Embed Size (px)
Citation preview

Text Mining and Topic Modeling
Padhraic SmythDepartment of Computer Science
University of California, Irvine

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Progress Report
• New deadline• In class, Thursday February 18th (not Tuesday)
• Outline• 3 to 5 pages maximum• Suggested content
• Brief restatement of the problem you are addressing (no need to repeat everything in your original proposal), e.g., ½ a page
• Summary of progress so far Background papers read Data preprocessing, exploratory data analysis Algorithms/Software reviewed, implemented, tested Initial results (if any)
• Challenges and difficulties encountered• Brief outline of plans between now and end of quarter
• Use diagrams, figures, tables, where possible• Write clearly: check what you write

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Road Map
• Topics covered• Exploratory data analysis and visualization• Regression• Classification• Text classification
• Yet to come….• Unsupervised learning with text (topic models)• Social networks• Recommender systems (including Netflix)• Mining of Web data

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Text Mining
• Document classification
• Information extraction• Named-entity extraction: recognize names of people, places, genes, etc
• Document summarization• Google news, Newsblaster
(http://www1.cs.columbia.edu/nlp/newsblaster/)
• Document clustering
• Topic modeling• Representing document as mixtures of topics
• And many more…

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Named Entity-Extraction
• Often a combination of• Knowledge-based approach (rules, parsers)• Machine learning (e.g., hidden Markov model)• Dictionary
• Non-trivial since entity-names can be confused with real names
• E.g., gene name ABS and abbreviation ABS
• Also can look for co-references• E.g., “IBM today…… Later, the company announced…..”
• Useful as a preprocessing step for data mining,e.g., use entity-names to train a classifier to predict the category of an article

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Example: GATE/ANNIE extractor
• GATE: free software infrastructure for text analysis (University of Sheffield, UK)
• ANNIE: widely used entity-recognizer, part of GATEhttp://www.gate.ac.uk/annie/
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
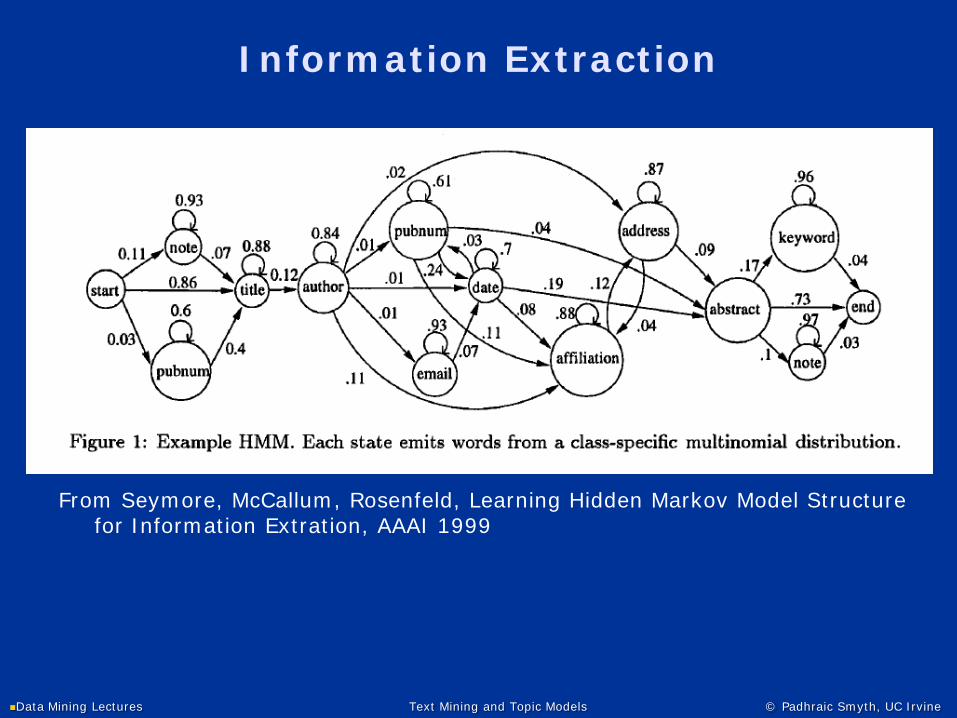
Information Extraction
From Seymore, McCallum, Rosenfeld, Learning Hidden Markov Model Structure for Information Extration, AAAI 1999

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Topic Models
• Background on graphical models
• Unsupervised learning from text documents• Motivation• Topic model and learning algorithm• Results
• Extensions• Topics over time, author topic models, etc

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Pennsylvania Gazette
1728-1800
80,000 articles
25 million words
www.accessible.com

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Enron email data
250,000 emails
28,000 authors
1999-2002
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
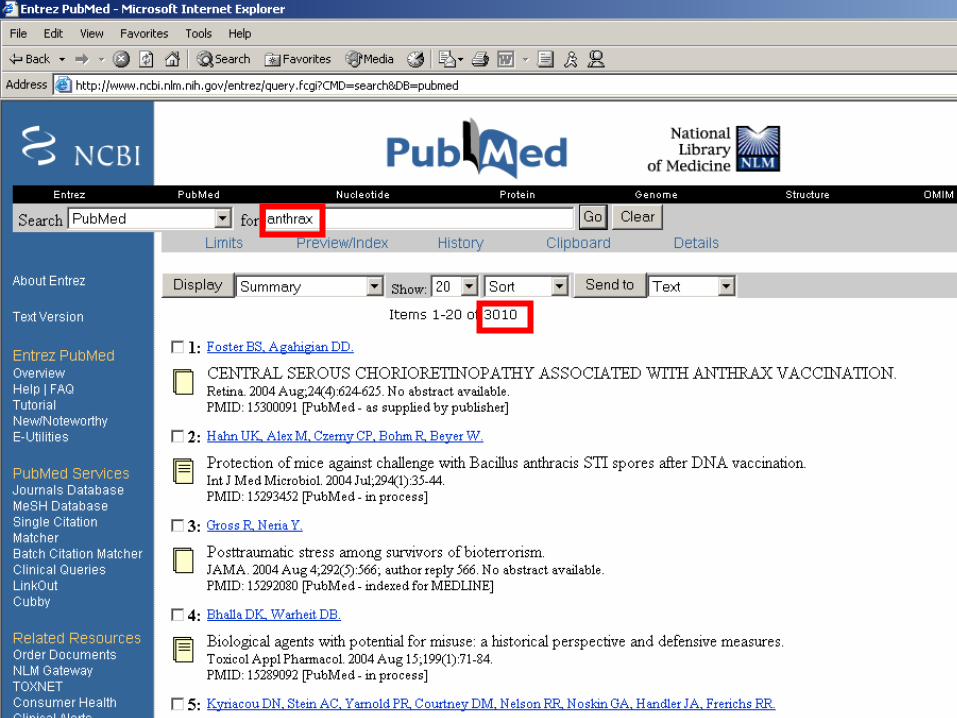
Other Examples of Large Corpora
• CiteSeer digital collection:• 700,000 papers, 700,000 authors, 1986-2005
• MEDLINE collection• 16 million abstracts in medicine/biology
• US Patent collection
• and many more....

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Unsupervised Learning from Text
• Large collections of unlabeled documents..• Web• Digital libraries• Email archives, etc
• Often wish to organize/summarize/index/tag these documents automatically
• We will look at probabilistic techniques for clustering and topic extraction from sets of documents

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Problems of Interest
• What topics do these documents “span”?
• Which documents are about a particular topic?
• How have topics changed over time?
• What does author X write about?
• Who is likely to write about topic Y?
• Who wrote this specific document?
• and so on…..

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Review Slides on Graphical Models

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Multinomial Models for Documents
• Example: 50,000 possible words in our vocabulary
• Simple memoryless model • 50,000-sided die
• a non-uniform die: each side/word has its own probability • to generate N words we toss the die N times
• This is a simple probability model:
• p( document | φ ) = Π p(word i | φ )
• to "learn" the model we just count frequencies• p(word i) = number of occurences of i / total number
• Typically interested in conditional multinomials, e.g.,• p(words | spam) versus p(words | non-spam)

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Real examples of Word Multinomials
)|( zwP
WORD PROB. PROBABILISTIC 0.0778
BAYESIAN 0.0671 PROBABILITY 0.0532
CARLO 0.0309 MONTE 0.0308
DISTRIBUTION 0.0257 INFERENCE 0.0253
PROBABILITIES 0.0253 CONDITIONAL 0.0229
PRIOR 0.0219.... ...
TOPIC 209
WORD PROB. RETRIEVAL 0.1179
TEXT 0.0853 DOCUMENTS 0.0527
INFORMATION 0.0504 DOCUMENT 0.0441 CONTENT 0.0242 INDEXING 0.0205
RELEVANCE 0.0159 COLLECTION 0.0146
RELEVANT 0.0136... ...
TOPIC 289
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
A Graphical Model for Multinomials
w1
φ
p( doc | φ ) = Π p(wi | φ )
p( w | φ )
w2 wn
φ = "parameter vector"
= set of probabilitiesone per word

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Another view....
φ
p( doc | φ ) = Π p(wi | φ )
wi
i=1:n
This is “plate notation”
Items inside the plateare conditionally independentgiven the variable outsidethe plate
There are “n” conditionallyindependent replicatesrepresented by the plate
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Being Bayesian....
φ
wi
i=1:n
αThis is a prior on our multinomial parameters,
e.g., a simple Dirichlet smoothing prior withsymmetric parameter α to avoid estimates of probabilities that are 0
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Being Bayesian....
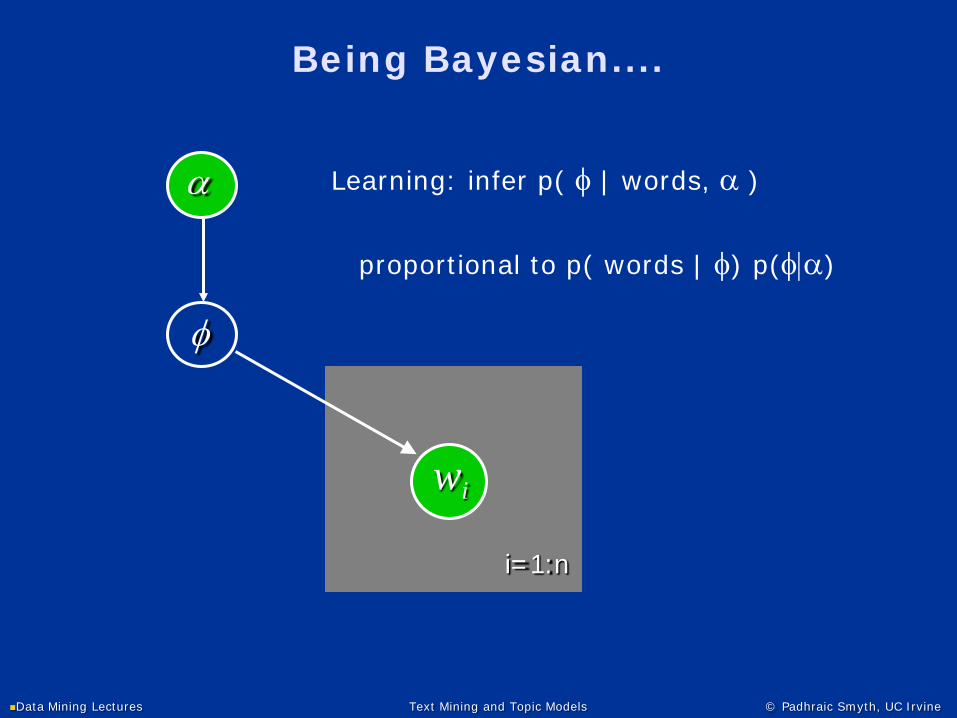
φ
Learning: infer p( φ | words, α )
proportional to p( words | φ) p(φ|α)
wi
i=1:n
α

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Multiple Documents
φ
wi 1:n
α
1:D
p( corpus | φ ) = Π p( doc | φ )

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Different Document Types
φ
wi 1:n
α
p( w | φ) is a multinomial over words

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Different Document Types
φ
wi 1:n
α
1:D
p( w | φ) is a multinomial over words
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
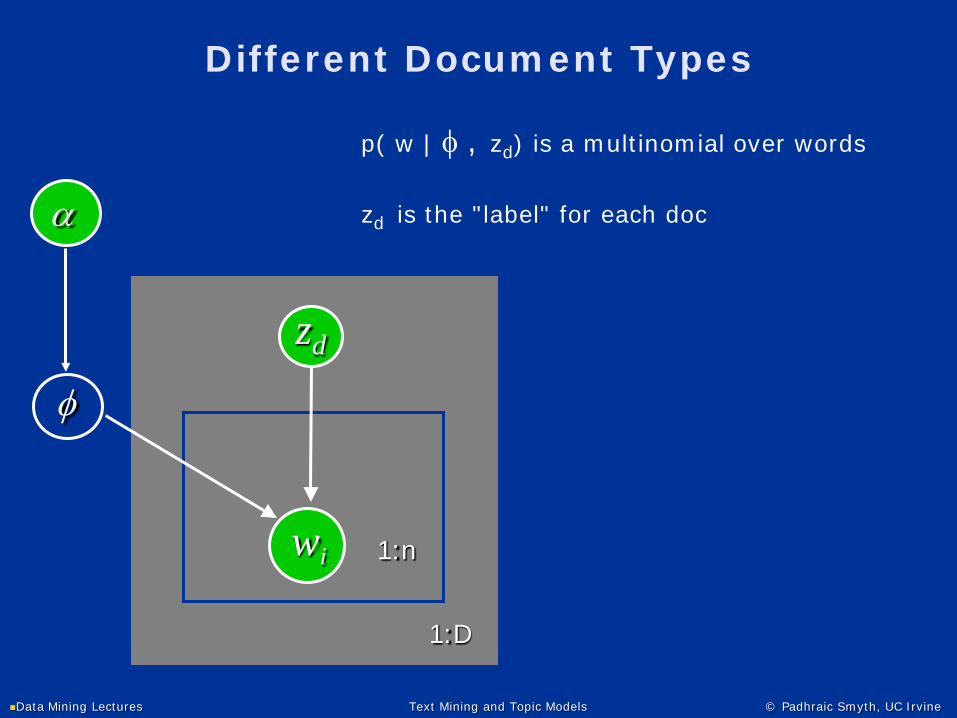
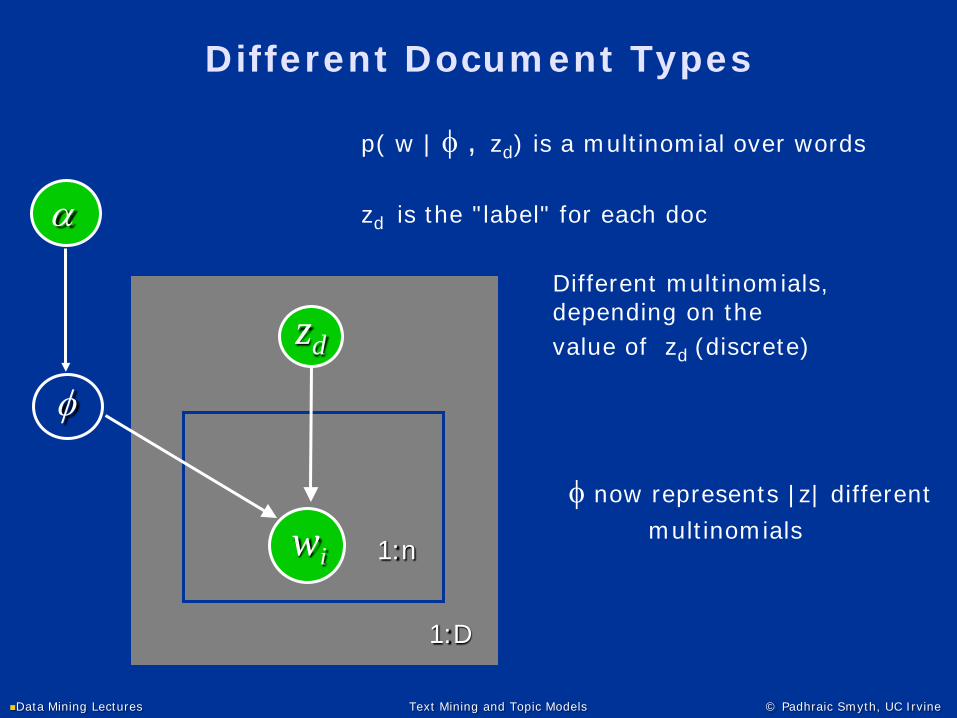
Different Document Types
φ
wi 1:n
α
1:D
zd
p( w | φ , zd) is a multinomial over words
zd is the "label" for each doc
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Different Document Types
φ
wi 1:n
α
1:D
zd
p( w | φ , zd) is a multinomial over words
zd is the "label" for each doc
Different multinomials, depending on thevalue of zd (discrete)
φ now represents |z| different
multinomials
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
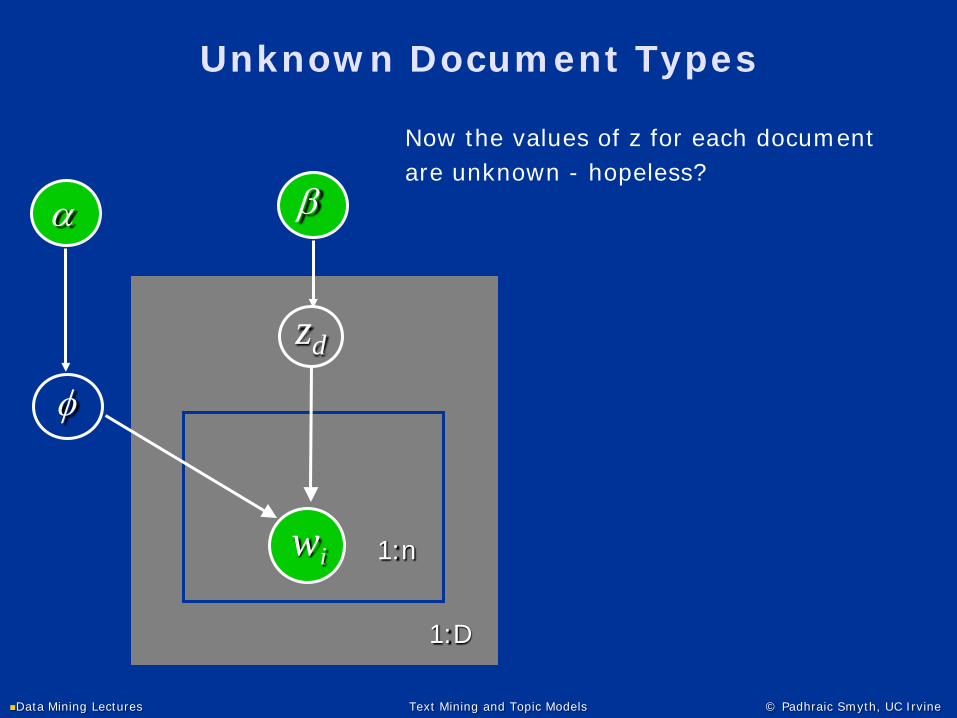
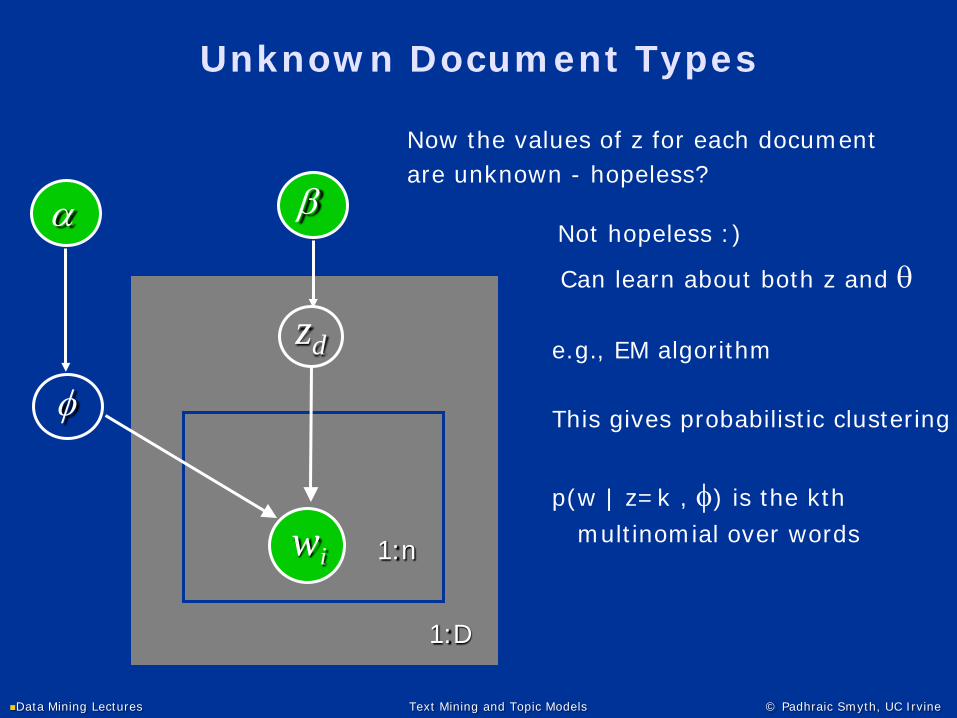
Unknown Document Types
φ
wi 1:n
α
1:D
zd
β
Now the values of z for each documentare unknown - hopeless?
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
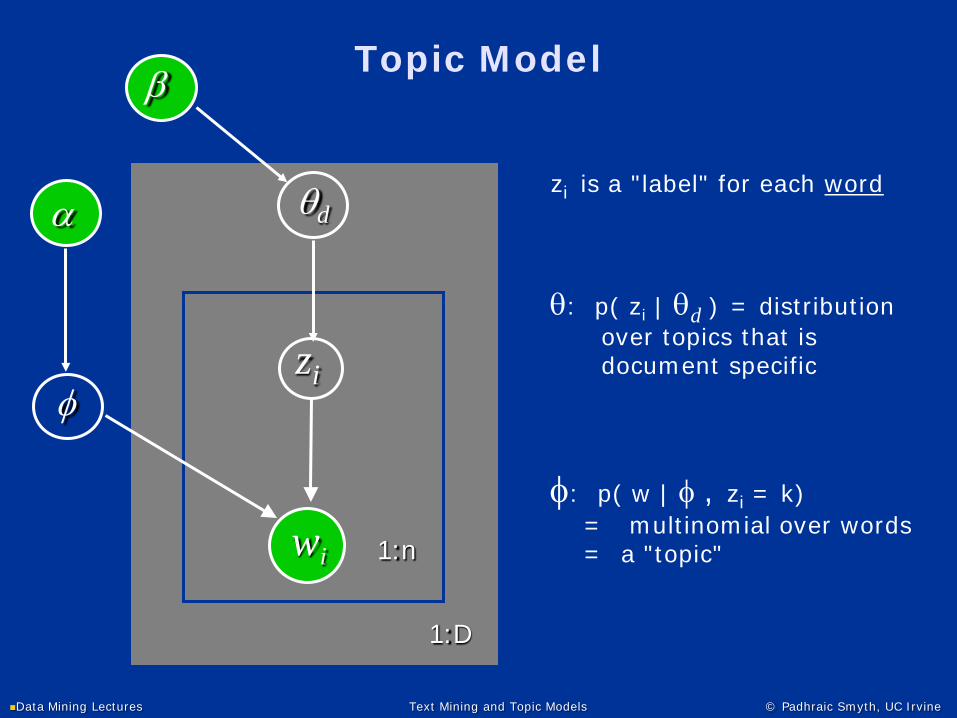
Unknown Document Types
φ
wi 1:n
α
Now the values of z for each documentare unknown - hopeless?
1:D
zd
βNot hopeless :)
Can learn about both z and θ
e.g., EM algorithm
This gives probabilistic clustering
p(w | z=k , φ) is the kth
multinomial over words
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
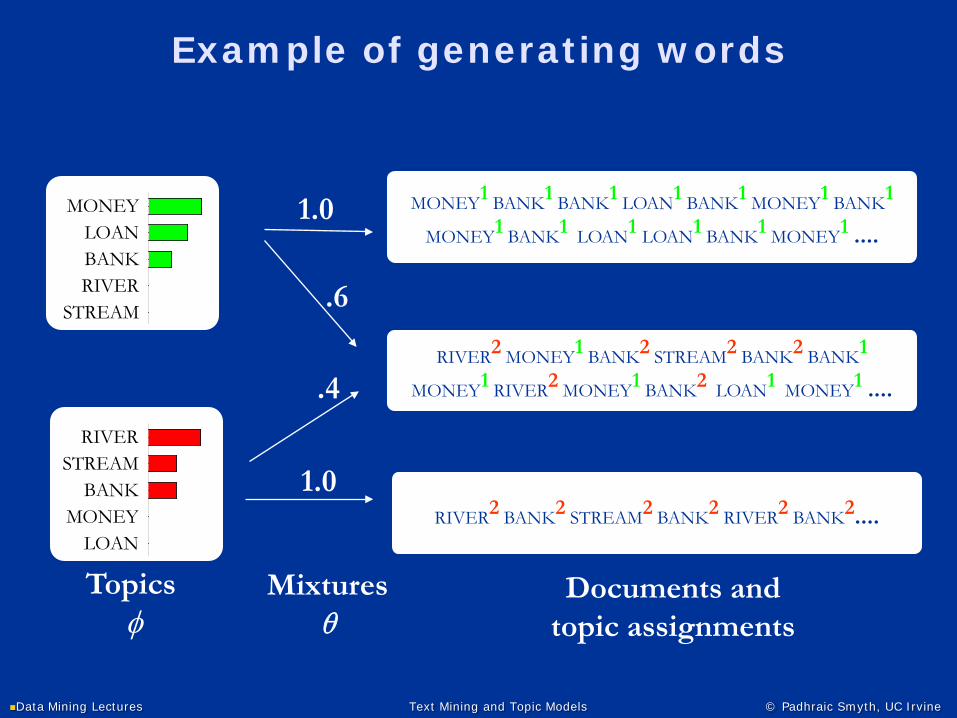
Topic Model
φ
wi 1:n
αzi is a "label" for each word
θ: p( zi | θd ) = distribution over topics that isdocument specific
φ: p( w | φ , zi = k) = multinomial over words= a "topic"
1:D
zi
θd
β
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
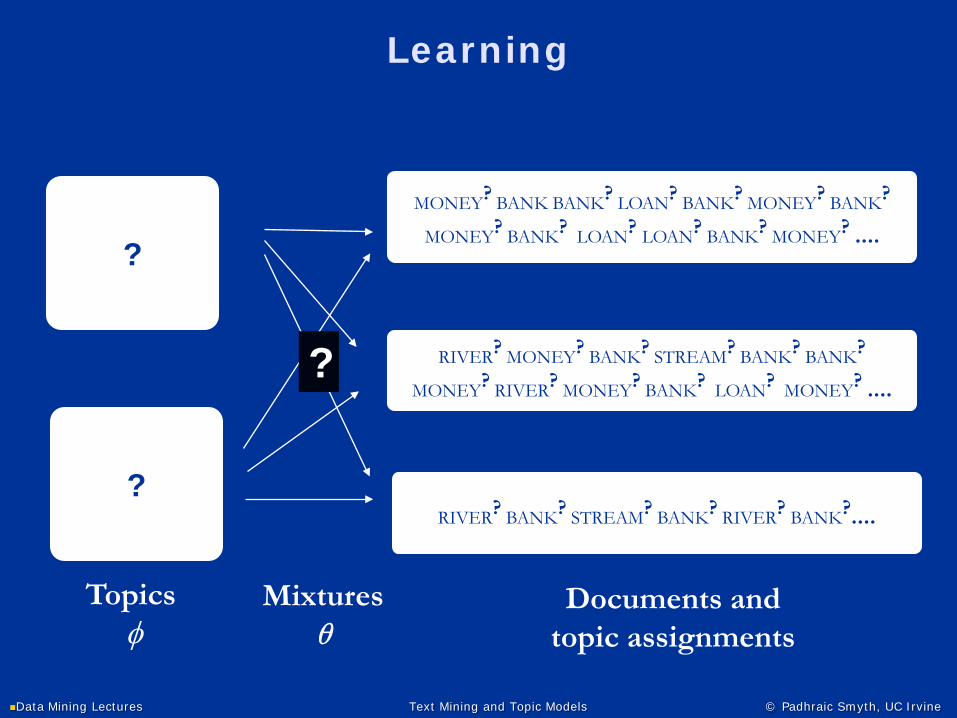
Topicsφ
.4
1.0
.6
1.0
MONEYLOANBANKRIVER
STREAM
RIVERSTREAM
BANKMONEY
LOAN
MONEY1 BANK1 BANK1 LOAN1 BANK1 MONEY1 BANK1
MONEY1 BANK1 LOAN1 LOAN1 BANK1 MONEY1 ....
Mixtures θ
Documents and topic assignments
RIVER2 MONEY1 BANK2 STREAM2 BANK2 BANK1
MONEY1 RIVER2 MONEY1 BANK2 LOAN1 MONEY1 ....
RIVER2 BANK2 STREAM2 BANK2 RIVER2 BANK2....
Example of generating words
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Topicsφ
?
?
MONEY? BANK BANK? LOAN? BANK? MONEY? BANK?
MONEY? BANK? LOAN? LOAN? BANK? MONEY? ....
Mixtures θ
RIVER? MONEY? BANK? STREAM? BANK? BANK?
MONEY? RIVER? MONEY? BANK? LOAN? MONEY? ....
RIVER? BANK? STREAM? BANK? RIVER? BANK?....
Learning
Documents and topic assignments
?

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Key Features of Topic Models
• Model allows a document to be composed of multiple topics• More powerful than 1 doc -> 1 cluster
• Completely unsupervised• Topics learned directly from data• Leverages strong dependencies at word level
• Learning algorithm• Gibbs sampling is the method of choice
• Scalable• Linear in number of word tokens• Can be run on millions of documents

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Document generation as a probabilistic process
• Each topic is a distribution over words• Each document a mixture of topics• Each word chosen from a single topic
1
( ) ( | ) ( )T
i i i ij
P w P w z j P z j=
= = =∑
From parameters
φ (j)
Fromparameters
θ (d)

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Learning the Model
• Three sets of latent variables we can learn• topic-word distributions φ• document-topic distributions θ• topic assignments for each word z
• Options:• EM algorithm to find point estimates of φ and θ
• e.g., Chien and Wu, IEEE Trans ASLP, 2008• Gibbs sampling
• Find p(φ | data), p(θ | data), p(z| data)• Can be slow to converge
• Collapsed Gibbs sampling• Most widely used method
[See also Asuncion, Welling, Smyth, Teh, UAI 2009 for additional discussion]

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Gibbs Sampling
• Say we have 3 parameters x,y,z, and some data
• Bayesian learning:• We want to compute p(x, y, z | data)• But frequently it is impossible to compute this exactly• However, often we can compute conditionals for individual
variables, e.g.,p(x | y, z, data)
• Not clear how this is useful yet, since it assumes y and z are known (i.e., we condition on them).

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Gibbs Sampling 2
• Example of Gibbs sampling:• Initialize with x’, y’, z’ (e.g., randomly)• Iterate:
• Sample new x’ ~ P(x | y’, z’, data)• Sample new y’ ~ P(y | x’, z’, data)• Sample new z’ ~ P(z | x’, y’, data)
• Continue for some number (large) of iterations• Each iteration consists of a sweep through the hidden
variables or parameters (here, x, y, and z)• Gibbs = a Markov Chain Monte Carlo (MCMC) method
In the limit, the samples x’, y’, z’ will be samples from the true joint distribution P(x , y, z | data)
This gives us an empirical estimate of P(x , y, z | data)

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Example of Gibbs Sampling in 2d
From online MCMC tutorial notes by Frank Dellaert, Georgia Tech

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Computation
• Convergence• In the limit, samples x’, y’, z’ are from P(x , y, z | data)• How many iterations are needed?
• Cannot be computed ahead of time• Early iterations are discarded (“burn-in”)• Typically monitor some quantities of interest to monitor
convergence• Convergence in Gibbs/MCMC is a tricky issue!
• Complexity per iteration• Linear in number of hidden variables and parameters• Times the complexity of generating a sample each time

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Gibbs Sampling for the Topic Model
• Recall: 3 sets of latent variables we can learn• topic-word distributions φ• document-topic distributions θ• topic assignments for each word z
• Gibbs sampling algorithm• Initialize all the z’s randomly to a topic, z1, ….. zN
• Iteration• For i = 1,…. N
Sample zi ~ p(zi | all other z’s, data)
• Continue for a fixed number of iterations or convergence
• Note that this is collapsed Gibbs sampling
• Sample from p(z1, ….. zN | data), “collapsing” over φ and θ
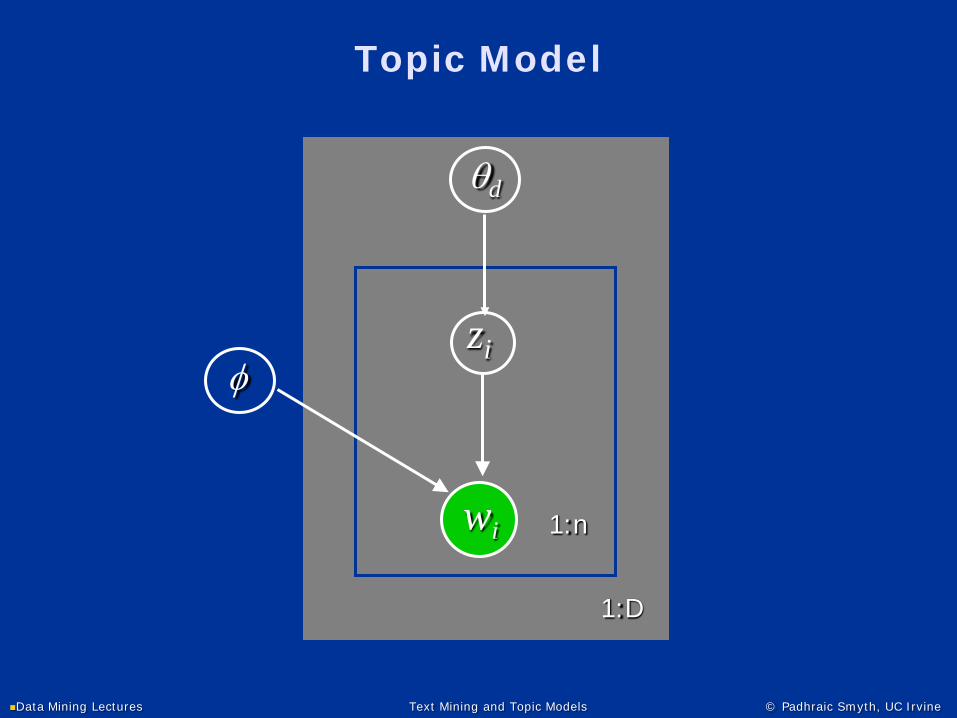
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Topic Model
φ
wi 1:n
1:D
zi
θd

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Sampling each Topic-Word Assignment
' '' '
( | )i i
td wti i i i
t d w tt w
n np z t zn T n W
α βα β
− −
− − −
+ += = ×
+ +∑ ∑
count of word wassigned to topic t
count of topic tassigned to doc d
probability that word iis assigned to topic t
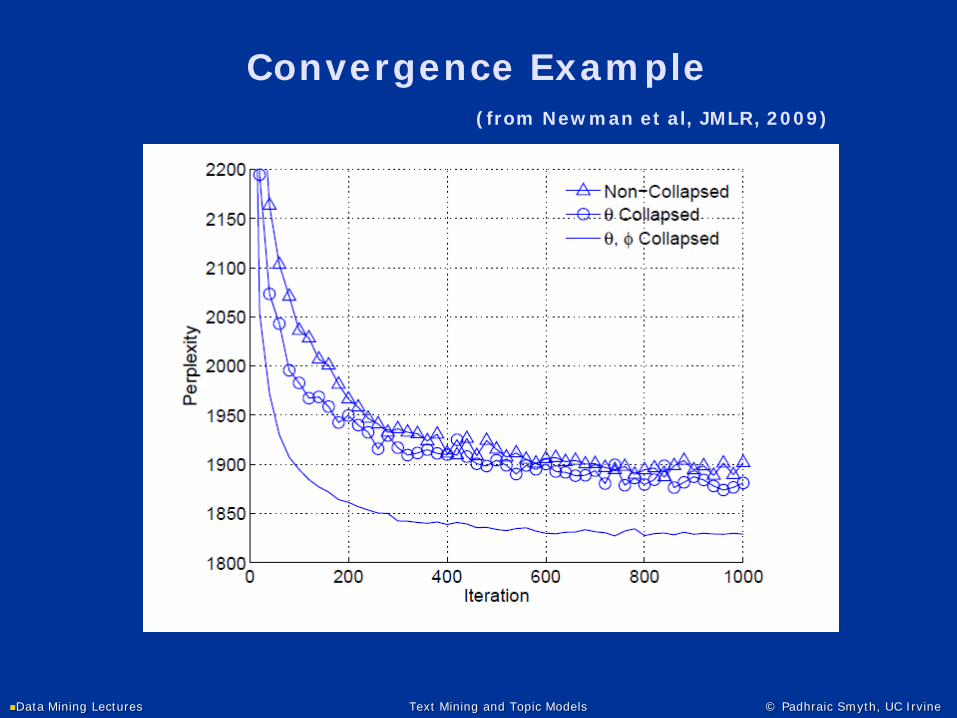
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Convergence Example(from Newman et al, JMLR, 2009)

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Complexity
• Time• O(N T) per iteration, where N is the number of “tokens”, T the
number of topics• For fast sampling, see “Fast-LDA”, Porteous et al, ACM SIGKDD, 2008;
also Yao, Mimno, McCallum, ACM SIGKDD 2009.• For distributed algorithms, see Newman et al., Journal of Machine
Learning Research, 2009, e.g., T = 1000, N = 100 million
• Space• O(D T + T W + N), where D is the number of documents and W
is the number of unique words (size of vocabulary)• Can reduce these size by using sparse matrices
• Store non-zero counts for doc-topic and topic-word • Only apply smoothing at prediction time

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
16 Artificial Documents
River Stream Bank Money Loan123456789
10111213141516
Can we recover the original topics and topic mixtures from this data?
documents

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Starting the Gibbs Sampling
River Stream Bank Money Loan123456789
10111213141516
• Assign word tokens randomly to topics (●=topic 1; ●=topic 2 )
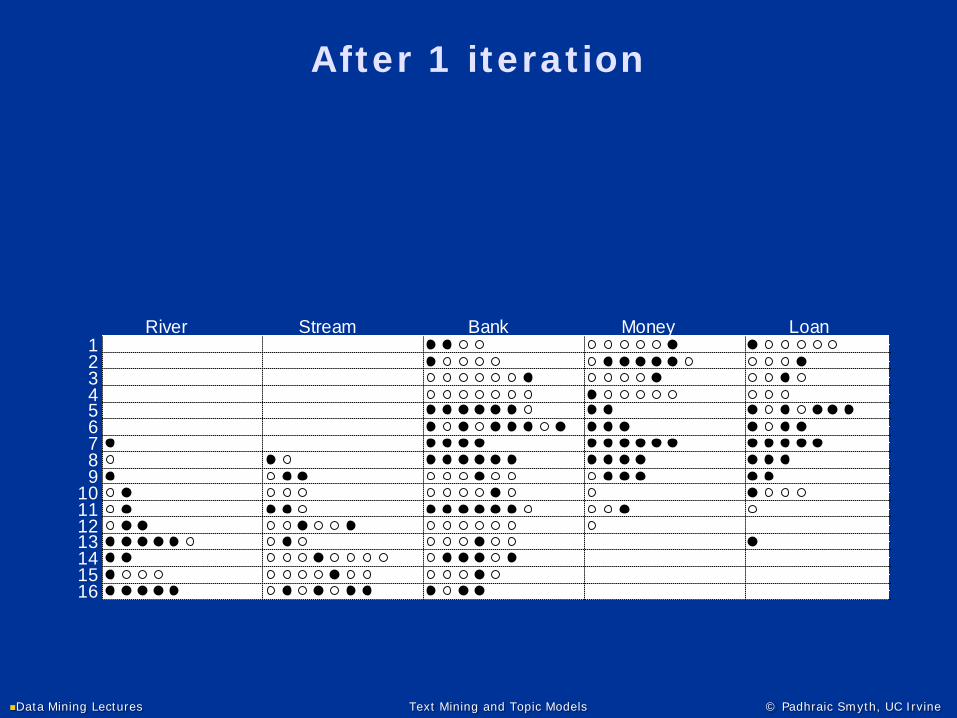
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
River Stream Bank Money Loan123456789
10111213141516
After 1 iteration
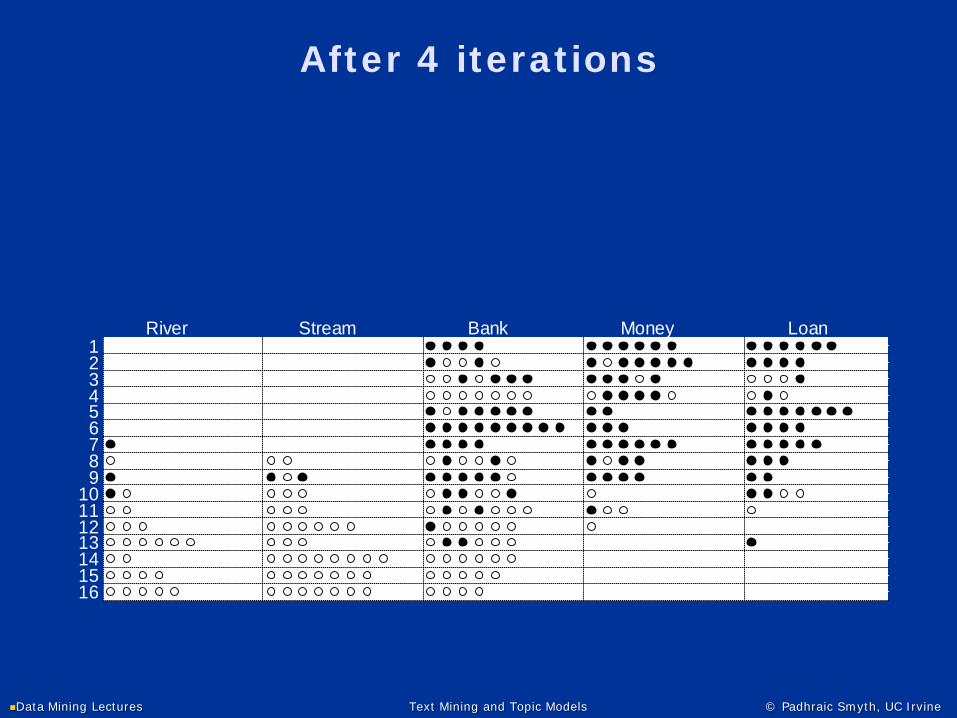
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
River Stream Bank Money Loan123456789
10111213141516
After 4 iterations
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
River Stream Bank Money Loan123456789
10111213141516
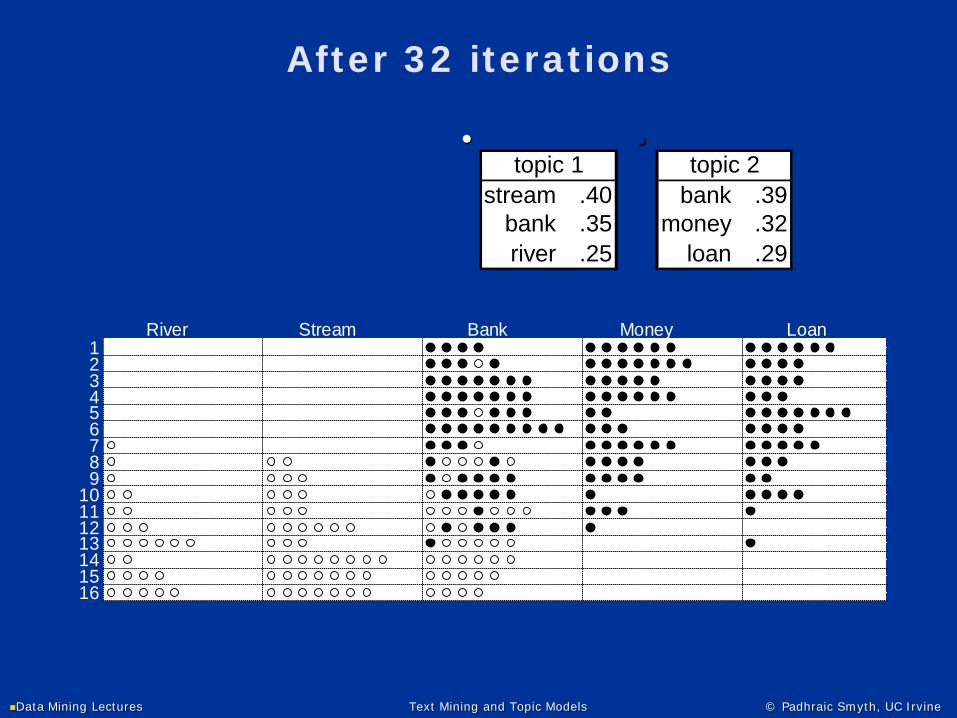
After 32 iterations
stream .40 bank .39bank .35 money .32river .25 loan .29
topic 1 topic 2● ●
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Software for Topic Modeling
psiexp.ss.uci.edu/research/programs_data/toolbox.htm
• Mark Steyver’s public-domain MATLAB toolbox for topic modeling on the Web

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
History of topic models
• origins in statistics: • latent class models in social science• admixture models in statistical genetics
• applications in computer science• Hoffman, SIGIR, 1999 • Blei, Jordan, Ng, JMLR 2003 (known as “LDA”)• Griffiths and Steyvers, PNAS, 2004
• more recent work• author-topic models: Steyvers et al, Rosen-Zvi et al, 2004• Hierarchical topics: McCallum et al, 2006• Correlated topic models: Blei and Lafferty, 2005• Dirichlet process models: Teh, Jordan, et al• large-scale web applications: Buntine et al, 2004, 2005• undirected models: Welling et al, 2004

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Topic = probability distribution over words
)|( zwPWORD PROB.
PROBABILISTIC 0.0778 BAYESIAN 0.0671
PROBABILITY 0.0532 CARLO 0.0309 MONTE 0.0308
DISTRIBUTION 0.0257 INFERENCE 0.0253
PROBABILITIES 0.0253 CONDITIONAL 0.0229
PRIOR 0.0219.... ...
TOPIC 209
WORD PROB. RETRIEVAL 0.1179
TEXT 0.0853 DOCUMENTS 0.0527
INFORMATION 0.0504 DOCUMENT 0.0441 CONTENT 0.0242 INDEXING 0.0205
RELEVANCE 0.0159 COLLECTION 0.0146
RELEVANT 0.0136... ...
TOPIC 289
Important point: these distributions are learned in a completely automated “unsupervised” fashion from the data
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
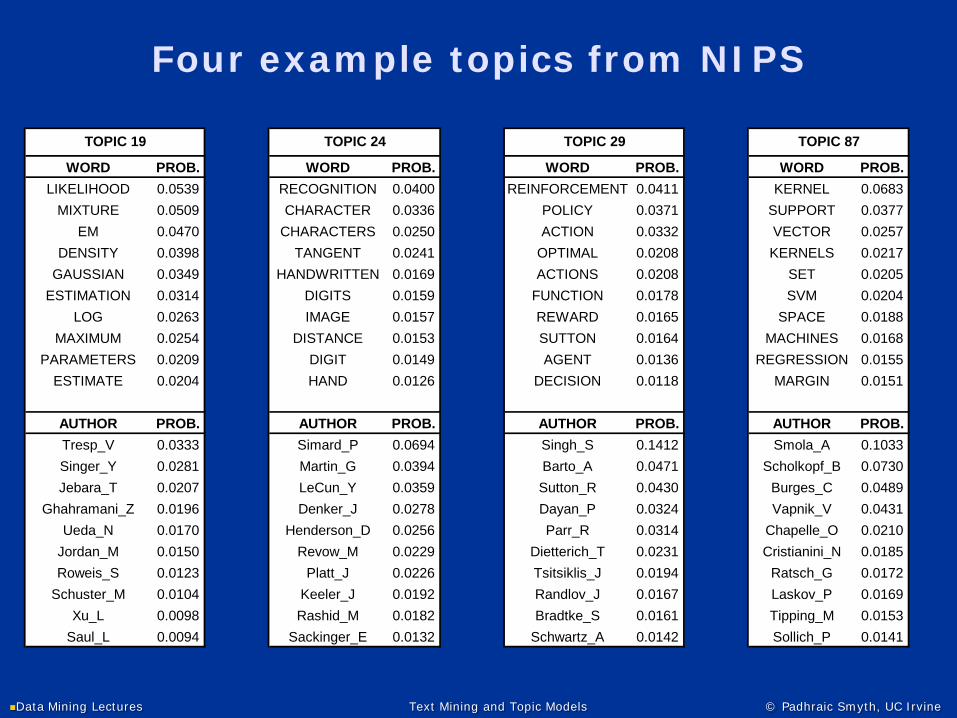
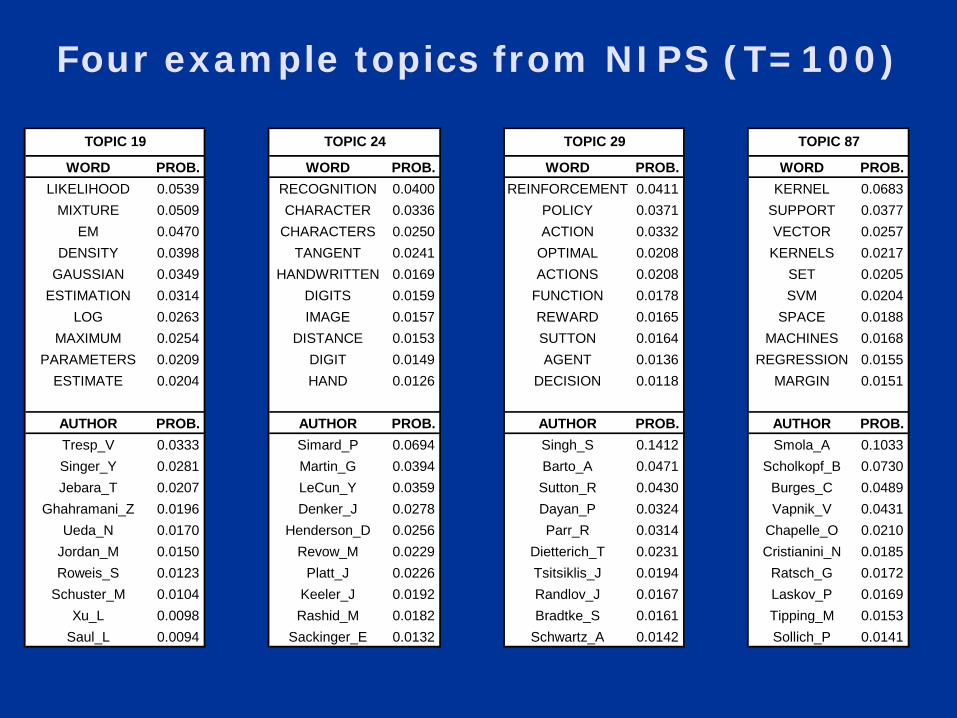
Four example topics from NIPS
WORD PROB. WORD PROB. WORD PROB. WORD PROB.LIKELIHOOD 0.0539 RECOGNITION 0.0400 REINFORCEMENT 0.0411 KERNEL 0.0683
MIXTURE 0.0509 CHARACTER 0.0336 POLICY 0.0371 SUPPORT 0.0377EM 0.0470 CHARACTERS 0.0250 ACTION 0.0332 VECTOR 0.0257
DENSITY 0.0398 TANGENT 0.0241 OPTIMAL 0.0208 KERNELS 0.0217GAUSSIAN 0.0349 HANDWRITTEN 0.0169 ACTIONS 0.0208 SET 0.0205
ESTIMATION 0.0314 DIGITS 0.0159 FUNCTION 0.0178 SVM 0.0204LOG 0.0263 IMAGE 0.0157 REWARD 0.0165 SPACE 0.0188
MAXIMUM 0.0254 DISTANCE 0.0153 SUTTON 0.0164 MACHINES 0.0168PARAMETERS 0.0209 DIGIT 0.0149 AGENT 0.0136 REGRESSION 0.0155
ESTIMATE 0.0204 HAND 0.0126 DECISION 0.0118 MARGIN 0.0151
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB.Tresp_V 0.0333 Simard_P 0.0694 Singh_S 0.1412 Smola_A 0.1033Singer_Y 0.0281 Martin_G 0.0394 Barto_A 0.0471 Scholkopf_B 0.0730Jebara_T 0.0207 LeCun_Y 0.0359 Sutton_R 0.0430 Burges_C 0.0489
Ghahramani_Z 0.0196 Denker_J 0.0278 Dayan_P 0.0324 Vapnik_V 0.0431Ueda_N 0.0170 Henderson_D 0.0256 Parr_R 0.0314 Chapelle_O 0.0210
Jordan_M 0.0150 Revow_M 0.0229 Dietterich_T 0.0231 Cristianini_N 0.0185Roweis_S 0.0123 Platt_J 0.0226 Tsitsiklis_J 0.0194 Ratsch_G 0.0172
Schuster_M 0.0104 Keeler_J 0.0192 Randlov_J 0.0167 Laskov_P 0.0169Xu_L 0.0098 Rashid_M 0.0182 Bradtke_S 0.0161 Tipping_M 0.0153
Saul_L 0.0094 Sackinger_E 0.0132 Schwartz_A 0.0142 Sollich_P 0.0141
TOPIC 19 TOPIC 24 TOPIC 29 TOPIC 87
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
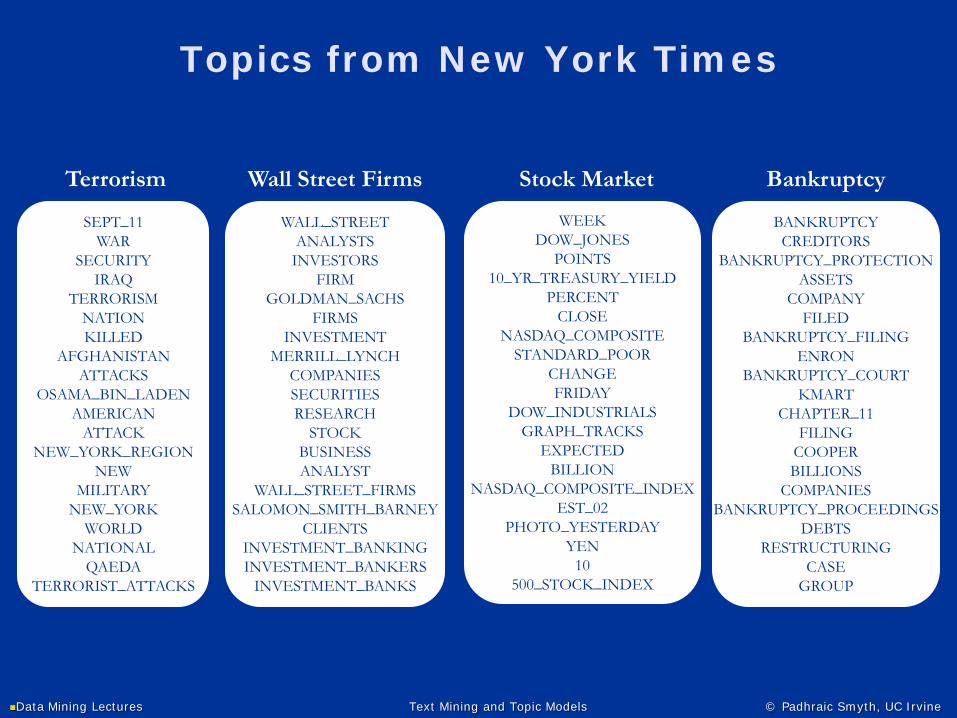
Topics from New York Times
WEEKDOW_JONES
POINTS10_YR_TREASURY_YIELD
PERCENTCLOSE
NASDAQ_COMPOSITESTANDARD_POOR
CHANGEFRIDAY
DOW_INDUSTRIALSGRAPH_TRACKS
EXPECTEDBILLION
NASDAQ_COMPOSITE_INDEXEST_02
PHOTO_YESTERDAYYEN
10500_STOCK_INDEX
WALL_STREETANALYSTS
INVESTORSFIRM
GOLDMAN_SACHSFIRMS
INVESTMENTMERRILL_LYNCH
COMPANIESSECURITIESRESEARCH
STOCKBUSINESSANALYST
WALL_STREET_FIRMSSALOMON_SMITH_BARNEY
CLIENTSINVESTMENT_BANKINGINVESTMENT_BANKERS
INVESTMENT_BANKS
SEPT_11WAR
SECURITYIRAQ
TERRORISMNATIONKILLED
AFGHANISTANATTACKS
OSAMA_BIN_LADENAMERICAN
ATTACKNEW_YORK_REGION
NEWMILITARY
NEW_YORKWORLD
NATIONALQAEDA
TERRORIST_ATTACKS
BANKRUPTCYCREDITORS
BANKRUPTCY_PROTECTIONASSETS
COMPANYFILED
BANKRUPTCY_FILINGENRON
BANKRUPTCY_COURTKMART
CHAPTER_11FILING
COOPERBILLIONS
COMPANIESBANKRUPTCY_PROCEEDINGS
DEBTSRESTRUCTURING
CASEGROUP
Terrorism Wall Street Firms Stock Market Bankruptcy

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Comparing Topics and Other Approaches
• Clustering documents• Computationally simpler…• But a less accurate and less flexible model
• LSI/LSA/SVD• Linear project of V-dim word vectors into lower dimensions• Less interpretable• Not generalizable
• E.g., authors or other side-information• Not as accurate
• E.g., precision-recall: Hoffman, Blei et al, Buntine, etc
• Probabilistic models such as topic Models • “next-generation” text modeling, after LSI• provide a modular extensible framework

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Clusters v. Topics
Hidden Markov Models in Molecular Biology: New Algorithms and ApplicationsPierre Baldi, Yves C Hauvin, Tim Hunkapiller, Marcella A. McClure
Hidden Markov Models (HMMs) can be applied to several important problems in molecular biology. We introduce a new convergent learning algorithm for HMMs that, unlike the classical Baum-Welch algorithm is smooth and can be applied on-line or in batch mode, with or without the usual Viterbi most likely path approximation. Left-right HMMs with insertion and deletion states are then trained to represent several protein families including immunoglobulins and kinases. In all cases, the models derived capture all the important statistical properties of the families and can be used efficiently in a number of important tasks such as multiple alignment, motif detection, andclassification.

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Clusters v. Topics
Hidden Markov Models in Molecular Biology: New Algorithms and ApplicationsPierre Baldi, Yves C Hauvin, Tim Hunkapiller, Marcella A. McClure
Hidden Markov Models (HMMs) can be applied to several important problems in molecular biology. We introduce a new convergent learning algorithm for HMMs that, unlike the classical Baum-Welch algorithm is smooth and can be applied on-line or in batch mode, with or without the usual Viterbi most likely path approximation. Left-right HMMs with insertion and deletion states are then trained to represent several protein families including immunoglobulins and kinases. In all cases, the models derived capture all the important statistical properties of the families and can be used efficiently in a number of important tasks such as multiple alignment, motif detection, and classification.
[cluster 88] model data models time neural figure state learning set parameters network probability number networks training function system algorithm hidden markov
One Cluster

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Clusters v. Topics
Hidden Markov Models in Molecular Biology: New Algorithms and ApplicationsPierre Baldi, Yves C Hauvin, Tim Hunkapiller, Marcella A. McClure
Hidden Markov Models (HMMs) can be applied to several important problems in molecular biology. We introduce a new convergent learning algorithm for HMMs that, unlike the classical Baum-Welch algorithm is smooth and can be applied on-line or in batch mode, with or without the usual Viterbi most likely path approximation. Left-right HMMs with insertion and deletion states are then trained to represent several protein families including immunoglobulins and kinases. In all cases, the models derived capture all the important statistical properties of the families and can be used efficiently in a number of important tasks such as multiple alignment, motif detection, andclassification.
[cluster 88] model data models time neural figure state learning set parameters network probability number networks training function system algorithm hidden markov
[topic 10] state hmm markov sequence models hidden states probabilities sequences parameters transition probability training hmms hybrid model likelihood modeling
[topic 37] genetic structure chain protein population region algorithms human mouse selection fitness proteins search evolution generation function sequence sequences genes
Multiple TopicsOne Cluster

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Examples of Topics learned from Proceedings of the National Academy of Sciences
Griffiths and Steyvers, PNAS, 2004
FORCESURFACE
MOLECULESSOLUTIONSURFACES
MICROSCOPYWATERFORCES
PARTICLESSTRENGTHPOLYMER
IONICATOMIC
AQUEOUSMOLECULARPROPERTIES
LIQUIDSOLUTIONS
BEADSMECHANICAL
HIVVIRUS
INFECTEDIMMUNODEFICIENCY
CD4INFECTION
HUMANVIRAL
TATGP120
REPLICATIONTYPE
ENVELOPEAIDSREV
BLOODCCR5
INDIVIDUALSENV
PERIPHERAL
MUSCLECARDIAC
HEARTSKELETALMYOCYTES
VENTRICULARMUSCLESSMOOTH
HYPERTROPHYDYSTROPHIN
HEARTSCONTRACTION
FIBERSFUNCTION
TISSUERAT
MYOCARDIALISOLATED
MYODFAILURE
STRUCTUREANGSTROM
CRYSTALRESIDUES
STRUCTURESSTRUCTURALRESOLUTION
HELIXTHREE
HELICESDETERMINED
RAYCONFORMATION
HELICALHYDROPHOBIC
SIDEDIMENSIONALINTERACTIONS
MOLECULESURFACE
NEURONSBRAIN
CORTEXCORTICAL
OLFACTORYNUCLEUS
NEURONALLAYER
RATNUCLEI
CEREBELLUMCEREBELLAR
LATERALCEREBRAL
LAYERSGRANULELABELED
HIPPOCAMPUSAREAS
THALAMIC
TUMORCANCERTUMORSHUMANCELLS
BREASTMELANOMA
GROWTHCARCINOMA
PROSTATENORMAL
CELLMETASTATICMALIGNANT
LUNGCANCERS
MICENUDE
PRIMARYOVARIAN

PARASITEPARASITES
FALCIPARUMMALARIA
HOSTPLASMODIUM
ERYTHROCYTESERYTHROCYTE
MAJORLEISHMANIA
INFECTEDBLOOD
INFECTIONMOSQUITOINVASION
TRYPANOSOMACRUZI
BRUCEIHUMANHOSTS
ADULTDEVELOPMENT
FETALDAY
DEVELOPMENTALPOSTNATAL
EARLYDAYS
NEONATALLIFE
DEVELOPINGEMBRYONIC
BIRTHNEWBORNMATERNAL
PRESENTPERIOD
ANIMALSNEUROGENESIS
ADULTS
CHROMOSOMEREGION
CHROMOSOMESKB
MAPMAPPING
CHROMOSOMALHYBRIDIZATION
ARTIFICIALMAPPED
PHYSICALMAPS
GENOMICDNA
LOCUSGENOME
GENEHUMAN
SITUCLONES
MALEFEMALEMALES
FEMALESSEX
SEXUALBEHAVIOROFFSPRING
REPRODUCTIVEMATINGSOCIALSPECIES
REPRODUCTIONFERTILITY
TESTISMATE
GENETICGERM
CHOICESRY
STUDIESPREVIOUS
SHOWNRESULTSRECENTPRESENTSTUDY
DEMONSTRATEDINDICATE
WORKSUGGEST
SUGGESTEDUSING
FINDINGSDEMONSTRATE
REPORTINDICATED
CONSISTENTREPORTS
CONTRAST
Examples of PNAS topics
MECHANISMMECHANISMSUNDERSTOOD
POORLYACTION
UNKNOWNREMAIN
UNDERLYINGMOLECULAR
PSREMAINS
SHOWRESPONSIBLE
PROCESSSUGGESTUNCLEARREPORT
LEADINGLARGELYKNOWN
MODELMODELS
EXPERIMENTALBASED
PROPOSEDDATA
SIMPLEDYNAMICSPREDICTED
EXPLAINBEHAVIOR
THEORETICALACCOUNTTHEORY
PREDICTSCOMPUTER
QUANTITATIVEPREDICTIONSCONSISTENTPARAMETERS

PARASITEPARASITES
FALCIPARUMMALARIA
HOSTPLASMODIUM
ERYTHROCYTESERYTHROCYTE
MAJORLEISHMANIA
INFECTEDBLOOD
INFECTIONMOSQUITOINVASION
TRYPANOSOMACRUZI
BRUCEIHUMANHOSTS
ADULTDEVELOPMENT
FETALDAY
DEVELOPMENTALPOSTNATAL
EARLYDAYS
NEONATALLIFE
DEVELOPINGEMBRYONIC
BIRTHNEWBORNMATERNAL
PRESENTPERIOD
ANIMALSNEUROGENESIS
ADULTS
CHROMOSOMEREGION
CHROMOSOMESKB
MAPMAPPING
CHROMOSOMALHYBRIDIZATION
ARTIFICIALMAPPED
PHYSICALMAPS
GENOMICDNA
LOCUSGENOME
GENEHUMAN
SITUCLONES
MALEFEMALEMALES
FEMALESSEX
SEXUALBEHAVIOROFFSPRING
REPRODUCTIVEMATINGSOCIALSPECIES
REPRODUCTIONFERTILITY
TESTISMATE
GENETICGERM
CHOICESRY
STUDIESPREVIOUS
SHOWNRESULTSRECENTPRESENTSTUDY
DEMONSTRATEDINDICATE
WORKSUGGEST
SUGGESTEDUSING
FINDINGSDEMONSTRATE
REPORTINDICATED
CONSISTENTREPORTS
CONTRAST
Examples of PNAS topics
MECHANISMMECHANISMSUNDERSTOOD
POORLYACTION
UNKNOWNREMAIN
UNDERLYINGMOLECULAR
PSREMAINS
SHOWRESPONSIBLE
PROCESSSUGGESTUNCLEARREPORT
LEADINGLARGELYKNOWN
MODELMODELS
EXPERIMENTALBASED
PROPOSEDDATA
SIMPLEDYNAMICSPREDICTED
EXPLAINBEHAVIOR
THEORETICALACCOUNTTHEORY
PREDICTSCOMPUTER
QUANTITATIVEPREDICTIONSCONSISTENTPARAMETERS

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
What can Topic Models be used for?
• Queries• Who writes on this topic?
e.g., finding experts or reviewers in a particular area
• What topics does this person do research on?
• Comparing groups of authors or documents
• Discovering trends over time
• Detecting unusual papers and authors
• Interactive browsing of a digital library via topics
• Parsing documents (and parts of documents) by topic
• and more…..

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
What is this paper about?
Empirical Bayes screening for multi-item associationsBill DuMouchel and Daryl Pregibon, ACM SIGKDD 2001
Most likely topics according to the model are…1. data, mining, discovery, association, attribute..2. set, subset, maximal, minimal, complete,…3. measurements, correlation, statistical, variation,4. Bayesian, model, prior, data, mixture,…..
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
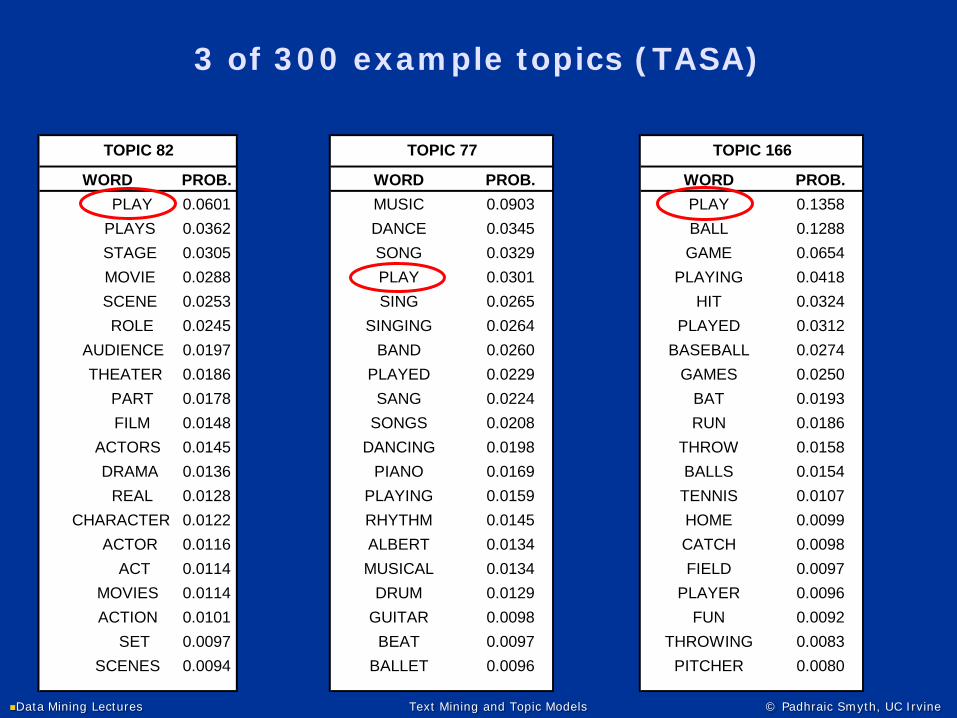
3 of 300 example topics (TASA)
WORD PROB. WORD PROB. WORD PROB. PLAY 0.0601 MUSIC 0.0903 PLAY 0.1358 PLAYS 0.0362 DANCE 0.0345 BALL 0.1288 STAGE 0.0305 SONG 0.0329 GAME 0.0654 MOVIE 0.0288 PLAY 0.0301 PLAYING 0.0418 SCENE 0.0253 SING 0.0265 HIT 0.0324 ROLE 0.0245 SINGING 0.0264 PLAYED 0.0312
AUDIENCE 0.0197 BAND 0.0260 BASEBALL 0.0274 THEATER 0.0186 PLAYED 0.0229 GAMES 0.0250
PART 0.0178 SANG 0.0224 BAT 0.0193 FILM 0.0148 SONGS 0.0208 RUN 0.0186
ACTORS 0.0145 DANCING 0.0198 THROW 0.0158 DRAMA 0.0136 PIANO 0.0169 BALLS 0.0154 REAL 0.0128 PLAYING 0.0159 TENNIS 0.0107
CHARACTER 0.0122 RHYTHM 0.0145 HOME 0.0099 ACTOR 0.0116 ALBERT 0.0134 CATCH 0.0098 ACT 0.0114 MUSICAL 0.0134 FIELD 0.0097
MOVIES 0.0114 DRUM 0.0129 PLAYER 0.0096 ACTION 0.0101 GUITAR 0.0098 FUN 0.0092 SET 0.0097 BEAT 0.0097 THROWING 0.0083
SCENES 0.0094 BALLET 0.0096 PITCHER 0.0080
TOPIC 82 TOPIC 166TOPIC 77

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Automated Tagging of Words (numbers & colors topic assignments)
A Play082 is written082 to be performed082 on a stage082 before a live093 audience082 or before motion270 picture004 or television004 cameras004 ( for later054 viewing004 by large202 audiences082). A Play082 is written082 because playwrights082 have something ... He was listening077 to music077 coming009 from a passing043 riverboat. The music077 had already captured006 his heart157 as well as his ear119. It was jazz077. Bix beiderbecke had already had music077 lessons077. He wanted268 to play077 the cornet. And he wanted268 to play077 jazz077... Jim296 plays166 the game166. Jim296 likes081 the game166 for one. The game166 book254 helps081 jim296. Don180 comes040 into the house038. Don180 and jim296 read254 the game166 book254. The boys020 see a game166 for two. The two boys020 play166 the game166....
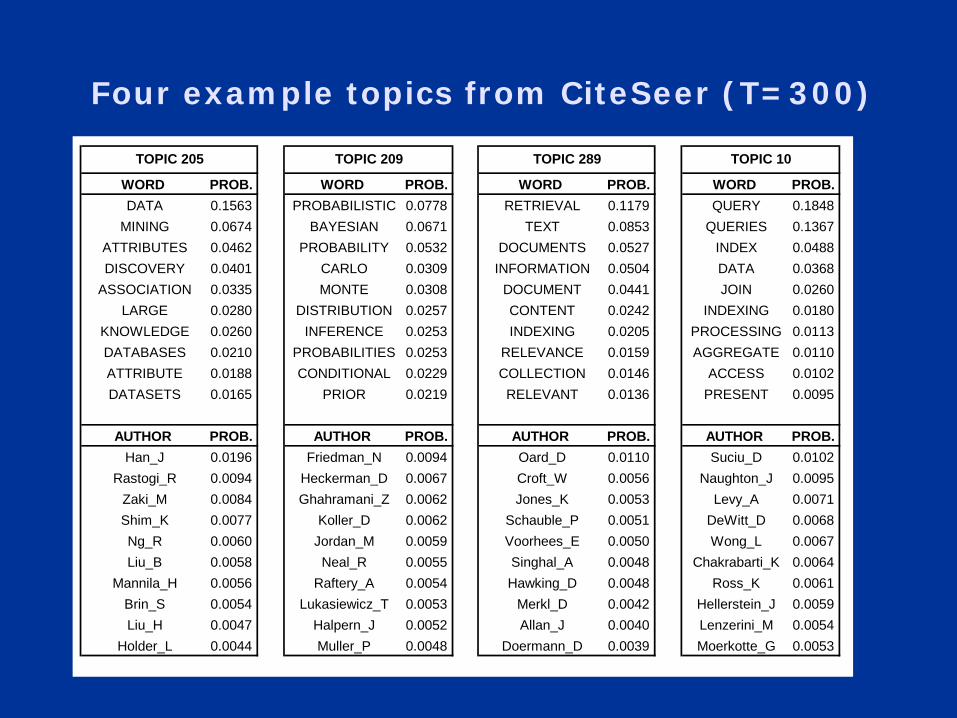
Four example topics from CiteSeer (T=300)
WORD PROB. WORD PROB. WORD PROB. WORD PROB. DATA 0.1563 PROBABILISTIC 0.0778 RETRIEVAL 0.1179 QUERY 0.1848
MINING 0.0674 BAYESIAN 0.0671 TEXT 0.0853 QUERIES 0.1367 ATTRIBUTES 0.0462 PROBABILITY 0.0532 DOCUMENTS 0.0527 INDEX 0.0488 DISCOVERY 0.0401 CARLO 0.0309 INFORMATION 0.0504 DATA 0.0368
ASSOCIATION 0.0335 MONTE 0.0308 DOCUMENT 0.0441 JOIN 0.0260 LARGE 0.0280 DISTRIBUTION 0.0257 CONTENT 0.0242 INDEXING 0.0180
KNOWLEDGE 0.0260 INFERENCE 0.0253 INDEXING 0.0205 PROCESSING 0.0113 DATABASES 0.0210 PROBABILITIES 0.0253 RELEVANCE 0.0159 AGGREGATE 0.0110 ATTRIBUTE 0.0188 CONDITIONAL 0.0229 COLLECTION 0.0146 ACCESS 0.0102 DATASETS 0.0165 PRIOR 0.0219 RELEVANT 0.0136 PRESENT 0.0095
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. Han_J 0.0196 Friedman_N 0.0094 Oard_D 0.0110 Suciu_D 0.0102
Rastogi_R 0.0094 Heckerman_D 0.0067 Croft_W 0.0056 Naughton_J 0.0095 Zaki_M 0.0084 Ghahramani_Z 0.0062 Jones_K 0.0053 Levy_A 0.0071 Shim_K 0.0077 Koller_D 0.0062 Schauble_P 0.0051 DeWitt_D 0.0068 Ng_R 0.0060 Jordan_M 0.0059 Voorhees_E 0.0050 Wong_L 0.0067 Liu_B 0.0058 Neal_R 0.0055 Singhal_A 0.0048 Chakrabarti_K 0.0064
Mannila_H 0.0056 Raftery_A 0.0054 Hawking_D 0.0048 Ross_K 0.0061 Brin_S 0.0054 Lukasiewicz_T 0.0053 Merkl_D 0.0042 Hellerstein_J 0.0059 Liu_H 0.0047 Halpern_J 0.0052 Allan_J 0.0040 Lenzerini_M 0.0054
Holder_L 0.0044 Muller_P 0.0048 Doermann_D 0.0039 Moerkotte_G 0.0053
TOPIC 205 TOPIC 209 TOPIC 289 TOPIC 10
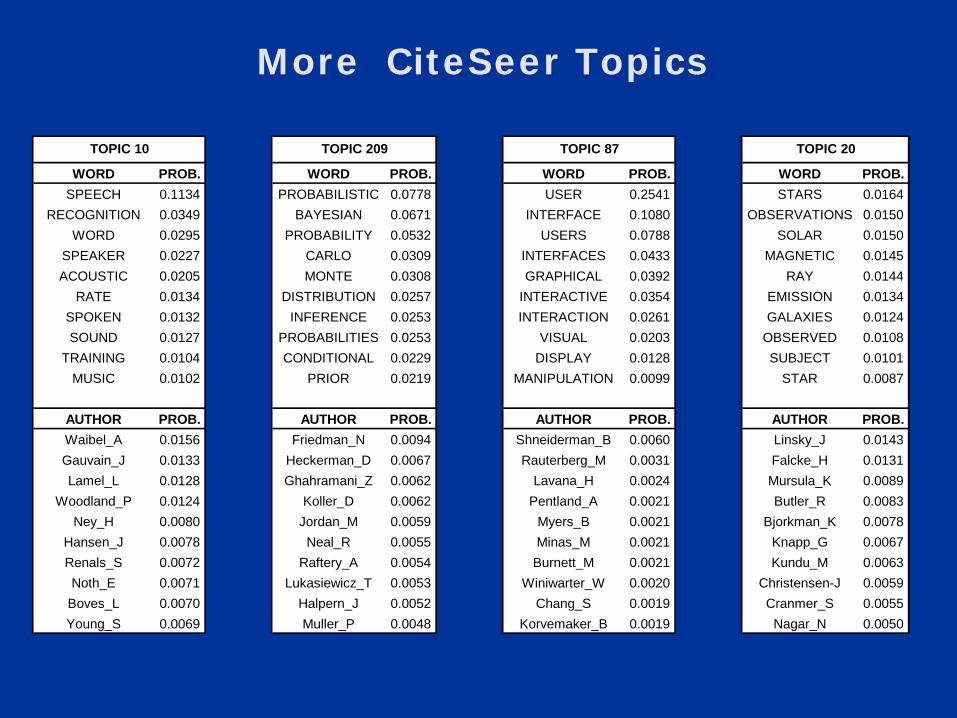
More CiteSeer Topics
WORD PROB. WORD PROB. WORD PROB. WORD PROB.SPEECH 0.1134 PROBABILISTIC 0.0778 USER 0.2541 STARS 0.0164
RECOGNITION 0.0349 BAYESIAN 0.0671 INTERFACE 0.1080 OBSERVATIONS 0.0150WORD 0.0295 PROBABILITY 0.0532 USERS 0.0788 SOLAR 0.0150
SPEAKER 0.0227 CARLO 0.0309 INTERFACES 0.0433 MAGNETIC 0.0145ACOUSTIC 0.0205 MONTE 0.0308 GRAPHICAL 0.0392 RAY 0.0144
RATE 0.0134 DISTRIBUTION 0.0257 INTERACTIVE 0.0354 EMISSION 0.0134SPOKEN 0.0132 INFERENCE 0.0253 INTERACTION 0.0261 GALAXIES 0.0124SOUND 0.0127 PROBABILITIES 0.0253 VISUAL 0.0203 OBSERVED 0.0108
TRAINING 0.0104 CONDITIONAL 0.0229 DISPLAY 0.0128 SUBJECT 0.0101MUSIC 0.0102 PRIOR 0.0219 MANIPULATION 0.0099 STAR 0.0087
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB.Waibel_A 0.0156 Friedman_N 0.0094 Shneiderman_B 0.0060 Linsky_J 0.0143Gauvain_J 0.0133 Heckerman_D 0.0067 Rauterberg_M 0.0031 Falcke_H 0.0131Lamel_L 0.0128 Ghahramani_Z 0.0062 Lavana_H 0.0024 Mursula_K 0.0089
Woodland_P 0.0124 Koller_D 0.0062 Pentland_A 0.0021 Butler_R 0.0083Ney_H 0.0080 Jordan_M 0.0059 Myers_B 0.0021 Bjorkman_K 0.0078
Hansen_J 0.0078 Neal_R 0.0055 Minas_M 0.0021 Knapp_G 0.0067Renals_S 0.0072 Raftery_A 0.0054 Burnett_M 0.0021 Kundu_M 0.0063Noth_E 0.0071 Lukasiewicz_T 0.0053 Winiwarter_W 0.0020 Christensen-J 0.0059
Boves_L 0.0070 Halpern_J 0.0052 Chang_S 0.0019 Cranmer_S 0.0055Young_S 0.0069 Muller_P 0.0048 Korvemaker_B 0.0019 Nagar_N 0.0050
TOPIC 10 TOPIC 209 TOPIC 87 TOPIC 20

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Temporal patterns in topics: hot and cold topics
• CiteSeer papers from 1986-2002, about 200k papers
• For each year, calculate the fraction of words assigned to each topic
• -> a time-series for topics• Hot topics become more prevalent• Cold topics become less prevalent
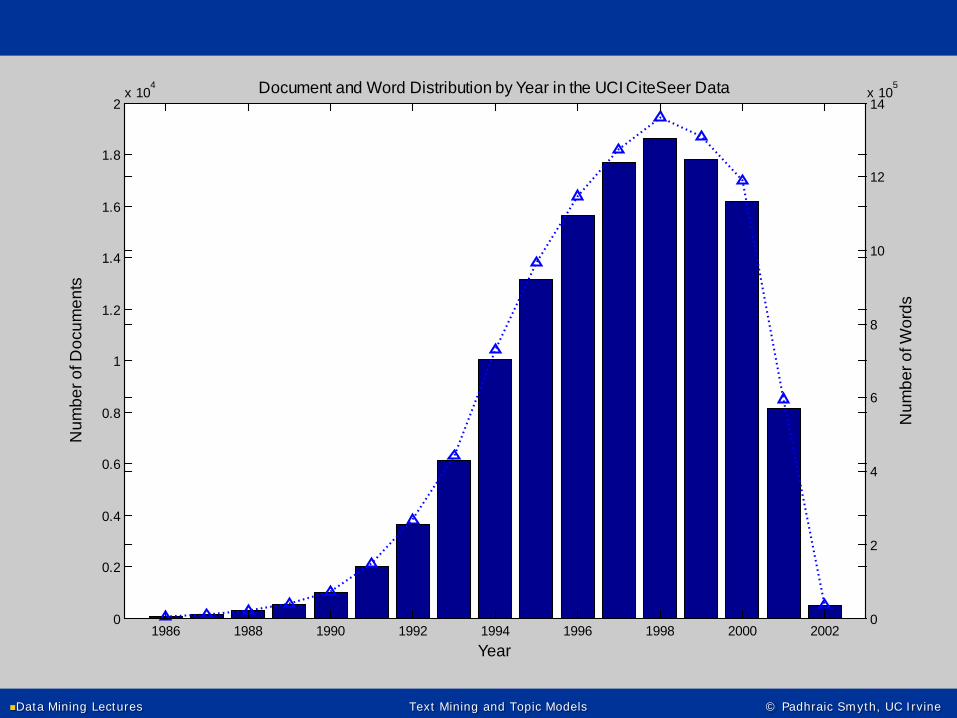
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
1986 1988 1990 1992 1994 1996 1998 2000 20020
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2x 10
4
Year
Num
ber o
f Doc
umen
tsDocument and Word Distribution by Year in the UCI CiteSeer Data
Num
ber o
f Wor
ds
0
2
4
6
8
10
12
14x 10
5
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20020
0.002
0.004
0.006
0.008
0.01
0.012
Year
Topi
c P
roba
bilit
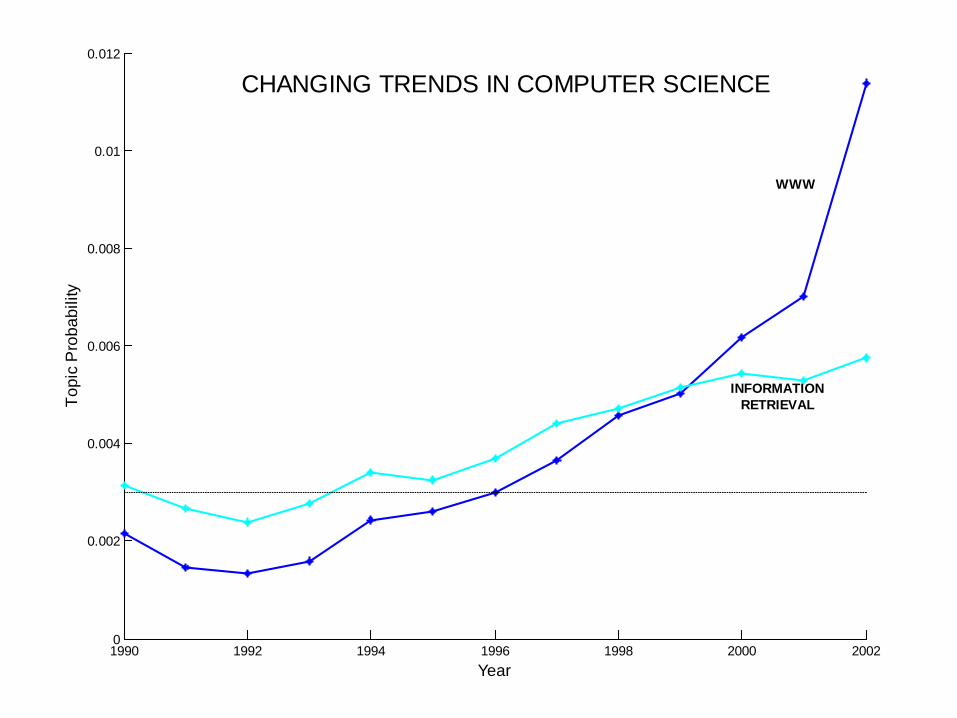
yCHANGING TRENDS IN COMPUTER SCIENCE
INFORMATIONRETRIEVAL
WWW
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20020
0.002
0.004
0.006
0.008
0.01
0.012
Year
Topi
c P
roba
bilit
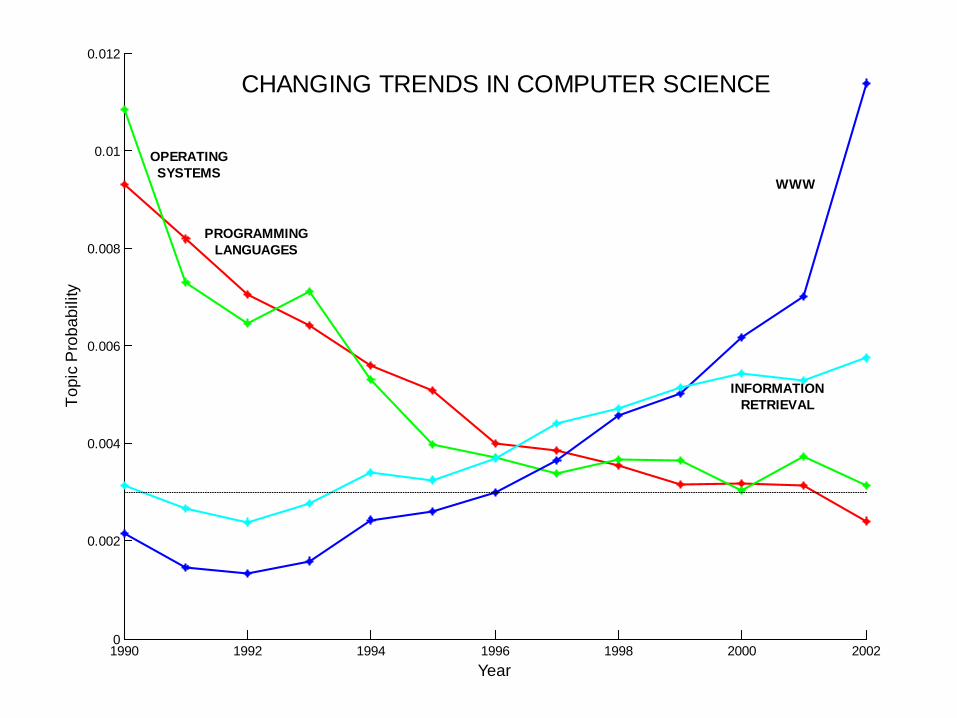
yCHANGING TRENDS IN COMPUTER SCIENCE
OPERATINGSYSTEMS
INFORMATIONRETRIEVAL
WWW
PROGRAMMINGLANGUAGES
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20021
2
3
4
5
6
7
8x 10
-3
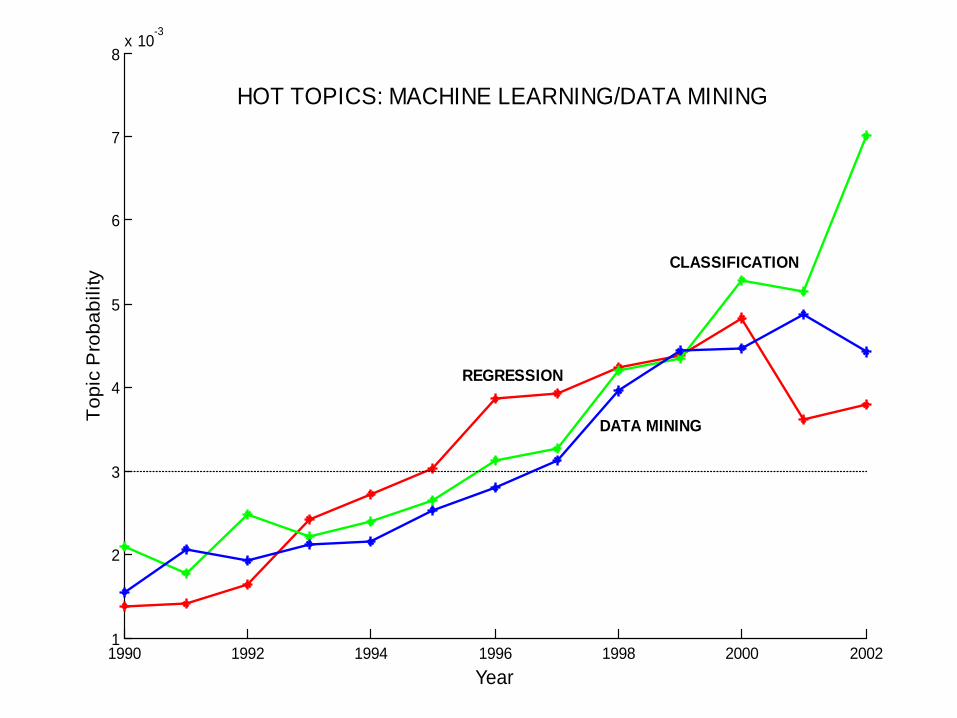
HOT TOPICS: MACHINE LEARNING/DATA MINING
Year
Topi
c P
roba
bilit
y
REGRESSION
DATA MINING
CLASSIFICATION
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20021.5
2
2.5
3
3.5
4
4.5
5
5.5x 10
-3
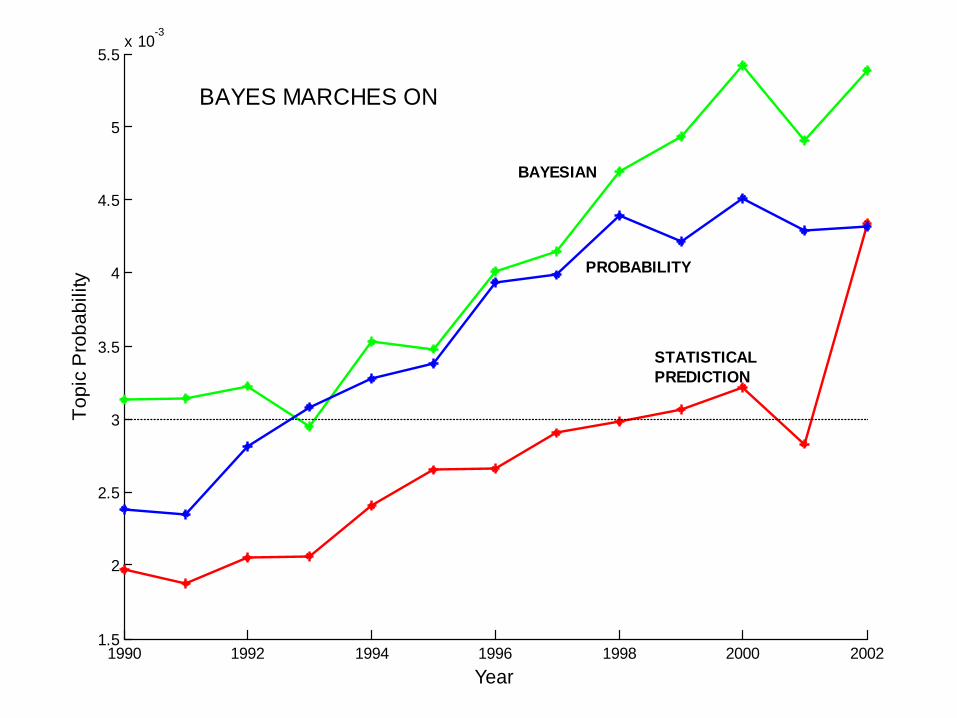
BAYES MARCHES ON
Year
Topi
c P
roba
bilit
y
BAYESIAN
PROBABILITY
STATISTICALPREDICTION
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20021
2
3
4
5
6
7
8
9x 10
-3
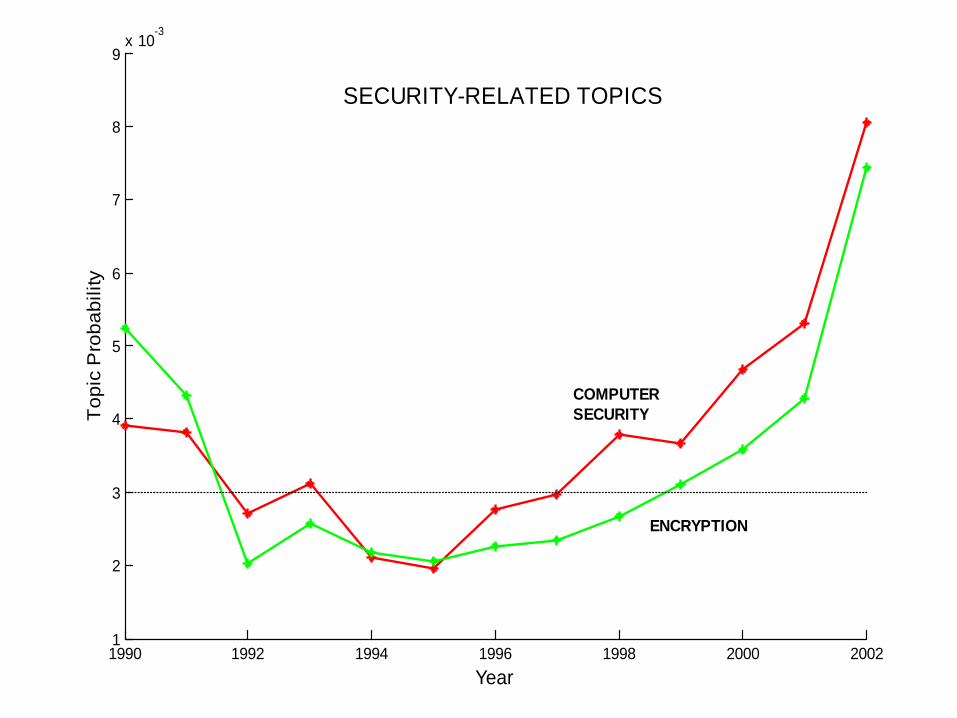
SECURITY-RELATED TOPICS
Year
Topi
c P
roba
bilit
y
COMPUTERSECURITY
ENCRYPTION
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
1990 1992 1994 1996 1998 2000 20020
0.002
0.004
0.006
0.008
0.01
0.012
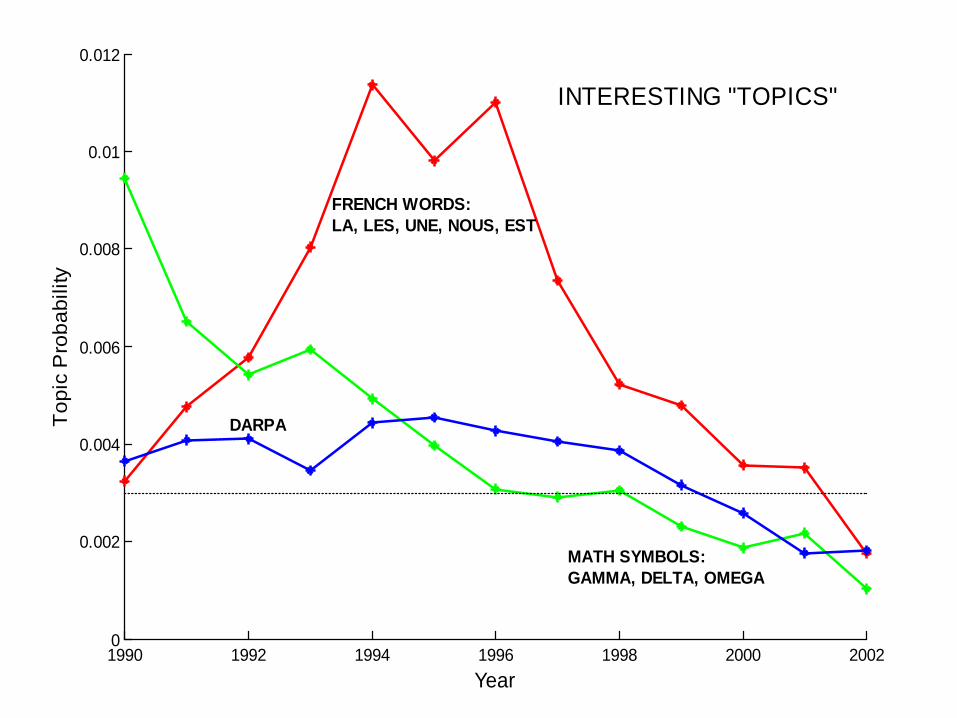
INTERESTING "TOPICS"
Year
Topi
c P
roba
bilit
y
FRENCH WORDS:LA, LES, UNE, NOUS, EST
MATH SYMBOLS:GAMMA, DELTA, OMEGA
DARPA
Four example topics from NIPS (T=100)
WORD PROB. WORD PROB. WORD PROB. WORD PROB.LIKELIHOOD 0.0539 RECOGNITION 0.0400 REINFORCEMENT 0.0411 KERNEL 0.0683
MIXTURE 0.0509 CHARACTER 0.0336 POLICY 0.0371 SUPPORT 0.0377EM 0.0470 CHARACTERS 0.0250 ACTION 0.0332 VECTOR 0.0257
DENSITY 0.0398 TANGENT 0.0241 OPTIMAL 0.0208 KERNELS 0.0217GAUSSIAN 0.0349 HANDWRITTEN 0.0169 ACTIONS 0.0208 SET 0.0205
ESTIMATION 0.0314 DIGITS 0.0159 FUNCTION 0.0178 SVM 0.0204LOG 0.0263 IMAGE 0.0157 REWARD 0.0165 SPACE 0.0188
MAXIMUM 0.0254 DISTANCE 0.0153 SUTTON 0.0164 MACHINES 0.0168PARAMETERS 0.0209 DIGIT 0.0149 AGENT 0.0136 REGRESSION 0.0155
ESTIMATE 0.0204 HAND 0.0126 DECISION 0.0118 MARGIN 0.0151
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB.Tresp_V 0.0333 Simard_P 0.0694 Singh_S 0.1412 Smola_A 0.1033Singer_Y 0.0281 Martin_G 0.0394 Barto_A 0.0471 Scholkopf_B 0.0730Jebara_T 0.0207 LeCun_Y 0.0359 Sutton_R 0.0430 Burges_C 0.0489
Ghahramani_Z 0.0196 Denker_J 0.0278 Dayan_P 0.0324 Vapnik_V 0.0431Ueda_N 0.0170 Henderson_D 0.0256 Parr_R 0.0314 Chapelle_O 0.0210
Jordan_M 0.0150 Revow_M 0.0229 Dietterich_T 0.0231 Cristianini_N 0.0185Roweis_S 0.0123 Platt_J 0.0226 Tsitsiklis_J 0.0194 Ratsch_G 0.0172
Schuster_M 0.0104 Keeler_J 0.0192 Randlov_J 0.0167 Laskov_P 0.0169Xu_L 0.0098 Rashid_M 0.0182 Bradtke_S 0.0161 Tipping_M 0.0153
Saul_L 0.0094 Sackinger_E 0.0132 Schwartz_A 0.0142 Sollich_P 0.0141
TOPIC 19 TOPIC 24 TOPIC 29 TOPIC 87
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
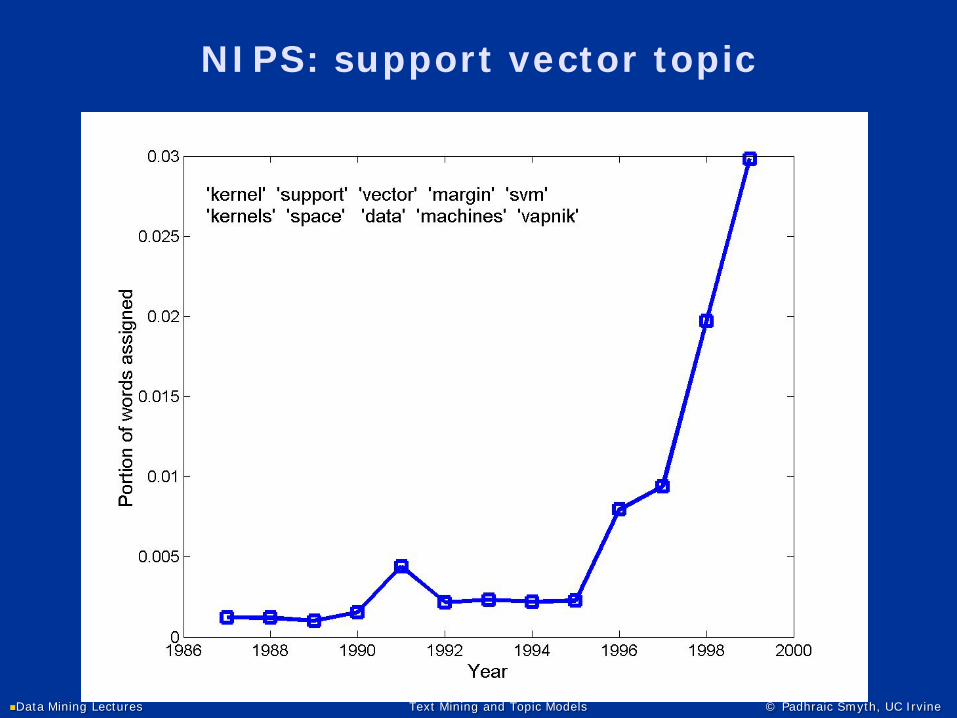
NIPS: support vector topic
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
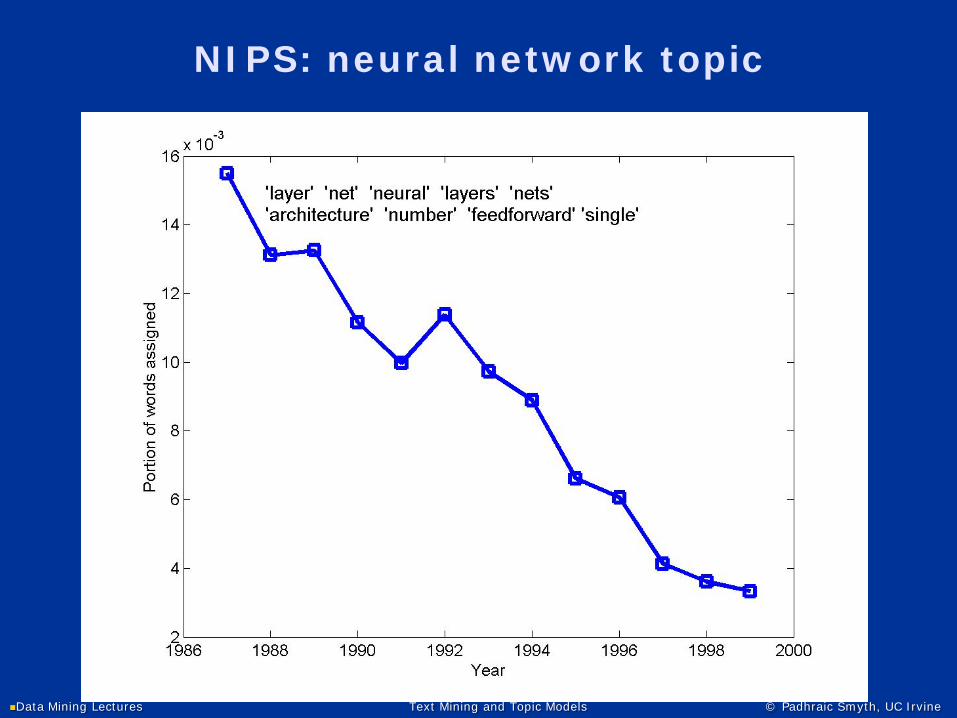
NIPS: neural network topic
time
to
pic
mas
s (in
ver
tical
hei
ght)
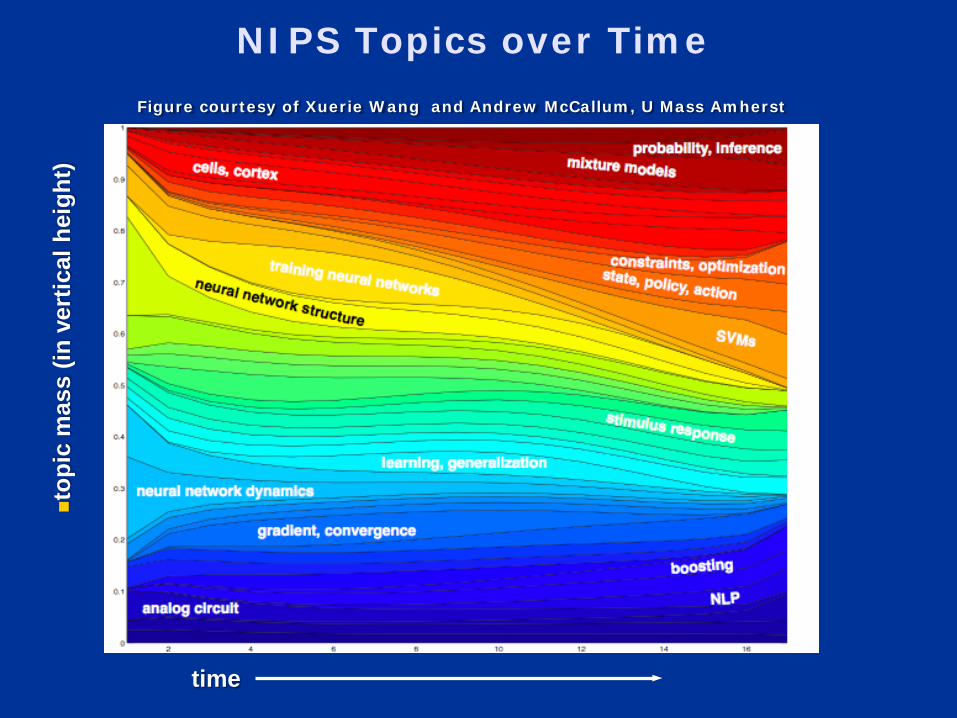
Figure courtesy of Xuerie Wang and Andrew McCallum, U Mass Amherst
NIPS Topics over Time

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
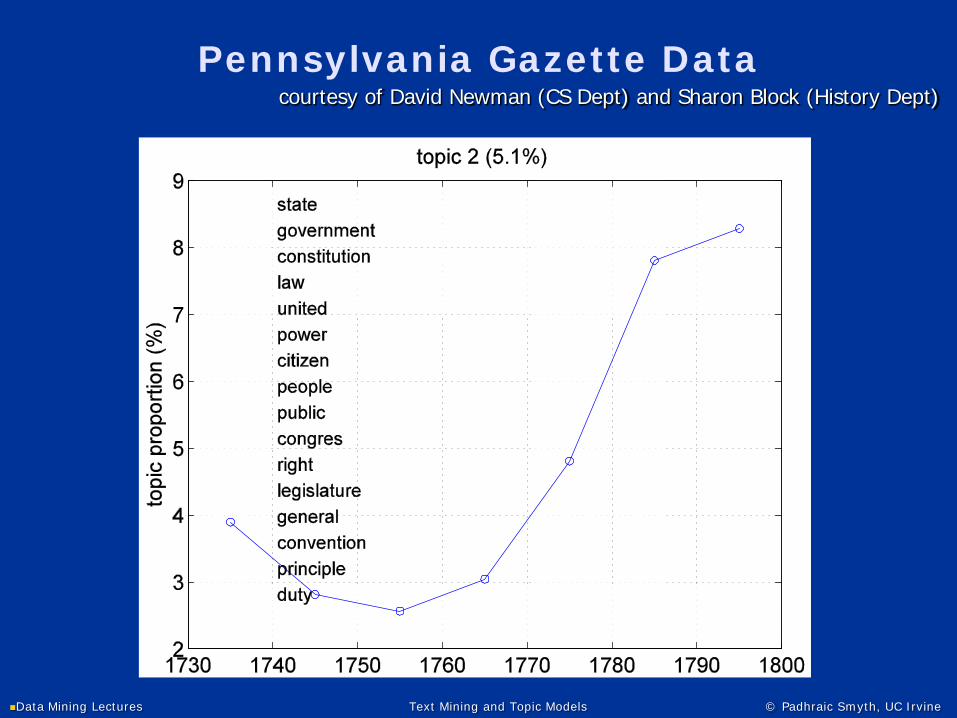
Pennsylvania Gazette
1728-1800
80,000 articles
(courtesy of David Newman & Sharon Block, UC Irvine)
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Pennsylvania Gazette Datacourtesy of David Newman (CS Dept) and Sharon Block (History Dept)
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
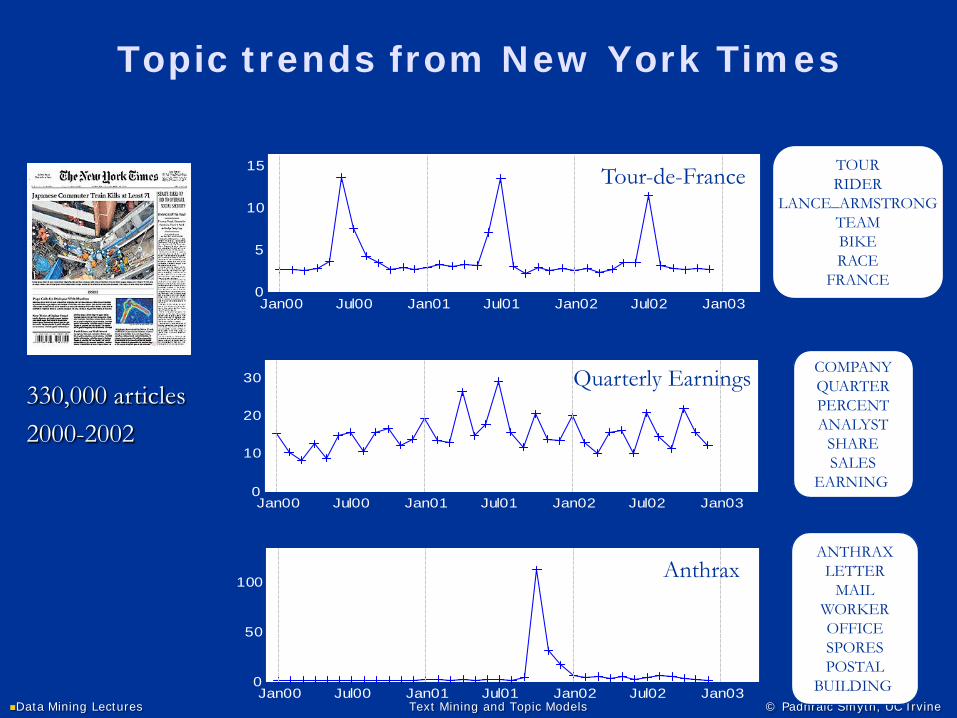
Topic trends from New York Times
TOURRIDER
LANCE_ARMSTRONGTEAMBIKERACE
FRANCEJan00 Jul00 Jan01 Jul01 Jan02 Jul02 Jan03
0
5
10
15 Tour-de-France
Jan00 Jul00 Jan01 Jul01 Jan02 Jul02 Jan030
10
20
30COMPANYQUARTERPERCENTANALYST
SHARESALES
EARNING
Quarterly Earnings
ANTHRAXLETTER
MAILWORKEROFFICESPORESPOSTAL
BUILDING Jan00 Jul00 Jan01 Jul01 Jan02 Jul02 Jan030
50
100Anthrax
330,000 articles2000-2002

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Enron email data
250,000 emails
28,000 authors
1999-2002

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Enron email: business topics
WORD PROB. WORD PROB. WORD PROB. WORD PROB.FEEDBACK 0.0781 PROJECT 0.0514 FERC 0.0554 ENVIRONMENTAL 0.0291
PERFORMANCE 0.0462 PLANT 0.028 MARKET 0.0328 AIR 0.0232PROCESS 0.0455 COST 0.0182 ISO 0.0226 MTBE 0.019
PEP 0.0446 CONSTRUCTION 0.0169 COMMISSION 0.0215 EMISSIONS 0.017MANAGEMENT 0.03 UNIT 0.0166 ORDER 0.0212 CLEAN 0.0143
COMPLETE 0.0205 FACILITY 0.0165 FILING 0.0149 EPA 0.0133QUESTIONS 0.0203 SITE 0.0136 COMMENTS 0.0116 PENDING 0.0129SELECTED 0.0187 PROJECTS 0.0117 PRICE 0.0116 SAFETY 0.0104
COMPLETED 0.0146 CONTRACT 0.011 CALIFORNIA 0.0110 WATER 0.0092SYSTEM 0.0146 UNITS 0.0106 FILED 0.0110 GASOLINE 0.0086
SENDER PROB. SENDER PROB. SENDER PROB. SENDER PROB.perfmgmt 0.2195 *** 0.0288 *** 0.0532 *** 0.1339
perf eval process 0.0784 *** 0.022 *** 0.0454 *** 0.0275enron announcements 0.0489 *** 0.0123 *** 0.0384 *** 0.0205
*** 0.0089 *** 0.0111 *** 0.0334 *** 0.0166*** 0.0048 *** 0.0108 *** 0.0317 *** 0.0129
TOPIC 23TOPIC 36 TOPIC 72 TOPIC 54
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
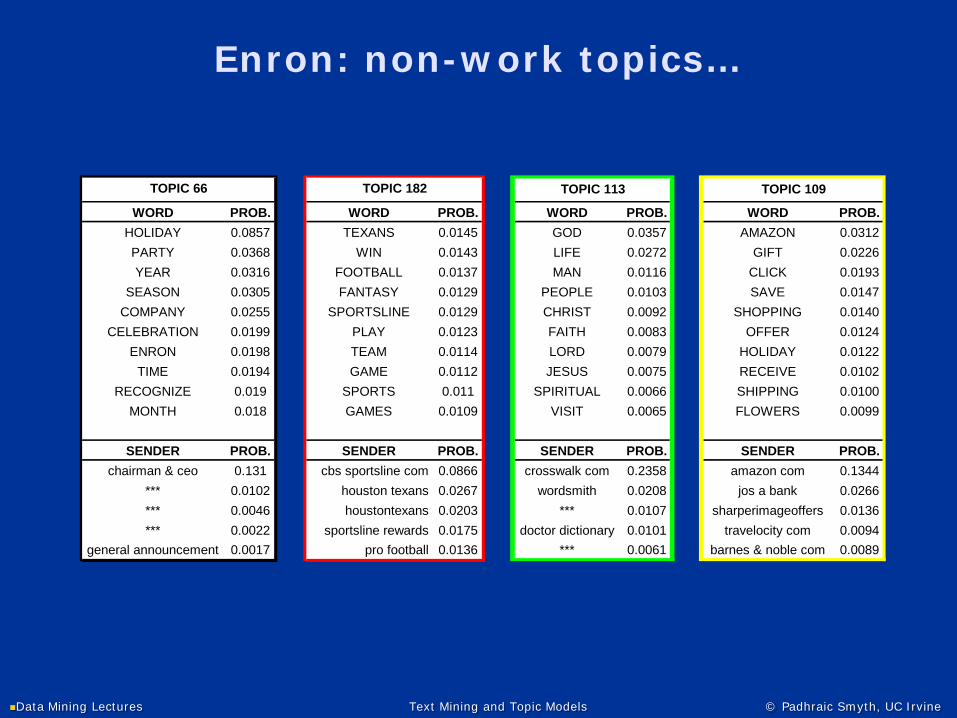
Enron: non-work topics…
WORD PROB. WORD PROB. WORD PROB. WORD PROB.HOLIDAY 0.0857 TEXANS 0.0145 GOD 0.0357 AMAZON 0.0312PARTY 0.0368 WIN 0.0143 LIFE 0.0272 GIFT 0.0226YEAR 0.0316 FOOTBALL 0.0137 MAN 0.0116 CLICK 0.0193
SEASON 0.0305 FANTASY 0.0129 PEOPLE 0.0103 SAVE 0.0147COMPANY 0.0255 SPORTSLINE 0.0129 CHRIST 0.0092 SHOPPING 0.0140
CELEBRATION 0.0199 PLAY 0.0123 FAITH 0.0083 OFFER 0.0124ENRON 0.0198 TEAM 0.0114 LORD 0.0079 HOLIDAY 0.0122
TIME 0.0194 GAME 0.0112 JESUS 0.0075 RECEIVE 0.0102RECOGNIZE 0.019 SPORTS 0.011 SPIRITUAL 0.0066 SHIPPING 0.0100
MONTH 0.018 GAMES 0.0109 VISIT 0.0065 FLOWERS 0.0099
SENDER PROB. SENDER PROB. SENDER PROB. SENDER PROB.chairman & ceo 0.131 cbs sportsline com 0.0866 crosswalk com 0.2358 amazon com 0.1344
*** 0.0102 houston texans 0.0267 wordsmith 0.0208 jos a bank 0.0266*** 0.0046 houstontexans 0.0203 *** 0.0107 sharperimageoffers 0.0136*** 0.0022 sportsline rewards 0.0175 doctor dictionary 0.0101 travelocity com 0.0094
general announcement 0.0017 pro football 0.0136 *** 0.0061 barnes & noble com 0.0089
TOPIC 109TOPIC 66 TOPIC 182 TOPIC 113
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
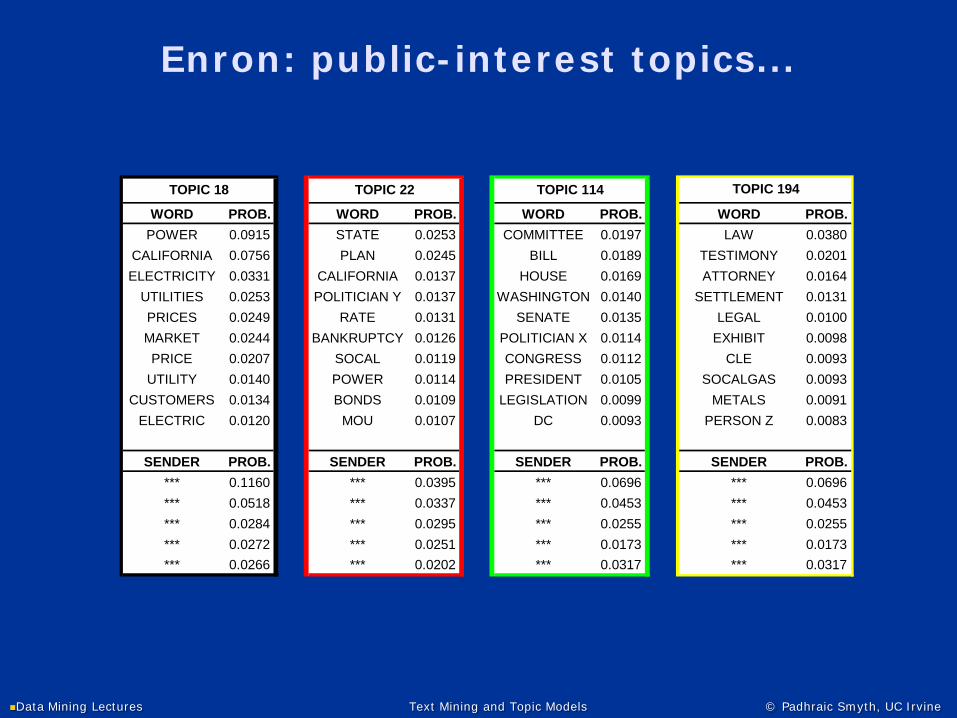
Enron: public-interest topics...
WORD PROB. WORD PROB. WORD PROB. WORD PROB.POWER 0.0915 STATE 0.0253 COMMITTEE 0.0197 LAW 0.0380
CALIFORNIA 0.0756 PLAN 0.0245 BILL 0.0189 TESTIMONY 0.0201ELECTRICITY 0.0331 CALIFORNIA 0.0137 HOUSE 0.0169 ATTORNEY 0.0164
UTILITIES 0.0253 POLITICIAN Y 0.0137 WASHINGTON 0.0140 SETTLEMENT 0.0131PRICES 0.0249 RATE 0.0131 SENATE 0.0135 LEGAL 0.0100MARKET 0.0244 BANKRUPTCY 0.0126 POLITICIAN X 0.0114 EXHIBIT 0.0098PRICE 0.0207 SOCAL 0.0119 CONGRESS 0.0112 CLE 0.0093
UTILITY 0.0140 POWER 0.0114 PRESIDENT 0.0105 SOCALGAS 0.0093CUSTOMERS 0.0134 BONDS 0.0109 LEGISLATION 0.0099 METALS 0.0091
ELECTRIC 0.0120 MOU 0.0107 DC 0.0093 PERSON Z 0.0083
SENDER PROB. SENDER PROB. SENDER PROB. SENDER PROB.*** 0.1160 *** 0.0395 *** 0.0696 *** 0.0696*** 0.0518 *** 0.0337 *** 0.0453 *** 0.0453*** 0.0284 *** 0.0295 *** 0.0255 *** 0.0255*** 0.0272 *** 0.0251 *** 0.0173 *** 0.0173*** 0.0266 *** 0.0202 *** 0.0317 *** 0.0317
TOPIC 194TOPIC 18 TOPIC 22 TOPIC 114
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
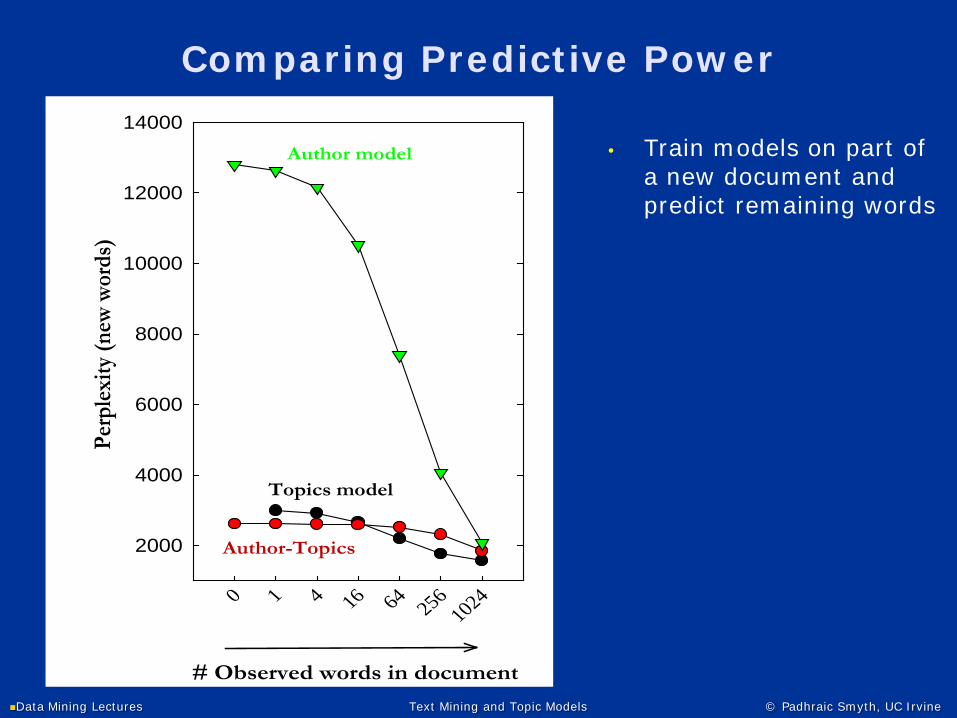
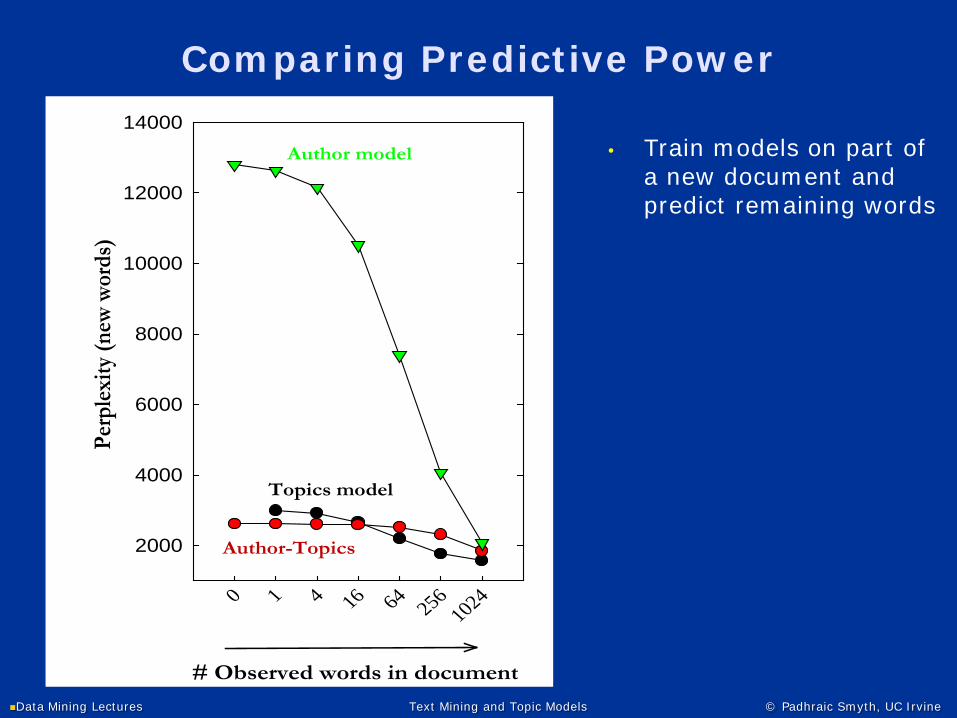
Comparing Predictive Power
• Train models on part of a new document and predict remaining words
0 1 4 16 64 256
1024
Perp
lexi
ty (n
ew w
ords
)
2000
4000
6000
8000
10000
12000
14000
# Observed words in document
Author model
Topics model
Author-Topics
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
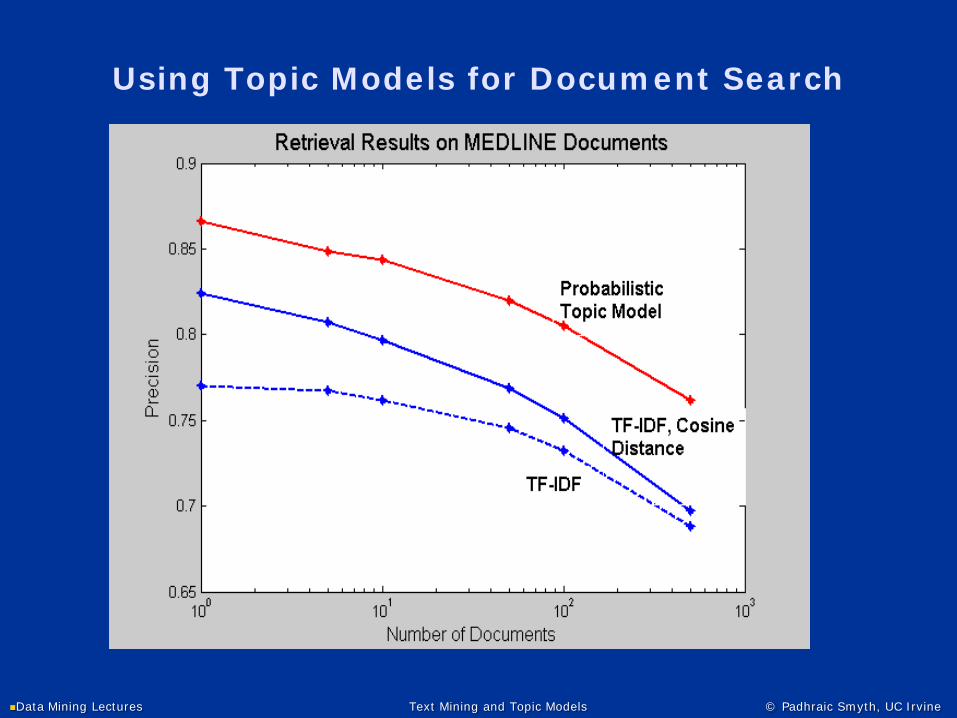
Using Topic Models for Document Search

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
References on Topic Models
Overviews:• Steyvers, M. & Griffiths, T. (2006). Probabilistic topic models. In T.
Landauer, D McNamara, S. Dennis, and W. Kintsch (eds), Latent Semantic Analysis: A Road to Meaning. Laurence Erlbaum
• D. Blei and J. Lafferty. Topic Models. In A. Srivastava and M. Sahami, editors, Text Mining: Theory and Applications. Taylor and Francis, 2009.
More specific:• Latent Dirichlet allocation
David Blei, Andrew Y. Ng and Michael Jordan. Journal of Machine Learning Research, 3:993-1022, 2003.
• Finding scientific topicsGriffiths, T., & Steyvers, M. (2004). Proceedings of the National Academy of Sciences, 101 (suppl. 1), 5228-5235
• Probabilistic author-topic models for information discovery M. Steyvers, P. Smyth, M. Rosen-Zvi, and T. Griffiths, in Proceedings of the ACM SIGKDD Conference on Data Mining and Knowledge Discovery, August 2004.

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
ADDITIONAL SLIDES
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
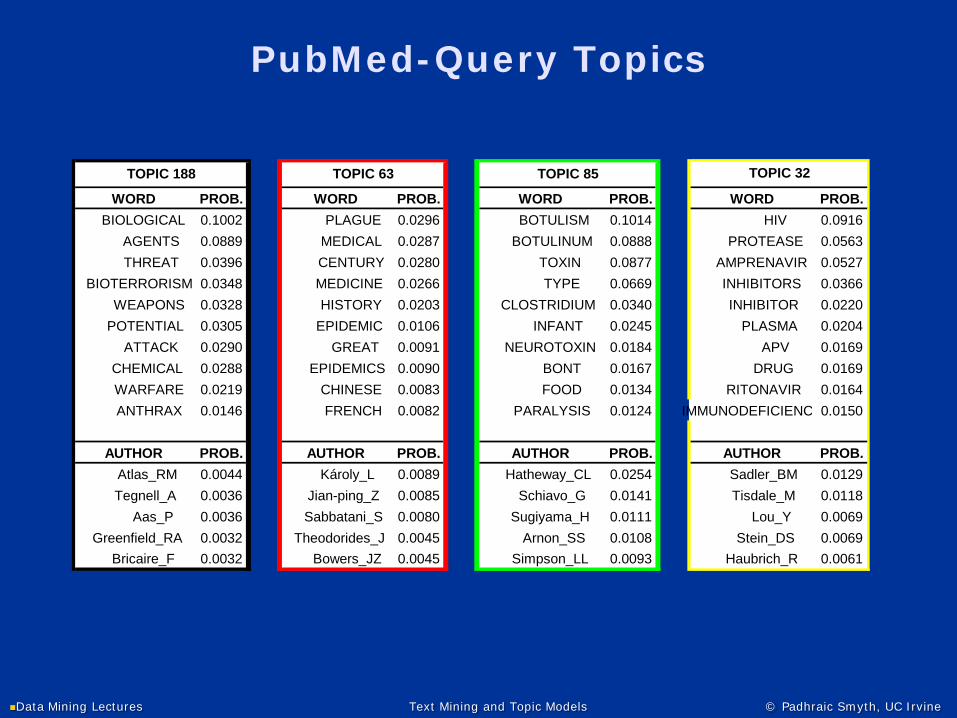
PubMed-Query Topics
WORD PROB. WORD PROB. WORD PROB. WORD PROB. BIOLOGICAL 0.1002 PLAGUE 0.0296 BOTULISM 0.1014 HIV 0.0916 AGENTS 0.0889 MEDICAL 0.0287 BOTULINUM 0.0888 PROTEASE 0.0563 THREAT 0.0396 CENTURY 0.0280 TOXIN 0.0877 AMPRENAVIR 0.0527
BIOTERRORISM 0.0348 MEDICINE 0.0266 TYPE 0.0669 INHIBITORS 0.0366 WEAPONS 0.0328 HISTORY 0.0203 CLOSTRIDIUM 0.0340 INHIBITOR 0.0220 POTENTIAL 0.0305 EPIDEMIC 0.0106 INFANT 0.0245 PLASMA 0.0204 ATTACK 0.0290 GREAT 0.0091 NEUROTOXIN 0.0184 APV 0.0169
CHEMICAL 0.0288 EPIDEMICS 0.0090 BONT 0.0167 DRUG 0.0169 WARFARE 0.0219 CHINESE 0.0083 FOOD 0.0134 RITONAVIR 0.0164 ANTHRAX 0.0146 FRENCH 0.0082 PARALYSIS 0.0124 IMMUNODEFICIENC 0.0150
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. Atlas_RM 0.0044 Károly_L 0.0089 Hatheway_CL 0.0254 Sadler_BM 0.0129 Tegnell_A 0.0036 Jian-ping_Z 0.0085 Schiavo_G 0.0141 Tisdale_M 0.0118 Aas_P 0.0036 Sabbatani_S 0.0080 Sugiyama_H 0.0111 Lou_Y 0.0069
Greenfield_RA 0.0032 Theodorides_J 0.0045 Arnon_SS 0.0108 Stein_DS 0.0069 Bricaire_F 0.0032 Bowers_JZ 0.0045 Simpson_LL 0.0093 Haubrich_R 0.0061
TOPIC 32TOPIC 188 TOPIC 63 TOPIC 85
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
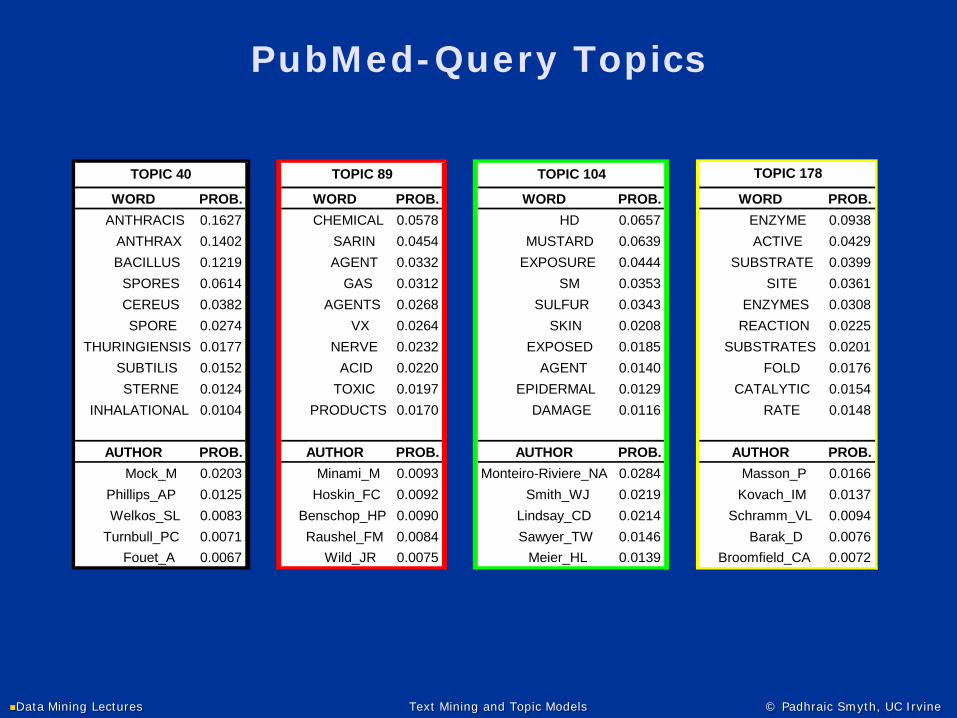
PubMed-Query Topics
WORD PROB. WORD PROB. WORD PROB. WORD PROB. ANTHRACIS 0.1627 CHEMICAL 0.0578 HD 0.0657 ENZYME 0.0938 ANTHRAX 0.1402 SARIN 0.0454 MUSTARD 0.0639 ACTIVE 0.0429 BACILLUS 0.1219 AGENT 0.0332 EXPOSURE 0.0444 SUBSTRATE 0.0399 SPORES 0.0614 GAS 0.0312 SM 0.0353 SITE 0.0361 CEREUS 0.0382 AGENTS 0.0268 SULFUR 0.0343 ENZYMES 0.0308 SPORE 0.0274 VX 0.0264 SKIN 0.0208 REACTION 0.0225
THURINGIENSIS 0.0177 NERVE 0.0232 EXPOSED 0.0185 SUBSTRATES 0.0201 SUBTILIS 0.0152 ACID 0.0220 AGENT 0.0140 FOLD 0.0176 STERNE 0.0124 TOXIC 0.0197 EPIDERMAL 0.0129 CATALYTIC 0.0154
INHALATIONAL 0.0104 PRODUCTS 0.0170 DAMAGE 0.0116 RATE 0.0148
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. Mock_M 0.0203 Minami_M 0.0093 Monteiro-Riviere_NA 0.0284 Masson_P 0.0166 Phillips_AP 0.0125 Hoskin_FC 0.0092 Smith_WJ 0.0219 Kovach_IM 0.0137
Welkos_SL 0.0083 Benschop_HP 0.0090 Lindsay_CD 0.0214 Schramm_VL 0.0094 Turnbull_PC 0.0071 Raushel_FM 0.0084 Sawyer_TW 0.0146 Barak_D 0.0076 Fouet_A 0.0067 Wild_JR 0.0075 Meier_HL 0.0139 Broomfield_CA 0.0072
TOPIC 178TOPIC 40 TOPIC 89 TOPIC 104
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
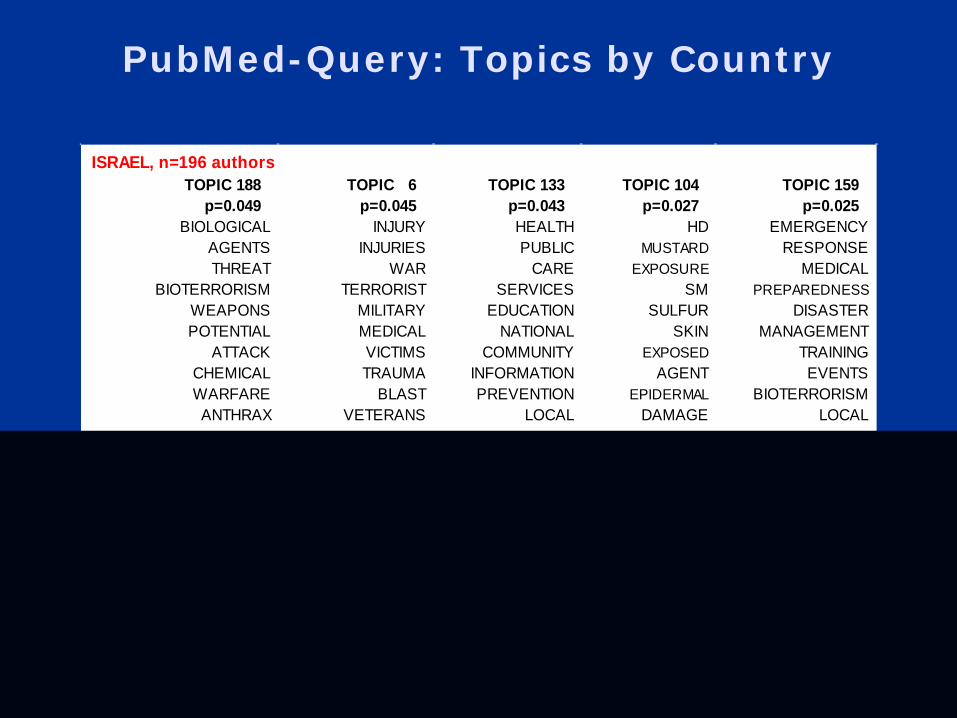
PubMed-Query: Topics by Country
ISRAEL, n=196 authors TOPIC 188 TOPIC 6 TOPIC 133 TOPIC 104 TOPIC 159
p=0.049 p=0.045 p=0.043 p=0.027 p=0.025 BIOLOGICAL INJURY HEALTH HD EMERGENCY
AGENTS INJURIES PUBLIC MUSTARD RESPONSE THREAT WAR CARE EXPOSURE MEDICAL
BIOTERRORISM TERRORIST SERVICES SM PREPAREDNESS WEAPONS MILITARY EDUCATION SULFUR DISASTER POTENTIAL MEDICAL NATIONAL SKIN MANAGEMENT
ATTACK VICTIMS COMMUNITY EXPOSED TRAINING CHEMICAL TRAUMA INFORMATION AGENT EVENTS
WARFARE BLAST PREVENTION EPIDERMAL BIOTERRORISM ANTHRAX VETERANS LOCAL DAMAGE LOCAL
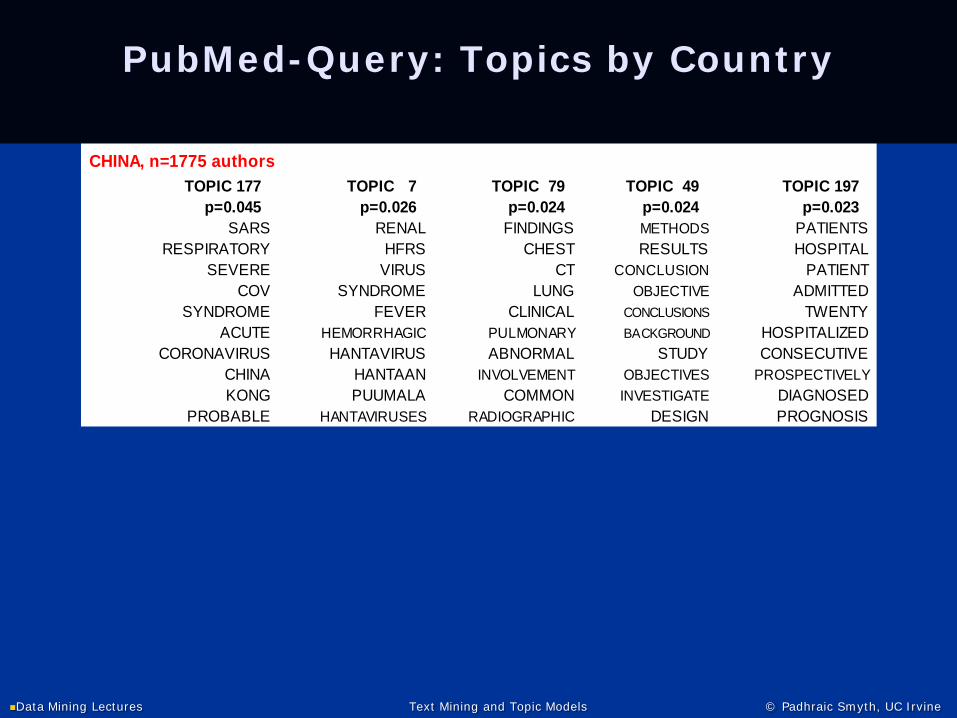
CHINA, n=1775 authors TOPIC 177 TOPIC 7 TOPIC 79 TOPIC 49 TOPIC 197
p=0.045 p=0.026 p=0.024 p=0.024 p=0.023 SARS RENAL FINDINGS METHODS PATIENTS
RESPIRATORY HFRS CHEST RESULTS HOSPITAL SEVERE VIRUS CT CONCLUSION PATIENT
COV SYNDROME LUNG OBJECTIVE ADMITTED SYNDROME FEVER CLINICAL CONCLUSIONS TWENTY
ACUTE HEMORRHAGIC PULMONARY BACKGROUND HOSPITALIZED CORONAVIRUS HANTAVIRUS ABNORMAL STUDY CONSECUTIVE
CHINA HANTAAN INVOLVEMENT OBJECTIVES PROSPECTIVELY KONG PUUMALA COMMON INVESTIGATE DIAGNOSED
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
POTENTIAL MEDICAL NATIONAL SKIN MANAGEMENT
ATTACK VICTIMS COMMUNITY EXPOSED TRAINING CHEMICAL TRAUMA INFORMATION AGENT EVENTS
WARFARE BLAST PREVENTION EPIDERMAL BIOTERRORISM ANTHRAX VETERANS LOCAL DAMAGE LOCAL
CHINA, n=1775 authors TOPIC 177 TOPIC 7 TOPIC 79 TOPIC 49 TOPIC 197
p=0.045 p=0.026 p=0.024 p=0.024 p=0.023 SARS RENAL FINDINGS METHODS PATIENTS
RESPIRATORY HFRS CHEST RESULTS HOSPITAL SEVERE VIRUS CT CONCLUSION PATIENT
COV SYNDROME LUNG OBJECTIVE ADMITTED SYNDROME FEVER CLINICAL CONCLUSIONS TWENTY
ACUTE HEMORRHAGIC PULMONARY BACKGROUND HOSPITALIZED CORONAVIRUS HANTAVIRUS ABNORMAL STUDY CONSECUTIVE
CHINA HANTAAN INVOLVEMENT OBJECTIVES PROSPECTIVELY KONG PUUMALA COMMON INVESTIGATE DIAGNOSED
PROBABLE HANTAVIRUSES RADIOGRAPHIC DESIGN PROGNOSIS
PubMed-Query: Topics by Country
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
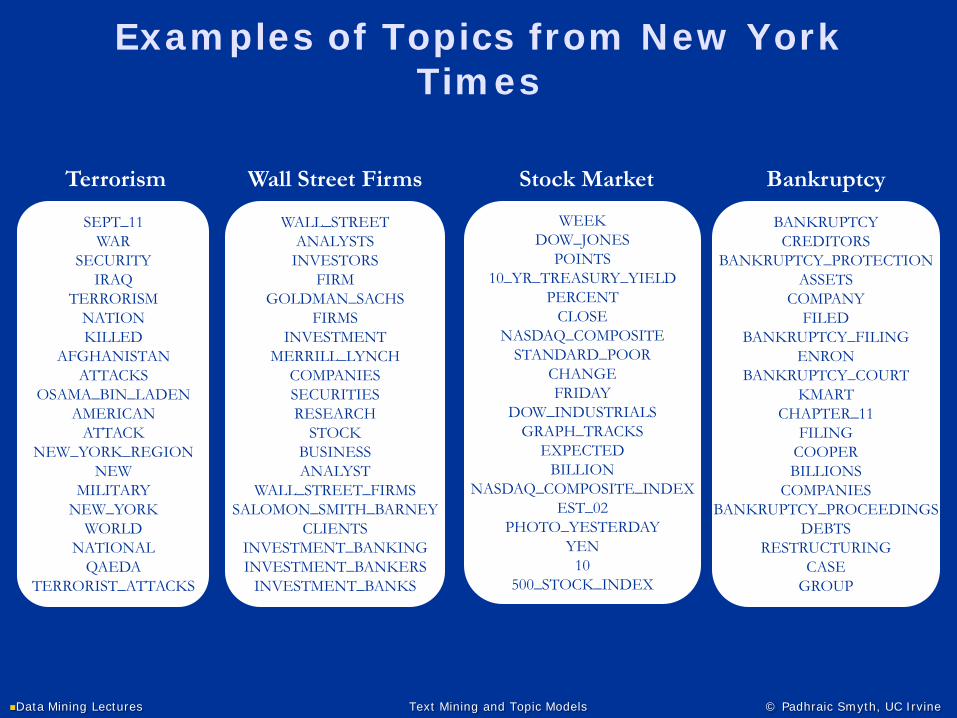
Examples of Topics from New York Times
WEEKDOW_JONES
POINTS10_YR_TREASURY_YIELD
PERCENTCLOSE
NASDAQ_COMPOSITESTANDARD_POOR
CHANGEFRIDAY
DOW_INDUSTRIALSGRAPH_TRACKS
EXPECTEDBILLION
NASDAQ_COMPOSITE_INDEXEST_02
PHOTO_YESTERDAYYEN
10500_STOCK_INDEX
WALL_STREETANALYSTS
INVESTORSFIRM
GOLDMAN_SACHSFIRMS
INVESTMENTMERRILL_LYNCH
COMPANIESSECURITIESRESEARCH
STOCKBUSINESSANALYST
WALL_STREET_FIRMSSALOMON_SMITH_BARNEY
CLIENTSINVESTMENT_BANKINGINVESTMENT_BANKERS
INVESTMENT_BANKS
SEPT_11WAR
SECURITYIRAQ
TERRORISMNATIONKILLED
AFGHANISTANATTACKS
OSAMA_BIN_LADENAMERICAN
ATTACKNEW_YORK_REGION
NEWMILITARY
NEW_YORKWORLD
NATIONALQAEDA
TERRORIST_ATTACKS
BANKRUPTCYCREDITORS
BANKRUPTCY_PROTECTIONASSETS
COMPANYFILED
BANKRUPTCY_FILINGENRON
BANKRUPTCY_COURTKMART
CHAPTER_11FILING
COOPERBILLIONS
COMPANIESBANKRUPTCY_PROCEEDINGS
DEBTSRESTRUCTURING
CASEGROUP
Terrorism Wall Street Firms Stock Market Bankruptcy
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
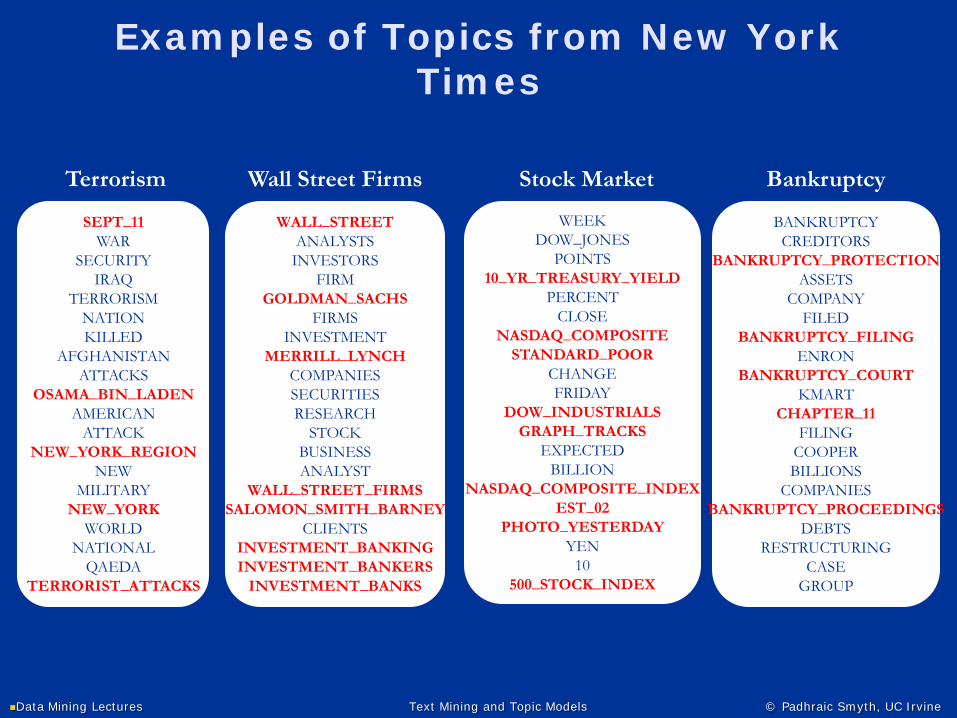
Examples of Topics from New York Times
WEEKDOW_JONES
POINTS10_YR_TREASURY_YIELD
PERCENTCLOSE
NASDAQ_COMPOSITESTANDARD_POOR
CHANGEFRIDAY
DOW_INDUSTRIALSGRAPH_TRACKS
EXPECTEDBILLION
NASDAQ_COMPOSITE_INDEXEST_02
PHOTO_YESTERDAYYEN
10500_STOCK_INDEX
WALL_STREETANALYSTS
INVESTORSFIRM
GOLDMAN_SACHSFIRMS
INVESTMENTMERRILL_LYNCH
COMPANIESSECURITIESRESEARCH
STOCKBUSINESSANALYST
WALL_STREET_FIRMSSALOMON_SMITH_BARNEY
CLIENTSINVESTMENT_BANKINGINVESTMENT_BANKERS
INVESTMENT_BANKS
SEPT_11WAR
SECURITYIRAQ
TERRORISMNATIONKILLED
AFGHANISTANATTACKS
OSAMA_BIN_LADENAMERICAN
ATTACKNEW_YORK_REGION
NEWMILITARY
NEW_YORKWORLD
NATIONALQAEDA
TERRORIST_ATTACKS
BANKRUPTCYCREDITORS
BANKRUPTCY_PROTECTIONASSETS
COMPANYFILED
BANKRUPTCY_FILINGENRON
BANKRUPTCY_COURTKMART
CHAPTER_11FILING
COOPERBILLIONS
COMPANIESBANKRUPTCY_PROCEEDINGS
DEBTSRESTRUCTURING
CASEGROUP
Terrorism Wall Street Firms Stock Market Bankruptcy
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
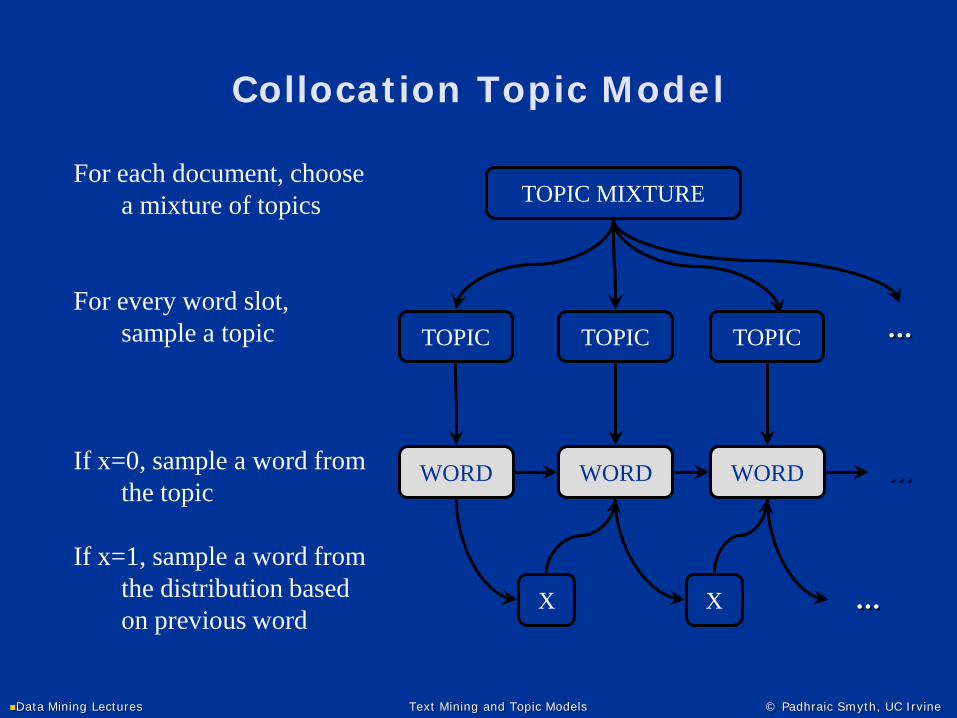
TOPIC MIXTURE
TOPIC
WORD
X
TOPIC
WORD
X
TOPIC
WORD
For each document, choose a mixture of topics
For every word slot, sample a topic
If x=0, sample a word from the topic
If x=1, sample a word from the distribution based on previous word
...
...
...
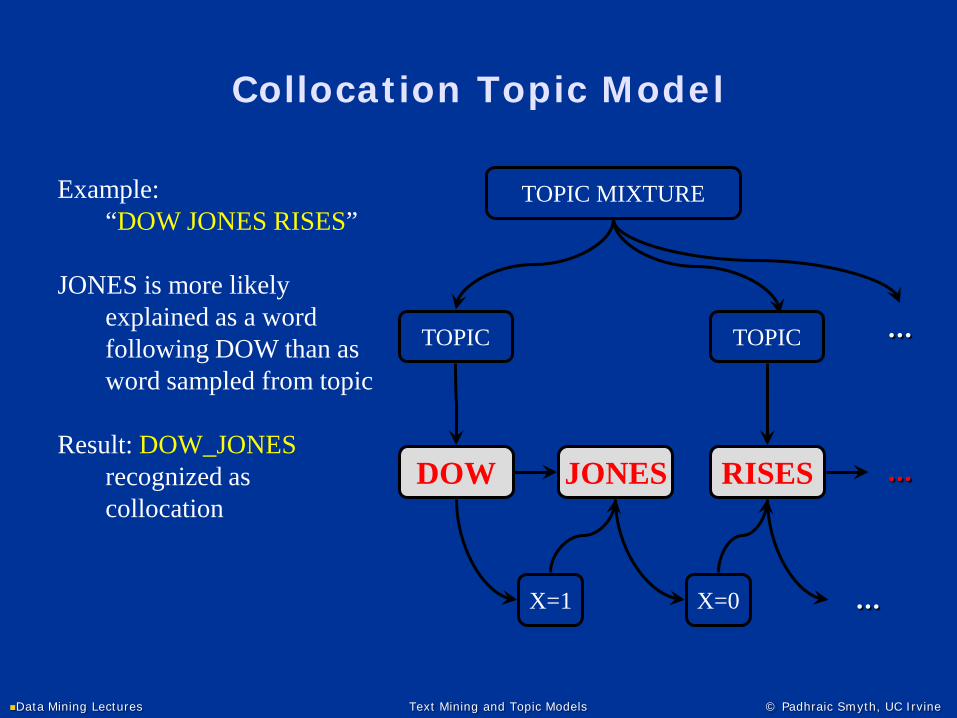
Collocation Topic Model
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
TOPIC MIXTURE
TOPIC
DOW
X=1
JONES
X=0
TOPIC
RISES
Example: “DOW JONES RISES”
JONES is more likely explained as a word following DOW than as word sampled from topic
Result: DOW_JONESrecognized as collocation
...
...
...
Collocation Topic Model
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
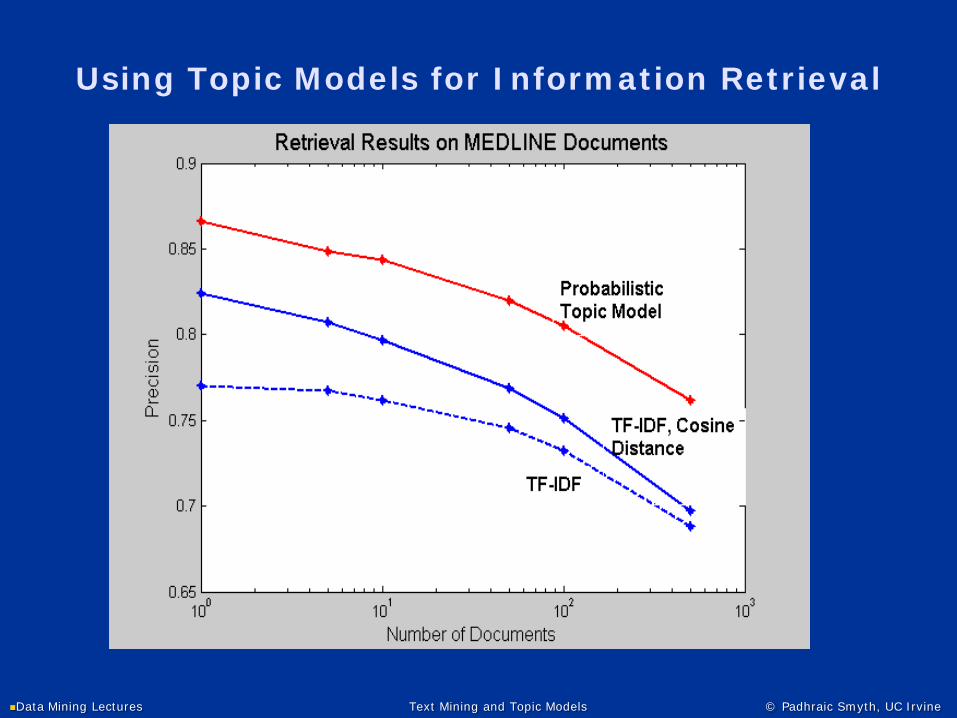
Using Topic Models for Information Retrieval

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Stability of Topics
• Content of topics is arbitrary across runs of model(e.g., topic #1 is not the same across runs)
• However, • Majority of topics are stable over processing time• Majority of topics can be aligned across runs
• Topics appear to represent genuine structure in data

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
20 40 60 80 100
10
20
30
40
50
60
70
80
90
1002
4
6
8
10
12
14
16
Comparing NIPS topics from the same Markov chain
KL
dist
ance
topics at t1=1000
Re-o
rder
ed to
pics
at t
2=20
00BEST KL = 0.54
WORST KL = 4.78
ANALOG .043 ANALOG .044CIRCUIT .040 CIRCUIT .040
CHIP .034 CHIP .037CURRENT .025 VOLTAGE .024VOLTAGE .023 CURRENT .023
VLSI .022 VLSI .023INPUT .018 OUTPUT .022
OUTPUT .018 INPUT .019CIRCUITS .015 CIRCUITS .015
FIGURE .014 PULSE .012PULSE .012 SYNAPSE .012
SYNAPSE .011 SILICON .011SILICON .011 FIGURE .010
CMOS .009 CMOS .009MEAD .008 GATE .009
t1 t2
FEEDBACK .040 ADAPTATION .051ADAPTATION .034 FIGURE .033
CORTEX .025 SIMULATION .026REGION .016 GAIN .025FIGURE .015 EFFECTS .016
FUNCTION .014 FIBERS .014BRAIN .013 COMPUTATIONAL .014
COMPUTATIONAL .013 EXPERIMENT .014FIBER .012 FIBER .013
FIBERS .011 SITES .012ELECTRIC .011 RESULTS .012
BOWER .010 EXPERIMENTS .012FISH .010 ELECTRIC .011
SIMULATIONS .009 SITE .009CEREBELLAR .009 NEURO .009
t1 t2

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
20 40 60 80 100
10
20
30
40
50
60
70
80
90
1002
4
6
8
10
12
14
16
Comparing NIPS topics from two different Markov chains
KL
dist
ance
topics from chain 1
Re-o
rder
ed to
pics
from
cha
in 2
BEST KL = 1.03
MOTOR .041 MOTOR .040TRAJECTORY .031 ARM .030
ARM .027 TRAJECTORY .030HAND .022 HAND .024
MOVEMENT .022 MOVEMENT .023INVERSE .019 INVERSE .021
DYNAMICS .019 JOINT .021CONTROL .018 DYNAMICS .018
JOINT .018 CONTROL .015POSITION .017 POSITION .015
FORWARD .014 FORWARD .015TRAJECTORIES .014 FORCE .014
MOVEMENTS .013 TRAJECTORIES .013FORCE .012 MOVEMENTS .012
MUSCLE .011 CHANGE .010
Chain 1 Chain 2

Outline
• Background on statistical text modeling
• Unsupervised learning from text documents• Motivation• Topic model and learning algorithm• Results
• Extensions• Author-topic models
• Applications• Demo of topic browser
• Future directions

Approach
• The author-topic model• extension of the topic model: linking authors and topics
• authors -> topics -> words
• learned from data • completely unsupervised, no labels
• generative model• Different questions or queries can be answered by
appropriate probability calculus• E.g., p(author | words in document)• E.g., p(topic | author)

Graphical Model
x
z
Author
Topic

Graphical Model
x
z
w
Author
Topic
Word

Graphical Model
x
z
w
Author
Topic
Word
n
Graphical Model
x
z
w
a
Author
Topic
Word
Dn
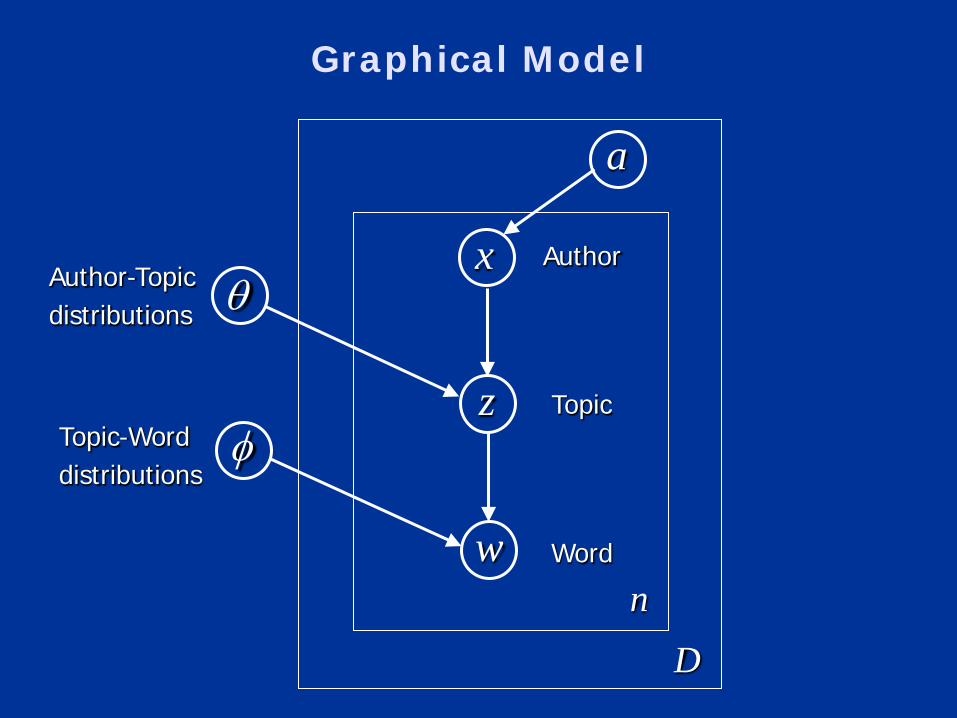
Graphical Model
x
z
w
a
Author
Topic
Word
θ
φ
Author-Topicdistributions
Topic-Worddistributions
Dn

Generative Process
• Let’s assume authors A1 and A2 collaborate and produce a paper• A1 has multinomial topic distribution θ1
• A2 has multinomial topic distribution θ2
• For each word in the paper:
1. Sample an author x (uniformly) from A1, A2
2. Sample a topic z from θX
3. Sample a word w from a multinomial topic distribution φz
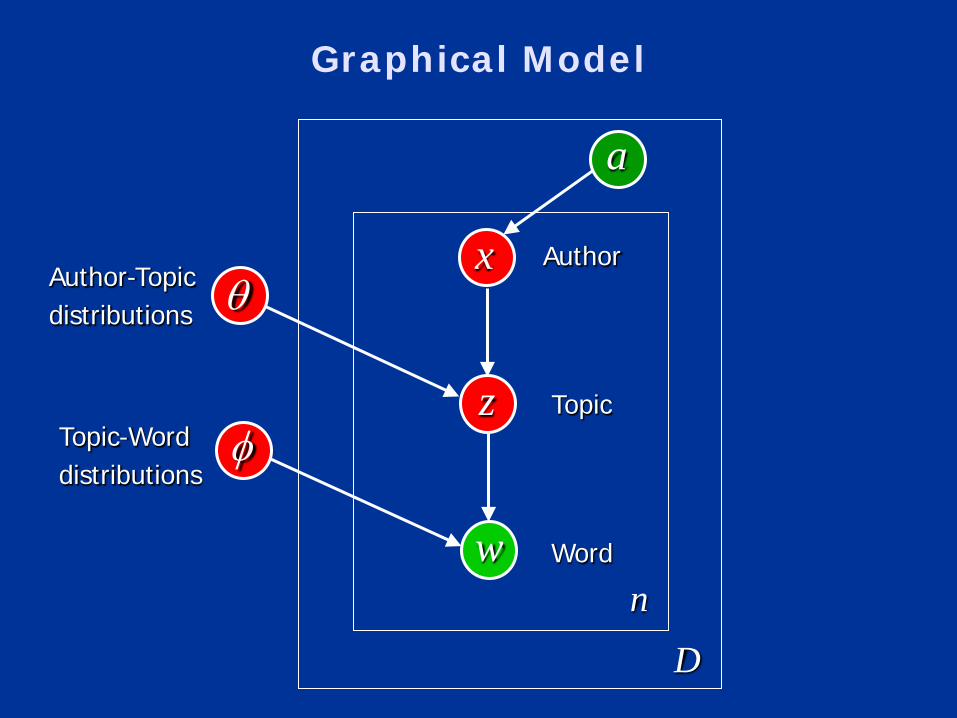
Graphical Model
x
z
w
a
Author
Topic
Word
θ
φ
Author-Topicdistributions
Topic-Worddistributions
Dn

Learning
• Observed• W = observed words, A = sets of known authors
• Unknown• x, z : hidden variables• Θ, φ : unknown parameters
• Interested in:• p( x, z | W, A) • p( θ , φ | W, A)
• But exact learning is not tractable
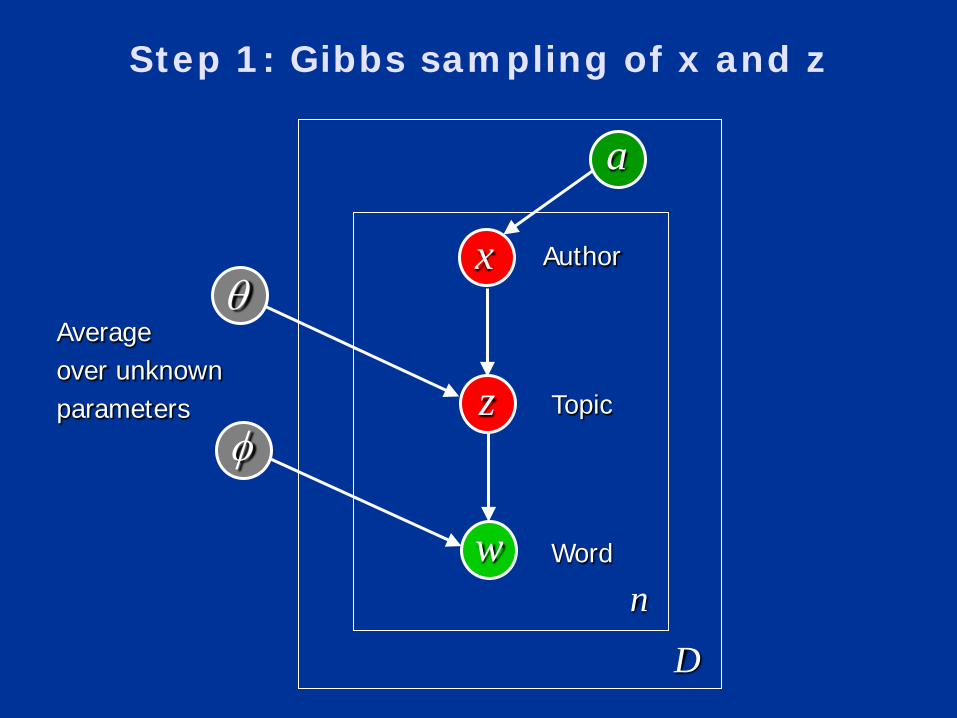
Step 1: Gibbs sampling of x and z
x
z
w
a
Author
Topic
Word
θ
φ
Dn
Averageover unknownparameters
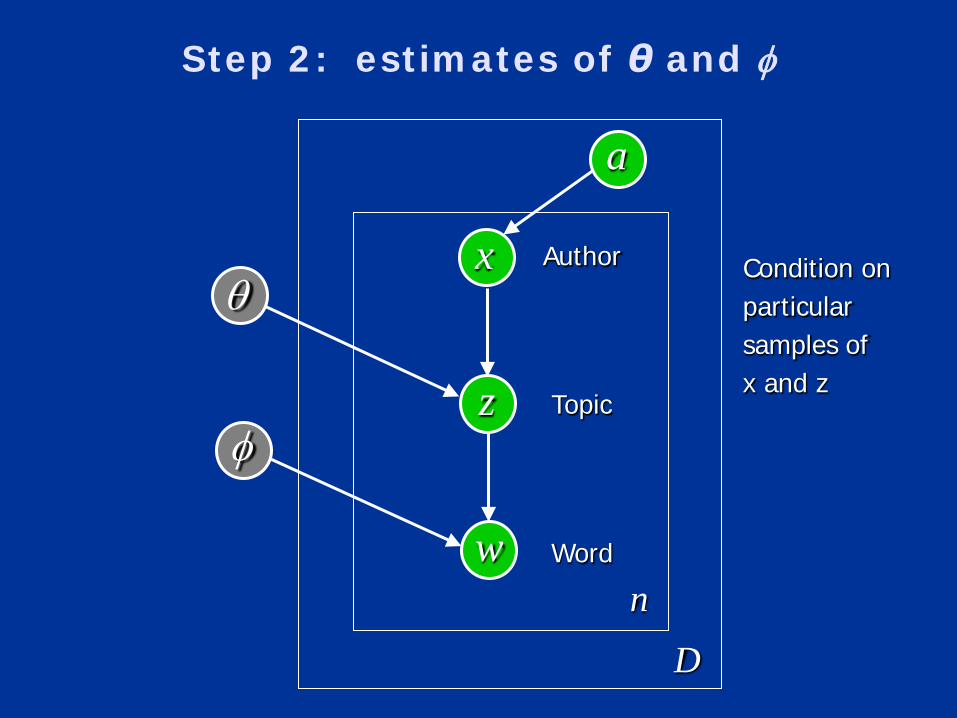
Step 2: estimates of θ and φ
x
z
w
a
Author
Topic
Word
θ
φ
Dn
Condition onparticular samples ofx and z

Gibbs Sampling
• Need full conditional distributions for variables
• The probability of assigning the current word i to topic j and author k given everything else:
number of times word w assigned to topic j
number of times topic j assigned to author k
∑∑ +
+
+
+∝=== −−−
' '' '
),,,,|,(j
ATkj
ATmj
mWT
jm
WTmj
diiiiii TCC
VCC
mwkxjzPα
αβ
βawxz
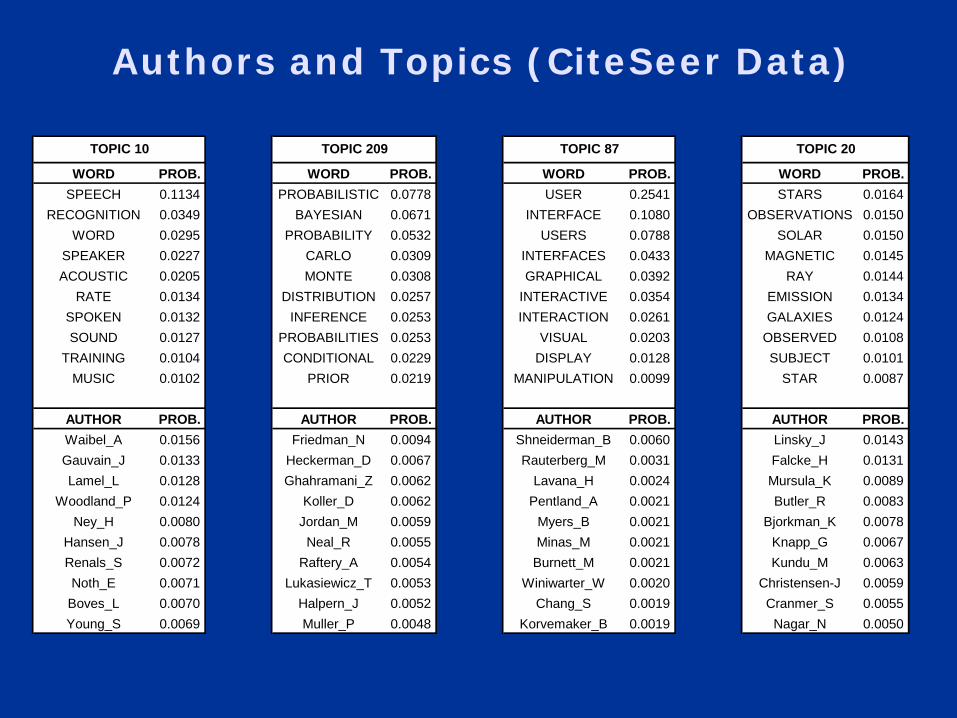
Authors and Topics (CiteSeer Data)
WORD PROB. WORD PROB. WORD PROB. WORD PROB.SPEECH 0.1134 PROBABILISTIC 0.0778 USER 0.2541 STARS 0.0164
RECOGNITION 0.0349 BAYESIAN 0.0671 INTERFACE 0.1080 OBSERVATIONS 0.0150WORD 0.0295 PROBABILITY 0.0532 USERS 0.0788 SOLAR 0.0150
SPEAKER 0.0227 CARLO 0.0309 INTERFACES 0.0433 MAGNETIC 0.0145ACOUSTIC 0.0205 MONTE 0.0308 GRAPHICAL 0.0392 RAY 0.0144
RATE 0.0134 DISTRIBUTION 0.0257 INTERACTIVE 0.0354 EMISSION 0.0134SPOKEN 0.0132 INFERENCE 0.0253 INTERACTION 0.0261 GALAXIES 0.0124SOUND 0.0127 PROBABILITIES 0.0253 VISUAL 0.0203 OBSERVED 0.0108
TRAINING 0.0104 CONDITIONAL 0.0229 DISPLAY 0.0128 SUBJECT 0.0101MUSIC 0.0102 PRIOR 0.0219 MANIPULATION 0.0099 STAR 0.0087
AUTHOR PROB. AUTHOR PROB. AUTHOR PROB. AUTHOR PROB.Waibel_A 0.0156 Friedman_N 0.0094 Shneiderman_B 0.0060 Linsky_J 0.0143Gauvain_J 0.0133 Heckerman_D 0.0067 Rauterberg_M 0.0031 Falcke_H 0.0131Lamel_L 0.0128 Ghahramani_Z 0.0062 Lavana_H 0.0024 Mursula_K 0.0089
Woodland_P 0.0124 Koller_D 0.0062 Pentland_A 0.0021 Butler_R 0.0083Ney_H 0.0080 Jordan_M 0.0059 Myers_B 0.0021 Bjorkman_K 0.0078
Hansen_J 0.0078 Neal_R 0.0055 Minas_M 0.0021 Knapp_G 0.0067Renals_S 0.0072 Raftery_A 0.0054 Burnett_M 0.0021 Kundu_M 0.0063Noth_E 0.0071 Lukasiewicz_T 0.0053 Winiwarter_W 0.0020 Christensen-J 0.0059
Boves_L 0.0070 Halpern_J 0.0052 Chang_S 0.0019 Cranmer_S 0.0055Young_S 0.0069 Muller_P 0.0048 Korvemaker_B 0.0019 Nagar_N 0.0050
TOPIC 10 TOPIC 209 TOPIC 87 TOPIC 20

Some likely topics per author (CiteSeer)
• Author = Andrew McCallum, U Mass:• Topic 1: classification, training, generalization, decision, data,…• Topic 2: learning, machine, examples, reinforcement, inductive,…..• Topic 3: retrieval, text, document, information, content,…
• Author = Hector Garcia-Molina, Stanford:- Topic 1: query, index, data, join, processing, aggregate….- Topic 2: transaction, concurrency, copy, permission, distributed….- Topic 3: source, separation, paper, heterogeneous, merging…..
• Author = Paul Cohen, USC/ISI:- Topic 1: agent, multi, coordination, autonomous, intelligent….- Topic 2: planning, action, goal, world, execution, situation…- Topic 3: human, interaction, people, cognitive, social, natural….

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Finding unusual papers for an author
Perplexity = exp [entropy (words | model) ]
= measure of surprise for model on data
Can calculate perplexity of unseen documents, conditioned on the model for a particular author

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Papers and Perplexities: M_Jordan
Factorial Hidden Markov Models 687
Learning from Incomplete Data 702

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Papers and Perplexities: M_Jordan
Factorial Hidden Markov Models 687
Learning from Incomplete Data 702
MEDIAN PERPLEXITY 2567

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Papers and Perplexities: M_Jordan
Factorial Hidden Markov Models 687
Learning from Incomplete Data 702
MEDIAN PERPLEXITY 2567
Defining and Handling Transient Fields in Pjama
14555
An Orthogonally Persistent JAVA 16021

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Papers and Perplexities: T_Mitchell
Explanation-based Learning for Mobile Robot Perception
1093
Learning to Extract Symbolic Knowledge from the Web
1196

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Papers and Perplexities: T_Mitchell
Explanation-based Learning for Mobile Robot Perception
1093
Learning to Extract Symbolic Knowledge from the Web
1196
MEDIAN PERPLEXITY 2837

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Papers and Perplexities: T_Mitchell
Explanation-based Learning for Mobile Robot Perception
1093
Learning to Extract Symbolic Knowledge from the Web
1196
MEDIAN PERPLEXITY 2837
Text Classification from Labeled and Unlabeled Documents using EM
3802
A Method for Estimating Occupational Radiation Dose…
8814

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Who wrote what?
A method1 is described which like the kernel1 trick1 in support1 vector1 machines1 SVMs1 lets us generalizedistance1 based2 algorithms to operate in feature1 spaces usually nonlinearly related to the input1 spaceThis is done by identifying a class of kernels1 which can be represented as norm1 based2 distances1 in Hilbert spaces It turns1 out that common kernel1 algorithms such as SVMs1 and kernel1 PCA1 are actually really distance1 based2 algorithms and can be run2 with that class of kernels1 too As well as providing1 a useful new insight1 into how these algorithms work the present2 work can form the basis1 for conceivingnew algorithms
This paper presents2 a comprehensive approach for model2 based2 diagnosis2 which includes proposals for characterizing and computing2 preferred2 diagnoses2 assuming that the system2 description2 is augmentedwith a system2 structure2 a directed2 graph2 explicating the interconnections between system2
components2 Specifically we first introduce the notion of a consequence2 which is a syntactically2
unconstrained propositional2 sentence2 that characterizes all consistency2 based2 diagnoses2 and show2
that standard2 characterizations of diagnoses2 such as minimal conflicts1 correspond to syntactic2
variations1 on a consequence2 Second we propose a new syntactic2 variation on the consequence2 known as negation2 normal form NNF and discuss its merits compared to standard variations Third we introduce a basic algorithm2 for computing consequences in NNF given a structured system2 description We show that if the system2 structure2 does not contain cycles2 then there is always a linear size2 consequence2 in NNF which can be computed in linear time2 For arbitrary1 system2 structures2 we show a precise connectionbetween the complexity2 of computing2 consequences and the topology of the underlying system2
structure2 Finally we present2 an algorithm2 that enumerates2 the preferred2 diagnoses2 characterized by a consequence2 The algorithm2 is shown1 to take linear time2 in the size2 of the consequence2 if the preference criterion1 satisfies some general conditions
Written by(1) Scholkopf_B
Written by(2) Darwiche_A
Test of model: 1) artificially combine abstracts from different authors 2) check whether assignment is to correct original author

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
The Author-Topic Browser Querying on
author Pazzani_M
Querying on topic relevant to author
Querying on document written
by author
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Comparing Predictive Power
• Train models on part of a new document and predict remaining words
0 1 4 16 64 256
1024
Perp
lexi
ty (n
ew w
ords
)
2000
4000
6000
8000
10000
12000
14000
# Observed words in document
Author model
Topics model
Author-Topics

Outline
• Background on statistical text modeling
• Unsupervised learning from text documents• Motivation• Topic model and learning algorithm• Results
• Extensions• Author-topic models
• Applications• Demo of topic browser
• Future directions

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
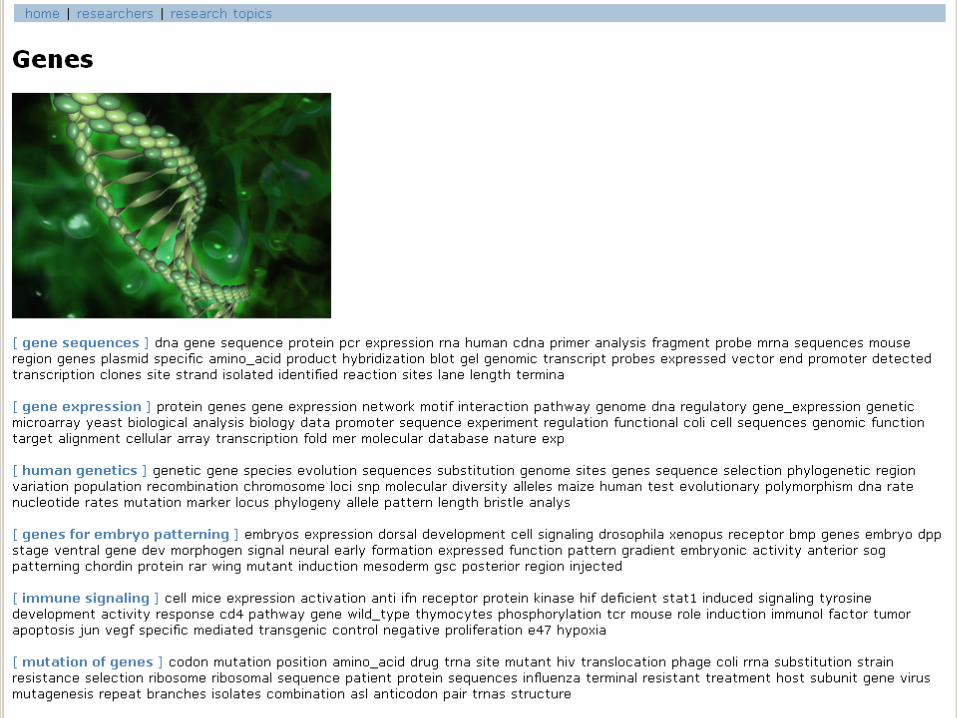
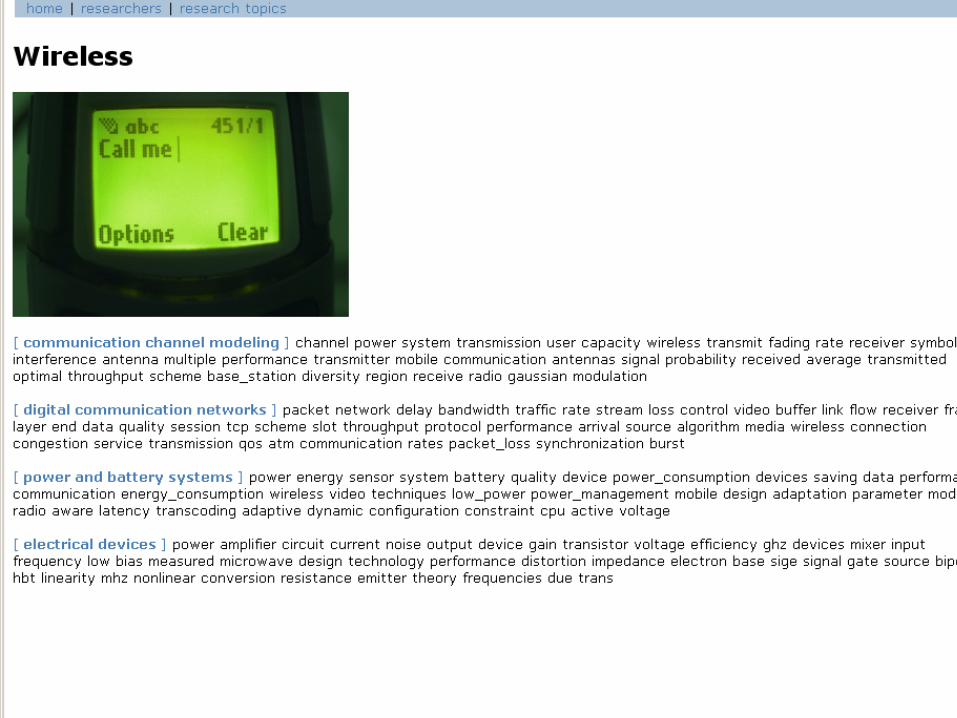
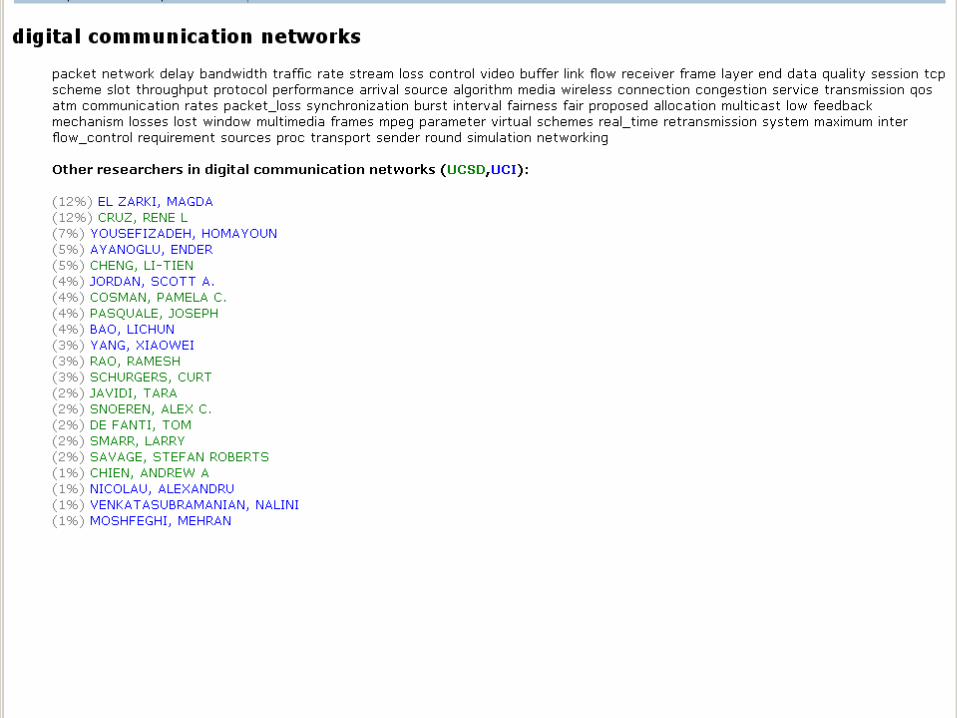
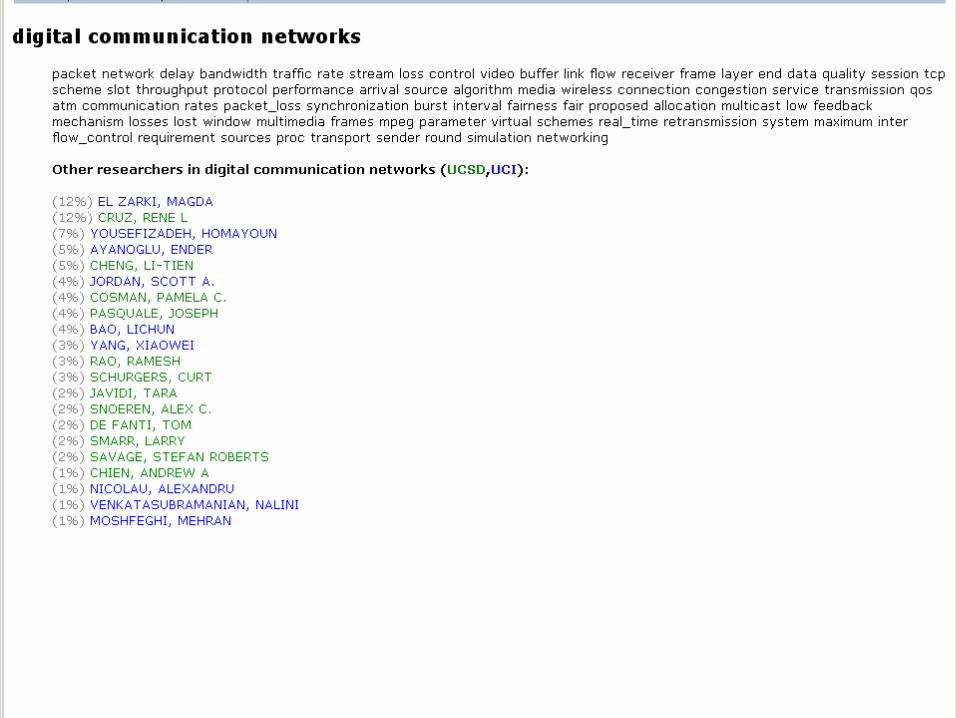
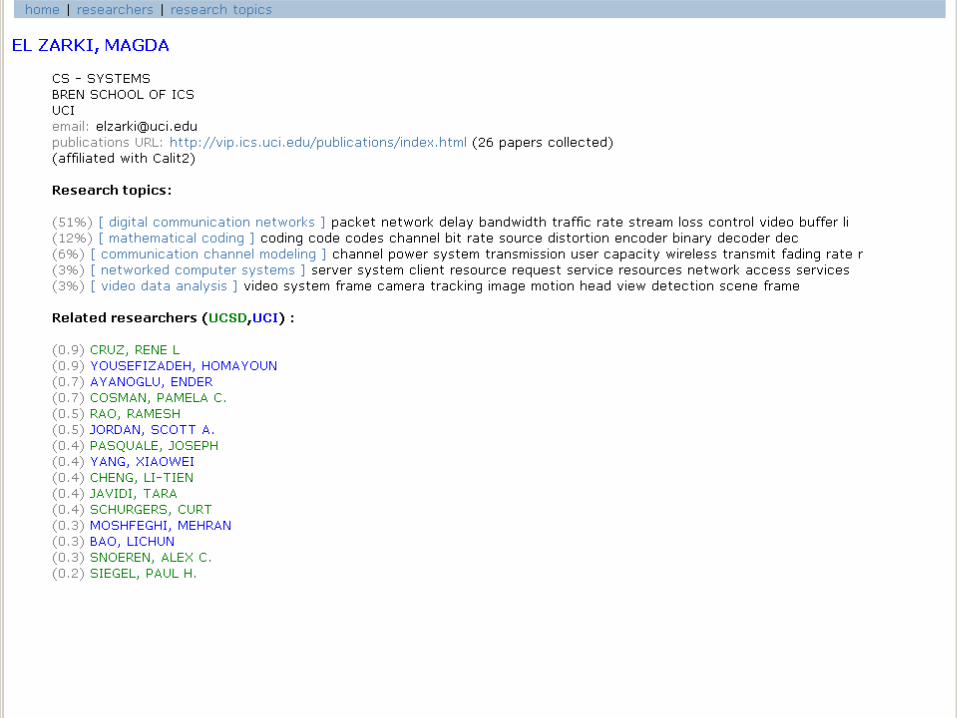
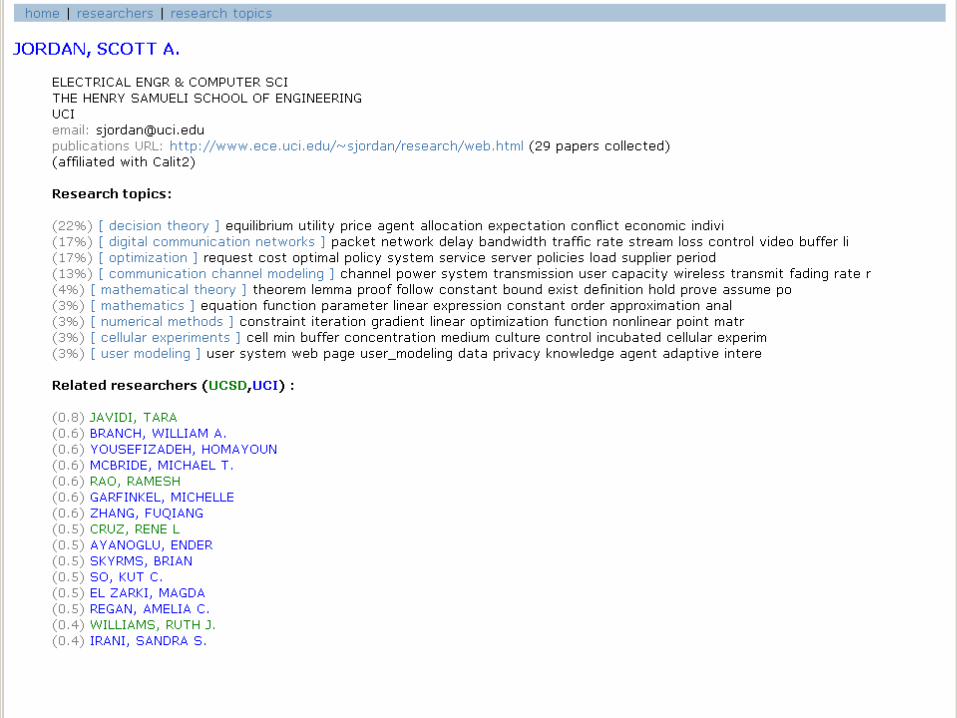
Online Demonstration of Topic Browserfor UCI and UCSD Faculty

Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine
Data Mining Lectures Text Mining and Topic Models © Padhraic Smyth, UC Irvine





























