Embed Size (px)
Citation preview

UNIVERSITÄT HANNOVER Institut für Photogrammetrie und Ingenieurvermessung
DIPLOMARBEIT
Untersuchung zur Verwendbarkeit der Software
eCognition für Zwecke der CORINE Landnutzungs –
Klassifikation
Vorgelegt von:
Bernd Haarmann
Juni 2001

Danksagung
Ich bedanke mich bei der Firma EFTAS Fernerkundung (Münster) für die freundliche
Bereitstellung der Landsat TM und der CORINE Szene. EFTAS unterstützte mich
außerdem mit Anregungen und Informationsmaterialien bei der Durchführung dieser
Diplomarbeit.
Erklärung Hiermit erkläre ich, dass ich die vorliegende Diplomarbeit selbstständig und nur mit
den angegebenen Hilfsmitteln angefertigt habe.
Hannover, den 6.6.2001
( Bernd Haarmann )

Inhalt I
Inhaltsverzeichnis
1. Einführung .............................................................................................................. 1
2. CORINE Land Cover .............................................................................................. 2
2.1 Methodisches Rahmenkonzept für CLC90........................................................ 3
2.1.1 Grundprinzipien für CLC ............................................................................. 3
2.1.2 Erfassungsmaßstab.................................................................................... 3
2.1.3 Definition der Erhebungseinheit.................................................................. 3
2.1.4 Erfassungsuntergrenze............................................................................... 4
2.1.5 Nomenklatur ............................................................................................... 5
2.2 Datenquellen für CLC 90................................................................................... 8
2.2.1 Basisdaten.................................................................................................. 8
2.2.2 Ergänzende Datenquellen .......................................................................... 9
2.2.3 Zusammenfassung und Nutzung der Datenquellen.................................. 10
2.3 Interpretation ................................................................................................... 10
2.4 Digitalisierung der Bodenbedeckungsdaten .................................................... 12
2.5 Validierung ...................................................................................................... 12
2.6 IMAGE/CLC2000............................................................................................. 13
2.6.1 IMAGE2000 .............................................................................................. 14
2.6.2 CLC2000................................................................................................... 15
3. eCognition............................................................................................................. 16
3.1 Multiresolution Segmentation .......................................................................... 18
3.2 Klassifikation ................................................................................................... 21
3.2.1 Membership Function ............................................................................... 21
3.2.1 Nearest Neighbor...................................................................................... 22
3.3 Class Hierarchy ............................................................................................... 24
3.4 Klassifikationsmerkmale.................................................................................. 25
3.5 Classification-based Segmentation (Klassenbasierende Segmentierung) ...... 27
3.6 Protocol Editor................................................................................................. 29
3.7 Import und Export von Bildern und Daten........................................................ 29
3.8 Genauigkeitsanalyse ....................................................................................... 30
3.9 Bildstatistik ...................................................................................................... 32

Inhalt II
4. Untersuchungen zur Verwendbarkeit von eCognition für Zwecke der CORINE
Landnutzungsklassifikation ....................................................................................... 33
4.1 Projekt 1: Klassifikation mit Landsat Szenen................................................... 33
4.1.1 Eingangsdaten.......................................................................................... 33
4.1.2 Probleme bei der Klassifikation von Landsat Daten.................................. 35
4.1.3 1. Segmentierung .................................................................................... 36
4.1.3.1 Auswahl der zur Segmentierung benutzten Kanäle............................ 37
4.1.3.2 Maßstab und Hierarchie ..................................................................... 40
4.1.3.3 Nachbarschaft .................................................................................... 45
4.1.4 Klassifikation............................................................................................. 46
4.1.4.1 Nearest Neighbor oder Membership Function.................................... 46
4.1.4.2 Klassifikation Level 1.......................................................................... 47
4.1.4.3 Klassifikation Level 3.......................................................................... 50
4.1.4.4 Klassifikation Level 2.......................................................................... 51
4.1.5 Classification-based Segmentation........................................................... 54
4.1.6 Klassifikation Level 3 (neu) ....................................................................... 55
4.1.7 Ergebnisse und Schlussfolgerungen aus Projekt 1................................... 57
4.2 Projekt 2: Klassifikation mit Landsat und ATKIS Daten ................................... 61
4.2.1 Eingangsdaten Projekt 2........................................................................... 61
4.2.2 1.Segmentation........................................................................................ 64
4.2.3 1.Klassifikation......................................................................................... 65
4.2.4 Classification-based Segmentation........................................................... 70
4.2.5 2. Klassifikation........................................................................................ 72
4.2.6 Ergebnisse Projekt 2................................................................................. 75
5. Kurze Ergebniszusammenfassung aus Projekt 1 und Projekt 2 ........................... 79
6.Ausblick ................................................................................................................. 80
7. Literaturverzeichnis............................................................................................... 81
8. Anhang: Inhaltsverzeichnis der CD:...................................................................... 83

1. Einführung 1
1. Einführung CORINE Land Cover (CLC) ist ein Projekt der Europäischen Union mit dem Ziel, ein
in Europa einheitliches Informationssystem über die Landnutzung zu besitzen.
Dieses Informationssystem soll neben Aufgaben der Bodenplanung vor allem
Aufgaben des Umweltschutzes dienen. Die erste Kampagne von CLC ist bei den
teilnehmenden Ländern von CORINE fast abgeschlossen. Da die für die Erfassung
genutzten Daten zum Teil noch aus den achtziger Jahren stammen, wird seitens der
EU über eine Aktualisierung von CORINE nachgedacht. Diese Aktualisierung hat den
Projektnamen CLC 2000.
Bei der Automatischen Erfassung von Satelliten- und Luftbildern hat es in den letzten
Jahren große Fortschritte gegeben. In einer der neusten Software Entwicklungen,
eCognition, wird versucht, die menschliche Wahrnehmung für Zwecke der
Bilderkennung nachzuahmen. Dieser Ansatz bitte neue Möglichkeiten der
Klassifizierung und der Bildsegmentierung.
Ziel dieser Diplomarbeit ist zu untersuchen, in wieweit sich eCognition für die
Erfassung von CLC 2000 eignet. Dabei sollen nur die Eingangsdaten genutzt
werden, die auch bei der realen Umsetzung dieser CORINE Kampagne zur
Verfügung stehen. Diese Eingangsdaten sind in Deutschland Landsat Satellitenbilder
und ATKIS Vektor-Daten. Bevor die eigentlichen Untersuchungen beschrieben
werden, wird das CORINE Projekt und die Software eCognition kurz vorgestellt.

2. CORINE Land Cover 2
2. CORINE Land Cover
CORINE steht für CoORdination of Information on the Enviroment und ist ein Projekt
der Europäischen Union mit dem Ziel der Bereitstellung von einheitlichen und
vergleichbaren umweltrelevanten Daten für ganz Europa. Heute nehmen 28
Europäische Länder an diesem Projekt teil. CORINE Land Cover (CLC) wurde 1985
von der Kommission der EU zusammen mit anderen Umwelt bezogenen Projekten,
wie z.B. CORINE Biotops oder CORINAIR, ins Leben gerufen, um einheitliche und
vergleichbare Bodenbedeckungsdaten bzw. Landnutzungsdaten für Europa zu
bekommen. Inzwischen ist die Europäische Umweltagentur – European Enviroment
Agency (EEA) - mit Sitz in Kopenhagen für CORINE verantwortlich, die ihrerseits
sogenannte Europäische Themenzentren –European Topic Centres (ETC) –
eingerichtet hat. Eines dieser Themenzentren ist das European Topic Centre on
Land Cover (ETC/LC), zu dessen Aufgaben u.a. die Projektkoordinierung, Forschung
und die Weiterentwicklung von CORINE Land Cover gehört. Der CORINE
Datenbestand bildet bei der EEA ein Element des Umweltinformations- und
Umweltbeobachtungsnetzwerkes EIONET (Environmental Information and
Observation Network).
Ende der achtziger Jahre wurde für CLC ein für ganz Europa geltendes
methodisches Rahmenkonzept entwickelt, indem beschrieben wird, welche Art von
Elementen erfasst werden sollen und auf welche Weise diese erfasst werden sollen.
Das methodische Rahmenkonzept wurde von den einzelnen Teilnehmerländern
benutzt, um national die Erhebung der Bodenbedeckung/Landnutzung
durchzuführen. In Deutschland wurde das Statistische Bundesamt (StBA) mit der
Leitung der Datenerhebung beauftragt. Hierfür schuf das Statistische Bundesamt
eine Datenerhebungsanleitung für CLC, welches das methodische Rahmenkonzept
der Europäischen Kommission umsetzte. Mit Hilfe dieser Anleitung führten private
Unternehmen die Datenerhebung durch. Die Ergebnisse dieser Datenerhebung
liegen heute CLC90 (Als Erfassungsjahr wurde 1990 angesetzt) vor. Das
Methodische Rahmenkonzept für CLC90 wird in diesem Kapitel vorgestellt.
Zur Zeit arbeiten die verantwortlichen Institute und Ämter daran eine Methode für ein
Update 2000 von CLC zu entwickeln. Dieses Update soll das Jahr 2000 als
Erfassungszeitpunkt haben und wird deshalb auch CLC2000 genannt. Da es sich bei
CLC2000 um eine Aktualisierung handelt und sich die zur Verfügung stehende
Technik verbessert hat, treten große Unterschiede, vor allem in der

2. CORINE Land Cover 3
Herstellungstechnik, zwischen den Projekten CLC90 und CLC2000 auf. Diese
Unterschiede und ein aktueller Stand der Entwicklung werden ebenfalls in diesem
Kapitel beschrieben.
2.1 Methodisches Rahmenkonzept für CLC90
2.1.1 Grundprinzipien für CLC
Da CORINE Land Cover neben dem gesamten CORINE Projekt auch anderen
Anwendern in ganz Europa einen größtmöglichen Nutzen bringen soll, gibt es hohe
Ansprüche in Sicht auf Homogenität, Vergleichbarkeit innerhalb und zwischen den
beteiligten Ländern, Vollständigkeit und Erfassungsgenauigkeit. Zum Einhalten
dieser Kriterien werden folgende vier Grundelemente definiert:
• Erfassungsmaßstab
• Definition der Erhebungseinheit
• Erfassungsuntergrenze
• Nomenklatur der Bodenbedeckung
2.1.2 Erfassungsmaßstab
Der Erfassungsmaßstab für CORINE Land Cover beträgt 1:100000. Mehrere Gründe
sind für diese Wahl ausschlaggebend. Kleinere Maßstäbe würden für den
Anwendungszweck CORINE zu grob sein. Auch würden dann aufgrund der hohen
Erfassungsuntergrenze einige Arten von Bodenbedeckungen vernachlässigt werden.
Ebenfalls für diesen Maßstab spricht, dass in fast allen Ländern ein Kartenwerk
dieses Maßstabes vorhanden ist. Außerdem ist dieser Maßstab dem
Bearbeitungszeitraum und dem Finanzvolumen angemessen.
2.1.3 Definition der Erhebungseinheit
Grundsätzlich kann die Beschaffenheit der Erdoberfläche nach dem Kriterium der Art
der Bodenbedeckung (Wald, Anbauflächen Wasserflächen usw.) oder nach der Art
der Bodennutzung (Forstwirtschaft, Landwirtschaft usw.) unterteilt werden. Weil

2. CORINE Land Cover 4
CORINE Informationen über den Zustand der Umwelt liefern will, hat man sich
grundsätzlich für die Bodenbedeckung als Grundlage für die Erhebungseinheiten
entschieden. In Ausnahmefällen wird aber auch die Bodennutzung als Kriterium
genutzt (z.B. 1.4.2 Sport und Freizeitanlagen).
Eine Erhebungseinheit entspricht entweder einem Gebiet homogener Bedeckung
(Wald, Grünland) oder ist eine Kombination mehrerer homogener Einheiten (z.B.
Strände und Dünen als eine Erhebungseinheit), die in einem räumlichen oder
semantischen Zusammenhang zueinander stehen. Benachbarte Einheiten sollen
sich im Gelände eindeutig voneinander unterscheiden und eine Einheit muss
abhängig vom Erfassungsmaßstab eine genügend große Fläche im Gelände
repräsentieren.
Da Satellitendaten die Realität mit Blick auf die Bodenbedeckung nicht unmittelbar
wiedergeben und die Realität der Bodenbedeckung auf Grund des Maßstabes
(Generalisierungsproblem) nicht in ihrer gesamten Komplexität dargestellt werden
kann, gelten für kartographische Bestandsaufnahmen folgende Anforderungen:
��Der thematische Inhalt einer Erhebungseinheit sollte den Anforderungen der
Nutzer entsprechen.
��Die Realität muss in angemessener Weise wiedergegeben werden.
2.1.4 Erfassungsuntergrenze
Die Erfassungsuntergrenze, also die Größe der kleinsten Erhebungseinheiten, wird
so festgelegt, dass sie drei elementaren Anforderungen entspricht:
��Lesbarkeit der gedruckten Karte.
��Möglichkeit der Darstellung aller für die Aufgabenstellung wichtigen
Bodenbedeckungsdaten.
��Gesundes Verhältnis zwischen Kosten für die Realisierung und Nutzen für die
Ziele des Projektes.
Um diesen Anforderungen zu entsprechen, hat man sich bei CORINE Land Cover für
25 ha als Erfassungsuntergrenze entschieden. Bei einem Maßstab von 1:100000

2. CORINE Land Cover 5
entspricht diese Fläche einem Quadrat mit 5 mm Seitenlänge oder einem Kreis mit
2,8 mm Radius (Abb.1).
Abb.1, Erfassungsuntergrenze
Linienhafte Objekte werden erst ab einer Breite von 100 m erfasst.
2.1.5 Nomenklatur
Eine Nomenklatur muss so aufgebaut sein, dass sie eine Reihe von Bedingungen
erfüllt:
• Sie muss alle in der Realität vorkommenden Bodenbedeckungsarten erfassen.
• Die Definitionen müssen so präzise sein, dass keine ungenauen oder
mehrdeutige Klassenzuordnungen möglich sind.
• Die verschiedenen Klassendefinitionen müssen die thematischen Anforderungen
erfüllen (bei CORINE: Zustand der Umwelt).
• Beim Definieren der einzelnen Klassen muss die Größe einer Erfassungseinheit
(mindestens 25 ha) und der Erhebungsmaßstab beachtet werden.
• Die einzelnen Klassen sollten sich aus den Basisinformationen (bei CLC vor allem
Satellitendaten) ableiten lassen.
• Wie bei der Erfassungsuntergrenze muss auch hier ein Kompromiss zwischen
Aufwand/Kosten und Anforderungen der Nutzer gefunden werden.
Ausgehend von den oben aufgeführten Bedingungen hat ein Sachverständigenrat
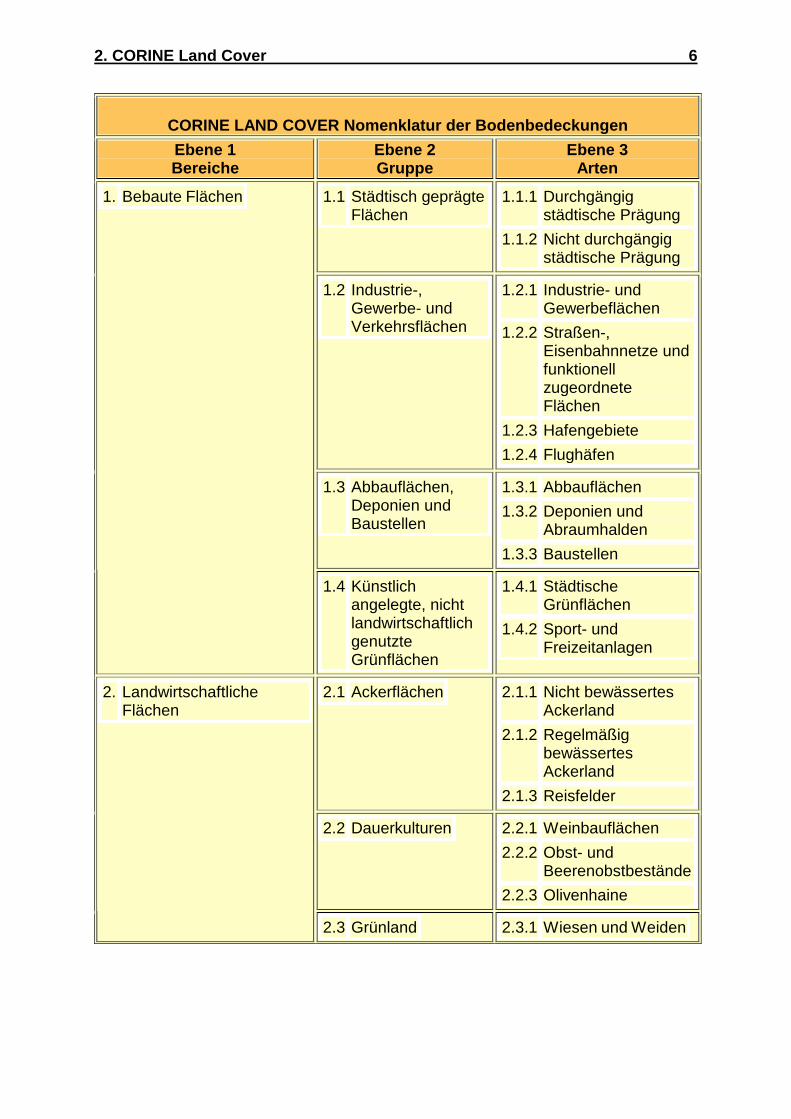
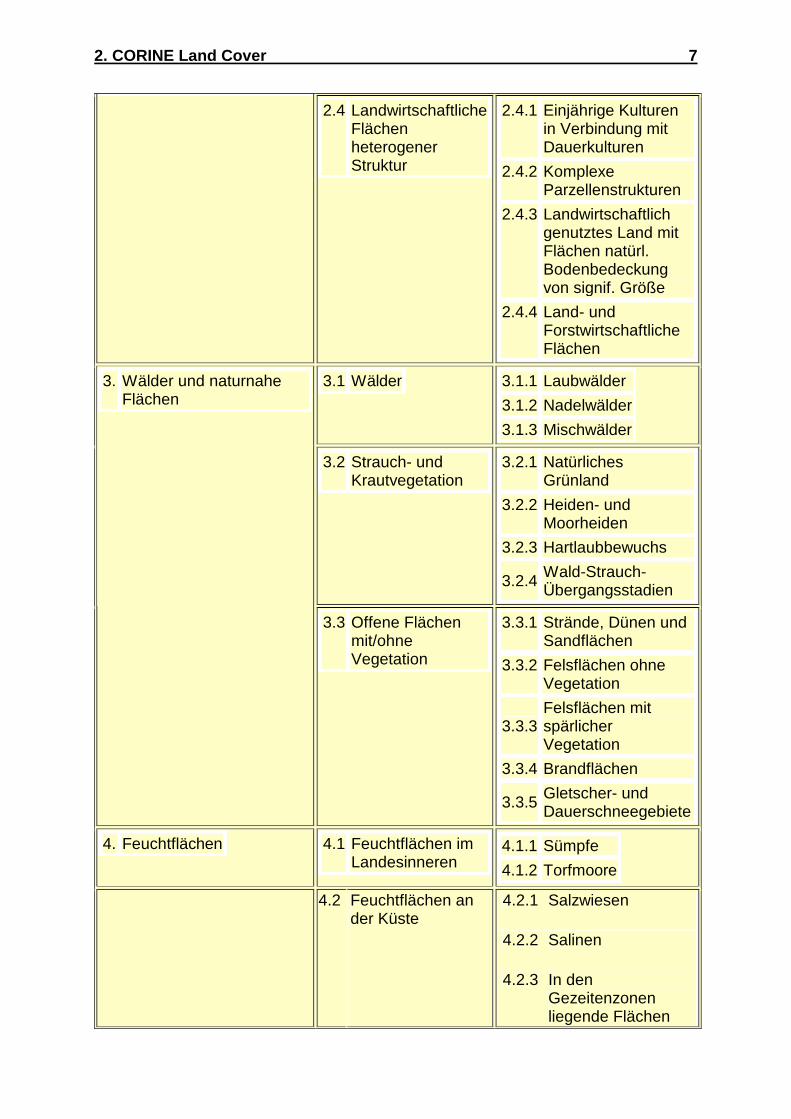
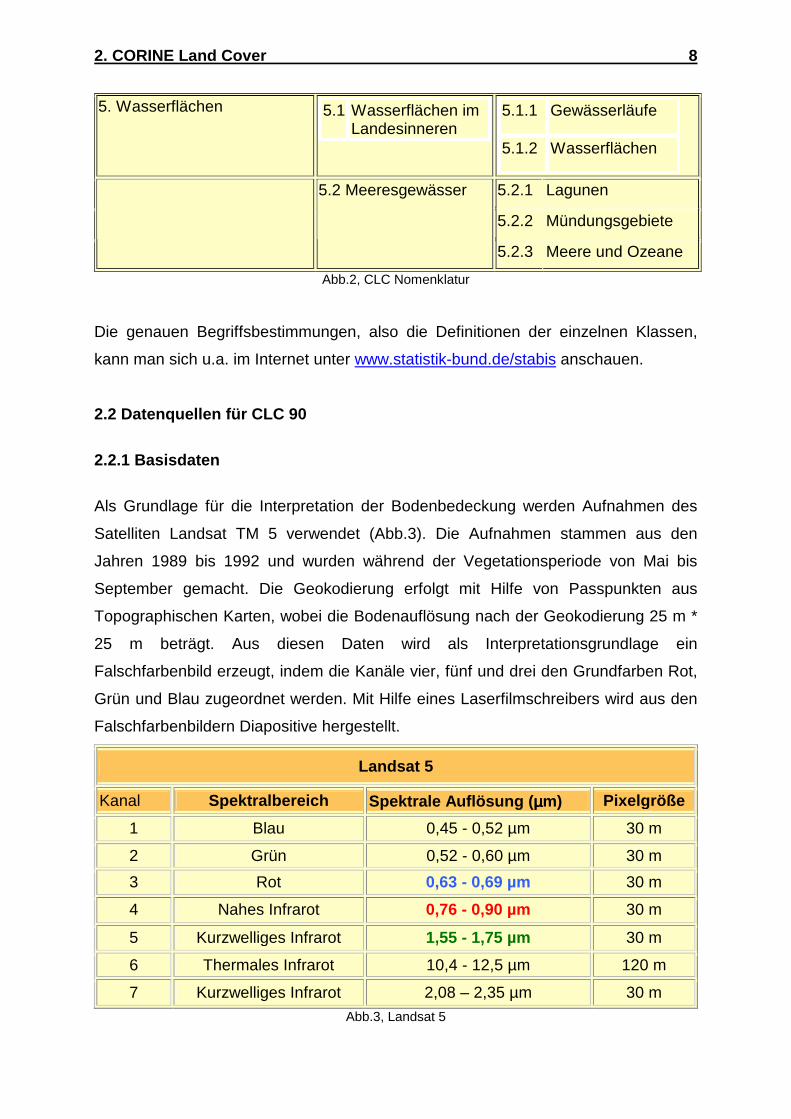
aus ganz Europa die CORINE Land Cover Nomenklatur entworfen (Abb.2). Sie
besteht aus drei Ebenen, wobei Ebene 1 eine grobe Einteilung in fünf Hauptarten der
Bodenbedeckung beschreibt, Ebene 2 ist bereits in 15 Positionen unterteilt und kann
für Arbeiten im Maßstäben von 1:500.000 bis 1:1.000.000 verwendet werden. Erst in
Ebene 3 sind die 44 Positionen enthalten, die für den Maßstab 1:100.000 entworfen
wurden.
2. CORINE Land Cover 6
CORINE LAND COVER Nomenklatur der Bodenbedeckungen Ebene 1 Bereiche
Ebene 2 Gruppe
Ebene 3 Arten
1.1 Städtisch geprägte Flächen
1.1.1 Durchgängig städtische Prägung
1.1.2 Nicht durchgängig städtische Prägung
1.2 Industrie-, Gewerbe- und Verkehrsflächen
1.2.1 Industrie- und Gewerbeflächen
1.2.2 Straßen-, Eisenbahnnetze und funktionell zugeordnete Flächen
1.2.3 Hafengebiete 1.2.4 Flughäfen
1.3 Abbauflächen, Deponien und Baustellen
1.3.1 Abbauflächen 1.3.2 Deponien und
Abraumhalden 1.3.3 Baustellen
1. Bebaute Flächen
1.4 Künstlich angelegte, nicht landwirtschaftlich genutzte Grünflächen
1.4.1 Städtische Grünflächen
1.4.2 Sport- und Freizeitanlagen
2.1 Ackerflächen 2.1.1 Nicht bewässertes Ackerland
2.1.2 Regelmäßig bewässertes Ackerland
2.1.3 Reisfelder 2.2 Dauerkulturen 2.2.1 Weinbauflächen
2.2.2 Obst- und Beerenobstbestände
2.2.3 Olivenhaine
2. Landwirtschaftliche Flächen
2.3 Grünland 2.3.1 Wiesen und Weiden
2. CORINE Land Cover 7
2.4 Landwirtschaftliche Flächen heterogener Struktur
2.4.1 Einjährige Kulturen in Verbindung mit Dauerkulturen
2.4.2 Komplexe Parzellenstrukturen
2.4.3 Landwirtschaftlich genutztes Land mit Flächen natürl. Bodenbedeckung von signif. Größe
2.4.4 Land- und Forstwirtschaftliche Flächen
3.1 Wälder 3.1.1 Laubwälder 3.1.2 Nadelwälder 3.1.3 Mischwälder
3.2 Strauch- und Krautvegetation
3.2.1 Natürliches Grünland
3.2.2 Heiden- und Moorheiden
3.2.3 Hartlaubbewuchs
3.2.4 Wald-Strauch-Übergangsstadien
3. Wälder und naturnahe Flächen
3.3 Offene Flächen mit/ohne Vegetation
3.3.1 Strände, Dünen und Sandflächen
3.3.2 Felsflächen ohne Vegetation
3.3.3Felsflächen mit spärlicher Vegetation
3.3.4 Brandflächen
3.3.5 Gletscher- und Dauerschneegebiete
4. Feuchtflächen 4.1 Feuchtflächen im Landesinneren
4.1.1 Sümpfe 4.1.2 Torfmoore
4.2 Feuchtflächen an der Küste
4.2.1 Salzwiesen
4.2.2 Salinen
4.2.3 In den Gezeitenzonen liegende Flächen
2. CORINE Land Cover 8
5. Wasserflächen 5.1 Wasserflächen im Landesinneren
5.1.1 Gewässerläufe
5.1.2 Wasserflächen 5.2.1 Lagunen
5.2.2 Mündungsgebiete
5.2 Meeresgewässer
5.2.3 Meere und Ozeane Abb.2, CLC Nomenklatur
Die genauen Begriffsbestimmungen, also die Definitionen der einzelnen Klassen,
kann man sich u.a. im Internet unter www.statistik-bund.de/stabis anschauen.
2.2 Datenquellen für CLC 90
2.2.1 Basisdaten
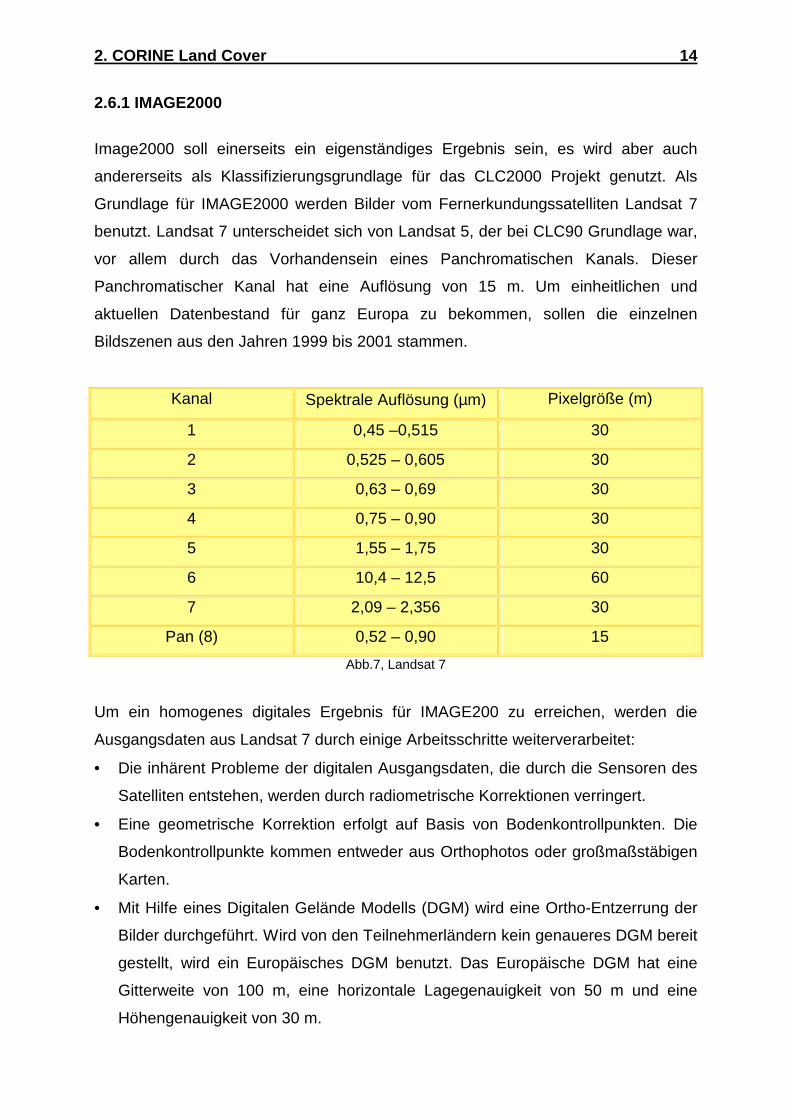
Als Grundlage für die Interpretation der Bodenbedeckung werden Aufnahmen des
Satelliten Landsat TM 5 verwendet (Abb.3). Die Aufnahmen stammen aus den
Jahren 1989 bis 1992 und wurden während der Vegetationsperiode von Mai bis
September gemacht. Die Geokodierung erfolgt mit Hilfe von Passpunkten aus
Topographischen Karten, wobei die Bodenauflösung nach der Geokodierung 25 m *
25 m beträgt. Aus diesen Daten wird als Interpretationsgrundlage ein
Falschfarbenbild erzeugt, indem die Kanäle vier, fünf und drei den Grundfarben Rot,
Grün und Blau zugeordnet werden. Mit Hilfe eines Laserfilmschreibers wird aus den
Falschfarbenbildern Diapositive hergestellt.
Landsat 5
Kanal Spektralbereich Spektrale Auflösung (µµµµm) Pixelgröße 1 Blau 0,45 - 0,52 µm 30 m
2 Grün 0,52 - 0,60 µm 30 m 3 Rot 0,63 - 0,69 µm 30 m
4 Nahes Infrarot 0,76 - 0,90 µm 30 m
5 Kurzwelliges Infrarot 1,55 - 1,75 µm 30 m
6 Thermales Infrarot 10,4 - 12,5 µm 120 m
7 Kurzwelliges Infrarot 2,08 – 2,35 µm 30 m Abb.3, Landsat 5

2. CORINE Land Cover 9
2.2.2 Ergänzende Datenquellen
Topographische Karten
Topographische Karten haben bei der Herstellung von CLC drei sehr wichtige
Aufgaben:
• Wie oben erwähnt sind sie Grundlage der Geokodierung der Landsat
Satellitenbilder.
• Sie sind das Kontrolldokument zur Überprüfung der geometrisch korrekten
Digitalisierung der Interpretationsfolie (wird später erläutert).
• Ergänzende thematische Informationen können aus ihnen abgeleitet werden.
Besonders für die dritte Aufgabe wird neben der TK 100 auch die amtliche
Topographische Karte 1:50.000 (TK 50) herangezogen. Sie liefert thematische
Zusatzinformationen zur Bodenbedeckung wie z.B.: die Lage von Grün- und
Parkanlagen, Sport- und Freizeitanlagen, Industriegebieten, Waldflächen und
Feuchtflächen.
Luftbilder
Luftbilder haben ebenfalls eine wichtige Rolle für den Aufbau der CLC Datenbank.
Auch für sie gibt es drei Verwendungen:
• Bei unsicherer Klassenzuordnung, als Interpretationshilfe
• Festlegung der genauen Begrenzung der Erhebungseinheiten, wenn diese auf
dem Satellitenbild nicht klar zu erkennen sind
• Überprüfung und Validierung der Kartierung der Bodenbedeckung
Zum Verständnis von Punkt zwei ist anzumerken, dass die räumliche Auflösung
eines Luftbildes weit höher ist als die von Landsat (1 bis 3 m gegenüber 25 m). Die
verwendeten Luftbilder haben einen Maßstab von 1:5.000 bis zu 1:70.000, sind in
der Regel panchromatische Aufnahmen und nur in Ausnahmen Farbfilme oder
Infrarotfilme.

2. CORINE Land Cover 10
2.2.3 Zusammenfassung und Nutzung der Datenquellen
Abb.4 zeigt ein Organigramm aller verwendeter Datenquellen und ihre Nutzung.
Abb.4, Zusammenfassung und Nutzung der Datenquellen
2.3 Interpretation
In einer Interpretationsfolie werden die Bodenbedeckungseinheiten gemäß CLC-
Nomenklatur auf Basis des geokodierten Satellitenbildes abgegrenzt und
zugeordnet. Die Interpretationsfolie wird hierfür über die Satellitenbildfolie gelegt,
wobei die Lage der Folien zueinander durch Passpunkte bestimmt ist. Als
Passpunkte werden die auf die Folien übertragenen Kartenblattecken der TK 100,
die gleichzeitig den Kartenfeldrand festlegen, genutzt. Um eine korrekte
Randanpassung benachbarter Kartenblätter zu erreichen, erfolgt die Abgrenzung
und Zuordnung der Bodenbedeckungseinheiten ca. 2 cm über den Kartenfeldrand
hinaus.
Die Interpretation von Satellitenbildern ist ein iterativer Annäherungsprozess. Zuerst
werden die Grenzen einer Erhebungseinheit in der Interpretationsfolie markiert
(Abgrenzung) und dann wird diese Einheit einer Klasse der Nomenklatur zugeordnet
(Zuordnung). Die Ergebnisse dieser Schritte werden durch einbeziehen ergänzender
Datenquellen immer weiter verbessert.

2. CORINE Land Cover 11
Abb.5, Ablaufschema des iterativen Prozesses bei CORINE
Die meisten Arbeitsschritte im Abb.5 erklären sich von selbst, besonders erklären
möchte ich hier noch was sich unter dem Arbeitsschritt „Ergänzende digitale
Bildverarbeitung“ verbirgt. Dabei werden u.a. Verarbeitungsverfahren wie
Hauptkomponententransformation, Vegetationsindex und automatische Klassifikation
zur Abgrenzung und Zuordnung von Bodenbedeckungsarten angewandt. Die dabei
erzielten Ergebnisse dienen vor allem als ergänzende Informationen laufender
Interpretationen, aber auch als Überprüfung vorhandener Ergebnisse.

2. CORINE Land Cover 12
2.4 Digitalisierung der Bodenbedeckungsdaten
Digitalisierungsgrundlage ist ausschließlich die Interpretationsfolie. Die Geokodierung
der digitalen Daten erfolgt durch Erfassen der Passpunkte. Dadurch wird das
Geodätische Bezugssystem der TK 100, nämlich das DHDN-
Koordinatenbezugssystem, übernommen. Das Digitalisieren der
Flächenabgrenzungen erfolgt durch Erfassen von Linienstützpunkten, die einen
Mindestabstand von 5 m in der Realität und eine Digitalisiergenauigkeit von +/- 0,1 –
0,2 mm haben müssen. Ein Referenzpunkt in der Mitte jeder Fläche, mit einer
Kennnummer, die dem entsprechenden Nomenklaturwert entspricht, dient der
Sachdatenerfassung.
Am fertigen digitalen Datenbestand werden eine Reihe von Prüfungen durchgeführt
mit dem Ziel eine bestmögliche Vollständigkeit, Richtigkeit und Lagegenauigkeit der
Digitalisierung zu erreichen.
2.5 Validierung Eine Validierung wird durchgeführt um ein Maß zu haben, wie gut die einzelnen
Klassen zugeordnet werden. Fehler in der Zuordnung können aus zwei Gründen
auftreten. Zum einen kann es sich um echte Zuordnungsfehler handeln, die während
des Herstellungsprozesses auftreten. Diese Art von Fehlern sollen durch die
Iterationen beim Herstellungsprozess und die umfangreichen Prüfungen minimiert
werden.
Die Ursache für eine Fehlzuordnung kann allerdings aber auch in der Methode der
Datenerhebung selbst liegen. Um diesen Fehler zu Beurteilen wird eine Validierung
durchgeführt. Man kann auch sagen, es wird getestet ob zwei Interpreten zum selben
Ergebnis kommen, wenn sie alle Anweisungen korrekt durchführen. Bei der
Validierung wird der Prozess der Datenerhebung mit den gleichen Datenquellen in
Stichprobengebieten nachvollzogen. Für die Stichprobengebiete weiß man die reale
Bodenbedeckungsart. Auf diese Weise kann man, mit Hilfe einer Konfusionsmatrix,
Aussagen darüber machen, wie groß der Anteil der korrekten Zuordnung zu den
einzelnen Klassen ist.

2. CORINE Land Cover 13
2.6 IMAGE/CLC2000
Der offizielle Abkürzung dieses Projektes lautet I&CLC2000. Das I steht für das
englische Wort Image (Bild). Ein Ziel dieses Projektes ist eine
Satellitenbilddatenbank (IMAGE2000) für ganz Europa, die aus einzelnen
Satellitenbildern zusammengesetzt ist, die nach einheitlichen Kriterien hergestellt
wurden. Ein weiteres Ziel ist die nationale und europäische Aktualisierung von
CLC90 zu CLC2000. Hieraus kann man das dritte Ziel dieses Projektes ableiten. Die
Erfassung von Landnutzungsänderungen von 1990 bis 2000.
Abb.6, Organigramm des Projektaufbaus von CLC 2000
Hauptverantwortlich für das I&ClC2000 Projekt ist die EEA. Sie arbeitet aber in
diesem Projekt eng mit dem Joint Research Centre (JRC) in Ispra zusammen. Das
JRC ist vor allem für die Umsetzung von IMAGE2000 verantwortlich. Der
Organisationsaufbau für das gesamte Projekt wird in Abb.6 verdeutlicht.
EEA Management CLC2000: • Koordination und Überwachung
der Herstellung • Datenbank Management
CLC2000 • Qualitätskontrolle von CLC2000 • Validierung von CLC 2000 • Datenintegration
JRC Entwicklung des Methodischen Rahmenkonzepts (Arbeitsanleitung) Management IMAGE2000: • Bereitstellung der Satellitendaten • Korrektion der Satellitenbilder • Datenbankmanagement
IMAGE2000 • Qualitätskontrolle IMAGE2000
Nationale CLC2000 Teams Koordination des nationalen CLC2000 Projektes Erstellen des nationalen CLC2000 mit IMAGE2000 als Interpretationsgrundlage Nationale Erfassung der Landnutzungsänderungen für CLC2000
2. CORINE Land Cover 14
2.6.1 IMAGE2000
Image2000 soll einerseits ein eigenständiges Ergebnis sein, es wird aber auch
andererseits als Klassifizierungsgrundlage für das CLC2000 Projekt genutzt. Als
Grundlage für IMAGE2000 werden Bilder vom Fernerkundungssatelliten Landsat 7
benutzt. Landsat 7 unterscheidet sich von Landsat 5, der bei CLC90 Grundlage war,
vor allem durch das Vorhandensein eines Panchromatischen Kanals. Dieser
Panchromatischer Kanal hat eine Auflösung von 15 m. Um einheitlichen und
aktuellen Datenbestand für ganz Europa zu bekommen, sollen die einzelnen
Bildszenen aus den Jahren 1999 bis 2001 stammen.
Kanal Spektrale Auflösung (µm) Pixelgröße (m)
1 0,45 –0,515 30
2 0,525 – 0,605 30
3 0,63 – 0,69 30
4 0,75 – 0,90 30
5 1,55 – 1,75 30
6 10,4 – 12,5 60
7 2,09 – 2,356 30
Pan (8) 0,52 – 0,90 15 Abb.7, Landsat 7
Um ein homogenes digitales Ergebnis für IMAGE200 zu erreichen, werden die
Ausgangsdaten aus Landsat 7 durch einige Arbeitsschritte weiterverarbeitet:
• Die inhärent Probleme der digitalen Ausgangsdaten, die durch die Sensoren des
Satelliten entstehen, werden durch radiometrische Korrektionen verringert.
• Eine geometrische Korrektion erfolgt auf Basis von Bodenkontrollpunkten. Die
Bodenkontrollpunkte kommen entweder aus Orthophotos oder großmaßstäbigen
Karten.
• Mit Hilfe eines Digitalen Gelände Modells (DGM) wird eine Ortho-Entzerrung der
Bilder durchgeführt. Wird von den Teilnehmerländern kein genaueres DGM bereit
gestellt, wird ein Europäisches DGM benutzt. Das Europäische DGM hat eine
Gitterweite von 100 m, eine horizontale Lagegenauigkeit von 50 m und eine
Höhengenauigkeit von 30 m.

2. CORINE Land Cover 15
• Die kartographische Projektion der Bilder erfolgt mit Hilfe der
Projektionsparameter der einzelnen Länder. In Grenzgebieten werden die
Projektionen beider Länder hergestellt.
• Für IMAGE2000 als Endergebnis wird eine einheitliche Projektion für ganz
Europa gewählt.
• Die Bilder werden durch Anwenden einer kubischen Resamplingsmethode
resampled. Die Bodenauflösung beträgt danach für die Kanäle 1 bis 7 25m und
für den panchromatischen Kanal 12,5 m.
• Um als Klassifizierungsgrundlage für CLC2000 zu dienen, werden Bildausschnitte
erzeugt, die den nationalen 1:100.000 Kartenreihen folgen.
2.6.2 CLC2000
Die Grundlegenden Elemente von CLC90, wie die Definition der Erfassungseinheit,
die Nomenklatur oder der Erfassungsmaßstab, wurden übernommen. Allerdings,
während die Erfassungsuntergrenze für Objekte weiterhin wie bei CLC90 25 ha
beträgt, ist sie für Landnutzungsänderungen auf 5 ha heruntergesetzt. Die
Landnutzungsänderungen (Change Detection) ergeben sich aus dem Vergleich der
90er Daten mit den 2000er Daten. Um diese Daten vergleichbar zu machen, muss
die 90er Geometrie mit der 2000er übereinstimmen. Die geometrische Korrektur von
CLC90 erfolgt mit Hilfe von IMAGE2000. IMAGE2000 ist auch die
Hauptinformationsquelle für die Change Detection, die Landenutzungs-
Klassifizierung und die spätere Validierung. Daneben können aber auch
Zusatzinformationen wie z.B. Atkis Daten genutzt werden. Der genaue Arbeitsablauf
zur Herstellung von CLC 2000 wird noch von der EEA entwickelt.

3. eCognition 16
3. eCognition
eCognition ist eine von der Firma Definiens (früher Delphi2) entwickelte Bildanalyse
Software. Definiens geht mit dieser Software neue Wege in der Bildinterpretation, in
dem sie versuchen, die menschliche Wahrnehmung von Bildern zu simulieren. Beim
Menschen ist die Wahrnehmung von Bildern ein sehr komplexer und hoch kognitiver
Prozess. Das eigentliche Sehen bildet hierbei mit dem Erfassen der visuellen
Eingangsdaten (Spektralinformationen) nur einen ersten Schritt. Beim weiteren
Wahrnehmungsprozess geht das Gehirn objektorientiert vor, d.h. es setzt das
Gesamtbild aus einzelnen Objekten zusammen. Das Erkennen der Objekte erfolgt
durch Vergleich der visuellen Eingangsdaten mit im Gehirn gespeicherten
Erinnerungen (innere Bilder). Ist ein Objekt erkannt, entsteht im Gehirn mit Hilfe
seiner Erfahrungen eine körperliche Vorstellung vom Objekt, d.h. man sieht in seiner
Vorstellung z.B. auch die im Bild nicht sichtbare Rückseite eines Objektes. Auch
werden alle im Gehirn gespeicherten Eigenschaften des Objektes mit der Vorstellung
verknüpft. Erkennt z.B. das Gehirn ein Objekt als Haus, so werden u.a. folgende
Eigenschaften damit verbunden: Ein Haus besteht aus Steinen, man kann darin
wohnen. Wenn jetzt im Bild benachbarte Objekte auf gleiche Weise erkannt wurden,
werden diese Objekte untereinander in Verbindung gebracht. Stehen nun mehrere
Häuser nebeneinander, so interpretieren wir daraus, dass es sich um eine Siedlung
handeln muss. Die im Gehirn entstandene Vorstellung der Siedlung bildet jetzt auch
ein Objekt, das ebenfalls körperlich ist und auch mit im Gehirn gespeicherten
Eigenschaften (z.B. besteht aus Häusern) verknüpft wird. Der Mensch kann beliebig
zwischen verschiedenen Auflösungen, also verschiedenen Objektgrößen, wechseln.
Auf diese Weise entsteht in Sekundenbruchteilen aus dem realen Ausgangsbild ein
virtuelles Bild im Gehirn. Aus diesen Ausführungen soll deutlich werden, dass die
menschliche Wahrnehmung nicht pixelorientiert sondern objektorientiert abläuft. Die
spektralen Werte der einzelnen Pixel reichen zum Erfassen der Umwelt (z.B. einer
Siedlung) nicht aus, sondern man braucht auch Kontextinformationen aus
benachbarten Objekten oder Unterobjekten aus denen ein Objekt zusammengesetzt
ist. Eine Siedlung besteht z.B. aus Häusern und Strassen, ein Haus besteht aus
Mauern und einem Dach.
Wie oben erwähnt versucht Definiens mit eCognition die menschliche Wahrnehmung
zu simulieren. Sie erreichen dabei natürlich nicht die Komplexität des menschlichen
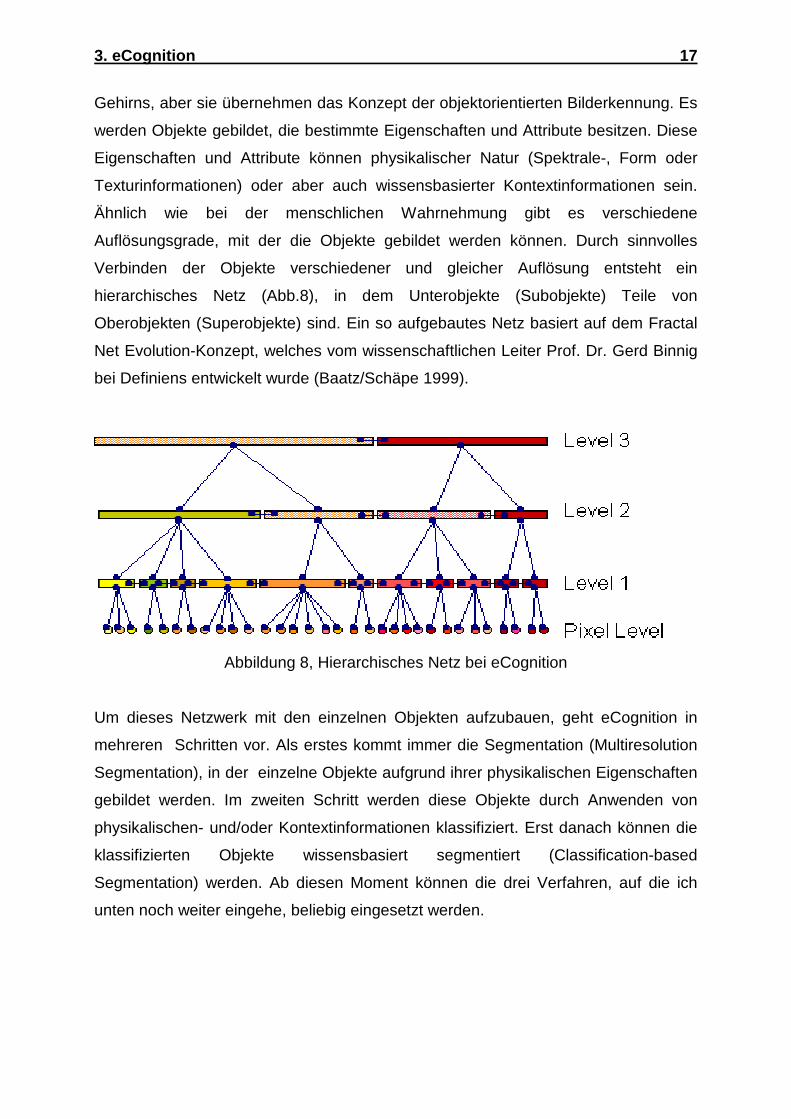
3. eCognition 17
Gehirns, aber sie übernehmen das Konzept der objektorientierten Bilderkennung. Es
werden Objekte gebildet, die bestimmte Eigenschaften und Attribute besitzen. Diese
Eigenschaften und Attribute können physikalischer Natur (Spektrale-, Form oder
Texturinformationen) oder aber auch wissensbasierter Kontextinformationen sein.
Ähnlich wie bei der menschlichen Wahrnehmung gibt es verschiedene
Auflösungsgrade, mit der die Objekte gebildet werden können. Durch sinnvolles
Verbinden der Objekte verschiedener und gleicher Auflösung entsteht ein
hierarchisches Netz (Abb.8), in dem Unterobjekte (Subobjekte) Teile von
Oberobjekten (Superobjekte) sind. Ein so aufgebautes Netz basiert auf dem Fractal
Net Evolution-Konzept, welches vom wissenschaftlichen Leiter Prof. Dr. Gerd Binnig
bei Definiens entwickelt wurde (Baatz/Schäpe 1999).
Abbildung 8, Hierarchisches Netz bei eCognition
Um dieses Netzwerk mit den einzelnen Objekten aufzubauen, geht eCognition in
mehreren Schritten vor. Als erstes kommt immer die Segmentation (Multiresolution
Segmentation), in der einzelne Objekte aufgrund ihrer physikalischen Eigenschaften
gebildet werden. Im zweiten Schritt werden diese Objekte durch Anwenden von
physikalischen- und/oder Kontextinformationen klassifiziert. Erst danach können die
klassifizierten Objekte wissensbasiert segmentiert (Classification-based
Segmentation) werden. Ab diesen Moment können die drei Verfahren, auf die ich
unten noch weiter eingehe, beliebig eingesetzt werden.

3. eCognition 18
3.1 Multiresolution Segmentation
Die Multiresolution Segmentation produziert, wie oben bereits erwähnt, wissensfreie
Bildobjekte, die in verschiedenen Auflösungen (Resolution) erstellt werden können.
Hinter dieser Segmentation steckt eine heuristische Optimierungs-Prozedur, die
versucht, die durchschnittliche Heterogenität der Bildobjekte bei einer gegebenen
Auflösung über das ganze Bild zu minimieren. Der mathematische Ansatz hierfür
wird unten beschrieben. Bevor die Prozedur durchgeführt wird, müssen einige
Parameter eingestellt werden.
Abb.9, Menü Fenster „Multi Resolution Segmentation“
Im oberen linken Feld des Multiresolution Menü Fensters (Abb. 9) sind die einzelnen
Bild Layer aufgeführt (Punkt 1 und 2). Bei der Segmentierung können die einzelnen
Layer verschieden stark in die Berechnung eingehen. Die Zahl vor einem Bild Layer
zeigt das Gewicht an, mit dem dieser Layer bei der Segmentierung eingeht, wobei

3. eCognition 19
z.B. der Wert 0 die Nichtbeachtung dieses Layers bedeutet. Für den Thermalkanal
von Landsat wäre z.B. aufgrund seiner geringen Auflösung eine Nichtbeachtung
sinnvoll. Hier kann ebenfalls eingestellt werden, ob ein Thematischer Layer (aus
einem GIS) bei der Segmentierung berücksichtigt werden soll oder nicht. Die
Grenzen (z.B. Flurstücksgrenzen aus der ALK) aus dem Thematischen Layer bleiben
beim Gebrauch dieser erhalten, d.h. in diesem Fall, dass ein Objekt nicht in zwei
Flurstücken liegen kann
In dem Fenster Level (Punkt 3) kann die Ebene ausgewählt werden, welche das
Segmentierungsergebnis im hierarchischen Netz einnehmen soll. Die Art der
Segmentation (Punkt 4) ist in den meisten Fällen, so auch bei allen in dieser Arbeit
vorkommenden Fälle, auf Normal eingestellt. Die andere Einstellung wäre eine
Linienanalyse, die auf Subobjekten basiert.
Der Maßstabsparameter (Punkt 5) ist ein abstrakter Wert und kann nicht direkt mit
einen herkömmlichen Bildmaßstab verglichen werden. Vielmehr ist er ein Maß für die
größte erlaubte Heterogenität eines Bildobjektes, wobei ein kleiner Maßstab nur eine
kleine Heterogenität zulässt. Wie und nach welchen Kriterien diese Heterogenität
bzw. die Homogenität berechnet wird, kann im Feld Composition of Homogeneity
Criterion (Punkt 6) genauer definiert werden. Die Homogenität, also die minimale
Heterogenität, wird durch einen Mix aus drei Kriterien berechnet, wobei jedes
Kriterium einzeln gewichtet werden kann. Diese Kriterien sind:
Color (Farbe): Die farbliche oder spektrale Heterogenität ist die Summe der
Standardabweichungen der Spektralwerte in jedem Layer Qc gewichtet mit dem unter
Punkt 1 eingestellten Gewicht für jeden Layer Wc.
� ∗=c
cc QWhC
Smoothness : Die „Glätte“ der Umrisslinie (geringe Randrauhigkeit) eines Objektes
ist ein Maß für die Grenzheterogenität. Diese wird berechnet, indem das Verhältnis
zwischen der Länge der Umrisslinie L eines Objektes zu der Länge der Linie B
bestimmt wird, die die Bounding Box dieses Objektes hat. Die Bounding Box ist ein
das Bildobjekt genau einschließendes Viereck.

3. eCognition 20
BLh S =
Compactness : Die Kompaktheit eines Objektes ist ebenfalls ein Maß für die
Grenzheterogenität. Sie wird bestimmt durch die Länge der Umrisslinie L geteilt
durch die Wurzel aus der Anzahl der Pixel N des Objektes.
NLhK =
Zusammen mit den einzelnen Gewichten ni für die Kriterien lautet die Formel für die
Heterogenität:
KKSSCC hnhnhnh ⋅+⋅+⋅=
Vor der ersten Segmentierung muss man sich entscheiden, ob man mit einer 4-fach
Nachbarschaft oder einer 8-fach (diagonal) Nachbarschaft arbeiten will (Punkt 7,
Abb.10). Diese Entscheudung gilt für das ganze Projekt und kann später nicht mehr
geändert werden. Nach Einstellen aller Parameter kann die „Multiresolution
Segmentation“ gestartet werden.
8-fach Nachbarschaft 4-fach Nachbarschaft
1 Objekt 2 Objekte Abb.10, Nachbarschaft

3. eCognition 21
3.2 Klassifikation
Die Klassifizierung der segmentierten Objekte erfolgt bei eCognition überwacht. Zur
Beschreibung der einzelnen Klassen für die überwachte Klassifizierung wird die
sogenannte „Class Hierarchy“ verwendet. In dieser Class Hierarchy können neben
den spektralen und geometrischen Eigenschaften auch wissensbasierte
Kontextinformationen zur Klassifizierung beschrieben werden. Ein weiterer
grundlegender Ansatz für die Klassifizierung bei eCognition ist die Verwendung von
Fuzzy Logic. Bei dem Fuzzy Logic Ansatz gibt es für bestimmte Merkmalswerte (z.B.
Spektralwerte) eines Objektes nicht nur die beiden Aussagen „nein“ (0) und „ja“ (1)
zu einer Klassenzuordnung, sondern die Aussagen reichen von 0 bis 1
(Zuweisungswert) und geben so die Wahrscheinlichkeit einer Klassenzugehörigkeit
an. Auf diese Weise können verschiedene Objektmerkmale, wie Spektralwert und
Geometrie, aber auch wissensbasierte Kontextinformationen, miteinander verglichen
und in Beziehung gebracht werden. Um die einzelnen Merkmalswerte in einen
Fuzzy-wert zu übersetzen, benutzt diese Software zwei Arten von
Klassifizierungsalgorithmen: Membership Function (Zugehörigkeitsfunktion) und
Nearest Neighbor. Der Nearest Neighbor Klassifikator wird in der Literatur meistens
Minimum Distance Klassifikator bezeichnet.
3.2.1 Membership Function
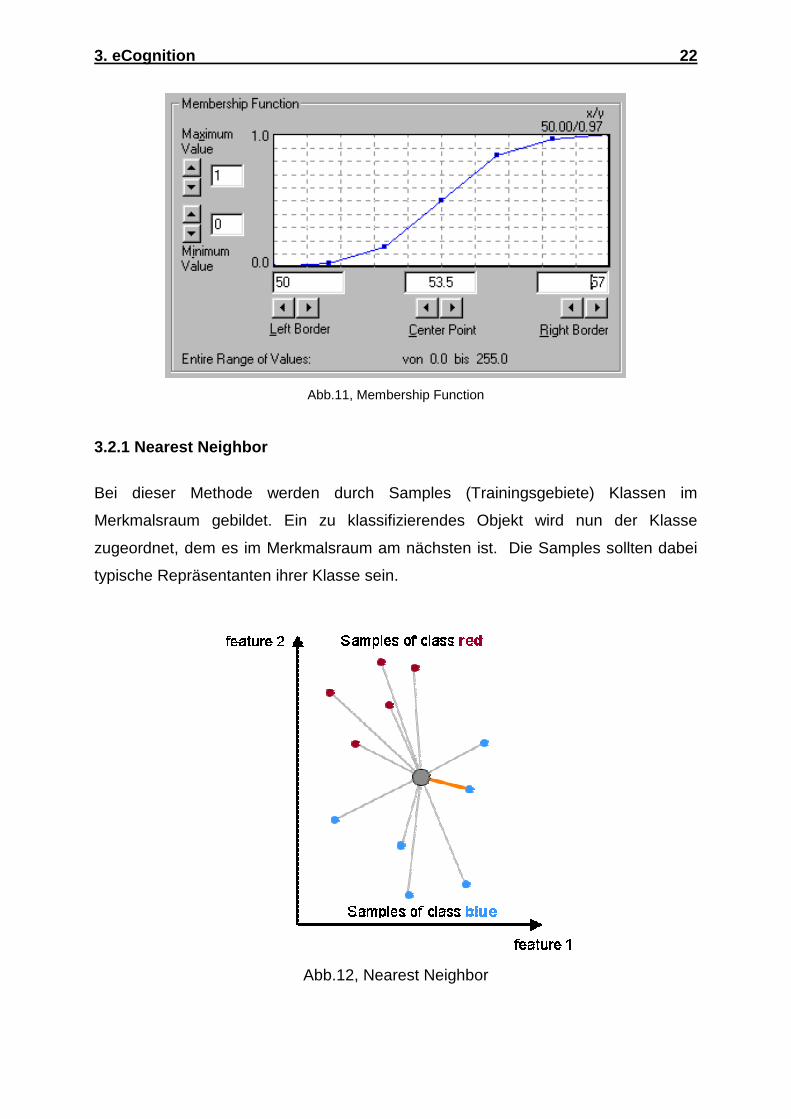
Eine Zugehörigkeitsfunktion ist eine einfache Methode, Merkmalswerte in einen
Zuweisungswert zu transformieren. Jedem Merkmalswert wird einfach ein
Zuweisungswert zugeordnet. In dem Beispiel Abb.11 werden die Spektralwerte
[0,255] den Zuweisungswerten [0,1] direkt zugeordnet. Die Spektralwerte kleiner als
50 haben den Wert 0, über 57 haben sie den Wert 1 und dazwischen folgt der Wert
der Zuordnungskurve. Bei der Membership Funktion können neben spektralen und
geometrischen Eigenschaften auch Kontextinformationen zur Klassifizierung genutzt
werden. Sind Samples für Klassen bestimmt worden, so können die
Zuweisungsfunktionen auch vom Programm berechnen werden.
3. eCognition 22
Abb.11, Membership Function
3.2.1 Nearest Neighbor
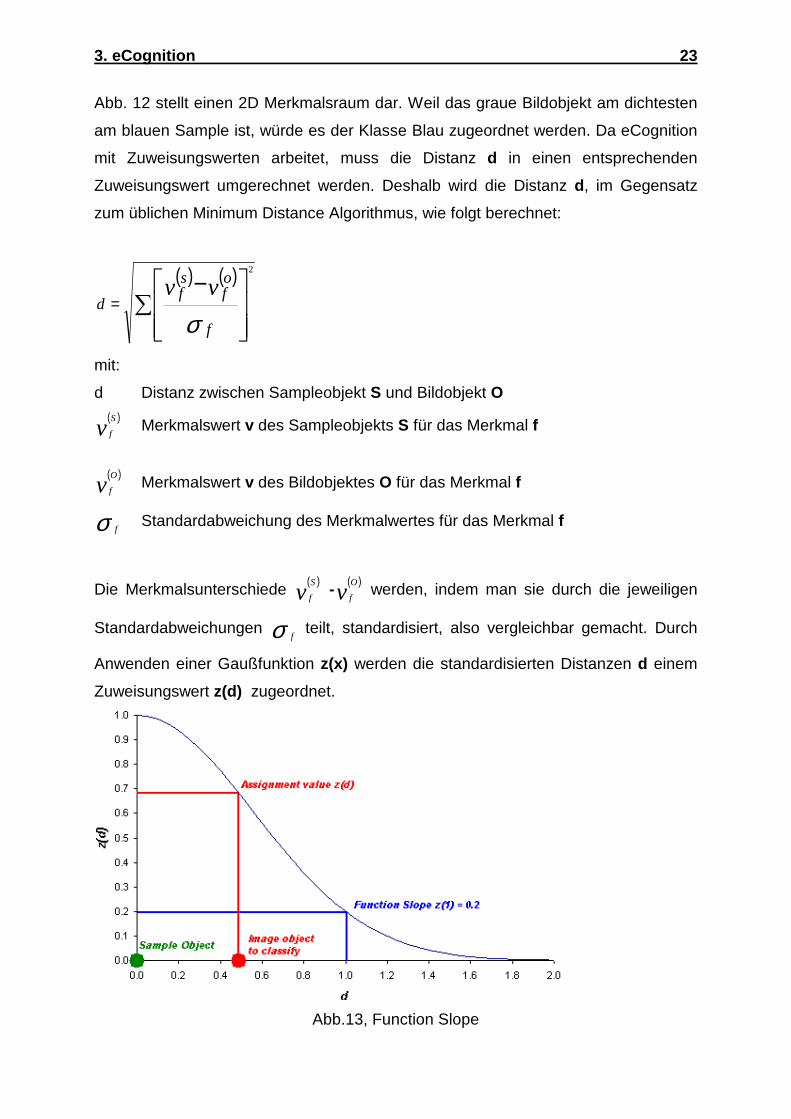
Bei dieser Methode werden durch Samples (Trainingsgebiete) Klassen im
Merkmalsraum gebildet. Ein zu klassifizierendes Objekt wird nun der Klasse
zugeordnet, dem es im Merkmalsraum am nächsten ist. Die Samples sollten dabei
typische Repräsentanten ihrer Klasse sein.
Abb.12, Nearest Neighbor
3. eCognition 23
Abb. 12 stellt einen 2D Merkmalsraum dar. Weil das graue Bildobjekt am dichtesten
am blauen Sample ist, würde es der Klasse Blau zugeordnet werden. Da eCognition
mit Zuweisungswerten arbeitet, muss die Distanz d in einen entsprechenden
Zuweisungswert umgerechnet werden. Deshalb wird die Distanz d, im Gegensatz
zum üblichen Minimum Distance Algorithmus, wie folgt berechnet:
( ) ( )�
���
�
���
� −=
σ f
of
sf
dvv
2
mit:
d Distanz zwischen Sampleobjekt S und Bildobjekt O ( )v S
f Merkmalswert v des Sampleobjekts S für das Merkmal f
( )v O
f Merkmalswert v des Bildobjektes O für das Merkmal f
σ f Standardabweichung des Merkmalwertes für das Merkmal f
Die Merkmalsunterschiede ( )v S
f - ( )v O
f werden, indem man sie durch die jeweiligen
Standardabweichungen σ f teilt, standardisiert, also vergleichbar gemacht. Durch
Anwenden einer Gaußfunktion z(x) werden die standardisierten Distanzen d einem
Zuweisungswert z(d) zugeordnet.
Abb.13, Function Slope

3. eCognition 24
Die Gaußkurve kann durch verändern der „Function Slope“ Einstellung beliebig
gestreckt oder gestaucht werden. In Abb.13 ist die Default Einstellung zu sehen mit
z(1)=0,2. 3.3 Class Hierarchy Auf die Class Hierarchy baut die gesamte Klassifizierung auf. In der Class Hierarchy
werden die einzelnen Klassen gebildet und mit ihren Merkmalen beschrieben.
Welche Merkmale dies sein können, wird unter dem Punkt
„Klassifizierungsmerkmale“ genauer erläutert. Die Beziehungen zwischen den
einzelnen Klassen werden ebenfalls in der Class Hierarchy definiert. Hierbei
unterscheidet eCognition zwischen zwei Arten von Beziehungen und besitzt
deswegen auch zwei Hierarchien.
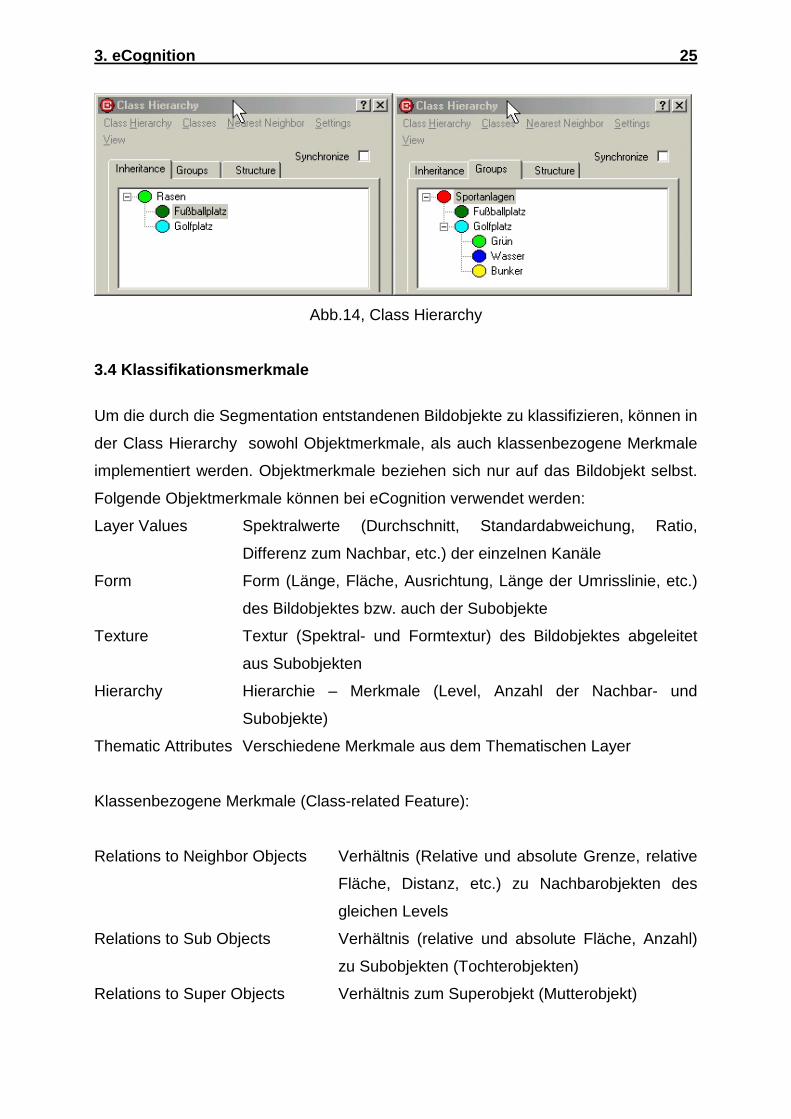
Die erste Hierarchie ist die „Inheritance“ (Vererbung), in ihr werden von Mutterklasse
zur Tochterklasse Klassifikationsmerkmale vererbt. Wäre z.B. ein Fußballplatz und
ein Golfplatz zu klassifizieren, würde man zuerst eine Mutterklasse „Rasen“ bilden,
die z.B. durch Spektralmerkmale klassifiziert würde. Wenn man jetzt die Klassen
„Fußballplatz“ und „Golfplatz“ zu Tochterklassen von „Rasen“ macht (Abb.14),
kriegen sie auch die Spektralattribute vererbt. „Fußballplatz“ und „Golfplatz“ brauchen
jetzt z.B. nur noch Formmerkmale, um klassifiziert zu werden.
Hinter „Groups“ (Gruppe) steckt die zweite mögliche Beziehungsart von
verschiedenen Klassen. Hierbei handelt es sich um semantische Beziehungen von
Klassen, die verschiedene Klassifizierungsmerkmale haben, deswegen werden auch
keine Merkmale an Tochterklassen vererbt. Im oben genannten Beispiel könnten die
Tochterklassen „Fußballplatz“ und „Golfplatz“ der Mutterklasse „Sportanlagen“
untergegliedert werden. Die Klasse „Golfplatz“ könnte ihrerseits die Tochterklassen
„Grün“, „Bunker“ , „Wasser“ etc. haben (Abb.14).
Eine dritte Klassen-Hierarchie ist die „Structure“ – Hierarchy. Während die oben
genannten Hierarchien zur Klassifizierung genutzt werden, werden in der „Structure“
– Hierarchy die Klassen ausgewählt und wahlweise zusammengefasst, die zur
wissensbasierten Segmentierung (Classification-based Segmentation) verwendet
werden.
3. eCognition 25
Abb.14, Class Hierarchy
3.4 Klassifikationsmerkmale Um die durch die Segmentation entstandenen Bildobjekte zu klassifizieren, können in
der Class Hierarchy sowohl Objektmerkmale, als auch klassenbezogene Merkmale
implementiert werden. Objektmerkmale beziehen sich nur auf das Bildobjekt selbst.
Folgende Objektmerkmale können bei eCognition verwendet werden:
Layer Values Spektralwerte (Durchschnitt, Standardabweichung, Ratio,
Differenz zum Nachbar, etc.) der einzelnen Kanäle
Form Form (Länge, Fläche, Ausrichtung, Länge der Umrisslinie, etc.)
des Bildobjektes bzw. auch der Subobjekte
Texture Textur (Spektral- und Formtextur) des Bildobjektes abgeleitet
aus Subobjekten
Hierarchy Hierarchie – Merkmale (Level, Anzahl der Nachbar- und
Subobjekte)
Thematic Attributes Verschiedene Merkmale aus dem Thematischen Layer
Klassenbezogene Merkmale (Class-related Feature):
Relations to Neighbor Objects Verhältnis (Relative und absolute Grenze, relative
Fläche, Distanz, etc.) zu Nachbarobjekten des
gleichen Levels
Relations to Sub Objects Verhältnis (relative und absolute Fläche, Anzahl)
zu Subobjekten (Tochterobjekten)
Relations to Super Objects Verhältnis zum Superobjekt (Mutterobjekt)

3. eCognition 26
Ein vollständige Auflistung aller zur Verfügung stehenden Klassifikationsmerkmale
und deren genauen Funktionsweisen sind im User Guide von eCognition unter „Basic
Concepts“ zu finden. Mit dem Hilfsmittel Feature View kann man sich die Werte der
einzelnen Merkmale für ein aktuelles Bild anzeigen lassen.
Da zur Klassifizierung in der Regel mehrere Klassifikationsmerkmale benötigt
werden, müssen diese durch Operatoren verbunden werden. eCognition besitzt fünf
Operatoren:
and (min) Der kleinste Zuweisungswert wird zurückgegeben
and (*) Produkt aus den einzelnen Zuweisungswerten
or (max) Der größte Zuweisungswert wird zurückgegeben
mean (arithm.) Arithmetischer Durchschnitt aller Zuweisungswerte
mean (geo) Geometrischer Durchschnitt aller Zuweisungswerte
Die einzelnen Operatoren können beliebig miteinander verwendet werden. Würde
man z.B. mit Hilfe der Operatoren einen Apfel beschreiben wollen, so könnte das
Ergebnis so aussehen:
Abb.15, Operatoren
Der Apfel ist rund und süß. Und er ist entweder Grün oder Rot aber nicht Gelb.
Sind einzelne Klassen gebildet und in das hierarchische Netzwerk eingebaut, kann
die überwachte Klassifizierung durchgeführt werden. Hierbei können einzelne oder
alle Level, wahlweise mit oder ohne klassenbezogener Merkmale, klassifiziert
werden, wobei klassenbezogene Merkmale nur auf eine schon vorhandene
Klassifikation wirken können. Bei der klassenbezogenen Klassifizierung stellt es ein
Problem dar, wenn die Klassifikation eines Objektes von der Klassifikation anderer
Objekte abhängt und sie selbst die Klassifikation der anderen Objekte beeinflusst.
Generell ist zu vermeiden, dass Klasse A für Klasse B und gleichzeitig Klasse B für

3. eCognition 27
Klasse A wichtigstes Klassifizierungsmerkmal ist, aber Ringverbindungen lassen sich
nicht immer ausschließen. Deswegen muss bei der klassenbezogenen
Klassifizierung die Anzahl der Iterationen mit angegeben werden.
3.5 Classification-based Segmentation (Klassenbasierende Segmentierung)
Zur klassenbasierenden Segmentierung von Bildobjekten stellt eCognition drei
klassenbasierende Operatoren zur Verfügung: die Fusion und die von den
Tochterobjekten abhängige Grenzkorrektion, die ihrerseits aus der Grenzoptimierung
und der Bildobjekt-Extraktion besteht. Grundlage für die Operatoren sind nicht die
Klassen, sondern die in der Class Hierarchy definierten Strukturen. Eine Struktur
kann aus einer oder mehreren Klassen bestehen.
Klassenbasierende Fusion Das Prinzip dieser Fusion ist einfach. Alle Bildobjekte die zu einer Struktur gehören
werden zusammen gefasst und bilden ein neues großes Bildobjekt.
Bildobjekte vor der Fusion
Bildobjekte nach der Fusion:
(Farben stehen für einzelne Strukturen)
Klassenbasierende Grenzkorrektion Die Grenzkorrekturen sorgen dafür, dass Subobjekte zur gleichen Struktur gehören
wie ihr Superobjekt.
Klassenbasierende Grenzoptimierung

3. eCognition 28
Die Regel für diesen Operator lautet: Subobjekte, die an der Grenze von
Superobjekten liegen und einer anderen Struktur als ihr Superobjekt angehören,
werden danach untersucht, ob ein Nachbarobjekt und das Superobjekt des
Nachbarobjekts der gleichen Struktur angehören. Ist dies der Fall, wird das
Subobjekt der anderen Struktur zugeordnet und die Grenzen der Superobjekte neu
berechnet.
Vor der Optimierung:
Nach der Optimierung:
Klassenbezogene Bildobjekt Extraktion Während bei der Optimierung nur die Grenzen der Superobjekte verschoben wurden,
werden bei der Extraktion neue Superobjekte gebildet. Die Regel für diesen Operator
lautet: Gehört ein Subobjekt nicht zur gleichen Struktur wie sein Superobjekt, so
bildet es ein neues Superobjekt.
Vor der Extraktion:

3. eCognition 29
Nach der Extraktion:
Nachdem ich das Grundkonzept der Segmentierung und Klassifizierung bei
eCognition beschrieben habe, möchte ich nun weitere wichtige Bausteine der
Software erwähnen. Standardanwendungen für Bildanalyse Software wie eine Lupe
oder die Farbzuweisungsmöglichkeiten für einzelne Kanäle etc. werden nicht
aufgeführt
3.6 Protocol Editor
Um Arbeitsschritte zu automatisieren, besitzt eCognition den Protocol Editor, in dem
Arbeitsabläufe gespeichert, ausgeführt und editiert werden können. Mit Hilfe des
Protokolls können die Arbeitsschritte bei verschiedenen Bildern und auch
unterschiedlichen Projekten angewandt werden. Zu denen vom Protokoll
gespeicherten Arbeitsschritten gehören: die verschiedenen Segmentierungs-
verfahren, das Löschen eines Levels aus der Hierarchie, das Laden einer Class
Hierarchy und das Klassifizieren.
3.7 Import und Export von Bildern und Daten eCognition kann alle gängigen Rasterformate importieren. Besitzen die Rasterbilder
Attribute (aus einem GIS), so können sie als Thematic Layer importiert werden, und
die Attribute können im Programm genutzt werden. Rasterbilder können ebenfalls als
TTA (Training and Test Area) genutzt werden. Hierbei dienen die Flächen des

3. eCognition 30
Rasterbildes entweder zur Festlegung von Trainingsgebieten für Samples oder als
Testflächen zur Überprüfung des Klassifikationsergebnisses. Bilder in Vektorformat
kann eCognition nicht verarbeiten.
Das Klassifikationsergebnis kann auf zwei Arten exportiert werden. Eine Möglichkeit
ist, dass jedes Bildobjekt eine eigene ID bekommt und dann dieser ID in der Attribute
Table das Klassifikationsergebnis und andere Merkmale des Bildobjektes
zugewiesen wird. Die andere Option ist, dass alle Bildobjekte, die einer Klasse
angehören, die gleiche ID bekommen und dass der ID nur noch die Farbe und der
Name der Klasse zugewiesen wird. Außerdem kann jeder Zeit das aktuelle Bild als
„Tif“ -Format exportiert werden.
3.8 Genauigkeitsanalyse
eCognition stellt zum Genauigkeitsabschätzung vier Methoden zur Verfügung:
Best Classification Result:
In der Regel besitzt jedes Bildobjekte mehrere Zuweisungswerte größer null. Das
Bildobjekt bekommt dann die Klasse mit dem größten Zuweisungswert (Best
Classification Result) zugeordnet. Dieser größte Zuweisungswert kann zwischen 0
und 100 Prozent liegen. Best Classification Result erstellt ein Thematisches Bild, in
dem für jedes Bildobjekt, farblich nach den prozentualen Anteil eingefärbt, der
Zuweisungswert abgebildet ist. Außerdem wird eine Tabelle erstellt, in der für jede
Klasse die Anzahl der Klassen, der kleinste und der größte Zuweisungswert, sowie
der Mittelwert mit Standardabweichung aufgelistet ist.
Classification Stability:
Unter Klassifikationsstabilität versteht eCognition wie sicher die Klassenzuweisung
im Vergleich zu anderen möglichen Zuweisungen ist. Dabei wird die Differenz
zwischen dem besten und zweitbesten Zuweisungswert für ein Bildobjekt gebildet.
Die Größe der Differenz wird sowohl Objektbezogen in einem Thematischen Bild
farblich skaliert dargestellt, als auch Klassenbezogen in einer Tabelle, zusammen mit
der Standardabweichung der Differenzen und den Maximalwerten, aufgelistet.
Error Matrix based on TTA Mask :

3. eCognition 31
Diese „Fehlermatrix” wird auch Konfusionsmatrix genannt. In dieser Matrix werden
die Ergebnisse der Klassifikation mit Testflächen verglichen. Die Testflächen, die als
TTA (Training und Test Area) vorher importiert wurden (s.o.), werden dabei als wahre
Ergebnisse im Sinne der Klassifikationsregeln angesehen. Das Berechnen der
Konfusionsmatrix mit Testflächen geschieht Pixel für Pixel. Aus der Konfusionsmatrix
kann man entnehmen, wieviel Prozent einer Klasse der Testfläche einer Klasse der
Klassifikation zugeordnet wurde. Aufgrund des Aufbaues einer Konfusionsmatrix
kann man aus ihrer Hauptdiagonalen für jede Klasse den Prozentsatz der richtigen
Klassifikation entnehmen.
Abb.16, Fehlermatrix
Aus dem Beispiel für eine Konfusionsmatrix (Abb.16) ist z.B. zu entnehmen, dass die
Klasse „water“ zu 100% und die Klasse „agriculture“ zu 91,4% richtig zugeordnet
wurde. 8.3% der Klasse „agriculture“ wurde als „rural“ klassifiziert.
Abb.17, Kartierung der korrekt klassifizierten Gebiete

3. eCognition 32
Außerdem wird ein Bild (Abb.17) erzeugt, in dem zu sehen ist, welche Flächen
korrekt und welche Flächen falsch klassifiziert wurden. Die Farbe Grün bedeutet
richtig erkannt, Rot falsch und bei Blau gab es keine Testflächen.
Error matrix based on Samples:
Die Konfusionsmatrix wird durch Vergleich der Sampleobjekte und der klassifizierten
Bildobjekte erstellt. Die Samples sollten andere sein als die, die für Nearest Neighbor
verwendet wurden, weil diese naturgemäß alle richtig klassifiziert wurden.
3.9 Bildstatistik
Die Bildstatistik ermöglicht dem Nutzer, sich für jede Klasse Klassifikationsmerkmale
anzeigen zu lassen. Für jedes Klassifikationsmerkmal kann die Summe, der
Mittelwert, die Standardabweichung und der Wertebereich aus den Merkmalswerten
der einzelnen Objekte einer Klasse gebildet werden. Auf diese Weise kann z.B.
schnell ermittelt werden, wie groß die Gesamtfläche einer Klasse ist oder wie groß
die Flächen dieser Klasse im Schnitt sind. Auch ist schnell zu ermitteln, wie groß der
größte und kleinste Spektralwert einer Klasse für einen bestimmten Kanal ist.

4. Projekt 1 33
4. Untersuchungen zur Verwendbarkeit von eCognition für Zwecke der CORINE Landnutzungsklassifikation
In den vorangegangenen Kapiteln wurde beschrieben, wie Daten von CLC90 erfasst
wurden und wie die Daten von CLC2000 erfasst werden sollen. Außerdem wurde die
neue Bildverarbeitungssoftware eCognition vorgestellt. Da die Herstellungskosten
von 6 Euro/km² bei CLC90 auf 3 Euro/km² bei CLC2000 halbiert werden sollen, die
Zeit zwischen Erfassen und Bereitstellen der Daten stark verkürzt werden soll und
die Technik sich weiterentwickelt hat, ist eine Überlegung, den kosten- und
zeitintensivsten Schritt, also die eigentliche Klassifizierung, bei der Erstellung von
CLC2000 Daten zu automatisieren oder zu halbautomatisieren.
Um CLC2000 Daten zu erstellen, stehen wie erwähnt die alten CLC90 Daten, die
Landsat Szenen und in Deutschland die ATKIS Daten zur Verfügung. Als
Endergebnis sollen dann neben CLC2000 auch die Landnutzungsänderungen
zwischen 1990 und 2000 bereitstehen. Die automatisierte Erfassung der
Landnutzungsänderungen soll in dieser Arbeit nicht untersucht werden.
Landsat Daten sind die Hauptinformationsträger. Deshalb wird in einem ersten Schritt
(Projekt 1: Klassifikation mit Landsat Szenen) überprüft, in wieweit mit Hilfe von
eCognition aus Landsat Szenen CORINE Daten abgeleitet werden können. Erst im
zweiten Schritt (Projekt 2: Klassifikation mit Landsat Szenen und ATKIS Daten)
werden auch ATKIS Daten als Zusatzinformationen genutzt. Die CLC90 Ergebnisse
werden nicht als Informationsträger für eine Klassifizierung herangezogen, weil sie
aufgrund ihres Alters für die CLC2000 Klassifikation nicht Aktuell genug sind. Sie
werden nur für das spätere Erfassen von Landnutzungsänderungen zwischen CLC90
und CLC2000 genutzt.
4.1 Projekt 1: Klassifikation mit Landsat Szenen
4.1.1 Eingangsdaten
Wenn überprüft werden soll, ob eine Prozedur zum korrekten Ergebnis kommt, ist es
ideal, wenn man das Ergebnis schon kennt. Da für CORINE mit CLC90 schon ein
Ergebnis vorliegt, ist es sinnvoll, dieses für eine spätere Kontrolle zu benutzen. Als
Ausgangsdaten werden jetzt solche verwendet, die den damaligen Ausgangsdaten
entsprechen. Die Landsat-Szene (Abb.18), die zur Klassifizierung der vorliegenden

4. Projekt 1 34
CORINE Daten führte, stammt vom 26.05.1992. Es ist eine Aufnahme des Landsat
TM 5 Satelliten mit 7 Kanälen. Die Szene zeigt den südlichen Teil der Stadt
Hannover und Teile des südlichen Umlandes. Ihr Ausmaß beträgt 12,5 * 12,5
Quadratkilometer und die Pixelauflösung ist 25 m (resampled). Die CORINE Szene
(Abb.19) zeigt das gleiche Gebiet mit den selben Abgrenzungen. Um die CORINE
Daten für eCognition nutzbar zu machen, müssen sie erst gerastert werden. Die
Rasterweite muss mit der Rasterweite von Landsat identisch sein, also 25 m. In
dieser CORINE Szene kommen 11 Klassen aus der CORINE Nomenklatur vor. Dies
erscheint auf dem ersten Blick, in Anbetracht von 44 Klassen der CORINE
Nomenklatur, recht wenig zu sein. Hierbei ist aber zu bedenken, dass viele Klassen
in Deutschland überhaupt nicht vorkommen und einige nur sehr selten auftreten.
Diese Ausgangsdaten wurden ausgewählt, weil für dieses Gebiet auch Landsat-
Daten von 2000 vorliegen und zwischen den Aufnahmezeitpunkten relativ große
Landnutzungsänderungen aufgetreten sind (EXPO Gelände).
Abb.18, Landsat 5 (Kanäle: 4-3-2)

4. Projekt 1 35
Abb. 19, CORINE Land Cover 90
4.1.2 Probleme bei der Klassifikation von Landsat Daten
Bei der Klassifikation von Bodenbedeckungsarten aus Landsat Daten treten eine
Reihe von Problemen auf. Die relativ großen Pixel von 25m*25m haben zur Folge,
dass unterschiedliche Objekte innerhalb eines erfassten Pixels in ihren spektralen
Eigenschaften nur gemittelt wiedergegeben werden. Das heißt, wenn innerhalb eines
Pixels zwei Objekte liegen, eines mit dem Grauwert 120 (z.B. Ackerfläche) und eines
mit dem Grauwert 190 (z.B. Wald) würde dieses Pixel den Wert 155 (sog. Mixel)
erhalten. Diese Mittelung erschwert die Zuordnung zu den korrekten Objekttypen.
Auch inkorrekte Zuordnungen können so entstehen, wenn z.B. der Wert 155 für
Wasser stehen würde. Die Kombination von mehreren Kanälen kann die Zuordnung
zwar wieder erleichtern und verringert die Wahrscheinlichkeit der inkorrekten
Zuordnung, das Problem bleibt aber erhalten.

4. Projekt 1 36
Ein weiterer Nachteil der großen Pixelgröße ist, dass Objekte, deren Ausdehnung
kleiner als 25 m ist und die zur Klassifikation wichtig wären, nicht erfasst werden
können. Ein Beispiel. Die Klasse 1.1.2 nicht durchgängig städtische Prägung
repräsentiert z.B. ein Gebiet von Einfamilienhäusern, Vorgärten und Ortsstraßen. Die
Klassifizierung dieser Klasse wäre einfach, wenn die einzelnen Objekte (Häuser,
Straßen) direkt erkannt werden könnten. Dieses ist aber nicht der Fall, weil die
Ausdehnung dieser einzelnen Objekte meistens kleiner als 25 m ist.
Geometrische Eigenschaften von Objekten können generell erst dann genutzt
werden, wenn ein bestimmtes Verhältnis von Objektgröße und Objektform zur
Pixelgröße vorhanden ist. Zur Erläuterung: Flächenhafte Objekte, deren Größe ein
vielfaches der Pixelgröße beträgt, bestimmen den spektralen Wert mehrerer
nebeneinander liegender Pixel. In der Mitte der Fläche entsprechen die
Spektralwerte in den Pixeln genau den Spektralwerten des Objektes (keine Mixel).
An dem Rand des Objektes entstehen, durch die Mittelung des Spektralwertes mit
den Spektralwerten aller Objekte im Pixel, Mixel (Ausnahme: Objekt- und Pixelrand
sind identisch). Diese Mixel und die Pixel im Zentrum repräsentieren die Geometrie
des Objektes. Weil Landsat eine Pixelgröße von 625 m2 (25 m * 25 m) hat und die
Objektgröße abhängig von der Objektform ein vielfaches der Pixelgröße sein muss,
muss ein Objekt mehrere tausend Quadratmeter groß sein, bevor die Form zur
Erfassung genutzt werden kann. Die Erkennbarkeit von Objekten im Satellitenbild
hängt außerdem noch vom Kontrast zu Nachbarobjekten (möglichst groß), von der
Objektform (Linienhafte Objekte werden z.B. oft besser erkannt) und der Lage des
Objektes im Vergleich zur Pixelausrichtung ab.
4.1.3 Segmentierung
Die bei der Segmentierung entstehenden Objekte sind die Informationsträger für die
spätere Klassifizierung. Deswegen muss beim Einstellen der Parameter für die
Segmentierung bedacht werden, welche Klassen später klassifiziert werden sollen
und vor allem auf welche Weise sie klassifiziert werden können. Die vor der
Segmentierung (im Kapitel eCognition erklärt) einzustellenden Parameter sind:
• Auswahl der Kanäle
• Maßstab (abgeleitet aus Homogenitätskriterien)
• Level in der Hierarchie
• Auswahl zwischen 4- und 8-fach Nachbarschaft
4. Projekt 1 37
4.1.3.1 Auswahl der zur Segmentierung benutzten Kanäle
Je mehr Kanäle von Landsat zur Segmentierung benutzt werden, um so länger
dauern die Berechnungen. Bei der in diesem Projekt benutzten relativ kleinen
Bildszene ist dieser Effekt nicht so ausgeprägt und fast zu vernachlässigen, aber mit
Hinblick auf spätere Anwendungen mit viel größeren Szenen ist es sinnvoll zu
überlegen, wie viele und welche Kanäle benutzt werden. Kanal 6 kann man aufgrund
seiner geringen Auflösung von der Segmentierung ausschließen. Bei den anderen
Kanälen wird überprüft in wieweit sie untereinander korreliert sind. Sind zwei oder
mehrere Kanäle stark korreliert, kann ein Kanal den bzw. die Anderen
repräsentieren, ohne dass große Informationsverluste auftreten. Die Berechnung der
spektralen Korrelation zwischen zwei Kanälen erfolgt im Merkmalsraum. Mit dem
Tool von eCognition „2D Feature Space Plot“ (2D Plot des Merkmalraums) können
Merkmale miteinander in Beziehung gebracht werden. Vergleicht man jetzt die
Spektralwerte verschiedener Kanäle auf diese Weise ergeben sich z.B. folgende
Abbildungen:
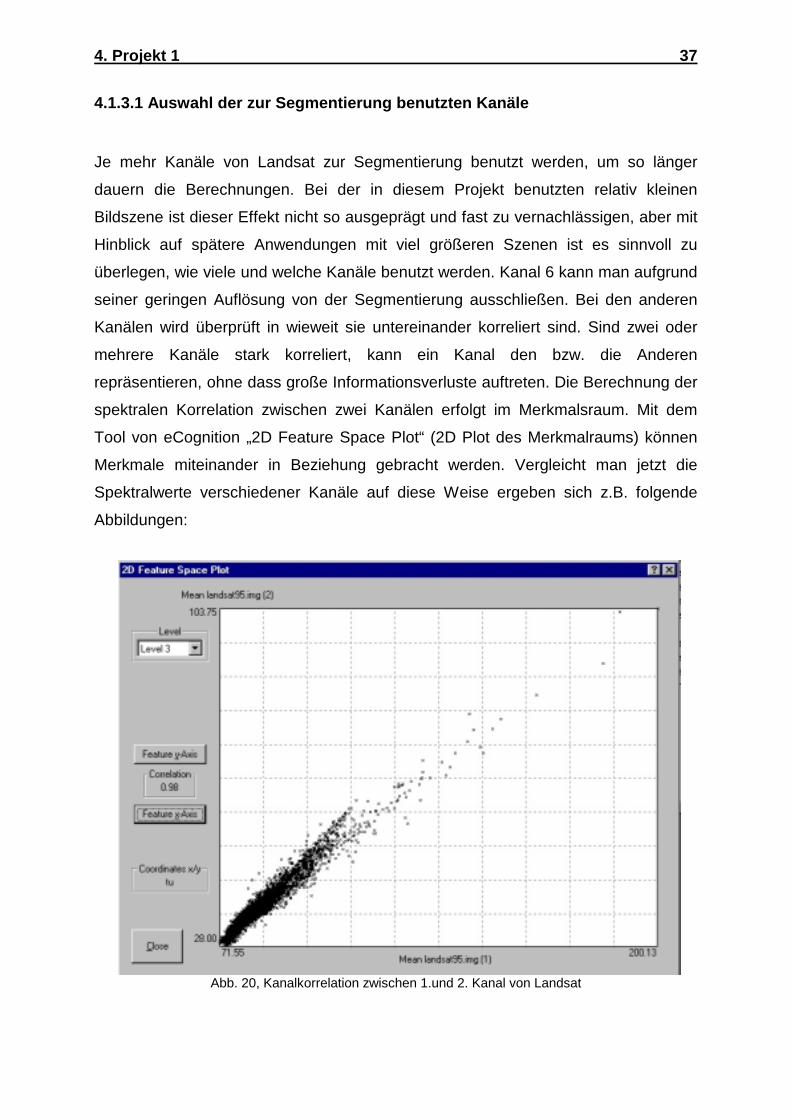
Abb. 20, Kanalkorrelation zwischen 1.und 2. Kanal von Landsat
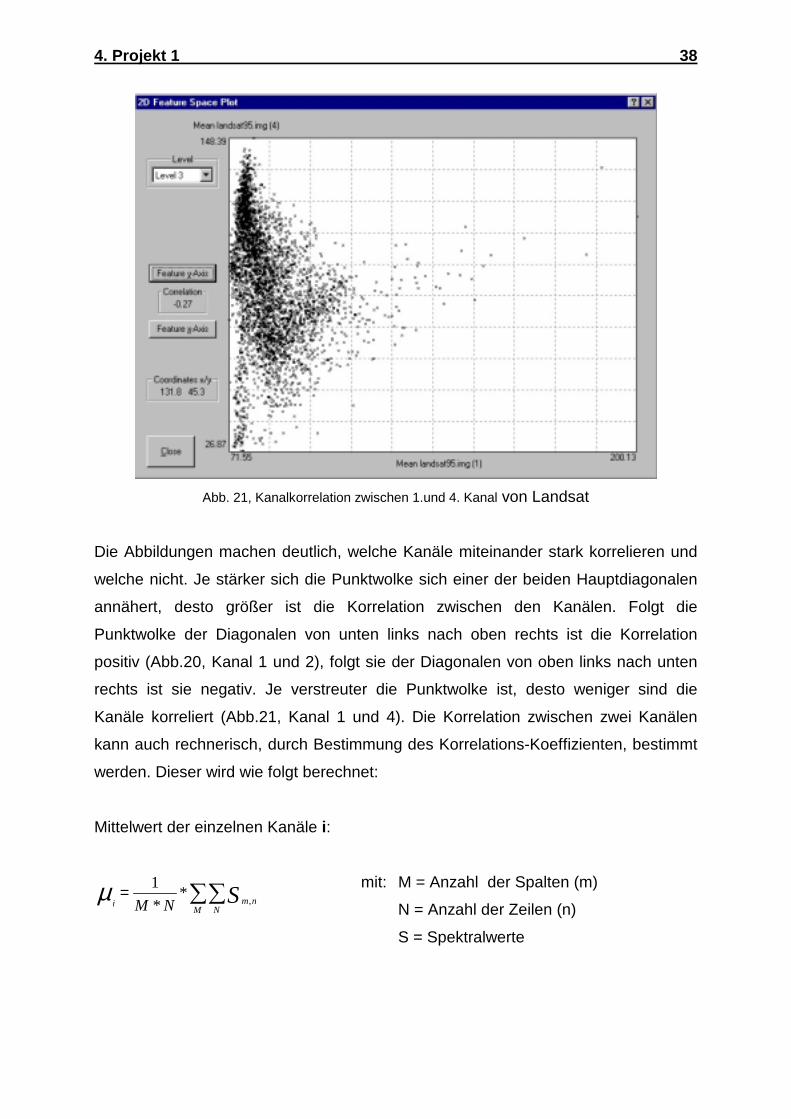
4. Projekt 1 38
Abb. 21, Kanalkorrelation zwischen 1.und 4. Kanal von Landsat
Die Abbildungen machen deutlich, welche Kanäle miteinander stark korrelieren und
welche nicht. Je stärker sich die Punktwolke sich einer der beiden Hauptdiagonalen
annähert, desto größer ist die Korrelation zwischen den Kanälen. Folgt die
Punktwolke der Diagonalen von unten links nach oben rechts ist die Korrelation
positiv (Abb.20, Kanal 1 und 2), folgt sie der Diagonalen von oben links nach unten
rechts ist sie negativ. Je verstreuter die Punktwolke ist, desto weniger sind die
Kanäle korreliert (Abb.21, Kanal 1 und 4). Die Korrelation zwischen zwei Kanälen
kann auch rechnerisch, durch Bestimmung des Korrelations-Koeffizienten, bestimmt
werden. Dieser wird wie folgt berechnet:
Mittelwert der einzelnen Kanäle i:
��=M N
nmi SNM ,*
*1µ mit: M = Anzahl der Spalten (m)
N = Anzahl der Zeilen (n)
S = Spektralwerte

4. Projekt 1 39
Standardabweichung der einzelnen Kanäle:
( )�� −−
=M N
i inmNM S µσ ,1*1 22
Kovarianz aus zwei Kanälen:
( ) ( )µµσ 2,,21,,12,11 * −−=�� SS nmM N
nm
Korrelationskoeffizient aus zwei Kanälen:
σσσρ 2
2
2
1
2,1
2,1 +=
Die Tabelle in Abb.21 zeigt die Korrelationskoeffizienten für alle möglichen
Kanalkombinationen: Die Koeffizienten sind mit 100 multipliziert, um eine
anschaulichere Darstellung in Prozenten zu haben.
Kanal 1 2 3 4 5 7
1 100% 98% 95% -27% 60% 78%
2 98% 100% 98% -19% 75% 84%
3 95% 98% 100% -28% 78% 90%
4 -27% -19% -28% 100% 10% -21%
5 60% 75% 78% 10% 100% 92%
7 78% 84% 90% -21% 92% 100% Abb.21, Korrelation zwischen den Kanälen
Die Koeffizienten in der Tabelle machen deutlich, dass die Kanäle 1, 2 und 3
(Sichtbares Licht) hoch miteinander korreliert sind. Außerdem ist der 7. Kanal mit
dem 3. und 5. Kanal hoch korreliert. Der 4. Kanal ist am wenigsten mit anderen
Kanälen korreliert. Daraus wird ersichtlich, dass die Kanäle 3, 4 und 5 alle 7 Kanäle
von Landsat 5 bei der Segmentierung genügend repräsentieren.

4. Projekt 1 40
Eine Alternative zu dem oben genannten Verfahren wäre eine Hauptkomponenten
Transformation der Landsat Szene. Das Ergebnis einer Hauptkomponenten
Transformation sind unkorrelierte Kanäle, die nach ihren abnehmenden Varianzen
sortiert sind. Der erste Kanal, auch erste Hauptkomponente genannt, besitzt
demnach die maximale Streuung der Grauwerte und somit auch die meiste
Bildinformation. Bereits beim 4. bzw. 5. Kanal (Hauptkomponente), so die
Erfahrungswerte bei Landsat Szenen, ist die Varianz so niedrig, dass der
Informationsgehalt dieser Kanäle gegen null geht. Eine Alternative zu dem Gebrauch
aller 7 Kanäle von Landsat, wäre also der Gebrauch der ersten drei oder vier
Hauptkomponenten dieser Szene. Die theoretisch-mathematische Funktionsweise
der Hauptkomponenten Transformation kann bei Krauss (1990) nachgelesen
werden.
4.1.3.2 Maßstab und Hierarchie
Bevor ein Segmentierungsmaßstab ausgewählt wird, muss überlegt sein, welche
Eigenschaften relativ kleine bzw. relativ große Objekte besitzen.
Der Grauwert des Segments wird aus den Grauwerten der einzelnen Pixel gemittelt.
Dadurch entstehen ähnliche Auswirkungen, wie bei der Mittelung der Spektral-
Informationen für ein Pixel. Ein Objekt, dass aus Pixel mit dem Grauwerten 100
(steht z.B. für Ackerland) und aus Pixel mit dem Grauwert 120 (steht z.B. für Wald)
zusammengesetzt ist, bekommt so einen gemittelten Grauwert zwischen 100 und
120. Dieser Grauwert (z.B. 110) könnte für eine andere Klasse, aber auch für keine
Klasse stehen. Dieses Problem wird größer, wenn bedacht wird, dass ein Objekt,
dessen Pixel aus den Grauwerten 90 (z.B. Wasser) und 120 (z.B. Wiesen) bestehen,
ebenfalls den gemittelten Grauwert 110 besitzt.. In beiden Fällen ist nicht unmittelbar
zu erkennen, aus welchen Werten sich der Grauwert zusammensetzt. Trotzdem sind
die Objekte voneinander zu unterscheiden, weil ihre Grauwerte unterschiedliche
Standardabweichungen besitzen. In ungünstigen Fällen ist es aber auch möglich,
dass Objekte, die sich aus unterschiedlichen Grauwertkombinationen
zusammensetzen, den gleichen Mittelwert und die gleiche Standardabweichung
haben. Die Standardabweichung der Grauwerte eines Objektes kann als Maß ihrer
spektralen Heterogenität angesehen werden. Ein Ziel der Segmentierung ist es,
diese spektrale Heterogenität der Objekte innerhalb bestimmter Grenzen (abhängig

4. Projekt 1 41
vom Bildmaßstab, siehe 3.1) zu halten. Im Idealfall der Segmentierung wäre die
spektrale Heterogenität, also die Standardabweichung, aller Objekte identisch. Auch
wenn dies in der Realität nicht ganz erreicht wird, ist der Wertebereich der einzelnen
Standardabweichungen beschränkt und die Standardabweichungen eigenen sich
nicht unbedingt zur Unterscheidung von Objekten. Die Tatsache, dass auch die
Heterogenität der Form bzw. der Grenzlinie bei der Segmentierung benutzt wird, soll
hier vernachlässigt werden. Aus den Ausführungen in diesem Abschnitt lassen sich
zwei Argumente für eine kleine Maßstabszahl ableiten. Zum einen lässt eine kleine
Maßstabszahl nur eine kleine Heterogenität zu, was im Allgemeinen bedeutet, dass
die Kombinationsmöglichkeiten von Grauwerten, die zu einem gemittelten Grauwert
führen, verringert werden und dass sich die einzelnen Grauwerte geringer vom
gemittelten Grauwert unterscheiden (geringe Streuung). Ein Grauwert ist also besser
einer Klasse zuzuordnen. Zum anderen bewirkt eine kleinere Maßstabszahl, dass die
Objekte kleiner werden (weniger Pixel). Dadurch wird der Informationsverlust
verringert, der durch die Mittelung der Grauwerte entsteht, weil bei kleinen Objekten
durch weniger Grauwerte gemittelt wird.
Ein weiterer Grund für eine kleine Bildmaßstabszahl und damit für kleinere Segmente
ist, dass bei größeren Objekten die Gefahr steigt, ein Segment zu erzeugen, dessen
Pixel verschiedene Klassen repräsentieren. In diesem Fall würde eine wahre
Klassengrenze durch das Segment hindurch laufen.
Zur späteren Klassifikation werden aber nicht nur spektrale sondern auch Form-
Informationen benötigt. Jedes Objekt setzt sich aus einzelnen Pixeln zusammen. Um
jetzt überhaupt eine Form erkennen zu können, benötigt das Objekt eine
Mindestanzahl von Pixeln. Diese Mindestanzahl ist abhängig von der Größe und der
Form des Objektes, vom dem das Segment abgeleitet wird. Ein Beispiel: Die Strasse
A hat eine Breite von 2 Pixel und die Strasse B eine Breite von 5 Pixel. Bei beiden
Objekten handelt es sich um längliche Objekte. Wenn der Segmentierungsmaßstab
jetzt so gewählt wird, dass vorzugsweise Segmente mit der Größe von 25 Pixel
entstehen (beide Objekte besitzen die gleiche Heterogenität), so würde ein Segment
bei der Strasse A die Länge von 8 Pixel (2 * 8 ≈ 25) und bei der Strasse B die Länge
von nur 5 Pixel (5 * 5 = 25) haben. Bei der Strasse A wäre so, im Gegensatz zur
Strasse B, der linienhafte Charakter des Objektes wiedergegeben. Es wird deutlich,
dass verschiedene Formen nur in Abhängigkeit vom Maßstab erkannt werden

4. Projekt 1 42
können und das Segmente eine Mindestgröße haben müssen, um überhaupt eine
charakteristische Form zu besitzen.
Textur-Informationen werden bei eCognition aus den Subobjekten abgeleitet. Hierbei
werden sowohl spektrale wie auch geometrische Eigenschaften des Subobjektes zur
Klassifizierung genutzt. Es ist offensichtlich, dass eine bestimmte Anzahl von
Subobjekten nötig ist, um überhaupt eine Textur zu erhalten und dass in der Regel
eine größere Anzahl von Subobjekten eine Textur besser erkennbar macht. Um
Textur-Informationen zu nutzen, braucht man also ein größeres Segment und damit
eine größere Maßstabszahl. Dies gilt insbesondere wenn die Textur aus der Form
der Subobjekte abgeleitet wird, da die Subobjekte selbst eine gewisse Größe haben
müssen, um eine Form zu repräsentieren.
Wenn neben den spektralen und geometrischen Eigenschaften von Subpixeln auch
ihre Klassenzugehörigkeiten als Klassifikator genutzt werden soll, ist es ebenfalls
sinnvoll, größere Segmente zu bilden, die aus mehreren Subobjekten
zusammengesetzt sind. Die Klassenzugehörigkeit der Subobjekte wird dabei wie
eine Textur genutzt.
Aus den Ausführungen wird deutlich, dass gute Gründe sowohl für kleinere als auch
für größere Segmente vorhanden sind. Es gibt jetzt zwei Möglichkeiten dieser
Tatsache Rechnung zu tragen. Entweder werden mittelgroße Segmente gebildet, die
einen Kompromiss aus groß und klein darstellen, oder es werden sowohl große als
auch kleine Segmente gebildet, aus denen dann die Informationen extrahiert werden.
Die zweite Möglichkeit ist offensichtlich die bessere. Da eCognition mit einem
hierarchischen Netzwerk arbeitet, dass auch verschiedene Auflösungen zulässt, ist
der zweite Ansatz auch einfach zu realisieren.
Abb.22, Hierarchisches Netzwerk der Segmentierung
Pixelebene
Level 1: Kleine Objekte
Level 2: Interpretationsebene
Level 3: Große Objekte

4. Projekt 1 43
Der Grundgedanke der Segmentierung ist, dass über der Pixelebene drei Level
gebildet werden (Abb.22). In Level 1 sollen bei der anschließenden Klassifikation die
Vorteile von kleinen Segmenten und in Level 3 die Vorteile von Großen Segmenten
genutzt werden. Level 3 bildet die mittlere Ebene, in der die Informationen
gesammelt und interpretiert werden.
In Level 1 sollen alle Vorteile von kleinen Segmenten genutzt werden. Die
entstehenden Segmente fassen nur wenige Pixel (die Anzahl ist kleiner als 5)
zusammen, so dass der Informationsverlust, der durch die Mittelung der Grauwerte
entsteht, gering ist. Um Segmente dieser Größe zu generieren, muss der
Segmentierungsmaßstab 3 oder kleiner betragen. Dies ist dann der Fall, wenn, wie
im Projekt, drei Kanäle von Landsat (3-5) mit jeweils dem Gewicht 1 zur
Segmentierung benutzt werden. Zur Erinnerung: Der Segmentierungsmaßstab ist
kein realer sondern ein abstrakter Wert, der eine größtmögliche Heterogenität
beschreibt. Bei Berechnung der Heterogenität gehen neben dem Maßstab auch die
Gewichte der einzelnen Layer ein. D.h., wenn sich die Summe der einzelnen
Gewichte erhöht, muss die Maßstabszahl auch relativ dazu erhöht werden, um ein
gleiches Ergebnis zu bekommen. Die Heterogenität setzt sich außerdem aus der
Grauwert-Heterogenität und der Grenz-Heterogenität zusammen. Weil in diesem
Level die Grauwerte genutzt werden sollen, wäre es logisch, die Grauwert-
Heterogenität in einem wesentlich höheren Maß als die Grenz-Heterogenität zu
verwenden. Eine Möglichkeit diesem Rechnung zu tragen wäre die Grenz-
Heterogenität mit nur 10% zu gewichten. Untersuchungen haben allerdings ergeben,
dass bei einem so kleinen Maßstab die Unterschiede der Segmentierungsergebnisse
marginal sind, selbst wenn die Grenz-Heterogenität mit 40% gewichtet wird. Aus
diesem Grund ist in diesem Level auch die Gewichtung der beiden Grenzparameter
Smoothness und Compactness zu vernachlässigen.
Die Vorteile von großen Segmenten soll in Level 3 genutzt werden. Hier besonders
der Vorteil, dass größere Segmente in der Lage sind, charakteristische Formen
darzustellen, die auf bestimmte Objekte in der Realität hinweisen. Wie unter dem
Punkt „Probleme bei der Klassifikation von Landsat Daten“ beschrieben, müssen die
Objekte in der Realität schon eine bestimmte Größe (mindestens mehrere tausend
Quadratmeter) haben, um ihre Form durch Pixel mit einer Kantenlänge von 25 m
darstellen zu können. Besitzt ein Objekt diese Größe, hängt es von 5 Faktoren ab, ob
der Segmentierungsalgorithmus das Objekt auch in einem Objekt (Bildsegment)

4. Projekt 1 44
zusammenfasst: Maßstab der Segmentierung, Größe des Objektes, Spektrale
Homogenität des Objektes, der Kontrast des Objektes zu Nachbarobjekten und die
gewählten Heterogenitätskriterien der Segmentierung. Diese fünf Faktoren sind eng
miteinander verbunden und voneinander abhängig. Die verschiedenen Objekte in der
Natur besitzen verschiedene Größen, haben eine unterschiedliche spektrale
Homogenität und der Kontrast zu benachbarten Objekten ist auch individuell. Für
jeden Objekttyp müsste demzufolge ein individueller Maßstab und bestimmte, auf
den Objekttyp bezogene, Heterogenitätskriterien gewählt werden. Dies ist natürlich
nicht realistisch. Es ist also vorher zu überlegen, welche Objekttypen überhaupt
aufgrund ihrer Form klassifiziert und damit vorher segmentiert werden sollen und
auch können. Bei dieser Überlegung muss auch mit einbezogen werden, welche
Formmerkmale zur Klassifikation von eCognition überhaupt genutzt werden können.
Bei einem Blick auf ein Landsat Bild wird deutlich, dass es kaum Objekte gibt, die
eine charakteristische Form besitzen, die sie von anderen unterscheidbar machen
würde. Die Umrissformen von Ackerflächen z.B. sind sehr vielseitig. Mal sind sie
rechteckig, mal sind sie dreieckig und ein anderes mal trapezförmig. Es ist
unmöglich, mit den von eCognition bereitgestellten Form-Klassifikatoren, diese
Formen nur einer Klasse zuzuordnen. Die einzige große Ausnahme bilden hier
längliche/linienhafte Objekte wie z.B. Straßen und Wasserwege. Diese Objekte
bilden zwar oft keine eigene Klasse in der CLC Nomenklatur (erst ab einer Breite von
100m), sind aber z.B. Strassen als solche erkannt, können diese Flächen später
besser einer Klasse zugeordnet werden. Von Vorteil in diesem Zusammenhang ist,
dass eCognition mit dem Formmerkmal „Length/Width“, solche länglichen Objekte
klassifizieren kann.
Level 2 bildet eine Art Interpretationsfolie, in der die Informationen aus Level 1 und
Level 3 zusammengefasst werden. Die Segmente dieses Levels sollten nicht zu groß
sein, damit die Möglichkeit, dass eine wahre CLC Klassengrenze durch ein Segment
läuft, minimiert wird. Die Objekte müssen aber groß genug sein, um aus Level 1
Textur-Informationen ableiten lassen zu können. Wie später begründet, werden nicht
Spektral- oder Form-Informationen der Subpixel als Textur genutzt, sondern die
Klassifikationen der Subpixel in Level 1 dienen als Textur.
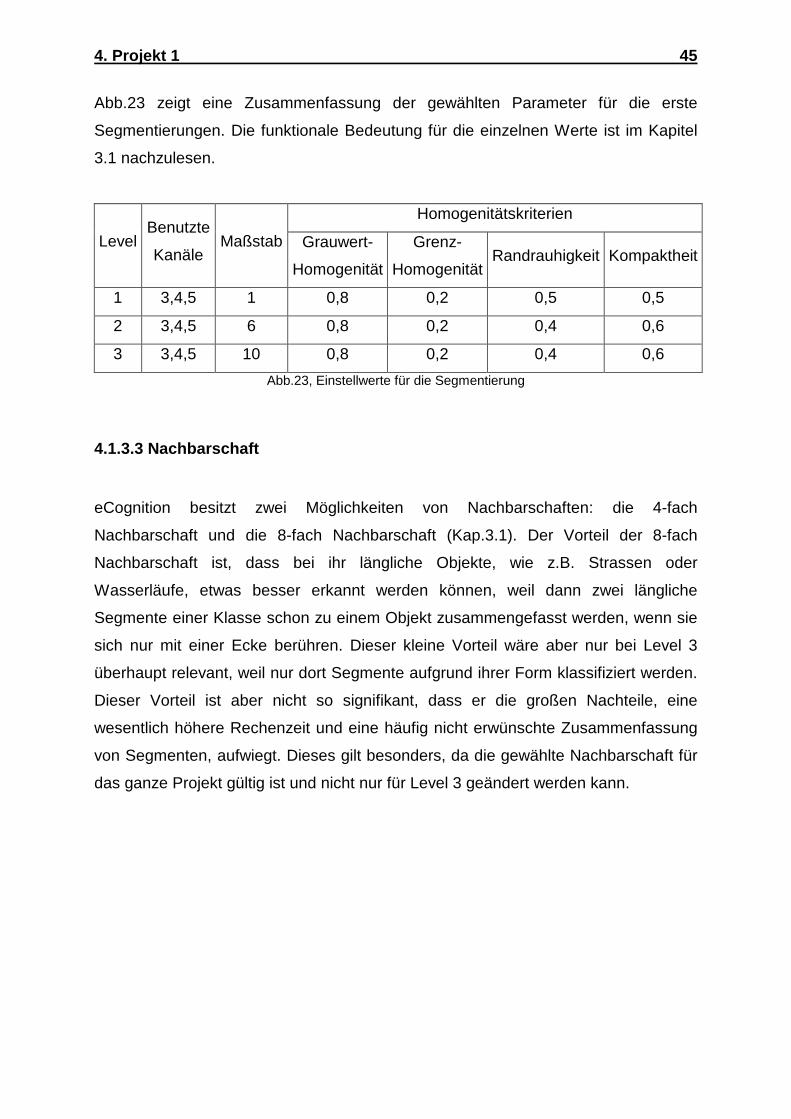
4. Projekt 1 45
Abb.23 zeigt eine Zusammenfassung der gewählten Parameter für die erste
Segmentierungen. Die funktionale Bedeutung für die einzelnen Werte ist im Kapitel
3.1 nachzulesen.
Homogenitätskriterien
Level Benutzte
Kanäle Maßstab Grauwert-
Homogenität
Grenz-
HomogenitätRandrauhigkeit Kompaktheit
1 3,4,5 1 0,8 0,2 0,5 0,5
2 3,4,5 6 0,8 0,2 0,4 0,6
3 3,4,5 10 0,8 0,2 0,4 0,6 Abb.23, Einstellwerte für die Segmentierung
4.1.3.3 Nachbarschaft
eCognition besitzt zwei Möglichkeiten von Nachbarschaften: die 4-fach
Nachbarschaft und die 8-fach Nachbarschaft (Kap.3.1). Der Vorteil der 8-fach
Nachbarschaft ist, dass bei ihr längliche Objekte, wie z.B. Strassen oder
Wasserläufe, etwas besser erkannt werden können, weil dann zwei längliche
Segmente einer Klasse schon zu einem Objekt zusammengefasst werden, wenn sie
sich nur mit einer Ecke berühren. Dieser kleine Vorteil wäre aber nur bei Level 3
überhaupt relevant, weil nur dort Segmente aufgrund ihrer Form klassifiziert werden.
Dieser Vorteil ist aber nicht so signifikant, dass er die großen Nachteile, eine
wesentlich höhere Rechenzeit und eine häufig nicht erwünschte Zusammenfassung
von Segmenten, aufwiegt. Dieses gilt besonders, da die gewählte Nachbarschaft für
das ganze Projekt gültig ist und nicht nur für Level 3 geändert werden kann.

4. Projekt 1 46
4.1.4 Klassifikation
4.1.4.1 Nearest Neighbor oder Membership Function
eCognition arbeitet nach der Methode der überwachten Klassifizierung. Bei der
Überwachten Klassifizierung werden Gebiete/Segmente, von denen die
Klassezugehörigkeit bekannt ist, dieser bekannten Klasse zugewiesen. Diese
Segmente dienen dann als Samples ihrer Klasse. Die restlichen Segmente werden
bei der Überwachten Klassifikation dann dem Sample, und damit auch der Klasse
des Samples, zugeordnet, denen sie am ähnlichsten sind. Ähnlich heißt in diesem
Zusammenhang, dass der Abstand im Merkmalsraum gering ist. Diese
Vorgehensweise entspricht der Nearest Neighbour Methode von eCognition. Die
Zweite Möglichkeit, die eCognition zur überwachten Klassifikation bereitstellt, ist die
Methode der Klassenzuordnung durch Zugehörigkeitsfunktionen (Membership
Function). Bei dieser Vorgehensweise werden, wie im Kapitel 3.2.1 Membership
Function beschrieben, für ausgewählte Kanäle Zuweisungsfunktionen gebildet, mit
deren Hilfe die einzelnen Segmente den Klassen zugeordnet werden. Der Verlauf
der Zuweisungsfunktionen kann, wenn Samples vorgegeben sind, vom Computer
berechnet aber auch manuell eingegeben werden. Es ist also zu überlegen, welche
Methode, Nearest Neighbor oder Membership Function, für die vorliegende
Anwendung besser geeignet ist.
Das entscheidende Kriterium bei dieser Wahl ist das Klassifikationsergebnis.
Untersuchungen haben ergeben, dass die Membership Methode besseres
Klassifikationsergebnisse bei Landsat erreicht. Allerdings ist der Arbeitsaufwand, um
zu guten Ergebnissen zu kommen, auch größer. Zur Erklärung: Beide Methoden
spannen im mehrdimensionalen Merkmalsraum Flächen oder Räume für bestimmte
Klassen auf. Diese Räume, die bei beiden Methoden verschieden aussehen, werden
Cluster genannt. Überschneiden sich diese Cluster nicht, ist es bei beiden Methoden
einfach, die Objekte den Klassen zuzuordnen. Erst bei Überschneidungen von
Clustern treten Klassifikationsprobleme auf. Weil eCognition nach dem Fuzzy Logic
Prinzip arbeitet, ist die Wahrscheinlichkeit einer Klassenzugehörigkeit nicht im
ganzen Cluster gleich. Bei Nearest Neighbor sinkt die Wahrscheinlichkeit mit dem
Abstand vom Sample. Dieser Abstand wird im mehrdimensionalen Raum berechnet
und es besteht keine Möglichkeit, ausgewählte Kanäle von Landsat höher zu

4. Projekt 1 47
bewerten. Bei der Membership Function ist der Verlauf der Zuweisungs-
Wahrscheinlichkeit innerhalb eines Clusters frei wählbar. Dieser Vorteil und der
Vorteil, dass die Zuweisungsfunktion für jeden einzelnen Kanal von Landsat
eingestellt werden kann, macht die Membership Function zur besseren Alternative,
auch wenn diese Einstellmöglichkeiten einen größeren Arbeitsaufwand bedeuten.
Der nächste Schritt, nach dem Bilden von Segmenten, ist ihre Klassifikation. Weil in
Level 2 die Informationen aus Level 1 und Level 3 zusammengefasst werden sollen,
müssen zuerst diese klassifiziert werden, bevor Level 2 klassifiziert werden kann.
4.1.4.2 Klassifikation Level 1
Die Abb.24, zeigt den Aufbau und Ablaufschritte der Klassifikation. Zuerst werden die
Segmente in Level 1 aufgrund der Grauwerte der Pixelebene klassifiziert. Die
Grauwerte der Pixelebene und Form-Charakteristika der Segmente in Level 3
werden dann zur Klassifikation von Level 3 genutzt. Als letztes wird Level 2 mit Hilfe
des Hierarchischen Netzes und den Klassifikationen der Level 1 bis 3 klassifiziert.
Abb.24, Schematische Zusammenfassung der Klassifizierungsschritte
Level 1 besteht aus kleinen Segmenten, die später als Textur für Level 2 dienen
sollen. Zur Klassifikation sollen die nur wenig gemittelten Grauwerte der Segmente
genutzt werden. Diese Standardmethode der Klassifikation basiert darauf, dass
gleiche Objekte annähernd gleiche Grauwerte in den Objekten erzeugen, mit denen
sie auch einer Klasse zugeordnet werden können.
L 3:
L 1: Grauwerte
L 2:
• Form • Grauwerte
• Klassifikation Level 1 • Klassifikation Level 3 • Klassifikation Level 2
Pixelebene

4. Projekt 1 48
Zur Klassifikation müssen die Klassen in der Class Hierarchy definiert werden. Zuerst
werden für die einzelnen Klassen Samples gebildet. Dies erfolgt mit Hilfe des Sample
Editors (Abb.25). Als Sample dienen Segmente von denen man die
Klassenzugehörigkeit weiß. Zu welcher Klasse ein Segment gehört kann entweder
direkt aus dem Landsat Bild oder aber, wenn dies nicht möglich ist, aus der
Topographischen Karte entnommen werden. Mit Hilfe dieser Sample kann für jeden
Kanal eine Zuweisungsfunktion berechnet werden. Hierbei werden nur die Kanäle
benutzt, die zur Charakterisierung der Klasse notwendig sind. Die Klasse Wasser
z.B. besitzt als einzige in den Kanälen 4 und 5 Grauwerte von unter 45 bzw. 42.
Deswegen reichen die Kanäle 4 und 5 zur Beschreibung der Klasse Wasser. Startet
man jetzt die Klassifikation, wird man feststellen, dass nicht alle Segmente
klassifiziert wurden. Bei den nicht klassifizierten Segmenten muss jetzt überprüft
werden, ob für sie ein neue Klasse mit eigenen Samplen gebildet werden muss, oder
ob dieses Segment einer schon bestehenden Klasse zugeordnet werden kann. Der
zweite Fall erfolgt indem die Zuweisungsfunktionen manuell verändert werden. Dies
würde dann erfolgen, wenn z.B. ein Segment in 3 von 4 Kanälen zu einer Klasse
dazu gehört und im 4. Kanal nur einen geringen Grauwertunterschied zum Sample
besitzt.
Abb.25, Sample Editor (hier: eine Ackerfläche)

4. Projekt 1 49
Das manuelle Verändern der Zuweisungsfunktionen ist ein iterativer Prozess, da
nach dem Ändern der Funktion, überprüft werden muss, ob nicht ein anderes
Segment jetzt falsch klassifiziert wurde. Auf diese Weise, also durch Bilden neuer
Klassen und Verändern der Zuweisungsfunktionen, werden allmählich alle Segmente
des Bildes einer Klasse zugeordnet. Zur Überprüfung, ob die Segmente der richtigen
Klasse zugeordnet wurden, wird die Topographische Karte genutzt.
Die Klassen in Level 1 sind nicht identisch mit den CORINE Klassen. Die CORINE
Klasse 211 nicht bewässertes Ackerland wird z.B. durch die 8 Klassen Acker 1 bis
Acker 8 repräsentiert. Diese 8 Klassen werden allerdings in der Class Hierarchy
unter Groups in der Klasse Acker zusammengefasst. Auf diese Weise können sie
alle zusammen angesprochen werden.
Abb.26, Klassifikationsergebnis Level 1

4. Projekt 1 50
4.1.4.3 Klassifikation Level 3
In Level 3 sind große Segmente gebildet worden. Neben dem Grauwert kann also
auch die Form zur Klassifikation genutzt werden. Wird nur der Grauwert zur
Klassifikation genutzt, sind die gleichen Arbeitsschritte notwendig wie in Level 1. Die
Zuweisungsfunktionen können nicht übernommen werden, weil sich der gemittelte
Grauwert von den einzelnen Grauwerten aus Level 1 unterscheidet. Wie bereits
erwähnt, bilden nur Strassen und Wasserläufe charakteristische Formen. Strassen
und Wasserläufe bilden ab einer Breite von 100 m eine eigene Klasse. Ist die Breite
der linienhaften Segmente kleiner als 100 m, was hier der Fall ist, ist es irrelevant zu
welcher Klasse das Segment gehört. Aus diesem Grund bilden Strasse und
Wasserlauf auch nur eine Klasse. Diese Klasse wird durch die Form-Klassifikatoren
„Length/Width“ und „Density“ (Dichte/Kompaktheit) beschrieben.
Abb.27, Klassifikationsergebnis Level 3

4. Projekt 1 51
Abb.27, zeigt das Klassifikationsergebnis von Level 3. Es wird deutlich, dass nicht
alle Wege und Wasserläufe durchgehend als linienhafte Objekte klassifiziert wurden.
An einigen Stellen wurde eine Nutzungsgrenze als linienhaftes Objekt klassifiziert.
Das weißt darauf hin, dass linienhafte Objekte, wie Wasserläufe, Strassen und
Schienen, nicht sicher mit eCognition aus Landsat Bildern klassifiziert werden
können.
4.1.4.4 Klassifikation Level 2
Level 2 kann als Interpretationsfolie angesehen werden, in der die Ergebnisse der
Klassifikationen von Level 1und Level 3 zusammengefasst werden. Die Segmente in
Level 2 sind natürlich Teil des Hierarchischen Netzes und dadurch mit Subobjekten
aus Level 1 und mit Superobjekten aus Level 3 verbunden. Zur Klassifikation werden
die Subobjekte aus Level 1 als eine Art Textur für Level 2 benutzt. eCognition stellt
zur Texturanalyse Operatoren zur Verfügung, die Spektral- und Form-Informationen
der Subobjekte zur Klassifizierung nutzen. Da die Objekte in Level 1 aufgrund schon
bereits erwähnter Gründe keine charakteristische Form besitzen, fallen Form-
Informationen zur Texturanalyse aus. Bei der Texturanalyse mit spektralen
Informationen können zwei Operatoren verwendet werden. Der Grauwert eines
Objektes wird durch Mittelung der Grauwerte von Subobjekten berechnet, hierbei ist
es natürlich auch möglich, eine Standardabweichung für den gemittelten Wert zu
berechnen. Die Standardabweichung des gemittelten Grauwertes ist das Ergebnis
des ersten Operators. Der zweite Operator berechnet den Kontrast, indem er die
Grauwerte der Subobjekte mit dem Grauwert des Objektes vergleicht. Beide
Operatoren erwiesen sich bei Untersuchungen als wenig geeignet für die hier
gestellte Aufgabe. Es war unmöglich bestimmte Standardabweichungen oder
Kontraste einzelnen Klassen sicher zuzuordnen. Dieser Effekt ist damit zu
begründen, dass bei der Segmentierung Flächen mit relativ gleichen Homogenitäten
entstehen und dass die Standardabweichung und der Kontrast auch als Maß für die
Homogenität einer Fläche angesehen werden können.
Aus diesen Gründen benutze ich die Klassifikationen der Subobjekte für die
Texturanalyse. Dieses Verfahren wird von eCognition Relations to Sub Objects
(Verhältnis zu den Subobjekten) genannt. Dieses Verhältnis kann durch vier
Merkmale beschrieben werden: relativer und absoluter Anteil einer Klasse an der

4. Projekt 1 52
Gesamtfläche des Objektes, Existenz einer Klasse und Anzahl der Objekte einer
Klasse. Weil die Größe eines Objektes nicht signifikant auf eine Klasse hinweist und
von der Größe eines Objektes die Absolut-Werte abhängen, sollten nur relative
Werte genutzt werden. Die bloße Existenz einer Klasse, also das vorhanden oder
nicht vorhanden sein, ist ein zu grobes Merkmal. Aus diesen Gründen habe ich mich
für den relativen Anteil einer Klasse als Klassifikationsmerkmal entschieden (Abb.28,
Rel. Area of Wald Sub Objects [1]). Wie hoch der relative Anteil einer Klasse an der
Gesamtfläche des Objektes sein muss, um das Objekt einer Klasse zuordnen zu
können, hängt von der Art der Klasse ab. Setzt sich die Klasse in Level 2 nur aus
einer Klasse in Level 1 zusammen, wie z.B. bei Wasserfläche oder Waldfläche, ist
nur eine Zuweisungsfunktion (Fuzzy-Logic) nötig. Diese sieht dann so aus, dass bis
einen bestimmten relativen Anteils-Wert die Zuweisung gleich null ist, sie ab dann
kontinuierlich ansteigt, bis sie den Wert 100 erreicht. Die Lage der Wendepunkte der
Zuweisungsfunktion hängt von der Klasse ab und unterscheidet sich auch stark von
Klasse zu Klasse. Bei Klassen aus Level 2, die sich aus zwei oder mehreren Klassen
aus Level 1 zusammen setzen können, wie z.B. 112 Nicht durchgängig Bebaut aus
Bebaut 2 und Städtische Grünflächen (beides Klassen aus Level 1), müssen mehrere
Zuweisungsfunktionen gebildet werden.
Die Klassenzuweisung in Level 2 nutzt auch die Klassifikationen in Level 3. Die
relativ großen Segmente in Level 3 haben eine stärkere Grauwertmittelung. Weil
aber bei der Segmentierung relativ homogene Flächen entstanden sind, kann ein
gemittelter Grauwert nicht aus beliebig kontrastreichen Grauwerten
zusammengesetzt sein. Die Klassen in Level 3 stehen für definierte Grauwerte.
Wenn ein Segment in Level 3 als Wasser klassifiziert wurde, kann davon
ausgegangen werden, dass in diesem Segment z.B. kein Wald vorhanden ist, weil
sich die Grauwerte von Wald und Wasser zu stark unterscheiden. Wird ein Segment
allerdings als Wiese klassifiziert, kann nicht sicher davon ausgegangen werden, dass
in diesem Segment z.B. keine Ackerflächen vorhanden sind, weil die Grauwerte von
bestimmten Wiesen und Ackerflächen zu ähnlich sind. Diese Erscheinungen müssen
bei der Klassifikation von Level 2 berücksichtigt werden. Dies erfolgt z.B. indem
gesagt wird, dass das Superobjekt der Klasse Ackerfläche entweder Ackerfläche
oder Wiese sein muss.
Segmente, die nicht oder nur mit geringer Wahrscheinlichkeit zugeordnet werden
können, können häufig aufgrund ihrer Beziehung zu Nachbarobjekten klassifiziert

4. Projekt 1 53
werden. Die Segmente in Level 2 besitzen nicht die erforderliche Größe, um eine
eigene Klasse zu bilden. Wenn z.B. ein Segment zu 100 Prozent von Objekten der
Klasse Wald umgeben ist, kann es der Klasse Wald zugewiesen werden (Abb.28,
Rel. Border to Wald [2] Neighbor Objects). Hierbei ist es unerheblich, ob es sich
wirklich um Wald handelt oder ob das Segment nur aus Gründen der Generalisierung
(hier: Auslassung) als Wald klassifiziert wird. Die relative Grenzlänge zu einer Klasse
muss natürlich auch in einen Zuweisungswert übersetzt werden. Tests haben
ergeben, dass erst bei einem sehr großen relativen Anteil an der Grenzlänge (bei
80% ist der Zuweisungswert erst 50 %) diese Klassifikationsregel genutzt werden
darf. Eine Ausnahme bilden hier die Objekte, deren Superobjekte als Strassen und
Flüsse klassifiziert wurden. Diese Objekte, die wie erwähnt keine eigene Klasse
besitzen, werden der Klasse zugeordnet, zudem sie den längsten Grenzanteil
besitzen (Abb.28, Existance of Strassen/Flüsse Super Objects [1] and Rel. Border to
Wald [2] Neighbor Objects). Folgende Abbildung zeigt die Klassenbeschreibung für
die Klasse Wald in Level 2:
Abb.28, Klassenbeschreibung Wald (Level 2)
Weil bei der Klassifikation von Level 2 auch die Klassifikationen anderer Objekte von
Level 2 genutzt werden (Nachbarschaftsbeziehungen), muss dieser Schritt iterativ
durchgeführt werden. Nach fünf Iterationsschritten sind keine Veränderungen im
Ergebnis zu erkennen.

4. Projekt 1 54
Abb.29, Klassifikationsergebnis Level 2
4.1.5 Classification-based Segmentation Die Klassifikation in Abb.29 könnte ein Endergebnis einer Bodenbedeckungs-
Klassifizierung sein. Für das CORINE Projekt muss aber noch die
Erfassungsuntergrenze von 25 ha bedacht werden. Viele Flächen haben nur kleinere
Ausmaße. Die Flächen, die zu einer Klasse gehören, bestehen auch noch aus vielen
Segmenten. Diese Segmente müssen zu einem Segment zusammen gefasst
werden. Erst jetzt können die Flächen sinnvoll nach ihrer Größe untersucht werden.
Nachdem dies geschehen ist, können auch kleinere Segmente, die zum Teil noch
nicht klassifiziert waren, einfacher zugewiesen werden. Dies ist möglich, weil
Nachbarschafts-Beziehungen jetzt besser und sicherer genutzt werden können
(Begründung folgt später).

4. Projekt 1 55
Um die Segmente in Level 2 wie beschrieben zusammenzufassen, muss erst Level 3
gelöscht werden, da sonst aufgrund des Hierarchischen Netzwerkes die
Segmentgrenzen von Level 3 auch in Level 2 erhalten bleiben würden. Die
fusionierten Segmente bilden ein neues 3. Level.
Die Classification-based Segmentation (Abb.30) ist eine wissensbasierende
Segmentierung. In der Structure Group der Class Hierarchy werden die Klassen
aufgeführt, die größere Segmente bilden sollen. Hierbei ist es auch möglich, zwei
Klassen zu einer Struktur zusammenzufassen. Die Klassen Bebaut 1 und Bebaut 3
werden zu einer Klasse zusammengefasst, weil die CORINE Klasse 1.2.1. Industrie
und Gewerbe sich hauptsächlich aus diesen Klassen zusammensetzt.
Abb.30, Classification based Segmentation
An dieser Stelle ein kleiner Exkurs: In den Legenden in Abb.26 und Abb.27 sind die
Klassen Acker 1, Acker 2 usw. und Bebaut 1, Bebaut 2 usw. zu sehen. Diese
Klassen sind Projekt-Klassen und nicht mit CORINE-Klassen gleichzusetzen. Die
Acker-Klassen werden in der Class Hierarchy unter dem Punkt Groups zu einer
Klasse Acker zusammengefasst. Diese wissensbasierte Zusammenfassung ist nur
möglich, weil diese einzelnen Acker-Klassen nur in der CORINE Klasse 2.1.1. nicht
bewässertes Ackerland vorkommen. Die Klassen Bebaut, Bebaut 2 usw. können
nicht in einer Klasse Bebaut zusammengefasst werden, da die einzelnen Bebaut-
Klassen für verschiedene CORINE Klassen stehen. Die Klasse Bebaut 2 steht z.B.
für 1.1.2. nicht durchgängig Bebaut, Bebaut 3 für 1.2.1. Industrie und Gewerbe und
die Klasse Bebaut 1 steht entweder für 1.1.1. städtisch geprägte Fläche oder 1.2.1.
Industrie und Gewerbe.
4.1.6 Klassifikation Level 3 (neu)
Bei der Software eCognition ist es nicht möglich, die Klassenbeschreibungen nur für
einzelne Level neu zu laden. Weil die Klassifizierungsregeln für das neue Level 3
Level 3(neu).Fusionierte Segmente
Level 2: Klassifikation

4. Projekt 1 56
geändert werden müssen, ist es notwendig die Klassenbeschreibungen aller Level zu
löschen, was zur Folge hat, dass kein Level mehr klassifiziert ist.
In der neuen Klassenbeschreibung werden die Level 1 und Level 2 auf die gleiche
Art und Weise klassifiziert, wie in der alten Klassenbeschreibung, mit der Ausnahme,
dass bei Level 2 diesmal Level 3 nicht genutzt werden kann. Dies wirkt sich vor allem
auf die Segmente aus, deren Supersegmente im alten Level 3 als Strassen und
Flüsse klassifiziert waren. Da diese Flächen aber im neuen Level 3 schon mit den
korrekten Flächen zusammengefasst sind, stellt dies kein Problem dar.
Abb.31, Klassenbeschreibung für Wald (Level 3)
Zur Klassifikation in Level 3 wird die Klassifikation von Level 2 als Textur
herangezogen (Abb.31, Rel. Area of Wald [2] Sub Objects [1]). In Abhängigkeit von
der Klasse muss ein Segment einen bestimmten Anteil von Subobjekten dieser
Klasse in Level 2 besitzen und eine Mindestgröße von 25 ha haben (Abb.31, Area),
um dieser Klasse zugewiesen zu werden. Die Segmente, die jetzt noch nicht
klassifiziert sind, vornehmlich Segmente mit weniger als 25 ha Fläche, werden nun
aufgrund anderer Eigenschaften klassifiziert. Hierbei spielen Nachbarschafts-
Beziehungen in Zusammenwirken mit der Texturanalyse die entscheidende Rolle
(Abb.31, Rel Border to Wald [3] Neighbor Objects). Die Nachbarschafts-Beziehungen
können nach der Classification-based Segmentation in Level 3 wesentlich robuster
genutzt werden, als dies bei der ersten Klassifikation von Level 2 der Fall war. Ein
Beispiel: Die rote Fläche in Abb.32 bildet in Level 2 ein einzelnes Segment. Dieses
Segment besitzt einen Grenzanteil von ca. 80 % zur Klasse Wald. Wenn in Level 2
bereits ein Grenzanteil zur Klasse Wald von 80 % den Zuweisungswert von 90 %

4. Projekt 1 57
bekommen würde, wäre dieses Segment fälschlich der Klasse Wald zugewiesen
worden. In Level 3 ist dieses Segment mit den benachbarten Segmenten der Klasse
Acker zusammengefasst worden, mit der Folge, dass das zusammengefasste
Segment einen wesentlich kleineren Grenzanteil zur Klasse Wald hat. Dem zu Folge
können die Grenzanteile für die Klassifikation in Level 3 wesentlich geringer gesetzt
werden.
Abb.32, Ein Segment
4.1.7 Ergebnisse und Schlussfolgerungen aus Projekt 1 Das Klassifikationsergebnis von Projekt 1 ist die Klassifikation in Level 3. In Projekt 1
soll überprüft werden, in wie weit eine Klassifikation nach CORINE nur mit Landsat
Daten möglich ist. Es ist also sinnvoll, dass Klassifikationsergebnis mit den CLC 90
Ergebnissen zu vergleichen. Die CLC 90 Ergebnisse dienen hier als Referenz-Daten.
Beim visuellen Vergleich der beiden Abbildungen 33 und 34 fällt schnell auf, dass die
Flächen einiger Klassen besser miteinander übereinstimmen, als bei anderen
Klassen. Außerdem ist zu erkennen, dass in den Randgebieten einige Flächen gar
nicht oder auch falsch klassifiziert wurden. Dies hängt hauptsächlich damit
zusammen, dass diese Flächen innerhalb des Kartenausschnittes zu klein sind. Eine
erste Schlussfolgerung vom Projekt 1 lautet dementsprechend, dass die
Eingangsdaten, also die Landsat Szene, größere Ausmaße haben muss, als das zu
klassifizierende Gebiet.
Um zu erläutern, welche CORINE Klassen gut und welche weniger gut klassifiziert
werden können, sind die Klassen in folgende 3 Gruppen eingeteilt.
Gruppe 1: Zu dieser Gruppe gehören die CORINE Klassen, die nur eine Art von
Bodenbedeckung repräsentieren. Die Bodenbedeckungen weisen demzufolge genau
auf die Klasse hin. Zu dieser Gruppe gehören: 141 Städtische Grünflächen, 211
Ackerflächen, 231 Wiesen und Weiden, 311 Laubwald und 512 Wasserflächen.

4. Projekt 1 58
Gruppe 2: Die Klassen dieser Gruppe zeichnen sich dadurch aus, dass sie
Kombinationen von Bodenbedeckungen besitzen können oder zum Teil auch
besitzen müssen. Die Art der Bodenbedeckungen und ihr Verhältnis zueinander ist
ausschlaggebend für die Klassifikation. Zu dieser Gruppe gehören: 111 Durchgängig
Bebaut, 112 nicht durchgängig Bebaut (besteht z.B. aus Grünflächen und bebauten
Flächen), 121 Industrie und Gewerbe, 243 Landwirtschaftliche Flächen und
natürliche Bodenbedeckung
Gruppe 3: Hier sind die Klassen zusammengefasst die Bodennutzungen
beschreiben, die nicht auf eine bestimmte Bodenbedeckung hinweisen. Zu dieser
Gruppe gehört: 142 Sport und Freizeit.
Anmerkung zur Gruppeneinteilung: Die Einteilung ist nur sehr grob und einige
Klassen bilden eher Mischformen, als das sie exakt einer Gruppe zugewiesen
werden könnten.
Die Klassen in Gruppe 1 sind am einfachsten und am genauesten zu klassifizieren.
Innerhalb dieser Gruppe sind die Klassen, deren Bodenbedeckungen besonders
charakteristische spektrale Eigenschaften besitzen, wie Laubwald oder Wasser, noch
sicherer zu klassifizieren. Die Klassen Wiesen und Weiden und Ackerland können je
nach Pflanzenart oder auch Wachstumsstand sehr ähnliche spektrale Werte
besitzen. Die Flächen dieser beiden Klassen liegen oft sehr verschachtelt
nebeneinander. Aufgrund dieser beiden Eigenschaften kann es für größere Flächen
schwer sein, sie der einen oder der anderen Klasse zuzuweisen. Je ausgeglichener
der Anteil beider Flächen an der Gesamtfläche wird, um so unsicherer wird eine
Zuweisung. Dieser Effekt ist auch die Erklärung dafür, dass Teile der Fläche Wiesen
und Weiden aus CORINE als Ackerland klassifiziert wurden. An dieser Stelle ist auch
zu erwähnen, dass die CORINE Daten keine 100 prozentige Richtigkeit besitzen,
sondern dass die Klassifikationen auch von den Interpretationen des Interpreten
abhängig sind.
Die Klassen in Gruppe 2 setzen sich aus mehreren Bodenbedeckungen zusammen.
Auch hier gilt: Je sicherer die einzelnen Bodenbedeckungen klassifiziert werden
können, um so sicherer ist aus den verschiedenen Bedeckungen eine Klasse
abzuleiten. Die Klasse 112 nicht durchgängig Bebaut setzt sich z.B. aus den
Bodenbedeckungen Grünland und Bebaut b (Klassen in Level2) zusammen. Weil
Grünland und Bebaut b sehr gut klassifiziert werden können, ist auch die Klasse 112
sehr gut aus ihr ableitbar. Dieses ist ebenfalls an dem guten Klassifikationsergebnis

4. Projekt 1 59
in Abb.34 zu sehen. Schwieriger wird es, wenn Kombinationen von
Bodenbedeckungen nicht eindeutig auf eine Klasse schließen lassen. Die
Kombination von versiegelten und bebauten Flächen kann z.B. auf die Klasse 111
durchgängig städtische Prägung aber auch auf die Klasse 121 Industrie und
Gewerbe hindeuten. Besonders schwer korrekt zu klassifizieren wird es, wenn die
spektralen Eigenschaften eines Gebietes nicht sicher auf eine Bodenbedeckung
hinweisen. So unterscheiden sich Abbauflächen spektral nur kaum von bestimmten
Ackerflächen (Rohland). Dieses macht es fast unmöglich, Abbauflächen zu
klassifizieren, wie auch der Abb.34 zu entnehmen ist. Der gleiche Effekt tritt auch
zwischen den Klassen Ackerland und Industrie auf. Nur leicht versiegelte Flächen
können die gleichen spektralen Eigenschaften besitzen, wie Ackerflächen.
Zur Gruppe 3 gehört die Klasse 142 Sport und Freizeit. Die Flächen dieser Klasse
werden zum Teil als Grünflächen und zum Teil als Laubwald klassifiziert. Die
Klassifikationen wiedersprechen sich nicht, nur handelt es sich bei der Klassifikation
mit eCognition um Bodenbedeckung und bei CORINE um Bodennutzung. Um von
bestimmten Bodenbedeckungen auf Bodennutzungen zu schließen, werden
Zusatzinformationen benötigt. Dass Zusatzinformationen für die Klassifikation
bestimmter Klassen benötigt werden, ist die Haupterkenntnis aus Projekt 1.
Abb.33, CLC90

4. Projekt 1 60
Abb.34, Klassifikationsergebnis Projekt 1

4. Projekt 2 61
4.2 Projekt 2: Klassifikation mit Landsat und ATKIS Daten
Das Ziel von Projekt 2 ist zu untersuchen, in wieweit Zusatzinformationen in
eCognition genutzt werden können, um eine CORINE Klassifikation aus Landsat
Daten zu unterstützen.
4.2.1 Eingangsdaten Projekt 2
Zum eigentlichen Ziel von CLC 2000 gehört auch eine Landnutzungsänderungs-
Klassifikation. Daher wird in diesem Projekt das gleiche Gebiet wie in Projekt 1
klassifiziert. Allerdings stammen die Satellitenaufnahmen diesmal von Landsat 7
(Abb.35) und wurden im April 2000 aufgenommen. Da in diesem Projekt ein anderes
Satellitenbild benutzt wird, kann auch überprüft werden, in wieweit die
Klassenbeschreibungen aus Projekt 1 für andere Szenen übernommen werden
können. Um die Klassenbeschreibungen übernehmen zu können, muss bei
eCognition die Anzahl der Kanäle und die Pixelgröße identisch sein mit denen aus
dem Ausgangsprojekt (Projekt 1). Deswegen kann auch der panchromatische Kanal
von Landsat 7 nicht genutzt werden. Die Pixelgröße beträgt dementsprechend 25 m
(resampled). Für die nördlichen 700 m der Szene liegen keine ATKIS Daten vor,
daher ist dieses Gebiet herausgeschnitten worden.
In Deutschland werden als Zusatzinformationen für das CLC 2000 Projekt ATKIS
Daten mit zur Verfügung gestellt. Aus diesem Grund werden auch in Projekt 2 ATKIS
Daten (Abb.36) als zusätzliche Informationsträger genutzt. ATKIS Daten liegen
üblicherweise in Vektorformat vor. Da eCognition nur Raster Daten verarbeiten kann,
müssen die ATKIS Daten vorher gerastert werden. Bevor gerastert wird muss
überlegt werden, welche Objektarten überhaupt gerastert werden können und welche
gerastert werden sollten. ATKIS Signaturen können nicht ohne weiteres gerastert
werden und der ATKIS Objektartenkatalog ist viel zu ausführlich für die CORINE
Klassifikation. Weil die Vektor Daten außerdem in verschiedenen Folien liegen, wäre
das Zusammenfassen in einem Raster Bild ohnehin nicht möglich. Deswegen sind 15
Klassen (Objekte) aus ATKIS ausgewählt worden, die eine CORINE Klassifikation
sinnvoll unterstützen.
Die Rasterauflösung der Eingangsdaten muss bei eCognition identisch sein.
Deswegen besteht das ATKIS Raster, wie das Landsat Raster, aus 25 m Pixeln. Eine
höhere Pixelauflösung würde die Lagegenauigkeit von ATKIS zwar besser nutzen

4. Projekt 2 62
und vor allem Detailgetreuer darstellen, aber eine höhere Auflösung war aus
technischen Gründen nicht möglich. Erklärung: Zur Herstellung des ATKIS
Rasterbildes wurde die Software ArcInfo und Erdas Imagine verwendet. Mit ArcInfo
wurden die 30 Klassen ausgewählt und so dargestellt, dass die Grenzpolygone nicht
sichtbar waren. Schwarze Polygone hätten sonst bei der Rasterung die Grauwerte zu
stark beeinflusst. Von dieser Darstellung wurde ein Screen-shot gemacht, der dann
mit Hilfe von Erdas Imagine wieder georeferenziert und in der korrekten Auflösung
gerastert wurde. Diese Herstellungstechnik ermöglicht keine viel bessere
Pixelauflösung als 25 m. Außerdem können die Klassenbeschreibungen aus Projekt
1 nur bei dieser Pixelgröße auch für Projekt 2 genutzt werden. Welche Auswirkungen
diese große Pixelgröße auf die Klassifikation hat, kann den Ergebnissen entnommen
werden.
Abb.35, Landsat 7 (Kanalkombination 4-3-2)

4. Projekt 2 63
Abb. 36, Gerastertes ATKIS Bild
Es existieren zwei Möglichkeiten bei eCognition das ATKIS Bild in das Projekt zu
importieren. Eine Möglichkeit ist, dass ATKIS Bild als weiteren Layer zu benutzen.
Dabei würden die Graustufen des ATKIS Bildes für einzelne Klassen stehen. Das
Problem bei dieser Methode ist, dass bei der Segmentierung Flächen
zusammengefasst werden und einen gemittelten Grauwert bekommen. Der
gemittelte Grauwert aus ATKIS Grauwerten wäre nur schwer einer bestimmten
Bodennutzung zuzuordnen. Infolgedessen fällt diese Möglichkeit des Importes aus.
Die zweite Möglichkeit ist das ATKIS Bild als Thematischen Layer in eCognition zu
importieren. Der Thematische Layer ist nicht von der Segmentierung betroffen. Um
das Bild als Thematischen Layer zu importieren, muss es erst wieder geokodiert
werden. Dies erfolgte durch einfache Grauwertzuweisung mit Hilfe von eCognition in
einem separaten Projekt.

4. Projekt 2 64
4.2.2 Segmentierung
Der grundsätzliche Aufbau des Klassifikationsalgorithmus aus Projekt 1 hat sich
bewährt und soll in Projekt 2 erhalten bleiben. Das heißt, das auch in Projekt 2 ein
Level mit kleinen Segmenten (Grauwerte), ein Level mit großen Segmenten (Form,
Grauwerte) und ein Level mit mittelgroßen Segmenten (Interpretationsfolie) erzeugt
wird. Für die Klassifikation der Interpretationsfolie sollen jetzt auch ATKIS Daten
verwendet werden. Die ATKIS Daten liegen als Thematischer Layer vor. Bei der
Segmentierung mit eCognition kann eingestellt werden, ob der Thematische Layer
zur Segmentierung benutzt wird oder nicht. Wenn der Thematische Layer zur
Segmentierung benutzt wird, werden bei ihm nicht Segmente zusammengefasst, wie
bei den anderen Layern (Landsat Kanäle), sondern die Teilflächen (Flächen einer
Klasse) des Thematischen Layers definieren „Obersegmente“. Das bedeutet, dass
die Segmente, die durch die Segmentierung der Landsat Kanäle entstehen, immer
innerhalb eines „Obersegmentes“ liegen. Beim verwenden dieses Ansatzes würden
die ATKIS Grenzen einfach auf das CORINE Projekt übertragen werden. Dieses
würde dann Sinn machen, wenn die ATKIS Grenzen als korrekt angesehen werden
würden und nur die Klassenart durch die Landsat Daten überprüft werden sollte. Weil
aber die Landsat Bilder einen aktuelleren Stand der Umwelt wiederspiegeln als die
ATKIS Daten, sollen die ATKIS Grenzen nicht berücksichtigt werden und damit auch
nicht der Thematische Layer zur Segmentierung. Um die Informationen eines
Thematischen Layers aber zur Klassifikation nutzen zu können, muss dieser zur
Segmentierung genutzt werden. Um diesen Wiederspruch zu lösen wird unter den
drei Level, die zur Klassifikation der Landsat Bilder genutzt werden, ein neues Level
eingeführt. Dieses Level soll eine „eins zu eins“ Kopie des Thematischen Layers
werden. Um dies zu erreichen, werden in Level 1 kleinst mögliche Segmente (1
Pixel) gebildet und der Thematische Layer wird zur Segmentierung mit benutzt. Die
Level 2 bis 4 entstehen auf die gleiche Art und Weise wie die korrespondierenden
Level 1 bis 3 in Projekt 1 (Abb.37). Das heißt auch, dass sie ohne Verwendung des
Thematischen Layers entstehen.

4. Projekt 2 65
Abb.37, Segmente des Hierarchischen Netzwerkes für Projekt 2
4.2.3 1.Klassifikation Genau wie in Projekt 1 Level 2 soll in Projekt 2 Level 3 die Informationen aus den
anderen Level bündeln und zur Klassifikation nutzen. Level 2 und Level 4 des
Projektes 2 übernehmen die gleichen Aufgaben wie Level 1 und Level 3 in Projekt 1.
Neu ist Level 1, in dem ATKIS Informationen als „Textur“ für Level 3 bereitgestellt
werden (Abb.38).
Abb.38 , Hierarchisches Netz der Klassifikation
Level 4: Große Segmente
Level 2: Kleine Segmente
Pixelebene (Landsat)
Level 3: Interpretationsebene
Level 1: Kleinste Segmente
Thematischer Layer: ATKIS
L 4: Form, Grauwerte
L 2: Grauwerte
L 3: Level 1, Level 2,Level 3, Level 4
Pixelebene: Landsat
L 1: ATKIS Daten
Thematischer Layer:

4. Projekt 2 66
Klassifikation Level 1: Da in der „Interpretationsebene“ Level 3 aus beschriebenen
Gründen nicht direkt auf den Thematischen Layer zurückgegriffen werden kann, soll
Level 1 als Bindeglied zwischen ATKIS Daten und Klassifikation dienen. Hierzu
bekommen die Segmente in Level 1 einfach die entsprechende ATKIS Klasse
zugewiesen. Dieses erfolgt mit Hilfe des Klassifikationsmerkmals „Thematic
Attributes“(Abb.39). Da die Segmente in Level 1 nur aus einem Pixel bestehen, ist
Level 1 mit dem Thematischen Layer und damit mit den ATKIS Daten identisch
(Abb.40).
Abb. 39, Klassenbeschreibung für die ATKIS Klasse Wald (Level 1)
Abb.40, Klassifikationsergebnis Level 1 (ATKIS Klassen)

4. Projekt 2 67
Klassifikation Level 2: In Level 2 soll, wie bereits erläutert, der Vorteil von kleinen
Objekten genutzt werden. Der nur wenig gemittelte Grauwert wird zur Klassifikation
genutzt und das Klassifikationsergebnis dient als Textur für die Klassifikation von
Level 3. Bei der Klassifikation können im Prinzip die Klassen aus Projekt 1 für Level 1
übernommen werden. Allerdings haben sich die Spektralwerte und damit auch die
Grauwerte für die einzelnen Klassen verändert. Dieses liegt vor allem an dem
unterschiedlichen Aufnahmezeitpunkt der beiden Landsat Szenen. Das
Reflektionsverhalten von Vegetation verändert sich im Laufe des Jahreszyklus und
auch die spektralen Eigenschaften der Atmosphäre unterscheiden sich bei
verschiedenen Zeitpunkten. Die einzelnen Zuweisungsfunktionen, die bestimmte
Spektralwerte bestimmten Klassen zuordnen, müssen dementsprechend für die
meisten Klassen neu bestimmt werden. Für einige Klassen kann es notwendig sein,
neue Unterklassen zu bilden oder Unterklassen zu streichen. Die Klasse Acker z.B.
kann je nach Szene aus 6 oder auch aus 10 Unterklassen Acker (Acker 1,...,Acker 6
bzw. Acker 10) bestehen. Dieser gesamte Prozess ist, wie in Projekt 1 beschrieben,
iterativ. Für das Klassifikationsergebnis ist es unerheblich, ob die gleichen oder
andere Flächen als Sample für die Klassen verwändet werden.
Abb. 41, Klassifikation Landsat Daten (Level 2)

4. Projekt 2 68
Klassifikation Level 4: Level 4 entspricht Level 3 aus Projekt 1 und soll vor allem die
Vorteile von großen Segmenten nutzen. Die Vorgehensweise zur Klassifikation von
Level 4 entspricht der von Level 2. Auch hier müssen die Zuweisungsfunktionen für
die Grauwerte neu bestimmt werden. Die Formmerkmale für bestimmte Klassen
(Strassen und Flüsse) können allerdings aus Projekt 1 übernommen werden.
Klassifikation Level 3: Level 3 besteht aus mittelgroßen Segmenten, die groß genug
sind, um die größere Anzahl von Segmenten in Level 1 und Level 2 als „Textur“ zu
benutzen, aber auch klein genug, um nicht auf zwei verschiedenen
Bodennutzungsarten zu liegen. Bei der Klassifikation von Level 3 werden die
Klassifikationen der anderen Level sinnvoll miteinander genutzt. Ein Grundgedanke
hierbei ist, dass Klassifikationsergebnis in Level 2, also aus Landsat Daten, mit dem
Klassifikationsergebnis aus Level 1, also aus ATKIS Daten, zu vergleichen. Deuten
beide Klassifikationsergebnisse auf die gleiche Landnutzung hin, so kann mit hoher
Wahrscheinlichkeit davon ausgegangen werden, dass diese Landnutzung auch in
der Realität vorliegt. Die Abb.42 zeigt die Implementierung dieses Ansatzes am
Beispiel der Klasse 5.1.2 Wasserflächen. Bei diesem Beispiel wird auch deutlich,
dass verschiedene ATKIS Klassen zu einer CORINE Klasse gehören. Die ATKIS
Klassen Absetzbecken und Wasserflächen werden bei CORINE in der Klasse 5.1.2
Wasserflächen zusammengefasst. Welche Rolle Level 4 bei der Klassifikation von
Level 3 spielt, ist ebenfalls an diesem Beispiel gut zu erkennen. In Level 4 wird die
Klasse Strassen und Flüsse aufgrund ihrer Form klassifiziert. Strassen oder Flüsse
bilden erst ab einer Breite von 100 m eine eigene Klasse bei CORINE.
Abb.42, Klassenbeschreibung der Klasse 512 Wasserflächen (Level3)

4. Projekt 2 69
Sind jetzt Strassen oder Flüsse schmaler als diese 100 m, müssen sie einer sie
umgebenden Fläche zugeordnet werden, damit sie nicht unklassifiziert bleiben.
Dieses erfolgt in Level 3 durch die Klassenbeschreibungen: Existance of Strassen
und Flüsse 4 Super Objects [1] und Rel. Border to 512 Wasserflächen Neighbor
Objects (Abb.42).
Das Beispiel einer Klassenbeschreibung für die Klasse 512 Wasserflächen zeigt
relativ einfache Klassifizierungsregeln. Dies ist für alle Klassen der Fall, die sich nur
aus einer Klasse des Landsat Levels (Level 2) ableiten lassen. Zum besseren
Verständnis werden ab jetzt die Klassen in Level 2, die ja zur Klassifikation des
Landsat Bildes genutzt werden, Landsat Klassen genannt. Kompliziertere
Klassenbeschreibungen haben die CORINE Klassen (Level 3), die sich aus
mehreren Landsat Klassen ableiten lassen. Dieses soll die Abb.43 verdeutlichen, in
der die Klasse 2.3.1 Wiesen und Weiden beschrieben ist. Ackerflächen mit jungen
Bewuchs haben häufig ähnliche spektrale Eigenschaften wie Wiesen oder Weiden
und sind deswegen im Landsat Bild nur schwer voneinander zu trennen. Es besteht
also eine gewisse Wahrscheinlichkeit, dass Wiesen und Weiden fälschlicher Weise
als Ackerland klassifiziert werden und andersherum. Wie bereits beschrieben,
werden die Landsat Klassifikation und die ATKIS Klassifikation miteinander
verglichen. Ist z.B. eine Fläche im Landsat Bild als Ackerland und im ATKIS Bild als
Wiese klassifiziert worden, besteht eine hohe Wahrscheinlichkeit, dass die Landsat
Klassifikation falsch war. Diese Wahrscheinlichkeit steigt, wenn diese Fläche zu
einem großen Teil von Flächen mit Wiesen und Weiden umgeben ist. Die
Implementierung dieser Regeln ist in Abb.43 in dem Block unter dem zweiten
and(min) zu finden.
Abb.43, Klassenbeschreibung der Klasse 231 Wiesen und Weiden (Level 3)

4. Projekt 2 70
Der dritte Block stellt wieder den Optimal Fall dar, dass ATKIS und Landsat Daten
übereinstimmen. Auf diese und vergleichbare Weise können alle CORINE Klassen
beschrieben werden.
Bei der Betrachtung des Klassifikationsergebnisses (Abb.44) fallen sofort die
schwarzen Flächen auf. Das sind Flächen, bei denen die ATKIS und die Landsat
Klassifikation nicht übereinstimmten und auch keine anderen Regeln sie einer Klasse
sicher zuordnen konnten. 85 bis 90 % des Gebietes konnten aber einer Klasse
zugeordnet werden. Dieser Wert ist als sehr positiv anzusehen, besonders wenn
berücksichtigt wird, dass die Klassifikationskriterien sehr streng sind und damit die
Klassifikationsgenauigkeit sehr hoch ist.
Abb.44, Klassifikationsergebnis Level 3
4.2.4 Classification-based Segmentation
Ziel dieses Arbeitsschrittes ist die Anzahl der unklassifizierten Flächen weiter zu
minimieren. Viele dieser Flächen sind für den menschlichen Betrachter leicht einer
Klasse zuzuordnen. Das eCognition diese Flächen nicht zuordnen konnte, liegt
häufig an folgendem Grund. Die Abb.45 zeigt eine unklassifizierte Fläche (Rote
Fläche), die der menschlichen Betrachter korrekterweise der Klasse 2.1.1 Ackerland

4. Projekt 2 71
zuordnen würde, weil die Fläche zu 100 % von Ackerland umgeben ist und zu klein
ist, um eine eigene Klasse zu bilden.
Abb.45, Unklassifizierte Flächen
In dem bisherigen Klassifikationsansatz bekamen Flächen bereits bei einem
Grenzanteil von 80 Prozent zu einer Klasse A, eine sehr hohe Wahrscheinlichkeit
zugewiesen, auch dieser Klasse A zuzugehören. Weil aber viele der unklassifizierten
Flächen aus mehreren Segmenten bestehen (Abb.45, Fläche recht unter der roten
Fläche) und sie damit einen Großteil ihrer Grenzen ebenfalls zu unklassifizierten
Segmenten haben, können sie nicht über Nachbarschaftsbeziehungen klassifiziert
werden. Eine Lösung dieses Problems wäre, benachbarte unklassifizierte Segmente
mit Hilfe der Classification-based Segmentation zu einem Segment
zusammenzufassen. Dieses zusammengefasste Segment könnte dann aufgrund von
Nachbarschaftsbeziehungen klassifiziert werden. Ein Problem dieses Ansatzes ist
es, dass auch große unklassifizierte Flächen zu einem Segment zusammengefasst
werden. Und je größer dieses Segment wird, desto größer wird die
Wahrscheinlichkeit, dass Teile dieses Segmentes zu verschiedenen Klassen
gehören. Es müssen also nur die unklassifizierte Flächen zusammengefasst werden,
die zu einer Klasse gehören. Weil aber die Klassenzugehörigkeit dieser Segmente
unbekannt ist, kann dies nicht wissensbasiert geschehen. Die einzige Möglichkeit,
die zur Verfügung steht, ist spektrale Informationen für die Segmentierung zu nutzen,
in der Annahme, dass unklassifizierte Segmente mit gleichen spektralen
Eigenschaften zu einer Klasse gehören. Um diesen Ansatz zu realisieren, sind einige
Arbeitsschritte notwendig. Zur Erinnerung: Level 3 zeigt das vorläufige
Klassifikationsergebnis (Abb.44). Um bei der späteren Segmentierung mit Hilfe der
Spektral-Informationen die Klassengrenzen dieser Klassifikation zu erhalten, werden
die Segmente der einzelnen Klassen durch die Classification-based Segmentation in

4. Projekt 2 72
Level 4 zu einem Segment verbunden (Abb.47). Hierzu muss vorher der alte Level 4
gelöscht werden. Da in Level 4 die Klassengrenzen des vorläufigen Ergebnisses
stecken und weil diese Klassengrenzen aufgrund des Hierarchischen Netzaufbaus
von eCognition bei allen niedrigeren Level auch vorhanden sein müssen, kann Level
3 jetzt neu Segmentiert werden, ohne das die Klassengrenzen verloren gehen. Bei
dieser Segmentierung werden die alten Segmente in Level 3 durch neue ersetzt. Um
Segmente mit den geforderten Eigenschaften (groß genug, um
Nachbarschaftsbeziehungen besser zu nutzen, und klein genug, um nur einer Klasse
anzugehören) zu erzeugen, hat sich der Segmentierungs-Maßstab 20 bewährt.
Abb.46, Level 3 und 4 vor dem Arbeitsschritt
Abb.47, Level 3 und 4 nach dem Arbeitsschritt
4.2.5 2. Klassifikation
Nachdem Level 3 neu erzeugt wurde, soll es jetzt ebenfalls neu klassifiziert werden.
Allerdings müssen für die neuen Segmente in Level 3 auch neue
Klassenbeschreibungen erstellt werden, die den neuen Segmenten gerecht werden.
Außerdem beziehen sich die alten Klassenbeschreibungen auch auf das alte 4.
Level, welches gelöscht wurde. Da es nicht möglich ist, nur für ein Level eine neue
Klassenbeschreibung zu laden, müssen alle Klassenbeschreibungen gelöscht
werden. Das hat zur Folge, dass alle Klassifikationen (auch die für die ersten beiden
Level) gelöscht sind. Als nächstes werden neue Klassenbeschreibungen für die
Level 1 bis 3 geladen. Die Klassenbeschreibungen für Level 1 (ATKIS Level) und
Level 2 (Landsat Level) sind identisch mit ihren Vorgängern. Aus diesem Grund ist
auch die neue Klassifikation vom 1. und 2. Level identisch mit der alten. Erst jetzt
kann der neue Level 3 klassifiziert werden.
Level 4 (alt): wird gelöscht
Level 3 (alt): vorl. Klassifizierungsergebnis
Level 3 (neu): neu Segmentiert
Level 4 (neu): classif.-based Seg. von Lev. 3 (alt)

4. Projekt 2 73
Die Klassifikation vom neuen 3. Level verfolgt einen ähnlichen Ansatz wie die des
alten 3. Level. Der Hauptansatz ist wieder, dass die ATKIS Klassifikation und die
Landsat Klassifikation miteinander verglichen werden. Dieser Ansatz sei noch mal
durch das Beispiel für die Klasse 1.2.1 Industrie und Gewerbe (Abb.48) genauer
beschrieben. Ein Segment muss eines von vier Kriterien erfüllen, um dieser Klasse
zugeordnet zu werden. Zur Erinnerung: Der Operator or(max) , der die 4 Kriterien
verbindet, erzeugt kein „ja“ oder „nein“ für eine Klassenzugehörigkeit, sondern einen
Zuweisungswert, der eine Wahrscheinlichkeit der Klassenzugehörigkeit beschreibt.
Die 4 Kriterien lauten im einzelnen:
��Das Segment besitzt einen bestimmten Anteil der ATKIS Klasse Parkplatz und
einen bestimmten Anteil der Landsat Klasse Schotter 2 als Subobjekt. - Für diese
Landsat Szene reichte diese Beschreibung aus. Für andere Szenen wäre es aber
sinnvoll, Nachbarschaftsbeziehungen zur Klasse 121 mit zu benutzen / Unter
bestimmter Anteil können abhängig von der Klasse ganz unterschiedliche Werte
gemeint sein.
��Das Segment besitzt einen bestimmten Anteil der Landsat Klasse Bebaut 2 als
Subobjekt und einen gewissen Grenzanteil zur Klasse 121 Industrie und
Gewerbe (min. größer 50%). - Die Klasse Bebaut 2 steht für alle bebauten
Flächen. Erst durch die Nachbarschaftsbeziehungen können diese Segmente der
Klasse 121 zugewiesen werden.
��Das Segment besitzt entweder einen bestimmten Anteil der Landsat Klassen
Bebaut b 2 oder Bebaut c 2 oder Schotter 2 und einen bestimmten Anteil der
ATKIS Klasse Industrie als Subobjekt.
��Das Segment besitzt eine gewisse Größe (kleiner als 5 ha) oder ein bestimmtes
Länge/Breite Verhältnis und einen bestimmten Grenzanteil zur Klasse 121
Industrie (min. größer 50%). - Das Kriterium kleiner als 5 ha trifft aufgrund des
relativ großen Segmentierungs-Maßstabes fast nur auf vorher unklassifizierte
Gebiete zu. Das Kriterium Länge/Breite versucht die Wege und Flüsse zu
erkennen, die bei der bisherigen Klassifikation durch die Klasse Strassen und
Flüsse (Level 4) noch nicht detektiert wurden.

4. Projekt 2 74
Abb.48, Klassenbeschreibung 121 Industrie und Gewerbe (Level 3)
Das Ergebnis der Klassifikation von Level 3 zeigt Abb.49. In dieser Abbildung sind
immer noch unklassifizierte Flächen auszumachen, die nicht sicher einer Klasse
zugeordnet werden können. Diese Flächen müssen in einem weiteren Schritt
manuell oder durch heranziehen von weiteren Daten klassifiziert werden. Viele
unklassifizierte Flächen liegen am Rand der Szene. Dass lässt den Schluss zu, das
einige Klassenbeschreibungen in Randgebieten der Szene nicht richtig wirken. Dem
zu Folge sollten die Eingangsdaten einen größeren Ausschnitt des Gebietes
vorhalten, als das Gebiet, das klassifiziert werden soll. Die Klassen sind noch nicht
nach der Erfassungsuntergrenze von 25 ha untersucht worden. Erst müssen die
unklassifizierten Flächen einer Klasse zugewiesen werden, weil sich dadurch die
Größe einer Klasse noch ändern kann. Dass es mit eCognition möglich ist, nur
Klassen mit einer Größe von mehr als 25 ha zu klassifizieren, wurde bereits in
Projekt 1 bewiesen.

4. Projekt 2 75
Abb.49, Klassifikationsergebnis von Projekt 2
4.2.6 Ergebnisse Projekt 2
Zur Beurteilung eines Klassifikationsergebnisses ist die Konfusionstafel (engl. Error
Matrix) ein geeignetes Mittel (Ute Gangkofner,1996). In ihr werden das
Klassifikationsergebnis und die Referenzdaten gegenüber gestellt. Zum Erzeugen
von Referenzdaten werden für alle in der Realität vorkommenden Klassen
Stichproben genommen, deren Lage zufällig ist. Um für alle Klassen ausreichend
Stichproben zu bekommen, werden zuerst die Flächen für alle Klassen gesucht und
dann, innerhalb dieser Flächen, die Stichproben zufällig verteilt. Dieser Schritt ist
notwendig, weil sonst die Klassen, die nur wenig Fläche bedecken, zu wenig
Stichproben bekommen würden oder aber die Anzahl der Stichproben zu groß
werden würde. Die Klassenzuordnung der Stichproben erfolgte mit Hilfe der Landsat
Daten, der ATKIS Daten, einer Topographischen Karte und Ortskenntnisse. Die
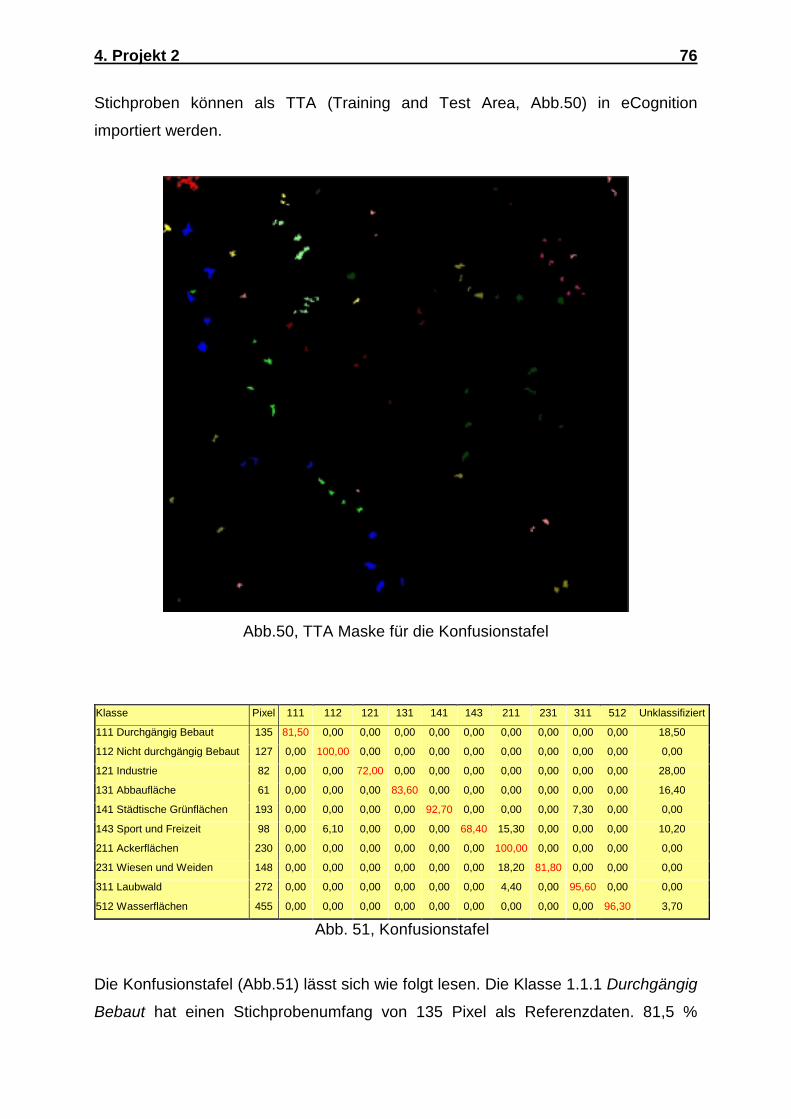
4. Projekt 2 76
Stichproben können als TTA (Training and Test Area, Abb.50) in eCognition
importiert werden.
Abb.50, TTA Maske für die Konfusionstafel
Klasse Pixel 111 112 121 131 141 143 211 231 311 512 Unklassifiziert
111 Durchgängig Bebaut 135 81,50 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 18,50
112 Nicht durchgängig Bebaut 127 0,00 100,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00
121 Industrie 82 0,00 0,00 72,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 28,00
131 Abbaufläche 61 0,00 0,00 0,00 83,60 0,00 0,00 0,00 0,00 0,00 0,00 16,40
141 Städtische Grünflächen 193 0,00 0,00 0,00 0,00 92,70 0,00 0,00 0,00 7,30 0,00 0,00
143 Sport und Freizeit 98 0,00 6,10 0,00 0,00 0,00 68,40 15,30 0,00 0,00 0,00 10,20
211 Ackerflächen 230 0,00 0,00 0,00 0,00 0,00 0,00 100,00 0,00 0,00 0,00 0,00
231 Wiesen und Weiden 148 0,00 0,00 0,00 0,00 0,00 0,00 18,20 81,80 0,00 0,00 0,00
311 Laubwald 272 0,00 0,00 0,00 0,00 0,00 0,00 4,40 0,00 95,60 0,00 0,00
512 Wasserflächen 455 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 96,30 3,70 Abb. 51, Konfusionstafel
Die Konfusionstafel (Abb.51) lässt sich wie folgt lesen. Die Klasse 1.1.1 Durchgängig
Bebaut hat einen Stichprobenumfang von 135 Pixel als Referenzdaten. 81,5 %

4. Projekt 2 77
dieser Pixel wurden bei der Klassifikation auch dieser Klasse korrekt zugeordnet. 0 %
der Pixel wurden unkorrekt einer anderen Klasse zugeordnet. 18,5 % der Pixel sind
bei der Klassifikation unklassifiziert geblieben. Bei der Betrachtung der Werte in der
Konfusionstafel ist zu erkennen, dass die korrekte Klassenzuweisungen für einzelne
Klassen zwischen 68,4 % und 100% liegen. Wobei 100 % für die korrekte Zuweisung
mit Sicherheit ein zu optimistischer Wert ist, der durch den relativ kleinen
Stichprobenumfang begründet ist. Die einzelnen Werte zeigen nur Tendenzen und
keine absoluten Werte.
Bei der Fehlerbetrachtung sind nicht die unklassifizierten Flächen, sondern die falsch
klassifizierten Flächen ein Problem. Hier fallen vor allem die Klassen 2.3.1 Wiesen
und Weiden und 1.4.3 Sport und Freizeit, mit einen Anteil der falsch zugewiesenen
Flächen von 18,2 % bzw. 21,4 %, auf. Die 18,2 % sind wegen des geringen
Stichprobenumfangs ein zu hoher Wert, aber aufgrund des Aufnahmezeitpunktes
(April) und dem davon abhängigen Wachstumszyklus der Pflanzen kommt es zu
Klassifizierungsunsicherheiten zwischen Ackerflächen und Wiesen. Ein späterer
Aufnahmezeitpunkt könnte dieses Problem minimieren. Die 21,4 % inkorrekter
Zuweisung der Klasse 1.4.3 Sport und Freizeit kann durch eine Unschärfe der
Klassendefinitionen bei CORINE begründet werden, denn ein Grossteil der
inkorrekten Klassifikation kann auf ein bewaldetes Tiergehege zurückgeführt werden.
Ein öffentliches Tiergehege kann bei CORINE sowohl der Klasse 1.4.3 Sport und
Freizeit als auch einer Wald Klasse zugeordnet werden. Das Gehege wurde bei
ATKIS als Laubwald geführt und dadurch wurde diese Fläche auch als Laubwald
klassifiziert. In den Referenzdaten wird dieses Gebiet aber als 1.4.3 Sport und
Freizeit geführt. Die teilweise auftretende Unschärfe der Klassendefinitionen bei
CORINE führte in diesem Fall zu der Fehlklassifikation.
Die beiden großen unklassifizierten Flächen in der Mitte des Bildes können auf
Landnutzungsänderungen zwischen dem Erfassungszeitpunkt von ATKIS und dem
Aufnahmezeitpunkt von Landsat zurückgeführt werden. Während in der Landsat
Szene dieses Gebiet bereits Bebaut ist (Expo-Gelände), weisen die ATKIS Daten für
dieses Gebiet noch Ackerflächen aus. Das lässt den Schluss zu, dass Flächen, in
denen ATKIS nicht mehr die reale Bodennutzung vorhält, in den meisten Fällen
unklassifiziert bleiben. Es ist deshalb zwingend notwendig die neuesten ATKIS Daten
zu verwenden.

4. Projekt 2 78
Ansonsten zeigen die hohen Anteile der korrekten Klassifikation in der
Konfusionstafel und auch das Klassifikationsergebnis in Abb.49, dass eine
automatische CORINE-Klassifikation aus Landsat Daten und ATKIS Daten in weiten
Teilen möglich ist. Es bleibt allerdings notwendig einige Gebiete manuell oder mit
Hilfe anderer Software Produkte zu klassifizieren.

5. Zusammenfassung 79
5. Kurze Ergebniszusammenfassung aus Projekt 1 und Projekt 2
Die Frage, ob die Software eCognition für Zwecke der CORINE Landnutzungs-
Klassifikation verwendet werden kann, kann positiv beantwortet werden, wenn auch
mit einigen Einschränkungen. Klassen, die nur eine Bodenbedeckung beinhalten,
können schon sehr gut nur aus Landsat Szenen klassifiziert werden, vorausgesetzt
die Landsat Szene wurde zu einem geeigneten Zeitpunkt (z.B. Mai) aufgenommen.
Um Klassen, die eine Bodennutzung beschreiben, zu klassifizieren, sind häufig
ATKIS Daten notwendig. Es ist anzunehmen, dass das Klassifikationsergebnis noch
verbessert wird, wenn die ATKIS Daten in einer besseren Auflösung hergestellt und
verwendet werden können. Eine höhere Auflösung der ATKIS Daten würde auf jeden
Fall bedeuten, dass aus ihnen linienhafte Objekte wie z.B. Strassen oder Flüsse
besser detektiert werden können. Dieses wäre sehr wichtig für die Klassifikation, weil
es mit eCognition häufig unmöglich ist, z.B. eine Autobahn zu klassifizieren. Dafür
reicht die Auflösung von 25 m Pixelgröße des Landsat Bildes nicht aus.
Die beiden Projekte haben weiterhin aufgezeigt, dass der Klassifikationsalgorithmus
nur dann an den Rändern der Klassifikationsgebiete funktioniert, wenn die
Eingangdaten über die Grenzen des Klassifikationsgebietes hinausragen.
Projekt 2 machte deutlich, dass es generell möglich ist, die Klassenbeschreibungen
und damit auch den Klassifikationsalgorithmus auf andere Projekte zu übertragen. Es
ist aber notwendig, die Grauwert-Zuweisungen für jede Szene neu durchzuführen.

6. Ausblick 80
6.Ausblick Ziel bei der Klassifikation nach CORINE ist es, die Landnutzungs-Klassifikation und
die Landnutzungsänderungs-Klassifikation so weit wie möglich zu automatisieren.
Diese Diplomarbeit kann natürlich nur erste Schritte zu diesem Endziel aufzeigen. Es
müssen noch weitere Untersuchungen folgen, um das gesteckte Ziel zu erreichen.
Als erstes müsste die Übertragbarkeit des Klassifikationsalgorithmus auf andere
Gebiete getestet werden. In anderen Gebieten treten dann auch andere CORINE
Klassen auf, die im Untersuchungsgebiet nicht vorkamen. Zum Beispiel wurde im
Untersuchungsgebiet die Klassifizierung der Klasse 3.1.2 Nadelwälder nicht
überprüft. Es muss also auch noch untersucht werden, ob die übrigen CORINE
Klassen ebenfalls mit der Software eCognition erfasst werden können.
Die Auflösung des ATKIS Bildes im Projekt 2 wird der eigentlichen Genauigkeit der
ATKIS Daten nicht gerecht. Es müssen andere Ansätze für die Vektor-Raster
Transformation gefunden werden, die bessere Ergebnisse liefern. Wenn das
Importieren höher aufgelöster Rasterdaten es nicht ermöglicht linienhafte Objekte
(z.B. Strassen) besser zu erfassen, muss untersucht werden, in wieweit andere
Software Produkte für die Lösung dieses Problems genutzt werden können.
Die Ergebnisse dieser Diplomarbeit sollten auch noch mit den Ergebnissen anderer
Forschungsarbeiten verglichen werden. Hierbei wäre von besonderem Interesse,
welche Ergebnisse andere Software Produkte liefern. Auch könnte Untersucht
werden, welche Klassifikationsergebnisse bei der Verwendung von anderen
Eingangsdaten (z.B. IKONOS Daten) entstehen.
Untersuchungen zur automatisierten Erfassung der Landnutzungsänderung
zwischen zwei CORINE Kampagnen waren nicht Teil dieser Diplomarbeit. Hierauf
wird aber in Zukunft ein Schwerpunkt der Forschung liegen.

7. Literatur 81
7. Literaturverzeichnis
Baatz/Schäpe 1999 Baatz, M., Schäpe, A.: eCognition, Online Hilfe und
Software Tutorial. München: Definiens AG, 1999
Gangkofner 1996 Gangkofner, U.: Methodische Untersuchung zur Vor- und
Nachbereitung der Maximum Likelihood Klassifizierung optischer
Fernerkundungsdaten, München: GEOBUCH - Verlag, 1996
Kraus/Schneider 1988 Kraus, K., Schneider, W.: Fernerkundung Band
1,Physikalische Grundlagen und Aufnahmetechniken. Bonn: Ferd. Dümmlers
Verlag, 1988
Kraus 1990 Kraus, K.: Fernerkundung Band 2, Auswertung photographischer
und digitaler Bilder, Bonn: Ferd. Dümmlers Verlag, 1990
Schmidt 2000 Schmidt, R.: Untersuchung des Bildanalysesystems eCognition,
Hannover, 2000
Stolz 1998 Stolz, R.: Die Verwendung der Fuzzy Logic Theorie zur
wissensbasierten Klassifikation von Fernerkundungsdaten, München:
GEOBUCH - Verlag, 1998
CORINE Land Cover Datenerhebungsanleitung für CORINE, Statistisches
Bundesamt, 1996
CORINE Land Cover – Update 2000 Technical Reference Document, EEA, 2000
eCognition User Guide der Software eCognition, München, 2000

7. Literatur 82
Internetadressen
http://www.definiens.com Homepage der Firma Definiens
http://etc.satellus.se Homepage des European Topic Centre
http://org.eea.ea.int Homepage der Europäischen Umweltagentur
http://www.statistik-bund.de/stabis Homepage des Statistischen Bundesamtes
http://www.jrc.org Homepage des Joint Research Centre
(Ispra)

8. Anhang 83
8. Anhang: Inhaltsverzeichnis der CD:
Projekt 1:
CORINE90.dpr Gesamtes Projekt 1
Landsat92.img Landsat Szene (als Layer importieren)
CORINE90Prot.dpt Ablauf - Protokoll von Projekt 1
CORCLASSHI.dkb 1.Klassenbeschreibung
CORCLASSHI2.dkb 2.Klassenbeschreibung
TTACORINE90.ASC Test Area (Referenzdaten CLC90)
TABLECORINE90TTA.txt Anhang zu TTACORINE90
Projekt 2:
CORINE2000.2bb.dpr Gesamtes Projekt 2
Landsat2000kl.img Landsat 7 Szene (Kanal 1 – 5 und 7)
Landsat20001kl.img Landsat 7 (Kanal 6/TIR)
Cor2000.2bb.dpt Ablauf – Protokoll von Projekt 2
Cor2000.2.dkb 1.Klassenbeschreibung
Cor2000.2bb.dkb 2.Klassenbeschreibung

8. Anhang 84
Atkis2000layer2.ASC ATKIS Daten (Thematischer Layer)
Atkis2000table2.txt Anhang für Atkis2000layer2
TTA.ASC Test Area (Referenz Daten)
TTAtable.txt Anhang für TTA
Diplomarbeit.doc Word Dokument der Diplomarbeit





























