Embed Size (px)
Citation preview

Trabajo Practico N 12 Minería de Datos
CATEDRA: Actualidad Informática
Ingeniería del Software III
Titular: Mgter. Horacio Kuna
JTP: Lic. Sergio Caballero
Auxiliar: Yachesen Facundo
CARRERAS: Analista en Sistemas de Computación
Licenciatura en Sistemas de Información
Facultad de Ciencias Exactas Químicas y Naturales
UNaM
Alumnos:
∗ Ganz Nancy
∗ Gauler Emanuel
∗ González Veronica
∗ Markiewiech Irina

Contenido Introducción ................................................................................................................................. 3
Origen ........................................................................................................................................... 4
Fundamentos ................................................................................................................................ 4
Tipos de Modelos ......................................................................................................................... 5
Marco de Utilización ..................................................................................................................... 5
Software más utilizados ............................................................................................................... 7
Características............................................................................................................................ 8
RAPID Miner........................................................................................................................... 8
Tanagra .................................................................................................................................. 9
Ejercicio Práctico .......................................................................................................................... 10
RapidMiner .............................................................................................................................. 10
Tanagra .................................................................................................................................... 14
Comparación de resultados entre RapidMiner y Tanagra ......................................................... 19
Conclusión ................................................................................................................................... 20
Bibliografía .................................................................................................................................. 21

Introducción
Se define a la Minería de datos como el proceso mediante el cual se extrae
conocimiento comprensible y útil que previamente era desconocido desde bases de
datos, en diversos formatos, en forma automática. Es decir que la Minería de datos
plantea dos desafíos, por un lado trabajar con grandes bases de datos y por el otro
aplicar técnicas que conviertan en forma automática estos datos en conocimiento.

Origen La idea de Minería de Datos no es nueva. Ya desde los años sesenta los estadísticos manejaban términos como Data Fishing, Data Mining (DM) o Data Archaeology con la idea de encontrar correlaciones sin una hipótesis previa en bases de datos con ruido.
A principios de los años ochenta, Rakesh Agrawal, GioWiederhold, Robert Blum y Gregory Piatetsky-Shapiro entre otros, empezaron a consolidar los términos de Minería de Datos y KDD.
Esta tecnología ha sido un buen punto de encuentro entre personas pertenecientes al ámbito académico y al de los negocios.
La evolución de sus herramientas en el transcurso del tiempo puede dividirse en cuatro etapas principales:
• Colección de Datos (1960). • Acceso de Datos (1980). • Almacén de Datos y Apoyo a las Decisiones (principios de la década de 1990). • Minería de Datos Inteligente.(-nales de la década de 1990).
Fundamentos Las técnicas de Data Mining son el resultado de un largo proceso de investigación y
desarrollo de productos. Esta evolución comenzó cuando los datos de negocios fueron
almacenados por primera vez en computadoras, y continuó con mejoras en el acceso a los
datos, y más recientemente con tecnologías generadas para permitir a los usuarios
navegar a través de los datos en tiempo real. Data Mining toma este proceso de evolución
más allá del acceso y navegación retrospectiva de los datos, hacia la entrega de
información prospectiva y proactiva. Data Mining está listo para su aplicación en la
comunidad de negocios porque está soportado por tres tecnologías que ya están
suficientemente maduras:
• Recolección masiva de datos.
• Potentes computadoras con multiprocesadores.
• Algoritmos de Data Mining.

Tipos de Modelos Los modelos pueden ser de dos tipos, predictivos o descriptivos.
Predictivos: Este tipo de modelo tiene como objetivo la estimación de valores desconocidos de variables de interés.
• Clasificación, el objetivo es predecir a que clase pertenece una nueva instancia de una base de datos, considerando que los atributos pueden asumir valores discretos.
• Regresión, en este caso el valor a predecir es numérico.
Descriptivos: Exploran las propiedades de los datos examinados con el objetivo de generar etiquetas o agrupaciones.
• Clustering, se trata de analizar datos para generar etiquetas. • Correlación, se utiliza para determinar el grado de similitud de los valores de dos
variables numéricas. • Reglas de asociación, tiene como objetivo encontrar relaciones no explicitas entre
atributos, se utiliza típicamente en el análisis del contenido de un carrito de compra. • Reglas de asociación secuencial, se utiliza para determinar los patrones secuenciales en
los datos basados en el tiempo.
Marco de Utilización • Detección de fraudes: Se puede considerar una técnica de clasificación. Se usa en
corporaciones para prevenir procesos “peligrosos”. El algoritmo se encarga de analizar transacciones y categorizar las que sean ilegítimas mediante la identificación de características comunes.
• Análisis de riesgos de crédito: Aplicación similar a la anterior pero con la existencia de técnicas tradicionales para realizarlo. Por ejemplo mejorando el método de asignación de puntos con minería de datos.
• Clasificación de cuerpos celestes: Esta aplicación se puede incluir en el reconocimiento de patrones de imágenes.
• Minería de texto: debido a la gran cantidad de páginas en red, es necesario tecnologías como la minería de datos para clasificar y detectar patrones particulares en la información.

• Negocios: En lugar de enviar determinadas promociones u ofertas a todos los clientes, mediante técnica de minería de datos se puede obtener una lista de clientes que tengan una mayor probabilidad de interesarse por una determinada oferta o promoción.
• Hábitos de compra en supermercados: Este es el ejemplo típico de minería de datos. Se basa en colocar los productos de una determinada forma para que se incremente el número de ventas.
• Patrones de fuga: Se usa sobre todo en empresas de banca y telecomunicaciones. A través de características de personas que anteriormente se dieron de baja en la empresa para pasarse a la competencia, se hace un estudio de que personas son las más propensas a esto, para poderles hacer ofertas personalizadas con la finalidad de lograr su permanencia.
• Recursos humanos: Gracias a la minería de datos se pueden obtener las características de sus empleados de mayor éxito y estos patrones aplicarlos a los futuros empleados de la empresa.
• Comportamiento en Internet: Obteniendo la información de un usuario (de forma más o menos legítima) se crea un perfil de usuario para ofrecerle una determinada información u otra a la hora de visitar páginas webs.
• Terrorismo: Gracias a la minería de datos el ejército de los EE.UU ha identificado al líder de los atentados del 11-S y a otros tres integrantes.
• Juegos: Gracias al estudio de jugadas de fin de partida en juegos como el ajedrez, se han conseguido patrones de juegos para obtener resultados positivos en estos juegos. En este campo hay numerosas investigaciones abiertas.
• Genética: El objetivo principal del estudio de la Genética es sabes cómo los cambios en el ADN fomentan la aparición de determinadas enfermedades, como el cáncer. Muy importante para la prevención de estas enfermedades. La minería de datos se puede utilizar para esta tarea.
• Ingeniería Eléctrica: En este campo, las técnicas de minería de datos se han usado de manera cuantitativa para monitorizar las condiciones de instalación de alta tensión.

Software más utilizados
Software Comercial
∗ Intelligent Miner
∗ Clementine
∗ Enterprise Miner
∗ Microstrategy
∗ Darwin
∗ CART
∗ Data Surveyor
∗ GainSmarts
∗ Knowledge Seeker
∗ Polyanalyst
∗ SGI MineSet
∗ Wizsoft/Wizwhy
∗ Pattern Recognition Workbench (PRW)
Open Source:
∗ WEKA
∗ Rapid Miner
∗ Tanagra
∗ Pentaho

Características
RAPID Miner
RapidMiner, antes llamado YALE, es un ambiente de experimentos en aprendizaje automático
y minería de datos que se utiliza para tareas de minería de datos tanto en investigación como
en el mundo real. Permite a los experimentos componerse de un gran número de operadores
anidables arbitrariamente, que se detallan en archivos XML y se hacen con la interfaz gráfica
de usuario de RapidMiner. ofrece más de 500 operadores para todos los principales
procedimientos de máquina de aprendizaje, y también combina esquemas de aprendizaje y
evaluadores de atributos del entorno de aprendizaje Weka. Está disponible como una
herramienta stand-alone para el análisis de datos y como motor para minería de datos que
puede integrarse en tus propios productos.
Características:
• Escrito en Java. • El proceso de descubrimiento de conocimiento es modelado como árboles de
operación. • El lenguaje de encriptación permite automáticamente una gran cantidad de
experimentos • Posee una interfaz gráfica, línea comando, y API de Java para usar RapidMiner desde
tus propios programas • Una gran cantidad de extensiones (plugins). • Las aplicaciones incluyen: Text Mining, Multimedia Mining, etc. • Los procesos de KD se modelan como árboles simples del operador que es intuitivo y
de gran alcance • Los árboles o las sub-estructuras del operador se pueden ahorrar como bloques
huecos para la reutilización posterior • El concepto de varias capas de la opinión de los datos asegura de manipulación de
datos eficiente y transparente • Es un software de tipo Open-Source con licencia GNU GPL, basado en JAVA. • Trabaja bajo las plataformas Windows y Linux.

Tanagra
Es un software libre de MINERÍA DE DATOS para fines académicos y de investigación. Se propone un conjunto de métodos de minería de datos a partir del análisis exploratorio de datos, aprendizaje estadístico, el aprendizaje de la máquina y el área de bases de datos.
Implementa diferentes algoritmos de aprendizaje supervisado, especialmente una construcción interactiva y visual de los árboles de decisión, así como también otros paradigmas, como la agrupación, análisis factorial, paramétricas y no paramétricas estadísticas, reglas de asociación, la selección de características y los algoritmos de construcción.
El objetivo principal de Tanagra es dar a los investigadores y estudiantes una herramienta fácil de usar para la minería de datos, y permitiendo analizar tanto los datos reales o sintéticas. Además propone a los investigadores una arquitectura que les permite añadir fácilmente sus propios métodos de minería de datos.
Características:
• Proyecto de código abierto. • Fácil de utilizar. • Actúa más como una plataforma experimental. • Puede ser considerado como una herramienta pedagógica para aprender las técnicas
de programación. • TANAGRA no incluye un amplio conjunto de fuentes de datos, acceso directo a bases
de datos, Data Warehouse, limpieza de datos, la utilización interactiva. • Propone varios métodos de minería de datos a partir de análisis exploratorio de datos,
aprendizaje estadístico, aprendizaje automático y base de datos. • Provee varios paradigmas de aprendizaje supervisado, agrupamiento, análisis
factorial, reglas de asociación, etc. • Integración con Excel a través de pluggins que hoy día con las últimas versiones
(2010) se mantienen disponibles, el inconveniente se genera al tratar grandes volúmenes de datos donde la plataforma de tanagra no es capaz de procesar dichas cantidades de datos.
Ejercicio Práctico
RapidMiner
En este ejemplo, se trabaja con el conjunto de datos “Hongos-convertidas”, que es una base de datos que descargamos de internet y luego se aplica a este el algoritmo denominado K-Means. Para ello debemos:
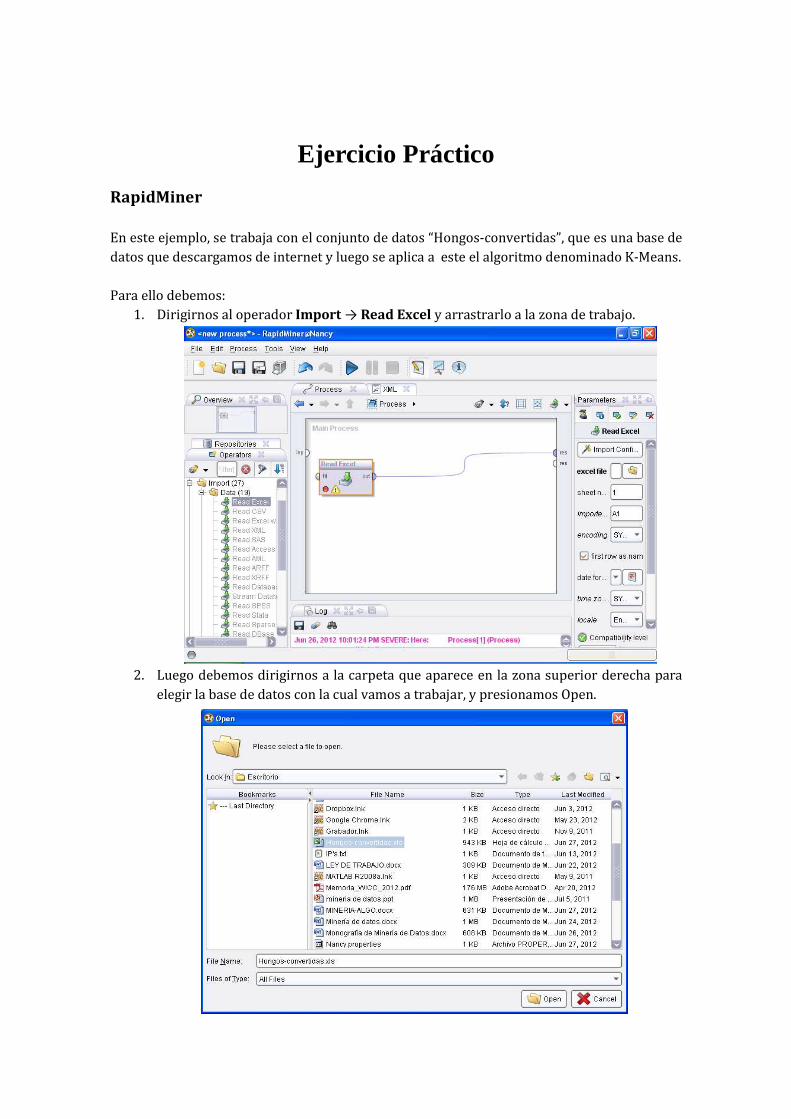
1. Dirigirnos al operador Import → Read Excel y arrastrarlo a la zona de trabajo.
2. Luego debemos dirigirnos a la carpeta que aparece en la zona superior derecha para
elegir la base de datos con la cual vamos a trabajar, y presionamos Open.
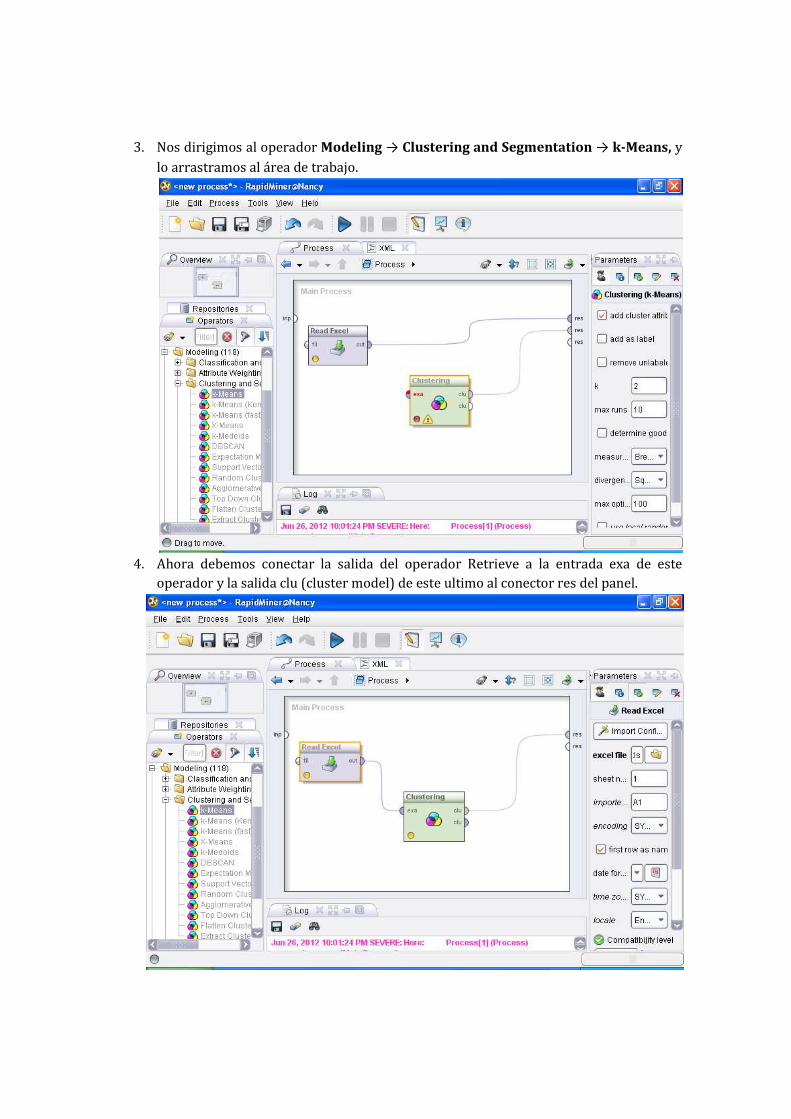
3. Nos dirigimos al operador Modeling → Clustering and Segmentation → k-Means, y
lo arrastramos al área de trabajo.
4. Ahora debemos conectar la salida del operador Retrieve a la entrada exa de este
operador y la salida clu (cluster model) de este ultimo al conector res del panel.
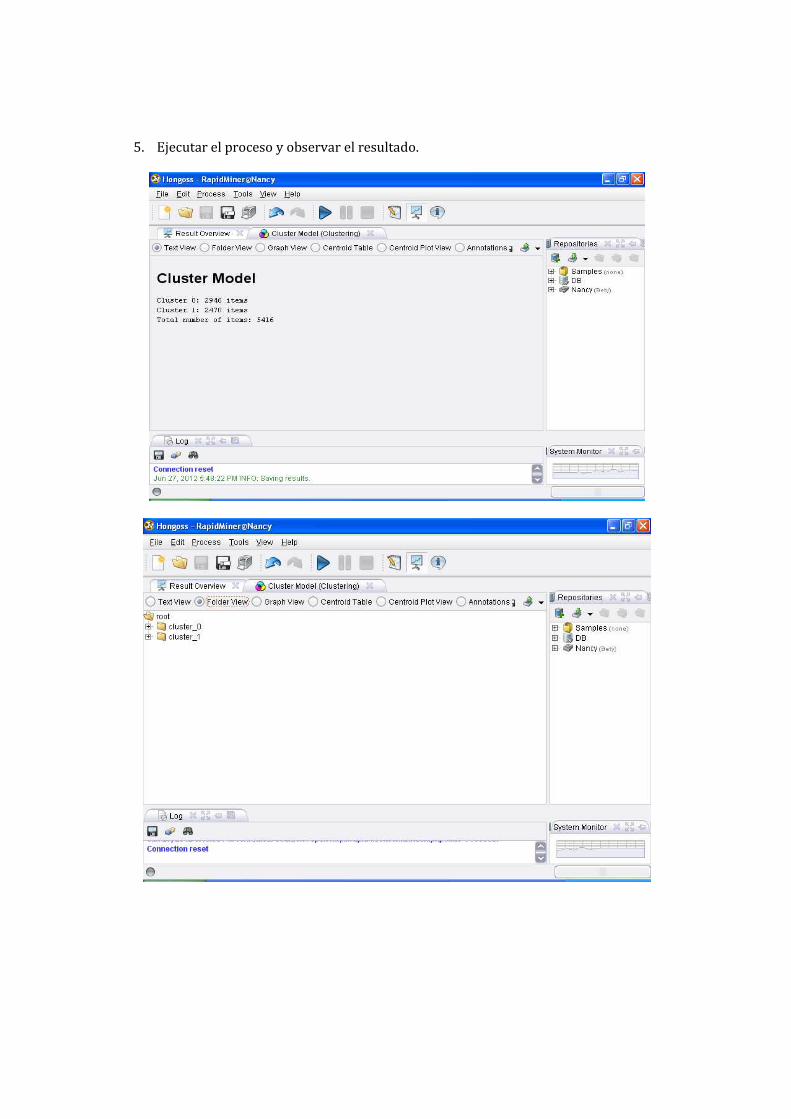
5. Ejecutar el proceso y observar el resultado.
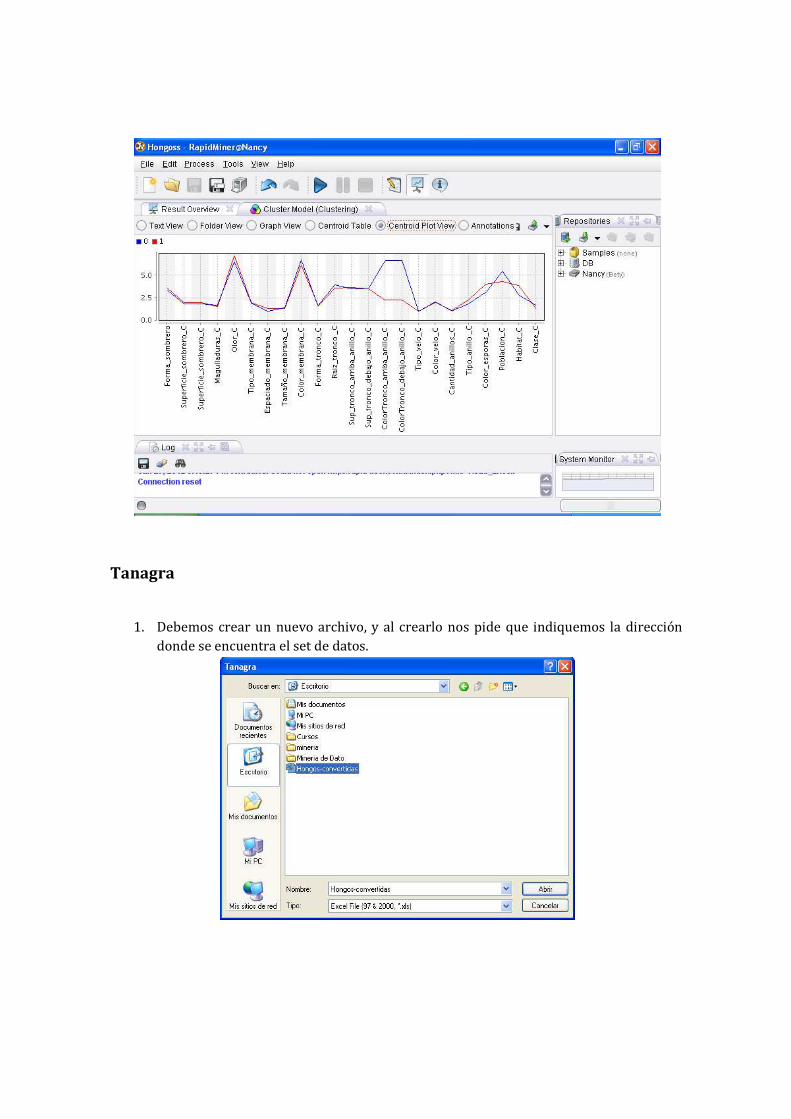
Tanagra
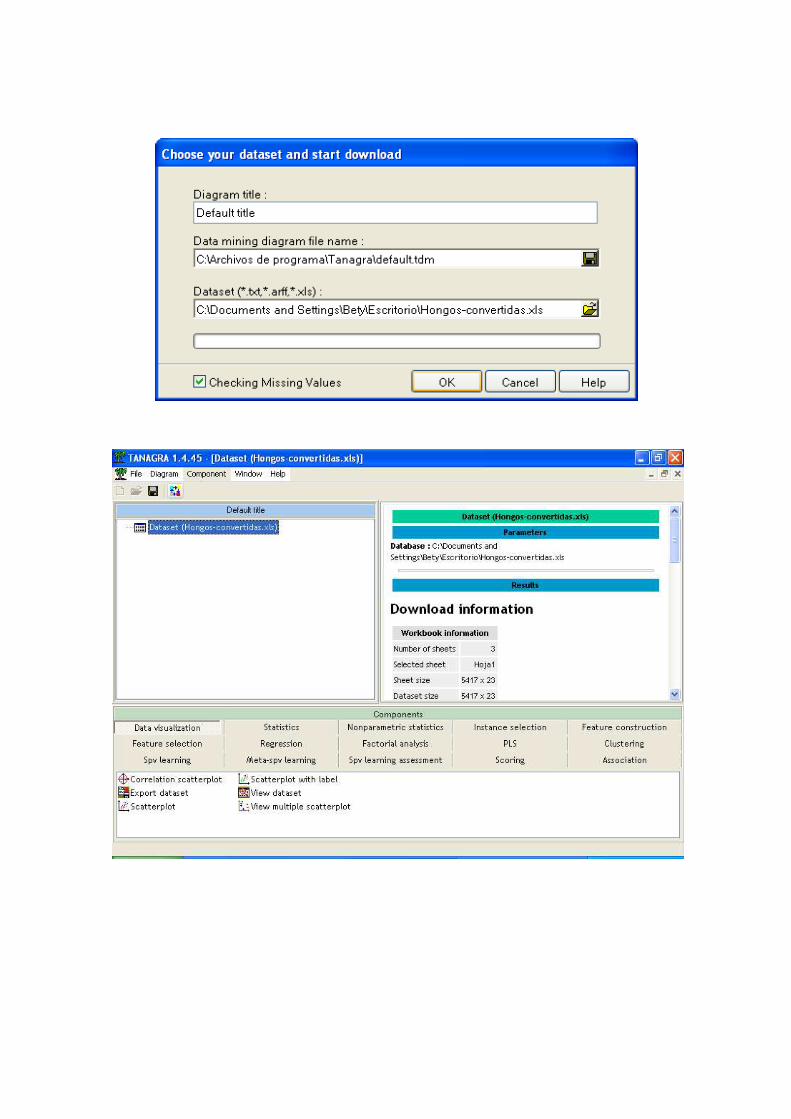
1. Debemos crear un nuevo archivo, y al crearlo nos pide que indiquemos la dirección donde se encuentra el set de datos.
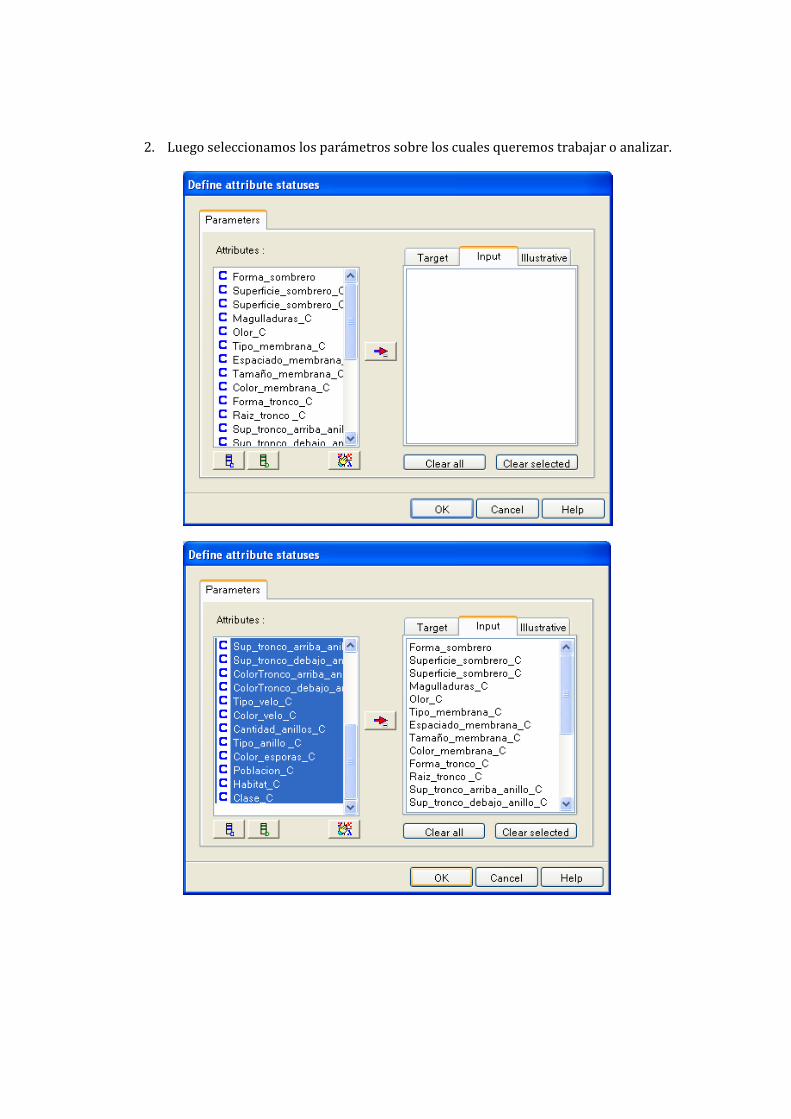
2. Luego seleccionamos los parámetros sobre los cuales queremos trabajar o analizar.
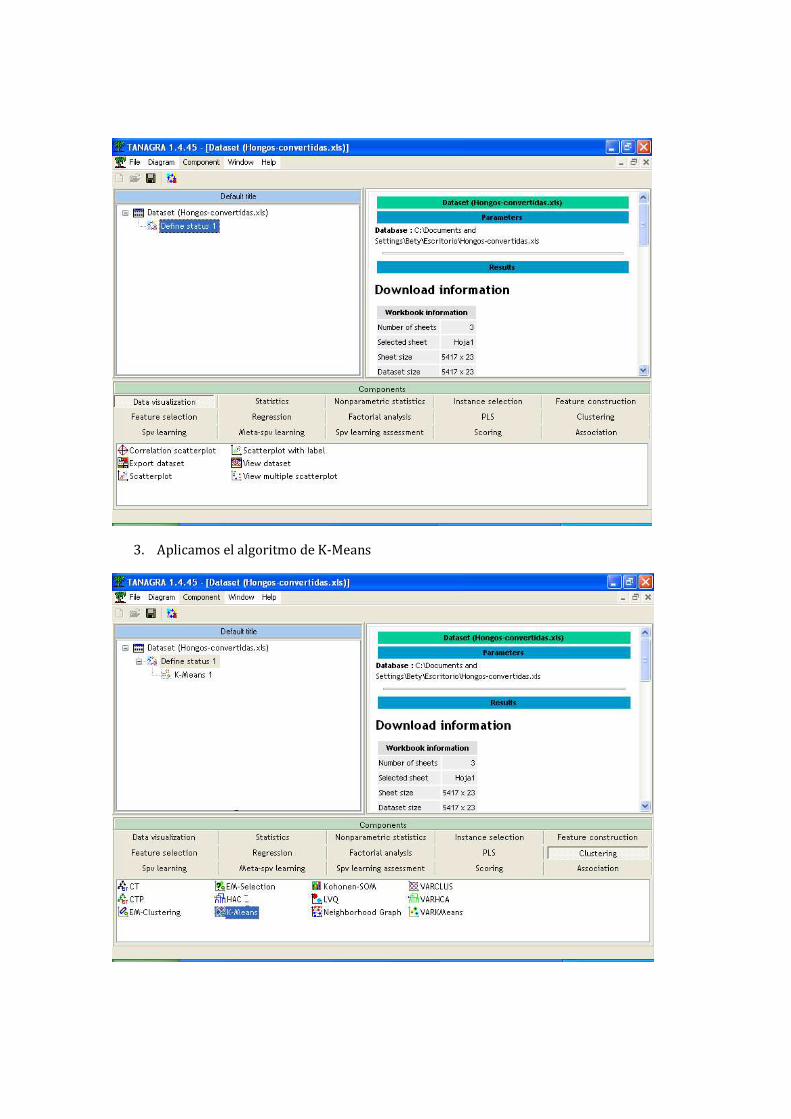
3. Aplicamos el algoritmo de K-Means
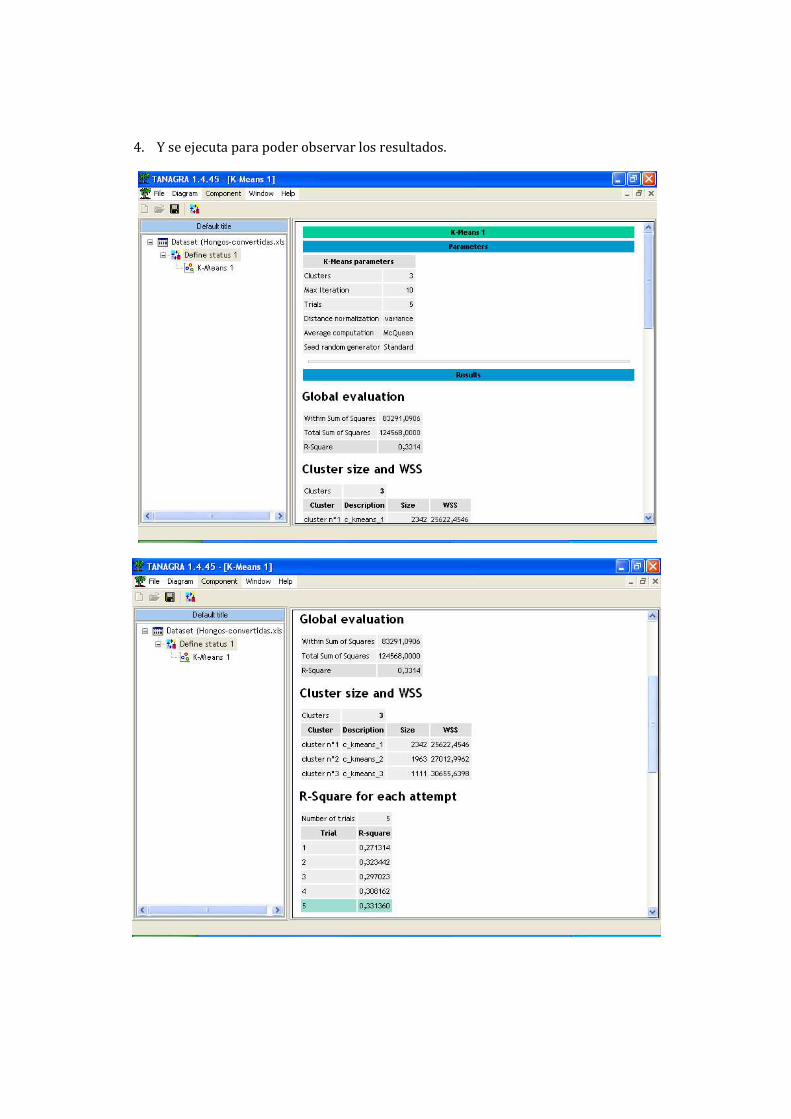
4. Y se ejecuta para poder observar los resultados.

Comparación de resultados entre RapidMiner y Tanagra
En cuanto a Rapid Miner como podemos apreciar en el ejemplo realizado, se divide la muestra en
dos clúster donde en el clúster 0 se agruparon 2946 tuplas y en clúster 1 se agruparon 2470 tuplas,
de un total de 5416.
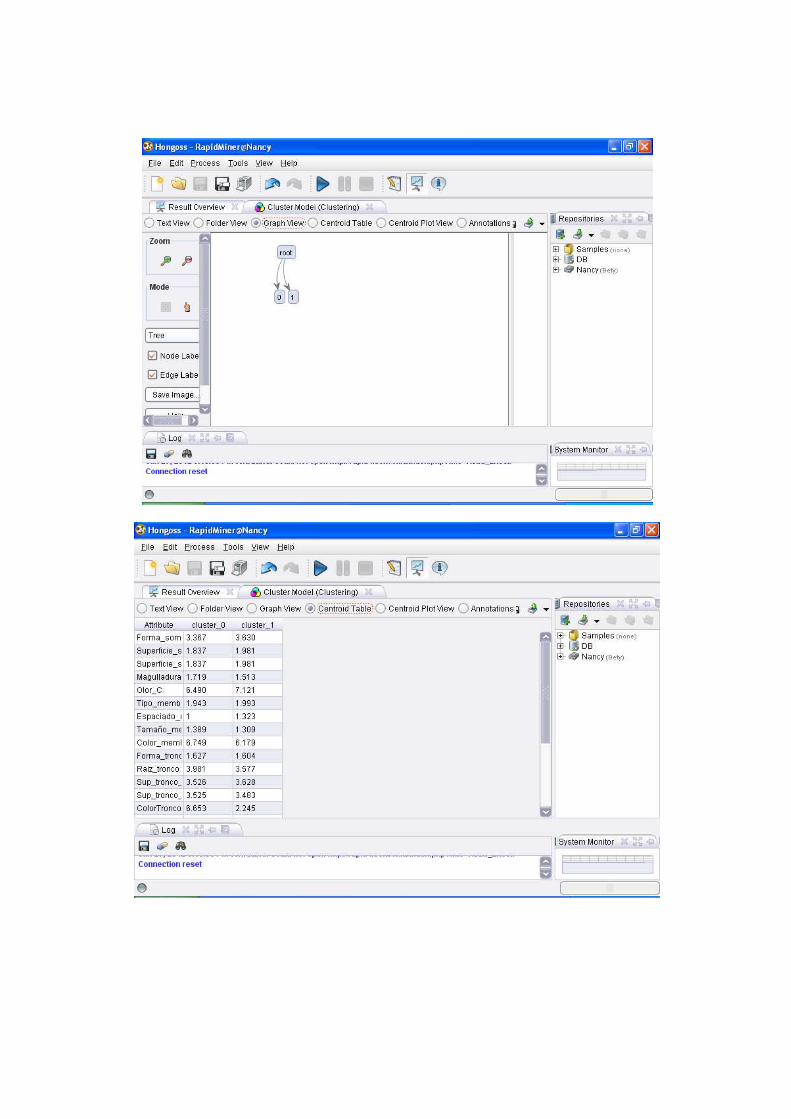
Se puede ver que este software nos brinda la posibilidad de varias vistas, entre ellas la de un árbol
de carpetas en que nos separa los datos según los clúster armados, así como también nos muestra
un grafico de los clúster.
Otra posibilidad es la tabla de centroides en el cual se muestra una media de cada atributo de los
distintos clúster, por ejemplo en cuanto a la forma del sombrero del hongo para el clúster 0 el
centroide es de 3.367, para el clúster 1 es de 3.630 y así sucesivamente.
Y podemos apreciar una vista de trazo de los centroides para una mejor apreciación.
Podemos comenzar a variar la cantidad de clúster para apreciar mayor información y podemos
aplicar distintos métodos de clustrización.
En cuanto a Tanagra en el ejercicio realizado se divide el set de datos en 3 clúster, con distancias
de normalización variantes.
El clúster numero 1 tiene un tamaño de 2342.
El clúster numero 2 tiene un tamaño de 1963.
El clúster numero 3 tiene un tamaño de 1111.
También proporciona una tabla con los centroides de los distintos clúster, por ejemplo: en cuanto
a la forma del sombrero del hongo el clúster 1 tiene un centroide de 3.19, el clúster 2 tiene un
centroide de 3.93 y el clúster 3 tiene un centroide de 3.29.
Como se aprecia en cuanto a los centroides de los clústers en ambos Softwares proporcionan
resultados muy parecidos. RapidMiner proporciona muchas vistas para analizar los datos, Tanagra
es más limitado, aunque permite la aplicación de determinados algoritmos que RapidMiner no lo
aborda.

Conclusión
La capacidad para almacenar datos ha crecido en los últimos años, en contrapartida, la capacidad
para procesarlos y utilizarlos no ha ido a la par. Por este motivo, la Minería de Datos se presenta
como una tecnología de apoyo para explorar, analizar, comprender y aplicar el conocimiento
obtenido usando grandes volúmenes de datos. Descubrir nuevos caminos que nos ayuden en la
identificación de interesantes estructuras en los datos es una de las tareas fundamentales de la
misma.
En el ámbito comercial, resulta interesante encontrar patrones ocultos de consumo de los clientes
para poder explorar nuevos horizontes. Como predecir el comportamiento de un futuro cliente,
basándose en los datos históricos de clientes que presentaron el mismo perfil, ayuda a poder
retenerlo durante el mayor tiempo posible.
En resumen, la Minería de Datos se presenta como una tecnología emergente, con varias ventajas:
por un lado, resulta un buen punto de encuentro entre los investigadores y las personas de
negocios; por otro, ahorra grandes cantidades de dinero a una empresa y abre nuevas
oportunidades de negocios. Además, no hay duda de que trabajar con esta tecnología implica
cuidar un sin número de detalles debido a que el producto final involucra toma de decisiones.

Bibliografía Presentación de Minería de Datos suministrada por la cátedra
[i] http://campusvirtual.unex.es/cala/epistemowikia/index.php?title=Miner%C3%ADa_de_Datos
[i] http://www.dataprix.com/171-evoluci-n-historia-miner-datos
[i] http://www.observatoriopoliticasocial.org/index.php?option=com_content&view=article&id=984&Itemid=242
[i] http://ia-eduactiva.wikispaces.com/HERRAMIENTAS+DE+APRENDIZAJE+MINERIA+DE+DATOS
[i] http://mineriadedatos.wikispaces.com/TANAGRA
[i] http://mscerts.programming4.us/es/711058.aspx
[i] http://aquelopana.bligoo.com/content/view/245837/Rapid-Miner.html#.T-tpfhfQzgI
[i] http://exa.unne.edu.ar/depar/areas/informatica/SistemasOperativos/Mineria_Datos_Vallejos.pdf





























