Embed Size (px)
Citation preview

SplunkとOracle ZFS Storage Appliance Oracle テクニカル・ホワイト・ペーパー | 2015 年 9 月

SplunkとOracle ZFS Storage Appliance
目次
はじめに ......................................................................... 1
構成例概要 ....................................................................... 2
Forwarder を使用する理由 ...................................................... 2
Oracle ZFS Storage Appliance の構成 ........................................... 3
Indexer の構成 ................................................................ 4
Universal Forwarder のインストール ................................................ 5
Oracle ZFS Storage Appliance からのデータ収集 ..................................... 6
タイムスタンプを解析するための Forwarder の構成 ............................... 6
Oracle ZFS Storage Appliance からのデータセット収集 ............................... 8
get_datasets.py スクリプト ................................................. 8
スクリプトの定義 ............................................................. 8
Oracle ZFS Storage Appliance のデータセット・データの使用 ......................... 9
例:I/O操作のグラフ化 ....................................................... 12
例:ドリルダウン・データによる I/O操作のグラフ化............................. 15
Oracle ZFS Storage Appliance からのストレージ・データ収集 ........................ 17
get_storage.py スクリプト ................................................. 17
スクリプトの定義 ............................................................ 17
Oracle ZFS Storage Appliance のストレージ・データの使用 .......................... 18
Oracle ZFS Storage Appliance のストレージ・データを使用した予測 .................. 19
Oracle ZFS Storage Appliance からのログ収集 ...................................... 21
get_logs.py スクリプト .................................................... 21
Monitor の定義 ............................................................... 22
Oracle ZFS Storage Appliance のログ・データの使用 ................................ 24
結論 ............................................................................ 25
参考資料 ........................................................................ 26
付録 A:get_datasets.py の Python コード ....................................... 27
付録 B:get_storage.py の Pythonコード ......................................... 28
付録 C:get_logs.py の Python コード ............................................ 29
付録 D:zfs_session.py の Pythonコード ......................................... 31
付録 E:Oracle ZFS Storage Appliance への非特権ユーザーの追加 ..................... 35
付録 F:RESTful インタフェースの有効化............................................ 36

SplunkとOracle ZFS Storage Appliance
1
はじめに
Splunk Enterpriseは、様々なソースからマシンデータを収集するために多くの組織が使用してい
る運用インテリジェンス・プラットフォームです。収集されたデータはエンド・ツー・エンドのイ
ンフラストラクチャの監視に使用され、サービス低下の回避やパフォーマンス・ボトルネックなど
のトラブルシューティングに役立てられます。また、Splunkには、リソースが過負荷の状態になる
可能性のあるタイミングを判別するのに有効な、予測分析ツールも用意されています。
このホワイト・ペーパーでは、Oracle ZFS Storage Applianceからデータを収集するための基本事
項、データ収集の負荷を分散できるSplunkインフラストラクチャの基本事項、および収集したデー
タをインデックス化するためのSplunk Enterpriseの構成方法について説明します。例では、特に
パフォーマンスのボトルネックの予測に役に立つ、収集したデータの使用方法について説明します。
このホワイト・ペーパーは、Splunk Enterpriseのコマンドライン・インタフェース(CLI)と
Oracle ZFS Storage Applianceの知識を既にお持ちの方を対象にしています。

SplunkとOracle ZFS Storage Appliance
2
構成例概要
Splunk Enterprise インフラストラクチャでは、さまざまな方法でマシンデータを収集できます。
Splunk インフラストラクチャの中心部にあるのは Indexer ノードです。Indexer ノードは一次デー
タをイベントに変換し、結果をインデックスに配置します。また、検索リクエストに応答してイン
デックスを検索します。1
小規模構成の場合は、Splunk の他の基本的な処理(データ入力や検索の管理など)も Indexer で実
行できますが、大規模構成の場合は、そうした処理を他のマシンで実行させることができます。こ
のようなデータの入力操作を担当するマシンは Forwarder と呼ばれます。Forwarder ノードでは、
データの転送に必要なコンポーネントのみを含む専用バージョンの Splunk Enterprise が実行され
ます。2
Forwarderを使用する理由
特に大規模な環境では、Splunk インフラストラクチャ内で Indexer ノードの負荷が極めて高くなる
可能性があります。データ入力のタスクはすぐに累積する可能性があるため、サーバーと帯域の狭
いネットワークでパフォーマンスが低下する恐れがあります。Forwarder を使用すると、多数の小
規模マシンまたは仮想マシン(VM)にマシン・リソースを分散させることができるため、生成され
たネットワーク・トラフィックを平準化しやすくなります。
監視対象のシステムがネットワーク全体に分散している環境では、Indexer への接続が失われた場
合は Forwarder で自動的にデータがキューイングされるのに対し、データを直接 Indexer にスト
リーミングしている場合は、ネットワークが停止している間にイベントが失われる恐れがあります。
Forwarder を使用するもう 1 つのメリットは、関連するマシンからのデータをグループ化できるこ
とです。これにより、Indexer上の関連イベントへのアクセスが高速化します。
1 http://docs.splunk.com/Splexicon:Indexer 2 http://docs.splunk.com/Splexicon:Forwarder

SplunkとOracle ZFS Storage Appliance
3
図1:分散されたSplunkインフラストラクチャ
図 1 は分散された Splunk インフラストラクチャの例を示しています。このインフラストラクチャ
には異なる機能を持つ 3 つのグループが含まれ、各グループは相互間のルーティングが制限されて
いる独立したサブネット上に存在します。各グループには 1 台以上の Oracle ZFS Storage
Appliance があり、そこに保存されたデータは Forwarder により一次データが加工され、Indexer
に転送されます。
このホワイト・ペーパーでは、開発環境に存在する Oracle ZFS Storage Appliance のデータを
Forwarder で収集し、Indexer に転送する方法について詳しく説明します。
この例では、Splunk Enterprise 6.2 がすでにインストールされた Indexer ノードと Splunk
Universal Forwarder がインストールされた Oracle Linux 7.1 が稼働するサーバー各 1 台を含む環
境を想定しています。しかし、このホワイト・ペーパーで説明する概念は、OS には依存しません。
Splunk Forwarder は、Oracle Solaris および他の OS でも使用できます。Python 言語と Phython を
使った必須モジュールが使用できる限り、ここで説明する実装が適用可能です。
Oracle ZFS Storage Applianceの構成
OS8.3 およびそれ以前が実行されている Oracle ZFS Storage Appliance 上で Representational
State Transfer(REST)(RESTful とも呼ばれます)インタフェースにアクセスするには、最初に
REST を有効にする必要があります。RESTful API を有効にする方法について詳しくは、付録 F を参
照してください。OS8.4 以降が実行されている Oracle ZFS Storage Appliance では、デフォルトで、
APIが有効にされています。
ユーザー環境

SplunkとOracle ZFS Storage Appliance
4
Indexerの構成
Forwarder からデータを受け取るには、先にデータを受信できるように Indexer を設定しておく必
要があります。そのために、Receiver プロセスを実行します。Indexer のコマンドライン・インタ
フェースで次のコマンドを使用して Receiver プロセスを有効化します。
splunk enable listen 9997
なお、Splunk Forwarder では通常ポート 9997 を使用してデータを送信しますが、未使用のポート
をどれでも指定することができます。Indexer に認証されているセッションがまだ存在しない場合
は、ユーザー名とパスワードの入力を求めるプロンプトが表示されます。
Receiver を設定すると、Indexer が受信するファイルまたはストリームのデータ入力が自動的に追
加されます。
図2:SplunkのWebインタフェースからのReceiverの追加
図 2 に示すとおり、Receiver は Indexer の Web GUI から設定することもできます。「Settings」メ
ニューの下の Data セクションで「Forwarding and receiving」を選択します。「Receive data」
の下で「Add new」をクリックし、Receiverのポート番号を入力します。
Receiver の設定が完了すると、Forwarder から Receiver に転送されてきたデータは自動的に取込
まれます。

SplunkとOracle ZFS Storage Appliance
5
Universal Forwarderのインストール
Linux Forwarder のインストールと設定のおおまかな手順は次のとおりです。
1. まだ、実行していない場合は、Splunk Universal Forwarderをダウンロードし、Splunkのドキュ
メントに従って Linux マシンにインストールします3。Oracle Linux の場合は、お使いのアーキ
テクチャ用の RPM ファイルを使用して yum または rpm でインストールします。Forwarder は任
意のシステム・ユーザーで実行できます。root 以外のユーザーで実行する場合は、この後指定す
る入力の読み込みに必要な権限がそのユーザーに付与されていることを確認してください。
2. Forwarder をインストールしたディレクトリを環境変数$SPLUNK_HOME に設定します。デフォ
ルトを使用して RPM パッケージから Forwarder をインストールすると、このディレクトリは
/opt/splunkforwarder になります。$PATH 変数に Splunk の実行ファイルが存在する場所
を追加し、Splunk Forwarder を起動します。シェルの初期化スクリプトに export 行を追加して、
この設定を自動化することもできます。初めて Splunk を起動したときには、ライセンス条項へ
の同意を促す内容が表示されます。Splunk の起動時に、コマンドに“—accept-license”を
付加すると、ライセンス条項に同意することを示しており、この表示がされなくなります。
export SPLUNK_HOME=/opt/splunkforwarder
export PATH=${PATH}:${SPLUNK_HOME}/bin
splunk start --accept-license
3. Splunk admin のデフォルト・パスワードは、次のコマンドを使用して変更する必要があります。
Forwarder 上の CLI セッションがまだ認証されていない場合は、ユーザー名とパスワードの入力
を求めるプロンプトが表示されます。新規インストールの場合、プロンプトが表示されたら、
Splunkのユーザー名に adminを使用し、パスワードに changeme を使用します。
splunk edit user admin -password <New_Splunk_Admin_Password> \ -
role admin
4. 特定の受信 Indexer を指定するよう、Forwarder を設定します。ホストは、IP アドレスまたは
ホスト名のいずれかで指定します。Splunk の通信に使用するデフォルト・ポートは 9997 ですが、
この設定は Indexer 側で簡単に変更できます。
splunk add forward-server <host>:<port>
Splunk Forwarder のパッケージには Web インタフェースが付属していません。Forwarder はコマン
ドラインまたは構成ファイルを使用して設定する必要があります。
3 本書の執筆時点では、http://docs.splunk.com/Documentation/Splunk/latest/Forwarding/Deployanix から
ドキュメントを入手できます。

SplunkとOracle ZFS Storage Appliance
6
Oracle ZFS Storage Applianceからのデータ収集
Oracle ZFS Storage Appliance からデータを収集する方法は多数存在します。この方法には、ブラ
ウザ・ユーザー・インタフェース(BUI)、コマンドライン・インタフェース(CLI)、および
Representational State Transfer(REST)インタフェースがあります。REST インタフェースが
もっとも柔軟性があるため、このホワイト・ペーパーでは、Oracle ZFS Storage Appliance とのす
べてのやり取りにこれを使用します。REST インタフェースからは、リクエストされたデータが
Splunkで容易に解析できる JavaScript Object Notation(JSON)形式で返されます。
タイムスタンプを解析するためのForwarderの構成
Oracle ZFS Storage Appliance のログに使用されているタイムスタンプの形式は、Splunk では即
座に認識できません。ログの JSON 形式に含まれるタイムスタンプを Splunk で検出して解析できる
ようにするには、ファイル$SPLUNK_HOME/etc/system/local/props.conf を編集し、次の行
を追加します。
[host::<hostname_regex>]
TIME_PREFIX = “timestamp"
MAX_TIMESTAMP_LOOKAHEAD = 22
TIME_FORMAT = “%Y%m%dT%H:%M:%S”
TZ = UTC # Dependent on environment
<hostname_regex>は、正規表現を入力するフィールドで、Oracle ZFS Storage Appliance のホ
スト名に一致させる必要があります。例えば開発環境グループの Oracle ZFS Storage Appliance
が全て dev-zfs で始まる場合、ホスト行は次のようになります。
[host::dev-zfs*]
TIME_PREFIX 行は、タイムスタンプが含まれている行を示しており、
MAX_TIMESTAMP_LOOKAHEAD 行では、その行内でタイムスタンプが開始する場所を定義します。
上に指定したこれらの値は、Oracle ZFS Storage Appliance JSON 出力の実際のタイムスタンプの
値です。
最後の行では、Oracle ZFS Storage Appliance のタイムスタンプ文字列の形式を定義します(示さ
れているタイムスタンプ形式は、このホワイト・ペーパーのすべての例において有効ですが、
Problemサービスなど、REST API の一部のセクションでは、他の形式を使用します)。
なお、Oracle ZFS Storage Appliance からログを収集している Forwarder が Splunk インフラスト
ラクチャ内に複数ある場合は、Forwarder ごとにこの変更を行う必要があります。このタイムスタ
ンプに関する設定を行う必要があるのは Forwarder であって、Indexerではありません。
お使いの環境によっては、タイムゾーンに 1 行を追加することが必要になる場合があります。ベス
ト・プラクティスでは、システムの内部時刻に協定世界時(UTC)ゾーンを使用して、オペレー
ティング・システムでローカル・タイムゾーンを設定することを推奨しています。通常、Oracle
ZFS Storage Appliance はこの方法で構成されており、前に示したように TZ 行が必要になります。
これを確認するには、次のコマンドを実行します。
curl –k –u <user> https://<appliance>:215/api/service/v1/services/ntp
返される日付行が“GMT+0000 (UTC)”で終了している場合、TZ行を使用する必要があります。
Forwarder の構成ファイルに加えられたすべての変更内容は、Splunk が再起動されて初めて有効に

SplunkとOracle ZFS Storage Appliance
7
なります。現在有効になっている設定に影響を与えないようにして、ファイルの妥当性をチェック
するには、コマンド splunk btool check –debug を実行します。

SplunkとOracle ZFS Storage Appliance
8
Oracle ZFS Storage Applianceからのデータセット収集
Splunk はデータ駆動型であり、Oracle ZFS Storage Appliance には連携する動作項目が多数含ま
れています。REST サービスでは、Oracle ZFS Storage Appliance のデータセットにアクセスでき
るため、ユーザーは Splunk に取り入れるさまざまなメトリックや詳細情報を収集できます。使用
可能なデータセットについて詳しくは、『Oracle ZFS Storage Appliance Analytics Guide』を参
照してください。
Splunk にデータセットを取り込むには、Forwarder が Oracle ZFS Storage Appliance にログオン
してデータを収集し、そのデータを stdout に書き込むためのスクリプトが必要になります。
get_datasets.pyスクリプト
付録 A に示されている get_datasets.py スクリプト(そして、付録 D の関連モジュール
zfs_session.py)は、データセットを収集して、JSON 形式で出力する例を示しています。
get_datasets.py スクリプトの使用方法は、次のとおりです。
usage: get_datasets.py -d DATASET [DATASET ...]
-k KEYFILE -u USERNAME [-1]
zfs_appliances [zfs_appliances ...]
『Analytics Guide』に記載されているいずれかのデータセット(もしくは複数のデータセット)を指
定できます。KEYFILE は、スクリプトがアクセスする Oracle ZFS Storage Appliance に関する情報が
格納された JSON ファイルです。USERNAME は、すべての Oracle ZFS Storage Appliance に対するログ
オン・ユーザーを示します。ここでは、すべての Oracle ZFS Storage Appliance は、同じスクリプト
でアクセスされ、さらに同じログイン認証情報が指定されていると仮定しています。
このスクリプトを実行すると、コマンドラインで渡した Oracle ZFS Storage Appliance ユーザー
名のパスワードの入力を求めるプロンプトが表示されます。REST インタフェースの検索クエリには、
非特権ユーザーを使用することを強くお勧めします。非特権ユーザーは、Oracle ZFS Storage
Appliance の BUI で作成できます。このユーザーの作成時に、割り当てる必要がある唯一のロール
は、Analytics への読取り専用アクセスです(非特権ユーザーの追加例は、付録 E を参照してくだ
さい)。スクリプトを使ってパスワードの設定を自動化する方法は多数存在します。必ずお使いの
環境のセキュリティ・ポリシーに沿った方法を実装してください。
スクリプトの定義
Splunk でスクリプトを実行し、その出力を読み込むには、最初にこのスクリプトを Splunk にアク
セスできる場所に配置する必要があります。通常は$SPLUNK_HOME/bin/scripts で示したディ
レクトリに配置します。
次に、ファイル$SPLUNK_HOME/etc/system/local/inputs.conf に次のスクリプト行を追加
します。
[script://<script_name> <script_parameters>]
interval = <seconds>
sourcetype = _json
これは、特にこのような追加のパラメータを指定して、ラッパー・スクリプトを使用するスクリプ

SplunkとOracle ZFS Storage Appliance
9
トをコールする場合にお勧めします。これにより、Splunk のパーサーが誤って固有の文字の解釈を
間違えることがなくなります。次に、ラッパー・スクリプト get_datasets.sh を示します。
#!/bin/bash
/opt/splunkforwarder/bin/scripts/get_datasets.py \
-d io.bytes[op] io.bytes nic.kilobytes[direction] \
nfs3.ops[share] nfs3.ops[op] nfs4.ops[share] nfs4.ops[op] \
-k /opt/splunkforwarder.tmp/get_datasets.key –u reporter \
dev-zfs-1 dev-zfs-2]
次に、inputs.conf の例を示します。
[script:///opt/splunkforwarder/bin/scripts/get_datasets.sh]
interval = 60
sourcetype = _json
なお、sourcetype は_json と指定する必要があります。そうしないと、Splunk で出力を正しく
解析できないことがあります。また、スクリプトはフル・パス名で指定する必要があります。これ
により、スクリプト定義行のコロンの後に、スラッシュが 3 つ表示されます。interval 値では、ス
クリプトの実行間隔時間を秒単位で設定します。
このスクリプトを実行すると、スクリプトが最後に実行された時間から 1 秒間隔で、複数のデータ
セットのデータが収集されます。スクリプトが最初に起動されると、以前の 24 時間のデータが収
集されます。
粒度が低くても問題がないデータセットの場合、スクリプトにパラメータ-1 を渡します。これに
より、指定したデータセットごとに、現時点から単一データ・ポイントが返されます。
次に、30秒ごとに単一データセットを収集する例を示します(ラッパーは使用しません)。
[script:///opt/splunkforwarder/bin/scripts/get_datasets.py \
-d cpu.utilization[mode] \
-k /opt/splunkforwarder.tmp/get_datasets2.key –u reporter \
dev-zfs-1 dev-zfs-2 ]
interval = 30
sourcetype = _json
ここでは、別の keyfile が指定されています。複数の行から同一のスクリプトがコールされた場合、
特にスクリプトが異なる間隔で実行されている場合など、競合を回避するために別の keyfile を使
用することをお勧めします。これは、keyfile には最後のアクセス時間も格納され、この値が、ス
クリプト間で正確に共有されていない可能性があるためです。
inputs.conf に上記行の追加をした後、Splunk を再起動します。これにより Forwarder が収集し
たデータは、自動的に Indexerに渡されます。
Oracle ZFS Storage Applianceのデータセットの使用
スクリプトによってデータが生成され始めると、Forwarder から Indexer に自動的にデータが転送

SplunkとOracle ZFS Storage Appliance
10
されます。この様子は、Searchスクリーンの“What to Search”セクションで確認できます。
図3:SplunkインタフェースのWhat to Searchセクション
「Data Summary」ボタンをクリックすると、Splunk がデータを収集しているホストのリストが表示
されます。なお、Splunk のデフォルトでは、Oracle ZFS Storage Appliance のホスト名ではなく
Forwarder のホスト名が“Host”として使用されます。
図4:Data Summary
Forwarder のホスト名をクリックすると、Indexer が Forwarder から収集したすべてのレコードが
読み込まれます。Splunk インフラストラクチャに含まれる各 Forwarder が、Host 列の下にリスト
されます。
複数の Oracle ZFS Storage Appliance から 1 つの Forwarder にレポートされている状況では、そ
の Forwarder のすべてのレコードに対して検索を行うことができます。この例では、Forwarder に
レポートしている 1つのマシンのデータについてレポートされます。

SplunkとOracle ZFS Storage Appliance
11
図5:レコードの展開
図 5 を見ると、“i ”列の下に矢印があり、レコードを展開して操作ができるようになっています。
最初のレコードの「>」をクリックします。
図6:レコードを展開した状態

SplunkとOracle ZFS Storage Appliance
12
展開したレコード内で extracted_host というフィールドを探し、左側のボックスをクリックし
ます。すると、上の“Selected”領域にフィールドが移動するため、1 つの Oracle ZFS Storage
Appliance についての Indexer によるソートがかなり容易になります。この選択内容は、Forwarder
から転送されたすべてのレコードに適用されます。この操作は永続的であるため、別の Oracle ZFS
Storage Appliance を対象にする場合でも、他の検索にこの操作を繰り返す必要はありません。
“I ”列の矢印を再度クリックすると、開いていたウィンドウが閉じます。これにより、
extracted_host フィールドはログ・レコードの host として表示されます。extracted_host
の値をクリックすると、オプション・リストが表示されます。
図7:検索の作成
「New search」をクリックすると、その Oracle ZFS Storage Appliance のみを対象とする検索が
作成されます。同じポップアップ・メニューから他のフィールドを検索に追加することができます。
nfs4.ops[op]のデータセット値をクリックして、検索を NFSv4 操作イベントに制限し、ほかの
データセットが含まれないようにします。
図8:検索への追加
検索が作成されると、検索用のコマンドラインが上部に表示されます。必要に応じて、手動で編集
できます。
例:I/O操作のグラフ化
ドリルダウン情報によるデータの抽出とグラフ化の例として、前の図で示したように、必要な
Oracle ZFS Storage Appliance に対して検索を作成します。必要なホストに返された多数のイベン
トに対して検索を行い、特定のデータセットを検出して、前に示したように検索に追加できます。
しかし、この場合、単に手動で検索を編集する方が速い可能性があります。このような場合、
dataset フィールドに spath コマンドを追加すると、検索が高速化されます。そのとき、対象とす

SplunkとOracle ZFS Storage Appliance
13
る特定のデータセット(この場合は、io.bytes)の search コマンドに対して、検索結果を入力
しパイプできます。
* | spath host | search host="aie-zs3-2b" | spath dataset | search dataset="io.bytes"
図9:検索の編集
この情報からグラフを作成する場合は、検索に変換コマンド4を追加します。
次の例では、value フィールドを使用して、合計 I/O をグラフ化しています。search コマンドに
timechart avg(value)を追加することにより、示されている期間ごとに平均化された値でグラ
フが作成されます。また、‘as “IO Bytes”’を使用すると、グラフの value フィールドの名前を
変更できるようになります。グラフのスタイルや形式を変更するには、プルダウン・メニューを使
用します。この例では、合計 I/Oをバイト単位の面グラフで示しています。
* | spath host | search host="aie-zs3-2b" | spath dataset | search
dataset="io.bytes" | timechart avg(value) as "IO Bytes"
図10:合計I/Oバイト数の平均
前の例では、Oracle ZFS Storage Appliance の I/O を 5 分ごとに平均化していましたが、この場合、
4 変換コマンドは、各イベントの指定されたセル値を数値に"変換"し、統計の作成を目的として Splunkで使用
できるようにします。
変換コマンドには chart、timechart、stats、top、rare、contingency、および highlight が含ま
れます。検索結果データをカラムチャート、棒グラフ、線グラフ、面グラフ、円グラフなどの視覚表現に必要
なデータ構造体に変換する場合は、変換コマンドが必要です。

SplunkとOracle ZFS Storage Appliance
14
高 I/O の短時間のスパイクが、平均化操作において平滑化されてしまうため、データが十分正確に
は表示されていない可能性があります。データを表示する別の方法として、ある期間にわたって値
の表を作成し、chart コマンドを使用してグラフを描画する方法があります。
* | spath host | search host="aie-zs3-2b" | spath dataset | search
dataset="io.bytes" | table value, _time, | chart values(value) as "IO
Bytes/sec" by _time
図11:tableおよびgraphコマンドの使用
図 10 のグラフは、Oracle ZFS Storage Appliance の I/O が、1,200B/秒周辺で平均化されているこ
とを明確に示しています。一方、図 11 は、10,000B/秒を超えるスパイクが時々発生していること
を示しています。
グラフ化するデータが多すぎると警告が発生し、結果が切り捨てられてしまう場合があります。グ
ラフの最後の部分にマウスを移動させると、プロットされた最後の時間が、グラフの最初の部分か
ら 1,000 秒(または、16 分 40 秒)経過していることが判別できます。ただし、以降のデータ・ポ
イントはプロットされていません。このようなスタイルのグラフは、図 12 で示しているように、
15分以下の期間を使用する場合に適しています。

SplunkとOracle ZFS Storage Appliance
15
図12:15分の期間の使用
例:ドリルダウン・データによるI/O操作のグラフ化
Oracle ZFS Storage Appliance の合計 I/O をグラフ化するのは有効な方法ですが、全体像が把握で
きないことがあります。io.bytes データセットを使用した前のグラフでは、負荷が、読み込み、
書き込み、またはその両方に対して偏っているのかどうかについて判別することができません。合
計 I/O にドリルダウンするには、代わりに、データセット io.bytes[op]を使用します。データ
セットの名前の後に、角括弧で囲まれた記述子を配置すると、より詳しい情報が使用できます。図
13 に示すように、io.bytes[op]の場合、value に示される合計 I/O は、フィールド read およ
び write の操作によって細分化されます。
図13:io.bytes[op]イベント
データセットとして io.bytes[op]を使用して、図 12 のグラフで使用されている検索を変更し、
最後の例で read および write を使用するように table および chart コマンドを変更すること
により、データの両方の部分を同時に表示します(図 14を参照)。
* | spath host | search host="aie-zs3-2b" | spath dataset | search
dataset="io.bytes[op]" | table read, write, _time, | chart values(read) as
Read, values(write) as Write by _time
SplunkとOracle ZFS Storage Appliance
16
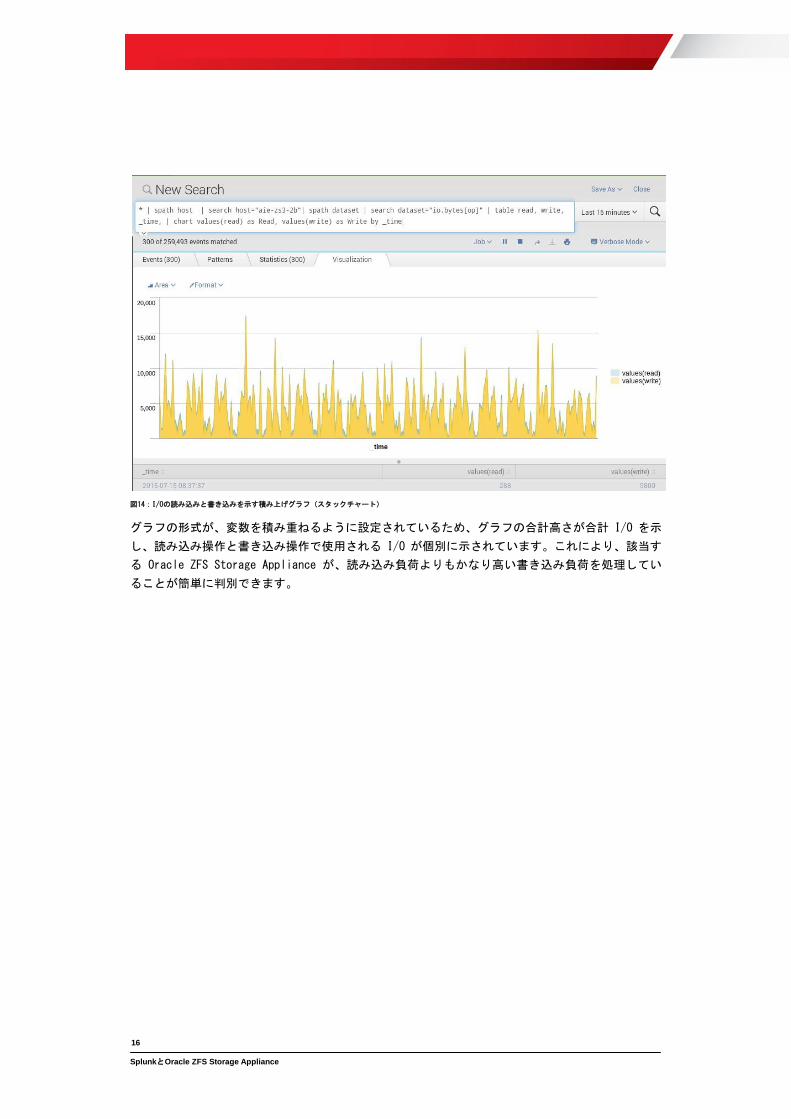
図14:I/Oの読み込みと書き込みを示す積み上げグラフ(スタックチャート)
グラフの形式が、変数を積み重ねるように設定されているため、グラフの合計高さが合計 I/O を示
し、読み込み操作と書き込み操作で使用される I/O が個別に示されています。これにより、該当す
る Oracle ZFS Storage Appliance が、読み込み負荷よりもかなり高い書き込み負荷を処理してい
ることが簡単に判別できます。

SplunkとOracle ZFS Storage Appliance
17
Oracle ZFS Storage Applianceからのストレージ・データ収集
データセットが提供するメトリック・データ情報の場合と同様の方法により、Oracle ZFS Storage
Appliance からストレージ情報を収集できます。再度、Forwarder にログオンしてデータを収集し
て処理し、そのデータを stdout に書き込むためのスクリプトが必要になります。一例として、付
録 Bの get_storage.py スクリプトを示します。
get_storage.pyスクリプト
このスクリプトは、get_datasets.py よりもかなり単純です。使用方法は、次のとおりです。
usage: get_storage.py -k KEYFILE -u USERNAME
zfs_appliances [zfs_appliances ...]
get_datasets.py を実行する際にセキュリティにおいて注意する点はすべて、keyfile と
username パラメータを使用する get_storage.py の場合と同様です。
Oracle ZFS Storage Appliance からデータを読み込むスクリプトを開発する際に重要な点は、デー
タをプレビューして、レコードを適切に処理するのに必要なデータが Splunk に存在するのを確認
することです。ストレージ検索クエリに対する JSON 出力には、ホスト識別子およびタイムスタン
プが存在しません。したがって、これらのフィールドを JSON オブジェクトに追加するコードが重
要になります。
このスクリプトでは、プールを構成するデバイスに関する情報が破棄され、明確にするために情報
はスクラブされます。この情報がユーザーにとって価値がある場合、情報を含めるようにスクリプ
トを修正する必要があります。
スクリプトの定義
再度、ラッパー・スクリプトを使用します。
#!/bin/bash
/opt/splunkforwarder/bin/scripts/get_storage.py \
-k /opt/splunkforwarder/tmp/get_storage.key –u reporter \
dev-zfs-1 dev-zfs-2
以前と同様、ファイル$SPLUNK_HOME/etc/system/local/inputs.conf に下記スクリプト行
を追加します。
[script:///opt/splunkforwarder/bin/scripts/get_storage.sh]
interval = 60
sourcetype = _json
Forwarder を再起動すると、スクリプトの実行が開始されます。

SplunkとOracle ZFS Storage Appliance
18
Oracle ZFS Storage Applianceのストレージ・データの使用
この例では、get_storage.py スクリプトが 1 分間に 1 回実行され、Oracle ZFS Storage
Appliance 上の各プールに対して JSON オブジェクトが返されます。次に、このオブジェクトの 1 例
を示します。
{
"asn": "fd4ccdd9-02e0-c467-90cb-a383680c21c3",
"available": 958106216960.0,
"dedupratio": 100,
"host": "aie-zs3-2b",
"owner": "aie-zs3-2b",
"peer": "00000000-0000-0000-0000-000000000000",
"pool": "pool0",
"profile": "cache_stripe:mirror:log_mirror",
"status": "online",
"timestamp": "20150716T13:57:52",
"total": 8933531975680.0,
"used": 7975425758720.0
}
このデータの有効な視覚化は、使用中のディスク領域と使用可能なディスク領域を示す円グラフで
す。必要なホストの検索に続けて、必要なプールでの検索を作成することにより、プール内での空
き領域と使用中の領域の比率が簡単に表示できます。
* | spath host | search host=”aie-zs3-2b” | spath pool | search pool=”pool0” |
dedup available, used | stats avg(available) as Free, avg(used) as Used |
transpose
図15:プールの使用領域を示す円グラフ
dedup コマンドを使用すると、追加する最新のレコードのみが返されます。

SplunkとOracle ZFS Storage Appliance
19
Oracle ZFS Storage Applianceのストレージ・データを使用した予測
この例の get_storage.py スクリプトでは、ファイル・システムに関する情報を返すこともできま
す。このコードでは、取得される情報を保有しているのは、pool0 内のファイル・システムのみです。
Splunk でファイル・システム・データを取り込んだ状態になれば、ファイル・システムで使用中の
領域に関する検索を書き込むのは単純なプロセスになります。
* | spath filesystem | search filesystem="*tinyfs" | timechart
sum(eval(space_total/1048576)) as UsedMB
図16:ファイル・システムで使用中の領域
この例のスクリプトでは、1~3 分ごとにランダムに、1MB のファイルをマウントされているファイ
ル・システムに書き込みます。その結果、使用中の領域が着実に増加していきます。
将来の使用領域を予測するには、Splunk の predict コマンドを使用します。ユーザーは、このコ
マンドを使用して、多数のモデリング・アルゴリズムのいずれかを時間ベースのデータに適用する
ことにより、将来の傾向を予測できます。predict コマンドは、timechart コマンドの出力を
predict にパイプすることにより、簡単に起動できます。
* | spath filesystem | search filesystem="*tinyfs" | timechart
sum(eval(space_total/1048576)) as UsedMB | predict “UsedMB” future_timespan=250

SplunkとOracle ZFS Storage Appliance
20
図17:ファイル・システムでの将来の使用領域の予測
この例は、実際の状況と比較して単純化し過ぎている感がありますが、Splunk の predict コマン
ドの能力と有用性をわかりやすく示しています。

SplunkとOracle ZFS Storage Appliance
21
Oracle ZFS Storage Applianceからのログ収集
Splunk からするとログ・ファイルは充実したデータ・ソースであり、 Oracle ZFS Storage
Appliance では大量のデータがログに記録されます。このデータは 5 つの異なるログ(アラート、
監査、障害、phone-home、およびシステム)に分散されます。5システム・ログを別のサーバーに転
送する機能を持つ標準の syslog プロトコルで表示されるのはシステム・ログのみです。REST イン
タフェースを使用すると、必要なログをすべて簡単に収集できます。
Splunk にログを取り込むには、3 つの手順を実行する必要があります。最初の手順はログ収集です。
これは、次のスクリプトで実行します。
get_logs.pyスクリプト
付録 C にリストされている get_logs.py スクリプトは、Forwarder ノードで定期的に実行される
ように設計されているスクリプトでログを収集する方法を示す例です。
スクリプトで表示される get_logs.py の使用方法は次のとおりです。
usage: get_logs.py –k KEYFILE –u USERNAME
-p LOGPATH –t LOGTYPE [LOGTYPE …] [-F]
<zfs_appliances>
以前と同様、スクリプトごとに別の keyfile を使用する必要があります。LOGPATH は、ログが書き
込まれるディレクトリで、1つ以上の LOGTYPEを指定する必要があります。
このスクリプトを実行すると、コマンドラインで渡した Oracle ZFS Storage Appliance ユーザー
名のパスワードの入力を求めるプロンプトが表示されます。今回も、REST インタフェースの検索ク
エリには、非特権ユーザーを使用することを強くお勧めします。
そして、Oracle ZFS Storage Appliance に対してスクリプトそのものの認証が行われ、指定したロ
グ・タイプのエントリのうち、前回このスクリプトを実行した後に生成されたものが収集されます。
また、Forwarder 上の所定のパスに<zfs_appliance>.<logtype>.log という形式のファイル
を書き込まれ、前回のログ・ファイルは Linux の logrotate コマンドと同様の方法で入れ替えら
れます。
監査ログがリクエストされた場合は、パラメータ-F を使用して特殊なフィルタを適用し、BUI、
CLI、または REST インタフェースへのセッションのログインまたはログアウトごとに書き込みが行
われないようにすることができます。監査ファイルの大半はこれらのエントリで占められますが、
これらのエントリを Splunk に渡してインデックス化しても役に立たないことが多いためこのよう
なフィルタ処理をおこないます。
ログ・データの収集に Splunk Forwarder を使用する場合の問題の 1 つは、元のソース・データが
他の Oracle ZFS Storage Appliance のログと混ざってしまう可能性がある点です。1 つの Oracle
ZFS Storage Appliance のログを検索できるようにするには、各ログ・エントリにスクリプトで
“host”という名前のフィールドを追加し、元のソースを正しく識別できるようにします。
5 各ログ・タイプについて詳しくは、Oracle ZFS Storage Appliance のドキュメントを参照してください。

SplunkとOracle ZFS Storage Appliance
22
スクリプトは、$SPLUNK_HOME/bin/scripts などの適切な場所にインストールし、コマンド
chmod +x get_logs.py を使用して実行権限を付与する必要があります。スクリプトによるログ
の書き込み先として使用される所定のファイルパスが存在する必要があり、スクリプトを実行する
ユーザーによる書き込みが可能になっている必要があります。
このスクリプトは、定期的に実行する必要があります。Linux およびほかの UNIX 型オペレーティン
グ・システムでは、プロセスを実行するスケジュールを定義するために、cron と呼ばれるサービ
スが使用できます。Oracle Linux システムの例では、次の行をファイル/etc/crontab に追加す
ることにより、ログ収集プロセスが 15分ごとに実行されるようにスケジュール設定されます。
0,15,30,45 * * * * /usr/local/bin/get_logs.py –u reporter \
–p /var/log/splunk –k /opt/splunkforwarder/tmp/dev_log.dat \
–t alert audit fault system –F dev-zfs-1 dev-zfs-2
スクリプトを配置して定期的な実行の設定が整ったら、2つ目の手順は、Forwarder の構成です。
3つ目の手順では、Forwarder にログの読み込みを指示します。
Monitorの定義
Splunk Monitor は、指定したディレクトリの変更の有無を監視して、新しいデータを Indexer に渡
すプロセスです。この例のスクリプトではファイルにログを書き込むため、ファイルが配置される
ディレクトリで変更の有無を監視するように Forwarder に指示する必要があります。
get_logs.py スクリプトの<filepath>引数が Monitor の<source>になります。
監視対象のディレクトリにあるファイルで発生した変更は Forwarder で認識され、即座に処理が実
行されます。
ファイルの Monitor を追加するには、$SPLUNK_HOME/etc/system/local/inputs.conf を編
集して次の行を追加します。
[monitor://<source>]
sourcetype = _json
ファイル・パスが/var/log/splunk/である場合、次のようになります。
[monitor:///var/log/splunk]
sourcetype = _json
blacklist = \.(gz|bz2|z|zip)$
なお、sourcetype は_json と指定する必要があります。そうしないと、Splunk でログを正しく
解析できません。
Splunk のログ処理のデフォルト動作は最適化されていないため、このスクリプトは古いログ・ファ
イルの圧縮には対応していません。ログ・ファイル名が変更されているだけであれば、ログが入れ
替わったことがわかり、再度読み取られることはありませんが、ファイル名が変更されて圧縮され
ている場合、Splunkでは圧縮を解除して再度解析するため、イベントが重複してしまいます。

SplunkとOracle ZFS Storage Appliance
23
ログの入替えに圧縮が使用されている場合は、前のコードで示したようにブラックリスト・ルール
を追加すると、指定したパターンで終わるファイルは処理されなくなります。
コマンドラインから Monitor を追加する場合は、次の行を使用します。
$ splunk add monitor <source> -sourcetype _json
なお、コマンドラインを使用する場合は、ディレクトリ名をスラッシュ(/)で終わりにする必要
があります。
新しい設定を有効にするには、次のコマンドで Forwarder を再起動する必要があります。
splunk restart

SplunkとOracle ZFS Storage Appliance
24
Oracle ZFS Storage Applianceのログ・データの使用
前のセクションのデータセットおよびストレージ・データの場合と同様に、スクリプトによって監
視対象のディレクトリにデータが生成され始めると、Forwarder から Indexer に自動的にデータが
転送されます。
例:ログインのグラフ化
データセットおよびストレージの検索と同様の方法で、ログイン情報の検索を作成できます。この例
では、ワイルドカードを使用して、すべてのログインをさまざまなインタフェースと一致させます。
* | spath host | search host=”aie-7120b” | spath summary | search summary=”User
logged in”
図18:ログインの検索
次の例では、検索コマンドに“timechart count”を追加して、ログイン数の時系列グラフを作成
しています。グラフのスタイルや形式を変更するには、プルダウン・メニューを使用します。
* | spath host | search host=”aie-7120b” | spath summary | search summary=”User
logged in” | timechart count
図19:検索の視覚化

SplunkとOracle ZFS Storage Appliance
25
結論
Oracle ZFS Storage Appliance 上で RESTful API を活用すると、すべてのログとデータセットを
Splunk にインポートすることができ、組織のインフラストラクチャを包括的に概観することができ、
必要に応じて詳細までドリルダウンすることもできます。
本書で提供している Python スクリプトは、Oracle ZFS Storage Appliance からさまざまなタイプ
のデータを抽出する場合の RESTful API の使用方法を説明するために書かれたものであるため、入
力パラメータに対する適切なエラー・チェックや失敗したコマンドについてのエラー・レポートが
提供されない可能性があります。この点を考慮して例を使用してください。
本番環境のプログラムを作成する場合は、ユーザー入力を十分にチェックして障害の性質をユー
ザーが十分に理解できる詳しい診断エラー・メッセージを出力するようなコードを記述するように
してください。Oracle ZFS Storage Appliance に対するユーザー認証は、さらに自動化することが
できますが、この方法は演習として残してあります。

SplunkとOracle ZFS Storage Appliance
26
参考資料
このドキュメントで説明した製品に関連する追加情報については、次のリソースを参照してください。
Oracle RESTful API のドキュメント
https://docs.oracle.com/cd/E51475_01/html/E52433/index.html
Oracle ZFS Storage Appliance のホワイト・ペーパーおよびこのテーマに関する資料
http://www.oracle.com/technetwork/jp/server-storage/sun-unified-
storage/documentation/index.html
「 Oracle ZFS Storage Applianceの RESTful APIの使用」
(http://www.oracle.com/technetwork/jp/server-storage/sun-unified-
storage/documentation/restfulapi-zfssa-0914-2284451-ja.pdf)
Oracle ZFS Storage Appliance Analytics Guide
http://docs.oracle.com/cd/E56021_01/html/E55853/docinfo.html
Oracle ZFS Storage Appliance 製品情報
http://www.oracle.com/jp/storage/nas/overview/index.html
Oracle ZFS Storage Appliance ドキュメント・ライブラリ(インストール、分析、顧客
サービス、管理ガイドなど):
http://www.oracle.com/technetwork/documentation/oracle-unified-ss-193371.html
『Oracle ZFS Storage Appliance Administration Guide』は Oracle ZFS Storage
Appliance のヘルプ・コンテキストでも参照できます。
Oracle ZFS Storage Appliance のヘルプ機能には、ブラウザ・ユーザー・インタフェース
からアクセスできます。
Splunkに関する情報とドキュメント
http://splunk.vccorp.net/

SplunkとOracle ZFS Storage Appliance
27
付録A:get_datasets.py
#!/usr/bin/python
# Copyright (c) 2015, Oracle and/or its affiliates. All rights reserved.
""" Collect either a single or a set of data points for each dataset passed via the
command line from each specified ZFS storage appliance and format it in a way to
make Splunk ingestion simple. If a single data point is specified, it will be taken
for the current second, otherwise the data will be collected starting from the last
time the script was run as stored in the keyfile and be returned with an object for
each one second interval. If there is no start time available, collect the last 60
seconds of data.
"""
import json
import sys
import os
import zfs_session
def get_datasets(host, args):
""" Drilldown dataset data are accumulated over time, and getting a dump
of the information for a long timespan may take quite a bit of time.
This function will return the data in one second intervals since the last time
the script was run against the host (as determined by an entry in the key
file) up to the present moment. """
# Get current ZFS appliance's time host.get_zfssa_curtime()
for dataset_name in args.datasets:
if args.onetime:
# Override the timespan set in get_zfssa_curtime() to one second
host.urlspan = "data?start=now&seconds=1"
host.url = "{0}/api/analytics/v1/datasets/{1}/{2}".\
format(host.urlbase, dataset_name, host.urlspan)
dataset_array = host.get_data()['data']
if args.onetime:
# A dataset without drilldown data will not be in the list format
# expected below - recast it into one
dataset_array = [dataset_array]
for dataset in dataset_array:
# Add identifying fields to the JSON object and flatten the
# object for better ingestion
dataset['host'] = host.name
dataset['dataset'] = dataset_name
dataset = zfs_session.flatten_dataset_json(dataset)
print json.dumps(dataset, sort_keys=True, indent=2)
def main():
args = zfs_session.getargs()
for hostname in args.zfs_appliances:
# Create the host object
host = zfs_session.Host(hostname, args)
get_datasets(host, args)
host.save_session(args)
if name == ' main ':
# redefine stdout to be unbuffered
sys.stdout = os.fdopen(sys.stdout.fileno(), 'w', 0)
main()

SplunkとOracle ZFS Storage Appliance
28
付録B:get_storage.py
#!/usr/bin/python
# Copyright (c) 2015, Oracle and/or its affiliates. All rights reserved.
""" Collect pool information from a ZFS storage appliance """
import json
import sys
import os
import zfs_session
def get_filesystems(host):
# Only query for the filesystems in the default project
host.url = "{0}/projects/default/filesystems".format(host.url)
filesystems = host.get_data()
if not filesystems:
print "No filesystems found"
sys.exit(1)
for fs in filesystems['filesystems']: fs['filesystem'] =
fs.pop('canonical_name')
# A host and a timestamp are important to Splunk
fs['host'] = host.name
fs['timestamp'] = host.timestamp
# Delete data uninteresting to Splunk
del fs['source']
print json.dumps(fs, sort_keys=True, indent=2)
def get_pools(host):
host.url = "{0}/api/storage/v1/pools".format(host.urlbase)
pools = host.get_data()
if not pools:
print "No pools found"
sys.exit(1)
for pool in pools['pools']:
host.url = "{0}{1}".format(host.urlbase, pool['href'])
pooldetail = host.get_data()
pooldetail['pool']['pool'] = pooldetail['pool'].pop('name')
# A host and a timestamp are important to Splunk
pooldetail['pool']['host'] = host.name
pooldetail['pool']['timestamp'] = host.timestamp
pooldetail['pool'] = zfs_session.flatten_storage_json(
pooldetail['pool'])
print json.dumps(pooldetail['pool'], sort_keys=True, indent=2)
# Only collect filesystem data for pool0
if pooldetail['pool']['pool'] == 'pool0':
get_filesystems(host)
def main():
args = zfs_session.getargs()
for hostname in args.zfs_appliances:
# Create the host object
host = zfs_session.Host(hostname, args)
host.get_zfssa_curtime()
get_pools(host)
host.save_session(args)
if name == ' main ':
# redefine stdout to be unbuffered
sys.stdout = os.fdopen(sys.stdout.fileno(), 'w', 0)
main()

SplunkとOracle ZFS Storage Appliance
29
付録C:get_logs.py
#!/usr/bin/python
# Copyright (c) 2015, Oracle and/or its affiliates. All rights reserved.
"""Collect logs from an Oracle ZFS Storage Appliance. The logs are returned in
JSON format and will be rotated as needed."""
import json
import sys
import os
import glob
import zfs_session
def rotate_logs(filename, args):
"""Rotate the log files in a similar manner to the logrotate command"""
loglist = sorted(glob.glob(filename + '.*'))
if args.keep_logs == 0 or args.keep_logs >= 1000:
log_num_len = 3
args.keep_logs = 1000
else:
log_num_len = len(str(args.keep_logs - 1))
if len(loglist) == args.keep_logs:
loglist.pop()
latest = len(loglist)
for myfile in reversed(loglist):
logstr = '.' + str(latest).zfill(log_num_len)
os.rename(myfile, filename + logstr)
latest -= 1
os.rename(filename, filename + '.' + str(latest).zfill(log_num_len))
return
def find_last_logs(filename):
"""Find the last time a log entry was written to the extant logfile and return
all entries with that timestamp."""
try:
with open(filename, 'r') as fp:
oldlog = json.load(fp)
fp.close()
lastlogs = []
last_time = oldlog[-1]['timestamp']
for entry in reversed(oldlog):
if entry['timestamp'] == last_time:
lastlogs.append(entry)
return lastlogs
except IOError:
return None
except AttributeError as err:
print "Error ", err, " opening ", filename
sys.exit(6)
def get_logs(host, args):
""" Retrieve the logs from the appliance, parse and filter them as
required, then write them to the appropriate field. """
# Get current ZFS appliance's time
host.get_zfssa_curtime()
for logtype in args.logtype:
filename = '{0}/{1}.{2}.log'.format(args.logpath, host.name, logtype)
# Find the last log entry written, if any
if os.path.exists(filename):
last_logs = find_last_logs(filename)
if len(last_logs) != 0:
last_time = last_logs[0]['timestamp']

SplunkとOracle ZFS Storage Appliance
30
else:
last_time = None
else:
last_logs = []
last_time = None
if not last_time:
host.url = "{0}/api/log/v1/logs/{1}".format(host.urlbase, logtype)
else:
host.url = "{0}/api/log/v1/logs/{1}?start={2}".format(host.urlbase,
logtype,
last_time)
# The appliance returns the logs in a dictionary with a single key:value
# pair, with the key of 'logs' and a value of a list of all the
# pertinent entries. We only need the list.
log_array = host.get_data()['logs']
for log_entry in log_array[:]:
# Using slicing to be able to modify log_array even as we iterate
# through it.
log_entry['host'] = host.name
if args.filter and logtype == 'audit':
if log_entry['summary'].find("User logged") != -1 or \
log_entry['summary'].find("Browser session") != -1:
log_array.remove(log_entry)
# Compare the last log entries written with the new log entries
# collected and discard any matches in the new log
for test_entry in last_logs:
for log_entry in log_array[:]:
if cmp(test_entry, log_entry) == 0:
log_array.remove(log_entry)
continue
if len(log_array) > 0:
# Only rotate logs and write a new log file if there are new entries
if os.path.exists(filename):
rotate_logs(filename, args)
try:
with open(filename, 'w') as fp:
json.dump(log_array, fp, sort_keys=True, indent=2)
fp.close()
except IOError as e:
print 'I/O error({0}) writing {1}: {2}'.format(e.errno,
filename,
e.strerror)
def main():
args = zfs_session.getargs()
# Define how many logs are to be kept, up to 1000. Zero is the same as 1000
args.keep_logs = 15
for hostname in args.zfs_appliances:
# Create the host object
host = zfs_session.Host(hostname, args) get_logs(host, args)
host.save_session(args)
if __name == " main ":
# redefine stdout to be unbuffered
sys.stdout = os.fdopen(sys.stdout.fileno(), 'w', 0)
main()

SplunkとOracle ZFS Storage Appliance
31
付録D:zfs_session.py
# Copyright (c) 2015, Oracle and/or its affiliates. All rights reserved.
import requests
import json
import sys
import time
import argparse
import getpass
import base64
class Host(object):
""" Host class for storing ZFS Storage Appliance data and methods for
authentication and REST data retreival """
Def __init (self, hostname, args):
""" Define the host object and create placeholders for variables to
be set at a later time, then log into the appliance. """
self.name = hostname
self.xauth = None
self.url = None
self.urlbase = None
self.urlspan = None
self.last_access_time = None
self.client = None
self.timestamp = None
self.open_session(args)
def save_session(self, args):
""" Copy the configuration for the host to a JSON object and write
the JSON object to a keyfile. Note that the keyfile is not intended to
be shared with other processes.
"""
try: # to read the keyfile
with open(args.keyfile, 'r') as fp:
tmp_dict = json.load(fp)
fp.close()
except IOError:
tmp_dict = {self.name: {}}
if self.name not in tmp_dict.keys():
tmp_dict[self.name] = {}
# The xauth token should not be stored in clear text. encode()
# will use the Vigenere cipher to encrypt it, using the password as
# a key.
tmp_dict[self.name]['xauth'] = encode(args.password, self.xauth)
tmp_dict[self.name]['url'] = self.url
tmp_dict[self.name]['urlbase'] = self.urlbase
tmp_dict[self.name]['urlspan'] = self.urlspan
tmp_dict[self.name]['last_access_time'] = self.last_access_time
try:
with open(args.keyfile, 'w') as fp:
json.dump(tmp_dict, fp, sort_keys=True, indent=2)
fp.close()
except IOError as e:
print 'I/O error({0}) writing {1}: {2}'.format(e.errno,
args.keyfile,
e.strerror)
def open_session(self, args):
""" Read args.keyfile and if a JSON object exists for the host
self.name, populate the host object, otherwise define the URL base.
"""
try:
with open(args.keyfile, 'r') as fp:
tmp_dict = json.load(fp)
fp.close()
if self.name in tmp_dict.keys():

SplunkとOracle ZFS Storage Appliance
32
self.xauth = decode(args.password, tmp_dict[self.name]['xauth'])
self.url = tmp_dict[self.name]['url']
self.urlbase = tmp_dict[self.name]['urlbase']
self.last_access_time = tmp_dict[self.name]['last_access_time']
self.urlspan = tmp_dict[self.name]['urlspan']
else:
self.urlbase = "https://{0}:215".format(self.name)
except IOError:
# No keyfile at all
self.urlbase = "https://{0}:215".format(self.name)
self.define_client(args)
def define_client(self, args):
""" Define the Sessions object used to authenticate to and interact with
the ZFS appliance.
"""
self.client = requests.Session()
# Do not verify appliance's self-signed certificate
self.client.verify = False
self.url = "{0}/api/access/v1".format(self.urlbase)
# Can we log in with our old key?
try:
self.client.headers.update({'X-Auth-Session': self.xauth})
obj = self.client.get(self.url)
obj.raise_for_status()
except requests.exceptions.HTTPError:
# No self.xauth found, log in with the username and password
try:
# Having X-Auth-Session defined in the headers overrides the
# existence of X-Auth-User and X-Auth-Key
del self.client.headers['X-Auth-Session']
self.client.headers.update({'X-Auth-User': args.username})
self.client.headers.update({'X-Auth-Key': args.password})
obj = self.client.post(self.url)
obj.raise_for_status()
# Remove X-Auth-User and X-Auth-Key and add X-Auth-Session
del self.client.headers['X-Auth-User']
del self.client.headers['X-Auth-Key']
self.xauth = obj.headers['x-auth-session']
self.client.headers.update(
{'X-Auth-Session': obj.headers['x-auth-session']})
except:
print 'Error with user/pw authenticaton: {0}'.format(
sys.exc_info()[0])
sys.exit(2)
except:
print 'Error {0}'.format(sys.exc_info()[0])
sys.exit(3)
return self
def get_zfssa_curtime(self):
""" It cannot be assumed that the system running the script will be
synchronized with the appliances being polled. Pull one second of arc
size data from the storage appliance to define our base time.
"""
self.url = \
'{0}/api/analytics/v1/datasets/arc.size/data?start=now&seconds=1'.\
format(self.urlbase)
nowstr = self.get_data()['data']['startTime']
nowobj = time.strptime(nowstr, "%Y%m%dT%H:%M:%S")
nowflt = time.mktime(nowobj)
# While the timespan is not always needed, the overhead of adding it
# here is very low and allows the same function to be called for both
# single data points and drilldowns.
if self.last_access_time is not None:
# Get the data since it was last collected
lasttime = self.last_access_time
else:

SplunkとOracle ZFS Storage Appliance
33
# Get last hour's data if being run for the first time
lasttime = nowflt - 3600
self.last_access_time = nowflt
timespan = nowflt - lasttime
self.urlspan = "data?start={0}&seconds={1}".format(
time.strftime("%Y%m%dT%H:%M:%S", time.localtime(lasttime)),
int(timespan))
self.timestamp = "{0}".format(time.strftime("%Y%m%dT%H:%M:%S",
time.localtime(nowflt)))
def get_data(self):
""" Make the HTTP call using self.url and return a JSON object after
stripping off the outer ['data'] wrapper """
# noinspection PyBroadException
try:
obj = self.client.get(self.url)
obj.raise_for_status()
except:
print 'Error with REST call: {0}'.format(sys.exc_info()[0])
print 'URL = {0}'.format(self.url)
sys.exit(2)
else:
return obj.json()
#########################################################################
# Below are functions that do not act on the host object.
#########################################################################
def flatten_dataset_json(dataset): """
Flatten the JSON object returned by the appliance. It is assumed that the
object has already had its outer data wrapper stripped off.
"""
dataset['timestamp'] = dataset.pop('startTime')
# Bring the total value to the top level.
dataset['value'] = dataset['data']['value']
del dataset['data']['value']
# Handle breakdown data
try:
# The inner dictionaries only exist for datasets for which there
# are breakdowns available.
for tmpdict in dataset['data']['data']:
dataset[tmpdict['key']] = tmpdict['value']
except KeyError:
pass
# Delete unused fields
del dataset['sample']
del dataset['samples']
del dataset['data']
return dataset
def flatten_storage_json(storage): """
Flatten the storage object returned by the appliance. It is assumed that
the object has already had its outer data wrapper stripped off.
"""
# Try dropping vdev details and other uneeded sub-objects some of which may
# not always exist in the object
objlist = 'vdev', 'log', 'spare', 'errors', 'scrub', 'cache'
for subobj in objlist:
try:
del storage[subobj]
except KeyError:
pass
# Flatten usage data
try:
# The inner dictionary 'usage' is brought up a level
for name, value in storage['usage'].iteritems():
storage[str(name)] = value
del storage['usage']

SplunkとOracle ZFS Storage Appliance
34
except KeyError:
pass
return storage
def encode(key, clear):
# Encode a string using the Vigenere cipher
coded = []
for idx in range(len(clear)):
# Rotate through the key string to get the key character
key_c = key[idx % len(key)]
# Add the ord() values of the clear and key characters, modulo
# the size of the character set (256) and append the result to the
# encoded string
coded.append(chr(ord(clear[idx]) + ord(key_c) % 256))
# Ensure the coded string is a pure text string
return base64.urlsafe_b64encode("".join(coded))
def decode(key, base64str):
# Decode a string using the Vigenere cipher
clear = []
# Ensure that base64str is not a unicode string or decoding from base64
# will crash
coded = base64.urlsafe_b64decode(str(base64str))
for idx in range(len(coded)):
key_c = key[idx % len(key)]
clear.append(chr((256 + ord(coded[idx]) - ord(key_c)) % 256))
return "".join(clear)
def getargs(): """
Parse the command line arguments. Note that this function does not do any
checking as to whether the arguments are appropriate for the particular
script being run.
"""
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--datasets', nargs='+', type=str)
parser.add_argument('-k', '--keyfile', type=str)
parser.add_argument('-u', '--username', type=str)
parser.add_argument('-p', '--logpath', type=str)
parser.add_argument('-t', '--logtype', nargs='+', type=str)
parser.add_argument('-F', '--filter', dest='filter', action='store_true')
parser.add_argument('-1', '--onetime', dest='onetime', action='store_true')
parser.add_argument('zfs_appliances', nargs='+', type=str)
parser.set_defaults(filter=False, onetime=False)
args = parser.parse_args()
# The user may wish to automate the password input based on local
# security concerns; this prompts for a password each time the program
# is run.
if not args.password:
args.password = getpass.getpass(
"Enter password for user {0}".format(args.username))
return args

SplunkとOracle ZFS Storage Appliance
35
付録E:Oracle ZFS Storage Applianceへの非特権ユーザーの追加
Oracle ZFS Storage Appliance の場合、データの読み込みのみであれば、RESTful API にログイン
するユーザーに管理権限を付与する必要はありません。従って RESTful API にアクセスするには、
管理権限を持たない新規ユーザーを作成する必要があります。
図20:ユーザー構成スクリーン
このユーザーを作成するには、Oracle ZFS Storage Appliance の Web ブラウザ・ユーザー・インタ
フェース( BUI)にログインします。 root などの特権ユーザーとしてログインします。
「Configuration」、「Users」の順にクリックします。ユーザーのリストの上にあるプラス記号を
クリックし、Add User スクリーンを表示します。
図21:ユーザーの追加
最初に、ボタンをクリックしてこのユーザーを“Local Only”にします。新規ユーザーの名前を入
力します。この例では、ユーザー名“reporter”を使用します。必要に応じてユーザーのフルネー
ムを入力し、パスワードを 2回入力します。
最後に、ウィンドウ下部にあるロールがどれもチェックされていないことを確認します。ユーザー
にロールを割り当てなければ、権限は何も割り当てられません。

SplunkとOracle ZFS Storage Appliance
36
付録F:RESTfulインタフェースの有効化
Oracle ZFS Storage Appliance OS8.3 およびそれ以前では、Oracle ZFS Storage Appliance 上の
RESTful インタフェースは、アクセスする前に有効化する必要があります。これを実行するには、
ブラウザ・ユーザー・インタフェース(BUI)を使用します。BUI にログインし、メニュー項目
「Configuration」をクリックします。Services ページが表示されます。ページ下部の Remote
Access セクションに、REST というラベルの付いた行があります。インジケータが緑色でない場合
は、次の図に示す「オン/オフ」ボタンをクリックします。REST インタフェースの有効/無効はこの
ボタンで切り替わります。
図22:RESTインタフェースの有効化

C O N N E C T W I T H U S
blogs.oracle.com/oracle
facebook.com/oracle
twitter.com/oracle
oracle.com
Copyright © 2015, Oracle and/or its affiliates. All rights reserved.本文書は情報提供のみを目的として提供されており、
facebook.com/oracle ここに記載される内容は予告なく変更されることがあります。本文書は、その内容に誤りがないことを保証
するものではなく、また、口頭による明示または法律による黙示を問わず、特定の目的に対する商品性もしくは適合性についての
黙示的な保証を含め、いかなる他の保証や条件も提供するものではありません。オラクル社は本文書に関するいかなる法的責任も
明確に否認し、twitter.com/oracle 本文書によって直接的または間接的に確立される契約義務はないものとします。本文書はオラク
ルの書面による許可を前もって得ることなく、いかなる目的のためにも、電子または印刷を含むいかなる形式や手段によっても再
作成または送信することはできません。
Oracle および Java は Oracle およびその子会社、関連会社の登録商標です。その他の名称はそれぞれの会社の商標です。
Intel および Intel Xeon は Intel Corporation の商標または登録商標です。すべての SPARC 商標はライセンスに基づいて使用される
SPARC International, Inc.の商標または登録商標です。AMD、Opteron、AMD ロゴおよび AMD Opteron ロゴは、Advanced Micro
Devices の商標または登録商標です。UNIX は、The Open Group の登録商標です。0615
Splunk と Oracle ZFS Storage Appliance、
2015 年 8 月、バージョン 2.0
著者:Joseph Hartley、Application Integration Engineering