Embed Size (px)
Citation preview

Machine LearningLa Transformation des Méthodes d’Analyse
en Economie & Finance
Sylvain BARTHELEMYSylvain BARTHELEMYSylvain BARTHELEMYSylvain BARTHELEMYDirecteur Général, TAC ECONOMICS
MeetupMeetupMeetupMeetup LumenAILumenAILumenAILumenAIMars 2018 – Pau

2
Contexte
Cette présentation a été réalisée par Sylvain
BARTHELEMY, Directeur Général de TAC ECONOMICS,
lors d’un « Meetup » sur le Machine Learning,
organisé par LumenAI à Pau en mars 2018.

3
TAC ECONOMICS
� Société de recherche appliquée en économie et en finance, qui
accompagne les groupes à l’international au travers de notes, de signaux
d’alerte et d’échanges.
� Une société qui existe depuis 25 ans. Issue d’une rencontre entre un
économiste « qualitatif » et un « quantitatif ».
� Une clientèle de banques au départ, puis des industriels (gros et moins
gros) et des gestionnaires d’actifs.
� Environ 20 salariés, installés au nord de Rennes… et en Inde !
� Quatre grands domaines d’activité: (1) les abonnements aux outils de
mesure du risque pays, (2) les études stratégiques, (3) les développements
spécifiques, (4) les études pour la Commission Européenne et les Nations
Unies… et l’enseignement.

1. Machine learning, IA et « Big Data »
2. Risque Pays, Macroéconomie et Machine Learning
3. Typologie des PME Françaises et Cartes de Kohonen
4. Profils de Reprise Economique après les Crises
5. Evolution du métier de diagnostic de risque
« entreprise »
6. Text Mining sur la Presse Internationale
4
Plan de l’intervention

Machine Learning, IA et Big Data
5
6
Les grands concepts du « big data »
Réseaux de Neurones
Deep Learning
Big Data
Machine Learning
Smart Data
R
Python
Cassandra
MongoDB
MySQL
AlgorithmesGénétiques
Forêts Aléatoires
Intelligence Artificielle
Apprentissage Profond
Cloud HadoopSVM
Arbres Récursif
Spark
MapReduce
NoSQL
Tensor Processing Unit/Google
GPU/NVidia
Xeon Phi/Intel
TensorFlow
Theano
Torch
AWS
Open Source
API
7
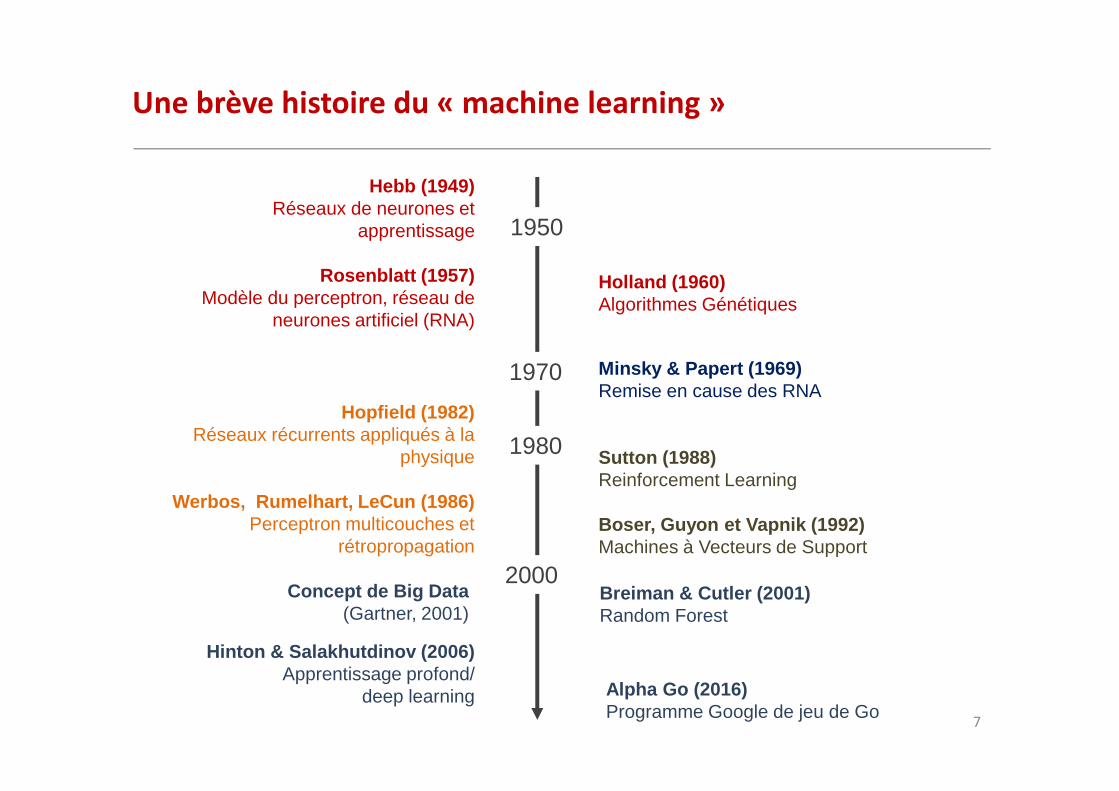
Une brève histoire du « machine learning »
1950
1980
1970
2000
Hebb (1949)Réseaux de neurones et
apprentissage
Rosenblatt (1957)Modèle du perceptron, réseau de
neurones artificiel (RNA)
Minsky & Papert (1969)Remise en cause des RNA
Hopfield (1982)Réseaux récurrents appliqués à la
physique
Werbos, Rumelhart, LeCun (1986)Perceptron multicouches et
rétropropagation
Breiman & Cutler (2001)Random Forest
Hinton & Salakhutdinov (2006)Apprentissage profond/
deep learning
Sutton (1988)Reinforcement Learning
Boser, Guyon et Vapnik (1992)Machines à Vecteurs de Support
Alpha Go (2016)Programme Google de jeu de Go
Holland (1960)Algorithmes Génétiques
Concept de Big Data(Gartner, 2001)

8
Les 2 grandes familles de méthodes & algorithmes
METHODES SUPERVISEESJe souhaite classer/expliquer des cas observés ou des évènements historiques précis
Exemples: des crises pays, défaillances d’entreprises, pics d’inflation, hausse de l’endettement, etc….
Outils: économétrie, analyses linéaires discriminantes, réseaux de neurones de type perceptron, SVM, forêts aléatoires, etc…
METHODES NON SUPERVISEESJe souhaite observer des régularités dans les données, des
groupes d’individus similaires,des périodes qui se ressemblent
Exemples: des familles crises pays, de groupes d’entreprises qui se ressemblent, des « patterns » économiques, des analogies
entre pays, etc….
Outils: analyses en composantes principales, k-means, méthodes de clustering (CAH etc.), cartes auto-organisatrices, etc…
9
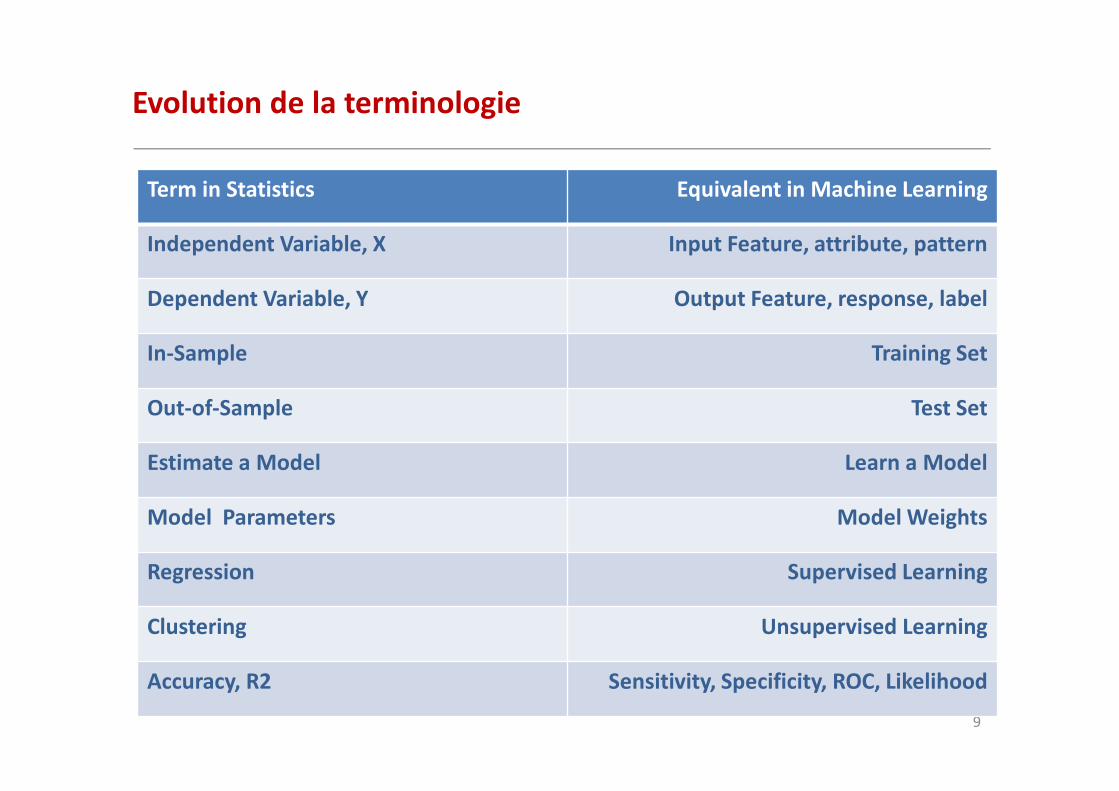
Evolution de la terminologie
Term in Statistics Equivalent in Machine Learning
Independent Variable, X Input Feature, attribute, pattern
Dependent Variable, Y Output Feature, response, label
In-Sample Training Set
Out-of-Sample Test Set
Estimate a Model Learn a Model
Model Parameters Model Weights
Regression Supervised Learning
Clustering Unsupervised Learning
Accuracy, R2 Sensitivity, Specificity, ROC, Likelihood

� Très performants pour identifier des patterns, des combinaisons
critiques (non linéaires): cas du skieur, modèles à deux variables,
signaux faibles et apprentissage en temps réel.
� Beaucoup d’entre eux sont presque entièrement « automatisables »
(à la différence des approches économétriques traditionnelles)
� Attention au risque de sur-apprentissage, au « machine learning
sauvage », aux risques de bases de données « poubelles » (données
erronées, pas de notion d’intégration/stationnarité, liens
économiques), phénomènes de « taches solaires », attention au
sampling, etc…
� Certains algorithmes sont des « boites noires »… mais pas tous !
10
A quoi servent ces algorithmes ?

Potentiel du « big data » par secteur
11

12
L’écosystème du « big data » en 2017

Risque Pays, Macroéconomie et Machine Learning
13

Prévoir les crises économiques et financières
� De nombreuses études empiriques sur le risque pays et les
indicateurs avancés de crises économiques et financières:
Krugman (1979), Obstfeld (1994), Cantor and Packer (1996),
Eichengreen et al. (1996), Frankel and Rose (1996), Goldstein
(1996), Goldstein and Turner (1996), Kaminsky and Reinhart
(1999), Komulainen and Lukkarila (2003) , …
� Mais malgré les classifications existantes, un très grand
nombre de crises économiques et financières ont laissé les
observateurs perplexes.
� Le manque de relations causales homogènes et des
interactions complexes rendent l’identification ex-ante des
facteurs de risque extrêmement difficile.
14

Equilibres Fondamentaux TAC ECONOMICS
15

Des combinaisons « simples » existent elles ?
Les crises sont en rouge
16
171717
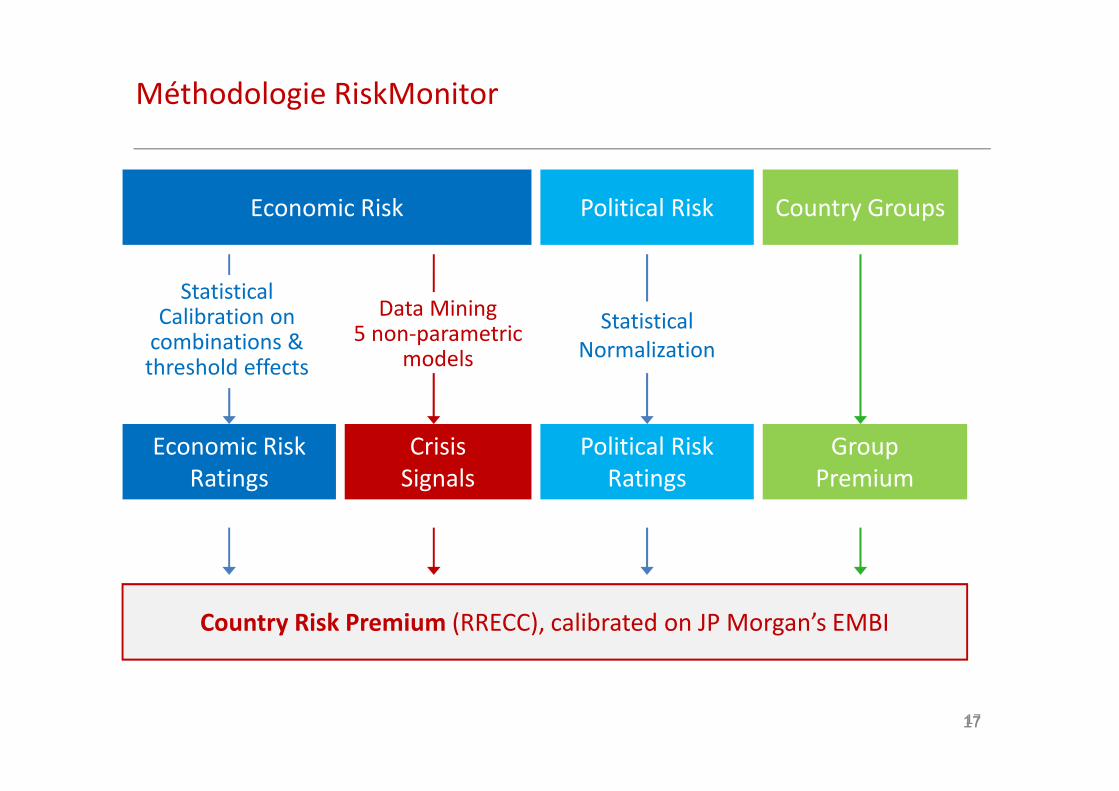
Méthodologie RiskMonitor
Economic Risk
Crisis
Signals
Political Risk
Economic Risk
Ratings
Political Risk
Ratings
Group
Premium
Country Risk Premium (RRECC), calibrated on JP Morgan’s EMBI
Country Groups
Statistical Calibration on
combinations & threshold effects
Data Mining 5 non-parametric
models
Statistical
Normalization

Early Warning à différents horizons
� L’outil « Early Warning » fonctionne à l’aide d’une combinaison de méthodes de data-mining à apprentissage supervisé:
– Réseau de Neurones
– SVM
– Random Forest
– Recursive Partitioning
– Logit
� Les outils sont calibrés sur des historiques de crises observées sur la totalité de l’échantillon depuis 1970 (bootstrapping/cross validation pour sélection)
18

Similarités et Crises Pays
19
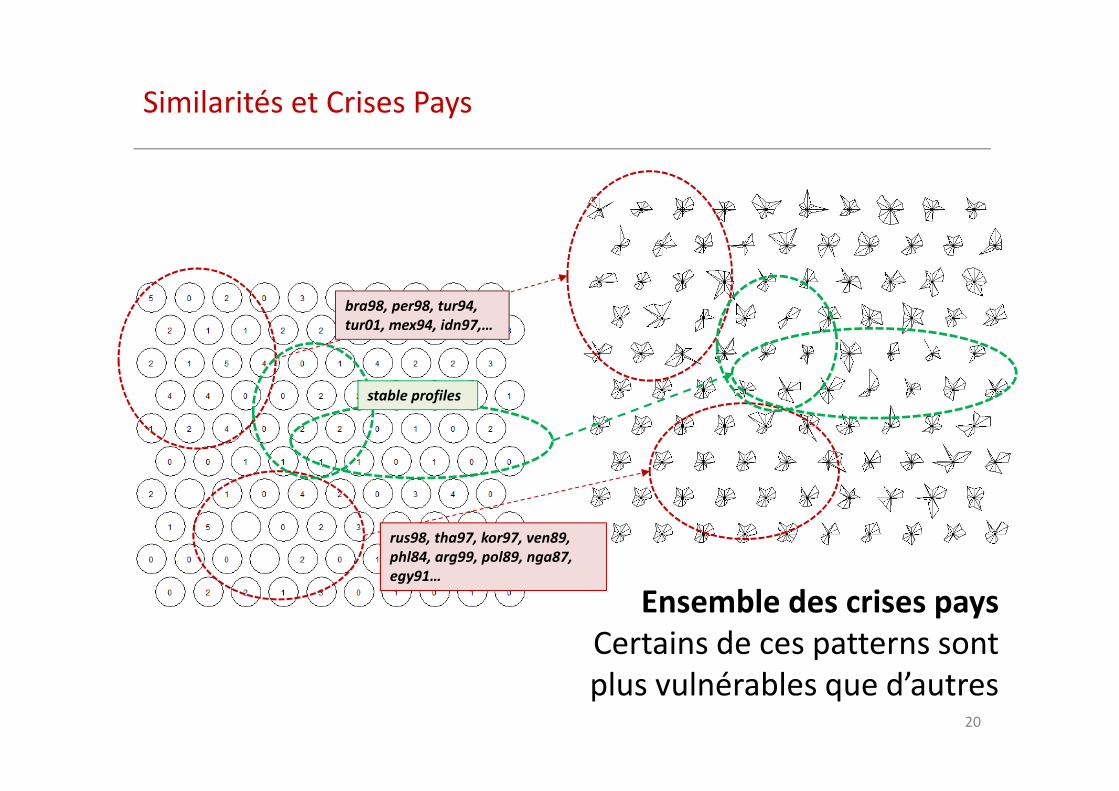
Similarités et Crises Pays
Ensemble des crises pays
Certains de ces patterns sont
plus vulnérables que d’autres
bra98, per98, tur94,
tur01, mex94, idn97,…
rus98, tha97, kor97, ven89,
phl84, arg99, pol89, nga87,
egy91…
stable profiles
20
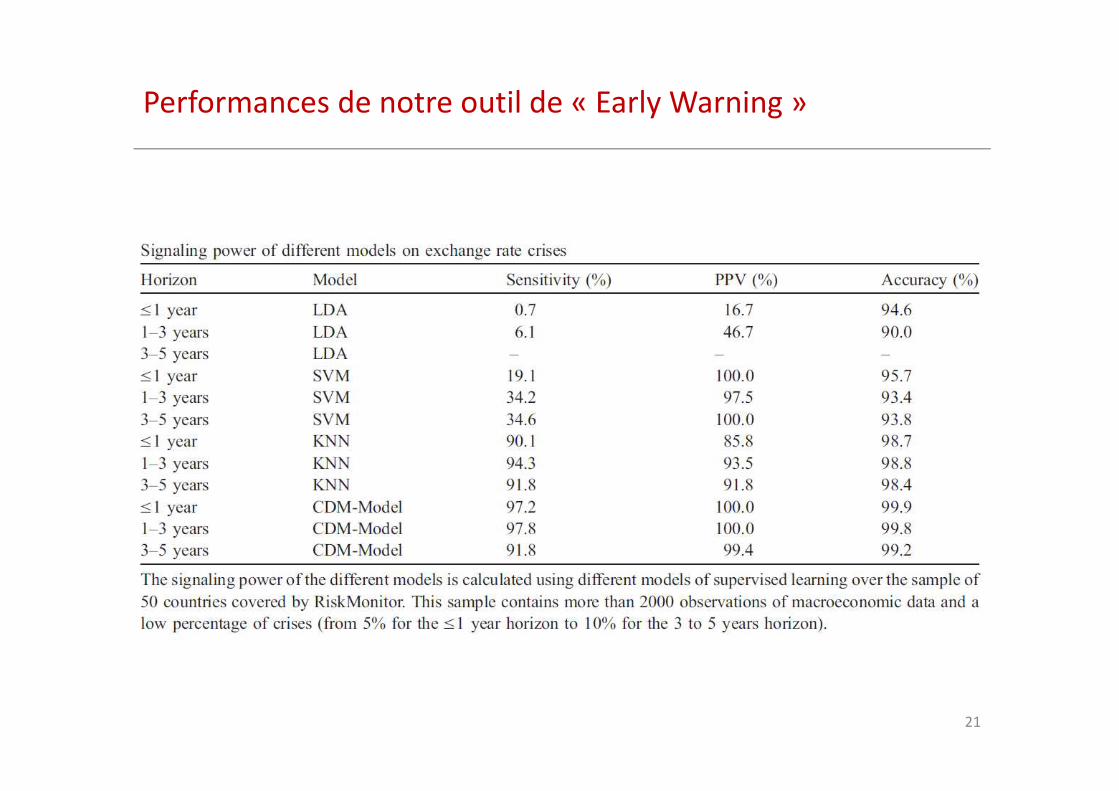
Performances de notre outil de « Early Warning »
21

Exemple sur la crise de la Thaïlande en 1997
22
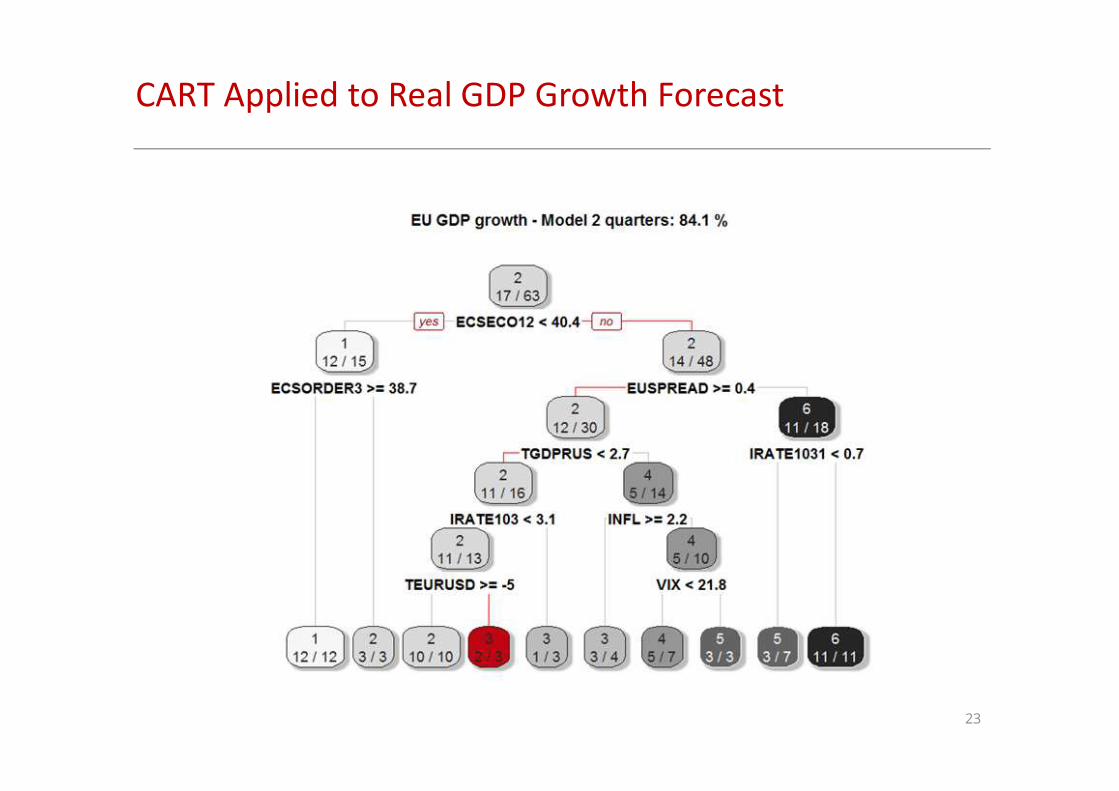
23
CART Applied to Real GDP Growth Forecast
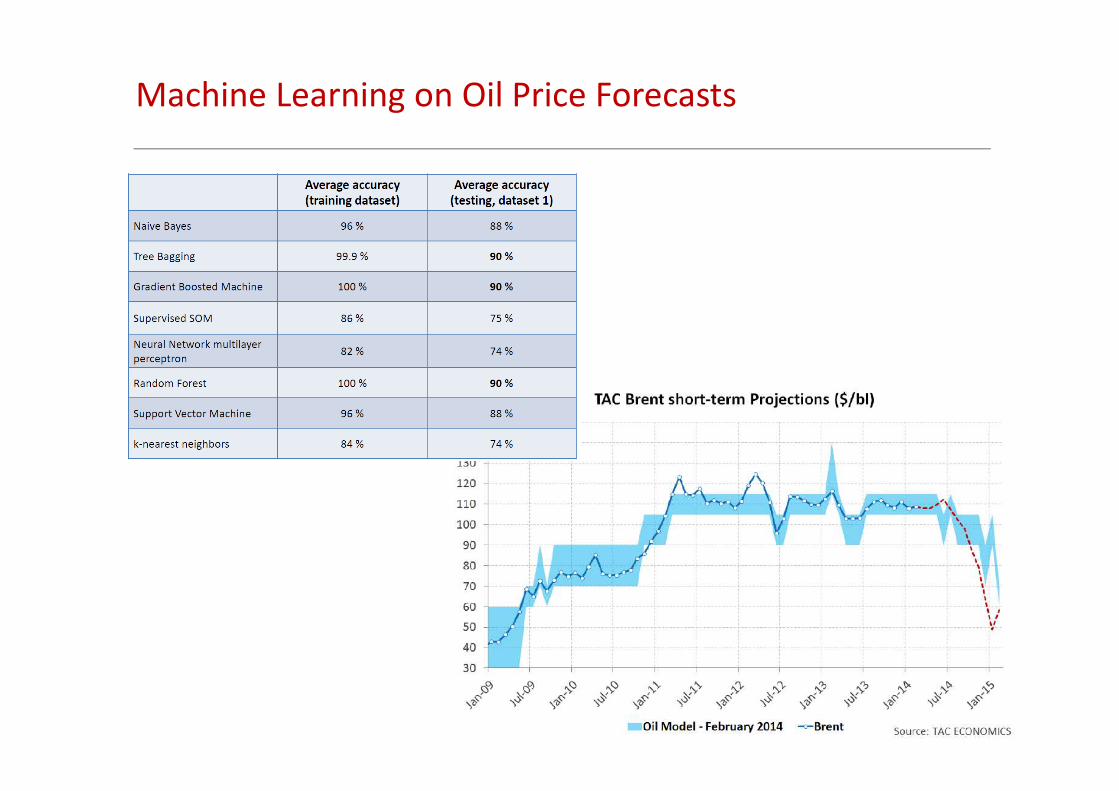
24
Machine Learning on Oil Price Forecasts

25
Archetypal of Political Risk

Typologie des PME Françaises et Cartes de Kohonen
26

Objectif
• En 2001, le MINEFI / Secrétariat d’Etat aux PME, lance une étude visant à aider les TPE française: « l’évaluation des entreprises afin de faciliter l’accès au crédit ».
• Or il existe une extrême diversité de la population des TPE et leurs besoins sont différent (garagiste, PME innovante, boulanger,…). Les critères de taille et de secteur sont-ils suffisants ?
• Peut-on utiliser des indicateurs quantitatifs et qualitatifs pour classer ces PME différemment ? Pourrait-on se baser sur la théorie économique des mondes de production de Salais & Storper pour les distinguer entre elles?
� Données comptables sur près de 150 000 entreprises françaises et une enquête réalisée par l’EM Lyon sur 459 PME de moins de 50 salariés et CA <7mn € (des TPE majoritairement).
27

Exemple d’indicateurs utilisés
Variable Valeur Variable Valeur
VF1
Endettement financier / fonds
propres nets. VQ1
Nombre de concurrent sur l’activité
principale
VF2
Excédent brut d’exploitation /
chiffre d’affaires hors-taxes VQ2
Part de produits nouveaux depuis
deux ans sur le marché
VF3
Endettement financier / capacité
d’autofinancement VQ3
Innovations techniques au cours de
deux années précédentes
VF4
Acquisitions corporelles /
(Acquisitions corporelles et
incorporelles) VQ4
Part du sur-mesure par rapport au
standard dans la fabrication
VF5
BFRE / (fonds propres nets +
endettement financier) VQ5
% du CA réalisé avec les principaux
clients
VF6
Capacité d’autofinancement /
fonds propres nets VQ6 code NAF
28

Quels algorithmes pour identifier une typologie ?
• Les cartes auto-organisatrices (SOM) ont donné des résultats
très intéressants pour comprendre la typologie des TPE
françaises (Kohonen 1995, Kaski 1997).
• Les SOM sont des projections non linéaires d’espaces
multidimensionnels dans un espace à dimensions réduites.
• Dans une « grille » SOM, les unités sont connectées par des
relations de voisinage. Des données visuellement proches
sont généralement des données similaires.
29
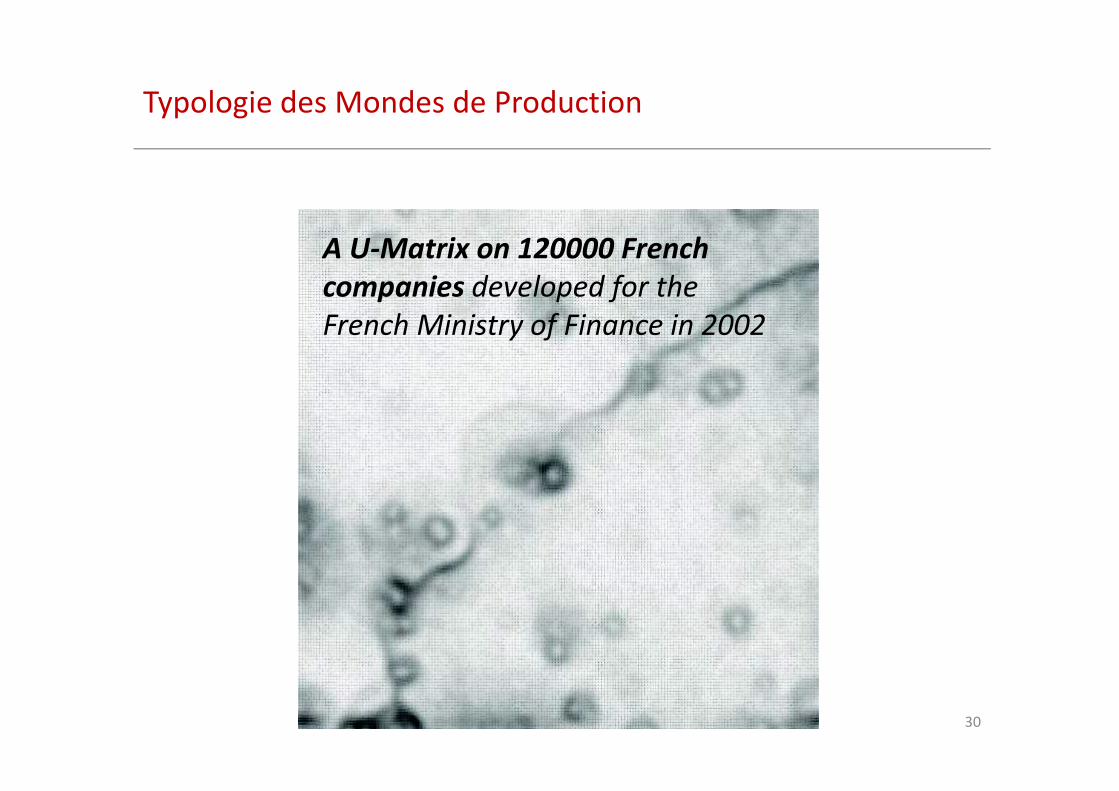
Typologie des Mondes de Production
A U-Matrix on 120000 French
companies developed for the
French Ministry of Finance in 2002
30
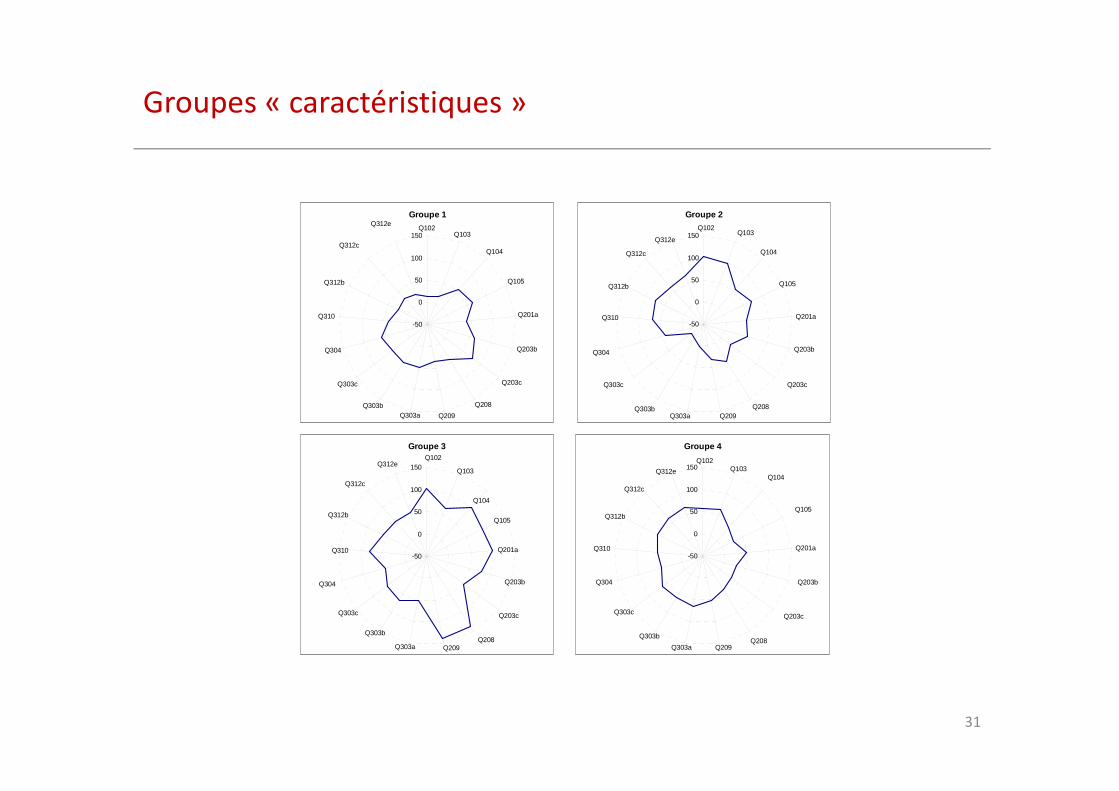
Groupes « caractéristiques »
Groupe 1Q312e
Q312c
Q312b
Q310
Q304
Q303c
Q303bQ303a Q209
Q208
Q203c
Q203b
Q201a
Q105
Q104
Q103Q102
-50
0
50
100
150
Groupe 2
Q312e
Q312c
Q312b
Q310
Q304
Q303c
Q303bQ303a Q209
Q208
Q203c
Q203b
Q201a
Q105
Q104
Q103Q102
-50
0
50
100
150
Groupe 3Q102
Q103
Q104
Q105
Q201a
Q203b
Q203c
Q208Q209Q303a
Q303b
Q303c
Q304
Q310
Q312b
Q312c
Q312e
-50
0
50
100
150
Groupe 4
Q312e
Q312c
Q312b
Q310
Q304
Q303c
Q303b
Q303a Q209Q208
Q203c
Q203b
Q201a
Q105
Q104Q103
Q102
-50
0
50
100
150
31

Interface web pour comparer une entreprises
par rapport à son groupe de référence (forces / faiblesses)
32

Profils de reprise économique après les crises
33

Database and list of crises
� A sample of 104 emerging markets and advanced economies.
� Annual macroeconomic and financial indicators from the IMF,
World Bank, OECD and BIS databases over the period 1973-
2007.
� List of crises extracted from the Gourinchas / Obstfeld
database (2012).

Database and list of crises
• Focus on three types of country crises:
– Currency crises: devaluation >25% and +10% in the annual rate of depreciation - criterion of Frankel and Rose (1996)
– Systemic Banking Crises: dating from Caprio & Klingebieland Laeven and Valencia (2010).
– External Default: dating from Reinhart and Rogoff (2009)
• A list of 244 crises, with 60 episodes of systemic banking crises, 178 currency crises and 52 defaults (the sum is not 244 because of “multiple” crises or “mutations”).
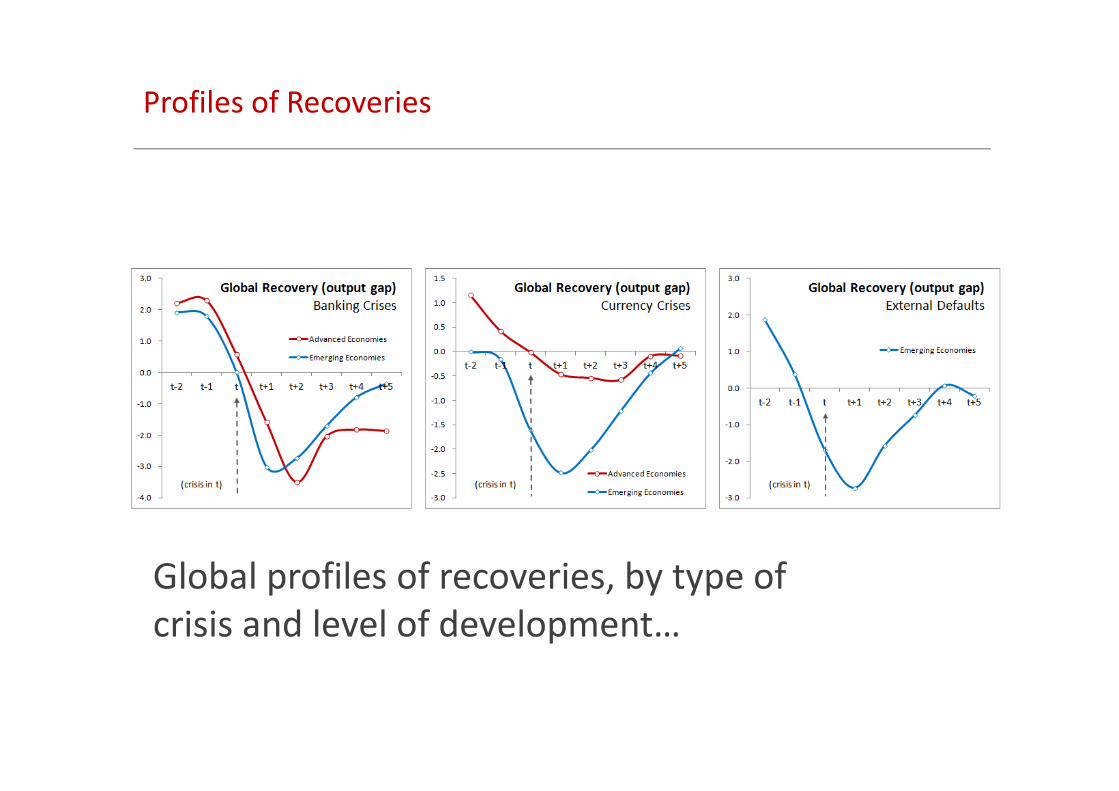
Profiles of Recoveries
Global profiles of recoveries, by type of
crisis and level of development…
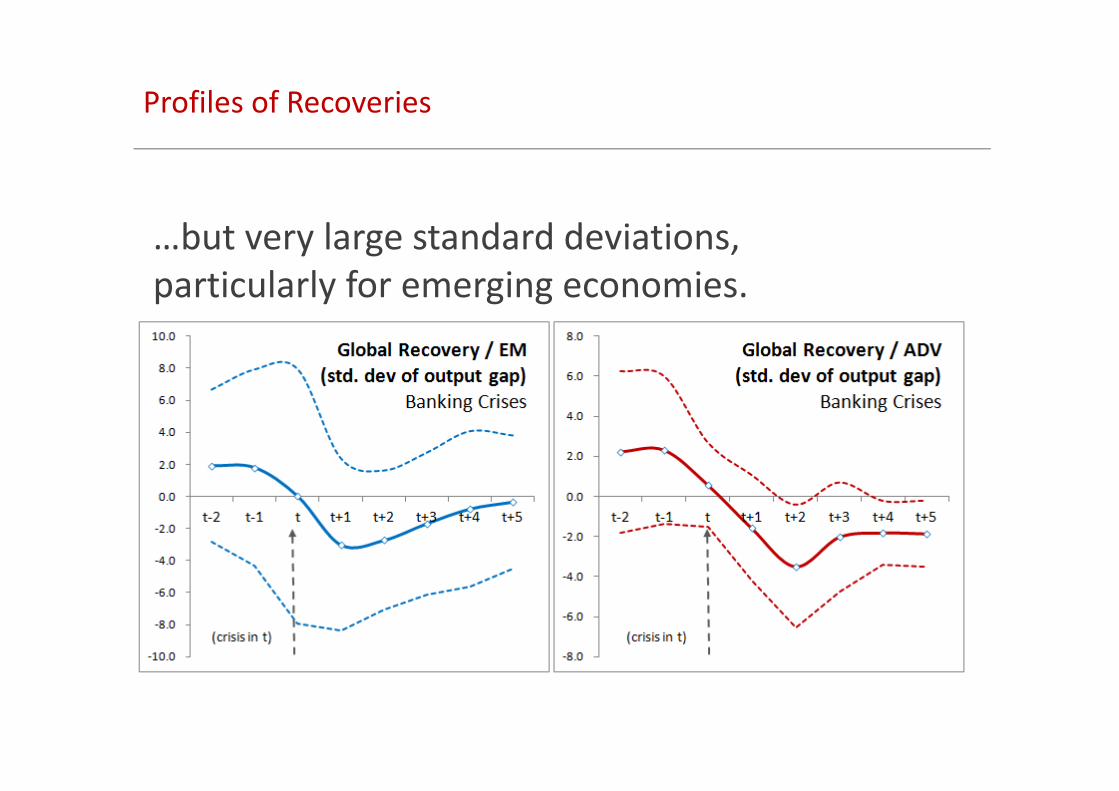
Profiles of Recoveries
…but very large standard deviations,
particularly for emerging economies.

Profiles of Recoveries
Various SOM conducted on all recovery profiles
Start with random profiles… …after training we see the “main profiles”
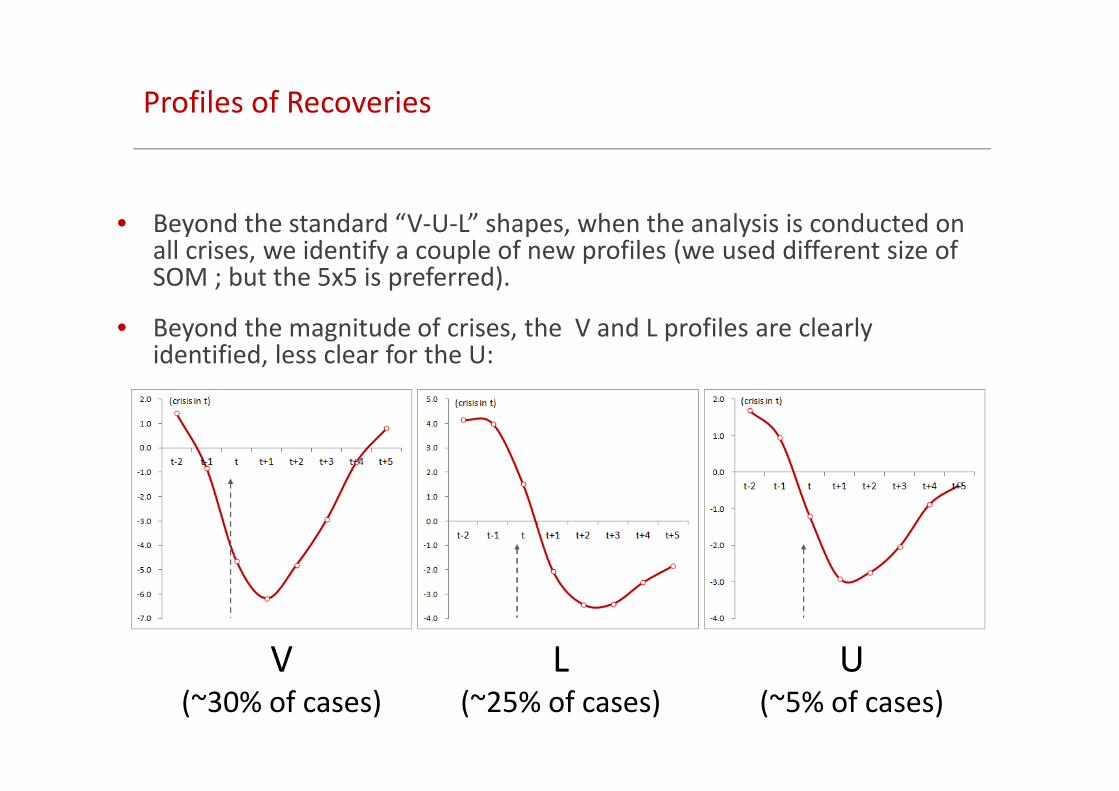
Profiles of Recoveries
• Beyond the standard “V-U-L” shapes, when the analysis is conducted on all crises, we identify a couple of new profiles (we used different size of SOM ; but the 5x5 is preferred).
• Beyond the magnitude of crises, the V and L profiles are clearly identified, less clear for the U:
V(~30% of cases)
L(~25% of cases)
U(~5% of cases)
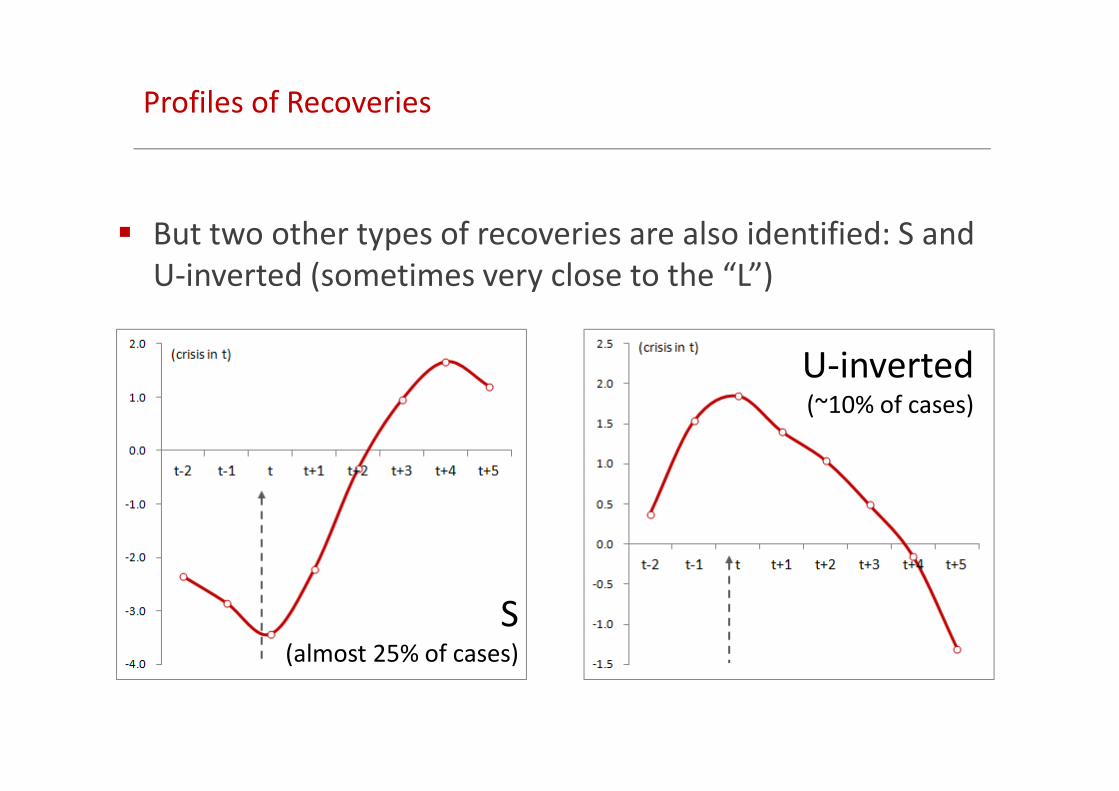
Profiles of Recoveries
� But two other types of recoveries are also identified: S and
U-inverted (sometimes very close to the “L”)
U-inverted(~10% of cases)
S(almost 25% of cases)

Profiles of Recoveries
Crises V U L S U-inv Other
Banking 31% 3% 37% 17% 9% 3%
Currency 35% 7% 19% 26% 7% 4%
Default 23% 0% 27% 31% 12% 8%
Multiple 25% 5% 30% 18% 15% 8%
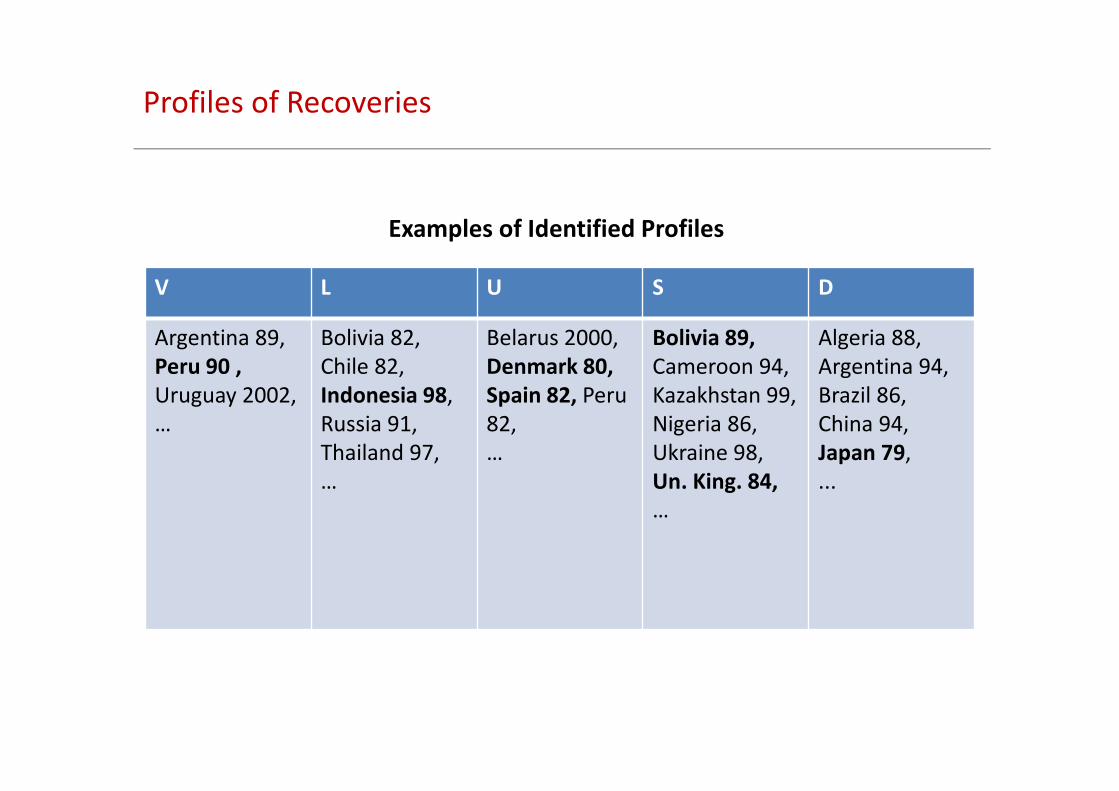
Profiles of Recoveries
V L U S D
Argentina 89,
Peru 90 ,
Uruguay 2002,
…
Bolivia 82,
Chile 82,
Indonesia 98,
Russia 91,
Thailand 97,
…
Belarus 2000,
Denmark 80,
Spain 82, Peru
82,
…
Bolivia 89,
Cameroon 94,
Kazakhstan 99,
Nigeria 86,
Ukraine 98,
Un. King. 84,
…
Algeria 88,
Argentina 94,
Brazil 86,
China 94,
Japan 79,
...
Examples of Identified Profiles

Evolution du métier de diagnostic de risque « entreprise »
43

� Open Data– Dispositions communautaire (directives 2003/98 et 2013/37)
et française (circulaire du 26 mai 2011) imposent gratuité des données
publiques et exceptionnellement un système de redevances
potentiellement défavorable aux « acteurs majeurs ».
� Réduction des obligations de publication bilancielles– levée des
obligation des publications des TPE et de certaines.
� NTIC / big data / cloud
Capacité de stockage des données accrue, coûts marginaux de stockage et
de diffusion de l’information décroissants voire nuls. Environnement
technologique favorable à de nouveaux entrants low-cost
� Méthodes d’extraction des connaissances et de « data mining »
Environnement scientifique favorable (Moody’s Analytics, Baromètre des
TPE de Fiducial/IFOP, CreditSafe avec DFCG, Observatoire des PME de BPI,
Projet Ratings du BIPE etc…)44
De nouvelles tendances de marché

45
� Agrégateur d’un grand nombre
de sources de données (dont
CreditSafe, D&B, Experian,…)
� Données quantitatives et
qualitatives en « temps réel »
� Données mises à jour et
accessibles en temps réel.
� Data solutions, marketing et
« global business »:
prospection, campagnes
marketing, tracking de
fournisseurs, conflits d’intérêt,
acquisitions potentielles, …
Emergence de nouvelles opportunités
OneSource/Avention

46
� Associe un logiciel de
comptabilité à un score
performant et à de
l’information d’entreprises.
� La base de données est remplie
par les entreprises elles-
mêmes.
� Propose des facilités d’accès
aux prêts pour les PME ayant
uploadé leurs comptes et
acceptées une analyse
financière de ceux-ci via un
accord avec Capital One et
Wells Fargo.
Emergence de nouvelles opportunités
QuickBooks Financing

Text Mining sur la Presse Internationale
47

48
The database of News & Tweets
� A list of 1000 websites, newspapers, information
providers and blogs, in different languages.
� Possibility to extent the dataset to larger databases,
such as Lexis Nexis or Factiva.
� Every 3 hours our web-crawlers store the
information published on these websites on
internal databases (approx. 20,000 per day).
� A different set of crawlers extract and store tweets
on a pre-defined list of keywords or corporates.
However, limitations imposed by Tweeter (GNIP,
Datasift, Topsy,…).

49
Sentiment Analysis by Country & Corporate
� Every day, internal algorithms estimate the
sentiment using different techniques, on all
“articles” and tweets.
� The techniques used for the identification of
sentiment polarisation are similar to Brandtology
(iSentia).
� With the number of news and tweets, we also
calculate a “buzz index” for each country, corporate
or theme analysed.

50
Extraction of Hot Topics in the News
� An internal algorithm to extract most important
articles and topics, on a daily, weekly and monthly
basis.
� The list of key topics is available on a large sample
of countries and some multinational companies.
� The list can be modified to include any theme or
keyword.
� Topics automatically published on our portal in real-
time.

51
TAC Mood Index by Country

52
Sentiment Analysis: Turkey

53
Sentiment Analysis: Macron

Conclusion
54

55
Des mutations profondes
� Plus de données, de meilleurs modèles, plus de
puissance de calcul, plus de puissance de stockage.
� L’économétrie a aussi évolué depuis 30 ans, mais ces
nouvelles méthodes, outils et données changent notre
métier plus profondément encore.
� Les systèmes vont continuer à s’automatiser de plus en
plus dans les années qui viennent.
� Les « acteurs » de l’analyse et de la prévision ne sont plus
les mêmes qu’il y a 10 ans et le « data scientist » devient
roi.

56
Une opportunité qu’il faut savoir saisir
� Le « data scientist » informaticien, statisticien, économiste existe-t-
il vraiment ?
� Plutôt que des menaces, ces évolutions sont aussi de formidables
opportunités.
� Il faudra toujours des analystes pour concevoir, estimer et contrôler
les systèmes… et éviter qu’un Random Forest ne prévoit une ère
glacière car vous avez placé la sonde de température dans un frigo
par erreur.
� La connaissance « métier » va (re-)devenir fondamentale. L’analyste
qui sait marier sa compréhension des données, ses connaissances
théoriques, ses connaissances du métier à une meilleure
connaissance des principes généraux des méthodes du machine
learning « moderne », aura un avantage comparatif considérable…
� … mais il ne faut pas rater le train !

Des résultats statistiques remarquables
ne disent pas que
les modèles ne se trompent jamais !
57
Attention à ne pas chercher la boule de cristal
Merci de votre Attention
58

59
Nous Contacter
Sylvain Barthélémy
Commercial et Communication
Tel: +33 (0)2 99 39 31 40 – www.taceconomics.com





![Trésorier et acquisition - TAC ECONOMICS...- Inventaire des flux [douments, ash, titres, …] o Vérification des prérequis - Gouvernance & Autorisations - Pouvoirs et Limites Bancaires](https://img.pdfslide.tips/doc/110x75/5f200d8c5ebda059030451d9/trsorier-et-acquisition-tac-economics-inventaire-des-flux-douments-ash.jpg)























