Embed Size (px)
Citation preview

The W W W: History, Hypertext,
Implementation, Interface(s), and Contemporary Design
Lynch and Horton, Web Style Guide 3nd Ed.,http://www.webstyleguide.com/wsg3/
Nielsen, useit.com

Overview
• The Internet-based world wide web in historical context– Among the most profound changes of recent centuries
• Human culture always “information based”, … and now is, as any time, interesting
– But, ideas of WWW not new ideas ... and where they came from (intellectually) can be useful to determine where it might go … as in, the lessons of history …
• The first graphic user interface for WWW changed everything– Interns’ summer project
• Web site design - the interface to the WWW • Essentially omitted by Shneiderman & Plaisant text
– Differences between interface design for stand alone systems and for the web– Principles of interface design applied– Some elements:
• Information architecture, • Pages, • Site use and navigation, • Empirical studies

An Information Based Description of the History of Civilization
• But, first …
• Call it “computing in the anthropologic context …”
• Much of what follows, is toward the end of understanding the past … to understand the present … to predict-imagine-invent the future …

An Information Based Description of the History of Civilization
• But, first …
• Call it “computing in the anthropologic context …”
• Much of what follows, is toward the end of understanding the past … to understand the present … to predict-imagine-invent the future …
• To help humanity, find fame

An Information Based Description of the History of Civilization
• But, first …
• Call it “computing in the anthropologic context …”
• Much of what follows, is toward the end of understanding the past … to understand the present … to predict-imagine-invent the future …
• To help humanity, find fame
• Or patent it and find fortune

An Information Based Description of the History of Civilization
• Will/have computers provide the enabling technology for a “new renaissance”?
– i.e., will/have computers enable a qualitative change in the nature of history and culture and …?
– The New Renaissance: Computers and the Next Level of Civilization• Douglas S. Robertson, Oxford University Press, 1998
• Based on idea that change/discontinuities occur at certain points, often technologically enabled
– E.g., war and nuclear weapons
• Focus, here, is on amount of information available to an individual

An Information Based Description of the History of Civilization
• 5 broad categories of civilization – Differ principly (or at least among other things) by method used to store
and handle information– “Quantum leaps” for each categories
• The Categories:– Level 0 - Pre-Language– Level 1 - Language– Level 2 - Writing– Level 3 - Printing– Level 4 – Computers
• Will estimate amount of information stored for each category– Uses metric for n bits / character, then n chars / word, then n words stored, and
available to an individual• But, any number of metrics might be used

An Information Based Description of the History of Civilization
• Level 0 - Pre-Language - 107 bits of information– Perhaps most difficult to evaluate is the smallest quantity of information– Lacking language, individual essentially limited to contents of own mind– Lower bound might be set by noting that epic poems such as the Iliad,
– which contain abut 5 million bits have been memorized
• Level 1- Language - 109 bits of information– … plus the information content of the rest of the village, clan, or tribe
• perhaps 50 to 1,000 times individual• i.e., the number of people to whom an individual can talk
– and each of whom is an “information repository”• Estimates take into account redundancy of information

An Information Based Description of the History of Civilization
• Level 2 – Writing - 1011 bits of information– Total of recorded (hand-written) information
– Greatest accumulation in library of Alexandria • 532,000 scrolls in 3rd century B.C.
– Rough estimate of information content• Iliad and Odyssey were divided into twenty four
books each – if Iliad contains 5m bits, and 1/24 size of scroll, – Then, Alexandria about 100 billion bits 1011 bits
• Level 3 - Printing - 1017 bits of information– Total of printed information
– Hundreds of libraries larger than Alexandria– Information so vast individual can’t comprehend
• daily output can exceed individual’s
comprehension

An Information Based Description of the History of Civilization
• Level 4 – Computers - 1021 bits of information– Total of electronically recorded information
• Amount of printed information relatively trivial in comparison to total
– Accelerating rate of information production– Total amount of information relatively unimportant
• Level 3 exceeds an individual’s ability to use
– What’s new with computers is that:• “Computers multiply ability to find, analyze, and make
use of vast quantities of information, thereby circumventing the information limits that bedeviled Level 3 civilization”
• Information Increase far greater than increase associated with change from Level 2 to Level 3
– “Ability to easily find and utilize entire information stock of a civilization will be hallmark of a Level 4 civilization”
– … and how, exactly, would you do that?

Whew!

Hypertext, … and the W W W
• Hypertext– Once, a vision– Connections among information elements …resemble connections among ideas …
– Early 20th century examples (and probably Plato, too)– Doing it old-school, Bush’s (film-based) MEMEX– Berners-Lee, Internet, hypertext, www
• And a student project

BTW, …
• Hypertext– Once, a vision– Connections among information elements …resemble connections among ideas …

Overview
• Orienting ideas:– The www is “hypertext” … though of a limited form
• Connections among information elements that resemble connections among ideas …
• Early 20th century examples (and probably Plato, too)– Doing it old-school, e.g., Bush’s (film-based) MEMEX– Berners-Lee, Internet, hypertext, www
• And a student project
• Designing web sites:– Guidelines quite useful– Entails:
• Organization and access of information– Site design, information architecture, navigation
• Display of information– Page design

Organizing (and retrieving) Information
• Organizing (and retrieving) Information is a really old challenge …– As in library at Alexandria
• Even pre-electronic storage information structure has evolved– Scrolls books
• Essentially linear structure– Read more or less start to finish– Though structuring within books
• Table of contents, index, annotation, etc.
• Have been ideas and efforts to make printed form of information (words and pictures):
– More accessible– More like how people …
• Think• Use information and ideas
– Non-linear

World Wide Web = Hypertext
• Real “power” and interest in Internet only arose well after its implementation
– Just a system that works in nuclear warfare …– Relatively few people cared about ftp, bbs, …
• At least “few” compared to current use of WWW
• Interest and use of Internet arose only after:
1. Specification of WWW some decade after the network itself• i.e., how to go from one file/document to another via its address … the link
2. And then only with design of a graphic user interface for it!• Text-based browsers not too neat (at least to non-computer types)• How to “navigate” easily and with use of pictures/images/icons
• Essential idea of “navigation” among documents dates back much further
– Will see a few

Early Ideas about Non-Linear Information Organization
• Paul Otlet, 1895– A really big box of index cards
• H. G. Wells, 1938– “World Brain”
• Vannever Bush, 1945– Memex – memory extender
• J. C. R. Licklider, 1960– Man-computer symbiosis
• Doug Englebart, 1963– Augmentation of human intellect
• Ted Nelson, 1965– Coined term “hypertext”

Paul OtletUniversal Network for Information and Documentation, ~1880
• Founding father of information science– Universal Decimal Classification– Responsible for widespread use of 3x5 index cards
• Remember card catalogs?
• Universal Network for Information and Documentation
– All world’s knowledge interlinked and made available remotely
• Even without know exactly how …– Commercial service answering questions – Indexed information stored on cards in cabinets plus
original documents• 1895: 400,000 entries• 1934: 15,000,000
– All hardcopy and searchable!– Moved from original location with Germany’s invasion of
Belgium, taken to museum in 1993
• In fact somewhat different from hypertext, in that “associations”, or links, are derived from the classification

H. G. Wells“World Brain”, ~1930
• H. G. Wells, as in “War of the Worlds”– Also, a popularizer of science
• “World Brain” – More modestly, “World Encyclopedia”
• Or, at least, a global information system– Book of essays, 1938, when 72
• Audience of 5,000 at Northwestern University– Reprinted 1971, 1994
• "The Brain Organization of the Modern World" – "...a sort of mental clearing house for the mind, a depot
where knowledge and ideas are received, sorted, summarized, digested, clarified and compared."
– Automated system with microfilm suggested for storage medium
• “… any student, in any part of the world, will be able to sit with his projector in his own study at his or her convenience to examine any book, any document, in an exact replica."
• Perhaps, though, ideas were more related to notion of emergent intelligent systems …

Vannevar Bush MEMEX – Memory Extender, ~1940
• MIT professor 25 years, etc.– Claude Shannon (information theory) was student
• Roosevelt’s science advisor in WWII • Invented continuous intergraph, or
Differential Analyses– Essentially, Charles Babbage’s Difference Engine with shafts driven
by motors– Analog computing solutions to differential equations (gears, etc.)– Big and handmade

Bush's MEMEX, 1945
• "As We May Think", 1945– MEMory EXtender system– Atlantic Monthly!
• Problem: – “new knowledge not reaching the people
who would benefit from it”– Concerned about the explosion of
scientific literature which made it impossible even for specialists to follow developments in a field,
• Solution:– “A Memex is a device in which an
individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.”
– desk, slanting screens, buttons, levers, and keyboard
• “A memex looked like a desk with two pen-ready touch screen monitors and a scanner surface. It had several gigabytes of storage space filled with textual and graphic, indexed, information”

Bush's MEMEX, 1945
• Microfilm projectors for viewing different information
– uses mircofilm for storage – new material can be added via microfilm
or by direct entry via ‘‘dry photography''– supports indexing, cross referencing,
keywords .
• Supports indexing, cross referencing, keywords
– supports associative indexing via links and creation of ``trails'' which can later be followed
– allows annotations comments, and marginal notes .
– envisions multimedia i/o: other senses, such as, speech and audio
• Associative indexing– "The process of tying things together is
the important thing.“– New profession of ``trail blazing"– Trail building and trail following by user

J.C.R. (Lick) LickliderMan-Computer Symbiosis, ~1960
• “ManComputer Symbiosis”, 1960– “The hope is that, in not too many years, human brains and computing machines will be coupled together
very tightly and that the resulting partnership will think as no human brain has ever thought and process data in a way not approached by the informationhandling machines we know today.”
– A seminal paper
• “Galactic Network”, 1962– Papers at BBN envisioning networked computer– Vision of Internet
• Prerequisite to achieving mancomputer symbiosis – Immediate Goals:
• time sharing of computers among many users• interactive realtime system for information processing and retrieval• large scale information storage and retrieval • electronic i/o for display and communication of correlated symbolic and pictorial information
– Intermediate Goals: • facilitation of human cooperation in the design and programming of large systems• combined speech recognition, handprinted character recognition, and light pen editing
– Long Term Goals: • natural language understanding (syntax, semantics, pragmatics) • speech recognition of arbitrary computer users• heuristic programming

Douglas EngelbartAugmentation of Human Intellect, ~1960
• Turing Award, 1998
• Augmentation of human intellect (1963) – “... increasing the capability of man to approach a complex
problem situation, gain comprehension to suit his particular needs, and to derive solutions to problems.”
– Recognized his ideas built on Bush's idea of a machine that would aid human cognition
– hierarchical structures for ordinary documents– group creation and problem solving
• NLS System (1965 1968):– outline editors for idea development – hypertext linking – tele-conferencing, word processing, e-mail
• System required:– mouse pointing device for on-screen selection: Invented the mouse
(1965) as a replacement for light pens for use in his NLS system– a one-hand chording device for keyboard entry – full windowing software environment – on-line help systems– concept of consistency in user interfaces

Ted Nelson“Hypertext”, ~1960
• In 1965, Nelson coined the word "hypertext" (non-linear text) and defined it as: – “… a body of written or pictorial material
interconnected in a complex way that it could not be conveniently represented on paper."
• From Dream Machines – Describes hypergrams (branching pictures),
hypermaps (with transparent overlays), and branching movies
• Vision of a "docuverse" (document universe) – Extension of document ties that could combine
contributions from people with no formal ties – a global ‘‘docuverse''– "everything should be available to everyone. Any
user should be able to follow origins and links of material across boundaries of documents, servers, networks, and individual implementations. There should be a unified environment available to everyone providing access to this whole space." [Nelson, 1987]

The Internet and Non-Linear Information Organization
• History of Berners-Lee specification
• History of Mosaic

Invention of the WWW1990
• ARPANET, 1969 – then, NSFNET – then, Internet
– DOD sponsored distributed network with alternate routes to withstand nuclear attack
– Internet Protocol added, 1978
• Tim Berners-Lee– CERN
• Organisation européenne pour la recherche nucléaire
• European Organization for Nuclear Research
– 1980, ENQUIRE• Hypertext with linked pages
– 1989, First proposal for “large hypertext system”
• BTW, ACM SIGWEB 1st Conference ~1988
– 1990, with Robert Caillau standards for www published

Invention of the WWW 1990
• 1990, CERN phone book first document on WWW
– 1st web server a NeXT designed by Steve Jobs
– info.cern.ch
• 1st web browser– Tim Berners-Lee– Text only
• Paul Kuntz, 1991– Brought NeXT software back to
Stanford Linear Accelerator Center– Louise Addis adapted for VM/CMS
os on IBM mainframe– Display center’s documents
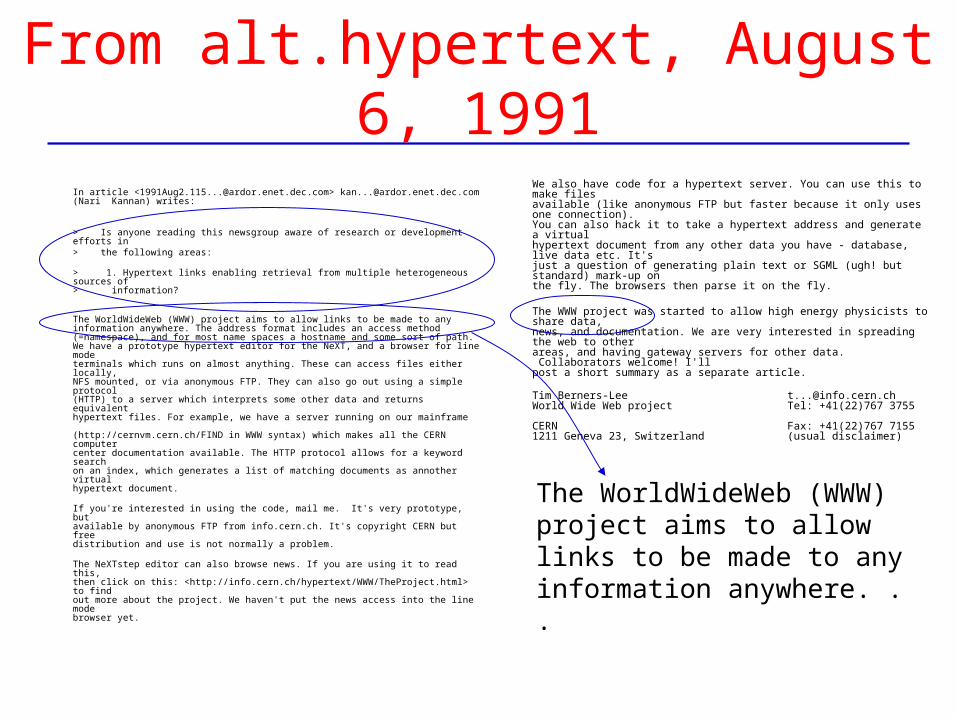
From alt.hypertext, August 6, 1991
In article <[email protected]> [email protected] (Nari Kannan) writes:
> Is anyone reading this newsgroup aware of research or development efforts in > the following areas:
> 1. Hypertext links enabling retrieval from multiple heterogeneous sources of > information?
The WorldWideWeb (WWW) project aims to allow links to be made to any information anywhere. The address format includes an access method (=namespace), and for most name spaces a hostname and some sort of path. We have a prototype hypertext editor for the NeXT, and a browser for line mode terminals which runs on almost anything. These can access files either locally, NFS mounted, or via anonymous FTP. They can also go out using a simple protocol (HTTP) to a server which interprets some other data and returns equivalent hypertext files. For example, we have a server running on our mainframe (http://cernvm.cern.ch/FIND in WWW syntax) which makes all the CERN computer center documentation available. The HTTP protocol allows for a keyword search on an index, which generates a list of matching documents as annother virtual hypertext document.
If you're interested in using the code, mail me. It's very prototype, but available by anonymous FTP from info.cern.ch. It's copyright CERN but free distribution and use is not normally a problem.
The NeXTstep editor can also browse news. If you are using it to read this, then click on this: <http://info.cern.ch/hypertext/WWW/TheProject.html> to find out more about the project. We haven't put the news access into the line mode browser yet.
We also have code for a hypertext server. You can use this to make files available (like anonymous FTP but faster because it only uses one connection). You can also hack it to take a hypertext address and generate a virtual hypertext document from any other data you have - database, live data etc. It's just a question of generating plain text or SGML (ugh! but standard) mark-up on the fly. The browsers then parse it on the fly.
The WWW project was started to allow high energy physicists to share data, news, and documentation. We are very interested in spreading the web to other areas, and having gateway servers for other data. Collaborators welcome! I'll post a short summary as a separate article.
Tim Berners-Lee [email protected] World Wide Web project Tel: +41(22)767 3755 CERN Fax: +41(22)767 7155 1211 Geneva 23, Switzerland (usual disclaimer)
The WorldWideWeb (WWW) project aims to allow links to be made to any information anywhere. . .

Popularization of WWW
• Early adopters of www were universities, centers, etc.
– As with ARPANET
• Text based browsers with embedded links
– Primitive functionality and interface elements
• Erwise and Viola, 1992– For X-windows– 1st graphical browsers outside NeXT-based
• Mosaic– Code still available! (checked, 9/25/12)
• ftp://ftp.ncsa.uiuc.edu/Mosaic/– Marc Andreesen and Eric Bina
• Undergraduate students at UIUC and working at NCSA• Used computers belonging to UIUC to develop, so belonged to
university• 1993 demo:
– http://www.totic.org/nscp/demodoc/demo.html
– Strongly support of integrate multimedia– Responsive to bug fixes– Mosaic – Netscape Navigator
• Jim Clark, founded SGI• “browser wars”

Hypertext - Introduction
• “Hypertext” - what it is
• You all know what it is – – idea is part of ubiquitous
information systems … www– “google it” is part of the language
• People just use hypertext systems and somewhat correctly view it as the natural way to present information electronically
– e.g., Help with “links” to other information, web browsers
• “User-directed information access and retrieval”
– not bounded so much by linear presentation
Example:

Hypertext as a Directed Graph
• Formally, a hypertext is a (labeled) directed graph (or network)– G = (V, E)– Information items can be viewed as nodes (or concepts)– Ability to move (navigate) to another information item can be viewed as links
• A hypertext system is made of nodes (concepts) and links (relationships)– Node usually represents a single concept or idea. – Node can contain text, graphics, animation, audio, video, images or programs.

Nodes: Information Units
• Again, WWW is an example of simple (primitive) hypertext
– Untyped nodes and links
• Nodes can be typed – E.g., detail, proposition, collection,
summary, observation, issue– thereby carrying semantic information
• Nodes are connected to other nodes by links
• Links also can be typed also, e.g., supports, refutes
– The node from which a link originates is called the reference and the node at which a link ends is called the referent.
– They are also referred to as anchors.
• The contents of a node are displayed by activating links

Sup - A Cognitive Account of Hypertext: Reading and Writing Models
• Some argue that hypertext parallels human cognition and facilitates exploration.– We think in nonlinear chunks, which we try to associate with each other and build a network of
concepts.
• When we read a book, – we go back and forth a number of times to refer to previously read material, – to make notes, and to jump to topics using the table of contents or the index.
• When we set out to write a document we first develop an outline of ideas. – Then, we brainstorm, write down on paper, organize, revise, reorganize and repeat the cycle till
we are satisfied with the outcome - a coherent document.
• In fact, we have been forced to adapt to traditional, linear text because of representation on paper.
• To understand hypertext, it is useful to understand how people read and write
documents.
• Reading and writing models have been developed by cognitive psychologists that can be used to understand non-linear thinking by human

And Now the W W W
• Is the WWW a hypertext/hypermedia?– Yes
• Will it solve the problems, as described by Bush?– You tell me - and why or why not.
• Importantly, the WWW allows not only non-linear access to information, but also connectivity among (potentially) all the electronic information sources on Earth.– Now, will the WWW solve ....
• Recall, the two components of a hypertext system:– a “database” which describes: “concepts”/nodes, “relations”/links,
interaction mechanisms for traversing the network, and display mechanisms for presenting node content/information

Web Site Design

Web Site Design
• HCI and the Web – – Knowledge of interface design, applied to web
• Web is a different sort of system … – Not just an “interface”, though principles (and techniques) apply
• Site Design– Structure and information architecture
• Page design– Page scanning and canonical form– Visual logic and hierarchy

Web is Different, but …
1. Software system design principles are same– Much of web design literature “comes in at the bottom”
• I.e., for novice (untrained) designers• Though may apply principles, do not provide broader disciplinary context
– Student of computer science understands ideas about software engineering and principles of design
• E.g., Lynch and Horton “team roles” and SE project members
2. Interface design principles, are same for “web-based” (or browser-based) systems and “stand-alone” systems
– E.g., Shneiderman’s 8 “Golden Rules”, Togazini’s principles
3. Web is not “hypertext” (yet), yet many lessons of even pre-web hypertext are relevant
– E.g., “lost in hyperspace”, pre-WWW study, cf. SIGWEB

1. Software Design Principles are Same
• Project stages of L&H reflect, different emphases, but same stages

1. Software Design Principles are Same
• … or similar

1. Software Design Principles are Same
• … or similar
• Here, provide detail specific to web sites

2. Interface Design Principles are Same
• Have had a close look at:– Guidelines, principles, and theories

Guidelines, Principles, and Theories
• Guidelines (most specific)– Specific and practical
• Cure for design problems, caution dangers, shared language and terminology
– Accumulates (and encapsulates) past experience and best practices
• “blinking is bad, never use it”– May be: too specific, incomplete, hard to
apply, and sometimes wrong– Lowest level
• Principles (“rules of thumb”)– “Rules that distill out the principles of
effective user interfaces”• E.g., Determine users’ skill level
– More general and flexible than guideline
• High level theories and models– Goal is to describe objects and actions with
consistent terminology• Allowing comprehensible explanations to
support communication and teaching– Other theories are predictive
• E.g., reading, pointing, and typing times
Theories
Guidelines
Principles

… and recall, Principles: Shneiderman’s “8 Golden Rules of Interface Design”
• Schneiderman’s 8 rules (principles):
1. Strive for consistency2. Cater to universal usability3. Offer informative feedback4. Design dialogs to yield closure5. Prevent errors6. Permit easy reversal of actions7. Support internal locus of control8. Reduce short term memory

Nielsen’s Principles for Usable Design
• Meet expectations– 1. Match the real world– 2. Consistency & standards– 3. Help & documentation
• User is the boss– 4. User control & freedom– 5. Visibility of system status– 6. Flexibility & efficiency
• Handle errors– 7. Error prevention– 8. Recognition, not recall– 9. Error reporting, diagnosis, and recovery
• Keep it simple– 10. Aesthetic & minimalist design

(even) Toggazinni’s 16 Principles
• Anticipation
• Autonomy
• Color blindness
• Consistency
• Defaults
• Efficiency
• Explorable interfaces
• Fitts’s Law
• Human interface objects
• Latency reduction
• Learnability
• Metaphors
• Protect users’ work
• Readability
• Track state
• Visible navigation

Web Site Design differs from User Interface Design
• WWW not same kind of interactive system, as “computer interface”
• (at least as discussed in traditional HCI literature)– Looong latency
• 1/10 – 1/30 second required for perceptual continuity• 1 sec continuity of interaction
– i.e., “immediate response”• ~ 10 (or 5-30) seconds for task continuity
– So, response time from web is at limit of task continuity
• Different, and not an interactive system with “immediate” response– not to be studied in same way many elements of interfaces are – and maybe principle focus and principles of design yet to evolve
• Thus www, acts as information repository, and other things– Whether for “knowledge”, shopping, chatting, ..., but not traditional system– Hence, focus on information architecture

Difference Between Web Design and GUI Design – Nielsen
• Designing for Web different from designing traditional user interfaces– Designer has to give up full control
• Share responsibility for the UI with users and their client hardware/software.
• Device Diversity– In traditional GUI design, control every pixel on the screen
• Designing to abstract UI specification is hard
• The User Controls Navigation– Can jump straight into the middle of a site from a search engine!
• On Web, users move between sites at a very rapid pace and the borders between different designs (i.e., sites) are very fluid

3. Web is Different from (Visionary) Hypertextwith respect to types of links/associations
• Bottom line, hypertext and Web can both be modeled as G (V,E)– For hypertext, edges are undirected and labeled (with anything!)– For web, edges are directed and unlabeled
• Though, who would know edges undirected (browser makes transparent)• Web 2.0 and higher aim to provide (semantic) labels
– Promise of the future?
• So, current realization of “world wide repository of knowledge” is really quite primitive– But, it is still revolutionary in sheer quantity of information stored,
indexed (sort of), and retrievable– And, we are early on in implementation
• 2012 – 1991 = 21– And, all appreciate what next steps need to
• Moore’s law is on our side (though that’s just for computers)

About Web DesignAs Presented by L&H and Nielsen
• Recall, hypertext– Goal of hypertext:
• “an electronic medium in which information presentation and access mirrors human cognition and thus can be more efficient and effective as a medium for communication (than printing)”
• also, admittedly early on in development of use and evolution of techniques– And, yes, WWW is hypertext, at least in limited sense
• But, technology (of network access) is really young, and slow:– bandwidth limitations drive much of “practical/applied” web site design
• And, yes, television held great promise, too, …, but that’s another story • Note, that much of what users see in Web sites (and even “good” web
sites) is driven by economic factors - advertising, rather than “user-centered” design
– i.e., design in which user’s (vs. the business’) best interests are design goal– often, real goal of site is to sell advertising
• Nonetheless, our focus is on user-centered design
– Design in which user can access information efficiently and effectively, etc.– Perhaps, not a bad place to start in general
• entirely appropriate for many sites

About Nielsen and Style Guide
• Yale Style Manual sometimes seem “quaint”
– “quaint” because of their focus on technology in a domain in which two years sees significant change in technology
• Again, we’re just (historically) getting started– HTML 2.0, 3.0, 4.0, 5.0, …. Javascript, …, ASP, …, XML,
XHTML, …, and Java programs to run in the browser window

Site: Design – Issues and Tasks, 1(Overview of L&H 3)
• Or, from a “computer science software engineering” perspective, – What should the design document (specifications) include
• Preliminary Design Decisions– Purpose of site– Objectives– Audience
• Surfers, novice/occasional users, expert/frequent users, international users• Design strategies are different for
– Surfers, Training, Teaching, Education, Reference
• Interface Design– Web pages versus conventional document design– Design precedents in print– Make Web pages free-standing– Who, What, When, Where
• Interface design issues for Web– User-centered design (of course), Clear navigation aids, Provide context

Site: Design – Issues and Tasks, 2 (Overview of L&H 3)
• Information Access issues– Give users direct access– Consider bandwidth and interaction– Simplicity, Consistency, Design stability, Feedback and dialog, Design for the
disabled
• Links & navigation– Provide context, Button bars help
• Site Design– Organizing information
• Chunking information: Hierarchy, Relationships, Function– Site structure
• Sequence, Grid, Hierarchy, Web– Site elements
• Home pages, Graphic or text menus, Audience for home page, "Related sites", Bibliographies, indexes, appendices, FAQ’s, etc.

About Information Architecture

About Information Architecture
• About “architecture”:– Architecture is about design …
• 1. the profession of designing buildings, open areas, communities, and other artificial constructions and environments
– For computer organization (computer architecture)– About compromises, experience, …, and design principles
• Information structuring on WWW is almost exclusively about web site design
– Thus, is changing rapidly due to:– Change in hardware and software technologies: – HTML and variants expanding functionalities, also on server side, asp, …– Uses for web – information dissemination, e-commerce, pure advertising, …– Users – literacy, expertness, expectations, populations, …

About Information Architecture
• “Information architecture”– Can, in fact, be considered quite generally
• Of “labeled link hypertext”, a library, email folders, …
• Term “information architecture” used for web sites because they are today (again) primarily information repositories– With (again) quite primitive information access mechanisms
• Lynch and Horton:
– “In the context of web site design, information architecture describes the overall conceptual models and general designs used to plan, structure, and assemble a site. Every web site has an information architecture, but information architecture techniques are particularly important to large, complex web sites …”
– This is what they mean on Monster.com

About Information Architecturesome “definitions”
• R. S. Wurman in Information Architects, 1996:– the individual who organizes the patterns inherent in data, making the complex
clear– a person who creates the structure or map of information which allows others to
find their personal paths to knowledge– the emerging 21st century professional occupation addressing the needs of the
age focused upon clarity; human understanding and the science of the organization of information
• Louis Rosenfeld, “Making the Case for Information Architecture” at ASIS 2000 IA Summit:
– “Information architecture involves the design of organization, labeling, navigation, and searching systems to help people find and manage information more successfully.”

About Information Architecturesome “definitions”
• … and from Monster.com– Sacha Cohen, “Becoming an Information Architect: Work as a Web Site
Strategist”– in monster.com, http://technology.monster.com/articles/infoarchitect/
• Monster.com: First, what exactly is information architecture?
– Mattie Langenberg: Information architecture, as the name implies, is basically about taking content and creating a structure to present that content to an audience. Whether the content is intended for a private audience on an intranet or for the public, it is the information architect's job to ensure that information is well-organized and presented in an easily accessible interface.

Information Architecture
• Aims of information architecture (L&H):– Organize site content into taxonomies and hierarchies of information– Communicate conceptual overviews and overall site organization to
design team and clients– Research and design core site navigation concepts– Set standards and specifications for
• Handling of html semantic markup• Format and handling of text content
– Design and implement search optimization standards and strategies
• Encompasses a broad range of design and planning disciplines
• In fact, to create cohesive, coherent user experience – combine:– Technical design– User interface– Graphic design

Orientation to Web Site Design, 2
• Web page and site design– Web page and site design combines (and this is not a short list):
1. traditional editorial approaches to documents 2. graphic design 3. user interface design4. information design5.“programming” skills optimize HTML code, graphics, & text within Web
pages
• There is a challenge in adapting a relatively primitive authoring and layout tool (HTML) to purposes it was never really intended to serve (graphic page design).
• Web serves as an information system and is relatively new– It can usefully be considered a new medium for which design is evolving
• Will see other differences as well (Nielsen)

How to Organize Information (L&H)Principles and Guidelines!
• Inventory site content– What is available, what is needed
• Establish a hierarchical outline of content– Will likely serve as site structure!
• Create a controlled vocabulary
– Allows consistent identification of content, site structure, and navigation elements
• Chunking: Divide content into logical units for consistent modular structure– Page is basic (and essential) unit for presentation and WWW (Tim said so)
• Draw diagrams that show site structure
• Create rough outlines of pages with list of core navigation links
• Analyze system by testing organization interactively with real users
• Revise as needed

Site Structure
• How information elements of site organized– “Conceptually”, i.e., the information architecture– As presented to the user:
• Through information presentation(s) generally• Navigation elements reinforce
• Mental model– How user thinks about (forms an internal representation of) site– An important issue in interactive systems, not covered much by Shneiderman– Both:
• Conceptual structure of the domain of information/knowledge presented by site– (or more task for interactive systems generally)
• Navigational structure of site
• Usually, “site structure” ~= “mental model” ~= hierarchy– Which is, of course, only an approximation
• Much said in “popular” design literature about “site structure”, but it boils down to hierarchies
– Because (again) the web is not hypertext – simple “goto” relations only for link structure and navigation
– Because logn is powerful! – as all computer scientists know!

A “Browse Interface”
• Recall what you know about menus …
• Note correspondence with hierarchy of web pages
• Call it a “browse interface” to the web site contents, hierarchically structured content, or whatever, much of what is relevant to menu design is relevant here
– Wide vs. shallow, number of alternatives, importance of menu labels, etc.
• Note that the mental model follows in part from interaction with content and structure

Site Use in Practice
• In practice, typically sites use all of above:– Site hierarchy with standard navigational links– Topical (“see also”) links to create a web
• And user “navigates” through (or forages in) site for information– Using both navigational links and search

Site Search as Navigation
• “Conceptually properly placed” items still, of course, need to be accessed– Proper and useful info. arch. (categorization, keywords, etc.) important in search
• Despite efficiencies of hierarchies, pages often (must) be accessed through search facilities
– Implications for information architecture: Can’t handle everything in conceptual structure– Implications for navigation: Allow search, deal with orientation (more later)
• See practical limitations of “browse interface”

Structure - Books and Web Pages
• Modern book design and typography done within constraints of expectations for books
– Margins, white space, page nums, index, toc, …– Ancient book design was not better
• Constraints (conventions) are result of long process of often trial and error evolution of form
– And most evolution eliminates bad ideas– “Prefer the standard to the offbeat”
• Chicago Manual of Style
• Within constraints still possible to be creative
• L&H point out that book design is in fact facilitated (“enabled”) by established conventions
• Web is at fairly early (or “adolescent”, L&H) stage in development of conventions
– Though not infancy – people learn, medium adapts• A lot of really bad stuff is gone, but some remains

Page Structure – and Navigation
• Relevant as it affects navigation
• Will look at “forms”, or layouts for pages here, and more about aesthetics, etc. next time

L&H: “Canonical Form in Web Pages”Where to put things on pages and why
• Pictorial composition– For, e.g., home pages– From art composition theory
• Middle and corner of plane attract early attention
– “Rule of thirds”• Center of interest within a grid
that divides both dimensions in thirds
• Text reading patterns typically more useful
– “Guttenberg Z”, “reading gravity”• Attention flows down a page
with reluctance to reverse downward scanning

Page Scanning: Empirical Evidence
• “Know thy user … empirically”
• Eye-tracking studies by – Poynter Institute (http://eyetrack.poynter.org/)
• Readers start scanning with many fixations in upper left of page
• Gaze then follows Gutenberg Z pattern down page
• Only later does typical reader lightly scan right of page
– Jakob Nielsen (http://www.useit.com/eyetracking/)
• Intense fixations across top, then, down left edge of page – “F pattern”
• Combination (learned) reading pattern and (learned) web page reading

Eye Tracking Studies
• Eye tracking well-known technique for inferring attention
– eyetools.com focuses on web usability
• Record eye gaze, and map time or number of fixations to psuedo-color
– E.g., “golden triangle” below

Eye Tracking Studies
• “F-Shaped Pattern for Reading Web Content”
– http://www.useit.com/alertbox/reading_pattern.html– Nielsen, 2009, Eyetracking Web Usability
• Three components of web page reading (in general, and depends on site and task):
– First, a horizontal movement• Across upper part of content area
– Next, second horizontal movement• Shorter area than first
– Finally, vertical movement• Often slow and systematic
– Solid stripe on eyetracking heatmap
• Or slower
– Spottier heatmap

Eye Tracking Studies
• “F-Shaped Pattern for Reading Web Content”
– http://www.useit.com/alertbox/reading_pattern.html– Nielsen, 2009, Eyetracking Web Usability
• Three components of web page reading (in general, and depends on site and task):
– First, a horizontal movement• Across upper part of content area
– Next, second horizontal movement• Shorter area than first
– Finally, vertical movement• Often slow and systematic
– Solid stripe on eyetracking heatmap
• Or slower
– Spottier heatmap

F-pattern only a General Shape
• Left: “About us” section of corporate web site• Mid: Product page on e-commerce site• Right: Search engine results page (SERP)

Some Implications of F-pattern
• Demonstrates need to not create text, etc., as if in printed document
– Users don't read text thoroughly in a word-by-word manner
– Exhaustive reading rare, especially when users conducting search
• First two paragraphs must state most important information.
• Start subheads, paragraphs, and bullet points with information-carrying words
– Words that users will notice when scanning down left side of content in final stem of their F-behavior.

User’s Expectations of Web Pages
• Users have viewed a lot of web pages
• Have developed expectations about how to efficiently find information on a web page (and in a web site)
– Recall, information foraging discussion
• This is learned behavior, just as how to read a book is a learned behavior
• Effective design should exploit what is known about learned behavior
• Will see some examples

Expectations - Information Location
• Software Usability Research Laboratory (SURL), Wichita State University– “Preliminary Examination of Global Expectations of Users’ Mental Models for E-Commerce Web Layouts”
• Pretty interesting (also, next page) – New form of web pages - “cultural”, as reading
– But, “Until we have a Chicago Manual of Style for the web…”

Expectations Information Location
• Software Usability Research Laboratory (SURL), Wichita State University

L&H: A Canonical Page Design
• Adolescence vs. infancy
– Expectations of users established
• Can serve as basis for page template / grid
– (which would be more detailed and include graphic elements)

Current Tools Reflect Form UbiquityUTPA Computer Science, 2008
• Design provided by tool
– Content management system
• “De facto standard”

Current Tools Reflect Form Ubiquity UTPA Computer Science, 2013
• Design provided by tool
– Content management system
• “De facto standard”

End
• .





























