Embed Size (px)
Citation preview

Centro de Investigacion y de Estudios Avanzadosdel Instituto Politecnico Nacional
Laboratorio de Tecnologıas de Informacion
Estudio comparativo de descriptores detextura para el desarrollo de un metodo
computacional de segmentacionautomatica de lesiones de mama en
ultrasonografıas
Tesis que presenta:
Refugio Ivan Rivera Islas
Para obtener el grado de:
Maestro en Ciencias de la Computacion
Director de la Tesis:Dr. Wilfrido Gomez Flores
Cd. Victoria, Tamaulipas, Mexico. septiembre, 2012


© Derechos reservados porRefugio Ivan Rivera Islas
2012


Esta investigacion fue parcialmente financiada mediante el proyecto No. 370353 del ConsejoNacional de Ciencia y Tecnologıa (CONACyT)
This research was partially funded by project number 370353 from National Council of Science andTechnology (CONACyT)


La tesis presentada por Refugio Ivan Rivera Islas fue aprobada por:
Dr. Jose Juan Garcıa Hernandez
Dr. Jose Gabriel Ramırez Torres
Dr. Wilfrido Gomez Flores, Director
Cd. Victoria, Tamaulipas, Mexico., 20 de septiembre de 2012


”Newton fue el mas grande genio que ha existido y tambien el mas afortunado dado que solo sepuede encontrar una vez un sistema que rija el mundo.”
Joseph Louis Lagrange (1736–1813)


Agradecimientos
A mis padres y hermanos por el amor y apoyo incondicional que siempre me han brindado.
A mi novia Veronica Ruız por su larga espera, amor y apoyo en todo momento.
Al Dr. Wilfrido Gomez Flores por su amistad, apoyo y asesorıa brindada.
A mis revisores, el Dr. Jose Juan Garcıa Hernandez y el Dr. Jose Gabriel Ramırez Torres por sus tanacertadas observaciones y recomendaciones.
A todos los investigadores del CINVESTAV por el conocimiento brindado durante mi estancia en lamaestrıa.
Al personal administrativo por su disponibilidad y servicio eficiente que me brindaron.
A mis companeros: Eduardo, Arturo, Lazaro y Marcos por su amistad y apoyo.
Al Consejo Nacional de Ciencia y Tecnologıa (CONACyT) por el apoyo financiero ofrecido.
Al Centro de Investigacion y Estudios Avanzados del Instituto Politecnico Nacional por la ensenanzaacademica de alta calidad que me brindo durante mi estancia de estudios de maestrıa.


Indice General
Indice General I
Indice de Figuras V
Indice de Tablas VII
Indice de Algoritmos IX
Publicaciones XI
Resumen XIII
Abstract XV
Nomenclatura XVII
1. Introduccion 1
1.1. Antecedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2. Motivacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2.1. Social . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2.2. Cientıfica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3. Planteamiento del Problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.4. Hipotesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.5. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.5.1. Objetivo general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.5.2. Objetivos especıficos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.6. Metodologıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.7. Organizacion del trabajo de tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2. Estado del arte 13
2.1. Texturas y sus descriptores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2. Metodos de segmentacion automatica de ultrasonografıas de mama. . . . . . . . . . 14
2.3. Tecnicas de preprocesamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.4. Tecnicas de clasificacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5. Analisis ROC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.6. Metricas de desempeno para metodos de segmentacion . . . . . . . . . . . . . . . . 21
2.7. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
i

3. Marco teorico 25
3.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.2. Preprocesamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2.1. Tecnicas para mejorar el contraste . . . . . . . . . . . . . . . . . . . . . . 26
3.2.1.1. Enfoque difuso . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2.1.2. Tecnica CLAHE . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.1.3. Tecnica Auto-CLAHE . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2.1.4. Tecnica FAHE . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2.2. Tecnicas de reduccion del speckle . . . . . . . . . . . . . . . . . . . . . . . 31
3.2.2.1. Filtro Kuan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.2.2.2. Filtro mediana . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.2.2.3. Filtro anisotropico + Gabor I y II . . . . . . . . . . . . . . . . . . 33
3.3. Extraccion y seleccion de caracterısticas . . . . . . . . . . . . . . . . . . . . . . . . 35
3.3.1. Matriz de co-ocurrencia de niveles de gris (GLCM) . . . . . . . . . . . . . . 35
3.3.2. Descriptores de Textura (DT) . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.3.3. Normalizacion y discretizacion . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.3.4. Ordenamiento de caracterısticas . . . . . . . . . . . . . . . . . . . . . . . . 42
3.3.4.1. FDR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.3.4.2. mRMR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.4. Tecnicas de clasificacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.4.1. Analisis discriminante lineal de Fisher (FLDA) . . . . . . . . . . . . . . . . 44
3.4.2. Maquina de vectores de soporte (SVM) . . . . . . . . . . . . . . . . . . . . 45
3.4.3. Redes de funcion de base radial (RBFN) . . . . . . . . . . . . . . . . . . . 47
3.4.4. bootstrap .632+ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.5. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4. Metodologıa 53
4.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.2. Preprocesamiento, extraccion y seleccion de caracterısticas . . . . . . . . . . . . . . 54
4.2.1. Preprocesamiento de la imagen. . . . . . . . . . . . . . . . . . . . . . . . . 54
4.2.2. Extraccion de caracterısticas de textura. . . . . . . . . . . . . . . . . . . . 56
4.2.3. Seleccion de las caracterısticas . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.2.3.1. Enfoque de variacion del error . . . . . . . . . . . . . . . . . . . . 64
4.2.3.2. Metodo de mınima distancias . . . . . . . . . . . . . . . . . . . . 68
4.3. Clasificacion: evaluacion de clasificadores . . . . . . . . . . . . . . . . . . . . . . . 73
4.4. Postprocesamiento y ajuste del contorno de la ROI . . . . . . . . . . . . . . . . . . 76
4.4.1. Metodo de postprocesamiento . . . . . . . . . . . . . . . . . . . . . . . . . 76
4.4.2. Ajuste del contorno de la ROI . . . . . . . . . . . . . . . . . . . . . . . . . 83
4.5. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
ii

5. Resultados: metodo propuesto 895.1. Metodo propuesto para la segmentacion automatica en USM . . . . . . . . . . . . 905.2. Evaluacion y resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 925.3. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
6. Conclusiones y trabajo futuro 976.1. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 976.2. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
Bibliografıa 101
iii


Indice de Figuras
1.1. Metodologıa propuesta: esquema global . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1. Matriz de confusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.1. Fusificacion de una imagen de ultrasonido de mama . . . . . . . . . . . . . . . . . 283.2. Tecnica CLAHE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.3. Tecnica FAHE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.4. Aplicacion de las tecnicas para mejorar el contraste . . . . . . . . . . . . . . . . . . 343.5. Aplicacion de las tecnicas para reducir el artefacto speckle . . . . . . . . . . . . . . 353.6. Generacion de la GLCM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373.7. Maquina de vectores de soporte . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.8. Topologıa de la red RBF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.1. Distribucion histologica de los tipos de lesion de las imagenes de USM . . . . . . . 544.2. Mascaras de rejilla . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564.3. Aplicacion de las mascaras de etiquetas y de clase para generar las imagenes celda . 574.4. Dimensionalidad de las caracterısticas de textura . . . . . . . . . . . . . . . . . . . 584.5. Graficas de error bootstrap .632+ para ambos criterios de ordenamiento de carac-
terısticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.6. Enfoque de variacion del error . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 654.7. Valores mopt obtenidos con el Algoritmo 1 para un valor de p = 0.01. . . . . . . . . 664.8. Errores bootstrap .632+ correspondientes a las mopt obtenidas. . . . . . . . . . . . 674.9. Graficas de distancias Euclidianas. . . . . . . . . . . . . . . . . . . . . . . . . . . . 694.10. Comparativa entre los valores de distancia ρ . . . . . . . . . . . . . . . . . . . . . 704.11. Distribucion porcentual de los DT seleccionados . . . . . . . . . . . . . . . . . . . 734.12. Curva en el espacio ROC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 744.13. Plantilla de regiones para eliminar FP . . . . . . . . . . . . . . . . . . . . . . . . . 774.14. Eliminacion de FP. (a) imagen original de USM recortada. Se muestra el contorno
de la lesion (lınea blanca) para tener una referencia visual de las regiones clasificadascomo lesion en IQr; (b) imagen de clasificacion binaria recortada; (c) resultado de laeliminacion de regiones correspondientes con FP. . . . . . . . . . . . . . . . . . . 77
4.15. Umbralado global . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 784.16. Suavizado morfologico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 804.17. Seleccion de la ROI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 824.18. Casos posibles para la posicion de la curva C en el algoritmo de Chan-Vese . . . . . 844.19. Ajuste fino del contorno de la ROI . . . . . . . . . . . . . . . . . . . . . . . . . . 864.20. Esquema general del metodo de postprocesamiento y ajuste del contorno de la ROI . 86
5.1. Esquema global del metodo propuesto . . . . . . . . . . . . . . . . . . . . . . . . . 91
v

5.2. Imagenes de USM segmentadas con el metodo propuesto . . . . . . . . . . . . . . 94
vi

Indice de Tablas
2.1. Tecnicas de reduccion del speckle . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2. Tecnicas de clasificacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.3. Metodos de segmentacion automatica de lesiones de mama en imagenes de USM . . 222.4. Resultados de trabajos relacionados con analisis de DT. . . . . . . . . . . . . . . . 23
3.1. Descriptores de textura de la GLCM . . . . . . . . . . . . . . . . . . . . . . . . . . 393.2. Descripcion de terminos para la generacion de los DT . . . . . . . . . . . . . . . . 403.3. Funciones nucleo para la SVM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.1. Tecnicas de preprocesamiento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 554.2. Combinaciones de tecnicas de preprocesamiento . . . . . . . . . . . . . . . . . . . 554.3. Ejemplo de caracterısticas de textura ordenadas por FDR y mRMR . . . . . . . . . 604.4. Valores mınimos de error bootstrap .632+ . . . . . . . . . . . . . . . . . . . . . . 634.5. Subconjunto de caracterısticas seleccionadas . . . . . . . . . . . . . . . . . . . . . 724.6. Resultados de analisis ROC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
5.1. Comparativa entre metodos de segmentacion. . . . . . . . . . . . . . . . . . . . . . 95
vii


Indice de Algoritmos
1. Enfoque de variacion del error . . . . . . . . . . . . . . . . . . . . . . . . . . . . 642. Seleccion de la ROI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 823. Algoritmo Chan-Vese para delinear la ROI. . . . . . . . . . . . . . . . . . . . . . . 85
ix


Publicaciones
Ivan Rivera-Islas, W. Gomez, “Analytical Study of Texture Features Based on Gray-Level Co-ocurrenceMatrix For Automatic Segmentation of Breast Ultrasound”. XXIII Congresso Brasileiro de EngenhariaBiomedica (CBEB). 1 al 5 de Octubre de 2012, Pernambuco, Brasil. (Aceptado)
Ivan Rivera-Islas, W. Gomez, “Comparative Analysis of Preprocessing Techniques for ExtractingCo-occurrence Texture Features for Automatic Segmentation of Breast Ultrasound”. IEEE NuclearScience Symposium, Medical Imaging Conference (NSS/MIC). 29 de Octubre al 3 de Noviembre de2012, Anaheim, California, EUA. (Aceptado)
xi


Resumen
Estudio comparativo de descriptores de textura para el desarrollo de unmetodo computacional de segmentacion automatica de lesiones de mama
en ultrasonografıas
por
Refugio Ivan Rivera IslasLaboratorio de Tecnologıas de Informacion
Centro de Investigacion y de Estudios Avanzados del Instituto Politecnico Nacional, 2012Dr. Wilfrido Gomez Flores, Director de tesis
En este trabajo se propone un metodo de segmentacion automatica de lesiones de mama en ultra-
sonografıas basado en descriptores de textura, los cuales son extraıdos de la matriz de co-ocurrencia
de niveles de gris (GLCM), y cuyo objetivo es alcanzar un nivel mayor al 90 % de exactitud. Se
implemento una metodologıa para determinar los elementos funcionales para cumplir con tal fin.
Dichos elementos son: tecnicas de preprocesamiento de la imagen, el subconjunto de caracterısticas
de textura mas representativo (mayor capacidad descriptiva), la tecnica de clasificacion, y el meto-
do de postprocesamiento y ajuste de contorno. Para determinar las tecnicas de preprocesamiento
se evaluaron cuatro tecnicas de mejoramiento de contraste (enfoque difuso, CHAHE, Auto-CLAHE
Y FAHE) y cuatro tecnicas de filtro de suavizado (Kuan, mediana, anisotropico + Gabor I y II),
las cuales fueron combinadas. Tambien se consideraron las opciones de utilizar una sola tecnica o
ninguna. Por tanto, se generaron 25 combinaciones de preprocesamiento. Por otra parte, se eva-
luaron 352 caracterısticas que se originaron de utilizar 22 descriptores de textura extraıdos de la
GLCM para cada una de las direcciones θ = 0, 45, 90, 135 y distancias d = 1, 2, 3, 4; y cuya
cuantificacion fue de 64 niveles de gris. Dado que el preprocesamiento de la imagen impacta sobre
la seleccion de caracterısticas, esta ultima se realizo simultaneamente para las 25 combinaciones de
preprocesamiento. Se utilizaron dos criterios de ordenamiento de caracterısticas: la razon de Fisher y
el criterio de mınima-redundancia-maxima-relevancia (mRMR). Se aplico el enfoque de variacion del
xiii

error y el metodo de mınimas distancias para determinar tanto el numero mınimo de caracterısti-
cas ordenadas (bajo ambos criterios de ordenamiento), como la combinacion de preprocesamiento,
respectivamente. Se empleo analisis ROC para evaluar tres tecnicas de clasificacion: maquinas de
vectores de soporte con funcion kernel (SVMk), red de funcion de base radial (RBFN) y analisis lineal
discriminante de Fisher (FLDA). Por ultimo, se propuso un metodo de postprocesamiento basado en
umbralado global y operaciones morfologicas para definir claramente la ROI, una vez definida esta,
se empleo el algoritmo de Chan-Vese para ajustar el contorno de la ROI al contorno de la lesion.
Los elementos funcionales para el metodo propuesto resultaron ser los siguientes: CLAHE y sin filtro
para el preprocesamiento, de las 352 caracterısticas se selecciono un subconjunto con las primeras
125 caracterısticas ordenadas con el criterio mRMR y la SVMk resulto ser la tecnica de clasificacion
con mayor rendimiento.
xiv

Abstract
Comparative analysis of texture descriptors for implement amethod of automatic segmentation of breast lesions on
ultrasound images
by
Refugio Ivan Rivera IslasInformation Technology Laboratory
Center for Research and Advanced Studies of the National Polytechnic Institute, 2012Dr. Wilfrido Gomez Flores, Advisor
In this work we propose a method of automatic segmentation of breast lesions on ultrasound ima-
ges (BUS) based on gray level co-occurrence matrix (GLCM) texture descriptors. The goal of the
proposed method is achieving a segmentation accuracy greater than 90 %. A methodology was im-
plemented to achieve this goal, which defines the preprocessing technique, the most representative
texture feature subset, the classifier with the best performance and postprocessing method and
contour delineation. Preprocessing technique. There were implemented four contrast enhancement
methods (fuzzy approach, CHAHE, Auto-CLAHE Y FAHE) and four smoothing filters (Kuan, me-
dian, anisotropic diffusion I and II) for speckle reduction. These methods were combined in pairs of
contrast-filter, also the possibilities of single method or not preprocessing were considered. Feature
selection. 352 texture features were generated of the GLCM using 22 texture descriptors for four
distances (d = 1, 2, 3, 4), four directions (θ = 0, 45, 90, 135 ) and 64 gray levels of quantization.
The texture features were sorted using two criteria: Fisher’s discriminant ratio (FDR) and minimal-
redundancy-maximal-relevance (mRMR). The approach of variation of error and minimum distances
were used for determined optimal number of texture features as well as the preprocessing techni-
que. Classification techniques. Three classifiers were evaluated with ROC analisys: Fisher’s linear
discriminant analysis (FLDA), radial basis functions networks (RBFN), and support vector machine
with RBF kernel (SVMk). A postprocessing method based on global threshold and morphological
xv

operations was proposed. The Chan-Vese algorithm was used to delineate contour.The results of the
methodology were the following: the preprocessing technique “CLAHE without filtering” attached
the best performance, by using 125 of 352 texture features sorted by mRMR criterion. The classifier
with the best performance was SVMk.
xvi

Nomenclatura
Acronimos principales
CaMa Cancer de mamaIARC Agencia Internacional de Investigacion en CancerOMS Organizacion Mundial de la SaludMG MastografıaUS UltrasonidoUSM Ultrasonido de mamaCAD Diagnostico asistido por computadoraDT Descriptores de texturaROI Region de InteresGLCM Matriz de co-ocurrencia de niveles de grisROC Caracterısticas operador receptorFLDA Analisis lineal discriminante de FisherSVM Maquinas de vectores de soporteRBFN Red de funcion de base radialFP Falso positivoFN Falso negativoVP Verdadero positivoVN Verdadero negativoFDR Razon discriminante de FishermRMR Mınima-redundancia-maxima-relevancia

Sımbolos y notacionΩm Subconjunto de m caracterısticas ordenadas.mopt Numero de caracterısticas a partir del cual el error bootstrap .632+ se vuelve
despreciable segun el umbral definido.ρ(i) Es la distancia Euclidiana entre el origen y el punto (mopt(i), error .632 + (i)),
donde i representa cada una de la N combinaciones de preprocesamiento. Portanto i = 1, 2, 3, . . . , N .
I Imagen de ultrasonido de mama.IQ Imagen binaria (resultado de la clasificacion).Ir Imagen de ultrasonido de mama recortada un 30 % de la parte inferior.IQr Imagen binaria recortada un 30 % de la parte inferior (resultado de la clasifica-
cion).IQr+− Imagen binaria recortada (resultado de la clasificacion) con los falsos-positivos
por regiones.IB Imagen binarizada con el metodo de umbralado global (Otsu).ISB Imagen binarizada con el metodo de umbralado global (Otsu) y modificada con
operaciones morfologicas.IROI Imagen binaria con la ROI definida.φ∗ Imagen segmentada.
xviii

1Introduccion
1.1 Antecedentes
El cancer de mama (CaMa) es una enfermedad en la que se desarrollan celulas malignas en los te-
jidos de la mama [1]. Este padecimiento se ha convertido en la primera causa de muerte por neoplasias
malignas en la mujer a nivel mundial, el cual representa el 16 % de los canceres femeninos [1, 2, 3].
Estadısticas del ano 2008 proporcionadas por la Agencia Internacional de Investigacion en Cancer
(IARC, por sus siglas en ingles) revelan que cada ano aparecen alrededor de 1,384,155 de nuevas inci-
dencias [3], de las cuales mas del 50 % ocurren en paıses con niveles socioeconomicos altos. El riesgo
de enfermar para estos paıses es mayor, aunque el numero de muertes es menor en contraste con
los paıses de nivel socioeconomico bajo, donde se observa lo contrario [4]. Este fenomeno se origina
principalmente porque en los paıses en desarrollo el acceso a los servicios medicos es deficiente [2, 4].
La falta de infraestructura o de recursos especializados origina una deteccion tardıa del padecimiento.
Lo anterior se traduce como una reduccion en la eficacia del tratamiento contra el CaMa y, por tanto,
la reduccion de las posibilidades de supervivencia del paciente. Es claro que una deteccion precoz es la
piedra angular para un tratamiento exitoso, como lo manifiesta la Organizacion Mundial de la Salud
1

2 1.1. Antecedentes
(OMS) [2]. En consecuencia, gobiernos y organizaciones enfocadas en combatir el CaMa impulsan
planes estrategicos que fomenten esta accion de forma eficiente, considerando los factores de riesgo
relacionados con esta enfermedad como son: la edad, el retraso en la vida reproductiva, antecedentes
hereditarios, la exposicion prolongada a estrogenos y estilos de vida [2, 5]. En estos ultimos se destaca
el sedentarismo, la obesidad y el consumo de alcohol, que representan el 27 % de las muertes en el
mundo por CaMa en los paıses de ingresos altos y el 18 % en los paıses de ingresos medios y bajos [6].
En Mexico, el cancer de mama se ha convertido en un problema de salud publica debido al in-
cremento gradual y sostenido de dicha enfermedad. En el ano 2006 se posiciono como la primera
causa de muerte en la mujer, desplazando al cancer cervicouterino en mujeres mayores de 25 anos
de edad [4]. Se sabe que en 2008 la incidencia de este padecimiento fue de 7.57 casos por cada 100
mil habitantes, siendo el Distrito Federal, Sinaloa y San Luis Potosı los tres estados con mayor nivel
de incidencias; por el contrario, Estado de Mexico, Chiapas y Tlaxcala poseen los niveles mas bajos [5].
La OMS recomienda a los gobiernos de cada paıs incluir estrategias como el diagnostico tem-
prano y el tamizaje en sus programas para la deteccion precoz del CaMa. En Mexico, el diagnostico
temprano se basa en promover actividades de educacion a la poblacion y al personal de salud para
identificar sıntomas y signos de la enfermedad en etapas tempranas, las cuales estan relacionadas con
la difusion de la autoexploracion mamaria. Por otro lado, el plan de tamizaje consiste en la deteccion
de una enfermedad en fase preclınica a traves de pruebas que puedan ser aplicadas de forma rapida
y extendida a la poblacion en riesgo, aparentemente sana [4].
La autoexploracion de mama es una tecnica de deteccion de lesiones mamarias basada en la
palpacion y observacion que hace la mujer en sus propias mamas y es recomendable practicarla cada
mes, una vez aparecida la menarca [1]. La ventaja de esta tecnica es la deteccion de lesiones de al
menos 1 cm y en casos superficiales de hasta 0.5 cm. La desventaja es que la lesion puede detectarse
en un estado avanzado de crecimiento. Aun con esta desventaja, la autoexploracion es importante
ya que puede llegar a mejorar el pronostico del paciente cuando se detecta en las primeras etapas

1. Introduccion 3
clınicas de la enfermedad.
En el plan de tamizaje se destacan dos elementos: un examen clınico, en el cual se genera un
historial clınico donde se incluyen los antecedentes hereditarios relacionados con lesiones de mama y
las exploraciones periodicas realizadas por un experto de la salud. El otro elemento es la mamografıa
(MG, tambien conocida como mastografıa), la cual es considerada como la tecnica mas efectiva para
la deteccion del cancer de mama en etapas tempranas [2, 7]. La MG es una imagen plana de la
glandula mamaria que se obtiene con rayos-X [1]. Este estudio es particularmente util para detectar
lesiones no palpables (menores a 0.5 cm), microcalcificaciones, asimetrıas en la densidad mamaria
y distorsion de la arquitectura de la glandula mamaria [1]. La principal ventaja de la MG es su sen-
sibilidad [8], es decir, detecta lesiones muy pequenas como las microcalcificaciones (< 1mm), las
cuales segun su tamano, morfologıa y distribucion pueden indicar el inicio de un proceso canceroso.
Sin embargo, la MG depende fuertemente de la densidad del tejido mamario, ya que si la mama es
muy densa (principalmente en mujeres jovenes) puede ser incapaz de detectar lesiones no calcificadas
[7, 8].
Adicionalmente a la mamografıa existe el ultrasonido de mama (USM), que es la tecnica coad-
yuvante mas importante para deteccion de lesiones de mama. El USM es una imagen que se genera
con las diversas intensidades de retorno producidas por las ondas acusticas de alta frecuencia que
se emiten sobre el tejido mamario [9, 10]. Esta tecnica presenta la caracterıstica de diferenciar entre
lesiones quısticas (simples o complejas) y masas solidas, ademas de que mejora la evaluacion de
mamas densas en pacientes jovenes [8] con respecto a la mamografıa. Por otro lado, se ha demos-
trado que puede distinguir entre lesiones de mama malignas y benignas con base en la morfologıa y
texturas que presentan [7]. Dadas las caracterısticas del USM, cada vez aumenta mas el interes por
utilizar esta tecnica para la deteccion del cancer de mama; segun estadısticas, mas de uno de cada
cuatro investigadores emplean imagenes de USM [7]. Otro factor importante por el cual las imagenes
de USM han tomado relevancia en la deteccion de lesiones de mama, es por su contribucion en la
reduccion del numero de biopsias innecesarias que se practican como resultado de una mamografıa

4 1.1. Antecedentes
no conclusiva. Asimismo, el USM al ser mas especıfico que la mamografıa [8] puede determinar, en
muchos casos, el tipo de lesion (benigna o maligna) antes de realizar una biopsia. El beneficio de
esta tecnica no solo evita el dolor fısico que una biopsia puede provocar por ser una tecnica invasiva,
sino tambien reduce la carga emocional que se genera en el paciente.
Por otro lado, es importante que el personal especializado (radiologos) tenga la tecnica adecuada
y el cuidado necesario para operar los equipos de adquisicion de imagenes para obtener mamografıas
y ultrasonidos de mama utiles para el diagnostico [4]. El radiologo tambien se ve involucrado en la
interpretacion de las imagenes, lo cual depende de la experiencia y el entrenamiento del especialista
y, que bajo ciertas circunstancias, puede ocasionar conflicto en la precision del diagnostico. Por
tanto, se han propuesto sistemas de Diagnostico Asistido por Computadora (CAD, por sus siglas
en ingles), cuyo objetivo es analizar las imagenes por medio de algoritmos computacionales con el
fin de ayudar a los radiologos a interpretarlas. Estos sistemas generalmente se componen por cuatro
bloques funcionales [7]:
1. Preprocesamiento de la imagen. Se aplican tecnicas para mejorar la calidad de la imagen:
mejoramiento del contraste y reduccion del artefacto speckle1 en imagenes de ultrasonido.
Estos dos elementos en ocasiones provocan que las imagenes de USM pierdan caracterısticas
importantes utilizadas por otros bloques del CAD y que son necesarias para elevar la precision
en el diagnostico.
2. Segmentacion. Se lleva a cabo la separacion de la lesion y del tejido adyacente, en otras
palabras, se realiza la deteccion de la lesion, ya sea en forma automatica o semiautomatica.
3. Extraccion y seleccion de caracterısticas. Se obtienen los atributos numericos mas relevantes
(morfologicos y de textura) que caracterizan a las lesiones de mama con el fin de distinguirlas
en benignas o carcinomas.
1Modelado como un tipo de ruido multiplicativo, representa una de las principales causas de degradacion de laimagen. En la literatura medica es tratado como un artefacto de distraccion, ya que tiende a degradar la resolucion ydeteccion de objetos [11].

1. Introduccion 5
4. Clasificacion. Determinar si la lesion es benigna o maligna basado en sus atributos, es decir,
diagnostica la lesion.
1.2 Motivacion
1.2.1 Social
Actualmente el ultrasonido de mama se ha convertido en una alternativa importante para la
deteccion del cancer de mama. Ahora bien, si no es tan sensible como la mamografıa, la cual detecta
calcificaciones del orden de micras, sı es mas especıfico en el sentido de diferenciar, con alta preci-
sion, entre lesiones quısticas (benignas y malignas) y masas solidas. Dicha especificidad se vuelve un
elemento clave en la interpretacion de posibles lesiones, ya que contribuye a mejorar la calidad del
diagnostico, lo cual conlleva a una disminucion del numero de biopsias innecesarias que se practican
como consecuencia de la confusion en la interpretacion de la mamografıa provocada por la aparicion
de falsos positivos. Ademas el USM mejora la deteccion del cancer de mama en pacientes jovenes
(menores a 35 anos) con mamas de tejido denso. El USM tambien puede verse como una opcion
viable para la deteccion temprana del cancer de mama en paıses en desarrollo que no cuenten con la
infraestructura para practicar mamografıas. Cabe resaltar que una mamografıa tiene un costo mucho
mayor que un USM, ademas de que este ultimo se lleva a cabo con mayor rapidez y es mas seguro
porque no expone al paciente y al personal medico a la radiacion ionizante que se emite en una
mamografıa.
1.2.2 Cientıfica
Los ultrasonidos de mama son mas dependientes del operador que la mamografıa [7], por lo que
es mas compleja su interpretacion. Por ello se necesita de personal altamente capacitado y con mu-
cha experiencia en este campo para realizar un diagnostico certero. A pesar del buen entrenamiento
que puede llegar a tener un radiologo, su diagnostico siempre va acompanado de un elemento sub-

6 1.3. Planteamiento del Problema
jetivo que bajo ciertas circunstancias puede sesgar dicho diagnostico. Por ello se recomienda el uso
de herramientas computacionales (CAD) para asistir a los radiologos en la deteccion y diagnostico
de lesiones. Estos sistemas implementan metodos de segmentacion automatica para la deteccion de
lesiones que pueden sugerir al radiologo donde enfocarse dentro del USM, y con ello disminuir la
complejidad y subjetividad mencionada.
A pesar de que existe un abanico extenso de trabajos cientıficos relacionados con los algoritmos
que se implementan en los sistemas CAD, todavıa hay mucho por hacer, ya que es una area en
desarrollo dentro de la investigacion. Muchos de los trabajos publicados enfocados al desarrollo de
algoritmos de segmentacion automatica de imagenes de USM se basan en descriptores de texturas2
(DT). Estos algoritmos reportan tener un alto grado de efectividad, la cual se cree puede ser mejorada
dado que no han sido analizados sistematicamente los principales descriptores de texturas conocidos
y su interaccion entre ellos. Ademas, existen otros factores que pueden contribuir en gran medida a
mejorar el diagnostico de lesiones de mama, y que todavıa no han sido explorados en conjunto, como
son las tecnicas de reduccion del speckle, el mejoramiento de contraste, y las diferentes tecnicas de
clasificacion.
1.3 Planteamiento del Problema
Sea f(x, y) la imagen de ultrasonido de mama que contiene una lesion. El problema de seg-
mentacion consiste en dividir f(x, y) en dos regiones disjuntas de texturas b1(x, y) y b2(x, y) que
corresponde a la lesion y al fondo, respectivamente, tal que, b1(x, y) ∨ b2(x, y) = f(x, y). Sea
xi = (ti, yi) para i = 1, . . . , n, un conjunto de entrenamiento con n muestras independientes, donde
ti es un vector p−dimensional de descriptores de textura e yi es la respuesta de la muestra i, es
decir, toma valores 0 o 1 para distinguir las dos regiones (o clases) b1(x, y) o b2(x, y). Sea rxi(tj) una
regla de prediccion (o clasificador) entrenada con un conjunto xi y un vector de prueba tj extraıdo
de un conjunto de prueba xj = (tj, yj) para 1, . . . ,m, muestras independientes. El problema de
2Representacion computacional (numerica) de una textura [12]

1. Introduccion 7
segmentacion automatica consiste en minimizar una funcion de error e = Err(Q[yi, rxi(ti)]), donde
la notacion Q[y, r] indica la discrepancia entre el valor de prediccion r y la respuesta verdadera y,
que para una situacion dicotomica se define como:
Q[y, r] =
0 si r = y
1 si r 6= y(1.1)
1.4 Hipotesis
Existe un subconjunto representativo de descriptores de texturas que pueden ser utilizados para
detectar de forma automatica las regiones sospechosas que representan lesiones en una imagen de
ultrasonido de mama, con al menos un 90 % de exactitud.
1.5 Objetivos
1.5.1 Objetivo general
Desarrollar una metodo computacional de segmentacion automatica de lesiones de mama en
ultrasonografıas, basado en un analisis comparativo de descriptores de texturas y cuya exactitud sea
mayor al 90 %.
1.5.2 Objetivos especıficos
1. Contribuir al estado del arte con un analisis de caracterısticas de texturas para identificar
aquellas que mejoren, en mayor medida, la claridad y exactitud de la deteccion de la region de
interes (ROI) que contiene una lesion de mama.

8 1.6. Metodologıa
2. Contribuir al estado del arte con un analisis de diversas tecnicas de preprocesamiento para
definir cual de ellas mejora, en mayor medida, los resultados del proceso de extraccion y
seleccion de caracterısticas para el problema planteado en este trabajo.
3. Contribuir al estado del arte con un analisis de evaluacion de tecnicas de clasificacion, fre-
cuentemente utilizadas en los problemas de segmentacion automatica de lesiones de mama en
ultrasonografıas, para determinar la que mejor desempeno ofrezca.
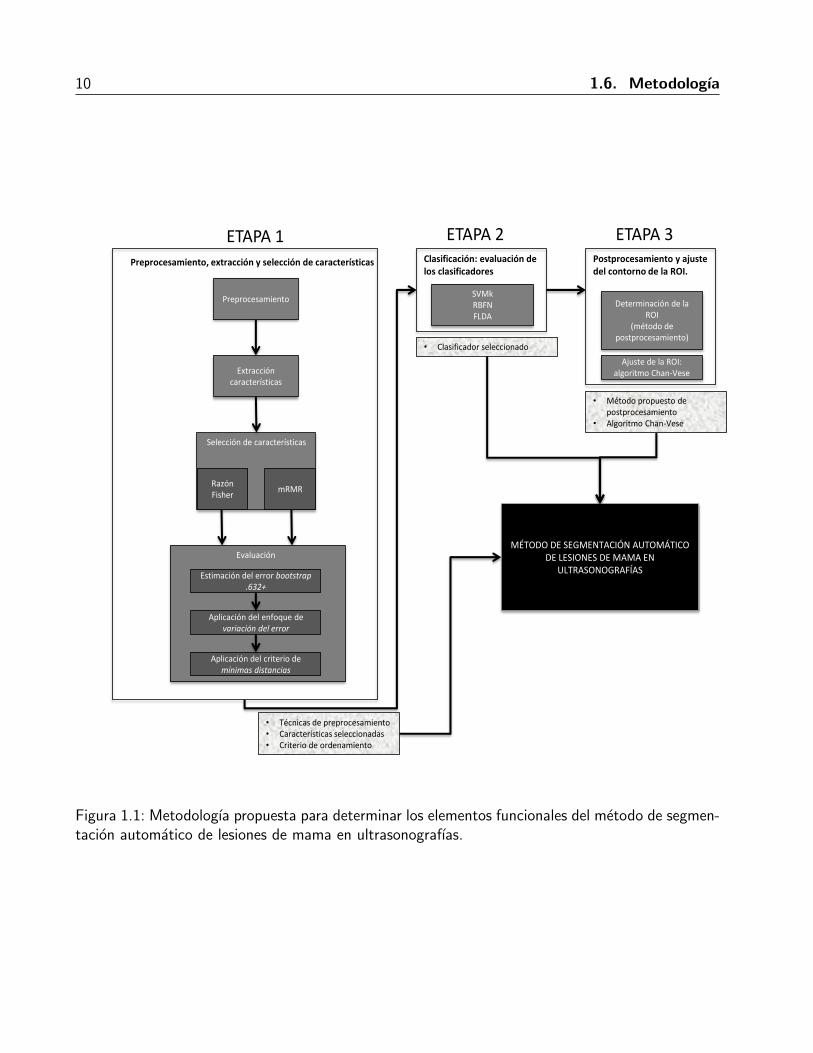
1.6 Metodologıa
En este trabajo se propone una metodologıa para determinar los elementos funcionales que
componen al metodo de segmentacion automatica de lesiones de mama en ultrasonografıas, y el
cual se presenta como resultado final de esta investigacion. La metodologıa esta compuesta por tres
etapas:
1. Preprocesamiento, extraccion y seleccion de caracterısticas. Se determinan tanto las tecnicas de
preprocesamiento de la imagen que contribuyen a mejorar el proceso de extraccion y seleccion
de caracterısticas, como el subconjunto con el menor numero de caracterısticas y con la mayor
capacidad descriptiva para categorizar una region de la imagen de ultrasonido de mama en
lesion o fondo. Para determinar las tecnicas de preprocesamiento se evaluan cuatro tecnicas de
mejoramiento de contraste y cuatro tecnicas de filtros de suavizado, las cuales son combinadas.
Tambien se consideran las opciones de utilizar una sola tecnica o ninguna. Por tanto, se generan
25 combinaciones de preprocesamiento. Por otra parte, se evaluan 352 caracterısticas que se
originaran de utilizar 22 descriptores de textura de la matriz de co-ocurrencia de niveles de
gris (GLCM, por sus siglas en ingles) para cada una de las direcciones θ = 0, 45, 90, 135 y
distancias d = 1, 2, 3, 4; cuya cuantificacion es de 64 niveles de gris. Dada la dependencia entre
las tecnicas de preprocesamiento y la seleccion de caracterısticas, ambas evaluaciones se realizan
de manera simultanea. Tambien, se evaluan dos criterios de ordenamiento de caracterısticas:
la razon discriminante de Fisher (FDR) y el criterio de mınima-redundancia-maxima-relevancia

1. Introduccion 9
(mRMR) para determinar cual de ellos minimiza en mayor medida el numero de caracterısticas.
La evaluacion de las tecnicas de preprocesamiento, de las caracterısticas y de los criterios
de ordenamiento, se realizan a traves de la estimacion del error bootstrap .632+ para cada
combinacion de preprocesamiento y cada conjunto de caracterısticas ordenado, el cual fue
analizado empleando el enfoque de variacion del error y el metodo de mınimas distancias.
2. Clasificacion: evaluacion de clasificadores. Con las caracterısticas de textura seleccionadas en
la etapa anterior, se entrenaron tres clasificadores y se evaluo su desempeno utilizando analisis
ROC (Caracterıstica Operativa del Receptor). Dichos clasificadores son: maquinas de vectores
de soporte con funcion kernel (SVMk), red de funcion de base radial (RBFN) y analisis lineal
discriminante de Fisher (FLDA).
3. Postprocesamiento y ajuste del contorno de la ROI. Se propone un metodo de postprocesa-
miento basado en una tecnica de umbralado global y operaciones morfologicas, que al ser
combinados con los resultados de la clasificacion logran eliminar los falsos positivos y falsos
negativos, y al mismo tiempo, definir la ROI. Para ajustar finamente el contorno de la ROI al
contorno real de la lesion se emplea el metodo de contornos activos de Chan-Vese.
Cabe resaltar que la primera y segunda etapa estan enfocadas a la determinacion de la ROI. En
la Figura 1.1 se muestra el esquema global de la metodologıa propuesta.
10 1.6. Metodologıa
Preprocesamiento
Extracción características
Razón Fisher
Selección de características
mRMR
Evaluación
Estimación del error bootstrap .632+
Aplicación del enfoque de variación del error
Aplicación del criterio de mínimas distancias
Preprocesamiento, extracción y selección de características
SVMk RBFN FLDA
Clasificación: evaluación de los clasificadores
Determinación de la ROI
(método de postprocesamiento)
Postprocesamiento y ajuste del contorno de la ROI.
Ajuste de la ROI: algoritmo Chan-Vese
• Técnicas de preprocesamiento • Características seleccionadas • Criterio de ordenamiento
• Clasificador seleccionado
• Método propuesto de postprocesamiento
• Algoritmo Chan-Vese
MÉTODO DE SEGMENTACIÓN AUTOMÁTICO DE LESIONES DE MAMA EN
ULTRASONOGRAFÍAS
ETAPA 1 ETAPA 2 ETAPA 3
Figura 1.1: Metodologıa propuesta para determinar los elementos funcionales del metodo de segmen-tacion automatico de lesiones de mama en ultrasonografıas.

1. Introduccion 11
1.7 Organizacion del trabajo de tesis
Este trabajo esta compuesto por seis capıtulos. En el Capıtulo 1 se da una introduccion que
contextualiza la importancia que tiene la investigacion hoy en dıa sobre el cancer de mama, ademas se
describen algunos de los principales metodos de diagnostico. Por otra parte, se ofrece una justificacion
para la elaboracion de este trabajo y se plantea el esquema global de su realizacion. En el Capıtulo 2
se presenta el estado del arte, en el cual se exponen algunos de los principales trabajos relacionados
con este trabajo de tesis y de los elementos que los componen. En el Capıtulo 3 se presenta el marco
teorico, en el cual se definen las bases teoricas de los metodos involucrados en el desarrollo de este
trabajo de tesis. En el Capıtulo 4 se presenta la metodologıa propuesta para la creacion de un metodo
de segmentacion automatico de lesiones de mama en ultrasonografıas. En el Capıtulo 5 se presenta
la evaluacion y resultados del metodo propuesto en el Capıtulo 4. En el Capıtulo 6 se presentan las
conclusiones finales y el trabajo futuro.


2Estado del arte
2.1 Texturas y sus descriptores
Una textura se interpreta como la variacion en el patron de color o de intensidad en escalas
menores a las escalas de interes [13, 14]. La textura ayuda al sistema visual humano a identificar la
forma y el material del que estan conformados los objetos [12], por ejemplo, un tejido de lesion en
imagenes de ultrasonido de mama. Haralick et al. [15] proponen analizar texturas de tres diferentes
tipos de imagenes: fotomicrografıas de arena, fotos aereas y de satelite empleando estadısticas de
segundo orden generadas con la matriz de co-ocurrencia de niveles de gris (GLCM). Estas estadısticas,
tambien conocidas como descriptores de texturas (DT), son la representacion matematica de las
caracterısticas de una textura que pueden interpretarse por un algoritmo computacional [12]. Haralick
define 14 DT: energıa (f1), contraste (f2), correlacion (f3), suma de cuadrados (f4), momento de
diferencia inversa (f5), suma de promedios (f6), suma de varianza (f7), suma de entropıa (f8),
entropıa (f9), diferencia de varianza (f10), diferencia de entropıa (f11), medida de informacion de
correlacion 1 (f12), medida de informacion de correlacion 2 (f13), coeficiente de maxima correlacion
(f14). Ademas, sugiere extender el uso de los DT propuestos para otros tipos de imagenes.
13

14 2.2. Metodos de segmentacion automatica de ultrasonografıas de mama.
2.2 Metodos de segmentacion automatica de
ultrasonografıas de mama.
Chen et al. [16] utilizan caracterısticas de texturas para diferenciar con alta precision entre le-
siones de mama benignas y malignas en ultrasonografıas. Con lo que se comprueba la eficiencia del
analisis de textura con otros tipos de imagenes diferentes a las utilizadas en [15]. Este hecho mo-
tivo el interes de los investigadores para emplear imagenes de ultrasonido en la deteccion de lesiones
de mama [7]. Sin embargo, existen desventajas que complican la interpretacion y analisis de este tipo
de imagenes, como son: calidad pobre de la imagen causadas por el artefacto speckle [7, 17, 18, 19],
bajo contraste [7, 8], bordes borrosos y sombras acusticas [17].
Los sistemas CAD analizan los ultrasonidos de mama por medio de algoritmos computacionales
con el fin de ayudar a los radiologos a interpretarlas. Estos sistemas generalmente se componen por
cuatro etapas funcionales [7]: preprocesamiento de la imagen, segmentacion, extraccion y seleccion de
caracterısticas y clasificacion. Muchos de los algoritmos implementados en estos sistemas se enfocan
en la segmentacion, la cual se encarga de separar la lesion del tejido adyacente, lo que sirve como
referencia al radiologo para la interpretacion de la imagen. La mayorıa de estos algoritmos dependen de
la seleccion manual de la region de interes o ROI, e inicializacion manual del contorno [17] de manera
que se incluye un elemento subjetivo. Automatizar la etapa de segmentacion o al menos disminuir
notablemente la intervencion manual es una tarea complicada. Para ello se han sugerido diversas
metodologıas que en su mayorıa se componen de dos modulos: i) deteccion automatica de la ROI y
ii) delineacion del contorno de la ROI. En el primero hay tres etapas principales: preprocesamiento,
donde se reduce el artefacto speckle y se mejora el contraste [17, 20, 21]; seleccion de caracterısticas
(texturas, morfologicas y basadas en modelos [7]); y clasificacion. En el segundo modulo se realiza el
ajuste del contorno de la ROI detectada al contorno de la lesion. Para esto ultimo se han propuesto
modelos como: contornos activos mejor conocidos como snakes, umbralado del histograma, campos
aleatorios de Markov, redes neuronales, region de crecimiento, watershed, entre otros [21].

2. Estado del arte 15
De los trabajos mas recientes que fueron analizados especıficamente para la deteccion automatica
de lesiones de mama en ultrasonografıas, se destacan los propuestos por Liu et al. [20], Shan et al.
[17] y Liu et al. [21].
Liu et al. [20] realizan la deteccion de la ROI a traves de un metodo de clasificacion supervi-
sada de textura, para lo cual, comienzan por la reduccion del artefacto speckle y mejoramiento del
contraste de la imagen a traves de la implementacion de un tecnica difusa. Posteriormente, dividen
la imagen utilizando una retıcula, cuyos elementos son cuadrados del mismo tamano, y se extraen
las caracterısticas de textura de cada elemento para generar un vector de caracterısticas. Despues se
computa la GLCM y se calculan cuatro descriptores de textura: entropıa (f9), contraste (f2), suma
de promedios (f6) y suma de entropıa (f8) [15]. El autor no justifica el uso de estos. A continuacion,
cada elemento de la retıcula es clasificado en region de “tejido normal” o en region candidata de
“lesion de mama” empleando maquinas de vectores de soporte con funcion nucleo de base radial
(KSVM). Para delinear la posible lesion dentro de una ROI se define un metodo basado en proba-
bilidades de distancias y en el modelo de contornos activos propuesto por Osher y Sethian [22]. Los
contornos activos pueden clasificarse en: “basado en bordes” o “basado en regiones”. El primero se
emplea para encontrar los lımites de la posible lesion basandose en informacion local de los bordes.
El segundo se emplea para modelar la informacion estadıstica global de los patrones del artefacto
speckle.
En el metodo propuesto por Shan et al. [17] emplean la seleccion automatica de un punto semilla
[23] como punto inicial de una ROI, posteriormente utilizan el metodo de crecimiento de region
para delinear burdamente la ROI. Se corta una area de forma rectangular que cubre la ROI para
garantizar que se cubre toda la ROI resultante y se eliminan las partes correspondientes al fondo de
la imagen. La principal contribucion de este trabajo, como lo senalan los autores, es la extraccion
de caracterısticas multi-dominio, que consiste en suponer que cada pıxel corresponde a una de las
siguientes dos clases: lesion o fondo de la imagen. Para distinguir entre estas dos clases se utilizan
tres caracterısticas de la imagen: fase de orientacion y maxima energıa (PMO), distancia radial (RD)

16 2.2. Metodos de segmentacion automatica de ultrasonografıas de mama.
y textura e intensidad caracterıstica (JP). Posteriormente, una red neuronal perceptron multicapa
(MLP) clasifica los pıxeles de la imagen. Por otra parte, para reducir el artefacto speckle y mejorar la
calidad de la imagen se emplea la tecnica de difusion anisotropica de reduccion del speckle (SRAD)
[19].
En el trabajo de Liu et al. [21] se propuso un metodo considerado completamente automatico
para clasificar lesiones en ultrasonidos de mama. El metodo esta dividido en dos partes: i) genera-
cion automatica de las ROI y ii) clasificacion de las ROI. Para realizar la primera parte los autores
siguen el mismo procedimiento descrito en [20]. La segunda parte consiste en distribuir “puntos de
clasificacion” en cada ROI (cuyo contraste fue previamente mejorado a traves de una tecnica difu-
sa) empleando una funcion de vecindad. Para clasificar cada punto se forman cinco ventanas a su
alrededor y se calcula la GLCM de cada una considerando cinco distancias (d = 1, . . . , 5) y cuatro
orientaciones (θ= 0°,45°,90°,135°). Posteriormente, a partir de las GLCM se calculan los siguientes
descriptores de textura para formar un vector de caracterısticas: entropıa (f9), contraste (f2), suma
de promedios (f6) y suma de entropıa (f8) [15]. Finalmente, la clasificacion de los “puntos de clasi-
ficacion” se realizan mediante SVM con funcion de base radial.
Cuando se emplea la GLCM para la extraccion de caracterısticas de texturas como en [20, 21],
la dimensionalidad del vector de caracterısticas se vuelve un problema debido a que se generan
caracterısticas redundantes que no aportan informacion relevante para la caracterizacion de la imagen,
lo que incrementa el tiempo de computo. El numero de caracterısticas esta en funcion del numero de
distancias d, orientaciones θ, niveles de cuantificacion (8, 32, 64, 128, 256, . . . ) y DT que se deseen
procesar. Por ejemplo, en [21] emplean cinco distancias y cuatro orientaciones por lo que se generarıan
20 GLCM’s. Los autores emplean cada una de las GLCM para cada una de las cinco ventanas de
cada uno de los n “puntos de clasificacion”, por lo que se tendrıan 100 × n GLCM’s en total y se
generarıan 100× n× 4DT de caracterısticas de texturas. Dada esta problematica se han propuesto
metodologıas que intentan obtener los descriptores de textura que sean mas representativos para
caracterizar un ultrasonido de mama. Algunos de estos trabajos se reportan en [24] y [25].

2. Estado del arte 17
Sohail et al. [24] proponen un metodo para seleccionar de forma optima un subconjunto de DT
para imagenes medicas de ultrasonido a traves de algoritmos geneticos empleando un enfoque mul-
tiobjetivo. Este metodo emplea la GLCM y la matriz de longitud de corrimiento de nivel de gris
(GLRLM) [26] para obtener los DT a seleccionar. A partir de la GLCM evalua los catorce DT pro-
puestos en [15] y cinco propuestos en [27], mientras que de la GLRLM se evaluan once DT: cinco de
[26] y seis de [28, 29] dando un total de 30 DT. Para poder trabajar con los 30 DT el autor normaliza
sus valores, esto en consecuencia a la diferencia entre rangos de valores entre la GLCM y GLRLM.
Por otro lado, define el criterio para la seleccion multiobjetivo basandose en la combinacion de los
conceptos de distancia inter-clase y divergencia intra-clase, donde el objetivo principal es: seleccio-
nar un subconjunto de descriptores de textura que (i) maximice la distancia entre todas las clases y
(ii) minimice la divergencia con los miembros de cada clase para mejorar la separabilidad de las clases.
Gomez et al. [25] analizan el comportamiento de 22 DT calculados a partir de la GLCM. Los
autores primeramente segmentan la imagen empleando un algoritmo basado en la transformada
Watershed. Posteriormente se recorta la mınima area rectangular que cubre la lesion para despues
extraer las caracterıstica de la GLCM. Un paso importante que se describe en este trabajo es la
cuantificacion uniforme de niveles de gris con la finalidad de mejorar la precision de la GLCM, ya que
a mayor niveles de gris incluidos en la GLCM, se obtiene mayor precision en la informacion extraıda.
Para extraer los DT de la GLCM se consideraron 10 distancias (d = 1, 2, ..., 10), cuatro orienta-
ciones (θ= 0°,45°,90°,135°) y seis cuantificaciones de niveles de gris (L = 8, 16, 32, 64, 128, 256).
Cada GLCM es normalizada para calcular sus probabilidades. Para reducir la alta dimensionalidad
generada por los valores de distancia, orientacion y cuantificacion de niveles de gris al obtener las
caracterısticas de las texturas se empleo la tecnica de informacion mutua de acuerdo al criterio de
mınima-redundancia-maxima-relevancia (mRMR) [30]. Para la clasificacion de la lesion de mama se
utilizo FLDA [31].
Hasta ahora no se han mencionado resultados de ninguno de los trabajos descritos, ya que se
mostraran al final de este capıtulo con la intencion de realizar una comparativa que clarifique la

18 2.3. Tecnicas de preprocesamiento
eficiencia de cada uno de los trabajos respecto a los demas, ası como las tecnicas que utilizan y
las caracterısticas del conjunto de datos con el cual realizaron sus experimentos. A continuacion se
describen algunas tecnicas de preprocesamiento y de clasificacion utilizadas por los trabajos descri-
tos, ası como de las distintas metricas que se emplean para medir el rendimiento de los metodos de
segmentacion automatica de lesiones en imagenes de ultrasonido.
2.3 Tecnicas de preprocesamiento
La reduccion del artefacto speckle esta relacionada con el mejoramiento de la calidad de la ima-
gen, lo que es relevante para procesar texturas en imagenes de USM. El artefacto speckle dificulta
la observacion visual e interpretacion en las imagenes de USM [7], asimismo, afecta la precision en
tareas como la deteccion de regiones y segmentacion [19]. Por ello se han propuesto diversas tecni-
cas (ver Tabla 2.1)1 cuya tarea principal es remover el artefacto speckle sin destruir caracterısticas
importantes de la imagen [19].
Enfoque TecnicaFiltros lineales Gaussiano [32]
Kuan [33], Frost y Lee [34]
Filtros no lineales
MedianaDifusion no lineal (SRAD [19], SFSPD [35])Operadores morfologicos [36]MAP [37]Geometricos
Dominio WaveletWavelet shrinkageWavelet despeckling under Bayesian frameworkWavelet filtering and diffusion
Enfoque de ComposicionEspacialesFrecuenciales
Tabla 2.1: Tecnicas de reduccion del speckle.
Para mejorar el contraste de una imagen de USM pueden utilizarse las tecnicas de reduccion del
1Las tecnicas no referenciadas fueron tomadas de [7]

2. Estado del arte 19
speckle mencionadas en la Tabla 2.1, dado que realizan ambas tareas al mismo tiempo cuando se
emplean. Por otro lado, hay que destacar dos enfoques adicionales: tecnicas basadas en la ecualizacion
del histograma [38, 39, 40, 41] y basadas en el dominio difuso [8].
2.4 Tecnicas de clasificacion
Dentro del area de reconocimiento de patrones, la clasificacion es una tarea que permite diferen-
ciar entre tipos de tejidos, es decir, determinar si una region de interes corresponde con una lesion o
no, o distinguir si una lesion es benigna o maligna. Los metodos de clasificacion se pueden dividir en
dos categorıas: supervisados y no supervisados. Durante la fase de entrenamiento de un clasificador
supervisado, se cuenta con un conocimiento a priori de las clases a las que pertenecen los patrones
de entrada. Por otro lado, en la clasificacion no supervisada no se tiene ningun conocimiento pre-
vio sobre las clases de los patrones de entrada, sino que son agrupados de acuerdo con un criterio
de similitud dado. Algunos de los clasificadores mas comunes en el procesamiento de imagenes se
muestran en la Tabla 2.2.
Enfoque TecnicaClasificadores lineales Analisis lineal discriminante (LDA) [42, 43, 44, 45]
Regresion logıstica [7]
Redes Neuronales Artificiales (RNA) Retro-propagacion (BP) [46]Mapas auto-organizados(SOM) [7]Redes neuronales jerarquicas [16]Red de funcion de base radial (RBFN) [47, 45]
Maquinas de vectores de soporte (SVM) Kernel SVM [20, 21, 46]Difuso SVM [48]
Tabla 2.2: Tecnicas de clasificacion.

20 2.5. Analisis ROC
2.5 Analisis ROC
Este analisis es ampliamente utilizado para medir el rendimiento de sistemas de clasificacion o
diagnostico cuyas respuestas son dicotomicas [49]. Esto significa que una instancia clasificada puede
adoptar uno de dos posibles valores de clase: positivo (p) o negativo (n), es decir, enfermo o sano,
respectivamente. Por tanto, se generan cuatro posibles relaciones entre el valor real de la instancia
(denotados con mayusculas, P o N) y el valor de prediccion arrojado por el sistema de clasificacion
(denotados con minusculas, p o n). Dichas relaciones se definen en la denominada matriz de confusion
que se muestra en la Figura 2.1, donde VP es un verdadero positivo, diagnostico positivo y enfermedad
presente; VN es un verdadero negativo, diagnostico negativo y enfermedad ausente; FP es un falso
positivo, diagnostico positivo y enfermedad ausente; y FN es un falso negativo, diagnostico negativo
y enfermedad presente.
!!!!!!!!!!!!
! ! Clase!real!
Valor!de!predicción!
! P" N"
p" Verdadero0Positivo!(VP)!
Falso0Positivo!(FP)!
n" Falso0Negativo!(FN)!
Verdadero0Negativo!(VN)!
!!!!!!!!!!!!!
Figura 2.1: Matriz de confusion.
El analisis ROC define ocho metricas basadas en las cuatro relaciones de la matriz de confusion:
sensibilidad (SE), especificidad (EP), probabilidad de falsa alarma (PFA), probabilidad de falsa holgu-
ra (PFH), valor de prediccion positivo (VPP), valor de prediccion negativo (VPN), exactitud (EXC)
y probabilidad del error (PE). Las metricas anteriores se encuentran en el rango de [0, 1]. Las dos
primeras metricas son las de mas amplio uso para medir la eficiencia de un sistema de clasificacion
respecto a la proporcion de VP contra FP. Dado que entre mas VP se obtengan y menos FP, el
clasificador presenta mejor rendimiento [50]. Para medir dicha proporcion se utiliza la denominada
area bajo la curva (ABC), que es una metrica que se entiende como la probabilidad de que un sistema
de clasificacion categorice a una instancia positiva mas alto que a una negativa.

2. Estado del arte 21
2.6 Metricas de desempeno para metodos de segmentacion
Debido a que un metodo de segmentacion de imagenes de mama basicamente realiza una cla-
sificacion de pıxeles en dos clases: lesion o fondo, se puede extrapolar el analisis ROC para definir
metricas que proporcionen informacion relevante sobre la calidad y rendimiento del metodo propues-
to con respecto a un “estandar de oro”2. A continuacion se describen metricas para medir distintos
aspectos de los metodos de segmentacion automatica de lesiones de mama en ultrasonografıas que
emplean caracterısticas de texturas.
1. Error de area. Esta metrica mide las diferencias de las estimaciones entre las areas delineadas
por un radiologo y el metodo de segmentacion. Para ello se definen tres medidas de error: VP
(verdadero positivo), FN (falso negativo) y FP (falso positivo) [52] de las cuales se derivan:
la sensibilidad (SE), especificidad (ES) y exactitud (EXC), que se asemejan a las mencionadas
en el analisis ROC.
2. Efectividad de generacion de la ROI [20, 21]. Esta metrica se encarga de medir la efectividad
del metodo automatico de generacion de la ROI a traves de precision ratio (PR, similar a VPP)
y recall ratio (RR, similar a SE).
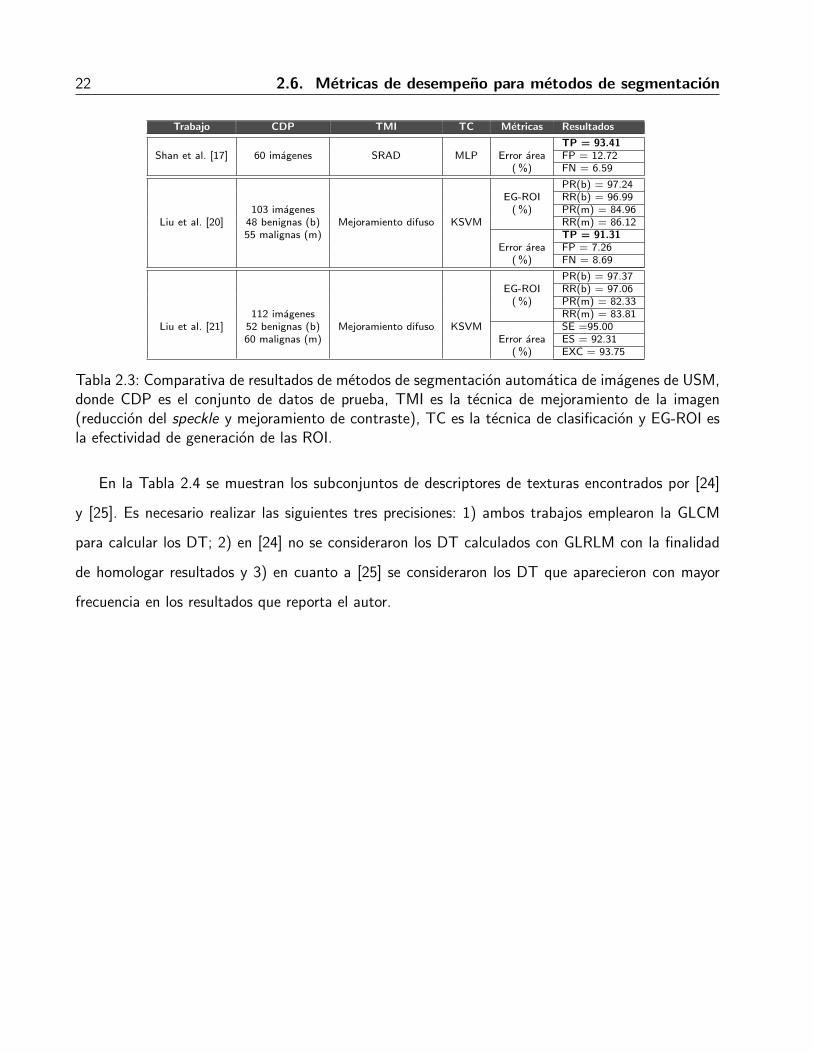
En la Tabla 2.3 se muestran los resultados reportados por tres trabajos relevantes [17, 20, 21],
descritos en la Seccion 2.2, para la segmentacion automatica de lesiones de mama en ultrasonografıas.
2Termino acunado para establecer una referencia con el cual pueda ser comparado el metodo propuesto. Paralos metodos de segmentacion automatica generalmente se les compara con imagenes marcadas manualmente porhumanos expertos (radiologos) [17, 20, 51]
22 2.6. Metricas de desempeno para metodos de segmentacion
Trabajo CDP TMI TC Metricas Resultados
Shan et al. [17]TP = 93.41
60 imagenes SRAD MLP Error area FP = 12.72( %) FN = 6.59
Liu et al. [20]
PR(b) = 97.24EG-ROI RR(b) = 96.99
103 imagenes ( %) PR(m) = 84.9648 benignas (b) Mejoramiento difuso KSVM RR(m) = 86.1255 malignas (m) TP = 91.31
Error area FP = 7.26( %) FN = 8.69
Liu et al. [21]
PR(b) = 97.37EG-ROI RR(b) = 97.06
( %) PR(m) = 82.33112 imagenes RR(m) = 83.81
52 benignas (b) Mejoramiento difuso KSVM SE =95.0060 malignas (m) Error area ES = 92.31
( %) EXC = 93.75
Tabla 2.3: Comparativa de resultados de metodos de segmentacion automatica de imagenes de USM,donde CDP es el conjunto de datos de prueba, TMI es la tecnica de mejoramiento de la imagen(reduccion del speckle y mejoramiento de contraste), TC es la tecnica de clasificacion y EG-ROI esla efectividad de generacion de las ROI.
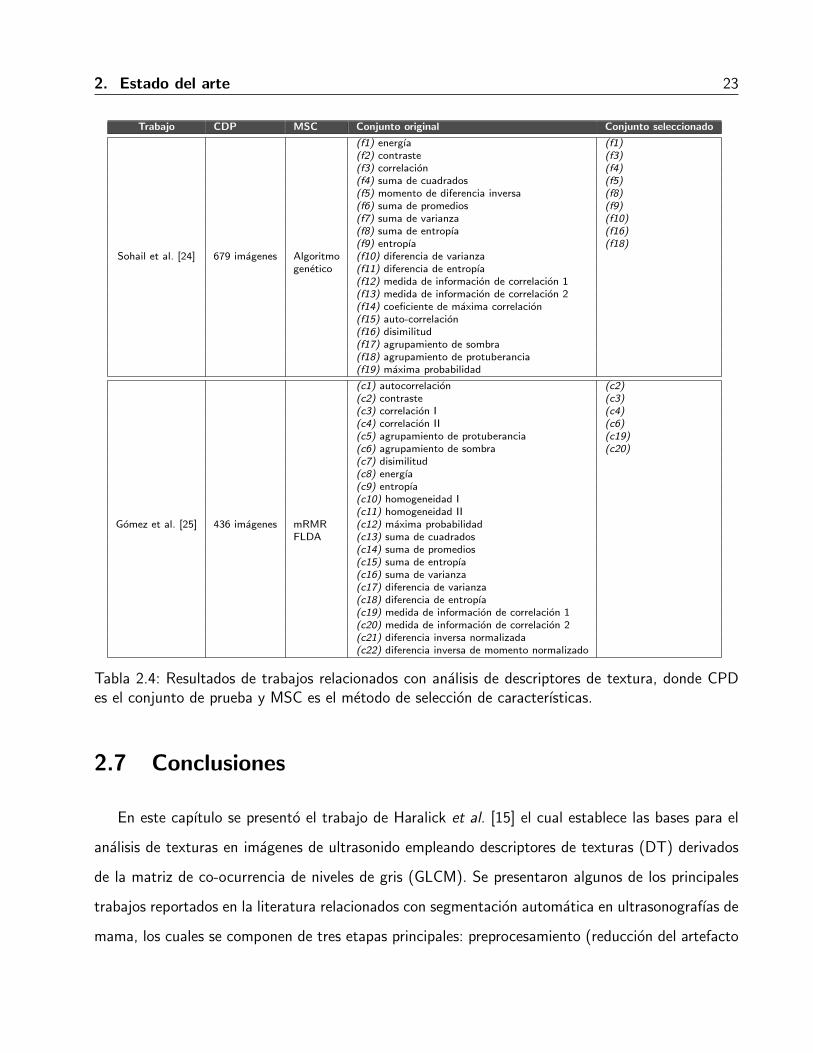
En la Tabla 2.4 se muestran los subconjuntos de descriptores de texturas encontrados por [24]
y [25]. Es necesario realizar las siguientes tres precisiones: 1) ambos trabajos emplearon la GLCM
para calcular los DT; 2) en [24] no se consideraron los DT calculados con GLRLM con la finalidad
de homologar resultados y 3) en cuanto a [25] se consideraron los DT que aparecieron con mayor
frecuencia en los resultados que reporta el autor.
2. Estado del arte 23
Trabajo CDP MSC Conjunto original Conjunto seleccionado
(f1) energıa (f1)(f2) contraste (f3)(f3) correlacion (f4)(f4) suma de cuadrados (f5)(f5) momento de diferencia inversa (f8)(f6) suma de promedios (f9)(f7) suma de varianza (f10)(f8) suma de entropıa (f16)(f9) entropıa (f18)
Sohail et al. [24] 679 imagenes Algoritmo (f10) diferencia de varianzagenetico (f11) diferencia de entropıa
(f12) medida de informacion de correlacion 1(f13) medida de informacion de correlacion 2(f14) coeficiente de maxima correlacion(f15) auto-correlacion(f16) disimilitud(f17) agrupamiento de sombra(f18) agrupamiento de protuberancia(f19) maxima probabilidad
(c1) autocorrelacion (c2)(c2) contraste (c3)(c3) correlacion I (c4)(c4) correlacion II (c6)(c5) agrupamiento de protuberancia (c19)(c6) agrupamiento de sombra (c20)(c7) disimilitud(c8) energıa(c9) entropıa(c10) homogeneidad I(c11) homogeneidad II
Gomez et al. [25] 436 imagenes mRMR (c12) maxima probabilidadFLDA (c13) suma de cuadrados
(c14) suma de promedios(c15) suma de entropıa(c16) suma de varianza(c17) diferencia de varianza(c18) diferencia de entropıa(c19) medida de informacion de correlacion 1(c20) medida de informacion de correlacion 2(c21) diferencia inversa normalizada(c22) diferencia inversa de momento normalizado
Tabla 2.4: Resultados de trabajos relacionados con analisis de descriptores de textura, donde CPDes el conjunto de prueba y MSC es el metodo de seleccion de caracterısticas.
2.7 Conclusiones
En este capıtulo se presento el trabajo de Haralick et al. [15] el cual establece las bases para el
analisis de texturas en imagenes de ultrasonido empleando descriptores de texturas (DT) derivados
de la matriz de co-ocurrencia de niveles de gris (GLCM). Se presentaron algunos de los principales
trabajos reportados en la literatura relacionados con segmentacion automatica en ultrasonografıas de
mama, los cuales se componen de tres etapas principales: preprocesamiento (reduccion del artefacto

24 2.7. Conclusiones
speckle y mejoramiento de contraste), extraccion de caracterısticas basadas en la GLCM y clasifica-
cion, en esta ultima emplean tecnicas como la maquina de vectores de soporte con funcion de nucleo
y redes neuronales. Estos trabajos presentan un buen desempeno pero no dejan claro como fueron
seleccionadas las caracterısticas de texturas empleadas. Otros trabajos de relevancia en el analisis de
texturas son los que presentan Sohail et al. [24] y Gomez et al. [25], los cuales evaluan conjuntos de
descriptores de texturas basados en la GLCM para problemas relacionados con imagenes de ultraso-
nido, aunque no precisamente para el problema de segmentacion automatica, pero de alguna forma
aportan informacion relevante para dicho problema, como es la determinacion optima del nivel de
cuantificacion de niveles de gris para la generacion de la GLCM.
Otro elemento fundamental que se presento en este capıtulo son las metricas con las cuales se
mide la eficacia tanto de las tecnicas de clasificacion como de los metodos de segmentacion de
imagenes de ultrasonido de mama. Para evaluar las tecnicas de clasificacion se utilizo el analisis ROC
y para los metodos de segmentacion, metricas basadas en las diferencias de areas entre la segmen-
tacion manual y la segmentacion automatica.
De lo anterior se observa que los DT derivados de la GLCM son caracterısticas importantes de
las texturas con las cuales se pueden obtener buenos resultados para el problema de segmentacion
automatica en ultrasonografıas. Sin embargo, existen elementos que no han sido explorados y con
los que se cree, se puede mejorar los resultados reportados en la literatura. Uno de estos elementos
es la seleccion metodologica y objetiva de las caracterısticas de texturas basadas en la GLCM, dado
que lo que se reporta en la literatura se realiza de forma heurıstica. Otro elemento es la evaluacion
de diversas tecnicas de preprocesamiento y clasificacion para determinar las que mejor se ajusten a
dicho problema y mejoren los resultados.

3Marco teorico
3.1 Introduccion
En este capıtulo se describen teoricamente las diversas herramientas y tecnicas empleadas en
este trabajo de tesis. El capıtulo esta estructurado en tres secciones: preprocesamiento, extraccion y
seleccion de caracterısticas, y clasificacion. En la seccion de preprocesamiento se definen las tecni-
cas para mejorar el contraste y de reduccion del artefacto speckle. En la seccion de extraccion y
seleccion de caracterısticas se describen los descriptores de texturas relacionadas con la matriz de
co-ocurrencia de niveles de gris, ası como los criterios de ordenamiento de dichas caracterısticas. En
la seccion de clasificacion se detallan tres clasificadores: uno lineal y dos no lineales. Por otra parte, se
presenta la descripcion de la tecnica de estimacion del error de clasificacion llamada bootstrap .632+.
25

26 3.2. Preprocesamiento
3.2 Preprocesamiento
El preprocesamiento de una imagen es una etapa importante en la mayorıa de los sistemas de
procesamiento digital de imagenes, debido a que durante el proceso de adquisicion de la imagen, esta
se contamina con algun tipo de ruido o son alteradas sus caracterısticas (como contraste, iluminacion,
etc.) [53], por lo que es necesario aplicar tecnicas que mejoren la calidad de la imagen sin que se pierda
informacion relevante. Las imagenes de ultrasonido de mama presentan dos principales inconvenientes
cuando se trabaja con ellas [20]: el artefacto speckle, que se puede modelar como ruido multiplicativo,
y el bajo contraste. A continuacion se describen algunas tecnicas relevantes de preprocesamiento, las
cuales estan relacionadas con el problema de clasificacion basado en caracterısticas de texturas.
3.2.1 Tecnicas para mejorar el contraste
3.2.1.1. Enfoque difuso
Las tecnicas que implementan el enfoque difuso ofrecen una marco de trabajo no lineal basado
en el conocimiento de un dominio en particular, con el fin de hacer frente a las ambiguedades y va-
guedades que regularmente se presentan en imagenes de ultrasonido de mama [54, 8]. Por ejemplo,
las formas de las lesiones, bordes mal definidos o las diferentes densidades que presentan los tumores.
La tecnica difusa implementada en este trabajo se basa en el trabajo publicado por de Guo
et al. [8]. Este enfoque normaliza los niveles de gris, g, de la imagen de ultrasonido de mama
en un rango entre [gmin, gmax]. Posteriormente aplica un proceso de fusificacion, el cual consiste en
mapear los valores de los niveles de gris de la imagen con sus correspondientes valores de pertenencia
(comprendidos entre [0, 1]), en relacion a una determinada categorıa (lesion o fondo), a traves de
una funcion de membresıa de tipo sigmoidal. Esta funcion se muestra en la Ecuacion 3.1, donde x y
z son el primero y ultimo maximo local respectivamente, del histograma de la imagen h(g), e y es
el valor umbral que divide los grados de pertenencia correspondientes con lo que se considera lesion

3. Marco teorico 27
o fondo en la imagen, esto es:
f(g;x, y, z) =
0 g ≤ x
(g−x)2
(y−x)(z−x)x ≤ g ≤ y
1− (g−z)2(z−y)(z−x)
y ≤ g ≤ z
1 g ≥ z
(3.1)
Para determinar el valor de y se emplea el principio de maxima entropıa, el cual consiste en dividir
en dos partes h(g) para cada nivel de intensidad, esto es, sea t = 1, . . . ,M el valor de intensidad
actual, donde M es el valor maximo de intensidad, entonces h1(t) comprende el intervalo [h(1), h(t)]
y h2(t) esta en el rango [h(t+ 1), h(M)]. Las entropıas H1 y H2, a partir de h1 y de h2, se calculan
como:
H1(t) = −t∑i=1
p(i)
p(t)lnp(i)
p(t)
H2(t) = −M∑
i=t+1
p(i)
1− p(t) lnp(i)
1− p(t)
(3.2)
donde p(t) =∑t
i=1 p(i) y p(i) es la probabilidad por nivel de intensidad. Posteriormente se suman
las entropıas para cada nivel de intensidad. Por tanto, y sera el nivel de intensidad donde la suma
de ambas entropıas se maximice:
y = arg maxt
(H1(t) +H2(t)) (3.3)
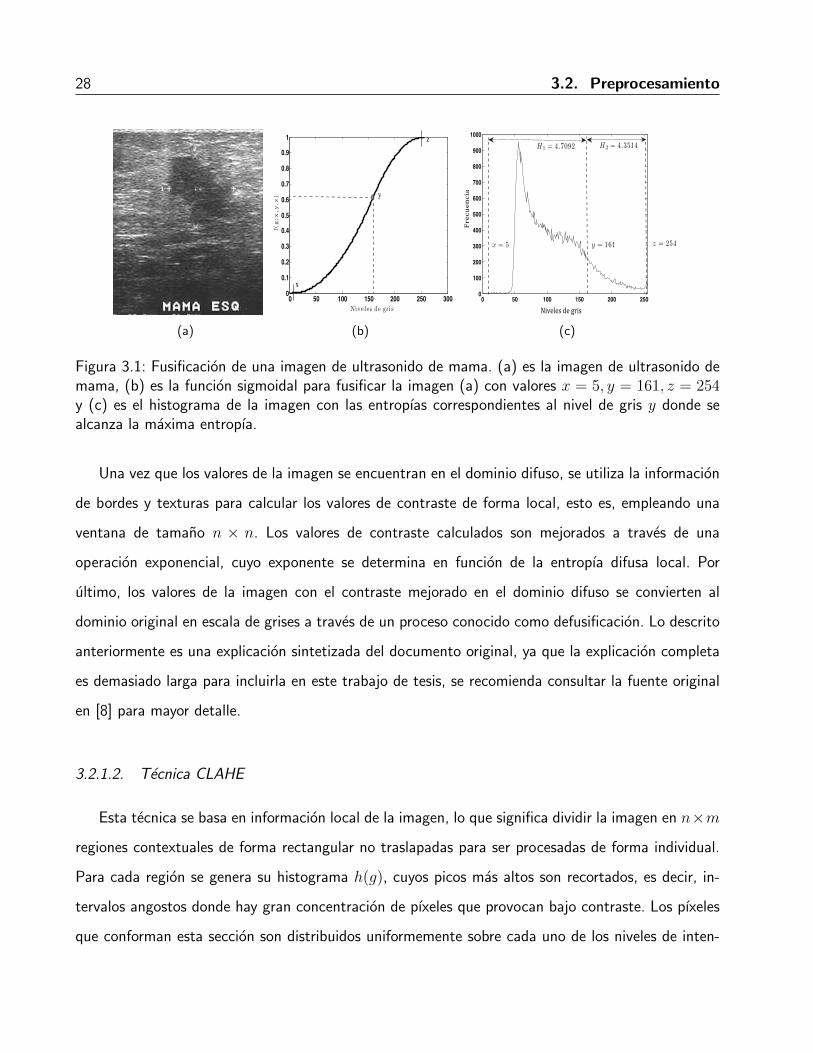
En la Figura 3.1 se muestra un ejemplo de la grafica de la funcion de membresıa y sus respectivos
valores x, y, z para una imagen de USM.
28 3.2. Preprocesamiento
(a)
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
(b)
######################
##
#
0 50 100 150 200 2500
100
200
300
400
500
600
700
800
900
1000
H1 = 4.7092 H2 = 4.3514
x = 5 y = 161 z = 254
Niveles#de#gris#
Frecuencia#
(c)
Figura 3.1: Fusificacion de una imagen de ultrasonido de mama. (a) es la imagen de ultrasonido demama, (b) es la funcion sigmoidal para fusificar la imagen (a) con valores x = 5, y = 161, z = 254y (c) es el histograma de la imagen con las entropıas correspondientes al nivel de gris y donde sealcanza la maxima entropıa.
Una vez que los valores de la imagen se encuentran en el dominio difuso, se utiliza la informacion
de bordes y texturas para calcular los valores de contraste de forma local, esto es, empleando una
ventana de tamano n × n. Los valores de contraste calculados son mejorados a traves de una
operacion exponencial, cuyo exponente se determina en funcion de la entropıa difusa local. Por
ultimo, los valores de la imagen con el contraste mejorado en el dominio difuso se convierten al
dominio original en escala de grises a traves de un proceso conocido como defusificacion. Lo descrito
anteriormente es una explicacion sintetizada del documento original, ya que la explicacion completa
es demasiado larga para incluirla en este trabajo de tesis, se recomienda consultar la fuente original
en [8] para mayor detalle.
3.2.1.2. Tecnica CLAHE
Esta tecnica se basa en informacion local de la imagen, lo que significa dividir la imagen en n×mregiones contextuales de forma rectangular no traslapadas para ser procesadas de forma individual.
Para cada region se genera su histograma h(g), cuyos picos mas altos son recortados, es decir, in-
tervalos angostos donde hay gran concentracion de pıxeles que provocan bajo contraste. Los pıxeles
que conforman esta seccion son distribuidos uniformemente sobre cada uno de los niveles de inten-
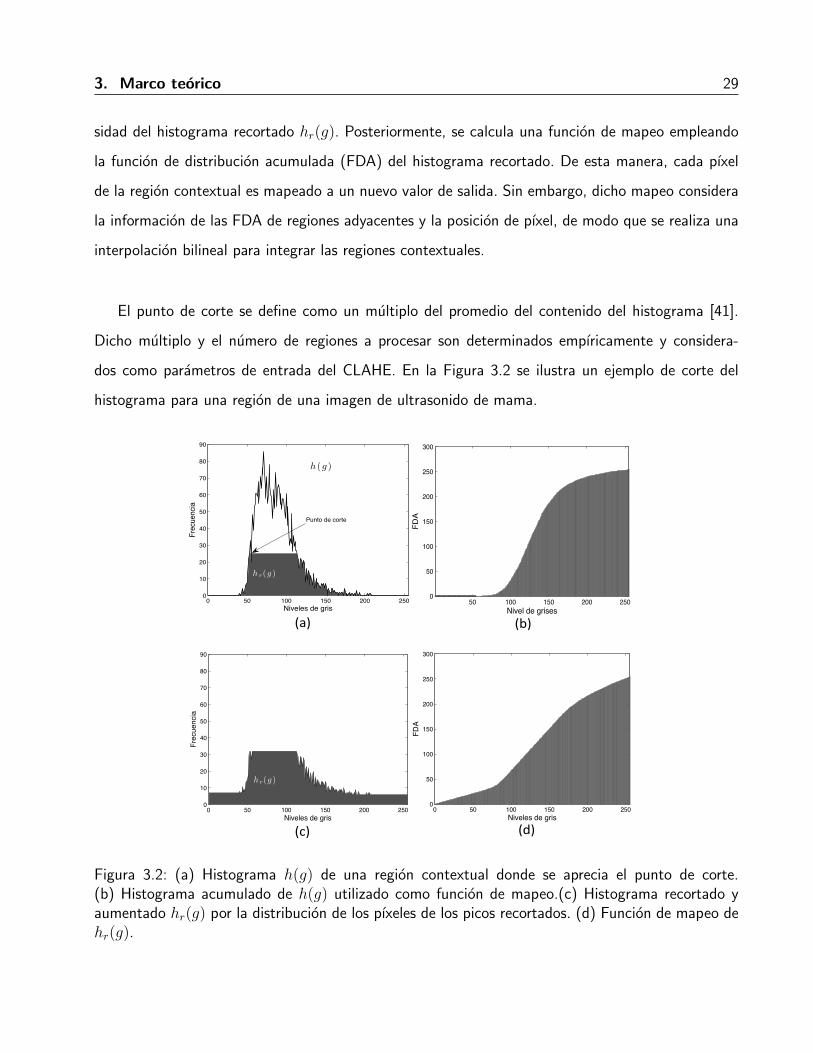
3. Marco teorico 29
sidad del histograma recortado hr(g). Posteriormente, se calcula una funcion de mapeo empleando
la funcion de distribucion acumulada (FDA) del histograma recortado. De esta manera, cada pıxel
de la region contextual es mapeado a un nuevo valor de salida. Sin embargo, dicho mapeo considera
la informacion de las FDA de regiones adyacentes y la posicion de pıxel, de modo que se realiza una
interpolacion bilineal para integrar las regiones contextuales.
El punto de corte se define como un multiplo del promedio del contenido del histograma [41].
Dicho multiplo y el numero de regiones a procesar son determinados empıricamente y considera-
dos como parametros de entrada del CLAHE. En la Figura 3.2 se ilustra un ejemplo de corte del
histograma para una region de una imagen de ultrasonido de mama.
0 50 100 150 200 2500
10
20
30
40
50
60
70
80
90
Niveles de gris
Frec
uenc
ia
h(g)
Punto de corte
h r(g )
0 50 100 150 200 2500
10
20
30
40
50
60
70
80
90
Niveles de gris
Frec
uenc
ia
h r(g )
50 100 150 200 2500
50
100
150
200
250
300
Nivel de grises
FDA
0 50 100 150 200 2500
50
100
150
200
250
300
Niveles de gris
FDA
'(a)'
'(b)'
'(c)'
'(d)'
Figura 3.2: (a) Histograma h(g) de una region contextual donde se aprecia el punto de corte.(b) Histograma acumulado de h(g) utilizado como funcion de mapeo.(c) Histograma recortado yaumentado hr(g) por la distribucion de los pıxeles de los picos recortados. (d) Funcion de mapeo dehr(g).

30 3.2. Preprocesamiento
3.2.1.3. Tecnica Auto-CLAHE
Esta tecnica es una modificacion del CLAHE [41], la cual consiste en determinar, a traves del
principio de maxima entropıa descrito en el enfoque difuso, el valor del punto de corte de forma
automatica empleando la siguiente expresion:
c = 1− h(y)
max(h)(3.4)
donde h(·) es el histograma de la region, e y es el umbral (nivel de gris) calculado con la Ecuacion 3.3.
3.2.1.4. Tecnica FAHE
Esta tecnica es un hıbrido entre el CLAHE [41] y el enfoque difuso [8]. Primeramente la imagen
es dividida en regiones contextuales, similar al CLAHE, posteriormente cada region es fusificada
siguiendo el principio de maxima entropıa con la finalidad de establecer el porcentaje de pertenencia
de cada pıxel tanto a la lesion como al fondo de la imagen. Una vez procesadas todas las regiones,
se realiza la integracion de las mismas a traves de una interpolacion bilineal. Por ultimo, se defusifica
la imagen por regiones y se vuelve a integrar. En la Figura 3.3 se ilustra el diagrama a bloques de
esta tecnica.

3. Marco teorico 31
1.'Imagen'original'normalizada'
2.'División'por'regiones'
3.'Funciones'de'fusificación'por'región'
7.'Imagen'integrada'y'mejorada'
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
0 50 100 150 200 250 3000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Nive l e s de gri s
f(g;x,y,z)
z
y
x
G1'
4.'Funciones'de'defusificación'por'región'
5.'Fusificación'bilineal'
6.'Defusificación'bilineal'
Figura 3.3: Tecnica FAHE.
3.2.2 Tecnicas de reduccion del speckle
Los filtros suavizantes son tecnicas para reducir el ruido o artefactos que contaminan y degra-
dan la calidad de una imagen. En una imagen de ultrasonido de mama el artefacto speckle es una
caracterıstica inherente que provoca un impacto negativo en la imagen. Para reducirlo, se han pro-
puesto diversos filtros en los dominios del espacio y la frecuencia. Si se disena un filtro en el dominio
espacial, el valor de cada pıxel se modifica en funcion de las intensidades de sus vecinos (dentro de
una ventana definida) dado un operador lineal o no lineal. Por otro lado, si el filtro de disena en el
dominio de la frecuencia, una banda especıfica del espectro es atenuada para reducir su influencia
en los valores de intensidad de los pıxeles.
Cuando se construye un filtro para imagenes de ultrasonido de mama, debe considerarse el
compromiso entre el grado de suavizado y la preservacion de detalles finos como los bordes de las
lesiones. Por tanto, varias propuestas se han enfocado a balancear estos dos elementos.

32 3.2. Preprocesamiento
3.2.2.1. Filtro Kuan
El filtro Kuan es un filtro lineal que pertenece a la categorıa de los filtros promedio adaptativo,
los cuales se adaptan a las propiedades de la imagen localmente y, de manera selectiva, eliminan
elementos espurios de diferentes partes de la imagen. El filtro Kuan es uno de los mas utilizados para
reducir el artefacto speckle [7, 53]. Este considera un modelo de speckle como y = x + (n − 1)x,
donde n es el ruido multiplicativo estacionario con media unitaria, x es el pıxel original (sin ruido), e
y es el pıxel observado (con ruido). Ademas, se basa en el criterio del mınimo error cuadratico medio
para estimar el valor de x, es decir, x [33], el cual se define como:
x = y +σ2x(y − y)
σ2x +
(y2 + σ2x)
L
(3.5)
donde σ2x =
Lσ2y − y2
L+ 1y L =
1
σ2n
. y y σy son la media y desviacion estandar de y estimadas
localmente (dentro de una ventana de tamano fijo) y L =
(y
σy
)2
=1
σ2n
.
3.2.2.2. Filtro mediana
El filtro mediana es considerado como no lineal y de orden estadıstico [7]. Este modifica el
valor de cada pıxel I(x, y) con I ′(x, y), el cual representa el valor de la mediana Me de los valores
ordenados, x1, x2, x3, . . . , xn de los pıxeles que integran su ventana de vecindad R(x, y). Esto es,
I ′(x, y) = Me(R(x, y)), donde la mediana queda definida como:
Me =
xn+1
2n =impar
xn2
+ xn+12
2n =par
(3.6)

3. Marco teorico 33
3.2.2.3. Filtro anisotropico + Gabor I y II
Este filtro es una modificacion del trabajo publicado por Miguel Aleman-Flores et al.[55] el cual
se basa en el filtro de difusion anisotropico (FDAp) guiado por descriptores de textura. Dado que
el tejido mamario presenta diversas texturas, estas pueden ser caracterizadas a partir de filtros de
Gabor. El modelo matematico del FDAp se expresa por la ecuacion diferencial parcial siguiente:
∂I(x, y)
∂t= ∇ · [c (|∇R (x, y)|)∇I (x, y)] (3.7)
donde I es la imagen con ruido,∇ y∇· son el gradiente y el operador de divergencia, respectivamente.
|·| es la magnitud y c(·) es el coeficiente de difusion. Para este ultimo, se puede emplear una de las
dos definiciones expresadas en las Ecuaciones 3.8 y 3.9, los cuales dan origen al nombre de la tecnica
como I y II, respectivamente.
c · [∇I (x, y)] = exp[−(|∇I(x,y)|ρ)2] (3.8)
c · [∇I (x, y)] =[1 + (|∇I (x, y)|ρ)2
]−1(3.9)
donde ρ es una constante que controla la extension de la difusion. El termino R en la Ecuacion 3.7,
denota el vector formado por las respuestas de la familia de filtros de Gabor aplicados a la imagen I.
En [55], la imagen con ruido I es convolucionada con los kernels de Gabor, h, cuyos coeficientes
son calculados por medio de la configuracion heurıstica de la frecuencia espacial, k, y escala, σ.
Nosotros creemos que este enfoque no es el mas adecuado, ya que k y σ estan relacionados con
el tamano del ancho de la imagen (w, en pıxeles), el cual varıa entre las imagenes de ultrasonido.
Por tanto, sugerimos calcular los filtros de Gabor en el dominio de la frecuencia como se muestra a

34 3.2. Preprocesamiento
continuacion:
H (u, v) = exp
−1
2
[(u′ − u0)2
σ2u
+v′2
σ2v
]+ exp
−1
2
[(u′ + u0)2
σ2u
+v′2
σ2v
](3.10)
donde σu = σv = 1/2πσ, con σ = 0.31/u0 y u0 denota la frecuencia radial, cuyos valores son
calculados como 1√
2, 2√
2, 4√
2, ..., y (w/4)√
2 ciclos/ancho de la imagen, u′ = u cos θ+ v sin θ y
v′ = v cos θ − u sin θ donde las orientaciones θ toman valores 0, π4, π
2, 3π
4.
Finalmente, por el teorema de convolucion, la imagen I se filtra con los kernels de Gabor, lo que
se expresa como:
I (x, y) ∗ h (x, y) = F−1 H (u, v) · F [I (x, y)] (3.11)
donde F y F−1 son la transformada de Fourier y su inversa, respectivamente.
En las Figuras 3.4 y 3.5 se muestran los resultados de la aplicacion de las cuatro tecnicas de
mejora de contraste y de reduccion del artefacto speckle (filtros), respectivamente, en una imagen
de ultrasonido de mama.
Imagen'original' Difuso' CLAHE'
AutoPCLAHE''' FAHE''
(a)Imagen'original' Difuso' CLAHE'
AutoPCLAHE''' FAHE''
(b)Imagen'original' Difuso' CLAHE'
AutoPCLAHE''' FAHE''
(c)
Imagen'original' Difuso' CLAHE'
AutoPCLAHE''' FAHE''(d)
Imagen'original' Difuso' CLAHE'
AutoPCLAHE''' FAHE''(e)
Figura 3.4: Aplicacion de las tecnicas para mejorar el contraste (a) imagen original, (b) enfoquedifuso, (c) CLAHE, (d) auto-CLAHE y (e) FAHE.

3. Marco teorico 35
Imagen'original' Difuso' CLAHE'
AutoPCLAHE''' FAHE''
(a)
Original Mediana Anisotrópico + Gabor 1
Anisotrópico + Gabor 2 Kuan
(b)
Original Mediana Anisotrópico + Gabor 1
Anisotrópico + Gabor 2 Kuan
(c)
Original Mediana Anisotrópico + Gabor 1
Anisotrópico + Gabor 2 Kuan
(d)
Original Mediana Anisotrópico + Gabor 1
Anisotrópico + Gabor 2 Kuan
(e)
Figura 3.5: Aplicacion de las tecnicas para reducir el artefacto speckle (a) imagen original, (b) filtromediana, (c) filtro anisotropico + Gabor I, (d) filtro anisotropico + Gabor II y (e) filtro Kuan.
3.3 Extraccion y seleccion de caracterısticas
En la mayorıa de los problemas de clasificacion se recurre previamente a la extraccion y seleccion
de caracterısticas con la intencion de reducir la dimensionalidad de las mismas; dado que el numero
de caracterısticas que presenta este tipo de problemas suele ser generalmente grande.
En las imagenes de ultrasonido de mama las caracterısticas se pueden agrupar en cuatro categorıas
[7]: de textura, morfologicas, basada en modelos y descriptores de caracterısticas. Para efectos de
este trabajo solo se consideran caracterısticas de textura que se basan en la matriz de co-ocurrencia
de niveles de gris y que a continuacion se describen.
3.3.1 Matriz de co-ocurrencia de niveles de gris (GLCM)
La textura es una propiedad que se encuentra presente en las imagenes digitales y puede ser
utilizada para caracterizar objetos dentro de la misma. La textura puede definirse como la distribucion
espacial (estadısticos) de las variaciones tonales de color [12, 15]. Haralick et al. en [15] proponen
obtener caracterısticas de textura a traves de la relacion espacial de un conjunto de niveles de gris.
A esta relacion se le conoce como matriz de co-ocurrencia de niveles de gris (GLCM, por sus siglas
en ingles), la cual se define como:

36 3.3. Extraccion y seleccion de caracterısticas
Cd,θ(i, j, d, θ) =
∥∥∥∥∥∥∥∥∥
((x1, y1), (x2, y2))|x2 − x1 = d cos(θ), y2 − y1 = d sin(θ),
I(x1, y1) = i, I(x2, y2) = j
∥∥∥∥∥∥∥∥∥ (3.12)
donde d y θ son la distancia y direccion, respectivamente, a la que se encuentran dos niveles de gris i
y j (uno del otro) correspondientes a los pıxeles (x1, y1) y (x2, y2). I(· ) es la funcion que devuelve el
nivel de gris de un pıxel y ‖· ‖ es el numero de parejas de pıxeles que satisfacen la condicion espacial
para los niveles de gris. En la Figura 3.6 (a) se ilustra la relacion espacial (d, θ) entre dos pıxeles. En
la Figura 3.6 (b) se da un ejemplo de la generacion de una GLCM.
El numero de niveles de gris es un aspecto importante a considerar para la generacion de la
GLCM, dado que entre mayor sea este, mayor sera el coste computacional. Por ello es necesario
realizar un proceso de cuantificacion (o escalamiento) de niveles de gris, de tal forma que se reduzca
el coste computacional sin que se vea afectada la informacion relevante de la textura. Gomez et al.
en [25] sugieren utilizar 64 niveles de gris.
3.3.2 Descriptores de Textura (DT)
Los DT se entienden como la representacion matematica de las propiedades que presentan las
texturas [12]. Estos proporcionan informacion textural de la imagen, la cual puede utilizarse para
caracterizar una determinada region. En la Tabla 3.1 se definen 22 descriptores de textura basados
en la GLCM y en la Tabla 3.2 se definen los terminos empleados en el calculo de los DT de la Tabla 3.1

3. Marco teorico 37
0" 1" 2" 3 6" 5" 6" 7" 8"
0" 0" 0" 2( 0 0" 0" 0" 0" 0"
1" 0"" 1( 0" 0 0" 1( 0" 0" 0"
2" 0" 0" 0" 2 0" 0" 0" 0" 0"
3" 0" 0" 0" 0 0" 2( 0" 0" 0"
4" 0" 0" 0" 0 0" 0" 0" 0" 0"
5" 0" 0" 0" 0 0" 0" 2( 1( 0"
6" 0" 0" 0" 0 0" 0" 0" 1( 1(
7" 1( 0" 0" 0 0" 0" 0" 0" 0"
8" 0" 0" 0" 0 0" 0" 0" 0" 1(
x24,y24"
x24,y24"
x24,y24
x14,y14 x24,y24"
1 1 5 6 8 8
2 3 5 7 0 2
0 2 3 5 6 7
Imagen"original"""
Niveles"de"gris"
Matriz"de"CoLocurrencia"de"niveles"de"gris"(GLCM)"
20"
Valores"de"los"niveles"de"gris"de"la"imagen"
original"""
GLCM"(d=1,4Ө=40°)"
d=2,4Ө=0°4
d=2,4Ө=90°4
(a)
0" 1" 2" 3 6" 5" 6" 7" 8"
0" 0" 0" 2( 0 0" 0" 0" 0" 0"
1" 0"" 1( 0" 0 0" 1( 0" 0" 0"
2" 0" 0" 0" 2 0" 0" 0" 0" 0"
3" 0" 0" 0" 0 0" 2( 0" 0" 0"
4" 0" 0" 0" 0 0" 0" 0" 0" 0"
5" 0" 0" 0" 0 0" 0" 2( 1( 0"
6" 0" 0" 0" 0 0" 0" 0" 1( 1(
7" 1( 0" 0" 0 0" 0" 0" 0" 0"
8" 0" 0" 0" 0 0" 0" 0" 0" 1(
x24,y24"
x24,y24"
x24,y24
x14,y14 x24,y24"
1 1 5 6 8 8
2 3 5 7 0 2
0 2 3 5 6 7
Imagen"original"""
Niveles"de"gris"
Matriz"de"CoLocurrencia"de"niveles"de"gris"(GLCM)"
20"
Valores"de"los"niveles"de"gris"de"la"imagen"
original"""
GLCM"(d=1,4Ө=40°)"
d=2,4Ө=0°4
d=2,4Ө=90°4
(b)
Figura 3.6: Generacion de la GLCM para una imagen con nueve niveles de gris. (a) relacion espacialentre dos pıxeles para las cuatro distintas orientaciones (0, 45, 90 y 135) a una distancia de 2.(b) ejemplo de la GLCM con orientacion de θ = 0 y una distancia d = 1 generada a partir de unaimagen en escala de grises.

38 3.3. Extraccion y seleccion de caracterısticas
DT Descripcion Ecuacion Referencia
f1 Auto-correlacion∑i
∑j
(i · j)p(i, j) [27]
f2 Contraste∑i
∑j
|i− j|2p(i, j)
f3 Correlacion I∑i
∑j
(i− µx)(j − µy)p(i, j)σxσy
[56]
f4 Correlacion II∑i
∑j
(i · j)p(i, j)− µxµyσxσy
[27]
f5 Agrupamiento de protuberan-
cia
∑i
∑j
(i+ j − µx − µy)4p(i, j) [27]
f6 Agrupamiento de sombras∑i
∑j
(i+ j − µx − µy)3p(i, j) [27]
f7 Disimilaridad∑i
∑j
|i− j| · p(i, j) [27]
f8 Energıa∑i
∑j
p(i, j)2 [27]
f9 Entropıa −∑i
∑j
p(i, j) · log(p(i, j)) [27]
f10 Homogeneidad I∑i
∑j
p(i, j)
1 + |i− j|f11 Homogeneidad II
∑i
∑j
p(i, j)
1 + |i− j|2[27]
f12 Maxima probabilidad maxi,j
p(i, j) [27]
f13 Suma de cuadrados∑i
∑j
(i− ν)2p(i, j) [15]
f14 Suma de promedios2L∑i=2
i · px+y(i) [15]
f15 Suma de entropıa −2L∑i=2
px+y(i) · log(px+y(i)) [15]
f16 Suma de varianza2L∑i=2
(i− F15)2 · px+y(i) [15]
f17 Diferencia de varianzaL−1∑i=0
i2 · px−y(i) [15]
f18 Diferencia de entropıa −L−1∑i=0
px−y(i) · log(px−y(i)) [15]
f19 Medida de informacion de co-
rrelacion I
H(X, Y )−H1(X, Y )
max(H(X), H(Y ))[15]

3. Marco teorico 39
f20 Medida de informacion de co-
rrelacion II
(1− exp[−2(H2(X, Y )−H(X, Y ))])1/2 [15]
f21 Diferencia inversa normaliza-
da
∑i
∑j
p(i, j)
1 + |i− j|2/L
[57]
f22 Momento de diferencia inver-
so normalizado
∑i
∑j
p(i, j)
1 + (i− j)2/L [57]
Tabla 3.1: Descriptores de textura de la GLCM.

40 3.3. Extraccion y seleccion de caracterısticas
Termino Definicionp(i, j) Valor de la probabilidad del elemento (i, j) en la GLCM
Ng Numero de niveles de gris cuantificados en la imagen.
px(i) Probabilidad marginal de la suma de probabilidades de losrenglones para la columna i, =
∑Ngj=1 p(i, j)
py(j) Probabilidad marginal de la suma de probabilidades de lascolumnas para el renglon j, =
∑Ngi=1 p(i, j)
µx, µy, σx, σy Son los promedios y desviaciones estandar de px y py
px+y(k)Ng∑i=1
Ng∑j=1
p(i, j)
i+j=k
, k = 2, 3, · · · , 2Ng
px−y(k)Ng∑i=1
Ng∑j=1
p(i, j)
|i−j|=k
, k = 0, 1, · · · , Ng − 1
H(X) y H(Y ) Son las entropıas de px y py respectivamente.
H(X, Y ) −Ng∑i=1
Ng∑j=1
P (i, j) log(P (i, j))
H1(X, Y ) −Ng∑i=1
Ng∑j=1
P (i, j) log(px(i)py(j))
H2(X, Y ) −Ng∑i=1
Ng∑j=1
Px(i)py(j) log(px(i)py(j))
Tabla 3.2: Descripcion de terminos para la generacion de los DT.

3. Marco teorico 41
3.3.3 Normalizacion y discretizacion
Normalizacion. Es un proceso de transformacion de valores de datos con distintos rangos dinami-
cos a un rango unico. Para ello se emplea la siguiente ecuacion:
x = mins + (maxs −mins)
(x−min
max−min
)(3.13)
donde maxs y mins son los valores maximo y mınimo, respectivamente, para el rango de valores
al que se desea transformar. Generalmente, max y min representan el valor maximo y mınimo del
rango de valores de los datos originales. x es el valor original de un dato en particular y x es su valor
normalizado.
Discretizacion. Un aspecto a considerar cuando se desea procesar informacion es el dominio en
el que se encuentran los valores de los datos. Por ejemplo, los datos generalmente se normalizan
en un rango de valores continuos [a, b], pero la mayorıa de las veces los algoritmos que procesaran
dicha informacion requieren los datos con valores discretos. Por tanto, la discretizacion consiste en
transformar valores que se encuentran en el dominio continuo al dominio discreto [58]. Para realizar
esta transformacion se puede emplear una tecnica basada en cuantiles. Esto es, sea A un conjunto
de valores continuos definido como: A = x|x ∈ [a, b], para a, b ∈ Z, entonces se calcula el numero
de intervalos a discretizar m aplicando la Ecuacion 3.14 donde c es un parametro de entrada definido
empıricamente para limitar el numero de intervalos. Posteriormente, se obtienen los valores de los
cuantiles que representan los valores de corte de cada uno de los m intervalos, para ello se emplea la
Ecuacion 3.15, donde p(k) =k
mpara k = 1, 2, 3, . . . ,m−1 y Q(·) es la funcion cuantil. Por ultimo,
se determina a que intervalo discreto pertenece cada valor continuo empleando el siguiente criterio:
si qi < x ≤ qi+1 entonces xdiscreto = i+ 1.
m = min(log 2(|A|),√|A|/c) (3.14)
q1, q2, · · · qm = Q(A, p(k)) (3.15)

42 3.3. Extraccion y seleccion de caracterısticas
3.3.4 Ordenamiento de caracterısticas
Ordenar las caracterısticas de acuerdo con su capacidad para describir un objeto simplifica el
proceso de seleccion de caracterısticas, ya que una vez ordenadas solo se tiene que determinar cuantas
de ellas seran consideradas para la clasificacion. Dos de las principales criterios de ordenamiento de
caracterısticas son la razon discriminante de Fisher (FDR) y el criterio de mınima-redundancia-
maxima-relevancia (mRMR).
3.3.4.1. Razon discriminante de Fisher (FDR)
El criterio FDR se basa en las medias y varianzas de cada caracterıstica en relacion a cada una
de las dos clases (e.g. lesion o fondo). De esta manera se cuantifica el poder discriminatorio de cada
caracterıstica entre dos clases equiprobables [59]. La FDR se define como:
FDR =(m1 −m2)2
(σ21 + σ2
2)(3.16)
donde m y σ2 son la media y la varianza de una caracterıstica en particular asociada a la clase
(subındices) 1 o 2.
Para determinar el orden de las caracterısticas, se calcula el FDR para cada caracterıstica y se
ordenan en forma descendente.
3.3.4.2. Criterio de mınima-redundancia-maxima-relevancia (mRMR)
El criterio mRMR es una derivacion del criterio de Maxima Dependencia (MD) [30]. Este ultimo
tiene como proposito encontrar a partir de un espacio M-dimensional de caracterısticas, RM , un
subespacio de m caracterısticas, Rm, (con m < M) que generen la maxima dependencia respecto a
los valores de clase c. Sea S = xi, i = 1, . . . ,m un subespacio de m caracterısticas, entonces el

3. Marco teorico 43
criterio MD se define como max(I(S, c)), donde I es la informacion mutua definida como:
I(xi, c) = H (xi) +H (c)−H (xi, c) (3.17)
donde H (xi) y H (c) son las entropıas de la caracterıstica i y de los valores de clase c, respectiva-
mente, y H (xi, c) es la entropıa conjunta de la caracterıstica i y de la clase c.
Encontrar la MD de un conjunto de caracterısticas es una tarea difıcil, debido a la alta di-
mensionalidad y calculos complejos que esto implica, es por eso que Peng et al. [30] proponen el
criterio mRMR, el cual esta seccionado en dos partes. La primera es encontrar las caracterısticas
que maximicen la relevancia, que son aquellas que satisfacen la Ecuacion 3.18 y que representan una
aproximacion al criterio MD.
maxD(S, c), D =1
m
∑xi∈S
I(xi; c) (3.18)
La segunda parte consiste en minimizar la redundancia (R) entre las caracterısticas seleccionadas
con maxima relevancia, es decir, si dos variables presentan alta dependencia, entonces el poder
discriminatorio no disminuira si se excluye alguna de ellas. La Ecuacion 3.19 puede aplicarse para
seleccionar las caracterısticas mutuamente excluyentes bajo la condicion de mınima redundancia.
minR(S),R =1
m2
∑xi,xj∈S
I(xi;xj) (3.19)
Por ultimo, se combinan ambas condiciones (caracterısticas con maxima relevancia y mınima
redundancia). Para lo cual se emplea el operador Φ(D,R) y cuyo maximo optimiza D y R si-
multaneamente, esto es:
maxΦ(D,R), Φ = D −R (3.20)
En la practica se puede utilizar un metodo incremental para encontrar el conjunto de carac-

44 3.4. Tecnicas de clasificacion
terısticas Φ(D,R). Para lo cual, supongamos que se tiene un conjunto de datos de entrada con M
caracterısticas X = xi, i = 1, . . . ,M, la variable de clase, c, y un subconjunto de m caracterısticas
S = xi, i = 1, . . . ,m. La tarea es seleccionar la m−esima caracterıstica del conjunto X−Sm−1.Esto se hace mediante la seleccion de la caracterıstica que maximice Φ(·). El algoritmo incremental
optimiza la Ecuacion 3.20 a traves de la Ecuacion 3.21 que se muestra a continuacion:
maxxj∈X−Sm−1
I(xj; c)−1
m− 1
∑xi∈Sm−1
I(xj;xi)
(3.21)
3.4 Tecnicas de clasificacion
3.4.1 Analisis discriminante lineal de Fisher (FLDA)
El FLDA es una tecnica estadıstica que busca combinaciones lineales de caracterısticas que
pueden emplearse para realizar la separacion de un conjunto de datos en dos clases y es considerada
como un clasificador lineal. Lo anterior se realiza a traves de la proyeccion de los datos de entrada
en una direccion determinada. En otros terminos, es un algoritmo que emplea una transformacion
matematica de un espacio de entrada d−dimensional a un espacio de salida (d − 1)−dimensional
[43, 44, 45], cuyo numero de clases C = 2. La Ecuacion 3.22 ındica que cada elemento del conjunto
Y = y1, y2, y3, . . . , yn es la proyeccion de cada elemento de X = x1, x2, x3, . . . , xn en la
direccion w:
yi = wTxi, i = 1, . . . , n (3.22)

3. Marco teorico 45
Para calcular los valores de direccion w se aplica la Ecuacion 3.23, donde µ1 y µ2 son las medias
de los datos pertenecientes a la clase 1 y clase 2, respectivamente:
w = SW−1(µ1 − µ2) (3.23)
SW es la matriz de covarianza intra-clase la cual se define como:
SW =C∑i=1
E[(X − µi) (X − µi)T
](3.24)
3.4.2 Maquina de vectores de soporte (SVM)
La SVM es un clasificador que se basa en el principio de minimizacion del riesgo estructural (SRM,
Structural Risk Minimization), en lugar de la minimizacion del riesgo empırico (ERM, Empirical Risk
Minimization). Es decir, las SVM no se centran en construir modelos que cometan pocos errores en
la etapa de entrenamiento, sino mejorar la capacidad de generalizacion. Por tanto, disminuir el riesgo
de cometer errores con futuros datos [47].
Lo anterior se puede expresar de la siguiente forma: sea un conjunto x de N datos y sus co-
rrespondientes clases, yn ∈ +1,−1 , n = 1, . . . , N . Encontrar el hiperplano wTx + b = 0 que
sea capaz de discriminar entre ambas clases y que presente la mayor separacion d, respecto a los
vectores de soporte (que son hiperplanos paralelos que pasan por los puntos de datos mas cercanos
al hiperplano discriminante), donde w representa la pendiente y b el desplazamiento al origen. En la
Figura 3.7 se muestra un ejemplo de la SVM para dos clases y dos dimensiones.
Dado que la intencion de las SVM es encontrar las w y b que generen el hiperplano con mayor
separabilidad entre este y los vectores de soporte, se puede interpretar como un problema de opti-
mizacion, donde las restricciones estan dadas por los vectores de soporte y la funcion objetivo por
maximizacion de d1 + d2.

46 3.4. Tecnicas de clasificacion
clase A
clase B
H1
d 2
d 1
x2
x1
d ′2
d ′1
H ′2
H ′1
H2
H0
H ′0
Vectores'de'soporte'para''H1'y'H2'''
Vectores'de'soporte'para''H’1'y'H’2'''
Figura 3.7: Maquina de vectores de soporte. En la imagen se muestran dos hiperplanos (lıneas rectasH0 y H ′0) capaces de discriminar los datos entre las clases A y B. Es notorio que H0 presenta unamayor separacion respecto a los vectores de soporte H1 y H2 que H ′0 con respecto a H ′1 y H ′2 , estoes, d1 + d2 > d′1 + d′2. Por tanto, H0 presenta mayor capacidad de generalizacion, lo que significa,menor riesgo de error al clasificar datos desconocidos.
Lo visto sobre SVM hasta este momento atiende a un caso de clasificacion linealmente separable,
lo cual es interesante unicamente desde un punto de vista teorico, ya que en la practica la mayorıa
de los problemas son no linealmente separables. Para este tipo de problemas se ha propuesto una
solucion matematicamente elegante, la cual consiste en mapear el espacio dimensional original a otro
espacio k (mayor), donde las clases sean separables satisfactoriamente, esto es, x ∈ Rm −→ y ∈ Rk
[45]. Resolver el problema de optimizacion mencionado anteriormente para un espacio k de mayor
dimensionalidad representa mayor complejidad, por lo que es posible expresar la solucion en termi-
nos del espacio original empleando funciones denominadas nucleo (kernel). Algunas de las funciones
nucleo mas comunes se muestran en la Tabla 3.3.

3. Marco teorico 47
Funcion Ecuacion Parametros
Lineal k(xi, xj) = xTi · xj ————————-
Polinomialhomogenea
k(xi, xj) =(xTi · xj
)nOrden del polinomio n.
Polinomial nohomogenea
k(xi, xj) =(xTi · xj + 1
)nOrden del polinomio n.
Gaussiana (RBF) k(xi, xj) = exp (−γ‖xi − xj‖2)Para γ > 0. Algunasveces γ = 1/2σ.
Sigmoidal k(xi, xj) = tanh(axTi · xj + b)Para algunos valores dea > 0 y b < 0.
Tabla 3.3: Funciones nucleo para la SVM.
3.4.3 Redes de funcion de base radial (RBFN)
La RBFN es una red de neuronas que se puede aplicar a un problema de clasificacion, en donde
el nivel de activacion para cada neurona esta determinado por la distancia entre el vector de carac-
terısticas de entrada x y un vector prototipo asociado a cada neurona ci [47, 45], esto es ‖x− ci‖,que representa la distancia Euclidiana entre ambos vectores. Este tipo de red presenta una topologıa
invariante de tres capas. La primera capa es de entrada y se encarga de distribuir los datos de entrada
hacia las neuronas ocultas. La segunda capa, denominada oculta, procesa las entradas x a traves de
funciones no lineales conocidas como de base radial φi(‖x − ci‖). Dentro de las funciones de base
radial mas utilizadas se encuentra la funcion Gaussiana:
φi(‖x− ci‖) = exp
(−‖x− ci‖
2
2σ2i
)(3.25)
La ultima capa genera la salida final de la red a traves de la combinacion lineal de los pesos w
con la salida de cada neurona activada en la capa oculta, esto es:
y = w0 +M∑i=1
wiφ(‖x− ci‖) (3.26)
En la Figura 3.8 se muestra la topologıa de una red RBF.

48 3.4. Tecnicas de clasificacion
x1
x2
xn-1
xn
w1
w2
wi-1
wi
w0
φi = exp −x(n) − Ci
σ i2
⎛⎝⎜
⎞⎠⎟
y = w0 + wiφi (n)i=1
m
∑
φ1
φ2
φi−1
φi
Figura 3.8: Topologıa de la red RBF.
El entrenamiento de una red RBF se divide en dos etapas para determinar los parametros: centros
c, radios σ y pesos sinapticos w.
La primera etapa es de tipo no supervisado (no se conoce el valor de la clase), dentro de esta se
divide el espacio de caracterısticas en diferentes clases o grupos, donde cada clase es representada
por una neurona y cuyo elemento central ci es el prototipo de activacion derivado del vector x. Para
determinar las clases se pueden utilizar algoritmos de agrupamiento como el k-medias. Por otro lado,
los radios σi pueden ser determinados calculando la distancia Euclidiana media de los centros de
cada RBF a los p centros mas proximos.
La segunda etapa es de tipo supervisado y consiste en determinar los pesos sinapticos w de la
capa de salida. Para ello se minimizan las diferencias entre las salidas de la red y las salidas deseadas,
lo cual se puede lograr a traves del metodo de la matriz pseudoinversa, que se define como:
W = G+S = (GTG)−1GTS (3.27)
donde G es una matriz de tamano N patrones por (i− 1) neuronas ocultas que contiene las activa-
ciones de las neuronas de la capa oculta para los patrones de entrada x(n), S es la matriz de salidas
deseadas de tamano N × k neuronas de salida, y W la matriz de pesos.

3. Marco teorico 49
3.4.4 Estimacion del error bootstrap .632+
Al emplear tecnicas de clasificacion supervisadas como las mencionadas anteriormente, se vuelve
indispensable conocer las prestaciones que ofrecen con respecto al conjunto de datos que se utiliza
para entrenar y probar dicha tecnica. Estas prestaciones se pueden interpretar como una medida
para determinar si el conjunto de datos es el apropiado para entrenar al clasificador, y en caso de
no serlo, buscar alguna variante que mejore dicho resultado. Una de las tecnicas mas utilizadas para
determinar dichas prestaciones es la tecnica bootstrap .632+.
Para describir esta tecnica es necesario definir lo que es un conjunto bootstrap, el error de resti-
tucion (eRSBn ) y error bootstrap dejando uno fuera (eLOOBSn ) dado que el error bootstrap .632+ se
encuentra definido en funcion de estos errores.
Sea un conjunto de entrenamiento X = x1, x2, x3, . . . , xn con n observaciones y cada obser-
vacion queda definida como xi = (ti, yi), donde ti es un vector de caracterısticas p−dimensional y
yi es el valor de clase o respuesta verdadera. Una regla de prediccion puede expresarse como rX(ti),
lo que significa que dicha regla esta entrenada con el conjunto X y predecira el valor para ti. Por
tanto, se puede definir la discrepancia entre el valor predicho con la regla de prediccion para ti y el
valor verdadero yi como:
Q [yi, rx(ti)] =
0 si r = y
1 si r 6= y(3.28)
Dado un conjunto de datos X con n muestras o vectores de patrones. Un conjunto bootstrap,
x∗ = x∗1, x∗2, x∗3, . . . , x∗n, de tamano n se forma tomando muestras aleatorias con remplazo de X,
lo que significa que una muestra puede volverse a seleccionar, por tanto, aparecer varias veces en el
mismo conjunto. Por otro lado, las muestras que no fueron consideradas en el conjunto constituyen

50 3.4. Tecnicas de clasificacion
el conjunto de prueba.
El error de restitucion eRSBn se obtiene promediando el numero de discrepancias generado con
una regla de prediccion entrenada con el mismo conjunto de prueba, esto es:
eRSBn =1
n
n∑i=1
Q [yi, rX(ti)] (3.29)
Para obtener el error bootstrap dejando uno fuera (eLOOBSn ) primero se generan B conjuntos
bootstrap de tamano n, esto es, x∗1, x∗2, x∗3, . . . , x∗B. Despues se determina si una muestra x∗bi
se encuentra o no en el b−esimo conjunto bootstrap. Para lo cual se emplea el siguiente criterio:
Ibi =
1 si N bi = 0
0 si N bi > 0
(3.30)
donde N bi es el numero de veces que la muestra se incluye en el b−esimo conjunto bootstrap.
Posteriormente se calculan las discrepancias de las muestras no contenidas en los B conjuntos
bootstrap, es decir, usando el conjunto de prueba, esto es:
Qbi = Q [yi, rX∗b(ti)] (3.31)
Por ultimo, el error bootstrap dejando uno fuera (eLOOBSn ) queda definido como:
eLOOBSn =1
n
n∑i=1
Ei (3.32)
donde
Ei =
∑b
IbiQbi∑
b
Ii(3.33)

3. Marco teorico 51
Una vez definido el error de restitucion y el error bootstrap dejando uno fuera se define el error
bootstrap e.632+n como:
e.632+n = weLOOBSn + (1− w) eRSBn (3.34)
donde w = .632
1−.368R, R es la tasa de traslape relativo:
R =eLOOBSn − eRSBn
γ − eRSBn
(3.35)
y γ es la tasa de error de no-informacion:
γ =n∑i=1
n∑j=1
Q [yi, rx(tj)]
/n2 (3.36)
3.5 Conclusiones
En este capıtulo se mostro el fundamento teorico de cada una de las tecnicas mas relevantes
implementadas en este trabajo de tesis, las cuales fueron tomadas de la literatura especializada. Estas
tecnicas estan enfocadas en resolver distintos aspectos para el problema de segmentacion automatica
de lesiones de mama en ultrasonografıas, como son: reduccion del artefacto speckle y mejoramiento
del contraste en la etapa de preprocesamiento de la imagen, donde cabe destacar que derivado de la
combinacion entre algunas tecnicas o algunos de los elementos que las componen, surgieron nuevas
tecnicas como el Auto-CLAHE y el FAHE. En la seleccion y extraccion de caracterısticas se expusieron
los principales elementos para el analisis de texturas como son: la matriz de co-ocurrencia de niveles de
gris, que a grandes rasgos, es la matriz de frecuencias de la relacion de niveles de gris en una distancia
y direccion determinada; y los descriptores de texturas que son la representacion numerica de las
texturas y los cuales se derivan de la matriz de co-ocurrencia. Por otra parte, se describieron tecnicas
de preprocesamiento de informacion como son la normalizacion y discretizacion, las cuales actuan
sobre los valores de los descriptores de texturas que son utilizados por los metodos de ordenamiento

52 3.5. Conclusiones
de caracterısticas para seleccionar el subconjunto optimo. Dichos metodos de ordenamiento son: la
razon discriminante de Fisher y mınima-redundancia-maxima-relevancia. Por ultimo, se describieron
tres tecnicas de clasificacion: maquinas de vectores de soporte (SVM), analisis lineal discriminante
de Fisher (FLDA) y red de funcion de base radial (RBFN), ası como, el error bootstrap .632+ cuyo
proposito es evaluar las tecnicas de clasificacion considerando el conjunto de datos de entrenamiento
y prueba.

4Metodologıa
4.1 Introduccion
En este capıtulo se detalla el enfoque propuesto basado en caracterısticas de textura extraıdas de
la GLCM para construir una metodo de segmentacion automatica de lesiones de mama en ultrasono-
grafıas. Para implementar dicho enfoque fue necesario evaluar diversas tecnicas de preprocesamiento,
seleccionar el subconjunto de caracterısticas de textura mas representativo para caracterizar una re-
gion en fondo o lesion en una imagen de USM. Tambien se evaluaron tres tecnicas de clasificacion
con la finalidad de encontrar la que proporcione mejores prestaciones para detectar la ROI utilizando
el subconjunto de caracterısticas seleccionado. Por otra parte, se describe un metodo de postprocesa-
miento para mejorar el resultado de la clasificacion. Por ultimo, se detalla el algoritmo de Chan-Vese
para ajustar el contorno de la ROI al de la lesion en la imagen de USM. La estructura de este capıtulo
esta compuesta por tres secciones: i) preprocesamiento, extraccion y seleccion de caracterısticas, ii)
clasificacion: evaluacion de los clasificadores y iii)postprocesamiento y ajuste del contorno de la ROI.
53
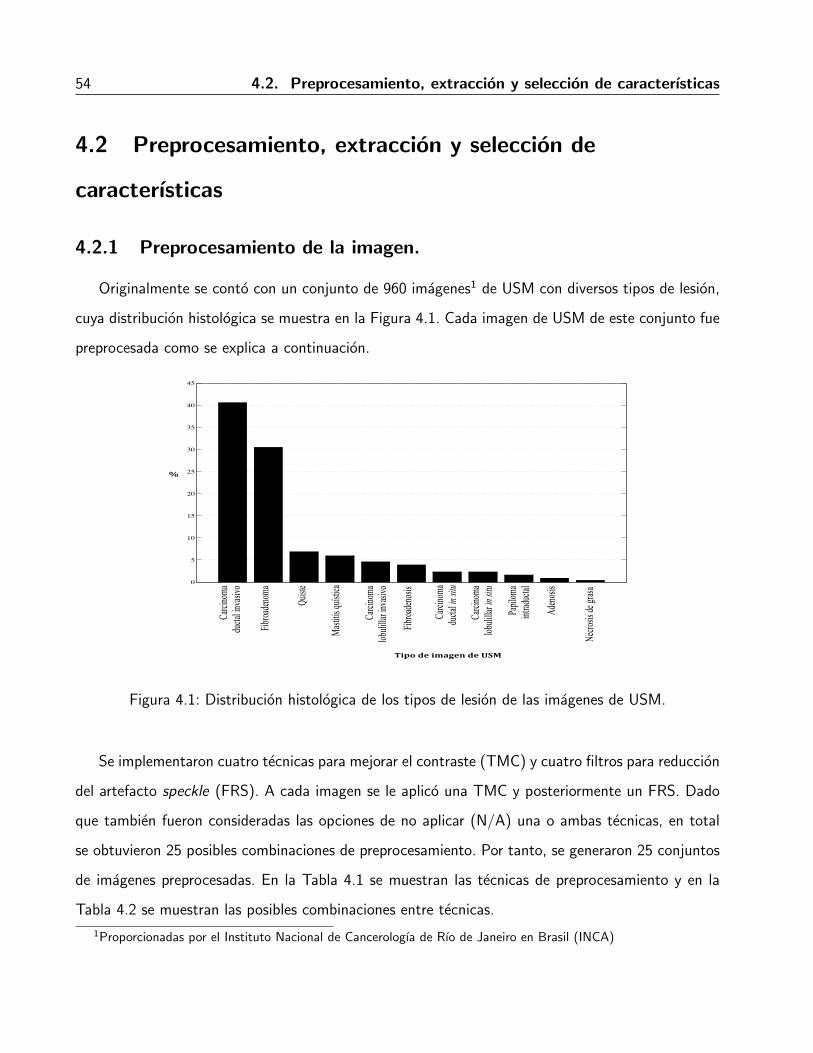
54 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas
4.2 Preprocesamiento, extraccion y seleccion de
caracterısticas
4.2.1 Preprocesamiento de la imagen.
Originalmente se conto con un conjunto de 960 imagenes1 de USM con diversos tipos de lesion,
cuya distribucion histologica se muestra en la Figura 4.1. Cada imagen de USM de este conjunto fue
preprocesada como se explica a continuacion.
!!!!!
!!!!!!!!!!!!!!!!!!
!!!!!
!!!!!!!!!!!!!!!!!!
0
5
10
15
20
25
30
35
40
45
Carci
noma
du
ctal in
vasiv
o
Fibroa
deno
ma
Quist
e
Masti
tis qu
ística
Carci
noma
lob
ulilla
r inva
sivo
Fibroa
deno
sis
Carci
noma
du
ctal in
situ
Carci
noma
lob
ulilla
r in sit
u
Papil
oma
intrad
uctal
Aden
osis
Necro
sis de
grasa
%"
Tipo"de"imagen"de"USM"
Figura 4.1: Distribucion histologica de los tipos de lesion de las imagenes de USM.
Se implementaron cuatro tecnicas para mejorar el contraste (TMC) y cuatro filtros para reduccion
del artefacto speckle (FRS). A cada imagen se le aplico una TMC y posteriormente un FRS. Dado
que tambien fueron consideradas las opciones de no aplicar (N/A) una o ambas tecnicas, en total
se obtuvieron 25 posibles combinaciones de preprocesamiento. Por tanto, se generaron 25 conjuntos
de imagenes preprocesadas. En la Tabla 4.1 se muestran las tecnicas de preprocesamiento y en la
Tabla 4.2 se muestran las posibles combinaciones entre tecnicas.
1Proporcionadas por el Instituto Nacional de Cancerologıa de Rıo de Janeiro en Brasil (INCA)

4. Metodologıa 55
id TMC id FRS0 N/A 0 N/A1 Enfoque difuso 1 Mediana2 CLAHE 2 Anisotropico + Gabor I3 Auto-CLAHE 3 Anisotropico + Gabor II4 FAHE 4 Kuan
Tabla 4.1: Tecnicas de preprocesamiento.
id Combinacion de preprocesamiento1 002 013 024 035 046 107 118 129 13
10 1411 2012 2113 2214 2315 2416 3017 3118 3219 3320 3421 4022 4123 4224 4325 44
Tabla 4.2: Combinaciones de tecnicas de preprocesamiento: TMC+FRS.

56 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas
4.2.2 Extraccion de caracterısticas de textura.
En este apartado se explica el procedimiento de extraccion de caracterısticas de textura en los
siguientes pasos:
1. Generacion de mascaras de rejilla. En cada imagen del conjunto original de imagenes de USM
se delineo la lesion de forma manual tomando como referencia las marcas sobre la imagen
generadas por el radiologo experto. Posteriormente, se genero una mascara de rejilla rectangular
de acuerdo con las dimensiones de la imagen, donde cada celda tiene un tamano 16 × 16
pıxeles (este tamano fue tomado de la literatura [20, 21], ya que se ha visto que es una
region suficiente para evaluar texturas para imagenes de USM). A partir de esta mascara se
generaron dos mascaras adicionales: mascara de etiquetas, para cada celda se le asigna un valor
numerico unico (Figura 4.2(b)) y mascara de clase, se asigna el numero ’1’ para las celdas
correspondientes a la clase lesion (dichas celdas se consideran la region de interes o ROI) y el
numero ’0’ para las de clase fondo (Figura 4.2(c)). Se considero que si pıxeles de fondo y lesion
compartıan el area de una celda, entonces en la mascara de clases se asignaba ’1’ cuando al
menos el 60 % de los pıxeles pertenecıan a la lesion, en caso contrario se asignaba un ’0’.
(a)
1
2
3
4
5
6
7
8
9
10
11
25
28
32
74
78
12
13
14
15
17
22
33
36
37
39
40
44
45
49
52
54
56
55
48
23 31 47
3830 46
41 57
60
63
64
61 70
19
65 73
18 26 34 42 50 58 66
27 35 43 51 59 67 75
20 68 76
21 29 53 61 69 77
71 79
2416 72 80
(b) (c)
Figura 4.2: Mascaras de rejilla. (a) Imagen original de USM, (b) mascara de etiquetas y (c) mascarade clase, donde la region blanca representa a la lesion o ROI y la oscura al fondo de la imagen.
2. Separacion y seleccion de imagenes celda. Para cada imagen de los 25 conjuntos generados en la
Seccion 4.2.1, se aplicaron las mascaras de etiquetas y de clase (ver Figura 4.3) con la finalidad

4. Metodologıa 57
de dividir la imagen original preprocesada en pequenas imagenes de tamano igual al de la celda
de la mascara, de ahı que las nombremos imagenes celda. Al mismo tiempo, separarlas en dos
subconjuntos, uno correspondiente a la clase lesion y el otro a la clase fondo. Por otro lado,
el tamano de cada subconjunto resulta ser demasiado grande, y en terminos computacionales,
demasiado costoso. Por ello fue necesario tomar una muestra de forma aleatoria de 10000
imagenes celda de cada subconjunto.
Figura 4.3: Aplicacion de las mascaras de etiquetas y de clase para generar las imagenes celda. Enla imagen se aprecia la superposicion de la rejilla sobre la imagen, donde cada celda esta mapeadacon un valor de etiqueta y un valor de clase (El borde negro representa la ROI).
Hasta este momento se han obtenido 25 conjuntos de imagenes celda, uno para cada combina-
cion de preprocesamiento. Cada conjunto contiene 20,000 muestras, donde 10,000 pertenecen
a la clase lesion y el resto a la clase fondo.
3. Generacion de la GLCM. Para cada imagen celda de los 25 conjuntos se generaron las GLCMs
para cuatro direcciones (θ = 0, 45, 90, 135) y cuatro distancias (d = 1, 2, 3, 4) para una
cuantificacion de 64 niveles de gris. En total se obtuvieron 16 GLCMs por cada imagen celda.
4. Generacion de los DT. Para cada GLCM generada en el paso 3, se calcularon los 22 DT
descritos en la Tabla 3.1. En total, para cada imagen celda su vector de caracterısticas esta
conformado por 16 GLCMs × 22 DT, es decir, 352 caracterısticas de textura (Ver Figura 4.4
(a)). Por otro lado, se generaron 25 conjuntos de vectores de caracterısticas (ver Figura 4.4
(b)), uno por cada combinacion de preprocesamieto.
58 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas!!!!!!!!!!!!!!
!!!
Distancia 1 2 3 4
Dirección 0° 45° 90° 135° 0° 45° 90° 135° 0° 45° 90° 135° 0° 45° 90° 135° Clase
DT (f1-f22)
1 -
22
23 -
44
45 -
66
67 -
88
89 -
110
111
- 132
133
- 154
155
- 176
177
- 198
199
- 220
221
- 242
243
- 264
265
- 286
287
- 308
309
- 330
331
- 352
(a)
1' 2' 3' 4' 5' 6' 7' 347' 348' 349' 350' 351' 352' C'!!!'
1' 2' 3' 4' 5' 6' 7' 347' 348' 349' 350' 351' 352' C'!!!'
1' 2' 3' 4' 5' 6' 7' 347' 348' 349' 350' 351' 352' C'!!!'
!!!'
1' 2' 3' 4' 5' 6' 7' 347' 348' 349' 350' 351' 352' C'!!!'
1'
2'
3'
!!!'20000'
Imágen
es'celda'
!!!'
!!!'
CaracterísWcas'clase'
25'conjuntos'de'
entrenam
iento,'se
gún'la'
combinación'de'
preprocesamiento'
(b)
Figura 4.4: Dimensionalidad de las caracterısticas de textura. (a) composicion del vector de carac-terısticas para cada imagen celda segun fueron extraıdos de la GLCM (b) agrupacion de los vectoresde caracterısticas por imagen celda para cada combinacion de preprocesamiento. Adicionalmente acada vector se le agrego la clase a la que pertenece la imagen celda.

4. Metodologıa 59
5. Preprocesamiento de las caracterısticas. Dado que los valores calculados de las caracterısticas
de texturas en el paso 4 se encuentran en distintos rangos de valores y en el dominio continuo,
es necesario aplicar un proceso de normalizacion y discretizacion, de tal forma que todos los va-
lores se encuentren en el mismo rango y con valores discretos. Esto, dado que algunas tecnicas
empleadas mas adelante en este capıtulo requieren la informacion normalizada o discretizada,
ejemplo de estas son las tecnicas de clasificacion y de ordenamiento de caracterısticas.
La normalizacion y discretizacion se realizo con las tecnicas expuestas en la Seccion 3.3.3, y
cuyo rango de valores se establecio entre [−1, 1] para los valores normalizados y 15 intervalos
para la discretizacion. Es importante mencionar que estos procesos se aplicaron para cada
caracterıstica individualmente, dados los distintos rangos de valores que presentan entre ellas.
En resumen se generaron 25 conjuntos de entrenamiento normalizados y 25 discretizados.
4.2.3 Seleccion de las caracterısticas
La seleccion de caracterısticas consiste en descartar aquellas caracterısticas que no aporten infor-
macion relevante para describir algun objeto en particular. Esto con el fin de reducir la dimensiona-
lidad, o en otros terminos, reducir el costo computacional. En nuestro caso, el objeto es la imagen
celda que puede ser clasificada como lesion o fondo, cuyo vector de caracterısticas esta conformado
por 352 caracterısticas de textura. Para cumplir con el objetivo de reducir la dimensionalidad se
propone realizar los pasos descritos a continuacion.
1. Ordenar las caracterısticas. Para ello se emplearon dos criterios: la razon discriminante de Fis-
her(FDR) y mınima-redundancia-maxima-relevancia (mRMR), ambos descritos en el Capıtulo
3. Para el criterio FDR se utilizaron los 25 conjuntos de imagenes celda normalizados y para
el mRMR los 25 discretizados, ya que ası lo requieren dichas tecnicas. En la Tabla 4.3 se
muestran las primeras 10 (de 352) caracterısticas ordenadas empleando los dos criterios men-
cionados para las primeras tres combinaciones de preprocesamiento. Cada caracterıstica de
textura esta definida bajo la nomenclatura: “f#/θ/d”, donde f# es uno de los DT descritos
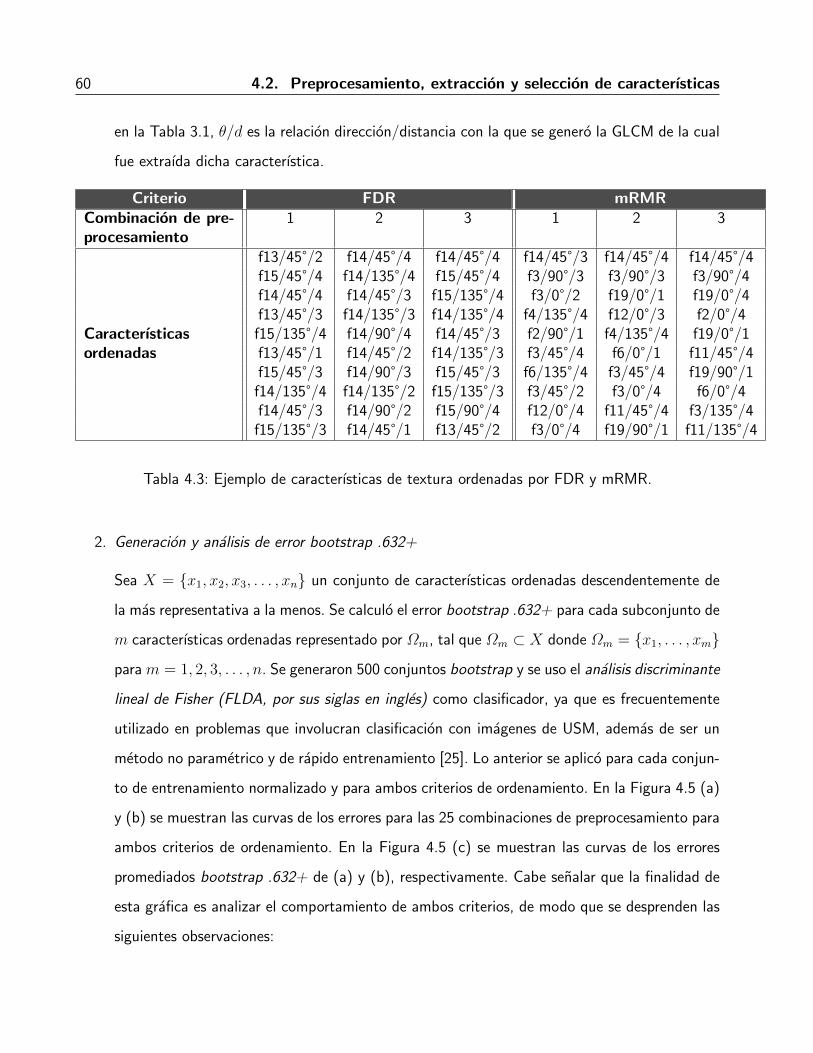
60 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas
en la Tabla 3.1, θ/d es la relacion direccion/distancia con la que se genero la GLCM de la cual
fue extraıda dicha caracterıstica.
Criterio FDR mRMRCombinacion de pre-procesamiento
1 2 3 1 2 3
Caracterısticasordenadas
f13/45°/2 f14/45°/4 f14/45°/4 f14/45°/3 f14/45°/4 f14/45°/4f15/45°/4 f14/135°/4 f15/45°/4 f3/90°/3 f3/90°/3 f3/90°/4f14/45°/4 f14/45°/3 f15/135°/4 f3/0°/2 f19/0°/1 f19/0°/4f13/45°/3 f14/135°/3 f14/135°/4 f4/135°/4 f12/0°/3 f2/0°/4
f15/135°/4 f14/90°/4 f14/45°/3 f2/90°/1 f4/135°/4 f19/0°/1f13/45°/1 f14/45°/2 f14/135°/3 f3/45°/4 f6/0°/1 f11/45°/4f15/45°/3 f14/90°/3 f15/45°/3 f6/135°/4 f3/45°/4 f19/90°/1
f14/135°/4 f14/135°/2 f15/135°/3 f3/45°/2 f3/0°/4 f6/0°/4f14/45°/3 f14/90°/2 f15/90°/4 f12/0°/4 f11/45°/4 f3/135°/4
f15/135°/3 f14/45°/1 f13/45°/2 f3/0°/4 f19/90°/1 f11/135°/4
Tabla 4.3: Ejemplo de caracterısticas de textura ordenadas por FDR y mRMR.
2. Generacion y analisis de error bootstrap .632+
Sea X = x1, x2, x3, . . . , xn un conjunto de caracterısticas ordenadas descendentemente de
la mas representativa a la menos. Se calculo el error bootstrap .632+ para cada subconjunto de
m caracterısticas ordenadas representado por Ωm, tal que Ωm ⊂ X donde Ωm = x1, . . . , xmpara m = 1, 2, 3, . . . , n. Se generaron 500 conjuntos bootstrap y se uso el analisis discriminante
lineal de Fisher (FLDA, por sus siglas en ingles) como clasificador, ya que es frecuentemente
utilizado en problemas que involucran clasificacion con imagenes de USM, ademas de ser un
metodo no parametrico y de rapido entrenamiento [25]. Lo anterior se aplico para cada conjun-
to de entrenamiento normalizado y para ambos criterios de ordenamiento. En la Figura 4.5 (a)
y (b) se muestran las curvas de los errores para las 25 combinaciones de preprocesamiento para
ambos criterios de ordenamiento. En la Figura 4.5 (c) se muestran las curvas de los errores
promediados bootstrap .632+ de (a) y (b), respectivamente. Cabe senalar que la finalidad de
esta grafica es analizar el comportamiento de ambos criterios, de modo que se desprenden las
siguientes observaciones:

4. Metodologıa 61
a) El error mınimo es muy semejante para ambos criterios de ordenamiento (Ver Tabla 4.4).
b) Los primeros Ωm para m ≤ 200 (del punto A al punto B) representan las caracterısticas
mas representativas, dado que hay un descenso importante en el error. Por otro lado,
para los Ωm donde m > 200 (del punto B al punto C) el descenso del error es pequeno,
por lo que las caracterısticas asociadas pueden ser descartadas.
c) Para los Ωm donde m ≤ 200 (del punto A al punto B) existe una separacion considerable
entre las curvas, lo que indica que el criterio mRMR necesita menos caracterısticas que
FDR para generar el mismo error.
Si no se tomaran en cuenta las observaciones anteriores, probablemente el enfoque mas natural
y simple serıa seleccionar un valor de m, donde el error bootstrap .632+ sea mınimo, denotado
por mopt. Entonces, considerando este criterio de seleccion se tendrıa que para FDR mopt = 348
y para mRMR mopt = 328. Por tanto, la reduccion de la dimensionalidad no es representativa
dado que el valor de mopt para ambos criterios de ordenamiento es un numero cercano al
numero maximo de caracterısticas (n=352). Por ello, se propuso un enfoque basado en las
observaciones anteriores con el fin de encontrar un mopt, de tal forma que se reduzca la
dimensionalidad sin perder en gran medida la capacidad descriptiva de las caracterısticas. A
dicho enfoque se le llamo variacion del error, el cual se describe en el siguiente apartado.
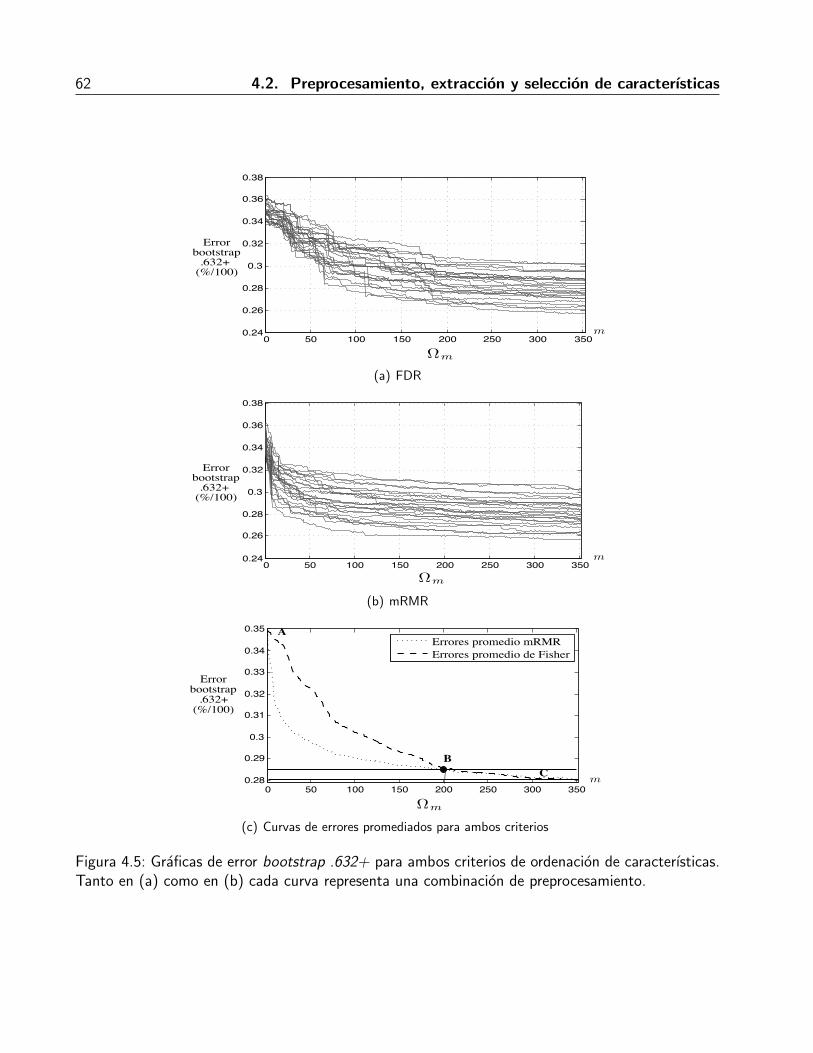
62 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas
0 50 100 150 200 250 300 3500.24
0.26
0.28
0.3
0.32
0.34
0.36
0.38
m
Errorbootstrap
.632+ (%/100)
Ωm
(a) FDR
0 50 100 150 200 250 300 3500.24
0.26
0.28
0.3
0.32
0.34
0.36
0.38
m
Errorbootstrap
.632+ (%/100)
Ωm
(b) mRMR
0 50 100 150 200 250 300 3500.28
0.29
0.3
0.31
0.32
0.33
0.34
0.35
Errores promedio mRMRErrores promedio de Fisher
A
Ωm
m
Errorbootstrap
.632+(%/100)
BC
(c) Curvas de errores promediados para ambos criterios
Figura 4.5: Graficas de error bootstrap .632+ para ambos criterios de ordenacion de caracterısticas.Tanto en (a) como en (b) cada curva representa una combinacion de preprocesamiento.
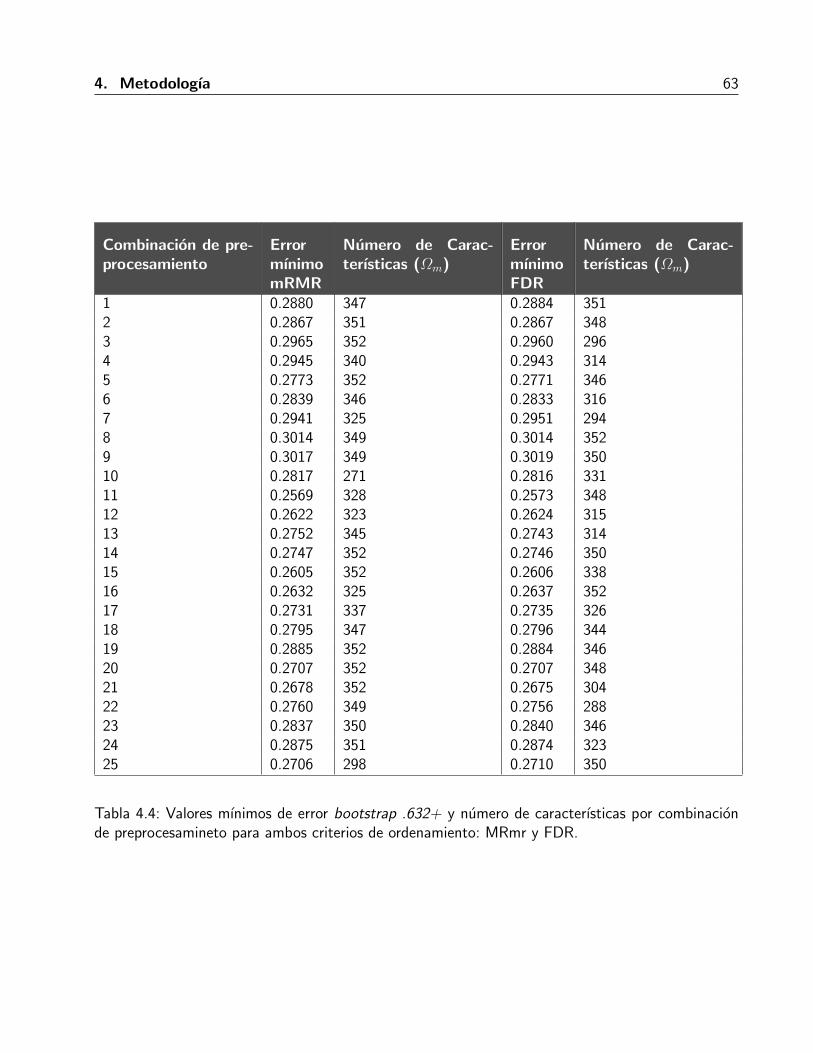
4. Metodologıa 63
Combinacion de pre-procesamiento
ErrormınimomRMR
Numero de Carac-terısticas (Ωm)
ErrormınimoFDR
Numero de Carac-terısticas (Ωm)
1 0.2880 347 0.2884 3512 0.2867 351 0.2867 3483 0.2965 352 0.2960 2964 0.2945 340 0.2943 3145 0.2773 352 0.2771 3466 0.2839 346 0.2833 3167 0.2941 325 0.2951 2948 0.3014 349 0.3014 3529 0.3017 349 0.3019 35010 0.2817 271 0.2816 33111 0.2569 328 0.2573 34812 0.2622 323 0.2624 31513 0.2752 345 0.2743 31414 0.2747 352 0.2746 35015 0.2605 352 0.2606 33816 0.2632 325 0.2637 35217 0.2731 337 0.2735 32618 0.2795 347 0.2796 34419 0.2885 352 0.2884 34620 0.2707 352 0.2707 34821 0.2678 352 0.2675 30422 0.2760 349 0.2756 28823 0.2837 350 0.2840 34624 0.2875 351 0.2874 32325 0.2706 298 0.2710 350
Tabla 4.4: Valores mınimos de error bootstrap .632+ y numero de caracterısticas por combinacionde preprocesamineto para ambos criterios de ordenamiento: MRmr y FDR.

64 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas
4.2.3.1. Enfoque de variacion del error
Este criterio establece que el valor de mopt se puede encontrar definiendo el punto donde la
variacion del error en terminos absolutos,
∣∣∣∣ ∆y
∆m
∣∣∣∣, comienza a disminuir por debajo de un umbral th,
definido como una fraccion p de la diferencia entre el error bootstrap .632+ maximo (Errmax) y
mınimo (Errmin) generado para Ωm. Esto es, th = |Errmax−Errmin|·p. Primeramente es necesario
encontrar los maximos locales consecutivos, de manera que un maximo previo sera mayor en mag-
nitud que su consecuente y las variaciones entre ambos no son mayores que ellos. Posteriormente,
se obtiene un subconjunto conformado por aquellos maximos que sean menor o igual que th. Por
ultimo, el punto mopt se encuentra en el argumento del primer maximo de dicho subconjunto. En el
Algoritmo 1 se describe este enfoque.
Algoritmo 1 Enfoque de variacion del errorEntrada: numero total de caracterısticas n, tolerancia p,
error maximo Errmax, error mınimo ErrminSalida: Numero optimo de caracterısticas mopt
1: l← n− 12: th← |Errmax − Errmin|p3: para i← 1 : k
hacer
4: M =
∣∣∣∣ ∆yi∆mi
∣∣∣∣ , . . . , ∣∣∣∣ ∆yk∆mk
∣∣∣∣5: [maxV alue,mopt]← max(M)6: si (maxV alue ≤ th) entonces7: devolver mopt
8: si no9: i← mopt
10: devolver mopt
En la Figura 4.6 se muestra un ejemplo de la representacion grafica del enfoque de variacion del
error para una combinacion de preprocesamiento.
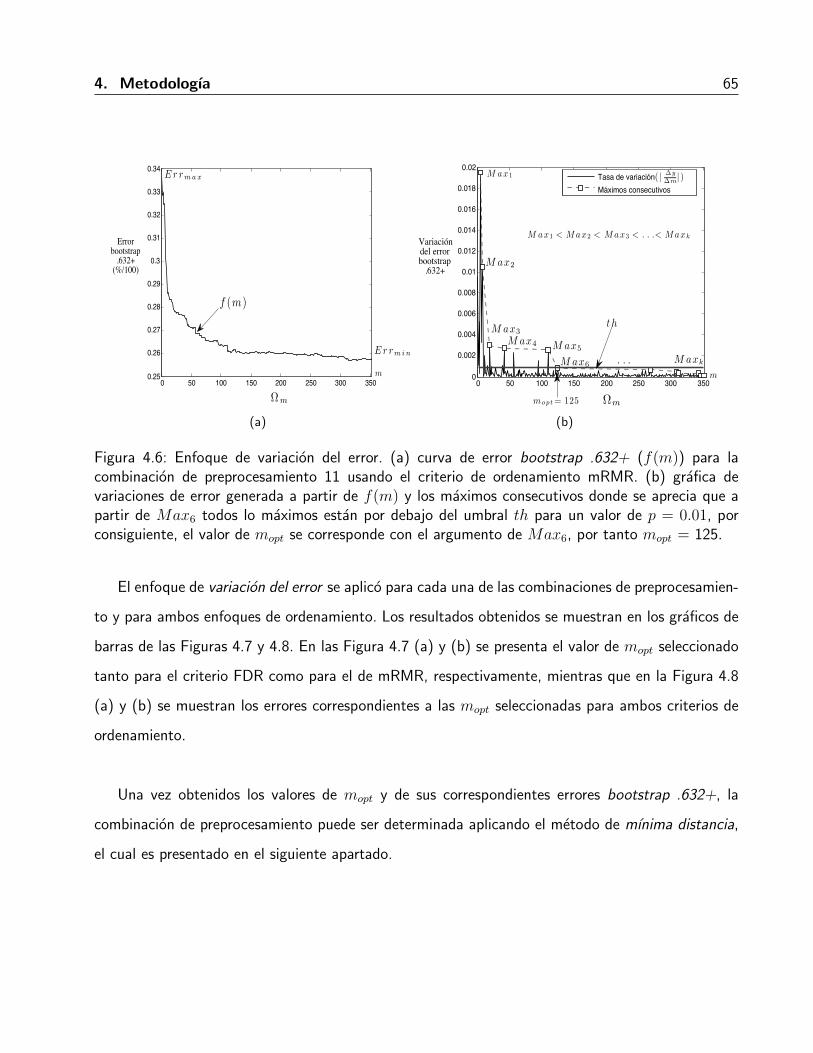
4. Metodologıa 65
0 50 100 150 200 250 300 3500.25
0.26
0.27
0.28
0.29
0.3
0.31
0.32
0.33
0.34E r rm a x
E r rm i n
Ωm
Errorbootstrap.632+(%/100)
f (m)
m
(a)
0 50 100 150 200 250 300 3500
0.002
0.004
0.006
0.008
0.01
0.012
0.014
0.016
0.018
0.02
Tasa de variaciónMáximos consecutivos
Variacióndel errorbootstrap
.632+
m
M ax3
M ax4 M ax5
. . .M ax6
( | ∆y∆m| )
th
M axk
M ax1
M ax1 < M ax2 < M ax3 < . . .< M axk
M ax2
Ωmmopt = 125
(b)
Figura 4.6: Enfoque de variacion del error. (a) curva de error bootstrap .632+ (f(m)) para lacombinacion de preprocesamiento 11 usando el criterio de ordenamiento mRMR. (b) grafica devariaciones de error generada a partir de f(m) y los maximos consecutivos donde se aprecia que apartir de Max6 todos lo maximos estan por debajo del umbral th para un valor de p = 0.01, porconsiguiente, el valor de mopt se corresponde con el argumento de Max6, por tanto mopt = 125.
El enfoque de variacion del error se aplico para cada una de las combinaciones de preprocesamien-
to y para ambos enfoques de ordenamiento. Los resultados obtenidos se muestran en los graficos de
barras de las Figuras 4.7 y 4.8. En las Figura 4.7 (a) y (b) se presenta el valor de mopt seleccionado
tanto para el criterio FDR como para el de mRMR, respectivamente, mientras que en la Figura 4.8
(a) y (b) se muestran los errores correspondientes a las mopt seleccionadas para ambos criterios de
ordenamiento.
Una vez obtenidos los valores de mopt y de sus correspondientes errores bootstrap .632+, la
combinacion de preprocesamiento puede ser determinada aplicando el metodo de mınima distancia,
el cual es presentado en el siguiente apartado.
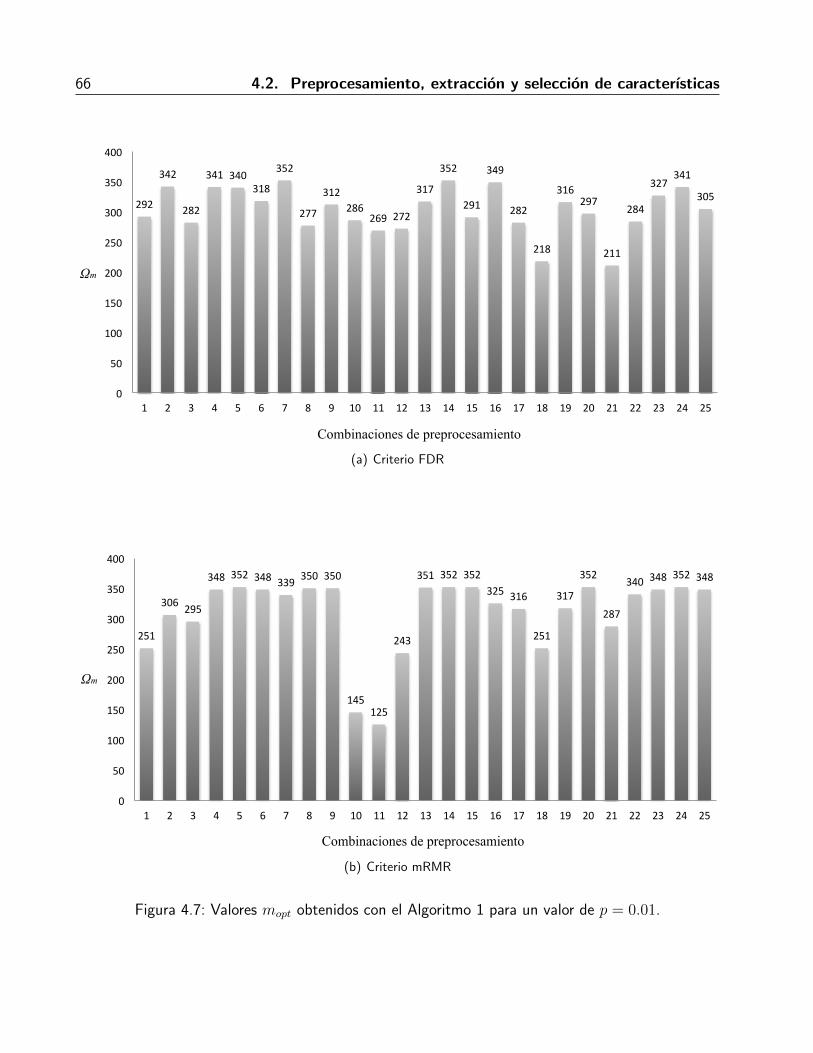
66 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas
292,
342,
282,
341, 340,318,
352,
277,
312,286,
269, 272,
317,
352,
291,
349,
282,
218,
316,297,
211,
284,
327,341,
305,
0,
50,
100,
150,
200,
250,
300,
350,
400,
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
Combinaciones de preprocesamiento
Ωm
(a) Criterio FDR
251,
306, 295,
348, 352, 348, 339, 350, 350,
145,125,
243,
351, 352, 352,325, 316,
251,
317,
352,
287,
340, 348, 352, 348,
0,
50,
100,
150,
200,
250,
300,
350,
400,
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
Ωm
Combinaciones de preprocesamiento
(b) Criterio mRMR
Figura 4.7: Valores mopt obtenidos con el Algoritmo 1 para un valor de p = 0.01.
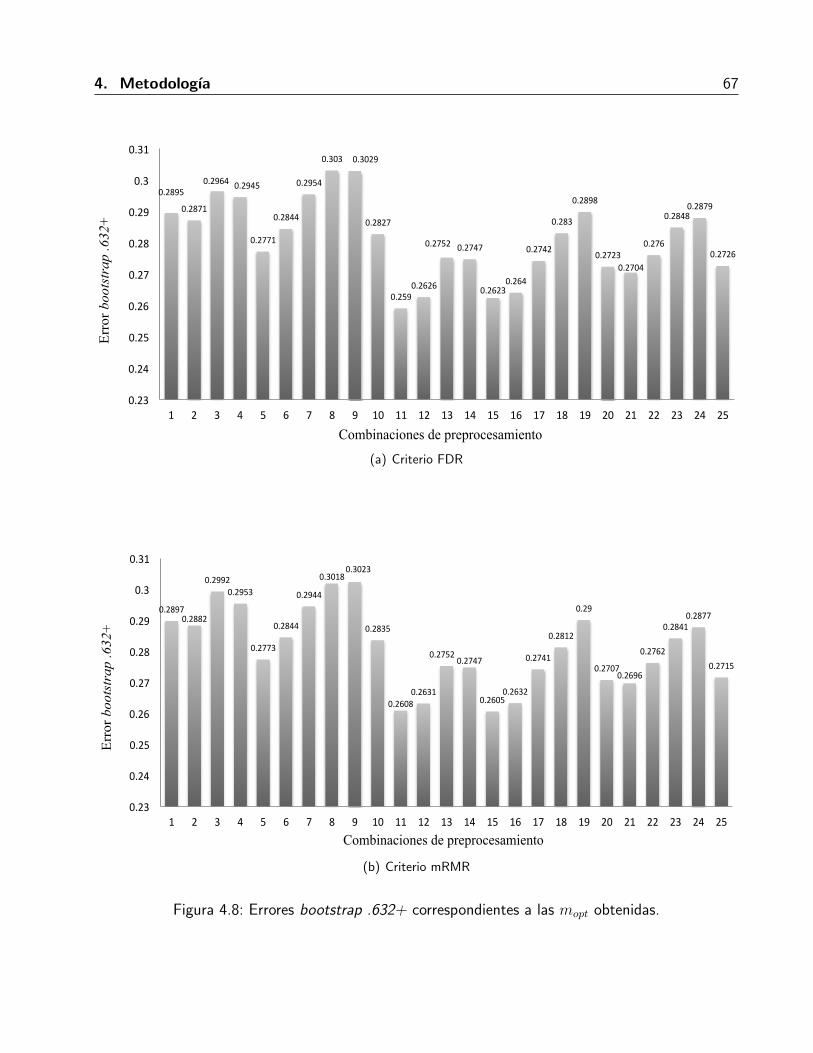
4. Metodologıa 67
0.2895,
0.2871,
0.2964, 0.2945,
0.2771,
0.2844,
0.2954,
0.303, 0.3029,
0.2827,
0.259,0.2626,
0.2752, 0.2747,
0.2623,0.264,
0.2742,
0.283,
0.2898,
0.2723,0.2704,
0.276,
0.2848,0.2879,
0.2726,
0.23,
0.24,
0.25,
0.26,
0.27,
0.28,
0.29,
0.3,
0.31,
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
Combinaciones de preprocesamiento
Err
or b
oots
trap
.632
+
(a) Criterio FDR
0.2897,0.2882,
0.2992,0.2953,
0.2773,
0.2844,
0.2944,
0.3018,0.3023,
0.2835,
0.2608,0.2631,
0.2752,0.2747,
0.2605,0.2632,
0.2741,
0.2812,
0.29,
0.2707,0.2696,
0.2762,
0.2841,0.2877,
0.2715,
0.23,
0.24,
0.25,
0.26,
0.27,
0.28,
0.29,
0.3,
0.31,
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,Combinaciones de preprocesamiento
Err
or b
oots
trap
.632
+
(b) Criterio mRMR
Figura 4.8: Errores bootstrap .632+ correspondientes a las mopt obtenidas.

68 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas
4.2.3.2. Metodo de mınima distancias.
El objetivo de este metodo es encontrar aquella combinacion de preprocesamiento que mini-
mice tanto el valor de mopt como su correspondiente error bootstrap .632+. Supongamos que se
grafican en un plano cartesiano las coordenadas (mopt, error.632+) correspondientes a las diferentes
combinaciones de preprocesamiento para cada criterio de ordenamiento. Sin embargo, dado que los
valores de mopt y error.632+ estan en rangos distintos, se normalizan entre [0, 1]. Entonces, cada
coordenada estara asociada a cada una de la 25 combinaciones de preprocesamiento de la forma
(mopt(i), error.632+(i)), para i = 1, . . . , 25. Por tanto, aquellos puntos mas cercanos al origen pre-
sentan el menor numero de caracterısticas y el menor error bootstrap .632+ simultaneamente. Para
determinar la combinacion de preprocesamiento i∗ cuyo punto se encuentra mas cercano al ori-
gen, se obtienen las distancias Euclidianas ρ(i) entre el origen y los puntos (mopt(i), error.632+(i)),
empleando las siguientes ecuaciones:
ρ(i) =√mopt(i)2 + error.632+(i)2
i∗ =25
arg mini=1
(ρ(i))
(4.1)
El metodo de mınima distancias se aplico para ambos criterios de ordenamiento. En la Figura
4.9 se muestran las distancias Euclidianas representadas por lıneas, entre el origen y cada punto
correspondiente a una combinacion de preprocesamiento. En las graficas de las Figuras 4.10 (a) y
(b) se muestra una comparativa entre los valores numericos (representados por las barras) de las
distancias Euclidianas para cada combinacion de preprocesamiento. En estas graficas se aprecia la
combinacion de preprocesamiento mas cercana al origen (barra en negro, aunque cabe aclarar que
para (b) el valor es tan cercano al origen que el tamano de la barra es muy reducido) para cada
criterio de ordenamiento.
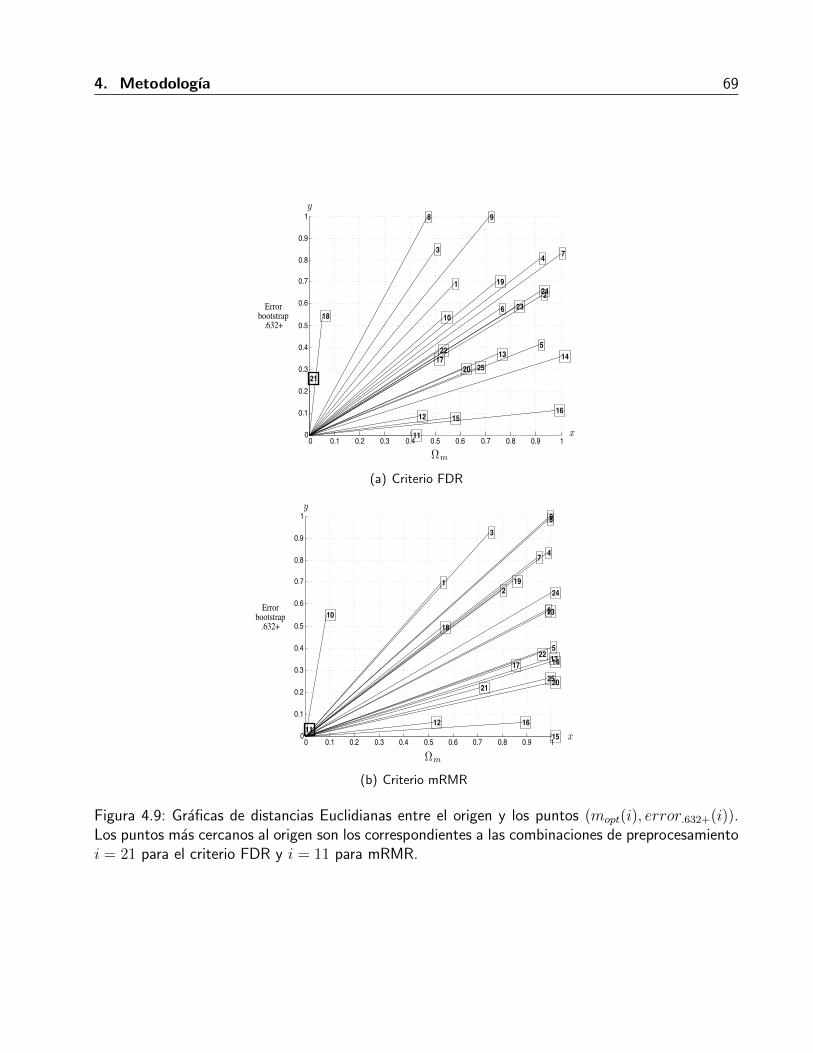
4. Metodologıa 69
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
12
34
5
6
7
8 9
10
11
12
13 14
1516
17
18
19
2021
22
23
24
25
Errorbootstrap.632+
Ωm
y
x
(a) Criterio FDR
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
12
3
4
5
6
7
89
10
1112
1314
15
16
17
18
19
2021
22
23
24
25
Ωm
x
y
Errorbootstrap.632+
(b) Criterio mRMR
Figura 4.9: Graficas de distancias Euclidianas entre el origen y los puntos (mopt(i), error.632+(i)).Los puntos mas cercanos al origen son los correspondientes a las combinaciones de preprocesamientoi = 21 para el criterio FDR y i = 11 para mRMR.
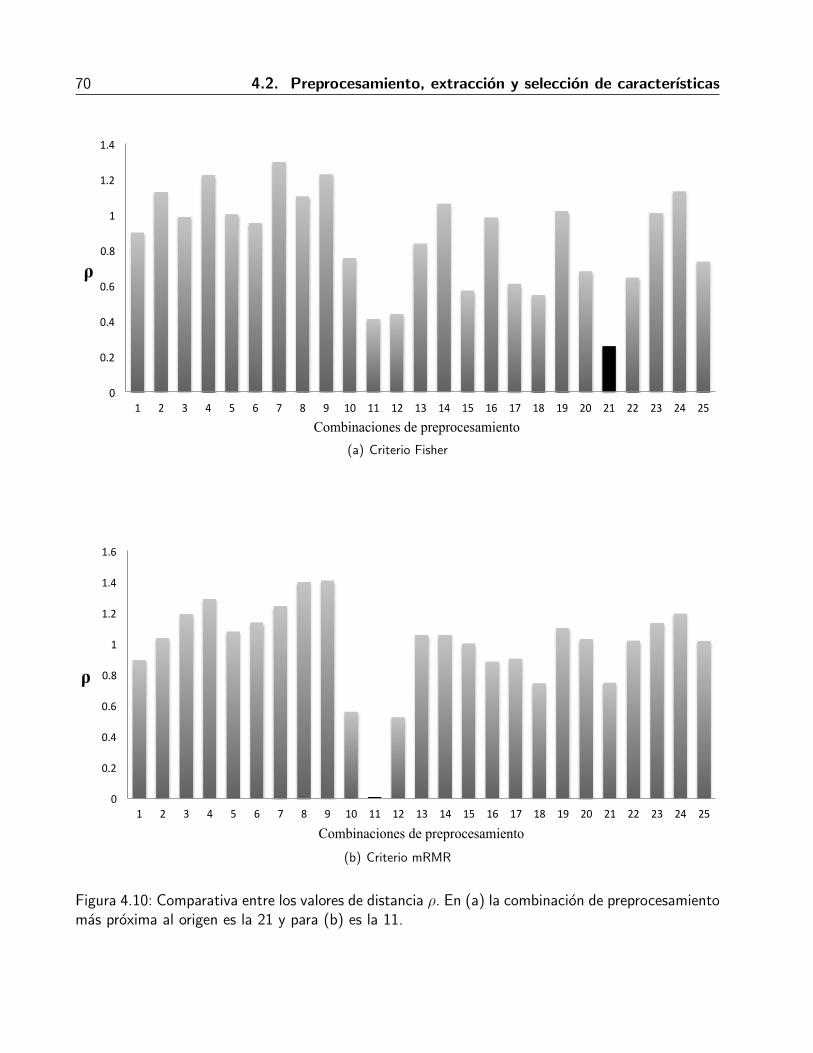
70 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas
0,
0.2,
0.4,
0.6,
0.8,
1,
1.2,
1.4,
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
Combinaciones de preprocesamiento
ρ
(a) Criterio Fisher
0,
0.2,
0.4,
0.6,
0.8,
1,
1.2,
1.4,
1.6,
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
Combinaciones de preprocesamiento
ρ
(b) Criterio mRMR
Figura 4.10: Comparativa entre los valores de distancia ρ. En (a) la combinacion de preprocesamientomas proxima al origen es la 21 y para (b) es la 11.

4. Metodologıa 71
De lo expuesto en esta seccion se resalta lo siguiente:
Se presento un procedimiento para seleccionar el subconjunto de caracterısticas de textura basado en
la GLCM para reducir la dimensionalidad para el problema de segmentacion automatica de lesiones
de mama en ultrasonografıas. Por otra parte, se evaluaron 25 combinaciones de preprocesamiento de
la imagen con la finalidad de identificar aquella que favorece mas al proceso de seleccion de carac-
terısticas. Para ello se consideraron dos criterios de ordenamiento de caracterısticas: FDR y mRMR.
Los resultados generados en cada uno de los apartados, y en particular, los que se muestran en las
graficas de la Figura 4.10 arrojan que para el criterio FDR la combinacion de preprocesamiento que
presenta el menor numero de caracterısticas y error bootstrap .632+ simultaneamente, es el conjunto
21, el cual corresponde a la tecnica de contraste FAHE y sin filtro. En cuanto al criterio mRMR es
el conjunto 11 correspondiente a la tecnica de contraste CLAHE y sin filtro. La comparacion entre
los valores de ρ para FDR como para mRMR indica cual de los dos criterios adoptar. Para esto
solamente se tomo el menor de ambos. Esto es, FDR presento un valor ρ = 0.2585, mientras que
para mRMR ρ = 0.0066. Por tanto, el criterio mRMR resulto ser el mas adecuado.
De lo anterior se concluye que las primeras 125 de 352 caracterısticas ordenadas bajo el criterio de
mRMR para la combinacion de preprocesamiento 11, es el subconjunto de caracterısticas optimo,
dado que se descartan aquellas caracterısticas redundantes dejando unicamente las mas relevantes,
reduciendo notablemente la dimensionalidad del conjunto de datos. Esto beneficia en gran medida
al proceso de clasificacion que se describe en la Seccion 4.3. En la Tabla 4.5 se muestra el subcon-
junto de caracterısticas optimo y en la Figura 4.11 se muestra la distribucion porcentual de los DT
correspondientes a las caracterısticas seleccionadas.
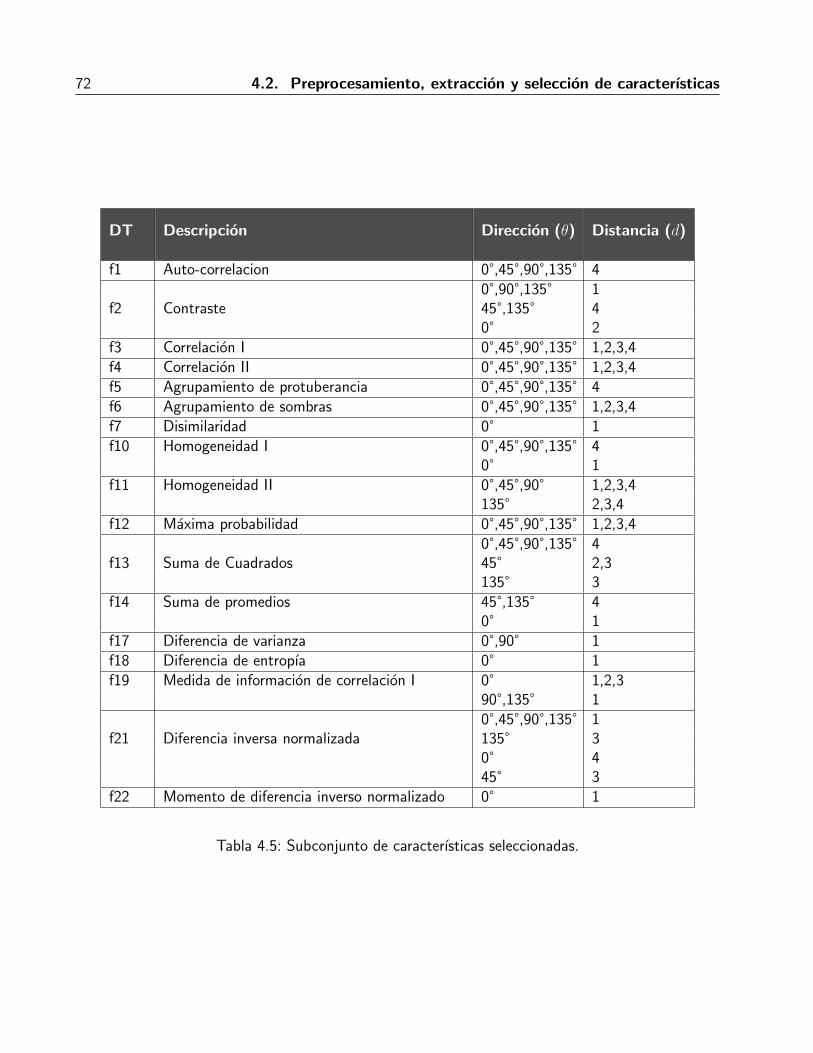
72 4.2. Preprocesamiento, extraccion y seleccion de caracterısticas
DT Descripcion Direccion (θ) Distancia (d)
f1 Auto-correlacion 0°,45°,90°,135° 40°,90°,135° 1
f2 Contraste 45°,135° 40° 2
f3 Correlacion I 0°,45°,90°,135° 1,2,3,4f4 Correlacion II 0°,45°,90°,135° 1,2,3,4f5 Agrupamiento de protuberancia 0°,45°,90°,135° 4f6 Agrupamiento de sombras 0°,45°,90°,135° 1,2,3,4f7 Disimilaridad 0° 1f10 Homogeneidad I 0°,45°,90°,135° 4
0° 1f11 Homogeneidad II 0°,45°,90° 1,2,3,4
135° 2,3,4f12 Maxima probabilidad 0°,45°,90°,135° 1,2,3,4
0°,45°,90°,135° 4f13 Suma de Cuadrados 45° 2,3
135° 3f14 Suma de promedios 45°,135° 4
0° 1f17 Diferencia de varianza 0°,90° 1f18 Diferencia de entropıa 0° 1f19 Medida de informacion de correlacion I 0° 1,2,3
90°,135° 10°,45°,90°,135° 1
f21 Diferencia inversa normalizada 135° 30° 445° 3
f22 Momento de diferencia inverso normalizado 0° 1
Tabla 4.5: Subconjunto de caracterısticas seleccionadas.

4. Metodologıa 73
DescripciónAuto%correlacion:.[2]ContrasteCorrelación.ICorrelación.IIAgrupamiento.de.protuberanciaAgrupamiento.de.sombrasDisimilaridad
3.2.
4.8.
12.8. 12.8.
3.2.
12.8.
0.8.
4.
12.12.8.
5.6.
2.4.1.6.
0.8.
4.
5.6.
0.8.
0.
2.
4.
6.
8.
10.
12.
14.
F1. F2. F3. F4. F5. F6. F7. F10. F11. F12. F13. F14. F17. F18. F19. F21. F22.
Descriptores.de.Textura.
%.
Figura 4.11: Distribucion porcentual de los DT seleccionados.
4.3 Clasificacion: evaluacion de clasificadores
En esta seccion se presenta una evaluacion de tres de los clasificadores mas utilizados en la
literatura y frecuentemente empleados en problemas de clasificacion con imagenes de USM [20, 21,
25, 60]. Estos clasificadores son las maquinas de vectores de soporte con funcion de nucleo de base
radial (SVMk), analisis lineal discriminante de Fisher (FLDA) y red de funcion de base radial (RBFN).
En el Capıtulo 3 se mostro el fundamento teorico de estos clasificadores. La finalidad de la evaluacion
es determinar cual de ellos presenta mejores prestaciones para clasificar imagenes celda en lesion o
fondo empleando un conjunto de entrenamiento generado a partir de las caracterısticas seleccionadas
en la Seccion 4.2. El procedimiento de evaluacion se describe en los siguientes pasos:
1. A partir del conjunto de entrenamiento se generaron 50 conjuntos bootstrap para entrena-
miento y 50 para prueba, esto para cada uno de los tres clasificadores.
2. Se entreno cada clasificador con cada conjunto bootstrap de entrenamiento y se clasifico cada
conjunto bootstrap de prueba.
3. Para evaluar los resultados de la clasificacion del paso anterior se utilizo analisis ROC, donde
se calculo el area bajo la curva (ABC) generada en el espacio ROC determinado por los valores
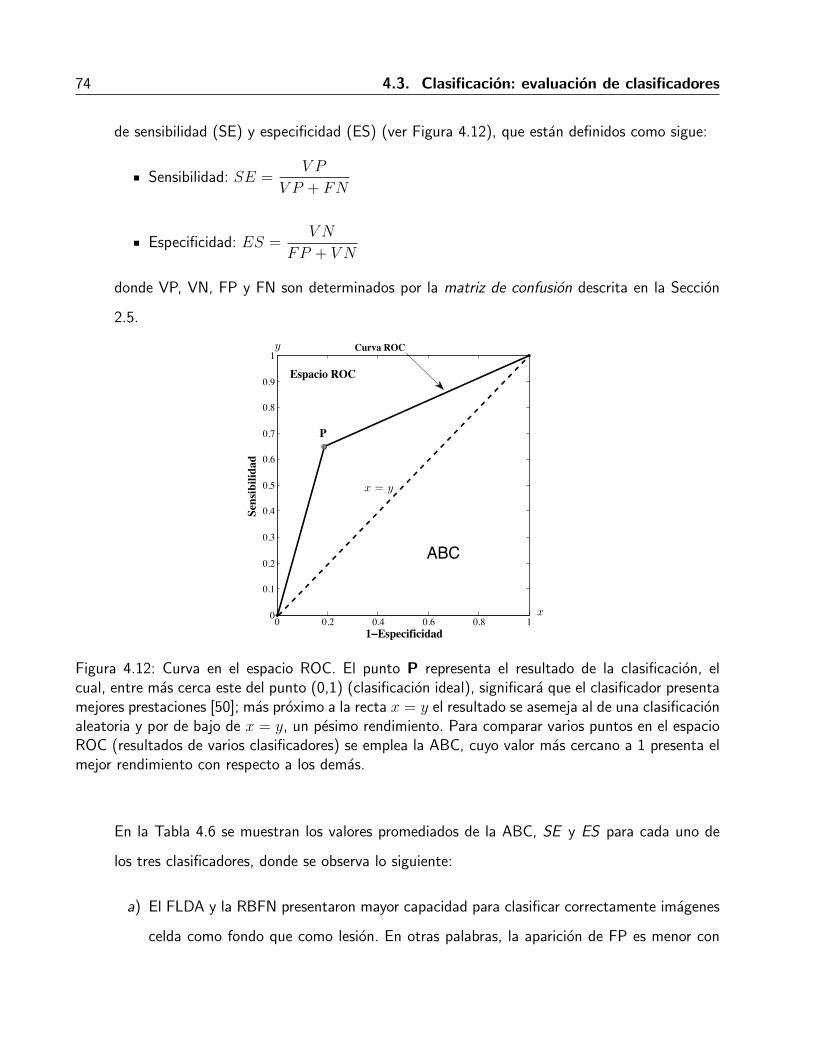
74 4.3. Clasificacion: evaluacion de clasificadores
de sensibilidad (SE) y especificidad (ES) (ver Figura 4.12), que estan definidos como sigue:
Sensibilidad: SE =V P
V P + FN
Especificidad: ES =V N
FP + V N
donde VP, VN, FP y FN son determinados por la matriz de confusion descrita en la Seccion
2.5.
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1−Especificidad
Sens
ibili
dad
P
Espacio ROC
Curva ROC
ABC
x = y
x
y
Figura 4.12: Curva en el espacio ROC. El punto P representa el resultado de la clasificacion, elcual, entre mas cerca este del punto (0,1) (clasificacion ideal), significara que el clasificador presentamejores prestaciones [50]; mas proximo a la recta x = y el resultado se asemeja al de una clasificacionaleatoria y por de bajo de x = y, un pesimo rendimiento. Para comparar varios puntos en el espacioROC (resultados de varios clasificadores) se emplea la ABC, cuyo valor mas cercano a 1 presenta elmejor rendimiento con respecto a los demas.
En la Tabla 4.6 se muestran los valores promediados de la ABC, SE y ES para cada uno de
los tres clasificadores, donde se observa lo siguiente:
a) El FLDA y la RBFN presentaron mayor capacidad para clasificar correctamente imagenes
celda como fondo que como lesion. En otras palabras, la aparicion de FP es menor con

4. Metodologıa 75
respecto a la aparicion de los FN.
b) La SVMk presento capacidad similar para clasificar correctamente imagenes celda como
fondo y como lesion.
c) De los tres clasificadores el SVMk presenta una ABC mayor, por tanto, es la que se
aproxima mas a la clasificacion ideal.
ClasificadorArea bajo lacurva (ABC)
Sensibilidad(SE)
Especificidad(ES)
FLDA 0.8004 0.6648 0.8089RBFN (neuronas = 480) 0.8031 0.7080 0.7544SVMk (σ = 1.9) 0.8149 0.7129 0.7104
Tabla 4.6: Resultados de analisis ROC. El numero de neuronas para la RBFN fue determinado previaexperimentacion, se comenzo con una neurona y se concluyo con 1500. Se observo que a partirde la neurona 480 los valores para las metricas ROC ya no variaban, por tanto, este numero deneuronas fue seleccionado. Para SVMk se considero σ = 2 propuesto en [20, 21] y se realizo unaexperimentacion considerando el intervalo [1,3] con una granularidad de 0.3 donde se observo que σ= 1.9 presento el mejor desempeno.
De las observaciones anteriores se deduce que el clasificador SVMk es el que presento mejor
desempeno con respecto al FLDA y RBFN, dado que la ABC es mayor. Sin embargo, a pesar
de que se puede considerar el rendimiento de la SVMk como ”bueno”, ya que la ABC es mayor
a 0.8, existe un porcentaje considerable de apariciones de FP y FN de alrededor del 29 %, los
cuales tienen que ser reducidos. Para ello se propone el proceso de postprocesamiento que se
describe en la Seccion 4.4.

76 4.4. Postprocesamiento y ajuste del contorno de la ROI
4.4 Postprocesamiento y ajuste del contorno de la ROI
En esta seccion se presenta un metodo de postprocesamiento cuya finalidad es reducir los FP y
FN generados por la clasificacion de imagenes celda en una imagen de USM, con el fin de determinar
la region de interes (ROI). Una vez conocida la ROI es necesario ajustar finamente su contorno al
borde de la lesion. Para ello se utilizo el algoritmo de Chan-Vese.
4.4.1 Metodo de postprocesamiento
Este metodo necesita como entrada la imagen de USM original (I) y la imagen (IQ) que es el
resultado de la clasificacion. IQ es una imagen binaria cuyos valores correspondientes a 1 representan a
la lesion y 0 al fondo. Esta imagen se construye con la mascara de etiquetas, mencionada en la Seccion
4.2.2, en donde el valor de cada pıxel dentro de cada etiqueta es cambiado a 0 o 1, dependiendo del
resultado de la clasificacion de su respectiva imagen celda. A continuacion se presentan los 4 pasos
del metodo de postprocesamiento:
1. Eliminacion de FP por regiones. Dado que en las imagenes de USM las capas de grasa sub-
cutanea y capas musculares aparecen tanto en la parte inferior como superior de la imagen
[20, 21], se presume que la region correspondiente a la lesion se encuentra en el centro de la
imagen. Debido a esto, el resto de la imagen se puede considerar como fondo. Por lo que se
propone realizar las siguientes acciones:
Recortar el 30 % de la parte inferior tanto de I como IQ y denominar las imagenes
resultantes como Ir e IQr, respectivamente.
Considerar como fondo el 10 % de la parte superior de IQr, ası como las regiones conexas
con las esquinas.
Considerar como fondo las regiones aisladas de tamano igual al de una imagen celda
(16× 16 pıxeles).

4. Metodologıa 77
Los porcentajes mencionados fueron determinados despues de evaluar las 960 imagenes que
se utilizaron en la Seccion 4.2.1, donde se observo que la lesion se encontraba por encima del
30 % de la parte inferior de la imagen y por debajo del 10 % de la parte superior de la imagen
en promedio. Las esquinas son medidas de acotamiento para eliminar la mayor cantidad de FP,
dado que la lesion difıcilmente aparecera en estas regiones. En la Figura 4.13 se muestran tanto
el area de recorte como las regiones consideradas como fondo. En la Figura 4.14 se muestra
el resultado de la aplicacion de los acciones anteriores.
!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!
R!
!
30%!
aaaaa!
10%!
15%!
15%! D"
D"
D"D"
D"
D"
Figura 4.13: Plantilla de regiones para eliminar FP. La region en gris marcada con la letra R es laregion recortada para I como para IQ. Las regiones en gris marcadas con la letra D son consideradascomo fondo. La region en blanco es la region en donde se asume se encuentra la lesion.
(a) Ir (b) IQr (c) IQr+−
Figura 4.14: Eliminacion de FP. (a) imagen original de USM recortada. Se muestra el contornode la lesion (lınea blanca) para tener una referencia visual de las regiones clasificadas como lesionen IQr; (b) imagen de clasificacion binaria recortada; (c) resultado de la eliminacion de regionescorrespondientes con FP.

78 4.4. Postprocesamiento y ajuste del contorno de la ROI
2. Binarizacion de la imagen. La imagen Ir es binarizada a traves de un umbral global determinado
por el metodo de Otsu [61]. Esta tecnica de umbralado divide los niveles de gris de la imagen
en dos clases, C1 = [0, 1, 2, ...k] y C2 = [k+1, . . . , L−1] para k = 0, 1, 2, . . . , L−1, donde L
es el numero total de niveles de gris. Posteriormente, se calcula para toda k, la varianza entre
clases representada por σ2B(k). Finalmente, se determina el umbral optimo k∗ que maximice a
σ2B(k), definido como:
σ2B(k∗) = max
0≤k≤−Lσ2B(k) (4.2)
Una vez determinado el umbral k∗, la imagen es binarizada mediante el siguiente criterio:
IB(x, y) =
1 si Ir(x, y) > k∗
0 si Ir(x, y) ≤ k∗(4.3)
donde IB(x, y) es la imagen umbralada. En la Figura 4.15 se muestra un ejemplo del proceso
de binarizacion usando el metodo de Otsu.
Figura 4.15: Umbralado global. (a) imagen de USM recortada, Ir; (b) imagen Ir binarizada con elmetodo de Otsu, IB.
3. Suavizado morfologico. Dado que la imagen binarizada con el metodo de Otsu no presenta for-
mas bien definidas de los posibles objetos (regiones en blanco en la Figura 4.15(b)), se propone

4. Metodologıa 79
aplicar una apertura morfologica, la cual se realiza mediante la aplicacion secuencial de dos
operadores basicos: erosion y dilatacion. Estos operadores utilizan un elemento estructurante
con forma y tamano definido de acuerdo a las estructuras que se desean remover o extraer en
la imagen [32].
La erosion de una imagen f con un elemento estructurante b en cualquier punto (x, y) se
define como el valor mınimo en la region que cubre b cuando su centro esta sobre (x, y), esto
se expresa como:
[f b](x, y) = minf(x− s, y − t), para (s, t) ∈ b (4.4)
La dilatacion de una imagen f con un elemento estructurante b en cualquier punto (x, y) se
define como el valor maximo en la region que cubre b cuando su centro esta sobre (x, y), esto
es:
[f ⊕ b](x, y) = maxf(x− s, y − t), para (s, t) ∈ b (4.5)
Una vez definas la dilatacion y la erosion, la apertura morfologica se define como una erosion
seguida de una dilatacion con el mismo elemento estructurante:
I b = (I b)⊕ b (4.6)
Para aplicar el suavizado morfologico se escogio un elemento estructurante de tipo disco, que
involucra definir el tamano del radio del disco r, el cual se establecio con un valor de 11. Se
escogio esta forma al observar que era la mas cercana a la forma de una lesion de mama en las
imagenes de USM analizadas para este estudio. En cuanto al tamano del radio, este se ajusto al

80 4.4. Postprocesamiento y ajuste del contorno de la ROI
probar valores de r = 1, 2, 3, . . . , 25. En la Ecuacion 4.7 se expresa el suavizado morfologico.
ISB = IB b(f, r) (4.7)
donde ISB es la imagen resultante del suavizado morfologico, IB es la imagen binarizada con
el metodo de Otsu, b(·) es el elemento estructurante con forma f =’disco’ y radio r = 11. En
la Figura 4.16 se muestra el suavizado morfologico sobre la imagen binarizada con el metodo
de Otsu.
(a) IB (b) ISB
Figura 4.16: Suavizado morfologico. En (b) se aprecia la definicion de cuatro regiones en blanco,mientras que en (a) hay multiples regiones.
4. Seleccion de la ROI. Dado que en IQr+− se presentan tanto FP como FN, los cuales dificultan
la visualizacion clara de la ROI y en ISB existen varias posibles ROI’s, de las cuales no se
tiene la certeza de que alguna sea la correcta; es necesario relacionar tanto a IQr+− como ISB
de tal forma que se eliminen FP y FN y, al mismo tiempo, seleccionar la ROI correcta. Para

4. Metodologıa 81
realizar lo anterior se necesita encontrar la region en ISB cuya area correspondiente en IQr+−
presente la cantidad mayor de elementos (pıxeles) considerados como lesion, respecto a las
demas regiones. Lo anterior se expresa como:
i∗ = maxRi∈IQr+−
∩ISBA(Ri) (4.8)
donde A(Ri) es el area de la region i para i = 1, 2, 3, . . . , n, cuyas regiones se derivan de la
interseccion entre IQr+− e ISB. i∗ es el identificador de la region seleccionada en ISB con el
area mayor.
Para implementar la Ecuacion 4.8 consideramos a IQr+− e ISB como matrices de tamano M×Ny cada elemento de estas matrices se define como IQr+−(x, y) e ISB(x, y) respectivamente,
donde x = 1, 2, 3, . . . ,M y y = 1, 2, 3, . . . , N . Entonces, se aplica el Algoritmo 2, en el cual
primeramente se etiquetan las regiones en ISB, despues realiza una multiplicacion elemento
por elemento entre IQr+− y la imagen con las regiones etiquetadas; dado que IQr+− es binaria, el
resultado de la multiplicacion es la interseccion entre ambas imagenes, por lo que las regiones
resultantes se mantienen etiquetadas. En seguida, se determina la cantidad de elementos que
componen a cada region resultante etiquetada y se selecciona la mayor. Por ultimo, una vez
que se conoce la etiqueta de la region con la cantidad mayor de elementos, las demas regiones
en ISB desaparecen (se consideran como fondo) dejando unicamente la region correspondiente
a la etiqueta seleccionada, mejor conocida como ROI (ver Figura 4.17).

82 4.4. Postprocesamiento y ajuste del contorno de la ROI
3
1 4
2
(a) ISB etiquetada.
3
42
(b) IQr+−∩ ISB etiquetada (c) Region seleccionada IROI
Figura 4.17: Seleccion de la ROI.
Algoritmo 2 Seleccion de la ROIEntrada: Resultados de la clasificacion IQr+− ,
Imagen binarizada y suavizada ISBSalida: Imagen con la ROI seleccionada IROI
1: IEtiquetas ← Etiquetar regiones en ISB con 4-conectividad2: IInterseccion(x, y)← IQr+−(x, y) · IEtiquetas(x, y) ∀(x, y)3: numEtiquetas← obtener numero de regiones etiquetadas en IEtiquetas4: areaMaxima← 05: Rsel ← 06: para i = 1 : NumEtiquetas
hacer7: areaActual← contarElementos(IInterseccion(x, y) ∀(x, y)|IInterseccion(x, y) = i)8: si (areaMaxima ≤ areaActual) entonces9: areaMaxima← areaActual
10: Rsel ← i11: IROI(x, y)← 0 ∀(x, y)|IEtiquetas(x, y) 6= Rsel
12: IROI(x, y)← 1 ∀(x, y)|IEtiquetas(x, y) = Rsel
13: devolver IROI

4. Metodologıa 83
4.4.2 Ajuste del contorno de la ROI
Una vez definida la ROI, el siguiente paso es delinear finamente su contorno de tal manera que
este se ajuste lo mayor posible al borde real de la lesion. Para esto se utilizo el algoritmo Chan-
Vese [62], cuya idea principal es minimizar una funcional de energıa basada en el contraste de la
imagen, por tanto, no es dependiente del gradiente para detectar el borde del objeto a delinear. Esta
tecnica asume que una imagen u0 esta formada por dos regiones con intensidades aproximadamente
constantes con distintos valores ui0 y uo0 entre ellas. Ademas, se asume que el objeto para ser detectado
es representado por la region con el valor ui0 y cuyo borde se representa por C0. Entonces se tiene
que u0 ≈ ui0 dentro del objeto [o dentro(C0)], y u0 ≈ uo0 fuera del objeto [o fuera(C0)]. Ahora,
consideremos el termino de “ajuste” expresado como:
F1(C) + F2(C) =
∫dentro(C)
|u0(x, y)− c1|2dxdy +
∫fuera(C)
|u0(x, y)− c2|2dxdy (4.9)
donde C es cualquier otra curva variable, y las constantes c1, c2, son los valores promedio de u0
dentro y fuera de C respectivamente. Se tiene que, el borde del objeto C0 representa la minimizacion
del termino de ajuste, esto es,
infCF1(C) + F2(C) ≈ 0 ≈ F1(C0) + F2(C0).
De lo anterior se desprenden cuatro casos: 1) si la curva C esta fuera del objeto entonces
F1(C) > 0 y F2(C) ≈ 0; 2) si la curva C esta dentro del objeto, F1(C) ≈ 0 y F2(C) > 0; 3) si la
curva C esta dentro y fuera del objeto, entonces F1(C) > 0 y F2(C) > 0; y 4) si C = C0, entonces
la energıa de ajuste es minimizada. Estos casos se ilustran en la Figura 4.18.
Dado que el modelo representado en la Ecuacion 4.9 esta formulado para minimizar la energıa, este
se puede ver como un caso particular del problema de “mınima particion”, por tanto, para resolver este
problema, y al mismo tiempo, generalizar el modelo, es necesario homologar los terminos en funcion

84 4.4. Postprocesamiento y ajuste del contorno de la ROI
Caso'1' Caso'2'
Caso'3' Caso'4'
Figura 4.18: Casos posibles para la posicion de la curva C (contornos en blanco). La figura al centrode cada imagen (en gris oscuro) representa al objeto del cual se desea obtener el contorno.
de la funcional de energıa, del metodo de conjunto de nivel y de la ecuacion de Euler-Lagrange.
La reformulacion del modelo se expresa como:
Fε(c1, c2, φ) = µ
∫Ω
δε(φ(x, y))|5φ(x, y)|dxdy
+ ν
∫Ω
Hε(φ(x, y))dxdy
+ λ1
∫Ω
|u0(x, y)− c1|2Hε(φ(x, y))dxdy
+ λ2
∫Ω
|u0(x, y)− c2|2(1−Hε(φ(x, y)))dxdy
(4.10)
donde Ω es la imagen original, µ, ν (generalmente ν = 0), λ1 y λ2 son parametros de ajuste para la
longitud, el area y el suavizado (λ1 = λ2) de la curva φ, respectivamente. φ,Hε y δε son las funciones
homologadas para la curva C, funcion escalon unitario y la funcion delta Dirac, respectivamente.
Para Hε y δε se tiene que ε→ 0, por tanto, estas quedan definidas como se muestran a continuacion:
Hε(z) =1
2
(1 +
2
πarctan
(zε
))δε = H ′ε
(4.11)
En el Algoritmo 3 se describe el metodo para encontrar el contorno φ que minimice Fε(c1, c2, φ). El

4. Metodologıa 85
termino PDE se refiere a la ecuacion parcial diferencial dependiente del tiempo (t).
Algoritmo 3 Algoritmo Chan-Vese para delinear la ROI.Entrada: µ, λ, φ0, numIteraciones y u0
Salida: φ∗
1: Inicializar φ0 ← φ0
2: n← 03: repetir
4: Calcular c1(φn) =
∫Ωu0(x, y)Hε(φ(x, y))dxdy∫
ΩHε(φ(x, y))dxdy
y c2(φn) =
∫Ωu0(x, y)(1−Hε(φ(x, y)))dxdy∫
Ω(1−Hε(φ(x, y)))dxdy
5: Resolver la PDE:∂φ
∂t= δε(φ)
[µ div
( 5φ|5φ|
)− ν − λ1(u0 − c1)2 + λ2(u0 − c2)2
]para obtener φn+1
6: n = n+ 17: hasta que (solucion estacionaria o n < numIteraciones )8: devolver φ∗
Una implementacion de este algoritmo fue tomada del sitio en Internet en [63] para ser utilizada
en este trabajo. En la Figura 4.19 se muestra un ejemplo donde, dada una ROI en una imagen (φ0),
esta es delineada finamente para ajustar su contorno al de la lesion.
En la Figura 4.20 se presenta a manera de resumen el esquema general del metodo de postpro-
cesamiento y ajuste del contorno de la ROI.

86 4.4. Postprocesamiento y ajuste del contorno de la ROI
(a) Contorno de la ROI(φ0) sobre la imagen origi-nal
(b) Ajuste fino del contorno(φ∗) realizado con el algo-ritmo de Chan-Vese sobre laimagen original
Figura 4.19: Ajuste fino del contorno de la ROI. En (a) se aprecia que el contorno es mas espiculadoy disforme, mientras que en (b) el contorno es mas suave y ajustado a la lesion. Los parametrosutilizados para este ejemplo fueron λ1 = λ2 = 2, µ = 23 y el numero de iteraciones fueron 2000.
'EYqueta'con'más'elementos'
Ir IB ISB IEtiquetas
∩
IROI
φ*
a)' b)' c)' d)'
e)' f)' g)'
h)'
i)'
IQr IQr−
+ IQr−
+ ∩ IEtiquetas
Figura 4.20: Esquema general del metodo de postprocesamiento y ajuste del contorno de la ROI.a)imagen original recortada (30 %), b)binarizacion empleando el metodo de Otsu, c) suavizado mor-fologico, d) etiquetado de las posibles ROI’s, e) resultado de la clasificacion recortado, f) eliminacionde FP por regiones, g) criterio de seleccion de la ROI, h)ROI seleccionada y i) ajuste del contornode la ROI con el algoritmo de Chan-Vese.

4. Metodologıa 87
Para finalizar la descripcion de esta seccion es necesario realizar las siguientes precisiones:
1. Para visualizar la segmentacion sobre la imagen completa es necesario agregar la region recor-
tada a la imagen segmentada, dicha region debe ser considerada como fondo.
2. Antes de aplicar el algoritmo de Chan-Vese la imagen original puede ser suavizada por alguna
tecnica de filtrado para mejorar los resultados del algoritmo. Para este trabajo se utilizo el
filtro anisotropico + Gabor II descrito en el Capıtulo 3, dado que este filtro trabaja de forma
adecuada con los algoritmos que emplean contornos activos, ya que preserva en cierta medida,
la informacion relevante relacionada con los bordes [55].
4.5 Conclusiones
En este capıtulo se presentaron las tres etapas de la metodologıa propuesta. En la primera,
preprocesamiento, extraccion y seleccion de caracterısticas, se determino el subconjunto optimo de
caracterısticas de textura basadas en la matriz de co-ocurrencia de niveles de gris para el problema
de segmentacion automatica de lesiones de mama en ultrasonografıas, cuyas caracterısticas que
lo conforman (125 de 352) se muestran en la Tabla 4.5. Tambien se determinaron las tecnicas
de preprocesamiento de la imagen y el criterio de ordenamiento de caracterısticas que contribuyen
en mayor medida a mejorar el proceso de seleccion de estas. Las tecnicas son: CLAHE para el
mejoramiento de contraste y sin filtro para la reduccion del artefacto speckle; en cuanto al criterio
de ordenamiento, el mas adecuado resulto ser el de mınima-redundancia-maxima-relevancia. En la
etapa de clasificacion se evaluaron tres clasificadores empleando analisis ROC, estos clasificadores
son: maquina de vectores de soporte con funcion de nucleo, analisis lineal discriminante de Fisher
y red de funcion de base radial; donde la maquina de vectores de soporte con funcion de nucleo
de base radial fue la que presento mayor rendimiento con respecto a las otras dos tecnicas de
clasificacion. En la etapa de postprocesamiento y ajuste del contorno de la ROI se propuso un metodo
de postprocesamiento basado en umbralado global (metodo de Otsu) y operaciones morfologicas, a
traves del cual se logro identificar de forma clara la region de interes o ROI, ya que se eliminan en gran

88 4.5. Conclusiones
medida, falsos positivos y falsos negativos que surgen como resultado de la etapa de clasificacion.
Por otra parte, se implemento un algoritmo basado en contornos activos para ajustar el contorno de
la ROI.

5Resultados: metodo propuesto
En este capıtulo se presenta como resultado final de este trabajo, el metodo propuesto para la
segmentacion automatica de lesiones de mama en imagenes de ultrasonido de mama, el cual se
derivo de la metodologıa descrita en el Capıtulo 4. Tambien se presenta la experimentacion y los
resultados de la evaluacion del metodo propuesto.
89

90 5.1. Metodo propuesto para la segmentacion automatica en USM
5.1 Metodo propuesto para la segmentacion automatica de
lesiones de mama en imagenes de USM
El metodo se compone de tres modulos principales: preprocesamiento de la imagen, clasificacion,
y postprocesamiento y ajuste del contorno, los cuales se detallan a continuacion.
Preprocesamiento de la imagen.
1. La imagen original de ultrasonido de mama es recortada un 30 % de la parte inferior,
dado que no es necesario procesar toda la imagen como se mostro en la Seccion 4.4.1.
Por lo que en lo sucesivo se utilizara esta imagen recortada.
2. Se aplica la tecnica CLAHE para mejorar el contraste. Los parametros utilizados son:
divisiones de la imagen en 4× 4 y el punto de corte con valor de 0.3.
Clasificacion.
1. Generacion de imagenes celda. De la imagen preprocesada se generan dos mascaras de
rejilla: la mascara rectangular de celdas de tamano 16 × 16 pıxeles, y la mascara de
etiquetas; la primera mascara funciona como plantilla para extraer cada imagen celda, y
la segunda, para identificar cada imagen celda y conocer su ubicacion dentro de la imagen
de USM.
2. Extraccion de caracterısticas. Una vez generadas las imagenes celda, de cada una de estas
se extraen las 125 caracterısticas de textura basadas en la GLCM que se muestran en la
Tabla 4.5.
3. Clasificar imagen celda. Cada imagen celda es clasificada como lesion (1) o fondo (0),
para lo cual se utiliza la maquina de vectores de soporte con funcion de nucleo de base
radial (SVMk), la cual se entrena con el conjunto de datos normalizados correspondiente
a la combinacion de preprocesamiento 11 que se menciono en la Seccion 4.2.2 y con
un valor de σ = 1.9. Despues de que cada imagen celda es clasificada, los pıxeles de

5. Resultados: metodo propuesto 91
su respectiva region en la mascara de etiquetas adoptan el valor de la clase, por lo que
al final se genera una nueva imagen binaria como resultado de la clasificacion. En esta
imagen se espera tener una primera aproximacion a lo que es la ROI.
Postprocesamiento y ajuste del contorno. En este modulo se define de forma mas precisa la
ROI a traves de la aplicacion del metodo de postprocesamiento propuesto en la Seccion 4.4.1,
con la salvedad de que ya no es necesario recortar la imagen, dado que este paso se realizo en
el modulo de preprocesamiento. Por otra parte, para ajustar el contorno de la ROI al contorno
verdadero de la lesion se aplica el metodo de Chan-Vese descrito en la Seccion 4.4.2, cuyos
valores de los parametros son λ1 = λ2 = 2, µ = 23 y el numero de iteraciones es de 2000.
En la Figura 5.1 se presenta el esquema global del metodo propuesto.
Preprocesamiento%(CLAHE)%
Clasificación%
Generación'de'imágenes'celda'
Extracción'de'las'125'caracterísYcas'seleccionadas'
para'cada'imagen'celda'
Clasificar'cada'imagen'celda'con'
SVMk'
Postprocesamiento%y%
ajuste%del%contorno%
Imagen'de'USM'original'
Imagen'de'USM'segmentada'
automáYcamente'
Figura 5.1: Esquema global del metodo propuesto.

92 5.2. Evaluacion y resultados
5.2 Evaluacion y resultados
Para evaluar el rendimiento del metodo de segmentacion propuesto se emplearon tres metricas:
exactitud (EXC), sensibilidad (SE) y especificidad (ES), las cuales son consideradas como las mas
comunmente utilizadas para evaluar sistemas de clasificacion en escenarios clınicos [21]. Para aplicar
estas metricas se emplearon 114 imagenes1 de USM con diversos tipos de lesiones que fueron seg-
mentadas tanto por radiologos expertos como por el metodo propuesto. Las imagenes segmentadas
por los radiologos se consideraron como el estandar de oro. Cabe aclarar que estas 114 imagenes son
independientes al conjunto de imagenes que se utilizo en el Capıtulo 4 y solamente fueron empleadas
para la evaluacion del metodo propuesto.
Las metricas mencionadas estan basadas en el error de area, lo que significa encontrar la diferencia
entre las areas consideradas como lesion tanto de las imagenes segmentadas por el radiologo como
por el metodo propuesto. Para esto es necesario determinar los falsos positivos (FP), falsos negativos
(FN), verdaderos positivos (VP) y verdaderos negativos (VN). Los cuales se definen como:
FP =|Aa ∪ Am −Am|
Am
FN =|Aa ∪ Am −Aa|
Am
V P =|Aa ∩ Am|Am
V N =¬|Aa ∪ Am|Am
(5.1)
donde Am es el area de la lesion determinada por la segmentacion humana y Aa es el area de la
lesion segmentada por el metodo propuesto.
Una vez definidos los FP, FN, VP y VN en terminos del error de area; la exactitud, sensibilidad
1Proporcionadas por el Instituto Nacional de Cancerologıa de Rıo de Janeiro en Brasil (INCA)

5. Resultados: metodo propuesto 93
y especificidad quedan definidos en funcion de estos, como se muestra a continuacion:
EXC =(V P + TN)
(V P + V N + FP + FN)
SE =V P
(V P + FN)
SP =V N
(V N + FP )
(5.2)
En la Figura 5.2 se muestran dos casos de imagenes segmentadas tanto con el metodo propuesto
como de forma manual. Ademas, los respectivos bordes de las regiones consideradas como lesion
para cada tipo de segmentacion, son sobrepuestos para resaltar las diferencias de forma visual. Cabe
senalar que en la Figura 5.2 (c) los bordes con ambos metodos se aprecian muy similares, en cuanto
a 5.2 (f) existen diferencias notorias en algunas regiones del area generada por el borde correspon-
diente al metodo propuesto, sin embargo, gran parte del area generada manualmente es coincidente.
En la Tabla 5.1 se muestran los resultados de la segmentacion de las 114 imagenes de USM con
el metodo propuesto y una comparativa con otro metodo de segmentacion similar. Se observa que
el metodo propuesto presenta una exactitud mayor que el metodo en [21] y por encima del 90 %, lo
cual sugiere que ofrece resultados confiables y buenos al segmentar lesiones de mama en imagenes de
USM. Por otra parte, tambien se observa que el metodo propuesto presenta menor sensibilidad pero
mayor especificidad que [21]. Esto significa que el metodo propuesto es proclive a generar en mayor
cantidad FP que [21], aunque este ultimo tiende a generar en mayor cantidad FN que el metodo
propuesto.
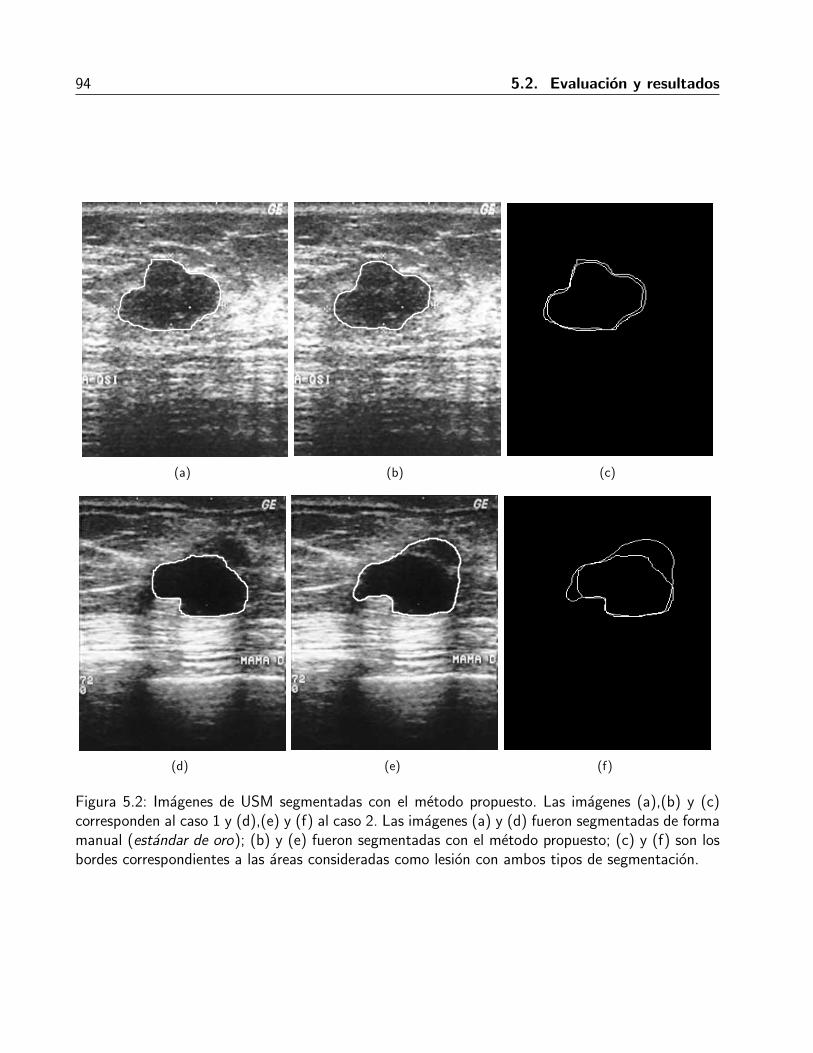
94 5.2. Evaluacion y resultados
(a) (b) (c)
(d) (e) (f)
Figura 5.2: Imagenes de USM segmentadas con el metodo propuesto. Las imagenes (a),(b) y (c)corresponden al caso 1 y (d),(e) y (f) al caso 2. Las imagenes (a) y (d) fueron segmentadas de formamanual (estandar de oro); (b) y (e) fueron segmentadas con el metodo propuesto; (c) y (f) son losbordes correspondientes a las areas consideradas como lesion con ambos tipos de segmentacion.

5. Resultados: metodo propuesto 95
Metodo de segmentacion Imagenes de USM EXC ( %) SE ( %) ES ( %)Metodo propuesto 114 95.56 85.79 96.69
Metodo en [21] 112 93.75 95.0 92.31
Tabla 5.1: Comparativa entre metodos de segmentacion.
Se considero evaluar la velocidad del metodo propuesto, por lo que se identifico que el tiempo
de procesamiento para algunas de las etapas funcionales como: la clasificacion de imagenes celda
y el ajuste de contorno, estan en funcion del tamano de la imagen, por tanto, entre mayor sea
esta, mayor sera el tiempo de procesamiento. El tamano promedio para las 114 imagenes es de
263 X 303 pıxeles. Se evaluo el tiempo promedio de procesamiento del conjunto de imagenes, el
cual resulto ser de 23.5 segundos. El metodo propuesto se implemento en MATLAB R2011a en
una PC con procesador Intel Core i5 de cuatro nucleos a 2.5 Ghz del cual se utilizaron solamen-
te dos nucleos y con memoria RAM de 4 GB. En [21] el tiempo promedio por imagen es de 19.7
segundos, su metodo fue implementado en una PC Core 2 con memoria de 2 GB, los autores no
dan mayor detalle sobre el lenguaje sobre el cual fue implementado su metodo, ni del tamano de
las imagenes que utilizaron. El tiempo promedio obtenido por el metodo propuesto puede reducirse
significativamente al hacer una implementacion del mismo en un lenguaje compilado como C o C++.
En terminos generales, se puede decir que el metodo propuesto es una alternativa confiable y
competitiva respecto a otros metodos de segmentacion de lesiones de mama en ultrasonografıas.
5.3 Conclusiones
En este capıtulo se presento a manera de resultado el metodo propuesto para segmentar lesiones
de mama en imagenes de ultrasonido sin intervencion humana. Este metodo cuenta con tres modulos
principales: preprocesamiento de la imagen, clasificacion, y postprocesamiento y ajuste de contorno
de la ROI. Para la evaluacion del metodo se utilizaron las siguientes metricas: exactitud (EXC), sen-

96 5.3. Conclusiones
sibilidad (SE) y especificidad (ES), cuyos valores son: EXC=95.56 %, SE=85.79 % y ES=96.69 %.
El metodo propuesto fue comparado con un metodo similar reportado en la literatura y cuyos resul-
tados son: EXC=93.75 %, SE=95.0 % y ES=92.31 %. Lo anterior revela que el metodo propuesto
presenta una exactitud alta aunque tiende a generar mas falsos positivos que el metodo reportado
en la literatura, caso contrario es lo que sucede con los falsos negativos. En terminos generales, el
metodo propuesto es confiable y competitivos con respecto a otros metodos.

6Conclusiones y trabajo futuro
6.1 Conclusiones
El cancer de mama se ha convertido en una de las principales causas de muerte en la mujer
alrededor del mundo y, por tanto, es considerado un problema de salud publica. Distintos gobiernos
han implementado medidas preventivas para disminuir la tasa de mortalidad por este padecimiento.
Dentro de dichas medidas se encuentra el plan de tamizaje, el cual involucra a la mamografıa como
principal fuente de diagnostico y al ultrasonido de mama (USM) como tecnica coadyuvante a la
mamografıa. En fechas recientes ha surgido un especial interes por desarrollar metodos confiables
de diagnostico de lesiones de mama en USM, lo cual no pretende minimizar la utilidad de la ma-
mografıa, sino de mejorar la interpretacion del diagnostico en general por parte del personal experto
(radiologo) para evitar biopsias innecesarias, dolor fısico, y en consecuencia, el dano psicologico que
estas pueden llegar a ocasionar en el paciente.
En este trabajo se propuso un metodo de segmentacion automatica de lesiones de mama en
imagenes de USM basado en descriptores de textura extraıdos de la matriz de co-ocurrencia de nive-
97

98 6.1. Conclusiones
les de gris (GLCM) con la finalidad de alcanzar un nivel mayor al 90 % de exactitud. Cabe destacar
que el termino “automatico” indica que durante el proceso de segmentacion no existe intervencion
humana en ninguna etapa, lo cual elimina la posible subjetividad introducida en el algoritmo de seg-
mentacion. Se implemento una metodologıa que determino los elementos funcionales para cumplir
con tal fin. Dichos elementos son: tecnicas de preprocesamiento, el subconjunto de caracterısticas
mas representativo, la tecnica de clasificacion y el metodo de postprocesamiento y ajuste de contorno.
Para determinar las tecnicas de preprocesamiento se evaluaron cuatro tecnicas de mejoramiento
de contraste y cuatro tecnicas de filtro de suavizado, las cuales fueron combinadas. Tambien se consi-
deraron las opciones de utilizar una sola tecnica o ninguna. Por tanto, se generaron 25 combinaciones
de preprocesamiento. Por otra parte, se evaluaron 352 caracterısticas que se originaron de utilizar 22
descriptores de textura extraıdos de la GLCM para cada una de las direcciones θ = 0, 45, 90, 135 y
distancias d = 1, 2, 3, 4; y cuya cuantificacion fue de 64 niveles de gris. Dado que el preprocesamiento
de la imagen impacta sobre la seleccion de caracterısticas, esta ultima se realizo simultaneamente
para las 25 combinaciones de preprocesamiento. Se utilizaron dos criterios de ordenamiento de ca-
racterısticas: la razon de Fisher y el criterio de mınima-redundancia-maxima-relevancia (mRMR). Se
aplico el enfoque de variacion del error y el metodo de mınimas distancias para determinar tanto el
numero mınimo de caracterısticas ordenadas (bajo los dos criterios de ordenamiento), como la com-
binacion de preprocesamiento, respectivamente. En conclusion, se determino que 125 caracterısticas
de textura ordenadas bajo el criterio de mRMR representan al subconjunto optimo (ver Tabla 4.5 en
el Capıtulo 4) que disminuye la dimensionalidad si afectar la calidad descriptiva de las caracterısticas.
La combinacion de preprocesamiento que contribuyo a obtener dicho subconjunto de caracterısticas
fue la 11 (CLAHE y sin filtro). Cabe resaltar que tanto para el criterio de ordenamiento FDR como
para mRMR no fue necesario aplicar alguna de las tecnicas de filtrado, lo que sugiere que la infor-
macion de textura esta mayormente contenida en el speckle adherido a las imagenes de USM, por
lo que al afectar este, tambien se ve afectada informacion de textura que podrıa ser relevante para
distinguir rasgos caracterısticos de algun objeto contenido en la imagen.

6. Conclusiones y trabajo futuro 99
La seleccion de caracterısticas realizada en este trabajo de tesis contribuye en la reduccion de la
dimensionalidad del espacio de caracterısticas hasta en un 64 %. El objetivo es remover caracterısti-
cas que no aportan informacion relevante y al mismo tiempo preservar la calidad en los resultados
de la clasificacion. Es importante resaltar que en la literatura especializada relacionada con la seg-
mentacion automatica de lesiones en USM no existıa un enfoque similar al propuesto en esta tesis,
donde se analice metodologicamente un conjunto extenso de caracterısticas de textura (basadas en
la GLCM). Es notable que en los trabajos reportados en [20, 21] emplearon un conjunto de carac-
terısticas de textura menor al utilizado en esta tesis. Sin embargo, no reportan ningun modelo teorico
o experimental para determinar dicho conjunto de caracterısticas.
Por otra parte, derivado de la seleccion de caracterısticas se observo que 17 de 22 DT fueron em-
pleados para resolver el problema de la seleccion automatica de lesiones de mama en ultrasonografıas;
donde la correlacion I y II, agrupamiento de sombras, homogeneidad I y la maxima probabilidad son
los DT que aportan mayor informacion descriptiva. Esto ultimo confirma, en cierta medida, que los
cinco DT mencionados estan fuertemente involucrados en el analisis de texturas en imagenes de
USM, dado que tambien han sido reportados en trabajos similares dentro de la literatura (Gomez et
al. [25], Huber et al. [64], Sivaramakrishna et al. [65]).
Las 125 caracterısticas seleccionadas se emplearon en tres tecnicas de clasificacion: maquinas
de vectores de soporte con funcion kernel (SVMk), red de funcion de base radial y analisis lineal
discriminante de Fisher. Estos clasificadores fueron evaluados con analisis ROC para determinar cual
de ellos presentaba el mejor desempeno, siendo la SVMk el clasificador ganador.
Generalmente los resultados de las tecnicas de clasificacion suelen presentar un porcentaje de
error, el cual es compensado al aplicar algun tipo de postprocesamiento. En este trabajo se propuso
un metodo de postprocesamiento basado en la tecnica de umbralado global de Otsu y operaciones
morfologicas para eliminar la mayor cantidad posible de falsos-positivos y falsos-negativos, con lo
cual poder descubrir claramente la ROI. Posteriormente, se utilizo el algoritmo de Chan-Vese para

100 6.2. Trabajo futuro
ajustar el contorno de la ROI al contorno de la lesion.
En resumen, el metodo propuesto de segmentacion automatica de lesiones de mama en imagenes
de ultrasonido quedo configurado de la siguiente manera: la imagen de ultrasonido es preprocesada
con la tecnica CLAHE, posteriormente la imagen es dividida en imagenes celda y por cada una de estas
se extraen las 125 caracterısticas seleccionadas. Luego, cada imagen celda es clasificada con la SVMk
como lesion (1) o fondo (0) y unidas posteriormente, por tanto se genera una imagen binaria, la cual se
utiliza para definir la region de interes con el metodo de postprocesamiento propuesto. Por ultimo, se
utiliza el algoritmo de Chan-Vese para ajustar el contorno de la region de interes y delinearlo finamente
al contorno de la lesion. Para evaluar el metodo propuesto se segmento un conjunto de 114 imagenes
de ultrasonido y se obtuvieron los siguientes resultados: exactitud=95.56 %, sensibilidad=85.79 % y
especificidad=96.69 %. Por tanto se cumplio con el objetivo de superar el 90 % de exactitud.
6.2 Trabajo futuro
Si bien es cierto que el conjunto de caracterısticas seleccionado contribuyo en gran medida a
lograr el nivel de exactitud alcanzado, tambien es cierto que se genera un porcentaje considerable de
falsos positivos, y aunque estos sean tratados en el postprocesamiento, creemos que pueden verse
disminuidos si se incluye otra variedad de caracterısticas tales como: matriz de longitud de corrimiento
de niveles de gris (GLRLM) y las basadas en la morfologıa de la lesion.

Bibliografıa
[1] M. E. Brandan and Y. Villasenor. Deteccion del cancer de mama: estado de la mamografıa en
mexico. Cancerologıa, 1:147–162, 2006.
[2] Organizacion Mundial de la Salud (OMS). Cancer de mama: prevencion y control, Octubre
2011. URL: http://www.who.int/topics/cancer/breastcancer/es/index1.html.
[3] GLOBOCAN Agencia Internacional de Investigacion en Cancer, IARC. Cancer incidence and
mortality worldwide in 2008, Octubre 2011. URL: http://globocan.iarc.fr/factsheets/
populations/factsheet.asp?uno=900.
[4] Secretarıa de Salud and Subsecretarıa de Prevencion and Promocion de la Salud. Programa de
accion especifıco 2007-2012, Cancer de mama, 2008. Primera edicion.
[5] Instituto Nacional de Estadıstica y Geografıa, INEGI. Estadısticas a proposito del dıa mundial
contra el cancer, datos nacionales, 2011.
[6] G. Danaei, S. Vander Hoorn, AD. Lopez, CJ. Murray, and M. Ezzati. Causes of cancer in the
world: comparative risk assessment of nine behavioural and environmental risk factors. Lancet,
366(19):1784–1793, 2005.
[7] H. D. Cheng, J. Shan, W. Ju, Y. Guo, and L. Zhang. Automated breast cancer detection and
classification using ultrasound images: A survey. Pattern Recognition, 43(1):299–317, 2010.
[8] Y. Guo, H. D. Cheng, J. Huang, J. Tian, W. Zhao, L. Sun, and Y. Su. Breast ultrasound image
enhancement using fuzzy logic. Ultrasound in Medicine & Biology, 32(2):237–247, 2006.
[9] A. Vargas, L. M. Amescua-Guerrax, Me. A. Bernal, and C. Pineda. Principios fısicos basicos
del ultrasonido, sonoanatomıa del sistema musculoesqueletico y artefactos ecograficos. Acta
Ortopedica Mexicana, 22(6):361–373, 2008.
101

102 BIBLIOGRAFIA
[10] K. M. Kelly, J. Dean, Sung-Jae Lee, and W. S. Comulada. Breast cancer detection: radiolo-
gists’ performance using mammography with and without automated whole-breast ultrasound.
European Radiology, 20(11):2557–2564, 2010.
[11] S. Gupta, R. C. Chauhan, and S. C. Saxena. Locally adaptive wavelet domain bayesian processor
for denoising medical ultrasound images using speckle modelling based on rayleigh distribution.
IEE Proceedings Vision, Image & Signal Processing, 152(1):129 – 135, 2005.
[12] A. A. Mascaro, C. A. B. Mello, W. P. Santos, and G. D. C. Cavalcanti. Mammographic images
segmentation using texture descriptors. In Engineering in Medicine and Biology Society, 2009.
EMBC 2009. Annual International Conference of the IEEE, pages 3653–3656, 2009.
[13] Dar-Ren Chen, Ruey-Feng Chang, Chii-Jen Chen, Ming-Feng Ho, Shou-Jen Kuo, Shou-Tung
Chen, Shin-Jer Hung, and W. K. Moon. Classification of breast ultrasound images using fractal
feature. Clinical Imaging, 29(4):235–245, 2005.
[14] M. Petrou and P. Garcıa Sevilla. Image processing: dealing with texture. John Wiley & Sons
Inc., 1st edition, 2006.
[15] R. M. Haralick, K. Shanmugam, and Its’Hak Dinstein. Textural features for image classification.
IEEE Transactions on Systems, Man and Cybernetics, SMC-3(6):610–621, 1973.
[16] Dar-Ren Chen, Ruey-Feng Chang, Yu-Len Huang, Yi-Hong Chou, Chui-Mei Tiu, and Po-Pang
Tsai. Texture analysis of breast tumors on sonograms. Seminars in Ultrasound, CT, and MRI,
21(4):308–316, 2000.
[17] J. Shan, Y. Wang, and H. D. Cheng. Completely automatic segmentation for breast ultra-
sound using multiple-domain features. In 2010 IEEE 17th International Conference on Image
Processing (ICIP), pages 1713 – 1716, September 2010.
[18] A.N. Evans and M.S. Nixon. Speckle filtering in ultrasound images for feature extraction. In
International Conference on Acoustic Sensing and Imaging, pages 44 – 49, March 1993.

BIBLIOGRAFIA 103
[19] Y. Yu and S.T. Acton. Speckle reducing anisotropic diffusion. IEEE Transactions on Image
Processing, 11(11):1260 – 1270, 2002.
[20] B. Liu, H. D. Cheng, J. Huang, J. Tian, J. Liu, and X. Tang. Automated segmentation of
ultrasonic breast lesions using statistical texture classification and active contour based on
probability distance. Ultrasound in Medicine & Biology, 35(8):1309–1324, 2009.
[21] B. Liu, H. D. Cheng, J. Huang, J. Tian, J. Liu, and X. Tang. Fully automatic and segmentation-
robust classification of breast tumors based on local texture analysis of ultrasound images.
Pattern Recognition, 43(1):280–298, 2010.
[22] S. Osher and J. A. Sethian. Front propagating with curvature-dependent speed: Algorithms
based on hamilton-jacobi formulations. Journal of Computational Physics, 79(1):12–49, 1988.
[23] J. Shan, H. D. Cheng, and Y. Wang. A novel automatic seed point selection algorithm for breast
ultrasound images. In 19th International Conference on Pattern Recognition, 2008. ICPR 2008.,
pages 1–4, December 2008.
[24] A. S. M. Sohail, P. Bhattacharya, S. P. Mudur, and S. Krishnamurthy. Selection of optimal tex-
ture descriptors for retrieving ultrasound medical images. In 2011 IEEE International Symposium
on Biomedical Imaging: From Nano to Macro, pages 10–16, March-April 2011.
[25] W. Gomez, W. C. A. Pereira, and A. F. C. Infantosi. Analysis of co-ocurrence texture statistics
as a function of gray-level quantization for classifying ultrasound. IEEE Transactions on Medical
Imaging, DOI: 10.1109/TMI.2012.2206398, 2012.
[26] M. M. Galloway. Texture analysis using gray level run lengths. Computer Graphics and Image
Processing, 4(2):172–179, 1975.
[27] L.-K. Soh and C. Tsatsoulis. Texture analysis of sar sea ice imagery using gray level co-
occurrence matrices. IEEE Transactions on Geoscience and Remote Sensing, 37(2):780 – 795,
1999.

104 BIBLIOGRAFIA
[28] A. Chu, C. M. Sehgal, and J. F. Greenleaf. Use of gray value distribution of run lengths for
texture analysis. Pattern Recognition Letters, 11(6):415–419, 1990.
[29] B. V. Dasarathy and E. B. Holder. Image characterizations based on joint gray level—run length
distributions. Pattern Recognition Letters, 12(8):497–502, 1991.
[30] H. Peng, F. Long, and C. Ding. Feature selection based on mutual information: criteria of
max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 27(8):1226 – 1238, 2005.
[31] A. V. Alvarenga, W. C. A. Pereira, A. F. C. Infantosi, and C. M. Azevedo. Complexity curve
and grey level co-occurrence matrix in the texture evaluation of breast tumor on ultrasound
images. Medical Physics, 34(2):379–387, 2007.
[32] Erik Cuevas, Daniel Zaldıvar, and Marco Perez. Procesamiento digital de imagenes con Matlab
y Simulink. Alfaomega Ra-Ma, 1st edition, 2010.
[33] D. T. Kuan, A. A. Sawchuk, T. C. Strand, and P. Chavel. Adaptive noise smoothing filter
for images with signal-dependent noise. IEEE Transactions on Pattern Analysis and Machine
Intelligence, PAMI-7(2):165–177, 1985.
[34] A. Lopes, R. Touzi, and E. Nezry. Adaptive speckle filters and scene heterogeneity. IEEE
Transactions on geoscience and remote sensing, 28(6):992–1000, 1990.
[35] Y. Zhang, H. D. Cheng, J. Tian, J. Huang, and X. Tang. Fractional subpixel diffusion and
fuzzy logic approach for ultrasound speckle reduction. Pattern Recognition, 43(8):2962–2970,
August 2010.
[36] R. C. Gonzalez and R. E. Woods. Digital Image Processing. Pearson, Prentice Hall, 3th edition,
2008.
[37] A. Achim, A. Bezerianos, and P. Tsakalides. Ultrasound image denoising via maximum a
posteriori estimation of wavelet coefficients. In Engineering in Medicine and Biology Society,

BIBLIOGRAFIA 105
2001. Proceedings of the 23rd Annual International Conference of the IEEE, volume 3, pages
2553 – 2556, 2001.
[38] Yu-Len Huang, Dar-Ren Chen, and Ya-Kuang Liu. Breast cancer diagnosis using image retrieval
for different ultrasonic systems. In 2004 International Conference on Image Processing , 2004.
ICIP ’04., volume 5, pages 2957–2960, 2004.
[39] Yu-Ren Lai, Kuo-Liang Chung, Chyou-Hwa Chen, Guei-Yin Lin, and Chao-Hsin Wang. Novel
mean-shift based histogram equalization using textured regions. Expert Systems with Applica-
tions, 39(3):2750–2758, 2012.
[40] H. D. Cheng and X. J. Shi. A simple and effective histogram equalization approach to image
enhancement. Digital Signal Processing, 14(2):158–170, 2004.
[41] Karel Zuiderveld. Contrast Limited Adaptive Histograph Equalization. Graphic Gems IV. San
Diego: Academic Press Professional, 1994.
[42] S. Yasuoka, Y. Kang, K. Morooka, and H. Nagahashi. Texture classification using hierarchical
discriminant analysis. In 2004 IEEE International Conference on Systems, Man and Cybernetics,
volume 7, pages 6395–6400, 2004.
[43] G. Junying and Z. Youwei. Generalized kernel function fisher discriminant for pattern recognition.
In 2002 6th International Conference on Signal Processing, volume 2, pages 1075 – 1078, 2002.
[44] Q. Du and N. H. Younan. Dimensionality reduction and linear discriminant analysis for hy-
perspectral image classification. In 12th International Conference Knowledge-Based Intelligent
Information and Engineering Systems, KES 2008, volume 5179/2008, pages 392–399, 2008.
[45] Sergios Theodoridis and Konstantinos Koutroumbas. Pattern Recognition. Elsevier, Academic
Press, 3rd edition, 2006.
[46] Yu-Len Huang. Computer-aided diagnosis using neural networks and support vector machines
for breast ultrasonography. Journal of Medical Ultrasound, 17(1):17–24, 2009.

106 BIBLIOGRAFIA
[47] J. T. Palma Mendez and et al. Inteligencia Artificial. Tecnicas, metodos y aplicaciones. McGraw-
Hill, 1st edition, 2008.
[48] X. Shi, H. Cheng, and L. Hu. Mass detection and classification in breast ultrasound images
using fuzzy svm. In JCIS-2006 Proceedings. DOI:10.2991/jcis.2006.257.
[49] Scheipers U., C. Perrey, S. Siebers, C. Hansen, and H. Ermert. A tutorial on the use of roc
analysis for computer-aided diagnostic systems. Ultrasonic Imaging, 27(3):181–198, 2005.
[50] Tom Fawcett. An introduction to roc analysis. Pattern Recognition Letters, 27(8):861–874,
2006.
[51] A. Madabhushi and D. N. Metaxas. Combining low-, high-level and empirical domain knowledge
for automated segmentation of ultrasonic breast lesions. IEEE Transactions on Medical Imaging,
22(2):155–169, 2003.
[52] J. K. Udupa, P. K. Saha, G. J. Grevera, Y. Zhuge, V. R. LaBlanc, H. Schmidt, C. Imielins-
ka, L. M. Currie, P. Molholt, and Y. Jin. A methodology for evaluating image segmentation
algorithms. DOI: 10.1117/12.467166.
[53] Gonzalo P. Martinsanz and Jesus M. de la Cruz Garcıa. Vision por computador, imagenes
digitales y aplicaciones. Alfaomega Ra-Ma, 2nd edition, 2008.
[54] A. Anzueto-Rios, J. A. Moreno-Cadenas, and F. Gomez-Castaneda. Fuzzy technique for image
enhancement using b-spline. In 52nd IEEE International Midwest Symposium on Circuits and
Systems, 2009. MWSCAS ’09., pages 869–872, 2009.
[55] M. Aleman-Flores, L. Alvarez, and V. Caselles. Texture-oriented anisotropic filtering and geode-
sic active contours in breast tumor ultrasound segmentation. Journal of mathematical imaging
and vision, 28(1):81–97, 2007.

BIBLIOGRAFIA 107
[56] M. Bevk and I. Kononenko. A statistical approach to texture description of medical images: a
preliminary study. In Proceedings of the 15th IEEE Symposium on Computer-Based Medical
Systems (CBMS’02), pages 239–244, 2002.
[57] D. A. Clausi. An analysis of co-occurrence texture statistics as a function of grey level quanti-
zation. Can. J. Remote Sensing, 28(1):45–62, 2002.
[58] S. Garcıa, J. Luengo, J. A. Saez, V. Lopez, and F. Herrera. A survey of discretization techniques:
taxonomy and empirical analysis in supervised learning. IEEE Transactions on Knowledge and
Data Engineering, DOI: 10.1109/TKDE.2012.35, 2012.
[59] S. Theodoridis, A. Pikrakis, K. Koutroumbas, and D. Cavouras. Introduction to pattern recog-
nition, a MATLAB ®Approach. Elsevier, academic press, 2010.
[60] Yu-Len Huang and Dar-Ren Chen. Support vector machines in sonography application to
decision making in the diagnosis of breast cancer. Journal of Clinical Imaging, 29(3):179 – 184,
2005.
[61] Nobuyuki Otsu. A threshold selection method from gray-level histograms. IEEE Transactions
on Systems, Man, and Cybernetics, 9(1):62–66, 1979.
[62] T. F. Chan and L. A. Vese. Active contours without edges. IEEE Transactions on image
processing, 10(2):266–277, 2001.
[63] Shawn Lankton. Active contour matlab code demo, April 2012. URL: http://www.
shawnlankton.com/category/vision/.
[64] S. Huber, J. Danes, I. Zuna, J. Teubner, M. Medl, and S. Delorme. Relevance of sonographic
b-mode criteria and computer-aided ultrasonic tissue characterization in differential/diagnosis
of solid breast masses. Ultrasound in Medicine and Biology, 26(8):1243–1252, 2000.

108 BIBLIOGRAFIA
[65] R. Sivaramakrishna, K. A. Powell, M. L. Lieber, W. A. Chilcote, and R. Shekhar. Texture
analysis of lesions in breast ultrasound images. Computerized Medical Imaging and Graphics,
26(5):303–307, 2002.





























