Embed Size (px)
Citation preview

UNIVERSIDAD AUTONOMA METROPOLITANA
UNIDAD IZTAPALAPA
CIENCIAS BASICAS E INGENIEHA
LIC. EN COMPUTACION
TLASIFICACIÓN POR ARBOLES DE DECISION. ’’
México D. F. Febrero de I99 7.

UNIVERSIDAD A UTONOMA METROPOLITANA
UNIDAD IZTAPALAPA
CIENCIAS BASICAS E INGENIERIA
LIC. EN COMPUTACION
“CLASIFICACION POR ARBOLES DE DECISION. ”
ALUMNAS :
AMADOR CUEVAS SARA ROSA. SALAS HERNANDEZ ELIZABETH M.
PROFESORA : & Y I ~ ~-~C.,&QJ).
C2@?Ol)
ALMA EDITH MARTINEZ LICONA
México D. F. Febrero de I997
......._. ..... ....._... .:..:: ..._ ............._..... .._. . .. i................. . .../.... .:... :. . ..:. . .. ... . . . . . . . . . . ... ..... . .. . . . . . . . . . . . . . . . . . . . . . . .:.. .__. _ _ ._,... > ..._.._. ..............,.. ”....,. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .,. ... ................................................. . . . . . . . . . . ...... . . . . . . . . . . . . . ..... .. ,

I N D I C E
Introduccion. Capítulo l. Instalación del clasificador de casos.
Requerimientos mínimos del sistema. Instalación.
Capítulo 2. Ejecución del clasificador de casos. Especificaciones del archivo de entrada. Ejecución del Clasificador de Casos.
Capítulo 3. Salida del Clasificador de Casos. Reglas de producción.
9 9
10 22
13 13

INTRODUCCION
Muchas aplicaciones de Inteligencia Artificial de practica importancia están
basados en la construcción de un modelo del conocimiento usado por un humano. En
algunos casos, las tareas que un experto realiza pueden ser pensadas como una
clasificación -asignando cosas a categorías o a clases determinadas por sus propiedades.
Por ejemplo, muchas diagnósticos médicos involucran una clasificación. En el Garvan
Institute of Medical Research, mas de 600 muestras de tiroides producidos cada año son
analizados por un sistema experto. Una muestra en particular puede contener ya
comentarios de diagnósticos, pero el proceso puede ser pensado como una secuencia de
pequeñas decisiones sobre cada una de los setenta y tantos posibles diagnósticos
comentados son relevantes para la muestra en cuestión. Cada una de tales decisiones
son conceptualmente una clasificación SVNO basada en propiedades que incluyen las
medidas de la muestra y la información de respaldo tal como la fuente de la muestra. En
un modelo de clasificación, la conexión entre clases y propiedades puede ser definida por
algunos tan simple como un flujo o un tan complicado y estructurado como un proceso
manual. Si nosotros restringimos nuestra discusión a modelos ejecutables - estos pueden
ser representados como un programa de computadora - estos son dos muy diferentes
sentidos en los que pueden ser construidos. En el presente trabajo y corno parte medular
del mismo analizaremos un algoritmo llamado ID3 el cual forma parte un conjunto de
programas llamado C4.5.
Revisemos algunos términos que serán de gran utilidad:
Descripción valor-atributo: Los datos que serán analizados deben estar en un archivo
plano -toda la información sobre un objeto o caso debe ser expresada en términos de
una colección fija de propiedades o atributos. Cada atributo puede ser discreto o tener
1

MANUAL DE USUARIO.
valores numéricos, pero los atributos usados para describir un caso deben no variar de
una caso a otro.
Clases predefinidas: Las categorías que para los casos han sido asignadas deben
haber sido establecidas con anterioridad.
Clases discretas: Este requisito tiene to do con las categorías que para cada caso esta
asignado. Las clases deben ser cuidadosamente delineadas -cada caso pertenece o no
a una clase en particular - y este debe tener mas casos que clases. Un grupo de tareas
que no tienen clases discretas son considerados con predicción de valores continuos
tal como el precio del oro o la temperatura a la cual una aleación se fundirá.
Similarmente tareas en las cuales clases con valores continuos son rotas dentro de
categorías tal como duro, flexible, suave deben ser aproximadas con cuidado.
Datos suficientes: Procesos de generalización inductiva para identificar patrones en
datos, como nota acerca de esto. El tema fundamental si vale, patrones robustos no
pueden ser distinguidos con coincidencias cambiantes. Como esta diferenciación
usualmente depende de pruebas estadísticas de un género u otro, deben ser
suficientes casos los que pertenezcan a estas pruebas para que estas sean efectivas.
La cantidad de datos requerido es afectado por factores tal como el numero de
propiedades y clases y la complejidad del modelo de clasificación; cuando este
aumenta, mas datos serán necesarios para construir un modelo formal, Un modelo
sencillo puede algunas veces ser identificado con un manojo de casos, pero un modelo
de clasificación detallado usualmente requiere cientos o algunos miles de casos
preparados.
Modelos lógicos de clasificación: El programa construye solo clasificadores que
pueden ser expresados como un árbol de decisión o conjuntos de reglas de
producción. Estas formas, esencialmente restringen la descripción de una clase a una
expresión lógica donde las primitivas son sentencias sobre 10s valores de atributos
Particulares. Una forma común de modelo de clasificación que no satisface este
requerimiento es el discriminante lineal.
2

INTRODUCCION
Ahora revisemos algunos temas que facilitaran el entendimiento del programa
desarrollado.
0 Arboles de decisión: Este programa genera una clasificación en la forma de un &bol
de decisión, una estructura que es :
a) una hoja, que indicaría un clase, o
b) un nodo de decisión, que indicaría algunas pruebas que contiene el valor de un atributo
simple, con una rama y un subarbol por cada posible resultado de la prueba.
Un árbol de decisión puede ser usado para clasificar un caso comenzando por la raíz del
árbol y moviéndose atravez de este hasta que una hoja es encontrada. En cada nodo de
decisión (no una hoja), los resultados del caso para la prueba, en el nodo son
determinados por la raíz del subarbol correspondiente a su resultado. Donde estos
procesos finalmente nos llevan a una hoja, la clase del caso es determinada por el
recorrido hacia la hoja.
3

CAPITULO 1 INSTALACION
INSTALACIóN DEL CLASIFICADOR DE CASOS.
REQUERIMIENTOS MíNIMOS DEL SISTEMA.
Antes de realizar la instalación del CLASlflCADOR DE CASOS es necesario que
se asegure de que su sistema de computo cuente con las siguientes características
mínimas:
8 El disco para realizar la instalación del CLASlFlCADOR DE CASOS.
8 8 megabytes de memoria RAM.
8 Un procesador 386SX para agilizar la ejecución.
e Sistema operativo MS-DOS versión 3.3.
8 Microsoft Windows 3.1.
8 Un drive A de alta densidad de 3.5”.
8 9 Mb de espacio disponible en disco duro, para almacenar el software.
8 Un monitor de resolución EGA (recomendado uno VGA a colores).
0 Un mouse que sea soportado por la versión de Windows con la que cuente
INSTALACI~N.
Para instalar el CLASIFICADOR DE CASOS realize los siguiente pasos:
1. Introduzca el disco número 3 que contiene el archivo de instalación en la
unidad A de 3.5”
2. Cambie a la raíz de la unidad C y asegurece que no exista el directorio
C:\PROYECTO, de existir este renombrelo.
3. Teclee la siguiente línea de comando
C:\A:INSTALA
4. El sistema le irá pidiendo los discos de instalación conforme los vaya
necesitando.
5
MANUAL DE USUARIO
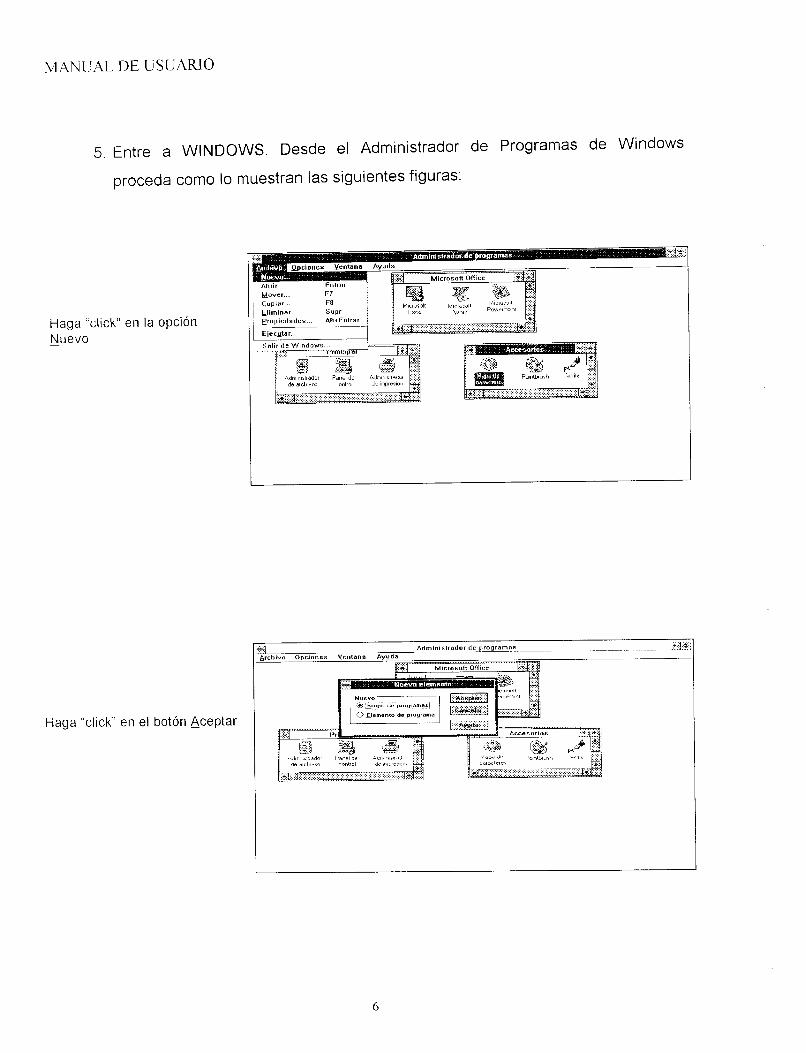
5. Entre a WINDOWS. Desde el Administrador de Programas de Windows
proceda como lo muestran las siguientes figuras:
Haga "click" en la opción - Nuevo
Haga "click" en el botón Aceptar
CAPITULO I INSTALACION
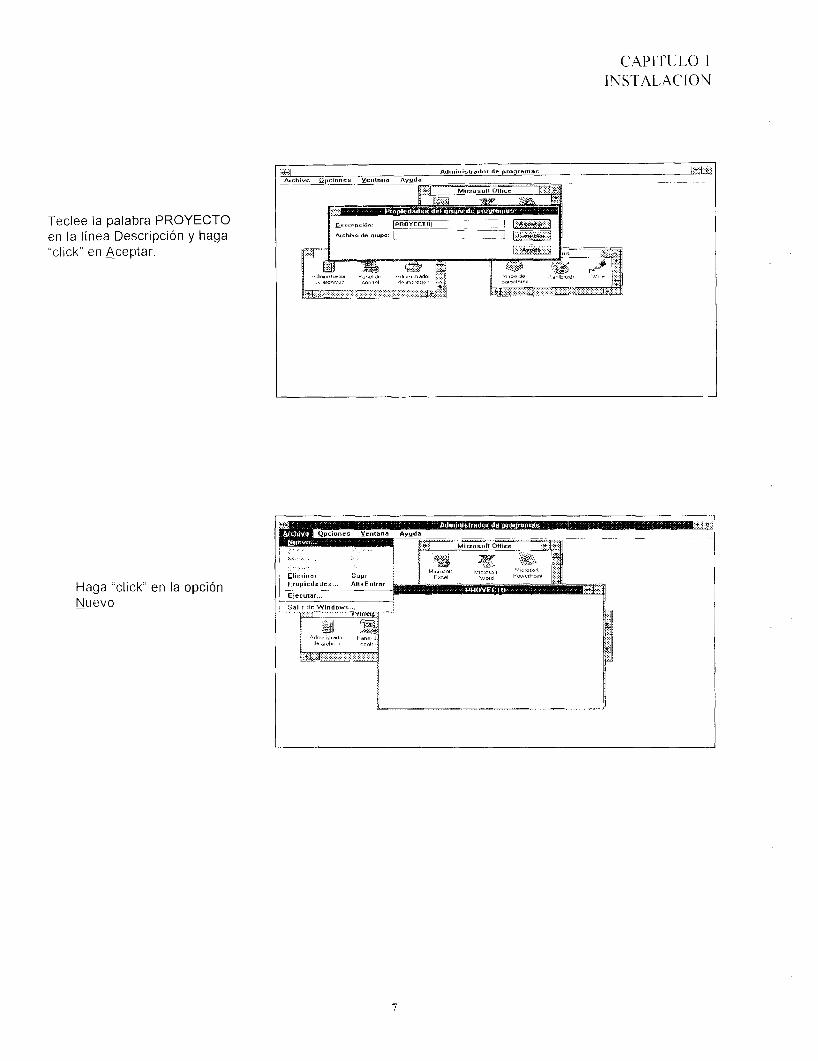
Teclee la palabra PROYECTO en la línea Descripción y haga "cllck" en Aceptar.
Haga "click" en la opción - Nuevo
$T&$:.:.:.:.:.:.:..:: :. .. i".".
. . . . . . . . . . , . . . . . . . . . . . .

MANUAL DE USUARIO
Haga “click” en el botón Aceptar
En Descripción teclee CLASIFICADOR y en la Línea de comando C:\PROYECTO\PROYECTO.EXE, después haga “click” en el botón - Cambiar icono para selecionar una imagen, haga “click” en Aceptar.
Archivo Opciones Yeniana Ayuda Administrador de proqrarnas
L ínea de comando: IC~\moyEcro\PROYFCTO E
I ” I , . . ................ #mFj ...... ..*.:.... , ,
8

CAPITULO 2 EECUCION DEL CLASIFICADOR
EJECUCIóN DEL CLASIFICADOR DE CASOS.
Para poder ejecutar el CLASlFlCADOR DE CASOS es necesario contar con el
archivo que contenga los casos que se clasificaran.
a) Especificaciones del archivo de entrada.
1. Debe ser un archivo tipo texto (con extensión “txt”) escrito en un editor de
palabras no muy sofisticado, es decir, un editor que no introduzca caracteres
especiales dentro del formato de escritura y de guardado.
2. Debe ser escrito en forma sencilla, no debe contener titulos ni frases centradas.
3. Debe contener como primer renglon los nombres de los atributos separados por
un espacio solamente, colocando la palabra “clase” como última columna.
4. Los casos deben ser escritos en forma horizontal, es decir, se escribirán los
valores de los atributos separados por un espacio y al final la clase a la que
pertenece el caso, no se permiten casos que contengan valores desconocidos en
algún atributo.
5. Los casos deben ser separados por un ENTER.
6. En caso de introducir valores numéricos éstos deberan ser escritos en forma
común, es decir, se deberá escribir la cifra incluyendo el punto decimal si así lo
requiere.
9

MANUAL DE USUARIO
Un ejemplo de un archivo de entrada sería:
outlook temp humidity windy class
sunny 75 70 true play
overcast 81 75 false play
sunn!^ 85 85 false !play
rain 68 80 false play
sumy 69 70 false play
rain 75 80 false play
overcast 72 90 false play
rain 70 96 true play
sulug~ 80 90 true !pia\.
overcast 64 65 true pia!.
rain 71 80 true !play
overcast 83 75 false p lq .
rain 65 70 true !play
sulmy 72 95 false !play
b) Ejecución del CLASlflCADOR DE CASOS.
Una vez de que este seguro de que el formato del (los) archivo (S) de entrada
cumplen con lo especificado anteriormente se debe ejecutar el clasificador, para esto se
debe proceder como sigue:
De “click” en el icono correspondiente al CLASIFICADOR.

CAPITULO 2 EJECUCION DEL CLASIFICADOR
Haga menú
“click’ en la opción Abrir del - Procesamiento
inicia Aplicacion: Procesamiento del archivo que contiene los casos a clasificar. Revisión Archivos: Visualización de archivos con extensión TXT. Salir: Finalizar el procesamiento.
Seleccione la unidad, el directorio y el nombre del archivo que se procesará, y espere
unos momentos. En caso de desear visualizar los archivos generados que contienen las
reglas de producción seleccione el botón correspondiente.
Para dar por terminada la aplicación haga “click> en el botón Salir de la ventana
Procesamiento de Archivos,después seleccione la opción Salir del menú Archivo.
11

CAPITULO 3
SALIDA DEL CLASIFICADOR DE CASOS:
Como resultado de la ejecución del clasificador son generados dos archivos tipo
texto que son:
1. REGLASN.TXT. Contiene las reglas de producción obtenidas del recorrido del árbol
generado a partir del archivo de entrada.
2. REGLASP.TXT. Contiene las reglas de producción obtenidas del recorrido del árbol
podado derivado del árbol original.
En donde la interpretación de ambos archivos será la siguiente:
Si outlook = overcast entonces Play
Si outlook = rain y windy = false entonces Play
Si outlook = rain y windy = true entonces !Play
Si outlook = sunny y humidity <=82.00 entonces Play
Si outlook = sunny y humidity ~ 8 2 . 0 0 entonces !Play
Las palabras en negritas no incluyen en el archivo, pero es la interpretación que
se deberá dar al leer las reglas de producción.


I N D I C E
Introduccion. Capítulo 1. Construyendo árboles de decisión.
Divide y vencerás Una ilustración Evaluación de pruebas Criterio de ganancia Criterio de razón de ganancia
Capítulo 2. De los arboles a las reglas. Generalizando reglas simples Clase conjunto de reglas. Clasificando clase y escogiendo una por default.
Capítulo 3. Podando arboles de decisión. ¿Cuándo simplificar?. Error basado en el podado. Ejemplo: Demócratas y Republicanos. Estimación de porcentajes de error para arboles
Capítulo 4. Implementación del algoritmo ID3. Estructuras utilizadas Descripción del programa Código fuente
13 16 17 22
27 28 30 34 35
37 37 40 43

INTRODUCCION
INTRODUCCION
En el presente trabajo y como parte medular del mismo analizaremos un
algoritmo llamado ID3 el cual forma parte de un conjunto de programas llamado C4.5.
La base de clasificación de estos programas es un metodo inductivo.
Se mencionará el algoritmo y se explicará la implementación, que se realizara
en el presente trabajo, mencionaremos las estructuras utilizadas para su
implementación as¡ como la interpretación de los resultados obtenidos con la
ejecución del algoritmo añadiendo el archivo fuente..
1

CAPITULO 1 CONSTRUYENDO ARBOLES DE DECISION
CONSTRUYENDO ARBOLES DE DECISIóN
DIVIDE Y VENCERAS El esqueleto del método de Hunt's para la construcción de árboles de decisión de
un conjunto T de casos preparados es elegantemente simple. Sean las clases
denotadas por { C I , C2, . . . , Ck}. Se tienen tres posibilidades:
O T contiene uno o más casos, todos pertenecientes a una clase simple Cj: El árbol
de decisión para T es una hoja que identifica a la clase Cj
O T no contiene casos: El árbol de decisión es nuevamente una hoja, pero la clase
asociada con la hoja debe ser determinada de otra información distinta a la de T. Por
ejemplo, la hoja deber ser escogida de acuerdo con algún conocimiento profundo del
dominio, tal como la clase global mayoritaria. C4.5 usa la clase más frecuente de el
padre de este nodo.
0 T contiene casos que pertenecen a una mezcla de clases: En esta situación la
idea es depurar T en subconjuntos de casos que son, o que parecen ser dirigidos
hacia, colecciones de clases simples de casos. Una prueba T 70 es escogida,
basada en un atributo simple, que tiene una o más salidas mutuamente exclusivas {
O,, O2 , . . . , O, }. T es dividido en subconjuntos T,, T2 ,...., T,, donde Ti contiene todos los
casos en T que tiene salida Oi de la prueba elegida. El árbol de decisión de T
consiste de un nodo de decisión identificando la prueba, y una rama para cada
posible salida. (The same tree-building machinery). El mismo mecanismo de
construcción de árboles es aplicado recursivamente a cada subconjunto de casos
preparados, tal que la i-ésima rama conduce a el árbol de decisión construido del
subconjunto Ti de casos preparados.
3
MANUAL TECNICO
UNA ILUSTRACIóN
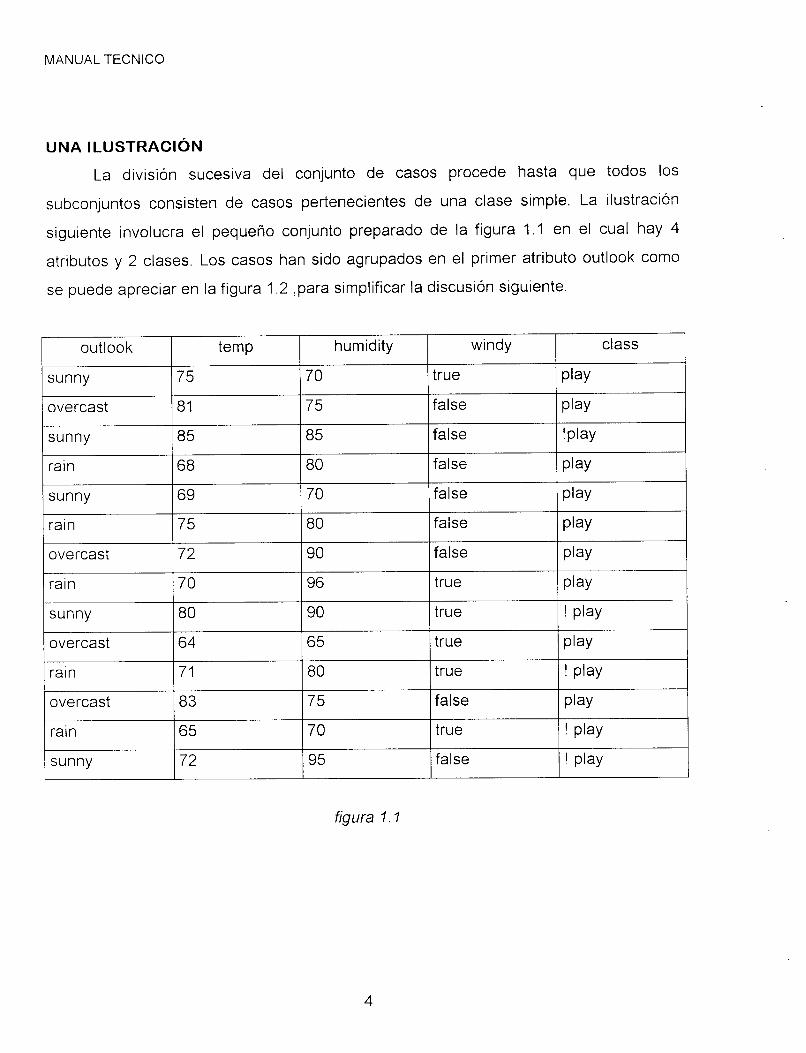
La división sucesiva del conjunto de casos procede hasta que todos los
subconjuntos consisten de casos pertenecientes de una clase simple. La ilustración
siguiente involucra el pequeño conjunto preparado de la figura 1 .I en el cual hay 4
atributos y 2 clases. Los casos han sido agrupados en el primer atributo outlook como
se puede apreciar en la figura 1.2 ,para simplificar la discusión siguiente.
figura l . I
4
CAPITULO 1 CONSTRUYENDO ARBOLES DE DECISION
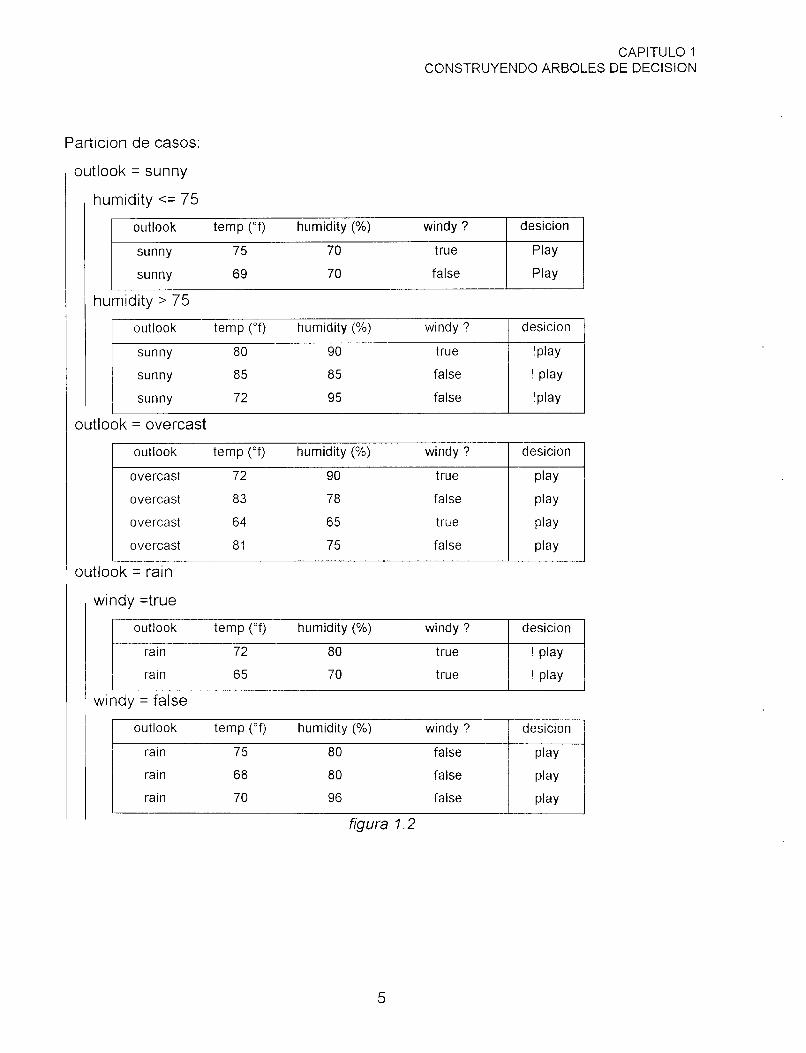
Particion de casos:
outlook = sunny
I humidity <= 75
I outlook temp ('9 humidity (%) windy ? I desicion I
sunny 75 70 true Play
I sunny 69 70 false I Play I I I I
humidity > 75
outlook temp ("9 humidity (YO) windy ?
sunny 72 95 false
! play sunny 85 85 false
!play sunny 80 90 true
desicion
!play
outlook = overcast
outlook temp ("9 humidity (YO) windy ?
overcast 72 90 true
overcast 83 78 false
overcast 64 65 true
overcast 81 75 false
outlook = rain
I windy =true
desicion
outlook temp ("9 humidity (%) windy ?
rain 72 80 true
desicion
! play rain 65 70 true ! play
~
I windy = false
outlook temp ("9 humidity (%) windy ?
rain 70 96 false Play rain 68 80 false Play rain 75 80 false
desicion
Play
figura 1.2
5

MANUAL TECNICO
Puesto que estos casos no todos pertenecen a la misma clase, el algoritmo divide
y venceras intenta dividirlos en subconjuntos. Aún no se ha discutido la manera en que
una prueba es escogida, para este ejemplo, supóngase que la prueba es outlook con
tres salidas, outlook = sunny, outlook = overcast y outlook = rain. El grupo de enmedio
contiene sólo casos de clase Play pero el primero y el tercer subconjuntos todavía
tienen clases mezcladas. Si el primer subconjunto está además dividido por una prueba
sobre humidity, con salidas humidity <= 75 y humidity > 75, y el tercer subconjunto por
una prueba sobre windy, con salidas windy = true y windy = false, cada uno de los
subconjuntos puede ahora contener casos de una clase simple. Las divisiones finales
de los subconjuntos y el correspondiente árbol de decisión es mostrado en la figura 1.2
EVALUACIóN DE PRUEBAS
Cualquier prueba que divide a T en una forma no trivial, para que por lo menos
dos de los subconjuntos {Ti} no estén vacíos, eventualmente resultarán en una partición
dentro de subconjuntos de clase simple, aunque todos o más de ellos contienen un caso
preparado. Sin embargo, el proceso de construcción de árboles no tiene la intención de
sólo encontrar alguna partición, sino construir un árbol que descubra la estructura de el
dominio y así tener un poder predictivo. A causa de que, necesitamos un número
significativo de casos para cada hoja o, ponerla de otra manera, la partición debe tener
tan pocos bloques como posibles. Idealmente, nos gustaría escoger una prueba en
cada etapa para que el árbol final sea pequeño.
Puesto que estamos buscando para un árbol de decisión compacto, ¿ Porqué no
exploramos todos los posibles árboles y seleccionamos el más simple ?.
Desafortunadamente, el problema de encontrar el árbol de decisión más pequeño
consistente con el conjunto entrenador es NP-completo. Un número asombroso de
árboles podría haber sido examinado -- por ejemplo, existen más de 4 x106 árboles de
decisión que son consistentes con el conjunto pequeñito preparado de la figura 1-1 .
6

CAPITULO 1 CONSTRUYENDO ARBOLES DE DECISION
CRITERIO DE GANANCIA.
Supóngase nuevamente que tenemos una posible prueba con n salidas que
particionan al conjunto T de casos preparados en subconjuntos T,, T2, , , , , T,. Si esta
prueba es evaluada sin explorar subsecuentes divisiones de las Ti’s, la única
información disponible como guía es la distribución de clases en T y sus subconjuntos.
Ya que necesitaremos frecuentemente referirnos a la distribución de clases en esta
sección, alguna notación nos ayudará. Si S es cualquier conjunto de casos, freq(Ci,S)
representa el número de casos en S que pertenecen a la clase Ci. Usaremos también la
notación universal en la cual IS1 denota el número de casos en el conjunto S.
El experimento original CLS de Hunt consideraba varias rúbricas bajo las cuales
una prueba debe ser evaluada. Muchas de estas fueron basadas en el criterio de
fecuencia de clase. Por ejemplo, CLSl fue restringido a problemas con dos clases,
positivo y negativo, y prefería pruebas con una salida cuyo subconjunto de casos
asociados contenía:
0 Sólo casos positivos; o, aquel faltante,
0 Sólo casos negativos; o aquellos faltantes,
El mayor número de casos positivos.
Aunque su programa usaba un criterio simple en este género, Hunt sugirió que
una aproximación basada en información teórica podría tener ventajas. Cuando construí
el precursor de ID3, olvidé este sugerencia hasta que la posibilidad de usar información
basada en métodos fue promovida independientemente por Peter Gacs.
El ID3 original usaba un criterio llamado ganador, definido abajo. La información
teórica que refuerza este criterio puede ser dada en una declaración: La información
transmitida por un mensaje depende de su probabilidad y puede ser medida en bits
como menos el algoritmo en base 2 de esta probabilidad. Así, por ejemplo, si hay ocho
mensajes igualmente probables, la información transmitida por cualquiera de ellos es -
10g2(l/8) o 3 bits.
Imagine que se selecciona un caso aleatoriamente de el conjunto S de casos y se
declara que este pertenece a alguna clase C,. Este mensaje tiene probabilidad:
7

MANUAL TECNICO
f ~ ( Cj, S )
IS1
y así la información que este transmite es
- log2 freq(C,,S) bits
IS1 Para encontrar la información esperada de tal mensaje *referente a los miembros
de la clase*, sumamos sobre las clases en proporción a sus precuencias en S, dando:
Cuando aplicamos a el conjunto de casos preparados, info(T) mide la cantidad
promedio de información necesaria para identificar la clase de un caso en T. (Esta
cantidad es también conocida como la entropia de el conjunto S.)
Ahora considere una medida similar después de que T ha sido particionada de
acuerdo con las n salidas de una prueba X . La información esperada requerida puede
ser encontrada como la suma pesada sobre los subconjuntos, como:
n
info, (TI = IT,I X info(Ti) i = l IT1
La cantidad
gain(X) = info (T) - info,(T)
mide la información ganada por la partición de T de acuerdo con la prueba X. El
criterio ganador, entonces, seleccciona un conjunto para maximizar esta información
ganada ( la cual es también conocida como la información mutua entre la prueba X y la
clase ) .
Como una ilustración concreta, considere nuevamente el conjunto preparado de
la figura 1 .l. Hay dos clases, nueve casos pertenecen a Play y cinco a Don’t Play, así
info(T) = -9114 X IOg2(9/14) - 5/14 X IOg2(5/14) = 0.940 bits.
8

CAPITULO 1 CONSTRUYENDO ARBOLES DE DECISION
(Recuerde, esta representa la información promedio necesaria para identificar la
clase de un caso en T.) Después de usar outlook para dividir T en tres subconjuntos, el
resultado es dado por
infox(T) =5/14 X (-2/5 X IOg2(2/5) - 315 X l0g2(3/5))
+ 4/14 X (-414 X IOg2(4/4) - 014 X IOg2(O/4))
+ 5/14 X (-3/5 X IOg2(3/5) - 215 X IOg2(2/5))
= 0.694 bits.
La información ganada por esta prueba es por Io tanto 0.940 - 0.694 = 0.246 bits.
Ahora suponga que, en lugar de dividir T en el atributo outlook, lo hemos particionado
en el atributo windy. Esto podría haber dado dos subconjuntos, uno con tres casos Play
y tres Don’t Play, el otro con seis casos Play y dos Don’t Play. El cálculo similar es
infoX(T) = 6/14 X (-3/6 X l0g2(3/6) - 3/6 X l0g2(3/6))
+ 8/14 x (-6/8 x 10g2(6/8) - 218 x 10g2(2/8))
= 0.892 bits.
Para una ganancia de 0.048 bits, la cual es menor que el resultado ganador de la
prueba previa. El criterio de ganancia podría entonces preferir la prueba en outlook
sobre la prueba más reciente en windy.
CRITERIO RAZóN DE GANANCIA.
Por algunos años la selección de una prueba en ID3 fue hecha en base a el
criterio de ganancia. Aunque este da bastantes buenos resultados, este criterio tiene
una seria deficiencia ( este tiene una tendencia marcada en favor de pruebas con
muchas salidas). Podemos ver esto considerando una labor de diagnóstico médico
hipotético en la cual uno de los atributos contiene una identificación del paciente. Ya
que cada identificación es pensada a ser única, particionando cualquier conjunto de
casos preparados en los valores de este atributo conducirá a un número grande de
subconjuntos, cada uno conteniendo justo un caso. Ya que todos estos subconjuntos de
casos únicos necesariamente contienen casos de una clase simple, infox(T) = O, así la
información de gananciasal usar este atributo para particionar el conjunto de casos
9

MANUAL TECNICO
preparados es máxima. Desde el punto de vista de la predicción, sin embargo, tal
dlvisión es totalmente inútil.
La tendencia inherente en el criterio de ganancia puede ser rectificada por un
género de normalización en el cual la ganancia evidente atribuible para pruebas con
muchas salidas es ajustada. Considera el volumen de información de un mensaje
perteneciente a un caso que no indica la clase a la cual pertenece el caso, excepto la
salida de la prueba. Por analogía con la definición de info(S), tenemos n
splithfo(X) = i = l
esta representa la información potencial generada por la división de T en n
subconjuntos, mientras que la información de ganancia mide la información pertinente
para la clasificación que surge de la misma división. Entonces,
gain ratio (X) = gain (X) / split info (X)
expresa la proporción de información generada por la división que es útil, es decir, que
parece útil para clasificación. Si la divisón es casi trivial, la información dividida será
pequeña y esta razón será inestable. Para evitar esto, el criterio de razón de ganancia
selecciona una prueba para maximizar la razón de arriba, sujeta a la restricción de que
la información de ganancia debe ser grande ( por lo menos tan grande como el
promediode ganancias sobre todas las pruebas examinadas).
Es evidente que el atributo de identificación del paciente no será clasificado
hondamente por este criterio. Si hay k clases, como antes, el numerador (información de
ganancia) es cuando más log2(k). El denominador, en cambio, es log2(n) donde n es el
número de casos preparados, ya que cada caso tiene una única salida. Parece
razonable suponer que el número de casos preparados es mucho más grande que el
número de clases, así la razón debería tener un valor pequeño.
Para continuar la ilustración previa, la prueba en outlook produce tres
subconjuntos conteniendo cinco, cuatro, y cinco casos respectivamente. La información
dividida es calculada como
10

CAPITULO 1 CONSTRUYENDO ARBOLES DE DECISION
-5/14 X l0g2(5/14) - 4/14 X IOg2(4/I 4) - 511 4 X IOg2(5/I 4)
o 1.577 bits. Para esta prueba, cuya ganancia es 0.246 (como antes), la razón de
ganancia es 0.246/1.577 = O. 156.
11

CAPITULO 2 DE LOS ARBOLES A LAS REGLAS
DE LOS ARBOLES A LAS REGLAS
Como se observó en la sección previa, es posible podar un árbol de decisión
para que sea más simple y más exacto. Aunque los árboles podados son más
compactos que los originales, pueden a pesar de eso ser engorrosos, complejos e
inescrutables. Si deseamos nuestra clasificación para proveer un discernimiento de
una predicción exacta en casos no vistos, hay aún una forma de hacerlo.
Los árboles de decisión grandes son difíciles de entender porque cada nodo
tiene un contexto especíifco establecido por las salidas de las pruebas de nodos
antecedentes. El árbol de decisión de la figura 2-1 a cerca de la detección de las
condiciones de hipotiroides fue generado de datos suministrados por el Instituto
Garvan de Investigación Médica en Sidney. El último nodo de la prueba TT4
measured, da la clase compensated hypothyroid si la respuesta es t, esto no sugiere
que la presencia de TT4 entre los ensayos pedidos es suficiente para diagnosticar
compensated hypothyroidism. Esta prueba tiene sentido sólo cuando lee en
conjunción con las salidas de pruebas anteriores. Cada prueba en el árbol tiene un
Único contexto que es crucial para entenderlo y puede ser verdaderamente difícil
seguir una huella de los cambios continuos de contexto mientras se busca a lo largo
del árbol.
Otra complicación surge porque la estructura del árbol puede causar
subconceptos individuales al ser fragmentado. Considere la tarea artificial simple en
la cual hay cuatro atributos binarios, F, G I J, y K, y dos clases, YES y NO. Cada
caso de clase YES tiene cualquiera de los dos F y G ambos con valor 1 , o J y K con
valor 1 , como se expresa en el árbol de decisión de la figura 2-2. El i rbo l contiene
dos subárboles idénticos de esa prueba para J y K ambos siendo 1 , Este
subconcepto simple ha sido dividido para que aparezca dos veces en el árbol, lo
cual hace al árbol más difícil de entender. La réplica no es precisamente una
13

MANUAL TECNICO
aberración de este árbol en particular ( cualquier árbol para este concepto debe
necesariamente dividir cualquiera de los dos el subconcepto F=G=I o el
subconcepto J=K=I. Hay sólo dos maneras de ir a todas partes con este problema:
definiendo atributos nuevos, y más tareas específicas tales como F=G=I, como
FRINGE, o trasladando lejos de la representación del árbol de decisión
clasificador. Esta sección se enfoca a la última aproximación.
del
I TSH <= 6: negativo
TSH > 6:
FTI <= 64:
TSH medido = f: negativo
TSH medido = t:
T4U medido = f:
TSH <= 17: hipotiroides compensada
TSH < 17: hipotiroides primaria
T4U medido = t:
cirugía de tiroides = f: hipotiroides primaria
cirugía de tiroides = t: negativo*
FTI > 64:
U
con tiroxina = t: negativo
con tiroxina = f: I I TSH medido = f: negativo
I I S H medido = t:
I cirugía de tiroides = t: negativo
cirugía de tiroides = f:
TT4 > 150: negativo
TT4 <= 150:
TT4 medida = f: hipotiroides primaria
TT4 medida = t: hipotiroides compensada
Figura 2-1. Árbol de decisión para condiciones de hipotiroides.
14

CAPITULO 2 DE LOS ARBOLES A LAS REGLAS
F = O :
I J = O : n o
J = l :
K = O : no
K = l : s i
F = l :
G = l : s i
G = O :
J = O : n o
J = l :
K = O : n o
K = l : s i
Figura 2-2. Arbol simple de decisión para F = G = 1 o J = K = 1
En cualquier árbol de decisión, la condición que debe ser satisfecha cuando
un caso es clasificado por una hoja puede ser encontrada rastreando todas las
salidas de las pruebas a lo largo de el camino de la raíz a la hoja. En el árbol de la
figura 2-2, la hoja más profunda YES es asociada con las salidas F = l , G=O, J=l I y
K= l ; cualquier caso que satisfaga estas condiciones será mapeado hacia la hoja
YES.
Podríamos de esta manera escribir “Si F= l y G=O y J= l y K=l entonces la
clase es YES’, Io cual de repente tiene la forma de la regla de producción oblicua.
De hecho, si el camino a cada hoja fuerá transformado en una regla de producción
de esta forma, la colección resultante de reglas podría clasificar casos exactamente
como el árbol lo hace. Como una consecuencia de su árbol origen, las partes “si” de
las reglas podrían ser mutuamente exclusivas y exhaustivas, así el orden de las
reglas podría no importar.
15

MANUAL TECNICO
Estamos haciendo el enfoque en reglas de producción con respecto a
algunas hojas, así podemos establecer una base más precisa para hablar acerca de
ellas. Una regla como la de arriba se escribirá:
Si F= l
G=O
J = l
K= 1
entonces clase YES
Con el entendimiento de que la condición de la regla anterior hecha arriba es
interpretada como una conjunción. Diremos que una regla cubre un caso si el caso
satisface las condiciones anteriores de la regla.
Generalizando reglas simples
Reescribiendo al árbol como una colección de reglas, una para cada hoja en
el árbol, podría no resultar en algo más simple que el árbol, ya que podría ser una
regla por cada hoja. Sin embargo, podemos ver que el antecedente de las reglas
individuales puede contener condiciones irrelevantes. En la regla de arriba, la
conclusión no es afectada por los valores de F y G. La regla puede ser
generalizada borrando esas condiciones superfluas sin afectar su exactitud, dejando
la regla más sencilla
Si J =I
K =I
entonces clase YES.
¿Cómo podemos decidir cuándo una condición puede ser borrada? Sea la regla R
es de la forma :
Si A entonces es clase C
y una regla más general R"
Si A " entonces es clase C,
16

CAPITULO 2 DE LOS ARBOLES A LAS REGLAS
donde A " es obtenida borrando una condición X de las condiciones A. La setial de
la importancia de la condición X debe ser encontrada en los casos preparados
usados para la construcción del árbol de decisión. Cada caso que satisface la
anterior A " pertenece o no pertenece a la clase designada C, y satisface o no
satisface a la condición X. El número de casos en cada uno de esos cuatro grupos
puede ser organizado dentro de una tabla eventual de 2 x 2 :
Clase C Otras clases
Satisface la condición X
E2 y2 No satisface la condición X
E1 Y1
I I I
Ya que estamos viendo sólo a los casos que satisfacen A" , aquéllos que
satisfacen la condición X también son cubiertos por la regla original R. Hay Y1+ El
de tales casos, El de ellos siendo agrupados por R ya que pertenecen a alguna otra
clase que C. Similarmente, aquéllos casos que satisfacen A " pero no a X pueden
ser cubiertos por la regla generalizada R " pero no por la regla original. Hay Y2 + E2
de ellos con E2 errores. Ya que R " también cubre todos los casos que satisface R ,
el número total de casos cubiertos por R " es Y, + El + Y2 + E2.
Mi primer experimento con reglas simplificadas usaba una prueba de
importancia en esta tabla eventual para decidir si la condición X deberá ser borrada.
CLASE CONJUNTO DE REGLAS
El proceso de generalización de reglas se repite para cada ruta en el árbol de
decisión sin simplificar. Las reglas derivadas de algunas rutas pueden tener un
índice de errror alto inaceptable o pueden duplicar reglas derivadas de otra rutas,
así el proceso usualmente produce menos reglas que el número de hojas en el
árbol.
17

MANUAL TECNICO
Una complicación causada por la generalización es que las reglas acaban
por ser mutuamente exclusivas y exhaustivas; serán casos que satisfacen las
condiciones de más de una regla o, si las reglas inexactas son descartadas, de
ninguna. Una regla de producción completa interpretada debe especificar cómo
estos casos serán clasificados. En la última situación, es convencional definir una
retirada o regla default que está en juego cuando ninguna otra regla cubre un caso.
Dediciendo que hacer en la anterior situación usualmente llamada resolución del
conflicto y adoptando el esquema de C4.5 es quizás lo más simple: las reglas son
ordenadas y la primer regla que cubre un caso es tomada como la operativa. En
consecuencia necesitamos algún método para establecer la prioridad de las reglas y
para decidir una clasificación por default.
En un trabajo anterior, desarrollé un esquema para clasificar todas las reglas
y para seleccionar un subconjunto de ellas, todas como una operación compuesta.
Aunque trabajó razonablemente bien, los conjuntos resultantes de reglas eran aún
difíciles de entender ( el orden de las reglas era importante, pero parecía arbitrario).
Supóngase que, del conjunto de todas las reglas anteriormente
desarrolladas, seleccionamos un subconjunto S de reglas para cubrir una clase
particular C. El desempeño de este subconjunto puede ser sumado por el número
de casos preparados cubiertos por S que no pertenecen a la clase C (los positivos
falsos), y el número de clase C de casos preparados que no son cubiertos por
ninguna regla en S (los negativos falsos). El valor del subconjunto S de reglas es
evaluado usando el Principio de Descripción de Longitud Mínima (MDL). Este
provee una base para compensar la exactitud de una teoría ( aquí, un subconjunto
de reglas ) , nuevamente esto es complejo.
El uso de el Principio MDL es muy simple : un Transmisor y un Receptor
ambos tienen identicas copias de un conjunto de casos preparados, pero la copia
del Transmisor también especifica la clase de cada caso mientras que en la copia
del Receptor falta toda la información de la clase. El Transmisor debe comunicar
esta información faltante a el Receptor transmitiendo una teoría de clasificación
18

CAPITULO 2 DE LOS ARBOLES A LAS REGLAS
junto con las exepciones de esta teoría. El Transmisor puede escoger la
complejidad de la teoría que envía ( una teoría relativamente simple con un número
importante de exepciones, o una teoría más completa con menos exepciones. El
Principio MDL formula que la mejor teoría derivable de los datos preparados
minimizará el número de bits requeridos para codificar el mensaje total consistente
en la teoría junto con sus exepciones asociadas.
La información que ha sido transmitida aquí es la identidad de los casos
preparados pertenecientes a la clase C, usando algún esquema de codificación
para la teoría (subconjunto S de reglas) y exepciones. El esquema usado por el
sistema es aproximado, ya que intenta encontrar un límite inferior en el número de
bits en alguna codificación en lugar de escoger una codificación particular. La idea
general puede ser resumida como sigue:
Codificar una regla, debemos especificar cada condición en su lado
izquierdo. El lado derecho no necesita ser codificado, ya que todas las reglas en el
subconjunto conciernen a la misma clase C. Hay una pequeña complicación: las
condiciones deben ser enviadas en algún orden, pero el orden no es importante ya
que las condiciones estan juntas. Si existen x condiciones en el lado izquierdo,
existen x! ordenes posibles que pueden ser enviados, todas ellas equivalentes
desde el punto de vista de especificación de la regla, Por Io tanto, los bits
requeridos para enviar algún orden en particular debe ser reducido por un “crédito”
de log2(x!).
Codificar un conjunto de reglas requiere la suma de los bits para codificar
cada regla, menos un crédito similar para la clasificación de la regla (ya que todas
las clasificaciones de reglas para una clase simple son equivalentes)
Las exepciones son codificadas indicando cual de los casos cubiertos por la
regla S son positivos falsos y cuales de aquellos no cubiertos son negativos falsos.
Si la regla cubre r de los n ca S pre rados, con fp po~[os fa)ys y fn negativos
falsos, el número de bits requ lL r os p 17 a codificar las exe ¡ones S
log2 r + log2 n-r.
19

MANUAL TECNICO
f P fn
El primer término son los bits necesarios para indicar los positivos falsos
entre los casos cubiertos por las reglas y el segundo término da una expresión
similar para identificar los negativos falsos entre los casos no cubiertos.
El valor de un subconjunto S particular es medido por la suma de la longitud
del código para reglas y exepciones ( la suma más pequeña, mejora la teoría
representada por S).
A menudo los esquemas de codificación tienden a sobreestimar el número de
bits requeridos para codificar una teoría relativa a conjuntos de exepciones. Esto
puede ser explicado en parte por el hecho que conjuntos de atributos son a veces
redundandes, as¡ que diferentes teorías pueden ser funcionalmente identicas.
Mientras que el papel de una teoría para una clase es identificar un subconjunto de
los casos preparados, diferentes conjuntos de reglas que denotan el mismo
subconjunto de casos son intercambiables, aunque ellos puedan tener diferentes
codificaciones. Siguiendo Quinlan y Rivers el sistema se compenda por este efecto
por el uso de una suma pesada
bits exeptuados + W * bits teoría.
Donde W es un factor menor que uno. Ahora, un valor apropiado de W
dependerá de la probabilidad de dos teoría describiendo la misma colección de
casos, las cuales a su vez dependerán sobre el grado de redundancia en los
atributos. C4.5 usa un valor por default de 0.5, el cual puede ser además reducido
por la R opción (Capítulo 9) cuando parece probable que los atributos tienen un
grado insólito de traslapo ( Afortunadamente, el algoritmo no parece ser
particularmente sensible a el valor de W).
La tarea, entonces, es encontrar un subconjunto S de reglas para la clase C
que minirnizen esta codificación total. Esto es similar a la tarea de regularización de
reglas discutida antes (encontrar un subconjunto de las condiciones que minimizan
el índice de error pesimista de la regla) pero, considerando que la ambiciosa
eliminación aproximada usada es razonablemente satisfactoria. En cambio, el
20

CAPITULO 2 DE LOS ARBOLES A LAS REGLAS
sistema considera todos los posibles subconjuntos de las reglas para una clase, si
no existen también muchos de ellos, y usa una simulación reforzada para encontrar
un buen subconjunto. Para el último, el sistema repetidamente selecciona una de
las reglas aleatoriamente y lo considera incluido en el subconjunto S ( si este no
está ), o borrado ( si este está). Esta acción produce un cambio AB en el total de
bits para codificar el subconjunto “más exepcional” y, si este cambio es benéfico,
esto es automáticamente aceptado. Si la acción incrementa el largo total de
codificación para que AB sea positivo, el cambio para S es aceptado con
probabilidad e- donde K es una especie de temperatura sintética. Para
gradualmente reducir K mientras los cambios son explorados, el sistema tiende a
converger a un conj de reglas con codificación cercana al mínimo.
La selección de subconjuntos de reglas es nuevamente ilustrado por el
dominio hipotiroides con reglas para la clase primaria hipotiroides. Para esta clase,
el árbol de decisión obtenido de 2,514 casos preparados dio tres reglas cuyos
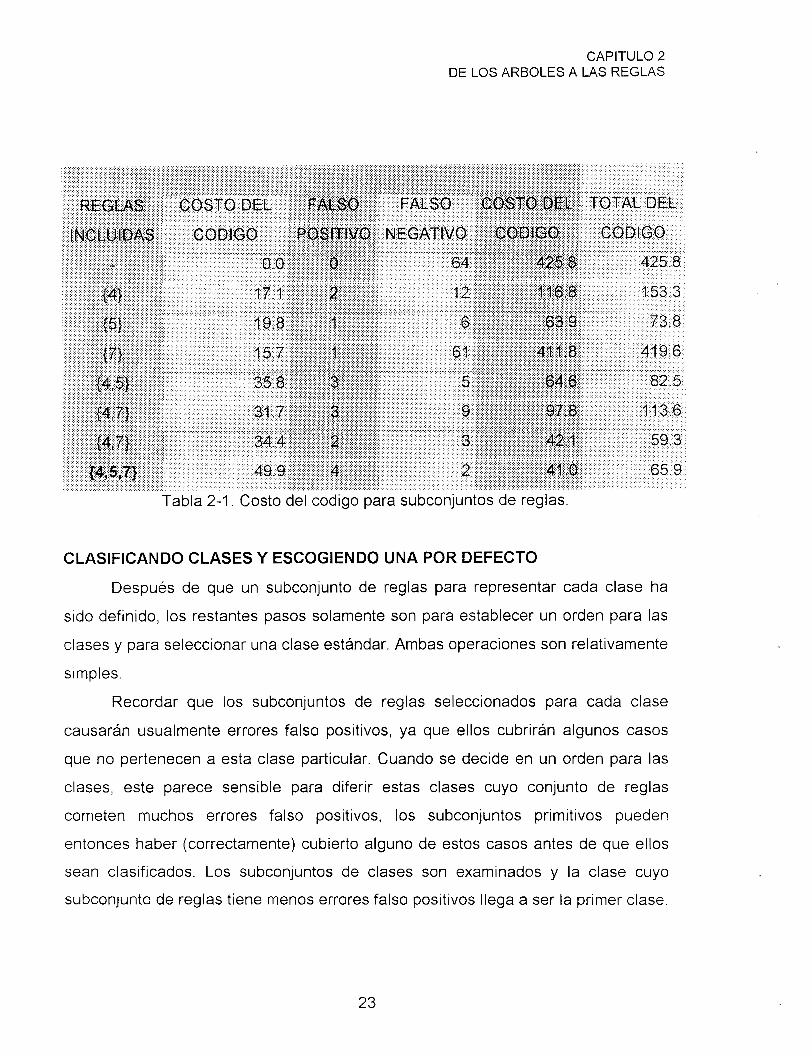
números de identidad pasan a ser 4, 5, y 7. La tabla 2-1 resume el análisis de los
ocho posibles subconjuntos de estas reglas. El último renglón de la tabla puede ser
explicado como sigue:
El costo de la codificación para el conjunto de las tres reglas es la suma de los
costos de la codificación para las reglas individuales, menos el ordenamiento
credit. Las reglas individuales tienen costos de código de 17.1 ~ 19.8, y 15.7 bits
respectivamente y, ya que existen 3! formas de ordenarlas, el costo de la teoría
es de 17.1 + 19.8 + 15.7 - log2(6).
Existen cuatro casos falsos positivos de los 66 casos cubiertos por estas
reglas y dos falsos negativos de los restantes 2,448 casos, así el código exepción
requiere
4 2 bits
21

MANUAL TECNICO
Usando el valor por default W=0.5, el costo de la codificación total es
entonces 41 .O + 0.5 * 49.9.
22
CAPITULO 2 DE LOS ARBOLES A LAS REGLAS
CLASIFICANDO CLASES Y ESCOGIENDO UNA POR DEFECTO
Después de que un subconjunto de reglas para representar cada clase ha
sido definido, los restantes pasos solamente son para establecer un orden para las
clases y para seleccionar una clase estándar. Ambas operaciones son relativamente
simples.
Recordar que los subconjuntos de reglas seleccionados para cada clase
causarán usualmente errores falso positivos, ya que ellos cubrirán algunos casos
que no pertenecen a esta clase particular. Cuando se decide en un orden para las
clases, este parece sensible para diferir estas clases cuyo conjunto de reglas
cometen muchos errores falso positivos, los subconjuntos primitivos pueden
entonces haber (correctamente) cubierto alguno de estos casos antes de que ellos
sean clasificados. Los subconjuntos de clases son examinados y la clase cuyo
subconjunto de reglas tiene menos errores falso positivos llega a ser la primer clase.
23

MANUAL TECNICO
Los falso positivos en los restantes casos preparados son recalculados, la
siguiente clase seleccionada, y así.
Una selección razonable para la clase estándar podría ser aquel que aparece
más frecuentemente en el conjunto entrenador. Sin embargo, la clase estándar será
usada solamente cuando un caso no es cubierto por algunas reglas seleccionadas,
así estas reglas deben representar alguna parte determinada de esta. El sistema
simplemente escoge como la estándar la clase que contiene más casos preparados
no cubiertos por alguna regla, decidiendo vínculo en favor de la clase con mayor
fecuencia absoluta.
Después de que el orden de la clase y la clase estándar han sido
establecidas, el conjunto de reglas compuesto es un subconjunto de un proceso
final refinado. Si hay una o más reglas cuya omisión podría actualmente reducir el
número de errores clasificados en los casos preparados, la primera de tal regla es
descartada y el conjunto verificado nuevamente. Este paso es diseñado para
permitir un escrutinio final global de el conjunto de reglas como un todo ,en el
contexto del camino este será usado.
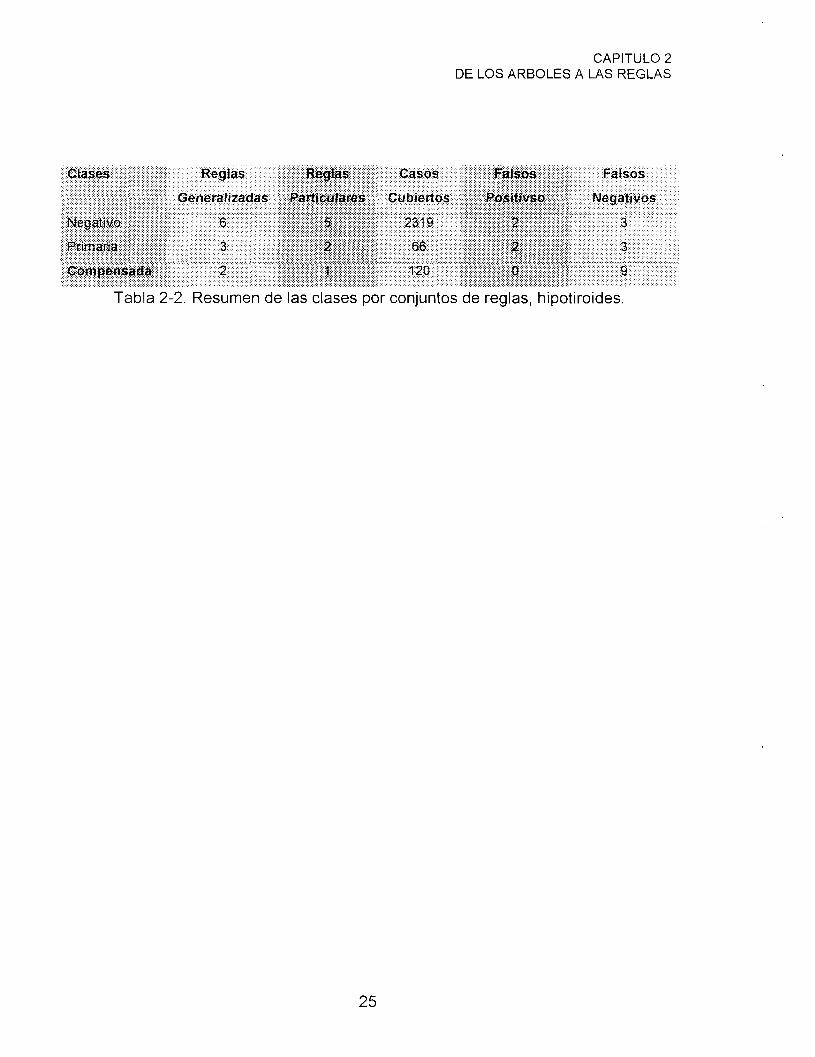
En nuestro ejemplo de hipotiroides, la situación después de que el conjunto
de reglas ha sido establecido para cada clase es resumido en la tabla 2-2. Las
reglas para hipotiroides compensada, sin positivos falsos, son colocadas primero,
seguidas del subconjunto de reglas para hipotiroides primaria, y finalmente las
reglas para la clase negativa. Hay 8 casos preparados de hipotiroides compensada
que no son cubiertos por alguna regla, más que el número de alguna otra clase, así
esta llega a ser la clase estándar. En el conjunto de reglas final (mostrado en la
figura 2-3), la exactitud predicha para cada regla aparece en corchete cuadrado.
Estas reglas representan una teoría más amigable que el árbol de decisión de la
figura 2-1, y aún las reglas son apenas tan exactas como el &bol: ambas dan sólo
ocho errores (0.06%) cuando se clasifican 1258 casos no vistos.
24
CAPITULO 2 DE LOS ARBOLES A LAS REGLAS
Tabla 2-2. Resumen de las clases por conjuntos de reglas, hipotiroides.
25

MANUAL TECNICO
Si tiroxine = f
cirugía de tiroides = f
TSH > 6
TT4 <= 150
FTI > 64
entonces clase hipotiroides compensada
Si cirugía de tiroides = f
TSH > 6
FTI <= 64
(98.9%)
entonces clase hipotiroides primaria (95.6%)
Si tiroxine = f
TT4 medido = f
TSH > 6
entonces clase hipotiroides primaria (45.3%)
Si TSH <= 6
entonces clase negativa (99.9%)
Si tiroxine = t
FTI > 64
entonces clase negativa (99.5%)
Si TSH medida = f
entonces clase negativa (99.5%)
Si TT4 > 150
entonces clase negativa(99.4Oh)
Si cirugía de tiroides = t
entonces clase negativa (92.7%)
Si ninguna de las arriba
entonces clase hipotiroides compensada
Figura 2.3. Reglas finales para el ejemplo de hitpotiroidez.
26

CAPITULO 3 PODANDO ARBOLES DE DECISION
PODANDO ARBOLES DE DECISIóN
El método de particionamiento recursivo de construcción de árboles de decisión
descrito en el capítulo 2 continuará para subdividir el conjunto de casos preparados hasta
que cada subconjunto en la partición contenga casos de una clase simple, o hasta que
ninguna prueba ofrezca alguna mejoría. El resultado es a menudo un árbol muy complejo
que "sobreajuste de datos" por inducir más estructuras de las que son justificadas por los
casos preparados.
Este efecto es prontamente visto en el ejemplo extremo de datos aleatorios en la
cual la clase de cada caso no tiene relación con sus valores de atributos. Construí una
base de datos artificial de este género con diez atributos, cada uno de los cuales tomaba
el valor de O o 1 con igual probabilidad. La clase fue también binaria, si con probabilidad
0.25 y no con probabilidad 0.75. Mil casos generados aleatoriamente fueron divididos en
un conjunto preparado de 500 y un conjunto prueba de 500. Para estos datos, la rutina
inicial de árbol de construcción de C4.5 produce un árbol sin sentido de 11 9 nodos que
tiene un porcentaje de error de más de 35% en los casos de prueba.
Este pequeño ejemplo ilustra el doble peligro que puede venir por ser demasiado
incauto en la aceptación de el árbol inicial: este es a menudo extremadamente complejo, y
puede tener actualmente un mayor porcentaje de error que un árbol más simple. Para los
anteriores datos aleatorios, un árbol compuesto de sólo las hojas no podría tener un
porcentaje de error esperado de 25% en casos no vistos, todavía el &bol elaborado es
notablemente inexacto.. . . .
25

MANUAL TECNICO
~ C U Á N D O SIMPLIFICAR?
Existen básicamente dos maneras en las cuales el método de particionamiento
recursivo puede ser modificado para producir árboles más simples: decidiendo no dividir
un conjunto de casos preparados en alguno más amplio, o eliminando retrospectivamente
alguna de las estructuras establecidas arriba con particionamiento recursivo.
La aproximación anterior, algunas veces llamada parando o prepodando, tiene la
atracción de que el tiempo no es desperdiciado reuniendo estructuras que no son usadas
en el árbol final simplificado. La aproximación típica es mirar la mejor manera de
fraccionamiento de un subconjunto y evaluar la división desde el punto de vista del
significado estadístico, ganancia de información, reducción de error o cualquiera. Si este
avalúo cae debajo de algún umbral, la división es rechazada y el árbol para el
subconjunto es justo la hoja más apropiada. Sin embargo, como Breiman y otros señalan,
tales reglas de parado no son sencillas de hacer bien - un umbral demasiado alto puede
concluir antes la división el beneficio de la subsecuente división llega a ser evidente,
mientras que un valor demasiado bajo resulta en una simplificación pequeña.
En un período, use un criterio de parada basado en la prueba X' de importancia
estadística. El resultado fue bastante satisfactorio en algunos dominios pero fue
desnivelado, de manera que abandone esta aproximación; C4.5, al igual que CART,
ahora seguimos el segundo camino. El proceso de divide y vencerás está dando rienda
libre y el árbol desbordado que es producido es entonces podado. El cálculo adicional
invertido en construir partes del árbol que es subsecuentemente descartado puede ser
substancial, pero este costo es desplazado contra el beneficio debido a una exploración
más completa de particiones posibles. El desarrollo y podado de árboles es más lento
pero más fiable.
Podar un árbol de decisión casi invariablemente causará a éste una mayor
clasificación errónea de los casos preparados. Consecuentemente, las hojas del arb01
podado no necesariamente contendrán casos de una clase simple, hemos encontrado un
fenómeno en el capítulo anterior. En lugar de una clase asociada con una hoja, allí
26

CAPITULO 3 PODANDO ARBOLES DE DECISION
nuevamente estará una distribución de clase especificada, para cada clase, la
probabilidad de que un caso preparado y la hoja pertenezcan a esta clase.
Esta modificación puede ligeramente afectar la determinación de la clase más
probable para un caso no visto.
Árbol de decisión original:
physician fee freeze = n;
adoption of the budget resolution = y: democrat (151)
adoption of the budget resolution = u: democrat (1)
adoption of the budget resolution = n:
education spending = n : democrat (6)
education spending = y 1 democrat (9)
education spending = u : republican (1)
physician fee freeze = y;
synfuels corporation cutback = n: republican (97/3)
synfuels corporation cutback = u: republican (4)
synfuels corporation cutback = y:
duty free exports = y: democrat (2)
duty free exports = u: republican (1)
duty free exports = n:
education spending = n: democrat (5/2)
education spending = y: republican (13/2)
education spending = u: democrat ( I )
physician fee freeze = u;
water project cost sharing = n: democrat (O)
water project cost sharing = y: democrat (4)
water project cost sharing = u:
mx missile = n: republican (O)
mx missile = y: democrat (3/1)
mx missile = u: republican (2)
27

MANUAL TECNICO
DESPUÉS DEL PODADO:
physician fee freeze = n: democrat (
physician fee freeze = y: republican
physician fee freeze = u;
1 68/2.6)
(1 2311 3.9)
mx missile = n: democrat (311 .I )
mx missile = y: democrat (412.2)
mx missile = u: republican (211)
Figura 3-1. Árbol de decisión antes y después del podado
ERROR BASADO EN EL PODADO
Los árboles de decisión son usualmente simplificados por eliminación de uno o
más árboles y reemplazando estos por hojas; como cuando construimos árboles, la clase
asociada con una hoja se encuentra por la examinación de los casos preparados
cubiertos por la hoja y escogiendo la clase más frecuente. Además C4.5 permite
reemplazar un subárbol por una de éstas ramas. Ambas operaciones son ilustradas en la
fig. 3-1 que muestra un árbol de decisión derivado de datos de votantes al congreso antes
y después del podado. (Para el árbol no podado, recordar que (N) o (N/E), apareciendo
después de la hoja indica que la hoja cubre N casos preparados, E erróneamente,
números similares para el árbol podado se explican a continuación). El subárbol
adoption of the budget resolution = y: democrat
adoption of the budget resolution = u: democrat
adoption of the budget resolution = n:
education spending = n : democrat
education spending = y : democrat
education spending = u : republican
ha sido reemplazado por la hoja demócrata, el subárbol
28

CAPITULO 3 PODANDO ARBOLES DE DECISION
synfuels corporation cutback = n: republican
synfuels corporation cutback = u: republican
synfuels corporation cutback = y:
duty free exports = y: democrat
duty free exports = u: republican
duty free exports = n:
education spending = n: democrat
education spending = y: republican
education spending = u: democrat
ha sido reemplazado por la hoja republicano, y el subárbol
water project cost sharing = n: democrat
water project cost sharing = y: democrat
water project cost sharing = u:
mx missile = n: republican
mx missile = y: democrat
mx missile = u: republican
ha sido reemplazado por el subárbol de su tercera rama.
Supóngase que fuerá posible predecir el porcentaje de error de un árbol y de sus
subárboles (incluyendo las hojas). Esto podría inmediatamente sugerir el siguiente
razonamiento simple de podado: comenzando desde el fondo del árbol y examinando
cada subárbol que no sea hoja. Si reemplazamos de este subárbol con una hoja, o con su
rama más frecuentemente usada, podríamos llegar a una predicción con menor porcentaje
de error, entonces podar el árbol es correcto, recordando que el porcentaje de error
estimado para todos los arboles que incluyen este serán afectados. Ya que el porcentaje
de error para el árbol completo decrece cuando el porcentaje de error de alguno de sus
subárboles es reducido, este proceso llevará a un árbol cuya predicción de porcentaje de
error es mínima con respecto a la forma aceptable de podado.
29

MANUAL TECNICO
¿Cómo podemos predecir este porcentaje de error?. Es claro que el porcentaje de
error en el conjunto preparado del cual el árbol fue construido (error de resubstitución, en
la terminología de Breiman y otros) no proporciona una estimación satisfactoria; en lo que
al conjunto preparado se refiere, el podado siempre incrementa el error. En el árbol de la
figura 3-1 , el primer árbol reemplazado separa 1 Republicano de 167 Demócratas (sin
errores en el conjunto entrenador), así podar este subárbol de la hoja demócrata causa a
uno de los casos preparados a ser mal clasificado. El segundo subárbol clasifica mal a 7
casos preparados cuando ordena 11 Demócratas y 112 Republicanos, pero esto aumenta
a 11 errores cuando el árbol es reemplazado por la hoja republicano.
Esta búsqueda como una manera de predecir porcentajes de error conduce
nuevamente a dos técnicas. La primera tecnica predice el porcentaje de error del árbol y
sus subárboles usando un nuevo conjunto de casos que es distinto del conjunto
preparado. Puesto que estos casos no fueron examinados al mismo tiempo que el árbol
fue construido, la estimacijn obtenida de ellos es claramente imparcial y, si existen
bastantes de ellos, fiable. Ejemplos de tales técnicas son:
Costo-Complejidad del podado, en el cual el porcentaje de error estimado de un árbol
es planeado como la suma pesada de su complejidad y su error en los casos
preparados, con los casos distintos usados principalmente para determinar un peso
apropiado.
Simplificado-Error del podado, el cual evalúa el porcentaje de error del árbol y sus
componentes directamente en el conjunto de casos separados.
El inconveniente asociado con esta familia de técnicas es simplemente que
algunos de los datos disponibles deben ser reservados para el conjunto separado, así el
árbol original debe ser construido de un conjunto entrenador más pequeño. Esto puede no
ser una desventaja cuando los datos son abundantes, pero puede conducir a arboles
inferiores cuando los datos son escasos. Una manera acerca de este problema es usar
una aproxlmación de validación-cruzada. En esencia, los casos disponibles son divididos
en C bloques de igual tamaño y, para cada bloque, un árbol es construido por casos en
30

CAPITULO 3 PODANDO ARBOLES DE DECISION
todos los otros bloques y probados por casos en el bloque “holdout”. Para valores
moderados de C, se supone que el árbol es construido para todos pero un bloque no
diferirá mucho del árbol construido para todos los datos. Por supuesto, C arboles deben
ser grandes en lugar de solamente uno. Ver Breiman (1984)
La aproximación aceptada en C4.5 pertenece a la segunda familia de técnicas que
usan solo el conjunto preparado del cual el árbol fue construido. La estimación
resubstituida original de porcentaje de error es ajustada para reflejar esta tendencia de la
estimación. En un trabajo anterior, desarrolle un método llamado podado pesimista,
inspirado por una corrección estadística, que efectivamente incrementó el número de
errores observados de cada hoja por 0.5. C4.5 ahora emplea una estimación mucho más
pesimista como sigue.
Cuando N casos preparados son cubiertos por una hoja, E de ellos
incorrectamente, el porcentaje de error de resubstitución para esta hoja es de E/N. Sin
embargo, podemos estimar esto como algo sencillo observando E “eventos” en N
ensayos. Si este conjunto de N casos preparados pudiera ser contemplado como un
ejemplo (el cual, por supuesto, no lo es), podríamos preguntar como este resultado nos
determina acerca de la probabilidad de un evento (error) por encima de la población
entera de casos cubiertos por esta hoja. La probabilidad de error no puede ser
determinada exactamente, pero tiene para ella misma una (posterior) distribución
probabilistica que es usualmente resumida por un par de limites de confianza. Para un
nivel de confianza dado CF, el límite superior de esta probabilidad puede ser encontrada
por el límite de confianza de una distribución binomial; así el límite superior se escribirá
UcF (E,N) . Entonces, C4.5 simplemente iguala el porcentaje de error predicho a la hoja
con este límite superior, basado en el argumento de que el árbol ha sido construido para
minimizar el porcentaje de error observado. Ahora, esta descripción viola las nociones
estadísticas de muestre0 y limites de confianza, así que el razonamiento debería tomarse
como un gran grano de sal. Como muchos heurísticos con cuestionables refuerzos, no
31

MANUAL TECNICO
obstante las estimaciones que estos producen parecen frecuentemente proporcionar
resultados aceptables.
Para simplificar la contabilidad, los errores estimados para las hojas y subárboles
son calculados asumiendo que ellos fueron usados para clasificar un conjunto de casos
no vistos del mismo tamaño que el conjunto preparado. Así que, una hoja cubre N casos
preparados con un porcentaje de error estimado de UCF(E,N) el cual podría aumentar para
una predicción de N * UcF(E,N) errores. Similarmente, el número de errores predichos
asociados con un (sub)árbol es solamente la suma de los errores predichos de estas
ramas.
EJEMPLO : DEMóCRATAS Y REPUBLICANOS.
Para ilustrar que está pasando, regresaremos a el ejemplo de la ilustración 3-1. El
subárbol
education spending = n : democrat (6)
education spending = y : democrat (9)
education spending = u : republican (1 )
no tiene errores asociados en el conjunto preparado. Para esta primera hoja, N=6, E=O, y
(usando un nivel de confianza por default del 25% dado por C4.5), UZ5% (0,6) = 0.206, así
que el número estimado de errores si esta hoja fue usada para clasificar 6 casos no vistos
es 6 x 0.206. Para las hojas restantes, UZ5% (0,9) = 0.143 y ( 0 , l ) = 0.750, asÍ que el
número de errores para este subárbol esta dado por
6 x 0.206 + 9 x O. 143 + 1 x 0.750 = 3.273
Si el subárbol fue reemplazado por la hoja demócrata, esta podría cubrir los
mismos 16 casos con un error, así los errores estimados correspondientes serán
16 X U25% (1:16) = 16 X 0.157 = 2.512
Puesto que el subárbol existente tiene un gran número de errores estimados, este
es podado para una hoja.
El subárbol anterior es como sigue:
32

CAPITULO 3 PODANDO ARBOLES DE DECISION
adoption of the budget resolution = y: democrat (1 51 )
adoption of the budget resolution = u: democrat (1 )
adoption of the budget resolution = n: democrat (16/1)
el número de errores estimados para este subárbol es
151 x UZ5% (0,151) + 1 x UZ5% (0 , l ) + 2.512 (de arriba)
el cual se convierte en 4.642. Si este subárbol fue reemplazado por la hoja demócrata, el
error estimado sería 168 x UZ5% (0,168) = 2.61 O. El porcentaje de error estimado para la
hoja nuevamente es menor que para el subárbol, así este subárbol es también podado
para una hoja.
ESTIMACIóN DE PORCENTAJES DE ERROR PARA ARBOLES
Los números (NIE) de las hojas del árbol podado en la figura 3-1 puede ahora ser
explicado como antes, N es el número de casos preparados cubiertos por la hoja. E es
precisamente el número de errores estimados de un conjunto de N casos no vistos que
fueron clasificados por el árbol.
La suma de errores estimados de las hojas, dividido por el número de casos en el
conjunto entrenador, proporciona una estimación inmediata del porcentaje de error del
árbol podado en casos no vistos. Para este árbol, la suma de los errores estimados de las
hojas es 20.8 para un conjunto entrenador de tamaño 300. Para esta estimación,
entonces, el árbol podado clasificará mal el 6.9% de casos no vistos.
El resumen de resultados sobre los casos preparados y un conjunto de casos
probados aparece en la figura 3-2. Para este conjunto de datos particular, el porcentaje
de error del árbol podado es mayor que para el de un árbol no podado para los datos
preparados, pero, como se esperaba, el árbol podado tiene un porcentaje de error menor
que el árbol original para casos no vistos. La estimación aquí del 6.9% queda fuera por
ser algo mayor que el porcentaje de error observado sobre casos no vistos que es del 3%.
Sobre diez maneras de validacion-cruzada, sin embargo, el promedio actual y 10s
porcentajes de error estimados sobre casos no vistos 5.3% y 5.6% respectivamente, son más estrechos,
33

MANUAL TECNICO
Evaluacion en datos entrenadore (300 casos):
Antes del Podado Después del Podado
Tamaño Errores Tamaño Errores Estimación
25 8(2.7%) 7 13(4.3%) (6.9%)
Evaluacion en datos de prueba (1 35 casos):
Antes del Podado Después del Podado
Tamaño Errores Tamaño Errores Estimación
25 7(5.2%) 7 4(3.0%) (6.9%)
Figura 3-4. Resultados de los votos del Congreso.
34

CAPITULO 4 IMPLEMENTACION DEL ALGORITMO ID3
IMPLEMENTACION DEL ALGORITMO ID3.
En el presente capitulo se Iistara el programa con el que se realizó la
implementación del algoritmo descrito en los capítulos anteriores, se incluye el programa
completo, así como una lista de las estructuras utilizadas para dicho fin y una breve
explicación del mismo.
Las estructuras utilizadas para la implementación del algoritmo descrito en capítulos
anteriores, fueron las siguientes:
ARRESUM typedef struct arresum{
float sum1 ; float sum2;
}SUMAS;
PAQUETE struct Paquete{ int num-atributos;
>; typedef struct Paquete PAQUETE;
int posicion;
PAQUETE1 struct Paquetel {
struct ListaSencilla int char
1; typedef struct Paquetel
struct PaqueteDecision{ float
*apuntador; posicion; Atributo[GO];
PAQUETEI;
PAQUETEDECISION
PorcientoError; struct ArbolDecision *DirCaso;
1; typedef struct PaqueteDecision PAQUETEDECISION;
35
MANUAL TECNICO
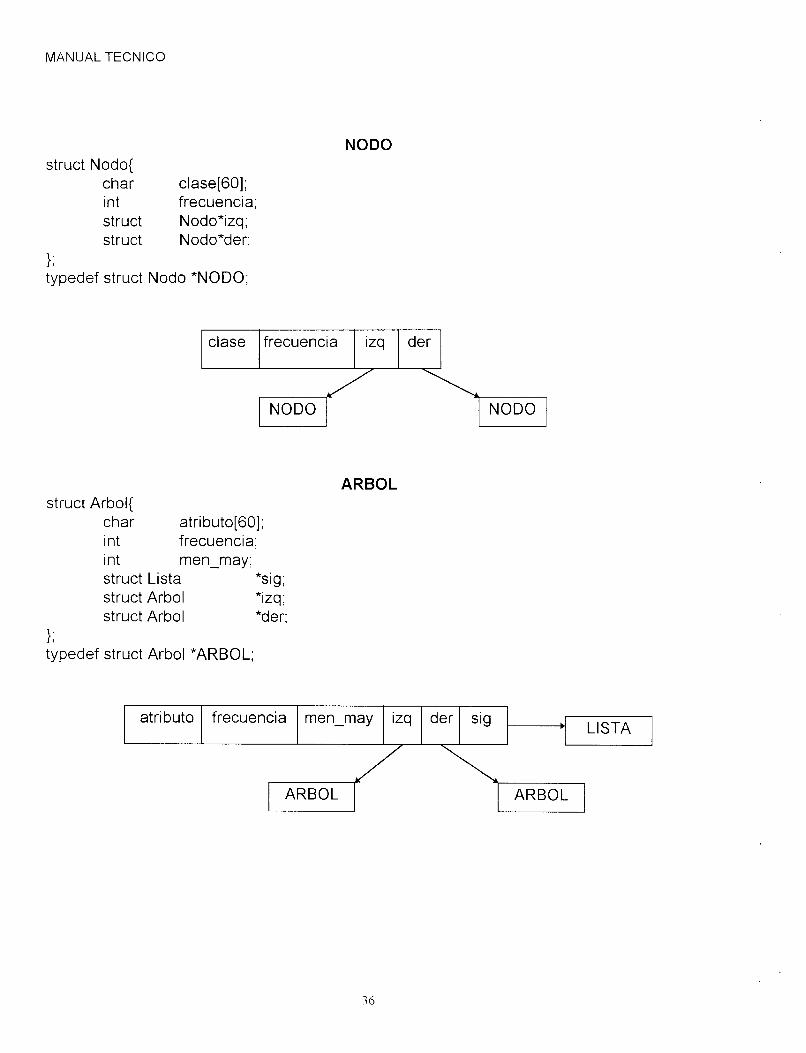
NODO struct Nodo{
char clase[60]; int frecuencia; struct Nodo*izq; struct Nodo*der;
typedef struct Nodo *NODO; 1;
I NODO I I NODO 1
ARBOL struct Arbol{
char atributo[60]; int frecuencia; int men-may; struct Lista *sig; struct Arbol *izq; struct Arbol *der;
1; typedef struct Arbol *ARBOL;
atributo sig der izq men-may frecuencia LISTA
ARBOL ARBOL
36

CAPITULO 4 IMPLEMENTACION DEL ALGORITMO ID3
LISTA struct Lista{
char clase[60]; float frecclase; struct Lista *sig;
I ; typedef struct Lista *LISTA;
clase NODO sig frecclase
LISTASENCILLA struct ListaSencilla{
char Salida[GO]; Int frecuencia; Int men-may; struct ListaSencilla *sublista;
>; typedef struct ListaSencilla "LISTASENCILLA;
salida LISTASENCILLA sublista men-may freccuencia
LISTASALIDA struct Listasalida{
char Atributo[GO]; int posición; float ganancia; struct Listasalida *sig; struct ListaSencilla *sublista;
I: typedef struct LlstaSalida *LISTASALIDA;
37

MANUAL TECNICO
Atributo posicion LISTASENCILLA
1 LISTASALIDA 1
ARBOLDECISI~N struct ArbolDecision{
char Valor[GO]; char Clase[GO]; struct ArbolDecision *sig; struct ArbolDecision "subraiz;
typedef struct ArbolDecision *ARBOLDECISION; 1;
Valor ARBOLDECISION Posicion Clase
I ARBOLDECISION I
Descripción del programa:
Inicialización de las estructuras a utilizar. 0 Abertura del archivo con los casos a procesar.
Cálculo del número de lecturas al archivo. Se procesa el archivo de la siguiente manera:
0 Lectura del encabezado del archivo, obteniendo de esto la lista de atributos presentes en los casos, estos atributos se guardaran en la variable CabAtributo la cual es de tipo LISTASALIDA.
0 Procesar el archivo atributo por atributo determinando los distintos valores de estos. exceptuando la última columna dando como resultado una lista de salidas por atributo la cual se guardara en la variable CabSalidas de tipo ARBOL. Para la última columna se formará una lista de clases la cual se almacenara en la varlable CabClase de tipo NODO.
0 Si las distintas salidas del atributo fueran números, se determinará un rango basado en el cálculo de la Entropía de éstos, de esta manera se generará el árbol

CAPITULO 4 IMPLEMENTACION DEL ALGORITMO ID3
ClasiSal de tipo ARBOL en cuya raíz se almacenará el número de casos menores o iguales a la Entropía y en el hijo derecho aquellos mayores que la misma. Cálculo del “info” en base a la estructura CabClase. Cálculo del “infox” ,”ganancia”, “splitinfox” y “razón de ganancia” por atributo . Seleccion de la máxima “razón de ganancia’’ tomando el atributo correspondiente a ésta como la raiz (subraiz) del árbol de decision, guardando dicho árbol en la variable RAlZ de tipo ARBOLDECISION. En la variable ListaVaIores de tipo LISTASENCILLA se almacenará la lista con las salidas del atributo seleccionado como raíz. Se recorrerá ListaValores de tal manera que se seleccionarán del archivo en turno aquellos casos casos cuya salida en ese atributo coincida con el nodo actual de esta lista, eliminando de los casos el atributo en cuestión, obteniendose así un archivo con los casos seleccionados. Ver figura sig.
7 1 outlook temp humidity wind!. class
m sunny 75 70 tnle play
overcast 81 75 false play
sunny 85 85 false !play
rain 68 80 false play
sunn?‘ 69 70 false play
rain 75 80 false play
overcast 72 90 false pia!.
rain 70 96 true play
sunny 80 90 true !play
d
7 1 overcast 64 65 true play
I outlook = rain I temp humidity windy class
68 80 false play
75 80 false play
70 96 truc pia!.
Con el archivo generado anteriormente se realiza una llamada recursiva clasificar todos los casos originales.
hasta
0 Se obtienen las reglas de produccion del árbol generado anteriormente escribiendo
0 El árbol generado anteriormente se somete a un algoritmo de podado que consiste en: estas en un archivo de texto llamado REGLASN.TXT.
0 Determinar el número de errores y aciertos producidos al clasificar cada caso. 0 Apartir de las hojas del árbol se calcula el porcentaje de error de cada una de
ellas (el porcentaje de error se iguala al límite superior del intervalo de confianza de una distribución binomial, con nivel de confianza por defautl del 25% para el algoritmo de clasificación ID3).

MANUAL TECNICO
0 Se realiza una comparación de los porcentajes de error antes y después del podado, definiendo que si el porcentaje de error después de podado es menor entoces se procede con el mismo en caso contrario no se realizan cambios.
Se obtienen las reglas de produccion del árbol podado generado anteriormente escribiendo estas en un archivo de texto llamado REGLASP.TXT. Consulte capítulo correspondiente.
40

CAPITULO 5 CODIGO FUENTE
CODIGO FUENTE #Include #Include #Include #Include #Include #Include #Include #Include #include
<stdio.h> <math. h> idlr . h> <conlo. h> <stdlib.h> <string.h> ifcntl. h> <ctype. h> <lo. h>
typedef struct arresumi float suml; float sum2;
1 SUMAS ; . . . . . . . . . . . . . . . . . . . . . . . . . . ARBOL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . struct Nodo[
char clase [ 601 ; / * Contlene el nombre de la clase * / lnt frecuencia; / * frecuencla de la clase * / struct Nodo *izq; struct Nodo *der;
1 ; typedef struct Nodo *NODO;
struct Arbol{ char atributo [ 601 ; / * Contiene el nombre del atributo * / Int frecuencia; / * frecuencia del atributo * / lnt menmay; struct Lista * s l g ; /*apuntador a la lista de sus clases*/ struct Arbol *Izq; struct Arboi *der;
1 ; typedef struct Arbol *ARBOL;
struct Lista( char clase [ 601 ; float frecclase; struct Lista * s i g ;
1 ; typedef struct Lista *LISTA;
/ * Contiene el nombre de la clase * / / * frecuencia de la clase * /
struct LlstaSencllla{ char Salida[GO]; / * Contiene el nombre de las salldas * / lnt frecuencia; / * de los atributos * / lnt men may; struct ListaSencIlla "sublista;
typedef struct LlstaSencilla *LISTASENCILLA; I ;
struct LlstaSallda( char Atributo[GO]; / * En la lista principal contlene el * /
int posiclon; / * En la lista pricipal contiene la * /
float ganancia; / * Contiene la razon de ganancia del * / struct LlstaSallda "sig; / * atrlbuto * / struct LlstaSencllla *subllsta;
/ * nombre del atributo * /
/*posiclon en la que se encuentra dentro del archivo * /
typedef struct LlstaSallda *LISTASALIDA; 1 ;
struct Paquete{ lnt num-atrlbutos; lnt poslclon;
~.
typedef struct Paquete PAQUETE; : I
43

MANUAL TECNICO
struct Paqueteclase( lnt frecuencla; char clase [ 601 ;
1 ; typedef struct Paqueteclase PAQUETECLASE; struct Paquetel(
struct ListaSencllla *apuntador; int char
1 ; typedef struct Paquete1 struct ArbolDecisioni
char char l n t int lnt struct ArbolDeclsion struct ArbolDeclsion
1 ;
poslcion; Atrlbuto [ 601 ;
PAQUETE1 ;
Valor[GO]; / * valor del atributo * / Clase[6O] ; / * clase * / Posiclon; / * poslciCn del atributo en el archlvo * / Errores; / * casos m a l clasificados * / Casos; / * n€mero de casos clasiflcados * / *s1g; "subralz;
typedef struct ArbolDeclslon *ARBOLDECISION; struct PaqueteDecisloni
float PorcientoError; struct ArbolDeclsion *DirCaso;
1 ; typedef struct PaqueteDecislon PAQUETEDECISION; Int num arch=O,Podarlhoja=O; float I l r n l t e = ~ . O E - Z O ;
SUMAS Fentropla(ARB0L SubRalz); vold claslflca-arbol(float entrop1,ARBOL arbolorlg,ARBOL **arbolfin); SUXAS SumEntropla (lnt frec, char atrib [ 601 ) ; lnt abre-archlvo(char nombre[]); vo id arbol-binario(f1oat entropi,ARBOL *orlgen,ARBOL *destino); float log2 (float x) ; float determina-rango(ARB0L CabSalldas,int tot-casos);
/ S - - - - - - - - - - - - - - - - - - - - - - - - D E C L A ~ C I O N DE FUNCIONES-----------------------*/
INICIALIZA L O S CAMPOS DE LA LISTA ORDENADA Y LA PONE A NULL * /
vold Iniclalizar(NOD0 *Cabeza){ (*Cabeza) =NULL; (*Cabeza) ->izq=NULL; (*Cabeza) ->der=NULL; ¡*Cabeza) ->frecuencia=l; strcpy ( (*Cabeza) ->clase, " " ) ;
/ veld InlclaLlsta(L1STASALIDA *Cabeza) i
(*Cabeza) =NULL; (*Cabeza)->sig=NULL; (*Cabeza)->sublista=NULL; ("Cabeza) ->poslcion=@; (*Cabeza)->[email protected]; strcpy ( ("Cabeza) ->Atributo, " ' I ) ;
1 , ,*----""---------"""""""""""""""""""""""""""" * / vold InlclaArbolDecislon(ARBOLDEC1SION *Cabeza){
1 *Cabeza) =NULL; 1 *Cabeza'! ->slg=NULL; '*Cabeza) ->subralz=NULL: strcpy ( í*Cabeza) - > V a l o r , " " i ; strcpy 1, (*Cabeza) ->Clase, ' I " ) ; I"Cabezaj->Poslclon = O; (*Cabeza) ->Errores = 0; (*Cabeza)->Casos = O;j
44

CAPITULO 5 CODIGO FUENTE
vold InlciArbLls(ARB0L *Cabeza) { ("Cabeza) =NULL; (*Cabeza) ->izq=NULL; (*Cabeza)->der=NULL; (*Cabeza) ->sig=NULL; (*Cabeza) ->frecuencia=l; (*Cabeza)->menmay=O; strcpy ( (*Cabeza) ->atributo, " ' I ) ;
1
/*""""""---"""""""----""""""""""-""-"""""""* / vo;d IniclaLlsSen(LISTASENC1LLA *Cabeza)(
(*Cabeza) =NULL; (*Cabeza)->subllsta=NULL; strcpy ( (*Cabeza) ->Sailda, " " ) ; (*Cabeza) ->frecuencia = O; (*Cabeza) ->menmay = O;
1
/,""""""""""""""""""""""""""""---"-"""""-* / NODO CreaNodo (char clase [ 601 ) [
struct Nodo "Nuevacabeza;
Nuevacabeza= (NOD0)malloc (sizeof (struct Nodo) j ; Nuevacabeza->frecuencia = 1; strcpy(NuevaCabeza->clase,clase); Nuevacabeza->lzq = NULL; NuevaCabeza->der = NULL; return (Nuevacabeza) ;
1 /*~"""""""~_~~"~""""""""""""~-""""--"---"-"""-* / ARBOLDECISION CreaRalz(char valor[60],char clase[60])(
struct ArbolDeclslon "Nuevacabeza;
NuevaCabeza=(ARBOLDECISION)malloc(sizeof(struct ArbolDecision)); Nuevacabeza->sig = NULL; Nuevacabeza->subraiz = NULL; strcpy(NuevaCabeza->Valor,valor) ; strcpy(NuevaCabeza->Clase, clase) ; Nuevacabeza->Poslclon = O; Nuevacabeza->Errores = O; Nuevacabeza->Casos = O; return (Nuevacabeza) ;
/~~~~""""""""""""------"""""""""---------"-------------"~ LISTASENCILLA CreaNodoSub(char sallda[60],int frecuencla,int menmay j(
/
struct Listasenellla *Nuevacabeza;
NuevaCabeza=(LISTASENCILLA)malloc(sizeof(struct LlstaSencilla)); strcpy(NuevaCabeza->Salida,sallda); Nuevacabeza->frecuencia = frecuencia; Nuevacabeza->men-may = men-may; Nuevacabeza->subllsta = NULL; return(NuevaCabeza);
/~ " " "~~~~~~~~~~"" " " " " " " " - - " " " " " " " "~-~" - " " " " - - - - - " " * LISTA CreaLlsta(char clase[60]) {
struct Llsta *Nuevacabeza;
NuevaCabeza=(LISTA)malloc(sizeof(struct Llsta)); Nuevacabeza->frecclase = 1; strcpy (Nuevacabeza->clase, clase) ; Nuevacabeza->slg = NULL; return (Nuevacabeza) ;
/
45

MANUAL TECNICO
LISTASALIDA CreaSalida(char Atrlbuto[GO]){ /*---"""""""""""---""""""""""----"-""""""""""-*/
struct LlstaSallda *Nuevacabeza;
NuevaCabeza=(LISTASALIDA)malloc(sizeof(struct ListaSallda)); Nuevacabeza->poslcion = O; Nuevacabeza->ganancia = 0.0; s t r c p y ( N u e v a C a b e z a - > A t r l b u t o , A t r l b u t o ) ; Nuevacabeza->slg = NULL; Nuevacabeza->sublista = NULL; return (Nuevacabeza) ; )
/ * / ARBOL CreaArbol (char atrlbuto [ 601 i { str-~ct Arbol *Nuevacabeza;
NuevaCabeza=(ARBGL)malloc(sizeof(struct Arbol)); Nuevacabeza->frecuencia = 1; Nuevacabeza->men may = o ; strcpy (Nuevacabeya->atributo, atributo) ; Nuevacabeza->lzq = NULL; Nuevacabeza->der = NULL; Nuevacabeza->sig = NULL; return (Nuevacabeza) ; 1
/*""""""""""""""""""""""""""------"-------------* volci LlberaLista(L1STA *SubLista){
/
lf ( (*SubLlsta) I = NULL ) [ LlberaLlsta(&(*SubLlsta)->sig); free (*SubLlsta) ; *SubLista=NULL; 1 )
/*--"""""""""""""-----"""""""""""""-""""""-* / veld LlberaArbol(ARB0L *SubRalz)[
If (*SubRalz !=NULL) [ LlberaArbol ( & (*SubRaiz) ->lzq) ; LlberaLlsta ( & (*SubRalz) - > s l g ) ; LlberaArbol ( & ("SubRaiz) ->der) ; free (*SubRalz) ; *SubRalz=NULL; ] ]
/ vola LlberaNodo(NGDG *SubRaiz){
If (*SubRalz !=NULL) [ LiberaNodo ( & (*SubRalz) ->lzq) ; LiberaNodo ( & (*SubRalz) ->der) ; free ("SubRaiz) ; *SubRaiz=NULL; ) )
*""""----""""""""-"""""""-""""""""""""""- * / v o l a LlberaListaSencllla(LISTASENC1LLA *SubLista){
If ( (*SubLista) ! = NULL ) { LiberaListaSencilla(&(*SubLlsta)->sublista); free (*SubLlsta) ; *SubLlsta=NULL; ) ]
/*--""----"""""----"""""""---""""--""""""""""-"" * /
46

CAPITULO 5 CODIGO FUENTE
veld InsertarInfo(NOD0 *CabezaTemp,NODO Nuevo) ( lnt dlferencla = O;
If (*CabezaTemp==NULL) *CabezaTemp = Nuevo;
else [ diferencia = s t rcmp((*CabezaTemp)->clase ,Nuevo->clase) ; lf (dlferencla < O) InsertarInfo ( & (*CabezaTemp) ->der, Nuevo
if(diferencia > O) InsertarInfo ( & (*CabezaTemp) ->izq, Nuevo
if (diferencia == O) ( ((*CabezaTernp)->frecuencia++); free(Nuev0); } ] 1
vold lnsertar (NODO *Cabeza, char clase [ 601 ) ( struct Nodo *Aux=NULL; Aux = CreaNodo(c1ase); InsertarInfo(Cabeza,Aux); }
"
vold InsertaLista(char clase[GO],LISTA *InlcLlsta)( /*~~~""~~""""~""""----"""""""""""""""""""-
if ( ! strcrnp ( (*InicLista) ->clase, clase) )
else ( (*InicLlsta)->frecclase++;
if ( (*InicLista)->slg!=NULL)
else InsertaLista (clase, & (*InlcLlsta) - > s i g ) ;
!*InlcLlsta)->slg=CreaLista(clase); ) 1
v o l d InsertaAtrlb(LISTASAL1DA *InlcLlsta,char atrlbuto[GO]) i lf ( '*lnlcLlstaj !=NULL)
else InsertaAtrib ( & (*InicLista) - > s i g , atrlbuto) ;
(*InlcLista) =Creasalida (atributoj ; ) /*~""""-~"""~~"""""""""--"""~"""~""-~"""~" vo ld InsertaMax(LISTASAL1DA *InicLista,float ganancia,lnt posiclon){ lnt l=l;
LISTASALIDA aux=*InicLlsta; while( (1 ! = posiclon) & & (aux ! = NULL) j {
aux=aux->sig; It+; 1
aux->ganancla=ganancla; aux-?poslc~on=poslclon; }
void InsInfoSalida(ARB0L *CabezaTernp,ARBOL Nuevo,char sallda[60])! lnt dlferencla = O; LISTA Aux=NULL;
If (*CabezaTemp==NULLj { *CabezaTernp = Nuevo;
(*CabezaTemp)->sig = CreaLista(sa1ida); ) else (
dlferencla = strcrnp((*CabezaTemp)->atrlbuto,Nuevo->atributo); ~f (dlferencla < O!
lf (dlferencla ? o )
If (dlferencla == 0 ) [
InsInfoSallda ( & (*CabezaTemp) ->der, Nuevo, sallda) ;
InsInfoSallda ( & f *CabezaTernp) -?lzq, Nuevo, sallda) ;
((*CabezaTemp)->frecuencla++j; Aux= (*CabezaTempi - > s ; g ; InsertaLlsta (sallda, &Aux) ; free(Nuev0); 1 )
- * /
" * /
* /
* /
* /
" * /
47

MANUAL TECNICO
/*"""-~~~~"""""""""""--"""""""""~""""""-"-~""- INSERTA EN LA LISTA LA INFORMFlCION CON LA AYUDA DE
LA FUNCION INSERTAINFO
vold lnssallda(ARB0L *Cabeza,char clase[60],char sallda[60]) { * /
struct Arbol *Aux=NULL;
PAQUETE lee-encabezado(char *buf,LISTASALIDA *CabAtributo) i 1nt 1=0,1 = o ; char atrlbuto [ 601 ='"I;
PAQUETE paquete;
paquete.num atr¡butos=O; whllei (bufT]] !='\r') & & (1<50) ) i
~f (buf [ I ] ! = I ' )
else { atrlbuto [ 11 = buf [ 7 ] ;
atributo[l]='\O'; InsertaAtrib(&(*CabAtributo),atributo); / * inserta en cola de atributos*/ paquete.num ~ atributos++: 1=-1; )
I + + ; I++; )
paquete. poslclon=] ; return (paquete) ; ]
/*~~""-~""""""""""""""""""""""""""""""""-* / * lmprlmlr funclon * / / * ~ ~ " - ~ ~ " " ~ ~ " " " - ~ ~ " " " - - - - - " " " - - - - " " " ~ " " " ~ " " " ~ " " " ~ ~ " " ~ " ~ float calculalnfo(int numerador,lnt denomlnador) {
/
/
f ioat divi=O, lnf o=O ;
dlvi = (numerador*l.O)/ (denominador*l.O); lnfo=info-dlvi*logZ(divi); return (lnf o) ; )
/*"-~~"-~~""-~~""""""""""""""""""""""~""""" / * lmprlmlr funclon * /
flcat Info(NOD0 SubRalz,lnt num-casos,float m f o ) {
* /
/
float l n fode r=O, ln fo lzq=O, In focab=0 ;
lf (SubRalz!=NULL) { ~nfo~zq=lnfo+InfoiSubRalz->lzq,num-casos,lnfo); lnfocab = calculalnfo(SubRalz->frecuencla,nuIn-casosI; L n f o d e r = l n f o + I n f o ( S u b R a i z > d e r , n u m c a s o s , l n f o ) ; return!lnfolzq+~nfoder+infocab); 1
return(lnfolzq+lnfoder+¡nfocab); } /*"~~""""~""""""--"""--""-"""""-~""-~""~""""-~"~ / * Imprimir funcion * / /"-~"""""""""""--""--""""""""-~~""""""""""""-* f-loat calculainfox (int denomlnador, LISTA SubLista) {
/
/
float dlvl=O,lnfo=O;
L f (SubLlsta==NULL; return ( O i ;
lnfo=calculalnfox(denomlnador,SubLlsta->slg); d~v~=~SubL~sta->frecclase*l.O;/~denom~nador*~.O); lnfo=lnfo-dlvl*logZ idlvl) ; return (Info) ; )
else {
I

CAPITULO 5 CODIGO FUENTE
/*~~"~-~~~~_~""""""""""""""""""""""--"---"""""~ / float Infox(ARB0L SubRaiz,int num-casos,float info){
float lnfoder=O,lnfoizq=O,infocab=O;
If ( SubRaiz ! =NULL) { infoizq=lnfo+Infox(SubRaiz->izq,num casos,info); lnfocab = ((SubRaiz->frecuencia*l.Ol/(num-casos*l.O) )*calculainfox(SubRalz
lnfoder=lnfo+Infox(SubRalz->der,num ~ casos,lnfo); return(lnfolzq+lnfoder+lnfocab); ]
>frecuencla,SubRalz->slg);
return(lnfolzq+lnfoder+lnfocab);] /*-----"""""""""""""""""-------------""-""""""----~ i-ioat SplltInfox(ARB0L SubRalz,lnt num-casos,float Info){
/
float lnfoder=O,infolzq=O,lnfocab=O;
If (SubRalz !=NULL) { infolzq=lnfo+SplitInfox(SubRaiz->izq,num casos,mfo); infocab = - (SubRaiz->frecuencia*l. O) / (nu&-casos*l. O) * l o g 2 ( (SubRaiz-
lnfoder=lnfo+SplitInfox(SubRaiz->der,num-casos,info); return(infoizq+lnfoder+infocab); ]
>frecuencia*l.O)/(num-casos*l.O) ) ;
return(lnfolzq+infoder+infocab);) /*-""""-------""-"""""""-------"""""""----""""""-""* LISTASALIDA Mezcla (LISTASALIDA p, LISTASALIDA q ) {
/
LISTASALIDA r=NULL,Mezcla=NULL;
lf ( ( p==NULL I 1 ( q==NULL) ) prlntf ("LISTAS VACIAS") ;
lf( p->ganancla <= q->ganancla) i r=p ; p=p->s1g;)
r=q; else {
q=q->s1g; 1 Mezcla=r; whlle ( ( p!=NULL) & & (q!=NULL)
If (p->ganancia<=q->ganancia) { r->slg=p; r=p ; p=p->s1g; )
r->slg=q; r=q; q=q->slg;)
else {
1 f (p==NULL)
else
return (Mezcla) ; )
r->slg=q;
r->sig=p;
/~""~~""~~""""~~"""""""-~""""""---"------------"----- void Divlde(LISTASAL1DA *CabLista,LISTASALIDA *Aux) {
* /
LISTASALIDA Auxl=NULL;
49

MANUAL TECNICO
/*"""_-"----""""""""""""""""""""""""""""----* / veld OrdenaLlsta(LISTASAL1DA *CabLlsta){ LISTASALIDA Aux=NULL;
If (*CabLista !=NULL) { ~f ( (*CabLista) - ? s i g ! =NULL) {
Dlvide (CabLlsta, &Aux) ; OrdenaLista(CabL1sta); OrdenaLista (&Aux) ; *CabLlsta=Mezcla(*CabLista,Aux); ] )
/ veld IniciallzaCabezas(NOD0 *CabClase,ARBOL *CabSalldas,ARBOL *ClaslSal,LISTASALIDA *CabAtributo,LISTASENCILLA *LlstaValores){
Inlcxallzar(&(*CabClase)); InlciaLlsta(&(*CabAtributo)); InlciArbLls ( & ("CabSalidas) ) ; InlclArbLls ( & (*ClasiSal) ) ; InlclaLlsSen(&(*LlstaValores));
1 /'--""""------------"""""""""""""""""""-"""""-* / veld SlDlglto(ARB0L *CabSalldas,ARBOL *ClasiSal,lnt numpcasos)[ char cadl[6O]="",cad2[60]=""; lnt pundec=O, slgno=O, l=O, tam=O; f-loat entropla=O, entropl=O;
1 f ( lsdiglt ( (*CabSalldas) ->atrlbuto[O] ) 1 1 ( (*CabSalldas) ->atrlbuto[Ol = = I . ' ) ) { entropla = determlna rango(*CabSalldas,num casos); / * calcula la entropia * / entropl = entropla; strcpy(cad2, ecvt (entropia, 10, &pundec, &signo) ) ; / * en pundec se guarda * / tam=strlen(cadZ) ; / * la poslclon del punto,en slgno se lndlca * / for(l=O;l<=pundec;lt+) / * sl ei nLmero es posltivo o negatlvo * /
cadl [pundec] = ' . ' ; for(l=pundectl;i<=tam;l++)
cad1 [tam] = ' \O ' ; (*ClasiSal) = CreaArbol(cadl);/* menor o igual a entropla * / (*ClaslSal)->frecuencia = O; (*ClaslSal)-?menmay = -1; (*ClasiSal)->der = CreaArbol(cadi);/* mayor a entropla * / (*ClasiSal)->der->frecuencia = O; (*ClaslSal)-?der->men-may = 1; (*ClaslSal)->lzq = NULL;
-
cad1 [ i] =cad2 [ i] ;
cadl [ I ] =cad2 [i-1] ;
arbol binarlo (entropl, & (*CabSalldas) , & (*ClaslSal) ) ; } else {
-
*ClaslSal = "CabSalldas; *CabSalidas = NULL; )
/ * ~ ~ ~ " " ~ ~ ~ " " " " ~ ~ " " " ~ " - - ~ ~ " " " ~ ~ " " " " - " " - - - - - " - - - - - - - - - - - - - * / * lmprlmlr funclon * /
veld Calcularazonganancla(ARB0L CabSalldas,LISTASALIDA *CabAtrlbuto,lnt num casos,lnt 1 , float lnfoj {
/
/
float lnfox,splltlnfox,ganancla: double razonqanancldx=O;
lnfox=infox (CabSalldas,num-casos, O) ; ganancla=-Lnfo-infox; s p i l t l n f o x = S p l l t I n f o x ( C a b S a l l d a s , n u m casos,O); ~f (splltlnfox == O) / * porque ¡a claslflcaclcn sobre este atrlbuto * /
else
InsertaMax(&(*CabAtributo),razongananclax,j); )
razongananclax = O; / * es amblgua * /
razongananclax=ganancia/splitinfox;
50

CAPITULO 5 CODIGO FUENTE
void Recorresublista(LISTASENC1LLA *Sublista,char atrlbuto[60],lnt frecuencia,lnt menmay) {
~f (*Subllsta!=NULL) Recorresubl~sta(&(*Sublista)->subllsta,atributo,frecuencia,men-may);
*Subllsta=CreaNodoSub(atrlbuto,frecuencla,men-may); ) else
/*-------"""""""--"""""""""""""""""""""""""-*/ void InsertaSublista(char atrlbuto[60],lnt frecuencla,lnt men-may,LISTASALIDA *CabAtrlbuto, lnt 1 ) {
LISTASALIDA aux=NULL;
aux = *CabAtrlbuto; while ( ( aux->pos1clon!=]) & & (aux!=NULL))
aux = aux->slg; ~f(aux->poslcion==~i
R e c o r r e s u b l ~ s t a ( & a u x - > s u b l l s t a , a t r ~ b u t o , f r e c u e n c i a , m e n - m a y ) ; ) /
iilt lee-atributos(char *buf,LISTASENCILLA *ListaAtrlb){ lnt 1=0 , j=O,poslclon=O; char atributo [ 601 ="" ;
while( (buf[j] !='\r') & & (j<50) 1 { lf (buf [ I ] ! = ' ' )
else { atrlbuto [ I] = buf [ j I ;
atributo [ 11 = ' \O ' ; posiclont+;
1=-1; ] I + + ; 1 + t ; ]
Recorresubl~sta(&(*ListaAt~~b),atributo,pos~cion,O);
return (O) ; ] /
veld EscArcProd(F1LE *fp,ARBOLDECISION RAIZ,ARBOLDECISION AuxSub,char cadena[200]){ ARBOLDECISION AuxRaiz=RAIZ; lnt tam; char espaclo [O] =" ";
whlle (AuxRalz !=NULL) [ If ( ( lsdlgit (AuxRaiz->Valor [O] ) ) 1 1 (AuxRaiz->Valor [O] == ' . ' ) ) {
If (AuxRaiz->sig!=NULLj
else strcat (cadena, "<="j ;
strcat (cadena, " > " ) ; ] strcat(cadena,AuxRaiz->Valor); strcat (cadena, espacloj ; lf(AuxRalz->subralz==NULL)
if ( ! strcmp (AuxRalz->Clase, " ' I ) ) / * no claslflcado * /
else ( / * ya claslflcado * / AuxRalz = AuxRalz->slg;
strcat(cadena,AuxRaiz->Clase); fprintf (fp, " % S ",cadena) ; lf ( ( lsdigit (AuxRalz->Valor [O] ) ) 1 1 (AuxRalz->Valor [O] == ' . ' ) ) {
if (AuxRaiz->sig!=NULL)
else tam=strlen(cadena) - strlen(AuxRa1z->Valor) - strlen(AuxRai2->Clase) - 3;
tam=strlen(cadena) - strlen (AuxRalz->Valor) ~~ strlen(RuxRalz->Clase) - 2 ; ] else
cadenaítaml='\O'; tam=strlen(cadena) - strlen(AuxRalz->Valor) - strlen(AuxRa1z->Clase) - 1;
fprlntf (fp. "\n"' : I . AuxRalz = AuxRalz->slg;]
51

MANUAL TECNICO
else ~f(AuxRaiz->subralz ! = NULL) {
AuxSub=AuxRalz; AuxRaiz=AuxRaiz->subraiz; EscArcProd(fp,AuxRalz,AuxSub, cadena) ; tam=strlen(cadena) - strlen (AuxRalz->Valor) - 1; cadena[tam]='\O'; lf ( ( isdlgit (AuxSub->Valor [ O] ) ) 1 I (AuxSub->Valor [ O] == ' . ' ) ) {
if(AuxSub->sig!=NULL) tam=strlen(cadena) - strlen (AuxSub->Valor) - 3;
tam=strlen(cadena) - strlen(AuxSub->Valor) -. 2; 1 else
else tam=strlen (cadena) - strlen(AuxSub->Valor) - 1.; cadena [tam] = ' \O ' ; AuxRaiz=AuxSub->sig; ) / * f l n if * / } / * fin while * /
I /*"-------""""""""--""""""""""""""""""""""""- * / vold EscTltulos (FILE *fp, char nombre [13] j {
fprlntf(fp," REGLAS DE PRODUCCION OBTENIDAS APARTIR DEL ARBOL DE DECISION
fprlntf (fp, "\n") ; tprlntf (fp, " DEL ANALISIS DEL ARCHIVO ' : ' S , \n",nombre) ; fprlntf (fp, "\n") ; fprlntf (fp, "\n") ; ]
GENERADO\n" ) ;
/*~----------""""--"""""--""""""""-""""---"""""""-* / veld EscRegProd(ARBOLDECISI0N Ralz,char nombre[l3]){
FILE *fp; char cadena [2OO] ="" ; ARBOLDECISION AuxSub=NULL;
lf ( ( fp=fopen(nombre, "w+") ) == NULL ) { prlntf("N0 SE PUEDE ABRIR EL ARCHIVO PARA GENERAR LAS REGLAS DE PRODUCCION"); exlt (1) ; 1
EscTltulos (fp,nombre) ; EscArcProd(fp,Ralz,AuxSub, cadenaj ; fciose ifp) ; 1
else {
1
vold CreaSubllsta(ARB0L CabSalldas,LISTASALIDA *CabAtributo,lnt I ) { ~f (CabSalidas ! = NULL) {
CreaSubllsta(CabSalldas->lzq,&(*CabAtributo),]); InsertaSubllsta(CabSalldas->atrlbuto,CabSalidas->frecuencia,CabSall~as-
>menmay, & ("CabAtrlbuto) , j ) ;
I /"---------"--------""""""""""""""""""-------------"""* / PAQUETEl Irflnllsta(LISTASAL1DA CabAtributo){
CreaSublista(CabSa1idas->der,&(*CabAtributo),j); }
PAQUETE1 paquete; LISTASENCILLA AUX=NULL,LlstaSal=NULL;
while(CabAtribut0->slg!=NULL)
AUX = CabAtrlbuto->sublista; ir!iclai~sSen (&LlstaSal: ; whlle ;AUX !=NULL) {
CabAtrlbuto=CabAtributo->slg;
Recorresubllsta(&L~staSal,AUX->Sal~da,AUX->frecuencla,AUX->men-~mayj ; AUX= AUX->subilsta;i
paquete.poslclon=CabAtrlbuto->poslclon; paquete.apuntador=LlstaSal; strepy(paquete.Atrlbuto,CabAtr1buto->Atr1buto); r e t u r n (paquete) ;
52

CAPITULO 5 CODIGO FUENTE
* / void escrlbearchlvo (char renglon [5O], lnt pa) {
lnt tam=@;
tamzstrlen (renglon) ; lseek (pa, O, 2) ; If (wrlte (pa, renglon, tam) !=tam)
printf ("Error de escritura") ;
liit CreaAbreArc (char nombre [13] j [ lnt pa;
~f ( (pa=-creat (nombre, O) ) ==-1) { prlntf ("NO SE PUEDE CREAR EL ARCHIVO (-CREAT) " ) ;
return (I) ; ]
- close (pa) ; If ( (pa=open(nombre, O-WRONLY, O) ) ==-1) {
prlntf ("NO SE PUEDE ABRIR EL ARCHIVO") ; exlt(1); )
return (pa) ;
I
v o l d EscribeEncabezado(1nt posicion,char buffer[50],lnt pb){ lnt num esp=l, 7 =O, posenca=0; char auxsallda [ G O ] = ' I T ' ;
whlle ( [buffer[posenca] !='\r')&&(buffer[posenca] !='\n')&&(posenca<50)&&(buffer[posenca] !='\xO' / ) i
if (buffer[posenca]==' ' )
lf (num esp==poslclon) { num-esp++;
if (Fosiclon ! =I) posenca+t ;
whlle (buffer [posenca] ! = I ' j posenca++;
~f(posicion == I ) { posenca++; num-esp++; ) }/*fin de If espaclo=poslclon*/
else ( auxsalida [ J ] =buffer [posenca] ; I++; posenca++; ]/*fin else*/ ]/*fin del while de retorno de carro*/
escrlbearchivo(auxsallda,pbj; escrlbearchivo ("\n", pb) ; }
PAQUETECLASE CornparaFrecClase(1nt primerafrec,NODO CabClase,char prlrneraclase[GO]j { PAQUETECLASE paquete;
if(CabC1ase->frecuencla>prlmerafrec){ paquete.frecuencla = CabClase->frecuencia; strcpy(paquete.clase,CabClase->clase); return (paquete) ; I
paquete.frecuencla = prlmerafrec; strcpy(paquete.clase,prlmeraclase); return(paquete) ; 1 j
else [
* / PAQUETECLASE IniciaPaqClase(voidj {
PAQUETECLASE paquete;
paquete.frecuencla=O; strcpy (paquete. clase, " " ) ; return (paquete j ; ,
53

CAPITULO 5 CODIGO FUENTE
/ *_~" " " " " " "~_~"____________________"" " " " " " "~~~~~~* / veld escribearchivo(char renglon[50],int pa){
lnt tam=0;
tam=strlen(renglon); lseek (pa, O, 2) ; if (wrlte (pa, renglon, tam) !=tam)
) /*"""""""""""""""""""""""""""""""""""""* / lnt CreaAbreArc (char nombre [ 131 ) {
printf ("Error de escritura") ;
lnt pa;
if ( (pa=-creat (nombre, O) ) ==-1) { printf ("NO SE PUEDE CREAR EL ARCHIVO (-CREAT) " ) ;
return (1) ; 1 - close (pa) ; If ( (pa=open (nombre, O-WRONLY, O) ) ==-1) {
printf ("NO SE PUEDE ABRIR EL ARCHIVO") ; exlt(1); )
1 /*~~""""""""""""""~""""""""""""----~~""--------~*
return (pa) ;
/ void EscribeEncabezado(int posicion,char buffer[50l,int pb) {
lnt num esp=l,j=O,posenca=O; char auxsalida [ 601 ="" ;
while ( (buffer[posenca] !='\r')&&(buffer[posenca] !='\n')&&(posenca<5O)&&(buffer[posenca] !='\xO' 1 ) i
if (buffer [posenca] = = I ' )
if (num esp==posicion) { num-esp++;
1f (poslclon! =I) posenca++;
while (buffer[posenca] ! = I ' ) posenca++;
If (poslclon == 1) { posenca++; num-esp++; ) )/*fin de If espaclo=posicion*/
else { auxsalida [ 1 ] =buffer [posenca] ; I + + ; posencatt; )/*fm else*/ }/*fin del while de retorno de carro*/
escrlbearchivo(auxsallda,pb); escrlbearchivo ("\n", pb) ; )
/*""""-~""""~"""-"""""""""""""""""""""""" PAQUETECLASE ComparaFrecClaseiint prlmerafrec,NODO CabClase,char primeraclase[60]) { PAQUETECLASE paquete;
* /
if(CabC1ase->frecuencia>primerafrec){ paquete.frecuencia = CabClase->frecuencia; strcpy(paquete.clase,CabClase->clase); return (paquete) ; )
paquete.frecuencia = primerafrec; strcpy(paquete.clase,primeraclase); return!paquetej;] ]
else {
/*""~"""""~"""""-""--"""""""""""""""-""""-~"* PAQUETECLASE InlclaPaqClase (vold) (
/
PAQUETECLASE paquete;
paquete.frecuencla=O; strcpy(paquete.clase, " " ) ; return (paquete) ;
53

MANUAL TECNICO
/*---"""""--"""""""""""""""""""""""""""""- * / PAQUETECLASE clasemasPfrecuente(N0DO CabClase,int primerafrec,char primeraclase[hO])(
PAQUETECLASE paqizq,paqraiz,paqder;
paqizq=InlclaPaqClase(); paqralz=In:claPaqClase(); paqder=InlciaPaqClase();
~f (CabClase !=NULL) { paqlzq = clasemas-frecuente(CabClase->izq,pr~merafrec,pr~meraclase); paqralz = ComparaFrecClase(paqizq.frecuencia,CabClase,paqizq.clase); paqder = clase~mas_frecuente(CabClase->der,paqra:z.frecuencia,paqraiz.clase);
I else (
paqder.frecuenc1a = prlmerafrec; strcpy(paqder.clase,prlmeraclase);
1
return (paqder) ;
vold CreaSubArch(int pa,lnt pb,long int tamani0,LISTASENCILLA ListaValores,int resto, ~ n t po~:clon) { lnt num esp=l,posenca=0,~=O,7=O,veces=O,band=O,band=O,frecuenc~a=O,alto = O , termino = O; char bu?fer[5O]="", auxbuf [60]="",auxsalida[60]=""; PAQUETE pnumatrlb; LISTASALIDA CabAuxlllar;
/*---------------"""""""""""""-""-"""""""""""""-*/
alto = tamanlo/50; InlciaLista(&CabAuxlliar); l s e e k (pa, O, O) ; - read(pa, buffer, 50) ; buffer[50]='\0'; pnumatrib = lee-encabezado(buffer,&CabAuxillar); EscribeEncabezado(posiclon,buffer,pb); posenca=pnumatrib.poslclon+Z; / * por retorno de carro y salto de llnea * / for(veces=l;veces<=alto+l;veces++){ / * ntmero de lecturas * /
while !posenca<50 i { li- (veces==(alto+l) ) & & (posenca>=resto) )
else ( posenca = 50;
while( (buffer[posenca] !='\r')&&(buffer[posenca] !='\n')&&(posenca<50)&&(buffer[pos enca] !='\xO')) (
If ( (veces== (alto+l) ) & & (posenca>=resto) )
else { posenca = 50;
~f (buffer [posenca] = = I ' ) ( termlno = O; num-esp++;) lf (num esp==poslclon) [
if (nüm-esp ! = I ) posenca++;
whlle ( (buffer [posenca] ! = I ' ) & & (posencai50) ) { termlno = O; auxbuf[l]=buffer[posenca]; / * guarda el valor a comparar * / it+;
posenca++; )/*fin de whlle de distlnto de espacio*/ lf (posenca == 50)
termlno = 1; If !posenca<=50) (
auxbuf [1]='\0'; if (lsdlglt (auxbuf [O] ) 1 I (auxbuf [O]=='. ' ) ) (
lf!LlstaValores->men may==-1) { / * menor o igual * / If ( atof (auxbuf) <=atof (Listavalores->Salida) )

CAPITULO 5 CODIGO FUENTE
band = 1; } else / * mayor * /
If ( atof (auxbuf) >atof (Listavalores->Salida) )
else band = 1; )
if(!strcmp(auxbuf,ListaValores->Salida)) band= 1 ; posenca++; lf (num esp!=l)
posenca"; num-esp++; ] )
~f ( (termlno == 1) & & (buffer[posencal ! = ' I ) ) {
while( (buffer[posenca] ! = I ' j & & (posenca<50) ) {
-
else {
termmo = O;
auxbuf[l]=buffer[posenca]; /*guarda el valor a comparar*/ I++;
posenca++; ) if (posenca == 50)
termlno = 1; else (
auxbuf[i]='\O'; if (isdigit (auxbuf [O] ) I I (auxbuf [O] == ' . ' ) ) {
if(ListaVa1ores->men may==-1) { / * menor o igual * / if( atof(auxbuf)<=atof(ListaValores->Salida) )
band = 1; } else / * mayor * /
If ( atof (auxbuf) >atof (LlstaValores~>Sallda) )
else band = 1; )
If ( ! strcmp (auxbuf, LlstaValores->Sallda) )
If (posenca<50) { band=l ; ] )
If( (]==O)&& (buffer[posenca]==' ' j ) posenca++; auxsalida[ J ] =buffer[posenca] ; j ++; posencatt;}
)/*fin if num esp == posiclonk/ ) }/*fin del whlle de retorno de carro*/
if (posencai50) { If (band==l j {
auxsalida[~]='\O'; frecuencia++; If( frecuencla <= LlstaValores->frecuencia)
If( frecuencia < Llstavalores->frecuencia)
else
strcpy(auxsalida, " ' I ) ; posenca=posenca+2; band=O ;
i=O ; num - esp=l;)
strcpy (auxsallda, " " ) ;
If (terrnlno==O) 1=0 ;
poseneat+; num-esp=l; I / * fln de lf band==l * /
escrlbearchlvo(auxsallda,pb);
escrlbearchlvo ("\n",pb) ;
escrlbearchlvo ( " ' I , pb) ;
j = O .
else {
7 = o ;
I / * fln de posenca < 50 * / else [ / * posenca >= 50 * /
If (band==l) {

MANUAL TECNICO
lf (resto>O) { lf (alto==O) {
auxsalida [ j ] = ' \O ' ; frecuencia++;
lf( frecuencla <= Listavalores->frecuencia) escrlbearchivo(auxsallda,pb);
if( frecuencia < Llstavalores->frecuencia) escribearchlvo ( "\n" , pb) ;
escribearchivo ( I ' ' I , pb) ; else
strcpy (auxsalida, " " ) ; posenca=posenca+2; band=O; 7 =o; 1=0;
num esp=l; ] else {
-
if (veces == alto ) {
- read (pa, buffer, resto) ; buffer[resto]='\O'; 1
- read(pa,buffer,50); else
posenca=O;
If (buffer[posenca]=='\n') { auxsallda[j]='\O'; frecuencia++; lf( frecuencia <= Listavalores->frecuencia)
lf( frecuencia < LlstaValores->frecuencia)
else
strcpy (auxsallda, " " ) ; posenca=posenca+2; band=O ; 7 =o; 1=o; num esp=l; ]
veces++- 1 1
escrlbearchlvo(auxsalida,pb);
escrlbearchlvo ("\n", pb) ;
escrlbearchivo ( " ' I , pb) ;
else{ / * else resto == O * /
if (veces == alto ) [ if (veces <= altotlj [
- read (pa, buffer, resto) ; buffer[resto]='\O'; }
~ read(pa,buffer,50); else
posenca=O; I If (buffer [posenca] = = I \n' j {
auxsalida[j]='\O';
frecuencia++; if( frecuencia <= Listavalores->frecuencia)
If( frecuencia < Listavalores->frecuencia)
eise
strcpy (auxsallda, ' I " : ; posenca=posenca+2; band=O ; j = O ; l=o ; num esp=l; 1 / * fin else resto > 0 * / veces++; 1
/ * modif * /
escrlbearchivo(auxsalida,pb);
escrlbearchlvo("\n",pb) ;
escrlbearchlvo ( " " , pb) ;
56

CAPITULO 5 CODIGO FUENTE
] / * fin If band == 1 * / } / * fin else posenca < 50 * / 1 /*fin while posenca<=50*/
I if (veces == alto ) {
read(pa, buffer, resto) ; buffer[resto]='\~'; 1
- read(pa, buffer, 50) ;
else
posenca=O; ] /*fin del for veces * /
~ c l o s e (pb) ; LlberaLlstaSalida(&CabAuxlllar);
I /*~"""~~~"""~""""""""""""""""""-~""""""~~"-* / lnt lee-archlvo(char nombre[l3],ARBOLDECISION *RAIZ,ARBOLDECISION RAIZTEM,lnt vez) { long lnt tamanlo=O; ARBOLDECISION SUBRAIZ=NULL; NODO CabClase; ARBOL CabSalidas,ClasiSal; LISTASALIDA CabAtrlbuto; LISTASENCILLA LlstaValores; PAQUETE pnurnatrlb; PAQUETE1 LlstaValoresStr; PAQUETECLASE paqueteclase; char buffer [ 5 0 ] = I " ' ,
auxbuf [ 601 =" " , auxsallda [ 601 ="" , nomarch2 [ 131 ="", retorno [ O] = I " ' , cadparch[ 61 ="" ; lnt l=O, num casos=O, veces, j =O, num esp=l, p=O, posenca=O, resto=O, poslcion=O; lnt pa,pb,primerafrec=O; /*manejadores de archivo*/ float info=O;
pa=abre archlvo (nombre) ; InlclaArbolDecision(&SUBRAIZ); inlclallzaCabezas(&CabClase,&CabSalidas,&ClasiSal,&CabAtributo,&LlstaValores); tamanlo = fllelength(pa) -1; resto = tamanlo d 50;
~ read(pa, buffer, 50) ; buffer[50]='\0'; pnumatrib = lee-encabezado(buffer,&CabAtributo); p=pnumatrlb.posiclon+2; / * por retorno de carro y salto de llnea * / posenca=p;
for(l=l;~<=pnumatrlb.numatrlbutos;l++)( / * ntmero de atributos * / num esp=l; forTveces=l;veces<=(tamanio/50)+l;veces++) / * nfmero de lecturas * / while( ( buffer[p] !='\O') & & ( p<50 ) ) { / * mlentras tenga algo en el arreglo * /
If ( (veces== (tamanio/50+1) ) & & (p>=resto) ) {
else { lf [ (buffer[p] ! = I ')&&(buffer[p] !='\r')&&[buffer[p] '='\n')&&(
p=5O; 1
( , n u r n _ e s p = = ~ ) I 1 (num esp==pnumatrlb.num atrlbutos+l) ) ) { auxbuf fi] = buffer[p] ; l++; j
~f(buffer[p] == ' ' 1 {/*se ha encontrado un espacio o sea otra salida * / e l s e
auxbuf[l]='\O'; / * de un atrlbuto * / If (num esp==~ j
nilm ~ esp++; i=O; ) strcpy (auxsalida, auxbuf) ;
else lf(buffer[pl=='\r') {/*se ha llegado al final de una linea o sea de un*/
/ * caso y se analizara el slguiente * / auxbuf [l]='\O'; If ( (strcmp[auxbuf,"") )&&(strcmp(auxsalida,"")) ) {
If ( 7 = = l ) / * solo para el prlmer atrlbuto reallza el arbol. de c l a s e s * /
Insertar [ &CabClase, auxbuf) ; /*construye rbol de clases*/
57

MANUAL TECNICO
inssa1:da (&CabSalidas, auxbuf, auxsalida) ; /*construye rbol de
strcpy (auxbuf, " ' I ) ; strcpy(auxsalida, " " ) ; :=O; num casos++;]/*fin de strcmp*/
salldas para cada atributo*/
num-esp=l; E++;) /*f:n de buffer[p]=='\r' * / p++;
I /*fin while buffer[p]!='\O' . . . * /
strcpy (buffer, " ' I ) ; ifiveces == (tarnan:o/50) ) { / * solo lee el resto, es la t1t:ma lectura * /
read(pa,buffer, resto) ; buffer[resto~='\~';
~ read(pa,buffer,50); else / * realiza lecturas de tamano 50 * /
p=O ; )/*f:n for veces numero de lecturas*/ auxbuf [i] = ' \O' ; if ( (strcmp(auxbuf,"") )&&(strcmp(auxsalida,"")) ) (
lf ( j = = l ) / * solo para el primer atributo realiza el arbol de clases * /
insertar(&CabClase,auxbuf); /*construye rbol de clases*/ :nssal:da(&CabSal:das,auxbuf,auxsalida); /*construye rbol de salldas para cada
l=O; num casos++; 1 atributo*/
- 1 : (J==lj
~ f ( (CabClase->izq==NULL) &&(CabClase->der==NULL) ) { / * s1 e l arbol de clases solo contlene una clase * /
strcpy(RA1ZTEM->Clase,CabClase->clase); ~ close (pa) ; :f(CabSal:das ! = NULL) LiberaArbol(&CabSalidas); If (CabClase ! = NULL) LiberaNodo(&CabClase);
return (O) ; ]
lf(CabAtr1buto->sig==NULL){
lf(CabAtributo ! = NULL) LlberaListaSalida(&CabAtributo);
else {
pr:rnerafrec=CabClase->frecuencia; paqueteclase = clase " mas frecuente(CabClase,prlmerafrec,CabClase->clase); strcpy(RA1ZTEM->Clase,paqueteclase.clase); - c l o s e (pa) ; lf(CabSa1idas ! = NULL) LiberaArboli&CabSalidas); :f (CabClase ! = NULL) LiberaNodo(&CabClase); :f(CabAtrlbuto ! = NULL) LiberaL:staSallda(&CabAtrlbutoj; return (O j ; j ]
:f ( j = = 1 ) / * calcula e l lnfo solo una vez cuando se esta analizando el pr:mer strlbuto * /
inf o=Inf o ( CabClase, num-casos, O j ; S ~ D l g ~ t o ( & C a b S a l ~ d a s , & C l a s i S a l , n u m _ c a s o s ) ; Calcularazongananc~a(ClasiSal,&CabAtributo,num-casos,j,info); Iseek(pa,O,O); / * posiciona el apuntador al in1c:o del archivo * /
buffer[501='\0'; p=posenca; num casos=O; CreaSubl:sta(C¡aslSal,&CabAtrlbuto,j); :f (CabSa1:das ! = NULL) LlberaArbol (&CabSalldas) ; L f (C1as:Sal ! = NULL) L:beraArboli&ClaslSal);
read(pa,buffer,50); / * vuelve a leer e l archlvo en un buffer de tamauo 50 * /
i /+f-:n for 2 numero de atributos*/ ? f KabClase I = NULL) LlberaNodo(&CabClase!; OrdenaLlsta (&CabAtrlbuto) ; I,1 s~aValoresStr=Irflnllsta (CabAtrlbuto) ; LlsfaValores=LlstaValoresStr.apuntador: poslclon=LlstaValoresStr.pos~clon; If (vez==O)
else { RAIZTEM = CreaRalz (LlstaValoresStr.Atr:buto, " " ) ;
58

CAPITULO 5 CODIGO FUENTE
p?-q~zTEM->subralz = CreaRaiz(ListaValoresStr.Atribut0,""); PAIZTEM = RAIZTEM->subralz;)
SUBRAIZ = RAIZTEM; if(CabAtrlbut0 ! = NULL) LiberaLlstaSallda(&CabAtributo); whlle(ListaValores!=NULL) {
num arch++; strcpy(nomarch2,"a"); 1toa (num-arch, cad-arch, 10) ; strcat(nomarch2,cad-arch); strcat (nomarch2, " . xxx") ; pb=CreaAbreArc (nomarch2) ; RAIZTEM->slg = CreaRaiz (LlstaValores->Salida, " ' I ) ; RAIZTEM=RAIZTEM->slg;
CreaSubArch(pa,pb, tamanio,LlstaValores, resto,posicion) ; pb=abre_archlvoinomarch2); lseek (pb, fllelength(pb) -2, O) ; - read (pb, retorno, I ) ; lf (retorno[O]=='\r')
lseek (pb, filelength(pb) -2, O) ; write (pb, "\xlA", 1) ; close (pb) ;
lee-archivo (nomarch2, & (*RAIZ) ,RAIZTEM, 1) ; ~1sta~alores=L1staValores->sublista;
I /*fin whlle LlstaValores"/
- close (pa) ; * W I Z = SUBRAIZ;
1f (CabSalldas ! = NULL) LlberaArbol (&CabSalldas) ; ~f (ClaslSal ! = NULL) LlberaArbol (&ClaslSal) ; If (CabClase ! = NULL) LlberaNodo(&CabClase); lf (CabAtrlbuto ! = NULL) LlberaListaSalida (&CabAtrlbuto) ; ~f(LlstaValores ! = NULL) LlberaLlstaSencilla(&LlstaValores); return (O 1 ; ]/*fin funclon*/ / * ~ ~ ~ ~ " " " ~ ~ ~ ~ ~ ~ ~ ~ " " " " " ~ " " " " " " ~ ~ " " " " " " - - ~ " " " " - " " " - * .~nt abre-archlvo(char nom-arch[l3]) {
/
lnt pa; If ( (pa=open (nom-arch, O-RDONLY, O ) ) ==-1) {
prlntf ("NO SE PUEDE ABRIR EL ARCHIVO") ; exlt (I); 1
return (pa) ; ) /*~~-""----""""--"""""--""""--"""""-"""----""""""" lnt. Busca-poslclon(char Valor[GO],LISTASENCILLA ListaAtrlb) (
* /
l n t poslcion=O,bandera=O; while( (ListaAtrib!=NULL) & & (bandera==O) ) {
lf ( ! strcmp (Valor, LlstaAtrlb->Sallda) ) { poslclon = ListaAtrlb->frecuencia; bandera = 1; ]
LlstaAtrib = ListaAtrlb->subllsta;] return (posiclon) ; 1
/*--""--"""-""""---""""-""""""""""""""""""""""* / lnt poner-poslclon(ARBOLDEC1SION *RAIZ,LISTASENCILLA ListaAtrib){
ARBOLDECISION TempoRalz,AuxRaiz;
TempoRaiz = *RAIZ; lf (TempoRalz ! = NULL) (
l€ ( ! strcmp(TempoRa1z->Clase, " " ) & & (TempoRalz->subraiz==NULLj )
RuxKalz = TempoRalz->slg; whll e ( AuxRal z =NULL j {
TempoKalz->Poslc>on = Busca-poslclon(TempoRalz->Valor,LlstaAtrlb);
lf ( ! strcmp íAuxRalz->Clase, "" j & & (AuxRalz->subralz==NULL) )
rf( AuxRalz->subralz!=NULL)
AuxRalz AuxRalz->slg;)]
AuxKalz->Posiclon = Busca ~ poslclon(AuxRalz->Valor,LlstaAtr-b);
poner poslclon(&AuxRalz->subralz,LlstaAtrlb);
return(0);)
59

MANUAL TECNICO
/*""""""""""~--""~""""""""""""""""""-"""-""*/ char *Busca-Clase(LISTASENCILLA Iniciocaso) {
whlle(InlcloCaso->subllsta!=NULL) / * * /
return(InlcloCaso->Sallda); InlcloCaso=InlcloCaso->subllsta;
~ n t determina-clase(ARB0LDECISION *RAIZ,LISTASENCILLA *InicloCaso) i nKBOLDECISION TempoRalz=NULL,TempoSalida=NULL; LISTASENCILLA TempoCaso=NULL; lnt Poslclon=O,bandera=O; char Salida [ 601 ="" , ClaseArbol [ 601 = I " ' , Clasecaso [ 601 ="";
TempoRalz = *RAIZ; whl ie ( ! strcmp (TempoRalz->Clase, " " ) & & (TempoRaiz->slg ! = NULL) ) {
I'os1clon = TempoRaiz->Poslclon; 'CempoCaso = *InlcloCaso; while( (TempoCaso ! = NULL) & & (TempoCaso->frecuencia ! = Poslclon) )
TempoCaso = TempoCaso->sublista;
strcpy(Sallda,TempoCaso->Salida); TempoSalida = TempoRalz->sig; while( (TempoSallda!=NULL) & & (bandera == O) ) {
lf( (TempoCaso ! = NULL) & & (TempoCaso->frecuencia == Poslcion) ) {
if ( (Isdigit (TempoSalida->Valor[O] ) ) I I (TempoSalida->Valor[Ol = = l . ' /*If 2*/
if ( atof (Salida) <= atof (TempoSallda->Valor ) ) if(TempoSal1da->subraiz==NULL){
else { TempoRaiz=TempoSalida; bandera=l;l
TempoRaiz=TempoSalida->subraiz; bandera=l;) else {
TempoSallda=TempoSallda->sig; lf(TempoSa1ida->subraiz==NULL){
else { TempoRalz=TempoSalida; bandera=l;]
TempoRalz=TempoSalida->subraiz; bandera=l;)) else
lf( !strcmp(TempoSalida->Valor,Sallda) ) if(TempoSa1ida->subraiz==NULL) (
else { TempoRaiz=TempoSallda; banderazl;]
TempoRalz=TempoSalida->subralz; bandera=l;] TempoSalida = TempoSalida->slg;) bandera=O;]]
strcpy (ClaseArbol, " ' I ) ; lf ( (TempoRaiz->slg==NULL) & & (strcmp (TempoRaiz->Clase, " " ) ) )
l f ( (TempoRalz->subralz==NULL) & & (strcmp (TempoRalz->Clase, " " ) )
l f ( strcmp (ClaseArbol, " " ) ) [
strcpy (ClaseArbol, TempoRaiz->Clase) ;
strcpy(ClaseArbol,TempoRalz->Clase);
strcpy(ClaseCaso,Busca_Clase(*InlcloCaso) 1 ; ~f(!strcmp(ClaseArbol,ClaseCaso))
TempoRalz->Casos = TempoRaiz->Casos + 1; else
TempoRalz->Errores = TempoRaiz->Errores + l;] return (O) ; I
60

CAPITULO 5 CODIGO FUENTE
lnt determina-error(ARBOLDECISI0N *RAIZ,char nom-arch[l3]) ( lnt pa, resto=O,p=O,num esp,veces=O, i=O; long lnt tamanio=O; char buffer 1501 ="", auxbuf [ 601 ; PAQUETE pnumatrib; LISTASENCILLA InicioCaso=NULL; LISTASALIDA CabAtrlbuto;
-
InlclaLlsta(&CabAtrlbuto); pa=abre-archlvo(nom-arch); tamanlo = filelength(pa)-1; resto = tamanio % 50;
buffer [50] ='\O' ; pnumatrlb = lee-encabezado(buffer,&CabAtributo); p=pnumatrlb.posiciontZ; / * por retorno de carro y salto de linea * / num-esp=l; for(veces=l;veces<=(tamanio/5O)tl;vecestt)( / * n€mero de lecturas * /
- read(pa, buffer, 50) ;
while( ( buffer[p]!='\O') & & ( p<50 ) ) ( / * mlentras tenga algo en el arreglo * / if ( (buffer[p] ! = I ' ) & & (buffer[p] !='\r') & & (buffer[p] !='\n') ) {
else auxbuf [1] = buffer[p]; i+t; }
lf( (buffer[p] == ' ' ) 1 I (buffer[p] == '\r') ) { / * se ha encontrado un espaclo o sea otra sallda de un atrlbuto o se termino un caso*/
auxbuf [i] = ' \O' ; Recorresublista(&InicioCaso,auxbuf,num-esp,O); / * inserta al final * / num esp++; i=O; strcpy (auxbuf, " " ) ; lf ibuffer[p] == '\r') {
determina-clase ( & (*RAIZ) , &Iniciocaso) ; LiberaListaSencilla(&InicioCaso);
num-esp = 1; ] ) p++; 1 /*fin while buffer[p]!='\O' . . . * /
strcpy (buffer, " " ) ; lf(veces == (tamanlo/50) ) ( / * solo lee el resto, es la fltlma lectura * /
read(pa, buffer, resto) ; buffer [resto] = ' \O' ; ] el s e / * reallza lecturas de tamano 50 * /
read(pa,buffer,50); p=O; l/*fln for veces numero de lecturas*/
-
If ( strcmp (auxbuf, " ' I ) ) { auxbuf[l]='\O'; Recorresubllsta (&InlcloCaso, auxbuf ,num-esp, O) ; / * inserta al final * / determina-clase ( & (*RAIz), &InlcloCaso) ; LlberaListaSencilla(&Inlclocaso); num esp++; l=O; strcpy(auxbuf, " " ) ; ]
return (O) ; -
/*~~""~"""~""""--"""~"""""""""""-~"""-""---"-----* lnt claslflca(char nom-arch[l3] ,ARBOLDECISION *RAIZ) (
/
lnt pa; char buffer [50]=""; LISTASENCILLA ListaAtrib;
pa=abre-archlvo(nom-arch); InlclaLlsSen(&ListaAtrlb);
/ * crea lista con atributos y posiclones * / lee atrlbutos(buffer,&LlstaAtrlb); / * graba poslclones en el rbol de declslcn * / poner~poslcloni&(*RAIZi ,LlstaAtrib); close (pa) ; / * determlna el n€mero de errores y aclertos en la claslficaclCn y los
determina-error ( & (*RAIZ) ,nom-arch) ; returni0) ; )
- read (pa, buffer, 50) ;
guarda en el rbol de decisiCn * /
/*~~"""~"-~""""""""""""""""""""""""""""""- * /

MANUAL TECNICO
void Podarl(ARBOLDECIS1ON *TempoRaiz, int Casos, lnt Errores){ ARBOLDECISION Llbre=NULL;
Llbre = (*TempoRalz) ->s ig ; (*TempoRaiz)->Casos = Casos; (*TempoRaiz)->Errores = Errores; c*TempoRalz)->subraiz = Libre->subralz; ("TempoRalz) - > s l g = Llbre->slg; free (ilbre) ;
i
v o l d Podar2(ARBOLDECISION "TempoRaiz, 1nt Casos, lnt Errores){ ARBOLDECISION Llbre=NULL;
Llbre = ("TempoRalz) - > s l g ; ("TempoRaiz) ->Casos = Casos; (*TempoRaiz)->Errores = Errores; (*TempoRaiz)->Position = Libre->Position; (*TempoRaiz)->subraiz = Libre->subraiz; (*TempoRaiz) ->si9 = Libre->sig; strcpy((*TempoRaiz)->Clase,Libre->Clase); free (Libre) ;
/ float U21 (lnt Errores, 1nt Casos) {
float porcenta~e = O,sumando=O,sumandoraiz=O;
sumandoralz = Errores*(l-Errores/Casos); sumando = 1.15*sqrt( sumandoraiz + 0.330625 ) ;
porcenta~e =(Errores + 0.66125 + sumando)/(Casos + 1.3225);
return (porcenta] e) ; I /*"""~~""""""""----"""""""-~~""""""""~""""""~"* / PAQUETEDECISION Inicia-paquete(void)( PAQUETEDECISION paquete;
paquete.Porc1entoError = O; paquete.DlrCaso = NULL; return (paquete) ;
1
/*""~~~"""~~""""""""---""""~~~""""""~""""--~"-----~* PAQUETEDECISION podar arbol(ARBOLDECISI0N *RAIZ,int profundidad){ PAQUETEDECISION ~2,paGuete; ARBOLDECISION TempoRalz=NULL,AuxRaiz=NULL; lnt Casos=O,Errores=O; float Porc~entoEl=O,PorcientoE2=0,PorcientoPodado=O,Porc~entoSinPodar=O;
P2 = lnlcla paquete ( ) ; paquete = lnicla-paquete(); TempoRalz = *RAIZ; lf(TempoRaiz->subraiz!=NULL){
/
~
podar arbol(&TempoRalz->subralz,O); / * recursividad * / lf ( (Podar?¡ho]a==l) & & (TernpoRaiz->Poslclon==O) & & (TempoRalz-
>subralz '=NULL) & & ( ! strcmp (TempoRaiz->Clase, " " ) ) ) { Podarlho~a=O; AuxRalz=TempoRalz->subralz->slg; strcpy!TempoRalz->Clase,AuxRalz->Clase);
TempoRa;z->Casos=AuxRalz->Casos; TempoRalz->Errores=AuxRalz->Errores;
TempoRalz->subralz=AuxRaiz->subralz; free (AuxRalz) ; AuxRalz=TempoRalz->subralz; free (AuxRalz i ; }
podar-arbol(&TempoRaiz->slg,profundldad+l); / * recursivldad * / ) ] If (TempoRalz->slg'=NULL) {
else

CAPITULO 5 CODIGO FUENTE
~f(TernpoRaiz->sig!=NULL) {
else { / * Casos mal claslficados, total de casos cubiertos * / p2 = podar_arbol (&TempoRaIz->s ig ,profundidad+l ) ; / * recurslvldad * /
paquete.~orciento~rror = U25(TempoRaiz->Errores,TempoRaiz->Casos+TempoRaiz-
paquete.DirCaso = TempoRaiz; return (paquete) ; I
PorcientoEl = ~25(TempoRaiz->Errores,TempoRaiz->Casos+TempoRaiz->ErroreS) ,' 1f(~empoRalz->Casos>=PZ.DirCaso->Casos){ / * TempoRalz Clasifica m S Casos
>Errores) ;
lf (strcmp (TempoRaiz->Clase, " " ) & & (TempoRaiz->subraiz==NULL) )
correctamente que P2 * /
>Errores; / * total de casos cublertos * / Casos = ~empoRalz->Casos + TempoRaiz->Errores + P2.DlrCaso->Cas05 + P2.DlrCaso-
if(!strcmp(TempoRaiz->clase,~~.DirCaso->Clase)) / * son iguales * / Errores = TempoRaiz->Errores + P2.DirCaso->Errores;
else / * son diferentes * / Errores = TempoRaiz->Errores + P2.DirCaso->Casos + P2.DlrCaso-
>Errores; PorclentoE2 = U25(Errores,Casos); porclentopodado = Casos * PorcientoE2; / * hojas ya podadas * / PorcientoSlnPodar = (TempoRalz->Casos+TempoRalz->Errores) * POrCientoEl
if(porc1entoPodado < PorcientoSinPodar ) { / * se recomienda podar * / +(P2.DirCaso->Casos+P2.DirCaso->Errores) * P2.PorcientoError;
Podarl(&TempoRa~z,TempoRaiz->Casos+P~.DirCaso->~:a~os,Errores) ;
paquete.PorclentoError = PorclentoE2; paquete.DlrCaso = TempoRalz; If ( (profundldad==l) & & (TempoRaiz->slg==NULL) )
return (paquete) ; 1
paquete.PorcientoError x PorclentoEl; paquete.DirCaso = TempoRaiz; return (paquete) ; ) 1
Podarlho]a=l;
else { / * sin podar * /
else ( / * P2 clasifica m S casos correctamente que TempoRaiz * / Casos = TempoRalz->Casos + TempoRaiz->Errores + P2.DlrCaso->Casos + P2.DirCaso-
1f(!strcmp(TempoRaiz->Clase,P2.DirCaso->Clase)) / * son iguales * /
else / * son dlferentes, se debe verificar cuantas clases son * /
PorclentoE2 = U25(Errores,Casos); / * los errores correctamente * /
>Errores; / * total de casos cubiertos * /
Errores = TempoRalz->Errores + P2.DirCaso->Errores;
Errores = P2.DlrCaso->Errores + TempoRaiz->Casos + TempoRaiz->Errores;
PorcientoPodado = Casos * PorclentoE2; / * holas ya podadas * / PorcientoSlnPodar = (TempoRaiz->Casos+TempoRalz->Errores) * PorclentoEl
+(P2.DlrCaso->Casos+PZ.DirCaso->Errores) * P2.PorclentoError; lf(PorcientoPodado < PorcientoSinPodar ) {
Podar2(&TempoRaiz,TempoRaiz->Casos+PZ.DirCaso->Casos,Errores); paquete.PorclentoError = PorclentoE2;
paquete.DlrCaso = TempoRalz; if((profundldad==l)&&(TempoRalz->sig==NULL))
return (paquete) ; ]
paquete.PorcientoError = PorclentoEl; paquete.DlrCaso = TempoRalz; return (paquete) ; J 1 )
Podarlho]a=l;
else{ / * sln podar * /
else return (paquete) ;
I / * - vold BorrarTemporales(vo1d: {
* /
system("de1 * . xxx") ;
63

MANUAL TECNICO
/ void lee-datos(char nomparch[13])[ ARBOLDECISION RAIZ=NULL, RAIZTEM=NULL;
1n:claArbolDeclslon (&RAIZ) ; In i c l aArbo lDec i s ion (&RAIZTEM); lee-archlvo (nom-arch, &RAIZ, RAIZTEM, O) ; EscRegProd(RAIZ,"reglasn.txt");/* escrlbe las reglas de producciCn a un archivo * / claslflca (nom-arch, &RAIZ) ; / * clasifica casos no vistos * / podar-arbol ( &RAI Z , O) ; / * realiza el podado del arbol * / EscRegProd(RAIZ,"reglasp.txt");/* escribe las reglas de producciCn a un archivo * / BorrarTemporales ( ) ; exlt (1) ;
I . . . . . . . . . . . . . . . . . . . . . . . . . . FUNCIONES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
float l og2 (float x) { lf ( x < Ilmite) return (O ) ; else return (log (x) ) ;
!
SUMAS SumEntropia (int frec, char atrib [ 6 0 ] ) ( /*regresa un arreglo de float's*/ /*~~~~""""~"""-~"""""""""""""~""""-~""""""~-"* /
double numatrlb=O; SUMAS arresum;
arresum.sum1 = O; arresum.sum2 = O;
numatrlb = atof (atrib) ; arresum.sum2 = arresum.sum2 + (numatr1b)"frec; return (arresumj ;
/*~~~"""""""~"""""""~"""""""""""""~~""""""-*/ float determlnaprango(ARBOL CabSalidas,int tot-casos) ( SUMAS arrentrop; float entropia70;
lf (tot casos<=l)
else ( return(l.OE+37);
arrentrop = Fentropla(CabSa1idas); entropia = (arrentrop.sum2*1.0)/(tot-casos*l.O); return (entropla) ; 1
I /*~~~~~~~~~~~~~-~""-""""""""""-----""""""""""""""~-~-*/ SUMAS Fentropla(ARB0L SubRalz)( /*regresa arreglo de float*/
SUMAS lnfoder, infolzq, Infocab;
xnfoder.suml=O; lnfolzq.suml=O; :nf ocab . suml=0 ; lnfoder.sum2=0; infolzq.sum2=0; lnfocab.sum2=0;
lf (SubRalz !=NULL) ( lnfolzq = Fentropla!SubRalz->lzq); lnfocab = SumEntropla(SubRalz->frecuencla,SubRalz~>atrlbuto): lnfoder = Fentropla(SubRalz->der); ~nfo~zq.suml=~nfo~zq.suml+~nfoder.suml+~nfocab.sum~; ~nfo~zq.sum2=~nfo~zq.sum2+~nfoder.sum2+~nfocab.sum2; return(lnfo1zq) ; j
returniinfoizq) ; else
I /*~~~~"""~~~~~~~~""""""""""""""""""""""""""""* /

CAPITULO 5 CODIGO FUENTE
v o l d llsta-destlno(ARBOL *nodo,LISTA origen)( char clase [ 601 ; LISTA aux;
whlle ( orlgen!=NULL) { strcpy (clase, orlgen->clase) ; ~f ( (*nodo) ->slg==NULL) (
(*nodo)->sig=CreaLlsta(clase); aux = (*nodo) - > s l g ; aux->frecclase=origen->frecclase; /*(*nodo)->frecuencla=origen->frecclase;*/ ] / * mucho o10 aqui se encuentra el
error * / else {
orlgen = origen->sig; 1 InsertaLista (clase, & (*nodo) - > s l g ) ; I
i
/*--""_-""-"""""""-"""-""--"""""--""~-""---"""-* / veld arbol-binarlo(f1oat entropi,ARBOL *origen,ARBOL *destino)(
if(*orlgen!=NULL) { arbol-blnario (entropi, & (*origen) ->izq, & (*destino) ) ;
if (atof ( (*origen) ->atributo) <= entropi) { (*destino)->frecuencia = (*destino)->frecuenc~a + (*origen)->frecuencia; llsta-destino(&(*destino),(*origen)->sig); ] / * funcion para llsta * /
(*destino)->der->frecuencia = (*destlno)->der->frecuencia + (*origen)-
llsta-destino(&(*destino)->der,(*orlgen)->sig);] / * funclon para lista * /
else {
>frecuencia;
arbol-blnario (entropl, & (*origen) ->der, & (*destino) ) ; LlberaArbol ( & (*origen) ) ; }
. . . . . . . . . . . . . . . . . . . . . . . . . . PRINCIPAL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . / void maln (lnt argv, char *argc [ I )
clrscr ( ) ; gotOxy(20, 9 ) ; prlntf ("PROCESANDO ARCHIVO, ESPERE UN MOMENTO.. . " ) ; lee-datos (argc [ I ] ) ;
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . : I
65





























