Embed Size (px)
Citation preview

The Effect of Collection Organization and Query Locality on IR Performance
2003/07/28
Park, Dae-Won([email protected])

Contents
Introduction of Distributed IR Related Works System Architecture Query Locality Experiments Conclusions

Introduction(1)
Distributed IR System 연구 목적
Content 증가에 따른 검색 성능의 유지 향상 Decrease query response time, maintain effectiven
ess 관련 연구
Caching ( Martin and Russell,1991; Markatos,1999) Collection selection ( Voorhees,1995; Callan,1995; Frenc
h,1999; Xu and Croft, 1999) Partial replication (Lu and Mackinley, 1999)

Introduction(2)
In this paper Use previous works
Collection selection, partial replication Use collection organization
Determine when and how to use collection selection and replication
Classify collection organizations as either by topic, source, or random

Related Works
Architecture IR versus database systems Unstructured data versus structured data
IR versus the web Static collection : case law, journal articles,,,
Caching Collection selection

Related Works : Architecture(1)
architecture for parallel and distributed IRHarman et al.,1991
Show the feasibility of a distributed IR system by developing a prototype architecture
Burkowski,1990, Burkowski et al., 1995 Simulation study which measures the retrieval performance o
f a distributed IR system Two strategies for distributing a fixed workload
Equally distribute the text collection Split servers into query evaluation group and document retrieval

Related Works : Architecture(2)
Couvreur et al.,1994 Analyze the performance and cost factors Three different hardware architectures
Hawking,1997 Design and implement a parallel IR system, PADRE
97, on a collection of workstations Central process : check user command, broadcast to the
IR engines and merge results

Related Works : Architecture(3)
Cahoon and Mckinley,1996 & Cahoon,1999 Distributed IR system based on INQUERY Collection
Uniformly distributed Up to 128GB using a variety of workloads
Measure performance as a function of system parameters such as client command rate, number of document collections, , ,

Related Works : Caching
Markatos, 1999 Caches web queries and their results
Require exact match ( 단점 ) Increase locality by determining query similarity to replica
s

Related Works : Collection selection(1)
Working on how to select the most relevant collection for a given query Danzig et al., 1991
Use a hierarchy of brokers to maintain indices Support Boolean keyword matching
Voorhees et al., 1995 Exploit similarity between a new query and relevance judg
ments for previous queries

Related Works : Collection selection(2)
Callan et al., 1995 Adapt the document inference network to ranking collecti
ons by replacing the document node with the collection node
Store the collection ranking inference network with document frequencies and term frequencies
Xu an Croft, 1999 Propose cluster-based language model for collection sele
ction Apply clustering algorithms to organize document into coll
ections based on topics, and then apply the approach of Callan et al.,1995 to select the most relevant collections

System Architecture(1)
Architecture for a distributed information retrieval system base on INQUERY
Client 1
Client 2
Client 3
Client m
Connection Broker
INQUERY Server 1
INQUERY Server 2
INQUERY Server 3
Collections
INQUERY Server n

System Architecture(2)
use collection selector
Client 1
Client 2
Client 3
Client m
Connection Broker
Collection Selector
INQUERY Server 1
INQUERY Server 2
INQUERY Server 3
Collections
INQUERY Server n
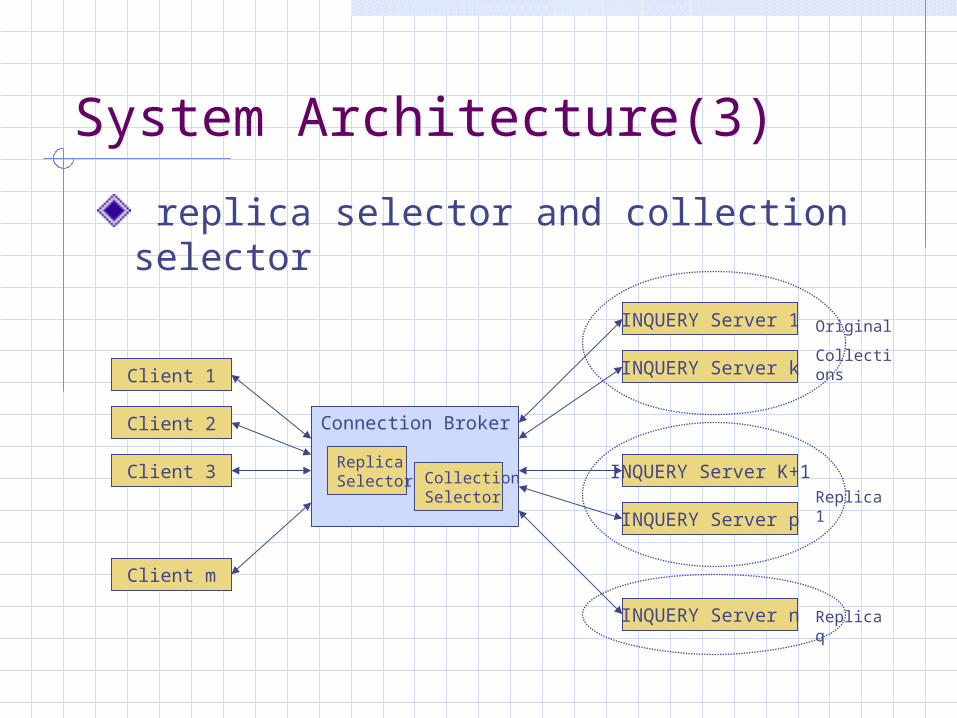
System Architecture(3)
replica selector and collection selector
Client 1
Client 2
Client 3
Client m
Connection Broker
Replica Selector Collection
Selector
INQUERY Server 1
INQUERY Server k
Original
Collections
INQUERY Server K+1
INQUERY Server pReplica 1
INQUERY Server n Replica q

System Architecture(4)
Collection Set of documents No overlaps between documents in any two
collections Organized either by topic, source(for
example, newspaper, journals,,, ), or randomly
Connection Brokers A process that keeps track of all registered
clients and INQUERY servers

System Architecture(5)
Connection Brokers A process that keeps track of all registered
clients and INQUERY servers Forward command to the appropriate servers Maintain intermediate result
Merge result with other results Send the final result to the client

System Architecture(6)
Collection selector Choose the most relevant collections from
some set of collections on a query-by-query basis
Maintain a collection selection database with collection level information for each collection

System Architecture(7)
Replica selector Replicate a portion of the original collection
(if the same or related queries repeat) Build a partial replica for the whole
Subset of the original collection

Collection Organization
Collection access skew When queries are relevant to a few collections and
collection selection concentrates queries in these collections
Model using a Zipf-like function Z(i) = c/i1-, where c=1/ (1/j1-), 1 <= i <= C

Query Locality
If users repeatedly issue queries on the same topics, a set of document will receive more hits, which results in query locality Partial replication off-load the services on
original collections Correlation with collection access skew
If query locality is low, collections accessed uniformly
If query locality is high, collection access may range from uniform to highly skewed

Experiments(1)
Demonstrate the performance impact of collection organization and query locality256 GB of data using 9 servers 8 servers : store the original collections 9th server : store 32 GB partial replica or
partition the data further
Include collection selector and replica selector in the connection broker

Experiments(2)
Random Organization(1) Randomly partition data over collections

Experiments(3)
Random Organization(2) Randomly partition data over collections

Experiments(4)
Source Organization Collections are organized by source

Experiments(5)
Source Organization Collections are organized by source

Experiments(6)
Topic organization Collections are organized by source

Experiments(7)
Topic organization Collections are organized by source

Conclusions
Effect of query locality and collection organization on the design and performance of IR system Collection selection improves performance
significantly when either collection access is fairly uniform or collections are organized based on topics
Query locality enables partial replication to improve performance over collection selection with partitioning





























