Embed Size (px)
Citation preview

STATA for Beginners INTENSIVE
พชญ จงวฒนากล
1

ความหมายของเศรษฐมต
• เศรษฐมตเปนการวดทางเศรษฐศาสตร
(Economic measurement)
• เศรษฐมต หมายถง การวเคราะหทางปรมาณเก&ยวกบปรากฎการณหรอพฤตกรรมทางเศรษฐศาสตร โดยอาศยทฤษฎและขอมลท&สงเกตไดแลวนามาอธบายความสมพนธโดยวธวนจฉยท&เหมาะสม (Samualson)
2

กระบวนการทางเศรษฐมต
• เลอกทฤษฎและต 6งสมมตฐาน• สรางแบบจาลองทางคณตศาสตรตามทฤษฎ• สรางแบบจาลองทางเศรษฐมต• รวมรวมขอมล (ประกอบดวย ขอเทจจรงท&ปรากฎ หรอส&งท&สงเกตได)
• ประมาณการ (estimate) คาพารามเตอร (parameter)
• การวเคราะหทางสถตทดสอบความเช&อม&นและความนาเช&อถอ• การทานายหรอพยากรณ (forecast)
• การประยกตใชเพ&อนาไปสนโยบายตางๆ
3

1. เลอกทฤษฎและต�งสมมตฐาน
• ทฤษฎการบรโภคของเคนส กลาววา รายไดท&ใชจายได (Disposable Income) เปนตวแปรท&สาคญท&สดในการกาหนดรายจายเพ&อการบรโภค ดงน 6นเม&อสมมตใหปจจยอ&น ๆ คงท& ฟงกชนการบรโภคจงข 6นอยกบรายไดท&ใชจายไดแตเพยงอยางเดยว
4
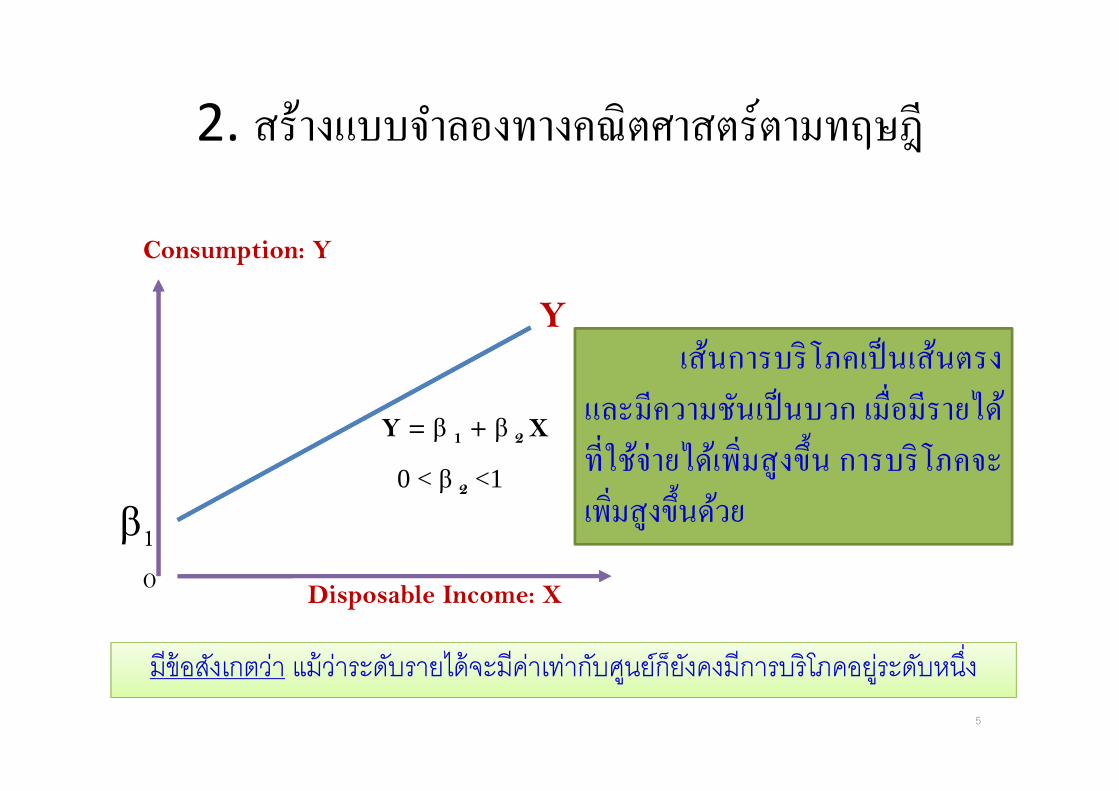
2. สรางแบบจาลองทางคณตศาสตรตามทฤษฎ
Consumption: Y
Disposable Income: X
β1
0
Y
มขอสงเกตวา แมวาระดบรายไดจะมคาเทากบศนยกยงคงมการบรโภคอยระดบหน&ง
เสนการบรโภคเปนเสนตรง และมความชนเปนบวก เม*อมรายไดท*ใชจายไดเพ*มสงข�น การบรโภคจะเพ*มสงข�นดวย
Y = β 1 + β 2X
0 < β 2 <1
5

3. สรางแบบจาลองทางเศรษฐมต
• U คอ ตวรบกวน (disturbance term) หรอ error term
เกดข 6นจาก อทธพลของตวแปรอ&นๆท&ไมไดนามาศกษาในแบบจาลอง หรอกลาวไดวา เปนสวนท&ไมสามารถอธบายไดจากแบบจาลองท&สรางข 6น
Y = β 1 + β 2X + U
6

4. รวมรวมขอมล
• Personal Consumption Expenditures (PCE)
– > U.S. Bureau of Labor Statistics
• Real GDP
– > World Bank
• สมมตใชขอมลต 6งแตป 1960 - 2005
7
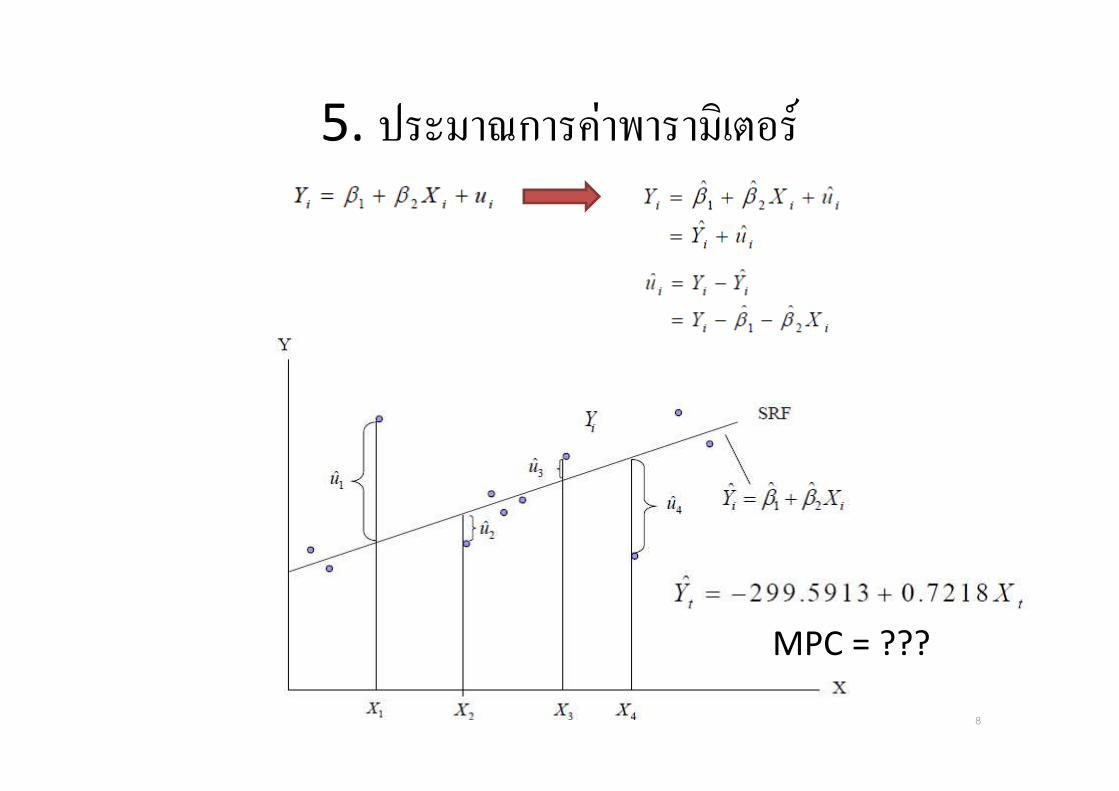
5. ประมาณการคาพารามเตอร
MPC = ???
8

6. การวเคราะหทางสถตทดสอบความเช*อม*นและความนาเช*อถอ
• MPC = 0.72
– มระดบนยสาคญท&เทาไร (ตางจากศนยหรอไม)
– ตรงตามทฤษฎไหม (ทดสอบระดบนยสาคญดวย)
– ถามตวแปรตนมากกวา 2 ตวแปร• ปญหา Multicolinearlity ???
• ปญหา Heterosckedasticity ???
• ปญหา Autocorrelation ???
0 < β 2 <1
9

7. การทานายหรอพยากรณ (forecast)
• สมมตตองการพยากรณคา mean consumption expenditure ในป 2006
• ถา GDP ในป 2006 มคา 11,319.4 พนลานดอลลารสหรฐ จะได
• ดงน 6น การทานาย mean consumption expenditure มคา 7,870.75 พนลานดอลลารสหรฐ
• แตถาตวเลขจรงๆ ของ ป 2006 เทากบ 8,044 พนลานดอลลารสหรฐ• แสดงวาการทานายของแบบจาลองดงกลาวต&ากวาความเปนจรงไป 174
พนลานดอลลารสหรฐ• หรอเกด forecast error 174 พนลานดอลลารสหรฐ 10

7. การทานายหรอพยากรณ (forecast)
• สมมตวา ปธน ตองการเสนอใหลดภาษเงนไดบคคลธรรมดา (income tax) ลง
• คาถามคอ นโยบายดงกลาวจะเกดผลกระทบตอ Consumption
expenditure และ การจางงานอยางไร
11

7. การทานายหรอพยากรณ (forecast)
• ตามทฤษฎเศรษฐศาสตรมหภาค ถามการเปล&ยนแปลงใน income
จะสงผลตอการเปล&ยนแปลงใน investment expenditure
ซ&งจะวดไดโดย income multiplier
• ดงน 6นการเพ&มข 6น (หรอลดลง) ของการลงทนหน&งดอลลารสหรฐ จะนาไปสการเพ&มข 6น (หรอลดลง) ของรายได 3.57 ดอลลารสหรฐ
12

8. การประยกตใชเพ*อนาไปสนโยบายตางๆ
• สมมตใหเม&อทาการประมาณคาแบบจาลองการบรโภคไดดงน 6
• และสมมตวา ถารฐบาลเช&อวา consumer expenditure มคาประมาณ 8,750 พนลานเหรยญดอลลารสหรฐ โดยจะสามารถคงอตราการวางงาน (unemployment rate) อยท& 4.2% (ชวงตนของ 2006) อยากทราบวาระดบของ income ควรจะเปนเทาไรจงเปนการการนตถงเปาหมาย consumer expenditure ณ ท& 8,750 พนลานเหรยญดอลลารสหรฐ ได
13

8. การประยกตใชเพ*อนาไปสนโยบายตางๆ
• เม&อทาการคานวณปรากฎวา ระดบรายได (income) ควรอยท& 12,537 พนลานเหรยญดอลลารสหรฐ จงจะทาใหได consumer
expenditure ท& 8,750 พนลานเหรยญดอลลารสหรฐ
• และการท&จะทาใหระดบรายได (income) ตามเกณฑดงกลาวน 6น รฐบาลตองผสมผสานนโยบายตางๆ เพ&อใหบรรลเปาหมาย– Fiscal policy
– Monetary policy
14

ประเภทของขอมล
ถาอยากวดความสง…..
15

ขอมลท*แบงตามเวลาและตวอยางในการเกบรวบรวมขอมลแบงออกไดเปน 4 ประเภทหลกๆ
• Cross - sectional data
• Time – series data
• Panel or Longitudinal data
• Pooled Cross – sectional data
16
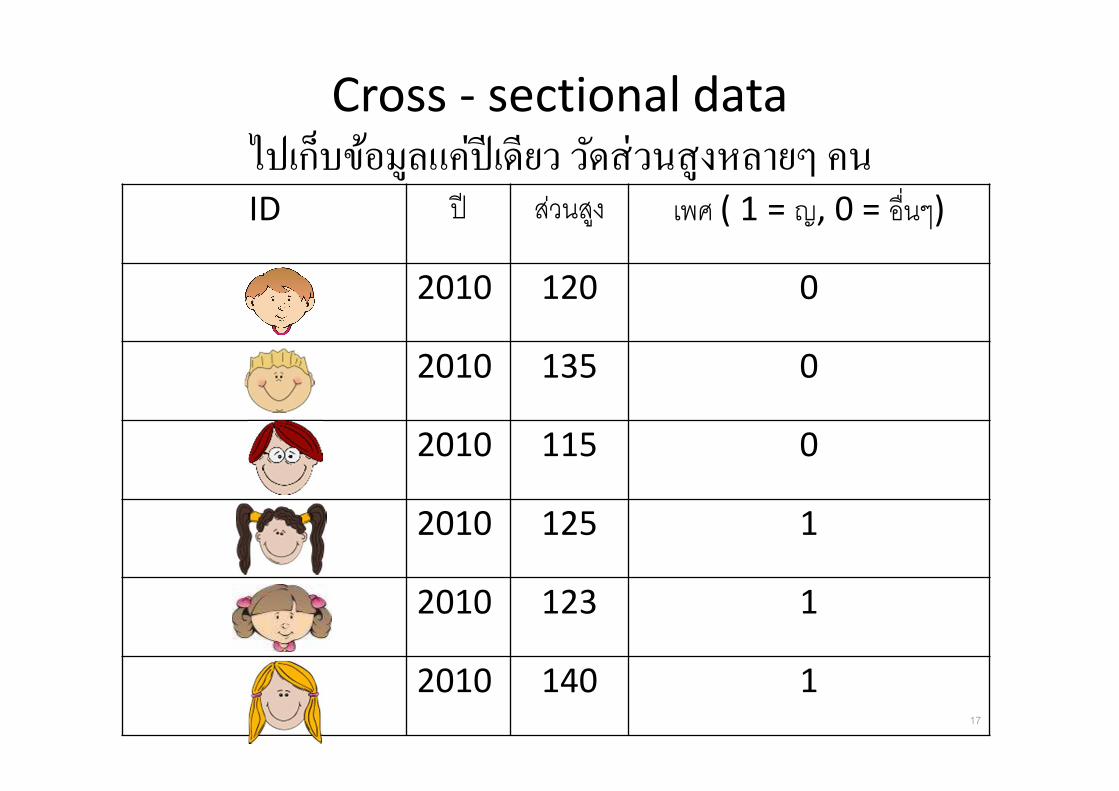
Cross - sectional dataไปเกบขอมลแคปเดยว วดสวนสงหลายๆ คนID ป สวนสง เพศ ( 1 = ญ, 0 = อ&นๆ)
2010 120 0
2010 135 0
2010 115 0
2010 125 1
2010 123 1
2010 140 117
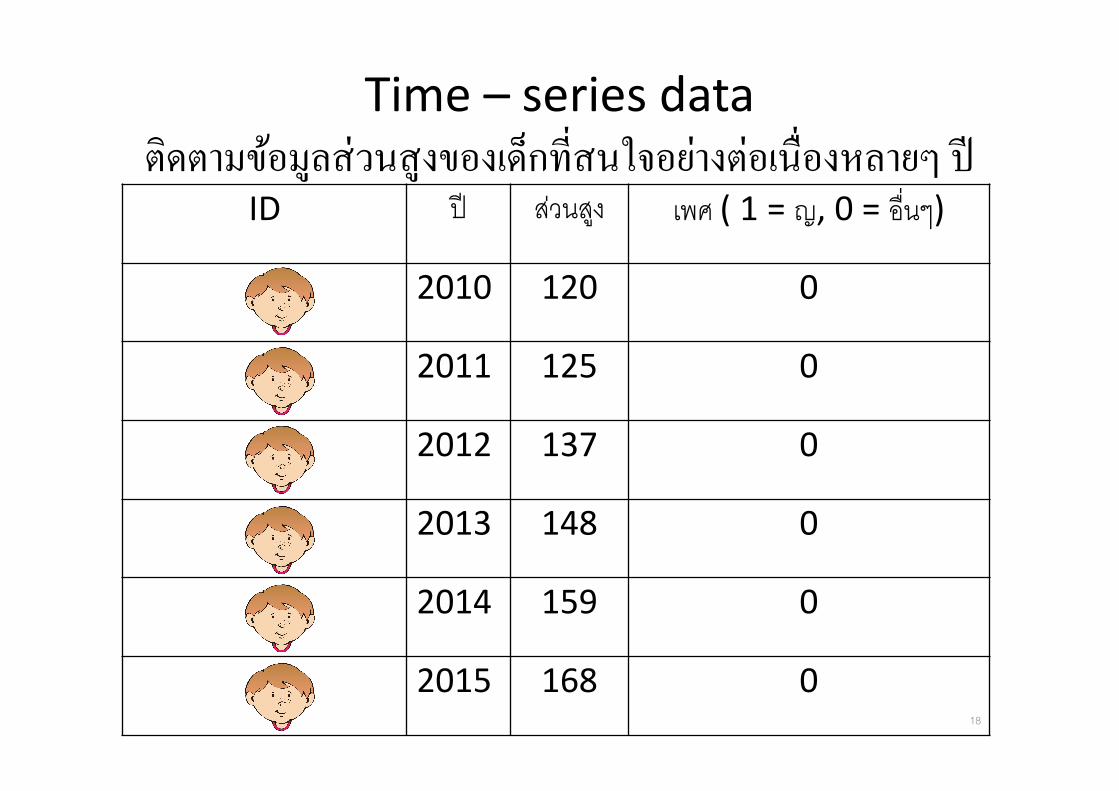
Time – series data
ตดตามขอมลสวนสงของเดกท*สนใจอยางตอเน*องหลายๆ ปID ป สวนสง เพศ ( 1 = ญ, 0 = อ&นๆ)
2010 120 0
2011 125 0
2012 137 0
2013 148 0
2014 159 0
2015 168 018
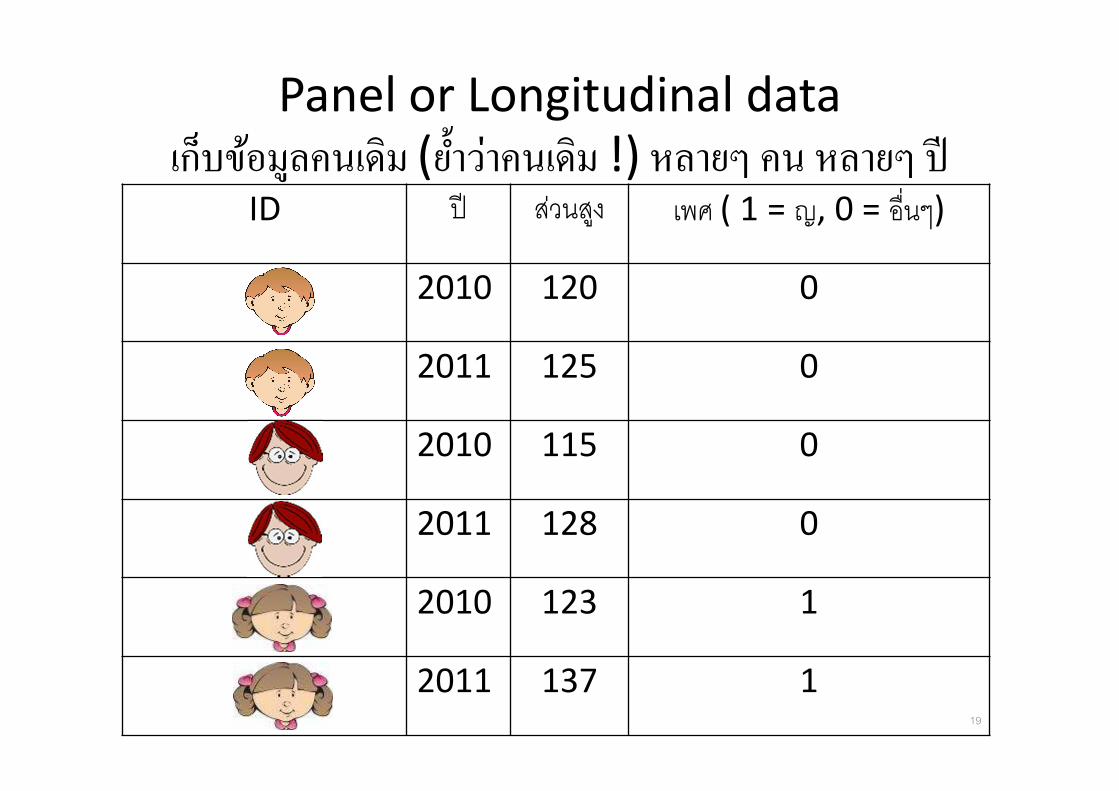
Panel or Longitudinal data
เกบขอมลคนเดม (ย �าวาคนเดม !) หลายๆ คน หลายๆ ป ID ป สวนสง เพศ ( 1 = ญ, 0 = อ&นๆ)
2010 120 0
2011 125 0
2010 115 0
2011 128 0
2010 123 1
2011 137 119
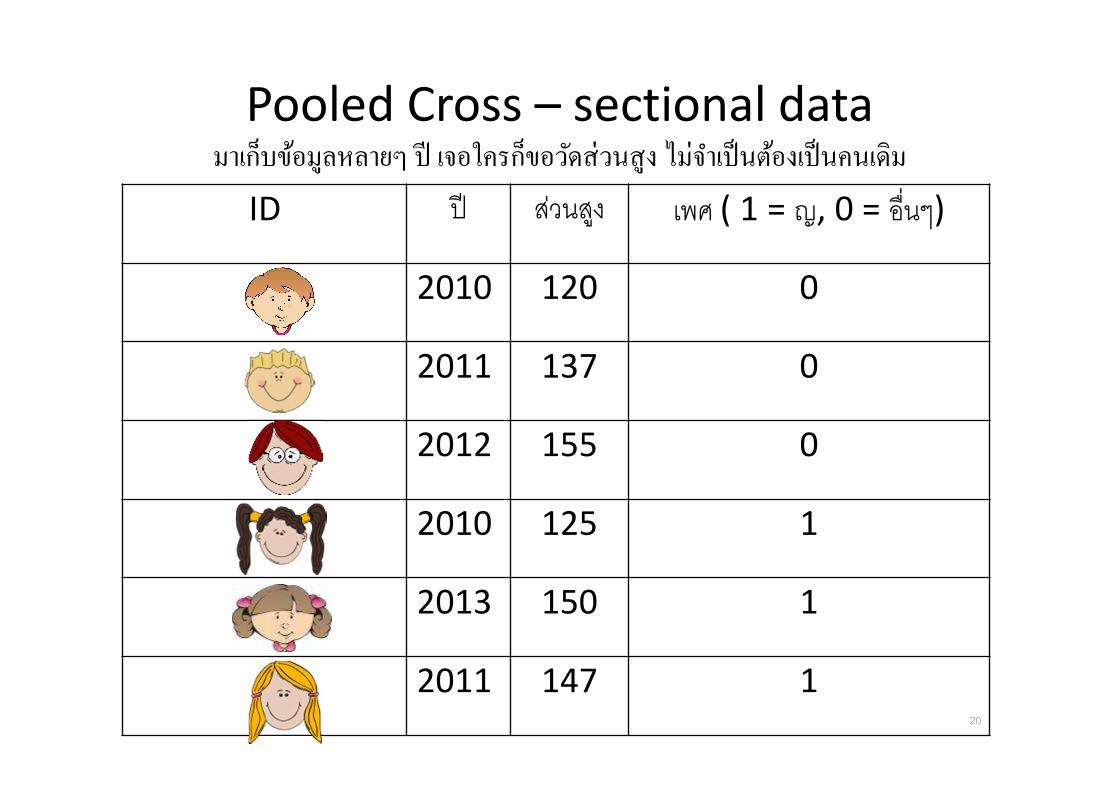
Pooled Cross – sectional dataมาเกบขอมลหลายๆ ป เจอใครกขอวดสวนสง ไมจาเปนตองเปนคนเดม
ID ป สวนสง เพศ ( 1 = ญ, 0 = อ&นๆ)
2010 120 0
2011 137 0
2012 155 0
2010 125 1
2013 150 1
2011 147 120

ตวแปรหน (dummy variable)
• “ตวแปรหน” (Dummy variables) เปน ขอมลท&สรางข 6นโดยนกวจย ในกรณซ&งปจจยท&มผลกระทบตอตวแปรตามไมสามารถวดออกเปนตวเลขไดท 6งน 6เพราะปจจยเหลาน 6อยในรปเชงคณภาพ (Qualitative variable) เชน อาชพ ศาสนา เพศ
21

ประเภทขอมล(จาแนกตามแหลงท*มาของขอมล )
• ขอมลปฐมภม (Primary Data) เปนขอมลท&ผ ใชหรอหนวยงานท&ใชเปนผ ทาการเกบขอมลดวยตนเอง ด 6วยวธการ– วธการสมภาษณ – การทดลอง -> Experimental Economics
– การสงเกตการณ – เกบแบบสอบถามเอง -> Google forms แลวไปแปะใน FB เพ&อน
• ขอมลปฐมภมเปนขอมลท&มรายละเอยดตรงตามท&ผ ใชตองการ แตมกจะเสยเวลาในการจดหาและมคาใชจายสงไปเดนเกบแบบสอบถามเอง
22

ประเภทขอมล(จาแนกตามแหลงท*มาของขอมล )
• ขอมลทตยภม (Secondary Data) เปนขอมลท&ผ ใชไมไดเกบรวบรวมเอง แตมผ อ&นหรอ หนวยงานอ&นๆ ทาการเกบรวบรวมไวแลว เชน จากรายงาน ท&พมพแลว หรอยงไมไดพมพของ หนวยงานของรฐบาล สมาคม บรษท สานกงานวจย นกวจย วารสาร หนงสอพมพ เปนตน
• การนาเอาขอมลเหลาน 6มาใชเปนการประหยดเวลาและคาใชจาย แตในบางคร 6งขอมลอาจจะไมตรงกบความตองการของผใช หรอมรายละเอยดไมเพยงพอท&จะนาไปวเคราะห
• นอกจากน 6ในบางคร 6ง ขอมลน 6นอาจมความผดพลาดและผใชมกจะไมทราบขอผดพลาดดงกลาว ซ&งอาจมผลกระทบตอการสรปผล ดงน 6น ผ ท&จะนาขอมลทตยภมมาใชควรระมดระวงและตรวจสอบคณภาพขอมลกอนท&จะนาไปวเคราะห
23

ตวอยางแหลงขอมลทตยภม (Secondary Data)
• เสยเงน– ผลการสารวจผใชแรงงาน (labor force survey) สานกงานสถตแหงชาต
– ขอมลการคาระหวางประเทศขององคการสหประชาชาต uncomtrade
– ขอมลการใชสทธพเศษทางภาษศลกากร FTA
• สานกสทธประโยชนทางการคา กรมการคาตางประเทศ กระทรวงพาณชย
– ฐานขอมลเอกชน ซ&งไปซ 6อขอมลมาอกทอดหน&ง หรอไปเอามาจากแหลงท&ฟร• CEIC -> จฬาฯ มธ ABAC , มสธ ไมม
• Bloomberg
24

ตวอยางแหลงขอมลทตยภม (Secondary Data)
• ไมเสยเงนยนดเผยแพร (บางสวนอาจเสยเงนบาง)• ธนาคารแหงประเทศไทย (www. bot.or.th)
– ประเภทขอมล: ขอมลเศรษฐกจมหภาค รายไดการเงน การคลง รายงานภาวะเศรษฐกจ บทความ งานวจย นโยบายการเงน
• กระทรวงการคลง (www.mof.go.th)
– ประเภทขอมล: การคลง รายรบ ภาษรายงานสถานะการคลง
• กระทรวงพาณชย (www.moc.go.th)
– ประเภทขอมล: ภาวะและสถตการคา ขอมลการสงออกและนาเขาดชนราคา พระราชบญญตท&เก&ยวกบการคา
25

ตวอยางแหลงขอมลทตยภม (Secondary Data)
• สานกคณะกรรมการพฒนาเศรษฐกจและสงคมฯ (www.
nesdb.go.th )– ประเภทขอมล: การผลต รายไดการจางงาน แผนพฒนาเศรษฐกจรายงานภาวะ
เศรษฐกจ
• ตลาดหลกทรพยแหงประเทศไทย (www.set.or.th)
– ประเภทขอมล: ราคาหน ขอมลของบรษทจดทะเบยน สถตเก&ยวกบการซ 6อขายหน
• International Monetary Fund (www.imf.org)– ประเภทขอมล: นโยบายการเงน ขอมลดานการเงนระหวางประเทศ งานวจยดาน
การเงน
26

ตวอยางแหลงขอมลทตยภม (Secondary Data)
• World Bank (www.worldbank.org)
ประเภทขอมล: นโยบายการคลง การพฒนา งานวจยท&เก&ยวกบเศรษฐศาสตรทกสาขา
• Bank of International Settlement (www.bis.org )
– ประเภทขอมล: การเงน และการธนาคาร นโยบายและงานวจยดานการเงนและการธนาคาร
• World Trade Organization (www.wto.org)
– ประเภทขอมล: ดานการคาระหวางประเทศ งานวจย
27

ตวอยางแหลงขอมลทตยภม (Secondary Data)
• ปกปด ยากท&จะไดมา แตรวามนม
• ขอมลจากบรษทเอกชนตางๆ เชน– ยอดขาย
– ตนทน
28

ประมาณคา, คานวณ, estimate, รน ดวยโปรแกรม STATA
29

STATA
• Stata is a general-purpose statistical software package created in 1985 by StataCorp. Most of its users work in research, especially in the fields of economics, sociology, political science, biomedicine and epidemiology.
• Stata's capabilities include data management, statistical analysis, graphics, simulations, regression analysis (linear and multiple), and custom programming.
30
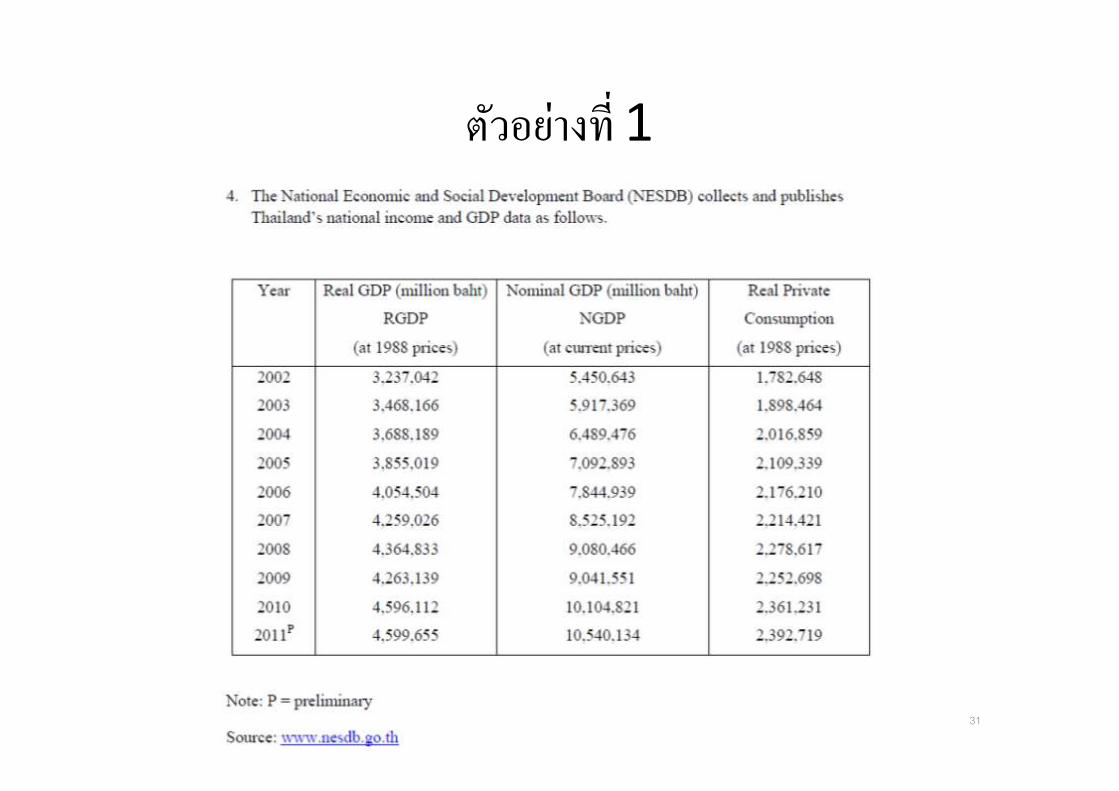
ตวอยางท* 1
31

summarize
• summarize = เปนการสรป data ท 6งหมด
• ใน Thesis ตองแสดงการสรป data ทกคร 6ง !
32

codebook
• codebook บอก detail ของแตละ variable
33

describe
• describe -> บอกวาตวแปรแตละตวมการเกบขอมลแบบไหน
• ลองพมพ describe year ด34
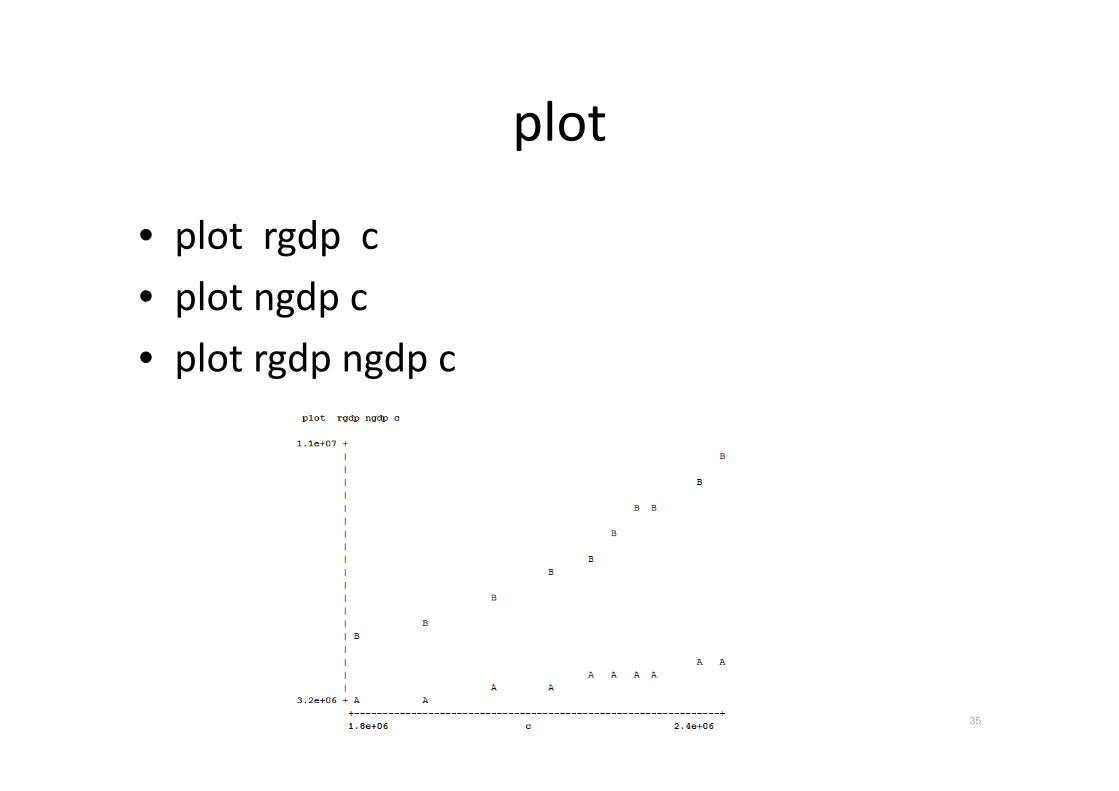
plot
• plot rgdp c
• plot ngdp c
• plot rgdp ngdp c
35
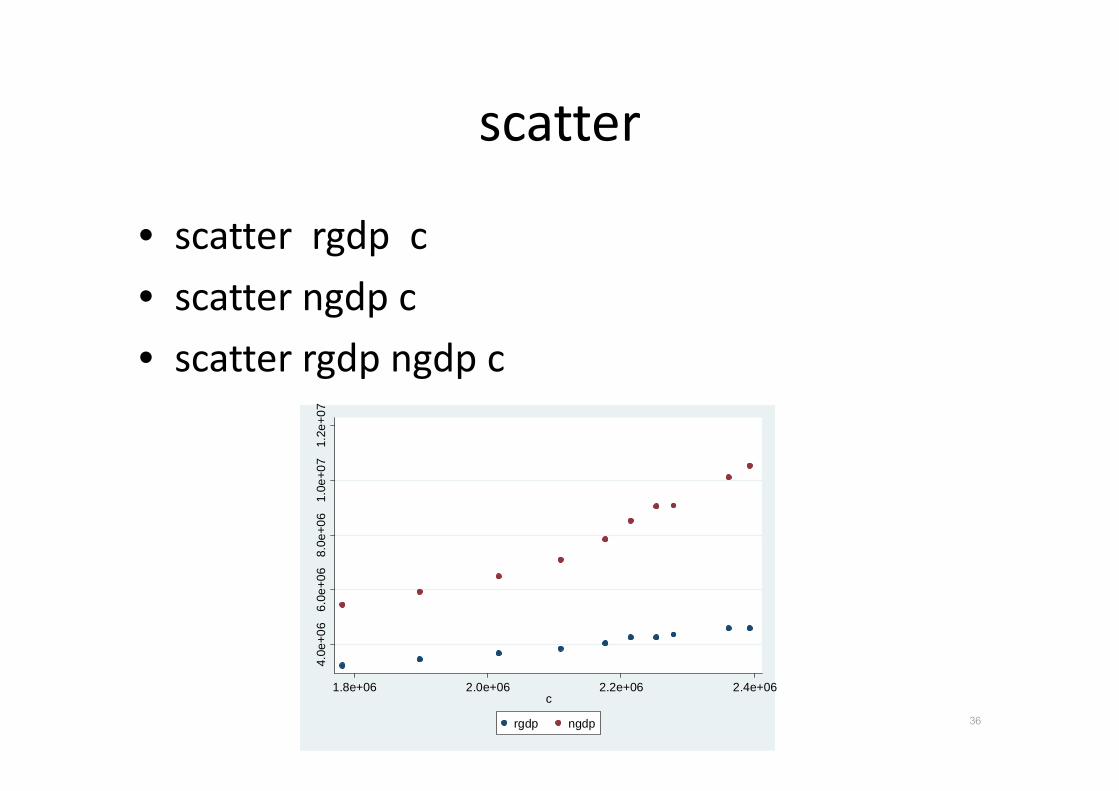
scatter
• scatter rgdp c
• scatter ngdp c
• scatter rgdp ngdp c
36
4.0e
+06
6.0e
+06
8.0e
+06
1.0e
+07
1.2e
+07
1.8e+06 2.0e+06 2.2e+06 2.4e+06c
rgdp ngdp

correlate
• correlate rgdp ngdp
• corr rgdp c
• corr
• ใน Thesis ตองแสดง correlate ของตวแปรตนท 6งหมดดวย !37

โจทย
• generate rgdp_mill = rgdp / 1000000
• rename rgdp_mill rgdp_mil
• gen ngdp_mil = ngdp / 1000000
• gen consumption_mil = c / 1000000
• Plot ???
• line rgdp_mil year38

โจทย
• reg rgdp_mil consumption_mil
39
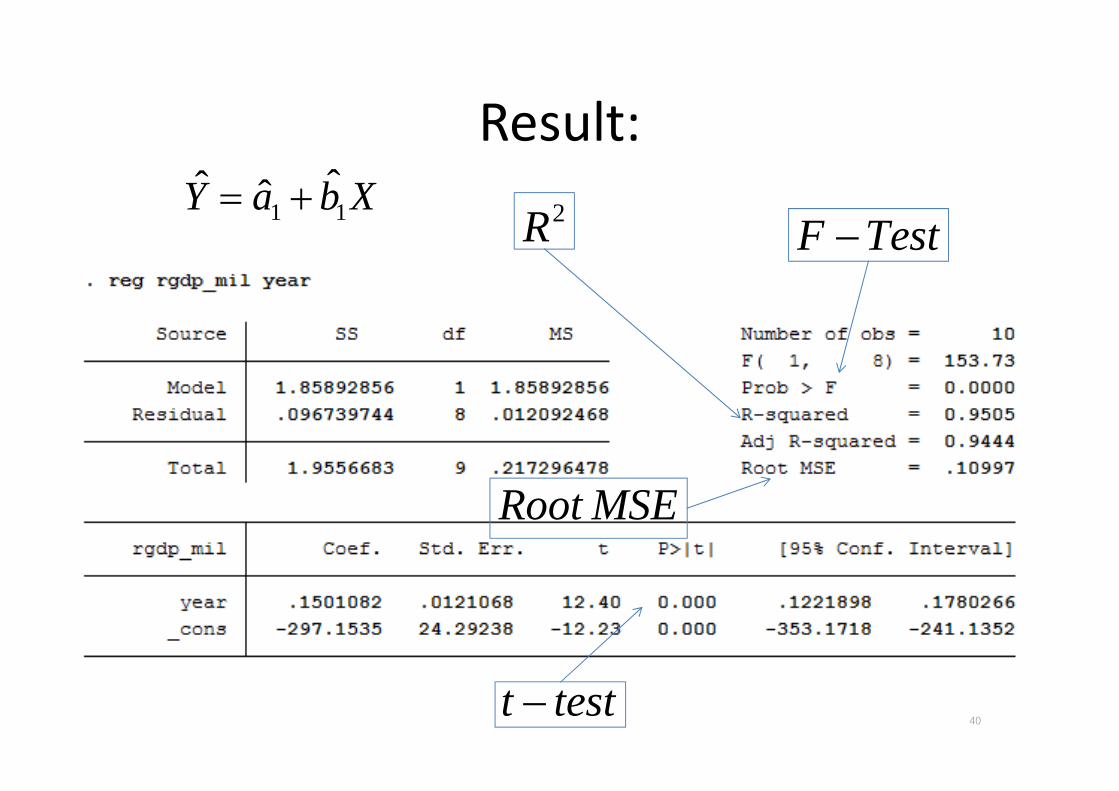
Result:
40
2R F Test−
t test−
1 1ˆ ˆY a b X= +
Root MSE
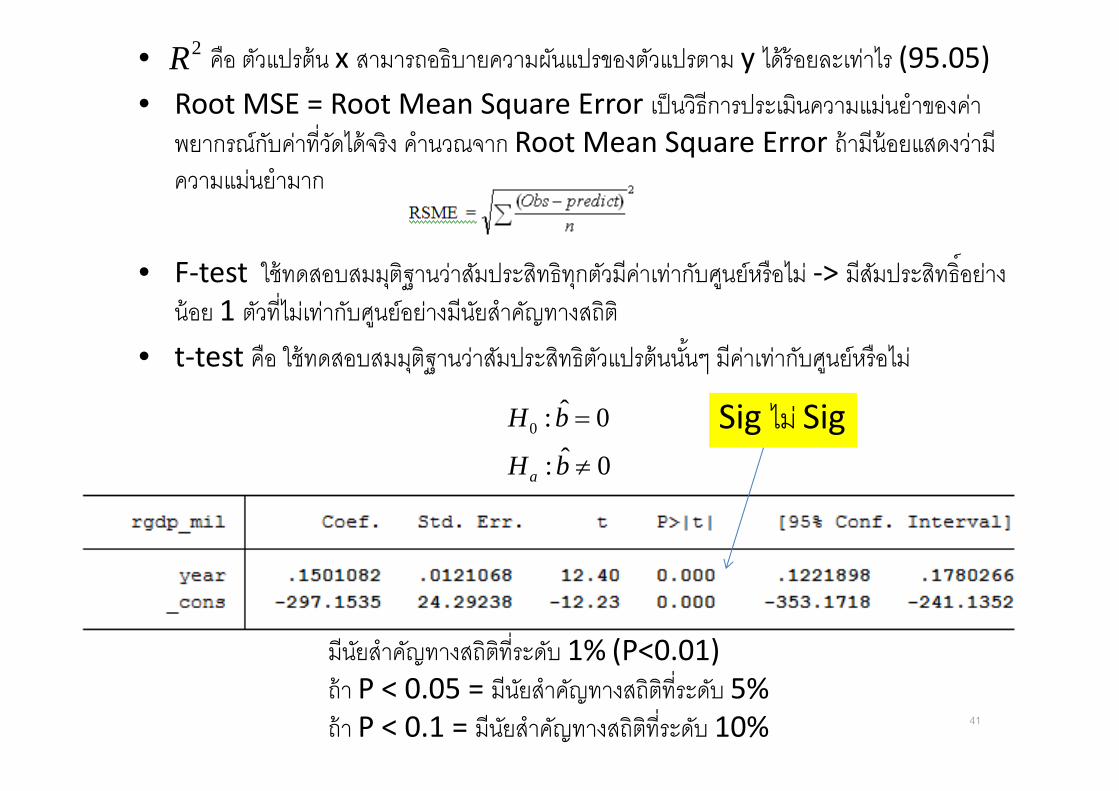
• คอ ตวแปรตน x สามารถอธบายความผนแปรของตวแปรตาม y ไดรอยละเทาไร (95.05)
• Root MSE = Root Mean Square Error เปนวธการประเมนความแมนยาของคาพยากรณกบคาท&วดไดจรง คานวณจาก Root Mean Square Error ถามนอยแสดงวามความแมนยามาก
• F-test ใชทดสอบสมมตฐานวาสมประสทธทกตวมคาเทากบศนยหรอไม -> มสมประสทธMอยางนอย 1 ตวท&ไมเทากบศนยอยางมนยสาคญทางสถต
• t-test คอ ใชทดสอบสมมตฐานวาสมประสทธตวแปรตนน 6นๆ มคาเทากบศนยหรอไม
41
2R
0ˆ: 0
ˆ: 0a
H b
H b
=
≠
มนยสาคญทางสถตท&ระดบ 1% (P<0.01)
ถา P < 0.05 = มนยสาคญทางสถตท&ระดบ 5% ถา P < 0.1 = มนยสาคญทางสถตท&ระดบ 10%
Sig ไม Sig

เวลาทาตารางใน Thesis ใหทาในรปแบบประมาณน�หาม Copy มาด�อๆ
ตวแปรตน OLS
year 0.150***
(.012)
constant -297.153***
(24.29)
Observation 10
R-square 95.05
F-Test 153.73***
42
หมายเหต ในวงเลบคอ SE , *** หมายถง มนยสาคญทางสถตท&ระดบ 1%,
** มนยสาคญทางสถตท&ระดบ 5% , และ * มนยสาคญทางสถตท&ระดบ 10%
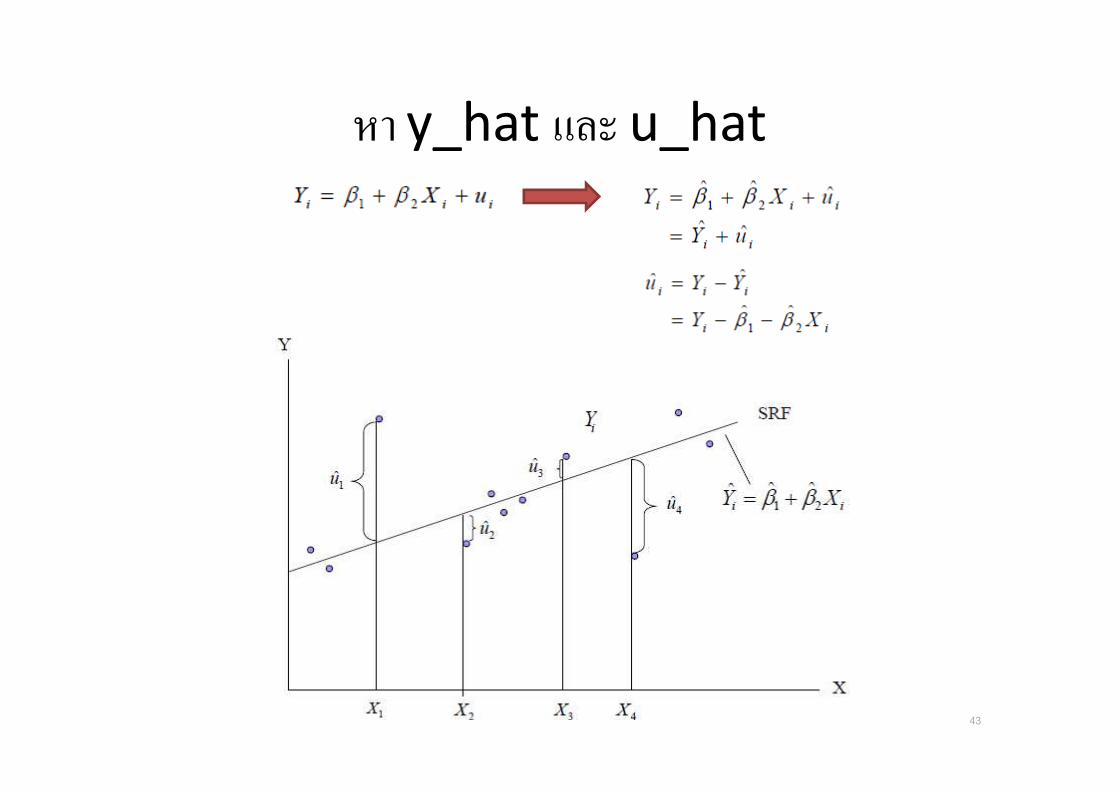
หา y_hat และ u_hat
43
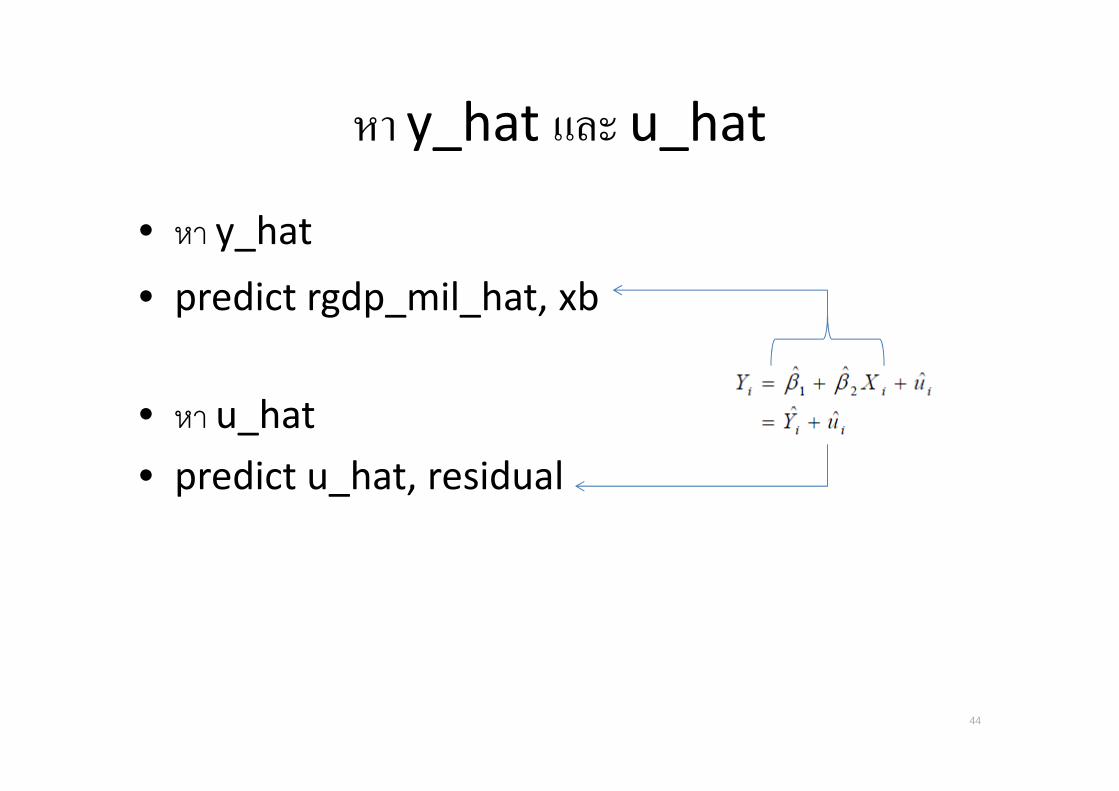
หา y_hat และ u_hat
• หา y_hat
• predict rgdp_mil_hat, xb
• หา u_hat
• predict u_hat, residual
44
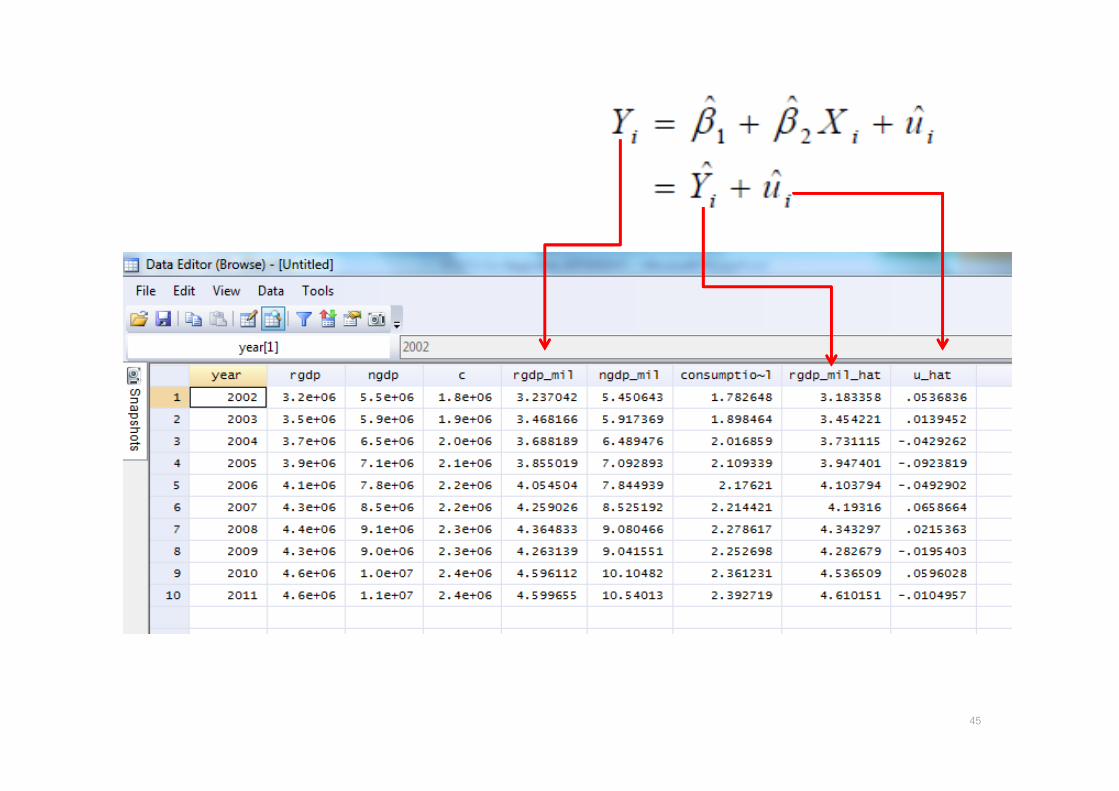
45
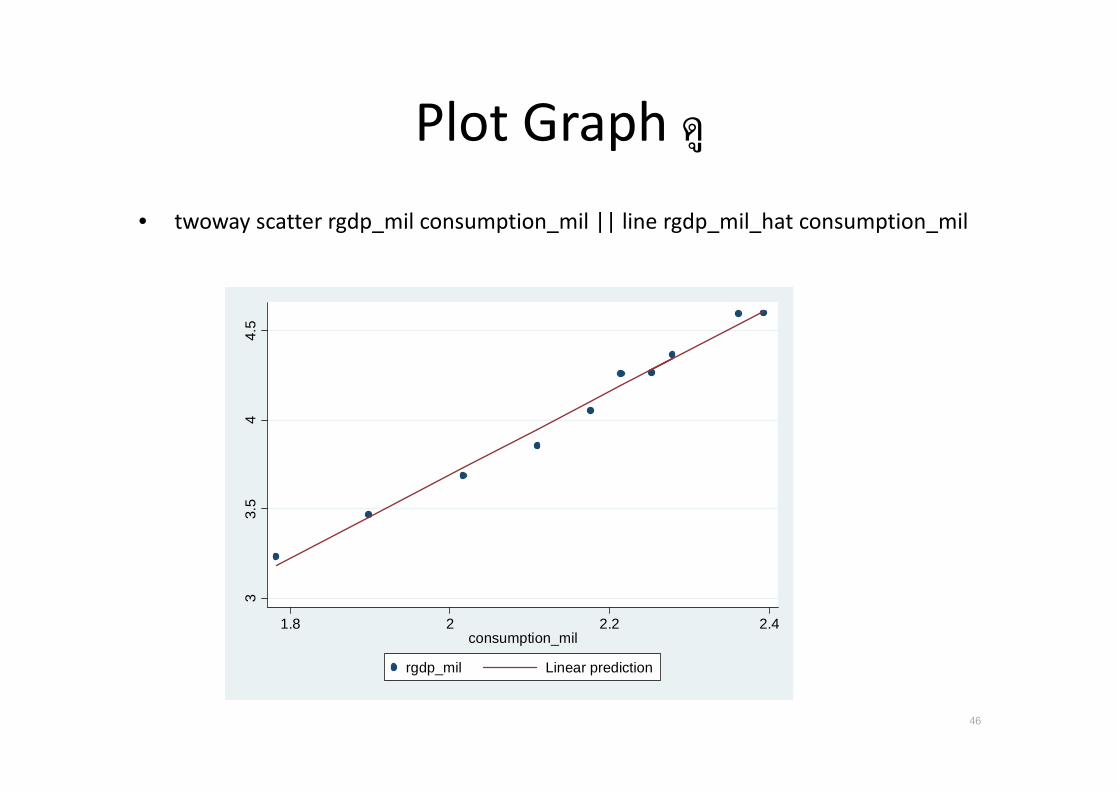
Plot Graph ด
• twoway scatter rgdp_mil consumption_mil || line rgdp_mil_hat consumption_mil
46
33.
54
4.5
1.8 2 2.2 2.4consumption_mil
rgdp_mil Linear prediction

โจทย
• ลองทาสมการท&สองด
47
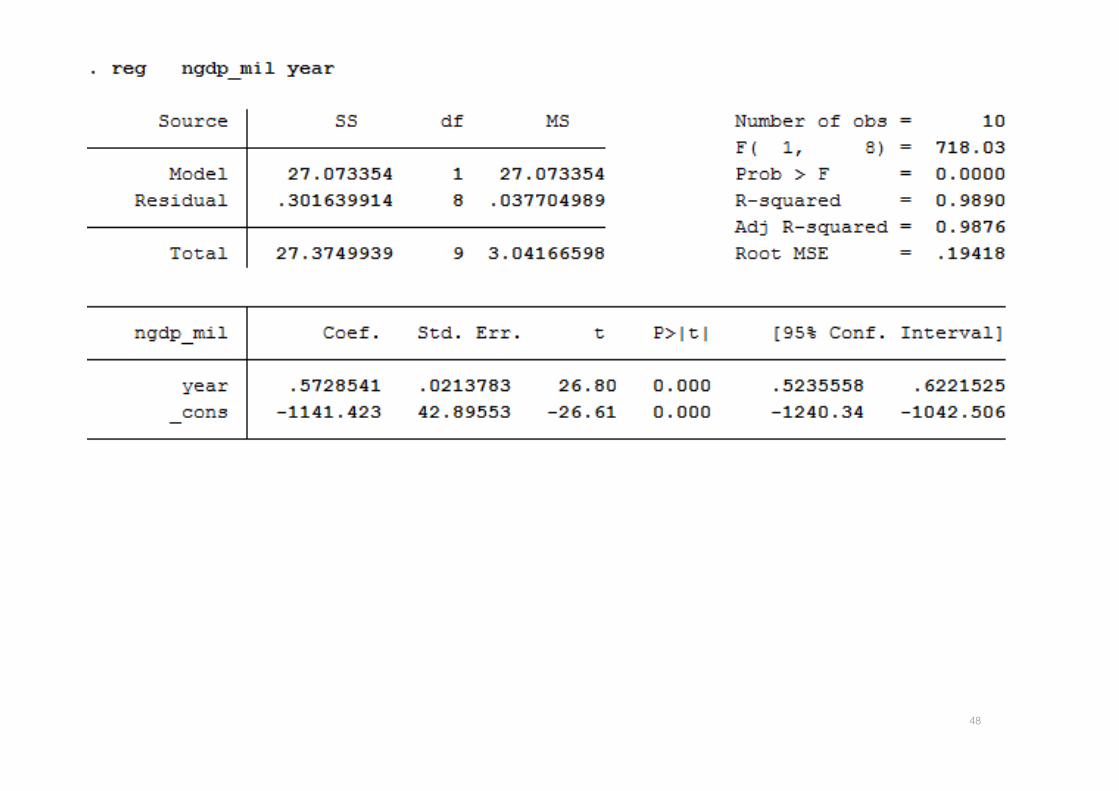
48
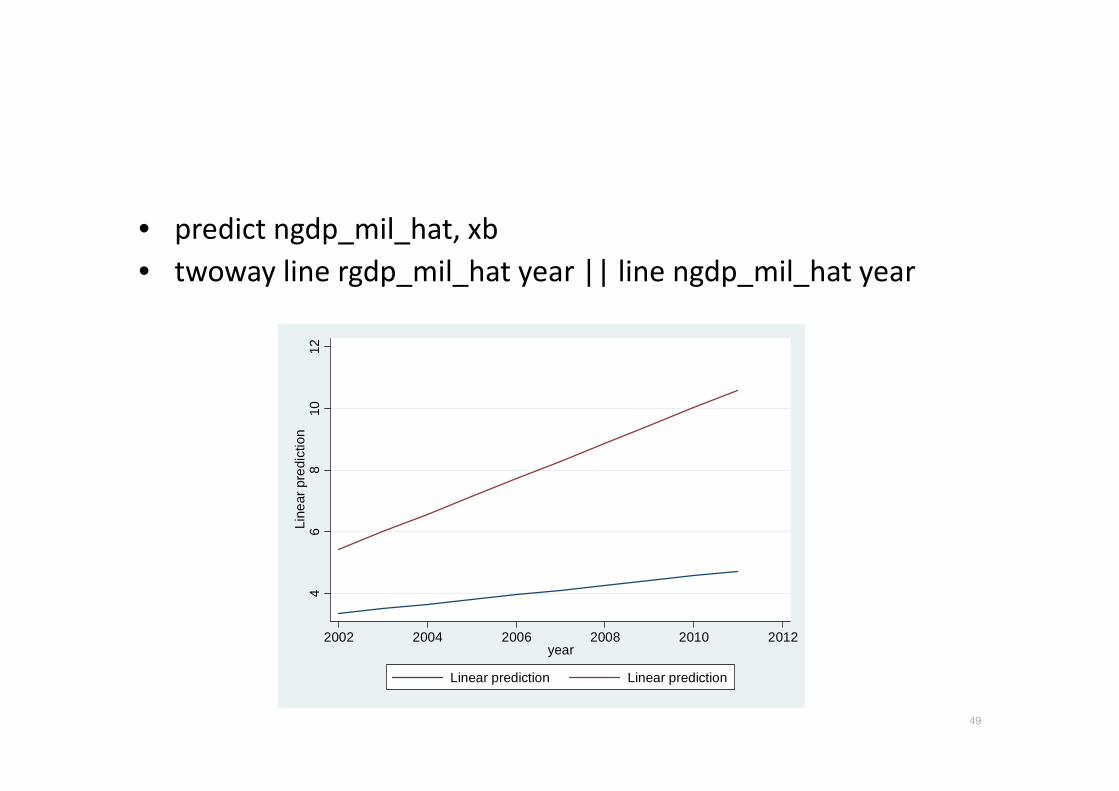
• predict ngdp_mil_hat, xb
• twoway line rgdp_mil_hat year || line ngdp_mil_hat year
49
46
810
12Li
near
pre
dict
ion
2002 2004 2006 2008 2010 2012year
Linear prediction Linear prediction

• 1. หา MPC
• 2. หา multiplier
50

• MPC = 0.422
• Multiplier = 1.73
• แลวถาไมตองหารดวย 1,000,000 หละ ผลยงคงเทาเดมไหม
• reg c rgdp51
1
1multiplier
MPC=
−

ตผล
แบบจาลอง การตผล
X เปล&ยนแปลง 1 หนวย Y เปล&ยนแปลงไป ��หนวย
X เปล&ยนแปลง 100หนวย Y เปล&ยนแปลงไป ��เปอรเซนต
X เปล&ยนแปลง 1 เปอรเซนต Y เปล&ยนแปลงไป �� ∗ 0.01หนวย
X เปล&ยนแปลง 1 เปอรเซนต Y เปล&ยนแปลงไป ��เปอรเซนตหรอคอ Elasticity
52
0 1Y Xβ β= +
0 1lnY Xβ β= +
0 1 lnY Xβ β= +
0 1ln lnY Xβ β= +

ตวแปรหน Dummy Variable
53

Dummy Variable
• บางคร 6งตวแปรตนท&เราตองการ estimate น 6น ไมสามารถหาคาเปนตวเลขได• ตวแปรพวกน 6 ยกตวอยางเชน เพศ เช 6อชาต ส ศาสนา ภมภาค (เหนอ ใต ออก ตก) • ยกตวอยางสถานการณคอ การหาความแตกตางระหวางคาจางแรงงานในเพศ
หญง – ชาย • เน&องจาก เพศ ไมสามารถ กาหนด คาเปนตวเลขไดอยาง ตวแปรอ&นๆ เชน คาจาง
ผลผลต ตนทน ความสง อณหภม • ดงน 6น ตวแปรหน หรอ dummy variable จงถกหยบนามาใชแกปญหาการ
estimate ตวแปรเหลาน 6• โดยท&วๆ ไปจะ สมมต ตวเลขข 6นมา เชน ใหเพศหญง= 1 และ ใหเพศชาย = 0 แลว
จงคอยนาไป estimate
54

Average salary of public school
teachers by state, 1986
• gives data on average salary (in dollars) of public
school teachers in 50 states and the District of
Columbia for the year 1985.
• These 51 areas are classified into three
geographical regions:
• (1) Northeast and North Central (21 states in all),
• (2) South (17 states in all),
• (3) West (13 states in all).
55

แบบจาลอง
• West คอ ถา D2i และ D3i = 0
• แลวทาไมเขต west ไมตองม dummy เหมอนเขตอ&นๆ ???
56

ส*งท*ควรระวง• 1. ถากาหนดตวแปรเชงคณภาพดวยกน m จานวน เวลากาหนดลงใน
model จะใชไดเพยงแค m-1 ตวเทาน 6น ยกตวอยางขางตน ตองการดภมภาคแค 3 สวน แตในตว model ใช dummy แค 2 สวนเทาน 6น เพราะมนจะเกดปญหาท&เรยกวา dummy variable trap ซ&งมาจากการเกด pefect collinearity หรอ perfect multicollinearity เกดข 6น (ยกเวนถา estimate แบบกาหนดไมใหม constant ออกมา)
• 2. ตวแปรเชงคณภาพท&ไมไดใสลงไปในโมเดล (ใชเลข 0 ท 6งหมด) เคาเรยกวา base, benchmark, control, comparison, reference, or omitted category
• คาถาม จากตวอยางขางตน ภมภาคไหนเปน benchmark ???
• 3. ตว intercept หรอ constant term จะบงบอกถง mean value ของตวแปรท&เปน benchmark 57

ส*งท*ควรระวง
• 4. คาพารามเตอร หนา dummy variable เรยกวา differential intercept coefficients น&นคอถาจะด effect ของแตละภมภาค กใหเอา พารามเตอร หนา ตวแปร dummy มาบวกกบ ตวแปร intercept อยางเชนท&เราทากราฟรปภเขา ตางระดบขางตน
• 5. ตว benchmark เราสามารถกาหนดเองได อยากใหเปน south แทน west กยอมได
• 6. ถาเราตองการใสตวแปร dummy ใหครบทก ประเภท (เอาท 6ง 3 ภมภาค) กยอมทาได แตตอง estimate แบบกาหนดใหไมมคา constant ออกมา
• 7. ถามวาแบบไหนดกวากน ใหเลอกเอาแบบม constant
58
รนเลย
• เปดไฟล ex9.1
59
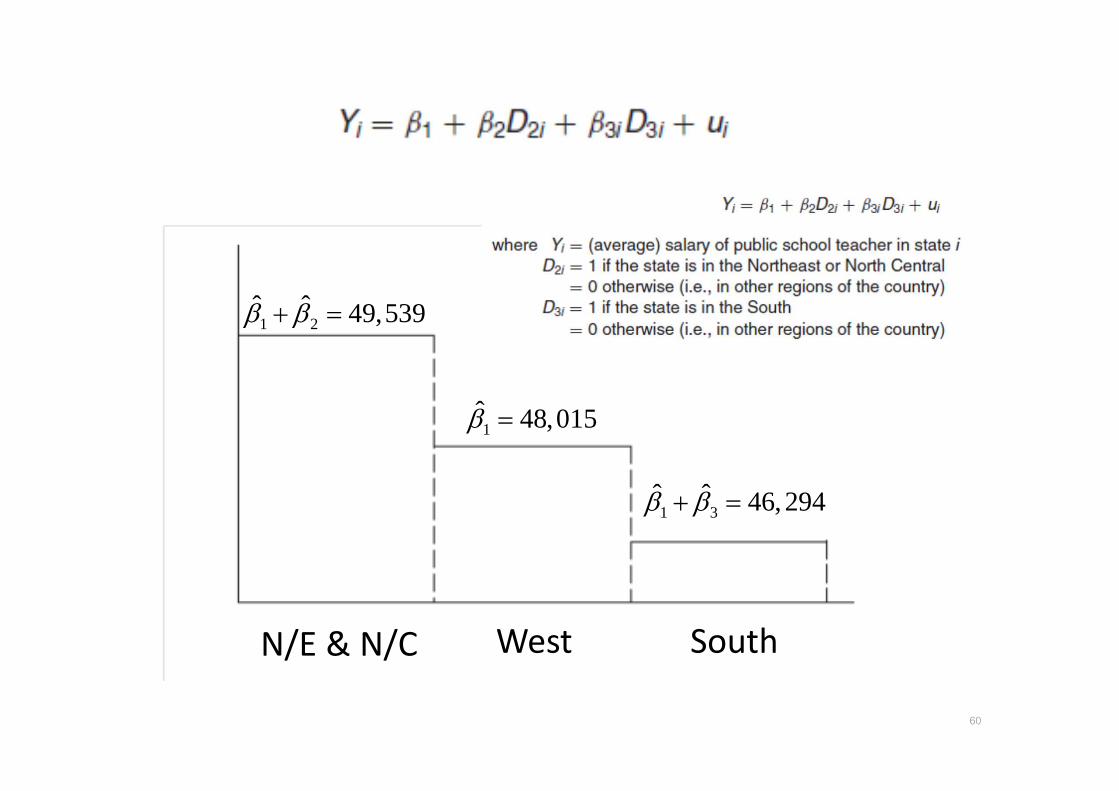
60
WestN/E & N/C South
1 48 15ˆ ,0β =
1 2ˆ 4 ,539ˆ 9β β+ =
1 3ˆ 4 ,294ˆ 6β β+ =

• ลองดแบบไมม constant
• reg salary d1 d2 d3, nocon
61

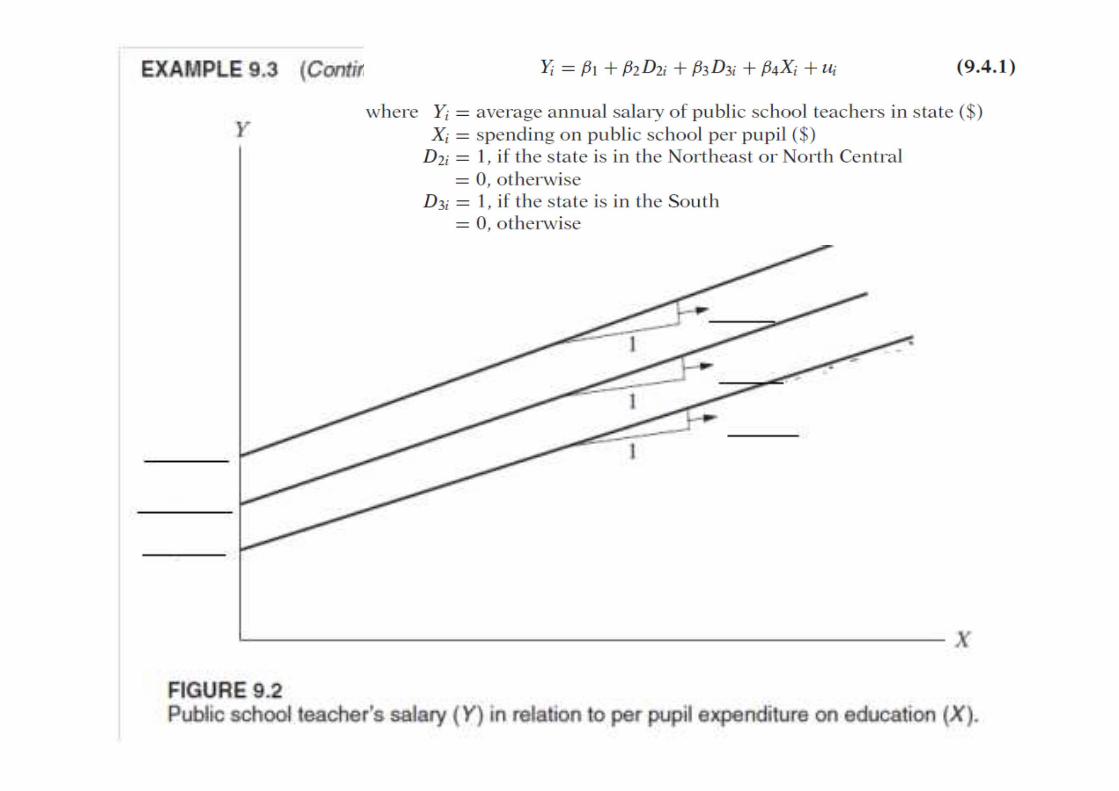
ตวอยางของ Model ท*มท�งตวแปรเชงคณภาพและปรมาณ (โมเดลเดมแตเพ*มคาใชจายลกหลานตอคนเขาไป)
• reg salary d2 d3 spending
62
63
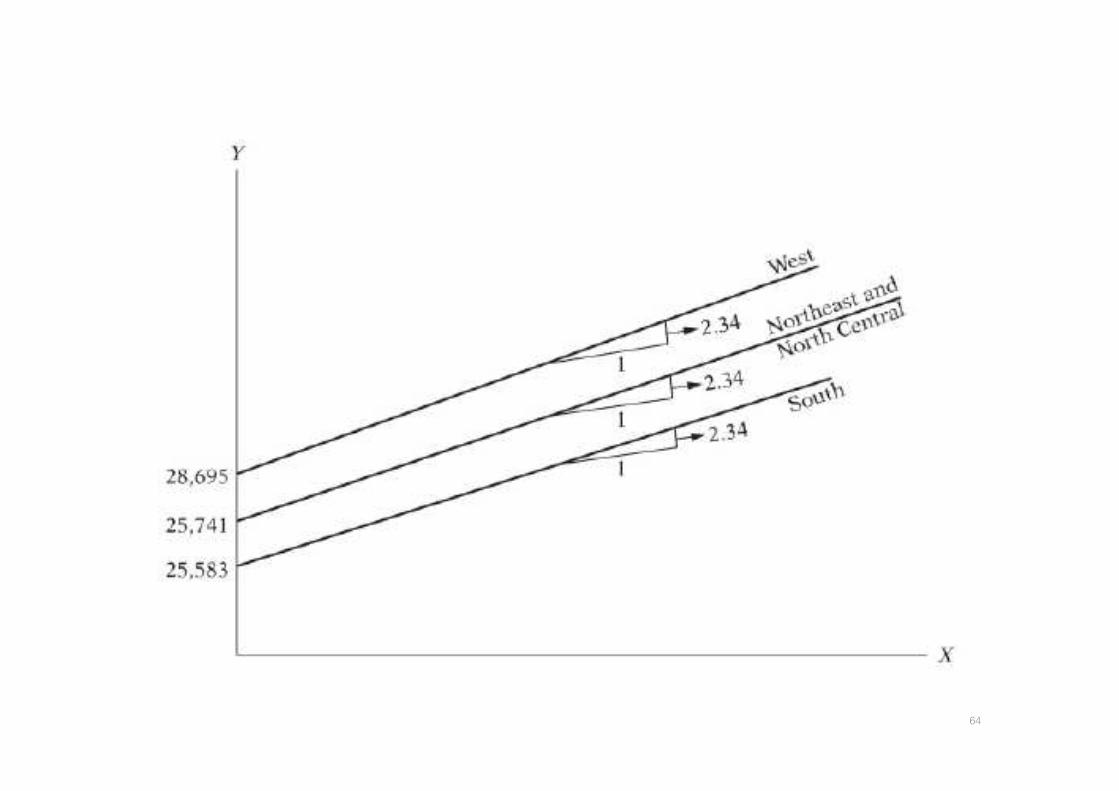
64

แบบจาลองท*มท�งตวแปรเชงปรมาณ และตวแปรเชงคณภาพ โดยอาจจะมการเปล*ยนแปลงโครงสรางจากตวแปรท�งสอง
65

เปด ex9.2 page 287
• gen DX = dum* income
• reg saving income dum DX
66

67

Interaction ของตวแปร dummy 2 ตว ท*แตกตางกน
• จากตวอยางถาตองการหา ชม การทางานเฉล&ย ของท 6งผหญงท&ไมไดเปนคนขาวและไมไดเปนสเปน จะออกแบบ Model อยางไร
• ตอบ เอา ตวแปร dummy ท 6งสอง มาคณกน
68

• รายละเอยดของแตละ Coefficients คอ
69

ผลลพธ
70

แบบฝกหด
• สรปใหดหนอยวาแตละประเภทตองดคา coefficient ตวไหนบาง
71
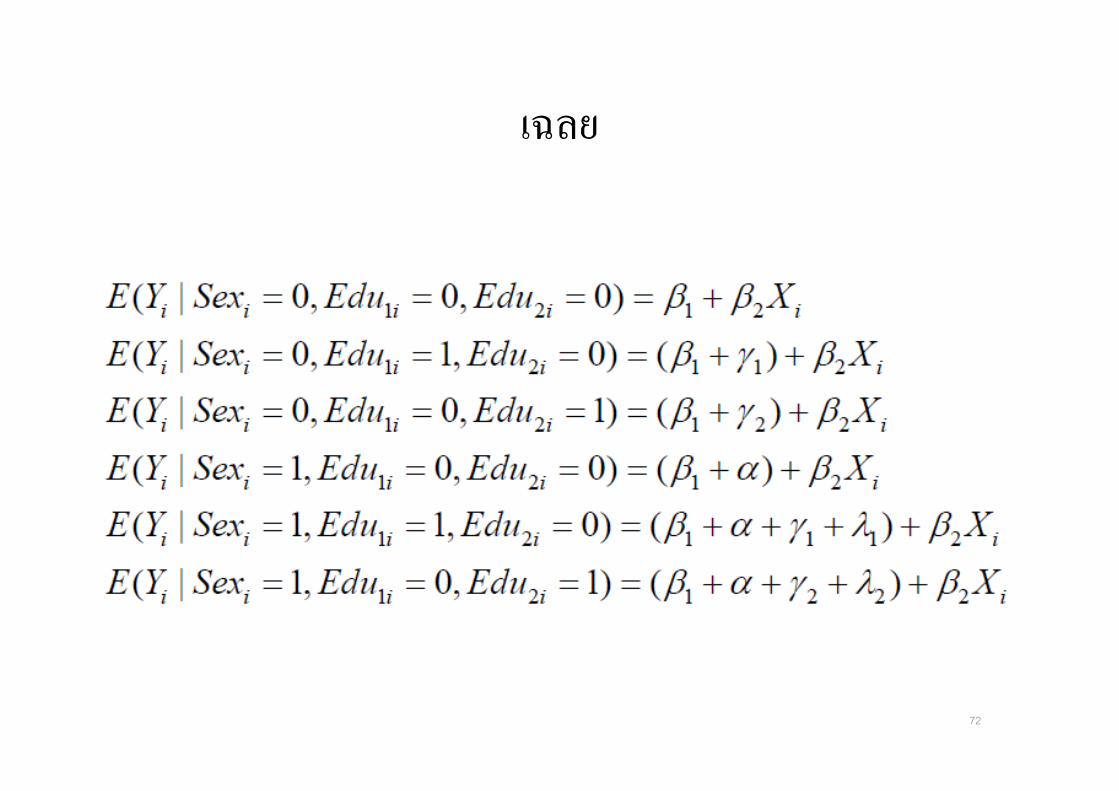
เฉลย
72

ถาตวแปรตนมมากกวา 1 ตว ตองระวงปญหาดงตอไปน�
Multicollinearity
Heteroscedasticity
Autocorrelation
73

Multicollinearity
74

Multicollinearity
• คอสภาพท&เกดสหสมพนธ ( Correlation) กนเองระหวางตวแปรอสระในระดบคอนขางสง
• เอางายๆ คอ ตวแปรทางขวามอ มความสมพนธกนเอง
• มนจะทาใหคานวณไมออก
• ถงคานวณออกกม&วซ&ว เคร&องหมายรวนไปหมด จากลบเปนบวก จากบวกเปนลบ
• ตวอยาง เชน อตราการเสยชวตหลงคลอดของทารก ข 6นอยกบระยะเวลาต 6งครรภ (สปดาห) และ น 6าหนกทารกแรกเกด(กก.)
75

รไดอยางไร
• จะรไดอยางไรวาเกด Collinearity หรอ Multicollinearity
ข 6นแลวเม&อเราทาการวเคราะหขอมลโดย Multiple regression
• คา R – Square สง แต ตวแปรตนไม significant
• ใช Scatter plot หาความสมพนธระหวางตวแปรตน
• ทดสอบหาคาสหสมพนธระหวางตวแปรอสระแตละตว– STATA ใชคาส&งอะไรหาคาสหสมพนธ ???
76

เปดไฟล ex10.5 page 333
• reg y x2 x3
• เหนอะไรไหม สงเกต R-square และ คา p-value
77
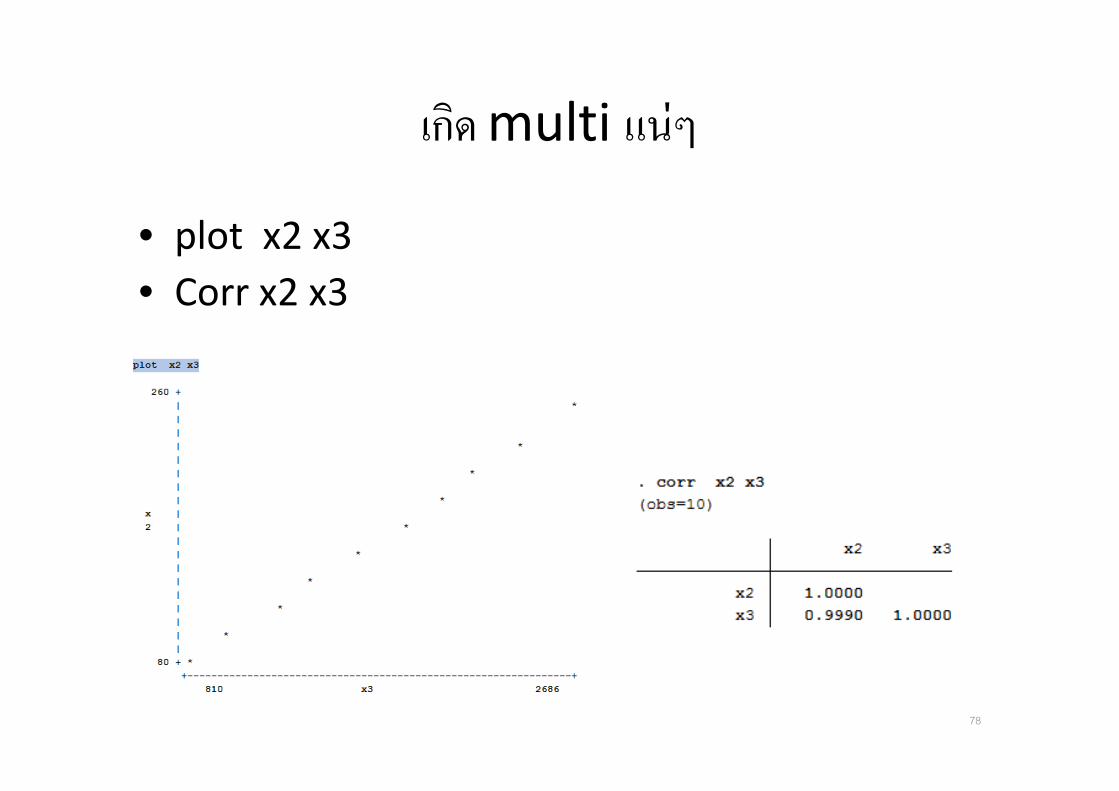
เกด multi แนๆ
• plot x2 x3
• Corr x2 x3
78

จะทาอยางไรเม*อตองเผชญกบปญหา Collinearity
หรอ Multicollinearity
• ตดตวแปรท&ม Collinearity หรอ Multicollinearity ออกสกตวท 6งไป
• รวมตวแปรท&ม Collinearity กนใหเปนตวแปรใหมท&ยงใหความสมพนธกบตวแปรตามอย– สวนสงและน 6าหนก เปนตวแปรอสระท&ม Correlation กนคอนขางมาก เรา
อาจจะเปล&ยนไปใชตวแปรใหมคอ ดชนมวลกาย แทน กจะตดปญหา Collinearity ได
• ยอมรบวาตองม Collinearity หรอ Multicollinearity แนๆ เพราะบางคร 6งเรากไมมทางเลอกท&ดกวาน 6
79

เปดไฟล ex10.5 page 333
• หา corr สมการขางตน• รนสมการ
• มปญหา multi หรอไม
80
1 2 3 4ln ln lndc y w I uβ β β β= + + + +

gen lnc = ln(c)
gen lnyd = ln( yd)
gen lnw = ln(w)
corr i lnyd lnw
81
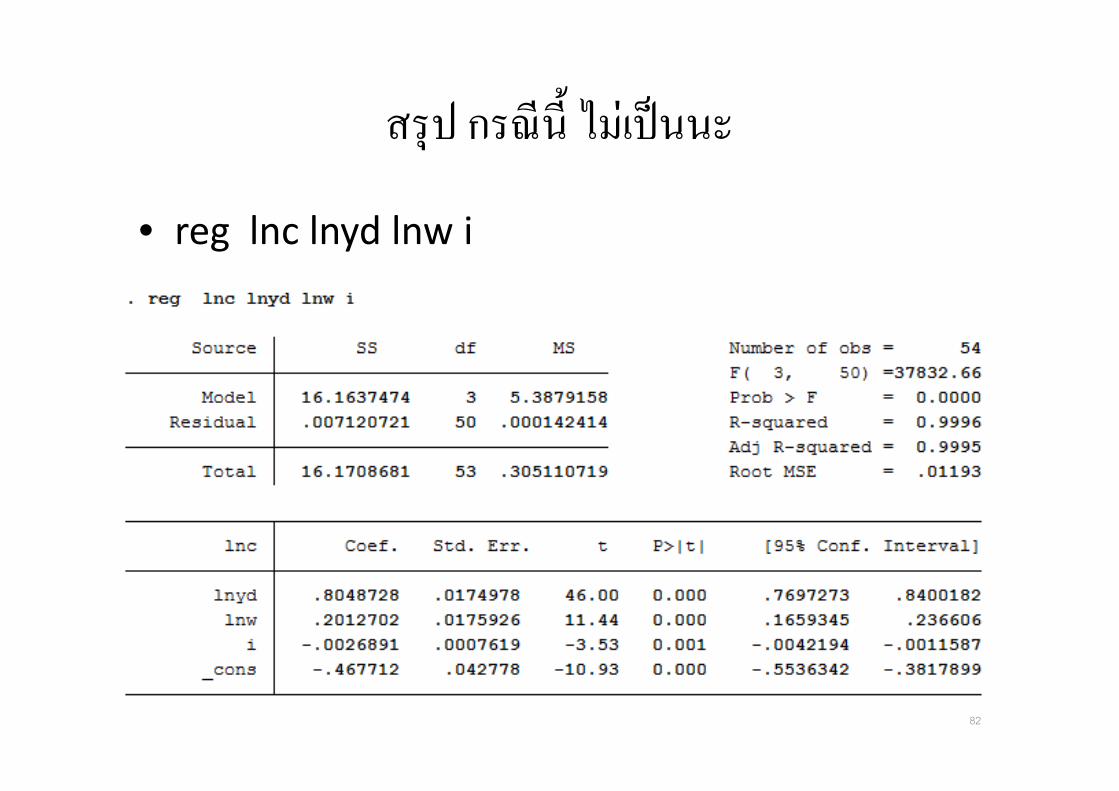
สรป กรณน� ไมเปนนะ
• reg lnc lnyd lnw i
82

Heteroscedasticity
83

Heteroscedasticity
• ปญหา heteroscedasticity คอ การท&ความแปรปรวนของตวคลาดเคล&อนในแบบจาลองมความไมคงคงทโดยปญหาดงกลาวน 6จะเกดกบขอมลประเภท cross – section data ซ&งจะมผลทาใหการประมาณคาดวยวธ OLS ขาดลกษณะท&พงประสงคของตวประมาณคาท&ด
• ตวประมาณคาเหลาน 6นจะไมเปน Minimum Variance หรอไมม efficiency น&นเอง
• เน&องจากคาความแปรปรวนไมใชคาต&าสด ดงน 6นการทดสอบสถต เชน t-test และ F-test จะทาใหเกดความเขาใจผดได (ทาใหไมคอย significant)
84
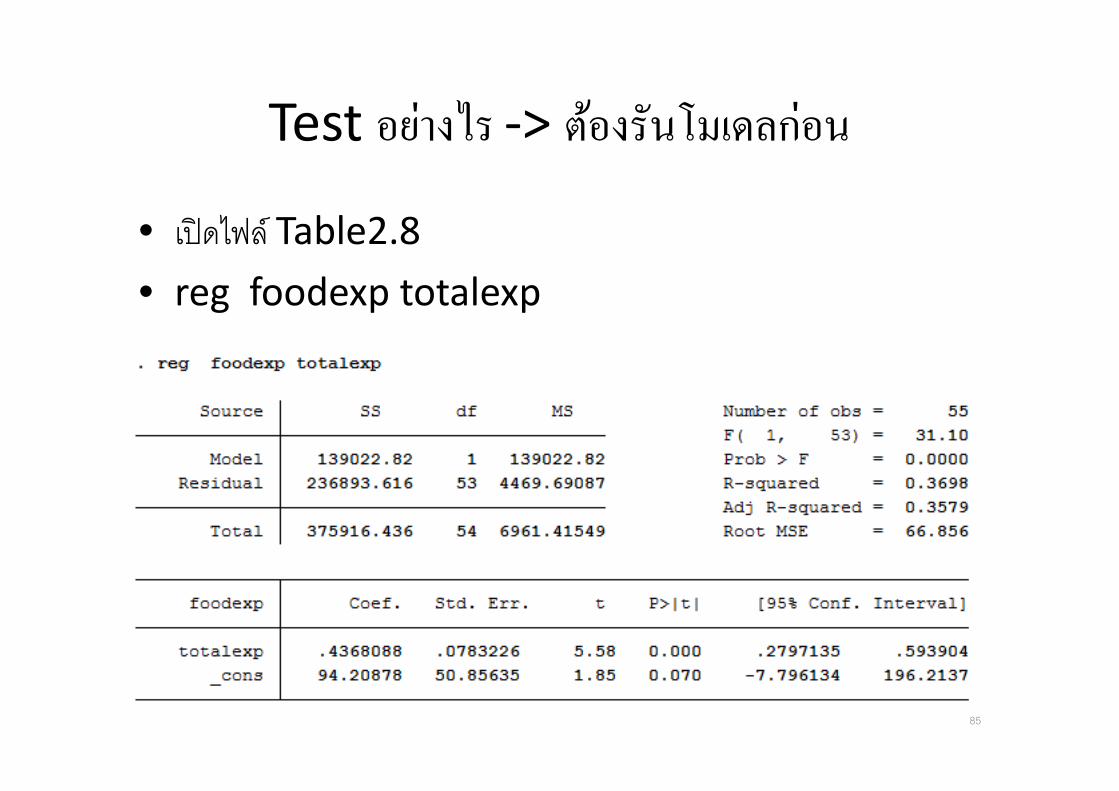
Test อยางไร -> ตองรนโมเดลกอน
• เปดไฟล Table2.8
• reg foodexp totalexp
85

Test
• White's test ->
• estat imtest, white
• Breusch-Pagan / Cook-Weisberg test
• estat hettest
• ถา significant แสดงวาเกด Hetero
86

87
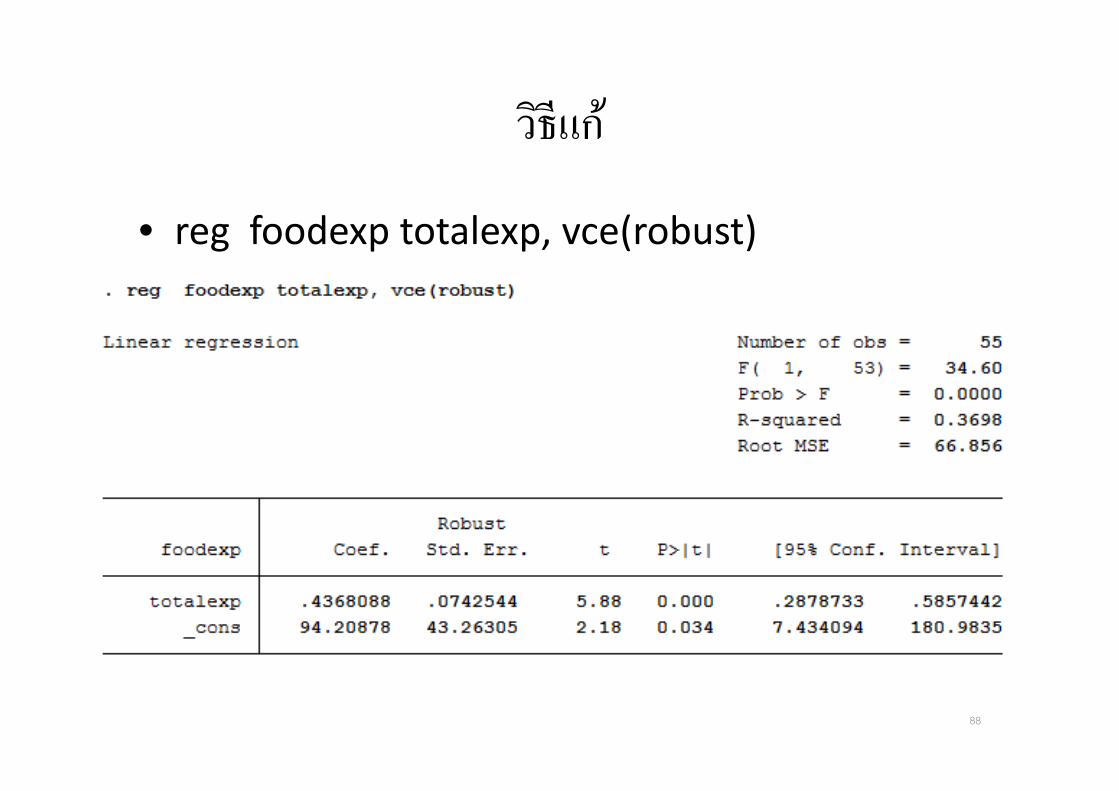
วธแก
• reg foodexp totalexp, vce(robust)
88

Autocorrelation
89

Autocorrelation
• คอ การท& error term มความสมพนธกนเอง • หรอ error term มความสมพนธกบเวลา จากกรณท&รปแบบของฟงกชน
ไมถกตอง
• โดยปญหา autocorrelation จะทาใหระดบนยสาคญทางสถตมคาสงกวาท&ควรจะเปน
• เปดไฟล ex7.4
• reg total_cost output90

• predict u_hat, residual
• gen t = _n
• line u_hat t
91
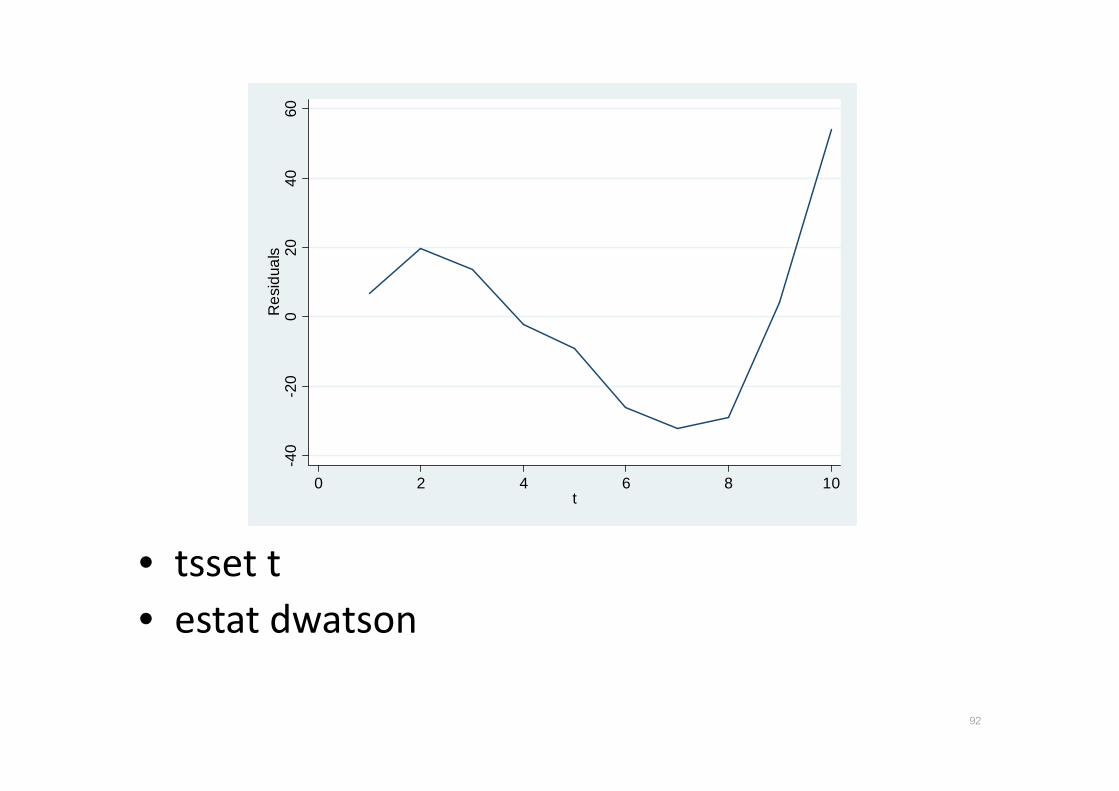
• tsset t
• estat dwatson
92
-40
-20
020
4060
Re
sidu
als
0 2 4 6 8 10t

• Durbin-Watson d-statistic( 2, 10) = .7157248
• n = 10
• k = 2
• Significant level = 5%
• เปดตาราง Durbin_Watson_tables.pdf
93
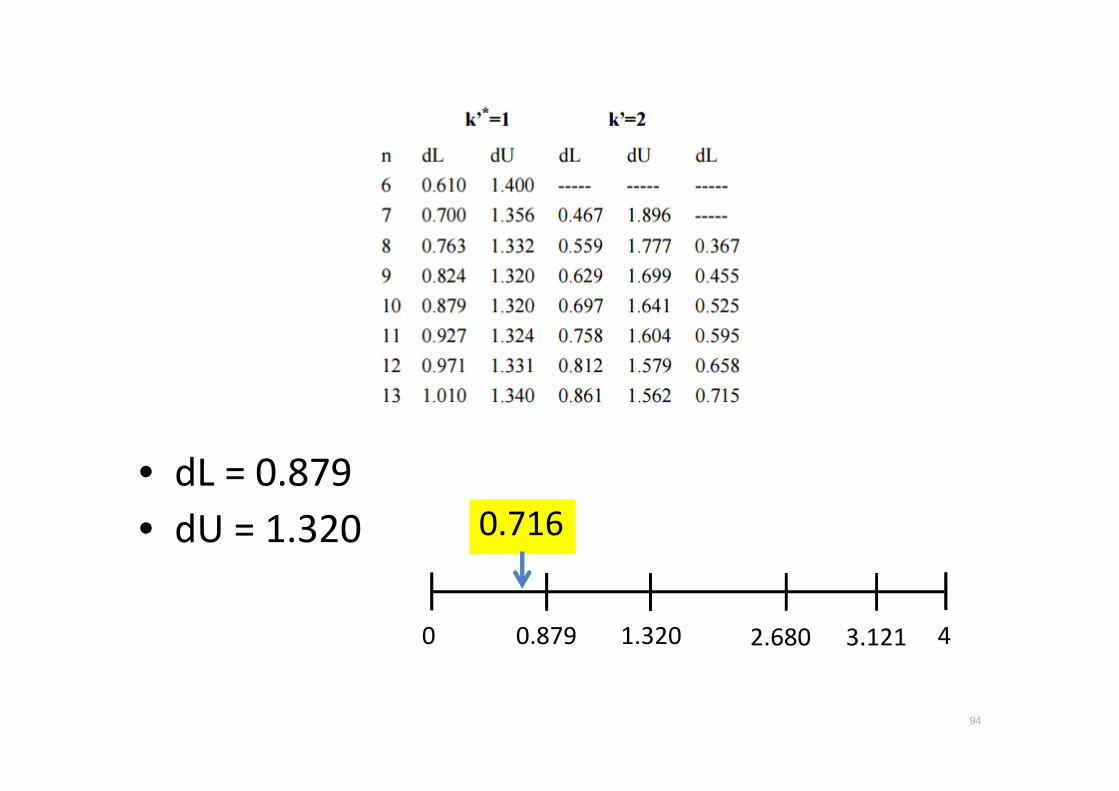
• dL = 0.879
• dU = 1.320
94
0 40.879 3.1211.320 2.680
0.716

แกปญหาไดโดย
• reg total_cost output, robust
• Robust เปนยาครอบจกรวาลท&แก auto ไดจนคา t-test ลดลงจากเดม แตจรงๆ แลวขอน 6เกดจาก omitted variable
95
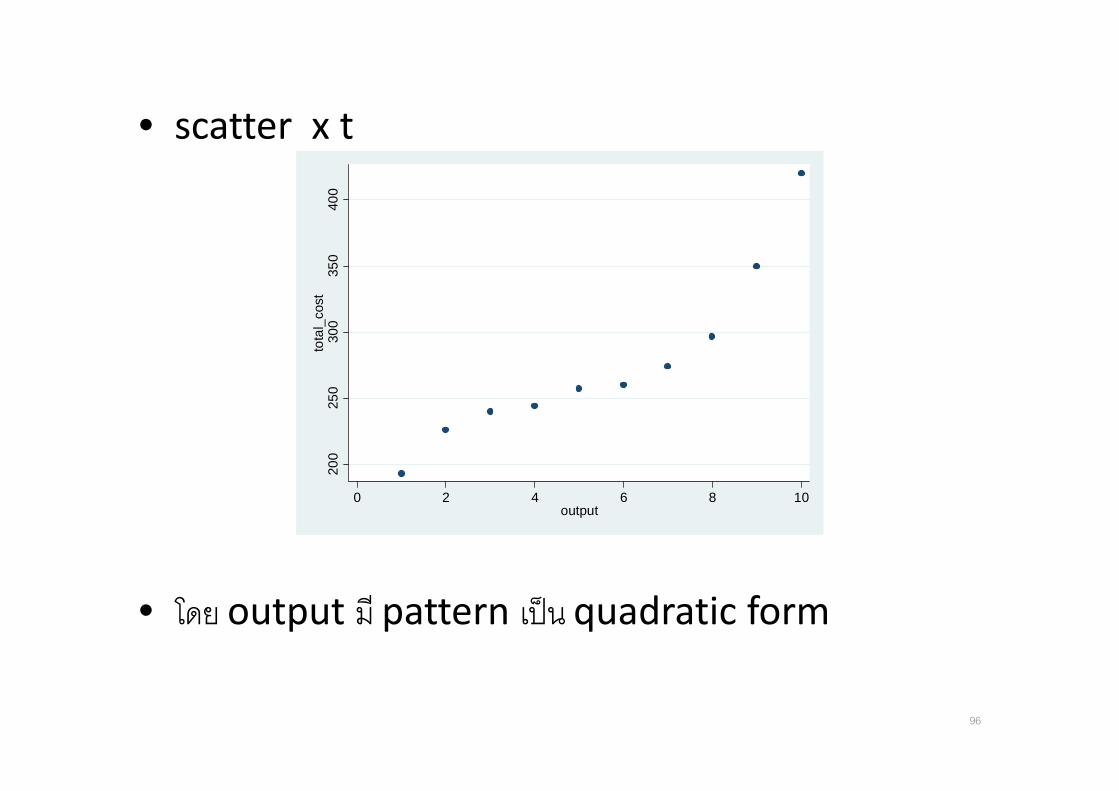
• scatter x t
• โดย output ม pattern เปน quadratic form
96
200
250
300
350
400
tota
l_co
st
0 2 4 6 8 10output

• gen output2 = output^2
• gen output3 = output^3
• reg total_cost output output2 output3
97
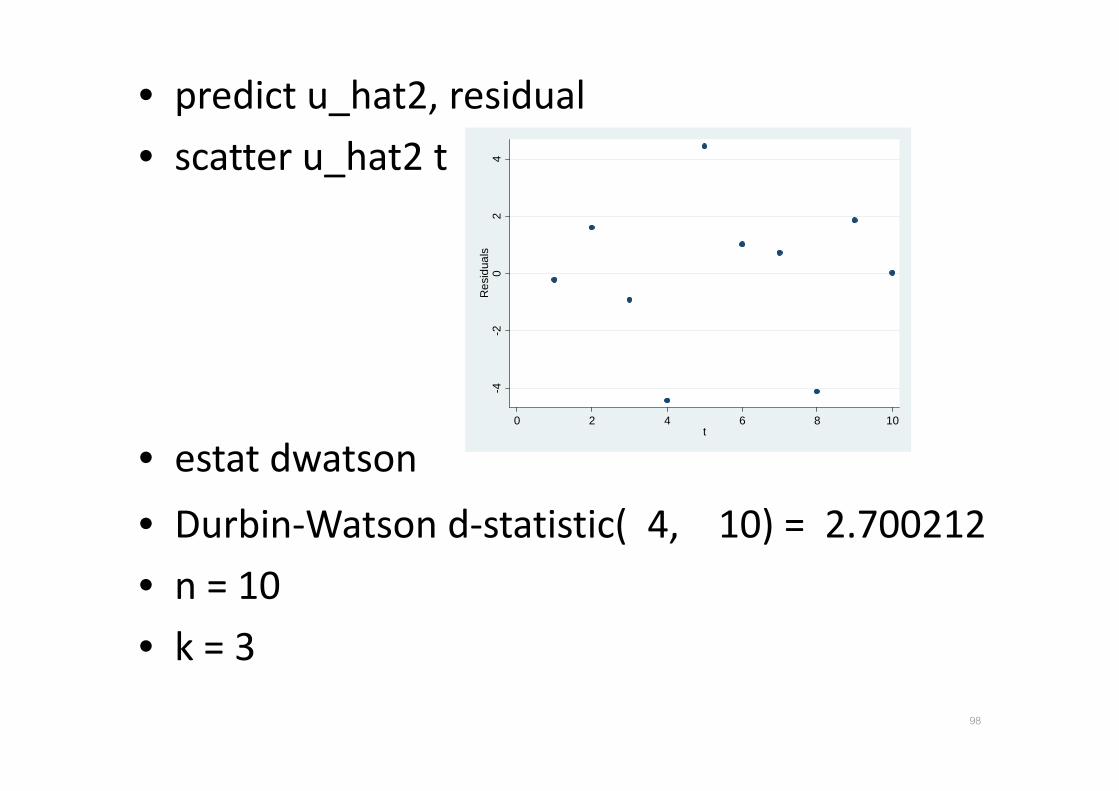
• predict u_hat2, residual
• scatter u_hat2 t
• estat dwatson
• Durbin-Watson d-statistic( 4, 10) = 2.700212
• n = 10
• k = 3
98
-4-2
02
4R
esi
dua
ls
0 2 4 6 8 10t
99
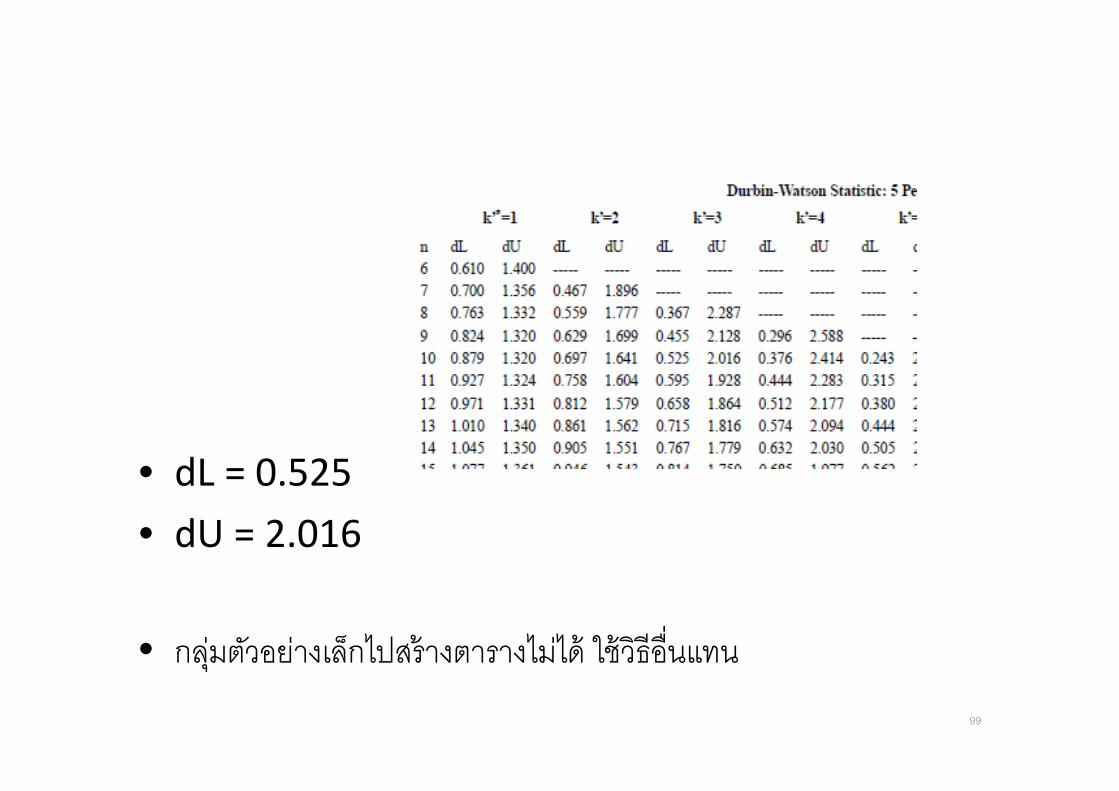
• dL = 0.525
• dU = 2.016
• กลมตวอยางเลกไปสรางตารางไมได ใชวธอ&นแทน

• Estat bgodfrey
• ไม significant แสดงวา no serial correlation
100

แบบฝกหด
101

Count Model
102

Probit Model
• ตวแปรตาม เปนตวแปรเชงคณภาพ แสดงไดดวยตวเลข 0 และ 1– ทางาน – ไมทางาน -> Labor
– เดนทาง – ไมเดนทาง ->
– ลมละลาย – ไมลมละลาย -> Industrial
• ไมสามารถทาการ estimate โดยใช OLS ได
• วธท&นยมคอ Probit model หรอ Logit model
103
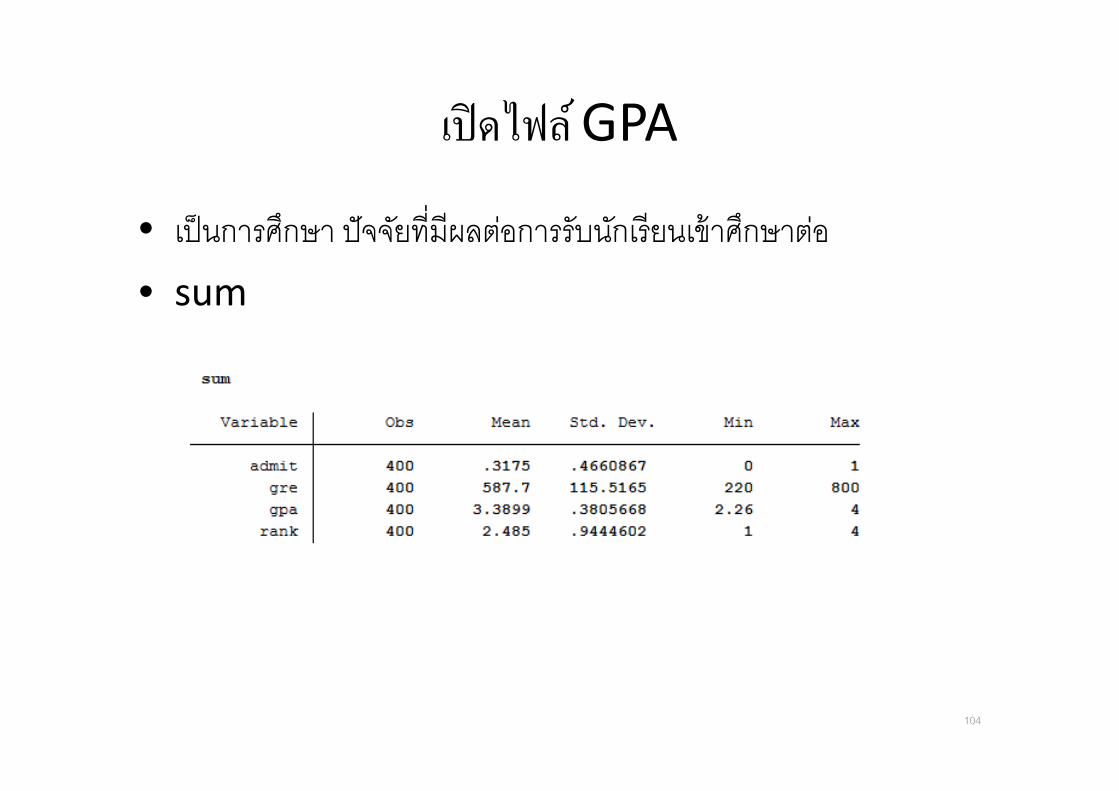
เปดไฟล GPA
• เปนการศกษา ปจจยท&มผลตอการรบนกเรยนเขาศกษาตอ
• sum
104
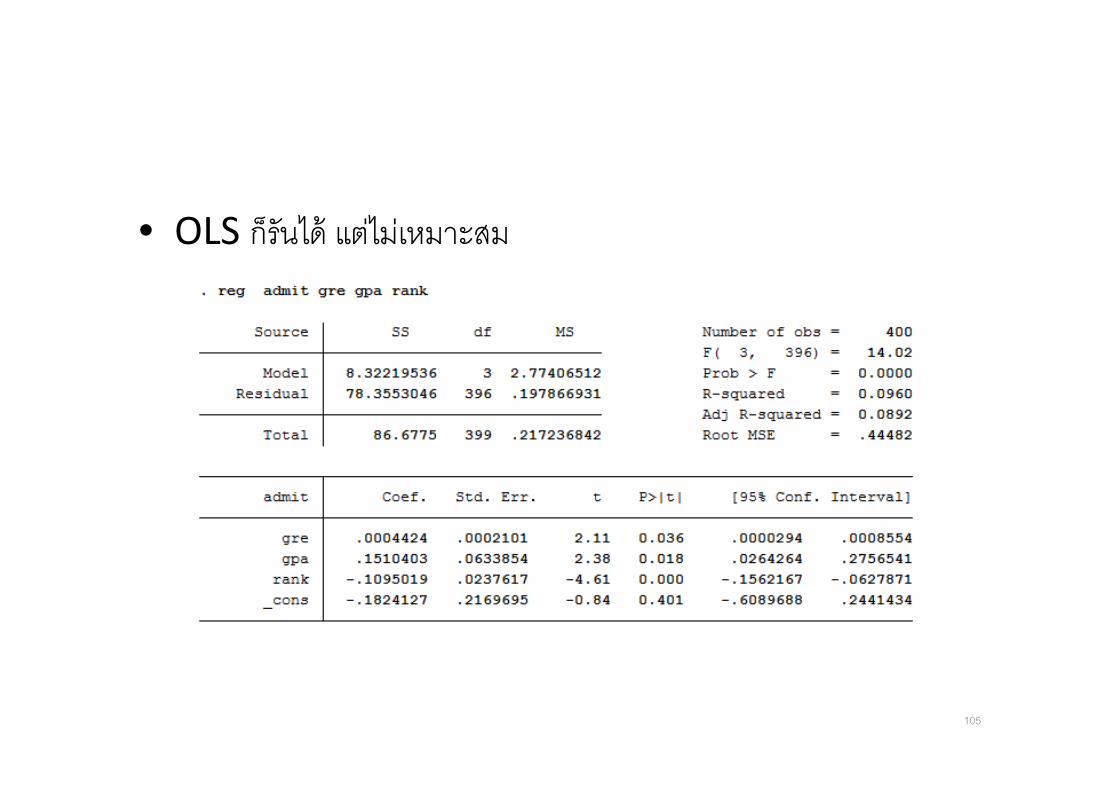
• OLS กรนได แตไมเหมาะสม
105

Probit model
• probit admit gre gpa rank
106
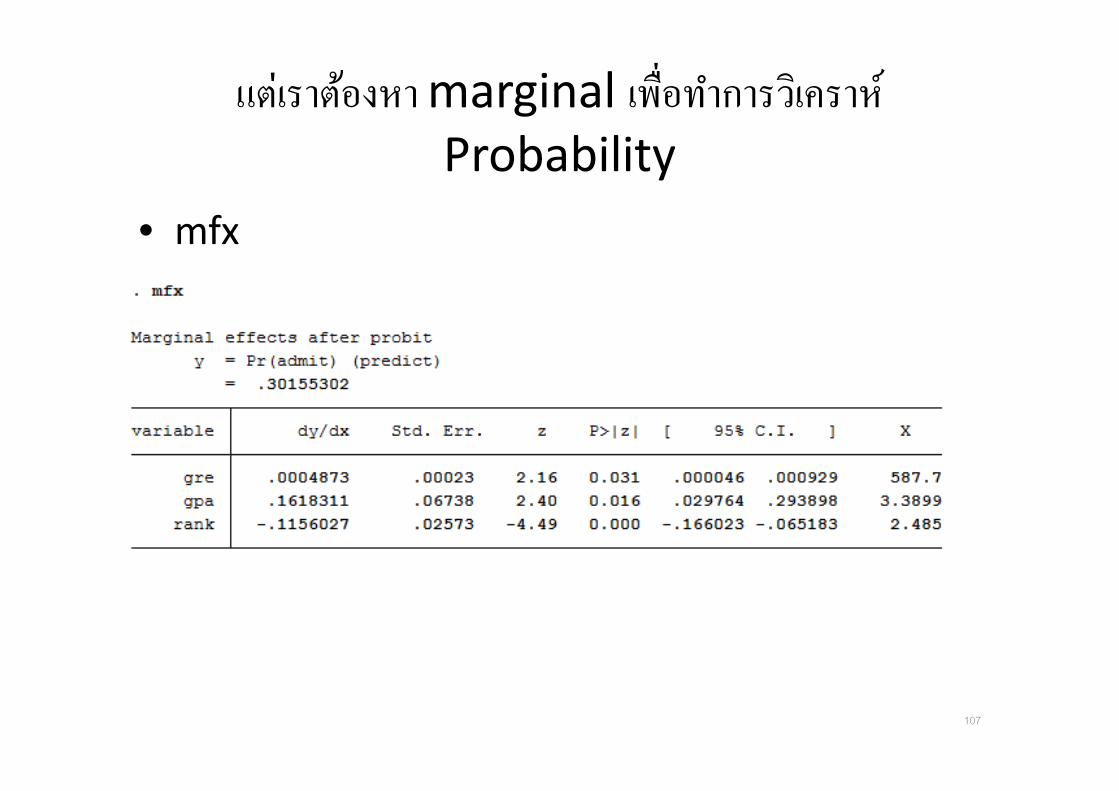
แตเราตองหา marginal เพ*อทาการวเคราห Probability
• mfx
107
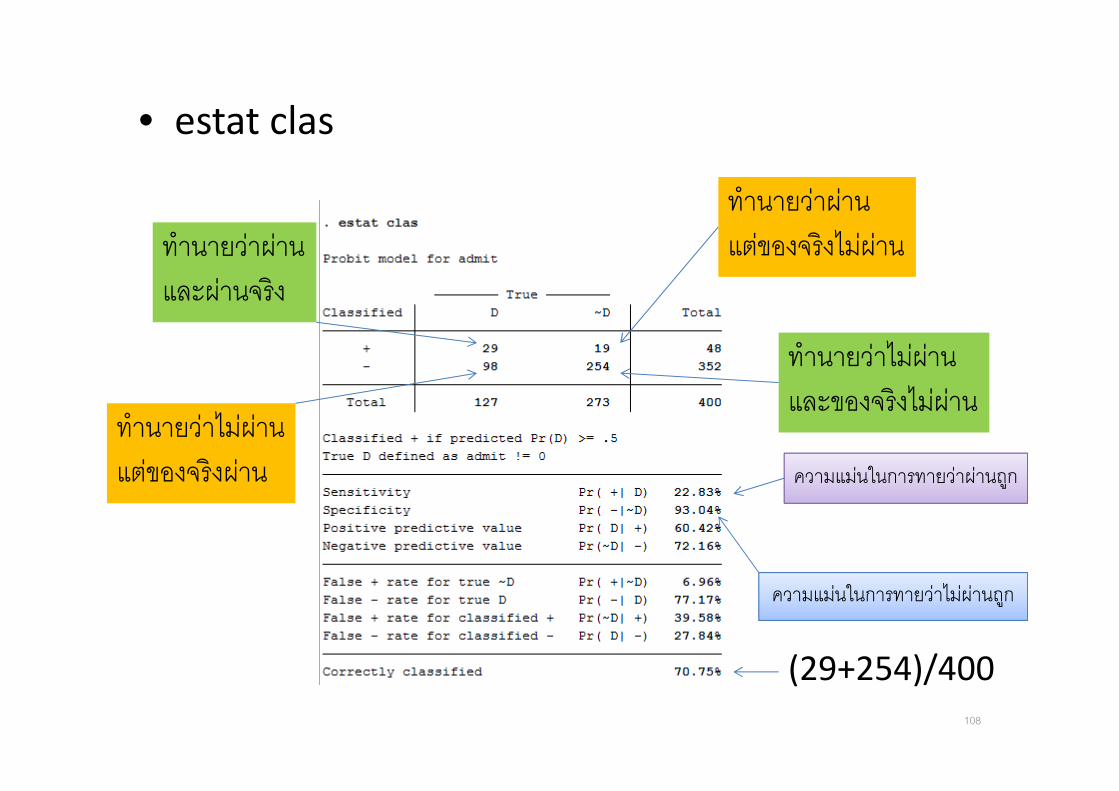
• estat clas
108
ทานายวาผานและผานจรง
ทานายวาผานแตของจรงไมผาน
ทานายวาไมผานแตของจรงผาน
ทานายวาไมผานและของจรงไมผาน
(29+254)/400
ความแมนในการทายวาผานถก
ความแมนในการทายวาไมผานถก

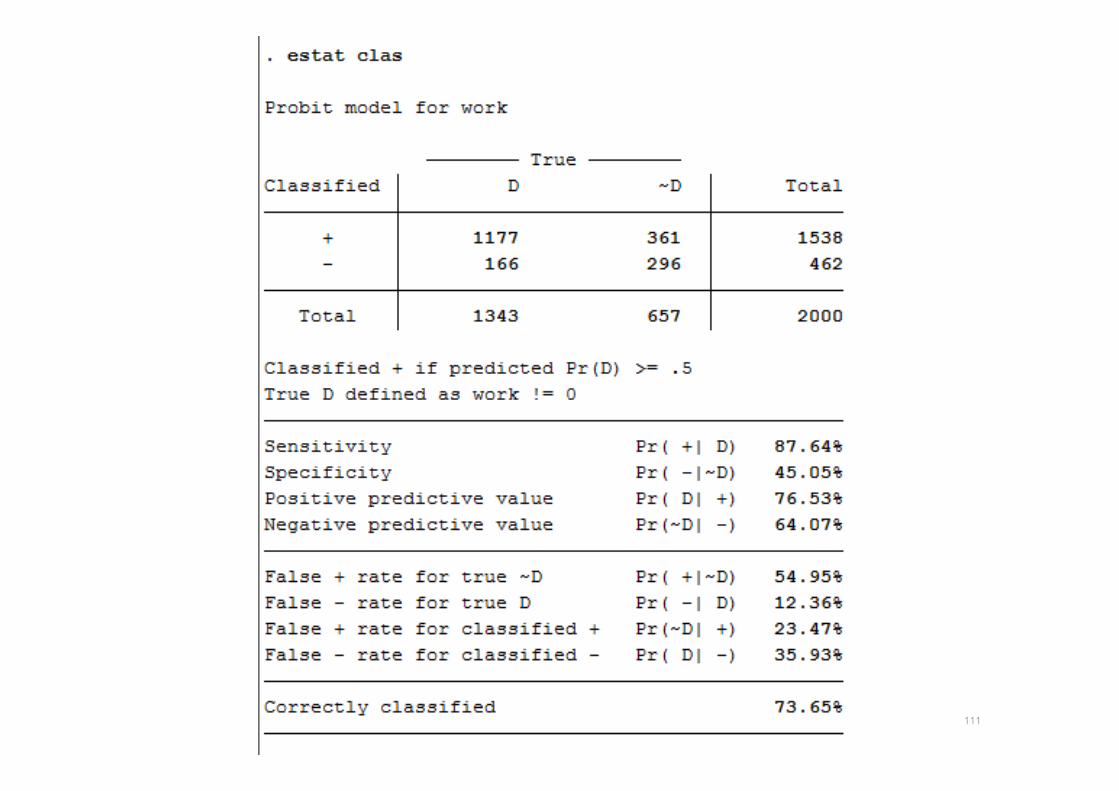
เปดไฟล womenwk
• ตวแปรตาม work
• ตวแปรตน age married children education
• sum work age married children education
• probit work age married children education, nolog
109

mfx , at(children =0)
110
111

ตวอยางงานวจย
• การประยกตใชแบบจาลองการจาแนกประเภทหลายตวแปร โลจท และโพรบท ในการทานายการลมเหลวของวสาหกจขนาดกลางและขนาดยอมในภาคตะวนออกเฉยงเหนอของประเทศไทย– เจง - ไมเจง
• ปจจยท&มผลตอความนาจะเปนในการเกดวกฤตคาเงนของประเทศเวยดนาม– เกด - ไมเกด
112

Gravity Model
• Dataset
• http://www.cepii.fr/CEPII/en/bdd_modele/pr
esentation.asp?id=8
• เปดไฟล
• col_regfile09
113

• sum
• gen lngdpo = ln( gdp_o+1)
• gen lngdpd = ln( gdp_d+1)
• gen lndis = ln( distw)
• gen lntrade = ln( flow+1)
• reg lntrade lngdpo lngdpd lndis
114

ทาแบบสอบถามไมยาก แตเหน*อยตอนเกบ
115

116
ตรงน 6ยงไมคอยมใครทาลองด…..

ใช Google ใหเกดประโยชน
117
scholar.google.co.th
118

ไปงานประชมวชาการบาง….
119

120

References:
• เอกสารประกอบการสอนวชา107411: Econometrics Iรศ.ดร. บณฑต ชยวชญชาต ภาควชาเศรษฐศาสตร มหาวทยาลยเกษตรศาสตร
• EE 325 Introductory Econometrics AjarnKaewkwan Tangtipongkul, Economics, Thammasat University
• เวปไซตสานกงานสถตแหงชาต• คมสน สรยะ เวปไซต TourismLogistics.com
• https://sites.google.com/site/mystatistics01/home
121















![Joomla for beginners - [ Joomlarabia.Com ]](https://img.pdfslide.tips/doc/110x75/55d05a63bb61ebcc578b4674/joomla-for-beginners-joomlarabiacom-.jpg)