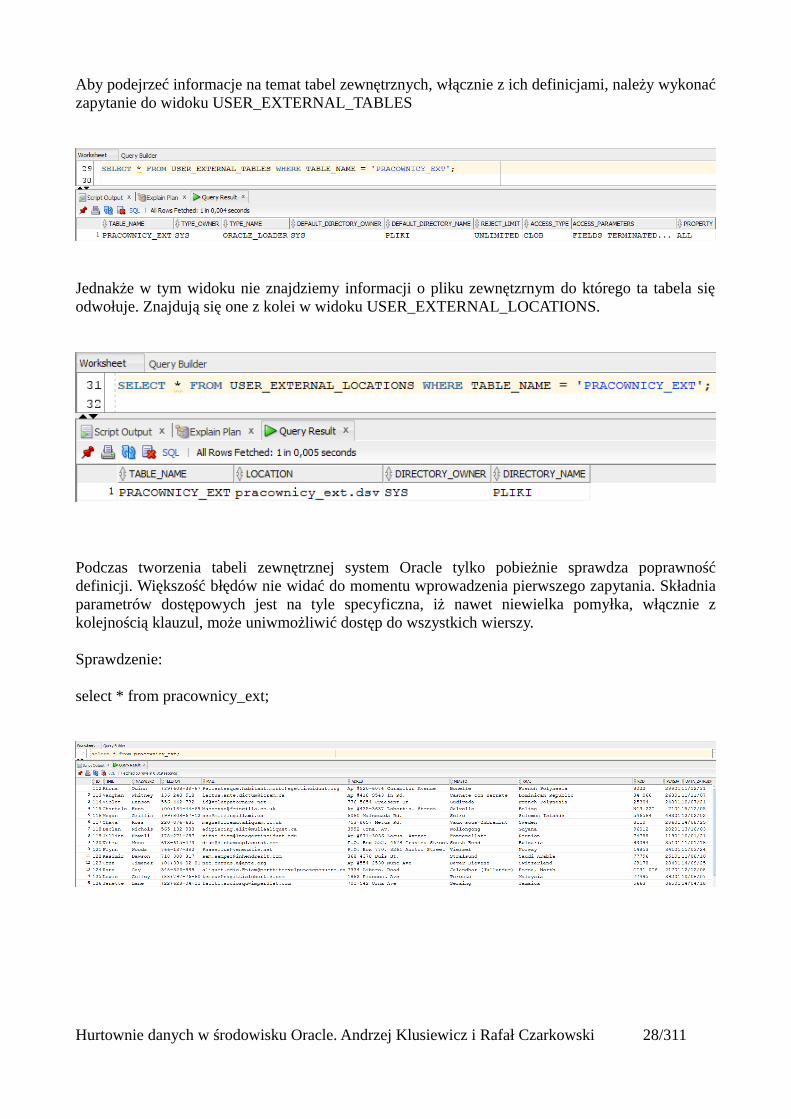
Aby podejrzeć informacje na temat tabel zewnętrznych, włącznie z ich definicjami, należy wykonaćzapytanie do widoku USER_EXTERNAL_TABLES
Jednakże w tym widoku nie znajdziemy informacji o pliku zewnętzrnym do którego ta tabela sięodwołuje. Znajdują się one z kolei w widoku USER_EXTERNAL_LOCATIONS.
Podczas tworzenia tabeli zewnętrznej system Oracle tylko pobieżnie sprawdza poprawnośćdefinicji. Większość błędów nie widać do momentu wprowadzenia pierwszego zapytania. Składniaparametrów dostępowych jest na tyle specyficzna, iż nawet niewielka pomyłka, włącznie zkolejnością klauzul, może uniwmożliwić dostęp do wszystkich wierszy.
Sprawdzenie:
select * from pracownicy_ext;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 28/311

Przy tworzeniu tabel zewnętrznym, mamy możliwość skorzystania z kilku opcji, które występują wprogramie SQL*Loader. Możemy wprowadzić opcje pominięcia rekordów (SKIP) i ograniczyć zwracane rekordy (WHEN).Nalezy wtedy jednak dodatkowo zaznaczyć jak ograniczone są rekordy poprzez wpis - RECORDSDELIMITED BY NEWLINE, w przeciwnym razie przy próbie wykonania pierwszego selecta na tejtabeli otrzymamy błąd i nie zostaną zwrócone żadne wiersze.
Mamy również możliwość utworzenia pliku dziennika, gdzie znajdziemy szczegóły operacjiładowania danych, pliku "złych" danych, gdzie znajdą się wiersze niespełniające warunkówklauzuli access parameters, oraz pliku odrzuconych rekordów, gdzie znajdą się wiersze, którychładowanie nie powiedzie się.
Tabele zewnętrzne mogą być zasilane z kilku plików naraz, wystarczy, że w klauzuli locationwymienimy nazwy plików, z których chcemy załadować dane do tabeli. Należy jednak pamietać otym, iż kolejność wymienienia tych plików ma znaczenie, chociażby na parametr SKIP, którybędzie dotyczył tylko pierwszego pliku.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 29/311
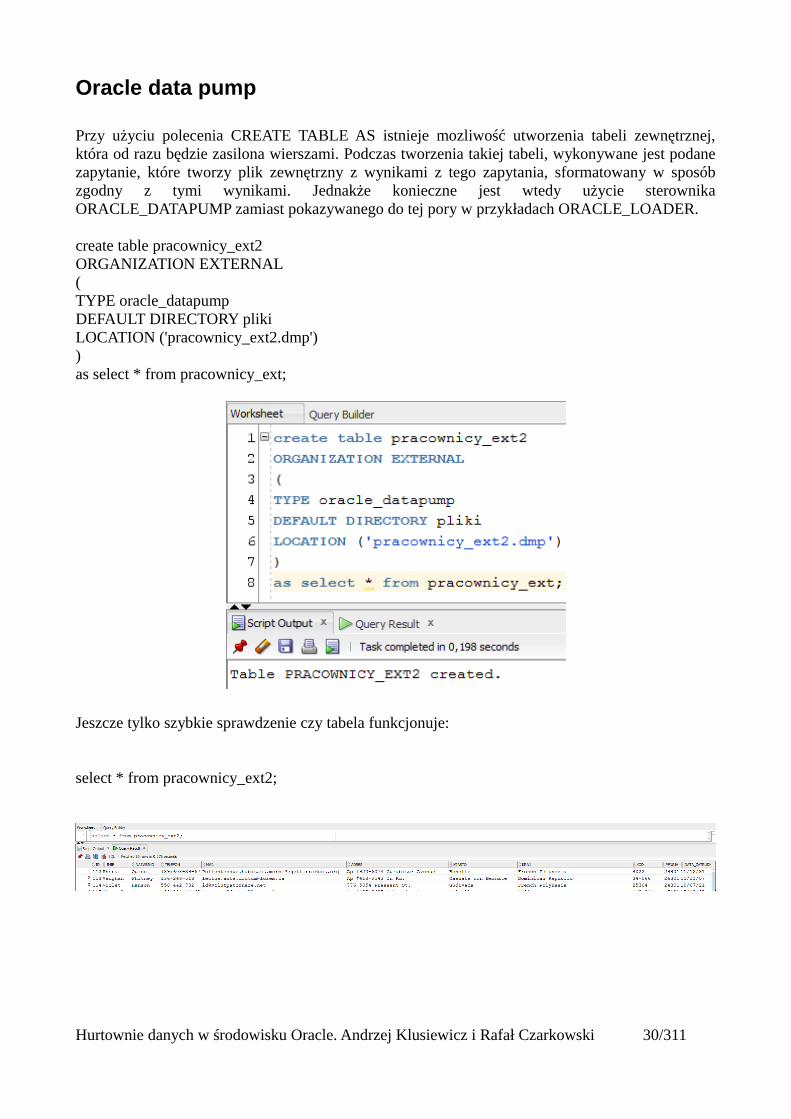
Oracle data pump
Przy użyciu polecenia CREATE TABLE AS istnieje mozliwość utworzenia tabeli zewnętrznej,która od razu będzie zasilona wierszami. Podczas tworzenia takiej tabeli, wykonywane jest podanezapytanie, które tworzy plik zewnętrzny z wynikami z tego zapytania, sformatowany w sposóbzgodny z tymi wynikami. Jednakże konieczne jest wtedy użycie sterownikaORACLE_DATAPUMP zamiast pokazywanego do tej pory w przykładach ORACLE_LOADER.
create table pracownicy_ext2ORGANIZATION EXTERNAL ( TYPE oracle_datapumpDEFAULT DIRECTORY plikiLOCATION ('pracownicy_ext2.dmp')) as select * from pracownicy_ext;
Jeszcze tylko szybkie sprawdzenie czy tabela funkcjonuje:
select * from pracownicy_ext2;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 30/311

Przy okazji jej utworzenia, stworzony został również plik 'pracownicy_ext2.dmp', który możnazamapować tabelą zewnętrzną na innym serwerze.
Teraz sprawdzimy, czy nie będzie problemu z utworzeniem kolejnej tabeli zewnętrznej, którawczyta dane z tego pliku (należy pamiętać, że nazwy kolumn muszą być identyczne jak te w pliku).
CREATE TABLE pracownicy_ext3(id int,imie varchar2(100),nazwisko varchar2(100),telefon varchar2(100),mail varchar2(100),adres varchar2(100),misto varchar2(100),kraj varchar2(100),kod varchar2(100),pensja number(10,2),data_zatrudnienia varchar2(100),numer int)ORGANIZATION EXTERNAL (TYPE oracle_datapumpDEFAULT DIRECTORY plikiLOCATION ('pracownicy_EXT2.dmp'));
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 31/311
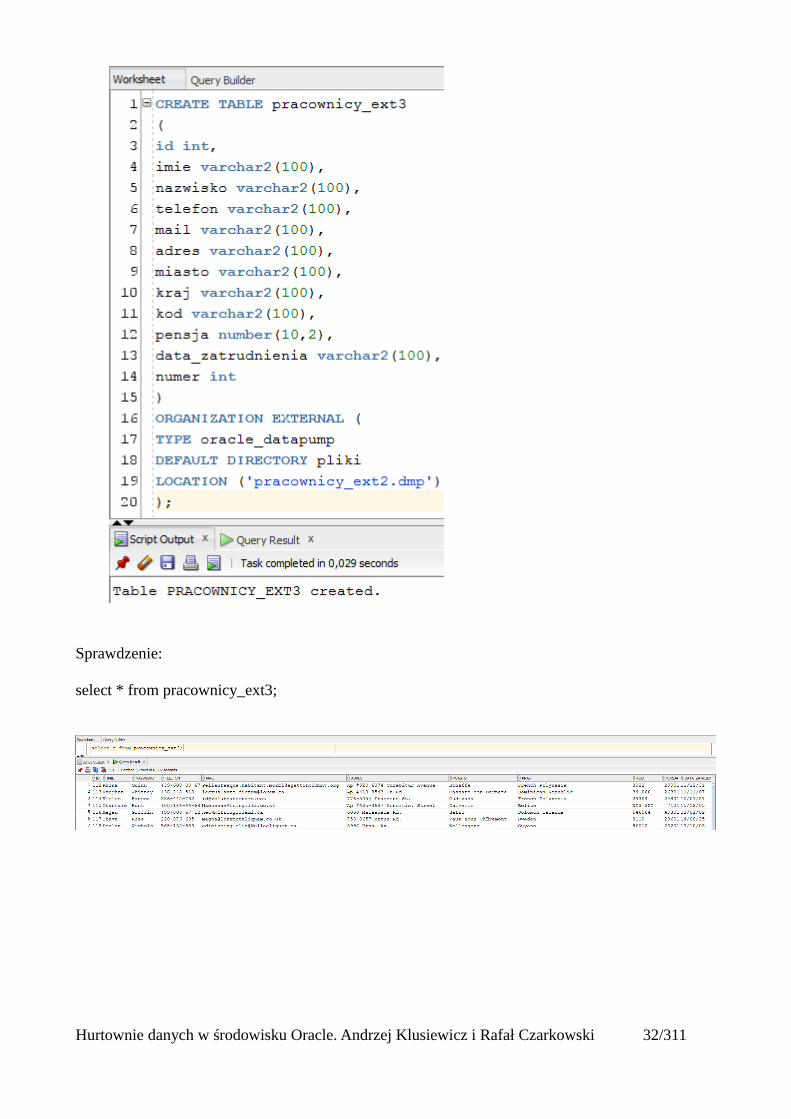
Sprawdzenie:
select * from pracownicy_ext3;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 32/311
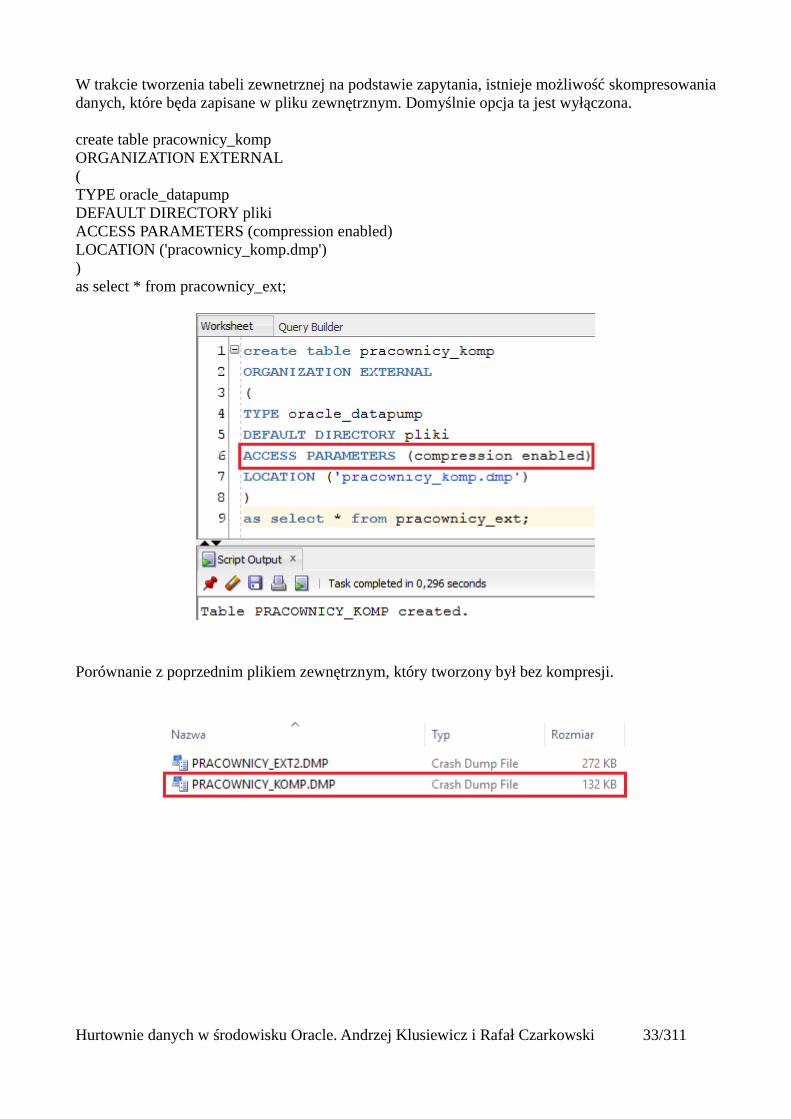
W trakcie tworzenia tabeli zewnetrznej na podstawie zapytania, istnieje możliwość skompresowaniadanych, które będa zapisane w pliku zewnętrznym. Domyślnie opcja ta jest wyłączona.
create table pracownicy_kompORGANIZATION EXTERNAL ( TYPE oracle_datapumpDEFAULT DIRECTORY plikiACCESS PARAMETERS (compression enabled)LOCATION ('pracownicy_komp.dmp')) as select * from pracownicy_ext;
Porównanie z poprzednim plikiem zewnętrznym, który tworzony był bez kompresji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 33/311
Modyfikowanie tabel zewnętrznych
Użytkownik może modyfikować definicje tabel zewnętrznych, w celu zmiany sposobu interpretacjipliku zewnętrznego przez system Oracle.
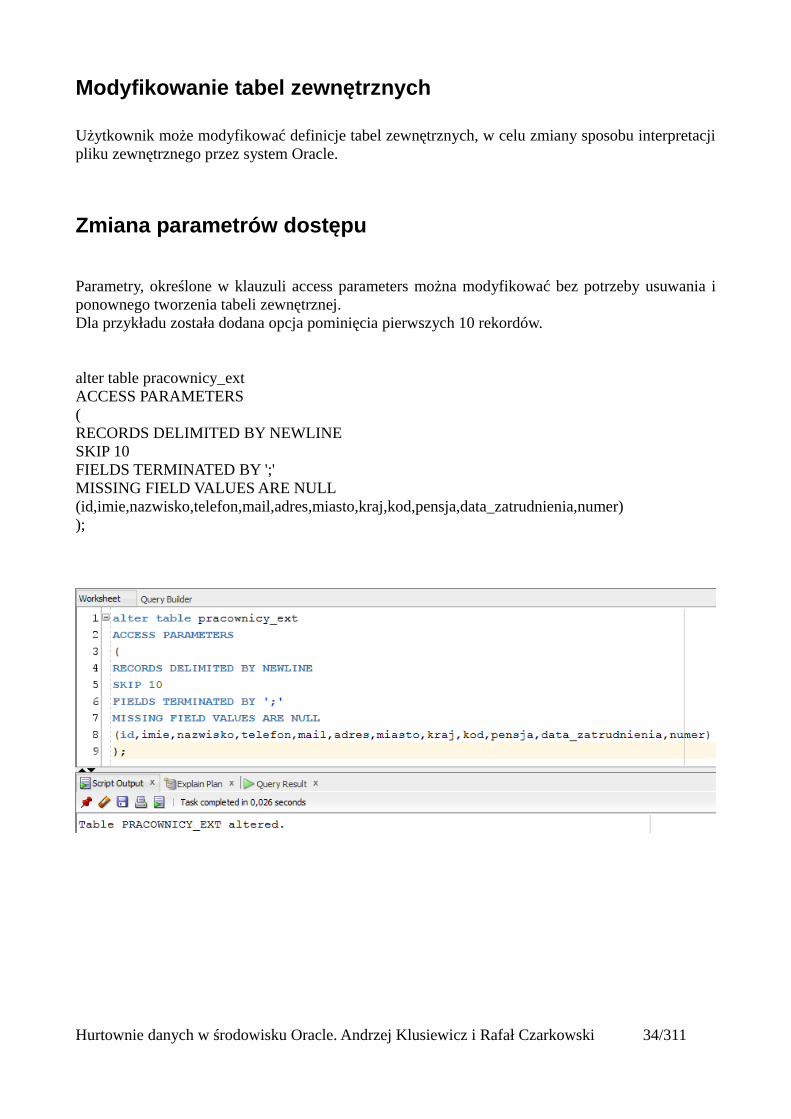
Zmiana parametrów dostępu
Parametry, określone w klauzuli access parameters można modyfikować bez potrzeby usuwania iponownego tworzenia tabeli zewnętrznej. Dla przykładu została dodana opcja pominięcia pierwszych 10 rekordów.
alter table pracownicy_extACCESS PARAMETERS(RECORDS DELIMITED BY NEWLINESKIP 10FIELDS TERMINATED BY ';'MISSING FIELD VALUES ARE NULL(id,imie,nazwisko,telefon,mail,adres,miasto,kraj,kod,pensja,data_zatrudnienia,numer));
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 34/311
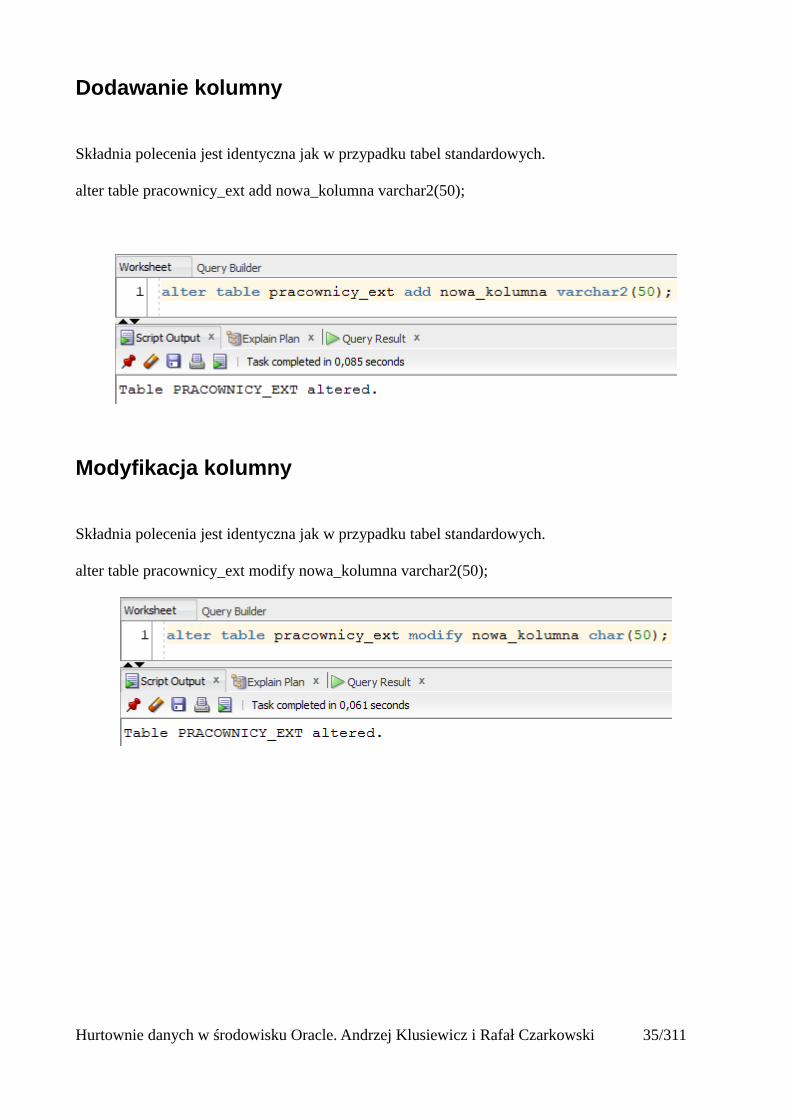
Dodawanie kolumny
Składnia polecenia jest identyczna jak w przypadku tabel standardowych.
alter table pracownicy_ext add nowa_kolumna varchar2(50);
Modyfikacja kolumny
Składnia polecenia jest identyczna jak w przypadku tabel standardowych.
alter table pracownicy_ext modify nowa_kolumna varchar2(50);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 35/311
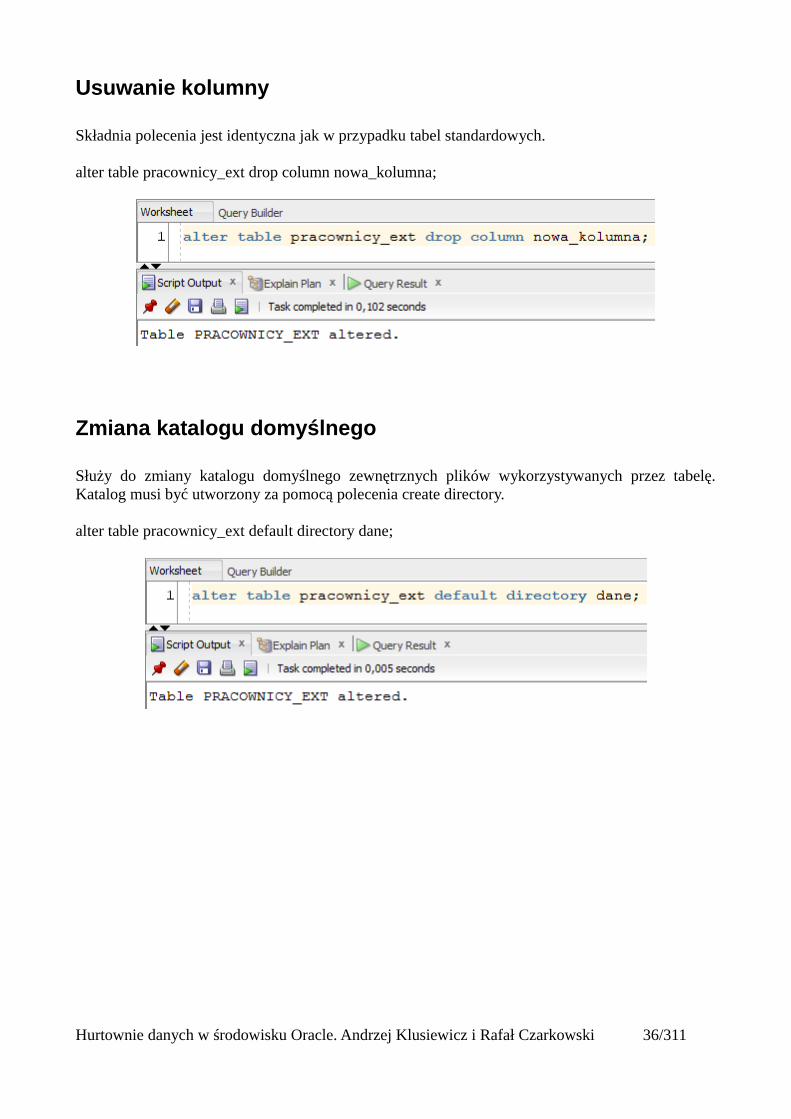
Usuwanie kolumny
Składnia polecenia jest identyczna jak w przypadku tabel standardowych.
alter table pracownicy_ext drop column nowa_kolumna;
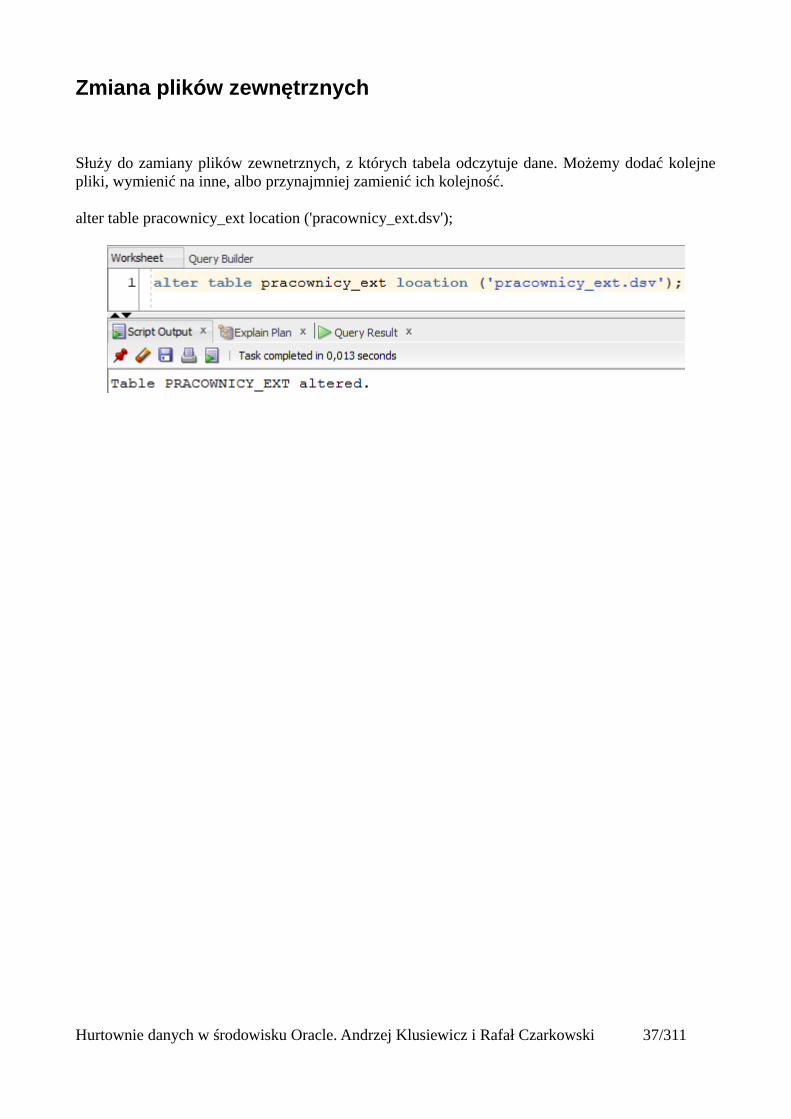
Zmiana katalogu domyślnego
Służy do zmiany katalogu domyślnego zewnętrznych plików wykorzystywanych przez tabelę.Katalog musi być utworzony za pomocą polecenia create directory.
alter table pracownicy_ext default directory dane;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 36/311
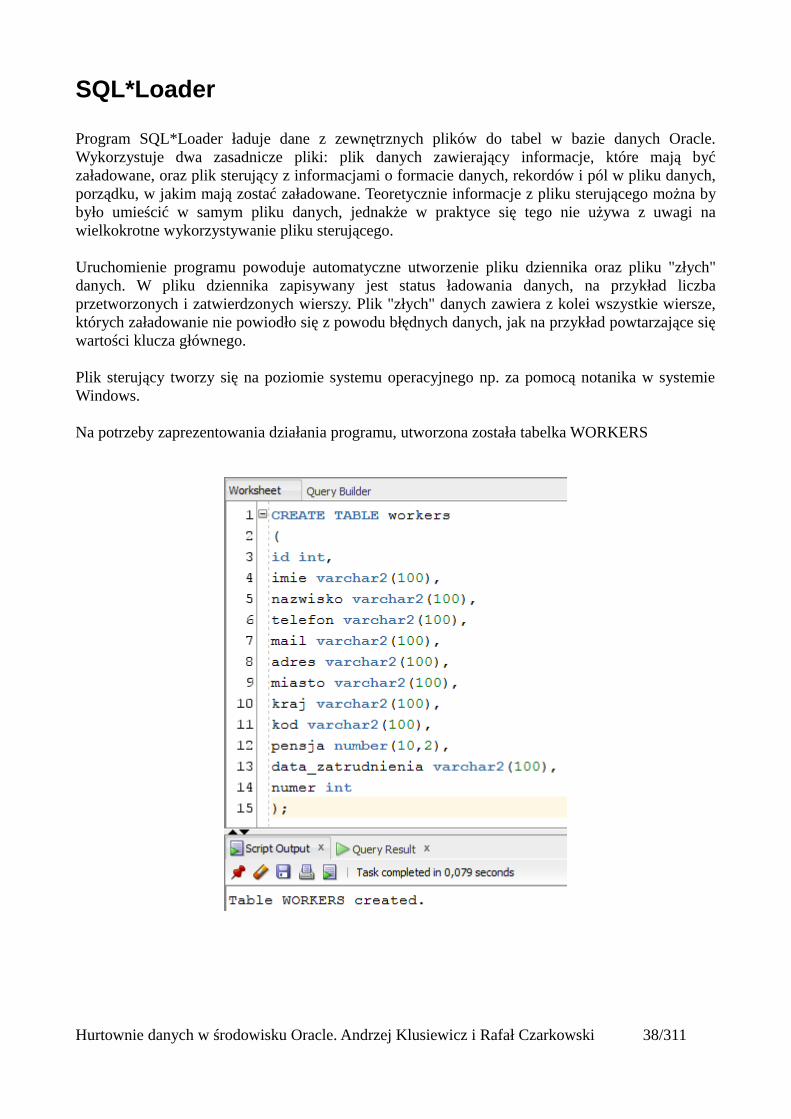
Zmiana plików zewnętrznych
Służy do zamiany plików zewnetrznych, z których tabela odczytuje dane. Możemy dodać kolejnepliki, wymienić na inne, albo przynajmniej zamienić ich kolejność.
alter table pracownicy_ext location ('pracownicy_ext.dsv');
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 37/311
SQL*Loader
Program SQL*Loader ładuje dane z zewnętrznych plików do tabel w bazie danych Oracle.Wykorzystuje dwa zasadnicze pliki: plik danych zawierający informacje, które mają byćzaładowane, oraz plik sterujący z informacjami o formacie danych, rekordów i pól w pliku danych,porządku, w jakim mają zostać załadowane. Teoretycznie informacje z pliku sterującego można bybyło umieścić w samym pliku danych, jednakże w praktyce się tego nie używa z uwagi nawielkokrotne wykorzystywanie pliku sterującego.
Uruchomienie programu powoduje automatyczne utworzenie pliku dziennika oraz pliku "złych"danych. W pliku dziennika zapisywany jest status ładowania danych, na przykład liczbaprzetworzonych i zatwierdzonych wierszy. Plik "złych" danych zawiera z kolei wszystkie wiersze,których załadowanie nie powiodło się z powodu błędnych danych, jak na przykład powtarzające sięwartości klucza głównego.
Plik sterujący tworzy się na poziomie systemu operacyjnego np. za pomocą notanika w systemieWindows.
Na potrzeby zaprezentowania działania programu, utworzona została tabelka WORKERS
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 38/311
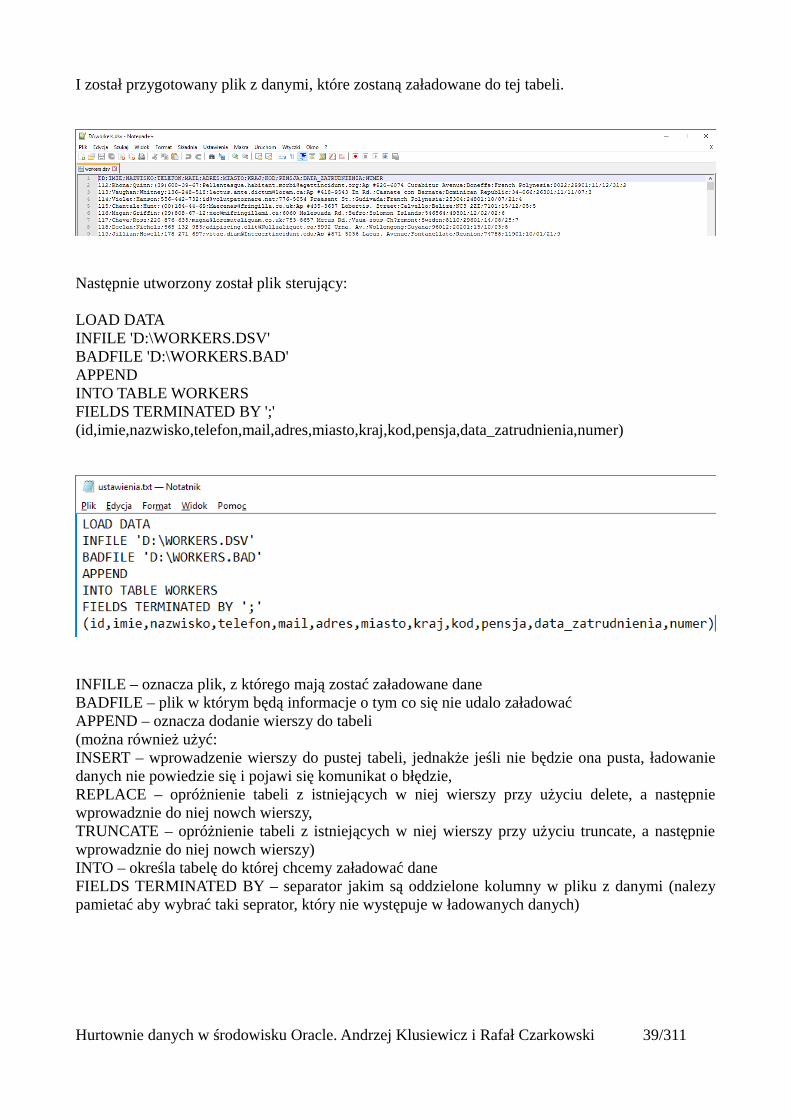
I został przygotowany plik z danymi, które zostaną załadowane do tej tabeli.
Następnie utworzony został plik sterujący:
LOAD DATAINFILE 'D:\WORKERS.DSV'BADFILE 'D:\WORKERS.BAD'APPENDINTO TABLE WORKERSFIELDS TERMINATED BY ';'(id,imie,nazwisko,telefon,mail,adres,miasto,kraj,kod,pensja,data_zatrudnienia,numer)
INFILE – oznacza plik, z którego mają zostać załadowane daneBADFILE – plik w którym będą informacje o tym co się nie udalo załadowaćAPPEND – oznacza dodanie wierszy do tabeli (można również użyć: INSERT – wprowadzenie wierszy do pustej tabeli, jednakże jeśli nie będzie ona pusta, ładowaniedanych nie powiedzie się i pojawi się komunikat o błędzie, REPLACE – opróżnienie tabeli z istniejących w niej wierszy przy użyciu delete, a następniewprowadznie do niej nowch wierszy, TRUNCATE – opróżnienie tabeli z istniejących w niej wierszy przy użyciu truncate, a następniewprowadznie do niej nowch wierszy)INTO – określa tabelę do której chcemy załadować daneFIELDS TERMINATED BY – separator jakim są oddzielone kolumny w pliku z danymi (nalezypamietać aby wybrać taki seprator, który nie występuje w ładowanych danych)
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 39/311
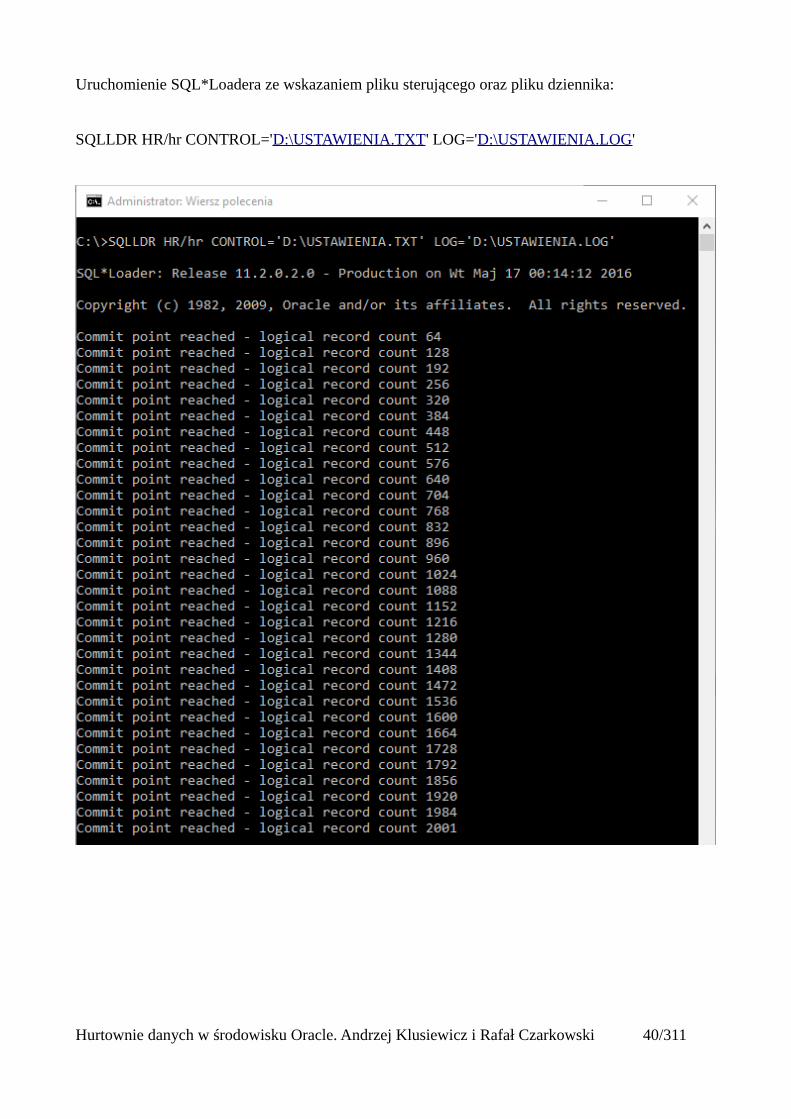
Uruchomienie SQL*Loadera ze wskazaniem pliku sterującego oraz pliku dziennika:
SQLLDR HR/hr CONTROL='D:\USTAWIENIA.TXT' LOG='D:\USTAWIENIA.LOG'
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 40/311

I sprawdzenie tabeli, czy została uzupełniona o nowe wiersze:
SELECT * FROM WORKERS;
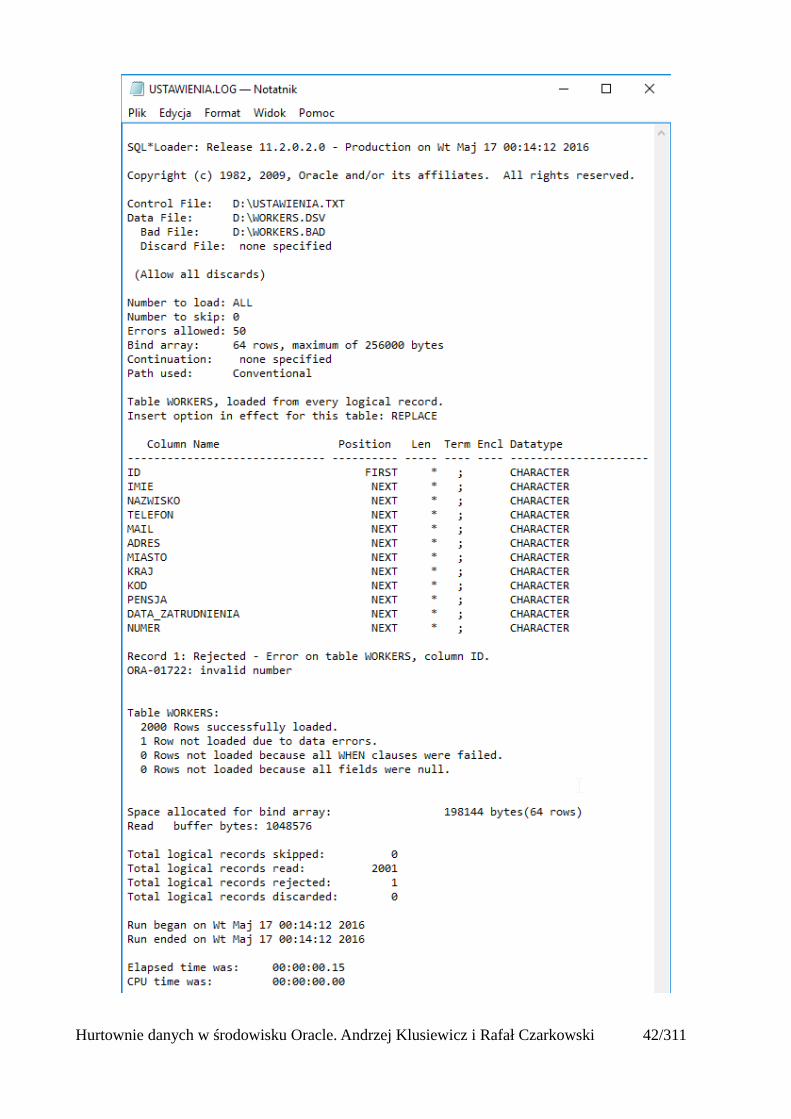
Dodatkowo w pliku dziennika możemy podejrzeć informacje o przebiegu ładowania danych.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 41/311
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 42/311
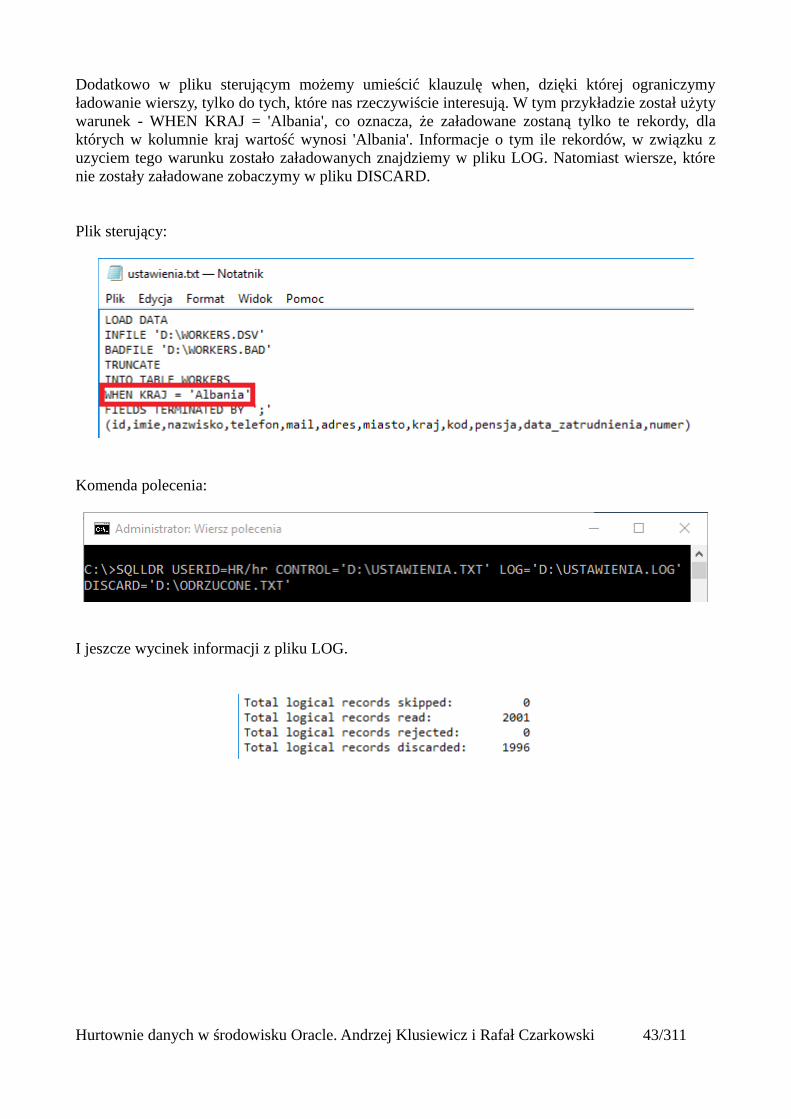
Dodatkowo w pliku sterującym możemy umieścić klauzulę when, dzięki której ograniczymyładowanie wierszy, tylko do tych, które nas rzeczywiście interesują. W tym przykładzie został użytywarunek - WHEN KRAJ = 'Albania', co oznacza, że załadowane zostaną tylko te rekordy, dlaktórych w kolumnie kraj wartość wynosi 'Albania'. Informacje o tym ile rekordów, w związku zuzyciem tego warunku zostało załadowanych znajdziemy w pliku LOG. Natomiast wiersze, którenie zostały załadowane zobaczymy w pliku DISCARD.
Plik sterujący:
Komenda polecenia:
I jeszcze wycinek informacji z pliku LOG.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 43/311
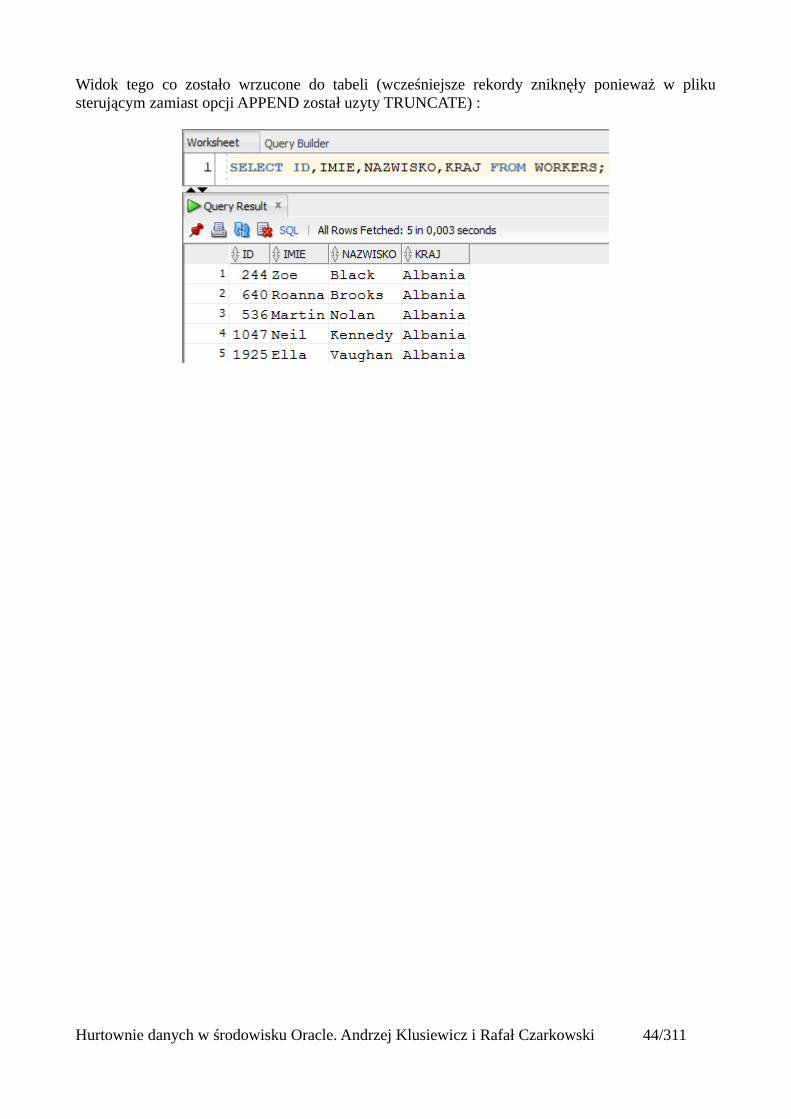
Widok tego co zostało wrzucone do tabeli (wcześniejsze rekordy zniknęły ponieważ w plikusterującym zamiast opcji APPEND został uzyty TRUNCATE) :
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 44/311

Podstawowe opcje jakie możemy użyć przy uruchamianiu SQL*Loadera:
USERID – nazwa użytkownika i hasło wykorzystywane podczas ładowania, oddzielone ukośnikiemCONTROL – nazwa pliku sterującegoLOG nazwa pliku dziennikaBAD – nazwa pliku "złych danych"DATA – nazwa pliku danychDISCARD – nazwa pliku odrzuconych rekordówDISCARDMAX – maksymalna ilość odrzuconych rekordów przedz zatrzymaniem ładowania. Domyślne dozwolone jest odrzucenie dowolnej liczby rekordów.SKIP – liczba logicznych rekordów w pliku wejściowym, które mają być pominiete przedz rozpoczęciem ładowania danych. Domyślna wartość wynosi 0.LOAD – liczba logicznych rekordów do załadowania. Domyślnie ładowane są wszystkie rekordy.ERRORS – dopuszczalna ilość błędów nie przerywających procesu ładowania. Domyślmnie wartość tego argumentu wynosi 50.ROWS – liczba rekordów ładowanych jednorazowo. Argument ten służy do podzielenia transakcji na kilka części podczas ładowania. Domyślna wartość dla konwencjonalnych ścieżek łądowania wynosi 64.SILENT – wyłącza wyświetlanie komunikatów podczas ładowania.
Wartości jakie można podać: HEADER - wyłączenie wyświetlania nagłówka programu SQL*LoaderFEEDBACK -wyłączenie wyświetlania komunikatów w punktach zatwierdzaniaERRORS – wyłączenie rejestrowania (w pliku dziennika) wszystkich rekordów, które
spowodowały błąd (ich liczba jest dalej rejestrowana)DISCARDS – wyłączenie rejestrowania (w pliku dziennika) wszytskich rekordów, które
zostały odrzucone (ich liczba jest dalej rejestrowana)ALL – wyłączenie wyświetlaniawszystkich wymienionych wcześniej informacji
DIRECT – zastosowanie ładowania Direct Path. Wartośc domyślna wynosi false.PARFILE – nazwa pliku parametrów zawierającego specyfikacje dodatkowych parametrów ładowania.PARALLEL - zastosowanie ładowania równoległego. Wartośc domyślna wynosi false.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 45/311
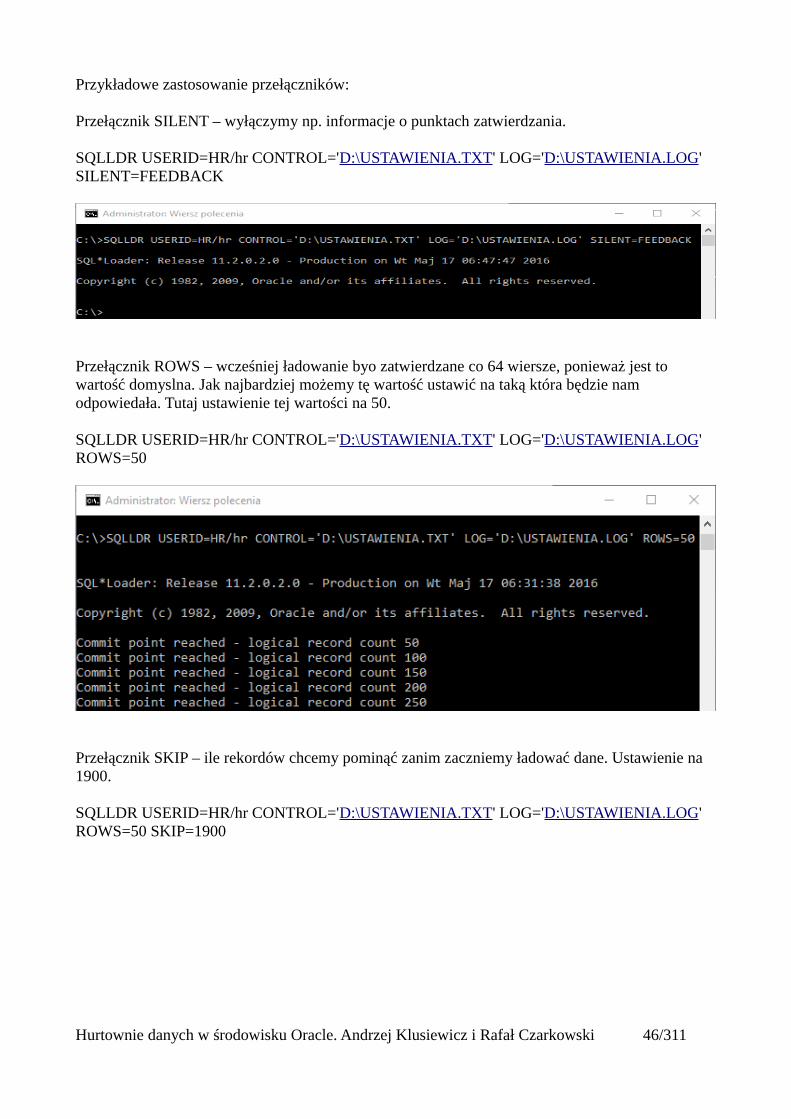
Przykładowe zastosowanie przełączników:
Przełącznik SILENT – wyłączymy np. informacje o punktach zatwierdzania.
SQLLDR USERID=HR/hr CONTROL='D:\USTAWIENIA.TXT' LOG='D:\USTAWIENIA.LOG' SILENT=FEEDBACK
Przełącznik ROWS – wcześniej ładowanie byo zatwierdzane co 64 wiersze, ponieważ jest to wartość domyslna. Jak najbardziej możemy tę wartość ustawić na taką która będzie nam odpowiedała. Tutaj ustawienie tej wartości na 50.
SQLLDR USERID=HR/hr CONTROL='D:\USTAWIENIA.TXT' LOG='D:\USTAWIENIA.LOG' ROWS=50
Przełącznik SKIP – ile rekordów chcemy pominąć zanim zaczniemy ładować dane. Ustawienie na 1900.
SQLLDR USERID=HR/hr CONTROL='D:\USTAWIENIA.TXT' LOG='D:\USTAWIENIA.LOG' ROWS=50 SKIP=1900
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 46/311
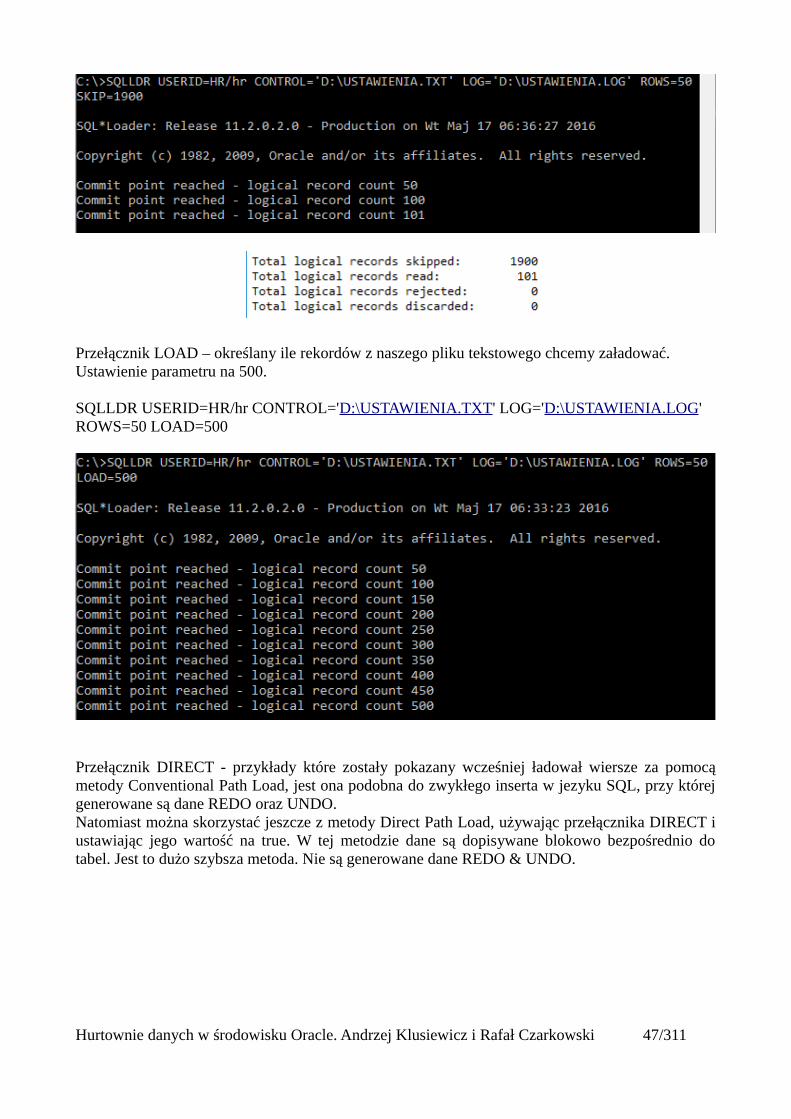
Przełącznik LOAD – określany ile rekordów z naszego pliku tekstowego chcemy załadować. Ustawienie parametru na 500.
SQLLDR USERID=HR/hr CONTROL='D:\USTAWIENIA.TXT' LOG='D:\USTAWIENIA.LOG' ROWS=50 LOAD=500
Przełącznik DIRECT - przykłady które zostały pokazany wcześniej ładował wiersze za pomocąmetody Conventional Path Load, jest ona podobna do zwykłego inserta w jezyku SQL, przy którejgenerowane są dane REDO oraz UNDO.Natomiast można skorzystać jeszcze z metody Direct Path Load, używając przełącznika DIRECT iustawiając jego wartość na true. W tej metodzie dane są dopisywane blokowo bezpośrednio dotabel. Jest to dużo szybsza metoda. Nie są generowane dane REDO & UNDO.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 47/311

Conventional Path Load Direct Path Load
domyślna tworzy bloki danych, które już są w formaciebloków danych Oracle
używa SQL-owej komendy INSERT i buforabudowanej tablicy wiązania (bind array) dozaładowania danych; w macierzy wiązania sąumieszczane wiersze czytane za jednym razem
nie używa SQL-owej komendy INSERT dowstawiania bloków do bazy
może spowalniać ładowanie jest szybsza od konwencjonalnej
konkuruje z innymi zasobami Oracle’a o zasobybazy
generowane bloki są bezpośrednio zapisywanedo bazy danych
generowane są dodatkowe nagłówki jakokomendy SQL-owe, następnie wysyłane doOracle’a i przetwarzane
używa procedur zarządzania przestrzenią douzyskania następnego obszaru (wskaźnik HWM)
czeka na wypełnienie bufora danymi lub nakoniec danych
wymusza zastosowanie niektórych więzówintegralności na wierszach tabeli (UNIQUE,PRIMARY, NULL)
używane są tylko puste bloki nie są wykonywane zapisy w plikach dziennika
SQLLDR USERID=HR/hr CONTROL='D:\USTAWIENIA.TXT' LOG='D:\USTAWIENIA.LOG' DIRECT=TRUE
I na koniec ciekawostka. Czy zastanawialiście się nad możliwością załadowania danychSQL*Loaderem do tabeli tymczasowej? Sprawdzamy.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 48/311
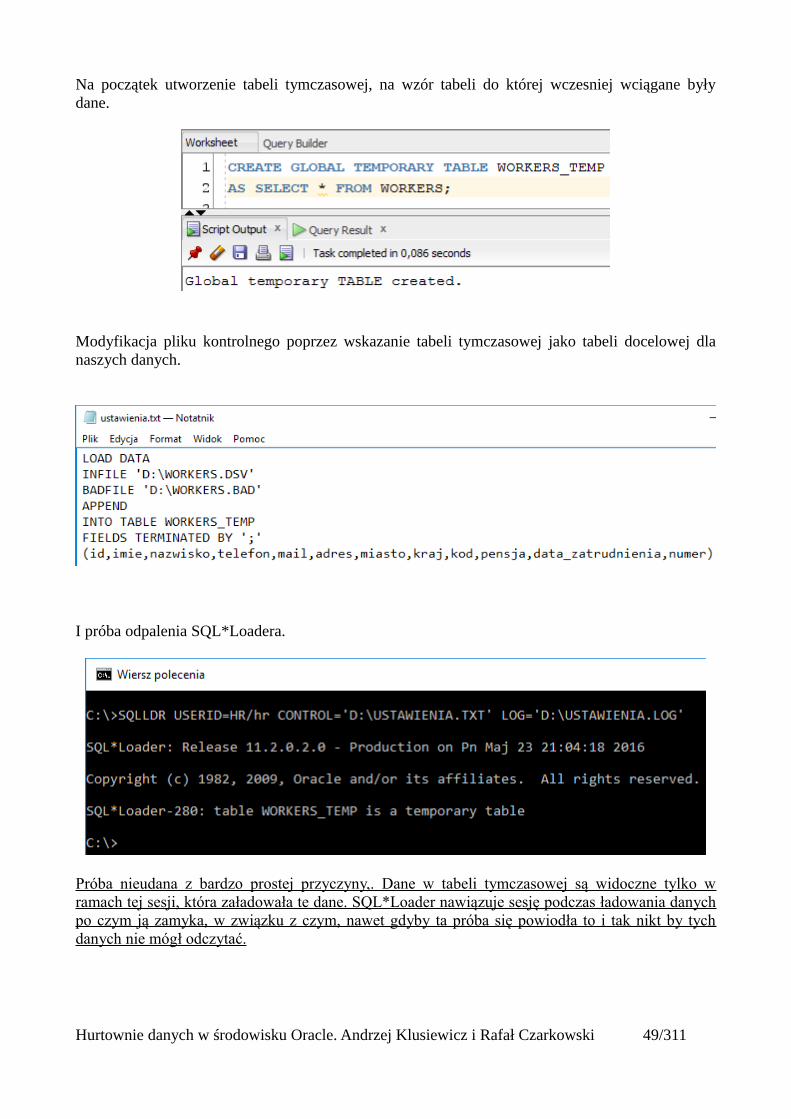
Na początek utworzenie tabeli tymczasowej, na wzór tabeli do której wczesniej wciągane byłydane.
Modyfikacja pliku kontrolnego poprzez wskazanie tabeli tymczasowej jako tabeli docelowej dlanaszych danych.
I próba odpalenia SQL*Loadera.
Próba nieudana z bardzo prostej przyczyny,. Dane w tabeli tymczasowej są widoczne tylko wramach tej sesji, która załadowała te dane. SQL*Loader nawiązuje sesję podczas ładowania danychpo czym ją zamyka, w związku z czym, nawet gdyby ta próba się powiodła to i tak nikt by tychdanych nie mógł odczytać.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 49/311

Export i Import danych.
Export i Import danych za pomocą programów EXP/IMP.
Poprzez narzędzie EXP można eksportować dane z bazy Oracle do postaci binarnej. Natomiastdzięki narzędziu IMP można dane importować z wyeksportowanego wcześniej pliku binarnego dobazy.
Przy użyciu tych programów można wyeksportować/zaimportować:-całą bazę-wybrany schemat-wybrane tabele-wybraną przestrzeń tabel
Przy eksporcie/imporcie należy podać następujące parametry:-USERID (kim chcemy wykonać eksport,podajemy nazwę użytkownika łamaną na jego hasło)-FILE (nazwa pliku z danymi, jaki ma zostać utworzony wraz ze ścieżką. Należy pamiętać o tym, iżfolder w którym chcemy utworzyć plik eksportu musimy wcześniej stworzyć sami)-LOG (opcjonalnie, nazwa pliku z logami, jaki ma zostać utworzony wraz ze ścieżką)-FULL/OWNER/TABLES/TABLESPACES (co chcemy eksportować)
Aby móc wykonać eksport całej bazy, dowolnego schematu lub dowolnej tabeli nalezy posiadaćrolę EXP_FULL_DATABASE, natomiast przy imporcie wymagana jest rolaIMP_FULL_DATABASE.
Export i import możemy równiez wykonać zdalnie, wystarczy, że po nazwie użytkownika i jegohaśle, po małpce podamy adres ip bazy danych, lub jej alias deskryptora połączeń z plikuTNSNAMES.ORA.
Poniżej kilka przykładów eksportów i importów:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 50/311
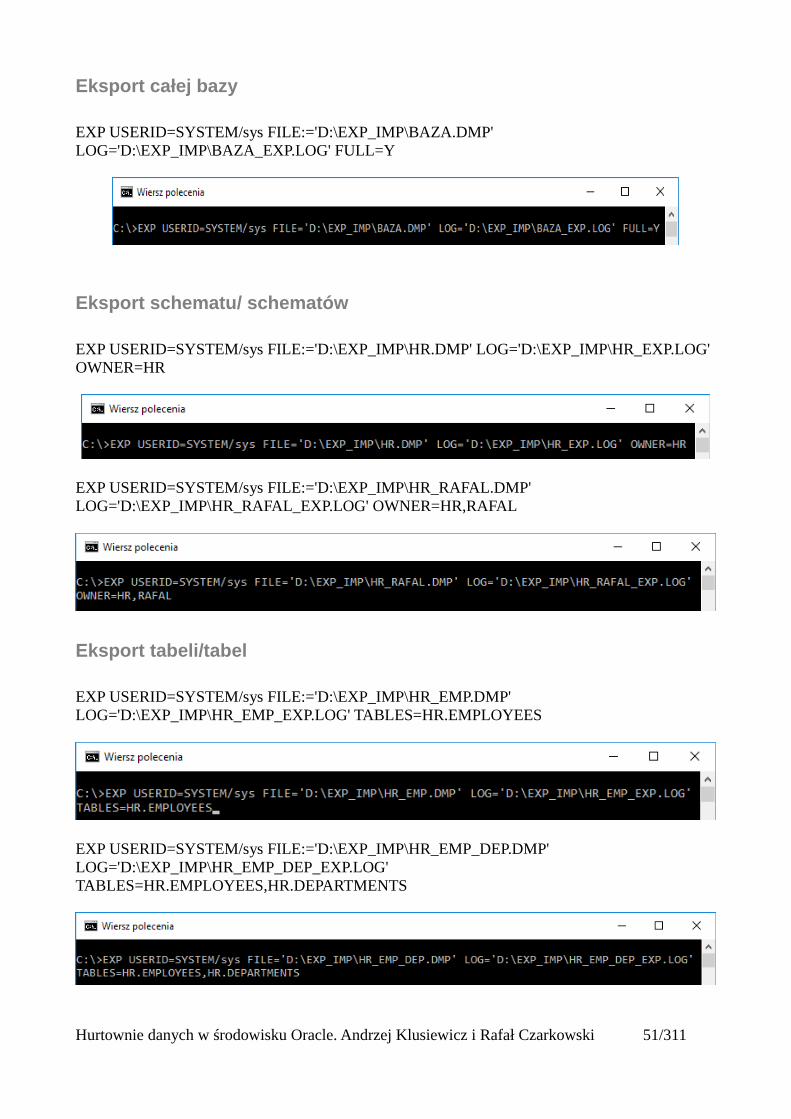
Eksport całej bazy
EXP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\BAZA.DMP' LOG='D:\EXP_IMP\BAZA_EXP.LOG' FULL=Y
Eksport schematu/ schematów
EXP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\HR.DMP' LOG='D:\EXP_IMP\HR_EXP.LOG' OWNER=HR
EXP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\HR_RAFAL.DMP' LOG='D:\EXP_IMP\HR_RAFAL_EXP.LOG' OWNER=HR,RAFAL
Eksport tabeli/tabel
EXP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\HR_EMP.DMP' LOG='D:\EXP_IMP\HR_EMP_EXP.LOG' TABLES=HR.EMPLOYEES
EXP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\HR_EMP_DEP.DMP' LOG='D:\EXP_IMP\HR_EMP_DEP_EXP.LOG' TABLES=HR.EMPLOYEES,HR.DEPARTMENTS
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 51/311
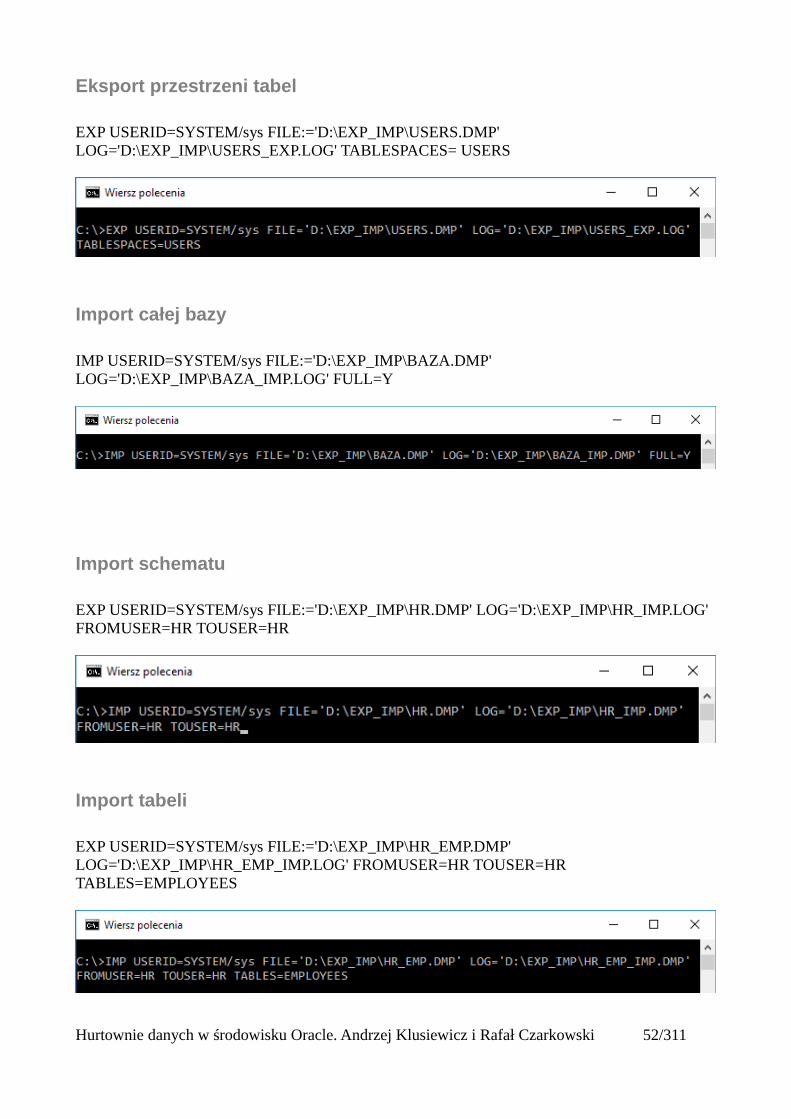
Eksport przestrzeni tabel
EXP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\USERS.DMP' LOG='D:\EXP_IMP\USERS_EXP.LOG' TABLESPACES= USERS
Import całej bazy
IMP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\BAZA.DMP' LOG='D:\EXP_IMP\BAZA_IMP.LOG' FULL=Y
Import schematu
EXP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\HR.DMP' LOG='D:\EXP_IMP\HR_IMP.LOG' FROMUSER=HR TOUSER=HR
Import tabeli
EXP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\HR_EMP.DMP' LOG='D:\EXP_IMP\HR_EMP_IMP.LOG' FROMUSER=HR TOUSER=HR TABLES=EMPLOYEES
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 52/311
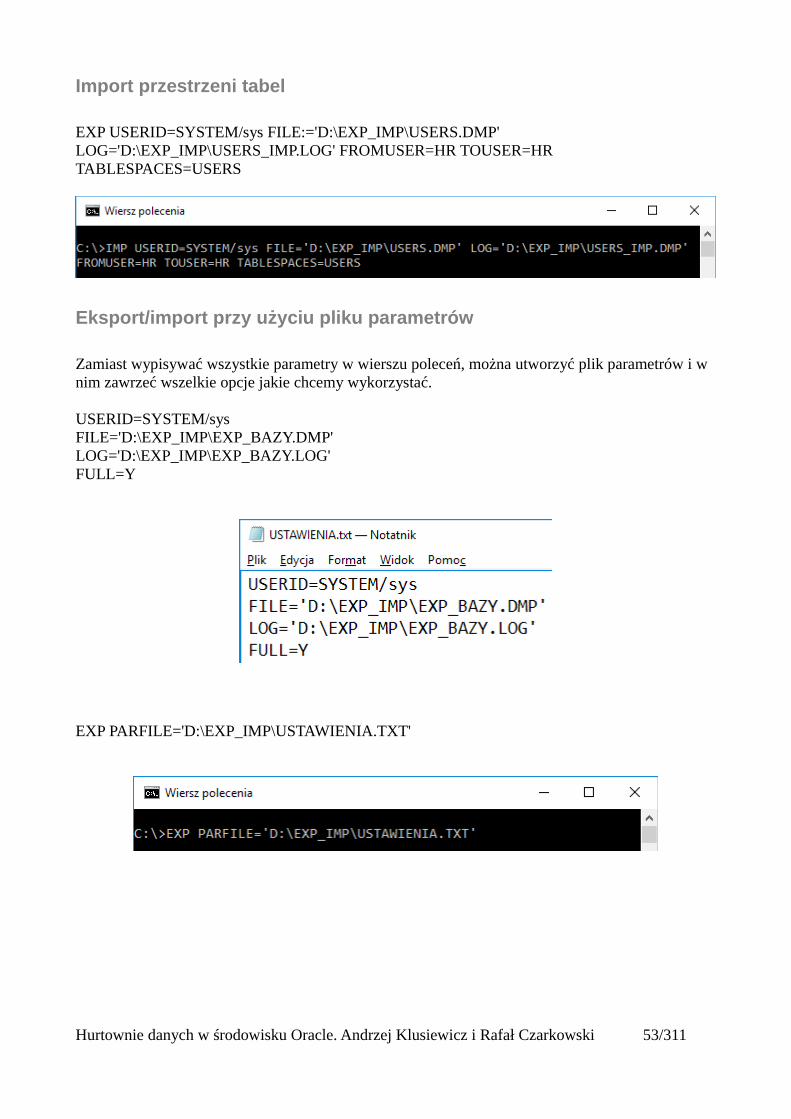
Import przestrzeni tabel
EXP USERID=SYSTEM/sys FILE:='D:\EXP_IMP\USERS.DMP' LOG='D:\EXP_IMP\USERS_IMP.LOG' FROMUSER=HR TOUSER=HR TABLESPACES=USERS
Eksport/import przy użyciu pliku parametrów
Zamiast wypisywać wszystkie parametry w wierszu poleceń, można utworzyć plik parametrów i w nim zawrzeć wszelkie opcje jakie chcemy wykorzystać.
USERID=SYSTEM/sysFILE='D:\EXP_IMP\EXP_BAZY.DMP'LOG='D:\EXP_IMP\EXP_BAZY.LOG'FULL=Y
EXP PARFILE='D:\EXP_IMP\USTAWIENIA.TXT'
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 53/311
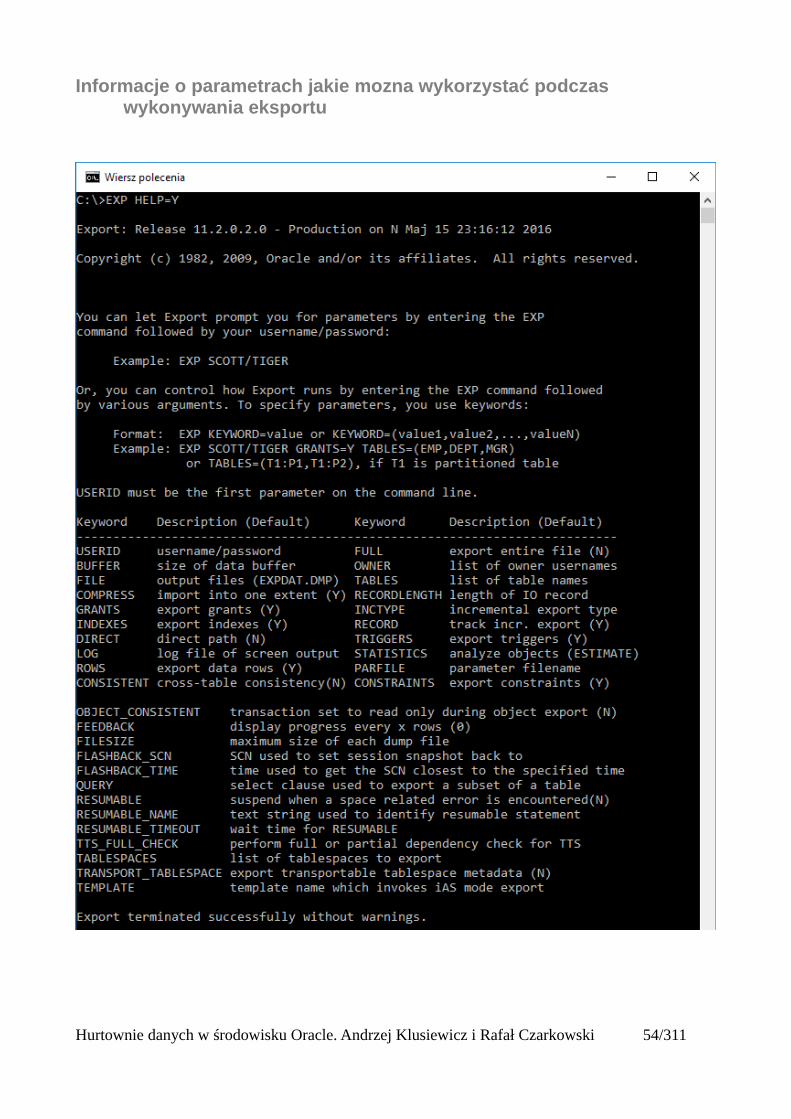
Informacje o parametrach jakie mozna wykorzystać podczas wykonywania eksportu
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 54/311
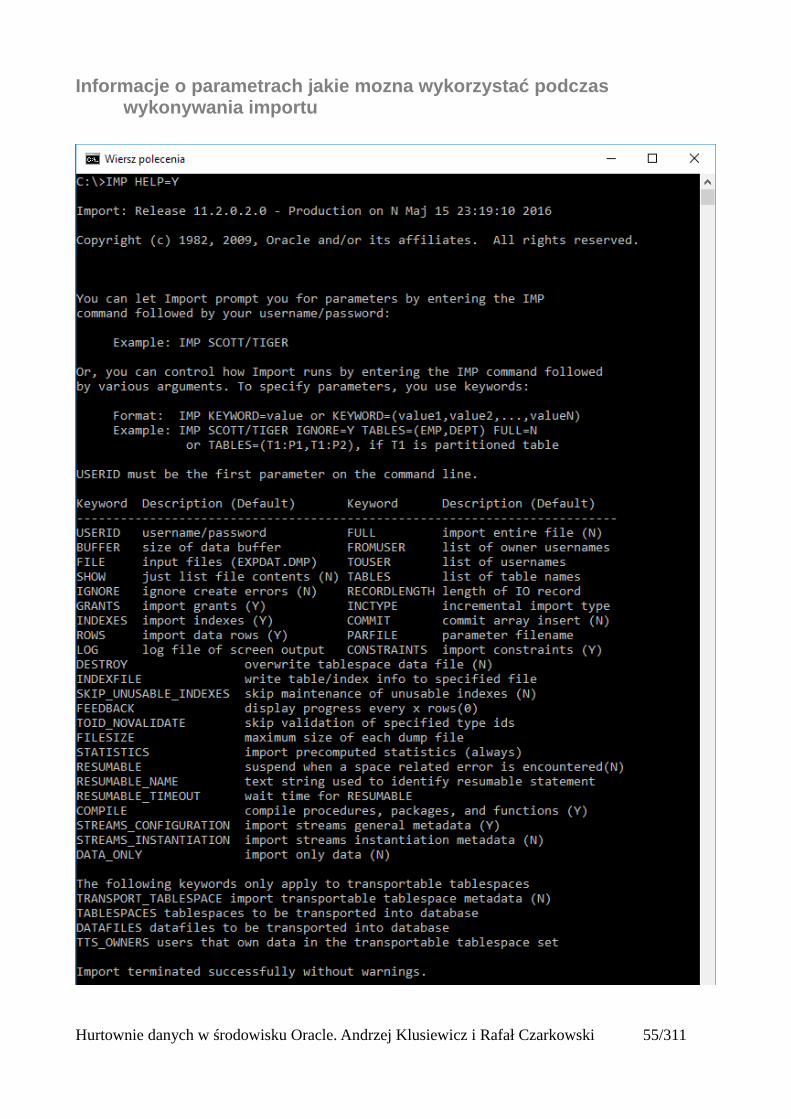
Informacje o parametrach jakie mozna wykorzystać podczas wykonywania importu
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 55/311
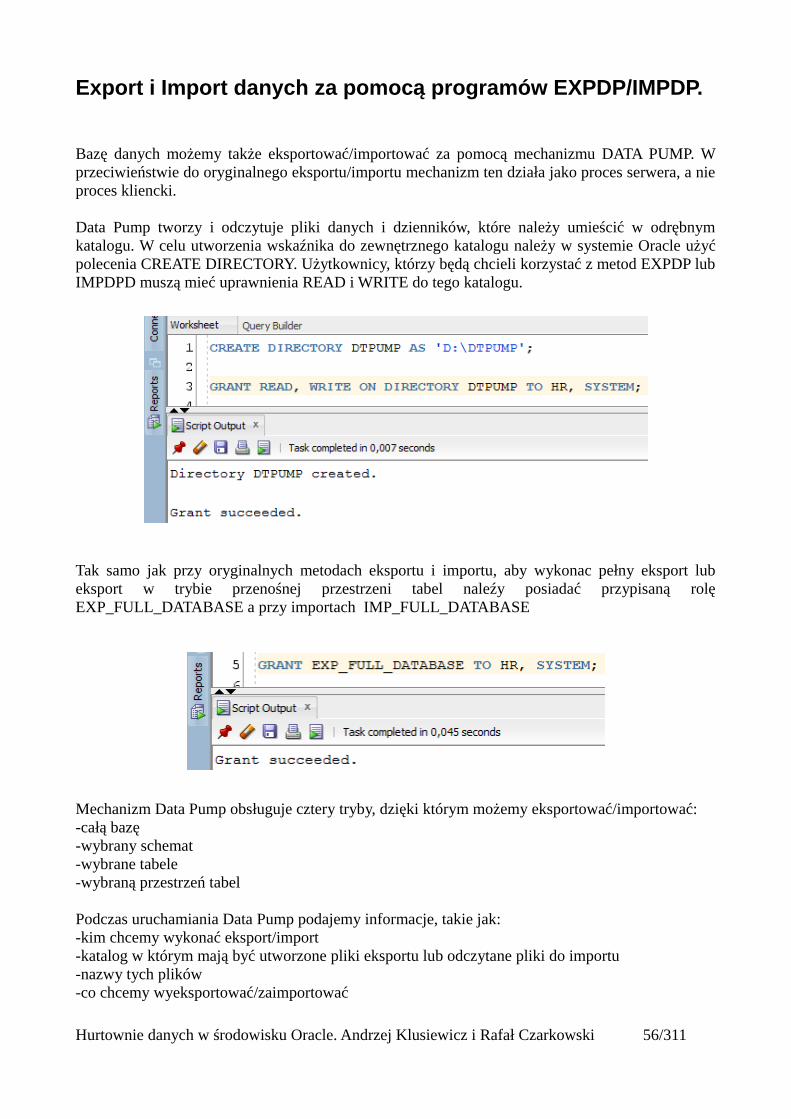
Export i Import danych za pomocą programów EXPDP/IMPDP.
Bazę danych możemy także eksportować/importować za pomocą mechanizmu DATA PUMP. Wprzeciwieństwie do oryginalnego eksportu/importu mechanizm ten działa jako proces serwera, a nieproces kliencki.
Data Pump tworzy i odczytuje pliki danych i dzienników, które należy umieścić w odrębnymkatalogu. W celu utworzenia wskaźnika do zewnętrznego katalogu należy w systemie Oracle użyćpolecenia CREATE DIRECTORY. Użytkownicy, którzy będą chcieli korzystać z metod EXPDP lubIMPDPD muszą mieć uprawnienia READ i WRITE do tego katalogu.
Tak samo jak przy oryginalnych metodach eksportu i importu, aby wykonac pełny eksport lubeksport w trybie przenośnej przestrzeni tabel naleźy posiadać przypisaną rolęEXP_FULL_DATABASE a przy importach IMP_FULL_DATABASE
Mechanizm Data Pump obsługuje cztery tryby, dzięki którym możemy eksportować/importować:-całą bazę-wybrany schemat-wybrane tabele-wybraną przestrzeń tabel
Podczas uruchamiania Data Pump podajemy informacje, takie jak:-kim chcemy wykonać eksport/import-katalog w którym mają być utworzone pliki eksportu lub odczytane pliki do importu-nazwy tych plików-co chcemy wyeksportować/zaimportować
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 56/311

Tak samo jak i przy EXP/IMP te czynności możemy zrobić zdalnie, ale nalezy pamiętać że pliki z danymi muszą być dostępne fizycznie dla serwera, na którym chcemy wykonać te operacje.
Dodatkowymi opcjalmi są polecenia EXCLUDE i INCLUDE, które umożliwiają określenie np. Które tabele mają byćeksportowane, a które należy z eksportu wykluczyć. Wyłączenie obiektu powoduje także wyłączenie wszystkich obiektów które od niego zależą.Poniżej kilka przykładów eksportów/importów:
Eksport całej bazy:
EXPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=BAZA.DMP LOGFILE=BAZA_EXPDP.LOG FULL=Y
Eksport schematu/schematów:
EXPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=HR.DMP LOGFILE=HR_EXPDP.LOG SCHEMAS=HR
EXPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=HR.DMP LOGFILE=HR_RAFAL_EXPDP.LOG SCHEMAS=HR,RAFAL
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 57/311
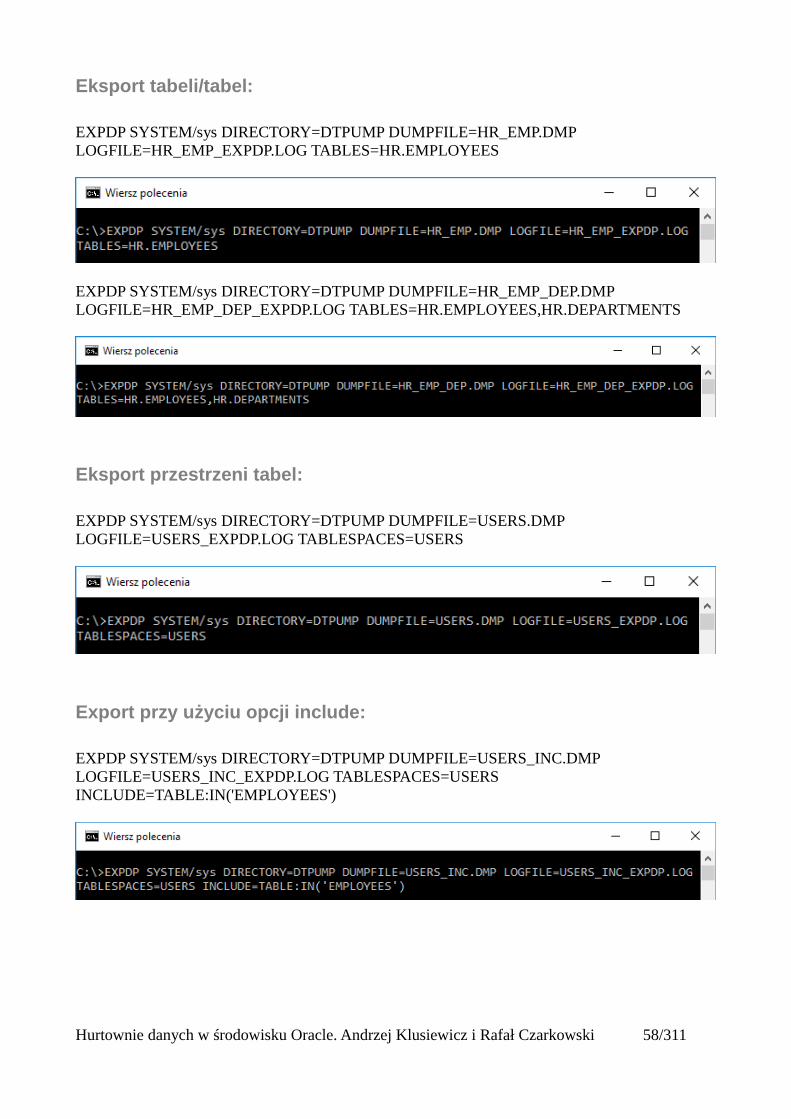
Eksport tabeli/tabel:
EXPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=HR_EMP.DMP LOGFILE=HR_EMP_EXPDP.LOG TABLES=HR.EMPLOYEES
EXPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=HR_EMP_DEP.DMP LOGFILE=HR_EMP_DEP_EXPDP.LOG TABLES=HR.EMPLOYEES,HR.DEPARTMENTS
Eksport przestrzeni tabel:
EXPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=USERS.DMP LOGFILE=USERS_EXPDP.LOG TABLESPACES=USERS
Export przy użyciu opcji include:
EXPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=USERS_INC.DMP LOGFILE=USERS_INC_EXPDP.LOG TABLESPACES=USERS INCLUDE=TABLE:IN('EMPLOYEES')
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 58/311
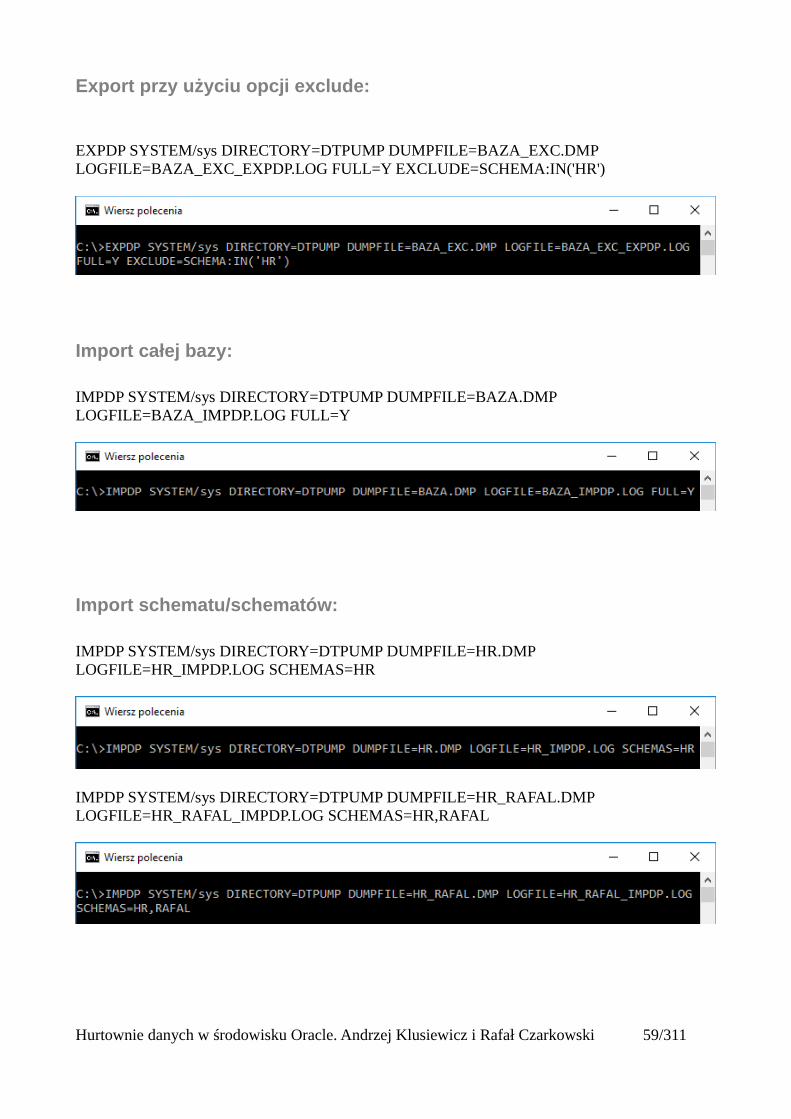
Export przy użyciu opcji exclude:
EXPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=BAZA_EXC.DMP LOGFILE=BAZA_EXC_EXPDP.LOG FULL=Y EXCLUDE=SCHEMA:IN('HR')
Import całej bazy:
IMPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=BAZA.DMP LOGFILE=BAZA_IMPDP.LOG FULL=Y
Import schematu/schematów:
IMPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=HR.DMP LOGFILE=HR_IMPDP.LOG SCHEMAS=HR
IMPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=HR_RAFAL.DMP LOGFILE=HR_RAFAL_IMPDP.LOG SCHEMAS=HR,RAFAL
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 59/311

Import tabeli/tabel:
IMPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=HR_EMP.DMP LOGFILE=HR_EMP_IMPDP.LOG TABLES=HR.EMPLOYEES
IMPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=HR_EMP_DEP.DMP LOGFILE=HR_EMP_DEP_IMPDP.LOG TABLES=HR.EMPLOYEES,HR.DEPARTMENTS
Import przestrzeni tabel:
IMPDP SYSTEM/sys DIRECTORY=DTPUMP DUMPFILE=USERS.DMP LOGFILE=USERS_IMPDP.LOG TABLESPACES=USERS
Informacje o parametrach jakie mozna wykorzystać podczas wykonywania eksportu i importu za pomocą data pump otrzymamy za pomocą poleceń:-EXPDP HELP=Y-IMPDP HELP=Y
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 60/311

Różnice pomiędzy EXP/IMP a EXPDP/IMPDP
Pomimo, iż używa się obu sposobów w tym samym celu, a więc do eksportu i importu danych,należy pamietać są to zupełnie dwa różne narzędzia a ich różnica nie polega jedynie na innejskładni czy parametrach.
Data Pump w przeciwieństwie do tradycyjnej metody działa jako proces serwera, dzieki czemu,nawet jeśli konsola w której uruchomiliśmy polecenie EXPDP lub IMPDP się zawiesi, albo nawetwyłączy to proces ten trwa nadal.Data Pump operuje na grupach plików, natomiast tradycyjna metoda na pojedynczych plikach.Data Pump używa plików znajdujących się bezpośrednio na serwerze (poprzez directory) ,natomiast tradycyjna metoda z komputera klienckiego lub serwera w zależności od tego gdzieuruchamiamy EXP/IMP.Metadane w tradycyjnej metodzie są trzymane w postaci instrukcji DDL, natomiast data pump jestreprezentowany w formacie dokumentu XML. Data pump domyslnie zrównolegla procesy eksporu/importu, natomiast tradycyjna metoda używapojedynczego strumienia.Data pump używa metody blokowej, natomiast tradycyjna metoda opiera się o bajty.Przy importowaniu schematu użytkownika za pomocą data pump, uzytkownik zostannie stworzonyod nowa, natomiast przy tradycyjnej metodzie wymagane jest wcześniejsze utworzenie go, adopiero potem import jego obiektów.Przy używaniu data pump możemy odtworzyć użytkownika/tabele/przestrzenie tabel/pliki danychw ogóle pod innymi nazwami/ściezkami za pomocą przełącznika REMAP (np.REMAP_TABLE=EMPLOYEES:PRACOWNICY).
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 61/311

Poziomy izolacji w Oracle
Wprowadzenie
Współbieżność działania operacji to cecha wszystkich współczesnych baz danych. Oznacza to, że jedna operacja może modyfikować dane podczas gdy inna te same dane odczytuje, lub dwie operacje odczytują te same dane. To pociąga za sobą pewne komplikacje odnoszące się do spójnościdanych i odczytu.
Przykładowo – jedna operacja odczytuje dane (SELECT1), odczytana liczba wierszy to 4. Inna sesja po SELECT1 wykonuje aktualizację tych samych wierszy (UPDATE1), oraz dodaje jeszcze jeden (INSERT1) i zatwierdza. Ponowne wykonanie operacji SELECT1 spowoduje odczytanie nowego wiersza oraz wierszy zmienionych. Wynik tej samej operacji będzie różny w kolejnych wykonaniach. To może prowadzić do niepożądanych sytuacji, np. gdy zechcemy dwukrotnie wykonać zapytanie by wyrzucić ten sam raport do dwóch różnych formatów plików.
W przypadku odczytu nowego wiersza mamy do czynienia z odczytem fantomowych, w przypadku odczytu zmienionej postaci wierszy mamy do czynienia z odczytami niemożliwymi do powtórzenia.
To co widzieć będzie operacja SELECT1 będzie zależeć od poziomu izolacji transakcji. W Oracle dostępne mamy trzy poziomy izolacji transakcji. Czwarta znana z innych baz danych – READ UNCOMMITTED nie jest wspierana przez Oracle. Dostępne w Oracle:
READ COMMITED – ten tryb jest domyślny dla Oracle. W tym trybie każde zapytanie widzi tylkozmiany które zostały zatwierdzone przed rozpoczęciem zapytania. Jeśli zapytanie zostanie wykonane ponownie, w wyniku będą uwzględnione ewentualne wykonane i zatwierdzone po pierwszym (lub w jego trakcie) uruchomieniu zapytania zmiany, w tym również wiersze usunięte i dodane.
SERIALIZABLE – w tym poziomie, tylko zmiany zatwierdzone przed rozpoczęciem transakcji oraz te wykonane w ramach danej transakcji (INSERT, UPDATE,DELETE) będą widoczne. W przypadku powtórzenia tego samego selecta nie będziemy tutaj mieli do czynienia z operacjami niemożliwymi do powtórzenia, ani z danymi fantomowymi.
READ ONLY – Widoczne są tylko zmiany zatwierdzone przed rozpoczęciem transakcji. Żadne zmiany nie są możliwe w ramach sesji mającej włączony ten poziom izolacji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 62/311

Włączanie poszczególnych trybów izolacji
READ COMMITTED
Alter session set isolation_level=read committed;
Alter system set isolation_level=read committed;
SERIALIZABLE
Alter session set isolation_level=serializable;
Alter system set isolation_level=serializable;
READ ONLY
Alter session set isolation_level=readonly;
Alter system set isolation_level=readonly;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 63/311
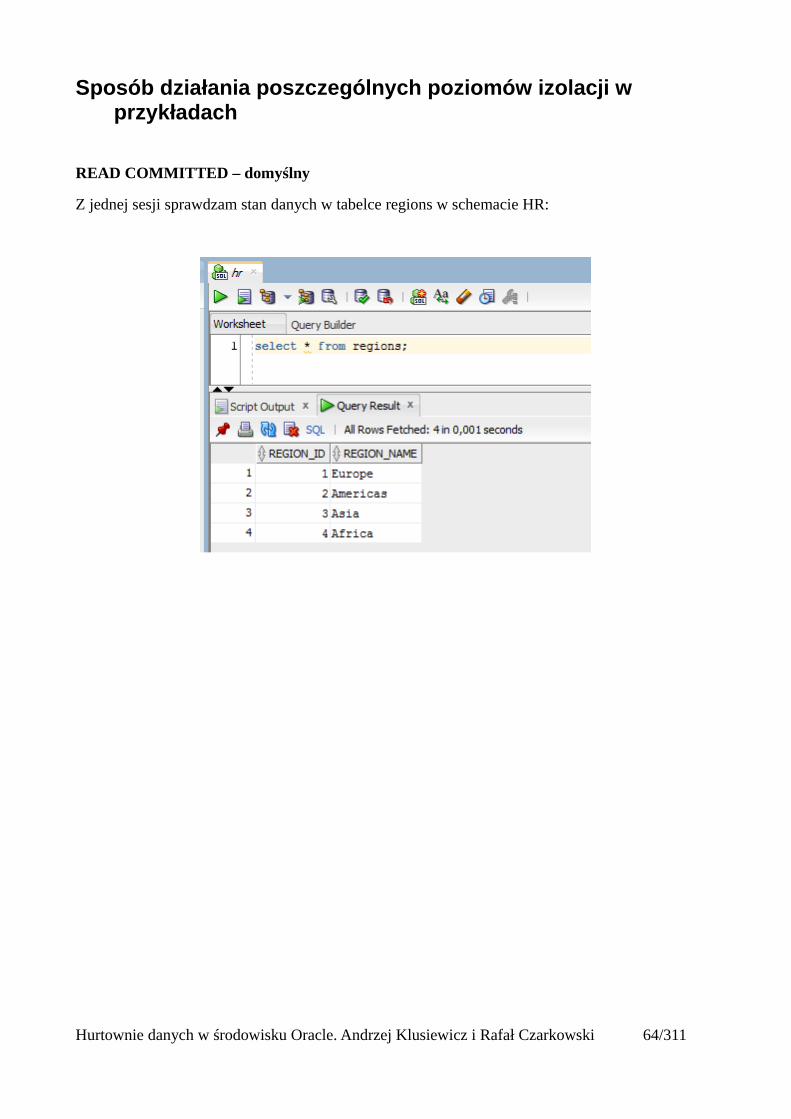
Sposób działania poszczególnych poziomów izolacji w przykładach
READ COMMITTED – domyślny
Z jednej sesji sprawdzam stan danych w tabelce regions w schemacie HR:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 64/311
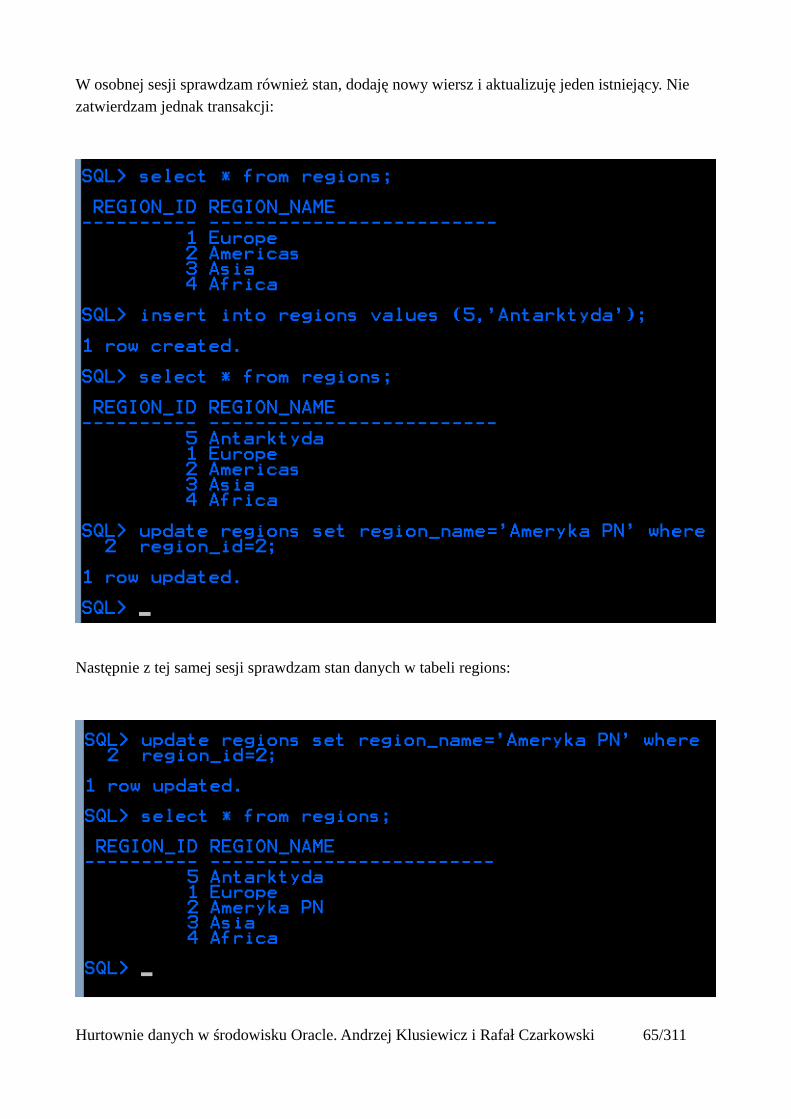
W osobnej sesji sprawdzam również stan, dodaję nowy wiersz i aktualizuję jeden istniejący. Nie zatwierdzam jednak transakcji:
Następnie z tej samej sesji sprawdzam stan danych w tabeli regions:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 65/311
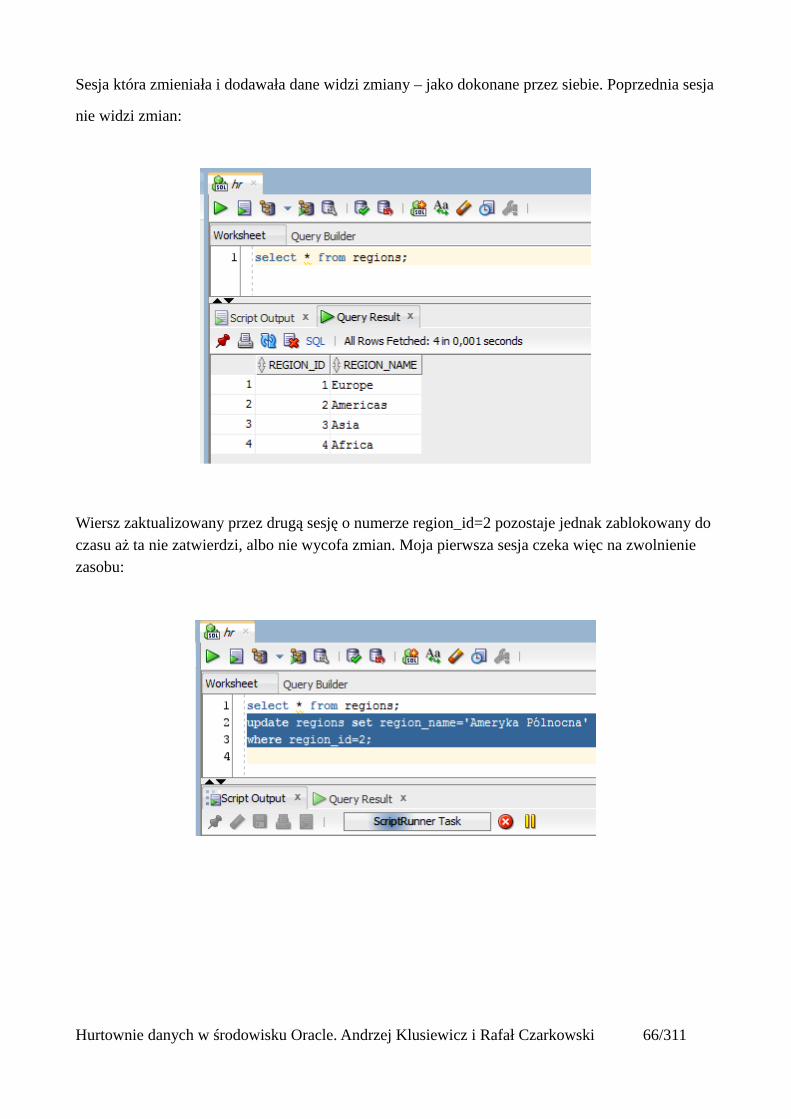
Sesja która zmieniała i dodawała dane widzi zmiany – jako dokonane przez siebie. Poprzednia sesja
nie widzi zmian:
Wiersz zaktualizowany przez drugą sesję o numerze region_id=2 pozostaje jednak zablokowany do czasu aż ta nie zatwierdzi, albo nie wycofa zmian. Moja pierwsza sesja czeka więc na zwolnienie zasobu:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 66/311
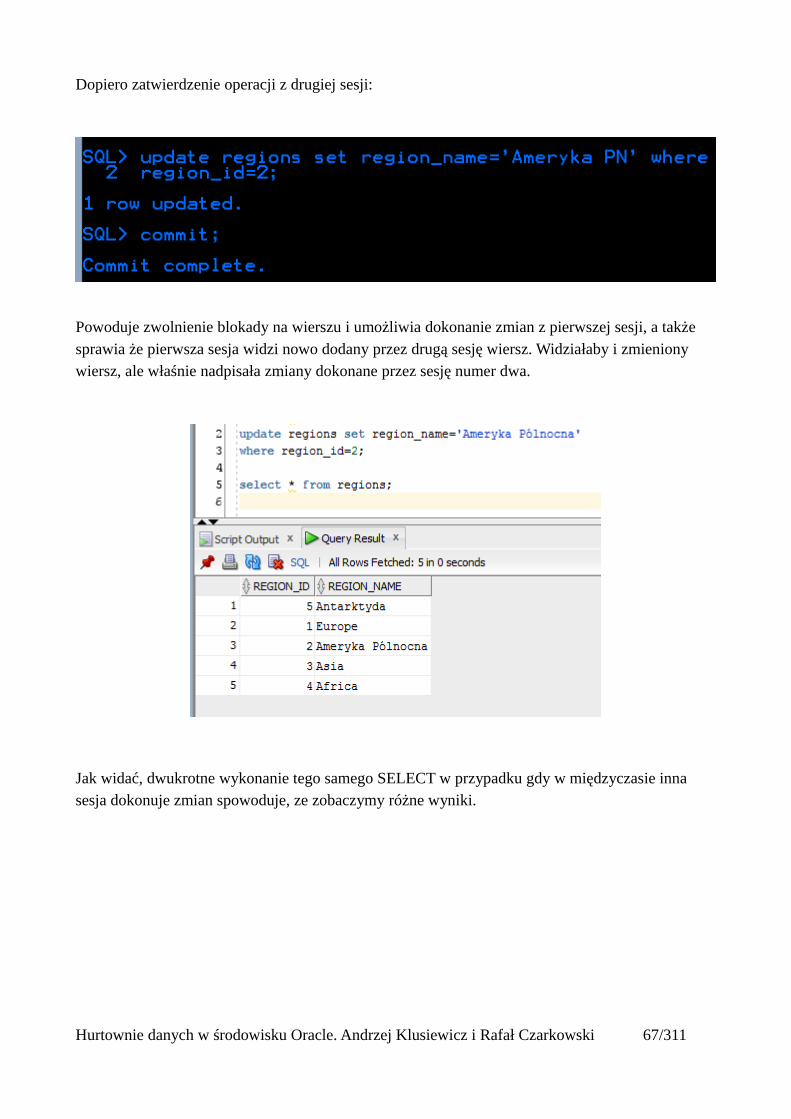
Dopiero zatwierdzenie operacji z drugiej sesji:
Powoduje zwolnienie blokady na wierszu i umożliwia dokonanie zmian z pierwszej sesji, a także sprawia że pierwsza sesja widzi nowo dodany przez drugą sesję wiersz. Widziałaby i zmieniony wiersz, ale właśnie nadpisała zmiany dokonane przez sesję numer dwa.
Jak widać, dwukrotne wykonanie tego samego SELECT w przypadku gdy w międzyczasie inna sesja dokonuje zmian spowoduje, ze zobaczymy różne wyniki.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 67/311
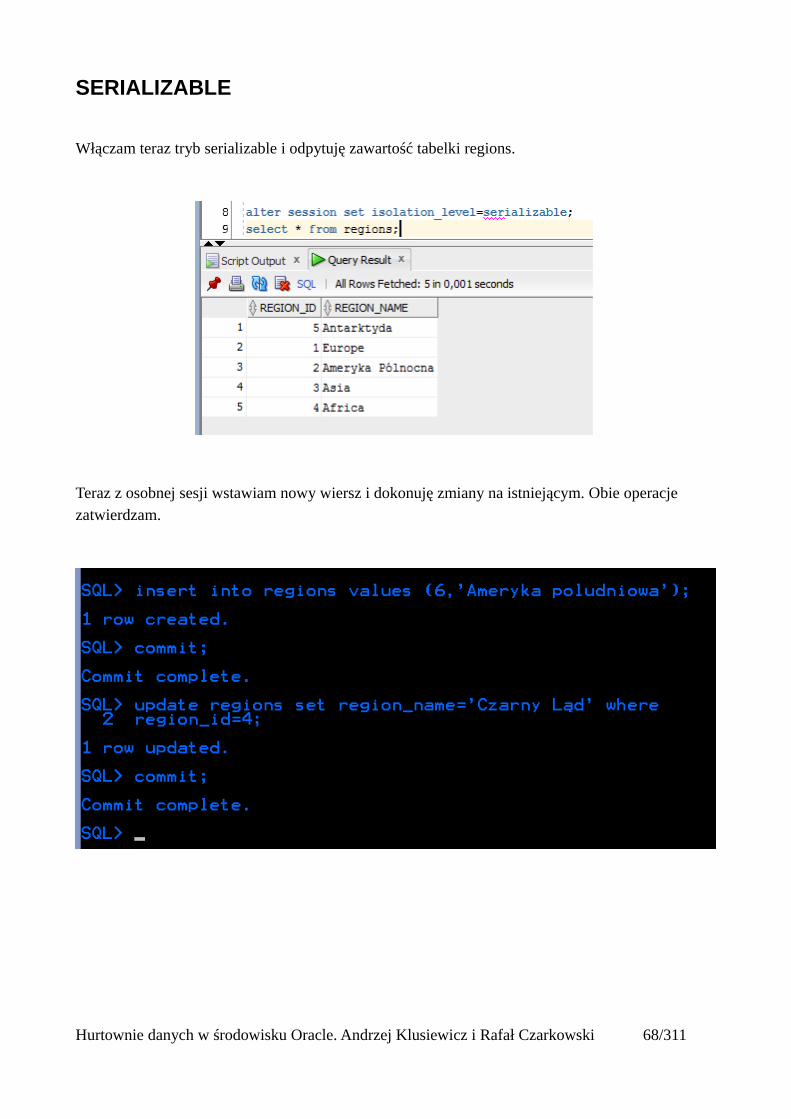
SERIALIZABLE
Włączam teraz tryb serializable i odpytuję zawartość tabelki regions.
Teraz z osobnej sesji wstawiam nowy wiersz i dokonuję zmiany na istniejącym. Obie operacje zatwierdzam.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 68/311
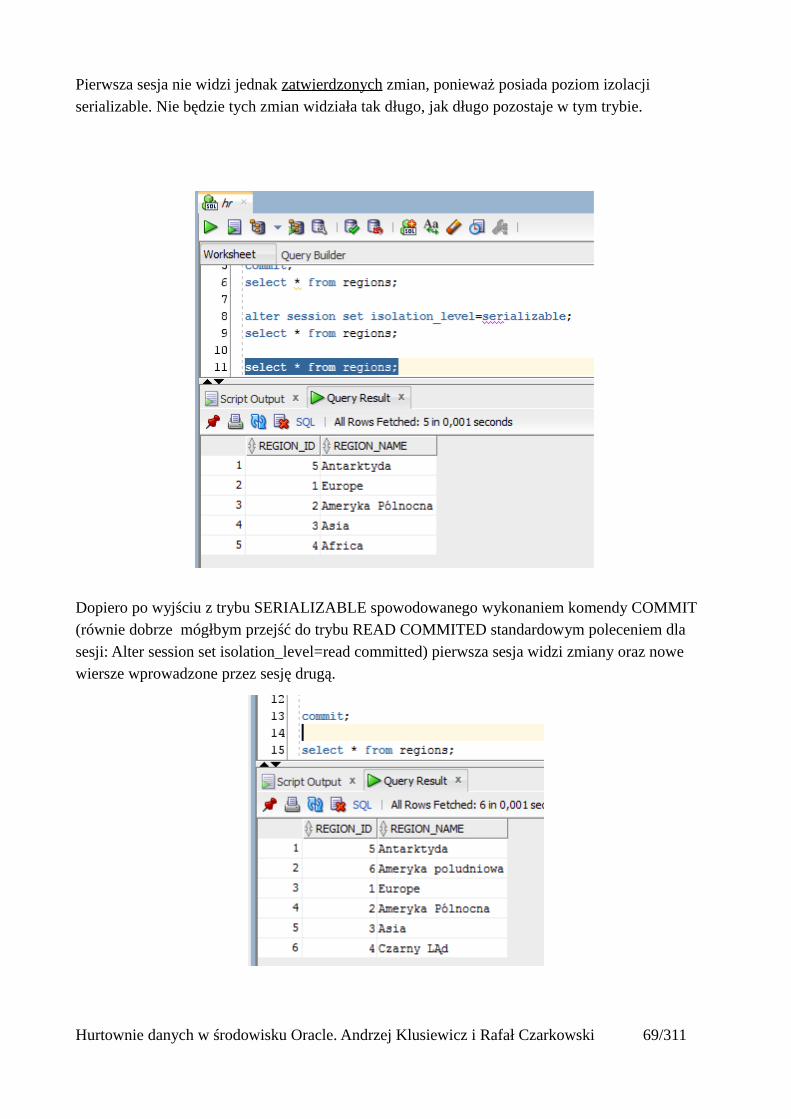
Pierwsza sesja nie widzi jednak zatwierdzonych zmian, ponieważ posiada poziom izolacji serializable. Nie będzie tych zmian widziała tak długo, jak długo pozostaje w tym trybie.
Dopiero po wyjściu z trybu SERIALIZABLE spowodowanego wykonaniem komendy COMMIT (równie dobrze mógłbym przejść do trybu READ COMMITED standardowym poleceniem dla sesji: Alter session set isolation_level=read committed) pierwsza sesja widzi zmiany oraz nowe wiersze wprowadzone przez sesję drugą.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 69/311
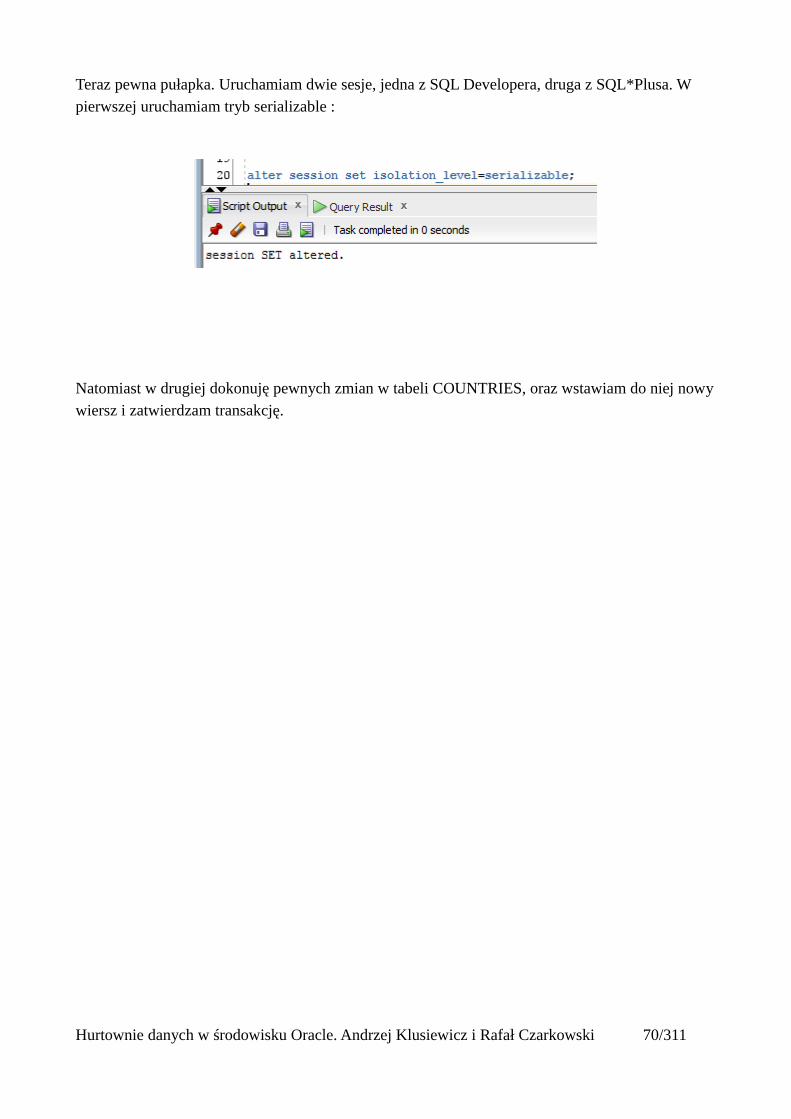
Teraz pewna pułapka. Uruchamiam dwie sesje, jedna z SQL Developera, druga z SQL*Plusa. W pierwszej uruchamiam tryb serializable :
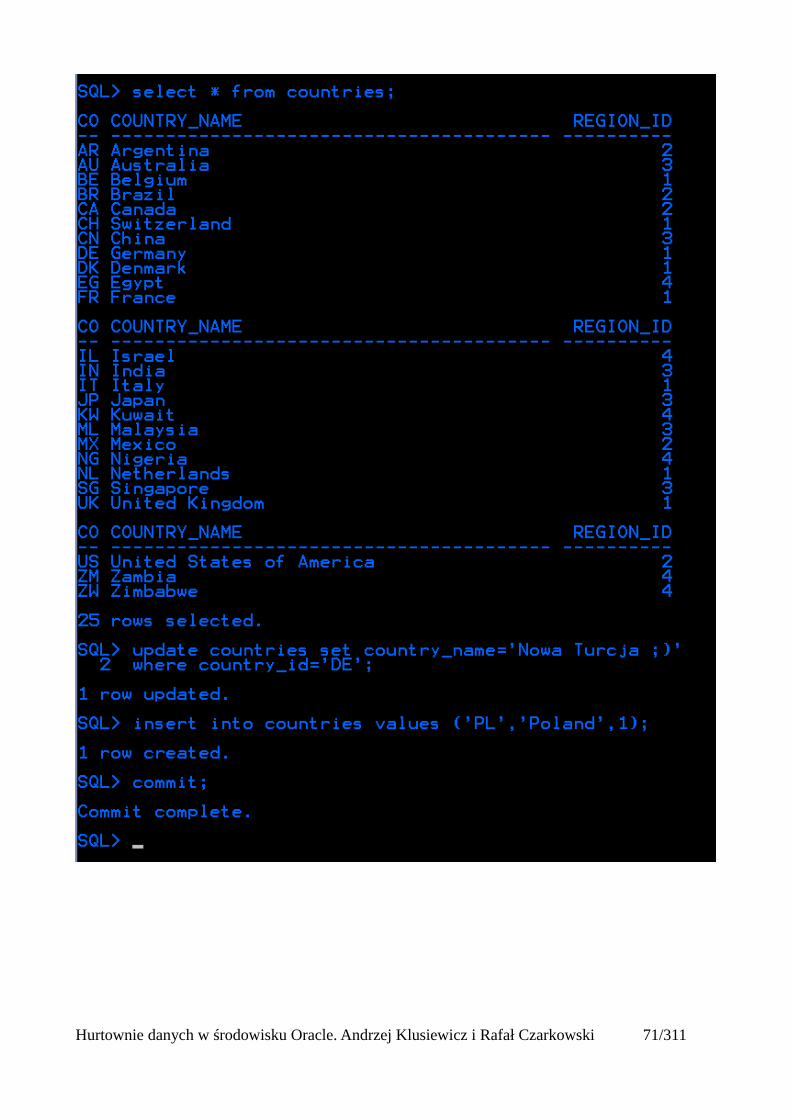
Natomiast w drugiej dokonuję pewnych zmian w tabeli COUNTRIES, oraz wstawiam do niej nowywiersz i zatwierdzam transakcję.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 70/311
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 71/311
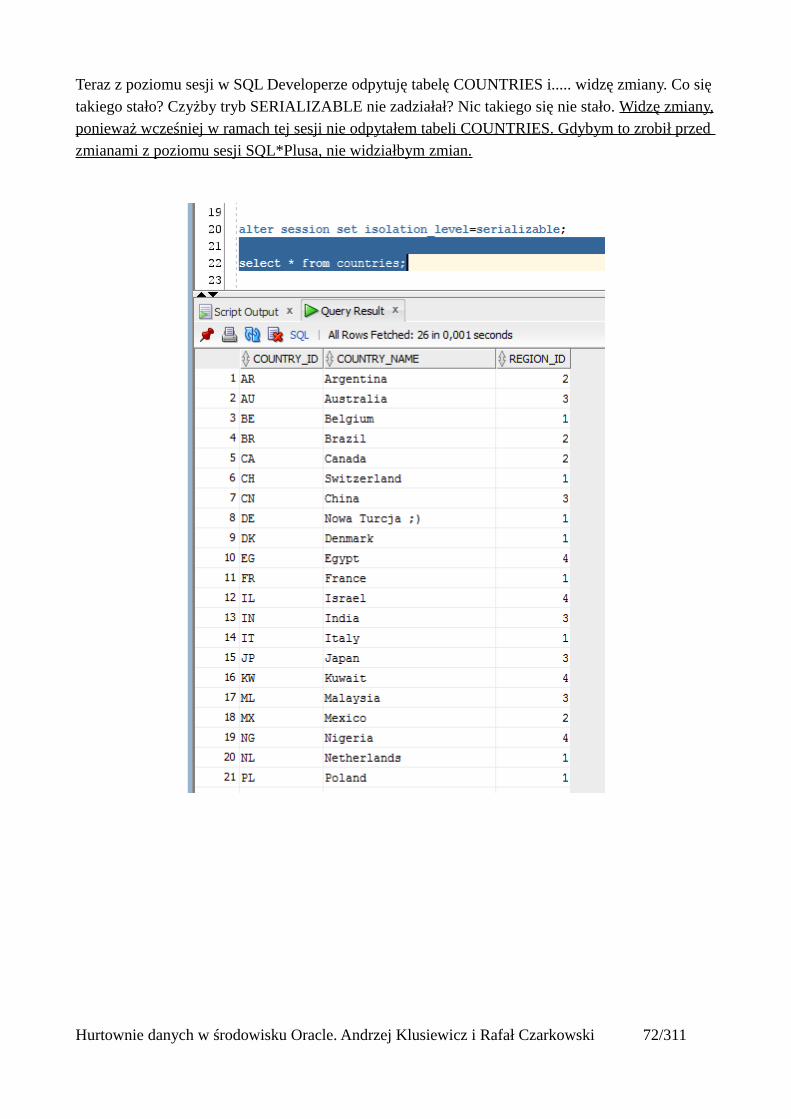
Teraz z poziomu sesji w SQL Developerze odpytuję tabelę COUNTRIES i..... widzę zmiany. Co się takiego stało? Czyżby tryb SERIALIZABLE nie zadziałał? Nic takiego się nie stało. Widzę zmiany,ponieważ wcześniej w ramach tej sesji nie odpytałem tabeli COUNTRIES. Gdybym to zrobił przed zmianami z poziomu sesji SQL*Plusa, nie widziałbym zmian.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 72/311

Tryb flashback
Istnieje możliwość przestawienia sesji w tryb flasback. Dzięki temu, będziemy widzieć stan bazy z określanego przez nas momentu z przeszłości. Dane te pochodzą z przestrzeni UNDO , więc musimy pamiętać o właściwym ustawieniu parametru undo_retention.Do tego zadania wykorzystujemy pakiet dbms_flashback, więc jeśli chcemy z niego korzystać z innego użytkownika niż sys musimy temu użytkownikowi nadać odpowiednie uprawnienia:
grant execute on dbms_flashback to hr;
Następnie dokonujemy kilku zmian po których odróżnimy aktualny stan od stanu po zmianach. Dobrze jest sobie zapisać kiedy zmiany miały miejsce:
update employees set salary=3000;commit;update departments set manager_id=100;commit; --13:37
Kolejnym krokiem jest włączenie trybu flashback. Musimy podać czas, z którego stan chcemy oglądać. Czas musi być podany jako timestamp:
begindbms_flashback.enable_at_time(to_timestamp('13:30:00 22-10-2011','hh24:mi:ss dd-mm-yyyy' ));end;
Możesz teraz zajrzeć do tabel które zmieniałeś:
select * from employees;select * from departments;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 73/311

Zauważ że widzisz te tabele w stanie z czasu który podałeś w enable_at_time, nie trzeba dorzucać as of timestamp - bo to jest tutaj jakby parametrem domyślnym. Minus jest taki, że mając włączony ten tryb nie możemy zmieniać nic w bazie. Baza działa w trybie flashback i jest tylko do odczytu. Nie możemy też wykonać żadnej operacji DDL. Oczywiście ograniczenie to dotyczy tylko aktualnej sesji.Aby wyłączyć tryb flashback stosujemy to:
begindbms_flashback.disable;end;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 74/311

Instrukcja Merge
Od wersji 9i mamy możliwość używania w Oracle instrukcji Merge. Instrukcja taumożliwia nam scalenie danych z dwóch tabel,czyli np zamianę części danych w tabeli nadane z innej tabeli. Dobrym przykładem z życia jest pobieranie opłat za energieelektryczną. Inkasent sprawdza stan licznika u klienta,a następnie nanosi zmiany welektrowni. Na potrzeby przykładu zbudowałem dwie tabele. Tabela elektrownia składając się zdwóch kolumn: nr_klienta oraz stan_licznika.
Create table elektrownia(nr_klienta number constraint klucz_glowny1 primary key,stan_licznika number);
Następnie uzupełniamy tabelę elektrownia przykładowymi wartościami .
Insert into elektrowania values(1,1200);Insert into elektrowania values(2,1500);Insert into elektrowania values(3,1000);Insert into elektrowania values(4,2000);Insert into elektrowania values(5,1900);Insert into elektrowania values(6,1600);Insert into elektrowania values(7,1800);Insert into elektrowania values(8,1100);Insert into elektrowania values(9,1400);Insert into elektrowania values(10,1600);Insert into elektrowania values(11,1900);Insert into elektrowania values(12,2100);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 75/311

Tabela inkasent_01 składająca się z tych samych kolumn. W kolumnie stan_licznika zwiększyłem wartości o 10% .
Create table inkasent_01 as select nr_klienta,stan_licznika * 1.1 stan_licznikafrom elektrownia
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 76/311

Teraz chcemy wprowadzić wartości z stan_licznika inkasenta do stan_licznika w elektrowni. Ułatwiamy sobie pracę stosujący merge,aby nie wstawiać każdej zmienionejwartości osobno używając update.
Merge into elektrownia using inkasent_01 on(elektrowani.nr_klienta=inkasent_0 1.nr_klienta)when matched then update set elektrowani.stan_licznika=inkasent_01.stan_licznika;
Po Merge into wpisujemy nazwę tabeli w której chcemy wprowadzić zmiany(elektrownia) .Po using nazwę tabeli z której wartości chcemy pobrać (inkasent_01). Równanie Po onwskazuje w jaki sposób w tabeli inkasent_01 ma zostać odnaleziony odpowiednik tegowiersza z tabeli Elektrownia. Dzięki temu system wie na podstawie którego wiersza wtabeli inkasent_01 ma zaktualizować wiersz w tabeli elektrownia .When matched thenokreśla czynność która ma zostać wykonana kiedy zostanie znaleziony odpowiednikwiersza w drugiej tabeli ,czyli update(zmiana) wartości w kolumnie stan_licznika z tabelielektrownia na wartości w kolumnie stan_licznika z tabeli inkasent_01.Powyżej wersja zużyciem pełnych nazw tabeli,poniżej z użyciem aliasów.
Merge into elektrownia e using inkasent_01 i on(elektrowani.nr_klienta=inkasent_0 1.nr_klienta)when matched then update set e.stan_licznika=i.stan_licznika;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 77/311

Po uruchomieniu instrukcji, stan tabeli elektrownia został zaktualizowany.
Select * from elektrownia ;
Instrukcje Merge możemy również zastosować do wstawianie nowych wierszy. Dobrymprzykładem będzie przedstawiciel handlowy który zbiera zamówienia od klientów z którymijuż współpracuje,oraz cały czas zdobywa nowych klientów. Na potrzeby przykładutworzymy tabele hurtownia z kolumnami nr_klienta oraz miesieczne_zamówienie .
create table hurtownia(nr_klienta number constraint klucz_glowny2 primary key,miesieczne_zamówienie number);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 78/311

Do tabeli wstawiamy 10 klientów.
insert into hurtownia values(1,5000);insert into hurtownia values(2,2000);insert into hurtownia values(3,4000);insert into hurtownia values(4,2500);insert into hurtownia values(5,6000);insert into hurtownia values(6,5000);insert into hurtownia values(7,1500);insert into hurtownia values(8,800);insert into hurtownia values(9,10000);insert into hurtownia values(10,3500);
Następnie tworzymy tabelę handlowiec_01 o takiej samej strukturze zwiększając wartościw kolumnie miesięczne zamówienie o 25%,oraz dodając dwóch nowych klientów
Create table handlowiec_01 as select nr_klienta,miesieczne_zamówienie*1.25miesieczne_zamówienie from hurtownia ;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 79/311

Insert into handlowiec_01 values (11,2000);Insert into handlowiec_01 values (12,1400);
Teraz chcemy jednocześnie zaktualizować miesieczne zamówienie naszychdotychczasowych klientów oraz wstawić do tabeli nowych klientów .
Merge into hurtownia h using handlowiec_01 hh on(h.nr_klienta=hh.nr_klienta)when matched then update set h.miesieczne_zamówienie=hh.miesieczne_zamówieniewhen not matched then insert (h.nr_klienta,h.miesieczne_zamówienie)values (hh.nr_klienta,hh.miesieczne_zamówienie);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 80/311

Po Merge into wpisujemy nazwę tabeli w której chcemy wprowadzić zmiany(hurtownia) pousing nazwę tabeli z której wartości chcemy pobrać (handlowiec_01). Po on warunekłączenia tabel,nr_klienta w tabeli hurtownia jest równy nr_klienta w tabeli handlowiec_01.When matched then okresla czynność która ma nastąpić gdy warunek on jestspełniony,czyli update(zmiana) wartości w kolumnie miesieczne_zamówienie z tabelihurtownia na wartości w kolumnie miesieczne_zamówieni z tabeli handlowiec_01.Whenno matched then określa czynność która ma nastąpić gdy warunek on nie jestspełniony,czyli insert(wstawienie) dwóch nowych wierszy.
Po uruchomieniu instrukcji, stan tabeli hurtownia został zaktualizowany.
Select * from hurtownia ;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 81/311

Kolejnym zastosowaniem Merge jest zmian wartości w więcej niż jednej kolumnie.Na potrzeby przykładu tworzymy tabele wypłaty pracowników składająca się z kolumn id_pracownika,pensja_pracownika,premia_pracownika
create table wyplaty ( id_pracownika number,pensja_pracownika number,premia_pracownika number);
Zapelniamy tabele 10 pracownikami
insert into wyplaty values(1,2000,500);insert into wyplaty values(2,2500,700);insert into wyplaty values(3,1500,300);insert into wyplaty values(4,2200,500);insert into wyplaty values(5,3000,500);insert into wyplaty values(6,2000,300);insert into wyplaty values(7,2200,600);insert into wyplaty values(8,2500,1000);insert into wyplaty values(9,2000,800);insert into wyplaty values(10,1800,500);
select * from wyplaty;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 82/311

Następnie tworzymy tabele wyplaty_aktualizacja o takiej samej strukturze.Zmieniamy wartości w 3 wierszach w kolumnach pensja_pracowniak,oraz premia_pracownika.
create table wyplaty_aktualizacja as select * from wyplaty ;
update wyplaty_aktualizacja set pensja_pracownika=pensja_pracownika+200 where id_pracownika in (3,5,6);update wyplaty_aktualizacja set premia_pracownika=premia_pracownika+500 where id_pracownika in (2,4,8);
select * from wyplaty_aktualizacja ;
Teraz chcemy wprowadzić zmiany do dwuch kolumn w tabeli wypłaty.
merge into wyplaty w using wyplaty_aktualizacja wa on(w.id_pracownika=wa.id_pracownika)when matched then update set w.pensja_pracownika=wa.pensja_pracownika, w.premia_pracownika=wa.premia_pracownika
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 83/311

Po Merge into wpisujemy nazwę tabeli w której chcemy wprowadzić zmiany(wyplaty) . Pousing nazwę tabeli z której wartości chcemy pobrać(wyplaty_aktualizacja). Równanie Poon wskazuje w jaki sposób w tabeli wyplaty_aktualizacja ma zostać odnalezionyodpowiednik tego wiersza z tabeli wyplaty. Dzięki temu system wie na podstawie któregowiersza w tabeli wyplaty_aktualizacje ma zaktualizować wiersz w tabeli wyplaty .Whenmatched then określa czynności którer mają zostać wykonana kiedy zostanie znalezionyodpowiednik wiersza w drugiej tabeli ,czyli update(zmiany) wartości w kolumnachpensja_pracownika,premia_pracownika z tabeli wyplaty na wartości w kolumnachpensja_pracownika,premia_pracownika z tabeli wyplaty_aktualizacja.
select * from wyplaty ;
Kolejnym zastosowanie instrukcji merge jest usównie wierszy.Dobry przykład to firmawindykacyjn.Część dłużników zwiększa swoje zaległości,a część je spłaca .Osoby którespłacą należność zostają skreślone z listy dłużników.Tworzymy tabele dłużnicy_majskładającej się z kolumn id_dłużnika oraz zaległości.
create table dłużnicy(id_dłużnika number constraint klucz_glowny3 primary key,zaległości number);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 84/311

Do tabeli wstawiamy 10 dłużników.
insert into dłużnicy values(1,5000);insert into dłużnicy values(2,8000);insert into dłużnicy values(3,20000);insert into dłużnicy values(4,4000);insert into dłużnicy values(5,15000);insert into dłużnicy values(6,22000);insert into dłużnicy values(7,18000);insert into dłużnicy values(8,3000);insert into dłużnicy values(9,16000);insert into dłużnicy values(10,12000);
select * from dłużnicy;
Następnie tworzymy tabelę dłużnicy_aktualizacja o takiej samej strukturze zwiększającwartości w kolumnie zaległości o 10%,oraz usuwając dwóch dłużników.
create table dłużnicy_aktualizacja as select id_dłużnika,zaległości*1.1 zaległości fromdłużnicy;delete from dłużnicy_aktualizacja where id_dłużnika in (2,6)
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 85/311

select * from dłużnicy_aktualizacja;
Teraz chcemy zaktualizować zadłużenie u dłużników którzy powiększyli swoje zaległościoraz usunąć z listy osoby które swoje zaległości spłaciły.
Merge into dłużnicy d using dłużnicy_aktualizacja da on(d.id_dłużnika=d2.id_dłużnika)when matched then update set d.zaległości=d2.zaległościdelete where id_dłużnika in (2,6);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 86/311
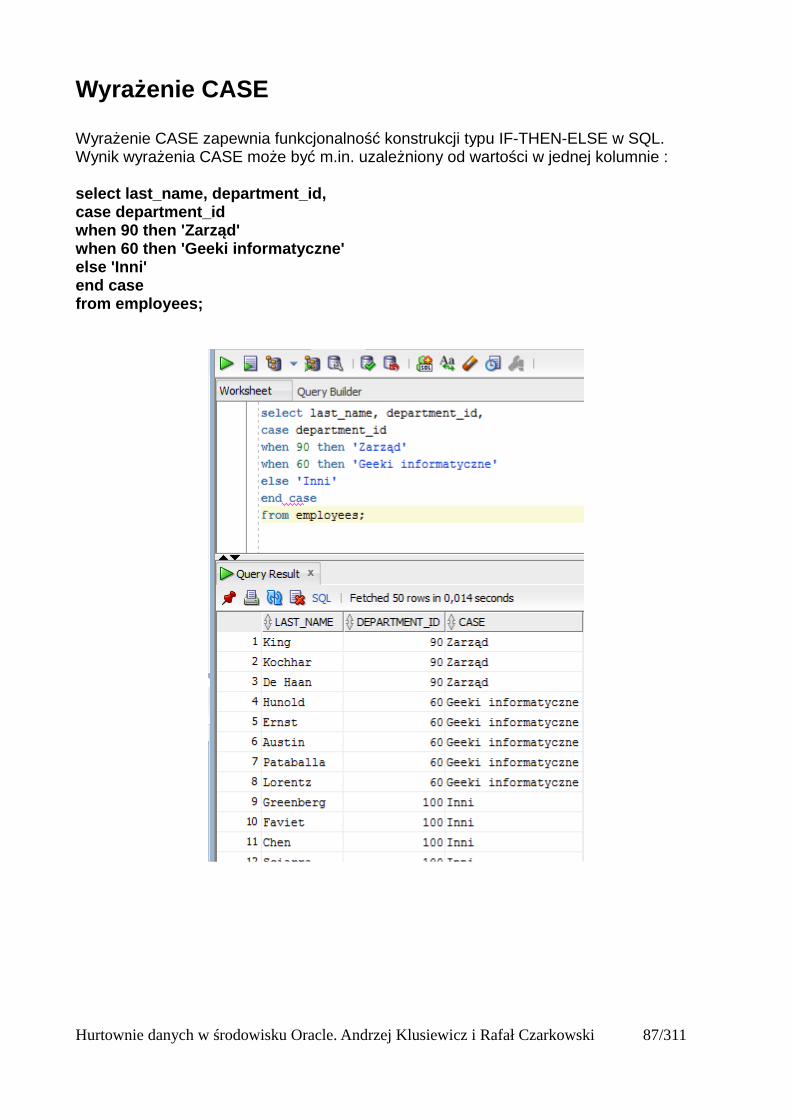
Wyrażenie CASE
Wyrażenie CASE zapewnia funkcjonalność konstrukcji typu IF-THEN-ELSE w SQL.Wynik wyrażenia CASE może być m.in. uzależniony od wartości w jednej kolumnie :
select last_name, department_id, case department_id when 90 then 'Zarząd'when 60 then 'Geeki informatyczne'else 'Inni'end casefrom employees;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 87/311
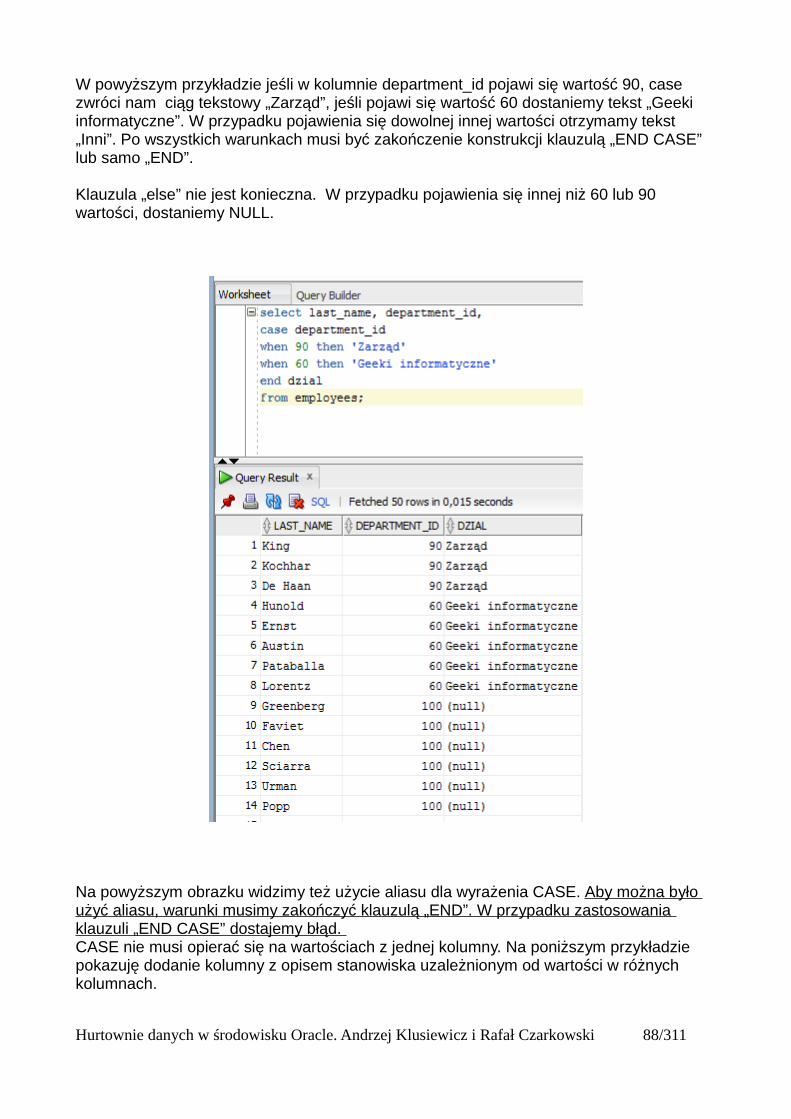
W powyższym przykładzie jeśli w kolumnie department_id pojawi się wartość 90, case zwróci nam ciąg tekstowy „Zarząd”, jeśli pojawi się wartość 60 dostaniemy tekst „Geeki informatyczne”. W przypadku pojawienia się dowolnej innej wartości otrzymamy tekst „Inni”. Po wszystkich warunkach musi być zakończenie konstrukcji klauzulą „END CASE” lub samo „END”.
Klauzula „else” nie jest konieczna. W przypadku pojawienia się innej niż 60 lub 90 wartości, dostaniemy NULL.
Na powyższym obrazku widzimy też użycie aliasu dla wyrażenia CASE. Aby można było użyć aliasu, warunki musimy zakończyć klauzulą „END”. W przypadku zastosowania klauzuli „END CASE” dostajemy błąd. CASE nie musi opierać się na wartościach z jednej kolumny. Na poniższym przykładzie pokazuję dodanie kolumny z opisem stanowiska uzależnionym od wartości w różnych kolumnach.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 88/311
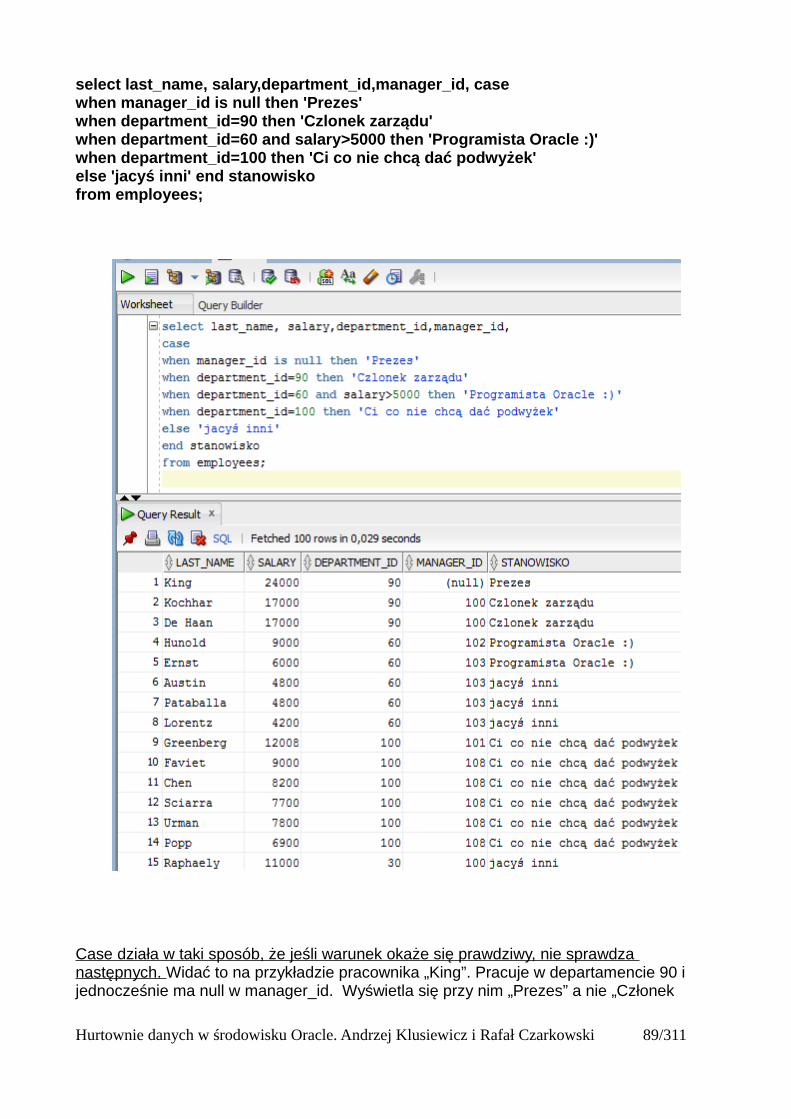
select last_name, salary,department_id,manager_id, case when manager_id is null then 'Prezes'when department_id=90 then 'Czlonek zarządu'when department_id=60 and salary>5000 then 'Programista Oracle :)'when department_id=100 then 'Ci co nie chcą dać podwyżek'else 'jacyś inni' end stanowiskofrom employees;
Case działa w taki sposób, że jeśli warunek okaże się prawdziwy, nie sprawdza następnych. Widać to na przykładzie pracownika „King”. Pracuje w departamencie 90 i jednocześnie ma null w manager_id. Wyświetla się przy nim „Prezes” a nie „Członek
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 89/311

zarządu”, ponieważ warunek pierwszy został spełniony (null w manager_id) i system nie sprawdzał kolejnego.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 90/311
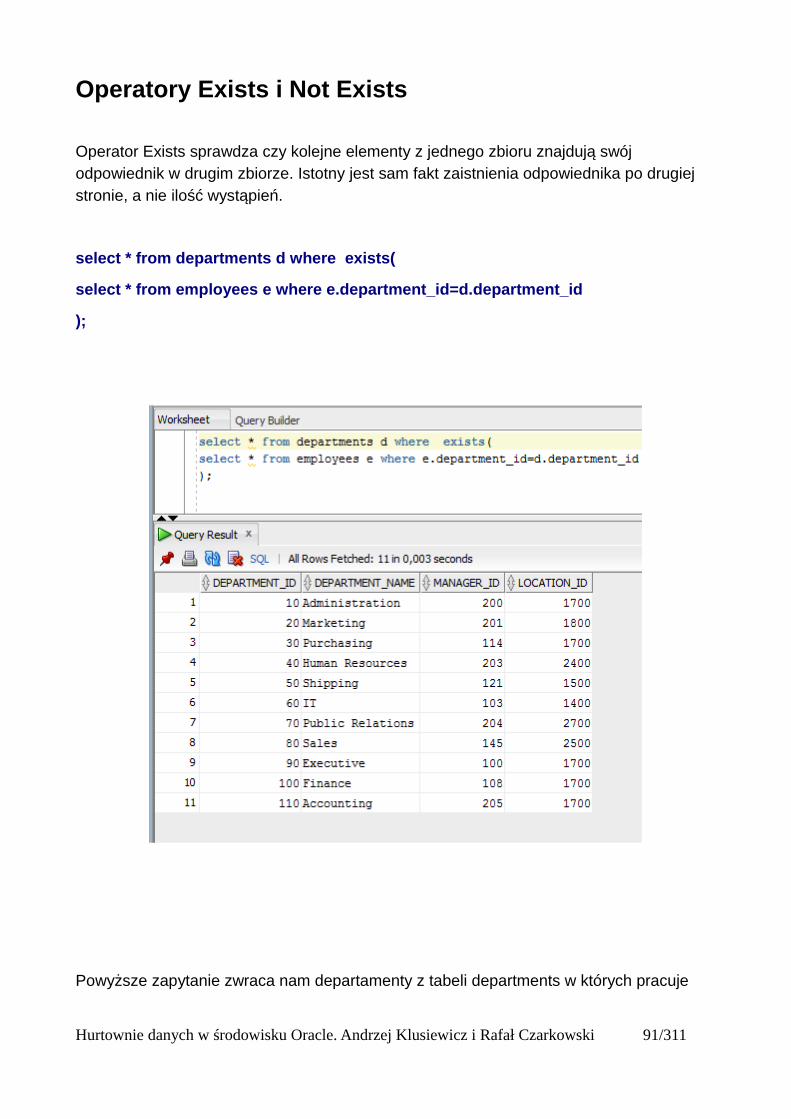
Operatory Exists i Not Exists
Operator Exists sprawdza czy kolejne elementy z jednego zbioru znajdują swój odpowiednik w drugim zbiorze. Istotny jest sam fakt zaistnienia odpowiednika po drugiej stronie, a nie ilość wystąpień.
select * from departments d where exists(
select * from employees e where e.department_id=d.department_id
);
Powyższe zapytanie zwraca nam departamenty z tabeli departments w których pracuje
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 91/311
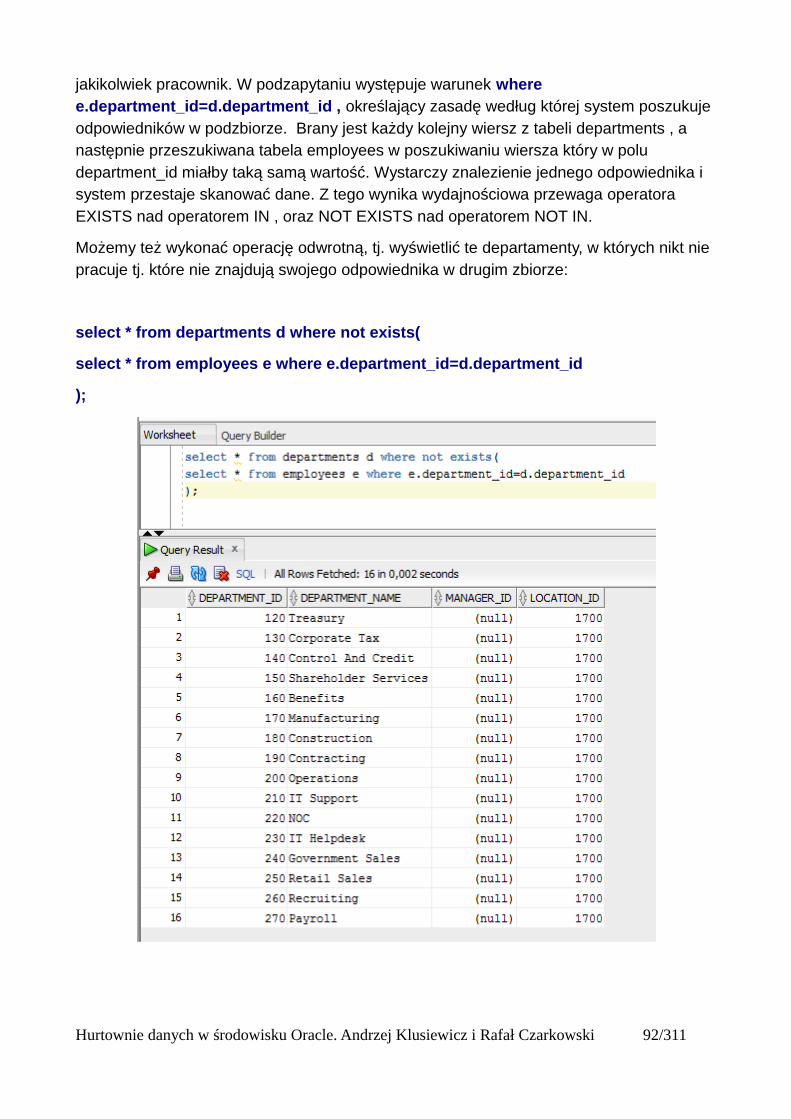
jakikolwiek pracownik. W podzapytaniu występuje warunek where e.department_id=d.department_id , określający zasadę według której system poszukuje odpowiedników w podzbiorze. Brany jest każdy kolejny wiersz z tabeli departments , a następnie przeszukiwana tabela employees w poszukiwaniu wiersza który w polu department_id miałby taką samą wartość. Wystarczy znalezienie jednego odpowiednika i system przestaje skanować dane. Z tego wynika wydajnościowa przewaga operatora EXISTS nad operatorem IN , oraz NOT EXISTS nad operatorem NOT IN.
Możemy też wykonać operację odwrotną, tj. wyświetlić te departamenty, w których nikt nie pracuje tj. które nie znajdują swojego odpowiednika w drugim zbiorze:
select * from departments d where not exists(
select * from employees e where e.department_id=d.department_id
);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 92/311

Grupowanie i funkcje agregujące
Funkcje agregujące
Funkcje agregujące, to takie funkcje, które zwracają jedną wartość wyliczoną na podstawie wielu wierszy. Wszystkie funkcje grupowe ignorują wiersze zawierające wartośćNULL w kolumnie, na której działają.
AVG
avg ([DISTINCT] wyrażenie) – funkcja oblicza wartość średnią wyrażenia dla wszystkich wierszy. W poniższym przykładzie jest to średnia zarobków pracowników.
COUNT
count ([DISTINCT] {wyrażenie|* }) – funkcja zwraca ilość wierszy dla których wyrażenie jest różne od NULL. Użycie gwiazdki powoduje zliczenie wszystkich wierszy w tabeli. W tym wypadku została wyświetlona ilość pracowników.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 93/311

MAX
max (wyrażenie), min(wyrażenie) – funkcje obliczają maksymalną i minimalną wartość wyrażenia, wartość wyrażenia może być liczbą, ciągiem znaków lub datą. W poniższym przykładzie zostały wyświetlone najwyższa i najniższa płaca. W przypadku daty zwraca najpóźniejszą, w przypadku tekstu, ostatni ciąg uszeregowany wg alfabetu.
SUM
sum ([DISTINCT] wyrażenie) – funkcja oblicza sumę wartości wyrażeń dla wszystkich wierszy.
Użycie klauzuli DISTINCT w powyższych funkcjach powoduje, że wiersze, dla których agregowane wyrażenie się powtarza, agregacji podlegają tylko jeden raz. Przykładowo jeśli do przykładu pokazanego powyżej dodamy „distinct” przed salary, otrzymamy sumę pensji bez powtórek – tj. jeśli pensję 2 osób będą takie same – wartość ich pensji policzona zostanie tylko raz:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 94/311

Grupowanie
group by
Grupowanie polega na podzieleniu zbioru wierszy na grupy, które mają pewną wspólną cechę. Grupowania dokonuje się w celu zastosowania funkcji agregujących nie w stosunku do całego zbioru wierszy, ale do poszczególnych grup wierszy. W celu zgrupowania rekordów należy dodać nową klauzulę GROUP BY wraz z wyspecyfikowaniem kolumny lub wyrażenia, według którego mają być pogrupowane wiersze. Na liście klauzuli SELECT mogą się znaleźć tylko kolumny i wyrażenia, według których zapytanie jest grupowane, oraz wywołania funkcji agregujących.
Przed dokonaniem grupowania można zastosować klauzulę WHERE, która wybierze tylko część wierszy z tabeli.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 95/311

Klazula having
Klauzula WHERE wykonuje się przed grupowaniem, a zatem nie można w tej klauzuli sprecyzować warunku zawierającego funkcje grupowe. Aby taki warunek zawrzeć w zapytaniu należy zastosować dodatkową klauzulę HAVING wraz z odpowiednim warunkiem. Jest ona odpowiednikiem klauzuli WHERE, tylko, że wykonuje się ona po procesie grupowania. W poniższym przykładzie najpierw wybrałem numery lokalizacji w których id managera nie jest puste. W drugim pogrupowane numery lokalizacji oraz ilość departamentów w danej lokalizacji ale tylko te w których jest przydzielony manager. W trzecim tylko te lokalizacje w których poza tym że jest przydzielony manager, ilość departamentów jest większa niż 1
.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 96/311

Rollup
Dodanie rollup do group by spowoduje wyświetlenie podsumowania dla każdej grupy. Poniżej przykład grupowania bez użycia rollup. Możemy wyświetlić sumę wypłat w danymdepartamencie dla ludzi podległych pod danego managera. Patrz przykład poniżej:
Bez funkcji ROLLUP moglibyśmy wyznaczyć sumę wypłat dla każdego z działów tworząc oddzielne zapytanie, bez grupowania po id managera:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 97/311

Natomiast jeśli zechcemy wyświetlić podsumowanie wypłat dla ludzi podległych jednemu managerowi (wraz z nim) ale również podsumowanie dla każdego działu jednocześnie, musimy zastosować rollup:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 98/311

Cube
Dodanie do instrukcji słowa kluczowego powoduje wygenerowanie podsumowań dla wszystkich możliwych kombinacji kolumn wymienionych w zapytaniu oraz dołączenie ogólnej wartości sumy. Poniżej widzimy pierwszą część wyniku jaki dało nam zastosowanie CUBE. Pierwsza część wyniku nie różni się on od wyniku zwracanego nam przez zastosowanie ROLLUP.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 99/311

W końcowej części wyniku widzimy czym różni się ROLLUP od CUBE: Poza podsumowaniem wypłat dla każdego departamentu i wypłat ludzi konkretnego managera w tym departamencie widzimy również podsumowanie wypłat dla ludzi danego managera we wszystkich departamentach razem wziętych, oraz podsumowanie całości.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 100/311
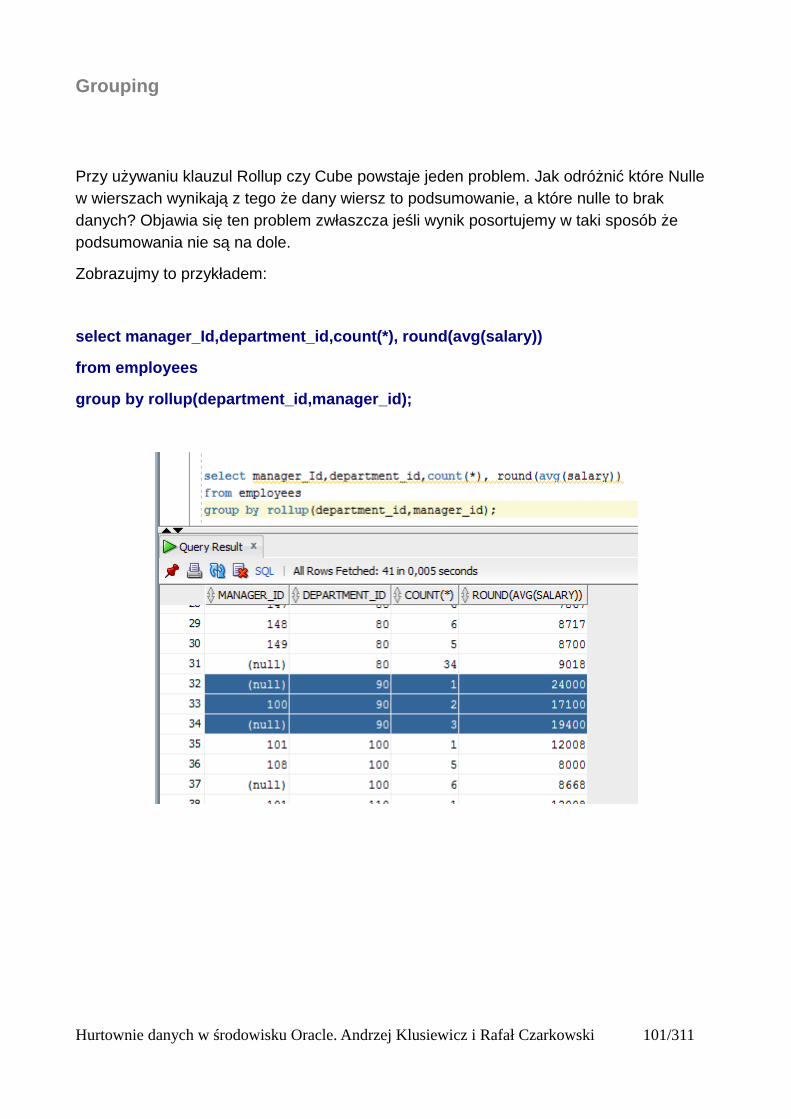
Grouping
Przy używaniu klauzul Rollup czy Cube powstaje jeden problem. Jak odróżnić które Nulle w wierszach wynikają z tego że dany wiersz to podsumowanie, a które nulle to brak danych? Objawia się ten problem zwłaszcza jeśli wynik posortujemy w taki sposób że podsumowania nie są na dole.
Zobrazujmy to przykładem:
select manager_Id,department_id,count(*), round(avg(salary))
from employees
group by rollup(department_id,manager_id);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 101/311
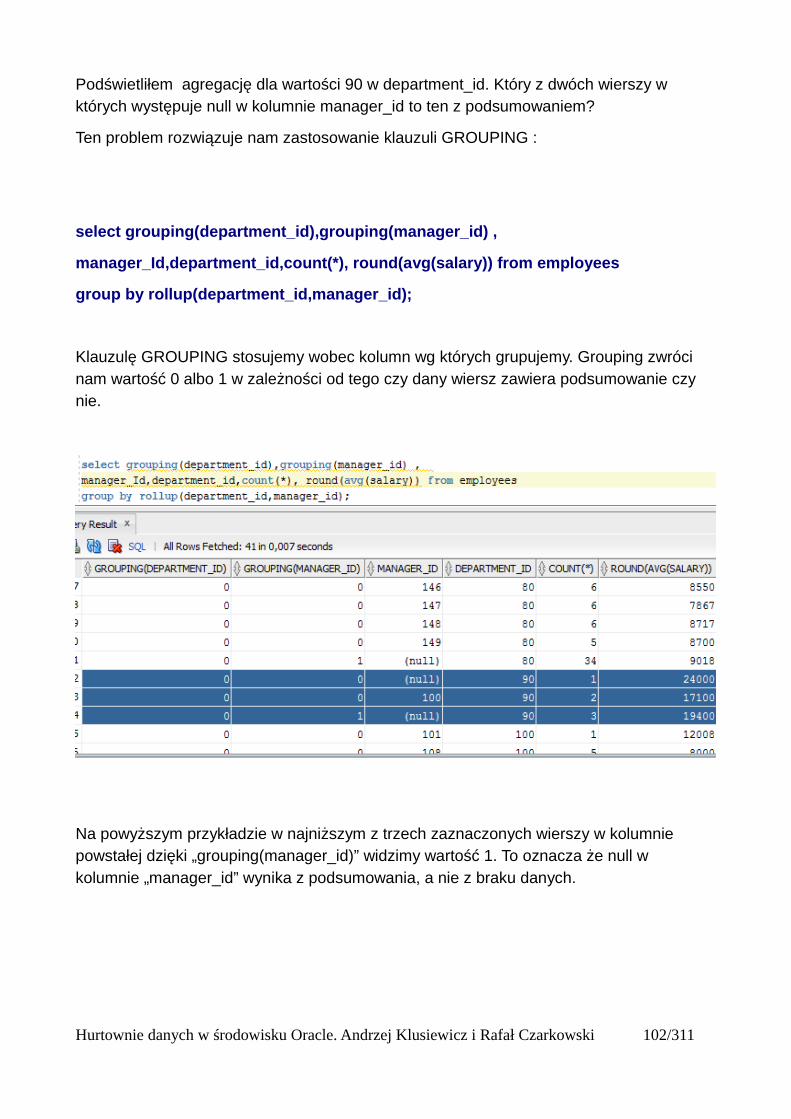
Podświetliłem agregację dla wartości 90 w department_id. Który z dwóch wierszy w których występuje null w kolumnie manager_id to ten z podsumowaniem?
Ten problem rozwiązuje nam zastosowanie klauzuli GROUPING :
select grouping(department_id),grouping(manager_id) ,
manager_Id,department_id,count(*), round(avg(salary)) from employees
group by rollup(department_id,manager_id);
Klauzulę GROUPING stosujemy wobec kolumn wg których grupujemy. Grouping zwróci nam wartość 0 albo 1 w zależności od tego czy dany wiersz zawiera podsumowanie czy nie.
Na powyższym przykładzie w najniższym z trzech zaznaczonych wierszy w kolumnie powstałej dzięki „grouping(manager_id)” widzimy wartość 1. To oznacza że null w kolumnie „manager_id” wynika z podsumowania, a nie z braku danych.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 102/311

Grouping sets
Wyrażenie GROUPING SETS umożliwia wyselekcjonowanie jedynie tych podsumowań wagregacji, które rzeczywiście chcemy uzyskać. Obliczanie wszystkich podsumowań na przykładprzy pomocy wyrażenia CUBE może być dosyć obciążającym procesem, szczególnie w przypadku,kiedy ich w ogóle nie potrzebujemy. Przykładowo uzyskanie podsumowania dla trzech wymiarów,da nam osiem poziomów sum pośrednich. Co w poniższym przykładzie, z tabeli, która posiada 48wierszy wygeneruje już 117 rekordów.
SELECT ODDZIAŁ, ROK, MIESIĄC, SUM(PRZYCHÓD) AS PRZYCHÓD, GROUPING_ID(ODDZIAŁ, ROK, MIESIĄC) AS GROUPING_ID FROM PRZYCHODYGROUP BY CUBE(ODDZIAŁ, ROK, MIESIĄC);
Jeśli potrzebujemy tylko kilka z tych poziomów, możemy właśnie użyć wyrażenia GROUPINGSETS i dokładnie okreslić które podsumowania z kostki nas interesują.
Dla przykładu zakładamy, że interesują nas wyłącznie podsumowania dla ODDZIAŁÓW i ROKU,oraz ROKU i MIESIĄCA
SELECT ODDZIAŁ, ROK, MIESIĄC, SUM(PRZYCHÓD) AS PRZYCHÓD, GROUPING_ID(ODDZIAŁ, ROK, MIESIĄC) AS GROUPING_ID FROM PRZYCHODYGROUP BY GROUPING SETS(ODDZIAŁ, ROK), (ROK, MIESIĄC);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 103/311
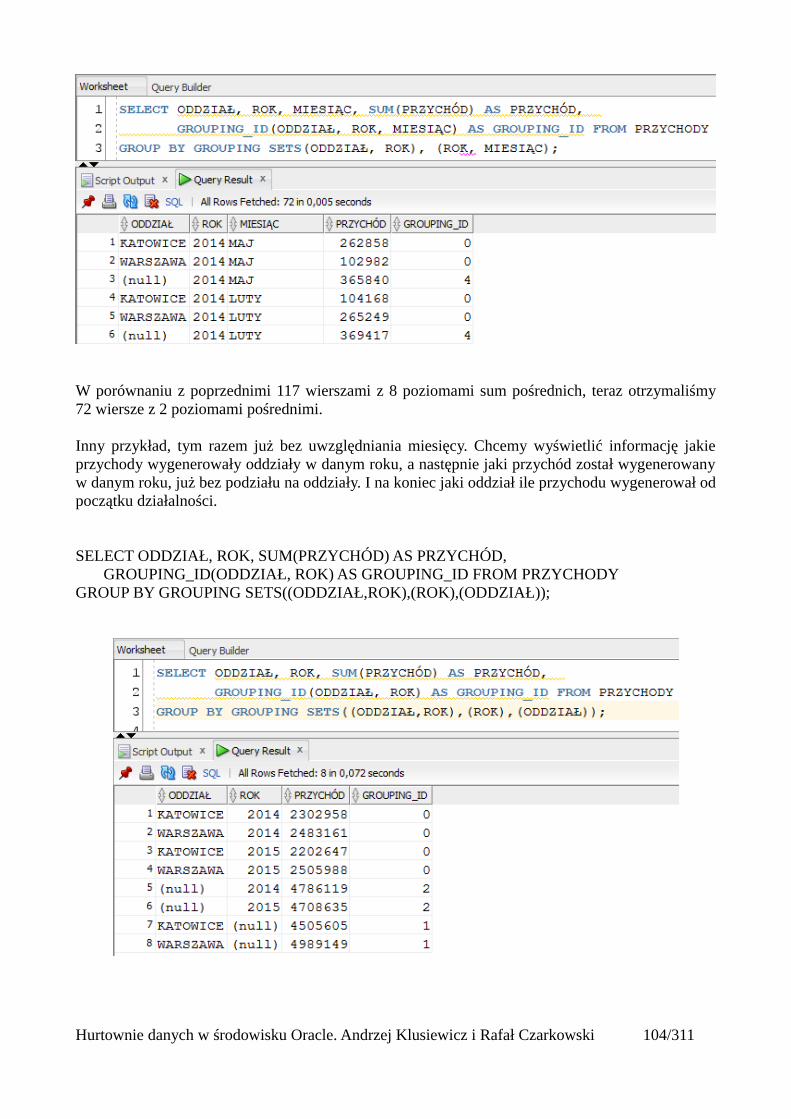
W porównaniu z poprzednimi 117 wierszami z 8 poziomami sum pośrednich, teraz otrzymaliśmy72 wiersze z 2 poziomami pośrednimi.
Inny przykład, tym razem już bez uwzględniania miesięcy. Chcemy wyświetlić informację jakieprzychody wygenerowały oddziały w danym roku, a następnie jaki przychód został wygenerowanyw danym roku, już bez podziału na oddziały. I na koniec jaki oddział ile przychodu wygenerował odpoczątku działalności.
SELECT ODDZIAŁ, ROK, SUM(PRZYCHÓD) AS PRZYCHÓD, GROUPING_ID(ODDZIAŁ, ROK) AS GROUPING_ID FROM PRZYCHODYGROUP BY GROUPING SETS((ODDZIAŁ,ROK),(ROK),(ODDZIAŁ));
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 104/311
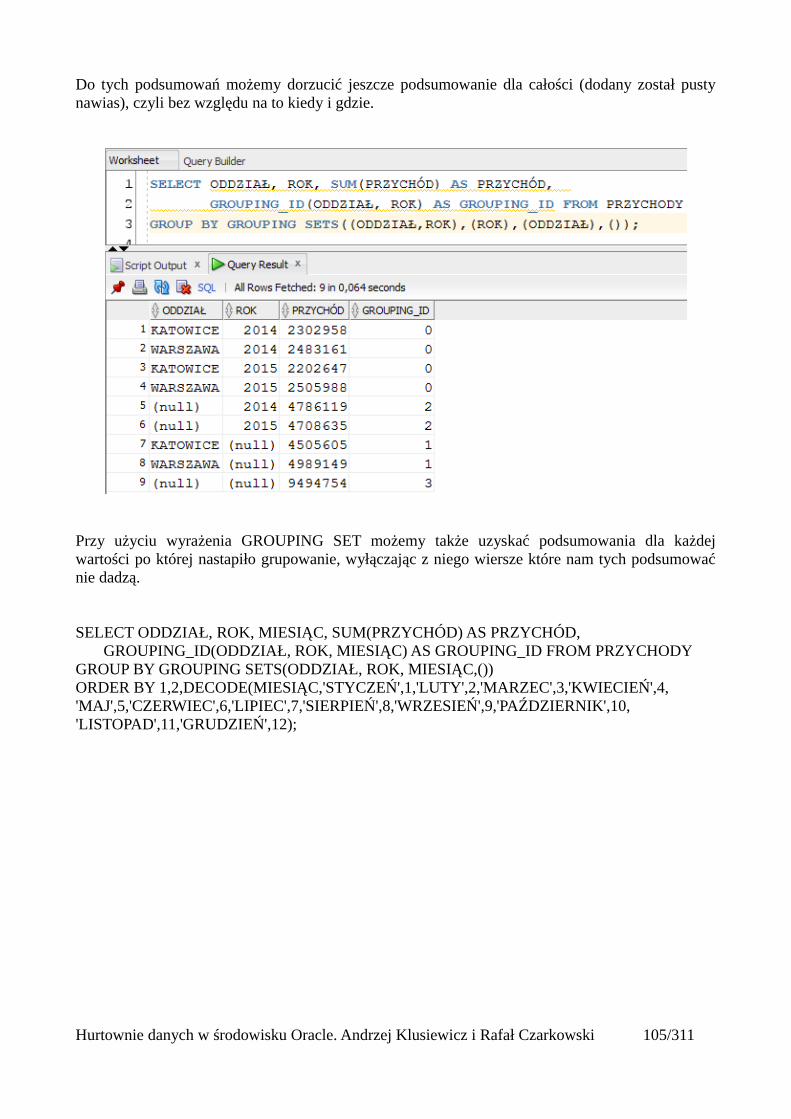
Do tych podsumowań możemy dorzucić jeszcze podsumowanie dla całości (dodany został pustynawias), czyli bez względu na to kiedy i gdzie.
Przy użyciu wyrażenia GROUPING SET możemy także uzyskać podsumowania dla każdejwartości po której nastapiło grupowanie, wyłączając z niego wiersze które nam tych podsumowaćnie dadzą.
SELECT ODDZIAŁ, ROK, MIESIĄC, SUM(PRZYCHÓD) AS PRZYCHÓD, GROUPING_ID(ODDZIAŁ, ROK, MIESIĄC) AS GROUPING_ID FROM PRZYCHODYGROUP BY GROUPING SETS(ODDZIAŁ, ROK, MIESIĄC,())ORDER BY 1,2,DECODE(MIESIĄC,'STYCZEŃ',1,'LUTY',2,'MARZEC',3,'KWIECIEŃ',4,'MAJ',5,'CZERWIEC',6,'LIPIEC',7,'SIERPIEŃ',8,'WRZESIEŃ',9,'PAŹDZIERNIK',10,'LISTOPAD',11,'GRUDZIEŃ',12);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 105/311
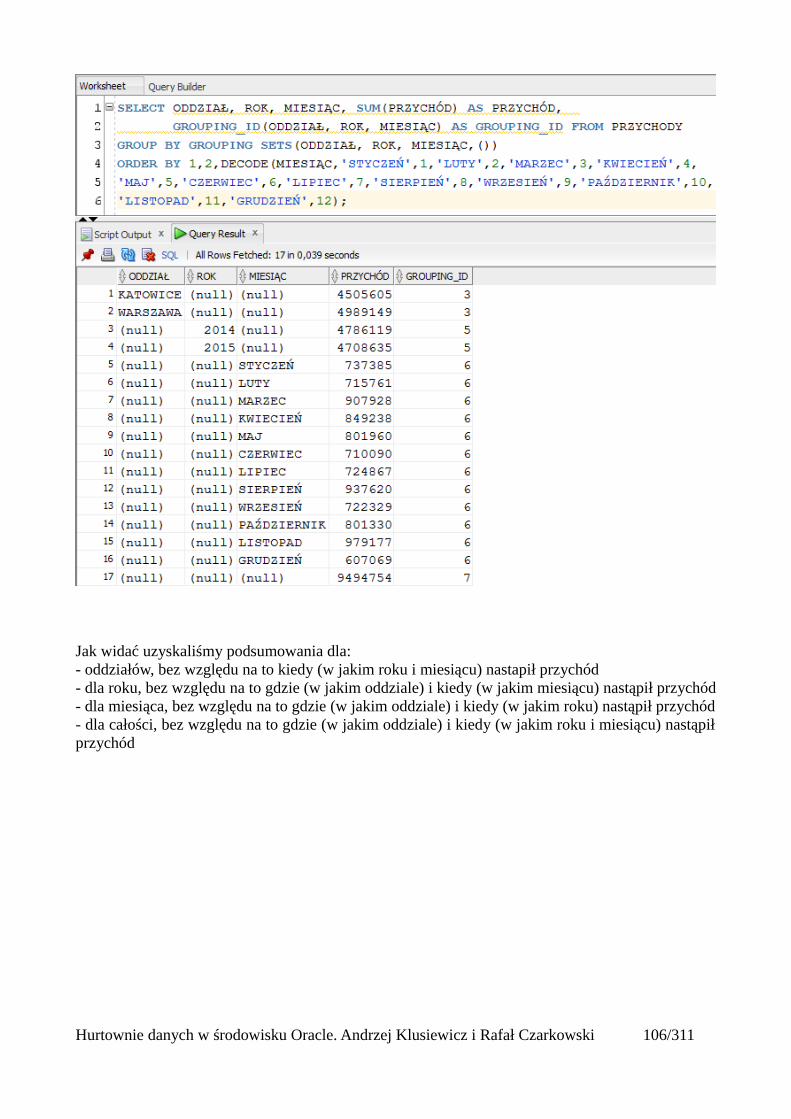
Jak widać uzyskaliśmy podsumowania dla:- oddziałów, bez względu na to kiedy (w jakim roku i miesiącu) nastapił przychód- dla roku, bez względu na to gdzie (w jakim oddziale) i kiedy (w jakim miesiącu) nastąpił przychód- dla miesiąca, bez względu na to gdzie (w jakim oddziale) i kiedy (w jakim roku) nastąpił przychód- dla całości, bez względu na to gdzie (w jakim oddziale) i kiedy (w jakim roku i miesiącu) nastąpiłprzychód
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 106/311
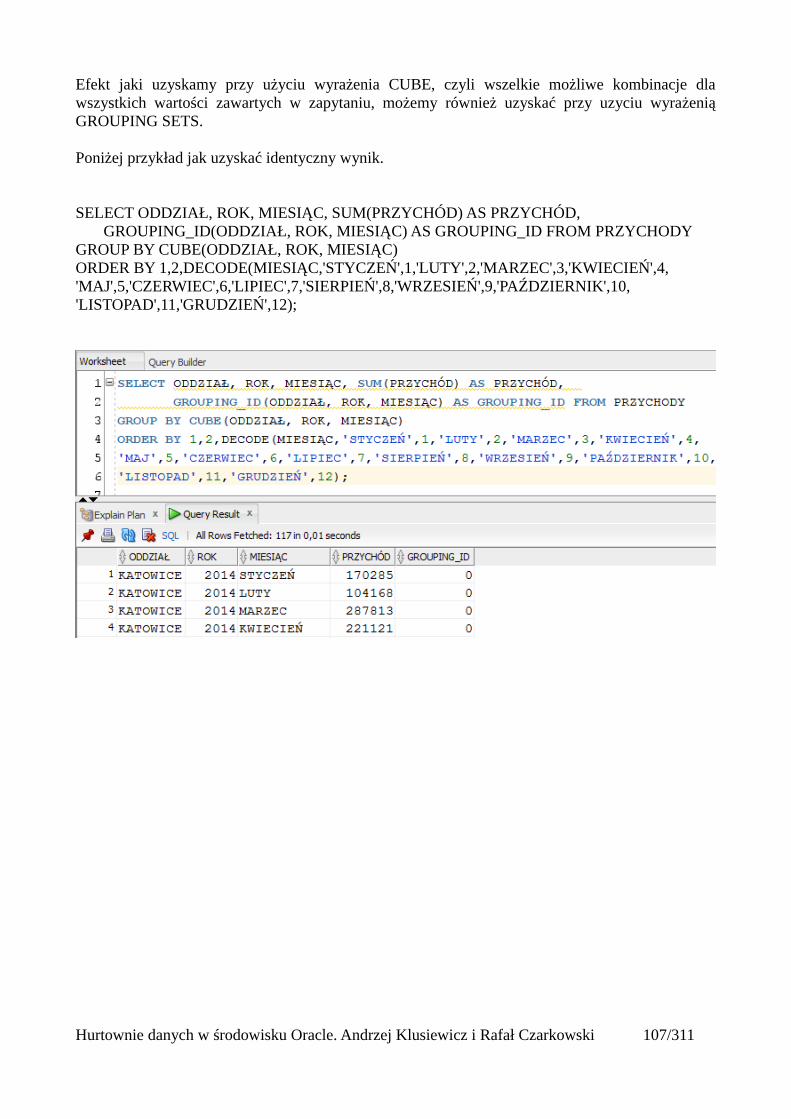
Efekt jaki uzyskamy przy użyciu wyrażenia CUBE, czyli wszelkie możliwe kombinacje dlawszystkich wartości zawartych w zapytaniu, możemy również uzyskać przy uzyciu wyrażeniąGROUPING SETS.
Poniżej przykład jak uzyskać identyczny wynik.
SELECT ODDZIAŁ, ROK, MIESIĄC, SUM(PRZYCHÓD) AS PRZYCHÓD, GROUPING_ID(ODDZIAŁ, ROK, MIESIĄC) AS GROUPING_ID FROM PRZYCHODYGROUP BY CUBE(ODDZIAŁ, ROK, MIESIĄC)ORDER BY 1,2,DECODE(MIESIĄC,'STYCZEŃ',1,'LUTY',2,'MARZEC',3,'KWIECIEŃ',4,'MAJ',5,'CZERWIEC',6,'LIPIEC',7,'SIERPIEŃ',8,'WRZESIEŃ',9,'PAŹDZIERNIK',10,'LISTOPAD',11,'GRUDZIEŃ',12);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 107/311

SELECT ODDZIAŁ, ROK, MIESIĄC, SUM(PRZYCHÓD) AS PRZYCHÓD, GROUPING_ID(ODDZIAŁ, ROK, MIESIĄC) AS GROUPING_ID FROM PRZYCHODYGROUP BY GROUPING SETS((ODDZIAŁ, ROK, MIESIĄC),(ODDZIAŁ, ROK),(ODDZIAŁ, MIESIĄC),(ROK, MIESIĄC),(ODDZIAŁ),(ROK),(MIESIĄC),())ORDER BY 1,2,DECODE(MIESIĄC,'STYCZEŃ',1,'LUTY',2,'MARZEC',3,'KWIECIEŃ',4,'MAJ',5,'CZERWIEC',6,'LIPIEC',7,'SIERPIEŃ',8,'WRZESIEŃ',9,'PAŹDZIERNIK',10,'LISTOPAD',11,'GRUDZIEŃ',12);
Jeszcze jeden przykład, jak uzyskać identyczny efekt używając operatora GROUPING SETS wzastępstwie dwóch zapytań połączonych operatorem zbiorowym.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 108/311
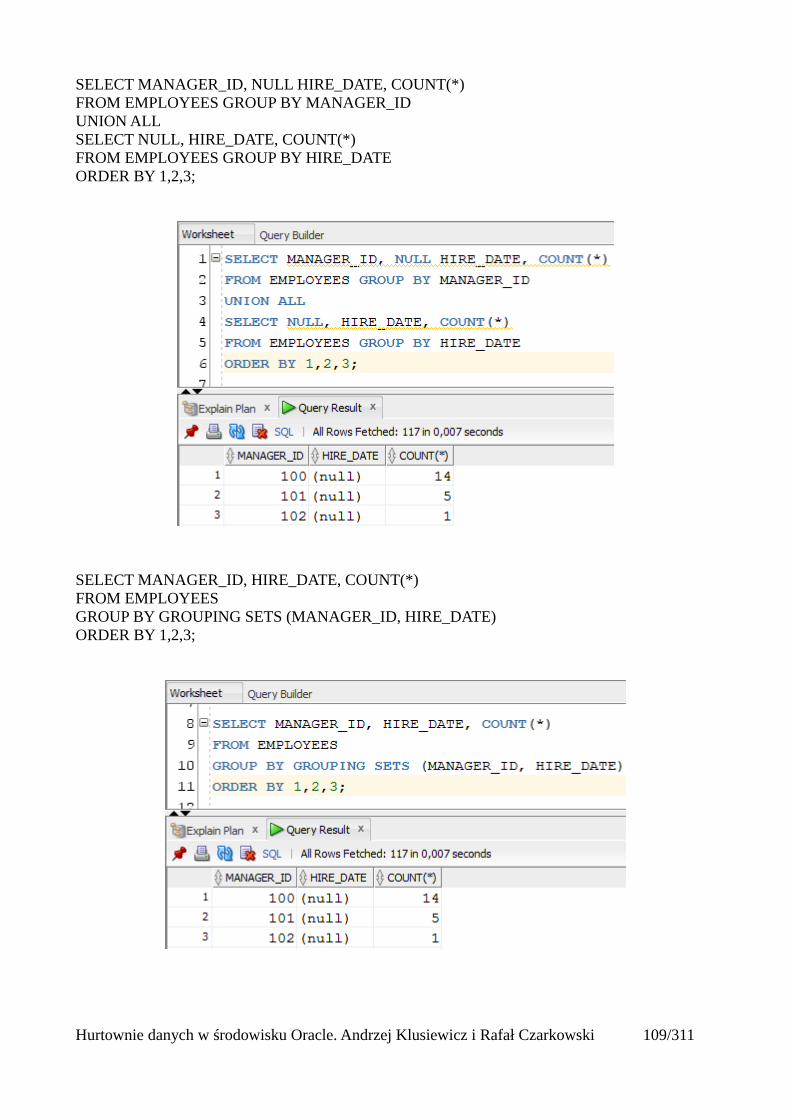
SELECT MANAGER_ID, NULL HIRE_DATE, COUNT(*)FROM EMPLOYEES GROUP BY MANAGER_IDUNION ALLSELECT NULL, HIRE_DATE, COUNT(*)FROM EMPLOYEES GROUP BY HIRE_DATEORDER BY 1,2,3;
SELECT MANAGER_ID, HIRE_DATE, COUNT(*)FROM EMPLOYEESGROUP BY GROUPING SETS (MANAGER_ID, HIRE_DATE)ORDER BY 1,2,3;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 109/311

Pivot (tabele przestawne)
Pivot (tabele przestawne) jest dostępny od wersji 11g Oracle. Umożliwia nam przestawianiekolumn w miejsce wierszy i odwrotnie. Jest to wspaniałe narzędzie analityczne, pozwala wygodnieprzeglądać np. tendencje. Pivot jest operacją agregującą. Przykład działania pivota:
Przed:
Po:
Prawda że czytelniej?Przejdziemy teraz całą ścieżkę krok po kroku. W pierwszej kolejności tworzymy tabelę:
create table wyniki_sprzedazy(okres varchar2(50),produkt varchar2(50),suma_przychodu number);
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 110/311

Następnie ładujemy do niej dane:
insert into wyniki_sprzedazy values('06-2013','Pralki',65040);insert into wyniki_sprzedazy values('07-2013','Pralki',31650);insert into wyniki_sprzedazy values('08-2013','Pralki',24678);insert into wyniki_sprzedazy values('06-2013','Telewizory',40600);insert into wyniki_sprzedazy values('07-2013','Telewizory',12300);insert into wyniki_sprzedazy values('08-2013','Telewizory',9004);insert into wyniki_sprzedazy values('06-2013','Lodówki',45080);insert into wyniki_sprzedazy values('07-2013','Lodówki',21600);insert into wyniki_sprzedazy values('08-2013','Lodówki',4670);commit;
Zajrzyjmy teraz do tabeli:
select * from wyniki_sprzedazy;
Dane przedstawione są w tej chwili w sposób płaski i mało czytelny. Zawartość tabeli reprezentujesprzedaż trzech produktów na przestrzeni trzech miesięcy.Przestawimy teraz troszeczkę te dane. Chcemy wyświetlić jak zmieniała się sprzedaż produktów naprzestrzeni czasu. Robimy pewnego rodzaju szachownicę gdzie jeden bok jest wyznaczany przezprodukty, a drugi przez okresy. Na przecięciu kolumn i wierszy ma znaleźć się suma sprzedażydanego produktu w danym okresie.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 111/311
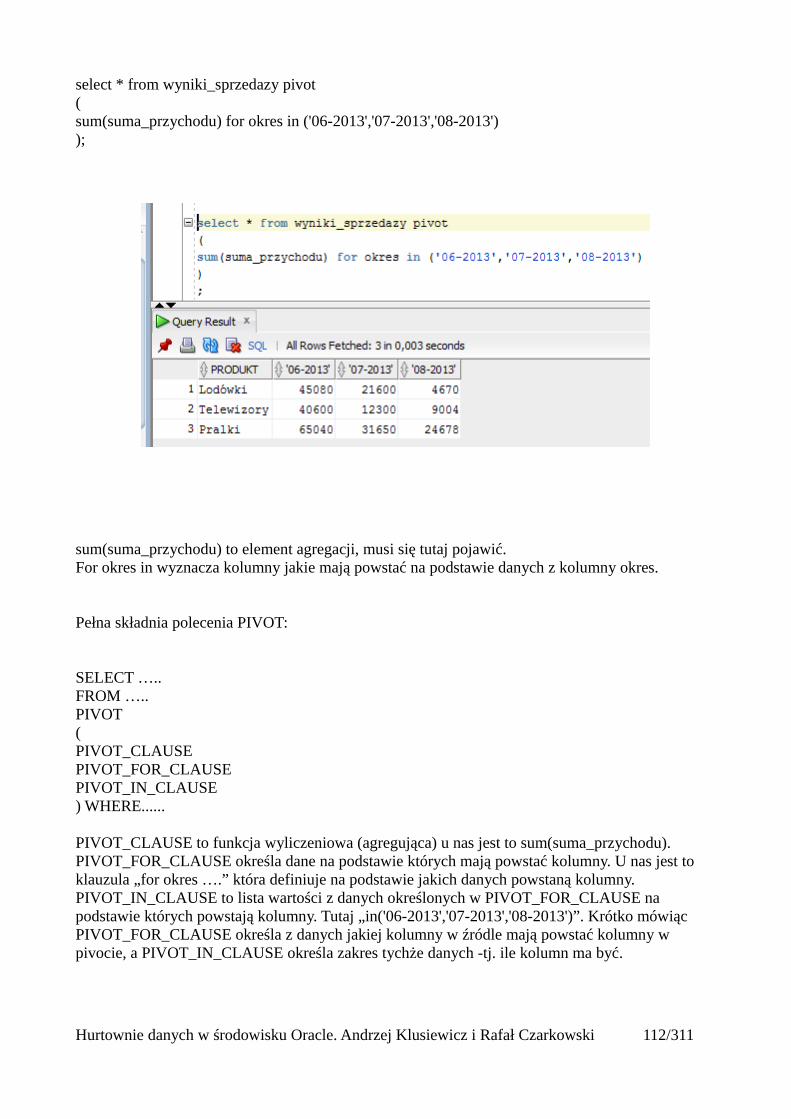
select * from wyniki_sprzedazy pivot(sum(suma_przychodu) for okres in ('06-2013','07-2013','08-2013'));
sum(suma_przychodu) to element agregacji, musi się tutaj pojawić.For okres in wyznacza kolumny jakie mają powstać na podstawie danych z kolumny okres.
Pełna składnia polecenia PIVOT:
SELECT …..FROM …..PIVOT(PIVOT_CLAUSEPIVOT_FOR_CLAUSEPIVOT_IN_CLAUSE) WHERE......
PIVOT_CLAUSE to funkcja wyliczeniowa (agregująca) u nas jest to sum(suma_przychodu).PIVOT_FOR_CLAUSE określa dane na podstawie których mają powstać kolumny. U nas jest to klauzula „for okres ….” która definiuje na podstawie jakich danych powstaną kolumny.PIVOT_IN_CLAUSE to lista wartości z danych określonych w PIVOT_FOR_CLAUSE na podstawie których powstają kolumny. Tutaj „in('06-2013','07-2013','08-2013')”. Krótko mówiąc PIVOT_FOR_CLAUSE określa z danych jakiej kolumny w źródle mają powstać kolumny w pivocie, a PIVOT_IN_CLAUSE określa zakres tychże danych -tj. ile kolumn ma być.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 112/311
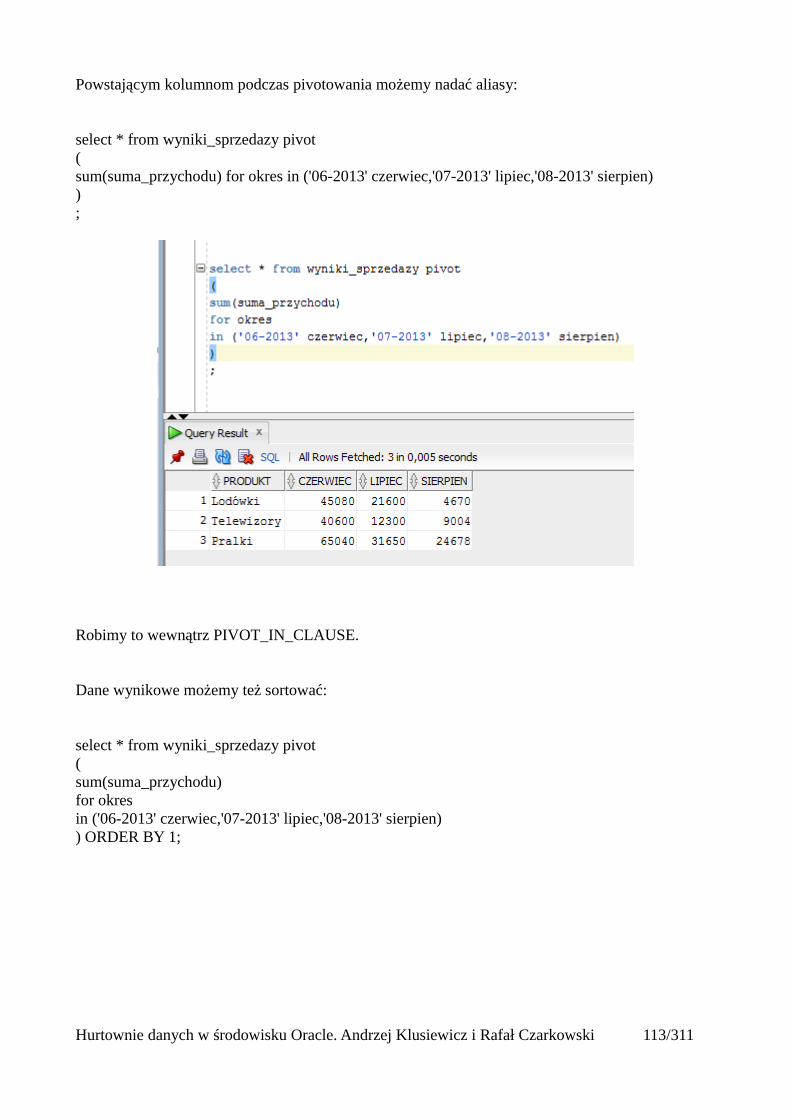
Powstającym kolumnom podczas pivotowania możemy nadać aliasy:
select * from wyniki_sprzedazy pivot(sum(suma_przychodu) for okres in ('06-2013' czerwiec,'07-2013' lipiec,'08-2013' sierpien));
Robimy to wewnątrz PIVOT_IN_CLAUSE.
Dane wynikowe możemy też sortować:
select * from wyniki_sprzedazy pivot(sum(suma_przychodu)for okresin ('06-2013' czerwiec,'07-2013' lipiec,'08-2013' sierpien)) ORDER BY 1;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 113/311

Klauzulę dotyczącą sortowania dajemy na samym końcu całego zapytania.Inny przykład – tym razem z użyciem schematu HR. Mamy w tabelce employees kolumny JOB_IDDEPARTMENT_ID. Job_id to indentyfikator zawodu wykonywanego przez pracownika,department_id to identyfikator departamentu w którym dany pracownik pracuje. Chcielibyśmy terazzrobić jakieś zestawienie obrazujące ilość pracowników na różnych stanowiskach w różnychdepartamentach. Zaczynamy więc od wykonania grupowania:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 114/311
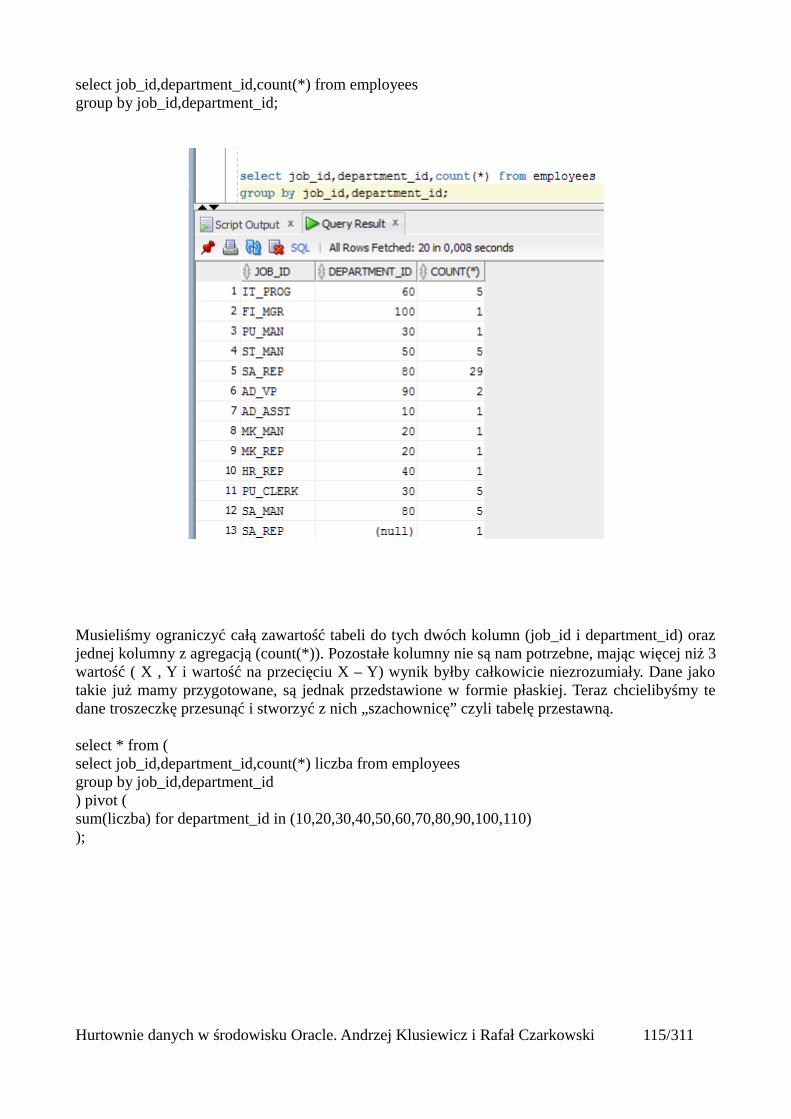
select job_id,department_id,count(*) from employeesgroup by job_id,department_id;
Musieliśmy ograniczyć całą zawartość tabeli do tych dwóch kolumn (job_id i department_id) orazjednej kolumny z agregacją (count(*)). Pozostałe kolumny nie są nam potrzebne, mając więcej niż 3wartość ( X , Y i wartość na przecięciu X – Y) wynik byłby całkowicie niezrozumiały. Dane jakotakie już mamy przygotowane, są jednak przedstawione w formie płaskiej. Teraz chcielibyśmy tedane troszeczkę przesunąć i stworzyć z nich „szachownicę” czyli tabelę przestawną.
select * from (select job_id,department_id,count(*) liczba from employeesgroup by job_id,department_id) pivot (sum(liczba) for department_id in (10,20,30,40,50,60,70,80,90,100,110));
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 115/311
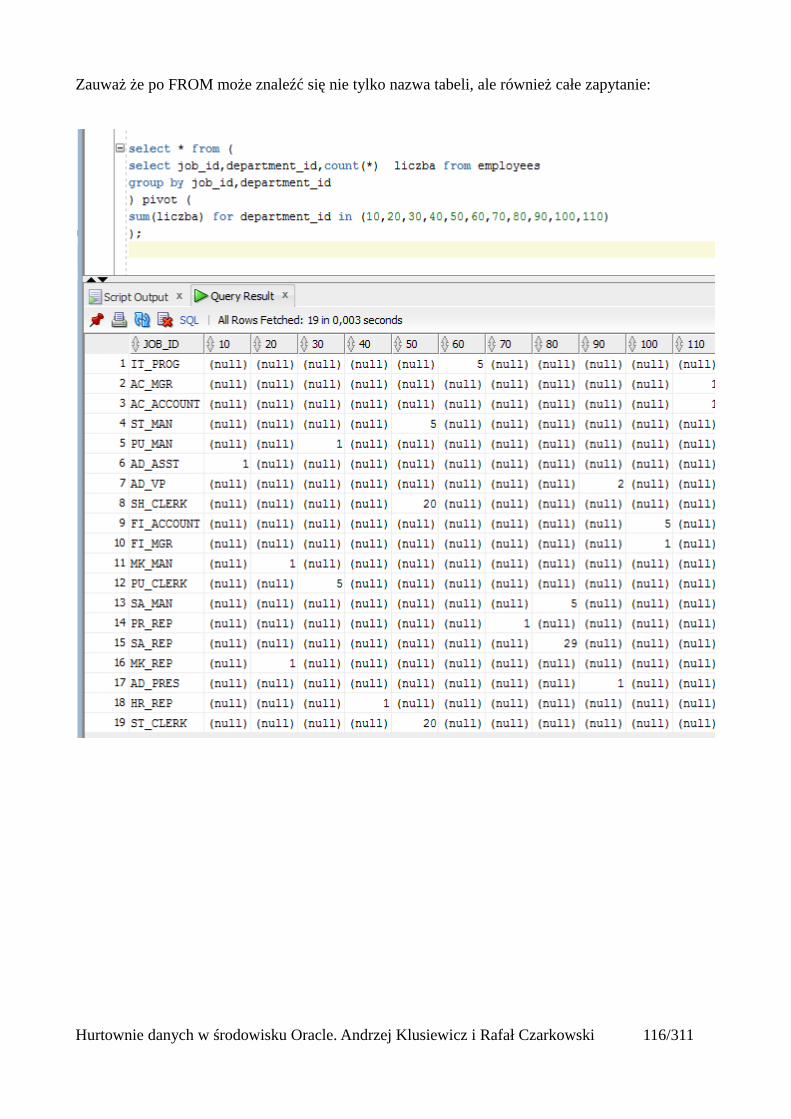
Zauważ że po FROM może znaleźć się nie tylko nazwa tabeli, ale również całe zapytanie:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 116/311
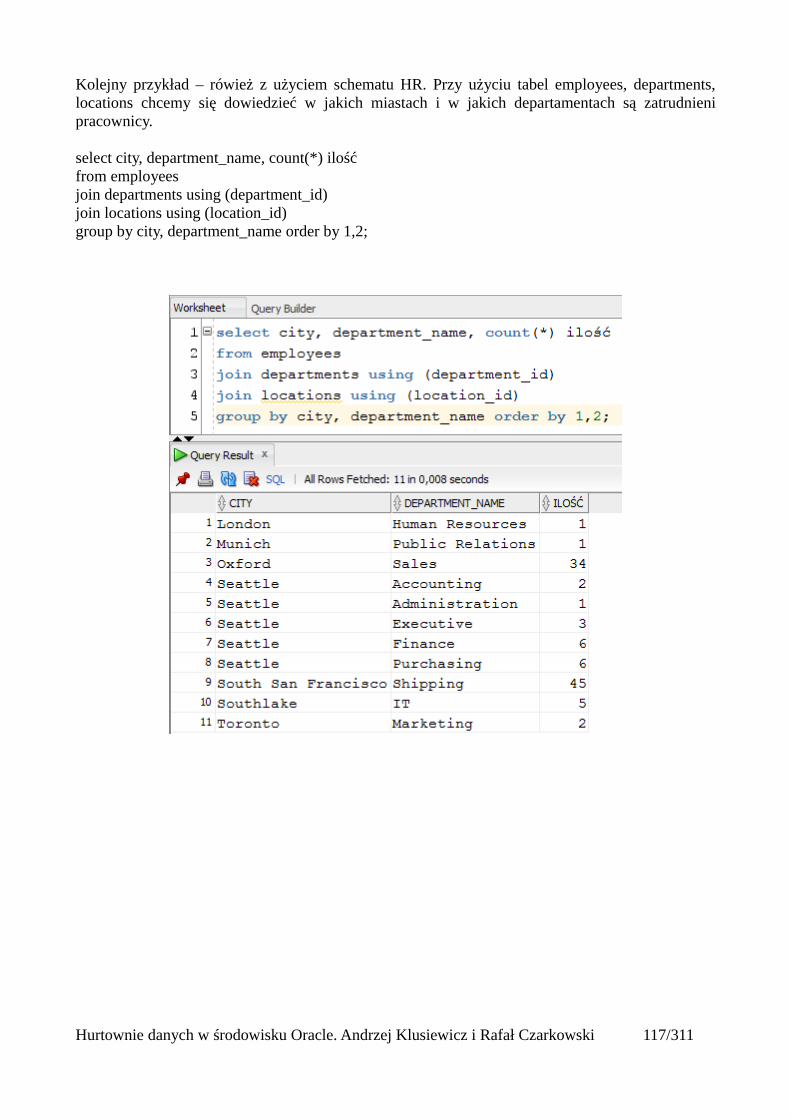
Kolejny przykład – rówież z użyciem schematu HR. Przy użyciu tabel employees, departments,locations chcemy się dowiedzieć w jakich miastach i w jakich departamentach są zatrudnienipracownicy.
select city, department_name, count(*) ilośćfrom employees join departments using (department_id) join locations using (location_id) group by city, department_name order by 1,2;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 117/311
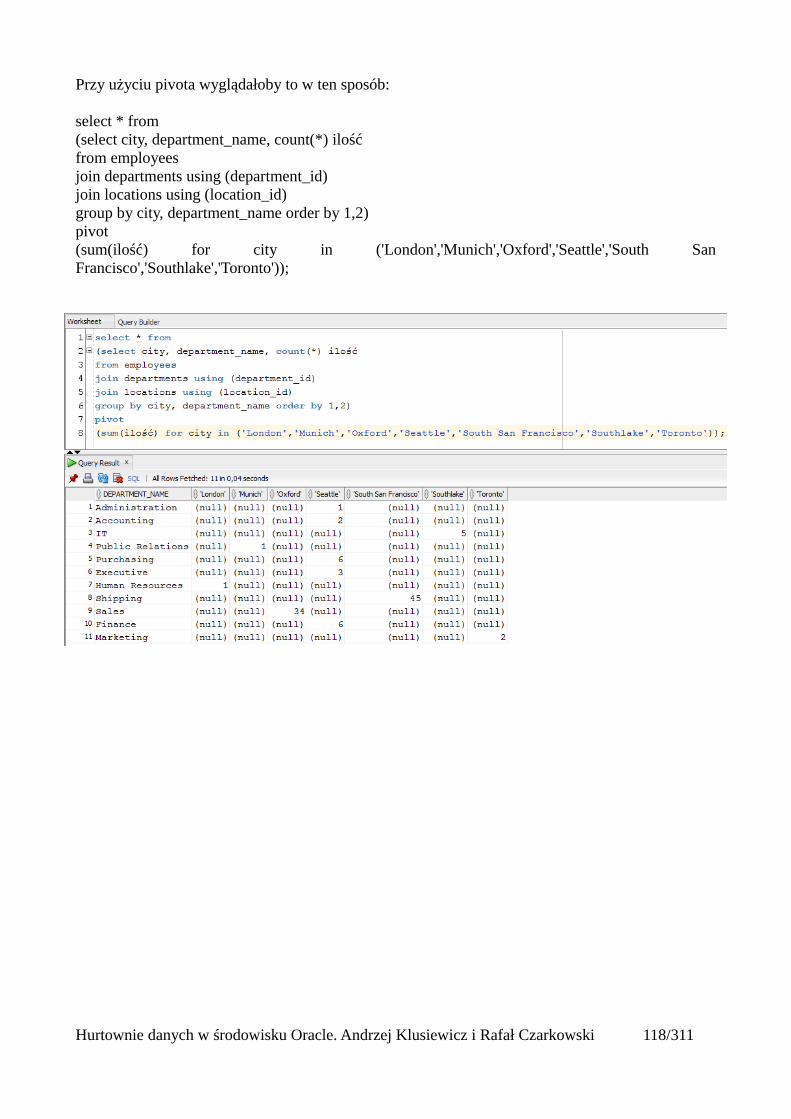
Przy użyciu pivota wyglądałoby to w ten sposób:
select * from(select city, department_name, count(*) ilośćfrom employees join departments using (department_id) join locations using (location_id) group by city, department_name order by 1,2)pivot(sum(ilość) for city in ('London','Munich','Oxford','Seattle','South SanFrancisco','Southlake','Toronto'));
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 118/311

Unpivot
Tabelę możemy przestawiać również w drugą stronę, czyli z kolumn zrobić znowu wiersze, zapomocą klauzuli UNPIVOT.Do tego celu najpierw stworzymy nową tabelę na podstawie ostatniego zapytania.
create table zatrudnienie asselect * from(select city, department_name, count(*) ilośćfrom employees join departments using (department_id) join locations using (location_id) group by city, department_name order by 1,2)pivot(sum(ilość) for city in ('London' London,'Munich' Munich,'Oxford' Oxford,'Seattle' Seattle,'South San Francisco'South_San_Francisco,'Southlake' Southlake,'Toronto' Toronto));
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 119/311
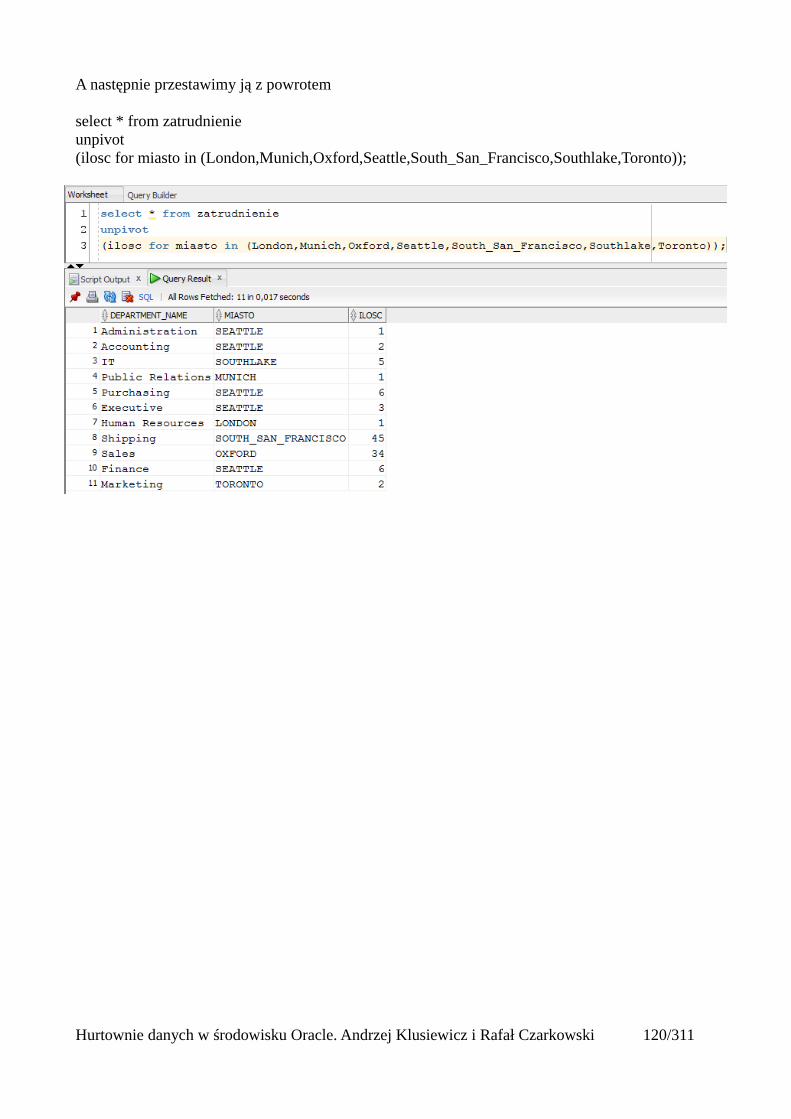
A następnie przestawimy ją z powrotem
select * from zatrudnienieunpivot(ilosc for miasto in (London,Munich,Oxford,Seattle,South_San_Francisco,Southlake,Toronto));
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 120/311

I jeszcze jeden przykład wykorzystania klauzuli UNPIVOT do samodzielnego przetestowania.
CREATE TABLE ODLEGLOSCI (MIASTO VARCHAR2(30), BIAŁYSTOK INT, BYDGOSZCZ INT, CZĘSTOCHOWA INT, GDAŃSK INT, GDYNIA INT, KATOWICE INT, KRAKÓW INT, LUBLIN INT, ŁODŹ INT, POZNAŃ INT, RADOM INT, SZCZECIN INT, WARSZAWA INT, WROCŁAW INT);
Insert into ODLEGLOSCI values ('BIAŁYSTOK',null,'345','379','327','342','429','408','214','295','428','237','574','177','476');Insert into ODLEGLOSCI values ('BYDGOSZCZ','345',null,'268','143','159','326','366','375','181','108','287','233','226','234');Insert into ODLEGLOSCI values ('CZĘSTOCHOWA','379','268',null,'395','414','62','102','246','107','233','156','426','205','149');Insert into ODLEGLOSCI values ('GDAŃSK','327','143','395',null,'20','456','486','435','294','245','369','288','284','377');Insert into ODLEGLOSCI values ('GDYNIA','342','159','414','20',null,'475','505','454','313','258','389','287','304','393');Insert into ODLEGLOSCI values ('KATOWICE','429','326','62','456','475',null,'69','273','169','280','196','467','259','169');Insert into ODLEGLOSCI values ('KRAKÓW','408','366','102','486','505','69',null,'227','192','335','171','527','252','236');Insert into ODLEGLOSCI values ('LUBLIN','214','375','246','435','454','273','227',null,'223','409','100','597','153','386');Insert into ODLEGLOSCI values ('ŁÓDŹ','295','181','107','294','313','169','192','223',null,'188','124','380','119','183');Insert into ODLEGLOSCI values ('POZNAŃ','428','108','233','245','258','280','335','409','188',null,'311','196','279','145');Insert into ODLEGLOSCI values ('RADOM','237','287','156','369','389','196','171','100','124','311',null,'501','93','288');Insert into ODLEGLOSCI values ('SZCZECIN','574','233','426','288','287','467','527','597','380','196','501',null,'454','309');Insert into ODLEGLOSCI values ('WARSZAWA','177','226','205','284','304','259','252','153','119','279','93','454',null,'301');Insert into ODLEGLOSCI values ('WROCŁAW','476','234','149','377','393','169','236','386','183','145','288','309','301',null);SELECT * FROM ODLEGLOSCI;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 121/311
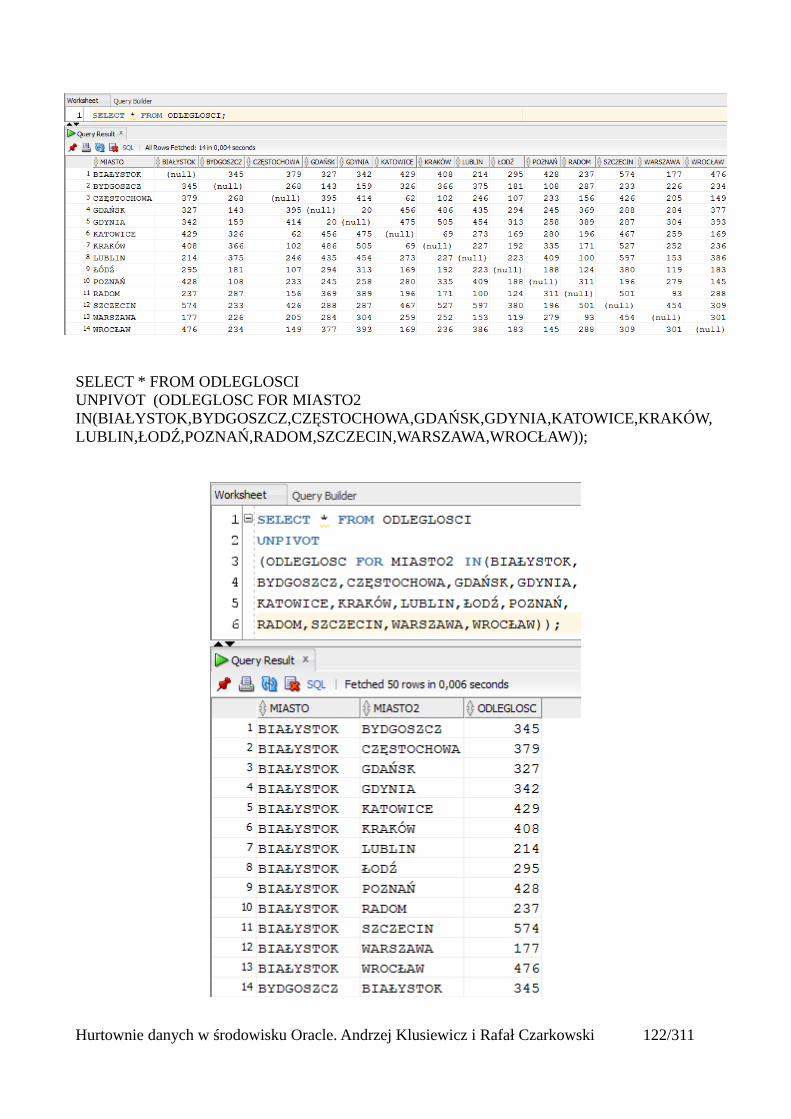
SELECT * FROM ODLEGLOSCIUNPIVOT (ODLEGLOSC FOR MIASTO2 IN(BIAŁYSTOK,BYDGOSZCZ,CZĘSTOCHOWA,GDAŃSK,GDYNIA,KATOWICE,KRAKÓW,LUBLIN,ŁODŹ,POZNAŃ,RADOM,SZCZECIN,WARSZAWA,WROCŁAW));
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 122/311

Wykorzystanie funkcji analitycznych
Funkcje analityczne stanowią analityczne rozszerzenie funkcji SQL i różnią się metodą działania oraz sposobem użycia od tradycyjnych funkcji SQLowych. Wyznaczając wynik dla bieżącego wiersza z reguły korzystają z informacji znajdujących się w wierszach sąsiednich. Podczas przetwarzania polecenia SQL wartości funkcji analitycznych są wyliczane po wszystkich składowych operacjach (połączeniach, selekcji wierszy, grupowaniu, selekcji grup itd.). Po nich następuje jedynie sortowanie. Funkcje analityczne są wykorzystywane wyłącznie w klauzulach SELECT oraz ORDER BYi nie mogą być używane w klauzulach WHERE, GROUP BY, HAVING. Działają wyłącznie na wierszach będących wynikiem zapytania i nie odrzuconych przez WHERE lub HAVING.Pozwalają na rozwiązanie problemów takich jak :„Znajdź N najlepszych „ (TopN),„Przelicz średnią na ruchomej grupie”Aby przejść do korzystania z funkcji analitycznych należy poznać terminologię z nimi związaną.
Partycje
Stanowią autonomiczne zbiory danych w ramach których funkcje analityczne przetwarzają dane.
Okna
Pozwalają na zdefiniowanie ruchomego zakresu, określanego oddzielnie dla każdego wiersza.
Bieżący wiersz
Wiersz dla którego w danym momencie wyznaczany jest wynik funkcji.
Ogólna składnia funkcji analitycznych
NAZWA_FUNKCJI (PARAMETRY) OVER (DEFINICJA ZBIORU)
Definicją zbioru może być definicja partycji, okna lub porządku wierszy w partycji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 123/311

Wprowadzenie do funkcji analitycznych na podstawie funkcji rankingu
Funkcje rankingu wyznaczają pozycję danego wiersza porównując go z wartościami innych wierszyw tej samej partycji. Podział zbioru danych na partycje pozwalają na stworzenie oddzielnych rankingów dla każdej partycji. Dzięki temu jesteśmy w stanie np. wyświetlić ranking najlepiej sprzedających się produktów w każdej kategorii. Do funkcji rankingu zaliczamy:
Składnia analitycznych funkcji rankingu
NAZWA_FUNKCJI() OVER ([PARTITION BY WYRAŻENIE] ORDER BY WYRAŻENIE2)
Klauzula PARTITION BY jest opcjonalna. ORDER BY musimy zastosować zawsze korzystają z funkcji rankingu. Nie jest to tylko martwa zasada. Jak logika wskazuje aby wyznaczyć ranking musimy ustalić kryteria wg których będzie przydzielane pierwsze, drugie i kolejne miejsca. Np. pracownicy wg wzrostu, zarobków czy sex appeal'u :)Z drugiej strony możemy ich „spartycjonować” i zrobić osobny ranking dla każdego z działów, albo zrobić konkurs na miss całej firmy :)
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 124/311
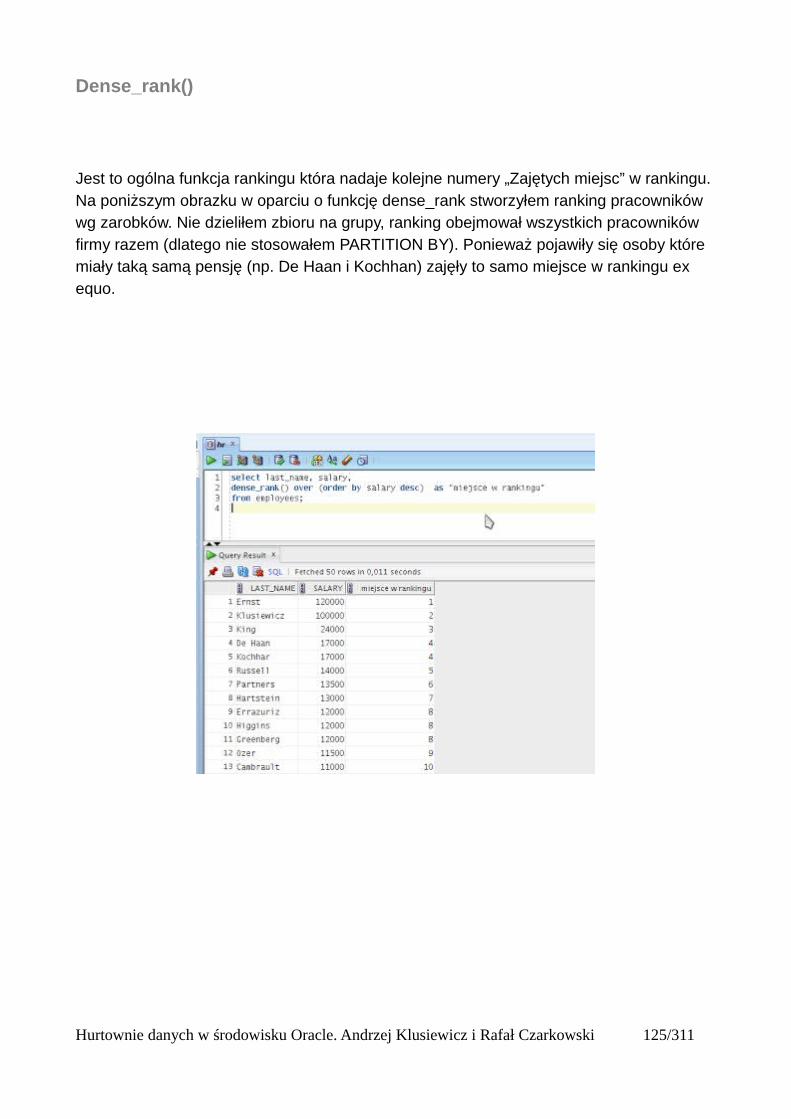
Dense_rank()
Jest to ogólna funkcja rankingu która nadaje kolejne numery „Zajętych miejsc” w rankingu.Na poniższym obrazku w oparciu o funkcję dense_rank stworzyłem ranking pracowników wg zarobków. Nie dzieliłem zbioru na grupy, ranking obejmował wszystkich pracowników firmy razem (dlatego nie stosowałem PARTITION BY). Ponieważ pojawiły się osoby które miały taką samą pensję (np. De Haan i Kochhan) zajęły to samo miejsce w rankingu ex equo.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 125/311
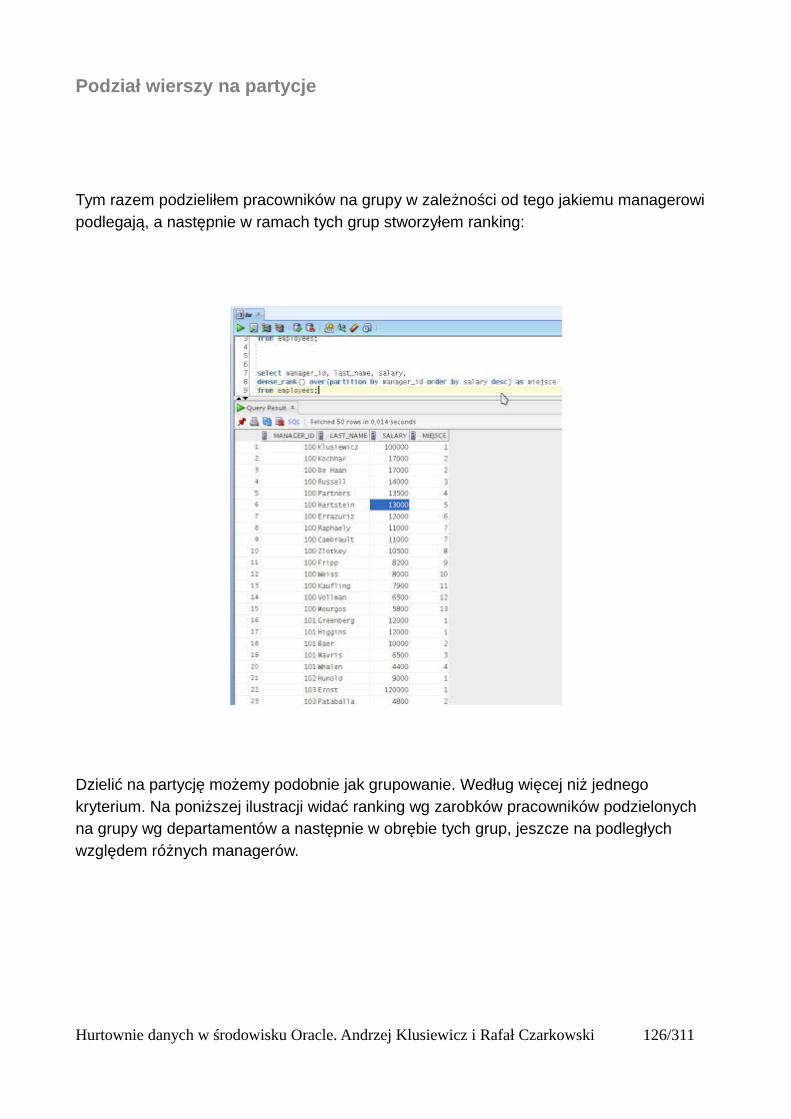
Podział wierszy na partycje
Tym razem podzieliłem pracowników na grupy w zależności od tego jakiemu managerowi podlegają, a następnie w ramach tych grup stworzyłem ranking:
Dzielić na partycję możemy podobnie jak grupowanie. Według więcej niż jednego kryterium. Na poniższej ilustracji widać ranking wg zarobków pracowników podzielonych na grupy wg departamentów a następnie w obrębie tych grup, jeszcze na podległych względem różnych managerów.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 126/311

Istotne drobiazgi....
1. Funkcje analityczne działają zawsze po grupowaniu, łączeniu tabel, warunku where i having. Operują na wyniku całego zapytania. Zostają wykonane jako ostatnie (chociaż przed sortowaniem). Poniższy przykład to obrazuje.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 127/311
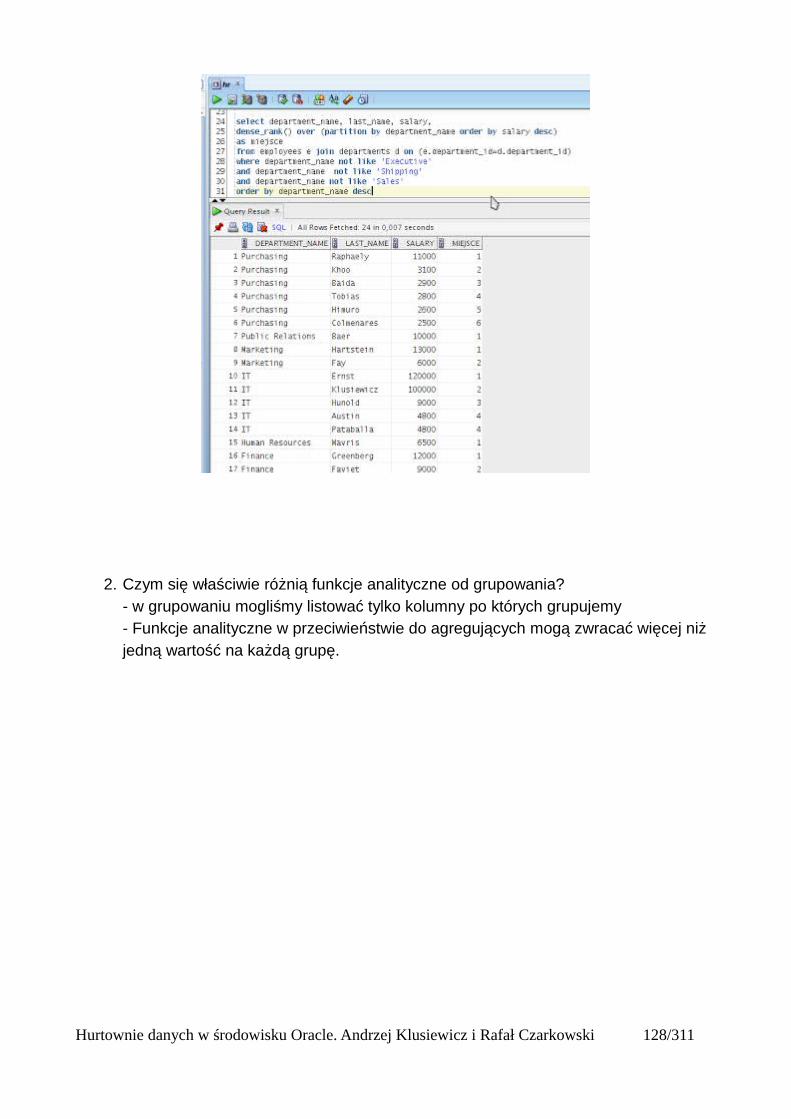
2. Czym się właściwie różnią funkcje analityczne od grupowania?- w grupowaniu mogliśmy listować tylko kolumny po których grupujemy- Funkcje analityczne w przeciwieństwie do agregujących mogą zwracać więcej niż jedną wartość na każdą grupę.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 128/311
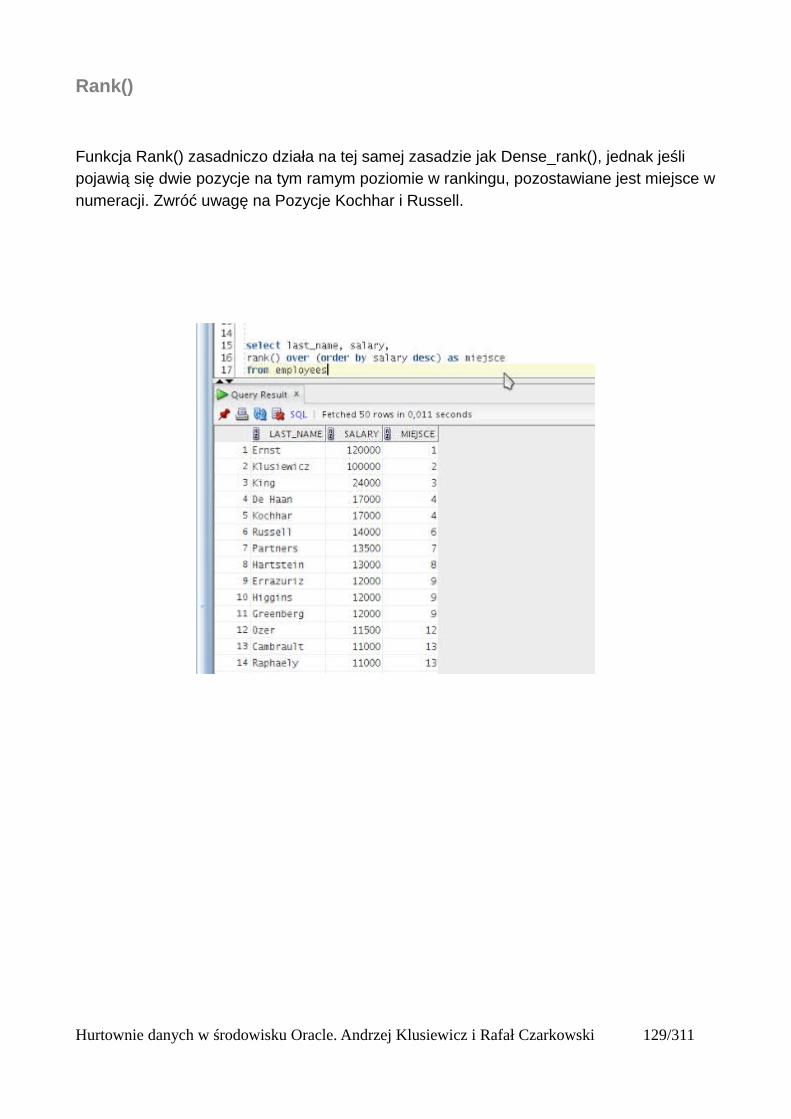
Rank()
Funkcja Rank() zasadniczo działa na tej samej zasadzie jak Dense_rank(), jednak jeśli pojawią się dwie pozycje na tym ramym poziomie w rankingu, pozostawiane jest miejsce wnumeracji. Zwróć uwagę na Pozycje Kochhar i Russell.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 129/311
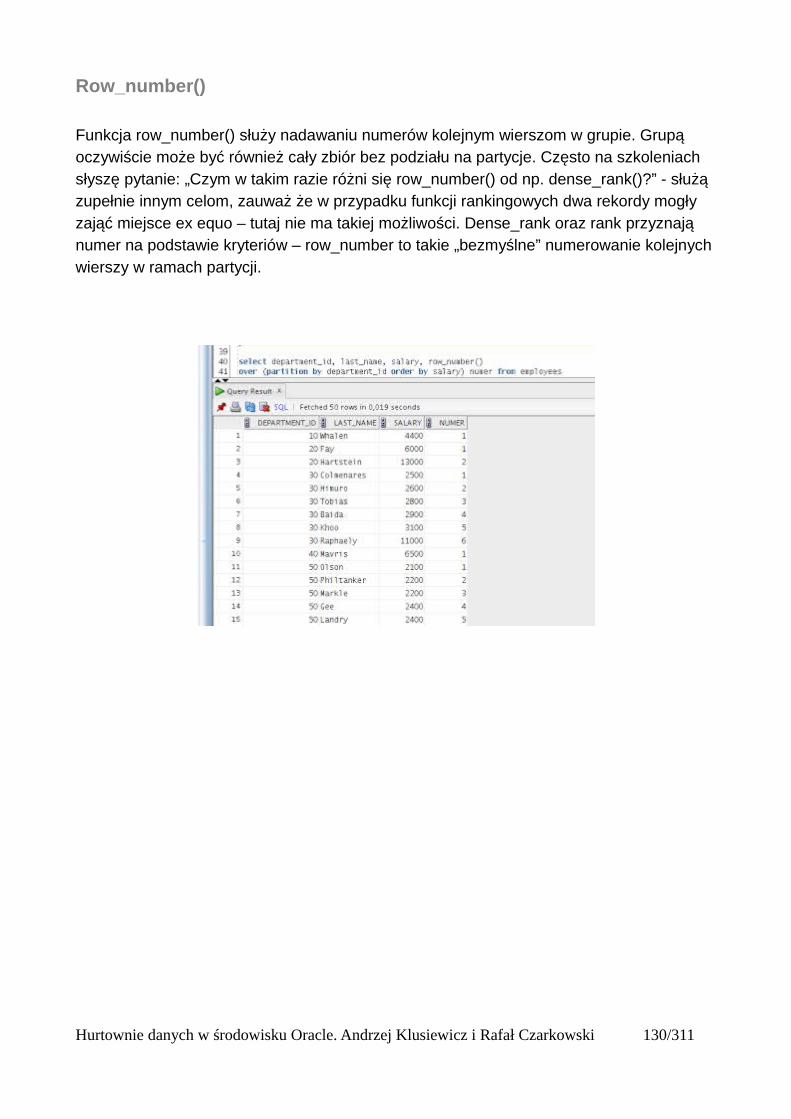
Row_number()
Funkcja row_number() służy nadawaniu numerów kolejnym wierszom w grupie. Grupą oczywiście może być również cały zbiór bez podziału na partycje. Często na szkoleniach słyszę pytanie: „Czym w takim razie różni się row_number() od np. dense_rank()?” - służą zupełnie innym celom, zauważ że w przypadku funkcji rankingowych dwa rekordy mogły zająć miejsce ex equo – tutaj nie ma takiej możliwości. Dense_rank oraz rank przyznają numer na podstawie kryteriów – row_number to takie „bezmyślne” numerowanie kolejnychwierszy w ramach partycji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 130/311
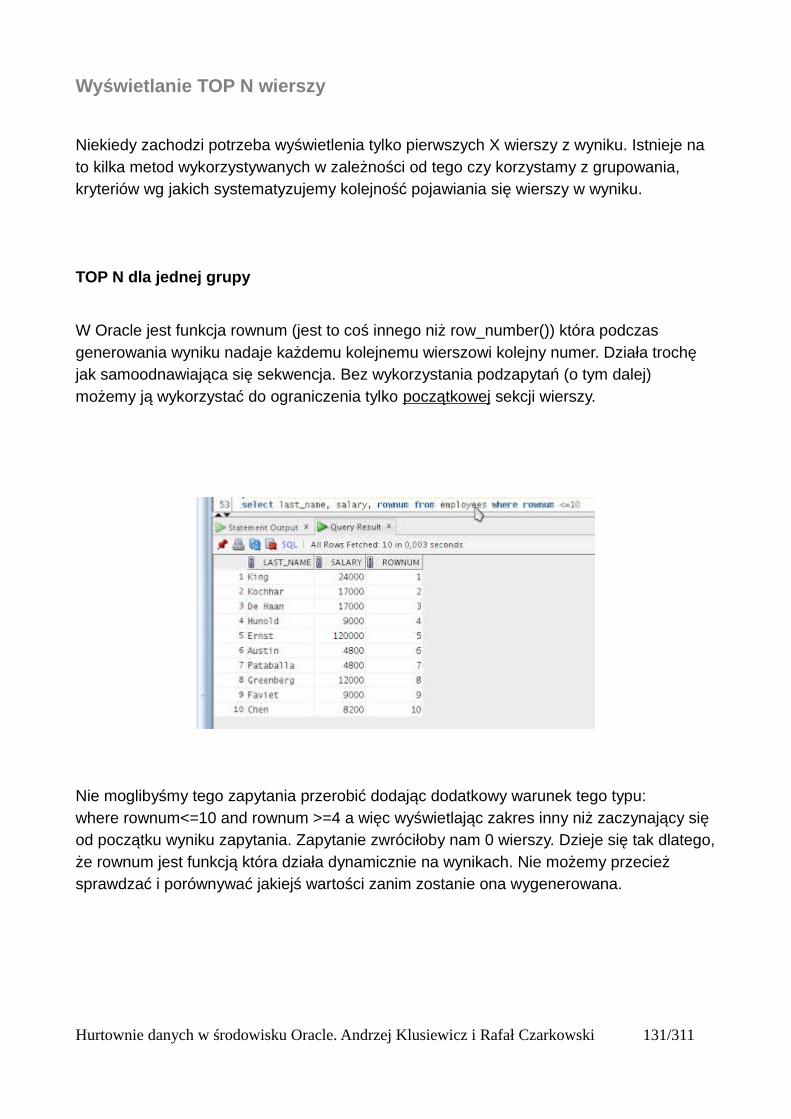
Wyświetlanie TOP N wierszy
Niekiedy zachodzi potrzeba wyświetlenia tylko pierwszych X wierszy z wyniku. Istnieje na to kilka metod wykorzystywanych w zależności od tego czy korzystamy z grupowania, kryteriów wg jakich systematyzujemy kolejność pojawiania się wierszy w wyniku.
TOP N dla jednej grupy
W Oracle jest funkcja rownum (jest to coś innego niż row_number()) która podczas generowania wyniku nadaje każdemu kolejnemu wierszowi kolejny numer. Działa trochę jak samoodnawiająca się sekwencja. Bez wykorzystania podzapytań (o tym dalej) możemy ją wykorzystać do ograniczenia tylko początkowej sekcji wierszy.
Nie moglibyśmy tego zapytania przerobić dodając dodatkowy warunek tego typu:where rownum<=10 and rownum >=4 a więc wyświetlając zakres inny niż zaczynający się od początku wyniku zapytania. Zapytanie zwróciłoby nam 0 wierszy. Dzieje się tak dlatego,że rownum jest funkcją która działa dynamicznie na wynikach. Nie możemy przecież sprawdzać i porównywać jakiejś wartości zanim zostanie ona wygenerowana.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 131/311
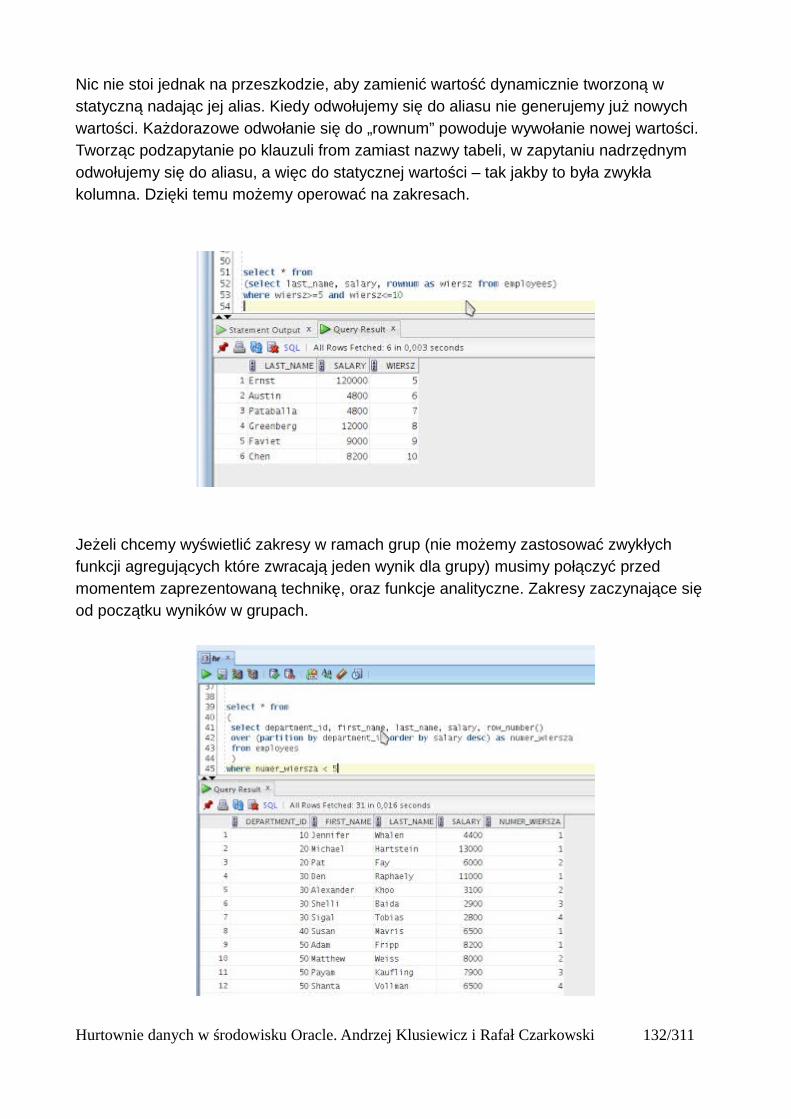
Nic nie stoi jednak na przeszkodzie, aby zamienić wartość dynamicznie tworzoną w statyczną nadając jej alias. Kiedy odwołujemy się do aliasu nie generujemy już nowych wartości. Każdorazowe odwołanie się do „rownum” powoduje wywołanie nowej wartości. Tworząc podzapytanie po klauzuli from zamiast nazwy tabeli, w zapytaniu nadrzędnym odwołujemy się do aliasu, a więc do statycznej wartości – tak jakby to była zwykła kolumna. Dzięki temu możemy operować na zakresach.
Jeżeli chcemy wyświetlić zakresy w ramach grup (nie możemy zastosować zwykłych funkcji agregujących które zwracają jeden wynik dla grupy) musimy połączyć przed momentem zaprezentowaną technikę, oraz funkcje analityczne. Zakresy zaczynające się od początku wyników w grupach.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 132/311
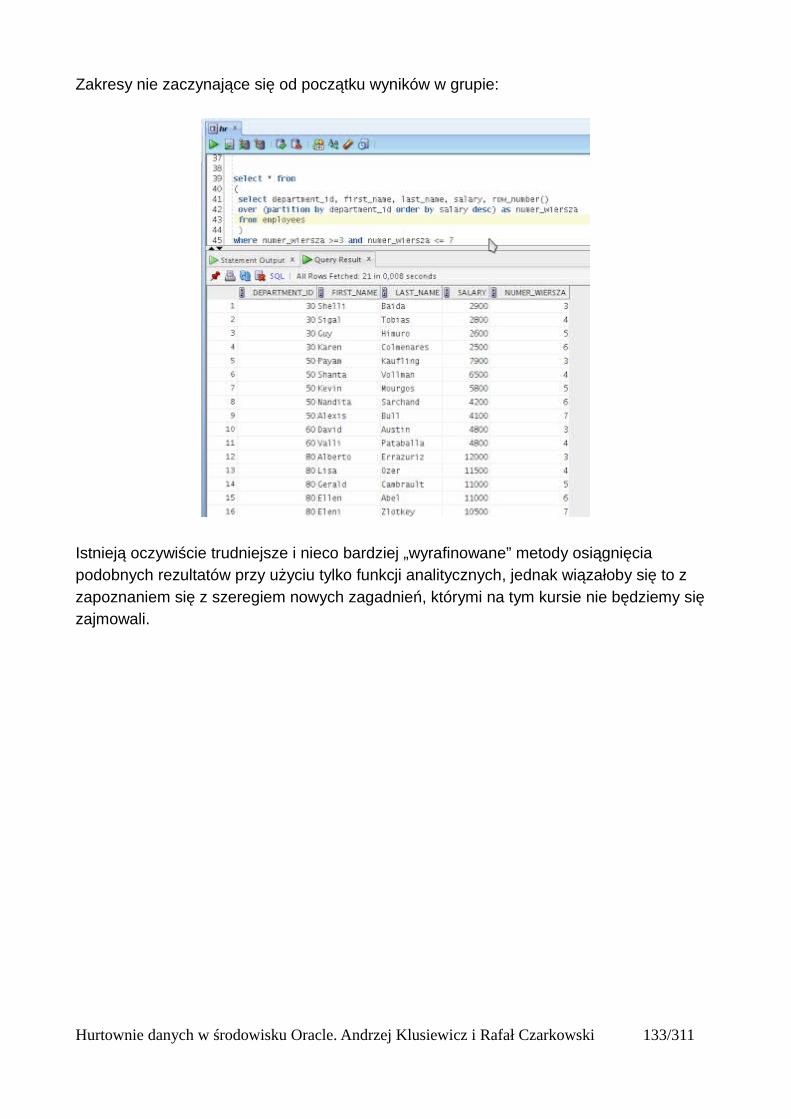
Zakresy nie zaczynające się od początku wyników w grupie:
Istnieją oczywiście trudniejsze i nieco bardziej „wyrafinowane” metody osiągnięcia podobnych rezultatów przy użyciu tylko funkcji analitycznych, jednak wiązałoby się to z zapoznaniem się z szeregiem nowych zagadnień, którymi na tym kursie nie będziemy się zajmowali.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 133/311

Funkcje strumieniowe
Istnieje możliwość tworzenia w PL/SQL na których wyniku możemy operować tak jak na tabeli – mam na myśli stosowanie SELECT, warunków WHERE i sortowania. Jest możliwość zastosowaniafunkcji zwracającej tablicę typu obiektowego, jednak stosowanie takich typów nie należy do wygodnych. Ponadto trzeba będzie poczekać na wynik do czasu aż wygeneruje się cały. Przypuśćmy, że chcemy dostać pierwsze X wierszy jak najszybciej. Reszta może zostać pobrana nieco później. Interesuje nas działanie podobne do wykonania zapytania SELECT na bardzo dużej tabeli w narzędziu takim jak SQL Developer. Stosunkowo szybko (o ile nie zastosowaliśmy np. sortowania) dostaniemy pierwsze 50 wierszy (tylko one zostały pobrane z bazy). Kolejne zostaną zfetchowane dopiero gdy przesuniemy suwak przy wyniku. Aby uzyskać taki efekt, możemy zastosować funkcję strumieniową – pipelined. Wiersze będą zwracane z funkcji jeden po drugim w takim tempie w jakim będą pobierane / generowane. Nie będziemy musieli czekać na wygenerowanie całego wyniku. Moim zdaniem ciekawa funkcjonalność w optymalizacji PL/SQL. Nic nie stoi też na przeszkodzie by użyć funkcji strumieniowych w połączeniu z typem obiektowym.
Zaczniemy od najprostszego przykładu. Stworzyłem funkcję zwracającą kolejne potęgi liczby 2. Funkcja będzie zwracać tablicę elementów typu number element po elemencie. Na wyniku tej funkcji wykorzystamy SELECT.
W pierwszej kolejności tworzę typ talicowy elementów typu number, widoczny w całym schemacie. Dalej tworzę funkcję która zwróci tyle kolejnych potęg liczby 2 ile podamy przez parametr.
Różnicę w stosunku do zwykłych funkcji zauważyć można w liniach 3, 7 i 9. W linii 3 zauważymy deklarację "PIPELINED", jest ona wymagana jeśli chcemy wykorzystywać funkcje w sposób opisanywcześniej. W linii 7 znajdziemy "pipe row". Oznacza on po prostu zwrot kolejnego elementu z funkcji. W linii 9 znajdziemy klauzulę return która jednak nic nie zwraca... Musi ona być z powodów formalnych. Sam zwrot danych zrealizowaliśmy już wcześniej z użyciem PIPE ROW :)
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 134/311
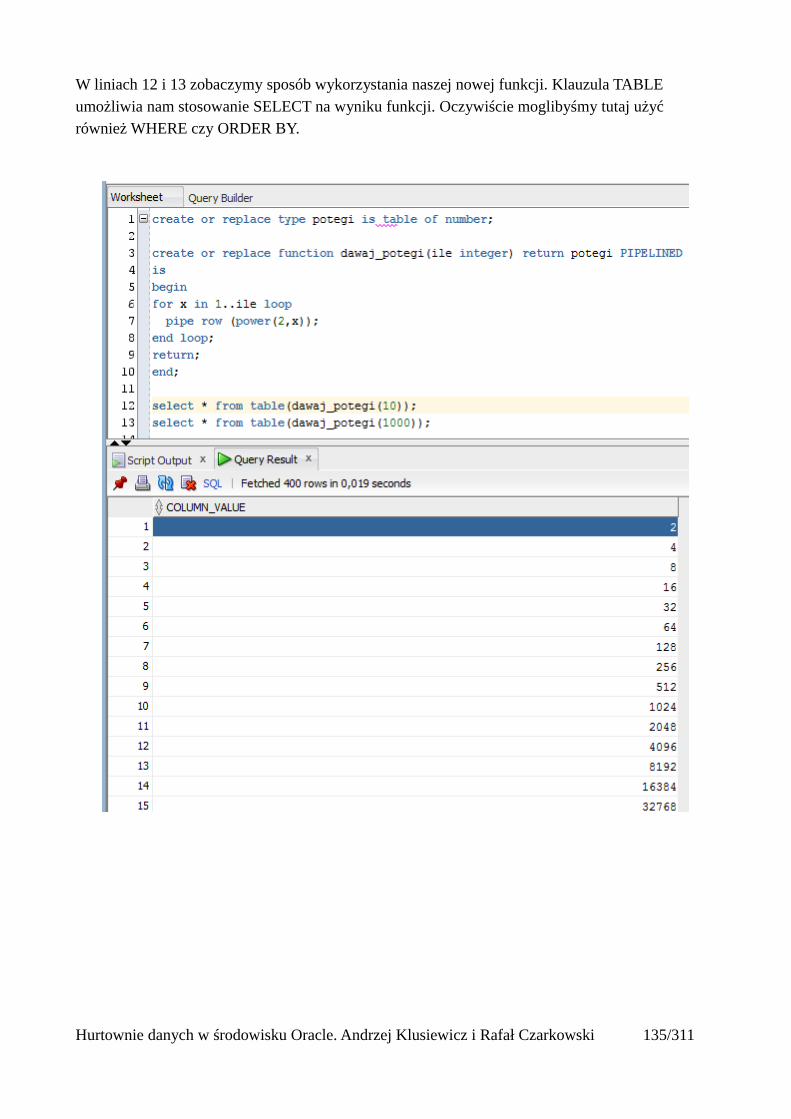
W liniach 12 i 13 zobaczymy sposób wykorzystania naszej nowej funkcji. Klauzula TABLE umożliwia nam stosowanie SELECT na wyniku funkcji. Oczywiście moglibyśmy tutaj użyć również WHERE czy ORDER BY.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 135/311
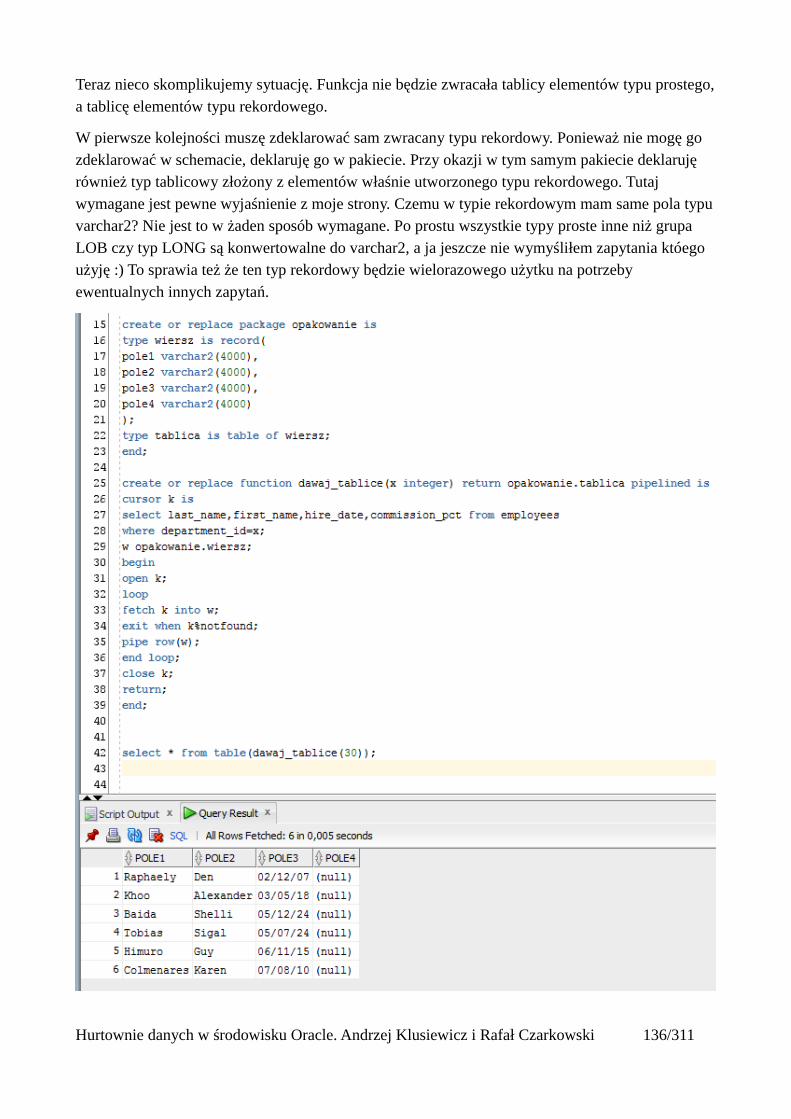
Teraz nieco skomplikujemy sytuację. Funkcja nie będzie zwracała tablicy elementów typu prostego,a tablicę elementów typu rekordowego.
W pierwsze kolejności muszę zdeklarować sam zwracany typu rekordowy. Ponieważ nie mogę go zdeklarować w schemacie, deklaruję go w pakiecie. Przy okazji w tym samym pakiecie deklaruję również typ tablicowy złożony z elementów właśnie utworzonego typu rekordowego. Tutaj wymagane jest pewne wyjaśnienie z moje strony. Czemu w typie rekordowym mam same pola typuvarchar2? Nie jest to w żaden sposób wymagane. Po prostu wszystkie typy proste inne niż grupa LOB czy typ LONG są konwertowalne do varchar2, a ja jeszcze nie wymyśliłem zapytania któego użyję :) To sprawia też że ten typ rekordowy będzie wielorazowego użytku na potrzeby ewentualnych innych zapytań.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 136/311

Dalej tworzę funkcję wykorzystującą ten typ tablicowy. Konstrukcyjnie niewiele tutaj zmian w stosunku do poprzedniej funkcji. Tyma razem jednak przetwarzam wynik zapytania. Może rzucić się w oczy linia 29 z deklaracją pojedynczego elementu do którego wrzucam zaczytany z kursora wiersz. Po co mi on potrzebny jeśli funkcja ma zwracać tablicę? Zwracać będzie tablicę, ale wierszo po wierszu. W linii 35 wywołuję PIPE ROW która nie może przecież zwrócić nam tablicy. Dlatego potrzebuję takiego elementu jako kontenera na kolejne zwracane wiersze.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 137/311
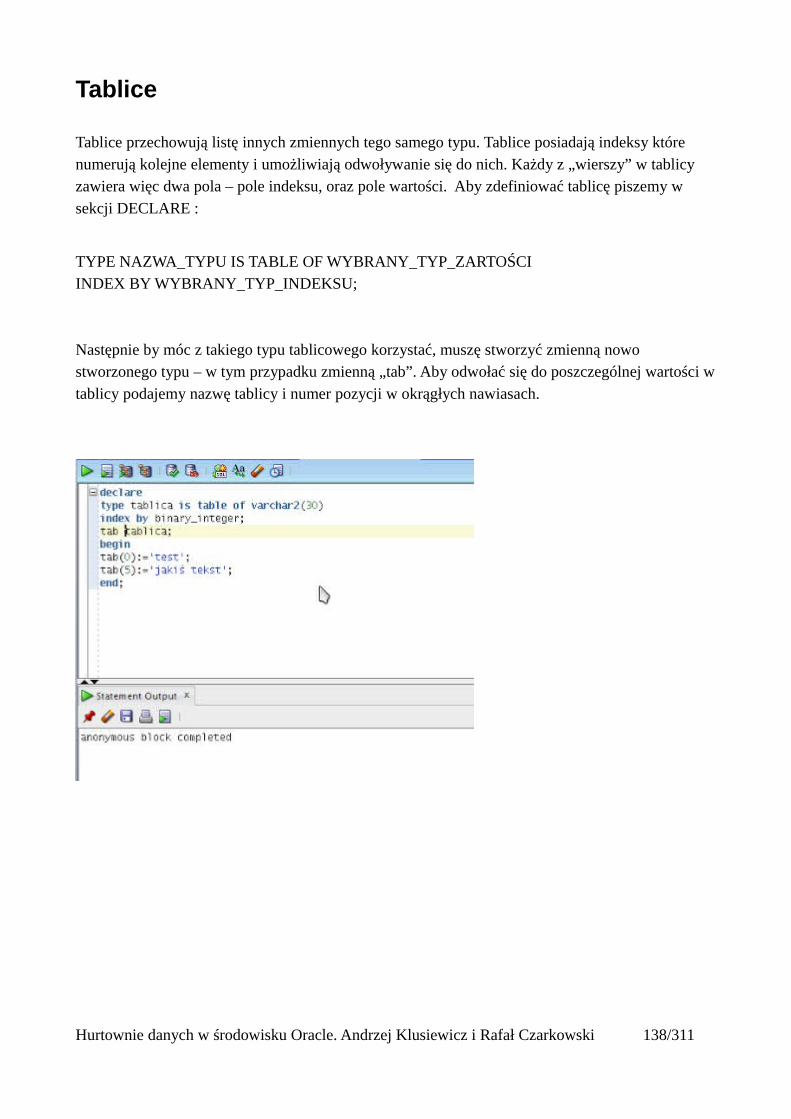
Tablice
Tablice przechowują listę innych zmiennych tego samego typu. Tablice posiadają indeksy które numerują kolejne elementy i umożliwiają odwoływanie się do nich. Każdy z „wierszy” w tablicy zawiera więc dwa pola – pole indeksu, oraz pole wartości. Aby zdefiniować tablicę piszemy w sekcji DECLARE :
TYPE NAZWA_TYPU IS TABLE OF WYBRANY_TYP_ZARTOŚCIINDEX BY WYBRANY_TYP_INDEKSU;
Następnie by móc z takiego typu tablicowego korzystać, muszę stworzyć zmienną nowo stworzonego typu – w tym przypadku zmienną „tab”. Aby odwołać się do poszczególnej wartości wtablicy podajemy nazwę tablicy i numer pozycji w okrągłych nawiasach.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 138/311
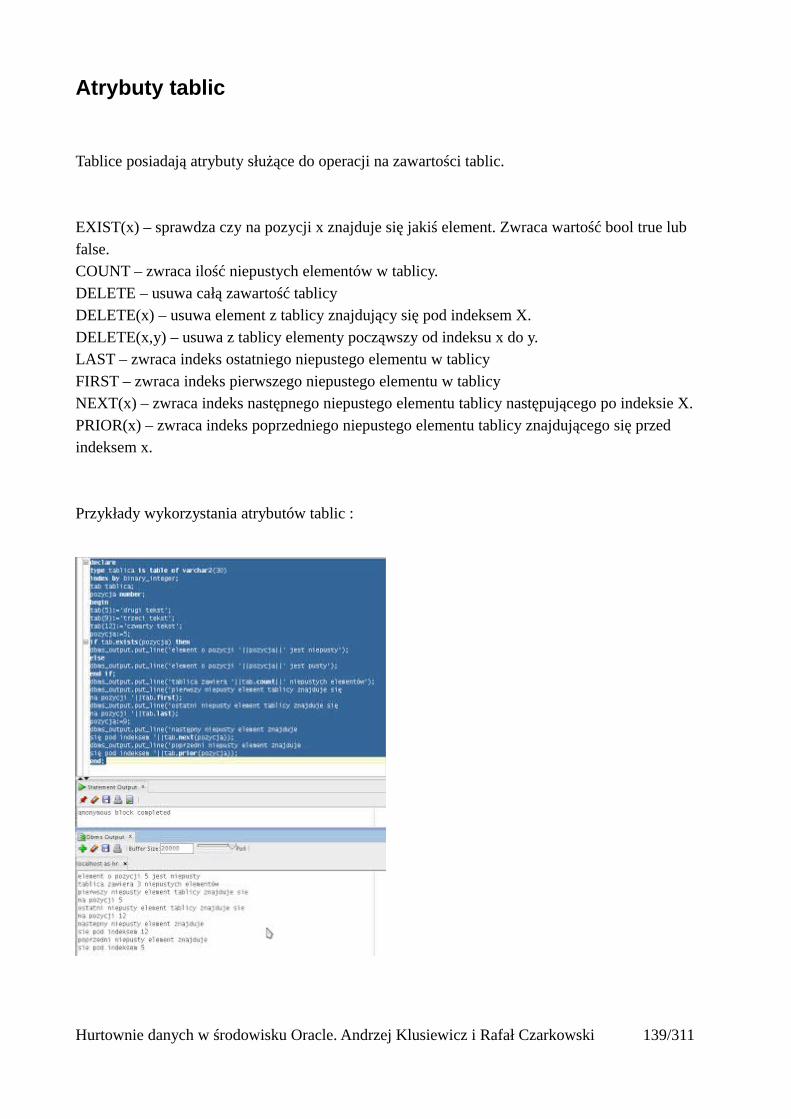
Atrybuty tablic
Tablice posiadają atrybuty służące do operacji na zawartości tablic.
EXIST(x) – sprawdza czy na pozycji x znajduje się jakiś element. Zwraca wartość bool true lub false.COUNT – zwraca ilość niepustych elementów w tablicy.DELETE – usuwa całą zawartość tablicyDELETE(x) – usuwa element z tablicy znajdujący się pod indeksem X.DELETE(x,y) – usuwa z tablicy elementy począwszy od indeksu x do y.LAST – zwraca indeks ostatniego niepustego elementu w tablicyFIRST – zwraca indeks pierwszego niepustego elementu w tablicyNEXT(x) – zwraca indeks następnego niepustego elementu tablicy następującego po indeksie X.PRIOR(x) – zwraca indeks poprzedniego niepustego elementu tablicy znajdującego się przed indeksem x.
Przykłady wykorzystania atrybutów tablic :
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 139/311
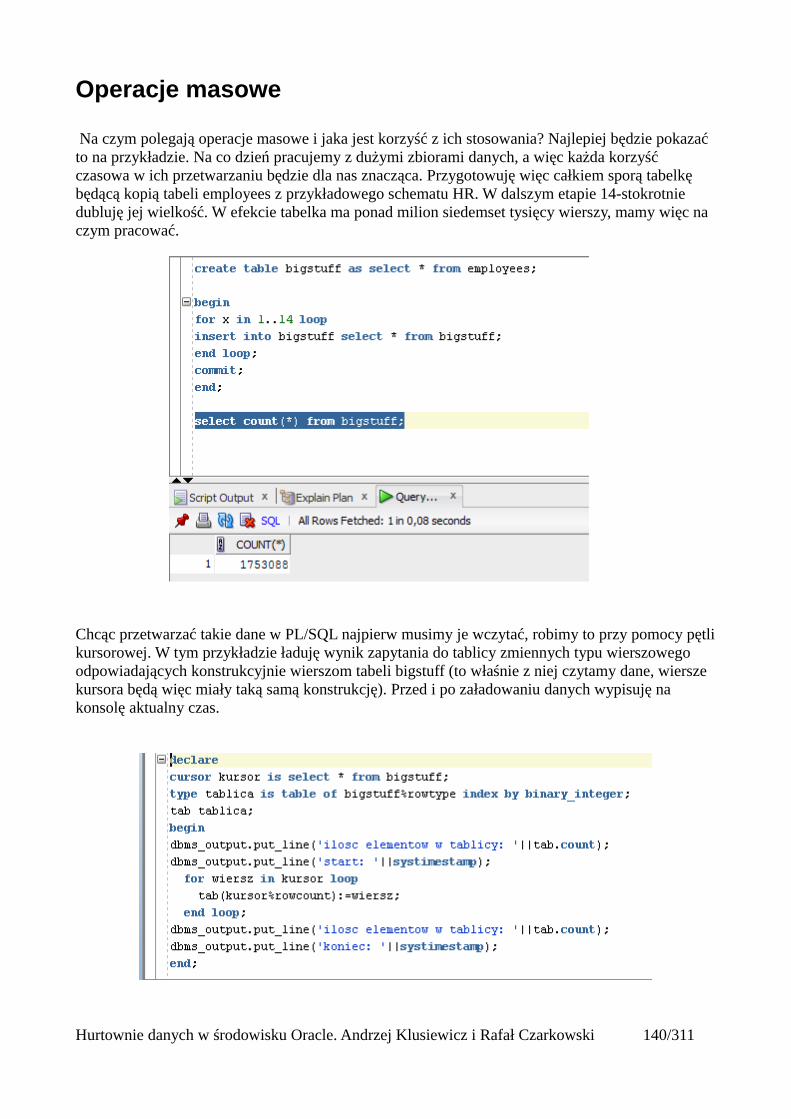
Operacje masowe
Na czym polegają operacje masowe i jaka jest korzyść z ich stosowania? Najlepiej będzie pokazać to na przykładzie. Na co dzień pracujemy z dużymi zbiorami danych, a więc każda korzyść czasowa w ich przetwarzaniu będzie dla nas znacząca. Przygotowuję więc całkiem sporą tabelkę będącą kopią tabeli employees z przykładowego schematu HR. W dalszym etapie 14-stokrotnie dubluję jej wielkość. W efekcie tabelka ma ponad milion siedemset tysięcy wierszy, mamy więc na czym pracować.
Chcąc przetwarzać takie dane w PL/SQL najpierw musimy je wczytać, robimy to przy pomocy pętlikursorowej. W tym przykładzie ładuję wynik zapytania do tablicy zmiennych typu wierszowego odpowiadających konstrukcyjnie wierszom tabeli bigstuff (to właśnie z niej czytamy dane, wiersze kursora będą więc miały taką samą konstrukcję). Przed i po załadowaniu danych wypisuję na konsolę aktualny czas.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 140/311

Po zakończeniu wykonywania skryptu na konsoli wyświetlone zostały wyniki. Widzimy że ładowanie prawie 2 milionów wierszy trwało 26 sekund.
Teraz nieco zmodyfikuję kod:
Jak widać zamiast pętli kursorowej (która przy okazji niejawnie otwiera i zamyka kursor) otwieram i zamykam kursor jawnie, ale zamiast fetchowania pojedynczych wierszy, fetchuję naraz cały kursor. W dodatku nie ma tu żadnej pętli... Konstrukcja konstrukcją, ale sprawdźmy efekty:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 141/311
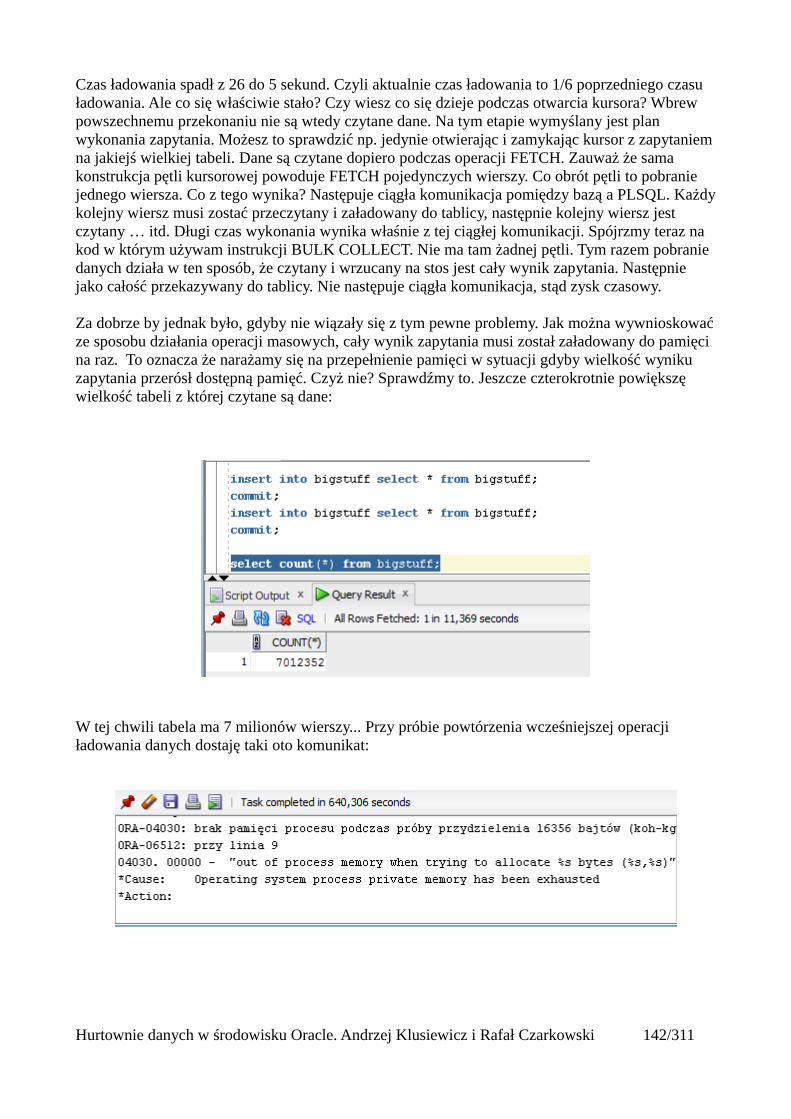
Czas ładowania spadł z 26 do 5 sekund. Czyli aktualnie czas ładowania to 1/6 poprzedniego czasu ładowania. Ale co się właściwie stało? Czy wiesz co się dzieje podczas otwarcia kursora? Wbrew powszechnemu przekonaniu nie są wtedy czytane dane. Na tym etapie wymyślany jest plan wykonania zapytania. Możesz to sprawdzić np. jedynie otwierając i zamykając kursor z zapytaniemna jakiejś wielkiej tabeli. Dane są czytane dopiero podczas operacji FETCH. Zauważ że sama konstrukcja pętli kursorowej powoduje FETCH pojedynczych wierszy. Co obrót pętli to pobranie jednego wiersza. Co z tego wynika? Następuje ciągła komunikacja pomiędzy bazą a PLSQL. Każdykolejny wiersz musi zostać przeczytany i załadowany do tablicy, następnie kolejny wiersz jest czytany … itd. Długi czas wykonania wynika właśnie z tej ciągłej komunikacji. Spójrzmy teraz na kod w którym używam instrukcji BULK COLLECT. Nie ma tam żadnej pętli. Tym razem pobranie danych działa w ten sposób, że czytany i wrzucany na stos jest cały wynik zapytania. Następnie jako całość przekazywany do tablicy. Nie następuje ciągła komunikacja, stąd zysk czasowy.
Za dobrze by jednak było, gdyby nie wiązały się z tym pewne problemy. Jak można wywnioskowaćze sposobu działania operacji masowych, cały wynik zapytania musi został załadowany do pamięci na raz. To oznacza że narażamy się na przepełnienie pamięci w sytuacji gdyby wielkość wyniku zapytania przerósł dostępną pamięć. Czyż nie? Sprawdźmy to. Jeszcze czterokrotnie powiększę wielkość tabeli z której czytane są dane:
W tej chwili tabela ma 7 milionów wierszy... Przy próbie powtórzenia wcześniejszej operacji ładowania danych dostaję taki oto komunikat:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 142/311

Co mogę na to poradzić? Mogę przetwarzać dane po kawałku. Np. po 500 tysięcy wierszy. Do tego służy dodatkowa klauzula limit 500000. Muszę tylko zadbać by załadować cały wynik, dodaję więcrównież pętlę która będzie czytała dane po kawałku aż się skończą:
Oczywiście nie może się obyć bez problemów :) System nie może kolekcjonować wszystkiego naraz do jednej tablicy ponieważ ponownie doprowadziłoby to do przepełnienia pamięci. Rozwiązano to w ten sposób, że każda kolejna porcja nadpisuje poprzednią. W kodzie powyżej wypisywałem na ekran ilość niepustych elementów w tablicy przy użyciu tab.count. To mi daje obraz na temat tego ile znajduje się elementów w tablicy po każdym fetchu z limitem. Wynik możemy obejrzeć poniżej:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 143/311
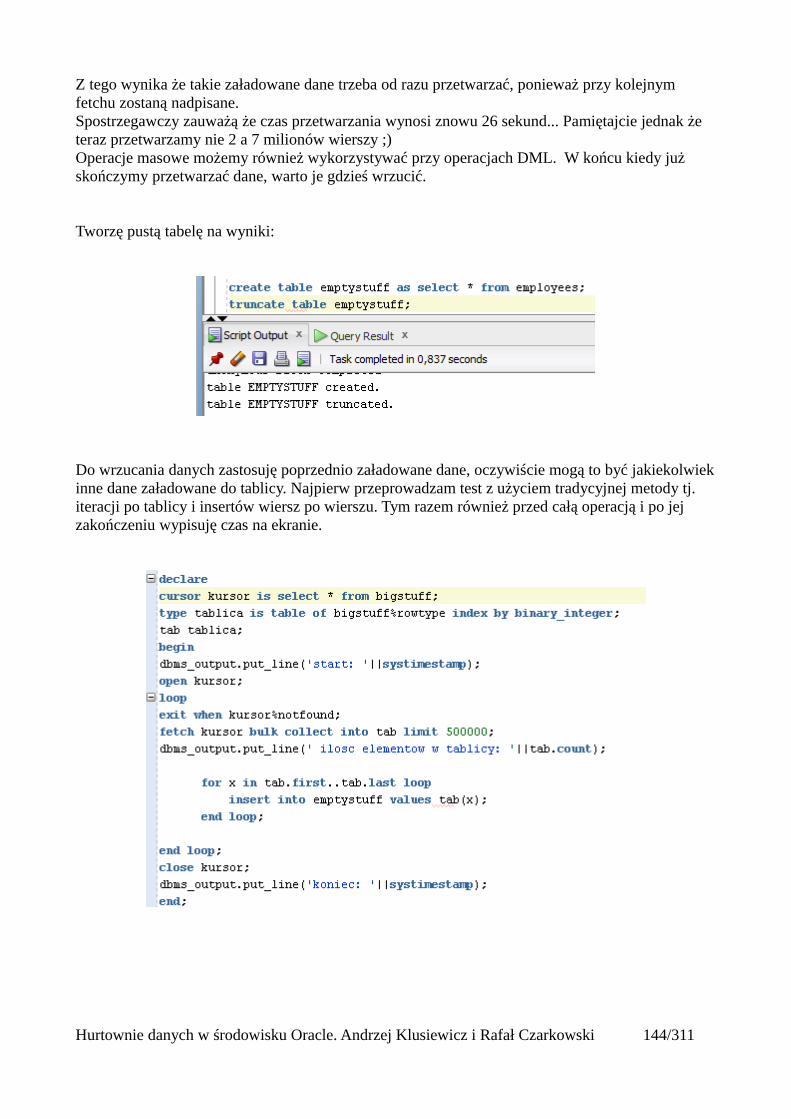
Z tego wynika że takie załadowane dane trzeba od razu przetwarzać, ponieważ przy kolejnym fetchu zostaną nadpisane.Spostrzegawczy zauważą że czas przetwarzania wynosi znowu 26 sekund... Pamiętajcie jednak że teraz przetwarzamy nie 2 a 7 milionów wierszy ;)Operacje masowe możemy również wykorzystywać przy operacjach DML. W końcu kiedy już skończymy przetwarzać dane, warto je gdzieś wrzucić.
Tworzę pustą tabelę na wyniki:
Do wrzucania danych zastosuję poprzednio załadowane dane, oczywiście mogą to być jakiekolwiekinne dane załadowane do tablicy. Najpierw przeprowadzam test z użyciem tradycyjnej metody tj. iteracji po tablicy i insertów wiersz po wierszu. Tym razem również przed całą operacją i po jej zakończeniu wypisuję czas na ekranie.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 144/311
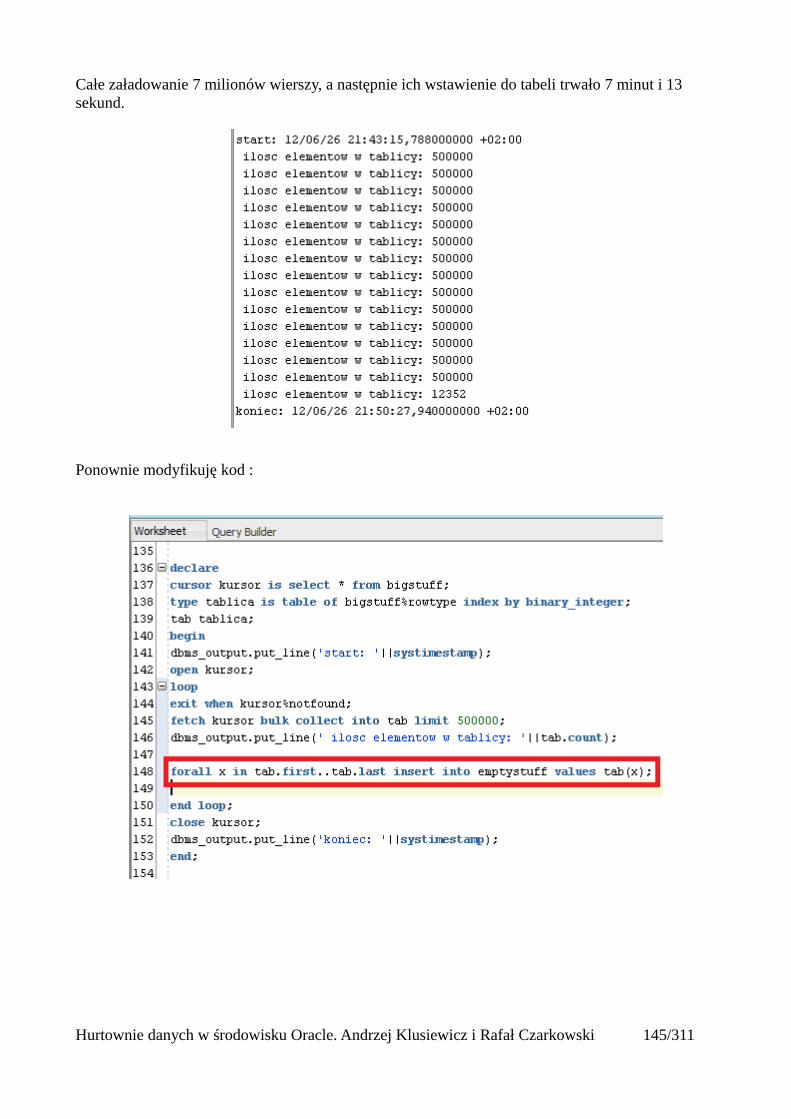
Całe załadowanie 7 milionów wierszy, a następnie ich wstawienie do tabeli trwało 7 minut i 13 sekund.
Ponownie modyfikuję kod :
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 145/311

Pojawiła się nowa instrukcja : FORALL. Działa podobnie jak BULK COLLECT przy ładowaniu danych do tablicy, tylko w drugą stronę. Cała tablica jest jednocześnie przekazywana do insertu. Ale jak wygląda zysk czasowy?Zamiast 7 minut i 14 sekund mamy 2 minuty i 8 sekund. W sumie przy użyciu operacji masowych zyskaliśmy
– przy ładowaniu danych do tablicy 1/6 czasu– przy wrzucaniu danych do bazy ok 1/3 czasu
Razem daje nam to całkiem przyzwoity wynik :)
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 146/311
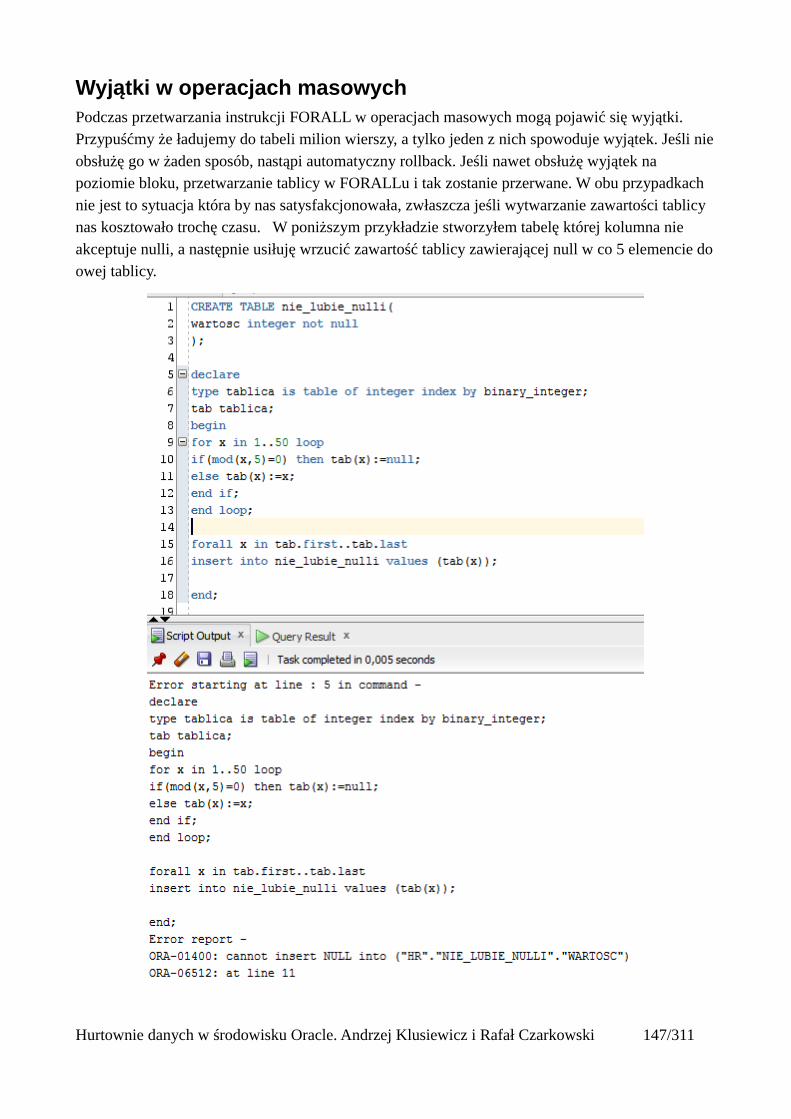
Wyjątki w operacjach masowychPodczas przetwarzania instrukcji FORALL w operacjach masowych mogą pojawić się wyjątki. Przypuśćmy że ładujemy do tabeli milion wierszy, a tylko jeden z nich spowoduje wyjątek. Jeśli nieobsłużę go w żaden sposób, nastąpi automatyczny rollback. Jeśli nawet obsłużę wyjątek na poziomie bloku, przetwarzanie tablicy w FORALLu i tak zostanie przerwane. W obu przypadkach nie jest to sytuacja która by nas satysfakcjonowała, zwłaszcza jeśli wytwarzanie zawartości tablicy nas kosztowało trochę czasu. W poniższym przykładzie stworzyłem tabelę której kolumna nie akceptuje nulli, a następnie usiłuję wrzucić zawartość tablicy zawierającej null w co 5 elemencie doowej tablicy.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 147/311
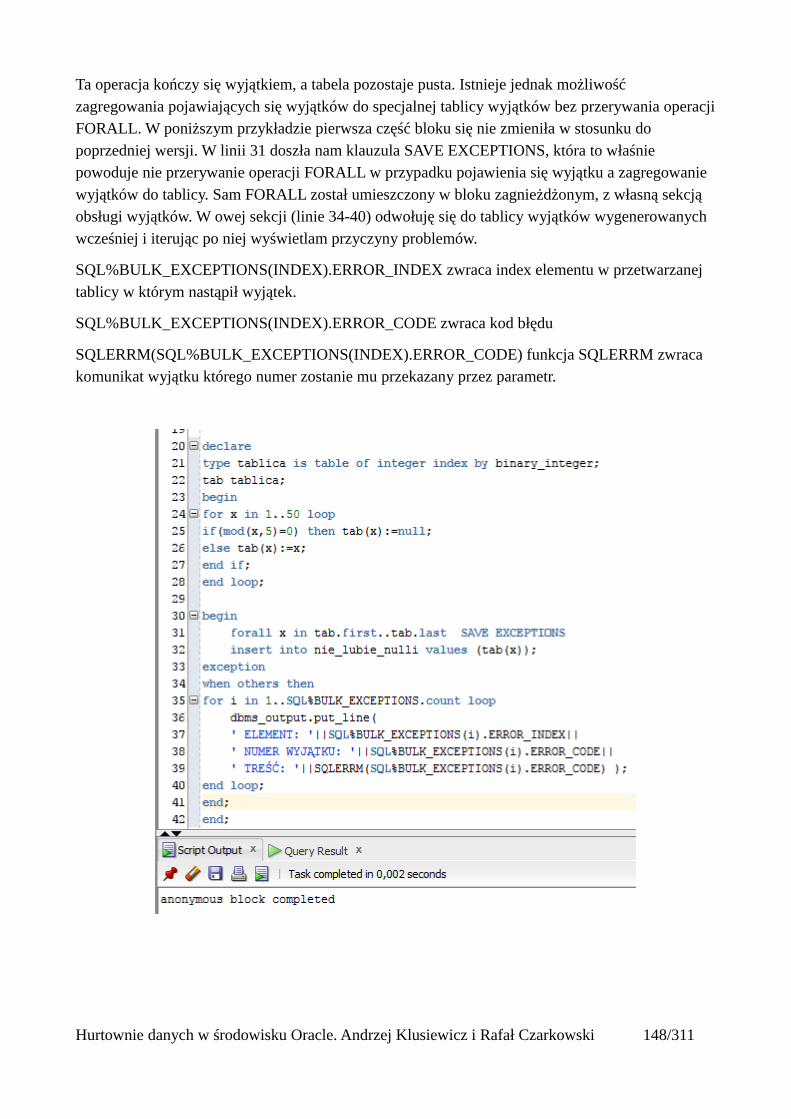
Ta operacja kończy się wyjątkiem, a tabela pozostaje pusta. Istnieje jednak możliwość zagregowania pojawiających się wyjątków do specjalnej tablicy wyjątków bez przerywania operacjiFORALL. W poniższym przykładzie pierwsza część bloku się nie zmieniła w stosunku do poprzedniej wersji. W linii 31 doszła nam klauzula SAVE EXCEPTIONS, która to właśnie powoduje nie przerywanie operacji FORALL w przypadku pojawienia się wyjątku a zagregowanie wyjątków do tablicy. Sam FORALL został umieszczony w bloku zagnieżdżonym, z własną sekcją obsługi wyjątków. W owej sekcji (linie 34-40) odwołuję się do tablicy wyjątków wygenerowanych wcześniej i iterując po niej wyświetlam przyczyny problemów.
SQL%BULK_EXCEPTIONS(INDEX).ERROR_INDEX zwraca index elementu w przetwarzanej tablicy w którym nastąpił wyjątek.
SQL%BULK_EXCEPTIONS(INDEX).ERROR_CODE zwraca kod błędu
SQLERRM(SQL%BULK_EXCEPTIONS(INDEX).ERROR_CODE) funkcja SQLERRM zwraca komunikat wyjątku którego numer zostanie mu przekazany przez parametr.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 148/311
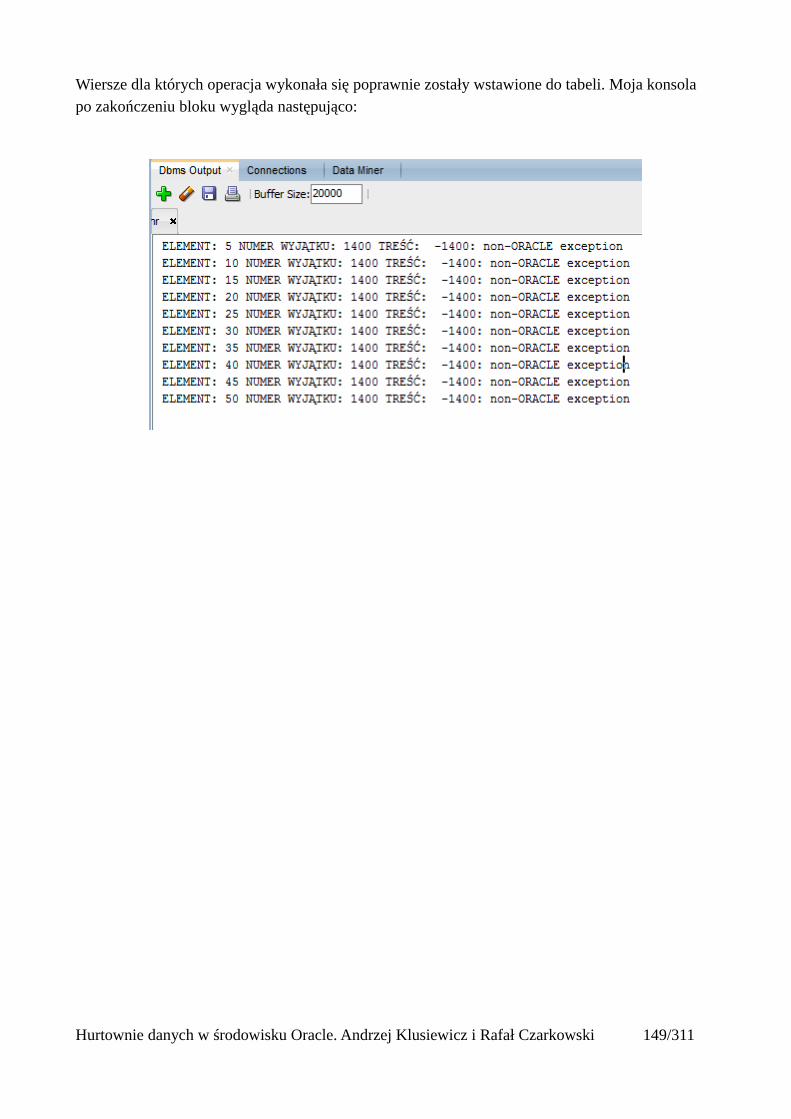
Wiersze dla których operacja wykonała się poprawnie zostały wstawione do tabeli. Moja konsola po zakończeniu bloku wygląda następująco:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 149/311

Widoki zmaterializowane
W przeciwieństwie do zwykłych widoków, widoki zmaterializowane przechowują dane iwykorzystują fizyczną przestrzeń dyskową przydzieloną bazie danych. Widoki zmateializowane sąwypełniane danymi generowanymi przez ich bazowe zapytania. Stosuje się je głównie w celupoprawy wydajności dla zapytań zawierających rozproszone dane (zapytania oparte o kilka tabel)lub zawierających podsumowania agregacji w wyniku grupowania. Dzięki nim możemy utworzyćkopię (zwaną też repliką) całej lub części tabeli źródłowej lub kopię wyniku zapytania opartego okilka tabel. Widoków zmaterializowanych używa się również w celu replikowania danychpomiędzy bazami. Nie trzeba powielać całej tabeli lub ograniczać się do danych tylko jednej tabeli.Replikując pojedynczą tabelę, można zastosować klauzulę WHERE, aby określić jedynie rekordyprzeznaczone do powielenia. Jeśli dane w tabeli (lub tabelach) źródłowej ulegną zmianie, możemypoprostu odświeżyć dane zawarte w widoku. Proceś odświeżania może odbywać się automatycznie,lub możemy go wywołać ręcznie. W wielu przypadkach baza może korzystać z dziennika widokuzmaterializowanego, aby przesyłać wyłącznie dane transakcji (zmian dokonanych w tabeliźródłowej). W przeciwnym razie baza danych dla lokalnego widoku zmaterializowanego będzierealizować operację pełnego odświeżania.
Aby utworzyć widok zmaterializowany należy posiadać uprawnienie systemowe CREATEMATERIALIZED VIEW, w przeciwnym razie, podczas próby utworzenia takiego widokuzobaczymy błąd ORA-01031.
GRANT CREATE MATERIALIZED VIEW TO HR;
Widoki zmaterializowane tworzymy tak samo jak zwykłe widoki, a więc na podstawie zapytania,którego wynik chcemy aby był przetrzymywany w widoku, dopisując dodatkowo frazęMATERIALIZED.
Poniżej przykład utworzenia prostego widoku zmaterializowanego, który będzie oparty o jednątabelę, bez użycia funkcji agregujących, w związku z czym otrzymamy poprostu kopię tabeliźródłowej.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 150/311
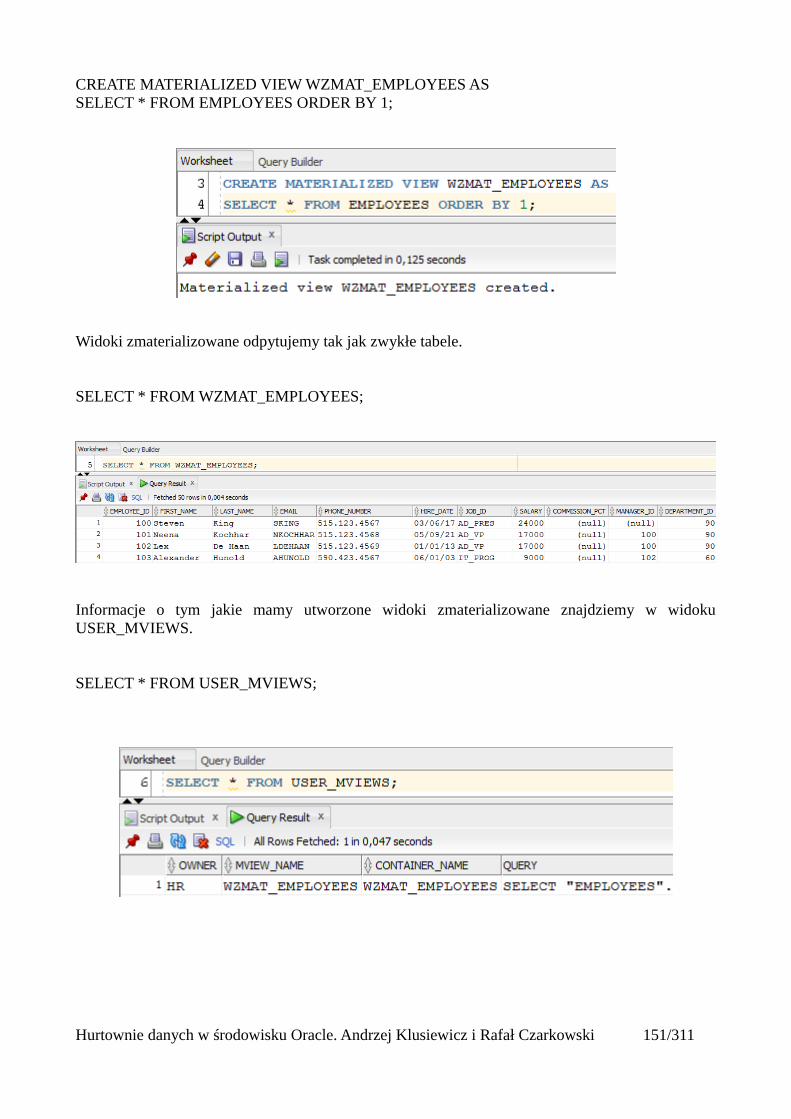
CREATE MATERIALIZED VIEW WZMAT_EMPLOYEES ASSELECT * FROM EMPLOYEES ORDER BY 1;
Widoki zmaterializowane odpytujemy tak jak zwykłe tabele.
SELECT * FROM WZMAT_EMPLOYEES;
Informacje o tym jakie mamy utworzone widoki zmaterializowane znajdziemy w widokuUSER_MVIEWS.
SELECT * FROM USER_MVIEWS;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 151/311
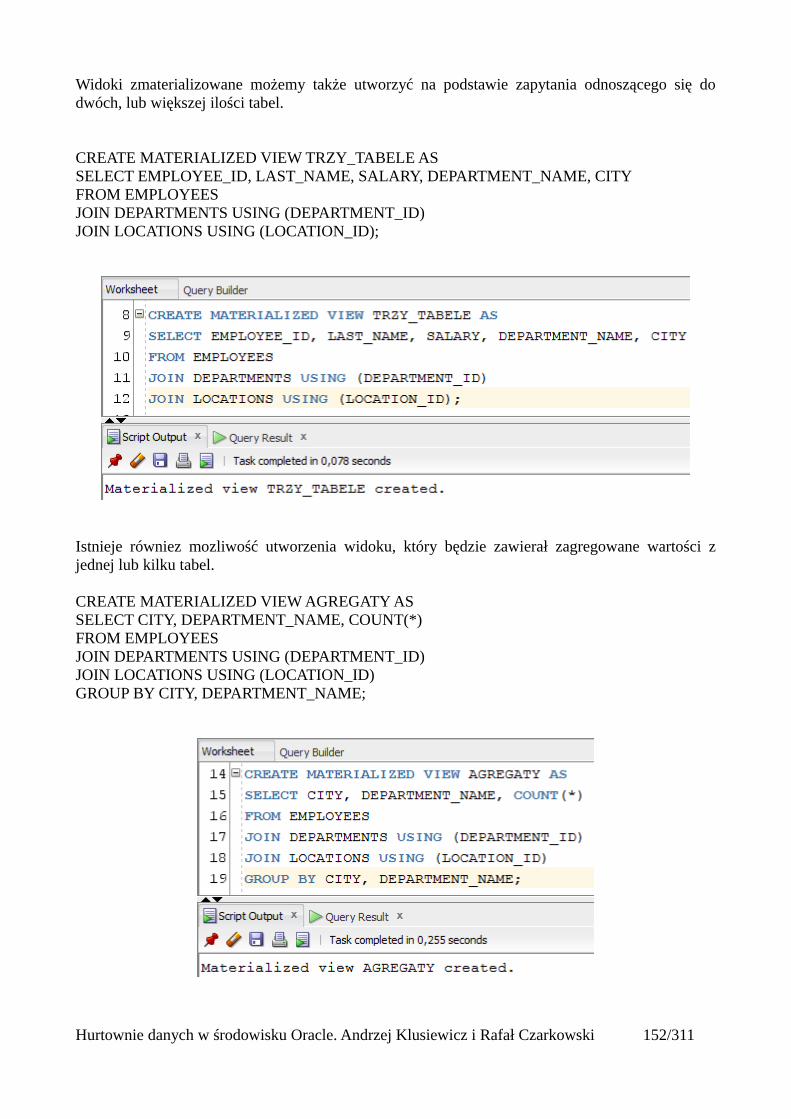
Widoki zmaterializowane możemy także utworzyć na podstawie zapytania odnoszącego się dodwóch, lub większej ilości tabel.
CREATE MATERIALIZED VIEW TRZY_TABELE ASSELECT EMPLOYEE_ID, LAST_NAME, SALARY, DEPARTMENT_NAME, CITYFROM EMPLOYEESJOIN DEPARTMENTS USING (DEPARTMENT_ID)JOIN LOCATIONS USING (LOCATION_ID);
Istnieje równiez mozliwość utworzenia widoku, który będzie zawierał zagregowane wartości zjednej lub kilku tabel.
CREATE MATERIALIZED VIEW AGREGATY ASSELECT CITY, DEPARTMENT_NAME, COUNT(*)FROM EMPLOYEESJOIN DEPARTMENTS USING (DEPARTMENT_ID)JOIN LOCATIONS USING (LOCATION_ID)GROUP BY CITY, DEPARTMENT_NAME;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 152/311
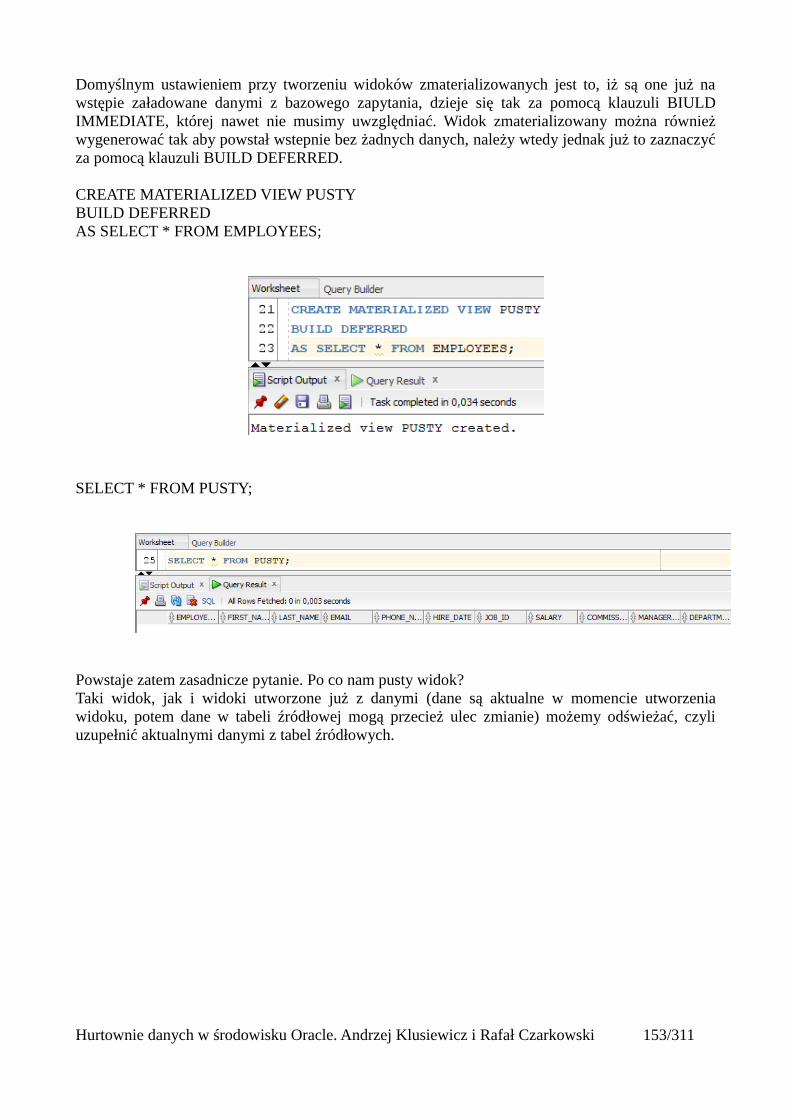
Domyślnym ustawieniem przy tworzeniu widoków zmaterializowanych jest to, iż są one już nawstępie załadowane danymi z bazowego zapytania, dzieje się tak za pomocą klauzuli BIULDIMMEDIATE, której nawet nie musimy uwzględniać. Widok zmaterializowany można równieżwygenerować tak aby powstał wstepnie bez żadnych danych, należy wtedy jednak już to zaznaczyćza pomocą klauzuli BUILD DEFERRED.
CREATE MATERIALIZED VIEW PUSTY BUILD DEFERRED AS SELECT * FROM EMPLOYEES;
SELECT * FROM PUSTY;
Powstaje zatem zasadnicze pytanie. Po co nam pusty widok?Taki widok, jak i widoki utworzone już z danymi (dane są aktualne w momencie utworzeniawidoku, potem dane w tabeli źródłowej mogą przecież ulec zmianie) możemy odświeżać, czyliuzupełnić aktualnymi danymi z tabel źródłowych.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 153/311
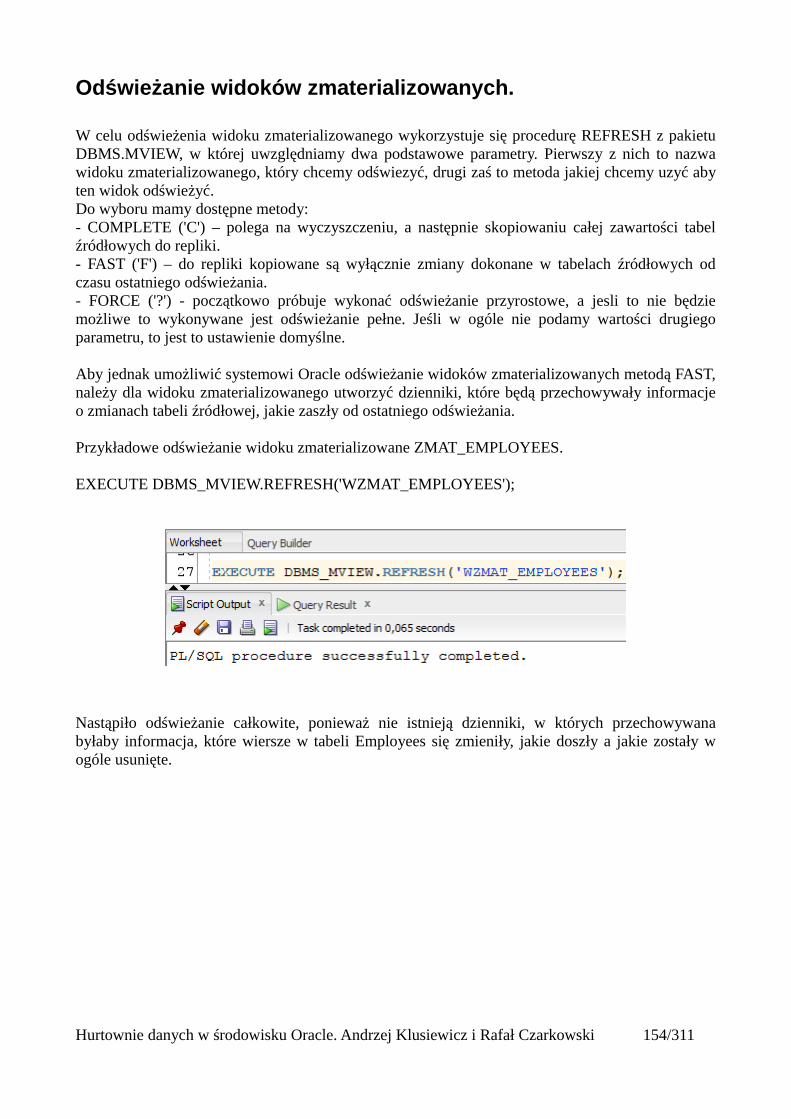
Odświeżanie widoków zmaterializowanych.
W celu odświeżenia widoku zmaterializowanego wykorzystuje się procedurę REFRESH z pakietuDBMS.MVIEW, w której uwzględniamy dwa podstawowe parametry. Pierwszy z nich to nazwawidoku zmaterializowanego, który chcemy odświezyć, drugi zaś to metoda jakiej chcemy uzyć abyten widok odświeżyć. Do wyboru mamy dostępne metody:- COMPLETE ('C') – polega na wyczyszczeniu, a następnie skopiowaniu całej zawartości tabelźródłowych do repliki.- FAST ('F') – do repliki kopiowane są wyłącznie zmiany dokonane w tabelach źródłowych odczasu ostatniego odświeżania.- FORCE ('?') - początkowo próbuje wykonać odświeżanie przyrostowe, a jesli to nie będziemożliwe to wykonywane jest odświeżanie pełne. Jeśli w ogóle nie podamy wartości drugiegoparametru, to jest to ustawienie domyślne.
Aby jednak umożliwić systemowi Oracle odświeżanie widoków zmaterializowanych metodą FAST,należy dla widoku zmaterializowanego utworzyć dzienniki, które będą przechowywały informacjeo zmianach tabeli źródłowej, jakie zaszły od ostatniego odświeżania.
Przykładowe odświeżanie widoku zmaterializowane ZMAT_EMPLOYEES.
EXECUTE DBMS_MVIEW.REFRESH('WZMAT_EMPLOYEES');
Nastąpiło odświeżanie całkowite, ponieważ nie istnieją dzienniki, w których przechowywanabyłaby informacja, które wiersze w tabeli Employees się zmieniły, jakie doszły a jakie zostały wogóle usunięte.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 154/311
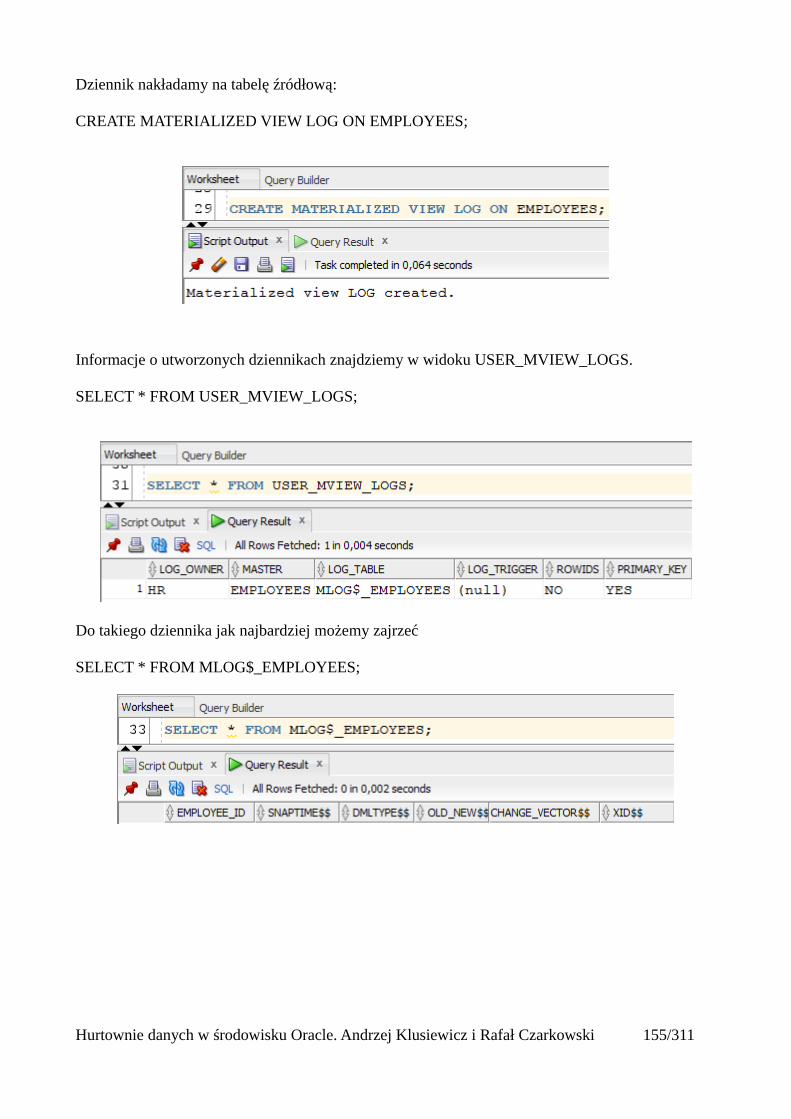
Dziennik nakładamy na tabelę źródłową:
CREATE MATERIALIZED VIEW LOG ON EMPLOYEES;
Informacje o utworzonych dziennikach znajdziemy w widoku USER_MVIEW_LOGS.
SELECT * FROM USER_MVIEW_LOGS;
Do takiego dziennika jak najbardziej możemy zajrzeć
SELECT * FROM MLOG$_EMPLOYEES;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 155/311
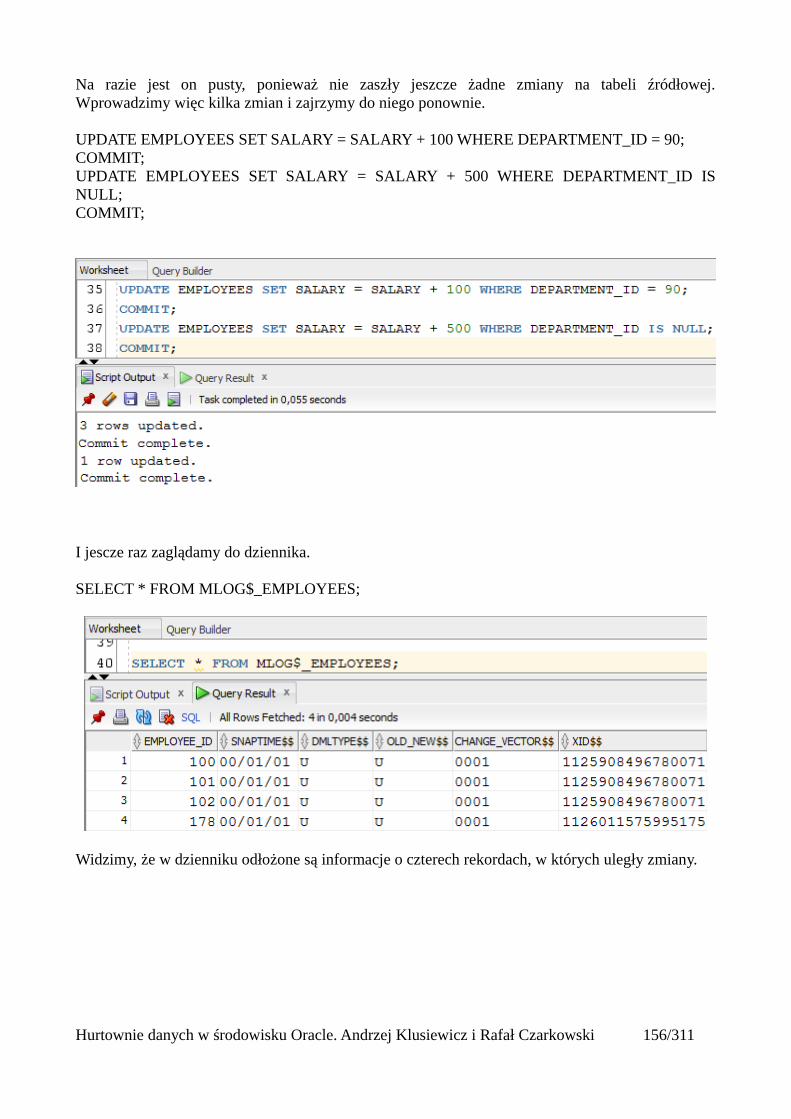
Na razie jest on pusty, ponieważ nie zaszły jeszcze żadne zmiany na tabeli źródłowej.Wprowadzimy więc kilka zmian i zajrzymy do niego ponownie.
UPDATE EMPLOYEES SET SALARY = SALARY + 100 WHERE DEPARTMENT_ID = 90;COMMIT;UPDATE EMPLOYEES SET SALARY = SALARY + 500 WHERE DEPARTMENT_ID ISNULL;COMMIT;
I jescze raz zaglądamy do dziennika.
SELECT * FROM MLOG$_EMPLOYEES;
Widzimy, że w dzienniku odłożone są informacje o czterech rekordach, w których uległy zmiany.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 156/311

Przy użyciu procedury REFRESH możemy też odświezyć kilka widoków na raz. Wystarczy nazwytych widoków podać jako pierwszy parametr, oddzielając je przecinkami, a nastepnie podaćinformację, w jaki sposób te widoki mają zostać odświeżone.
BEGINDBMS_MVIEW.REFRESH('WIDOK_ZMAT1,WIDOK_ZMAT2,WIDOK_ZMAT3','FC?');END;
W powyższym przykładzie WIDOK_ZMAT1 zostanie odświezony metodą FAST,WIDOK_ZMAT2 zostanie odświezony metodą COMPLETE, zaś WIDOK_ZMAT3 metodąFORCE.
Mamy równiez możliwość skorzystania z procedury REFRESH_ALL, która odświeży wszystkiewidoki zmaterializowane. Procedura ta nie przyjmuje żadnych parametrów i odświeża widoki jedenpo drugim.
EXECUTE DBMS.MVIEW.REFRESH_ALL;
Tworząc widoki zmaterializowane z myślą o ich późniejszym odświeżaniu, należy podaćinformację czy mają one bazować na wartościach kluczy głównych czy też na wartościachpseudokolumny RowID. Domyślnie, jeśli tego nie uwzględnimy będą bazowały na kluczachgłównych. Takie klucze oczywiście muszą istnieć na tabelach, na podstawie których tworzymywidoki zmaterializowane.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 157/311
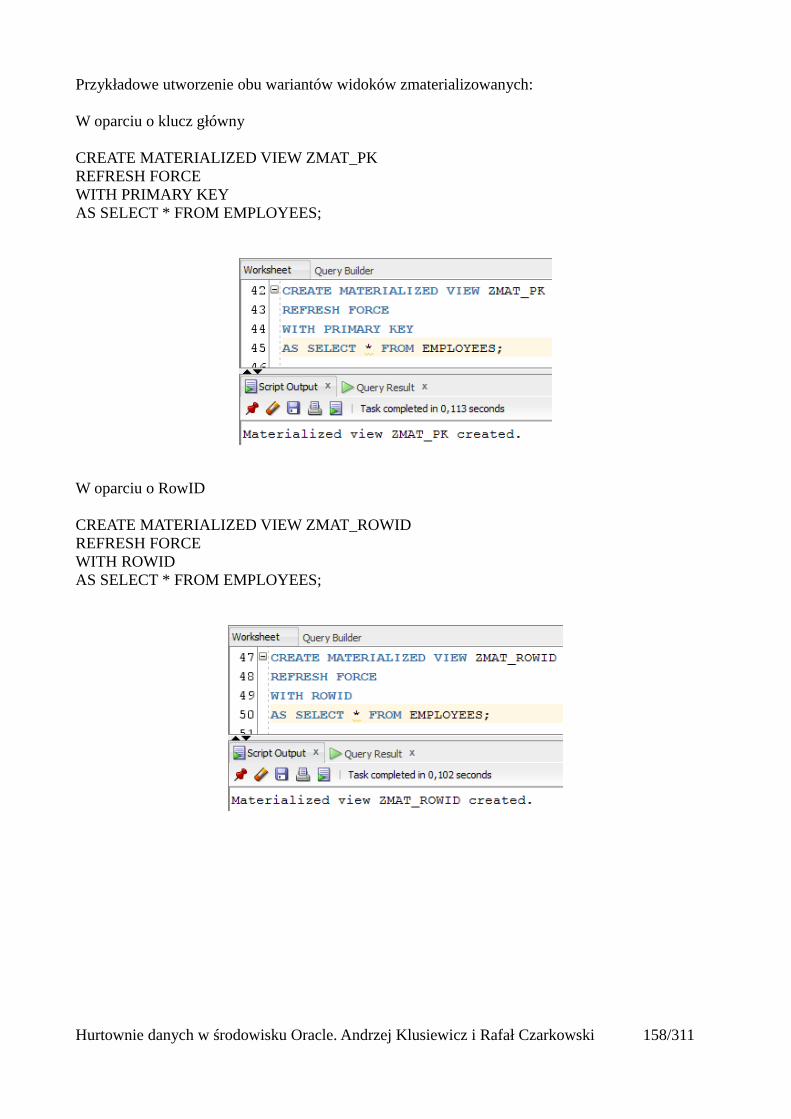
Przykładowe utworzenie obu wariantów widoków zmaterializowanych:
W oparciu o klucz główny
CREATE MATERIALIZED VIEW ZMAT_PKREFRESH FORCEWITH PRIMARY KEYAS SELECT * FROM EMPLOYEES;
W oparciu o RowID
CREATE MATERIALIZED VIEW ZMAT_ROWIDREFRESH FORCEWITH ROWIDAS SELECT * FROM EMPLOYEES;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 158/311
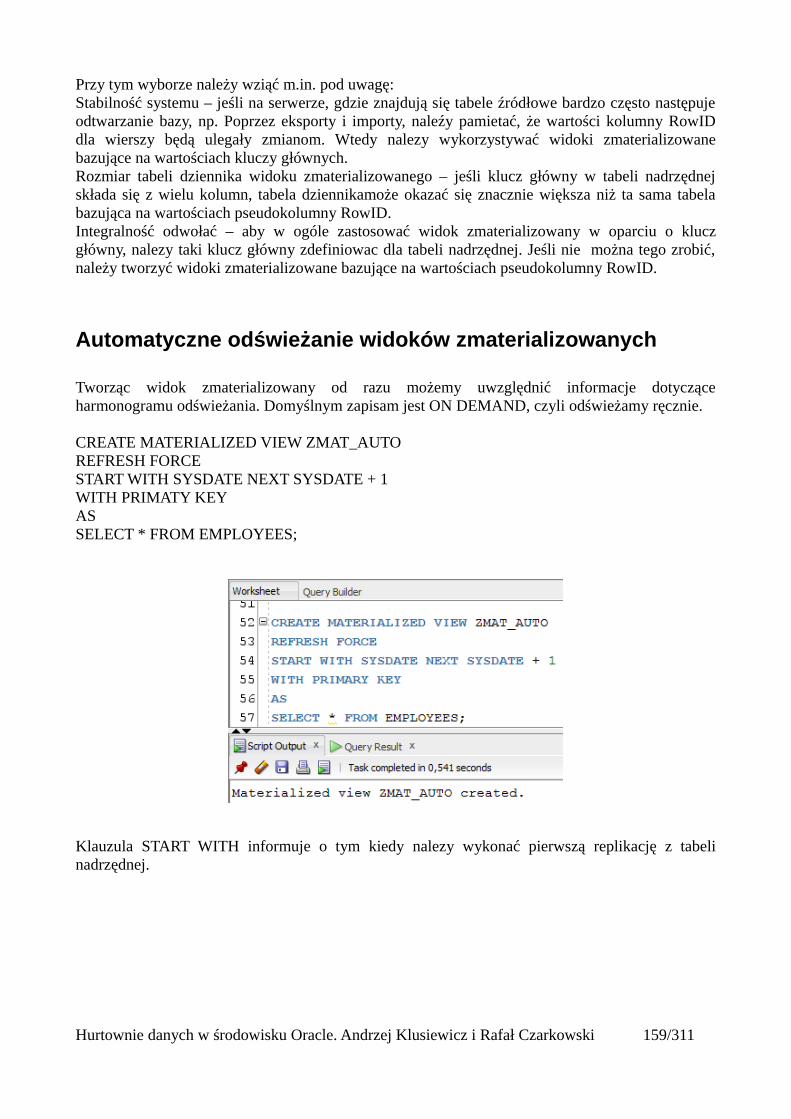
Przy tym wyborze należy wziąć m.in. pod uwagę:Stabilność systemu – jeśli na serwerze, gdzie znajdują się tabele źródłowe bardzo często następujeodtwarzanie bazy, np. Poprzez eksporty i importy, naleźy pamietać, że wartości kolumny RowIDdla wierszy będą ulegały zmianom. Wtedy nalezy wykorzystywać widoki zmaterializowanebazujące na wartościach kluczy głównych.Rozmiar tabeli dziennika widoku zmaterializowanego – jeśli klucz główny w tabeli nadrzędnejskłada się z wielu kolumn, tabela dziennikamoże okazać się znacznie większa niż ta sama tabelabazująca na wartościach pseudokolumny RowID.Integralność odwołać – aby w ogóle zastosować widok zmaterializowany w oparciu o kluczgłówny, nalezy taki klucz główny zdefiniowac dla tabeli nadrzędnej. Jeśli nie można tego zrobić,należy tworzyć widoki zmaterializowane bazujące na wartościach pseudokolumny RowID.
Automatyczne odświeżanie widoków zmaterializowanych
Tworząc widok zmaterializowany od razu możemy uwzględnić informacje dotycząceharmonogramu odświeżania. Domyślnym zapisam jest ON DEMAND, czyli odświeżamy ręcznie.
CREATE MATERIALIZED VIEW ZMAT_AUTOREFRESH FORCESTART WITH SYSDATE NEXT SYSDATE + 1WITH PRIMATY KEYASSELECT * FROM EMPLOYEES;
Klauzula START WITH informuje o tym kiedy nalezy wykonać pierwszą replikację z tabelinadrzędnej.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 159/311
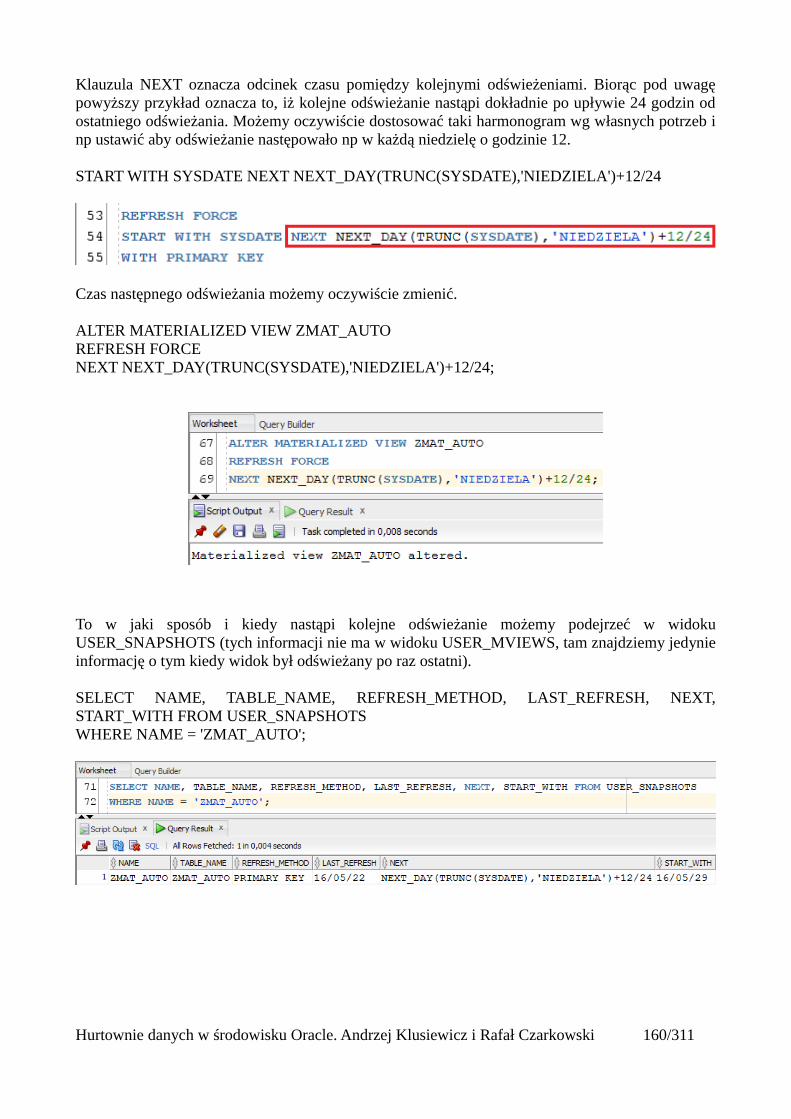
Klauzula NEXT oznacza odcinek czasu pomiędzy kolejnymi odświeżeniami. Biorąc pod uwagępowyższy przykład oznacza to, iż kolejne odświeżanie nastąpi dokładnie po upływie 24 godzin odostatniego odświeżania. Możemy oczywiście dostosować taki harmonogram wg własnych potrzeb inp ustawić aby odświeżanie następowało np w każdą niedzielę o godzinie 12.
START WITH SYSDATE NEXT NEXT_DAY(TRUNC(SYSDATE),'NIEDZIELA')+12/24
Czas następnego odświeżania możemy oczywiście zmienić.
ALTER MATERIALIZED VIEW ZMAT_AUTOREFRESH FORCENEXT NEXT_DAY(TRUNC(SYSDATE),'NIEDZIELA')+12/24;
To w jaki sposób i kiedy nastąpi kolejne odświeżanie możemy podejrzeć w widokuUSER_SNAPSHOTS (tych informacji nie ma w widoku USER_MVIEWS, tam znajdziemy jedynieinformację o tym kiedy widok był odświeżany po raz ostatni).
SELECT NAME, TABLE_NAME, REFRESH_METHOD, LAST_REFRESH, NEXT,START_WITH FROM USER_SNAPSHOTSWHERE NAME = 'ZMAT_AUTO';
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 160/311
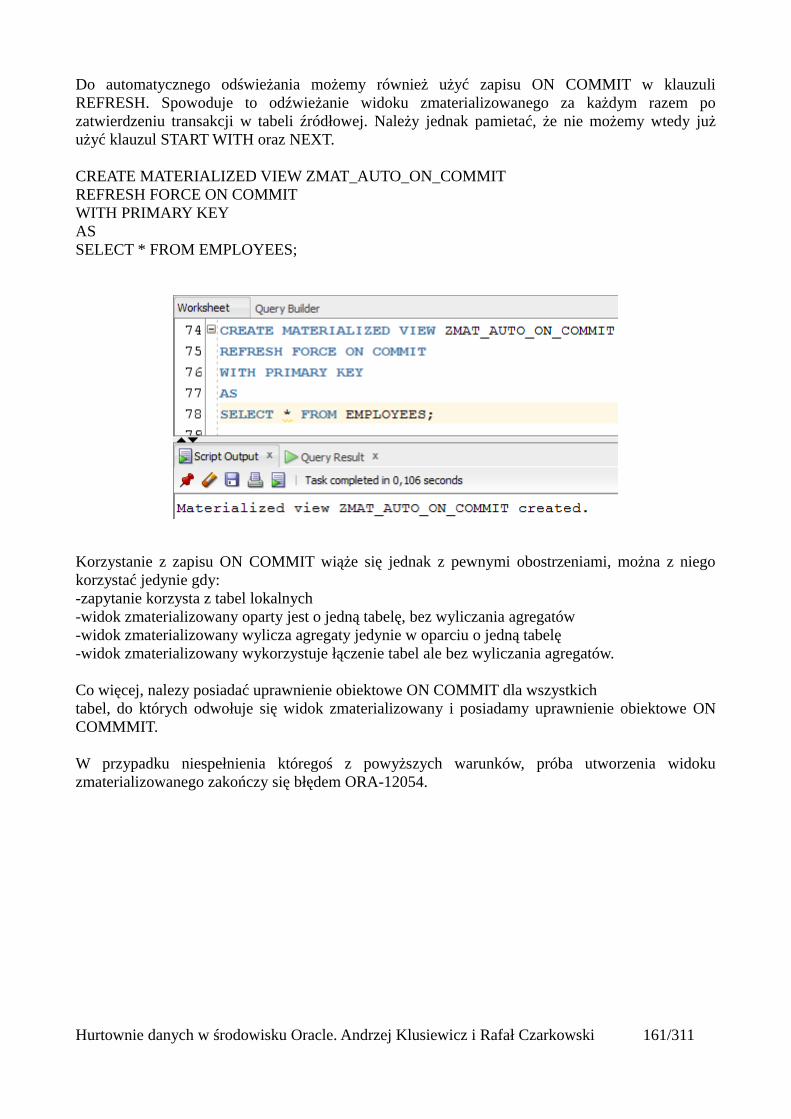
Do automatycznego odświeżania możemy również użyć zapisu ON COMMIT w klauzuliREFRESH. Spowoduje to odźwieżanie widoku zmaterializowanego za każdym razem pozatwierdzeniu transakcji w tabeli źródłowej. Należy jednak pamietać, że nie możemy wtedy jużużyć klauzul START WITH oraz NEXT.
CREATE MATERIALIZED VIEW ZMAT_AUTO_ON_COMMITREFRESH FORCE ON COMMITWITH PRIMARY KEYASSELECT * FROM EMPLOYEES;
Korzystanie z zapisu ON COMMIT wiąże się jednak z pewnymi obostrzeniami, można z niegokorzystać jedynie gdy:-zapytanie korzysta z tabel lokalnych-widok zmaterializowany oparty jest o jedną tabelę, bez wyliczania agregatów-widok zmaterializowany wylicza agregaty jedynie w oparciu o jedną tabelę-widok zmaterializowany wykorzystuje łączenie tabel ale bez wyliczania agregatów.
Co więcej, nalezy posiadać uprawnienie obiektowe ON COMMIT dla wszystkichtabel, do których odwołuje się widok zmaterializowany i posiadamy uprawnienie obiektowe ONCOMMMIT.
W przypadku niespełnienia któregoś z powyższych warunków, próba utworzenia widokuzmaterializowanego zakończy się błędem ORA-12054.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 161/311
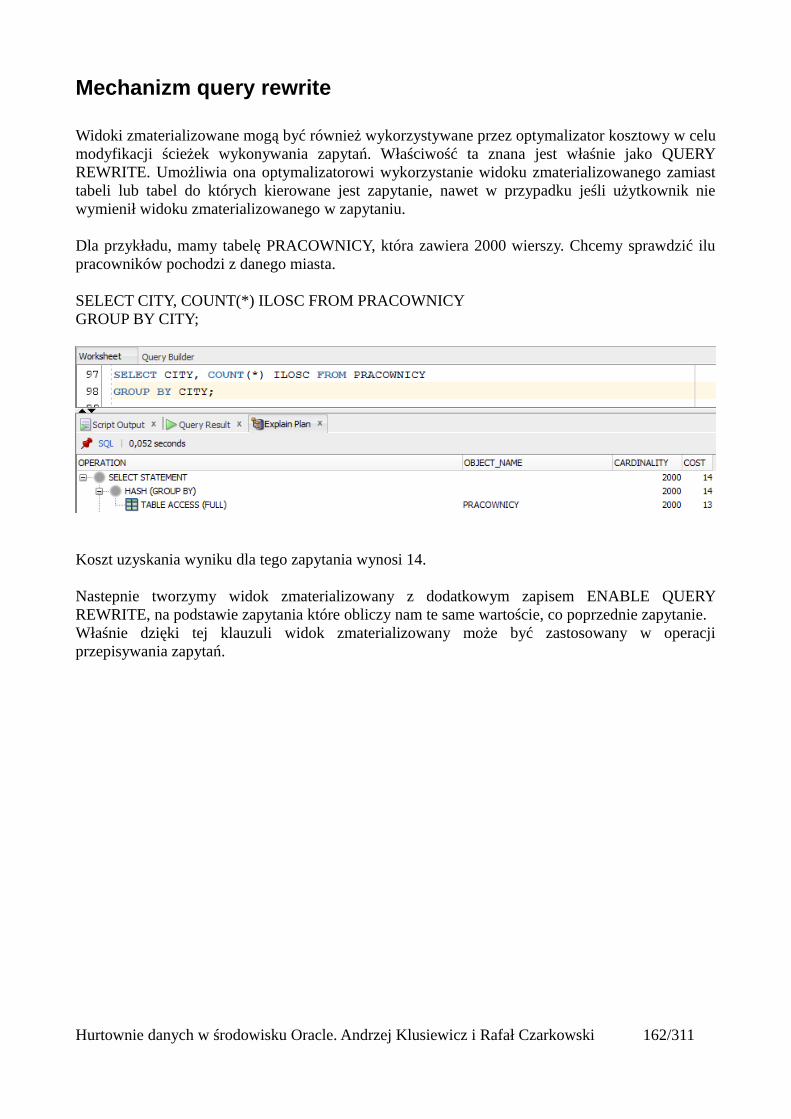
Mechanizm query rewrite
Widoki zmaterializowane mogą być również wykorzystywane przez optymalizator kosztowy w celumodyfikacji ścieżek wykonywania zapytań. Właściwość ta znana jest właśnie jako QUERYREWRITE. Umożliwia ona optymalizatorowi wykorzystanie widoku zmaterializowanego zamiasttabeli lub tabel do których kierowane jest zapytanie, nawet w przypadku jeśli użytkownik niewymienił widoku zmaterializowanego w zapytaniu.
Dla przykładu, mamy tabelę PRACOWNICY, która zawiera 2000 wierszy. Chcemy sprawdzić ilupracowników pochodzi z danego miasta.
SELECT CITY, COUNT(*) ILOSC FROM PRACOWNICYGROUP BY CITY;
Koszt uzyskania wyniku dla tego zapytania wynosi 14.
Nastepnie tworzymy widok zmaterializowany z dodatkowym zapisem ENABLE QUERYREWRITE, na podstawie zapytania które obliczy nam te same wartoście, co poprzednie zapytanie.Właśnie dzięki tej klauzuli widok zmaterializowany może być zastosowany w operacjiprzepisywania zapytań.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 162/311
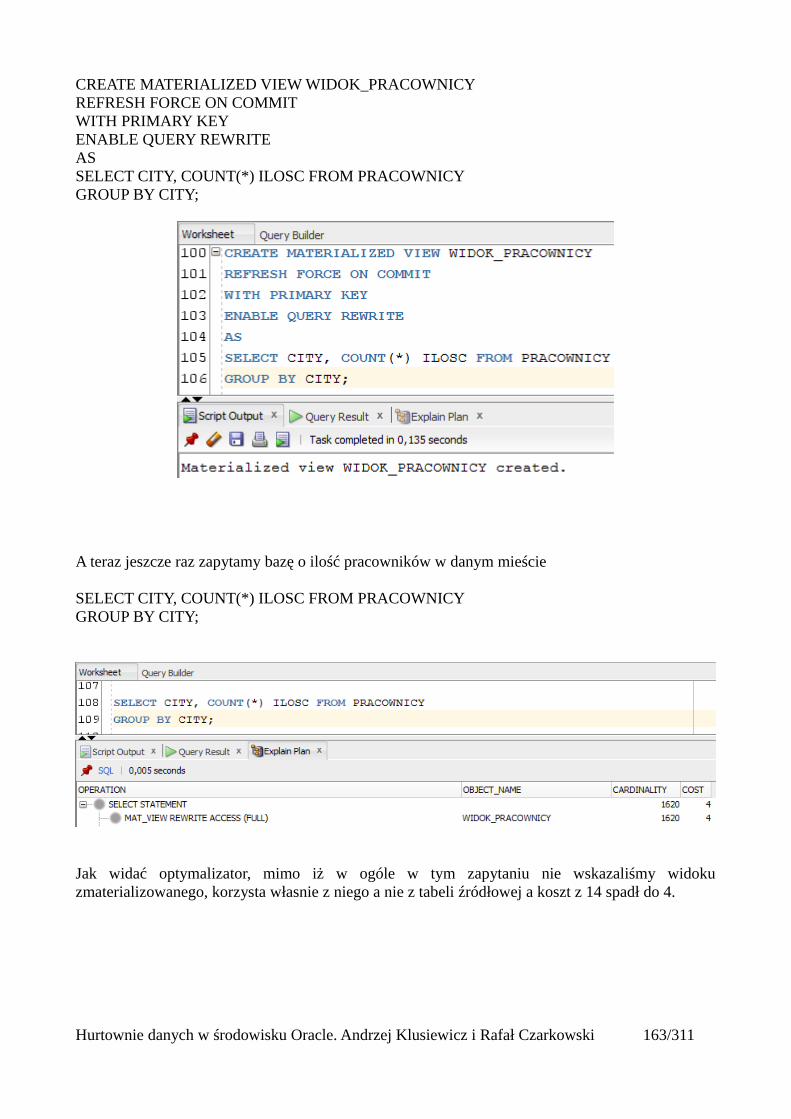
CREATE MATERIALIZED VIEW WIDOK_PRACOWNICYREFRESH FORCE ON COMMITWITH PRIMARY KEYENABLE QUERY REWRITEASSELECT CITY, COUNT(*) ILOSC FROM PRACOWNICYGROUP BY CITY;
A teraz jeszcze raz zapytamy bazę o ilość pracowników w danym mieście
SELECT CITY, COUNT(*) ILOSC FROM PRACOWNICYGROUP BY CITY;
Jak widać optymalizator, mimo iż w ogóle w tym zapytaniu nie wskazaliśmy widokuzmaterializowanego, korzysta własnie z niego a nie z tabeli źródłowej a koszt z 14 spadł do 4.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 163/311
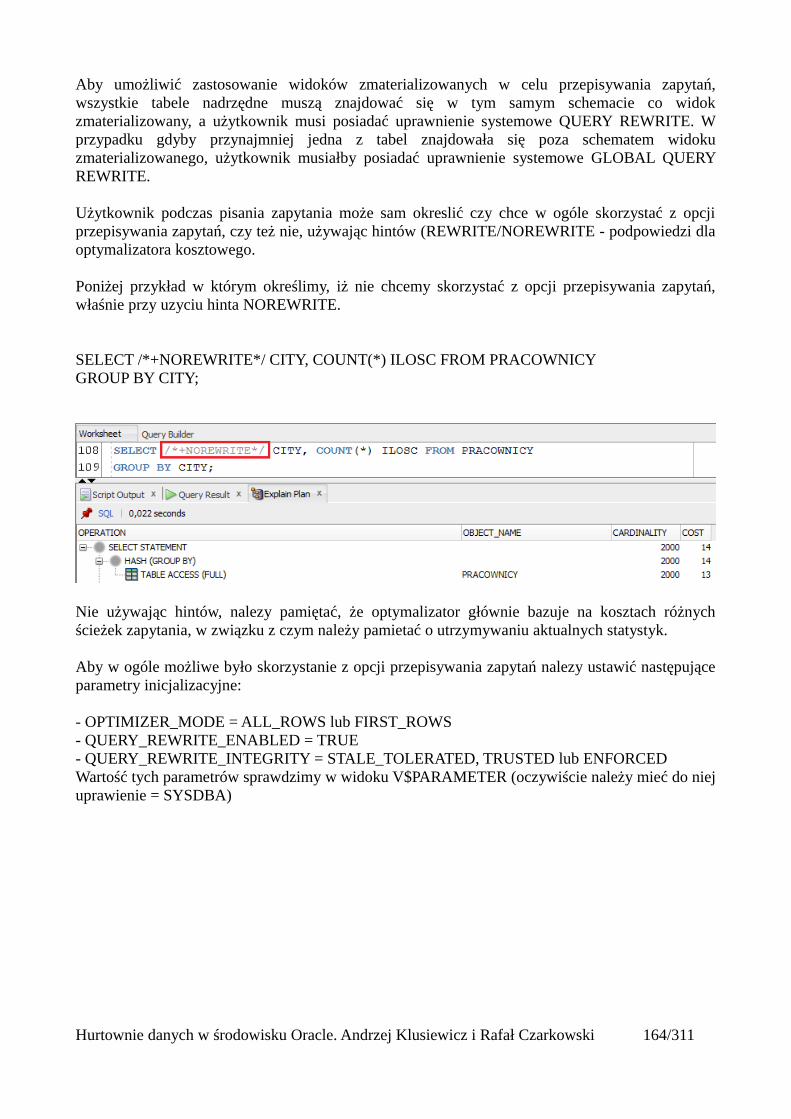
Aby umożliwić zastosowanie widoków zmaterializowanych w celu przepisywania zapytań,wszystkie tabele nadrzędne muszą znajdować się w tym samym schemacie co widokzmaterializowany, a użytkownik musi posiadać uprawnienie systemowe QUERY REWRITE. Wprzypadku gdyby przynajmniej jedna z tabel znajdowała się poza schematem widokuzmaterializowanego, użytkownik musiałby posiadać uprawnienie systemowe GLOBAL QUERYREWRITE.
Użytkownik podczas pisania zapytania może sam okreslić czy chce w ogóle skorzystać z opcjiprzepisywania zapytań, czy też nie, używając hintów (REWRITE/NOREWRITE - podpowiedzi dlaoptymalizatora kosztowego.
Poniżej przykład w którym określimy, iż nie chcemy skorzystać z opcji przepisywania zapytań,właśnie przy uzyciu hinta NOREWRITE.
SELECT /*+NOREWRITE*/ CITY, COUNT(*) ILOSC FROM PRACOWNICYGROUP BY CITY;
Nie używając hintów, nalezy pamiętać, że optymalizator głównie bazuje na kosztach różnychścieżek zapytania, w związku z czym należy pamietać o utrzymywaniu aktualnych statystyk.
Aby w ogóle możliwe było skorzystanie z opcji przepisywania zapytań nalezy ustawić następująceparametry inicjalizacyjne:
- OPTIMIZER_MODE = ALL_ROWS lub FIRST_ROWS- QUERY_REWRITE_ENABLED = TRUE- QUERY_REWRITE_INTEGRITY = STALE_TOLERATED, TRUSTED lub ENFORCEDWartość tych parametrów sprawdzimy w widoku V$PARAMETER (oczywiście należy mieć do niejuprawienie = SYSDBA)
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 164/311

SELECT NAME, VALUE FROM V$PARAMETERWHERE NAME IN ('optimizer_mode','query_rewrite_enabled','query_rewrite_integrity');
Domyślnie parametr QUERY_REWRITE_INTEGRITY jest ustawiony na ENFORCED. W tymtrybie muszą być sprawdzone wszelkie ograniczenia. Optymalizator wykorzystuje tylko dane zwidoków zmaterializowanychoraz tylko te relacje, które bazują na ograniczeniach ENABLEDVALIDATED primary, unique lub foreign key. W trybie TRUSTED optymalizator przyjmuje, żedane w widoku zmaterializowanym są aktualne oraz że relacje zadeklarowane w wymiarach iograniczeniach są poprawne. W trybie STALE_TOLERATED optymalizator wykorzystuje widokizmaterializowane ze świeżymi danymi oraz te kóre są poprawne, ale zawierają nieodświeżone dane.Możemy również ustawić wartość tego parametru na FORCE, wtedy optymalizator będzieprzepisywał zapytania w celu skorzystania z widoku zmaterializowanego nawet w przypadku, jeślikoszt oryginalnego zapytania będzie niższy.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 165/311

Tabele partycjonowane
Wraz ze wzrostem ilości wierszy w tabeli, spada wydajność systemu i rośnie czas potrzebny nazarządzanie nią. Coraz dłużej trwa wykonanie kopii zapasowej takiej tabeli, odtworzenie jej, jakrównież zapytania obejmujące całą tabelę będą trwały coraz dłużej. Problemy związane zwydajnością dużych tabel, jak i zarządzanie nimi mozna zmniejszyć, dzieląc tabelę na kilka części.Taka operacja zwana jest właśnie partycjonowaniem. Tabelę nazywamy wtedy tabeląpartycjonowaną, a jej części partycjami. Dzięki takiemu zabiegowi wydajność zapytań odnoszących się do tabeli może ulec poprawie,ponieważ nie będzie potrzeby przeszukania całej tabeli, a tylko jej jednej lub kilku części (partycji).Przy wykonaniu zapytania, optymalizator kosztowy sam będzie "wiedział" do ilu partycji będziepotrzebował "zajrzeć" aby dostać się do wymaganych danych.
Tworzenie tabeli partycjonowanej
Aby utworzyć tabelę partycjonowaną, nalezy przy poleceniu "create table" użyć klauzuli "partitionby" i zdefiniować w jaki sposób chcemy podzielić wiersze w tej tabeli na partycje. Mamymożliwość utworzenia tabeli partycjonowanej względem kluczy: - range partitioning (dane są mapowane do partycji w oparciu o zakresy wartości), - list partitioning (dane są mapowane na podstawie listy dyskretnych wartości), - hash partitioning (dane mapowane na podstawie wyliczeń Hash na kluczu partycjonowania –inaczej zwany partycjonowaniem mieszającym).
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 166/311
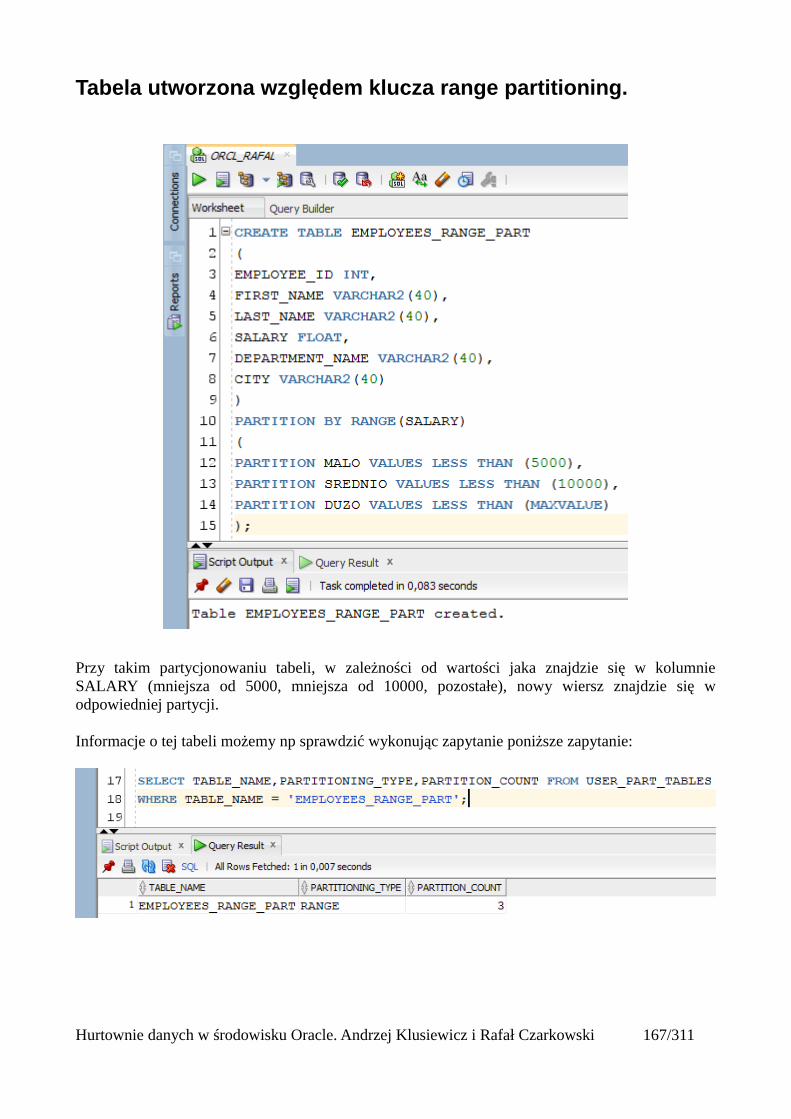
Tabela utworzona względem klucza range partitioning.
Przy takim partycjonowaniu tabeli, w zależności od wartości jaka znajdzie się w kolumnieSALARY (mniejsza od 5000, mniejsza od 10000, pozostałe), nowy wiersz znajdzie się wodpowiedniej partycji.
Informacje o tej tabeli możemy np sprawdzić wykonując zapytanie poniższe zapytanie:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 167/311
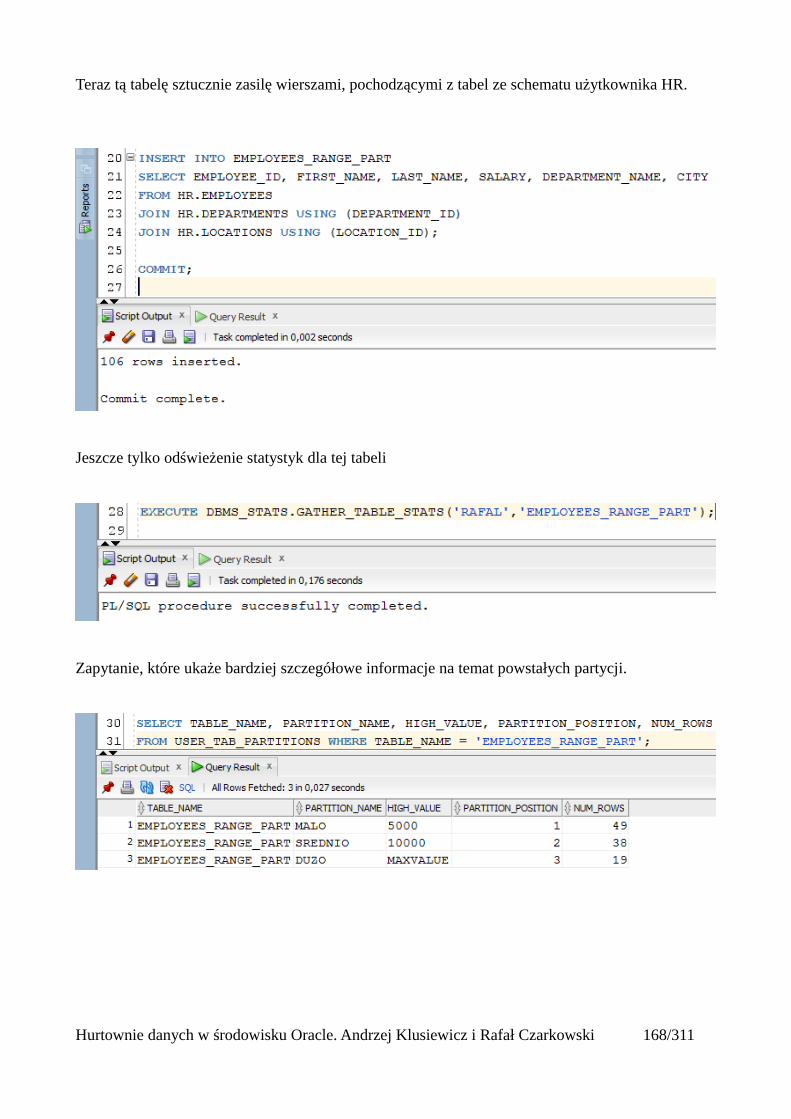
Teraz tą tabelę sztucznie zasilę wierszami, pochodzącymi z tabel ze schematu użytkownika HR.
Jeszcze tylko odświeżenie statystyk dla tej tabeli
Zapytanie, które ukaże bardziej szczegółowe informacje na temat powstałych partycji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 168/311

Tabela utworzona względem klucza list partitioning.
W tym przypadku, to w której partycji wyląduje dany wiersz zależy od wartości w kolumnie CITY.Jeśli np. nie będzie to żadne z wymienionych przez nas miast, przy tworzeniu partycji, to wtedy takirekord znajdzie się w ostatniej partycji poprzez zastosowanie klauzuli DEFAULT.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 169/311
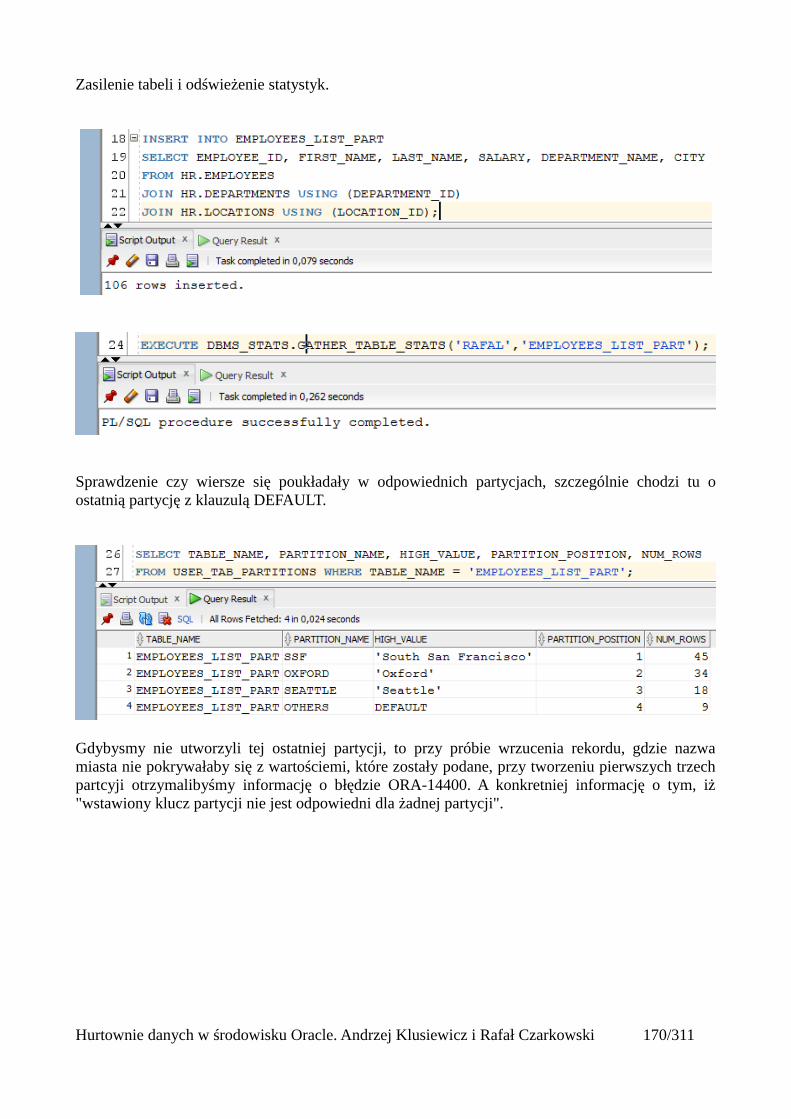
Zasilenie tabeli i odświeżenie statystyk.
Sprawdzenie czy wiersze się poukładały w odpowiednich partycjach, szczególnie chodzi tu oostatnią partycję z klauzulą DEFAULT.
Gdybysmy nie utworzyli tej ostatniej partycji, to przy próbie wrzucenia rekordu, gdzie nazwamiasta nie pokrywałaby się z wartościemi, które zostały podane, przy tworzeniu pierwszych trzechpartcyji otrzymalibyśmy informację o błędzie ORA-14400. A konkretniej informację o tym, iż"wstawiony klucz partycji nie jest odpowiedni dla żadnej partycji".
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 170/311
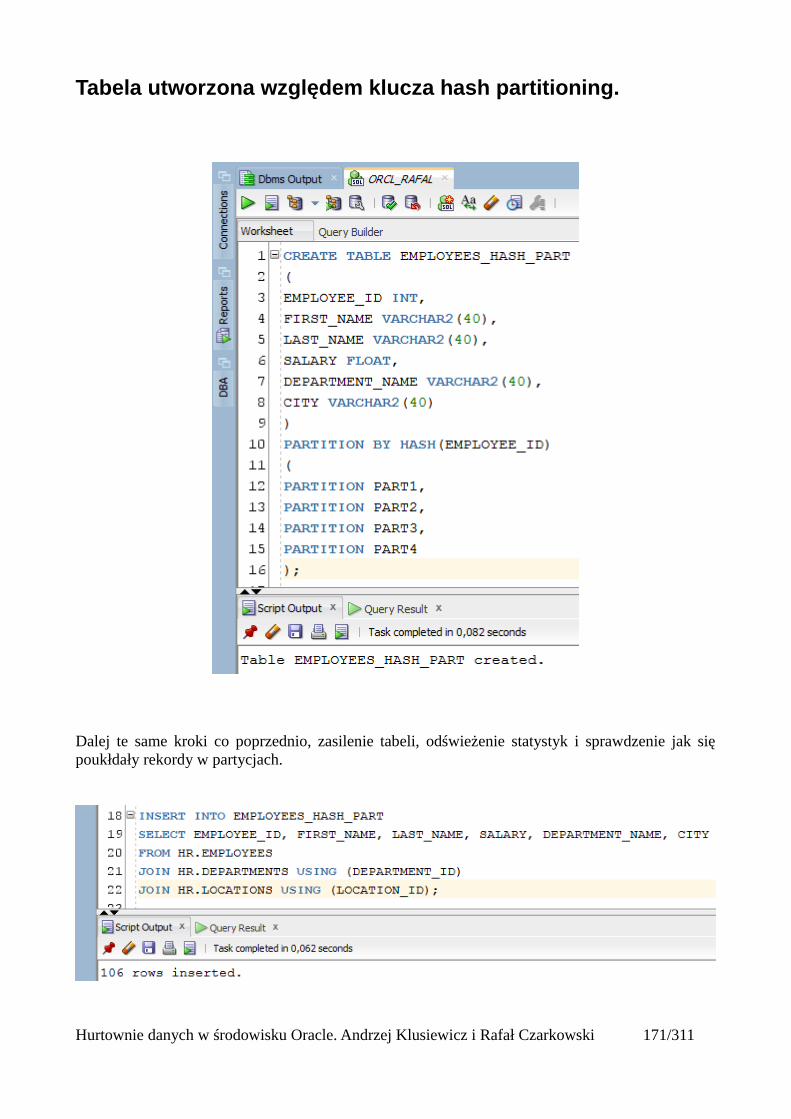
Tabela utworzona względem klucza hash partitioning.
Dalej te same kroki co poprzednio, zasilenie tabeli, odświeżenie statystyk i sprawdzenie jak siępoukłdały rekordy w partycjach.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 171/311
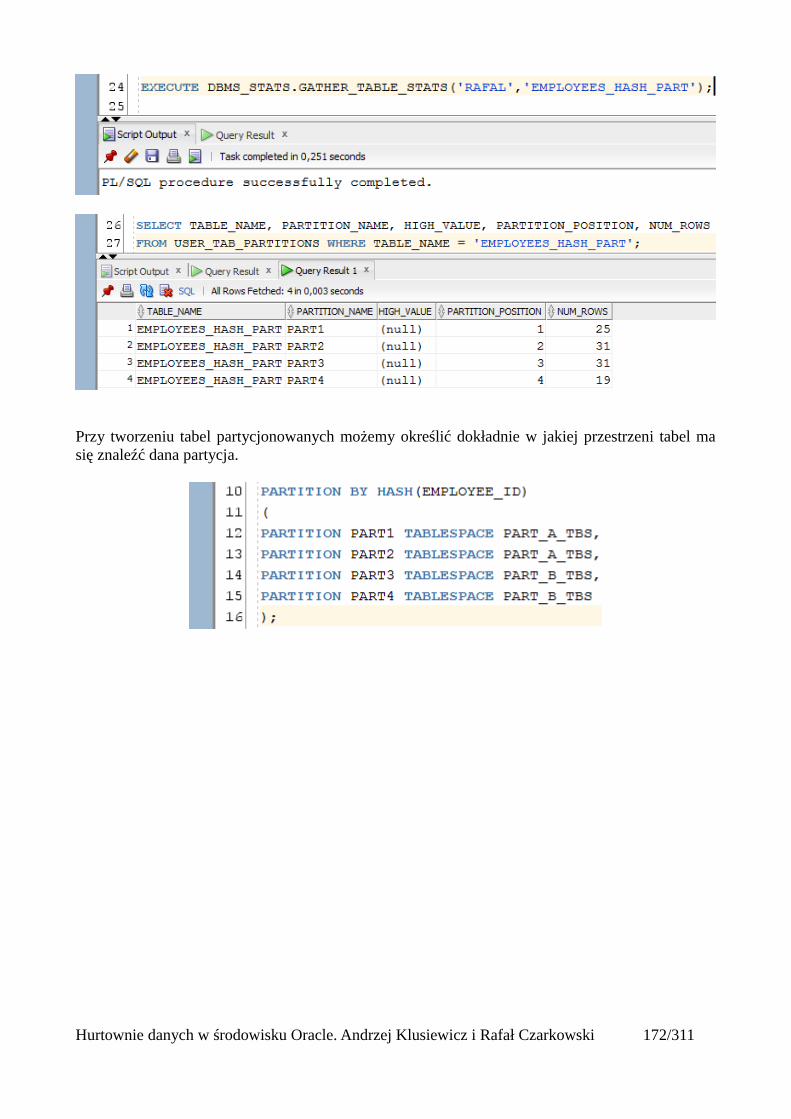
Przy tworzeniu tabel partycjonowanych możemy określić dokładnie w jakiej przestrzeni tabel masię znaleźć dana partycja.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 172/311
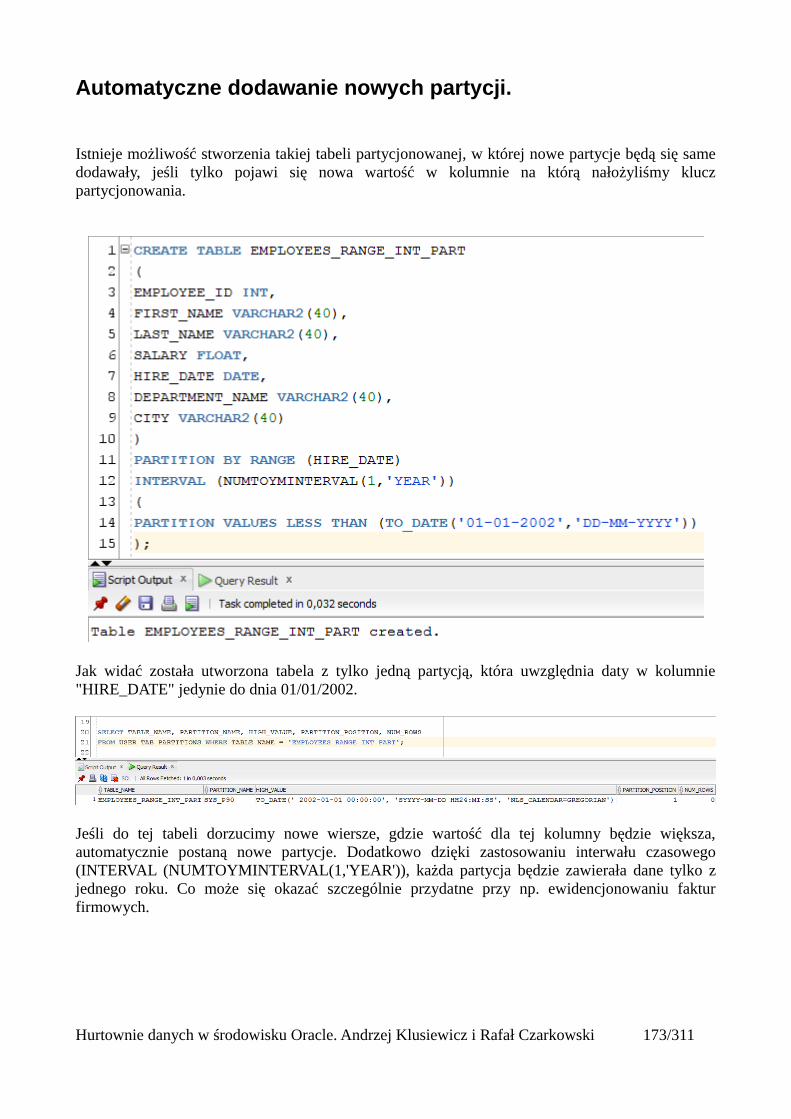
Automatyczne dodawanie nowych partycji.
Istnieje możliwość stworzenia takiej tabeli partycjonowanej, w której nowe partycje będą się samedodawały, jeśli tylko pojawi się nowa wartość w kolumnie na którą nałożyliśmy kluczpartycjonowania.
Jak widać została utworzona tabela z tylko jedną partycją, która uwzględnia daty w kolumnie"HIRE_DATE" jedynie do dnia 01/01/2002.
Jeśli do tej tabeli dorzucimy nowe wiersze, gdzie wartość dla tej kolumny będzie większa,automatycznie postaną nowe partycje. Dodatkowo dzięki zastosowaniu interwału czasowego(INTERVAL (NUMTOYMINTERVAL(1,'YEAR')), każda partycja będzie zawierała dane tylko zjednego roku. Co może się okazać szczególnie przydatne przy np. ewidencjonowaniu fakturfirmowych.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 173/311
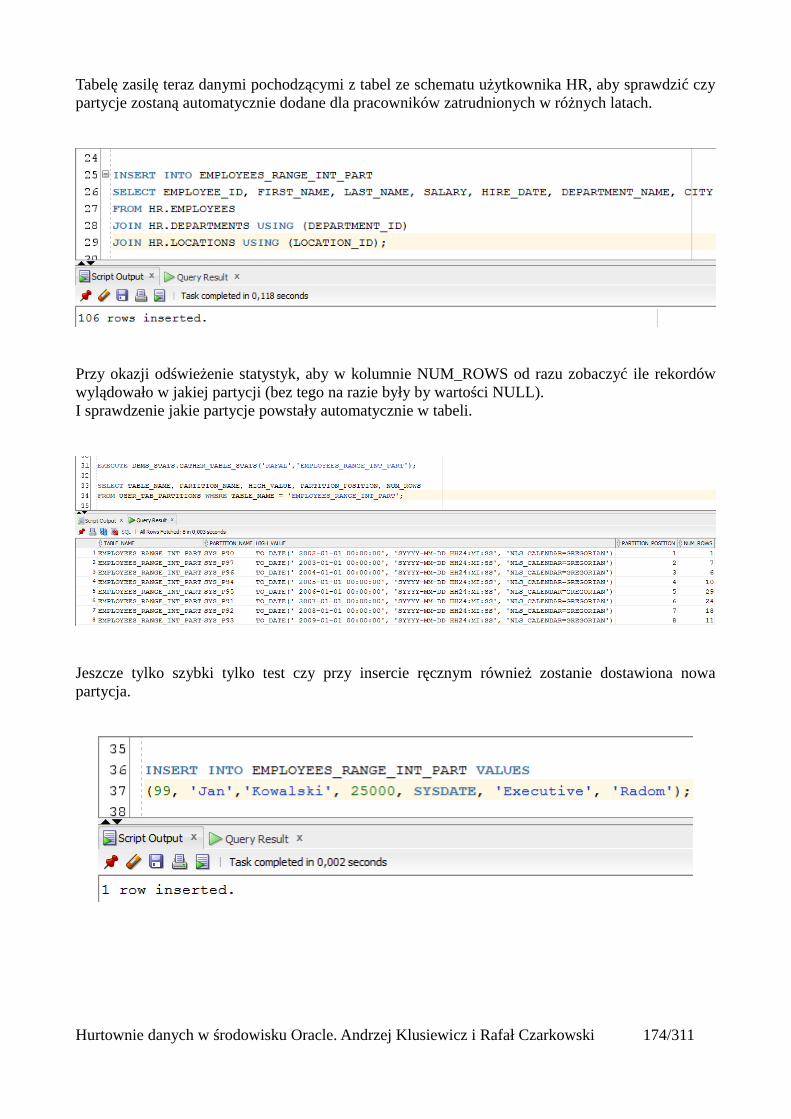
Tabelę zasilę teraz danymi pochodzącymi z tabel ze schematu użytkownika HR, aby sprawdzić czypartycje zostaną automatycznie dodane dla pracowników zatrudnionych w różnych latach.
Przy okazji odświeżenie statystyk, aby w kolumnie NUM_ROWS od razu zobaczyć ile rekordówwylądowało w jakiej partycji (bez tego na razie były by wartości NULL).I sprawdzenie jakie partycje powstały automatycznie w tabeli.
Jeszcze tylko szybki tylko test czy przy insercie ręcznym również zostanie dostawiona nowapartycja.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 174/311

Jak widać, doszła jeszcze jedna partycja, dla tego pojedynczego rekordu.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 175/311
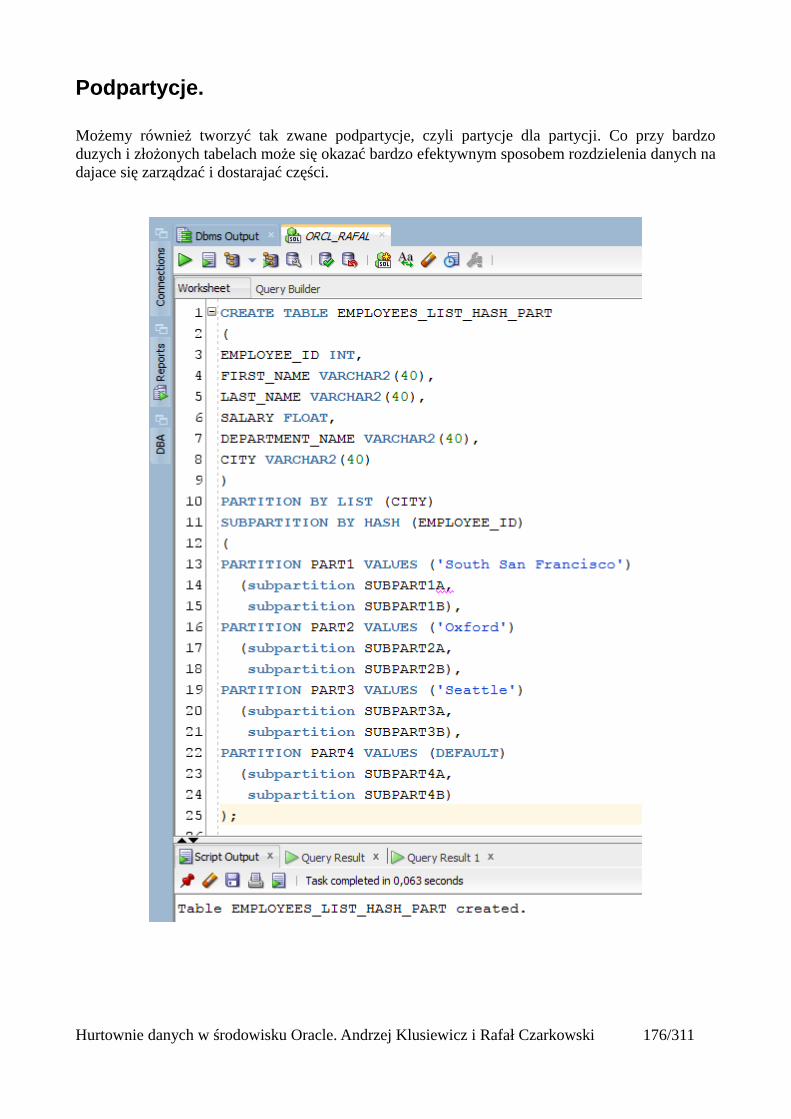
Podpartycje.
Możemy również tworzyć tak zwane podpartycje, czyli partycje dla partycji. Co przy bardzoduzych i złożonych tabelach może się okazać bardzo efektywnym sposobem rozdzielenia danych nadajace się zarządzać i dostarajać części.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 176/311
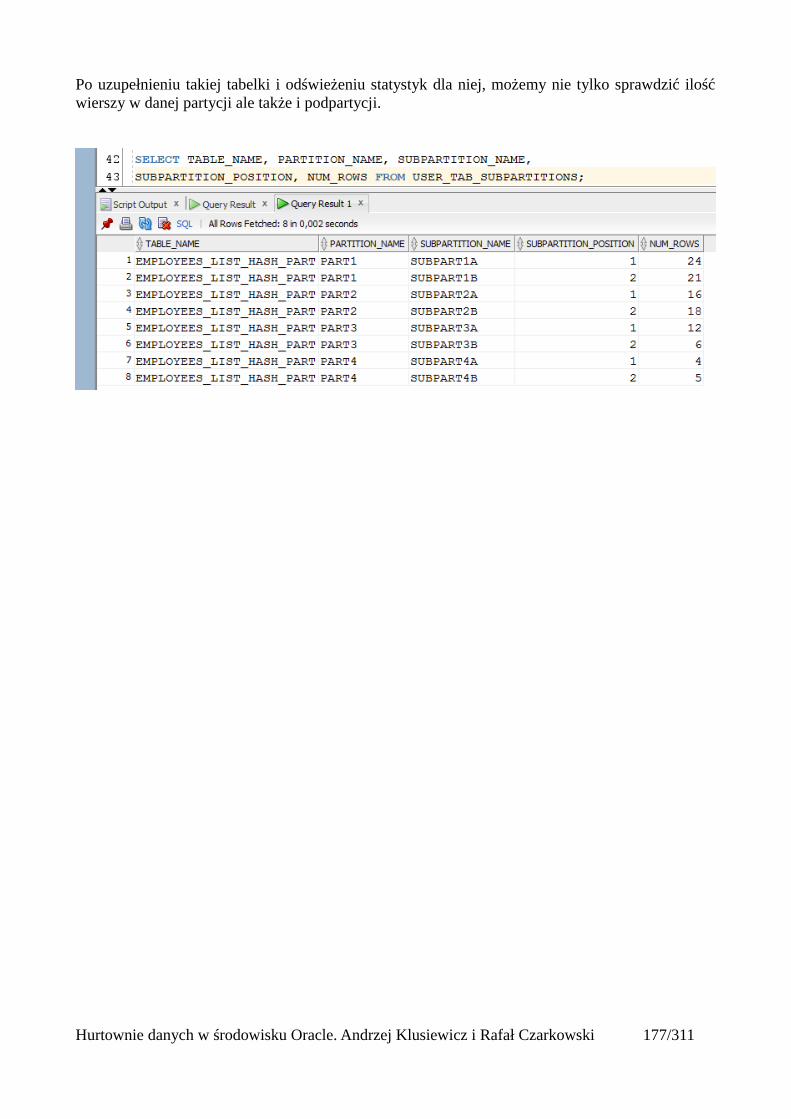
Po uzupełnieniu takiej tabelki i odświeżeniu statystyk dla niej, możemy nie tylko sprawdzić ilośćwierszy w danej partycji ale także i podpartycji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 177/311
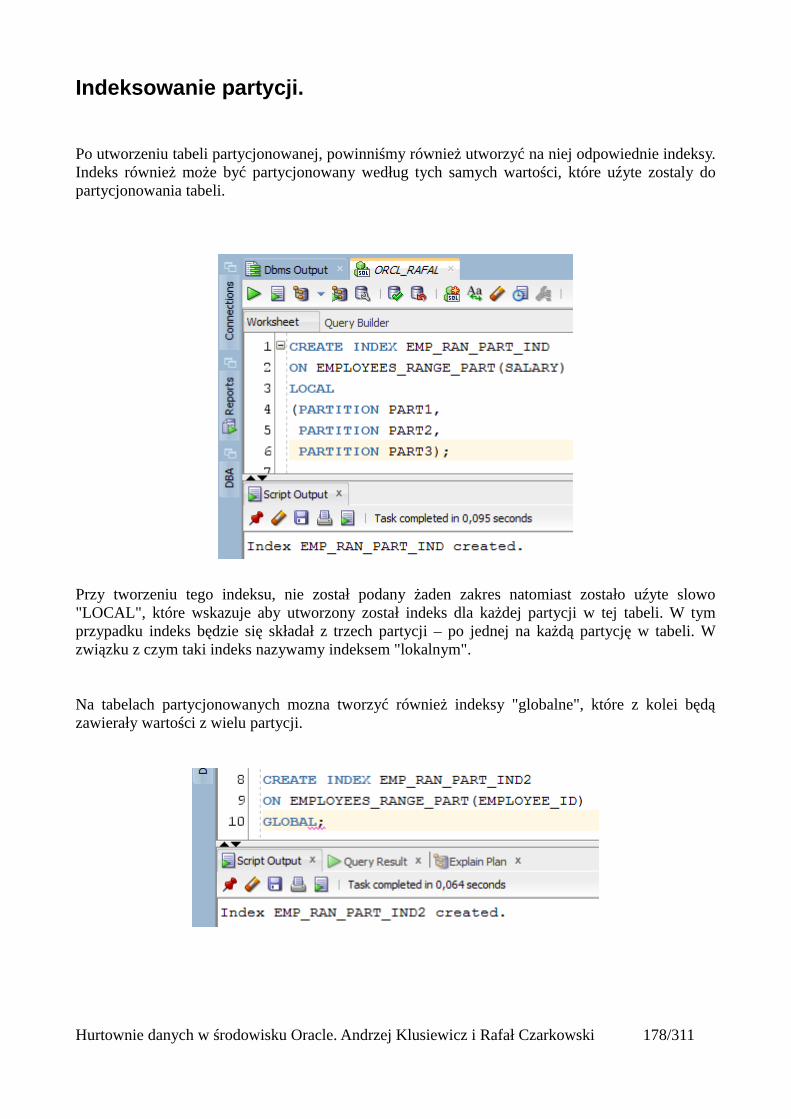
Indeksowanie partycji.
Po utworzeniu tabeli partycjonowanej, powinniśmy również utworzyć na niej odpowiednie indeksy.Indeks również może być partycjonowany według tych samych wartości, które uźyte zostaly dopartycjonowania tabeli.
Przy tworzeniu tego indeksu, nie został podany żaden zakres natomiast zostało uźyte slowo"LOCAL", które wskazuje aby utworzony został indeks dla każdej partycji w tej tabeli. W tymprzypadku indeks będzie się składał z trzech partycji – po jednej na każdą partycję w tabeli. Wzwiązku z czym taki indeks nazywamy indeksem "lokalnym".
Na tabelach partycjonowanych mozna tworzyć również indeksy "globalne", które z kolei będązawierały wartości z wielu partycji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 178/311
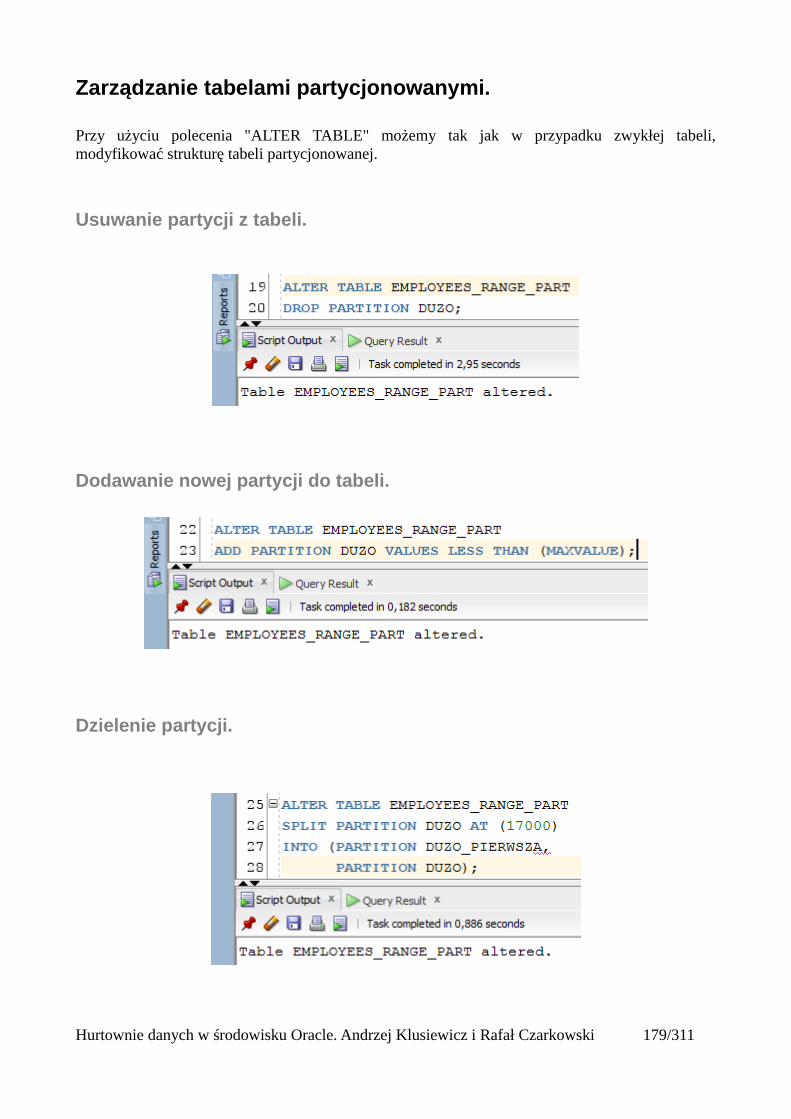
Zarządzanie tabelami partycjonowanymi.
Przy użyciu polecenia "ALTER TABLE" możemy tak jak w przypadku zwykłej tabeli,modyfikować strukturę tabeli partycjonowanej.
Usuwanie partycji z tabeli.
Dodawanie nowej partycji do tabeli.
Dzielenie partycji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 179/311
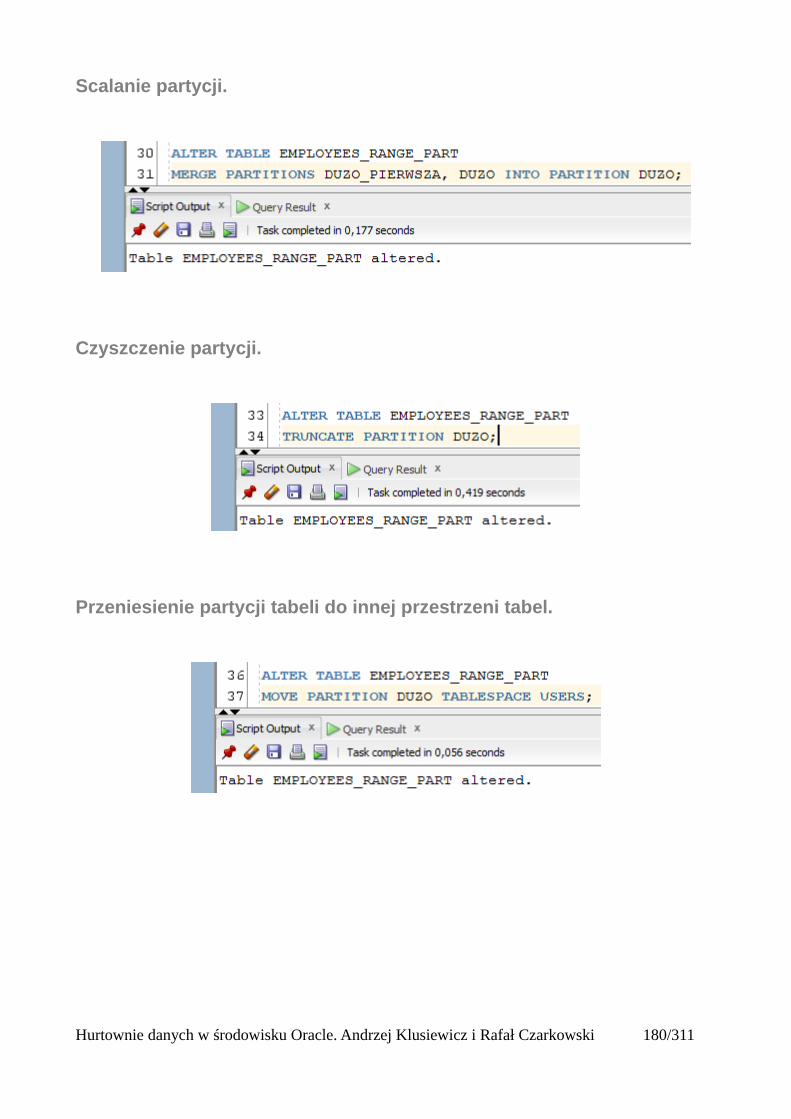
Scalanie partycji.
Czyszczenie partycji.
Przeniesienie partycji tabeli do innej przestrzeni tabel.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 180/311
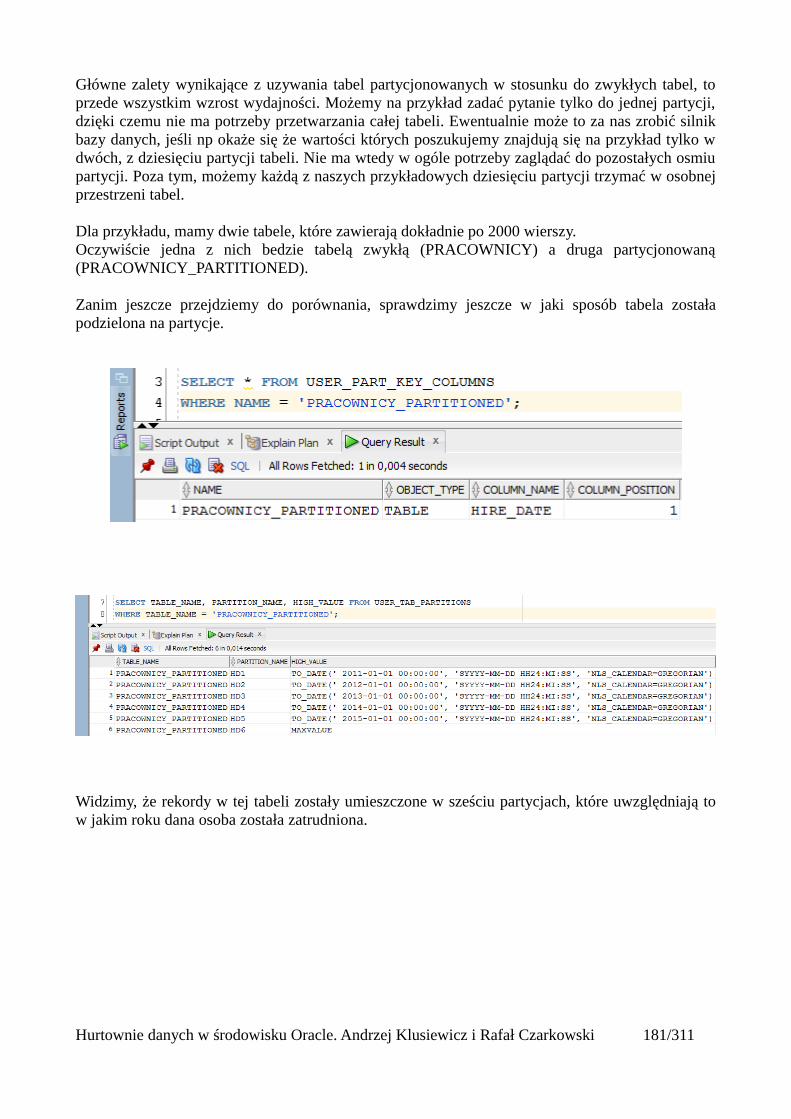
Główne zalety wynikające z uzywania tabel partycjonowanych w stosunku do zwykłych tabel, toprzede wszystkim wzrost wydajności. Możemy na przykład zadać pytanie tylko do jednej partycji,dzięki czemu nie ma potrzeby przetwarzania całej tabeli. Ewentualnie może to za nas zrobić silnikbazy danych, jeśli np okaże się że wartości których poszukujemy znajdują się na przykład tylko wdwóch, z dziesięciu partycji tabeli. Nie ma wtedy w ogóle potrzeby zaglądać do pozostałych osmiupartycji. Poza tym, możemy każdą z naszych przykładowych dziesięciu partycji trzymać w osobnejprzestrzeni tabel.
Dla przykładu, mamy dwie tabele, które zawierają dokładnie po 2000 wierszy. Oczywiście jedna z nich bedzie tabelą zwykłą (PRACOWNICY) a druga partycjonowaną(PRACOWNICY_PARTITIONED).
Zanim jeszcze przejdziemy do porównania, sprawdzimy jeszcze w jaki sposób tabela zostałapodzielona na partycje.
Widzimy, że rekordy w tej tabeli zostały umieszczone w sześciu partycjach, które uwzględniają tow jakim roku dana osoba została zatrudniona.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 181/311
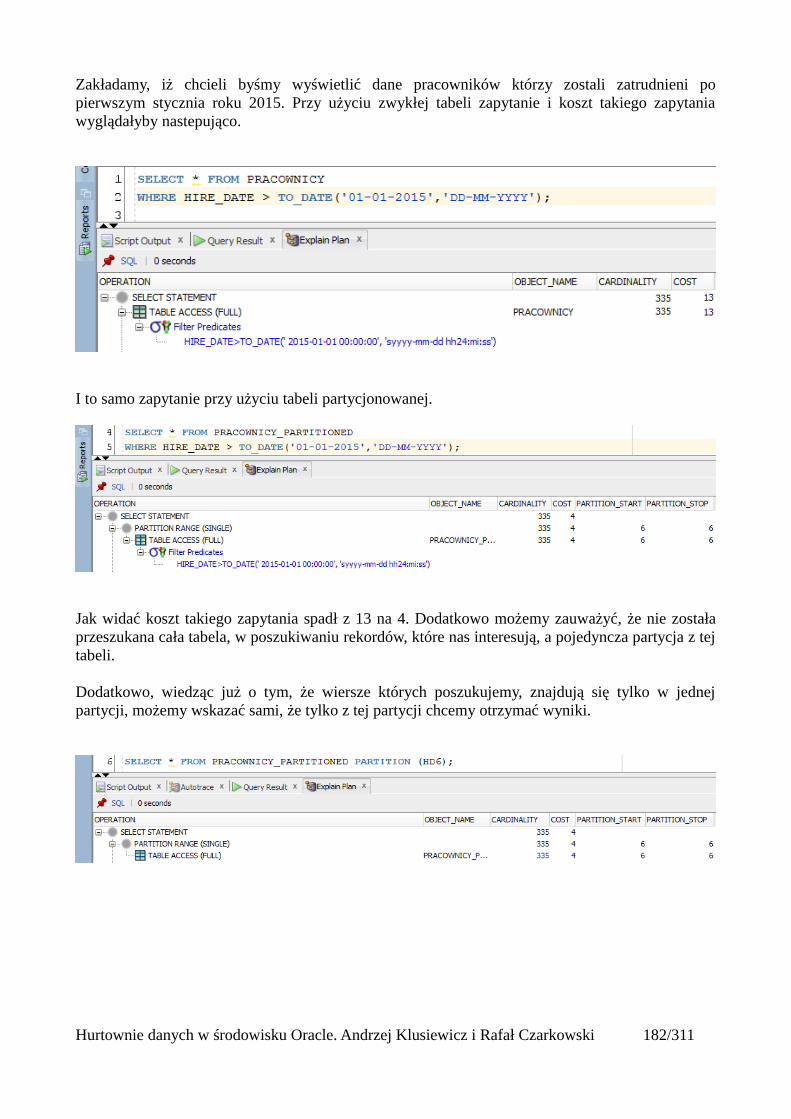
Zakładamy, iż chcieli byśmy wyświetlić dane pracowników którzy zostali zatrudnieni popierwszym stycznia roku 2015. Przy użyciu zwykłej tabeli zapytanie i koszt takiego zapytaniawyglądałyby nastepująco.
I to samo zapytanie przy użyciu tabeli partycjonowanej.
Jak widać koszt takiego zapytania spadł z 13 na 4. Dodatkowo możemy zauważyć, że nie zostałaprzeszukana cała tabela, w poszukiwaniu rekordów, które nas interesują, a pojedyncza partycja z tejtabeli.
Dodatkowo, wiedząc już o tym, że wiersze których poszukujemy, znajdują się tylko w jednejpartycji, możemy wskazać sami, że tylko z tej partycji chcemy otrzymać wyniki.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 182/311

Wprowadzenie do optymalizacji SQL
Niniejszy rozdział jest jedynie ogólnikowym wprowadzeniem do optymalizacji. Taki ogólny zarys, którego zasadniczym celem jest danie czytelnikowi poglądu na całość.Zasadniczo wszelkie optymalizacyjne problemy wynikają ze sposobu wykonywania zapytań. Zanim po wykonaniu zapytania otrzymamy z powrotem dane, musi zostać wykonane kilka czynności.
• Musi zostać sprawdzone czy obiekty do których się odwołujemy w ogóle istnieją i czy np. tabele posiadają kolumny do których chcemy uzyskać dostęp. W tym celu przeszukiwane są słowniki systemowe.
• Jeśli obiekty istnieją , musi zostać sprawdzone czy mamy uprawnienia do obiektów.• Musi zostać sprawdzona poprawność składniowa zapytania. • Muszą zostać sprawdzone dostępne struktury (np. indeksy) które można wykorzystać by
pobrać dane. • Musi zostać sprawdzone czy dane które chcemy pobrać znajdują się może w buforze
db_cache.• Muszą zostać wymyślone plany wykonania zapytania w oparciu o dostępne możliwości. Dla
tych planów muszą zostać oszacowane koszty, które następnie są porównywane w celu wybrania najlepszego.
• Wreszcie dane muszą zostać pobrane , przetworzone i zwrócone.
To w jaki sposób zapytanie jest wykonywane (myślę tutaj o algorytmach) zależy od kilku czynników. Na niektóre z nich możemy wpływać. O sposobie wykonania zapytania w nowszych wersjach Oracle decyduje optymalizator kosztowy. Opiera się on na informacjach statystycznych natemat obiektów do których odwołujemy się w zapytaniach. Dobiera odpowiednie algorytmy i metody dostępu do danych ,w taki sposób, by w efekcie wykonanie zapytania jak najmniej obciążało serwer, a jednocześnie wyniki zapytań były zwracane jak najszybciej. Efektywność wykonywania zapytania zależy w dużej mierze od zastosowanych do pobrania danych algorytmów, ale również od innych czynników. Zdarza się też, że optymalizator kosztowy nie może zastosować wydajnego algorytmu z powodu źle zaprojektowanych lub ubogich struktur danych. Optymalizator kosztowy dobiera algorytmy m.in. na podstawie statystyk. Statystyki najogólniej mówiąc są to informacje na temat obiektów np. tabel. Zawierają wiadomości na temat np. ilości wierszy w tabeli, ich zróżnicowania. Będę starał się jak najwięcej tłumaczyć metodą analogii. Odnieśmy się do pobierania danych jak dopodróży. Jeśli znajdujemy się w jakimś miejscu - dajmy na to w Gdyni i chcemy dostać się np. do Wrocławia musimy wybrać środek lokomocji ( odpowiedni algorytm dostępu do danych). W zależności od tego jaki wybierzemy, czas naszej podróży będzie krótszy lub dłuższy, oraz stopień naszego wysiłku poświęconego na dotarcie do celu będzie mniejszy lub większy. Wybierzemy oczywiście najszybszy i najmniej męczący sposób ( najmniej kosztowny explain plan – plan wykonania zapytania złożony z wybranych algorytmów). Warunkiem który musi być spełniony by nasza podróż przebiegała wygodnie i szybko, jest przede wszystkim możliwość wyboru jakiegoś środka lokomocji. Wyobraźmy sobie , że nie ma takich połączeń kolejowych, lotniczych ani autobusowych którymi moglibyśmy dotrzeć na miejsce. Nie dysponujemy też żadnym pojazdem silnikowym. Ponieważ infrastruktura jest uboga i nasze możliwości są bardzo ubogie – musimy wybrać najbardziej męczącą i najdłuższą , ale jednocześnie jedyną metodę – pójść na piechotę. Znajduje to oczywiście odzwierciedlenie w optymalizacji. Jeśli nie zadbamy o to by dać
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 183/311

optymalizatorowi kosztowemu właściwą strukturę (np. indeksy) , nie będzie mógł wykorzystać optymalnej metody dostępu do danych i wszędzie będzie chodził na piechotę. To właśnie powód dlaczego zadbanie o odpowiednie struktury jest tak istotne. Weźmy teraz do analizy inny przypadek. Znajdujemy się w pewnym miejscu. Chcemy dotrzeć do Wrocławia. Myślimy że znajdujemy się od niego 500 metrów więc podejmujemy spacer. Gdybyśmy znajdowali się 100km od Wrocławia, oczywiście wsiedlibyśmy w samochód i nim byśmy podróżowali. Co jednak gdybyśmy myśleli że znajdujemy się 500 metrów od celu a w rzeczywistości byli 10 km dalej? Wybralibyśmy nieoptymalny plan wykonania zapytania – poszli na piechotę. W efekcie nasza podróż niepotrzebnie by się wydłużyła. Wszystko przez to, że podjęliśmy decyzję od doborze algorytmu na podstawie nieprawdziwej informacji. Wybrany plan wykonania zapytania byłby optymalny gdyby nasze przypuszczenia co do odległości okazały się prawdziwe. Taką informację o odległości do celu (ilości danych do pobrania/przetworzenia) optymalizator kosztowy podejmuje na podstawie statystyk. Jeśli więc nasze statystyki będą nieaktualne , np. będą zawierały informacje o małej ilości wierszy w tabeli a w rzeczywistości okaże się że tych wierszy jest znacznie więcej, optymalizator kosztowy wybierze właściwy algorytm dla małych porcji danych, ale zdecydowanie nie właściwy dla dużych. Z tego powodu musimy dbać o to , by statystyki były jak najświeższe i zawierały informacje zgodne z prawdą. Oczywiście statystyki zawierają znacznie więcej informacji niż tylko ilość wierszy w tabeli, o tym będzie w kolejnych rozdziałach.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 184/311

Główne powody nieefektywnego wykonywania zapytań
Przejrzyjmy więc kilka powodów nieefektywnego wykonywania się zapytań:
• Ubogie struktury• Nieaktualne statystyki• Wybór nieoptymalnego planu wykonania zapytania• Źle skonstruowane zapytanie SQL.
Ubogie struktury. Przykładowo brak indeksów powoduje pełne skany tabel, tam gdzie w rzeczywistości nie jest to potrzebne. Dodanie właściwych struktur, zmniejszy ilość odczytów z dysku, a także obciążenie procesora, co spowoduje poprawę wydajności zapytań.
Nieaktualne statystyki. Nieaktualne statystyki powodują wybieranie przez optymalizator kosztowy nieodpowiednich planów wykonania zapytań, co efektuje spadkiem wydajności.
Wybór nieoptymalnego planu wykonania zapytania. Najczęściej wynika z nieaktualnych statystyk, ale może też być spowodowany np. nie wykorzystywaniem istniejących struktur z innych powodów. Przykładowo indeks istnieje, ale jego status to INVALID (spowodowany np. przeniesieniem indeksu do innego tablespace), co sprawia że nie można z niego skorzystać.
Źle skonstruowane zapytanie SQL. To może być np. wykorzystywanie UNION tam gdzie można zastosować UNION ALL, stosowanie HAVING tam gdzie można wykorzystać WHERE. Generalnie co do zasady – konstrukcje zapytań powodujące niepotrzebne obciążenie.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 185/311

Przykłady nieoptymalnie napisanych zapytań
1.
Źle:
select department_id, avg(salary) from employees group by department_id having department_id in (40,60,80);
Dobrze:
select department_id, avg(salary) from employees where department_id in (40,60,80) group by department_id;
Wyjaśnienie
Pierwsza wersja zapytania powoduje niepotrzebne wyliczanie średnich zarobków w departamentach. Wyliczenia te zostają usunięte po wyliczeniu. Lepszym rozwiązaniem jest najpierw usunięcie niepotrzebnych wierszy, a dopiero w dalszej kolejności wykonywanie wyliczeń.
2.
Źle:
select * from zamówienia_archiwalneunionselect * from zamówienia;
Dobrze:
select * from zamówienia_archiwalneunion allselect * from zamówienia;
Wyjaśnienie:
UNION powoduje sprawdzanie dwóch zbiorów pod kątem duplikatów. Jeśli wiemy że duplikatów na pewno nie ma, powinniśmy stosować UNION ALL.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 186/311

3.
Źle:
select * from employees where salary/12>1000;
Dobrze:
select * from employees where salary>1000*12;
Wyjaśnienie:
Oczywiście lepiej jest, jeśli operacja matematyczna mnożenia zostanie wykonana raz, na kwocie 1000$, niż operacja dzielenia dla każdej wartości salary jaka pojawi się w tabeli.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 187/311

Co więc możemy zrobić by zapytania na naszej bazie danych wykonywały się efektywnie?
• Poszukać tych zapytań które najbardziej obciążają• Odświeżyć statystyki obiektów • Odświeżyć statystyki systemowe• Potworzyć indeksy tam gdzie są potrzebne lub odbudować tam gdzie nie działają
efektywnie.• Poprawić struktury tam gdzie to potrzebne.
Nie zawsze jednak słaba wydajność wynika z w.w powodów. Możemy przecież mieć za mało pamięci RAM, słaby procesor lub nawet źle poustawiane bufory w SGA. Skąd możemy wiedzieć co jest przyczyną? By znaleźć pierwszy trop spójrz na poniższy wykres:
Jeśli sposób wykonywania zapytań zbliżony jest do sytuacji A tj. zapytania nie trwają długo, ale bardzo obciążają serwer, to przyczyna leży raczej w strukturach i statystykach. Jeśli bliżej do B tj. zapytania wykonują się długo, ale za to obciążenie jest niskie – to problem najprawdopodobniej wynika z słabego sprzętu lub złych ustawień buforów SGA. Wystarczy nawet nie dość szybki dysk twardy by zapytania długo trwały z powodu długiego oczekiwania na odczyt danych.Pamiętajmy też o tym, że wiele nieefektywnych zapytań obciążających procesor powoduje sytuację zbliżoną do B – po prostu pozostałe zapytania muszą poczekać na zwolnienie zajętych zasobów.Może też zdarzyć się tak, że do utrzymania dostajemy system napisany przez innego dostawcę i system ten działa nieoptymalnie.
Przykłady takich przyczyn:
• Złe zarządzanie połączeniami – np. wielokrotne łączenie się i rozłączanie tam gdzie można by było wykorzystać jedną sesję.
• Nie wykorzystywanie możliwości jakie daje nam shared_pool, brak współdzielenia kursorów. Niepotrzebne wielokrotne wymuszanie parsowania zapytań dla których mógłby zostać wykorzystany ten sam plan wykonania.
• Nie dostatecznie częste zatwierdzanie transakcji, co powoduje długotrwałe blokady zasobów• Wielkość plików dziennika powtórzeń jest zbyt mała i powoduje to częsty zrzut danych z
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 188/311

db_cache na dysk. • Niepotrzebne pobieranie całej zawartości tabeli, po to by potem wyświetlić z tego np. dwie
kolumny.• Pakiety skompilowane w trybie interpretted
Kilka wskazówek w projektowaniu struktur danych
• Twórz proste tabele jeśli to możliwe. • Stosuj przemyślane zapytania SQL i nie pobieraj danych których nie potrzebujesz.• Stosuj indeksy tylko tam gdzie to potrzebne i w taki sposób by miały szansę być
wykorzystane (np. indeks podwójny jeśli zachodzi taka potrzeba zamiast indeksu pojedynczego).
• Stosuj klucze obce i główne, by dane były spójne. Dzięki temu nie będzie duplikatów i „śmieciowych” danych.
• Wykorzystuj struktury takie jak widoki zmaterializowane czy tabele tymczasowe, jeśli mogąone zastąpić wielokrotne niepotrzebne wykonywanie podzapytań w kilku zapytaniach.
• Wykorzystuj tablice partycjonowane przy dużych wolumenach danych.• Zakładaj indeksy na kluczach obcych.• Zakładaj indeksy na często przeszukiwanych kolumnach• Pisz SQL tak by wykorzystywał indeksy• Pisz zapytania tak, by mogły wykorzystywać wcześniej stworzone plany wykonania.
Zdaję sobie sprawę że wiele z wymienionych tutaj rzeczy będzie dla Ciebie niejasne. Potraktuj to jako checkpoint do późniejszej optymalizacji Twoich rozwiązań. Przy okazji następnych rozdziałówwszystko się wyjaśni.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 189/311

Wprowadzenie do optymalizatora kosztowego
Kolejne kroki wykonywania zapytania SQL
Stworzenie kursora (CREATE CURSOR)
Kursor jest uchwytem do przestrzeni przeznaczonej na informacje niezbędne do przetworzenia zapytania. Podczas wykonywania zapytania kursor będzie zawierał pointer do aktualnie przetwarzanego wiersza. Jeśli miałeś do czynienia z PL/SQL – dane pobierane są w momencie fetchowania wiersza. Znajdziejsz tutaj wskaźnik na ten aktualnie pobierany wiersz. Kursory przetwarzane są liniowo wiersz po wierszu. Pointer będzie się przesuwał do kolejnego wiersza.
Parsowanie zapytania (PARSE)
Sprawdzane jest czy wcześniej zostało wykonane to zapytanie i czy można wykorzystać explain plan stworzony dla wcześniejszego zapytania. Explain plany będą znajdować się w shared_pool. Metodą analogii – wracając do naszego przykładu z podróżą. Jeśli jechałem w zeszłym tygodniu z Gdyni do Krakowa, stworzyłem sobie mapkę na której zaznaczyłem w jaki sposób mam dojechać z miejsca na miejsce. Oznaczyłem postoje, spośród kilku możliwych tras wybrałem jedną. Jeśli zechcę po raz kolejny jechać tą trasą a mam jeszcze mapkę (explain plan znajduje się nadal w shared_pool) mogę ją wykorzystać. Tak samo jeśli przyjdzie do mnie kolega i poprosi o wypożyczenie mu mapki , udostępnię mu ją by mógł zmniejszyć sobie ilość pracy związanej z planowaniem podróży. Tak to działa przy wykonywaniu zapytania. Jeśli wykonam zapytanie i powstanie przy tym plan jego wykonania ( explain plan - zawierający informacje co gdzie leży i jaksię do tego dobrać) to przy kolejnym wykonaniu tego samego zapytania mogę wykorzystać wcześniej stworzony plan. Zapytania innych użytkowników również mogą wykorzystać ten sam plan. Jeśli będę tym razem jechał z Łodzi do Krakowa, to mimo że cel jest ten sam trasa będzie się różnić i nie mogę wykorzystać wcześniej stworzonej mapki. Z tego właśnie powodu zapytania muszą być identyczne (co do spacji) by mogły współdzielić plan wykonania.W tym miejscu sprawdzana jest poprawność składniowa zapytania, fakt posiadania lub nie uprawnień do obiektów. Jeśli znalazł się w shared_pool plan wykonania który można wykorzystać, jest wykorzystywany. Jeśli go tam nie było, jest tworzony i wrzucany do shared_pool.
Opisanie wyniku (DESCRIBE)
Opisanie kształtu wyniku zapytania. W tym etapie sprawdzane jest jak będzie wyglądać wynik tj. jakie będzie zawierał kolumny i jakiego typu.
Definicja (DEFINE)
Definiowany jest typ danych oraz wielkość zmiennych używanych do pobierania wyniku zapytania.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 190/311

Podpinanie zmiennych (BIND)
W tym miejscu wszelkie zmienne zamieniane są na wartości – np. zmienne bindowane. Zauważ że sprawdzanie wartości zmiennych bindowanych odbywa się już po poszukiwaniu explain planu. Zapamiętaj to, bo będzie to ważne podczas jednej z technik optymalizacji.
Zrównoleglenie procesów (PARALLELIZE)
Niektóre elementy zapytania mogą być od siebie niezależne. Jeśli tak jest, powstaje kilka osobnych procesów w których te elementy są wykonywane równolegle zamiast liniowo. Dzięki temu zapytanie wykonuje się szybciej.
Wykonanie (EXECUTE)
Baza ma już wszystkie niezbędne informacje, więc zapytanie jest wykonywane. Jeśli jest to delete lub update, blokowane są odpowiednie wiersze do czasu zakonczenia transakcji.
Pobranie danych (FETCH)
Dane są pobierane wiersz po wierszu do zdefiniowanych w etapie DEFINE zmiennych. Wynik zapytania zwracany jest w postaci tabeli.
Zamknięcie kursora (CLOSE CURSOR)
Odpinana jest referencja do obszaru pamięci przeznaczonego na kursor dzięki czemu może zostać ponownie wykorzystana.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 191/311

Do czego służy optymalizator kosztowy?
Optymalizator kosztowy opierając się o statystyki i dostępne struktury danych wytwarza plany wykonania zapytania. Bierze pod uwagę dostępne indeksy i obmyśla kilka możliwości dostępu do danych. Powrót do analogii z podróżą: siadamy i mając za zadanie dotrzeć do Krakowa sprawdzamy różne możliwości. Mamy więc możliwość dotarcia pociągiem, samolotem, samochodem , motorem. W przypadku tych 2 ostatnich mogę jeszcze wybrać kilka możliwych dróg. Kiedy już będę miał wszystkie możliwości, usiądę i policzę ile czasu , oraz jak bardzo mnie zmęczy dotarcie do celu z wykorzystaniem każdej z tych możliwości. Wybiorę oczywiście tą najszybszą i najmniej męczącą. Optymalizator kosztowy określi koszt dla każdego planu wykonaniai wybierze ten plan który będzie miał najniższy koszt. W trakcie szacowania kosztów Twojego zapytania CBO (cost based optimizer – optymalizator kosztowy) może przetworzyć Twoje zapytanie na analogiczne, ale inaczej skonstruowane i wyliczyć koszt również dla tego analogicznego.
Optymalizator kosztowy określa podczas opracowywania planów 3 rzeczy. Koszt, selektywność i liczebność.
Selektywność
selektywność=ilość wierszy pobranych/całkowita ilość wierszy. Przykładowo z tabeli zawierającej milion wierszy pobierzemy 100 spełniających jakiś warunek.
Informacje statystyczne na temat tabel znajdziesz w słownikach: dba_tables, dba_tab_statistics, dba_tab_cols_statistics. Optymalizator kosztowy sprawdza np. jaką część wierszy stanowią wierszektóre spełniają warunek department_id=60. Informacje te sprawdza właśnie w statystykach oraz histogramach. Jeśli nie ma aktualnych statystyk dla tabeli wykorzystywany jest Dynamic Sampling.
Dynamic Sampling – Dynamiczne próbkowanie wykorzystywane jest gdy brak statystyk dla tabeli,lub gdy są one na tyle przestarzałe że nie można im ufać. Poziom próbkowania określa parametr optimizer_dynamic_sampling który możemy zweryfikować w słowniku v$parameter. Domyślnie ten parametr ustawiony jest na wartość 2. Dopuszczalne wartości mieszczą się w przedziale 0 do 2. 0 oznacza zupełne wyłączenie dynamicznego próbkowania. 1 – próbkowanie stosowane jest tylko w przypadku pełnego odczytu z obiektu (np. z tabeli). 2 to włączenie dynamic sampling, wyższe stopnie określają coraz bardziej agresywne próbkowanie.
Liczebność (cardinality)
cardinality=selektywność (( a właściwie jej stosunek procentowy do wszystkich wierszy w obiekcie) * całkowita liczba wierszy Określa oczekiwaną liczbę wierszy zwrocona w wyniku zapytania.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 192/311

Koszt (cost)
Jednostka niemetryczna. Określa szacunkową liczbę odczytów I/O niezbędną w celu wykonania zapytania. Wliczane są również operacje na pamięci operacyjnej, czy też cykle procesora niemniej ważne dla optymalizacji co ilość odczytów z dysku. W oparciu o tą wartość porównywane są plany wykonania.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 193/311
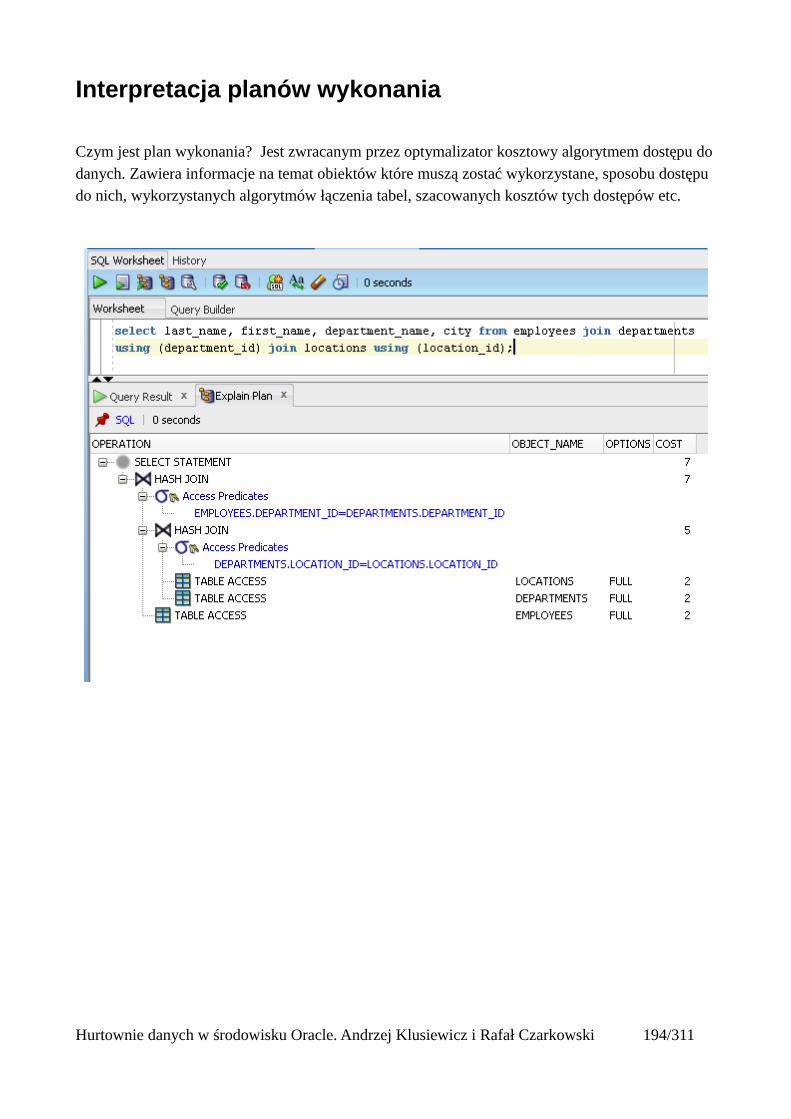
Interpretacja planów wykonania
Czym jest plan wykonania? Jest zwracanym przez optymalizator kosztowy algorytmem dostępu dodanych. Zawiera informacje na temat obiektów które muszą zostać wykorzystane, sposobu dostępu do nich, wykorzystanych algorytmów łączenia tabel, szacowanych kosztów tych dostępów etc.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 194/311
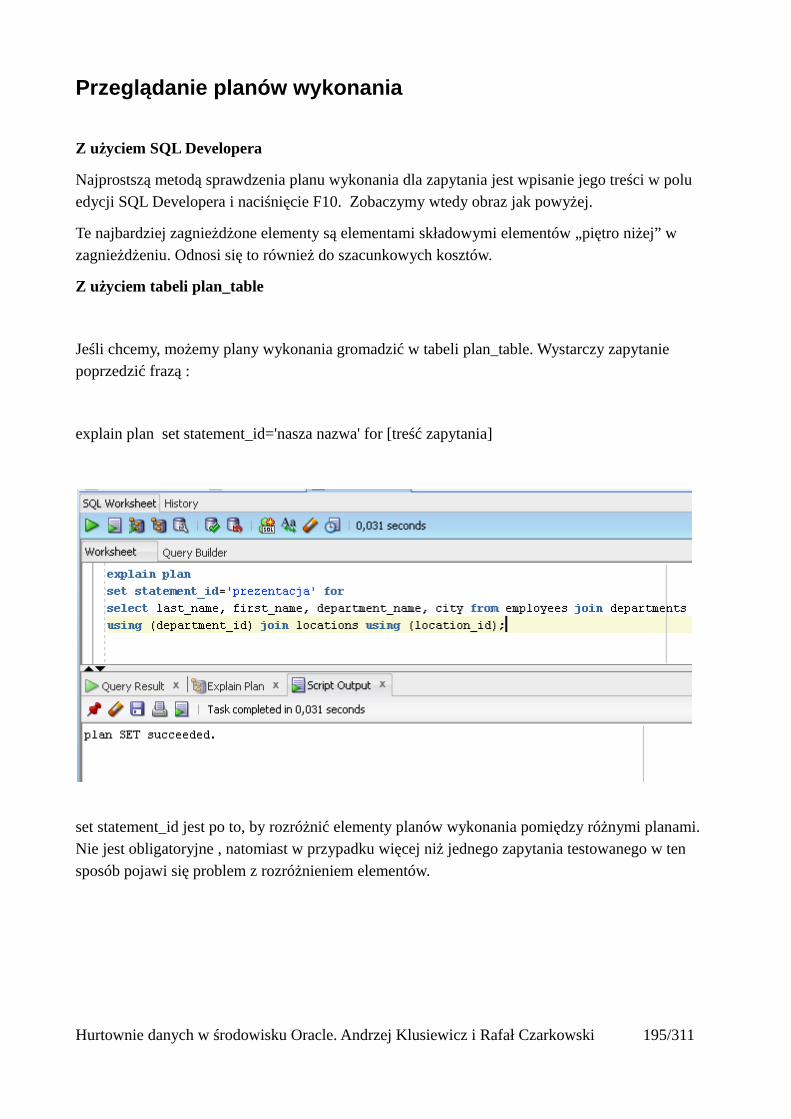
Przeglądanie planów wykonania
Z użyciem SQL Developera
Najprostszą metodą sprawdzenia planu wykonania dla zapytania jest wpisanie jego treści w polu edycji SQL Developera i naciśnięcie F10. Zobaczymy wtedy obraz jak powyżej.
Te najbardziej zagnieżdżone elementy są elementami składowymi elementów „piętro niżej” w zagnieżdżeniu. Odnosi się to również do szacunkowych kosztów.
Z użyciem tabeli plan_table
Jeśli chcemy, możemy plany wykonania gromadzić w tabeli plan_table. Wystarczy zapytanie poprzedzić frazą :
explain plan set statement_id='nasza nazwa' for [treść zapytania]
set statement_id jest po to, by rozróżnić elementy planów wykonania pomiędzy różnymi planami. Nie jest obligatoryjne , natomiast w przypadku więcej niż jednego zapytania testowanego w ten sposób pojawi się problem z rozróżnieniem elementów.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 195/311
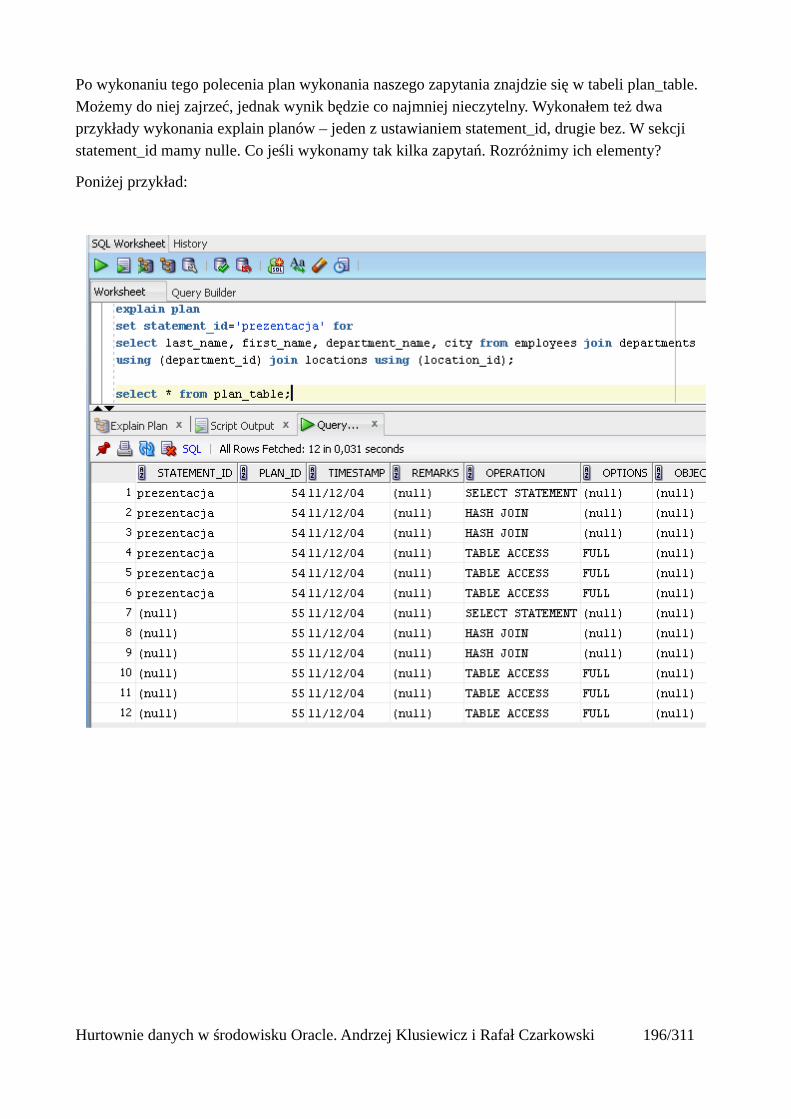
Po wykonaniu tego polecenia plan wykonania naszego zapytania znajdzie się w tabeli plan_table. Możemy do niej zajrzeć, jednak wynik będzie co najmniej nieczytelny. Wykonałem też dwa przykłady wykonania explain planów – jeden z ustawianiem statement_id, drugie bez. W sekcji statement_id mamy nulle. Co jeśli wykonamy tak kilka zapytań. Rozróżnimy ich elementy?
Poniżej przykład:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 196/311
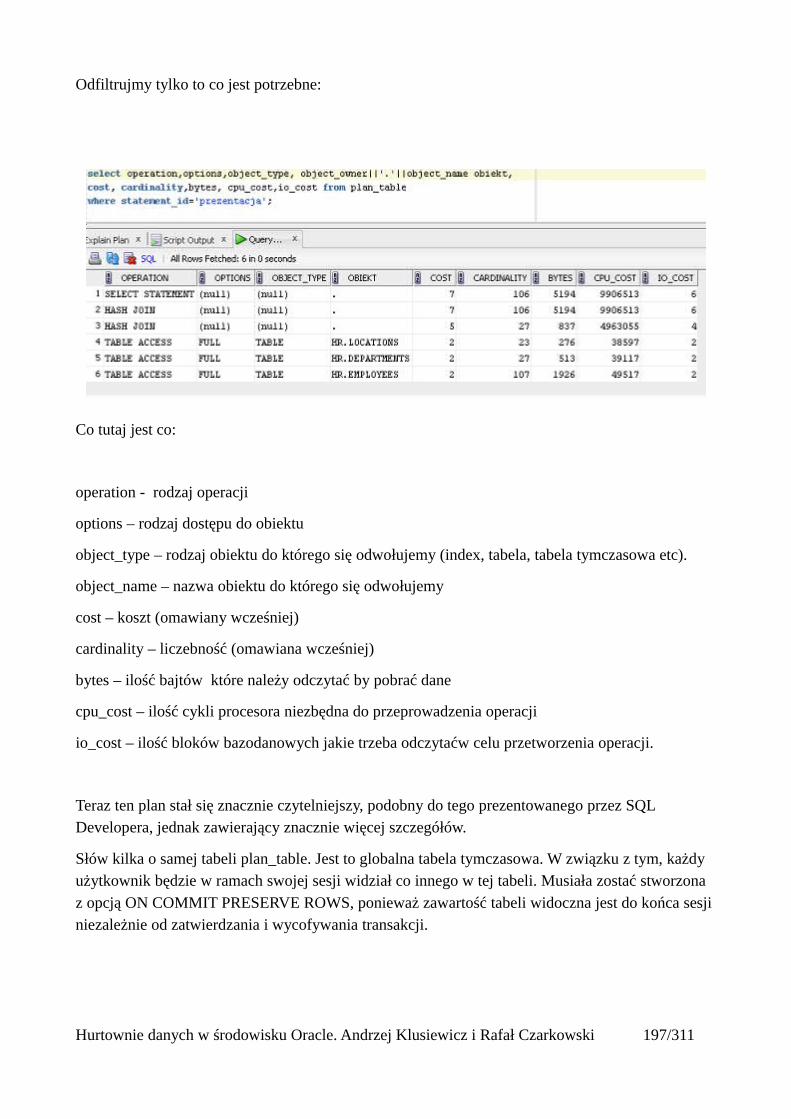
Odfiltrujmy tylko to co jest potrzebne:
Co tutaj jest co:
operation - rodzaj operacji
options – rodzaj dostępu do obiektu
object_type – rodzaj obiektu do którego się odwołujemy (index, tabela, tabela tymczasowa etc).
object_name – nazwa obiektu do którego się odwołujemy
cost – koszt (omawiany wcześniej)
cardinality – liczebność (omawiana wcześniej)
bytes – ilość bajtów które należy odczytać by pobrać dane
cpu_cost – ilość cykli procesora niezbędna do przeprowadzenia operacji
io_cost – ilość bloków bazodanowych jakie trzeba odczytaćw celu przetworzenia operacji.
Teraz ten plan stał się znacznie czytelniejszy, podobny do tego prezentowanego przez SQL Developera, jednak zawierający znacznie więcej szczegółów.
Słów kilka o samej tabeli plan_table. Jest to globalna tabela tymczasowa. W związku z tym, każdy użytkownik będzie w ramach swojej sesji widział co innego w tej tabeli. Musiała zostać stworzona z opcją ON COMMIT PRESERVE ROWS, ponieważ zawartość tabeli widoczna jest do końca sesji niezależnie od zatwierdzania i wycofywania transakcji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 197/311
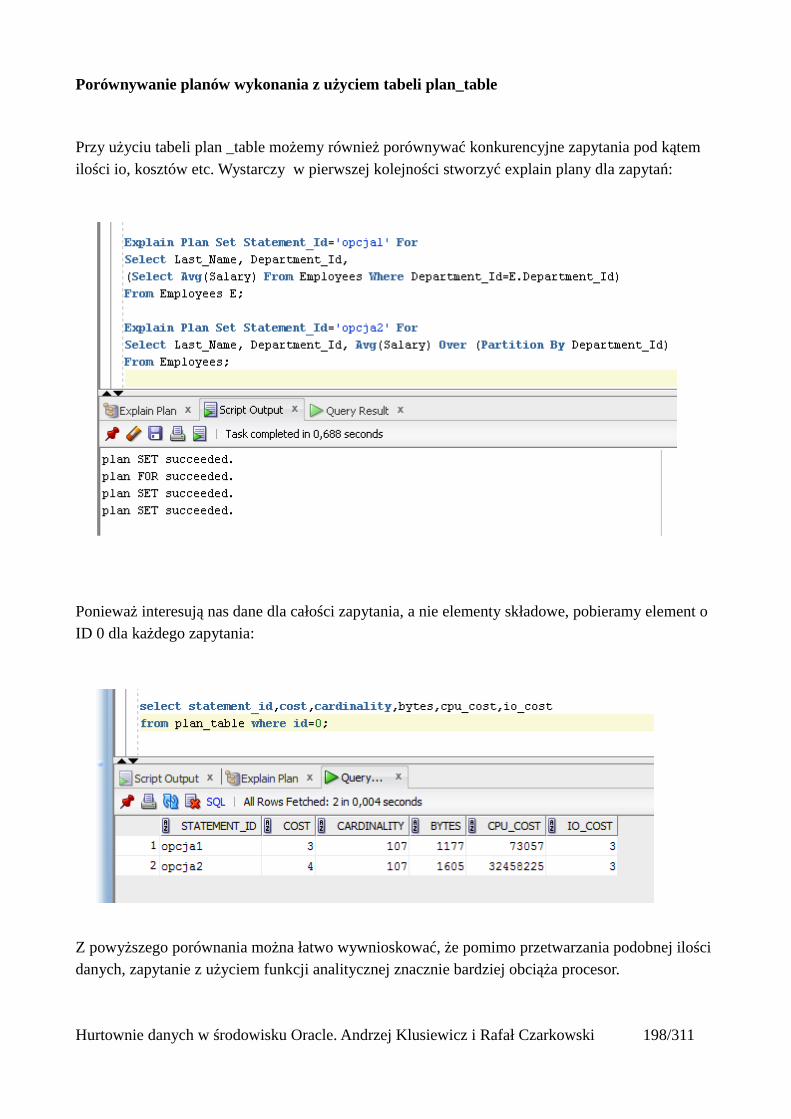
Porównywanie planów wykonania z użyciem tabeli plan_table
Przy użyciu tabeli plan _table możemy również porównywać konkurencyjne zapytania pod kątem ilości io, kosztów etc. Wystarczy w pierwszej kolejności stworzyć explain plany dla zapytań:
Ponieważ interesują nas dane dla całości zapytania, a nie elementy składowe, pobieramy element o ID 0 dla każdego zapytania:
Z powyższego porównania można łatwo wywnioskować, że pomimo przetwarzania podobnej ilości danych, zapytanie z użyciem funkcji analitycznej znacznie bardziej obciąża procesor.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 198/311

Metody dostępu do danych
Oracle w celu pobrania danych może zastosować różne metody. Może wykorzystywać przeszukiwanie tabel w całości, lub korzystać z indeksów w celu odnalezienia danych w tabelach. Poniżej zamieszczam listing różnych metod dostępu dostępnych dla tabel i dla indeksów.
Tabele Full Table ScanRowid ScanSample Table Scan
Indeksy Unique ScanRange ScanFull ScanFast Full ScanSkip ScanIndex Join
Dane mogą zostać pobrane przy użyciu wymienionych wyżej metod, w zależności oczywiście od tego jakie możliwości mu damy (przypominamy sobie historię z trasą z Gdyni do Krakowa). W pierwszej kolejności omówię każdą z tych metod dostępu do danych. W żadnym wypadku nie pomijaj tego rozdziału! Znajomość tych metod i ich dobre zrozumienie jest bardzo ważne!
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 199/311
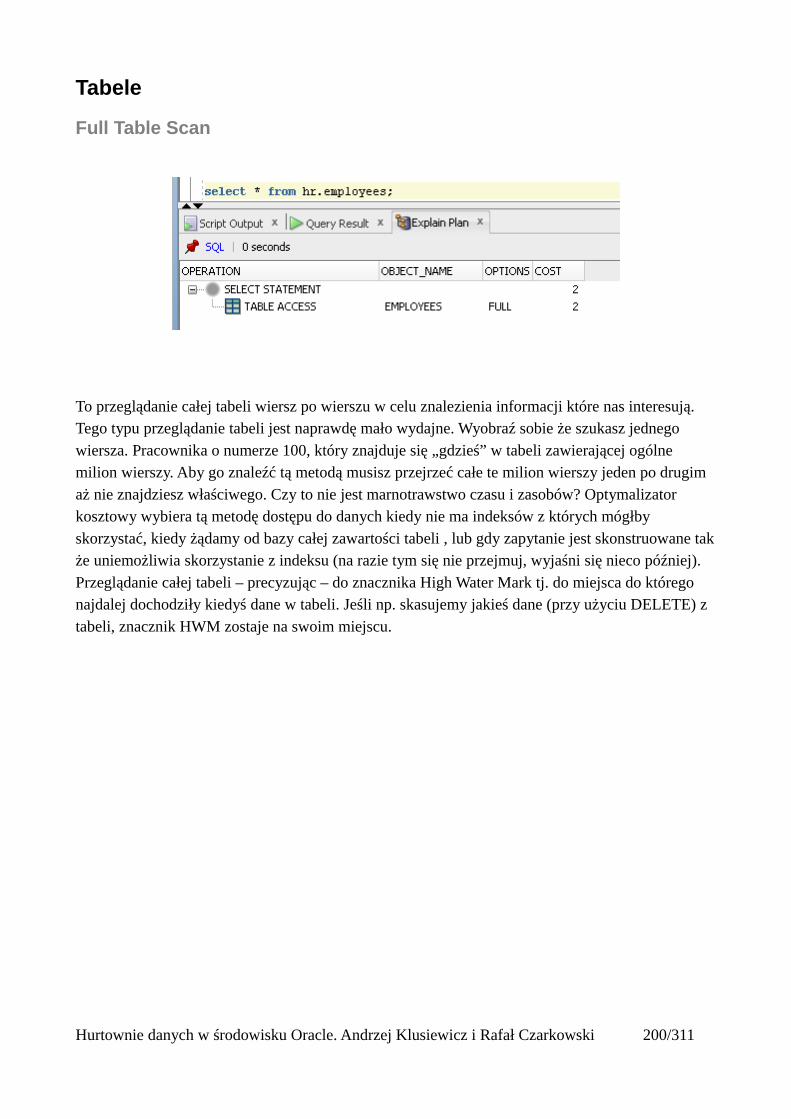
Tabele
Full Table Scan
To przeglądanie całej tabeli wiersz po wierszu w celu znalezienia informacji które nas interesują. Tego typu przeglądanie tabeli jest naprawdę mało wydajne. Wyobraź sobie że szukasz jednego wiersza. Pracownika o numerze 100, który znajduje się „gdzieś” w tabeli zawierającej ogólne milion wierszy. Aby go znaleźć tą metodą musisz przejrzeć całe te milion wierszy jeden po drugim aż nie znajdziesz właściwego. Czy to nie jest marnotrawstwo czasu i zasobów? Optymalizator kosztowy wybiera tą metodę dostępu do danych kiedy nie ma indeksów z których mógłby skorzystać, kiedy żądamy od bazy całej zawartości tabeli , lub gdy zapytanie jest skonstruowane także uniemożliwia skorzystanie z indeksu (na razie tym się nie przejmuj, wyjaśni się nieco później). Przeglądanie całej tabeli – precyzując – do znacznika High Water Mark tj. do miejsca do którego najdalej dochodziły kiedyś dane w tabeli. Jeśli np. skasujemy jakieś dane (przy użyciu DELETE) z tabeli, znacznik HWM zostaje na swoim miejscu.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 200/311
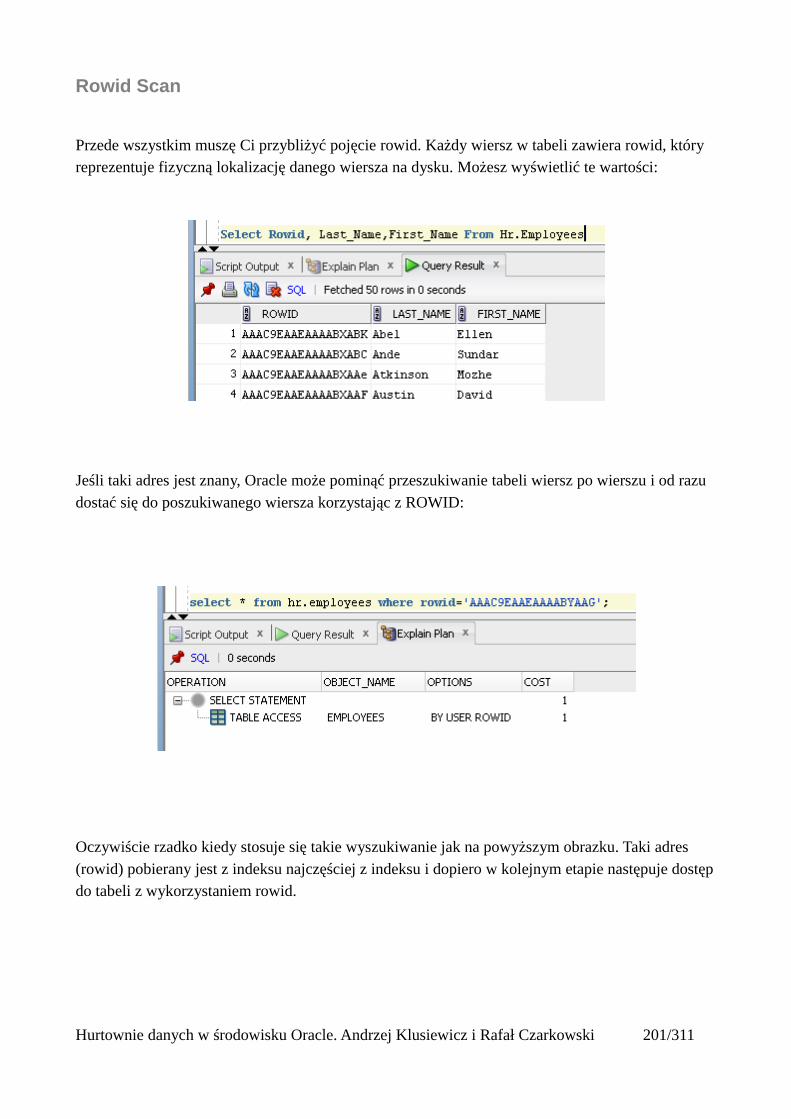
Rowid Scan
Przede wszystkim muszę Ci przybliżyć pojęcie rowid. Każdy wiersz w tabeli zawiera rowid, który reprezentuje fizyczną lokalizację danego wiersza na dysku. Możesz wyświetlić te wartości:
Jeśli taki adres jest znany, Oracle może pominąć przeszukiwanie tabeli wiersz po wierszu i od razu dostać się do poszukiwanego wiersza korzystając z ROWID:
Oczywiście rzadko kiedy stosuje się takie wyszukiwanie jak na powyższym obrazku. Taki adres (rowid) pobierany jest z indeksu najczęściej z indeksu i dopiero w kolejnym etapie następuje dostępdo tabeli z wykorzystaniem rowid.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 201/311
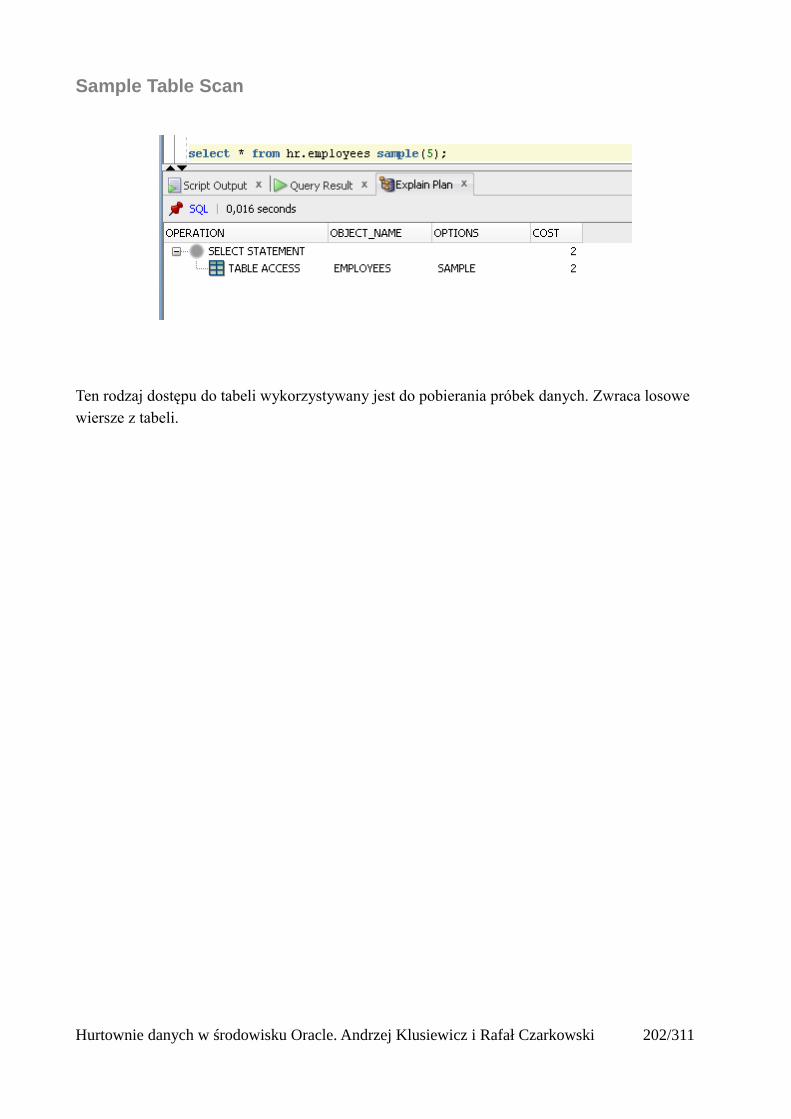
Sample Table Scan
Ten rodzaj dostępu do tabeli wykorzystywany jest do pobierania próbek danych. Zwraca losowe wiersze z tabeli.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 202/311

Indeksy
Co to jest index?
Jest obiektem bazodanowym niezależnym logicznie i fizycznie od tabeli. Pozwala uzyskać szybszy dostęp do danych. Indeksy zakłada się na kolumnę w tabeli, kilka kolumn naraz (do 32) . Bez nich wszystko będzie działać, jednak indeksy pozwolą nam szybciej dostać się do danych. Indeksy przechowują wartości kolumn na które są nakładane oraz ROWID wiersza.
Rodzaje indeksów
B-tree : Najczęściej wykorzystywane indeksy. Wykorzystuje się je tam gdzie dane w kolumnach naktóre zakłada się taki indeks są dość mocno zróżnicowane. Przykładowo nr pesel w tabeli ze wszystkimi obywatelami Polski. Nie przechowuje wartości nullowych. Tworzenie:
CREATE INDEX NAZWAINDEKSU ON NAZWATABELI(NAZWAKOLUMNY)
Bitmapowe: Wykorzystuje je się tam gdzie jest małe zróżnicowanie danych np. nazwa województwa w tabeli ze wszystkimi obywatelami Polski. Przechowuje wartości nullowe. Dostępnesą w wersji Enterprise.
CREATE BITMAP INDEX NAZWAINDEKSU ON NAZWATABELI(NAZWAKOLUMNY)
Złożone: Składają się z większej niż jedna ilości kolumn. Stosuje się je kiedy w warunku where, podczas łączenia tabel lub w grupowaniu występuje kilka kolumn naraz. Powinno się stosować w indeksie taką kolejność kolumn jak występuje w zapytaniach.
CREATE INDEX NAZWAINDEKSU ON NAZWATABELI(NAZWAKOLUMNY1, NAZWAKOLUMNY2)
Unikalne: Zakładane na te kolumny w których wartości są unikalne. Umożliwiają stosowanie unique scan.
CREATE UNIQUE INDEX NAZWAINDEKSU ON NAZWATABELI(NAZWAKOLUMNY)
Funkcyjne: Oparte na funkcjach które przetwarzają zawartość kolumn na które są nakładane. Stosuje się je kiedy w tabeli mamy dane nieprzetworzone, a wykorzystujemy przetworzone w zapytaniach.
CREATE INDEX NAZWAINDEKSU ON NAZWATABELI(NAZWAKOLUMNY*2)
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 203/311

Tabele zorganizowane indeksowo: To tabele o strukturze indeksu b-tree. Wykorzystuje się je często przy słownikach (w bazodanowym pojęciu). Taka tabela musi posiadać klucz główny.
CREATE TABLE NAZWATABELI(KOLUMNA1 TYPDANYCH PRIMARY KEY,KOLUMNA2 TYPDANYCH) ORGANIZATION INDEX;
Skany po indeksach
Unique Scan
Wiemy już że przeszukiwanie indeksów będzie szybsze niż przeszukiwanie tabeli. Wiemy też że indeksy przechowują rowidy wierszy.Jeżeli na kolumnie założymy indeks, Oracle będzie mógł go przeszukać pod kątem wartości przez nas podanych by odnaleźć rowid wiersza. Kolejność w tym przypadku jest taka:
1. Oracle przeszukuje indeks w poszukiwaniu wartości 1002. Znajduje wartość w indeksie i odczytuje przypisany do tej wartości rowid. 3. Poprzez rowid (adres fizyczny wiersza na dysku) Oracle dostaje się do wiersza w tabeli.
Ten rodzaj skanu wykorzystywany jest kiedy poszukujemy dane poprzez kolumnę z kluczem głównym, lub jeśli na kolumnie której dotyczy warunek nałożony jest indeks unikalny.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 204/311

Range Scan
Skan zakresowy, wykorzystywany jest kiedy stosujemy warunki typu < lub > na kolumnach na które założony jest index.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 205/311
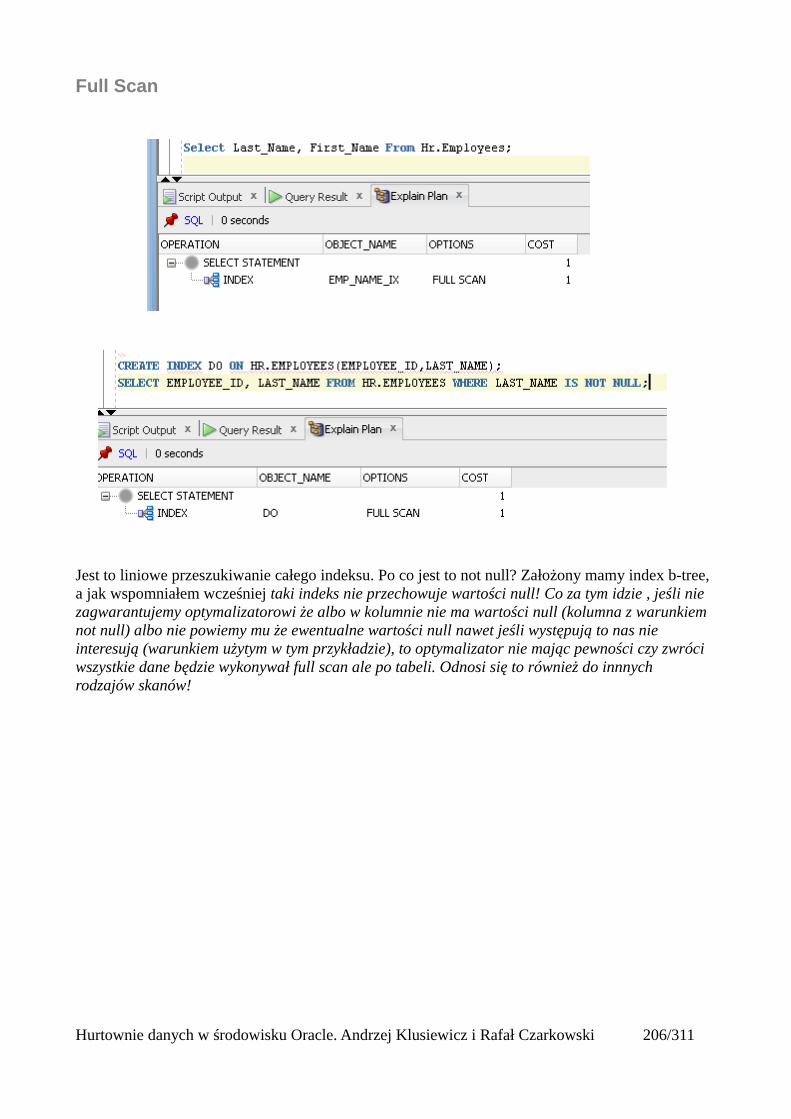
Full Scan
Jest to liniowe przeszukiwanie całego indeksu. Po co jest to not null? Założony mamy index b-tree, a jak wspomniałem wcześniej taki indeks nie przechowuje wartości null! Co za tym idzie , jeśli nie zagwarantujemy optymalizatorowi że albo w kolumnie nie ma wartości null (kolumna z warunkiem not null) albo nie powiemy mu że ewentualne wartości null nawet jeśli występują to nas nie interesują (warunkiem użytym w tym przykładzie), to optymalizator nie mając pewności czy zwróci wszystkie dane będzie wykonywał full scan ale po tabeli. Odnosi się to również do innnych rodzajów skanów!
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 206/311
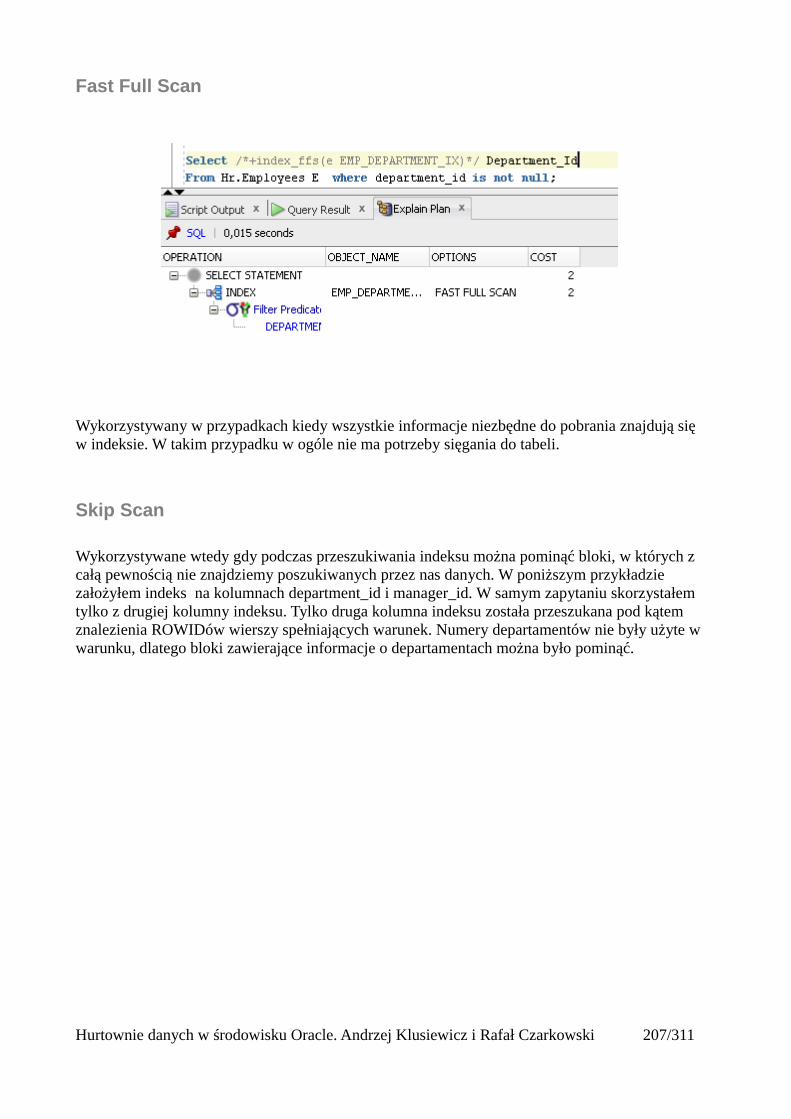
Fast Full Scan
Wykorzystywany w przypadkach kiedy wszystkie informacje niezbędne do pobrania znajdują się w indeksie. W takim przypadku w ogóle nie ma potrzeby sięgania do tabeli.
Skip Scan
Wykorzystywane wtedy gdy podczas przeszukiwania indeksu można pominąć bloki, w których z całą pewnością nie znajdziemy poszukiwanych przez nas danych. W poniższym przykładzie założyłem indeks na kolumnach department_id i manager_id. W samym zapytaniu skorzystałem tylko z drugiej kolumny indeksu. Tylko druga kolumna indeksu została przeszukana pod kątem znalezienia ROWIDów wierszy spełniających warunek. Numery departamentów nie były użyte w warunku, dlatego bloki zawierające informacje o departamentach można było pominąć.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 207/311
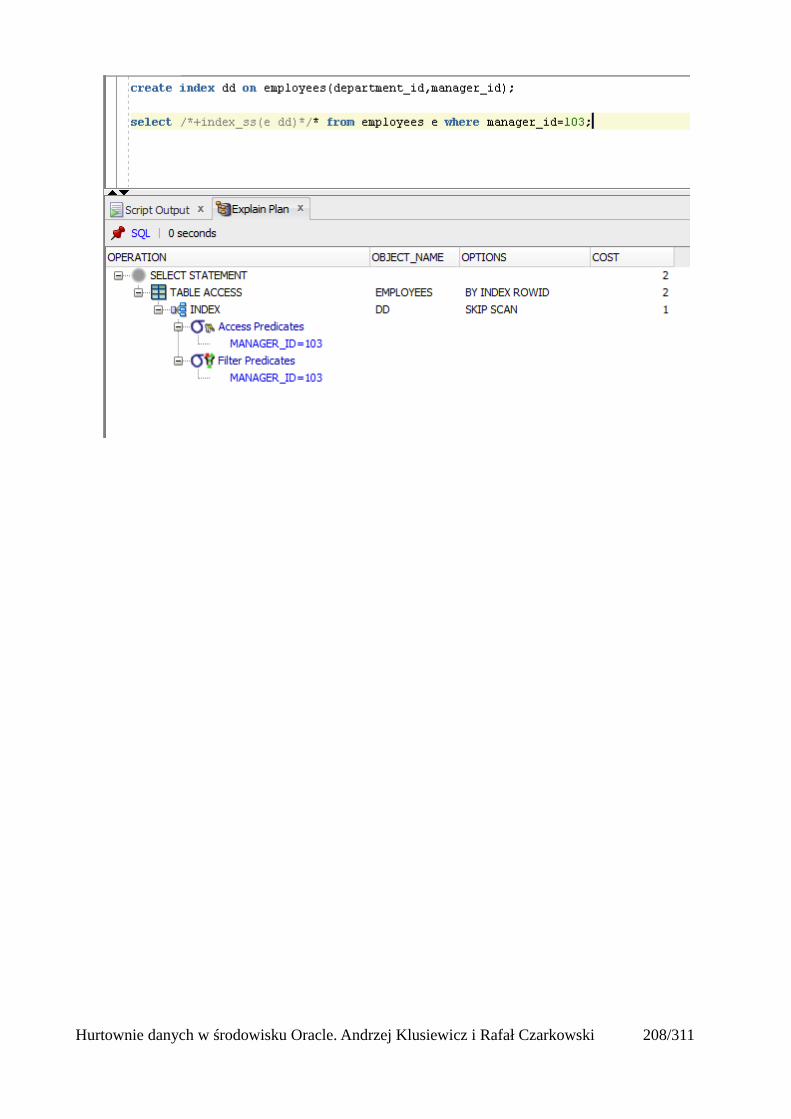
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 208/311
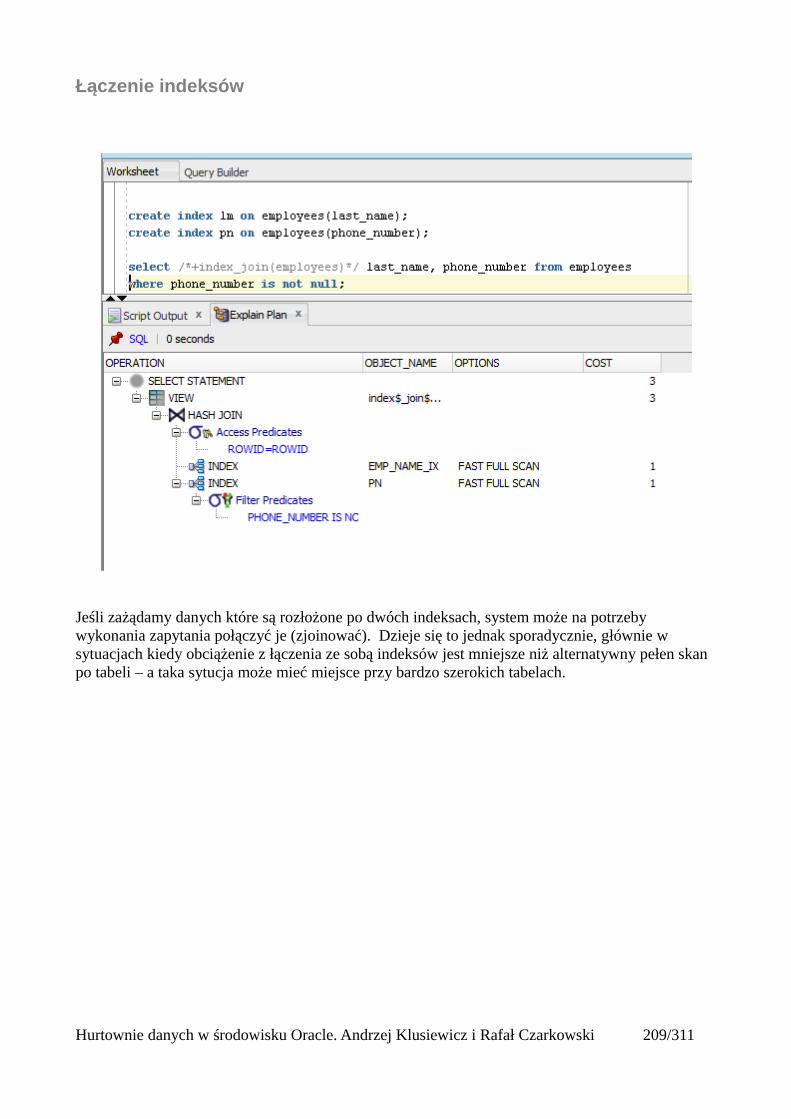
Łączenie indeksów
Jeśli zażądamy danych które są rozłożone po dwóch indeksach, system może na potrzeby wykonania zapytania połączyć je (zjoinować). Dzieje się to jednak sporadycznie, głównie w sytuacjach kiedy obciążenie z łączenia ze sobą indeksów jest mniejsze niż alternatywny pełen skan po tabeli – a taka sytucja może mieć miejsce przy bardzo szerokich tabelach.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 209/311
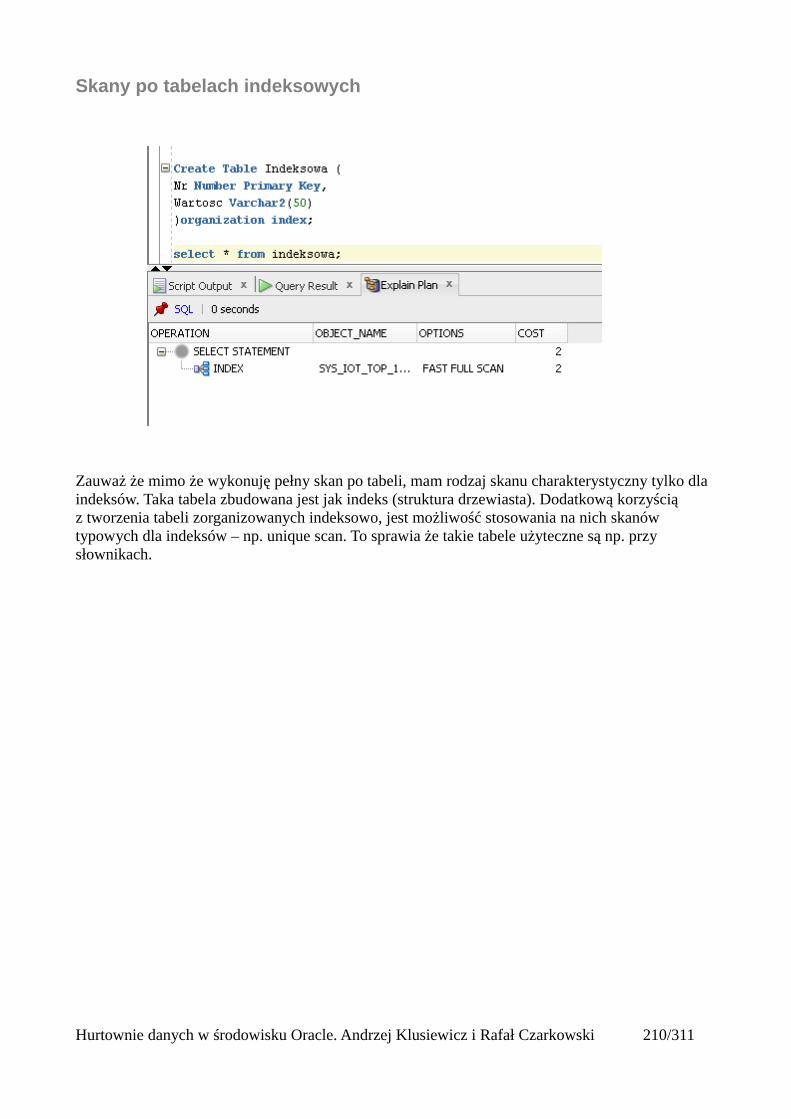
Skany po tabelach indeksowych
Zauważ że mimo że wykonuję pełny skan po tabeli, mam rodzaj skanu charakterystyczny tylko dla indeksów. Taka tabela zbudowana jest jak indeks (struktura drzewiasta). Dodatkową korzyścią z tworzenia tabeli zorganizowanych indeksowo, jest możliwość stosowania na nich skanów typowych dla indeksów – np. unique scan. To sprawia że takie tabele użyteczne są np. przy słownikach.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 210/311

Operatory złączeniowe
Kiedy wykorzystujemy łączenie tabel w zapytaniach (joiny) , łączenie ich może odbywać się na kilka sposobów. Poniżej ich lista i charakterystyka.
Nested loops
Działa to w oparciu o pętle zagnieżdżone. Podczas łączenia dwóch tabel bierzemy wiersz z jednej tabeli i przeszukujemy całą druga tabelę w poszukiwaniu odpowiedników. Stosowany najczęściej kiedy jedna z tabel jest mała.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 211/311
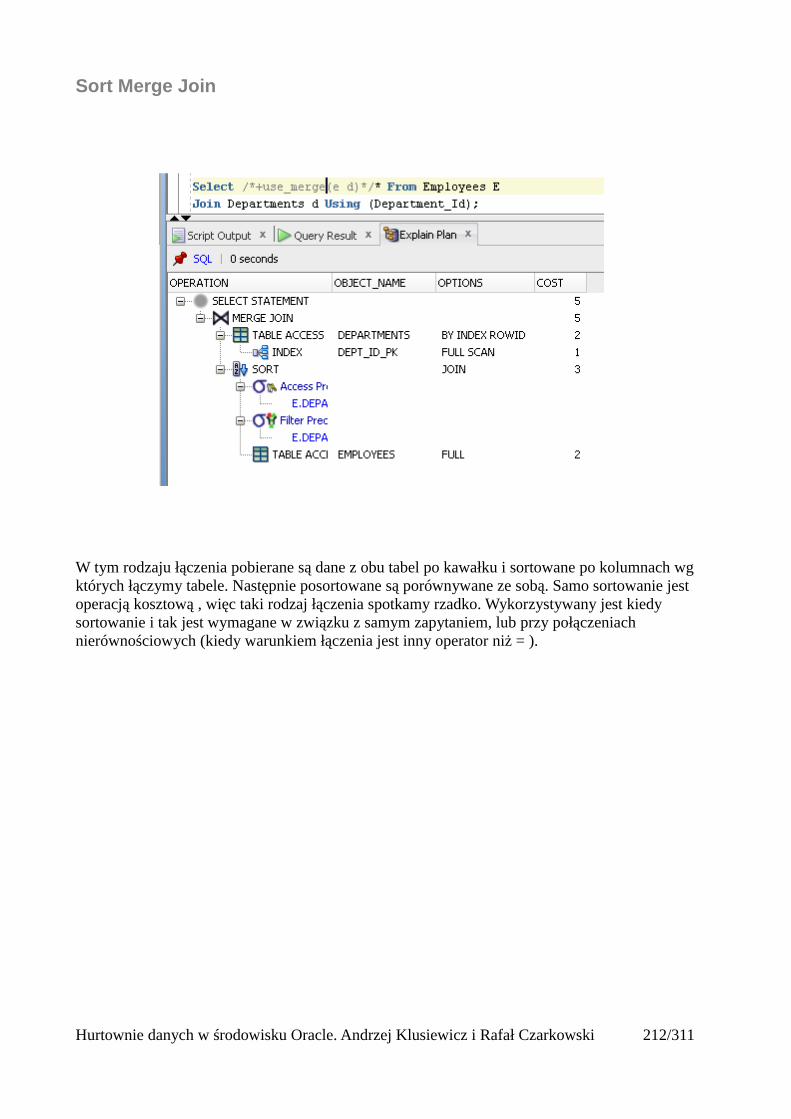
Sort Merge Join
W tym rodzaju łączenia pobierane są dane z obu tabel po kawałku i sortowane po kolumnach wg których łączymy tabele. Następnie posortowane są porównywane ze sobą. Samo sortowanie jest operacją kosztową , więc taki rodzaj łączenia spotkamy rzadko. Wykorzystywany jest kiedy sortowanie i tak jest wymagane w związku z samym zapytaniem, lub przy połączeniach nierównościowych (kiedy warunkiem łączenia jest inny operator niż = ).
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 212/311
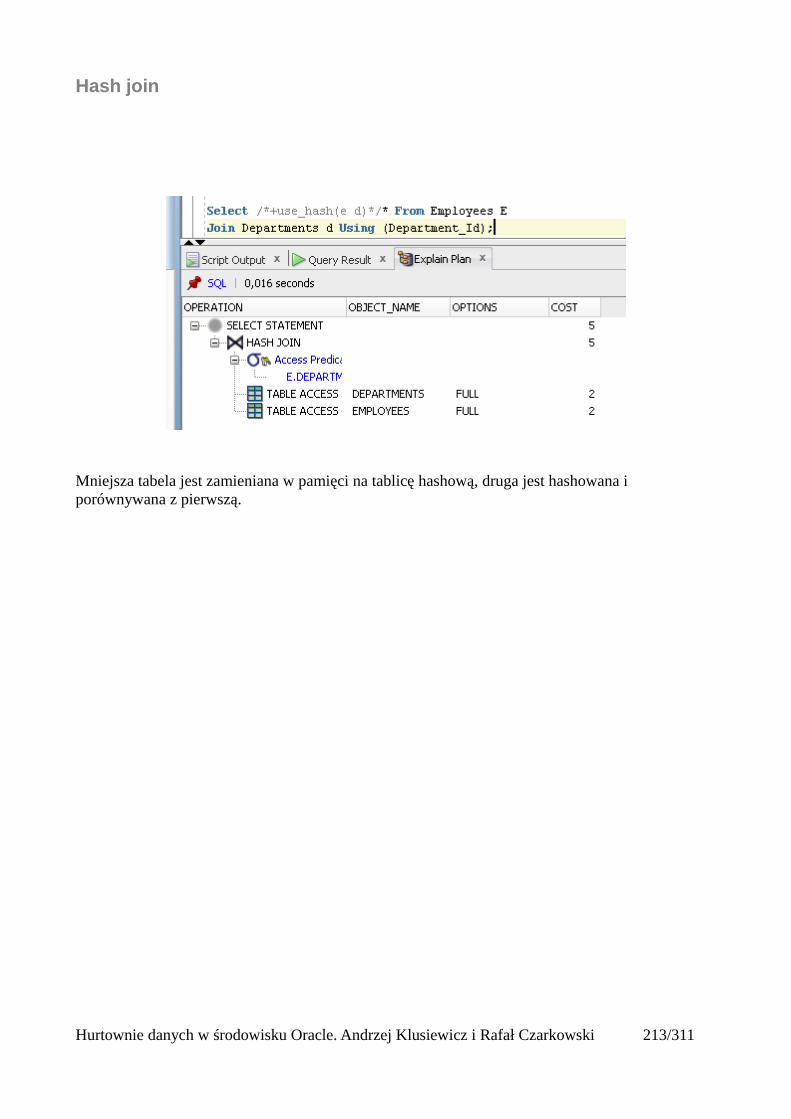
Hash join
Mniejsza tabela jest zamieniana w pamięci na tablicę hashową, druga jest hashowana i porównywana z pierwszą.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 213/311
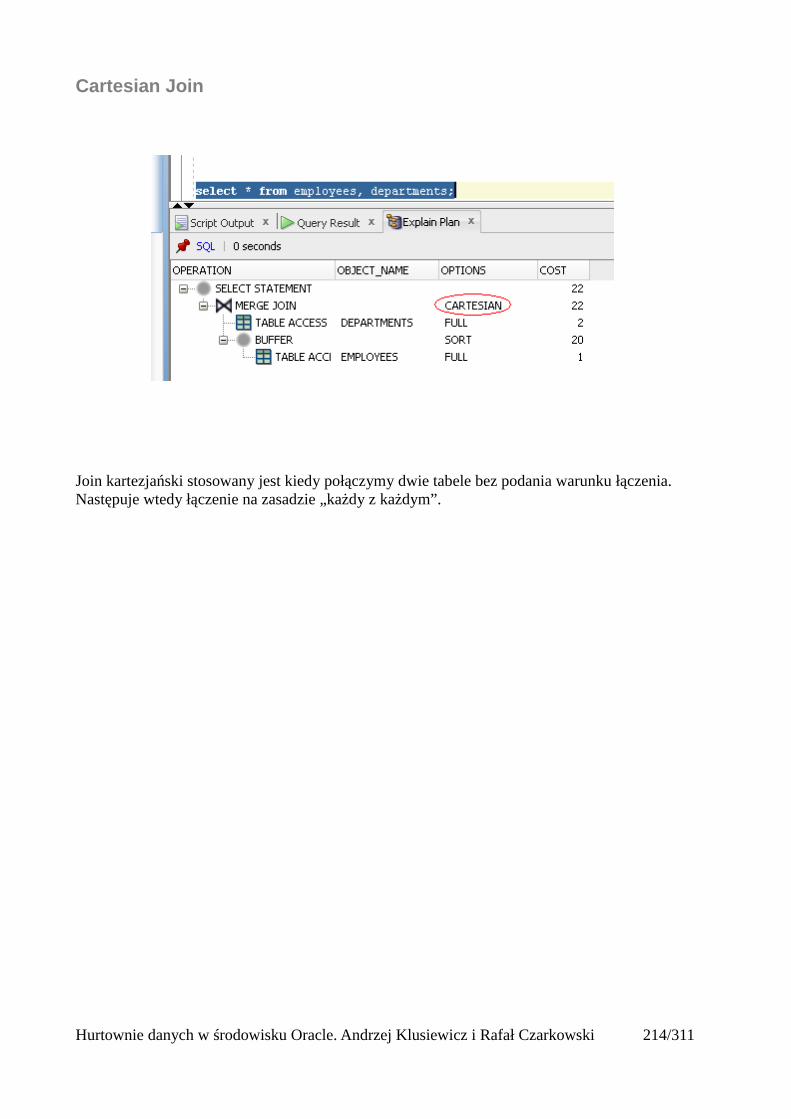
Cartesian Join
Join kartezjański stosowany jest kiedy połączymy dwie tabele bez podania warunku łączenia. Następuje wtedy łączenie na zasadzie „każdy z każdym”.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 214/311
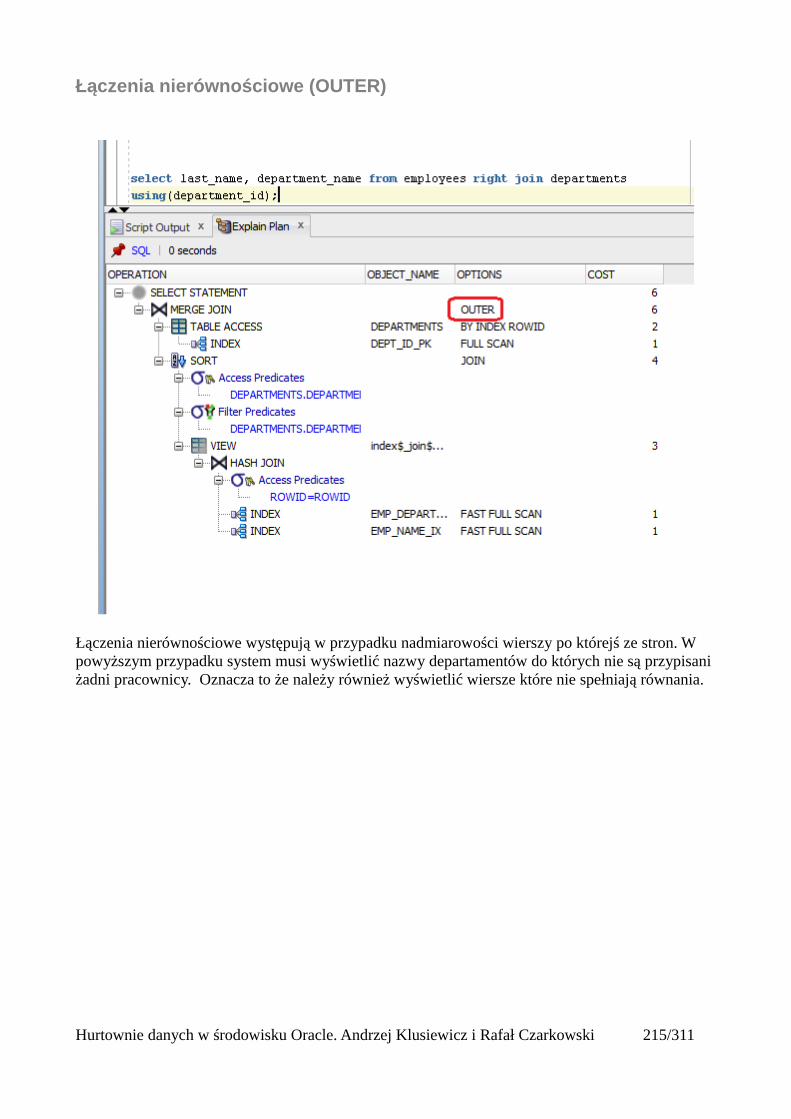
Łączenia nierównościowe (OUTER)
Łączenia nierównościowe występują w przypadku nadmiarowości wierszy po którejś ze stron. W powyższym przypadku system musi wyświetlić nazwy departamentów do których nie są przypisani żadni pracownicy. Oznacza to że należy również wyświetlić wiersze które nie spełniają równania.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 215/311
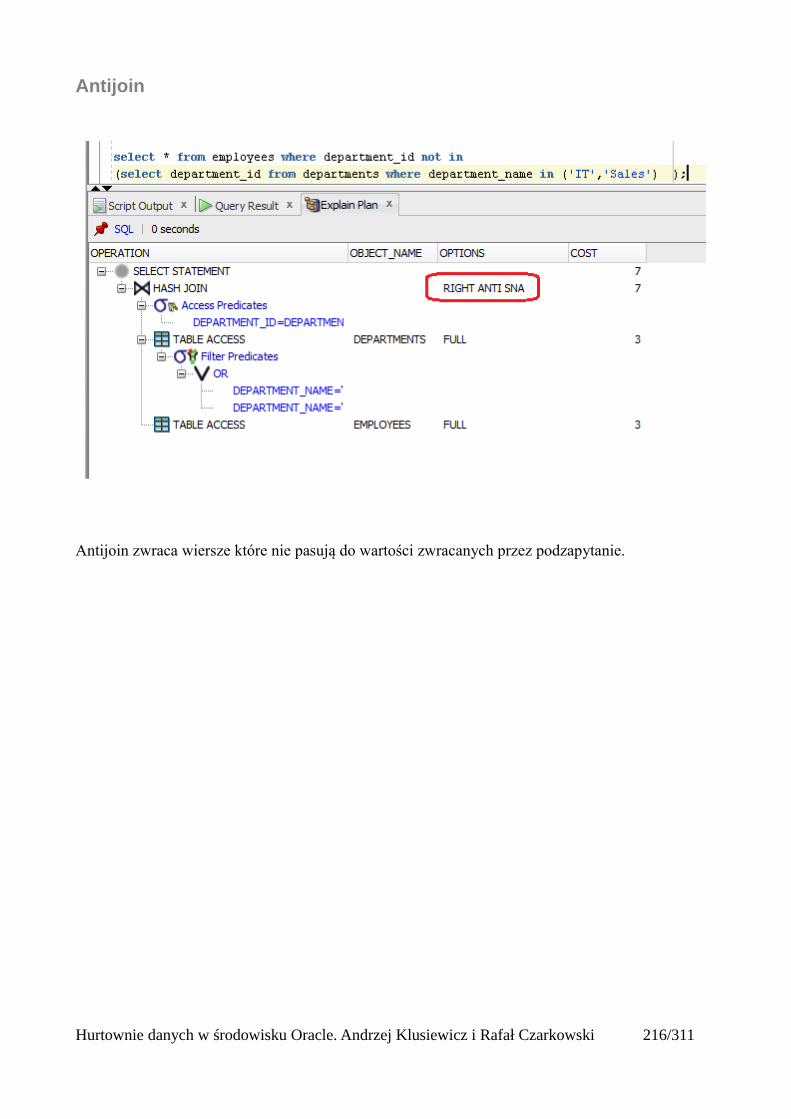
Antijoin
Antijoin zwraca wiersze które nie pasują do wartości zwracanych przez podzapytanie.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 216/311
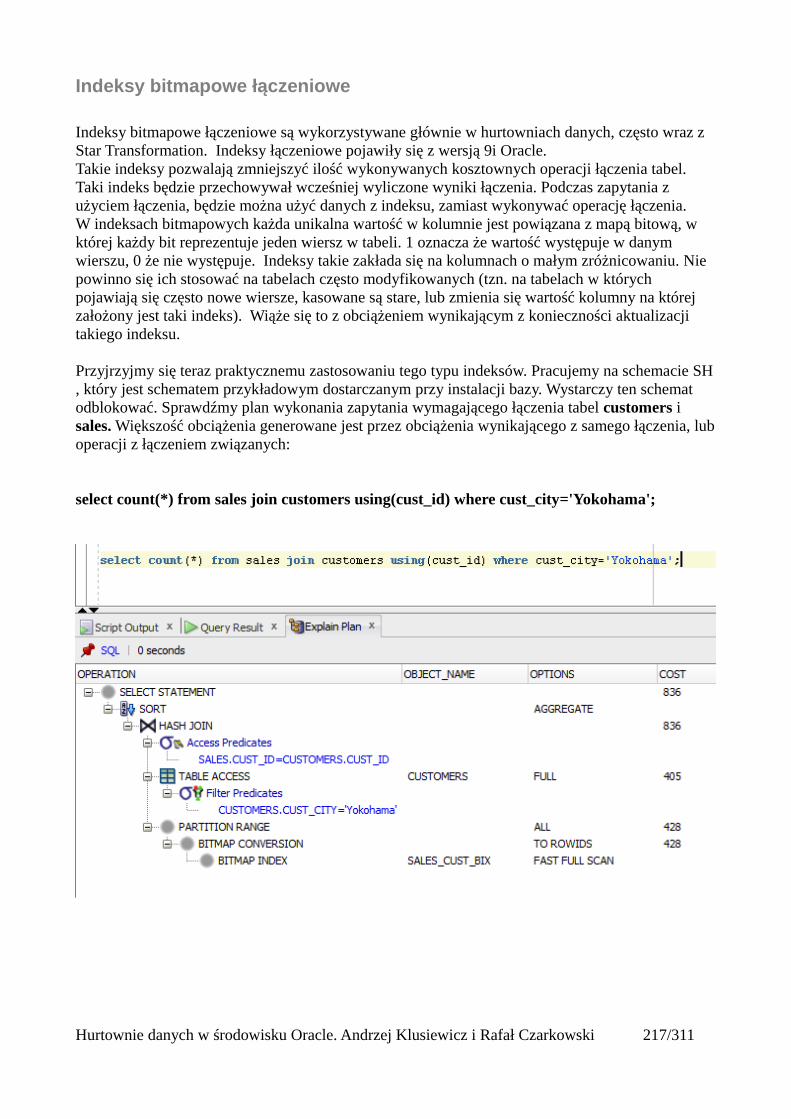
Indeksy bitmapowe łączeniowe
Indeksy bitmapowe łączeniowe są wykorzystywane głównie w hurtowniach danych, często wraz z Star Transformation. Indeksy łączeniowe pojawiły się z wersją 9i Oracle.Takie indeksy pozwalają zmniejszyć ilość wykonywanych kosztownych operacji łączenia tabel. Taki indeks będzie przechowywał wcześniej wyliczone wyniki łączenia. Podczas zapytania z użyciem łączenia, będzie można użyć danych z indeksu, zamiast wykonywać operację łączenia.W indeksach bitmapowych każda unikalna wartość w kolumnie jest powiązana z mapą bitową, w której każdy bit reprezentuje jeden wiersz w tabeli. 1 oznacza że wartość występuje w danym wierszu, 0 że nie występuje. Indeksy takie zakłada się na kolumnach o małym zróżnicowaniu. Nie powinno się ich stosować na tabelach często modyfikowanych (tzn. na tabelach w których pojawiają się często nowe wiersze, kasowane są stare, lub zmienia się wartość kolumny na której założony jest taki indeks). Wiąże się to z obciążeniem wynikającym z konieczności aktualizacji takiego indeksu.
Przyjrzyjmy się teraz praktycznemu zastosowaniu tego typu indeksów. Pracujemy na schemacie SH, który jest schematem przykładowym dostarczanym przy instalacji bazy. Wystarczy ten schemat odblokować. Sprawdźmy plan wykonania zapytania wymagającego łączenia tabel customers i sales. Większość obciążenia generowane jest przez obciążenia wynikającego z samego łączenia, luboperacji z łączeniem związanych:
select count(*) from sales join customers using(cust_id) where cust_city='Yokohama';
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 217/311
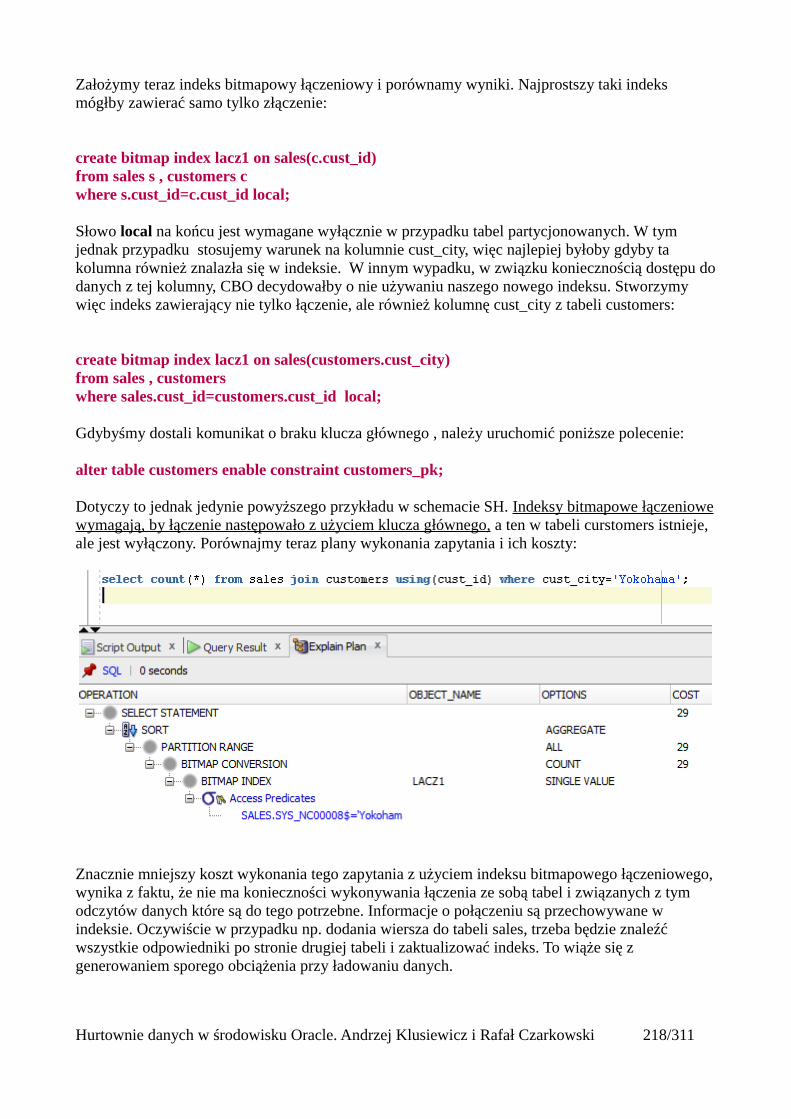
Założymy teraz indeks bitmapowy łączeniowy i porównamy wyniki. Najprostszy taki indeks mógłby zawierać samo tylko złączenie:
create bitmap index lacz1 on sales(c.cust_id) from sales s , customers cwhere s.cust_id=c.cust_id local;
Słowo local na końcu jest wymagane wyłącznie w przypadku tabel partycjonowanych. W tym jednak przypadku stosujemy warunek na kolumnie cust_city, więc najlepiej byłoby gdyby ta kolumna również znalazła się w indeksie. W innym wypadku, w związku koniecznością dostępu dodanych z tej kolumny, CBO decydowałby o nie używaniu naszego nowego indeksu. Stworzymy więc indeks zawierający nie tylko łączenie, ale również kolumnę cust_city z tabeli customers:
create bitmap index lacz1 on sales(customers.cust_city) from sales , customers where sales.cust_id=customers.cust_id local;
Gdybyśmy dostali komunikat o braku klucza głównego , należy uruchomić poniższe polecenie:
alter table customers enable constraint customers_pk;
Dotyczy to jednak jedynie powyższego przykładu w schemacie SH. Indeksy bitmapowe łączeniowewymagają, by łączenie następowało z użyciem klucza głównego, a ten w tabeli curstomers istnieje, ale jest wyłączony. Porównajmy teraz plany wykonania zapytania i ich koszty:
Znacznie mniejszy koszt wykonania tego zapytania z użyciem indeksu bitmapowego łączeniowego,wynika z faktu, że nie ma konieczności wykonywania łączenia ze sobą tabel i związanych z tym odczytów danych które są do tego potrzebne. Informacje o połączeniu są przechowywane w indeksie. Oczywiście w przypadku np. dodania wiersza do tabeli sales, trzeba będzie znaleźć wszystkie odpowiedniki po stronie drugiej tabeli i zaktualizować indeks. To wiąże się z generowaniem sporego obciążenia przy ładowaniu danych.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 218/311
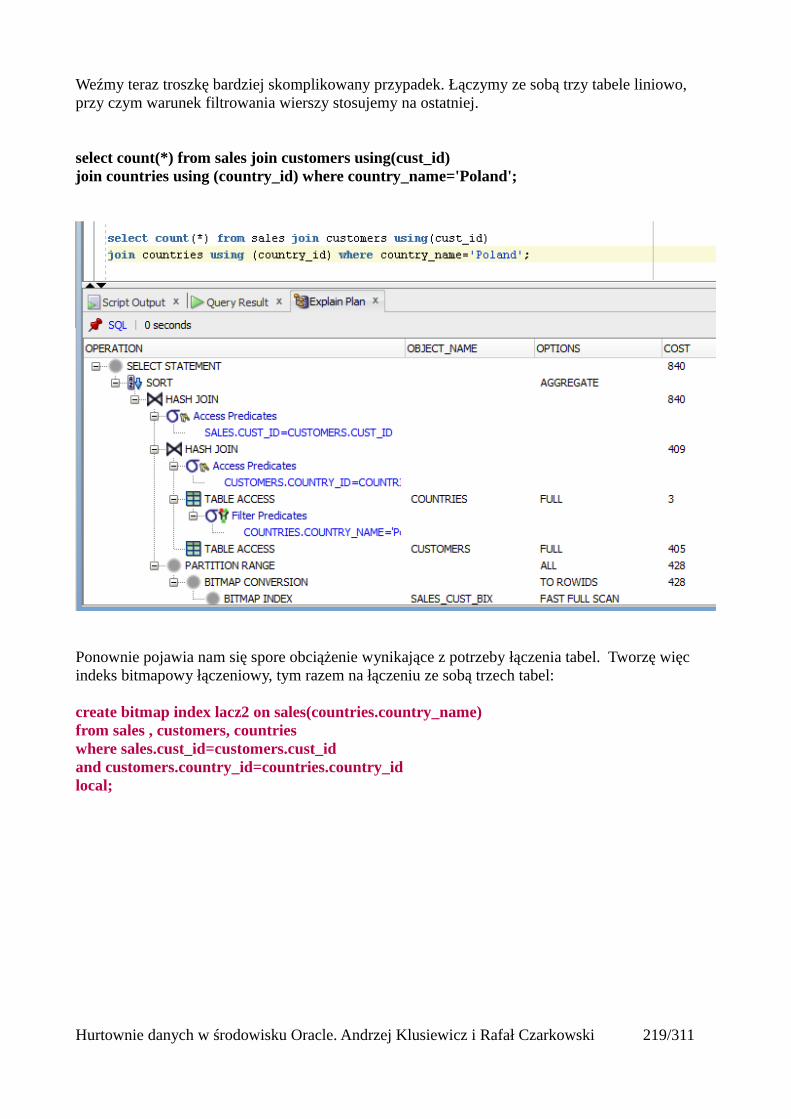
Weźmy teraz troszkę bardziej skomplikowany przypadek. Łączymy ze sobą trzy tabele liniowo, przy czym warunek filtrowania wierszy stosujemy na ostatniej.
select count(*) from sales join customers using(cust_id)join countries using (country_id) where country_name='Poland';
Ponownie pojawia nam się spore obciążenie wynikające z potrzeby łączenia tabel. Tworzę więc indeks bitmapowy łączeniowy, tym razem na łączeniu ze sobą trzech tabel:
create bitmap index lacz2 on sales(countries.country_name) from sales , customers, countries where sales.cust_id=customers.cust_idand customers.country_id=countries.country_idlocal;
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 219/311
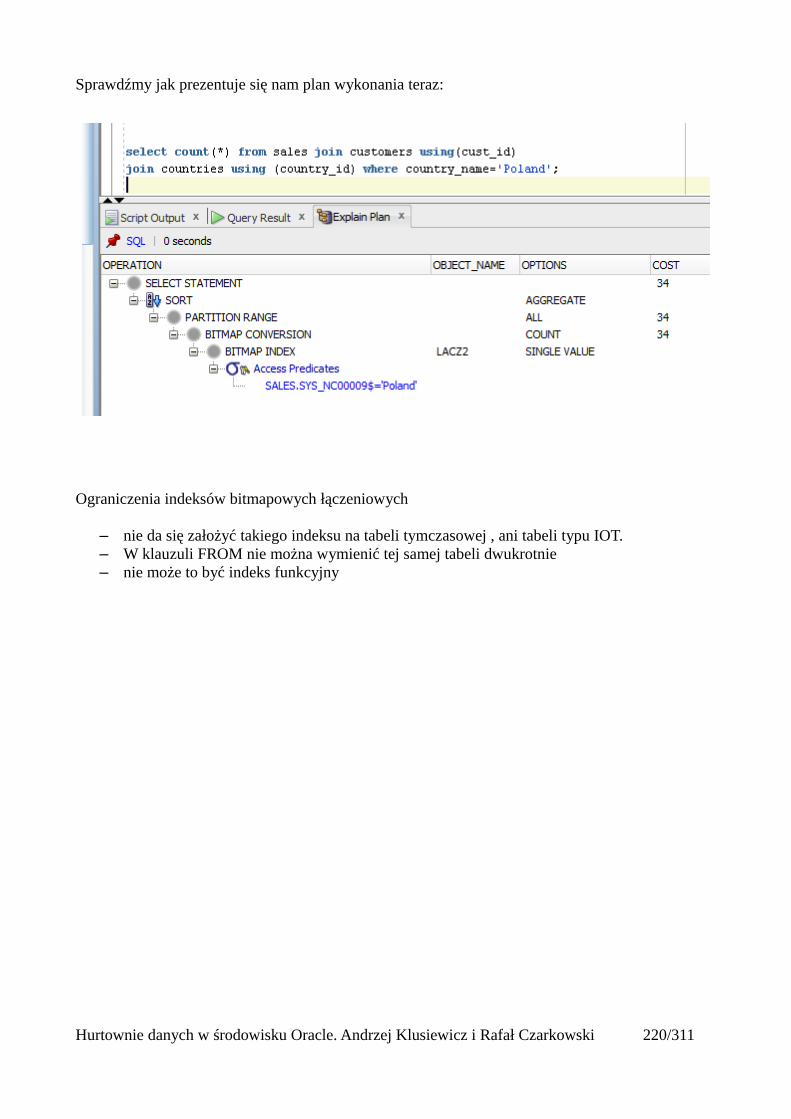
Sprawdźmy jak prezentuje się nam plan wykonania teraz:
Ograniczenia indeksów bitmapowych łączeniowych
– nie da się założyć takiego indeksu na tabeli tymczasowej , ani tabeli typu IOT.– W klauzuli FROM nie można wymienić tej samej tabeli dwukrotnie – nie może to być indeks funkcyjny
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 220/311

Statystyki
Czym są statystyki?
W skrócie statystyki są zbiorem informacji statystycznych na temat tabel, kolumn i indeksów. Zawierają informacje o np. ilości wierszy w tabeli, ich zróżnicowaniu, największej i najmniejszej wartości występującej w kolumnie. W oparciu o te informacje, optymalizator kosztowy (CBO) podejmuje decyzje o algorytmie dostępu do danych (przypominamy sobie analogię do podróży i różnych środków transportu z rozdziału o wprowadzeniu do optymalizacji), szacuje koszty. Należy je odświeżać, bo w przeciwnym przypadku CBO opierając się o nieprawdziwe informacje pochodzące z przedawnionych statystyk podejmować będzie decyzje błędne odnośnie doboru algorytmów i metod dostępu do danych. Oracle odświeża statystyki podczas tak zwanego „Maintance Window” który domyślnie przypada od 22 do 6 rano. Generuje nowe statystyki dla tychobiektów które ich nie mają wygenerowanych , odświeża dla tych które mają status STALE. Status STALE otrzymywują gdy zmieni się więcej niż 10% wierszy. . W wersji 10g Oracle, automatyzacja generowania statystyk związana była z procedurą GATHER_STATS_PROG wywoływanym przez job o nazwie GATHER_STATS_JOB. Przy użyciu słowników :
– DBA_SCHEDULER_JOBS– DBA_SCHEDULER_SCHEDULES
możemy odnaleźć szczegóły dotyczące częstotliwości odświeżania statystyk. W wersji 11g job ten nie jest już widoczny. Informacje o szczegółach automatycznego generowania statystyk znajdziemyw słowniku DBA_AUTOTASK_CLIENT_JOB .
Rodzaje statystyk
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 221/311

Statystyki tabel
Zawierają informacje o :– ilości wierszy w tabeli– ilości bloków zajmowanych przez tabelę– średnia długość wierszy
Słownik: DBA_TAB_STATISTICS
Statystyki indeksów
Zawierają informacje o :– ilości poziomów w drzewie indeksu– ilości unikalnych wartości (lub ich kombinacji) w kolumnie (lub kolumnach) na którą został
założony indeks.
Słownik: DBA_IND_STATISTICS
Statystyki systemowe
Zawierają informacje o :– wydajności I/O– wydajności procesora
Statystyki kolumn
Zawierają informacje o:– ilości unikalnych wartości w kolumnie– ilości nulli w kolumnie– średniej długości wartości w kolumnie– maksymalnej wartości– minimalnej wartości – zróżnicowanie danych w kolumnie.
Słownik: DBA_TAB_COL_STATISTICS
Histogramy
Same statystyki zawierają informacje podstawowe o zróżnicowaniu zawartości kolumn – takie jak
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 222/311

np. maksymalna czy minimalna wartość oraz ilości unikalnych wartości w kolumnie. Histogramy zawierają znacznie bardziej szczegółowe informacje o zróżnicowaniu. Znajdziesz tutaj np. informacje o częstotliwości występowania konkretnych wartości. Zasadniczo informacje dotyczące histogramów znajdziesz w tej samej tabeli co statystyki tj. DBA_TAB_COL_STATISTICS i dodatkowo w DBA_TAB_HISTOGRAMS.
Generalnie tworzenie histogramów jest najbardziej czasochłonne podczas odświeżania statystyk.Dzięki histogramom możesz wywnioskować jaki rodzaj indeksu można nałożyć na daną kolumnę. Pamiętaj że indeks bitmapowy nakładamy tam gdzie zróżnicowanie w kolumnie jest małe, indeks b-tree tam gdzie zróżnicowanie jest duże. Jeśli się pomylisz, może się okazać że optymalizator kosztowy nie będzie chciał wykorzystywać indeksu.
Odświeżanie statystyk i histogramów
W przypadku gdyby automatyczne dobowe odświeżanie statystyk nie wystarczyło, możemy odświeżać statystyki ręcznie. Jest to konieczne np. wtedy gdy tabela zmieniana jest bardzo często.
Odświeżanie statystyk systemowych:
EXECUTE DBMS_STATS.GATHER_SYSTEM_STATS;
Odświeżanie statystyk indeksu:
EXECUTE DBMS_STATS.GATHER_INDEX_STATS('nazwaschematu','nazwaindeksu');
Odświeżanie statystyk tabeli
EXECUTE DBMS_STATS.GATHER_TABLE_STATS('nazwaschematu','nazwatabeli');
Takie wywołanie spowoduje odświeżenie statystyk i histogramów dla tabeli którą wskażemy, ale również dla indeksów założonych na kolumny w tej tabeli.
Odświeżanie statystyk schematu
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 223/311

EXECUTE DBMS_STATS.GATHER_SCHEMA_STATS('nazwaschematu');
Takie wywołanie odświeży statystyki i histogramy dla wszystkich tabel i wszystkich indeksów w schemacie.
Odświeżanie statystyk całej bazy danych
EXECUTE DBMS_STATS.GATHER_DATABASE_STATS;
Wszystkie statystyki w całej bazie zostaną odświeżone. Baardzo czasochłonna operacja.
Kasowanie statystyk
EXECUTE DBMS_STATS.DELETE_TABLE_STATS('hr', 'employees');
Blokowanie statystyk
EXECUTE DBMS_STATS.LOCK_TABLE_STATS('HR','EMPLOYEES');
Używane jest gdy chcemy zablokować stan kiedy nie ma statystyk dla obiektów, a chcemy by zawsze wykorzystywał DYNAMIC SAMPLING, albo kiedy chcemy zatrzymać statystyki w pewnym momencie tak by nie były automatycznie odświeżane.
Odblokowujemy w ten sposób:
EXECUTE DBMS_STATS.UNLOCK_TABLE_STATS('HR','EMPLOYEES');
Jeśli zablokujesz statystyki dla tabeli, wszystkie statystyki zależne (np. statystyki indeksów) również zostaną zablokowane.
Odtwarzanie statystyk
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 224/311

Czasami odświeżanie statystyk idzie w złym kierunku, i chcielibyśmy przywrócić stan statystyk np.sprzed odświeżenia. Za każdym razem kiedy odświeżamy statystyki, ich poprzednia wersja jest zachowywana byśmy mogli przywrócić ich stan. Wykorzystujemy w tym celu procedurę restore_table_stats z pakietu dbms_stats:
Execute Dbms_Stats.Restore_Table_Stats(Ownname=>'hr', tabname=>'employees',as_of_timestamp=>to_timestamp('05-12-2011 12:00:00','dd-mm-yyyy hh24:mi:ss'));
Historia statystyk
Zawsze możemy sprawdzić kiedy były generowane statystyki dla tabeli, dzięki czemu będziemy wiedzieli np. do którego miejsca przywrócić statystyki. Aby obejrzeć historię statystyk przeglądamysłownik DBA_TAB_STATS_HISTORY.
SELECT * FROM DBA_TAB_STATS_HISTORY WHERE TABLE_NAME='EMPLOYEES';
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 225/311

Prosty interfejs WEBowy dla hurtowni – Oracle Apex
Instalacja poprzez PL/SQL Gateway
Instalacja poprzez PL/SQL Gateway odbywa się już po stronie serwera bazodanowego. Nie potrzebujemy w tej instalacji serwerów aplikacji, apex zainstalowany w ten sposób podnosi się razem z instancją bazy danych. Niestety taka instalacja powoduje że wszystkie obciążenia wynikające z ruchu HTTP do i z aplikacji obciążają serwer bazy danych. Cała operacja przebiega zpoziomu serwera na którym jest baza danych. Pobieramy najnowszego APEX'a (na dzień 28-03-2013 był jest to APEX w wersji 4.2) i rozpakowujemy go na dysku. Następnie przechodzimy do tego rozpakowanego katalogu z poziomu linii poleceń.
Uruchamiamy skrypt apexins z poziomu SQL*Plusa jako użytkownik SYS. Istotne jest to, byśmy uprzednio przeszli w konsoli do katalogu w którym znajduje się rozpakowany APEX. Po nazwie skryptu podajemy jeszcze 4 parametry:
1. Nazwa skryptu
2. Tablespace w którym zostanie zainstalowany APEX.
3. Tablespace w którym będą lądowały obrazki uploadowane przez użytkowników
4. Nazwa tablespace tymczasowego który będzie wykorzystywany podczas instalacji
5. Wirtualny katalog w którym przechowywane będą obrazki.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 226/311
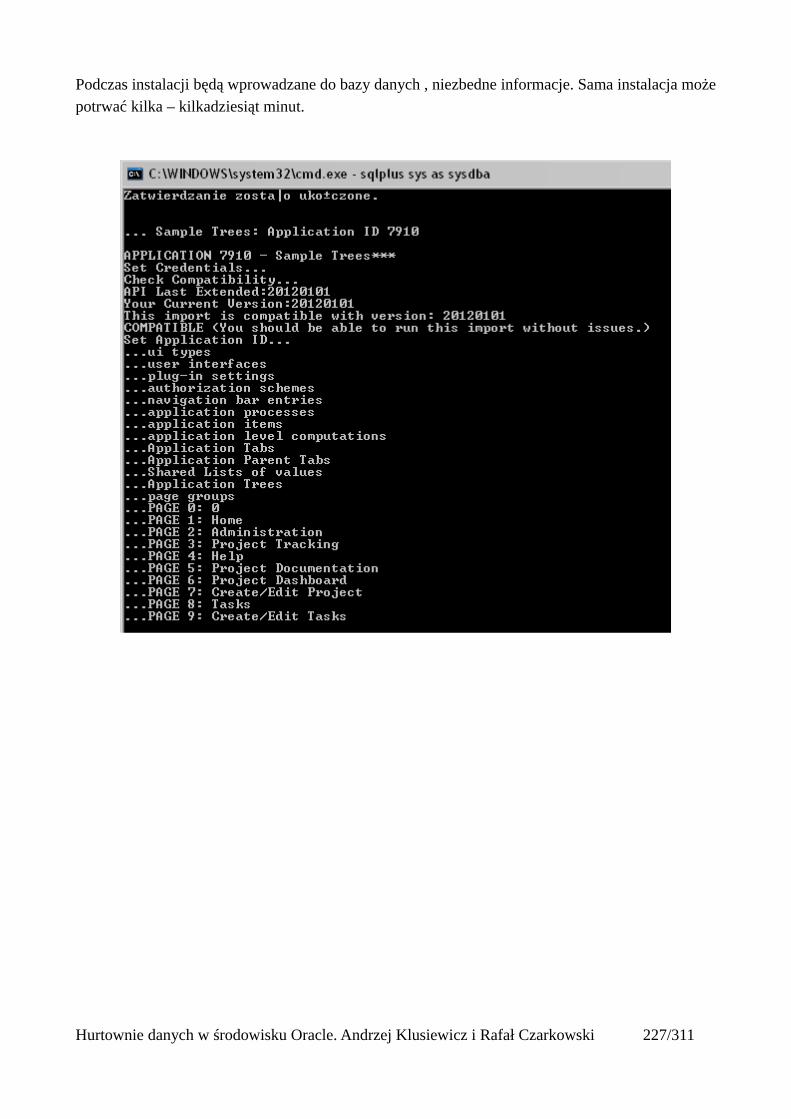
Podczas instalacji będą wprowadzane do bazy danych , niezbedne informacje. Sama instalacja możepotrwać kilka – kilkadziesiąt minut.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 227/311
Nawet jeśli skrypt chwilami „zawiśnie” , nie przejmujemy się. Na końcu powinniśmy dostać komunikat „Procedura PL/SQL została zakończona pomyślnie”, oraz powinno nas wylogować z SQL*PLusa.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 228/311
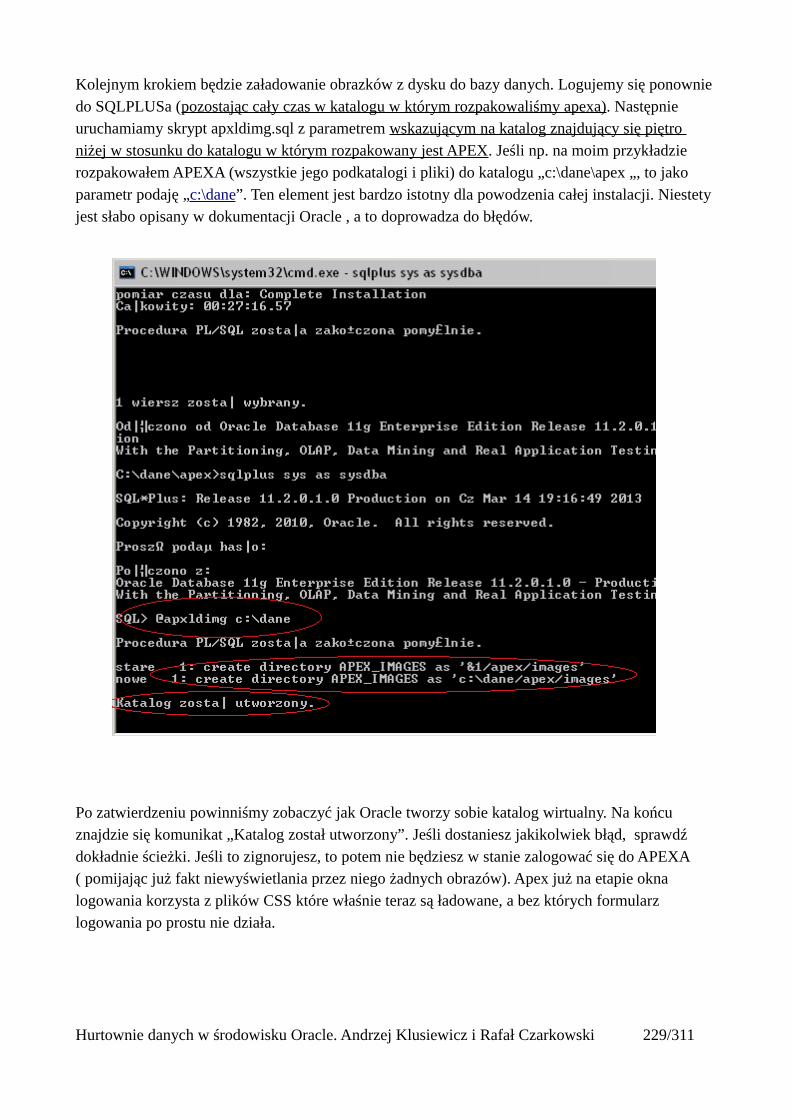
Kolejnym krokiem będzie załadowanie obrazków z dysku do bazy danych. Logujemy się ponownie do SQLPLUSa (pozostając cały czas w katalogu w którym rozpakowaliśmy apexa). Następnie uruchamiamy skrypt apxldimg.sql z parametrem wskazującym na katalog znajdujący się piętro niżej w stosunku do katalogu w którym rozpakowany jest APEX. Jeśli np. na moim przykładzie rozpakowałem APEXA (wszystkie jego podkatalogi i pliki) do katalogu „c:\dane\apex „, to jako parametr podaję „c:\dane”. Ten element jest bardzo istotny dla powodzenia całej instalacji. Niestety jest słabo opisany w dokumentacji Oracle , a to doprowadza do błędów.
Po zatwierdzeniu powinniśmy zobaczyć jak Oracle tworzy sobie katalog wirtualny. Na końcu znajdzie się komunikat „Katalog został utworzony”. Jeśli dostaniesz jakikolwiek błąd, sprawdź dokładnie ścieżki. Jeśli to zignorujesz, to potem nie będziesz w stanie zalogować się do APEXA ( pomijając już fakt niewyświetlania przez niego żadnych obrazów). Apex już na etapie okna logowania korzysta z plików CSS które właśnie teraz są ładowane, a bez których formularz logowania po prostu nie działa.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 229/311
Na koniec poinformuje nas o załadowaniu obrazów i wróci do konsoli SQL*Plusa:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 230/311
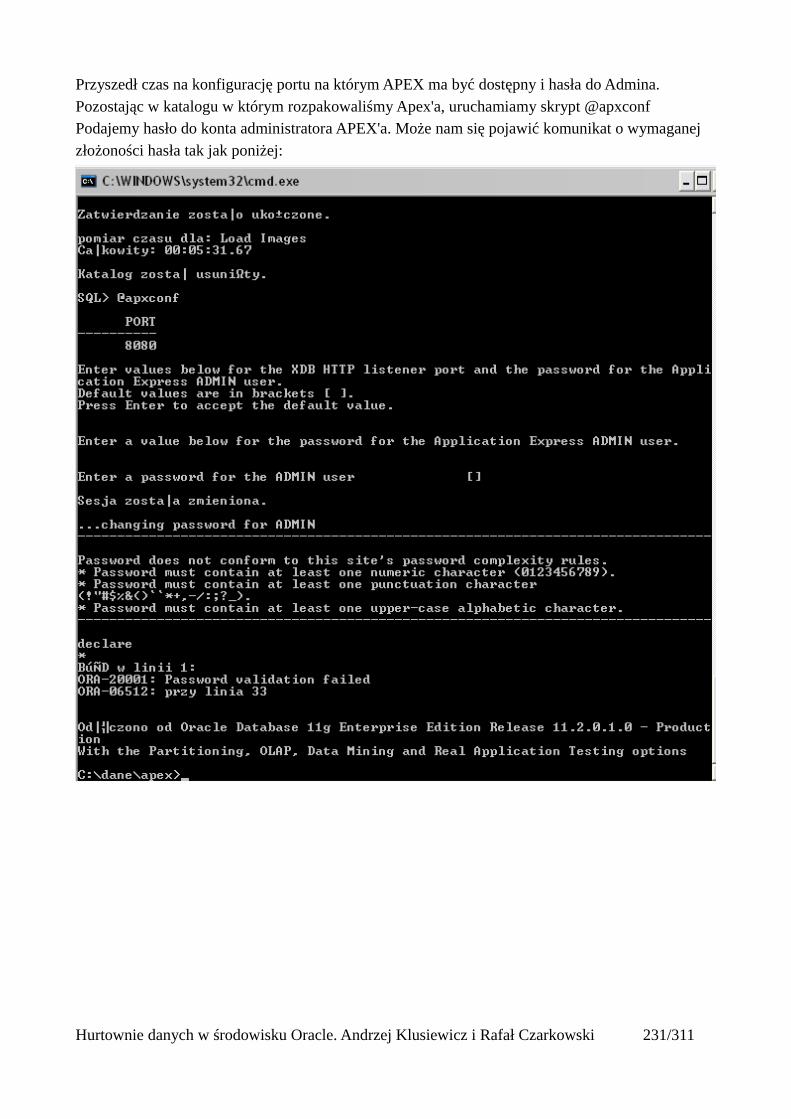
Przyszedł czas na konfigurację portu na którym APEX ma być dostępny i hasła do Admina. Pozostając w katalogu w którym rozpakowaliśmy Apex'a, uruchamiamy skrypt @apxconf Podajemy hasło do konta administratora APEX'a. Może nam się pojawić komunikat o wymaganej złożoności hasła tak jak poniżej:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 231/311
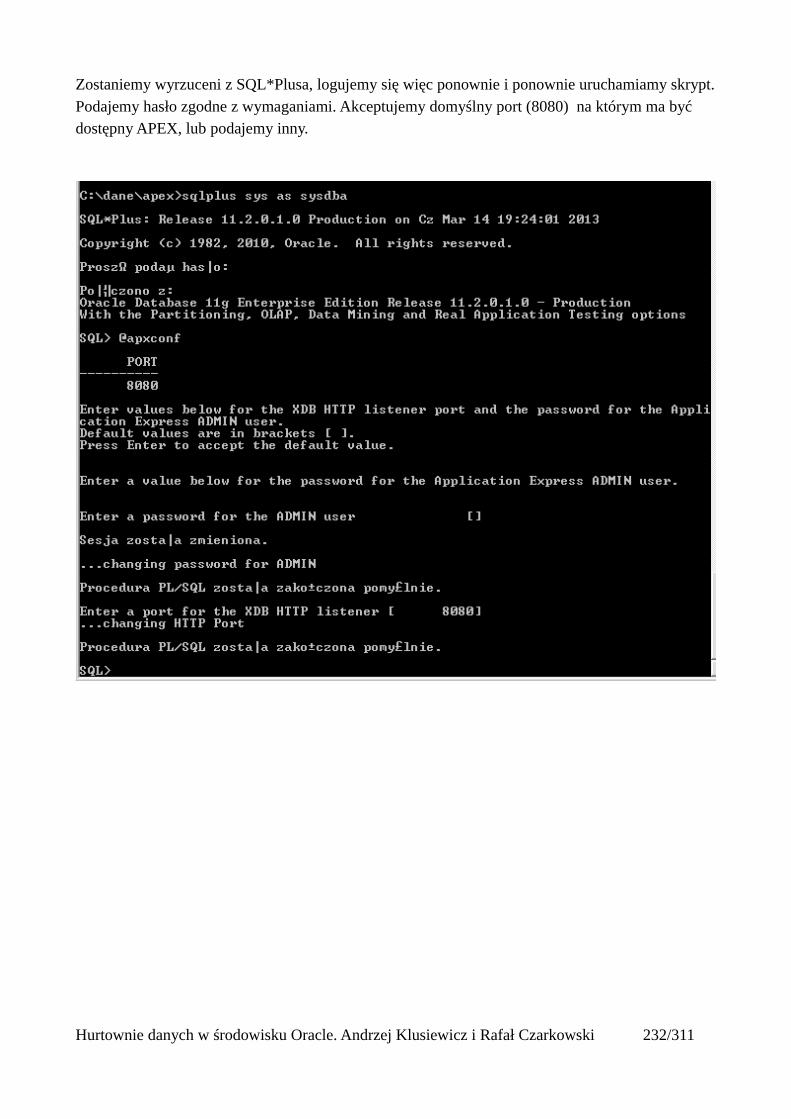
Zostaniemy wyrzuceni z SQL*Plusa, logujemy się więc ponownie i ponownie uruchamiamy skrypt.Podajemy hasło zgodne z wymaganiami. Akceptujemy domyślny port (8080) na którym ma być dostępny APEX, lub podajemy inny.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 232/311
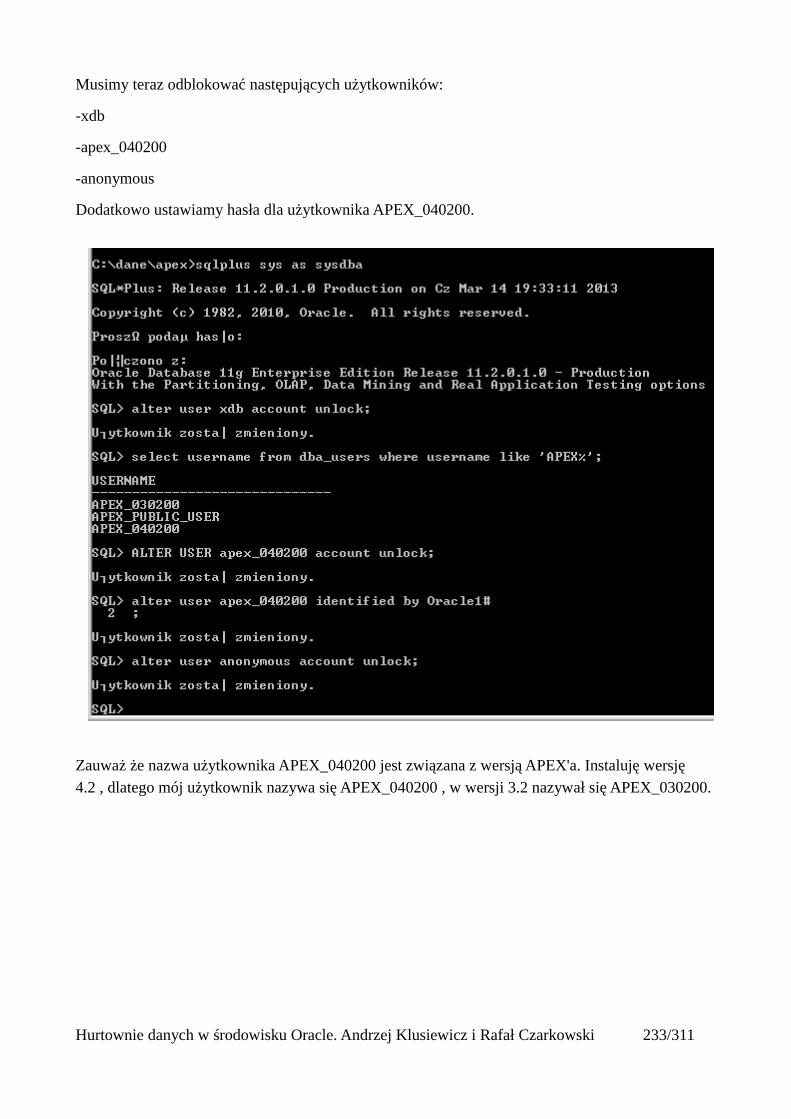
Musimy teraz odblokować następujących użytkowników:
-xdb
-apex_040200
-anonymous
Dodatkowo ustawiamy hasła dla użytkownika APEX_040200.
Zauważ że nazwa użytkownika APEX_040200 jest związana z wersją APEX'a. Instaluję wersję 4.2 , dlatego mój użytkownik nazywa się APEX_040200 , w wersji 3.2 nazywał się APEX_030200.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 233/311
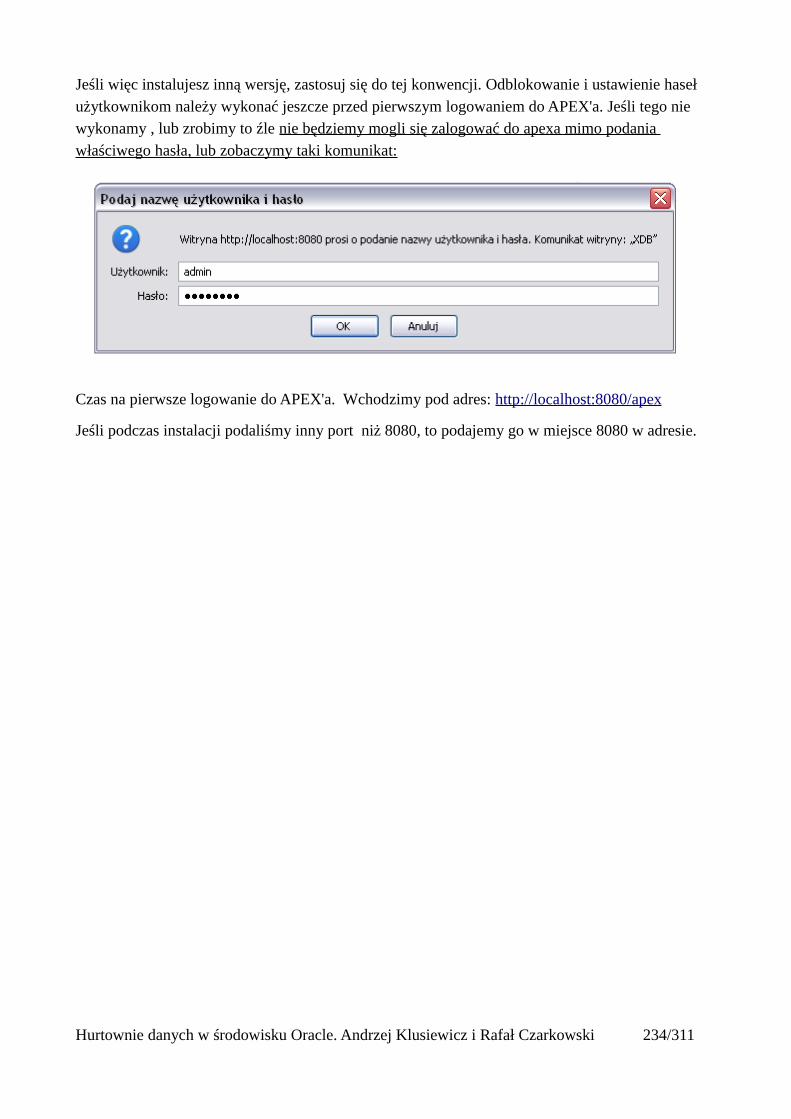
Jeśli więc instalujesz inną wersję, zastosuj się do tej konwencji. Odblokowanie i ustawienie haseł użytkownikom należy wykonać jeszcze przed pierwszym logowaniem do APEX'a. Jeśli tego nie wykonamy , lub zrobimy to źle nie będziemy mogli się zalogować do apexa mimo podania właściwego hasła, lub zobaczymy taki komunikat:
Czas na pierwsze logowanie do APEX'a. Wchodzimy pod adres: http://localhost:8080/apex
Jeśli podczas instalacji podaliśmy inny port niż 8080, to podajemy go w miejsce 8080 w adresie.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 234/311
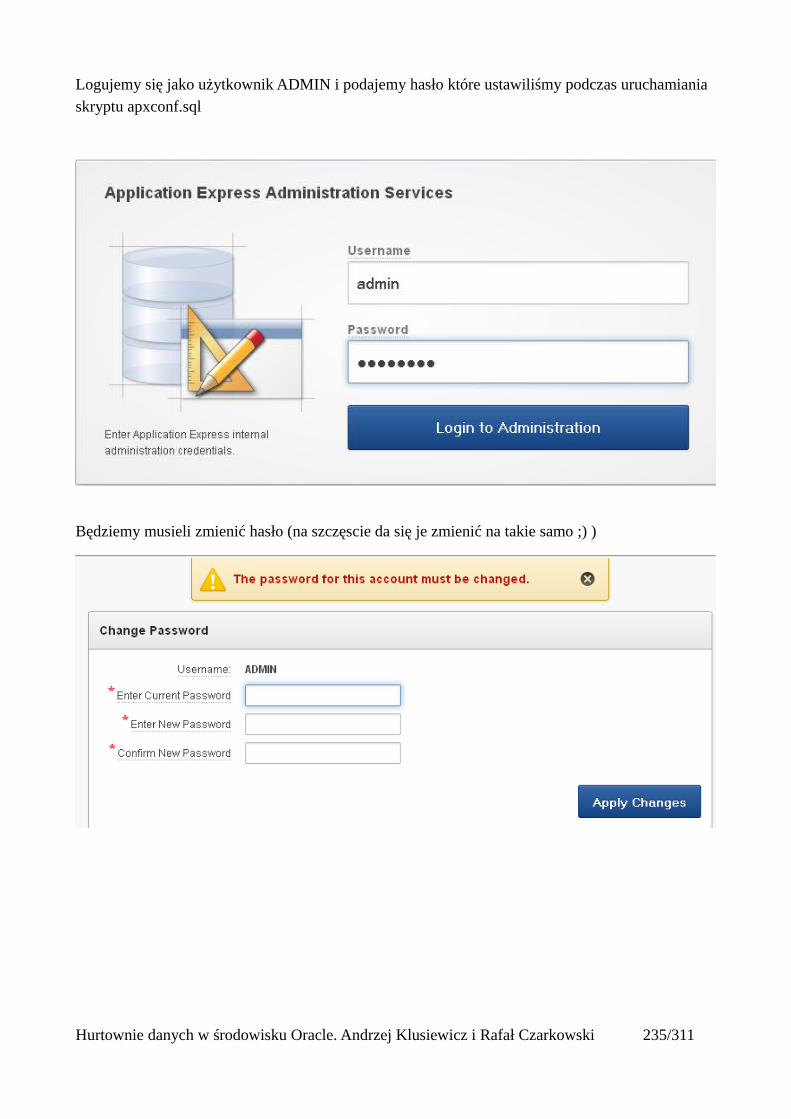
Logujemy się jako użytkownik ADMIN i podajemy hasło które ustawiliśmy podczas uruchamiania skryptu apxconf.sql
Będziemy musieli zmienić hasło (na szczęscie da się je zmienić na takie samo ;) )
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 235/311
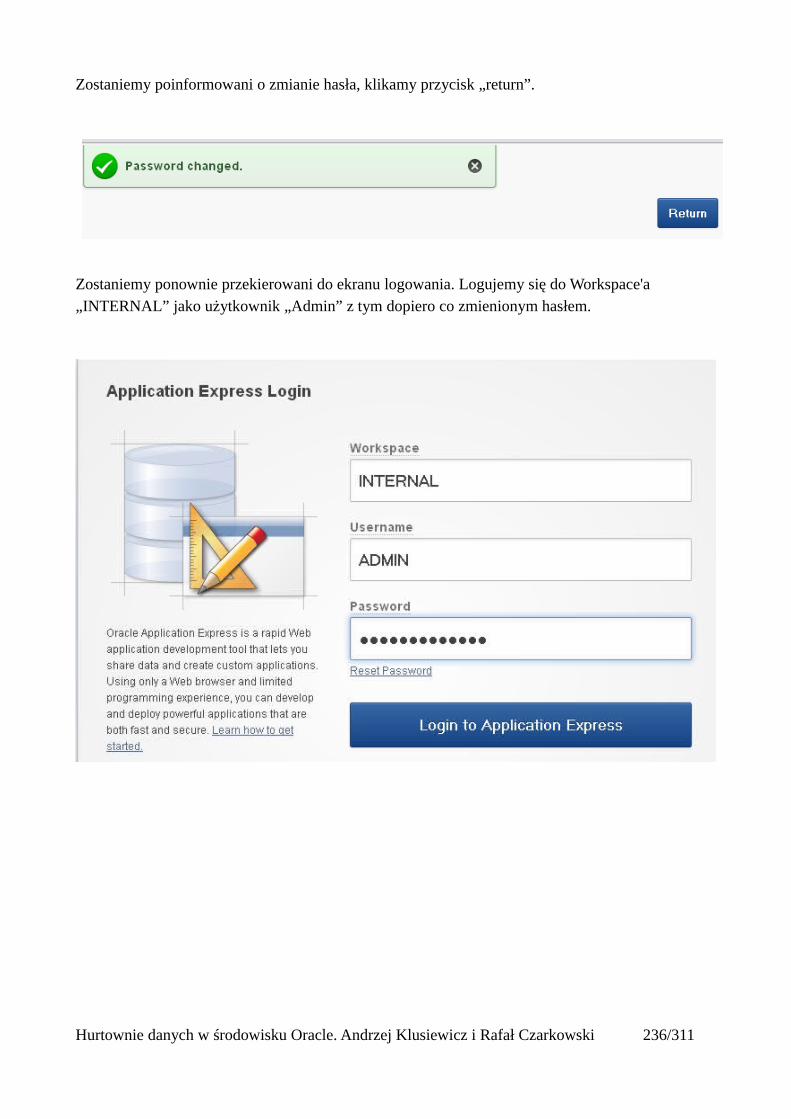
Zostaniemy poinformowani o zmianie hasła, klikamy przycisk „return”.
Zostaniemy ponownie przekierowani do ekranu logowania. Logujemy się do Workspace'a „INTERNAL” jako użytkownik „Admin” z tym dopiero co zmienionym hasłem.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 236/311
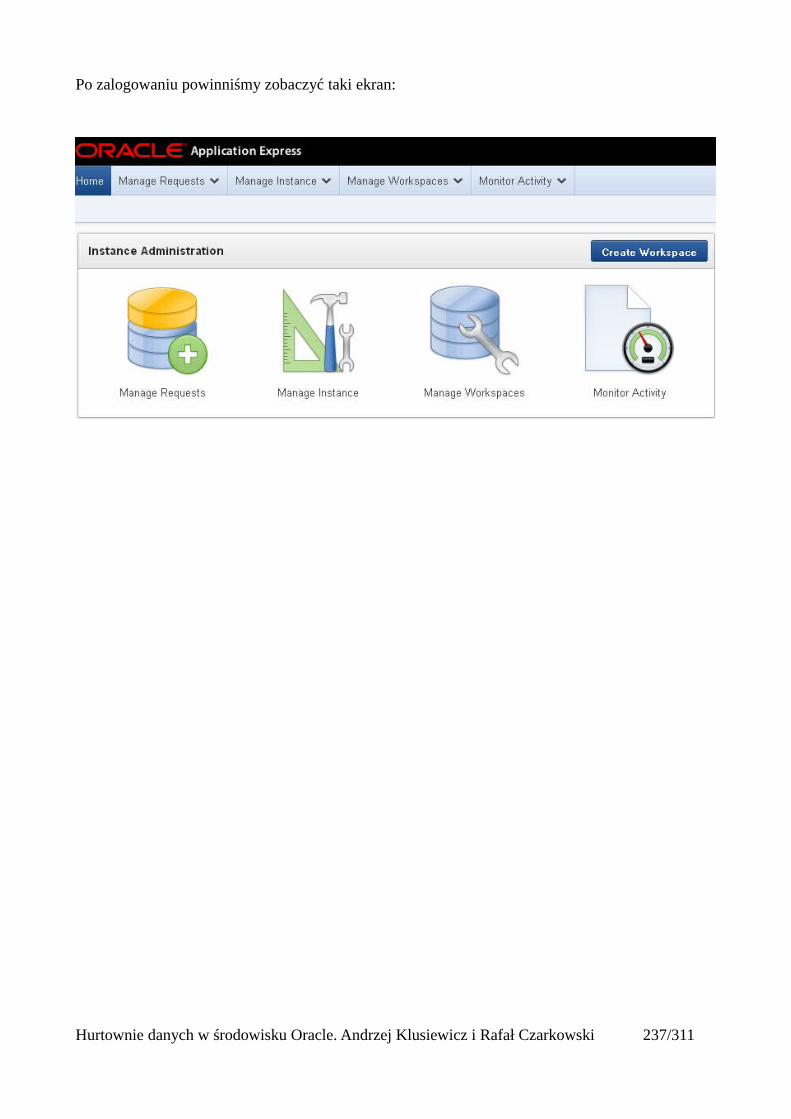
Po zalogowaniu powinniśmy zobaczyć taki ekran:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 237/311
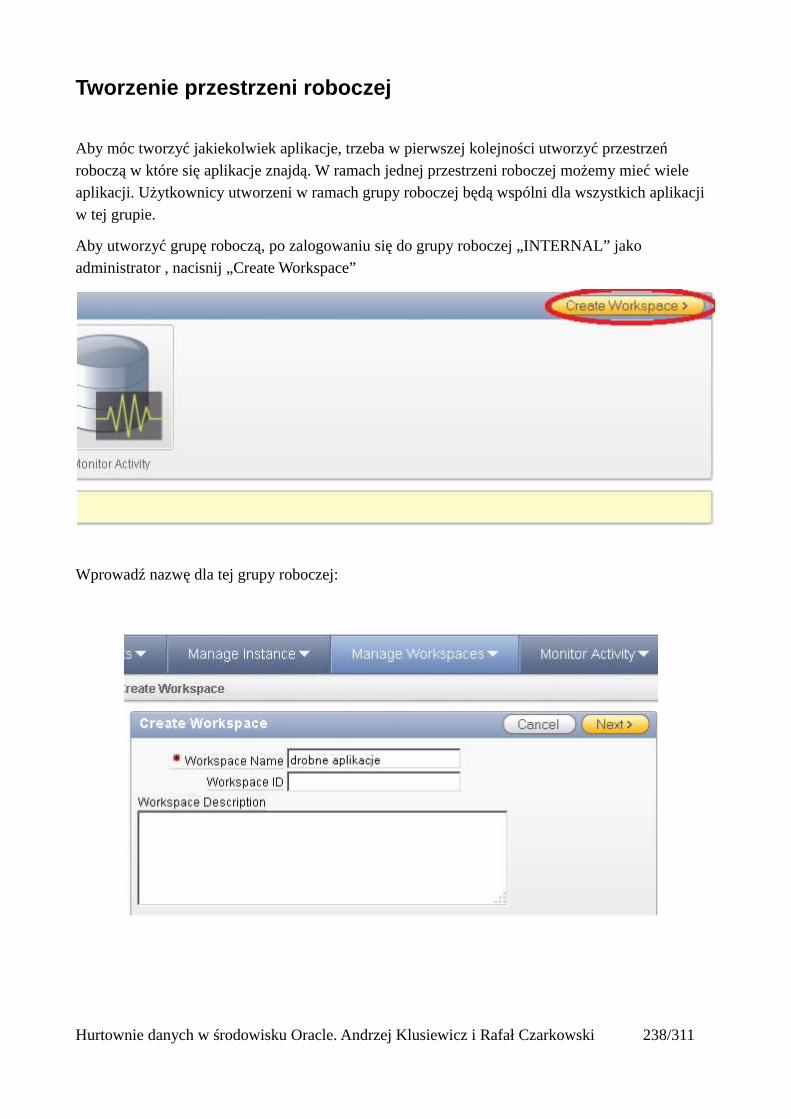
Tworzenie przestrzeni roboczej
Aby móc tworzyć jakiekolwiek aplikacje, trzeba w pierwszej kolejności utworzyć przestrzeń roboczą w które się aplikacje znajdą. W ramach jednej przestrzeni roboczej możemy mieć wiele aplikacji. Użytkownicy utworzeni w ramach grupy roboczej będą wspólni dla wszystkich aplikacji w tej grupie.
Aby utworzyć grupę roboczą, po zalogowaniu się do grupy roboczej „INTERNAL” jako administrator , nacisnij „Create Workspace”
Wprowadź nazwę dla tej grupy roboczej:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 238/311
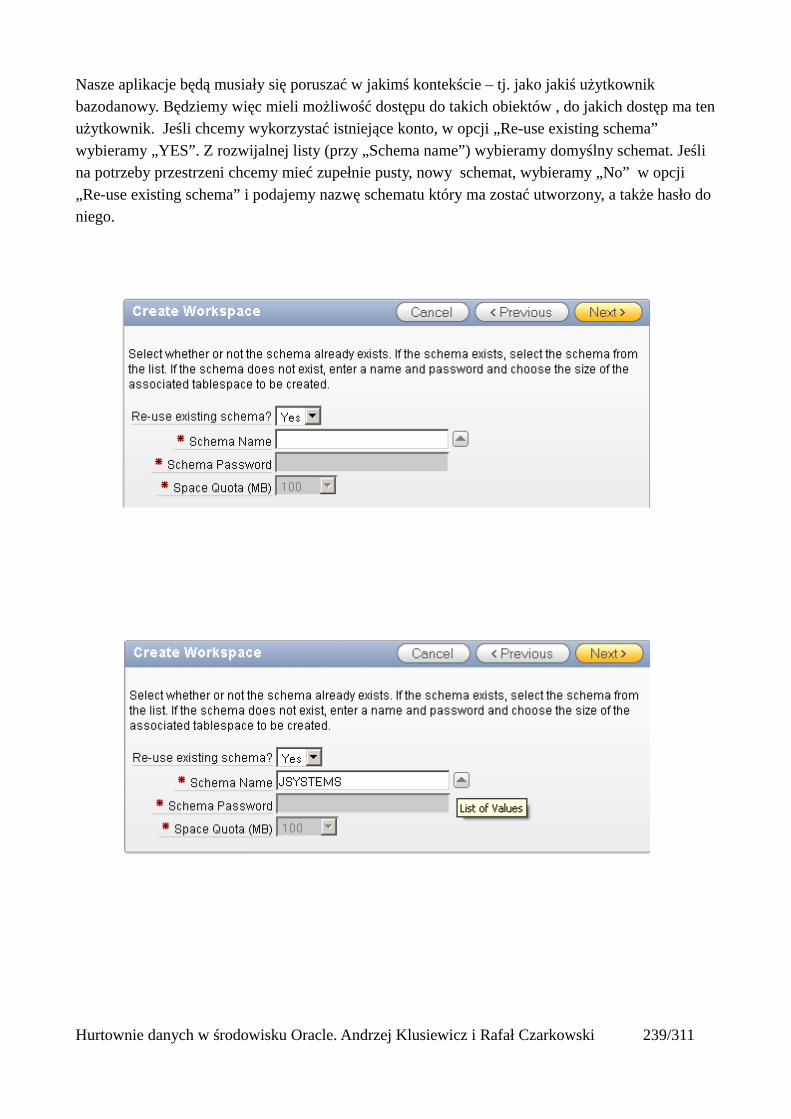
Nasze aplikacje będą musiały się poruszać w jakimś kontekście – tj. jako jakiś użytkownik bazodanowy. Będziemy więc mieli możliwość dostępu do takich obiektów , do jakich dostęp ma tenużytkownik. Jeśli chcemy wykorzystać istniejące konto, w opcji „Re-use existing schema” wybieramy „YES”. Z rozwijalnej listy (przy „Schema name”) wybieramy domyślny schemat. Jeśli na potrzeby przestrzeni chcemy mieć zupełnie pusty, nowy schemat, wybieramy „No” w opcji „Re-use existing schema” i podajemy nazwę schematu który ma zostać utworzony, a także hasło do niego.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 239/311
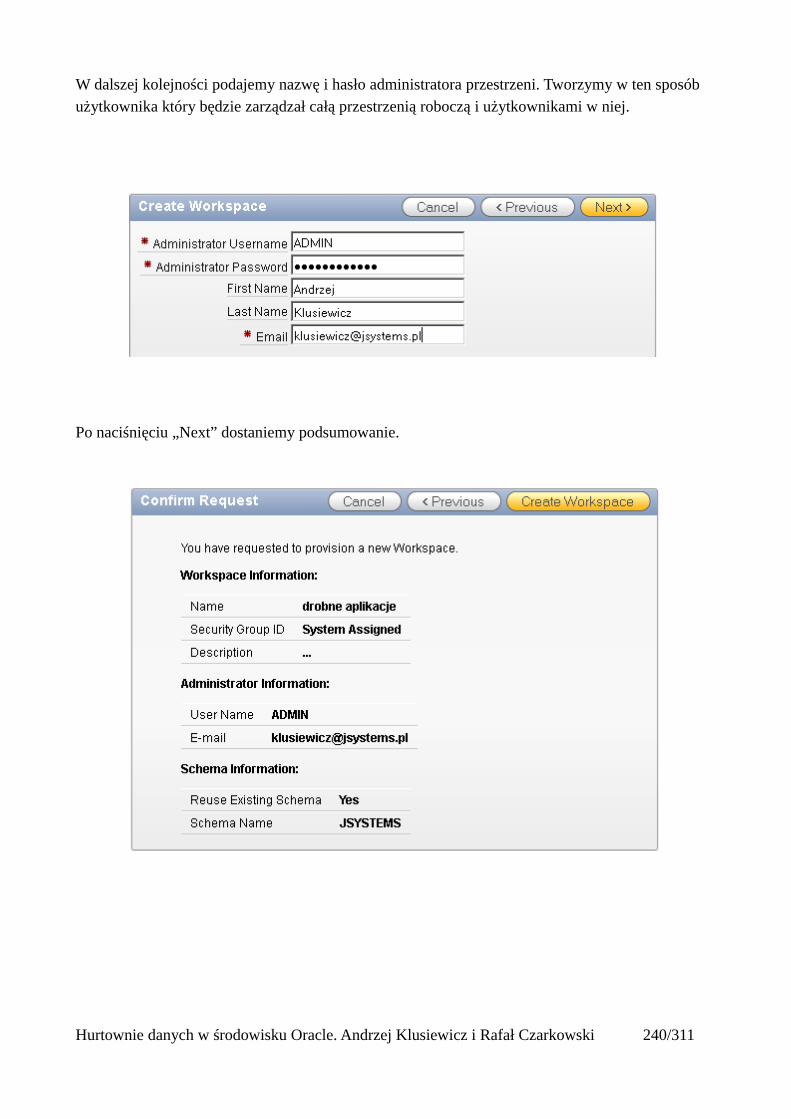
W dalszej kolejności podajemy nazwę i hasło administratora przestrzeni. Tworzymy w ten sposób użytkownika który będzie zarządzał całą przestrzenią roboczą i użytkownikami w niej.
Po naciśnięciu „Next” dostaniemy podsumowanie.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 240/311
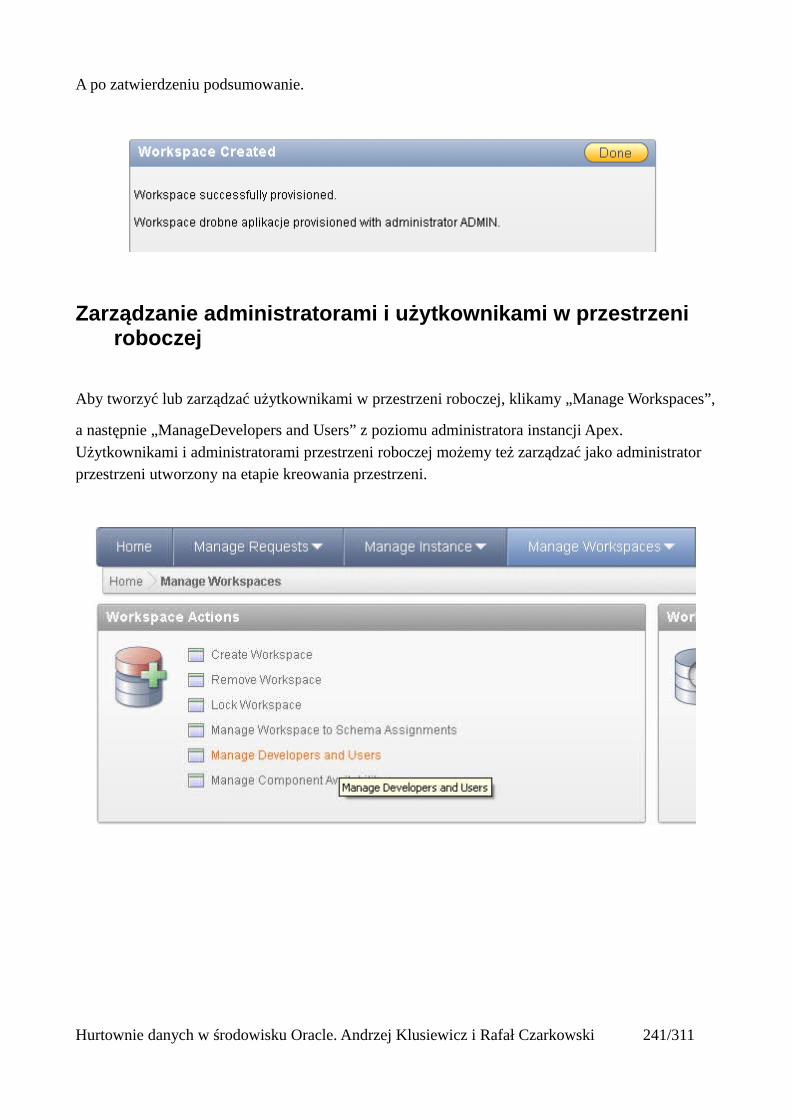
A po zatwierdzeniu podsumowanie.
Zarządzanie administratorami i użytkownikami w przestrzeni roboczej
Aby tworzyć lub zarządzać użytkownikami w przestrzeni roboczej, klikamy „Manage Workspaces”,
a następnie „ManageDevelopers and Users” z poziomu administratora instancji Apex. Użytkownikami i administratorami przestrzeni roboczej możemy też zarządzać jako administrator przestrzeni utworzony na etapie kreowania przestrzeni.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 241/311
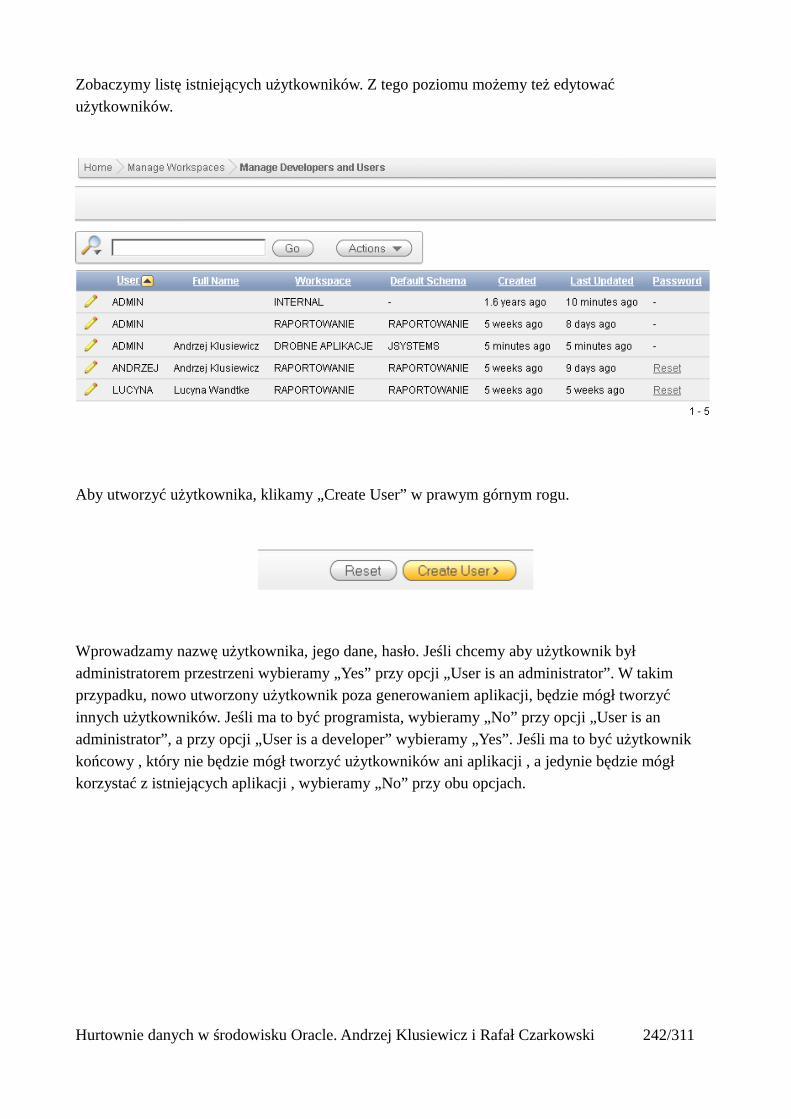
Zobaczymy listę istniejących użytkowników. Z tego poziomu możemy też edytować użytkowników.
Aby utworzyć użytkownika, klikamy „Create User” w prawym górnym rogu.
Wprowadzamy nazwę użytkownika, jego dane, hasło. Jeśli chcemy aby użytkownik był administratorem przestrzeni wybieramy „Yes” przy opcji „User is an administrator”. W takim przypadku, nowo utworzony użytkownik poza generowaniem aplikacji, będzie mógł tworzyć innych użytkowników. Jeśli ma to być programista, wybieramy „No” przy opcji „User is an administrator”, a przy opcji „User is a developer” wybieramy „Yes”. Jeśli ma to być użytkownik końcowy , który nie będzie mógł tworzyć użytkowników ani aplikacji , a jedynie będzie mógł korzystać z istniejących aplikacji , wybieramy „No” przy obu opcjach.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 242/311
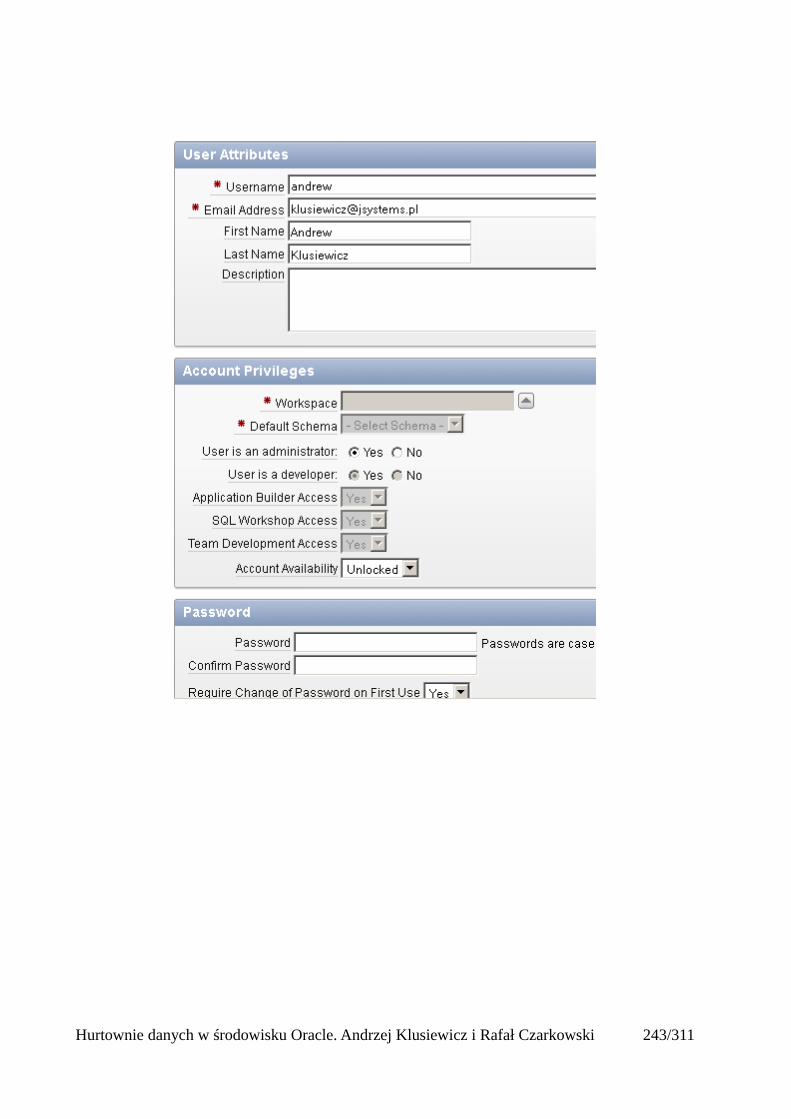
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 243/311
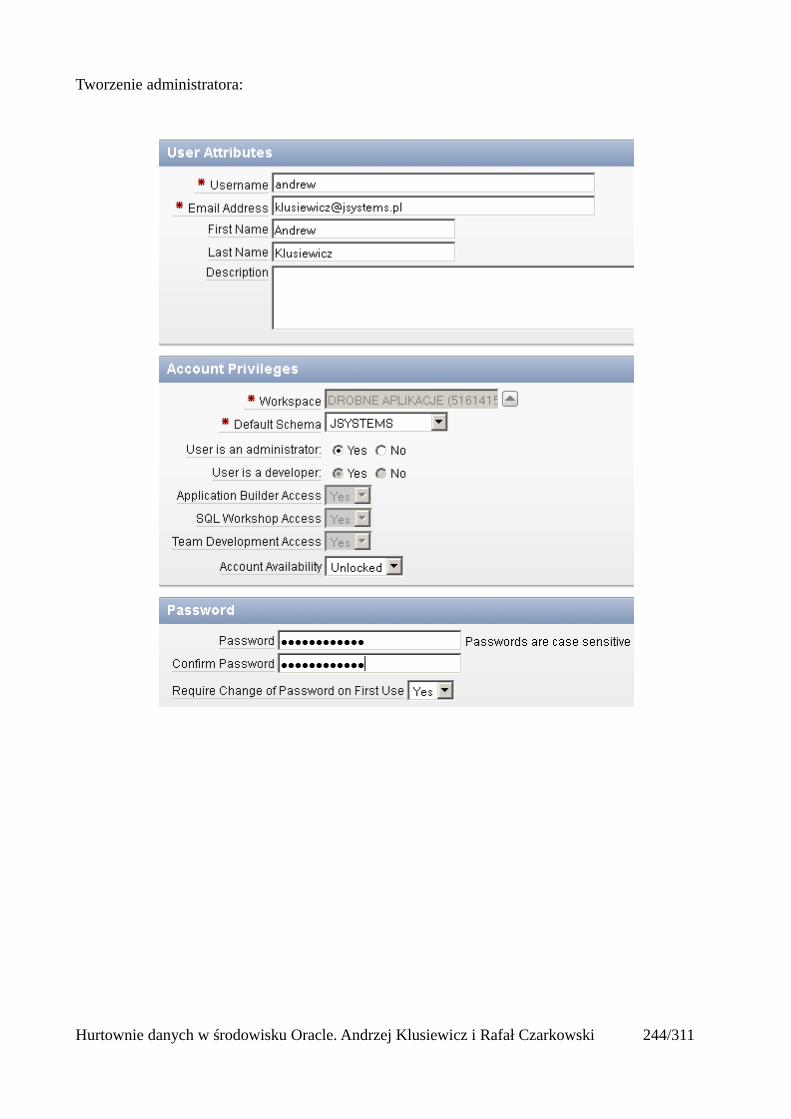
Tworzenie administratora:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 244/311
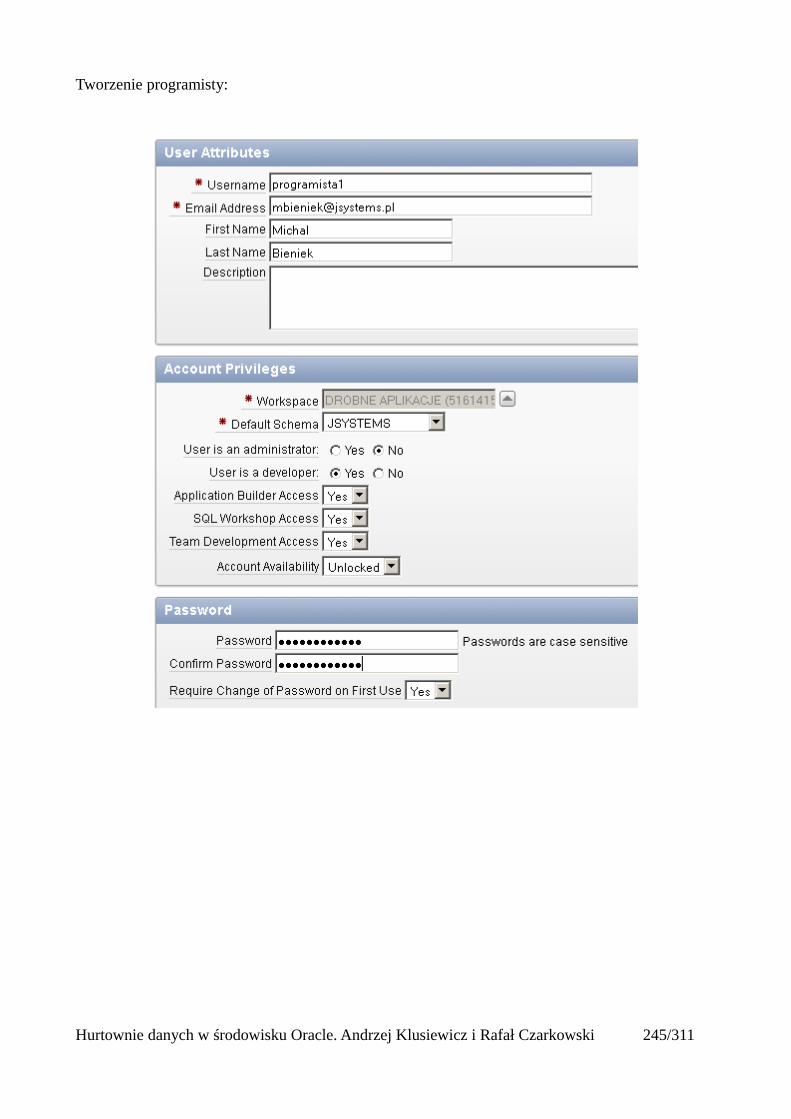
Tworzenie programisty:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 245/311
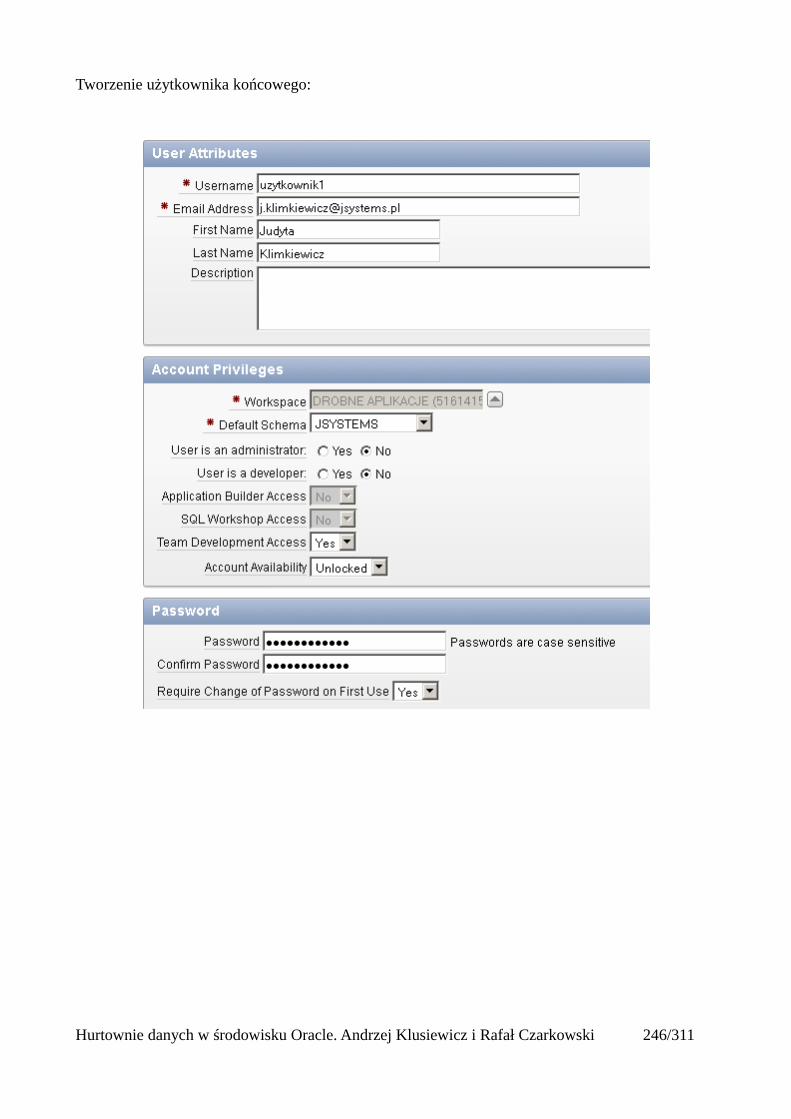
Tworzenie użytkownika końcowego:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 246/311
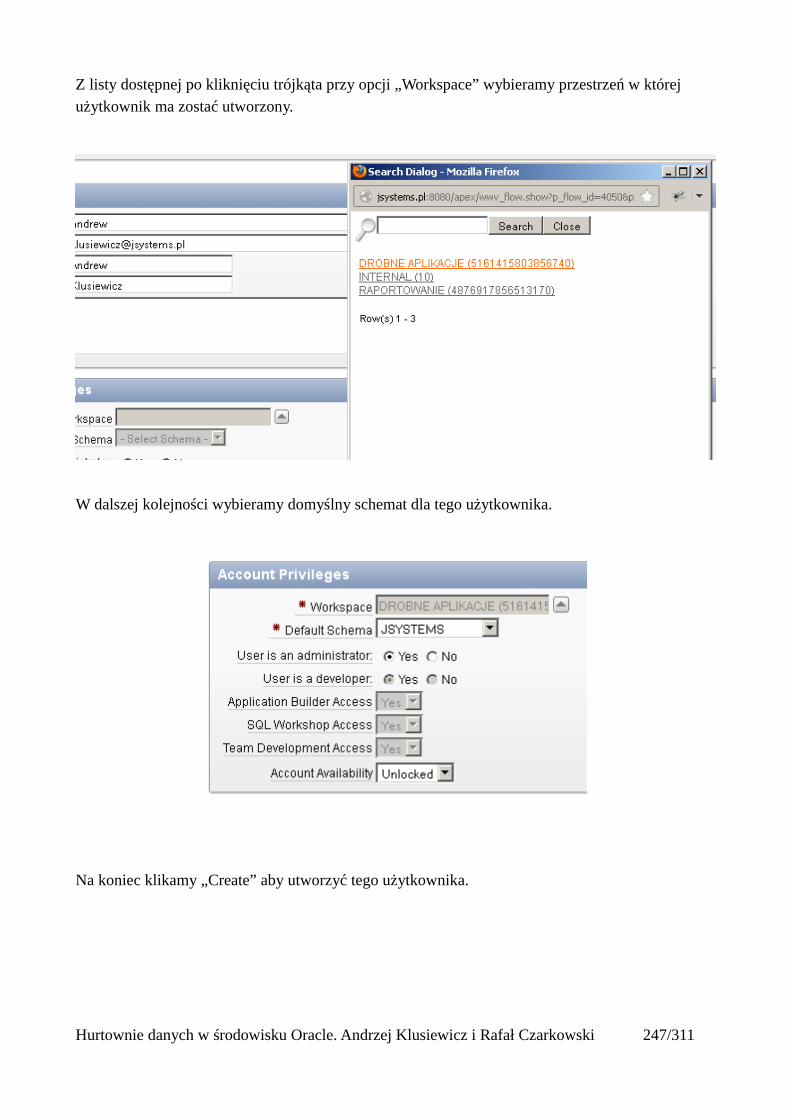
Z listy dostępnej po kliknięciu trójkąta przy opcji „Workspace” wybieramy przestrzeń w której użytkownik ma zostać utworzony.
W dalszej kolejności wybieramy domyślny schemat dla tego użytkownika.
Na koniec klikamy „Create” aby utworzyć tego użytkownika.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 247/311
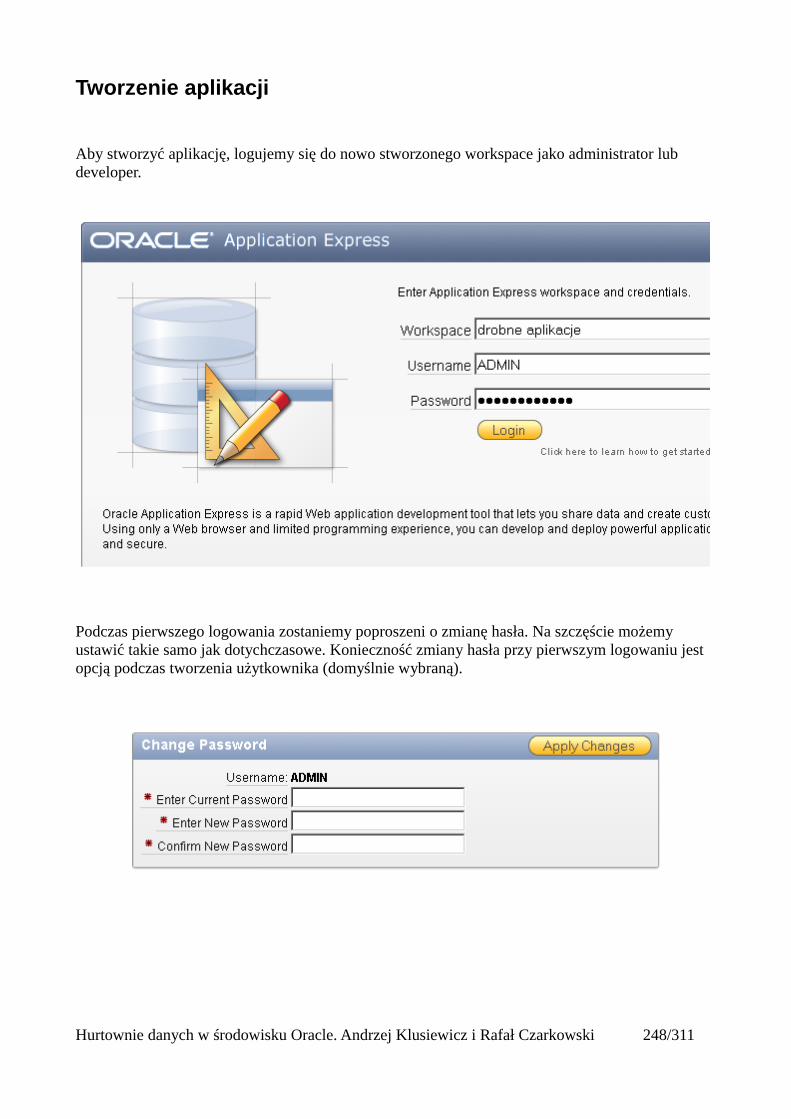
Tworzenie aplikacji
Aby stworzyć aplikację, logujemy się do nowo stworzonego workspace jako administrator lub developer.
Podczas pierwszego logowania zostaniemy poproszeni o zmianę hasła. Na szczęście możemy ustawić takie samo jak dotychczasowe. Konieczność zmiany hasła przy pierwszym logowaniu jest opcją podczas tworzenia użytkownika (domyślnie wybraną).
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 248/311

Po zalogowaniu wybieramy „Application Builder”
Na razie mamy tylko jedną aplikację przykładową. Aby stworzyć własną, klikamy „Create” znajdujące się w prawym górnym rogu.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 249/311
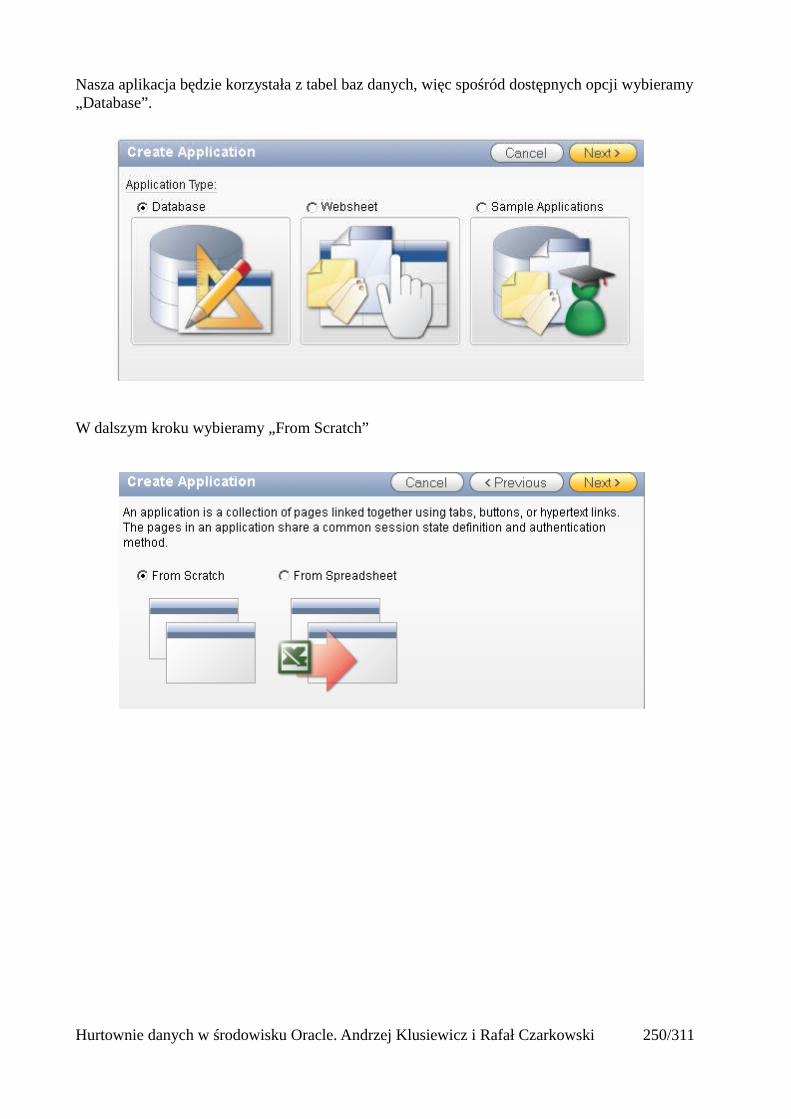
Nasza aplikacja będzie korzystała z tabel baz danych, więc spośród dostępnych opcji wybieramy „Database”.
W dalszym kroku wybieramy „From Scratch”
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 250/311
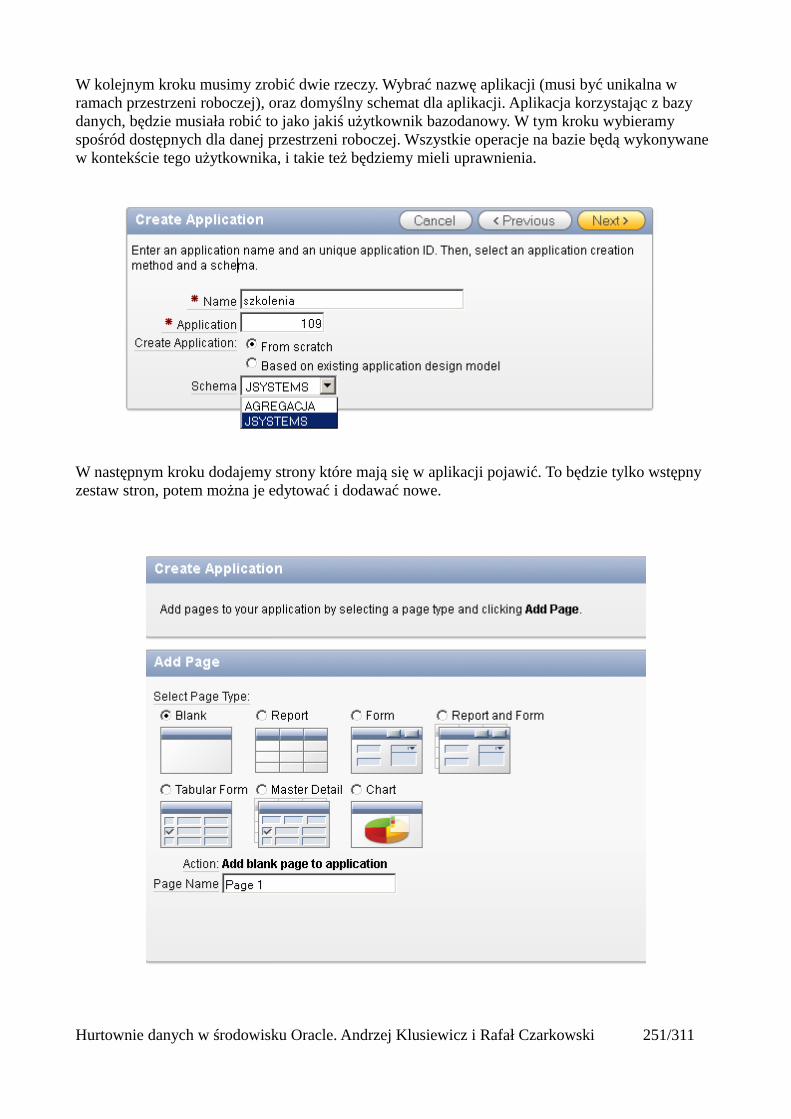
W kolejnym kroku musimy zrobić dwie rzeczy. Wybrać nazwę aplikacji (musi być unikalna w ramach przestrzeni roboczej), oraz domyślny schemat dla aplikacji. Aplikacja korzystając z bazy danych, będzie musiała robić to jako jakiś użytkownik bazodanowy. W tym kroku wybieramy spośród dostępnych dla danej przestrzeni roboczej. Wszystkie operacje na bazie będą wykonywane w kontekście tego użytkownika, i takie też będziemy mieli uprawnienia.
W następnym kroku dodajemy strony które mają się w aplikacji pojawić. To będzie tylko wstępny zestaw stron, potem można je edytować i dodawać nowe.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 251/311
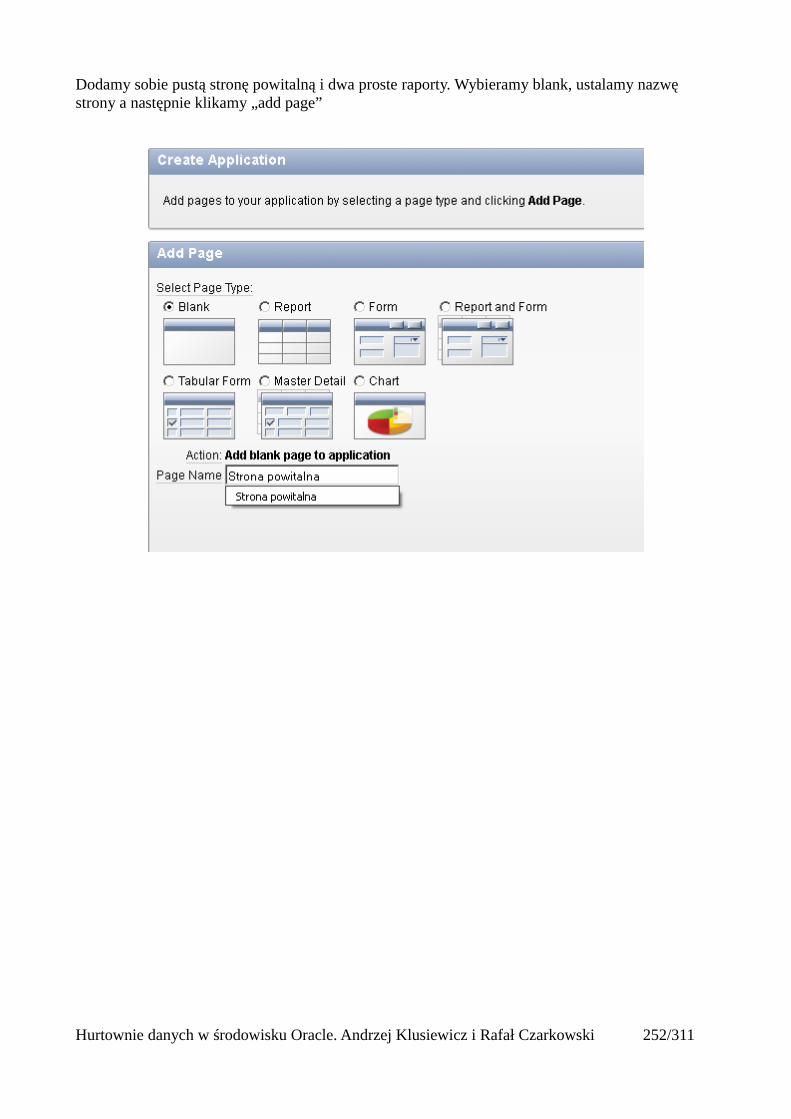
Dodamy sobie pustą stronę powitalną i dwa proste raporty. Wybieramy blank, ustalamy nazwę strony a następnie klikamy „add page”
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 252/311
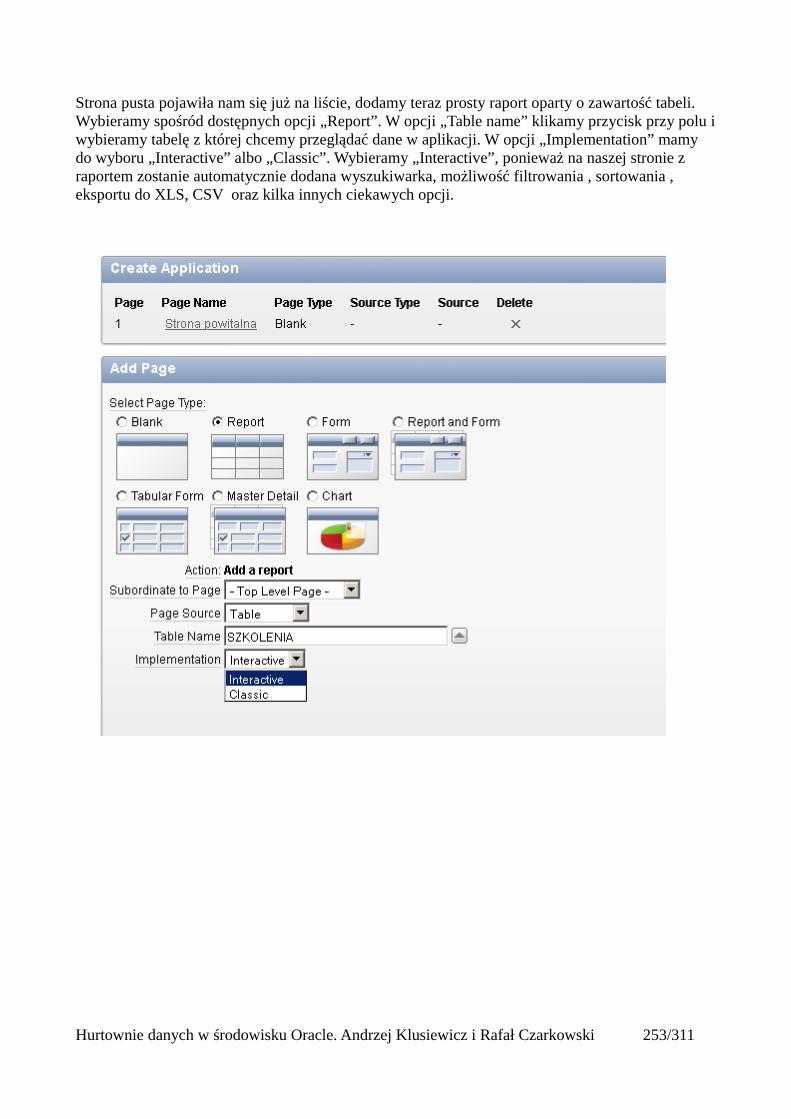
Strona pusta pojawiła nam się już na liście, dodamy teraz prosty raport oparty o zawartość tabeli. Wybieramy spośród dostępnych opcji „Report”. W opcji „Table name” klikamy przycisk przy polu iwybieramy tabelę z której chcemy przeglądać dane w aplikacji. W opcji „Implementation” mamy do wyboru „Interactive” albo „Classic”. Wybieramy „Interactive”, ponieważ na naszej stronie z raportem zostanie automatycznie dodana wyszukiwarka, możliwość filtrowania , sortowania , eksportu do XLS, CSV oraz kilka innych ciekawych opcji.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 253/311
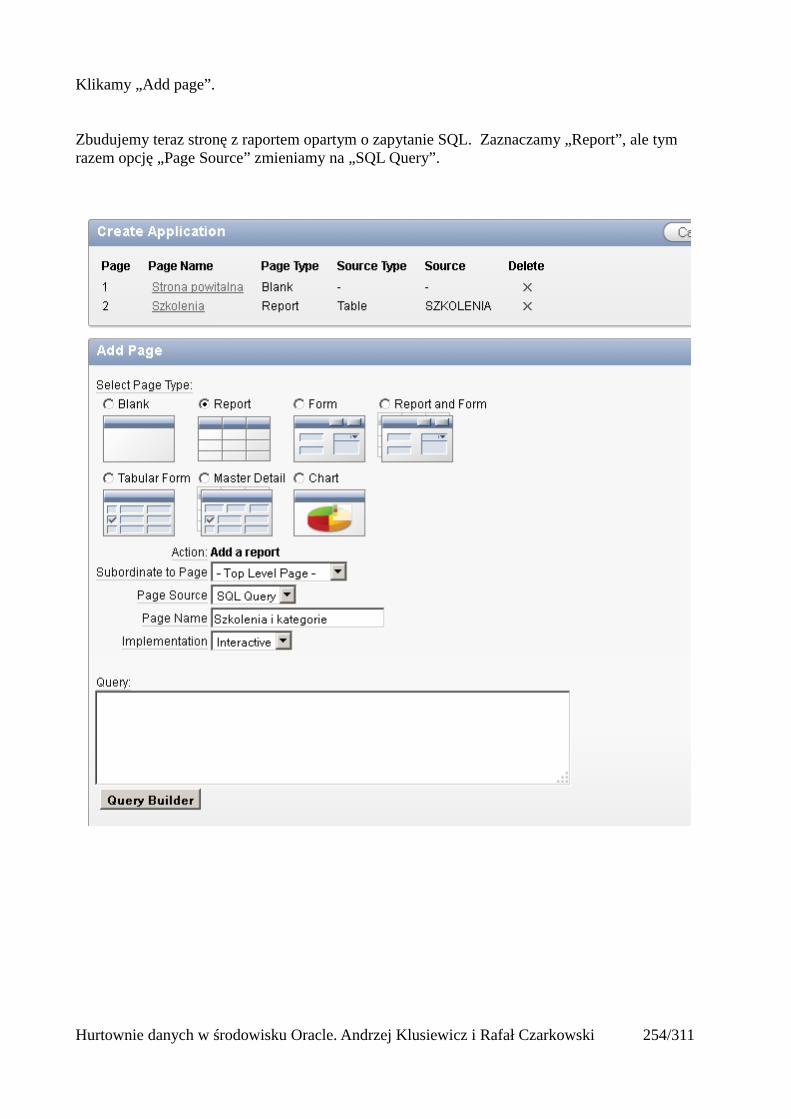
Klikamy „Add page”.
Zbudujemy teraz stronę z raportem opartym o zapytanie SQL. Zaznaczamy „Report”, ale tym razem opcję „Page Source” zmieniamy na „SQL Query”.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 254/311
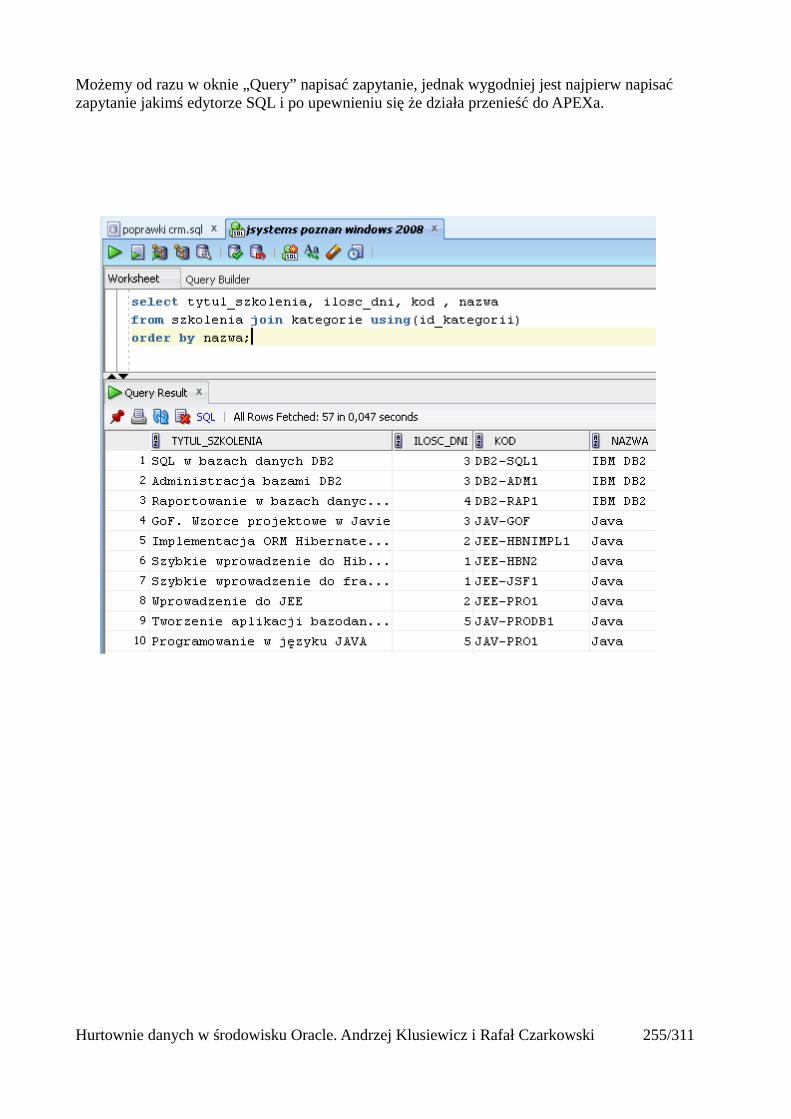
Możemy od razu w oknie „Query” napisać zapytanie, jednak wygodniej jest najpierw napisać zapytanie jakimś edytorze SQL i po upewnieniu się że działa przenieść do APEXa.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 255/311
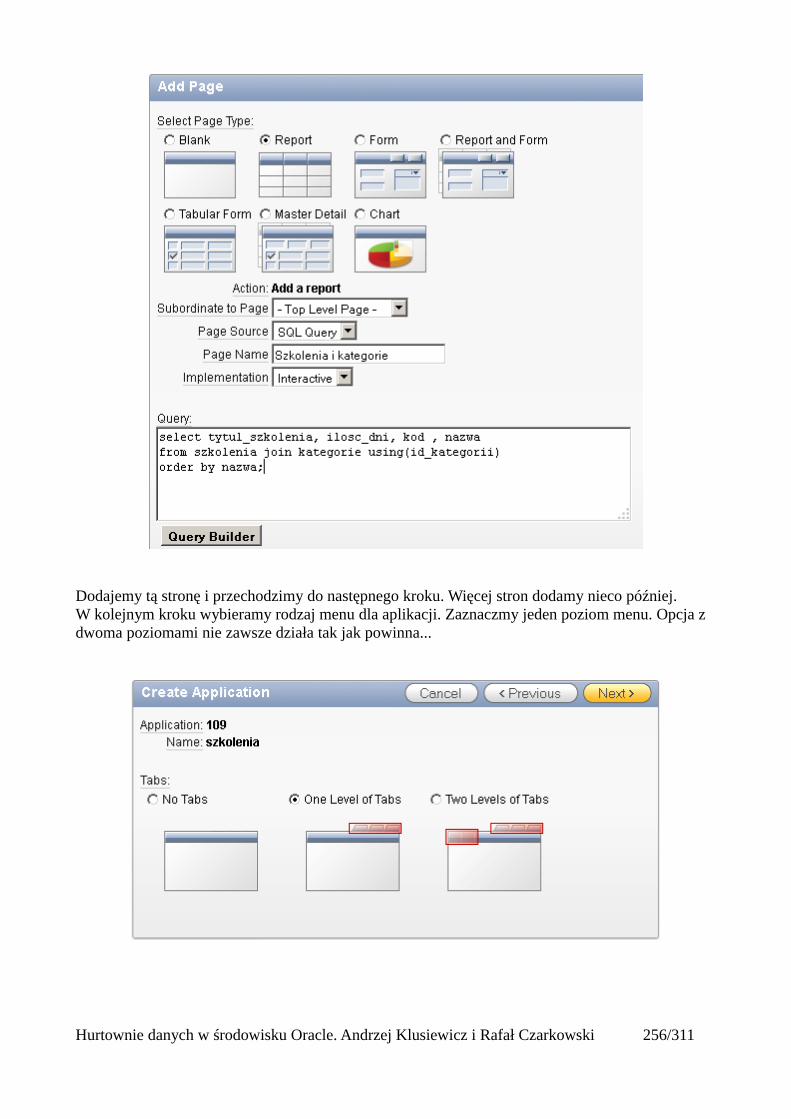
Dodajemy tą stronę i przechodzimy do następnego kroku. Więcej stron dodamy nieco później.W kolejnym kroku wybieramy rodzaj menu dla aplikacji. Zaznaczmy jeden poziom menu. Opcja z dwoma poziomami nie zawsze działa tak jak powinna...
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 256/311
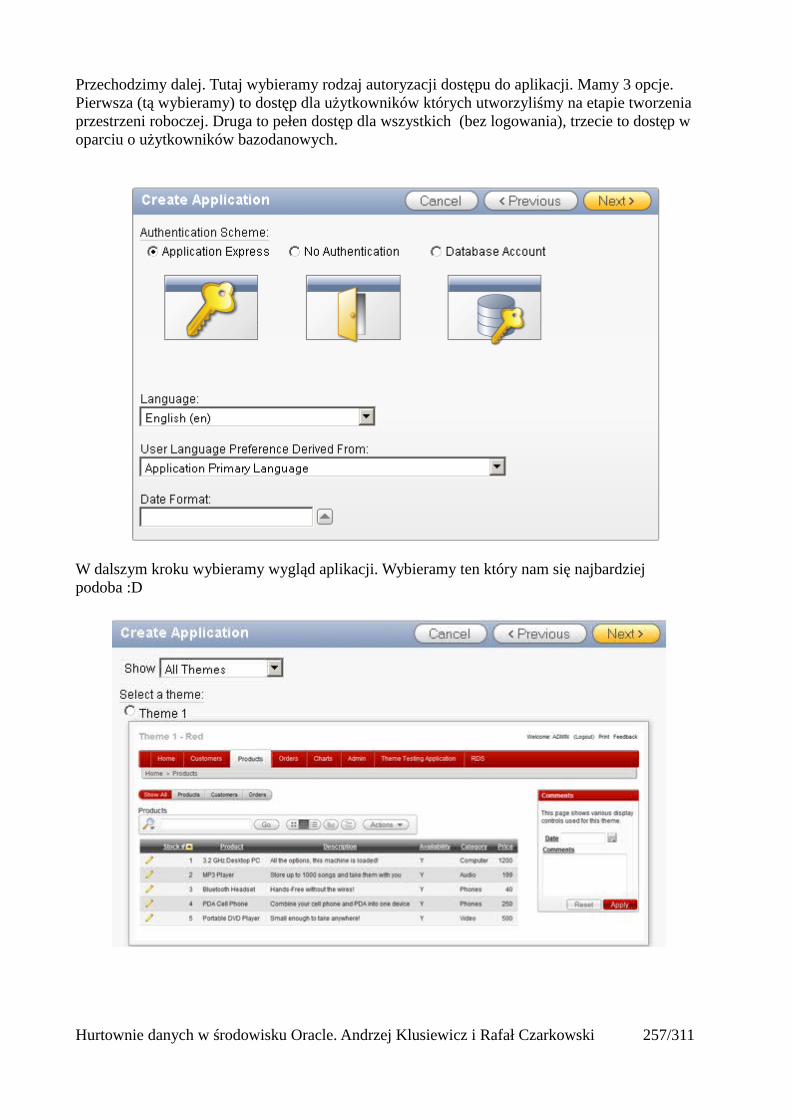
Przechodzimy dalej. Tutaj wybieramy rodzaj autoryzacji dostępu do aplikacji. Mamy 3 opcje. Pierwsza (tą wybieramy) to dostęp dla użytkowników których utworzyliśmy na etapie tworzenia przestrzeni roboczej. Druga to pełen dostęp dla wszystkich (bez logowania), trzecie to dostęp w oparciu o użytkowników bazodanowych.
W dalszym kroku wybieramy wygląd aplikacji. Wybieramy ten który nam się najbardziej podoba :D
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 257/311
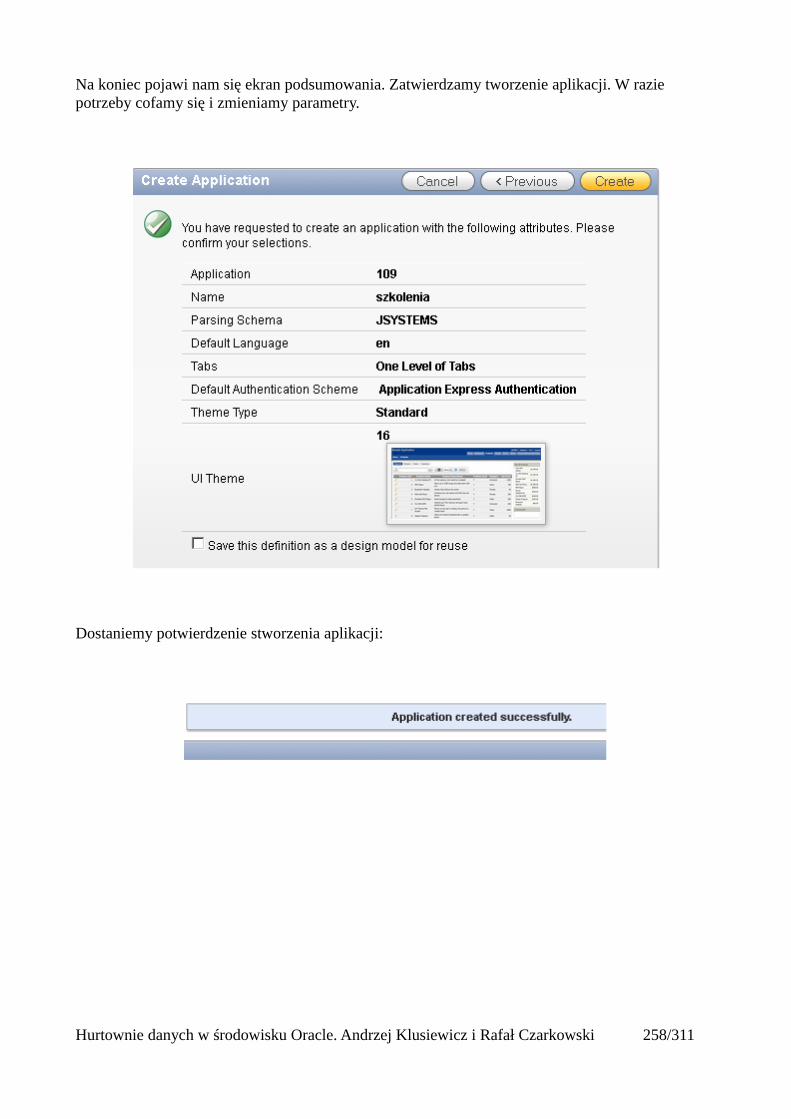
Na koniec pojawi nam się ekran podsumowania. Zatwierdzamy tworzenie aplikacji. W razie potrzeby cofamy się i zmieniamy parametry.
Dostaniemy potwierdzenie stworzenia aplikacji:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 258/311
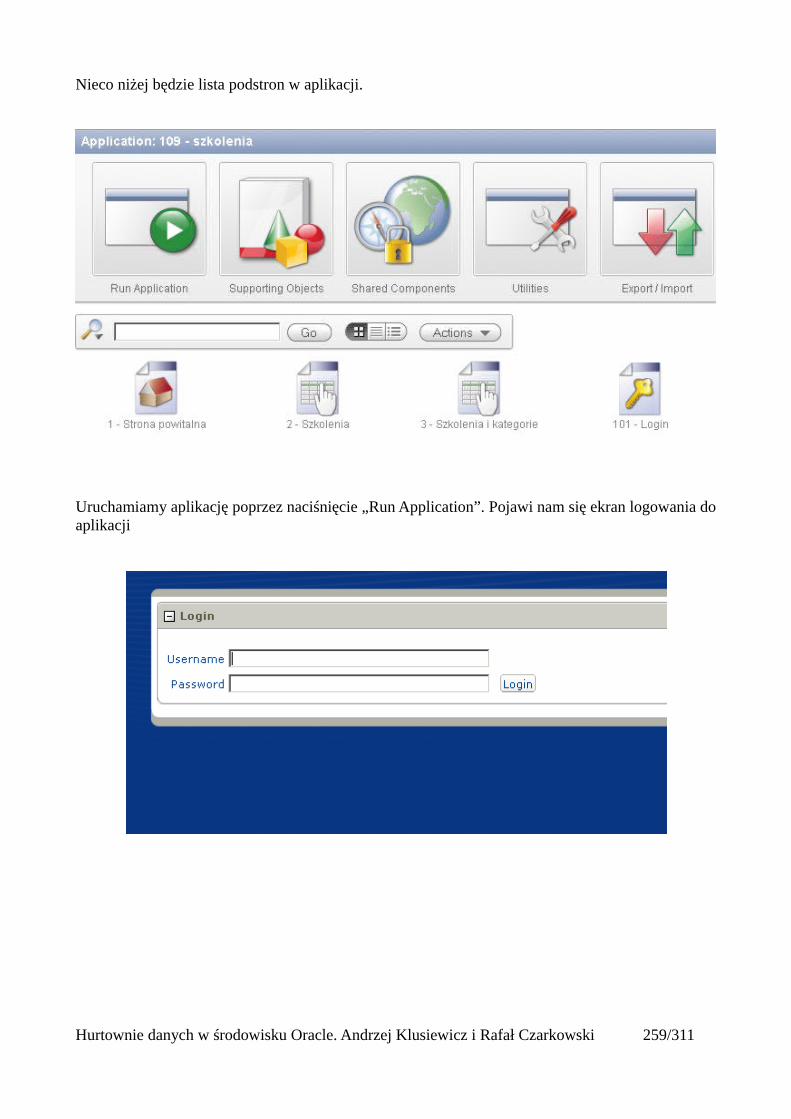
Nieco niżej będzie lista podstron w aplikacji.
Uruchamiamy aplikację poprzez naciśnięcie „Run Application”. Pojawi nam się ekran logowania doaplikacji
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 259/311
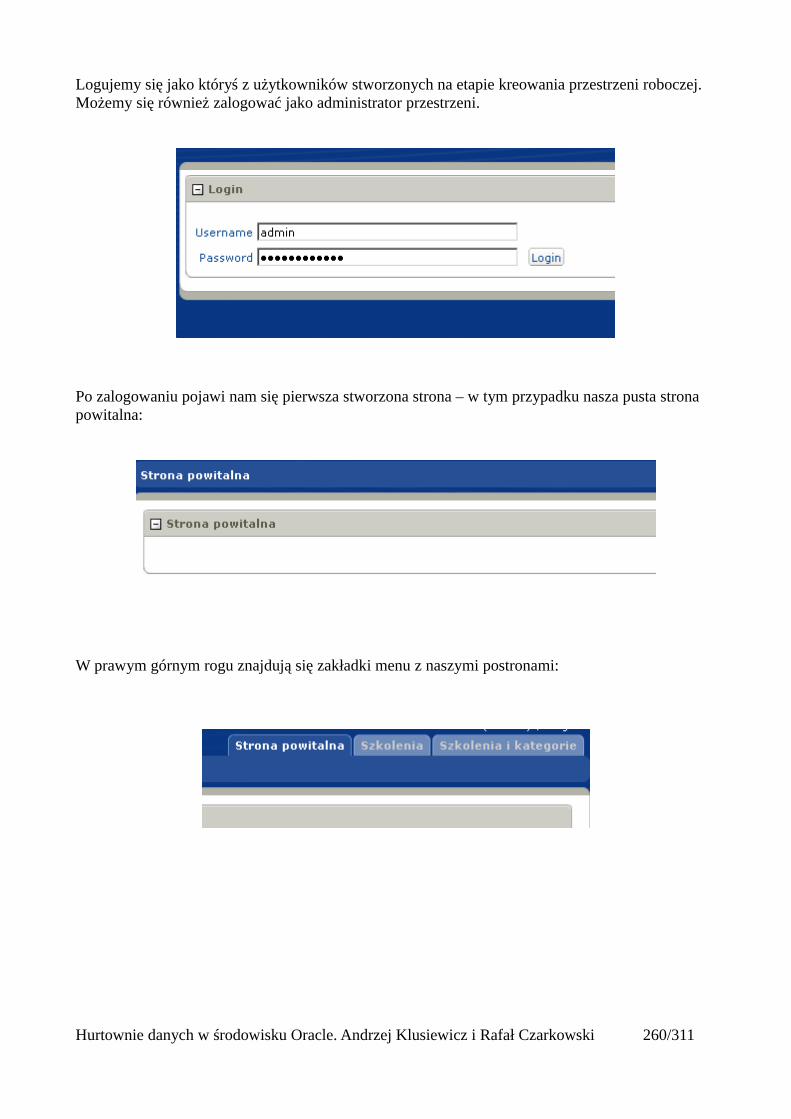
Logujemy się jako któryś z użytkowników stworzonych na etapie kreowania przestrzeni roboczej. Możemy się również zalogować jako administrator przestrzeni.
Po zalogowaniu pojawi nam się pierwsza stworzona strona – w tym przypadku nasza pusta strona powitalna:
W prawym górnym rogu znajdują się zakładki menu z naszymi postronami:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 260/311
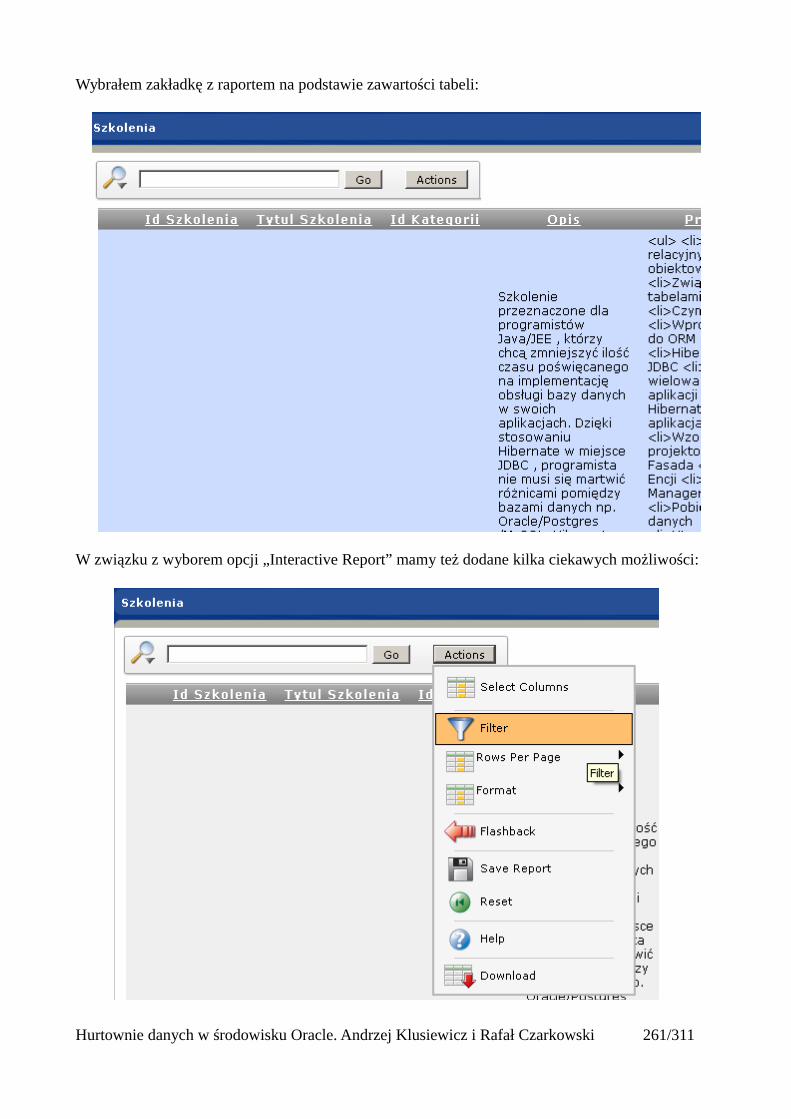
Wybrałem zakładkę z raportem na podstawie zawartości tabeli:
W związku z wyborem opcji „Interactive Report” mamy też dodane kilka ciekawych możliwości:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 261/311

Przy każdym wierszu , mamy ikonkę widoku szczegółowego:
Po jej kliknięciu zobaczymy ekran z danymi z jednego wybranego wiersza.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 262/311

Podstrona z raportem na podstawie zapytania SQL:
Dodawanie raportów
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 263/311
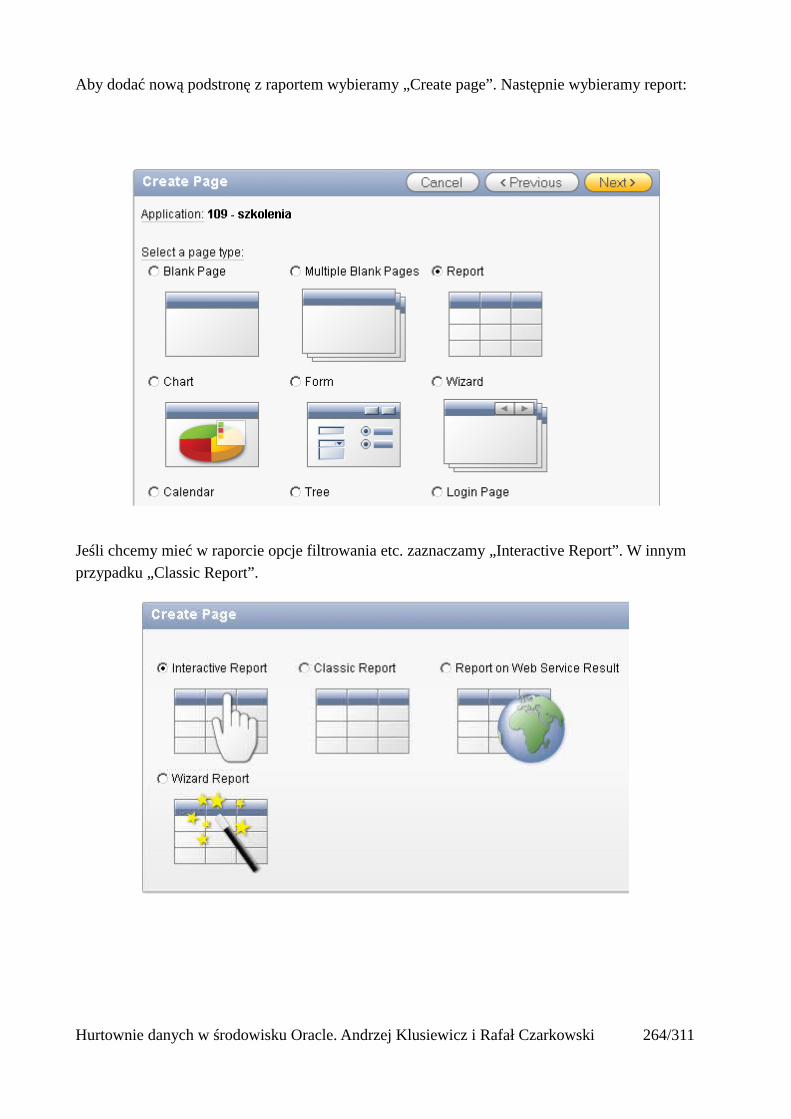
Aby dodać nową podstronę z raportem wybieramy „Create page”. Następnie wybieramy report:
Jeśli chcemy mieć w raporcie opcje filtrowania etc. zaznaczamy „Interactive Report”. W innym przypadku „Classic Report”.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 264/311
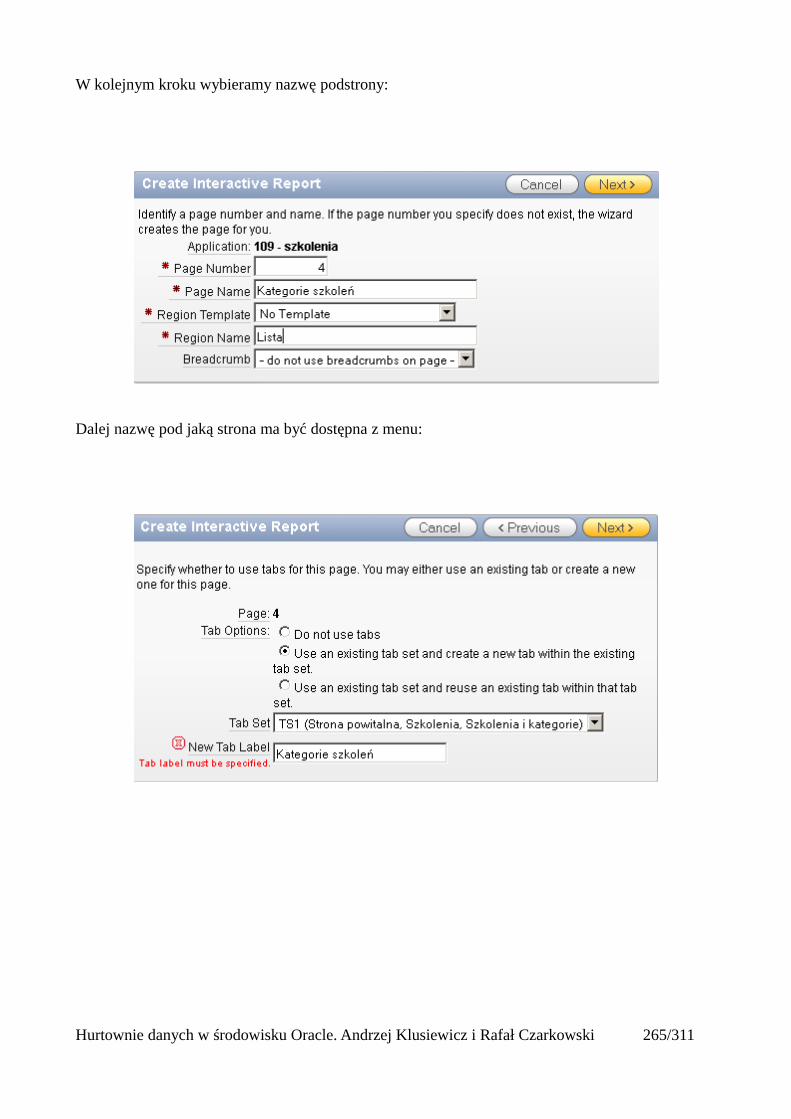
W kolejnym kroku wybieramy nazwę podstrony:
Dalej nazwę pod jaką strona ma być dostępna z menu:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 265/311
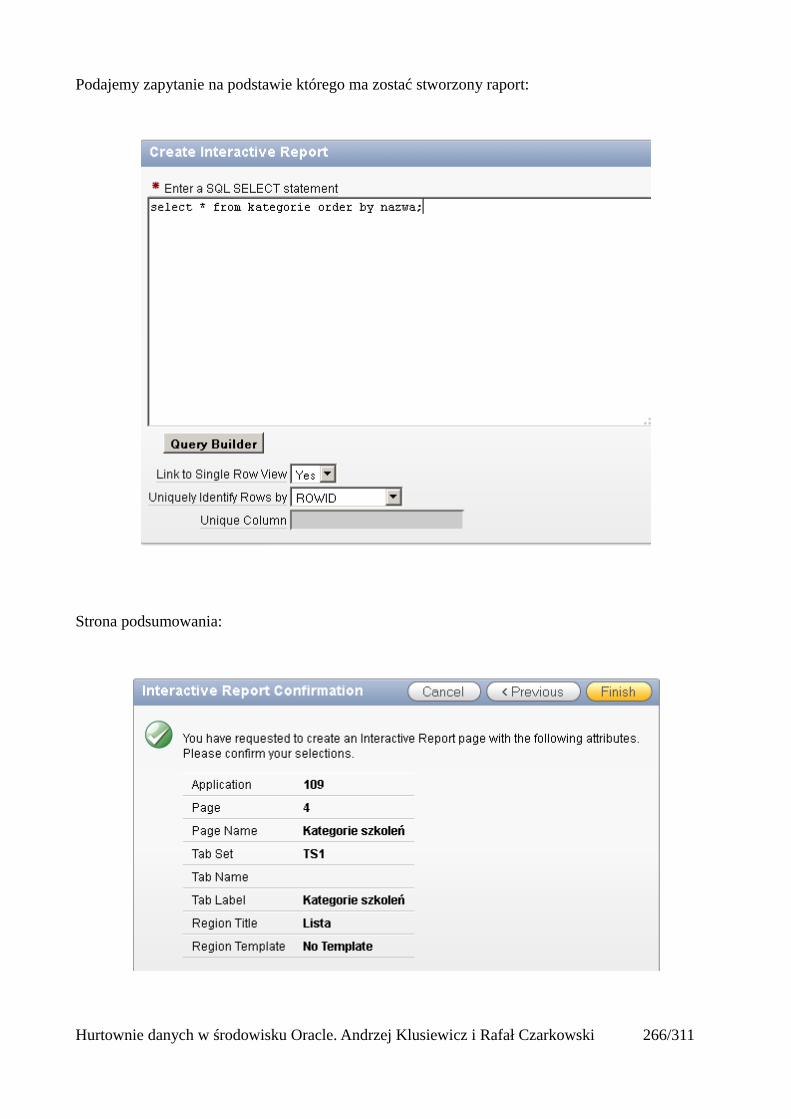
Podajemy zapytanie na podstawie którego ma zostać stworzony raport:
Strona podsumowania:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 266/311
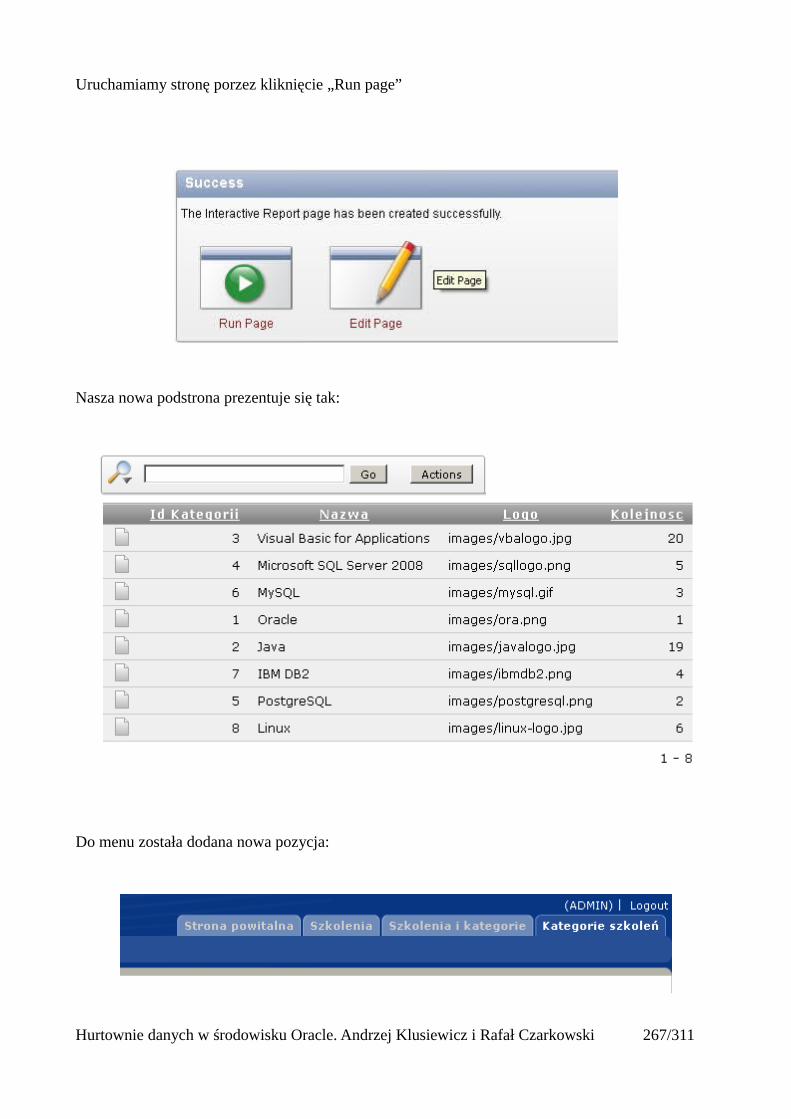
Uruchamiamy stronę porzez kliknięcie „Run page”
Nasza nowa podstrona prezentuje się tak:
Do menu została dodana nowa pozycja:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 267/311
Edycja stron
Jeśli zechcemy zmienić stronę, np. zapytanie w raporcie, wybieramy „Application Builder”, wchodzimy do naszej aplikacji:
Z listy dostępnej po kliknięciu prawym przyciskiem myszy na wybranej podstronie wybieramy „Edit”.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 268/311
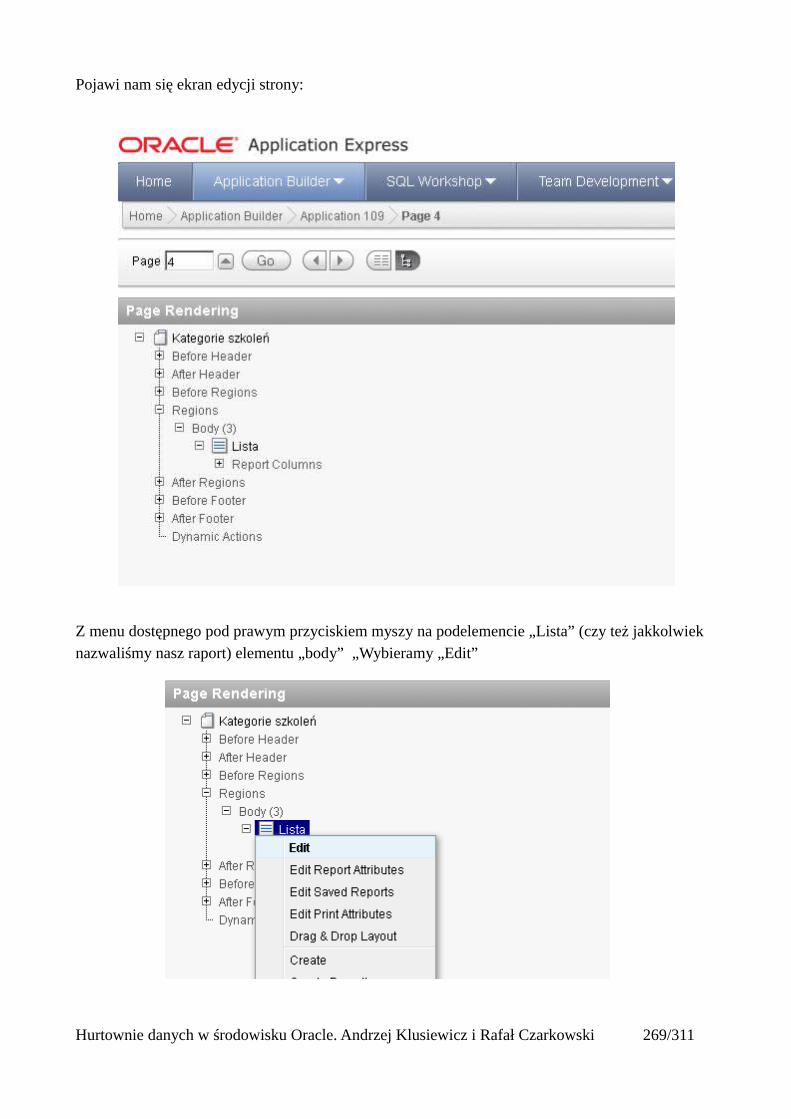
Pojawi nam się ekran edycji strony:
Z menu dostępnego pod prawym przyciskiem myszy na podelemencie „Lista” (czy też jakkolwiek nazwaliśmy nasz raport) elementu „body” „Wybieramy „Edit”
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 269/311
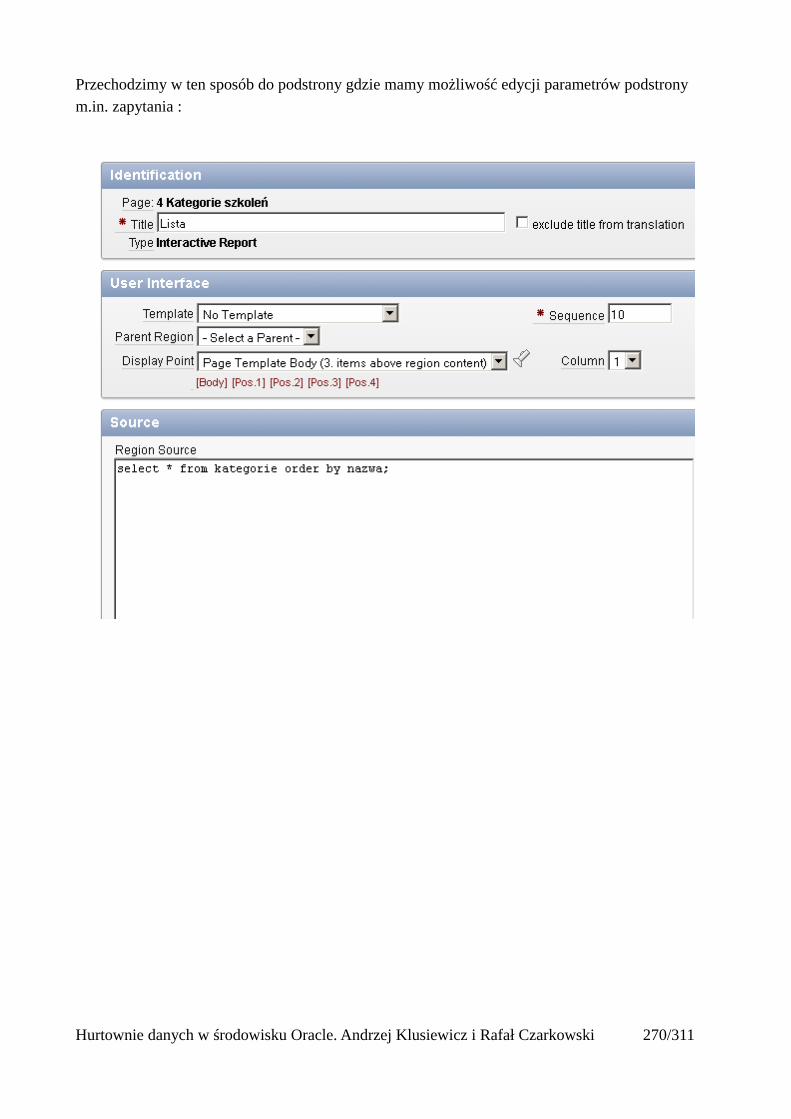
Przechodzimy w ten sposób do podstrony gdzie mamy możliwość edycji parametrów podstrony m.in. zapytania :
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 270/311
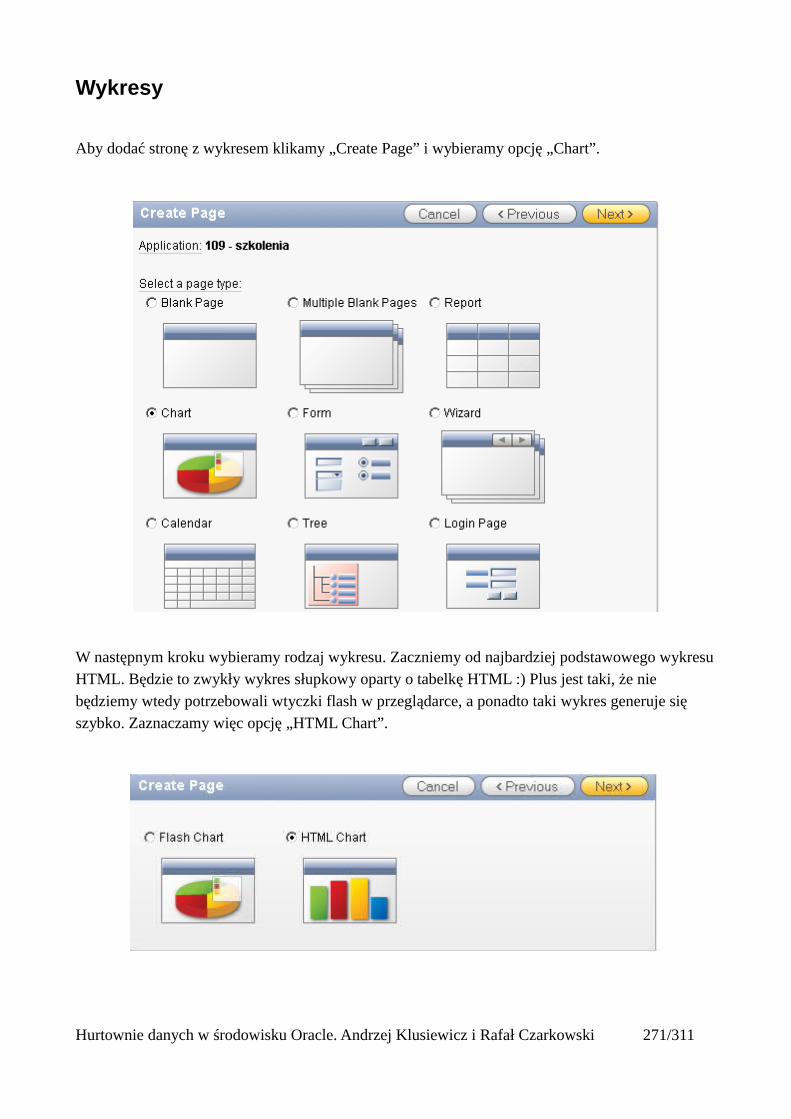
Wykresy
Aby dodać stronę z wykresem klikamy „Create Page” i wybieramy opcję „Chart”.
W następnym kroku wybieramy rodzaj wykresu. Zaczniemy od najbardziej podstawowego wykresuHTML. Będzie to zwykły wykres słupkowy oparty o tabelkę HTML :) Plus jest taki, że nie będziemy wtedy potrzebowali wtyczki flash w przeglądarce, a ponadto taki wykres generuje się szybko. Zaznaczamy więc opcję „HTML Chart”.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 271/311
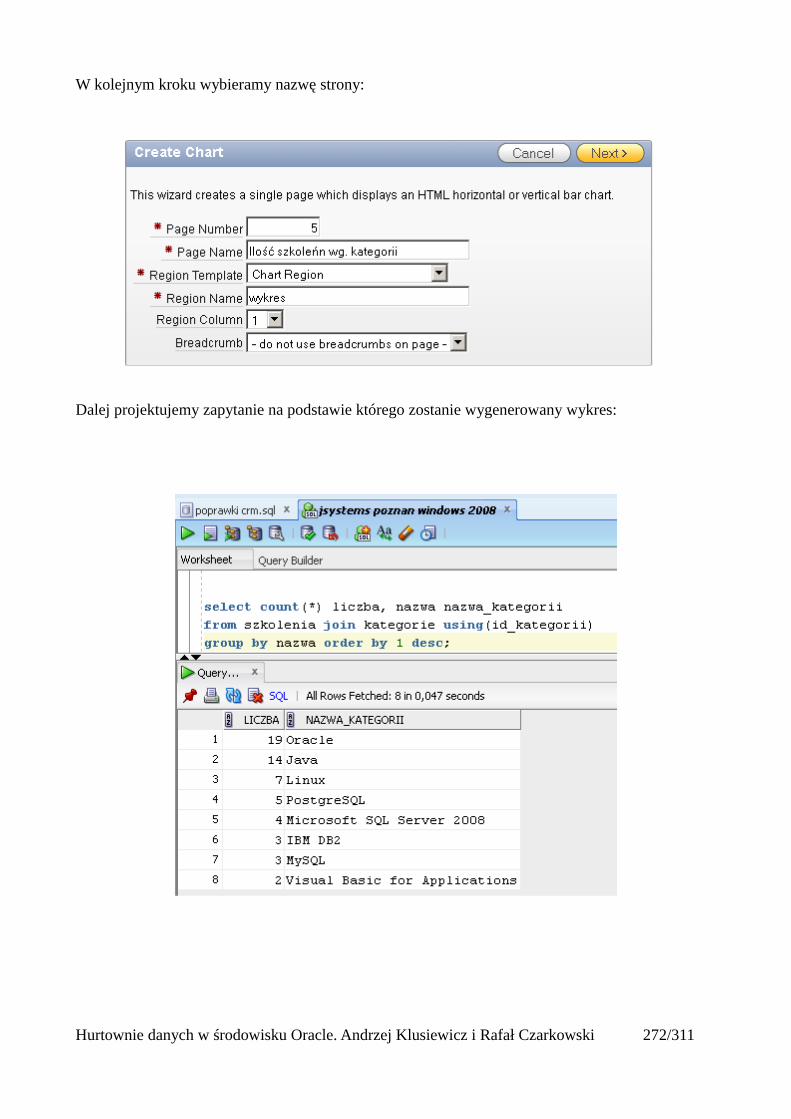
W kolejnym kroku wybieramy nazwę strony:
Dalej projektujemy zapytanie na podstawie którego zostanie wygenerowany wykres:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 272/311
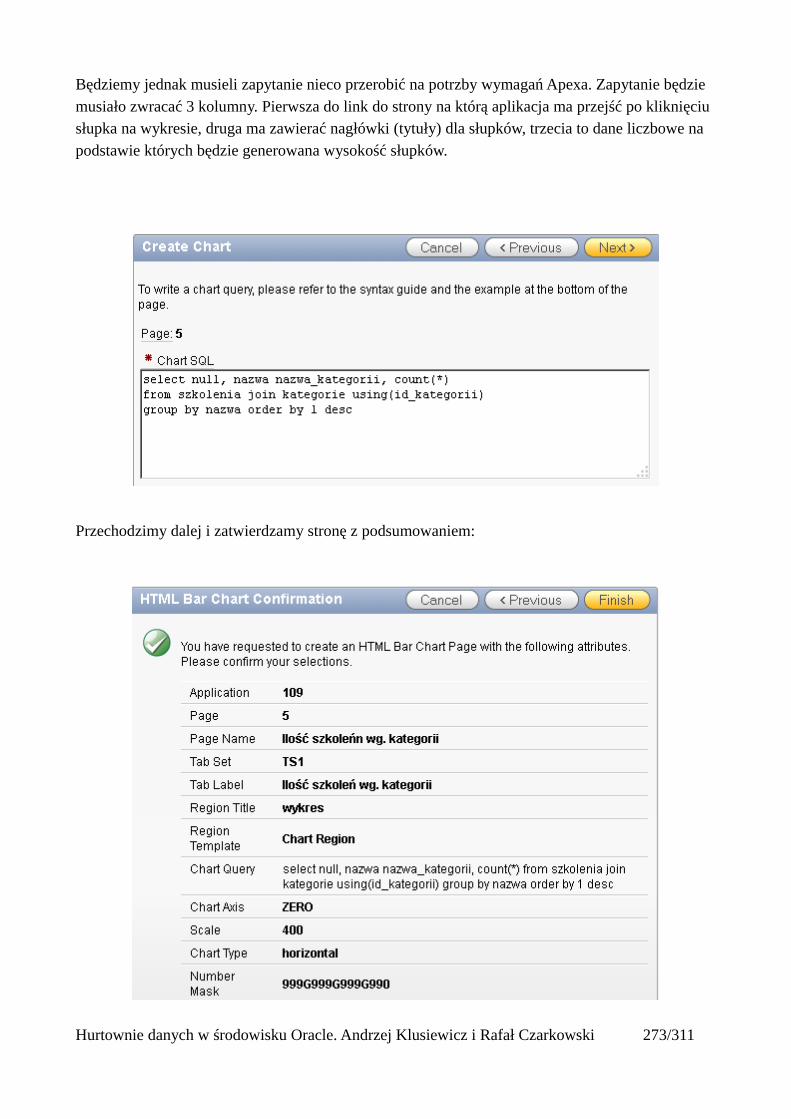
Będziemy jednak musieli zapytanie nieco przerobić na potrzby wymagań Apexa. Zapytanie będzie musiało zwracać 3 kolumny. Pierwsza do link do strony na którą aplikacja ma przejść po kliknięciu słupka na wykresie, druga ma zawierać nagłówki (tytuły) dla słupków, trzecia to dane liczbowe na podstawie których będzie generowana wysokość słupków.
Przechodzimy dalej i zatwierdzamy stronę z podsumowaniem:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 273/311
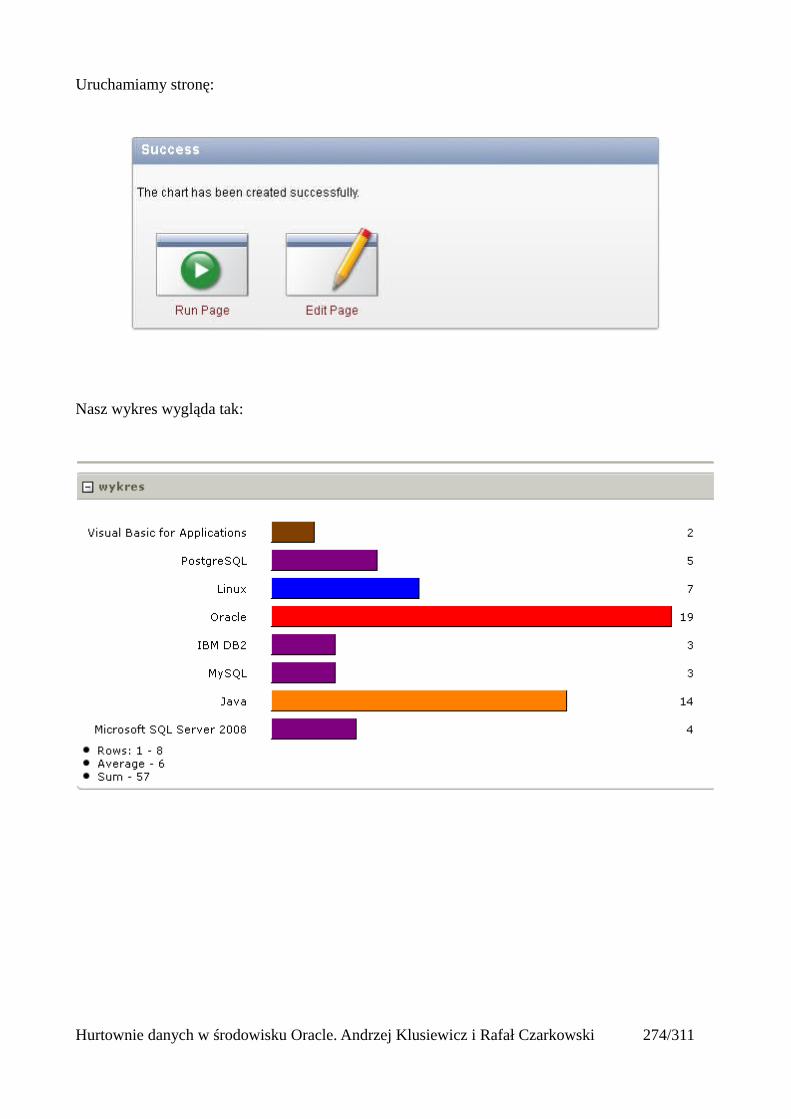
Uruchamiamy stronę:
Nasz wykres wygląda tak:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 274/311
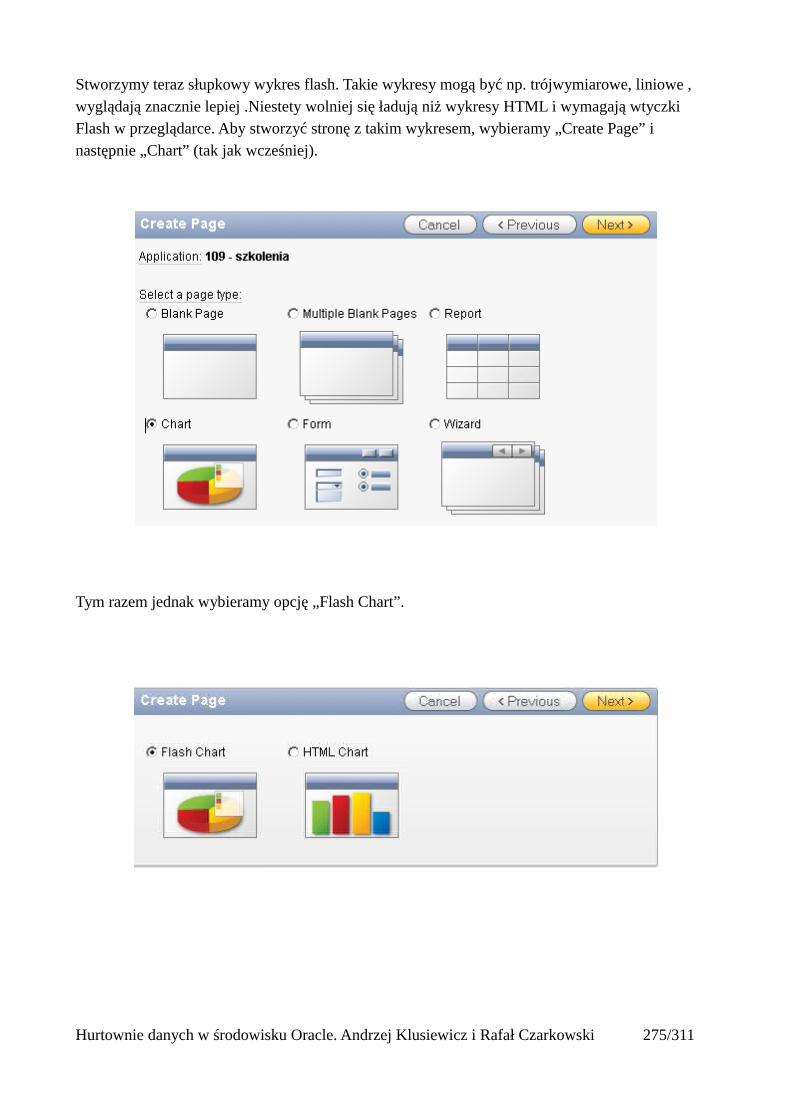
Stworzymy teraz słupkowy wykres flash. Takie wykresy mogą być np. trójwymiarowe, liniowe , wyglądają znacznie lepiej .Niestety wolniej się ładują niż wykresy HTML i wymagają wtyczki Flash w przeglądarce. Aby stworzyć stronę z takim wykresem, wybieramy „Create Page” i następnie „Chart” (tak jak wcześniej).
Tym razem jednak wybieramy opcję „Flash Chart”.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 275/311
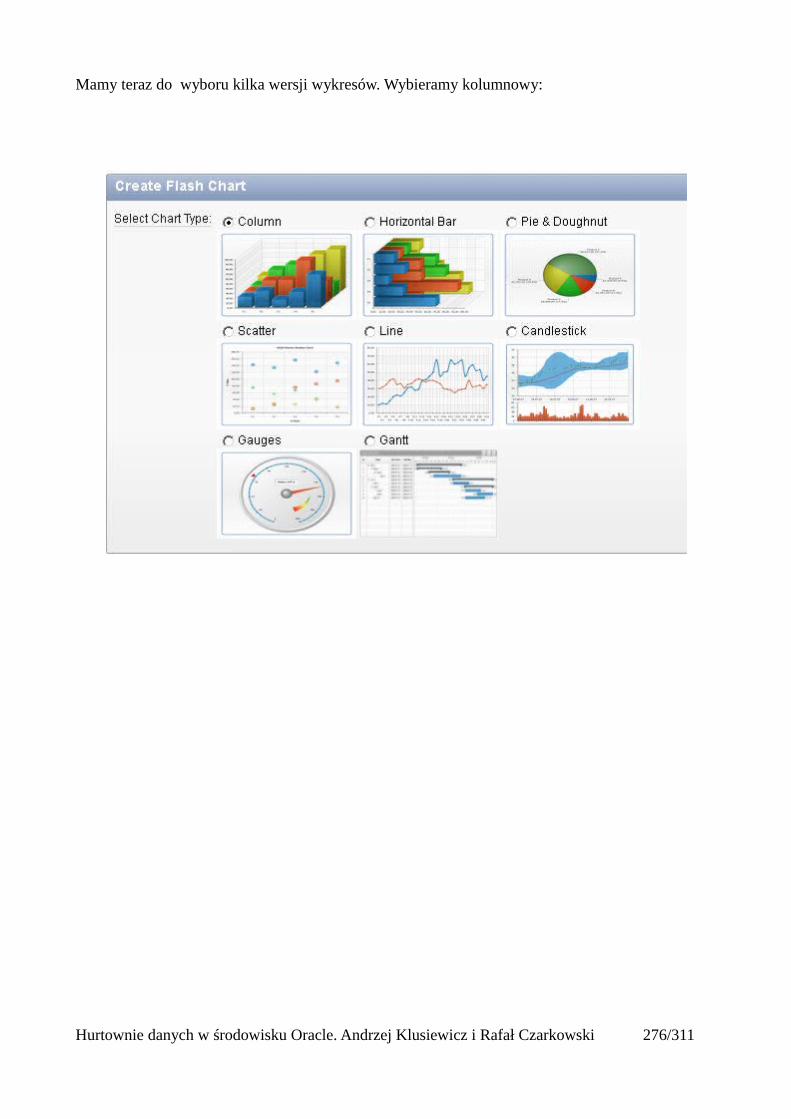
Mamy teraz do wyboru kilka wersji wykresów. Wybieramy kolumnowy:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 276/311
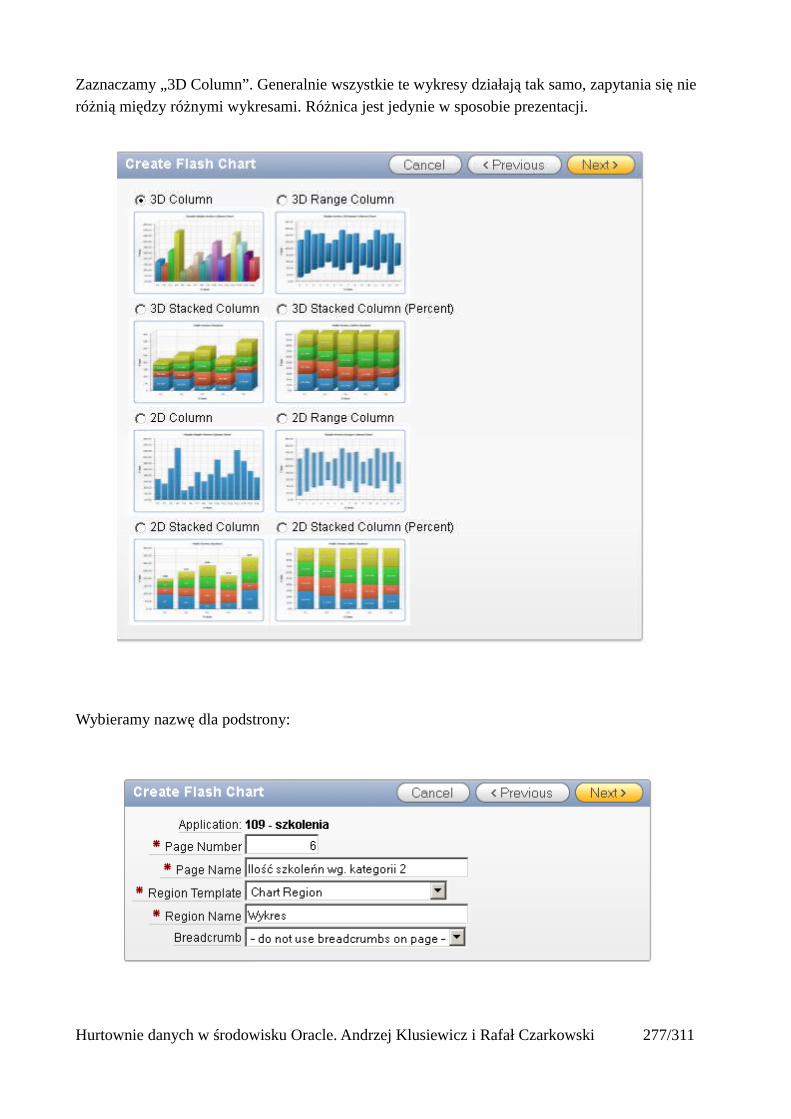
Zaznaczamy „3D Column”. Generalnie wszystkie te wykresy działają tak samo, zapytania się nie różnią między różnymi wykresami. Różnica jest jedynie w sposobie prezentacji.
Wybieramy nazwę dla podstrony:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 277/311
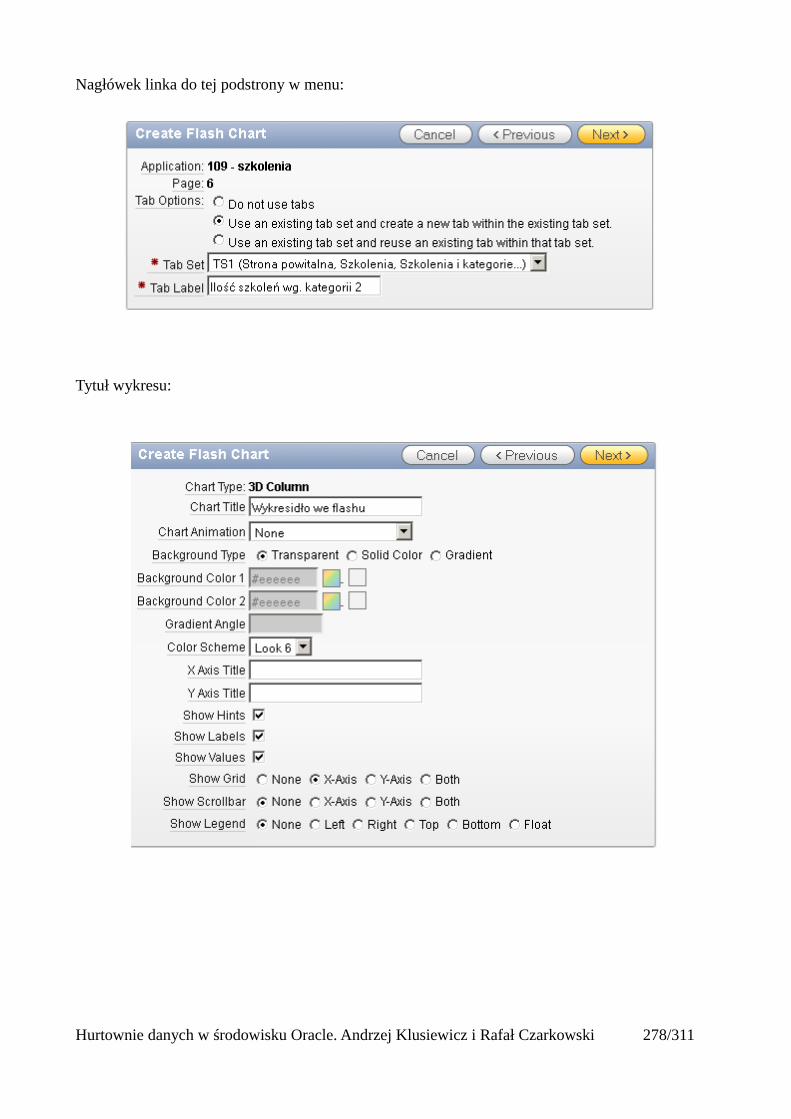
Nagłówek linka do tej podstrony w menu:
Tytuł wykresu:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 278/311
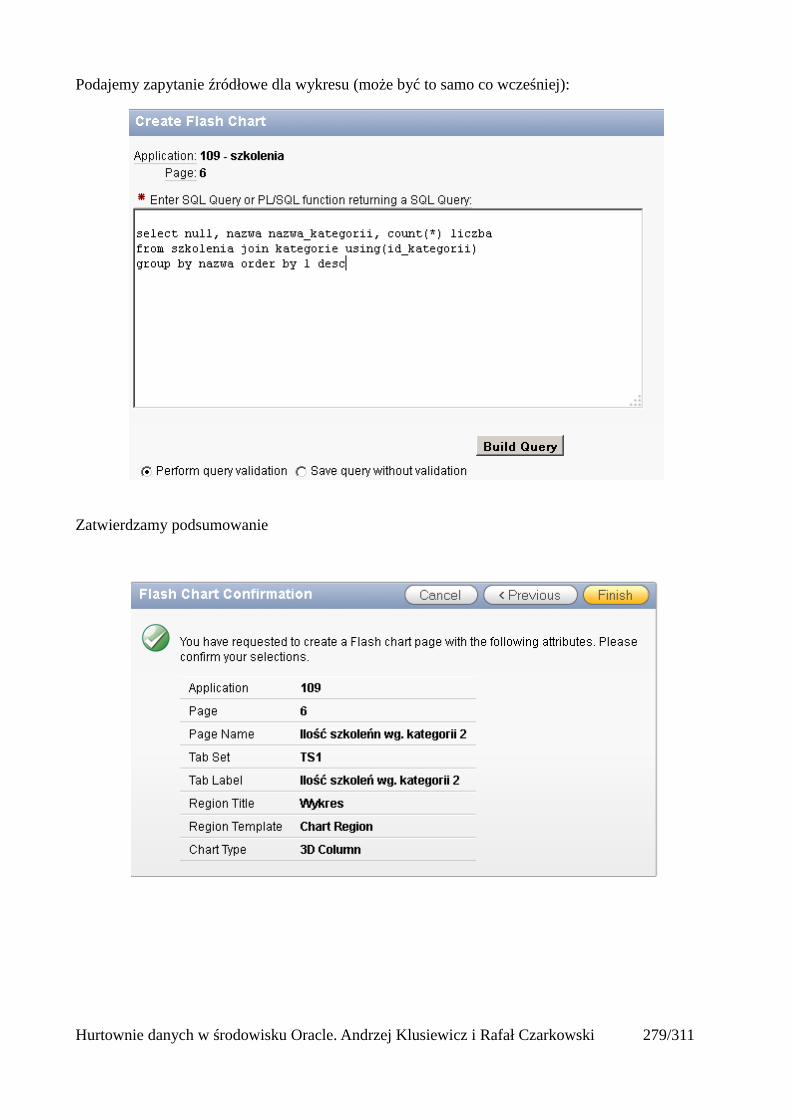
Podajemy zapytanie źródłowe dla wykresu (może być to samo co wcześniej):
Zatwierdzamy podsumowanie
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 279/311

Po uruchomieniu podstrony będziemy musieli nieco poczekać na załadowanie wykresu, cóż taka cecha flasha :) Jeśli więc preferujemy szybki dostęp do informacji, wybieramy wykresy HTML.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 280/311
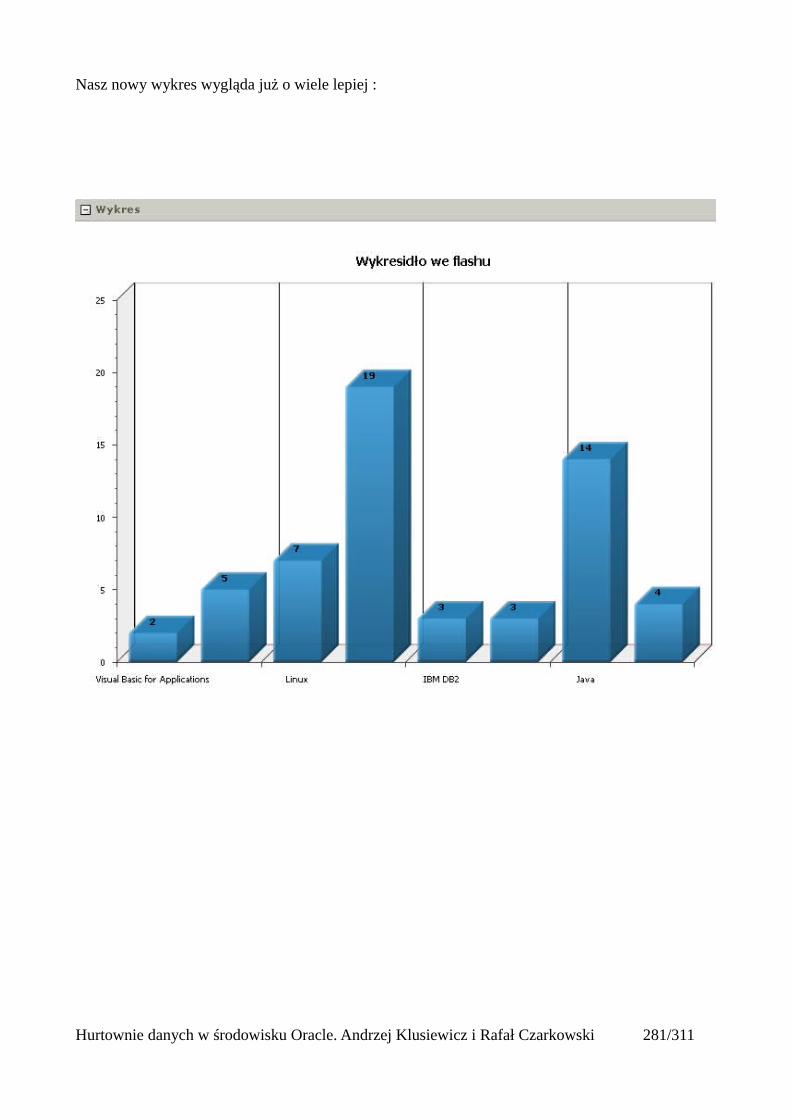
Nasz nowy wykres wygląda już o wiele lepiej :
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 281/311
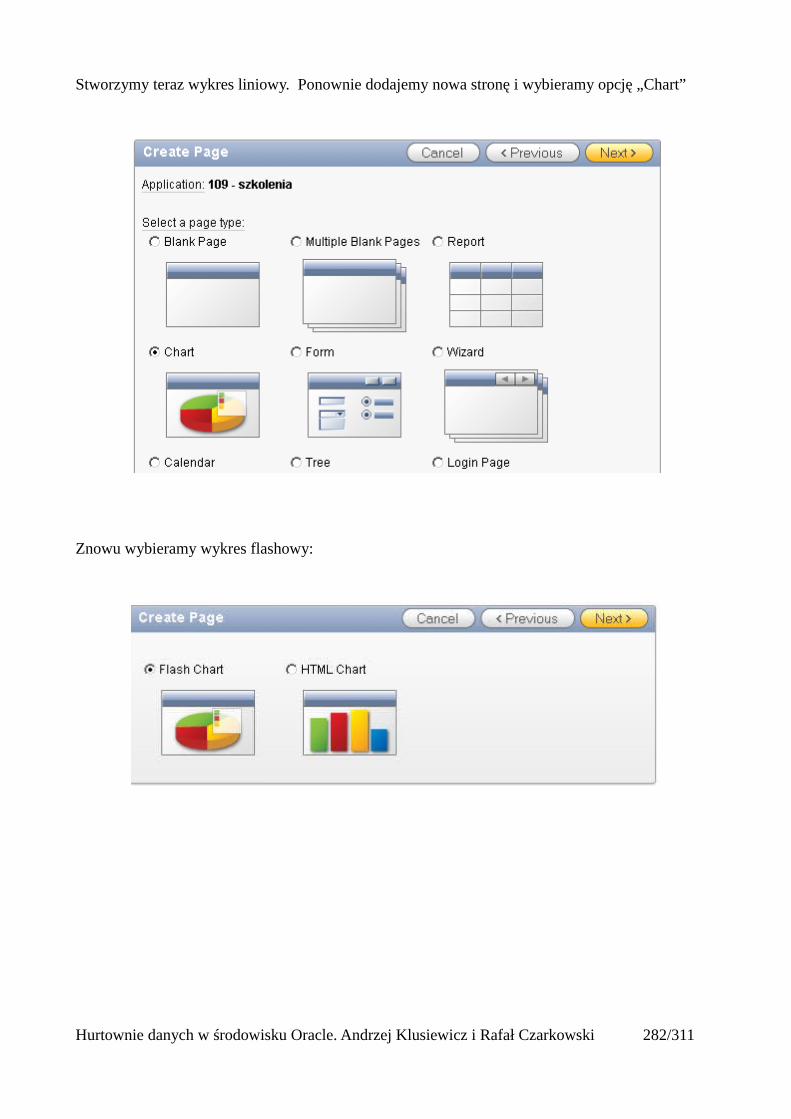
Stworzymy teraz wykres liniowy. Ponownie dodajemy nowa stronę i wybieramy opcję „Chart”
Znowu wybieramy wykres flashowy:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 282/311
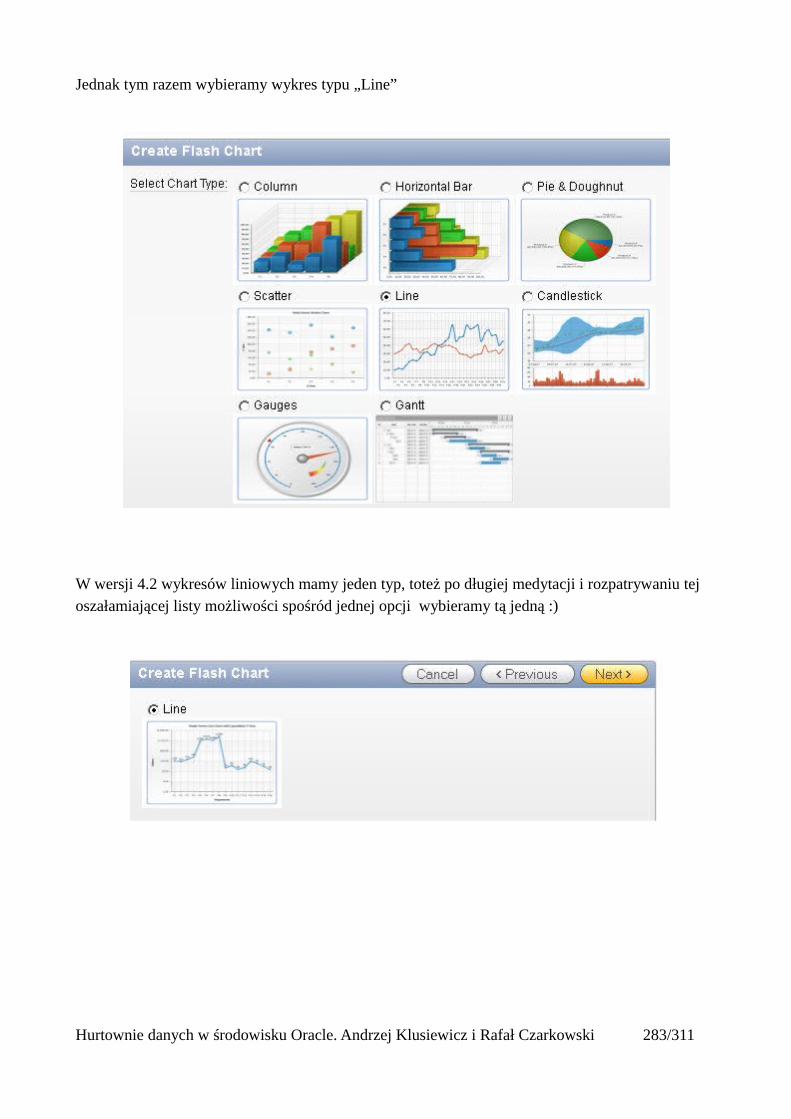
Jednak tym razem wybieramy wykres typu „Line”
W wersji 4.2 wykresów liniowych mamy jeden typ, toteż po długiej medytacji i rozpatrywaniu tej oszałamiającej listy możliwości spośród jednej opcji wybieramy tą jedną :)
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 283/311
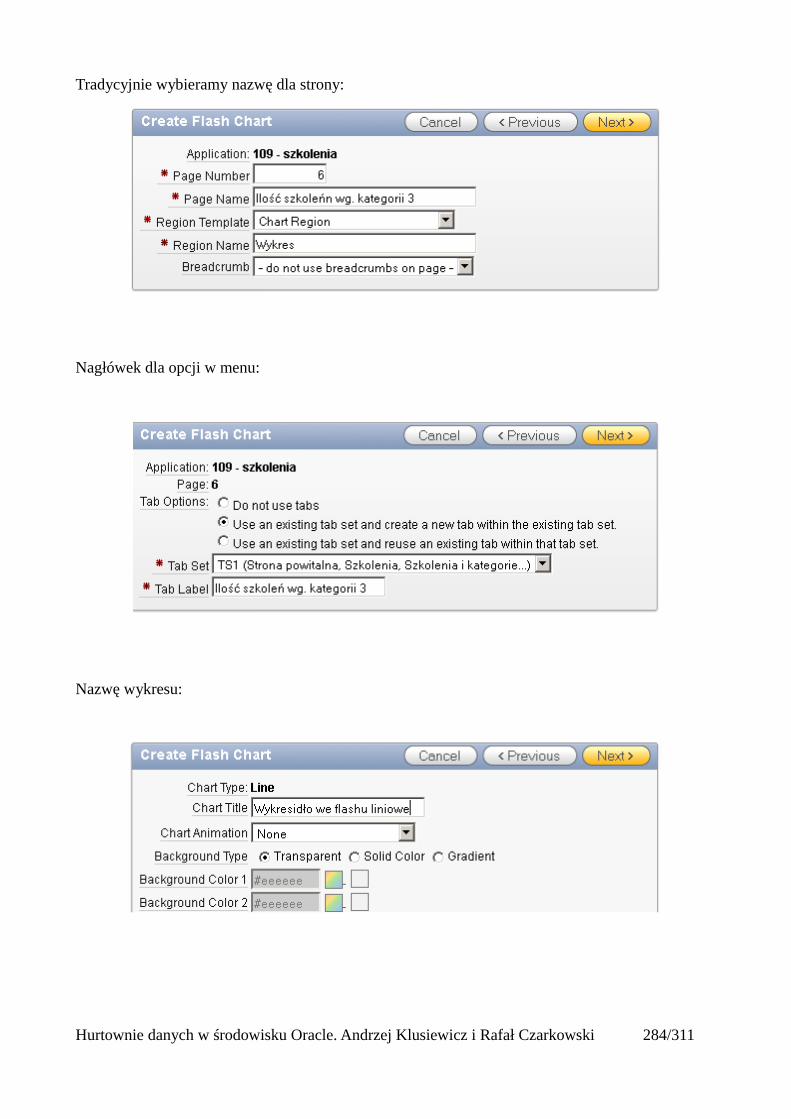
Tradycyjnie wybieramy nazwę dla strony:
Nagłówek dla opcji w menu:
Nazwę wykresu:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 284/311
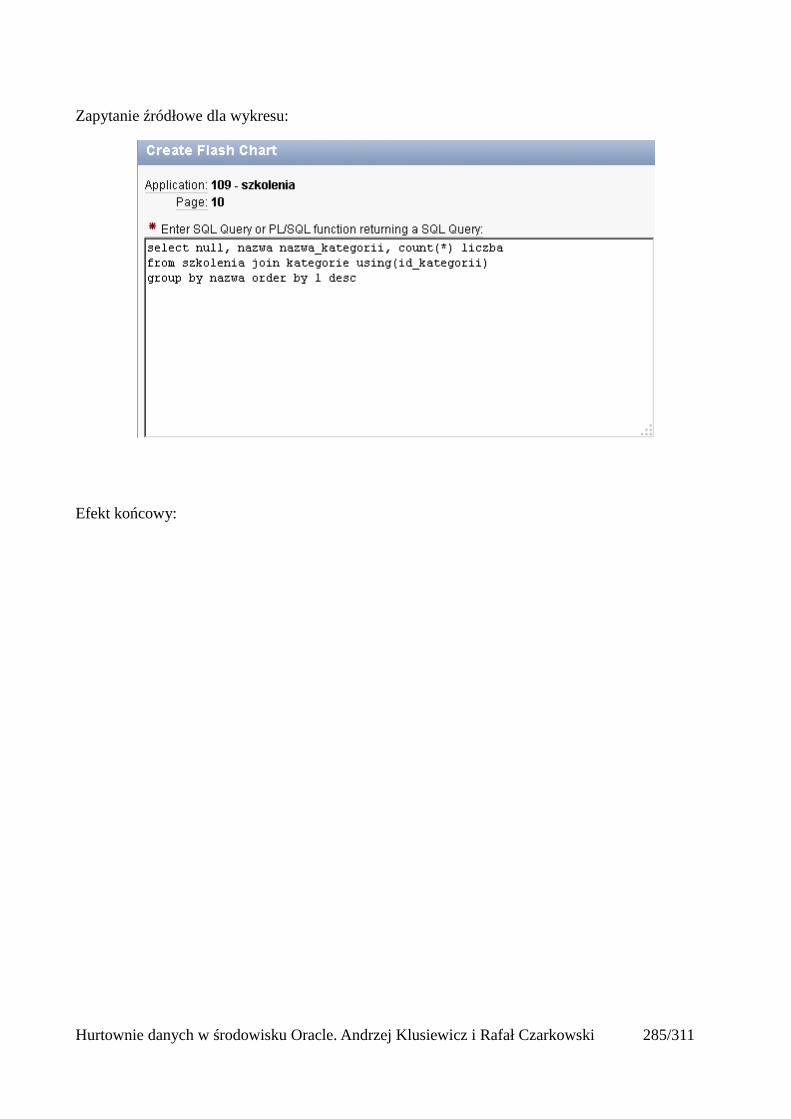
Zapytanie źródłowe dla wykresu:
Efekt końcowy:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 285/311
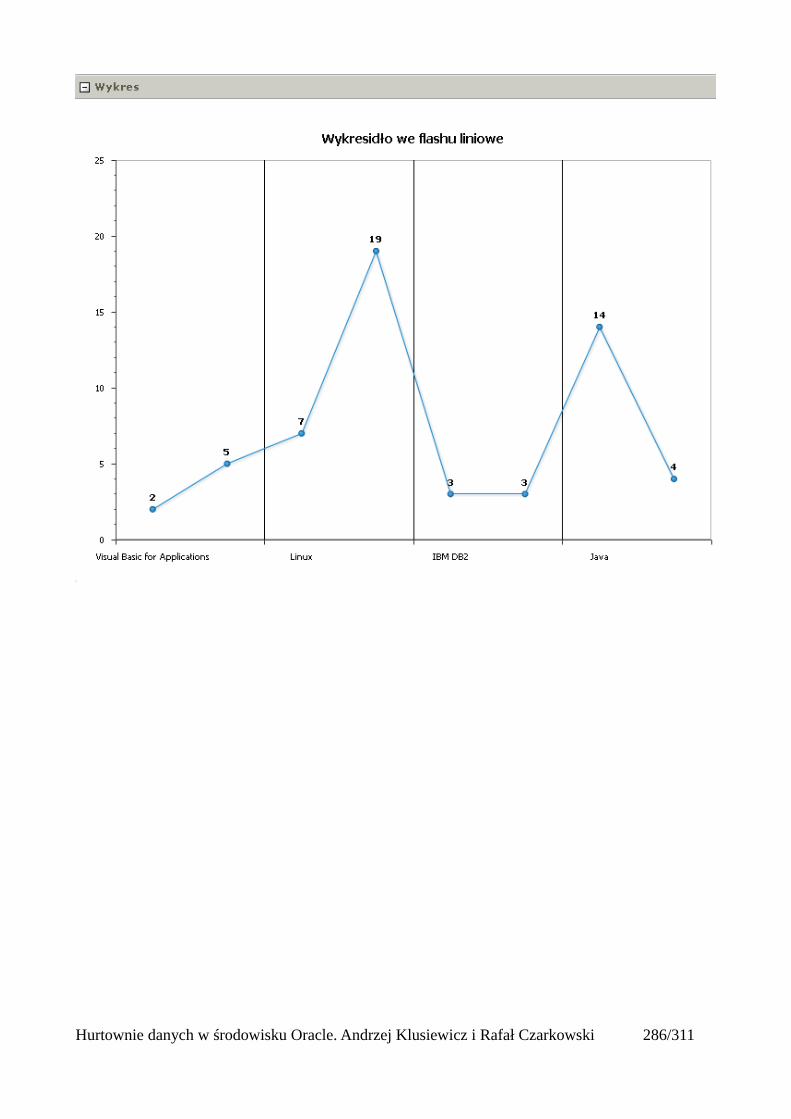
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 286/311
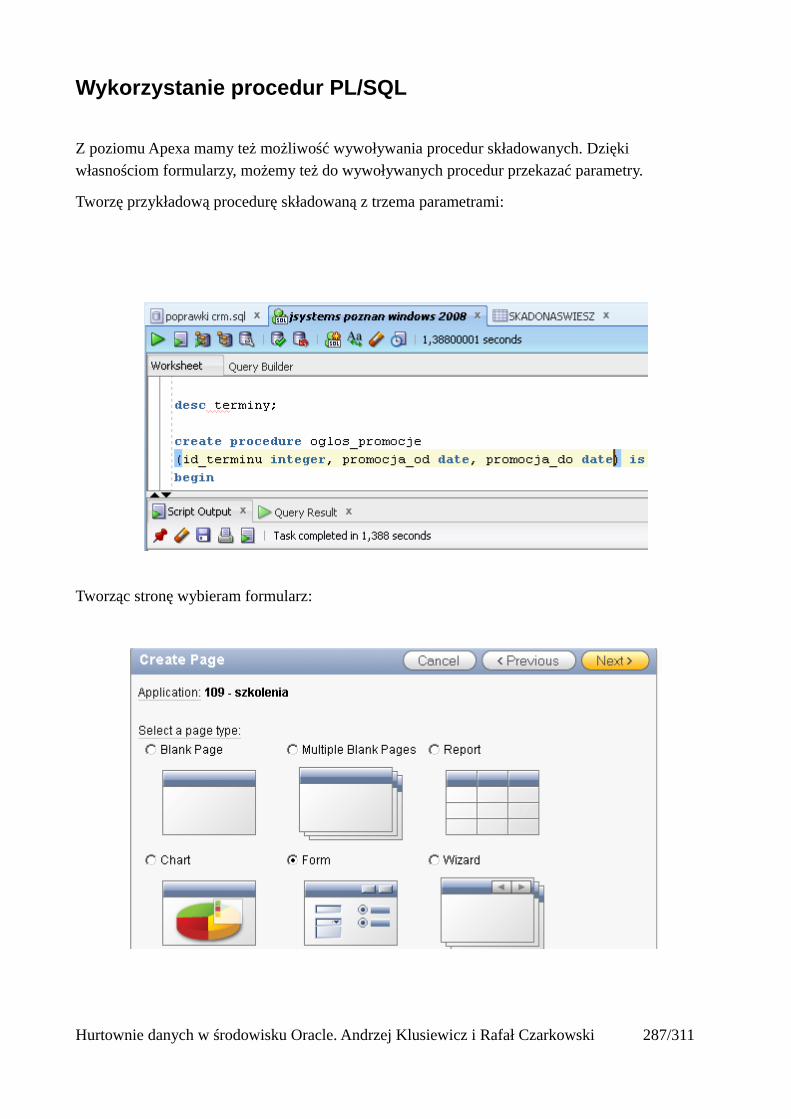
Wykorzystanie procedur PL/SQL
Z poziomu Apexa mamy też możliwość wywoływania procedur składowanych. Dzięki własnościom formularzy, możemy też do wywoływanych procedur przekazać parametry.
Tworzę przykładową procedurę składowaną z trzema parametrami:
Tworząc stronę wybieram formularz:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 287/311
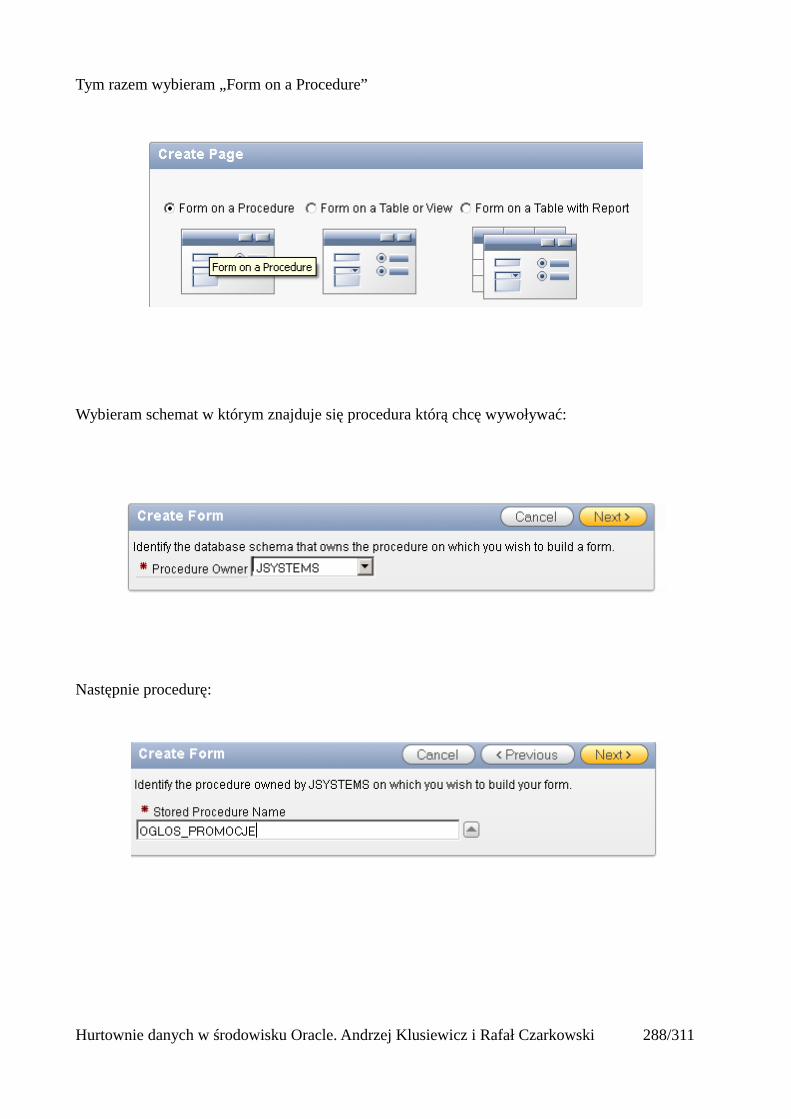
Tym razem wybieram „Form on a Procedure”
Wybieram schemat w którym znajduje się procedura którą chcę wywoływać:
Następnie procedurę:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 288/311
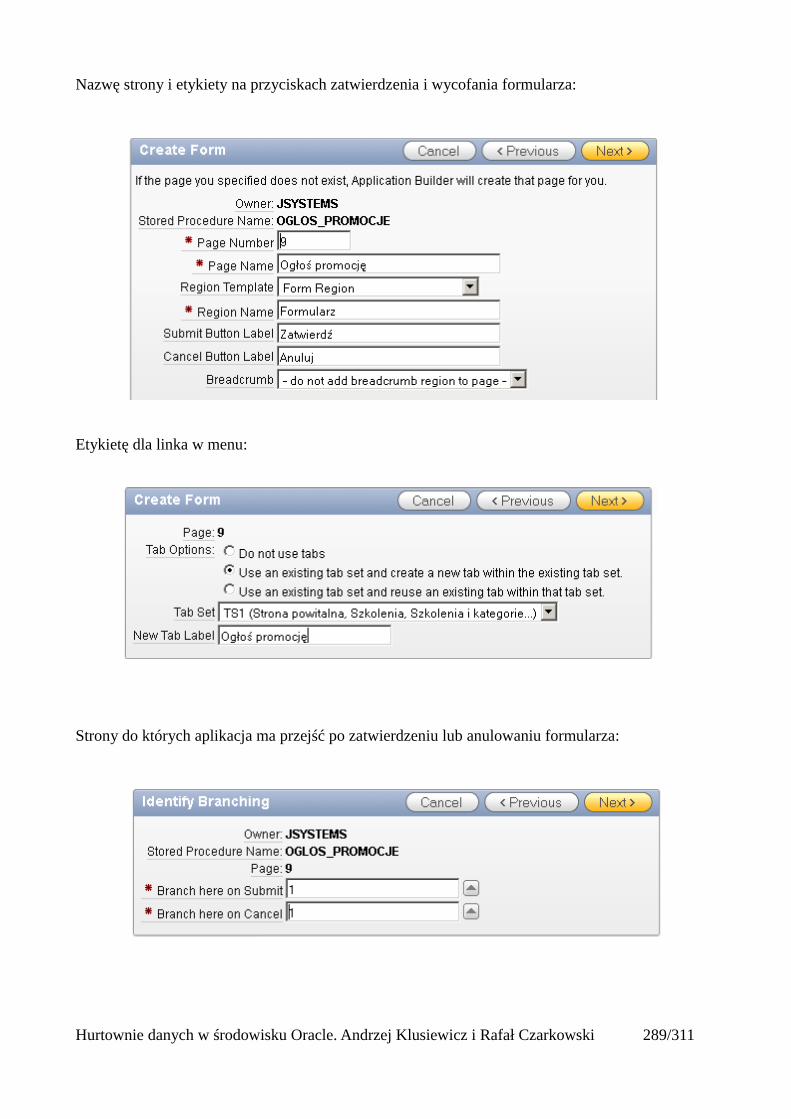
Nazwę strony i etykiety na przyciskach zatwierdzenia i wycofania formularza:
Etykietę dla linka w menu:
Strony do których aplikacja ma przejść po zatwierdzeniu lub anulowaniu formularza:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 289/311

Etykiety które pojawią się w formularzu dla parametrów procedury. Mogę również udostępnić tylkowybrane parametry. Ciekawą opcją jest „Display Type”. Daje nam możliwość wyboru typu pola.
Opcje:
• Date Picker to mini kalendarz który umożliwi nam wygodne wprowadzanie dat
• Display Only to parametr którego nie będziemy mogli zmieniać
• Hidden to parametr ukryty. Nie będzie go widać w formularzu
• Password to pole tekstowe którego treść zostanie przy wprowadzaniu „wykropkowana”
• Tekstaera to duże pole tekstowe – np. do dodawania komentarzy czy opisów
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 290/311
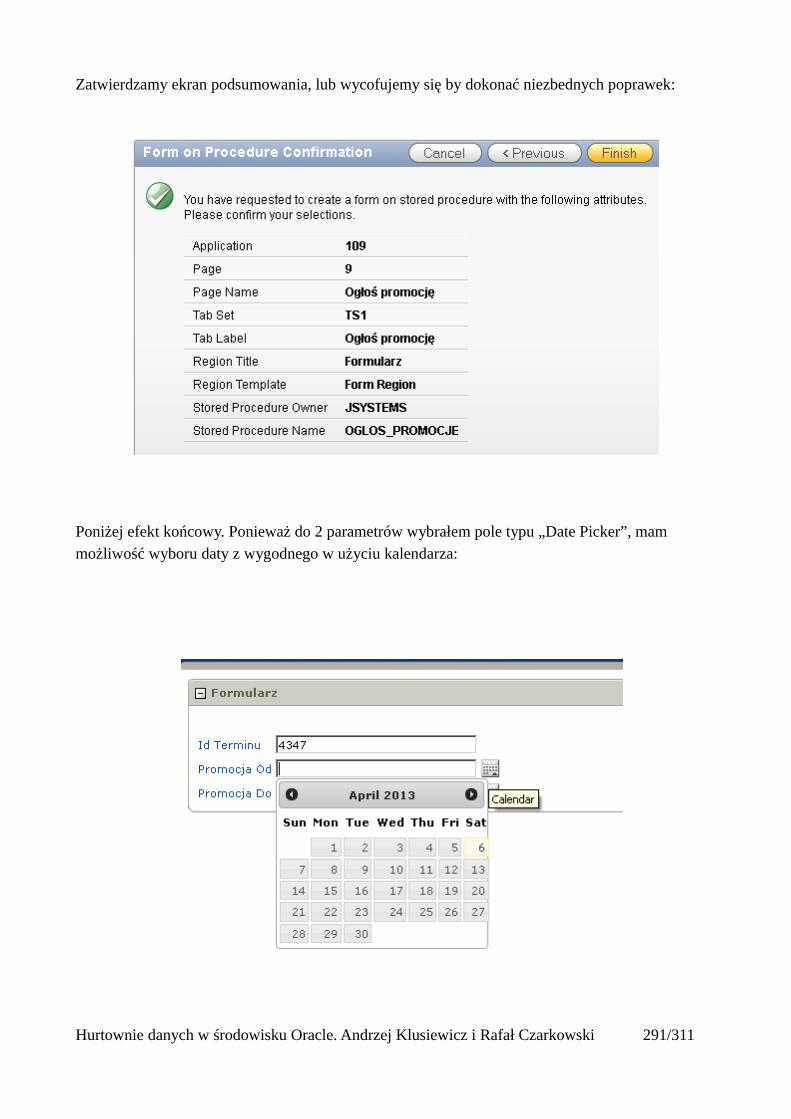
Zatwierdzamy ekran podsumowania, lub wycofujemy się by dokonać niezbednych poprawek:
Poniżej efekt końcowy. Ponieważ do 2 parametrów wybrałem pole typu „Date Picker”, mam możliwość wyboru daty z wygodnego w użyciu kalendarza:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 291/311
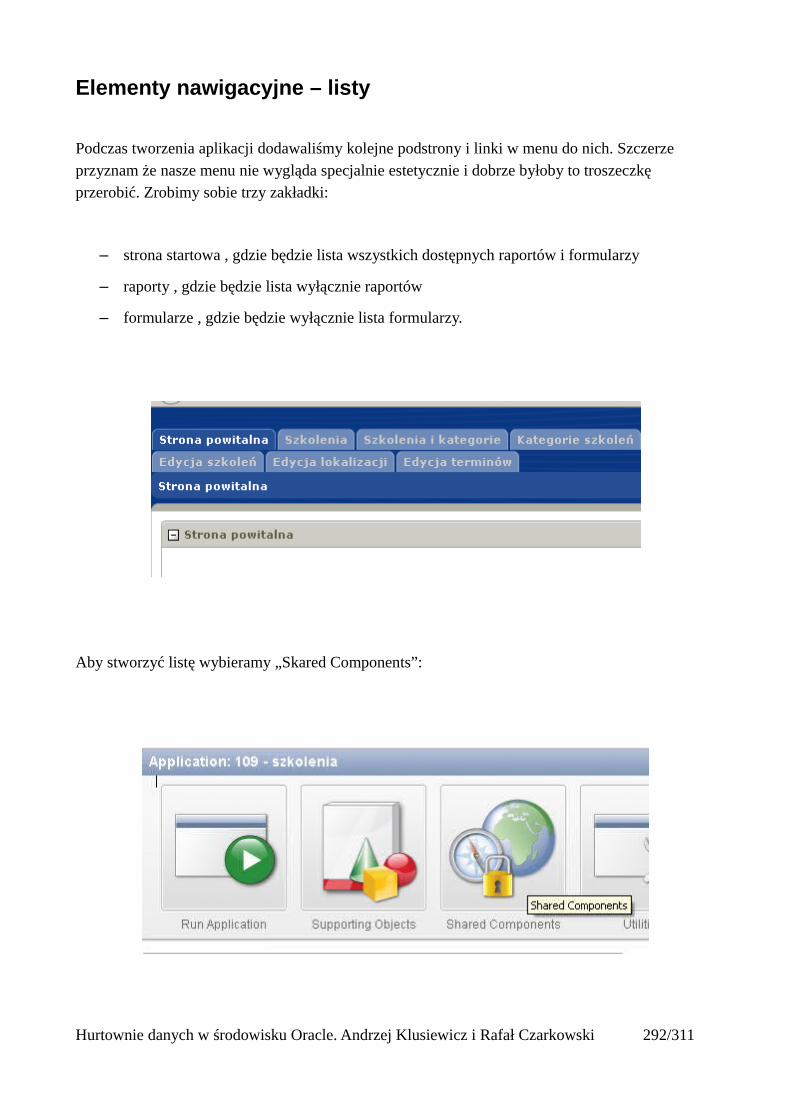
Elementy nawigacyjne – listy
Podczas tworzenia aplikacji dodawaliśmy kolejne podstrony i linki w menu do nich. Szczerze przyznam że nasze menu nie wygląda specjalnie estetycznie i dobrze byłoby to troszeczkę przerobić. Zrobimy sobie trzy zakładki:
– strona startowa , gdzie będzie lista wszystkich dostępnych raportów i formularzy
– raporty , gdzie będzie lista wyłącznie raportów
– formularze , gdzie będzie wyłącznie lista formularzy.
Aby stworzyć listę wybieramy „Skared Components”:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 292/311
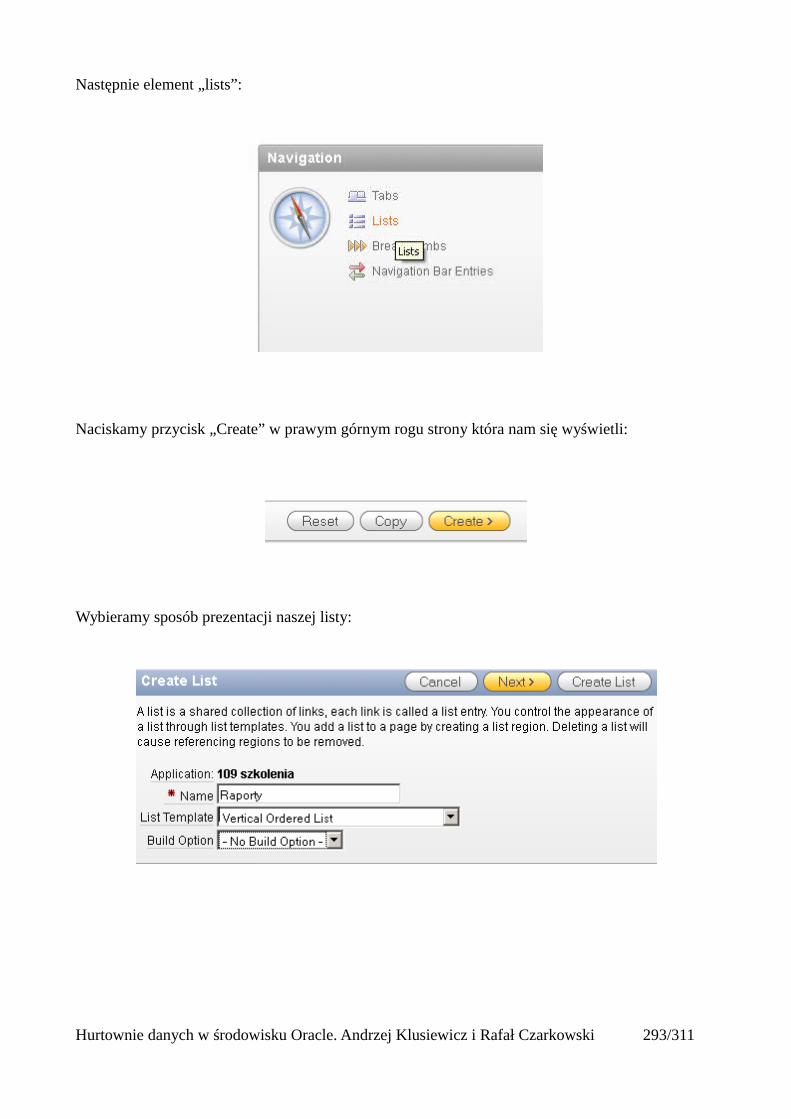
Następnie element „lists”:
Naciskamy przycisk „Create” w prawym górnym rogu strony która nam się wyświetli:
Wybieramy sposób prezentacji naszej listy:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 293/311
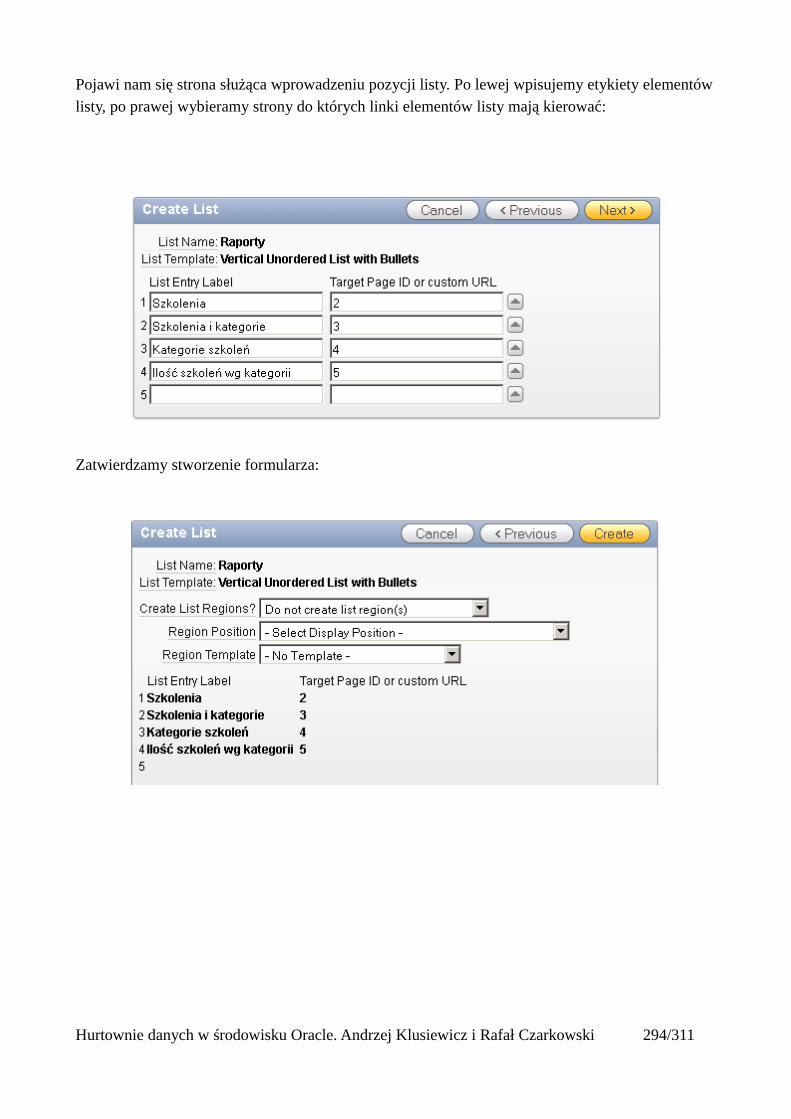
Pojawi nam się strona służąca wprowadzeniu pozycji listy. Po lewej wpisujemy etykiety elementówlisty, po prawej wybieramy strony do których linki elementów listy mają kierować:
Zatwierdzamy stworzenie formularza:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 294/311
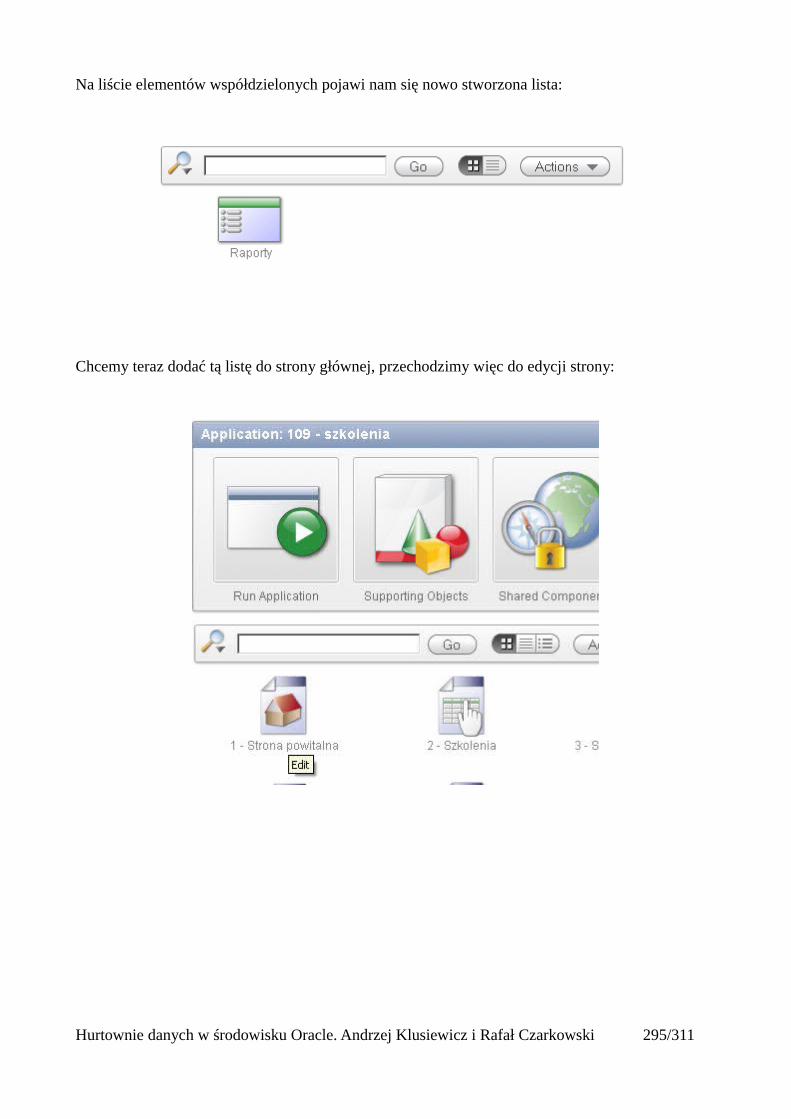
Na liście elementów współdzielonych pojawi nam się nowo stworzona lista:
Chcemy teraz dodać tą listę do strony głównej, przechodzimy więc do edycji strony:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 295/311
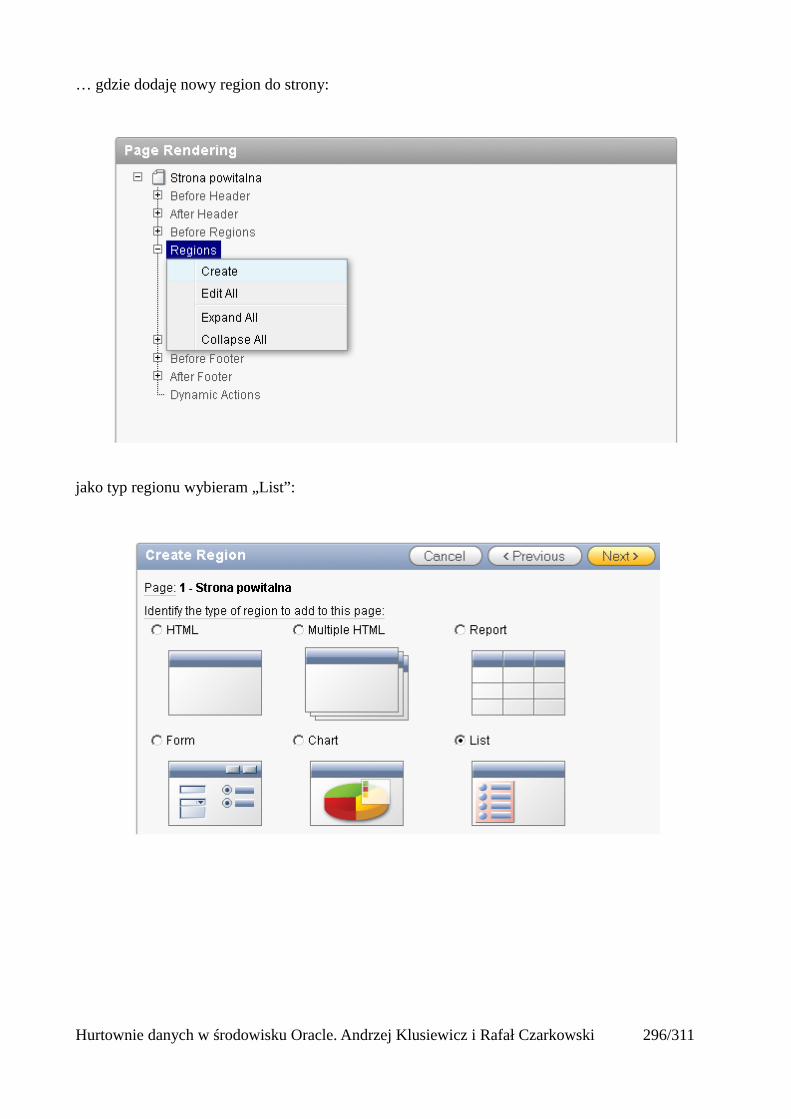
… gdzie dodaję nowy region do strony:
jako typ regionu wybieram „List”:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 296/311
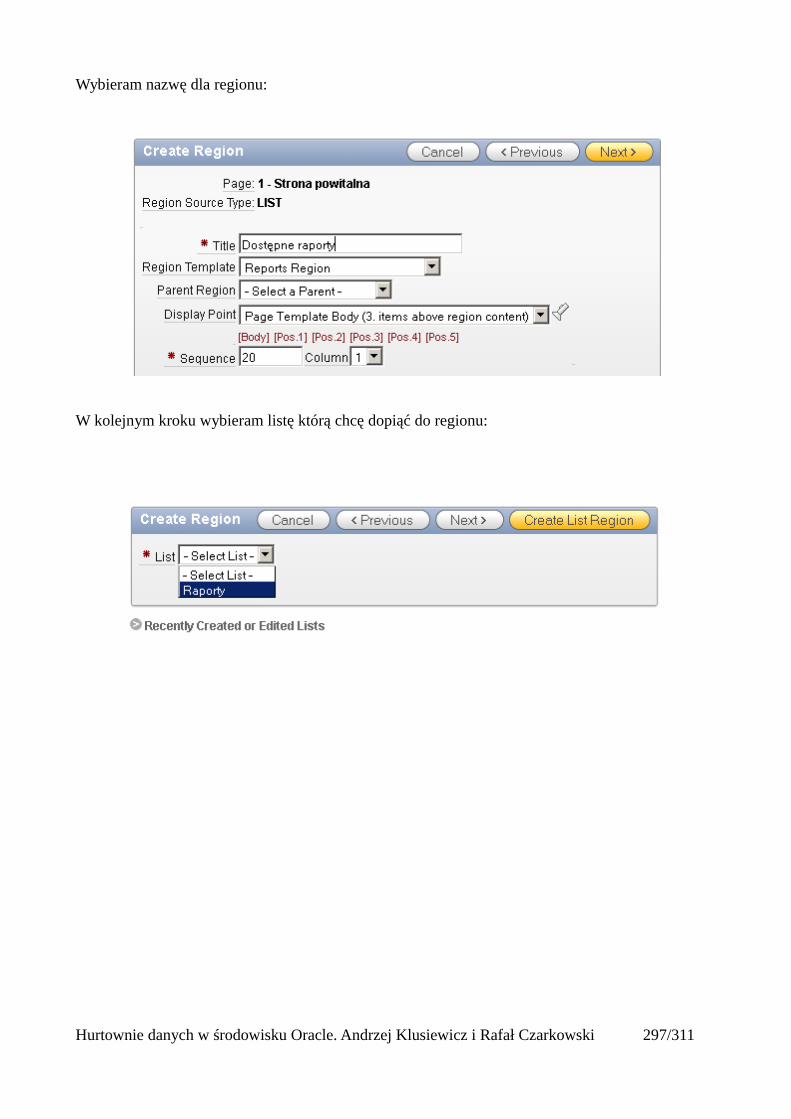
Wybieram nazwę dla regionu:
W kolejnym kroku wybieram listę którą chcę dopiąć do regionu:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 297/311
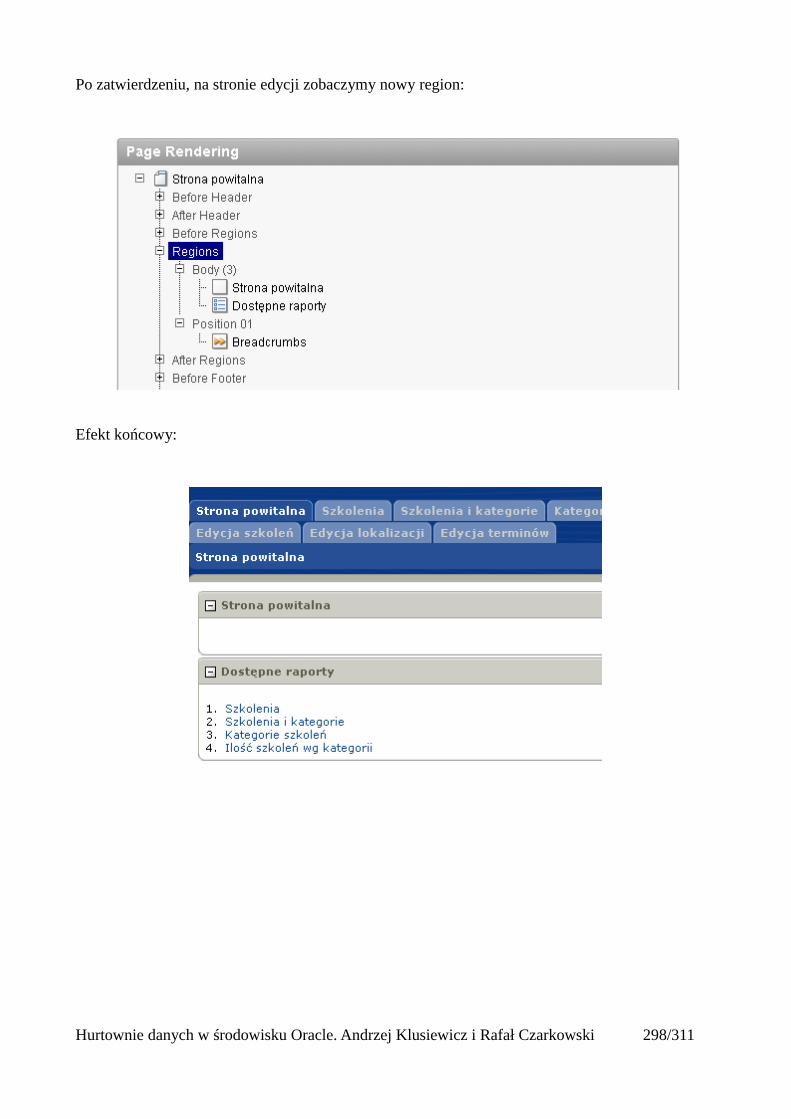
Po zatwierdzeniu, na stronie edycji zobaczymy nowy region:
Efekt końcowy:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 298/311
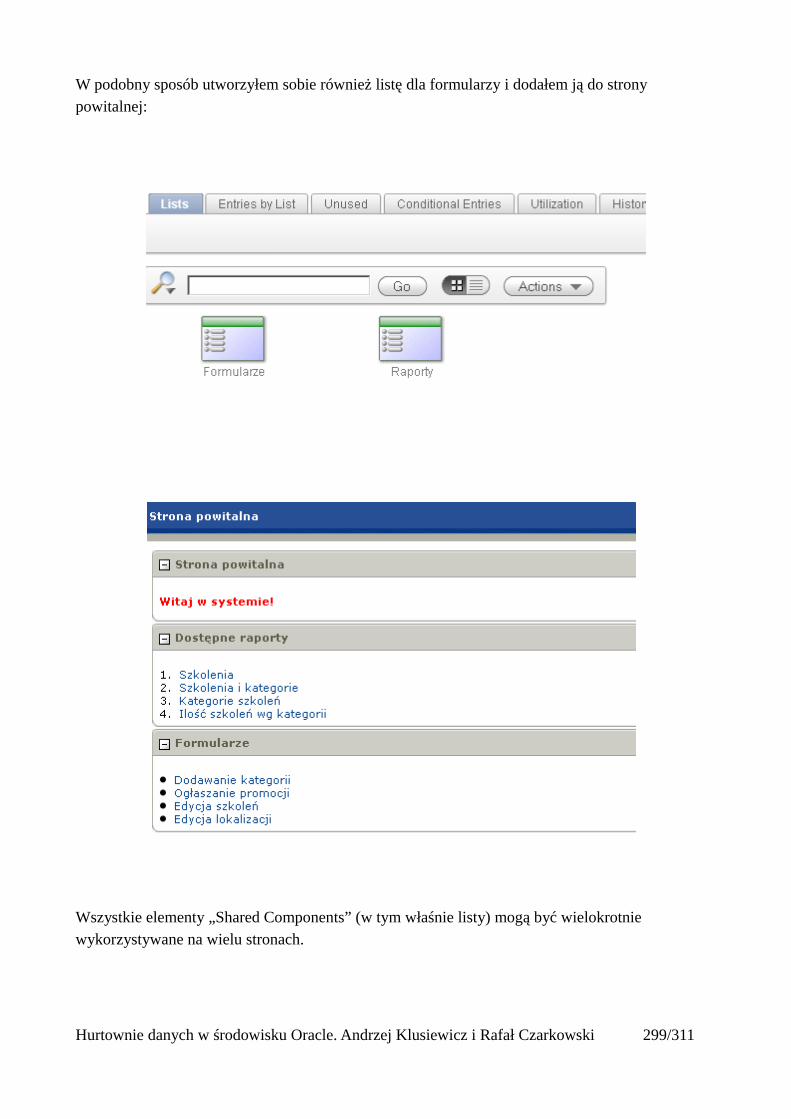
W podobny sposób utworzyłem sobie również listę dla formularzy i dodałem ją do strony powitalnej:
Wszystkie elementy „Shared Components” (w tym właśnie listy) mogą być wielokrotnie wykorzystywane na wielu stronach.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 299/311
Zarządzanie menu
Chcemy nieco uporządkować interfejs programu. W poprzednim rozdziale stworzyliśmy już elementy współdzielone z listami, teraz pozmieniamy kilka pozycji w menu. Ponieważ chcieliśmy usunąć z menu nadmiar linków, a mieć tylko trzy, czyli „strona główna” , „raporty”, „formularze” przechodzimy do edycji menu.
Aby to zrobić , z sekcji „navigation” panelu „shared components” wybieramy link „tabs”:
Zobaczymy taki ekran:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 300/311
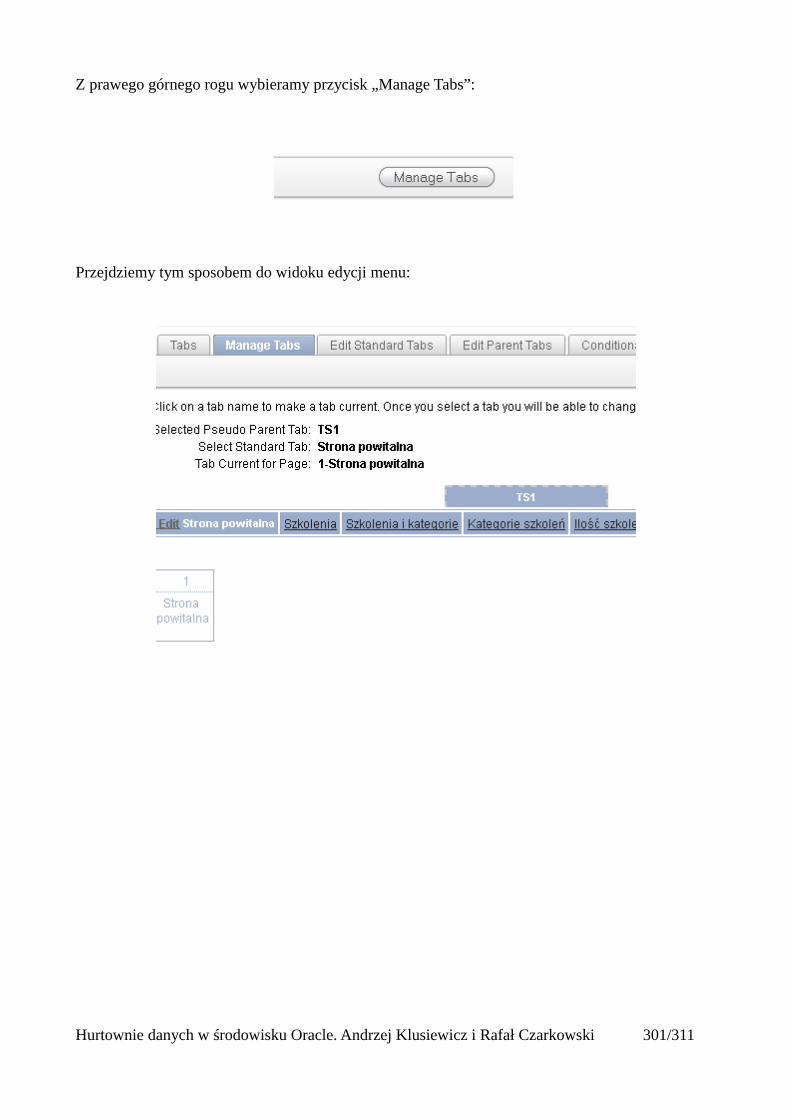
Z prawego górnego rogu wybieramy przycisk „Manage Tabs”:
Przejdziemy tym sposobem do widoku edycji menu:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 301/311
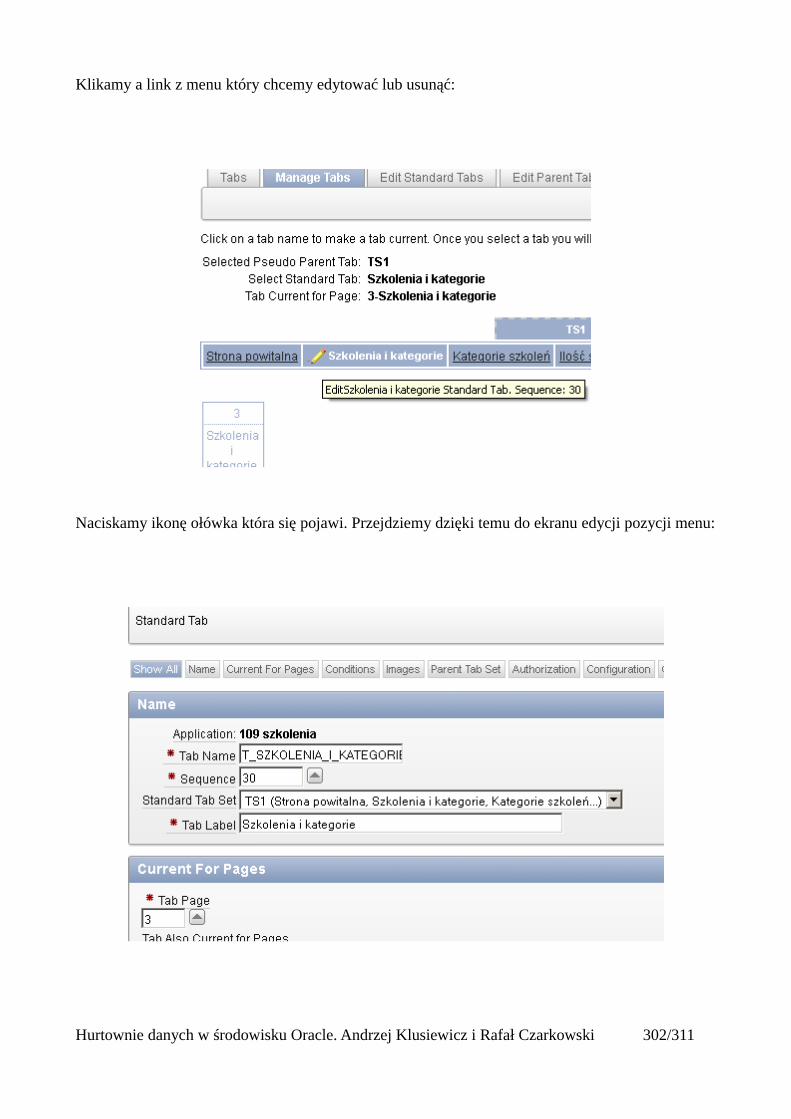
Klikamy a link z menu który chcemy edytować lub usunąć:
Naciskamy ikonę ołówka która się pojawi. Przejdziemy dzięki temu do ekranu edycji pozycji menu:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 302/311
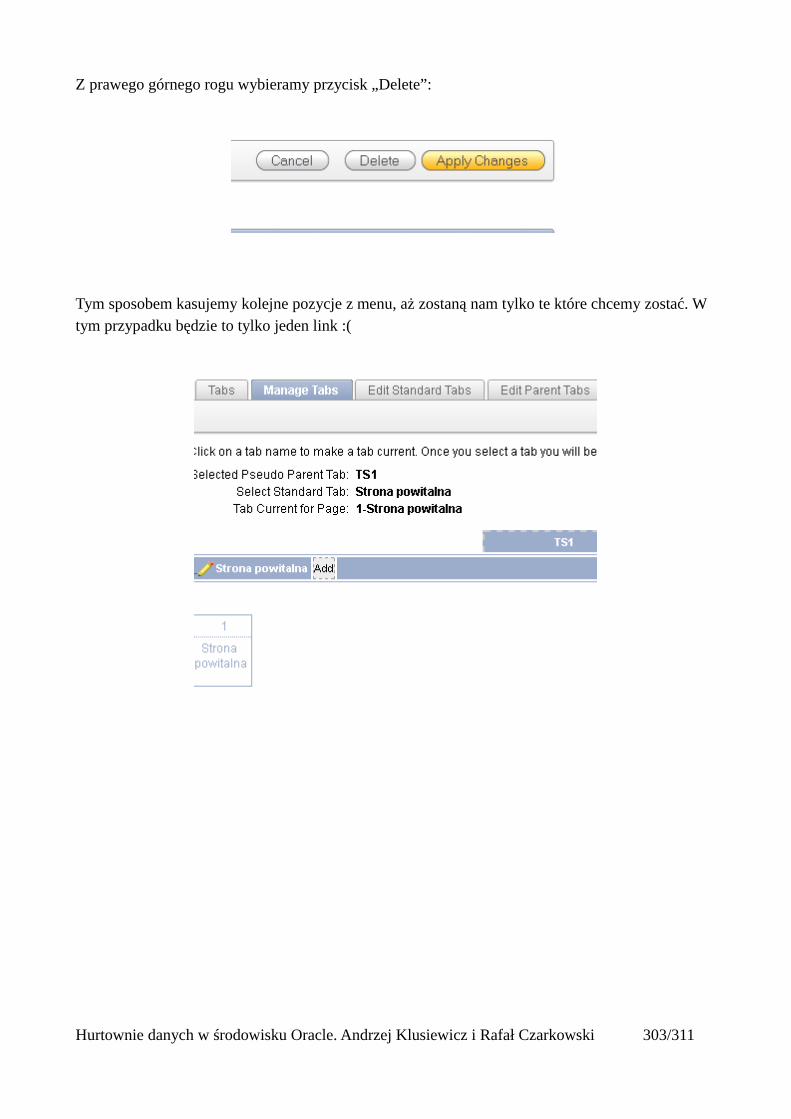
Z prawego górnego rogu wybieramy przycisk „Delete”:
Tym sposobem kasujemy kolejne pozycje z menu, aż zostaną nam tylko te które chcemy zostać. W tym przypadku będzie to tylko jeden link :(
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 303/311
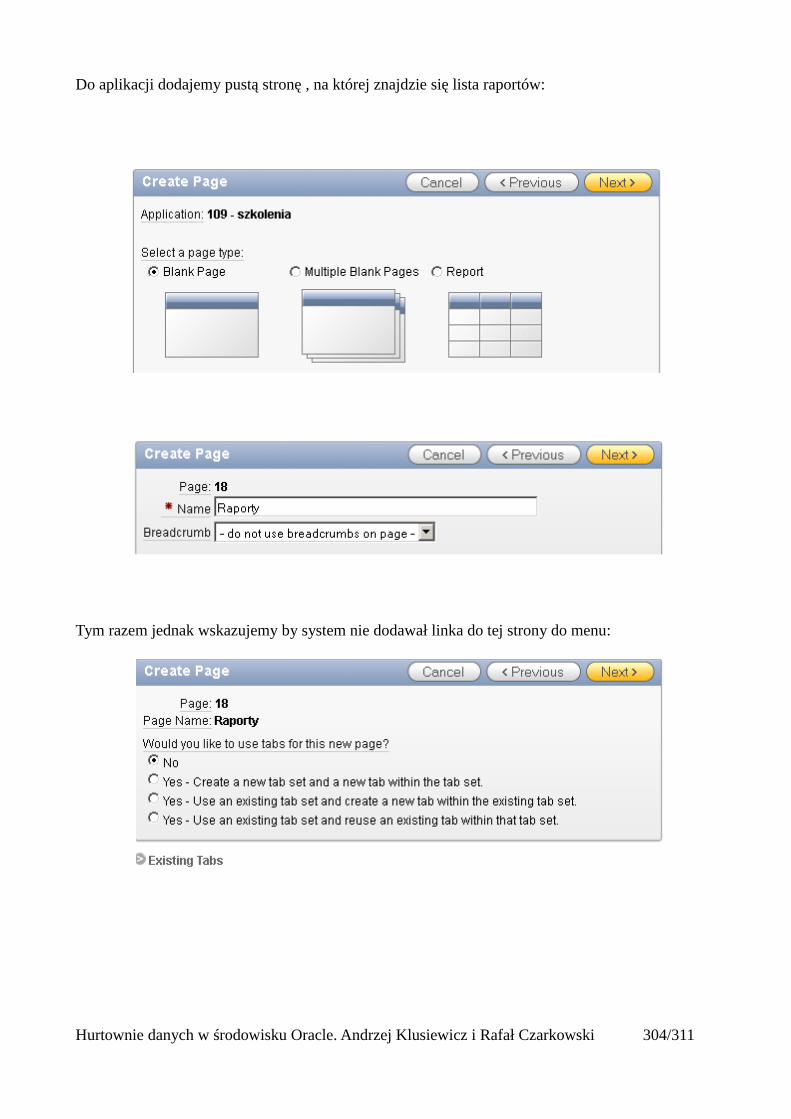
Do aplikacji dodajemy pustą stronę , na której znajdzie się lista raportów:
Tym razem jednak wskazujemy by system nie dodawał linka do tej strony do menu:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 304/311
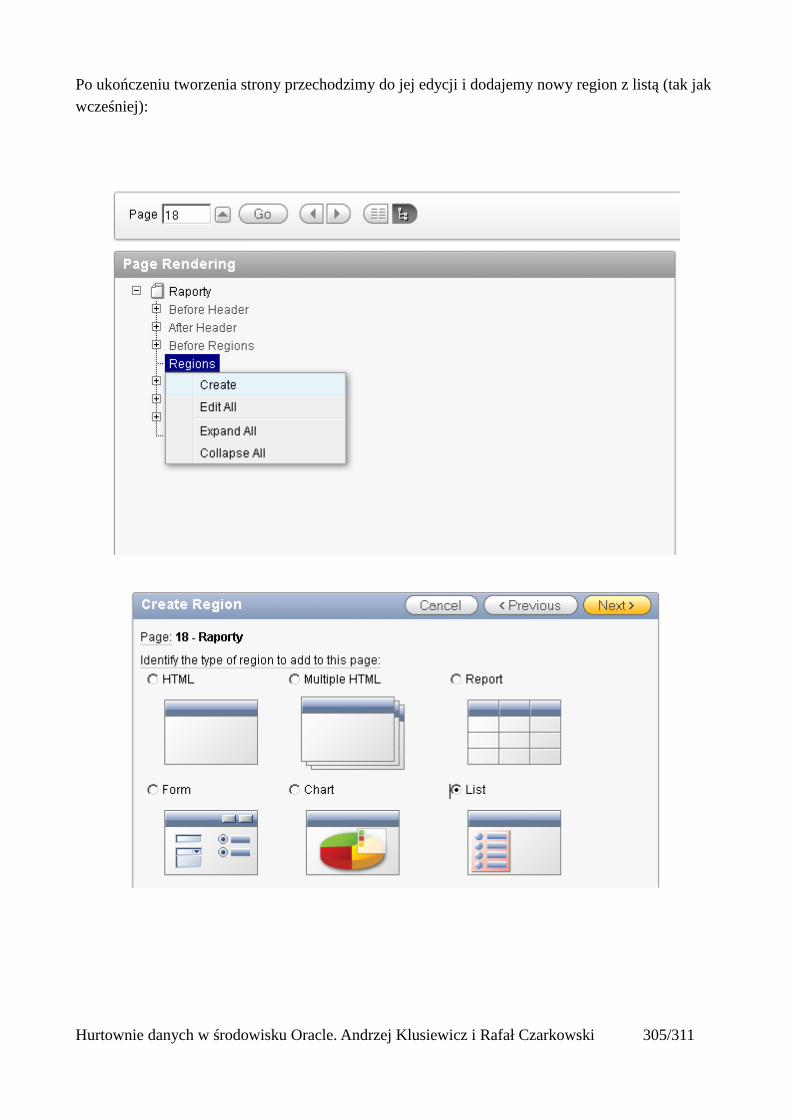
Po ukończeniu tworzenia strony przechodzimy do jej edycji i dodajemy nowy region z listą (tak jak wcześniej):
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 305/311
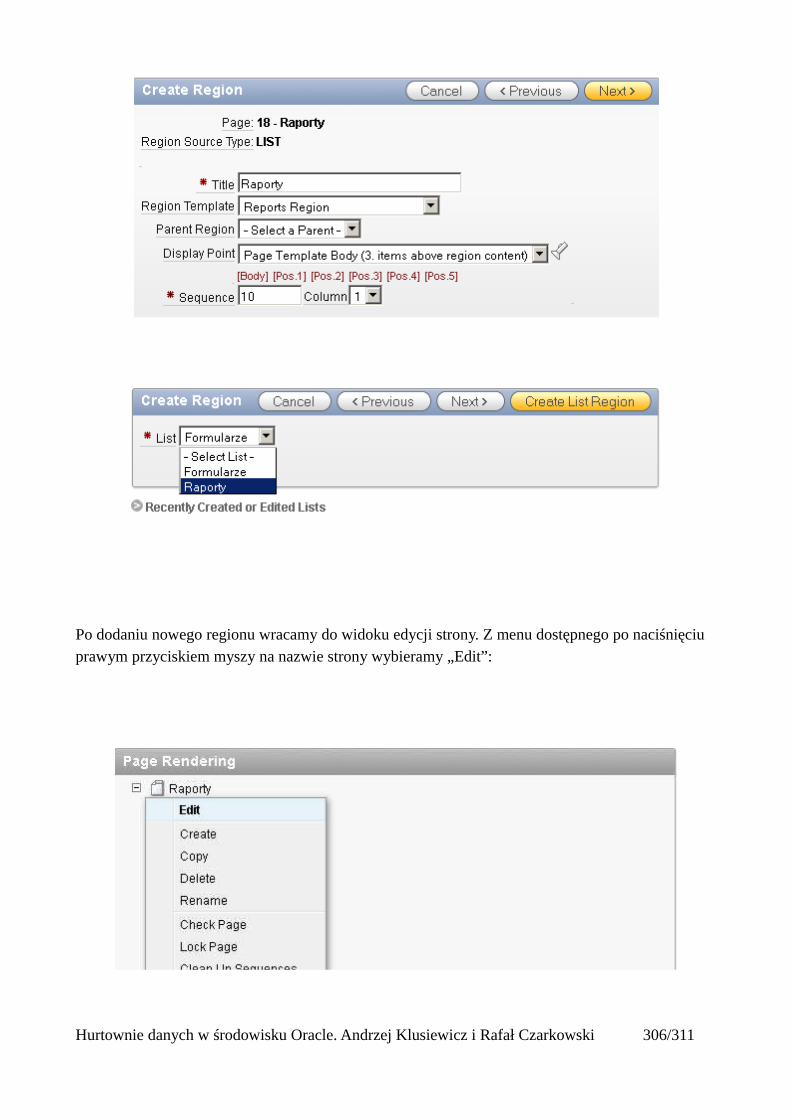
Po dodaniu nowego regionu wracamy do widoku edycji strony. Z menu dostępnego po naciśnięciu prawym przyciskiem myszy na nazwie strony wybieramy „Edit”:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 306/311
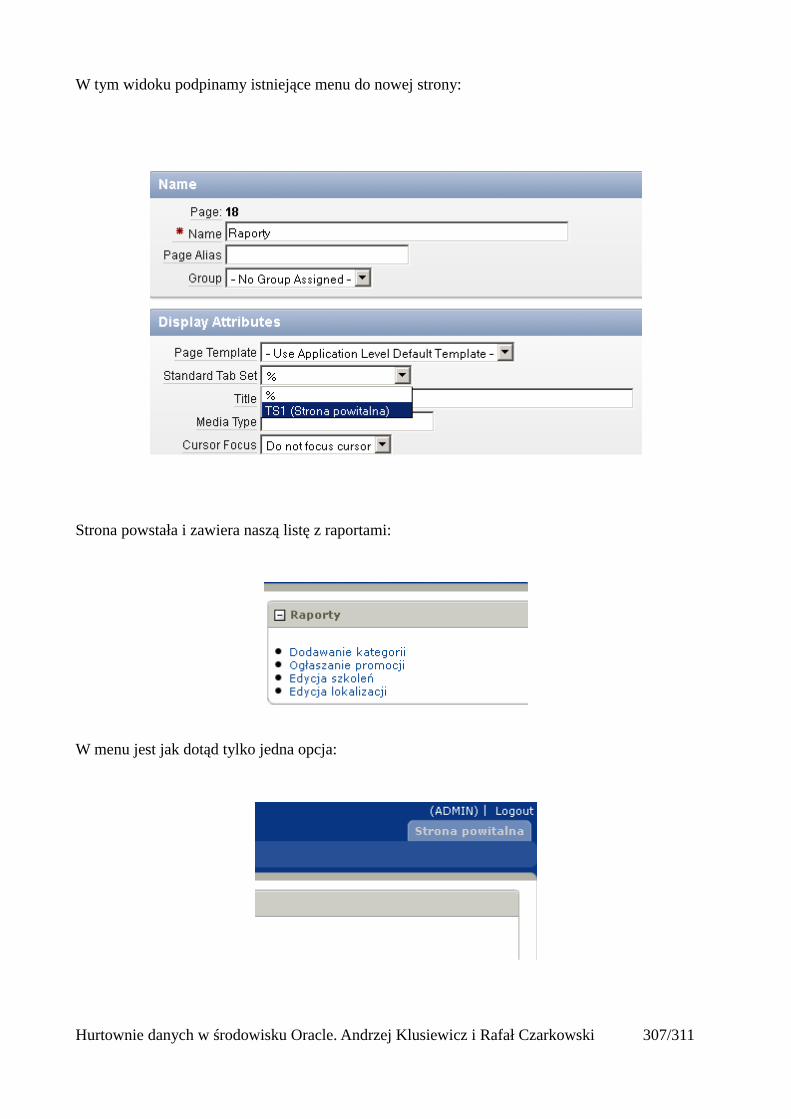
W tym widoku podpinamy istniejące menu do nowej strony:
Strona powstała i zawiera naszą listę z raportami:
W menu jest jak dotąd tylko jedna opcja:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 307/311
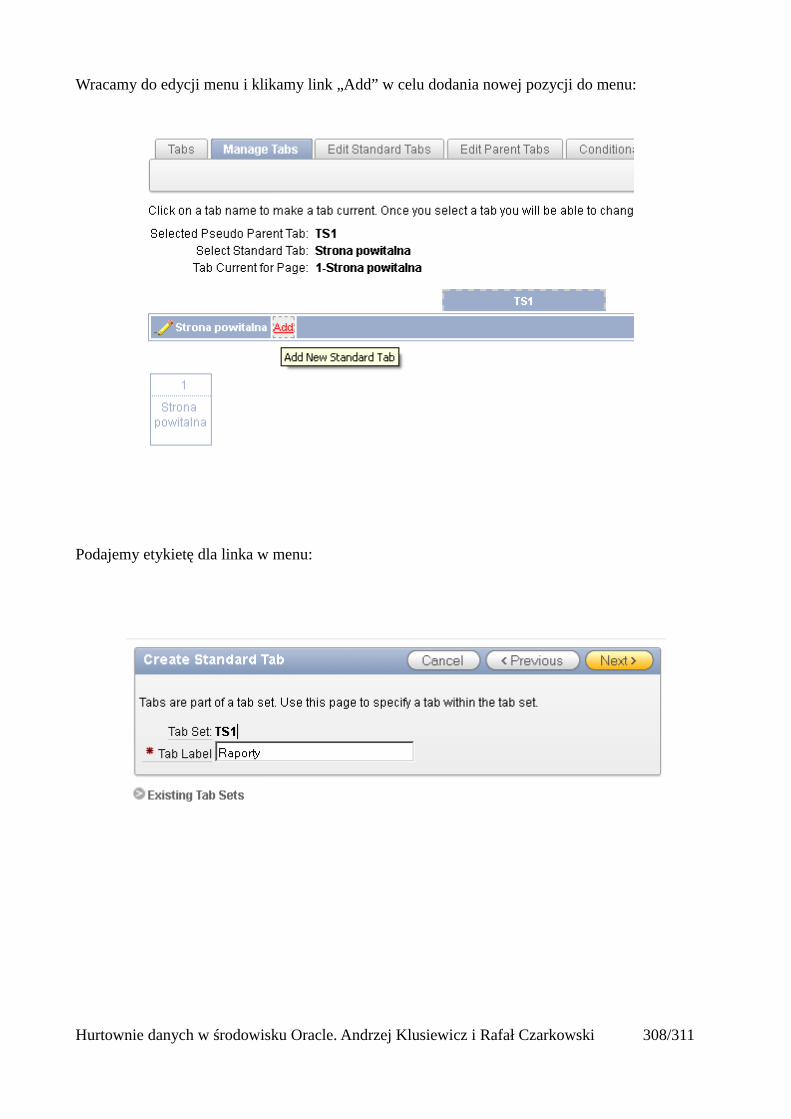
Wracamy do edycji menu i klikamy link „Add” w celu dodania nowej pozycji do menu:
Podajemy etykietę dla linka w menu:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 308/311
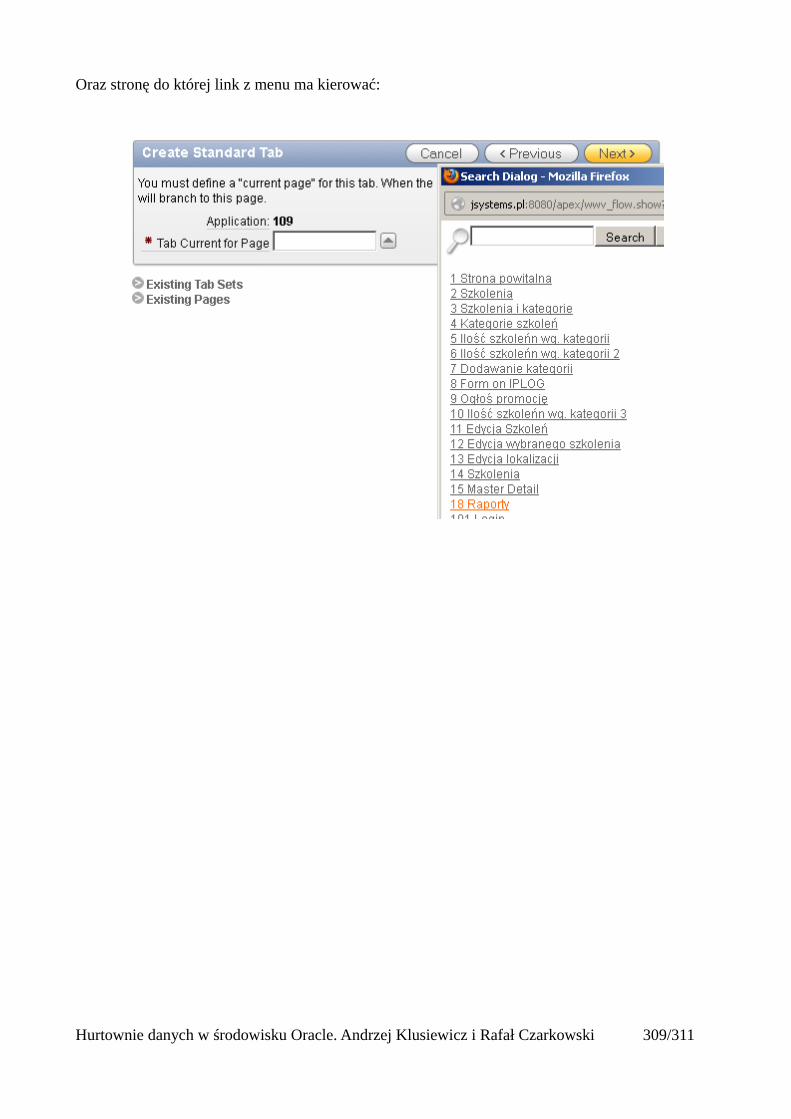
Oraz stronę do której link z menu ma kierować:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 309/311
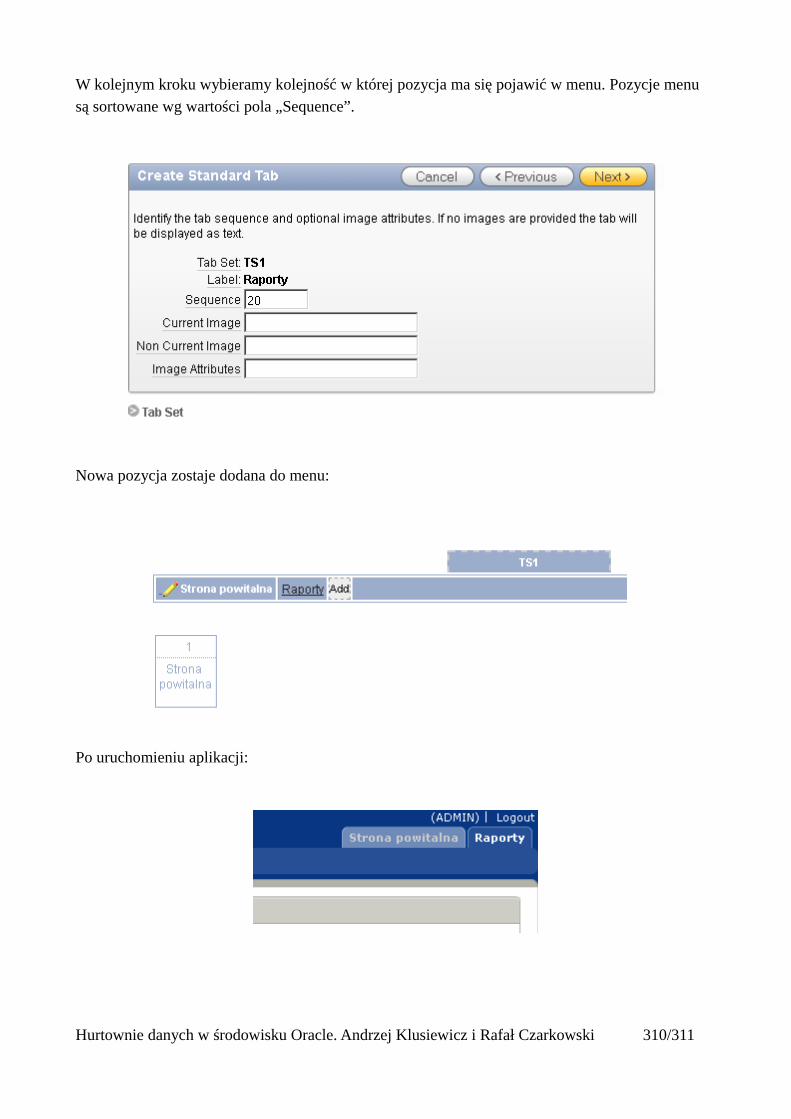
W kolejnym kroku wybieramy kolejność w której pozycja ma się pojawić w menu. Pozycje menu są sortowane wg wartości pola „Sequence”.
Nowa pozycja zostaje dodana do menu:
Po uruchomieniu aplikacji:
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 310/311
W ten sam sposób tworzę też drugą stronę, tym razem z formularzami i dodaję ją do menu.
Hurtownie danych w środowisku Oracle. Andrzej Klusiewicz i Rafał Czarkowski 311/311





























