Embed Size (px)
Citation preview

Statistiques et Probabilités 2
Mohamed BOUTAHAR 1
4 octobre 2005
1Département de mathématiques case 901, Faculté des Sciences de Luminy. 163 Av.de Luminy 13288 MARSEILLE Cedex 9, et GREQAM, 2 rue de la vieille charité 13002.e-mail : [email protected]

Table des matières
1 Distributions de probabilité discrètes 41 Inégalités classiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.1 Inégalité de Markov . . . . . . . . . . . . . . . . . . . . . . . . 41.2 Inégalité de Bienaymé-Tchebychev . . . . . . . . . . . . . . . 4
2 Indépendance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.1 Variables indépendantes . . . . . . . . . . . . . . . . . . . . . 52.2 Distributions marginales . . . . . . . . . . . . . . . . . . . . . 5
3 Fonction génératrice . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Distributions de probabilité continues 71 Densité de probabilité, moments . . . . . . . . . . . . . . . . . . . . . 72 Fonction caractéristique . . . . . . . . . . . . . . . . . . . . . . . . . 83 Indépendance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.1 Distributions marginales . . . . . . . . . . . . . . . . . . . . . 93.2 Variables indépendantes . . . . . . . . . . . . . . . . . . . . . 9
4 Fonction de répartition . . . . . . . . . . . . . . . . . . . . . . . . . . 104.1 Cas scalaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.2 Cas d’un couple aléatoire . . . . . . . . . . . . . . . . . . . . . 10
5 Distributions usuelles . . . . . . . . . . . . . . . . . . . . . . . . . . . 115.1 Loi uniforme . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115.2 Loi de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . 115.3 Loi exponentielle . . . . . . . . . . . . . . . . . . . . . . . . . 115.4 Loi gamma . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115.5 Loi de Cauchy . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6 Transformation des variables aléatoires . . . . . . . . . . . . . . . . . 126.1 Cas discret . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126.2 Cas continu . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
7 Suite de variables aléatoires . . . . . . . . . . . . . . . . . . . . . 137.1 Loi de Khi-deux . . . . . . . . . . . . . . . . . . . . . . . . . 137.2 Loi de Student . . . . . . . . . . . . . . . . . . . . . . . . . . 137.3 Loi de Fisher . . . . . . . . . . . . . . . . . . . . . . . . . . . 147.4 Loi de la moyenne et variance empirique . . . . . . . . . . . . 14
1

TABLE DES MATIÈRES 2
3 Description d’une série statistique 151 Généralités, Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . 152 Distribution des fréquences . . . . . . . . . . . . . . . . . . . . . . . . 16
2.1 Cas discret . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2 Cas continu . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.3 Distribution des fréquences . . . . . . . . . . . . . . . . . . . . 172.4 Représentation graphique des distributions de fréquences . . . 18
3 Caractéristiques de tendance centrale . . . . . . . . . . . . . . . . . . 183.1 Définition : . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4 Caractéristiques de dispersion . . . . . . . . . . . . . . . . . . . . . . 184.1 La dispersion en termes d’intervalles . . . . . . . . . . . . . . 194.2 La dispersion en termes d’écarts . . . . . . . . . . . . . . . . . 19
5 Moments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4 Liaisons entre variables statistiques 220.1 La distribution marginale . . . . . . . . . . . . . . . . . . . . 230.2 La distribution conditionnelle . . . . . . . . . . . . . . . . . . 23
1 L’ajustement, régression simple . . . . . . . . . . . . . . . . . . . . . 241.1 Coefficient de corrélation linéaire : . . . . . . . . . . . . . . . . 241.2 Ajustement par la méthode des moindres carrés . . . . . . . . 241.3 Qualité d’ajustement . . . . . . . . . . . . . . . . . . . . . . . 25
5 Estimation statistique et test d’hypothèses 291 Estimation ponctuelle des paramètres . . . . . . . . . . . . . . . . . . 29
1.1 Choix des estimateurs . . . . . . . . . . . . . . . . . . . . . . 291.2 Construction des estimateurs . . . . . . . . . . . . . . . . . . 30
2 Estimation par intervalle de confiance et Tests . . . . . . . . . . . . . 312.1 Intervalle de confiance pour la moyenne d’une population gaussi-
enne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.2 Comparaison d’une moyenne théorique et d’une moyenne ob-
servée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.3 Comparaison des moyennes de deux échantillons indépendants. 322.4 Comparaison des moyennes de deux séries appariés. . . . . . . 33
2.5 Intervalle de confiance pour la variance d’une population gaussi-enne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.6 Comparaison d’une variance théorique et d’une variance ob-servée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.7 Comparaison des variances de deux échantillons indépendants 343 Analyse de la variance . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.1 Comparaison simultanée de plusieurs moyennes . . . . . . . . 353.2 Comparaison simultanée de plusieurs variances . . . . . . . . . 36

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 3
6 EXERCICES 371 Distributions de Probabilité Discrètes . . . . . . . . . . . . . . . . . 372 Distributions de Probabilité Continues . . . . . . . . . . . . . . . . . 383 Estimation et tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40

Chapitre 1
Distributions de probabilitédiscrètes
1 Inégalités classiques
1.1 Inégalité de Markov
Theorem 1 Soit X une variable aléatoire à valeurs dans un espace dénombrable Eavec E ⊂ R, alors pour tout a > 0,
P (|f(X)| ≥ a) ≤ E(|f(X)|)a
. (1.1)
Preuve : On a
E(|f(X)|) =Xxk∈E
|f(xk)| pk
=Xxk∈A
|f(xk)| pk +Xxk∈A
|f(xk)| pk,
où A = {xk ∈ E, |f(xk)| ≥ a} , et A est le complémentaire de A dans E. DoncE(|f(X)|) ≥
Xxk∈A
|f(xk)| pk
≥Xxk∈A
apk,
de plusP
xk∈A pk = P (X ∈ A) = P (|f(X)| ≥ a).¤
1.2 Inégalité de Bienaymé-Tchebychev
Theorem 2 Soit X une variable aléatoire à valeurs dans E, alors pour tout ε > 0
P (|X −EX| ≥ ε) ≤ σ2Xε2
. (1.2)
4

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 5
Preuve : On applique l’inégalité de Markov (1.1) avec f(t) = |t− EX|2 , a =ε2.¤
2 Indépendance
2.1 Variables indépendantes
Soit X et Y deux variables aléatoires. On dit que X et Y sont indépendantes si
P (X ∈ A, Y ∈ B) = P (X ∈ A)P (Y ∈ B). (1.3)
2.2 Distributions marginales
Soit E1 × E2 et le couple aléatoire X = (X1, X2)0, où chaque Xi est à valeurs
dans Ei. La distribution marginale de la variable Xi est définie par Pi(A) =P (Xi ∈ A),∀A ∈ F .
Theorem 3 Soit X et Y deux variables aléatoires discrètes à valeurs dans E1 etE2,et indépendantes, soit f : E1 → R, et g : E2 → R, telles que f(X) et g(Y ) sontintégrables alors f(X)g(Y ) est intégrable et
E(f(X)g(Y )) = E(f(X))E(g(Y )) (1.4)
Preuve : Posons Z = (X,Y ) et h(Z) = f(X)g(Y ), alors Z est à valeurs dansE = E1 × E2, de plus d’après l’hypothèse d’indépendance P ((X,Y ) = (x, y)) =P (X = x)P (Y = y). Donc
E(|h(Z)|) =Xzk∈E
|h(zk)|P (Z = zk)
=Xxk,yl
|f(xk)| |g(yl)|P (X = xk)P (Y = yl)
=Xxk
|f(xk)|P (X = xk)Xyl
|g(yl)|P (Y = yl)
car f(X) et g(Y ) sont intégrables, donc E(|h(Z)|) < ∞, par conséquent h(Z) estintégrable. Par un raisonnement analogue à ci-dessus, mais sans la valeur absolueon obtient l’égalité (1.4). ¤
Theorem 4 (Variance d’une somme de variables aléatoires indépendantes). SoitX1 et X2 2 variables aléatoires indépendantes, alors
V (X1 +X2) = V (X1) + V (X2). (1.5)

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 6
Preuve :V (X1 +X2) = V (X1) + V (X2) + 2 cov(X1,X2),
où cov(X1,X2) = E((X1 − EX1)(X2 − EX2)) est la covariance de X1 et X2,mais d’après (1.4) on a cov(X1, X2) = E((X1 − EX1)(X2 − EX2)) = E((X1 −EX1))E((X2 −EX2)) = 0.¤Remarque : Si deux variables aléatoires X et Y sont indépendantes alors elles
sont non covariées (cov(X,Y ) = 0).
3 Fonction génératrice
Soit X une variable discrète à valeurs dans N.
Definition 1 On appelle fonction génératrice de X, l’application gX : C → Cdéfinie par :
gX(s) = E(sX) =∞Xk=0
skP (X = k), |s| ≤ 1.
La connaissance de la fonction génératrice gX permet le calcul des moments deX, en effet on a
EX = g0X(1) et E(X2) = g00X(1) + g0X(1), (1.6)
où g0X et g00X sont les dérivées première et seconde de la fonction gX .
Theorem 5 Soit X et Y deux variables aléatoires indépendantes à valeurs dans N,alors
gX+Y (s) = gX(s)gY (s) (1.7)
Preuve : gX+Y (s) = E(sX+Y ) = E(sXsY ) = E(sX)E(sY ), d’après (1.4). ¤.

Chapitre 2
Distributions de probabilitécontinues
Soit X une variable aléatoire à valeurs dans E ⊂ R ou Rd, si E est non dénom-brable, alors on dit que X est une variable continue.
1 Densité de probabilité, moments
Soit X = (X1, X2) un couple aléatoire à valeurs dans R2, et soit fX une fonctionde R2 dans R+ intégrable et telle queZ
R2fX(x)dx = 1. (2.1)
On dit que X admet la densité de probabilité fX si pour tout A ⊂ R2
P (X ∈ A) =
ZA
fX(x)dx.
Soit g : R2 → R, telle queRR2 |g(x)| fX(x)dx < ∞, alors on définit l’espérance
mathématique de g(X) par
E(g(X)) =
ZR2g(x)fX(x)dx, (2.2)
en particulier i) si E(g(X)) existe avec g(x1, x2) = gi(x) = xi, 1 ≤ i ≤ 2, alors ondéfinit l’espérance mathématique du couple X par
E(X) =
E(X1)
E(X2)
=
RR2 x1fX(x)dxRR2 x2fX(x)dx
.
7

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 8
ii) si E(g(X)) existe avec g(x1, x2) = gigj(x) = xixj, 1 ≤ i ≤ 2, 1 ≤ j ≤ 2, alors ondéfinit la matrice de covariance du couple aléatoire X = (X1, X2) par
V (X) =
µV (X1) cov(X1, X2)
cov(X2,X1) V (X2)
¶,
où
cov(X1, X2) = cov(X2, X1) = E(X1X2)−E(X1)E(X2)
=
ZR2x1x2fX(x)dx−
ZR2x1fX(x)dx
ZR2x2fX(x)dx.
2 Fonction caractéristique
Soit X un couple aléatoire à valeurs dans R2.
Definition 2 On appelle fonction caractéristique de X, l’application φX : R2 →C définie par :
φX(u) = φX(u1, u2) = E(ei(u1X1+u2X2)), avec i2 = −1.
La connaissance de la fonction caractéristique φX permet le calcul des momentsde X, en effet si X est une variable aléatoire, on a
Theorem 6 Si on suppose de plus que E(Xk) < ∞ et que la fonction φ est declasse C∞, alors
E(Xk) =φ(k)(0)
ik(2.3)
où φ(k) est la dérivée d’ordre k de la fonction φ.
Preuve : D’après la formule de Taylor φ(t) =P∞
k=0φ(k)(0)tk
k!= E(eitX) =
E(P∞
k=0(itX)k
k!) =
P∞k=0
(it)k
k!E(Xk).¤.
Theorem 7 Si deux couples aléatoires à valeurs dans R2 ont la même fonctioncaractéristique, alors ils ont la même loi, c’est à dire la même densité.
Preuve : On se limite au cas où φX = φY = φ est intégrable, dans ce cas lethéorème résulte de l’application du théorème d’inversion de Fourier
fX(x) = fY (x) =1
(2π)2
ZR2e−i(x1u1+x2u2)φ(u1, u2)du1u2.¤

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 9
3 Indépendance
3.1 Distributions marginales
SoientX et Y deux variables aléatoires à valeurs dans R tels que (X,Y )0 admettela densité fX,Y (x, y). Alors on définit les densités marginales de X et de Y par
fX(x) =
ZRfX,Y (x, y)dy et fY (y) =
ZRfX,Y (x, y)dx
3.2 Variables indépendantes
Soient X et Y deux variables aléatoires à valeurs dans R.On dit que X et Y sontindépendantes si
P (X ∈ A, Y ∈ B) = P (X ∈ A)P (Y ∈ B). (2.4)
En utilisant le théorème de Fubini, et les mêmes arguments que le théorème 3 onobtient le théorème
Theorem 8 Soit X et Y deux variables aléatoires à valeurs dans R indépendantes,soit f : R → R, et g : R → R, telles que f(X) et g(Y ) sont intégrables alorsf(X)g(Y ) est intégrable et
E(f(X)g(Y )) = E(f(X))E(g(Y )) (2.5)
Theorem 9 (admi) Soit X = (X1,X2)de densité fX(x), et tel que les Xi, 1 ≤ i ≤ 2,soient des variables aléatoires indépendantes. On a alors
fX(x1, x2) = fX1(x1)fX2(x2), (2.6)
où fXi est la densité marginale de la variable Xi.Réciproquement si fX a la forme (2.6) où les fXi , 1 ≤ i ≤ 2 sont des densités deprobabilité, alors les Xi, 1 ≤ i ≤ 2, sont indépendantes et les fXi
sont les densitésdes Xi.
Theorem 10 Soit X = (X1,X2) de densité fX(x) et de fonction caractéristiqueφX(u). Pour que les variables aléatoires Xi, 1 ≤ i ≤ 2, soient indépendantes, il fautet il suffit que
φX(u1, u2) = φX1(u1)φX2
(u2), (2.7)
où φXiest la fonction caractéristique de la variable Xi.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 10
Preuve : Supposons que lesXk sont indépendantes, alors fX(x1, x2) = fX1(x1)fX2(x2),donc
φX(u) =
ZR2ei(u1x1+u2x2)fX(x)dx =
ZR2eiu1x1eiu2x2fX1(x1)fX2(x2)dx1dx2,
donc d’après Fubini
φX(u) =
ZReiu1x1fX1(x1)dx1
ZReiu2x2fX2(x2)dx2 = φX1
(u1)φX2(u2).
Inversement, supposons que (2.7) est satisfaite, Soit X̃j, 1 ≤ j ≤ 2, une suite de vari-ables indépendantes telles que chaque X̃j ait la même loi que Xj, et X̃ = (X̃1, X̃2).D’après la partie directe du théorème :
φX̃(u1, u2) = φX̃1(u1)φX̃2
(u2),
et comme φX̃i(ui) = φXi
(ui), on a φX̃(u) = φX(u), donc, par le théorème 7 X et X̃ont la même loi ; d’après le théorème 9 fX(x1, x2) = fX̃(x1, x2) = fX1(x1)fX2(x2).¤
4 Fonction de répartition
4.1 Cas scalaire
Soit X une variable aléatoire de densité f(x), la fonction de répartition de Xest définie par : F : R→ [0, 1] et F (t) = P (X ≤ t) =
R t−∞ f(x)dx.
Remarque : F est une fonction non décroissante telle que F (−∞) = 0, F (+∞) = 1,et F 0(t) = f(t).
4.2 Cas d’un couple aléatoire
Soit X = (X1,X2) un couple aléatoire de densité f(x), la fonction de répartitionde X est définie par : F : R2 → [0, 1] et si t = (t1, t2) alors
F (t) = P (X ≤ t) = P (X1 ≤ t1,X2 ≤ t2) =
Z t1
−∞
Z t2
−∞f(x1, x2)dx1dx2.
On a aussi
f(t1, , t2) =∂2F (t1, t2)
∂t1∂t2.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 11
5 Distributions usuelles
5.1 Loi uniforme
On dit que X suit une loi uniforme sur [a, b], noté X Ã U [a, b], si elle admet ladensité
fX(x) =1
b− a1[a,b](x) =
½1
b−a si x ∈ [a, b]0 sinon.
(2.8)
On montre que E(X) = (a+ b)/2, V (X) = (b− a)2/12, φX(u) =eiub−eiuaiu(b−a) .
5.2 Loi de Gauss
On dit que X suit une loi de Gauss de moyenne m et de variance σ2, notéX Ã N(m,σ2), si elle admet la densité
fX(x) =1
σ√2π
e−(x−m)22σ2 ,∀x ∈ R. (2.9)
On montre que E(X) = m,V (X) = σ2, φX(u) = eium−σ2u2
2 .
5.3 Loi exponentielle
On dit que X suit une loi exponentielle de paramètre λ > 0, noté X Ã E(λ), sielle admet la densité
fX(x) =
½λe−λx si x ≥ 00 sinon.
(2.10)
On montre que E(X) = 1λ, V (X) = 1
λ2, φX(u) =
λλ−iu .
5.4 Loi gamma
On dit que X suit une loi gamma de paramètres α > 0 et β > 0, noté X ÃΓ(α, β), si elle admet la densité
fX(x) =
½ βα
Γ(α)xα−1e−βx si x ≥ 0
0 sinon,(2.11)
où Γ(α) =R∞0
tα−1e−tdt.
On montre que E(X) = αβ, V (X) = α
β2, φX(u) =
³1− iu
β
´−α.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 12
5.5 Loi de Cauchy
On dit que X suit une loi Cauchy , noté X Ã C, si elle admet la densité
fX(x) =1
π(1 + x2),∀x ∈ R. (2.12)
Une variable de Cauchy n’admet pas d’espérance mathématique carZ ∞
−∞x+fX(x)dx
Z ∞
−∞x−fX(x)dx =
Z ∞
0
x
π(1 + x2)dx = +∞.
6 Transformation des variables aléatoires
6.1 Cas discret
Exemple : Soit X la variable aléatoire définie parxi 0 1 -1 2P (X(ω) = xi 0.25 0.2 0.25 0.3On définit la variable aléatoire Y = X(X + 1), alors Y prends ses valeurs dans
{0, 2, 6} avec la loi de probabilité suivante : yi 0 2 6P (Y (ω) = yi) 0.5 0.2 0.3
Theorem 11 Si X est une variable aléatoire discrète à valeurs dans E, et g uneapplication injective, alors Y = g(X) est une variable aléatoire discrète à valeursdans g(E), ayant la même loi de probabilité que X : P (Y (ω) = yi) = P (X(ω) =xi), yi = g(xi).
6.2 Cas continu
Soit Y = X2, oùX Ã N(0, 1) donc Y est à valeurs dans R+ donc fY (y) = 0 ∀y ≤0. Si y ≥ 0, on a FY (y) = P (Y ≤ y) = P (−√y ≤ X ≤ √y) = 1√
2π
R √y−√y e
−x2
2 =
2√2π
R √y0
e−x2
2 donc fY (y) = F 0Y (y) =
1√2πy
e−y2
2 , c’est à dire que Y Ã X 2(1). Si latransformation g n’est pas bijective, on utilise souvent la fonction de répartitionpour calculer la loi de Y = g(X). Cependant si g est bijective on a le théorème
Theorem 12 Soit X = (X1,X2) un couple aléatoire de densité fX , et soit g uneapplication de R2 dans R2. On définit la transformée de X par g : Y = g(X) =(g1(X), g2(X)). On suppose que g vérifie les conditions suivantes :i) g est définie sur un ouvert U ⊂ R2 tel que
P (X ∈ U) =
ZU
fX(x)dx = 1,

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 13
et g est bijective d’inverse g−1 = (g−11 , g−12 ).ii) les dérivées partielles de g (resp. de g−1 ) existent et sont continues sur U (resp.sur V = g(U) ).iii) Le déterminant jacobien de g, défini par
J(g(x)) =∂g1(x)
∂x1
∂g2(x)
∂x2− ∂g1(x)
∂x2
∂g2(x)
∂x16= 0, ∀x ∈ U.
Alors Y admet une densité fY donnée par
fY (y) =
(fX(g
−1(y))¯̄̄∂g−11 (y)
∂y1
∂g−12 (y)
∂y2− ∂g−11 (y)
∂y2
∂g−12 (y)
∂y1
¯̄̄si y ∈ V = g(U)
0 sinon,(2.13)
Exemple Soit (X1,X2) un couple aléatoire suivant une loi uniforme sur [0, 1]2
et le couple aléatoire Y = g(X) avec g(x1, x2) = (x1x2 , x1 + x2).g est une application bijective d’inverse g−1(y1, y2) = ( y1y2
y1+1, y2y1+1
), les autreshypothèses du théorème ci-dessus sont satisfaites, de plus
J(g−1(y)) =∂g−11 (y)∂y1
∂g−12 (y)∂y2
− ∂g−11 (y)∂y2
∂g−12 (y)∂y1
= det
y2(y1+1)2
y1y1+1−y2
(y1+1)21
y1+1
=y2
(y1 + 1)2.
Par conséquent
fY (y) =
½ y2(y1+1)2
si y ∈ V = g(U)
0 sinon.
7 Suite de variables aléatoires
7.1 Loi de Khi-deux
On dit que X suit une loi Khi-deux à n degrés de liberté , noté X Ã X 2(n), siX Ã Γ(n
2, 12).
Remarque : on montre que si X =Pn
k=1 Z2k où (Zk, 1 ≤ k ≤ n) est une suite de
variables aléatoires indépendantes et identiquement distribuées (i.i.d.) suivant uneloi gaussienne N(0, 1), alors X Ã X 2(n)
7.2 Loi de Student
On dit que X suit une loi Student à n degrés de liberté , noté X Ã t(n), siX = Z√
Y/n, Z Ã N(0, 1), Y Ã X 2(n), et Z et Y sont indépendantes.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 14
7.3 Loi de Fisher
On dit queX suit une loi Fisher à (n1, n2) degrés de liberté , notéX Ã F (n1, n2),si X = Y1/n1
Y2/n2, Yi à X 2(ni), i = 1, 2 et Y1 et Y2 sont indépendantes.
7.4 Loi de la moyenne et variance empirique
Theorem 13 (Fisher) (Xk, 1 ≤ k ≤ n) est une suite de variables aléatoires indépen-dantes et identiquement distribuées (i.i.d.) suivant une loi gaussienne N(m,σ2).Alors
X =1
n
nXk=1
Xk, bσ2x = 1
n
nXk=1
(Xk −X)2
qui désignent respectivement la moyenne et la variance empirique de la suite (Xk, 1 ≤k ≤ n) sont telles que
X Ã N(m,σ2
n),n bσ2xσ2
à X 2(n− 1),
X et n bσ2xσ2
sont indépendantes.

Chapitre 3
Description d’une série statistique
1 Généralités, Définitions
1. La statistique : C’est l’étude des phénomènes préalablement exprimés sousforme numérique.2. L’unité statistique : C’est l’élément de l’ensemble que l’on veut étudier, exem-ple : un étudiant est une unité statistique lorsque l’on étudie une classe.3. Le caractère : C’est l’aspect de l’unité statistique que l’on retient dans l’analyse.4. L’échantillon : C’est un sous-ensemble d’une population statistique.5. La variable statistique : C’est l’expression numérique du caractère observé surles unités statistiques considérés.i) La variable statistique x est dite discrète lorsqu’elle ne peut prendre que desvaleurs isolées :
x1, x2, ..., xk, où x1 < x2 < ... < xk.
Exemple : le nombre de chevaux fiscaux d’une voiture ; le nombre d’enfants dansune famille,...ii) La variable statistique x est dite continue lorsqu’elle peut prendre n’importequelle valeur d’un intervalle [a, b]. Exemple : la durée en minute d’une conversationtéléphonique. Dans ce cas l’intervalle des valeurs possibles est divisé en k classes
[a0, a1[, [a1, a2[, ..., [ak−1, ak], où a0 = a < a1 < ... < ak−1 < ak = b.
ah−1 et ah sont les frontières de la h-ième classe, xh =ah−1+ah
2est le centre de celle-ci.
6. La série statistique : C’est à la fois :i) L’ensemble des valeurs {x1, x2, ..., xk} (resp. des classes de valeur
{[a0, a1[, [a1, a2[, ..., [ak−1, ak]})
de la variable x.ii) Le nombre d’observation associé à chaque valeurs xi (resp. à chaque classe).
15

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 16
0 1 2 3 4
2040
6080
x
ni
0 1 2 3 4
5010
015
020
025
0
x
nicu
mul
ees
Fig. 3.1 — Fréquences absolues (à gauche) et fréquences absolues cumulées (à droite)du nombre de garçons.
2 Distribution des fréquences
2.1 Cas discret
-Si dans une série statistique résultant de n observations, on a trouvé ni fois lavaleur xi, ni représente la fréquence absolue de cette valeur et le rapport fi = ni
n
représente sa fréquence relative.-L ’expression
Pji=1 ni est appelée fréquence cumulée absolue des valeurs de x in-
férieures ou égales à xj.-L ’expression
Pji=1 fi est appelée fréquence cumulée relative des valeurs de x in-
férieures ou égales à xj.Exemple : L’unité statistique étant la famille de quatre enfants dont l’aîné a
moins de 16 ans, on s’intéresse au nombre x de garçons qui la compose. L’étudestatistique suivante porte sur un échantillon de 250 familles (voir graphique 3.1)
Valeurs de x 0 1 2 3 4
Fréquence absolue ni 13 61 93 65 18Fréquence relative fi 0,052 0,244 0,372 0,260 0,072
Fréquence absolue cumulée 13 74 167 232 250Fréquence relative cumulée 0,052 0,296 0,668 0,928 1
2.2 Cas continu
On appelle fréquence absolue de la hième classe la nombre nh d’observations dontles valeurs appartiennent à cette classe. Le nombre fh = nh
nreprésente la fréquence

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 17
50 100 150 200
5010
015
020
025
030
035
0
x
nh
Fig. 3.2 — Histogramme des fréquences absolues de la durée de service du guichetde la poste.
relative de la hième classe.-L ’expression
Phi=1 ni est appelée fréquence cumulée absolue des h premières classes.
-L ’expressionPj
i=1 fi est appelée fréquence cumulée relative des h premières classes.Exemple : On s’intéresse à la durée x de service d’un guichet de la poste qui
peut servir au plus un client à la fois. On a relevé la durée de service de 1000 clientsconsécutifs. L’unité de temps est la seconde, les résultats sont résumés par le tableausuivant (voir aussi graphique 3.2)
Classes de [0 ,30[ [30,60[ [60,90[ [90,120[ [120,150[ [150,180[ [180,240[
valeurs de x
Fréquence 369 251 148 98 65 43 26
absolue nhFréquence 0,369 0,251 0,148 0,098 0,065 0,043 0,026
relative fhFréquence 369 620 768 866 931 974 1000
absolue cumulée
Fréquence 0,369 0,620 0,768 0,866 0,931 0,974 1
relative cumulée
2.3 Distribution des fréquences
L’ensemble des k valeurs xi (resp. des k classes) et les effectifs ni correspondants,constitue la distribution de fréquences de la variable x.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 18
2.4 Représentation graphique des distributions de fréquences
On peut porter en ordonnée les fréquences absolues. Dans le cas discret on ob-tient un diagramme en bâtons. Dans le cas continu, on construit un histogrammede fréquences, l’aire de chaque classe devant être proportionnelle à son effectif cor-respondant.
3 Caractéristiques de tendance centrale
3.1 Définition :
Ce sont des indicateurs qui permettent de synthétiser l’ensemble de la série statis-tique en faisant ressortir une position centrale de la valeur du caractère étudié.1. La médiane : C’est la valeur xm de la variable x qui partage les éléments dela série statistique, préalablement classés par ordre de valeurs croissantes, en deuxgroupes d’effectifs égaux : 50 % des valeurs observées sont inférieures à xm et 50 %sont supérieures.Dans le cas continu, elle est donnée par
xm = aj−1 +aj − aj−1
nj(n
2−
jXi=1
ni),
sachant que xm appartient à [aj−1, aj[.2. Le mode :Variable discrète : c’est la valeur pour laquelle la fréquence est maximale.Variable continue : la classe modale est celle pour laquelle la fréquence est maximale.Lorsqu’il y a une seule valeur ou classe modale, la distribution est dite unimodale.3. La moyenne.-La moyenne x de k valeurs distinctes x1, ..., xk, et de fréquences n1, ..., nk :
x =1
n
kXi=1
nixi, n =kXi=1
ni.
-La moyenne x de n valeurs distribuées en k classes [a0, a1[, ..., [ak−1, ak[ et d’effectifsn1, ..., nk :
x =1
n
kXi=1
nixi, xi =ai−1 + ai
2.
4 Caractéristiques de dispersion
Deux séries de même nature peuvent présenter des caractéristiques de tendancecentrale voisines, mais différer quant à la dispersion de leurs valeurs par rapport àla tendance centrale.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 19
4.1 La dispersion en termes d’intervalles
i). Intervalle de variation ou étendue : C’est la différence entre les valeursextrêmes de la variable ou entre les centres de classes extrêmes xk − x1.ii). L’intervalle interquartile : Si l’on peut diviser x1, ..., xk en quatre classes
[x1, Q1[, [Q1, Q2[, [Q2, Q3[, [Q3, xk] ayant toutes la même fréquence n4, alors Q1, Q2,
et Q3 sont appelés respectivement premier, deuxième et troisième quartiles.Dans le cas continu
Q1 = aj−1 +aj − aj−1
nj(n
4−
jXi=1
ni), Q3 = aj−1 +aj − aj−1
nj(3n
4−
jXi=1
ni).
[Q1, Q3] est l’intervalle interquartile.
4.2 La dispersion en termes d’écarts
L’origine retenue pour le calcul des écarts étant une caractéristique de tendancecentrale, les écarts ne traduiront la dispersion que si l’on considère leur valeur absolueou leurs puissances paires.i). Les écarts absolus :-L’ écart absolu par rapport à la médiane eM = 1
n
Pki=1 ni |xi −M | , M est la
médiane de la série.-L’ écart absolu par rapport à la moyenne arithmétique ex = 1
n
Pki=1 ni |xi − x|.
ii). Variance, écart-type :-Variance : V (x) = bσ2x = 1
n
Pki=1 ni(xi − x)2.
-Ecart-type : bσx.Proposition 14 pour tout a ∈ R, on a
V (a+ x) = V (x), V (ax) = a2V (x),
et
V (x) =1
n
kXi=1
nix2i − (x)2.
Exemples :Exemple 1. La distribution des salaires annuels dans une population contenant
n = 14890442 actifs, ( le nombre d’individus Ni touchant le salaire si exprimé eneuros) est distribuée comme suit :

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 20
0 e+00 2 e+05 4 e+05 6 e+05 8 e+05 1 e+06
0.0
e+00
4.0
e+06
8.0
e+06
1.2
e+07
salaire
N.in
divi
dus
Fig. 3.3 — Le nombre d’individus N ayant comme salaire s
si (en C= ) Ni
10000 1158326520000 204537230000 68324040000 34974050000 183280100000 36250200000 7975500000 10151000000 305
.
Le salaire moyen est donné par
s =1
n
9Xi=1
Nisi = 13862.81C=,
la variance et l’écart-type sont donnés par :
V (s) =1
n
9Xi=1
Ni(si − s)2 = 133496156, bσs = 11554.05,le premier, deuxième et troisième quartiles sont

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 21
Q1 = 10435.56, Q2 = 14338.53 et Q3 = 18241.5.
Remarque. Le salaire médian qui est égal à sm = Q2 est différent du salairemoyen s.Exemple 2. Dans une classe constituée de deux groupes G1 et G2, la note obtenue
dans l’examen de statistique est distribuée comme suit :
Groupe 1 9 10 9 9 8.5 9.5 10 10 7 9 9 9 8.5 9.5 8Groupe 2 2 10 1 9 4 9.5 10 10 7 9 9 17 12 9.5 16
La moyenne de la classe est égale à x = 9.La moyenne du groupe 1 est égale à xG1 = 9, et la moyenne du groupe 2 est aussi
égale à xG2 = 9. Cependant les deux groupes, même s’ils ont la même moyenne, sontcomplètement différents. En effet dans le groupe 1, la plupart des notes tournentautour de la moyenne globale 9, les étudiants ont presque le même niveau. Le groupe2 est plus hétérogène, il y a des étudiants faibles (notes :1,2 et 4) et des étudiantsforts (notes : 12,16 et 17). Si on calcule la variance de chaque groupe on trouve:
VG1 = 0.6428571 ce qui donne un écart-type de σG1 =0.8017837.VG2 = 19.10714 ce qui donne un écart-type de σG2 = 4.371172.VG2 > VG1 , en conclusion plus la variance est grande plus l’échantillon est
hétérogène.
5 Moments
Le moment d’ordre r de la variable x par rapport à l’origine x0 est défini par
mr(x0) =1
n
kXi=1
ni(xi − x0)r.
Si x0 = 0 les moments sont dits simples et notés mr.Si x0 = x les moments sont dits centrés et notés µr.
Proposition 15 On a
µ2 = m2 −m21, µ3 = m3 − 3m1m2 + 3m
31,
µ4 = m3 − 4m1m3 + 6m31m2 − 3m4
1.

Chapitre 4
Liaisons entre variablesstatistiques
Definition 3 Une série double à deux indices est définie par l’observation de n cou-ples de valeur tels que :i) Cas discret : x prends les valeurs x1, ..., xp et y prends les valeurs y1, ..., yr, et àchaque couple de valeur (xi, yj)1≤i≤p;1≤j≤r on associe :-Sa fréquence absolue ni,j qui est le nombre de fois où (x, y) = (xi, yj).-Sa fréquence relative fi,j =
ni,jn.
ii) Cas continu : Les valeurs observées pour x et pour y sont regroupées respective-ment en p et r classes [a0, a1[,[a1, a2[,...,[ap−1, ap], resp. [b0, b1[, [b1, b2[ ,..., [br−1, br],et ni,j est le nombre d’observations pour lesquelles ai−1 ≤ x ≤ ai, et bj−1 ≤ y ≤ bj.
Exemple : sur 200 personnes de même âge et de même sexe on en dénombre 25dont la taille y est comprise entre 165 et 167 cm et le poids x entre 60 et 65 kg ;30 dont la taille entre 167 et 169 et le poids entre 60 et 65 kg ; le reste est tel que55 ≤ x ≤ 60 et 160 ≤ y ≤ 165.On peut représenter les données par
y(taille) 160− 165 165-167 167− 169 Totauxpartiels
x(poids)
55− 60 145 0 0 14560− 65 0 25 30 55Totaux 145 25 30 200partiels
Les résultats sont présentés souvent avec un tableau à double entrée(ou matrice)comme suit
22

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 23
y y1 . . . yj . . . yr Totauxpartiels
x
x1 n1,1 . . . n1,j . . . n1,r n1,• =Pr
j=1 n1,j...
......
......
......
xi ni,1 . . . ni,j . . . ni,r ni,• =Pr
j=1 ni,j...
......
......
......
xp np,1 . . . np,j . . . np,r np,• =Pr
j=1 np,jTotaux n•,1 = . . . n•,j = . . . n•,r = n =
Pi,j ni,j
partielsPp
i=1 ni,1Pp
i=1 ni,jPp
i=1 ni,r
0.1 La distribution marginale
La distribution marginale de x se lit sur la dernière colonne du tableau ; elleconcerne les fréquences de x considérées isolément : le nombre d’observations pourlesquelles x = xi (resp. x appartient à la classe [ai−1, ai[) est ni,• =
Prj=1 ni,j. De
même, les fréquences de la distribution marginale de y se lisent dans la dernière lignedu tableau. On définit :-les moyennes marginales x et y :
x =1
n
pXi=1
ni,•xi et y =1
n
rXj=1
n•,jyj.
-les variances marginales
σ2x =1
n
pXi=1
ni,•(xi − x)2 et σ2y =1
n
rXj=1
n•,j(yj − y)2.
0.2 La distribution conditionnelle
A chaque valeur fixée xi correspond la distribution conditionnelle de y sachantx = xi d’effectifs ni,1, ..., ni,r. On définit :- la moyenne conditionnelle de y sachant x = xi :
yi =1
ni,•
rXj=1
ni,jyj.
- la variance conditionnelle de y sachant x = xi :
bσ2xi(y) = 1
ni,•
rXj=1
ni,j(yj − yi)2.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 24
De même on définit :- la moyenne conditionnelle de x sachant y = yj :
xj =1
n•,j
pXi=1
ni,jxi.
- la variance conditionnelle de x sachant y = yj :
bσ2yj(x) = 1
n•,j
pXi=1
ni,j(xi − xj)2.
1 L’ajustement, régression simple
1.1 Coefficient de corrélation linéaire :
C’est un nombre sans dimension destiné à mesurer l’intensité de liaison entre lesvariations de x et celles de y. Il a pour expression
r =cov(x, y)bσxbσy , où cov(x, y) =
1
n
Xi,j
ni,j(xi − x)(yj − y).
Definition 4 Etant donné un ensemble de points de coordonnées (xi, yi), 1 ≤ i ≤ nformant un nuage dans le plan XOY , l’ajustement consiste à choisir une courbecontinue qui résume le nuage. Cette courbe a pour but d’expliquer comment y varieen fonction de x.
1.2 Ajustement par la méthode des moindres carrés
Le type d’ajustement étant préalablement choisi, la courbe d’ajustement de y enx, d’équation y = f(x), est dite des moindres carrés si f est telle que
Pni=1 d
2i soit
minimale où di = yi − f(xi)
1.2.1 l’ajustement linéaire : droite des moindres carrés
Lorsque le nuage est rectiligne on choisit f(x) = ax+ b. La droite des moindrescarrés est donnée par y = bax+bb, où
ba =cov(x, y)bσ2x ,bb = y − bax , où cov(x, y) = 1
n
nXi=1
(xi − x)(yi − y),
bσ2x =1
n
nXi=1
(xi − x)2, x =1
n
nXi=1
xi, y =1
n
nXi=1
yi.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 25
Proposition 16i) |r| ≤ 1,ii) r2 = ba1 ba2, où ba1 (resp. ba2) est le coefficient directeur de la droite d’ajustementde y en x (resp. de x en y).
1.3 Qualité d’ajustement
Pour juger de la bonne qualité de l’ajustement on définit le coefficient
R2 =bσ2y − SSR/nbσ2y , SSR =
nXi=1
e2i ,
SSR est la somme des carrés des résidus, avec ei = yi − (bb + baxi) le résidu quicorrespond à l’observation yi.
R2 est un réel toujours inférieur à 1.Si R2 est proche de 1 alors l’ajustement est de bonne qualité.Si R2 est proche de 0 alors l’ajustement est de mauvaise qualité.Exemples :Exemple 1) On reprend l’exemple de la distribution des salaires, le graphique 3.3
nous suggère que le nombre d’individus décroît lorsque le salaire croit, le rythme dedécroissance est exponentiel. On peut donc déduire que le coefficient de corrélationlinéaire est négatif ; en effet on trouve r = −0.3005368. Pour expliquer N en fonctionde s, nous allons faire une transformation logarithmique. En effet en posant y =ln(N) et x = ln(s), le graphique 4.1 montre qu’il y a une relation linéaire en y et x.
Le coefficient de corrélation linéaire est r = −0.998564. Un ajustement linéairede y en x est bien justifié. On trouve bb = 37.241 et ba = −2.305. La droite desmoindres carrés est donnée par y = −2.305x+ 37.241.
La somme des carrés des résidus SSR = 0.2012 est très faible.Le coefficientR2 = 0.9971 est proche de 1, on peut donc affirmer que l’ajustement
est de bonne qualité.En résumé, on peut donc supposer que le nombre d’individus N est lié au salaire
s par la relation
N(s) = e−2.305 ln(s)+37.241 = 1.491286× (1016)s−2.305.
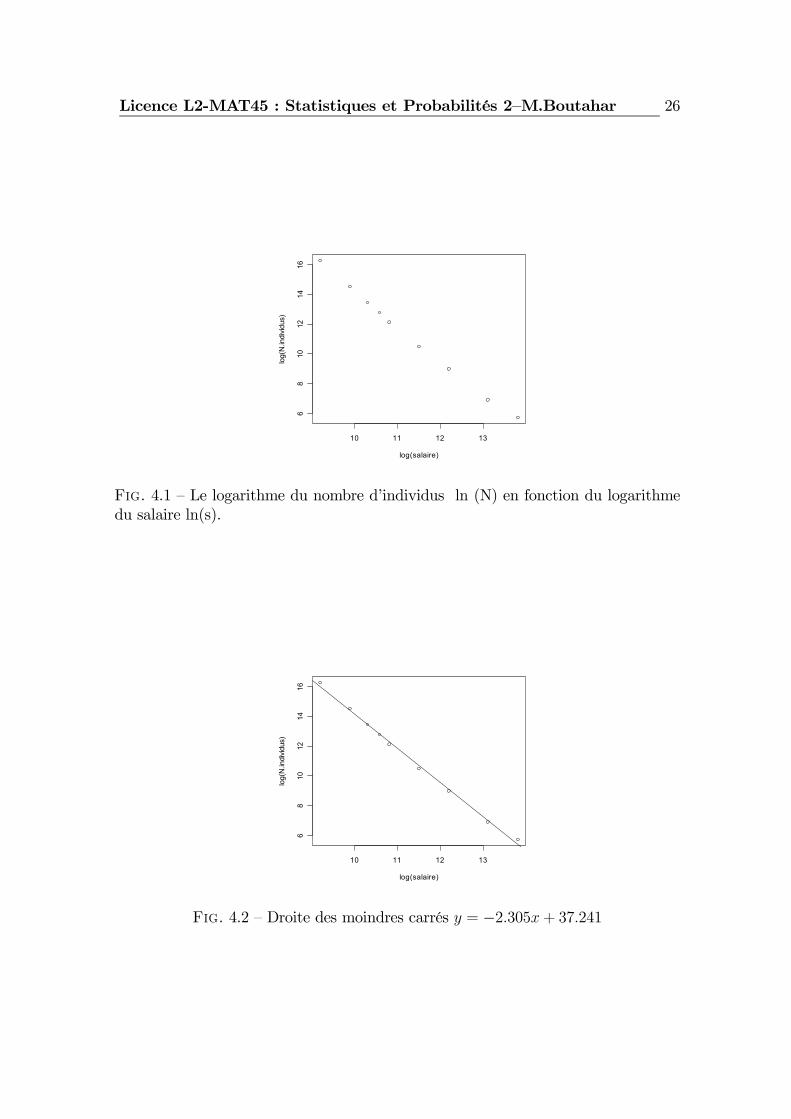
Exemple 2) En l’absence de mortalité, on souhaite décrire l’évolution dans letemps de la croissance d’une population de bactéries. Des numérations faites tousles jours à partir du 2e donne les résultats suivants (voir le graphique 4.3) :
Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 26
10 11 12 13
68
1012
1416
log(salaire)
log(
N.in
divi
dus)
Fig. 4.1 — Le logarithme du nombre d’individus ln (N) en fonction du logarithmedu salaire ln(s).
10 11 12 13
68
1012
1416
log(salaire)
log(
N.in
divi
dus)
Fig. 4.2 — Droite des moindres carrés y = −2.305x+ 37.241

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 27
2 4 6 8 10 12
020
0040
0060
00
jours
N.b
acté
ries
Fig. 4.3 — Evolution des bactéries.
ti (jours) 2 3 4 5 6 7 8 9 10 11 12Ni
(bactéries)55 90 135 245 403 665 1100 1810 3000 4450 7350
,
D’après le graphique 4.3 le nombre de bactéries croit de manière rapide (expo-nentiel). On peut donc déduire que le coefficient de corrélation linéaire entre le nom-bre de bactéries N et la variable temps t est positif ; en effet on trouve r = 0.8596725.Pour expliquer N en fonction de t, nous allons faire une transformation logarithmiqueseulement de la variable N (car c’est la variable qui a des valeurs très grandes). Eneffet en posant y = ln(N) et x = t, le graphique 4.4 montre qu’il y a une relationlinéaire en y et x.
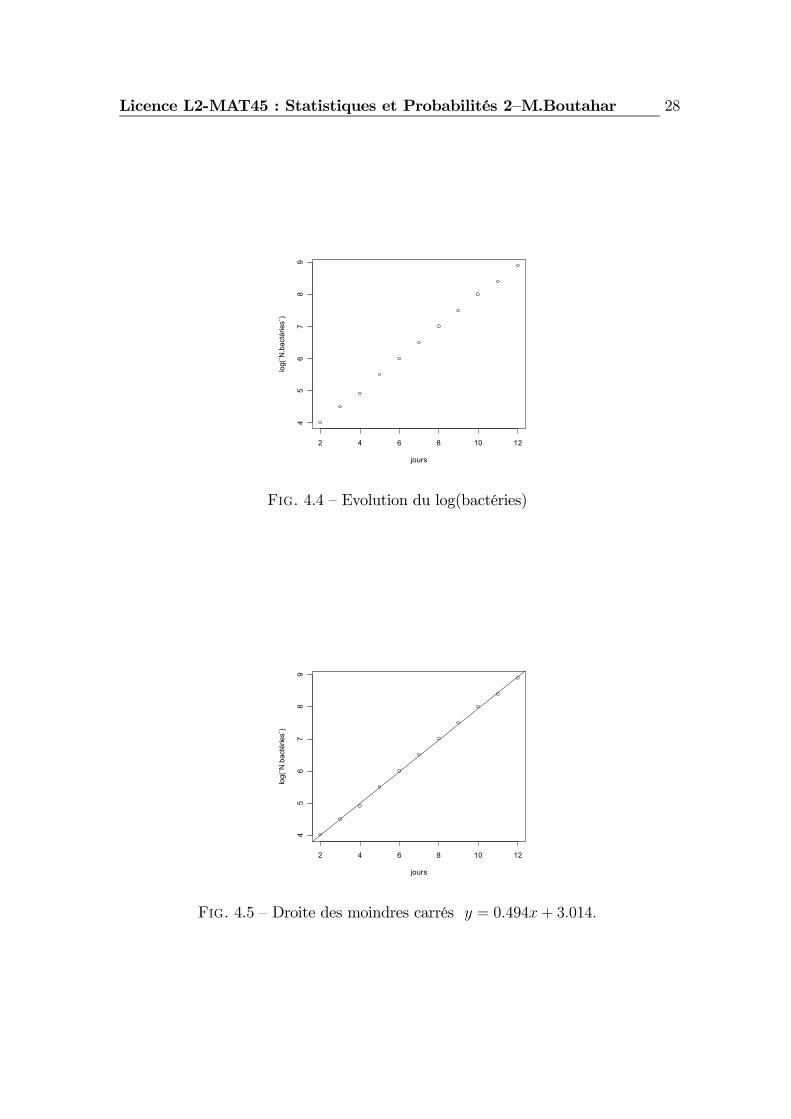
Le coefficient de corrélation linéaire est r = 0.9916918. Un ajustement linéairede y en x est bien justifié. On trouve bb = 3.014 et ba = 0.494. La droite des moindrescarrés est donnée par y = 0.494x+ 3.014.
La somme des carrés des résidus SSR = 0.04499 est très faible.Le coefficient R2 = 0.9993 est très proche de 1, on peut donc affirmer que
l’ajustement est de très bonne qualité.En résumé, on déduit que l’évolution du nombre de bactéries en fonction des
jours suit l’équation
N(t) = e0.494t+3.014 = 20.36871e0.494t.
Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 28
2 4 6 8 10 12
45
67
89
jours
log(
`N.b
acté
ries`
)
Fig. 4.4 — Evolution du log(bactéries)
2 4 6 8 10 12
45
67
89
jours
log(
`N.b
acté
ries`
)
Fig. 4.5 — Droite des moindres carrés y = 0.494x+ 3.014.

Chapitre 5
Estimation statistique et testd’hypothèses
L’estimation a pour but de chercher, à travers l’examen d’un échantillon, uneinformation quantitative à propos d’un paramètre θL’ estimation est dite ponctuelle lorsque l’on se propose de substituer à la valeur
θ un nombre unique θ̂ construit à partir d’un échantillonnage, exemple : x est unestimateur ponctuel de la moyenne m.L’ estimation est dite par intervalle de confiance lorsque l’on se propose de con-
struire à partir de l’échantillon un intervalle [a, b] qui peut contenir θ avec uneprobabilité 1-α : P (a ≤ θ ≤ b) = 1− α, α fixé à l’avance. On dit alors que [a, b] estun intervalle de confiance au niveau α pour θ.Les tests d’hypothèses servent à valider une caractéristique d’une population à
travers l’examen d’un échantillon, ils sont aussi utilisés pour comparer des carac-téristiques entre plusieurs populations.
1 Estimation ponctuelle des paramètres
1.1 Choix des estimateurs
Pour un paramètre θ, il est possible d’imaginer plusieurs estimateurs, θ̂, con-struits à partir d’un même échantillon ; il convient donc de retenir l’estimateur quidonnera la meilleure approximation possible de θ. Cela suppose que :i) E(θ̂) = θ, on dit que l’estimateur est sans biais.ii) θ̂ converge en probabilité vers θ lorsque la taille n de l’échantillon tends vers
l’infini : ∀ > 0, P (¯̄̄θ̂ − θ
¯̄̄> )→ 0, lorsque n→∞, on dit que θ̂ est consistant.
iii) La variance de θ̂ soit minimale.Remarque : Il existe pour la variance de θ̂ une borne inférieure, dite borne de
29

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 30
Cramer-Rao, :V (θ̂) ≥ I(θ)−1,
où
I(θ) = E((∂ logL(θ,X)
∂θ)2)
matrice d’information de Fisher ;
L(θ,X) =nYi=1
fXi(Xi, θ)
la vraisemblance de l’échantillon, fXi(x, θ) est la densité de Xi.
Si V (θ̂) = I(θ)−1, on dit que l’estimateur θ̂ est efficace.
1.2 Construction des estimateurs
Il existe plusieurs estimateurs, on se contente dans ce cours de définir deux types :
1.2.1 Estimateur des moindres carrés
C’est la méthode introduite dans le paragraphe 4.1 (ajustement et régressionlinéaire).
1.2.2 Estimateur du maximum de vraisemblance
C’est le point θ̂ qui rend maximale la vraisemblance L(θ,X) =Qn
i=1 fXi(Xi, θ)
considérée comme fonction de θ, il est souvent solution de ∂ logL(θ,X)∂θ
= 0.Exemple. Soit (Xt, 1 ≤ t ≤ n) une suite i.i.d de variables aléatoires ayant la
densitéf(x) = θe−θx1{x>0},
où θ > 0 est un paramètre inconnu.Alors
L(θ,X) =nYi=1
fXi(Xi, θ) = θnnYi=1
e−θXi ,
logL(θ,X) = n log θ − θnXi=1
Xi,
∂ logL(θ,X)
∂θ=
n
θ−
nXi=1
Xi,

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 31
donc
θ̂ =1
X, X =
1
n
nXi=1
Xi.
2 Estimation par intervalle de confiance et Tests
Soit θ̂ un estimateur de θ, la construction d’un intervalle de confiance est baséesur un pivot pv = f(θ̂), dont la loi ne dépend pas de θ.
2.1 Intervalle de confiance pour la moyenne d’une popula-tion gaussienne
On suppose que Xi à N(m,σ2), 1 ≤ i ≤ n.
2.1.1 σ connu
Le pivot est donné par pv =√nX−m
σ, en effet X = 1
n
Pni=1Xi à N(m,σ2/n),
donc pv à N(0, 1). On lit alors dans la table de Gauss le quantile u1−α2tel que
P (N(0, 1) ∈ [−u1−α2, u1−α
2]) = 1 − α donc P (pv ∈ [−u1−α
2, u1−α
2]) = 1 − α, par
conséquent P (m ∈ [X − u1−α2
σ√n, X + u1−α
2
σ√n]) = 1 − α; l’ intervalle de confiance
au niveau α pour m est alors donné par
Iα = [x− u1−α2
σ√n, x+ u1−α
2
σ√n]. (5.1)
2.1.2 σ inconnu
L’intervalle ci-dessus est inutilisable car il dépend de σ, donc il faut estimer cedernier, le pivot est donné par pv =
√nX−m
S, où S2 = 1
n−1Pn
1(Xi−X)2, qui est unestimateur empirique et sans biais de la variance σ2.On a (n−1)S2
σ2à X 2(n−1), et donc pv à t(n−1), loi de Student à (n-1) degrés de lib-
erté. On lit alors dans la table de Student t1−α2tel que P (t(n−1) ∈ [−t1−α
2, t1−α
2]) =
1− α; l’ intervalle de confiance au niveau α pour m est alors donné par
I 0α = [x− t1−α2
s√n, x+ t1−α
2
s√n]. (5.2)
2.2 Comparaison d’une moyenne théorique et d’une moyenne
observée
On attribue la valeur m0 pour moyenne du caractère dans une population eton veut juger le bien fondé de cette hypothèse en se basant sur un échantillon. On

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 32
effectue alors le test d’hypothèse : H0 : m = m0
contreH1 : m 6= m0
où m est la moyenne théorique. On considère alors√nX−m0
Squi suit, sous H0,
une loi de Student à (n-1) degrés de liberté. Soit la quantile t1−α2tel que P (t(n−1) ∈
[−t1−α2, t1−α
2]) = 1− α.
Si¯̄̄√
nX−m0
S
¯̄̄≤ t1−α
2alors on ne peut pas refuser H0 au seuil de signification α.
2.3 Comparaison des moyennes de deux échantillons indépen-dants.
Soit deux échantillons aléatoires d’observations provenant de deux populationsP1 et P2 et de moyenne X et Y respectivement. En général X 6= Y ,il s’agitd’expliquer cette différence.
On suppose que X Ã N(mx, σ2x), Y Ã N(my, σ
2y), X et Y sont deux échantillons
indépendants, on désire effectuer le test H0 : mx = my
contreH1 : mx 6= my.
On utilise D = X − Y , qui est un bon indicateur de l’écart entre les deuxmoyennes.i) Cas σ2x et σ
2y connues : Sous H0 :
Drσ2xnx+σ2yny
à N(0, 1), on fixe α (0,01 ou 0,05) et
on lit dans la table de Gauss u1−α/2 tel que P (|N(0, 1)| > u1−α/2) = α, l’intervallecritique au seuil α est donné par
Im =]−∞,−u1−α/2s
σ2xnx+
σ2yny][[u1−α/2
sσ2xnx+
σ2yny
,∞[,
décision : si d = x− y ∈ Im on rejette H0.ii) Cas σ2x et σ
2y inconnues :
ii.1 Cas des grands échantillons (nx ≥ 30 et ny ≥ 30) : On peut remplacer σ2x (resp. σ2x ) par S
2x =
1nx−1
Pnx1 (Xi −X)2 (resp. S2y), et donc l’intervalle critique au seuil
α est donné par
Im =]−∞,−u1−α/2s
s2xnx+
s2yny][[u1−α/2
ss2xnx+
s2yny
,∞[, (5.3)

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 33
décision : si d ∈ Im on rejette H0.
ii.2) Cas des petits échantillons :a) σ2x = σ2y = σ2. On montre alors que sous H0 :
Dr(nx−1)S2x+(ny−1)S2y
nx+ny−2q
1nx+ 1ny
Ã
t(nx + ny − 2) avec D = X − Y , donc l’intervalle critique au seuil α est donné par
Im =]−∞,−t1−α/2f(x, y)][[t1−α/2f(x, y),∞[, (5.4)
où
f(x, y) =
s(nx − 1)s2x + (ny − 1)s2y
nx + ny − 2
s1
nx+1
ny, (5.5)
décision : si d = x− y ∈ Im on rejette H0.
b) σ2x 6= σ2y.On détermine l’angle θ (exprimé en degré) défini par 0 < θ ≤ 45◦ telque
tan θ =sx/√nx
sY /√ny
, (5.6)
il faut choisir les indices X et Y de telle sorte que sx/√nx ≤ sY /
√ny.
La table de Sukhatme, donne pour un seuil de signification α et en fonction deν1 = nX − 1 et ν2 = nY − 1 et θ le nombre ε tel que SH = X−Yr
S2xnx+S2yny
vérifie
P (|SH| ≥ ε) = α.
Si |SH| ≥ ε alors on rejette H0.
2.4 Comparaison des moyennes de deux séries appariés.
Soit deux séries de n observations X1, ...,Xn de moyenne X et Y1, ..., Yn demoyenne Y. Ici l’observation Xi est appariée à Yi. On pose Di = Xi − Yi, S
2D =
1n−1
Pn1(Di −D)2,D = 1
n
Pni=1Di.
Pour tester H0 : mx = my
contreH1 : mx 6= my,
on considère
T =√nD
SD.
Si n est grand, disons supérieur à 30, T est assimilée à une variable centréeréduite de Gauss ; si n est petit et si D suit une loi de Gauss, T suit une loi deStudent à (n− 1) degrés de liberté.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 34
2.5 Intervalle de confiance pour la variance d’une popula-tion gaussienne
On a le pivot pv = (n−1)S2σ2
à X 2(n−1), loi de Khi-deux à (n-1) degrés de liberté.On lit alors dans la table de Khi-deux xa et xb tels que P (xa ≤ X 2(n− 1) ≤ xb) =1− α. L’ intervalle de confiance au niveau α pour σ2 est donné par :
Iv = [(n− 1)s2
xb,(n− 1)s2
xa].
2.6 Comparaison d’une variance théorique et d’une varianceobservée
On attribue la valeur σ20 pour variance du caractère dans une population et onveut juger le bien fondé de cette hypothèse en se basant sur un échantillon. Oneffectue alors le test d’hypothèse : H0 : la variance du caractère dans la population est σ20
contreH1 : non H0.
Sous H0,(n−1)S2
σ20Ã X 2(n − 1) donc si (n−1)S2
σ20∈ [xa, xb] alors on ne peut pas
refuser l’hypothèse H0.
2.7 Comparaison des variances de deux échantillons indépen-dants
On veut tester H0 : σ2x = σ2ycontreH1 : σx 6= σy.
On calcul les rapports S2xS2yet S2y
S2xet on considère le plus grand parmi les deux :
i. Si S2xS2y
>S2yS2x, on décidera à l’aide du rapport S2x
S2y, comme suit : on a sous H0 :
S2xS2yà F (nx − 1, ny − 1), loi de Fisher-Snédécor à (nx − 1, ny − 1) degrés de liberté,
donc l’intervalle critique au seuil α est donné par
Iα = [fα,∞[, avec P (F (nx − 1, ny − 1) > fα) = α, (5.7)
décision : si s2xs2y∈ Iα on rejette H0.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 35
ii. Si S2xS2y≤ S2y
S2x, on décidera à l’aide du rapport S2y
S2x, comme suit : on a sous
H0 :S2yS2xà F (ny − 1, nx − 1), loi de Fisher-Snédécor à (ny − 1, nx − 1) degrés de
liberté, donc l’intervalle critique au seuil α est donné par
Iα = [fα,∞[, avec P (F (ny − 1, nx − 1) > fα) = α,
décision : si s2ys2x∈ Iα on rejette H0.
3 Analyse de la variance
Le but est de comparer plusieurs séries d’observations d’une variable X afin dedécider s’elles proviennent de populations dans lesquelles X a la même moyenne oula même variance.On considère k échantillons gaussiens Ei = {xi,1, ..., xi,ni} , 1 ≤ i ≤ k indépen-
dants.On désigne par m1, ...,mk les moyennes de X dans les populations P1, ..., Pk
respectivement d’où sont extraits les échantillons E1, ..., Ek.On suppose que X a la même variance σ20 dans les populations P1, ..., Pk. On
définit la variance intraclasse, par
S2intra =1
n− k
kXi=1
νis2i , νi = ni − 1, (5.8)
s2i =1
ni − 1niXj=1
(xi,j − xi)2, xi =
1
ni
niXj=1
xi,j.
On définit la variance interclasse, par
S2inter =1
k − 1kXi=1
ni(xi − x)2 , (5.9)
x =1
n
kXi=1
niXj=1
xi,j, n =kXi=1
ni.
3.1 Comparaison simultanée de plusieurs moyennes
On veut tester H0 : m1 = m2 = ... = mk
contreH1 : ∃i 6= j tels que mi 6= mj.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 36
On a sous H0 :S2interS2intra
à F (k − 1, n − k), loi de Fisher-Snédécor à (k − 1, n− k)
degrés de liberté, donc l’intervalle critique au seuil α est donné par
Iα = [fα,∞[, avec P (F (k − 1, n− k) > fα) = α, (5.10)
décision : si S2interS2intra
∈ Iα on rejette H0.
3.2 Comparaison simultanée de plusieurs variances
On veut tester H0 : σ21 = σ22 = ... = σ2kcontreH1 : ∃i 6= j tels que σ2i 6= σ2j .
3.2.1 Test de Neyman et Pearson
On suppose que n1 = n2 = ... = nk et on considère la variable aléatoire
NP =
¡bσ21 bσ22... bσ2k¢ 1k1k
¡bσ21 + bσ22 + ...+ bσ2k¢ , (5.11)
bσ2i = 1
ni
niXj=1
(xi,j − xi)2.
On a sous H0, NP suit une loi tabulée par Neyman et Pearson. Remarquonsque NP ≤ 1. Soit lα tel que P (NP ≤ lα) = α, donc l’intervalle critique au seuil αest donné par
Iα = [0, lα[,
décision : si NP ∈ Iα on rejette H0.
3.2.2 Test de Barlett
On considère la statistique
B =1
λ
((n− k) lnS2intra −
kXj=1
νi ln s2i
), (5.12)
λ = 1 +1
3(k − 1)½1
ν1+1
ν2....+
1
νk− 1
n− k
¾, νk = nk − 1.
Sous H0, B Ã X 2(k − 1) . Soit x21−α tel que P(X 2(k − 1) ≥ x21−α) = α.Décision : si B ∈ [x21−α,+∞[ alors on rejette H0.

Chapitre 6
EXERCICES
1 Distributions de Probabilité Discrètes
Exercice 1. On lance simultanément deux dés, soit la variable aléatoire S =X+Y , où X est le chiffre obtenu avec le dé 1 et Y est le chiffre obtenu avec le dé 2.Calculer la probabilité que S = 10.Exercice 2. Dans une population atteinte d’une maladie, on extrait un échantil-
lon de 20 personnes. On suppose que la probabilité qu’une personne, prise au hasarddans l’échantillon, soit touchée par la maladie est égale à 1
4.
i) Quelle est la probabilité qu’il y ait exactement 5 malades ?ii) Quelle est la probabilité pour que le nombre de malades soit supérieur ou
égal à 10 ?Exercice 3. Calculer la moyenne et la variance d’une variable aléatoire binomialed’ordre n et de paramètre p.Exercice 4. Soient X1, ...,Xn n variables aléatoires discrètes indépendantes et iden-tiquement distribuées, de variance σ2. Calculer l’écart type de 1
n
Pni=1Xi.
Exercice 5. (Loi géométrique) On dit que T suit une loi géométrique de paramètrep ∈ [0, 1] si P (T = n) = p(1− p)n−1 pour tout n ≥ 1.Calculer la fonction génératrice, la moyenne et la variance de T .Exercice 5. Soit X une variable prenant ses valeurs dans N. Montrer que
E(X) =∞Xn=1
P (X ≥ n).
Exercice 7. (Approximation polynomiale de Bernstein) Soit f une fonction continuede [0, 1] dans R, on définit le polynôme de Bernstein associé à f
Pn(x) =nX
k=0
f(k
n)Ck
nxk(1− x)n−k.
37

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 38
On introduit pour chaque x ∈ [0, 1] une suite (Xn, n ≥ 0) de variables aléatoires deBernoulli, mutuellement indépendantes, de même loi P (Xn = 1) = x, P (Xn = 0) =1− x.i) Préciser la loi de Sn = X1 + ...+Xn, en déduire que
Pn(x) = E(f(Snn)).
ii) Montrez que pour tout ε > 0 il existe δ(ε) tel que¯̄̄̄E(f(
Snn))− f(x)
¯̄̄̄≤ P (
¯̄̄̄Snn− x
¯̄̄̄< δ(ε))ε+ 2MP (
¯̄̄̄Snn− x
¯̄̄̄≥ δ(ε));
où M = maxx∈[0,1] |f(x)| .iii) Montrez l’inégalité
|Pn(x)− f(x)| ≤ ε+ 2Mx(1− x)
δ2(ε)
1
n.
iv) En déduire que le polynôme Pn converge uniformément vers f sur [0, 1].
2 Distributions de Probabilité Continues
Exercice 1.(Loi Uniforme) SoitX une variable aléatoire suivant une loi uniformesur un intervalle [a,b], notée U[a,b], donc de densité
f(x) =
½1
b−a si x ∈ [a, b]0 sinon
i) Calculer E(X) , σ(X),ii) Calculer la fonction de répartition F (t) ainsi que la fonction caractéristique ϕ(t)de X.Exercice 2. Soit X la variable aléatoire ayant la fonction caractéristique
ϕ(t) = e−t2
2 .
Calculez E(X) , σ(X),Exercice 3. Soit X la variable aléatoire à valeurs dans R+ et ayant la densitéf(x) = e−αx.i) Calculez α,E(X) et σ(X),ii) Calculez la fonction de répartition F (t) ainsi que la fonction caractéristique ϕ(t)de X.iii)Déterminer un intervalle [a, b] tel que P (X ∈ [a, b]) ≥ 96%.
Exercice 4. La variable aléatoire suit la loi uniforme sur l’intervalle [−1, 2]. Calculez

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 39
la loi de Y = |X|.Exercice 5. La variable aléatoire suit une loi normale de moyenne 0 et de variance1.Déterminez la loi de Z = X2 + 2X.Exercice 6. Soient λ > 0, et la fonction f définie sur R par f(x) = 1
2λe−λ|x|.
i) Montrer que f est une densité de probabilité.
ii) Soit X une variable aléatoire de densité de probabilité f . Déterminer la fonc-tion de répartition F de X.
iii) On effectue le changement de variable Y = |X| . Déterminer la loi de prob-abilité de Y . Calculer E(Y ) et var(Y ).Exercice 7. Le couple aléatoire prend ses valeurs dans ]0, 1[×]0, 1[ avec la densité
de probabilité f(x1, x2) = x1 + x2.Calculez les densités marginales de X1 et X2 , les variables aléatoires X1 et X2 sont-elles indépendantes ?Exercice 8. Le couple aléatoire prend ses valeurs dans ]0,+∞[×]0,+∞[ avec ladensité de probabilité f(x1, x2) = e−x1−x2 .i)Les variables aléatoires X1 et X2 sont-elles indépendantes ?ii) Calculez E(X1), E(X2) et cov(X1, X2).Exercice 9. Le couple aléatoire prend ses valeurs dans le domaine D suivant
D = {x1 > 0, x2 > 0, x1 + x2 < 1} ,
avec la densité de probabilité f(x1, x2) = K(x1 + x2).i) Calculez K.ii)Les variables aléatoires X1 et X2 sont-elles indépendantes ?iii) Calculez E(X1), E(X2) et cov(X1, X2)iv) Déterminer les lois marginales de X1 et X2.Exercice 10.Soit X une variable aléatoire de densité de probabilité
f(x) =
½a(4− x) si 0 ≤ x ≤ 40 sinon ;
i) Calculer a.ii) Déterminer la fonction caractéristique φ de X.iii) Soient X1 et X2 deux variables aléatoires indépendantes et ayant la même
loi que X. On effectue le changement de variables
Y1 = X1 cos θ +X2 sin θ, Y2 = −X1 sin θ +X2 cos θ, θ ∈ [0, π].
Déterminer la loi de probabilité du couple (Y1, Y2).

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 40
Exercice 11. SoientX1 etX2 deux variables aléatoires indépendantes identique-ment distribuées selon la loi exponentielle de paramètre λ. Trouvez la distributiondu couple Y = (Y1, Y2) donné par
Y1 =X1
X2, Y2 = X2
1 +X22 .
Exercice 12. Soit X une variable aléatoire non-négative et intégrable, de fonctionde répartition F (x). La formule suivante
E(X) =
Z ∞
0
(1− F (x))dx,
est vraie. Démontrez-la dans le cas où X admet une densité de probabilité.
3 Estimation et tests
Exercice 1. En l’absence de mortalité, la croissance de toute population debactéries est modélisée par l’équation N(t) = N0e
kt, où N(t) est le nombre debactéries à l’instant t et N0 est le nombre de bactéries à l’instant initial t = 0.L’unité de temps choisie est un jour (24 heures). Les nombres N0 et k dépendent dutype de population bactérienne considérée.On s’intéresse à une population particulière. Des numérations faites tous les jours
à partir du 2e donne les résultats suivants :
ti 2 3 4 5 6 7 8 9 10 11 12Ni 55 90 135 245 403 665 1100 1810 3000 4450 7350
,
avec ti :jour de l’observation, Ni : nombre de bactéries au jour ti.On pose yi = ln(Ni) et Y (t) = ln(N(t)) = ln(N0) + kt, où ln représente le
logarithme népérien.
i) Calculer les moyennes des observations ti et yi ainsi que les écarts types de cesobservations.
ii) Par la méthode des moindres carrés, déterminer la droite de régression deY en t. Calculer le coefficient de corrélation des séries d’observations ainsi que lerésidu quadratique moyen.
iii) Ecrire le modèle théorique ajusté aux données (ti, Ni) auquel conduisent lesestimations de N0 et k.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 41
iv) Au bout d’un jour, quelle est l’estimation du nombre de bactéries ? Au boutde combien de jours peut-on prévoir que le nombre de bactéries sera 2000 fois celuidu nombre initial ?Exercice 2. La distribution des revenus soumis à l’impôt a été étudiée par
Pareto qui a proposé le modèle théorique N = Ama, où N est le nombre derevenus supérieurs ou égaux à m,A et a sont des constantes à estimer. Pour uneannée, on observe les revenus d’une population soumis à l’impôt et on a obtenu :
mi Ni
10000 1158326520000 204537230000 68324040000 34974050000 183280100000 36250200000 7975500000 10151000000 305
.
i) On pose y = ln(N), x = ln(m) et b = ln(A). Le modèle proposé équivaut ày = ax+ b.Calculer le coefficient de corrélation associé aux couples (xi, yi) où xi = ln(mi)
et yi = ln(Ni).ii) Par la méthode des moindres carrés, calculer les valeurs a et b ajustées aux couples(xi, yi).iii) Déduire de ce qui précède le modèle théorique de Pareto.iv) Calculer le nombre le plus probable de revenus supérieurs ou égaux à 300 000.Exercice 3. Soit (Xi)1≤i≤n une suite i.i.d selon la loi N(0, σ2) avec σ2 inconnue.i) Calculer l’estimateur du maximum de vraisemblance bσ 2 de σ2 .ii) Montrer que le moment d’ordre 4 de X1 est 3σ2.Exercice 4. On suppose que (Xi), 1 ≤ i ≤ n, est une suite i.i.d suivant une loi
de Pareto de paramètres (x0, θ), (x0 > 0, θ > 2) donc de densité
fθ(x) =
(θx0
¡x0x
¢θ+1si x > x0
0 si x ≤ x0.
i) On suppose que x0 = 1. Calculer l’estimateur du maximum de vraisemblancebθ de θ.Exercice 5. Une agence immobilière se propose d’estimer le prix de vente moyen
X des maisons à Marseille. On suppose que X Ã N(m,σ2).Elle constitue à cet effet, un échantillon aléatoire de 25 maisons vendues récemment,le prix moyen étant x25 = 148000 euros et l’écart-type estimé est s = 62000 euros.

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 42
i) Calculer un intervalle de confiance au niveau α = 0.05 pour le prix de vente moyende ces maisons vendues récemment.ii) On a entendu récemment qu’un ami a acquis une maison pour 206000 euros.Est-ce plausible, ou cette information est-elle entachée d’erreur ?
Exercice 6. Le poids d’une variété d’animaux de 1 ans d’un certain élevage suitsensiblement une loi de Gauss de moyenne 80kg et d’écart type 12kg. On considèreun échantillon de 16 animaux dont le poids moyen est de 73,5 kg.Faut-il écarter l’hypothèse selon laquelle l’échantillon n’est pas représentatif de
l’élevage : i) au seuil de signification α = 0.05 ?ii)au seuil de signification α = 0.01?Exercice 7. Le taux de glycémie à jeun d’une population d’adultes est sup-
posé distribué suivant une loi de Gauss d’espérance mathématique 0.80g/l. Sur unéchantillon de 12 personnes on a trouvé les mesures suivantes :
0.60 0.90 0.74 0.96 0.85 1.05 0.80 0.93 1.17 0.70 0.84 0.75
i) Calculer le taux moyen de glycémie à jeun des personnes de l’échantillon.ii) Au seuil de signification α = 0.05, ce taux moyen est-il compatible avec le
taux moyen de la population ?Exercice 8. Lors du développement d’une espèce de crustacés, on compte l’in-
tervalle X (en jours) entre deux mues larvaires fixées. Pour un premier lot d’animaux,on a obtenu les résultats suivants :
intervalle X 11 12 13 14 15 16 17 18nombre d’animaux 2 6 17 18 9 4 2 0
Pour un second lot d’animaux, élevés dans un milieu plus riche destiné à accélérerle développement, on a obtenu les résultats suivants :
intervalle X 11 12 13 14 15 16 17 18nombre d’animaux 3 7 21 12 5 2 0 1
i) Calculer les estimations de l’espérance mathématique m1 et de l’écart type bσ1relatif au premier lot, ainsi que de l’espérance mathématique m2 et de l’écart typebσ2 relatif au second lot.ii) Au seuil de signification α = 0.05, tester l’hypothèse nulle : H0 : m1 = m2.Exercice 9. On a déterminé dans le sang le taux d’une certaine protéine chez
des sujets atteints d’une maladie. On a trouvé
152 148 139 135 143 130 143 144 138 137 140 148 142 135 145

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 43
i) Donner une estimation de la moyenne et de la variance du taux de la protéinede la population d’où extrait cet échantillon.ii) Calculer l’intervalle de confiance à 95% de la moyenne.Afin de déterminer si ce taux de protéine est normal et pouvoir se servir de ce
dosage comme aide au diagnostic, on a étudié un lot de 13 témoins, on a trouvé140 143 137 127 130 138 135 141 136 132 134 135 133iii) Donner une estimation de la moyenne et de la variance de la population des
témoins.iv) Les témoins et les patients ont-ils des variances significativement différentes
au seuil de signification α = 0.05.v) Au seuil de signification α = 0.05, tester l’hypothèse nulle : H0 : m1 = m2,où m1 et m2 est le taux de la protéine chez les patients et les témoins respective-
ment.Exercice 10. Dans une certaine population, les hommes adultes se répartissent
en deux catégories, l’une P1 constituée de nomades et l’autre P2 constituée d’agricul-teurs. On se propose de comparer les tailles des individus de P1 et P2. Soit X (resp.Y ) la variable aléatoire taille des individus de P1 (resp. P2) supposée gaussienne.On a prélevé au hasard dans P1 (resp. P2) un échantillon E1 (resp. E2) et on aobtenu
E1 175 176 179 177 180 180 178 183 176 178 177 177 178
E2 165 176 174 187 192 169 171 170 177 173 171 167 170
i) Calculer les estimations de l’espérance mathématique mX et de l’écart typeσX relatif à E1, ainsi que de l’espérance mathématique mY et de l’écart type σYrelatif à E2.ii) Calculer les intervalles de confiance au niveau α = 0.05 pour mX et mY .iii)Au seuil de signification α = 0.01, tester l’hypothèse nulle : H0 : σ2X = σ2Y .iv)Au seuil de signification α = 0.05, tester l’hypothèse nulle : H0 : mX = mY .Exercice 11. Pour deux séries indépendantes de taille respectivement nx = 13,
et ny = 21 on a trouvé S2x = 105, S2y = 75.
Au seuil de signification α = 0.01, tester l’hypothèse nulle : H0 : σ2X = σ2Y .Exercice 12. Cinq laboratoires utilisent cinq méthodes différentes pour déter-
miner le taux de protéine du sang. On suppose que la variable aléatoire "taux dela protéine" suit un loi de Gauss. Chaque laboratoire Li, 1 ≤ i ≤ 5, effectue lesmesures sur un échantillon aléatoire Ei de taille ni, xi le taux moyen de la protéinepar ce laboratoire et bσi l’écart type des mesures à xi. On a trouvé les résultats :
Ei E1 E2 E3 E4 E5ni 10 15 10 20 10xi 152 150 148 151 153bσ2i 18 21 28 18 26

Licence L2-MAT45 : Statistiques et Probabilités 2—M.Boutahar 44
i) Calculer les variances intraclasse et interclasse des mesures relatives aux 5laboratoiresii) Peut-on refuser, au seuil de signification α = 0.10, l’homogénéité des variances
des taux de la protéine auxquelles conduisent les 5 méthodes ?, si non donner uneestimation de cette variance commune.iii) On admet qu’il y a homogénéité des variances, étudier l’homogénéité, au
seuil de signification α = 0.05, des moyennes des taux de la protéine auxquellesconduisent les 5 méthodes.Exercice 13. Dans une cimenterie, six fours rotatifs ont été chargés et réglés
pour fabriquer une même quantité de ciment. On prélève cinq éprouvettes dansla fabrication de chaque four et on mesure la charge de rupture à la traction R,exprimée en kg/cm2, de ces éprouvettes. On a obtenu
F1 13.1 11 12.8 12.3 14F2 12.8 12.9 11.5 12.3 12.5F3 12.7 13.7 14.1 14.5 14F4 13.6 14.7 13.5 14 14F5 13.5 14.5 14.2 15 14.7F6 10 13.7 14 14.1 14.7
i) Calculer les variances intraclasse (dans les fours) et interclasse (entre les fours)des observations précédentes.ii) Au seuil de signification α = 0.05, peut-on considérer qu’il y a homogénéité
des dispersions des résistances à la rupture ? Pour cela utiliser les deux tests : le testNeyman et Pearson et le test de Barlett.iii) En admettant l’homogénéité des dispersions, étudier l’homogénéité, au seuil
de signification α = 0.05, de cette production.





























