Embed Size (px)
Citation preview

Tema 1: Estadıstica descriptiva
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 1

Introduccion
Queremos estudiar una caracterıstica o variable en una poblacion.
Ejemplos:
• Nivel de expresion de un gen concreto de interes en un individuo
• Cantidad de albumina por litro de suero sanguıneo de una persona
• Longitud de los peces de una cierta especie en un lago
• Marca de libro electronico preferida por un comprador
• Numero de libros que un espanol lee al ano
A veces es imposible o demasiado caro observar la variable en todala poblacion, ası que se extrae una muestra. Llamamos individuo oelemento a cada miembro de la poblacion o de la muestra.
Objetivo de la Estadıstica Descriptiva: Hacer una descripcionsencilla (numerica o grafica) de la informacion contenida en lamuestra.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 2

Clases importantes de variables estadısticas
Variables cualitativas
Son cualidades o atributos de los individuos. No son un numero: nopodemos operar con sus valores.
Ejemplos:
• Sexo de un individuo: hombre o mujer (variable categorica onominal: sus valores no tienen un orden natural)
• Grado de reacciones secundarias a un tratamiento oncologico (alto,medio, bajo). Esta es una variable ordinal: sus valores se ordenan.
• Tiempo (soleado, lluvioso, parcialmente cubierto, ...) en una zona
• Presencia/ausencia o grado (nada, poco, mucho) de expresion deun gen
A veces se codifica cada una de las cualidades con un numero. Porej., si la variable cualitativa es el sexo, podemos asignar a hombresel numero 0 y a mujeres el numero 1.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 3

Tomamos una muestra (estadıstica) de tamano n: observamos ndatos, que agrupamos en K categorıas o clases.
Ejemplo 1.1: Variable = Color de ojos de un estudiante de gradoen la UAM.Categorıa= Marron, verde, azul, otros ⇒ K =Llamamos frecuencia absoluta al numero de estudiantes de lamuestra observados en cada una de las categorıas:
n1 = 31, n2 = 5, n3 = 9, n4 = 10 ⇒ n =
La proporcion de datos observados en cada clase fi =nin
se
denomina frecuencia relativa. Observemos que siempre fi ≥ 0 yf1 + f2 + . . .+ fK = 1.
f1 = , f2 = , f3 = , f4 = .
Representaciones graficas: diagrama de barras, diagrama desectores, . . . .
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 4

Color = c(31,5,9,10)
barplot(Color,main="Color de ojos estudiantes UAM",
names.arg=c("Marron","Verde","Azul","Otros"))
pie(Color,labels=c("Marron","Verde","Azul","Otros"))
Marron Verde Azul Otros
Color de ojos estudiantes UAM
05
1015
2025
30
Marron
Verde
Azul
Otros
Color de ojos estudiantes UAM
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 5

Variables cuantitativas
Miden algo cuantificable en cada individuo. Toman valoresnumericos.
Una variable discreta o discontinua es una variable cuantitativa quesolo puede tomar una cantidad finita o numerable de valores.
Ejemplos: Numero de hijos de una familia, numero de goles de unequipo en cada partido, numero de accesos diarios a una paginaweb, numero de mutaciones en un fragmento de ADN.
Las variables continuas pueden tomar una cantidad infinita nonumerable de valores. El conjunto de posibles valores de unavariable continua es un intervalo (finito o infinito) de la recta real.
Ejemplos: La estatura o el peso de una persona (las medidasbiometricas en general), el nivel de alcohol en sangre de unindividuo, el contenido en hierro de un mineral.
En la practica siempre hay un lımite de precision en el numero dedıgitos con el que expresamos una variable continua.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 6

Descripcion grafica de variables cuantitativas
Variables discretas: diagrama de barras
Ejemplo 1.2: Se realiza un examen tipo test con 5 preguntas a ungrupo de estudiantes.
No respuestascorrectas No estudiantes (ni )
Frecuenciarelativa fi
0 31 112 93 204 55 2
n = 1
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 7
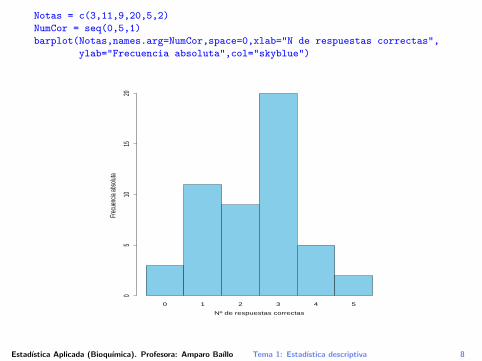
Notas = c(3,11,9,20,5,2)
NumCor = seq(0,5,1)
barplot(Notas,names.arg=NumCor,space=0,xlab="N de respuestas correctas",
ylab="Frecuencia absoluta",col="skyblue")
0 1 2 3 4 5
Nº de respuestas correctas
Frec
uenc
ia ab
solut
a
05
1015
20
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 8

Variables continuas: histograma
Se agrupan los datos en una serie de clases o intervalos A1, . . . ,Ak .Calculamos la frecuencia absoluta ni de cada intervalo Ai (no deobservaciones en Ai ). Cada dato debe pertenecer a solo una clase.
Se representan los lımites de los intervalos sobre el eje de abscisas.Luego se dibujan rectangulos cuya base es el intervalo y cuyo areaes la frecuencia absoluta de cada intervalo (ni ).
En la practica, dadas unas observaciones, elegimos nosotros ellımite inferior del primer intervalo y la amplitud.
Por ejemplo, se determina primero el rango de valores de los datos(maximo - mınimo de las observaciones).Luego se subdivide el rango en m intervalos iguales. Es habitualtomar m '
√n, siendo n el numero total de observaciones.
A veces se utiliza la frecuencia relativa fi en lugar de la frecuenciaabsoluta ni . Entonces el area bajo el histograma es 1.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 9

Ejemplo 1.3: Chargaff (1955) constato que los ratios de adeninafrente a timina y de guanina frente a citosina eran cercanos a launidad en un elevado numero de muestras de ADN. Estaobservacion apoyo la teorıa de la estructura en doble helice delADN propuesta por Watson y Crick (1953). A continuacion semuestran las composiciones base (en %) de algunos ADN (ficherode datos DNAComposition.txt). Estudiar si las distribuciones delos ratios A/T y G/C son proximas a 1.
DNACompositionTissue Adenine Guanine Cytosine ThymineCalf_thymus 27.3 22.7 21.6 28.4Calf_thymus 28.2 21.5 22.5 27.8Beef_spleen 27.9 22.7 20.8 27.3Beef_spleen 27.7 22.1 21.8 28.4Beef_liver 28.8 21.0 21.1 29.0Beef_pancreas 27.8 21.9 21.7 28.5Beef_kidney 28.3 22.6 20.9 28.2Sheep_thymus 29.3 21.4 21.0 28.3Sheep_liver 29.3 20.7 20.8 29.2Sheep_spleen 28.0 22.3 21.1 28.6Man_thymus 30.9 19.9 19.8 29.4Man_liver 30.3 19.5 19.9 30.3Man_spleen 29.2 21.0 20.4 29.4Sarcina_lutea 13.4 37.1 37.1 12.4Wheet_germ 27.3 22.7 22.8 27.1Yeast 31.3 18.7 17.1 32.9Pneumococcus_type_III 29.8 20.5 18.0 31.6Vaccinia_virus 29.5 20.6 20.0 29.9
Página 1
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 10

Datos=read.table("DNAComposition.txt",header=TRUE)
A=Datos$Adenine
G=Datos$Guanine
C=Datos$Cytosine
Th=Datos$Thymine
hist(A/Th,freq=FALSE)
Histogram of A/T
A/T
Den
sity
0.95 1.00 1.05 1.10
02
46
810
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 11
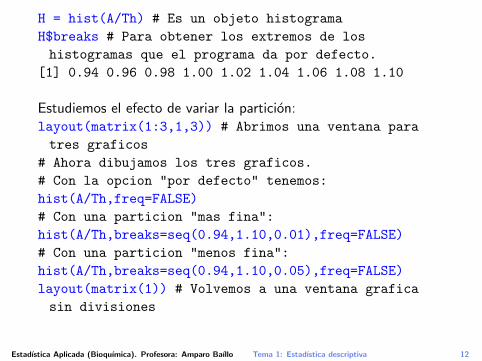
H = hist(A/Th) # Es un objeto histograma
H$breaks # Para obtener los extremos de los
histogramas que el programa da por defecto.
[1] 0.94 0.96 0.98 1.00 1.02 1.04 1.06 1.08 1.10
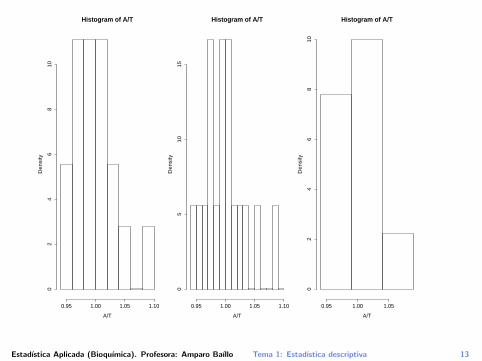
Estudiemos el efecto de variar la particion:layout(matrix(1:3,1,3)) # Abrimos una ventana para
tres graficos
# Ahora dibujamos los tres graficos.
# Con la opcion "por defecto" tenemos:
hist(A/Th,freq=FALSE)
# Con una particion "mas fina":
hist(A/Th,breaks=seq(0.94,1.10,0.01),freq=FALSE)
# Con una particion "menos fina":
hist(A/Th,breaks=seq(0.94,1.10,0.05),freq=FALSE)
layout(matrix(1)) # Volvemos a una ventana grafica
sin divisiones
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 12
Histogram of A/T
A/T
De
nsi
ty
0.95 1.00 1.05 1.10
02
46
81
0
Histogram of A/T
A/T
De
nsi
ty
0.95 1.00 1.05 1.10
05
10
15
Histogram of A/T
A/T
De
nsi
ty0.95 1.00 1.05
02
46
81
0
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 13

Resumen numerico de datos cuantitativos
Medidas de centralizacion, posicion o localizacion
Informan acerca de la posicion alrededor de la cual se “centran” odistribuyen los datos x1, . . . , xn (muestra aleatoria).
media muestral = x =x1 + x2 + . . .+ xn
n=
∑ni=1 xin
Ejemplo 1.3 (cont.):
sum(A)
[1] 504.3
length(A)
[1] 18
sum(A)/length(A)
[1] 28.01667
mean(A)
[1] 28.01667
mean(A/Th)
[1] 0.9986737
Ejemplo 1.2 (cont.):
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 14

La mediana es el dato que ocupa el lugar central respecto a losdatos ordenados x(1), x(2), . . . , x(n).
Si el tamano muestral es impar (n = 2m + 1), med = x(m+1).
Ejemplo 1.4: 13 ovejas comieron una hierba venenosa. Las horasque tardaron en morir fueron: 44, 27, 24, 24, 36, 36, 44, 44, 120,29, 36, 36 y 36. Calcular la media y la mediana.H = c(44,27,24,24,36,36,44,44,120,29,36,36,36)
Hord = sort(H)
Hord
[1] 24 24 27 29 36 36 36 36 36 44 44 44 120
length(Hord)
[1] 13
n = length(Hord)
Hord[(n+1)/2]
[1] 36
median(H)
[1] 36
mean(H)
[1] 41.23077
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 15

Ejemplo 1.4: Cuando el tamano muestral es pequeno, podemoshacer un grafico de puntos (dot diagram):
S = stripchart(H, method = "stack", offset = .5, at = .1,
pch = 19, cex=2,
main = "Ejemplo ovejas y hierba venenosa",
xlab = "Horas hasta morir")
40 60 80 100 120
Ejemplo ovejas y hierba venenosa
Horas hasta morir
●●
●● ●●●●●
●●●
●
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 16

Si el tamano muestral es par (n = 2m), med =x(m) + x(m+1)
2.
Ejemplo 1.5: Un laboratorio realiza seis determinaciones de laconcentracion de albumina en una misma muestra de suerosanguıneo humano:
42.5 41.6 42.1 41.9 41.1 42.2.
Calcular la media y la mediana.
Ejemplo 1.2 (cont.):
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 17

Ejemplo 1.3 (cont.):median(A/Th)
[1] 0.9965986
RatioATOrd=sort(A/Th)
RatioATOrd
[1] 0.9430380 0.9513678 0.9612676 0.9753521 0.9754386 0.9790210
[7] 0.9866221 0.9931034 0.9931973 1.0000000 1.0034247 1.0035461
[13] 1.0073801 1.0143885 1.0219780 1.0353357 1.0510204 1.0806452
mean(c(RatioATOrd[9],RatioATOrd[10]))
[1] 0.9965986
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 18

Medidas de dispersion o variabilidad
Dispersion respecto a la media
La media es un valor representativo de la variable de interes en lapoblacion o en la muestra. Por tanto, es util para compararpoblaciones o muestras entre sı.
Sin embargo, lo bien o lo mal que la media represente a la muestradepende de la dispersion de esta.
Si los datos estan agrupados cerca de la media, esta sera muyrepresentativa de la localizacion de los datos.
Por el contrario, si los datos estan muy dispersos, la media no seraun buen representante de las observaciones.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 19

Ejemplo 1.6:
Nota obtenida2 3 4 5 6 7 8 9 10
No alumnos grupo A 0 0 0 40 60 0 0 0 0No alumnos grupo B 1 5 15 24 31 18 4 1 1No alumnos grupo C 6 12 14 18 24 9 3 5 9
Nota
1098765432
Fre
cu
en
cia
60
50
40
30
20
10
0
Grupo A
Página 1
Nota
1098765432
Fre
cu
en
cia
60
50
40
30
20
10
0
Grupo B
Página 1
Nota
1098765432F
recu
en
cia
60
50
40
30
20
10
0
Grupo C
Página 1
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 20

Podemos medir las discrepancias de los individuos respecto a lamedia mediante las diferencias
x1 − x , x2 − x , . . . , xn − x .
Desventaja: La suma de estas discrepancias es cero.Por ello definimos las discrepancias de los individuos respecto a lamedia como las diferencias al cuadrado
(x1 − x)2, (x2 − x)2, . . . , (xn − x)2.
Cuantificamos la dispersion de la muestra x1, . . . , xn en torno a lamedia mediante la varianza muestral
s2 =1
n − 1
n∑i=1
(xi − x)2.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 21

Ejemplo 1.2 (cont.):
Ejemplo 1.6 (cont.):
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 22

Ejemplo 1.3 (cont.):var(A)
[1] 14.70265
sum((A-mA)^2)/(n-1)
[1] 14.70265
var(A/Th)
[1] 0.001183893
var(G/C)
[1] 0.002202818
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 23

Una medida mas conveniente de la dispersion es la desviaciontıpica s, que se define como la raız cuadrada de la varianza s2:
Ejemplo 1.3 (cont.):
sd(A)
[1] 3.834403
sqrt(var(A))
[1] 3.834403
El coeficiente de variacion CV =s
|x |es una medida normalizada de
la variabilidad de los datos.
Ejemplo 1.3 (cont.):
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 24

Ejemplo 1.4 (cont.):
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 25

Dispersion respecto a la mediana: cuartiles y cuantiles
De manera analoga a la mediana, se definen los cuartiles:
I El primer cuartil Q1 es un valor que deja la cuarta parte de losdatos “a la izquierda” cuando se ordenan de menor a mayor ylas tres cuartas partes a la derecha.
I El segundo cuartil Q2 es la mediana.
I El tercer cuartil Q3 deja las tres cuartas parte de los datos “a laizquierda” cuando se ordenan de menor a mayor y la cuartaparte a la derecha.
En general, para β ∈ (0, 1) se llama “cuantil β”, qβ, o “percentil100β” al valor que deja una proporcion β de los datos “a laizquierda” (es decir, una proporcion β de los datos son menoresque el) y el resto “a la derecha” (es decir, son mayores).
Con esta notacion, q0.25 = Q1, q0.5 = Q2, q0.75 = Q3.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 26

En la practica hay varios metodos para calcular el cuantil β de unamuestra. Todos hacen una media ponderada de dos observacionesconsecutivas x(j) y x(j+1) de la muestra ordenada queaproximadamente dejan una proporcion β de los datos “a laizquierda”.
Para un tamano muestral n grande, los resultados de todos losmetodos son parecidos. R es el programa que ofrece un mayornumero (9) de maneras de calcular los cuantiles.
Ejemplo 1.3 (cont.):
quantile(A,0.25)
25 %
27.825
quantile(A,0.75)
n − 1
4+ 1 = ⇒ Q1 =
3(n − 1)
4+ 1 = ⇒ Q3 =
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 27

Ejemplo 1.2 (cont.):
Ejemplo 1.5 (cont.):
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 28

En general, hay varias maneras (parecidas) de calcular un cuantil apartir de la muestra. Podemos utilizar esta (Type 7 de R): siβ(n − 1) + 1 no es un numero entero, entonces se interpola entrelas observaciones ordenadas que estan en la posicion [β(n− 1) + 1]y [β(n − 1)] + 2, donde [z ] denota la parte entera de z :
β(n − 1) + 1 = k + r con k entero y 0 ≤ r < 1
qβ = (1− r)x(k) + r x(k+1)
Ejemplo 1.3 (cont.):
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 29

El rango intercuartılico (RI) es la diferencia entre el primer y eltercer cuartil: RI = Q3 − Q1.
Si separamos los datos ordenados en cuatro grupos con el mismonumero de observaciones, el RI mide la distancia entre los dosgrupos mas extremos.
Para visualizar estas medidas de dispersion respecto a la medianase utiliza el diagrama de caja (box plot).
Es especialmente util para comparar grupos de datos entre sı.
Para construir el diagrama de caja de la muestra, calculamos Q1,Q2, Q3, RI y los lımites inferior y superior del diagrama
LI = La menor observacion en el intervalo[Q1 − 1.5 · RI,Q3 + 1.5 · RI]
LS = La mayor observacion en el mismo intervalo
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 30

Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 31
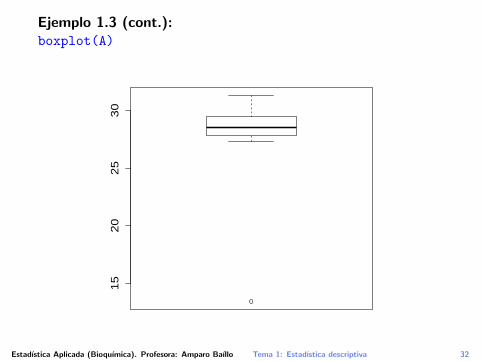
Ejemplo 1.3 (cont.):boxplot(A)
15
20
25
30
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 32

Ejemplo 1.3 (cont.):boxplot(A/Th,G/C)
1 2
0.95
1.00
1.05
1.10
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 33

Estadıstica descriptiva de dos variables (bivariante)
Ahora estamos interesados en dos variables estadısticas X e Y oun vector bidimensional (X ,Y ) en cada individuo de una poblacion.
X −→ x1, x2, . . . , xnY −→ y1, y2, . . . , yn
}−→ (x1, y1), . . . , (xn, yn)
Ejemplo 1.7: Se examinan soluciones patron de fluoresceina en unespectrometro, obteniendose las intensidades de fluorescencia:
Concentracion, pg/ml (X ) 0 2 4 6 8 10 12
Intensidad (Y ) 2.1 5.0 9.0 12.6 17.3 21.0 24.7
X = c(0,2,4,6,8,10,12)
Y = c(2.1,5.0,9.0,12.6,17.3,21.0,24.7)
plot(X,Y)
0 2 4 6 8 10 125
1015
2025
X
Y
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 34

En general, los objetivos de analizar observaciones bivariantes (=vectores) son:
I Entender mejor la relacion entre las dos variables. A partir de lainformacion muestral deseamos encontrar una relacion funcionalaproximada entre Y y X : Y ' g(X ).
I Predecir o aproximar el valor de una de ellas (digamos la Y )cuando se conoce el valor de la otra: y = g(x).
Es util en calibracion (analisis instrumental):
Se toman una serie de materiales de los que se conoce la conoce laconcentracion (X ) de un cierto analito. Estos patrones decalibracion se miden (Y ) en el instrumento analıtico bajo lasmismas condiciones que posteriormente se utilizaran con losmateriales de ensayo.
Aquı estudiamos un ajuste lineal entre Y y X , es decir,g(x) = a + bx , recta de pendiente b y ordenada en el origen a.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 35

Covarianza muestral entre X e Y :
covx ,y =1
n − 1
n∑i=1
(xi − x)(yi − y)
Ejemplo 1.7 (cont.):xi 0 2 4 6 8 10 12
yi 2.1 5.0 9.0 12.6 17.3 21.0 24.7
xi − x -6 -4 -2 0 2 4 6
yi − y -11.0 -8.1 -4.1 -0.5 4.2 7.9 11.6
xiyi 0 10.0 36.0 75.6 138.4 210.0 296.4
mX=mean(X); mY=mean(Y)
n = length(X)
cov(X,Y)
[1] 36.03333
sum((X-mX)*(Y-mY))/(n-1)
[1] 36.03333
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 36

Ejemplo 1.3 (cont.): ¿Que pendiente tendra aproximadamente larecta que mejor ajuste los datos de adenina frente a timina?
plot(A,Th)
15 20 25 30
1520
2530
A
T
Este grafico se denomina diagrama de dispersion de T frente a A.
Dibujar el diagrama de dispersion de X e Y es el primer pasoesencial al intentar estudiar la relacion entre estas dos variables.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 37

La recta de regresion de Y sobre X es la recta g(x) = a + bx queminimiza el error cuadratico medio
ECM =1
n
n∑i=1
(yi − a− bxi )2.
Es decir, los valores a y b se obtienen minimizando la suma decuadrados de distancias verticales de los puntos a la recta:
b =covx ,ys2x
a = y − bx
x
y
(xi,y
i)
ei
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 38

Ejemplo 1.7 (cont.):lm(Y~X)
Call:
lm(formula = Y ~ X)
Coefficients:
(Intercept) X
1.518 1.930
zz = lm(Y~X)
plot(X,Y)
abline(zz)
0 2 4 6 8 10 12
510
1520
25
X
Y
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 39
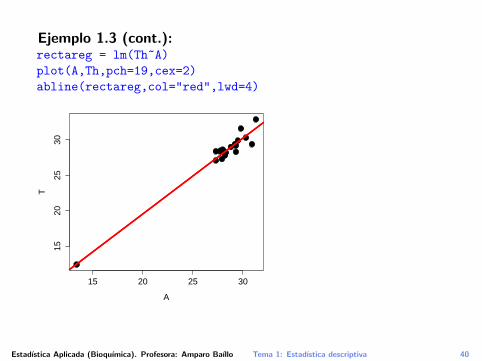
Ejemplo 1.3 (cont.):rectareg = lm(Th~A)
plot(A,Th,pch=19,cex=2)
abline(rectareg,col="red",lwd=4)
15 20 25 30
1520
2530
A
T
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 40

El coeficiente de correlacion
r =covx ,y√s2x s
2y
=covx ,ysxsy
mide el grado de relacion lineal entre X e Y .
Solo puede tomar valores entre -1 y 1.
Una correlacion r cercana a 1 indica un alto grado de ajuste linealde y en terminos de x . Se dice que hay una alta “correlacionpositiva” o “relacion lineal directa” entre ambas variables (alaumentar los valores de una de ellas aumentan los correspondientesvalores de la otra).
Un r cercano a -1 indica tambien un alto grado de ajuste lineal dey en terminos de x pero en este caso hay una “correlacionnegativa” o “relacion lineal inversa” entre ambas variables.
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 41

Un r cercano a 0 se interpreta como una debil asociacion linealentre x e y .
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 42

A menudo la relacion lineal g(x) = a + bx no sera la que mejordescriba la relacion entre X e Y , o simplemente no tendra sentido.
Ejemplo 9: En 1990 y 1991 se tomaron muestras de percas y aguaen 53 lagos de Florida para estudiar los factores ambientalesrelacionados con la contaminacion por mercurio de estos peces. Semidio, por ejemplo, la alcalinidad del agua (mg CaCO3 l−1). Elgrafico representa los valores medios de alcalinidad frente a laconcentracion media de mercurio (ppm) para los 53 lagos.
0 20 40 60 80 100 120 1400
0.2
0.4
0.6
0.8
1
1.2
1.4
Alcalinidad
Con
cent
raci
ón d
e m
ercu
rio
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 43

Ejemplo 9 (cont.):Lago Alcalinidad Mercurio Lago Alcalinidad MercurioAlligator 5.9 1.23 Lochloosa 55.4 0.34Annie 3.5 1.33 Louisa 3.9 0.84Apopka 116.0 0.04 Miccasukee 5.5 0.50Blue Cypress 39.4 0.44 Minneola 6.3 0.34Brick 2.5 1.20 Monroe 67.0 0.28Bryant 19.6 0.27 Newmans 28.8 0.34Cherry 5.2 0.48 Ocean Pond 5.8 0.87Crescent 71.4 0.19 Ocheese Pond 4.5 0.56Deer Point 26.4 0.83 Okeechobee 119.1 0.17Dias 4.8 0.81 Orange 25.4 0.18Dorr 6.6 0.71 Panasoffkee 106.5 0.19Down 16.5 0.50 Parker 53.0 0.04Eaton 25.4 0.49 Placid 8.5 0.49East Tohopekaliga 7.1 1.16 Puzzle 87.6 1.10Farm-13 128.0 0.05 Rodman 114.0 0.16George 83.7 0.15 Rousseau 97.5 0.10Griffin 108.5 0.19 Sampson 11.8 0.48Harney 61.3 0.77 Shipp 66.5 0.21Hart 6.4 1.08 Talquin 16.0 0.86Hatchineha 31.0 0.98 Tarpon 5.0 0.52Iamonia 7.5 0.63 Tohopekaliga 25.6 0.65Istokpoga 17.3 0.56 Trafford 81.5 0.27Jackson 12.6 0.41 Trout 1.2 0.94Josephine 7.0 0.73 Tsala Apopka 34.0 0.40Kingsley 10.5 0.34 Weir 15.5 0.43Kissimmee 30.0 0.59 Wildcat 17.3 0.25
Yale 71.8 0.27
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 44

Si modelizamos la relacion entre X e Y incorrectamente, nuestromodelo no dara predicciones fiables de valores desconocidos de Yen funcion de valores conocidos de X .
Una solucion sencilla es transformar las variables Y y/o Xmediante una funcion no lineal (log x , x2, ex , . . . ) y calcular larecta de regresion entre las variables transformadas.
Ejemplo 9 (cont.):
0 20 40 60 80 100 120 140−4
−3
−2
−1
0
1
x
log
(y)
0 1 2 3 4 5−4
−3
−2
−1
0
1
log(x)
log
(y)
0 0.2 0.4 0.6 0.8 1−4
−3
−2
−1
0
1
1/x
log
(y)
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
1.2
1.4
1/x
y
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 45

Ejemplo 10: Peso del cerebro (en g) en funcion del peso corporal(en kg) para 62 especies de mamıferos (Fuente: Allison &Sacchetti 1976, Science)
0 2000 4000 6000 80000
1000
2000
3000
4000
5000
6000
Peso cuerpo (en kg)
Pe
so c
ere
bro
(e
n g
)
Elefante africano
Elefante asiático
Humano
−5 0 5 10
−2
0
2
4
6
8
10
Log(Peso cuerpo)
Lo
g(P
eso
ce
reb
ro)
Estadıstica Aplicada (Bioquımica). Profesora: Amparo Baıllo Tema 1: Estadıstica descriptiva 46





























