Embed Size (px)
Citation preview

VU MIF
Jurgita Markevičiūtė
Statistika ILaboratoriniai rudens semestrui
VILNIAUS UNIVERSITETASMATEMATIKOS IR INFORMATIKOS FAKULTETAS
2014

Turinys
1 Įvadas 31.1 Paskaitų planas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Reikalavimai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Paskaitos 62.1 Pirmos paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 R – bendrieji faktai . . . . . . . . . . . . . . . . . . . . . . . . 62.1.2 Pavyzdžiai . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.1.3 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 Antros paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . . . 112.2.1 Įvadinės pastabos . . . . . . . . . . . . . . . . . . . . . . . . . 112.2.2 Keli statistikos uždavinių pavyzdžiai . . . . . . . . . . . . . . 112.2.3 Kintamųjų tipai . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2.4 Imtys ir jų grafinės charakteristikos . . . . . . . . . . . . . . . 152.2.5 Imtys ir jų skaitinės charakteristikos . . . . . . . . . . . . . . 172.2.6 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 Trečios paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . . . 202.3.1 Duomenų įrašymas ir programavimo pavyzdžiai . . . . . . . . 202.3.2 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.4 Ketvirtos paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . 272.4.1 (Pseudo)atsitiktinių skaičių generavimas . . . . . . . . . . . . 272.4.2 Apie R funkcijas ir source komandą . . . . . . . . . . . . . . . 292.4.3 Programavimo pavyzdžiai . . . . . . . . . . . . . . . . . . . . 292.4.4 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.5 Penktos paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . . 332.5.1 Vienmačiai duomenys: aprašomoji statistika ir duomenų pir-
minė analizė . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.5.2 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.6 Šeštos paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . . . 412.6.1 Dvimačiai duomenys: aprašomoji statistika ir duomenų prie-
šanalizė . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 412.6.2 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
2.7 Septintos paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . . 472.7.1 Daugiamačiai duomenys: aprašomoji statistika ir duomenų
priešanalizė . . . . . . . . . . . . . . . . . . . . . . . . . . . . 472.7.2 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
2.8 Aštuntos paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . . 532.8.1 Centrinė ribinė teorema ir didžiųjų skaičių dėsnis . . . . . . . 53
1

2.8.2 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 582.9 Devintos paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . . 60
2.9.1 Sprendžiamoji statistika: parametrų įverčiai . . . . . . . . . . 602.9.2 Intervaliniai įverčiai . . . . . . . . . . . . . . . . . . . . . . . . 622.9.3 Užduotis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
2.10 Dešimtos paskaitos konspektas . . . . . . . . . . . . . . . . . . . . . . 682.10.1 Sprendžiamoji statistika: hipotezių tikrinimas (viena imtis) . . 682.10.2 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
2.11 Vienuoliktos paskaitos konspektas . . . . . . . . . . . . . . . . . . . . 742.11.1 Sprendžiamoji statistika: hipotezių tikrinimas (dvi imtys) . . . 742.11.2 Užduotys . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
3 Laboratoriniai darbai 823.1 Aprašymas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 823.2 Duomenų rinkiniai . . . . . . . . . . . . . . . . . . . . . . . . . . . . 833.3 Pirmas laboratorinis darbas . . . . . . . . . . . . . . . . . . . . . . . 88
3.3.1 I dalis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 883.3.2 II dalis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
3.4 Antras laboratorinis darbas . . . . . . . . . . . . . . . . . . . . . . . 903.4.1 I dalis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 903.4.2 II dalis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
3.5 Trečias laboratorinis darbas . . . . . . . . . . . . . . . . . . . . . . . 933.5.1 I dalis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 933.5.2 II dalis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
2

1Įvadas
Statistikos kursas skirtas supažindinti studentus su svarbiausiomis statistikos sąvo-komis. Išsiaiškinti pagrindinius tikimybių teorijos faktus, kuriais remiasi statistika.Laboratorinių darbų metu studentas turi išmokti apskaičiuoti aprašomosios statisti-kos charakteristikų reikšmes, atlikti statistinę bei grafinę duomenų analizę (dėmesysskiriamas statistinei „filosofijai“, o ne matematiniam griežtumui).
Laboratoriniai darbai atliekami su statistiniu paketu R. Po šio kurso studentasturi gebėti dirbti su jau esamomis R komandomis, susirasti reikalingas komandas irpaketus, jei jie nėra standartiniai, taip pat parašyti savarankiškai reikalingas funkci-jas.
Laboratoriniams darbams naudojama literatūra yra:
• R. Lapinskas. Įvadas į statistiką su R. , 2005.
Visi laboratorinių darbų uždaviniai paimti iš šio konspekto arba yra analogiškišio konspekto uždaviniams.
1.1 Paskaitų planasPaskaitos vyks rudens semestre pirmadieniais. Paskaitų plane skyriai nurodyti iš R.Lapinsko konspekto. Paskaitų planas:
3

09 08 1 sk: Aprašomoji statistika09 15 2 sk: R – bendrieji faktai09 22 3 sk: Duomenų įrašymas ir programavimo pavyzdžiai09 29 3 sk: Duomenų įrašymas ir programavimo pavyzdžiai10 06 Pirmojo laboratorinio darbo atsiskaitymas10 13 4 sk: Vienmačiai duomenys: aprašomoji statistika ir duomenų priešanalizė10 20 5 sk: Dvimačiai duomenys: aprašomoji statistika ir duomenų priešanalizė priešanalizė10 27 6 sk: Daugiamačiai duomenys: aprašomoji statistika ir duomenų priešanalizė11 03 7 sk: Centrinė ribinė teorema ir didžiųjų skaičių dėsnis11 10 Antrojo laboratorinio darbo atsiskaitymas11 17 8 sk: Sprendžiamoji statistika: parametrų įverčiai11 24 9 sk: Sprendžiamoji statistika: hipotezių tikrinimas (viena imtis)12 01 10 sk: Sprendžiamoji statistika: hipotezių tikrinimas (dvi imtys)12 08 Trečiojo laboratorinio darbo atsiskaitymas12 15 "Skolų atsiskaitymas"
Paskaitų planas gali būti pakoreguotas semestro eigoje. Laboratorinių darbųužduotys ir atsiskaitymų datos nesikeis.
1.2 ReikalavimaiGalutinis balas išskirstomas tokiomis proporcijomis:
• Laboratoriniai darbai 20% + aktyvumas laboratorinių metu 10%
• Tarpinis egzaminas + egzaminas 70%
Laboratorinių darbų atsiskaitymo reikalavimai:
• Kiekvienam laboratoriniam darbui reikia parašyti trumpą ataskaitą (iki 6 psl.).
• Paskaitų skirtų atsiskaitymams metu, studentai turės trumpai pristatyti savoatliktą užduotį ir pateikti ataskaitą bei atsakyti į dėstytojos pateiktus klausi-mus;
• Dėstytojas išklausęs pristatymą ir peržiūrėjęs ataskaitą, rezultatus paskelbs posavaitės.
• Visi trys laboratoriniai darbai galutiniame vertinime turės vienodus svorius.Galutinio vertinimo formulė:Tarkime, kad studentas iš trijų laboratorinių dešimties balų vertinimo skalėjegavo l1, l2 ir l3 pažymius, tada galutinis pažymys g yra
g := l1 + l2 + l33 · 0, 2.
• Jei studentas neatliko laboratorinio darbo laiku arba negalėjo jo atsiskaitytinumatytu laiku, tą galės padaryti gruodžio 15 d. (per "Skolų atsiskaitymą").Šiuo metu laboratorinis darbas bus vertinamas dešimties balų vertinimo skalėjeatimant vieną balą. T.y., jei studentas laiku atsiskaitydamas gautų pažymį l,tai skolų atsiskaitymo metu jo pažymys bus l − 1.
4

Aktyvumo reikalavimai
• Kiekvienos laboratorinių darbų paskaitos metu pateikiamos 2-3 užduotys, ku-rias studentai turi atlikti. Už visas gerai atliktas užduotis skiriamas 1 taškas,jei atliktos ne visos užduotys arba jos atliktos neteisingai, balas atitinkamaimažinamas. Semestro metu reikia surinkti 7 taškus, norint gauti pilną balągalutiniame pažymyje.
• Užduotys atliekamos tik paskaitų metu. Vėliau atlikti negalima. Nespėjus atsi-skaityti paskaitos metu, R kodas turi būti išsiųstas iki paskaitos galo dėstytojai.Kai R kodas bus patikrintas, dėstytoja pateiks įvertinimą internete.
5

2Paskaitos
2.1 Pirmos paskaitos konspektas
2.1.1 R – bendrieji faktaiR instaliacija
Svetainėje www.r-project.org nuvairuokite į CRAN ir pasirinkite iš kur parsisiųstinaujausią programos R versiją. Beje, R yra atnaujinamas kas pusę metų, todėlrinkitės naujausią veikiančia, o ne bandomąją versiją.
Suinstaliavus programą R pas Jus atsiras tik bazinės bibliotekos. Paprastai jųdarbui neužtenka. Tačiau instaliuotis po vieną biblioteką taip pat sudėtingas darbas.R naudotojų palengvinimui yra sudaryti bibliotekų rinkiniai pagal tematiką ("Taskviews"). Puslapyje http://cran.at.r-project.org/ kairiajame meniu pasirinkę"Task Views", rasite visų rinkinių sąrašą. Norint juos susiinstaliuot reikia atliktitokius veiksmus:
install.packages("ctv")library("ctv")install.views("...")
Rekomenduoju susiinstaliuoti šiuos rinkinius:
• Distributions: Probability Distributions
• Econometrics: Computational Econometrics
• Finance: Empirical Finance
• Graphics: Graphic Displays & Dynamic Graphics & Graphic Devices & Visu-alization
• gR: gRaphical Models in R
• Multivariate: Multivariate Statistics
6

• OfficialStatistics: Official Statistics & Survey Methodology
• Optimization: Optimization and Mathematical Programming
• TimeSeries: Time Series Analysis
R ekranas
Atidarę programą R Jūs matote beveik tuščią ekraną. Jame beveik nėra komandiniųmygtukų. Todėl visas komandas turėsite rašyti patys.
Meniu eilutėje spragtelėkite ant Help skyriaus.
1. Pasirinkę FAQ on R, matome DPK (=dažniausiai pateikiamus klausimus) apieR ir atsakymus į juos. Štai vienas šio dokumento naudojimo pavyzdžių: įjun-gus R, pakraunami tik pagrindiniai paketai (package). Dauguma specializuotųfunkcijų yra kituose R paketuose. Spragtelėję ant R Add-On Packages, pama-tysime visų (šios R versijos) paketų sąrašą.
2. Pasirinkę FAQ on R for Windows, pamatysime html tipo dokumentą, kuriamerasime (Windows aplinkoje dirbančiam) R vartotojui svarbią informaciją.
3. Pasirinkę R functions (text)… ir langelyje Help on surinkę, pvz., mean|OK, pa-matysime anglišką funkcijos mean aprašymą. Jei norite pamatyti šios funkcijostekstą, surinkite R lange mean. R yra objektiškai orientuota kalba, kas reiškia,kad, pvz., funkcija mean pirmiausiai patikrina savo argumento (objekto) klasę,o jau paskui taiko jam tinkamą metodą. Funkcijos aprašymas, o taip pat jostekstas atrodo komplikuotas, kadangi į juos įtraukta trim opcija, diagnostiniaižingsniai ir nurodymai, ką daryti, kai vektorius x turi praleistų reikšmių (taidažnai pasitaiko realiuose uždaviniuose).
4. Pasirinkę Html help, pakliūtume į puslapį su daugeliu sąsajų (link’ų). Sąsajosgali mus nukreipti į An Introduction to R, The R language definition, WritingR extensions ar kitus skyrius. Šiuos tekstus (tiksliau, hipertekstus) lengva skai-tyti, kadangi juose galima keliauti iš vienos vietos į kitą, naudojantis vidinėmissąsajomis.
5. Meniu punkte Help, pasirinkę Search help.. galite ieškoti informacijos pa-gal raktinius žodžius. Tą patį rezultatą gautumėte surinkę lange komandą :help.search("mean"). Tačiau tokiu atveju informacijos ieškoma tik Jūsų kom-piuteryje esančioje informacijoje.
6. Pasirinkę Help punktą search.r-project.org... informacijos ieškote internetetarp R naudotojų diskusijų. Tą patį galima pasiekti su komanda RSiteSe-arch("mean").
Komandas galite rašyti tiesiogiai į R ekraną. Tačiau tai ne visada yra patogu.Rekomenduoju R lango meniu punkte File paspausti New script. Atsidariusiamelange galite rašyti komandas, funkcijas, jas redaguoti ir keisti. Taip rašomas kodasbus tvarkingesnis ir aiškiau suprantamas. Parašytą funkciją galite nukopijuoti į Rlangą arba ant jos paspaudus CTRL+R komanda bus įvykdyta automatiškai. Taippat R kodus galite rašyti bet kuriame tekstiniame redaktoriuje. Tačiau patogiausitie, kurie susieti su paketu R. Pavyzdžiui nemokami yra Tinn-R arba Emacs.
7

Rašydami R kodą savo patogumui (ir atsiskaitymo aiškumui) rašykite komentarusprie kodo. R pakete komentarai yra pradedami # ženklu.
R paketai ir duomenų rinkiniai
R funkcijos yra apjungtos į paketus (= packages (angl.)), kurie gali būti prisijungtiprie darbinės srities arba, kai nebereikalingos, atjungti. Įjungiant R, automatiš-kai instaliuojamos septyni paketai. Jei neturite reikalingos bibliotekos, ją galitesusiinstaliuoti keliais būdais:
• Juos galima atsisiųsti iš http://cran.hu.r-project.org/ ir išzipuoti į R pa-keto library direktorijoje.
• Jei jūsų kompiuteris prijungtas prie interneto ir įjungta kuri nors internetonaršyklė, surinkite install.packages(...).
Jei esate R aplinkoje ir norite prijungti kokį nors paketą, surinkite komandąlibrary(...).
Tolimesniame darbe dažnai naudosimės į R įmontuotais duomenų rinkiniais. No-rėdami gauti sąrašą rinkinių, prijungtų prie dabartinio paieškos kelio, surinkime da-ta(). Jei norite pamatyti duomenų rinkinius tik viename konkrečiame pakete taisurinkite komandą data(package=”...”), o jei visų instaliuotų paketų duomenų rinki-nius - data(package = .packages(all.available = TRUE)).
Kiekvieną R paketą sudaro dviejų rūšių objektai: duomeniniai (data sets) irfunkciniai (functions). Visus pavyzdžiui paketo base objektus galime pamatyti sulibrary(help=base).
Norint dirbti su kokiu nors duomenų rinkiniu reikia, kad paketas, kuriame yrašie duomenys, būtų užkrautas ir surinkti komandą data(...). Tačiau su šia komandanegalite operuoti duomenų vardais. Norint, kad duomenų rinkinio stulpelių pava-dinimai taptų pasiekiami (su salyga, kad paieškos kelyje nėra kitų kintamųjų sušių stulpelių vardais), surinkime attach(...). Darbą su duomenų rinkiniu baigus, jįtikslinga atjungti: detach(...).
Surinkite dabar kurią nors iš komandų demo(graphics) demo(image) ir pamatysitedaug gražių paveikslėlių!
R turi daug funkcijų ir jas visa nėra lengva įsiminti, todėl ryžtingai naudokitėsvisomis įmanomomis pagalbos priemonėmis. Jau žinome funkciją help(image) ir jossinonimą ?image. Pagalbos failo pabaigoje paprastai yra Examples skyrelis, kuria-me yra funkcijos taikymo pavyzdžių. Juos apžvelgti galima ir tiesiogiai, pvz., suexample(image).
R literatūra, konferencija, archyvai
Yra nemažai literatūros, skirtos darbui su R paketu. Daug jos patalpinta internete.
2.1.2 PavyzdžiaiŠiuo adresu galite rasti trumpą R pagrindinių komandų kortelę: http://cran.r-project.org/doc/contrib/Short-refcard.pdf. Bet tai nėra vienintelės gali-mos R komandos!!!
8

R kalboje kintamųjų priskyrimui naudojamas ženklas "<-", o ne lygybė. Lygybėtaip pat galima, tačiau geriau jos nenaudoti. Lygybę patartina naudoti sulyginantreiškinius, o ne priskiriant vardus.
Sudarykime skaitinį vektorių R programoje, kuriame eina iš eilės 15 natūriniųskaičių:
x1 <- 1:15x2 <- seq(1, 15)x3 <- c(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15)
Atspausdinę visus sukurtus vektorius matysime, kad gavome tą patį:
> x1[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15> x2[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15> x3[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Pažymėsime, kad R vartoja vektorinę aritmetiką, t.y. operacijos
x1^3
rezultatas (13, 23, . . . , 153). O dabar išbrėškime pirmąjį grafiką:
z<-(0:100)/10plot(z,sin(z),type="l")lines(z,(sin(z))^3,lty=2)lines(z,(sin(z))^10,lty=3)legend(0,-0.5,c("1","3","10"),lty=c(1,2,3))
Apskaičiuokime mūsų vektorių x1 bei z vidurkius, standartinius nuokrypius irpagrindinius 5 skaičius:
mean(x1)mean(z)sd(x1)sd(z)summary(x1)summary(z)
Parašykime savo funkcijas, kaip apskaičiuoti skaitinio vektoriaus vidurkį. Pirma-sis trumpasis variantas yra:
mean.mano <- function(x){sum(x)/length(x)}mean.mano(x1)
Antrasis variantas:
mano.mean <- function(x){
n <- length(x)suma <- 0
9

for(i in 1:n)suma <- suma + x[i]
m <- suma/nreturn(m)
}mano.mean(x1)
Nors abi funkcijos duoda tą patį rezultatą, tačiau rekomenduojama naudoti pir-moji, nes ji greičiau skaičiuoja.
Pasiimkime duomenis iš R paketo car Davis, kuriame pateikti 200 reguliariai už-siiminėjančių sportu asmenų (vyrų=M ir moterų=F) duomenys apie jų svorį (tikrąjįweight ir praneštąjį repwt) bei ūgį (tikrąjį height ir praneštąjį repht):
library(car)data(Davis)attach(Davis)
Surinkę komandą
height[sex=="M"]
gauname tik vyrų (Male) ūgius. Kadangi skaičiavimo procedūra dabar aiški, moterųūgio vidurkį apskaičiuosime iš karto:
mean(height[sex=="F"])
Visus height įrašus suskirstyti į dvi grupes galima ir kitaip (su funkcija tapply):
tapply(height,sex,mean)
Baigę dirbti su duomenimis atjunkime juos:
detach(Davis)
2.1.3 Užduotys1. Sukurkite bet kokį 100 ilgio vektorių x su R. Apskaičiuokite y = sin(x), z =
(x− 2)/5 bei v = x2/3.
2. Apskaičiuokite x, y, z, v vidurkius bei standartinius nuokrypius.
3. Parašykite funkciją, kuri apskaičiuotų
u =100∑i=1
xi − xsd(x) ,
čia x yra vektoriaus x vidurkis, o sd(x) yra vektoriaus x standartinis nuokrypis.
10

2.2 Antros paskaitos konspektas
2.2.1 Įvadinės pastabosŠiame kurse mes mokysimės dirbti su aprašomosios matematinės statistikos progra-ma R ir jo taikymais iliustruojant pradines matematinės statistikos sąvokas. Šiuometu egzistuoja labai daug statistikai skirtų komputerinių paketų, o tarp jų kūrėjųvyksta ganėtinai aštri konkurencija. Programinę įrangą galima klasifikuoti, remiantisįvairiais kriterijais. Jei kalbėtume apie kainą, tai vienai grupei priklauso komerciniaiproduktai (juos reikia pirkti, “piratinių” kopijų naudojimas yra ir amoralus, ir bau-džiamas). Jai priklauso tokie statistiniai paketai kaip SAS, SPSS, Statistica, Stat-graphics, S-Plus, Stata, Gauss, Ox, TSP, Minitab, EViews (=Econometric Views) irt.t. Kitai grupei priklauso nemokami (free) produktai (dėl suprantamų priežasčių, jiekartais yra menkesnės kokybės, bet ne visada). Į šią grupę kartais pakliūna komerci-nių paketų senesnės versijos (pvz., NCSS 6.0 Junior versija), nekomercinių organiza-cijų produktai (pvz., Europos Sąjungos statistikos departamento (Eurostat’o) laikoeilučių analizei skirta DEMETRA) arba įvairių entuziastų (arba jų grupių) kūryba(pvz., Herman’o J. Bierens’o ekonometrikai skirtas EasyReg 2000 arba Luke Tier-ney sukurtas produktas XLISP-STAT). Skyrium stovi pasaulinės (programuojančių)statistikų bendruomenės GNU programos pagrindu1 kuriamas produktas R) – taisparčiai vystomas tarptautinis projektas, kuris jau dabar leidžia spręsti praktiškaivisus statistikos uždavinius.
Kitas paketų klasifikavimo kriterijus galėtų būti statistinės analizės komandųvykdymo būdas. Dauguma aukščiau išvardintų paketų turi meniu tipo komandų sis-temą – norint apskaičiuoti, tarkime, (imties) vidurkį, užtenka pateiktajame komandųsąraše spragtelėti ant Mean langelio ir ekrane bus pateiktas skaičiavimo rezultatas.Kito tipo paketuose (programuojamuose paketuose) komandą mean(x) komandinia-me lange reiktų surinkti pačiam ir tik po to pamatytume rezultatą. Abu būdai turiprivalumų ir trūkumų. Pirmasis būdas paprastesnis (nereikia mokytis gana greitaiužmirštamų komandų), tačiau reikia būti tikram, kad po surenkama komanda sle-piasi būtent ta funkcija kurios Jūs tikitės. Antrasis būdas statistikos profesionaluiteikia daugiau galimybių. Pažymėsime, kad kai kurie antrojo tipo produktai (pvz.,S-Plus, SAS) dabar turi abi galimybes. Antra vertus, dauguma pirmo tipo produktųdabar irgi turi didesnes ar mažesnes programavimo galimybes (pvz., toks yra SPSS arEviews). R iš esmės yra programavimo kalba su specializuota (statistikos reikmėmsskirta) aplinka. Kai kas iš R vystymo branduolio (The R Development Core Team)mano, kad meniu variantas apskritai nereikalingas, tačiau progresas šia kryptimi yraakivaizdus. Mes R paketo meniu galimybėmis nesinaudosime. R yra nemokamas(ir labai geros kokybės) produktas. R yra “jaunesnysis” komercinio S-Plus paketo“brolis”. Šių dviejų kalbų sintaksė praktiškai ta pati, nors programiniai interpreta-vimo principai skiriasi. Dauguma S kalba parašytų programų veikia ir R aplinkoje.R projekto internetinis adresas yra http://www.r-project.org/.
2.2.2 Keli statistikos uždavinių pavyzdžiaiPanagrinėkime vieną būdingą statistikos uždavinį:Užduotis 2.1 Norint patikrinti teiginį, kad Lietuvos gyventojų ūgis kasmet didė-ja, 2000 metais buvo išmatuotas tūkstančio atsitiktinai paimtų vyrų (jų amžius buvo
11
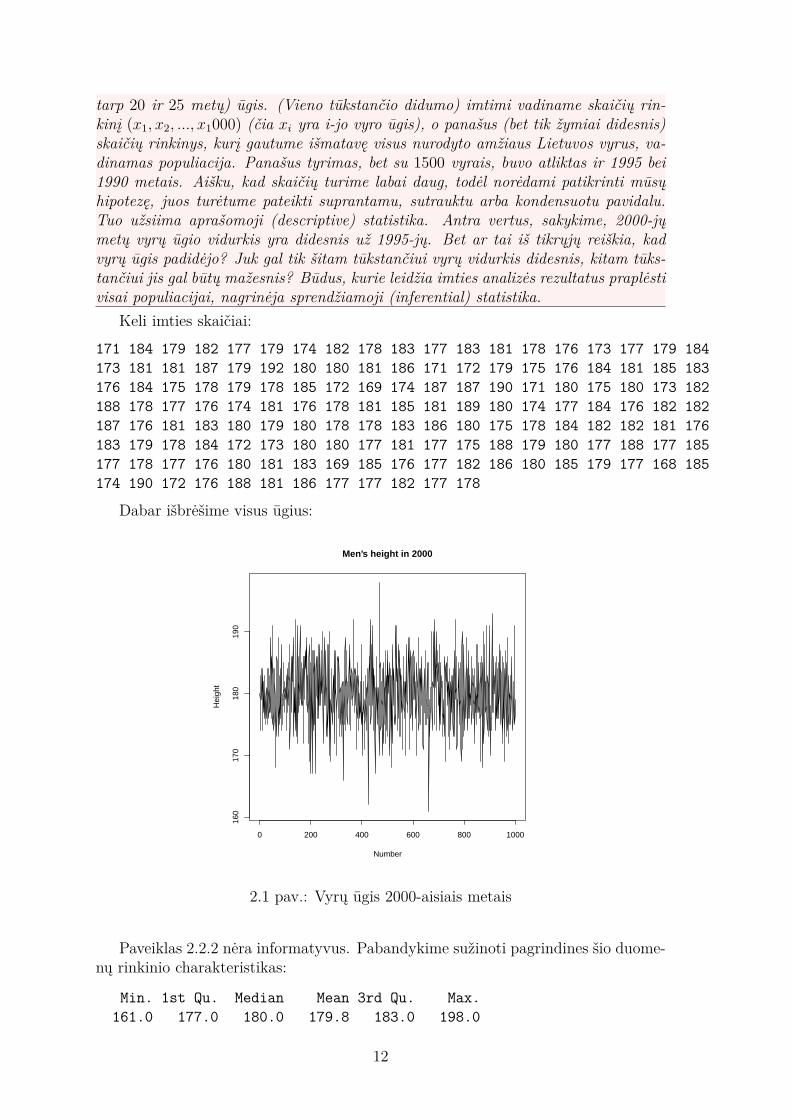
tarp 20 ir 25 metų) ūgis. (Vieno tūkstančio didumo) imtimi vadiname skaičių rin-kinį (x1, x2, ..., x1000) (čia xi yra i-jo vyro ūgis), o panašus (bet tik žymiai didesnis)skaičių rinkinys, kurį gautume išmatavę visus nurodyto amžiaus Lietuvos vyrus, va-dinamas populiacija. Panašus tyrimas, bet su 1500 vyrais, buvo atliktas ir 1995 bei1990 metais. Aišku, kad skaičių turime labai daug, todėl norėdami patikrinti mūsųhipotezę, juos turėtume pateikti suprantamu, sutrauktu arba kondensuotu pavidalu.Tuo užsiima aprašomoji (descriptive) statistika. Antra vertus, sakykime, 2000-jųmetų vyrų ūgio vidurkis yra didesnis už 1995-jų. Bet ar tai iš tikrųjų reiškia, kadvyrų ūgis padidėjo? Juk gal tik šitam tūkstančiui vyrų vidurkis didesnis, kitam tūks-tančiui jis gal būtų mažesnis? Būdus, kurie leidžia imties analizės rezultatus praplėstivisai populiacijai, nagrinėja sprendžiamoji (inferential) statistika.
Keli imties skaičiai:171 184 179 182 177 179 174 182 178 183 177 183 181 178 176 173 177 179 184173 181 181 187 179 192 180 180 181 186 171 172 179 175 176 184 181 185 183176 184 175 178 179 178 185 172 169 174 187 187 190 171 180 175 180 173 182188 178 177 176 174 181 176 178 181 185 181 189 180 174 177 184 176 182 182187 176 181 183 180 179 180 178 178 183 186 180 175 178 184 182 182 181 176183 179 178 184 172 173 180 180 177 181 177 175 188 179 180 177 188 177 185177 178 177 176 180 181 183 169 185 176 177 182 186 180 185 179 177 168 185174 190 172 176 188 181 186 177 177 182 177 178
Dabar išbrėšime visus ūgius:
0 200 400 600 800 1000
160
170
180
190
Men's height in 2000
Number
Hei
ght
2.1 pav.: Vyrų ūgis 2000-aisiais metais
Paveiklas 2.2.2 nėra informatyvus. Pabandykime sužinoti pagrindines šio duome-nų rinkinio charakteristikas:
Min. 1st Qu. Median Mean 3rd Qu. Max.161.0 177.0 180.0 179.8 183.0 198.0
12
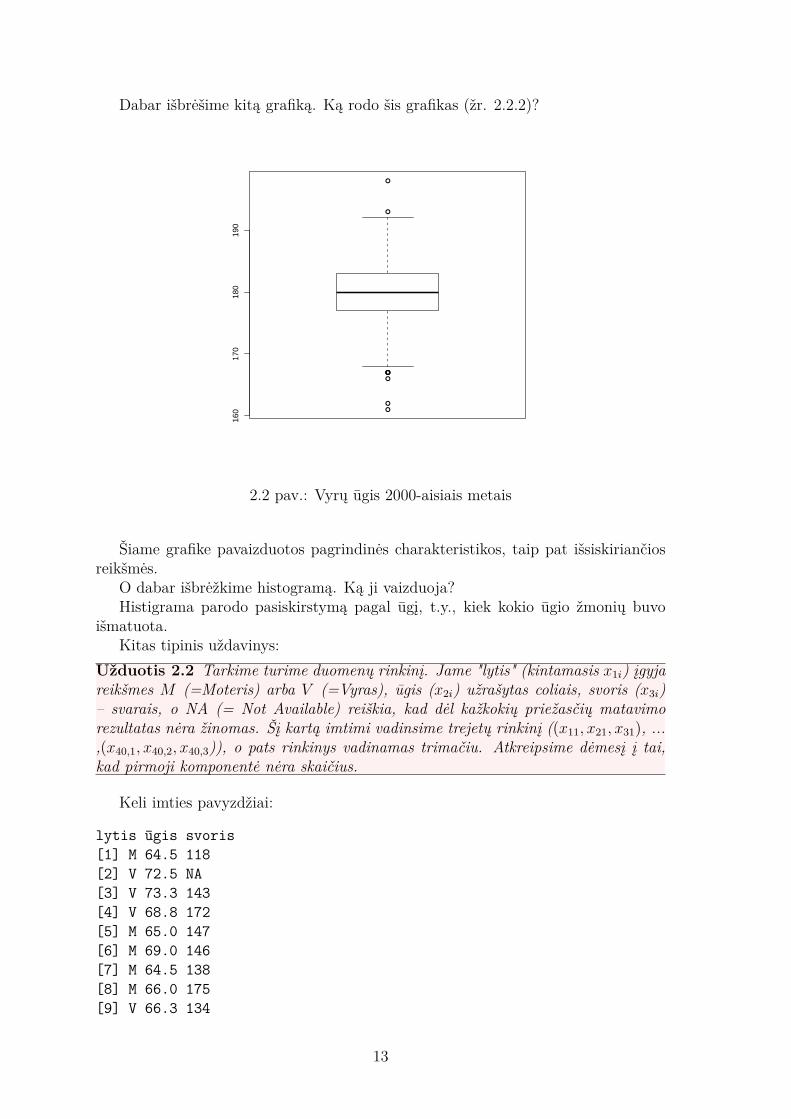
Dabar išbrėšime kitą grafiką. Ką rodo šis grafikas (žr. 2.2.2)?
●●●
●
●
●
●
●
●
160
170
180
190
2.2 pav.: Vyrų ūgis 2000-aisiais metais
Šiame grafike pavaizduotos pagrindinės charakteristikos, taip pat išsiskiriančiosreikšmės.
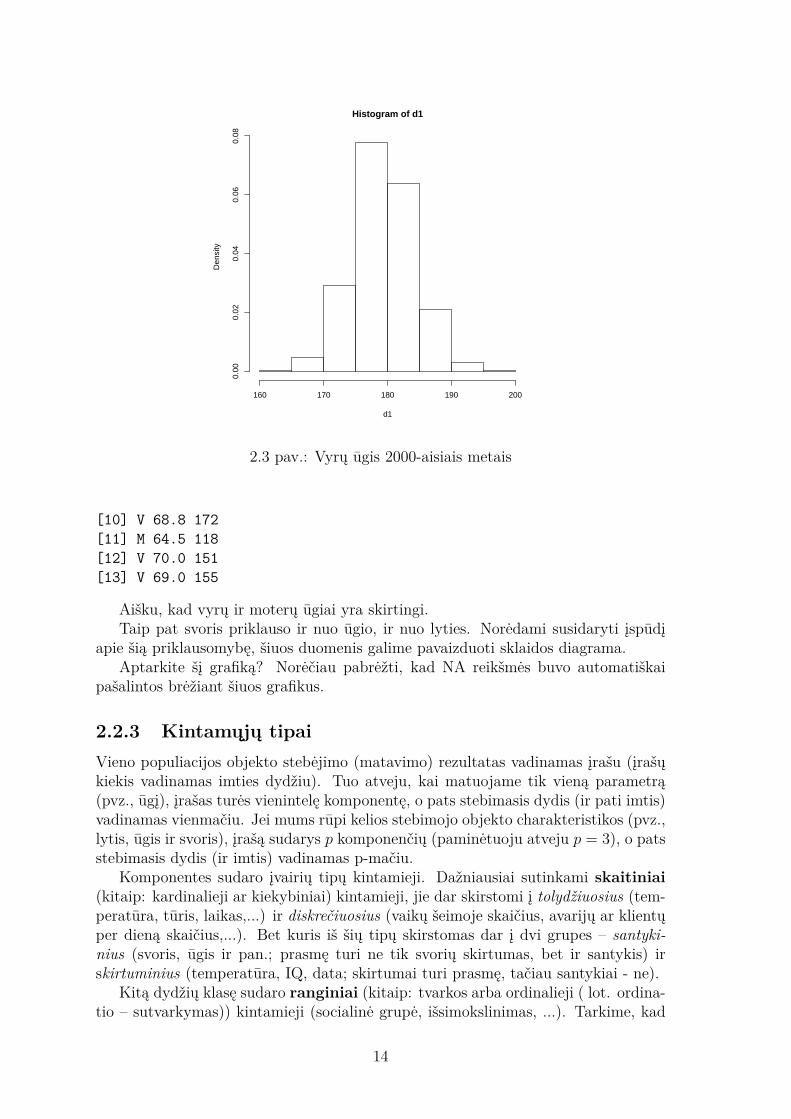
O dabar išbrėžkime histogramą. Ką ji vaizduoja?Histigrama parodo pasiskirstymą pagal ūgį, t.y., kiek kokio ūgio žmonių buvo
išmatuota.Kitas tipinis uždavinys:
Užduotis 2.2 Tarkime turime duomenų rinkinį. Jame "lytis" (kintamasis x1i) įgyjareikšmes M (=Moteris) arba V (=Vyras), ūgis (x2i) užrašytas coliais, svoris (x3i)– svarais, o NA (= Not Available) reiškia, kad dėl kažkokių priežasčių matavimorezultatas nėra žinomas. Šį kartą imtimi vadinsime trejetų rinkinį ((x11, x21, x31), ...,(x40,1, x40,2, x40,3)), o pats rinkinys vadinamas trimačiu. Atkreipsime dėmesį į tai,kad pirmoji komponentė nėra skaičius.
Keli imties pavyzdžiai:
lytis ūgis svoris[1] M 64.5 118[2] V 72.5 NA[3] V 73.3 143[4] V 68.8 172[5] M 65.0 147[6] M 69.0 146[7] M 64.5 138[8] M 66.0 175[9] V 66.3 134
13
Histogram of d1
d1
Den
sity
160 170 180 190 200
0.00
0.02
0.04
0.06
0.08
2.3 pav.: Vyrų ūgis 2000-aisiais metais
[10] V 68.8 172[11] M 64.5 118[12] V 70.0 151[13] V 69.0 155
Aišku, kad vyrų ir moterų ūgiai yra skirtingi.Taip pat svoris priklauso ir nuo ūgio, ir nuo lyties. Norėdami susidaryti įspūdį
apie šią priklausomybę, šiuos duomenis galime pavaizduoti sklaidos diagrama.Aptarkite šį grafiką? Norėčiau pabrėžti, kad NA reikšmės buvo automatiškai
pašalintos brėžiant šiuos grafikus.
2.2.3 Kintamųjų tipaiVieno populiacijos objekto stebėjimo (matavimo) rezultatas vadinamas įrašu (įrašųkiekis vadinamas imties dydžiu). Tuo atveju, kai matuojame tik vieną parametrą(pvz., ūgį), įrašas turės vienintelę komponentę, o pats stebimasis dydis (ir pati imtis)vadinamas vienmačiu. Jei mums rūpi kelios stebimojo objekto charakteristikos (pvz.,lytis, ūgis ir svoris), įrašą sudarys p komponenčių (paminėtuoju atveju p = 3), o patsstebimasis dydis (ir imtis) vadinamas p-mačiu.
Komponentes sudaro įvairių tipų kintamieji. Dažniausiai sutinkami skaitiniai(kitaip: kardinalieji ar kiekybiniai) kintamieji, jie dar skirstomi į tolydžiuosius (tem-peratūra, tūris, laikas,...) ir diskrečiuosius (vaikų šeimoje skaičius, avarijų ar klientųper dieną skaičius,...). Bet kuris iš šių tipų skirstomas dar į dvi grupes – santyki-nius (svoris, ūgis ir pan.; prasmę turi ne tik svorių skirtumas, bet ir santykis) irskirtuminius (temperatūra, IQ, data; skirtumai turi prasmę, tačiau santykiai - ne).
Kitą dydžių klasę sudaro ranginiai (kitaip: tvarkos arba ordinalieji ( lot. ordina-tio – sutvarkymas)) kintamieji (socialinė grupė, išsimokslinimas, ...). Tarkime, kad
14
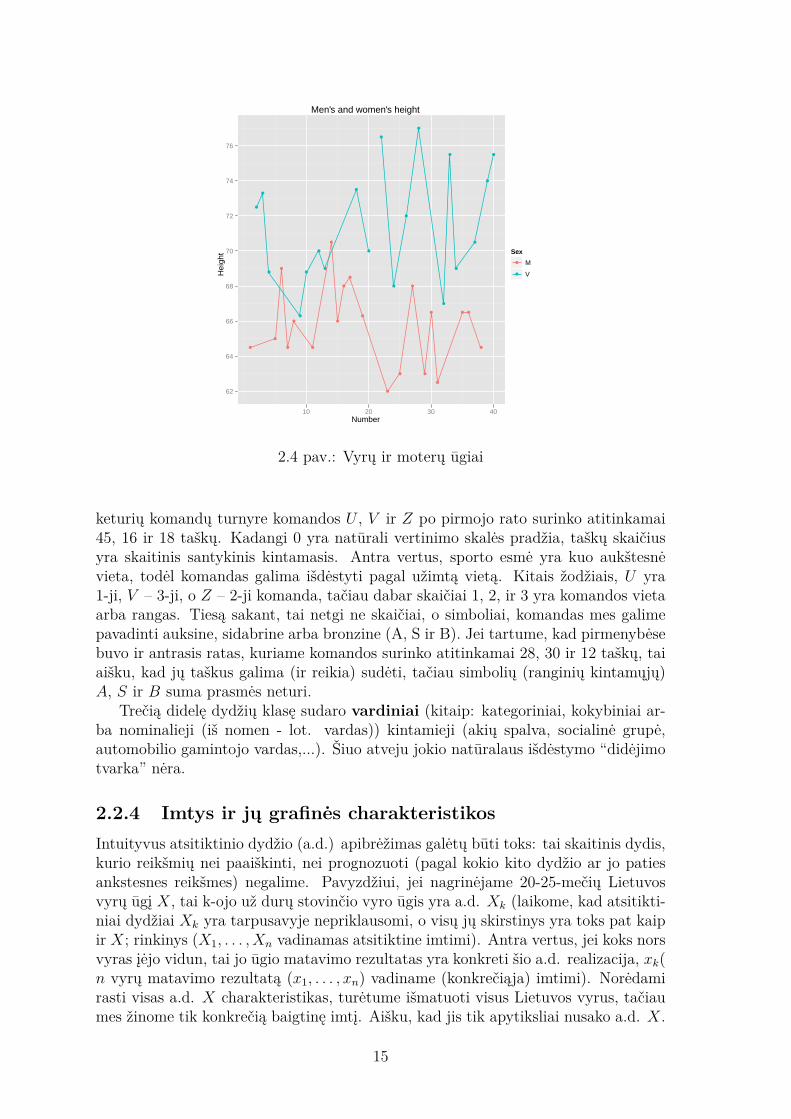
Men's and women's height
Number
Hei
ght
62
64
66
68
70
72
74
76
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
10 20 30 40
Sex
● M
● V
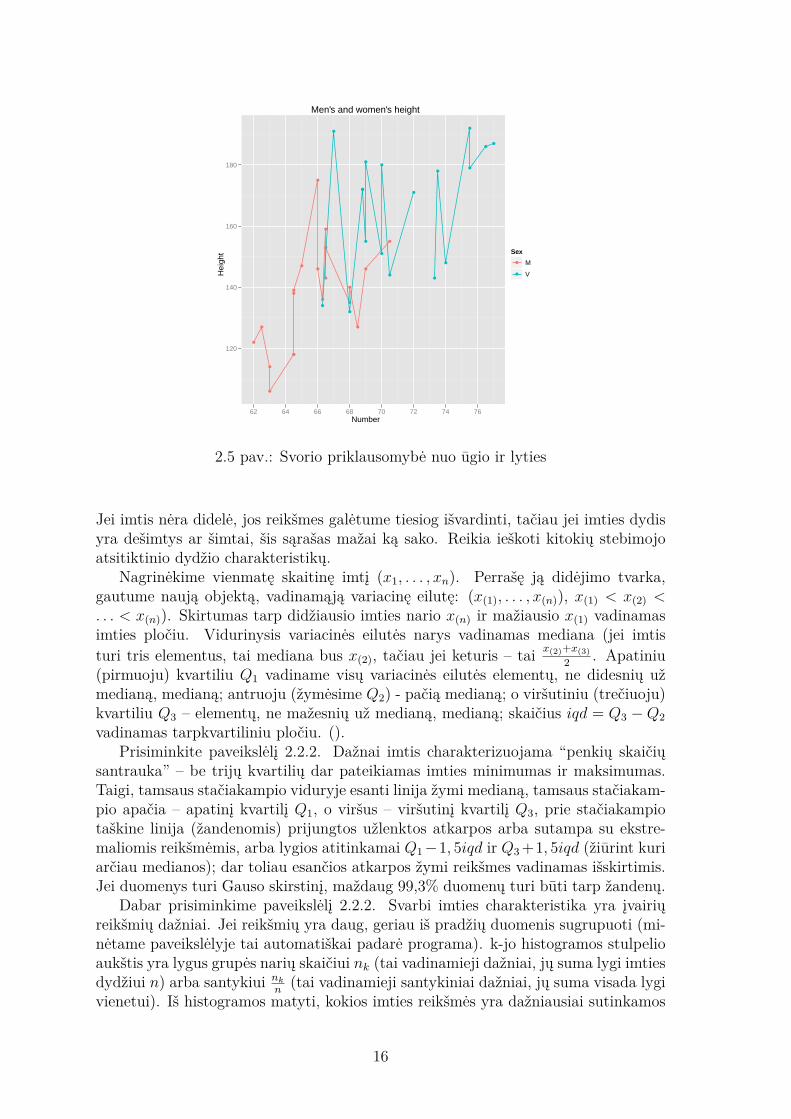
2.4 pav.: Vyrų ir moterų ūgiai
keturių komandų turnyre komandos U , V ir Z po pirmojo rato surinko atitinkamai45, 16 ir 18 taškų. Kadangi 0 yra natūrali vertinimo skalės pradžia, taškų skaičiusyra skaitinis santykinis kintamasis. Antra vertus, sporto esmė yra kuo aukštesnėvieta, todėl komandas galima išdėstyti pagal užimtą vietą. Kitais žodžiais, U yra1-ji, V – 3-ji, o Z – 2-ji komanda, tačiau dabar skaičiai 1, 2, ir 3 yra komandos vietaarba rangas. Tiesą sakant, tai netgi ne skaičiai, o simboliai, komandas mes galimepavadinti auksine, sidabrine arba bronzine (A, S ir B). Jei tartume, kad pirmenybėsebuvo ir antrasis ratas, kuriame komandos surinko atitinkamai 28, 30 ir 12 taškų, taiaišku, kad jų taškus galima (ir reikia) sudėti, tačiau simbolių (ranginių kintamųjų)A, S ir B suma prasmės neturi.
Trečią didelę dydžių klasę sudaro vardiniai (kitaip: kategoriniai, kokybiniai ar-ba nominalieji (iš nomen - lot. vardas)) kintamieji (akių spalva, socialinė grupė,automobilio gamintojo vardas,...). Šiuo atveju jokio natūralaus išdėstymo “didėjimotvarka” nėra.
2.2.4 Imtys ir jų grafinės charakteristikosIntuityvus atsitiktinio dydžio (a.d.) apibrėžimas galėtų būti toks: tai skaitinis dydis,kurio reikšmių nei paaiškinti, nei prognozuoti (pagal kokio kito dydžio ar jo patiesankstesnes reikšmes) negalime. Pavyzdžiui, jei nagrinėjame 20-25-mečių Lietuvosvyrų ūgį X, tai k-ojo už durų stovinčio vyro ūgis yra a.d. Xk (laikome, kad atsitikti-niai dydžiai Xk yra tarpusavyje nepriklausomi, o visų jų skirstinys yra toks pat kaipir X; rinkinys (X1, . . . , Xn vadinamas atsitiktine imtimi). Antra vertus, jei koks norsvyras įėjo vidun, tai jo ūgio matavimo rezultatas yra konkreti šio a.d. realizacija, xk(n vyrų matavimo rezultatą (x1, . . . , xn) vadiname (konkrečiąja) imtimi). Norėdamirasti visas a.d. X charakteristikas, turėtume išmatuoti visus Lietuvos vyrus, tačiaumes žinome tik konkrečią baigtinę imtį. Aišku, kad jis tik apytiksliai nusako a.d. X.
15
Men's and women's height
Number
Hei
ght
120
140
160
180
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
62 64 66 68 70 72 74 76
Sex
● M
● V
2.5 pav.: Svorio priklausomybė nuo ūgio ir lyties
Jei imtis nėra didelė, jos reikšmes galėtume tiesiog išvardinti, tačiau jei imties dydisyra dešimtys ar šimtai, šis sąrašas mažai ką sako. Reikia ieškoti kitokių stebimojoatsitiktinio dydžio charakteristikų.
Nagrinėkime vienmatę skaitinę imtį (x1, . . . , xn). Perrašę ją didėjimo tvarka,gautume naują objektą, vadinamąją variacinę eilutę: (x(1), . . . , x(n)), x(1) < x(2) <. . . < x(n)). Skirtumas tarp didžiausio imties nario x(n) ir mažiausio x(1) vadinamasimties pločiu. Vidurinysis variacinės eilutės narys vadinamas mediana (jei imtisturi tris elementus, tai mediana bus x(2), tačiau jei keturis – tai x(2)+x(3)
2 . Apatiniu(pirmuoju) kvartiliu Q1 vadiname visų variacinės eilutės elementų, ne didesnių užmedianą, medianą; antruoju (žymėsime Q2) - pačią medianą; o viršutiniu (trečiuoju)kvartiliu Q3 – elementų, ne mažesnių už medianą, medianą; skaičius iqd = Q3 −Q2vadinamas tarpkvartiliniu pločiu. ().
Prisiminkite paveikslėlį 2.2.2. Dažnai imtis charakterizuojama “penkių skaičiųsantrauka” – be trijų kvartilių dar pateikiamas imties minimumas ir maksimumas.Taigi, tamsaus stačiakampio viduryje esanti linija žymi medianą, tamsaus stačiakam-pio apačia – apatinį kvartilį Q1, o viršus – viršutinį kvartilį Q3, prie stačiakampiotaškine linija (žandenomis) prijungtos užlenktos atkarpos arba sutampa su ekstre-maliomis reikšmėmis, arba lygios atitinkamai Q1−1, 5iqd ir Q3 +1, 5iqd (žiūrint kuriarčiau medianos); dar toliau esančios atkarpos žymi reikšmes vadinamas išskirtimis.Jei duomenys turi Gauso skirstinį, maždaug 99,3% duomenų turi būti tarp žandenų.
Dabar prisiminkime paveikslėlį 2.2.2. Svarbi imties charakteristika yra įvairiųreikšmių dažniai. Jei reikšmių yra daug, geriau iš pradžių duomenis sugrupuoti (mi-nėtame paveikslėlyje tai automatiškai padarė programa). k-jo histogramos stulpelioaukštis yra lygus grupės narių skaičiui nk (tai vadinamieji dažniai, jų suma lygi imtiesdydžiui n) arba santykiui nk
n(tai vadinamieji santykiniai dažniai, jų suma visada lygi
vienetui). Iš histogramos matyti, kokios imties reikšmės yra dažniausiai sutinkamos
16

(arba - labiausiai tikėtinos), reikšmių ribos, simetriškumas ir pan.Nauji uždaviniai atsiranda, nagrinėjant daugiamates imtis. Dabar labai dažnai
mums rūpi ne tik kiekvienos komponentės individualios reikšmės, bet ir jų ryšiai.Daugiamačių imčių tyrimas paprastai pradedamas nuo jų elementų sklaidos diagra-mos brėžimo (sklaidos diagramos brėžiamos tarp dviejų elementų). Jos gali parodytiar ryšys tarp kintamųjų yra tiesinis, netiesinis ir kartais galima nuspėti netiesiškumoprigimtį. Pabrėžtina, kad sklaidos diagrama vienareikšmiškai nepasako, kad vienąkintamąjį galima prognozuoti kitu.
2.2.5 Imtys ir jų skaitinės charakteristikosNors grafinės charakteristikos yra labai naudingos, tačiau skaitinės yra pagrindinėssprendžiant statistinius uždavinius. Dabar pakalbėsime apie momentus.
Vieną imties “centro” charakteristiką jau žinome – tai mediana. Kita, dar popu-liaresnė imties (x1, . . . , xn) charakteristika, yra jo (empirinis) vidurkis x: tai imtiesreikšmių aritmetinis vidurkis
x = 1n
n∑j=1
xj.
Jei imtis yra pateikta dažnių lentele, t.y., reikšmė x1 imtyje kartojasi n1 kartą, reikš-mė x2 − n2 kartus ir t.t.), vidurkį galima perrašyti kitokiu pavidalu:
x = 1n
N∑j=1
njxj.
čia N yra skirtingų imties reikšmių skaičius. Jei imties histograma yra maždaugsimetrinė, tai mediana ir vidurkis yra beveik vienodi, tačiau priešingu atveju jie galipastebimai skirtis.
Pažymėsime, kad viena (vienintelė!) nenormaliai didelė imties reikšmė (išskirtis)gali pastebimai pakeisti vidurkį, tuo tarpu mediana išskirtims mažiau jautri. Taippat dvi imtys turinčios tą patį vidurkį gali visiškai skirtis (jų išsibarstymas gali būtilabai ne vienodas). Imties reikšmių išsibarstymo matu galėtų būti imties reikšmiųvidutinis nuotolis nuo vidurkio, t.y.
1n
n∑j=1|xj − x|,
tačiau populiaresnis yra imties vidutinis kvadratinis nuokrypis
s2 = 1n
n∑j=1
(xj − x)2.
Pažymėsime, kad dėl tam tikrų priežasčių (kurias sužinosite paskaitų metu) pa-prastai vartojamas kiek “pataisytas” vidutinis kvadratinis nuokrypis: skaičius
s2 = 1n− 1
n∑j=1
(xj − x)2.
17

vadinamas imties (empirine) dispersija. Beje, jei xi matuojami, pvz., centimetrais(cm), tai s2 dimensija bus cm2 . Dydžio s =
√s2 (jis vadinamas imties standarti-
niu nuokrypiu arba tiesiog standartu) dimensija jau bus cm , t.y., lygiai tokia patikaip ir xi, todėl būtent jis, standartas, ir yra populiariausia reikšmių išsibarstymocharakteristika.
Vidurkio ir vidutinio kvadratinio nuokrypio sąvokas galima apibendrinti: skaičius
ak = 1n
n∑j=1
xkj , k ∈ N
vadinamas k-ju (pradiniu) imties momentu, o skaičius
mk = 1n
n∑j=1
(xj − x)k, k ∈ N
k – ju centriniu momentu. Kitaip sakant, vidurkis yra pirmasis momentas, o vidutiniskvadratinis nuokrypis – antrasis centrinis momentas. Iš principo, kiekvienai imčiaigalime apskaičiuoti be galo daug momentų, tačiau minėti du yra svarbiausi: vidurkisyra imties “centro”, o standartas – imties reikšmių išsibarstymo charakteristikos.
Jei iš kiekvieno imties nario atimsime vidurkį, tai naujoji imtis bus vadinamacentruota. Jei centruotos imties kiekvieną narį dar padalinsime iš standarto, tainaujoji imtis bus vadinama (centruota ir) normuota. Histogramos forma nuo šiųtransformacijų nesikeičia, tačiau normuotos imties vidurkis visuomet 0, o standartas– 1.
Jei tiriamoji imtis ((x1, y1), . . . , (xn, yn)) yra dvimatė skaitinė, tai kiekvieną kom-ponentę vėl galima charakterizuoti jos vidurkiu ir standartu. Antra vertus, dabaryra dar viena, komponenčių ryšį nusakanti, skaitinė charakteristika – tai vadina-masis normuotų komponenčių mišrusis momentas arba Pirsono (Pearson) empiriniskoreliacijos koeficientas r:
r = 1n
n∑j=1
(xj − xsx
)(yj − ysy
).
Galima įrodyti, kad visuomet −1 ≤ r ≤ 1. Jei r neigiamas, tai x’sui didėjant, y,apskritai kalbant, mažėja, o jei teigiamas, tai x’sui didėjant y irgi didėja.
Kita svarbi dvimačio skaitinio duomenų masyvo charakteristika yra (y’ko) regre-sijos (x’so atžvilgiu) tiesė: tai “arčiausiai visų sklaidos diagramos taškų esanti” tiesėy = b0 + b1x. Tiksliau kalbant, iš visų galimų tiesių y = β0 + β1x pasirinksime tokią,kuriai jos atitinkamų taškų atstumų nuo sklaidos diagramos taškų kvadratų sumayra mažiausia, t.y. ieškosime funkcijos
RSS = RSS(β0, β1) =n∑j=1
(yj − (β0 + β1xj))2 =n∑j=1
ε2j
minimumo pagal β0 ir β1.
2.2.6 Užduotys1. R’e yra duomenų rinkinys Orange. Kas taip per duomenys? Įkelkite juos į
darbalaukį.
18

2. Išbrėžkite stulpelių grafikus.
3. Apskaičiuokite pagrindines skaitines charakteristikas.
19
2.3 Trečios paskaitos konspektas
2.3.1 Duomenų įrašymas ir programavimo pavyzdžiaiDuomenų rinkimas ir įrašymas dažnai užima daugiau laiko negu jų statistinė analizė.Tačiau tai būtinas statistinio tyrimo etapas. Kiekvienas R duomenų objektas visuo-met turi du vidinius požymius (tipą (mode) ir ilgį (length)) ir dar gali turėti vienąar kelis papildomus požymius (attributes) (pvz., klasę (class) ar matavimų skaičių(dimension)). Žemiau esančioje lentelėje pateikta šių faktų santrauka.
Objektas Galimi tipai Ar galima nau-doti skirtingustipus vienameobjekte?
Klasė
Vektorius (vec-tor)
logical, integer, doub-le, complex, character,raw, list
ne Tokia kaip mo-de(x)
Vardinis kin-tamasis =faktorius (fac-tor)
Skaitinis ar simbolinis ne factor
Ranginis kinta-masis (orderedfactor)
Skaitinis ar simbolinis ne factor ordered
Masyvas (array) Skaitinis, simbolinis,kompleksinis ar loginis
ne NULL
Matrica (mat-rix)
Skaitinis, simbolinis,kompleksinis ar loginis
ne matrix
Duomenų siste-ma (data frame)
Skaitinis, simbolinis,kompleksinis ar loginis
taip data.frame
Laiko eilutė(ts=time series)
Skaitinis, simbolinis,kompleksinis ar loginis
taip ts
Sąrašas (list) Skaitinis, simbolinis,kompleksinis, loginis,funkcija, reiškinys arformulė
taip list
Duomenų įrašymas rankomis
Pradėsime nuo atvejo, kai duomenys įrašomi rankomis į R programą.
Skaitiniai vektoriai ir matricos Įrašykime vektorių į R ranka. Pirmasis būdas:
sk1 <- c(1, 2, 3, 3, 3, 3, 4, 4, 4, 5, 6, 6)sk2 <- c(1, 2, rep(3, 4), rep(4,3), 5, rep(6,2))length(sk1); length(sk2)length(sk1) == length(sk2)
Kai duomenų yra daug geriau yra daryti taip:
20

sk4 <- matrix(1) # Įvedėme skaičių 1 – tai bus matricos# elementas su indeksais (1,1)sk4 <- edit(sk4) # Atsidarys R Data Editor langas;# kai lentelę užpildysite, langą uždarykitesk4 <- as.vector(sk4)
Galima patikrinti kiek objektų turime darbinėje aplinkoje:
ls() # Visi objektairm(list=ls(all=TRUE)) # Pašalina visus objektusrm(skve1a,skve1b,skve2,skve3) # Pašalina tik konkrečius objektus
Vektorių sukūrimas:
sk5 <- 3:7sk6 <- seq(0.3,0.7,0.1)sk7<- (3:7)/10
Matricos įrašymas. Žemiau yra matrica Pastas, kurioje pateikti duomenys apiedvidešimties siuntinių svorį, atstumą, kuriuo juos reikėjo pristatyti, ir realią prista-tymo kainą.
Šią matricą galimą įrašyti kaip ilgą vektorių, o po to suteikti jam matricos struk-tūrą ir dar, gal būt, stulpelių vardus.
Pastas <- c(2, 1.9, 1.5, 4.4, 1.7, 5, 9.2, 3.9, 8, 3.3, 8, 1, 11,2.6, 6, 14.5, 1.1, 15.5, 14, 12.1, 0.3, 4.5, 0.7, 0.8, 1.1, 2.4, 6.6,3.2, 3.5, 4.1, 4.4, 0.6, 5.1, 5.9, 6.2, 6.5, 2.7, 7, 7.5, 8.1, 160,53, 80, 280, 90, 209, 160, 145, 250, 95, 202, 100, 240, 47, 115, 240,160, 1260, 190, 160)Pastas <- matrix(Pastas,ncol=3)colnames(Pastas) <- c("kaina","svoris","atstumas")Pastas.df <- as.data.frame(Pastas) #Duomenų sistemos struktūra
Palyginkime matricos ir duomenų sistemos požymius:
attributes(Pastas)attributes(Pastas.df)
Dar kartą pažymėsime, kad ir matricą lengviau įrašyti, naudojantis edit komanda.Matricos Pastas 18-oje eilutėje yra klaida – atstumas turi būti 260, o ne 1260. Ją
ištaisome:
Pastas[18,3] <- 260Pastas[18,”atstumas”] <- 260
Sukurkime diagonalinę matricą:
m1 <- diag(rep(1,3))
Jau mokame matricas sudauginti bei transponuoti. Norint suskaičiuoti jos at-virkštinę, turime naudotis komanda:
m2 <- matrix(1:9,3,3)solve(m2)solve(m2^2)
21

Kompleksiniai ir loginiai vektoriai. Kompleksinius vektorius rankomis įrašytitenka retai. Dažniausiai tai būna kai kurių funkcijų reikšmės.
roots <- polyroot(c(1,2,3))mode(roots)
Čia vektorius c(1, 2, 3) yra polinomo 1+2·x+3·x2 koeficientų vektorius; funkcijospolyroot reikšmė yra šio polinomo (dviejų kompleksinių jungtinių) šaknų vektorius.
Loginiai vektoriai irgi paprastai atsiranda kaip kai kurių (palyginimo) operacijųrezultatai.
x <- 1:5x > 1xT <- x>1!xTx <= 4(x > 1)|(x <= 4)(x > 1) & (x <= 4)x[(x>1)&(x<=4)]
Simboliniai vektoriai ir matricos. Dažniausiai simboliniai vektoriai reikalinginorint priskirti vardus stulpeliams arba eilutėms; išskirti kintamuosius pagal grupes,šalis ar pan.
simbve1 <- "kaina"simbve1 <- matrix(simbve1)simbve1 <- edit(simbve1)simbve1
Simbolinės matricos (jų visi elementai turi būti simboliniai!) įrašinėjamos retai.Jei to prireiktų – naudokite edit funkciją. R objektų tipai (mode) turi tam tikrąhierarchiją, kurią, ne visai tiksliai kalbant, galima užrašyti taip: logical < integer <double < complex < character. Prievartinis tipo keitimas yra atliekamas iš žemesnėshierarchijos tipo į aukštesnį, bet ne atvirkščiai. Priskiriant reikšmes, pirmiausiaipatikrinamas abiejų pusių tipas, o paskui priskiriamasis objektas įgyja aukštesnįtipą.
v <- vector(mode="numeric",length=4)v[3:4] <- 3:4mode(v)storage.mode(v)v[2] <- "foo"vstorage.mode(v)
Duomenų sistemos. Matricoje Pastas iš tikrųjų yra ir ketvirtas stulpelis, būtentdidumas: pašto skyriuje siuntiniai dar skirstomi į didelius ir mažus. Štai tas stulpelis:
didumas <- c(rep("mazas",10),rep("didelis",10))
22

Skaitinę matricą Pastas ir simbolinę matricą(-stulpelį) didumas galima apjungti įnaują matricą pastas:
pastas <- cbind(Pastas,didumas)
Deja, visi matricos elementai turi būti vieno tipo, todėl cbind automatiškai paverčiavisus matricos pastas elementus (aukštesnės hierarchijos) simboliniais kintamaisiais(atsispausdinkite matricą pastas).
Vardiniai kintamieji (faktoriai). Didumas nėra paprastas vardų rinkinys, jį su-daro vardinio kintamojo didumas reikšmės mazas ir didelis. Norėdami tai pabrėžti,jam suteiksime specialią vadinamojo faktoriaus struktūrą. Išoriškai skirtumas nėradidelis – naujo kintamojo reikšmės dabar rašomos be kabučių, tačiau šįkart atsiradodar vienas požymis, būtent Levels:
didumasf <- factor(didumas)didumasfattributes(didumasf)
Aišku, kad įrašų lentelėse daug kartų rašyti žodžius mazas ir didelis nepatogu,juos galima užkoduoti, pvz., simboliais 0 ir 1.
Pažymėsime, kad prijungdama prie skaitinio objekto (mūsų atveju, skaitinės mat-ricos Pastas) simbolinį vektorių didumas, funkcija data.frame automatiškai paverčiajį faktoriumi:
pastas <- data.frame(Pastas,didumas)attach(pastas)class(didumas)tapply(kaina,didumas,mean)
Ranginiai kintamieji. Didelis vistik "didesnis" už mažas – kitais žodžiais, kin-tamąjį didumasf galime interpretuoti kaip ranginį. R kalboje tai galima užrašytitaip
didumaso <- ordered(didumas,levels=c("mazas","didelis"))didumasosummary(didumaso)attributes(didumaso)
Sąrašai. Sąrašas (list) yra pagrindinis R objektas, jis naudojamas, kai reikia ap-jungti skirtingos prigimties objektus į vieną naują objektą. Pažymėsime, kad dau-gumos R funkcijų reikšmė yra būtent sąrašas. Štai būdingas pavyzdys. Aišku, kadkaina (žr. matricą Pastas) priklauso nuo kintamojo atstumas. Kadangi, didėjantatstumui, kaina turėtų didėti, galima tikėtis tokios (regresinės) priklausomybės:
kaina = a + b \cdot atstumas + paklaida .
Nežinomus (regresijos) koeficientus a ir b, remdamasi matricos Pastas duomeni-mis, skaičiuoja R funkcija lm:
23

attach(pastas)kaina.lin <- lm(kaina~atstumas)mode(kaina.lin)names(kaina.lin)kaina.lin\$coeff
Sąrašai natūraliai atsiranda, sudarant kai kurias anketas:
anketa <- list(pavarde="Jonaitis Jonas", issilavinimas="magistras",vaikai=2, vaiku.amzius=c(7,5))
Matome, kad sąrašo komponentės gali būti ir skirtingos prigimties ir skirtingo ilgio.Funkcija unlist paverčia sąrašą vektoriumi.
Duomenų importas ir eksportas
Dažnai tenka apdoroti duomenis, kurie pateikti ne R formatu (pvz., Excel, SAS,SPSS ar dar kitokiu formatu). R turi paketą foreign, kuris gali daugumą šių duo-menų importuoti (perskaityti patiems). Lengviausia importuoti tekstinius failus,kuriuos galima nuskaityti su base paketo funkcijomis scan arba read.table. Štai kelipavyzdžiai. Tarkime, kad tekstiniame faile import1.txt yra įrašytas vektorius 1234.Perkelkite šį failą į R darbinę direktoriją (priminsime: ją galima sužinoti su getwd())ir komandiniame lange surinkite
x <- scan(file="Data/import1.txt")x
Skaitinius vektorius galima importuoti ir taip: surinkite
x <- scan()
ir, spragtelėję Enter, atidarykite import.txt, pasižymėkite jį visą ir su Copy + Pasteperkelkite į R konsolę. Du kartus spragtelėję Enter, turėsite R vektorių x.
Jei šio vektoriaus koordinatės būtų viena nuo kitos atskirtos kableliu, tai rinktume
x <- scan(file="Data/import1.txt",sep=”,”)
Tarkime, failas import2.txt yra matricos pavidalo (pirmoje eilutėje yra kintamųjųvardai). Jį importuoti galime taip:
x <- read.table(file="Data/import2.txt",header=T)xmode(x)class(x)
Pažymėsime, kad failas import2.txt yra mano puslapyje pateikto duomenų rin-kinio bwages.dat pirmos keturios eilutės. Norėdami importuoti visą šį failą (jamestulpeliai vardų neturi, todėl juos sukursime), elgsimės taip:
bwages <- read.table(file="Data/bwages.dat",header=F, col.names=c("wage","lnwage","educ","exper","lnexper","lneduc","male"))
Jame yra 1472 Belgijos šeimų stebėjimų rezultatai. Kintamieji čia tokie:
24

• wage – neapmokestintos šeimos nario valandinės pajamos (Belgijos frankais)
• lnwage = log(wage)
• educ – išsilavinimo lygis (1 – žemas,…, 5 - aukštas)
• exper – profesinis patyrimas (metais)
• lnexper = log(1+exper)
• lneduc = log(educ)
• male – 1 (jei vyras) ir 0 (jei moteris)
R duomenų failus galima eksportuoti į daugumą populiarių formatų. Pvz., pir-mąsias dešimt R duomenų rinkinio bwages eilutes galima eksportuoti į darbinę di-rektoriją ASCII formatu (sukurtasis failas vadinsis bw.txt):
write.table(bwages[1:10,],file="Data/bw.txt",row.names=F,col.names=F)write.table(bwages[1:10,],file="Data/bw.txt")
(šiuo atveju eilutės bus sunumeruotos, o stulpeliai turės vardus).O štai dar vienas paprastas importo būdas: pasižymėkite (apšvieskite) reikalingą
lentelę *.txt arba *.xls faile ir paspauskite Ctrl+C; po to R komandiniame langesurinkite vieną iš komandų
read.delim2("clipboard") (arba read.delim("clipboard"))read.delim2("clipboard",header=FALSE)
Panašiai galima ir eksportuoti: jei x yra duomenų sistema, atspausdinkite
write.table(x,"clipboard",sep="\t")
Jei turime duomenis *.csv formatu juos galime importuoti naudojantis koman-domis
read.csv()read.csv2()
2.3.2 Užduotys1. Iš paketo MASS duomenų rinkinio Cars93 išrinkite tik tuos duomenis, kurie
susiję su small ir sporty automobiliais. Kiekvienoje iš šių grupių apskaičiuokiteparametro MPG.highway vidurkį bei standartinį nuokrypį ir išbrėžkite histog-ramas.
2. MASS paketo duomenų rinkinyje Cars93 pašalinkite small ir sporty automobi-lių įrašus. Gautojoje duomenų sistemoje pašalinkite automobilius, kurių svorisweight didesnis už 3000 (svarų) ir cilindrų Cylinders skaičius didesnis už 5.
3. Sugeneruokime 2000 Cauchy atsitiktinių skaičių (internete paieškokite infor-macijos apie Cauchy skirstinį) ir paimkime jų sveikąsias dalis:
25

RC <- rcauchy(2000)rc <- floor(RC)
Ar yra šiame vektoriuje reikšmė 347? 13? O praleistosios reikšmės simbolisNA? Š įuždavinį galima spręsti įvairiai.
1) sort(rc)2) table(rc)3) barplot(table(rc))4) which(rc==347)5) length(which(rc==347))6) 347 %in% rc7) rc[rc==347]8) length(rc[rc==347])
26

2.4 Ketvirtos paskaitos konspektas
2.4.1 (Pseudo)atsitiktinių skaičių generavimasRealūs stebėjimų rezultatai retai elgiasi "taip kaip reikia" (pvz., dauguma statistikosmodelių reikalauja, kad stebėjimai turėtų Gauso skirstinį, o tuo tarpu matavimorezultatų histograma nelabai panaši į varpo pavidalo kreivę). Norint geriau supras-ti statistikos metodus, dažnai tikslinga nagrinėti "dirbtinius" duomenų objektus. Rmoka generuoti "teisingus" (t.y., turinčius reikalingą skirstinį) (beveik) atsitiktiniusskaičius, kurių histogramos, p reikšmės, modelių paklaidos ir t.t. jau elgiasi "tinka-mai".
Pradėkime nuo atsitiktinių skaičių, turinčių Puasono skirstinį, generavimo.
?rpoisrpois(20,3)rpois(20,3)sort(rpois(20,3))
Panagrinėkime dar vieną pavyzdį. Tarkime, kad 10 kartų šauname į taikinį,o pataikymo tikimybė yra 0, 30. Aišku, kad sėkmingų šūvių skaičius yra atsitik-tinis dydis, turintis binominį skirstinį su parametrais 10 ir 0, 3 (jo vidurkis lygusnp = 10 · 0, 3 = 3). Imituoti tokius eksperimentus galime su funkcija rbinom (josžemiau esantis variantas pateikia sėkmių skaičių kiekviename iš 200 įsivaizduojamųeksperimentų):
#I variantasrb <- rbinom(200,10,0.3)rbmean(rb)table(rb)rbbarplot(table(rb))
#II variantasplot(table(rb), type = "h", col = "red", lwd=10, main="rbinom(200,10,0.3)")
Tikimybių ir santykinių dažnių artumą galime pavaizduoti lentele
round(rbind(table(rb)/200,dbinom(0:8,10,0.3)),4)
arba grafiškai
plot(0:10,dbinom(0:10,10,0.3))lines(as.integer(names(table(rb))),table(rb)/200,type="h")
Jei diskrečiųjų atsitiktinių dydžių dažnius brėžiame su barplot komanda (arbaplot su opcija "h"), tai tolydžiuoju atveju tam naudojame empirinį tankio atitikmenį– histogramą. Palyginkime dvi imtis, kurių viena yra tolygioji su parametrais −1 ir1, o kita - normalioji (Gauso) su parametrais 0 ir
√3/3 (abiejų imčių vidurkiai ir
dispersijos sutampa, ar ne?):
27

par(mfrow=c(1,2))hist(runif(10,-1,1))hist(rnorm(10,0,sqrt(3)/3))
Matome, kad tuomet, kai imtys nedidelės, netgi skirtingų a.d. histogramos gali būtilabai panašios. O dabar pabandykitehist(runif(1000,-1,1),freq=F)x <- seq(-1,1,length=100)lines(x,dunif(x,-1,1),lty=2)hist(rnorm(1000,0,sqrt(3)/3),freq=F)xx <- seq(-3,3,length=100)lines(xx,dnorm(xx,0,sqrt(3)/3),lty=2)
Parašykime programą skaičiui π skaičiuoti. Tokias programas geriau rašyti nekomandiniame lange. Elgsimės taip. Komandiniame lange pradėkime rašyti (bear-gumentę) funkciją py:py <- function(){}
Toliau ją rašysime kokio nors redaktoriaus lange (standartinis Windows’inio R re-daktorius yra Notepad’as): surinkitepy <- edit(py)
Notepad’o lange perrašysime# funkcija py (Monte Carlo metodasfunction(){opar <- par(mfrow=c(1,2))on.exit(par(opar))xx <- c(-1,1,1,-1,-1)yy <- c(-1,-1,1,1,-1)plot(xx,yy,type="l")x <- cos(seq(0,2*pi,length=100))y <- sin(seq(0,2*pi,length=100))polygon(x,y,col=3)points(runif(500,-1,1),runif(500,-1,1),pch="*")xxx <- runif(100000,-1,1)yyy <- runif(100000,-1,1)s <- numeric(50)for(i in 1:50) {s[i] <-4*sum(ifelse(xxx[1:(2000*i)]^2+yyy[1:(2000*i)]^2<=1,1,0))/(2000*i)cat("ciklo zingsnis=",i,"\n")}plot(1:50,s,type="l")lines(1:50,rep(pi,50))s[50]}
Uždarykite Notepad’o langą (į klausimą Do you want to save the changes? atsakykiteYes) ir surinkępy()
po kiek laiko pamatysite komputavimo rezultatą.
28

2.4.2 Apie R funkcijas ir source komandąYra dar viena galimybė, kuri sudėtingesnėms funkcijoms dažnai būna patogi. Darbi-niame kataloge atidarykime naują tekstinį failą seka.txt (arba, dar geriau, seka.R).Jame parašykite dvi eilutes
x <- 1:10print(x) # Ne x , bet būtent print(x)!
ir jo neuždarę (bet išsaugoję su File|Save) R konsolės meniu eilutėje pasirinkiteFile|Source R code... ir, nuvairavę į darbinį katalogą, spragtelėkite ant seka.R:
getwd()setwd("...")source("Data/seka.txt")
Jei source eilutę pakeistumėte į
source("Data/seka.txt",echo=T)
2.4.3 Programavimo pavyzdžiaiIšsiaiškinkime funkcijas
apply(X,MARGIN, FUN,...)lapply(X,FUN,...)sapply(X,FUN,...,simplify=TRUE,USE.NAMES=TRUE)tapply(X,INDEX,FUN=NULL,...,simplify=TRUE)
I pavyzdys
set.seed(1)a1 <- rpois(10,11)a2 <- rpois(10,12)a3 <- rpois(10,13)a4 <- rpois(10,14)am <- cbind(a1,a2,a3,a4)amapply(am,1,mean)rowMeans(am)apply(am,2,mean)lapply(am,mean)adf <- data.frame(a1,a2,a3,a4)lapply(adf,mean)sapply(adf,mean)rbind(a1,a2)tapply(a1,a2,mean)m.am <- apply(am,2,mean)m.am<13am[,m.am<13]m.adf <- lapply(adf, mean)adf[m.adf<13]
29

II pavyzdys
Sudarysime sąrašą aList, kurio 1-sis elementas aList[[1]] nurodys matricos am 1-osioseilutės narių lygių 11-kai numerius, 2- asis elementas aList[[2]] nurodys matricos am2-osios eilutės narių lygių 11-kai numerius ir t.t. (aišku, kad aList turi būti sąrašas,kadangi 11-tukų skaičius kiekvienoje eilutėje gali skirtis).
aList <- apply(am, 1, function(x) which(x == 11))aList[1:3]for(i in 1:10) assign(paste("A", i, sep=""), aList[[i]])A3
III pavyzdys
Trūkstamų reikšmių (NA) pakeitimas:
dd <- data.frame(a=c(1,2,NA,4),b=c(NA,2,3,4))dddd2 <- apply(dd,2,function(x) replace(x, is.na(x), 0))dd2class(dd2)dd3 <- data.frame(apply(dd,2,function(x) replace(x, is.na(x), 0)))class(dd3)dd4 <- lapply(dd,function(x) replace(x, is.na(x), 0))dd5 <- data.frame(lapply(dd,function(x) replace(x, is.na(x), 0)))
IV pavyzdys
Vektoriaus x ilgis 81000, jis sudarytas iš 0 ir 1. Iš tikrųjų vektorių x sudaro 9000grupių po 9 elementus, todėl bus vaizdžiau, jei jį užrašysime matricos xx pavidalu(atsitiktinį vektorių x sugeneruosime su ?sample funkcija)
x <- sample(0:1,9000,replace=TRUE,prob=c(1,9))xx <- matrix(x,ncol=9)xx[1:3,]
Jei grupėje (eilutėje) yra bent vienas nulis, tai mūsų tikslas yra pakeisti visusnarius į dešinę nuo jo nuliais. Tai galima atlikti bent kelias būdais, tačiau pradėtivertėtų su vienu ilgio 9 vektoriumi. Pirmoji procedūra galėtų būti tokia:
FillWith <- function(vec,SearchForOne=0,ReplaceNextValues=0){print(vec)pp <- which(vec==SearchForOne)print(pp)if (length(pp)>0) vec[min(pp):length(vec)] <- ReplaceNextValuesvec}FillWith(sample(0:1,9,replace=TRUE,prob=c(1,9)))FillWith(sample(0:1,9,replace=TRUE,prob=c(1,9)))
30

apply(xx[1:3,],1,FillWith)as.vector(apply(xx,1,FillWith))for(i in 2:9) xx[,i] <- xx[,i] & xx[,i-1]xx[1:3,]
Čia pateikėme gražų R funkcijos pavyzdį. Pirmasis jos argumentas vec yra skai-tinis vektorius (ateityje tai bus bet kuri matricos xx eilutė). Argumentas Search-ForOne gali būti bet koks, tačiau jei jo vėliau nenurodysime, ieškosime skaičiaus 0.Panašiai yra ir su argumentu ReplaceNextValues – narius dešiniau pirmojo 0 galimepakeisti bet kokiu nurodytu skaičiumi, tačiau jei nieko nerašysime, funkcija FillWi-th pakeis jį skaičiumi 0. Funkcija which ieško, kurioje vietoje yra 0 (pp yra arbanenulinio ilgio vektorius, nurodantis 0 vietas, arba, jei 0 nėra, nulinio ilgio "tuščias"vektorius; jei pp ilgis ne nulis, visi vec elementai į dešinę nuo skaičiaus min(pp) buspakeisti nurodytu skaičiumi).
V pavyzdys
Panagrinėkime funkciją mappply:
bwages <- read.table("Data/bwages.dat", h=F, col.names=c("wage","lnwage","educ","exper","lnexper","lneduc","male"))attach(bwages)wage.e <- split(wage,educ)sapply(wage.e,mean)sapply(split(wage,male),mean)wage.e0 <- split(wage[male==0],educ[male==0])wage.e1 <- split(wage[male==1],educ[male==1])wage.St <- mapply(t.test,wage.e0,wage.e1)wage.St[3,]
Taigi kokia bebūtų išsilavinimo grupė, atlyginimų vidurkiai neabejotinai skiriasi.
2.4.4 Užduotys1. Duomenų sistemoje ship yra pateikti kelių metų duomenys:
Year Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec1967 42523 46029 47485 46692 46479 48513 42316 45717 48208 47761 47807 477721968 46020 49516 50905 50226 50678 53124 47252 47522 52612 53800 52019 497051969 48864 53281 54668 53740 53346 56421 49603 52326 56724 57257 54335 520951970 49714 53919 54750 53190 53791 56790 49703 51976 55427 53458 50711 508741971 49931 55236 57168 56257 56568 60148 51856 54585 58468 58182 57365 552411972 54963 59775 62049 61767 61772 64867 56032 61044 66672 66557 65831 628691973 63112 69557 72101 71172 71644 75431 66602 70112 74499 76404 75505 706391974 71248 78072 81391 80823 82391 86527 77487 83347 88949 89892 85144 75406
Apskaičiuokite kiekvienų metų vidurkį ir dispersiją.
2. Inventorizuojant sandėlį, buvo aprašytas kiekvienos dėžės turinys:
31

g <- sample(letters,100,replace=TRUE) # g=gaminio i-ojoje dėžėje vardask <- rpois(100,20) # k=gaminių kiekis i-ojoje dėžėjegk <- data.frame(g,k)
Apskaičiuokite: a) kelios dėžės su gaminiais a, b ir t.t. yra sandėlyje, ir b) kelia, b ir t.t. gaminiai yra sandėlyje.
3. Ilgo vektoriaus
x <- rnorm(1000)
duomenis sugrupuokite po 10, kiekvienoje grupėje apskaičiuokite vidurkį, o poto – šio naujo vidurkių vektoriaus standartą.
32

2.5 Penktos paskaitos konspektas
2.5.1 Vienmačiai duomenys: aprašomoji statistika ir duo-menų pirminė analizė
Ne kartą matėme, kad norint susidaryti įspūdį apie duomenis, juos būtina aprašytitrumpais, vaizdžiais ir suprantamais terminais. Tuo užsiima aprašomoji statistika,kuri šiam reikalui naudoja grafines priemones (stulpelines diagramas, stačiakampesdiagramas, kvantilių grafikus, histogramas, tankio grafikus) arba nagrinėja skaitinesimčių charakteristikas (modą, kvantilius, medianą, empirinius momentus). Kitasstatistinės analizės žingsnis būtų išvadų apie imtį darymas (populiacijos parametrųįverčiai, jų pasikliovimo intervalai, hipotezių tikrinimas). Tuo užsiima sprendžiamo-ji statistika, tačiau prieš taikant jos metodus būtina atlikti duomenų priešanalizę(exploratory data analysis, eda), kuri turi atsakyti į kelis pagrindinius klausimus:
• Ar (skaitiniai) duomenys yra (beveik) normalūs?
• Gal duomenyse yra išskirčių ar klaidų?
• Jei duomenys buvo surinkti vienodais laiko intervalais, ar jie nėra koreliuoti?
Aprašomoji statistika ir priešanalizė yra glaudžiai susiję procesai, todėl juos nagri-nėsime kartu.
Vardiniai kintamieji
Grįžkime prie duomenų rinkinio bwages.dat. Priminsime, kad tiriamojo žmogaus iš-silavinimas yra (skaičiais užkoduotas) vardinis (tiksliau, ranginis) kintamasis educ.Nors įrašų sistema pakankamai aiški (pirmiausiai įrašyti žemiausio išsilavinimo asme-nys, paskui – aukštesnio išsilavinimo ir t.t.), tačiau atsakyti į paprasčiausią klausimą– kiek asmenų yra kiekvienoje grupėje – be komputerio būtų nelengva.
• Tai galime sudėti į lentelę.
• Gautąją lentelę galime pavaizduoti grafiškai.
• Taip pat galime palyginti vyrų ir moterų išsilavinimą. Atrodo, kad mote-rų išsilavinimas aukštesnis, tačiau “tikslų” (skaitinį) atsakymą pateiksime tiksprendžiamosios statistikos skyriuje.
#Nuskaitomi duomenysbwages <- read.table("Data/bwages.dat", h=F, col.names=c("wage","lnwage","educ","exper","lnexper","lneduc","male"))attach(bwages)#Kintamasis zymintis issilavinimaeduc#Duomenys lentelejetable(educ)#Stulpeline diagramabarplot(educ) #Blogaipar(mfrow=c(1,2))
33

barplot(table(educ))barplot(100*table(educ)/length(educ))box()#Vytu ir moteru issilavinimo palyginimasbarplot(table(educ[male==1]))title(main="Vyrai")barplot(table(educ[male==0]))title(main="Moterys")#Mediana dalinai parodo vyru ir moteru issilavinimo skirtuma.median(educ[male==1])median(educ[male==0])
Vietoje stulpelinių diagramų (barplot) kartais tikslinga brėžti taškines diagra-mas (su dotchart). Yra psichologų surinkti duomenys apie tai, kaip įvairių profesijųžmonės vertina savo gyvenimą. Funkcijos dotchart ir barplot kintamuosius brėžia tatvarka, kuria jie pateikiami, bet tai ne visada yra informatyvu, geriau kintamojo molreikšmes išdėstyti didėjimo tvarka. Taigi mažiausiai gyvenimu patenkinti yra (dauguždirbantys!) dantistai, o (beveik) labiausiai – universitetų dėstytojai.
#Taskiniu diagramu brezimasprof <- c(’Accountant’, ’Administrative assistant’, ’Garment worker’,’Cook’, ’Dentist’, ’General practictioner’, ’Graduate student’,’High level manager’, ’Low level manager’, ’Mechanical engineer’,’Mechanic’, ’Minister/priest/rabbi’, ’Nurse’, ’Professor’,’Sales clerk’, ’Server’, ’Taxi driver’)mol <- c(34, 29, 27, 36, 20, 40, 35, 32, 30, 31, 30, 32, 37, 37, 27,28, 36) # mol = Meaning Of Life = Gyvenimo prasmėpar(mfrow=c(1,2))# Brėžiame kairįjį grafiką:dotchart(mol,labels=prof,main=’Dot chart’,xlab=’Meaning of life score’)# Brėžiame dešinįjį grafiką:names(mol) <- profdotchart(sort(mol),main="Dot chart",xlab="Meaning of life score")
Skaitiniai kintamieji
Histogramos Skaitinių kintamųjų atveju vietoje funkcijos barplot naudosime funk-ciją hist. Ištirkime kintamojo wage elgesį. Dauguma klasikinių statistikos kriterijųreikalauja, kad tiriamasis skaitinis kintamasis būtų normalus (arba "beveik norma-lus"). Matome, kad wage logaritmo tankis yra labiau simetriškas, taigi kintamasislog(wage) yra "labiau normalus". Apskritai, jei kintamasis y yra teigiamas, o skirsti-nys nėra simetriškas, tai dažnai Box – Cox’o transformacija "pagerina normalumą".Šis metodas siūlo vietoje y nagrinėti naują kintamąjį tλ(y):
tλ(y) ={
yλ−1λ
jei λ¬0log(y) jei λ = 0
Parametrą λ siūloma rinktis iš intervalo (−2, 2).Prisiminkime domenų rinkinį Davis. Parašysime funkciją, kuri išbrėš dvi – moterų
ir vyrų ūgio - histogramas. Ūgis paprastai yra "pavyzdingai" normalus, todėl moterų
34
histograma kelia nusistebėjimą – ten arba yra įrašymo klaida arba tyrimuose dalyvavopatalogiškai mažo ūgio moteris. Pasirodo vienoje eilutėje ūgis sukeistas vietomissu svoriu. Ištaisykime šią klaidą. Histogramos ir empirinio tankio grafikai leidžiasusidaryti teisingą skirstinio formos vaizdą.
#Duomenys ’bwages’par(mfrow=c(1,2))hist(wage)hist(log(wage))
#Duomenys ’Davis’library(car)data(Davis)Davis[1:4,]attach(Davis)
#Funkcija: Vyru ir moteru ugio histogramosdvi.hist <- function(){opar<-par(mfrow=c(1,2))on.exit(par(opar))tapply(height,sex,hist)invisible()}dvi.hist()
#######Klaidos radimas ir taisymas#Yra viena išskirtissort(height)[1:8]# Kurioje eilutėje? 12which.min(height)# Pasidairykime šios eilutės aplinkojeDavis[(12-4):(12+4),]# Priežastis aiški: ūgis ir svoris sukeisti vietomis# Sukuriame Davis kopiją. Joje ištaisome klaidasdavis <- Davisdavis[12,2] <- 57davis[12,3] <- 166#Nauji duomenysdavis[(12-4):(12+4),]attach(davis)#Nauja moteru ugio histograma# Moterų ūgio vektoriushF <- height[sex=="F"]# Moterų ūgio histogramahist(hF,probability=T)# "Suglodinta" histogramalines(density(hF))# Brėžiame atitinkamą normaląjį tankis
35

xx <- seq(min(hF),max(hF),length=100)lines(xx,dnorm(xx,mean(hF),sd(hF)),lty=2)
Kvantilių grafikai Lyginant tiriamą skirstinį su normaliuoju, dažnai tikslingaremtis vadinamuoju kvantilių grafiku. Teoriniame šio grafiko variante x ašyje ati-dedami standartinio normaliojo skirstinio kvantiliai, o y ašyje – tiriamojo skirstiniokvantiliai. Jei tiriamasis skirstinys yra beveik normalus, tai gauti taškai bus prak-tiškai ant tiesės.
xx <- seq(0,1,length=100)xxplot(qnorm(xx),qnorm(xx,10,5))
qqnorm(hF)qqline(hF) #tiese per 1-jį ir 3-jį kvartilius
Kaip atrodo nenormaliųjų dydžių kvantilių grafikai? Palyginkime normaluji skirs-tini su Stjudento skirstiniu.
#Normaliojo is Stjudento skirstiniu palyginimaiforma.t <- function(df){opar <- par(mfrow=c(1,2))on.exit(par(opar))x <- seq(0,1,length=1000)xx <- qnorm(x)plot(xx,dnorm(xx),type="l",main=paste("t,df=",df))lines(xx,dt(xx,df),col=2)plot(qnorm(x),qt(x,df),main=paste("t,df=",df))Y <- qt(c(0.25, 0.75),df)X <- qnorm(c(0.25, 0.75))slope <- diff(Y)/diff(X)int <- Y[1] - slope * X[1]abline(int, slope)}forma.t(3)
Stjudento tankio (raudona spalva) "uodegos" yra "sunkesnės" už normaliąsias. Kvan-tilių grafike tai atitinka tą faktą, kad taškai dešinėje yra aukščiau kvantilių tiesės, okairėje – žemiau.
Panaudosime sukauptas žinias ir patikrinsime vyrų atlyginimo normalumą.
attach(bwages)par(mfrow=c(1,2))w1 <- wage[male==1]qqnorm(w1)qqline(w1)qqnorm(log(w1))qqline(log(w1))detach(bwages)
36

Kvantilių grafikai labai efektyviai išryškina išskirtis. Iš tikrųjų:
library(car)data(Davis)attach(Davis)par(mfrow=c(1,2))qqnorm(height[sex=="F"])qqline(height[sex=="F"])qqnorm(weight[sex=="F"])qqline(weight[sex=="F"])detach(Davis)detach("package:car")par(mfrow=c(1,1))
Stačiakampės diagramos Stačiakampės diagramos yra naudingos tiriant skirs-tinio simetriškumą ir ieškant išskirčių. Jų brėžimas remiasi kintamojo kvartiliais.Panagrinėkime wage ir log(wage) atvejus. Štai trys praktiškai ekvivalenčios funkci-jos, skaičiuojančios kvartilius (t.y., kvantilius, atitinkančius 1/4, 2/4, 3/4; atkreipkitedėmesį į skirtumus). Taip pat išbrėžkime stačiakampes diagramas.
attach(bwages)quantile(wage)fivenum(wage)summary(wage)
par(mfrow=c(2,1))boxplot(wage,horizontal=T,col=3)boxplot(log(wage),horizontal=T,col=3)
Pažymėsime, kad wage diagrama yra labai nesimetriška (yra daug reikšmių deši-niau 3-iojo kvartilio arba, kitais žodžiais, yra daug žmonių, turinčių dideles pajamas).Antra vertus, nemažai didelių nuokrypių nuo medianos matome ir log(wage) atveju,tačiau nereiktų užmiršti, kad netgi normaliuoju atveju maždaug vienas stebėjimas iš100 (arba 14 iš 1472) gali būti už žandenų.
R turi funkciją identify, kuri leidžia identifikuoti taškus sklaidos diagramose. Šifunkcija leidžia identifikuoti išskirtis ir stačiakampėse diagramose, tačiau šiuo atvejuidentify argumentus reikia nurodyti specialiu būdu:
library(car)data(Prestige)?Prestigeattach(Prestige)boxplot(income)identify(rep(1,length(income)),income,labels=rownames(Prestige))
Matome, kad penkių kategorijų žmonių uždarbis yra "nenormaliai" didelis. No-rėdami nustatyti jų specialybes, naudosime funkciją identify. Kai ši komanda busįvykdyta, pereikime į grafikos langą, pasirodžiusį kryželį nuvarykime kairiau, deši-niau ar virš norimos išskirties ir spragtelėkime kairiuoju klavišu. Norėdami darbąbaigti, spragtelėkite dešiniuoju klavišu.
37

Skaitinės charakteristikos Iki šiol nagrinėjome grafines imties charakteristikas.Labai lakoniškos yra skaitinės charakteristikos. Jau žinome, kad skaitinės imties"centrinę" reikšmę nusakome mediana arba vidurkiu. Deja, net viena didelė išskirtisgali smarkiai iškreipti vidurkį, kitais žodžiais, tokios imties vidurkis smarkiai nu-kryps nuo populiacijos vidurkio. Įverčio atsparumą išskirtims galima padidinti "nu-pjaunant" didžiausias ir mažiausias reikšmes. Simetrinio skirstinio atveju vidurkis irmediana skiriasi nedaug
mean(wage)mean(wage,trim=0.1)mean(wage,trim=0.2)mean(wage,trim=0.5)median(wage)mean(log(wage))mean(log(wage),trim=0.1)median(log(wage))
Štai dar vienas pavyzdys: asimetrinio skirstinio atveju vidurkis ir mediana nesu-tampa. Paskutinėje eilutėje esanti funkcija locator leidžia pasirinkti legendos rėmelioviršutinį kairįjį tašką – spragtelėkite ten su kairiuoju pelės klavišu.
x <- rexp(100,rate = .5)hist(x,main ="Mean and Median of a Skewed Distribution")abline(v=mean(x),col=2,lty=2,lwd=2)abline(v=median(x),col=3,lty=3,lwd=2)ex12 <- expression(bar(x)==sum(over(x[i],n),i==1,n),hat(x)==median(x[i],i==1,n)) # Formulių grafikuoselegend(locator(1),ex12, col = 2:3, lty=2:3, lwd=2)
Aišku, kad vienu, centrą charakterizuojančiu skaičiumi, reiškinių aprašyti neįma-noma. Nesunku įsivaizduoti imtį, kurios visos reikšmės koncentruojasi ties vidurkiuir kitą imtį, kurios kai kurios reikšmės yra smarkiai nutolusios nuo vidurkio. Šiųdviejų imčių vidurkiai gali sutapti, tačiau jie skirsis savo reikšmių išsibarstymo di-dumu. Pastarąjį galima charakterizuoti keliais būdais, dažniausiai tam naudojamadispersija.
Prisiminkime, kad duomenų rinkinyje Davis moterų ūgis buvo pateiktas klaidin-gai. Todėl standartinis nuokrypis itin skiriasi abiem atvejais:
attach(Davis)sd(height[sex=="F"])attach(davis)sd(height[sex=="F"])
Matėme, kad mediana yra atsparesnė klaidoms nei vidurkis. Ja pagrįstas reikšmiųišsibarstymo matas yra vadinamas MAD (median average deviation) ir apibrėžiamasformule
mediana|xi −mediana(x)| · 1, 4826
38

Kitais žodžiais, pirmiausia reikia apskaičiuoti duomenų rinkinio x medianą, iš kiek-vienos rinkinio reikšmės atimti medianą, apskaičiuoti naujojo rinkinio modulių me-dianą ir dar padauginti iš 1, 4826 (dauginame tam, kad normaliojo skirstinio atvejuMAD sutaptų su standartu). Dar viena išsibarstymo charakteristika yra pagrįstaskirtumu tarp 3-jo ir 1-jo kvartilių. Norint kad Gauso skirstinio atveju šis skirtumasbūtų artimesnis standartui, reikia įvesti korekcinį daugiklį
1qnorm(0, 75)− qnorm(0, 25) = 0, 7413.
1/Imties normalumui tikrinti galima taip pat naudoti jo trečiąjį ir ketvirtąjį mo-
mentus, tiksliau kalbant, imties asimetrijos koeficientą
ask = 1n
n∑i=1
(xi − (x)sd(x)
)3
ir imties ekscesą
ask = 1n
n∑i=1
(xi − (x)sd(x)
)4
Skirstinių su simetrišku (vidurkio atžvilgiu) tankiu asimetrijos koeficientas lygus0, o normaliojo dėsnio ekscesas lygus 3. Taigi nuokrypiai nuo šių reikšmių signalizuojaapie galimą imties nenormalumą. R neturi funkcijų ask ir eks, todėl parašykite jaspatys.
##MAD (median average deviation)mad(height[sex=="F"])## IQRIQR(hF)attach(Davis)IQR(height[sex=="F"])IQR(hF)*0.7413IQR(height[sex=="F"])*0.7413#Asimetrija ir ekscesasask <- function(x){sum((x-mean(x))^3)/(length(x)*(sd(x))^3)}eks <- function(x){sum((x-mean(x))^4)/(length(x)*(sd(x))^4)}attach(bwages)ask(wage)eks(wage)ask(lnwage)eks(lnwage)ask(lnwage[male==1])eks(lnwage[male==1])ask(lnwage[male==0])eks(lnwage[male==0])par(mfrow=c(1,2))hist(lnwage[male==1])hist(lnwage[male==0])
39

Funkcija eda.shape Aukščiau aptarėme įvairias grafines ir skaitines imties cha-rakteristikas. Visas šias procedūras tikslinga pateikti viena funkcija, kurią pavadin-sime eda.shape:
eda.shape <- function(x){opar <- par(mfrow=c(2,2));on.exit(par(opar))hist(x);boxplot(x)plot(density(x));x <- sort(x)lines(x,dnorm(x,mean(x),sd(x)),col=2)qqnorm(x);qqline(x)cat("Vidurkis=",mean(x),", Mediana=",median(x),"(simetriniu atveju turi beveik sutapti)", # Tekstą papildome komentaru"\nStandartas=",sd(x),", MAD=",mad(x), # Simbolis “\n” nurodo: toliau"(kai nera isskirciu, turi beveik sutapti)", # esantį tekstą spausdinti iš"\nAsimetrijos koeficientas=",ask(x), # naujos eilutės"(simetriniu atveju turi buti 0)","\nEkscesas=",eks(x),"(normaliuoju atveju turi buti 3)\n")}
eda.shape(hF)
2.5.2 Užduotys1. n = 15 kartų pakartokime Bernulio eksperimentus su sėkmės tikimybe p = 0, 3.
Tokio eksperimentų sėkmių skaičių X galima modeliuoti arba su funkcija
rbinom(1,15,0.3)
arba su
sum(sample(c(0,1),15,replace=TRUE,prob=c(0.7,0.3))).
Kuo skiriasi šios dvi procedūros?.
2. Gaisrų skaičius Vilniaus rajone turi Puasono skirstinį su vidurkiu 1,2 darbodienomis ir su vidurkiu 1,5 nedarbo dienomis. Imituokite 52 savaičių gaisrųsuvestinę. Apskaičiuokite kiekvienos savaitės dienos empirinį gaisrų vidurkį.Išbrėžkite grafikus.
40

2.6 Šeštos paskaitos konspektas
2.6.1 Dvimačiai duomenys: aprašomoji statistika ir duome-nų priešanalizė
Kaip ir vieno kintamojo atveju, nagrinėjant du kintamuosius, paprastai kyla klausi-mai apie kiekvieno jų skirstinio formą ar parametrus. Antra vertus, dabar atsirandanauja tema apie jų tarpusavio ryšius. Jos sprendimas priklauso nuo kintamųjų tipo.Ar išsilavinimo lygis priklauso nuo lyties? (abu kintamieji vardiniai). Ar priklausoatlyginimas nuo lyties? (pirmasis kintamasis skaitinis, antrasis vardinis). Ar pri-klauso atlyginimas nuo patyrimo (metais)? (abu kintamieji skaitiniai). Šiems beipanašiems klausimas ir skirtas 5 skyrius.
Vardiniai kintamieji
bwages duomenų rinkinyje turime informacijos apie tiriamųjų asmenų lytį male irišsilavinimą educ. Ar galima teigti, kad moterys (o gal vyrai?) yra labiau išsilavinę?
bwages <- read.table("Data/bwages.dat", h=F, col.names=c("wage","lnwage","educ","exper","lnexper","lneduc","male"))attach(bwages)(me <- table(male,educ))(em <- table(educ,male))
Štai funkcija marginals, sumuojanti gautąsias lenteles pagal eilutes ir stulpelius:marginals <- function (x){if(class(x) != ’matrix’) stop("Turite pateikti matrica")row.sums <- apply(x,1,sum)row.names <- c(rownames(x),"Total")col.names <- c(colnames(x),"Total")x <- cbind(x,row.sums)col.sums <- apply(x,2,sum)x <- rbind(x,col.sums)rownames(x) <- row.namescolnames(x) <- col.namesx}
emm <- matrix(em, ncol = 2)rownames(emm) <- unique(educ)colnames(emm) <- unique(male)smem <- marginals(em)smem <- marginals(emm)
Kokias nors išvadas apie kintamųjų educ ir male priklausomybę sunku daryti,kadangi vyrų yra žymiai daugiau ir tiesiog lyginti skaičius atitinkamuose langeliuoseneverta. Pavyzdžiui, smme lentelėje 5-joje educ grupėje moterų yra 132 (iš 579), ovyrų 200 (iš 893; aišku, kad teisingiau būtų lyginti 132/579 = 0, 228 su 200/893 =0.224).
41

new.smem <- (smem/smem[,"Total"])[-6,-3]new.smemprop.table(em,1) # Procentai eiluteseprop.table(em,2) # Procentai stulpeliuoseprop.table(em,NULL) # Procentai
Grįžkime prie išsilavinimo tyrimo. Matėme, kad aukščiausiose išsilavinimo gru-pėse dominuoja moterys, o žemiausiose – vyrai. Taigi atrodo, kad lytis turi įtakosišsilavinimui, tačiau tai patvirtinti statistikos testų skaitmeniniais rezultatais galėsi-me tik 10 skyriuje. Tik ką nustatytas faktas bus ypač vaizdus, jei jį pavaizduosimegrafiškai.
barplot(new.smem,beside=T,legend=c("female", "male"))
Nors kintamieji educ ir male yra skirti vardiniams kintamiesiems (faktoriams)koduoti, tačiau jie apiforminti kaip skaitiniai kintamieji. Kartais kintamojo klasėnėra svarbi, tačiau kai kurios funkcijos reikalauja, kad kintamasis būtų, tarkime,faktorius. Pakeisti klasę nėra sunku:
r <- rpois(10,3)rclass(r)rf <- factor(r)rfclass(rf)rr <- as.numeric(rf)rrclass(rr)
Žemiau pateikiame funkciją jitt, kuri, kai skirtingų reikšmių "mažai", išbrėžia kelisgrafikų variantus. Imtis r1 yra sudaryta iš n atsitiktinių skaičių, kurių kiekvienasžymi sėkmių skaičių, atlikus keturis bandymus (sėkmės tikimybė lygi 0.45), o imtisr2 - iš n panašių skaičių (bet sėkmės tikimybė dabar kiek didesnė – 0.55). Grafikasplot(v1,v2) šį kartą mažai informatyvus, nes daug taškų (ir neaišku kiek) "sulimpa"į vieną. Tokiu atveju naudinga funkcija jitter (jitter (angl.) ≈ triukšmas) – jikiekvieną tašką truputį pastumia į šoną (bet kiekvieną skirtingai), ir dabar aiškiaumatyti, keli taškai buvo sulipę į vieną. Atkreipkite dėmesį į tai, kad priklausomai nuokintamojo klasės funkcija plot brėžia vis kitokį grafiką – R yra objektiškai orientuotaprogramavimo kalba!
Mišrus atvejis: vardiniai ir skaitiniai kintamieji
Ar diskriminuojamos Belgijoje moterys? Tiksliau kalbant, ar priklauso atlyginimowage (tai skaitinis kintamasis) dydis nuo lyties male (tai vardinis kintamasis)? Išprincipo, galėtume pasinaudoti tuo, ką jau žinome – kintamąjį wage galėtume skai-dyti į grupes, o paskui tirti šių dviejų vardinių kintamųjų sąveikos lentelę. Suskai-dykime atlyginimą į keturias grupes pagal kiek padailintas kvartilių reikšmes (taiatlieka funkcija cut). Kiekvienoje grupėje yra maždaug vienodas įrašų skaičius. Da-bar patyrinėkime lyties ir atlyginimo sąveikos lentelę. Matome, kad mažų atlyginimų
42

grupėse moterų daugiau, o didelių – mažiau (diskriminacija!). Antra vertus, grupuo-dami duomenis, kiek sugrubinome tiriamą paveikslą. Nesunku panašų tyrimą atliktiir su negrupuotais duomenimis. Grafike matome, kad abiejose grupėse atlyginimųskirstiniai nesimetriški ir turi daug išskirčių. Taip pat matome, kad vyrų atlyginimųir mediana ir visi kvantiliai didesni nei moterų.
summary(wage)wagecut(wage,breaks=c(80,320,410,520,1920))table(cut(wage,breaks=c(80,320,410,520,1920)))mw <- table(male,cut(wage,breaks=c(80,320,410,520,1920)))mwsmmw <- marginals(mw)smmw(smmw/smmw[,"Total"])[-3,-5]barplot((smmw/smmw[,"Total"])[-3,-5],beside=T,legend=c("female","male"), col=c(2,7))
boxplot(wage[male==0],wage[male==1],names=c("female","male"),col=3)tapply(wage,male,summary)
O štai dar du vyrų ir moterų atlyginimų palyginimo variantai: a) pagrįstas tankiofunkcija density ir b) pagrįstas skirtumais tarp empirinių skirstinio funkcijų:
w1 <- wage[male==1]w0 <- wage[male==0]par(mfrow=c(1,2))plot(density(w0),main="density - w0 vs. w1 ",xlab="",col=4)lines(density(w1),col=2)legend(600,.003,c("female","male"),lty=1,col = c(4,2))plot(c(sort(w0),max(w0)),(0:length(w0))/length(w0),type="S",col=4)lines(c(sort(w1),max(w1)),(0:length(w1))/length(w1),type="S",col=2)legend(700,.82,c("female","male"),lty=1,col = c(4,2))
Nagrinėdami empirines skirstinio funkcijas matome, kad raudonoji kreivė yravisur žemiau, kas dar kartą įrodo, kad vyrų atlyginimai yra didesni.
Dar ištirkime atlyginimo wage priklausomybę nuo išsilavinimo educ.
boxplot(wage[educ==1],wage[educ==2],wage[educ==3],wage[educ==4],wage[educ ==5],names=c("1","2","3","4","5"))with(bwages,boxplot(wage~educ))plot(factor(educ),wage)
Skaitiniai kintamieji
Vienas dažnai sutinkamų uždavinių yra dviejų skaitinių kintamųjų, prognozinio (ar-ba prediktoriaus arba regresoriaus, arba nepriklausomo) kintamojo x ir (modelio)atsako (arba priklausomo kintamojo) y, sąveikos tyrimas. Tokie modeliai vadina-mi regresiniais, o dažniausiai nagrinėjami keli klausimai: 1) kaip, žinant x reikšmę,
43

prognozuoti y reikšmę? 2) kaip palyginti du (ar kelis) modelius (Jei turime du Bel-giją aprašančius modelius, kuris iš jų "teisingesnis"? Jei Belgijos ir Lietuvos modeliainedaug skiriasi, tai gal tik dėl imčių atsitiktinumo?) ir t.t.
Tirkime du skaitinius kintamuosius weight ir height iš duomenų rinkinio davis.Atkreipsime dėmesį, kad x ir y ašys abiejuose grafikuose skiriasi – vyrai apskritai yraaukštesni ir sunkesni. Tai bus lengviau pastebėti, jei abu grafikus išbrėšime vienamepaveiksle. Matome, kad didėjant ūgiui svoris apskritai didėja. Kaip šią tendeniją,kurią akis lengvai pagauna, išreikšti matematiškai? Kadangi svoris nuo ūgio priklausotiesiškai, būtų protinga per abiejų grafikų taškų debesėlių "vidurį" išbrėžti tiesę, kuriviena ar kita prasme būtų "arčiausiai" visų taškų. Vienas iš galimų tiesės parinkimoprincipų yra mažiausių kvadratų metodas. Tarkime, kad kiekvienas atsako matavimorezultatas yi nuo prediktoriaus xi priklauso taip (tai vadinamasis tiesinės regresijosmodelis):
yi = α + βxi + εi, i = 1, 2, . . . , n;
kitais žodžiais, y ir x priklausomybė tiesinė, bet ją kiek gadina atsitiktinės paklaidosεi. Tiesės koeficientus α ir β tikslinga parinkti taip, kad paklaidų kvadratų suma(dažnai žymima RSS(α, β) būtų minimali (tai vadinamasis mažiausių kvadratų me-todas):
minα,β
RSS(α, β) = minα,β
n∑i=1
(yi − (α + βxi)2
R pakete šią procedūrą atlieka funkcija lm (lm=Linear Model (angl. tiesinis mode-lis)). Iš tikrųjų
par(mfrow=c(1,2))Fhw1 <- lm(wF~hF)Fhw1summary(Fhw1)plot(hF,wF)lines(hF,Fhw1$fit)Mhw1 <- lm(wM~hM)Mhw1summary(Mhw1)plot(hM,wM)lines(hM,Mhw1$fit)
Remdamiesi šiuo tyrimu, galėtume pasiūlyti formules "optimaliam" svoriui apskai-čiuoti: tarkime, 170 cm ūgio moteris turėtų sverti 170 · 0, 623 − 45, 67 = 60, 24 kg.Vyrų svorio formulę trumpai galėtume suformuluoti taip: svoris lygus ūgiui−100,kitaip sakant 170 cm ūgio vyras turėtų sverti 70kg.
Mažiausių kvadratų metodas turi daug gerų savybių, tačiau norint, kad jos ga-liotų, reikia tam tikrų sąlygų. Jos formuluojamos paklaidų terminais:
1. Paklaidų dispersija neturi priklausyti nuo i;
2. Paklaidos turi turėti normalųjį skirstinį.
Išbrėžkime grafiškai:
44

par(mfrow=c(1,4))plot(Fhw1)
Kiekviename grafike nurodyta po tris taškus, kurie, vadovaujantis vienu ar kituprincipu turėtų būti pripažinti išskirtimis. Tai įrašai 16, 26, 29, 63, 80. Pašalinkimejuos iš hF ir wF:hFn <- hF[-c(16,26,29,63,80)]wFn <- wF[-c(16,26,29,63,80)]hFn <- hF[-c(16,26,29,63,80)]wFn <- wF[-c(16,26,29,63,80)]Fhw1n <- lm(wFn~hFn)par(mfrow=c(1,4))plot(Fhw1n)
Pirmas iš kairės grafikas rodo, kad visos modelio paklaidos daugmaž homogeniškaitelpa juostoje nuo –10 iki +10, taigi visos dispersijos beveik lygios. Antras iš kairėsgrafikas rodo, kad paklaidos beveik normalios
Rūšiavimas Ilgų skaitinių vektorių perrašymas didėjimo tvarka yra gana dauglaiko reikalaujanti procedūra. Štai keli paprastesni pavyzdžiai.x1 <- rbinom(10,20,.4)x1sort(x1)order(x1)x1[order(x1)]
Kartais matricą ar duomenų sistemą reikia surūšiuoti, tarkime, pirmojo stulpeliodidėjimo tvarka.x2 <- rbinom(10,20,.4)x3 <- rbinom(10,20,.4)xx <- data.frame(x1,x2,x3)xxxx[order(x1),]
Dirbkime su StatLabs duomenų rinkiniu.statlab <- read.csv2("Data/statlab.csv")attach(statlab)oo <- order(MTHGHT,MTWGT)SL <- statlab[oo,]SL[1210:1296,]
scatterplot(SL$MTHGHT,SL$MTWGT)source("eda.shape.R")eda.shape(SL$MTHGHT)eda.shape(SL$MTWGT)
Savarankiškai įsitikinkite (pvz., su eda.shape), kad x koordinatė (t.y., MTHGHT)turi beveik normalųjį skirstinį, tuo tarpu MTWGT – tikrai ne. Pastarąjį faktą galimapaaiškinti bent dviem priežastimis: 1) nesveiku gyvenimo būdu ir 2) svoris propor-cingas tūriui, o pastarasis – ūgio kubui (normaliojo a.d. kubas nėra normalusis).
45

2.6.2 Užduotys1. Bibliotekoje MASS yra duomenų rinkinys mammals. Atlikite duomenų prieša-
nalizę, identifikuokite išskirtis. Sudarykite du regresinius modelius 1) brain bo-dy ir 2) log(brain) log(body). Kuris iš jųtinkamesnis?
2. Kodėl šie du grafikai skiriasi?
par(mfrow=c(1,2))x <- runif(50,-15,20)y <- -x^2+rnorm(50,sd=2.5)plot(x,y,t="l")oo <- order(x)plot(x[oo],y[oo],type="l")
46

2.7 Septintos paskaitos konspektas
2.7.1 Daugiamačiai duomenys: aprašomoji statistika ir duo-menų priešanalizė
Dažnai tiriamas reiškinys yra aprašomas modeliu, kuriame yra daugiau kaip du kin-tamieji. Paprastai čia susiduriama su keliomis problemomis, kaip antai, patogus duo-menų pateikimas, duomenų vizualizacija, tinkamas modelio parinkimas. Kai kuriosiš problemų sprendžiamos kiek apibendrinant dvimatį atvejį, tačiau yra ir specifiniųdaugiamačių aspektų. Pradėkime nuo duomenų pateikimo.
Duomenų pertvarkos
Tarkime turime duomenis, kuriuose yra vardinių kintamųjų. Ir šie vardiniai kin-tamieji užkoduoti skaičiais nuo 1 iki n arba ne skaitiniais vardais. Turime įmonės"Geronda" duomenis apie darbuotojų amžių, lytį ir padalinio numerį kuriame dar-buotojas dirba.
##Pirmasgeronda <- read.table("Data/geronda.txt", h=T)gerondaclass(geronda)
Dažnai duomenų sistema pateikiama dar kitokiu pavidalu, įvedant vadinamuosiusžymimuosius (= dummy (angl.)) kintamuosius. Šie kintamieji priskiria kiekvienamvardiniam kintamajam atskirą stulpelį ir šiame stulpelyje priskiria 1 jei sąlyga yraišpildyta ir 0, jei ne.
##Antrasp1 <- ifelse(geronda[,"pa"]==1,1,0)p2 <- ifelse(geronda[,"pa"]==2,1,0)p3 <- ifelse(geronda[,"pa"]==3,1,0)geronda.d <- data.frame(geronda[,-3],p1,p2,p3)geronda.d
Taip pat, kartais patogiau ne skaičiais užkoduotus vardinius kintamuosius per-koduoti. Tą mes padarysime lyties kintamajam: vyrams priskirsime 1, o moterims0:
###Treciassex <- ifelse(geronda[,"ly"]==’v’,1,0)geronda.m <- data.frame(geronda.d[,-2],sex)
Kitas patogus duomenų pertvarkymas yra jų sutrumpinimas ir nereikalingų stul-pelių atsisakymas. Tai patogu daryti, kai ne visi duomenys yra reikalingi arba turimaperteklinė informacija. Pavyzdžiui, failas bwages yra didelis ir su juo ne visuometpatogu dirbti. Imdami tik kas dešimtą bwages eilutę ir išmesdami visus logaritmųstulpelius, sukurkime mažesnį jo variantą Bwages:
47
### Ketvirtasbwages <- read.table("Data/bwages.dat", h=F, col.names=c("wage","lnwage","educ","exper","lnexper","lneduc","male"))attach(bwages)Bwages <- data.frame(bwages[seq(1,1472,10),c(1,3,4,7)],
row.names = as.character(1:148))Bwages
Grafinė analizė
Akis labai geras matavimo instrumentas, tačiau jau trimatėse sklaidos diagramoseji gana sunkiai įžiūri tendencijas. Iš tikrųjų, panagrinėkime funkciją scatterplot3d ištokio pat pavadinimo paketo.
Matome, kad jau trimačiu atveju sklaidos diagrama mažai naudinga (o kai ma-tavimų skaičius didesnis, jos apskritai neįmanoma nubrėžti). Tai paaiškina, kodėldaugiamačiu atveju dažniausiai apsiribojama įvairiais pavidalais pateikiama dvima-čių ryšių analize. Pradėkime nuo bendro pobūdžio pastabos. R funkcijos plot, boxp-lot, barplot, matplot (ir dar daug kitų) yra bendrinės, t.y., jų reikšmės priklauso nuoargumento tipo. Štai lentelė, kurioje pateikta mums reikalingų faktų santrauka.
• vektorius matrica duomenų siste-ma
plot x - koordinatėsnumeris, y – ko-ordinatės reikš-mė
x - pirmasis stul-pelis, y - antrasisstulpelis
brėžia daugsklaidos diagra-mų: x - vienasstulpelis, y -kitas
boxplot vienas stačia-kampis visamvektoriui
vienas stačia-kampis visaimatricai
vienas stačia-kampis kiekvie-nam stulpeliui(kintamajam)
barplot po stulpelį kiek-vienai koordina-tei, jo aukštis ly-gus koordinatėsreikšmei
po stulpelį kiek-vienam matricosstulpeliui, ei-lutės skiriamosspalvomis
neapibrėžta
matplot x - koordinatėsnumeris, y - ko-ordinatės reikš-mė su žyma
x - eilutėsnumeris, y -stulpelių reikš-mės (kiekvienamstulpeliui savažyma)
x - eilutėsnumeris, y -stulpelių reikš-mės (kiekvienamstulpeliui savažyma)
Štai kelios šios lenteles iliustracijos:
### Sestas## 6.1pois.v <- rpois(5,3)pois.vbarplot(pois.v, col=7)box()
48

## 6.2pois.m <- matrix(rpois(20,3),ncol=5)pois.mbarplot(pois.m,beside=T, col=c(3,5,6,7))## 6.3opar = par(mfrow = c(1,2))matplot(pois.v,type="b")matplot(pois.m,type="b")par(opar)
Grįžkime prie duomenų sistemos Bwages. Funkcija plot turėtų išbrėžti daug sklai-dos diagramų, rodančių kiekvieno stulpelio priklausomybę nuo kitų. Deja, šie grafikaimažai informatyvūs, nes daug taškų "sulimpa". Funkcija jitter duomenų sistemomsneapibrėžta, todėl taškus "padrebinkime" patys.
### Septintas## 7.1plot(Bwages)## 7.2Bw.jitt <- Bwages+data.frame(rep(0,148),runif(148,-0.2,0.2),runif(148,-0.01,0.01),runif(148,-0.05,0.05))plot(Bw.jitt)
Mums labiausiai rūpi pirmoji eilutė – matome, kad didėjant išsilavinimui atlygi-nimas didėja, nuo patyrimo jis priklauso paraboliškai (kaip manote, kodėl?), o vyrųatlyginimas, apskritai, didesnis nei moterų.
Panagrinėkime funkciją pairs – jos išbrėžtas grafikas panašus į funkcijos plot,tačiau ji pateikia žymiai daugiau variantų.
### Astuntassource("panel.R")pairs(Bw.jitt, upper.panel=panel.smooth, diag.panel=panel.hist,lower.panel=panel.cor)
Čia upper.panel nurodo, kas bus virš įstrižainės (base paketo funkcija panel.smoothišbrėž kreivę, einančią per taškų "debesėlio" vidurį – jau turėjome tokios kreivės pa-vyzdį (regresijos tiesę), bet dabar remiamasi kitokiais principais (kreivę apskaičiuosneparametrinio glodinimo funkcija lowess)). Opcija diag.panel nurodo kas dar, bekintamojo vardo, bus ant įstrižainės. Opcija lower.panel nurodo, kas bus po įstri-žaine, ji apskaičiuoja koreliacijos koeficiento tarp atitinkamų kintamųjų modulį; ko-eficiento skaitmenų didumas proporcingas koreliacijos koeficiento reikšmei – tai, kadkoreliacijos koeficientas tarp educ ir male praktiškai neįžiūrimas, reiškia, kad jis be-veik 0).
Kita funkcija, labai naudinga tiriant daugiamačius duomenis, yra coplot(y ∼ x|a)arba coplot(y ∼ x|a ∗ b). Ji brėžia keletą y sklaidos diagramų x atžvilgiu (visoms areikšmėms arba, atitinkamai, visoms porų (a, b) reikšmėms). Norint, kad duomenųsistemos Bwages atveju educ ir male būtų "teisingai" traktuojami, reikėtų pabrėžti,kad jie faktoriai. coplot taip pat leidžia pasirinkti du sąlyginius kintamuosius, mespasirinksime educf ir malef.
49

### Devintas## 9.1educf <- as.factor(educ)malef <- as.factor(male)Bwf <- data.frame(wage,exper,educf,malef)rm(educf,malef)detach(Bwages)coplot(wage~exper|malef, panel=panel.smooth,data=Bwf)## 9.2coplot(wage~exper|educf*malef,panel=panel.smooth,data=Bwf)
Štai dar vienas coplot funkcijos vartojimo pavyzdys (čia įdomiausios yra duomenųrinkinio VADeaths transformacijos – duomenų formatą gana dažnai reikia keisti).
### Desimtasdata(VADeaths)VADeathsdr <- c(VADeaths)drn <- length(dr)rep(ordered(rownames(VADeaths)),length=n)gl(2,5,n, labels= c("M", "F"))gl(2,10, labels= c("rural", "urban"))d.VAD <- data.frame (Drate=dr, age=rep(ordered(rownames(VADeaths)),length=n),gender=gl(2,5,n,labels= c("M", "F")), site=gl(2,10, labels=c("rural", "urban")))d.VADmode(d.VAD)class(d.VAD)coplot(Drate ~ as.numeric(age) | gender * site, data = d.VAD,
panel = panel.smooth)
Kografikų metodas yra smarkiai patobulintas lattice bibliotekoje. PanagrinėkimeCars93 duomenis iš MASS bibliotekos. Pagrindinė lattice idėja yra grafinį langąsuskaidyti į keletą polangių (paprastai jie nusakomi kokiu nors sąlygos kintamuoju).Funkcijos (jų vardai natūralūs, tačiau skiriasi nuo įprastų – pvz., rašome histogramir bwplot vietoje, atitinkamai, hist ir boxplot) naudoja formulių sintaksę. Vienmačiųgrafikų atveju kairiąją formulės ženklo ∼ pusę paliekame tuščią.
### Vienuoliktas## 11.1library(lattice)library(MASS)data(Cars93)histogram( ~ Max.Price | Cylinders , data = Cars93)## 11.2bwplot( ~ Max.Price | Cylinders , data = Cars93)
Su lattice taip pat galima brėžti (sąlygines) sklaidos diagramas (tik vietoje plotreikės rašyti xyplot ir , be to, naudoti formulių sintaksę)). Tendencijos yra aiškios:
50

kuo didesnis automobilio svoris, tuo mažiau mylių su vienu kuro galonu galima nu-važiuoti. Antra vertus, šias tendencijas geriausiai pavaizduoti regresijos tiesėmis.Funkciją, brėžiančią šias tieses lattice atveju, teks parašyti patiems. Dar vienaspavyzdys funkcija densityplot.
## 11.3attach(Cars93)xyplot(MPG.highway ~ Weight | Type)## 11.4plot.regression=function(x,y) # Ženklas “=” yra ženklo “<-” sinonimas{panel.xyplot(x,y)panel.abline(lm(y~x))}trellis.device(bg="gray")xyplot(MPG.highway ~ Weight | Type, panel = plot.regression)### 11.5d1 <- rnorm(100)d2 <- runif(100)densityplot(~ d1 + d2, auto.key = TRUE)
Skaitinės charakteristikos
Jau žinome, kad dažnai naudingos imčių skaitinės charakteristikos. Daugiamačiuatveju be vidurkio (ar medianos) ir standarto (ar IQD) dar naudojama imties kore-liacijos matrica. Pradėsime nuo vienmačių skaitinių charakteristikų.
round(apply(bwages,2,summary),2)round(apply(bwages,2,sd),2)round(cor(bwages),2)
Matome, kad, pvz., paprastasis (Pearson’o) koreliacijos koeficientas tarp educ irmale lygus –0,14. Kadangi tai ranginiai kintamieji, vietoje paprastojo reikia skai-čiuoti ranginį (Spearman’o) koreliacijos koeficientą. Jis pagrįstas ne kintamojo reikš-mėmis, bet jų rangais (vieta).
### Tryliktasattach(bwages)x <- cbind(educ,male,rank(educ),rank(male))cor(educ,male) # Pearson’o koeficientascor(rank(educ),rank(male)) # Spearman’o koeficientas
2.7.2 Užduotys1. Išsiaiškinkite plot.table ir mosaicplot funkcijas. Išnagrinėkite duomenų rinkinį
UCBAdmissions.
2. Matricoje
vv <- matrix(rnorm(100),ncol=4)
51

yra pateikti keturmačio vektoriaus stebėjimų rezultatai. Šio vektoriaus kova-riacinę ir koreliacinę matricas galima suskaičiuoti su
Var <- var(vv)Cor <- cor(vv)).
Dabar tarkime, kad matricos vv nežinome, bet žinome tik jos kovariacinę 4×4matricą Var. Apskaičiuokite koreliacinę matricą Cor.
52

2.8 Aštuntos paskaitos konspektas
2.8.1 Centrinė ribinė teorema ir didžiųjų skaičių dėsnisCentrinė ribinė teorema (vienmatis atvejis)
Tarkime, kad κn yra sėkmių skaičius po n Bernulio eksperimentų su sėkmės tikimybep. Gerai žinoma, kad tikimybė P (κn = k) =
(nk
)pkqn−k, k = 0, 1, . . . , n, o tikimybė
P(κn ≤ x) =
0 x < 0∑[x]k=0
(nk
)pkqn−k x ∈ [0, n]
1 x ≥ n
čia [x] žymi sveikąją skaičiaus x dalį. Kai n nėra didelis, šias tikimybes nėra sunkuapskaičiuoti tiesiogiai, tačiau augant n skaičiavimai darosi vis sudėtingesni. Kai ndidelis, abi šias tikimybes galima gana sėkmingai apskaičiuoti, naudojant normalųjįskirstinį. Pavyzdžiui,
P(κn ≤ x) = P(κn − np√
npq≤ x− np√npq
= x∗)
= P (κn ≤ x∗√npq + np) ≈ Φ(x), x ∈ R,
čia Φ yra standartinio normaliojo skirstinio funkcija. Vietoje matematinio šio faktoįrodymo, pateiksime grafines iliustracijas.
#Pimasn <- 10p <- 0.2x <- seq(-3,3,length=100)P <- pbinom(x*sqrt(n*p*(1-p))+n*p,n,p)plot(x,P,type="S")lines(x,pnorm(x))
Normaliosios aproksimacijos tikslumas gerėja didėjant n (tikslumas taip pat ge-resnis, kai p arti 0.5). Norėdami tuo įsitikinti, parašykime funkciją b.sim (žemiauyra tvarkingo funkcijos rašymo pavyzdys; deja, tai ne Notepad’o darbas…):
#Antrasb.sim <- function(){opar <- par(mfcol = c(3, 3))on.exit(par(opar))x <- seq(-3, 3, length = 100)
for(p in c(0.3,0.5, 0.95)){
for(n in c(25, 100, 500)){
P <- pbinom(x * sqrt(n * p * (1 - p)) + n * p, n, p)plot(x, P, type = "S", main = paste("n =", n, ", p =", p))lines(x, pnorm(x))
}
53

}}b.sim()
Tiesą sakant, aproksimacijų tikslumo skirtumai tarp p = 0.3, 0.5 ir 0.95 nela-bai pastebimi – akis blogai skiria skirstinio funkcijas (integralines charakteristikas),ji geriau pastebi diferencialinius skirtumus. Parašysime atitinkamą funkciją bb.sim.Priminsime, kad standartinis normalus skirstinys yra praktiškai sukoncentruotas in-tervale (−2, 2), todėl k vidiniame cikle kinta tarp np− 2√npq ir np+ 2√npq.
#Trečiasbb.sim <- function(){opar <- par(mfcol = c(3, 3))on.exit(par(opar))
for(p in c(0.3, 0.5, 0.95)){
for(n in c(25, 75, 225)){k <- ceiling(n * p - 2 * sqrt(n * p * (1 - p))):
floor(n * p + 2 * sqrt(n * p * (1 - p)))P <- dbinom(k, n, p)plot(k, P, main = paste("n =", n, ", p =", p))lines(k, dnorm((k - n * p)/sqrt(n * p * (1 - p)))/
sqrt(n * p * (1 - p)))}
}}bb.sim()
Muavro ir Laplaso teorema yra atskiras vadinamosios centrinės ribinės teoremos(CRT) atvejis. Pasirodo, kad vietoje Bernulio a.d. galime paimti beveik bet kokiusnepriklausomus vienodai pasiskirsčiusius a.d. (su baigtine dispersija) – kai n dide-lis, jų normuota suma Zn = displaystyleSn−ESn√
DSnturės (beveik) standartinį normalųjį
skirstinį (tai ir vadinama CRT). Šitai paaiškina, kodėl normalusis dėsnis taip daž-nai sutinkamas gyvenime – stebimą reiškinį nusako daug maždaug vienos svarbospriežasčių.
Grafiškai "įrodykime" CRT nepriklausomų a.d., turinčių tolygų skirstinį intervale[−1, 1] sekai. Deja, jau dviejų tokių dydžių sumos tankio išraiška gana sudėtinga,todėl sumos tankį pakeisime histograma.
#Ketvirtasuni.sim <- function(){opar <- par(mfcol = c(1, 3))on.exit(par(opar))
for(i in c(1,5,15)){
rr <- numeric(1000)
54

for(n in 1:1000) {rr[n] <- sum(runif(i,-1,1))}rr <- rr*sqrt(3/i)hist(rr,prob=T,main=paste("Demenu skaicius=",i))k <- seq(-3,3,length=100)lines(k, dnorm(k),col=2)
}}uni.sim()
Dar kartą parodysime, kad didėjant n skirstinys tampa vis labiau "normalus"histogramų pagalba.
#Penktas#5.1library(animation)oopt = ani.options(interval = 0.1, nmax = ifelse(interactive(),
150, 2))op = par(mar = c(3, 3, 1, 0.5), mgp = c(1.5, 0.5,
0), tcl = -0.3)clt.ani(type = "s")par(op)#5.2saveHTML({
par(mar = c(3, 3, 1, 0.5), mgp = c(1.5, 0.5, 0), tcl = -0.3)ani.options(interval = 0.1, nmax = ifelse(interactive(),
150, 10))clt.ani(type = "h")
}, img.name = "clt.ani", htmlfile = "clt.ani.html", ani.height = 500,ani.width = 600, title = "Demonstration of the Central Limit Theorem",description = c("This animation shows the distribution of the sample",
"mean as the sample size grows."))#5.3## other distributions: Chi-square with df = 5 (mean = df,# var = 2*df)f = function(n) rchisq(n, 5)clt.ani(FUN = f, mean = 5, sd = sqrt(2 * 5),type=’l’)
ani.options(oopt)
Tokį patį rezultatą galime gauti ir kvantilių funkcijų pagalba:
#ŠeštasCLT_normal <- function(n, m){
z <- rep(0,n)for(i in 1:n){
u <- sum(runif(m,0,1))z[i] <- (u-m/2)/(m/12)
}
55

return(z)}## test the normal generator using various values of mpar(mfrow=c(2,2))m <- 1x <- CLT_normal(100000, m)qqnorm(x, main=paste("QQ normal m=", m))qqline(x, col="red")
m <- 6x <- CLT_normal(100000, m)qqnorm(x, main=paste("QQ normal m=", m))qqline(x, col="red")
m <- 12x <- CLT_normal(100000, m)qqnorm(x, main=paste("QQ normal m=", m))qqline(x, col="red")
m <- 30x <- CLT_normal(100000, m)qqnorm(x, main=paste("QQ normal m=", m))qqline(x, col="red")
Centrinė ribinė teorema (daugiamatis atvejis)
CRT galioja ir daugiamačiu atveju. Tiksliau, jei stebime (pvz., dvimačių) atsitiktiniųvektorių seką (X1i, X2i), i = 1, . . . , n, tai "gerais" atvejais jų normuotos sumos Znkonverguoja į dvimatį normalųjį skirstinį (o "dar geresniais" atvejais - Zn tankiskonverguoja į dvimatį normalųjį tankį. Deja, jau žinome, kad daugiamačiu atvejugrafinės galimybės gana ribotos. Štai vienas iš variantų (funkcija persp3d, ji turi labaidaug opcijų), leidžiantis vizualizuoti dvimatę tankio funkciją. Prieš kreipdamiasi įfunkciją persp3d, iš vektorių x1 ir x2 reikšmių turime sukurti stačiakampę gardelęir kiekviename jos taške apskaičiuoti funkciją mvdnorm (tai atlieka funkciją outer,daugiklis 10 išryškina tankio kalvos pavidalo formą):
#Septintas#7.1mvdnorm <- function(x1,x2,a1=0,a2=0,s1=1,s2=1,ro=0){F1 <- 1/(2*pi*s1*s2*sqrt(1-ro^2))F2 <- -1/(2*(1-ro^2))S1 <- (x1-a1)^2/s1^2S2 <- -2*ro*(x1-a1)*(x2-a2)/(s1*s2)S3 <- (x2-a2)^2/s2^2z <- F1*exp(F2*(S1+S2+S3))z}x1 <- seq(-3,3,len=50)
56

x2 <- x1z <- outer(x1,x2,function(x1,x2) mvdnorm(x1,x2,ro=0.75))persp3d(x1,x2,z,theta=130,phi=15,scale=FALSE,axes=FALSE,
main="ro=0,75", col = "pink")#7.2x1 <- seq(-15,15,len=50)x2 <- x1z <- outer(x1,x2,function(x1,x2) mvdnorm(x1,x2,a1=1,a2=-1,s1=1,s2=4, ro=0.85))persp3d(x1,x2,z,theta=130,phi=15,scale=FALSE,axes=FALSE,
main="ro=0,85", col = "green")
Geresnį supratimą apie tankio paviršiaus formą susidarysime, išbrėžę jo lygiolinijas. Tai galime atlikti su funkcija contour (atkreipsime dėmesį: kuo ρ modulisarčiau 1, tuo elipsės labiau "ištemptos"). Beje, MASS pakete yra funkcija mvrnorm,kuri generuoja daugiamačius normaliuosius a.d.. Lygio linijų grafikas yra papildytassugeneruotų taškų vaizdais. Matome, kad tai būdingas sklaidos diagramos paveikslas,kitais žodžiais, dažnai stebime būtent dvimatį normalųjį skirstinį.
#Aštuntaspar(mfrow=c(1,2))x1 <- seq(-3,3,len=50)x2 <- x1z <- outer(x1,x2,function(x1,x2) mvdnorm(x1,x2,ro=0.75))contour(x1,x2,z,main="ro = 0,75")library(MASS)Sigma <- matrix(c(1,0.75,0.75,1),2,2)mvn <- mvrnorm(100,c(0,0),Sigma)contour(x1, x2, z,main="ro = 0,75")points(mvn[,1],mvn[,2],pch=16,cex=0.5)
Koreliacijos koeficientas ρ rodo vektoriaus koordinčių ryšio tamprumą (jei stebi-me dvimatį normalųjį a.d., sąlyga ρ = 0 yra ekvivalenti koordinačių nepriklausomu-mui). Nesunku įsitikinti, kad tik tuomet, kai |ρ| didesnis už maždaug 0.6 elipsinėstruktūra darosi ryškesnė (jei ρ lygus, pvz., 0.8 tai, žinant stebimojo atsitiktinio vek-toriaus pirmąją koordinatę y1, galima gana tiksliai prognozuoti antrosios koordinatėsy2 reikšmę).
Dar keli žodžiai apie dviejų kintamųjų funkcijų (jų grafikai – paviršiai) vizualiza-ciją. Jau minėjome du variantus: funkcijas persp ir contour. Čia aptarsime dar dvifunkcijas: image ir filled.contour.
#Devintaspar(mfrow=c(1,1))dens <- function(x, y) { dnorm(x) * dnorm(y) }x <- seq(-3, 3, len = 40)y <- seq(-3, 3, len = 30)g <- expand.grid(x, y)mat <- matrix(dens(g[,1], g[,2]), nrow = 40, ncol = 30)image(x,y,mat)win.graph()
57

persp(x,y,mat)win.graph()filled.contour(x,y,mat)win.graph()contour(x,y,mat)
Didžiųjų skaičių dėsnis
Be CRT tikimybių teorijoje svarbų vaidmenį vaidina dar viena didelė ribinių teoremųklasė – tai didžiųjų skaičių dėsniai (DSD). Jei X1, X2, . . . n.v.p.a.d. seka su vidurkiuEXi = a, tai galima įrodyti, kad Sn/n→ a, kai n→∞ (pagal tikimybę).
Iš DSD išplaukia, kad imties vidurkis x (arba dispersija s2) konveguoja į populia-cijos vidurkį a (atitinkamai, dispersiją σ2), santykinis dažnis konverguoja į tikimybę,empirinė skirstinio funkcija – į teorinę skirstinio funkciją.
DSD pailiustruosime dviem pavyzdžiais. Pirmiausiai, parodysime, kad didinantdėmenų skaičių, imties vidurkis artėja į populiacijos vidurkį.
#DešimtasDSD <- function(){n4 <- rnorm(10^4)xx <- numeric(1000)for(i in 1:1000) xx[i] <- mean(n4[1:(10*i)])n <- seq(10,10000,10)plot(n,xx,type="l")n4 <- rnorm(10^4)xx <- numeric(1000)for(i in 1:1000) xx[i] <- mean(n4[1:(10*i)])n <- seq(10,10000,10)lines(n,xx,lty=2)lines(n,rep(0,1000))}DSD()
Kitas pavyzdys
#Vienuoliktaslln.ani(FUN = function(n, mu) rchisq(n, df = mu), mu = 5, cex = 0.6)
2.8.2 Užduotys1. Pakete visualizationTools yra funkcija LLN, kuri vaizduoja didžiųjų skaičių
dėsnį. Išsiaiškinkite šią funkciją. Ką daro komandos:
par(ask=FALSE)LLN(n=100,distr="normal",fun=mean,param=list(mean=2,sd=0.5),col=2)par(ask=TRUE)
2. Pakete visualizationTools yra funkcija CLT, kuri vaizduoja centrinę ribinę teo-remą. Išsiaiškinkite šią funkciją. Ką daro komandos:
58

CLT(fun=mean,times=100,distribution=c("normal","weibull","gamma","normal","beta"),param=list(list(mean=0,sd=0.01,n=100),list(shape=1,scale=3,n=100),list(n=100,shape=0.1),list(mean=2,sd=0.1,n=100),list(n=100,shape1=1,shape2=2)),seed=123,col=c(rep("grey",5),"green"))
59

2.9 Devintos paskaitos konspektas
2.9.1 Sprendžiamoji statistika: parametrų įverčiaiNors matematinės statistikos tikslas yra įvertinti visos populiacijos parametrus, ta-čiau ji gali remtis tik jos dalimi – imtimi. Jau žinome, kad iš DSD išplaukia, kadpopuliacijos vidurkis maždaug lygus imties vidurkiui, tačiau jei norėtume apskai-čiuoti ne populiacijos vidurkį, bet kitus ją aprašančio skirstinio parametrus, reikėtųkitokių samprotavimų (žemiau aptarsime du metodus – momentų ir didžiausio ti-kėtinumo). Bet kuriuo atveju, dėl atsitiktinės imties prigimties, gautasis įvertis (jisvadinamas taškiniu) bus tik apytiksliai lygus populiacijos vidurkiui ar parametrųreikšmėms. Norint nusakyti įverčio paklaidą, galima remtis pasikliauties intervalais– tai toks atsitiktinis intervalas, kuris su didele tikimybe uždengia atitinkamų po-puliacijos parametrų reikšmes. Aišku, matematika turėtų pasiūlyti metodus, kaipsurasti patį "geriausią" (pvz., trumpiausią) tokį intervalą.
Taškiniai įverčiai
Tarkime, kad turimi duomenys neprieštarauja hipotezei, jog stebimasis a.d. turitam tikrą skirstinį, priklausantį nuo vieno ar kelių nežinomų parametrų. Parametrųįverčiams rasti naudojami keli metodai - paprastas, bet nelabai tikslus momentųmetodas, ir sudėtingesnis, bet tikslesnis (nes įverčių dispersijos mažesnės) didžiausiotikėtinumo (DT) metodas. Dažnai (pvz., binominio, Puasono ar normaliojo skirstinioatvejais) abu įverčiai sutampa, tačiau kartais išspręsti DT lygtis nėra lengva.
Tarkime, kad stebimojo a.d. X skirstinio funkcija F (x) priklauso nuo nežinomop-mačio parametro θ. Iš DSD žinome, kad l-tasis imties (arba empirinis) momentasapytiksliai lygus l-tajam populiacijos momentui (tikrajam). Jei a.d. X turi pmomen-tų, tai galima sudaryti p lygčių su p nežinomaisiais sistemą. Jei ją galima išspręsti θatžvilgiu, tai sprendinys θ vadinamas parametro θ momentų metodo įverčiu.
Sunkiau yra su geresniuoju DT įverčiu. Tarkime, kad a.d. X turi tankį f(x; θ).Funkcija
L(θ) =n∏k=1
f(xk; θ)
kaip ir jos logaritmas
l(θ) = logL(θ)
vadinamos DT funkcijomis. Visos DT procedūros tikslas yra rasti tokias θ reikšmes,su kuriomis l(θ) arba L(θ) įgyja didžiausią reikšmę.
Momentų ir DT metodų įverčiai sutampa ne visuomet. Tarkime, X turi tolygųskirstinį intervale [0, θ]; čia θ yra nežinomas dešinysis intervalo galas. Momentųmetodas siūlo tokį nežinomo parametro įvertį θMM = 2x, o didžiausio tikėtinumo– kitokį: θDT = maxi xi. Įvertis θMM yra nepaslinktas, t.y. EθMM = θ, tačiauEθDT = nθ
n+1 . Tačiau žinant poslinkį, įvertį galima pataisyti. Toliau imkime pavyzdį,kai θ = 1:
#Pirmassim.unif <- function(n)
60

{mm <- numeric(500)dtm <- numeric(500)for (i in 1:500){
ru <- runif(n,0,1)mm[i] <- 2*mean(ru)dtm[i] <- ((n+1)/n)*max(ru)
}boxplot(mm,dtm)title(main=paste("n=",n))cat("E(theta1)=",mean(mm),"E(theta2)=",mean(dtm),"\n")cat("D(theta1)=",var(mm),"D(theta2)=",var(dtm),"\n")
}sim.unif(10)sim.unif(100)
Kadangi θMM = 2x a.d. suma, tai pagal CRT šis a.d. yra maždaug normalus.Galima įrodyti, kad θMM turi nesimetrišką tankį. Abu tankiai, didėjant n, kaupiasiapie tikrąją θ reikšmę (todėl galima vis tiksliau "atkurti" θ), tačiau antrasis tankisyra labiau sukoncentruotas apie θ ir todėl jis tai daro "geriau".
#Antrastheta <- function(n){x <- seq(1-3/sqrt(3*n),1+3/sqrt(3*n),length=100)y <- ifelse(x<0|x>(n+1)/n, 0,n*n*((n*x/(n+1))^(n-1))/(n+1))plot(x,y,type="l")lines(x,dnorm(x,1,1/sqrt(3*n)),col=2)title(main=paste("n=",n))}par(mfrow=c(1,2))theta(5)theta(50)
R programos privalumai išaiškėja sudėtingais atvejais. Panagrinėkime gama skirs-tinį. Šio a.d. tankis priklauso nuo dviejų nežinomų parametrų – formos parametroa ir mastelio parametro c:
f(x; a, c) = 1caΓ(a)x
a−1e−x/c1(0,∞)(x), a, c > 0.
Jo vidurkis EX = ac ir dispersija DX = ac2. Momentų metodo įverčiai yraEaMM = x2
s2 ir EcMM = s2
x. Deja, šie įverčiai nelabai tikslūs. DT įverčiai yra
randami sprendžiant netiesinę lygtį ir čia gali pagelbėti R:
#Treciaspar(mfrow=c(1,2))x <- (1:100)/10
61

plot(x,dgamma(x,2.5),type="l")gama <- rgamma(500,2.5)hist(gama,prob=TRUE)lines(density(gama))
#Ketvirtasmean(gama)^2/var(gama)var(gama)/mean(gama)mlgamma <- function(x) -sum(dgamma(gama,shape= x[1],scale= x[2],log = TRUE))mle <- nlm(mlgamma, c(shape = 2.4, scale = 1), hessian = TRUE)mle$estimatesolve( mle$hessian)avals <- seq( 0.5, 10, len = 101)svals <- seq( 0.2, 5, len = 101)grid <- matrix( 0.0, nrow = 101, ncol = 101)for (i in seq( along = avals)){for (j in seq( along = svals)){grid[ i, j] <- mlgamma( c( avals[ i], svals[ j]))}}min(grid)par(mfrow=c(1,1))contour(avals, svals, grid, levels = seq(900,1100, 50))points( mle$estimate[1], mle$estimate[2], pch = "+", cex = 1.5)title( xlab = "a", ylab = "s")
2.9.2 Intervaliniai įverčiaiPraėjusiame skyrelyje buvo paaiškinta, kaip galima rasti nežinomo parametro θ įver-čius. Būtų gerai, jei sugebėtume nurodyti, kiek gautasis įvertis skiriasi nuo tikrosiosparametro reikšmės.
Pradėsime vienu pavyzdžiu. Iš DSD žinome, kad, didėjant imties dydžiui, jo vi-durkis konverguoja į populiacijos vidurkį. Antra vertus, nedideliems n šie du skaičiaigali pastebimai skirtis. Pamodeliuokime šį reiškinį – kelis kartus generuokime po 10N(0, 1) atsitiktinių skaičių ir apskaičiuokime jų empirinius vidurkius ir standartus:
#Penktasrn <- rnorm(10)rnmean(rn)sd(rn)rn <- rnorm(10)rnmean(rn)sd(rn)
Matome, kad imties rn vidurkis (kaip ir standartas) gana pastebimai kinta. Geraibūtų, jei kartu galėtume nurodyti ir daromą paklaidą. Tada nežinomo vidurkio a(kai žinoma dispersija σ) lygmens α pasikliauties intervalas yra
[x+ z1σ√n
; x+ z2σ√n
],
62

čia simboliu z(α) pažymėjome standartinio normaliojo skirstinio α-ąjį kvantilį, z1 =z(α1), z2 = z(α + α1), 0 ≤ α1 <≤ 1− α. Šis intervalas trumpiausias, kai α1 = 1−α
2 .Jei α = 0, 95, tai normaliojo dėsnio kvantiliai yra:
#Sestasqnorm(0.975)qnorm(0.95)qnorm(0.9)qnorm(0.025)qnorm(0.05)qnorm(0.1)
Grįžkime prie mūsų pavyzdžio (Penktas). Kadangi σ = 1, n = 10, o "tikrasis"vidurkis 0, tai pažiūrėkime, ar jis priklauso intervalams:
#Septintas#Funkcija skaiciuojanti vidurkio pasiklaiutinaji intervala, kai zinoma dispersija:vid.int <- function(x, alpha=0.05, sigma = 1){
n <- length(x)vid <- mean(x)q <- 1 - alpha/2k <- vid - qnorm(q)*sigma/sqrt(n)d <- vid + qnorm(q)*sigma/sqrt(n)cat("[",k,";",d,"]","\n", sep="")
}vid.int(rn1)vid.int(rn2)vid.int(rn1, alpha = 0.1)vid.int(rn2, alpha = 0.1)
Tiriant realius duomenys, populiacijos dispersija σ2 žinoma retai. Tokiais atve-jais, logiška vietoje nežinomo σ2 imti jo nepaslinktą įvertį s2. Tada pasikliautinasintervalas yra [
x+ tn−1
(1− α2
)· s√
n; x+ tn−1
(1 + α
2
)· s√
n
]
čia tn(α) yra Stjudento su n laisvės laipsnių α eilės kvantilis. Grįžkime prie pavyzdžio:
#Astuntas#Funkcija skaiciuojanti vidurkio pasiklaiutinaji intervala, kai nezinoma dispersija:vid.int.s <- function(x, alpha=0.05){
n <- length(x)vid <- mean(x)std <- sd(x)q1 <- alpha/2q2 <- 1-q1k <- vid + qt(q1,(n-1))*std/sqrt(n)
63

d <- vid + qt(q2,(n-1))*std/sqrt(n)cat("[",k,";",d,"]","\n", sep="")
}vid.int.s(rn1)vid.int.s(rn2)vid.int.s(rn1, alpha = 0.1)vid.int.s(rn2, alpha = 0.1)
Padarysime dar vieną pastabą. Mes netvirtiname, kad nežinomas vidurkis vi-suomet yra pasikliauties intervalo viduje – jei pasikliauties (pasitikėjimo) tikimybėα = 0, 95, tai mes tvirtiname tik tiek, kad pasikliauties intervalas (maždaug) 95procentams imčių uždengs vidurkį (taigi kartais galime suklysti, bet tai bus retai).Patikrinsime savo teiginį.
#Devintasconf <- function(){t.lo <- qt(0.005,19)t.up <- qt(0.995,19)coef.lo <- t.lo/sqrt(20)coef.up <- t.up/sqrt(20)up <- numeric(1000)lo <- numeric(1000)sk <- 0for(i in 1:1000){rn <- rnorm(20)m <- mean(rn)st <- sd(rn)lo[i] <- m+coef.lo*stup[i] <- m+coef.up*stsk <- sk+ifelse(lo[i]>0|up[i]<0,0,1)}plot(1:1000,up,type="l",ylim=c(min(lo),max(up)),ylab="conf.int")lines(1:1000,lo,col=2)lines(1:1000,rep(0,1000))cat("Daznis=",sk/1000,"\n")}conf()
Kai stebime normalųjį a.d. X su nežinomais vidurkiu ir dispersija, dispersijos σ2
lygmens α pasikliauties intervalas atrodo taip: (n− 1)s2
χ2n−1
(1+α
2
) ; (n− 1)s2
χ2n−1
(1−α
2
) ,
čia χ2n(α) yra chi kvadrato su n laisvės laipsniais α eilės kvantilis. Pagal mūsų
pavyzdį:
64

#Desimtas#Funkcija skaiciuojanti dispersijos pasiklaiutinaji intervala:disp.int <- function(x, alpha=0.05){
n <- length(x)std <- sd(x)q1 <- alpha/2q2 <- 1-q1k <- ((n-1)*std)/(qchisq(q2,(n-1)))d <- ((n-1)*std)/(qchisq(q1,(n-1)))cat("[",k,";",d,"]","\n", sep="")
}disp.int(rn1)disp.int(rn2)disp.int(rn1, alpha = 0.1)disp.int(rn2, alpha = 0.1)
Štai funkcija, kuri pateikia geometrinę dispersijos pasikliauties intervalo interpre-taciją:
#Vienuoliktaschi <- function(){x <- seq(0,12,length=400)plot(x,dchisq(x,4),type="l", main=expression(paste(alpha,"=0,9")))lines(x,rep(0,400))xx.lo <- seq(0,qchisq(0.05,3),length=50)XX.lo <- c(xx.lo,-sort(-xx.lo),0)YY.lo <- c(rep(0,50),dchisq(-sort(-xx.lo),4),0)polygon(XX.lo,YY.lo,col="yellow")xx.up <- seq(qchisq(0.95,3),12,length=50)XX.up <- c(xx.up,-sort(-xx.up),xx.up[1])YY.up <- c(rep(0,50),dchisq(-sort(-xx.up),4),0)polygon(XX.up,YY.up,col="yellow")}chi()
Dar viena funkcija dispersijos pasikliautiniems intervalams skaičiuoti:
#Dvyliktasconf.var <- function(x,conf.level=0.95){n <- length(x)s1 <- var(x)s1*(n-1)/c(qchisq((1+conf.level)/2,n-1),qchisq((1-conf.level)/2,n-1))}conf.var(rn1)conf.var(rn2)
65

Matome, kad "tikroji" dispersijos reikšmė priklauso pasikliauties intervalui (jeitokį eksperimentą pakartosime daug kartų, tai tik maždaug penkis kartus iš šimtosuklysime, teigdami, kad gautasis intervalas uždengia populiacijos dispersiją).
Dabar aptarkime binominį atvejį. Paskutiniuose rinkimuose už Laimės žiburiopartiją balsavo 13, 2% rinkėjų. Po metų buvo atlikta sociologinė apklausa, kuriojeiš 1000 apklaustųjų 170 pareiškė, kad, jei rinkimai būtų rytoj, jie balsuotų už šiąpartiją. Ar suderinami šie duomenys su LŽP oponentų teigimu, kad "šitai dar niekonereiškia"? Oponentų teiginį galima iššifruoti taip: šios partijos gerbėjų procentasnepasikeitė, o padidėjimą galima paaiškinti imties atsitiktinumu. Formalizuokimejų teiginį. Tarkime, kad p yra tikimybė, kad rinkėjas rytoj balsuotų už LŽP, t.y.,p =(kiek bus "už")/(turi balso teisę)= 0, 132. Simboliu p∗ pažymėkime šios tikimybėsempirinį ekvivalentą: p∗ =(kiek "už" buvo tarp apklaustųjų)/1000 = 0, 17. Tikslūs(dabartinio) p pasikliauties intervalo rėžiai užrašomi gana komplikuotai, tačiau nau-dojant R paketą to nesijaučia:
#Tryliktasbinom.test(170,1000,p=0.132)binom.test(170, 1000, p = 0.132, conf.level = 0.9)binom.test(170,1000,p=0.132,alt="g")
Taigi, centrinis nežinomos proporcijos p pasikliauties intervalas neuždengia 0, 132,todėl apklausos duomenys paneigia oponentų teiginį – LŽP gerbėjų dalis per metuspadidėjo ir su tikimybe 0, 95 yra nurodytame intervale.
Iki šiol nagrinėjome tikslų nežinomos tikimybės p pasikliauties intervalą. Apy-tikslį intervalą nesunku gauti iš CRT. R’e tai atlieka funkcija prop.test:
#Keturioliktasprop.test(170,1000)prop.test(170,1000)$conf.intprop.test(170,1000,alt="less")$conf.int
Žemiau pateiktas funkcijos mle.pois, brėžiančios Puasono skirstinio tikėtinumofunkcijos grafiką, kodas. Pažymėsime, kad nedidelių papildomų komplikacijų atsi-randa dėl to, kad viename grafike norime išbrėžti dvi kreives (tikėtinumo funkcijosir jos logaritmo) su dviem y ašimis, grafiko kairėje ir dešinėje.
#Penkioliktasmle.pois <- function(){x <- rpois(5,10)lhat <- mean(x)lambda <- seq(lhat-2*sqrt(lhat),lhat+2*sqrt(lhat),by=0.01)lambda <- lambda[lambda>0]likelihood <- exp(-lambda*length(x))*lambda^sum(x)/prod(gamma(x+1))x2 <- rpois(5,10)lhat2 <- mean(x2)lambda2 <- seq(lhat2-2*sqrt(lhat2),lhat2+2*sqrt(lhat2),by=0.01)lambda2 <- lambda2[lambda2>0]likelihood2 <- exp(-lambda2*length(x2))*lambda2^sum(x2)/prod(gamma(x2+1))
66

par(mar=c(5,4,4,4))yMIN.log <- min(min(log(likelihood),min(log(likelihood2))))yMAX.log <- max(max(log(likelihood),max(log(likelihood2))))plot(lambda,log(likelihood),type="l",ylim=c(yMIN.log,yMAX.log))lines(lambda2,log(likelihood2),lty=2)MAX <- which.max(likelihood)MAX2 <- which.max(likelihood2)yMIN <- min(min(likelihood,min(likelihood2)))yMAX <- max(max(likelihood),max(likelihood2))arrows(lambda[MAX],log(likelihood)[MAX],lambda[MAX],yMIN.log,col=3)arrows(lambda2[MAX2],log(likelihood2)[MAX2],lambda2[MAX2],yMIN.log,col=3, lty=2)par(new=T)plot(lambda,likelihood,type="l",ylim=c(yMIN,yMAX),col=2,axes=F, xlab="",ylab="")axis(side=4,col=2)lines(lambda2,likelihood2,lty=2,col=2)mtext("likelihood",side=4,line=2,col=2)print(list(mean=lhat,mean2=lhat2))}mle.pois()
2.9.3 Užduotis1. Pakete MASS yra funkcija fitdistr, kuri skaičiuoja daugelio (įskaitant gama ir
Veibulo) skirstinių parametrų DT įverčius. Generuokite 200 gama atsitiktiniųskaičių, įvertinkite skirstinio parametrus aukščiau aprašytu metodu ir naudo-dami fitdistr funkciją. Palyginkite rezultatus.
2. Dispersijos pasiliauties intervalas siaurėja, kai n didėja, tačiau iš jo išraiškos tonesimato. Parašykite funkciją, kuri išbrėžtų tai iliustruojantį grafiką.
67

2.10 Dešimtos paskaitos konspektas
2.10.1 Sprendžiamoji statistika: hipotezių tikrinimas (vienaimtis)
Pasikliauties intervalų skaičiavimas yra glaudžiai susijęs su hipotezių tikrinimu. Pir-muoju atveju randame intervalą, kuriame turėtų būti nežinoma parametro reikšmė.Antruoju atveju tariame, kad parametras turi konkrečią reikšmę ir klausiame, ar šiprielaida (hipotezė) yra suderinama su turimais duomenimis. Vienas iš šios prob-lemos sprendimo variantų yra toks: jei tinkamai parinktas pasikliauties intervalasuždengia hipotetinę reikšmę, tai (kiek diplomatiškai) sakome, kad turimi duomenysneprieštarauja mūsų hipotezei. Dažniausiai ta pati R funkcija skaičiuoja ir pasi-kliauties intervalus ir tikrina hipotezes. Dauguma šiame skyriuje aptariamų testųpriklauso base ir/arba stats (=classical test) paketams.
Hipotezės apie proporciją
Pradėkime hipotezėmis apie nežinomas tikimybes (proporcijas populiacijoje). Tąuždavinį, kurį anksčiau formulavome intervalų terminais, dabar spręsime kitaip. LŽPoponentai teigia, kad, nežiūrint apklausos rezultatų, šiai partijai prijaučiančių dalisliko ta pati. Šis teiginys vadinamas pagrindine1 (arba nuline) hipoteze ir žymimasH0.Kadangi pagal DSD santykinis dažnis turi būti maždaug lygus "tikrajai" tikimybeip, tai"nedidelės" skirtumo reikšmės turėtų liudyti hipotezės H0 naudai, o "didelės"– prieš ją. Taigi esminis klausimas yra toks: ar skirtumas 0, 17 − 0, 132 = 0, 038didelis. Formuluojant hipotezių terminais H0 : p = p0 = 0.132, o alternatyvi hipotezėHA : p 6= p0. Tikimybė P (|N | ≥ z∗) vadinama kriterijaus p reikšme (p-value), jei jimažesnė už kriterijaus reikšmingumo lygmenį α (jo standartinė reikšmė 0.05) - H0atmetame ir priimame H1. Altrenatyvi hipotezė taip pat gali būti "daugiau" arba"mažiau":
#Pirmasprop.test(170,1000,p=0.132,alt="two.sided")prop.test(170,1000,p=0.132,alt="greater")prop.test(170,1000,p=0.132,alt="less")
Pavyzdys 2.1 Išspręsime vieną uždavinį (žr. ČM1, 171 psl., 7 uždavinys). Naujomedikamento reklamoje teigiama, kad jis sukelia pašalines reakcijas ne daugiau kaip1% pacientų. Ištyrus 1000 vaistą vartojusių ligonių nustatyta, kad pašalinį poveikįpajuto 32 ligoniai. Ar duomenys neprieštarauja reklaminiam teiginiui? (α = 0.05).
Nulinė hipotezė suformuluota uždavinyje - H0 : p ≤ p0 = 0.01. Jei ši hipotezė būtųteisinga, nežinomos tikimybės p įvertis p (t.y., procentas ligonių, pajutusių pašalinįpoveikį) turėtų būti maždaug lygus (arba mažesnis už) p0. Kadangi p = 32/1000 yramaždaug tris kartus didesnis už p0, kyla įtarimas, kad ko gero teisinga ne hipotezėH0, o HA : p > p0. Šią procedūra atliksime tiek su tiksliu testu, tiek su apytiksliu:
#Antrasbinom.test(32,1000,p=0.01,alt="greater")prop.test(32,1000,p=0.01,alt="greater",correct=FALSE)
68

Taigi abiem atvejais nulinę hipotezę atmetame.
Hipotezės apie vidurkį
Norėdami patikrinti, ar kintamojo vidurkis įgyja konkrečią reikšmę, remsimės Stu-dent’o kriterijumi t.test. Šį kriterijų naudojame, kai populiacija yra (maždaug) nor-mali (jei taip nėra, tuomet neparametriniai testai (pvz., Wilcoxon’o ranginis kriteri-jus) labiau tinka populiacijos centro nustatymui).
Anksčiau nagrinėjome duomenų rinkinį davis (jame buvo pateikti duomenys apietikrąjį ir praneštąjį apklaustųjų asmenų ūgį ir svorį). Patikrinkime hipotezę, kadmoterys teisingai pranešė savo ūgį (tiksliau kalbant, kad moterų tikrojo ūgio vidurkislygus praneštojo ūgio vidurkiui).
#Treciasattach(davis)davisF <- davis[sex=="F",]detach(davis)attach(davisF)dim(davisF)mean(height)var(height)mean(repht)mean(repht,na.rm=T)
Anksčiau matėme, kad moterų ūgis hF turi beveik normalųjį skirstinį, todėlhipotezę formuluosime vidurkių terminais: H0 : a = 162, 1980, H1 : a 6= 162, 1980(čia a yra tikrojo ūgio vidurkis):
#Ketvirtast.test(height,mu=mean(repht,na.rm=T))
Taigi, testas rodo, kad moterys savo ūgį pranešė teisingai.Hipotezių apie vidurkį tikrinimas yra pagrįstas Student’o kriterijaus p reikšmių
skaičiavimu. Štai funkcija p.value, kuri pateikia grafinę šio skaičiavimo interpretaciją:
#Penktasp.value<-function(t, df){z1 <- seq(-3, 3, 0.01)tankis <- dt(z1, df)PlotasKairiau <- round(pt(t,df), 3)PlotasDesiniau <- round(1 - PlotasKairiau, 3)plot(z1, tankis, type = "l",xlab = "x", ylab =paste("Student’o tankio su",as.character(df),"l.l. grafikas"),main = paste("t = ",t))text(-2, 0.33, paste("Plotas kairiau t = ",100 * PlotasKairiau,"%"), cex = 1.2)text(2, 0.33, paste("Plotas desiniau t = ",100 * PlotasDesiniau,"%"), cex = 1.2)
69

z2 <- seq(-3, 3, 0.05)height2 <- dt(z2, df)len <- length(z2[z2 > t])segments(z2[z2 > t], rep(0,len), z2[z2 > t],height2[z2 > t])cat("p.value=",PlotasDesiniau, "\n")}p.value(1.5,20)
Pareto skirstinys
Populiariausios populiacijos centro charakteristikos yra jos vidurkis ir mediana. Mesjau aptarėme Student’o kriterijų hipotezėms apie vidurkį tikrinti. Deja, jis nėra tiks-lus, jei nagrinėjame nedidelę imtį iš akivaizdžiai nenormalios populiacijos. Be to, šistestas apskritai nepritaikomas, jei nagrinėjamasis a.d. neturi baigtinio vidurkio (taiatitinka gana populiarų ekonometrijoje "sunkių uodegų" atvejį). Imtyse su sunkiomisuodegomis yra (gal ir nedaug, bet) "didelių" reikšmių (Lietuvoje yra žmonių, turinčiųlabai dideles pajamas (teisybė, jų nedaug); internetu kartas nuo karto perduodamilabai dideli failai ir pan.). Abiem šiais atvejais remsimės Wilcoxon’o kriterijumimedianoms. Tačiau prieš tai pakalbėkime apie Pareto skirstinį.
Sakome, kad a. d. X turi Pareto skirstinį, jei jo tankis yra pavidalo
p(x) = cx−(c+1)1(0,∞)(x).
Šis a.d. turi baigtinį vidurkį, tik kai c > 1: EX = cc−1 . Tačiau šis skirstinys turi visus
momentus mažesnius iki c. Todėl jei c ≤ 1, tai egzistuoja mediana visuomet mX =c√
2. Vidurkio egzistavimas yra glaudžiai susijęs su ’uodegos sunkumu": kuo sunkesnėuodega (t.y., kuo lėčiau artėja į nulį tikimybė P (X > x), kai x → ∞), tuo mažiaumomentų turi a.d. X. Parašysime keturias R funkcijas, kurios skaičiuos Paretotankio funkciją dpareto, skirstinio funkciją ppareto, kvantilius qpareto ir generuosPareto atsitiktinius skaičius rpareto:
#Sestas#6.1dpareto <- function(x,c){if(c<=0)stop("c turi buti > 0")ifelse(x<1,0,c/x^(c+1))}
ppareto <- function(q,c){if(c<=0)stop("c turi buti > 0")ifelse(q<1,0,1-1/q^c)}
qpareto <- function(p,c){
70

if(c<=0) stop("c turi buti > 0")if(any(p<0)|any(p>1))stop("p turi buti tarp 0 ir 1")q_(1-p)^(-1/c)q}
rpareto <- function(n,c){if(c<=0) stop("c turi buti >0")rp <- runif(n)^(-1/c)rp}
Išbrėšime tris Pareto imčių histogramas:
#Septintaspdf(file="pareto histogramos.pdf")opar <- par(mfrow = c(1,3))hist(rpareto(100, 5))hist(rpareto(100, 2))hist(rpareto(100,0.5))par(opar)dev.off()
Hipotezės apie medianą
Priminsime, kad duomenų rinkinio bwages poaibį w0 (w1) sudaro duomenys apieBelgijos moterų (atitinkamai, vyrų) atlyginimus. Ar galime teigti, kad moterų atly-ginimas yra toks pat kaip ir vyrų? Abi procedūros, tvirtina, kad vyrų atlyginimasdidesnis. Tačiau ar negalima šio skirtumo paaiškinti vien imties atsitiktinumu?
#Astuntabwages <- read.table("bwages.txt", h=F, col.names=c("wage","lnwage","educ","exper","lnexper","lneduc","male"))attach(bwages)tapply(wage,male,mean)tapply(wage,male,median)
Šį klausimą galima suformuluoti kaip hipotezių tikrinimo uždavinį. Deja, taipformuluoti uždavinį negerai, nes moterų atlyginimo imtis yra aiškiai nenormalus.Normalumą patikrinsime su Shapiro ir Wilk’o kriterijumi, kuris atmeta hipotezęapie duomenų normalumą:
#Devintas#9.1w0 <- wage[male==0]w1 <- wage[male==1]shapiro.test(w0)
71

Tai, kad w0 skirstinys nėra normalus – pusė bėdos. Blogiau yra tai, kad, atrodo,jis turi sunkias uodegas ir galimas daiktas neturi baigtinio (teorinio) vidurkio:#9.2source("eda.shape.R")eda.shape(w0)
Tokiu įtartinu atveju geriau hipotezes formuluoti medianoms:#9.3wilcox.test(w0,mu=median(w1),alt="l")wilcox.test(w1,mu=median(w0),alt="g")
Suderinamumo kriterijai
Daugelis statistinių procedūrų galioja tik tuomet, kai populiacija turi konkretų (pvz.,normalųjį)skirstinį. Aptarsime du kriterijus, kurie leidžia patikrinti hipotezes apie stebimojoa.d. skirstinį. Pirmasis jų yra χ2 kriterijus, kuris taikomas kaip diskretiems taip irtolydiems a.d. Jis pagrįstas tuo, kad (tuomet kai teisinga nulinė hipotezė apie skirsti-nį) empiriniai dažniai negali labai skirtis nuo teorinių. Taikant χ2 kriterijų, tolydžiusduomenis reikia grupuoti, dėl ko prarandama dalis informacijos. Todėl tolydžių ste-bėjimų atveju geriau taikyti kitą, būtent Kolmogorovo kriterijų (žr. ?ks.test), kurisremiasi tuo, kad (tuomet kai teisinga nulinė hipotezė apie skirstinį) empirinė skirs-tinio funkcija negali labai skirtis nuo teorinės. Kolmogorovo kriterijaus pagrindinistrūkumas yra tas, kad hipotetinės skirstinio funkcijos parametrai turi būti žinomi išanksto, jų negalime vertinti iš imties.Pavyzdys 2.2 Pateikti klasikiniai Bortkiewicz’iaus duomenys apie skaičių žmonių,užmuštų arklio kanopos smūgiu 10-tyje prūsų armijos korpusų per 20 metų (1875-1894). Kadangi kareivių korpuse daug, o tokios mirties tikimybė maža, tikėtina, kadmirčių skaičius turi (diskretųjį) Puasono skirstinį. Šią hipotezę tikrinsime su χ2
kriterijumi. Iš pradžių šio testo reikalingas statistikas apskaičiuosime "rankomis":
#Desimtas#10.1B <- as.matrix(read.table("bort.txt"))Bwm <- weighted.mean(B[1,],B[2,]/200)wmcbind(B[2,],200*dpois(0:4,wm),(B[2,]-200*dpois(0:4,wm))^2/
(200*dpois(0:4,wm)))B2 <- c(B[2,1:3],B[2,4]+B[2,5])pB2 <- c(dpois(0:2,wm),dpois(3,wm)+dpois(4,wm))sB2 <- sum((B2-200*pB2)^2/(200*pB2))sB21-pchisq(sB2,4-2)
Visus skaičiavimus gali pagreitinti funkcija chisq.test. Vienintelė problema čia ta,kad ši funkcija taria, kad l.l. skaičius lygus k-1, o ne mums reikalingas k-2.
#10.2r <- 1-sum(pB2)
72

pB2 <- c(dpois(0:2,wm),dpois(3,wm)+dpois(4,wm)+r)chiB2 <- chisq.test(B2,p=pB2)chiB2
Gavome neteisingą laisvės laipsnių skaičių ir todėl neteisingą p-reikšmę. Rankomisįrašome teisingą laisvės laipsnių skaičių:
#10.31-pchisq(chiB2$statistic,2)
2.10.2 Užduotys1. Genų jungimasi ir paveldimumą valdo tikimybiniai dėsniai. Snedecor’as yra pa-
teikęs tokius kukurūzo chlorofilo paveldimumo duomenis: tarp 1103 savidulkiųheterozigotinių žalių sėjinukų, 854 buvo žali, o 249 – geltoni. Teorija tvirtina,kad šis santykis turėtų būti lygus 3:1. Atspausdinkite turimus ir prognozuoja-mus dažnius. Patikrinkite ar šie duomenys neprieštarauja teorijai.
2. JAV gimstančių kūdikių svoris turi maždaug normalų skirstinį su vidurkiu115, 2 uncijos (= 3, 2659 kg). Pediatras surinko duomenis apie 20-ties smarkiairūkančių moterų pagimdytų vaikų svorį – jo vidurkis buvo 114, 0, o s = 4, 3.Patikrinkite hipotezę, kad rūkančių moterų pagimdytų vaikų svoris mažesnisnegu visoje populiacijoje.
73

2.11 Vienuoliktos paskaitos konspektas
2.11.1 Sprendžiamoji statistika: hipotezių tikrinimas (dviimtys)
R pakete yra daug statistinių kriterijų skirtų dviejų populiacijų parametrų lyginimui,kitais žodžiais, hipotezėms H0 : θ1 = θ2 (čia θ1 ir θ2 yra tie patys abiejų populiacijųparametrai) tikrinti. Štai trumpa šių kriterijų apžvalga.
• Dviejų populiacijų proporcijų lygybės testas prop.test.
• Dviejų požymių nepriklausomumo testai fisher.test ar chisq.test (tai vadina-mieji dažnių lentelių uždaviniai).
• Dviejų populiacijų Stjudento kriterijus t.test – jis skirtas hipotezei H0 : a1 = a2tikrinti (čia a1 ir a2 yra populiacijų vidurkiai). Jei duomenų rinkiniai nedideli,jie turėtų būti maždaug normalūs. Šis testas turi keletą variantų: jį galimataikyti suporuotiems įrašams, o taip pat tam atvejui, kai populiacijų dispersijosnėra lygios.
• Dviejų populiacijų Vilkoksono testas wilcox.test. Šiuo atveju nulinė hipotezėtvirtina, kad abiejų populiacijų skirstiniai sutampa, o alternatyva – kad skirs-tiniai skiriasi tik postūmiu (normaliuoju atveju tai reikštų, kad nesutampavidurkiai).
• Kolmogorovo ir Smirnovo dviejų populiacijų kriterijus ks.test. Nulinė hipotezėteigia, kad abi populiacijos turi tą patį (tolydų) skirstinį.
Hipotezės apie proporcijas
Turime duomenų benefits failą, kuriame pateikti 4877 įrašai apie netekusius darbodarbininkus JAV 1982-1991 metais. Be kitų duomenų, jame pateikti faktai apiedarbininkų odos spalvą (fiktyvus kintamasis nwhite lygus 1, jei ne baltasis, ir 0 –jei baltasis) ir ar gavo bedarbystės pašalpą (fiktyvus kintamasis y lygus 1, jei gavo).Kadangi faile benefits (skaitinių) kintamųjų yra net 22, o vienas įrašas užima keturiaseilutes, todėl importuoti šį failą į R šį kartą reikia ne su read.table:
#Pirmasbenefits <- scan("benefits.dat",what=list(rep(0,22)),multi.line=T)head(matrix(unlist(benefits),byrow=T,ncol=22))
Kintamasis nwhite yra įrašytas 10-ajame šios matricos stulpelyje, o y – 22-ajame:
#Antrasnwhite <- matrix(unlist(benefits),byrow=T,ncol=22)[,10]y <- matrix(unlist(benefits),byrow=T,ncol=22)[,22]benef <- data.frame(nwhite,y)rm(nwhite,y,benefits)attach(benef)tapply(y,nwhite,mean)
74

Kintamasis y įgyja tik dvi reikšmes, todėl jo teorinis vidurkis yra ne kas kita kaipvienetukų (t.y., gavusiųjų pašalpą) dalis visoje populiacijoje. Matome, kad šių vidur-kių įverčiai abiejose imtyse beveik lygūs: (0.682 =)p0 ≈ p1(= 0.694), kitais žodžiaislabai panašu, kad visoje populiacijoje pašalpą gavusių baltųjų dalis p0 yra lygi pa-šalpą gavusių nebaltųjų daliai p1. Hipotezę H0 : p0 = p1 galima patikrinti keliaisbūdais.
1 būdas: Taikysime proporcijų lygybę tikrinantį testą prop.test. Į jį kreiptisgalima įvairiai, mes pradėsime nuo požymių sąveikos lentelės skaičiavimo.
#Treciastableb <- table(benef)tablebprop.test(cbind(tableb[,2],tableb[,1]))
Šio kriterijaus p-reikšmė lygi 0, 5712, todėl nėra jokio pagrindo atmesti nulinę hipo-tezę.
2 būdas: Nulinę hipotezę galima interpretuoti kaip hipotezę, kad abiejose popu-liacijose pašalpą gavusiųjų dalys yra lygios. Šios hipotezės (apie požymio homogeniš-kumą) tikrinimas pagrįstas chi2 statistika, kuri, kai hipotezė H0 teisinga, neturėtųbūti "didelė":
chi2 =2∑i=1
2∑j=1
(oij − ni·n·j/n)2
ni·n·j/n.
chi2 reikšmę pirmiausiai apskaičiuosime "rankomis":
#Ketvirtassource("marginals.r")marginals(tableb)chi.statistic <- function(tb){
a <- array(0, dim(tb)-1)l1 <- nrow(tb)l2 <- ncol(tb)for(i in 1:nrow(a)){
for(j in 1:ncol(a)){
a[i,j] <- tb[i, l2]*tb[l1, j]/tb[l1,l2]}
}tb1 <- tb[-3,-3]stat <- sum((tb1-a)^2/a)return(stat)
}chi.statistic(marginals(tableb))
Tą patį rezultatą galime gauti ir su summary
#Penktassummary(tableb)
75
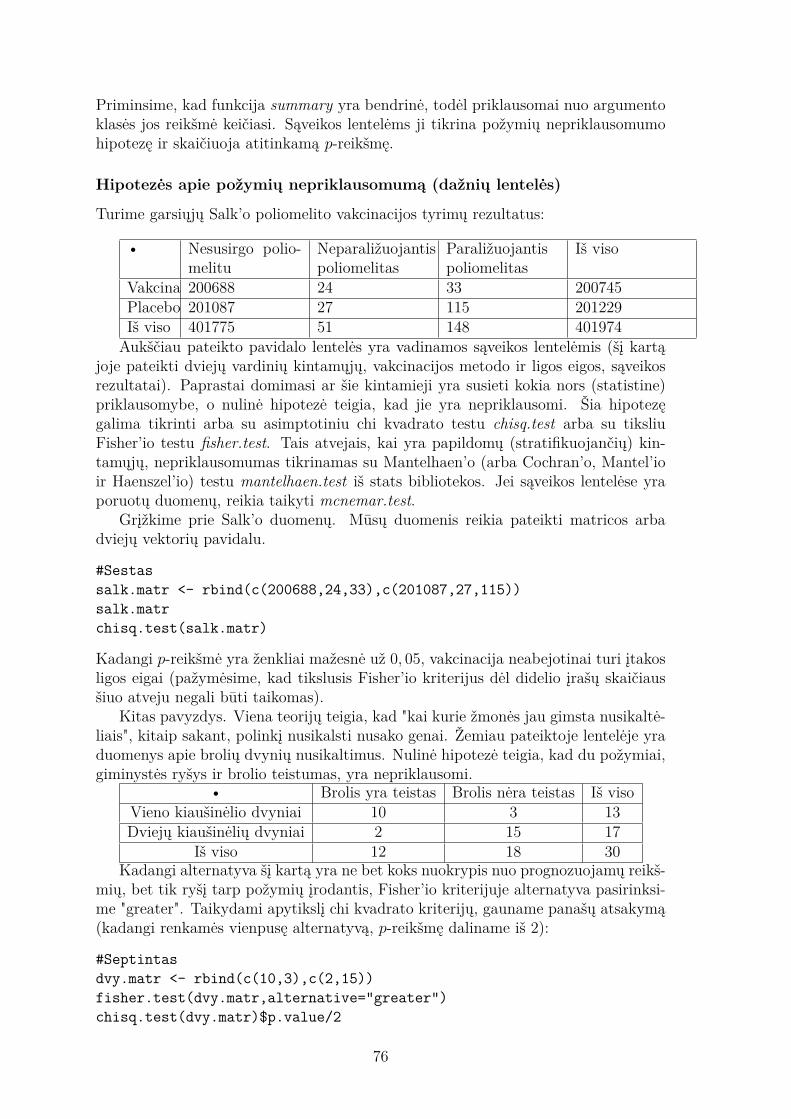
Priminsime, kad funkcija summary yra bendrinė, todėl priklausomai nuo argumentoklasės jos reikšmė keičiasi. Sąveikos lentelėms ji tikrina požymių nepriklausomumohipotezę ir skaičiuoja atitinkamą p-reikšmę.
Hipotezės apie požymių nepriklausomumą (dažnių lentelės)
Turime garsiųjų Salk’o poliomelito vakcinacijos tyrimų rezultatus:
• Nesusirgo polio-melitu
Neparaližuojantispoliomelitas
Paraližuojantispoliomelitas
Iš viso
Vakcina 200688 24 33 200745Placebo 201087 27 115 201229Iš viso 401775 51 148 401974
Aukščiau pateikto pavidalo lentelės yra vadinamos sąveikos lentelėmis (šį kartąjoje pateikti dviejų vardinių kintamųjų, vakcinacijos metodo ir ligos eigos, sąveikosrezultatai). Paprastai domimasi ar šie kintamieji yra susieti kokia nors (statistine)priklausomybe, o nulinė hipotezė teigia, kad jie yra nepriklausomi. Šia hipotezęgalima tikrinti arba su asimptotiniu chi kvadrato testu chisq.test arba su tiksliuFisher’io testu fisher.test. Tais atvejais, kai yra papildomų (stratifikuojančių) kin-tamųjų, nepriklausomumas tikrinamas su Mantelhaen’o (arba Cochran’o, Mantel’ioir Haenszel’io) testu mantelhaen.test iš stats bibliotekos. Jei sąveikos lentelėse yraporuotų duomenų, reikia taikyti mcnemar.test.
Grįžkime prie Salk’o duomenų. Mūsų duomenis reikia pateikti matricos arbadviejų vektorių pavidalu.
#Sestassalk.matr <- rbind(c(200688,24,33),c(201087,27,115))salk.matrchisq.test(salk.matr)
Kadangi p-reikšmė yra ženkliai mažesnė už 0, 05, vakcinacija neabejotinai turi įtakosligos eigai (pažymėsime, kad tikslusis Fisher’io kriterijus dėl didelio įrašų skaičiausšiuo atveju negali būti taikomas).
Kitas pavyzdys. Viena teorijų teigia, kad "kai kurie žmonės jau gimsta nusikaltė-liais", kitaip sakant, polinkį nusikalsti nusako genai. Žemiau pateiktoje lentelėje yraduomenys apie brolių dvynių nusikaltimus. Nulinė hipotezė teigia, kad du požymiai,giminystės ryšys ir brolio teistumas, yra nepriklausomi.
• Brolis yra teistas Brolis nėra teistas Iš visoVieno kiaušinėlio dvyniai 10 3 13Dviejų kiaušinėlių dvyniai 2 15 17
Iš viso 12 18 30Kadangi alternatyva šį kartą yra ne bet koks nuokrypis nuo prognozuojamų reikš-
mių, bet tik ryšį tarp požymių įrodantis, Fisher’io kriterijuje alternatyva pasirinksi-me "greater". Taikydami apytikslį chi kvadrato kriterijų, gauname panašų atsakymą(kadangi renkamės vienpusę alternatyvą, p-reikšmę daliname iš 2):
#Septintasdvy.matr <- rbind(c(10,3),c(2,15))fisher.test(dvy.matr,alternative="greater")chisq.test(dvy.matr)$p.value/2
76

Taigi, kokį kriterijų betaikytume, nulinę hipotezę reikia neabejotinai atmesti.Dar vienas pavyzdys. Imkime žalius duomenis, kuriuos reikia apdoroti. Ar didėja
žmogaus svoris su amžiumi? Į šį klausimą atsakyti nėra lengva – tam reikėtų dau-giamečių stebėjimų. Norėdami pailiustruoti metodus, modeliuokime du stulpelius:ob (=obesity=nutukimas: 1-nutukęs, 0-ne) ir agegr (=age group=amžiaus grupė:1-jauniausi, …, 11-vyriausi). Tarkime, kad nutukimo tikimybė didėja su amžiumi.Štai vienas iš galimų modeliavimo (ir tikimybių pasirinkimo) variantų:
#Astuntas#8.1agegr <- sample(1:11,200,repl=T)ob <- numeric(200)for(i in 1:200) ob[i] <- sample(1:0,1,prob=c(pr <- agegr[i]/12,1-pr))mytable1 <- table(ob,agegr)mytable1
Nulinę hipotezę "svoris nepriklauso nuo amžiaus" galima patikrinti ir su summaryfunkcija (kai jos argumentas – dvimatė lentelė, atsakymas praktiškai sutampa suchisq.test rezultatu:
#8.2summary(mytable1)chisq.test(mytable1)
Dar vienas variantas:
#8.3mytable2 <- xtabs(~ob+agegr)mytable2summary(mytable2)
Dar vieną galimybę (atsakymas, teisybė, nėra kompaktiškas, bet užtai panašus įSAS’o) suteikia paketo gregmisc funkcija CrossTable.
#8.4install.packages("gregmisc")library(gregmisc)cross.ob <- CrossTable(agegr, ob, expected = TRUE)names(cross.ob)cross.ob$chisq
Kaip visuomet, grafikai irgi gali būti naudingi:
#Devintaspar(mfrow=1:2)plot(jitter(agegr),jitter(ob))barplot(mytable2,beside=TRUE)
77

Hipotezės apie vidurkius
Štai klasikiniai Student’o duomenys apie papildomas miego valandas (buvo tiriamosdvi grupės po 10 žmonių, grupės vartojo du skirtingus migdomuosius vaistus). Ka-dangi kiekvienoje grupėje duomenys beveik normalūs, o jų dispersijos lygios remsimėsStudent’o dviejų imčių su lygiomis dispersijomis testu:
#Vienuoliktasdata(sleep)sleepattach(sleep)shapiro.test(extra[group==1])shapiro.test(extra[group==2])var.test(extra[group == 1], extra[group == 2])t.test(extra[group == 1], extra[group == 2],var.equal=T)
Taigi nors grupių grupių vidurkiai pastebimai skiriasi (atitinkamai, 0,75 ir 2,33papildomo miego valandos), t statistikos reikšmė –1,8608 nėra tiek didelė, kad nuli-nę hipotezę atmestume su standartiniu 5% reikšmingumo lygmeniu. Antra vertus,"slidi" 7,9% p reikšmė reiškia, kad bandymus geriausia būtų pakartoti su didesniužmonių skaičiumi. Iš tikrųjų, jei teisinga alternatyva, tai, pvz., 95% vidurkių skirtu-mo pasikliauties intervalo formulė
(X − Y )± t0,025(2n− 2)√
2s2p/n ≈ a± c/
√n.
Paskutiniam teiginiui pailiustruoti parašysime funkciją t.testas, kuri įrodys, kad kain didelis, galime atskirti net labai artimas hipotezes.
#Dvyliktast.testas <- function(){opar <- par(mfrow = c(1, 2))on.exit(par(opar))p.reiksme <- numeric(100)vid.skirtumas <- numeric(100)for(i in 1:100){
imtis1 <- rnorm(i * 10, 0, 1)imtis2 <- rnorm(i * 10, 0.2, 1)vid.skirtumas[i] <- mean(imtis1) - mean(imtis2)p.reiksme[i] <- t.test(imtis1, imtis2)$p.value
}imties.dydis <- (1:100) * 10plot(imties.dydis, vid.skirtumas, type = "l")lines(imties.dydis, rep(-0.2, 100), lty = 2)plot(imties.dydis, p.reiksme, type = "l")lines(imties.dydis, rep(0.05, 100), lty = 2)}opar <- par(mfrow = c(1,2))t.testas()
78

t.testas()par(opar)
Iki šiol nagrinėjome atvejį, kai stebėjome dvi nesusijusias populiacijas. Prisimin-kime, kad rinkinyje davis turėjome duomenis apie tikrąjį ir praneštajį svorį ir ūgį(tai žmonių, reguliariai užsiimančių fizinėmis pratybomis, svoris ir ūgis; pamatysi-me, kad jie gana gerai žino savo svorį, bet prasčiau ūgį). Naudosime porinį Studentokriterijų, nes poros yra susijusios:
#Tryliktaslibrary(car)data(davis)attach(davis)t.test(weight[sex=="M"],repwt[sex=="M"],paired=T)t.test(weight[sex=="F"],repwt[sex=="F"],paired=T)t.test(height[sex=="F"],repht[sex=="F"],paired=T)t.test(height[sex=="F"],repht[sex=="F"],paired=T)
Hipotezės apie "centrų" lygybę
9 skyriuje nagrinėjome bwages duomenų rinkinį ir, remdamiesi Wilcoxon’o (rangųženklų) kriterijumi, tikrinome hipotezę H0 : med(w0) = 422, 8220(= med(w1)) su al-ternatyva H1 : med(w0) < 422, 8220. Panašias (bet ne tapačias) hipotezes galima su-formuluoti taip: H0 : med(w0) = med(w1) su alternatyva H1 : med(w0) < med(w1).Taikydami Wilcoxon’o (rangų sumų) kriterijų dviem imtims, gauname
#Keturioliktasbwages <- read.table("bwages.txt", h=F, col.names=c("wage","lnwage","educ","exper","lnexper","lneduc","male"))attach(bwages)w0 <- wage[male==0]w1 <- wage[male==1]wilcox.test(w0,w1)
taigi nulinę hipotezę vėl neabejotinai atmetame.Pavyzdys 2.3 Marketingo padalinys nori išsiaiškinti, kuris iš dviejų naujų gaminiųbus labiau perkamas. Kadangi skonis yra pakankamai subjektyvus kriterijus, poten-cialūs pirkėjai buvo prašomi įvertinti abu gaminius skaičiais nuo 0 iki 4. Pirmąjįgaminį vertino n = 15, o antrąjį gaminį – m = 15 pirkėjų. Atrodo, kad antrasisgaminys vertinamas geriau, tačiau kaip šitai (jei tai tiesa) pagrįsti? Vienas iš būdųyra toks - apjunkime abi imtis į vieną ir išdėstykime įverčius didėjimo tvarka. Jeipirmasis gaminys būtų tiek pat geras kaip ir antrasis, tai pirmojo gaminio įverčiaibūtų daugmaž tolygiai išsidėstę jungtinėje imtyje. Kiekvienam įverčiui priskirkimejo rangą, t.y., vietą bendroje sekoje (apskaičiuojam vidutinius rangus). Tada apskai-čiuojame svorinę rangų sumą. Formaliai žiūrint, Wilcoxon’o rangų sumų (kitaip –Mann’o ir Whitney’o) testas yra skirtas tolydiesiems a.d. ir tikrina hipotezę, kad"a.d. X ir Y skirstiniai yra vienodi" su alternatyva "skirstiniai skiriasi". Iš tikrųjų,šio testo taikymas kiek siauresnis – alternatyva yra "skirstiniai skiriasi postūmiu".
#Penkioliktasm <- 15
79

n <- 15x <- c(3, 2, 3, 0, 1, 0, 2, 1, 0, 0, 4, 3, 2, 0, 3)y <- c(4, 2, 2, 0, 3, 3, 1, 2, 2, 4, 3, 2, 3, 2, 2)wilcox.test(x,y)
Hipotezės apie skirstinių lygybę
Tarkime, kad, stebėdami a.d. X ir Y gavome dvi imtis. Pagal šias imtis norimenustatyti, ar X ir Y skirstiniai (atitinkamai, F ir G) sutampa. Šią hipotezę galimatikrinti keliais būdais, o būdo pasirinkimas priklauso nuo alternatyvos. Jei alternaty-vioji hipotezė yra, kad skirstiniai nėra lygūs bent vienam x, taikysime Kolmogorovo-Smirnovo dviejų imčių testą (jis taikomas, kai abi skirstinio funkcijos tolydžios). Jeiskirstinio funkcijos skiriasi tik postūmiu, taikysime Wilcoxon’o rangų sumos testąwilcox.test iš stats arba, kai imčių dydžiai nėra dideli, wilcox.exact iš exacRankTests(stebimieji dydžiai dabar gali būti ir ranginiai). Tuo atveju, kai tikrinama "sukeičia-mumo" (exchangeability) galimybė, taikysime keitinių testą perm.test iš exacRank-Tests paketo (stebimieji dydžiai turi įgyti sveikas reikšmes).
Štai dvi paprastos funkcijos, kurios brėžia empirinės skirstinio funkcijos grafikus:
#Sesioliktasplot.sdf <- function(x)
plot(c(min(x),sort(x)),c(0:length(x)/length(x)),type="s")lines.sdf <- function(x,col=2)
lines(c(min(x),sort(x)),c(0:length(x)/length(x)),type="s",col=col)plot.sdf(rnorm(50))lines.sdf(rnorm(50))lines.sdf(rnorm(50),col=3)curve(pnorm,-2,2,add=T)
Išbandykime KS testą su dviem nedidelėmis imtimis:
#Septynioliktas#17.1rst <- rt(50,2)rn <- rnorm(50)plot.sdf(rst)lines.sdf(rn)ks.test(rst,rn)wilcox.test(rst,rn)
Taigi, KS testas nemato pagrindo atmesti hipotezę apie skirstinių lygybę. Antravertus, kai imtys didesnės, skirtumai išryškėja.
#17.2rst <- rt(500,2)rn <- rnorm(500)plot.sdf(rst)lines.sdf(rn)ks.test(rst,rn)wilcox.test(rst,rn)
80

Matome, kad KS testas beveik atmeta hipotezę apie skirstinių lygybę, tuo tarpukai Vilkoksono testas to nesiūlo. Antra vertus, jei dvi imtys skiriasi tik postūmiu,rezultatai atrodo taip:
#Astuonioliktasset.seed(1)rg <- rgamma(5,shape=2)rg1 <- rgamma(20,shape=2)op <- par(mfrow=c(1,2))plot.sdf(rg)lines.sdf(rg1)rg2 <- rg1+0.5plot.sdf(rg)lines.sdf(rg2)par(op)ks.test(rg,rg1)ks.test(rg,rg2)wilcox.test(rg,rg1)wilcox.test(rg,rg2)
2.11.2 Užduotys1. Remdamiesi duomenų rinkinio bwages duomenimis, patikrinkite ar vyrai ir mo-
terys yra vienodai išsilavinę.
2. Duomenų rinkinyje sleep kiekvienoje grupėje buvo tik po 10 įrašų. Todėl tiks-linga pakartoti hipotezę apie papildomo miego trukmės lygybę abiejose gru-pėse, naudojant neparametrinį Wilcoxon’o kriterijų. Šią analizę atlikite suwilcox.test.
3. Pakete MASS yra duomenų rinkinys Aids2. Ar vienoda šiame sąraše esančiųvyrų ir moterų amžiaus struktūra?
81

3Laboratoriniai darbai
Atliekant laboratorinį darbą studentai privalo parašyti trumpą (iki 6 lapų) darboaprašymą su įdėtais R’o kodais ir komentarais ties kiekviena eilute. Pvz, kaip turibūti pateiktas R kodas:
# sukuriamas pirmas kintamasisx <- rnorm(10)
# sukuriamas antras kintamasisy <- rnorm(10,1,1)
# apskaičiuojama x ir y sumaz <- x + y
# apskaičiuojamas z vidurkis ir dispersijamean(z)var(z)
Pastaba: Darbo ataskaitai nepakanka tik R kodo. Turi būti pateiktas ir apra-šymas bei išvados ir grafikai, jei reikalauja užduotis.
Pirmame darbo lape turi būti nurodyta studento vardas, pavardė, specialybė beigrupė. Taip pat nurodomas laboratorinio darbo pavadinimas, pvz., „1 laboratorinisdarbas. Prancūzijos makroekonominiai rodikliai“
3.1 AprašymasDarbą sudaro dvi dalys: analizė su generuotais ir tikrais duomenimis. Duomenųsąrašas yra pateiktas kitame poskyryje. Kiekvienam studentui priskirtas originalusduomenų rinkinys, kurį studentas turi pats susirasti įvairiose duomenų bazėse. Duo-menų laikotarpis turi būti ilgiausias įmanomas (pvz., Lietuvos atveju nuo 1995 m. irketvirtiniai duomenys, jei juos pateikia Statistikos departamentas). Užduotis visiemsbendra, tačiau turi būti atliekama atskirai, nes realūs duomenys visų skirtingi.
82

3.2 Duomenų rinkiniai1. Lietuvos BVP (GDP), galutinis vartojimas (final consumption expenditures),
kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
2. Latvijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
3. Estijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
4. Lenkijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
5. Vokietijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
6. Prancūzijos BVP (GDP), galutinis vartojimas (final consumption expenditu-res), kapitalas (gross capital formation), eksportas (export of good and servi-ces), importas (import of good and services).
7. Italijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
8. Graikijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
9. Suomijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
10. Švedijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
11. Norvegijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
12. Ispanijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
13. Portugalijos BVP (GDP), galutinis vartojimas (final consumption expenditu-res), kapitalas (gross capital formation), eksportas (export of good and servi-ces), importas (import of good and services).
83

14. Olandijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
15. Danijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
16. Belgijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
17. Austrijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
18. Jungtinės Karalystės BVP (GDP), galutinis vartojimas (final consumptionexpenditures), kapitalas (gross capital formation), eksportas (export of goodand services), importas (import of good and services).
19. Jungtinių valstijų BVP (GDP), galutinis vartojimas (final consumption expen-ditures), kapitalas (gross capital formation), eksportas (export of good andservices), importas (import of good and services).
20. Airijos BVP (GDP), galutinis vartojimas (final consumption expenditures),kapitalas (gross capital formation), eksportas (export of good and services),importas (import of good and services).
21. Lietuvos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
22. Latvijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
23. Estijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
24. Lenkijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
25. Vokietijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
26. Prancūzijos populiacija (population), gimstamumas (fertility), mirtingumas(mortality), santuokos (marriages), skyrybos (divorces).
27. Italijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
28. Graikijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
84

29. Suomijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
30. Švedijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
31. Norvegijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
32. Ispanijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
33. Portugalijos populiacija (population), gimstamumas (fertility), mirtingumas(mortality), santuokos (marriages), skyrybos (divorces).
34. Olandijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
35. Danijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
36. Belgijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
37. Austrijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
38. Jungtinės Karalystės populiacija (population), gimstamumas (fertility), mir-tingumas (mortality), santuokos (marriages), skyrybos (divorces).
39. Jungtinių valstijų populiacija (population), gimstamumas (fertility), mirtingu-mas (mortality), santuokos (marriages), skyrybos (divorces).
40. Airijos populiacija (population), gimstamumas (fertility), mirtingumas (mor-tality), santuokos (marriages), skyrybos (divorces).
41. Lietuvos vyriausybės pajamos (total general governement revenue), vyriausy-bės išlaidos (total general governement expenditure), nedarbo lygis (unemplo-yment rate), dirbančiųjų skaičius (employment).
42. Latvijos vyriausybės pajamos (total general governement revenue), vyriausybėsišlaidos (total general governement expenditure), nedarbo lygis (unemploymentrate), dirbančiųjų skaičius (employment).
43. Estijos vyriausybės pajamos (total general governement revenue), vyriausybėsišlaidos (total general governement expenditure), nedarbo lygis (unemploymentrate), dirbančiųjų skaičius (employment).
44. Lenkijos vyriausybės pajamos (total general governement revenue), vyriausy-bės išlaidos (total general governement expenditure), nedarbo lygis (unemplo-yment rate), dirbančiųjų skaičius (employment).
85

45. Vokietijos vyriausybės pajamos (total general governement revenue), vyriausy-bės išlaidos (total general governement expenditure), nedarbo lygis (unemplo-yment rate), dirbančiųjų skaičius (employment).
46. Prancūzijos vyriausybės pajamos (total general governement revenue), vyriau-sybės išlaidos (total general governement expenditure), nedarbo lygis (unemp-loyment rate), dirbančiųjų skaičius (employment).
47. Italijos vyriausybės pajamos (total general governement revenue), vyriausybėsišlaidos (total general governement expenditure), nedarbo lygis (unemploymentrate), dirbančiųjų skaičius (employment).
48. Graikijos vyriausybės pajamos (total general governement revenue), vyriausy-bės išlaidos (total general governement expenditure), nedarbo lygis (unemplo-yment rate), dirbančiųjų skaičius (employment).
49. Suomijos vyriausybės pajamos (total general governement revenue), vyriausy-bės išlaidos (total general governement expenditure), nedarbo lygis (unemplo-yment rate), dirbančiųjų skaičius (employment).
50. Švedijos vyriausybės pajamos (total general governement revenue), vyriausybėsišlaidos (total general governement expenditure), nedarbo lygis (unemploymentrate), dirbančiųjų skaičius (employment).
51. Norvegijos vyriausybės pajamos (total general governement revenue), vyriau-sybės išlaidos (total general governement expenditure), nedarbo lygis (unemp-loyment rate), dirbančiųjų skaičius (employment).
52. Ispanijos vyriausybės pajamos (total general governement revenue), vyriausy-bės išlaidos (total general governement expenditure), nedarbo lygis (unemplo-yment rate), dirbančiųjų skaičius (employment).
53. Portugalijos vyriausybės pajamos (total general governement revenue), vyriau-sybės išlaidos (total general governement expenditure), nedarbo lygis (unemp-loyment rate), dirbančiųjų skaičius (employment).
54. Olandijos vyriausybės pajamos (total general governement revenue), vyriausy-bės išlaidos (total general governement expenditure), nedarbo lygis (unemplo-yment rate), dirbančiųjų skaičius (employment).
55. Danijos vyriausybės pajamos (total general governement revenue), vyriausybėsišlaidos (total general governement expenditure), nedarbo lygis (unemploymentrate), dirbančiųjų skaičius (employment).
56. Belgijos vyriausybės pajamos (total general governement revenue), vyriausybėsišlaidos (total general governement expenditure), nedarbo lygis (unemploymentrate), dirbančiųjų skaičius (employment).
57. Austrijos vyriausybės pajamos (total general governement revenue), vyriausy-bės išlaidos (total general governement expenditure), nedarbo lygis (unemplo-yment rate), dirbančiųjų skaičius (employment).
86

58. jungtinės Karalystės vyriausybės pajamos (total general governement revenue),vyriausybės išlaidos (total general governement expenditure), nedarbo lygis(unemployment rate), dirbančiųjų skaičius (employment).
59. jungtinių valstijų vyriausybės pajamos (total general governement revenue),vyriausybės išlaidos (total general governement expenditure), nedarbo lygis(unemployment rate), dirbančiųjų skaičius (employment).
60. Airijos vyriausybės pajamos (total general governement revenue), vyriausybėsišlaidos (total general governement expenditure), nedarbo lygis (unemploymentrate), dirbančiųjų skaičius (employment).
87

3.3 Pirmas laboratorinis darbasŠiems laboratoriniams darbams reikės R. Lapinsko konspekto "Įvadas į statistiką suR" 1-3 skyrių.
3.3.1 I dalis• Aritmetinė ir geometrinė progresija.
– Sukurkite aritmetinę ir geometrinę progresijas (aritmetinę (geometrinę)progresiją pateikite kaip funkcijos ar.pr(n,a1,d) (atitinkamai, geo.pr(n,b1,q)) reikšmę);
– Viename grafike išbrėžkite dalinių progresijos sumų ir pačios progresijoskreives.
– Progresijas sukurkite trim būdais: apibrėždami jas rekurentiškai, naudo-dami bendrojo nario formulę ir naudodami R vektorinę aritmetiką (pvz.,progresiją 1, 2, 4, 8 galima užrašyti kaip 2(0 : 3)).
• Fibonači skaičiai:
– Parašykite funkciją, kuri sukurtų n narių Fibonači seką (priminsime: taiseka, tenkinanti sąlygą a1 = 1, a2 = 1, ak+2 = ak + ak+1 ),
– Išbrėžkite jos grafiką,– paskutiniojo skaitmens reikšmių histogramą.
• Skaičių generavimas.
– Ką atlieka funkcijos runif, rnorm, rpois, rt, rbinom?– Sugeneruokite 1000 ilgio vektorių su rpois funkcija su parametru λ = 3.
Visus vektoriaus elementus mažesnius už 3 pakeiskite nuliu, o elementuslygius 3 – devynetuku;
– tą pat atlikite su matrica rpm <- matrix(rpois(999,3),nrow=333);– iš šios matricos pašalinkite eilutes, kuriose yra bent vienas 3;– iš šios matricos pašalinkite eilutes, sudarytas vien iš 3;– eilutėse, kurių pirmas elementas lygus 3, kitus du pakeiskite jų kvadratais.– Ką daro funkcija x <- rnorm(1000)?– Sugeneruokite 1000 duomenų su funkcija rnorm. Duomenis sugrupuokite
po 10, kiekvienoje grupėje apskaičiuokite vidurkį, o po to – šio naujovidurkių vektoriaus standartinį nuokrypį.
• Naudodamiesi R funkcijomis išbrėžkite normaliojo, Stjudento, eksponentinio,tolygiojo skirstinių pasiskirstymo bei tankio funkcijas. Išbrėžkite diskrečiųjųskirstinių Binominio ir Puasono pasiskirstymo funkcijas.
88

3.3.2 II dalis• Nuskaitykite savo turimų realių duomenų rinkinį.
• Nustatykite duomenų rinkinio tipą ir klasę.
• Pakeiskite turimų duomenų klasę į bet kurią kitą Jums žinomą.
• Paverskite duomenis vienu vektoriumi.
• Sukurkite vardinių duomenų vektorių. Prijunkite jį prie pradinio savo turimųduomenų rinkinio.
89

3.4 Antras laboratorinis darbasŠiems laboratoriniams darbams reikės R. Lapinsko konspekto "Įvadas į statistiką suR" 4-5 skyrių.
3.4.1 I dalis• Išskirtys (outliers) dažnai signalizuoja apie tai, kad imtyje yra “nereguliarių”
stebėjimų arba “klaidų”. Nėra standartinių rekomendacijų, ką daryti su iš-skirtimis (dažnai išskirtys tiesiog atmetamos, tačiau jei keli taškai prieštaraujamūsų modeliui, tai gal tiesiog modelis blogas?). Kaip ten bebūtų, pabandyki-me aptarti, ką vadinti išskirtimis ir kaip jų efektą susilpninti. Dažnai teikiamarekomendacija atmesti duomenis, kurie netelpa į intervalą mean ± 3sd (trijųsigmų taisyklė); deja ji nėra visuomet gera, nes tuomet, kai turime išskirčiųkaip vidurkis taip ir standartas gali būti toli nuo “tikrųjų”. Tokiu atveju tiks-lingiau naudotis “atspariomis” statistikomis, pvz., mediana ar MAD(medianaverage deviation):
mediana|xi −mediana(x)| · 1.4826
Nagrinėkime duomenų vektorių x
0.378 -22.831 1.123 -10.789 0.191 0.168 0.552 1.192 1.767 0.170-1.108 -1.714 6.045 -1.424 -1.226 -26.948 1.875 -2.059 -0.491 0.010-9.526 0.216 -0.479 -27.457 1.148 -3.852 -0.859 -1.338 -0.037 0.9120.831 0.132 -0.887 0.144 0.042 3.145 -0.546 321.202 0.612 0.0671.910 0.952 -0.738 -4.508 23.327 0.564 3.658 0.885 -0.116 5.2320.205 -3.820 -0.236 -0.386 0.727 -3.817 -2.584 -1.514 20.013 -0.160-0.374 -0.183 -0.368 1.156 -2.995 -1.222 0.041 -0.589 0.993 0.2230.043 -2.175 0.576 0.540 -0.179 -4.750 0.585 -1.999 -0.830 -0.6534.030 1.472 -0.302 0.509 3.809 1.811 -19.947 -1.860 4.351 0.0581.021 1.986 1.389 -0.136 0.459 0.766 -17.920 1.940 1.646 1.211
Keturiuose polangiuose išbrėžkite keturias stačiakampes diagramas: 1) pa-čių duomenų x, 2) rinkinyje x palikite tik duomenis telpančius į intervalą[mean(x)− 3 ∗ sd(x),mean(x) + 3 ∗ sd(x)], 3) rinkinyje x palikite tik duomenistarp 0,025-ojo ir 0,975-jo kvantilių, 4) teorija rekomenduoja rinkinyje x paliktitik duomenis iš intervalo [median(x)−3, 5∗mad(x),median(x)+3, 5∗mad(x)].
• Išbrėžkite dvi Lorenz’o kreives, kurios atitiktų atvejus, kai ūkių pajamos turia) normąlųjį skirstinį su vidurkiu 0 ir standartiniu nuokrypiu 5000 (imtį suda-rykite tik iš teigiamų šio objekto elementų) ir b) Pareto skirstinį su parametruc = 2. Interpretuokite Lorenz’o kreivę.
• Pateiksime procedūrą, kuri generuoja vadinamąjį dvimodalinį (t.y. tokį, kuriotankis turi dvi modas (lokaliuosius maksimumus)) skirstinį.
two.mod <- function(n){
90

x <- numeric(n)for(i in 1:n) if (runif(1)<0.3) x[i]<-rnorm(1) else x[i]<-rnorm(1,mean=5)return(x)}
Generuokime 1000 šių atsitiktinių skaičių ir išbrėžkime jų histogramą.
par(mfrow=c(1,2))y<-two.mod(1000)hist(y,prob=T)lines(density(y))
median(y)[1] 4.445219
Kaip toli yra šis medianos įvertis nuo tikrosios? Aišku, kad aprašytąją mode-liavimo procedūrą galime pakartoti daug kartų ir taip ištirti, tarkime, skirstiniomedianos kintamumą(pvz., rasti jos pasikliauties intervalą arba bent įvertintijos tarpkvartilinį atstumą IQD). Deja, praktikos uždaviniuose paprastai turimetik vieną imtį ir teoriškai įvertinti mūsų(aiškiai nenormalaus) skirstinio media-nos IQD nėra lengva. Tokiu atveju galima taikyti vadinamąjį savirankos (=bootstrap (angl.)) metodą, kuris siūlo imti naujas imtis ne iš populiacijos, bettik iš turimos imties. Galima įrodyti,kad tam tikromis sąlygomis abu metodaiduoda panašų rezultatą.
y.boot <- sample(y,1000,replace=T)hist(y.boot,main="bootstrap",prob=T)lines(density(y.boot))
median(y.boot)[1] 4.338387
O dabar UŽDUOTIS. i) Generuokite 500 imčių po 600 skaičių su two.mod funk-cija. Apskaičiuokite kiekvienos imties medianą ir raskite jos IQD. ii) Paimkitedar vieną imtį sudarykite 500 jo butstrepinių kopijų ir apskaičiuokite medianosIQD. Palyginkite abu įverčius.
3.4.2 II dalis• Savo turimam duomenų rinkiniui apskaičiuokite pagrindines skaitines charak-
teristikas: vidurkį, dispersiją, standartinį nuokrypį, maksimumą, minimumą.
• Išbrėžkite grafiką, kuris vaizduoja šias charakteristikas.
• Išbrėžkite turimų duomenų grafikus. Kokias tendencijas matote? Pakomen-tuokite galimas priežastis.
• Pagal savo turimus duomenis atsakykite į vieną iš klausimų:
91

– Išbrėžkite galutinio vartojimo ir importo bei galutinio vartojimo ir ekspor-to sklaidos diagramas. Šiame grafike uždėkite regresijos tiesę. Ar turimirodikliai yra susiję?
– Išbrėžkite gimstamumo ir santuokų skaičiaus bei mirtingumo ir santuokųskaičiaus sklaidos diagramas. Šiame grafike uždėkite regresijos tiesę. Arturimi rodikliai yra susiję?
– Išbrėžkite vyriausybės pajamų ir dirbančiųjų bei vyriausybės išlaidų irdirbančiųjų sklaidos diagramas. Šiame grafike uždėkite regresijos tiesę.Ar turimi rodikliai yra susiję?
92

3.5 Trečias laboratorinis darbasŠiems laboratoriniams darbams reikės R. Lapinsko konspekto "Įvadas į statistiką suR" 6-9 skyrių.
3.5.1 I dalis• Pakete animation yra funkcija clt.ani, kuri vaizduoja centrinę ribinę teoremą.
Išsiaiškinkite šia funkciją. Išsiaiškinkite tekstą:
oopt = ani.options(interval = 0.1, nmax = 150)op = par(mar = c(3, 3, 1, 0.5), mgp = c(1.5, 0.5, 0), tcl = -0.3)clt.ani(type = "s")par(op)
• Pakete animation yra funkcija lln.ani, kuri vaizduoja didžiųjų skaičių dėsnį.Išsiaiškinkite šia funkciją. Išsiaiškinkite tekstą:
oopt = ani.options(interval = 0.01, nmax = 150)lln.ani(pch = ".")
lln.ani(function(n, mu) rchisq(n, df = mu), mu = 5, cex = 0.6)
• Štai funkcija, kuri pateikia geometrinę dispersijos pasikliauties intervalo inter-pretaciją:
chi <- function(){# funkcija chix <- seq(0,12,length=400)plot(x,dchisq(x,4),type="l", # Laisvės laipsnių skaičius =4main=expression(paste(alpha,"=0,9"))) # Gali būti net formulės!lines(x,rep(0,400))xx.lo <- seq(0,qchisq(0.05,3),length=50) # Reikšmingumo lygmuo 0,9XX.lo <- c(xx.lo,-sort(-xx.lo),0)YY.lo <- c(rep(0,50),dchisq(-sort(-xx.lo),4),0)polygon(XX.lo,YY.lo,col="yellow") # Nuspalvinsime kairiąją uodegą# (iki 0,05-jo kvantilio))xx.up <- seq(qchisq(0.95,3),12,length=50)XX.up <- c(xx.up,-sort(-xx.up),xx.up[1])YY.up <- c(rep(0,50),dchisq(-sort(-xx.up),4),0)polygon(XX.up,YY.up,col="yellow") # Nuspalvinsime dešinę uodegą;# jos plotas irgi lygus (1-0,9)/2}
Pateikite vidurkio pasikliautinojo intervalo, kai dispersija žinoma, geometrinęinterpretaciją.
• Pasiimkite duomenis Insurance paketą iš paketo MASS.
93

1. Nustatykite kiekvieno kintamojo tipą ir klasę.2. Kiek įrašų yra kiekvienoje Age grupėje?3. Atspausdinkite lentelę, kurios eilutėse būtų Group, stulpeliuose - Age, o
langeliuose – suminė Claims reikšmė.4. Išbrėžkite Claims stačiakampes diagramas kiekvienai District reikšmei.5. Identifikuokite išskirtis.
3.5.2 II dalis• Savo turimam realių duomenų rinkiniui apskaičiuokite koreliacijos koeficientų
matrica (tie kurie nagrinėja BVP ir susijusius duomenis, BVP išimkite).
• Parašykite funkciją, kuri atspausdintų tik tuos (ne ant įstrižainės esančius) koe-ficientus, kurių modulis didesnis už 0,5 (kartu su atitinkamų eilučių ir stulpeliųvardais).
• Savo turimiems duomenims suformuluokite „logiškas“ hipotezes apie vidurkiųlygybę skaičiams ir/arba proporcijų lygybę ir patikrinkite šias hipotezes.
94





























