Embed Size (px)
Citation preview

UNIVERSIDAD TÉCNICA PARTICULAR DE LOJA La Universidad Católica de Loja
ÁREA TÉCNICA
TÍTULO DE INGENIERO CIVIL
Implementación de herramientas de modelización estocástica de las
series hidrológicas en el HydroVLab.
TRABAJO DE TITULACIÓN
AUTORA: Alverca Rivas, Aidé Margoth
DIRECTOR: Oñate Valdivieso, Fernando Rodrigo, PhD
LOJA – ECUADOR
2016

Esta versión digital, ha sido acreditada bajo la licencia Creative Commons 4.0, CC BY-NY-SA: Reconocimiento-No comercial-Compartir igual; la cual permite copiar, distribuir y comunicar públicamente la obra, mientras se reconozca la autoría original, no se utilice con fines comerciales y se permiten obras derivadas, siempre que mantenga la misma licencia al ser divulgada. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.es
Septiembre, 2016

ii
APROBACIÓN DEL DIRECTOR DEL TRABAJO DE TITULACIÓN
Doctor.
Fernando Oñate Valdivieso
DOCENTE DE LA TITULACIÓN
De mi consideración:
El presente trabajo de titulación: Implementación de herramientas de modelización
estocástica de series hidrológicas en el HydroVLab realizado por Aidé Margoth Alverca
Rivas, ha sido orientado y revisado durante su ejecución, por cuanto se aprueba la
presentación del mismo.
Loja, abril del 2016
f)-----------------------------------------------

iii
DECLARACIÓN DE AUTORÍA Y CESIÓN DE DERECHOS
“Yo Alverca Rivas Aidé Margoth declaro ser autora del presente trabajo de titulación:
Implementación de herramientas de modelización estocástica de series hidrológicas en
el HydroVLab, de la Titulación de Ingeniería Civil, siendo PhD. Fernando Rodrigo Oñate
Valdivieso director del presente trabajo; y eximo expresamente a la Universidad Técnica
Particular de Loja y a sus representantes legales de posibles reclamos o acciones
legales. Además certifico que las ideas, conceptos, procedimiento y resultados vertidos
en el presente trabajo investigativo, son de mi exclusiva responsabilidad.
Adicionalmente declaro conocer y aceptar la disposición del Art. 88 del Estatuto
Orgánico de la Universidad Técnica Particular de Loja que en su parte pertinente
textualmente dice: “Forman parte del patrimonio de la Universidad la propiedad
intelectual de investigaciones, trabajos científicos o técnicos y tesis de grado o trabajos
de titulación que se realicen con el apoyo financiero, académico o institucional
(operativo) de la Universidad”.
f)-----------------------------------------------
Autor: Alverca Rivas Aidé Margoth
Cédula: 1900433531

iv
DEDICATORIA
Dedico este trabajo a:
Dios y a mis padres…

v
AGRADECIMIENTO
Le agradezco en primer lugar a Dios, el haberme permitido llegar a éste punto de mi
vida. Sin él, dudo que aún estuviera presente en este mundo.
A mis padres y hermano, que siempre han estado apoyándome en los estudios, con sus
palabras de aliento y reproche, las mismas que me han dado ánimos de seguir adelante.
Al Ph. D. Fernando Oñate director de éste trabajo investigativo, por su gran paciencia
que tiende al infinito positivo.
Y a todos mis compañeros, amigos y familiares, que de una u otra manera facilitaron la
culminación de éste trabajo.
A todos ellos, Gracias…
Aidé

vi
ÍNDICE DE CONTENIDOS
CARÁTULA………………………………………………………………………………………i
APROBACIÓN DEL DIRECTOR DEL TRABAJO DE TITULACIÓN .............................. ii
DECLARACIÓN DE AUTORÍA Y CESIÓN DE DERECHOS .........................................iii
DEDICATORIA ............................................................................................................ iv
AGRADECIMIENTO ..................................................................................................... v
ÍNDICE DE CONTENIDOS .......................................................................................... vi
ÍNDICE DE FIGURAS ................................................................................................. viii
ÍNDICE DE TABLAS ..................................................................................................... x
RESUMEN .................................................................................................................... 1
ABSTRACT................................................................................................................... 2
INTRODUCCIÓN .......................................................................................................... 3
CAPÍTULO I: ESTADO DEL ARTE .............................................................................. 5
CAPÍTULO II: MATERIALES Y MÉTODOS ................................................................. 7
2.1. Metodología Box-Jenkins. .................................................................................. 8
2.2. Series de tiempo. ............................................................................................... 8
2.3. Estacionariedad. ................................................................................................. 8
2.3.1. Función de autocorrelación. ......................................................................... 8
2.3.2. Error estándar. ........................................................................................... 11
2.3.3. t estadístico. ............................................................................................... 11
2.3.4. T. crítico ..................................................................................................... 11
2.3.5. Estadístico “d” de Durbin – Watson. ........................................................... 11
2.3.6. Prueba de raíz unitaria. .............................................................................. 12
2.3.7. Transformación de las series no estacionarias........................................... 13
2.4. Estacionalidad. ................................................................................................. 14
2.4.1. Transformación de una serie de tiempo estacional a estacionaria. ............ 14
2.5. Modelos Box-Jenkins. ...................................................................................... 16
2.5.1. Autorregresivo – AR (p). ............................................................................ 16
2.5.2. Media móvil – MA (q). ................................................................................ 17

vii
2.5.3. Autorregresivo de media móvil – ARMA (p, q)............................................ 18
2.5.4. Autorregresivo integrado de media móvil – ARIMA (p, d, q). ...................... 18
2.5.5. Estacional autorregresivo integrado de media móvil – SARIMA (p, d, q) (P, D,
Q). ....................................................................................................................... 19
2.5.6. Proceso de construcción de los modelos no estacionales. ......................... 20
2.5.7. Proceso de construcción del modelo estacional SARIMA. ......................... 22
2.6. Metodología de programación. ......................................................................... 22
2.6.1. Descripción de las herramientas virtuales. ................................................. 23
2.6.2. Descripción del software utilizado para el desarrollo de las herramientas. . 23
2.6.3. Manuales de uso de cada una de las herramientas. .................................. 25
2.6.4. Diagramas de flujo. .................................................................................... 25
CAPÍTULO III: ANÁLISIS DE RESULTADOS ............................................................ 33
3.1. Utilización y análisis de las herramientas desarrolladas. .................................. 34
3.1.1. Autorregresivo – AR (p). ............................................................................ 34
3.1.2. Media móvil – MA (q). ................................................................................ 40
3.1.3. Autorregresivo de media móvil – ARMA (p, q)............................................ 44
3.1.4. Autorregresivo integrado de media móvil – ARIMA (p, d, q). ...................... 47
3.1.5. Estacional autorregresivo integrado de media móvil – SARIMA (p, d, q)
(P, D, Q). ............................................................................................................. 54
3.2. Comparación de resultados entre cada método desarrollado. .......................... 60
3.2.1. Pronósticos en los modelos: AR, MA y ARMA. .......................................... 60
3.2.2. Pronósticos en los modelos: ARIMA y SARIMA. ........................................ 63
CONCLUSIONES ....................................................................................................... 66
RECOMENDACIONES ............................................................................................... 67
BIBLIOGRAFÍA ........................................................................................................... 68
ANEXOS ..................................................................................................................... 71
Anexo 1. Coeficientes de MacKinonn para el cálculo de los valores de Tau (τ) críticos.
................................................................................................................................ 72
Anexo 2. Series de tiempo utilizadas. ...................................................................... 73

viii
ÍNDICE DE FIGURAS
Figura 2.1. Metodología de Box – Jenkins. ................................................................ 20
Figura 2.2. Lenguaje Visual Basic de la Página Web AR_p.aspx.vb .......................... 24
Figura 2.3. Lenguaje HTML de la Página Web AR_p.aspx......................................... 25
Figura 2.4. Diagrama de flujo del modelo autorregresivo. .......................................... 26
Figura 2.5. Diagrama de flujo del modelo de media móvil. ......................................... 27
Figura 2.6. Diagrama de flujo del modelo autorregresivo de media móvil. .................. 29
Figura 2.7. Diagrama de flujo del modelo autorregresivo integrado de media móvil. .. 31
Figura 2.8. Diagrama de flujo del modelo estacional autorregresivo integrado de media
móvil. .......................................................................................................................... 32
Figura 3.1. Recorte de página del modelo AR del gráfico de la serie. ........................ 35
Figura 3.2. Recorte de página del modelo AR de los correlogramas. ......................... 35
Figura 3.3. Recorte de página del modelo AR de la prueba de raíz unitaria. .............. 36
Figura 3.4. Recorte de página del modelo AR de las variables del modelo. ............... 37
Figura 3.5. Recorte de página del modelo AR del análisis de residuos. ..................... 37
Figura 3.6. Recorte de página del modelo AR de los pronósticos. ............................. 38
Figura 3.7. Recorte de página del modelo AR del resultado de la regresión. ............. 39
Figura 3.8. Recorte de página del modelo MA de los correlogramas.......................... 40
Figura 3.9. Recorte de página del modelo MA de las variables del modelo. ............... 41
Figura 3.10. Recorte de página del modelo MA del análisis de residuos. ................... 41
Figura 3.11. Recorte de página del modelo MA de los pronósticos. ........................... 42
Figura 3.12. Recorte de página del modelo MA del resultado de la regresión. ........... 43
Figura 3.13. Recorte de página del modelo ARMA de las variables del modelo. ........ 44
Figura 3.14. Recorte de página del modelo ARMA del análisis de residuos. .............. 45
Figura 3.15. Recorte de página del modelo ARMA de los pronósticos. ...................... 45
Figura 3.16. Recorte de página del modelo ARMA del resultado de la regresión. ...... 47
Figura 3.17. Recorte de página del modelo ARIMA del gráfico de la serie. ................ 48
Figura 3.18. Recorte de página del modelo ARIMA de los correlogramas. ................. 48
Figura 3.19. Recorte de página del modelo ARIMA de la prueba de raíz unitaria. ...... 49
Figura 3.20. Recorte de página del modelo ARIMA de la serie diferenciada. ............. 49
Figura 3.21. Recorte de página del modelo ARIMA de las variables del modelo. ....... 50
Figura 3.22. Recorte de página del modelo ARIMA del análisis de residuos. ............. 51
Figura 3.23. Recorte de página del modelo ARIMA de los pronósticos. ..................... 51
Figura 3.24. Recorte de página del modelo ARIMA del resultado de la regresión. ..... 53
Figura 3.25. Recorte de página del modelo ARIMA del resultado de la regresión. ..... 54
Figura 3.26. Recorte de página del modelo SARIMA del gráfico de la serie. .............. 55
Figura 3.27. Recorte de página del modelo SARIMA de la pre-diferenciación............ 55

ix
Figura 3.28. Recorte de página del modelo SARIMA de la transformación de
estacionalidad. ............................................................................................................ 56
Figura 3.29. Recorte de página del modelo SARIMA de los correlogramas. .............. 56
Figura 3.30. Recorte de página del modelo SARIMA de la prueba de raíz unitaria. ... 57
Figura 3.31. Recorte de página del modelo SARIMA de las variables del modelo. .... 57
Figura 3.32. Recorte de página del modelo SARIMA del análisis de residuos............ 58
Figura 3.33. Recorte de página del modelo SARIMA de los pronósticos. ................... 58
Figura 3.34. Recorte de página del modelo SARIMA del resultado de la regresión. ... 60
Figura 3.35. Pronósticos de los modelos AR, MA y ARMA. ........................................ 62
Figura 3.36. Pronósticos de los modelos ARIMA y SARIMA. ..................................... 64

x
ÍNDICE DE TABLAS
Tabla 2.1. Cuatro transformaciones de estacionalidad. .............................................. 15
Tabla 2.2. Características de los modelos AR (p). ...................................................... 16
Tabla 2.3. Características de los modelos MA (q)...................................................... 17
Tabla 2.4. Características de los modelos ARMA (p, q). ............................................. 18
Tabla 3.1. Pronósticos de los modelos AR, MA y ARMA. ........................................... 61
Tabla 3.2. Coeficientes para la evaluación de los modelos: AR, MA y ARMA. ............ 62
Tabla 3.3. Pronósticos de los modelos ARIMA y SARIMA para la misma serie de tiempo.
................................................................................................................................... 63
Tabla 3.4. Coeficientes para la evaluación de los modelos ARIMA y SARIMA. .......... 65
Tabla 4.1. Serie diferenciada de la Tabla 4.2 ............................................................. 73
Tabla 4.2. Serie de datos de caudal de la estación arenal oyente boquerón. ............. 74
Tabla 4.3. Temperatura máxima absoluta del aire a la sombra................................... 75
Tabla 4.4. Primera diferencia de los datos de la Tabla 4.5 ......................................... 76
Tabla 4.5. Serie de datos reales utilizados para compararlos con los pronósticos (AR,
MA, ARMA). ................................................................................................................ 77
Tabla 4.6. Serie de datos reales utilizados para compararlos con los pronósticos
(ARIMA, SARIMA). ..................................................................................................... 77

1
RESUMEN
Conocer los pronósticos de las series de tiempo es de gran importancia en distintas
áreas de estudio, ya que ayuda a tomar medidas preventivas o posibles soluciones.
Lamentablemente, el cálculo de tales pronósticos sigue un proceso complejo. La
metodología desarrollada en la presente investigación es la de Box-Jenkins, la misma
que se puede aplicar a cualquier serie de tiempo univariante. La selección del modelo
óptimo se simplifica por medio de la programación y se aplica varios test para determinar
el modelo más adecuado. Esta metodología se ha implementado en el laboratorio virtual
de hidrología HydroVLab utilizando Visual Studio 2010.
En la fase de resultados, se ha podido ver que los datos obtenidos siguen un patrón
similar a los observados, y además cumplen con los requerimientos de aceptación. Por
lo tanto se consigue pronósticos coherentes.
PALABRAS CLAVE: Series de tiempo, Pronósticos, Box-Jenkins, ARIMA, SARIMA

2
ABSTRACT
Know the forecasts of the time series is of great important in different study areas, this
help to take preventive measures or possible solutions. Unfortunately, the calculate of
forecasts have a complex process. The methodology developed in this investigation is
the Box-Jenkins, the same that can be applied to any univariate time series. The
selection of optimal model is simplified with programming and several test is applied to
determine the most appropriate model. This methodology has been implemented in the
virtual laboratory of hidrology “HydroVLab” using Visual Studio 2010.
In the phase of results, it has been seen that the data follow a pattern similar to those
observed, and also meet the requirements of acceptance. Of this way consistent
forecasts is achieved.
KEYWORDS: Time series, Forecasts, Box-Jenkins, ARIMA, SARIMA

3
INTRODUCCIÓN
En Ingeniería Civil, es de suma importancia la estimación de valores de diseño de obras
en general. Existen varias metodologías para el efecto como son los modelos
determinísticos, causa y efecto o modelos estadísticos. Pero cuando se desea realizar
pronóstico a corto o mediano plazo los modelos estocásticos son los de mejor aplicación
en casos como: pronósticos de los niveles de un embalse, precipitaciones, caudales,
entre otros y evitar posibles tragedias o a su vez tomar medidas preventivas.
En el presente trabajo investigativo, se pretende desarrollar técnicas estocásticas de
predicción, para su posterior implementación en el laboratorio virtual de hidrología
“HydroVLab”.
Los objetivos del presente trabajo investigativo son los siguientes:
Implementar herramientas de modelización estocástica de series hidrológicas en
el HydroVLab.
Desarrollar metodologías para el modelamiento estocástico de series
hidrológicas: Modelos auto regresivos, auto regresivos de medias móviles, de
descomposición lineal, multivariados.
Implementar herramientas en el HydroVLab.
Validar las herramientas implementadas.
Para alcanzar los objetivos planteados, se realizó una recopilación de varias
metodologías: modelos autorregresivos, de media móvil, autorregresivos de media
móvil, autorregresivos integrados de media móvil y estacional autorregresivo integrado
de media móvil. Éstas metodologías fueron evaluadas aplicándolas a series de datos
reales, para posteriormente realizar su implementación en el HydroVLab, empleando
Microsoft Visual Studio 2010.
El presente trabajo se realizó gracias al apoyo del Departamento de Geología, Minas e
Ingeniería Civil que facilitó el acceso a las series de datos analizadas, a bases de datos
bibliográficas y prestó la asesoría técnica correspondiente. El principal inconveniente
que se tuvo que sortear, es la reducida información bibliográfica sobre el proceso de
construcción de los modelos estocásticos.

4
El presente trabajo de fin de titulación, se encuentra organizado en los siguientes
capítulos:
Capítulo 1: Breve descripción de los métodos predictivos, utilidad que tienen en
diferentes áreas de estudio, algunas investigaciones en las que han sido
aplicados.
Capítulo 2: Conceptos básicos, pasos para la construcción de cada uno de los
modelos desarrollados, metodología de programación utilizada para la
generación de los algoritmos.
Capítulo 3: Análisis y comparación de los resultados obtenidos con cada modelo.
Conclusiones, recomendaciones y anexos que se utilizaron para describir de
mejor manera los métodos.
Para una mejor comprensión de los métodos predictivos, se ilustra el proceso de
construcción de cada modelo con una serie de tiempo. De ésta manera se puede
visualizar las características y diferencias que posee cada modelo.

1. CAPÍTULO I:
ESTADO DEL ARTE

6
Los estadísticos George E. P. Box y Gwilym Jenkins a quienes se atribuye el nombre de
esta metodología (Hudak & Liu, 1992-1994), desarrollaron en 1970 una serie de
modelos predictivos con el fin de obtener pronósticos que se acerquen lo más posible a
la realidad, dejando que los propios datos de la variable nos indiquen sus características
(Universidad Autónoma de Madrid, 2004).
Esta metodología consiste en estimar un modelo por medio de tres fases: identificación,
estimación y chequeo del diagnóstico, el cual debe dar como resultado pronósticos
óptimos (Hudak & Liu, 1992-1994).
En la práctica, se han utilizado ampliamente en distintas áreas de estudio tales como:
medicina (Otoom, Alshraideh, López de Ipiña, Bravo, & Hisham, 2015) emplearon el
modelo ARIMA para modelar el azúcar en la sangre en tiempo real; en electricidad
(Kwangbok, Choongwan, & Taehoon , 2014) se utiliza modelos SARIMA en combinación
de modelos de Red Neuronal Artificial (modelo híbrido superior), para calcular el
pronóstico del presupuesto anual del costo de energía en instituciones educativas; en
economía: (Ghahramani & Thavaneswaran, 2006) se realiza una comparación de los
modelos ARMA procesados con errores GARCH y los procesados con mínimos
cuadrados, mostrando superioridad los modelados con errores GARCH; también
(Shamsuddin & Holmes, 1997) afirma que la exactitud predictiva del modelo ARMA
multivariante no es estadísticamente diferente de la del modelo ARMA univariante;
Los modelos Box-Jenkins han sido comparados con otros métodos, en algunos casos
se afirma la superioridad de los mismos (sobre los modelos basados en Markov (Otoom
et al., 2015)) y en otros se los combina para obtener un modelo mejorado( (Ghahramani
& Thavaneswaran, 2006), (Gairaa, Khellaf, Messlem, & Chellali, 2016)).
El objetivo del presente estudio es desarrollar los principales modelos Box-Jenkins,
subirlos a la plataforma virtual de la Universidad, y brindar a la comunidad interesada
una herramienta informática para facilitar y optimizar el uso de éstos modelos, así como
obtener pronósticos adecuados.

2. CAPÍTULO II:
MATERIALES Y MÉTODOS

8
2.1. Metodología Box-Jenkins.
En ocasiones es muy difícil o no se conoce las determinantes de la variable que se
requiere pronosticar o no se dispone de las variables explicativas, es aquí en donde los
modelos Box-Jenkins muestran una superioridad, ya que éstos modelos realizan las
predicciones basándose en el pasado de la misma variable (Holton, 2007).
Dentro de la metodología Box-Jenkins existen varias restricciones para las series de
tiempo, como por ejemplo la estacionariedad, si la serie es no estacionaria se la debe
transformar hasta alcanzar tal condición (Bowerman et al., 2007).
El propósito de Box y Jenkins, es identificar un modelo que describa el conjunto de datos
pero con el número mínimo de elementos, es decir obtener una ecuación lo más
reducida posible pero que a la vez cumpla los requerimientos para su aceptación
(Gujarati & Porter, 2010).
Por ello, en la presente investigación se describen los conceptos básicos y el
procedimiento a desarrollar para la construcción de modelos que pertenecen a esta
metodología, con el fin de obtener los óptimos para su posterior aplicación en los
pronósticos.
2.2. Series de tiempo.
“Los datos de una serie de tiempo son una secuencia de observaciones ordenadas en
forma natural con respecto al tiempo” (Holton, 2007). En esta investigación se utiliza la
metodología de Box – Jenkins cuya aplicación es especialmente adecuada para series
con más de 50 observaciones (Vasileiadou & Vliegenthart, 2013) , cuya variable debe
ser univariante.
2.3. Estacionariedad.
La metodología de Box – Jenkins describe series estacionarias, por lo tanto la serie a
pronosticar también debe serlo (Bowerman et al. 2007). La estacionariedad ocurre
cuando la media y varianza son constantes en el tiempo (Hernández Alonso, 2007).
2.3.1. Función de autocorrelación.
Autocorrelación.
Representa la relación que existe entre los datos de la serie separados k periodos de
tiempo, en un intervalo entre +1 y -1 (Bowerman et al. 2007). Si la correlación es positiva

9
las observaciones se mueven juntas con pendiente creciente, y si es negativa de manera
decreciente (Autocorrelación, 2007).
Correlograma.
La representación gráfica de los valores de las autocorrelaciones a diferentes rezagos
de tiempo se denomina correlograma (Universidad Autónoma de Madrid, 2004).
La extensión del correlograma inicia desde k=1 hasta la longitud del rezago, que se
define como un tercio o la cuarta parte de la longitud de la serie de tiempo (Gujarati &
Porter, 2010). Se debe calcular el coeficiente de correlación simple y parcial para cada
uno de los rezagos.
En esta investigación se considera una longitud de rezago máxima de 40, ya que es
suficiente para notar el comportamiento de la serie.
Función de autocorrelación simple (FAC).
Según, (Bowerman, O'Connell, & Koehler, 2007): “Es una lista, o una gráfica de las
autocorrelaciones en los desfasamientos k=1,2,…..”.
La autocorrelación simple en el rezago k, denotada por ρk, se define como:
n
bt
2t
kn
bt
ktt
k
)zz(
)zz)(zz(
Ecuación 1.
Dónde:
)1bn(
z
z
n
bt
t
Ecuación 2.
Función de autocorrelación parcial (FACP).
Según, Bowerman et al. (2007): “Es una lista, o una gráfica de las autocorrelaciones
parciales de la muestra en los desfasamientos k=1,2,…..”.
La autocorrelación parcial en el rezago k es:
1kk si k = 1 Ecuación 3.

10
1k
1j
jj,1k
1k
1j
jkj,1kk
kk
1
si k = 2,3,…. Ecuación 4.
Dónde:
jk,1kkkj,1kkj para j = 1,2,….., k-1 Ecuación 5.
Significancia estadística de las autocorrelaciones.
Es importante conocer en que rezago los coeficientes de autocorrelación son
estadísticamente significativos, ya que esto es de gran ayuda para obtener un orden
tentativo del modelo (Gujarati & Porter, 2010).
Intervalos de confianza al 95%.
Bartlett (citada en Gujarati & Porter, 2010) demostró que “si una serie de tiempo es
puramente aleatoria, es decir, si es una muestra de ruido blanco, los coeficientes de
autocorrelación muestrales ρˆk son aproximadamente ρˆk ~ N (0, 1/n)”
Es decir, los coeficientes de correlación se encuentran normalmente distribuidos, con
media cero y varianza igual a 1 sobre el tamaño de la muestra, tales coeficientes se
calculan y grafican para saber hasta que rezago son estadísticamente significativos
(Gujarati & Porter, 2010).
Considerando las propiedades de la distribución normal, los intervalos de confianza de
95% se calculan con la siguiente ecuación (Gujarati & Porter, 2010):
n/1*96.1obPr Ecuación 6.
Estadístico “Q” de Ljung-Box
Otra manera de evaluar la significancia estadística de los coeficientes de
autocorrelación, es por medio del estadístico de Ljung-Box el cual consiste en una
prueba que se utiliza para determinar si una serie es de ruido blanco (Gujarati & Porter,
2010).
En esta investigación, se utiliza el estadístico de Ljung-Box porque sus propiedades son
superiores al Q estadístico de Box-Pierce.
mkn
)2n(nLBm
1k
2k2
Ecuación 7.

11
2.3.2. Error estándar.
El error estándar es la raíz cuadrada de la varianza y se calcula con el fin de medir la
precisión de los valores estimados (Gujarati & Porter, 2010).
ianzavaree Ecuación 8.
2.3.3. t estadístico.
El t estadístico es la relación que existe entre el coeficiente estimado y su
correspondiente error estándar (Gujarati & Porter, 2010).
ee/t Ecuación 9.
2.3.4. T. crítico
El estadístico tau (τ) crítico de MacKinnon, se utiliza para evaluar la hipótesis nula dentro
del análisis de raíz unitaria. Este estadístico está en función del número de datos de la
serie y de ciertos coeficientes ya establecidos, los cuales han sido obtenidos de
(MacKinnon, 2010) y se muestran en el Anexo 1.
El valor tau (τ) crítico se evalúa para el 1%, 5% y 10% de probabilidad, y para tres
posibles modelos que puede adoptar la serie en estudio (Gujarati & Porter, 2010).
Su cálculo se realiza con la siguiente ecuación:
3
3
2
21crítico
TTT.
Ecuación 10.
Dónde: T es el número de datos de la serie y,
β son los coeficientes obtenidos del Anexo 1.
2.3.5. Estadístico “d” de Durbin – Watson.
El estadístico de Durbin – Watson, se calcula con el fin de detectar la presencia de
autocorrelación en los residuos y de una regresión espuria (Gujarati & Porter, 2010).
T
1t
2
t
T
2t
21tt
e
)ee(
d Ecuación 11.

12
Dónde: et, es el residual a la observación en el tiempo t.
T, es el número de datos de la serie de tiempo.
Si el coeficiente de determinación es mayor a éste estadístico, entonces se tiene una
regresión espuria (Gujarati & Porter, 2010).
M. G. Kendall y W. R. Buckland (citada en Gujarati & Porter, 2010), afirman que “la
correlación se describe como espuria si es inducida por el método de manejo de datos
y no está presente en la información original.” Por lo tanto, si se realiza la regresión
sobre una serie de este tipo, los resultados carecerían de sentido (Gujarati & Porter,
2010).
2.3.6. Prueba de raíz unitaria.
Una manera diferente de determinar la estacionariedad en una serie, es utilizar la prueba
de raíz unitaria. Si se presenta una raíz igual a 1 en la ecuación característica del
modelo, entonces la serie es no estacionaria caso contrario es estacionaria, además
este test sirve para detectar la presencia de una serie explosiva (Bowerman et al. 2007).
Se dice que una serie es explosiva cuando tiene un crecimiento desmedido mostrando
un comportamiento poco lógico (Universidad Autónoma de Madrid, 2004).
Existen varias pruebas de raíz unitaria, una de las más populares y utilizada en esta
investigación es la de Dickey – Fuller, la cual se basa en la siguiente regresión:
t1tt uYY Ecuación 12.
Dónde: )1(
11
La prueba de Dickey – Fuller se calcula para tres posibles modelos en los cuales se
evalúa la hipótesis nula de que δ=0:
Caminata aleatoria:
t1tt uYY Ecuación 13.
Caminata aleatoria con deriva:
t1t1t uYY Ecuación 14.

13
Camina aleatoria con deriva alrededor de una tendencia determinista:
t1t21t uYtY Ecuación 15.
La serie es estacionaria si se rechaza la hipótesis nula, caso contrario no lo es
(Bowerman et al., 2007).
Es importante señalar que los valores críticos de la prueba tau para evaluar la hipótesis
nula son diferentes para cada uno de los modelos de la prueba DF.
El procedimiento de cálculo es el siguiente: Se estima los coeficientes de los tres
posibles modelos de la prueba DF mediante mínimos cuadrados ordinarios (MCO); se
divide el coeficiente de Yt-1 entre su error estándar para obtener el estadístico tau (τ) y
se calcula el tau crítico de MacKinnon (Gujarati & Porter, 2010).
EL método de mínimos cuadrados ordinarios, es un método bastante conocido dentro
de análisis de regresión debido a sus propiedades estadísticas. El objetivo principal de
este método, es estimar coeficientes de tal manera que minimicen la suma de errores al
cuadrado, para mayor información se recomienda revisar el libro “Econometría 5ta ed.”
de los autores: Gujarati & Porter.
Si el valor absoluto del estadístico tau (τ) es mayor al crítico de MacKinnon, se rechaza
la hipótesis nula y la serie es estacionaria. Caso contrario, si el valor tau (τ) calculado
no supera el tau crítico, se acepta la hipótesis nula y la serie es no estacionaria (Gujarati
& Porter, 2010).
Cabe recalcar que si δ>0, el modelo no se considera ya que la serie sería explosiva
(Gujarati & Porter, 2010). Además, δ puede tomar únicamente valores menores a 0,
debido a que está relacionada directamente con el coeficiente de correlación.
2.3.7. Transformación de las series no estacionarias.
Como ya se mencionó anteriormente, para aplicar los modelos Box-Jenkins la serie de
tiempo en análisis debe ser estacionaria. Si no lo es, se debe realizar una transformación
para lograr su estacionariedad. El método que se utiliza en esta investigación es la
diferenciación de la serie (Bowerman et al., 2007).

14
A continuación se explica el procedimiento que se ejecuta para realizar la diferenciación:
Dada una serie de tiempo no estacionaria: n21 y,.....,y,y se obtiene la primera
diferencia: 1nnn233122 yyz,.....,yyz,yyz y se analiza si la nueva
serie es o no estacionaria, en caso de no serlo se procede a obtener las segundas
diferencias, este proceso se repite hasta llegar a la estacionariedad, así la serie
estacionaria se denomina como serie de trabajo. Cabe recalcar que por lo general no
se necesita más de dos diferenciaciones (Bowerman et al., 2007).
2.4. Estacionalidad.
La estacionalidad se presenta en una serie, cuando ésta se construye con datos
registrados trimestral, mensual, semanal, entre otros, y conservan patrones similares de
comportamiento (Antunez Irgoin, 2011).
2.4.1. Transformación de una serie de tiempo estacional a estacionaria.
Por lo general una serie de tiempo estacional, tiene una variabilidad considerable
respecto a su varianza. Una manera de estabilizar la varianza es por medio del uso de
una transformación de pre-diferenciación (Bowerman et al., 2007).
En ésta investigación, se utiliza como transformación de pre-diferenciación la raíz
cuadrada, raíz cuarta y los logaritmos naturales de la serie en estudio, se procede a
examinar sus respectivas desviaciones estándar, de las cuales se elige la que tiene un
valor intermedio. No se escoge la serie con menor valor de desviación para evitar una
transformación excesiva (Bowerman et al., 2007).
Es importante recordar, que la desviación estándar es una medida de cuan alejados
están los datos de su media aritmética (Murray R., 1997).
Una vez que se estabiliza la varianza, se procede a estabilizar la media con el fin de
obtener una serie de tiempo estacionaria, para lo cual se realiza una transformación de
estacionalidad (Bowerman et al., 2007).
La transformación de estacionalidad consiste en obtener las diferencias regulares y
estacionales de la serie seleccionada de la transformación de pre-diferenciación. Se
realiza cuatro transformaciones de estacionalidad, las cuales se visualiza de mejor
manera en la Tabla 2.1

15
Tabla 2.1. Cuatro transformaciones de estacionalidad.
(1) zt=yt* (2) zt=yt
*- y*t-1 (3) zt=yt
* - y*t-L (4) zt=yt
*-y*t-1-y
*t-L +y*
t-1
z1=y1*
z2=y2* z2=yt2
*- y*1
. z3=y3*- y*
2
. .
. .
. .
. . zL+1= y*L+1 - y*
1
. . zL+2= y*L+2 - y*
2 zL+2= y*L+2 - y*
L+1 - y*2 + y*
1
. . . zL+3= y*L+3 - y*
L+2 - y*3 + y*
2
. . . .
. . . .
zn=yn* zn=yn
*- y*n-1 zt=yn
* - y*n-L zn= y*
n - y*n-1 - y*
n-L + y*n-L-1
Fuente: (Bowerman et al. 2007) Elaboración: Elaboración propia
Dónde: L, representa la estacionalidad, por ejemplo: L=4 si se trata de datos
trimestrales y L=12 si son mensuales.
Yt*, es la serie luego de la transformación de pre-diferenciación.
Zt, es la serie generada con la transformación de estacionalidad.
En la Tabla 2.1, la primera columna representa los valores pre-diferenciados originales,
la segunda genera la primera diferencia regular, la tercera produce la primera diferencia
estacional y la cuarta muestra la primera diferencia regular y estacional (Bowerman et
al., 2007).
Para seleccionar la serie adecuada, se examina la función de autocorrelación simple
(FAC) y la función de autocorrelación parcial (FACP) que se obtiene a partir de los
valores de Zt, tanto en el nivel no estacional como en el estacional.
Según Bowerman et al. (2007), en el nivel no estacional el comportamiento de la FAC y
FACP está descrito en los desfasamientos 1 a (L-3), y en el nivel estacional por
desfasamientos iguales a L, 2L, 3L y 4L.
Como criterio adicional para la selección de la serie que genera datos estacionarios, se
obtiene la desviación estándar de cada una de las series calculadas en la Tabla 2.1 y
se escoge la serie con menor desviación estándar.

16
2.5. Modelos Box-Jenkins.
La metodología Box-Jenkins, se divide principalmente en:
- Modelos autorregresivos (AR).
- Modelos de media móvil (MA).
- Modelos autorregresivos de media móvil (ARMA).
- Modelos autorregresivos integrados de media móvil (ARIMA).
- Modelos estacionales autorregresivos integrados de media móvil (SARIMA).
A continuación se presenta la definición y las características de cada uno de los modelos
señalados, así como su respectivo proceso de construcción.
2.5.1. Autorregresivo – AR (p).
Se los denomina modelos autorregresivos, porque generan el presente o futuro en
función de su propio pasado, donde “p” indica el número de retardos necesarios
(Universidad Autónoma de Madrid, 2008). Se los representa por medio de la siguiente
ecuación:
tptp2t21t1t ay....yyy Ecuación 16.
Dónde: yt, es la serie de tiempo.
δ, es la media del proceso.
at, es un término de error aleatorio.
Φ1, Φ2,…., Φp, son coeficientes desconocidos que relacionan a yt con su
pasado.
Algunas de las características principales de este modelo, se muestran en la Tabla 2.2
Tabla 2.2. Características de los modelos AR (p).
TIPO CARACTERÍSTICA
FAC Decrece de manera exponencial, pero sin llegar a anularse.
FACP
Presenta autocorrelaciones parciales diferentes de cero en
los desfasamientos 1, 2,…., p, y autocorrelaciones parciales
iguales a cero en los demás desfasamientos.
Sigue Tabla 2.2…

17
Continúa Tabla 2.2
Intercepto δ )...1( p21
μ=media del proceso.
Pronósticos Tienden a la media del proceso a medida que aumenta la
longitud de la predicción.
Fuente: Adaptado de (Bowerman et al., 2007) y (Universidad Autónoma de Madrid, 2008) Elaboración: Elaboración propia
2.5.2. Media móvil – MA (q).
Los procesos de media móvil son procesos de memoria limitada, se los llama así ya que
muestran variación en los pronósticos hasta una longitud de predicción igual a “q”, luego
de éste son iguales a su media (Universidad Autónoma de Madrid, 2008).
tqtq2t21t1t aa....aay Ecuación 17.
Dónde: yt, es la serie de tiempo.
δ, es la media del proceso.
at, es un término de error aleatorio.
θ1, θ2,…., θp, son coeficientes que relacionan a yt con sus
correspondientes errores pasados, los cuales deben ser
estadísticamente independientes.
Las características principales de este modelo, se muestran en la Tabla 2.3
Tabla 2.3. Características de los modelos MA (q).
TIPO CARACTERÍSTICA
FAC
Las autocorrelaciones son diferentes de cero en los
desfasamientos 1, 2,…., q, e iguales a cero en los demás
desfasamientos.
FACP Decrece de manera exponencial, pero sin llegar a anularse.
Intercepto δ
μ=media del proceso.
Pronósticos
Son iguales a la media del proceso cuando la longitud de la
predicción es mayor al orden del modelo (q), esto sucede
debido a la memoria limitada que los caracteriza.
Fuente: Adaptado de (Bowerman et al., 2007) y (Universidad Autónoma de Madrid, 2008) Elaboración: Elaboración propia.

18
2.5.3. Autorregresivo de media móvil – ARMA (p, q).
Los modelos ARMA, son procesos en los que Yt está explicada no solo por sus retardos,
sino también por perturbaciones aleatorias, es decir es una combinación de los modelos
autorregresivos (AR) y de medias móviles (MA) (Bowerman et al., 2007).
tqtq2t21t1ptp2t21t1t aa....aay....yyy Ecuación 18.
Dónde: yt, es la serie de tiempo.
δ, es la media del proceso.
at, es un término de error aleatorio.
Φ1, Φ2,…., Φp, θ1, θ2,…., θp, son como ya se mencionó: parámetros que
relacionan a yt con su pasado y sus errores.
En la Tabla 2.4 se presentan las principales características.
Tabla 2.4. Características de los modelos ARMA (p, q).
TIPO CARACTERÍSTICA
FAC Decrece de manera exponencial, pero sin llegar a anularse.
FACP Decrece de manera exponencial, pero sin llegar a anularse.
Intercepto δ )...1( p21
μ=media del proceso.
Pronósticos
Después de “q” períodos, los pronósticos se aproximan a la
media del proceso conforme aumenta la longitud de
predicción.
Fuente: Adaptado de (Bowerman et al., 2007) y (Universidad Autónoma de Madrid, 2008) Elaboración: Elaboración propia.
2.5.4. Autorregresivo integrado de media móvil – ARIMA (p, d, q).
Como ya se mencionó anteriormente, para utilizar la metodología de Box-Jenkins se
requiere que la serie sea estacionaria. Ahora bien, muchas veces ésta condición no se
cumple, por lo cual es obligatorio diferenciar la serie, el número de diferencias
necesarias para llegar a la estacionariedad es denotado por “d”, respectivamente “p” y
“q” indican el número de retardos y perturbaciones aleatorias (Bowerman et al., 2007).
Se representa con la siguiente ecuación:
tqtq2t21t1ptp2t21t1t aa....aaz....zzz Ecuación 19.

19
Dónde: zt, es la serie de tiempo diferenciada estacionaria.
δ, es la media del proceso.
at, es un término de error aleatorio.
Φ1, Φ2,…., Φp, θ1, θ2,…., θp, son como ya se mencionó: parámetros que
relacionan a zt con su pasado y sus errores.
Una vez que se ha diferenciado la serie obteniendo la nueva serie estacionaria, dicha
serie muestra un comportamiento igual al modelo ARMA, razón por la cual no se
mencionan las características de este modelo (Gujarati & Porter, 2010).
Es importante aclarar que, los pronósticos ya no se aproximan a la media, sino a una
línea recta que inicia de Y (d) con una pendiente igual a la media del proceso Zt, que
es la nueva serie diferenciada estacionaria (Universidad Autónoma de Madrid, 2008).
2.5.5. Estacional autorregresivo integrado de media móvil – SARIMA (p, d, q)
(P, D, Q).
Este modelo se emplea en series que tienen periodicidad, con períodos estacionales “L”
menores a un año. Con el fin de modelar los patrones de comportamiento presentes en
este tipo de series, se considera retardos regulares (1, 2, 3,…) y estacionales (L, 2L,
3L,…) (Bowerman et al., 2007).
Antes de iniciar con el cálculo del modelo en sí, es necesario realizar dos
transformaciones: una de pre-diferenciación y otra de estacionalidad, para de esta
manera estabilizar tanto la varianza como la media (Bowerman et al., 2007).
El modelo general está descrito por la siguiente ecuación:
PLtL,PL2tL,2LtL,1ptp2t21t1t z....zzz....zzz
tQLtL,QL2tL,2LtL,1qtq2t21t1 aa....aaa....aa Ecuación 20.
Dónde: zt, es la serie transformada estacionaria.
L, 2L, 3L,…, son los desfasamientos estacionales.
1, 2, 3,…, son los desfasamientos regulares.
P, es el orden autorregresivo estacional.
p, es el orden autorregresivo regular.

20
Q, es el orden de media móvil estacional.
q, es el orden de media móvil regular.
L, es el valor de la periodicidad. Por ejemplo: si la serie es mensual L=12,
si es trimestral L=4.
Las propiedades de la función de autocorrelación (FAC) y de la autocorrelación parcial
(FACP) de este modelo, son análogas a las propiedades de los métodos descritos
anteriormente. La diferencia es que se debe tomar en cuenta los desfasamientos
estacionales para identificar el orden P y Q (Bowerman et al., 2007).
2.5.6. Proceso de construcción de los modelos no estacionales.
Los modelos no estacionales son: el modelo autorregresivo (AR), de medias móviles
(MA), autorregresivo de medias móviles (ARMA) y autorregresivo integrado de medias
móviles (ARIMA).
Antes de iniciar con el proceso de construcción, se debe realizar un análisis de
estacionariedad con el fin de evitar realizar una regresión espuria, que por lo general
aparece en series no estacionarias (Gujarati & Porter, 2010).
Una vez que se afirma que la serie de tiempo a trabajar es estacionaria, se procede a
calcular el modelo siguiendo cada una de las fases descritas a continuación. En caso
de que el modelo estimado no cumpla con las condiciones establecidas, se debe volver
a estimarlo tomando un nuevo orden del modelo (p, d, q), por tal razón la metodología
Box-Jenkins es un proceso iterativo (Figura 2.1) (Gujarati & Porter, 2010).
Figura 2.1. Metodología de Box – Jenkins.
Fuente: (Gujarati & Porter, 2010)

21
Identificación.
En la fase de identificación, los datos de la serie se usan para generar la función de
autocorrelación simple y parcial (correlograma), con el fin de identificar el orden del
modelo y proceder a la estimación del mismo (Universidad Autónoma de Madrid, 2008).
Es decir, el objetivo es encontrar un modelo que se ajuste de mejor manera a la serie
bajo estudio, tomando los valores más apropiados para p, d y q. En esta fase es
importante aplicar el principio de parsimonia para la selección del modelo más adecuado
(Hanke, 2010).
“El principio de parsimonia se refiere a la preferencia por los modelos sencillos por
encima de los modelos complejos” (Hanke, 2010).
Estimación.
Una vez identificados los valores de p, d, q, el siguiente paso es determinar los
coeficientes de los términos autorregresivos y de medias móviles a incluir en el modelo.
Para la estimación se recurre a procedimientos de estimación no lineal, en ésta
investigación se ha utilizado el método de mínimos cuadrados no lineales (MCNL)
(Bowerman et al., 2007).
El método de mínimos cuadrados no lineales (MCNL), se basa al igual que los mínimos
cuadrados ordinarios (MCO) en determinar los valores de los parámetros que reduzcan
la suma de residuos al cuadrado. La gran diferencia es que en el caso de MCNL, este
proceso se realiza en forma iterativa. Para obtener mayor información del cálculo que
se realiza, se sugiere revisar (Chapra & Canale, 2007).
Verificación del modelo.
Una de las maneras más simples de comprobar si el modelo estimado es correcto, es
probar que los residuales sean de ruido blanco (Bowerman et al., 2007). Pero también
existen otros criterios de evaluación, en este caso se ha considerado además el
coeficiente de determinación (R2). Es decir, de todos los modelos estimados se escoge
el modelo que tenga el mayor coeficiente de determinación, y que además sus residuos
sean de ruido blanco o puramente aleatorio.
Cabe recalcar que si el modelo no cumple con las condiciones mencionadas, se debe
volver a calcular el modelo con un nuevo orden (p, d, q), es decir se repite el proceso
desde la fase de identificación (Gujarati & Porter, 2010).

22
Predicción.
Ya que se ha obtenido un modelo adecuado y suficiente, se procede a determinar los
pronósticos requeridos de la serie de tiempo. Es fundamental recordar si se realizó o no
alguna transformación o diferenciación a la serie de tiempo, ya que al momento de
calcular las predicciones se debe “deshacer” tales cambios. Por ejemplo, si la serie de
tiempo fue diferenciada una vez, entonces se la debe volver a integrar para obtener el
pronóstico correcto (Bowerman et al., 2007).
La metodología de Box y Jenkins, se utiliza con bastante popularidad ya que los
pronósticos calculados con los modelos seleccionados son bastante confiables. “Una
razón de la popularidad del proceso de construcción de modelos ARIMA es su éxito en
el pronóstico” (Gujarati & Porter, 2010).
2.5.7. Proceso de construcción del modelo estacional SARIMA.
Para la construcción de un modelo SARIMA, se sigue los siguientes pasos:
- Se realiza una transformación de pre-diferenciación y una de estacionalidad con
el fin de obtener la serie de trabajo, tales transformaciones se han descrito en la
sección 2.3.1.
- Se obtiene la FAC y FACP de la serie, y se identifica un orden tentativo tanto
para p,d,q en el nivel no estacional, y P,D,Q en el nivel estacional.
- Ya que se ha identificado el orden, se procede a calcular el modelo por medio
del método de mínimos cuadrados no lineales (MCNL) hasta obtener su
convergencia (Bowerman et al., 2007).
- Una vez estimados los parámetros, se evalúa la consistencia del modelo para su
posterior aplicación en los pronósticos. Los criterios de evaluación son los
mismos que se utiliza en los modelos no estacionales. En caso de cumplir con
los requerimientos, el modelo se acepta y se puede pronosticar con el mismo,
caso contrario se vuelve a elegir el orden p, d, q y P, D, Q hasta obtener un
modelo aceptable.
2.6. Metodología de programación.
En la presente sección se describe las herramientas informáticas utilizadas para el
desarrollo de los modelos Box-Jenkins en el HydroVLab, así como la ubicación de los
manuales y los diagramas de flujo de cada método.

23
2.6.1. Descripción de las herramientas virtuales.
La programación de cada uno de los modelos se realizó en Microsoft Visual Studio 2010,
con el lenguaje de programación denominado: Visual Basic.
Se puede encontrar los modelos en:
“http://www.hydrovlab.utpl.edu.ec/SIMULACI%C3%93N/pAnalisisEstocastico/tabid/141
/language/es-ES/Default.aspx”
2.6.2. Descripción del software utilizado para el desarrollo de las herramientas.
El software base que se utiliza en la presente investigación es Microsoft Visual Studio
2010. A continuación se presenta una breve descripción de los principales componentes
que se utilizaron.
Microsoft Visual Studio 2010.
Es un software completo e ideal para el desarrollo de páginas web, además trabaja con
varios lenguajes de programación como: Visual Basic, Visual C#, Visual C++ y Visual
F# facilitando la creación de diversos proyectos (MSDN Library, 2001).
“Visual Studio es un conjunto completo de herramientas de desarrollo para la generación
de aplicaciones web ASP.NET, Servicios Web XML, aplicaciones de escritorio y
aplicaciones móviles” (MSDN Library, 2001).
Página Web.
Las páginas web en la presente investigación, han sido desarrolladas por medio de
asp.net, bajo el lenguaje de programación: Visual Basic. El sitio web al que se enlazan
cada uno de los métodos es: http://www.hydrovlab.utpl.edu.ec/.
Es importante saber que para acceder de manera completa a las herramientas virtuales
del HYDROVLAB, es necesario registrarse por medio de un usuario y contraseña.
Lenguaje de Visual Basic
Visual Basic es un lenguaje de programación que permite desarrollar de manera simple
y accesible, diversos contenidos informáticos gráficos. Por tal razón, es uno de los
lenguajes más populares y conocidos en el mundo de la programación (Rodriguez
Bucarelly & Rodriguez Bucarelly, 2008).
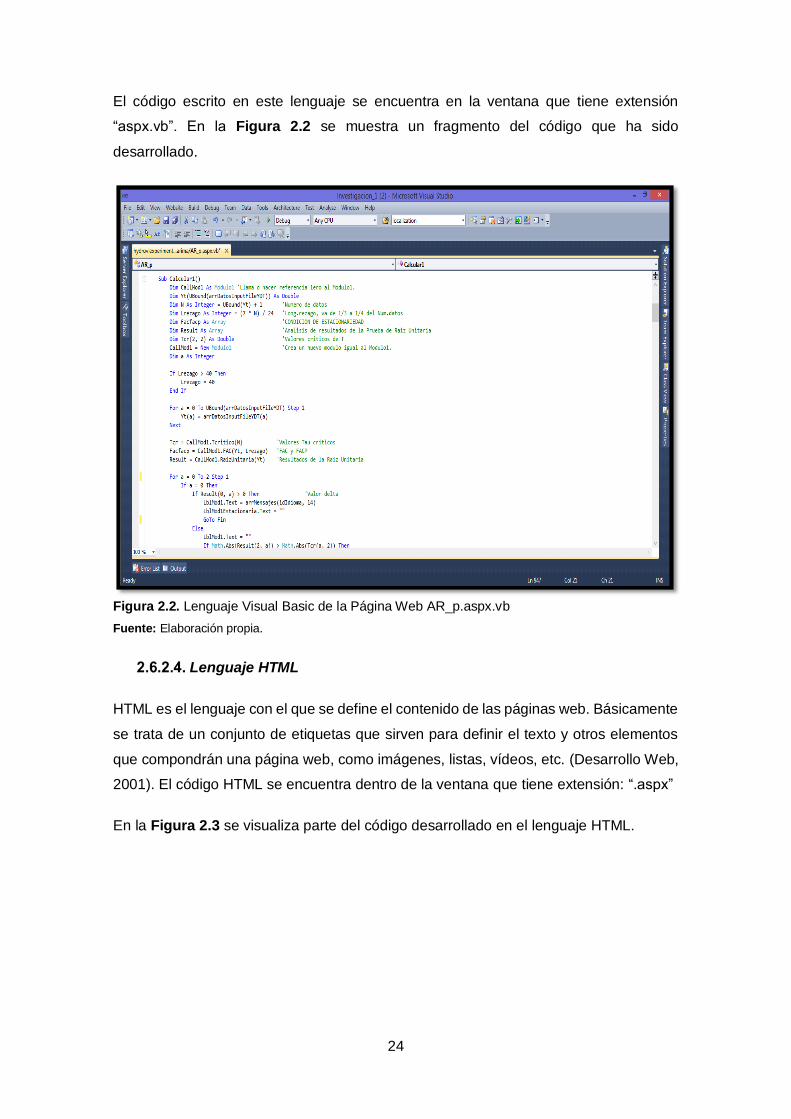
24
El código escrito en este lenguaje se encuentra en la ventana que tiene extensión
“aspx.vb”. En la Figura 2.2 se muestra un fragmento del código que ha sido
desarrollado.
Figura 2.2. Lenguaje Visual Basic de la Página Web AR_p.aspx.vb
Fuente: Elaboración propia.
Lenguaje HTML
HTML es el lenguaje con el que se define el contenido de las páginas web. Básicamente
se trata de un conjunto de etiquetas que sirven para definir el texto y otros elementos
que compondrán una página web, como imágenes, listas, vídeos, etc. (Desarrollo Web,
2001). El código HTML se encuentra dentro de la ventana que tiene extensión: “.aspx”
En la Figura 2.3 se visualiza parte del código desarrollado en el lenguaje HTML.

25
Figura 2.3. Lenguaje HTML de la Página Web AR_p.aspx
Fuente: Elaboración propia.
Hojas de estilo.
Las hojas de estilo se encuentran predefinidas y contienen el formato del HYDROVLAB,
las mismas que trabajan bajo la extensión: “.css”. Estas hojas se cargaron con
anterioridad al proyecto, para poderlas aplicar a todos los elementos contenidos dentro
de las páginas desarrolladas.
2.6.3. Manuales de uso de cada una de las herramientas.
Se han colocado manuales al inicio de cada una de las páginas, a los cuales se puede
acceder presionando el botón “Descargar manual”, se ha realizado esto con el fin de
brindar mayor comprensión de los métodos y facilidad de uso a los usuarios.
2.6.4. Diagramas de flujo.
Para el desarrollo de las herramientas se consideró necesario realizar diagramas de
flujo, con el objetivo de facilitar la comprensión de los métodos y disminuir el grado de
complejidad de la programación.
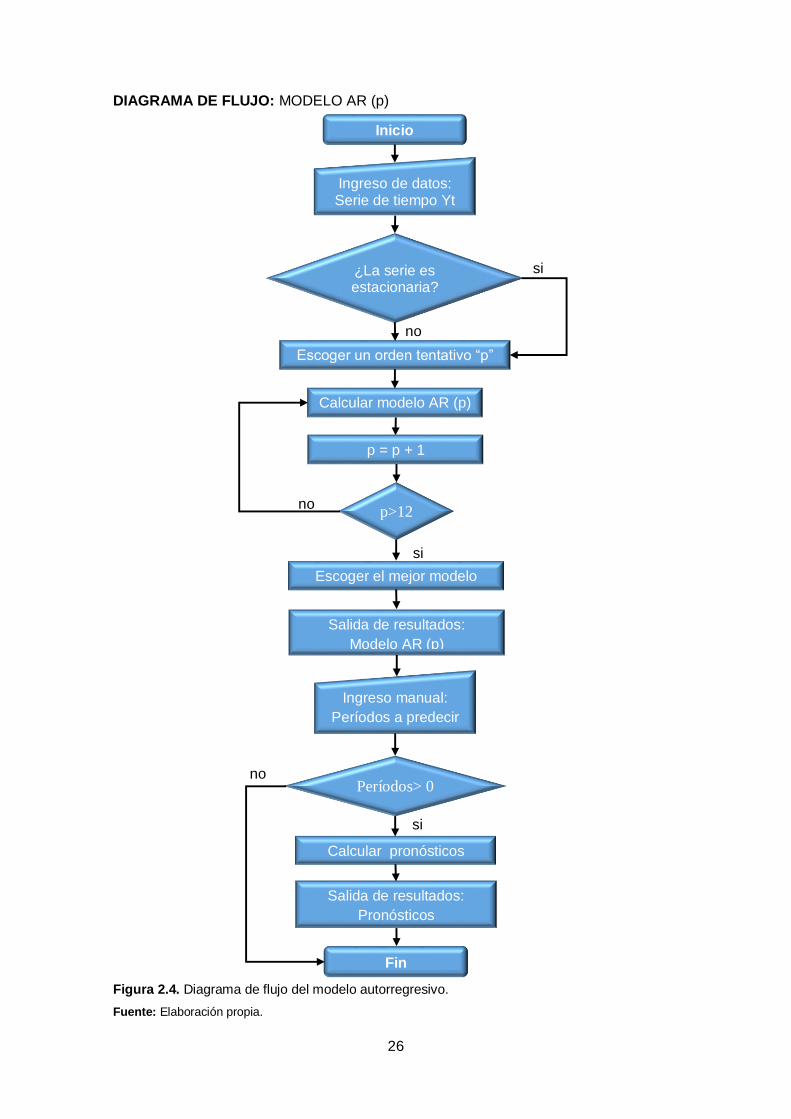
26
DIAGRAMA DE FLUJO: MODELO AR (p)
Figura 2.4. Diagrama de flujo del modelo autorregresivo.
Fuente: Elaboración propia.
Inicio
Fin
Escoger un orden tentativo “p”
¿La serie es estacionaria?
Ingreso de datos: Serie de tiempo Yt
p>12
p = p + 1
Escoger el mejor modelo
Salida de resultados:
Modelo AR (p)
Ingreso manual:
Períodos a predecir
Períodos> 0
Calcular pronósticos
Calcular modelo AR (p)
Salida de resultados:
Pronósticos
si
no
si
no
si
no
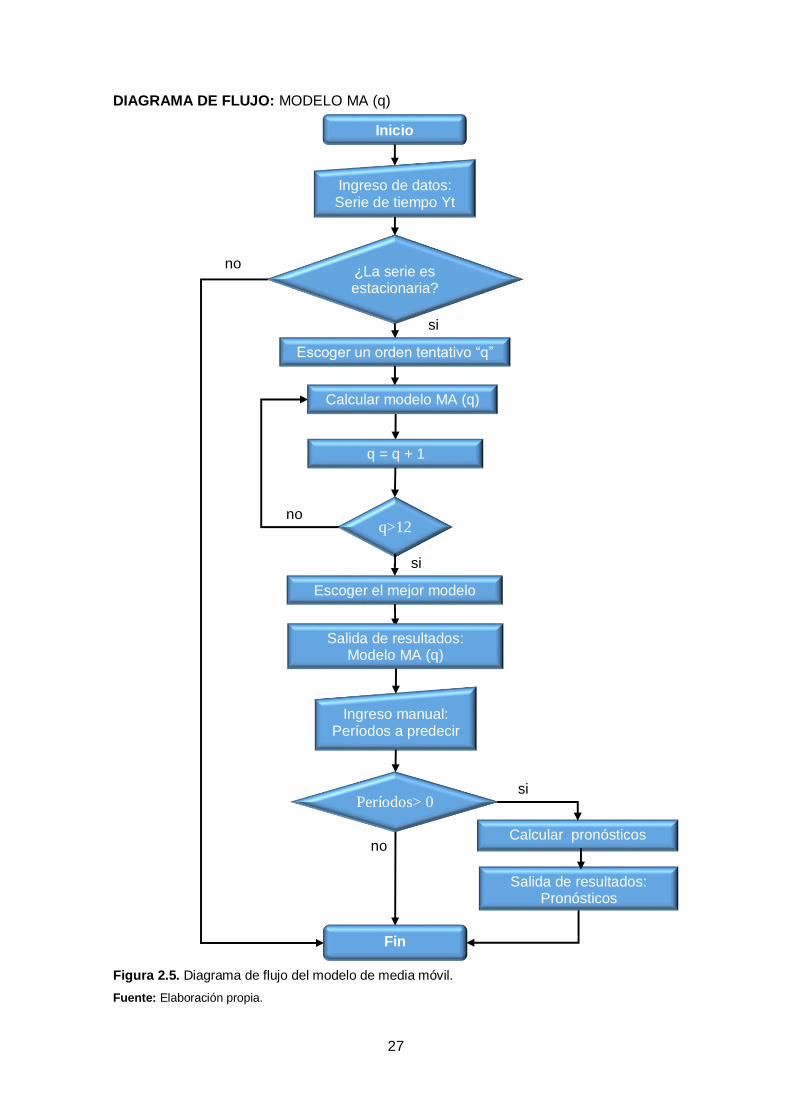
27
DIAGRAMA DE FLUJO: MODELO MA (q)
Figura 2.5. Diagrama de flujo del modelo de media móvil.
Fuente: Elaboración propia.
Inicio
Fin
Escoger un orden tentativo “q”
¿La serie es estacionaria?
Ingreso de datos: Serie de tiempo Yt
q>12
q = q + 1
Escoger el mejor modelo
Salida de resultados: Modelo MA (q)
Ingreso manual: Períodos a predecir
Períodos> 0
Calcular pronósticos
Calcular modelo MA (q)
Salida de resultados: Pronósticos
si
si
si
no
no
no
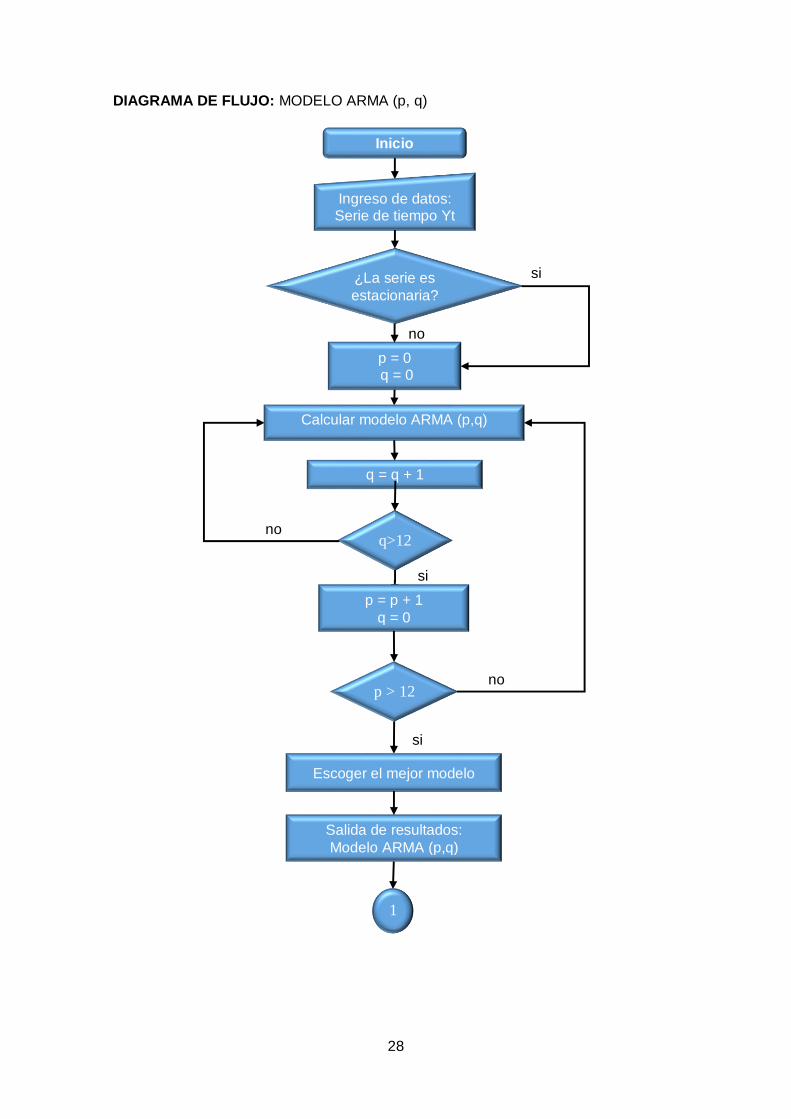
28
DIAGRAMA DE FLUJO: MODELO ARMA (p, q)
Inicio
p = 0 q = 0
¿La serie es
estacionaria?
Ingreso de datos: Serie de tiempo Yt
q>12
q = q + 1
p = p + 1
q = 0
Calcular modelo ARMA (p,q)
p > 12
Escoger el mejor modelo
Salida de resultados:
Modelo ARMA (p,q)
1
si
si
si
no
no
no
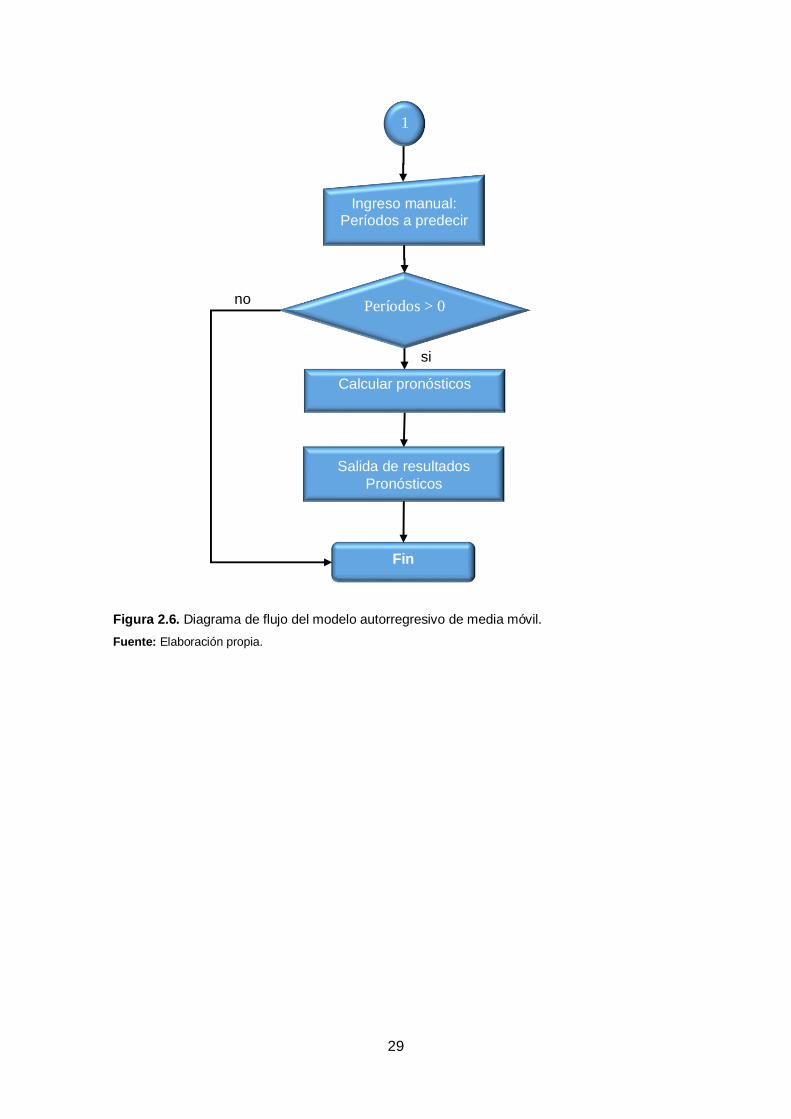
29
Figura 2.6. Diagrama de flujo del modelo autorregresivo de media móvil.
Fuente: Elaboración propia.
Fin
Períodos > 0
Calcular pronósticos
1
Ingreso manual: Períodos a predecir
Salida de resultados
Pronósticos
no
si
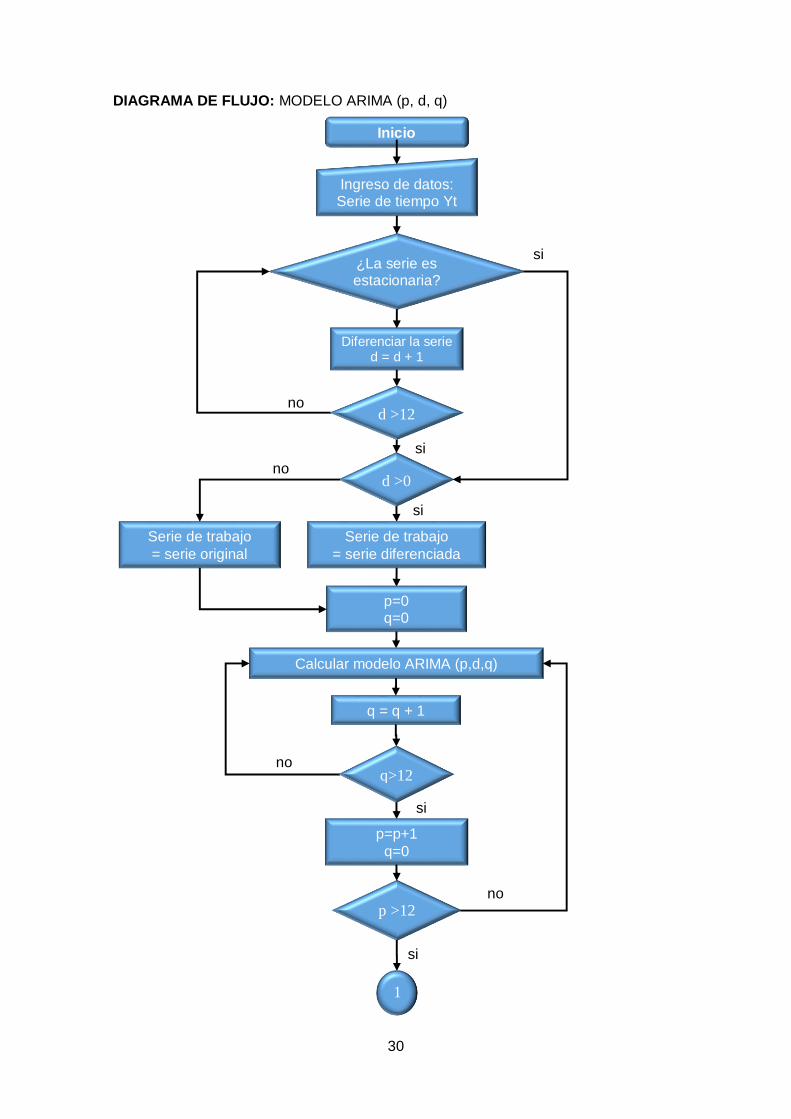
30
DIAGRAMA DE FLUJO: MODELO ARIMA (p, d, q)
Inicio
Diferenciar la serie d = d + 1
¿La serie es estacionaria?
Ingreso de datos: Serie de tiempo Yt
d >0
Serie de trabajo
= serie original Serie de trabajo
= serie diferenciada
d >12
p=0 q=0
q = q + 1
Calcular modelo ARIMA (p,d,q)
q>12
p >12
p=p+1 q=0
1
si
si
si
si
no
no
no
no
si
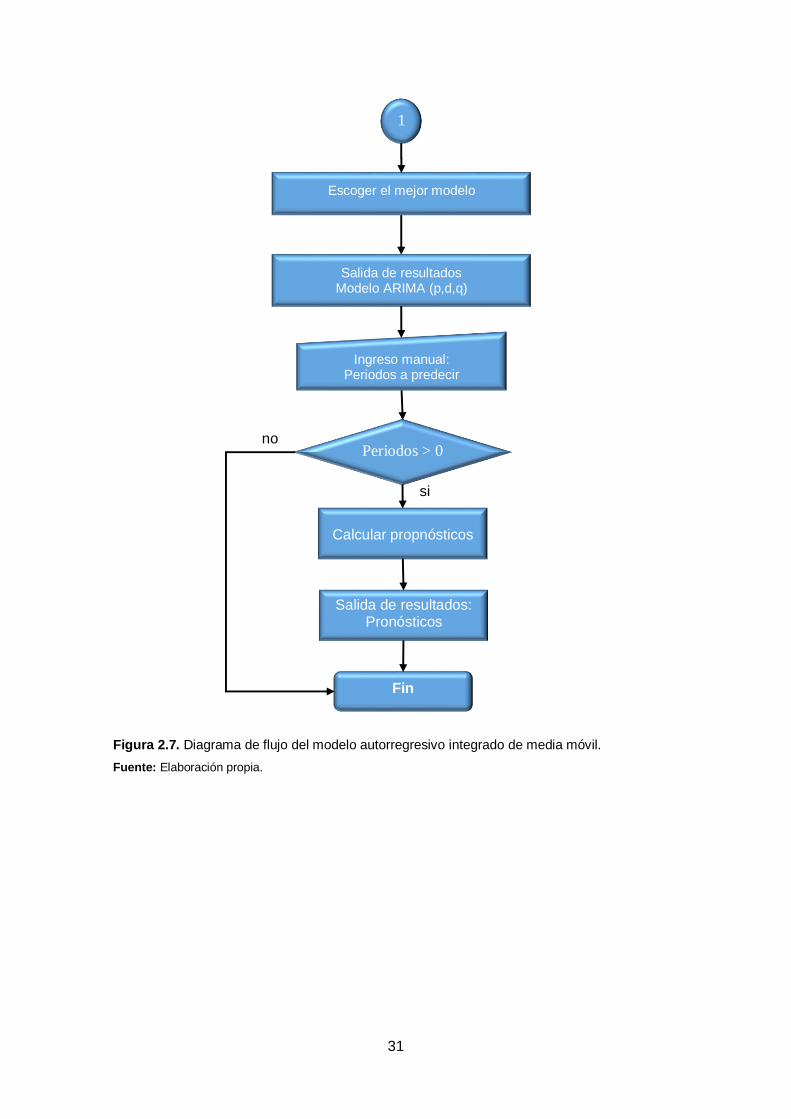
31
Figura 2.7. Diagrama de flujo del modelo autorregresivo integrado de media móvil.
Fuente: Elaboración propia.
1
Escoger el mejor modelo
Salida de resultados Modelo ARIMA (p,d,q)
Ingreso manual: Periodos a predecir
Calcular propnósticos
Periodos > 0
Salida de resultados: Pronósticos
Fin
si
no
32
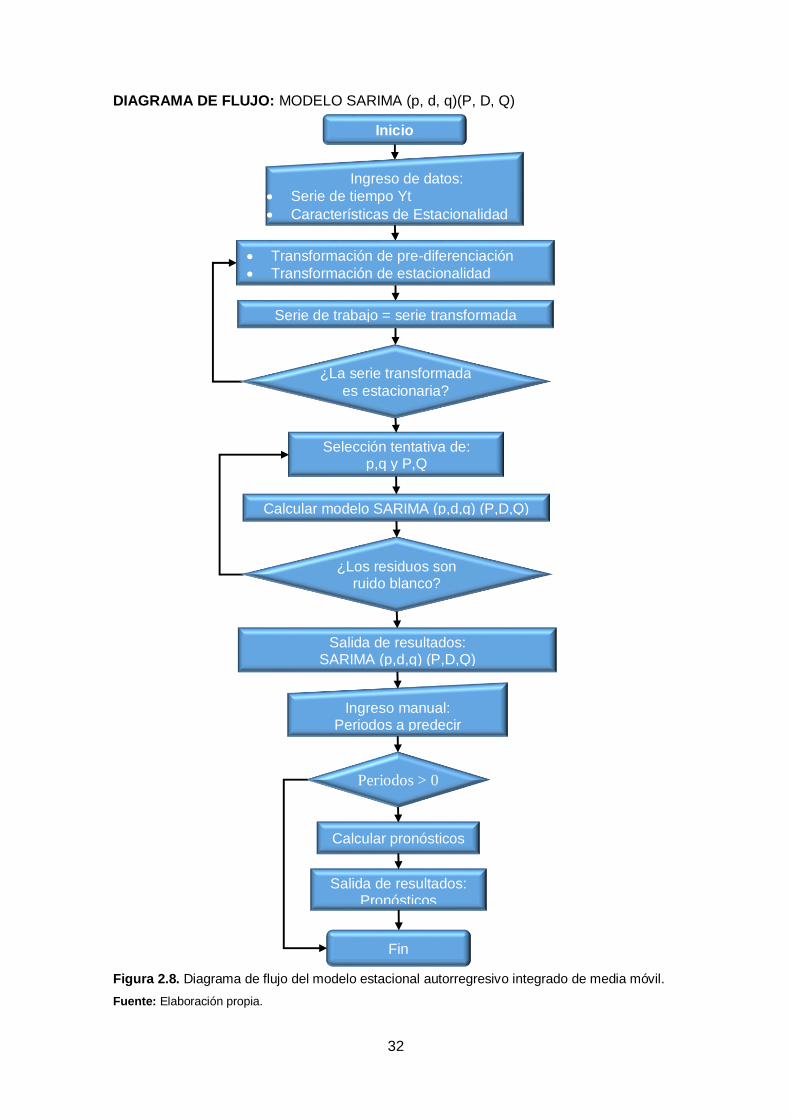
DIAGRAMA DE FLUJO: MODELO SARIMA (p, d, q)(P, D, Q)
Figura 2.8. Diagrama de flujo del modelo estacional autorregresivo integrado de media móvil.
Fuente: Elaboración propia.
Inicio
Ingreso de datos:
Serie de tiempo Yt
Características de Estacionalidad
Calcular modelo SARIMA (p,d,q) (P,D,Q)
Selección tentativa de: p,q y P,Q
¿La serie transformada
es estacionaria?
Transformación de pre-diferenciación
Transformación de estacionalidad
Serie de trabajo = serie transformada
¿Los residuos son ruido blanco?
Salida de resultados: SARIMA (p,d,q) (P,D,Q)
Ingreso manual: Periodos a predecir
Periodos > 0
Salida de resultados: Pronósticos
Calcular pronósticos
Fin

3. CAPÍTULO III:
ANÁLISIS DE RESULTADOS

34
3.1. Utilización y análisis de las herramientas desarrolladas.
A continuación se presenta un análisis y una breve descripción de los cálculos realizados en
cada uno de los modelos.
Para conocer de una manera más detallada el uso de las herramientas, se recomienda
descargar el manual del usuario, el cual se lo puede conseguir al presionar el botón
“DESCARGAR MANUAL” contenido en la página de cada modelo.
3.1.1. Autorregresivo – AR (p).
Para ilustrar el presente método, se utilizó los datos de la Tabla 4.1, Anexo 2, que
corresponden a la primera diferencia de los datos de caudal originales (Tabla 4.2, Anexo 2).
Primero se debe realizar un análisis de estacionariedad de la serie actual, para lo cual se
procede a examinar: el gráfico, la función de autocorrelación simple (FAC), la función de
autocorrelación parcial (FACP) y el test de raíz unitaria de Dickey-Fuller de la serie de tiempo.
Gráfico de la serie.
“Si al parecer los n valores fluctúan con variación constante respecto de una media constante
μ, entonces es razonable pensar que la serie temporal es estacionaria” (Bowerman et al.
2007).
Debido a que en este caso los datos de la serie oscilan alrededor la media (Figura 3.1), el
gráfico sugiere que se podría tratar de una serie estacionaria, lo cual se comprobará con los
análisis que se muestran más adelante.
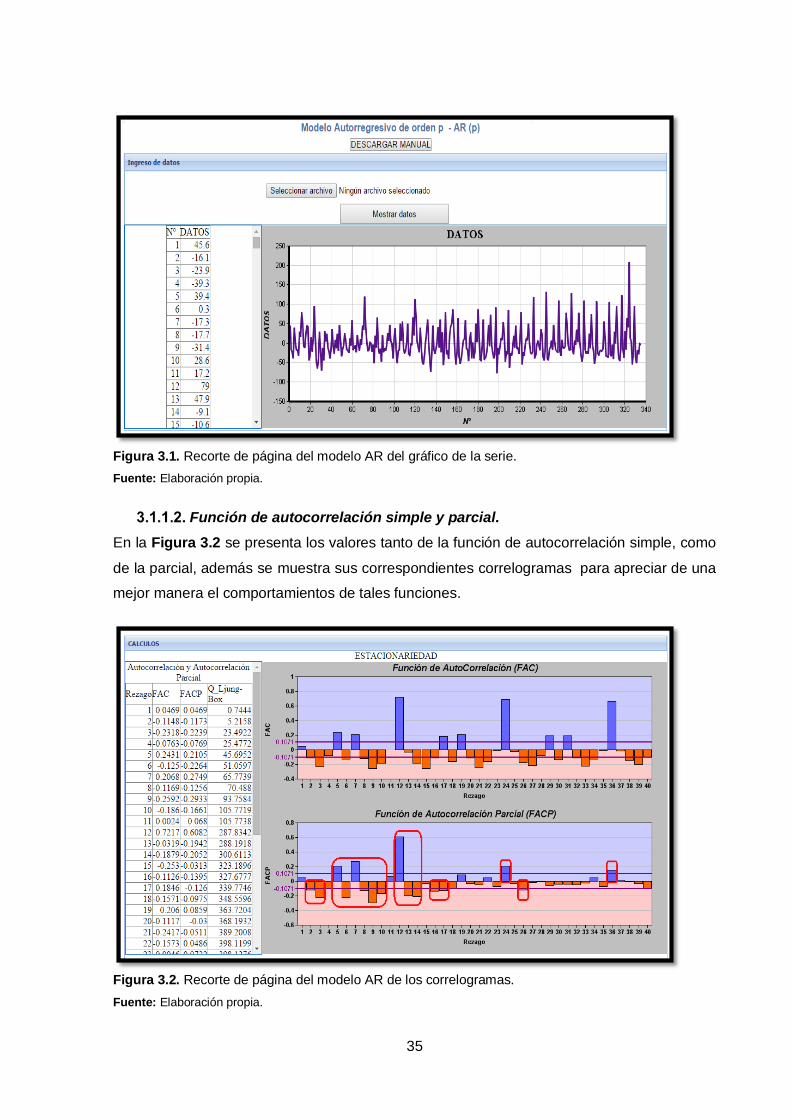
35
Figura 3.1. Recorte de página del modelo AR del gráfico de la serie.
Fuente: Elaboración propia.
Función de autocorrelación simple y parcial.
En la Figura 3.2 se presenta los valores tanto de la función de autocorrelación simple, como
de la parcial, además se muestra sus correspondientes correlogramas para apreciar de una
mejor manera el comportamientos de tales funciones.
Figura 3.2. Recorte de página del modelo AR de los correlogramas.
Fuente: Elaboración propia.

36
Prueba de raíz unitaria de Dickey-Fuller.
Como un último análisis de estacionariedad se realiza la prueba de Dickey-Fuller, con la cual
se determinará de manera contundente si se trata o no de una serie estacionaria.
Como ya se mencionó anteriormente en la sección 2.2.6, la serie es estacionaria si el valor
absoluto del estadístico tau (τ) es mayor al crítico de MacKinnon, caso contrario no lo es.
Figura 3.3. Recorte de página del modelo AR de la prueba de raíz unitaria.
Fuente: Elaboración propia.
Se puede ver claramente en la Figura 3.3 que los valores absolutos de estadístico tau “t”
superan a los absolutos críticos de MacKinnon, por lo tanto la serie es estacionaria.
Orden “p” del modelo.
Los correlogramas son bastante útiles a la hora de elegir el orden tentativo del modelo, ya que
se está estudiando los modelos autorregresivos se debe examinar la función de
autocorrelación parcial. En el gráfico de esta función (Figura 3.2), se puede ver que existen
correlaciones significativas en los rezagos: 2, 3, 5, 6, 7, 8, 9, 10, 12 y otros, pero el que
sobresale aún más es el rezago 12, por lo tanto el orden tentativo seleccionado es p=12,
además éste es el orden máximo que se permite en la programación del modelo.
Estimación del modelo.
Cabe recalcar que en la presente investigación se ha considerado un orden máximo de p=12,
ya que la mayoría de series contienen datos mensuales, además si se considera un orden
mayor no se cumple con el principio de parsimonia.
En esta fase se calculan 12 modelos por medio del método de mínimos cuadrados no lineales
(MCNL), de los cuales se escoge el modelo que tiene mayor coeficiente de determinación, y
que además los residuales sean puramente aleatorios.

37
En la Figura 3.4 se presenta el valor de cada variable resultante de la estimación del modelo
autorregresivo de orden 12, así como su correspondiente ecuación.
Figura 3.4. Recorte de página del modelo AR de las variables del modelo.
Fuente: Elaboración propia.
Análisis de residuos.
La mayoría de las autocorrelaciones se encuentran dentro de las bandas (Figura 3.5), a
excepción de los desfasamientos 1, 2 y 12, a pesar de que se ha considerado estos rezagos
en el modelo, lo que significa que los residuos no son puramente aleatorios, pese a ello se
continúa con el cálculo a fin de describir el proceso que siguen los modelos autorregresivos.
Figura 3.5. Recorte de página del modelo AR del análisis de residuos.
Fuente: Elaboración propia.
Pronósticos.
Una vez que se ha estimado y validado el modelo, es factible realizar el cómputo de los
pronósticos (Hanke, 2010).
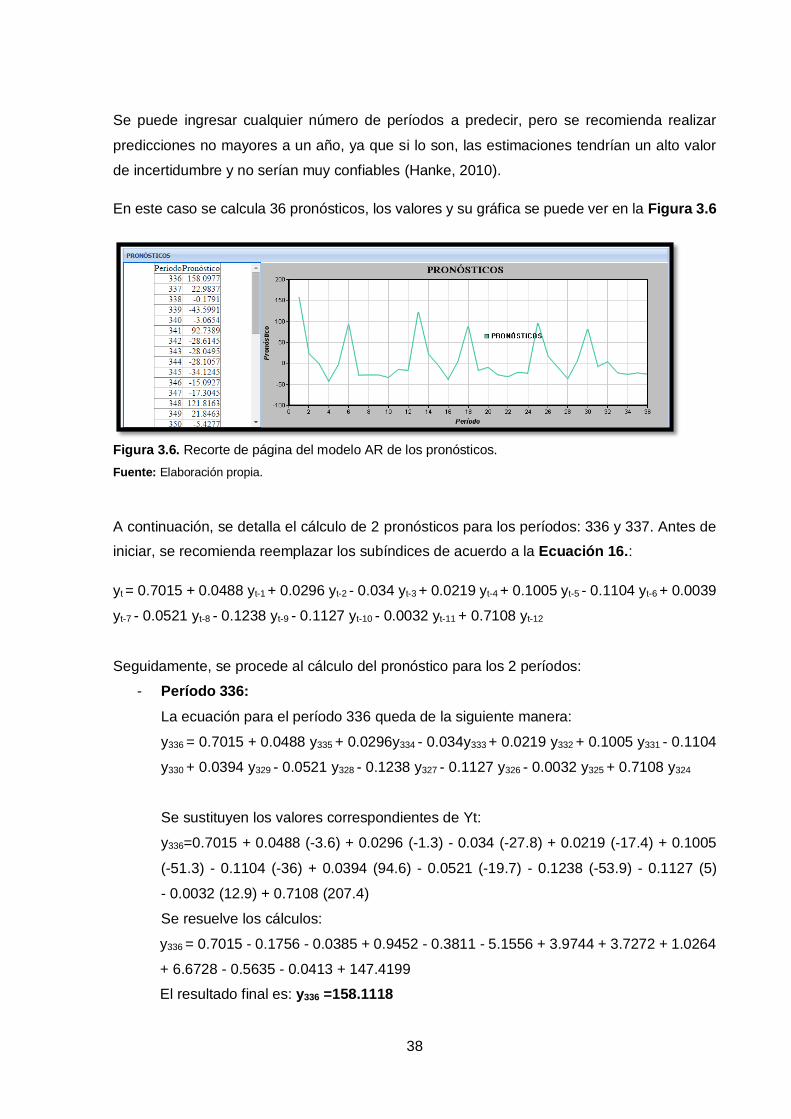
38
Se puede ingresar cualquier número de períodos a predecir, pero se recomienda realizar
predicciones no mayores a un año, ya que si lo son, las estimaciones tendrían un alto valor
de incertidumbre y no serían muy confiables (Hanke, 2010).
En este caso se calcula 36 pronósticos, los valores y su gráfica se puede ver en la Figura 3.6
Figura 3.6. Recorte de página del modelo AR de los pronósticos.
Fuente: Elaboración propia.
A continuación, se detalla el cálculo de 2 pronósticos para los períodos: 336 y 337. Antes de
iniciar, se recomienda reemplazar los subíndices de acuerdo a la Ecuación 16.:
yt = 0.7015 + 0.0488 yt-1 + 0.0296 yt-2 - 0.034 yt-3 + 0.0219 yt-4 + 0.1005 yt-5 - 0.1104 yt-6 + 0.0039
yt-7 - 0.0521 yt-8 - 0.1238 yt-9 - 0.1127 yt-10 - 0.0032 yt-11 + 0.7108 yt-12
Seguidamente, se procede al cálculo del pronóstico para los 2 períodos:
- Período 336:
La ecuación para el período 336 queda de la siguiente manera:
y336 = 0.7015 + 0.0488 y335 + 0.0296y334 - 0.034y333 + 0.0219 y332 + 0.1005 y331 - 0.1104
y330 + 0.0394 y329 - 0.0521 y328 - 0.1238 y327 - 0.1127 y326 - 0.0032 y325 + 0.7108 y324
Se sustituyen los valores correspondientes de Yt:
y336=0.7015 + 0.0488 (-3.6) + 0.0296 (-1.3) - 0.034 (-27.8) + 0.0219 (-17.4) + 0.1005
(-51.3) - 0.1104 (-36) + 0.0394 (94.6) - 0.0521 (-19.7) - 0.1238 (-53.9) - 0.1127 (5)
- 0.0032 (12.9) + 0.7108 (207.4)
Se resuelve los cálculos:
y336 = 0.7015 - 0.1756 - 0.0385 + 0.9452 - 0.3811 - 5.1556 + 3.9744 + 3.7272 + 1.0264
+ 6.6728 - 0.5635 - 0.0413 + 147.4199
El resultado final es: y336 =158.1118
39
- Período 337:
Para éste período la ecuación es:
y337 = 0.7015 + 0.0488 y336 + 0.0296y335 - 0.034y334 + 0.0219 y333 + 0.1005 y332 - 0.1104
y331 + 0.0394 y330 - 0.0521 y329 - 0.1238 y328 - 0.1127 y327 - 0.0032 y326 + 0.7108 y325
Al reemplazar los valores de Yt, se tiene:
y337=0.7015 + 0.0488 (158.1118) + 0.0296 (-3.6) - 0.034 (-1.3) + 0.0219 (-27.8)
+ 0.1005 (-17.4) - 0.1104 (-51.3) + 0.0394 (-36) - 0.0521 (-94.6) - 0.1238 (-19.7)
- 0.1127 (-53.9) - 0.0032 (5) + 0.7108 (12.9)
Se resuelve los cálculos:
y337 = 0.7015 + 7.7159 - 0.1066 + 0.0442 - 0.6088 - 1.7487 + 5.6635 - 1.4184 - 4.9287
+ 2.4389 + 6.0745 - 0.016 + 9.1693
El resultado final es: y337 =22.9806
La diferencia entre el pronóstico aquí calculado y el obtenido con página, se debe al número
de decimales.
Finalmente, se genera la regresión del modelo sobre la serie original, en la Figura 3.7 se
puede ver que éstas son bastante similares.
Figura 3.7. Recorte de página del modelo AR del resultado de la regresión.
Fuente: Elaboración propia.
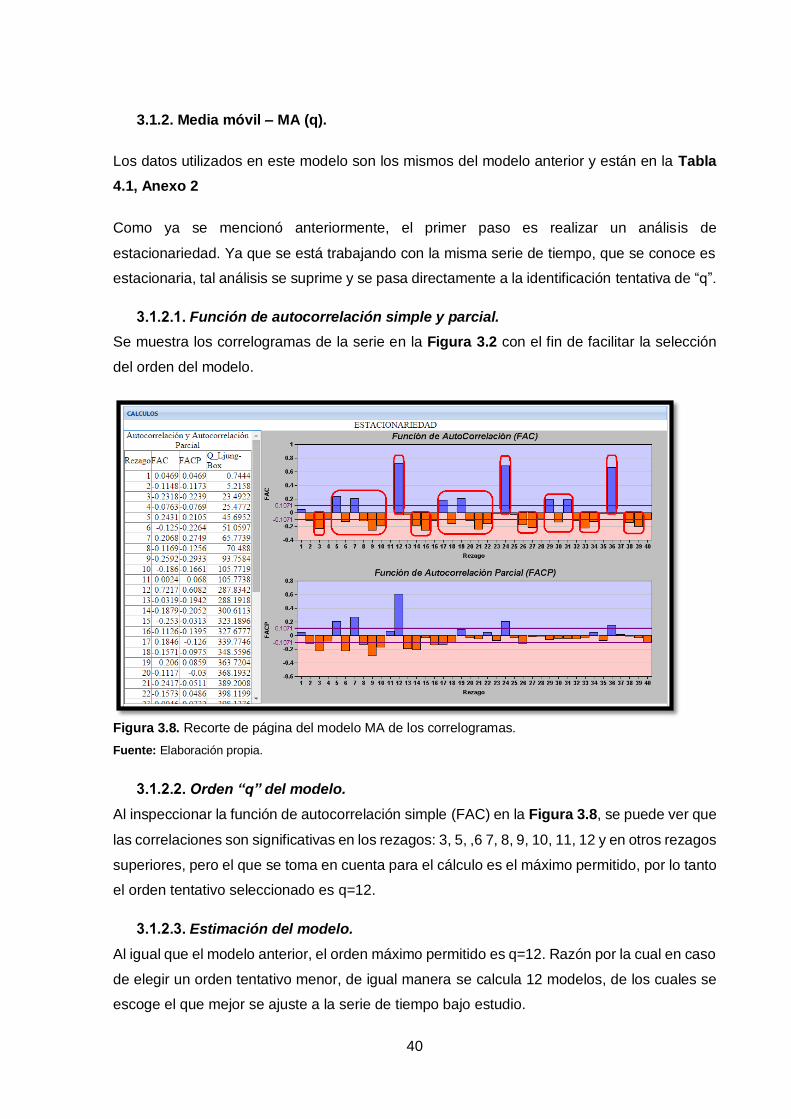
40
3.1.2. Media móvil – MA (q).
Los datos utilizados en este modelo son los mismos del modelo anterior y están en la Tabla
4.1, Anexo 2
Como ya se mencionó anteriormente, el primer paso es realizar un análisis de
estacionariedad. Ya que se está trabajando con la misma serie de tiempo, que se conoce es
estacionaria, tal análisis se suprime y se pasa directamente a la identificación tentativa de “q”.
Función de autocorrelación simple y parcial.
Se muestra los correlogramas de la serie en la Figura 3.2 con el fin de facilitar la selección
del orden del modelo.
Figura 3.8. Recorte de página del modelo MA de los correlogramas.
Fuente: Elaboración propia.
Orden “q” del modelo.
Al inspeccionar la función de autocorrelación simple (FAC) en la Figura 3.8, se puede ver que
las correlaciones son significativas en los rezagos: 3, 5, ,6 7, 8, 9, 10, 11, 12 y en otros rezagos
superiores, pero el que se toma en cuenta para el cálculo es el máximo permitido, por lo tanto
el orden tentativo seleccionado es q=12.
Estimación del modelo.
Al igual que el modelo anterior, el orden máximo permitido es q=12. Razón por la cual en caso
de elegir un orden tentativo menor, de igual manera se calcula 12 modelos, de los cuales se
escoge el que mejor se ajuste a la serie de tiempo bajo estudio.
41
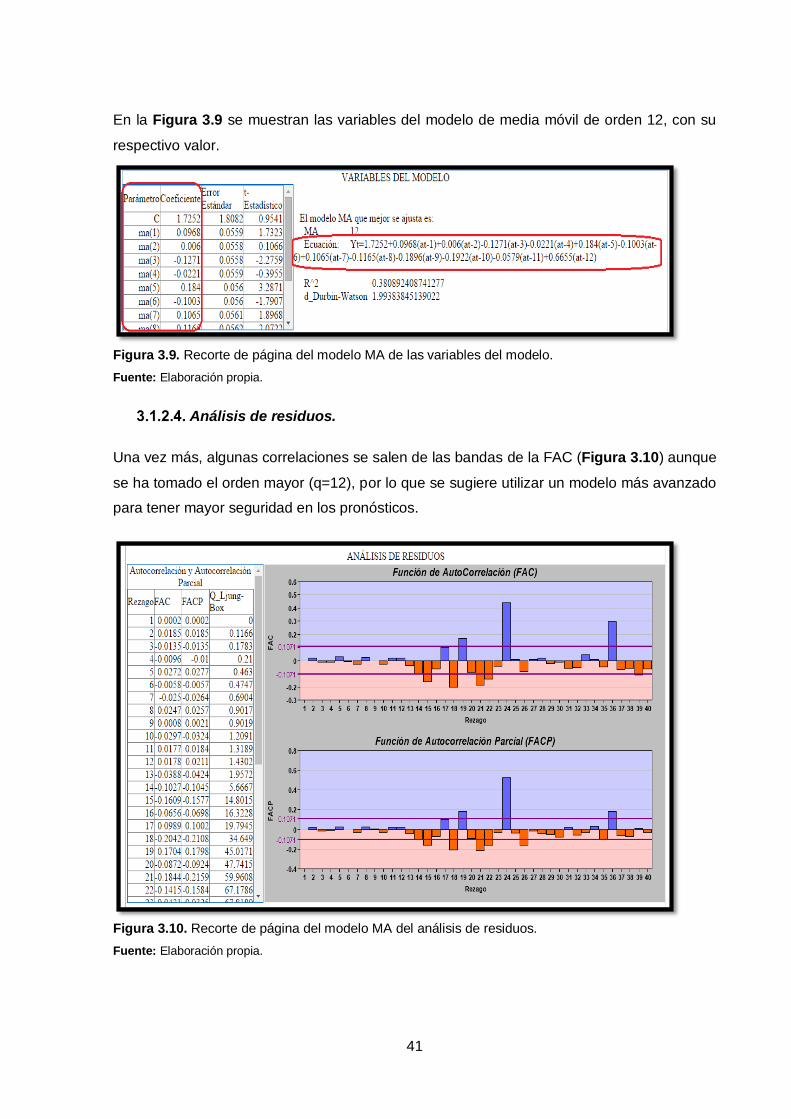
En la Figura 3.9 se muestran las variables del modelo de media móvil de orden 12, con su
respectivo valor.
Figura 3.9. Recorte de página del modelo MA de las variables del modelo.
Fuente: Elaboración propia.
Análisis de residuos.
Una vez más, algunas correlaciones se salen de las bandas de la FAC (Figura 3.10) aunque
se ha tomado el orden mayor (q=12), por lo que se sugiere utilizar un modelo más avanzado
para tener mayor seguridad en los pronósticos.
Figura 3.10. Recorte de página del modelo MA del análisis de residuos.
Fuente: Elaboración propia.

42
Pronósticos.
Al igual que en el caso anterior, se calcula 36 pronósticos y sus valores con su gráfica
correspondiente se presenta en la Figura 3.11.
Figura 3.11. Recorte de página del modelo MA de los pronósticos.
Fuente: Elaboración propia.
La linealidad que presentan los pronósticos a partir del período 12, se considera normal debido
a las propiedades de los modelos de media móvil. Pues como se menciona en la sección
2.5.2, éstos modelos son de memoria limitada ya que presentan variación en los pronósticos
hasta una longitud igual a “q” (Universidad Autónoma de Madrid, 2008), en este caso q=12,
luego de éste son iguales a su media.
Para obtener los pronósticos de este modelo, se hace referencia a la Ecuación 17. Además,
es necesario tener los residuales resultantes de la regresión.
yt = 1.7252 + 0.0968 at-1 + 0.0060 at-2 - 0.1271 at-3 - 0.0221 at-4 + 0.184 at-5 - 0.1003 at-6 + 0.1065
at-7 - 0.1165 at-8 - 0.1896 at-9 - 0.1922 at-10 - 0.0579 at-11 + 0.6655 at-12
- Período 336:
La ecuación para el período 336 queda de la siguiente manera:
y336 = 1.7252 + 0.0968 a335 + 0.0060 a334 - 0.1271 a333 - 0.0221 a332 + 0.184 a331 - 0.1003
a330 + 0.1065 a329 - 0.1165 a328 - 0.1896 a327 - 0.1922 a326 - 0.0579 a325 + 0.6655 a324
Se sustituyen los valores correspondientes de Yt:
y336 = 1.7252 + 0.0968 (-9.005) + 0.0060 (-3.606) - 0.1271 (-1.017) - 0.0221 (-12.32)
+ 0.184 (-44.29) - 0.1003 (-14.85) + 0.1065 (38.83) - 0.1165 (-25.34) - 0.1896 (-13.65)
- 0.1922 (41.48) - 0.0579 (-7.336) + 0.6655 (149.9)
43
Se resuelve las operaciones:
y336 = 1.7252 - 0.8717 - 0.0216 + 0.1293 + 0.2723 - 8.1494 + 1.4895 + 4.1354 + 2.9521
+ 2.5880 - 7.9725 + 0.4248 + 99.7585
El resultado final es: y336 =96.4599
- Período 337:
Para el período 337, la ecuación es:
yt337 = 1.7252 + 0.0968 a336 + 0.0060 a335 - 0.1271 a334 - 0.0221 a333 + 0.184 a332 - 0.1003
a331 + 0.1065 a330 - 0.1165 a329 - 0.1896 a328 - 0.1922 a327 - 0.0579 a326 + 0.6655 a325
Al reemplazar los valores de Yt, se tiene:
yt337 = 1.7252 + 0.0968 (0) + 0.0060 (-9.005) - 0.1271 (-3.606) - 0.0221 (-1.017) + 0.184
(-12.32) - 0.1003 (-44.29) + 0.1065 (-14.85) - 0.1165 (38.83) - 0.1896 (-25.34) - 0.1922
(13.65) - 0.0579 (41.48) + 0.6655 (-7.336)
Se resuelve los cálculos:
yt337 = 1.7252 + 0 - 0.0540 + 0.4583 + 0.0225 - 2.2669 + 4.4423 - 1.5815 - 4.5237
+ 4.8045 + 2.6235 - 2.4017 - 4.8821
El resultado final es: y337 =-1.6336
Nuevamente, las diferencias entre pronósticos se deben al número de decimales.
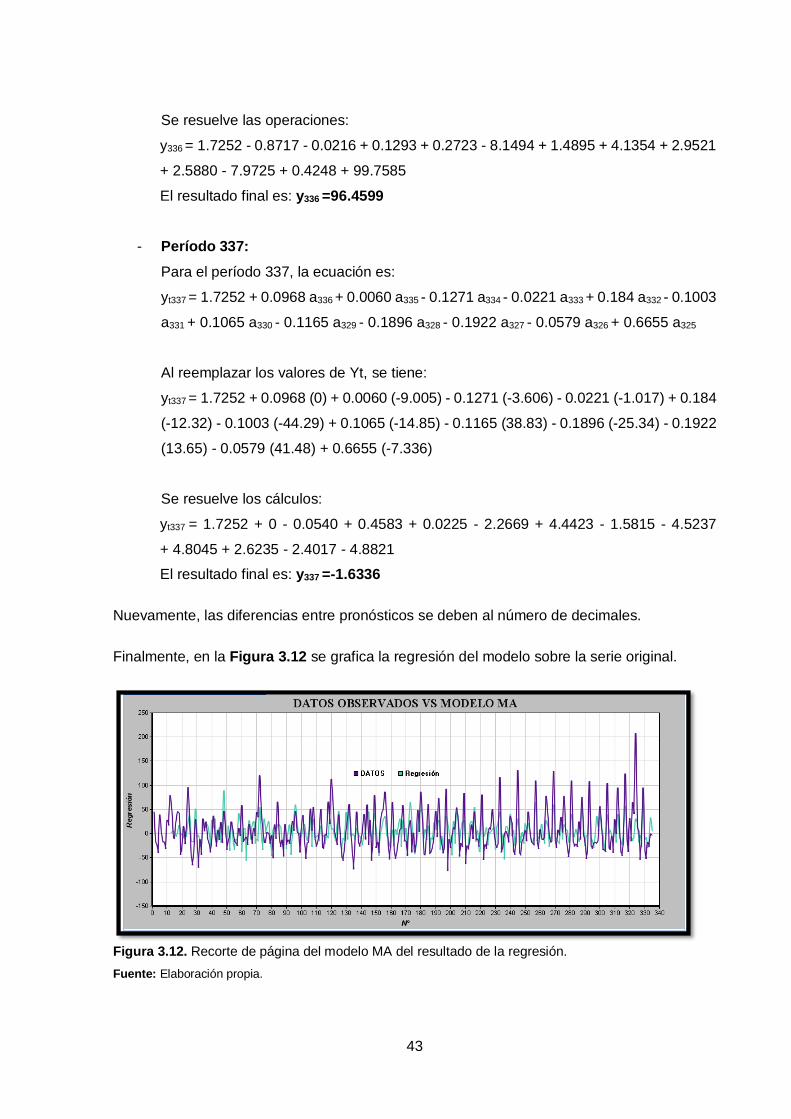
Finalmente, en la Figura 3.12 se grafica la regresión del modelo sobre la serie original.
Figura 3.12. Recorte de página del modelo MA del resultado de la regresión.
Fuente: Elaboración propia.

44
3.1.3. Autorregresivo de media móvil – ARMA (p, q).
Al igual que los métodos anteriores, se utiliza los datos de la Tabla 4.1, Anexo 2. De esta
serie se conoce que es estacionaria, y por tal razón se pasa directamente a la identificación
del modelo.
Orden “p” y “q” del modelo.
Como ya se indicó en la sección 2.4.1.3, las características de los correlogramas resultantes
de la FAC y FACP decrecen de una manera bastante similar, por lo que no son de gran ayuda
al momento de identificar un orden tentativo tanto para “p” como para “q”.
Estimación del modelo.
Con el objetivo de brindar al usuario el método ARMA más aceptable y considerando que no
se tiene una estimación previa para “p” y “q”, se ha optado por realizar el cálculo de una serie
de modelos que van desde el orden ARMA (0,1) hasta ARMA (12,12).
Es decir, se computa un total de 168 modelos, de los cuales se selecciona el que tenga un
mayor coeficiente de determinación y que a su vez, los residuos sean puramente aleatorios.
Este procedimiento se realiza en el algoritmo escrito para la automatización del modelo, el
cual da como resultado el modelo ARMA (12,7) que se visualiza en la Figura 3.13.
Figura 3.13. Recorte de página del modelo ARMA de las variables del modelo.
Fuente: Elaboración propia.
Análisis de residuos.
En la Figura 3.14, se puede ver que aunque se ha tomado un orden p=12, la correlación en
este rezago es significativa. Pero a diferencia de los modelos anteriores, se tiene menor
número de correlaciones significativas.
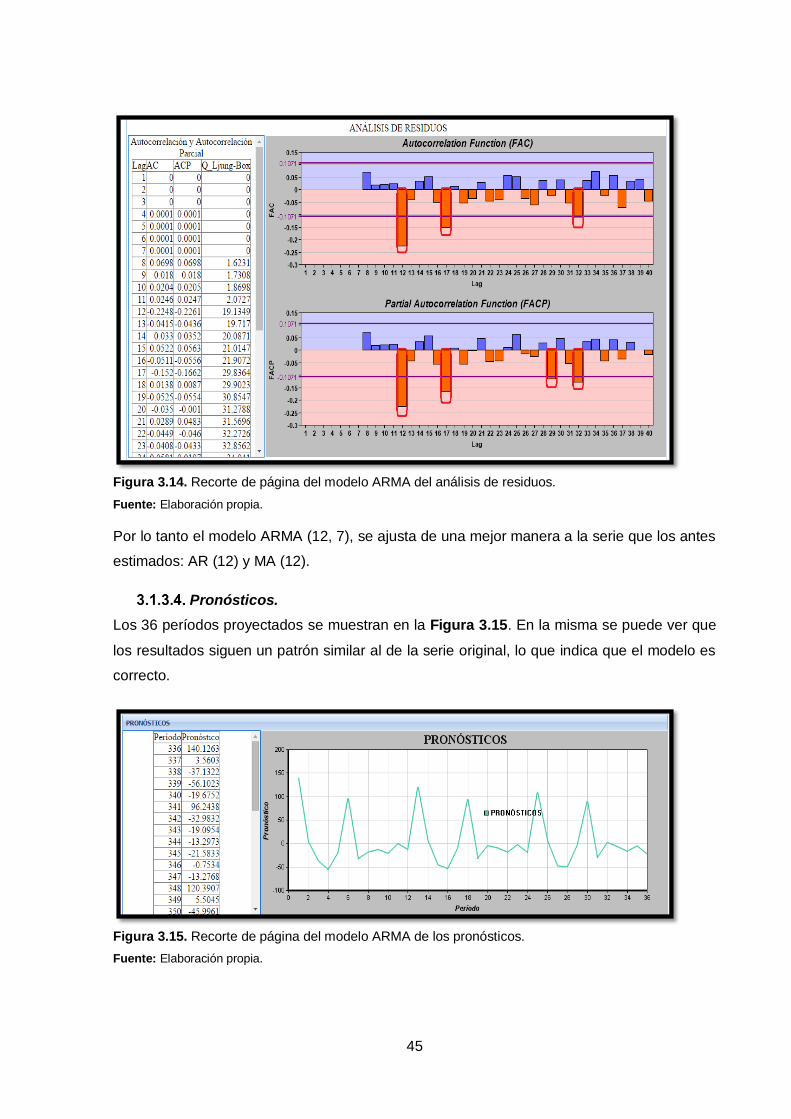
45
Figura 3.14. Recorte de página del modelo ARMA del análisis de residuos.
Fuente: Elaboración propia.
Por lo tanto el modelo ARMA (12, 7), se ajusta de una mejor manera a la serie que los antes
estimados: AR (12) y MA (12).
Pronósticos.
Los 36 períodos proyectados se muestran en la Figura 3.15. En la misma se puede ver que
los resultados siguen un patrón similar al de la serie original, lo que indica que el modelo es
correcto.
Figura 3.15. Recorte de página del modelo ARMA de los pronósticos.
Fuente: Elaboración propia.

46
Para calcular los pronósticos con la ecuación estimada del modelo, se sigue el proceso
detallado en los períodos 336 y 337. De la Ecuación 18 se tiene:
yt = 3.0065 - 0.1625 yt-1 - 0.2622 yt-2 - 0.2462 yt-3 - 0.1996 yt-4 - 0.022 yt-5 - 0.271 yt-6 + 0.0255 yt-
7 - 0.0919 yt-8 - 0.1441 yt-9 - 0.1875 yt-10 - 0.0793 yt-11 + 0.5615 yt-12 + 0.3104 at-1 + 0.492 at-2 +
0.3525 at-3 + 0.3053 at-4 + 0.1532 at-5 + 0.344 at-6 - 0.0253 at-7
- Período 336:
y336 = 3.0065 - 0.1625 y335 - 0.2622 y334 - 0.2462 y333 - 0.1996 y332 - 0.022 y331 - 0.271
y330 + 0.0255 y329 - 0.0919 y328 - 0.1441 y327 - 0.1875 y326 - 0.0793 y325 + 0.5615 y324
+ 0.3104 a335 + 0.492 a334 + 0.3525 a333 + 0.3053 a332 + 0.1532 a331 + 0.344 a330 - 0.0253
a329
Se reemplaza en la ecuación los valores de yt y at:
y336 = 3.0065 - 0.1625 (-3.6) - 0.2622 (-1.3) - 0.2462 (-27.8) - 0.1996 (-17.4) - 0.022
(-51.3) - 0.271 (-36) + 0.0255 (94.6) - 0.0919 (-19.7) - 0.1441 (-53.9) - 0.1875 (5)
- 0.0793 (12.9) + 0.5615 (207.4) + 0.3104 (-6.4592) + 0.492 (-24.0101) + 0.3525
(13.2941) + 0.3053 (-2.5252) + 0.1532 (-0.3687) + 0.344 (-5.1401) - 0.0253 (-9.6475)
Se obtiene:
y336 = 3.0065 + 0.585 + 0.3409 + 6.8444 + 3.4730 + 1.1286 + 9.756 + 2.4123 + 1.8104
+ 7.76699 - 0.9375 - 1.02297 + 116.4551 - 2.0049 - 11.81297 + 4.6268 - 0.7709
- 0.0565 - 1.7682 + 0.2441
El resultado es: y336 =140.1355
- Período 337:
y337 = 3.0065 - 0.1625 y336 - 0.2622 y335 - 0.2462 y334 - 0.1996 y333 - 0.022 y332 - 0.271
y331 + 0.0255 y330 - 0.0919 y329 - 0.1441 y328 - 0.1875 y327 - 0.0793 y326 + 0.5615 y325
+ 0.3104 a336 + 0.492 a335 + 0.3525 a334 + 0.3053 a333 + 0.1532 a332 + 0.344 a331 - 0.0253
a330
Se reemplaza en la ecuación los valores de yt y at:
y337 = 3.0065 - 0.1625 (140.1355) - 0.2622 (-3.6) - 0.2462 (-1.3) - 0.1996 (-27.8) - 0.022
(-17.4) - 0.271 (-51.3) + 0.0255 (-36) - 0.0919 (94.6) - 0.1441 (-19.7) - 0.1875 (-53.9)
- 0.0793 (5) + 0.5615 (12.9) + 0.3104 (0) + 0.492 (-6.4592) + 0.3525 (-24.0101)
+ 0.3053 (13.2941) + 0.1532 (-2.5252) + 0.344 (-0.3687) - 0.0253 (-5.1401)
47
Se resuelve los cálculos:
y337 = 3.0065 - 22.7720 + 0.9439 + 0.3201 + 5.5489 + 0.3828 + 13.9023 - 0.918 - 8.6937
+ 2.8388 + 10.1063 - 0.3965 + 7.2434 + 0 - 3.1779 - 8.4636 + 4.0587 - 0.3869 - 0.1268
+ 0.1300
El resultado es: y337 =3.5463
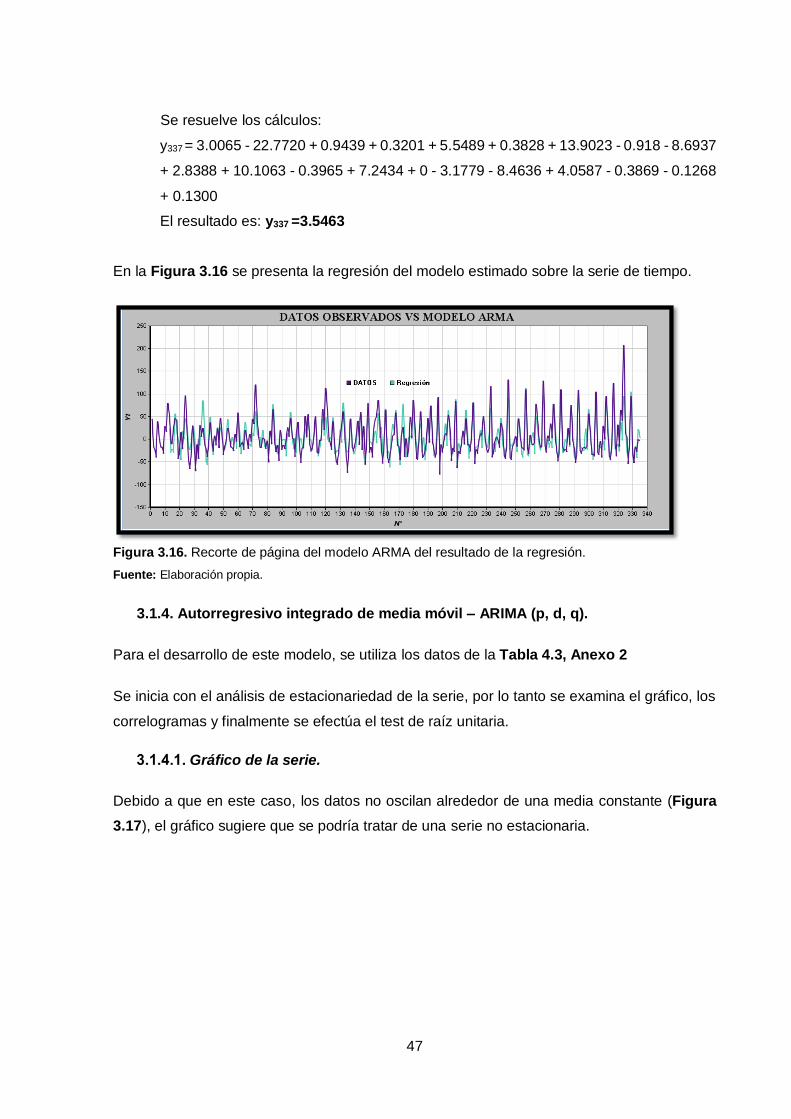
En la Figura 3.16 se presenta la regresión del modelo estimado sobre la serie de tiempo.
Figura 3.16. Recorte de página del modelo ARMA del resultado de la regresión.
Fuente: Elaboración propia.
3.1.4. Autorregresivo integrado de media móvil – ARIMA (p, d, q).
Para el desarrollo de este modelo, se utiliza los datos de la Tabla 4.3, Anexo 2
Se inicia con el análisis de estacionariedad de la serie, por lo tanto se examina el gráfico, los
correlogramas y finalmente se efectúa el test de raíz unitaria.
Gráfico de la serie.
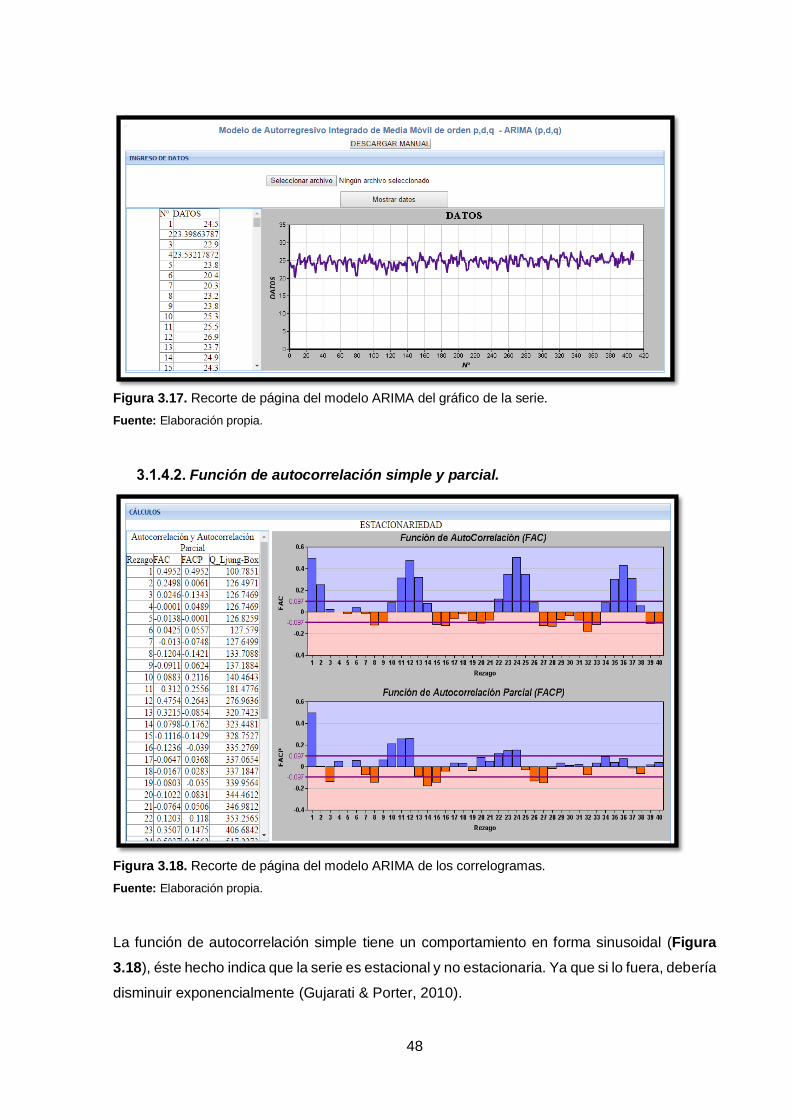
Debido a que en este caso, los datos no oscilan alrededor de una media constante (Figura
3.17), el gráfico sugiere que se podría tratar de una serie no estacionaria.
48
Figura 3.17. Recorte de página del modelo ARIMA del gráfico de la serie.
Fuente: Elaboración propia.
Función de autocorrelación simple y parcial.
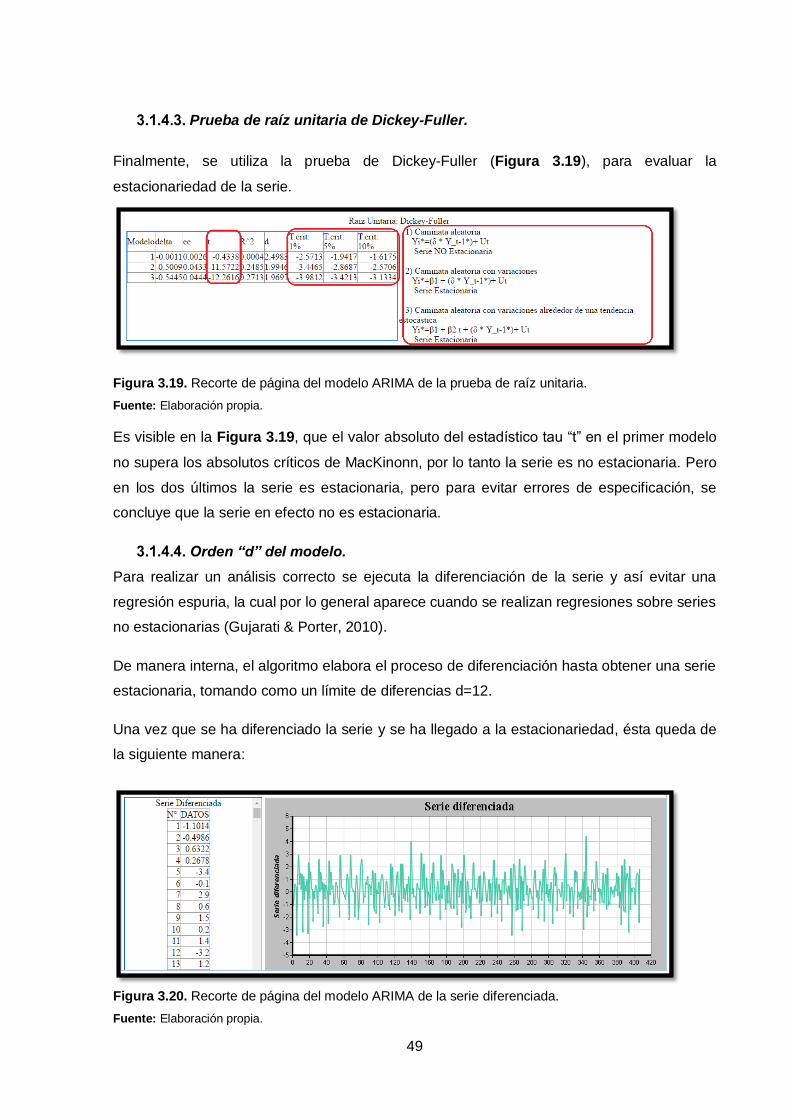
Figura 3.18. Recorte de página del modelo ARIMA de los correlogramas.
Fuente: Elaboración propia.
La función de autocorrelación simple tiene un comportamiento en forma sinusoidal (Figura
3.18), éste hecho indica que la serie es estacional y no estacionaria. Ya que si lo fuera, debería
disminuir exponencialmente (Gujarati & Porter, 2010).
49
Prueba de raíz unitaria de Dickey-Fuller.
Finalmente, se utiliza la prueba de Dickey-Fuller (Figura 3.19), para evaluar la
estacionariedad de la serie.
Figura 3.19. Recorte de página del modelo ARIMA de la prueba de raíz unitaria.
Fuente: Elaboración propia.
Es visible en la Figura 3.19, que el valor absoluto del estadístico tau “t” en el primer modelo
no supera los absolutos críticos de MacKinonn, por lo tanto la serie es no estacionaria. Pero
en los dos últimos la serie es estacionaria, pero para evitar errores de especificación, se
concluye que la serie en efecto no es estacionaria.
Orden “d” del modelo.
Para realizar un análisis correcto se ejecuta la diferenciación de la serie y así evitar una
regresión espuria, la cual por lo general aparece cuando se realizan regresiones sobre series
no estacionarias (Gujarati & Porter, 2010).
De manera interna, el algoritmo elabora el proceso de diferenciación hasta obtener una serie
estacionaria, tomando como un límite de diferencias d=12.
Una vez que se ha diferenciado la serie y se ha llegado a la estacionariedad, ésta queda de
la siguiente manera:
Figura 3.20. Recorte de página del modelo ARIMA de la serie diferenciada.
Fuente: Elaboración propia.

50
En la Figura 3.20 los datos se mueven alrededor de una media constante, a diferencia de lo
que ocurre en la Figura 3.17, éste es un claro indicio de estacionariedad.
Orden “p” y “q” del modelo.
Con el fin de determinar el modelo ARMA que mejor se ajuste a la serie diferenciada, no se
realiza una estimación previa para “p” y “q”, sino que se calcula una serie de modelos y se
escoge el más adecuado.
Estimación del modelo.
La estimación se realiza con los mismos criterios aplicados al método ARMA, con la diferencia
de que no se trabaja con la serie original, sino que el modelo se calcula a partir de la serie
diferenciada estacionaria (zt).
Nuevamente, se deduce los 168 modelos y se opta por el que presente un mayor ajuste a la
serie de trabajo.
El modelo así obtenido es un ARIMA (11, 1, 10), es decir 11 coeficientes de regresión, 10 de
medias móviles y 1 diferencia. Las variables determinadas se exponen en la Figura 3.21.
Figura 3.21. Recorte de página del modelo ARIMA de las variables del modelo.
Fuente: Elaboración propia.
Análisis de residuos.
En la Figura 3.22, se puede ver que aún existen correlaciones significativas a pesar de que
ya se estimó un modelo bastante amplio, por tal razón éste es el modelo ARIMA que de una
mejor manera describe los datos de la serie.
La razón por la cual se tiene correlaciones significativas en los residuos, se debe a la
estacionalidad de la serie. Por tal razón se considera necesario utilizar el modelo SARIMA
para obtener mejores resultados.
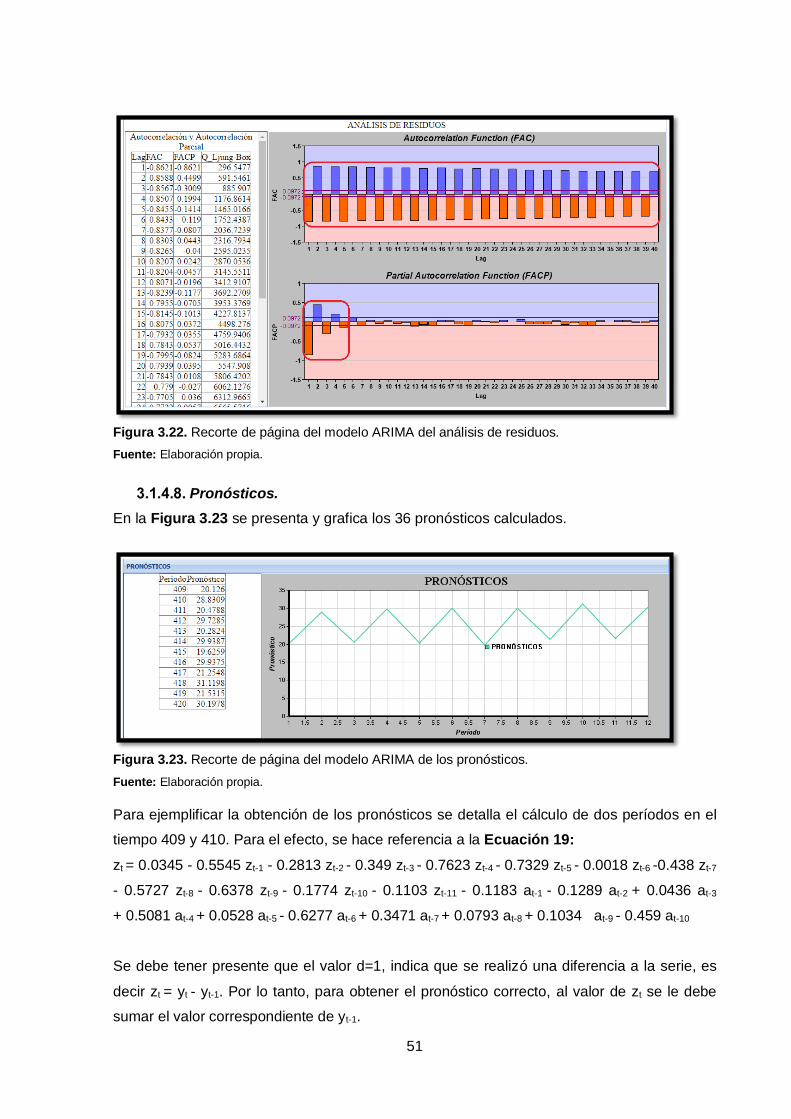
51
Figura 3.22. Recorte de página del modelo ARIMA del análisis de residuos.
Fuente: Elaboración propia.
Pronósticos.
En la Figura 3.23 se presenta y grafica los 36 pronósticos calculados.
Figura 3.23. Recorte de página del modelo ARIMA de los pronósticos.
Fuente: Elaboración propia.
Para ejemplificar la obtención de los pronósticos se detalla el cálculo de dos períodos en el
tiempo 409 y 410. Para el efecto, se hace referencia a la Ecuación 19:
zt = 0.0345 - 0.5545 zt-1 - 0.2813 zt-2 - 0.349 zt-3 - 0.7623 zt-4 - 0.7329 zt-5 - 0.0018 zt-6 -0.438 zt-7
- 0.5727 zt-8 - 0.6378 zt-9 - 0.1774 zt-10 - 0.1103 zt-11 - 0.1183 at-1 - 0.1289 at-2 + 0.0436 at-3
+ 0.5081 at-4 + 0.0528 at-5 - 0.6277 at-6 + 0.3471 at-7 + 0.0793 at-8 + 0.1034 at-9 - 0.459 at-10
Se debe tener presente que el valor d=1, indica que se realizó una diferencia a la serie, es
decir zt = yt - yt-1. Por lo tanto, para obtener el pronóstico correcto, al valor de zt se le debe
sumar el valor correspondiente de yt-1.

52
- Período 409:
z409 = 0.0345 - 0.5545z408 - 0.2813z407 - 0.349 z406 - 0.7623 z405 - 0.7329 z404 - 0.0018
z403 - 0.438 z402 - 0.5727 z401 - 0.6378 z400 - 0.1774 z399 - 0.1103 z398 - 0.1183 a408
- 0.1289 a407 + 0.0436 a406 + 0.5081 a405 + 0.05228 a404 - 0.6277 a403 + 0.3471 a402
+ 0.0793 a401 + 0.1034 a400 - 0.459 a399
Se reemplaza en la ecuación los valores de zt y at:
z409 = 0.0345 - 0.5545 (1.8) - 0.2813 (-2.4) - 0.349 (1.1) - 0.7623 (1.5) - 0.7329 (1.2)
- 0.0018 (-0.9) - 0.438 (-1) - 0.5727 (0.3) - 0.6378 (0.3) - 0.1774 (0) - 0.1103 (0.3)
- 0.1183 (-3.8583) - 0.1289 (4.0304) + 0.0436 (-3.6256) + 0.5081 (5.4763) + 0.0528
(-4.8411) - 0.6277 (3.6906) + 0.3471 (-5.3330) + 0.0793 (5.9660) + 0.1034 (-4.5987)
- 0.459 (5.1349)
Se obtiene:
z409 = 0.0345 - 0.9980 + 0.6751 - 0.3839 – 1.1434 – 0.8795 + 0.00162 + 0.438 – 0.1718
– 0.1913 + 0 – 0.0331 + 0.4564 – 0.5195 - 0.1581 + 2.7825 – 0.2556 – 2.3166 – 1.8511
+ 0.4731 – 0.4755 – 2.3569
En dónde: z409 = - 6.873
El pronóstico para el período 409 es:
y409= z409 + y408
y409= - 6.873+ 27
y409= 20.127
- Período 410:
z410 = 0.0345 - 0.5545z409 - 0.2813z408 - 0.349 z407 - 0.7623 z406 - 0.7329 z405 - 0.0018
z404 + 0.438 z403 - 0.5727 z402 - 0.6378 z401 - 0.1774 z400 - 0.1103 z399 - 0.1183 a409
- 0.1289 a408 + 0.0436 a407 + 0.5081 a406 + 0.0528 a405 - 0.6277 a404 + 0.3471 a403
+ 0.0793 a402 + 0.1034 a401 - 0.459 a400
Se reemplaza en la ecuación los valores de zt y at:
z410 = 0.0345 - 0.5545 (-6.873) - 0.2813 (1.8) - 0.349 (-2.4) - 0.7623 (1.1) - 0.7329 (1.5)
- 0.0018 (1.2) - 0.438 (-0.9) - 0.5727 (-1) - 0.6378 (0.3) - 0.1774 (0.3) - 0.1103 (0)
- 0.1183 (0) - 0.1289 (-3.8583) + 0.0436 (4.0304) + 0.5081 (-3.6256) + 0.0528 (5.4763)
- 0.6277 (-4.8411) + 0.3471 (3.6906) + 0.0793 (-5.3330) + 0.1034 (5.9660) - 0.459
(-4.5987)
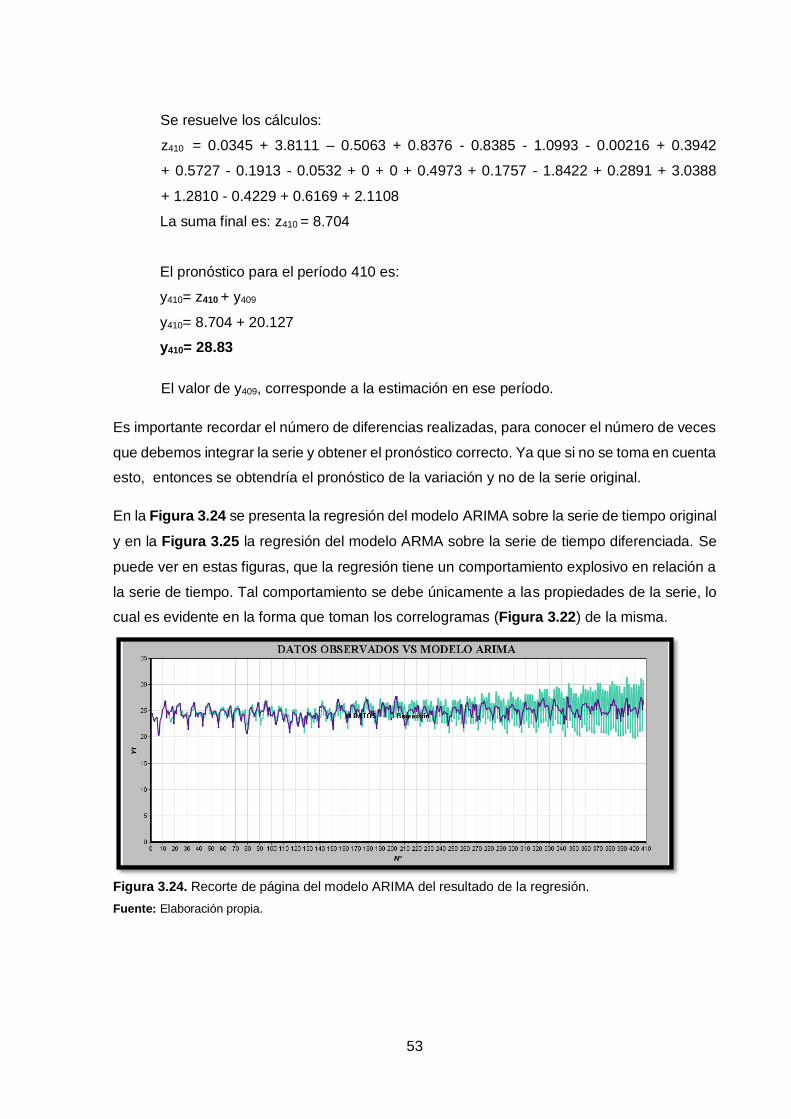
53
Se resuelve los cálculos:
z410 = 0.0345 + 3.8111 – 0.5063 + 0.8376 - 0.8385 - 1.0993 - 0.00216 + 0.3942
+ 0.5727 - 0.1913 - 0.0532 + 0 + 0 + 0.4973 + 0.1757 - 1.8422 + 0.2891 + 3.0388
+ 1.2810 - 0.4229 + 0.6169 + 2.1108
La suma final es: z410 = 8.704
El pronóstico para el período 410 es:
y410= z410 + y409
y410= 8.704 + 20.127
y410= 28.83
El valor de y409, corresponde a la estimación en ese período.
Es importante recordar el número de diferencias realizadas, para conocer el número de veces
que debemos integrar la serie y obtener el pronóstico correcto. Ya que si no se toma en cuenta
esto, entonces se obtendría el pronóstico de la variación y no de la serie original.
En la Figura 3.24 se presenta la regresión del modelo ARIMA sobre la serie de tiempo original
y en la Figura 3.25 la regresión del modelo ARMA sobre la serie de tiempo diferenciada. Se
puede ver en estas figuras, que la regresión tiene un comportamiento explosivo en relación a
la serie de tiempo. Tal comportamiento se debe únicamente a las propiedades de la serie, lo
cual es evidente en la forma que toman los correlogramas (Figura 3.22) de la misma.
Figura 3.24. Recorte de página del modelo ARIMA del resultado de la regresión.
Fuente: Elaboración propia.
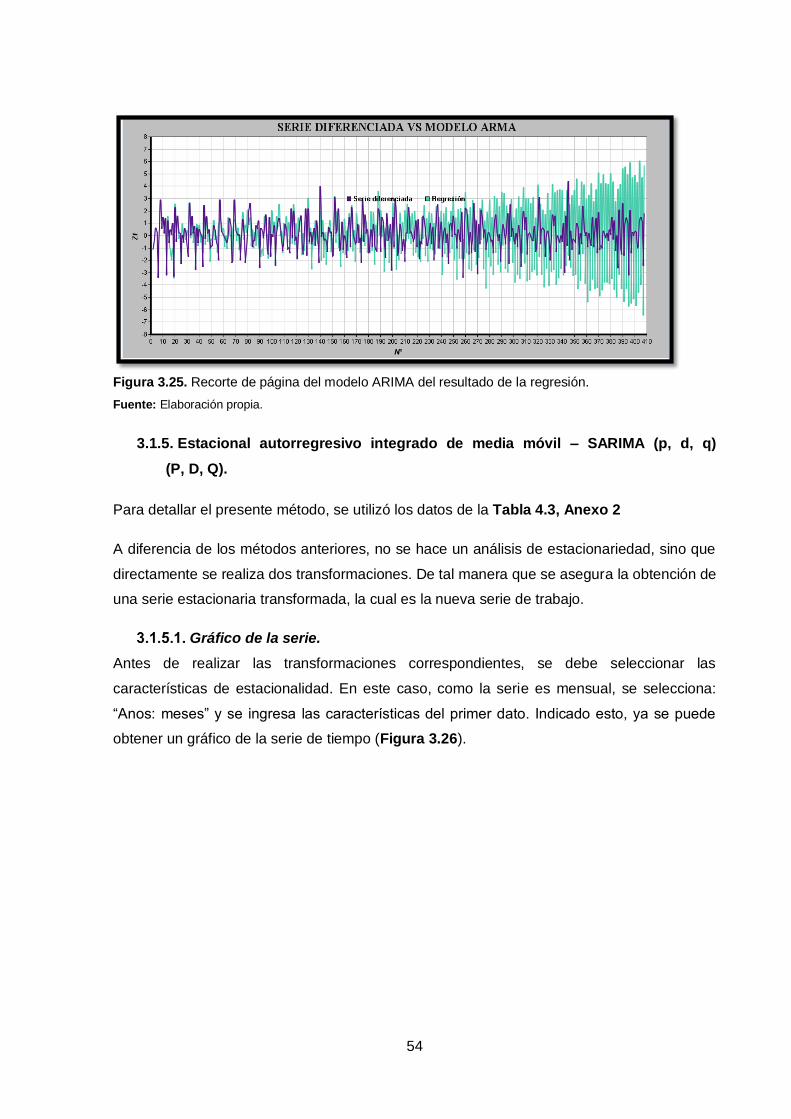
54
Figura 3.25. Recorte de página del modelo ARIMA del resultado de la regresión.
Fuente: Elaboración propia.
3.1.5. Estacional autorregresivo integrado de media móvil – SARIMA (p, d, q)
(P, D, Q).
Para detallar el presente método, se utilizó los datos de la Tabla 4.3, Anexo 2
A diferencia de los métodos anteriores, no se hace un análisis de estacionariedad, sino que
directamente se realiza dos transformaciones. De tal manera que se asegura la obtención de
una serie estacionaria transformada, la cual es la nueva serie de trabajo.
Gráfico de la serie.
Antes de realizar las transformaciones correspondientes, se debe seleccionar las
características de estacionalidad. En este caso, como la serie es mensual, se selecciona:
“Anos: meses” y se ingresa las características del primer dato. Indicado esto, ya se puede
obtener un gráfico de la serie de tiempo (Figura 3.26).
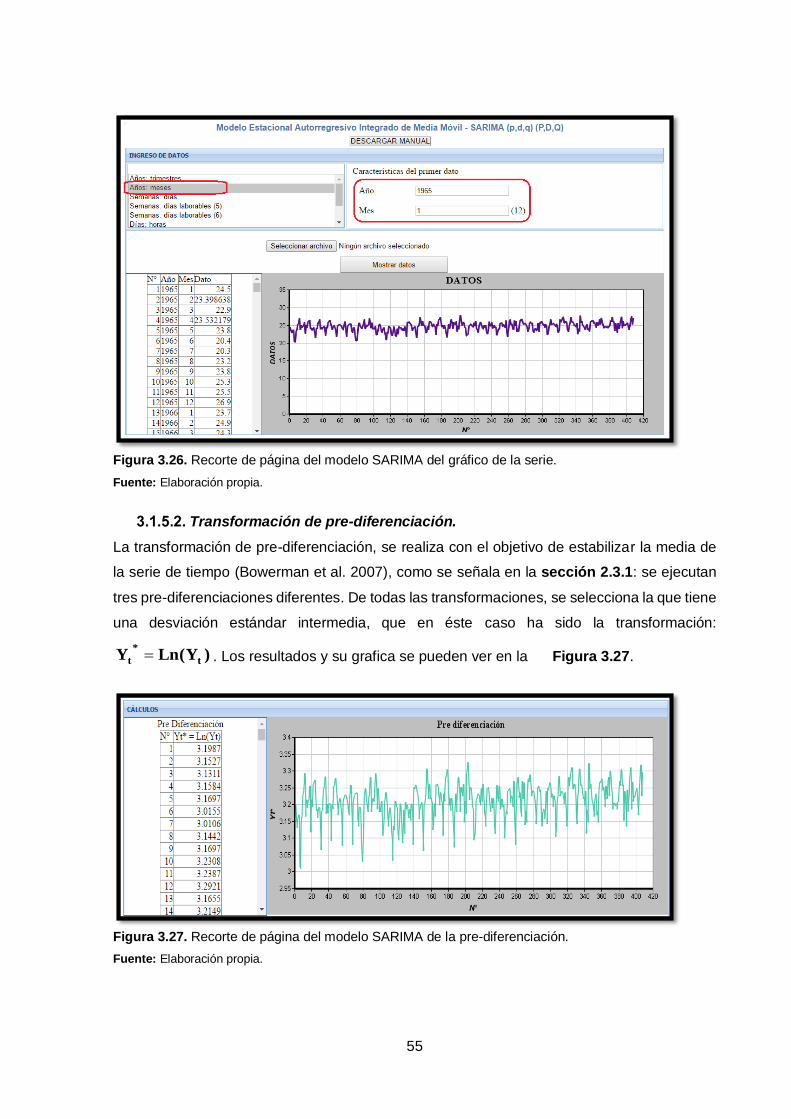
55
Figura 3.26. Recorte de página del modelo SARIMA del gráfico de la serie.
Fuente: Elaboración propia.
Transformación de pre-diferenciación.
La transformación de pre-diferenciación, se realiza con el objetivo de estabilizar la media de
la serie de tiempo (Bowerman et al. 2007), como se señala en la sección 2.3.1: se ejecutan
tres pre-diferenciaciones diferentes. De todas las transformaciones, se selecciona la que tiene
una desviación estándar intermedia, que en éste caso ha sido la transformación:
)Y(LnY t
*
t . Los resultados y su grafica se pueden ver en la Figura 3.27.
Figura 3.27. Recorte de página del modelo SARIMA de la pre-diferenciación.
Fuente: Elaboración propia.
56
Transformación de estacionalidad.
Como ya se estabilizó la media, entonces corresponde ahora estabilizar la varianza, lo cual
se consigue por medio de la transformación de estacionalidad. En éste caso, de las
transformaciones realizadas se escoge la que tiene una desviación estándar menor, dando
como resultado la que se presenta en la Figura 3.28.
Figura 3.28. Recorte de página del modelo SARIMA de la transformación de estacionalidad.
Fuente: Elaboración propia.
Tal como se puede ver en la Figura 3.28, la serie transformada oscila alrededor de una media
constante y su varianza es poco variable, por tal razón se presume que la nueva serie es
estacionaria.
Función de autocorrelación simple y parcial.
A pesar de las transformaciones realizadas a la serie de tiempo original, no está demás
comprobar su estacionariedad por medio de los correlogramas y del test de raíz unitaria.
Figura 3.29. Recorte de página del modelo SARIMA de los correlogramas.
Fuente: Elaboración propia.

57
Ya que la mayoría de correlaciones se encuentran dentro de los límites de confianza (Figura
3.29), es posible decir que la serie transformada es estacionaria. Tal afirmación se podría
verificar con la prueba de raíz unitaria de Dickey-Fuller.
Prueba de raíz unitaria de Dickey-Fuller.
Figura 3.30. Recorte de página del modelo SARIMA de la prueba de raíz unitaria.
Fuente: Elaboración propia.
En efecto, la suposición de que la serie transformada es estacionaria, se confirma con éste
test, debido que los valores absolutos de “t” son mayores a los absolutos de MacKinonn
(Figura 3.30).
Orden p,d,q y P,D,Q del modelo.
En este modelo, las minúsculas correspondes al orden regular y las mayúsculas al estacional.
El orden “d” y “D” se identifican en la transformación de estacionalidad, de acuerdo al número
y tipo de diferencias realizadas.
Los órdenes “p, q” y “P, Q”, en cambio se identifican en el nivel no estacional y estacional de
los correlogramas respectivamente.
Estimación del modelo.
Como ya se ha identificado los órdenes del modelo, se procede a realizar su estimación por
medio del método de mínimos cuadrados no lineales (MCNL), hasta llegar a su convergencia.
A continuación en la Figura 3.31, se presentan los resultados obtenidos.
Figura 3.31. Recorte de página del modelo SARIMA de las variables del modelo.
Fuente: Elaboración propia.
58
Análisis de residuos.
Se considera que el modelo SARIMA (8, 0, 0) (0, 1, 1) es bastante adecuado, pues sus
residuales presentan características de ruido blanco, ya que todas las correlaciones se
encuentran dentro de los límites de confianza (Figura 3.32).
Figura 3.32. Recorte de página del modelo SARIMA del análisis de residuos.
Fuente: Elaboración propia.
Pronósticos.
Los pronósticos realizados con éste modelo, al igual que los anteriores son 36 y se los
visualiza en la Figura 3.33.
Figura 3.33. Recorte de página del modelo SARIMA de los pronósticos.
Fuente: Elaboración propia.
Es importante recordar las transformaciones que se realizaron a la serie, con el fin de revertir
estos cambios y obtener los pronósticos adecuados (Bowerman et al., 2007).

59
Para ilustrar más detalladamente la obtención de los pronósticos, a continuación se presenta
el cálculo de una predicción correspondiente al período 409. De la ecuación general
(Ecuación 20) de modelos SARIMA, se obtiene la específica de éste modelo:
zt = 0.0012 + 0.1885 zt-1 + 0.1694 zt-2 + 0.0767 zt-3 + 0.1232 zt-4 - 0.0443 zt-5 - 0.0012 zt-6 + 0.0839
zt-7 - 0.112 zt-8 - 0.7106 at-12
Debido a las transformaciones realizadas, se tiene que:
zt = y*t - y*
t-L ; yt*= Ln (yt)
Por lo tanto, se debe calcular de manera normal zt, una vez calculado su valor, se lo deja en
términos de yt*. Finalmente, se obtiene el antilogaritmo de yt
*, y ese es el pronóstico requerido.
Además, es necesario realizar el cálculo de los residuales, ya que se tiene componentes de
media móvil.
- Período 409:
z409 = 0.0012 + 0.1885 zt-1 + 0.1694 zt-2 + 0.0767 zt-3 + 0.1232 zt-4 - 0.0443 zt-5 - 0.0012
zt-6 + 0.0839 zt-7 - 0.112 zt-8 - 0.7106 at-12
Se reemplaza en la ecuación los valores de zt y at:
z409 = 0.0012 + 0.1885 (0.0292) + 0.1694 (0.0405) + 0.0767 (0.0073) + 0.1232 (0.0038)
- 0.0443 (0.0022) - 0.0012 (-0.0084) + 0.0839 (-0.0358) - 0.112 (0.111) - 0.7106
(-0.0338)
Se resuelve las multiplicaciones:
z409 = 0.0012 + 0.0055 + 0.0069 + 0.0006 + 0.0005 – 0.00009746 + 0.00001 – 0.003004
– 0.01243 + 0.024
z409 = 0.02317
Se pasa zt a términos de yt*:
y*409 = zt409 + y*
397
y*409= 0.02317 + 3.2108
y*409= 3.23397
Finalmente, el pronóstico para el período 337 es:
y409= exp (y*409)
y409= exp (3.23397)
y409= 25.3802
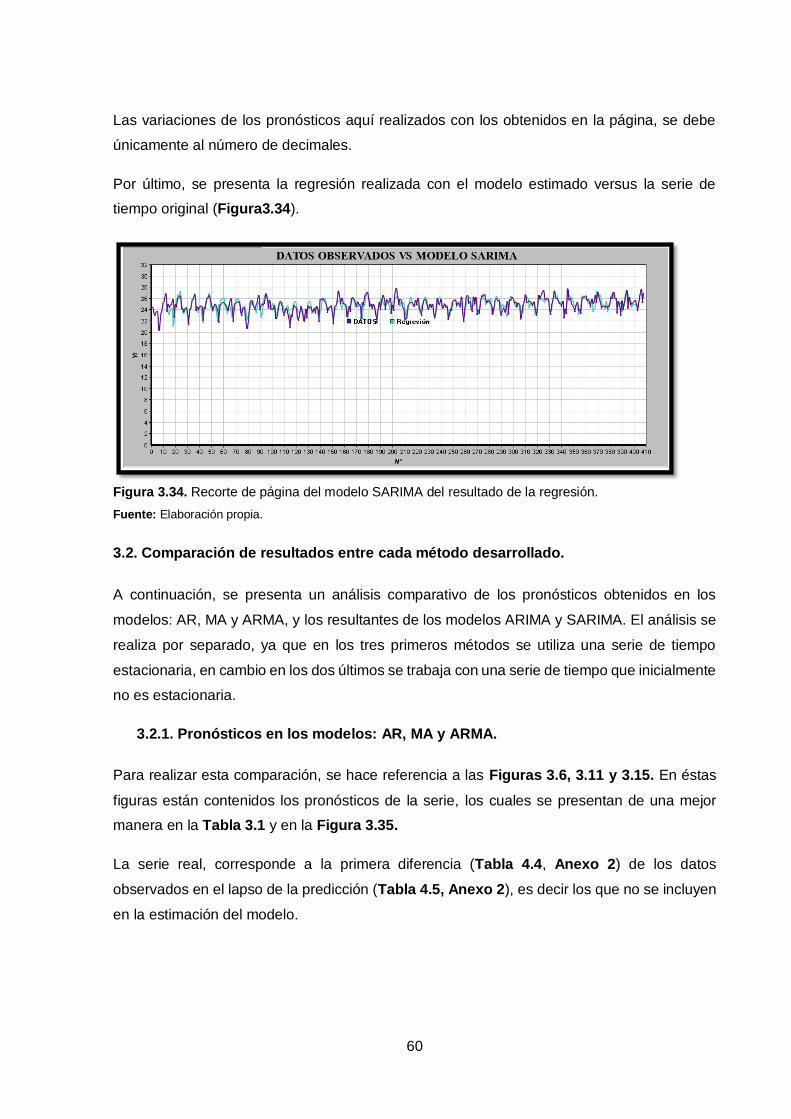
60
Las variaciones de los pronósticos aquí realizados con los obtenidos en la página, se debe
únicamente al número de decimales.
Por último, se presenta la regresión realizada con el modelo estimado versus la serie de
tiempo original (Figura3.34).
Figura 3.34. Recorte de página del modelo SARIMA del resultado de la regresión.
Fuente: Elaboración propia.
3.2. Comparación de resultados entre cada método desarrollado.
A continuación, se presenta un análisis comparativo de los pronósticos obtenidos en los
modelos: AR, MA y ARMA, y los resultantes de los modelos ARIMA y SARIMA. El análisis se
realiza por separado, ya que en los tres primeros métodos se utiliza una serie de tiempo
estacionaria, en cambio en los dos últimos se trabaja con una serie de tiempo que inicialmente
no es estacionaria.
3.2.1. Pronósticos en los modelos: AR, MA y ARMA.
Para realizar esta comparación, se hace referencia a las Figuras 3.6, 3.11 y 3.15. En éstas
figuras están contenidos los pronósticos de la serie, los cuales se presentan de una mejor
manera en la Tabla 3.1 y en la Figura 3.35.
La serie real, corresponde a la primera diferencia (Tabla 4.4, Anexo 2) de los datos
observados en el lapso de la predicción (Tabla 4.5, Anexo 2), es decir los que no se incluyen
en la estimación del modelo.
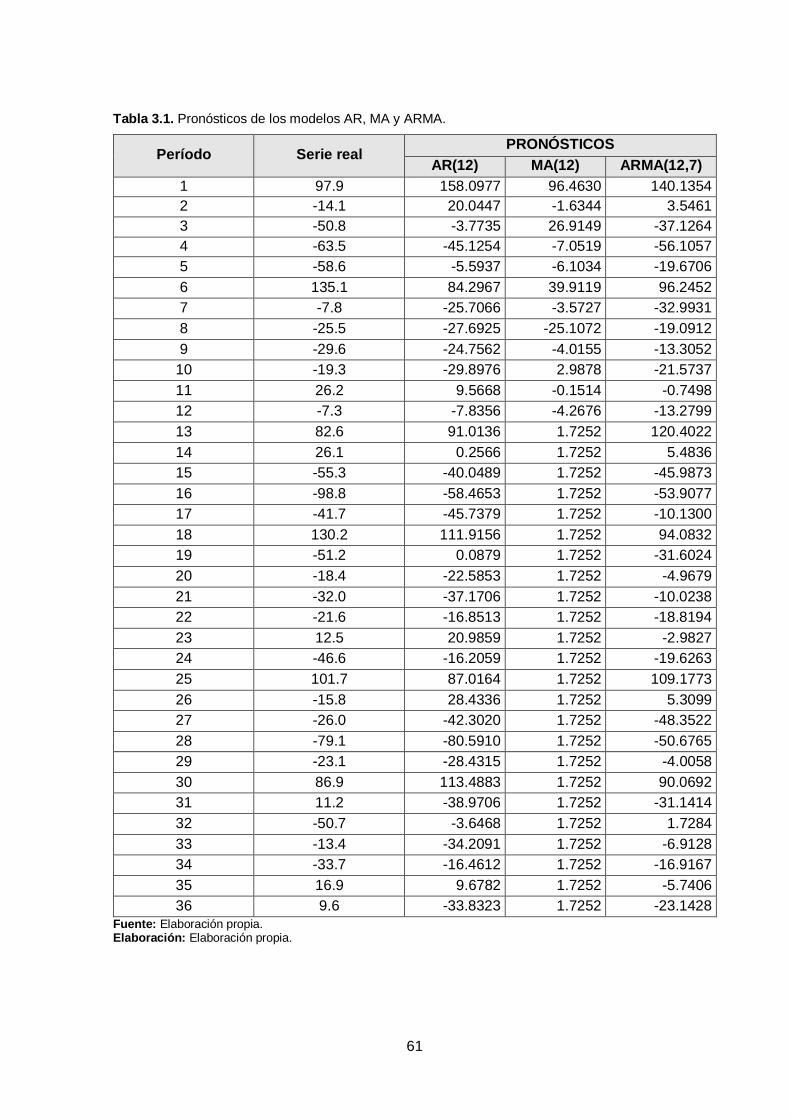
61
Tabla 3.1. Pronósticos de los modelos AR, MA y ARMA.
Período Serie real PRONÓSTICOS
AR(12) MA(12) ARMA(12,7)
1 97.9 158.0977 96.4630 140.1354
2 -14.1 20.0447 -1.6344 3.5461
3 -50.8 -3.7735 26.9149 -37.1264
4 -63.5 -45.1254 -7.0519 -56.1057
5 -58.6 -5.5937 -6.1034 -19.6706
6 135.1 84.2967 39.9119 96.2452
7 -7.8 -25.7066 -3.5727 -32.9931
8 -25.5 -27.6925 -25.1072 -19.0912
9 -29.6 -24.7562 -4.0155 -13.3052
10 -19.3 -29.8976 2.9878 -21.5737
11 26.2 9.5668 -0.1514 -0.7498
12 -7.3 -7.8356 -4.2676 -13.2799
13 82.6 91.0136 1.7252 120.4022
14 26.1 0.2566 1.7252 5.4836
15 -55.3 -40.0489 1.7252 -45.9873
16 -98.8 -58.4653 1.7252 -53.9077
17 -41.7 -45.7379 1.7252 -10.1300
18 130.2 111.9156 1.7252 94.0832
19 -51.2 0.0879 1.7252 -31.6024
20 -18.4 -22.5853 1.7252 -4.9679
21 -32.0 -37.1706 1.7252 -10.0238
22 -21.6 -16.8513 1.7252 -18.8194
23 12.5 20.9859 1.7252 -2.9827
24 -46.6 -16.2059 1.7252 -19.6263
25 101.7 87.0164 1.7252 109.1773
26 -15.8 28.4336 1.7252 5.3099
27 -26.0 -42.3020 1.7252 -48.3522
28 -79.1 -80.5910 1.7252 -50.6765
29 -23.1 -28.4315 1.7252 -4.0058
30 86.9 113.4883 1.7252 90.0692
31 11.2 -38.9706 1.7252 -31.1414
32 -50.7 -3.6468 1.7252 1.7284
33 -13.4 -34.2091 1.7252 -6.9128
34 -33.7 -16.4612 1.7252 -16.9167
35 16.9 9.6782 1.7252 -5.7406
36 9.6 -33.8323 1.7252 -23.1428
Fuente: Elaboración propia. Elaboración: Elaboración propia.
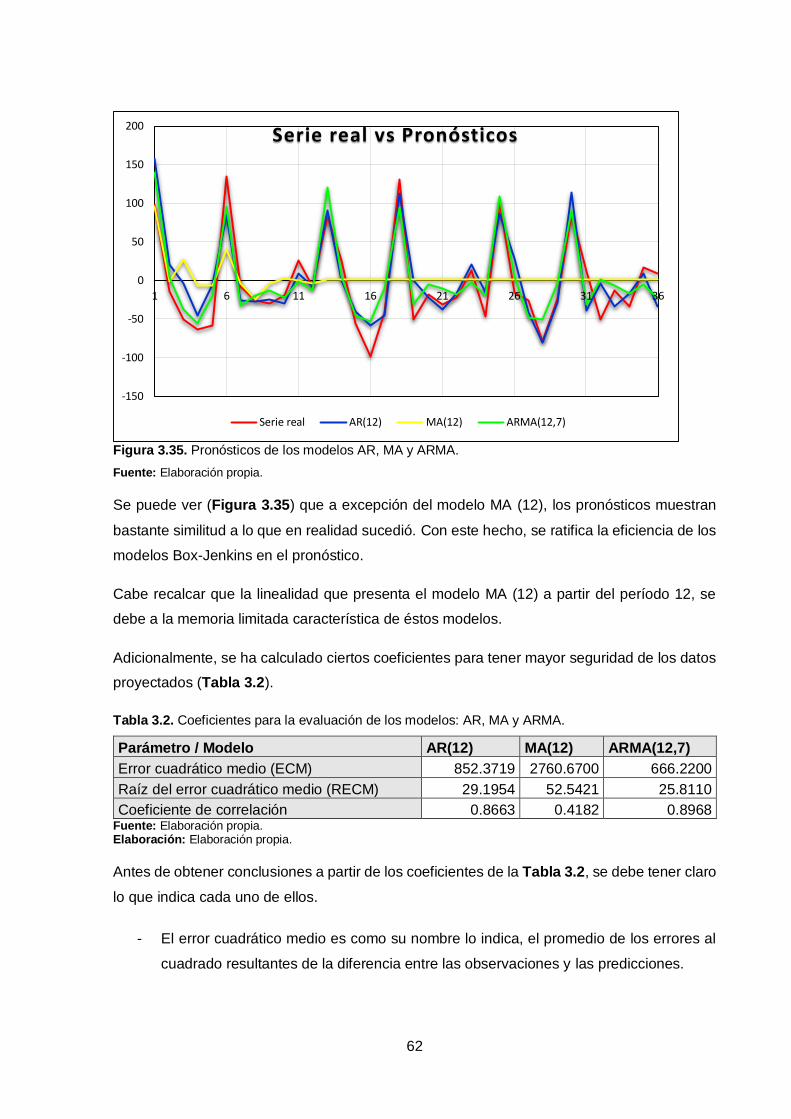
62
Figura 3.35. Pronósticos de los modelos AR, MA y ARMA.
Fuente: Elaboración propia.
Se puede ver (Figura 3.35) que a excepción del modelo MA (12), los pronósticos muestran
bastante similitud a lo que en realidad sucedió. Con este hecho, se ratifica la eficiencia de los
modelos Box-Jenkins en el pronóstico.
Cabe recalcar que la linealidad que presenta el modelo MA (12) a partir del período 12, se
debe a la memoria limitada característica de éstos modelos.
Adicionalmente, se ha calculado ciertos coeficientes para tener mayor seguridad de los datos
proyectados (Tabla 3.2).
Tabla 3.2. Coeficientes para la evaluación de los modelos: AR, MA y ARMA.
Parámetro / Modelo AR(12) MA(12) ARMA(12,7)
Error cuadrático medio (ECM) 852.3719 2760.6700 666.2200
Raíz del error cuadrático medio (RECM) 29.1954 52.5421 25.8110
Coeficiente de correlación 0.8663 0.4182 0.8968 Fuente: Elaboración propia. Elaboración: Elaboración propia.
Antes de obtener conclusiones a partir de los coeficientes de la Tabla 3.2, se debe tener claro
lo que indica cada uno de ellos.
- El error cuadrático medio es como su nombre lo indica, el promedio de los errores al
cuadrado resultantes de la diferencia entre las observaciones y las predicciones.
-150
-100
-50
0
50
100
150
200
1 6 11 16 21 26 31 36
Serie real vs Pronósticos
Serie real AR(12) MA(12) ARMA(12,7)
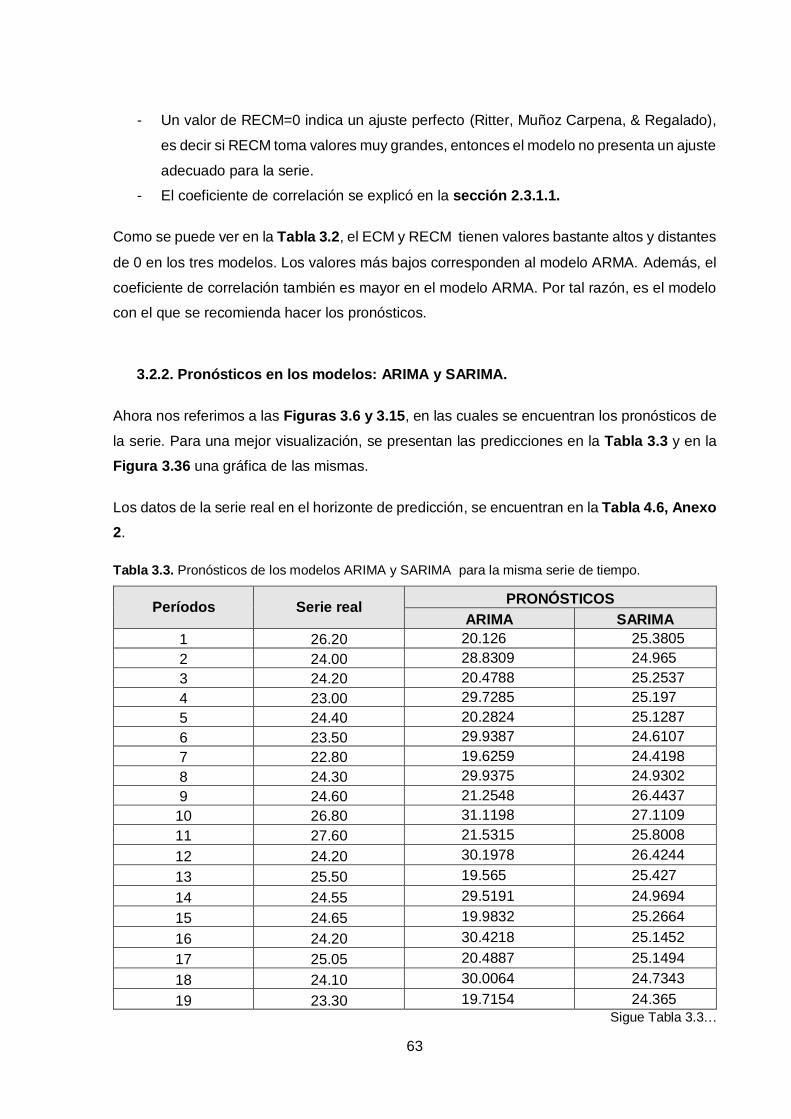
63
- Un valor de RECM=0 indica un ajuste perfecto (Ritter, Muñoz Carpena, & Regalado),
es decir si RECM toma valores muy grandes, entonces el modelo no presenta un ajuste
adecuado para la serie.
- El coeficiente de correlación se explicó en la sección 2.3.1.1.
Como se puede ver en la Tabla 3.2, el ECM y RECM tienen valores bastante altos y distantes
de 0 en los tres modelos. Los valores más bajos corresponden al modelo ARMA. Además, el
coeficiente de correlación también es mayor en el modelo ARMA. Por tal razón, es el modelo
con el que se recomienda hacer los pronósticos.
3.2.2. Pronósticos en los modelos: ARIMA y SARIMA.
Ahora nos referimos a las Figuras 3.6 y 3.15, en las cuales se encuentran los pronósticos de
la serie. Para una mejor visualización, se presentan las predicciones en la Tabla 3.3 y en la
Figura 3.36 una gráfica de las mismas.
Los datos de la serie real en el horizonte de predicción, se encuentran en la Tabla 4.6, Anexo
2.
Tabla 3.3. Pronósticos de los modelos ARIMA y SARIMA para la misma serie de tiempo.
Períodos Serie real PRONÓSTICOS
ARIMA SARIMA
1 26.20 20.126 25.3805
2 24.00 28.8309 24.965
3 24.20 20.4788 25.2537
4 23.00 29.7285 25.197
5 24.40 20.2824 25.1287
6 23.50 29.9387 24.6107
7 22.80 19.6259 24.4198
8 24.30 29.9375 24.9302
9 24.60 21.2548 26.4437
10 26.80 31.1198 27.1109
11 27.60 21.5315 25.8008
12 24.20 30.1978 26.4244
13 25.50 19.565 25.427
14 24.55 29.5191 24.9694
15 24.65 19.9832 25.2664
16 24.20 30.4218 25.1452
17 25.05 20.4887 25.1494
18 24.10 30.0064 24.7343
19 23.30 19.7154 24.365
Sigue Tabla 3.3…
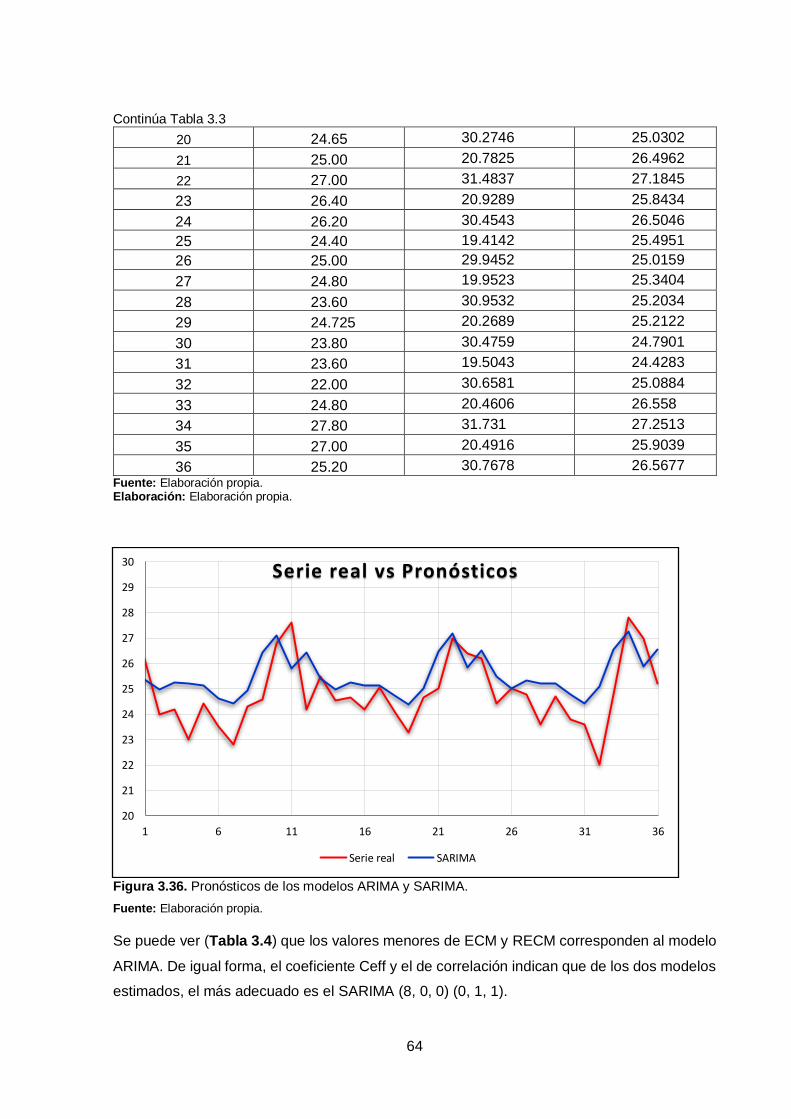
64
Continúa Tabla 3.3
20 24.65 30.2746 25.0302
21 25.00 20.7825 26.4962
22 27.00 31.4837 27.1845
23 26.40 20.9289 25.8434
24 26.20 30.4543 26.5046
25 24.40 19.4142 25.4951
26 25.00 29.9452 25.0159
27 24.80 19.9523 25.3404
28 23.60 30.9532 25.2034
29 24.725 20.2689 25.2122
30 23.80 30.4759 24.7901
31 23.60 19.5043 24.4283
32 22.00 30.6581 25.0884
33 24.80 20.4606 26.558
34 27.80 31.731 27.2513
35 27.00 20.4916 25.9039
36 25.20 30.7678 26.5677 Fuente: Elaboración propia. Elaboración: Elaboración propia.
Figura 3.36. Pronósticos de los modelos ARIMA y SARIMA.
Fuente: Elaboración propia.
Se puede ver (Tabla 3.4) que los valores menores de ECM y RECM corresponden al modelo
ARIMA. De igual forma, el coeficiente Ceff y el de correlación indican que de los dos modelos
estimados, el más adecuado es el SARIMA (8, 0, 0) (0, 1, 1).
20
21
22
23
24
25
26
27
28
29
30
1 6 11 16 21 26 31 36
Serie real vs Pronósticos
Serie real SARIMA

65
Tabla 3.4. Coeficientes para la evaluación de los modelos ARIMA y SARIMA.
Parámetro / Modelo ARIMA(11,1,10) SARIMA(8,0,0)(0,1,1)
Error cuadrático medio (ECM) 28.3184 1.4388
Raíz del error cuadrático medio (RECM) 5.3215 1.3326
Coeficiente de correlación -0.0325 0.6959 Fuente: Elaboración propia. Elaboración: Elaboración propia.
Por lo tanto, se concluye que el mejor modelo para describir los datos de la serie es el proceso
SARIMA (8, 0, 0) (0, 1, 1).

66
CONCLUSIONES
- En cada uno de los métodos, el algoritmo de programación realiza el cálculo de una
serie de modelos, de los cuales se elige el que presente un mayor ajuste a la serie de
datos, y que además proporcione pronósticos más cercanos a la realidad.
- En los métodos ARMA y ARIMA se deduce 168 modelos, que van desde el orden (0,1)
a (12,12). Es decir, se calcula todos los procesos posibles que podría adoptar la serie
de tiempo en estudio, con lo que se asegura que de todos se escoge el modelos más
óptimo.
- El modelo de media móvil (MA) ejecuta el cálculo correspondiente solo si la serie de
tiempo es estacionaria, caso contrario no realiza procedimiento alguno.
- En el modelo SARIMA admite únicamente datos positivos, debido a las
transformaciones que realiza posteriormente a la serie de datos.
- No se puede afirmar que un método en particular es mejor para realizar pronósticos,
ya que esto depende únicamente de las propiedades de la serie de tiempo y de sus
correlogramas.
- De los modelos que se aplican a series estacionarias (AR, MA y ARMA), el que se
adapta mejor a la serie en éste caso puntual, es el modelo ARMA. Pero esto no
siempre es así, ya que esto depende únicamente de las propiedades de la serie de
tiempo.
- El objetivo de los modelos Box-Jenkins, es estimar un modelo que permita obtener los
pronósticos más probables dentro de un 95% de confianza. Es decir, de todas las
series probables futuras, localiza la más que tiene una mayor probabilidad de
ocurrencia.
- En el laboratorio virtual de hidrología “HydroVLab”, se ha implementado cada una de
las herramientas desarrolladas, previo a su validación luego de una serie de pruebas.

67
RECOMENDACIONES
- Para futuras investigaciones, se podría ampliar los métodos al análisis de series de
tiempo multivariantes, ya que aquí únicamente se han estudiado las univariantes.
- En los modelos SARIMA, se recomienda implementar una transformación diferente a
las utilizadas, con el fin de permitir el uso de datos negativos. Ya que actualmente, en
la página se debe ingresar únicamente datos positivos.
- Para generar un modelo adecuado de predicción, se debe tener al menos 50 datos o
más, y así obtener mayor precisión en los resultados.
- Se sugiere realizar el análisis de otras metodologías predictivas y comparar con las
aquí desarrolladas. Una vez más se hace énfasis, en que el mejor modelo ya sea de
la familia Box-Jenkins u otra metodología, depende solamente de las características
de la serie de tiempo.

68
BIBLIOGRAFÍA
Antunez Irgoin, C. H. (2011). Análisis de series de tiempo. Lima.
Barquero, A. V. (26 de Junio de 2009). erevistas. Obtenido de
http://www.erevistas.csic.es/ficha_articulo.php?url=oai:revistas.uptc.edu.co:article/83
&oai_iden=oai_revista726
Bowerman, B. L., O'Connell, R. T., & Koehler, A. B. (2007). Pronósticos, series de tiempo y
regresión. Un enfoque aplicado. Monterrey: Thomson.
Campus Virtual Birtuala. (19 de Julio de 2007). Recuperado el 25 de Febrero de 2016, de
Campus Virtual/Birtuala:
http://cvb.ehu.es/open_course_ware/castellano/social_juri/metodos_econometricos_a
nalisis_datos/materiales_estudio/AUTOC4b.pdf
Chapra, S., & Canale, R. (2007). Métodos numéricos para ingenieros 5ta ed. México: McGraw
Hill.
De Arce, R., & Mahía, R. (22 de Febrero de 2016). Modelos Arima. Programa Citius-Técnicas
de previsión de variables financieras. UDI Economía e Informática. Obtenido de
https://www.uam.es/personal_pdi/economicas/anadelsur/pdf/Box-Jenkins.PDF
Desarrollo Web. (1 de Enero de 2001). Recuperado el 22 de Febrero de 2016, de Desarrollo
Web: http://www.desarrolloweb.com/articulos/que-es-html.html
Gairaa, K., Khellaf, A., Messlem, Y., & Chellali, F. (2016). Estimation
ofthedailyglobalsolarradiationbasedonBox–Jenkins. Renewable and Sustainable
Energy Reviews, Vol. 57, 238-249. Obtenido de
http://www.scopus.com/record/display.uri?eid=2-s2.0-
84952926141&origin=resultslist&sort=plf-
f&src=s&st1=box+jenkins&st2=&sid=74F1DFCC371B3EA9D5AE990A52A990A6.FZg
2ODcJC9ArCe8WOZPvA%3a20&sot=b&sdt=b&sl=26&s=TITLE-ABS-
KEY%28box+jenkins%29&relpos=0&citeCnt=0&
Ghahramani, M., & Thavaneswaran, A. (2006). Financial applications of ARMA models with
GARCH errors. The Journal of Risk Finance, Vol. 7 lss 5, 525-543. Obtenido de
http://www.emeraldinsight.com/doi/abs/10.1108/15265940610712678
Gujarati, D. N., & Porter, D. C. (2010). Econometría. México D. F: McGraw-Hill.
Hanke, J. E. (2010). Pronósticos en los negocios. México D. F: Pearson Educación.

69
Hernández Alonso, J. (2007). Análisis de series temporales económicas II. España: ESIC.
Holton, W. J. (2007). Pronósticos para los negocios con forecastX basado en Excel. México
D. F: McGraw-Hill.
Hudak, G. B., & Liu, L. -M. (1992-1994). Forecasting and Time Series Analysis Using the SCA
System. Scientific Computing Associates Corp., vol. 1.
Kwangbok, J., Choongwan, K., & Taehoon , H. (2014). An estimation model for determining
annual energy cost budget in educational facilities using SARIMA (seasonal
autoregressive integrated moving average) and ANN (artificial neural network).
ScienceDirect, 71-79.
MacKinnon, J. (2010). Critical values for cointegration tests. Quens's Economics Department
Working Paper, No. 1227.
MSDN Library. (2001). Recuperado el 22 de Febrero de 2016, de MSDN Library:
https://msdn.microsoft.com/es-es/library/fx6bk1f4(v=vs.100).aspx
Murray R., S. (1997). Estadística Schaum 2da ed. Chile: McGraw Hill.
Otoom, M., Alshraideh, H., López de Ipiña, D., Bravo, J., & Hisham, M. A. (2015). Real-Time
Statistical Modeling of Blood Sugar. Journal of Medical Systems, vol. 39, 1-6.
Ritter, A., Muñoz Carpena, R., & Regalado, C. (s.f.). Capacidad de predicción de modelos
aplicados a la ZNS: Herramienta informática para la adecuada evaluación de la bondad
de ajuste con significación estadística. ZONA NO SATURADA, X, 259-254.
Recuperado el 4 de Marzo de 2016, de
http://www.zonanosaturada.com/zns11/publications/p259.pdf
Rodriguez Bucarelly, C. M., & Rodriguez Bucarelly, P. A. (2008). Visual basic 6.0. Orientado
a bases de datos 2da ed.
Shamsuddin, A. F., & Holmes, R. A. (1997). Cointegration test of the monetary theory of
inflation and forecasting accuracy of the univariate and vector ARMA models of
inflation. Journal of Economic Studies, Vol. 2 lss 5, 294-306. Obtenido de
http://www.emeraldinsight.com/doi/full/10.1108/01443589710175816
Taneja, K., Ahmad, S., Ahmad, K., & Attri, S. D. (2016). Time series analysis of aerosol optical
depth over New Delhi using. Atmospheric Pollution Research, 1-12. Obtenido de
http://ac.els-cdn.com/S1309104215301082/1-s2.0-S1309104215301082-

70
main.pdf?_tid=65c2edb2-e56f-11e5-93cd-
00000aacb361&acdnat=1457470411_d8750d37e726070f2f13c2c8d844ee0e
Universidad Autónoma de Madrid. (2004). Recuperado el 25 de Febrero de 2016, de
www.uam.es:
https://www.uam.es/docencia/predysim/prediccion_unidad3/3_5_doc1.pdf
Universidad Autónoma de Madrid. (2008). Recuperado el 25 de Febrero de 2016, de
www.uam.es: https://www.uam.es/personal_pdi/economicas/anadelsur/pdf/Box-
Jenkins.PDF
Valderrey Sanz, P. (2012). Predicción económica y empresarial. Madrid: StarBook Editorial.
Vasileiadou, E., & Vliegenthart, R. (2013). Studyng dynamic social process with ARIMA
modeling. Taylor & Francis Group, 693-708.

71
4. ANEXOS
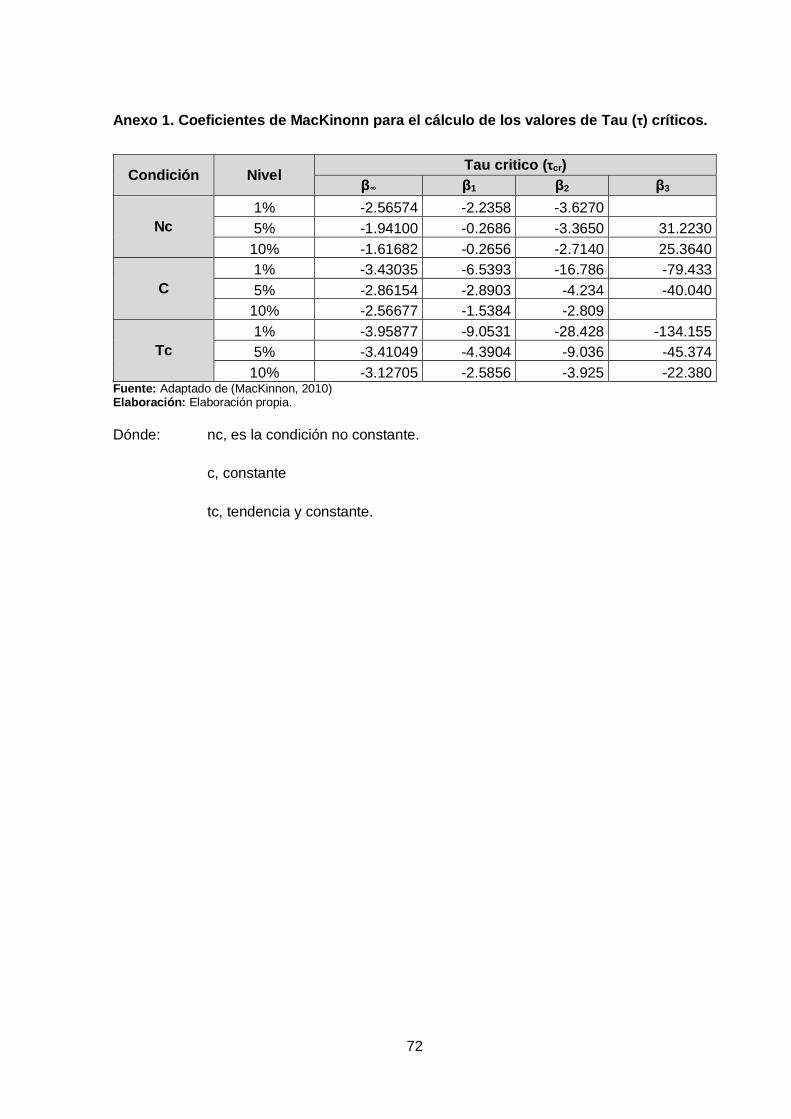
72
Anexo 1. Coeficientes de MacKinonn para el cálculo de los valores de Tau (τ) críticos.
Condición Nivel Tau critico (τcr)
β∞ β1 β2 β3
Nc
1% -2.56574 -2.2358 -3.6270
5% -1.94100 -0.2686 -3.3650 31.2230
10% -1.61682 -0.2656 -2.7140 25.3640
C
1% -3.43035 -6.5393 -16.786 -79.433
5% -2.86154 -2.8903 -4.234 -40.040
10% -2.56677 -1.5384 -2.809
Tc
1% -3.95877 -9.0531 -28.428 -134.155
5% -3.41049 -4.3904 -9.036 -45.374
10% -3.12705 -2.5856 -3.925 -22.380 Fuente: Adaptado de (MacKinnon, 2010) Elaboración: Elaboración propia.
Dónde: nc, es la condición no constante.
c, constante
tc, tendencia y constante.
73
Anexo 2. Series de tiempo utilizadas.
Tabla 4.1. Serie diferenciada de la Tabla 4.2
t zt t zt t Zt T zt t zt t zt t zt t zt t zt t zt t zt t zt t zt t zt
1 45.6 25 14.3 49 8.2 73 42.2 97 2.6 121 65.2 145 -23 169 -14 193 -5.7 217 -14 241 21.3 265 38.8 289 -3.5 313 13.2
2 -16.1 26 -47.8 50 -33.8 74 5.4 98 0.3 122 3.9 146 27.8 170 -16 194 -24 218 -12 242 -36 266 -6.1 290 -20 314 -39
3 -23.9 27 -64.8 51 -16.6 75 -19.1 99 -38.5 123 -9.1 147 -56 171 -46 195 -39 219 -26 243 -44 267 -18 291 -52 315 -45
4 -39.3 28 -40.2 52 -5.4 76 -18.8 100 8.9 124 -23 148 -23 172 8.9 196 -30 220 6.3 244 -19 268 -17 292 -35 316 -16
5 39.4 29 28.8 53 25 77 2.3 101 38 125 39.1 149 79.2 173 26.7 197 92.5 221 79.9 245 131 269 129 293 108 317 124
6 0.3 30 -23.5 54 5.3 78 -0.2 102 -19.5 126 -12 150 -29 174 -39 198 -78 222 -54 246 -40 270 -16 294 -25 318 -12
7 -17.3 31 -70.3 55 -16.7 79 -20.9 103 -51.7 127 -49 151 -17 175 1.3 199 -12 223 -23 247 -45 271 -29 295 -32 319 -38
8 -17.7 32 -12.3 56 -19 80 -3.7 104 -19.4 128 -55 152 -40 176 -39 200 -29 224 -32 248 -17 272 7.2 296 -20 320 31.7
9 -31.4 33 -43.5 57 -24.8 81 -50.4 105 -18.2 129 -31 153 22.2 177 -22 201 -6.4 225 -3.8 249 -9.7 273 -3.3 297 -19 321 -16
10 28.6 34 30.1 58 11.4 82 18.6 106 50.8 130 3.5 154 43 178 49.2 202 12 226 11.4 250 6.6 274 34.8 298 -20 322 64.1
11 17.2 35 5.3 59 -4.9 83 -10.6 107 6.1 131 28.3 155 50.3 179 3.4 203 9.1 227 8.6 251 -16 275 2.9 299 -15 323 42.1
12 79 36 24 60 58.7 84 66 108 54.6 132 61 156 86.5 180 86.7 204 53.2 228 49.4 252 45.7 276 77.8 300 55.9 324 207
13 47.9 37 -11.1 61 -16.8 85 -10 109 -12.1 133 2 157 31.9 181 24.3 205 23.1 229 2.5 253 4.8 277 2.8 301 17 325 12.9
14 -9.1 38 -21.5 62 -13.6 86 -27.2 110 -26.3 134 -40 158 -23 182 -43 206 -47 230 -23 254 -18 278 -27 302 -33 326 5
15 -10.6 39 -38.5 63 -6.4 87 -13.5 111 -19.5 135 -74 159 -54 183 -45 207 -21 231 -29 255 -21 279 -48 303 -34 327 -54
16 23.9 40 -16.8 64 -22.8 88 -47.2 112 0.8 136 -23 160 -22 184 -4.4 208 -28 232 -21 256 -24 280 -30 304 -38 328 -20
17 45 41 36.2 65 19.6 89 20.3 113 49.6 137 45.3 161 64.2 185 60.5 209 84.3 233 117 257 109 281 110 305 105 329 94.6
18 42.2 42 -6 66 -2.2 90 -23.1 114 -28.8 138 -18 162 -35 186 -41 210 -63 234 -38 258 -21 282 -16 306 -30 330 -36
19 -43.2 43 -26.6 67 -19.8 91 -12.6 115 -31.7 139 -26 163 -52 187 -39 211 -26 235 -31 259 -31 283 -27 307 -34 331 -51
20 -32.1 44 8 68 10.7 92 -19.8 116 -2.3 140 -15 164 -41 188 -29 212 -32 236 -4.7 260 8.8 284 -22 308 -4.3 332 -17
21 15.3 45 -13.2 69 -4.7 93 -5.4 117 -3.8 141 3.6 165 -17 189 -7.6 213 -13 237 5.7 261 -12 285 -27 309 -40 333 -28
22 -21.8 46 23.6 70 44.5 94 25.2 118 66.2 142 40.5 166 7.8 190 46.4 214 17.9 238 -4.9 262 -13 286 24.5 310 29.3 334 -1.3
23 12 47 -19.4 71 34.7 95 6.5 119 20.5 143 -12 167 10 191 -7 215 -10 239 -18 263 -8.3 287 -12 311 0.2 335 -3.6
24 95.8 48 46.2 72 119.7 96 46.5 120 113.2 144 59.8 168 58 192 73 216 45.6 240 35.4 264 77.9 288 75.2 312 95
Fuente: INSTITUTO NACIONAL DE METEOROLOGÍA E HIDROLOGÍA. Elaboración: Elaboración propia
74
Tabla 4.2. Serie de datos de caudal de la estación arenal oyente boquerón.
t yt t yt t yt t yt t yt t yt t yt t yt t yt t yt t yt t yt t yt t yt
1 235.1 25 464.8 49 225.8 73 356.1 97 306.6 121 446.4 145 411.9 169 462.1 193 451.8 217 324.4 241 307.4 265 340.6 289 544.7 313 500.8
2 280.7 26 479.1 50 234.0 74 398.3 98 309.2 122 511.6 146 388.6 170 448.1 194 446.1 218 310.9 242 328.7 266 379.4 290 541.2 314 514.0
3 264.6 27 431.3 51 200.2 75 403.7 99 309.5 123 515.5 147 416.4 171 432.3 195 422.5 219 299.0 243 292.9 267 373.3 291 521.5 315 475.5
4 240.7 28 366.5 52 183.6 76 384.6 100 271.0 124 506.4 148 360.7 172 386.3 196 383.1 220 273.0 244 249.1 268 355.2 292 469.7 316 430.1
5 201.4 29 326.3 53 178.2 77 365.8 101 279.9 125 483.2 149 338.0 173 395.2 197 352.8 221 279.3 245 230.4 269 338.4 293 434.4 317 414.4
6 240.8 30 355.1 54 203.2 78 368.1 102 317.9 126 522.3 150 417.2 174 421.9 198 445.3 222 359.2 246 361.5 270 466.9 294 542.6 318 538.0
7 241.1 31 331.6 55 208.5 79 367.9 103 298.4 127 509.8 151 388.4 175 382.9 199 367.5 223 305.0 247 321.7 271 451.0 295 517.3 319 526.0
8 223.8 32 261.3 56 191.8 80 347.0 104 246.7 128 460.7 152 371.1 176 384.2 200 355.1 224 282.1 248 277.2 272 422.0 296 485.7 320 488.5
9 206.1 33 249.0 57 172.8 81 343.3 105 227.3 129 405.8 153 331.5 177 345.5 201 326.2 225 250.3 249 260.7 273 429.2 297 465.8 321 520.2
10 174.7 34 205.5 58 148.0 82 292.9 106 209.1 130 375.0 154 353.7 178 323.4 202 319.8 226 246.5 250 251.0 274 425.9 298 447.0 322 504.4
11 203.3 35 235.6 59 159.4 83 311.5 107 259.9 131 378.5 155 396.7 179 372.6 203 331.8 227 257.9 251 257.6 275 460.7 299 426.6 323 568.5
12 220.5 36 240.9 60 154.5 84 300.9 108 266.0 132 406.8 156 447.0 180 376.0 204 340.9 228 266.5 252 241.8 276 463.6 300 411.6 324 610.6
13 299.5 37 264.9 61 213.2 85 366.9 109 320.6 133 467.8 157 533.5 181 462.7 205 394.1 229 315.9 253 287.5 277 541.4 301 467.5 325 818.0
14 347.4 38 253.8 62 196.4 86 356.9 110 308.5 134 469.8 158 565.4 182 487.0 206 417.2 230 318.4 254 292.3 278 544.2 302 484.5 326 830.9
15 338.3 39 232.3 63 182.8 87 329.7 111 282.2 135 429.8 159 542.3 183 444.2 207 369.9 231 295.4 255 274.7 279 517.5 303 451.2 327 835.9
16 327.7 40 193.8 64 176.4 88 316.2 112 262.7 136 355.8 160 488.7 184 399.3 208 349.2 232 266.4 256 254.2 280 469.4 304 417.4 328 782.0
17 351.6 41 177.0 65 153.6 89 269.0 113 263.5 137 332.7 161 467.1 185 394.9 209 321.4 233 245.8 257 230.0 281 439.4 305 379.9 329 762.3
18 396.6 42 213.2 66 173.2 90 289.3 114 313.1 138 378.0 162 531.3 186 455.4 210 405.7 234 362.8 258 339.0 282 549.0 306 484.7 330 856.9
19 438.8 43 207.2 67 171.0 91 266.2 115 284.3 139 360.5 163 496.1 187 414.0 211 342.9 235 324.9 259 318.2 283 533.0 307 455.0 331 820.9
20 395.6 44 180.6 68 151.2 92 253.6 116 252.6 140 334.7 164 444.0 188 375.5 212 316.5 236 294.2 260 287.0 284 506.1 308 420.8 332 769.6
21 363.5 45 188.6 69 161.9 93 233.8 117 250.3 141 319.5 165 403.4 189 347.0 213 284.2 237 289.5 261 295.8 285 484.0 309 416.5 333 752.2
22 378.8 46 175.4 70 157.2 94 228.4 118 246.5 142 323.1 166 386.3 190 339.4 214 270.9 238 295.2 262 284.0 286 457.0 310 376.3 334 724.4
23 357.0 47 199.0 71 201.7 95 253.6 119 312.7 143 363.6 167 394.1 191 385.8 215 288.8 239 290.3 263 271.0 287 481.5 311 405.6 335 723.1
24 369.0 48 179.6 72 236.4 96 260.1 120 333.2 144 352.1 168 404.1 192 378.8 216 278.8 240 272.0 264 262.7 288 469.5 312 405.8 336 719.5
Fuente: INSTITUTO NACIONAL DE METEOROLOGÍA E HIDROLOGÍA. Elaboración: Elaboración propia
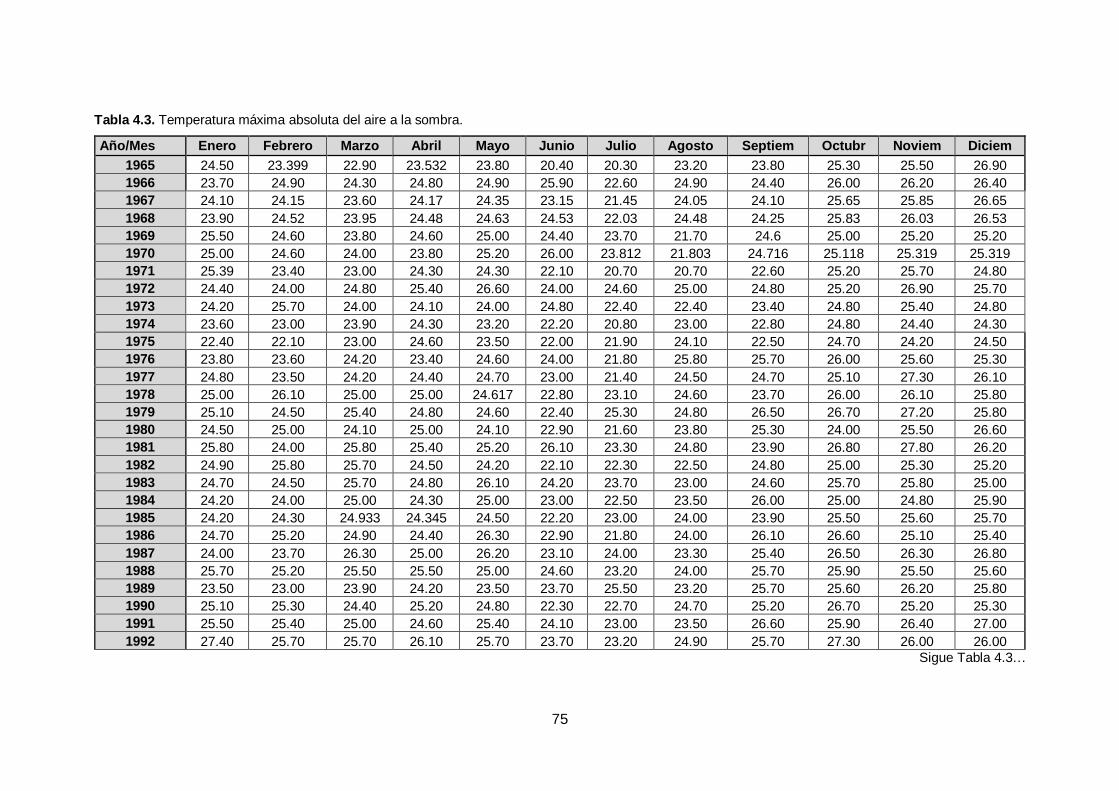
75
Tabla 4.3. Temperatura máxima absoluta del aire a la sombra.
Año/Mes Enero Febrero Marzo Abril Mayo Junio Julio Agosto Septiem Octubr Noviem Diciem
1965 24.50 23.399 22.90 23.532 23.80 20.40 20.30 23.20 23.80 25.30 25.50 26.90
1966 23.70 24.90 24.30 24.80 24.90 25.90 22.60 24.90 24.40 26.00 26.20 26.40
1967 24.10 24.15 23.60 24.17 24.35 23.15 21.45 24.05 24.10 25.65 25.85 26.65
1968 23.90 24.52 23.95 24.48 24.63 24.53 22.03 24.48 24.25 25.83 26.03 26.53
1969 25.50 24.60 23.80 24.60 25.00 24.40 23.70 21.70 24.6 25.00 25.20 25.20
1970 25.00 24.60 24.00 23.80 25.20 26.00 23.812 21.803 24.716 25.118 25.319 25.319
1971 25.39 23.40 23.00 24.30 24.30 22.10 20.70 20.70 22.60 25.20 25.70 24.80
1972 24.40 24.00 24.80 25.40 26.60 24.00 24.60 25.00 24.80 25.20 26.90 25.70
1973 24.20 25.70 24.00 24.10 24.00 24.80 22.40 22.40 23.40 24.80 25.40 24.80
1974 23.60 23.00 23.90 24.30 23.20 22.20 20.80 23.00 22.80 24.80 24.40 24.30
1975 22.40 22.10 23.00 24.60 23.50 22.00 21.90 24.10 22.50 24.70 24.20 24.50
1976 23.80 23.60 24.20 23.40 24.60 24.00 21.80 25.80 25.70 26.00 25.60 25.30
1977 24.80 23.50 24.20 24.40 24.70 23.00 21.40 24.50 24.70 25.10 27.30 26.10
1978 25.00 26.10 25.00 25.00 24.617 22.80 23.10 24.60 23.70 26.00 26.10 25.80
1979 25.10 24.50 25.40 24.80 24.60 22.40 25.30 24.80 26.50 26.70 27.20 25.80
1980 24.50 25.00 24.10 25.00 24.10 22.90 21.60 23.80 25.30 24.00 25.50 26.60
1981 25.80 24.00 25.80 25.40 25.20 26.10 23.30 24.80 23.90 26.80 27.80 26.20
1982 24.90 25.80 25.70 24.50 24.20 22.10 22.30 22.50 24.80 25.00 25.30 25.20
1983 24.70 24.50 25.70 24.80 26.10 24.20 23.70 23.00 24.60 25.70 25.80 25.00
1984 24.20 24.00 25.00 24.30 25.00 23.00 22.50 23.50 26.00 25.00 24.80 25.90
1985 24.20 24.30 24.933 24.345 24.50 22.20 23.00 24.00 23.90 25.50 25.60 25.70
1986 24.70 25.20 24.90 24.40 26.30 22.90 21.80 24.00 26.10 26.60 25.10 25.40
1987 24.00 23.70 26.30 25.00 26.20 23.10 24.00 23.30 25.40 26.50 26.30 26.80
1988 25.70 25.20 25.50 25.50 25.00 24.60 23.20 24.00 25.70 25.90 25.50 25.60
1989 23.50 23.00 23.90 24.20 23.50 23.70 25.50 23.20 25.70 25.60 26.20 25.80
1990 25.10 25.30 24.40 25.20 24.80 22.30 22.70 24.70 25.20 26.70 25.20 25.30
1991 25.50 25.40 25.00 24.60 25.40 24.10 23.00 23.50 26.60 25.90 26.40 27.00
1992 27.40 25.70 25.70 26.10 25.70 23.70 23.20 24.90 25.70 27.30 26.00 26.00
Sigue Tabla 4.3…
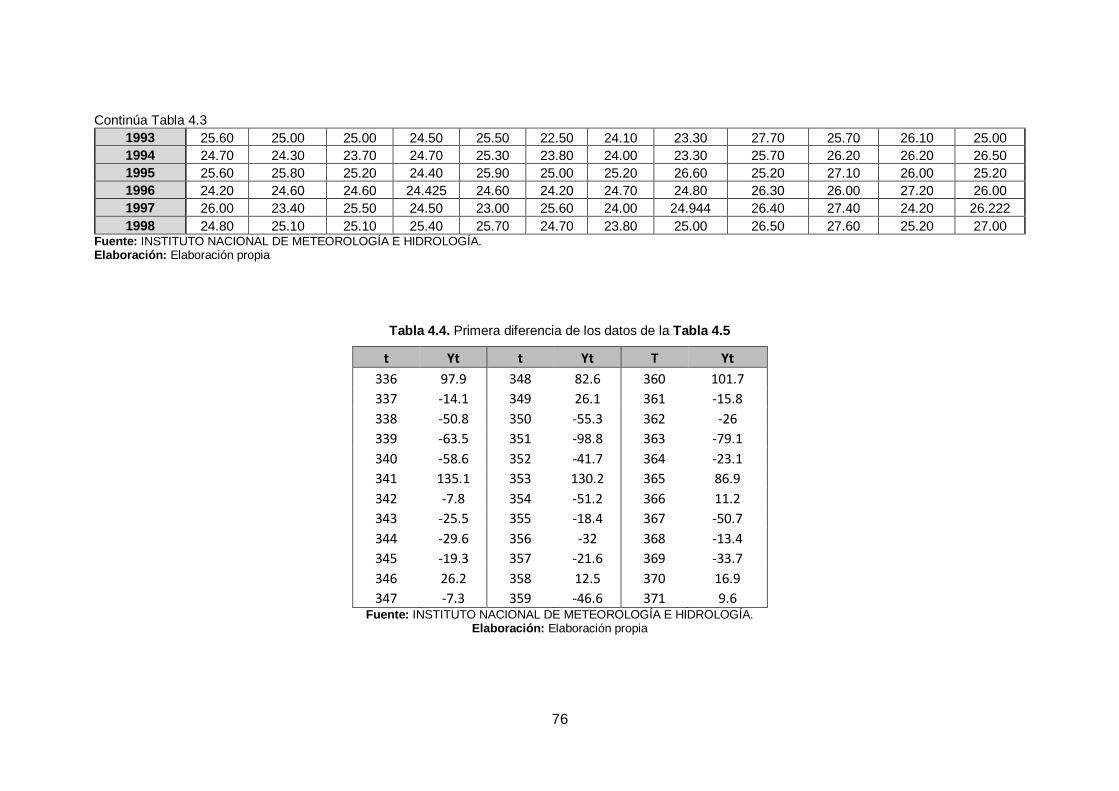
76
Continúa Tabla 4.3
1993 25.60 25.00 25.00 24.50 25.50 22.50 24.10 23.30 27.70 25.70 26.10 25.00
1994 24.70 24.30 23.70 24.70 25.30 23.80 24.00 23.30 25.70 26.20 26.20 26.50
1995 25.60 25.80 25.20 24.40 25.90 25.00 25.20 26.60 25.20 27.10 26.00 25.20
1996 24.20 24.60 24.60 24.425 24.60 24.20 24.70 24.80 26.30 26.00 27.20 26.00
1997 26.00 23.40 25.50 24.50 23.00 25.60 24.00 24.944 26.40 27.40 24.20 26.222
1998 24.80 25.10 25.10 25.40 25.70 24.70 23.80 25.00 26.50 27.60 25.20 27.00 Fuente: INSTITUTO NACIONAL DE METEOROLOGÍA E HIDROLOGÍA. Elaboración: Elaboración propia
Tabla 4.4. Primera diferencia de los datos de la Tabla 4.5
t Yt t Yt T Yt
336 97.9 348 82.6 360 101.7
337 -14.1 349 26.1 361 -15.8
338 -50.8 350 -55.3 362 -26
339 -63.5 351 -98.8 363 -79.1
340 -58.6 352 -41.7 364 -23.1
341 135.1 353 130.2 365 86.9
342 -7.8 354 -51.2 366 11.2
343 -25.5 355 -18.4 367 -50.7
344 -29.6 356 -32 368 -13.4
345 -19.3 357 -21.6 369 -33.7
346 26.2 358 12.5 370 16.9
347 -7.3 359 -46.6 371 9.6 Fuente: INSTITUTO NACIONAL DE METEOROLOGÍA E HIDROLOGÍA.
Elaboración: Elaboración propia
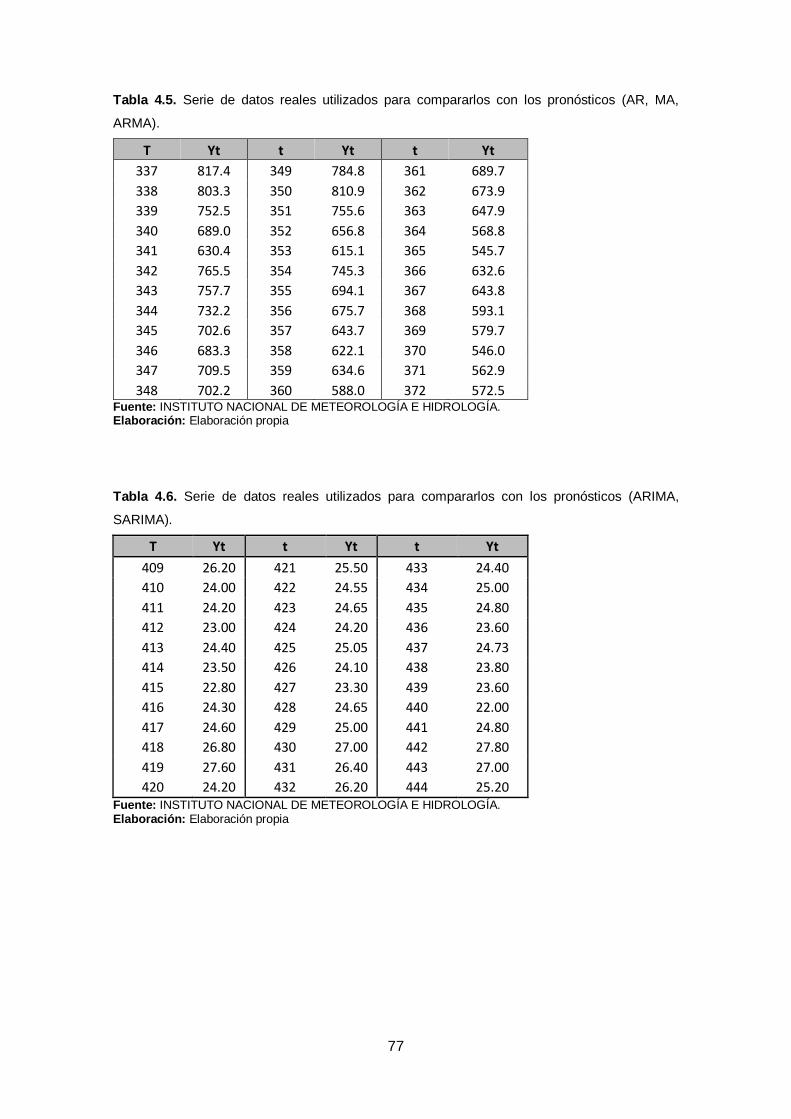
77
Tabla 4.5. Serie de datos reales utilizados para compararlos con los pronósticos (AR, MA,
ARMA).
T Yt t Yt t Yt
337 817.4 349 784.8 361 689.7
338 803.3 350 810.9 362 673.9
339 752.5 351 755.6 363 647.9
340 689.0 352 656.8 364 568.8
341 630.4 353 615.1 365 545.7
342 765.5 354 745.3 366 632.6
343 757.7 355 694.1 367 643.8
344 732.2 356 675.7 368 593.1
345 702.6 357 643.7 369 579.7
346 683.3 358 622.1 370 546.0
347 709.5 359 634.6 371 562.9
348 702.2 360 588.0 372 572.5 Fuente: INSTITUTO NACIONAL DE METEOROLOGÍA E HIDROLOGÍA. Elaboración: Elaboración propia
Tabla 4.6. Serie de datos reales utilizados para compararlos con los pronósticos (ARIMA,
SARIMA).
T Yt t Yt t Yt
409 26.20 421 25.50 433 24.40
410 24.00 422 24.55 434 25.00
411 24.20 423 24.65 435 24.80
412 23.00 424 24.20 436 23.60
413 24.40 425 25.05 437 24.73
414 23.50 426 24.10 438 23.80
415 22.80 427 23.30 439 23.60
416 24.30 428 24.65 440 22.00
417 24.60 429 25.00 441 24.80
418 26.80 430 27.00 442 27.80
419 27.60 431 26.40 443 27.00
420 24.20 432 26.20 444 25.20 Fuente: INSTITUTO NACIONAL DE METEOROLOGÍA E HIDROLOGÍA. Elaboración: Elaboración propia


























