1
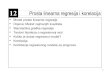
Mirza Muhi ima greka, kod viestrukog regresionog modela na slici
sa etri strelice u boji. strelice trebaju da idu na kolonu coef a
ne na std errorMirza Muhi poto radim ovaj zadatak to je on stavio
moe li neko samo da kae ta je "prediktor", je li to varijabla sales
ili su one druge 3. to je odreivanje adekvatne veliine uzorka1.
TESTIRANJE HIPOTEZA
Hipoteza je tvrdnja koju je mogue empirijski provjeriti. Nulta
hipoteza uvijek odraava status-quo situaciju. Drugim rijeima,
ukoliko se ne odbaci nulta hipoteza onda ne treba poduzimati
nikakve korektivne akcije dok alternativna hipoteza odraava ono to
istraiva smatra da je istina. Hipoteza moe biti postavljena
jednosmjerno, dvosmjerno i viesmjerno.Kriterij koji koristimo za
prihvatanje ili odbacivanje nulte hipoteze naziva se nivoom
statistike znaajnosti a izraava se preko p-vrijednosti. Dakle,
p-vrijednost nije nita drugo nego vjerovatnoa da dobijemo rezultat
toliko razliit od onog kojeg bi imali pod pretpostavkom da je nulta
hipoteza istinita. Ukoliko je p4/200
Cooks distance je mjera koja pokazuje veliinu uticaja pojedinane
opservacije na model.Vrijednosti >1 su razlog za zabrinutost
(Cook and Weisberg , 1988).
2.3. Detekcija ekstremnih vrijednosti: Leverageopet kucati
naredbe jednu iza drugi da bi se neto desilo :)C: predict lev,
leverage
C: list sales airplay attract adverts lev if
lev>(2*3+2)/200
Leverage pokazuje uticaj koji pojedinana opservacija ima na
procjenjene beta koeficijente. Poelno je ispitati sve opservacije
koje imaju vrijednost za lev > (2k+2)/n.
k = broj nezavisnih varijabli,
n = veliina uzorka.
2.4. Detekcija ekstremnih vrijednosti: DFITopet dvije naredbe u
nizu
C: predict dfit, dfits
C: list sales airplay attract adverts dfit if
abs(dfit)>2*sqrt(3/200)
DFIT pokazuje razliku izmeu predviene vrijednosti kada je
opservacija ukljuena u model i kada nije. Kao i Cooks distance, ovo
je mjera uticaja opservacije na model u cjelini. Poeljno je
provjeriti sve opservacije koje imaju dfit > 2*sqrt(k/n). U ovom
primjeru to su opservacije sa dfit>0.245
2.5. Detekcija ekstremnih vrijednosti: DFBETAC: dfbeta
C: list sales airplay attract adverts _dfbeta_1 if
abs(_dfbeta_1)>2/sqrt(200)
DFBETA pokazuje razliku izmeu vrijednosti koeficijenta kada je
opservacija ukljuena u model i kada nije. Izraunava se za svaku
varijablu posebno. Poeljno je provjeriti sve opservacije koje imaju
dfbeta > 2/sqrt(n). U ovom primjeru dfbeta > 0.141
2.6. Detekcija ekstremnih vrijednosti: Partial plots
C: avplots
C: avplots, mlabel(id)
Traiti take koje se ba izdvajaju iz gomile.
3. Ne postoji savrena multikolinearnost (Multicollinearity)3.1.
Simptomi multikolinearnosti Znatno vee standardne greke uz znatno
nie vrijednosti t-statistike,
Neoekivane promjene u veliini ili predznaku koeficijenata,
Nesignifikantni koeficijenti uprkos visokom R2.
3.2. Pokazatelji multikolinearnostiC: quietly regress sales
airplay attract advertsC: vif
4. Linearnost (Linearity)Pod ovim se podrazumjeva da su veze
koje modeliramo izmeu nezavisnih varijabli i prosjene vrijednosti
zavisne varijable linearnog tipa.
4.1. Linearnost: Provjera prirode vezeKod proste regresije
dovoljno je nacrtati dijagram rasipanja izmeu X i Y.C: twoway (lfit
sales adverts) (scatter sales adverts) (lowess sales adverts)4.2.
Linearnost residulas vs predictors
C: predict r, resid
C: scatter airplay
C: scatter attract
C: scatter adverts
Jedan od naina je da nacrtamo dijagram rasipanja reziduala i
svake nezavisne varijable. Na dobijenim dijagramima ne bi trebalo
biti jasno izraenog nelinearnog uzorka.4.3. Linearnost acrplot
C: acprplot airplay, lowess lsopts(bwidth(1))
C: acprplot attract, lowess lsopts(bwidth(1))
C: acprplot adverts, lowess lsopts(bwidth(1))
dobije se isto ono to i prije sa ukljuenom linijom regresije
5. Homoskedastinost (Homoscedasticity)
Varijansa reziduala oko predvienih vrijednosti zavisne varijable
treba da je priblino jednaka za sve predviene vrijednosti. Ukoliko
je ova pretpostavka naruena pojavljuje se problem
heteroskedastinosti.
5.1. Grafiki metodi za provjeru heteroskedastinosti
C: rvfplot, yline(0) Prikazana su 4 mogua sluaja
5.2. Testovi za provjeru heteroskedastinosti C: estat imtest
C: estat hettest
Treba skontat ta se gleda
6. Nema autokorelacije (Independet errors)Ova pretpostavka se
ogleda u tome da izmeu reziduala bilo koje dvije opservacije ne
postoji korelacija.6.1. Tesiranje pretpostavke o nezavisnosti:
Durbin-Watson test
6.2. Tesiranje pretpostavke o nezavisnosti: vizuelna provjeraC:
predict r, residual
C: scatter r id
7. i ima normalan raspored (Normally distributed errors)
7.1. Provjera da i ima normalan raspored Kernel densityC:
predict r, resid
C: kdensity r, normal
slika koja se dobije prikazuje normalnu distribuciju i nau
distribuciju. gleda se koliko oblik odstupa
7.2. Provjera da i ima normalan raspored: P-P plot
C: pnorm r
7.3. Provjera da i ima normalan raspored: Q-Q plotC: qnorm r
7.4. Provjera da i ima normalan raspored: testovi
C: swilk r
C: sktest r
Treba skontati ta se gleda, koji parametar
8. Pravilna specifikacija modela1. Nezavisne varijable
(prediktori) ne smiju biti u korelaciji sa "eksternim varijablama
(no simultaneity bias)
2. Ukljuene sve relevantne varijable (no ommited variables)
3. Iskljuene sve irelevantne varijable (no irrelevant
variables)C: estat ovtest
C: estat ovtest, rhs
1 predstavlja nagib regresione linije. Ako se vrijednost
nezavisna varijable (adbudget) povea za 1$ prodae se dodatnih 0,096
komada.
Drugim rijeima, ako poveamo budet za oglaavanje za 100$ u
prosjeku emo prodati dodatnih 9,6 komada.
0 = _cons
Taka u kojoj regresiona linija sijee Y-osu. Bez ulaganja u
oglaavanje (x=0) prodali bi 134.139 komada.
1 individualni doprinos nezavisne varijable X1(adverts) prodaji.
Ako se budet za oglaavanje povea za 1$ prodae se dodatnih 0,085
komada uz uslova da su ostale nezavisne varijable
nepromijenjene.
2 individualni doprinos nezavisne varijable X2(airplay) prodaji.
Ako se broj putanja na radiju povea za 1 prodae se dodatnih 3.367
komada uz uslova da su ostale nezavisne varijable
nepromijenjene.
3 individualni doprinos nezavisne varijable X3(attract) prodaji.
Ako se atraktivnost banda poraste za 1 prodae se dodatnih 11.086
komada uz uslova da su ostale nezavisne varijable
nepromijenjene.
0 = _cons
U konkretnom sluaju nema smisla i ne tumai se posebno.
Ako je najvea VIF vrijednost vea od 10 onda postoji razlog za
zabrinutost.
Tolerance (1/VIF) ispod 0,1 ukazuje na znaajan problem.
Tolerance (1/VIF) ispod 0,2 ukazuje na potencijalni problem.
Ako je VIF prosjek znatno vei od 1 onda postoji mogunost da je
regresija pristrasna (biased).