Embed Size (px)
Citation preview

Tecnicas de Aproximacao para a Betweenness emRedes de Grande Dimensao
Filipe Pascoal Martins Carapeto
Dissertacao para obtencao do Grau de Mestre em
Engenharia Informatica e de Computadores
Orientadores: Prof. Alexandre Paulo Lourenco Francisco
Prof. Luıs Manuel Silveira Russo
Juri
Presidente: Prof. Jose Carlos Alves Pereira Monteiro
Orientador: Prof. Alexandre Paulo Lourenco Francisco
Vogal: Prof. Bruno Emanuel da Graca Martins
Novembro 2015


Abstract
Oe studo e analise de grafos e actualmente uma importante area de investigacao com
aplicacoes em diversas areas. A Betweenness Centrality destaca-se, dentro das medi-
das de centralidade, pela forma como exprime a importancia e influencia de um no na rede
sendo o seu calculo pretendido para muitas redes. No entanto, com o advento da globalizacao
da tecnologia, cada vez surgem redes maiores cuja analise e necessaria, como por exemplo
as redes sociais. Para redes como essas, tipicamente com tamanho na ordem dos milhoes de
nos, o calculo exacto da Betweenness Centrality e proibitivo. Assim sendo, torna-se essencial
explorar alternativas que possam eficientemente aproximar esta medida de centralidade. Este
trabalho apresenta um estudo de varias tecnicas utilizadas actualmente no calculo aproximado
da Betweenness Centrality. Este trabalho propoe tambem algumas alternativas, utilizando con-
ceitos como Community Finding e k-core como forma de melhorar o desempenho dos metodos
de aproximacao.
Keywords: Betweenness Centrality , Complex Networks , Centrality Indicators , Centrality
Estimation
i


Resumo
Th e study and analysis of networks is, today, an important area of research that serves
many different areas. Betweenness Centrality is a centrality measure that stands out for
the way in which it expresses the importance and influence of a given node in a network, which
makes its computing desired for many real world networks. However, with the rise of the glob-
alization of tecnhology, there is a need to analyse bigger and bigger networks like, for example,
social networks. For networks such as these, which usually have millions of nodes, the exact
calculation of Betweenness Centrality is infeasible. As such, it is essential to explore new alter-
natives that can efficiently estimate this centrality measure, with a low error margin. This article(?)
contains a brief study of several tecnhiques that are used in the estimation of Betweenness Cen-
trality. It also contains several new approaches based on concepts like Community Finding and
k-core.
Palavras-chave: Betweenness Centrality , Redes Complexas , Medidas de Centralidade ,
Estimacao de Valores
iii


Tabela de Conteudos
Abstract i
Resumo iii
1 Introducao 1
1.1 Problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Objectivos do Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Trabalho Relacionado 3
2.1 Notacao e Conceitos Basicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Betweeness Centrality como metrica de centralidade . . . . . . . . . . . . . . . . . 4
2.3 Algoritmos para o Calculo de APSP . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.3.1 MBFS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3.2 Floyd-Warshall . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3.3 Johnson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4 Brandes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.5 Vertex Sampling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.6 Representacoes de Grafos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.7 Abordagem a seguir . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.7.1 K-cores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.7.2 Community Finding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 Abordagem 21
v

3.1 Implementacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.1 Community Finding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.2 K-Cores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1.3 Calculo Exacto e Aproximado da Betweenness . . . . . . . . . . . . . . . . 23
3.1.4 Heurısticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.5 Avaliacao dos Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.2 Redes Utilizadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2.1 Redes Sinteticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2.2 Redes Reais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.3 Avaliacao de Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3.1 Redes Sinteticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3.2 Redes Reais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4 Conclusoes 39
Bibliography 40
vi

Lista de Tabelas
2.1 Algoritmos para o calculo de ASPS . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Estrategias de Seleccao de Pivo, com base na Tabela 1 do trabalho de Brandes e
Pich[7]) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Resumo dos Algoritmos Revistos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
vii


Lista de Figuras
2.1 Exemplo de varias camadas de k-cores (imagem retirada do paper de Batagelj e
Zaversnik) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2 Exemplo de execucao do Louvain method (imagem retirada do artigo original do
Louvain method [3]) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Testes com taxa variavel sobre redes completamente aleatorias . . . . . . . . . . 29
3.4 Testes com taxa fixa sobre redes completamente aleatorias de tamanho 10000 . . 29
3.5 Testes com taxa variavel sobre redes com comunidades bem definidas . . . . . . 30
3.6 Testes com taxa fixa sobre redes comunidades bem definidas de tamanho 10000 30
3.7 Performance Completa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.8 Performance das Heurısticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.9 Distribuicao dos valores da Betweenness para o 1º top100 . . . . . . . . . . . . . 34
3.10 Distribuicao dos valores da Betweenness para o 2º top100 . . . . . . . . . . . . . 34
3.11 Distribuicao dos valores da Betweenness para o 3º top100 . . . . . . . . . . . . . 35
3.12 Louvain sobre as redes reais com a heurıstica RanDeg . . . . . . . . . . . . . . . 35
3.13 Louvain sobre as redes reais com a heurıstica CSLD . . . . . . . . . . . . . . . . . 36
3.14 LLP sobre as redes reais com a heurıstica RanDeg . . . . . . . . . . . . . . . . . 37
3.15 LLP sobre as redes reais com a heurıstica CSLD . . . . . . . . . . . . . . . . . . . 37
ix


Capıtulo 1
Introducao
De uma forma geral, a analise da centralidade de um vertice/arco dentro de um grafo serve
para avaliar a sua importancia relativa dentro desse mesmo grafo. Esta analise surge
essencialmente no contexto do estudo de redes sociais (esferas de influencia, comunidades,
grupos de trabalho, etc...) mas e tambem pertinente em diversas outras areas como construcao
civil (estradas mais usadas da rede, colocacao optima de linhas de transportes publicos, etc...);
telecomunicacoes/redes de computadores (quais os nos determinantes para o funcionamento
da rede, qual o no raiz na rede de computadores) entre outras.
Apesar deste conceito generico, nao existe consenso quanto a forma de quantificar objectiva-
mente a centralidade de um vertice/arco. Este facto faz com que existam varias medidas de
centralidade que capturam diferentes nocoes do conceito de centralidade. As principais medi-
das de centralidade sao pois degree centrality, closeness centrality, eigenvector centrality e, a
que vamos estudar, betweeness centrality [12, 16].
1.1 Problema
Visto que para redes suficientemente grandes e impossıvel o calculo exacto da betweeness
centrality, geralmente recorre-se a amostragem de vertices. Actualmente nao existe um criterio
de escolha de vertices para amostragem que produza resultados de qualidade, independente-
mente da topologia da rede. E necessario explorar novas alternativas que nos permitam fazer
uma escolha mais informada.
1

2 CAPITULO 1. INTRODUCAO
1.2 Objectivos do Trabalho
Este trabalho tem como objectivo explorar alternativas de vertex sampling para o calculo aprox-
imado da medida betweenness centrality em grafos com milhoes de nos e ligacoes. Ao longo
deste relatorio e feita uma analise resumida as tecnicas existentes para o calculo exacto e aprox-
imado da betweenness centrality e finalmente sao exploradas novas alternativas baseadas nos
k-cores do grafo e em community finding. E ainda proposto um plano de trabalho para experi-
mentalmente se verificar a validade, ou nao, das alternativas propostas.

Capıtulo 2
Trabalho Relacionado
2.1 Notacao e Conceitos Basicos
Primeiramente vou introduzir a notacao que sera usada ao longo desta tese e tambem enunciar
algumas definicoes necessarias.
No contexto deste trabalho um grafo e um tuplo G = (V,E), em que V representa o conjunto de
vertices (ou nos), com n = |V |, e E o conjunto de arcos (ou ligacoes), com m = |E|. Por uma
questao de simplicidade assume-se que todos os grafos sao ligados e nao-orientados. Note-se
que os algoritmos e/ou estruturas de dados apresentados neste trabalho geralmente necessitam
apenas de ligeiras modificacoes se considerarmos tambem grafos orientados, sendo que farei
a devida distincao sempre que for pertinente. De referir ainda que os grafos poderao conter
self-loops e arcos multiplos.
Seja ω uma funcao que faz corresponder um peso a cada arco. Assume-se que ω(e) > 0 para
qualquer e ∈ E para grafos pesados e assume-se que ω(e) = 1 para grafos nao-pesados.
Defina-se um caminho entre u ∈ V e v ∈ V como uma sequencia de vertices e arcos consec-
utivos com inıcio em u e fim em v. O custo de um caminho e a soma do peso dos arcos nele
contidos. Um caminho mais curto entre u e v e um caminho entre eles com menor peso e o
seu custo sera representado por d(u, v).
Quando necessario, serao pontualmente introduzidos conceitos mais especıficos.
3

4 CAPITULO 2. TRABALHO RELACIONADO
2.2 Betweeness Centrality como metrica de centralidade
A betweeness centrality (daqui em diante simplesmente designada por betweeness) representa
a proporcao de caminhos mais curtos, em todo o grafo, que passam por um dado vertice. Esta
definicao pode ser modificada para se definir a betweenness de um arco.
Para s, t, v ∈ V, seja σst o numero de caminhos mais curtos entre s e t e seja σst(v) o numero
de caminhos mais curtos entre s e t que passam por v. Entao, a betweeness de um vertice v e
dada por:
BC(v) =∑s6=v 6=t
σst(v)
σst(2.1)
Analogamente, podemos definir o conceito de edge betweenness como o numero de caminhos
mais curtos entre todos os pares de vertices que passam num dado arco [18].
O valor de betweenness de um vertice pode ser apresentado de forma absoluta ou pode ser
facilmente normalizado, quer em termos do valor mais alto verificado dentro do grafo quer em
termos do seu valor maximo ((n− 1) ∗ (n− 2)).
Apesar de este trabalho se focar na betweenness de vertices, ao longo dele tecerei algumas
consideracoes sobre o calculo da betweenness para arcos.
2.3 Algoritmos para o Calculo de APSP
Como vimos, o calculo da betweenness envolve calcular o caminho mais curto entre todo e
qualquer par de vertices, conhecido como o problema do All-Pair-Shortest-Paths (APSP). Como
tal, a complexidade geral de qualquer algoritmo que calcule betweenness sera dominada pelo
calculo desses caminhos mais curtos.
Intuitivamente podemos pensar que a forma mais simples de calcular a betweeness de um
vertice, w, seria calcular os caminhos mais curtos entre qualquer par de vertices (u, v), para
cada par (u, v) calcular a percentagem desses caminhos que passam por w e somar todas
as percentagens (obtendo BC(w)). Claro que esta abordagem seria extremamente limitativa e
simplesmente repetir este processo para cada vertice seria computacionalmente pesado.
Existem varios algoritmos que, com menor ou maior eficiencia, podem ser usados para calcular
a betweenness exacta de todos os vertices de um grafo (ver Tabela 1).

2.3. ALGORITMOS PARA O CALCULO DE APSP 5
Table 2.1: Algoritmos para o calculo de ASPS
Algoritmo Comp. Temporal Comp. Espacial Grafos Pesados
Floyd-Warshall O(n3) O(n2) X
Johnson O(n2 ∗ log(n) + nm) O(n2) X
MBFS O(nm) O(n2) 7
Neste trabalho irei apenas abordar o algoritmo de Brandes mais a frente, uma vez que e necessario
fazer uma distincao entre os algoritmos de Floyd-Warshall, Johnson e Multiplas BFSs (daqui em
diante MBFS) que nao sao especificamente orientados para o calculo da betweenness e o al-
goritmo de Brandes que tem esse como seu principal objectivo. Apesar disso, qualquer um
dos algoritmos dos algoritmos de Floyd-Warshall,Johnson ou MBFS pode ser modificado para o
calculo da betweenness, na verdade o proprio algoritmo de Brandes e um algoritmo de Dijkstra
modificado.
2.3.1 MBFS
Se G for um grafo nao-pesado, uma procura em largura primeiro (BFS) a partir de um vertice
s ∈ V pode ser usada para encontrar um caminho mais curto entre s e qualquer u ∈ V , em
O(m). Mais concretamente, uma BFS encontra todos os caminhos mais curtos a partir de s
[11]. Logo, se executarmos n BFSs (a partir de cada vertice) obtemos caminhos mais curtos
entre todos os pares de vertices. Este algoritmo corre em O(nm), sendo que m varia entre n− 1
(grafos esparsos) e n2 (grafos densos), logo tem uma complexidade quadratica no pior caso.
Sejam s, v, u ∈ V , seja Q uma fila (FIFO), seja V isitado(v) uma funcao que retorna 1 caso v
ja tenha sido visitado durante a BFS e 0 caso contrario e seja π(v) um funcao que retorna o
predecessor de v. A implementacao de uma BFS a partir de s e a seguinte:
1. Inicializar uma fila Q com os vertices do grafo
2. Enquanto Q nao estiver vazia, executar o passo 3
3. u = proximo elemento na fila e para cada v seu vizinho executar o passo 4
4. Se V isitado(v) = 0
(a) V isitado(v) = 1 ; d(s, v) = d(s, u) + 1 ; π(v) = u ; insere-se v no fim da fila

6 CAPITULO 2. TRABALHO RELACIONADO
2.3.2 Floyd-Warshall
Uma forma de acelerar o processo de calculo da betweenness centrality, em comparacao com a
abordagem simplista que envolve calcular isoladamente os caminhos mais curtos entre qualquer
par de vertices, consiste em calcular a centralidade de todos os vertices nao-sequencialmente,
usando alguma forma de progressao que permita melhorar as estimativas da centralidade dos
vertices ate se chegar ao valor optimo. O algoritmo de Floyd-Warshall [14] consegue faze-lo
computando ate n2 caminhos mais curtos em O(n3).
A componente principal deste algoritmo sao os seguintes tres ciclos:
Sejam u, v ∈ V e seja dist uma matriz n ∗ n em que dist[u][v] = ω(u, v) (dist[u][v] = ∞ se
(u, v) /∈ E), o algoritmo de Floyd-Warshall consiste nos seguintes tres ciclos:
1. Para cada k de 0 a n executar o passo 2.
2. Para cada i de 0 a n executar o passo 3.
3. Para cada j de 0 a n
(a) Se dist[i][j] > dist[i][k] + dist[k][j] entao dist[i][j]← dist[i][k] + dist[k][j]
A cada passo deste algoritmo sao calculados os caminhos mais curtos que usam nos intermedios
entre 0 e k (k nos intermedios entre a fonte e o destino). Isto significa que em cada passo este
algoritmo, potencialmente, melhora a estimativa de todos os caminhos mais curtos no grafo
(isto implica que em cada k passo o algoritmo execute um varrimento completo da matriz de
adjacencias, O(V 2)). Nao obstante a sua eficiencia, o facto de ter uma complexidade tempo-
ral polinomial de grau 3 torna este algoritmo demasiado pesado para grafos com um numero
consideravel de vertices.
2.3.3 Johnson
A semelhanca do algoritmo de Floyd-Warshall, este tambem tinha originalmente como objectivo
apenas computar os caminhos mais curtos entre todos os pares de vertices de um grafo [19].
No entanto, mais tarde Brandes propos o seu algoritmo para o calculo da betweenness [6] e
demonstrou, como veremos mais a frente, que algoritmos como o de Johnson, com as devidas
modificacoes, podem ser tambem eles usados com o mesmo proposito.
Este algoritmo consiste em quatro passos:

2.4. BRANDES 7
1. Adicionar um novo vertice s ao grafo de tal forma que este se liga a todos os outros com
arcos com custo 0
2. Usar o algoritmo de Bellman-Ford a partir de s, calculando o caminho mais curto, d(s, u),
de s a todos os outros vertices
3. Atribuir novos pesos a cada arco seguindo a formula ω(u, v) = ω(u, v)+d(s, u)−d(s, v) em
que ω(u, v) = peso do arco, d(s, u) e d(s, v) os valores calculados em 2., para os vertices
de origem e destino respectivamente.
4. Remover v e executar o algoritmo de Dijkstra a partir de cada vertice.
Este algoritmo tem uma complexidade de O(n2 ∗ logn + nm) o que significa que para grafos
esparsos e mais rapido que o algoritmo de Floyd-Warshall.
Algumas consideracoes sobre este algoritmo:
• Se o grafo contiver ciclos negativos, o algoritmo Bellman-Ford termina sem resultado.
• Se o grafo nao tiver arcos com peso negativo (como e o caso do problema em estudo),
apenas o passo 4. e necessario (isto corresponde ao algoritmo de Brandes para grafos
pesados como veremos de seguida).
2.4 Brandes
De grosso modo, o algoritmo de Brandes consiste no aproveitamento de uma serie de pro-
priedades dos caminhos mais curtos entre os vertices de um grafo. Toda a informacao sobre
a influencia de um vertice v nos caminhos mais curtos entre outros pares de vertices pode ser
obtida atraves apenas de uma procura efectuada a partir de v (Dijkstra para grafos pesados e
BFS para grafos nao-pesados). Assim, e suficiente efectuar n procuras a partir de cada um dos
vertices. Assim sendo temos uma complexidade de n ∗ O(m + n ∗ logn) para grafos pesados
(Dijkstra com recurso a min-priority queue implementado por um Fibonacci heap) e n ∗ O(m)
para grafos nao-pesados (BFS, no pior caso, explora todos os arcos). Existe esta diferenca
entre grafos pesados e nao-pesados pois a BFS encontra caminhos com menor numero de ar-
cos, ao inves de menor peso, logo, a mesma nao resulta em grafos pesados (nao e garantida a
desigualdade triangular).
Antes de mais, defina-se o conjunto de predecessores de um vertice v em caminhos mais
curtos a partir de s (vertice raiz da procura) da seguinte forma:

8 CAPITULO 2. TRABALHO RELACIONADO
Ps(v) = {u ∈ V : {u, v} ∈ E, d(s, v) = d(s, u) + ω(u, v)}
Segundo Brandes, a dependencia, δ, de um vertice s ∈ V a qualquer outro v ∈ V e dada por:
δs(v) =∑
w:v∈Ps(w)
σsvσsw· (1 + δs(w)) (2.2)
Nao e completamente intuitivo o porque de uma procura dos caminhos mais curtos de um vertice
para todos os outros ser suficiente para se conhecer a influencia de outros vertices sobre esse
mesmo. Os varios lemas enunciados por Brandes [6] permitem que se chegue a essa conclusao.
Esses lemas podem ser resumidos nas seguintes propriedades, que estao reflectidas na formula
2.2:
• Para s, v ∈ V e sendo u ∈ Ps(v) entao o numero de caminhos mais curtos comecando
em s, acabando em v e tendo (u, v) como ultimo arco e igual ao numero de caminhos
mais curtos entre s e u. Isto significa que qualquer algoritmo que resolva o problema
SSSP (neste caso Dijkstra e BFS) pode ser usado para fazer contagem de caminhos mais
curtos.
• Cada vertice tem pelo menos um caminho mais curto por sucessor a passar por si, mais
todos os caminhos que atravessem os seus sucessores. Este lema torna possıvel que a
influencia de um no u sobre v possa ser calculada de forma recursiva e incremental (a
medida que se aprofunda a procura).
• Para s, u, v ∈ V , se existe um dado caminho mais curto de s a v passando por u, que
representa, por exemplo, 1/2 dos caminhos mais curtos entre s e v essa proporcao ira
manter-se a medida que a procura prosseguir. Se a partir de v forem descobertos n cam-
inhos mais curtos entre s e outros vertices, bastara multiplicar a proporcao por n para se
calcular a dependencia de s a u. Isto significa que as proporcoes de caminhos mais curtos
sao propagadas atraves dos sucessores.
Para se implementar na pratica a formula (2) basta guardar, durante a execucao de uma BFS
(ou Dijkstra) a partir de s:
• A dependencia de s a cada outro vertice
• Uma lista de antecessores por cada vertice visitado
No final de cada procura a partir de s actualiza-se a betweenness de cada outro vertice (somar
a dependencia de v a u a betweenness de u). Devido a este facto nao e necessario o usual

2.5. VERTEX SAMPLING 9
espaco quadratico, apenas uma linha e computada de cada vez sendo descartada apos a soma
das dependencias. Assim sendo, o espaco necessario e O(n +m) (o vector final de valores de
betweenness e O(n) e o grafo representado por listas de adjacencia ocupa ESPACO O(n+m).
Nota: Para grafos nao-orientados e necessario dividir por 2 a betweenness de cada vertice.
Nota: Como e possıvel verificar, o algoritmo de Brandes sobre grafos pesados e identico ao
algoritmo de Johnson (n execucoes Dijkstra a partir de cada vertice) enquanto que a versao
para grafos nao-pesados corresponde ao algoritmo MBFS.
O melhor algoritmo exacto revisto neste relatorio e o de Brandes. No entanto, corremos a nossa
implementacao em Java (sobre a framework Webgraph), que utiliza como base o algoritmo de
Brandes, sobre um grafo com cerca de 22 milhoes de vertices e cada BFS demora aproxi-
madamente 1 minuto. Neste caso, o algoritmo de Brandes levaria varios dias ate terminar. Isto
significa que, apesar de este algoritmo ter uma complexidade aceitavel, mesmo essa se torna
incomportavel para grafos com milhoes de vertices/arcos (e.g. redes sociais). Logo, torna-se
necessario explorar outras alternativas. Esta e a motivacao para a proxima seccao.
2.5 Vertex Sampling
Como foi mencionado anteriormente, mesmo a nossa melhor opcao para o calculo exacto da
betweenness e ineficiente quando lidamos com grafos extremamente grandes, como acon-
tece neste trabalho. Ficamos entao diante dois cenarios: encontrar um algoritmo que de al-
guma forma tenha um melhor desempenho que o de Brandes ou enveredar pelo caminho da
amostragem. Como ja foi mencionado, o algoritmo de Brandes tem complexidade O(nm) que
para muitas categorias de problemas seria considerada uma complexidade aceitavel (ainda para
mais temos de relembrarmo-nos que estamos a lidar maioritariamente com grafos esparsos, i.d.
m e da ordem de O(n)). Alem de nao ser objectivo deste trabalho, isto significa que nao e
expectavel que se consiga melhorar a nossa escolha para computacao exacta.
Vou entao focar-me no conceito de vertex sampling. Este conceito consiste em fazer os calculos
da betweenness sobre apenas alguns dos vertices do grafo, cortando drasticamente no numero
de computacoes necessarias.
A amostragem em si podera ser feita de forma completamente aleatoria ou com base em algum
criterio ou heurıstica. Em qualquer dos casos, a solucao passa por escolher uma percentagem
(fixa ou dinamica) dos vertices do grafo como amostra representativa, calcular a betweenness e
extrapolar para o caso geral.

10 CAPITULO 2. TRABALHO RELACIONADO
Geralmente os algoritmos de vertex sampling podem ser divididos nas seguintes categorias [10]:
1. Estimar os valores da betweenness de todos os vertices do grafo - neste caso, o importante
nao sao os valores em si mas a importancia relativa entre os vertices (rank ).
2. Aproximar o valor da betweenness de um vertice, em particular em menor tempo que o
necessario para calcular a betweenness de todos os vertices (O(nm)).
Vou debrucar-me sobre alguns exemplos de vertex sampling que contribuıram com conceitos
importantes, ou que considero relevantes no ambito deste trabalho.
Eppstein e Wang[13] foram dos primeiros a sugerir que se estimasse o valor exacto de medi-
das de centralidade (neste caso concreto para a closeness centrality ) executando apenas uma
fraccao das procuras necessarias. Baseando-se no facto de muitas redes sociais apresentarem
o fenomeno do small world [24], os autores concluıram que uma amostra de log(n) vertices e
geralmente suficiente para se estimar o valor exacto da closenness centrality com uma elevada
probabilidade.
No seguimento da introducao do algoritmo de Brandes, mais tarde Brandes e Pich[7], baseando-
se na sugestao de Eppstein e Wang, propuseram que a amostragem tambem poderia ser apli-
cada ao calculo da betweenness.
No artigo mencionado, Brandes e Pich introduzem varias estrategias/heurısticas para a seleccao
da amostra (ou vertices pivos, como denominados por eles). Segue-se uma breve descricao das
estrategias enunciadas:
Random - Pivos escolhidos uniformemente e aleatoriamente
RanDeg - Visto que vertices com um grau elevado provavelmente terao varios caminhos mais
curtos a passar por eles, uma alternativa e escolher pivos com probabilidade proporcional ao
seu grau.
Nota: Nas seguintes estrategias, apenas o primeiro pivo e escolhido aleatoriamente.
MaxMin - Esta estrategia escolhe como proximo pivo o vertice o mais longe possıvel dos ante-
riores pivos (aquele que maximiza a distancia ao pivo mais proximo mais especificamente), de
forma a obter uma amostra uniformemente distribuıda pelo grafo.
MaxSum - Segundo o mesmo princıpio da anterior estrategia, e escolhido o pivo que maximiza
a soma das distancias aos anteriores pivos.
MinSum - Ao contrario da anterior, esta estrategia escolhe o pivo que minimiza a soma das
distancias aos anteriores pivos. Esta estrategia resulta num conjunto de pivos ligados em volta
do pivo inicial.

2.5. VERTEX SAMPLING 11
Mixed - Estrategia mista que combina as estrategias Random, MaxMin e MinSum de forma
round robin.
Table 2.2: Estrategias de Seleccao de Pivo, com base na Tabela 1 do trabalho de Brandes ePich[7])
Estrategia Regra
Random uniformemente aleatorio
RanDeg aleatorio com probabilidade proporcional ao grau
MaxMin nao-pivo que maximiza a distancia mınima aos anteriores pivos
MaxSum nao-pivo que maximiza a soma das distancias aos anteriores pivos
MinSum nao-pivo que minimiza a soma das distancias aos anteriores pivos
Mixed alterna entre MaxMin, MaxSum e Random
De uma forma geral, as experiencias realizadas por Brandes e Pich demonstraram que, de
entre as estrategias sugeridas, a seleccao aleatoria e a que produz melhores resultados e tal
acontece devido essencialmente as diferentes topologias dos grafos usados (certas topologias
tem caracterısticas que invalidam o uso de certas heurısticas na escolha dos pivos). No entanto,
sugerem que se experimente com estrategias ainda mais sofisticadas.
Ate agora, os exemplos que vimos escolhem uma amostra de tamanho k, em que k e uma
percentagem fixa do numero total de vertices (na verdade, Brandes e Pich experimentaram com
varios valores).
No entanto, varios autores exploram o conceito de amostragem adaptativa [22]. Amostragem
adaptativa consiste em nao estabelecer o numero de amostras a priori mas faze-lo depender da
informacao obtida atraves das amostras ja recolhidas.
Por exemplo, Bader et al [1] sugeriram um algoritmo de amostragem adaptativa para o calculo
de vertices com alta centralidade, em que sao escolhidos aleatoriamente vertices para amostra
ate a soma das dependencias parciais (soma parcial da funcao δu(v) introduzida no algoritmo
de Brandes), S, de qualquer vertice u ∈ V a um certo vertice v ∈ V , ultrapassar um valor pre-
definido. No final da amostragem BC(v) e estimado por nSk em que k e o numero de amostras.
Note-se que uma execucao do algoritmo apenas produz resultados para um vertice em particu-
lar.
Neste caso, a estimativa e algo optimista (assume que a dependencia a v sera igual para todos
os vertices do grafo) mas produz resultados perto do valor exacto. E compreensıvel que assim
seja, visto que o algoritmo proposto por Bader et al lida maioritariamente com vertices com
uma betweenness elevada. No entanto, a amostragem aleatoria geralmente sobreestima em

12 CAPITULO 2. TRABALHO RELACIONADO
demasia a betweenness de vertices perto de um pivo. Sanders et al [17] vao mais longe e
sugerem o seu proprio metodo de acumulacao de dependencias, de forma a que nao exista
essa sobreestimativa para os vertices menos importantes do grafo.
Chehreghani [10] tambem propoe um algoritmo para o calculo da betweenness de um vertice,
v ∈ V , em particular, em que cada vertice i e escolhido para amostra com probabilidade pi e a
betweenness de v e estimada como a media dos valores δi(v)pi
em cada iteracao. Nesse trabalho,
o autor discute as condicoes que um metodo de amostragem deve satisfazer de forma a mini-
mizar o erro de aproximacao. Chehreghani sugere uma forma de calculo para as probabilidades
pi, que depende apenas da distancia de v a todos os outros vertices, que garante que, para
cada dois vertices i e i′, pi ≥ pi′ ⇔ δi(v) ≥ δi′(v). Ou seja, vertices com maior dependencia de
v tem maior probabilidade de ser escolhidos para amostra.
Table 2.3: Resumo dos Algoritmos Revistos
Algoritmo Seleccao Tamanho da Amostra Objectivo
Uniforme c/Heurıstica Fixo Adaptativo All Vertex One Vertex
Brandes X X X X
Madduri X X X
Sanders X X X
Chehreghani X X X X
De uma forma geral, os algoritmos de vertex sampling correm em tempo O(Tm) e O(Tm +
Tnlog(n)) para grafos nao-pesados e pesados, respectivamente, em que T e o numero de
amostras. Como vimos, alguns algoritmos tem por objectivo estimar a centralidade de um no
ou de alguns nos em particular, enquanto que outros tem como objectivo obter o rank relativo
entre todos os vertices. Estes algoritmos diferem entre si predominantemente no metodo de
seleccao das amostras. De notar ainda que a maioria das abordagens de vertex sampling (se
nao mesmo todas) sao facilmente paralelizaveis, visto que geralmente cada uma das T amostra-
gens pode ser executada de forma independente.
2.6 Representacoes de Grafos
Ate agora pudemos observar varias alternativas para a computacao da metrica de betweenness
centrality para um ou mais vertices, com maior ou menor eficiencia. No entanto, a eficiencia
desse calculo nao esta apenas ligada a escolha do algoritmo em si, mas tambem a representacao

2.6. REPRESENTACOES DE GRAFOS 13
escolhida para os grafos. Inclusivamente, nalguns casos, a escolha do algoritmo e a escolha da
representacao nao sao independentes.
Por exemplo, o algoritmo de Floyd-Warshall pressupoe a representacao do grafo usando uma
matriz de adjacencias, pois a cada n passos do loop mais exterior ele efectua um varrimento
sobre todos os caminhos possıveis (O(n2)). Ja os algoritmos de Johnson e Brandes (para grafos
pesados) tem como base o algoritmo de Dijkstra que tipicamente usa representacoes esparsas
(por exemplo, lista de adjacencias). No caso do algoritmo de Brandes para grafos nao-pesados
(BFS), a representacao usada tambem e esparsa.
Tambem e importante notar que os algoritmos revistos diferem quanto ao output retornado.
Os algoritmos de Floyd-Warshall, Johnson, MBFF e, em geral, algoritmos que calculem APSP,
necessitam de O(n2) para representar o output (por exemplo, uma matriz), enquanto que no
algoritmo de Brandes, e no ambito deste trabalho, basta retornar um array de tamanho O(n)
com os valores da betweenness dos vertices.
Note-se que se for pretendido o calculo da betweenness para arcos e necessario que cada arco
possua um identificador e que o mesmo seja guardado.
Como vemos, os algoritmos no ambito deste problema geralmente usam uma representacao
esparsa, pois a eficiencia da representacao depende muito da topologia dos grafos com que es-
tamos a lidar. No caso particular deste trabalho, lidamos com grafos sociais que tipicamente sao
grafos bastante esparsos (m << n2, com m geralmente na ordem de n). Assim, a representacao
escolhida devera tirar partido desse factor.
Existem algumas alternativas que combinam a eficiencia das operacoes (nao modificantes) so-
bre matrizes, com o facto de apenas representarem os arcos existentes (a semelhanca das listas
de adjacencia). Estruturas como Compressed Sparse Row (CSR) ou Compressed Sparse Col-
umn (CSC) sao ideais para representar matrizes esparsas, pois utilizam apenas espaco O(m) e
O(m2 ) se a matriz for simetrica (grafos nao-orientados), e permitem acessos em tempo constante
(no entanto nao permitem acessos aleatorios).
Com o advento da globalizacao da tecnologia, os grafos sociais ou webgraphs, cuja analise
e pretendida, sao geralmente grafos com milhoes de nos e arcos que nao sao passıveis de
ser armazenados, de formas tradicionais, em memoria principal sendo que os algoritmos so-
bre grafos se tornam ineficientes sobre memoria secundaria. Assim, normalmente recorre-se a
compressao dos grafos de forma a tentar contornar esse problema.
Antes de mais convem introduzir o conceito de webgraph (nao confundir com a framework Web-
Graph[4]). Um webgraph e um grafo orientado que tem como nos URLs e que contem um arco
entre x e y, sempre que a pagina x contenha uma referencia para a pagina y. Geralmente, e

14 CAPITULO 2. TRABALHO RELACIONADO
usado um webgraph para representar a World Wide Web, ou uma parte dela.
No caso concreto dos grafos sociais/webgraphs geralmente a representacao escolhida tira par-
tido dos seguintes factores:
1. O grau dos vertices seguem aproximadamente uma distribuicao power-law (ou de Pareto)
2. Localidade: a maioria das ligacoes sao locais (e.g. no caso de webgraphs, isto significa
que dois nos ligados entre si geralmente estao lexicograficamente proximos).
3. Similaridade: Nos fisicamente proximos (ou lexicograficamente no caso dos URLs) tem
geralmente muitos sucessores em comum.
Recentemente tem surgido varias diferentes formas de representacao comprimida de grafos.
Destaco as k2-trees [9] e a WebGraph [4].
As k2-trees sao uma forma de representar matrizes esparsas atraves de arvores k2-unarias (de
altura h = logk(n) com k e variavel) que comprimem os bits da matriz. Esta representacao tira
partido sobretudo da esparsidade dos grafos sociais/webgraphs e do fenomeno de clustering,
bastante comum nesse tipo de grafos.
A framework WebGraph possui varios mecanismos de compressao que tiram sobretudo partido
das propriedades dos webgraphs. Em primeiro lugar, a WebGraph utiliza codigos-zeta para cod-
ificar os vertices do grafo (de forma a tirar partido da distribuicao de Pareto dos mesmos). Esta
framework possui tambem um conjunto de algoritmos de compressao das listas de adjacencia
do grafo que tiram partido das propriedades de localidade, similaridade e consecutividade do
grafo. A WebGraph tem ainda formas de melhorar a eficiencia do acesso ao grafo comprimido,
como o uso de lazy iteration.
No caso das redes sociais, os autores da WebGraph utilizam community finding (como veremos
na seccao de Layered Label Propagation) para reordenar os vertices e atribuir identificadores,
de forma a tirar partido das propriedades deste tipo de grafos, descritas anteriormente.
Os resultados experimentais de Navarro et al [9] demonstram que em comparacao com outras
representacoes compactas (incluindo a WebGraph) as k2-trees tem, regra geral, tempos de
acesso maior, mas apresentam um melhor tradeoff entre espaco ocupado e tempo de acesso.
Para os objectivos deste trabalho foi escolhida como representacao de grafos a framework Web-
Graph pois, embora possam existir metodos mais recentes que sejam mais eficientes em algum
aspecto, consideramos que esta e a alternativa melhor documentada e que fornece uma melhor
base para quem a quiser utilizar.

2.7. ABORDAGEM A SEGUIR 15
2.7 Abordagem a seguir
Como ficou patente ao longo do ultimo capıtulo, o calculo exacto da betweenness de todos os
vertices para grafos de grande dimensao e impensavel, sendo o calculo exacto da betweenness
de apenas um vertice um problema igualmente complexo. Foi visto que a solucao passa por
estimar os valores de betweenness pretendidos atraves de vertex sampling e foram observadas
varias variantes desse conceito.
Tambem vimos que qualquer estrategia/heurıstica de seleccao de amostras se defronta com o
desafio de produzir resultados igualmente aproximados para variadas topologias de grafos e de
nao sobreestimar vertices menos importantes situados em clusters. Alem disso, as estrategias
de seleccao optimas (cujo valor esperado equivale a betweenness exacta) necessitam de pre-
computacoes que tornam a complexidade incomportavel para grafos com milhoes de ligacoes,
inutilizando assim o princıpio do vertex sampling.
Idealmente, poderıamos escolher como amostra apenas os vertices mais representativos do
grafo, por exemplo os vertices mais centrais de cada cluster ou vertices que sirvam de ponte
entre varios clusters. E preciso ainda ter em conta que quando se escolhe um vertice para
amostra, calcula-se parte da betweenness dos restantes vertices mas nao do proprio. Essa
escolha e subjectiva pois existem varios criterios para determinar quais os grupos coesos de
um grafo. Existem varios conceitos que descrevem esses grupos, como: cliques; n–cliques;
n–clans; n–clubs; k–plexes; k–cores; lambda sets [2]; vertices representantes de comunidades;
vertices que ligam diversas comunidades; etc... Alguns autores definiram o seu proprio conceito
de ”vertice representativo da rede” e concordantemente implementaram algoritmos de sampling.
Por exemplo Tang et al [28] relacionam o problema de seleccionar vertices representativos em
redes cujos vertices possuem atributos (e.g. o interesse dessa pessoa num dado assunto) alem
de arcos com o Dominating Set Problem, cuja a resolucao foi provada NP-hard, e sugerem
duas estrategias de sampling que aproximam a solucao desse problema, (”Statistical Stratified
Sample” (ou S3) e ”Strategic Sampling” for Diversity” (ou SSD)).
Este trabalho baseia-se nalguns destes conceitos, mais especificamente k-core e community
finding, que serao detalhados em seguida.
2.7.1 K-cores
Antes de mais convem definir a degenerescencia de um grafo. Um grafo, G, k-degenerado
e um grafo nao-orientado cujos sub-grafos contem, pelo menos, um vertice de grau ≤ k. A
degenerescencia de G e o menor valor de k para o qual G e k-degenerado. A degenerescencia

16 CAPITULO 2. TRABALHO RELACIONADO
tambem pode ser vista como o maximo mınimo grau de um grafo.
Um k-core [27] de G e um sub-grafo ligado de G cujos vertices tem grau≥ k. A degenerescencia
de G e o maior valor de k tal que G tem um k-core. Define-se ainda o core number de um vertice
como o maior valor de k para o qual o vertice pertence a um k-core de G.
Como vimos, existem varios conceitos que descrevem formalmente grupos coesos de um grafo,
ou clusters. Para a maioria desses conceitos, determinar esses grupos e computacionalmente
difıcil (NP-hard ou quadratico, pelo menos). No entanto, determinar os k-cores de um grafo e
um problema, aparentemente, mais simples e existem alguns algoritmos que o fazem em tempo
linear [2, 23].
Figura 2.1: Exemplo de varias camadas de k-cores (imagem retirada do paper de Batagelj eZaversnik)
Actualmente, o algoritmo mais eficiente na determinacao dos k-cores de um grafo e o de Batagelj
e Zaversnik que fa-lo em O(m) ao sequencialmente remover do grafo os vertices de menor para
o maior grau. Este algoritmo recebe como input um grafo representado por listas de adjacencias
e devolve um array, de n posicoes, contendo o core number de todos os vertices do grafo.
2.7.2 Community Finding
Apesar da importancia da identificacao de comunidades num grafo a verdade e que nao existe
consenso quanto a definicao de comunidade. Isto faz com que haja varias nocoes de comu-
nidade e faz com que os resultados de algoritmos de community finding estejam inteiramente
dependentes do algoritmo e das metricas de qualidade escolhidos. Nao existe forma de verificar
se os conjuntos identificados sao, de facto, comunidades (e.g. no caso do grafo ser uma rede
social real).
Intuitivamente, uma comunidade e um sub-grafo cujos vertices possuem mais ligacoes entre
eles do que com o resto do grafo [12]. Esta e a base da maioria das definicoes de comunidade.
Como ja foi mencionado, muitos problemas relacionados com clustering sao NP-hard. Mais

2.7. ABORDAGEM A SEGUIR 17
especificamente, a maioria das variantes do problema de graph partioning sao NP-hard [15],
o que inclui problemas como minimum-bissection e geralmente community finding (depende
da forma como esta e feita). Isto significa que, em geral, os algoritmos de community finding
tambem produzem resultados aproximados.
Existem varios tipos de algoritmos para a deteccao de comunidades [3], nomeadamente: algo-
ritmos divisivos detectam ligacoes entre comunidades e removem-nos da rede [18], algoritmos
aglomerativos agregam comunidades semelhantes recursivamente e metodos de optimizacao
visam maximizar uma funcao objectivo [25]. Alem da variedade de algoritmos, existem tambem
varias medidas para avaliar a qualidade das particoes, sendo que geralmente a sua maximizacao
constitui a funcao objectivo do algoritmo. A medida mais utilizada na definicao de comunidades
e a modularidade [25].
A modularidade de uma particao e um valor real que toma, no maximo, valor 1 e representa a
densidade de ligacoes dentro de comunidades em relacao a ligacoes entre comunidades. Seja
G um grafo nao-orientado e pesado, seja A a sua matriz de adjacencias, seja ki o grau do vertice
i, seja m o numero total de arcos em G (nao esquecer que arcos com peso contam como arcos
multiplos), seja ci a comunidade a que i pertence e seja delta(ci, cj) uma funcao que devolve
1 se ci e cj pertencerem a mesma comunidade e 0 caso contrario. A modularidade de uma
particao define-se como:
Q =1
2m
∑i,j
[Aij −
kikj2m
]δ(ci, cj) (2.3)
De notar que a optimizacao exacta da modularidade e tambem um problema computacional-
mente difıcil (NP-Completo na verdade [8]).
Como foi dito, existem varias alternativas para identificacao de comunidades. Neste trabalho,
iremos focar apenas as duas mais utilizadas: o Louvain Method e o Layered Label Propagation
(LLP), que veremos em seguida.
2.7.2.1 Layered Label Propagation (LLP)
O algoritmo de LLP [5] foi inicialmente projectado com o objectivo de produzir uma ordenacao
relativa entre os vertices, tirando partido das propriedades de localidade e similaridade do grafo,
que torne mais eficiente a representacao compacta do grafo (usando representacoes como a
WebGraph).

18 CAPITULO 2. TRABALHO RELACIONADO
A ideia do Label Propagation consiste em percorrer varias vezes todos os vertices de um grafo
ate que sejam identificadas as comunidades, utilizando propagacao de etiquetas. No inıcio de
cada iteracao todos os vertices tem uma etiqueta indicativa do seu cluster /comunidade (na 1ª
iteracao cada no tem uma etiqueta diferente). Em cada iteracao e actualizada a etiqueta de
cada no de acordo com uma regra pre-definida. Quando nao e possıvel actualizar mais nenhum
vertice o algoritmo termina.
O algoritmo LLP baseia a sua regra de actualizacao no Absolute Pott Model (APM). Enquanto
que em Standard Label Propagation a regra de actualizacao atribui a cada no a etiqueta mais
frequente na sua vizinhanca no APM cada no fica com a etiqueta que maximiza a equacao
ki − γ(vi − ki), em que γ e chamado factor de discount (se γ = 0 o algoritmo e igual a Standard
Label Propagation). Um problema do APM e que nao existem resultados que justifiquem qual o
valor de discount a usar devido a diversidade das estruturas das comunidades (quanto maior o
valor de γ mais pequenas e densas serao as comunidades identificadas).
A cada iteracao, o LLP produz uma ordenacao com base nas etiquetas actuais dos vertices. Na
ordenacao actual um no x aparecera primeiro que um no y se:
• x e y sao de clusters distintos (etiquetas diferentes) e o cluster de x aparece primeiro que
o de y (mantem a ordem relativa entre os clusters) ou se
• x e y pertencem ao mesmo cluster (etiquetas iguais) e x aparece primeiro que y na
ordenacao (i.d. x e y mantem a ordem relativa anterior).
De forma a tirar partido da diversidade do factor de discount, em cada iteracao escolhe-se o
factor γk, aleatoriamente, de entre o conjunto {0} ∪ {2−i, i = 0, ..., k}.
O tempo de execucao do LLP depende dos factores de discount e do criterio de paragem (e.g.
o Louvain Method so para quando nao e possıvel maximizar mais a modularidade). Os autores
mencionam que, usando o seu setting usual, o LLP tem uma velocidade de 800.000 arcos/s.
No ambito deste trabalho, nao nos interessa a ordenacao devolvida per se mas as etiquetas
finais que representam as comunidades identificadas.
2.7.2.2 Louvain Method
O Louvain Method [3] e um algoritmo que, a semelhanca do Label Propagation, iterativamente
percorre um grafo tentando maximizar uma funcao objectivo. Neste caso tenta-se maximizar o
ganho da modularidade. Como foi visto anteriormente, a optimizacao da modularidade e um

2.7. ABORDAGEM A SEGUIR 19
problema NP-Completo, no entanto, a maximizacao da modularidade para um vertice individual-
mente e relativamente simples.
Ao contrario do algoritmo LLP, que retorna uma ordenacao dos vertices, o Louvain Method pro-
duz uma hierarquia de comunidades do grafo que permite analisar as suas comunidades camada
a camada, o que no fim e equivalente (o LLP produz uma ordenacao por iteracao).
Este algoritmo repete iterativamente duas fases:
1. Para cada no i, adicionar i a comunidade que maximiza o ganho na modularidade (se essa
comunidade nao existir o no i fica na comunidade onde estava). Inicialmente existem n nos
e n comunidades.
2. Agregar as comunidades identificadas na 1ª fase da seguinte forma: o peso dos arcos entre
os novos nos e igual a soma dos arcos entre os nos das duas comunidades respectivas;
arcos entre nos da mesma comunidade tornam-se self-loops.
Estas fases sao repetidas ate nao ser possıvel maximizar a modularidade.
Figura 2.2: Exemplo de execucao do Louvain method (imagem retirada do artigo original doLouvain method [3])
Apesar da complexidade exacta do algoritmo ser desconhecida, os autores afirmam que este
aparenta correr em tempo O(n log(n)), sendo que a maioria das computacoes acontece durante
a optimizacao da modularidade na primeira iteracao [3].
Os autores acrescentam que a velocidade do Louvain Method pode ser melhorada se forem us-
adas heurısticas simples, por exemplo removendo os nos de grau 1 (folhas) do grafo e adicionando-
os de novo apos a identificacao das comunidades, utilizacao de limites para o caso de paragem

20 CAPITULO 2. TRABALHO RELACIONADO
(a semelhanca da amostragem adaptativa), entre outras.
Como foi visto ao longo dos dois ultimos capıtulos, o vertex sampling lida com o problema da
computacao da betweenness em tempo util, para grafos muito grandes. No entanto, coloca em
causa a qualidade da solucao. De todos os metodos de amostragem vistos ate aqui ainda nao
existe nenhum que garanta uma boa aproximacao para os valores da betweenness de todos os
vertices do grafo (nao esquecer que neste caso quer-se aproximar a ordenacao relativa entre os
vertices), pelo menos nao para qualquer possıvel topologia do grafo. Torna-se necessario con-
tinuar a explorar alternativas para a estrategia de seleccao de amostras. E nesse contexto que
este trabalho propoe que se combine os conceitos de k-core e community finding, introduzidos
neste capıtulo, com a metodologia do vertex sampling.
Se uma rede contiver grupos coesos que se encontram ligados entre si por apenas algumas
ligacoes, entao todos os caminhos mais curtos entre esses grupos terao que passar obrigato-
riamente por alguma dessas ligacoes. Alem disso, intuitivamente esses grupos devem partilhar
varias caracterısticas (a semelhanca das comunidades na vida real). Isto significa que, de uma
forma geral, se pode considerar cada grupo coeso de um grafo como um todo, sem grande
(relativamente) perda de informacao.
E entao razoavel que se considere que uma boa estrategia de amostragem passa por escolher
poucos vertices com muito em comum e varios com muitas diferencas. Isto e, varios vertices
de comunidades diferentes, visto que escolher muitos vertices dentro da mesma comunidade,
em teoria, nao nos traz tantos ganhos de informacao quanto poderia. Uma estrategia admissıvel
tambem pode ser escolher vertices que sirvam de ponte entre varias comunidades.
Concretamente, propoe-se que se identifique a hierarquia de comunidades ou os k-cores do
grafo antes da amostragem. Em seguida, ao inves de se seleccionar as amostras espalhadas
uniformemente pelo grafo (ou usando outro criterio), escolhe-se as amostras com base nos
grupos coesos identificados. No caso de se usar community finding, um exemplo da seleccao de
amostras podera ser: se no topo da hierarquia existirem apenas duas comunidades c1, c2 entao
escolhe-se metade da amostra contida em cada uma delas; se no nıvel directamente abaixo da
hierarquia temos c11 ∈ c1 e c21, c22 ∈ c2 entao escolhe-se 50%, 25%, 25% da percentagem das
amostras sobre c11,c21 e c22 respectivamente. Pode-se elaborar uma estrategia semelhante
para os k − cores do grafo.
De notar que se se pretender conhecer os arcos com maior betweenness bastara olhar para os
arcos incidentes nos vertices de maior betweenness (visto que estes serao, tipicamente, aqueles
que servem de ponte entre comunidades).

Capıtulo 3
Abordagem
3.1 Implementacao
Para a segunda parte da tese comecei por implementar ou re-aproveitar os algoritmos necessarios
e estruturas necessarias para as funcionalidades pretendidas. Essas funcionalidades sao: a
identificacao de comunidades; identificacao de k-cores; calculo exacto da betweenness; calculo
aproximado da betweenness; heurısticas para a escolha de samples; avaliacao dos resultados.
3.1.1 Community Finding
Para a identificacao de comunidades implementei o Louvain method com base no codigo feito por
V. Blondel et al [3] e aproveitei a implementacao do algoritmo LLP proporcionada pela biblioteca
LAW.
A implementacao do Louvain Method consiste em ciclicamente inserir e remover nos em difer-
entes comunidades (inicialmente cada no comeca na sua propria comunidade) de forma a maxi-
mizar a modularidade. Enquanto o aumento da modularidade for maior que um certo valor (neste
caso concreto 0), o algoritmo continua. O algoritmo, em cada passo, insere cada no numa das
comunidades circundantes ate encontrar a que maximiza o ganho da modularidade da particao
actual. Para os calculos necessarios, o algoritmo utiliza arrays de inteiros que contem respec-
tivamente o id das comunidades existentes, grau total de vertices dentro de cada comunidade,
grau total de vertices apenas dentro de cada comunidade, numero de arcos entre um dado no
e as comunidades circundantes e id das comunidades circundantes a um no, sendo que cada
um destes arrays tem como tamanho maximo o numero de nos da rede. Tal como os autores
21

22 CAPITULO 3. ABORDAGEM
mencionam, a complexidade final do algoritmo nao e conhecida mas parece aproximar-se de
(N ∗ log(N)).
Como mencionei anteriormente o algoritmo LLP ja se encontra implementado na biblioteca LAW.
No entanto o algoritmo LLP, ao contrario do Louvain Method, produz uma hierarquia de etiquetas
(neste caso comunidades), por definicao sao 11 nıveis diferentes. Visto que para a finalidade
que pretendemos necessitamos de uma unica atribuicao no-comunidade foi necessario escrever
algum codigo adicional. Simplesmente corre-se o algoritmo LLP uma vez, produzindo os 11
nıveis, e em seguida, dentro da hierarquia, escolhemos o nıvel que produz a particao com maior
modularidade (a semelhanca do Louvain). A semelhanca do Louvain, o codigo adicional feito
para o LLP utiliza como estruturas dois arrays de inteiros contendo o grau total de vertices
dentro de cada comunidade e o grau total de vertices apenas dentro de cada comunidade e um
Set contendo os ids das comunidades identificadas. Este codigo adicional corre em tempo linear
visto que as operacoes percorrem sequencialmente as estruturas mencionadas.
Q =1
2m
∑i,j
[Ai −kikj2m
]δ(ci, cj) (3.4)
De notar que para ambos o Louvain Method e o LLP o calculo da modularidade nao e feito
usando a formula usual (ver formula 3.4), pois esta tornaria a complexidade quadratica, mas
sim utilizando a seguinte formula (ver formula 3.5) que apesar de identica aproveita-se das
informacoes sobre as comunidades para calcular a modularidade em tempo linear. E preciso
realcar que no caso do Louvain Method os ındices de tot e in sao actualizados a medida que
o algoritmo insere e remove nos das comunidades (nao tendo de fazer calculos adicionais) en-
quanto que no codigo desenvolvido para o LLP e necessario percorrer todos os vertices duas
vezes de forma a calcular os ındices destes arrays (na verdade seria possıvel fazer tudo isto
apenas com uma iteracao).
Q =1
2m
∑i
[ini −tot2i2m
] (3.5)

3.1. IMPLEMENTACAO 23
3.1.2 K-Cores
O algoritmo implementado para determinacao dos k-cores de um grafo foi o de Batagelj e Zaver-
snik [2], tal como ja foi mencionado a melhor opcao actualmente uma vez que corre em O(m).
Este algoritmo consiste em inicialmente calcular o grau de todos os vertices do grafo e ordena-
los por ordem crescente de grau. Depois basta percorrer a lista de vertices uma vez, sempre
que passamos por um vertice determinamos o seu core number como sendo igual ao seu grau.
Em seguida subtraımos 1 ao grau de todos os vizinhos desse vertice cujo grau ainda e superior
ao seu. Como e facil de verificar este algoritmo na verdade corre em tempo O(max(m,n)) visto
que esse e o tempo necessario para o calculo do grau dos vertices e as restantes operacoes sao
lineares. Uma vez que se considera que tipicamente m >= n− 1 (e sempre verdade para redes
ligadas) e de uma forma geral m >> n entao podemos estabelecer a complexidade como sendo
O(m). Uma vez que e necessario determinar o tamanho da rede e se um vertice pertence ou
nao aos vizinhos de outro em tempo linear, geralmente e preciso escolher uma representacao do
grafo adequada (tipicamente listas de adjacencia) que permita operacoes como verificar vizinhos
ou tamanho da rede em tempo linear, neste caso tal nao foi preciso visto que a representacao
em WebGraph ja suporta essas operacoes.
Foram usadas listas simples para armazenar a informacao necessaria, i.e. graus e core numbers
dos nos. No final da execucao do algoritmo obtemos uma lista de pares No - Core-Number do
no.
3.1.3 Calculo Exacto e Aproximado da Betweenness
Como ja foi mencionado anteriormente, este trabalho foca-se na aproximacao dos valores da
betweenness dos vertices de um grafo (relembro que existe tambem a Edge Betweenness Cen-
trality) atraves do conceito de Vertex Sampling. No entanto outros autores exploraram abor-
dagens diferentes, nomeadamente Riondato e Kornaropoulos implementaram uma solucao que
aproxima os valores da betweenness atraves do sampling de caminhos ao inves de vertices [26].
Alem da abordagem ser fundamentalmente diferente da minha eles tambem provaram, atraves
de demonstracoes com o auxılio da VC-Dimension, que e possıvel aproximar a betweenness
com qualidade com um tamanho de amostra variavel independente do numero de vertices da
rede (mais particularmente dependente duma propriedade do grafo chamada Vertex Diameter,
a qual nao abordarei neste trabalho). Chegou-se a considerar de alguma forma incorporar o
conceito de sampling de caminhos neste trabalho mas concluiu-se que apesar dessa questao
estar dentro do ambito deste projecto seria melhor deixa-la para possıveis estudos futuros de
forma a ser aprofundada convenientemente.

24 CAPITULO 3. ABORDAGEM
Para o calculo da betweeness utilizei o codigo em Java desenvolvido pelo meu orientador, Prof.
Alexandre Francisco. O codigo original permite especificar o numero de threads a serem uti-
lizadas (cada thread executa uma ou mais BFS’s) e a percentagem de sampling, i.e. se quere-
mos o valor exacto (sample de 100%) ou valor aproximado (qualquer percentagem <100%).
Para o calculo aproximado da betweenness fiz codigo identico ao do Prof. Alexandre Francisco
com a diferenca de que o programa em vez de receber uma percentagem recebe uma lista
contendo os pivos seleccionados por alguma heurıstica, como veremos mais a frente.
3.1.4 Heurısticas
No contexto desta tese uma heurıstica consiste numa estrategia de escolha de pivos como
sample, i.e.vertices a partir dos quais comecar uma BFS (no sentido do calculo aproximado da
betweenness de vertices ao longo dessa BFS).
Para a escolha de samples implementei as duas principais heurısticas sugeridas por Brandes
no seu paper [7] mais 5 heurısticas desenhadas por mim.
Passo a detalhar as 7 heurısticas:
1. Simple (S) – Heurıstica que escolhe pivos dentro de cada comunidade identificada de
forma uniformemente aleatoria
2. Largest Degree (LD) – Heurıstica que escolhe pivos dentro de cada comunidade identifi-
cada com probabilidade proporcional ao grau do vertice
3. Community Size (CS) – Heurıstica que escolhe aleatoriamente um numero de pivos den-
tro de cada comunidade identificada, esse numero e tanto maior quanto o tamanho da
comunidade
4. Community Size & Largest Degree (CSLD) – Heurıstica que mistura as duas heurısticas
anteriores. Em primeiro lugar determina o numero de pivos a escolher dentro de cada
comunidade com base no seu tamanho (quanto maior maior o numero) em seguida escolhe
esse numero de vertices em cada comunidade com probabilidade proporcional ao grau do
vertice.
5. K-core (Kcore) – Heurıstica que escolhe consecutivamente pivos do maior para o menor
k-core de um grafo. Por exemplo se se pretender 10 pivos num grafo com um 5-core de 4
vertices, um 4-core de 12 vertices e por aı adiante, entao serao escolhidos os 4 vertices
do 5-core e 6 outros vertices do 4-core (relembro que todos os membros do 5-core formam
obrigatoriamente o 4-core tambem).

3.1. IMPLEMENTACAO 25
6. Random (Brandes) (bRanDeg) – Heurıstica que escolhe pivos de forma uniformemente
aleatoria
7. RanDeg (Brandes) (bRandom) – Heurıstica que escolhe pivos com probabilidade propor-
cional ao grau do vertice
De notar que cada uma das heurısticas pode receber como argumento uma dada percentagem,
representando o numero de pivos a escolher. Caso nao receba esse argumento, por default
serao escolhidos log(n) pivos, em que n e o numero de vertices, visto que esse valor geralmente
e considerado suficiente para uma boa aproximacao de medidas de centralidade [13][1] (autores
como Riondato e Kornaropoulos mostraram que na verdade e possıvel aproximar a betweenness
com qualidade com samples menores e cujo tamanho nao depende da dimensao da rede). As
heurısticas desenvolvidas por mim recebem ainda um ficheiro contendo a comunidade de cada
vertice do grafo. No caso da heurıstica K-core ela recebe uma lista contendo pares Vertice -
Degenerescencia do Vertice (numero do maior k-core ao qual o vertice pertence).
Em termos de complexidade as heurısticas de Brandes correm em tempo linear proporcional ao
numero de pivos que se desejar, visto que efectuam uma escolha completamente aleatoria (no
caso da heurıstica RanDeg esta escolha nao e completamente aleatoria mas necessita apenas
de conhecer o peso total dos arcos do grafo).
As heurısticas desenhadas por mim necessitam de um ciclo inicial que percorre o ficheiro rece-
bido (contendo a comunidade de cada vertice) e um ciclo adicional que itera sobre cada comu-
nidade identificada e escolhe pivos com base no criterio dessa mesma heurıstica.
Assim sendo nenhuma heurıstica possui uma complexidade relevante no ambito geral do prob-
lema.
3.1.5 Avaliacao dos Resultados
O trabalho desenvolvido nesta tese foi avaliado globalmente quanto a duas caracterısticas:
1. Tempo de execucao
2. Qualidade da solucao, i.e. a aproximacao dos valores de betweenness obtidos aos exac-
tos.
Relembro que quando se pretende aproximar a betweenness para todos os vertices, como no
caso deste trabalho, e mais importante que a relacao de ordem (rank ) entre os vertices se

26 CAPITULO 3. ABORDAGEM
mantenha do que o valor obtido em si. Assim, a qualidade da solucao foi ser avaliada quanto a
ordenacao dos vertices por betweenness.
Apenas redes de pequena dimensao foram avaliadas quanto a qualidade da solucao, pois para
redes de grande dimensao geralmente nao e possıvel calcular os valores exactos da between-
ness (esse calculo e necessario mesmo que se pretenda apenas a ordenacao).
Habitualmente, quando se pretende testar metodos de community finding sobre redes e de-
sejavel que essas redes tenham as caracterısticas de redes reais. Assim, geralmente e pre-
ferıvel que os testes sejam feitos sobre exemplos de redes reais ao inves de modelos fictıcios
gerados com base em parametros. Isto nao invalida que se efectuem testes sobre redes fictıcias,
de forma a testar o correcto funcionamento dos metodos sobre certas topologias.
Para a avaliacao da qualidade foram escolhidos os ındices Kendall Tau e Spearman’s Correlation
(comparacao de vectores).
Ambos estes ındices de alguma forma indicam o quao semelhantes sao dois vectores em termos
da ordenacao relativa dos seus elementos. Adicionalmente ambas as correlacoes produzem val-
ores entre −1 (desacordo perfeito) e +1 (acordo perfeito). Valores perto do 0 deverao significar
independencia entre variaveis.
Kendall Tau – utiliza o calculo do numero de pares concordantes (um par de valores (Xi, Y i)
e (Xj, Y j) e concordante se Xi > Xj e Y i > Y j) para representar a semelhanca entre dois
vectores quando os seus elementos estao ordenados por valor.
Spearman’s Correlation – representa quao bem a relacao entre dois vectores pode ser descrita
utilizando uma funcao monotona (funcao que preserva a ordem entre elementos, e.g. uma
funcao estritamente crescente ou pelo menos nao-decrescente).
Para o Kendall Tau foi utilizada a implementacao da biblioteca LAW e para o Spearman’s Corre-
lation foi utilizada a implementacao do software R.
Relembro que os metodos a testar serao implementados na linguagem Java e sobre a famework
WebGraph.
3.2 Redes Utilizadas
Todas as redes utilizadas, reais ou nao, foram comprimidas utilizando o formato BV de forma a
tirar partido das propriedades deste formato, ja explicadas na primeira parte deste relatorio.

3.2. REDES UTILIZADAS 27
3.2.1 Redes Sinteticas
As redes sinteticas foram geradas aleatoriamente pelo software disponibilizado por Fortunato 1.
Foram utilizadas redes de tamanho 1000, 2000, 4000 e 10000 partilhando as seguintes carac-
terısticas: outdegree medio 10, outdegree maximo 100 e densidade E/V de 9, 5.
Estas redes sinteticas ainda foram divididas em redes com estrutura estritamente aleatoria e
redes com comunidades bem definidas (iguais as primeiras mas com mixing parameter = 0.1),
de forma a avaliar-se a diferenca da qualidade de solucao entre elas, principalmente para as
heurısticas que usam community finding.
Para as redes estritamente aleatorias foram geradas 5 redes de cada tamanho utilizando os
seguintes comandos:
1000 - ./benchmark -N 1000 -k 10 -maxk 100 -rand
2000 - ./benchmark -N 2000 -k 10 -maxk 100 -rand
4000 - ./benchmark -N 4000 -k 10 -maxk 100 -rand
10000 - ./benchmark -N 10000 -k 10 -maxk 100 -rand
Para as redes com comunidades bem definidas foram tambem geradas 5 de cada tamanho,
utilizando os seguintes comandos:
1000- ./benchmark -N 1000 -k 10 -maxk 100 -mu 0.1
2000- ./benchmark -N 2000 -k 10 -maxk 100 -mu 0.1
4000- ./benchmark -N 4000 -k 10 -maxk 100 -mu 0.1
10000- ./benchmark -N 10000 -k 10 -maxk 100 -mu 0.1
Quero apenas fazer notar que para a maioria dos parametros tentou-se escolher os valores com
algum bom senso mas a verdade e que nao ha um formato padrao aceite universalmente para
o tipo de redes que queremos simular (redes sociais).
3.2.2 Redes Reais
Foram tambem utilizadas redes reais para os testes efectuados. Estas consistem em tres difer-
entes redes disponibilizadas pelo LAW 2. Segue-se uma breve descricao:1https://sites.google.com/site/santofortunato/inthepress22http://law.di.unimi.it/datasets.php

28 CAPITULO 3. ABORDAGEM
Amazon-2008 – Uma rede simetrica que descreve a semelhanca entre livros na loja online da
Amazon (dados obtidos usando a API do servico de e-commerce da Amazon). Esta rede possui
735 323 nos e 5 158 388 arcos.
Enwiki-2010 – Esta rede e uma ’snapshot’ da pagina inglesa da Wikipedia em que nos sao
paginas e arcos sao ’links’ directos entre elas. Esta rede possui 4 206 785 nos e 101 355 853
arcos.
3.3 Avaliacao de Resultados
Em seguida o meu trabalho consistiu em avaliar a qualidade da solucao de cada heurıstica
para os valores aproximados da betweenness de redes de tamanhos diversos. Como ja foi
mencionado, para a avaliacao da qualidade foram utilizados os ındices Kendall Tau e Spear-
man’s Correlation (comparacao de vectores). Foi ainda medido o tempo de execucao de cada
heurıstica utilizando com recurso ao comando ’time’ da shell do linux (visto que este comando
permite destacar o tempo efectivamente dedicado a computacao dos resultados).
3.3.1 Redes Sinteticas
Para as redes sinteticas a avaliacao consistiu em comparar o vector dos valores exactos da
betweenness com o vector dos valores aproximados obtidos.
Cada heurıstica foi corrida cinco vezes sobre cada rede (cinco redes de cada tamanho) com um
sample default de valor log(n).
Em seguida testei tambem amostragem de taxa fixa sobre as redes de 10000 nos. Foram
testados sample rates de 0,25%,0,5% e 1%.
Os testes sobre as redes sinteticas foram entao divididos em quatro partes:
1. Testes com taxa variavel (log(N)) sobre redes completamente aleatorias (Figura 3.3)
2. Testes com taxa fixa (0,25%; 0,5% e 1%) sobre as redes completamente aleatorias de
tamanho 10000 (Figura 3.4).
3. Testes com taxa variavel (log(N)) sobre redes com comunidades bem definidas (Figura
3.5).
4. Testes com taxa fixa (0,25%; 0,5% e 1%) sobre as redes com comunidades bem definidas
de tamanho 10000 (Figura 3.6).
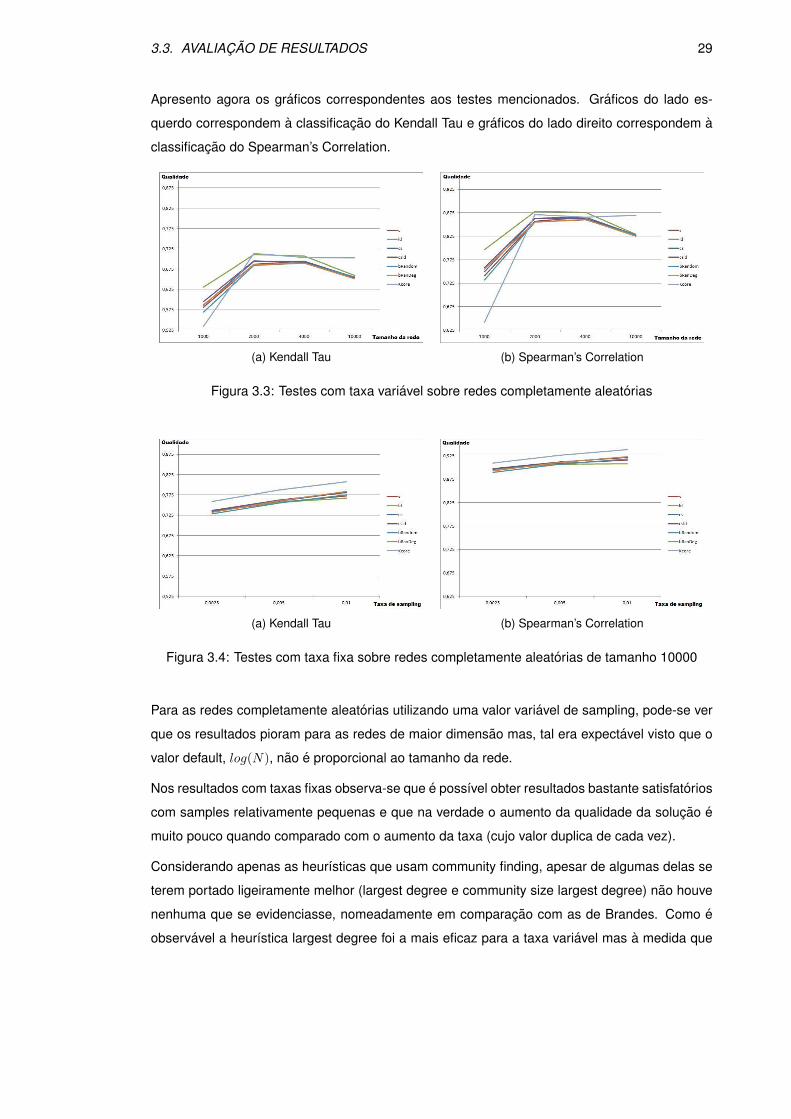
3.3. AVALIACAO DE RESULTADOS 29
Apresento agora os graficos correspondentes aos testes mencionados. Graficos do lado es-
querdo correspondem a classificacao do Kendall Tau e graficos do lado direito correspondem a
classificacao do Spearman’s Correlation.
(a) Kendall Tau (b) Spearman’s Correlation
Figura 3.3: Testes com taxa variavel sobre redes completamente aleatorias
(a) Kendall Tau (b) Spearman’s Correlation
Figura 3.4: Testes com taxa fixa sobre redes completamente aleatorias de tamanho 10000
Para as redes completamente aleatorias utilizando uma valor variavel de sampling, pode-se ver
que os resultados pioram para as redes de maior dimensao mas, tal era expectavel visto que o
valor default, log(N), nao e proporcional ao tamanho da rede.
Nos resultados com taxas fixas observa-se que e possıvel obter resultados bastante satisfatorios
com samples relativamente pequenas e que na verdade o aumento da qualidade da solucao e
muito pouco quando comparado com o aumento da taxa (cujo valor duplica de cada vez).
Considerando apenas as heurısticas que usam community finding, apesar de algumas delas se
terem portado ligeiramente melhor (largest degree e community size largest degree) nao houve
nenhuma que se evidenciasse, nomeadamente em comparacao com as de Brandes. Como e
observavel a heurıstica largest degree foi a mais eficaz para a taxa variavel mas a medida que

30 CAPITULO 3. ABORDAGEM
(a) Kendall Tau (b) Spearman’s Correlation
Figura 3.5: Testes com taxa variavel sobre redes com comunidades bem definidas
(a) Kendall Tau (b) Spearman’s Correlation
Figura 3.6: Testes com taxa fixa sobre redes comunidades bem definidas de tamanho 10000
o tamanho das amostras foi crescendo (sendo o tamanho da rede fixo em 10000) as melhores
heurısticas foram a community size largest degree e a bRanDeg (Brandes). Por outro lado, de
uma forma geral, a pior heurıstica revelou-se a bRandom (Brandes).
Consideremos ainda o caso particular da heurıstica Kcore. Como se pode ver no grafico para
os testes com taxa fixa, esta heurıstica comeca consideravelmente pior que as outras mas a
medida que o tamanho da rede aumenta a qualidade da solucao aumenta quase sempre e no
limite nao chega a decrescer, o que e impressionante considerando que o tamanho da amostra
aumenta de forma logarıtmica em relacao ao tamanho da rede. Para os testes com taxa variavel
esta heurıstica e de longe a que produz melhores resultados.
Estes resultados obtidos para a heurıstica Kcore (que, lembro, utiliza nao so uma heurıstica
diferente como nao faz uso de community finding) nao sao assim tao surpreendentes se nos
lembrarmos que estas redes tem estruturas aleatorias que muitas vezes nao permitem que as

3.3. AVALIACAO DE RESULTADOS 31
heurısticas que usam community finding tirem partido das propriedades habitualmente encon-
tradas em redes reais.
Para as redes com comunidades bem definidas ja era esperado que os resultados fossem mel-
hores para as heurısticas que usam community finding. No entanto houve uma melhoria de
qualidade notoria para todas as heurısticas (mais uma vez deixamos a analise da heurıstica
kcore para o fim).
Para estas redes a melhor heurıstica revelou-se a CS (community size), seguida de perto pela
CSLD (community size largest degree). Curiosamente a pior heurıstica foi a LD (largest degree),
uma das melhores para redes com estrutura completamente aleatoria.
Para os testes com percentagens fixas de sampling verifica-se que com samples ligeiramente
superiores a log(10000) (para as redes de 10000) a diferenca entre as heurısticas que usam CF
e as de Brandes acentuam-se ate ao valor de 0,5% e acima disso voltam aos valores observados
anteriormente. Tambem se observa que com percentagens ligeiramente maiores as melhores
heurısticas sao a CS e a S (simple heuristic).
Consideremos ainda a heurıstica Kcore, que foi claramente a pior de todas, o que ja era ex-
pectavel pelas razoes que apresentei anteriormente nas redes completamente aleatorias. Para
os testes com taxa fixa, curiosamente a qualidade da solucao decresceu ate as redes de tamanho
2000 e depois cresceu acentuadamente ate as redes de tamanho 10000, de tal forma que fico
fica a duvida se para redes maiores a heurıstica Kcore passaria as outras em termos de re-
sultados. Ja nos testes de taxa variavel, os resultados sao sempre piores que os das outras
heurısticas e as rectas da qualidade da solucao sao praticamente sempre paralelas as mesmas
(o que significa que um aumento da taxa, tendo o tamanho da rede fixa em 10000, nao devera
produzir melhores resultados que para as outras heurısticas).
Como ja foi referido, foi ainda medido o tempo de execucao para cada uma das seis heurısticas.
Visto que o mais importante neste caso era determinar possıveis discrepancias em termos da
performance das heurısticas o tempo foi apenas medido para os testes com taxa fixa e para as
redes completamente aleatorias (corresponde ao teste 2 que mencionei quanto aos valores da
betweenness).
O tempo medido corresponde a soma dos tempos usr e sys medidos pelo comando time do
Linux.
A figura 3.7 compara a performance completa de todas as heurısticas, i.e. algoritmo de com-
munity finding/k-core, heurıstica e calculo aproximado e exacto da betweenness, no caso das
heurısticas porpostas, e no caso das heurısticas de Brandes, o processo e semelhante mas sem
o algoritmo de community finding/k-core.
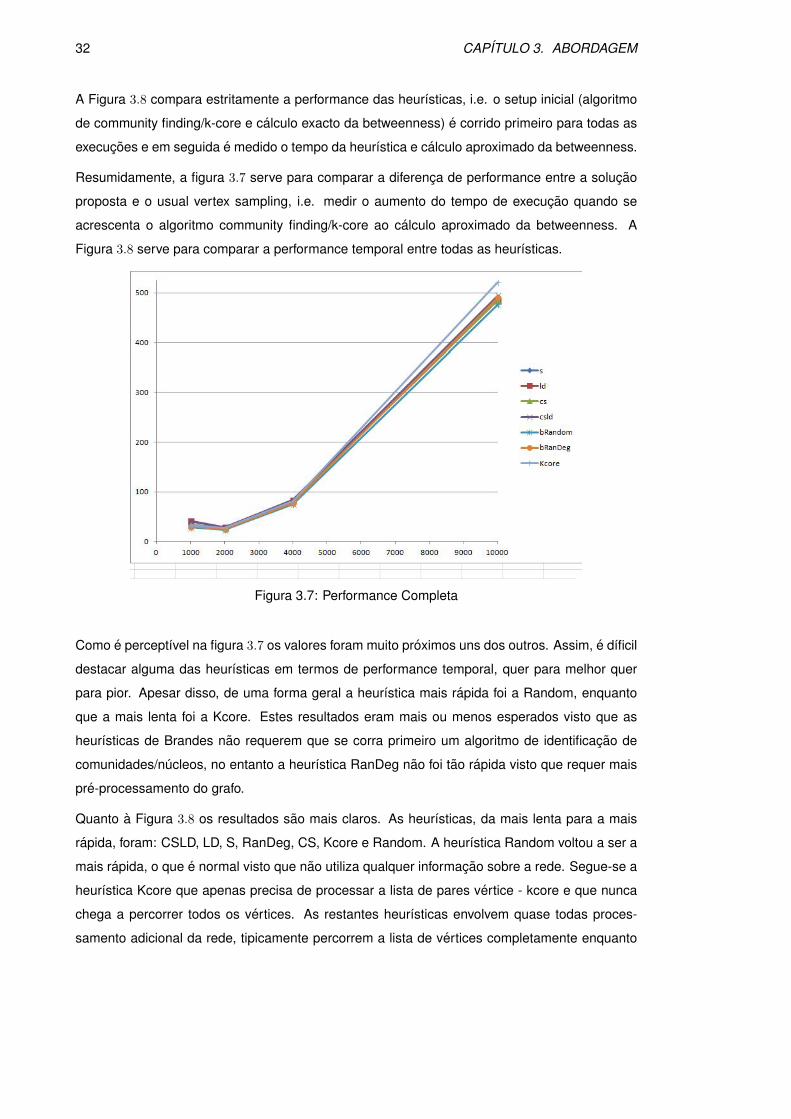
32 CAPITULO 3. ABORDAGEM
A Figura 3.8 compara estritamente a performance das heurısticas, i.e. o setup inicial (algoritmo
de community finding/k-core e calculo exacto da betweenness) e corrido primeiro para todas as
execucoes e em seguida e medido o tempo da heurıstica e calculo aproximado da betweenness.
Resumidamente, a figura 3.7 serve para comparar a diferenca de performance entre a solucao
proposta e o usual vertex sampling, i.e. medir o aumento do tempo de execucao quando se
acrescenta o algoritmo community finding/k-core ao calculo aproximado da betweenness. A
Figura 3.8 serve para comparar a performance temporal entre todas as heurısticas.
Figura 3.7: Performance Completa
Como e perceptıvel na figura 3.7 os valores foram muito proximos uns dos outros. Assim, e dıficil
destacar alguma das heurısticas em termos de performance temporal, quer para melhor quer
para pior. Apesar disso, de uma forma geral a heurıstica mais rapida foi a Random, enquanto
que a mais lenta foi a Kcore. Estes resultados eram mais ou menos esperados visto que as
heurısticas de Brandes nao requerem que se corra primeiro um algoritmo de identificacao de
comunidades/nucleos, no entanto a heurıstica RanDeg nao foi tao rapida visto que requer mais
pre-processamento do grafo.
Quanto a Figura 3.8 os resultados sao mais claros. As heurısticas, da mais lenta para a mais
rapida, foram: CSLD, LD, S, RanDeg, CS, Kcore e Random. A heurıstica Random voltou a ser a
mais rapida, o que e normal visto que nao utiliza qualquer informacao sobre a rede. Segue-se a
heurıstica Kcore que apenas precisa de processar a lista de pares vertice - kcore e que nunca
chega a percorrer todos os vertices. As restantes heurısticas envolvem quase todas proces-
samento adicional da rede, tipicamente percorrem a lista de vertices completamente enquanto
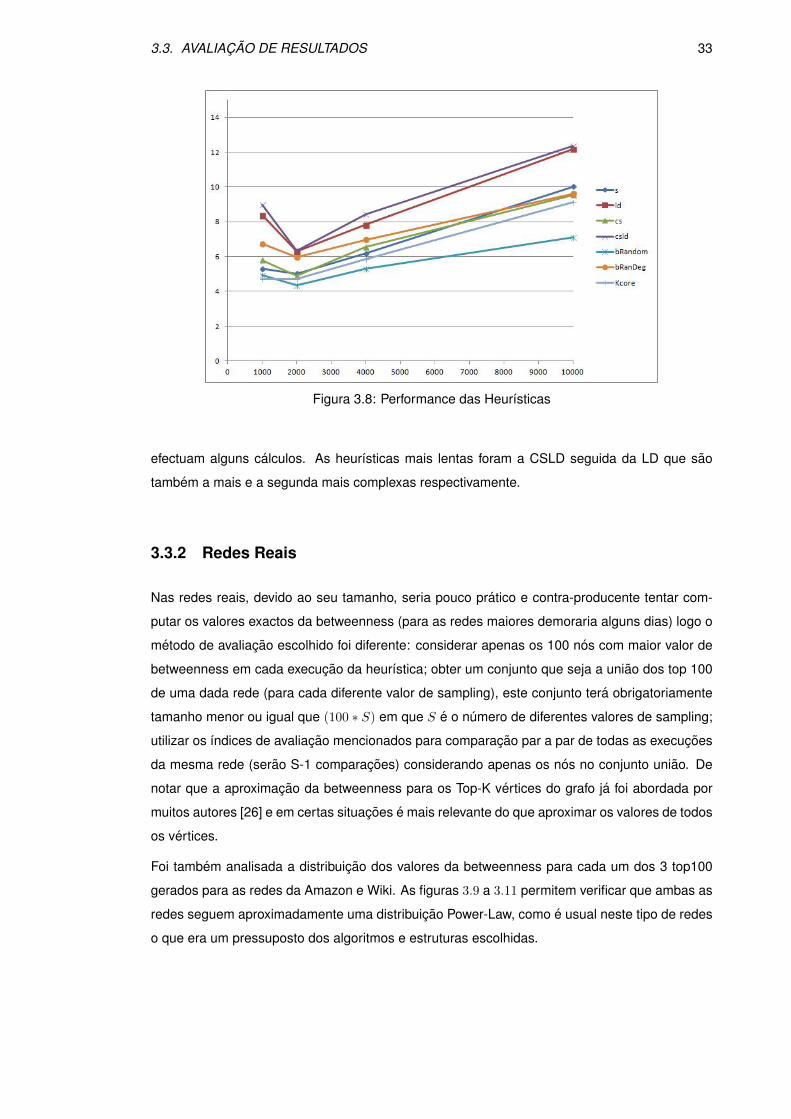
3.3. AVALIACAO DE RESULTADOS 33
Figura 3.8: Performance das Heurısticas
efectuam alguns calculos. As heurısticas mais lentas foram a CSLD seguida da LD que sao
tambem a mais e a segunda mais complexas respectivamente.
3.3.2 Redes Reais
Nas redes reais, devido ao seu tamanho, seria pouco pratico e contra-producente tentar com-
putar os valores exactos da betweenness (para as redes maiores demoraria alguns dias) logo o
metodo de avaliacao escolhido foi diferente: considerar apenas os 100 nos com maior valor de
betweenness em cada execucao da heurıstica; obter um conjunto que seja a uniao dos top 100
de uma dada rede (para cada diferente valor de sampling), este conjunto tera obrigatoriamente
tamanho menor ou igual que (100 ∗ S) em que S e o numero de diferentes valores de sampling;
utilizar os ındices de avaliacao mencionados para comparacao par a par de todas as execucoes
da mesma rede (serao S-1 comparacoes) considerando apenas os nos no conjunto uniao. De
notar que a aproximacao da betweenness para os Top-K vertices do grafo ja foi abordada por
muitos autores [26] e em certas situacoes e mais relevante do que aproximar os valores de todos
os vertices.
Foi tambem analisada a distribuicao dos valores da betweenness para cada um dos 3 top100
gerados para as redes da Amazon e Wiki. As figuras 3.9 a 3.11 permitem verificar que ambas as
redes seguem aproximadamente uma distribuicao Power-Law, como e usual neste tipo de redes
o que era um pressuposto dos algoritmos e estruturas escolhidas.
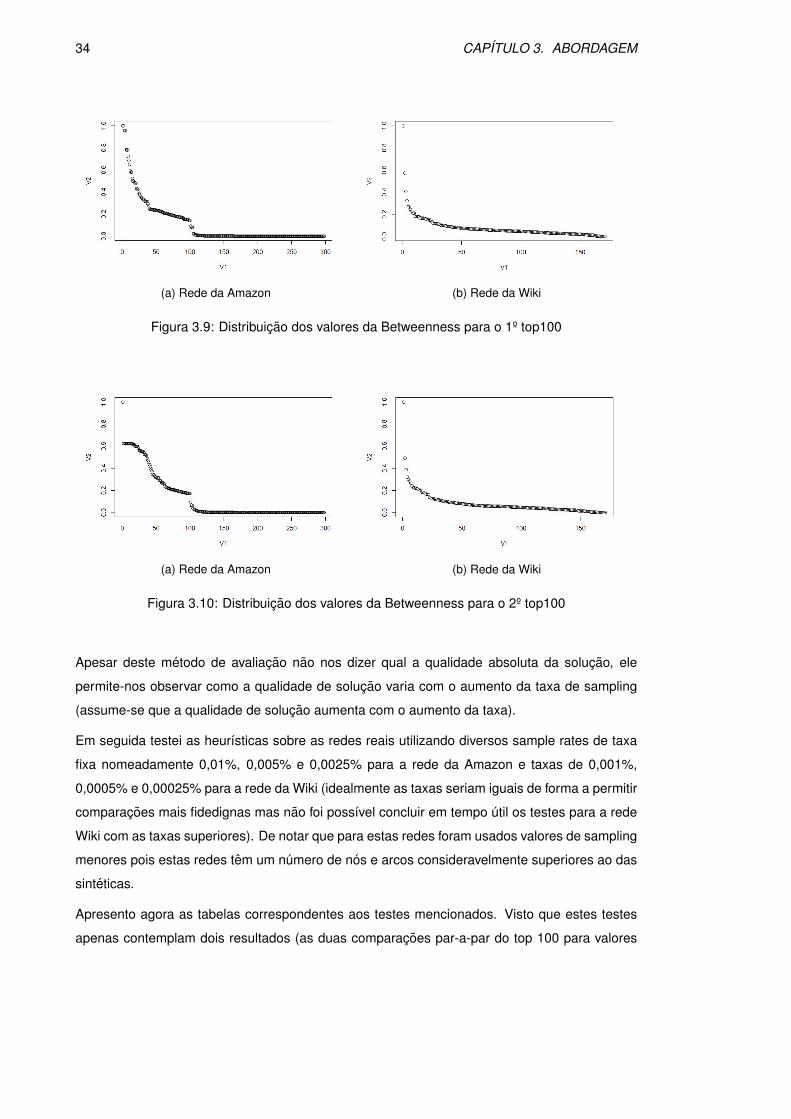
34 CAPITULO 3. ABORDAGEM
(a) Rede da Amazon (b) Rede da Wiki
Figura 3.9: Distribuicao dos valores da Betweenness para o 1º top100
(a) Rede da Amazon (b) Rede da Wiki
Figura 3.10: Distribuicao dos valores da Betweenness para o 2º top100
Apesar deste metodo de avaliacao nao nos dizer qual a qualidade absoluta da solucao, ele
permite-nos observar como a qualidade de solucao varia com o aumento da taxa de sampling
(assume-se que a qualidade de solucao aumenta com o aumento da taxa).
Em seguida testei as heurısticas sobre as redes reais utilizando diversos sample rates de taxa
fixa nomeadamente 0,01%, 0,005% e 0,0025% para a rede da Amazon e taxas de 0,001%,
0,0005% e 0,00025% para a rede da Wiki (idealmente as taxas seriam iguais de forma a permitir
comparacoes mais fidedignas mas nao foi possıvel concluir em tempo util os testes para a rede
Wiki com as taxas superiores). De notar que para estas redes foram usados valores de sampling
menores pois estas redes tem um numero de nos e arcos consideravelmente superiores ao das
sinteticas.
Apresento agora as tabelas correspondentes aos testes mencionados. Visto que estes testes
apenas contemplam dois resultados (as duas comparacoes par-a-par do top 100 para valores
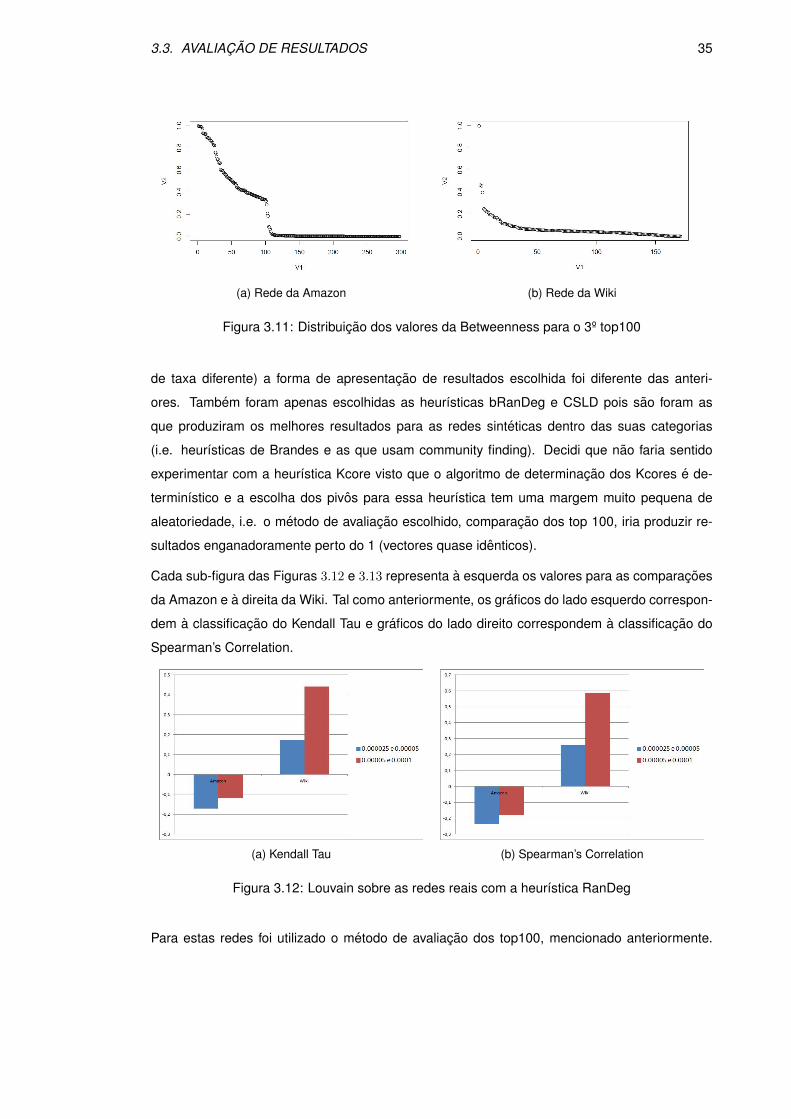
3.3. AVALIACAO DE RESULTADOS 35
(a) Rede da Amazon (b) Rede da Wiki
Figura 3.11: Distribuicao dos valores da Betweenness para o 3º top100
de taxa diferente) a forma de apresentacao de resultados escolhida foi diferente das anteri-
ores. Tambem foram apenas escolhidas as heurısticas bRanDeg e CSLD pois sao foram as
que produziram os melhores resultados para as redes sinteticas dentro das suas categorias
(i.e. heurısticas de Brandes e as que usam community finding). Decidi que nao faria sentido
experimentar com a heurıstica Kcore visto que o algoritmo de determinacao dos Kcores e de-
terminıstico e a escolha dos pivos para essa heurıstica tem uma margem muito pequena de
aleatoriedade, i.e. o metodo de avaliacao escolhido, comparacao dos top 100, iria produzir re-
sultados enganadoramente perto do 1 (vectores quase identicos).
Cada sub-figura das Figuras 3.12 e 3.13 representa a esquerda os valores para as comparacoes
da Amazon e a direita da Wiki. Tal como anteriormente, os graficos do lado esquerdo correspon-
dem a classificacao do Kendall Tau e graficos do lado direito correspondem a classificacao do
Spearman’s Correlation.
(a) Kendall Tau (b) Spearman’s Correlation
Figura 3.12: Louvain sobre as redes reais com a heurıstica RanDeg
Para estas redes foi utilizado o metodo de avaliacao dos top100, mencionado anteriormente.
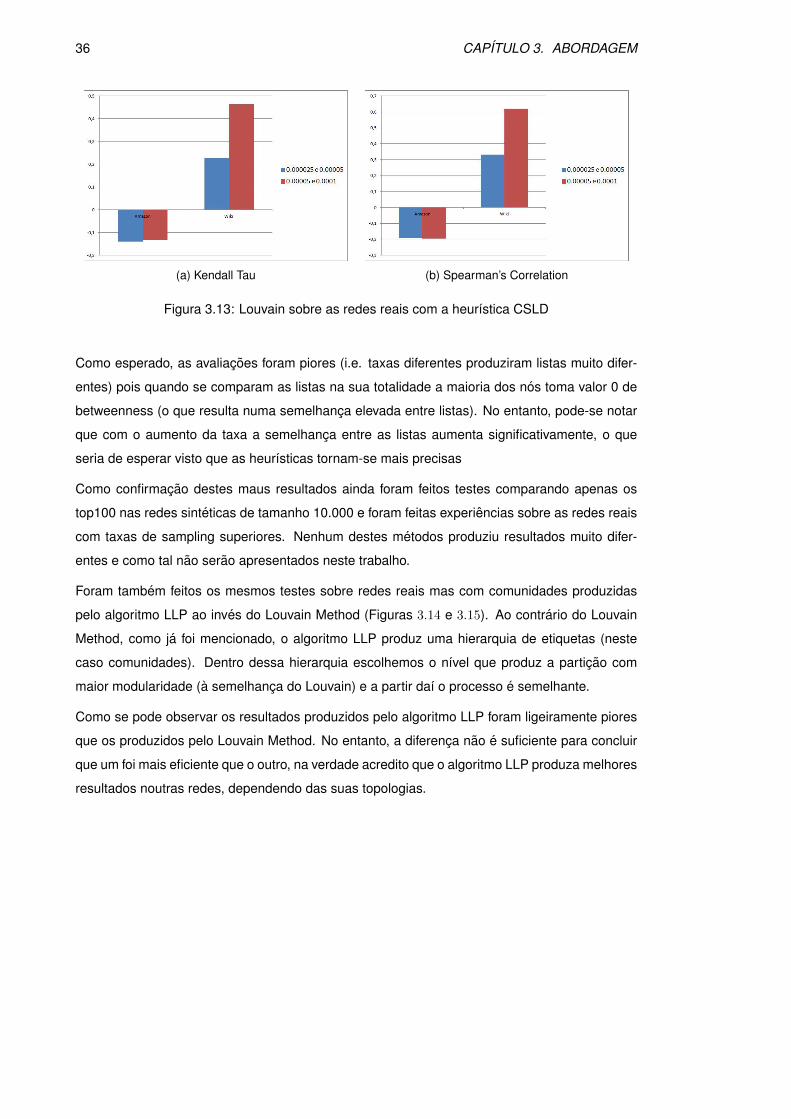
36 CAPITULO 3. ABORDAGEM
(a) Kendall Tau (b) Spearman’s Correlation
Figura 3.13: Louvain sobre as redes reais com a heurıstica CSLD
Como esperado, as avaliacoes foram piores (i.e. taxas diferentes produziram listas muito difer-
entes) pois quando se comparam as listas na sua totalidade a maioria dos nos toma valor 0 de
betweenness (o que resulta numa semelhanca elevada entre listas). No entanto, pode-se notar
que com o aumento da taxa a semelhanca entre as listas aumenta significativamente, o que
seria de esperar visto que as heurısticas tornam-se mais precisas
Como confirmacao destes maus resultados ainda foram feitos testes comparando apenas os
top100 nas redes sinteticas de tamanho 10.000 e foram feitas experiencias sobre as redes reais
com taxas de sampling superiores. Nenhum destes metodos produziu resultados muito difer-
entes e como tal nao serao apresentados neste trabalho.
Foram tambem feitos os mesmos testes sobre redes reais mas com comunidades produzidas
pelo algoritmo LLP ao inves do Louvain Method (Figuras 3.14 e 3.15). Ao contrario do Louvain
Method, como ja foi mencionado, o algoritmo LLP produz uma hierarquia de etiquetas (neste
caso comunidades). Dentro dessa hierarquia escolhemos o nıvel que produz a particao com
maior modularidade (a semelhanca do Louvain) e a partir daı o processo e semelhante.
Como se pode observar os resultados produzidos pelo algoritmo LLP foram ligeiramente piores
que os produzidos pelo Louvain Method. No entanto, a diferenca nao e suficiente para concluir
que um foi mais eficiente que o outro, na verdade acredito que o algoritmo LLP produza melhores
resultados noutras redes, dependendo das suas topologias.
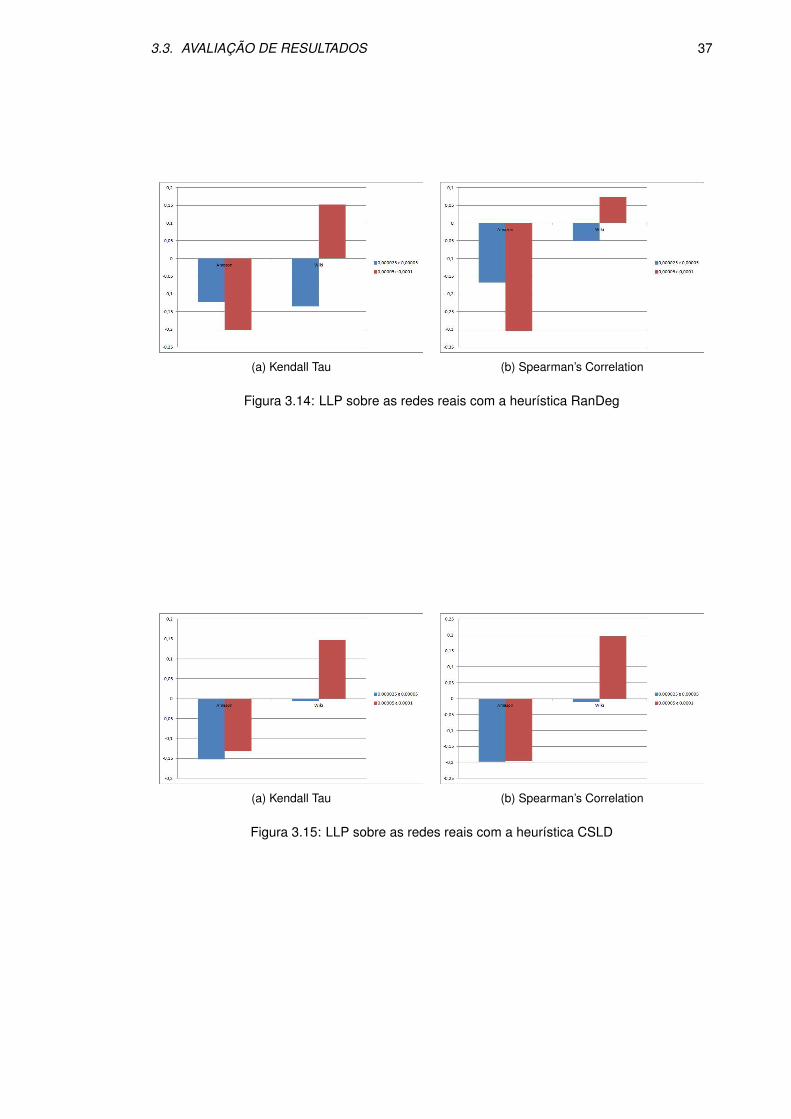
3.3. AVALIACAO DE RESULTADOS 37
(a) Kendall Tau (b) Spearman’s Correlation
Figura 3.14: LLP sobre as redes reais com a heurıstica RanDeg
(a) Kendall Tau (b) Spearman’s Correlation
Figura 3.15: LLP sobre as redes reais com a heurıstica CSLD


Capıtulo 4
Conclusoes
Re lembrando o que foi dito anteriormente, actualmente o calculo da betweenness centrality
e feito aplicando o algoritmo de Brandes a cada no na rede (desta forma resolvendo o
problema APSP). No entanto, como ja foi dito, para o tipo de redes objecto deste estudo, redes
de grande dimensao, este metodo e incomportavel. Assim, e essencial fazer amostragem de
vertices para a estimacao dos valores da betweenness. Penso que os resultados desta tese
permitem concluir que algoritmos de community finding e identificacao dos k-cores de uma rede
trazem-nos um ganho de informacao relevante para o nosso criterio de amostragem, mas esse
ganho esta dependente da topologia da rede. Como vimos, a qualidade da solucao e melhor
para redes que apresentam comunidades relativamente bem definidas ou que de uma forma
geral apresentem as propriedades caracterısticas de redes sociais: localidade e similaridade.
No entanto e importante mencionar que este ganho nao e tao relevante quanto inicialmente se
poderia pensar. E necessario continuar a explorar alternativas ou aprofundar as actuais de forma
a atingir-se um patamar de precisao satisfatorio no que toca a qualidade da solucao.
Por exemplo pode ser interessante guiar o calculo aproximado por novas tecnicas como amostragem
de caminhos [26], ao inves de nos. Com esta tecnica sao escolhidos varios pares de nos u − v
no grafo, que serao, respectivamente, origem e destino de um caminho no grafo para o qual
sera estimada a betweenness dos seus nos. No artigo em particular que menciono os caminhos
sao escolhidos de forma uniformemente aleatoria mas no futuro pode-se considerar criterios
mais apurados como, por exemplo, utilizar a informacao de community finding para amostrar
caminhos que comecem e acabem em comunidades diferentes ou escolher caminhos que con-
tenham os nos com maior grau. De notar que quer a amostragem de caminhos quer as tecnicas
sugeridas nesta tese podem ser adaptadas para o calculo de edge betweenness.
Outro exemplo de uma possibilidade a testar no futuro e a de sampling representativo [28] que,
39

40 CAPITULO 4. CONCLUSOES
muito resumidamente, consiste em determinar os nos mais representativos de uma rede de
acordo com uma serie de atributos que possuem.
Como trabalho futuro quero tambem testar a validade do uso de paralelizacao de tarefas para
o tipo de calculos pretendidos neste caso. Mais concretamente, quero verificar se o speedup
obtido por se juntar mais processadores e linear ou nao (i.e. se aumentar o numero de pro-
cessadores para o dobro implica um speedup de 2). Convem notar que a degradacao de per-
formance e geralmente inevitavel, no entanto se a percentagem de codigo nao paralelizavel for
muito baixa e possıvel obter speedups interessantes (segundo a lei de Amdahl 1, se 95% do
programa for paralelizavel, o speedup maximo e de 20 vezes o tempo original).
1https://en.wikipedia.org/wiki/Amdahl’s law

Bibliography
[1] BADER, D.A., KINTALI, S., MADDURI, K. & MIHAIL, M. (2007). Approximating Between-
ness Centrality. WAW’07 Proceedings of the 5th international conference on Algorithms and
models for the web-graph, pages 124-137 .
[2] BATAGELJ, V. & ZAVERSNIK, M. (2003). An O(m) Algorithm for Cores Decomposition of
Networks. Advances in Data Analysis and Classification, 2011. Volume 5, Number 2, 129-
145.
[3] BLONDEL, V.D., GUILLAUME, J., LAMBIOTTE, R. & LEFEBVRE, E. (2008). Fast unfolding of
communities in large networks. J. Stat. Mech. (2008) P10008.
[4] BOLDI, P. & VIGNA, S. (2004). The WebGraph Framework I: Compression Techniques.
WWW ’04 Proceedings of the 13th international conference on World Wide Web, Pages
595-602.
[5] BOLDI, P., M.ROSA, SANTINI, M. & VIGNA, S. (2011). Layered Label Propagation: A Mul-
tiResolution Coordinate-Free Ordering for Compressing Social Networks. WWW ’11 Pro-
ceedings of the 20th international conference on World wide web, Pages 587-596.
[6] BRANDES, U. (2001). A Faster Algorithm for Betweenness Centrality. Journal of Mathemati-
cal Sociology 25(2):163-177 .
[7] BRANDES, U. & PICH, C. (2007). Centrality Estimation in Large Networks. International
Journal of Bifurcation and Chaos 17 (2007), 7, pp. 2303-2318.
[8] BRANDES, U., DELLING, D., GAERTLER, M., GOERKE, R., HOEFER, M., NIKOLOSKI, Z. &
WAGNER, D. (2006). Maximizing Modularity is hard. ??.
[9] BRISABOA, N.R., LADRA, S. & NAVARRO, G. (2009). K2-trees for Compact Web Graph
Representation. SPIRE ’09 Proceedings of the 16th International Symposium on String Pro-
cessing and Information Retrieval, Pages 18-30.
41

42 BIBLIOGRAPHY
[10] CHEHREGHANI, M.H. (2013). An Efficient Algorithm for Approximate Betweenness Cen-
trality Computation. CIKM ’13 Proceedings of the 22nd ACM international conference on
Conference on information & knowledge management, pages 1489-1492.
[11] CORMEN, T.H., STEIN, C., RIVEST, R.L. & LEISERSON, C.E. (2009). Introduction to Algo-
rithms. The MIT Press, 3rd edn.
[12] DA F. COSTA, L., RODRIGUES, F.A., TRAVIESO, G. & BOAS, P.R.V. (2007). Characterization
of complex networks: A survey of measurements. Advances in Physics, Volume 56, pages
167 - 242, Issue 1.
[13] EPPSTEIN, D. & WANG, J. (2004). Fast approximation of centrality. Journal of Graph Algo-
rithms and Applications, 8(1):39–45.
[14] FLOYD, R.W. (1962). Algorithm 97: Shortest path. Communications of the ACM, 5(6):345.
[15] FORTUNATO, S. (2010). Community detection in graphs. Physics Reports 486, 75-174.
[16] FREEMAN, L.C. (1977). A Set of Measures of Centrality Based on Betweenness. Sociome-
try, 1977, Vol. 40, No. 1, 35-41.
[17] GEISBERGER, R., SANDERS, P. & SCHULTES, D. (2008). Better Approximation of Between-
ness Centrality. Proceedings of the Ninth Workshop on Algorithm Engineering and Experi-
ments (ALENEX).
[18] GIRVAN, M. & NEWMAN, M.E.J. (2001). Community structure in social and biological net-
works.
[19] JOHNSON, D.B. (1977). Efficient algorithms for shortest paths in sparse networks. Journal
of the ACM, Volume 24 Issue 1, Jan. 1977 Pages 1-13.
[20] LANCICHINETTI, A. & FORTUNATO, S. (2009). Benchmarks for testing community detection
algorithms on directed and weighted graphs with overlapping communities. Physical Review
E80, 016118.
[21] LANCICHINETTI, A., FORTUNATO, S. & RADICCHI, F. (2008). Benchmark graphs for testing
community detection algorithms. Physical Review E78, 046110.
[22] LIPTON, R.J. & NAUGHTON, J.F. (1990). Practical selectivity estimation through adaptive
sampling. SIGMOD ’90 Proceedings of the 1990 ACM SIGMOD international conference on
Management of data, Pages 1-11.

BIBLIOGRAPHY 43
[23] MATULA, D.W. & BECK, L.L. (1983). Smallest-Last Ordering and Clustering and Graph
Coloring Algorithms. Journal of the Association for Computing Machinery. Vol 30, No 3, July
1983, pp 417-427 .
[24] MILGRAM, S. (1967). The small world problem. Psychol. Today, 2:60–67 .
[25] NEWMAN, M.E.J. & GIRVAN, M. (2004). Finding and evaluating community structure in
networks. Phys. Rev. E 69, 026113.
[26] RIONDATO, M. & KORNAROPOULOS, E.M. (2014). Fast approximation of betweenness cen-
trality through sampling. WSDM’14.
[27] SEIDMAN, S.B. (1983). Network structure and minimum degree. Social Networks 5,
269–287 .
[28] TANGY, J., ZHANGY, C., CAIZ, K., ZHANGZ, L. & SUZ, Z. (2015). Sampling representative
users from large social networks. Twenty-Ninth AAAI Conference on Artificial Intelligence.






























