Embed Size (px)
Citation preview

Introduzione
Negli ultimi anni le reti di sensori wireless, note anche come WSN ( Wireless Sensor
Network) si stanno sempre più diffondendo nelle più importanti applicazioni di misura in
ambito civile, industriale e militare.
Il loro ampio utilizzo è dovuto alla sempre più crescente necessità di effettuare misure
di oggetti in movimento, di misurare quantità fisiche disposte in vaste aree geografiche, di
posizionare con grande flessibilità i sensori garantendo in tal modo la possibilità di effettuare
misure ovunque anche in ambienti ostili e remoti.
Le WSN sono composte da un numero relativamente alto di sensori detto anche nodi,
e un numero fisso di stazioni base in genere qualche unità, chiamate gateway, beacon, o sink.
Un nodo è un piccolo apparecchio elettronico o elettromeccanico, dotato di un
processore e di un transceiver.
Le reti di sensori senza fili sono in genere caratterizzate da:
- Compattezza: i nodi hanno dimensioni ridotte che ne permettono il facile
posizionamento in base alle specifiche dell’applicazione;
- Mancanza di infrastruttura dedicata: la rete è basata su protocolli di
comunicazione sviluppati ad hoc di tipo peer to peer;
- Alimentazione a basso consumo di energia, solitamente a batteria;
- Trasmissione su percorsi multipli del tipo multi hop;
- Basso flow data rate.
- Grande numero di nodi;
- Sincronizzazione delle informazioni e misure.
1

Così come nell’ambito della ricerca in cui team di ricercatori collaborano in modo
sinergico per ottenere un migliore risultato con maggior efficienza e maggiori profitti, anche
la collaborazione tra macchine porta alla realizzazione del prodotto o al raggiungimento
dell’obiettivo con maggior efficienza. Tale metodologia di lavoro ben si presta anche alle reti
di sensori. Infatti, in tali situazioni i sensori di una rete non operano isolati, ma collaborano
alla formazione del dato di misura, portando a termine un processo di data fusion. Possiamo
distinguere tre forme di collaborazione:
- multimodal fusion: è basata sulla collaborazione di sensori eterogenei
opportunamente distribuiti, i cui dati combinati migliorano la misura
effettuata, come nel caso di monitoraggio di fenomeni ambientali quali la
previsione dei terremoti;
- data shering technique: è basata sulla collaborazione tra sensori che
prelevano le stesse informazioni dal campo, come nelle operazioni di
rilevamento di sorgenti di rumore;
- confidence boost technique: è applicata quando più sensori devono osservare
lo stesso oggetto di misura in istanti temporali differenti per poi ottenere una
stima della misura, come l’inseguimento di oggetto in movimento.
In tale contesto affinché la fusione dei dati produca un risultato attendibile, è
necessario che i nodi siano sincronizzati rispetto a un certo riferimento temporale comune e
che l’esecuzione dei task avvenga con tempi certi. Pertanto, il sincronismo è fondamentale sia
nelle WSN per le tecniche di data fusion, sia nelle applicazioni inerenti i sistemi automatici di
misura.
Uno dei vantaggi offerto da un sistema wired è la possibilità di avere linee di trigger
dedicate: ciò permette di avere la sicurezza della ricezione contemporanea del messaggio, a
meno dell’inerzia deterministica insita del bus. Questa certezza viene persa dai sistemi di
interfaccia wireless, perchè le latenze introdotte sono aleatorie, quindi non stimabili a priori.
2

Si pone, pertanto, la necessità di una sincronizzazione dei clock locali degli strumenti,
che può essere di due tipi:
- Globale: I clock di tutti i nodi hanno lo stesso riferimento temporale, indicano cioè
tutti lo stesso tempo, quello di un clock di riferimento definito clock globale.
- Relativo: Ogni nodo conosce la relazione che intercorre tra il tempo misurato dal
suo clock e il tempo misurato dai clock degli altri nodi.
La assenza di sincronizzazione farebbe venire a mancare tutti i riferimenti di fase tra i
vari nodi rendendo di fatto impossibili misure che richiedono la correlazione dei nodi. Si
pensi ad esempio a misure di potenza istantanea fatta su sistemi multifase, piuttosto che ad
applicazione quale l’osservazione di eventi o variazioni come accade nei sistemi per la misura
della qualità dell’energia elettrica. In tale ambito si ha la necessità che i nodi siano
sincronizzati rispetto a un riferimento temporale comune e che l’esecuzione dei task di misura
avvenga con tempi certi. Nel monitoraggio distribuito della power quality (PQ), molti moduli
partecipano al processo di misura, e standard di settore specificano la massima incertezza del
riferimento temporale utilizzato. Lo standard IEC 61000-4-30 impone, per strumenti in classe
A, un’incertezza sul clock di riferimento che non deve superare ±20 ms per 50 Hz.
La sincronizzazione può essere effettuata attraverso l’aggiunta di elementi hardware,
quali moduli GPS. Tale tecnica, affidabile e consolidata, garantisce ottime precisioni, però,
presenta dei limiti di: costo dell’hardware, inoperatività in ambienti chiusi, consumo di
energia e tempi di start-up elevati (dell’ordine del minuto).
La soluzione alternativa a tale metodologia è l’utilizzo di protocolli software, senza la
necessità di aggiungere altro hardware.
In letteratura molte sono le soluzioni proposte, nelle quali gli algoritmi di
sincronizzazione si basano sull’approccio sender-receiver o receiver-receiver e sullo scambio
di messaggi di tipo one-way o two-way. Gli algoritmi del tipo sender-receiver sono
caratterizzati dall’invio periodico da parte del sender di messaggi contenenti il proprio valore
3

del clock ai vari receiver; mentre negli algoritmi di tipo receiver-receiver, la sincronizzazione
avviene tramite un invio periodico di messaggi di riferimento (che non contengono il valore
del clock) da parte di un sender e conseguente scambio di informazioni, tra i receiver, relative
al messaggio di riferimento ricevuto. In questo caso un set di ricevitori si sincronizza con un
altro set di ricevitori, e il sender resta non sicronizzato. Lo scambio di messaggi di tipo one-
way è caratterizzato dall’invio di messaggi, contenenti il valore del clock, da parte del sender
in modalità broadcast, a differenza della modalità two-way in cui si attua tra sender e receiver
uno scambio reciproco di messaggi relativi ai tempi.
Tra gli algoritmi presenti in letteratura, i protocolli: Reference Broadcasting
Synchronization (RBS), Timing-sync Protocol for Sensor Networks (TPSN) e Flooding Time
Synchronization Protocol (FTSP) sono quelli che esibisconi prestazioni migliori.
Il protocollo RBS è del tipo receiver-receiver. In questo protocollo un nodo master ha
l’unico scopo di inviare periodicamente un messaggio ai loro vicini; questo nodo non si
sincronizzerà con gli altri ricevitori. I ricevitori usano il tempo di arrivo dei messaggi, come
punto di riferimento per comparare i loro clock. I messaggi inviati dal master non contengono
nessun timestamp (valore del clock), perché non è importante esplicitare quando viene inviato
il messaggio.
Nella forma più semplice, il protocollo RBS può essere schematizzato come segue:
- un master invia in broadcast un reference packet ai receiver che sono
all’interno della sua area di copertura.
- ogni receiver memorizza il tempo di arrivo del pacchetto utilizzando il suo
clock locale
- i ricevitori si scambiano i valori registrati relativi al tempo di arrivo dei
reference packet quindi, calcolano i parametri per sincronizzarsi con i clock
degli altri nodi.
Il protocollo TPSN è del tipo sender-receiver con scambio di messaggi del tipo two-way.
4

La sincronizzazione viene ottenuta creando prima la struttura gerarchica nella rete per
poter garantire così la scalabilità della stessa, seguita poi dalla procedura vera e propria di
sincronizzazione, che avviene attraverso scambi di messaggi contenenti il valore del clock del
nodo nell’istante di invio del messaggio.
Il protocollo FTSP è del tipo sender-receiver con scambio dei messaggi del tipo one-
way; la sincronizzazione si ottiene tramite l’invio da parte di un sender di 8 messaggi
contenenti il proprio valore del clock, i receiver memorizzano l’istante di tempo in cui
ricevono i messaggi dal sender, ed eseguono una stima del tempo globale attraverso una
regressione lineare dei tempi del sender e di quelli del receiver.
Capitolo 1: Le reti di sensori collaborative
1.1 Le reti di sensori
Lo sviluppo delle tecniche nel campo della microelettronica, le notevoli capacità di
integrazione raggiunte che consentono di realizzare su di uno stesso circuito integrato unità di
elaborazione sempre più complesse ed eterogenee hanno dato sempre maggiore impulso allo
sviluppo di reti di sensori Error: Reference source not found-Error: Reference source not
found.
D’altra parte la necessità crescente di misurare quantità fisiche in vaste aree geografiche, la
necessità di posizionare con grande flessibilità i sensori garantendo di effettuare misure
ovunque, anche in ambienti ostici e remoti, la necessità di effettuare anche misure su oggetti
in movimento, ha spinto la diffusione di reti di sensori wireless Error: Reference source not
5

found.
I sistemi di misura tradizionali sono caratterizzati da un numero limitato di sensori che
convergono in unità di elaborazione complesse in grado di raccogliere informazioni rilevate
dai sensori stessi e di compiere le necessarie elaborazioni.
Le reti di sensori senza fili WSN sono costituite da nodi che presentano le seguenti
caratteristiche:
Compattezza: i nodi hanno dimensioni ridotte che ne permettono il facile
posizionamento in base alle specifiche dell’applicazione.
Nessuna infrastruttura dedicata: la rete è basata su protocolli di comunicazione
sviluppati ad hoc di tipo peer to peer.
Alimentazione normalmente a batteria e basso consumo di energia.
Trasmissione su percorsi multipli del tipo multi hop.
Basso flow data rate.
Grande numero di nodi.
Sincronizzazione delle informazioni e delle misure.
1.1.1 La collaborazione dei nodi sensore
Sin dal passato, in questo settore ed a qualsiasi livello, il termine “collaborazione”, inteso
come cooperazione tra individui o dispositivi per il raggiungimento di un determinato
obiettivo, è stato sempre sinonimo di miglioramento ed efficienza.
Si pensi ad esempio all’ambito della ricerca in cui team di ricercatori collaborano tra loro
in modo sinergico per ottenere un migliore risultato con maggiore efficienza e maggiori
profitti.
Così anche la collaborazione tra macchine porta alla realizzazione del prodotto o al
raggiungimento dell’obiettivo con maggior efficienza.
Tale metodologia di lavoro ben si presta anche alle reti di sensori, in cui la collaborazione
tra i vari nodi porta numerosi vantaggi.
6

1.1.2
Figura 1.1: Esempio di rete di sensori wireless
7

1.1.3 Esempi di reti collaborative
La collaborazione tra i vari sensori può essere diversa a seconda della specifica
applicazione considerata.
Le reti di sensori collaborative hanno un vasto campo di applicazione; sono molto diffuse
per l’identificazione, la localizzazione e l’inseguimento di una o più sorgenti stazionarie o in
movimento in una determinata area; localizzazione di sorgenti di rumore tramite misura
dell’energia delle onde sonore rilevate dai sensori disseminati nell’area di interesse; per scopi
militari quali il tracciamento della traiettoria di oggetti in movimento; tracciamento di una
mappa delle condizioni ambientali di un’area tramite misure di tipo eterogeneo; monitoraggio
e previsione di eventi sismici ed eruzioni vulcaniche; monitoraggio della salute della struttura
di un edificio; misure elettriche quali: misura di fase, misura di potenza tramite metodo
indiretto, misura del fattore di potenza in un impianto industriale e più in generale misure per
il “power management”.
Non esistendo in letteratura una definizione unica di “reti di sensori collaborative”,
possiamo osservare nelle varie applicazioni diverse forme di collaborazione tra i nodi sensore
Error: Reference source not found. Ad esempio, un nodo attivato potrebbe svolgere il compito
di attivare un nodo adiacente per la gestione di una possibile ricezione di segnale ed
un’eventuale elaborazione; in tal modo anche altri nodi adiacenti si attivano e la misurazione
basata su più nodi risulta essere più precisa rispetto all’utilizzo di un solo nodo, ottenendo
così anche un risparmio energetico.
Un settore di applicazione che fa uso di questo tipo di collaborazione è sicuramente quello
in cui la rete di sensori è adibita all’individuazione di una sorgente di rumore in una
determinata area geografica, come in Figura 1.2.
È evidente che per individuare la posizione è necessario che le misurazioni effettuate siano
compiute nello stesso istante di tempo, altrimenti la rilevazione sarà palesemente falsata.
8

Nelle reti wireless alcuni nodi posizionati lontano dal nodo principale (sink), potrebbero
non essere in grado di comunicare direttamente con questo a causa della limitata potenza di
trasmissione a disposizione. Dunque i sensori collaborano tra di loro instaurando una rete
multi-hop. Lo scambio di informazioni avviene tramite il passaggio delle stesse dal nodo
sorgente a quello adiacente fino a raggiungere il nodo sink. Questo consente di superare nelle
reti di sensori wireless i limiti imposti dalla distanza tra i nodi, potendo distribuire così in
modo opportuno i vari sensori nella regione d’interesse, come in Figura 1.3.
Figura 1.2: Localizzazione sorgenti di rumore
9

La sincronizzazione può essere usata per schemi di risparmio energetico e per incrementare
la vita delle reti. Per esempio, i sensori possono essere in stato inattivo per un tempo
appropriato, e attivarsi quando necessario. Algoritmi di scheduling, come il TDMA, usati per
condividere il canale di trasmissione nel dominio del tempo, per eliminare le collisioni e
risparmiare energia, si basano sulla sincronizzazione.
1.2 Classificazione delle reti collaborative
La collaborazione tra i nodi della rete può essere suddivisa in tre forme:
Collaborazione tra sensori eterogenei: “Multimodal Fusion”;
Collaborazione tra sensori che prelevano le stesse informazioni dal campo: “Data
Sharing Technique”;
Collaborazione tra sensori che non prelevano le stesse informazioni dal campo:
“Confidence Boost Technique”.
Analizziamo più nel dettaglio tali tecniche.
Figura 1.3: Disseminazione dei nodi
10

1.2.1 Multimodal Fusion
Poiché i vari oggetti della misura hanno caratteristiche diverse che possono essere captate
sfruttando sensori eterogenei opportunamente distribuiti, questa tecnica permette di aggregare,
in modo ottimale, i dati forniti dai diversi nodi, migliorando la misura (classificazione)
effettuata.
L’idea di base è che ogni sensore fornisce informazioni diverse sull’oggetto della misura,
garantendo così, anche in situazioni difficili di forte interferenza, un risultato alquanto
affidabile.
Combinando, per esempio, dati sismici ed acustici, è possibile localizzare ed inseguire più
veicoli in movimento in una determinata area. Una stretta correlazione temporale permette
una precisa localizzazione dell’oggetto.
1.2.2 Data Sharing Technique
Nelle applicazioni, i dati che caratterizzano l’oggetto della misura, sono estrapolati e
immagazzinati dai sensori della rete. Naturalmente, se i sensori forniscono un’informazione
sufficiente, come la posizione dei nodi nella rete, allora sarà possibile specificare la
corrispondenza, intesa come relazione, tra i vari dati. Data la limitata capacità temporale di
misura di un determinato nodo sensore e i possibili fenomeni di interferenza, una migliore
caratterizzazione dell’oggetto di misura può essere fornita mediante una condivisione dei dati
da parte dei vari nodi che costituiscono la rete.
Si tratta di una tecnica di collaborazione che sfrutta i dati provenienti da sensori che
osservano l’oggetto di misura dal suo stesso punto di vista.
1.2.3 Confidence Boost Technique
Questa tecnica assume un’importanza particolare nel caso in cui ho più sensori che
osservano lo stesso oggetto di misura.
11

In questo caso, la rete non consente una misura “diretta” del particolare fenomeno
considerato, ma effettua una stima di esso. In altre parole, si fa un’ipotesi sul possibile
risultato della misura e poi, si cerca di avallarla o meglio, di aumentarne il livello di
confidenza, grazie ad una stretta collaborazione tra i vari nodi della rete.
Per comprendere meglio come i sensori di una rete utilizzano le sopraccitate forme di
collaborazione per effettuare una determinata misura, non c’è niente di più opportuno che
andare ad analizzare, nella letteratura scientifica, le diverse applicazioni che ne fanno uso.
1.3 Applicazioni
L’importanza delle reti di sensori collaborative è sottolineata anche dal gran numero di
applicazioni presenti in letteratura. Analizzeremo dunque, alcuni di questi lavori, mettendone
in evidenza gli aspetti collaborativi.
1.3.1 Applicazioni ambientali
Il monitoraggio di fenomeni ambientali è sicuramente uno dei campi in cui le reti di
sensori collaborative hanno avuto un enorme successo.
In Error: Reference source not found gli autori descrivono una applicazione che consente,
attraverso la collaborazione di sensori di pressione e temperatura di determinare il livello e la
temperatura dell’acqua per cercare di prevedere eventuali terremoti.
La collaborazione è di tipo “multimodal fusion” ed avviene a livello del “data
concentrator” in cui appunto arrivano i dati forniti dai diversi sensori. In questa applicazione
lo scopo principale è sicuramente quello di avere un efficiente sistema di previsione dei
terremoti. È per questo motivo che la collaborazione tra i diversi sensori diventa
fondamentale. Infatti, sarebbe impossibile pensare di poter prevedere un terremoto senza una
razionale fusione dei dati acquisiti dai diversi nodi sensore, le cui misurazioni vengono
effettuare riferendosi a un comune e più preciso possibile riferimento temporale.
12

In Error: Reference source not found, gli autori affrontano un importante problema
ambientale. Infatti, in questo lavoro, viene descritta una rete di sensori wireless utilizzata per
il monitoraggio delle eruzioni vulcaniche, vedi Figura 1.4. A tale fine, vengono utilizzati dei
sensori acustici a bassa frequenza (102 Hz) detti infrasonici.
Questi array di sensori sono usati per identificare e localizzare eventuali scosse o
esplosioni, studiare la struttura interna del vulcano e differenziare eruzioni reali dal rumore di
altri segnali.
Questa rete, mostrata in Figura 1.5 è stata applicata ad un vulcano dell’Ecuador ed è costituita
da:
tre nodi acusici a bassa frequenza;
un nodo di aggregazione dei dati;
un nodo ricevitore GPS, usato per garantire la sincronizzazione tra i vari nodi
infrasonici;
una stazione wired finale per la raccolta dei dati.
I sensori infrasonici prelevano segnali acustici a bassa frequenza (fino a 50 Hz), trasmettono
Figura 1.4: Array di sensori per il monitoraggio di un vulcano
13

questi dati al nodo di aggregazione che trasmette il tutto su un link wireless di circa 10 Km ad
una stazione base wired dove i dati provenienti dall’array di sensori vengono immagazzinati,
visualizzati ed elaborati in tempo reale.
Per stabilire una base dei tempi comune per i segnali acquisiti dai vari sensori viene
introdotto un nodo ricevitore GPS che riceve un GPS time signal e trasmette via radio i dati ai
sensori infrasonici ed al nodo aggregatore.
In tale scenario un algoritmo di sincronizzazione performante potrebbe sostituire il
ricevitore GPS.
Anche se in questo lavoro si parla in particolare di nodi infrasonici, in realtà,
un’applicazione di questo tipo, richiede la collaborazione di sensori di diversa natura per poter
monitorare in modo ottimale il comportamento del vulcano. Poiché dunque, è necessario un
nodo accentratore che raccolga ed elabori unitamente i dati acquisiti dai diversi sensori, anche
in questo caso, abbiamo una rete collaborativa di tipo “multimodal fusion”.
1.3.2 Applicazioni militari o di sorveglianza
Le reti di sensori collaborative sono molto utilizzate anzi, spesso insostituibili, nel campo
militare o più in generale nel settore della sorveglianza. Diverse sono le possibili applicazioni:
monitoraggio del traffico o dei veicoli in un campo di battaglia, rilevamento ed inseguimento
di persone in una determinata area, ecc…
Figura 1.5: Architettura di misura per il monitoraggio del vulcano dell'Ecuador
14

In Error: Reference source not found, Donal McErlean ed altri affrontano un tipico
problema di carattere militare.
In questo lavoro viene sviluppata una struttura che consenta l’utilizzo di una rete di sensori
distribuiti wireless per il rilevamento e l’inseguimento di oggetti in movimento.
L’idea di base è quella di utilizzare un approccio di tipo decentralizzato, in modo da avere,
elaborando i dati all’interno della rete, un quadro di ciò che sta accadendo localmente prima
di riportare i risultati all’unità centrale. In tutto questo è di fondamentale importanza la
collaborazione tra i vari nodi della rete che dunque, consente di ridurre il numero di “falso
allarme” ed evita l’invio di tutti i dati rilevati dai sensori ad un’unità centrale di elaborazione.
La maggiore difficoltà consiste nell’elaborare i dati acquisiti dai vari sensori in modo
intelligente cercando di ridurre il più possibile il consumo di energia.
La collaborazione tra i nodi avviene cercando se e come i dati provenienti da diversi
sensori sono relazionati tra di loro e sfruttando poi queste osservazioni per stimare in modo
opportuno l’esistenza, la posizione ed il tipo di oggetto rilevato. Come osservato
precedentemente anche in questo scenario è di massima rilevanza la sincronizzazione
temporale.
La rete di sensori è costituita da vari nodi dispersi in una data zona da monitorare. Quando
un oggetto passa in tale zona viene immediatamente rilevato dalla rete. Naturalmente si
possono creare anche delle situazioni di falso allarme legate per esempio al passaggio di
oggetti non di interesse o ad errori di rilevamento. E’ qui che la collaborazione tra i vari
sensori della rete è importante: infatti, prima di avvisare l’unità centrale del rilevamento
effettuato, sprecando energia per la trasmissione, all’interno della rete, un opportuno
algoritmo che sfrutta la cooperazione tra i sensori o meglio, i dati da essi forniti, verifica la
veridicità dell’evento rilevato ed in caso positivo invia il dato all’unità centrale. Questo
dunque consente anche un grosso risparmio di energia.
15

Un’altra applicazione per la localizzazione di un oggetto in movimento è sviluppata in
Error: Reference source not found da Yu Hen Hu e Dan Li.
In questo lavoro è presentato un nuovo metodo per la localizzazione di sorgenti di rumore
(veicoli o persone in movimento) in una rete di sensori, basato su misure dell’energia acustica
associata a tali segnali. Questo metodo fa leva sulla proprietà dell’energia acustica che decade
esponenzialmente con la distanza dalla sorgente.
In questa applicazione si utilizzano sensori acustici localizzati in un’area da sorvegliare e,
solo grazie ad una analisi globale dei dati provenienti da tutti i sensori, è possibile localizzare
la sorgente di rumore e dunque il target desiderato. La comunicazione tra questi sensori
inoltre, è di tipo wireless. Si può dunque, parlare di rete collaborativa visto che l'insieme dei
dati, provenienti da sensori localizzati in posti diversi, sono tutti utili per effettuare la misura
che si desidera.
1.3.3 Applicazioni per analisi strutturale
In Error: Reference source not found, gli autori mettono in evidenza l’importanza di
monitorare la salute strutturale di edifici, ponti, ecc… in modo da poter prevedere eventuali
danni in caso di terremoti.
In passato questo monitoraggio veniva effettuato mediante dei sensori opportunamente
Figura 1.6: Rilevamento e inseguimento posizione oggetti
16

posizionati nella struttura da monitorare e collegati con un cavo al nodo finale (sink).
Tutto questo richiedeva enormi difficoltà di installazione della rete di sensori nonché costi
elevatissimi. Attualmente invece, si utilizza una comunicazione wireless che permette dunque,
di posizionare i vari sensori della rete in qualsiasi punto della struttura per monitorarne meglio
le eventuali vibrazioni. Questa rete è costituita da sensori di spostamento, estensimetri ed
accelerometri distribuiti nella struttura e che comunicano in modo wireless con il nodo sink
che poi provvede ad inviare i dati forniti, opportunamente compressi, alla stazione di
controllo. In questa applicazione c’è una forte collaborazione tra i vari nodi: infatti, per
ridurre il consumo di energia in fase di trasmissione viene utilizzato un approccio di tipo
”multi-hop“. Ogni sensore effettua la misura ed invia i dati “hop by hop” attraverso i nodi
vicini al nodo sink. Questo, come precedentemente accennato riduce il consumo di energia e
soprattutto permette ai vari sensori di non essere limitati ad essere posizionati vicino al nodo
sink per mantenersi nel range di ricezione della stazione di controllo. L’esistenza di una
sincronizzazione temporale tra i nodi permette di costruire una mappa attendibile di come
siano distribuire e si propaghino le sollecitazioni.
Figura 1.7: Analisi salute strutturale di ponti
1.4 La sincronizzazione temporale
Il largo impiego delle reti di sensori collaborative in molti campi applicativi sottolinea
17

l’importanza che questa tecnologia sta assumendo.
Alcune applicazioni, come quelle che consentono la localizzazione di un determinato
oggetto in movimento, addirittura non possono prescindere da una stretta collaborazione tra i
vari sensori o meglio, da un’analisi globale di tutti i dati da essi forniti.
La collaborazione in una rete di sensori è sinonimo di efficienza e, dunque, ottimizzazione
della misura effettuata Error: Reference source not found.
I principali vantaggi di una cooperazione tra i nodi sensori sono:
Aumento del tempo di vita della rete grazie ad una riduzione del consumo di
energia;
Riduzione della quantità di dati da trasmettere;
Sfruttamento ottimale della banda disponibile;
Possibilità di aumentare la distanza dai nodi periferici al nodo sink (multi-hop).
In ciascuno degli scenari accennati ed in molti altri casi ancora è essenziale che la
collaborazione tra i vari nodi avvenga basandosi su un “ filo comune”:
la sincronizzazione temporale nell’effettuazione delle misurazioni.
Nell’ambito delle misure elettroniche la sincronizzazione deve garantire il determinismo
temporale della misurazione pertanto si deve essere sicuri che avvenga al verificarsi di un
determinato evento di trigger e la precisione della sincronizzazione rispetto un clock master
deve essere caratterizzata da una tolleranza nota e fissa.
Come esempio si prenda in considerazione la misura di potenza istantanea, ovvero,
misurare la potenza che un ramo del circuito dissipa avendo a disposizione un voltmetro ed un
amperometro a valore istantaneo, per le misure di tensione e corrente di quel ramo.
Allora appare evidente che se questi due strumenti compiono le misure nello stesso istante
temporale il valore di potenza che ne risulterà sarà attendibile altrimenti, se gli strumenti
concludono le misure in istanti differenti, non si può asserire che la potenza calcolata sia
quella corretta.
18

In realtà, la possibilità di avere clock perfettamente sincroni è un aspetto puramente ideale
visto che si potrà presentare un offset fra un clock e l’altro.
Per questo motivo i protocolli di sincronizzazione adoperati per questi scopi vengono
classificati come algoritmi di precisione in cui l’offset massimo che si registra è molto
piccolo.
Sebbene l’utilizzo di un sistema wireless offre sicuramente una serie di benefici, la
contemporaneità delle misure pone dei limiti stringenti. Uno dei grossi vantaggi offerti da un
sistema wired è quando si invia un segnale, ad esempio un segnale di “ trigger”, si è sicuri
che viene ricevuto da tutti gli strumenti nello stesso istante temporale, a meno dell’inerzia
insita nel bus. Questa certezza viene persa dai sistemi di interfaccia wireless e le latenze
introdotte sono aleatorie, quindi non stimabili a priori.
È evidente che le reti di sensori collaborative hanno come vantaggio migliori prestazioni e
una riduzione del consumo energetico, ma in molti casi non possono prescindere dalla
necessità di sincronizzazione di tutti nodi della rete; infatti, nei casi precedentemente illustrati
è di fondamentale importanza che le misurazioni effettuate e quindi i dati raccolti siano
strettamente correlati tra di loro nel dominio del tempo. Tale stringente esigenza, e quindi
l'impiego di tali protocolli, implica un surplus computazionale a carico della rete per garantire
la contemporaneità delle misure. Per cui l'analisi dei vari protocolli presi di seguito in esame
deve tener conto di tale aspetto.
19

1.5 Bus di comunicazione wireless
I bus di comunicazione presi in considerazione per l’utilizzo con protocolli di
sincronizzazione sono il Wi-Fi, il Bluetooth e il ZigBee.
1.5.1 Wi-Fi o IEEE 802.11
Le reti Wi-Fi sono infrastrutture relativamente economiche e di veloce attivazione che
permettono di realizzare sistemi flessibili per la trasmissione di dati usando frequenze radio,
estendendo o collegando reti esistenti o creandone di nuove.
Lo standard che regolamenta tali reti è il IEEE 802.11 Error: Reference source not found;
nello standard originale si focalizza l'attenzione su tre distinti livelli fisici (Infrarosso -
Trasmissione radio con modulazione FHSS1 - Trasmissione radio con modulazione DSSS2) e
il livello MAC.
Figura 1.8: Esempio di rete Wi-Fi
Una rete wireless può essere un'estensione di una normale rete cablata, supportando tramite
1 FHSS Frequency Hopping Spread Spectrum
2 DSSS Direct Sequence Spread Spectrum
20

un access point, la connessione a dispositivi mobili o palmari predisposti, e a dispositivi fissi
(pc con scheda wireless interfacciata via PCI o recentemente via USB).
In generale le architetture per sistemi wireless sono basate su due tipologie di dispositivi :
- Access Point (AP)
- Wireless Terminal (WT)
Gli access point sono bridge che collegano la sottorete wireless con quella cablata, mentre
i wireless terminal sono dei dispostivi che usufruiscono dei servizi di rete. Gli AP possono
essere implementati sia in hardware (esistono dei dispositivi dedicati) che in software
appoggiandosi per esempio ad un pc, o notebook dotato sia dell’interfaccia wireless sia di una
scheda ethernet. Gli AP sono equipaggiati con antenne omnidirezionali o direzionali che
consentono di aumentarne la loro portata. Esistono inoltre soluzione integrate con AP + router
facilitando così le implementazioni di reti ibride wireless (WLAN) e wired (LAN).
I WT possono essere qualsiasi tipo di dispositivo come per esempio notebook, palmari,
pda, cellulari, o apparecchiature che interfacciano lo standard IEEE 802.11.
Le modalità di interconnessione sono due:
Ad-hoc Mode: indica l'impostazione nelle reti wireless dei terminali in modo da poter
comunicare direttamente tra loro senza l'utilizzo di un Access Point (AP).
Infrastructure Mode: nella modalità infrastruttura, invece i terminali comunicano tra
loro tramite un AP.
IEEE 802.11 usa come protocollo MAC il CSMA/CA (Carrier Sense Multiple Access /
Collision Avoidance), che utilizza un algoritmo specifico per evitare collisioni,
implementando un meccanismo di ascolto virtuale del traffico sulla portante. L' AP assegna
una priorità ad ogni client, in modo da rendere più efficiente la trasmissione dei pacchetti.
Lo standard IEEE 802.11 consente due possibili interfacce RF, della categoria SSS, nella
banda dei 2,4 MHz, realizzate con due tecniche di modulazione distinte :
- FHSS, dispersione di spettro a salto di frequenza
21

- DSSS, dispersione di spettro in banda base
La versione base propone l'uso della banda di frequenze dei 2.4GHz, la cosiddetta ISM
(Industrial, Scientific and Medical band) che è disponibile a libero uso dei privati, senza la
necessità di ottenere concessioni da parte degli enti pubblici. Lo standard 802.11a permette un
throughput massimo di 54 Mbps ad una frequenza di lavoro di 5,2 GHz. A causa dell'elevata
frequenza usata, vengono richiesti un maggior numero di AP rispetto allo standard 802.11b.
Nella seconda estensione, la 802.11b, abbiamo invece un throughput massimo di 11 Mbps,
100 metri di distanza , utilizzo della banda ISM a 2.4 GHz, con tecniche di modulazione
quali:
- DBPSK (Differential Binary Phase Shift Keying) per velocità da 1 Mbps
- DQPSK (Differential Quaternary Phase Shift Keying) per velocità da 2 Mbps
- QPSK/CCK (Quaternary Phase Shift Keying with Complementary Code Keying)
per velocità comprese tra 5,5 e 11 Mbps.
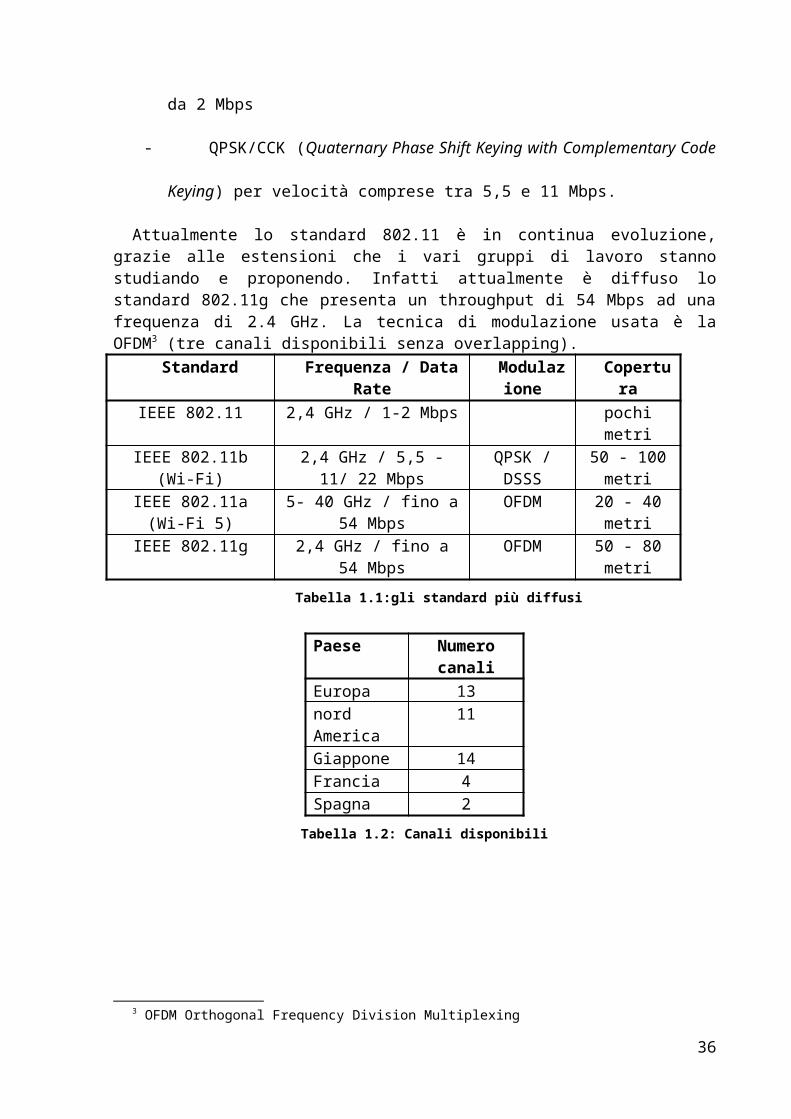
Attualmente lo standard 802.11 è in continua evoluzione, grazie alle estensioni che i vari gruppi di lavoro stanno studiando e proponendo. Infatti attualmente è diffuso lo standard 802.11g che presenta un throughput di 54 Mbps ad una frequenza di 2.4 GHz. La tecnica di modulazione usata è la OFDM3 (tre canali disponibili senza overlapping).
Standard Frequenza / Data Rate Modulazione
Copertura
IEEE 802.11 2,4 GHz / 1-2 Mbps pochi metriIEEE 802.11b (Wi-Fi) 2,4 GHz / 5,5 - 11/ 22 Mbps QPSK / DSSS 50 - 100 metri
IEEE 802.11a (Wi-Fi 5) 5- 40 GHz / fino a 54 Mbps OFDM 20 - 40 metriIEEE 802.11g 2,4 GHz / fino a 54 Mbps OFDM 50 - 80 metri
Tabella 1.1:gli standard più diffusi
Paese Numero canaliEuropa 13nord America 11Giappone 14Francia 4Spagna 2
Tabella 1.2: Canali disponibili
3 OFDM Orthogonal Frequency Division Multiplexing
22

1.5.2 Bluetooth o IEEE 802.15.1
Bluetooth è uno standard globale per comunicazioni wireless basato su un sistema radio a
basso costo e a corto raggio d’azione. Questa tecnologia facilita il rimpiazzo dei cavi di
collegamento tra dispositivi, quali stampanti, computer portatili, computer fissi, PDA, fax,
tastiere, joystick, mouse, e tutti questi dispositivi possono far parte di un sistema Bluetooth.
Oltre a sostituire i cavi, Bluetooth può anche agire da collegamento verso reti preesistenti,
agire da bridge, oppure può essere visto come un sistema per realizzare piccole reti ad hoc
quando ci si trova lontano da altre infrastrutture di rete. Lo standard IEEE 802.15.1 Error:
Reference source not found contiene una serie di specifiche che definiscono i vari livelli del
protocollo stesso. Una caratteristica peculiare delle specifiche Bluetooth consiste nel fatto che
esso non definisce solo un’interfaccia radio ma un intero stack software che permette ai
dispositivi di trovarsi a vicenda, scoprire quali servizi essi offrano e quindi usare tali servizi. Il
protocollo Bluetooth è organizzato a livelli, anche se alcune funzioni che esso offre sono
distribuite su più di un livello. La sezione radio è una parte fondamentale di un dispositivo
Bluetooth. I dispositivi Bluetooth operano nella banda ISM 2.4 GHz, che non richiede la
licenza delle frequenze utilizzate ma, e, proprio per questo, i dispositivi Bluetooth devono
essere molto tolleranti rispetto alle interferenze presenti. In USA e nella maggior parte
dell’Europa sono disponibili 83.5 MHz; in questa banda vengono allocati 79 canali RF
spaziati di 1 MHz. In Giappone, Francia e Spagna sono disponibili solo 23 canali RF sempre
spaziati di 1 MHz.
Localizzazione
Limiti di banda Canali RF
Usa e Europa
2.4000 – 2.4835 GHz
f=2402+k MHz, k=0,…,78
Francia 2.4465 - 2.4835 GHz
f=2454+k MHz, k=0,…,22
Spagna 2.4450 – 2.4750 GHz
f=2449+k MHz, k=0,…,22
Giappone 2.4710 – 2.4970 GHz
f=2473+k MHz, k=0,…,22
23

Tabella 1.3: Bande di frequenza Bluetooth
Bluetooth adotta la tecnica frequency hopping spread spectrum, quindi il canale fisico è
rappresentato da una sequenza pseudo casuale di 79 o 23 canali RF; i dispositivi progettati per
operare in paesi con un insieme ridotto di frequenze di hopping, non possono funzionare nei
paesi in cui sono disponibili tutti i canali RF previsti per la banda ISM 2.4 GHz, né viceversa.
La velocità di segnalazione è di 1Msimbolo/s e questo si traduce in una velocità di
trasferimento teorica di 1 Mbit/s poiché è stato scelto come schema di modulazione il GFSK4.
Il canale fisico è diviso in slot da 625µs, ed i dispositivi cambiano frequenza di trasmissione
prima di inviare ogni pacchetto; un pacchetto può durare uno, tre oppure cinque slot.
Figura 1.9: Slot Bluetooth
I dispositivi Bluetooth possono operare in due diverse modalità :
- Master
4 Gaussian shaped Frequency Shift Keying
24

- Slave
Questo non vuol dire che, a livello circuitale e costruttivo, vi siano delle differenze tra un
dispositivo che opera come master e uno che opera come slave. E’ il master che decide la
sequenza di hopping, gli slave che vogliono comunicare con un certo master devono
sincronizzarsi in frequenza e tempo con la sequenza di hopping del master. Una serie di slave
che operano insieme e sono sincronizzati con uno stesso master formano una cosiddetta
Piconet.
Figura 1.9: Struttura di una piconet
Una piconet può essere formata da un master ed un massimo di sette slave attivi, dove per
slave attivo si intende un’unità che rimane sincronizzata al master della piconet. Lo standard
Bluetooth prevede comunque, una modalità di funzionamento per i dispositivi (modalità park)
che permette di ampliare "virtualmente" la dimensione di una piconet, nel senso che alcuni
dispositivi, essenzialmente per limitare il consumo delle batterie, potranno dissociarsi
temporaneamente dall’attività della piconet, ma rimanere informati periodicamente dal master
in modo da poter rientrare attivamente nella piconet in qualsiasi momento, purché ovviamente
ci sia posto.
Oltre a controllare la sequenza di hopping, il master è il vero dominatore del mezzo
trasmissivo, nel senso che esso decide quando i dispositivi che fanno parte della propria
piconet possono trasmettere. Bluetooth distingue a questo proposito due tipi di traffico:
25

- Voce
- Dati
Il master decide quando gli slave possono trasmettere allocando degli slot per il traffico
voice e degli slot per il traffico dati. Per il traffico dati, uno slave può trasmettere solo in
risposta ad una trasmissione del master ad esso indirizzata, ovvero se il master durante uno
slot riservato al traffico data ha trasmesso un pacchetto indirizzato verso uno specifico slave,
il successivo slot è allocato automaticamente per una eventuale trasmissione di dati da parte
unicamente di quel particolare slave, a prescindere se esso abbia o non abbia effettivamente
dati da trasmettere. Per il traffico voce invece, gli slave trasmettono in slot riservati dal
master, a prescindere se siano stati destinatari di una precedente trasmissione oppure no. In
ogni caso, la comunicazione avviene sempre tra il master e uno slave, cosicché se uno slave
dovesse trasmettere un pacchetto ad un altro slave nella stessa piconet, tale pacchetto
dovrebbe comunque passare attraverso il master. Questo sistema di divisione degli slot
temporali fra 2 dispositivi si chiama Time Division Duplex (TDD). Abbiamo visto come il
numero degli slave attivi che compongono una piconet sia limitato a sette. Si può comunque
realizzare un’area di copertura più ampia (realizzando così una rete più grande) collegando
insieme più piconet, a formare quella che Bluetooth definisce Scatternet.
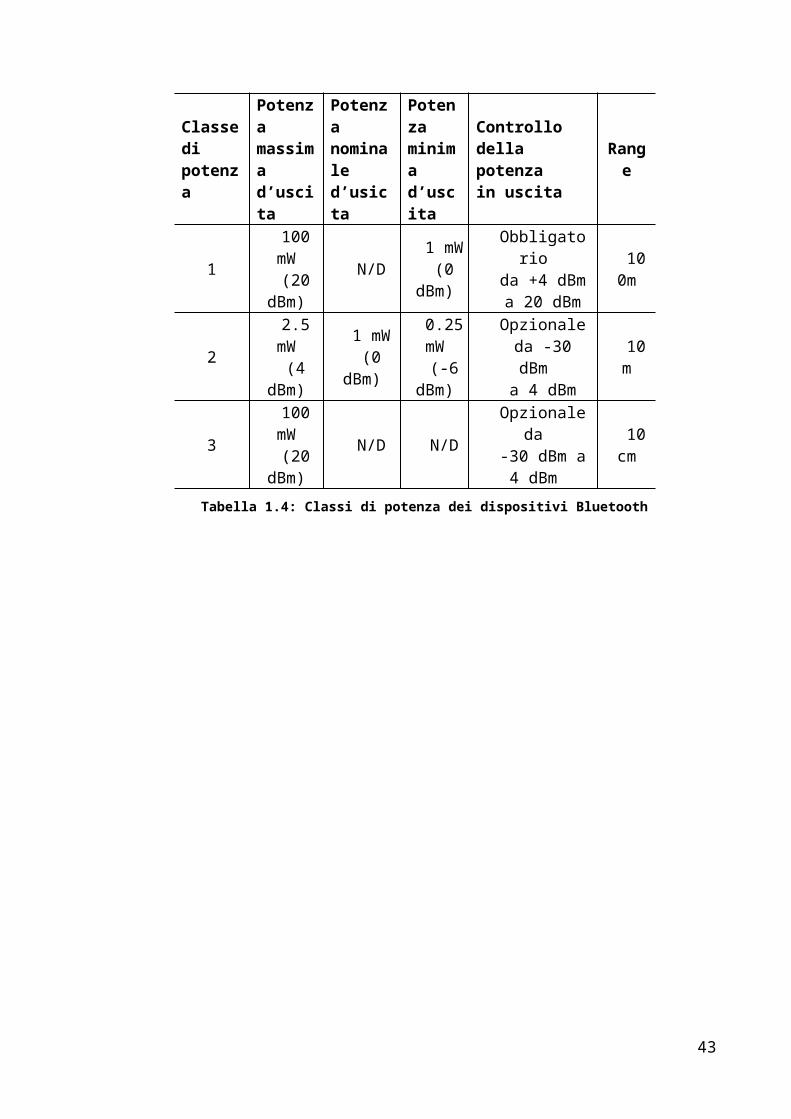
I dispositivi Bluetooth vengono divisi in 3 classi di potenza, a seconda della potenza
massima d’uscita del trasmettitore.
Classe di potenza
Potenzamassima d’uscita
Potenzanominale d’usicta
Potenzaminima d’uscita
Controllodella potenzain uscita
Range
1
100 mW
(20 dBm)
N/D1 mW
(0 dBm)
Obbligatorio da +4 dBm a 20 dBm
100m
2
2.5 mW
(4 dBm)
1 mW(0 dBm)
0.25 mW
(-6 dBm)
Opzionale da -30 dBm
a 4 dBm
10 m
26

3
100 mW
(20 dBm)
N/D N/DOpzionale da -30 dBm a 4
dBm
10cm
Tabella 1.4: Classi di potenza dei dispositivi Bluetooth
27

Capitolo 2: Protocolli di sincronizzazione
Di seguito verranno analizzati i principali algoritmi di sincronizzazione presenti in
letteratura.
2.1 La sincronizzazione
Per affrontare correttamente il problema della sincronizzazione di una rete di sensori
wireless, bisogna prima analizzare la questione in termini generali, spiegando le
caratteristiche che distinguono i vari tipi di protocolli ed in seguito è necessario esaminare
approfonditamente i protocolli di maggior interesse.
La sincronizzazione temporale è un aspetto molto importante nelle reti di sensori. A
differenza del caso di bus wired, per cui questo problema è stato ampliamente affrontato e
risolto, utilizzando linee di trigger aggiuntive, nei bus wireless esso è ancora oggetto di studio
e non sono state trovate finora soluzioni definitive. Come già detto, molte applicazioni che
utilizzano bus wireless necessitano che i clock locali dei singoli nodi siano sincronizzati,
richiedendo vari gradi di precisione.
Nei sistemi distribuiti, così come in una rete di sensori wireless, non c’è un clock globale o
una memoria comune. Ogni dispositivo ha il proprio clock e la propria nozione di tempo [1].
Questo fa sì che i vari clock possano facilmente discostarsi tra loro di alcuni secondi al
giorno, accumulando così un errore significativo nel tempo. Questa deriva dei clock è dovuta
al fatto che gli oscillatori hardware, sui quali si basano i clock, oscillano a frequenze
leggermente diverse tra di loro e a volte variano anche nel tempo a causa di fattori ambientali.
28

Pertanto, i vari clock non possono rimanere sincronizzati tra di loro per sempre.
Possiamo fare un’approssimazione delle caratteristiche principali di un oscillatore, le quali
vengono riportate di seguito [4]:
Accuracy: è la coerenza tra la frequenza nominale dell’oscillatore e la frequenza
effettiva. La differenza è il frequency error; il suo massimo è solitamente
specificato dal produttore. Gli oscillatori a cristallo, che si trovano nella maggior
parte degli apparecchi elettronici di consumo, hanno un’accuratezza che va da 100
ppm5 fino a 1 ppm.
Stabilità: è la tendenza dell’oscillatore a mantenere la stessa frequenza durante un
periodo di tempo. La stabilità della frequenza può essere suddivisa in stabilità di
breve periodo o di lungo periodo. La stabilità di breve periodo è dovuta
principalmente ai fattori ambientali, come variazioni di temperatura, tensione di
alimentazione e shock. La stabilità di lungo periodo è data, invece, da effetti più
sottili come l’invecchiamento dell’oscillatore.
La sincronizzazione diventa un problema importante e inevitabile che, tuttavia, potrebbe
essere risolto facilmente aggiungendo dei moduli GPS. Questa soluzione però presenta dei
limiti dovuti al fatto che un dispositivo GPS è troppo costoso per essere utilizzato con
dispositivi di misura economici, per esempio in una rete di sensori; il segnale potrebbe essere
non sempre disponibile dovunque, ad esempio all' interno di edifici o sott’ acqua. Inoltre i
dispositivi GPS comportano un elevato consumo di energia: i nodi sensori sono alimentati da
batterie e a volte sono disposti in punti difficilmente accessibili, quindi si auspica che la
batteria duri il più possibile. In ultimo rimane ancora da sottolineare che il GPS presenta
tempi di start-up dell’ordine del minuto.
La soluzione alternativa è data dall’utilizzo di protocolli software senza quindi la necessità
di aggiungere altro hardware.
Alcune proprietà intrinseche delle reti di sensori, come le risorse limitate di energia, di
5 ppm = parti per milione
29

memorizzazione, di calcolo e di larghezza di banda, combinate con un'alta densità dei nodi,
fanno sì che i metodi di sincronizzazione tradizionali non siano adatti per queste reti.
2.1.1 Il modello del clock
Come precedentemente spiegato, i dispositivi con capacità computazionali sono
equipaggiati con un computer clock che si basa su un oscillatore hardware.
Il computer clock implementa una funzione C(t) che approssima il tempo reale t. La
frequenza angolare dell’oscillatore hardware determina il tasso al quale il clock scorre. Il
tasso di un clock perfetto, che può essere scritto come , dovrebbe essere uguale ad 1,
invece a causa della variazione della frequenza dell’oscillatore, tutti i clock sono soggetti a
una deriva del clock (clock drift). Anche se la frequenza di un clock cambia durante il tempo
(a causa dei fattori prima enunciati), esso può essere approssimato bene da un oscillatore con
frequenza fissata. Quindi per un nodo i, si può approssimare il suo clock locale come [3]:
Equazione 2.1
Dove è il clock drift, e è l’offset del nodo del clock i rispetto ad un riferimento
globale ( in realtà anche e sono funzioni del tempo quindi andrebbe scritto e ,
però, per semplicità, si considerano non dipendenti dal tempo; ovviamente questa
semplificazione è valida solo se l’intervallo di tempo che si considera è breve, e cioè se
vengono eseguite spesso delle risincronizzazioni, come normalmente accade). Il drift è il tasso
(frequenza) del clock, mentre l’offset è la differenza tra il tempo locale del clock e il tempo
reale t. Usando sempre lo stesso modello del clock si possono comparare i clock di due nodi
in una rete, infatti dato il nodo 1 e il nodo 2 si ha [3] :
30

Equazione 2.1
dove è il relative drift (deriva relativa) tra il clock del nodo 1 e quello del nodo 2, e
è il relative offset tra i medesimi clock. Se i due clock fossero perfettamente sincronizzati
allora si avrebbe un relative drift uguale ad 1, il che significa che i due clock hanno la stessa
frequenza, quindi non divergono nel tempo; inoltre si avrebbe un relative offset uguale a 0, il
che significa che i due clock hanno lo stesso valore in t=0. Alcuni studi in letteratura usano lo
skew al posto del drift, lo skew è definito come la differenza tra le frequenze dei due clock,
invece del rapporto. Anche l’offset a volte è menzionato come phase offset.
2.1.2 I tipi di sincronizzazione
Il problema della sincronizzazione in una rete di n dispositivi corrisponde al problema di
uniformare i clock dei differenti dispositivi. La sincronizzazione può essere sia globale (si
cerca di eguagliare per tutti i vari dispositivi) o può essere locale (si cerca di eguagliare
solo per un set di nodi, solitamente quelli che sono spazialmente vicini tra di loro).
Correggere solo l’offset non è sufficiente per la sincronizzazione perchè in questo modo i
clock, dopo poco tempo, divergeranno e quindi saranno necessarie più sincronizzazioni anche
all’interno di un piccolo intervallo temporale. Molti schemi di sincronizzazione, per evitare
questo, correggono sia il drift sia l’offset. La definizione data fino ad ora, però, definisce la
forma più stringente di sincronizzazione.
In generale il problema della sincronizzazione può essere classificato in tre tipi [3]:
La prima è la più semplice forma di sincronizzazione e si occupa solo di dare un
ordine agli eventi. L’obiettivo di tale algoritmo è di essere capace di dire se un
evento è avvenuto prima o dopo un altro evento .
La seconda forma di sincronizzazione si basa sui clock relativi: ogni nodo ha il
proprio clock locale che conteggia il tempo in maniera indipendente e quindi ogni
31

nodo ha una nozione propria del tempo, ma ogni nodo mantiene le informazioni
circa il relative drift e il relative offset tra il proprio clock e i clock di tutti gli altri
clock dei nodi della rete, cosicchè in ogni istante il tempo locale del nodo può
essere convertito nel tempo locale degli altri nodi della rete.
La terza è la più complessa forma di sincronizzazione: il modello con scala dei
tempi globale, cioè i clock di tutti i nodi della rete hanno tutti lo stesso valore che è
dato dal clock di riferimento. Qui non c’è una nozione di tempo locale da mettere in
relazione con altre nozioni di tempo locali, ma c’è una nozione di tempo globale,
data da un clock di riferimento, che tutti condividono.
2.1.3 Classificazione dei protocolli di sincronizzazione
Le reti di sensori possono essere applicate a una grande varietà di applicazioni quindi un
solo protocollo di sincronizzazione non basta, ma esistono vari tipi di protocollo che si
adattano più o meno bene ad una data applicazione. I vari protocolli si possono classificare in
base a varie caratteristiche; si elencano di seguito le più importanti [1]:
a) Sincronizzazione Master-Slave o Sincronizzazione Peer-to-Peer:
Master-Slave: Un protocollo master-slave assegna ad un nodo il ruolo di
master e ad un altro nodo quello di slave. Il nodo slave considera come
tempo di riferimento quello del clock locale del master e cerca di
sincronizzarsi con esso. In genere, il nodo master richiede risorse
computazionali proporzionali al numero di slave; si scelgono, quindi, nodi
master con processori molto performanti o con carichi di lavoro minori.
Peer-to-Peer: Tutti i nodi possono comunicare direttamente con tutti gli altri
nodi della rete. Questo elimina il rischio di guasto del nodo master, che
potrebbe impedire ulteriori sincronizzazioni. La configurazione peer-to-peer
offre più flessibilità ma è anche più difficile da controllare.
b) Correzione del clock o clock indipendente:
32

Correzione del clock: Molti protocolli eseguono la correzione del clock locale
di ogni nodo, per fare in modo che dia lo stesso valore di quello scelto come
clock di riferimento, creando così una scala dei tempi globali. La correzione
può essere fatta sia in modo istantaneo sia in modo continuativo.
Clock indipendente: La correzione dei clock di ogni nodo non è una cosa
indispensabile per la sincronizzazione. Il protocollo RBS, per esempio,
costruisce una tabella dei parametri che mettono in relazione i clock locali di
ogni nodo tra di loro. I timestamp locali sono comparati usando la tabella.
Quando i timestamp sono scambiati tra i nodi sono trasformati nel valore del
clock locale del nodo ricevente. In questo modo è stata creata una scala dei
tempi globali, lasciando i clock locali indipendenti tra di loro, ed il fatto di
non dover correggere continuamente i clock fa risparmiare una considerevole
quantità di energia.
c) Sincronizzazione interna o Sincronizzazione esterna:
Sincronizzazione interna: In questo approccio non viene fornita una
sorgente esterna universale del tempo e, quindi, l’obiettivo è solo di
minimizzare la differenza tra i valori dei clock locali dei sensori.
Sincronizzazione esterna: In questo approccio è fornita una sorgente esterna
universale del tempo come l’ Universal Time Coordination (UTC6). Il clock
di riferimento diventa proprio l’UTC e tutti i clock locali si sincronizzano a
questo tempo di riferimento. Il protocollo NTP (protocollo di
sincronizzazione di internet) per esempio funziona in questo modo. Tuttavia,
molti protocolli nelle reti di sensori non implementano questa caratteristica di
sincronizzazione se non è necessaria per l’applicazione, questo perché di
6 Universal Time Coordination: è il più usato come riferimento temporale in applicazioni civili. Il riferimento
temporale è ottenuto come media pesata di oltre 200 clock atomici collocati in oltre 50 laboratori nazionali. Esso
viene calcolato dal BIPM, Bureau International des Poids et Misures, in Francia.
33

solito questo modello richiede un consumo di energia maggiore e nelle reti di
sensori il consumo di energia è un requisito critico.
d) Sincronizzazione Sender-to-Receiver o Sincronizzazione Receiver-to-
Receiver: Molti metodi esistenti sincronizzano un sender con un receiver
trasmettendo il valore corrente del proprio clock, in questo modo però la
sincronizzazione è affetta da un errore dovuto al tempo non deterministico che ci
impiega il messaggio per andare dal sender al receiver. Questo tempo è
chiamato time-critical path . Tuttavia esistono dei protocolli, come RBS, che
eseguono la sincronizzazione tra i ricevitori usando il tempo di arrivo di un
medesimo messaggio che arriva a tutti. In questo modo si elimina la maggior
parte del tempo non deterministico e quindi si riduce l’errore.
Sincronizzazione Sender-to-Receiver: Questo approccio tradizionale
solitamente avviene in tre passaggi.
Il nodo sender invia periodicamente un messaggio (chiamato timestamp)
con il valore del suo tempo locale al receiver.
Il receiver si sincronizza con il sender usando il timestamp che ha
ricevuto.
Il tempo che il messaggio impiega per andare dal sender al receiver è
calcolato misurando il tempo totale che intercorre da quando il receiver
richiede un timestamp al sender a quando arriva al receiver questo
messaggio di risposta. Quindi, come si può vedere, il tempo viene
calcolato su un viaggio del messaggio di andata e ritorno, e quindi diviso
per due.
Lo svantaggio di questo approccio è dovuto al fatto che questo tempo non è
deterministico: esso è dovuto ai ritardi nella rete ed al carico di lavoro dei
nodi che sono coinvolti nella sincronizzazione. I vari protocolli del tipo
34

sender-receiver si differenziano tra di loro in base a come stimano questo
tempo. Per esempio, alcuni valutano questo tempo calcolando la media su
molte prove, questo però aggiunge ulteriore carico di lavoro ai nodi e quindi
aumenta questo tempo.
Sincronizzazione Receiver-to-Receiver: Questo approccio sfrutta la proprietà
di avere un mezzo fisico che permette una trasmissione broadcast (un
sender, che trasmette contemporaneamente lo stesso messaggio a più
receiver, anche detta trasmissione punto-multipunto). Se due receiver
ricevono lo stesso messaggio da un sender, allora vuol dire che essi hanno
ricevuto il messaggio approssimativamente nello stesso istante. A questo
punto, invece di interagire con il sender, i receiver si scambiano
l’informazione circa il valore del clock locale nel quale hanno ricevuto lo
stesso messaggio e calcolano il loro offset mediante la differenza nei tempi di
ricezioni. L’indubbio vantaggio di questo metodo è la riduzione di quel
tempo che abbiamo considerato prima (time-critical path): con questo
metodo l’errore è dato solo dalla differenza nei tempi di propagazione del
messaggio ai vari receiver e nei tempi di ricevimento tra i vari receiver.
e) Scambio di messaggi one-way o two-way:
One-way: Lo scambio di messaggi di tipo one-way è caratterizzato dall’invio
di messaggi, contenenti il valore del clock, da parte del sender in modalità
broadcast a tutti i receiver. Lo scambio di messaggi è solo in un verso, infatti
i receiver non mandano mai i loro timestamp al sender. Quindi le uniche
informazioni che hanno i receiver per calcolare offset e drift sono: i
timestamp del sender e l’istante di arrivo dei timestamp del sender.
Two-way: C’è uno scambio reciproco di messaggi tra sender e receiver. Il
receiver manda al sender il suo timestamp, il sender registra l’istante
35
(secondo il suo clock) di arrivo del timestamp del receiver e manda al
receiver il proprio timestamp ed il valore dell’istante di arrivo del timestamp
precedentemente ricevuto da esso.
f) Reti Single-hop o Reti Multi-hop:
Comunicazione Single-hop: In una rete single-hop, ogni sensore può
direttamente comunicare e scambiare messaggi con qualsiasi altro nodo della
rete. Tuttavia, la maggior parte delle reti di sensori wireless si suddividono in
molti domini o in vicinati (i nodi all’interno di un dominio possono
comunicare tra di loro direttamente attraverso una trasmissione di un
messaggio sigle-hop). Le reti di sensori però solitamente sono molto estese e
questo rende quindi impossibile che un nodo riesca a comunicare
direttamente con tutti gli altri.
Comunicazione Multi-hop: La necessità di comunicazioni multi-hop nasce
dall’incremento delle dimensioni delle reti di sensori wireless. In tali reti i
sensori in un dominio comunicano con i sensori in un altro dominio
attraverso un sensore, che trovandosi in una posizione intermedia, riesce a
comunicare con entrambi.
g) Approccio basato sul livello MAC o Approccio standard :
Il livello MAC (Medium Access Control) è un sottolivello del livello Data
Link dell’ Open System Inteconnection conosciuto anche come modello
ISO/OSI, cioè l’insieme dei protocolli sui quali si basa la comunicazione
nelle reti a commutazione a pacchetto. Il livello MAC è responsabile delle
seguenti funzioni:
Fornisce l’affidabilità ai livelli superiori una volta che la connessione è
stabilità al livello fisico.
Previene le collisioni di trasmissione in modo tale che la trasmissione del
36

messaggio tra un sender ed uno o più receiver non interferisca con la
trasmissione di altri nodi.
La differenza tra i due approcci sta nel fatto che nell’approccio basato sul livello MAC il
protocollo esegue il timestamp del messaggio al livello MAC e quindi riduce l’errore nella
stima del tempo di viaggio del pacchetto (time-critical path). Questo però comporta sender più
complessi, quindi se non è possibile accedere al livello MAC, il timestamp viene eseguito al
livello applicazione: questo approccio è chiamato appunto approccio standard
2.1.4 I ritardi
Come è stato detto quando si è parlato della classificazione dei vari metodi di
sincronizzazione del tempo, tutti si basano sullo scambio di un insieme di messaggi tra i nodi.
Il non determinismo nelle dinamiche della rete come il tempo di propagazione o l'accesso
fisico al canale, fa sì che il compito della sincronizzazione sia un compito difficile e molto
importante. Il primo problema da risolvere per avere una sincronizzazione precisa è proprio
l’effetto del non determinismo, mentre tutti gli altri ritardi di tempo deterministici sono
facilmente compensabili.
Quando un nodo in una rete genera un timestamp da spedire a un altro nodo per la
sincronizzazione, il pacchetto che trasporta il timestamp presenterà un ritardo variabile fin
quando non raggiungerà il nodo di destinazione e sarà decodificato. Questo ritardo impedisce
al receiver di comparare esattamente il suo clock locale e sincronizzarlo accuratamente con
quello del nodo sender.
Il ritardo dato dalla decomposizione del pacchetto quando questo attraversa un
collegamento wireless tra due nodi può essere schematizzato [6] come segue:
37

Figura 2.10: Esempio del ritardo di decomposizione del pacchetto su di un link wireless
Si analizzano ora ogni componente di ritardo presenti in Figura 2.10.
a) Send time: quando un nodo decide di trasmettere un pacchetto, lo classifica come
un processo da eseguire; è necessario un certo tempo per la costruzione del
pacchetto al livello applicazione, dopo il quale viene inviato ai livelli sottostanti.
Questo tempo include il ritardo del pacchetto per raggiungere il livello MAC dal
livello applicazione: esso è altamente aleatorio, dovuto ai ritardi software
introdotti dal sistema operativo e dal carico di lavoro della CPU nel dato momento.
Può arrivare fino a centinaia di millisecondi. Il send time porta in conto anche il
tempo richiesto per trasferire il messaggio dall’host alla sua interfaccia di rete.
b) Access time: il pacchetto, una volta raggiunto il livello MAC, aspetta un certo
tempo per accedere al canale. Questo è forse il contributo più critico del ritardo a
cui un pacchetto è sottoposto, perchè è altamente aleatorio data la sua natura ed è
specifico del protocollo MAC utilizzato dal nodo, varia dai millisecondi fino a
qualche secondo e tutto questo dipende dal traffico sulla rete.
c) Transmission time: si riferisce al tempo utilizzato affinché, il pacchetto venga
trasmesso bit per bit dallo strato fisico sul link wireless. Questo ritardo è
deterministico e può essere stimato usando la dimensione del pacchetto e la
velocità di comunicazione: esso è dell’ordine di una decina di millisecondi.
d) Propagation time: tempo impiegato dal pacchetto per attraversare il link wireless
dal sender al receiver. Quando il sender e il receiver condividono l’accesso allo
stesso mezzo fisico, per esempio sono vicini in una rete wireless ad-hoc, questo
38

tempo è molto breve ed è semplicemente il tempo di propagazione del messaggio
attraverso il mezzo. Invece il tempo di propagazione domina il ritardo in reti WAN,
dove esso include il ritardo di accodamento e di smistamento ad ogni router quando
il messaggio attraversa la rete. Per nodi che sono a meno di 300 metri di distanza
questo tempo è deterministico ed è minore di un microsecondo.
e) Reception time: tempo impiegato per ricevere i bit e passarli a livello MAC (è il
reciproco del trasmission time del sender). È un ritardo deterministico e può essere
notevolmente ridotto se il nodo utilizza un transreceiver hardware ad alte
prestazioni.
f) Receive time: i bit sono riuniti per ricomporre il pacchetto, che viene trasferito al
livello applicazione dove viene decodificato. Questo tempo può cambiare in base al
ritardo variabile introdotto dal sistema operativo. Se il tempo di arrivo è stampato
in un livello abbastanza basso nel kernel del sistema operativo dell’ host, allora il
receive time non include l’overhead delle chiamate di sistema, e nemmeno il
trasferimento del messaggio dall’interfaccia di rete all’host.
2.1.5 requisiti
I requisiti per gli schemi di sincronizzazione per le reti di sensori sono Error: Reference
source not found:
efficienza energetica: come in tutti protocolli disegnati per le reti di sensori gli
schemi di sincronizzazione dovrebbero tenere conto delle limitate risorse
energetiche del nodo sensore.
scalabilità: molte applicazioni di reti di sensori necessitano dell'utilizzo di un
grande numero di sensori, per cui gli schemi di sincronizzazione dovrebbero
supportare un numero di nodi crescente ed un'alta densità nella rete.
precisione: la necessità di precisione, o accuracy, può variare significativamente a
39

seconda della specifica applicazione e dello scopo della sincronizzazione.
robustezza: le reti di sensori sono tipicamente posizionate per lunghi tempi di
funzionamento in ambienti ostili. Nel caso di guasto di alcuni nodi, lo schema di
sincronizzazione deve rimanere valido e funzionante per il resto della rete.
lifetime: il tempo sincronizzato ottenuto dall'algoritmo di sincronizzazione
dovrebbe essere istantaneo e permanere entro i limiti richiesti almeno per il tempo
necessario affinché la rete effettui la misurazione.
scope: gli schemi di sincronizzazione dovrebbero fornire una base dei tempi
globale per tutti i nodi della rete, o fornire una sincronizzazione locale solo tra un
ristretto numero di nodi. A causa dei problemi di scalabilità, la sincronizzazione
globale è difficile da raggiungere o troppo costosa in una rete di sensori ampia. D'
altro canto, una base dei tempi comuni per un grande numero di nodi potrebbe
essere necessaria per aggregare i dati collezionati dai nodi distanti, imponendo la
sincronizzazione globale.
costi e dimensioni: i nodi di sensori senza fili sono dispositivi molto piccoli ed
economici. Per cui, come notato prima, utilizzare un costoso o grande hardware su
un piccolo ed economico dispositivo non è una scelta logica per sincronizzare i
nodi di sensori. I metodi di sincronizzazione delle reti di sensori dovrebbero essere
sviluppati tenendo presente costi limitati e piccole dimensioni.
immediatezza: alcune applicazioni di rete di sensori, come il rilevamento di
emergenze, richiedono che l'evento che si verifica sia comunicato immediatamente
al nodo principale. In questo tipo di applicazioni, la rete non può tollerare alcun
tipo di ritardo quando la situazione di emergenza è rilevata.
2.2 I protocolli di sincronizzazione
Schemi di sincronizzazione tradizionale come NTP o GPS Error: Reference source not
40

found non sono appropriati per l’utilizzo in reti di sensori per i seguenti motivi: NTP Error:
Reference source not found è un protocollo complesso che lavora bene sincronizzando i
computer della rete Internet, ma non è sviluppato per tener conto dei limiti computazionali ed
energetici dei nodi di sensori; inoltre nelle sensor network la precisione richiesta deve essere,
nella maggior parte dei casi, più elevata. Un dispositivo GPS potrebbe essere troppo costoso
e, come precedentemente detto, può presentare problemi di disponibilità del segnale.
Comunemente, i protocolli che garantiscono i migliori risultati per quanto riguarda la
precisione richiesta, sono quelli che si basano sul metodo two-way-message. La
comunicazione tra i nodi avviene in entrambe le direzioni: ossia i due nodi si scambiano
informazioni sui propri tempi locali, in modo da poter stimare deriva e offset; però tale
approccio può comportare un sovraccarico della rete. Il metodo one-way-message è più
efficiente da un punto di vista energetico ma tipicamente meno preciso; tale metodo si basa
sull’invio da parte di un nodo master di messaggi broadcast, con cui i nodi slave possono
sincronizzarsi.
Per aumentare la precisione richiesta, si potrebbero valutare gli istanti temporali al livello
MAC riferendosi al preciso istante di tempo in cui il pacchetto viene inviato oppure ricevuto,
evitando così dei ritardi aleatori introdotti dai livelli superiori della pila protocollare.
Di seguito si presentano alcuni algoritmi presenti in letteratura, che potrebbero essere
appropriati per effettuare la sincronizzazione in una rete di sensori:
TPSN Timing-sync Protocol for Sensor Networks: Error: Reference source not
found la sincronizzazione viene ottenuta creando prima la struttura gerarchica nella
rete per poter garantire così la scalabilità della stessa, seguita poi dalla procedura
vera e propria di sincronizzazione. Il tutto avviene attraverso scambi di messaggi e
la procedura di sincronizzazione richiede che in questi messaggi sia presente
l'istante in cui quel pacchetto viene trasmesso. Tale protocollo sarà analizzato nel
dettaglio nei paragrafi che seguono.
41

FTSP Flooding Time Syncrnization Protocol: Error: Reference source not found la
sincronizzazione si ottiene tramite l'invio di una serie di messaggi di sincronismo
grazie ai quali i ricevitori valutano il tempo globale al quale sincronizzarsi,
stimando skew e offset dati dai data points ricevuti.
BSB Broadcast Synchronization over Bluetooth: Error: Reference source not found
la sincronizzazione avviene tra moduli Bluetooth. Il sender invia periodicamente
dei messaggi il cui contenuto non ha importanza e i receivers si sincronizzano,
scambiandosi l'informazione relativa all'arrivo del pacchetto dal sender ad ognuno
di essi. Il metodo BSB sfrutta il momento di ricezione di un bluetooth broadcast
message come riferimento per la sincronizzazione di ogni nodo. Il metodo si basa
sulla piccola differenza trovata nei ritardi dei messaggi di notifica che avvertono
l’host bluetooth circa la ricezione di un broadcast message. Questa notifica avviene
attraverso il Bluetooth Host Controller Interface (HCI), una parte dello standard
implementato nei moduli da diversi fornitori.
Figura 2.11: Analisi temporale BSB
In Figura 2.11: Analisi temporale BSBè stata anche inserita una sintetica analisi
temporale con lo scopo di indicare i vantaggi del metodo BSB.
Nei metodi classici dove il timestamp del master è propagato ai dispositivi che
42
si devono sincronizzare, tutti gli intervalli temporali presenti nella figura devono
essere presi in considerazione. In questo caso, TPC e TBT0 vogliono rappresentare il
tempo necessario per la formazione del messaggio, il tempo impiegato dal
protocollo di elaborazione del modulo bluetooth, il tempo per accedere al canale ed
il tempo richiesto per la trasmissione fisica. Questi tempi sono tipicamente i più
rilevanti contributi per il ritardo totale che la maggior parte delle reti esibiscono.
Tuttavia, sono tipicamente complicati da quantizzare data la loro natura non
deterministica. Da quando il PC invia comandi HCI al modulo bluetooth a quando
si ha la trasmissione reale del messaggio possono passare alcuni millisecondi.
Quando si utilizza il metodo BSB, il contributo di questi tempi non ha influenza
sull’accuracy. Data la velocità della luce possiamo assumere che il tempo di volo
tra il master e i differenti slave (TOFi) sarà irrilevante.
Nel BSB la differenza tra i tempi di arrivo ai nodi può solo essere dovuto ai ritardi
in ogni nodo: i receiver time TBTi e TUCi sono i più significativi.
RBS Reference Broadcast Synchronization: Error: Reference source not found
mentre gli algoritmi sopra elencati utilizzano un approccio sender-receiver, questo
protocollo utilizza un approccio receiver-receiver ovvero un set di ricevitori si
sincronizza con un altro set di ricevitori. In questo schema i nodi periodicamente
inviano un messaggio ai loro vicini. I ricevitori usano il tempo di arrivo dei
messaggi come punto di riferimento per comparare i loro clock. I messaggi non
contengono nessun timestamp, perché non è importante esplicitare quando viene
inviato il messaggio. Il protocollo rimuove completamente il send time e l’access
time come mostrato in Figura 2.12: Analisi del percorso critico per un tradizionale
protocollo di sincronizzazione (sinistra) e un RBS (destra).
43

Nella forma più semplice, il protocollo RBS può essere schematizzato come segue:
un sender invia un reference packet a due receivers
ogni receiver memorizza il tempo di arrivo del pacchetto utilizzando il suo
clock locale
i ricevitori si scambiano le loro osservazioni
PTP Precision Time Protocol: Error: Reference source not found il protocollo,
presente nello standard IEEE 1588, è sviluppato con lo scopo di essere utilizzato in
reti di strumenti di misura o sistemi di controllo, ovvero in quegli ambiti in cui la
precisione richiesta è molto elevata. L’accuracy del PTP dipende essenzialmente da
qual è la precisione con la quale si valutano i timestamp utilizzati per la
sincronizzazione e quindi, a che livello vengono valutati. Il protocollo divide la
topologia di un sistema distribuito in una rete di segmenti, abilitando la
comunicazione diretta tra i clock; questi segmenti denominati communication path,
possono contenere repeater e switch della stessa rete LAN.
I dispositivi che connettono i communication path, come ad esempio un router,
introducono possibili asimmetrie e ritardi variabili nella comunicazione. In ogni
communication path un clock è selezionato come master mentre tutti gli altri sono
catalogati come slave; la selezione del clock master avviene utilizzando il best
Figura 2.12: Analisi del percorso critico per un tradizionale protocollo di sincronizzazione
(sinistra) e un RBS (destra).
44

master clock algorithm definito nello standard.
In Figura 2.13: Esempio di PTP timing hierarchy si riporta un esempio di gerarchia
dei clock:
Figura 2.13: Esempio di PTP timing hierarchy
Svolta questa prima fase, la sincronizzazione avviene attraverso lo scambio di
messaggi tra un master clock e uno slave clock al fine di calcolare, attraverso i
timestamp presenti nei messaggi, il delay one-way e l’offset tra master e slave
clock.
Figura 2.14: Scambio di messaggi PTP
Il master clock invia un sync message una volta ogni due secondi nella
45

configurazione di default; il messaggio contiene informazioni sul clock e un
timestamp stimato T1, il quale indica il tempo di trasmissione del messaggio stesso.
Le informazioni sul clock contengono l’identificazione e l’accuracy del master
clock. Quando uno slave clock riceve un sync message, valuta e memorizza un
timestamp T2 del tempo di avvenuta ricezione del sync message. Data la difficoltà
di valutare con esattezza il timestamp nel preciso istante di trasmissione del sync
message, il master clock può trasmettere un follow_up message il quale contiene un
valore più accurato del timestamp T1.
Uno slave clock invia periodicamente un delay request message e memorizza il
tempo di trasmissione misurando il timestamp T3; quando un master clock riceve il
messaggio, invia un delay response message, contenente il timestamp T4 ovvero il
tempo di avvenuta ricezione del messaggio del corrispondente request message.
Lo slave calcola il ritardo tra master e slave clock dms e il ritardo tra slave e master
clock dsm utilizzando i timestamp precedentemente elencati si ha:
Lo slave calcola il one way delay dw e l’offset dal master clock ofm:
L’offset dal master clock è impiegato per correggere la frequenza del clock.
ARSP Adaptive-Rate Time Synchronization Protocol: Error: Reference source not
found tale protocollo (in uno scenario single-hop) è caratterizzato da M nodi di cui
2 svolgono (tramite elezione dinamica) il ruolo di Synchronization Master (SM) e
Reference Master (RM).
46

Figura 2.15: Protocollo ARSP WSN single-hop
La linea punteggiata rappresenta l’invio del pacchetto di sincronizzazione broadcast
dal Synchronization Master agli altri nodi.
La linea piena rappresenta l’invio broadcast del time reference da parte del
Reference Master.
La linea tratteggiata rappresenta la trasmissione dei pacchetti di stato da ogni nodo
verso il Reference Master.
La particolarità principale rispetto al TPSN è costituita dal ruolo del Reference
Master che analizza lo stato di sincronizzazione della rete e data la percentuale di
nodi all’interno dei limiti di tolleranza, adatta il tempo di risincronizzazione
basandosi su un approccio probabilistico e adattativo. Ciascuna sincronizzazione
successiva implica l’assegnazione del nuovo ruolo di ciascun nodo secondo la
seguente politica:
k = passo di sincronizzazione
M = numero totale nodi
s = k mod M ( nodo adibito a SM al passo k)
m = (k + 1) mod M ( nodo adibito a RM al passo k)
o all’accensione ogni nodo azzera il proprio tempo e l’intervallo di
risincronizzazione Ik viene posto a un valore adeguato alle richieste di
47

accuracy dell’applicazione considerata.
o partendo da k = 1, si ha:
dopo un intervallo Ik il nodo SM misura il suo tempo locale Tsk, poi invia
tale valore insieme al suo numero identificativo e al valore Ik a tutti gli altri
nodi (linea punteggiata in figura).
o gli M-1 nodi destinatari misurano il tempo di arrivo Tik del pacchetto di
sincronizzazione. Il nodo m diventa RM e memorizza il tempo Tmk
o RM stima il valore medio del tempo di latenza di comunicazione dk
poi invia a tutti i nodi Tmk, il suo identificativo m e dk in un pacchetto
reference con timestamp TRk (linea piena in figura).
o tutti i nodi (incluso SM) impostano il loro tempo pari a TRk + dk
o ogni nodo compara il tempo Tik del pacchetto di sincronizzazione con il
tempo Tmk da cui si ottiene un pacchetto di stato pari a 1 o 0 a seconda se
inferiore o maggiore dell’errore massimo consentito.
o nell’ultimo passo RM colleziona i pacchetti di stato e aumenta o diminuisce
il valore dell’intervallo di risincronizzazione a seconda del numero di nodi
all’interno del margine di errore di sincronizzazione.
Il carico computazionale è uniformemente distribuito temporalmente data la natura
dinamica nell’assegnazione dei compiti ai vari nodi e quindi si ha
un’ottimizzazione in termini di risparmio energetico.
Time Synchronization with Extended Clock Model: Error: Reference source not
found è una variante del TPSN e si basa sullo scambio di 3 messaggi.
48

Si modella la variazione della deriva del clock e si sviluppa un algoritmo per
stimare e compensare la deriva. Nel frattempo l’offset del clock è corretto
continuamente eliminando le discontinuità temporali che sono il principale lato
negativo degli esistenti protocolli. Tale studio ipotizza che il ritardo di tutti i
messaggi sia costante. In tale modo il nodo i può stimare il tempo locale del nodo j
in due istanti diversi e calcolarsi il drift e offset al tempo finale. Inoltre si considera
che sia possibile attuare variazioni sulle caratteristiche del clock, in modo da
eliminare l’offset, tramite aumento o diminuzione graduale della frequenza del
clock.
La stima e la deriva dell’offset di ci è basata sulla trasmissione di tre messaggi
consecutivi, come Figura 2.16 Il nodo j spedisce il messaggio di informazione del
tempo al suo tempo locale cj(t0) al nodo i. Il messaggio contiene il timestamp cj(t0).
Il nodo i riceve il messaggio al tempo locale ci(t1) e spedisce indietro un messaggio
di risposta immediatamente. Il nodo j inserisce il timestamp nel messaggio di
risposta dal nodo i al tempo cj(t2). Al tempo locale cj(t3) il nodo j spedisce un altro
messaggio contenente cj(t2) e cj(t3) al nodo i, che riceve il messaggio al tempo
locale ci(t4). Al tempo globale t4 i timestamp conosciuti dal nodo i sono cj(t0), ci(t1),
cj(t2), cj(t3), ci(t4). Assumiamo che il ritardo di tutti i messaggi sia costante. Allora il
nodo i può stimare il tempo locale del nodo j al tempo globale t1 come:
Figura 2.16: Sincronizzazione tramite tre messaggi
49

Ancora, il nodo i può stimare il tempo locale del nodo j al tempo globale t4 come:
la sua deriva in t4 come:
e il suo offset in t4 come:
Se la deriva di ci non è zero, ci e cj funzionano a frequenze diverse. Per cui noi
possiamo cambiare l’offset di ci aggiustando gradualmente la deriva di ci. In altre
parole, le correzioni dell’offset e la compensazione della deriva possono essere
raggiunte facendo variare la deriva gradualmente in accordo con alcune regole.
Al tempo globale t4, la deriva di(t4) può essere positiva o negativa, ciò significa che
ci va più velocemente o lentamente di cj. Inoltre, l’offset oi(t4) può essere negativo o
positivo, ciò significa che ci è avanti o indietro a cj. Per cui si prospettano quattro
differenti casi che vengono discussi nel seguito:
1) di(t4) > 0 e oi(t4) < 0
In questo caso, al tempo globale t4, ci è indietro a cj ma va più velocemente
di cj. Per cui il nodo i può gradualmente diminuire la sua frequenza fino al
momento in cui ci raggiunge cj (oi(t)=0) e la frequenza di ci eguaglia quella
di cj (di(t)=0). La Error: Reference source not found mostra la variazione
della deriva e dell’offset di ci. Il tempo globale quando la deriva e l’offset
50

raggiungono zero è denotato come t5. Allora, noi possiamo calcolare
l’integrale della deriva da t4 a t5 come:
dalla Error: Reference source not foundb abbiamo:
per cui
In Error: Reference source not founda l’integrale precedente può essere
semplicemente calcolato come:
e dalle ultime due formule otteniamo:
Quando il nodo i rileva questo caso al suo tempo locale ci(t4), diminuisce
linearmente la sua deriva fin quando il suo tempo locale diventa ci(t5).
Allora la sua deriva e il suo offset saranno zero.
2) di(t4) > 0 e oi(t4) > 0
Figura 2.17 Caso 1, (a) la variazione della deriva; (b) la variazione dell'offset
51

In questo caso, la deriva di ci è ridotta linearmente a –di(t4), poi linearmente
incrementata a zero come in Error: Reference source not found. Nel
frattempo l’offset di ci è portato a zero lungo la curva in Error: Reference
source not foundb. Similmente al caso 1, noi possiamo ottenere ci(t5), ci(t6),
ci(t7).
3) di(t4) < 0 e oi(t4) > 0
In questo caso, la deriva di ci è incrementata linearmente a zero come in
Error: Reference source not found. Mentre l’offset di ci è decrementato a
zero lungo la curva in Error: Reference source not foundb.
4) di(t4) < 0 e oi(t4) < 0
In questo caso la deriva di ci è incrementata linearmente a –di(t4), poi
linearmente decrementata a zero come in Error: Reference source not
founda. Mentre l’offset di ci è portato a zero lungo la curva illustrata in
Error: Reference source not foundb.
Figura 2.18: Caso 2 , (a) la variazione della deriva; (b) la variazione dell'offset
Figura 2.19: Caso 3, (a) la variazione della deriva; (b) la variazione
dell'offset
52

Data l’architettura a microcontrollore utilizzata, si è ritenuto opportuno scegliere tra i
precedenti protocolli di sincronizzazione il TPSN ed il FTSP, in quanto sembrano i più adatti
all’implementazione su tale hardware; inoltre essi permettono di analizzare sia il metodo one-
way-message sia il metodo two-way-message.
2.3 Time-sync protocol for sensor networks (TPSN)
Il TPSN è una semplice soluzione al problema della sincronizzazione nonché scalabile ed
efficiente.
Il primo passo del protocollo è creare una topologia gerarchica nella rete. Ad ogni nodo è
associato un livello in questa struttura gerarchica; un nodo di livello i può comunicare con un
nodo di livello i-1.
Solo un nodo ha il livello 0 e questo viene chiamato root node. Questa fase dell’algoritmo
prende il nome di level discovery phase.
Stabilita una gerarchia nella rete, il root node inizia la seconda fase del protocollo,
chiamata synchronization phase, nella quale un nodo di livello i si sincronizza con un nodo di
livello i-1. In generale, un nodo può agire come gateway per la sensor network ed il mondo
esterno può agire come root node; l’elemento che esegue questo compito, può essere
equipaggiato con un ricevitore GPS il quale svolge il ruolo di UTC . Negli ambienti più ostili
in cui non si vuole assegnare per sempre allo stesso nodo il ruolo di root node della rete, si
può affidare periodicamente la funzione di root node ai nodi che compongono la sensor
Figura 2.20: Caso 4, (a) la variazione della deriva; (b) la variazione dell'offset
53

network, usando lo stesso algoritmo di elezione adottato per eleggere il root.
2.3.1 Level discovery phase
Il root node, nodo con livello 0, inizia la fase inviando un level discovery packet
contenente i suoi parametri di identità e livello. I nodi vicini al root ricevono questo pacchetto
e si autoassegnano il livello 1. Questi, assegnatosi il livello, inviano un nuovo level discovery
packet. La level discovery phase termina solo quando ogni nodo della rete ha assegnato un
livello, fornendo così, una struttura gerarchica della rete con un solo nodo di livello 0.
Esistono comunque delle casistiche ambigue che il protocollo dovrà gestire come quando
un nuovo nodo si collega alla rete dopo che la level discovery phase è già stata completata. In
egual modo, un nodo che è collegato alla rete potrebbe non ricevere il level discovery packet a
causa delle collisioni a livello MAC. In entrambi i casi, non sarà assegnato nessun livello
della gerarchia; tuttavia, ogni nodo ha bisogno di essere all’interno di un livello per potersi
sincronizzare con il root node.
Così, quando un nodo viene impiegato in una sensor network, aspetta un tempo fisso per
assegnarsi un livello. Se, all’interno di questo tempo non riceve nessun level discovery packet,
va in timeout e invia un level request message. I nodi vicini, ricevendo questo pacchetto,
rispondono con un messaggio in cui è inserito il loro livello. Così, il nuovo nodo si
autoassegna un livello, di valore incrementato di uno rispetto al più piccolo livello che ha
ricevuto7; tutto ciò permette l’inserimento nella gerarchia.
I nodi possono anche cessare, in maniera casuale, la loro funzione a causa di rotture o di
mal funzionamenti. Una situazione del genere è problematica quando, ad esempio, un nodo di
livello i non ha più nessun vicino di livello i-1. In questo scenario, il nodo non può ottenere
nessun riscontro con un acknowledgement per il suo synchronization pulse packet; pertanto, il
nodo di livello i potrebbe non essere capace di sincronizzarsi col root node. È stato dimostrato
che quando sono presenti delle collisioni, un nodo potrebbe ritrasmettere il synchonization
7 Potrebbe essere visto come un local level discovery phase.
54

pulse packet aspettando un tempo aleatorio; dopo aver trasmesso il synchronization pulse
packet un fissato numero di volte senza ricevere nessun riscontro, il nodo comprende di aver
perso tutti i suoi vicini di livello superiore e invia un level request message8. Ricevendo una
risposta a questo pacchetto, il nodo si assegna automaticamente un nuovo livello.
Un ulteriore casistica da prendere in considerazione, è quando un root node “muore”; i
nodi di livello 1 non potranno ricevere nessun acknowledgement packet e andranno in
timeout. Piuttosto che inviare un level request packet eseguiranno l’algoritmo di elezione del
leader e il leader eletto prende la funzione di root node. Il nodo eletto dà inizio alla ripetizione
del level discovery phase.
2.3.2 Synchronization Phase
Nella synchronization phase si effettua la sincronizzazione tra una coppia di nodi usando
l’approccio classico sender-receiver Error: Reference source not found per compiere
l’handshake. Per meglio comprendere come questo avvenga, si consideri la seguente figura:
Figura 2.21: Esempio di scambio di messaggi tra la coppia di nodi
Nella Figura 2.16 T1 e T4 rappresentano i tempi misurati dal clock locale del nodo A;
analogamente, T2 e T3 del nodo B. Il tempo T1 è l’istante in cui il nodo A invia un
synchronization pulse packet a B e contenente il livello di A e il valore di T1. Il nodo B
riceve questo pacchetto all’istante T2 uguale a T1+∆+d; ∆ e d rappresentano rispettivamente,
8 Il synchronization pulse packet può essere solo ricevuto dai nodi di livello i-1 quando questo pacchetto
viene inviato dal nodo i. Se un nodo di livello superiore, ad esempio i-2, riceve il pacchetto, lo esclude. Il level
request message lo possono accettare tutti i nodi.
55

il drift9 del clock tra la coppia dei nodi ed il ritardo di propagazione. Nell’istante T3, B invia
un acknowledgement packet ad A contenente il livello di B e i valori di T1, T2 e T3. Il nodo A
riceve questo pacchetto all’istante T4.
Assumendo che il drift e il ritardo si mantengano costanti nel breve tempo di scambio di
messaggi, A può calcolare ∆ e d come:
Conoscendo il drift il nodo A può correggere il suo clock in maniera accurata ed essere
sincronizzato col nodo B. Ancora una volta si mette in evidenza che questa procedura avviene
attraverso la tecnica sender-receiver nel quale il receiver sincronizza il suo clock con quello
del sender .
Questo scambio di messaggi inizia dopo che il root node inizia la sychronization phase
inviando un time sync packet; ricevendo tale pacchetto, i nodi appartenenti al livello 1,
attendono un tempo aleatorio10 prima che inizino il two-way message con il root node.
Ricevuta come risposta, un acknowledgement packet da parte del root, i nodi di livello 1
possono adattare il loro clock a quello del root node. I nodi di livello 2 vengono informati di
questo scambio di messaggi tra il livello 0 e livello 1; presa informazione di questo scambio, i
nodi di livello 2 attendono un tempo casuale dopo il quale iniziano lo scambio di messaggi
con il livello 1. Questo assicura che i nodi del livello 2 inizino la fase di sincronizzazione
dopo che i nodi di livello 1 si sono già sincronizzati col root node. Bisogna mettere in
evidenza che un nodo invia come risposta ad un sychronization pulse packet un
acknowledgement packet, ciò assicura che non si formino livelli multipli di sincronizzazione
nella rete. Questo processo ha come riscontro finale il fatto che tutti i nodi sono sincronizzati
9 Il drift è definito come differenza tra il global time e il local time.
10 Questo permette di evitare la contesa tra i nodi.
56

con il root node. In una sensor network la collisione tra pacchetti nella rete può avvenire
frequentemente. Per gestire questo aspetto, un nodo aspetta un acknowledgement e se questo
non arriva entro un determinato istante temporale, il nodo va in timeout e ritrasmette il
sychronization pulse packet. Questo processo termina quando il two-way-message è
completamente avvenuto.
2.3.3 Analisi degli errori
Si vuole ora mettere a confronto le varie sorgenti di errore dei protocolli TPSN e RBS. In
Error: Reference source not found viene messo in evidenza l’efficienza del protocollo RBS
sull’NTP e pertanto può essere usato come confronto per misurare le performance di TPSN
verso l’NTP. Per questa analisi si introduce il concetto di tempo reale ovvero il tempo
misurato da un clock ideale come mostrato nella seguente figura:
Si utilizzeranno le lettere maiuscole per indicare i tempi misurati dal clock locale e le
lettere minuscole per indicare il tempo misurato dal clock ideale.
Dato lo scenario schematizzato in Figura 2.22 dove i tempi T1 e T2 sono quelli misurati
dai clock dei rispettivi nodi; si può derivare il seguente set di equazioni:
Figura 2.22: Esempio di drift tra i clock locali dei nodi
57

In queste relazioni SA, PA→B, RB rappresentano il tempo speso per inviare il pacchetto (send
time + access time + transmission time) al nodo A, propagation time tra A e B ed il tempo
speso per ricevere il pacchetto (reception time + receive time) valutati al nodo B. Tutti questi
tempi sono quantificati dal clock ideale. Dt1A→B rappresenta il drift tra i nodi A e B al tempo t.
Il nodo B replica con un pacchetto all’stante T3, che è ricevuto da A all’istante T4. Si
derivano le seguenti equazioni:
Dove . può essere diviso in due componenti come segue:
Nella precedente equazione il termine può essere positivo o negativo e
rappresenta il relativo drift tra i nodi A e B dal tempo t1 al tempo t4. La Error: Reference
source not found rappresenta in maniera grafica la definizione di drift e di drift relativo tra la
coppia di nodi. Sottraendo all’equazione che esplicita T2 a quella che esplicita T4 ed usando
la prima e l’ultima equazione scritta si ottiene:
Nella precedente equazione , e rappresentano l’incertezza al sender, al
receiver e nel tempo di propagazione. Questi termini sono dati dalle seguenti equazioni:
Il fine è calcolare per correggere il clock a T4.
58

L’errore è dato da:
Il TPSN è un algoritmo sender-receiver a differenza dell’RBS che è un algoritmo receiver-
receiver. Nell’RBS, due ricevitori si scambiano le informazioni temporali circa i messaggi
che hanno ricevuto da un sender comune. Supponendo che i due nodi A e B ricevono il
pacchetto comune all’istante T2 e T3 rispettivamente, generato da C all’istante T1. Possiamo
ottenere le seguenti equazioni:
Il nodo B invia l’informazione T3 in un pacchetto separato, il quale è ricevuto da A
all’istante T4. L’espressione dell’errore può essere sviluppato come segue:
Analizziamo ogni fattore individualmente:
Incertezza associata al dispositivo sender : come visto nell’equazione
dell’errore che precede, il protocollo RBS elimina completamente l’incertezza a
lato sender. Tale risultato farebbe propendere per l’approccio receiver-receiver, ma
è da considerare che l’architettura dei nodi sensori menzionata in letteratura
permette allo strato applicazione di gestire il modulo radio garantendo una notevole
flessibilità e quindi la possibilità di generare il timestamp dei pacchetti a livello
MAC. Per cui a differenza del RBS, dove non è inviato alcun timestamp ma il
59

tempo è calcolato a livello applicazione, nel caso del TPSN l’unico fattore di errore
è dovuto all’incertezza del tempo di trasmissione, che è un dato deterministico e
quindi tali considerazioni motivano l’uso dell’approccio sender-receiver.
Incertezza del tempo di propagazione : sia TPSN ed RBS soffrono di
variazione nel tempo di propagazione. Nel protocollo TPSN si utilizzano solo link
simmetrici e su ogni link la variazione può essere trascurata. Nel caso del
protocollo RBS l’errore è tra due distinte coppie di nodi e, pertanto, può essere
relativamente ampio in funzione della distanza tra i nodi; nel caso migliore l’RBS
presenta un errore rispetto al TPSN doppio.
Incertezza associata al dispositivo receiver : valutando i tempi di arrivo e
ricezione dei pacchetti a livello MAC, il TPSN rimuove completamente il receive
time; così, diventa solo il reception time. Anche considerando il RBS con
timestamp a livello MAC, è evidente dalle equazioni relative all’errore, che le
prestazioni del TPSN sono doppie rispetto al RBS.
In conclusione si può asserire che il protocollo TPSN fornisce delle prestazioni migliori
rispetto all’RBS anche se è presente un contributo aggiuntivo nel termine di errore che è
l’incertezza del sender. Questa analisi può essere estesa al confronto tra l’approccio sender-
receiver e quello receiver-receiver.
2.3.4 Prestazioni
Questo protocollo è stato implementato su un hardware MICA Motes, sul quale era installato
un sistema operativo Tiny OS, mentre la comunicazione radio era garantita da un modulo RF
del tipo RFM TR100. Nel MICA Motes il controlloer era un ATMEGA103L con frequenza
operativa 4Mhz. Le prove effettuate in [5] hanno dato i seguenti risultati: l’errore medio
misurato è stato uguale a 16,9 us con un errore massimo di 44 us e con un errore minimo di
0 us.
60

.Figura 2.23 : Istogramma relativo all’errore misurato nelle prove effettuate in simulazione
61








![[Antonio Dieguez] Determinismo Tecnológico](https://img.pdfslide.tips/doc/110x75/577c83931a28abe054b57b8b/antonio-dieguez-determinismo-tecnologico.jpg)




















