Embed Size (px)
Citation preview


1
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO
Escola Politécnica – Departamento de Eletrônica e de Computação
Centro de Tecnologia, bloco H, sala H-217, Cidade Universitária.
Rio de Janeiro – RJ – CEP 21949-900
Este exemplar é de propriedade da Universidade Federal do Rio de Janeiro, que
poderá incluí-lo em base de dados, armazenar em computador, microfilmar ou adotar
qualquer forma de arquivamento.
É permitida a menção, reprodução parcial ou integral e a transmissão entre
bibliotecas deste trabalho, sem modificação de seu texto, em qualquer meio que esteja
ou venha a ser fixado, para pesquisa acadêmica, comentários e citações, desde que sem
finalidade comercial e que seja feita a referência bibliográfica completa.
Os conceitos expressos neste trabalho são de responsabilidade do autor e do
orientador.

2
Magalhães, Pedro da Silveira
Framework de ETL (Extração-Transformação-Carga)
utilizando processamento em paralelo por técnica de pipeline /
Pedro da Silveira Magalhães – Rio de Janeiro: UFRJ/POLI-
COPPE, 2013.
XI, 42 p.: il.; 29,7 cm.
Orientador: Antônio Cláudio Gómez de Sousa
Projeto (graduação) – UFRJ/POLI/Departamento de
Eletrônica e de Computação – COPPE, 2013.
Referências Bibliográficas: p. 40-42.
1. [Extração]. 2. [Transformação]. 3. [Carga]. 4. [ETL]. I. de Souza,
Antônio Cláudio Gómez. II. Universidade Federal do Rio de
Janeiro, Poli/COPPE. III. Título.

3
DEDICATÓRIA
Dedico este trabalho a minha família que esteve presente em toda minha
graduação.

4
AGRADECIMENTO
“Agradeço ao professor Antônio Cláudio Gomez por ter me orientado durante o
Projeto de Graduação. Agradeço também a empresa Stone Age por ter me dado a
liberdade de muitas vezes abdicar do trabalho colocando sempre a formação do
profissional a frente.”

5
RESUMO
Projeto de Graduação apresentado à Escola Politécnica/COPPE/UFRJ como
parte dos requisitos necessários para a obtenção do grau de Engenheiro de Computação
e Informação.
FRAMEWORK DE ETL (EXTRAÇÃO-TRANSFORMAÇÃO-CARGA)
UTILIZANDO PROCESSAMENTO PARALELO POR TÉCNICA DE PIPELINE.
Pedro da Silveira Magalhães
Março/2013
Orientador: Antônio Cláudio Gómez de Sousa
Curso: Engenharia de Computação e Informação
Um ciclo de ETL (extract, transform e load), refere-se a um processo no
domínio de banco de dados muito utilizado em sistemas de Data Warehouse. Esse ciclo
envolve três etapas distintas: a extração de dados de fontes, transformação dos dados e a
carga no sistema alvo.
Um ciclo ETL pode ser consideravelmente complexo e problemas podem
ocorrer quando esses processos são modelados de maneira incorreta. Na maioria das
vezes os dados advindos do sistema transacional são de baixa qualidade, apresentando
problemas como: domínio de dados mal definidos, erros de digitação, heterogeneidade
das fontes de dados envolvidas, etc. Para lidar com esses desafios e complexidade, as
empresas estão cada vez mais investindo em ferramentas de ETL, ao invés de criar seus
processos a partir do zero. Ao utilizar um ferramental de apoio, as chances de sucesso
aumentam, pois permitem auto documentação, visualização do fluxo de dados,
reutilização de componentes, design estruturado e padronizado, desempenho e
consequentemente maior produtividade e qualidade.
O objetivo do projeto é criar um framework capaz de apoiar o processo de
construção/execução de um ciclo ETL entregando os benefícios anteriormente citados.

6
Palavras-Chave: Extração, Transformação, Carga, Data Warehouse, ETL

7
ABSTRACT
Undergraduate Project presented to POLI/COPPE/UFRJ as a partial fulfillment
of requirements for the degree of Computer and Information Engineer.
ETL Framework using parallel processing by pipeline technique.
Pedro da Silveira Magalhães
March/2013
Advisor: Antônio Cláudio Gómez de Sousa
Course: Computer and Information Engineering
ETL cycle (extraction, transform and load), refers to a process in the context of
database systems widely used in the Data Warehouse. This cycle involves three distinct
steps: data sources extraction, data transformation and load on the target system.
ETL cycle can be considerably complex and problems may occur when these
processes are modeled incorrectly. Most often the data from the transactional system are
of low quality, presenting problems as: the data poorly defined, typing errors,
heterogeneity of data sources involved, etc.. To deal with these challenges and
complexity, companies are increasingly investing in ETL tools instead of creating their
processes from scratch. When using supporting tools, the chances of success increase
because they allow self documentation, visualization of data flow, component reuse,
structured and standardized design, better performance, higher productivity and quality.
The project goal is to create a framework able to support the process of
building / running ETL cycle delivering the benefits mentioned above.
Keywords: extract, transform, Data Warehouse, ETL.

8
SIGLAS
ETL: Extract, Transform, Load
XML: eXtensible Markup Language
IDE: Integrated Development Enviroment
CSV: Comma Separate Value
HTML: HyperText Markup Language
ODS: Operational Data Store
MDM: Master Data Management
XSD: XML Schema Definition

9
Sumário
Sumário .................................................................................................................................................... 9
Capítulo 1: Introdução ................................................................................................................10
1.1. Contextualização ............................................................................................ 10
1.2. Motivação ....................................................................................................... 10
1.3. Objetivo .......................................................................................................... 11
1.4. Metodologia .................................................................................................... 12
1.5. Estrutura do documento .................................................................................. 12
Capítulo 2: Ciclo ETL ...................................................................................................................14
2.1. Introdução ....................................................................................................... 14
1.6. Extract (Extração)........................................................................................... 14
1.7. Transform (Transformação) ........................................................................... 14
1.8. Load (Carga) ................................................................................................... 15
1.9. Exemplo prático – Duas Abordagens ............................................................. 15
Capítulo 3: Extreme DataStream ............................................................................................18
1.10. Introdução ....................................................................................................... 18
1.11. Fluxo de Dados ............................................................................................... 19
1.12. Metadados – Layout ....................................................................................... 22
1.13. Nós de Processamento .................................................................................... 24
1.14. Arestas ............................................................................................................ 27
Capítulo 4: Implementação .......................................................................................................28
1.15. Visão geral ...................................................................................................... 28
1.16. Padrões de Projeto .......................................................................................... 28
1.17. Diagrama de Classes ....................................................................................... 29
1.18. O problema Produtor-Consumidor ................................................................. 34
1.19. Criando Novos Nós de Processamento ........................................................... 38
Capítulo 5: Exemplo de Uso – Paralelismo ........................................................................40
1.20. Introdução ....................................................................................................... 40
1.21. O Problema ..................................................................................................... 40
1.22. Hardware Utilizado......................................................................................... 40
1.23. Grafos Utilizados ............................................................................................ 41
1.24. Resultados ....................................................................................................... 43
1.25. Conclusões ...................................................................................................... 45
Capítulo 6: Conclusões e Lições Aprendidas ....................................................................47
Referências ...........................................................................................................................................49

10
Capítulo 1:
Introdução
1.1. Contextualização
Falar que a análise de dados é de suma importância para as empresas é um
eufemismo. De fato, nenhum negócio pode sobreviver sem analisar os dados
disponíveis. Podemos mostrar situações como: analisar a aceitação de um suco de frutas
baseando-se em dados de vendas históricos, verificar sazonalidade de vendas de
determinado produto, prever fraudes em cartões de crédito baseando-se no
comportamento passado do cliente, encontrar correlações entre eventos (Ex.: temporada
de furacões e venda de produtos não perecíveis). Todas essas situações são indicativos
suficientes para concluir que a análise de dados está à frente de qualquer negócio.
Assim, esta pode ser definida como o processo de inspecionar, higienizar, transformar e
modelar os dados com o objetivo de retirar informação, conclusões e ajudar no processo
decisório de uma empresa.
1.2. Motivação
Atualmente os dados estão presentes em vários meios digitais como bases de
dados de transações, posts do Facebook, Twitter, redes de sensores, logs de transações,
mensagens de texto, e-mail e etc. Tendo em vista que os dados já estão presentes e na
maioria das vezes digitalizados, o grande desafio se dá na
disponibilização/processamento/armazenamento desse dado para o usuário final, seja
ele outro sistema ou um indivíduo. Essa informação apresenta três tipos de
caraterísticas: possuem grandes volumes, da ordem de bilhões de registros, possuem
velocidades diferentes (eventos ocorrendo em diferentes janelas de tempo, como taxa de
amostragem de um sensor, compras em sites da internet e posts de redes sociais.) e
possuem com grande variedade de fontes de dados. Esses “3Vs” (volume, variedade e
velocidade) descrevem, segundo Gartner, que é a consultoria líder em pesquisa de
tecnologia da informação no mundo, o conceito de Big Data.

11
1.3. Objetivo
Dado o cenário anteriormente explicitado, temos a convicção que a análise de
dados pode ser uma área bem complexa. Ela possui diversas facetas, técnicas, apoiados
por diversos nomes, em diferentes negócios. A mineração de dados pode ser entendida
como a técnica que foca na modelagem e descoberta de conhecimento para realizar
predições. A parte de Inteligência de Negócios cobre a análise de dados utilizando
informações do negócio, utilizando consultas agregadas e respondendo a perguntas
descritivas do tipo On-line Analytical Processing (OLAP). Por exemplo, quantas
escovas de dente foram vendidas entre abril e maio no estado do RJ. A análise preditiva
foca na aplicação de modelos para realizar previsões . Por exemplo, baseado em um
histórico de transações bancárias, qual a probabilidade de uma determinada transação
ser fraudulenta ou não.
Todas as análises acima citadas partem do pressuposto de que já foi realizado
um prévio tratamento nos dados. Que estes já foram higienizados, estruturados,
padronizados e transformados. A esse ciclo damos o nome de Extract, Transform and
Load (ETL).
O ciclo de ETL envolve a extração dos dados de diversas fontes, a
transformação do dado (padronização, higienização, junção de diversas fontes, etc) e a
carga no sistema alvo, normalmente um banco de dados. O ciclo de ETL pode envolver
uma considerável complexidade, e grandes problemas operacionais podem ocorrer caso
seja mal modelado. Por ser um processo de natureza complexa, o ciclo ETL é
normalmente apoiado por ferramentas de mercado. Essas ferramentas trazem algumas
vantagens em relação ao processo normal, onde o desenvolvedor cria aplicações para
realizar a extração/transformação/carga dos dados. São elas: auto documentação
(permitem a visualização do fluxo de dados graficamente), reutilização de componentes,
design estruturado e padronizado, melhor desempenho (paralelismo) e consequente
aumento de produtividade e qualidade do processo.
Assim, o objetivo deste projeto é criar um framework capaz de apoiar o processo
de construção/execução de um ciclo ETL oferecendo os benefícios anteriormente
citados. Esse framework possibilitará a paralelização de processos e utilizará a técnica
de pipeline para prover ganhos de desempenho sobre a metodologia tradicional.

12
1.4. Metodologia
Para o desenvolvimento do nosso projeto adotamos o modelo de
desenvolvimento de software sequencial, conhecido como modelo em cascata.
Escolhemos esse modelo, pois partimos de requisitos e fases bem definidas, pois já
existem ferramentas parecidas como a que vamos construir. Assim nosso projeto ficou
constituído em cinco fases: Levantamento de requisitos, Projeto do Sistema,
Construção, Integração. Durante a construção realizamos testes unitários e de integração
em componentes críticos do sistema. Ao final, foram realizamos testes de validação para
verificar aderência com os requisitos.
Como se trata de um framework que deve ser extensível, tentamos criar nossas
classes bem desacopladas e com alto grau de coesão. Para isso, fizemos usos de alguns
padrões de projeto como: Fábrica Abstrata (Abstract Factory) e Singleton.
Por ser extensível, considerá-lo-emos como um framework caixa-cinza, ou seja,
já possui componentes e funcionalidades prontas, porém é permitido a partir da
extensão e inserção de novas classes, a criação de novos componentes e
funcionalidades. Mostraremos como estendê-lo na seção “Criando Novos Nós de
Processamento”
Utilizamos a linguagem Object Pascal, que é uma extensão da linguagem Pascal
com suporte a Orientação a Objeto, para o desenvolvimento do nosso framework. A
IDE utilizada foi a Borland Delphi Enterprise 7.
1.5. Estrutura do documento
Esse projeto de final de graduação está dividido em seis capítulos:
- Introdução: começamos o capítulo contextualizando e mostrando ao leitor em que área
da Engenharia de Computação estamos abordando. Em seguida, descreveremos qual a
motivação do projeto e os objetivos que queremos alcançar. Descreveremos as
ferramentas e o modelo de ciclo de vida que iremos utilizar.
- Ciclo ETL: nesse capítulo situaremos o leito no que se refere a um ciclo ETL.

13
Descreveremos cada uma das etapas do ciclo (Extração/Transformação/Carga) e
daremos alguns exemplos. Ao final mostraremos duas abordagens de criação de um
ciclo ETL e listaremos suas vantagens e desvantagens.
- Extreme DataStream: descreveremos para o leitor o principal componente do
framework. Definiremos alguns conceitos pertinentes as projeto como fluxo de dados,
metadados, nós de processamento e arestas. Mostraremos como definir esses conceitos
em nossa abstração de grafo utilizando uma estrutura XML.
- Implementação: mostraremos nesse capítulo artefatos como diagramas de classe,
diagrama de sequência. No nível de código fonte mostraremos quais padrões de projeto
utilizamos. Definiremos o problema de produtor-consumidor e como ele se adequa em
nossa necessidade. Por fim, mostraremos como é possível estender o framework para a
criação de novos nós de processamento.
- Exemplo de Uso – Paralelismo: partiremos para um caso de uso onde mostraremos a
capacidade de paralelizar um determinado ciclo ETL, descreveremos o problema e o
hardware utilizado. Mostraremos quatro versões de grafos e analisaremos a execução
dos mesmo, mostrando os resultado e as conclusões.
- Conclusões e Lições Aprendidas: nesse capítulo faremos um apanhado geral sobre o
projeto. O que aprendemos, quais pontos altos e baixos, erros e acertos durante o projeto
e das ferramentas escolhidas.

14
Capítulo 2:
Ciclo ETL
2.1. Introdução
Um ciclo de ETL (Extract, Transform e Load), refere-se a um processo no
domínio de banco de dados muito utilizado para realizar carga em sistemas de Data
Warehouse, Operational Data Store (ODS) e Datamarts. Também é vastamente
utilizado na área de integração de dados, migração de dados e Master Data
Management (MDM). Este ciclo envolve três etapas distintas: extração, transformação e
carga.
1.6. Extract (Extração)
A primeira parte de um ciclo ETL envolve extrair dados de sistemas fontes.
Esses sistemas podem ser bem heterogêneas, com dados em diversos formatos, e devem
ser consolidados para realizar a carga no Data Warehouse. Alguns formatos comuns de
dados incluem: banco de dados relacionais e arquivos planos, como arquivo CSV,
XML, HTML e etc.
Outra maneira de realizar o processo de ETL é a utilizando dados online, ou
seja, conforme os dados vão chegando através de um fluxo de dados, são tratados,
transformados e carregados no sistema alvo.
Uma etapa intrínseca à extração se refere a tratar somente dados em formatos
esperados e descartar dados de fontes desconhecidos. Ou seja, os dados advindos dos
sistemas fonte devem estar em um padrão ou estrutura previamente conhecidos.
1.7. Transform (Transformação)
Nessa fase é aplicadas uma série de regras e funções sobre os dados vindos da
etapa de extração para transformá-los em entradas para o processo de carga. Alguns
processos desta fase são:
1. Ordenação de um arquivo por uma determinada chave.
2. Selecionar somente algumas informações. Por exemplo, se o arquivo fonte tiver três
tipos de informações (nome, idade e nacionalidade) e queremos utilizar somente nome e

15
idade.
3. Padronização: como os arquivos podem vir de diversas fontes, podemos ter atributos
que representam a mesma informação, mas com dados diferentes. Exemplo: Em um
arquivo podemos ter masculino igual à “1” e feminino igual “2” e em outro Masculino
igual a “M” e Feminino igual a “F”.
4. Derivação de um novo cálculo. Por exemplo, valor_venda =
quantidade*preco_unitario.
5. Junção de múltiplas fontes de dados por chaves de junção. Podemos também efetuar
duplicação de registros.
Podemos agregar registros para formar um dado estatístico. Por exemplo, sumarizar
múltiplas linhas de um arquivo de transações para ter o total de vendas por loja, total de
vendas por região, etc.
6. Transpor o arquivo original, isto é, linhas viram colunas e colunas viram linhas.
7. Dividir um arquivo CSV em arquivos separados, um para cada coluna
8. Validar e buscar dados em tabelas ou arquivos de referência.
9. Aplicar qualquer tipo de validação simples ou complexa no dado. Por exemplo,
validar se um determinado campo apresenta uma data válida. Caso haja alguma exceção
poderá haver rejeição parcial ou completa.
1.8. Load (Carga)
A fase de carga é o momento em que os dados advindos da etapa anterior são
carregados no sistema alvo, que normalmente é um Data Warehouse. Essas cargas, em
sua maioria, são realizadas periodicamente (diariamente, semanalmente ou
mensalmente). Isso ocorre, porque o DW é usualmente utilizado para guardar
informações históricas. Conforme os dados são carregados no sistema, o banco de dados
é responsável por tratar as condições de integridade dos dados que estão sendo
inseridos, como por exemplo, realizar uma validação de data, disparar uma trigger para
atualizar outra tabela, tratar a unicidade de um dado.
1.9. Exemplo prático – Duas Abordagens
O ciclo de ETL pode envolver uma grande complexidade e problemas podem
ocorrer caso este seja mal modelado. Descreveremos sucintamente um exemplo de ciclo
ETL e mostraremos duas abordagens para sua construção. Em seguida, mostraremos

16
suas vantagens e desvantagens.
Figura 1 - Representação de um ciclo ETL, utilizando um grafo.
Acima apresentamos um ciclo ETL, descrito como um grafo.
Clientes.txt e Itens.txt: arquivos de entrada do ciclo ETL.
Leitor de arquivos: realizar leitura dos arquivos de entrada.
Consulta Receita: processo responsável por realizar uma consulta à Receita
Federal, utilizando CPF como chave e trazendo o nome da pessoa.
Cálculo da Nota Fiscal: A partir dos itens, o processo calcula a nota fiscal.
Ordenação: realiza a ordenação dos arquivos, um pela chave fkCliente e outra
pela chave pkCliente.
Junção: realiza a junção dos arquivos vindos das arestas nove e onze, utilizando
as chaves fkCliente e pkCliente.
Escritor de Arquivos: realizar a escrita do arquivo final em disco.
Arquivo de Saída: arquivo final do processo.
Abordagem Monolítica:
Nessa abordagem todo o ciclo ETL é criado a partir do zero, e todas as
transformações dos dados são realizadas através um único programa, seja ele um
executável ou um script. Imagine o ciclo completo ETL descrito acima sendo executado
apenas por uma aplicação. Teríamos um total acoplamento, uma baixa coesão e sem
possibilidade de reutilização dos componentes (dependendo da modelagem essa
reutilização pode ser dá em nível de código fonte apenas). Toda manutenção/evolução
seria feita em apenas um componente, o que acarretaria possíveis novos erros de difícil
rastreabilidade.

17
Abordagem um módulo por nó de processamento:
Nessa abordagem temos um executável/script por nó de processamento, onde um
nó X possui como entrada o arquivo A1 e uma saída A2. A saída do nó X será a entrada
para o nó Y. Assim o ciclo segue, onde a saída de um nó de processamento é entrada
para outro. Nessa abordagem, todos os nós de processamento devem possuir uma
maneira de ler/escrever no disco já que esta é à maneira de comunicação entre eles.
Para a descrição das vantagens e desvantagens entre as duas abordagens
chamaremos a monolítica, de abordagem A, e a outra de abordagem B. Na abordagem
A temos a vantagem em relação a B de realizarmos menos E/S no disco. Isso acarreta
um ganho de desempenho por não utilizar um dos recursos mais lentos do computador,
que é o acesso ao disco físico. Em contrapartida, na abordagem B podemos paralelizar o
ciclo ETL, ou seja, utilizar melhor os recursos de CPU em detrimento do E/S. Em um
ciclo ETL do tipo CPU bound, onde o maior tempo é gasto utilizando a CPU, o ciclo B
tende a possuir um melhor desempenho em relação ao A, pois realiza um melhor uso
dos recursos conseguindo paralelizar as tarefas. No exemplo acima, utilizando a
abordagem B, poderíamos executar os nós de processamento “Leitor de Arquivos”,
“Cálculo da Nota Fiscal” e “Ordenação por fkCliente” concorrentemente com “Leitor
de Arquivos”, “Consulta a Receita”, “Valida Node” e “Ordenação por pkCliente”.
Na abordagem A temos baixíssima reutilização apenas em nível de código fonte.
Na abordagem B, os nós de processamento são módulos separados e podemos
intercambiá-los para criar novos ciclos ETL.
Apresentaremos nas próximas seções nossa abordagem para a criação do ciclo
ETL, e tentaremos unir o melhor das duas abordagens anteriormente citadas, ou seja, um
ganho de produtividade por reutilização de nós de processamento sem perda de
desempenho.

18
Capítulo 3:
Extreme DataStream
1.10. Introdução
Ferramentas de ETL são construídas para poupar esforço (tempo e dinheiro)
eliminando, quase em sua totalidade, a escrita de código. Dentre algumas vantagens
podemos citar: auto documentação (permitem a visualização do fluxo de dados
graficamente), reutilização de componentes, design estruturado e padronizado, melhor
desempenho (paralelismo).
Nessas ferramentas podemos modelar o ciclo ETL utilizando a abstração de um
grafo, onde as arestas representam os dados fluindo de um processo para o outro, e os
vértices representam os nós de processamento. Podemos utilizar como exemplo a figura
já citada na seção anterior.
O objetivo do framework Extreme DataStream é permitir a execução de um
fluxo ETL, além de prover uma biblioteca onde novos nós podem ser incorporados ao
sistema de maneira simples. Não será desenvolvido nenhum tipo de interface gráfica
para a criação do fluxo ETL. Utilizaremos um arquivo XML para a descrição do fluxo
em si. Quando falarmos de nós, vértices ou blocos, estaremos nos referindo a nós de
processamento, ou seja, estruturas que realizam efetivamente o processo dos dados.
Quanto falarmos em arestas, estaremos no referindo ao o fluxo de dados flui através dos
nós de processamento, como os nós de processamento são interligados.
Conforme visto, nas duas abordagens anteriores, temos vantagens e
desvantagens. Abaixo citamos as resumidamente:
Abordagem Monolítica (Abordagem A)
- Vantagens: Menor quantidade de E/S no disco rígido em relação à abordagem
B, acarretando melhor desempenho.
- Desvantagens: Baixa reutilização, apenas em nível de código fonte.
Abordagem um módulo por nó de processamento (Abordagem B)
- Vantagens: Alta reutilização em nível de componentes. Possibilidade de
paralelizar o processo.
- Desvantagens: Baixo desempenho, pois os nós se comunicam através de

19
arquivos, ou seja, o arquivo gerado por um nó é entrada para o próximo nó.
Em nosso framework, tentaremos unir o melhor das duas abordagens, ou seja,
um alto desempenho com possibilidade de paralelismo, sem a necessidade de criação de
arquivos intermediários entre os processos e reutilização em nível de componentes.
Para não haver necessidade da criação de arquivos intermediários, utilizaremos a
memória RAM da máquina, ou seja, cada nó de processamento será uma unidade
autônoma provendo/consumindo dados de um buffer. Em alguns nós poderá haver a
necessidade de criação de arquivos temporários, como por exemplo, uma ordenação de
um arquivo que não cabe fisicamente na memória. Fica claramente evidenciado que
temos um problema clássico de produtor-consumidor, que será abordado nas próximas
seções. Resolvendo esse problema, estaremos retirando a única desvantagem da
abordagem B, e permanecendo com todas as suas vantagens. Claro que, neste momento,
não estamos levando em consideração o tempo gasto na sincronização entre os
processos/threads.
O desenvolvedor do ciclo ETL deverá descrever seu grafo utilizando um arquivo
XML, em um formato específico, que será descrito na próxima seção. Não é intuito
desse Projeto de Graduação, criar uma ferramenta de apoio para a criação desse grafo.
1.11. Fluxo de Dados
Para descrever nosso grafo do ciclo ETL utilizaremos um documento em
formato XML. Para garantirmos que esse documento esteja corretamente formatado, a
ferramenta utilizará um XML Schema.
Um arquivo que contenha as definições da linguagem XML Schema é chamado
de XML Schema Definition (XSD), o qual descreve a estrutura de um documento XML.
Essa linguagem foi amplamente utilizada no desenvolvimento da nota fiscal eletrônica
brasileira. Abaixo demonstramos o conteúdo do XSD. Explicaremos em detalhes cada
uma das seções desse documento nas próximas seções.
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified" attributeFormDefault="unqualified">
<xs:element name="etlManager"
type="ETL_MANAGER_TYPE"></xs:element>

20
<xs:complexType name="ETL_MANAGER_TYPE">
<xs:sequence>
<xs:element name="metadatas" type="METADATA_LIST"/>
<xs:element name="phases" type="PHASE_LIST"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="METADATA_LIST">
<xs:sequence>
<xs:element name="metadata" type="METADATA_TYPE"
minOccurs="1" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="METADATA_TYPE">
<xs:sequence>
<xs:element name="field" type="FIELD_TYPE" minOccurs="1"
maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:string" use="required"/>
<xs:attribute name="memory" type="xs:integer" use="required"/>
</xs:complexType>
<xs:complexType name="FIELD_TYPE">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="type" type="FIELD_ENUM" use="required"/>
<xs:attribute name="size" type="xs:integer"
use="required"/>
<xs:attribute name="initialPos" type="xs:integer"
use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:simpleType name="FIELD_ENUM">
<xs:restriction base="xs:string">
<xs:enumeration value="string"/>
<xs:enumeration value="integer"/>
<xs:enumeration value="byte"/>
<xs:enumeration value="longInt"/>

21
</xs:restriction>
</xs:simpleType>
<xs:complexType name="PHASE_LIST">
<xs:sequence>
<xs:element name="phase" type="PHASE_TYPE" minOccurs="1"
maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="PHASE_TYPE">
<xs:sequence>
<xs:element name="edges" type="EDGE_LIST"/>
<xs:element name="processes" type="PROCESS_LIST"/>
</xs:sequence>
<xs:attribute name="id" type="xs:integer" use="required"/>
</xs:complexType>
<xs:complexType name="EDGE_LIST">
<xs:sequence>
<xs:element name="edge" type="EDGE_TYPE" minOccurs="1"
maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="PROCESS_LIST">
<xs:sequence>
<xs:element name="process" type="PROCESS_TYPE" minOccurs="1"
maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="PROCESS_TYPE">
<xs:sequence>
<xs:any maxOccurs="unbounded" processContents="skip"/>
</xs:sequence>
<xs:attribute name="id" type="xs:string" use="required"/>
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="EDGE_TYPE">

22
<xs:attribute name="fromProcess" type="xs:string"
use="required"/>
<xs:attribute name="fromPort" type="xs:integer"
use="required"/>
<xs:attribute name="toProcess" type="xs:string"
use="required"/>
<xs:attribute name="toPort" type="xs:integer" use="required"/>
<xs:attribute name="metadata" type="xs:string"
use="required"/>
</xs:complexType>
</xs:schema>
1.12. Metadados – Layout
Metadados são dados sobre outros dados. No nosso contexto, os metadados farão
a descrição dos dados que trafegam entre as arestas do nosso ciclo ETL. Esses
metadados serão sempre formatados como registros de tamanho fixo.
Em um registro de tamanho fixo, um campo sempre começa e termina no
mesmo lugar em todos os registros. Por exemplo:
Pedro da Silveira Magalhaes 01000022421030RJ
Jose Carlos da Silva 00900033920103SP
Renata Souza 00080010103242MG
Luis Felipe 00150000123242BA
O conjunto de dados acima representa um arquivo onde seus registros possuem
tamanho fixo.
Nome – Posição Inicial = 1 – Posição Final = 30
Renda – Posição Inicial = 30 – Posição Final= 36
CEP – Posição Inicial = 36 – Posição Final = 44
UF – Posição Inicial = 44 – Posição Final = 46
Para o caso citado acima, o registro possui um tamanho de 46 bytes. Não são
necessários delimitadores, pois todos os campos possuem tamanho fixo.
Abaixo, descrevemos o XSD para a sessão de declaração de metadados:
<xs:complexType name="METADATA_TYPE">
<xs:sequence>

23
<xs:element name="field" type="FIELD_TYPE" minOccurs="1"
maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:string" use="required"/>
<xs:attribute name="memory" type="xs:integer" use="required"/>
</xs:complexType>
<xs:complexType name="FIELD_TYPE">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="type" type="FIELD_ENUM" use="required"/>
<xs:attribute name="size" type="xs:integer" use="required"/>
<xs:attribute name="initialPos" type="xs:integer"
use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:simpleType name="FIELD_ENUM">
<xs:restriction base="xs:string">
<xs:enumeration value="string"/>
<xs:enumeration value="integer"/>
<xs:enumeration value="byte"/>
<xs:enumeration value="longInt"/>
</xs:restriction>
</xs:simpleType>
Na seção “metadata” devemos definir um ID único para nosso metadado.
Quando um dado flui de um nó para outro, esta informação deverá ser armazenada na
aresta que interliga esses dois nós. O dado permanece na aresta, alocado na memória
RAM do computador, e o tamanho do buffer de alocação é configurado através da tag
“memory”. Em outros termos, a tag “memory” define o tamanho máximo da fila no
problema produtor-consumidor. Destacamos uma seção apenas para descrever o
processo de produtor-consumidor.
Na seção “field” descrevemos informações sobre o campo do registro de

24
tamanho fixo. Para isso temos os seguintes atributos:
- type: representa um tipo enumerado que define o tipo de dado no campo. Pode ser
string, integer, byte ou um longInt. Apesar de termos listados todos esses tipos de
campos, somente está implementado na solução o campo do tipo string.
- initialPos: define onde o campo começa dentro do registro de tamanho fixo.
- size: define o tamanho do campo.
Destacamos abaixo um exemplo de um metadado definido:
<metadata id="Metadata0" memory="40000">
<field type="string" size="2" initialPos="0">VALOR</field>
<field type="string" size="2" initialPos="2">CRLF</field>
</metadata>
1.13. Nós de Processamento
São as estruturas que efetivamente realizam o trabalho sobre os dados. O intuito
do projeto não é prover os mais variados tipos de transformações sobre os dados, e sim
uma maneira simples para o desenvolvedor criar os seus próprios nós de processamento.
A criação de nós bem coesos e flexíveis garante ao desenvolvedor do fluxo de ETL uma
maior reutilização dos blocos já criados. Alguns exemplos de nós de processamento são:
- nó capaz de realizar a ordenação de um arquivo a partir de uma chave.
- nó capaz de retirar a duplicidade de registros, utilizando a escolha de uma
chave única.
- nó capaz de realizar a junção de dois fluxos de dados utilizando uma chave de
junção.
- nó capaz de filtrar os registros de um fluxo de dados utilizando uma expressão
lógica / matemática.
Os nós de processamento possuem como entrada fluxos de dados. Esses fluxos
de dados pode se originar de qualquer recurso do sistema, seja um disco físico, a própria
memória RAM ou uma interface de rede, bastando para isso criar nós específicos.
Abaixo descrevemos o XSD somente da seção de criação de nós de
processamento.
<xs:complexType name="PROCESS_LIST">
<xs:sequence>
<xs:element name="process" type="PROCESS_TYPE" minOccurs="1"

25
maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="PROCESS_TYPE">
<xs:sequence>
<xs:any maxOccurs="unbounded" processContents="skip"/>
</xs:sequence>
<xs:attribute name="id" type="xs:string" use="required"/>
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:complexType>
Na seção “process” definimos um nó de processamento que fará parte do nosso ciclo
ETL. Esses nós devem conter sempre o atributo “id” e o atributo “type”. O “id” define
unicamente um processo dentro do ciclo, enquanto o “type” define o tipo do processo.
Para executar nossos exemplos criamos apenas três tipos de processos, que são eles
FileReader, FileWriter e Factorial.
- FileReader
Nó responsável pela leitura de um arquivo texto de tamanho fixo.
Exemplo:
<process id="FileReader0" type="FileReader">
<recordSize>4</recordSize>
<filePath>D:\Projetos\Factorial.txt</filePath>
</process>
O tamanho do registro do arquivo é indicado pela tag “recordSize”. O caminho do
arquivo é indicado pela tag “filePath”. Esse leitor possui a capacidade de ler partes
segmentadas do arquivo de entrada, dependendo da quantidade de arestas de saída
ligadas a ele. Considere o trecho de ciclo ETL abaixo, onde o “FileReader” aparece
lendo como entrada o arquivo “Numeros.txt” e ligado a três processos que são
responsáveis por realizar um cálculo de score.

26
Figura 2 - Exemplo de Utilização do FileReader para realizar paralelismo
Assim o nó “FileReader” se comportará da seguinte maneira: ele entregará
blocos de registros aos nós conectados a ele, utilizando uma política de round-robin.
Dessa maneira, conseguiremos paralelizar o cálculo do score, onde cada um dos nós
“CalculaScore” executará sua tarefa em um processador. Mais a frente mostraremos um
exemplo prático e os resultados obtidos com esse paralelismo.
- FileWritter
Nó responsável pela escrita dos dados em disco. Análogo ao “FileReader”, esse escritor
de arquivos possui a capacidade de receber N fluxos de dados, ou seja, podemos
conectar quantas arestas quisermos em um nó do tipo “FileWriter”. Cada uma dessas
arestas será conectada a uma porta diferente. Assim o “FileWriter” lerá cada fluxo de
dados utilizando um política de round-roubin e escrevendo o resultado em arquivo
físico, diretamente no disco rígido.
Exemplo:
<process id="FileWriter0" type="FileWriter">
<filePath>D:\Factorial_out.txt</filePath>
</process>
O caminho do arquivo de saída, o qual será efetivamente gravado em disco, é indicado
pela tag “filePath”.
- Factorial
Nó responsável pelo cálculo do fatorial de um número. Esse nó, por ser muito
específico, provavelmente não apresenta nenhuma utilização prática. Ele foi apenas
criado para demostrar a capacidade da ferramenta de realizar tarefas em paralelo.
Exemplo:

27
<process id="Factorial1" type="Factorial">
<factorialField>VALOR</factorialField>
</process>
A tag “factorialField” indica qual campo deverá ser calculado o fatorial.
1.14. Arestas
Quando ligamos um nó de processamento a outro, criamos uma aresta. Os dados
que trafegam de um nó pra outro ficam temporariamente armazenados na aresta, em um
buffer na memória RAM da máquina.
Abaixo descrevemos o XSD somente da seção de criação de nós de
processamento.
<xs:complexType name="EDGE_TYPE">
<xs:atribute name="fromProcess" type="xs:string"
use="required"/>
<xs:attribute name="fromPort" type="xs:integer"
use="required"/>
<xs:attribute name="toProcess" type="xs:string"
use="required"/>
<xs:attribute name="toPort" type="xs:integer" use="required"/>
<xs:attribute name="metadata" type="xs:string"
use="required"/>
</xs:complexType>
A tag “fromProcess” e “fromPort” indica de qual nó/porta parte a aresta. A tag
“toProcess” e “toPort” indica em qual nó/porta a aresta chega. Assim para definir uma
aresta, ou seja, de onde ela parte até onde ela chega, devemos defini-la com duas tuplas:
(fromProcess, fromPort) e (toProcess e toPort). A tag “metadata” indica o formato dos
dados que trafegam na aresta.
Abaixo segue um exemplo de definição de duas arestas.
<edges>
<edge fromProcess="FileReader0" fromPort="0"
toProcess="Factorial1" toPort="0" metadata="Metadata0"/>
<edge fromProcess="Factorial1" fromPort="0"
toProcess="FileWriter0" toPort="0" metadata="Metadata1"/>
</edges>

28
Capítulo 4:
Implementação
1.15. Visão geral
Para modelar nosso framework partimos dos conceitos chaves como: porta,
processo, aresta e fases. Modelamos seus relacionamos através de um modelo
conceitual que em seguida deu entrada no nosso diagrama de classes. Utilizamos o
diagrama de sequência apenas para descrever o problema de Produtor-Consumidor.
Utilizando o diagrama de classes, fica claro como deve ser feita a extensão do
código para a criação de novos componentes. Na seção “Criando Novos Nós de
Processamento” será mostrado como estender o framework para a criação de novos
componentes.
1.16. Padrões de Projeto
Descreve uma solução geral que pode ser utilizada para um problema recorrente
no desenvolvimento de software orientado a objetos. Assim os padrões de projeto
definem relações e interações entre as classes/objetos em um nível de abstração mais
alto.
Os padrões de projeto têm como objetivo facilitar as reutilizações de soluções e
estabelecer um vocabulário comum facilitando documentação e o entendimento do
código gerado.
Em nossa implementação utilizamos dois padrões de projeto:
* Factory (Fábrica)
Objetivo
- Criar um objeto sem expor a lógica de instanciação ao cliente
- Criação de um novo objeto através de uma interface comum
Utilização
- Cliente necessita de um produto, mas ao invés de criá-lo diretamente, ele pede
à fábrica por um novo produto, provendo a informação sobre o tipo de objeto
que ele precisa.

29
- A fábrica instancia um novo produto concreto e retorna ao cliente o objeto
recentemente criado.
- O cliente utiliza o objeto como um produto abstrato sem se preocupar com sua
implementação concreta.
Vantagem
- Conseguir adicionar um novo produto sem alterar a interface de criação,
alterando apenas a fábrica. Existem certas implementações de fábrica que
permite a inclusão de novos tipos concretos sem alterar a fábrica.
* Singleton
Às vezes é importante termos apenas uma instância da classe. Usualmente
singletons são utilizadas para centralizar o gerenciamento de recursos internos ou
externos provendo um ponto global de acesso.
Objetivo
- Garantir que apenas uma instância da classe será criada
- Prover um ponto de acesso global ao objeto
Figura 3 - Modelo de classes do padrão Singleton
Utilização
O padrão Singleton define a operação getInstance, a qual expõe uma única
instância a ser acessada pelos clientes. O método getInstance é responsável por
criar uma única instância da classe caso ela ainda não tenha sido criado e
retorná-la.
1.17. Diagrama de Classes

30
Figura 4 - Diagrama de Classes (Visão de Processos)
A classe TProcessFactory, juntamente com a classe abstrata TProcess,
representa a implementação do padrão de projeto Fábrica. Esta Fábrica
(TProcessFactory) é responsável pela criação dos nós de processamento do sistema.
Cada nó de processamento é executado em threads separadas, por isso a classe TProcess
é filha da classe Thread. Para criação de um novo nó devemos passar a sua descrição
representada pela classe TProcessDescription.
Cada processo possui uma lista de portas de saídas e entradas, representadas
respectivamente, pelas classes TInputCollection e TOutputCollection. Estas duas classes
utilizam outra Fábrica (TPortFactory) que é responsável pela criação da porta de
comunicação.

31
Figura 5 - Diagrama de Classes (Visão Comunicação entre Processos)
A classe TPortFactory juntamente com a classe TPortDescription implementa
novamente o padrão Fábrica. Essa fábrica é responsável pela criação tanto de portas de
saída (classe abstrata TOutput) como portas de entrada (classe abstrata TInput).

32
As classes TFixedRecordOutput e TFixedRecordInput representam as portas de
saída e entrada respectivamente, que tratam os registros de tamanho fixo. Essas duas
classes utilizam a classe TDataPacket (sua dependência se dá pela classe TPort que é
pai das classes TInput e TOutput e possuí um atributo do tipo TDataPacket) que abstrai
um ResultSet (um conjunto de registros). Esta classe é onde os dados são armazenados
para posterior escrita deles no buffer de transferência.
Figura 6 - Diagrama de Classes (Visão Comunicação entre Processos - Classes Abstratas)
A classe TEdge abstrai a aresta que liga duas portas de nós de processamento.
Nessa classe se encontra o buffer responsável pelo armazenamento do TDataPacket.
O método Write da classe TOutput escreve dados para a classe TDataPacket. Assim que
o buffer do TDatapacket está cheio, ele é escrito no TBuffer, utilizando o método Write.
A parte de leitura é análoga. Na seção Diagrama de Sequência descreveremos essa
interação.

33
Figura 7 - Diagrama de Classes (Visão Metadados)
A estrutura de classes acima é responsável pela leitura do XML que define o
grafo. Temos como classe raiz, a classe TETLGraphXML que é implementada
utilizando o padrão de projeto Singleton. Tomamos essa decisão por precisar de um
ponto único de acesso à abstração do grafo.

34
Figura 8 - Diagrama de Classes (Visão Controlador do Grafo)
A classe TGraphManager é interface para gerenciamento da execução do grafo. Ao
criarmos a TPhase, criaremos todos os processes dessa fase. Para isso, utilizei
novamente o padrão de projeto fábrica, representado pelas classes TProcessFactory e
TProcess. A classe TPhase possui o método Launch(), que quando chamado executa a
fase do grafo. Cada processo e fase é executado em threads separada. Além destas
threads, temos a classe TWacthDogThread que verifica de tempos em tempos o estado
de execução dos processos.
1.18. O problema Produtor-Consumidor
O problema de produtor-consumidor é um exemplo clássico de sincronização.
Ele estabelece os processos concorrentes que compartilham uma área de escrita/leitura.

35
O produtor é responsável por gerar os dados que serão disponibilizados na área de
leitura/escrita. Concorrentemente, o consumidor estará lendo e removendo os dados
dessa área. O problema é ter certeza que o produtor não tentará adicionar dados na área
de leitura/escrita quando estiver cheia ,e que o consumidor não tentará remover dados
quando a área estiver vazia.
Assim, quando temos a área de escrita/leitura cheia o produtor deve esperar até
que haja espaço. O mesmo ocorre para o consumidor que deve esperar até que exista
alguma informação na área para ser consumida. Assim que o produtor coloca dados na
área de leitura/escrita ele avisa o consumidor, para ele iniciar o processamento. Quando
o consumidor retira dados da área ele avisa ao produtor. Essa solução é atingida através
de uma comunicação entre processos, que pode ser implementada utilizando recursos do
sistema operacional como semáforos e mutexes.
Abaixo mostramos uma solução retirada do Wikipédia, que é a mesma que
utilizaremos ao abordar o problema em nosso projeto. Ela utiliza o recurso de semáforos
para realizar a sincronização entre processos.
semaphore fillCount = 0; // itens produzidos
semaphore emptyCount = BUFFER_SIZE; // espaço remanescente
procedure producer() {
while (true) {
item = produceItem();
down(emptyCount);
putItemIntoBuffer(item);
up(fillCount);
}
}
procedure consumer() {
while (true) {
down(fillCount);
item = removeItemFromBuffer();
up(emptyCount);
consumeItem(item);
}
}
No contexto de nossa aplicação nos deparamos com o problema de produtor

36
consumidor no momento de trafegar os dados entres os nós de processamento. Para
ilustramos o problema do produtor-consumidor no contexto de nossa aplicação
utilizamos o diagrama de sequências abaixo:
Figura 9 - Diagrama de sequência mostrando o problema do Produtor-Consumidor
A classe TOutput é responsável pela escrita dos dados, utilizando a chamada ao
método Write da classe TEdge. A classe TEdge escreve no buffer, realizando a tratativa
do problema produtor-consumidor. Ela verifica se possui espaço no buffer pelo o
semáforo EmptyCount. Caso haja espaço, ela realiza a escrita e notifica o outro
semáforo FillCount que os dados podem ser consumidos. Caso não haja ela “dorme” e
espera o outro processo acordá-la.

37
A classe TInput é responsável pela leitura dos dados, utilizando a chamada ao
método Read da classe TEdge. Ela verifica se possui algum dados no buffer, verificando
o semáforo FillCount. Caso haja dados para serem consumidos, ela realiza a leitura do
dado. Caso não haja, ela “dorme” e espera o outro processo acordá-la.
Abaixo colocamos dois trechos de código, um do método Write e outro do
método Read da classe TEdge, em linguagem pascal.
procedure TEdge.Write(Content: PAnsiChar; Size: integer);
begin
//espera ter uma unidade disponivel no semaforo
WaitForSingleObject(EmptyCount, INFINITE);
//move informações para o buffer ponteiro por pt
Move(Size, pt^, SizeOf(Integer));
pt := pt + SizeOf(Integer);
Move(Content^, pt^, Size);
pt := FBuffer;
//incrementa o semaforo com uma unidade
ReleaseSemaphore(FillCount, 1, nil);
end;
function TEdge.Read(var Content: PAnsiChar; var Size: integer):
boolean;
begin
EOF := true;
WaitForSingleObject(FillCount, INFINITE);
//lê o tamanho dos dados do buffer
Move(pt^, Size, SizeOf(Integer));
pt := pt + SizeOf(Integer);
if (Size <> -1) then
begin
Move(pt^, FContent^, Size);
Content := FContent;
EOF := false;
end;
//reseta ponteiro
pt := FBuffer;
ReleaseSemaphore(EmptyCount, 1, nil);
end;

38
1.19. Criando Novos Nós de Processamento
Um dos objetivos do framework é a possibilidade de estendê-lo e criar novos
componentes (novos nós de processamento). Para isso montamos nossa estrutura de
classes de modo que esta tarefa fosse bem simples, bastando para isso realizar a
extensão de classes do framework.
Para a criação de novos nós de processamento devemos estender a classe
TProcess e inserir um novo tipo de nó na fábrica TProcessFactory. As informações
sobre o nó, ou seja, os metadados do nó estão disponíveis através da propriedade
FXMLNode herdada da classe TProcess. Para acessar as portas de entrada e saída
utilizamos as propriedades FInputCollection do tipo TInputCollection e
FOutputCollection do tipo TOutputCollection, que são herdadas da classe TProcess.
Abaixo colocamos trechos de código mostrando a inclusão do nó Fatorial
type
TFactorial = class(TProcess)
....
public
procedure Run(); override;
procedure TFactorial.Run;
...
begin
while (InputPort.Read(Value)) do //le dados da porta de entrada
begin
move(Value^, FNumberStr[1], 2); //valor a ser calculado
FactorialStr := IntToStr(GetFatorial(StrToInt(FNumberStr)));
....
OutStr := FOutNumber + #13#10;
OutPutPort.Write(Pansichar(OutStr)); //valor fatorial
end
InputPort.Close(); //fecha porta de entrada
OutPutPort.Close(); //fecha a porta de saída
end;
type
TProcessFactory = class
....

39
class function TProcessFactory.GetProcess(ProcessDesc:
TProcessDescription): TProcess;
begin
...
if (ProcessDesc.ProcessType = 'Factorial') then
begin
Result := TFactorial.Create(ProcessDesc.PhaseID,
ProcessDesc.ProcessID);
Exit;
end;
end;

40
Capítulo 5:
Exemplo de Uso – Paralelismo
1.20. Introdução
O objeto desta seção é demonstrar a utilização do framework para a execução de
um processo ETL. Para demonstrar a capacidade de realizar paralelismo utilizaremos
quatro tipos de grafo. Todos os grafos possuem a mesma saída, porém utilizam níveis
de paralelismo diferentes. Mostraremos o ganho em paralelizar o ciclo ETL através
desses exemplos.
1.21. O Problema
O problema que trataremos é bastante simples e capaz de ser paralelizado. Ele
consiste em calcular o fatorial de uma lista de números. Para aumentar a utilização de
CPU, ao invés de calcular apenas uma vez o fatorial do número, realizaremos esse
procedimento 10 vezes.
- Entrada do problema (lista de números):
Um arquivo texto, com 35.126.784 números inteiros, variando de 1 a 10, separador por
CR+LF. Esse arquivo possui um total de 140.507.136 bytes, ou seja, 35.126.784 * 4
bytes (2 bytes representando os números e mais 2 bytes de CR+LF).
- Saída
Um arquivo texto, com 35.126.784 números inteiros, variando de 1 a 3.628.800,
separados por CF+LF. Esse arquivo possui um total de 316.141.056 bytes, ou seja.
35.126.784 * 9 bytes (7 bytes representando o resultado do fatorial e mais 2 bytes de
CR+LF).
1.22. Hardware Utilizado
O objetivo do exemplo de uso é demonstrar o paralelismo e o ganho de
desempenho no ciclo ETL. Nosso ciclo possui a característica de ser CPU Bound. Dado
isso necessitamos descrever o processador e sua quantidade de núcleos.
O processador utilizado será o Core i3 da família de processadores Intel,
destinado a Desktops x86-64. Ele possui o recurso de Hyper-Threading que lhe
41
possibilita simular a existência de um maior número de núcleos, fazendo com que o seu
desempenho aumente. Mais especificamente este processador possuí dois núcleos de
processamento físico e dois virtuais, ou seja, ele possuí dois núcleos de processamento
físico e simula mais dois.
A tecnologia Hyper-Threading é uma tecnologia usada em processadores que
realizam a simulação de mais dois núcleos. Essa técnica é utilizada para oferecer uma
maior eficiência na utilização de recursos do processador. Segundo a Intel, o uso dessa
tecnologia oferece um aumento de desempenho de até 30%.
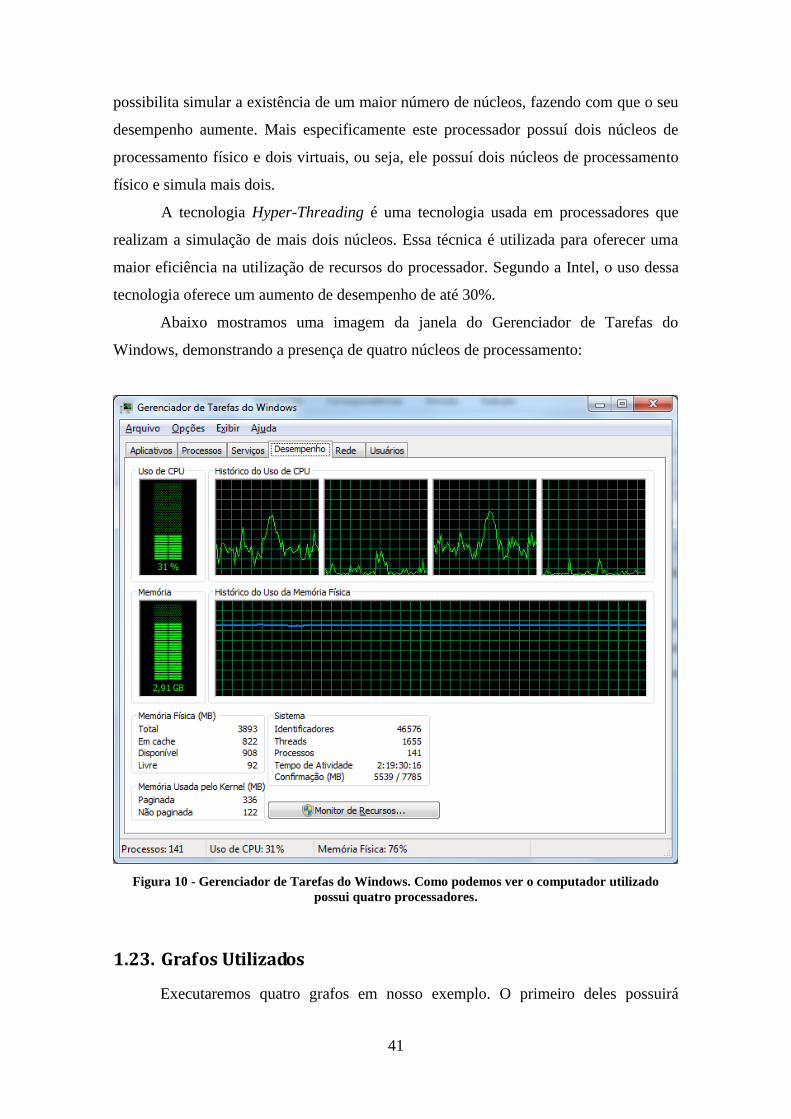
Abaixo mostramos uma imagem da janela do Gerenciador de Tarefas do
Windows, demonstrando a presença de quatro núcleos de processamento:
Figura 10 - Gerenciador de Tarefas do Windows. Como podemos ver o computador utilizado
possui quatro processadores.
1.23. Grafos Utilizados
Executaremos quatro grafos em nosso exemplo. O primeiro deles possuirá

42
apenas um nó de cálculo de fatorial, o segundo dois, e assim sucessivamente. Para
exemplificar o grafo segue abaixo uma figura do grafo com um nó de processamento e
outro com quatro nós de processamento.
Figura 11 - Representação do grafo com apenas um nó de cálculo de fatorial
<edges>
<edge fromProcess="FileReader0" fromPort="0"
toProcess="Factorial1" toPort="0" metadata="Metadata0"/>
<edge fromProcess="Factorial1" fromPort="0"
toProcess="FileWriter0" toPort="0" metadata="Metadata1"/>
</edges>
Acima apresentamos a listagem de arestas do grafo com um nó de
processamento de fatorial.
Figura 12 - Representação do grafo com quatro nós de cálculo de fatorial

43
<edges>
<edge fromProcess="FileReader0" fromPort="0"
toProcess="Factorial1" toPort="0" metadata="Metadata0"/>
<edge fromProcess="FileReader0" fromPort="1"
toProcess="Factorial2" toPort="0" metadata="Metadata0"/>
<edge fromProcess="FileReader0" fromPort="2"
toProcess="Factorial3" toPort="0" metadata="Metadata0"/>
<edge fromProcess="FileReader0" fromPort="3"
toProcess="Factorial4" toPort="0" metadata="Metadata0"/>
<edge fromProcess="Factorial1" fromPort="0"
toprocess="FileWriter0" toPort="0" metadata="Metadata1"/>
<edge fromProcess="Factorial2" fromPort="0"
toProcess="FileWriter0" toPort="1" metadata="Metadata1"/>
<edge fromProcess="Factorial3" fromPort="0"
toProcess="FileWriter0" toPort="2" metadata="Metadata1"/>
<edge fromProcess="Factorial4" fromPort="0"
toProcess="FileWriter0" toPort="3" metadata="Metadata1"/>
</edges>
Acima apresentamos um XML de exemplo com um grafo com quatro nós de
processamento do cálculo do fatorial.
1.24. Resultados
Realizamos a medição da execução dos grafos utilizando o aplicativo do
Windows “Monitor de Desempenho” (perfmon.exe).
- Execução do Grafo com um nó de Fatorial
Consumo de CPU médio: 25,13%
Tempo total: 135.532 milissegundos
Figura 13 - Uso de CPU x Tempo – um processador

44
- Execução do Grafo com dois nós de Fatorial
Consumo de CPU médio: 51,76%
Tempo total: 80.995 milissegundos
Figura 14- Uso de CPU x Tempo – dois processadores
- Execução do Grafo com três nós de Fatorial
Consumo de CPU médio: 72,02%
Tempo total: 74.110 milissegundos
Figura 15- Uso de CPU x Tempo – três processadores
- Execução do Grafo com quatro nós de Fatorial
Consumo de CPU médio: 99,22%

45
Tempo total: 68.484 milissegundos
Figura 16- Uso de CPU x Tempo – quatro processadores
1.25. Conclusões
Processos Tempo(ms) Consumo de CPU Fator (CPU) Fator(Tempo)%
Um 135.532 25,13% - -
Dois 80.995 51,76% 2,06 0,40239
Três 74.110 72,02% 1,39 0,085
Quatro 68.484 99,02% 1,37 0,07591
Figura 17 - Tabela com indicadores e demonstrativo dos resultados.
A coluna “Fator (CPU)” representa o quanto se aumenta de consumo da CPU de
uma execução para outra. A coluna “Fator (Tempo)” representa quanto se diminuiu de
tempo de uma execução para outra.
Conforme esperado, conseguimos diminuir o tempo de a execução da tarefa
utilizando paralelismo. Quando comparamos os casos de “um processo” e outro com
“dois processos” de fatorial, o consumo de CPU aumentou em 2,06 vezes e
conseguimos uma diminuição de tempo da ordem de 0,40 ou 40%. Ou seja, dobramos a
quantidade de processos utilizados, e conseguimos um ganho de tempo bem próximo de
dois 50%. Porém, nos outros casos nosso ganho já foi bem inferior, mesmo dobrando o

46
tempo de consumo do CPU. Na minha visão esse ganho não foi tão expressivo, pois
conforme citado na seção “Hardware utilizado”, o computador utilizado possui dois
cores físicos e dois virtuais. Segunda a Intel, o ganho de desempenho do processador
virtual é de até 30% mas conforme verificado em nossos exemplos o ganho foi em torno
de 8-9%.
Figura 18- Gráfico Consumo de CPU x Número de processos
O gráfico acima mostrar o Consumo de CPU x Tempo gasto para execução dos
grafos. Podemos ver que o a linha em vermelho (tempo gasto) que liga o “processo um”
ao “processo dois”, possui o menor coeficiente angular. Ou seja, a maior eficiência
(aumento do número de CPUs proporcional à diminuição do tempo gasto), foi atingida
nessa fase. Nos outros, casos essa eficiência não foi expressiva, ou seja, o coeficiente
angular ficou mais próximo de zero.

47
Capítulo 6:
Conclusões e Lições Aprendidas
Nesse momento torna-se necessário verificar se os objetivos propostos foram
atingidos. Para isso, revisitaremos a seção “1.3 Objetivo” onde citamos as seguintes
vantagens:
- Auto-documentação: quando utilizamos a abstração de um grafo para demonstrar o
ciclo ETL, conseguimos visualizar facilmente o fluxo de dados e as dependências entre
os nós de processamento. Além disso, como os nós de processamento são coesos fica
fácil compreender qual é a responsabilidade/objetivo de cada nó. Nossa abstração ainda
é feita em baixo nível, utilizando arquivos XML. Idealmente deveria haver uma
ferramenta capaz de plotar/editar o grafo de ciclo de ETL visualmente.
- Reutilização de componentes: utilizando padrões de projeto, boas práticas de
arquitetura de código e uma linguagem orientada a objetos, foi possível criar um
framework simples de ser estendido. Com isto ficou facilitada a tarefa e criar novos
componentes, assim como reutilizar componentes previamente criados.
- Melhor desempenho: por utilizarmos técnica de pipeline e paralelismo, obtivemos um
desempenho melhor do que técnicas tradicionais de tratamento de dados. Realizamos o
mesmo tratamento citado no capítulo 5 criando um executável para o processo, e o
tempo total ficou em torno de 153.121 milissegundos. Logo, até no primeiro grafo de
exemplo, conseguimos ter um ganho de desempenho.
- Aumento de produtividade e qualidade do processo: O aumento de produtividade e
qualidade do processo só será percebido com o passar do tempo, onde novos
componentes serão incluídos no framework.
Partindo da proposta inicial de criação de um framework que permitisse
paralelismo e pipeline, conseguimos concluir o objeto. No que tange ao ferramental de
apoio, utilizamos a linguagem object pascal do ambiente de desenvolvimento da
Borland, que carece de uma maior comunidade de desenvolvedores, bibliotecas de
apoio e documentação. Para um sistema mais robusto acredito que deveria ter escolhido
a linguagem C++. Porém, por ser uma linguagem onde possuíamos maior domínio,
consegui atingir o objetivo dentro de um prazo aceitável.

48
Utilizamos o ciclo de vida em cascata por já possuir uma definição bem clara
dos requisitos, e conforme esperado, o mesmo se adequou ao processo de engenharia de
software.
O trabalho final foi importante para meu aprendizado em áreas como arquitetura
de código (utilizando padrões de projeto), concorrência de processos/threads, XML, e
XML Schema.

49
Referências
1. Producer-Consumer Problem, Wikipédia. Disponível em:
<https://en.wikipedia.org/wiki/Producer%E2%80%93consumer_problem>.
Acessado em 15 jun. 2013
2. Factory Pattern, OODesign.com – Object Oriented Design. Disponível em:
<http://www.oodesign.com/factory-pattern.html>. Acessado em 15 jun. 2013.
3. Singleton Pattern, OODesign.com – Object Oriented Design. Disponível em:
< http://www.oodesign.com/singleton-pattern.html >. Acessado em 15 jun.
2013.
4. XML Schema Tutorial, w3schools.com. Disponível em:
<http://www.w3schools.com/schema/>. Acessado em 15 jun. 2013.





























