Embed Size (px)
DESCRIPTION
Statistik. Introduktion Deskriptiv statistik Sandsynslighedregning. Introduktion. Kasper K. Berthelsen, Institut f. Mat. Fag 8 Kursusgange Individuel mundtlig eksamen (7-skala) Udgangspunkt i opgaver Software: SPSS – I kan hente en CD hos…. Flyskræk!. Passer overskriften? - PowerPoint PPT Presentation
Citation preview

Statistik
Introduktion
Deskriptiv statistik
Sandsynslighedregning

Introduktion
Kasper K. Berthelsen, Institut f. Mat. Fag 8 Kursusgange Individuel mundtlig eksamen (7-skala) Udgangspunkt i opgaver Software: SPSS – I kan hente en CD hos…

Flyskræk! Passer overskriften?
Politiken 6/12-’07
Er du tryg ved at flyve?
Ja: 86% i 2005 83% i 2007
Er der virkelig sket en ændring eller kunne det lige så godt være tilfældigt?
Svaret kommer til sidst i kurset ;-)
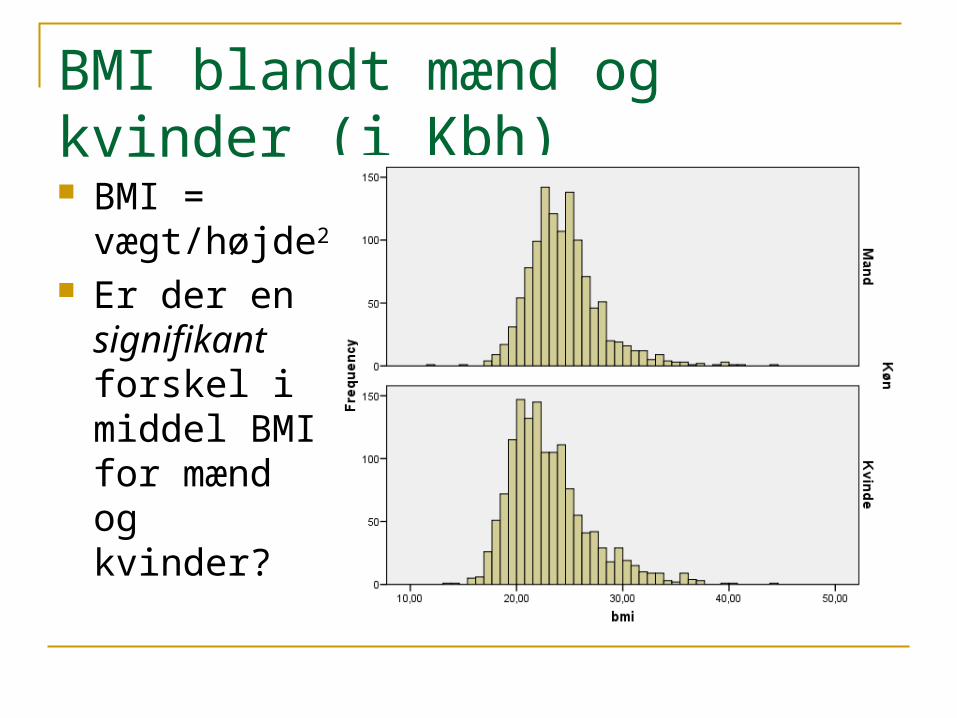
BMI blandt mænd og kvinder (i Kbh) BMI =
vægt/højde2
Er der en signifikant forskel i middel BMI for mænd og kvinder?
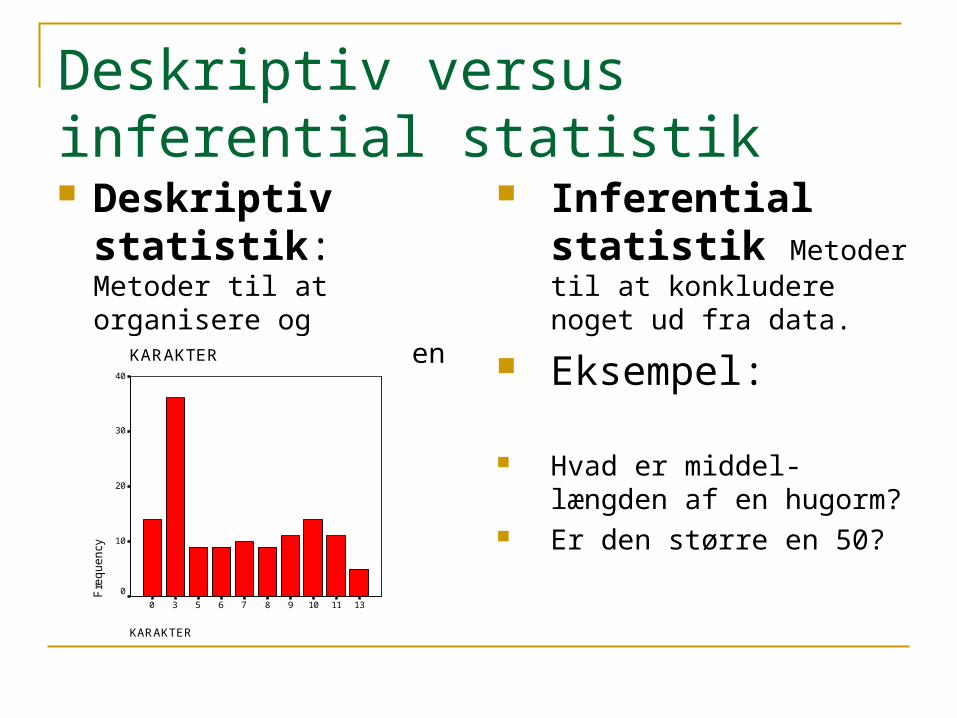
Deskriptiv versus inferential statistik Deskriptiv statistik:
Metoder til at organisere og præsentere data på en informativ måde.
Inferential statistik Metoder til at konkludere noget ud fra data.
Eksempel: Hvad er middel-længden af
en hugorm? Er den større en 50?
KARAKTER
KARAKTER
1311109876530
Fre
qu
en
cy
40
30
20
10
0

Nogle definitioner Population: Mængden af alle ”individer” vi er
interesserede i. fx alle virksomheder i DK
Parameter: Et deskriptivt mål for populationen (for eksempel middelværdi og varians).
fx gennemsnits antal ansatte
Sample/stikprøve: Mængde af data taget fra en delmængde af populationen
fx 10 tilfældigt udvalgte virksomheder
Statistik: Et deskriptivt mål for stikprøven.fx gennemsnits antal ansatte blandt de 10.
Variabel: En karakteristik af populationen eller stikprøven fx antal ansatte, omsætning, region, type

Diskrete og kontinuerte data
Diskrete data
Katagoriske data, for eksempel:
Hvilken øjenfarve?
1. Brun
2. Blå
3. Grøn
4. Grå
Kontinuerte data
Data, der er reelle tal, eks: Højde Vægt Temperatur Hastighed Osv....

Data hierarki Interval skala fx. højde.
Data kan placeres på en skala, hvor man kan sammenligne afstande mellem data punkter.
Kan også behandles som ordinale eller nominale data
Ordinal skala fx. løngruppe (lav, middel, høj)
Data kan ordnes på en skala. Beregninger kan baseres på ordningen.
Kan opfattes som nominale data.
Nominal skala fx. farve (rød,grøn,blå) Kun beregninger baseret på antal obs. i hver kategori må
udføres. Kan ikke opfattes som ordnede eller interval data.

Percentiler og kvartiler Den P’te percentil af en mængde data punkter, er
den værdi hvor P % af dataene ligger under. Positionen af den P’te percentil er givet ved
(n+1)P/100, hvor n er antallet af data punkter. Kvartiler er de procent point, der inddeler data i
kvarte. 1. kvartil er 25 percentilen. Under denne ligger 25 % af
data. 2. kvartil er 50 percentilen. Under denne ligger 50 % af
data. Kaldes også medianen. 3. kvartil er 75 percentilen. Under denne ligger 75 % af
data. Den interkvartile range defineres som afstanden
mellem den første og den tredje kvartil.

Ordinale data - karakterer
Karakter
14 10,9 10,9 10,9
36 28,1 28,1 39,1
9 7,0 7,0 46,1
9 7,0 7,0 53,1
10 7,8 7,8 60,9
9 7,0 7,0 68,0
11 8,6 8,6 76,6
14 10,9 10,9 87,5
11 8,6 8,6 96,1
5 3,9 3,9 100,0
128 100,0 100,0
0
3
5
6
7
8
9
10
11
13
Total
ValidFrequency Percent Valid Percent
CumulativePercent

Central lokation i stikprøve Stikprøvens størrelse: n Gennemsnit: Interval data Median: Den midterste observation Interval og ordinal Mode: Den observation, der forekommer med størst frekvens Interval, ordinal og nominal
n
iixn
x1
1
Statistics
KARAKTER128
0
6,05
6,00
3
Valid
Missing
N
Mean
Median
Mode
Frekvens = antal gange en observation forekommer
SPSS: Analyze→Descriptive Statistics→Frequencies

Variation (interval data)
Range: største – mindste observation
Stikprøve varians
Standard afvigelse 2ss
1
/
1
)(2
11
2
1
2
2
n
nxx
n
xxs
n
ii
n
ii
n
ii
Statistics
KARAKTER128
0
3,686
13,588
Valid
Missing
N
Std. Deviation
Variance
Bemærk: n-1 og ikke n.

Populations parametre
Populationens størrelse:
Populations middelværdi:
Populations varians:
Populations spredning:
N
xN
i i
1
22
)(
2
N
xN
i i 1
N
Bemærk: N og ikke N-1.
Deskriptive mål for populationen

Grafik præsentation: HistogramAntal $ brugt af 184 kunder i en butik.
31 kunder brugte for mellem 350$ og 450 $
SPSS: Graphics→…
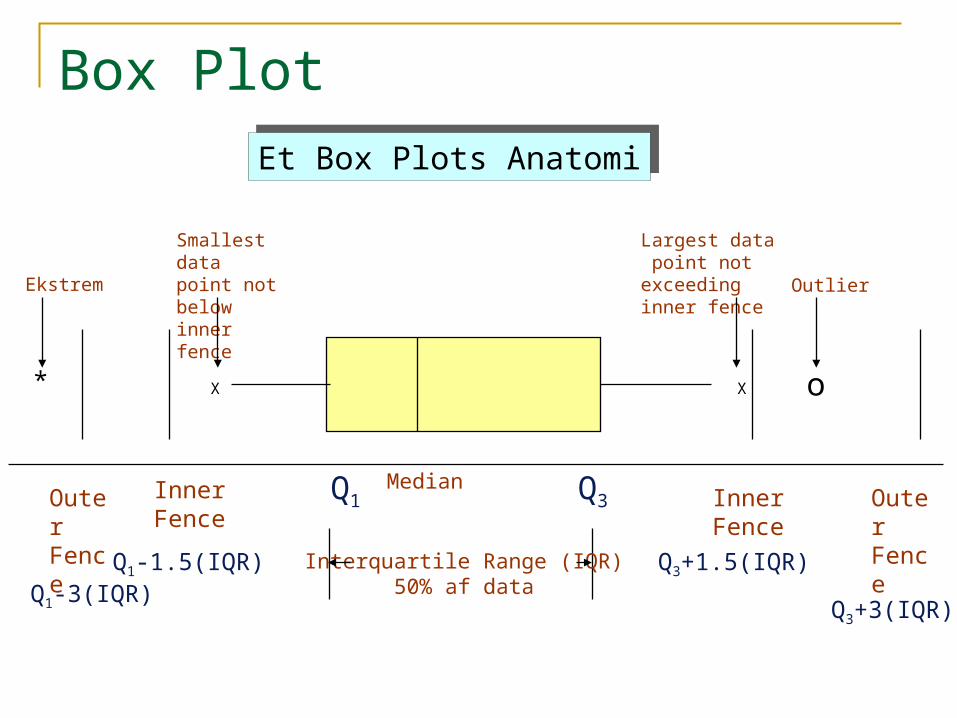
X X o*
MedianQ1 Q3InnerFence
InnerFence
OuterFence
OuterFence
Interquartile Range (IQR)50% af data
Smallest data point not below inner fence
Largest data point not exceeding inner fence OutlierEkstrem
Q1-3(IQR)Q1-1.5(IQR) Q3+1.5(IQR)
Q3+3(IQR)
Et Box Plots AnatomiEt Box Plots Anatomi
Box Plot

Box Plots for BMI

Sandsynligheder
MængderHændelserSandsynlighederRegler for sandsynligheder

Sandsynligheder En sandsynlighed er et kvantitativt mål for usikkerhed – et mål der
udtrykker styrken af vores tro på forekomsten af en usikker begivenhed.
En sandsynlighed er et reelt tal mellem 0 og 1. 0 = sker aldrig 1 = sker altid Ex: Sandsynligheden for regn i morgen er 0,5 Ex: Sandsynligheden for at få 7 rigtige i lotto er 0,000000001
I modsætning til deterministiske hændelser: Det er juleaften den 24. december I morgen står solen op kl. 8.04
Forskellige statistiske retninger: Klassisk Frekventistisk (jeres, fortrinsvist) Subjektiv (Bayesiansk)
Den klassiske sandsynlighedsteori blev udviklet i 1600 tallet – inspireret af Casino spil!

Lidt om mængder
En mængde er en samling af elementer Eksempel: A={1,2,3,4} eller A={plat, krone}
Den tomme mængde A=Ø, indeholder ingen elementer Den universelle mængde S, indeholder alle elementer Komplementet af en mængde A, er mængden Ā, der indeholder alle
elementer i S, der ikke er i A. Eksempel: S={1,2,3,4,5,6} og A={1,4,6}. Så er Ā={2,3,5}
2,3,5
A
1, 4, 6
Ā
S
Venn Diagram

Mere om mængder
Fællesmængden af A og B, A ∩ B, er mængden, der indeholder de elementer, der er i både A og B
Foreningsmængden af A og B, A U B, er mængden, der indeholder de elementer, der er i A eller B eller begge
A ∩ B1, 2 3 4, 5
6
A BS
1, 2 4, 56
A B
S
3A U B
A={1,2,3}B={3,4,5}A ∩ B={3}
A={1,2,3}B={3,4,5}A U B={1,2,3,4,5}

Den tomme mængde
To mængder er disjunkte, hvis fællesmængden A ∩ B=Ø
1, 2, 3 4, 56
A BS
A={1,2,3}B={4,5}A ∩ B={Ø}

Mere om sandsynlighed Eksperiment:
Handling, der leder frem til et af flere mulige udfald Fx. Kast med en terning eller Vælg 10 tilfældige
virksomheder. Udfald:
Observation eller måling Fx: Antal øjne på en terning eller 10 navngivne
virksomheder.

Mere om sandsynlighed
Udfaldsrum: En liste af mulige udfald af eksperimentet, lig med den
universelle mængde S={o1,o2,…,ok} Udfaldene skal være ”udtømmende” Eksempler:
Terningkast: S={1,2,3,4,5,6} – S={1,2,3,4,5} duer ikke! Møntkast: S={plat, krone} – S={plat} duer ikke
Udfaldene skal være disjunkte Terningkast S={1,2,3,4,5,6} – S={1-2,2-3,3-4,4-5,5-6} dur
ikke!
Oi er i’te udfald af k mulige.

Hændelser
En simpel hændelse er et udfald i udfaldsrummet Eksempel: Terningkast – en 6’er er en simpel
hændelse En hændelse er en mængde af en eller flere simple
hændelser i et udfaldsrummet Eksempel: Terningkast – A={2,3,4} er en hændelse
Sandsynligheden for en hændelse, A, betegnes P(A) P(A) er summen af sandsynlighederne for de simple
hændelser i A Eksempel: P(A)=P(2)+P(3)+P(4)=1/6+1/6+1/6=3/6

Hændelser Antag at alle simple hændelser forekommer med lige
stor sandsynlighed. Da er sandsynligheden for en hændelse A givet ved:
Eksempel: Terningkast – lige sandsynlighed for alle udfald. Lad A={1,2,4} n(A) = 3n(S) = 6 P(A) = 3/6 = 0.5
S i elementer antal Ai elementer antal
)(
)()()(
n(S)An
SnAnAP

Regler for sandsynlighed
Givet et udfaldsrum S={o1,o2,…,ok} da skal sandsynlighederne opfylde:
Eksempel: Terningkast – lige sandsynlighed for alle udfald:
k
1ii
i
P(o 2)
i alle for P(o0 1)
1)
1)
Ahændelse enhver for 1,P(A)0 også dermed og
6
1
1)i 6
1
6
1
6
1
6
1
6
1
6
1P(o
6
1P(6)P(5)P(4)P(3)P(2)P(1)
,6}{1,2,3,4,5S
i

Flere regler
Sandsynligheden for Ā: P(Ā)=1-P(A)
Sandsynligheden for Ø: P(Ø)=0
Sandsynligheden for S: P(S)=1
Fællesmængden for hændelserne A og B, A ∩ B, er hændelsen, der forekommer, når både A og B forekommer
Sandsynligheden for A ∩ B, P(A ∩ B), kaldes den simultane sandsynlighed (joint probability)

Betinget sandsynlighed
Den betingede sandsynlighed P(A|B) er sandsynligheden for hændelsen A, givet at vi ved at hændelsen B allerede er indtruffet:
A)P(A)|P(B
B)P(B)|P(AB)P(A
ligeledes eller
P(A)
A)P(BA)|P(B og
P(B)
B)P(AB)|P(A

AT& T IBM Total
Telecommunication 40 10 50
Computers 20 30 50
Total 60 40 100
Frekvenser
AT& T IBM Total
Telecommunication .40 .10 .50
Computers .20 .30 .50
Total .60 .40 1.00
Sandsynligheder
2.050.0
10.0
)(
)()(
TP
TIBMPTIBMP
Sandsynligheden for at et projekt udføres af IBM givet at det er et telekommunikations-projekt:
Eksempel (Kontingenstabel)

Additionsreglen
Sandsynligheden for foreningen mellem to mængder A og B, A U B, er givet som: P(A U B) = P(A) + P(B) – P(A ∩ B)
Hvis A og B er disjunkte hændelser, er P(A ∩ B) = 0 og dermed: P(A U B) = P(A) + P(B)
Eksempel: Sansynlighed for at et projekt er IBM eller Telekom:
0,80
0,10 0,50 0,40
T) P(IBM - P(T) P(IBM) T U P(IBM
)





























